---
license: apache-2.0
language:
- en
- zh
library_name: transformers
pipeline_tag: text-generation
tags:
- llm
- nanbeige
---
# 1. Introduction
Nanbeige4-3B-Thinking is a **3B-parameter reasoning model** within the fourth-generation Nanbeige LLM family.
It showcases that even compact models can achieve advanced reasoning abilities through continuous enhancements in data quality and training methodologies.
To support research and technological advancement in the open-source community, we have open-sourced the Nanbeige4-3B-Thinking model together with its technical methodology.
# 2. Model Summary
Pre-Training
* We constructed a comprehensive **23T-tokens** training corpus from web texts, books, code, and papers, meticulously filtered through a hybrid strategy of tagging-based scoring and retrieval-based recalling.
This foundation was then augmented with **knowledge-dense and reasoning-intensive synthetic data**, including Q&A pairs, textbooks, and Long-COTs, which significantly benefited the downstream task performance.
* We designed an innovative **FG-WSD (Fine-Grained Warmup-Stable-Decay)** training scheduler, meticulously refining the conventional WSD approach.
This scheduler was implemented with a **fine-grained, quality-progressive data curriculum**, dividing the Stable stage into multiple phases with progressively improved data mixtures. Compared to the vanilla WSD, our method achieved notable performance gains. During the Decay stage, we increased the proportion of math, code, synthetic QA, and synthetic Long-COT data to further enhance reasoning capabilities.
| Stage | Training Tokens | Learning Rate |
|-------------------------------|-----------------|-----------------------|
| Warmup Stage | 0.1T | 0 ——> 4.5e-4 |
| Diversity-Enriched Stable Stage| 12.4T | Constant 4.5e-4 |
| High-Quality Stable Stage | 6.5T | Constant 4.5e-4 |
| Decay and Long-Context Stage | 4T | 4.5e-4 ——> 1.5e-6 |
Post-Training
* **SFT phase.** We constructed a collection of over **30 million** high-quality Long Chain-of-Thought (Long-CoT) samples to support **multi-stage curriculum learning**.
By integrating both rule-based and model-based verification methods, we not only ensured sample accuracy but also enhanced the comprehensiveness and instructional value of each training example compared to alternative candidates.
This rich diversity in instructions and high response quality equipped the model to achieve outstanding performance across a variety of benchmarks.
* **Distill.** Following SFT, we employed the Nanbeige flagship reasoning model as the teacher model to distill the Nanbeige4-3B-Thinking model, and further enhanced the performance.
We observed that on-policy distillation provides greater benefits for mathematical reasoning tasks, while off-policy distillation is more effective for general tasks such as human-preference alignment.
* **RL phase.** We then advanced to a **multi-stage, on-policy reinforcement learning phase**.
This approach leverages **verifiable rewards** to enhance reasoning capability and a **preference reward model** to improve alignment, utilizing a carefully filtered blend of real-world and synthetic data calibrated for appropriate difficulty.
# 3. Model Performance
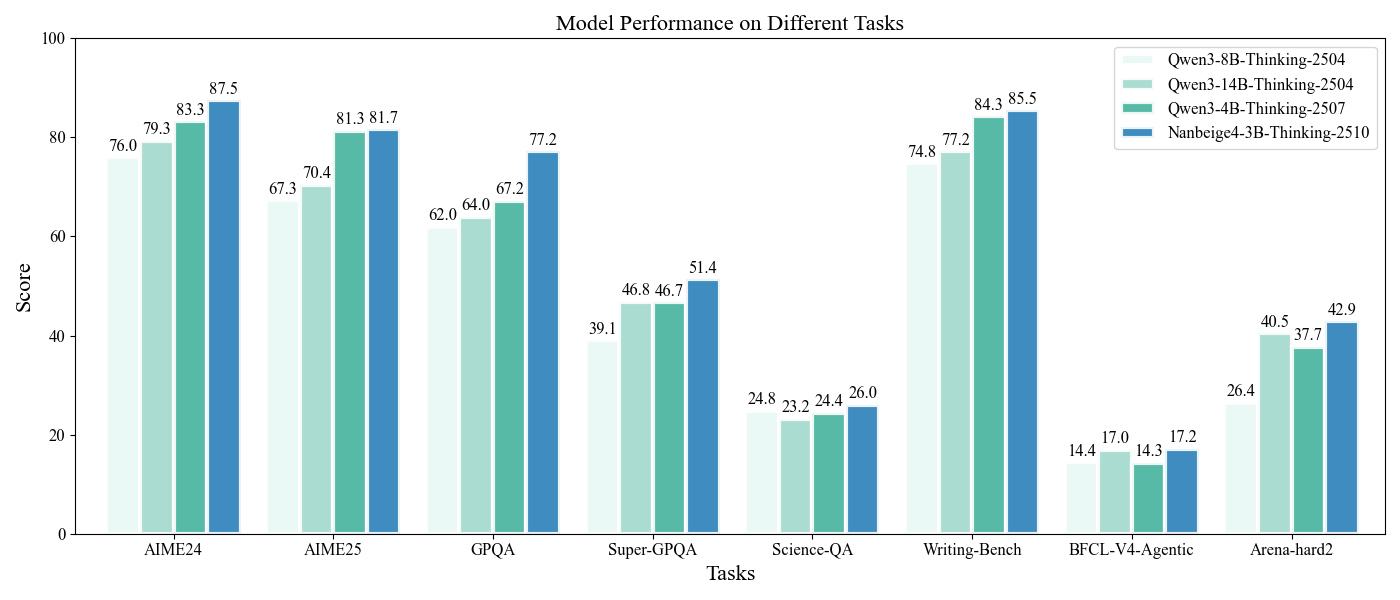
For model performance comparison, we benchmark our model against recent reasoning LLMs from the Qwen3 series.
All models are evaluated under identical configurations to ensure fairness.
The results show that our model outperforms the baselines across a range of mainstream benchmarks, including **math, science, creative writing, tool use, and human preference alignment**.
| Model | AIME24 | AIME25 | GPQA | Super-GPQA | Science-QA | Writing-Bench | BFCL-V4-Agentic | Arena-hard2 |
|----------------|--------|--------|------|------------|------------|--------------|----------------|-------------|
| Qwen3-8B-Thinking-2504 | 76.0 | 67.3 | 62.0 | 39.1 | 24.8 | 74.8 | 14.4 | 26.4 |
| Qwen3-14B-Thinking-2504 | 79.3 | 70.4 | 64.0 | 46.8 | 23.2 | 77.2 | 17.0 |40.5 |
| Qwen3-4B-Thinking-2507 | 83.3 | 81.3 | 67.2 | 46.7 | 24.4 | 84.3 | 14.3 | 37.7 |
| **Nanbeige4-3B-Thinking-2510** | **87.5** | **81.7** | **77.2** | **51.4** | **26.0** | **85.5** | **17.2** | **42.9** |
## 4. Quickstart
For the chat scenario:
```
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
'Nanbeige/Nanbeige4-3B-Thinking-2510',
use_fast=False,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
'Nanbeige/Nanbeige4-3B-Thinking-2510',
torch_dtype='auto',
device_map='auto',
trust_remote_code=True
)
messages = [
{'role': 'user', 'content': 'Which number is bigger, 9.11 or 9.8?'}
]
prompt = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=False
)
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors='pt').input_ids
output_ids = model.generate(input_ids.to('cuda'), eos_token_id=166101)
resp = tokenizer.decode(output_ids[0][len(input_ids[0]):], skip_special_tokens=True)
print(resp)
```
For the tool use scenario:
```
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
'Nanbeige/Nanbeige4-3B-Thinking-2510',
use_fast=False,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
'Nanbeige/Nanbeige4-3B-Thinking-2510',
torch_dtype='auto',
device_map='auto',
trust_remote_code=True
)
messages = [
{'role': 'user', 'content': 'Help me check the weather in Beijing now'}
]
tools = [{'type': 'function',
'function': {'name': 'SearchWeather',
'description': 'Find out current weather in a certain place on a certain day.',
'parameters': {'type': 'dict',
'properties': {'location': {'type': 'string',
'description': 'A city in china.'},
'required': ['location']}}}}]
prompt = tokenizer.apply_chat_template(
messages,
tools,
add_generation_prompt=True,
tokenize=False
)
input_ids = tokenizer(prompt, add_special_tokens=False, return_tensors='pt').input_ids
output_ids = model.generate(input_ids.to('cuda'), eos_token_id=166101)
resp = tokenizer.decode(output_ids[0][len(input_ids[0]):], skip_special_tokens=True)
print(resp)
```
# 5. Limitations
While we place great emphasis on the safety of the model during the training process, striving to ensure that its outputs align with ethical and legal requirements, it may not completely avoid generating unexpected outputs due to the model's size and probabilistic nature. These outputs may include harmful content such as bias or discrimination. Please don't propagate such content. We do not assume any responsibility for the consequences resulting from the dissemination of inappropriate information.
# 6. Citation
If you find our model useful or want to use it in your projects, please kindly cite this Huggingface project.
# 7. Contact
If you have any questions, please raise an issue or contact us at nanbeige@126.com.