---
base_model:
- QiWang98/VideoRFT-SFT-3B
- Qwen/Qwen2.5-VL-3B-Instruct
datasets:
- QiWang98/VideoRFT-Data
language:
- en
license: apache-2.0
metrics:
- accuracy
pipeline_tag: video-text-to-text
library_name: transformers
---
# 🎥 VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning
This repository contains the **VideoRFT** model, presented in the paper [VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning](https://huggingface.co/papers/2505.12434).
📖 Paper
│ 💻 Code
│ 📀 CoT Dataset
│ 📀 RL Dataset
│ 🤗 Models
## 📰 News
- [2025/09/19] Our paper has been **accepted to NeurIPS 2025** 🎉!
- [2025/06/01] We released our 3B Models ([🤗VideoRFT-SFT-3B](https://huggingface.co/QiWang98/VideoRFT-SFT-3B) and [🤗VideoRFT-3B](https://huggingface.co/QiWang98/VideoRFT-3B)) to huggingface.
- [2025/05/25] We released our 7B Models ([🤗VideoRFT-SFT-7B](https://huggingface.co/QiWang98/VideoRFT-SFT) and [🤗VideoRFT-7B](https://huggingface.co/QiWang98/VideoRFT)) to huggingface.
- [2025/05/20] We released our Datasets ([📀CoT Dataset](https://huggingface.co/datasets/QiWang98/VideoRFT-Data) and [📀RL Dataset](https://huggingface.co/datasets/QiWang98/VideoRFT-Data)) to huggingface.
- [2025/05/18] Our paper is released on [ArXiv](https://arxiv.org/abs/2505.12434), and we have open-sourced our code on [GitHub](https://github.com/QiWang98/VideoRFT)!
## 🔎 Overview
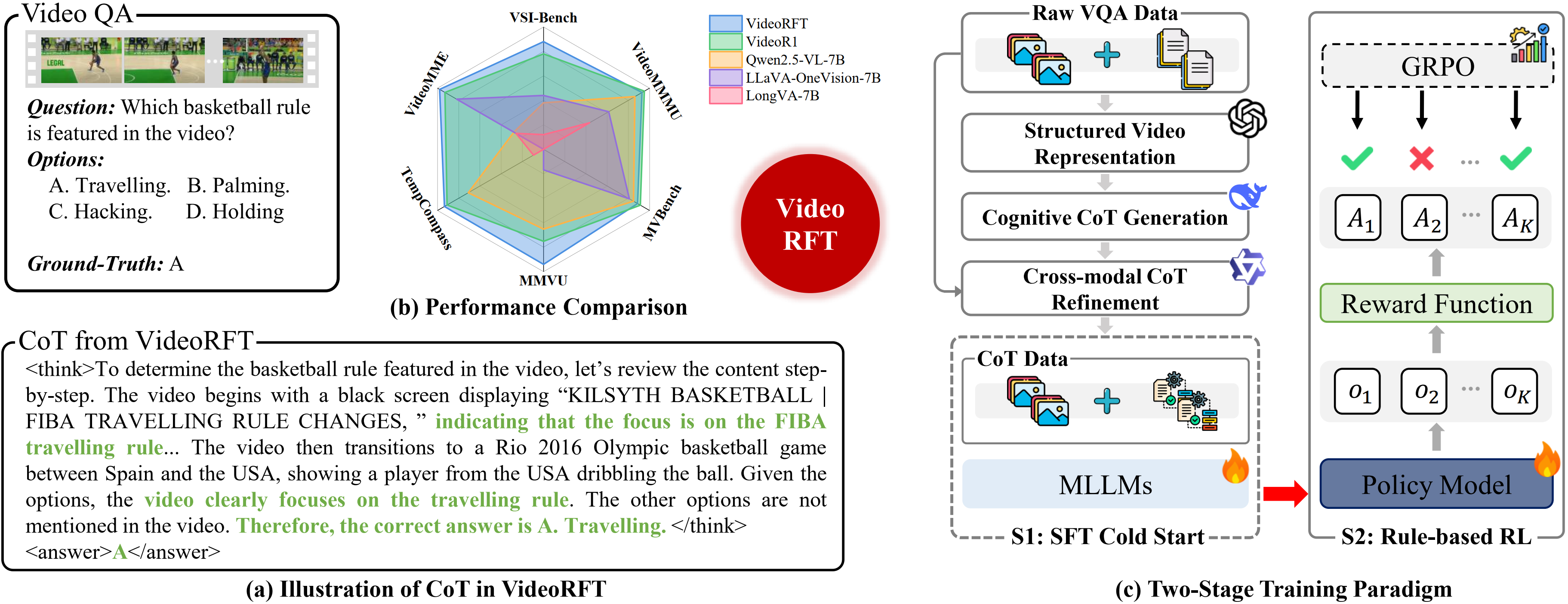
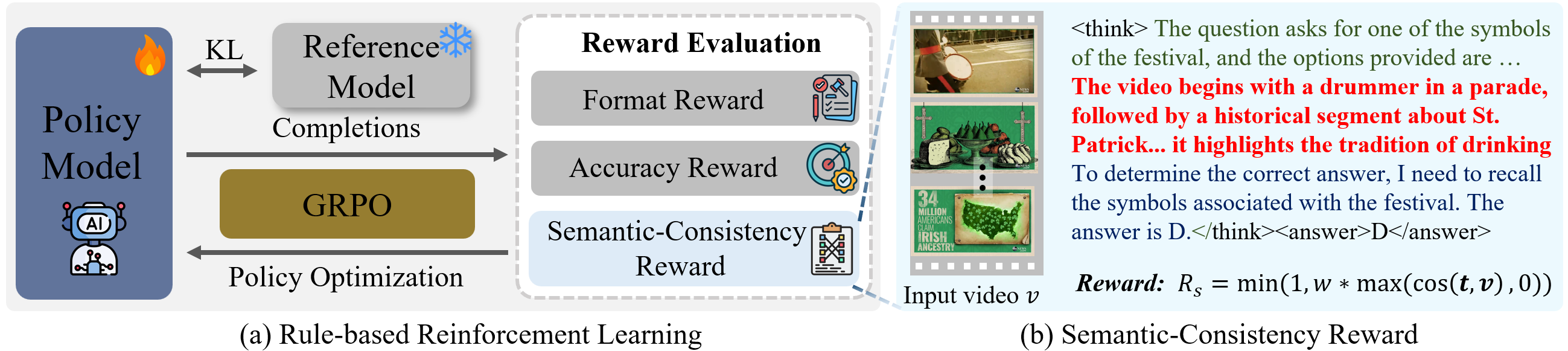
Reinforcement fine-tuning (RFT) has shown great promise in achieving humanlevel reasoning capabilities of Large Language Models (LLMs), and has recently been extended to MLLMs. Nevertheless, reasoning about videos, which is a fundamental aspect of human intelligence, remains a persistent challenge due to the complex logic, temporal and causal structures inherent in video data. To fill this gap, we propose VideoRFT, a novel approach that extends the RFT paradigm to cultivate human-like video reasoning capabilities in MLLMs. VideoRFT follows the standard two-stage scheme in RFT: supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations, followed by reinforcement learning (RL) to improve generalization. A central challenge to achieve this in the video domain lies in the scarcity of large-scale, high-quality video CoT datasets. We address this by building a fully automatic CoT curation pipeline. First, we devise a cognitioninspired prompting strategy to elicit a reasoning LLM to generate preliminary CoTs based solely on rich, structured, and literal representations of video content. Subsequently, these CoTs are revised by a visual-language model conditioned on the actual video, ensuring visual consistency and reducing visual hallucinations. This pipeline results in two new datasets VideoRFT-CoT-102K for SFT and VideoRFT-RL-310K for RL. To further strength the RL phase, we introduce a novel semantic-consistency reward that explicitly promotes the alignment between textual reasoning with visual evidence. This reward encourages the model to produce coherent, context-aware reasoning outputs grounded in visual input. Extensive experiments show that VideoRFT achieves state-of-the-art performance on six video reasoning benchmarks.
## ✨ Methodology
To overcome the scarcity of video CoTs, we develop a scalable, cognitively inspired pipeline for high-quality video CoT dataset construction.
To further strength the RL phase, we introduce a novel semantic-consistency reward that explicitly promotes the alignment between textual reasoning with visual evidence.
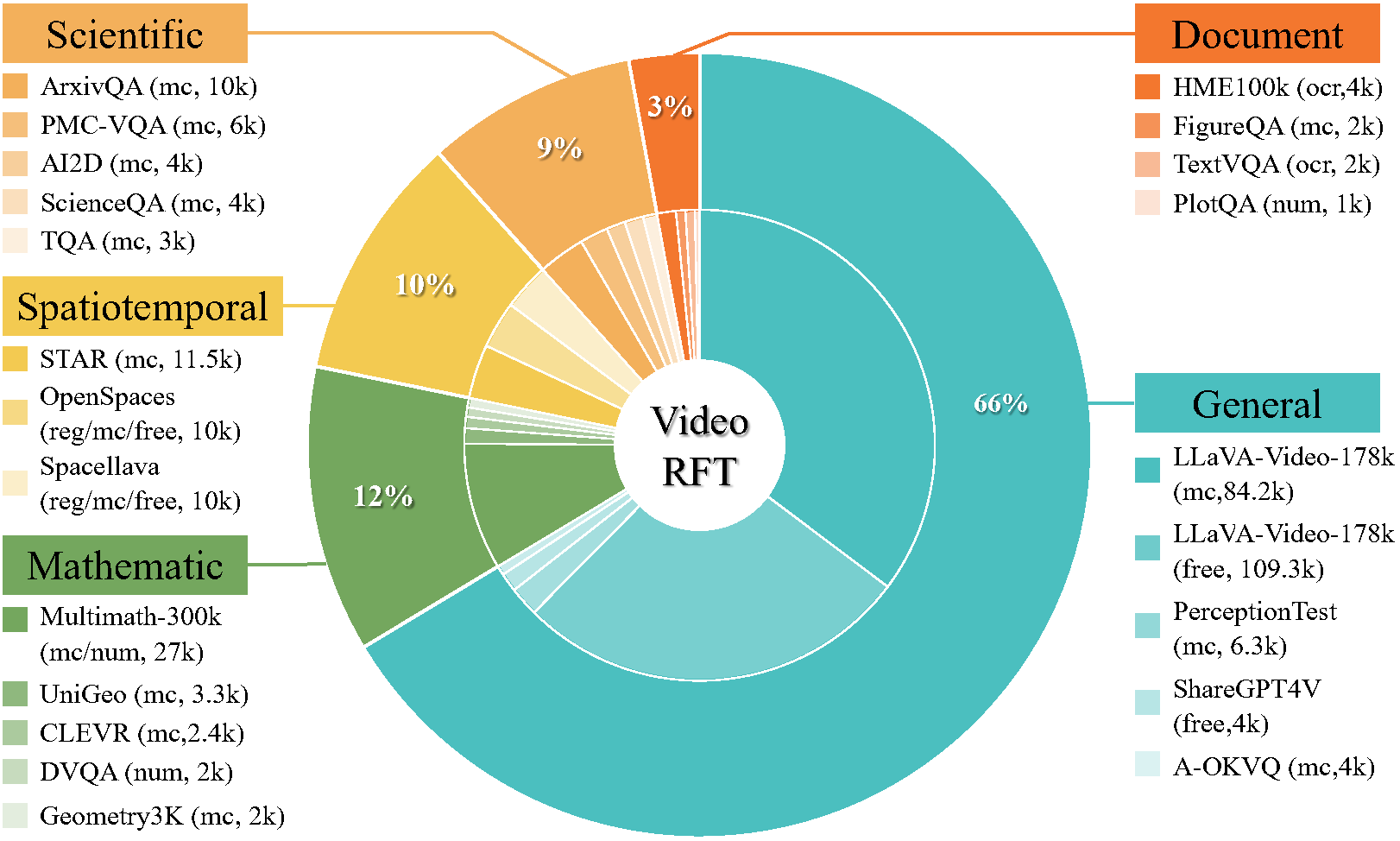
## 📀 Datasets
Based on above pipeline, we construct two large-scale datasets, i.e., [📀VideoRFT-CoT-102K](https://huggingface.co/datasets/QiWang98/VideoRFT-Data) and [📀VideoRFT-RL-310K](https://huggingface.co/datasets/QiWang98/VideoRFT-Data).
## 🛠️ Set up
### Requirements
* `Python >= 3.11`
* `Pytorch >= 2.5.1`
* `transformers == 4.51.3`
* `vLLM == 0.7.3`
* `trl == 0.16.0`
### Installation
```bash
git clone https://github.com/QiWang98/VideoRFT
cd VideoRFT
# Create and activate environment
conda create -n VideoRFT python=3.11
conda activate VideoRFT
bash setup.sh
# Install decord for improved video processing
cd src/qwen-vl-utils
pip install -e .[decord]
```
## 🚀 Training
### Supervised Fine-Tuning (SFT)
We begin with supervised fine-tuning on the VideoRFT-CoT dataset for one epoch:
```bash
bash ./src/scripts/run_sft_video.sh
```
This step can be skipped by directly using our pretrained SFT models, available at [🤗VideoRFT-SFT-7B](https://huggingface.co/QiWang98/VideoRFT-SFT) or [🤗VideoRFT-SFT-3B](https://huggingface.co/QiWang98/VideoRFT-SFT-3B).
### Reinforcement Learning (RL)
Next, perform reinforcement learning using the VideoRFT-RL dataset:
```bash
bash ./src/scripts/run_grpo_video.sh
```
To enable faster training via vLLM acceleration:
```bash
bash ./src/scripts/run_grpo_vllm_qwen25vl.sh
```
> **Note:** During training, we adopt the following settings for efficiency:
* **VIDEO PIXELS**: 128 × 28 × 28
* **FPS FRAMES**: 16
All frame-related configurations can be adjusted in `src/qwen-vl-utils`.
## 📈 Inference & Evaluation
> During inference, we increase the maximum frame resolution and length to boost performance:
* **VIDEO PIXELS**: 256 × 28 × 28
* **FPS FRAMES**: 32
You can configure these parameters in `src/qwen-vl-utils`.
> We evaluate all models under a unified decoding configuration following the official Qwen2.5-VL demo:
* `top_p = 0.001`
* `temperature = 0.01`
### Evaluation Procedure
1. Download preprocessed evaluation JSONs from: [[🤗 eval](https://huggingface.co/datasets/Video-R1/Video-R1-eval)]
2. Download the video data from the official sites of each benchmark and organize them as specified in the JSON files.
3. Run the evaluation across all benchmarks:
```bash
bash ./src/eval_bench.sh
```
## Quick Inference Code
```python
import numpy as np
import torch
from longvu.builder import load_pretrained_model
from longvu.constants import (
DEFAULT_IMAGE_TOKEN,
IMAGE_TOKEN_INDEX,
)
from longvu.conversation import conv_templates, SeparatorStyle
from longvu.mm_datautils import (
KeywordsStoppingCriteria,
process_images,
tokenizer_image_token,
)
from decord import cpu, VideoReader
tokenizer, model, image_processor, context_len = load_pretrained_model(
"./checkpoints/longvu_qwen", None, "cambrian_qwen",
)
model.eval()
video_path = "./examples/video1.mp4"
qs = "Describe this video in detail"
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
fps = float(vr.get_avg_fps())
frame_indices = np.array([i for i in range(0, len(vr), round(fps),)])
video = []
for frame_index in frame_indices:
img = vr[frame_index].asnumpy()
video.append(img)
video = np.stack(video)
image_sizes = [video[0].shape[:2]]
video = process_images(video, image_processor, model.config)
video = [item.unsqueeze(0) for item in video]
qs = DEFAULT_IMAGE_TOKEN + "
" + qs
conv = conv_templates["qwen"].copy()
conv.append_message(conv.roles[0], qs)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(model.device)
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=video,
image_sizes=image_sizes,
do_sample=False,
temperature=0.2,
max_new_tokens=128,
use_cache=True,
stopping_criteria=[stopping_criteria],
)
pred = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
```
## 🙏 Acknowledgements
We gratefully acknowledge the contributions of the open-source community, particularly [DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1), [Open-R1](https://github.com/huggingface/open-r1), and [R1-V](https://github.com/Deep-Agent/R1-V).
## 📚 Citations
If you find this work helpful, please consider citing:
```
@article{VideoRFT,
title={VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning},
author={Wang, Qi and Yu, Yanrui and Yuan, Ye and Mao, Rui and Zhou, Tianfei},
journal={arXiv preprint arXiv:2505.12434},
year={2025}
}
```