
repo
string | pull_number
int64 | instance_id
string | issue_numbers
list | base_commit
string | patch
string | test_patch
string | problem_statement
string | hints_text
string | created_at
timestamp[s] | language
string | label
string |
|---|---|---|---|---|---|---|---|---|---|---|---|
getlogbook/logbook
| 183
|
getlogbook__logbook-183
|
[
"94"
] |
1d999a784d0d8f5f7423f25c684cc1100843ccc5
|
diff --git a/logbook/handlers.py b/logbook/handlers.py
--- a/logbook/handlers.py
+++ b/logbook/handlers.py
@@ -20,6 +20,7 @@
except ImportError:
from sha import new as sha1
import traceback
+import collections
from datetime import datetime, timedelta
from collections import deque
from textwrap import dedent
@@ -1014,14 +1015,42 @@ class MailHandler(Handler, StringFormatterHandlerMixin,
The default timedelta is 60 seconds (one minute).
- The mail handler is sending mails in a blocking manner. If you are not
+ The mail handler sends mails in a blocking manner. If you are not
using some centralized system for logging these messages (with the help
of ZeroMQ or others) and the logging system slows you down you can
wrap the handler in a :class:`logbook.queues.ThreadedWrapperHandler`
that will then send the mails in a background thread.
+ `server_addr` can be a tuple of host and port, or just a string containing
+ the host to use the default port (25, or 465 if connecting securely.)
+
+ `credentials` can be a tuple or dictionary of arguments that will be passed
+ to :py:meth:`smtplib.SMTP.login`.
+
+ `secure` can be a tuple, dictionary, or boolean. As a boolean, this will
+ simply enable or disable a secure connection. The tuple is unpacked as
+ parameters `keyfile`, `certfile`. As a dictionary, `secure` should contain
+ those keys. For backwards compatibility, ``secure=()`` will enable a secure
+ connection. If `starttls` is enabled (default), these parameters will be
+ passed to :py:meth:`smtplib.SMTP.starttls`, otherwise
+ :py:class:`smtplib.SMTP_SSL`.
+
+
.. versionchanged:: 0.3
The handler supports the batching system now.
+
+ .. versionadded:: 1.0
+ `starttls` parameter added to allow disabling STARTTLS for SSL
+ connections.
+
+ .. versionchanged:: 1.0
+ If `server_addr` is a string, the default port will be used.
+
+ .. versionchanged:: 1.0
+ `credentials` parameter can now be a dictionary of keyword arguments.
+
+ .. versionchanged:: 1.0
+ `secure` can now be a dictionary or boolean in addition to to a tuple.
"""
default_format_string = MAIL_FORMAT_STRING
default_related_format_string = MAIL_RELATED_FORMAT_STRING
@@ -1039,7 +1068,7 @@ def __init__(self, from_addr, recipients, subject=None,
server_addr=None, credentials=None, secure=None,
record_limit=None, record_delta=None, level=NOTSET,
format_string=None, related_format_string=None,
- filter=None, bubble=False):
+ filter=None, bubble=False, starttls=True):
Handler.__init__(self, level, filter, bubble)
StringFormatterHandlerMixin.__init__(self, format_string)
LimitingHandlerMixin.__init__(self, record_limit, record_delta)
@@ -1054,6 +1083,7 @@ def __init__(self, from_addr, recipients, subject=None,
if related_format_string is None:
related_format_string = self.default_related_format_string
self.related_format_string = related_format_string
+ self.starttls = starttls
def _get_related_format_string(self):
if isinstance(self.related_formatter, StringFormatter):
@@ -1148,20 +1178,63 @@ def get_connection(self):
"""Returns an SMTP connection. By default it reconnects for
each sent mail.
"""
- from smtplib import SMTP, SMTP_PORT, SMTP_SSL_PORT
+ from smtplib import SMTP, SMTP_SSL, SMTP_PORT, SMTP_SSL_PORT
if self.server_addr is None:
host = '127.0.0.1'
port = self.secure and SMTP_SSL_PORT or SMTP_PORT
else:
- host, port = self.server_addr
- con = SMTP()
- con.connect(host, port)
+ try:
+ host, port = self.server_addr
+ except ValueError:
+ # If server_addr is a string, the tuple unpacking will raise
+ # ValueError, and we can use the default port.
+ host = self.server_addr
+ port = self.secure and SMTP_SSL_PORT or SMTP_PORT
+
+ # Previously, self.secure was passed as con.starttls(*self.secure). This
+ # meant that starttls couldn't be used without a keyfile and certfile
+ # unless an empty tuple was passed. See issue #94.
+ #
+ # The changes below allow passing:
+ # - secure=True for secure connection without checking identity.
+ # - dictionary with keys 'keyfile' and 'certfile'.
+ # - tuple to be unpacked to variables keyfile and certfile.
+ # - secure=() equivalent to secure=True for backwards compatibility.
+ # - secure=False equivalent to secure=None to disable.
+ if isinstance(self.secure, collections.Mapping):
+ keyfile = self.secure.get('keyfile', None)
+ certfile = self.secure.get('certfile', None)
+ elif isinstance(self.secure, collections.Iterable):
+ # Allow empty tuple for backwards compatibility
+ if len(self.secure) == 0:
+ keyfile = certfile = None
+ else:
+ keyfile, certfile = self.secure
+ else:
+ keyfile = certfile = None
+
+ # Allow starttls to be disabled by passing starttls=False.
+ if not self.starttls and self.secure:
+ con = SMTP_SSL(host, port, keyfile=keyfile, certfile=certfile)
+ else:
+ con = SMTP(host, port)
+
if self.credentials is not None:
- if self.secure is not None:
+ secure = self.secure
+ if self.starttls and secure is not None and secure is not False:
con.ehlo()
- con.starttls(*self.secure)
+ con.starttls(keyfile=keyfile, certfile=certfile)
con.ehlo()
- con.login(*self.credentials)
+
+ # Allow credentials to be a tuple or dict.
+ if isinstance(self.credentials, collections.Mapping):
+ credentials_args = ()
+ credentials_kwargs = self.credentials
+ else:
+ credentials_args = self.credentials
+ credentials_kwargs = dict()
+
+ con.login(*credentials_args, **credentials_kwargs)
return con
def close_connection(self, con):
@@ -1175,7 +1248,7 @@ def close_connection(self, con):
pass
def deliver(self, msg, recipients):
- """Delivers the given message to a list of recpients."""
+ """Delivers the given message to a list of recipients."""
con = self.get_connection()
try:
con.sendmail(self.from_addr, recipients, msg.as_string())
@@ -1227,7 +1300,7 @@ class GMailHandler(MailHandler):
def __init__(self, account_id, password, recipients, **kw):
super(GMailHandler, self).__init__(
- account_id, recipients, secure=(),
+ account_id, recipients, secure=True,
server_addr=("smtp.gmail.com", 587),
credentials=(account_id, password), **kw)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -158,6 +158,10 @@ def status_msgs(*msgs):
extras_require = dict()
extras_require['test'] = set(['pytest', 'pytest-cov'])
+
+if sys.version_info[:2] < (3, 3):
+ extras_require['test'] |= set(['mock'])
+
extras_require['dev'] = set(['cython']) | extras_require['test']
extras_require['execnet'] = set(['execnet>=1.0.9'])
|
diff --git a/tests/test_mail_handler.py b/tests/test_mail_handler.py
--- a/tests/test_mail_handler.py
+++ b/tests/test_mail_handler.py
@@ -7,6 +7,11 @@
from .utils import capturing_stderr_context, make_fake_mail_handler
+try:
+ from unittest.mock import Mock, call, patch
+except ImportError:
+ from mock import Mock, call, patch
+
__file_without_pyc__ = __file__
if __file_without_pyc__.endswith('.pyc'):
__file_without_pyc__ = __file_without_pyc__[:-1]
@@ -104,3 +109,126 @@ def test_group_handler_mail_combo(activation_strategy, logger):
assert len(related) == 2
assert re.search('Message type:\s+WARNING', related[0])
assert re.search('Message type:\s+DEBUG', related[1])
+
+
+def test_mail_handler_arguments():
+ with patch('smtplib.SMTP', autospec=True) as mock_smtp:
+
+ # Test the mail handler with supported arguments before changes to
+ # secure, credentials, and starttls
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr=('server.example.com', 465),
+ credentials=('username', 'password'),
+ secure=('keyfile', 'certfile'))
+
+ mail_handler.get_connection()
+
+ assert mock_smtp.call_args == call('server.example.com', 465)
+ assert mock_smtp.method_calls[1] == call().starttls(
+ keyfile='keyfile', certfile='certfile')
+ assert mock_smtp.method_calls[3] == call().login('username', 'password')
+
+ # Test secure=()
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr=('server.example.com', 465),
+ credentials=('username', 'password'),
+ secure=())
+
+ mail_handler.get_connection()
+
+ assert mock_smtp.call_args == call('server.example.com', 465)
+ assert mock_smtp.method_calls[5] == call().starttls(
+ certfile=None, keyfile=None)
+ assert mock_smtp.method_calls[7] == call().login('username', 'password')
+
+ # Test implicit port with string server_addr, dictionary credentials,
+ # dictionary secure.
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr='server.example.com',
+ credentials={'user': 'username', 'password': 'password'},
+ secure={'certfile': 'certfile2', 'keyfile': 'keyfile2'})
+
+ mail_handler.get_connection()
+
+ assert mock_smtp.call_args == call('server.example.com', 465)
+ assert mock_smtp.method_calls[9] == call().starttls(
+ certfile='certfile2', keyfile='keyfile2')
+ assert mock_smtp.method_calls[11] == call().login(
+ user='username', password='password')
+
+ # Test secure=True
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr=('server.example.com', 465),
+ credentials=('username', 'password'),
+ secure=True)
+
+ mail_handler.get_connection()
+
+ assert mock_smtp.call_args == call('server.example.com', 465)
+ assert mock_smtp.method_calls[13] == call().starttls(
+ certfile=None, keyfile=None)
+ assert mock_smtp.method_calls[15] == call().login('username', 'password')
+ assert len(mock_smtp.method_calls) == 16
+
+ # Test secure=False
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr=('server.example.com', 465),
+ credentials=('username', 'password'),
+ secure=False)
+
+ mail_handler.get_connection()
+
+ # starttls not called because we check len of method_calls before and
+ # after this test.
+ assert mock_smtp.call_args == call('server.example.com', 465)
+ assert mock_smtp.method_calls[16] == call().login('username', 'password')
+ assert len(mock_smtp.method_calls) == 17
+
+ with patch('smtplib.SMTP_SSL', autospec=True) as mock_smtp_ssl:
+ # Test starttls=False
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr='server.example.com',
+ credentials={'user': 'username', 'password': 'password'},
+ secure={'certfile': 'certfile', 'keyfile': 'keyfile'},
+ starttls=False)
+
+ mail_handler.get_connection()
+
+ assert mock_smtp_ssl.call_args == call(
+ 'server.example.com', 465, keyfile='keyfile', certfile='certfile')
+ assert mock_smtp_ssl.method_calls[0] == call().login(
+ user='username', password='password')
+
+ # Test starttls=False with secure=True
+ mail_handler = logbook.MailHandler(
+ from_addr='from@example.com',
+ recipients='to@example.com',
+ server_addr='server.example.com',
+ credentials={'user': 'username', 'password': 'password'},
+ secure=True,
+ starttls=False)
+
+ mail_handler.get_connection()
+
+ assert mock_smtp_ssl.call_args == call(
+ 'server.example.com', 465, keyfile=None, certfile=None)
+ assert mock_smtp_ssl.method_calls[1] == call().login(
+ user='username', password='password')
+
+
+
+
+
+
|
SMTP Handler STARTTLS
Due to the lack of documentation on this handler it took a little digging to work out how to get it to work...
One thing that confused me was the "secure" argument. Python SMTPLib starttls() accepts two optional values: a keyfile and certfile - but these are only required for _checking_ the identity. If neither are specified then SMTPLib will still try establish an encrypted connection but without checking the identity. If you do not specify an argument to Logbook, it will not attempt to establish an encrypted connection at all.
So, if you want a tls connection to the SMTP server but don't care about checking the identity you can do `secure = []` which will pass the `if self.secure is not None`, however if you do `secure = True` you will get an error because you cannot unpack a boolean! (as logbook populates the arguments using: `conn.starttls(*self.secure)`).
It'd help if the documentation explained the arguments for the mail handlers.
|
You're right. A simple solution is to use `secure = ()`, but I agree it has to be better documented.
| 2015-12-03T01:44:29
|
python
|
Easy
|
rigetti/pyquil
| 399
|
rigetti__pyquil-399
|
[
"398",
"398"
] |
d6a0e29b2b1a506a48977a9d8432e70ec699af34
|
diff --git a/pyquil/parameters.py b/pyquil/parameters.py
--- a/pyquil/parameters.py
+++ b/pyquil/parameters.py
@@ -31,9 +31,11 @@ def format_parameter(element):
out += repr(r)
if i == 1:
- out += 'i'
+ assert np.isclose(r, 0, atol=1e-14)
+ out = 'i'
elif i == -1:
- out += '-i'
+ assert np.isclose(r, 0, atol=1e-14)
+ out = '-i'
elif i < 0:
out += repr(i) + 'i'
else:
|
diff --git a/pyquil/tests/test_parameters.py b/pyquil/tests/test_parameters.py
--- a/pyquil/tests/test_parameters.py
+++ b/pyquil/tests/test_parameters.py
@@ -14,6 +14,8 @@ def test_format_parameter():
(1j, 'i'),
(0 + 1j, 'i'),
(-1j, '-i'),
+ (1e-15 + 1j, 'i'),
+ (1e-15 - 1j, '-i')
]
for test_case in test_cases:
|
DEFGATEs are not correct
There is a problem with DEFGATEs that has manifested itself in the `phase_estimation` module of Grove (brought to our attention here: https://github.com/rigetticomputing/grove/issues/145).
I have traced the problem to commit d309ac11dabd9ea9c7ffa57dd26e68b5e7129aa9
Each of the below test cases should deterministically return the input phase, for both `phase_estimation` and `estimate_gradient`. With this commit, result is not correct and nondeterministic for phase=3/4.
```
import numpy as np
import scipy.linalg
import pyquil.api as api
from grove.alpha.phaseestimation.phase_estimation import phase_estimation
from grove.alpha.jordan_gradient.gradient_utils import *
from grove.alpha.jordan_gradient.jordan_gradient import estimate_gradient
qvm = api.QVMConnection()
trials = 1
precision = 8
for phase in [1/2, 1/4, 3/4, 1/8, 1/16, 1/32]:
Z = np.asarray([[1.0, 0.0], [0.0, -1.0]])
Rz = scipy.linalg.expm(-1j*Z*np.pi*phase)
p = phase_estimation(Rz, precision)
out = qvm.run(p, list(range(precision)), trials)
wf = qvm.wavefunction(p)
bf_estimate = measurements_to_bf(out)
bf_explicit = '{0:.16f}'.format(bf_estimate)
deci_estimate = binary_to_real(bf_explicit)
print('phase: ', phase)
print('pe', deci_estimate)
print('jg', estimate_gradient(phase, precision, n_measurements=trials, cxn=qvm))
print('\n')
```
DEFGATEs are not correct
There is a problem with DEFGATEs that has manifested itself in the `phase_estimation` module of Grove (brought to our attention here: https://github.com/rigetticomputing/grove/issues/145).
I have traced the problem to commit d309ac11dabd9ea9c7ffa57dd26e68b5e7129aa9
Each of the below test cases should deterministically return the input phase, for both `phase_estimation` and `estimate_gradient`. With this commit, result is not correct and nondeterministic for phase=3/4.
```
import numpy as np
import scipy.linalg
import pyquil.api as api
from grove.alpha.phaseestimation.phase_estimation import phase_estimation
from grove.alpha.jordan_gradient.gradient_utils import *
from grove.alpha.jordan_gradient.jordan_gradient import estimate_gradient
qvm = api.QVMConnection()
trials = 1
precision = 8
for phase in [1/2, 1/4, 3/4, 1/8, 1/16, 1/32]:
Z = np.asarray([[1.0, 0.0], [0.0, -1.0]])
Rz = scipy.linalg.expm(-1j*Z*np.pi*phase)
p = phase_estimation(Rz, precision)
out = qvm.run(p, list(range(precision)), trials)
wf = qvm.wavefunction(p)
bf_estimate = measurements_to_bf(out)
bf_explicit = '{0:.16f}'.format(bf_estimate)
deci_estimate = binary_to_real(bf_explicit)
print('phase: ', phase)
print('pe', deci_estimate)
print('jg', estimate_gradient(phase, precision, n_measurements=trials, cxn=qvm))
print('\n')
```
| 2018-04-20T17:39:41
|
python
|
Hard
|
|
marcelotduarte/cx_Freeze
| 2,220
|
marcelotduarte__cx_Freeze-2220
|
[
"2210"
] |
639141207611f0edca554978f66b1ed7df3d8cdf
|
diff --git a/cx_Freeze/winversioninfo.py b/cx_Freeze/winversioninfo.py
--- a/cx_Freeze/winversioninfo.py
+++ b/cx_Freeze/winversioninfo.py
@@ -12,16 +12,16 @@
__all__ = ["Version", "VersionInfo"]
+# types
+CHAR = "c"
+WCHAR = "ss"
+WORD = "=H"
+DWORD = "=L"
+
# constants
RT_VERSION = 16
ID_VERSION = 1
-# types
-CHAR = "c"
-DWORD = "L"
-WCHAR = "H"
-WORD = "H"
-
VS_FFI_SIGNATURE = 0xFEEF04BD
VS_FFI_STRUCVERSION = 0x00010000
VS_FFI_FILEFLAGSMASK = 0x0000003F
@@ -32,6 +32,8 @@
KEY_STRING_TABLE = "040904E4"
KEY_VAR_FILE_INFO = "VarFileInfo"
+COMMENTS_MAX_LEN = (64 - 2) * 1024 // calcsize(WCHAR)
+
# To disable the experimental feature in Windows:
# set CX_FREEZE_STAMP=pywin32
# pip install -U pywin32
@@ -82,7 +84,7 @@ def to_buffer(self):
data = data.to_buffer()
elif isinstance(data, str):
data = data.encode("utf-16le")
- elif isinstance(fmt, str):
+ elif isinstance(data, int):
data = pack(fmt, data)
buffer += data
return buffer
@@ -142,7 +144,9 @@ def __init__(
value_len = value.wLength
fields.append(("Value", type(value)))
elif isinstance(value, Structure):
- value_len = calcsize("".join([f[1] for f in value._fields]))
+ value_len = 0
+ for field in value._fields:
+ value_len += calcsize(field[1])
value_type = 0
fields.append(("Value", type(value)))
@@ -199,7 +203,8 @@ def __init__(
self.valid_version: Version = valid_version
self.internal_name: str | None = internal_name
self.original_filename: str | None = original_filename
- self.comments: str | None = comments
+ # comments length must be limited to 31kb
+ self.comments: str = comments[:COMMENTS_MAX_LEN] if comments else None
self.company: str | None = company
self.description: str | None = description
self.copyright: str | None = copyright
@@ -221,6 +226,8 @@ def stamp(self, path: str | Path) -> None:
version_stamp = import_module("win32verstamp").stamp
except ImportError as exc:
raise RuntimeError("install pywin32 extension first") from exc
+ # comments length must be limited to 15kb (uses WORD='h')
+ self.comments = (self.comments or "")[: COMMENTS_MAX_LEN // 2]
version_stamp(os.fspath(path), self)
return
@@ -263,17 +270,18 @@ def version_info(self, path: Path) -> String:
elif len(self.valid_version.release) >= 4:
build = self.valid_version.release[3]
+ # use the data in the order shown in 'pepper'
data = {
- "Comments": self.comments or "",
- "CompanyName": self.company or "",
"FileDescription": self.description or "",
"FileVersion": self.version,
"InternalName": self.internal_name or path.name,
+ "CompanyName": self.company or "",
"LegalCopyright": self.copyright or "",
"LegalTrademarks": self.trademarks or "",
"OriginalFilename": self.original_filename or path.name,
"ProductName": self.product or "",
"ProductVersion": str(self.valid_version),
+ "Comments": self.comments or "",
}
is_dll = self.dll
if is_dll is None:
@@ -311,6 +319,7 @@ def version_info(self, path: Path) -> String:
string_version_info = String(KEY_VERSION_INFO, fixed_file_info)
string_version_info.children(string_file_info)
string_version_info.children(var_file_info)
+
return string_version_info
|
diff --git a/tests/test_winversioninfo.py b/tests/test_winversioninfo.py
--- a/tests/test_winversioninfo.py
+++ b/tests/test_winversioninfo.py
@@ -9,7 +9,12 @@
import pytest
from generate_samples import create_package, run_command
-from cx_Freeze.winversioninfo import Version, VersionInfo, main_test
+from cx_Freeze.winversioninfo import (
+ COMMENTS_MAX_LEN,
+ Version,
+ VersionInfo,
+ main_test,
+)
PLATFORM = get_platform()
PYTHON_VERSION = get_python_version()
@@ -97,6 +102,14 @@ def test___init__with_kwargs(self):
assert version_instance.debug is input_debug
assert version_instance.verbose is input_verbose
+ def test_big_comment(self):
+ """Tests a big comment value for the VersionInfo class."""
+ input_version = "9.9.9.9"
+ input_comments = "TestComment" + "=" * COMMENTS_MAX_LEN
+ version_instance = VersionInfo(input_version, comments=input_comments)
+ assert version_instance.version == "9.9.9.9"
+ assert version_instance.comments == input_comments[:COMMENTS_MAX_LEN]
+
@pytest.mark.parametrize(
("input_version", "version"),
[
|
Cannot freeze python-3.12 code on Windows 11
**Describe the bug**
Cannot freeze python 3.12 code on Windows 11 Pro amd64 using cx_Freeze 6.16.aplha versions, last I tried is 20.
This was working fine three weeks ago, but suddenly it started to fail like this:
```
copying C:\Users\jmarcet\scoop\apps\openjdk17\17.0.2-8\bin\api-ms-win-core-console-l1-2-0.dll -> C:\Users\jmarcet\src\movistar-u7d\build\exe.win-amd64-3.12\api-ms-win-core-console-l1-2-0.dll
copying C:\Users\jmarcet\scoop\apps\python312\3.12.1\python312.dll -> C:\Users\jmarcet\src\movistar-u7d\build\exe.win-amd64-3.12\python312.dll
WARNING: cannot find 'api-ms-win-core-path-l1-1-0.dll'
copying C:\Users\jmarcet\scoop\persist\python312\Lib\site-packages\cx_Freeze\bases\console-cpython-312-win_amd64.exe -> C:\Users\jmarcet\src\movistar-u7d\build\exe.win-amd64-3.12\movistar_epg.exe
copying C:\Users\jmarcet\scoop\persist\python312\Lib\site-packages\cx_Freeze\initscripts\frozen_application_license.txt -> C:\Users\jmarcet\src\movistar-u7d\build\exe.win-amd64-3.12\frozen_application_license.txt
data=72092
Traceback (most recent call last):
File "C:\Users\jmarcet\src\movistar-u7d\setup.py", line 25, in <module>
setup(
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\__init__.py", line 68, in setup
setuptools.setup(**attrs)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\__init__.py", line 103, in setup
return distutils.core.setup(**attrs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\core.py", line 185, in setup
return run_commands(dist)
^^^^^^^^^^^^^^^^^^
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\core.py", line 201, in run_commands
dist.run_commands()
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\dist.py", line 969, in run_commands
self.run_command(cmd)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\dist.py", line 963, in run_command
super().run_command(command)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\dist.py", line 988, in run_command
cmd_obj.run()
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\command\build.py", line 131, in run
self.run_command(cmd_name)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\cmd.py", line 318, in run_command
self.distribution.run_command(command)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\dist.py", line 963, in run_command
super().run_command(command)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\setuptools\_distutils\dist.py", line 988, in run_command
cmd_obj.run()
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\command\build_exe.py", line 284, in run
freezer.freeze()
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\freezer.py", line 731, in freeze
self._freeze_executable(executable)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\freezer.py", line 323, in _freeze_executable
self._add_resources(exe)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\freezer.py", line 794, in _add_resources
version.stamp(target_path)
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\winversioninfo.py", line 240, in stamp
handle, RT_VERSION, ID_VERSION, string_version_info.to_buffer()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\jmarcet\scoop\apps\python312\current\Lib\site-packages\cx_Freeze\winversioninfo.py", line 96, in to_buffer
data = pack(fmt, data)
^^^^^^^^^^^^^^^
struct.error: 'H' format requires 0 <= number <= 65535
```
**To Reproduce**
```
git clone -b next https://github.com/jmarcet/movistar-u7d
cd movistar-u7d
pip install --force --no-cache --pre --upgrade --extra-index-url https://marcelotduarte.github.io/packages/cx_Freeze
pip install -r requirements-win.txt
python .\setup.py build
```
**Expected behavior**
Frozen artifacts saved under `build` dir
**Desktop (please complete the following information):**
- Platform information: Windows 11 Pro
- OS architecture: amd64
- cx_Freeze version: [cx_Freeze-6.16.0.dev20-cp312-cp312-win_amd64.whl](https://marcelotduarte.github.io/packages/cx-freeze/cx_Freeze-6.16.0.dev20-cp312-cp312-win_amd64.whl)
- Python version: 3.12.1
**Additional context**
I had initially reported it on #2153
|
Please check the version installed of cx_Freeze and setuptools with `pip list`.
Successfully installed aiofiles-23.2.1 aiohttp-3.9.1 aiosignal-1.3.1 asyncio-3.4.3 asyncio_dgram-2.1.2 attrs-23.2.0 cx-Logging-3.1.0 **cx_Freeze-6.16.0.dev9** defusedxml-0.8.0rc2 filelock-3.13.1 frozenlist-1.4.1 httptools-0.6.1 idna-3.6 lief-0.14.0 multidict-6.0.4 prometheus-client-0.7.1 psutil-5.9.8 pywin32-306 sanic-22.6.2 sanic-prometheus-0.2.1 sanic-routing-22.3.0 **setuptools-68.2.2** tomli-2.0.1 ujson-5.9.0 websockets-10.4 wheel-0.41.2 wmi-1.5.1 xmltodict-0.13.0 yarl-1.9.4
You should update your requirements-win.txt, insert the first line:
--extra-index-url https://marcelotduarte.github.io/packages/
OR install the new development release after the requirements. Also, update setuptools.
@marcelotduarte I still have the same issue
```
> pip list
Package Version
------------------ ------------
aiofiles 23.2.1
aiohttp 3.9.1
aiosignal 1.3.1
astroid 3.0.2
asttokens 2.4.1
asyncio 3.4.3
asyncio-dgram 2.1.2
attrs 23.2.0
bandit 1.7.6
certifi 2023.11.17
charset-normalizer 3.3.2
colorama 0.4.6
cx-Freeze 6.16.0.dev23
cx_Logging 3.1.0
decorator 5.1.1
defusedxml 0.7.1
dill 0.3.7
executing 2.0.1
filelock 3.13.1
frozenlist 1.4.1
gitdb 4.0.11
GitPython 3.1.41
httpie 3.2.2
httptools 0.6.1
idna 3.6
ipython 8.20.0
isort 5.13.2
jedi 0.19.1
lief 0.15.0
markdown-it-py 3.0.0
matplotlib-inline 0.1.6
mccabe 0.7.0
mdurl 0.1.2
multidict 6.0.4
parso 0.8.3
pbr 6.0.0
pip 23.2.1
platformdirs 4.1.0
prometheus-client 0.7.1
prompt-toolkit 3.0.43
psutil 5.9.8
pure-eval 0.2.2
Pygments 2.17.2
pylint 3.0.3
pynvim 0.5.0
PySocks 1.7.1
pywin32 306
PyYAML 6.0.1
requests 2.31.0
requests-toolbelt 1.0.0
rich 13.7.0
ruff 0.1.11
sanic 22.6.2
sanic-prometheus 0.2.1
sanic-routing 22.3.0
setuptools 69.0.3
six 1.16.0
smmap 5.0.1
stack-data 0.6.3
stevedore 5.1.0
tomli 2.0.1
tomlkit 0.12.3
traitlets 5.14.1
ujson 5.9.0
urllib3 2.1.0
wcwidth 0.2.13
websockets 10.4
wheel 0.42.0
WMI 1.5.1
xmltodict 0.13.0
yarl 1.9.4
```
| 2024-01-25T06:06:14
|
python
|
Easy
|
pytest-dev/pytest-django
| 1,108
|
pytest-dev__pytest-django-1108
|
[
"1106"
] |
6cf63b65e86870abf68ae1f376398429e35864e7
|
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -362,8 +362,15 @@ def _get_option_with_source(
@pytest.hookimpl(trylast=True)
def pytest_configure(config: pytest.Config) -> None:
- # Allow Django settings to be configured in a user pytest_configure call,
- # but make sure we call django.setup()
+ if config.getoption("version", 0) > 0 or config.getoption("help", False):
+ return
+
+ # Normally Django is set up in `pytest_load_initial_conftests`, but we also
+ # allow users to not set DJANGO_SETTINGS_MODULE/`--ds` and instead
+ # configure the Django settings in a `pytest_configure` hookimpl using e.g.
+ # `settings.configure(...)`. In this case, the `_setup_django` call in
+ # `pytest_load_initial_conftests` only partially initializes Django, and
+ # it's fully initialized here.
_setup_django(config)
@@ -470,8 +477,7 @@ def get_order_number(test: pytest.Item) -> int:
@pytest.fixture(autouse=True, scope="session")
def django_test_environment(request: pytest.FixtureRequest) -> Generator[None, None, None]:
- """
- Ensure that Django is loaded and has its testing environment setup.
+ """Setup Django's test environment for the testing session.
XXX It is a little dodgy that this is an autouse fixture. Perhaps
an email fixture should be requested in order to be able to
@@ -481,7 +487,6 @@ def django_test_environment(request: pytest.FixtureRequest) -> Generator[None, N
we need to follow this model.
"""
if django_settings_is_configured():
- _setup_django(request.config)
from django.test.utils import setup_test_environment, teardown_test_environment
debug_ini = request.config.getini("django_debug_mode")
|
diff --git a/tests/test_manage_py_scan.py b/tests/test_manage_py_scan.py
--- a/tests/test_manage_py_scan.py
+++ b/tests/test_manage_py_scan.py
@@ -144,6 +144,37 @@ def test_django_project_found_invalid_settings_version(
result.stdout.fnmatch_lines(["*usage:*"])
+@pytest.mark.django_project(project_root="django_project_root", create_manage_py=True)
+def test_django_project_late_settings_version(
+ django_pytester: DjangoPytester,
+ monkeypatch: pytest.MonkeyPatch,
+) -> None:
+ """Late configuration should not cause an error with --help or --version."""
+ monkeypatch.delenv("DJANGO_SETTINGS_MODULE")
+ django_pytester.makepyfile(
+ t="WAT = 1",
+ )
+ django_pytester.makeconftest(
+ """
+ import os
+
+ def pytest_configure():
+ os.environ.setdefault('DJANGO_SETTINGS_MODULE', 't')
+ from django.conf import settings
+ settings.WAT
+ """
+ )
+
+ result = django_pytester.runpytest_subprocess("django_project_root", "--version", "--version")
+ assert result.ret == 0
+
+ result.stdout.fnmatch_lines(["*This is pytest version*"])
+
+ result = django_pytester.runpytest_subprocess("django_project_root", "--help")
+ assert result.ret == 0
+ result.stdout.fnmatch_lines(["*usage:*"])
+
+
@pytest.mark.django_project(project_root="django_project_root", create_manage_py=True)
def test_runs_without_error_on_long_args(django_pytester: DjangoPytester) -> None:
django_pytester.create_test_module(
|
`pytest --help` fails in a partially configured app
having a difficult time narrowing down a minimal example -- the repo involved is https://github.com/getsentry/sentry
I have figured out _why_ it is happening and the stacktrace for it:
<summary>full stacktrace with error
<details>
```console
$ pytest --help
/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/trio/_core/_multierror.py:511: RuntimeWarning: You seem to already have a custom sys.excepthook handler installed. I'll skip installing Trio's custom handler, but this means MultiErrors will not show full tracebacks.
warnings.warn(
Traceback (most recent call last):
File "/Users/asottile/workspace/sentry/.venv/bin/pytest", line 8, in <module>
sys.exit(console_main())
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/_pytest/config/__init__.py", line 190, in console_main
code = main()
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/_pytest/config/__init__.py", line 167, in main
ret: Union[ExitCode, int] = config.hook.pytest_cmdline_main(
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/hooks.py", line 286, in __call__
return self._hookexec(self, self.get_hookimpls(), kwargs)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/manager.py", line 93, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/manager.py", line 84, in <lambda>
self._inner_hookexec = lambda hook, methods, kwargs: hook.multicall(
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 208, in _multicall
return outcome.get_result()
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 80, in get_result
raise ex[1].with_traceback(ex[2])
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 187, in _multicall
res = hook_impl.function(*args)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/_pytest/helpconfig.py", line 152, in pytest_cmdline_main
config._do_configure()
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/_pytest/config/__init__.py", line 1037, in _do_configure
self.hook.pytest_configure.call_historic(kwargs=dict(config=self))
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/hooks.py", line 308, in call_historic
res = self._hookexec(self, self.get_hookimpls(), kwargs)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/manager.py", line 93, in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/manager.py", line 84, in <lambda>
self._inner_hookexec = lambda hook, methods, kwargs: hook.multicall(
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 208, in _multicall
return outcome.get_result()
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 80, in get_result
raise ex[1].with_traceback(ex[2])
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pluggy/callers.py", line 187, in _multicall
res = hook_impl.function(*args)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pytest_django/plugin.py", line 367, in pytest_configure
_setup_django(config)
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/pytest_django/plugin.py", line 238, in _setup_django
blocking_manager = config.stash[blocking_manager_key]
File "/Users/asottile/workspace/sentry/.venv/lib/python3.10/site-packages/_pytest/stash.py", line 80, in __getitem__
return cast(T, self._storage[key])
KeyError: <_pytest.stash.StashKey object at 0x1066ab520>
```
</details>
</summary>
basically what's happening is the setup is skipped here: https://github.com/pytest-dev/pytest-django/blob/6cf63b65e86870abf68ae1f376398429e35864e7/pytest_django/plugin.py#L300-L301
normally it sets the thing that's being looked up here: https://github.com/pytest-dev/pytest-django/blob/6cf63b65e86870abf68ae1f376398429e35864e7/pytest_django/plugin.py#L358
which then fails to lookup here: https://github.com/pytest-dev/pytest-django/blob/6cf63b65e86870abf68ae1f376398429e35864e7/pytest_django/plugin.py#L238
something about sentry's `tests/conftest.py` initializes enough of django that `pytest-django` takes over. but since the setup has been skipped it fails to set up properly. I suspect that #238 is playing poorly with something.
of note this worked before I upgraded `pytest-django` (I was previously on 4.4.0 and upgraded to 4.7.0 to get django 4.x support)
will try and narrow down a smaller reproduction...
|
That’s a fun one! Hopefully using `config.stash.get()` calls and acting only on non-`None` values will be enough to fix the issue...
here's a minimal case:
```console
==> t.py <==
WAT = 1
==> tests/__init__.py <==
==> tests/conftest.py <==
import os
def pytest_configure():
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 't')
from django.conf import settings
settings.WAT
```
| 2024-01-29T14:22:15
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 2,597
|
marcelotduarte__cx_Freeze-2597
|
[
"2596"
] |
df2c8aef8f92da535a1bb657706ca4496b1c3352
|
diff --git a/cx_Freeze/finder.py b/cx_Freeze/finder.py
--- a/cx_Freeze/finder.py
+++ b/cx_Freeze/finder.py
@@ -537,7 +537,10 @@ def _replace_package_in_code(module: Module) -> CodeType:
# Insert a bytecode to set __package__ as module.parent.name
codes = [LOAD_CONST, pkg_const_index, STORE_NAME, pkg_name_index]
codestring = bytes(codes) + code.co_code
- consts.append(module.parent.name)
+ if module.file.stem == "__init__":
+ consts.append(module.name)
+ else:
+ consts.append(module.parent.name)
code = code_object_replace(
code, co_code=codestring, co_consts=consts
)
diff --git a/cx_Freeze/hooks/scipy.py b/cx_Freeze/hooks/scipy.py
--- a/cx_Freeze/hooks/scipy.py
+++ b/cx_Freeze/hooks/scipy.py
@@ -18,12 +18,18 @@
def load_scipy(finder: ModuleFinder, module: Module) -> None:
"""The scipy package.
- Supported pypi and conda-forge versions (lasted tested version is 1.11.2).
+ Supported pypi and conda-forge versions (lasted tested version is 1.14.1).
"""
source_dir = module.file.parent.parent / f"{module.name}.libs"
if source_dir.exists(): # scipy >= 1.9.2 (windows)
- finder.include_files(source_dir, f"lib/{source_dir.name}")
- replace_delvewheel_patch(module)
+ if IS_WINDOWS:
+ finder.include_files(source_dir, f"lib/{source_dir.name}")
+ replace_delvewheel_patch(module)
+ else:
+ target_dir = f"lib/{source_dir.name}"
+ for source in source_dir.iterdir():
+ finder.lib_files[source] = f"{target_dir}/{source.name}"
+
finder.include_package("scipy.integrate")
finder.include_package("scipy._lib")
finder.include_package("scipy.misc")
|
diff --git a/samples/scipy/test_scipy.py b/samples/scipy/test_scipy.py
--- a/samples/scipy/test_scipy.py
+++ b/samples/scipy/test_scipy.py
@@ -1,8 +1,6 @@
"""A simple script to demonstrate scipy."""
-from scipy.stats import norm
+from scipy.spatial.transform import Rotation
if __name__ == "__main__":
- print(
- "bounds of distribution lower: {}, upper: {}".format(*norm.support())
- )
+ print(Rotation.from_euler("XYZ", [10, 10, 10], degrees=True).as_matrix())
|
cx-Freeze - No module named 'scipy._lib.array_api_compat._aliases'
**Prerequisite**
This was previously reported in the closed issue #2544, where no action was taken. I include a minimal script that produces the problem for me.
**Describe the bug**
When running the compiled executable, i get the following error:
```
PS C:\dat\projects\gazeMapper\cxFreeze\build\exe.win-amd64-3.10> .\test.exe
Traceback (most recent call last):
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\Lib\site-packages\cx_Freeze\initscripts\__startup__.py", line 141, in run
module_init.run(f"__main__{name}")
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\Lib\site-packages\cx_Freeze\initscripts\console.py", line 25, in run
exec(code, main_globals)
File "C:\dat\projects\gazeMapper\cxFreeze\test.py", line 1, in <module>
from scipy.spatial.transform import Rotation
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\spatial\__init__.py", line 110, in <module>
from ._kdtree import *
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\spatial\_kdtree.py", line 4, in <module>
from ._ckdtree import cKDTree, cKDTreeNode
File "_ckdtree.pyx", line 11, in init scipy.spatial._ckdtree
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\sparse\__init__.py", line 293, in <module>
from ._base import *
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\sparse\_base.py", line 5, in <module>
from ._sputils import (asmatrix, check_reshape_kwargs, check_shape,
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\sparse\_sputils.py", line 10, in <module>
from scipy._lib._util import np_long, np_ulong
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\_lib\_util.py", line 18, in <module>
from scipy._lib._array_api import array_namespace, is_numpy, size as xp_size
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\_lib\_array_api.py", line 21, in <module>
from scipy._lib.array_api_compat import (
File "C:\dat\projects\gazeMapper\cxFreeze\.venv\lib\site-packages\scipy\_lib\array_api_compat\numpy\__init__.py", line 16, in <module>
__import__(__package__ + '.linalg')
ModuleNotFoundError: No module named 'scipy._lib.array_api_compat._aliases'
```
**To Reproduce**
Two files:
test.py
```python
from scipy.spatial.transform import Rotation
print(Rotation.from_euler('XYZ', [10, 10, 10], degrees=True).as_matrix())
```
setup.py:
```python
import cx_Freeze
import pathlib
import sys
import site
path = pathlib.Path(__file__).absolute().parent
def get_include_files():
# don't know if this is a bad idea, it certainly didn't help
files = []
# scipy dlls
for d in site.getsitepackages():
d=pathlib.Path(d)/'scipy'/'.libs'
if d.is_dir():
for f in d.iterdir():
if f.is_file() and f.suffix=='' or f.suffix in ['.dll']:
files.append((f,pathlib.Path('lib')/f.name))
return files
build_options = {
"build_exe": {
"optimize": 1,
"packages": [
'numpy','scipy'
],
"excludes":["tkinter"],
"zip_include_packages": "*",
"zip_exclude_packages": [],
"silent_level": 1,
"include_msvcr": True
}
}
if sys.platform.startswith("win"):
build_options["build_exe"]["include_files"] = get_include_files()
cx_Freeze.setup(
name="test",
version="0.0.1",
description="test",
executables=[
cx_Freeze.Executable(
script=path / "test.py",
target_name="test"
)
],
options=build_options,
py_modules=[]
)
```
**Expected behavior**
exe runs
**Desktop (please complete the following information):**
- Windows 11 Enterprise
- amd64
- cx_Freeze version 7.2.2
- Python version 3.10
- Numpy 2.1.1
- Scipy 1.14.1
**Additional context**
at `\.venv\Lib\site-packages\scipy\_lib\array_api_compat` there is no `_aliases.py`, only `__init__.py` with the following content:
```python
__version__ = '1.5.1'
from .common import * # noqa: F401, F403
```
`_aliases.py` does exist at `\.venv\Lib\site-packages\scipy\_lib\array_api_compat\common`
Both files are packed into library.zip (whole scipy tree is)
|
Changing the config to `"zip_exclude_packages": ['scipy']`, things work. I assume it should work just fine/the same from the zip file. This will be my workaround for now
| 2024-10-02T02:42:26
|
python
|
Easy
|
rigetti/pyquil
| 1,149
|
rigetti__pyquil-1149
|
[
"980"
] |
07db509c5293df2b4624ca6ac409e4fce2666ea1
|
diff --git a/pyquil/device/_isa.py b/pyquil/device/_isa.py
--- a/pyquil/device/_isa.py
+++ b/pyquil/device/_isa.py
@@ -13,8 +13,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
-from collections import namedtuple
-from typing import Union
+import sys
+from typing import Any, Dict, List, Optional, Sequence, Tuple, Union
import networkx as nx
import numpy as np
@@ -22,35 +22,64 @@
from pyquil.quilatom import Parameter, unpack_qubit
from pyquil.quilbase import Gate
-THETA = Parameter("theta")
-"Used as the symbolic parameter in RZ, CPHASE gates."
+if sys.version_info < (3, 7):
+ from pyquil.external.dataclasses import dataclass
+else:
+ from dataclasses import dataclass
DEFAULT_QUBIT_TYPE = "Xhalves"
DEFAULT_EDGE_TYPE = "CZ"
+THETA = Parameter("theta")
+"Used as the symbolic parameter in RZ, CPHASE gates."
+
-Qubit = namedtuple("Qubit", ["id", "type", "dead", "gates"])
-Edge = namedtuple("Edge", ["targets", "type", "dead", "gates"])
-_ISA = namedtuple("_ISA", ["qubits", "edges"])
+@dataclass
+class MeasureInfo:
+ operator: Optional[str] = None
+ qubit: Optional[int] = None
+ target: Optional[Union[int, str]] = None
+ duration: Optional[float] = None
+ fidelity: Optional[float] = None
-MeasureInfo = namedtuple("MeasureInfo", ["operator", "qubit", "target", "duration", "fidelity"])
-GateInfo = namedtuple("GateInfo", ["operator", "parameters", "arguments", "duration", "fidelity"])
-# make Qubit and Edge arguments optional
-Qubit.__new__.__defaults__ = (None,) * len(Qubit._fields)
-Edge.__new__.__defaults__ = (None,) * len(Edge._fields)
-MeasureInfo.__new__.__defaults__ = (None,) * len(MeasureInfo._fields)
-GateInfo.__new__.__defaults__ = (None,) * len(GateInfo._fields)
+@dataclass
+class GateInfo:
+ operator: Optional[str] = None
+ parameters: Optional[Sequence[Union[str, float]]] = None
+ arguments: Optional[Sequence[Union[str, float]]] = None
+ duration: Optional[float] = None
+ fidelity: Optional[float] = None
-class ISA(_ISA):
+@dataclass
+class Qubit:
+ id: int
+ type: Optional[str] = None
+ dead: Optional[bool] = None
+ gates: Optional[Sequence[Union[GateInfo, MeasureInfo]]] = None
+
+
+@dataclass
+class Edge:
+ targets: Tuple[int, ...]
+ type: Optional[str] = None
+ dead: Optional[bool] = None
+ gates: Optional[Sequence[GateInfo]] = None
+
+
+@dataclass
+class ISA:
"""
Basic Instruction Set Architecture specification.
- :ivar Sequence[Qubit] qubits: The qubits associated with the ISA.
- :ivar Sequence[Edge] edges: The multi-qubit gates.
+ :ivar qubits: The qubits associated with the ISA.
+ :ivar edges: The multi-qubit gates.
"""
- def to_dict(self):
+ qubits: Sequence[Qubit]
+ edges: Sequence[Edge]
+
+ def to_dict(self) -> Dict[str, Any]:
"""
Create a JSON-serializable representation of the ISA.
@@ -80,19 +109,17 @@ def to_dict(self):
}
:return: A dictionary representation of self.
- :rtype: Dict[str, Any]
"""
- def _maybe_configure(o, t):
- # type: (Union[Qubit,Edge], str) -> dict
+ def _maybe_configure(o: Union[Qubit, Edge], t: str) -> Dict[str, Any]:
"""
Exclude default values from generated dictionary.
- :param Union[Qubit,Edge] o: The object to serialize
- :param str t: The default value for ``o.type``.
+ :param o: The object to serialize
+ :param t: The default value for ``o.type``.
:return: d
"""
- d = {}
+ d: Dict[str, Any] = {}
if o.gates is not None:
d["gates"] = [
{
@@ -127,13 +154,12 @@ def _maybe_configure(o, t):
}
@staticmethod
- def from_dict(d):
+ def from_dict(d: Dict[str, Any]) -> "ISA":
"""
Re-create the ISA from a dictionary representation.
- :param Dict[str,Any] d: The dictionary representation.
+ :param d: The dictionary representation.
:return: The restored ISA.
- :rtype: ISA
"""
return ISA(
qubits=sorted(
@@ -150,7 +176,7 @@ def from_dict(d):
edges=sorted(
[
Edge(
- targets=[int(q) for q in eid.split("-")],
+ targets=tuple(int(q) for q in eid.split("-")),
type=e.get("type", DEFAULT_EDGE_TYPE),
dead=e.get("dead", False),
)
@@ -161,13 +187,12 @@ def from_dict(d):
)
-def gates_in_isa(isa):
+def gates_in_isa(isa: ISA) -> List[Gate]:
"""
Generate the full gateset associated with an ISA.
- :param ISA isa: The instruction set architecture for a QPU.
+ :param isa: The instruction set architecture for a QPU.
:return: A sequence of Gate objects encapsulating all gates compatible with the ISA.
- :rtype: Sequence[Gate]
"""
gates = []
for q in isa.qubits:
@@ -211,6 +236,7 @@ def gates_in_isa(isa):
gates.append(Gate("XY", [THETA], targets))
gates.append(Gate("XY", [THETA], targets[::-1]))
continue
+ assert e.type is not None
if "WILDCARD" in e.type:
gates.append(Gate("_", "_", targets))
gates.append(Gate("_", "_", targets[::-1]))
@@ -220,7 +246,7 @@ def gates_in_isa(isa):
return gates
-def isa_from_graph(graph: nx.Graph, oneq_type="Xhalves", twoq_type="CZ") -> ISA:
+def isa_from_graph(graph: nx.Graph, oneq_type: str = "Xhalves", twoq_type: str = "CZ") -> ISA:
"""
Generate an ISA object from a NetworkX graph.
@@ -230,7 +256,7 @@ def isa_from_graph(graph: nx.Graph, oneq_type="Xhalves", twoq_type="CZ") -> ISA:
"""
all_qubits = list(range(max(graph.nodes) + 1))
qubits = [Qubit(i, type=oneq_type, dead=i not in graph.nodes) for i in all_qubits]
- edges = [Edge(sorted((a, b)), type=twoq_type, dead=False) for a, b in graph.edges]
+ edges = [Edge(tuple(sorted((a, b))), type=twoq_type, dead=False) for a, b in graph.edges]
return ISA(qubits, edges)
diff --git a/pyquil/device/_main.py b/pyquil/device/_main.py
--- a/pyquil/device/_main.py
+++ b/pyquil/device/_main.py
@@ -15,7 +15,7 @@
##############################################################################
import warnings
from abc import ABC, abstractmethod
-from typing import List, Tuple
+from typing import Any, Dict, List, Optional, Tuple, Union
import networkx as nx
import numpy as np
@@ -42,7 +42,7 @@
class AbstractDevice(ABC):
@abstractmethod
- def qubits(self):
+ def qubits(self) -> List[int]:
"""
A sorted list of qubits in the device topology.
"""
@@ -54,7 +54,7 @@ def qubit_topology(self) -> nx.Graph:
"""
@abstractmethod
- def get_isa(self, oneq_type="Xhalves", twoq_type="CZ") -> ISA:
+ def get_isa(self, oneq_type: str = "Xhalves", twoq_type: str = "CZ") -> ISA:
"""
Construct an ISA suitable for targeting by compilation.
@@ -65,7 +65,7 @@ def get_isa(self, oneq_type="Xhalves", twoq_type="CZ") -> ISA:
"""
@abstractmethod
- def get_specs(self) -> Specs:
+ def get_specs(self) -> Optional[Specs]:
"""
Construct a Specs object required by compilation
"""
@@ -86,7 +86,7 @@ class Device(AbstractDevice):
:ivar NoiseModel noise_model: The noise model for the device.
"""
- def __init__(self, name, raw):
+ def __init__(self, name: str, raw: Dict[str, Any]):
"""
:param name: name of the device
:param raw: raw JSON response from the server with additional information about this device.
@@ -102,23 +102,25 @@ def __init__(self, name, raw):
)
@property
- def isa(self):
+ def isa(self) -> Optional[ISA]:
warnings.warn("Accessing the static ISA is deprecated. Use `get_isa`", DeprecationWarning)
return self._isa
- def qubits(self):
+ def qubits(self) -> List[int]:
+ assert self._isa is not None
return sorted(q.id for q in self._isa.qubits if not q.dead)
def qubit_topology(self) -> nx.Graph:
"""
The connectivity of qubits in this device given as a NetworkX graph.
"""
+ assert self._isa is not None
return isa_to_graph(self._isa)
- def get_specs(self):
+ def get_specs(self) -> Optional[Specs]:
return self.specs
- def get_isa(self, oneq_type=None, twoq_type=None) -> ISA:
+ def get_isa(self, oneq_type: Optional[str] = None, twoq_type: Optional[str] = None) -> ISA:
"""
Construct an ISA suitable for targeting by compilation.
@@ -130,7 +132,7 @@ def get_isa(self, oneq_type=None, twoq_type=None) -> ISA:
"make an ISA with custom gate types, you'll have to do it by hand."
)
- def safely_get(attr, index, default):
+ def safely_get(attr: str, index: Union[int, Tuple[int, ...]], default: Any) -> Any:
if self.specs is None:
return default
@@ -144,8 +146,8 @@ def safely_get(attr, index, default):
else:
return default
- def qubit_type_to_gates(q):
- gates = [
+ def qubit_type_to_gates(q: Qubit) -> List[Union[GateInfo, MeasureInfo]]:
+ gates: List[Union[GateInfo, MeasureInfo]] = [
MeasureInfo(
operator="MEASURE",
qubit=q.id,
@@ -200,9 +202,9 @@ def qubit_type_to_gates(q):
]
return gates
- def edge_type_to_gates(e):
- gates = []
- if e is None or "CZ" in e.type:
+ def edge_type_to_gates(e: Edge) -> List[GateInfo]:
+ gates: List[GateInfo] = []
+ if e is None or isinstance(e.type, str) and "CZ" in e.type:
gates += [
GateInfo(
operator="CZ",
@@ -212,7 +214,7 @@ def edge_type_to_gates(e):
fidelity=safely_get("fCZs", tuple(e.targets), DEFAULT_CZ_FIDELITY),
)
]
- if e is not None and "ISWAP" in e.type:
+ if e is None or isinstance(e.type, str) and "ISWAP" in e.type:
gates += [
GateInfo(
operator="ISWAP",
@@ -222,7 +224,7 @@ def edge_type_to_gates(e):
fidelity=safely_get("fISWAPs", tuple(e.targets), DEFAULT_ISWAP_FIDELITY),
)
]
- if e is not None and "CPHASE" in e.type:
+ if e is None or isinstance(e.type, str) and "CPHASE" in e.type:
gates += [
GateInfo(
operator="CPHASE",
@@ -232,7 +234,7 @@ def edge_type_to_gates(e):
fidelity=safely_get("fCPHASEs", tuple(e.targets), DEFAULT_CPHASE_FIDELITY),
)
]
- if e is not None and "XY" in e.type:
+ if e is None or isinstance(e.type, str) and "XY" in e.type:
gates += [
GateInfo(
operator="XY",
@@ -242,7 +244,7 @@ def edge_type_to_gates(e):
fidelity=safely_get("fXYs", tuple(e.targets), DEFAULT_XY_FIDELITY),
)
]
- if e is not None and "WILDCARD" in e.type:
+ if e is None or isinstance(e.type, str) and "WILDCARD" in e.type:
gates += [
GateInfo(
operator="_",
@@ -254,6 +256,7 @@ def edge_type_to_gates(e):
]
return gates
+ assert self._isa is not None
qubits = [
Qubit(id=q.id, type=None, dead=q.dead, gates=qubit_type_to_gates(q))
for q in self._isa.qubits
@@ -264,10 +267,10 @@ def edge_type_to_gates(e):
]
return ISA(qubits, edges)
- def __str__(self):
+ def __str__(self) -> str:
return "<Device {}>".format(self.name)
- def __repr__(self):
+ def __repr__(self) -> str:
return str(self)
@@ -284,17 +287,17 @@ class NxDevice(AbstractDevice):
def __init__(self, topology: nx.Graph) -> None:
self.topology = topology
- def qubit_topology(self):
+ def qubit_topology(self) -> nx.Graph:
return self.topology
- def get_isa(self, oneq_type="Xhalves", twoq_type="CZ"):
+ def get_isa(self, oneq_type: str = "Xhalves", twoq_type: str = "CZ") -> ISA:
return isa_from_graph(self.topology, oneq_type=oneq_type, twoq_type=twoq_type)
- def get_specs(self):
+ def get_specs(self) -> Specs:
return specs_from_graph(self.topology)
def qubits(self) -> List[int]:
return sorted(self.topology.nodes)
- def edges(self) -> List[Tuple[int, int]]:
- return sorted(tuple(sorted(pair)) for pair in self.topology.edges) # type: ignore
+ def edges(self) -> List[Tuple[Any, ...]]:
+ return sorted(tuple(sorted(pair)) for pair in self.topology.edges)
diff --git a/pyquil/device/_specs.py b/pyquil/device/_specs.py
--- a/pyquil/device/_specs.py
+++ b/pyquil/device/_specs.py
@@ -13,104 +13,105 @@
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
+import sys
import warnings
-from collections import namedtuple
+from typing import Any, Dict, Optional, Sequence, Tuple
import networkx as nx
-QubitSpecs = namedtuple(
- "_QubitSpecs",
- [
- "id",
- "fRO",
- "f1QRB",
- "f1QRB_std_err",
- "f1Q_simultaneous_RB",
- "f1Q_simultaneous_RB_std_err",
- "T1",
- "T2",
- "fActiveReset",
- ],
-)
-EdgeSpecs = namedtuple(
- "_QubitQubitSpecs",
- [
- "targets",
- "fBellState",
- "fCZ",
- "fCZ_std_err",
- "fCPHASE",
- "fCPHASE_std_err",
- "fXY",
- "fXY_std_err",
- "fISWAP",
- "fISWAP_std_err",
- ],
-)
-_Specs = namedtuple("_Specs", ["qubits_specs", "edges_specs"])
-
-
-class Specs(_Specs):
+if sys.version_info < (3, 7):
+ from pyquil.external.dataclasses import dataclass
+else:
+ from dataclasses import dataclass
+
+
+@dataclass
+class QubitSpecs:
+ id: int
+ fRO: Optional[float]
+ f1QRB: Optional[float]
+ f1QRB_std_err: Optional[float]
+ f1Q_simultaneous_RB: Optional[float]
+ f1Q_simultaneous_RB_std_err: Optional[float]
+ T1: Optional[float]
+ T2: Optional[float]
+ fActiveReset: Optional[float]
+
+
+@dataclass
+class EdgeSpecs:
+ targets: Tuple[int, ...]
+ fBellState: Optional[float]
+ fCZ: Optional[float]
+ fCZ_std_err: Optional[float]
+ fCPHASE: Optional[float]
+ fCPHASE_std_err: Optional[float]
+ fXY: Optional[float]
+ fXY_std_err: Optional[float]
+ fISWAP: Optional[float]
+ fISWAP_std_err: Optional[float]
+
+
+@dataclass
+class Specs:
"""
Basic specifications for the device, such as gate fidelities and coherence times.
- :ivar List[QubitSpecs] qubits_specs: The specs associated with individual qubits.
- :ivar List[EdgesSpecs] edges_specs: The specs associated with edges, or qubit-qubit pairs.
+ :ivar qubits_specs: The specs associated with individual qubits.
+ :ivar edges_specs: The specs associated with edges, or qubit-qubit pairs.
"""
- def f1QRBs(self):
+ qubits_specs: Sequence[QubitSpecs]
+ edges_specs: Sequence[EdgeSpecs]
+
+ def f1QRBs(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of single-qubit randomized benchmarking fidelities (for individual gate
operation, normalized to unity) from the specs, keyed by qubit index.
:return: A dictionary of 1Q RB fidelities, normalized to unity.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.f1QRB for qs in self.qubits_specs}
- def f1QRB_std_errs(self):
+ def f1QRB_std_errs(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of the standard errors of single-qubit randomized
benchmarking fidelities (for individual gate operation, normalized to unity)
from the specs, keyed by qubit index.
:return: A dictionary of 1Q RB fidelity standard errors, normalized to unity.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.f1QRB_std_err for qs in self.qubits_specs}
- def f1Q_simultaneous_RBs(self):
+ def f1Q_simultaneous_RBs(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of single-qubit randomized benchmarking fidelities (for simultaneous gate
operation across the chip, normalized to unity) from the specs, keyed by qubit index.
:return: A dictionary of simultaneous 1Q RB fidelities, normalized to unity.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.f1Q_simultaneous_RB for qs in self.qubits_specs}
- def f1Q_simultaneous_RB_std_errs(self):
+ def f1Q_simultaneous_RB_std_errs(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of the standard errors of single-qubit randomized
benchmarking fidelities (for simultaneous gate operation across the chip, normalized to
unity) from the specs, keyed by qubit index.
:return: A dictionary of simultaneous 1Q RB fidelity standard errors, normalized to unity.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.f1Q_simultaneous_RB_std_err for qs in self.qubits_specs}
- def fROs(self):
+ def fROs(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of single-qubit readout fidelities (normalized to unity)
from the specs, keyed by qubit index.
:return: A dictionary of RO fidelities, normalized to unity.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.fRO for qs in self.qubits_specs}
- def fActiveResets(self):
+ def fActiveResets(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of single-qubit active reset fidelities (normalized to unity) from the
specs, keyed by qubit index.
@@ -119,31 +120,28 @@ def fActiveResets(self):
"""
return {qs.id: qs.fActiveReset for qs in self.qubits_specs}
- def T1s(self):
+ def T1s(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of T1s (in seconds) from the specs, keyed by qubit index.
:return: A dictionary of T1s, in seconds.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.T1 for qs in self.qubits_specs}
- def T2s(self):
+ def T2s(self) -> Dict[int, Optional[float]]:
"""
Get a dictionary of T2s (in seconds) from the specs, keyed by qubit index.
:return: A dictionary of T2s, in seconds.
- :rtype: Dict[int, float]
"""
return {qs.id: qs.T2 for qs in self.qubits_specs}
- def fBellStates(self):
+ def fBellStates(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of two-qubit Bell state fidelities (normalized to unity)
from the specs, keyed by targets (qubit-qubit pairs).
:return: A dictionary of Bell state fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
warnings.warn(
DeprecationWarning(
@@ -153,73 +151,66 @@ def fBellStates(self):
)
return {tuple(es.targets): es.fBellState for es in self.edges_specs}
- def fCZs(self):
+ def fCZs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of CZ fidelities (normalized to unity) from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of CZ fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fCZ for es in self.edges_specs}
- def fISWAPs(self):
+ def fISWAPs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of ISWAP fidelities (normalized to unity) from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of ISWAP fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fISWAP for es in self.edges_specs}
- def fISWAP_std_errs(self):
+ def fISWAP_std_errs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of the standard errors of the ISWAP fidelities from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of ISWAP fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fISWAP_std_err for es in self.edges_specs}
- def fXYs(self):
+ def fXYs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of XY(pi) fidelities (normalized to unity) from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of XY/2 fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fXY for es in self.edges_specs}
- def fXY_std_errs(self):
+ def fXY_std_errs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of the standard errors of the XY fidelities from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of XY fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fXY_std_err for es in self.edges_specs}
- def fCZ_std_errs(self):
+ def fCZ_std_errs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of the standard errors of the CZ fidelities from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of CZ fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
return {tuple(es.targets): es.fCZ_std_err for es in self.edges_specs}
- def fCPHASEs(self):
+ def fCPHASEs(self) -> Dict[Tuple[int, ...], Optional[float]]:
"""
Get a dictionary of CPHASE fidelities (normalized to unity) from the specs,
keyed by targets (qubit-qubit pairs).
:return: A dictionary of CPHASE fidelities, normalized to unity.
- :rtype: Dict[tuple(int, int), float]
"""
warnings.warn(
DeprecationWarning(
@@ -229,7 +220,7 @@ def fCPHASEs(self):
)
return {tuple(es.targets): es.fCPHASE for es in self.edges_specs}
- def to_dict(self):
+ def to_dict(self) -> Dict[str, Any]:
"""
Create a JSON-serializable representation of the device Specs.
@@ -270,7 +261,6 @@ def to_dict(self):
}
:return: A dctionary representation of self.
- :rtype: Dict[str, Any]
"""
return {
"1Q": {
@@ -303,13 +293,12 @@ def to_dict(self):
}
@staticmethod
- def from_dict(d):
+ def from_dict(d: Dict[str, Any]) -> "Specs":
"""
Re-create the Specs from a dictionary representation.
- :param Dict[str, Any] d: The dictionary representation.
+ :param d: The dictionary representation.
:return: The restored Specs.
- :rtype: Specs
"""
return Specs(
qubits_specs=sorted(
@@ -332,7 +321,7 @@ def from_dict(d):
edges_specs=sorted(
[
EdgeSpecs(
- targets=[int(q) for q in e.split("-")],
+ targets=tuple(int(q) for q in e.split("-")),
fBellState=especs.get("fBellState"),
fCZ=especs.get("fCZ"),
fCZ_std_err=especs.get("fCZ_std_err"),
@@ -350,7 +339,7 @@ def from_dict(d):
)
-def specs_from_graph(graph: nx.Graph):
+def specs_from_graph(graph: nx.Graph) -> Specs:
"""
Generate a Specs object from a NetworkX graph with placeholder values for the actual specs.
|
diff --git a/pyquil/device/tests/test_device.py b/pyquil/device/tests/test_device.py
--- a/pyquil/device/tests/test_device.py
+++ b/pyquil/device/tests/test_device.py
@@ -55,10 +55,10 @@ def test_isa(isa_dict):
Qubit(id=3, type="Xhalves", dead=True),
],
edges=[
- Edge(targets=[0, 1], type="CZ", dead=False),
- Edge(targets=[0, 2], type="CPHASE", dead=False),
- Edge(targets=[0, 3], type="CZ", dead=True),
- Edge(targets=[1, 2], type="ISWAP", dead=False),
+ Edge(targets=(0, 1), type="CZ", dead=False),
+ Edge(targets=(0, 2), type="CPHASE", dead=False),
+ Edge(targets=(0, 3), type="CZ", dead=True),
+ Edge(targets=(1, 2), type="ISWAP", dead=False),
],
)
assert isa == ISA.from_dict(isa.to_dict())
@@ -115,7 +115,7 @@ def test_specs(specs_dict):
],
edges_specs=[
EdgeSpecs(
- targets=[0, 1],
+ targets=(0, 1),
fBellState=0.90,
fCZ=0.89,
fCZ_std_err=0.01,
@@ -127,7 +127,7 @@ def test_specs(specs_dict):
fCPHASE_std_err=None,
),
EdgeSpecs(
- targets=[0, 2],
+ targets=(0, 2),
fBellState=0.92,
fCZ=0.91,
fCZ_std_err=0.20,
@@ -139,7 +139,7 @@ def test_specs(specs_dict):
fCPHASE_std_err=None,
),
EdgeSpecs(
- targets=[0, 3],
+ targets=(0, 3),
fBellState=0.89,
fCZ=0.88,
fCZ_std_err=0.03,
@@ -151,7 +151,7 @@ def test_specs(specs_dict):
fCPHASE_std_err=None,
),
EdgeSpecs(
- targets=[1, 2],
+ targets=(1, 2),
fBellState=0.91,
fCZ=0.90,
fCZ_std_err=0.12,
diff --git a/pyquil/tests/test_quantum_computer.py b/pyquil/tests/test_quantum_computer.py
--- a/pyquil/tests/test_quantum_computer.py
+++ b/pyquil/tests/test_quantum_computer.py
@@ -194,8 +194,8 @@ def test_device_stuff():
assert nx.is_isomorphic(qc.qubit_topology(), topo)
isa = qc.get_isa(twoq_type="CPHASE")
- assert sorted(isa.edges)[0].type == "CPHASE"
- assert sorted(isa.edges)[0].targets == [0, 4]
+ assert isa.edges[0].type == "CPHASE"
+ assert isa.edges[0].targets == (0, 4)
def test_run(forest):
|
Change the namedtuples in device.py to dataclasses
As discussed in #961, using `dataclasses` instead of `namedtuples` would greatly improve readability, understanding, and use of the structures in the `device` module.
| 2020-01-02T19:58:40
|
python
|
Hard
|
|
pallets-eco/flask-wtf
| 512
|
pallets-eco__flask-wtf-512
|
[
"511"
] |
b86d5c6516344f85f930cdd710b14d54ac88415c
|
diff --git a/src/flask_wtf/__init__.py b/src/flask_wtf/__init__.py
--- a/src/flask_wtf/__init__.py
+++ b/src/flask_wtf/__init__.py
@@ -5,4 +5,4 @@
from .recaptcha import RecaptchaField
from .recaptcha import RecaptchaWidget
-__version__ = "1.0.0"
+__version__ = "1.0.1.dev0"
diff --git a/src/flask_wtf/form.py b/src/flask_wtf/form.py
--- a/src/flask_wtf/form.py
+++ b/src/flask_wtf/form.py
@@ -56,7 +56,7 @@ def wrap_formdata(self, form, formdata):
return CombinedMultiDict((request.files, request.form))
elif request.form:
return request.form
- elif request.get_json():
+ elif request.is_json:
return ImmutableMultiDict(request.get_json())
return None
diff --git a/src/flask_wtf/recaptcha/validators.py b/src/flask_wtf/recaptcha/validators.py
--- a/src/flask_wtf/recaptcha/validators.py
+++ b/src/flask_wtf/recaptcha/validators.py
@@ -30,7 +30,7 @@ def __call__(self, form, field):
if current_app.testing:
return True
- if request.json:
+ if request.is_json:
response = request.json.get("g-recaptcha-response", "")
else:
response = request.form.get("g-recaptcha-response", "")
|
diff --git a/tests/test_recaptcha.py b/tests/test_recaptcha.py
--- a/tests/test_recaptcha.py
+++ b/tests/test_recaptcha.py
@@ -80,7 +80,8 @@ def test_render_custom_args(app):
app.config["RECAPTCHA_DATA_ATTRS"] = {"red": "blue"}
f = RecaptchaForm()
render = f.recaptcha()
- assert "?key=%28value%29" in render
+ # new versions of url_encode allow more characters
+ assert "?key=(value)" in render or "?key=%28value%29" in render
assert 'data-red="blue"' in render
|
Update to Request.get_json() in Werkzeug 2.1.0 breaks empty forms
Similar to #510 - the get_json() change in Werkzeug 2.1.0 https://github.com/pallets/werkzeug/issues/2339 breaks any empty submitted form (not json).
From form.py:
```
def wrap_formdata(self, form, formdata):
if formdata is _Auto:
if _is_submitted():
if request.files:
return CombinedMultiDict((request.files, request.form))
elif request.form:
return request.form
elif request.get_json():
return ImmutableMultiDict(request.get_json())
```
If the form is an empty ImmutableMultiDict - it falls into the get_json() code which is then checking that the content-type header has been set to application/json.
Possible solution would be to change elif request.get_json() to elif request.is_json()
Expected Behavior:
Empty form submits should be allowed as they were. In the case of an empty form - None should be returned from the wrapper.
Environment:
- Python version: 3.8
- Flask-WTF version: 1.0.0
- Flask version: 2.1
| 2022-03-31T15:26:26
|
python
|
Easy
|
|
pytest-dev/pytest-django
| 979
|
pytest-dev__pytest-django-979
|
[
"978"
] |
b3b679f2cab9dad70e318f252751ff7659b951d1
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -167,7 +167,7 @@ def _django_db_helper(
serialized_rollback,
) = False, False, None, False
- transactional = transactional or (
+ transactional = transactional or reset_sequences or (
"transactional_db" in request.fixturenames
or "live_server" in request.fixturenames
)
|
diff --git a/tests/test_database.py b/tests/test_database.py
--- a/tests/test_database.py
+++ b/tests/test_database.py
@@ -287,11 +287,16 @@ def test_reset_sequences_disabled(self, request) -> None:
marker = request.node.get_closest_marker("django_db")
assert not marker.kwargs
- @pytest.mark.django_db(transaction=True, reset_sequences=True)
+ @pytest.mark.django_db(reset_sequences=True)
def test_reset_sequences_enabled(self, request) -> None:
marker = request.node.get_closest_marker("django_db")
assert marker.kwargs["reset_sequences"]
+ @pytest.mark.django_db(transaction=True, reset_sequences=True)
+ def test_transaction_reset_sequences_enabled(self, request) -> None:
+ marker = request.node.get_closest_marker("django_db")
+ assert marker.kwargs["reset_sequences"]
+
@pytest.mark.django_db(databases=['default', 'replica', 'second'])
def test_databases(self, request) -> None:
marker = request.node.get_closest_marker("django_db")
|
4.5.1: reset_sequences=True fails on MariaDB/MySQL
Firstly, thanks for maintaining such a powerful and useful testing library for Django.
On to the bug:
- OS: Windows 10
- Python: 3.9.1
- pytest-6.2.5
- py-1.11.0
- pluggy-1.0.0
- Django: 3.2.10
Example:
@pytest.mark.django_db(reset_sequences=True)
def test_reset_sequences():
assert True
Output:
ERROR my_test.py::test_reset_sequences - AssertionError: reset_sequences cannot be used on TestCase instances
|
It's missing `transaction=True`. Needs a better error message.
Did it work on pytest-django 4.4.0? If yes, then I'll make it work again.
Thanks for the fast response! Yes it works on 4.5.0
| 2021-12-07T14:17:20
|
python
|
Easy
|
rigetti/pyquil
| 177
|
rigetti__pyquil-177
|
[
"176"
] |
e10881922b799ab015f750d07156f03b2bca7046
|
diff --git a/pyquil/kraus.py b/pyquil/kraus.py
--- a/pyquil/kraus.py
+++ b/pyquil/kraus.py
@@ -50,9 +50,8 @@ def _create_kraus_pragmas(name, qubit_indices, kraus_ops):
:rtype: str
"""
- prefix = "PRAGMA ADD-KRAUS {} {}".format(name, " ".join(map(str, qubit_indices)))
pragmas = [Pragma("ADD-KRAUS",
- qubit_indices,
+ [name] + list(qubit_indices),
"({})".format(" ".join(map(format_parameter, np.ravel(k)))))
for k in kraus_ops]
return pragmas
|
diff --git a/pyquil/tests/test_quil.py b/pyquil/tests/test_quil.py
--- a/pyquil/tests/test_quil.py
+++ b/pyquil/tests/test_quil.py
@@ -520,11 +520,11 @@ def test_kraus():
ret = pq.out()
assert ret == """X 0
-PRAGMA ADD-KRAUS 0 "(0.0+0.0i 1.0+0.0i 1.0+0.0i 0.0+0.0i)"
-PRAGMA ADD-KRAUS 0 "(0.0+0.0i 0.0+0.0i 0.0+0.0i 0.0+0.0i)"
+PRAGMA ADD-KRAUS X 0 "(0.0+0.0i 1.0+0.0i 1.0+0.0i 0.0+0.0i)"
+PRAGMA ADD-KRAUS X 0 "(0.0+0.0i 0.0+0.0i 0.0+0.0i 0.0+0.0i)"
X 1
-PRAGMA ADD-KRAUS 1 "(0.0+0.0i 1.0+0.0i 1.0+0.0i 0.0+0.0i)"
-PRAGMA ADD-KRAUS 1 "(0.0+0.0i 0.0+0.0i 0.0+0.0i 0.0+0.0i)"
+PRAGMA ADD-KRAUS X 1 "(0.0+0.0i 1.0+0.0i 1.0+0.0i 0.0+0.0i)"
+PRAGMA ADD-KRAUS X 1 "(0.0+0.0i 0.0+0.0i 0.0+0.0i 0.0+0.0i)"
"""
# test error due to bad normalization
with pytest.raises(ValueError):
|
`ADD-KRAUS` does not pass the gate name to `Pragma` constructor
As is `ADD-KRAUS` is broken, but the fix is easy.
| 2017-11-09T01:17:37
|
python
|
Hard
|
|
pytest-dev/pytest-django
| 323
|
pytest-dev__pytest-django-323
|
[
"322"
] |
274efdfd48e806830e08d003d93af1e6070eb2b3
|
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -539,6 +539,20 @@ def _template_string_if_invalid_marker(request):
else:
dj_settings.TEMPLATE_STRING_IF_INVALID.fail = False
+
+@pytest.fixture(autouse=True, scope='function')
+def _django_clear_site_cache():
+ """Clears ``django.contrib.sites.models.SITE_CACHE`` to avoid
+ unexpected behavior with cached site objects.
+ """
+
+ if django_settings_is_configured():
+ from django.conf import settings as dj_settings
+
+ if 'django.contrib.sites' in dj_settings.INSTALLED_APPS:
+ from django.contrib.sites.models import Site
+ Site.objects.clear_cache()
+
# ############### Helper Functions ################
|
diff --git a/tests/test_environment.py b/tests/test_environment.py
--- a/tests/test_environment.py
+++ b/tests/test_environment.py
@@ -3,9 +3,12 @@
import os
import pytest
+from django.contrib.sites.models import Site
+from django.contrib.sites import models as site_models
from django.core import mail
from django.db import connection
from django.test import TestCase
+from pytest_django.lazy_django import get_django_version
from pytest_django_test.app.models import Item
@@ -215,3 +218,26 @@ def test_more_verbose_with_vv_and_reusedb(self, testdir):
"*PASSED*"])
assert ("*Destroying test database for alias 'default' ('*')...*"
not in result.stdout.str())
+
+
+@pytest.mark.skipif(
+ get_django_version() < (1, 8),
+ reason='Django 1.7 requires settings.SITE_ID to be set, so this test is invalid'
+)
+@pytest.mark.django_db
+@pytest.mark.parametrize('site_name', ['site1', 'site2'])
+def test_clear_site_cache(site_name, rf, monkeypatch):
+ request = rf.get('/')
+ monkeypatch.setattr(request, 'get_host', lambda: 'foo.com')
+ Site.objects.create(domain='foo.com', name=site_name)
+ assert Site.objects.get_current(request=request).name == site_name
+
+
+@pytest.mark.django_db
+@pytest.mark.parametrize('site_name', ['site1', 'site2'])
+def test_clear_site_cache_check_site_cache_size(site_name, settings):
+ assert len(site_models.SITE_CACHE) == 0
+ site = Site.objects.create(domain='foo.com', name=site_name)
+ settings.SITE_ID = site.id
+ assert Site.objects.get_current() == site
+ assert len(site_models.SITE_CACHE) == 1
|
Tests with django sites framework onetoonefield causes unexpected behavior
Assume you have a model:
```
class Customer(models.Model):
site = models.OneToOneField('sites.Site')
```
And when using the sites middleware, without setting SITE_ID, the site is looked up and cached based on the requests host information: https://github.com/django/django/blob/master/django/contrib/sites/models.py#L12
This causes unexpected behavior if testing a multi tenant site, as the request.site object will be the one from the SITE_CACHE, that might have an already populated _request.site.customer_ from previous execution.
I will submit a proposal for fixing this, as it can cause plenty of pain when debugging :)
| 2016-04-01T13:38:30
|
python
|
Easy
|
|
pytest-dev/pytest-django
| 1,189
|
pytest-dev__pytest-django-1189
|
[
"1188"
] |
6d5c272519037031f0b68d78dca44727b860d65e
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -129,8 +129,8 @@ def _get_databases_for_test(test: pytest.Item) -> tuple[Iterable[str], bool]:
test_cls = getattr(test, "cls", None)
if test_cls and issubclass(test_cls, TransactionTestCase):
- serialized_rollback = getattr(test, "serialized_rollback", False)
- databases = getattr(test, "databases", None)
+ serialized_rollback = getattr(test_cls, "serialized_rollback", False)
+ databases = getattr(test_cls, "databases", None)
else:
fixtures = getattr(test, "fixturenames", ())
marker_db = test.get_closest_marker("django_db")
|
diff --git a/tests/test_database.py b/tests/test_database.py
--- a/tests/test_database.py
+++ b/tests/test_database.py
@@ -432,6 +432,28 @@ def test_db_access_3(self):
)
+def test_django_testcase_multi_db(django_pytester: DjangoPytester) -> None:
+ """Test that Django TestCase multi-db support works."""
+
+ django_pytester.create_test_module(
+ """
+ import pytest
+ from django.test import TestCase
+ from .app.models import Item, SecondItem
+
+ class TestCase(TestCase):
+ databases = ["default", "second"]
+
+ def test_db_access(self):
+ Item.objects.count() == 0
+ SecondItem.objects.count() == 0
+ """
+ )
+
+ result = django_pytester.runpytest_subprocess("-v", "--reuse-db")
+ result.assert_outcomes(passed=1)
+
+
class Test_database_blocking:
def test_db_access_in_conftest(self, django_pytester: DjangoPytester) -> None:
"""Make sure database access in conftest module is prohibited."""
|
django.test.TestCase with multiples database doesn't create secondary db in 4.11.0
With the 4.11.0 version, if a Django TestCase is setup to use multiples database with the `databases` attribute, only the default database is created on runtime.
```
class Test(TestCase):
databases = {"default", "db2"}
```
Trying to add the decorator `@pytest.mark.django_db(databases=['default', 'db2'])` on the class doesn't work either.
The problem seems to come from the line [133 in pytest_django/fixtures.py](https://github.com/pytest-dev/pytest-django/blob/6d5c272519037031f0b68d78dca44727b860d65e/pytest_django/fixtures.py#L133)
The line tries to get an attribute from the test function and not from the test class.
```
databases = getattr(test_cls, "databases", None)
```
This fixes the problem with Django TestCase without altering pytest.mark.django_db
PS : the line 132 (serialized_rollback) seems to be broken also. I have not tried using _serialized_rollback_, so I can't confirm.
|
Ouch, silly mistake! I will fix and do a patch release. Thanks for the report.
| 2025-04-03T18:40:04
|
python
|
Hard
|
rigetti/pyquil
| 1,492
|
rigetti__pyquil-1492
|
[
"1486"
] |
76c95c2b5ccdca93cce6f2b972dafda5a680ee13
|
diff --git a/pyquil/api/_abstract_compiler.py b/pyquil/api/_abstract_compiler.py
--- a/pyquil/api/_abstract_compiler.py
+++ b/pyquil/api/_abstract_compiler.py
@@ -102,12 +102,15 @@ def __init__(
self._timeout = timeout
self._client_configuration = client_configuration or QCSClientConfiguration.load()
- self._compiler_client = CompilerClient(client_configuration=self._client_configuration, request_timeout=timeout)
if event_loop is None:
event_loop = asyncio.get_event_loop()
self._event_loop = event_loop
+ self._compiler_client = CompilerClient(
+ client_configuration=self._client_configuration, request_timeout=timeout, event_loop=self._event_loop
+ )
+
self._connect()
def get_version_info(self) -> Dict[str, Any]:
diff --git a/pyquil/api/_compiler_client.py b/pyquil/api/_compiler_client.py
--- a/pyquil/api/_compiler_client.py
+++ b/pyquil/api/_compiler_client.py
@@ -13,10 +13,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
+import asyncio
from contextlib import contextmanager
from dataclasses import dataclass
-from typing import Iterator, Optional, List
+from typing import Iterator, List, Optional
+import qcs_sdk
import rpcq
from qcs_api_client.client import QCSClientConfiguration
from rpcq.messages import TargetDevice as TargetQuantumProcessor
@@ -151,7 +153,13 @@ class CompilerClient:
Client for making requests to a Quil compiler.
"""
- def __init__(self, *, client_configuration: QCSClientConfiguration, request_timeout: float = 10.0) -> None:
+ def __init__(
+ self,
+ *,
+ client_configuration: QCSClientConfiguration,
+ request_timeout: float = 10.0,
+ event_loop: Optional[asyncio.AbstractEventLoop] = None,
+ ) -> None:
"""
Instantiate a new compiler client.
@@ -164,17 +172,19 @@ def __init__(self, *, client_configuration: QCSClientConfiguration, request_time
self.base_url = base_url
self.timeout = request_timeout
+ if event_loop is None:
+ event_loop = asyncio.get_event_loop()
+ self._event_loop = event_loop
def get_version(self) -> str:
"""
Get version info for compiler server.
"""
- with self._rpcq_client() as rpcq_client: # type: rpcq.Client
- version: Optional[str] = rpcq_client.call("get_version_info").get("quilc")
- if version is None:
- raise ValueError("Expected compiler version info to contain a 'quilc' field.")
- return version
+ async def _get_quilc_version() -> str:
+ return await qcs_sdk.get_quilc_version()
+
+ return self._event_loop.run_until_complete(_get_quilc_version())
def compile_to_native_quil(self, request: CompileToNativeQuilRequest) -> CompileToNativeQuilResponse:
"""
|
diff --git a/test/unit/conftest.py b/test/unit/conftest.py
--- a/test/unit/conftest.py
+++ b/test/unit/conftest.py
@@ -1,6 +1,5 @@
import json
import os
-from pathlib import Path
from typing import Dict, Any
import numpy as np
diff --git a/test/unit/test_compiler_client.py b/test/unit/test_compiler_client.py
--- a/test/unit/test_compiler_client.py
+++ b/test/unit/test_compiler_client.py
@@ -14,6 +14,14 @@
# limitations under the License.
##############################################################################
+from test.unit.utils import patch_rpcq_client
+
+try:
+ from unittest.mock import AsyncMock
+except ImportError: # 3.7 requires this backport of AsyncMock
+ from asyncmock import AsyncMock
+
+import qcs_sdk
import rpcq
from _pytest.monkeypatch import MonkeyPatch
from pytest import raises
@@ -22,16 +30,15 @@
from pyquil.api._compiler_client import (
CompilerClient,
- GenerateRandomizedBenchmarkingSequenceResponse,
- GenerateRandomizedBenchmarkingSequenceRequest,
- ConjugatePauliByCliffordResponse,
+ CompileToNativeQuilRequest,
+ CompileToNativeQuilResponse,
ConjugatePauliByCliffordRequest,
+ ConjugatePauliByCliffordResponse,
+ GenerateRandomizedBenchmarkingSequenceRequest,
+ GenerateRandomizedBenchmarkingSequenceResponse,
NativeQuilMetadataResponse,
- CompileToNativeQuilResponse,
- CompileToNativeQuilRequest,
)
from pyquil.external.rpcq import CompilerISA, compiler_isa_to_target_quantum_processor
-from test.unit.utils import patch_rpcq_client
def test_init__sets_base_url_and_timeout(monkeypatch: MonkeyPatch):
@@ -70,12 +77,11 @@ def test_get_version__returns_version(mocker: MockerFixture):
client_configuration = QCSClientConfiguration.load()
compiler_client = CompilerClient(client_configuration=client_configuration)
- rpcq_client = patch_rpcq_client(mocker=mocker, return_value={"quilc": "1.2.3"})
+ version_mock = AsyncMock(return_value="1.2.3")
+ get_quilc_version_mock = mocker.patch("qcs_sdk.get_quilc_version", version_mock)
assert compiler_client.get_version() == "1.2.3"
- rpcq_client.call.assert_called_once_with(
- "get_version_info"
- )
+ assert get_quilc_version_mock.call_count == 1
def test_compile_to_native_quil__returns_native_quil(
@@ -99,7 +105,7 @@ def test_compile_to_native_quil__returns_native_quil(
topological_swaps=3,
qpu_runtime_estimation=0.1618,
),
- )
+ ),
)
request = CompileToNativeQuilRequest(
program="some-program",
@@ -130,12 +136,12 @@ def test_compile_to_native_quil__returns_native_quil(
)
-def test_conjugate_pauli_by_clifford__returns_conjugation_result(
- mocker: MockerFixture
-):
+def test_conjugate_pauli_by_clifford__returns_conjugation_result(mocker: MockerFixture):
client_configuration = QCSClientConfiguration.load()
compiler_client = CompilerClient(client_configuration=client_configuration)
- rpcq_client = patch_rpcq_client(mocker=mocker, return_value=rpcq.messages.ConjugateByCliffordResponse(phase=42, pauli="pauli"))
+ rpcq_client = patch_rpcq_client(
+ mocker=mocker, return_value=rpcq.messages.ConjugateByCliffordResponse(phase=42, pauli="pauli")
+ )
request = ConjugatePauliByCliffordRequest(
pauli_indices=[0, 1, 2],
@@ -151,7 +157,7 @@ def test_conjugate_pauli_by_clifford__returns_conjugation_result(
rpcq.messages.ConjugateByCliffordRequest(
pauli=rpcq.messages.PauliTerm(indices=[0, 1, 2], symbols=["x", "y", "z"]),
clifford="cliff",
- )
+ ),
)
@@ -161,7 +167,9 @@ def test_generate_randomized_benchmarking_sequence__returns_benchmarking_sequenc
client_configuration = QCSClientConfiguration.load()
compiler_client = CompilerClient(client_configuration=client_configuration)
- rpcq_client = patch_rpcq_client(mocker=mocker, return_value=rpcq.messages.RandomizedBenchmarkingResponse(sequence=[[3, 1, 4], [1, 6, 1]]))
+ rpcq_client = patch_rpcq_client(
+ mocker=mocker, return_value=rpcq.messages.RandomizedBenchmarkingResponse(sequence=[[3, 1, 4], [1, 6, 1]])
+ )
request = GenerateRandomizedBenchmarkingSequenceRequest(
depth=42,
@@ -181,5 +189,5 @@ def test_generate_randomized_benchmarking_sequence__returns_benchmarking_sequenc
gateset=["some", "gate", "set"],
seed=314,
interleaver="some-interleaver",
- )
+ ),
)
|
Get version info requests to quilc should go through the QCS SDK
Currently, the qcs-sdk handles all external requests to `quilc` _except_ for getting version info. We need add a method for getting that data to QCS SDK Rust (see [this issue](https://github.com/rigetti/qcs-sdk-rust/issues/205)), then follow-up and use it here.
This supports #1485
|
Good catch!
| 2022-11-03T16:56:26
|
python
|
Hard
|
pallets-eco/flask-wtf
| 264
|
pallets-eco__flask-wtf-264
|
[
"227"
] |
f306c360f74362be3aac89c43cdc7c37008764fb
|
diff --git a/flask_wtf/_compat.py b/flask_wtf/_compat.py
--- a/flask_wtf/_compat.py
+++ b/flask_wtf/_compat.py
@@ -6,9 +6,11 @@
if not PY2:
text_type = str
string_types = (str,)
+ from urllib.parse import urlparse
else:
text_type = unicode
string_types = (str, unicode)
+ from urlparse import urlparse
def to_bytes(text):
diff --git a/flask_wtf/csrf.py b/flask_wtf/csrf.py
--- a/flask_wtf/csrf.py
+++ b/flask_wtf/csrf.py
@@ -8,128 +8,94 @@
:copyright: (c) 2013 by Hsiaoming Yang.
"""
-import os
-import hmac
import hashlib
-import time
-from flask import Blueprint
-from flask import current_app, session, request, abort
+import os
+import warnings
+from functools import wraps
+
+from flask import Blueprint, current_app, request, session
+from itsdangerous import BadData, URLSafeTimedSerializer
+from werkzeug.exceptions import BadRequest
from werkzeug.security import safe_str_cmp
-from ._compat import to_bytes, string_types
-try:
- from urlparse import urlparse
-except ImportError:
- # python 3
- from urllib.parse import urlparse
+from ._compat import FlaskWTFDeprecationWarning, string_types, urlparse
__all__ = ('generate_csrf', 'validate_csrf', 'CsrfProtect')
-def generate_csrf(secret_key=None, time_limit=None, token_key='csrf_token', url_safe=False):
- """Generate csrf token code.
-
- :param secret_key: A secret key for mixing in the token,
- default is Flask.secret_key.
- :param time_limit: Token valid in the time limit,
- default is 3600s.
- """
+def _get_secret_key(secret_key=None):
if not secret_key:
- secret_key = current_app.config.get(
- 'WTF_CSRF_SECRET_KEY', current_app.secret_key
- )
+ secret_key = current_app.config.get('WTF_CSRF_SECRET_KEY', current_app.secret_key)
if not secret_key:
- raise Exception('Must provide secret_key to use csrf.')
+ raise Exception('Must provide secret_key to use CSRF.')
+
+ return secret_key
- if time_limit is None:
- time_limit = current_app.config.get('WTF_CSRF_TIME_LIMIT', 3600)
- if token_key not in session:
- session[token_key] = hashlib.sha1(os.urandom(64)).hexdigest()
-
- if time_limit:
- expires = int(time.time() + time_limit)
- csrf_build = '%s%s' % (session[token_key], expires)
- else:
- expires = ''
- csrf_build = session[token_key]
-
- hmac_csrf = hmac.new(
- to_bytes(secret_key),
- to_bytes(csrf_build),
- digestmod=hashlib.sha1
- ).hexdigest()
- delimiter = '--' if url_safe else '##'
- return '%s%s%s' % (expires, delimiter, hmac_csrf)
-
-
-def validate_csrf(data, secret_key=None, time_limit=None, token_key='csrf_token', url_safe=False):
- """Check if the given data is a valid csrf token.
-
- :param data: The csrf token value to be checked.
- :param secret_key: A secret key for mixing in the token,
- default is Flask.secret_key.
- :param time_limit: Check if the csrf token is expired.
- default is True.
+def generate_csrf(secret_key=None, token_key='csrf_token'):
+ """Generate a CSRF token. The token is cached for a request, so multiple
+ calls to this function will generate the same token.
+
+ During testing, it might be useful to access the signed token in
+ ``request.csrf_token`` and the raw token in ``session['csrf_token']``.
+
+ :param secret_key: Used to securely sign the token. Default is
+ ``WTF_CSRF_SECRET_KEY`` or ``SECRET_KEY``.
+ :param token_key: key where token is stored in session for comparision.
"""
- delimiter = '--' if url_safe else '##'
- if not data or delimiter not in data:
- return False
- try:
- expires, hmac_csrf = data.split(delimiter, 1)
- except ValueError:
- return False # unpack error
+ if not getattr(request, token_key, None):
+ if token_key not in session:
+ session[token_key] = hashlib.sha1(os.urandom(64)).hexdigest()
- if time_limit is None:
- time_limit = current_app.config.get('WTF_CSRF_TIME_LIMIT', 3600)
+ s = URLSafeTimedSerializer(_get_secret_key(secret_key), salt='wtf-csrf-token')
+ setattr(request, token_key, s.dumps(session[token_key]))
- if time_limit:
- try:
- expires = int(expires)
- except ValueError:
- return False
+ return getattr(request, token_key)
- now = int(time.time())
- if now > expires:
- return False
- if not secret_key:
- secret_key = current_app.config.get(
- 'WTF_CSRF_SECRET_KEY', current_app.secret_key
- )
+def validate_csrf(data, secret_key=None, time_limit=None, token_key='csrf_token'):
+ """Check if the given data is a valid CSRF token. This compares the given
+ signed token to the one stored in the session.
- if token_key not in session:
+ :param data: The signed CSRF token to be checked.
+ :param secret_key: Used to securely sign the token. Default is
+ ``WTF_CSRF_SECRET_KEY`` or ``SECRET_KEY``.
+ :param time_limit: Number of seconds that the token is valid. Default is
+ ``WTF_CSRF_TIME_LIMIT`` or 3600 seconds (60 minutes).
+ :param token_key: key where token is stored in session for comparision.
+ """
+
+ if not data or token_key not in session:
return False
- csrf_build = '%s%s' % (session[token_key], expires)
- hmac_compare = hmac.new(
- to_bytes(secret_key),
- to_bytes(csrf_build),
- digestmod=hashlib.sha1
- ).hexdigest()
+ s = URLSafeTimedSerializer(_get_secret_key(secret_key), salt='wtf-csrf-token')
- return safe_str_cmp(hmac_compare, hmac_csrf)
+ if time_limit is None:
+ time_limit = current_app.config.get('WTF_CSRF_TIME_LIMIT', 3600)
+ try:
+ token = s.loads(data, max_age=time_limit)
+ except BadData:
+ return False
-class CsrfProtect(object):
- """Enable csrf protect for Flask.
+ return safe_str_cmp(session[token_key], token)
- Register it with::
- app = Flask(__name__)
- CsrfProtect(app)
-
- And in the templates, add the token input::
+class CsrfProtect(object):
+ """Enable CSRF protection globally for a Flask app.
- <input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
+ ::
- If you need to send the token via AJAX, and there is no form::
+ app = Flask(__name__)
+ csrf = CsrfProtect(app)
- <meta name="csrf_token" content="{{ csrf_token() }}" />
+ Checks the ``csrf_token`` field sent with forms, or the ``X-CSRFToken``
+ header sent with JavaScript requests. Render the token in templates using
+ ``{{ csrf_token() }}``.
- You can grab the csrf token with JavaScript, and send the token together.
+ See the :ref:`csrf` documentation.
"""
def __init__(self, app=None):
@@ -140,24 +106,19 @@ def __init__(self, app=None):
self.init_app(app)
def init_app(self, app):
- self._app = app
- app.jinja_env.globals['csrf_token'] = generate_csrf
- app.config.setdefault(
- 'WTF_CSRF_HEADERS', ['X-CSRFToken', 'X-CSRF-Token']
- )
- app.config.setdefault('WTF_CSRF_SSL_STRICT', True)
app.config.setdefault('WTF_CSRF_ENABLED', True)
app.config.setdefault('WTF_CSRF_CHECK_DEFAULT', True)
- app.config.setdefault('WTF_CSRF_METHODS', ['POST', 'PUT', 'PATCH'])
+ app.config['WTF_CSRF_METHODS'] = set(app.config.get(
+ 'WTF_CSRF_METHODS', ['POST', 'PUT', 'PATCH', 'DELETE']
+ ))
+ app.config.setdefault('WTF_CSRF_HEADERS', ['X-CSRFToken', 'X-CSRF-Token'])
+ app.config.setdefault('WTF_CSRF_SSL_STRICT', True)
- # expose csrf_token as a helper in all templates
- @app.context_processor
- def csrf_token():
- return dict(csrf_token=generate_csrf)
+ app.jinja_env.globals['csrf_token'] = generate_csrf
+ app.context_processor(lambda: {'csrf_token': generate_csrf})
@app.before_request
def _csrf_protect():
- # many things come from django.middleware.csrf
if not app.config['WTF_CSRF_ENABLED']:
return
@@ -171,15 +132,17 @@ def _csrf_protect():
return
view = app.view_functions.get(request.endpoint)
+
if not view:
return
- if self._exempt_views or self._exempt_blueprints:
- dest = '%s.%s' % (view.__module__, view.__name__)
- if dest in self._exempt_views:
- return
- if request.blueprint in self._exempt_blueprints:
- return
+ if request.blueprint in self._exempt_blueprints:
+ return
+
+ dest = '%s.%s' % (view.__module__, view.__name__)
+
+ if dest in self._exempt_views:
+ return
self.protect()
@@ -190,85 +153,119 @@ def _get_csrf_token(self):
for key in request.form:
if key.endswith('csrf_token'):
csrf_token = request.form[key]
+
if csrf_token:
return csrf_token
- for header_name in self._app.config['WTF_CSRF_HEADERS']:
+ for header_name in current_app.config['WTF_CSRF_HEADERS']:
csrf_token = request.headers.get(header_name)
+
if csrf_token:
return csrf_token
+
return None
def protect(self):
- if request.method not in self._app.config['WTF_CSRF_METHODS']:
+ if request.method not in current_app.config['WTF_CSRF_METHODS']:
return
if not validate_csrf(self._get_csrf_token()):
- reason = 'CSRF token missing or incorrect.'
- return self._error_response(reason)
+ self._error_response('CSRF token missing or incorrect.')
- if request.is_secure and self._app.config['WTF_CSRF_SSL_STRICT']:
+ if request.is_secure and current_app.config['WTF_CSRF_SSL_STRICT']:
if not request.referrer:
- reason = 'Referrer checking failed - no Referrer.'
- return self._error_response(reason)
+ self._error_response('Referrer checking failed - no Referrer.')
good_referrer = 'https://%s/' % request.host
+
if not same_origin(request.referrer, good_referrer):
- reason = 'Referrer checking failed - origin does not match.'
- return self._error_response(reason)
+ self._error_response('Referrer checking failed - origin does not match.')
request.csrf_valid = True # mark this request is csrf valid
def exempt(self, view):
- """A decorator that can exclude a view from csrf protection.
-
- Remember to put the decorator above the `route`::
+ """Mark a view or blueprint to be excluded from CSRF protection.
- csrf = CsrfProtect(app)
+ ::
- @csrf.exempt
@app.route('/some-view', methods=['POST'])
+ @csrf.exempt
def some_view():
- return
+ ...
+
+ ::
+
+ bp = Blueprint(...)
+ csrf.exempt(bp)
+
"""
+
if isinstance(view, Blueprint):
self._exempt_blueprints.add(view.name)
return view
+
if isinstance(view, string_types):
view_location = view
else:
view_location = '%s.%s' % (view.__module__, view.__name__)
+
self._exempt_views.add(view_location)
return view
def _error_response(self, reason):
- return abort(400, reason)
+ raise CsrfError(reason)
def error_handler(self, view):
- """A decorator that set the error response handler.
+ """Register a function that will generate the response for CSRF errors.
- It accepts one parameter `reason`::
+ .. deprecated:: 0.14
+ Use the standard Flask error system with
+ ``@app.errorhandler(CsrfError)`` instead. This will be removed in
+ version 1.0.
+
+ The function will be passed one argument, ``reason``. By default it will
+ raise a :class:`~flask_wtf.csrf.CsrfError`. ::
@csrf.error_handler
def csrf_error(reason):
return render_template('error.html', reason=reason)
- By default, it will return a 400 response.
+ Due to historical reasons, the function may either return a response
+ or raise an exception with :func:`flask.abort`.
"""
- self._error_response = view
+
+ warnings.warn(FlaskWTFDeprecationWarning(
+ '"@csrf.error_handler" is deprecated. Use the standard Flask error '
+ 'system with "@app.errorhandler(CsrfError)" instead. This will be'
+ 'removed in 1.0.'
+ ), stacklevel=2)
+
+ @wraps(view)
+ def handler(reason):
+ response = current_app.make_response(view(reason))
+ raise CsrfError(response.get_data(as_text=True), response=response)
+
+ self._error_response = handler
return view
-def same_origin(current_uri, compare_uri):
- parsed_uri = urlparse(current_uri)
- parsed_compare = urlparse(compare_uri)
+class CsrfError(BadRequest):
+ """Raise if the client sends invalid CSRF data with the request.
- if parsed_uri.scheme != parsed_compare.scheme:
- return False
+ Generates a 400 Bad Request response with the failure reason by default.
+ Customize the response by registering a handler with
+ :meth:`flask.Flask.errorhandler`.
+ """
- if parsed_uri.hostname != parsed_compare.hostname:
- return False
+ description = 'CSRF token missing or incorrect.'
- if parsed_uri.port != parsed_compare.port:
- return False
- return True
+
+def same_origin(current_uri, compare_uri):
+ current = urlparse(current_uri)
+ compare = urlparse(compare_uri)
+
+ return (
+ current.scheme == compare.scheme
+ and current.hostname == compare.hostname
+ and current.port == compare.port
+ )
diff --git a/flask_wtf/form.py b/flask_wtf/form.py
--- a/flask_wtf/form.py
+++ b/flask_wtf/form.py
@@ -1,16 +1,14 @@
# coding: utf-8
import warnings
-import werkzeug.datastructures
-from flask import request, session, current_app
+from flask import current_app, request, session
from jinja2 import Markup
-from wtforms.compat import with_metaclass
+from werkzeug.datastructures import MultiDict
from wtforms.ext.csrf.form import SecureForm
-from wtforms.form import FormMeta
from wtforms.validators import ValidationError
-from wtforms.widgets import HiddenInput, SubmitInput
+from wtforms.widgets import HiddenInput
-from ._compat import text_type, string_types, FlaskWTFDeprecationWarning
+from ._compat import FlaskWTFDeprecationWarning, string_types, text_type
from .csrf import generate_csrf, validate_csrf
try:
@@ -70,7 +68,7 @@ def __init__(self, formdata=_Auto, obj=None, prefix='', csrf_context=None,
formdata = formdata.copy()
formdata.update(request.files)
elif request.get_json():
- formdata = werkzeug.datastructures.MultiDict(request.get_json())
+ formdata = MultiDict(request.get_json())
else:
formdata = None
@@ -94,25 +92,24 @@ def __init__(self, formdata=_Auto, obj=None, prefix='', csrf_context=None,
def generate_csrf_token(self, csrf_context=None):
if not self.csrf_enabled:
return None
- return generate_csrf(self.SECRET_KEY, self.TIME_LIMIT)
+
+ return generate_csrf(secret_key=self.SECRET_KEY)
def validate_csrf_token(self, field):
if not self.csrf_enabled:
return True
- if hasattr(request, 'csrf_valid') and request.csrf_valid:
+
+ if getattr(request, 'csrf_valid', False):
# this is validated by CsrfProtect
return True
- if not validate_csrf(field.data, self.SECRET_KEY, self.TIME_LIMIT):
+
+ if not self.validate_csrf_data(field.data):
raise ValidationError(field.gettext('CSRF token missing'))
def validate_csrf_data(self, data):
- """Check if the csrf data is valid.
+ """Check if the given data is a valid CSRF token."""
- .. versionadded: 0.9.0
-
- :param data: the csrf string to be validated.
- """
- return validate_csrf(data, self.SECRET_KEY, self.TIME_LIMIT)
+ return validate_csrf(data, secret_key=self.SECRET_KEY, time_limit=self.TIME_LIMIT)
def is_submitted(self):
"""Consider the form submitted if there is an active request and
|
diff --git a/tests/base.py b/tests/base.py
--- a/tests/base.py
+++ b/tests/base.py
@@ -1,10 +1,12 @@
from __future__ import with_statement
-from flask import Flask, render_template, jsonify
-from wtforms import StringField, HiddenField, SubmitField
-from wtforms.validators import DataRequired
+from unittest import TestCase as _TestCase
+
+from flask import Flask, jsonify, render_template
from flask_wtf import FlaskForm
from flask_wtf._compat import text_type
+from wtforms import HiddenField, StringField, SubmitField
+from wtforms.validators import DataRequired
def to_unicode(text):
@@ -37,7 +39,7 @@ class SimpleForm(FlaskForm):
pass
-class TestCase(object):
+class TestCase(_TestCase):
def setUp(self):
self.app = self.create_app()
self.client = self.app.test_client()
diff --git a/tests/templates/csrf_macro.html b/tests/templates/csrf_macro.html
--- a/tests/templates/csrf_macro.html
+++ b/tests/templates/csrf_macro.html
@@ -1,3 +1,3 @@
{% macro render_csrf_token() %}
- <input type="hidden" name="csrf_token" value="{{ csrf_token() }}">
+ <input name="csrf_token" type="hidden" value="{{ csrf_token() }}">
{% endmacro %}
diff --git a/tests/test_csrf.py b/tests/test_csrf.py
--- a/tests/test_csrf.py
+++ b/tests/test_csrf.py
@@ -1,21 +1,13 @@
from __future__ import with_statement
import re
-from flask import Blueprint
-from flask import render_template
-from flask_wtf.csrf import CsrfProtect
-from flask_wtf.csrf import validate_csrf, generate_csrf
-from .base import TestCase, MyForm, to_unicode
+import warnings
-csrf_token_input = re.compile(
- r'name="csrf_token" type="hidden" value="([0-9a-z#A-Z-\.]*)"'
-)
+from flask import Blueprint, abort, render_template, request
+from flask_wtf._compat import FlaskWTFDeprecationWarning
+from flask_wtf.csrf import CsrfError, CsrfProtect, generate_csrf, validate_csrf
-
-def get_csrf_token(data):
- match = csrf_token_input.search(to_unicode(data))
- assert match
- return match.groups()[0]
+from .base import MyForm, TestCase
class TestCSRF(TestCase):
@@ -59,9 +51,9 @@ def test_invalid_csrf(self):
response = self.client.post("/", data={"name": "danny"})
assert response.status_code == 400
- @self.csrf.error_handler
- def invalid(reason):
- return reason
+ @self.app.errorhandler(CsrfError)
+ def handle_csrf_error(e):
+ return e, 200
response = self.client.post("/", data={"name": "danny"})
assert response.status_code == 200
@@ -86,8 +78,9 @@ def test_invalid_secure_csrf3(self):
assert response.status_code == 400
def test_valid_csrf(self):
- response = self.client.get("/")
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/')
+ csrf_token = request.csrf_token
response = self.client.post("/", data={
"name": "danny",
@@ -96,8 +89,9 @@ def test_valid_csrf(self):
assert b'DANNY' in response.data
def test_prefixed_csrf(self):
- response = self.client.get('/')
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/')
+ csrf_token = request.csrf_token
response = self.client.post('/', data={
'prefix-name': 'David',
@@ -106,8 +100,9 @@ def test_prefixed_csrf(self):
assert response.status_code == 200
def test_invalid_secure_csrf(self):
- response = self.client.get("/", base_url='https://localhost/')
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/', base_url='https://localhost/')
+ csrf_token = request.csrf_token
response = self.client.post(
"/",
@@ -161,8 +156,10 @@ def test_invalid_secure_csrf(self):
assert b'not match' in response.data
def test_valid_secure_csrf(self):
- response = self.client.get("/", base_url='https://localhost/')
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/', base_url='https://localhost/')
+ csrf_token = request.csrf_token
+
response = self.client.post(
"/",
data={"name": "danny"},
@@ -177,8 +174,9 @@ def test_valid_secure_csrf(self):
assert response.status_code == 200
def test_valid_csrf_method(self):
- response = self.client.get("/")
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/')
+ csrf_token = request.csrf_token
response = self.client.post("/csrf-protect-method", data={
"csrf_token": csrf_token
@@ -189,17 +187,19 @@ def test_invalid_csrf_method(self):
response = self.client.post("/csrf-protect-method", data={"name": "danny"})
assert response.status_code == 400
- @self.csrf.error_handler
- def invalid(reason):
- return reason
+ @self.app.errorhandler(CsrfError)
+ def handle_csrf_error(e):
+ return e, 200
response = self.client.post("/", data={"name": "danny"})
assert response.status_code == 200
assert b'token missing' in response.data
def test_empty_csrf_headers(self):
- response = self.client.get("/", base_url='https://localhost/')
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/', base_url='https://localhost/')
+ csrf_token = request.csrf_token
+
self.app.config['WTF_CSRF_HEADERS'] = list()
response = self.client.post(
"/",
@@ -215,8 +215,10 @@ def test_empty_csrf_headers(self):
assert response.status_code == 400
def test_custom_csrf_headers(self):
- response = self.client.get("/", base_url='https://localhost/')
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/', base_url='https://localhost/')
+ csrf_token = request.csrf_token
+
self.app.config['WTF_CSRF_HEADERS'] = ['X-XSRF-TOKEN']
response = self.client.post(
"/",
@@ -239,9 +241,10 @@ def test_testing(self):
self.app.testing = True
self.client.post("/", data={"name": "danny"})
- def test_csrf_exempt(self):
- response = self.client.get("/csrf-exempt")
- csrf_token = get_csrf_token(response.data)
+ def test_csrf_exempt_view_with_form(self):
+ with self.client:
+ self.client.get('/', base_url='https://localhost/')
+ csrf_token = request.csrf_token
response = self.client.post("/csrf-exempt", data={
"name": "danny",
@@ -257,7 +260,7 @@ def test_validate_csrf(self):
def test_validate_not_expiring_csrf(self):
with self.app.test_request_context():
- csrf_token = generate_csrf(time_limit=False)
+ csrf_token = generate_csrf()
assert validate_csrf(csrf_token, time_limit=False)
def test_csrf_token_helper(self):
@@ -265,8 +268,9 @@ def test_csrf_token_helper(self):
def withtoken():
return render_template("csrf.html")
- response = self.client.get('/token')
- assert b'#' in response.data
+ with self.client:
+ response = self.client.get('/token')
+ assert re.search(br'token: ([0-9a-zA-Z\-._]+)', response.data)
def test_csrf_blueprint(self):
response = self.client.post('/bar/foo')
@@ -281,8 +285,9 @@ def test_csrf_token_macro(self):
def withtoken():
return render_template("import_csrf.html")
- response = self.client.get('/token')
- assert b'#' in response.data
+ with self.client:
+ response = self.client.get('/token')
+ assert request.csrf_token in response.data.decode('utf8')
def test_csrf_custom_token_key(self):
with self.app.test_request_context():
@@ -296,16 +301,31 @@ def test_csrf_custom_token_key(self):
# However, the custom key can validate as well
assert validate_csrf(custom_csrf_token, token_key='oauth_state')
- def test_csrf_url_safe(self):
- with self.app.test_request_context():
- # Generate a normal and URL safe CSRF token
- default_csrf_token = generate_csrf()
- url_safe_csrf_token = generate_csrf(url_safe=True)
+ def test_old_error_handler(self):
+ with warnings.catch_warnings(record=True) as w:
+ warnings.simplefilter('always', FlaskWTFDeprecationWarning)
+
+ @self.csrf.error_handler
+ def handle_csrf_error(reason):
+ return 'caught csrf return'
+
+ self.assertEqual(len(w), 1)
+ assert issubclass(w[0].category, FlaskWTFDeprecationWarning)
+ assert 'app.errorhandler(CsrfError)' in str(w[0].message)
+
+ rv = self.client.post('/', data={'name': 'david'})
+ assert b'caught csrf return' in rv.data
+
+ with warnings.catch_warnings(record=True) as w:
+ warnings.simplefilter('always', FlaskWTFDeprecationWarning)
+
+ @self.csrf.error_handler
+ def handle_csrf_error(reason):
+ abort(401, 'caught csrf abort')
- # Verify they are not the same and the URL one is truly URL safe
- assert default_csrf_token != url_safe_csrf_token
- assert '#' not in url_safe_csrf_token
- assert re.match(r'^[a-f0-9]+--[a-f0-9]+$', url_safe_csrf_token)
+ self.assertEqual(len(w), 1)
+ assert issubclass(w[0].category, FlaskWTFDeprecationWarning)
+ assert 'app.errorhandler(CsrfError)' in str(w[0].message)
- # Verify we can validate our URL safe key
- assert validate_csrf(url_safe_csrf_token, url_safe=True)
+ rv = self.client.post('/', data={'name': 'david'})
+ assert b'caught csrf abort' in rv.data
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -1,18 +1,8 @@
from __future__ import with_statement
-import re
+from flask import request
-from .base import TestCase, MyForm, to_unicode
-
-csrf_token_input = re.compile(
- r'name="csrf_token" type="hidden" value="([0-9a-z#A-Z-\.]*)"'
-)
-
-
-def get_csrf_token(data):
- match = csrf_token_input.search(to_unicode(data))
- assert match
- return match.groups()[0]
+from .base import MyForm, TestCase, to_unicode
class TestValidateOnSubmit(TestCase):
@@ -93,18 +83,20 @@ def test_ajax(self):
assert response.status_code == 200
def test_valid_csrf(self):
+ with self.client:
+ self.client.get('/')
+ csrf_token = request.csrf_token
- response = self.client.get("/")
- csrf_token = get_csrf_token(response.data)
-
- response = self.client.post("/", data={"name": "danny",
- "csrf_token": csrf_token})
+ response = self.client.post('/', data={
+ 'name': 'danny',
+ 'csrf_token': csrf_token
+ })
assert b'DANNY' in response.data
def test_double_csrf(self):
-
- response = self.client.get("/")
- csrf_token = get_csrf_token(response.data)
+ with self.client:
+ self.client.get('/')
+ csrf_token = request.csrf_token
response = self.client.post("/two_forms/", data={
"name": "danny",
@@ -114,6 +106,4 @@ def test_double_csrf(self):
def test_valid_csrf_data(self):
with self.app.test_request_context():
- form = MyForm()
- csrf_token = get_csrf_token(form.csrf_token())
- assert form.validate_csrf_data(csrf_token)
+ assert MyForm().validate_csrf_data(request.csrf_token)
|
Make it easier to access a CSRF token in automated tests
If you want to run your automated tests with CSRF enabled (which is a good idea if it's enabled in production), there's no good built-in way to do so. Even the tests for this project [use regular expressions to parse the CSRF token out of the page](https://github.com/lepture/flask-wtf/blob/3c9dcf5cc/tests/test_csrf.py#L10-L18), which is brittle and confusing. It would be better to provide some way to access the CSRF token in the Flask test client itself.
I've written a GitHub Gist that walks though how I implemented this myself, but maybe Flask-WTF could change some internals to make it cleaner and easier? https://gist.github.com/singingwolfboy/2fca1de64950d5dfed72
| 2016-10-13T04:41:57
|
python
|
Hard
|
|
rigetti/pyquil
| 421
|
rigetti__pyquil-421
|
[
"384"
] |
9612be90f91405ecbc089b3496f1c85d9c177cc8
|
diff --git a/pyquil/noise.py b/pyquil/noise.py
--- a/pyquil/noise.py
+++ b/pyquil/noise.py
@@ -296,22 +296,51 @@ def damping_after_dephasing(T1, T2, gate_time):
# You can only apply gate-noise to non-parametrized gates or parametrized gates at fixed parameters.
NO_NOISE = ["RZ"]
-NOISY_GATES = {
- ("I", ()): (np.eye(2), "NOISY-I"),
- ("RX", (np.pi / 2,)): (np.array([[1, -1j],
- [-1j, 1]]) / np.sqrt(2),
- "NOISY-RX-PLUS-90"),
- ("RX", (-np.pi / 2,)): (np.array([[1, 1j],
- [1j, 1]]) / np.sqrt(2),
- "NOISY-RX-MINUS-90"),
- ("RX", (np.pi,)): (np.array([[0, -1j],
- [-1j, 0]]),
- "NOISY-RX-PLUS-180"),
- ("RX", (-np.pi,)): (np.array([[0, 1j],
- [1j, 0]]),
- "NOISY-RX-MINUS-180"),
- ("CZ", ()): (np.diag([1, 1, 1, -1]), "NOISY-CZ"),
-}
+ANGLE_TOLERANCE = 1e-10
+
+
+class NoisyGateUndefined(Exception):
+ """Raise when user attempts to use noisy gate outside of currently supported set."""
+ pass
+
+
+def get_noisy_gate(gate_name, params):
+ """
+ Look up the numerical gate representation and a proposed 'noisy' name.
+
+ :param str gate_name: The Quil gate name
+ :param Tuple[float] params: The gate parameters.
+ :return: A tuple (matrix, noisy_name) with the representation of the ideal gate matrix
+ and a proposed name for the noisy version.
+ :rtype: Tuple[np.array, str]
+ """
+ params = tuple(params)
+ if gate_name == "I":
+ assert params == ()
+ return np.eye(2), "NOISY-I"
+ if gate_name == "RX":
+ angle, = params
+ if np.isclose(angle, np.pi / 2, atol=ANGLE_TOLERANCE):
+ return (np.array([[1, -1j],
+ [-1j, 1]]) / np.sqrt(2),
+ "NOISY-RX-PLUS-90")
+ elif np.isclose(angle, -np.pi / 2, atol=ANGLE_TOLERANCE):
+ return (np.array([[1, 1j],
+ [1j, 1]]) / np.sqrt(2),
+ "NOISY-RX-MINUS-90")
+ elif np.isclose(angle, np.pi, atol=ANGLE_TOLERANCE):
+ return (np.array([[0, -1j],
+ [-1j, 0]]),
+ "NOISY-RX-PLUS-180")
+ elif np.isclose(angle, -np.pi, atol=ANGLE_TOLERANCE):
+ return (np.array([[0, 1j],
+ [1j, 0]]),
+ "NOISY-RX-MINUS-180")
+ elif gate_name == "CZ":
+ assert params == ()
+ return np.diag([1, 1, 1, -1]), "NOISY-CZ"
+ raise NoisyGateUndefined("Undefined gate and params: {}{}\n"
+ "Please restrict yourself to I, RX(+/-pi), RX(+/-pi/2), CZ")
def _get_program_gates(prog):
@@ -384,21 +413,18 @@ def _decoherence_noise_model(gates, T1=30e-6, T2=30e-6, gate_time_1q=50e-9,
key = (g.name, tuple(g.params))
if g.name in NO_NOISE:
continue
- if key in NOISY_GATES:
- matrix, _ = NOISY_GATES[key]
- if len(targets) == 1:
- noisy_I = noisy_identities_1q[targets[0]]
- else:
- if len(targets) != 2:
- raise ValueError("Noisy gates on more than 2Q not currently supported")
-
- # note this ordering of the tensor factors is necessary due to how the QVM orders
- # the wavefunction basis
- noisy_I = tensor_kraus_maps(noisy_identities_2q[targets[1]],
- noisy_identities_2q[targets[0]])
+ matrix, _ = get_noisy_gate(g.name, g.params)
+
+ if len(targets) == 1:
+ noisy_I = noisy_identities_1q[targets[0]]
else:
- raise ValueError("Cannot create noisy version of {}. ".format(g) +
- "Please restrict yourself to CZ, RX(+/-pi/2), I, RZ(theta)")
+ if len(targets) != 2:
+ raise ValueError("Noisy gates on more than 2Q not currently supported")
+
+ # note this ordering of the tensor factors is necessary due to how the QVM orders
+ # the wavefunction basis
+ noisy_I = tensor_kraus_maps(noisy_identities_2q[targets[1]],
+ noisy_identities_2q[targets[0]])
kraus_maps.append(KrausModel(g.name, tuple(g.params), targets,
combine_kraus_maps(noisy_I, [matrix]),
# FIXME (Nik): compute actual avg gate fidelity for this simple
@@ -434,13 +460,13 @@ def _noise_model_program_header(noise_model):
# obtain ideal gate matrix and new, noisy name by looking it up in the NOISY_GATES dict
try:
- ideal_gate, new_name = NOISY_GATES[k.gate, tuple(k.params)]
+ ideal_gate, new_name = get_noisy_gate(k.gate, tuple(k.params))
# if ideal version of gate has not yet been DEFGATE'd, do this
if new_name not in defgates:
p.defgate(new_name, ideal_gate)
defgates.add(new_name)
- except KeyError:
+ except NoisyGateUndefined:
print("WARNING: Could not find ideal gate definition for gate {}".format(k.gate),
file=sys.stderr)
new_name = k.gate
@@ -468,11 +494,10 @@ def apply_noise_model(prog, noise_model):
new_prog = _noise_model_program_header(noise_model)
for i in prog:
if isinstance(i, Gate):
- key = (i.name, tuple(i.params))
- if key in NOISY_GATES:
- _, new_name = NOISY_GATES[key]
+ try:
+ _, new_name = get_noisy_gate(i.name, tuple(i.params))
new_prog += Gate(new_name, [], i.qubits)
- else:
+ except NoisyGateUndefined:
new_prog += i
else:
new_prog += i
|
diff --git a/pyquil/tests/test_noise.py b/pyquil/tests/test_noise.py
--- a/pyquil/tests/test_noise.py
+++ b/pyquil/tests/test_noise.py
@@ -208,3 +208,17 @@ def test_apply_noise_model():
assert i.command in ['ADD-KRAUS', 'READOUT-POVM']
elif isinstance(i, Gate):
assert i.name in NO_NOISE or not i.params
+
+
+def test_apply_noise_model_perturbed_angles():
+ eps = 1e-15
+ p = Program(RX(np.pi / 2 + eps)(0), RX(np.pi / 2 - eps)(1), CZ(0, 1), RX(np.pi / 2 + eps)(1))
+ noise_model = _decoherence_noise_model(_get_program_gates(p))
+ pnoisy = apply_noise_model(p, noise_model)
+ for i in pnoisy:
+ if isinstance(i, DefGate):
+ pass
+ elif isinstance(i, Pragma):
+ assert i.command in ['ADD-KRAUS', 'READOUT-POVM']
+ elif isinstance(i, Gate):
+ assert i.name in NO_NOISE or not i.params
|
Adding decoherence noise models fails when `RX` angles are perturbed from +/-pi or +/-pi/2
Two ways to fix this:
1. Quick: allow angles to deviate from pi within some tolerance (e.g., 10^{-10}) that is much stricter than any anticipated gate error.
2. Slow: actually implement a mechanism to translate arbitrary pyquil gates (including parameters) to symbolic or numeric matrices. This would have to be able to resolve the default gateset AND check the program for `defgates` and extract those when applicable. As a benefit, we could support helpers for noise models for arbitrary gates.
|
@mpharrigan what are your thoughts?
Is this an issue in practice? Can we do quick in the near term and slow eventually in the context of noise models for arbitrary gates
Yeah, it was an issue for me today when I tried to add noise after compiling the program an external user wants to simulate with noise. I am happy to do the quick fix first
| 2018-05-03T19:00:14
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 2,759
|
marcelotduarte__cx_Freeze-2759
|
[
"2738"
] |
aee3a1a3195a358e814c4fcbdc116e192132bbf5
|
diff --git a/cx_Freeze/_compat.py b/cx_Freeze/_compat.py
--- a/cx_Freeze/_compat.py
+++ b/cx_Freeze/_compat.py
@@ -7,6 +7,7 @@
from pathlib import Path
__all__ = [
+ "ABI_THREAD",
"BUILD_EXE_DIR",
"EXE_SUFFIX",
"EXT_SUFFIX",
@@ -21,8 +22,9 @@
PLATFORM = sysconfig.get_platform()
PYTHON_VERSION = sysconfig.get_python_version()
+ABI_THREAD = sysconfig.get_config_var("abi_thread") or ""
-BUILD_EXE_DIR = Path(f"build/exe.{PLATFORM}-{PYTHON_VERSION}")
+BUILD_EXE_DIR = Path(f"build/exe.{PLATFORM}-{PYTHON_VERSION}{ABI_THREAD}")
EXE_SUFFIX = sysconfig.get_config_var("EXE")
EXT_SUFFIX = sysconfig.get_config_var("EXT_SUFFIX")
diff --git a/cx_Freeze/executable.py b/cx_Freeze/executable.py
--- a/cx_Freeze/executable.py
+++ b/cx_Freeze/executable.py
@@ -11,6 +11,7 @@
from typing import TYPE_CHECKING
from cx_Freeze._compat import (
+ ABI_THREAD,
EXE_SUFFIX,
IS_MACOS,
IS_MINGW,
@@ -74,12 +75,17 @@ def base(self) -> Path:
@base.setter
def base(self, name: str | Path | None) -> None:
- # The default base is the legacy console, except for
+ # The default base is the legacy console, except for Python 3.13t and
# Python 3.13 on macOS, that supports only the new console
- if IS_MACOS and sys.version_info[:2] >= (3, 13):
- name = name or "console"
- else:
+ version = sys.version_info[:2]
+ if (
+ version <= (3, 13)
+ and ABI_THREAD == ""
+ and not (IS_MACOS and version == (3, 13))
+ ):
name = name or "console_legacy"
+ else:
+ name = name or "console"
# silently ignore gui and service on non-windows systems
if not (IS_WINDOWS or IS_MINGW) and name in ("gui", "service"):
name = "console"
diff --git a/cx_Freeze/freezer.py b/cx_Freeze/freezer.py
--- a/cx_Freeze/freezer.py
+++ b/cx_Freeze/freezer.py
@@ -22,11 +22,13 @@
from setuptools import Distribution
from cx_Freeze._compat import (
+ ABI_THREAD,
BUILD_EXE_DIR,
IS_CONDA,
IS_MACOS,
IS_MINGW,
IS_WINDOWS,
+ PYTHON_VERSION,
)
from cx_Freeze.common import get_resource_file_path, process_path_specs
from cx_Freeze.exception import FileError, OptionError
@@ -1035,9 +1037,10 @@ def _default_bin_includes(self) -> list[str]:
# MSYS2 python returns a static library.
names = [name.replace(".dll.a", ".dll")]
else:
+ py_version = f"{PYTHON_VERSION}{ABI_THREAD}"
names = [
f"python{sys.version_info[0]}.dll",
- f"python{sys.version_info[0]}{sys.version_info[1]}.dll",
+ f"python{py_version.replace('.','')}.dll",
]
python_shared_libs: list[Path] = []
for name in names:
@@ -1113,7 +1116,7 @@ def _default_bin_excludes(self) -> list[str]:
def _default_bin_includes(self) -> list[str]:
python_shared_libs: list[Path] = []
# Check for distributed "cx_Freeze/bases/lib/Python"
- name = "Python"
+ name = f"Python{ABI_THREAD.upper()}"
for bin_path in self._default_bin_path_includes():
fullname = Path(bin_path, name).resolve()
if fullname.is_file():
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -97,7 +97,8 @@ def build_extension(self, ext) -> None:
library_dirs.append(get_config_var("LIBPL"))
if not ENABLE_SHARED or IS_CONDA:
library_dirs.append(get_config_var("LIBDIR"))
- libraries.append(f"python{get_python_version()}")
+ abi_thread = get_config_var("abi_thread") or ""
+ libraries.append(f"python{get_python_version()}{abi_thread}")
if get_config_var("LIBS"):
extra_args.extend(get_config_var("LIBS").split())
if get_config_var("LIBM"):
@@ -275,38 +276,48 @@ def get_extensions() -> list[Extension]:
os.environ.get("CI", "") != "true"
or os.environ.get("CIBUILDWHEEL", "0") != "1"
)
+ abi_thread = get_config_var("abi_thread") or ""
+ version = sys.version_info[:2]
extensions = [
Extension(
"cx_Freeze.bases.console",
["source/bases/console.c", "source/bases/_common.c"],
optional=optional,
- ),
- Extension(
- "cx_Freeze.bases.console_legacy",
- ["source/legacy/console.c"],
- depends=["source/legacy/common.c"],
- optional=optional
- or (sys.version_info[:2] >= (3, 13) and IS_MACOS),
- ),
+ )
]
-
- if IS_MINGW or IS_WINDOWS:
+ if (
+ version <= (3, 13)
+ and abi_thread == ""
+ and not (IS_MACOS and version == (3, 13))
+ ):
extensions += [
Extension(
- "cx_Freeze.bases.Win32GUI",
- ["source/legacy/Win32GUI.c"],
+ "cx_Freeze.bases.console_legacy",
+ ["source/legacy/console.c"],
depends=["source/legacy/common.c"],
- libraries=["user32"],
optional=optional,
- ),
- Extension(
- "cx_Freeze.bases.Win32Service",
- ["source/legacy/Win32Service.c"],
- depends=["source/legacy/common.c"],
- extra_link_args=["/DELAYLOAD:cx_Logging"],
- libraries=["advapi32"],
- optional=optional,
- ),
+ )
+ ]
+ if IS_MINGW or IS_WINDOWS:
+ if version <= (3, 13) and abi_thread == "":
+ extensions += [
+ Extension(
+ "cx_Freeze.bases.Win32GUI",
+ ["source/legacy/Win32GUI.c"],
+ depends=["source/legacy/common.c"],
+ libraries=["user32"],
+ optional=optional,
+ ),
+ Extension(
+ "cx_Freeze.bases.Win32Service",
+ ["source/legacy/Win32Service.c"],
+ depends=["source/legacy/common.c"],
+ extra_link_args=["/DELAYLOAD:cx_Logging"],
+ libraries=["advapi32"],
+ optional=optional,
+ ),
+ ]
+ extensions += [
Extension(
"cx_Freeze.bases.gui",
["source/bases/Win32GUI.c", "source/bases/_common.c"],
|
diff --git a/tests/test_executables.py b/tests/test_executables.py
--- a/tests/test_executables.py
+++ b/tests/test_executables.py
@@ -12,6 +12,7 @@
from cx_Freeze import Executable
from cx_Freeze._compat import (
+ ABI_THREAD,
BUILD_EXE_DIR,
EXE_SUFFIX,
IS_MACOS,
@@ -241,14 +242,18 @@ def test_executables(
("icon.ico", "icon.icns", "icon.png", "icon.svg"),
),
]
-if IS_MACOS and sys.version_info[:2] >= (3, 13):
+if (
+ sys.version_info[:2] <= (3, 13)
+ and ABI_THREAD == ""
+ and not (IS_MACOS and sys.version_info[:2] == (3, 13))
+):
TEST_VALID_PARAMETERS += [
- ("base", None, "console-"),
+ ("base", None, "console_legacy-"),
+ ("base", "console_legacy", "console_legacy-"),
]
else:
TEST_VALID_PARAMETERS += [
- ("base", None, "console_legacy-"),
- ("base", "console_legacy", "console_legacy-"),
+ ("base", None, "console-"),
]
if IS_WINDOWS or IS_MINGW:
TEST_VALID_PARAMETERS += [
diff --git a/tests/test_freezer.py b/tests/test_freezer.py
--- a/tests/test_freezer.py
+++ b/tests/test_freezer.py
@@ -12,6 +12,7 @@
from cx_Freeze import Freezer
from cx_Freeze._compat import (
+ ABI_THREAD,
BUILD_EXE_DIR,
EXE_SUFFIX,
IS_CONDA,
@@ -99,19 +100,20 @@ def test_freezer_default_bin_includes(tmp_path: Path, monkeypatch) -> None:
monkeypatch.chdir(tmp_path)
freezer = Freezer(executables=["hello.py"])
+ py_version = f"{PYTHON_VERSION}{ABI_THREAD}"
if IS_MINGW:
- expected = f"libpython{PYTHON_VERSION}.dll"
+ expected = f"libpython{py_version}.dll"
elif IS_WINDOWS:
- expected = f"python{PYTHON_VERSION.replace('.','')}.dll"
+ expected = f"python{py_version.replace('.','')}.dll"
elif IS_CONDA: # macOS or Linux
if IS_MACOS:
- expected = f"libpython{PYTHON_VERSION}.dylib"
+ expected = f"libpython{py_version}.dylib"
else:
- expected = f"libpython{PYTHON_VERSION}.so*"
+ expected = f"libpython{py_version}.so*"
elif IS_MACOS:
- expected = "Python"
+ expected = f"Python{ABI_THREAD.upper()}"
elif ENABLE_SHARED: # Linux
- expected = f"libpython{PYTHON_VERSION}.so*"
+ expected = f"libpython{py_version}.so*"
else:
assert freezer.default_bin_includes == []
return
|
Replace _PyMem_RawStrdup with strdup
Per https://github.com/python/cpython/issues/127991#issuecomment-2547810583
Fixes #2568
| 2024-12-30T01:37:43
|
python
|
Easy
|
|
marcelotduarte/cx_Freeze
| 2,583
|
marcelotduarte__cx_Freeze-2583
|
[
"2572"
] |
cf4dc4997e54208d90d4bdc419276da6af39dbc4
|
diff --git a/cx_Freeze/executable.py b/cx_Freeze/executable.py
--- a/cx_Freeze/executable.py
+++ b/cx_Freeze/executable.py
@@ -116,7 +116,7 @@ def init_module_name(self) -> str:
:rtype: str
"""
- return f"{self._internal_name}__init__"
+ return f"__init__{self._internal_name}"
@property
def init_script(self) -> Path:
@@ -143,7 +143,7 @@ def main_module_name(self) -> str:
:rtype: str
"""
- return f"{self._internal_name}__main__"
+ return f"__main__{self._internal_name}"
@property
def main_script(self) -> Path:
@@ -231,10 +231,10 @@ def target_name(self, name: str | None) -> None:
for invalid in STRINGREPLACE:
name = name.replace(invalid, "_")
name = os.path.normcase(name)
- if not name.isidentifier():
+ self._internal_name: str = name
+ if not self.init_module_name.isidentifier():
msg = f"target_name is invalid: {self._name!r}"
raise OptionError(msg)
- self._internal_name: str = name
def validate_executables(dist: Distribution, attr: str, value) -> None:
diff --git a/cx_Freeze/initscripts/__startup__.py b/cx_Freeze/initscripts/__startup__.py
--- a/cx_Freeze/initscripts/__startup__.py
+++ b/cx_Freeze/initscripts/__startup__.py
@@ -124,8 +124,8 @@ def run() -> None:
"""Determines the name of the initscript and execute it."""
name = get_name(sys.executable)
try:
- # basically, the basename of the executable plus __init__
- module_init = __import__(name + "__init__")
+ # basically is __init__ plus the basename of the executable
+ module_init = __import__(f"__init__{name}")
except ModuleNotFoundError:
# but can be renamed when only one executable exists
num = BUILD_CONSTANTS._EXECUTABLES_NUMBER # noqa: SLF001
@@ -137,5 +137,5 @@ def run() -> None:
)
raise RuntimeError(msg) from None
name = get_name(BUILD_CONSTANTS._EXECUTABLE_NAME_0) # noqa: SLF001
- module_init = __import__(name + "__init__")
- module_init.run(name + "__main__")
+ module_init = __import__(f"__init__{name}")
+ module_init.run(f"__main__{name}")
|
diff --git a/tests/test_cli.py b/tests/test_cli.py
--- a/tests/test_cli.py
+++ b/tests/test_cli.py
@@ -10,16 +10,16 @@
import pytest
from generate_samples import create_package, run_command
+from cx_Freeze._compat import BUILD_EXE_DIR, EXE_SUFFIX
+
if TYPE_CHECKING:
from pathlib import Path
-SUFFIX = ".exe" if sys.platform == "win32" else ""
-
SOURCE = """
test.py
print("Hello from cx_Freeze")
command
- cxfreeze test.py --target-dir=dist --excludes=tkinter
+ cxfreeze --script test.py --target-dir=dist --excludes=tkinter
"""
@@ -28,7 +28,7 @@ def test_cxfreeze(tmp_path: Path) -> None:
create_package(tmp_path, SOURCE)
output = run_command(tmp_path)
- file_created = tmp_path / "dist" / f"test{SUFFIX}"
+ file_created = tmp_path / "dist" / f"test{EXE_SUFFIX}"
assert file_created.is_file(), f"file not found: {file_created}"
output = run_command(tmp_path, file_created, timeout=10)
@@ -49,15 +49,30 @@ def test_cxfreeze_additional_help(tmp_path: Path) -> None:
assert "usage: " in output
+def test_cxfreeze_target_name_not_isidentifier(tmp_path: Path) -> None:
+ """Test cxfreeze --target-name not isidentifier, but valid filename."""
+ create_package(tmp_path, SOURCE)
+ output = run_command(
+ tmp_path,
+ "cxfreeze --script test.py --target-name=12345 --excludes=tkinter",
+ )
+
+ file_created = tmp_path / BUILD_EXE_DIR / f"12345{EXE_SUFFIX}"
+ assert file_created.is_file(), f"file not found: {file_created}"
+
+ output = run_command(tmp_path, file_created, timeout=10)
+ assert output.startswith("Hello from cx_Freeze")
+
+
def test_cxfreeze_deprecated_behavior(tmp_path: Path) -> None:
"""Test cxfreeze deprecated behavior."""
create_package(tmp_path, SOURCE)
tmp_path.joinpath("test.py").rename(tmp_path / "test2")
output = run_command(
- tmp_path, "cxfreeze --target-dir=dist --excludes=tkinter test2"
+ tmp_path, "cxfreeze --install-dir=dist --excludes=tkinter test2"
)
- file_created = tmp_path / "dist" / f"test2{SUFFIX}"
+ file_created = tmp_path / "dist" / f"test2{EXE_SUFFIX}"
assert file_created.is_file(), f"file not found: {file_created}"
output = run_command(tmp_path, file_created, timeout=10)
@@ -73,7 +88,7 @@ def test_cxfreeze_deprecated_option(tmp_path: Path) -> None:
)
assert "WARNING: deprecated" in output
- file_created = tmp_path / "dist" / f"test{SUFFIX}"
+ file_created = tmp_path / "dist" / f"test{EXE_SUFFIX}"
assert file_created.is_file(), f"file not found: {file_created}"
output = run_command(tmp_path, file_created, timeout=10)
@@ -127,12 +142,12 @@ def test_cxfreeze_include_path(tmp_path: Path) -> None:
create_package(tmp_path, SOURCE_TEST_PATH)
output = run_command(tmp_path)
- executable = tmp_path / "dist" / f"advanced_1{SUFFIX}"
+ executable = tmp_path / "dist" / f"advanced_1{EXE_SUFFIX}"
assert executable.is_file()
output = run_command(tmp_path, executable, timeout=10)
assert output == OUTPUT1
- executable = tmp_path / "dist" / f"advanced_2{SUFFIX}"
+ executable = tmp_path / "dist" / f"advanced_2{EXE_SUFFIX}"
assert executable.is_file()
output = run_command(tmp_path, executable, timeout=10)
assert output == OUTPUT2
diff --git a/tests/test_executables.py b/tests/test_executables.py
--- a/tests/test_executables.py
+++ b/tests/test_executables.py
@@ -232,6 +232,7 @@ def test_executables(
("init_script", "console", "console.py"),
("target_name", None, f"test{EXE_SUFFIX}"),
("target_name", "test1", f"test1{EXE_SUFFIX}"),
+ ("target_name", "12345", f"12345{EXE_SUFFIX}"),
("target_name", "test-0.1", f"test-0.1{EXE_SUFFIX}"),
("target_name", "test.exe", "test.exe"),
("icon", "icon", ("icon.ico", "icon.icns", "icon.png", "icon.svg")),
@@ -279,12 +280,6 @@ def test_valid(option, value, result) -> None:
OptionError,
"target_name cannot contain the path, only the filename: ",
),
- (
- Executable,
- {"script": "test.py", "target_name": "0test"},
- OptionError,
- "target_name is invalid: ",
- ),
],
ids=[
"executables-invalid-empty",
@@ -292,7 +287,6 @@ def test_valid(option, value, result) -> None:
"executable-invalid-base",
"executable-invalid-init_script",
"executable-invalid-target_name",
- "executable-invalid-target_name-isidentifier",
],
)
def test_invalid(
|
Why is Executable target_name has to be A valid identifier?
In https://github.com/marcelotduarte/cx_Freeze/blob/7.2.1/cx_Freeze/executable.py#L234 target_name is required to be a valid identifier.
Is there any reason for that? I removed that condition and it seems to work fine.
my
target_name="6578e4ecf0464d7fb253de58"
|
Maybe a regression - issue #884 fixed by #889
| 2024-09-23T03:32:58
|
python
|
Easy
|
rigetti/pyquil
| 745
|
rigetti__pyquil-745
|
[
"744"
] |
98dec8330958af4723b7befb51345cea182a886c
|
diff --git a/pyquil/noise.py b/pyquil/noise.py
--- a/pyquil/noise.py
+++ b/pyquil/noise.py
@@ -324,10 +324,24 @@ def damping_after_dephasing(T1, T2, gate_time):
:param float gate_time: The gate duration.
:return: A list of Kraus operators.
"""
- damping = damping_kraus_map(p=1 - np.exp(-float(gate_time) / float(T1))) \
- if T1 != INFINITY else [np.eye(2)]
- dephasing = dephasing_kraus_map(p=.5 * (1 - np.exp(-2 * gate_time / float(T2)))) \
- if T2 != INFINITY else [np.eye(2)]
+ assert T1 >= 0
+ assert T2 >= 0
+
+ if T1 != INFINITY:
+ damping = damping_kraus_map(p=1 - np.exp(-float(gate_time) / float(T1)))
+ else:
+ damping = [np.eye(2)]
+
+ if T2 != INFINITY:
+ gamma_phi = float(gate_time) / float(T2)
+ if T1 != INFINITY:
+ if T2 > 2 * T1:
+ raise ValueError("T2 is upper bounded by 2 * T1")
+ gamma_phi -= float(gate_time) / float(2 * T1)
+
+ dephasing = dephasing_kraus_map(p=.5 * (1 - np.exp(-2 * gamma_phi)))
+ else:
+ dephasing = [np.eye(2)]
return combine_kraus_maps(damping, dephasing)
|
diff --git a/pyquil/tests/test_noise.py b/pyquil/tests/test_noise.py
--- a/pyquil/tests/test_noise.py
+++ b/pyquil/tests/test_noise.py
@@ -70,7 +70,7 @@ def test_damping_after_dephasing():
dephasing = dephasing_kraus_map(p=.5 * (1 - np.exp(-.2)))
ks_ref = combine_kraus_maps(damping, dephasing)
- ks_actual = damping_after_dephasing(10, 10, 1)
+ ks_actual = damping_after_dephasing(20, 40 / 3., 2.)
np.testing.assert_allclose(ks_actual, ks_ref)
|
T2 noise model is wrong when T1 is finite
In particular, a damping noise model with T1 will lead to a contribution to the dephasing rate 1/T2 that equals 1/(2*T1).
| 2018-12-21T19:49:19
|
python
|
Hard
|
|
pytest-dev/pytest-django
| 231
|
pytest-dev__pytest-django-231
|
[
"228"
] |
1f279deb0d46c4f7dd161945b50f6e2add85793a
|
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -51,6 +51,9 @@ def pytest_addoption(parser):
group._addoption('--nomigrations',
action='store_true', dest='nomigrations', default=False,
help='Disable Django 1.7 migrations on test setup')
+ group._addoption('--no-force-no-debug',
+ action='store_true', dest='noforcenodebug', default=False,
+ help='Disable forcing DEBUG setting to False on test setup')
parser.addini(CONFIGURATION_ENV,
'django-configurations class to use by pytest-django.')
group._addoption('--liveserver', default=None,
@@ -236,7 +239,8 @@ def _django_test_environment(request):
if django_settings_is_configured():
from django.conf import settings
from .compat import setup_test_environment, teardown_test_environment
- settings.DEBUG = False
+ if not request.config.getvalue('noforcenodebug'):
+ settings.DEBUG = False
setup_test_environment()
request.addfinalizer(teardown_test_environment)
|
diff --git a/tests/test_django_settings_module.py b/tests/test_django_settings_module.py
--- a/tests/test_django_settings_module.py
+++ b/tests/test_django_settings_module.py
@@ -244,6 +244,31 @@ def test_debug_is_false():
assert r.ret == 0
+def test_debug_no_force(testdir, monkeypatch):
+ monkeypatch.delenv('DJANGO_SETTINGS_MODULE')
+ testdir.makeconftest("""
+ from django.conf import settings
+
+ def pytest_configure():
+ settings.configure(SECRET_KEY='set from pytest_configure',
+ DEBUG=True,
+ DATABASES={'default': {
+ 'ENGINE': 'django.db.backends.sqlite3',
+ 'NAME': ':memory:'}},
+ INSTALLED_APPS=['django.contrib.auth',
+ 'django.contrib.contenttypes',])
+ """)
+
+ testdir.makepyfile("""
+ from django.conf import settings
+ def test_debug_is_true():
+ assert settings.DEBUG is True
+ """)
+
+ r = testdir.runpytest('--no-force-no-debug')
+ assert r.ret == 0
+
+
@pytest.mark.skipif(not hasattr(django, 'setup'),
reason="This Django version does not support app loading")
@pytest.mark.django_project(extra_settings="""
|
why DEBUG is hardcoded to False?
Hi
https://github.com/pytest-dev/pytest-django/blob/master/pytest_django/plugin.py#L239
this looks not too flexible
I tried a lot of things before i found this hardcode - i needed to understand why my liveserver fails, and it returned just standard 500 instead of debug page, and debug is set to True in my test settings
So i think this hardcode should be removed to respect test settings
|
IIRC the setup with Django's testrunner is also False, to reflect what would be used in production, but I am not certain.
:+1: for a way to configure/override this.
ok i'll prepare PR
| 2015-04-10T13:35:34
|
python
|
Easy
|
rigetti/pyquil
| 1,477
|
rigetti__pyquil-1477
|
[
"1476"
] |
57f0501c2d2bc438f983f81fd5793dc969a04ed3
|
diff --git a/pyquil/quil.py b/pyquil/quil.py
--- a/pyquil/quil.py
+++ b/pyquil/quil.py
@@ -874,9 +874,9 @@ def __add__(self, other: InstructionDesignator) -> "Program":
p = Program()
p.inst(self)
p.inst(other)
- p._calibrations = self.calibrations
- p._waveforms = self.waveforms
- p._frames = self.frames
+ p._calibrations = self.calibrations.copy()
+ p._waveforms = self.waveforms.copy()
+ p._frames = self.frames.copy()
p._memory = self._memory.copy()
if isinstance(other, Program):
p.calibrations.extend(other.calibrations)
|
diff --git a/test/unit/test_program.py b/test/unit/test_program.py
--- a/test/unit/test_program.py
+++ b/test/unit/test_program.py
@@ -56,3 +56,31 @@ def test_parameterized_readout_symmetrization():
p += RX(symmetrization[0], 0)
p += RX(symmetrization[1], 1)
assert parameterized_readout_symmetrization([0, 1]).out() == p.out()
+
+
+def test_adding_does_not_mutate():
+ # https://github.com/rigetti/pyquil/issues/1476
+ p1 = Program(
+ """
+DEFCAL RX(pi/2) 32:
+ FENCE 32
+ NONBLOCKING PULSE 32 "rf" drag_gaussian(duration: 3.2e-08, fwhm: 8e-09, t0: 1.6e-08, anh: -190000000.0, alpha: -1.8848698349348032, scale: 0.30631340170943533, phase: 0.0, detuning: 1622438.2425563578)
+ FENCE 32
+
+RX(pi/2) 32
+"""
+ )
+ original_p1 = p1.copy()
+ p2 = Program(
+ """
+DEFCAL RX(pi/2) 33:
+ FENCE 33
+ NONBLOCKING PULSE 33 "rf" drag_gaussian(duration: 2e-08, fwhm: 5e-09, t0: 1e-08, anh: -190000000.0, alpha: -0.9473497322033984, scale: 0.25680107985232403, phase: 0.0, detuning: 1322130.5458282642)
+ FENCE 33
+
+RX(pi/2) 33
+"""
+ )
+ p_all = p1 + p2
+ assert p1 == original_p1
+ assert p1.calibrations != p_all.calibrations
diff --git a/test/unit/test_quil.py b/test/unit/test_quil.py
old mode 100755
new mode 100644
|
Adding two `Program`s together unexpectedly mutates first `Program`
Pre-Report Checklist
--------------------
- [x] I am running the latest versions of pyQuil and the Forest SDK
- [x] I checked to make sure that this bug has not already been reported
Issue Description
-----------------
Summary: when adding two Programs together, like p1 + p2, the first program p1 gets mutated — p1.calibrations will as a result contain the combined calibrations. But I would have expected both p1 and p2 to remain unchanged.
I believe the reason for issue is that in the source code, it uses `p.calibrations.extend(other.calibrations)`
which mutates the original’s list
. https://github.com/rigetti/pyquil/blob/master/pyquil/quil.py#L882
How to Reproduce
----------------
### Code Snippet
```python
print("@@@ p32 before adding")
print(p32)
print("@@@ p33 before adding")
print(p33)
p_all = p32 + p33
print("@@@ p32 after adding <-- here is the unexpected behavior")
print(p32)
print("@@@ p33 after adding")
print(p33)
print("@@@ p_all after adding")
print(p_all)
```
### Error Output
```
@@@ p32 before adding
DEFCAL RX(pi/2) 32:
FENCE 32
NONBLOCKING PULSE 32 "rf" drag_gaussian(duration: 3.2e-08, fwhm: 8e-09, t0: 1.6e-08, anh: -190000000.0, alpha: -1.8848698349348032, scale: 0.30631340170943533, phase: 0.0, detuning: 1622438.2425563578)
FENCE 32
RX(pi/2) 32
@@@ p33 before adding
DEFCAL RX(pi/2) 33:
FENCE 33
NONBLOCKING PULSE 33 "rf" drag_gaussian(duration: 2e-08, fwhm: 5e-09, t0: 1e-08, anh: -190000000.0, alpha: -0.9473497322033984, scale: 0.25680107985232403, phase: 0.0, detuning: 1322130.5458282642)
FENCE 33
RX(pi/2) 33
@@@ p32 after adding <-- here is the unexpected behavior
DEFCAL RX(pi/2) 32:
FENCE 32
NONBLOCKING PULSE 32 "rf" drag_gaussian(duration: 3.2e-08, fwhm: 8e-09, t0: 1.6e-08, anh: -190000000.0, alpha: -1.8848698349348032, scale: 0.30631340170943533, phase: 0.0, detuning: 1622438.2425563578)
FENCE 32
DEFCAL RX(pi/2) 33:
FENCE 33
NONBLOCKING PULSE 33 "rf" drag_gaussian(duration: 2e-08, fwhm: 5e-09, t0: 1e-08, anh: -190000000.0, alpha: -0.9473497322033984, scale: 0.25680107985232403, phase: 0.0, detuning: 1322130.5458282642)
FENCE 33
RX(pi/2) 32
@@@ p33 after adding
DEFCAL RX(pi/2) 33:
FENCE 33
NONBLOCKING PULSE 33 "rf" drag_gaussian(duration: 2e-08, fwhm: 5e-09, t0: 1e-08, anh: -190000000.0, alpha: -0.9473497322033984, scale: 0.25680107985232403, phase: 0.0, detuning: 1322130.5458282642)
FENCE 33
RX(pi/2) 33
@@@ p_all after adding
DEFCAL RX(pi/2) 32:
FENCE 32
NONBLOCKING PULSE 32 "rf" drag_gaussian(duration: 3.2e-08, fwhm: 8e-09, t0: 1.6e-08, anh: -190000000.0, alpha: -1.8848698349348032, scale: 0.30631340170943533, phase: 0.0, detuning: 1622438.2425563578)
FENCE 32
DEFCAL RX(pi/2) 33:
FENCE 33
NONBLOCKING PULSE 33 "rf" drag_gaussian(duration: 2e-08, fwhm: 5e-09, t0: 1e-08, anh: -190000000.0, alpha: -0.9473497322033984, scale: 0.25680107985232403, phase: 0.0, detuning: 1322130.5458282642)
FENCE 33
RX(pi/2) 32
RX(pi/2) 33
```
Environment Context
-------------------
Operating System: macOS Monterey
Python Version (`python -V`): 3.9.13
Quilc Version (`quilc --version`): N/A
QVM Version (`qvm --version`): N/A
Python Environment Details (`pip freeze` or `conda list`):
```
Package Version
----------------------------- -----------
aiohttp 3.8.1
aiohttp-retry 2.4.6
aiosignal 1.2.0
alabaster 0.7.12
ansiwrap 0.8.4
anyio 3.6.1
appdirs 1.4.4
argon2-cffi 21.3.0
argon2-cffi-bindings 21.2.0
asteval 0.9.26
asttokens 2.0.5
async-timeout 4.0.2
asyncssh 2.10.1
atpublic 3.0.1
attrs 20.3.0
Babel 2.10.1
backcall 0.2.0
beautifulsoup4 4.11.1
benchmark-quantum-gates 0.5.0
bitarray 2.5.1
black 22.3.0
bleach 5.0.0
cachetools 5.0.0
certifi 2021.10.8
cffi 1.15.0
charset-normalizer 2.0.12
click 8.1.3
colorama 0.4.4
commonmark 0.9.1
configobj 5.0.6
coverage 6.3.3
cryptography 37.0.2
cvxopt 1.3.0
cvxpy 1.2.0
cycler 0.11.0
debugpy 1.6.3
decorator 5.1.1
defusedxml 0.7.1
dictdiffer 0.9.0
diskcache 5.4.0
distro 1.7.0
docutils 0.17.1
dpath 2.0.6
dulwich 0.20.35
dvc 2.10.2
dvc-render 0.0.5
dvclive 0.8.0
ecos 2.0.10
entrypoints 0.4
executing 0.8.3
fastjsonschema 2.15.3
flake8 4.0.1
flake8-black 0.3.2
flake8-docstrings 1.6.0
flatten-dict 0.4.2
flufl.lock 7.0
fonttools 4.33.3
forest-benchmarking 0.8.0
frozenlist 1.3.0
fsspec 2022.3.0
ftfy 6.1.1
funcy 1.17
future 0.18.2
future-fstrings 1.2.0
gitdb 4.0.9
GitPython 3.1.27
google-api-core 2.7.3
google-api-python-client 2.47.0
google-auth 2.6.6
google-auth-httplib2 0.1.0
googleapis-common-protos 1.56.1
gprof2dot 2021.2.21
grandalf 0.6
h11 0.9.0
httpcore 0.11.1
httplib2 0.20.4
httpx 0.15.5
idna 3.3
imagesize 1.3.0
importlib-metadata 4.11.3
iniconfig 1.1.1
ipykernel 6.13.0
ipympl 0.9.2
ipython 8.3.0
ipython-genutils 0.2.0
ipywidgets 7.7.0
iso8601 0.1.16
isort 5.10.1
jedi 0.18.1
Jinja2 3.1.2
joblib 1.1.0
json5 0.9.8
jsonschema 4.5.1
jupyter-client 7.3.1
jupyter-core 4.10.0
jupyter-lsp 1.5.1
jupyter-server 1.17.0
jupyter-server-mathjax 0.2.5
jupyterlab 3.4.2
jupyterlab-git 0.34.2
jupyterlab-lsp 3.10.1
jupyterlab-pygments 0.2.2
jupyterlab-server 2.13.0
jupyterlab-widgets 1.1.0
kaleido 0.2.1
kiwisolver 1.4.2
lark 0.11.3
lmfit 1.0.3
mailchecker 4.1.16
Mako 1.2.1
MarkupSafe 2.1.1
matplotlib 3.5.2
matplotlib-inline 0.1.3
mccabe 0.6.1
mistune 0.8.4
mpmath 1.2.1
msgpack 0.6.2
multidict 6.0.2
mypy-extensions 0.4.3
nanotime 0.5.2
nbclassic 0.3.7
nbclient 0.6.3
nbconvert 6.5.0
nbdime 3.1.1
nbformat 5.4.0
nest-asyncio 1.5.5
networkx 2.8
notebook 6.4.11
notebook-shim 0.1.0
numexpr 2.8.1
numpy 1.21.0
oauth2client 4.1.3
osqp 0.6.2.post5
packaging 21.3
pandas 1.4.2
pandocfilters 1.5.0
papermill 2.3.4
parso 0.8.3
pathspec 0.9.0
patsy 0.5.2
pexpect 4.8.0
phonenumbers 8.12.48
pickleshare 0.7.5
Pillow 9.1.0
pip 22.2.2
platformdirs 2.5.2
plotly 5.8.0
pluggy 1.0.0
prometheus-client 0.14.1
prompt-toolkit 3.0.29
protobuf 3.20.1
psutil 5.9.0
ptyprocess 0.7.0
pure-eval 0.2.2
py 1.11.0
pyaml 21.10.1
pyarrow 5.0.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycodestyle 2.8.0
pycparser 2.21
pydantic 1.9.0
pydocstyle 6.1.1
pydot 1.4.2
PyDrive2 1.10.1
pyflakes 2.4.0
pygit2 1.9.1
Pygments 2.12.0
pygtrie 2.4.2
PyJWT 1.7.1
pyOpenSSL 22.0.0
pyparsing 3.0.9
pyquil 3.1.0
pyrsistent 0.18.1
pytest 7.1.2
pytest-cov 3.0.0
pytest-depends 1.0.1
pytest-profiling 1.7.0
python-benedict 0.25.1
python-dateutil 2.8.2
python-fsutil 0.6.0
python-rapidjson 1.6
python-slugify 6.1.2
pytz 2022.1
PyYAML 6.0
pyzmq 22.3.0
qcs-api-client 0.20.13
qdldl 0.1.5.post2
qpu-hybrid-benchmark-trueq 0.5.8
qutip 4.7.0
qutip-qip 0.2.1
requests 2.27.1
retry 0.9.2
retrying 1.3.3
rfc3339 6.2
rfc3986 1.5.0
rich 12.4.1
rigetti-qpu-hybrid-benchmark 0.5.24
rpcq 3.10.0
rsa 4.8
ruamel.yaml 0.17.21
ruamel.yaml.clib 0.2.6
scikit-learn 1.1.0
scikit-optimize 0.9.0
scipy 1.8.0
scmrepo 0.0.19
scs 3.2.0
seaborn 0.11.2
Send2Trash 1.8.0
setuptools 63.4.1
setuptools-scm 6.4.2
shortuuid 1.0.9
shtab 1.5.4
six 1.16.0
smmap 5.0.0
sniffio 1.2.0
snowballstemmer 2.2.0
soupsieve 2.3.2.post1
Sphinx 4.5.0
sphinx-autodoc-typehints 1.18.1
sphinx-rtd-theme 0.4.3
sphinxcontrib-applehelp 1.0.2
sphinxcontrib-devhelp 1.0.2
sphinxcontrib-htmlhelp 2.0.0
sphinxcontrib-jsmath 1.0.1
sphinxcontrib-qthelp 1.0.3
sphinxcontrib-serializinghtml 1.1.5
stack-data 0.2.0
statsmodels 0.13.2
sympy 1.10.1
tables 3.7.0
tabulate 0.8.9
tenacity 8.0.1
terminado 0.13.3
text-unidecode 1.3
textwrap3 0.9.2
threadpoolctl 3.1.0
tinycss2 1.1.1
tokenize-rt 4.2.1
toml 0.10.2
tomli 2.0.1
tornado 6.1
tqdm 4.64.0
traitlets 5.2.0
trueq 2.13.1
typing_extensions 4.2.0
uncertainties 3.1.6
uritemplate 4.1.1
urllib3 1.26.9
voluptuous 0.13.1
wcwidth 0.2.5
webencodings 0.5.1
websocket-client 1.3.2
wheel 0.37.1
widgetsnbextension 3.6.0
xmltodict 0.13.0
yarl 1.7.2
zc.lockfile 2.0
zipp 3.8.0
```
| 2022-09-20T22:23:51
|
python
|
Hard
|
|
pytest-dev/pytest-django
| 881
|
pytest-dev__pytest-django-881
|
[
"513"
] |
bb9e86e0c0141a30d07078f71b288026b6e583d2
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -304,7 +304,7 @@ def admin_client(db, admin_user):
from django.test.client import Client
client = Client()
- client.login(username=admin_user.username, password="password")
+ client.force_login(admin_user)
return client
|
diff --git a/tests/test_fixtures.py b/tests/test_fixtures.py
--- a/tests/test_fixtures.py
+++ b/tests/test_fixtures.py
@@ -49,6 +49,17 @@ def test_admin_client_no_db_marker(admin_client):
assert force_str(resp.content) == "You are an admin"
+# For test below.
+@pytest.fixture
+def existing_admin_user(django_user_model):
+ return django_user_model._default_manager.create_superuser('admin', None, None)
+
+
+def test_admin_client_existing_user(db, existing_admin_user, admin_user, admin_client):
+ resp = admin_client.get("/admin-required/")
+ assert force_str(resp.content) == "You are an admin"
+
+
@pytest.mark.django_db
def test_admin_user(admin_user, django_user_model):
assert isinstance(admin_user, django_user_model)
|
admin_client is not checking for login success
`client.login` inside `admin_client` can return `False` in the case when there's an existing admin user with a password set to something other than `'password'`. Perhaps, `admin_client` should use `force_login` instead?
|
Seems sensible
Can you provide a failing test and fix in a PR?
Sure, I'll do that in the next couple of days.
| 2020-10-09T12:42:31
|
python
|
Easy
|
pytest-dev/pytest-django
| 869
|
pytest-dev__pytest-django-869
|
[
"660"
] |
9d91f0b5492c136d4cd9d6012672783171b4034c
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -1,5 +1,3 @@
-# -*- coding: utf-8 -*-
-
import os
import sys
import datetime
diff --git a/pytest_django/asserts.py b/pytest_django/asserts.py
--- a/pytest_django/asserts.py
+++ b/pytest_django/asserts.py
@@ -23,10 +23,10 @@ def assertion_func(*args, **kwargs):
__all__ = []
assertions_names = set()
assertions_names.update(
- set(attr for attr in vars(TestCase) if attr.startswith('assert')),
- set(attr for attr in vars(SimpleTestCase) if attr.startswith('assert')),
- set(attr for attr in vars(LiveServerTestCase) if attr.startswith('assert')),
- set(attr for attr in vars(TransactionTestCase) if attr.startswith('assert')),
+ {attr for attr in vars(TestCase) if attr.startswith('assert')},
+ {attr for attr in vars(SimpleTestCase) if attr.startswith('assert')},
+ {attr for attr in vars(LiveServerTestCase) if attr.startswith('assert')},
+ {attr for attr in vars(TransactionTestCase) if attr.startswith('assert')},
)
for assert_func in assertions_names:
diff --git a/pytest_django/compat.py b/pytest_django/compat.py
deleted file mode 100644
--- a/pytest_django/compat.py
+++ /dev/null
@@ -1,12 +0,0 @@
-# This file cannot be imported from until Django sets up
-try:
- # Django 1.11+
- from django.test.utils import setup_databases, teardown_databases # noqa: F401, F811
-except ImportError:
- # In Django prior to 1.11, teardown_databases is only available as a method on DiscoverRunner
- from django.test.runner import setup_databases, DiscoverRunner # noqa: F401, F811
-
- def teardown_databases(db_cfg, verbosity):
- DiscoverRunner(verbosity=verbosity, interactive=False).teardown_databases(
- db_cfg
- )
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -1,9 +1,7 @@
"""All pytest-django fixtures"""
-from __future__ import with_statement
import os
-import warnings
from contextlib import contextmanager
from functools import partial
@@ -91,7 +89,7 @@ def django_db_setup(
django_db_modify_db_settings,
):
"""Top level fixture to ensure test databases are available"""
- from .compat import setup_databases, teardown_databases
+ from django.test.utils import setup_databases, teardown_databases
setup_databases_args = {}
@@ -164,7 +162,7 @@ def _disable_native_migrations():
class MigrateSilentCommand(migrate.Command):
def handle(self, *args, **kwargs):
kwargs["verbosity"] = 0
- return super(MigrateSilentCommand, self).handle(*args, **kwargs)
+ return super().handle(*args, **kwargs)
migrate.Command = MigrateSilentCommand
@@ -320,7 +318,7 @@ def rf():
return RequestFactory()
-class SettingsWrapper(object):
+class SettingsWrapper:
_to_restore = []
def __delattr__(self, attr):
@@ -370,8 +368,8 @@ def live_server(request):
The address the server is started from is taken from the
--liveserver command line option or if this is not provided from
the DJANGO_LIVE_TEST_SERVER_ADDRESS environment variable. If
- neither is provided ``localhost:8081,8100-8200`` is used. See the
- Django documentation for its full syntax.
+ neither is provided ``localhost`` is used. See the Django
+ documentation for its full syntax.
NOTE: If the live server needs database access to handle a request
your test will have to request database access. Furthermore
@@ -385,27 +383,9 @@ def live_server(request):
"""
skip_if_no_django()
- import django
-
addr = request.config.getvalue("liveserver") or os.getenv(
"DJANGO_LIVE_TEST_SERVER_ADDRESS"
- )
-
- if addr and ":" in addr:
- if django.VERSION >= (1, 11):
- ports = addr.split(":")[1]
- if "-" in ports or "," in ports:
- warnings.warn(
- "Specifying multiple live server ports is not supported "
- "in Django 1.11. This will be an error in a future "
- "pytest-django release."
- )
-
- if not addr:
- if django.VERSION < (1, 11):
- addr = "localhost:8081,8100-8200"
- else:
- addr = "localhost"
+ ) or "localhost"
server = live_server_helper.LiveServer(addr)
request.addfinalizer(server.stop)
@@ -458,14 +438,14 @@ def _assert_num_queries(config, num, exact=True, connection=None, info=None):
num,
"" if exact else "or less ",
"but {} done".format(
- num_performed == 1 and "1 was" or "%d were" % (num_performed,)
+ num_performed == 1 and "1 was" or "{} were".format(num_performed)
),
)
if info:
msg += "\n{}".format(info)
if verbose:
sqls = (q["sql"] for q in context.captured_queries)
- msg += "\n\nQueries:\n========\n\n%s" % "\n\n".join(sqls)
+ msg += "\n\nQueries:\n========\n\n" + "\n\n".join(sqls)
else:
msg += " (add -v option to show queries)"
pytest.fail(msg)
diff --git a/pytest_django/live_server_helper.py b/pytest_django/live_server_helper.py
--- a/pytest_django/live_server_helper.py
+++ b/pytest_django/live_server_helper.py
@@ -1,8 +1,4 @@
-import six
-
-
-@six.python_2_unicode_compatible
-class LiveServer(object):
+class LiveServer:
"""The liveserver fixture
This is the object that the ``live_server`` fixture returns.
@@ -10,7 +6,6 @@ class LiveServer(object):
"""
def __init__(self, addr):
- import django
from django.db import connections
from django.test.testcases import LiveServerThread
from django.test.utils import modify_settings
@@ -39,17 +34,13 @@ def __init__(self, addr):
liveserver_kwargs["static_handler"] = _StaticFilesHandler
- if django.VERSION < (1, 11):
- host, possible_ports = parse_addr(addr)
- self.thread = LiveServerThread(host, possible_ports, **liveserver_kwargs)
+ try:
+ host, port = addr.split(":")
+ except ValueError:
+ host = addr
else:
- try:
- host, port = addr.split(":")
- except ValueError:
- host = addr
- else:
- liveserver_kwargs["port"] = int(port)
- self.thread = LiveServerThread(host, **liveserver_kwargs)
+ liveserver_kwargs["port"] = int(port)
+ self.thread = LiveServerThread(host, **liveserver_kwargs)
self._live_server_modified_settings = modify_settings(
ALLOWED_HOSTS={"append": host}
@@ -69,41 +60,13 @@ def stop(self):
@property
def url(self):
- return "http://%s:%s" % (self.thread.host, self.thread.port)
+ return "http://{}:{}".format(self.thread.host, self.thread.port)
def __str__(self):
return self.url
def __add__(self, other):
- return "%s%s" % (self, other)
+ return "{}{}".format(self, other)
def __repr__(self):
return "<LiveServer listening at %s>" % self.url
-
-
-def parse_addr(specified_address):
- """Parse the --liveserver argument into a host/IP address and port range"""
- # This code is based on
- # django.test.testcases.LiveServerTestCase.setUpClass
-
- # The specified ports may be of the form '8000-8010,8080,9200-9300'
- # i.e. a comma-separated list of ports or ranges of ports, so we break
- # it down into a detailed list of all possible ports.
- possible_ports = []
- try:
- host, port_ranges = specified_address.split(":")
- for port_range in port_ranges.split(","):
- # A port range can be of either form: '8000' or '8000-8010'.
- extremes = list(map(int, port_range.split("-")))
- assert len(extremes) in (1, 2)
- if len(extremes) == 1:
- # Port range of the form '8000'
- possible_ports.append(extremes[0])
- else:
- # Port range of the form '8000-8010'
- for port in range(extremes[0], extremes[1] + 1):
- possible_ports.append(port)
- except Exception:
- raise Exception('Invalid address ("%s") for live server.' % specified_address)
-
- return host, possible_ports
diff --git a/pytest_django/migrations.py b/pytest_django/migrations.py
--- a/pytest_django/migrations.py
+++ b/pytest_django/migrations.py
@@ -2,7 +2,7 @@
from pytest_django.lazy_django import get_django_version
-class DisableMigrations(object):
+class DisableMigrations:
def __init__(self):
self._django_version = get_django_version()
@@ -10,7 +10,4 @@ def __contains__(self, item):
return True
def __getitem__(self, item):
- if self._django_version >= (1, 9):
- return None
- else:
- return "notmigrations"
+ return None
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -8,6 +8,7 @@
import inspect
from functools import reduce
import os
+import pathlib
import sys
import types
@@ -39,22 +40,11 @@
from .lazy_django import django_settings_is_configured, skip_if_no_django
-try:
- import pathlib
-except ImportError:
- import pathlib2 as pathlib
-
SETTINGS_MODULE_ENV = "DJANGO_SETTINGS_MODULE"
CONFIGURATION_ENV = "DJANGO_CONFIGURATION"
INVALID_TEMPLATE_VARS_ENV = "FAIL_INVALID_TEMPLATE_VARS"
-PY2 = sys.version_info[0] == 2
-
-# pytest 4.2 handles unittest setup/teardown itself via wrapping fixtures.
-_pytest_version_info = tuple(int(x) for x in pytest.__version__.split(".", 2)[:2])
-_handle_unittest_methods = _pytest_version_info < (4, 2)
-
_report_header = []
@@ -303,11 +293,11 @@ def _get_option_with_source(option, envname):
dc, dc_source = _get_option_with_source(options.dc, CONFIGURATION_ENV)
if ds:
- _report_header.append("settings: %s (from %s)" % (ds, ds_source))
+ _report_header.append("settings: {} (from {})".format(ds, ds_source))
os.environ[SETTINGS_MODULE_ENV] = ds
if dc:
- _report_header.append("configuration: %s (from %s)" % (dc, dc_source))
+ _report_header.append("configuration: {} (from {})".format(dc, dc_source))
os.environ[CONFIGURATION_ENV] = dc
# Install the django-configurations importer
@@ -330,7 +320,7 @@ def pytest_report_header():
return ["django: " + ", ".join(_report_header)]
-@pytest.mark.trylast
+@pytest.hookimpl(trylast=True)
def pytest_configure():
# Allow Django settings to be configured in a user pytest_configure call,
# but make sure we call django.setup()
@@ -354,13 +344,7 @@ def _classmethod_is_defined_at_leaf(cls, method_name):
try:
f = method.__func__
except AttributeError:
- pytest.fail("%s.%s should be a classmethod" % (cls, method_name))
- if PY2 and not (
- inspect.ismethod(method)
- and inspect.isclass(method.__self__)
- and issubclass(cls, method.__self__)
- ):
- pytest.fail("%s.%s should be a classmethod" % (cls, method_name))
+ pytest.fail("{}.{} should be a classmethod".format(cls, method_name))
return f is not super_method.__func__
@@ -409,12 +393,6 @@ def _restore_class_methods(cls):
cls.tearDownClass = tearDownClass
-def pytest_runtest_setup(item):
- if _handle_unittest_methods:
- if django_settings_is_configured() and is_django_unittest(item):
- _disable_class_methods(item.cls)
-
-
@pytest.hookimpl(tryfirst=True)
def pytest_collection_modifyitems(items):
# If Django is not configured we don't need to bother
@@ -523,33 +501,21 @@ def _django_setup_unittest(request, django_db_blocker):
# Fix/patch pytest.
# Before pytest 5.4: https://github.com/pytest-dev/pytest/issues/5991
# After pytest 5.4: https://github.com/pytest-dev/pytest-django/issues/824
- from _pytest.monkeypatch import MonkeyPatch
+ from _pytest.unittest import TestCaseFunction
+ original_runtest = TestCaseFunction.runtest
def non_debugging_runtest(self):
self._testcase(result=self)
- mp_debug = MonkeyPatch()
- mp_debug.setattr("_pytest.unittest.TestCaseFunction.runtest", non_debugging_runtest)
-
- request.getfixturevalue("django_db_setup")
-
- cls = request.node.cls
-
- with django_db_blocker.unblock():
- if _handle_unittest_methods:
- _restore_class_methods(cls)
- cls.setUpClass()
- _disable_class_methods(cls)
+ try:
+ TestCaseFunction.runtest = non_debugging_runtest
- yield
+ request.getfixturevalue("django_db_setup")
- _restore_class_methods(cls)
- cls.tearDownClass()
- else:
+ with django_db_blocker.unblock():
yield
-
- if mp_debug:
- mp_debug.undo()
+ finally:
+ TestCaseFunction.runtest = original_runtest
@pytest.fixture(scope="function", autouse=True)
@@ -591,12 +557,7 @@ def _django_set_urlconf(request):
if marker:
skip_if_no_django()
import django.conf
-
- try:
- from django.urls import clear_url_caches, set_urlconf
- except ImportError:
- # Removed in Django 2.0
- from django.core.urlresolvers import clear_url_caches, set_urlconf
+ from django.urls import clear_url_caches, set_urlconf
urls = validate_urls(marker)
original_urlconf = django.conf.settings.ROOT_URLCONF
@@ -629,7 +590,7 @@ def _fail_for_invalid_template_variable():
``pytest.mark.ignore_template_errors``
"""
- class InvalidVarException(object):
+ class InvalidVarException:
"""Custom handler for invalid strings in templates."""
def __init__(self):
@@ -677,7 +638,7 @@ def __mod__(self, var):
"""Handle TEMPLATE_STRING_IF_INVALID % var."""
origin = self._get_origin()
if origin:
- msg = "Undefined template variable '%s' in '%s'" % (var, origin)
+ msg = "Undefined template variable '{}' in '{}'".format(var, origin)
else:
msg = "Undefined template variable '%s'" % var
if self.fail:
@@ -732,7 +693,7 @@ def _django_clear_site_cache():
# ############### Helper Functions ################
-class _DatabaseBlockerContextManager(object):
+class _DatabaseBlockerContextManager:
def __init__(self, db_blocker):
self._db_blocker = db_blocker
@@ -743,7 +704,7 @@ def __exit__(self, exc_type, exc_value, traceback):
self._db_blocker.restore()
-class _DatabaseBlocker(object):
+class _DatabaseBlocker:
"""Manager for django.db.backends.base.base.BaseDatabaseWrapper.
This is the object returned by django_db_blocker.
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,5 +1,4 @@
#!/usr/bin/env python
-# -*- coding: utf-8 -*-
import codecs
import os
@@ -28,11 +27,10 @@ def read(fname):
license='BSD-3-Clause',
packages=['pytest_django'],
long_description=read('README.rst'),
- python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
+ python_requires='>=3.5',
setup_requires=['setuptools_scm>=1.11.1'],
install_requires=[
- 'pytest>=3.6',
- 'pathlib2;python_version<"3.4"',
+ 'pytest>=5.4.0',
],
extras_require={
'docs': [
@@ -42,17 +40,10 @@ def read(fname):
'testing': [
'Django',
'django-configurations>=2.0',
- 'six',
],
},
classifiers=['Development Status :: 5 - Production/Stable',
'Framework :: Django',
- 'Framework :: Django :: 1.8',
- 'Framework :: Django :: 1.9',
- 'Framework :: Django :: 1.10',
- 'Framework :: Django :: 1.11',
- 'Framework :: Django :: 2.0',
- 'Framework :: Django :: 2.1',
'Framework :: Django :: 2.2',
'Framework :: Django :: 3.0',
'Framework :: Django :: 3.1',
@@ -60,8 +51,6 @@ def read(fname):
'License :: OSI Approved :: BSD License',
'Operating System :: OS Independent',
'Programming Language :: Python',
- 'Programming Language :: Python :: 2.7',
- 'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
|
diff --git a/pytest_django_test/app/migrations/0001_initial.py b/pytest_django_test/app/migrations/0001_initial.py
--- a/pytest_django_test/app/migrations/0001_initial.py
+++ b/pytest_django_test/app/migrations/0001_initial.py
@@ -1,6 +1,4 @@
-# -*- coding: utf-8 -*-
# Generated by Django 1.9a1 on 2016-06-22 04:33
-from __future__ import unicode_literals
from django.db import migrations, models
diff --git a/pytest_django_test/compat.py b/pytest_django_test/compat.py
deleted file mode 100644
--- a/pytest_django_test/compat.py
+++ /dev/null
@@ -1,4 +0,0 @@
-try:
- from urllib2 import urlopen, HTTPError
-except ImportError:
- from urllib.request import urlopen, HTTPError # noqa: F401
diff --git a/pytest_django_test/db_helpers.py b/pytest_django_test/db_helpers.py
--- a/pytest_django_test/db_helpers.py
+++ b/pytest_django_test/db_helpers.py
@@ -31,7 +31,7 @@ def get_db_engine():
return _settings["ENGINE"].split(".")[-1]
-class CmdResult(object):
+class CmdResult:
def __init__(self, status_code, std_out, std_err):
self.status_code = status_code
self.std_out = std_out
@@ -64,7 +64,7 @@ def skip_if_sqlite_in_memory():
def _get_db_name(db_suffix=None):
name = TEST_DB_NAME
if db_suffix:
- name = "%s_%s" % (name, db_suffix)
+ name = "{}_{}".format(name, db_suffix)
return name
@@ -72,7 +72,7 @@ def drop_database(db_suffix=None):
name = _get_db_name(db_suffix)
db_engine = get_db_engine()
- if db_engine == "postgresql_psycopg2":
+ if db_engine == "postgresql":
r = run_cmd("psql", "postgres", "-c", "DROP DATABASE %s" % name)
assert "DROP DATABASE" in force_str(
r.std_out
@@ -94,7 +94,7 @@ def db_exists(db_suffix=None):
name = _get_db_name(db_suffix)
db_engine = get_db_engine()
- if db_engine == "postgresql_psycopg2":
+ if db_engine == "postgresql":
r = run_cmd("psql", name, "-c", "SELECT 1")
return r.status_code == 0
@@ -111,7 +111,7 @@ def db_exists(db_suffix=None):
def mark_database():
db_engine = get_db_engine()
- if db_engine == "postgresql_psycopg2":
+ if db_engine == "postgresql":
r = run_cmd("psql", TEST_DB_NAME, "-c", "CREATE TABLE mark_table();")
assert r.status_code == 0
return
@@ -136,7 +136,7 @@ def mark_database():
def mark_exists():
db_engine = get_db_engine()
- if db_engine == "postgresql_psycopg2":
+ if db_engine == "postgresql":
r = run_cmd("psql", TEST_DB_NAME, "-c", "SELECT 1 FROM mark_table")
# When something pops out on std_out, we are good
diff --git a/pytest_django_test/settings_base.py b/pytest_django_test/settings_base.py
--- a/pytest_django_test/settings_base.py
+++ b/pytest_django_test/settings_base.py
@@ -1,5 +1,3 @@
-import django
-
ROOT_URLCONF = "pytest_django_test.urls"
INSTALLED_APPS = [
"django.contrib.auth",
@@ -20,9 +18,6 @@
"django.contrib.messages.middleware.MessageMiddleware",
]
-if django.VERSION < (1, 10):
- MIDDLEWARE_CLASSES = MIDDLEWARE
-
TEMPLATES = [
{
diff --git a/pytest_django_test/settings_postgres.py b/pytest_django_test/settings_postgres.py
--- a/pytest_django_test/settings_postgres.py
+++ b/pytest_django_test/settings_postgres.py
@@ -2,7 +2,7 @@
# PyPy compatibility
try:
- from psycopg2ct import compat
+ from psycopg2cffi import compat
compat.register()
except ImportError:
@@ -11,9 +11,7 @@
DATABASES = {
"default": {
- "ENGINE": "django.db.backends.postgresql_psycopg2",
+ "ENGINE": "django.db.backends.postgresql",
"NAME": "pytest_django_should_never_get_accessed",
- "HOST": "localhost",
- "USER": "",
}
}
diff --git a/pytest_django_test/urls.py b/pytest_django_test/urls.py
--- a/pytest_django_test/urls.py
+++ b/pytest_django_test/urls.py
@@ -1,8 +1,8 @@
-from django.conf.urls import url
+from django.urls import path
from .app import views
urlpatterns = [
- url(r"^item_count/$", views.item_count),
- url(r"^admin-required/$", views.admin_required_view),
+ path("item_count/", views.item_count),
+ path("admin-required/", views.admin_required_view),
]
diff --git a/pytest_django_test/urls_overridden.py b/pytest_django_test/urls_overridden.py
--- a/pytest_django_test/urls_overridden.py
+++ b/pytest_django_test/urls_overridden.py
@@ -1,6 +1,6 @@
-from django.conf.urls import url
+from django.urls import path
from django.http import HttpResponse
urlpatterns = [
- url(r"^overridden_url/$", lambda r: HttpResponse("Overridden urlconf works!"))
+ path("overridden_url/", lambda r: HttpResponse("Overridden urlconf works!"))
]
diff --git a/tests/conftest.py b/tests/conftest.py
--- a/tests/conftest.py
+++ b/tests/conftest.py
@@ -3,7 +3,6 @@
from textwrap import dedent
import pytest
-import six
from django.conf import settings
try:
@@ -58,7 +57,7 @@ def django_testdir(request, testdir, monkeypatch):
# Pypy compatibility
try:
- from psycopg2ct import compat
+ from psycopg2cffi import compat
except ImportError:
pass
else:
@@ -81,9 +80,6 @@ def django_testdir(request, testdir, monkeypatch):
'django.contrib.messages.middleware.MessageMiddleware',
]
- if django.VERSION < (1, 10):
- MIDDLEWARE_CLASSES = MIDDLEWARE
-
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
@@ -118,7 +114,7 @@ def django_testdir(request, testdir, monkeypatch):
test_app_path = tpkg_path.join("app")
# Copy the test app to make it available in the new test run
- shutil.copytree(six.text_type(app_source), six.text_type(test_app_path))
+ shutil.copytree(str(app_source), str(test_app_path))
tpkg_path.join("the_settings.py").write(test_settings)
monkeypatch.setenv("DJANGO_SETTINGS_MODULE", "tpkg.the_settings")
diff --git a/tests/test_database.py b/tests/test_database.py
--- a/tests/test_database.py
+++ b/tests/test_database.py
@@ -1,5 +1,3 @@
-from __future__ import with_statement
-
import pytest
from django.db import connection
from django.test.testcases import connections_support_transactions
diff --git a/tests/test_db_setup.py b/tests/test_db_setup.py
--- a/tests/test_db_setup.py
+++ b/tests/test_db_setup.py
@@ -1,6 +1,5 @@
import pytest
-from pytest_django.lazy_django import get_django_version
from pytest_django_test.db_helpers import (
db_exists,
drop_database,
@@ -453,33 +452,7 @@ def test_a():
result.stdout.fnmatch_lines(["*PASSED*test_a*"])
-@pytest.mark.skipif(
- get_django_version() >= (1, 9),
- reason=(
- "Django 1.9 requires migration and has no concept of initial data fixtures"
- ),
-)
-def test_initial_data(django_testdir_initial):
- """Test that initial data gets loaded."""
- django_testdir_initial.create_test_module(
- """
- import pytest
-
- from .app.models import Item
-
- @pytest.mark.django_db
- def test_inner():
- assert [x.name for x in Item.objects.all()] \
- == ["mark_initial_data"]
- """
- )
-
- result = django_testdir_initial.runpytest_subprocess("--tb=short", "-v")
- assert result.ret == 0
- result.stdout.fnmatch_lines(["*test_inner*PASSED*"])
-
-
-class TestNativeMigrations(object):
+class TestNativeMigrations:
""" Tests for Django Migrations """
def test_no_migrations(self, django_testdir):
diff --git a/tests/test_django_settings_module.py b/tests/test_django_settings_module.py
--- a/tests/test_django_settings_module.py
+++ b/tests/test_django_settings_module.py
@@ -3,7 +3,6 @@
If these tests fail you probably forgot to run "python setup.py develop".
"""
-import django
import pytest
@@ -308,10 +307,6 @@ def test_debug_is_false():
assert r.ret == 0
-@pytest.mark.skipif(
- not hasattr(django, "setup"),
- reason="This Django version does not support app loading",
-)
@pytest.mark.django_project(
extra_settings="""
INSTALLED_APPS = [
@@ -329,10 +324,7 @@ class TestApp(AppConfig):
name = 'tpkg.app'
def ready(self):
- try:
- populating = apps.loading
- except AttributeError: # Django < 2.0
- populating = apps._lock.locked()
+ populating = apps.loading
print('READY(): populating=%r' % populating)
""",
"apps.py",
@@ -342,10 +334,7 @@ def ready(self):
"""
from django.apps import apps
- try:
- populating = apps.loading
- except AttributeError: # Django < 2.0
- populating = apps._lock.locked()
+ populating = apps.loading
print('IMPORT: populating=%r,ready=%r' % (populating, apps.ready))
SOME_THING = 1234
@@ -360,10 +349,7 @@ def ready(self):
from tpkg.app.models import SOME_THING
def test_anything():
- try:
- populating = apps.loading
- except AttributeError: # Django < 2.0
- populating = apps._lock.locked()
+ populating = apps.loading
print('TEST: populating=%r,ready=%r' % (populating, apps.ready))
"""
@@ -372,10 +358,7 @@ def test_anything():
result = django_testdir.runpytest_subprocess("-s", "--tb=line")
result.stdout.fnmatch_lines(["*IMPORT: populating=True,ready=False*"])
result.stdout.fnmatch_lines(["*READY(): populating=True*"])
- if django.VERSION < (2, 0):
- result.stdout.fnmatch_lines(["*TEST: populating=False,ready=True*"])
- else:
- result.stdout.fnmatch_lines(["*TEST: populating=True,ready=True*"])
+ result.stdout.fnmatch_lines(["*TEST: populating=True,ready=True*"])
assert result.ret == 0
diff --git a/tests/test_environment.py b/tests/test_environment.py
--- a/tests/test_environment.py
+++ b/tests/test_environment.py
@@ -1,5 +1,3 @@
-from __future__ import with_statement
-
import os
import pytest
@@ -8,7 +6,6 @@
from django.core import mail
from django.db import connection
from django.test import TestCase
-from pytest_django.lazy_django import get_django_version
from pytest_django_test.app.models import Item
@@ -57,11 +54,11 @@ def test_two(self):
def test_invalid_template_variable(django_testdir):
django_testdir.create_app_file(
"""
- from django.conf.urls import url
+ from django.urls import path
from tpkg.app import views
- urlpatterns = [url(r'invalid_template/', views.invalid_template)]
+ urlpatterns = [path('invalid_template/', views.invalid_template)]
""",
"urls.py",
)
@@ -95,10 +92,7 @@ def test_ignore(client):
)
result = django_testdir.runpytest_subprocess("-s", "--fail-on-template-vars")
- if get_django_version() >= (1, 9):
- origin = "'*/tpkg/app/templates/invalid_template_base.html'"
- else:
- origin = "'invalid_template.html'"
+ origin = "'*/tpkg/app/templates/invalid_template_base.html'"
result.stdout.fnmatch_lines_random(
[
"tpkg/test_the_test.py F.*",
@@ -163,11 +157,11 @@ def test_for_invalid_template():
def test_invalid_template_variable_opt_in(django_testdir):
django_testdir.create_app_file(
"""
- from django.conf.urls import url
+ from django.urls import path
from tpkg.app import views
- urlpatterns = [url(r'invalid_template/', views.invalid_template)]
+ urlpatterns = [path('invalid_template', views.invalid_template)]
""",
"urls.py",
)
@@ -255,14 +249,9 @@ def test_verbose_with_v(self, testdir):
"""Verbose output with '-v'."""
result = testdir.runpytest_subprocess("-s", "-v")
result.stdout.fnmatch_lines_random(["tpkg/test_the_test.py:*", "*PASSED*"])
- if get_django_version() >= (2, 2):
- result.stderr.fnmatch_lines(
- ["*Destroying test database for alias 'default'*"]
- )
- else:
- result.stdout.fnmatch_lines(
- ["*Destroying test database for alias 'default'...*"]
- )
+ result.stderr.fnmatch_lines(
+ ["*Destroying test database for alias 'default'*"]
+ )
def test_more_verbose_with_vv(self, testdir):
"""More verbose output with '-v -v'."""
@@ -275,37 +264,22 @@ def test_more_verbose_with_vv(self, testdir):
"*PASSED*",
]
)
- if get_django_version() >= (2, 2):
- result.stderr.fnmatch_lines(
- [
- "*Creating test database for alias*",
- "*Destroying test database for alias 'default'*",
- ]
- )
- else:
- result.stdout.fnmatch_lines(
- [
- "*Creating test database for alias*",
- "*Destroying test database for alias 'default'*",
- ]
- )
+ result.stderr.fnmatch_lines(
+ [
+ "*Creating test database for alias*",
+ "*Destroying test database for alias 'default'*",
+ ]
+ )
def test_more_verbose_with_vv_and_reusedb(self, testdir):
"""More verbose output with '-v -v', and --create-db."""
result = testdir.runpytest_subprocess("-s", "-v", "-v", "--create-db")
result.stdout.fnmatch_lines(["tpkg/test_the_test.py:*", "*PASSED*"])
- if get_django_version() >= (2, 2):
- result.stderr.fnmatch_lines(["*Creating test database for alias*"])
- assert (
- "*Destroying test database for alias 'default' ('*')...*"
- not in result.stderr.str()
- )
- else:
- result.stdout.fnmatch_lines(["*Creating test database for alias*"])
- assert (
- "*Destroying test database for alias 'default' ('*')...*"
- not in result.stdout.str()
- )
+ result.stderr.fnmatch_lines(["*Creating test database for alias*"])
+ assert (
+ "*Destroying test database for alias 'default' ('*')...*"
+ not in result.stderr.str()
+ )
@pytest.mark.django_db
diff --git a/tests/test_fixtures.py b/tests/test_fixtures.py
--- a/tests/test_fixtures.py
+++ b/tests/test_fixtures.py
@@ -4,10 +4,10 @@
fixtures are tested in test_database.
"""
-from __future__ import with_statement
import socket
from contextlib import contextmanager
+from urllib.request import urlopen, HTTPError
import pytest
from django.conf import settings as real_settings
@@ -17,9 +17,7 @@
from django.test.testcases import connections_support_transactions
from django.utils.encoding import force_str
-from pytest_django.lazy_django import get_django_version
from pytest_django_test.app.models import Item
-from pytest_django_test.compat import HTTPError, urlopen
@contextmanager
@@ -322,7 +320,7 @@ def test_settings_before(self):
from django.conf import settings
assert (
- "%s.%s" % (settings.__class__.__module__, settings.__class__.__name__)
+ "{}.{}".format(settings.__class__.__module__, settings.__class__.__name__)
== "django.conf.Settings"
)
TestLiveServer._test_settings_before_run = True
@@ -335,18 +333,14 @@ def test_change_settings(self, live_server, settings):
def test_settings_restored(self):
"""Ensure that settings are restored after test_settings_before."""
- import django
from django.conf import settings
assert TestLiveServer._test_settings_before_run is True
assert (
- "%s.%s" % (settings.__class__.__module__, settings.__class__.__name__)
+ "{}.{}".format(settings.__class__.__module__, settings.__class__.__name__)
== "django.conf.Settings"
)
- if django.VERSION >= (1, 11):
- assert settings.ALLOWED_HOSTS == ["testserver"]
- else:
- assert settings.ALLOWED_HOSTS == ["*"]
+ assert settings.ALLOWED_HOSTS == ["testserver"]
def test_transactions(self, live_server):
if not connections_support_transactions():
@@ -417,12 +411,9 @@ def test_serve_static_with_staticfiles_app(self, django_testdir, settings):
"""
django_testdir.create_test_module(
"""
- from django.utils.encoding import force_str
+ from urllib.request import urlopen
- try:
- from urllib2 import urlopen
- except ImportError:
- from urllib.request import urlopen
+ from django.utils.encoding import force_str
class TestLiveServer:
def test_a(self, live_server, settings):
@@ -445,28 +436,6 @@ def test_serve_static_dj17_without_staticfiles_app(self, live_server, settings):
with pytest.raises(HTTPError):
urlopen(live_server + "/static/a_file.txt").read()
- @pytest.mark.skipif(
- get_django_version() < (1, 11), reason="Django >= 1.11 required"
- )
- def test_specified_port_range_error_message_django_111(self, django_testdir):
- django_testdir.create_test_module(
- """
- def test_with_live_server(live_server):
- pass
- """
- )
-
- result = django_testdir.runpytest_subprocess("--liveserver=localhost:1234-2345")
- result.stdout.fnmatch_lines(
- [
- "*Specifying multiple live server ports is not supported in Django 1.11. This "
- "will be an error in a future pytest-django release.*"
- ]
- )
-
- @pytest.mark.skipif(
- get_django_version() < (1, 11, 2), reason="Django >= 1.11.2 required"
- )
def test_specified_port_django_111(self, django_testdir):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
@@ -516,16 +485,11 @@ class MyCustomUser(AbstractUser):
)
django_testdir.create_app_file(
"""
- from tpkg.app import views
+ from django.urls import path
- try:
- from django.urls import path
- except ImportError:
- from django.conf.urls import url
+ from tpkg.app import views
- urlpatterns = [url(r'admin-required/', views.admin_required_view)]
- else:
- urlpatterns = [path('admin-required/', views.admin_required_view)]
+ urlpatterns = [path('admin-required/', views.admin_required_view)]
""",
"urls.py",
)
@@ -556,9 +520,6 @@ def test_custom_user_model(admin_client):
django_testdir.create_app_file("", "migrations/__init__.py")
django_testdir.create_app_file(
"""
-# -*- coding: utf-8 -*-
-from __future__ import unicode_literals
-
from django.db import models, migrations
import django.utils.timezone
import django.core.validators
diff --git a/tests/test_unittest.py b/tests/test_unittest.py
--- a/tests/test_unittest.py
+++ b/tests/test_unittest.py
@@ -1,7 +1,6 @@
import pytest
from django.test import TestCase
-from pytest_django.plugin import _pytest_version_info
from pytest_django_test.app.models import Item
@@ -161,16 +160,8 @@ def test_pass(self):
result = django_testdir.runpytest_subprocess("-v", "-s")
expected_lines = [
"* ERROR at setup of TestFoo.test_pass *",
+ "E * TypeError: *",
]
- if _pytest_version_info < (4, 2):
- expected_lines += [
- "E *Failed: <class 'tpkg.test_the_test.TestFoo'>.setUpClass should be a classmethod", # noqa:E501
- ]
- else:
- expected_lines += [
- "E * TypeError: *",
- ]
-
result.stdout.fnmatch_lines(expected_lines)
assert result.ret == 1
@@ -217,7 +208,7 @@ def test_setUpClass_mixin(self, django_testdir):
"""
from django.test import TestCase
- class TheMixin(object):
+ class TheMixin:
@classmethod
def setUpClass(cls):
super(TheMixin, cls).setUpClass()
@@ -289,7 +280,7 @@ def test_multi_inheritance_setUpClass(self, django_testdir):
# Using a mixin is a regression test, see #280 for more details:
# https://github.com/pytest-dev/pytest-django/issues/280
- class SomeMixin(object):
+ class SomeMixin:
pass
class TestA(SomeMixin, TestCase):
diff --git a/tests/test_urls.py b/tests/test_urls.py
--- a/tests/test_urls.py
+++ b/tests/test_urls.py
@@ -1,14 +1,11 @@
import pytest
from django.conf import settings
+from django.urls import is_valid_path
from django.utils.encoding import force_str
@pytest.mark.urls("pytest_django_test.urls_overridden")
def test_urls():
- try:
- from django.urls import is_valid_path
- except ImportError:
- from django.core.urlresolvers import is_valid_path
assert settings.ROOT_URLCONF == "pytest_django_test.urls_overridden"
assert is_valid_path("/overridden_url/")
@@ -22,21 +19,18 @@ def test_urls_client(client):
def test_urls_cache_is_cleared(testdir):
testdir.makepyfile(
myurls="""
- from django.conf.urls import url
+ from django.urls import path
def fake_view(request):
pass
- urlpatterns = [url(r'first/$', fake_view, name='first')]
+ urlpatterns = [path('first', fake_view, name='first')]
"""
)
testdir.makepyfile(
"""
- try:
- from django.urls import reverse, NoReverseMatch
- except ImportError: # Django < 2.0
- from django.core.urlresolvers import reverse, NoReverseMatch
+ from django.urls import reverse, NoReverseMatch
import pytest
@pytest.mark.urls('myurls')
@@ -58,32 +52,29 @@ def test_something_else():
def test_urls_cache_is_cleared_and_new_urls_can_be_assigned(testdir):
testdir.makepyfile(
myurls="""
- from django.conf.urls import url
+ from django.urls import path
def fake_view(request):
pass
- urlpatterns = [url(r'first/$', fake_view, name='first')]
+ urlpatterns = [path('first', fake_view, name='first')]
"""
)
testdir.makepyfile(
myurls2="""
- from django.conf.urls import url
+ from django.urls import path
def fake_view(request):
pass
- urlpatterns = [url(r'second/$', fake_view, name='second')]
+ urlpatterns = [path('second', fake_view, name='second')]
"""
)
testdir.makepyfile(
"""
- try:
- from django.urls import reverse, NoReverseMatch
- except ImportError: # Django < 2.0
- from django.core.urlresolvers import reverse, NoReverseMatch
+ from django.urls import reverse, NoReverseMatch
import pytest
@pytest.mark.urls('myurls')
|
Import pathlib from pytest
As discussed on #636 when all supported versions of pytest offer an import of `pathlib`, use that rather than direct dependency on `pathlib2`
| 2020-09-19T18:49:07
|
python
|
Easy
|
|
pytest-dev/pytest-django
| 664
|
pytest-dev__pytest-django-664
|
[
"662"
] |
5000ff814584e67eda6085f36a3644f6a834f6c2
|
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -120,7 +120,10 @@ def _handle_import_error(extra_message):
def _add_django_project_to_path(args):
def is_django_project(path):
- return path.is_dir() and (path / 'manage.py').exists()
+ try:
+ return path.is_dir() and (path / 'manage.py').exists()
+ except OSError:
+ return False
def arg_to_path(arg):
# Test classes or functions can be appended to paths separated by ::
@@ -130,7 +133,6 @@ def arg_to_path(arg):
def find_django_path(args):
args = map(str, args)
args = [arg_to_path(x) for x in args if not x.startswith("-")]
- args = [p for p in args if p.is_dir()]
if not args:
args = [pathlib.Path.cwd()]
|
diff --git a/tests/test_manage_py_scan.py b/tests/test_manage_py_scan.py
--- a/tests/test_manage_py_scan.py
+++ b/tests/test_manage_py_scan.py
@@ -83,3 +83,15 @@ def test_django_project_found_invalid_settings_version(django_testdir, monkeypat
result = django_testdir.runpytest_subprocess('django_project_root', '--help')
assert result.ret == 0
result.stdout.fnmatch_lines(['*usage:*'])
+
+
+@pytest.mark.django_project(project_root='django_project_root',
+ create_manage_py=True)
+def test_runs_without_error_on_long_args(django_testdir):
+ django_testdir.create_test_module("""
+ def test_this_is_a_long_message_which_caused_a_bug_when_scanning_for_manage_py_12346712341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234112341234112451234123412341234123412341234123412341234123412341234123412341234123412341234123412341234():
+ assert 1 + 1 == 2
+ """)
+
+ result = django_testdir.runpytest_subprocess('-k', 'this_is_a_long_message_which_caused_a_bug_when_scanning_for_manage_py_12346712341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234123412341234112341234112451234123412341234123412341234123412341234123412341234123412341234123412341234123412341234', 'django_project_root')
+ assert result.ret == 0
|
OSError on long command-line args
In the logic of django_find_project there exist these lines:
```
def find_django_path(args):
args = map(str, args)
args = [arg_to_path(x) for x in args if not x.startswith("-")]
args = [p for p in args if p.is_dir()]
...
```
Unfortunately, this means that if there are really long command-line args that this can get a `OSError: [Errno 36] File name too long: ...` which prevents me from, for example, using really long args to pytest's `-k` option.
Thanks for looking into this.
|
Please consider creating a failing test and fix for this yourself.
I assume the `args = [p for p in args if p.is_dir()]` should be turned into a loop that try/catches any OSError and ignores it.
/cc @voidus for the pathlib change that appears to trigger this
| 2018-10-16T19:19:27
|
python
|
Easy
|
pytest-dev/pytest-django
| 970
|
pytest-dev__pytest-django-970
|
[
"329",
"956"
] |
904a99507bfd2d9570ce5d21deb006c4ae3f7ad3
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -20,7 +20,8 @@
import django
_DjangoDbDatabases = Optional[Union["Literal['__all__']", Iterable[str]]]
- _DjangoDb = Tuple[bool, bool, _DjangoDbDatabases]
+ # transaction, reset_sequences, databases, serialized_rollback
+ _DjangoDb = Tuple[bool, bool, _DjangoDbDatabases, bool]
__all__ = [
@@ -28,6 +29,7 @@
"db",
"transactional_db",
"django_db_reset_sequences",
+ "django_db_serialized_rollback",
"admin_user",
"django_user_model",
"django_username_field",
@@ -151,9 +153,19 @@ def _django_db_helper(
marker = request.node.get_closest_marker("django_db")
if marker:
- transactional, reset_sequences, databases = validate_django_db(marker)
+ (
+ transactional,
+ reset_sequences,
+ databases,
+ serialized_rollback,
+ ) = validate_django_db(marker)
else:
- transactional, reset_sequences, databases = False, False, None
+ (
+ transactional,
+ reset_sequences,
+ databases,
+ serialized_rollback,
+ ) = False, False, None, False
transactional = transactional or (
"transactional_db" in request.fixturenames
@@ -162,6 +174,9 @@ def _django_db_helper(
reset_sequences = reset_sequences or (
"django_db_reset_sequences" in request.fixturenames
)
+ serialized_rollback = serialized_rollback or (
+ "django_db_serialized_rollback" in request.fixturenames
+ )
django_db_blocker.unblock()
request.addfinalizer(django_db_blocker.restore)
@@ -175,10 +190,12 @@ def _django_db_helper(
test_case_class = django.test.TestCase
_reset_sequences = reset_sequences
+ _serialized_rollback = serialized_rollback
_databases = databases
class PytestDjangoTestCase(test_case_class): # type: ignore[misc,valid-type]
reset_sequences = _reset_sequences
+ serialized_rollback = _serialized_rollback
if _databases is not None:
databases = _databases
@@ -196,18 +213,20 @@ def validate_django_db(marker) -> "_DjangoDb":
"""Validate the django_db marker.
It checks the signature and creates the ``transaction``,
- ``reset_sequences`` and ``databases`` attributes on the marker
- which will have the correct values.
+ ``reset_sequences``, ``databases`` and ``serialized_rollback`` attributes on
+ the marker which will have the correct values.
- A sequence reset is only allowed when combined with a transaction.
+ Sequence reset and serialized_rollback are only allowed when combined with
+ transaction.
"""
def apifun(
transaction: bool = False,
reset_sequences: bool = False,
databases: "_DjangoDbDatabases" = None,
+ serialized_rollback: bool = False,
) -> "_DjangoDb":
- return transaction, reset_sequences, databases
+ return transaction, reset_sequences, databases, serialized_rollback
return apifun(*marker.args, **marker.kwargs)
@@ -303,6 +322,27 @@ def django_db_reset_sequences(
# is requested.
+@pytest.fixture(scope="function")
+def django_db_serialized_rollback(
+ _django_db_helper: None,
+ db: None,
+) -> None:
+ """Require a test database with serialized rollbacks.
+
+ This requests the ``db`` fixture, and additionally performs rollback
+ emulation - serializes the database contents during setup and restores
+ it during teardown.
+
+ This fixture may be useful for transactional tests, so is usually combined
+ with ``transactional_db``, but can also be useful on databases which do not
+ support transactions.
+
+ Note that this will slow down that test suite by approximately 3x.
+ """
+ # The `_django_db_helper` fixture checks if `django_db_serialized_rollback`
+ # is requested.
+
+
@pytest.fixture()
def client() -> "django.test.client.Client":
"""A Django test client instance."""
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -33,6 +33,7 @@
from .fixtures import django_db_modify_db_settings_tox_suffix # noqa
from .fixtures import django_db_modify_db_settings_xdist_suffix # noqa
from .fixtures import django_db_reset_sequences # noqa
+from .fixtures import django_db_serialized_rollback # noqa
from .fixtures import django_db_setup # noqa
from .fixtures import django_db_use_migrations # noqa
from .fixtures import django_user_model # noqa
@@ -265,14 +266,17 @@ def pytest_load_initial_conftests(
# Register the marks
early_config.addinivalue_line(
"markers",
- "django_db(transaction=False, reset_sequences=False, databases=None): "
+ "django_db(transaction=False, reset_sequences=False, databases=None, "
+ "serialized_rollback=False): "
"Mark the test as using the Django test database. "
"The *transaction* argument allows you to use real transactions "
"in the test like Django's TransactionTestCase. "
"The *reset_sequences* argument resets database sequences before "
"the test. "
"The *databases* argument sets which database aliases the test "
- "uses (by default, only 'default'). Use '__all__' for all databases.",
+ "uses (by default, only 'default'). Use '__all__' for all databases. "
+ "The *serialized_rollback* argument enables rollback emulation for "
+ "the test.",
)
early_config.addinivalue_line(
"markers",
@@ -387,7 +391,12 @@ def get_order_number(test: pytest.Item) -> int:
else:
marker_db = test.get_closest_marker('django_db')
if marker_db:
- transaction, reset_sequences, databases = validate_django_db(marker_db)
+ (
+ transaction,
+ reset_sequences,
+ databases,
+ serialized_rollback,
+ ) = validate_django_db(marker_db)
uses_db = True
transactional = transaction or reset_sequences
else:
|
diff --git a/tests/test_database.py b/tests/test_database.py
--- a/tests/test_database.py
+++ b/tests/test_database.py
@@ -48,7 +48,12 @@ def non_zero_sequences_counter(db: None) -> None:
class TestDatabaseFixtures:
"""Tests for the different database fixtures."""
- @pytest.fixture(params=["db", "transactional_db", "django_db_reset_sequences"])
+ @pytest.fixture(params=[
+ "db",
+ "transactional_db",
+ "django_db_reset_sequences",
+ "django_db_serialized_rollback",
+ ])
def all_dbs(self, request) -> None:
if request.param == "django_db_reset_sequences":
return request.getfixturevalue("django_db_reset_sequences")
@@ -56,6 +61,10 @@ def all_dbs(self, request) -> None:
return request.getfixturevalue("transactional_db")
elif request.param == "db":
return request.getfixturevalue("db")
+ elif request.param == "django_db_serialized_rollback":
+ return request.getfixturevalue("django_db_serialized_rollback")
+ else:
+ assert False # pragma: no cover
def test_access(self, all_dbs: None) -> None:
Item.objects.create(name="spam")
@@ -113,6 +122,51 @@ def test_django_db_reset_sequences_requested(
["*test_django_db_reset_sequences_requested PASSED*"]
)
+ def test_serialized_rollback(self, db: None, django_testdir) -> None:
+ django_testdir.create_app_file(
+ """
+ from django.db import migrations
+
+ def load_data(apps, schema_editor):
+ Item = apps.get_model("app", "Item")
+ Item.objects.create(name="loaded-in-migration")
+
+ class Migration(migrations.Migration):
+ dependencies = [
+ ("app", "0001_initial"),
+ ]
+
+ operations = [
+ migrations.RunPython(load_data),
+ ]
+ """,
+ "migrations/0002_data_migration.py",
+ )
+
+ django_testdir.create_test_module(
+ """
+ import pytest
+ from .app.models import Item
+
+ @pytest.mark.django_db(transaction=True, serialized_rollback=True)
+ def test_serialized_rollback_1():
+ assert Item.objects.filter(name="loaded-in-migration").exists()
+
+ @pytest.mark.django_db(transaction=True)
+ def test_serialized_rollback_2(django_db_serialized_rollback):
+ assert Item.objects.filter(name="loaded-in-migration").exists()
+ Item.objects.create(name="test2")
+
+ @pytest.mark.django_db(transaction=True, serialized_rollback=True)
+ def test_serialized_rollback_3():
+ assert Item.objects.filter(name="loaded-in-migration").exists()
+ assert not Item.objects.filter(name="test2").exists()
+ """
+ )
+
+ result = django_testdir.runpytest_subprocess("-v")
+ assert result.ret == 0
+
@pytest.fixture
def mydb(self, all_dbs: None) -> None:
# This fixture must be able to access the database
@@ -160,6 +214,10 @@ def fixture_with_transdb(self, transactional_db: None) -> None:
def fixture_with_reset_sequences(self, django_db_reset_sequences: None) -> None:
Item.objects.create(name="spam")
+ @pytest.fixture
+ def fixture_with_serialized_rollback(self, django_db_serialized_rollback: None) -> None:
+ Item.objects.create(name="ham")
+
def test_trans(self, fixture_with_transdb: None) -> None:
pass
@@ -180,6 +238,16 @@ def test_reset_sequences(
) -> None:
pass
+ # The test works when transactions are not supported, but it interacts
+ # badly with other tests.
+ @pytest.mark.skipif('not connection.features.supports_transactions')
+ def test_serialized_rollback(
+ self,
+ fixture_with_serialized_rollback: None,
+ fixture_with_db: None,
+ ) -> None:
+ pass
+
class TestDatabaseMarker:
"Tests for the django_db marker."
@@ -264,6 +332,19 @@ def test_all_databases(self, request) -> None:
SecondItem.objects.count()
SecondItem.objects.create(name="spam")
+ @pytest.mark.django_db
+ def test_serialized_rollback_disabled(self, request):
+ marker = request.node.get_closest_marker("django_db")
+ assert not marker.kwargs
+
+ # The test works when transactions are not supported, but it interacts
+ # badly with other tests.
+ @pytest.mark.skipif('not connection.features.supports_transactions')
+ @pytest.mark.django_db(serialized_rollback=True)
+ def test_serialized_rollback_enabled(self, request):
+ marker = request.node.get_closest_marker("django_db")
+ assert marker.kwargs["serialized_rollback"]
+
def test_unittest_interaction(django_testdir) -> None:
"Test that (non-Django) unittests cannot access the DB."
diff --git a/tests/test_db_setup.py b/tests/test_db_setup.py
--- a/tests/test_db_setup.py
+++ b/tests/test_db_setup.py
@@ -56,6 +56,10 @@ def test_run_second_reset_sequences_decorator():
def test_run_first_decorator():
pass
+ @pytest.mark.django_db(serialized_rollback=True)
+ def test_run_first_serialized_rollback_decorator():
+ pass
+
class MyTestCase(TestCase):
def test_run_last_test_case(self):
pass
@@ -77,6 +81,7 @@ def test_run_second_transaction_test_case(self):
result.stdout.fnmatch_lines([
"*test_run_first_fixture*",
"*test_run_first_decorator*",
+ "*test_run_first_serialized_rollback_decorator*",
"*test_run_first_django_test_case*",
"*test_run_second_decorator*",
"*test_run_second_fixture*",
|
Tests using live_server fixture removing data from data migrations
I've created a simple test case to reproduce this behavior https://github.com/ekiro/case_pytest/blob/master/app/tests.py which fails after second test using live_server fixture.
MyModel objects are created in migration, using RunPython. It seems like after any test with live_server, every row from the database is truncated. Both, postgresql and sqlite3 was tested.
EDIT:
Tests
``` python
"""
MyModel objects are created in migration
Test results:
app/tests.py::test_no_live_server PASSED
app/tests.py::test_live_server PASSED
app/tests.py::test_live_server2 FAILED
app/tests.py::test_no_live_server_after_live_server FAILED
"""
import pytest
from .models import MyModel
@pytest.mark.django_db()
def test_no_live_server():
"""Passed"""
assert MyModel.objects.count() == 10
@pytest.mark.django_db()
def test_live_server(live_server):
"""Passed"""
assert MyModel.objects.count() == 10
@pytest.mark.django_db()
def test_live_server2(live_server):
"""Failed, because count() returns 0"""
assert MyModel.objects.count() == 10
@pytest.mark.django_db()
def test_no_live_server_after_live_server():
"""Failed, because count() returns 0"""
assert MyModel.objects.count() == 10
```
Feature/serialized rollback
|
That's because of the `transactional_db` fixture being used automatically by `live_server` (there is no need to mark it with `@pytest.mark.django_db`). There are several issues / discussions in this regard, but the last time I looked closer at this, there was no easy solution to this problem that comes with using data migrations.
A workaround is to use pytest fixtures to wrap your data migrations / data fixtures.
(btw: better put the tests inline in the issue rather than into an external resource that might change over time.)
I just hit this as well and it took me a long time to track it down, even though I'm reasonably familiar with Django's test framework and migrations.
This is actually a surprising performance tradeoff of Django's `TestCase`. It's documented here:
https://docs.djangoproject.com/en/1.9/topics/testing/overview/#rollback-emulation
In a regular Django test suite, the workaround consists in setting a `serialized_rollback = True` class attribute on the test case.
I don't know how to achieve the same effect with pytest-django's [dynamically generated test classes](https://github.com/pytest-dev/pytest-django/blob/3529fea78e9931434e1812268fe022e3fb30a9f2/pytest_django/fixtures.py#L107).
The following change "solves" the issue at the expense of unconditionally selecting the least efficient behavior.
``` diff
--- pytest_django/fixtures.py.orig 2016-04-27 17:12:25.000000000 +0200
+++ pytest_django/fixtures.py 2016-04-27 17:21:50.000000000 +0200
@@ -103,6 +103,7 @@
if django_case:
case = django_case(methodName='__init__')
+ case.serialized_rollback = True
case._pre_setup()
request.addfinalizer(case._post_teardown)
```
The following technique works, but I can't recommend it for rather obvious reasons...
``` python
import pytest
from django.core.management import call_command
from pytest_django.fixtures import transactional_db as _transactional_db
def _reload_fixture_data():
fixture_names = [
# Create fixtures for the data created by data migrations
# and list them here.
]
call_command('loaddata', *fixture_names)
@pytest.fixture(scope='function')
def transactional_db(request, _django_db_setup, _django_cursor_wrapper):
"""
Override a pytest-django fixture to restore the contents of the database.
This works around https://github.com/pytest-dev/pytest-django/issues/329 by
restoring data created by data migrations. We know what data matters and we
maintain it in (Django) fixtures. We don't read it from the database. This
causes some repetition but keeps this (pytest) fixture (almost) simple.
"""
try:
return _transactional_db(request, _django_db_setup, _django_cursor_wrapper)
finally:
# /!\ Epically shameful hack /!\ _transactional_db adds two finalizers:
# _django_cursor_wrapper.disable() and case._post_teardown(). Note that
# finalizers run in the opposite order of that in which they are added.
# We want to run after case._post_teardown() which flushes the database
# but before _django_cursor_wrapper.disable() which prevents further
# database queries. Hence, open heart surgery in pytest internals...
finalizers = request._fixturedef._finalizer
assert len(finalizers) == 2
assert finalizers[0].__qualname__ == 'CursorManager.disable'
assert finalizers[1].__qualname__ == 'TransactionTestCase._post_teardown'
finalizers.insert(1, _reload_fixture_data)
```
Would an option to conditionally enable `serialized_rollback` be a good solution?
I.e. something like
``` python
@pytest.mark.django_db(transaction=True, serialized_rollback=True)
def test_foo():
...
```
I think that would be good.
In my use case:
- the `transactional_db` fixture is triggered by `live_server`, but I wouldn't mind adding a `django_db` fixture to specify serialized rollback
- unrelated to pytest-django -- `case.serialized_rollback = True` still fails because Django attemps to deserialized objects in an order that doesn't respect FK constraints, I think that's a bug in Django
Ok, perfect :)
I don't have time to work on a fix right now, but adding such an option to the `django_db` marker should and setting `case.serialized_rollback = True` (like you did above) should be relatively straightforward.
Ticket for the Django bug I mentioned above: https://code.djangoproject.com/ticket/26552
@pelme -- does this pull request implement the "relatively straightforward" approach you're envisionning?
Thanks a lot for the PR. The implementation looks correct and what I imagined. I did not think of having a serialized_rollback fixture but it is indeed useful to be able to force this behaviour from other fixtures.
We would need a test for this too, but the implementation looks correct!
I'll try to find time to polish the patch (I haven't even run it yet). I need to get the aformentionned bug in Django fixed as well before I can use this.
Updated version of the hack above for pytest-django ≥ 3.0:
``` python
@pytest.fixture(scope='function')
def transactional_db(request, django_db_setup, django_db_blocker):
"""
Override a pytest-django fixture to restore the contents of the database.
This works around https://github.com/pytest-dev/pytest-django/issues/329 by
restoring data created by data migrations. We know what data matters and we
maintain it in (Django) fixtures. We don't read it from the database. This
causes some repetition but keeps this (pytest) fixture (almost) simple.
"""
try:
return _transactional_db(request, django_db_setup, django_db_blocker)
finally:
# /!\ Epically shameful hack /!\ _transactional_db adds two finalizers:
# django_db_blocker.restore() and test_case._post_teardown(). Note that
# finalizers run in the opposite order of that in which they are added.
# We want to run after test_case._post_teardown() flushes the database
# but before django_db_blocker.restore() prevents further database
# queries. Hence, open heart surgery in pytest internals...
finalizers = request._fixturedef._finalizer
assert len(finalizers) == 2
assert finalizers[0].__qualname__ == '_DatabaseBlocker.restore'
assert finalizers[1].__qualname__ == 'TransactionTestCase._post_teardown'
finalizers.insert(1, _reload_fixture_data)
```
Thanks for the update and sorry I couldn't get this into 3.0. I will try to get to this for the next release!
Is there any chance to see it in next release?
Thanks
@Wierrat
Yes, probably.
Can help us with a test for https://github.com/pytest-dev/pytest-django/pull/353 before that then please?
Hi folks,
what is the latest status of this? In particular I'm using pytest as my test runner with the StaticLiveServerTestCase class from Django. I've set the class attribute `serialized_rollback = True` but that seems to be in effect only when executing the first test from the sequence.
Just got caught by this one. Looking around it seems there have been some PR on this issue but none of them appear to have been merged.
Is there any particular reason this issue remain open?
> some PR
Likely/only https://github.com/pytest-dev/pytest-django/issues/329, no?
The last time I've asked about help with a test, and it has several conflicts (maybe only due to black).
I still suggest for anyone affected to help with that - I am not using it myself.
Thanks for the quick reply @blueyed.
My knowledge of pytest / pytest-django is minimal but I'll put that on my somday/maybe list! :D
Updated version of the above hack for pytest 5.2.1, pytest-django 3.5.1:
```python
from functools import partial
@pytest.fixture
def transactional_db(request, transactional_db, django_db_blocker):
# Restore DB content after all of transactional_db's finalizers have
# run. Finalizers are run in the opposite order of that in which they
# are added, so we prepend the restore to the front of the list.
#
# Works for pytest 5.2.1, pytest-django 3.5.1
restore = partial(_restore_db_content, django_db_blocker)
finalizers = request._fixture_defs['transactional_db']._finalizers
finalizers.insert(0, restore)
# Simply restoring after yielding transactional_db wouldn't work because
# it would run before transactional_db's finalizers which contains the truncate.
return transactional_db
def _restore_db_content(django_db_fixture, django_db_blocker):
with django_db_blocker.unblock():
call_command('loaddata', '--verbosity', '0', 'TODO your fixture')
```
I had to depend on the original `transactional_db` fixture instead of calling it as pytest no longer allows calling fixture functions directly. I then get the fixture def of the original fixture and prepend a finalizer to it. While inserting at index 1 still worked, I insert before all finalizers and use `django_db_blocker` in the restore function as that seems slightly less fragile.
Edit: removed unnecessary try finally.
@lukaszb
https://github.com/pytest-dev/pytest-django/issues/848
I use this version of pytest-django (https://github.com/pytest-dev/pytest-django/pull/721/files),
But still error.

While sorting my archives, I stumbled upon this attempt, which is probably not very useful but who knows. So here it is.
<details>
```diff
commit c1a6a3fe939d9516ec7cabe1dfd6903c512db22a
Author: Aymeric Augustin <aymeric.augustin@m4x.org>
Date: Thu Apr 28 11:51:06 2016 +0200
Add support for serialized rollback. Fix #329.
WORK IN PROGRESS - UNTESTED
diff --git a/docs/changelog.rst b/docs/changelog.rst
index 9b4c510..c50981c 100644
--- a/docs/changelog.rst
+++ b/docs/changelog.rst
@@ -3,6 +3,15 @@ Changelog
NEXT
----
+
+Features
+^^^^^^^^
+* Add support for serialized rollback in transactional tests.
+ Thanks to Piotr Karkut for `the bug report
+ <https://github.com/pytest-dev/pytest-django/issues/329>`_.
+
+Bug fixes
+^^^^^^^^^
* Fix error when Django happens to be imported before pytest-django runs.
Thanks to Will Harris for `the bug report
<https://github.com/pytest-dev/pytest-django/issues/289>`_.
diff --git a/docs/helpers.rst b/docs/helpers.rst
index 7c60f90..1860ee1 100644
--- a/docs/helpers.rst
+++ b/docs/helpers.rst
@@ -16,7 +16,7 @@ on what marks are and for notes on using_ them.
``pytest.mark.django_db`` - request database access
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-.. py:function:: pytest.mark.django_db([transaction=False])
+.. py:function:: pytest.mark.django_db([transaction=False, serialized_rollback=False])
This is used to mark a test function as requiring the database. It
will ensure the database is setup correctly for the test. Each test
@@ -38,6 +38,14 @@ on what marks are and for notes on using_ them.
uses. When ``transaction=True``, the behavior will be the same as
`django.test.TransactionTestCase`_
+ :type serialized_rollback: bool
+ :param serialized_rollback:
+ The ``serialized_rollback`` argument enables `rollback emulation`_.
+ After a `django.test.TransactionTestCase`_ runs, the database is
+ flushed, destroying data created in data migrations. This is the
+ default behavior of Django. Setting ``serialized_rollback=True``
+ tells Django to restore that data.
+
.. note::
If you want access to the Django database *inside a fixture*
@@ -54,6 +62,7 @@ on what marks are and for notes on using_ them.
Test classes that subclass Python's ``unittest.TestCase`` need to have the
marker applied in order to access the database.
+.. _rollback emulation: https://docs.djangoproject.com/en/stable/topics/testing/overview/#rollback-emulation
.. _django.test.TestCase: https://docs.djangoproject.com/en/dev/topics/testing/overview/#testcase
.. _django.test.TransactionTestCase: https://docs.djangoproject.com/en/dev/topics/testing/overview/#transactiontestcase
@@ -191,6 +200,16 @@ transaction support. This is only required for fixtures which need
database access themselves. A test function would normally use the
:py:func:`~pytest.mark.django_db` mark to signal it needs the database.
+``serialized_rollback``
+~~~~~~~~~~~~~~~~~~~~~~~
+
+When the ``transactional_db`` fixture is enabled, this fixture can be
+added to trigger `rollback emulation`_ and thus restores data created
+in data migrations after each transaction test. This is only required
+for fixtures which need to enforce this behavior. A test function
+would use :py:func:`~pytest.mark.django_db(serialized_rollback=True)`
+to request this behavior.
+
``live_server``
~~~~~~~~~~~~~~~
@@ -200,6 +219,12 @@ or by requesting it's string value: ``unicode(live_server)``. You can
also directly concatenate a string to form a URL: ``live_server +
'/foo``.
+Since the live server and the tests run in different threads, they
+cannot share a database transaction. For this reason, ``live_server``
+depends on the ``transactional_db`` fixture. If tests depend on data
+created in data migrations, you should add the ``serialized_rollback``
+fixture.
+
``settings``
~~~~~~~~~~~~
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
index cae7d47..ca2fc72 100644
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -64,7 +64,8 @@ def _django_db_setup(request,
request.addfinalizer(teardown_database)
-def _django_db_fixture_helper(transactional, request, _django_cursor_wrapper):
+def _django_db_fixture_helper(transactional, serialized_rollback,
+ request, _django_cursor_wrapper):
if is_django_unittest(request):
return
@@ -105,6 +106,7 @@ def _django_db_fixture_helper(transactional, request, _django_cursor_wrapper):
if django_case:
case = django_case(methodName='__init__')
+ case.serialized_rollback = serialized_rollback
case._pre_setup()
request.addfinalizer(case._post_teardown)
@@ -177,7 +179,9 @@ def db(request, _django_db_setup, _django_cursor_wrapper):
if 'transactional_db' in request.funcargnames \
or 'live_server' in request.funcargnames:
return request.getfuncargvalue('transactional_db')
- return _django_db_fixture_helper(False, request, _django_cursor_wrapper)
+ return _django_db_fixture_helper(
+ transaction=False, serialized_rollback=False,
+ request=request, _django_cursor_wrapper=_django_cursor_wrapper)
@pytest.fixture(scope='function')
@@ -192,7 +196,22 @@ def transactional_db(request, _django_db_setup, _django_cursor_wrapper):
database setup will behave as only ``transactional_db`` was
requested.
"""
- return _django_db_fixture_helper(True, request, _django_cursor_wrapper)
+ # TODO -- is request.getfuncargvalue('serialized_rollback') enough
+ # to add 'serialized_rollback' to request.funcargnames?
+ serialized_rollback = 'serialized_rollback' in request.funcargnames
+ return _django_db_fixture_helper(
+ transaction=True, serialized_rollback=serialized_rollback,
+ request=request, _django_cursor_wrapper=_django_cursor_wrapper)
+
+
+@pytest.fixture(scope='function')
+def serialized_rollback(request):
+ """Enable serialized rollback after transaction test cases
+
+ This fixture only has an effect when the ``transactional_db``
+ fixture is active, which happen as a side-effect of requesting
+ ``live_server``.
+ """
@pytest.fixture()
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
index d499e6f..204f16f 100644
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -372,6 +372,8 @@ def _django_db_marker(request):
request.getfuncargvalue('transactional_db')
else:
request.getfuncargvalue('db')
+ if marker.serialized_rollback:
+ request.getfuncargvalue('serialized_rollback')
@pytest.fixture(autouse=True, scope='class')
@@ -564,8 +566,9 @@ def validate_django_db(marker):
It checks the signature and creates the `transaction` attribute on
the marker which will have the correct value.
"""
- def apifun(transaction=False):
+ def apifun(transaction=False, serialized_rollback=False):
marker.transaction = transaction
+ marker.serialized_rollback = serialized_rollback
apifun(*marker.args, **marker.kwargs)
```
</details>
How does this relate to #919? Also, you have some unhandled conflict indicators in the code itself.
| 2021-11-29T10:28:09
|
python
|
Easy
|
rigetti/pyquil
| 191
|
rigetti__pyquil-191
|
[
"184"
] |
4fbcbd16a4963818daa73d700f7c26406ae19ec7
|
diff --git a/pyquil/quilbase.py b/pyquil/quilbase.py
--- a/pyquil/quilbase.py
+++ b/pyquil/quilbase.py
@@ -20,6 +20,7 @@
import numpy as np
from .slot import Slot
from six import integer_types, string_types
+from fractions import Fraction
class QuilAtom(object):
@@ -513,8 +514,10 @@ def format_parameter(element):
:param element: {int, float, long, complex, Slot} Formats a parameter for Quil output.
"""
- if isinstance(element, integer_types) or isinstance(element, float):
+ if isinstance(element, integer_types):
return repr(element)
+ elif isinstance(element, float):
+ return check_for_pi(element)
elif isinstance(element, complex):
r = element.real
i = element.imag
@@ -527,6 +530,33 @@ def format_parameter(element):
assert False, "Invalid parameter: %r" % element
+def check_for_pi(element):
+ """
+ Check to see if there exists a rational number r = p/q
+ in reduced form for which the difference between element/np.pi
+ and r is small and q <= 8.
+
+ :param element: float
+ :return element: pretty print string if true, else standard representation.
+ """
+ frac = Fraction(element / np.pi).limit_denominator(8)
+ num, den = frac.numerator, frac.denominator
+ sign = "-" if num < 0 else ""
+ if np.isclose(num / float(den), element / np.pi):
+ if num == 0:
+ return "0"
+ elif abs(num) == 1 and den == 1:
+ return sign + "pi"
+ elif abs(num) == 1:
+ return sign + "pi/" + repr(den)
+ elif den == 1:
+ return repr(num) + "*pi"
+ else:
+ return repr(num) + "*pi/" + repr(den)
+ else:
+ return repr(element)
+
+
def unpack_qubit(qubit):
"""
Get a qubit from an object.
|
diff --git a/pyquil/tests/test_quil.py b/pyquil/tests/test_quil.py
--- a/pyquil/tests/test_quil.py
+++ b/pyquil/tests/test_quil.py
@@ -40,7 +40,7 @@ def test_gate():
def test_defgate():
dg = DefGate("TEST", np.array([[1., 0.],
[0., 1.]]))
- assert dg.out() == "DEFGATE TEST:\n 1.0, 0.0\n 0.0, 1.0\n"
+ assert dg.out() == "DEFGATE TEST:\n 1.0, 0\n 0, 1.0\n"
test = dg.get_constructor()
tg = test(Qubit(1), Qubit(2))
assert tg.out() == "TEST 1 2"
@@ -64,7 +64,7 @@ def test_defgate_non_unitary_should_throw_error():
def test_defgate_param():
dgp = DefGate("TEST", [[1., 0.], [0., 1.]])
- assert dgp.out() == "DEFGATE TEST:\n 1.0, 0.0\n 0.0, 1.0\n"
+ assert dgp.out() == "DEFGATE TEST:\n 1.0, 0\n 0, 1.0\n"
test = dgp.get_constructor()
tg = test(Qubit(1))
assert tg.out() == "TEST 1"
@@ -236,21 +236,21 @@ def test_dagger():
RZ(pi, 0), CPHASE(pi, 0, 1),
CPHASE00(pi, 0, 1), CPHASE01(pi, 0, 1),
CPHASE10(pi, 0, 1), PSWAP(pi, 0, 1))
- assert p.dagger().out() == 'PSWAP(-3.141592653589793) 0 1\n' \
- 'CPHASE10(-3.141592653589793) 0 1\n' \
- 'CPHASE01(-3.141592653589793) 0 1\n' \
- 'CPHASE00(-3.141592653589793) 0 1\n' \
- 'CPHASE(-3.141592653589793) 0 1\n' \
- 'RZ(-3.141592653589793) 0\n' \
- 'RY(-3.141592653589793) 0\n' \
- 'RX(-3.141592653589793) 0\n' \
- 'PHASE(-3.141592653589793) 0\n'
+ assert p.dagger().out() == 'PSWAP(-pi) 0 1\n' \
+ 'CPHASE10(-pi) 0 1\n' \
+ 'CPHASE01(-pi) 0 1\n' \
+ 'CPHASE00(-pi) 0 1\n' \
+ 'CPHASE(-pi) 0 1\n' \
+ 'RZ(-pi) 0\n' \
+ 'RY(-pi) 0\n' \
+ 'RX(-pi) 0\n' \
+ 'PHASE(-pi) 0\n'
# these gates are special cases
p = Program().inst(S(0), T(0), ISWAP(0, 1))
- assert p.dagger().out() == 'PSWAP(1.5707963267948966) 0 1\n' \
- 'RZ(0.7853981633974483) 0\n' \
- 'PHASE(-1.5707963267948966) 0\n'
+ assert p.dagger().out() == 'PSWAP(pi/2) 0 1\n' \
+ 'RZ(pi/4) 0\n' \
+ 'PHASE(-pi/2) 0\n'
# must invert defined gates
G = np.array([[0, 1], [0 + 1j, 0]])
@@ -294,14 +294,14 @@ def test_phases():
p = Program(PHASE(np.pi)(1), CPHASE00(np.pi)(0, 1), CPHASE01(np.pi)(0, 1),
CPHASE10(np.pi)(0, 1),
CPHASE(np.pi)(0, 1))
- assert p.out() == 'PHASE(3.141592653589793) 1\nCPHASE00(3.141592653589793) 0 1\n' \
- 'CPHASE01(3.141592653589793) 0 1\nCPHASE10(3.141592653589793) 0 1\n' \
- 'CPHASE(3.141592653589793) 0 1\n'
+ assert p.out() == 'PHASE(pi) 1\nCPHASE00(pi) 0 1\n' \
+ 'CPHASE01(pi) 0 1\nCPHASE10(pi) 0 1\n' \
+ 'CPHASE(pi) 0 1\n'
def test_swaps():
p = Program(SWAP(0, 1), CSWAP(0, 1, 2), ISWAP(0, 1), PSWAP(np.pi)(0, 1))
- assert p.out() == 'SWAP 0 1\nCSWAP 0 1 2\nISWAP 0 1\nPSWAP(3.141592653589793) 0 1\n'
+ assert p.out() == 'SWAP 0 1\nCSWAP 0 1 2\nISWAP 0 1\nPSWAP(pi) 0 1\n'
def test_def_gate():
@@ -350,8 +350,8 @@ def qft3(q0, q1, q2):
prog = state_prep + qft3(0, 1, 2)
output = prog.out()
- assert output == 'X 0\nH 2\nCPHASE(1.5707963267948966) 1 2\nH 1\nCPHASE(0.7853981633974483) 0 ' \
- '2\nCPHASE(1.5707963267948966) 0 1\nH 0\nSWAP 0 2\n'
+ assert output == 'X 0\nH 2\nCPHASE(pi/2) 1 2\nH 1\nCPHASE(pi/4) 0 ' \
+ '2\nCPHASE(pi/2) 0 1\nH 0\nSWAP 0 2\n'
def test_control_flows():
@@ -574,3 +574,14 @@ def test_inline_alloc():
p = Program()
p += H(p.alloc())
assert p.out() == "H 0\n"
+
+
+# https://github.com/rigetticomputing/pyquil/issues/184
+def test_pretty_print_pi():
+ p = Program()
+ p += [RZ(0., 0), RZ(pi, 1), RZ(-pi, 2)]
+ p += [RZ(2 * pi / 3., 3), RZ(pi / 9., 4), RZ(pi / 8., 5)]
+ p += CPHASE00(-90 * pi / 2., 0, 1)
+ assert p.out() == 'RZ(0) 0\nRZ(pi) 1\nRZ(-pi) 2\nRZ(2*pi/3) 3\n' \
+ 'RZ(0.3490658503988659) 4\n' \
+ 'RZ(pi/8) 5\nCPHASE00(-45*pi) 0 1\n'
|
Parameters to gates that are nearly pi, pi/2, pi/4 etc should be printed using pi
Instead of this:
`RZ(-3.141592653589793) 0`
let's print this:
`RZ(-pi) 0` which is valid quil.
This will aid in program understanding.
|
Hint to implementers: look at the format_parameter function in quilbase
Hello,
I implemented this last night using np.float32 and fractions.Fraction. I wanted to verify the expected behavior before making a pull request. Here are some printed results, which after obvious adjustments to the test cases pass tests for python2 and python3.
```
input
=========
for i in range(12):
p = Program()
p += RZ(i*pi/91.,0)
print(p)
output
=========
RZ(0) 0
RZ(pi/91) 0
RZ(2*pi/91) 0
RZ(3*pi/91) 0
RZ(4*pi/91) 0
RZ(5*pi/91) 0
RZ(6*pi/91) 0
RZ(pi/13) 0
RZ(8*pi/91) 0
RZ(9*pi/91) 0
RZ(10*pi/91) 0
RZ(11*pi/91) 0
```
The main idea is to use fractions.Fraction to see if np.float32(element/np.pi) == np.float32(p/q) for some fraction p/q with q <= 140 (arbitrary cutoff). One important edge case to think about is
```
52*pi/91.
```
In python2 and python3,
```
52*pi/91. != 4*pi/7.
```
This is the main need for considering these subtleties.
Was this the sort of solution you had in mind?
You could use np.isclose instead of comparing floats directly to deal with your second issue.
This looks good, the only thing I'd change is just reducing q to be much smaller, maybe 8. We only want to pretty print in the simplest of common cases like 3pi/4, pi/8, etc. Anything beyond that doesn't come up very often.
Looking forward to checking out your PR!
| 2017-11-17T11:38:23
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 642
|
marcelotduarte__cx_Freeze-642
|
[
"566"
] |
485eb0330de934a6418afa42b2eb82f1948cf2d7
|
diff --git a/cx_Freeze/hooks.py b/cx_Freeze/hooks.py
--- a/cx_Freeze/hooks.py
+++ b/cx_Freeze/hooks.py
@@ -5,6 +5,9 @@
from cx_Freeze.common import rebuild_code_object
+MINGW = sysconfig.get_platform() == "mingw"
+WIN32 = sys.platform == "win32"
+
def initialize(finder):
"""upon initialization of the finder, this routine is called to set up some
automatic exclusions for various platforms."""
@@ -219,9 +222,9 @@ def load_cryptography_hazmat_bindings__padding(finder, module):
def load__ctypes(finder, module):
- """In Windows, the _ctypes module in Python >= 3.8 requires an additional dll
+ """In Windows, the _ctypes module in Python 3.8+ requires an additional dll
libffi-7.dll to be present in the build directory."""
- if sys.platform == "win32" and sys.version_info >= (3, 8) and sysconfig.get_platform() != "mingw":
+ if WIN32 and sys.version_info >= (3, 8) and not MINGW:
dll_name = "libffi-7.dll"
dll_path = os.path.join(sys.base_prefix, "DLLs", dll_name)
finder.IncludeFiles(dll_path, os.path.join("lib", dll_name))
@@ -683,7 +686,7 @@ def load_PyQt4_phonon(finder, module):
"""In Windows, phonon4.dll requires an additional dll phonon_ds94.dll to
be present in the build directory inside a folder phonon_backend."""
name, QtCore = _qt_implementation(module)
- if sys.platform == "win32":
+ if WIN32:
copy_qt_plugins("phonon_backend", finder, QtCore)
load_PySide_phonon = load_PyQt5_phonon = load_PyQt4_phonon
@@ -837,9 +840,9 @@ def load_site(finder, module):
def load_ssl(finder, module):
- """In Windows, the SSL module in Python >= 3.7 requires additional dlls to
+ """In Windows, the SSL module in Python 3.7+ requires additional dlls to
be present in the build directory."""
- if sys.platform == "win32" and sys.version_info >= (3, 7):
+ if WIN32 and sys.version_info >= (3, 7) and not MINGW:
for dll_search in ["libcrypto-*.dll", "libssl-*.dll"]:
for dll_path in glob.glob(os.path.join(sys.base_prefix, "DLLs", dll_search)):
dll_name = os.path.basename(dll_path)
@@ -850,24 +853,28 @@ def load_tkinter(finder, module):
"""the tkinter module has data files that are required to be loaded so
ensure that they are copied into the directory that is expected at
runtime."""
- if sys.platform == "win32":
+ if WIN32:
import tkinter
root_names = "tcl", "tk"
environ_names = "TCL_LIBRARY", "TK_LIBRARY"
version_vars = tkinter.TclVersion, tkinter.TkVersion
zipped = zip(environ_names, version_vars, root_names)
for env_name, ver_var, mod_name in zipped:
+ dir_name = mod_name + str(ver_var)
try:
lib_texts = os.environ[env_name]
except KeyError:
- lib_texts = os.path.join(sys.base_prefix, "tcl",
- mod_name + str(ver_var))
- targetPath = os.path.join("lib", "tkinter", mod_name)
+ if MINGW:
+ lib_texts = os.path.join(sys.base_prefix, "lib", dir_name)
+ else:
+ lib_texts = os.path.join(sys.base_prefix, "tcl", dir_name)
+ targetPath = os.path.join("lib", "tkinter", dir_name)
finder.AddConstant(env_name, targetPath)
finder.IncludeFiles(lib_texts, targetPath)
- dll_name = mod_name + str(ver_var).replace(".", "") + "t.dll"
- dll_path = os.path.join(sys.base_prefix, "DLLs", dll_name)
- finder.IncludeFiles(dll_path, os.path.join("lib", dll_name))
+ if not MINGW:
+ dll_name = dir_name.replace(".", "") + "t.dll"
+ dll_path = os.path.join(sys.base_prefix, "DLLs", dll_name)
+ finder.IncludeFiles(dll_path, os.path.join("lib", dll_name))
def load_tempfile(finder, module):
@@ -1006,7 +1013,7 @@ def missing_readline(finder, caller):
"""the readline module is not normally present on Windows but it also may
be so instead of excluding it completely, ignore it if it can't be
found"""
- if sys.platform == "win32":
+ if WIN32:
caller.IgnoreName("readline")
@@ -1014,7 +1021,7 @@ def load_zmq(finder, module):
"""the zmq package loads zmq.backend.cython dynamically and links
dynamically to zmq.libzmq."""
finder.IncludePackage("zmq.backend.cython")
- if sys.platform == "win32":
+ if WIN32:
# Not sure yet if this is cross platform
# Include the bundled libzmq library, if it exists
try:
@@ -1038,11 +1045,13 @@ def load_clr(finder, module):
def load_sqlite3(finder, module):
"""In Windows, the sqlite3 module requires an additional dll sqlite3.dll to
be present in the build directory."""
- if sys.platform == "win32":
+ if WIN32 and not MINGW:
dll_name = "sqlite3.dll"
dll_path = os.path.join(sys.base_prefix, "DLLs", dll_name)
+ if not os.path.exists(dll_path):
+ dll_path = os.path.join(sys.base_prefix, "Library", "bin", dll_name)
finder.IncludeFiles(dll_path, os.path.join("lib", dll_name))
- finder.IncludePackage('sqlite3')
+ finder.IncludePackage("sqlite3")
def load_pytest(finder, module):
import pytest
diff --git a/cx_Freeze/samples/bcrypt/setup.py b/cx_Freeze/samples/bcrypt/setup.py
--- a/cx_Freeze/samples/bcrypt/setup.py
+++ b/cx_Freeze/samples/bcrypt/setup.py
@@ -1,4 +1,4 @@
-'''A setup script to demonstrate build using bcrypt'''
+"""A setup script to demonstrate build using bcrypt"""
#
# Run the build process by running the command 'python setup.py build'
#
@@ -7,13 +7,10 @@
from cx_Freeze import setup, Executable
-setup(name='test_bcrypt',
- version='0.1',
- description='cx_Freeze script to test bcrypt',
+setup(name="test_bcrypt",
+ version="0.2",
+ description="cx_Freeze script to test bcrypt",
executables=[Executable("test_bcrypt.py")],
- options={
- 'build_exe': {'zip_include_packages': ["*"],
- 'zip_exclude_packages': [],
- #'includes': ['_cffi_backend']
- }
- })
+ options={"build_exe": {"excludes": ["tkinter"],
+ "zip_include_packages": ["*"],
+ "zip_exclude_packages": []}})
diff --git a/cx_Freeze/samples/cryptography/setup.py b/cx_Freeze/samples/cryptography/setup.py
--- a/cx_Freeze/samples/cryptography/setup.py
+++ b/cx_Freeze/samples/cryptography/setup.py
@@ -1,4 +1,4 @@
-# A setup script to demonstrate build using cffi (inside a cryptography pkg)
+"""A setup script to demonstrate build using cffi (used by cryptography)"""
#
# Run the build process by running the command 'python setup.py build'
#
@@ -7,11 +7,10 @@
from cx_Freeze import setup, Executable
-buildOptions = dict(zip_include_packages=["*"], zip_exclude_packages=[])
-executables = [Executable("test_crypt.py")]
-
-setup(name='test_crypt',
- version='0.1',
- description='cx_Freeze script to test cryptography',
- executables=executables,
- options=dict(build_exe=buildOptions))
+setup(name="test_crypt",
+ version="0.2",
+ description="cx_Freeze script to test cryptography",
+ executables=[Executable("test_crypt.py")],
+ options={"build_exe": {"excludes": ["tkinter"],
+ "zip_include_packages": ["*"],
+ "zip_exclude_packages": []}})
diff --git a/cx_Freeze/samples/sqlite/setup.py b/cx_Freeze/samples/sqlite/setup.py
--- a/cx_Freeze/samples/sqlite/setup.py
+++ b/cx_Freeze/samples/sqlite/setup.py
@@ -1,4 +1,4 @@
-# A setup script to demonstrate the use of sqlite3
+"""A setup script to demonstrate the use of sqlite3"""
#
# Run the build process by running the command 'python setup.py build'
#
@@ -7,11 +7,11 @@
from cx_Freeze import setup, Executable
-buildOptions = {"replace_paths": [("*", "")]}
-executables = [Executable("test_sqlite3.py")]
-
-setup(name='test_sqlite3',
- version='0.2',
- description='cx_Freeze script to test sqlite3',
- executables=executables,
- options=dict(build_exe=buildOptions))
+setup(name="test_sqlite3",
+ version="0.3",
+ description="cx_Freeze script to test sqlite3",
+ executables=[Executable("test_sqlite3.py")],
+ options={"build_exe": {"excludes": ["tkinter"],
+ "replace_paths": [("*", "")],
+ "zip_include_packages": ["*"],
+ "zip_exclude_packages": []}})
|
diff --git a/cx_Freeze/samples/cryptography/test_crypt.py b/cx_Freeze/samples/cryptography/test_crypt.py
--- a/cx_Freeze/samples/cryptography/test_crypt.py
+++ b/cx_Freeze/samples/cryptography/test_crypt.py
@@ -1,3 +1,3 @@
from cryptography.fernet import Fernet
-print('Hello cryptography', Fernet)
+print("Hello cryptography", Fernet)
diff --git a/cx_Freeze/samples/sqlite/test_sqlite3.py b/cx_Freeze/samples/sqlite/test_sqlite3.py
--- a/cx_Freeze/samples/sqlite/test_sqlite3.py
+++ b/cx_Freeze/samples/sqlite/test_sqlite3.py
@@ -29,4 +29,4 @@
f.write('%s\n' % line)
print('dump.sql created')
-con.close()
\ No newline at end of file
+con.close()
|
tkinter path error
Hi,
Got a problem with version mingw-w64-x86_64-python-cx_Freeze-6.0-1
Can't find path to tkinter (error: [Errno 2] No such file or directory: 'C:/msys64/mingw64/tcl/tcl8.6')
I try to add path in setup-freeze.py:
...
include_files = [
r"C:\msys64\mingw64\bin\tcl86.dll",
r"C:\msys64\mingw64\bin\tk86.dll",]
os.environ['TCL_LIBRARY'] = r'C:\msys64\mingw64\lib\tcl8.6'
os.environ['TK_LIBRARY'] = r'C:\msys64\mingw64\lib\tk8.6'
....
Got this error: error: [Errno 2] No such file or directory: 'C:/msys64/mingw64/Dlls/tcl86t.dll'
tcl86t.dll doesn't exist, my file is tcl86.dll
Thanks for help!
|
I try the sample:
https://github.com/anthony-tuininga/cx_Freeze/tree/master/cx_Freeze/samples/Tkinter
Got:
...
copying C:/msys64/mingw64/tcl/tcl8.6 -> build/exe.mingw-3.8/tcl
error: [Errno 2] No such file or directory: 'C:/msys64/mingw64/tcl/tcl8.6'
Can bypass error doing this:
- Create С:\msys64\mingw64\tcl directory and copy into it these directories:
C:\msys64\mingw64\lib\tcl8.6
C:\msys64\mingw64\lib\tk8.6
- Create С:\msys64\mingw64\Dlls directory and copy into it these files:
C:\msys64\mingw64\bin\tcl86.dll
C:\msys64\mingw64\bin\tk86.dll
- Rename these files in С:\msys64\mingw64\Dlls directory:
tcl86.dll -> tcl86t.dll
tk86.dll -> tk86t.dll
Same here, any basic MSYS2 installation triggers this bug.
Edit: I can exclude tcl and tk by spelling them correctly (case sensitive under mingw): [xpra changeset 25138](http://xpra.org/trac/changeset/25138/xpra)
| 2020-04-27T07:48:25
|
python
|
Easy
|
rigetti/pyquil
| 1,795
|
rigetti__pyquil-1795
|
[
"1719"
] |
ba4aaf50e788ee1aa2980e810fab60d2ce78348e
|
diff --git a/pyquil/api/__init__.py b/pyquil/api/__init__.py
--- a/pyquil/api/__init__.py
+++ b/pyquil/api/__init__.py
@@ -30,7 +30,7 @@
QVMCompiler,
)
from pyquil.api._qam import QAM, MemoryMap, QAMExecutionResult
-from pyquil.api._qpu import QPU
+from pyquil.api._qpu import QPU, QPUExecuteResponse
from pyquil.api._quantum_computer import (
QuantumComputer,
get_qc,
@@ -59,6 +59,7 @@
"MemoryMap",
"QAMExecutionResult",
"QPU",
+ "QPUExecuteResponse",
"QuantumComputer",
"get_qc",
"list_quantum_computers",
diff --git a/pyquil/control_flow_graph.py b/pyquil/control_flow_graph.py
--- a/pyquil/control_flow_graph.py
+++ b/pyquil/control_flow_graph.py
@@ -5,7 +5,11 @@
from quil import program as quil_rs
from typing_extensions import Self, override
-from pyquil.quilbase import AbstractInstruction, _convert_to_py_instruction, _convert_to_py_instructions
+from pyquil.quilbase import (
+ AbstractInstruction,
+ _convert_to_py_instruction,
+ _convert_to_py_instructions,
+)
class BasicBlock(quil_rs.BasicBlock):
diff --git a/pyquil/quilbase.py b/pyquil/quilbase.py
--- a/pyquil/quilbase.py
+++ b/pyquil/quilbase.py
@@ -1068,12 +1068,13 @@ class LogicalBinaryOp(quil_rs.BinaryLogic, AbstractInstruction):
def __new__(cls, left: MemoryReference, right: Union[MemoryReference, int]) -> Self:
"""Initialize the operands of the binary logical instruction."""
- operands = cls._to_rs_binary_operands(left, right)
- return super().__new__(cls, cls.op, operands)
+ destination = left._to_rs_memory_reference()
+ source = cls._to_rs_binary_operand(right)
+ return super().__new__(cls, cls.op, destination, source)
@classmethod
def _from_rs_binary_logic(cls, binary_logic: quil_rs.BinaryLogic) -> "LogicalBinaryOp":
- return super().__new__(cls, binary_logic.operator, binary_logic.operands)
+ return super().__new__(cls, binary_logic.operator, binary_logic.destination, binary_logic.source)
@staticmethod
def _to_rs_binary_operand(operand: Union[MemoryReference, int]) -> quil_rs.BinaryOperand:
@@ -1081,12 +1082,6 @@ def _to_rs_binary_operand(operand: Union[MemoryReference, int]) -> quil_rs.Binar
return quil_rs.BinaryOperand.from_memory_reference(operand._to_rs_memory_reference())
return quil_rs.BinaryOperand.from_literal_integer(operand)
- @staticmethod
- def _to_rs_binary_operands(left: MemoryReference, right: Union[MemoryReference, int]) -> quil_rs.BinaryOperands:
- left_operand = left._to_rs_memory_reference()
- right_operand = LogicalBinaryOp._to_rs_binary_operand(right)
- return quil_rs.BinaryOperands(left_operand, right_operand)
-
@staticmethod
def _to_py_binary_operand(operand: quil_rs.BinaryOperand) -> Union[MemoryReference, int]:
if operand.is_literal_integer():
@@ -1096,24 +1091,22 @@ def _to_py_binary_operand(operand: quil_rs.BinaryOperand) -> Union[MemoryReferen
@property
def left(self) -> MemoryReference:
"""The left hand side of the binary expression."""
- return MemoryReference._from_rs_memory_reference(super().operands.memory_reference)
+ return MemoryReference._from_rs_memory_reference(super().destination)
@left.setter
def left(self, left: MemoryReference) -> None:
- operands = super().operands
- operands.memory_reference = left._to_rs_memory_reference()
- quil_rs.BinaryLogic.operands.__set__(self, operands) # type: ignore[attr-defined]
+ destination = left._to_rs_memory_reference()
+ quil_rs.BinaryLogic.destination.__set__(self, destination) # type: ignore[attr-defined]
@property
def right(self) -> Union[MemoryReference, int]:
"""The right hand side of the binary expression."""
- return self._to_py_binary_operand(super().operands.operand)
+ return self._to_py_binary_operand(super().source)
@right.setter
def right(self, right: Union[MemoryReference, int]) -> None:
- operands = super().operands
- operands.operand = self._to_rs_binary_operand(right)
- quil_rs.BinaryLogic.operands.__set__(self, operands) # type: ignore[attr-defined]
+ source = self._to_rs_binary_operand(right)
+ quil_rs.BinaryLogic.source.__set__(self, source) # type: ignore[attr-defined]
def out(self) -> str:
"""Return the instruction as a valid Quil string. Raises an error if the instruction contains placeholders."""
@@ -1156,9 +1149,8 @@ class ArithmeticBinaryOp(quil_rs.Arithmetic, AbstractInstruction):
def __new__(cls, left: MemoryReference, right: Union[MemoryReference, int, float]) -> Self:
"""Initialize the operands of the binary arithmetic instruction."""
- left_operand = quil_rs.ArithmeticOperand.from_memory_reference(left._to_rs_memory_reference())
right_operand = _to_rs_arithmetic_operand(right)
- return super().__new__(cls, cls.op, left_operand, right_operand)
+ return super().__new__(cls, cls.op, left._to_rs_memory_reference(), right_operand)
@classmethod
def _from_rs_arithmetic(cls, arithmetic: quil_rs.Arithmetic) -> "ArithmeticBinaryOp":
@@ -1167,12 +1159,12 @@ def _from_rs_arithmetic(cls, arithmetic: quil_rs.Arithmetic) -> "ArithmeticBinar
@property
def left(self) -> MemoryReference:
"""The left hand side of the binary expression."""
- return MemoryReference._from_rs_memory_reference(super().destination.to_memory_reference())
+ return MemoryReference._from_rs_memory_reference(super().destination)
@left.setter
def left(self, left: MemoryReference) -> None:
quil_rs.Arithmetic.destination.__set__( # type: ignore[attr-defined]
- self, quil_rs.ArithmeticOperand.from_memory_reference(left._to_rs_memory_reference())
+ self, left._to_rs_memory_reference()
)
@property
@@ -1493,12 +1485,16 @@ def __new__(
right: Union[MemoryReference, int, float],
) -> "ClassicalComparison":
"""Initialize a new comparison instruction."""
- operands = (target._to_rs_memory_reference(), left._to_rs_memory_reference(), cls._to_comparison_operand(right))
- return super().__new__(cls, cls.op, operands)
+ rs_target, rs_left, rs_right = (
+ target._to_rs_memory_reference(),
+ left._to_rs_memory_reference(),
+ cls._to_comparison_operand(right),
+ )
+ return super().__new__(cls, cls.op, rs_target, rs_left, rs_right)
@classmethod
def _from_rs_comparison(cls, comparison: quil_rs.Comparison) -> Self:
- return super().__new__(cls, comparison.operator, comparison.operands)
+ return super().__new__(cls, comparison.operator, comparison.destination, comparison.lhs, comparison.rhs)
@staticmethod
def _to_comparison_operand(operand: Union[MemoryReference, int, float]) -> quil_rs.ComparisonOperand:
@@ -1522,35 +1518,29 @@ def _to_py_operand(operand: quil_rs.ComparisonOperand) -> Union[MemoryReference,
@property
def target(self) -> MemoryReference:
"""The target of the comparison."""
- return MemoryReference._from_rs_memory_reference(super().operands[0])
+ return MemoryReference._from_rs_memory_reference(super().destination)
@target.setter
def target(self, target: MemoryReference) -> None:
- operands = list(super().operands)
- operands[0] = target._to_rs_memory_reference()
- quil_rs.Comparison.operands.__set__(self, tuple(operands)) # type: ignore
+ quil_rs.Comparison.destination.__set__(self, target._to_rs_memory_reference()) # type: ignore
@property
def left(self) -> MemoryReference:
"""The left hand side of the comparison."""
- return MemoryReference._from_rs_memory_reference(super().operands[1])
+ return MemoryReference._from_rs_memory_reference(super().lhs)
@left.setter
def left(self, left: MemoryReference) -> None:
- operands = list(super().operands)
- operands[1] = left._to_rs_memory_reference()
- quil_rs.Comparison.operands.__set__(self, tuple(operands)) # type: ignore
+ quil_rs.Comparison.lhs.__set__(self, left._to_rs_memory_reference()) # type: ignore
@property
def right(self) -> Union[MemoryReference, int, float]:
"""The right hand side of the comparison."""
- return self._to_py_operand(super().operands[2])
+ return self._to_py_operand(super().rhs)
@right.setter
def right(self, right: MemoryReference) -> None:
- operands = list(super().operands)
- operands[2] = self._to_comparison_operand(right)
- quil_rs.Comparison.operands.__set__(self, tuple(operands)) # type: ignore
+ quil_rs.Comparison.rhs.__set__(self, quil_rs.ComparisonOperand(right._to_rs_memory_reference())) # type: ignore
def out(self) -> str:
"""Return the instruction as a valid Quil string."""
|
diff --git a/test/unit/__snapshots__/test_quilbase.ambr b/test/unit/__snapshots__/test_quilbase.ambr
--- a/test/unit/__snapshots__/test_quilbase.ambr
+++ b/test/unit/__snapshots__/test_quilbase.ambr
@@ -11,6 +11,18 @@
# name: TestArithmeticBinaryOp.test_out[SUB-left1-1]
'SUB b[1] 1'
# ---
+# name: TestArithmeticBinaryOp.test_pickle[ADD-left0-right0]
+ Arithmetic { operator: Add, destination: MemoryReference { name: "a", index: 0 }, source: MemoryReference(MemoryReference { name: "b", index: 0 }) }
+# ---
+# name: TestArithmeticBinaryOp.test_pickle[DIV-left3-4.2]
+ Arithmetic { operator: Divide, destination: MemoryReference { name: "c", index: 2 }, source: LiteralReal(4.2) }
+# ---
+# name: TestArithmeticBinaryOp.test_pickle[MUL-left2-1.0]
+ Arithmetic { operator: Multiply, destination: MemoryReference { name: "c", index: 2 }, source: LiteralInteger(1) }
+# ---
+# name: TestArithmeticBinaryOp.test_pickle[SUB-left1-1]
+ Arithmetic { operator: Subtract, destination: MemoryReference { name: "b", index: 1 }, source: LiteralInteger(1) }
+# ---
# name: TestCapture.test_out[Blocking]
'CAPTURE 123 q "FRAMEX" WAVEFORMY ro[0]'
# ---
@@ -20,6 +32,15 @@
# name: TestCapture.test_out[TemplateWaveform]
'NONBLOCKING CAPTURE 123 q "FRAMEX" flat(duration: 2.5, iq: 1+2.0i) ro[0]'
# ---
+# name: TestCapture.test_pickle[Blocking]
+ Capture { blocking: true, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, memory_reference: MemoryReference { name: "ro", index: 0 }, waveform: WaveformInvocation { name: "WAVEFORMY", parameters: {} } }
+# ---
+# name: TestCapture.test_pickle[NonBlocking]
+ Capture { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, memory_reference: MemoryReference { name: "ro", index: 0 }, waveform: WaveformInvocation { name: "WAVEFORMY", parameters: {} } }
+# ---
+# name: TestCapture.test_pickle[TemplateWaveform]
+ Capture { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, memory_reference: MemoryReference { name: "ro", index: 0 }, waveform: WaveformInvocation { name: "flat", parameters: {"duration": Number(Complex { re: 2.5, im: 0.0 }), "iq": Infix(InfixExpression { left: Number(Complex { re: 1.0, im: 0.0 }), operator: Plus, right: Number(Complex { re: 0.0, im: 2.0 }) })} } }
+# ---
# name: TestClassicalComparison.test_out[EQ-target0-left0-right0]
'EQ t[0] y[0] z[0]'
# ---
@@ -175,12 +196,6 @@
DEFCIRCUIT NiftyCircuit(%theta) a:
DECLARE ro BIT[1]
MEASURE a ro[0]
- DEFGATE ParameterizedGate(%theta) AS MATRIX:
- %theta, 0, 0, 0
- 0, %theta, 0, 0
- 0, 0, %theta, 0
- 0, 0, 0, %theta
-
'''
# ---
@@ -189,6 +204,8 @@
# ---
# name: TestDefFrame.test_out[Frame-Only].1
set({
+ '\tDIRECTION: "direction"',
+ '\tINITIAL-FREQUENCY: 0',
})
# ---
# name: TestDefFrame.test_out[With-Optionals]
@@ -209,6 +226,8 @@
# ---
# name: TestDefFrame.test_str[Frame-Only].1
set({
+ '\tDIRECTION: "direction"',
+ '\tINITIAL-FREQUENCY: 0',
})
# ---
# name: TestDefFrame.test_str[With-Optionals]
@@ -272,6 +291,18 @@
'''
# ---
+# name: TestDefGate.test_pickle[MixedTypes]
+ GateDefinition { name: "MixedTypes", parameters: ["X"], specification: Matrix([[Number(Complex { re: 0.0, im: 0.0 }), FunctionCall(FunctionCallExpression { function: Sine, expression: Variable("X") })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })]]) }
+# ---
+# name: TestDefGate.test_pickle[No-Params]
+ GateDefinition { name: "NoParamGate", parameters: [], specification: Matrix([[Number(Complex { re: 1.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 1.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 1.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 1.0, im: 0.0 })]]) }
+# ---
+# name: TestDefGate.test_pickle[ParameterlessExpression]
+ GateDefinition { name: "ParameterlessExpressions", parameters: [], specification: Matrix([[Number(Complex { re: 1.0, im: 0.0 }), Number(Complex { re: 1.2246467991473532e-16, im: 0.0 })], [Number(Complex { re: 1.2246467991473532e-16, im: 0.0 }), Prefix(PrefixExpression { operator: Minus, expression: Number(Complex { re: 1.0, im: 0.0 }) })]]) }
+# ---
+# name: TestDefGate.test_pickle[Params]
+ GateDefinition { name: "ParameterizedGate", parameters: ["X"], specification: Matrix([[FunctionCall(FunctionCallExpression { function: Cosine, expression: Variable("X") }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), FunctionCall(FunctionCallExpression { function: Cosine, expression: Variable("X") }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), FunctionCall(FunctionCallExpression { function: Cosine, expression: Variable("X") }), Number(Complex { re: 0.0, im: 0.0 })], [Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), Number(Complex { re: 0.0, im: 0.0 }), FunctionCall(FunctionCallExpression { function: Cosine, expression: Variable("X") })]]) }
+# ---
# name: TestDefGate.test_str[MixedTypes]
'''
DEFGATE MixedTypes(%X) AS MATRIX:
@@ -406,12 +437,6 @@
'''
# ---
-# name: TestDefWaveform.test_out[No-Params-Entries]
- '''
- DEFWAVEFORM Wavey:
-
- '''
-# ---
# name: TestDefWaveform.test_out[With-Param]
'''
DEFWAVEFORM Wavey(%x):
@@ -424,6 +449,12 @@
1+2.0i, %x, 3*%y
'''
# ---
+# name: TestDefWaveform.test_pickle[With-Param]
+ WaveformDefinition { name: "Wavey", definition: Waveform { matrix: [Variable("x")], parameters: ["x"] } }
+# ---
+# name: TestDefWaveform.test_pickle[With-Params-Complex]
+ WaveformDefinition { name: "Wavey", definition: Waveform { matrix: [Infix(InfixExpression { left: Number(Complex { re: 1.0, im: 0.0 }), operator: Plus, right: Number(Complex { re: 0.0, im: 2.0 }) }), Variable("x"), Infix(InfixExpression { left: Number(Complex { re: 3.0, im: 0.0 }), operator: Star, right: Variable("y") })], parameters: ["x", "y"] } }
+# ---
# name: TestDelayFrames.test_out[frames0-5.0]
'DELAY 0 "frame" 5'
# ---
@@ -598,6 +629,30 @@
# name: TestPulse.test_out[NonBlocking]
'NONBLOCKING PULSE 123 q "FRAMEX" WAVEFORMY'
# ---
+# name: TestPulse.test_pickle[Blocking]
+ Pulse { blocking: true, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "WAVEFORMY", parameters: {} } }
+# ---
+# name: TestPulse.test_pickle[BoxcarAveragerKernel]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "boxcar_kernel", parameters: {"duration": Number(Complex { re: 2.5, im: 0.0 }), "scale": Number(Complex { re: 1.0, im: 0.0 })} } }
+# ---
+# name: TestPulse.test_pickle[DragGaussianWaveform]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "drag_gaussian", parameters: {"alpha": Number(Complex { re: 1.0, im: 0.0 }), "anh": Number(Complex { re: 0.1, im: 0.0 }), "duration": Number(Complex { re: 2.5, im: 0.0 }), "fwhm": Number(Complex { re: 1.0, im: 0.0 }), "t0": Number(Complex { re: 1.0, im: 0.0 })} } }
+# ---
+# name: TestPulse.test_pickle[ErfSquareWaveform]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "erf_square", parameters: {"duration": Number(Complex { re: 2.5, im: 0.0 }), "pad_left": Number(Complex { re: 1.0, im: 0.0 }), "pad_right": Number(Complex { re: 0.1, im: 0.0 }), "risetime": Number(Complex { re: 1.0, im: 0.0 }), "scale": Number(Complex { re: 1.0, im: 0.0 })} } }
+# ---
+# name: TestPulse.test_pickle[FlatWaveform]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "flat", parameters: {"duration": Number(Complex { re: 2.5, im: 0.0 }), "iq": Infix(InfixExpression { left: Number(Complex { re: 1.0, im: 0.0 }), operator: Plus, right: Number(Complex { re: 0.0, im: 2.0 }) })} } }
+# ---
+# name: TestPulse.test_pickle[GaussianWaveform]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "gaussian", parameters: {"duration": Number(Complex { re: 2.5, im: 0.0 }), "fwhm": Number(Complex { re: 1.0, im: 0.0 }), "phase": Number(Complex { re: 0.1, im: 0.0 }), "t0": Number(Complex { re: 1.0, im: 0.0 })} } }
+# ---
+# name: TestPulse.test_pickle[HrmGaussianWaveform]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "hrm_gaussian", parameters: {"alpha": Number(Complex { re: 1.0, im: 0.0 }), "anh": Number(Complex { re: 0.1, im: 0.0 }), "duration": Number(Complex { re: 2.5, im: 0.0 }), "fwhm": Number(Complex { re: 1.0, im: 0.0 }), "second_order_hrm_coeff": Number(Complex { re: 0.5, im: 0.0 }), "t0": Number(Complex { re: 1.0, im: 0.0 })} } }
+# ---
+# name: TestPulse.test_pickle[NonBlocking]
+ Pulse { blocking: false, frame: FrameIdentifier { name: "FRAMEX", qubits: [Fixed(123), Variable("q")] }, waveform: WaveformInvocation { name: "WAVEFORMY", parameters: {} } }
+# ---
# name: TestRawCapture.test_out[Blocking]
'RAW-CAPTURE 123 q "FRAMEX" 0.5 ro[0]'
# ---
diff --git a/test/unit/test_qpu.py b/test/unit/test_qpu.py
--- a/test/unit/test_qpu.py
+++ b/test/unit/test_qpu.py
@@ -1,12 +1,22 @@
+import pickle
+from typing import Any
from unittest.mock import MagicMock, patch
import numpy as np
import pytest
-from qcs_sdk.qpu import MemoryValues
+from qcs_sdk import ExecutionData, ResultData
+from qcs_sdk.qpu import MemoryValues, QPUResultData, ReadoutValues
from qcs_sdk.qpu.api import ExecutionResult, ExecutionResults, Register
from rpcq.messages import ParameterSpec
-from pyquil.api import ConnectionStrategy, ExecutionOptions, ExecutionOptionsBuilder, RegisterMatrixConversionError
+from pyquil.api import (
+ ConnectionStrategy,
+ ExecutionOptions,
+ ExecutionOptionsBuilder,
+ QAMExecutionResult,
+ QPUExecuteResponse,
+ RegisterMatrixConversionError,
+)
from pyquil.api._abstract_compiler import EncryptedProgram
from pyquil.api._qpu import QPU
from pyquil.quil import Program
@@ -198,3 +208,37 @@ def test_submit_with_options(
client=qpu._client_configuration,
execution_options=execution_options,
)
+
+
+@pytest.mark.parametrize(
+ "input",
+ [
+ (
+ QAMExecutionResult(
+ executable=mock_encrypted_program,
+ data=ExecutionData(
+ result_data=ResultData.from_qpu(
+ QPUResultData(
+ mappings={"ro[0]": "q0", "ro[1]": "q1"},
+ readout_values={
+ "q0": ReadoutValues.from_integer([1, 1]),
+ "q1": ReadoutValues.from_real([1.1, 1.2]),
+ "q2": ReadoutValues.from_complex([complex(3, 4), complex(2.35, 4.21)]),
+ },
+ memory_values={"int": MemoryValues([2, 3, 4]), "real": MemoryValues([5.0, 6.0, 7.0])},
+ )
+ )
+ ),
+ )
+ ),
+ (
+ QPUExecuteResponse(
+ job_id="some-job-id", _executable=mock_encrypted_program, execution_options=ExecutionOptions.default()
+ )
+ ),
+ ],
+)
+def test_pickle_execute_responses(input: Any):
+ pickled_response = pickle.dumps(input)
+ unpickled_response = pickle.loads(pickled_response)
+ assert unpickled_response == input
diff --git a/test/unit/test_quilbase.py b/test/unit/test_quilbase.py
--- a/test/unit/test_quilbase.py
+++ b/test/unit/test_quilbase.py
@@ -1,4 +1,5 @@
import copy
+import pickle
from collections.abc import Iterable
from math import pi
from numbers import Complex, Number
@@ -187,6 +188,11 @@ def test_compile(self, program: Program, compiler: QPUCompiler):
except Exception as e:
raise AssertionError(f"Failed to compile the program: \n{program}") from e
+ def test_pickle(self, gate: Gate):
+ pickled = pickle.dumps(gate)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == gate
+
@pytest.mark.parametrize(
("name", "matrix", "parameters"),
@@ -261,6 +267,11 @@ def test_copy(self, def_gate: DefGate):
assert isinstance(copy.copy(def_gate), DefGate)
assert isinstance(copy.deepcopy(def_gate), DefGate)
+ def test_pickle(self, def_gate: DefGate, snapshot: SnapshotAssertion):
+ pickled = pickle.dumps(def_gate)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == snapshot
+
@pytest.mark.parametrize(
("name", "permutation"),
@@ -430,6 +441,11 @@ def test_convert(self, calibration: DefCalibration):
rs_calibration = _convert_to_rs_instruction(calibration)
assert calibration == _convert_to_py_instruction(rs_calibration)
+ def test_pickle(self, calibration: DefCalibration):
+ pickled = pickle.dumps(calibration)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == calibration
+
@pytest.mark.parametrize(
("qubit", "memory_reference", "instrs"),
@@ -468,6 +484,11 @@ def test_convert(self, measure_calibration: DefMeasureCalibration):
rs_measure_calibration = _convert_to_rs_instruction(measure_calibration)
assert measure_calibration == _convert_to_py_instruction(rs_measure_calibration)
+ def test_pickle(self, measure_calibration: DefMeasureCalibration):
+ pickled = pickle.dumps(measure_calibration)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == measure_calibration
+
@pytest.mark.parametrize(
("qubit", "classical_reg"),
@@ -511,11 +532,16 @@ def test_convert(self, measurement: Measurement):
rs_measurement = _convert_to_rs_instruction(measurement)
assert measurement == _convert_to_py_instruction(rs_measurement)
+ def test_pickle(self, measurement: Measurement):
+ pickled = pickle.dumps(measurement)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == measurement
+
@pytest.mark.parametrize(
("frame", "direction", "initial_frequency", "hardware_object", "sample_rate", "center_frequency", "channel_delay"),
[
- (Frame([Qubit(0)], "frame"), None, None, None, None, None, None),
+ (Frame([Qubit(0)], "frame"), "direction", 0.0, None, None, None, None),
(Frame([Qubit(1)], "frame"), "direction", 1.39, "hardware_object", 44.1, 440.0, 0.0),
],
ids=("Frame-Only", "With-Optionals"),
@@ -603,6 +629,12 @@ def test_convert(self, def_frame: DefFrame):
rs_def_frame = _convert_to_rs_instruction(def_frame)
assert def_frame == _convert_to_py_instruction(rs_def_frame)
+ def test_pickle(self, def_frame: DefFrame):
+ print(def_frame.to_quil())
+ pickled = pickle.dumps(def_frame)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == def_frame
+
@pytest.mark.parametrize(
("name", "memory_type", "memory_size", "shared_region", "offsets"),
@@ -673,6 +705,11 @@ def test_convert(self, declare: Declare):
rs_declare = _convert_to_rs_instruction(declare)
assert declare == _convert_to_py_instruction(rs_declare)
+ def test_pickle(self, declare: Declare):
+ pickled = pickle.dumps(declare)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == declare
+
@pytest.mark.parametrize(
("command", "args", "freeform_string"),
@@ -718,6 +755,11 @@ def test_convert(self, pragma: Pragma):
rs_pragma = _convert_to_rs_instruction(pragma)
assert pragma == _convert_to_py_instruction(rs_pragma)
+ def test_pickle(self, pragma: Pragma):
+ pickled = pickle.dumps(pragma)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == pragma
+
@pytest.mark.parametrize(
("qubit"),
@@ -765,6 +807,11 @@ def test_convert(self, reset_qubit: Reset):
rs_reset_qubit = _convert_to_rs_instruction(reset_qubit)
assert reset_qubit == _convert_to_py_instruction(rs_reset_qubit)
+ def test_pickle(self, reset_qubit: Reset):
+ pickled = pickle.dumps(reset_qubit)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == reset_qubit
+
@pytest.mark.parametrize(
("frames", "duration"),
@@ -798,6 +845,11 @@ def test_convert(self, delay_frames: DelayFrames):
rs_delay_frames = _convert_to_rs_instruction(delay_frames)
assert delay_frames == _convert_to_py_instruction(rs_delay_frames)
+ def test_pickle(self, delay_frames: DelayFrames):
+ pickled = pickle.dumps(delay_frames)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == delay_frames
+
@pytest.mark.parametrize(
("qubits", "duration"),
@@ -833,6 +885,11 @@ def test_convert(self, delay_qubits: DelayQubits):
rs_delay_qubits = _convert_to_rs_instruction(delay_qubits)
assert delay_qubits == _convert_to_py_instruction(rs_delay_qubits)
+ def test_pickle(self, delay_qubits: DelayQubits):
+ pickled = pickle.dumps(delay_qubits)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == delay_qubits
+
@pytest.mark.parametrize(
("qubits"),
@@ -863,6 +920,11 @@ def test_convert(self, fence: Fence):
rs_fence = _convert_to_rs_instruction(fence)
assert fence == _convert_to_py_instruction(rs_fence)
+ def test_pickle(self, fence: Fence):
+ pickled = pickle.dumps(fence)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == fence
+
def test_fence_all():
fa = FenceAll()
@@ -873,7 +935,6 @@ def test_fence_all():
@pytest.mark.parametrize(
("name", "parameters", "entries"),
[
- ("Wavey", [], []),
("Wavey", [Parameter("x")], [Parameter("x")]),
(
"Wavey",
@@ -881,7 +942,7 @@ def test_fence_all():
[complex(1.0, 2.0), Parameter("x"), Mul(complex(3.0, 0.0), Parameter("y"))],
),
],
- ids=("No-Params-Entries", "With-Param", "With-Params-Complex"),
+ ids=("With-Param", "With-Params-Complex"),
)
class TestDefWaveform:
@pytest.fixture
@@ -914,6 +975,12 @@ def test_convert(self, def_waveform: DefWaveform):
rs_def_waveform = _convert_to_rs_instruction(def_waveform)
assert def_waveform == _convert_to_py_instruction(rs_def_waveform)
+ def test_pickle(self, def_waveform: DefWaveform, snapshot: SnapshotAssertion):
+ print(def_waveform.to_quil())
+ pickled = pickle.dumps(def_waveform)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == snapshot
+
@pytest.mark.parametrize(
("name", "parameters", "qubit_variables", "instructions"),
@@ -926,7 +993,6 @@ def test_convert(self, def_waveform: DefWaveform):
[
Declare("ro", "BIT", 1),
Measurement(FormalArgument("a"), MemoryReference("ro")),
- DefGate("ParameterizedGate", np.diag([Parameter("theta")] * 4), [Parameter("theta")]),
],
),
],
@@ -974,6 +1040,12 @@ def test_convert(self, def_circuit: DefCircuit):
rs_def_circuit = _convert_to_rs_instruction(def_circuit)
assert def_circuit == _convert_to_py_instruction(rs_def_circuit)
+ def test_pickle(self, def_circuit: DefCircuit):
+ print(def_circuit.to_quil())
+ pickled = pickle.dumps(def_circuit)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == def_circuit
+
@pytest.mark.parametrize(
("frame", "kernel", "memory_region", "nonblocking"),
@@ -1035,6 +1107,11 @@ def test_convert(self, capture: Capture):
rs_capture = _convert_to_rs_instruction(capture)
assert capture == _convert_to_py_instruction(rs_capture)
+ def test_pickle(self, capture: Capture, snapshot: SnapshotAssertion):
+ pickled = pickle.dumps(capture)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == snapshot
+
@pytest.mark.parametrize(
("frame", "waveform", "nonblocking"),
@@ -1125,6 +1202,11 @@ def test_convert(self, pulse: Pulse):
rs_pulse = _convert_to_rs_instruction(pulse)
assert pulse == _convert_to_py_instruction(rs_pulse)
+ def test_pickle(self, pulse: Pulse, snapshot: SnapshotAssertion):
+ pickled = pickle.dumps(pulse)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == snapshot
+
@pytest.mark.parametrize(
("frame", "duration", "memory_region", "nonblocking"),
@@ -1186,6 +1268,11 @@ def test_convert(self, raw_capture: RawCapture):
rs_raw_capture = _convert_to_rs_instruction(raw_capture)
assert raw_capture == _convert_to_py_instruction(rs_raw_capture)
+ def test_pickle(self, raw_capture: RawCapture):
+ pickled = pickle.dumps(raw_capture)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == raw_capture
+
@pytest.mark.parametrize(
("frame", "expression"),
@@ -1260,32 +1347,37 @@ def test_convert(self, frame_mutation_instructions):
)
class TestSwapPhases:
@pytest.fixture
- def swap_phase(self, frame_a, frame_b):
+ def swap_phases(self, frame_a, frame_b):
return SwapPhases(frame_a, frame_b)
- def test_out(self, swap_phase: SwapPhases, snapshot: SnapshotAssertion):
- assert swap_phase.out() == snapshot
+ def test_out(self, swap_phases: SwapPhases, snapshot: SnapshotAssertion):
+ assert swap_phases.out() == snapshot
- def test_frames(self, swap_phase: SwapPhases, frame_a: Frame, frame_b: Frame):
- assert swap_phase.frameA == frame_a
- assert swap_phase.frameB == frame_b
- swap_phase.frameA = Frame([Qubit(123)], "NEW-FRAME")
- swap_phase.frameB = Frame([Qubit(123)], "NEW-FRAME")
- assert swap_phase.frameA == Frame([Qubit(123)], "NEW-FRAME")
- assert swap_phase.frameB == Frame([Qubit(123)], "NEW-FRAME")
+ def test_frames(self, swap_phases: SwapPhases, frame_a: Frame, frame_b: Frame):
+ assert swap_phases.frameA == frame_a
+ assert swap_phases.frameB == frame_b
+ swap_phases.frameA = Frame([Qubit(123)], "NEW-FRAME")
+ swap_phases.frameB = Frame([Qubit(123)], "NEW-FRAME")
+ assert swap_phases.frameA == Frame([Qubit(123)], "NEW-FRAME")
+ assert swap_phases.frameB == Frame([Qubit(123)], "NEW-FRAME")
- def test_get_qubits(self, swap_phase: SwapPhases, frame_a: Frame, frame_b: Frame):
+ def test_get_qubits(self, swap_phases: SwapPhases, frame_a: Frame, frame_b: Frame):
expected_qubits = set(frame_a.qubits + frame_b.qubits)
- assert swap_phase.get_qubits() == set([q.index for q in expected_qubits if isinstance(q, Qubit)])
- assert swap_phase.get_qubits(False) == expected_qubits
+ assert swap_phases.get_qubits() == set([q.index for q in expected_qubits if isinstance(q, Qubit)])
+ assert swap_phases.get_qubits(False) == expected_qubits
+
+ def test_copy(self, swap_phases: SwapPhases):
+ assert isinstance(copy.copy(swap_phases), SwapPhases)
+ assert isinstance(copy.deepcopy(swap_phases), SwapPhases)
- def test_copy(self, swap_phase: SwapPhases):
- assert isinstance(copy.copy(swap_phase), SwapPhases)
- assert isinstance(copy.deepcopy(swap_phase), SwapPhases)
+ def test_convert(self, swap_phases: SwapPhases):
+ rs_swap_phase = _convert_to_rs_instruction(swap_phases)
+ assert swap_phases == _convert_to_py_instruction(rs_swap_phase)
- def test_convert(self, swap_phase: SwapPhases):
- rs_swap_phase = _convert_to_rs_instruction(swap_phase)
- assert swap_phase == _convert_to_py_instruction(rs_swap_phase)
+ def test_pickle(self, swap_phases: SwapPhases):
+ pickled = pickle.dumps(swap_phases)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == swap_phases
@pytest.mark.parametrize(
@@ -1322,6 +1414,11 @@ def test_convert(self, move: ClassicalMove):
rs_classical_move = _convert_to_rs_instruction(move)
assert move == _convert_to_py_instruction(rs_classical_move)
+ def test_pickle(self, move: ClassicalMove):
+ pickled = pickle.dumps(move)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == move
+
@pytest.mark.parametrize(
("left", "right"),
@@ -1353,6 +1450,11 @@ def test_convert(self, exchange: ClassicalExchange):
rs_classical_exchange = _convert_to_rs_instruction(exchange)
assert exchange == _convert_to_py_instruction(rs_classical_exchange)
+ def test_pickle(self, exchange: ClassicalExchange):
+ pickled = pickle.dumps(exchange)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == exchange
+
@pytest.mark.parametrize(
("left", "right"),
@@ -1384,6 +1486,11 @@ def test_convert(self, convert: ClassicalConvert):
rs_classical_convert = _convert_to_rs_instruction(convert)
assert convert == _convert_to_py_instruction(rs_classical_convert)
+ def test_pickle(self, convert: ClassicalConvert):
+ pickled = pickle.dumps(convert)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == convert
+
@pytest.mark.parametrize(
("target", "left", "right"),
@@ -1420,6 +1527,11 @@ def test_convert(self, load: ClassicalLoad):
rs_classical_load = _convert_to_rs_instruction(load)
assert load == _convert_to_py_instruction(rs_classical_load)
+ def test_pickle(self, load: ClassicalLoad):
+ pickled = pickle.dumps(load)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == load
+
@pytest.mark.parametrize(
("target", "left", "right"),
@@ -1460,6 +1572,11 @@ def test_convert(self, store: ClassicalStore):
rs_classical_store = _convert_to_rs_instruction(store)
assert store == _convert_to_py_instruction(rs_classical_store)
+ def test_pickle(self, store: ClassicalStore):
+ pickled = pickle.dumps(store)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == store
+
@pytest.mark.parametrize(
("op", "target", "left", "right"),
@@ -1512,6 +1629,11 @@ def test_convert(self, comparison: ClassicalComparison):
rs_classical_comparison = _convert_to_rs_instruction(comparison)
assert comparison == _convert_to_py_instruction(rs_classical_comparison)
+ def test_pickle(self, comparison: ClassicalComparison):
+ pickled = pickle.dumps(comparison)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == comparison
+
@pytest.mark.parametrize(
("op", "target"),
@@ -1544,6 +1666,11 @@ def test_convert(self, unary: UnaryClassicalInstruction):
rs_classical_unary = _convert_to_rs_instruction(unary)
assert unary == _convert_to_py_instruction(rs_classical_unary)
+ def test_pickle(self, unary: UnaryClassicalInstruction):
+ pickled = pickle.dumps(unary)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == unary
+
@pytest.mark.parametrize(
("op", "left", "right"),
@@ -1595,6 +1722,11 @@ def test_convert(self, arithmetic: UnaryClassicalInstruction):
rs_classical_arithmetic = _convert_to_rs_instruction(arithmetic)
assert arithmetic == _convert_to_py_instruction(rs_classical_arithmetic)
+ def test_pickle(self, arithmetic: UnaryClassicalInstruction, snapshot: SnapshotAssertion):
+ pickled = pickle.dumps(arithmetic)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == snapshot
+
@pytest.mark.parametrize(
("op", "left", "right"),
@@ -1634,6 +1766,11 @@ def test_convert(self, logical: LogicalBinaryOp):
rs_classical_logical = _convert_to_rs_instruction(logical)
assert logical == _convert_to_py_instruction(rs_classical_logical)
+ def test_pickle(self, logical: LogicalBinaryOp):
+ pickled = pickle.dumps(logical)
+ unpickled = pickle.loads(pickled)
+ assert unpickled == logical
+
def test_include():
include = Include("my-cool-file.quil")
|
Make `QAMExecutionResult` serializable
Due to using non-picklable members from `qcs-sdk-python`, `QAMExecutionResult` is not itself serializable. We should add a way to pickle it, either by supporting pickling upstream or implementing it for `QAMExecutionResult` specifically.
|
This would also be useful for `pyquil.api._qpu.QPUExecuteResponse` so that programs can be submitted and retrieved in separate programs.
Yes this would be great. Also, instead of the program data/results disappearing after it's been retrieved by the user (as happens now, from what i understand), it would be great, if it stays available for some (even short) time after, say a day or two. That would allow users to handle potential intermittent retrieval/network/whatever issues (e.g. users tries to retrieve job data, rigetti server sends it over and marks as retrieved, removing relevant data, then something happens along the way and users does not see it... they then can't try to retrieve again, as server thinks that's been done and potentially got rid of it).
| 2024-07-29T16:23:59
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 2,443
|
marcelotduarte__cx_Freeze-2443
|
[
"2382",
"2433"
] |
c3b273e3246b5026808f91c315daaf980406a1da
|
diff --git a/cx_Freeze/hooks/multiprocessing.py b/cx_Freeze/hooks/multiprocessing.py
--- a/cx_Freeze/hooks/multiprocessing.py
+++ b/cx_Freeze/hooks/multiprocessing.py
@@ -43,16 +43,71 @@ def load_multiprocessing(finder: ModuleFinder, module: Module) -> None:
sys.exit()
# workaround: inject freeze_support call to avoid an infinite loop
from multiprocessing.spawn import freeze_support as _spawn_freeze_support
- from multiprocessing.context import BaseContext
- BaseContext._get_context = BaseContext.get_context
- def _get_freeze_context(self, method=None):
- ctx = self._get_context(method)
- _spawn_freeze_support()
- return ctx
- BaseContext.get_context = \
- lambda self, method=None: _get_freeze_context(self, method)
- # disable freeze_support, because it cannot be run twice
- BaseContext.freeze_support = lambda self: None
+ from multiprocessing.spawn import is_forking as _spawn_is_forking
+ from multiprocessing.context import BaseContext, DefaultContext
+ BaseContext.freeze_support = lambda self: _spawn_freeze_support()
+ DefaultContext.freeze_support = lambda self: _spawn_freeze_support()
+ if _spawn_is_forking(sys.argv):
+ main_module = sys.modules["__main__"]
+ main_spec = main_module.__spec__
+ main_code = main_spec.loader.get_code(main_spec.name)
+ _names = main_code.co_names
+ del main_module, main_spec, main_code
+ if "freeze_support" not in _names:
+ import BUILD_CONSTANTS as _contants
+ _ignore = getattr(_contants, "ignore_freeze_support_message", 0)
+ if not _ignore:
+ print(
+ '''
+ An attempt has been made to start a new process before the
+ current process has finished its bootstrapping phase.
+
+ This probably means that you are not using fork to start your
+ child processes and you have forgotten to use the proper idiom
+ in the main module:
+
+ if __name__ == "__main__":
+ freeze_support()
+ ...
+
+ To fix this issue, or to hide this message, refer to the documentation:
+ \
+ https://cx-freeze.readthedocs.io/en/stable/faq.html#multiprocessing-support
+ ''', file=sys.stderr)
+ #import os, signal
+ #os.kill(os.getppid(), signal.SIGHUP)
+ #sys.exit(os.EX_SOFTWARE)
+ _spawn_freeze_support()
+ # cx_Freeze patch end
+ """
+ code_string = module.file.read_text(encoding="utf_8") + dedent(source)
+ module.code = compile(
+ code_string,
+ module.file.as_posix(),
+ "exec",
+ dont_inherit=True,
+ optimize=finder.optimize,
+ )
+
+
+def load_multiprocessing_context(finder: ModuleFinder, module: Module) -> None:
+ """Monkeypath get_context to do automatic freeze_support."""
+ if IS_MINGW or IS_WINDOWS:
+ return
+ if module.file.suffix == ".pyc": # source unavailable
+ return
+ source = r"""
+ # cx_Freeze patch start
+ BaseContext._get_base_context = BaseContext.get_context
+ def _get_base_context(self, method=None):
+ self.freeze_support()
+ return self._get_base_context(method)
+ BaseContext.get_context = _get_base_context
+ DefaultContext._get_default_context = DefaultContext.get_context
+ def _get_default_context(self, method=None):
+ self.freeze_support()
+ return self._get_default_context(method)
+ DefaultContext.get_context = _get_default_context
# cx_Freeze patch end
"""
code_string = module.file.read_text(encoding="utf_8") + dedent(source)
|
diff --git a/tests/test_multiprocessing.py b/tests/test_multiprocessing.py
--- a/tests/test_multiprocessing.py
+++ b/tests/test_multiprocessing.py
@@ -21,14 +21,13 @@
SOURCE = """\
sample1.py
- import multiprocessing, sys
+ import multiprocessing
def foo(q):
- q.put('hello')
+ q.put("Hello from cx_Freeze")
- if __name__ == '__main__':
- if sys.platform == 'win32': # the conditional is unecessary
- multiprocessing.freeze_support()
+ if __name__ == "__main__":
+ multiprocessing.freeze_support()
multiprocessing.set_start_method('spawn')
q = multiprocessing.SimpleQueue()
p = multiprocessing.Process(target=foo, args=(q,))
@@ -36,25 +35,23 @@ def foo(q):
print(q.get())
p.join()
sample2.py
- import multiprocessing, sys
+ import multiprocessing
def foo(q):
- q.put('hello')
+ q.put("Hello from cx_Freeze")
- if __name__ == '__main__':
+ if __name__ == "__main__":
ctx = multiprocessing.get_context('spawn')
- if sys.platform == 'win32': # the conditional is unecessary
- ctx.freeze_support()
+ ctx.freeze_support()
q = ctx.Queue()
p = ctx.Process(target=foo, args=(q,))
p.start()
print(q.get())
p.join()
sample3.py
- if __name__ == "__main__":
+ if __name__ == "__main__":
import multiprocessing, sys
- if sys.platform == 'win32': # the conditional is unecessary
- multiprocessing.freeze_support()
+ multiprocessing.freeze_support()
multiprocessing.set_start_method('spawn')
mgr = multiprocessing.Manager()
var = [1] * 10000000
@@ -80,18 +77,22 @@ def foo(q):
}
)
"""
-EXPECTED_OUTPUT = ["hello", "hello", "creating dict...done!"]
+EXPECTED_OUTPUT = [
+ "Hello from cx_Freeze",
+ "Hello from cx_Freeze",
+ "creating dict...done!",
+]
def _parameters_data() -> Iterator:
methods = mp.get_all_start_methods()
for method in methods:
source = SOURCE.replace("('spawn')", f"('{method}')")
- for i, expected in enumerate(EXPECTED_OUTPUT):
+ for i, expected in enumerate(EXPECTED_OUTPUT, 1):
if method == "forkserver" and i != 3:
continue # only sample3 works with forkserver method
- sample = f"sample{i+1}"
- test_id = f"{sample},{method}"
+ sample = f"sample{i}"
+ test_id = f"{sample}-{method}"
yield pytest.param(source, sample, expected, id=test_id)
|
hooks: improve multiprocessing hook to work with pytorch
Fixes #2376
Version 7.1.0 (and 7.1.0.post0) break FastAPI/hypercorn
**Describe the bug**
When running a program built with cx_freeze starting version 7.1.0, it adds additional arguments, which hypercorn does not accept. These arguments seem to be related to multiprocessing integration.
This causes programs built with 7.1.0 or up, to no longer be functional.
A temporary workaround is to downgrade back to 7.0.0.
**To Reproduce**
All that is required is to run a hypercorn/FastAPI server (or it seems anything that uses multiprocessing) built with cx_Freeze on version 7.0.0 or 7.1.0.post0 (and also 7.1.0 was affected).
I added a full example to a reproduction repository:
https://github.com/Daniel-I-Am/cx_freeze-fastapi-repro
**Expected behavior**
I would expect programs that can be built with 7.0.0 to also be able to be built with 7.1.0.
**Desktop (please complete the following information):**
- Platform information: Docker `python:3.12-alpine` on linux
- OS architecture: amd64
- cx_Freeze version: 7.1.0.post0
- Python version: 3.12
|
## [Codecov](https://app.codecov.io/gh/marcelotduarte/cx_Freeze/pull/2382?dropdown=coverage&src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Marcelo+Duarte) Report
All modified and coverable lines are covered by tests :white_check_mark:
> Project coverage is 83.29%. Comparing base [(`cde0912`)](https://app.codecov.io/gh/marcelotduarte/cx_Freeze/commit/cde09120951af0c22f68ff81d1b8124127f920b7?dropdown=coverage&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Marcelo+Duarte) to head [(`6e97ef6`)](https://app.codecov.io/gh/marcelotduarte/cx_Freeze/pull/2382?dropdown=coverage&src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Marcelo+Duarte).
<details><summary>Additional details and impacted files</summary>
```diff
@@ Coverage Diff @@
## main #2382 +/- ##
=======================================
Coverage 83.29% 83.29%
=======================================
Files 27 27
Lines 4058 4058
=======================================
Hits 3380 3380
Misses 678 678
```
</details>
[:umbrella: View full report in Codecov by Sentry](https://app.codecov.io/gh/marcelotduarte/cx_Freeze/pull/2382?dropdown=coverage&src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Marcelo+Duarte).
:loudspeaker: Have feedback on the report? [Share it here](https://about.codecov.io/codecov-pr-comment-feedback/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=Marcelo+Duarte).
```python
from multiprocessing import Process, freeze_support
def f():
print("Hello from cx_Freeze")
if __name__ == "__main__":
freeze_support()
Process(target=f).start()
```
Potentially related broken case on macos without fastapi
@Daniel-I-Am I confirm the bug. I'll work on it.
@ntindle Can you check if #2435 is more related to your use case?
I think you're right that the issue you linked is more related
| 2024-06-07T00:14:01
|
python
|
Easy
|
rigetti/pyquil
| 1,714
|
rigetti__pyquil-1714
|
[
"1710"
] |
40739442d53c913f989728dd681926ca2aa11fe5
|
diff --git a/pyquil/quilbase.py b/pyquil/quilbase.py
--- a/pyquil/quilbase.py
+++ b/pyquil/quilbase.py
@@ -2750,12 +2750,12 @@ def frame(self) -> Frame:
def frame(self, frame: Frame) -> None:
quil_rs.FrameDefinition.identifier.__set__(self, frame) # type: ignore[attr-defined]
- def _set_attribute(self, name: str, value: Union[str, float]) -> None:
+ def set_attribute(self, name: str, value: Union[str, float]) -> None:
updated = super().attributes
updated.update({name: DefFrame._to_attribute_value(value)})
quil_rs.FrameDefinition.attributes.__set__(self, updated) # type: ignore[attr-defined]
- def _get_attribute(self, name: str) -> Optional[Union[str, float]]:
+ def get_attribute(self, name: str) -> Optional[Union[str, float]]:
value = super().attributes.get(name, None)
if value is None:
return None
@@ -2763,46 +2763,98 @@ def _get_attribute(self, name: str) -> Optional[Union[str, float]]:
return value.to_string()
return value.to_expression().to_number().real
+ def __getitem__(self, name: str) -> Union[str, float]:
+ if not isinstance(name, str):
+ raise TypeError("Frame attribute keys must be strings")
+ value = self.get_attribute(name)
+ if value is None:
+ raise AttributeError(f"Attribute {name} not found")
+ return value
+
+ def __setitem__(self, name: str, value: Union[str, float]) -> None:
+ if not isinstance(name, str):
+ raise TypeError("Frame attribute keys must be strings")
+ self.set_attribute(name, value)
+
@property
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use get_attribute('DIRECTION') instead.",
+ )
def direction(self) -> Optional[str]:
- return self._get_attribute("DIRECTION") # type: ignore
+ return self.get_attribute("DIRECTION") # type: ignore
@direction.setter
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('DIRECTION') instead.",
+ )
def direction(self, direction: str) -> None:
- self._set_attribute("DIRECTION", direction)
+ self.set_attribute("DIRECTION", direction)
@property
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('INITIAL-FREQUENCY') instead.", # noqa: E501
+ )
def initial_frequency(self) -> Optional[float]:
- return self._get_attribute("INITIAL-FREQUENCY") # type: ignore
+ return self.get_attribute("INITIAL-FREQUENCY") # type: ignore
@initial_frequency.setter
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('INITIAL-FREQUENCY') instead.", # noqa: E501
+ )
def initial_frequency(self, initial_frequency: float) -> None:
- self._set_attribute("INITIAL-FREQUENCY", initial_frequency)
+ self.set_attribute("INITIAL-FREQUENCY", initial_frequency)
@property
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use get_attribute('HARDWARE-OBJECT') instead.",
+ )
def hardware_object(self) -> Optional[str]:
- return self._get_attribute("HARDWARE-OBJECT") # type: ignore
+ return self.get_attribute("HARDWARE-OBJECT") # type: ignore
@hardware_object.setter
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('HARDWARE-OBJECT') instead.",
+ )
def hardware_object(self, hardware_object: str) -> None:
- self._set_attribute("HARDWARE-OBJECT", hardware_object)
+ self.set_attribute("HARDWARE-OBJECT", hardware_object)
@property
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use get_attribute('SAMPLE-RATE') instead.",
+ )
def sample_rate(self) -> Frame:
- return self._get_attribute("SAMPLE-RATE") # type: ignore
+ return self.get_attribute("SAMPLE-RATE") # type: ignore
@sample_rate.setter
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('SAMPLE-RATE') instead.",
+ )
def sample_rate(self, sample_rate: float) -> None:
- self._set_attribute("SAMPLE-RATE", sample_rate)
+ self.set_attribute("SAMPLE-RATE", sample_rate)
@property
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use get_attribute('CENTER-FREQUENCY') instead.",
+ )
def center_frequency(self) -> Frame:
- return self._get_attribute("CENTER-FREQUENCY") # type: ignore
+ return self.get_attribute("CENTER-FREQUENCY") # type: ignore
@center_frequency.setter
+ @deprecated(
+ version="4.0",
+ reason="Quil now supports generic key/value pairs in DEFFRAMEs. Use set_attribute('CENTER-FREQUENCY') instead.",
+ )
def center_frequency(self, center_frequency: float) -> None:
- self._set_attribute("CENTER-FREQUENCY", center_frequency)
- self._set_attribute("CENTER-FREQUENCY", center_frequency)
+ self.set_attribute("CENTER-FREQUENCY", center_frequency)
def __copy__(self) -> Self:
return self
|
diff --git a/test/unit/test_quilbase.py b/test/unit/test_quilbase.py
--- a/test/unit/test_quilbase.py
+++ b/test/unit/test_quilbase.py
@@ -518,32 +518,48 @@ def test_frame(self, def_frame: DefFrame, frame: Frame):
assert def_frame.frame == Frame([Qubit(123)], "new_frame")
def test_direction(self, def_frame: DefFrame, direction: Optional[str]):
- assert def_frame.direction == direction
+ assert def_frame.direction == direction is None if not direction else def_frame["DIRECTION"]
def_frame.direction = "tx"
assert def_frame.direction == "tx"
def test_initial_frequency(self, def_frame: DefFrame, initial_frequency: Optional[float]):
- assert def_frame.initial_frequency == initial_frequency
+ assert (
+ def_frame.initial_frequency == initial_frequency is None
+ if not initial_frequency
+ else def_frame["INITIAL-FREQUENCY"]
+ )
def_frame.initial_frequency = 3.14
assert def_frame.initial_frequency == 3.14
def test_hardware_object(self, def_frame: DefFrame, hardware_object: Optional[str]):
- assert def_frame.hardware_object == hardware_object
+ assert (
+ def_frame.hardware_object == hardware_object is None
+ if not hardware_object
+ else def_frame["HARDWARE-OBJECT"]
+ )
def_frame.hardware_object = "bfg"
assert def_frame.hardware_object == "bfg"
- def test_hardware_object(self, def_frame: DefFrame, hardware_object: Optional[str]):
- assert def_frame.hardware_object == hardware_object
+ def test_hardware_object_json(self, def_frame: DefFrame, hardware_object: Optional[str]):
+ assert (
+ def_frame.hardware_object == hardware_object is None
+ if not hardware_object
+ else def_frame["HARDWARE-OBJECT"]
+ )
def_frame.hardware_object = '{"string": "str", "int": 1, "float": 3.14}'
assert def_frame.hardware_object == '{"string": "str", "int": 1, "float": 3.14}'
def test_sample_rate(self, def_frame: DefFrame, sample_rate: Optional[float]):
- assert def_frame.sample_rate == sample_rate
+ assert def_frame.sample_rate == sample_rate is None if not sample_rate else def_frame["SAMPLE-RATE"]
def_frame.sample_rate = 96.0
assert def_frame.sample_rate == 96.0
def test_center_frequency(self, def_frame: DefFrame, center_frequency: Optional[float]):
- assert def_frame.center_frequency == center_frequency
+ assert (
+ def_frame.center_frequency == center_frequency is None
+ if not center_frequency
+ else def_frame.center_frequency
+ )
def_frame.center_frequency = 432.0
assert def_frame.center_frequency == 432.0
|
Make the `get_attribute` and `set_attribute` methods on `DefFrame` public.
`DefFrame` supports generic attributes but there is not a direct way to access any that aren't defined as a `@property` in the public API. One example is `channel_delay`. It was added to the constructor parameters in `V4`, but doesn't have an associated property and requires going through the underlying `quil` API to access it. We should make the current `_get_attribute` and `_set_attribute` methods public so any key/value pairs can be fetched or modified.
~The `DefFrame` `channel_delay` property wasn't carried over from V3. We should add a special `@property` definition for it so it works as it used to.~
|
Historical note: it wasn't carried over because it didn't exist, right? This is a new feature of the v2 translation backend.
And simultaneously, frames changed in the Quil spec to have dynamic key-value pairs. So I don't think the right answer here is to add more properties, but rather to allow looking them up by string key, and deprecating the property-based lookups.
Ah, yeah, that is correct, `channel_delay` is new to V4. We should make the current get/set attribute methods public, and point users to it instead.
| 2023-12-14T16:41:15
|
python
|
Hard
|
pytest-dev/pytest-django
| 910
|
pytest-dev__pytest-django-910
|
[
"909"
] |
762cfc2f2cea6eeb859c3ddba3ac06d1799d0842
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -147,6 +147,12 @@ class ResetSequenceTestCase(django_case):
django_case = ResetSequenceTestCase
else:
from django.test import TestCase as django_case
+ from django.db import transaction
+ transaction.Atomic._ensure_durability = False
+
+ def reset_durability():
+ transaction.Atomic._ensure_durability = True
+ request.addfinalizer(reset_durability)
test_case = django_case(methodName="__init__")
test_case._pre_setup()
|
diff --git a/tests/test_database.py b/tests/test_database.py
--- a/tests/test_database.py
+++ b/tests/test_database.py
@@ -1,7 +1,8 @@
import pytest
-from django.db import connection
+from django.db import connection, transaction
from django.test.testcases import connections_support_transactions
+from pytest_django.lazy_django import get_django_version
from pytest_django_test.app.models import Item
@@ -138,6 +139,12 @@ def test_fin(self, fin):
# Check finalizer has db access (teardown will fail if not)
pass
+ @pytest.mark.skipif(get_django_version() < (3, 2), reason="Django >= 3.2 required")
+ def test_durable_transactions(self, all_dbs):
+ with transaction.atomic(durable=True):
+ item = Item.objects.create(name="foo")
+ assert Item.objects.get() == item
+
class TestDatabaseFixturesAllOrder:
@pytest.fixture
|
Handle transaction.atomic(durable=True)
This argument will be introduced in Django 3.2: https://docs.djangoproject.com/en/3.2/topics/db/transactions/#controlling-transactions-explicitly
It's used to make sure that atomic blocks aren't nested and naturally this fails when running the test suite. The django `TestCase`-class handles this by setting `transaction.Atomic._ensure_durability = False` in `setUpClass` and setting it back to `True` on `tearDownClass`.
I'm not that familiar with the codebase but I wonder if it would make sense to adjust the non-transactional block in `_django_db_fixture_helper` with something like:
```python
transaction.Atomic._ensure_durability = False
def reset_durability():
transaction.Atomic._ensure_durability = True
request.addfinalizer(reset_durability)
```
| 2021-03-02T18:55:42
|
python
|
Easy
|
|
getlogbook/logbook
| 284
|
getlogbook__logbook-284
|
[
"283"
] |
b1532c4ca83b75efc5a09c02aa58642571ff0a41
|
diff --git a/logbook/queues.py b/logbook/queues.py
--- a/logbook/queues.py
+++ b/logbook/queues.py
@@ -604,7 +604,10 @@ class TWHThreadController(object):
queue and sends it to a handler. Both queue and handler are
taken from the passed :class:`ThreadedWrapperHandler`.
"""
- _sentinel = object()
+ class Command(object):
+ stop = object()
+ emit = object()
+ emit_batch = object()
def __init__(self, wrapper_handler):
self.wrapper_handler = wrapper_handler
@@ -621,17 +624,23 @@ def start(self):
def stop(self):
"""Stops the task thread."""
if self.running:
- self.wrapper_handler.queue.put_nowait(self._sentinel)
+ self.wrapper_handler.queue.put_nowait((self.Command.stop, ))
self._thread.join()
self._thread = None
def _target(self):
while 1:
- record = self.wrapper_handler.queue.get()
- if record is self._sentinel:
+ item = self.wrapper_handler.queue.get()
+ command, data = item[0], item[1:]
+ if command is self.Command.stop:
self.running = False
break
- self.wrapper_handler.handler.handle(record)
+ elif command is self.Command.emit:
+ (record, ) = data
+ self.wrapper_handler.handler.emit(record)
+ elif command is self.Command.emit_batch:
+ record, reason = data
+ self.wrapper_handler.handler.emit_batch(record, reason)
class ThreadedWrapperHandler(WrapperHandler):
@@ -663,8 +672,17 @@ def close(self):
self.handler.close()
def emit(self, record):
+ item = (TWHThreadController.Command.emit, record)
try:
- self.queue.put_nowait(record)
+ self.queue.put_nowait(item)
+ except Full:
+ # silently drop
+ pass
+
+ def emit_batch(self, records, reason):
+ item = (TWHThreadController.Command.emit_batch, records, reason)
+ try:
+ self.queue.put_nowait(item)
except Full:
# silently drop
pass
|
diff --git a/tests/test_queues.py b/tests/test_queues.py
--- a/tests/test_queues.py
+++ b/tests/test_queues.py
@@ -89,9 +89,24 @@ def test_multi_processing_handler():
assert test_handler.has_warning('Hello World')
+class BatchTestHandler(logbook.TestHandler):
+ def __init__(self, *args, **kwargs):
+ super(BatchTestHandler, self).__init__(*args, **kwargs)
+ self.batches = []
+
+ def emit(self, record):
+ super(BatchTestHandler, self).emit(record)
+ self.batches.append([record])
+
+ def emit_batch(self, records, reason):
+ for record in records:
+ super(BatchTestHandler, self).emit(record)
+ self.batches.append(records)
+
+
def test_threaded_wrapper_handler(logger):
from logbook.queues import ThreadedWrapperHandler
- test_handler = logbook.TestHandler()
+ test_handler = BatchTestHandler()
with ThreadedWrapperHandler(test_handler) as handler:
logger.warn('Just testing')
logger.error('More testing')
@@ -100,6 +115,50 @@ def test_threaded_wrapper_handler(logger):
handler.close()
assert (not handler.controller.running)
+ assert len(test_handler.records) == 2
+ assert len(test_handler.batches) == 2
+ assert all((len(records) == 1 for records in test_handler.batches))
+ assert test_handler.has_warning('Just testing')
+ assert test_handler.has_error('More testing')
+
+
+def test_threaded_wrapper_handler_emit():
+ from logbook.queues import ThreadedWrapperHandler
+ test_handler = BatchTestHandler()
+ with ThreadedWrapperHandler(test_handler) as handler:
+ lr = logbook.LogRecord('Test Logger', logbook.WARNING, 'Just testing')
+ test_handler.emit(lr)
+ lr = logbook.LogRecord('Test Logger', logbook.ERROR, 'More testing')
+ test_handler.emit(lr)
+
+ # give it some time to sync up
+ handler.close()
+
+ assert (not handler.controller.running)
+ assert len(test_handler.records) == 2
+ assert len(test_handler.batches) == 2
+ assert all((len(records) == 1 for records in test_handler.batches))
+ assert test_handler.has_warning('Just testing')
+ assert test_handler.has_error('More testing')
+
+
+def test_threaded_wrapper_handler_emit_batched():
+ from logbook.queues import ThreadedWrapperHandler
+ test_handler = BatchTestHandler()
+ with ThreadedWrapperHandler(test_handler) as handler:
+ test_handler.emit_batch([
+ logbook.LogRecord('Test Logger', logbook.WARNING, 'Just testing'),
+ logbook.LogRecord('Test Logger', logbook.ERROR, 'More testing'),
+ ], 'group')
+
+ # give it some time to sync up
+ handler.close()
+
+ assert (not handler.controller.running)
+ assert len(test_handler.records) == 2
+ assert len(test_handler.batches) == 1
+ (records, ) = test_handler.batches
+ assert len(records) == 2
assert test_handler.has_warning('Just testing')
assert test_handler.has_error('More testing')
|
ThreadedWrapperHandler does not forward batched emits as expected
I noticed that the `ThreadedWrapperHandler` does not forward batch emits in *batch form*. Thus, if a `ThreadedWrapperHandler` wraps a `MailHandler`, a mail is sent for each logging entry instead of one summarising mail.
I may be able to provide a PR but let me ask first: Is this something you would like to get addressed or is the current behaviour considered *working as intended*?
---
Also, many thanks for this logging package! I use it for pretty much everything I write in Python. :+1:
|
@lgrahl Thanks for the feedback!
I think this is a reasonable change to implement. At the most naive approach this will be equivalent to a for loop with `emit`, and at the more complex scenarios this will enable all sorts of optimizations. Sounds like a good idea!
| 2019-01-07T14:14:20
|
python
|
Hard
|
pytest-dev/pytest-django
| 888
|
pytest-dev__pytest-django-888
|
[
"846"
] |
c0d10af86eb737f5ac4ba42b1f4361b66d3c6c18
|
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -118,6 +118,12 @@ def pytest_addoption(parser):
type="bool",
default=True,
)
+ parser.addini(
+ "django_debug_mode",
+ "How to set the Django DEBUG setting (default `False`). "
+ "Use `keep` to not override.",
+ default="False",
+ )
group.addoption(
"--fail-on-template-vars",
action="store_true",
@@ -445,11 +451,15 @@ def django_test_environment(request):
"""
if django_settings_is_configured():
_setup_django()
- from django.conf import settings as dj_settings
from django.test.utils import setup_test_environment, teardown_test_environment
- dj_settings.DEBUG = False
- setup_test_environment()
+ debug_ini = request.config.getini("django_debug_mode")
+ if debug_ini == "keep":
+ debug = None
+ else:
+ debug = _get_boolean_value(debug_ini, False)
+
+ setup_test_environment(debug=debug)
request.addfinalizer(teardown_test_environment)
|
diff --git a/tests/test_django_settings_module.py b/tests/test_django_settings_module.py
--- a/tests/test_django_settings_module.py
+++ b/tests/test_django_settings_module.py
@@ -278,7 +278,7 @@ def test_settings():
assert result.ret == 0
-def test_debug_false(testdir, monkeypatch):
+def test_debug_false_by_default(testdir, monkeypatch):
monkeypatch.delenv("DJANGO_SETTINGS_MODULE")
testdir.makeconftest(
"""
@@ -307,6 +307,78 @@ def test_debug_is_false():
assert r.ret == 0
+@pytest.mark.parametrize('django_debug_mode', (False, True))
+def test_django_debug_mode_true_false(testdir, monkeypatch, django_debug_mode):
+ monkeypatch.delenv("DJANGO_SETTINGS_MODULE")
+ testdir.makeini(
+ """
+ [pytest]
+ django_debug_mode = {}
+ """.format(django_debug_mode)
+ )
+ testdir.makeconftest(
+ """
+ from django.conf import settings
+
+ def pytest_configure():
+ settings.configure(SECRET_KEY='set from pytest_configure',
+ DEBUG=%s,
+ DATABASES={'default': {
+ 'ENGINE': 'django.db.backends.sqlite3',
+ 'NAME': ':memory:'}},
+ INSTALLED_APPS=['django.contrib.auth',
+ 'django.contrib.contenttypes',])
+ """ % (not django_debug_mode)
+ )
+
+ testdir.makepyfile(
+ """
+ from django.conf import settings
+ def test_debug_is_false():
+ assert settings.DEBUG is {}
+ """.format(django_debug_mode)
+ )
+
+ r = testdir.runpytest_subprocess()
+ assert r.ret == 0
+
+
+@pytest.mark.parametrize('settings_debug', (False, True))
+def test_django_debug_mode_keep(testdir, monkeypatch, settings_debug):
+ monkeypatch.delenv("DJANGO_SETTINGS_MODULE")
+ testdir.makeini(
+ """
+ [pytest]
+ django_debug_mode = keep
+ """
+ )
+ testdir.makeconftest(
+ """
+ from django.conf import settings
+
+ def pytest_configure():
+ settings.configure(SECRET_KEY='set from pytest_configure',
+ DEBUG=%s,
+ DATABASES={'default': {
+ 'ENGINE': 'django.db.backends.sqlite3',
+ 'NAME': ':memory:'}},
+ INSTALLED_APPS=['django.contrib.auth',
+ 'django.contrib.contenttypes',])
+ """ % settings_debug
+ )
+
+ testdir.makepyfile(
+ """
+ from django.conf import settings
+ def test_debug_is_false():
+ assert settings.DEBUG is {}
+ """.format(settings_debug)
+ )
+
+ r = testdir.runpytest_subprocess()
+ assert r.ret == 0
+
+
@pytest.mark.django_project(
extra_settings="""
INSTALLED_APPS = [
|
Django debug should be optional
https://github.com/pytest-dev/pytest-django/blob/162263f338d863fddc14b0659f506d63799f78e1/pytest_django/plugin.py#L473
Currently django is hard codded to not allow debug. This means that static files are not served, even when debug is set as true. So in my tests when loading from staticfiles_storage the files are not found without a collect static. What is the expected way to deal with this?
|
I get having a default flag for DEBUG = False. But if in user's settings they explicitly specify DEBUG = True. I don't think the library should override it.
I prefer to run tests with ``DEBUG`` set to ``True``, and I can't seem to do that with pytest-django.
Am I missing something, or if I'm not, is there a workaround?
The benefit of doing this is that when a test fails because of an unhandled exception, the resulting screenshot contains debugging information.
Duplicate of #180.
This is done to match Django's behavior: https://docs.djangoproject.com/en/dev/topics/testing/overview/#other-test-conditions
But seems like Django has since added a [`--debug-mode` flag](https://docs.djangoproject.com/en/3.1/ref/django-admin/#test) to enable DEBUG. So we can probably do the same. I'll look into it now.
| 2020-10-16T21:52:32
|
python
|
Easy
|
marcelotduarte/cx_Freeze
| 2,857
|
marcelotduarte__cx_Freeze-2857
|
[
"2856"
] |
0be89ba63a67cfefcd73ee8520848c2bb9d1f17c
|
diff --git a/cx_Freeze/hooks/__init__.py b/cx_Freeze/hooks/__init__.py
--- a/cx_Freeze/hooks/__init__.py
+++ b/cx_Freeze/hooks/__init__.py
@@ -34,6 +34,15 @@ def load_aiofiles(finder: ModuleFinder, module: Module) -> None:
finder.include_package("aiofiles")
+def load_argon2(finder: ModuleFinder, module: Module) -> None:
+ """The argon2-cffi package requires the _cffi_backend module
+ (loaded implicitly).
+ """
+ if module.distribution is None:
+ module.update_distribution("argon2-cffi")
+ finder.include_module("_cffi_backend")
+
+
def load_babel(finder: ModuleFinder, module: Module) -> None:
"""The babel must be loaded as a package, and has pickeable data."""
finder.include_package("babel")
|
diff --git a/tests/test_hooks_argon2.py b/tests/test_hooks_argon2.py
new file mode 100644
--- /dev/null
+++ b/tests/test_hooks_argon2.py
@@ -0,0 +1,37 @@
+"""Tests for some cx_Freeze.hooks."""
+
+from __future__ import annotations
+
+from typing import TYPE_CHECKING
+
+import pytest
+from generate_samples import create_package, run_command
+
+from cx_Freeze._compat import BUILD_EXE_DIR, EXE_SUFFIX
+
+if TYPE_CHECKING:
+ from pathlib import Path
+
+pytest.importorskip("argon2", reason="Depends on extra package: argon2-cffi")
+
+SOURCE = """
+test_argon2.py
+ import argon2
+ from importlib.metadata import distribution, version
+
+ print("Hello from cx_Freeze")
+ print(argon2.__name__, version("argon2-cffi"))
+command
+ cxfreeze --script test_argon2.py build_exe
+"""
+
+
+def test_argon2(tmp_path: Path) -> None:
+ """Test if argon2-cffi is working correctly."""
+ create_package(tmp_path, SOURCE)
+ output = run_command(tmp_path)
+ executable = tmp_path / BUILD_EXE_DIR / f"test_argon2{EXE_SUFFIX}"
+ assert executable.is_file()
+ output = run_command(tmp_path, executable, timeout=10)
+ assert output.splitlines()[0] == "Hello from cx_Freeze"
+ assert output.splitlines()[1].startswith("argon2")
|
argon2-cffi metadata is missing on 7.2.4+
**Describe the bug**
argon2-cffi metadata is missing
```
File "permissions.py", line 104, in authenticate
File "passlib\context.py", line 2347, in verify
File "passlib\handlers\argon2.py", line 669, in verify
File "passlib\utils\handlers.py", line 2254, in _stub_requires_backend
File "passlib\utils\handlers.py", line 2156, in set_backend
File "passlib\utils\handlers.py", line 2163, in set_backend
File "passlib\utils\handlers.py", line 2188, in set_backend
File "passlib\utils\handlers.py", line 2311, in _set_backend
File "passlib\utils\handlers.py", line 2224, in _set_backend
File "passlib\handlers\argon2.py", line 716, in _load_backend_mixin
File "argon2\__init__.py", line 75, in __getattr__
File "importlib\metadata\__init__.py", line 998, in metadata
File "importlib\metadata\__init__.py", line 565, in from_name
importlib.metadata.PackageNotFoundError: No package metadata was found for argon2-cffi
```
Line 104 in permissions is effectively this:
```
from passlib.context import CryptContext
CryptContext(schemes=["argon2"]).verify(string1, string2)
```
**To Reproduce**
Hopefully the above is enough, this is a closed source application so I'd like to keep it to what's necessary.
**Expected behavior**
For the indirect import of argon2 via passlib to not fail when frozen.
**Screenshots**
Don't think that helps.
**Desktop (please complete the following information):**
- Platform information: Win10 and Win11
- OS architecture (e.g. amd64): amd64
- cx_Freeze version [e.g. 6.11]: 7.2.4 onwards. It works on 7.2.3. Still broken on 8.0.0
- Python version [e.g. 3.10]: 3.11
**Additional context**
Pinned cx-Freeze to 7.2.3 for now, tried some typical troubleshooting like putting argon2 into always include, as well as zip-exclude, to no success.
| 2025-03-26T07:38:23
|
python
|
Easy
|
|
rigetti/pyquil
| 1,133
|
rigetti__pyquil-1133
|
[
"1109"
] |
7210fbe56290121c44da97b9ec6eea032fcdb612
|
diff --git a/examples/1.3_vqe_demo.py b/examples/1.3_vqe_demo.py
--- a/examples/1.3_vqe_demo.py
+++ b/examples/1.3_vqe_demo.py
@@ -2,7 +2,6 @@
This is a demo of VQE through the forest stack. We will do the H2 binding from the Google paper
using OpenFermion to generate Hamiltonians and Forest to simulate the system
"""
-import sys
import numpy as np
import matplotlib.pyplot as plt
@@ -18,12 +17,14 @@
from pyquil.quil import Program
from pyquil.paulis import sX, sY, exponentiate, PauliSum
-from pyquil.gates import X, I
+from pyquil.gates import X
from pyquil.api import QVMConnection
from pyquil.unitary_tools import tensor_up
from grove.measurements.estimation import estimate_locally_commuting_operator
+QVM_CONNECTION = QVMConnection(endpoint="http://localhost:5000")
+
def get_h2_dimer(bond_length):
# Set molecule parameters.
@@ -60,7 +61,7 @@ def ucc_circuit(theta):
def objective_fun(
- theta, hamiltonian=None, quantum_resource=QVMConnection(endpoint="http://localhost:5000")
+ theta, hamiltonian=None, quantum_resource=QVM_CONNECTION
):
"""
Evaluate the Hamiltonian bny operator averaging
diff --git a/examples/qaoa_ansatz.py b/examples/qaoa_ansatz.py
--- a/examples/qaoa_ansatz.py
+++ b/examples/qaoa_ansatz.py
@@ -26,7 +26,6 @@
from pyquil.quil import Program
from pyquil.gates import H
from pyquil.paulis import sI, sX, sZ, exponentiate_commuting_pauli_sum
-from pyquil.api import QVMConnection
# Create a 4-node array graph: 0-1-2-3.
graph = [(0, 1), (1, 2), (2, 3)]
diff --git a/examples/website-script.py b/examples/website-script.py
--- a/examples/website-script.py
+++ b/examples/website-script.py
@@ -10,7 +10,7 @@
"""
from pyquil import Program, get_qc
-from pyquil.gates import *
+from pyquil.gates import H, CNOT
# construct a Bell State program
p = Program(H(0), CNOT(0, 1))
diff --git a/pyquil/api/_base_connection.py b/pyquil/api/_base_connection.py
--- a/pyquil/api/_base_connection.py
+++ b/pyquil/api/_base_connection.py
@@ -30,7 +30,6 @@
from pyquil.api._error_reporting import _record_call
from pyquil.api._errors import error_mapping, UserMessageError, UnknownApiError, TooManyQubitsError
from pyquil.api._logger import logger
-from pyquil.device import Specs, ISA
from pyquil.wavefunction import Wavefunction
TYPE_EXPECTATION = "expectation"
diff --git a/pyquil/api/_compiler.py b/pyquil/api/_compiler.py
--- a/pyquil/api/_compiler.py
+++ b/pyquil/api/_compiler.py
@@ -34,7 +34,7 @@
from urllib.parse import urljoin
from pyquil import __version__
-from pyquil.api._base_connection import ForestSession, get_session
+from pyquil.api._base_connection import ForestSession
from pyquil.api._qac import AbstractCompiler
from pyquil.api._error_reporting import _record_call
from pyquil.api._errors import UserMessageError
diff --git a/pyquil/api/_qpu.py b/pyquil/api/_qpu.py
--- a/pyquil/api/_qpu.py
+++ b/pyquil/api/_qpu.py
@@ -24,7 +24,7 @@
from pyquil import Program
from pyquil.parser import parse
-from pyquil.api._base_connection import ForestSession, get_session
+from pyquil.api._base_connection import ForestSession
from pyquil.api._error_reporting import _record_call
from pyquil.api._errors import UserMessageError
from pyquil.api._logger import logger
diff --git a/pyquil/api/_quantum_computer.py b/pyquil/api/_quantum_computer.py
--- a/pyquil/api/_quantum_computer.py
+++ b/pyquil/api/_quantum_computer.py
@@ -1199,7 +1199,7 @@ def hadamard(n, dtype=int):
H = np.array([[1]], dtype=dtype)
# Sylvester's construction
- for i in range(0, lg2):
+ for _ in range(0, lg2):
H = np.vstack((np.hstack((H, H)), np.hstack((H, -H))))
return H
diff --git a/pyquil/api/_qvm.py b/pyquil/api/_qvm.py
--- a/pyquil/api/_qvm.py
+++ b/pyquil/api/_qvm.py
@@ -34,7 +34,6 @@
from pyquil.api._config import PyquilConfig
from pyquil.api._error_reporting import _record_call
from pyquil.api._qam import QAM
-from pyquil.device import Device
from pyquil.gates import MOVE, MemoryReference
from pyquil.noise import apply_noise_model
from pyquil.paulis import PauliSum
diff --git a/pyquil/experiment/_memory.py b/pyquil/experiment/_memory.py
--- a/pyquil/experiment/_memory.py
+++ b/pyquil/experiment/_memory.py
@@ -20,7 +20,6 @@
import numpy as np
from pyquil.paulis import PauliTerm
-from pyquil.experiment._symmetrization import SymmetrizationLevel
def euler_angles_RX(theta: float) -> Tuple[float, float, float]:
diff --git a/pyquil/experiment/_setting.py b/pyquil/experiment/_setting.py
--- a/pyquil/experiment/_setting.py
+++ b/pyquil/experiment/_setting.py
@@ -24,10 +24,6 @@
from typing import Iterable, Tuple
from pyquil.paulis import PauliTerm, sI, is_identity
-from pyquil.experiment._memory import (
- pauli_term_to_measurement_memory_map,
- pauli_term_to_preparation_memory_map,
-)
if sys.version_info < (3, 7):
from pyquil.external.dataclasses import dataclass
diff --git a/pyquil/gates.py b/pyquil/gates.py
--- a/pyquil/gates.py
+++ b/pyquil/gates.py
@@ -14,18 +14,17 @@
# limitations under the License.
##############################################################################
from warnings import warn
-from typing import Any, Callable, Mapping, Optional, Tuple, Union, overload
+from typing import Callable, Mapping, Optional, Tuple, Union
+
+import numpy as np
from pyquil.quilatom import (
Addr,
Expression,
MemoryReference,
MemoryReferenceDesignator,
- Parameter,
ParameterDesignator,
- Qubit,
QubitDesignator,
- QubitPlaceholder,
unpack_classical_reg,
unpack_qubit,
)
@@ -382,7 +381,15 @@ def CPHASE10(angle: ParameterDesignator, control: QubitDesignator, target: Qubit
return Gate(name="CPHASE10", params=[angle], qubits=qubits)
-def CPHASE(angle: ParameterDesignator, control: QubitDesignator, target: QubitDesignator) -> Gate:
+# NOTE: We don't use ParameterDesignator here because of the following Sphinx error. This error
+# can be resolved by importing Expression, but then flake8 complains about an unused import:
+# Cannot resolve forward reference in type annotations of "pyquil.gates.CPHASE":
+# name 'Expression' is not defined
+def CPHASE(
+ angle: Union[Expression, MemoryReference, np.int_, int, float, complex],
+ control: QubitDesignator,
+ target: QubitDesignator,
+) -> Gate:
"""Produces a controlled-phase instruction::
CPHASE(phi) = diag([1, 1, 1, exp(1j * phi)])
diff --git a/pyquil/latex/_diagram.py b/pyquil/latex/_diagram.py
--- a/pyquil/latex/_diagram.py
+++ b/pyquil/latex/_diagram.py
@@ -23,7 +23,6 @@
from pyquil.quilbase import (
AbstractInstruction,
Wait,
- Reset,
ResetQubit,
JumpConditional,
JumpWhen,
@@ -404,7 +403,7 @@ def build(self):
self.index = 0
self.working_instructions = measures
- for instr in self.working_instructions:
+ for _ in self.working_instructions:
self._build_measure()
offset = max(self.settings.qubit_line_open_wire_length, 0)
diff --git a/pyquil/noise.py b/pyquil/noise.py
--- a/pyquil/noise.py
+++ b/pyquil/noise.py
@@ -468,7 +468,6 @@ def _decoherence_noise_model(
kraus_maps = []
for g in gates:
targets = tuple(t.index for t in g.qubits)
- key = (g.name, tuple(g.params))
if g.name in NO_NOISE:
continue
matrix, _ = get_noisy_gate(g.name, g.params)
diff --git a/pyquil/numpy_simulator.py b/pyquil/numpy_simulator.py
--- a/pyquil/numpy_simulator.py
+++ b/pyquil/numpy_simulator.py
@@ -18,7 +18,6 @@
import numpy as np
from numpy.random.mtrand import RandomState
-from pyquil import Program
from pyquil.gate_matrices import QUANTUM_GATES
from pyquil.paulis import PauliTerm, PauliSum
from pyquil.quilbase import Gate
diff --git a/pyquil/pyqvm.py b/pyquil/pyqvm.py
--- a/pyquil/pyqvm.py
+++ b/pyquil/pyqvm.py
@@ -15,8 +15,7 @@
##############################################################################
import warnings
from abc import ABC, abstractmethod
-from collections import defaultdict
-from typing import Type, Dict, Tuple, Union, List, Sequence
+from typing import Dict, List, Sequence, Type, Union
import numpy as np
from numpy.random.mtrand import RandomState
@@ -52,15 +51,6 @@
ClassicalDiv,
ClassicalMove,
ClassicalExchange,
- ClassicalConvert,
- ClassicalLoad,
- ClassicalStore,
- ClassicalComparison,
- ClassicalEqual,
- ClassicalLessThan,
- ClassicalLessEqual,
- ClassicalGreaterThan,
- ClassicalGreaterEqual,
Jump,
Pragma,
Declare,
diff --git a/pyquil/quil.py b/pyquil/quil.py
--- a/pyquil/quil.py
+++ b/pyquil/quil.py
@@ -39,7 +39,7 @@
unpack_classical_reg,
unpack_qubit,
)
-from pyquil.gates import MEASURE, H, RESET
+from pyquil.gates import MEASURE, RESET
from pyquil.quilbase import (
DefGate,
Gate,
@@ -65,7 +65,7 @@ class Program(object):
"""A list of pyQuil instructions that comprise a quantum program.
>>> from pyquil import Program
- >>> from pyquil.gates import *
+ >>> from pyquil.gates import H, CNOT
>>> p = Program()
>>> p += H(0)
>>> p += CNOT(0, 1)
diff --git a/pyquil/quilatom.py b/pyquil/quilatom.py
--- a/pyquil/quilatom.py
+++ b/pyquil/quilatom.py
@@ -289,7 +289,7 @@ def format_parameter(element: ParameterDesignator) -> str:
return str(element)
elif isinstance(element, Expression):
return _expression_to_string(element)
- assert False, "Invalid parameter: %r" % element
+ raise AssertionError("Invalid parameter: %r" % element)
ExpressionValueDesignator = Union[int, float, complex]
|
diff --git a/pyquil/api/tests/test_config.py b/pyquil/api/tests/test_config.py
--- a/pyquil/api/tests/test_config.py
+++ b/pyquil/api/tests/test_config.py
@@ -1,5 +1,4 @@
import pytest
-import os
from pyquil.api._config import PyquilConfig
from pyquil.api._errors import UserMessageError
diff --git a/pyquil/latex/tests/test_latex.py b/pyquil/latex/tests/test_latex.py
--- a/pyquil/latex/tests/test_latex.py
+++ b/pyquil/latex/tests/test_latex.py
@@ -3,7 +3,7 @@
from pyquil.quil import Program, Pragma
from pyquil.quilbase import Declare, Measurement, JumpTarget, Jump
from pyquil.quilatom import MemoryReference, Label
-from pyquil.gates import H, X, Y, RX, CZ, SWAP, MEASURE, CNOT, RESET, WAIT, MOVE
+from pyquil.gates import H, X, Y, RX, CZ, SWAP, MEASURE, CNOT, WAIT, MOVE
from pyquil.latex import to_latex, DiagramSettings
from pyquil.latex._diagram import split_on_terminal_measures
diff --git a/pyquil/tests/test_gate_matrices.py b/pyquil/tests/test_gate_matrices.py
--- a/pyquil/tests/test_gate_matrices.py
+++ b/pyquil/tests/test_gate_matrices.py
@@ -11,21 +11,16 @@
def test_singleq():
- I = QUANTUM_GATES["I"]
- assert np.isclose(I, np.eye(2)).all()
- X = QUANTUM_GATES["X"]
- assert np.isclose(X, np.array([[0, 1], [1, 0]])).all()
- Y = QUANTUM_GATES["Y"]
- assert np.isclose(Y, np.array([[0, -1j], [1j, 0]])).all()
- Z = QUANTUM_GATES["Z"]
- assert np.isclose(Z, np.array([[1, 0], [0, -1]])).all()
-
- H = QUANTUM_GATES["H"]
- assert np.isclose(H, (1.0 / np.sqrt(2)) * np.array([[1, 1], [1, -1]])).all()
- S = QUANTUM_GATES["S"]
- assert np.isclose(S, np.array([[1.0, 0], [0, 1j]])).all()
- T = QUANTUM_GATES["T"]
- assert np.isclose(T, np.array([[1.0, 0.0], [0.0, np.exp(1.0j * np.pi / 4.0)]])).all()
+ assert np.isclose(QUANTUM_GATES["I"], np.eye(2)).all()
+ assert np.isclose(QUANTUM_GATES["X"], np.array([[0, 1], [1, 0]])).all()
+ assert np.isclose(QUANTUM_GATES["Y"], np.array([[0, -1j], [1j, 0]])).all()
+ assert np.isclose(QUANTUM_GATES["Z"], np.array([[1, 0], [0, -1]])).all()
+
+ assert np.isclose(QUANTUM_GATES["H"], (1.0 / np.sqrt(2)) * np.array([[1, 1], [1, -1]])).all()
+ assert np.isclose(QUANTUM_GATES["S"], np.array([[1.0, 0], [0, 1j]])).all()
+ assert np.isclose(
+ QUANTUM_GATES["T"], np.array([[1.0, 0.0], [0.0, np.exp(1.0j * np.pi / 4.0)]])
+ ).all()
def test_parametric():
diff --git a/pyquil/tests/test_magic.py b/pyquil/tests/test_magic.py
--- a/pyquil/tests/test_magic.py
+++ b/pyquil/tests/test_magic.py
@@ -1,4 +1,12 @@
-from pyquil.magic import *
+from pyquil.magic import (
+ CNOT,
+ H,
+ I,
+ MEASURE,
+ X,
+ Program,
+ magicquil,
+)
@magicquil
diff --git a/pyquil/tests/test_noise.py b/pyquil/tests/test_noise.py
--- a/pyquil/tests/test_noise.py
+++ b/pyquil/tests/test_noise.py
@@ -3,7 +3,7 @@
import numpy as np
from unittest.mock import Mock
-from pyquil.gates import CZ, RZ, RX, I, H
+from pyquil.gates import CZ, I, RX, RZ
from pyquil.noise import (
pauli_kraus_map,
damping_kraus_map,
@@ -134,7 +134,6 @@ def test_decoherence_noise():
# verify that gate names are translated
new_prog = apply_noise_model(prog, m3)
- new_gates = _get_program_gates(new_prog)
# check that headers have been embedded
headers = _noise_model_program_header(m3)
diff --git a/pyquil/tests/test_numpy_simulator.py b/pyquil/tests/test_numpy_simulator.py
--- a/pyquil/tests/test_numpy_simulator.py
+++ b/pyquil/tests/test_numpy_simulator.py
@@ -5,7 +5,7 @@
from pyquil import Program
from pyquil.gate_matrices import QUANTUM_GATES as GATES
-from pyquil.gates import *
+from pyquil.gates import CCNOT, CNOT, H, MEASURE, RX, X
from pyquil.numpy_simulator import (
targeted_einsum,
NumpyWavefunctionSimulator,
@@ -195,7 +195,7 @@ def test_expectation():
def test_expectation_vs_ref_qvm(qvm, n_qubits):
- for repeat_i in range(20):
+ for _ in range(20):
prog = _generate_random_program(n_qubits=n_qubits, length=10)
operator = _generate_random_pauli(n_qubits=n_qubits, n_terms=5)
print(prog)
diff --git a/pyquil/tests/test_operator_estimation.py b/pyquil/tests/test_operator_estimation.py
--- a/pyquil/tests/test_operator_estimation.py
+++ b/pyquil/tests/test_operator_estimation.py
@@ -162,7 +162,7 @@ def test_no_complex_coeffs(forest):
[ExperimentSetting(TensorProductState(), 1.0j * sY(0))], program=Program(X(0))
)
with pytest.raises(ValueError):
- res = list(measure_observables(qc, suite, n_shots=2000))
+ list(measure_observables(qc, suite, n_shots=2000))
def test_max_weight_operator_1():
@@ -415,7 +415,7 @@ def test_measure_observables_no_symm_calibr_raises_error(forest):
exptsetting = ExperimentSetting(plusZ(0), sX(0))
suite = TomographyExperiment([exptsetting], program=Program(I(0)), symmetrization=0)
with pytest.raises(ValueError):
- result = list(measure_observables(qc, suite, calibrate_readout="plus-eig"))
+ list(measure_observables(qc, suite, calibrate_readout="plus-eig"))
def test_ops_bool_to_prog():
diff --git a/pyquil/tests/test_parameters.py b/pyquil/tests/test_parameters.py
--- a/pyquil/tests/test_parameters.py
+++ b/pyquil/tests/test_parameters.py
@@ -8,7 +8,6 @@
quil_cos,
quil_sqrt,
quil_exp,
- quil_cis,
_contained_parameters,
format_parameter,
quil_cis,
diff --git a/pyquil/tests/test_parser.py b/pyquil/tests/test_parser.py
--- a/pyquil/tests/test_parser.py
+++ b/pyquil/tests/test_parser.py
@@ -16,7 +16,37 @@
import numpy as np
import pytest
-from pyquil.gates import *
+from pyquil.gates import (
+ ADD,
+ AND,
+ CNOT,
+ CONVERT,
+ CPHASE00,
+ DIV,
+ EQ,
+ EXCHANGE,
+ Gate,
+ GE,
+ GT,
+ H,
+ IOR,
+ LE,
+ LOAD,
+ LT,
+ MEASURE,
+ MOVE,
+ MUL,
+ NOP,
+ NOT,
+ RESET,
+ RX,
+ STORE,
+ SUB,
+ SWAP,
+ WAIT,
+ X,
+ XOR,
+)
from pyquil.parser import parse
from pyquil.quilatom import MemoryReference, Parameter, quil_cos, quil_sin
from pyquil.quilbase import Declare, Reset, ResetQubit
diff --git a/pyquil/tests/test_paulis.py b/pyquil/tests/test_paulis.py
--- a/pyquil/tests/test_paulis.py
+++ b/pyquil/tests/test_paulis.py
@@ -776,7 +776,7 @@ def test_identity_no_qubit():
def test_qubit_validation():
with pytest.raises(ValueError):
- op = sX(None)
+ sX(None)
def test_pauli_term_from_str():
diff --git a/pyquil/tests/test_paulis_with_placeholders.py b/pyquil/tests/test_paulis_with_placeholders.py
--- a/pyquil/tests/test_paulis_with_placeholders.py
+++ b/pyquil/tests/test_paulis_with_placeholders.py
@@ -172,7 +172,7 @@ def test_ids():
# Not sortable
with pytest.raises(TypeError):
with pytest.warns(FutureWarning):
- t = term_1.id() == term_2.id()
+ term_1.id() == term_2.id()
def test_ids_no_sort():
@@ -669,7 +669,7 @@ def test_from_list():
with pytest.raises(ValueError):
# terms are not on disjoint qubits
- pterm = PauliTerm.from_list([("X", q[0]), ("Y", q[0])])
+ PauliTerm.from_list([("X", q[0]), ("Y", q[0])])
def test_ordered():
diff --git a/pyquil/tests/test_qpu.py b/pyquil/tests/test_qpu.py
--- a/pyquil/tests/test_qpu.py
+++ b/pyquil/tests/test_qpu.py
@@ -10,7 +10,6 @@
from pyquil.api._base_connection import Engagement, get_session
from pyquil.api._compiler import _collect_classical_memory_write_locations
from pyquil.api._config import PyquilConfig
-from pyquil.api._errors import UserMessageError
from pyquil.api._qpu import _extract_bitstrings
from pyquil.device import NxDevice
from pyquil.gates import I, X
@@ -246,12 +245,12 @@ def test_run_expects_executable(qvm, qpu_compiler):
p = Program(X(0))
with pytest.raises(TypeError):
- result = qc.run(p)
+ qc.run(p)
def test_qpu_not_engaged_error():
with pytest.raises(ValueError):
- qpu = QPU()
+ QPU()
def test_qpu_does_not_engage_without_session():
diff --git a/pyquil/tests/test_quantum_computer.py b/pyquil/tests/test_quantum_computer.py
--- a/pyquil/tests/test_quantum_computer.py
+++ b/pyquil/tests/test_quantum_computer.py
@@ -7,7 +7,6 @@
from pyquil import Program, get_qc, list_quantum_computers
from pyquil.api import QVM, QuantumComputer, local_forest_runtime
-from pyquil.tests.utils import DummyCompiler
from pyquil.api._quantum_computer import (
_symmetrization,
_flip_array_to_prog,
@@ -21,7 +20,7 @@
_check_min_num_trials_for_symmetrized_readout,
)
from pyquil.device import NxDevice, gates_in_isa
-from pyquil.gates import *
+from pyquil.gates import CNOT, H, I, MEASURE, RX, X
from pyquil.quilbase import Declare, MemoryReference
from pyquil.noise import decoherence_noise_with_asymmetric_ro
from pyquil.pyqvm import PyQVM
@@ -422,7 +421,7 @@ def test_qc_run(qvm, compiler):
qc = get_qc("9q-square-noisy-qvm")
bs = qc.run_and_measure(Program(X(0)), trials=3)
assert len(bs) == 9
- for q, bits in bs.items():
+ for _, bits in bs.items():
assert bits.shape == (3,)
diff --git a/pyquil/tests/test_quil.py b/pyquil/tests/test_quil.py
--- a/pyquil/tests/test_quil.py
+++ b/pyquil/tests/test_quil.py
@@ -406,7 +406,7 @@ def test_dagger():
assert p.dagger().out() == "DAGGER H 0\nDAGGER X 0\n"
p = Program(X(0), MEASURE(0, MemoryReference("ro", 0)))
- with pytest.raises(ValueError) as e:
+ with pytest.raises(ValueError):
p.dagger().out()
# ensure that modifiers are preserved https://github.com/rigetti/pyquil/pull/914
@@ -1376,7 +1376,7 @@ def test_placeholders_preserves_modifiers():
def _eval_as_np_pi(exp):
- eval(exp.replace("pi", repr(np.pi)).replace("theta[0]", "1"))
+ return eval(exp.replace("pi", repr(np.pi)).replace("theta[0]", "1"))
def test_params_pi_and_precedence():
@@ -1386,11 +1386,11 @@ def test_params_pi_and_precedence():
assert _eval_as_np_pi(trivial_pi) == _eval_as_np_pi(exp)
less_trivial_pi = "3 * theta[0] * 2 / (pi)"
- prog = Program(f"RX({trivial_pi}) 0")
+ prog = Program(f"RX({less_trivial_pi}) 0")
exp = str(prog[0].params[0])
- assert _eval_as_np_pi(trivial_pi) == _eval_as_np_pi(exp)
+ assert _eval_as_np_pi(less_trivial_pi) == _eval_as_np_pi(exp)
more_less_trivial_pi = "3 / (theta[0] / (pi + 1)) / pi"
- prog = Program(f"RX({trivial_pi}) 0")
+ prog = Program(f"RX({more_less_trivial_pi}) 0")
exp = str(prog[0].params[0])
- assert _eval_as_np_pi(trivial_pi) == _eval_as_np_pi(exp)
+ assert _eval_as_np_pi(more_less_trivial_pi) == _eval_as_np_pi(exp)
diff --git a/pyquil/tests/test_qvm.py b/pyquil/tests/test_qvm.py
--- a/pyquil/tests/test_qvm.py
+++ b/pyquil/tests/test_qvm.py
@@ -1,13 +1,11 @@
-import networkx as nx
import numpy as np
import pytest
from rpcq.messages import PyQuilExecutableResponse
from pyquil import Program
-from pyquil.api import QVM, ForestConnection, QVMCompiler
+from pyquil.api import ForestConnection, QVM
from pyquil.api._compiler import _extract_program_from_pyquil_executable_response
-from pyquil.device import NxDevice
from pyquil.gates import MEASURE, X, CNOT, H
from pyquil.quilbase import Declare, MemoryReference
diff --git a/pyquil/tests/test_reference_density_simulator.py b/pyquil/tests/test_reference_density_simulator.py
--- a/pyquil/tests/test_reference_density_simulator.py
+++ b/pyquil/tests/test_reference_density_simulator.py
@@ -4,7 +4,7 @@
import pyquil.gate_matrices as qmats
from pyquil import Program
-from pyquil.gates import *
+from pyquil.gates import CNOT, H, I, MEASURE, PHASE, RX, RY, RZ, X
from pyquil.pyqvm import PyQVM
from pyquil.reference_simulator import ReferenceDensitySimulator, _is_valid_quantum_state
from pyquil.unitary_tools import lifted_gate_matrix
diff --git a/pyquil/tests/test_reference_wavefunction_simulator.py b/pyquil/tests/test_reference_wavefunction_simulator.py
--- a/pyquil/tests/test_reference_wavefunction_simulator.py
+++ b/pyquil/tests/test_reference_wavefunction_simulator.py
@@ -922,7 +922,7 @@ def include_measures(request):
def test_vs_lisp_qvm(qvm, n_qubits, prog_length):
- for repeat_i in range(10):
+ for _ in range(10):
prog = _generate_random_program(n_qubits=n_qubits, length=prog_length)
lisp_wf = WavefunctionSimulator()
# force lisp wfs to allocate all qubits
@@ -960,7 +960,7 @@ def _generate_random_pauli(n_qubits, n_terms):
def test_expectation_vs_lisp_qvm(qvm, n_qubits):
- for repeat_i in range(20):
+ for _ in range(20):
prog = _generate_random_program(n_qubits=n_qubits, length=10)
operator = _generate_random_pauli(n_qubits=n_qubits, n_terms=5)
lisp_wf = WavefunctionSimulator()
diff --git a/pyquil/tests/test_unitary_tools.py b/pyquil/tests/test_unitary_tools.py
--- a/pyquil/tests/test_unitary_tools.py
+++ b/pyquil/tests/test_unitary_tools.py
@@ -3,7 +3,7 @@
from pyquil import Program
from pyquil import gate_matrices as mat
-from pyquil.gates import *
+from pyquil.gates import CCNOT, CNOT, CZ, H, MEASURE, PHASE, RX, RY, RZ, X, Y, Z
from pyquil.experiment import plusX, minusZ
from pyquil.paulis import sX, sY, sZ
from pyquil.unitary_tools import (
|
Ignore fewer flake8 style rules
If I remove everything other than `E501` (line length) and `F401` (unused imports), and run `flake8 pyquil`, I get 319 errors. At some point we should try to get rid of these, rather than ignoring them. I'll paste the output as a comment.
|
```
pyquil/magic.py:43:5: E743 ambiguous function definition 'I'
pyquil/gates.py:75:5: E743 ambiguous function definition 'I'
pyquil/gates.py:514:14: W503 line break before binary operator
pyquil/gates.py:900:11: E126 continuation line over-indented for hanging indent
pyquil/gate_matrices.py:90:1: E741 ambiguous variable name 'I'
pyquil/paulis.py:66:13: W503 line break before binary operator
pyquil/paulis.py:140:21: W503 line break before binary operator
pyquil/paulis.py:510:17: W503 line break before binary operator
pyquil/noise.py:464:9: F841 local variable 'key' is assigned to but never used
pyquil/noise.py:684:23: W503 line break before binary operator
pyquil/quilatom.py:387:17: W503 line break before binary operator
pyquil/quilatom.py:388:17: W503 line break before binary operator
pyquil/quilatom.py:437:17: W503 line break before binary operator
pyquil/quilatom.py:438:17: W503 line break before binary operator
pyquil/quilatom.py:521:17: W503 line break before binary operator
pyquil/quilatom.py:522:17: W503 line break before binary operator
pyquil/quilatom.py:528:17: W503 line break before binary operator
pyquil/quilatom.py:529:17: W503 line break before binary operator
pyquil/quilatom.py:627:17: W503 line break before binary operator
pyquil/quilatom.py:628:17: W503 line break before binary operator
pyquil/quilbase.py:751:17: W503 line break before binary operator
pyquil/quilbase.py:774:17: W503 line break before binary operator
pyquil/quilbase.py:858:21: W503 line break before binary operator
pyquil/quilbase.py:859:21: W503 line break before binary operator
pyquil/quilbase.py:860:21: W503 line break before binary operator
pyquil/latex/_ipython.py:79:34: E127 continuation line over-indented for visual indent
pyquil/tests/test_parser.py:19:1: F403 'from pyquil.gates import *' used; unable to detect undefined names
pyquil/tests/test_parser.py:29:25: F405 'Gate' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:30:32: F405 'Gate' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:34:25: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:35:30: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:36:30: F405 'SWAP' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:114:31: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:115:37: F405 'CPHASE00' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:116:30: F405 'Gate' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:117:31: F405 'Gate' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:123:50: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:184:31: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:185:37: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:196:27: F405 'RESET' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:197:26: F405 'WAIT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:198:25: F405 'NOP' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:204:43: F405 'STORE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:205:39: F405 'STORE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:206:43: F405 'LOAD' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:207:41: F405 'CONVERT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:208:42: F405 'EXCHANGE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:209:35: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:210:36: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:211:38: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:215:34: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:216:34: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:217:31: F405 'NOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:218:33: F405 'AND' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:219:33: F405 'IOR' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:220:34: F405 'MOVE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:221:33: F405 'XOR' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:222:36: F405 'ADD' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:223:36: F405 'SUB' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:224:36: F405 'MUL' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:225:36: F405 'DIV' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:226:37: F405 'ADD' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:227:37: F405 'SUB' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:228:37: F405 'MUL' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:229:37: F405 'DIV' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:231:18: F405 'EQ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:233:18: F405 'LT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:235:18: F405 'LE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:237:18: F405 'GT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:239:18: F405 'GE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:241:18: F405 'EQ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:243:18: F405 'LT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:245:18: F405 'LE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:247:18: F405 'GT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:249:18: F405 'GE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:251:18: F405 'EQ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:253:18: F405 'LT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:255:18: F405 'LE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:257:18: F405 'GT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:259:18: F405 'GE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:337:21: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:339:21: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:344:21: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:349:21: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parser.py:355:18: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:8:1: F403 'from pyquil.gates import *' used; unable to detect undefined names
pyquil/tests/test_numpy_simulator.py:53:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:61:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:61:26: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:69:20: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:69:26: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:77:20: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:77:26: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:77:32: F405 'CCNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:87:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:89:17: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:103:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:104:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:105:9: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:165:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:165:26: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:220:10: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:236:10: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_numpy_simulator.py:237:10: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_noise.py:123:5: F841 local variable 'new_gates' is assigned to but never used
pyquil/tests/test_noise.py:128:16: W503 line break before binary operator
pyquil/tests/test_reference_density_simulator.py:7:1: F403 'from pyquil.gates import *' used; unable to detect undefined names
pyquil/tests/test_reference_density_simulator.py:25:16: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:25:34: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:26:16: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:26:34: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:27:16: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:27:28: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:27:47: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:28:16: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:28:34: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:29:16: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:29:43: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:39:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:39:15: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:39:21: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:39:27: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:40:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:41:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:42:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:43:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:44:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:45:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:46:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:47:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:48:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:49:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:50:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:51:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:52:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:53:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:54:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:55:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:56:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:57:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:58:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:59:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:60:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:61:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:62:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:63:9: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:64:9: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:65:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:66:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:67:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:68:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:69:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:70:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:71:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:72:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:73:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:74:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:75:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:76:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:77:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:78:9: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:79:9: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:119:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:130:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:142:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:154:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:167:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:179:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:182:48: W503 line break before binary operator
pyquil/tests/test_reference_density_simulator.py:183:48: W503 line break before binary operator
pyquil/tests/test_reference_density_simulator.py:195:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:205:9: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:206:9: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:270:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:310:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:312:13: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_reference_density_simulator.py:329:23: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_gate_matrices.py:7:5: E741 ambiguous variable name 'I'
pyquil/tests/test_unitary_tools.py:6:1: F403 'from pyquil.gates import *' used; unable to detect undefined names
pyquil/tests/test_unitary_tools.py:16:25: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:16:31: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:16:37: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:23:25: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:23:31: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:23:37: F405 'Y' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:23:43: F405 'Z' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:33:17: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:33:23: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:33:35: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:52:21: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:52:39: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:53:21: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:53:39: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:54:21: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:54:33: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:54:52: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:55:21: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:55:39: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:56:21: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:56:48: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:66:42: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:66:48: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:66:54: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:118:20: E127 continuation line over-indented for visual indent
pyquil/tests/test_unitary_tools.py:125:20: E127 continuation line over-indented for visual indent
pyquil/tests/test_unitary_tools.py:281:32: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:285:32: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:289:32: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:293:32: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:299:32: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:303:32: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:307:32: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:313:32: F405 'RZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:317:32: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:318:32: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:323:32: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:324:32: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:327:32: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:328:32: F405 'CCNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:333:32: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:334:27: F405 'RY' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:342:32: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:343:32: F405 'CZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:346:32: F405 'PHASE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:347:32: F405 'CZ' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_unitary_tools.py:411:12: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_parameters.py:5:1: F811 redefinition of unused 'quil_cis' from line 5
pyquil/tests/test_quil.py:352:39: F841 local variable 'e' is assigned to but never used
pyquil/tests/test_quil.py:1313:5: F841 local variable 'less_trivial_pi' is assigned to but never used
pyquil/tests/test_quil.py:1318:5: F841 local variable 'more_less_trivial_pi' is assigned to but never used
pyquil/tests/test_operator_estimation.py:131:9: F841 local variable 'res' is assigned to but never used
pyquil/tests/test_operator_estimation.py:385:9: F841 local variable 'result' is assigned to but never used
pyquil/tests/test_paulis_with_placeholders.py:58:13: W503 line break before binary operator
pyquil/tests/test_paulis_with_placeholders.py:76:13: W503 line break before binary operator
pyquil/tests/test_paulis_with_placeholders.py:86:13: W503 line break before binary operator
pyquil/tests/test_paulis_with_placeholders.py:154:13: F841 local variable 't' is assigned to but never used
pyquil/tests/test_paulis_with_placeholders.py:302:18: W503 line break before binary operator
pyquil/tests/test_paulis_with_placeholders.py:303:18: W503 line break before binary operator
pyquil/tests/test_paulis_with_placeholders.py:304:18: W503 line break before binary operator
pyquil/tests/test_qpu.py:247:9: F841 local variable 'result' is assigned to but never used
pyquil/tests/test_qpu.py:252:9: F841 local variable 'qpu' is assigned to but never used
pyquil/tests/test_magic.py:1:1: F403 'from pyquil.magic import *' used; unable to detect undefined names
pyquil/tests/test_magic.py:4:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:6:5: F405 'H' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:7:5: F405 'CNOT' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:11:32: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:14:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:16:12: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:18:9: F405 'X' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:20:9: F405 'I' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:24:29: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:24:91: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:24:107: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:27:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:29:12: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:31:9: F405 'X' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:35:26: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:35:88: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:38:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:40:12: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:41:12: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:43:9: F405 'X' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:45:9: F405 'X' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:49:31: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:50:29: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:50:45: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:50:74: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:53:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:56:5: F405 'CNOT' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:60:38: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:63:2: F405 'magicquil' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:66:9: F405 'H' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:68:9: F405 'H' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_magic.py:72:40: F405 'Program' may be undefined, or defined from star imports: pyquil.magic
pyquil/tests/test_quantum_computer.py:20:1: F403 'from pyquil.gates import *' used; unable to detect undefined names
pyquil/tests/test_quantum_computer.py:24:1: F811 redefinition of unused 'DummyCompiler' from line 10
pyquil/tests/test_quantum_computer.py:53:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:53:26: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:151:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:151:26: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:217:13: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:218:13: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:219:13: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:220:13: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:221:13: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:222:13: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:238:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:238:26: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:238:38: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:241:17: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:257:20: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:257:26: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:257:38: F405 'CNOT' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:260:17: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:278:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:278:26: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:279:20: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:280:20: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:302:25: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:429:37: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:452:13: F405 'H' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:468:20: F405 'I' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:479:39: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:479:45: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:511:13: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:512:13: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:532:9: F405 'RX' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:533:9: F405 'MEASURE' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:573:42: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_quantum_computer.py:586:17: F405 'X' may be undefined, or defined from star imports: pyquil.gates
pyquil/tests/test_paulis.py:98:13: W503 line break before binary operator
pyquil/tests/test_paulis.py:348:18: W503 line break before binary operator
pyquil/tests/test_paulis.py:349:18: W503 line break before binary operator
pyquil/tests/test_paulis.py:350:18: W503 line break before binary operator
pyquil/tests/test_paulis.py:679:9: F841 local variable 'op' is assigned to but never used
pyquil/_parser/PyQuilListener.py:83:13: W503 line break before binary operator
pyquil/api/_quantum_computer.py:133:37: E127 continuation line over-indented for visual indent
pyquil/experiment/_main.py:58:26: W503 line break before binary operator
pyquil/experiment/_main.py:222:29: W503 line break before binary operator
```
| 2019-12-23T22:43:44
|
python
|
Hard
|
rigetti/pyquil
| 1,294
|
rigetti__pyquil-1294
|
[
"1156"
] |
b6ad4a9db8e7a6baae3af372bdaa166f725a678d
|
diff --git a/pyquil/api/_base_connection.py b/pyquil/api/_base_connection.py
--- a/pyquil/api/_base_connection.py
+++ b/pyquil/api/_base_connection.py
@@ -600,7 +600,7 @@ def _qvm_run(
measurement_noise: Optional[Tuple[float, float, float]],
gate_noise: Optional[Tuple[float, float, float]],
random_seed: Optional[int],
- ) -> np.ndarray:
+ ) -> Dict[str, np.ndarray]:
"""
Run a Forest ``run`` job on a QVM.
@@ -611,7 +611,7 @@ def _qvm_run(
)
response = post_json(self.session, self.sync_endpoint + "/qvm", payload)
- ram = response.json()
+ ram: Dict[str, np.ndarray] = {key: np.array(val) for key, val in response.json().items()}
for k in ram.keys():
ram[k] = np.array(ram[k])
diff --git a/pyquil/api/_qam.py b/pyquil/api/_qam.py
--- a/pyquil/api/_qam.py
+++ b/pyquil/api/_qam.py
@@ -41,6 +41,8 @@ class QAM(ABC):
pretend to be a QPI-compliant quantum computer.
"""
+ _memory_results: Dict[str, np.ndarray]
+
@_record_call
def __init__(self) -> None:
self.reset()
@@ -63,7 +65,7 @@ def load(
self._executable: Optional[
Union[QuiltBinaryExecutableResponse, PyQuilExecutableResponse]
] = executable
- self._memory_results: Optional[Dict[str, np.ndarray]] = defaultdict(lambda: None)
+ self._memory_results = defaultdict(lambda: None)
self.status = "loaded"
return self
diff --git a/pyquil/api/_qvm.py b/pyquil/api/_qvm.py
--- a/pyquil/api/_qvm.py
+++ b/pyquil/api/_qvm.py
@@ -538,7 +538,10 @@ def load(self, executable: Union[Program, PyQuilExecutableResponse]) -> "QVM":
"`Program`. You provided {}".format(type(executable))
)
- return cast("QVM", super().load(executable))
+ qvm = cast("QVM", super().load(executable))
+ for region in executable.declarations.keys():
+ self._memory_results[region] = np.ndarray((executable.num_shots, 0), dtype=np.int64)
+ return qvm
@_record_call
def run(self) -> "QVM":
@@ -565,7 +568,7 @@ def run(self) -> "QVM":
quil_program = self.augment_program_with_memory_values(quil_program)
- self._memory_results = self.connection._qvm_run(
+ results = self.connection._qvm_run(
quil_program=quil_program,
classical_addresses=classical_addresses,
trials=trials,
@@ -573,9 +576,7 @@ def run(self) -> "QVM":
gate_noise=self.gate_noise,
random_seed=self.random_seed,
)
-
- if "ro" not in self._memory_results or len(self._memory_results["ro"]) == 0:
- self._memory_results["ro"] = np.zeros((trials, 0), dtype=np.int64)
+ self._memory_results.update(results)
return self
diff --git a/pyquil/pyqvm.py b/pyquil/pyqvm.py
--- a/pyquil/pyqvm.py
+++ b/pyquil/pyqvm.py
@@ -211,7 +211,7 @@ def __init__(
# private implementation details
self._qubit_to_ram: Optional[Dict[int, int]] = None
self._ro_size: Optional[int] = None
- self._memory_results: Optional[Dict[str, np.ndarray]] = None
+ self._memory_results = {}
self.rs = np.random.RandomState(seed=seed)
self.wf_simulator = quantum_simulator_type(n_qubits=n_qubits, rs=self.rs)
@@ -226,7 +226,7 @@ def load(self, executable: Union[Program, PyQuilExecutableResponse]) -> "PyQVM":
# initialize program counter
self.program = program
self.program_counter = 0
- self._memory_results = None
+ self._memory_results = {}
# clear RAM, although it's not strictly clear if this should happen here
self.ram = {}
diff --git a/pyquil/quil.py b/pyquil/quil.py
--- a/pyquil/quil.py
+++ b/pyquil/quil.py
@@ -40,7 +40,7 @@
from rpcq.messages import NativeQuilMetadata
from pyquil._parser.parser import run_parser
-
+from pyquil.gates import MEASURE, RESET
from pyquil.noise import _check_kraus_ops, _create_kraus_pragmas, pauli_kraus_map
from pyquil.quilatom import (
Label,
@@ -58,7 +58,6 @@
unpack_classical_reg,
unpack_qubit,
)
-from pyquil.gates import MEASURE, RESET
from pyquil.quilbase import (
DefGate,
Gate,
@@ -100,7 +99,6 @@
match_calibration,
)
-
InstructionDesignator = Union[
AbstractInstruction,
DefGate,
@@ -140,6 +138,9 @@ def __init__(self, *instructions: InstructionDesignator):
# method. It is marked as None whenever new instructions are added.
self._synthesized_instructions: Optional[List[AbstractInstruction]] = None
+ # "ro" is always implicitly declared
+ self._declarations: Dict[str, Declare] = {"ro": Declare("ro", "BIT")}
+
self.inst(*instructions)
# Filled in with quil_to_native_quil
@@ -166,6 +167,11 @@ def frames(self) -> Dict[Frame, DefFrame]:
""" A mapping from Quil-T frames to their definitions. """
return self._frames
+ @property
+ def declarations(self) -> Dict[str, Declare]:
+ """ A mapping from declared region names to their declarations. """
+ return self._declarations
+
def copy_everything_except_instructions(self) -> "Program":
"""
Copy all the members that live on a Program object.
@@ -293,6 +299,9 @@ def inst(self, *instructions: InstructionDesignator) -> "Program":
elif isinstance(instruction, AbstractInstruction):
self._instructions.append(instruction)
self._synthesized_instructions = None
+
+ if isinstance(instruction, Declare):
+ self._declarations[instruction.name] = instruction
else:
raise TypeError("Invalid instruction: {}".format(instruction))
|
diff --git a/pyquil/tests/test_quil.py b/pyquil/tests/test_quil.py
--- a/pyquil/tests/test_quil.py
+++ b/pyquil/tests/test_quil.py
@@ -243,10 +243,26 @@ def test_prog_init():
assert p.out() == ("DECLARE ro BIT[1]\nX 0\nMEASURE 0 ro[0]\n")
-def test_classical_regs():
+def test_classical_regs_implicit_ro():
p = Program()
- p.inst(Declare("ro", "BIT", 2), X(0)).measure(0, MemoryReference("ro", 1))
- assert p.out() == ("DECLARE ro BIT[2]\nX 0\nMEASURE 0 ro[1]\n")
+ p.inst(Declare("reg", "BIT", 2), X(0)).measure(0, MemoryReference("reg", 1))
+ assert p.out() == "DECLARE reg BIT[2]\nX 0\nMEASURE 0 reg[1]\n"
+ assert p.declarations == {
+ "ro": Declare("ro", "BIT", 1),
+ "reg": Declare("reg", "BIT", 2),
+ }
+
+
+def test_classical_regs_explicit_ro():
+ p = Program()
+ p.inst(Declare("ro", "BIT", 2), Declare("reg", "BIT", 2), X(0)).measure(
+ 0, MemoryReference("reg", 1)
+ )
+ assert p.out() == "DECLARE ro BIT[2]\nDECLARE reg BIT[2]\nX 0\nMEASURE 0 reg[1]\n"
+ assert p.declarations == {
+ "ro": Declare("ro", "BIT", 2),
+ "reg": Declare("reg", "BIT", 2),
+ }
def test_simple_instructions():
diff --git a/pyquil/tests/test_qvm.py b/pyquil/tests/test_qvm.py
--- a/pyquil/tests/test_qvm.py
+++ b/pyquil/tests/test_qvm.py
@@ -6,6 +6,7 @@
from pyquil import Program
from pyquil.api import ForestConnection, QVM
from pyquil.api._compiler import _extract_program_from_pyquil_executable_response
+from pyquil.api._errors import QVMError
from pyquil.gates import MEASURE, X, CNOT, H
from pyquil.quilbase import Declare, MemoryReference
@@ -55,7 +56,44 @@ def test_qvm_run_only_pqer(forest: ForestConnection):
assert np.mean(bitstrings) > 0.8
-def test_qvm_run_no_measure(forest: ForestConnection):
+def test_qvm_run_region_declared_and_measured(forest: ForestConnection):
+ qvm = QVM(connection=forest)
+ p = Program(Declare("reg", "BIT"), X(0), MEASURE(0, MemoryReference("reg")))
+ nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
+ qvm.load(nq).run().wait()
+ bitstrings = qvm.read_memory(region_name="reg")
+ assert bitstrings.shape == (100, 1)
+
+
+def test_qvm_run_region_declared_not_measured(forest: ForestConnection):
+ qvm = QVM(connection=forest)
+ p = Program(Declare("reg", "BIT"), X(0))
+ nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
+ qvm.load(nq).run().wait()
+ bitstrings = qvm.read_memory(region_name="reg")
+ assert bitstrings.shape == (100, 0)
+
+
+# For backwards compatibility, we support omitting the declaration for "ro" specifically
+def test_qvm_run_region_not_declared_is_measured_ro(forest: ForestConnection):
+ qvm = QVM(connection=forest)
+ p = Program(X(0), MEASURE(0, MemoryReference("ro")))
+ nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
+ qvm.load(nq).run().wait()
+ bitstrings = qvm.read_memory(region_name="ro")
+ assert bitstrings.shape == (100, 1)
+
+
+def test_qvm_run_region_not_declared_is_measured_non_ro(forest: ForestConnection):
+ qvm = QVM(connection=forest)
+ p = Program(X(0), MEASURE(0, MemoryReference("reg")))
+ nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
+
+ with pytest.raises(QVMError, match='Bad memory region name "reg" in MEASURE'):
+ qvm.load(nq).run().wait()
+
+
+def test_qvm_run_region_not_declared_not_measured_ro(forest: ForestConnection):
qvm = QVM(connection=forest)
p = Program(X(0))
nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
@@ -64,6 +102,14 @@ def test_qvm_run_no_measure(forest: ForestConnection):
assert bitstrings.shape == (100, 0)
+def test_qvm_run_region_not_declared_not_measured_non_ro(forest: ForestConnection):
+ qvm = QVM(connection=forest)
+ p = Program(X(0))
+ nq = PyQuilExecutableResponse(program=p.out(), attributes={"num_shots": 100})
+ qvm.load(nq).run().wait()
+ assert qvm.read_memory(region_name="reg") is None
+
+
def test_roundtrip_pyquilexecutableresponse(compiler):
p = Program(H(10), CNOT(10, 11))
pqer = compiler.native_quil_to_executable(p)
|
QVM returns only MEASURE'd memory regions
Issue Description
-----------------
In #873, we attempted to enable the QVM (and, later, the QPU) to let the user do post-execution analysis on all memory regions, rather than just on the contents of `ro`. However, in https://github.com/rigetti/pyquil/blob/master/pyquil/api/_qvm.py#L544 we filter the memory regions that the QVM returns down to only those into which it `MEASURE`s. This is unexpected behavior, and this restriction should be lifted.
How to Reproduce
----------------
### Code Snippet
```python
from pyquil import get_qc, Program
qc = get_qc('2q-qvm')
qc.run(Program("DECLARE ro BIT\nDECLARE not_ro BIT\nMOVE ro 1\nMOVE not_ro 1\nMEASURE 0 ro[0]").wrap_in_numshots_loop(10))
qc.qam.read_memory(region_name="not_ro")
```
### Error Output
```
KeyError: 'not_ro'
```
Environment Context
-------------------
Operating System:
Python Version (`python -V`): Python 3.7.4
Quilc Version (`quilc --version`): 1.15.3 [25b95cb]
QVM Version (`qvm --version`): 1.15.2 [1b3d43a]
Python Environment Details (`pip freeze` or `conda list`): 💤
|
Even within the 'ro' memory region, it only returns those indices that are written to by measurements:
```
from pyquil import Program, get_qc
from pyquil.gates import CNOT, X, MEASURE
p = Program()
ro = p.declare("ro", "BIT", 4)
p += CNOT(0, 1)
p += X(2)
p += CNOT(2, 3)
p += MEASURE(0, ro[0])
p += MEASURE(3, ro[3])
p.wrap_in_numshots_loop(10)
qc = get_qc('9q-square-qvm')
ex = qc.compile(p)
result = qc.run(ex)
print(result)
```
gives
```
[[0 1]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]]
```
(Python 3.7.7, quilc 1.18.0, qvm 1.17.0)
Though it's possible cause of this case might be more linked to #1194
| 2021-01-20T18:46:33
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 2,358
|
marcelotduarte__cx_Freeze-2358
|
[
"2354"
] |
de2888d31d344c3d50994c4ecaaeb668bcc9b095
|
diff --git a/cx_Freeze/hooks/numpy.py b/cx_Freeze/hooks/numpy.py
--- a/cx_Freeze/hooks/numpy.py
+++ b/cx_Freeze/hooks/numpy.py
@@ -87,6 +87,20 @@ def load_numpy_core__add_newdocs(
finder.include_module("numpy.core._multiarray_tests")
+def load_numpy_core_overrides(finder: ModuleFinder, module: Module) -> None:
+ """Recompile the numpy.core.overrides module to limit optimization by
+ avoiding removing docstrings, which are required for this module.
+ """
+ code_string = module.file.read_text(encoding="utf_8")
+ module.code = compile(
+ code_string.replace("dispatcher.__doc__", "dispatcher.__doc__ or ''"),
+ os.fspath(module.file),
+ "exec",
+ dont_inherit=True,
+ optimize=min(finder.optimize, 1),
+ )
+
+
def load_numpy__distributor_init(finder: ModuleFinder, module: Module) -> None:
"""Fix the location of dependent files in Windows and macOS."""
if IS_LINUX or IS_MINGW:
|
diff --git a/tests/test_hooks_pandas.py b/tests/test_hooks_pandas.py
--- a/tests/test_hooks_pandas.py
+++ b/tests/test_hooks_pandas.py
@@ -24,7 +24,7 @@
@pytest.mark.datafiles(SAMPLES_DIR / "pandas")
def test_pandas(datafiles: Path) -> None:
"""Test that the pandas/numpy is working correctly."""
- output = run_command(datafiles)
+ output = run_command(datafiles, "python setup.py build_exe -O2")
executable = datafiles / BUILD_EXE_DIR / f"test_pandas{SUFFIX}"
assert executable.is_file()
|
cx_Freeze 7.0.0 and PyTorch 2.2.2+cu118: TypeError: argument docstring of add_docstring should be a str
**Describe the bug**
An error occurs when try to freeze pytorch project with cx-Freeze.
```
copying C:\Project\_build\venv\lib\site-packages\torch\functional.py -> C:\Project\_build\out\lib\torch\functional.py
Traceback (most recent call last):
File "C:\Project\_build\venv\Lib\site-packages\cx_Freeze\initscripts\__startup__.py", line 138, in run
module_init.run(name + "__main__")
File "C:\Project\_build\venv\Lib\site-packages\cx_Freeze\initscripts\console.py", line 17, in run
exec(code, module_main.__dict__)
File "project.py", line 1, in <module>
import torch
File "C:/Users/bw7715/OneDrive - Zebra Technologies/Projects/python_projects/cx_freeze_issues/p39_cx70_tf_np/_build/venv/lib/site-packages/torch/__init__.py", line 1215, in <module>
from .storage import _StorageBase, TypedStorage, _LegacyStorage, UntypedStorage, _warn_typed_storage_removal
File "C:\Project\_build\venv\lib\site-packages\torch\storage.py", line 14, in <module>
import numpy as np
File "C:\Project\_build\venv\lib\site-packages\numpy\__init__.py", line 173, in <module>
from . import core
File "C:\Project\_build\venv\lib\site-packages\numpy\core\__init__.py", line 24, in <module>
from . import multiarray
File "C:\Project\_build\venv\lib\site-packages\numpy\core\multiarray.py", line 86, in <module>
def empty_like(prototype, dtype=None, order=None, subok=None, shape=None):
File "C:\Project\_build\venv\lib\site-packages\numpy\core\overrides.py", line 178, in decorator
return array_function_dispatch(
File "C:\Project\_build\venv\lib\site-packages\numpy\core\overrides.py", line 158, in decorator
add_docstring(implementation, dispatcher.__doc__)
TypeError: argument docstring of add_docstring should be a str
```
**To Reproduce**
requirements.txt
```
--find-links https://download.pytorch.org/whl/cu118/torch_stable.html
cx_Freeze==7.0.0
torch==2.2.2+cu118
torchvision==0.17.2+cu118
```
freeze.bat
```
echo off
set WORKSPACE=%~dp0
set BUILD_DIRPATH=%WORKSPACE%\_build
set BASE_PYTHON_DIRPATH=C:\Program Files\Python39
set VENV_DIRPATH=%BUILD_DIRPATH%\venv
set TARGET_DIR=%BUILD_DIRPATH%\out
set SCRIPTS_DIRPATH=%VENV_DIRPATH%\Scripts
set PYTHON_EXE_PATH="%SCRIPTS_DIRPATH%\python.exe"
set FREEZER_EXE_PATH="%SCRIPTS_DIRPATH%\cxfreeze.exe"
set TARGET_NAME=project_out.exe
set PROJECT_SOURCE_PY_PATH=project.py
set PACKAGES=torch
"%BASE_PYTHON_DIRPATH%\python" -m venv "%VENV_DIRPATH%"
%PYTHON_EXE_PATH% -m pip install -r requirements.txt
rem %PYTHON_EXE_PATH% -m pip install --pre --extra-index-url https://marcelotduarte.github.io/packages/ cx_Freeze --upgrade
%FREEZER_EXE_PATH% build -O1 -O2 --include-msvcr --build-exe="%TARGET_DIR%" --target-name=%TARGET_NAME% --packages=%PACKAGES% --script=%PROJECT_SOURCE_PY_PATH%
"%TARGET_DIR%\%TARGET_NAME%"
```
project.py
```python
import torch
print(torch.__version__)
```
**Desktop (please complete the following information):**
- Platform information: Windows 10 and Ubuntu Linux 22.04
- OS architecture (e.g. amd64): 64bit
- cx_Freeze version: 7.0.0
- Python version: 3.9
pip list:
```
.\python.exe -m pip list
Package Version
----------------- ------------
cx_Freeze 7.0.0
cx_Logging 3.2.0
filelock 3.13.4
fsspec 2024.3.1
Jinja2 3.1.3
lief 0.14.1
MarkupSafe 2.1.5
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.4
pillow 10.3.0
pip 22.0.4
setuptools 69.5.1
sympy 1.12
torch 2.2.2+cu118
torchvision 0.17.2+cu118
typing_extensions 4.11.0
wheel 0.43.0
```
With `cx_Freeze==6.15.16` this project works.
|
When try to use `pip install --force --no-cache --pre --extra-index-url https://marcelotduarte.github.io/packages/ cx_Freeze` with `cx_Freeze-7.1.0.dev3-cp39-cp39-win_amd64` I get the same error.
I noticed also that with `cx_Freeze-7.1.0.dev3` there is an error during freezing:
```
Looking in indexes: https://pypi.org/simple, https://marcelotduarte.github.io/packages/
Collecting cx_Freeze
Downloading https://marcelotduarte.github.io/packages/cx-freeze/cx_Freeze-7.1.0.dev3-cp39-cp39-win_amd64.whl (2.0 MB)
---------------------------------------- 2.0/2.0 MB 1.4 MB/s eta 0:00:00
Collecting wheel<=0.43.0,>=0.42.0
Downloading wheel-0.43.0-py3-none-any.whl (65 kB)
---------------------------------------- 65.8/65.8 KB 107.6 kB/s eta 0:00:00
Collecting setuptools<70,>=62.6
Downloading setuptools-69.5.1-py3-none-any.whl (894 kB)
---------------------------------------- 894.6/894.6 KB 1.2 MB/s eta 0:00:00
Collecting lief<=0.15.0,>=0.12.0
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)'))': /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)'))': /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl
WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)'))': /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl
WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)'))': /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl
WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)'))': /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl
ERROR: Could not install packages due to an OSError: HTTPSConnectionPool(host='lief.s3-website.fr-par.scw.cloud', port=443): Max retries exceeded with url: /latest/lief/lief-0.15.0-cp39-cp39-win_amd64.whl (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)')))
```
But once it has appeared, the process goes on.
In version 7.0.0 these errors and warnings do not appear
```
Looking in links: https://download.pytorch.org/whl/cu118/torch_stable.html
Collecting cx_Freeze==7.0.0
Using cached cx_Freeze-7.0.0-cp39-cp39-win_amd64.whl (2.0 MB)
Collecting numpy==1.26.4
Using cached numpy-1.26.4-cp39-cp39-win_amd64.whl (15.8 MB)
Collecting torch==2.2.2+cu118
Using cached https://download.pytorch.org/whl/cu118/torch-2.2.2%2Bcu118-cp39-cp39-win_amd64.whl (2704.2 MB)
Collecting torchvision==0.17.2+cu118
Using cached https://download.pytorch.org/whl/cu118/torchvision-0.17.2%2Bcu118-cp39-cp39-win_amd64.whl (4.9 MB)
Collecting lief<0.15.0,>=0.12.0
Using cached lief-0.14.1-cp39-cp39-win_amd64.whl (2.2 MB)
Collecting cx-Logging>=3.1
Using cached cx_Logging-3.2.0-cp39-cp39-win_amd64.whl (26 kB)
```
> TypeError: argument docstring of add_docstring should be a str
I had already commented [here](https://github.com/marcelotduarte/cx_Freeze/issues/2280#issuecomment-1980922796):
"""
numpy uses its docstring, so remove the optimization that it works. The optimization works like described [here](https://docs.python.org/3/using/cmdline.html#cmdoption-O).
See also: https://github.com/numpy/numpy/issues/13248#issuecomment-480412876
"""
And complementing the comment, I can say that in the previous version, when you used -O -OO in reality only -O ended up being used and it gave you the impression of using complete optimization. Therefore with numpy only -O1 can be used. I'll see if there's a way to restrict the optimization to just the numpy module.
> ERROR: Could not install packages due to an OSError: HTTPSConnectionPool(host='lief.s3-website.fr-par.scw.cloud', ...
This is a server error when the protocols, certificates, have nothing to do with cx_Freeze. Alias is a pip command.
| 2024-04-25T07:35:01
|
python
|
Easy
|
pytest-dev/pytest-django
| 680
|
pytest-dev__pytest-django-680
|
[
"678"
] |
c1bdb8d61498f472f27b4233ea50ffa2bce42147
|
diff --git a/pytest_django/fixtures.py b/pytest_django/fixtures.py
--- a/pytest_django/fixtures.py
+++ b/pytest_django/fixtures.py
@@ -33,35 +33,35 @@
@pytest.fixture(scope="session")
-def django_db_modify_db_settings_xdist_suffix(request):
+def django_db_modify_db_settings_tox_suffix(request):
skip_if_no_django()
- from django.conf import settings
-
- for db_settings in settings.DATABASES.values():
-
- try:
- test_name = db_settings["TEST"]["NAME"]
- except KeyError:
- test_name = None
+ tox_environment = os.getenv("TOX_PARALLEL_ENV")
+ if tox_environment:
+ # Put a suffix like _py27-django21 on tox workers
+ _set_suffix_to_test_databases(suffix=tox_environment)
- if not test_name:
- if db_settings["ENGINE"] == "django.db.backends.sqlite3":
- continue
- test_name = "test_{}".format(db_settings["NAME"])
+@pytest.fixture(scope="session")
+def django_db_modify_db_settings_xdist_suffix(request):
+ skip_if_no_django()
+ xdist_suffix = getattr(request.config, "slaveinput", {}).get("slaveid")
+ if xdist_suffix:
# Put a suffix like _gw0, _gw1 etc on xdist processes
- xdist_suffix = getattr(request.config, "slaveinput", {}).get("slaveid")
- if test_name != ":memory:" and xdist_suffix is not None:
- test_name = "{}_{}".format(test_name, xdist_suffix)
+ _set_suffix_to_test_databases(suffix=xdist_suffix)
- db_settings.setdefault("TEST", {})
- db_settings["TEST"]["NAME"] = test_name
+
+@pytest.fixture(scope="session")
+def django_db_modify_db_settings_parallel_suffix(
+ django_db_modify_db_settings_tox_suffix,
+ django_db_modify_db_settings_xdist_suffix,
+):
+ skip_if_no_django()
@pytest.fixture(scope="session")
-def django_db_modify_db_settings(django_db_modify_db_settings_xdist_suffix):
+def django_db_modify_db_settings(django_db_modify_db_settings_parallel_suffix):
skip_if_no_django()
@@ -169,6 +169,24 @@ def handle(self, *args, **kwargs):
migrate.Command = MigrateSilentCommand
+def _set_suffix_to_test_databases(suffix):
+ from django.conf import settings
+
+ for db_settings in settings.DATABASES.values():
+ test_name = db_settings.get("TEST", {}).get("NAME")
+
+ if not test_name:
+ if db_settings["ENGINE"] == "django.db.backends.sqlite3":
+ continue
+ test_name = "test_{}".format(db_settings["NAME"])
+
+ if test_name == ":memory:":
+ continue
+
+ db_settings.setdefault("TEST", {})
+ db_settings["TEST"]["NAME"] = "{}_{}".format(test_name, suffix)
+
+
# ############### User visible fixtures ################
diff --git a/pytest_django/plugin.py b/pytest_django/plugin.py
--- a/pytest_django/plugin.py
+++ b/pytest_django/plugin.py
@@ -22,6 +22,8 @@
from .fixtures import django_db_keepdb # noqa
from .fixtures import django_db_createdb # noqa
from .fixtures import django_db_modify_db_settings # noqa
+from .fixtures import django_db_modify_db_settings_parallel_suffix # noqa
+from .fixtures import django_db_modify_db_settings_tox_suffix # noqa
from .fixtures import django_db_modify_db_settings_xdist_suffix # noqa
from .fixtures import _live_server_helper # noqa
from .fixtures import admin_client # noqa
|
diff --git a/tests/test_db_setup.py b/tests/test_db_setup.py
--- a/tests/test_db_setup.py
+++ b/tests/test_db_setup.py
@@ -288,7 +288,135 @@ def test_a():
assert conn_db2.vendor == 'sqlite'
db_name = conn_db2.creation._get_test_db_name()
- assert 'test_custom_db_name_gw' in db_name
+ assert db_name.startswith('test_custom_db_name_gw')
+ """
+ )
+
+ result = django_testdir.runpytest_subprocess("--tb=short", "-vv", "-n1")
+ assert result.ret == 0
+ result.stdout.fnmatch_lines(["*PASSED*test_a*"])
+
+
+class TestSqliteWithTox:
+
+ db_settings = {
+ "default": {
+ "ENGINE": "django.db.backends.sqlite3",
+ "NAME": "db_name",
+ "TEST": {"NAME": "test_custom_db_name"},
+ }
+ }
+
+ def test_db_with_tox_suffix(self, django_testdir, monkeypatch):
+ "A test to check that Tox DB suffix works when running in parallel."
+ monkeypatch.setenv("TOX_PARALLEL_ENV", "py37-django22")
+
+ django_testdir.create_test_module(
+ """
+ import pytest
+ from django.db import connections
+
+ @pytest.mark.django_db
+ def test_inner():
+
+ (conn, ) = connections.all()
+
+ assert conn.vendor == 'sqlite'
+ db_name = conn.creation._get_test_db_name()
+ assert db_name == 'test_custom_db_name_py37-django22'
+ """
+ )
+
+ result = django_testdir.runpytest_subprocess("--tb=short", "-vv")
+ assert result.ret == 0
+ result.stdout.fnmatch_lines(["*test_inner*PASSED*"])
+
+ def test_db_with_empty_tox_suffix(self, django_testdir, monkeypatch):
+ "A test to check that Tox DB suffix is not used when suffix would be empty."
+ monkeypatch.setenv("TOX_PARALLEL_ENV", "")
+
+ django_testdir.create_test_module(
+ """
+ import pytest
+ from django.db import connections
+
+ @pytest.mark.django_db
+ def test_inner():
+
+ (conn,) = connections.all()
+
+ assert conn.vendor == 'sqlite'
+ db_name = conn.creation._get_test_db_name()
+ assert db_name == 'test_custom_db_name'
+ """
+ )
+
+ result = django_testdir.runpytest_subprocess("--tb=short", "-vv")
+ assert result.ret == 0
+ result.stdout.fnmatch_lines(["*test_inner*PASSED*"])
+
+
+class TestSqliteWithToxAndXdist:
+
+ db_settings = {
+ "default": {
+ "ENGINE": "django.db.backends.sqlite3",
+ "NAME": "db_name",
+ "TEST": {"NAME": "test_custom_db_name"},
+ }
+ }
+
+ def test_db_with_tox_suffix(self, django_testdir, monkeypatch):
+ "A test to check that both Tox and xdist suffixes work together."
+ pytest.importorskip("xdist")
+ monkeypatch.setenv("TOX_PARALLEL_ENV", "py37-django22")
+
+ django_testdir.create_test_module(
+ """
+ import pytest
+ from django.db import connections
+
+ @pytest.mark.django_db
+ def test_inner():
+
+ (conn, ) = connections.all()
+
+ assert conn.vendor == 'sqlite'
+ db_name = conn.creation._get_test_db_name()
+ assert db_name.startswith('test_custom_db_name_py37-django22_gw')
+ """
+ )
+
+ result = django_testdir.runpytest_subprocess("--tb=short", "-vv", "-n1")
+ assert result.ret == 0
+ result.stdout.fnmatch_lines(["*PASSED*test_inner*"])
+
+
+class TestSqliteInMemoryWithXdist:
+
+ db_settings = {
+ "default": {
+ "ENGINE": "django.db.backends.sqlite3",
+ "NAME": ":memory:",
+ "TEST": {"NAME": ":memory:"},
+ }
+ }
+
+ def test_sqlite_in_memory_used(self, django_testdir):
+ pytest.importorskip("xdist")
+
+ django_testdir.create_test_module(
+ """
+ import pytest
+ from django.db import connections
+
+ @pytest.mark.django_db
+ def test_a():
+ (conn, ) = connections.all()
+
+ assert conn.vendor == 'sqlite'
+ db_name = conn.creation._get_test_db_name()
+ assert 'file:memorydb' in db_name or db_name == ':memory:'
"""
)
|
Correctly support DB access in parallel Tox testing
Hi!
Recently, I have migrated some Django projects to run their tests using [Tox](https://tox.readthedocs.io/en/latest/index.html). Because of the number of tests and Tox environments, it was configured to run tests in parallel. This required a similar approach as what's currently handled by `pytest-django` when running tests with `pytest-xdist`: **Database renaming to avoid collisions**.
A simple fixture like `django_db_modify_db_settings_xdist_suffix`, to add a suffix to database names, was enough to fix database collisions, so I wonder if `pytest-django` should also handle Tox testing in these scenarios. And, now more than ever, with Tox implementing real support for [parallel execution](https://github.com/tox-dev/tox/pull/1102).
I have the time to work on this, and provide what I've implemented so far, if this request is accepted!
|
Yes, it makes sense to use something like `django_db_modify_db_settings_tox_suffix` for this.
But maybe there could be a single `*_suffix` then?
It should also handle xdist in parallel tox then.
I think it depends on how Pytest's fixture resolution order works. If it's deterministic (by design, and this contract won't change), I think that separate fixtures make sense. If not, a single `django_db_modify_db_settings_parallel_suffix` could be enough to avoid different DB names with each run.
| 2018-12-17T19:28:35
|
python
|
Easy
|
rigetti/pyquil
| 203
|
rigetti__pyquil-203
|
[
"138"
] |
4229a22f98c37967635fbe7b29fcfadde2aea7d8
|
diff --git a/pyquil/quilbase.py b/pyquil/quilbase.py
--- a/pyquil/quilbase.py
+++ b/pyquil/quilbase.py
@@ -261,7 +261,7 @@ def format_matrix_element(element):
:param element: {int, float, complex, str} The parameterized element to format.
"""
- if isinstance(element, integer_types) or isinstance(element, (float, complex)):
+ if isinstance(element, integer_types) or isinstance(element, (float, complex, np.int_)):
return format_parameter(element)
elif isinstance(element, string_types):
return element
@@ -514,7 +514,7 @@ def format_parameter(element):
:param element: {int, float, long, complex, Slot} Formats a parameter for Quil output.
"""
- if isinstance(element, integer_types):
+ if isinstance(element, integer_types) or isinstance(element, np.int_):
return repr(element)
elif isinstance(element, float):
return check_for_pi(element)
|
diff --git a/pyquil/tests/test_quil.py b/pyquil/tests/test_quil.py
--- a/pyquil/tests/test_quil.py
+++ b/pyquil/tests/test_quil.py
@@ -582,3 +582,10 @@ def test_pretty_print_pi():
assert p.out() == 'RZ(0) 0\nRZ(pi) 1\nRZ(-pi) 2\nRZ(2*pi/3) 3\n' \
'RZ(0.3490658503988659) 4\n' \
'RZ(pi/8) 5\nCPHASE00(-45*pi) 0 1\n'
+
+
+# https://github.com/rigetticomputing/pyquil/issues/138
+def test_defgate_integer_input():
+ dg = DefGate("TEST", np.array([[1, 0],
+ [0, 1]]))
+ assert dg.out() == "DEFGATE TEST:\n 1, 0\n 0, 1\n"
|
Creating a gate with all integers throws an error
```python
>>> DefGate("A", np.array([[1, 0], [0, 1]])).out()
```
throws the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/steven/workspace/pyquil/pyquil/quilbase.py", line 208, in out
fcols = [format_matrix_element(col) for col in row]
File "/Users/steven/workspace/pyquil/pyquil/quilbase.py", line 208, in <listcomp>
fcols = [format_matrix_element(col) for col in row]
File "/Users/steven/workspace/pyquil/pyquil/quilbase.py", line 68, in format_matrix_element
assert False, "Invalid matrix element: %r" % element
AssertionError: Invalid matrix element: 1
```
The type of the integer in a numpy array of all ints is unexpected:
```python
>>> type(np.array([[1, 0], [0, 1]])[0][0])
<class 'numpy.int64'>
```
|
That is strange, it works for me.
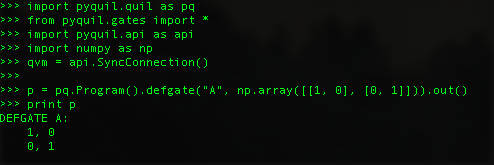
What's the different numpy versions?
Mine is 1.13.3
Might be a Python version thing. I'm on Python 3, numpy 1.13.3
I'm also affected by this. numpy 1.13.0, python 3.6.1 .
| 2017-11-27T06:20:43
|
python
|
Hard
|
rigetti/pyquil
| 221
|
rigetti__pyquil-221
|
[
"212"
] |
6890be97d997a3c3a38ddb36899cfb5677446194
|
diff --git a/pyquil/api/__init__.py b/pyquil/api/__init__.py
--- a/pyquil/api/__init__.py
+++ b/pyquil/api/__init__.py
@@ -18,7 +18,7 @@
"""
import warnings
-__all__ = ['QVMConnection', 'QPUConnection', 'Job', 'get_devices']
+__all__ = ['QVMConnection', 'QPUConnection', 'Job', 'get_devices', 'errors']
from pyquil.api.job import Job
from pyquil.api.qvm import QVMConnection
diff --git a/pyquil/api/_base_connection.py b/pyquil/api/_base_connection.py
--- a/pyquil/api/_base_connection.py
+++ b/pyquil/api/_base_connection.py
@@ -16,6 +16,8 @@
from __future__ import print_function
+import re
+
import requests
import sys
@@ -24,6 +26,8 @@
from six import integer_types
from urllib3 import Retry
+from pyquil.api.errors import QVMError, DeviceOfflineError, DeviceRetuningError, InvalidInputError, InvalidUserError, \
+ JobNotFoundError, MissingPermissionsError, error_mapping, UnknownApiError, TooManyQubitsError
from .job import Job
from ._config import PyquilConfig
@@ -33,127 +37,102 @@
TYPE_WAVEFUNCTION = "wavefunction"
-class BaseConnection(object):
- def __init__(self, async_endpoint, api_key, user_id, ping_time, status_time):
- self._session = requests.Session()
- retry_adapter = HTTPAdapter(max_retries=Retry(total=3,
- method_whitelist=['POST'],
- status_forcelist=[502, 503, 504, 521, 523],
- backoff_factor=0.2,
- raise_on_status=False))
-
- # We need this to get binary payload for the wavefunction call.
- self._session.headers.update({"Accept": "application/octet-stream"})
-
- self._session.mount("http://", retry_adapter)
- self._session.mount("https://", retry_adapter)
-
- config = PyquilConfig()
- self.api_key = api_key if api_key else config.api_key
- self.user_id = user_id if user_id else config.user_id
-
- self.async_endpoint = async_endpoint
-
- self.ping_time = ping_time
- self.status_time = status_time
-
- def get_job(self, job_id):
- """
- Given a job id, return information about the status of the job
-
- :param str job_id: job id
- :return: Job object with the status and potentially results of the job
- :rtype: Job
- """
- response = self._get_json(self.async_endpoint + "/job/" + job_id)
- return Job(response.json())
-
- def wait_for_job(self, job_id, ping_time=None, status_time=None):
- """
- Wait for the results of a job and periodically print status
-
- :param job_id: Job id
- :param ping_time: How often to poll the server.
- Defaults to the value specified in the constructor. (0.1 seconds)
- :param status_time: How often to print status, set to False to never print status.
- Defaults to the value specified in the constructor (2 seconds)
- :return: Completed Job
- """
- if ping_time is None:
- ping_time = self.ping_time
- if status_time is None:
- status_time = self.status_time
-
- count = 0
- while True:
- job = self.get_job(job_id)
- if job.is_done():
- break
-
- if status_time and count % int(status_time / ping_time) == 0:
- if job.is_queued():
- print("job {} is currently queued at position {}".format(job.job_id, job.position_in_queue()))
- elif job.is_running():
- print("job {} is currently running".format(job.job_id))
-
- time.sleep(ping_time)
- count += 1
-
- return job
-
- def _post_json(self, url, json):
- """
- Post JSON to the Forest endpoint.
-
- :param str url: The full url to post to
- :param dict json: JSON.
- :return: A non-error response.
- """
- headers = {
- 'X-Api-Key': self.api_key,
- 'X-User-Id': self.user_id,
- 'Content-Type': 'application/json; charset=utf-8'
- }
- res = self._session.post(url, json=json, headers=headers)
-
- # Print some nice info for unauthorized/permission errors.
- if res.status_code == 401 or res.status_code == 403:
- print("! ERROR:\n"
- "! There was an issue validating your forest account.\n"
- "! Have you run the pyquil-config-setup command yet?\n"
- "! The server came back with the following information:\n"
- "%s\n%s\n%s" % ("=" * 80, res.text, "=" * 80), file=sys.stderr)
- print("! If you suspect this to be a bug in pyQuil or Rigetti Forest,\n"
- "! then please describe the problem in a GitHub issue at:\n!\n"
- "! https://github.com/rigetticomputing/pyquil/issues\n", file=sys.stderr)
-
- # Print some nice info for invalid input or internal server errors.
- if res.status_code == 400 or res.status_code >= 500:
- print("! ERROR:\n"
- "! Server caught an error. This could be due to a bug in the server\n"
- "! or a bug in your code. The server came back with the following\n"
- "! information:\n"
- "%s\n%s\n%s" % ("=" * 80, res.text, "=" * 80), file=sys.stderr)
- print("! If you suspect this to be a bug in pyQuil or Rigetti Forest,\n"
- "! then please describe the problem in a GitHub issue at:\n!\n"
- "! https://github.com/rigetticomputing/pyquil/issues\n", file=sys.stderr)
-
- res.raise_for_status()
- return res
-
- def _get_json(self, url):
- """
- Get JSON from a Forest endpoint.
-
- :param str url: The full url to fetch
- :return: Response object
- """
- headers = {
- 'X-Api-Key': self.api_key,
- 'X-User-Id': self.user_id,
- 'Content-Type': 'application/json; charset=utf-8'
- }
- return requests.get(url, headers=headers)
+def wait_for_job(get_job_fn, ping_time=None, status_time=None):
+ """
+ Wait for job logic
+ """
+ count = 0
+ while True:
+ job = get_job_fn()
+ if job.is_done():
+ break
+
+ if status_time and count % int(status_time / ping_time) == 0:
+ if job.is_queued():
+ print("job {} is currently queued at position {}".format(job.job_id, job.position_in_queue()))
+ elif job.is_running():
+ print("job {} is currently running".format(job.job_id))
+
+ time.sleep(ping_time)
+ count += 1
+
+ return job
+
+
+def get_json(session, url):
+ """
+ Get JSON from a Forest endpoint.
+ """
+ res = session.get(url)
+ if res.status_code >= 400:
+ raise parse_error(res)
+ return res
+
+
+def post_json(session, url, json):
+ """
+ Post JSON to the Forest endpoint.
+ """
+ res = session.post(url, json=json)
+ if res.status_code >= 400:
+ raise parse_error(res)
+ return res
+
+
+def parse_error(res):
+ """
+ Every server error should contain a "status" field with a human readable explanation of what went wrong as well as
+ a "error_type" field indicating the kind of error that can be mappen to a Python type.
+
+ There's a fallback error UnknownError for other types of exceptions (network issues, api gateway problems, etc.)
+ """
+ body = res.json()
+
+ if body is None:
+ raise UnknownApiError(res.text)
+ elif 'error_type' not in body:
+ raise UnknownApiError(body)
+
+ error_type = body['error_type']
+ status = body['status']
+
+ if re.search(r"[0-9]+ qubits were requested, but the QVM is limited to [0-9]+ qubits.", status):
+ return TooManyQubitsError(status)
+
+ error_cls = error_mapping.get(error_type, UnknownApiError)
+ return error_cls(status)
+
+
+def get_session(api_key, user_id):
+ """
+ Create a requests session to access the cloud API with the proper authentication
+
+ :param str api_key: custom api key, if None will fallback to reading from the config
+ :param str user_id: custom user id, if None will fallback to reading from the config
+ :return: requests session
+ :rtype: Session
+ """
+ session = requests.Session()
+ retry_adapter = HTTPAdapter(max_retries=Retry(total=3,
+ method_whitelist=['POST'],
+ status_forcelist=[502, 503, 504, 521, 523],
+ backoff_factor=0.2,
+ raise_on_status=False))
+
+ session.mount("http://", retry_adapter)
+ session.mount("https://", retry_adapter)
+
+ # We need this to get binary payload for the wavefunction call.
+ session.headers.update({"Accept": "application/octet-stream"})
+
+ config = PyquilConfig()
+ session.headers.update({
+ 'X-Api-Key': api_key if api_key else config.api_key,
+ 'X-User-Id': user_id if user_id else config.user_id,
+ 'Content-Type': 'application/json; charset=utf-8'
+ })
+
+ return session
def validate_noise_probabilities(noise_parameter):
diff --git a/pyquil/api/errors.py b/pyquil/api/errors.py
new file mode 100644
--- /dev/null
+++ b/pyquil/api/errors.py
@@ -0,0 +1,142 @@
+
+class ApiError(Exception):
+ def __init__(self, server_status, explanation):
+ super(ApiError, self).__init__(self, server_status)
+ self.server_status = server_status
+ self.explanation = explanation
+
+ def __repr__(self):
+ return repr(str(self))
+
+ def __str__(self):
+ return self.server_status + "\n" + self.explanation
+
+
+class CancellationError(ApiError):
+ def __init__(self, server_status):
+ explanation = "Please try resubmitting the job again."
+ super(CancellationError, self).__init__(server_status, explanation)
+
+
+class DeviceOfflineError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The device you requested is offline. Use the following code to check for the
+currently available devices:
+
+ from pyquil.api import get_devices
+ print(get_devices())"""
+ super(DeviceOfflineError, self).__init__(server_status, explanation)
+
+
+class DeviceRetuningError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The device you requested is temporarily down for retuning. Use the following
+code to check for the currently available devices:
+
+ from pyquil.api import get_devices
+ print(get_devices())"""
+ super(DeviceRetuningError, self).__init__(server_status, explanation)
+ ApiError.__init__(self, server_status, explanation)
+
+
+class InvalidInputError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The server returned the above error because something was wrong with the HTTP
+request sent to it. This could be due to a bug in the server or a bug in your
+code. If you suspect this to be a bug in pyQuil or Rigetti Forest, then please
+describe the problem in a GitHub issue at:
+ https://github.com/rigetticomputing/pyquil/issues"""
+ super(InvalidInputError, self).__init__(server_status, explanation)
+ ApiError.__init__(self, server_status, explanation)
+
+
+class InvalidUserError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+There was an issue validating your Forest account!
+Have you run the `pyquil-config-setup` command yet?
+
+If you do not yet have a Forest account then sign up for one at:
+ https://forest.rigetti.com"""
+ super(InvalidUserError, self).__init__(server_status, explanation)
+ ApiError.__init__(self, server_status, explanation)
+
+
+class JobNotFoundError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The above job may have been deleted manually or due to some bug in the server.
+If you suspect this to be a bug then please describe the problem in a Github
+issue at:
+ https://github.com/rigetticomputing/pyquil/issues"""
+ super(JobNotFoundError, self).__init__(server_status, explanation)
+ ApiError.__init__(self, server_status, explanation)
+
+
+class MissingPermissionsError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+Your account may not be whitelisted for QPU access. To request the appropriate
+permissions please read the information located at:
+ https://forest.rigetti.com"""
+ super(MissingPermissionsError, self).__init__(server_status, explanation)
+ ApiError.__init__(self, server_status, explanation)
+
+
+class QPUError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The QPU returned the above error. This could be due to a bug in the server or a
+bug in your code. If you suspect this to be a bug in pyQuil or Rigetti Forest,
+then please describe the problem in a GitHub issue at:
+ https://github.com/rigetticomputing/pyquil/issues"""
+ super(QPUError, self).__init__(server_status, explanation)
+
+
+class QVMError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The QVM returned the above error. This could be due to a bug in the server or a
+bug in your code. If you suspect this to be a bug in pyQuil or Rigetti Forest,
+then please describe the problem in a GitHub issue at:
+ https://github.com/rigetticomputing/pyquil/issues"""
+ super(QVMError, self).__init__(server_status, explanation)
+
+
+class TooManyQubitsError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+You requested too many qubits on the QVM. More qubits are available when you use
+the queue. Pass the use_queue parameter to QVMConnection to enable additional
+qubits (however, each program will take longer to run). For example:
+
+ qvm = QVMConnection(use_queue=True)
+ qvm.run(twenty_qubit_program)
+
+See https://go.rigetti.com/connections for more info."""
+ super(TooManyQubitsError, self).__init__(server_status, explanation)
+
+
+class UnknownApiError(ApiError):
+ def __init__(self, server_status):
+ explanation = """
+The server has failed to return a proper response. Please describe the problem
+and copy the above message into a GitHub issue at:
+ https://github.com/rigetticomputing/pyquil/issues"""
+ super(UnknownApiError, self).__init__(server_status, explanation)
+
+
+# NB: Some errors are not included here if they are only returned by async endpoints
+# The source of truth for this mapping is the errors.py file on the server
+error_mapping = {
+ 'device_offline': DeviceOfflineError,
+ 'device_retuning': DeviceRetuningError,
+ 'invalid_input': InvalidInputError,
+ 'invalid_user': InvalidUserError,
+ 'job_not_found': JobNotFoundError,
+ 'missing_permissions': MissingPermissionsError,
+ 'qvm_error': QVMError,
+}
diff --git a/pyquil/api/job.py b/pyquil/api/job.py
--- a/pyquil/api/job.py
+++ b/pyquil/api/job.py
@@ -17,6 +17,7 @@
import base64
import warnings
+from pyquil.api.errors import CancellationError, QVMError, QPUError
from pyquil.parser import parse_program
from pyquil.wavefunction import Wavefunction
@@ -29,8 +30,9 @@ class Job(object):
They transition to RUNNING when they have been started
Finally they are marked as FINISHED, ERROR, or CANCELLED once completed
"""
- def __init__(self, raw):
+ def __init__(self, raw, machine):
self._raw = raw
+ self._machine = machine
@property
def job_id(self):
@@ -50,16 +52,19 @@ def result(self):
"""
The result of the job if available
throws ValueError is result is not available yet
- throws RuntimeError if server returned an error indicating program execution was not successful
+ throws ApiError if server returned an error indicating program execution was not successful
or if the job was cancelled
"""
if not self.is_done():
raise ValueError("Cannot get a result for a program that isn't completed.")
if self._raw['status'] == 'CANCELLED':
- raise RuntimeError("Job was cancelled: {}".format(self._raw['result']))
+ raise CancellationError(self._raw['result'])
elif self._raw['status'] == 'ERROR':
- raise RuntimeError("Server returned an error: {}".format(self._raw['result']))
+ if self._machine == 'QVM':
+ raise QVMError(self._raw['result'])
+ else: # self._machine == 'QPU'
+ raise QPUError(self._raw['result'])
if self._raw['program']['type'] == 'wavefunction':
return Wavefunction.from_bit_packed_string(
diff --git a/pyquil/api/qpu.py b/pyquil/api/qpu.py
--- a/pyquil/api/qpu.py
+++ b/pyquil/api/qpu.py
@@ -15,12 +15,12 @@
##############################################################################
import warnings
-import requests
from six import integer_types
+from pyquil.api import Job
from pyquil.quil import Program
-from ._base_connection import validate_run_items, TYPE_MULTISHOT, TYPE_MULTISHOT_MEASURE, get_job_id, BaseConnection
-from ._config import PyquilConfig
+from ._base_connection import validate_run_items, TYPE_MULTISHOT, TYPE_MULTISHOT_MEASURE, get_job_id, \
+ get_session, wait_for_job, post_json, get_json
def get_devices(async_endpoint='https://job.rigetti.com/beta', api_key=None, user_id=None):
@@ -31,17 +31,8 @@ def get_devices(async_endpoint='https://job.rigetti.com/beta', api_key=None, use
:return: set of online and offline devices
:rtype: set
"""
- config = PyquilConfig()
- api_key = api_key if api_key else config.api_key
- user_id = user_id if user_id else config.user_id
-
- headers = {
- 'X-Api-Key': api_key,
- 'X-User-Id': user_id,
- 'Content-Type': 'application/json; charset=utf-8'
- }
-
- response = requests.get(async_endpoint + '/devices', headers=headers)
+ session = get_session(api_key, user_id)
+ response = session.get(async_endpoint + '/devices')
return {Device(name, device) for (name, device) in response.json()['devices'].items()}
@@ -74,7 +65,7 @@ def __repr__(self):
return str(self)
-class QPUConnection(BaseConnection):
+class QPUConnection(object):
"""
Represents a connection to the QPU (Quantum Processing Unit)
"""
@@ -114,9 +105,12 @@ def __init__(self, device_name=None, async_endpoint='https://job.rigetti.com/bet
To suppress this warning, see Python's warning module.
""")
+ self.async_endpoint = async_endpoint
+ self.session = get_session(api_key, user_id)
+
+ self.ping_time = ping_time
+ self.status_time = status_time
- super(QPUConnection, self).__init__(async_endpoint=async_endpoint, api_key=api_key, user_id=user_id,
- ping_time=ping_time, status_time=status_time)
self.device_name = device_name
def run(self, quil_program, classical_addresses, trials=1):
@@ -130,20 +124,17 @@ def run(self, quil_program, classical_addresses, trials=1):
in `classical_addresses`.
:rtype: list
"""
- payload = self._run_payload(quil_program, classical_addresses, trials)
-
- response = self._post_json(self.async_endpoint + "/job", self._wrap_program(payload))
- job = self.wait_for_job(get_job_id(response))
- return job.result()
+ raise DeprecationWarning("""
+The QPU does not currently support arbitrary measure operations. For now, the
+only supported operation on the QPU is run_and_measure.""")
def run_async(self, quil_program, classical_addresses, trials=1):
"""
Similar to run except that it returns a job id and doesn't wait for the program to be executed.
See https://go.rigetti.com/connections for reasons to use this method.
"""
- payload = self._run_payload(quil_program, classical_addresses, trials)
- response = self._post_json(self.async_endpoint + "/job", self._wrap_program(payload))
- return get_job_id(response)
+ # NB: Throw the same deprecation warning as in run
+ return self.run(quil_program, classical_addresses, trials)
def _run_payload(self, quil_program, classical_addresses, trials):
if not isinstance(quil_program, Program):
@@ -172,7 +163,7 @@ def run_and_measure(self, quil_program, qubits, trials=1):
"""
payload = self._run_and_measure_payload(quil_program, qubits, trials)
- response = self._post_json(self.async_endpoint + "/job", self._wrap_program(payload))
+ response = post_json(self.session, self.async_endpoint + "/job", self._wrap_program(payload))
job = self.wait_for_job(get_job_id(response))
return job.result()
@@ -182,7 +173,7 @@ def run_and_measure_async(self, quil_program, qubits, trials):
See https://go.rigetti.com/connections for reasons to use this method.
"""
payload = self._run_and_measure_payload(quil_program, qubits, trials)
- response = self._post_json(self.async_endpoint + "/job", self._wrap_program(payload))
+ response = post_json(self.session, self.async_endpoint + "/job", self._wrap_program(payload))
return get_job_id(response)
def _run_and_measure_payload(self, quil_program, qubits, trials):
@@ -199,6 +190,34 @@ def _run_and_measure_payload(self, quil_program, qubits, trials):
return payload
+ def get_job(self, job_id):
+ """
+ Given a job id, return information about the status of the job
+
+ :param str job_id: job id
+ :return: Job object with the status and potentially results of the job
+ :rtype: Job
+ """
+ response = get_json(self.session, self.async_endpoint + "/job/" + job_id)
+ return Job(response.json(), 'QPU')
+
+ def wait_for_job(self, job_id, ping_time=None, status_time=None):
+ """
+ Wait for the results of a job and periodically print status
+
+ :param job_id: Job id
+ :param ping_time: How often to poll the server.
+ Defaults to the value specified in the constructor. (0.1 seconds)
+ :param status_time: How often to print status, set to False to never print status.
+ Defaults to the value specified in the constructor (2 seconds)
+ :return: Completed Job
+ """
+ def get_job_fn():
+ return self.get_job(job_id)
+ return wait_for_job(get_job_fn,
+ ping_time if ping_time else self.ping_time,
+ status_time if status_time else self.status_time)
+
def _wrap_program(self, program):
return {
"machine": "QPU",
diff --git a/pyquil/api/qvm.py b/pyquil/api/qvm.py
--- a/pyquil/api/qvm.py
+++ b/pyquil/api/qvm.py
@@ -14,17 +14,17 @@
# limitations under the License.
##############################################################################
-import json
-
from six import integer_types
+from pyquil.api import Job
from pyquil.quil import Program
from pyquil.wavefunction import Wavefunction
-from ._base_connection import BaseConnection, validate_noise_probabilities, validate_run_items, TYPE_MULTISHOT, \
- TYPE_MULTISHOT_MEASURE, TYPE_WAVEFUNCTION, TYPE_EXPECTATION, get_job_id
+from ._base_connection import validate_noise_probabilities, validate_run_items, TYPE_MULTISHOT, \
+ TYPE_MULTISHOT_MEASURE, TYPE_WAVEFUNCTION, TYPE_EXPECTATION, get_job_id, get_session, wait_for_job, \
+ post_json, get_json
-class QVMConnection(BaseConnection):
+class QVMConnection(object):
"""
Represents a connection to the QVM.
"""
@@ -58,10 +58,13 @@ def __init__(self, sync_endpoint='https://api.rigetti.com', async_endpoint='http
:param random_seed: A seed for the QVM's random number generators. Either None (for an
automatically generated seed) or a non-negative integer.
"""
- super(QVMConnection, self).__init__(async_endpoint=async_endpoint, api_key=api_key, user_id=user_id,
- ping_time=ping_time, status_time=status_time)
+ self.async_endpoint = async_endpoint
self.sync_endpoint = sync_endpoint
+ self.session = get_session(api_key, user_id)
+
self.use_queue = use_queue
+ self.ping_time = ping_time
+ self.status_time = status_time
validate_noise_probabilities(gate_noise)
validate_noise_probabilities(measurement_noise)
@@ -92,12 +95,12 @@ def run(self, quil_program, classical_addresses, trials=1):
"""
payload = self._run_payload(quil_program, classical_addresses, trials)
if self.use_queue:
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
job = self.wait_for_job(get_job_id(response))
return job.result()
else:
payload = self._run_payload(quil_program, classical_addresses, trials)
- response = self._post_json(self.sync_endpoint + "/qvm", payload)
+ response = post_json(self.session, self.sync_endpoint + "/qvm", payload)
return response.json()
def run_async(self, quil_program, classical_addresses, trials=1):
@@ -106,7 +109,7 @@ def run_async(self, quil_program, classical_addresses, trials=1):
See https://go.rigetti.com/connections for reasons to use this method.
"""
payload = self._run_payload(quil_program, classical_addresses, trials)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
return get_job_id(response)
def _run_payload(self, quil_program, classical_addresses, trials):
@@ -144,12 +147,12 @@ def run_and_measure(self, quil_program, qubits, trials=1):
"""
payload = self._run_and_measure_payload(quil_program, qubits, trials)
if self.use_queue:
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
job = self.wait_for_job(get_job_id(response))
return job.result()
else:
payload = self._run_and_measure_payload(quil_program, qubits, trials)
- response = self._post_json(self.sync_endpoint + "/qvm", payload)
+ response = post_json(self.session, self.sync_endpoint + "/qvm", payload)
return response.json()
def run_and_measure_async(self, quil_program, qubits, trials=1):
@@ -158,7 +161,7 @@ def run_and_measure_async(self, quil_program, qubits, trials=1):
See https://go.rigetti.com/connections for reasons to use this method.
"""
payload = self._run_and_measure_payload(quil_program, qubits, trials)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
return get_job_id(response)
def _run_and_measure_payload(self, quil_program, qubits, trials):
@@ -200,12 +203,12 @@ def wavefunction(self, quil_program, classical_addresses=None):
if self.use_queue:
payload = self._wavefunction_payload(quil_program, classical_addresses)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
job = self.wait_for_job(get_job_id(response))
return job.result()
else:
payload = self._wavefunction_payload(quil_program, classical_addresses)
- response = self._post_json(self.sync_endpoint + "/qvm", payload)
+ response = post_json(self.session, self.sync_endpoint + "/qvm", payload)
return Wavefunction.from_bit_packed_string(response.content, classical_addresses)
def wavefunction_async(self, quil_program, classical_addresses=None):
@@ -217,7 +220,7 @@ def wavefunction_async(self, quil_program, classical_addresses=None):
classical_addresses = []
payload = self._wavefunction_payload(quil_program, classical_addresses)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
return get_job_id(response)
def _wavefunction_payload(self, quil_program, classical_addresses):
@@ -252,12 +255,12 @@ def expectation(self, prep_prog, operator_programs=None):
"""
if self.use_queue:
payload = self._expectation_payload(prep_prog, operator_programs)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
job = self.wait_for_job(get_job_id(response))
return job.result()
else:
payload = self._expectation_payload(prep_prog, operator_programs)
- response = self._post_json(self.sync_endpoint + "/qvm", payload)
+ response = post_json(self.session, self.sync_endpoint + "/qvm", payload)
return response.json()
def expectation_async(self, prep_prog, operator_programs=None):
@@ -266,7 +269,7 @@ def expectation_async(self, prep_prog, operator_programs=None):
See https://go.rigetti.com/connections for reasons to use this method.
"""
payload = self._expectation_payload(prep_prog, operator_programs)
- response = self._post_json(self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
+ response = post_json(self.session, self.async_endpoint + "/job", {"machine": "QVM", "program": payload})
return get_job_id(response)
def _expectation_payload(self, prep_prog, operator_programs):
@@ -284,6 +287,34 @@ def _expectation_payload(self, prep_prog, operator_programs):
return payload
+ def get_job(self, job_id):
+ """
+ Given a job id, return information about the status of the job
+
+ :param str job_id: job id
+ :return: Job object with the status and potentially results of the job
+ :rtype: Job
+ """
+ response = get_json(self.session, self.async_endpoint + "/job/" + job_id)
+ return Job(response.json(), 'QVM')
+
+ def wait_for_job(self, job_id, ping_time=None, status_time=None):
+ """
+ Wait for the results of a job and periodically print status
+
+ :param job_id: Job id
+ :param ping_time: How often to poll the server.
+ Defaults to the value specified in the constructor. (0.1 seconds)
+ :param status_time: How often to print status, set to False to never print status.
+ Defaults to the value specified in the constructor (2 seconds)
+ :return: Completed Job
+ """
+ def get_job_fn():
+ return self.get_job(job_id)
+ return wait_for_job(get_job_fn,
+ ping_time if ping_time else self.ping_time,
+ status_time if status_time else self.status_time)
+
def _add_noise_to_payload(self, payload):
"""
Set the gate noise and measurement noise of a payload.
diff --git a/pyquil/job_results.py b/pyquil/job_results.py
--- a/pyquil/job_results.py
+++ b/pyquil/job_results.py
@@ -1,6 +1,11 @@
def wait_for_job(res, ping_time=0.5):
- raise DeprecationWarning(
- "The wait_for_job function is now deprecated. See https://go.rigetti.com/connections for more info.")
+ raise DeprecationWarning("""
+The wait_for_job function has been moved inside the QVMConnection or
+QPUConnection object. For instance:
+ job = qvm.wait_for_job(job_id)
+ print(job.result())
+
+See https://go.rigetti.com/connections for more info.""")
class JobResult(object):
|
diff --git a/pyquil/tests/test_api.py b/pyquil/tests/test_api.py
--- a/pyquil/tests/test_api.py
+++ b/pyquil/tests/test_api.py
@@ -154,8 +154,8 @@ def test_qpu_connection():
qpu = QPUConnection(device_name='fake_device')
program = {
- "type": "multishot",
- "addresses": [0, 1],
+ "type": "multishot-measure",
+ "qubits": [0, 1],
"trials": 2,
"quil-instructions": "H 0\nCNOT 0 1\n"
}
@@ -176,7 +176,7 @@ def mock_queued_response(request, context):
"result": [[0, 0], [1, 1]], "program": program})}
])
- result = qpu.run(BELL_STATE, [0, 1], trials=2)
+ result = qpu.run_and_measure(BELL_STATE, [0, 1], trials=2)
assert result == [[0, 0], [1, 1]]
with requests_mock.Mocker() as m:
@@ -192,7 +192,7 @@ def mock_queued_response(request, context):
}})}
])
- job = qpu.wait_for_job(qpu.run_async(BELL_STATE, [0, 1], trials=2))
+ job = qpu.wait_for_job(qpu.run_and_measure_async(BELL_STATE, [0, 1], trials=2))
assert job.result() == [[0, 0], [1, 1]]
assert job.compiled_quil() == Program(H(0), CNOT(0, 1))
assert job.topological_swaps() == 0
@@ -206,7 +206,7 @@ def mock_queued_response(request, context):
"result": [[0, 0], [1, 1]], "program": program})}
])
- job = qpu.wait_for_job(qpu.run_async(BELL_STATE, [0, 1], trials=2))
+ job = qpu.wait_for_job(qpu.run_and_measure_async(BELL_STATE, [0, 1], trials=2))
assert job.result() == [[0, 0], [1, 1]]
assert job.compiled_quil() is None
assert job.topological_swaps() is None
|
Meta-Issue: User Experience
We need to improve user experience in the following areas:
- [ ] jobs can get stuck indefinitely on 'job is currently running' if there were issues with background workers
- [x] errors from the sync QVM are returned as strings, they should throw as exception instead otherwise they could be used as results
- [x] errors from async QVM/QPU are thrown differently than when they come from the sync QVM. (as in, there's no pretty printing of the error like in _base_connection)
- [ ] measure function that takes ranges (ie. `program.measure([0..8], [0..8])`)
|
Somewhat related to: https://github.com/rigetticomputing/pyquil/issues/193
- [x] `run_and_measure` and likely other API calls will print periodic status updates that cannot be turned off. It would be nice to either add a flag to `run_and_measure` itself or make this configurable at the `QPUConnection`/`QVMConnection` level. Here is an example within a jupyter notebook that demonstrates this
@ntezak - take a look here: https://github.com/rigetticomputing/pyquil/pull/213
Got this warning message:
`DeprecationWarning: The wait_for_job function is now deprecated. See https://go.rigetti.com/connections for more info.`
But in the docs there's this example:
```
job = qvm.wait_for_job(job_id)
print(job.result())
```
It'd be more clear if the deprecation warning would have said something like "job_results.wait_for_job has moved to qvm.wait_for_job"
| 2017-12-14T00:42:27
|
python
|
Hard
|
marcelotduarte/cx_Freeze
| 2,204
|
marcelotduarte__cx_Freeze-2204
|
[
"2192"
] |
7bc86a407b93eef77bfba1d3e7d1f3c18de9f97b
|
diff --git a/cx_Freeze/freezer.py b/cx_Freeze/freezer.py
--- a/cx_Freeze/freezer.py
+++ b/cx_Freeze/freezer.py
@@ -88,8 +88,8 @@ def __init__(
self.path: list[str] | None = self._validate_path(path)
self.include_msvcr: bool = include_msvcr
self.target_dir = target_dir
- self.bin_includes: list[str] | None = bin_includes
- self.bin_excludes: list[str] | None = bin_excludes
+ self.bin_includes: list[str] = self._validate_bin_file(bin_includes)
+ self.bin_excludes: list[str] = self._validate_bin_file(bin_excludes)
self.bin_path_includes: list[str] = self._validate_bin_path(
bin_path_includes
)
@@ -289,7 +289,7 @@ def _freeze_executable(self, exe: Executable) -> None:
self._copy_top_dependency(source)
# Once copied, it should be deleted from the list to ensure
# it will not be copied again.
- name = Path(source.name)
+ name = os.path.normcase(source.name)
if name in self.bin_includes:
self.bin_includes.remove(name)
self.bin_excludes.append(name)
@@ -426,35 +426,36 @@ def _remove_version_numbers(filename: str) -> str:
return ".".join(parts)
return filename
- def _should_copy_file(self, path: Path) -> bool: # noqa: PLR0911
+ def _should_copy_file(self, path: Path) -> bool:
"""Return true if the file should be copied to the target machine.
- This is done by checking the bin_path_includes, bin_path_excludes,
- bin_includes and bin_excludes configuration variables using first
- the full file name, then just the base file name, then the file name
- without any version numbers.
+
+ This is done by checking the bin_includes and bin_excludes
+ configuration variables using first the full file name, then just the
+ base file name, then the file name without any version numbers.
+ Then, bin_path_includes and bin_path_excludes are checked.
Files are included unless specifically excluded but inclusions take
precedence over exclusions.
"""
# check the full path
- if path in self.bin_includes:
- return True
- if path in self.bin_excludes:
- return False
-
# check the file name by itself (with any included version numbers)
- filename = Path(path.name)
- if filename in self.bin_includes:
- return True
- if filename in self.bin_excludes:
- return False
-
# check the file name by itself (version numbers removed)
- filename = Path(self._remove_version_numbers(path.name))
- if filename in self.bin_includes:
- return True
- if filename in self.bin_excludes:
- return False
+ filename = Path(os.path.normcase(path.name))
+ filename_noversion = Path(self._remove_version_numbers(filename.name))
+ for binfile in self.bin_includes:
+ if (
+ path.match(binfile)
+ or filename.match(binfile)
+ or filename_noversion.match(binfile)
+ ):
+ return True
+ for binfile in self.bin_excludes:
+ if (
+ path.match(binfile)
+ or filename.match(binfile)
+ or filename_noversion.match(binfile)
+ ):
+ return False
# check the path for inclusion/exclusion
dirname = path.parent
@@ -508,6 +509,15 @@ def _validate_path(path: list[str | Path] | None = None) -> list[str]:
path.insert(index, os.fspath(dynload))
return path
+ @staticmethod
+ def _validate_bin_file(
+ filenames: Sequence[str | Path] | None,
+ ) -> list[str]:
+ """Returns valid filenames for bin_includes and bin_excludes."""
+ if filenames is None:
+ return []
+ return [os.path.normcase(filename) for filename in filenames]
+
@staticmethod
def _validate_bin_path(bin_path: Sequence[str | Path] | None) -> list[str]:
"""Returns valid search path for bin_path_includes and
@@ -522,15 +532,8 @@ def _validate_bin_path(bin_path: Sequence[str | Path] | None) -> list[str]:
return valid
def _verify_configuration(self) -> None:
- """Verify and normalize names and paths."""
- filenames = list(self.bin_includes or [])
- filenames += self._default_bin_includes()
- self.bin_includes = [Path(name) for name in filenames]
-
- filenames = list(self.bin_excludes or [])
- filenames += self._default_bin_excludes()
- self.bin_excludes = [Path(name) for name in filenames]
-
+ self.bin_includes += self._default_bin_includes()
+ self.bin_excludes += self._default_bin_excludes()
self.bin_path_includes += self._default_bin_path_includes()
self.bin_path_excludes += self._default_bin_path_excludes()
@@ -882,9 +885,8 @@ def _pre_copy_hook(self, source: Path, target: Path) -> tuple[Path, Path]:
C runtime libraries.
"""
# fix the target path for C runtime files
- norm_target_name = target.name.lower()
- if norm_target_name in self.runtime_files:
- target = self.target_dir / norm_target_name
+ if any(filter(target.match, self.runtime_files)):
+ target = self.target_dir / target.name
return source, target
def _post_copy_hook(
@@ -1000,11 +1002,12 @@ def _platform_add_extra_dependencies(
search_dirs: set[Path] = set()
for filename in dependent_files:
search_dirs.add(filename.parent)
- for filename in self.runtime_files:
- for search_dir in search_dirs:
- filepath = search_dir / filename
- if filepath.exists():
- dependent_files.add(filepath)
+ for search_dir in search_dirs:
+ for pattern in self.runtime_files:
+ for filename in search_dir.glob(pattern):
+ filepath = search_dir / filename
+ if filepath.exists():
+ dependent_files.add(filepath)
def _post_freeze_hook(self) -> None:
target_lib = self.target_dir / "lib"
@@ -1025,9 +1028,9 @@ def runtime_files(self) -> set[str]:
winmsvcr = import_module("cx_Freeze.winmsvcr")
if not self.include_msvcr:
# just put on the exclusion list
- self.bin_excludes.extend(list(map(Path, winmsvcr.FILES)))
+ self.bin_excludes.extend(winmsvcr.FILES)
return set()
- return winmsvcr.FILES
+ return set(winmsvcr.FILES)
class DarwinFreezer(Freezer, Parser):
diff --git a/cx_Freeze/winmsvcr.py b/cx_Freeze/winmsvcr.py
--- a/cx_Freeze/winmsvcr.py
+++ b/cx_Freeze/winmsvcr.py
@@ -7,47 +7,8 @@
from __future__ import annotations
FILES = (
+ "api-ms-win-*.dll",
# VC 2015 and 2017
- "api-ms-win-core-console-l1-1-0.dll",
- "api-ms-win-core-datetime-l1-1-0.dll",
- "api-ms-win-core-debug-l1-1-0.dll",
- "api-ms-win-core-errorhandling-l1-1-0.dll",
- "api-ms-win-core-file-l1-1-0.dll",
- "api-ms-win-core-file-l1-2-0.dll",
- "api-ms-win-core-file-l2-1-0.dll",
- "api-ms-win-core-handle-l1-1-0.dll",
- "api-ms-win-core-heap-l1-1-0.dll",
- "api-ms-win-core-interlocked-l1-1-0.dll",
- "api-ms-win-core-libraryloader-l1-1-0.dll",
- "api-ms-win-core-localization-l1-2-0.dll",
- "api-ms-win-core-memory-l1-1-0.dll",
- "api-ms-win-core-namedpipe-l1-1-0.dll",
- "api-ms-win-core-processenvironment-l1-1-0.dll",
- "api-ms-win-core-processthreads-l1-1-0.dll",
- "api-ms-win-core-processthreads-l1-1-1.dll",
- "api-ms-win-core-profile-l1-1-0.dll",
- "api-ms-win-core-rtlsupport-l1-1-0.dll",
- "api-ms-win-core-string-l1-1-0.dll",
- "api-ms-win-core-synch-l1-1-0.dll",
- "api-ms-win-core-synch-l1-2-0.dll",
- "api-ms-win-core-sysinfo-l1-1-0.dll",
- "api-ms-win-core-timezone-l1-1-0.dll",
- "api-ms-win-core-util-l1-1-0.dll",
- "api-ms-win-crt-conio-l1-1-0.dll",
- "api-ms-win-crt-convert-l1-1-0.dll",
- "api-ms-win-crt-environment-l1-1-0.dll",
- "api-ms-win-crt-filesystem-l1-1-0.dll",
- "api-ms-win-crt-heap-l1-1-0.dll",
- "api-ms-win-crt-locale-l1-1-0.dll",
- "api-ms-win-crt-math-l1-1-0.dll",
- "api-ms-win-crt-multibyte-l1-1-0.dll",
- "api-ms-win-crt-private-l1-1-0.dll",
- "api-ms-win-crt-process-l1-1-0.dll",
- "api-ms-win-crt-runtime-l1-1-0.dll",
- "api-ms-win-crt-stdio-l1-1-0.dll",
- "api-ms-win-crt-string-l1-1-0.dll",
- "api-ms-win-crt-time-l1-1-0.dll",
- "api-ms-win-crt-utility-l1-1-0.dll",
"concrt140.dll",
"msvcp140_1.dll",
"msvcp140_2.dll",
@@ -58,7 +19,9 @@
"vcomp140.dll",
"vcruntime140.dll",
# VS 2019
- "vcruntime140_1.dll",
"msvcp140_atomic_wait.dll",
"msvcp140_codecvt_ids.dll",
+ "vcruntime140_1.dll",
+ # VS 2022
+ "vcruntime140_threads.dll",
)
|
diff --git a/tests/test_command_build_exe.py b/tests/test_command_build_exe.py
--- a/tests/test_command_build_exe.py
+++ b/tests/test_command_build_exe.py
@@ -97,20 +97,6 @@ def test_build_exe_asmodule(datafiles: Path):
assert output.startswith("Hello from cx_Freeze")
-@pytest.mark.skipif(sys.platform != "win32", reason="Windows tests")
-@pytest.mark.datafiles(SAMPLES_DIR / "simple")
-def test_build_exe_simple_include_msvcr(datafiles: Path):
- """Test the simple sample with include_msvcr option."""
- command = BUILD_EXE_CMD + " --include-msvcr"
- output = run_command(datafiles, command)
-
- build_exe_dir = datafiles / BUILD_EXE_DIR
- executable = build_exe_dir / f"hello{SUFFIX}"
- assert executable.is_file()
- output = run_command(datafiles, executable, timeout=10)
- assert output.startswith("Hello from cx_Freeze")
-
-
@pytest.mark.datafiles(SAMPLES_DIR / "sqlite")
def test_build_exe_sqlite(datafiles: Path):
"""Test the sqlite sample."""
diff --git a/tests/test_winmsvcr.py b/tests/test_winmsvcr.py
--- a/tests/test_winmsvcr.py
+++ b/tests/test_winmsvcr.py
@@ -2,53 +2,17 @@
from __future__ import annotations
import sys
+from pathlib import Path
+from sysconfig import get_platform, get_python_version
import pytest
+from generate_samples import run_command
from cx_Freeze.winmsvcr import FILES
EXPECTED = (
+ "api-ms-win-*.dll",
# VC 2015 and 2017
- "api-ms-win-core-console-l1-1-0.dll",
- "api-ms-win-core-datetime-l1-1-0.dll",
- "api-ms-win-core-debug-l1-1-0.dll",
- "api-ms-win-core-errorhandling-l1-1-0.dll",
- "api-ms-win-core-file-l1-1-0.dll",
- "api-ms-win-core-file-l1-2-0.dll",
- "api-ms-win-core-file-l2-1-0.dll",
- "api-ms-win-core-handle-l1-1-0.dll",
- "api-ms-win-core-heap-l1-1-0.dll",
- "api-ms-win-core-interlocked-l1-1-0.dll",
- "api-ms-win-core-libraryloader-l1-1-0.dll",
- "api-ms-win-core-localization-l1-2-0.dll",
- "api-ms-win-core-memory-l1-1-0.dll",
- "api-ms-win-core-namedpipe-l1-1-0.dll",
- "api-ms-win-core-processenvironment-l1-1-0.dll",
- "api-ms-win-core-processthreads-l1-1-0.dll",
- "api-ms-win-core-processthreads-l1-1-1.dll",
- "api-ms-win-core-profile-l1-1-0.dll",
- "api-ms-win-core-rtlsupport-l1-1-0.dll",
- "api-ms-win-core-string-l1-1-0.dll",
- "api-ms-win-core-synch-l1-1-0.dll",
- "api-ms-win-core-synch-l1-2-0.dll",
- "api-ms-win-core-sysinfo-l1-1-0.dll",
- "api-ms-win-core-timezone-l1-1-0.dll",
- "api-ms-win-core-util-l1-1-0.dll",
- "api-ms-win-crt-conio-l1-1-0.dll",
- "api-ms-win-crt-convert-l1-1-0.dll",
- "api-ms-win-crt-environment-l1-1-0.dll",
- "api-ms-win-crt-filesystem-l1-1-0.dll",
- "api-ms-win-crt-heap-l1-1-0.dll",
- "api-ms-win-crt-locale-l1-1-0.dll",
- "api-ms-win-crt-math-l1-1-0.dll",
- "api-ms-win-crt-multibyte-l1-1-0.dll",
- "api-ms-win-crt-private-l1-1-0.dll",
- "api-ms-win-crt-process-l1-1-0.dll",
- "api-ms-win-crt-runtime-l1-1-0.dll",
- "api-ms-win-crt-stdio-l1-1-0.dll",
- "api-ms-win-crt-string-l1-1-0.dll",
- "api-ms-win-crt-time-l1-1-0.dll",
- "api-ms-win-crt-utility-l1-1-0.dll",
"concrt140.dll",
"msvcp140_1.dll",
"msvcp140_2.dll",
@@ -59,13 +23,52 @@
"vcomp140.dll",
"vcruntime140.dll",
# VS 2019
- "vcruntime140_1.dll",
"msvcp140_atomic_wait.dll",
"msvcp140_codecvt_ids.dll",
+ "vcruntime140_1.dll",
+ # VS 2022
+ "vcruntime140_threads.dll",
)
+PLATFORM = get_platform()
+PYTHON_VERSION = get_python_version()
+BUILD_EXE_DIR = f"build/exe.{PLATFORM}-{PYTHON_VERSION}"
+
+SAMPLES_DIR = Path(__file__).resolve().parent.parent / "samples"
+BUILD_EXE_CMD = "python setup.py build_exe --silent --excludes=tkinter"
+IS_WINDOWS = sys.platform == "win32"
+SUFFIX = ".exe" if IS_WINDOWS else ""
+
@pytest.mark.skipif(sys.platform != "win32", reason="Windows tests")
def test_files():
"""Test winmsvcr.FILES."""
assert EXPECTED == FILES
+
+
+@pytest.mark.skipif(sys.platform != "win32", reason="Windows tests")
+@pytest.mark.parametrize("include_msvcr", [False, True], ids=["no", "yes"])
+@pytest.mark.datafiles(SAMPLES_DIR / "sqlite")
+def test_build_exe_with_include_msvcr(datafiles: Path, include_msvcr: bool):
+ """Test the simple sample with include_msvcr option."""
+ command = BUILD_EXE_CMD
+ if include_msvcr:
+ command += " --include-msvcr"
+ output = run_command(datafiles, command)
+
+ build_exe_dir = datafiles / BUILD_EXE_DIR
+
+ executable = build_exe_dir / f"test_sqlite3{SUFFIX}"
+ assert executable.is_file()
+ output = run_command(datafiles, executable, timeout=10)
+ assert output.startswith("dump.sql created")
+
+ names = [
+ file.name.lower()
+ for file in build_exe_dir.glob("*.dll")
+ if any(filter(file.match, EXPECTED))
+ ]
+ if include_msvcr:
+ assert names != []
+ else:
+ assert names == []
|
api-ms-*.dll are copied regardless of `include_msvcr` value
Might be related to #367. Asked bout this behavior in discussion #2171.
I run a build workflow on github, as I do not own a microsoft machine. During the build, various api-ms-*.dll are copied from the PATH. I feel that this behavior is unwarranted.
Specific to the build:
* My [setup.py](https://github.com/BannerlordCE/pyCEStoriesEditor/blob/2f416a502c17de36822befa98a079b2a8952f98c/setup.py).
* The [build workflow](https://github.com/BannerlordCE/pyCEStoriesEditor/blob/2f416a502c17de36822befa98a079b2a8952f98c/.github/workflows/build.yml)
* Last [job](https://github.com/BannerlordCE/pyCEStoriesEditor/actions/runs/7430262647/job/20219746239) (please look at the *build* section)
Version of cx_Freeze: 6.15.12
It may yet be user error, in which case I apologize.
|
I can confirm this issue. With VS 2022 and PowerShell, there are new API-ms DLLs to exclude. I'll make a patch.
| 2024-01-17T00:27:25
|
python
|
Easy
|
HandmadeMath/HandmadeMath
| 167
|
HandmadeMath__HandmadeMath-167
|
[
"141"
] |
98748f702c8309e461294e7dbd2474974063f6da
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -52,7 +52,7 @@
#define HMM_ACOSF MyACosF
#define HMM_SQRTF MySqrtF
#include "HandmadeMath.h"
-
+
By default, it is assumed that your math functions take radians. To use
different units, you must define HMM_ANGLE_USER_TO_INTERNAL and
HMM_ANGLE_INTERNAL_TO_USER. For example, if you want to use degrees in your
@@ -62,7 +62,7 @@
#define HMM_ANGLE_INTERNAL_TO_USER(a) ((a)*HMM_TurnToDeg)
=============================================================================
-
+
LICENSE
This software is in the public domain. Where that dedication is not
@@ -162,7 +162,7 @@ extern "C"
&& !defined(HANDMADE_MATH_USE_RADIANS)
# define HANDMADE_MATH_USE_RADIANS
#endif
-
+
#define HMM_PI 3.14159265358979323846
#define HMM_PI32 3.14159265359f
#define HMM_DEG180 180.0
@@ -205,7 +205,7 @@ extern "C"
#if !defined(HMM_ANGLE_INTERNAL_TO_USER)
# if defined(HANDMADE_MATH_USE_RADIANS)
-# define HMM_ANGLE_INTERNAL_TO_USER(a) (a)
+# define HMM_ANGLE_INTERNAL_TO_USER(a) (a)
# elif defined(HANDMADE_MATH_USE_DEGREES)
# define HMM_ANGLE_INTERNAL_TO_USER(a) ((a)*HMM_RadToDeg)
# elif defined(HANDMADE_MATH_USE_TURNS)
@@ -370,7 +370,7 @@ typedef union HMM_Mat2
inline const HMM_Vec2 &operator[](int Index) const { return Columns[Index]; }
#endif
} HMM_Mat2;
-
+
typedef union HMM_Mat3
{
float Elements[3][3];
@@ -425,12 +425,12 @@ static inline float HMM_ToRad(float Angle)
{
#if defined(HANDMADE_MATH_USE_RADIANS)
float Result = Angle;
-#elif defined(HANDMADE_MATH_USE_DEGREES)
+#elif defined(HANDMADE_MATH_USE_DEGREES)
float Result = Angle * HMM_DegToRad;
#elif defined(HANDMADE_MATH_USE_TURNS)
float Result = Angle * HMM_TurnToRad;
#endif
-
+
return Result;
}
@@ -438,12 +438,12 @@ static inline float HMM_ToDeg(float Angle)
{
#if defined(HANDMADE_MATH_USE_RADIANS)
float Result = Angle * HMM_RadToDeg;
-#elif defined(HANDMADE_MATH_USE_DEGREES)
+#elif defined(HANDMADE_MATH_USE_DEGREES)
float Result = Angle;
#elif defined(HANDMADE_MATH_USE_TURNS)
float Result = Angle * HMM_TurnToDeg;
#endif
-
+
return Result;
}
@@ -451,12 +451,12 @@ static inline float HMM_ToTurn(float Angle)
{
#if defined(HANDMADE_MATH_USE_RADIANS)
float Result = Angle * HMM_RadToTurn;
-#elif defined(HANDMADE_MATH_USE_DEGREES)
+#elif defined(HANDMADE_MATH_USE_DEGREES)
float Result = Angle * HMM_DegToTurn;
#elif defined(HANDMADE_MATH_USE_TURNS)
float Result = Angle;
#endif
-
+
return Result;
}
@@ -1036,21 +1036,21 @@ static inline HMM_Vec4 HMM_NormV4(HMM_Vec4 A)
*/
COVERAGE(HMM_LerpV2, 1)
-static inline HMM_Vec2 HMM_LerpV2(HMM_Vec2 A, float Time, HMM_Vec2 B)
+static inline HMM_Vec2 HMM_LerpV2(HMM_Vec2 A, float Time, HMM_Vec2 B)
{
ASSERT_COVERED(HMM_LerpV2);
return HMM_AddV2(HMM_MulV2F(A, 1.0f - Time), HMM_MulV2F(B, Time));
}
COVERAGE(HMM_LerpV3, 1)
-static inline HMM_Vec3 HMM_LerpV3(HMM_Vec3 A, float Time, HMM_Vec3 B)
+static inline HMM_Vec3 HMM_LerpV3(HMM_Vec3 A, float Time, HMM_Vec3 B)
{
ASSERT_COVERED(HMM_LerpV3);
return HMM_AddV3(HMM_MulV3F(A, 1.0f - Time), HMM_MulV3F(B, Time));
}
COVERAGE(HMM_LerpV4, 1)
-static inline HMM_Vec4 HMM_LerpV4(HMM_Vec4 A, float Time, HMM_Vec4 B)
+static inline HMM_Vec4 HMM_LerpV4(HMM_Vec4 A, float Time, HMM_Vec4 B)
{
ASSERT_COVERED(HMM_LerpV4);
return HMM_AddV4(HMM_MulV4F(A, 1.0f - Time), HMM_MulV4F(B, Time));
@@ -1112,7 +1112,7 @@ COVERAGE(HMM_M2D, 1)
static inline HMM_Mat2 HMM_M2D(float Diagonal)
{
ASSERT_COVERED(HMM_M2D);
-
+
HMM_Mat2 Result = {0};
Result.Elements[0][0] = Diagonal;
Result.Elements[1][1] = Diagonal;
@@ -1124,12 +1124,12 @@ COVERAGE(HMM_TransposeM2, 1)
static inline HMM_Mat2 HMM_TransposeM2(HMM_Mat2 Matrix)
{
ASSERT_COVERED(HMM_TransposeM2);
-
+
HMM_Mat2 Result = Matrix;
Result.Elements[0][1] = Matrix.Elements[1][0];
Result.Elements[1][0] = Matrix.Elements[0][1];
-
+
return Result;
}
@@ -1137,29 +1137,29 @@ COVERAGE(HMM_AddM2, 1)
static inline HMM_Mat2 HMM_AddM2(HMM_Mat2 Left, HMM_Mat2 Right)
{
ASSERT_COVERED(HMM_AddM2);
-
+
HMM_Mat2 Result;
Result.Elements[0][0] = Left.Elements[0][0] + Right.Elements[0][0];
Result.Elements[0][1] = Left.Elements[0][1] + Right.Elements[0][1];
Result.Elements[1][0] = Left.Elements[1][0] + Right.Elements[1][0];
Result.Elements[1][1] = Left.Elements[1][1] + Right.Elements[1][1];
-
- return Result;
+
+ return Result;
}
COVERAGE(HMM_SubM2, 1)
static inline HMM_Mat2 HMM_SubM2(HMM_Mat2 Left, HMM_Mat2 Right)
{
ASSERT_COVERED(HMM_SubM2);
-
+
HMM_Mat2 Result;
Result.Elements[0][0] = Left.Elements[0][0] - Right.Elements[0][0];
Result.Elements[0][1] = Left.Elements[0][1] - Right.Elements[0][1];
Result.Elements[1][0] = Left.Elements[1][0] - Right.Elements[1][0];
Result.Elements[1][1] = Left.Elements[1][1] - Right.Elements[1][1];
-
+
return Result;
}
@@ -1167,7 +1167,7 @@ COVERAGE(HMM_MulM2V2, 1)
static inline HMM_Vec2 HMM_MulM2V2(HMM_Mat2 Matrix, HMM_Vec2 Vector)
{
ASSERT_COVERED(HMM_MulM2V2);
-
+
HMM_Vec2 Result;
Result.X = Vector.Elements[0] * Matrix.Columns[0].X;
@@ -1176,33 +1176,33 @@ static inline HMM_Vec2 HMM_MulM2V2(HMM_Mat2 Matrix, HMM_Vec2 Vector)
Result.X += Vector.Elements[1] * Matrix.Columns[1].X;
Result.Y += Vector.Elements[1] * Matrix.Columns[1].Y;
- return Result;
+ return Result;
}
COVERAGE(HMM_MulM2, 1)
static inline HMM_Mat2 HMM_MulM2(HMM_Mat2 Left, HMM_Mat2 Right)
{
ASSERT_COVERED(HMM_MulM2);
-
+
HMM_Mat2 Result;
Result.Columns[0] = HMM_MulM2V2(Left, Right.Columns[0]);
Result.Columns[1] = HMM_MulM2V2(Left, Right.Columns[1]);
- return Result;
+ return Result;
}
COVERAGE(HMM_MulM2F, 1)
static inline HMM_Mat2 HMM_MulM2F(HMM_Mat2 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_MulM2F);
-
+
HMM_Mat2 Result;
Result.Elements[0][0] = Matrix.Elements[0][0] * Scalar;
Result.Elements[0][1] = Matrix.Elements[0][1] * Scalar;
Result.Elements[1][0] = Matrix.Elements[1][0] * Scalar;
Result.Elements[1][1] = Matrix.Elements[1][1] * Scalar;
-
+
return Result;
}
@@ -1210,7 +1210,7 @@ COVERAGE(HMM_DivM2F, 1)
static inline HMM_Mat2 HMM_DivM2F(HMM_Mat2 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_DivM2F);
-
+
HMM_Mat2 Result;
Result.Elements[0][0] = Matrix.Elements[0][0] / Scalar;
@@ -1222,7 +1222,7 @@ static inline HMM_Mat2 HMM_DivM2F(HMM_Mat2 Matrix, float Scalar)
}
COVERAGE(HMM_DeterminantM2, 1)
-static inline float HMM_DeterminantM2(HMM_Mat2 Matrix)
+static inline float HMM_DeterminantM2(HMM_Mat2 Matrix)
{
ASSERT_COVERED(HMM_DeterminantM2);
return Matrix.Elements[0][0]*Matrix.Elements[1][1] - Matrix.Elements[0][1]*Matrix.Elements[1][0];
@@ -1230,7 +1230,7 @@ static inline float HMM_DeterminantM2(HMM_Mat2 Matrix)
COVERAGE(HMM_InvGeneralM2, 1)
-static inline HMM_Mat2 HMM_InvGeneralM2(HMM_Mat2 Matrix)
+static inline HMM_Mat2 HMM_InvGeneralM2(HMM_Mat2 Matrix)
{
ASSERT_COVERED(HMM_InvGeneralM2);
@@ -1260,7 +1260,7 @@ COVERAGE(HMM_M3D, 1)
static inline HMM_Mat3 HMM_M3D(float Diagonal)
{
ASSERT_COVERED(HMM_M3D);
-
+
HMM_Mat3 Result = {0};
Result.Elements[0][0] = Diagonal;
Result.Elements[1][1] = Diagonal;
@@ -1282,7 +1282,7 @@ static inline HMM_Mat3 HMM_TransposeM3(HMM_Mat3 Matrix)
Result.Elements[1][2] = Matrix.Elements[2][1];
Result.Elements[2][1] = Matrix.Elements[1][2];
Result.Elements[2][0] = Matrix.Elements[0][2];
-
+
return Result;
}
@@ -1290,9 +1290,9 @@ COVERAGE(HMM_AddM3, 1)
static inline HMM_Mat3 HMM_AddM3(HMM_Mat3 Left, HMM_Mat3 Right)
{
ASSERT_COVERED(HMM_AddM3);
-
+
HMM_Mat3 Result;
-
+
Result.Elements[0][0] = Left.Elements[0][0] + Right.Elements[0][0];
Result.Elements[0][1] = Left.Elements[0][1] + Right.Elements[0][1];
Result.Elements[0][2] = Left.Elements[0][2] + Right.Elements[0][2];
@@ -1303,7 +1303,7 @@ static inline HMM_Mat3 HMM_AddM3(HMM_Mat3 Left, HMM_Mat3 Right)
Result.Elements[2][1] = Left.Elements[2][1] + Right.Elements[2][1];
Result.Elements[2][2] = Left.Elements[2][2] + Right.Elements[2][2];
- return Result;
+ return Result;
}
COVERAGE(HMM_SubM3, 1)
@@ -1330,7 +1330,7 @@ COVERAGE(HMM_MulM3V3, 1)
static inline HMM_Vec3 HMM_MulM3V3(HMM_Mat3 Matrix, HMM_Vec3 Vector)
{
ASSERT_COVERED(HMM_MulM3V3);
-
+
HMM_Vec3 Result;
Result.X = Vector.Elements[0] * Matrix.Columns[0].X;
@@ -1344,8 +1344,8 @@ static inline HMM_Vec3 HMM_MulM3V3(HMM_Mat3 Matrix, HMM_Vec3 Vector)
Result.X += Vector.Elements[2] * Matrix.Columns[2].X;
Result.Y += Vector.Elements[2] * Matrix.Columns[2].Y;
Result.Z += Vector.Elements[2] * Matrix.Columns[2].Z;
-
- return Result;
+
+ return Result;
}
COVERAGE(HMM_MulM3, 1)
@@ -1358,7 +1358,7 @@ static inline HMM_Mat3 HMM_MulM3(HMM_Mat3 Left, HMM_Mat3 Right)
Result.Columns[1] = HMM_MulM3V3(Left, Right.Columns[1]);
Result.Columns[2] = HMM_MulM3V3(Left, Right.Columns[2]);
- return Result;
+ return Result;
}
COVERAGE(HMM_MulM3F, 1)
@@ -1378,7 +1378,7 @@ static inline HMM_Mat3 HMM_MulM3F(HMM_Mat3 Matrix, float Scalar)
Result.Elements[2][1] = Matrix.Elements[2][1] * Scalar;
Result.Elements[2][2] = Matrix.Elements[2][2] * Scalar;
- return Result;
+ return Result;
}
COVERAGE(HMM_DivM3, 1)
@@ -1387,7 +1387,7 @@ static inline HMM_Mat3 HMM_DivM3F(HMM_Mat3 Matrix, float Scalar)
ASSERT_COVERED(HMM_DivM3);
HMM_Mat3 Result;
-
+
Result.Elements[0][0] = Matrix.Elements[0][0] / Scalar;
Result.Elements[0][1] = Matrix.Elements[0][1] / Scalar;
Result.Elements[0][2] = Matrix.Elements[0][2] / Scalar;
@@ -1398,11 +1398,11 @@ static inline HMM_Mat3 HMM_DivM3F(HMM_Mat3 Matrix, float Scalar)
Result.Elements[2][1] = Matrix.Elements[2][1] / Scalar;
Result.Elements[2][2] = Matrix.Elements[2][2] / Scalar;
- return Result;
+ return Result;
}
COVERAGE(HMM_DeterminantM3, 1)
-static inline float HMM_DeterminantM3(HMM_Mat3 Matrix)
+static inline float HMM_DeterminantM3(HMM_Mat3 Matrix)
{
ASSERT_COVERED(HMM_DeterminantM3);
@@ -1415,7 +1415,7 @@ static inline float HMM_DeterminantM3(HMM_Mat3 Matrix)
}
COVERAGE(HMM_InvGeneralM3, 1)
-static inline HMM_Mat3 HMM_InvGeneralM3(HMM_Mat3 Matrix)
+static inline HMM_Mat3 HMM_InvGeneralM3(HMM_Mat3 Matrix)
{
ASSERT_COVERED(HMM_InvGeneralM3);
@@ -1550,7 +1550,7 @@ static inline HMM_Mat4 HMM_SubM4(HMM_Mat4 Left, HMM_Mat4 Right)
Result.Elements[3][2] = Left.Elements[3][2] - Right.Elements[3][2];
Result.Elements[3][3] = Left.Elements[3][3] - Right.Elements[3][3];
#endif
-
+
return Result;
}
@@ -1646,7 +1646,7 @@ static inline HMM_Mat4 HMM_DivM4F(HMM_Mat4 Matrix, float Scalar)
}
COVERAGE(HMM_DeterminantM4, 1)
-static inline float HMM_DeterminantM4(HMM_Mat4 Matrix)
+static inline float HMM_DeterminantM4(HMM_Mat4 Matrix)
{
ASSERT_COVERED(HMM_DeterminantM4);
@@ -1654,14 +1654,14 @@ static inline float HMM_DeterminantM4(HMM_Mat4 Matrix)
HMM_Vec3 C23 = HMM_Cross(Matrix.Columns[2].XYZ, Matrix.Columns[3].XYZ);
HMM_Vec3 B10 = HMM_SubV3(HMM_MulV3F(Matrix.Columns[0].XYZ, Matrix.Columns[1].W), HMM_MulV3F(Matrix.Columns[1].XYZ, Matrix.Columns[0].W));
HMM_Vec3 B32 = HMM_SubV3(HMM_MulV3F(Matrix.Columns[2].XYZ, Matrix.Columns[3].W), HMM_MulV3F(Matrix.Columns[3].XYZ, Matrix.Columns[2].W));
-
+
return HMM_DotV3(C01, B32) + HMM_DotV3(C23, B10);
}
COVERAGE(HMM_InvGeneralM4, 1)
// Returns a general-purpose inverse of an HMM_Mat4. Note that special-purpose inverses of many transformations
// are available and will be more efficient.
-static inline HMM_Mat4 HMM_InvGeneralM4(HMM_Mat4 Matrix)
+static inline HMM_Mat4 HMM_InvGeneralM4(HMM_Mat4 Matrix)
{
ASSERT_COVERED(HMM_InvGeneralM4);
@@ -1669,7 +1669,7 @@ static inline HMM_Mat4 HMM_InvGeneralM4(HMM_Mat4 Matrix)
HMM_Vec3 C23 = HMM_Cross(Matrix.Columns[2].XYZ, Matrix.Columns[3].XYZ);
HMM_Vec3 B10 = HMM_SubV3(HMM_MulV3F(Matrix.Columns[0].XYZ, Matrix.Columns[1].W), HMM_MulV3F(Matrix.Columns[1].XYZ, Matrix.Columns[0].W));
HMM_Vec3 B32 = HMM_SubV3(HMM_MulV3F(Matrix.Columns[2].XYZ, Matrix.Columns[3].W), HMM_MulV3F(Matrix.Columns[3].XYZ, Matrix.Columns[2].W));
-
+
float InvDeterminant = 1.0f / (HMM_DotV3(C01, B32) + HMM_DotV3(C23, B10));
C01 = HMM_MulV3F(C01, InvDeterminant);
C23 = HMM_MulV3F(C23, InvDeterminant);
@@ -1681,7 +1681,7 @@ static inline HMM_Mat4 HMM_InvGeneralM4(HMM_Mat4 Matrix)
Result.Columns[1] = HMM_V4V(HMM_SubV3(HMM_Cross(B32, Matrix.Columns[0].XYZ), HMM_MulV3F(C23, Matrix.Columns[0].W)), +HMM_DotV3(Matrix.Columns[0].XYZ, C23));
Result.Columns[2] = HMM_V4V(HMM_AddV3(HMM_Cross(Matrix.Columns[3].XYZ, B10), HMM_MulV3F(C01, Matrix.Columns[3].W)), -HMM_DotV3(Matrix.Columns[3].XYZ, C01));
Result.Columns[3] = HMM_V4V(HMM_SubV3(HMM_Cross(B10, Matrix.Columns[2].XYZ), HMM_MulV3F(C01, Matrix.Columns[2].W)), +HMM_DotV3(Matrix.Columns[2].XYZ, C01));
-
+
return HMM_TransposeM4(Result);
}
@@ -1743,7 +1743,7 @@ static inline HMM_Mat4 HMM_Orthographic_LH_NO(float Left, float Right, float Bot
HMM_Mat4 Result = HMM_Orthographic_RH_NO(Left, Right, Bottom, Top, Near, Far);
Result.Elements[2][2] = -Result.Elements[2][2];
-
+
return Result;
}
@@ -1757,7 +1757,7 @@ static inline HMM_Mat4 HMM_Orthographic_LH_ZO(float Left, float Right, float Bot
HMM_Mat4 Result = HMM_Orthographic_RH_ZO(Left, Right, Bottom, Top, Near, Far);
Result.Elements[2][2] = -Result.Elements[2][2];
-
+
return Result;
}
@@ -1773,7 +1773,7 @@ static inline HMM_Mat4 HMM_InvOrthographic(HMM_Mat4 OrthoMatrix)
Result.Elements[1][1] = 1.0f / OrthoMatrix.Elements[1][1];
Result.Elements[2][2] = 1.0f / OrthoMatrix.Elements[2][2];
Result.Elements[3][3] = 1.0f;
-
+
Result.Elements[3][0] = -OrthoMatrix.Elements[3][0] * Result.Elements[0][0];
Result.Elements[3][1] = -OrthoMatrix.Elements[3][1] * Result.Elements[1][1];
Result.Elements[3][2] = -OrthoMatrix.Elements[3][2] * Result.Elements[2][2];
@@ -1797,7 +1797,7 @@ static inline HMM_Mat4 HMM_Perspective_RH_NO(float FOV, float AspectRatio, float
Result.Elements[2][2] = (Near + Far) / (Near - Far);
Result.Elements[3][2] = (2.0f * Near * Far) / (Near - Far);
-
+
return Result;
}
@@ -1823,25 +1823,25 @@ static inline HMM_Mat4 HMM_Perspective_RH_ZO(float FOV, float AspectRatio, float
COVERAGE(HMM_Perspective_LH_NO, 1)
static inline HMM_Mat4 HMM_Perspective_LH_NO(float FOV, float AspectRatio, float Near, float Far)
-{
+{
ASSERT_COVERED(HMM_Perspective_LH_NO);
HMM_Mat4 Result = HMM_Perspective_RH_NO(FOV, AspectRatio, Near, Far);
Result.Elements[2][2] = -Result.Elements[2][2];
Result.Elements[2][3] = -Result.Elements[2][3];
-
+
return Result;
}
COVERAGE(HMM_Perspective_LH_ZO, 1)
static inline HMM_Mat4 HMM_Perspective_LH_ZO(float FOV, float AspectRatio, float Near, float Far)
-{
+{
ASSERT_COVERED(HMM_Perspective_LH_ZO);
HMM_Mat4 Result = HMM_Perspective_RH_ZO(FOV, AspectRatio, Near, Far);
Result.Elements[2][2] = -Result.Elements[2][2];
Result.Elements[2][3] = -Result.Elements[2][3];
-
+
return Result;
}
@@ -1962,7 +1962,7 @@ static inline HMM_Mat4 HMM_Scale(HMM_Vec3 Scale)
}
COVERAGE(HMM_InvScale, 1)
-static inline HMM_Mat4 HMM_InvScale(HMM_Mat4 ScaleMatrix)
+static inline HMM_Mat4 HMM_InvScale(HMM_Mat4 ScaleMatrix)
{
ASSERT_COVERED(HMM_InvScale);
@@ -2166,7 +2166,7 @@ static inline HMM_Quat HMM_MulQ(HMM_Quat Left, HMM_Quat Right)
Result.Y += Right.Elements[3] * +Left.Elements[1];
Result.Z += Right.Elements[0] * -Left.Elements[1];
Result.W += Right.Elements[1] * -Left.Elements[1];
-
+
Result.X += Right.Elements[1] * -Left.Elements[2];
Result.Y += Right.Elements[0] * +Left.Elements[2];
Result.Z += Right.Elements[3] * +Left.Elements[2];
@@ -2246,7 +2246,7 @@ COVERAGE(HMM_InvQ, 1)
static inline HMM_Quat HMM_InvQ(HMM_Quat Left)
{
ASSERT_COVERED(HMM_InvQ);
-
+
HMM_Quat Result;
Result.X = -Left.X;
Result.Y = -Left.Y;
@@ -2312,7 +2312,7 @@ static inline HMM_Quat HMM_SLerp(HMM_Quat Left, float Time, HMM_Quat Right)
Cos_Theta = -Cos_Theta;
Right = HMM_Q(-Right.X, -Right.Y, -Right.Z, -Right.W);
}
-
+
/* NOTE(lcf): Use Normalized Linear interpolation when vectors are roughly not L.I. */
if (Cos_Theta > 0.9995f) {
Result = HMM_NLerp(Left, Time, Right);
@@ -2324,7 +2324,7 @@ static inline HMM_Quat HMM_SLerp(HMM_Quat Left, float Time, HMM_Quat Right)
Result = _HMM_MixQ(Left, MixLeft, Right, MixRight);
Result = HMM_NormQ(Result);
}
-
+
return Result;
}
@@ -2528,6 +2528,19 @@ static inline HMM_Quat HMM_QFromAxisAngle_LH(HMM_Vec3 Axis, float AngleOfRotatio
}
+// implementation from
+// https://blog.molecular-matters.com/2013/05/24/a-faster-quaternion-vector-multiplication/
+COVERAGE(HMM_RotateQV3, 1)
+static inline HMM_Vec3 HMM_RotateQV3(HMM_Quat Q, HMM_Vec3 V)
+{
+ ASSERT_COVERED(HMM_RotateQV3);
+
+ HMM_Vec3 t = HMM_MulV3F(HMM_Cross(Q.XYZ, V), 2);
+ return HMM_AddV3(V, HMM_AddV3(HMM_MulV3F(t, Q.W), HMM_Cross(Q.XYZ, t)));
+}
+
+
+
#ifdef __cplusplus
}
#endif
@@ -2624,23 +2637,23 @@ static inline float HMM_Dot(HMM_Vec4 Left, HMM_Vec4 VecTwo)
ASSERT_COVERED(HMM_DotV4CPP);
return HMM_DotV4(Left, VecTwo);
}
-
+
COVERAGE(HMM_LerpV2CPP, 1)
-static inline HMM_Vec2 HMM_Lerp(HMM_Vec2 Left, float Time, HMM_Vec2 Right)
+static inline HMM_Vec2 HMM_Lerp(HMM_Vec2 Left, float Time, HMM_Vec2 Right)
{
ASSERT_COVERED(HMM_LerpV2CPP);
return HMM_LerpV2(Left, Time, Right);
}
COVERAGE(HMM_LerpV3CPP, 1)
-static inline HMM_Vec3 HMM_Lerp(HMM_Vec3 Left, float Time, HMM_Vec3 Right)
+static inline HMM_Vec3 HMM_Lerp(HMM_Vec3 Left, float Time, HMM_Vec3 Right)
{
ASSERT_COVERED(HMM_LerpV3CPP);
return HMM_LerpV3(Left, Time, Right);
}
COVERAGE(HMM_LerpV4CPP, 1)
-static inline HMM_Vec4 HMM_Lerp(HMM_Vec4 Left, float Time, HMM_Vec4 Right)
+static inline HMM_Vec4 HMM_Lerp(HMM_Vec4 Left, float Time, HMM_Vec4 Right)
{
ASSERT_COVERED(HMM_LerpV4CPP);
return HMM_LerpV4(Left, Time, Right);
|
diff --git a/test/categories/QuaternionOps.h b/test/categories/QuaternionOps.h
--- a/test/categories/QuaternionOps.h
+++ b/test/categories/QuaternionOps.h
@@ -274,3 +274,25 @@ TEST(QuaternionOps, FromAxisAngle)
EXPECT_NEAR(result.W, 0.707107f, 0.001f);
}
}
+
+TEST(QuaternionOps, RotateVector)
+{
+ {
+ HMM_Vec3 axis = HMM_V3(0.0f, 1.0f, 0.0f);
+ float angle = -HMM_PI32 / 2.0f;
+ HMM_Quat q = HMM_QFromAxisAngle_RH(axis, angle);
+ HMM_Vec3 result = HMM_RotateQV3(q, HMM_V3(1.0f, 0.0f, 0.0f));
+ EXPECT_NEAR(result.X, 0.0f, 0.001f);
+ EXPECT_NEAR(result.Y, 0.0f, 0.001f);
+ EXPECT_NEAR(result.Z, 1.0f, 0.001f);
+ }
+ {
+ HMM_Vec3 axis = HMM_V3(1.0f, 0.0f, 0.0f);
+ float angle = HMM_PI32 / 4.0f;
+ HMM_Quat q = HMM_QFromAxisAngle_RH(axis, angle);
+ HMM_Vec3 result = HMM_RotateQV3(q, HMM_V3(0.0f, 0.0f, 1.0f));
+ EXPECT_NEAR(result.X, 0.0f, 0.001f);
+ EXPECT_NEAR(result.Y, -0.707170f, 0.001f);
+ EXPECT_NEAR(result.Z, 0.707170f, 0.001f);
+ }
+}
|
Rotate point by quaterion
Hi. HMM implements few quaterion functions but is missing one for rotating a vec3 position by a quaterion. I believe this is a correct implementation, a sample from a md5 model viewer. Could it be added to this library ?
```
//source: http://tfc.duke.free.fr/coding/src/md5mesh.c
void
Quat_normalize (quat4_t q)
{
/* compute magnitude of the quaternion */
float mag = sqrt ((q[X] * q[X]) + (q[Y] * q[Y])
+ (q[Z] * q[Z]) + (q[W] * q[W]));
/* check for bogus length, to protect against divide by zero */
if (mag > 0.0f)
{
/* normalize it */
float oneOverMag = 1.0f / mag;
q[X] *= oneOverMag;
q[Y] *= oneOverMag;
q[Z] *= oneOverMag;
q[W] *= oneOverMag;
}
}
void
Quat_multQuat (const quat4_t qa, const quat4_t qb, quat4_t out)
{
out[W] = (qa[W] * qb[W]) - (qa[X] * qb[X]) - (qa[Y] * qb[Y]) - (qa[Z] * qb[Z]);
out[X] = (qa[X] * qb[W]) + (qa[W] * qb[X]) + (qa[Y] * qb[Z]) - (qa[Z] * qb[Y]);
out[Y] = (qa[Y] * qb[W]) + (qa[W] * qb[Y]) + (qa[Z] * qb[X]) - (qa[X] * qb[Z]);
out[Z] = (qa[Z] * qb[W]) + (qa[W] * qb[Z]) + (qa[X] * qb[Y]) - (qa[Y] * qb[X]);
}
void
Quat_multVec (const quat4_t q, const vec3_t v, quat4_t out)
{
out[W] = - (q[X] * v[X]) - (q[Y] * v[Y]) - (q[Z] * v[Z]);
out[X] = (q[W] * v[X]) + (q[Y] * v[Z]) - (q[Z] * v[Y]);
out[Y] = (q[W] * v[Y]) + (q[Z] * v[X]) - (q[X] * v[Z]);
out[Z] = (q[W] * v[Z]) + (q[X] * v[Y]) - (q[Y] * v[X]);
}
void
Quat_rotatePoint (const quat4_t q, const vec3_t in, vec3_t out)
{
quat4_t tmp, inv, final;
inv[X] = -q[X]; inv[Y] = -q[Y];
inv[Z] = -q[Z]; inv[W] = q[W];
Quat_normalize (inv);
Quat_multVec (q, in, tmp);
Quat_multQuat (tmp, inv, final);
out[X] = final[X];
out[Y] = final[Y];
out[Z] = final[Z];
}
```
|
Hi if you'd like to write a implementation, and PR it i would accept it. If not i'll get to this the next time i have time.
Thanks
- Zak
| 2023-10-29T17:36:05
|
c
|
Hard
|
libssh2/libssh2
| 219
|
libssh2__libssh2-219
|
[
"185"
] |
53ff2e6da450ac1801704b35b3360c9488161342
|
diff --git a/docs/libssh2_channel_request_auth_agent.3 b/docs/libssh2_channel_request_auth_agent.3
new file mode 100644
--- /dev/null
+++ b/docs/libssh2_channel_request_auth_agent.3
@@ -0,0 +1,22 @@
+.TH libssh2_channel_request_auth_agent 3 "1 Jun 2007" "libssh2 0.15" "libssh2 manual"
+.SH NAME
+libssh2_channel_request_auth_agent - request agent forwarding for a session
+.SH SYNOPSIS
+#include <libssh2.h>
+
+int
+libssh2_channel_request_auth_agent(LIBSSH2_CHANNEL *channel);
+
+.SH DESCRIPTION
+Request that agent forwarding be enabled for this SSH session. This sends the
+request over this specific channel, which causes the agent listener to be
+started on the remote side upon success. This agent listener will then run
+for the duration of the SSH session.
+
+\fIchannel\fP - Previously opened channel instance such as returned by
+.BR libssh2_channel_open_ex(3)
+
+.SH RETURN VALUE
+Return 0 on success or negative on failure. It returns
+LIBSSH2_ERROR_EAGAIN when it would otherwise block. While
+LIBSSH2_ERROR_EAGAIN is a negative number, it isn't really a failure per se.
diff --git a/example/.gitignore b/example/.gitignore
--- a/example/.gitignore
+++ b/example/.gitignore
@@ -20,6 +20,7 @@ sftp_write_nonblock
config.h.in
ssh2_exec
ssh2_agent
+ssh2_agent_forwarding
libssh2_config.h
libssh2_config.h.in
stamp-h2
diff --git a/example/CMakeLists.txt b/example/CMakeLists.txt
--- a/example/CMakeLists.txt
+++ b/example/CMakeLists.txt
@@ -57,6 +57,7 @@ set(EXAMPLES
sftpdir_nonblock
ssh2_exec
ssh2_agent
+ ssh2_agent_forwarding
ssh2_echo
sftp_append
subsystem_netconf
diff --git a/example/Makefile.am b/example/Makefile.am
--- a/example/Makefile.am
+++ b/example/Makefile.am
@@ -6,8 +6,8 @@ EXTRA_DIST = libssh2_config.h.in libssh2_config_cmake.h.in CMakeLists.txt
noinst_PROGRAMS = direct_tcpip ssh2 scp scp_nonblock scp_write \
scp_write_nonblock sftp sftp_nonblock sftp_write sftp_write_nonblock \
sftp_mkdir sftp_mkdir_nonblock sftp_RW_nonblock sftp_write_sliding \
- sftpdir sftpdir_nonblock ssh2_exec ssh2_agent ssh2_echo sftp_append \
- subsystem_netconf tcpip-forward
+ sftpdir sftpdir_nonblock ssh2_exec ssh2_agent ssh2_agent_forwarding \
+ ssh2_echo sftp_append subsystem_netconf tcpip-forward
if HAVE_SYS_UN_H
noinst_PROGRAMS += x11
diff --git a/example/ssh2_agent_forwarding.c b/example/ssh2_agent_forwarding.c
new file mode 100644
--- /dev/null
+++ b/example/ssh2_agent_forwarding.c
@@ -0,0 +1,292 @@
+/*
+ * Sample showing how to use libssh2 to request agent forwarding
+ * on the remote host. The command executed will run with agent forwarded
+ * so you should be able to do things like clone out protected git
+ * repos and such.
+ *
+ * The example uses agent authentication to ensure an agent to forward
+ * is running.
+ *
+ * Run it like this:
+ *
+ * $ ./ssh2_agent_forwarding 127.0.0.1 user "uptime"
+ *
+ */
+
+#include "libssh2_config.h"
+#include <libssh2.h>
+
+#ifdef HAVE_WINSOCK2_H
+# include <winsock2.h>
+#endif
+#ifdef HAVE_SYS_SOCKET_H
+# include <sys/socket.h>
+#endif
+#ifdef HAVE_NETINET_IN_H
+# include <netinet/in.h>
+#endif
+#ifdef HAVE_SYS_SELECT_H
+# include <sys/select.h>
+#endif
+# ifdef HAVE_UNISTD_H
+#include <unistd.h>
+#endif
+#ifdef HAVE_ARPA_INET_H
+# include <arpa/inet.h>
+#endif
+
+#ifdef HAVE_SYS_TIME_H
+# include <sys/time.h>
+#endif
+#include <sys/types.h>
+#include <stdlib.h>
+#include <fcntl.h>
+#include <errno.h>
+#include <stdio.h>
+#include <ctype.h>
+
+static int waitsocket(int socket_fd, LIBSSH2_SESSION *session)
+{
+ struct timeval timeout;
+ int rc;
+ fd_set fd;
+ fd_set *writefd = NULL;
+ fd_set *readfd = NULL;
+ int dir;
+
+ timeout.tv_sec = 10;
+ timeout.tv_usec = 0;
+
+ FD_ZERO(&fd);
+
+ FD_SET(socket_fd, &fd);
+
+ /* now make sure we wait in the correct direction */
+ dir = libssh2_session_block_directions(session);
+
+ if(dir & LIBSSH2_SESSION_BLOCK_INBOUND)
+ readfd = &fd;
+
+ if(dir & LIBSSH2_SESSION_BLOCK_OUTBOUND)
+ writefd = &fd;
+
+ rc = select(socket_fd + 1, readfd, writefd, NULL, &timeout);
+
+ return rc;
+}
+
+int main(int argc, char *argv[])
+{
+ const char *hostname = "127.0.0.1";
+ const char *commandline = "uptime";
+ const char *username = NULL;
+ unsigned long hostaddr;
+ int sock;
+ struct sockaddr_in sin;
+ LIBSSH2_SESSION *session;
+ LIBSSH2_CHANNEL *channel;
+ LIBSSH2_AGENT *agent = NULL;
+ struct libssh2_agent_publickey *identity, *prev_identity = NULL;
+ int rc;
+ int exitcode;
+ char *exitsignal = (char *)"none";
+ int bytecount = 0;
+
+#ifdef WIN32
+ WSADATA wsadata;
+ WSAStartup(MAKEWORD(2, 0), &wsadata);
+#endif
+ if(argc < 2) {
+ fprintf(stderr, "At least IP and username arguments are required.\n");
+ return 1;
+ }
+ /* must be ip address only */
+ hostname = argv[1];
+ username = argv[2];
+
+ if(argc > 3) {
+ commandline = argv[3];
+ }
+
+ rc = libssh2_init(0);
+ if(rc != 0) {
+ fprintf(stderr, "libssh2 initialization failed (%d)\n", rc);
+ return 1;
+ }
+
+ hostaddr = inet_addr(hostname);
+
+ /* Ultra basic "connect to port 22 on localhost"
+ * Your code is responsible for creating the socket establishing the
+ * connection
+ */
+ sock = socket(AF_INET, SOCK_STREAM, 0);
+
+ sin.sin_family = AF_INET;
+ sin.sin_port = htons(22);
+ sin.sin_addr.s_addr = hostaddr;
+ if(connect(sock, (struct sockaddr*)(&sin),
+ sizeof(struct sockaddr_in)) != 0) {
+ fprintf(stderr, "failed to connect!\n");
+ return -1;
+ }
+
+ /* Create a session instance */
+ session = libssh2_session_init();
+ if(!session)
+ return -1;
+
+ if(libssh2_session_handshake(session, sock) != 0) {
+ fprintf(stderr, "Failure establishing SSH session: %d\n", rc);
+ return -1;
+ }
+
+ /* Connect to the ssh-agent */
+ agent = libssh2_agent_init(session);
+ if(!agent) {
+ fprintf(stderr, "Failure initializing ssh-agent support\n");
+ rc = 1;
+ goto shutdown;
+ }
+ if(libssh2_agent_connect(agent)) {
+ fprintf(stderr, "Failure connecting to ssh-agent\n");
+ rc = 1;
+ goto shutdown;
+ }
+ if(libssh2_agent_list_identities(agent)) {
+ fprintf(stderr, "Failure requesting identities to ssh-agent\n");
+ rc = 1;
+ goto shutdown;
+ }
+ while(1) {
+ rc = libssh2_agent_get_identity(agent, &identity, prev_identity);
+ if(rc == 1)
+ break;
+ if(rc < 0) {
+ fprintf(stderr,
+ "Failure obtaining identity from ssh-agent support\n");
+ rc = 1;
+ goto shutdown;
+ }
+ if(libssh2_agent_userauth(agent, username, identity)) {
+ fprintf(stderr, "\tAuthentication with username %s and "
+ "public key %s failed!\n",
+ username, identity->comment);
+ }
+ else {
+ fprintf(stderr, "\tAuthentication with username %s and "
+ "public key %s succeeded!\n",
+ username, identity->comment);
+ break;
+ }
+ prev_identity = identity;
+ }
+ if(rc) {
+ fprintf(stderr, "Couldn't continue authentication\n");
+ goto shutdown;
+ }
+
+#if 0
+ libssh2_trace(session, ~0);
+#endif
+
+ /* Set session to non-blocking */
+ libssh2_session_set_blocking(session, 0);
+
+ /* Exec non-blocking on the remove host */
+ while((channel = libssh2_channel_open_session(session)) == NULL &&
+ libssh2_session_last_error(session, NULL, NULL, 0) ==
+ LIBSSH2_ERROR_EAGAIN) {
+ waitsocket(sock, session);
+ }
+ if(channel == NULL) {
+ fprintf(stderr, "Error\n");
+ exit(1);
+ }
+ while((rc = libssh2_channel_request_auth_agent(channel)) ==
+ LIBSSH2_ERROR_EAGAIN) {
+ waitsocket(sock, session);
+ }
+ if(rc != 0) {
+ fprintf(stderr, "Error, couldn't request auth agent, error code %d.\n",
+ rc);
+ exit(1);
+ }
+ else {
+ fprintf(stdout, "\tAgent forwarding request succeeded!\n");
+ }
+ while((rc = libssh2_channel_exec(channel, commandline)) ==
+ LIBSSH2_ERROR_EAGAIN) {
+ waitsocket(sock, session);
+ }
+ if(rc != 0) {
+ fprintf(stderr, "Error\n");
+ exit(1);
+ }
+ for(;;) {
+ /* loop until we block */
+ int rc;
+ do {
+ char buffer[0x4000];
+ rc = libssh2_channel_read(channel, buffer, sizeof(buffer) );
+ if(rc > 0) {
+ int i;
+ bytecount += rc;
+ fprintf(stderr, "We read:\n");
+ for(i = 0; i < rc; ++i)
+ fputc(buffer[i], stderr);
+ fprintf(stderr, "\n");
+ }
+ else {
+ if(rc != LIBSSH2_ERROR_EAGAIN)
+ /* no need to output this for the EAGAIN case */
+ fprintf(stderr, "libssh2_channel_read returned %d\n", rc);
+ }
+ }
+ while(rc > 0);
+
+ /* this is due to blocking that would occur otherwise so we loop on
+ this condition */
+ if(rc == LIBSSH2_ERROR_EAGAIN) {
+ waitsocket(sock, session);
+ }
+ else
+ break;
+ }
+ exitcode = 127;
+ while((rc = libssh2_channel_close(channel)) == LIBSSH2_ERROR_EAGAIN) {
+ waitsocket(sock, session);
+ }
+ if(rc == 0) {
+ exitcode = libssh2_channel_get_exit_status(channel);
+ libssh2_channel_get_exit_signal(channel, &exitsignal,
+ NULL, NULL, NULL, NULL, NULL);
+ }
+
+ if(exitsignal) {
+ printf("\nGot signal: %s\n", exitsignal);
+ }
+ else {
+ printf("\nEXIT: %d bytecount: %d\n", exitcode, bytecount);
+ }
+
+ libssh2_channel_free(channel);
+ channel = NULL;
+
+shutdown:
+
+ libssh2_session_disconnect(session,
+ "Normal Shutdown, Thank you for playing");
+ libssh2_session_free(session);
+
+#ifdef WIN32
+ closesocket(sock);
+#else
+ close(sock);
+#endif
+ fprintf(stderr, "all done\n");
+
+ libssh2_exit();
+
+ return 0;
+}
diff --git a/include/libssh2.h b/include/libssh2.h
--- a/include/libssh2.h
+++ b/include/libssh2.h
@@ -761,6 +761,8 @@ LIBSSH2_API int libssh2_channel_setenv_ex(LIBSSH2_CHANNEL *channel,
(unsigned int)strlen(varname), (value), \
(unsigned int)strlen(value))
+LIBSSH2_API int libssh2_channel_request_auth_agent(LIBSSH2_CHANNEL *channel);
+
LIBSSH2_API int libssh2_channel_request_pty_ex(LIBSSH2_CHANNEL *channel,
const char *term,
unsigned int term_len,
diff --git a/src/channel.c b/src/channel.c
--- a/src/channel.c
+++ b/src/channel.c
@@ -1021,6 +1021,158 @@ static int channel_request_pty(LIBSSH2_CHANNEL *channel,
"channel request-pty");
}
+/**
+ * channel_request_auth_agent
+ * The actual re-entrant method which requests an auth agent.
+ * */
+static int channel_request_auth_agent(LIBSSH2_CHANNEL *channel,
+ const char *request_str,
+ int request_str_len)
+{
+ LIBSSH2_SESSION *session = channel->session;
+ unsigned char *s;
+ static const unsigned char reply_codes[3] =
+ { SSH_MSG_CHANNEL_SUCCESS, SSH_MSG_CHANNEL_FAILURE, 0 };
+ int rc;
+
+ if(channel->req_auth_agent_state == libssh2_NB_state_idle) {
+ /* Only valid options are "auth-agent-req" and
+ * "auth-agent-req_at_openssh.com" so we make sure it is not
+ * actually longer than the longest possible. */
+ if(request_str_len > 26) {
+ return _libssh2_error(session, LIBSSH2_ERROR_INVAL,
+ "request_str length too large");
+ }
+
+ /*
+ * Length: 24 or 36 = packet_type(1) + channel(4) + req_len(4) +
+ * request_str (variable) + want_reply (1) */
+ channel->req_auth_agent_packet_len = 10 + request_str_len;
+
+ /* Zero out the requireev state to reset */
+ memset(&channel->req_auth_agent_requirev_state, 0,
+ sizeof(channel->req_auth_agent_requirev_state));
+
+ _libssh2_debug(session, LIBSSH2_TRACE_CONN,
+ "Requesting auth agent on channel %lu/%lu",
+ channel->local.id, channel->remote.id);
+
+ /*
+ * byte SSH_MSG_CHANNEL_REQUEST
+ * uint32 recipient channel
+ * string "auth-agent-req"
+ * boolean want reply
+ * */
+ s = channel->req_auth_agent_packet;
+ *(s++) = SSH_MSG_CHANNEL_REQUEST;
+ _libssh2_store_u32(&s, channel->remote.id);
+ _libssh2_store_str(&s, (char *)request_str, request_str_len);
+ *(s++) = 0x01;
+
+ channel->req_auth_agent_state = libssh2_NB_state_created;
+ }
+
+ if(channel->req_auth_agent_state == libssh2_NB_state_created) {
+ /* Send the packet, we can use sizeof() on the packet because it
+ * is always completely filled; there are no variable length fields. */
+ rc = _libssh2_transport_send(session, channel->req_auth_agent_packet,
+ channel->req_auth_agent_packet_len,
+ NULL, 0);
+
+ if(rc == LIBSSH2_ERROR_EAGAIN) {
+ _libssh2_error(session, rc,
+ "Would block sending auth-agent request");
+ }
+ else if(rc) {
+ channel->req_auth_agent_state = libssh2_NB_state_idle;
+ return _libssh2_error(session, rc,
+ "Unable to send auth-agent request");
+ }
+ _libssh2_htonu32(channel->req_auth_agent_local_channel,
+ channel->local.id);
+ channel->req_auth_agent_state = libssh2_NB_state_sent;
+ }
+
+ if(channel->req_auth_agent_state == libssh2_NB_state_sent) {
+ unsigned char *data;
+ size_t data_len;
+ unsigned char code;
+
+ rc = _libssh2_packet_requirev(
+ session, reply_codes, &data, &data_len, 1,
+ channel->req_auth_agent_local_channel,
+ 4, &channel->req_auth_agent_requirev_state);
+ if(rc == LIBSSH2_ERROR_EAGAIN) {
+ return rc;
+ }
+ else if(rc) {
+ channel->req_auth_agent_state = libssh2_NB_state_idle;
+ return _libssh2_error(session, LIBSSH2_ERROR_PROTO,
+ "Failed to request auth-agent");
+ }
+
+ code = data[0];
+
+ LIBSSH2_FREE(session, data);
+ channel->req_auth_agent_state = libssh2_NB_state_idle;
+
+ if(code == SSH_MSG_CHANNEL_SUCCESS)
+ return 0;
+ }
+
+ return _libssh2_error(session, LIBSSH2_ERROR_CHANNEL_REQUEST_DENIED,
+ "Unable to complete request for auth-agent");
+}
+
+/**
+ * libssh2_channel_request_auth_agent
+ * Requests that agent forwarding be enabled for the session. The
+ * request must be sent over a specific channel, which starts the agent
+ * listener on the remote side. Once the channel is closed, the agent
+ * listener continues to exist.
+ * */
+LIBSSH2_API int
+libssh2_channel_request_auth_agent(LIBSSH2_CHANNEL *channel)
+{
+ int rc;
+
+ if(!channel)
+ return LIBSSH2_ERROR_BAD_USE;
+
+ /* The current RFC draft for agent forwarding says you're supposed to
+ * send "auth-agent-req," but most SSH servers out there right now
+ * actually expect "auth-agent-req@openssh.com", so we try that
+ * first. */
+ if(channel->req_auth_agent_try_state == libssh2_NB_state_idle) {
+ BLOCK_ADJUST(rc, channel->session,
+ channel_request_auth_agent(channel,
+ "auth-agent-req@openssh.com",
+ 26));
+
+ /* If we failed (but not with EAGAIN), then we move onto
+ * the next step to try another request type. */
+ if(rc != 0 && rc != LIBSSH2_ERROR_EAGAIN)
+ channel->req_auth_agent_try_state = libssh2_NB_state_sent;
+ }
+
+ if(channel->req_auth_agent_try_state == libssh2_NB_state_sent) {
+ BLOCK_ADJUST(rc, channel->session,
+ channel_request_auth_agent(channel,
+ "auth-agent-req", 14));
+
+ /* If we failed without an EAGAIN, then move on with this
+ * state machine. */
+ if(rc != 0 && rc != LIBSSH2_ERROR_EAGAIN)
+ channel->req_auth_agent_try_state = libssh2_NB_state_sent1;
+ }
+
+ /* If things are good, reset the try state. */
+ if(rc == 0)
+ channel->req_auth_agent_try_state = libssh2_NB_state_idle;
+
+ return rc;
+}
+
/*
* libssh2_channel_request_pty_ex
* Duh... Request a PTY
diff --git a/src/libssh2_priv.h b/src/libssh2_priv.h
--- a/src/libssh2_priv.h
+++ b/src/libssh2_priv.h
@@ -452,6 +452,13 @@ struct _LIBSSH2_CHANNEL
/* State variables used in libssh2_channel_handle_extended_data2() */
libssh2_nonblocking_states extData2_state;
+ /* State variables used in libssh2_channel_request_auth_agent() */
+ libssh2_nonblocking_states req_auth_agent_try_state;
+ libssh2_nonblocking_states req_auth_agent_state;
+ unsigned char req_auth_agent_packet[36];
+ size_t req_auth_agent_packet_len;
+ unsigned char req_auth_agent_local_channel[4];
+ packet_requirev_state_t req_auth_agent_requirev_state;
};
struct _LIBSSH2_LISTENER
|
diff --git a/tests/CMakeLists.txt b/tests/CMakeLists.txt
--- a/tests/CMakeLists.txt
+++ b/tests/CMakeLists.txt
@@ -118,6 +118,7 @@ set(TESTS
public_key_auth_succeeds_with_correct_encrypted_rsa_key
keyboard_interactive_auth_fails_with_wrong_response
keyboard_interactive_auth_succeeds_with_correct_response
+ agent_forward_succeeds
)
if(CRYPTO_BACKEND STREQUAL "OpenSSL")
diff --git a/tests/test_agent_forward_succeeds.c b/tests/test_agent_forward_succeeds.c
new file mode 100644
--- /dev/null
+++ b/tests/test_agent_forward_succeeds.c
@@ -0,0 +1,51 @@
+#include "session_fixture.h"
+
+#include <libssh2.h>
+
+#include <stdio.h>
+
+const char *USERNAME = "libssh2"; /* configured in Dockerfile */
+const char *KEY_FILE_PRIVATE = "key_rsa";
+const char *KEY_FILE_PUBLIC = "key_rsa.pub"; /* configured in Dockerfile */
+
+int test(LIBSSH2_SESSION *session)
+{
+ int rc;
+ LIBSSH2_CHANNEL *channel;
+
+ const char *userauth_list =
+ libssh2_userauth_list(session, USERNAME, strlen(USERNAME));
+ if (userauth_list == NULL) {
+ print_last_session_error("libssh2_userauth_list");
+ return 1;
+ }
+
+ if (strstr(userauth_list, "publickey") == NULL) {
+ fprintf(stderr, "'publickey' was expected in userauth list: %s\n",
+ userauth_list);
+ return 1;
+ }
+
+ rc = libssh2_userauth_publickey_fromfile_ex(
+ session, USERNAME, strlen(USERNAME), KEY_FILE_PUBLIC, KEY_FILE_PRIVATE,
+ NULL);
+ if (rc != 0) {
+ print_last_session_error("libssh2_userauth_publickey_fromfile_ex");
+ return 1;
+ }
+
+ channel = libssh2_channel_open_session(session);
+ /* if (channel == NULL) { */
+ /* printf("Error opening channel\n"); */
+ /* return 1; */
+ /* } */
+
+ rc = libssh2_channel_request_auth_agent(channel);
+ if (rc != 0) {
+ fprintf(stderr, "Auth agent request for agent forwarding failed, error code %d\n",
+ rc);
+ return 1;
+ }
+
+ return 0;
+}
|
Agent forwarding
Is there any interest in implementing agent forwarding functionality in libssh2? At one point a patch was submitted (https://www.libssh2.org/mail/libssh2-devel-archive-2012-03/0114.shtml) but it looks like it wasn't merged in (https://www.libssh2.org/mail/libssh2-devel-archive-2012-03/0121.shtml).
| 2017-10-20T17:23:19
|
c
|
Hard
|
|
libssh2/libssh2
| 1,084
|
libssh2__libssh2-1084
|
[
"1084"
] |
f4f52ccc4d9a2d132a12df92bcee5e115359c3e3
|
diff --git a/.github/workflows/appveyor_docker.yml b/.github/workflows/appveyor_docker.yml
--- a/.github/workflows/appveyor_docker.yml
+++ b/.github/workflows/appveyor_docker.yml
@@ -21,6 +21,8 @@
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
name: AppVeyor Docker Bridge
diff --git a/.github/workflows/appveyor_status.yml b/.github/workflows/appveyor_status.yml
--- a/.github/workflows/appveyor_status.yml
+++ b/.github/workflows/appveyor_status.yml
@@ -21,6 +21,8 @@
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
name: AppVeyor Status Report
diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml
--- a/.github/workflows/ci.yml
+++ b/.github/workflows/ci.yml
@@ -1,3 +1,7 @@
+# Copyright (C) The libssh2 project and its contributors.
+#
+# SPDX-License-Identifier: BSD-3-Clause
+#
name: CI
on:
diff --git a/.github/workflows/cifuzz.yml b/.github/workflows/cifuzz.yml
--- a/.github/workflows/cifuzz.yml
+++ b/.github/workflows/cifuzz.yml
@@ -1,3 +1,7 @@
+# Copyright (C) The libssh2 project and its contributors.
+#
+# SPDX-License-Identifier: BSD-3-Clause
+#
name: CIFuzz
on: [pull_request]
diff --git a/.github/workflows/openssh_server.yml b/.github/workflows/openssh_server.yml
--- a/.github/workflows/openssh_server.yml
+++ b/.github/workflows/openssh_server.yml
@@ -21,6 +21,8 @@
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
name: OpenSSH Server Docker Image
diff --git a/.github/workflows/reuse.yml b/.github/workflows/reuse.yml
new file mode 100644
--- /dev/null
+++ b/.github/workflows/reuse.yml
@@ -0,0 +1,29 @@
+# Copyright (C) Daniel Stenberg
+# SPDX-FileCopyrightText: 2022 Free Software Foundation Europe e.V. <https://fsfe.org>
+#
+# SPDX-License-Identifier: BSD-3-Clause
+
+name: REUSE compliance
+
+on:
+ push:
+ branches:
+ - master
+ - '*/ci'
+ pull_request:
+ branches:
+ - master
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.sha }}
+ cancel-in-progress: true
+
+permissions: {}
+
+jobs:
+ check:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: REUSE Compliance Check
+ uses: fsfe/reuse-action@v1
diff --git a/.reuse/dep5 b/.reuse/dep5
new file mode 100644
--- /dev/null
+++ b/.reuse/dep5
@@ -0,0 +1,34 @@
+Format: https://www.debian.org/doc/packaging-manuals/copyright-format/1.0/
+Upstream-Name: libssh2
+Upstream-Contact: The libssh2 team <libssh2-devel@lists.haxx.se>
+Source: https://libssh2.org/
+
+# Test data
+Files: tests/openssh_server/* tests/ossfuzz/* tests/key_* tests/test_read_algos.txt
+Copyright: The libssh2 project and its contributors.
+License: BSD-3-Clause
+
+# Root files
+Files: NEWS README README.md RELEASE-NOTES
+Copyright: The libssh2 project and its contributors.
+License: BSD-3-Clause
+
+# Docs
+Files: docs/.gitignore docs/AUTHORS docs/BINDINGS.md docs/HACKING-CRYPTO docs/HACKING.md docs/INSTALL_CMAKE.md docs/Makefile.am docs/SECURITY.md docs/TODO docs/template.3 os400/README400
+Copyright: The libssh2 project and its contributors.
+License: BSD-3-Clause
+
+# vms files
+Files: vms/libssh2_config.h vms/libssh2_make_example.dcl vms/libssh2_make_help.dcl vms/libssh2_make_kit.dcl vms/libssh2_make_lib.dcl vms/man2help.c vms/readme.vms
+Copyright: The libssh2 project and its contributors.
+License: BSD-3-Clause
+
+# dot files
+Files: .checksrc .editorconfig .github/ISSUE_TEMPLATE/bug_report.md .github/SECURITY.md .github/stale.yml .gitignore example/.gitignore m4/.gitignore src/.gitignore tests/.gitignore
+Copyright: The libssh2 project and its contributors.
+License: BSD-3-Clause
+
+# autotools INSTALL
+Files: docs/INSTALL_AUTOTOOLS
+Copyright: Free Software Foundation, Inc.
+License: FSFULLR
diff --git a/CMakeLists.txt b/CMakeLists.txt
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -33,6 +33,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
include(CheckFunctionExists)
include(CheckSymbolExists)
diff --git a/LICENSES/BSD-2-Clause.txt b/LICENSES/BSD-2-Clause.txt
new file mode 100644
--- /dev/null
+++ b/LICENSES/BSD-2-Clause.txt
@@ -0,0 +1,9 @@
+Copyright <YEAR> <COPYRIGHT HOLDER>
+
+Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/LICENSES/BSD-3-Clause.txt b/LICENSES/BSD-3-Clause.txt
new file mode 100644
--- /dev/null
+++ b/LICENSES/BSD-3-Clause.txt
@@ -0,0 +1,11 @@
+Copyright (c) <year> <owner>.
+
+Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
+
+3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/LICENSES/FSFULLR.txt b/LICENSES/FSFULLR.txt
new file mode 100644
--- /dev/null
+++ b/LICENSES/FSFULLR.txt
@@ -0,0 +1,5 @@
+# Copyright Free Software Foundation, Inc.
+#
+# This file is free software; the Free Software Foundation gives
+# unlimited permission to copy and/or distribute it, with or without
+# modifications, as long as this notice is preserved.
diff --git a/LICENSES/MIT.txt b/LICENSES/MIT.txt
new file mode 100644
--- /dev/null
+++ b/LICENSES/MIT.txt
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) [year] [fullname]
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/LICENSES/curl.txt b/LICENSES/curl.txt
new file mode 100644
--- /dev/null
+++ b/LICENSES/curl.txt
@@ -0,0 +1,21 @@
+COPYRIGHT AND PERMISSION NOTICE
+
+Copyright (C) Daniel Stenberg, <daniel@haxx.se>, and many contributors.
+
+All rights reserved.
+
+Permission to use, copy, modify, and distribute this software for any purpose
+with or without fee is hereby granted, provided that the above copyright
+notice and this permission notice appear in all copies.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OF THIRD PARTY RIGHTS. IN
+NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
+DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
+OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE
+OR OTHER DEALINGS IN THE SOFTWARE.
+
+Except as contained in this notice, the name of a copyright holder shall not
+be used in advertising or otherwise to promote the sale, use or other dealings
+in this Software without prior written authorization of the copyright holder.
diff --git a/Makefile.am b/Makefile.am
--- a/Makefile.am
+++ b/Makefile.am
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
AUTOMAKE_OPTIONS = foreign nostdinc
SUBDIRS = src docs
diff --git a/Makefile.mk b/Makefile.mk
--- a/Makefile.mk
+++ b/Makefile.mk
@@ -3,10 +3,12 @@
# Makefile for building libssh2 with GCC-like toolchains.
# Use: make -f Makefile.mk [help|all|clean|dist|distclean|dyn|objclean|example|exampleclean|test|testclean]
#
-# Written by Guenter Knauf and Viktor Szakats
+# Copyright (C) Guenter Knauf
+# Copyright (C) Viktor Szakats
#
# Look for ' ?=' to find accepted customization variables.
#
+# SPDX-License-Identifier: BSD-3-Clause
#########################################################################
### Common
diff --git a/NMakefile b/NMakefile
--- a/NMakefile
+++ b/NMakefile
@@ -1,3 +1,6 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
+
!if "$(TARGET)" == ""
TARGET=Release
!endif
diff --git a/acinclude.m4 b/acinclude.m4
--- a/acinclude.m4
+++ b/acinclude.m4
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
dnl CURL_CPP_P
dnl
dnl Check if $cpp -P should be used for extract define values due to gcc 5
diff --git a/appveyor.yml b/appveyor.yml
--- a/appveyor.yml
+++ b/appveyor.yml
@@ -24,6 +24,8 @@
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
# https://www.appveyor.com/docs/windows-images-software/
diff --git a/buildconf b/buildconf
--- a/buildconf
+++ b/buildconf
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
echo "***" >&2
echo "*** Do not use buildconf. Instead, use: autoreconf -fi" >&2
diff --git a/ci/appveyor/docker-bridge.ps1 b/ci/appveyor/docker-bridge.ps1
--- a/ci/appveyor/docker-bridge.ps1
+++ b/ci/appveyor/docker-bridge.ps1
@@ -1,4 +1,6 @@
#!/usr/bin/env pwsh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
# Partially copied from https://github.com/appveyor/ci/blob/master/scripts/enable-rdp.ps1
diff --git a/ci/appveyor/docker-bridge.sh b/ci/appveyor/docker-bridge.sh
--- a/ci/appveyor/docker-bridge.sh
+++ b/ci/appveyor/docker-bridge.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
set -e
diff --git a/ci/checksrc.sh b/ci/checksrc.sh
--- a/ci/checksrc.sh
+++ b/ci/checksrc.sh
@@ -1,4 +1,6 @@
#!/usr/bin/env bash
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
set -e
diff --git a/cmake/CheckFunctionExistsMayNeedLibrary.cmake b/cmake/CheckFunctionExistsMayNeedLibrary.cmake
--- a/cmake/CheckFunctionExistsMayNeedLibrary.cmake
+++ b/cmake/CheckFunctionExistsMayNeedLibrary.cmake
@@ -32,6 +32,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
# - check_function_exists_maybe_need_library(<function> <var> [lib1 ... libn])
diff --git a/cmake/CheckNonblockingSocketSupport.cmake b/cmake/CheckNonblockingSocketSupport.cmake
--- a/cmake/CheckNonblockingSocketSupport.cmake
+++ b/cmake/CheckNonblockingSocketSupport.cmake
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
include(CheckCSourceCompiles)
# - check_nonblocking_socket_support()
diff --git a/cmake/CopyRuntimeDependencies.cmake b/cmake/CopyRuntimeDependencies.cmake
--- a/cmake/CopyRuntimeDependencies.cmake
+++ b/cmake/CopyRuntimeDependencies.cmake
@@ -32,6 +32,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
include(CMakeParseArguments)
diff --git a/cmake/FindLibgcrypt.cmake b/cmake/FindLibgcrypt.cmake
--- a/cmake/FindLibgcrypt.cmake
+++ b/cmake/FindLibgcrypt.cmake
@@ -32,6 +32,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
# - Try to find Libgcrypt
# This will define all or none of:
diff --git a/cmake/FindmbedTLS.cmake b/cmake/FindmbedTLS.cmake
--- a/cmake/FindmbedTLS.cmake
+++ b/cmake/FindmbedTLS.cmake
@@ -1,3 +1,6 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
+#
# - Try to find mbedTLS
# Once done this will define
#
diff --git a/cmake/Findwolfssl.cmake b/cmake/Findwolfssl.cmake
--- a/cmake/Findwolfssl.cmake
+++ b/cmake/Findwolfssl.cmake
@@ -1,3 +1,6 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
+#
# - Try to find wolfssl
# Once done this will define
# WOLFSSL_FOUND - System has wolfssl
diff --git a/cmake/max_warnings.cmake b/cmake/max_warnings.cmake
--- a/cmake/max_warnings.cmake
+++ b/cmake/max_warnings.cmake
@@ -1,4 +1,5 @@
# Copyright (C) Viktor Szakats
+# SPDX-License-Identifier: BSD-3-Clause
include(CheckCCompilerFlag)
diff --git a/config.rpath b/config.rpath
--- a/config.rpath
+++ b/config.rpath
@@ -24,6 +24,8 @@
# than 256 bytes, otherwise the compiler driver will dump core. The only
# known workaround is to choose shorter directory names for the build
# directory and/or the installation directory.
+#
+# SPDX-License-Identifier: FSFULLR
# All known linkers require a `.a' archive for static linking (except MSVC,
# which needs '.lib').
diff --git a/configure.ac b/configure.ac
--- a/configure.ac
+++ b/configure.ac
@@ -1,3 +1,8 @@
+# Copyright (C) The libssh2 project and its contributors.
+#
+# SPDX-License-Identifier: BSD-3-Clause
+#
+
# AC_PREREQ(2.59)
AC_INIT([libssh2],[-],[libssh2-devel@lists.haxx.se])
AC_CONFIG_MACRO_DIR([m4])
diff --git a/docs/CMakeLists.txt b/docs/CMakeLists.txt
--- a/docs/CMakeLists.txt
+++ b/docs/CMakeLists.txt
@@ -33,6 +33,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
transform_makefile_inc("Makefile.am" "${CMAKE_CURRENT_BINARY_DIR}/Makefile.am.cmake")
# Get 'dist_man_MANS' variable
diff --git a/docs/libssh2_agent_connect.3 b/docs/libssh2_agent_connect.3
--- a/docs/libssh2_agent_connect.3
+++ b/docs/libssh2_agent_connect.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_connect 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_connect - connect to an ssh-agent
diff --git a/docs/libssh2_agent_disconnect.3 b/docs/libssh2_agent_disconnect.3
--- a/docs/libssh2_agent_disconnect.3
+++ b/docs/libssh2_agent_disconnect.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_disconnect 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_disconnect - close a connection to an ssh-agent
diff --git a/docs/libssh2_agent_free.3 b/docs/libssh2_agent_free.3
--- a/docs/libssh2_agent_free.3
+++ b/docs/libssh2_agent_free.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_free 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_free - free an ssh-agent handle
diff --git a/docs/libssh2_agent_get_identity.3 b/docs/libssh2_agent_get_identity.3
--- a/docs/libssh2_agent_get_identity.3
+++ b/docs/libssh2_agent_get_identity.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_get_identity 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_get_identity - get a public key off the collection of public keys managed by ssh-agent
diff --git a/docs/libssh2_agent_get_identity_path.3 b/docs/libssh2_agent_get_identity_path.3
--- a/docs/libssh2_agent_get_identity_path.3
+++ b/docs/libssh2_agent_get_identity_path.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Will Cosgrove
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_get_identity_path 3 "6 Mar 2019" "libssh2" "libssh2"
.SH NAME
libssh2_agent_get_identity_path - gets the custom ssh-agent socket path
diff --git a/docs/libssh2_agent_init.3 b/docs/libssh2_agent_init.3
--- a/docs/libssh2_agent_init.3
+++ b/docs/libssh2_agent_init.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_init 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_init - init an ssh-agent handle
diff --git a/docs/libssh2_agent_list_identities.3 b/docs/libssh2_agent_list_identities.3
--- a/docs/libssh2_agent_list_identities.3
+++ b/docs/libssh2_agent_list_identities.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_list_identities 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_list_identities - request an ssh-agent to list of public keys.
diff --git a/docs/libssh2_agent_set_identity_path.3 b/docs/libssh2_agent_set_identity_path.3
--- a/docs/libssh2_agent_set_identity_path.3
+++ b/docs/libssh2_agent_set_identity_path.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Will Cosgrove
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_set_identity_path 3 "6 Mar 2019" "libssh2" "libssh2"
.SH NAME
libssh2_agent_set_identity_path - set an ssh-agent socket path on disk
diff --git a/docs/libssh2_agent_sign.3 b/docs/libssh2_agent_sign.3
--- a/docs/libssh2_agent_sign.3
+++ b/docs/libssh2_agent_sign.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_sign 3 "1 Oct 2022" "libssh2" "libssh2"
.SH NAME
libssh2_agent_sign - sign data, with the help of ssh-agent
diff --git a/docs/libssh2_agent_userauth.3 b/docs/libssh2_agent_userauth.3
--- a/docs/libssh2_agent_userauth.3
+++ b/docs/libssh2_agent_userauth.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daiki Ueno
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_agent_userauth 3 "23 Dec 2009" "libssh2" "libssh2"
.SH NAME
libssh2_agent_userauth - authenticate a session with a public key, with the help of ssh-agent
diff --git a/docs/libssh2_banner_set.3 b/docs/libssh2_banner_set.3
--- a/docs/libssh2_banner_set.3
+++ b/docs/libssh2_banner_set.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_banner_set 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_banner_set - set the SSH protocol banner for the local client
diff --git a/docs/libssh2_base64_decode.3 b/docs/libssh2_base64_decode.3
--- a/docs/libssh2_base64_decode.3
+++ b/docs/libssh2_base64_decode.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_base64_decode 3 "23 Dec 2008" "libssh2 1.0" "libssh2"
.SH NAME
libssh2_base64_decode - decode a base64 encoded string
diff --git a/docs/libssh2_channel_close.3 b/docs/libssh2_channel_close.3
--- a/docs/libssh2_channel_close.3
+++ b/docs/libssh2_channel_close.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_close 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_close - close a channel
diff --git a/docs/libssh2_channel_direct_streamlocal_ex.3 b/docs/libssh2_channel_direct_streamlocal_ex.3
--- a/docs/libssh2_channel_direct_streamlocal_ex.3
+++ b/docs/libssh2_channel_direct_streamlocal_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_direct_streamlocal_ex 3 "10 Apr 2023" "libssh2 1.11.0" "libssh2"
.SH NAME
libssh2_channel_direct_streamlocal_ex - Tunnel a UNIX socket connection through an SSH session
diff --git a/docs/libssh2_channel_direct_tcpip.3 b/docs/libssh2_channel_direct_tcpip.3
--- a/docs/libssh2_channel_direct_tcpip.3
+++ b/docs/libssh2_channel_direct_tcpip.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_direct_tcpip 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_direct_tcpip - convenience macro for \fIlibssh2_channel_direct_tcpip_ex(3)\fP calls
diff --git a/docs/libssh2_channel_direct_tcpip_ex.3 b/docs/libssh2_channel_direct_tcpip_ex.3
--- a/docs/libssh2_channel_direct_tcpip_ex.3
+++ b/docs/libssh2_channel_direct_tcpip_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_direct_tcpip_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_direct_tcpip_ex - Tunnel a TCP connection through an SSH session
diff --git a/docs/libssh2_channel_eof.3 b/docs/libssh2_channel_eof.3
--- a/docs/libssh2_channel_eof.3
+++ b/docs/libssh2_channel_eof.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_eof 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_eof - check a channel's EOF status
diff --git a/docs/libssh2_channel_exec.3 b/docs/libssh2_channel_exec.3
--- a/docs/libssh2_channel_exec.3
+++ b/docs/libssh2_channel_exec.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_exec 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_exec - convenience macro for \fIlibssh2_channel_process_startup(3)\fP calls
diff --git a/docs/libssh2_channel_flush.3 b/docs/libssh2_channel_flush.3
--- a/docs/libssh2_channel_flush.3
+++ b/docs/libssh2_channel_flush.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_flush 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_flush - convenience macro for \fIlibssh2_channel_flush_ex(3)\fP calls
diff --git a/docs/libssh2_channel_flush_ex.3 b/docs/libssh2_channel_flush_ex.3
--- a/docs/libssh2_channel_flush_ex.3
+++ b/docs/libssh2_channel_flush_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_flush_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_flush_ex - flush a channel
diff --git a/docs/libssh2_channel_flush_stderr.3 b/docs/libssh2_channel_flush_stderr.3
--- a/docs/libssh2_channel_flush_stderr.3
+++ b/docs/libssh2_channel_flush_stderr.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_flush_stderr 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_flush_stderr - convenience macro for \fIlibssh2_channel_flush_ex(3)\fP calls
diff --git a/docs/libssh2_channel_forward_accept.3 b/docs/libssh2_channel_forward_accept.3
--- a/docs/libssh2_channel_forward_accept.3
+++ b/docs/libssh2_channel_forward_accept.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_forward_accept 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_forward_accept - accept a queued connection
diff --git a/docs/libssh2_channel_forward_cancel.3 b/docs/libssh2_channel_forward_cancel.3
--- a/docs/libssh2_channel_forward_cancel.3
+++ b/docs/libssh2_channel_forward_cancel.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_forward_cancel 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_forward_cancel - cancel a forwarded TCP port
diff --git a/docs/libssh2_channel_forward_listen.3 b/docs/libssh2_channel_forward_listen.3
--- a/docs/libssh2_channel_forward_listen.3
+++ b/docs/libssh2_channel_forward_listen.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_forward_listen 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_forward_listen - convenience macro for \fIlibssh2_channel_forward_listen_ex(3)\fP calls
diff --git a/docs/libssh2_channel_forward_listen_ex.3 b/docs/libssh2_channel_forward_listen_ex.3
--- a/docs/libssh2_channel_forward_listen_ex.3
+++ b/docs/libssh2_channel_forward_listen_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_forward_listen_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_forward_listen_ex - listen to inbound connections
diff --git a/docs/libssh2_channel_free.3 b/docs/libssh2_channel_free.3
--- a/docs/libssh2_channel_free.3
+++ b/docs/libssh2_channel_free.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_free 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_free - free all resources associated with a channel
diff --git a/docs/libssh2_channel_get_exit_signal.3 b/docs/libssh2_channel_get_exit_signal.3
--- a/docs/libssh2_channel_get_exit_signal.3
+++ b/docs/libssh2_channel_get_exit_signal.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_get_exit_signal 3 "4 Oct 2010" "libssh2 1.2.8" "libssh2"
.SH NAME
libssh2_channel_get_exit_signal - get the remote exit signal
diff --git a/docs/libssh2_channel_get_exit_status.3 b/docs/libssh2_channel_get_exit_status.3
--- a/docs/libssh2_channel_get_exit_status.3
+++ b/docs/libssh2_channel_get_exit_status.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_get_exit_status 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_get_exit_status - get the remote exit code
diff --git a/docs/libssh2_channel_handle_extended_data.3 b/docs/libssh2_channel_handle_extended_data.3
--- a/docs/libssh2_channel_handle_extended_data.3
+++ b/docs/libssh2_channel_handle_extended_data.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_handle_extended_data 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_handle_extended_data - set extended data handling mode
diff --git a/docs/libssh2_channel_handle_extended_data2.3 b/docs/libssh2_channel_handle_extended_data2.3
--- a/docs/libssh2_channel_handle_extended_data2.3
+++ b/docs/libssh2_channel_handle_extended_data2.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_handle_extended_data2 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_handle_extended_data2 - set extended data handling mode
diff --git a/docs/libssh2_channel_ignore_extended_data.3 b/docs/libssh2_channel_ignore_extended_data.3
--- a/docs/libssh2_channel_ignore_extended_data.3
+++ b/docs/libssh2_channel_ignore_extended_data.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_ignore_extended_data 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_ignore_extended_data - convenience macro for \fIlibssh2_channel_handle_extended_data(3)\fP calls
diff --git a/docs/libssh2_channel_open_ex.3 b/docs/libssh2_channel_open_ex.3
--- a/docs/libssh2_channel_open_ex.3
+++ b/docs/libssh2_channel_open_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_open_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_open_ex - establish a generic session channel
diff --git a/docs/libssh2_channel_open_session.3 b/docs/libssh2_channel_open_session.3
--- a/docs/libssh2_channel_open_session.3
+++ b/docs/libssh2_channel_open_session.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_open_session 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_open_session - convenience macro for \fIlibssh2_channel_open_ex(3)\fP calls
diff --git a/docs/libssh2_channel_process_startup.3 b/docs/libssh2_channel_process_startup.3
--- a/docs/libssh2_channel_process_startup.3
+++ b/docs/libssh2_channel_process_startup.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_process_startup 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_process_startup - request a shell on a channel
diff --git a/docs/libssh2_channel_read.3 b/docs/libssh2_channel_read.3
--- a/docs/libssh2_channel_read.3
+++ b/docs/libssh2_channel_read.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_read 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_read - convenience macro for \fIlibssh2_channel_read_ex(3)\fP calls
diff --git a/docs/libssh2_channel_read_ex.3 b/docs/libssh2_channel_read_ex.3
--- a/docs/libssh2_channel_read_ex.3
+++ b/docs/libssh2_channel_read_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_read_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_read_ex - read data from a channel stream
diff --git a/docs/libssh2_channel_read_stderr.3 b/docs/libssh2_channel_read_stderr.3
--- a/docs/libssh2_channel_read_stderr.3
+++ b/docs/libssh2_channel_read_stderr.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_read_stderr 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_read_stderr - convenience macro for \fIlibssh2_channel_read_ex(3)\fP calls
diff --git a/docs/libssh2_channel_receive_window_adjust.3 b/docs/libssh2_channel_receive_window_adjust.3
--- a/docs/libssh2_channel_receive_window_adjust.3
+++ b/docs/libssh2_channel_receive_window_adjust.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_receive_window_adjust 3 "15 Mar 2009" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_receive_window_adjust - adjust the channel window
diff --git a/docs/libssh2_channel_receive_window_adjust2.3 b/docs/libssh2_channel_receive_window_adjust2.3
--- a/docs/libssh2_channel_receive_window_adjust2.3
+++ b/docs/libssh2_channel_receive_window_adjust2.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_receive_window_adjust2 3 "26 Mar 2009" "libssh2 1.1" "libssh2"
.SH NAME
libssh2_channel_receive_window_adjust2 - adjust the channel window
diff --git a/docs/libssh2_channel_request_auth_agent.3 b/docs/libssh2_channel_request_auth_agent.3
--- a/docs/libssh2_channel_request_auth_agent.3
+++ b/docs/libssh2_channel_request_auth_agent.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_request_auth_agent 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_request_auth_agent - request agent forwarding for a session
diff --git a/docs/libssh2_channel_request_pty.3 b/docs/libssh2_channel_request_pty.3
--- a/docs/libssh2_channel_request_pty.3
+++ b/docs/libssh2_channel_request_pty.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_request_pty 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_request_pty - convenience macro for \fIlibssh2_channel_request_pty_ex(3)\fP calls
diff --git a/docs/libssh2_channel_request_pty_ex.3 b/docs/libssh2_channel_request_pty_ex.3
--- a/docs/libssh2_channel_request_pty_ex.3
+++ b/docs/libssh2_channel_request_pty_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_request_pty_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_request_pty_ex - short function description
diff --git a/docs/libssh2_channel_request_pty_size.3 b/docs/libssh2_channel_request_pty_size.3
--- a/docs/libssh2_channel_request_pty_size.3
+++ b/docs/libssh2_channel_request_pty_size.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_request_pty_size 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_request_pty_size - convenience macro for \fIlibssh2_channel_request_pty_size_ex(3)\fP calls
diff --git a/docs/libssh2_channel_request_pty_size_ex.3 b/docs/libssh2_channel_request_pty_size_ex.3
--- a/docs/libssh2_channel_request_pty_size_ex.3
+++ b/docs/libssh2_channel_request_pty_size_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_request_pty_size_ex 3 "1 Jun 2007" "libssh2" "libssh2"
.SH NAME
libssh2_channel_request_pty_size_ex - TODO
diff --git a/docs/libssh2_channel_send_eof.3 b/docs/libssh2_channel_send_eof.3
--- a/docs/libssh2_channel_send_eof.3
+++ b/docs/libssh2_channel_send_eof.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_send_eof 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_send_eof - send EOF to remote server
diff --git a/docs/libssh2_channel_set_blocking.3 b/docs/libssh2_channel_set_blocking.3
--- a/docs/libssh2_channel_set_blocking.3
+++ b/docs/libssh2_channel_set_blocking.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_set_blocking 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_set_blocking - set or clear blocking mode on channel
diff --git a/docs/libssh2_channel_setenv.3 b/docs/libssh2_channel_setenv.3
--- a/docs/libssh2_channel_setenv.3
+++ b/docs/libssh2_channel_setenv.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_setenv 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_setenv - convenience macro for \fIlibssh2_channel_setenv_ex(3)\fP calls
diff --git a/docs/libssh2_channel_setenv_ex.3 b/docs/libssh2_channel_setenv_ex.3
--- a/docs/libssh2_channel_setenv_ex.3
+++ b/docs/libssh2_channel_setenv_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_setenv_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_setenv_ex - set an environment variable on the channel
diff --git a/docs/libssh2_channel_shell.3 b/docs/libssh2_channel_shell.3
--- a/docs/libssh2_channel_shell.3
+++ b/docs/libssh2_channel_shell.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_shell 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_shell - convenience macro for \fIlibssh2_channel_process_startup(3)\fP calls
diff --git a/docs/libssh2_channel_signal_ex.3 b/docs/libssh2_channel_signal_ex.3
--- a/docs/libssh2_channel_signal_ex.3
+++ b/docs/libssh2_channel_signal_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_signal_ex 3 "20 Apr 2023" "libssh2 1.11.0" "libssh2"
.SH NAME
libssh2_channel_signal_ex -- Send a signal to process previously opened on channel.
diff --git a/docs/libssh2_channel_subsystem.3 b/docs/libssh2_channel_subsystem.3
--- a/docs/libssh2_channel_subsystem.3
+++ b/docs/libssh2_channel_subsystem.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_subsystem 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_subsystem - convenience macro for \fIlibssh2_channel_process_startup(3)\fP calls
diff --git a/docs/libssh2_channel_wait_closed.3 b/docs/libssh2_channel_wait_closed.3
--- a/docs/libssh2_channel_wait_closed.3
+++ b/docs/libssh2_channel_wait_closed.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_wait_closed 3 "29 Nov 2007" "libssh2 0.19" "libssh2"
.SH NAME
libssh2_channel_wait_closed - wait for the remote to close the channel
diff --git a/docs/libssh2_channel_wait_eof.3 b/docs/libssh2_channel_wait_eof.3
--- a/docs/libssh2_channel_wait_eof.3
+++ b/docs/libssh2_channel_wait_eof.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_wait_eof 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_wait_eof - wait for the remote to reply to an EOF request
diff --git a/docs/libssh2_channel_window_read.3 b/docs/libssh2_channel_window_read.3
--- a/docs/libssh2_channel_window_read.3
+++ b/docs/libssh2_channel_window_read.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_window_read 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_window_read - convenience macro for \fIlibssh2_channel_window_read_ex(3)\fP calls
diff --git a/docs/libssh2_channel_window_read_ex.3 b/docs/libssh2_channel_window_read_ex.3
--- a/docs/libssh2_channel_window_read_ex.3
+++ b/docs/libssh2_channel_window_read_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_window_read_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_window_read_ex - Check the status of the read window
diff --git a/docs/libssh2_channel_window_write.3 b/docs/libssh2_channel_window_write.3
--- a/docs/libssh2_channel_window_write.3
+++ b/docs/libssh2_channel_window_write.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_window_write 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_window_write - convenience macro for \fIlibssh2_channel_window_write_ex(3)\fP calls
diff --git a/docs/libssh2_channel_window_write_ex.3 b/docs/libssh2_channel_window_write_ex.3
--- a/docs/libssh2_channel_window_write_ex.3
+++ b/docs/libssh2_channel_window_write_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_window_write_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_window_write_ex - Check the status of the write window
diff --git a/docs/libssh2_channel_write.3 b/docs/libssh2_channel_write.3
--- a/docs/libssh2_channel_write.3
+++ b/docs/libssh2_channel_write.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_write 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_write - convenience macro for \fIlibssh2_channel_write_ex(3)\fP
diff --git a/docs/libssh2_channel_write_ex.3 b/docs/libssh2_channel_write_ex.3
--- a/docs/libssh2_channel_write_ex.3
+++ b/docs/libssh2_channel_write_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_write_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_write_ex - write data to a channel stream blocking
diff --git a/docs/libssh2_channel_write_stderr.3 b/docs/libssh2_channel_write_stderr.3
--- a/docs/libssh2_channel_write_stderr.3
+++ b/docs/libssh2_channel_write_stderr.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_write_stderr 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_write_stderr - convenience macro for \fIlibssh2_channel_write_ex(3)\fP
diff --git a/docs/libssh2_channel_x11_req.3 b/docs/libssh2_channel_x11_req.3
--- a/docs/libssh2_channel_x11_req.3
+++ b/docs/libssh2_channel_x11_req.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_x11_req 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_channel_x11_req - convenience macro for \fIlibssh2_channel_x11_req_ex(3)\fP calls
diff --git a/docs/libssh2_channel_x11_req_ex.3 b/docs/libssh2_channel_x11_req_ex.3
--- a/docs/libssh2_channel_x11_req_ex.3
+++ b/docs/libssh2_channel_x11_req_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_channel_x11_req_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_channel_x11_req_ex - request an X11 forwarding channel
diff --git a/docs/libssh2_crypto_engine.3 b/docs/libssh2_crypto_engine.3
--- a/docs/libssh2_crypto_engine.3
+++ b/docs/libssh2_crypto_engine.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_crypto_engine 3 "22 Nov 2021" "libssh2" "libssh2"
.SH NAME
libssh2_crypto_engine - retrieve used crypto engine
diff --git a/docs/libssh2_exit.3 b/docs/libssh2_exit.3
--- a/docs/libssh2_exit.3
+++ b/docs/libssh2_exit.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_exit 3 "19 Mar 2010" "libssh2" "libssh2"
.SH NAME
libssh2_exit - global library deinitialization
diff --git a/docs/libssh2_free.3 b/docs/libssh2_free.3
--- a/docs/libssh2_free.3
+++ b/docs/libssh2_free.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_free 3 "13 Oct 2010" "libssh2" "libssh2"
.SH NAME
libssh2_free - deallocate libssh2 memory
diff --git a/docs/libssh2_hostkey_hash.3 b/docs/libssh2_hostkey_hash.3
--- a/docs/libssh2_hostkey_hash.3
+++ b/docs/libssh2_hostkey_hash.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_hostkey_hash 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_hostkey_hash - return a hash of the remote host's key
diff --git a/docs/libssh2_init.3 b/docs/libssh2_init.3
--- a/docs/libssh2_init.3
+++ b/docs/libssh2_init.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_init 3 "19 Mar 2010" "libssh2" "libssh2"
.SH NAME
libssh2_init - global library initialization
diff --git a/docs/libssh2_keepalive_config.3 b/docs/libssh2_keepalive_config.3
--- a/docs/libssh2_keepalive_config.3
+++ b/docs/libssh2_keepalive_config.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_keepalive_config 3 "12 Apr 2011" "libssh2" "libssh2"
.SH NAME
libssh2_keepalive_config - short function description
diff --git a/docs/libssh2_keepalive_send.3 b/docs/libssh2_keepalive_send.3
--- a/docs/libssh2_keepalive_send.3
+++ b/docs/libssh2_keepalive_send.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_keepalive_send 3 "13 Apr 2011" "libssh2" "libssh2"
.SH NAME
libssh2_keepalive_send - short function description
diff --git a/docs/libssh2_knownhost_add.3 b/docs/libssh2_knownhost_add.3
--- a/docs/libssh2_knownhost_add.3
+++ b/docs/libssh2_knownhost_add.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_add 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_add - add a known host
diff --git a/docs/libssh2_knownhost_addc.3 b/docs/libssh2_knownhost_addc.3
--- a/docs/libssh2_knownhost_addc.3
+++ b/docs/libssh2_knownhost_addc.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_addc 3 "28 May 2009" "libssh2 1.2" "libssh2"
.SH NAME
libssh2_knownhost_addc - add a known host
diff --git a/docs/libssh2_knownhost_check.3 b/docs/libssh2_knownhost_check.3
--- a/docs/libssh2_knownhost_check.3
+++ b/docs/libssh2_knownhost_check.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_check 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_check - check a host+key against the list of known hosts
diff --git a/docs/libssh2_knownhost_checkp.3 b/docs/libssh2_knownhost_checkp.3
--- a/docs/libssh2_knownhost_checkp.3
+++ b/docs/libssh2_knownhost_checkp.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_checkp 3 "1 May 2010" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_checkp - check a host+key against the list of known hosts
diff --git a/docs/libssh2_knownhost_del.3 b/docs/libssh2_knownhost_del.3
--- a/docs/libssh2_knownhost_del.3
+++ b/docs/libssh2_knownhost_del.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_del 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_del - delete a known host entry
diff --git a/docs/libssh2_knownhost_free.3 b/docs/libssh2_knownhost_free.3
--- a/docs/libssh2_knownhost_free.3
+++ b/docs/libssh2_knownhost_free.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_free 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_free - free a collection of known hosts
diff --git a/docs/libssh2_knownhost_get.3 b/docs/libssh2_knownhost_get.3
--- a/docs/libssh2_knownhost_get.3
+++ b/docs/libssh2_knownhost_get.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_get 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_get - get a known host off the collection of known hosts
diff --git a/docs/libssh2_knownhost_init.3 b/docs/libssh2_knownhost_init.3
--- a/docs/libssh2_knownhost_init.3
+++ b/docs/libssh2_knownhost_init.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_init 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_init - init a collection of known hosts
diff --git a/docs/libssh2_knownhost_readfile.3 b/docs/libssh2_knownhost_readfile.3
--- a/docs/libssh2_knownhost_readfile.3
+++ b/docs/libssh2_knownhost_readfile.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_readfile 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_readfile - parse a file of known hosts
diff --git a/docs/libssh2_knownhost_readline.3 b/docs/libssh2_knownhost_readline.3
--- a/docs/libssh2_knownhost_readline.3
+++ b/docs/libssh2_knownhost_readline.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_readline 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_readline - read a known host line
diff --git a/docs/libssh2_knownhost_writefile.3 b/docs/libssh2_knownhost_writefile.3
--- a/docs/libssh2_knownhost_writefile.3
+++ b/docs/libssh2_knownhost_writefile.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_writefile 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_writefile - write a collection of known hosts to a file
diff --git a/docs/libssh2_knownhost_writeline.3 b/docs/libssh2_knownhost_writeline.3
--- a/docs/libssh2_knownhost_writeline.3
+++ b/docs/libssh2_knownhost_writeline.3
@@ -1,6 +1,5 @@
-.\"
.\" Copyright (C) Daniel Stenberg
-.\"
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_knownhost_writeline 3 "28 May 2009" "libssh2" "libssh2"
.SH NAME
libssh2_knownhost_writeline - convert a known host to a line for storage
diff --git a/docs/libssh2_poll.3 b/docs/libssh2_poll.3
--- a/docs/libssh2_poll.3
+++ b/docs/libssh2_poll.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_poll 3 "14 Dec 2006" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_poll - poll for activity on a socket, channel or listener
diff --git a/docs/libssh2_poll_channel_read.3 b/docs/libssh2_poll_channel_read.3
--- a/docs/libssh2_poll_channel_read.3
+++ b/docs/libssh2_poll_channel_read.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_poll_channel_read 3 "14 Dec 2006" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_poll_channel_read - check if data is available
diff --git a/docs/libssh2_publickey_add.3 b/docs/libssh2_publickey_add.3
--- a/docs/libssh2_publickey_add.3
+++ b/docs/libssh2_publickey_add.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_add 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_publickey_add - convenience macro for \fIlibssh2_publickey_add_ex(3)\fP calls
diff --git a/docs/libssh2_publickey_add_ex.3 b/docs/libssh2_publickey_add_ex.3
--- a/docs/libssh2_publickey_add_ex.3
+++ b/docs/libssh2_publickey_add_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_add_ex 3 "1 Jun 2007" "libssh2" "libssh2"
.SH NAME
libssh2_publickey_add_ex - Add a public key entry
diff --git a/docs/libssh2_publickey_init.3 b/docs/libssh2_publickey_init.3
--- a/docs/libssh2_publickey_init.3
+++ b/docs/libssh2_publickey_init.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_init 3 "1 Jun 2007" "libssh2" "libssh2"
.SH NAME
libssh2_publickey_init - TODO
diff --git a/docs/libssh2_publickey_list_fetch.3 b/docs/libssh2_publickey_list_fetch.3
--- a/docs/libssh2_publickey_list_fetch.3
+++ b/docs/libssh2_publickey_list_fetch.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_list_fetch 3 "1 Jun 2007" "libssh2" "libssh2"
.SH NAME
libssh2_publickey_list_fetch - TODO
diff --git a/docs/libssh2_publickey_list_free.3 b/docs/libssh2_publickey_list_free.3
--- a/docs/libssh2_publickey_list_free.3
+++ b/docs/libssh2_publickey_list_free.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_list_free 3 "1 Jun 2007" "libssh2" "libssh2"
.SH NAME
libssh2_publickey_list_free - TODO
diff --git a/docs/libssh2_publickey_remove.3 b/docs/libssh2_publickey_remove.3
--- a/docs/libssh2_publickey_remove.3
+++ b/docs/libssh2_publickey_remove.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_remove 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_publickey_remove - convenience macro for \fIlibssh2_publickey_remove_ex(3)\fP calls
diff --git a/docs/libssh2_publickey_remove_ex.3 b/docs/libssh2_publickey_remove_ex.3
--- a/docs/libssh2_publickey_remove_ex.3
+++ b/docs/libssh2_publickey_remove_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_list_remove_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_publickey_list_remove_ex - TODO
diff --git a/docs/libssh2_publickey_shutdown.3 b/docs/libssh2_publickey_shutdown.3
--- a/docs/libssh2_publickey_shutdown.3
+++ b/docs/libssh2_publickey_shutdown.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_publickey_shutdown 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_publickey_shutdown - TODO
diff --git a/docs/libssh2_scp_recv.3 b/docs/libssh2_scp_recv.3
--- a/docs/libssh2_scp_recv.3
+++ b/docs/libssh2_scp_recv.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_scp_recv 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_scp_recv - request a remote file via SCP
diff --git a/docs/libssh2_scp_recv2.3 b/docs/libssh2_scp_recv2.3
--- a/docs/libssh2_scp_recv2.3
+++ b/docs/libssh2_scp_recv2.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_scp_recv2 3 "29 Jun 2015" "libssh2 1.6.1" "libssh2"
.SH NAME
libssh2_scp_recv2 - request a remote file via SCP
diff --git a/docs/libssh2_scp_send.3 b/docs/libssh2_scp_send.3
--- a/docs/libssh2_scp_send.3
+++ b/docs/libssh2_scp_send.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_scp_send 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_scp_send - convenience macro for \fIlibssh2_scp_send_ex(3)\fP calls
diff --git a/docs/libssh2_scp_send64.3 b/docs/libssh2_scp_send64.3
--- a/docs/libssh2_scp_send64.3
+++ b/docs/libssh2_scp_send64.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_scp_send64 3 "17 Apr 2010" "libssh2 1.2.6" "libssh2"
.SH NAME
libssh2_scp_send64 - Send a file via SCP
diff --git a/docs/libssh2_scp_send_ex.3 b/docs/libssh2_scp_send_ex.3
--- a/docs/libssh2_scp_send_ex.3
+++ b/docs/libssh2_scp_send_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_scp_send_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_scp_send_ex - Send a file via SCP
diff --git a/docs/libssh2_session_abstract.3 b/docs/libssh2_session_abstract.3
--- a/docs/libssh2_session_abstract.3
+++ b/docs/libssh2_session_abstract.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_abstract 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_abstract - return a pointer to a session's abstract pointer
diff --git a/docs/libssh2_session_banner_get.3 b/docs/libssh2_session_banner_get.3
--- a/docs/libssh2_session_banner_get.3
+++ b/docs/libssh2_session_banner_get.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_banner_get 3 "9 Sep 2011" "libssh2" "libssh2"
.SH NAME
libssh2_session_banner_get - get the remote banner
diff --git a/docs/libssh2_session_banner_set.3 b/docs/libssh2_session_banner_set.3
--- a/docs/libssh2_session_banner_set.3
+++ b/docs/libssh2_session_banner_set.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_banner_set 3 "9 Sep 2011" "libssh2" "libssh2"
.SH NAME
libssh2_session_banner_set - set the SSH protocol banner for the local client
diff --git a/docs/libssh2_session_block_directions.3 b/docs/libssh2_session_block_directions.3
--- a/docs/libssh2_session_block_directions.3
+++ b/docs/libssh2_session_block_directions.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_block_directions 3 "1 Oct 2008" "libssh2" "libssh2"
.SH NAME
libssh2_session_block_directions - get directions to wait for
diff --git a/docs/libssh2_session_callback_set.3 b/docs/libssh2_session_callback_set.3
--- a/docs/libssh2_session_callback_set.3
+++ b/docs/libssh2_session_callback_set.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_callback_set 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_callback_set - set a callback function
diff --git a/docs/libssh2_session_disconnect.3 b/docs/libssh2_session_disconnect.3
--- a/docs/libssh2_session_disconnect.3
+++ b/docs/libssh2_session_disconnect.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_disconnect 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_session_disconnect - convenience macro for \fIlibssh2_session_disconnect_ex(3)\fP calls
diff --git a/docs/libssh2_session_disconnect_ex.3 b/docs/libssh2_session_disconnect_ex.3
--- a/docs/libssh2_session_disconnect_ex.3
+++ b/docs/libssh2_session_disconnect_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_disconnect_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_disconnect_ex - terminate transport layer
diff --git a/docs/libssh2_session_flag.3 b/docs/libssh2_session_flag.3
--- a/docs/libssh2_session_flag.3
+++ b/docs/libssh2_session_flag.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_flag 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_flag - TODO
diff --git a/docs/libssh2_session_free.3 b/docs/libssh2_session_free.3
--- a/docs/libssh2_session_free.3
+++ b/docs/libssh2_session_free.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_free 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_free - frees resources associated with a session instance
diff --git a/docs/libssh2_session_get_blocking.3 b/docs/libssh2_session_get_blocking.3
--- a/docs/libssh2_session_get_blocking.3
+++ b/docs/libssh2_session_get_blocking.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_get_blocking 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_get_blocking - TODO
diff --git a/docs/libssh2_session_get_read_timeout.3 b/docs/libssh2_session_get_read_timeout.3
--- a/docs/libssh2_session_get_read_timeout.3
+++ b/docs/libssh2_session_get_read_timeout.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_get_read_timeout 3 "13 Jan 2023" "libssh2" "libssh2"
.SH NAME
libssh2_session_get_read_timeout - get the timeout for packet read functions
diff --git a/docs/libssh2_session_get_timeout.3 b/docs/libssh2_session_get_timeout.3
--- a/docs/libssh2_session_get_timeout.3
+++ b/docs/libssh2_session_get_timeout.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_get_timeout 3 "4 May 2011" "libssh2" "libssh2"
.SH NAME
libssh2_session_get_timeout - get the timeout for blocking functions
diff --git a/docs/libssh2_session_handshake.3 b/docs/libssh2_session_handshake.3
--- a/docs/libssh2_session_handshake.3
+++ b/docs/libssh2_session_handshake.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_handshake 3 "7 Oct 2010" "libssh2" "libssh2"
.SH NAME
libssh2_session_handshake - perform the SSH handshake
diff --git a/docs/libssh2_session_hostkey.3 b/docs/libssh2_session_hostkey.3
--- a/docs/libssh2_session_hostkey.3
+++ b/docs/libssh2_session_hostkey.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_hostkey 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_hostkey - get the remote key
diff --git a/docs/libssh2_session_init.3 b/docs/libssh2_session_init.3
--- a/docs/libssh2_session_init.3
+++ b/docs/libssh2_session_init.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_init 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_session_init - convenience macro for \fIlibssh2_session_init_ex(3)\fP calls
diff --git a/docs/libssh2_session_init_ex.3 b/docs/libssh2_session_init_ex.3
--- a/docs/libssh2_session_init_ex.3
+++ b/docs/libssh2_session_init_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_init_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_init_ex - initializes an SSH session object
diff --git a/docs/libssh2_session_last_errno.3 b/docs/libssh2_session_last_errno.3
--- a/docs/libssh2_session_last_errno.3
+++ b/docs/libssh2_session_last_errno.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_last_errno 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_last_errno - get the most recent error number
diff --git a/docs/libssh2_session_last_error.3 b/docs/libssh2_session_last_error.3
--- a/docs/libssh2_session_last_error.3
+++ b/docs/libssh2_session_last_error.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_last_error 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_last_error - get the most recent error
diff --git a/docs/libssh2_session_method_pref.3 b/docs/libssh2_session_method_pref.3
--- a/docs/libssh2_session_method_pref.3
+++ b/docs/libssh2_session_method_pref.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_method_pref 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_method_pref - set preferred key exchange method
diff --git a/docs/libssh2_session_methods.3 b/docs/libssh2_session_methods.3
--- a/docs/libssh2_session_methods.3
+++ b/docs/libssh2_session_methods.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_methods 3 "8 Nov 2021" "libssh2 1.11" "libssh2"
.SH NAME
libssh2_session_methods - return the currently active algorithms
diff --git a/docs/libssh2_session_set_blocking.3 b/docs/libssh2_session_set_blocking.3
--- a/docs/libssh2_session_set_blocking.3
+++ b/docs/libssh2_session_set_blocking.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_set_blocking 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_set_blocking - set or clear blocking mode on session
diff --git a/docs/libssh2_session_set_last_error.3 b/docs/libssh2_session_set_last_error.3
--- a/docs/libssh2_session_set_last_error.3
+++ b/docs/libssh2_session_set_last_error.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_set_last_error 3 "26 Oct 2015" "libssh2" "libssh2"
.SH NAME
libssh2_session_set_last_error - sets the internal error state
diff --git a/docs/libssh2_session_set_read_timeout.3 b/docs/libssh2_session_set_read_timeout.3
--- a/docs/libssh2_session_set_read_timeout.3
+++ b/docs/libssh2_session_set_read_timeout.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_set_read_timeout 3 "13 Jan 2023" "libssh2" "libssh2"
.SH NAME
libssh2_session_set_read_timeout - set timeout for packet read functions
diff --git a/docs/libssh2_session_set_timeout.3 b/docs/libssh2_session_set_timeout.3
--- a/docs/libssh2_session_set_timeout.3
+++ b/docs/libssh2_session_set_timeout.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_set_timeout 3 "4 May 2011" "libssh2" "libssh2"
.SH NAME
libssh2_session_set_timeout - set timeout for blocking functions
diff --git a/docs/libssh2_session_startup.3 b/docs/libssh2_session_startup.3
--- a/docs/libssh2_session_startup.3
+++ b/docs/libssh2_session_startup.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_startup 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_session_startup - begin transport layer
diff --git a/docs/libssh2_session_supported_algs.3 b/docs/libssh2_session_supported_algs.3
--- a/docs/libssh2_session_supported_algs.3
+++ b/docs/libssh2_session_supported_algs.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_session_supported_algs 3 "23 Oct 2011" "libssh2" "libssh2"
.SH NAME
libssh2_session_supported_algs - get list of supported algorithms
diff --git a/docs/libssh2_sftp_close.3 b/docs/libssh2_sftp_close.3
--- a/docs/libssh2_sftp_close.3
+++ b/docs/libssh2_sftp_close.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_close 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_close - convenience macro for \fIlibssh2_sftp_close_handle(3)\fP calls
diff --git a/docs/libssh2_sftp_close_handle.3 b/docs/libssh2_sftp_close_handle.3
--- a/docs/libssh2_sftp_close_handle.3
+++ b/docs/libssh2_sftp_close_handle.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_close_handle 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_close_handle - close filehandle
diff --git a/docs/libssh2_sftp_closedir.3 b/docs/libssh2_sftp_closedir.3
--- a/docs/libssh2_sftp_closedir.3
+++ b/docs/libssh2_sftp_closedir.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_closedir 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_closedir - convenience macro for \fIlibssh2_sftp_close_handle(3)\fP calls
diff --git a/docs/libssh2_sftp_fsetstat.3 b/docs/libssh2_sftp_fsetstat.3
--- a/docs/libssh2_sftp_fsetstat.3
+++ b/docs/libssh2_sftp_fsetstat.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_fsetstat 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_fsetstat - convenience macro for \fIlibssh2_sftp_fstat_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_fstat.3 b/docs/libssh2_sftp_fstat.3
--- a/docs/libssh2_sftp_fstat.3
+++ b/docs/libssh2_sftp_fstat.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_fstat 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_fstat - convenience macro for \fIlibssh2_sftp_fstat_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_fstat_ex.3 b/docs/libssh2_sftp_fstat_ex.3
--- a/docs/libssh2_sftp_fstat_ex.3
+++ b/docs/libssh2_sftp_fstat_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_fstat_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_fstat_ex - get or set attributes on an SFTP file handle
diff --git a/docs/libssh2_sftp_fstatvfs.3 b/docs/libssh2_sftp_fstatvfs.3
--- a/docs/libssh2_sftp_fstatvfs.3
+++ b/docs/libssh2_sftp_fstatvfs.3
@@ -1 +1,3 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.so man3/libssh2_sftp_statvfs.3
diff --git a/docs/libssh2_sftp_fsync.3 b/docs/libssh2_sftp_fsync.3
--- a/docs/libssh2_sftp_fsync.3
+++ b/docs/libssh2_sftp_fsync.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_fsync 3 "8 Apr 2013" "libssh2" "libssh2"
.SH NAME
libssh2_sftp_fsync - synchronize file to disk
diff --git a/docs/libssh2_sftp_get_channel.3 b/docs/libssh2_sftp_get_channel.3
--- a/docs/libssh2_sftp_get_channel.3
+++ b/docs/libssh2_sftp_get_channel.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_get_channel 3 "9 Sep 2011" "libssh2 1.4.0" "libssh2"
.SH NAME
libssh2_sftp_get_channel - return the channel of sftp
diff --git a/docs/libssh2_sftp_init.3 b/docs/libssh2_sftp_init.3
--- a/docs/libssh2_sftp_init.3
+++ b/docs/libssh2_sftp_init.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_init 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_init - open SFTP channel for the given SSH session.
diff --git a/docs/libssh2_sftp_last_error.3 b/docs/libssh2_sftp_last_error.3
--- a/docs/libssh2_sftp_last_error.3
+++ b/docs/libssh2_sftp_last_error.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_last_error 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_last_error - return the last SFTP-specific error code
diff --git a/docs/libssh2_sftp_lstat.3 b/docs/libssh2_sftp_lstat.3
--- a/docs/libssh2_sftp_lstat.3
+++ b/docs/libssh2_sftp_lstat.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_lstat 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_lstat - convenience macro for \fIlibssh2_sftp_stat_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_mkdir.3 b/docs/libssh2_sftp_mkdir.3
--- a/docs/libssh2_sftp_mkdir.3
+++ b/docs/libssh2_sftp_mkdir.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_mkdir 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_mkdir - convenience macro for \fIlibssh2_sftp_mkdir_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_mkdir_ex.3 b/docs/libssh2_sftp_mkdir_ex.3
--- a/docs/libssh2_sftp_mkdir_ex.3
+++ b/docs/libssh2_sftp_mkdir_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_mkdir_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_mkdir_ex - create a directory on the remote file system
diff --git a/docs/libssh2_sftp_open.3 b/docs/libssh2_sftp_open.3
--- a/docs/libssh2_sftp_open.3
+++ b/docs/libssh2_sftp_open.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_open 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_open - convenience macro for \fIlibssh2_sftp_open_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_open_ex.3 b/docs/libssh2_sftp_open_ex.3
--- a/docs/libssh2_sftp_open_ex.3
+++ b/docs/libssh2_sftp_open_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_open_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_open_ex - open filehandle for file on SFTP.
diff --git a/docs/libssh2_sftp_open_ex_r.3 b/docs/libssh2_sftp_open_ex_r.3
--- a/docs/libssh2_sftp_open_ex_r.3
+++ b/docs/libssh2_sftp_open_ex_r.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_open_ex_r 3 "10 Apr 2023" "libssh2" "libssh2"
.SH NAME
libssh2_sftp_open_ex_r - open filehandle for file on SFTP.
diff --git a/docs/libssh2_sftp_open_r.3 b/docs/libssh2_sftp_open_r.3
--- a/docs/libssh2_sftp_open_r.3
+++ b/docs/libssh2_sftp_open_r.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_open_r 3 "10 Apr 2023" "libssh2 1.11.0" "libssh2"
.SH NAME
libssh2_sftp_open_r - convenience macro for \fIlibssh2_sftp_open_ex_r(3)\fP calls
diff --git a/docs/libssh2_sftp_opendir.3 b/docs/libssh2_sftp_opendir.3
--- a/docs/libssh2_sftp_opendir.3
+++ b/docs/libssh2_sftp_opendir.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_opendir 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_opendir - convenience macro for \fIlibssh2_sftp_open_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_read.3 b/docs/libssh2_sftp_read.3
--- a/docs/libssh2_sftp_read.3
+++ b/docs/libssh2_sftp_read.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_read 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_read - read data from an SFTP handle
diff --git a/docs/libssh2_sftp_readdir.3 b/docs/libssh2_sftp_readdir.3
--- a/docs/libssh2_sftp_readdir.3
+++ b/docs/libssh2_sftp_readdir.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_readdir 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_readdir - convenience macro for \fIlibssh2_sftp_readdir_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_readdir_ex.3 b/docs/libssh2_sftp_readdir_ex.3
--- a/docs/libssh2_sftp_readdir_ex.3
+++ b/docs/libssh2_sftp_readdir_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_readdir_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_readdir_ex - read directory data from an SFTP handle
diff --git a/docs/libssh2_sftp_readlink.3 b/docs/libssh2_sftp_readlink.3
--- a/docs/libssh2_sftp_readlink.3
+++ b/docs/libssh2_sftp_readlink.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_readlink 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_readlink - convenience macro for \fIlibssh2_sftp_symlink_ex(3)\fP
diff --git a/docs/libssh2_sftp_realpath.3 b/docs/libssh2_sftp_realpath.3
--- a/docs/libssh2_sftp_realpath.3
+++ b/docs/libssh2_sftp_realpath.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_realpath 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_realpath - convenience macro for \fIlibssh2_sftp_symlink_ex(3)\fP
diff --git a/docs/libssh2_sftp_rename.3 b/docs/libssh2_sftp_rename.3
--- a/docs/libssh2_sftp_rename.3
+++ b/docs/libssh2_sftp_rename.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_rename 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_rename - convenience macro for \fIlibssh2_sftp_rename_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_rename_ex.3 b/docs/libssh2_sftp_rename_ex.3
--- a/docs/libssh2_sftp_rename_ex.3
+++ b/docs/libssh2_sftp_rename_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_rename_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_rename_ex - rename an SFTP file
diff --git a/docs/libssh2_sftp_rewind.3 b/docs/libssh2_sftp_rewind.3
--- a/docs/libssh2_sftp_rewind.3
+++ b/docs/libssh2_sftp_rewind.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_rewind 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_rewind - convenience macro for \fIlibssh2_sftp_seek64(3)\fP calls
diff --git a/docs/libssh2_sftp_rmdir.3 b/docs/libssh2_sftp_rmdir.3
--- a/docs/libssh2_sftp_rmdir.3
+++ b/docs/libssh2_sftp_rmdir.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_rmdir 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_rmdir - convenience macro for \fIlibssh2_sftp_rmdir_ex(3)\fP
diff --git a/docs/libssh2_sftp_rmdir_ex.3 b/docs/libssh2_sftp_rmdir_ex.3
--- a/docs/libssh2_sftp_rmdir_ex.3
+++ b/docs/libssh2_sftp_rmdir_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_rmdir_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_rmdir_ex - remove an SFTP directory
diff --git a/docs/libssh2_sftp_seek.3 b/docs/libssh2_sftp_seek.3
--- a/docs/libssh2_sftp_seek.3
+++ b/docs/libssh2_sftp_seek.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_seek 3 "22 Dec 2008" "libssh2 1.0" "libssh2"
.SH NAME
libssh2_sftp_seek - set the read/write position indicator within a file
diff --git a/docs/libssh2_sftp_seek64.3 b/docs/libssh2_sftp_seek64.3
--- a/docs/libssh2_sftp_seek64.3
+++ b/docs/libssh2_sftp_seek64.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_seek64 3 "22 Dec 2008" "libssh2" "libssh2"
.SH NAME
libssh2_sftp_seek64 - set the read/write position within a file
diff --git a/docs/libssh2_sftp_setstat.3 b/docs/libssh2_sftp_setstat.3
--- a/docs/libssh2_sftp_setstat.3
+++ b/docs/libssh2_sftp_setstat.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_setstat 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_setstat - convenience macro for \fIlibssh2_sftp_stat_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_shutdown.3 b/docs/libssh2_sftp_shutdown.3
--- a/docs/libssh2_sftp_shutdown.3
+++ b/docs/libssh2_sftp_shutdown.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_shutdown 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_shutdown - shut down an SFTP session
diff --git a/docs/libssh2_sftp_stat.3 b/docs/libssh2_sftp_stat.3
--- a/docs/libssh2_sftp_stat.3
+++ b/docs/libssh2_sftp_stat.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_stat 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_stat - convenience macro for \fIlibssh2_sftp_fstat_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_stat_ex.3 b/docs/libssh2_sftp_stat_ex.3
--- a/docs/libssh2_sftp_stat_ex.3
+++ b/docs/libssh2_sftp_stat_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_stat_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_stat_ex - get status about an SFTP file
diff --git a/docs/libssh2_sftp_statvfs.3 b/docs/libssh2_sftp_statvfs.3
--- a/docs/libssh2_sftp_statvfs.3
+++ b/docs/libssh2_sftp_statvfs.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_statvfs 3 "22 May 2010" "libssh2" "libssh2"
.SH NAME
libssh2_sftp_statvfs, libssh2_sftp_fstatvfs - get file system statistics
diff --git a/docs/libssh2_sftp_symlink.3 b/docs/libssh2_sftp_symlink.3
--- a/docs/libssh2_sftp_symlink.3
+++ b/docs/libssh2_sftp_symlink.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_symlink 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_symlink - convenience macro for \fIlibssh2_sftp_symlink_ex(3)\fP
diff --git a/docs/libssh2_sftp_symlink_ex.3 b/docs/libssh2_sftp_symlink_ex.3
--- a/docs/libssh2_sftp_symlink_ex.3
+++ b/docs/libssh2_sftp_symlink_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_symlink_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_symlink_ex - read or set a symbolic link
diff --git a/docs/libssh2_sftp_tell.3 b/docs/libssh2_sftp_tell.3
--- a/docs/libssh2_sftp_tell.3
+++ b/docs/libssh2_sftp_tell.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_tell 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_tell - get the current read/write position indicator for a file
diff --git a/docs/libssh2_sftp_tell64.3 b/docs/libssh2_sftp_tell64.3
--- a/docs/libssh2_sftp_tell64.3
+++ b/docs/libssh2_sftp_tell64.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_tell64 3 "22 Dec 2008" "libssh2 1.0" "libssh2"
.SH NAME
libssh2_sftp_tell64 - get the current read/write position indicator for a file
diff --git a/docs/libssh2_sftp_unlink.3 b/docs/libssh2_sftp_unlink.3
--- a/docs/libssh2_sftp_unlink.3
+++ b/docs/libssh2_sftp_unlink.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_unlink 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_sftp_unlink - convenience macro for \fIlibssh2_sftp_unlink_ex(3)\fP calls
diff --git a/docs/libssh2_sftp_unlink_ex.3 b/docs/libssh2_sftp_unlink_ex.3
--- a/docs/libssh2_sftp_unlink_ex.3
+++ b/docs/libssh2_sftp_unlink_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_unlink_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_unlink_ex - unlink an SFTP file
diff --git a/docs/libssh2_sftp_write.3 b/docs/libssh2_sftp_write.3
--- a/docs/libssh2_sftp_write.3
+++ b/docs/libssh2_sftp_write.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sftp_write 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_sftp_write - write SFTP data
diff --git a/docs/libssh2_sign_sk.3 b/docs/libssh2_sign_sk.3
--- a/docs/libssh2_sign_sk.3
+++ b/docs/libssh2_sign_sk.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_sign_sk 3 "1 Jun 2022" "libssh2 1.10.0" "libssh2"
.SH NAME
libssh2_sign_sk - Create a signature from a FIDO2 authenticator.
diff --git a/docs/libssh2_trace.3 b/docs/libssh2_trace.3
--- a/docs/libssh2_trace.3
+++ b/docs/libssh2_trace.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_trace 3 "26 Dec 2008" "libssh2 1.0" "libssh2"
.SH NAME
libssh2_trace - enable debug info from inside libssh2
diff --git a/docs/libssh2_trace_sethandler.3 b/docs/libssh2_trace_sethandler.3
--- a/docs/libssh2_trace_sethandler.3
+++ b/docs/libssh2_trace_sethandler.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_trace_sethandler 3 "15 Jan 2010" "libssh2" "libssh2"
.SH NAME
libssh2_trace_sethandler - set a trace output handler
diff --git a/docs/libssh2_userauth_authenticated.3 b/docs/libssh2_userauth_authenticated.3
--- a/docs/libssh2_userauth_authenticated.3
+++ b/docs/libssh2_userauth_authenticated.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_authenticated 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_authenticated - return authentication status
diff --git a/docs/libssh2_userauth_banner.3 b/docs/libssh2_userauth_banner.3
--- a/docs/libssh2_userauth_banner.3
+++ b/docs/libssh2_userauth_banner.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_banner 3 "1 Jun 2021" "libssh2 1.9.0" "libssh2"
.SH NAME
libssh2_userauth_banner - get the server's userauth banner message
diff --git a/docs/libssh2_userauth_hostbased_fromfile.3 b/docs/libssh2_userauth_hostbased_fromfile.3
--- a/docs/libssh2_userauth_hostbased_fromfile.3
+++ b/docs/libssh2_userauth_hostbased_fromfile.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_hostbased_fromfile 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_userauth_hostbased_fromfile - convenience macro for \fIlibssh2_userauth_hostbased_fromfile_ex(3)\fP calls
diff --git a/docs/libssh2_userauth_hostbased_fromfile_ex.3 b/docs/libssh2_userauth_hostbased_fromfile_ex.3
--- a/docs/libssh2_userauth_hostbased_fromfile_ex.3
+++ b/docs/libssh2_userauth_hostbased_fromfile_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_hostbased_fromfile_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_hostbased_fromfile_ex - TODO
diff --git a/docs/libssh2_userauth_keyboard_interactive.3 b/docs/libssh2_userauth_keyboard_interactive.3
--- a/docs/libssh2_userauth_keyboard_interactive.3
+++ b/docs/libssh2_userauth_keyboard_interactive.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_keyboard_interactive 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_userauth_keyboard_interactive - convenience macro for \fIlibssh2_userauth_keyboard_interactive_ex(3)\fP calls
diff --git a/docs/libssh2_userauth_keyboard_interactive_ex.3 b/docs/libssh2_userauth_keyboard_interactive_ex.3
--- a/docs/libssh2_userauth_keyboard_interactive_ex.3
+++ b/docs/libssh2_userauth_keyboard_interactive_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_keyboard_interactive_ex 3 "8 Mar 2008" "libssh2 0.19" "libssh2"
.SH NAME
libssh2_userauth_keyboard_interactive_ex - authenticate a session using
diff --git a/docs/libssh2_userauth_list.3 b/docs/libssh2_userauth_list.3
--- a/docs/libssh2_userauth_list.3
+++ b/docs/libssh2_userauth_list.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_list 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_list - list supported authentication methods
diff --git a/docs/libssh2_userauth_password.3 b/docs/libssh2_userauth_password.3
--- a/docs/libssh2_userauth_password.3
+++ b/docs/libssh2_userauth_password.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_password 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_userauth_password - convenience macro for \fIlibssh2_userauth_password_ex(3)\fP calls
diff --git a/docs/libssh2_userauth_password_ex.3 b/docs/libssh2_userauth_password_ex.3
--- a/docs/libssh2_userauth_password_ex.3
+++ b/docs/libssh2_userauth_password_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_password_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_password_ex - authenticate a session with username and password
diff --git a/docs/libssh2_userauth_publickey.3 b/docs/libssh2_userauth_publickey.3
--- a/docs/libssh2_userauth_publickey.3
+++ b/docs/libssh2_userauth_publickey.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_publickey 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_publickey - authenticate using a callback function
diff --git a/docs/libssh2_userauth_publickey_fromfile.3 b/docs/libssh2_userauth_publickey_fromfile.3
--- a/docs/libssh2_userauth_publickey_fromfile.3
+++ b/docs/libssh2_userauth_publickey_fromfile.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_publickey_fromfile 3 "20 Feb 2010" "libssh2 1.2.4" "libssh2"
.SH NAME
libssh2_userauth_publickey_fromfile - convenience macro for \fIlibssh2_userauth_publickey_fromfile_ex(3)\fP calls
diff --git a/docs/libssh2_userauth_publickey_fromfile_ex.3 b/docs/libssh2_userauth_publickey_fromfile_ex.3
--- a/docs/libssh2_userauth_publickey_fromfile_ex.3
+++ b/docs/libssh2_userauth_publickey_fromfile_ex.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_publickey_fromfile_ex 3 "1 Jun 2007" "libssh2 0.15" "libssh2"
.SH NAME
libssh2_userauth_publickey_fromfile_ex - authenticate a session with a public key, read from a file
diff --git a/docs/libssh2_userauth_publickey_frommemory.3 b/docs/libssh2_userauth_publickey_frommemory.3
--- a/docs/libssh2_userauth_publickey_frommemory.3
+++ b/docs/libssh2_userauth_publickey_frommemory.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_publickey_frommemory 3 "1 Sep 2014" "libssh2" "libssh2"
.SH NAME
libssh2_userauth_publickey_frommemory - authenticate a session with a public key, read from memory
diff --git a/docs/libssh2_userauth_publickey_sk.3 b/docs/libssh2_userauth_publickey_sk.3
--- a/docs/libssh2_userauth_publickey_sk.3
+++ b/docs/libssh2_userauth_publickey_sk.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_userauth_publickey_sk 3 "1 Jun 2022" "libssh2" "libssh2"
.SH NAME
libssh2_userauth_publickey_sk - authenticate a session with a FIDO2 authenticator
diff --git a/docs/libssh2_version.3 b/docs/libssh2_version.3
--- a/docs/libssh2_version.3
+++ b/docs/libssh2_version.3
@@ -1,3 +1,5 @@
+.\" Copyright (C) The libssh2 project and its contributors.
+.\" SPDX-License-Identifier: BSD-3-Clause
.TH libssh2_version 3 "23 Feb 2009" "libssh2" "libssh2"
.SH NAME
libssh2_version - return the libssh2 version number
diff --git a/example/CMakeLists.txt b/example/CMakeLists.txt
--- a/example/CMakeLists.txt
+++ b/example/CMakeLists.txt
@@ -33,6 +33,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
include(CopyRuntimeDependencies)
diff --git a/example/Makefile.am b/example/Makefile.am
--- a/example/Makefile.am
+++ b/example/Makefile.am
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
AUTOMAKE_OPTIONS = foreign nostdinc
EXTRA_DIST = CMakeLists.txt
diff --git a/example/direct_tcpip.c b/example/direct_tcpip.c
--- a/example/direct_tcpip.c
+++ b/example/direct_tcpip.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "libssh2_setup.h"
#include <libssh2.h>
diff --git a/example/scp.c b/example/scp.c
--- a/example/scp.c
+++ b/example/scp.c
@@ -1,6 +1,8 @@
/* Copyright (C) The libssh2 project and its contributors.
*
* Sample showing how to do a simple SCP transfer.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/scp_nonblock.c b/example/scp_nonblock.c
--- a/example/scp_nonblock.c
+++ b/example/scp_nonblock.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./scp_nonblock 192.168.0.1 user password /tmp/secrets
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/scp_write.c b/example/scp_write.c
--- a/example/scp_write.c
+++ b/example/scp_write.c
@@ -1,6 +1,8 @@
/* Copyright (C) The libssh2 project and its contributors.
*
* Sample showing how to do an SCP upload.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/scp_write_nonblock.c b/example/scp_write_nonblock.c
--- a/example/scp_write_nonblock.c
+++ b/example/scp_write_nonblock.c
@@ -1,6 +1,8 @@
/* Copyright (C) The libssh2 project and its contributors.
*
* Sample showing how to do an SCP non-blocking upload transfer.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp.c b/example/sftp.c
--- a/example/sftp.c
+++ b/example/sftp.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp 192.168.0.1 user password /tmp/secrets -p|-i|-k
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_RW_nonblock.c b/example/sftp_RW_nonblock.c
--- a/example/sftp_RW_nonblock.c
+++ b/example/sftp_RW_nonblock.c
@@ -6,6 +6,8 @@
* upload the file again to a given destination file.
*
* Using the SFTP server running on 127.0.0.1
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_append.c b/example/sftp_append.c
--- a/example/sftp_append.c
+++ b/example/sftp_append.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_append 192.168.0.1 user password localfile /tmp/remotefile
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_mkdir.c b/example/sftp_mkdir.c
--- a/example/sftp_mkdir.c
+++ b/example/sftp_mkdir.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_mkdir 192.168.0.1 user password /tmp/sftp_mkdir
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_mkdir_nonblock.c b/example/sftp_mkdir_nonblock.c
--- a/example/sftp_mkdir_nonblock.c
+++ b/example/sftp_mkdir_nonblock.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_mkdir_nonblock 192.168.0.1 user password /tmp/sftp_write_nonblock.c
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_nonblock.c b/example/sftp_nonblock.c
--- a/example/sftp_nonblock.c
+++ b/example/sftp_nonblock.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_nonblock 192.168.0.1 user password /tmp/secrets
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_write.c b/example/sftp_write.c
--- a/example/sftp_write.c
+++ b/example/sftp_write.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_write 192.168.0.1 user password sftp_write.c /tmp/secrets
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_write_nonblock.c b/example/sftp_write_nonblock.c
--- a/example/sftp_write_nonblock.c
+++ b/example/sftp_write_nonblock.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_write_nonblock 192.168.0.1 user password thisfile /tmp/storehere
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftp_write_sliding.c b/example/sftp_write_sliding.c
--- a/example/sftp_write_sliding.c
+++ b/example/sftp_write_sliding.c
@@ -6,6 +6,8 @@
* and path to copy, but you can specify them on the command line like:
*
* $ ./sftp_write_sliding 192.168.0.1 user password thisfile /tmp/storehere
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftpdir.c b/example/sftpdir.c
--- a/example/sftpdir.c
+++ b/example/sftpdir.c
@@ -6,6 +6,8 @@
* path, but you can specify them on the command line like:
*
* $ ./sftpdir 192.168.0.1 user password /tmp/secretdir
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/sftpdir_nonblock.c b/example/sftpdir_nonblock.c
--- a/example/sftpdir_nonblock.c
+++ b/example/sftpdir_nonblock.c
@@ -6,6 +6,8 @@
* path, but you can specify them on the command line like:
*
* $ ./sftpdir_nonblock 192.168.0.1 user password /tmp/secretdir
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/ssh2.c b/example/ssh2.c
--- a/example/ssh2.c
+++ b/example/ssh2.c
@@ -11,6 +11,8 @@
* -i authenticate using keyboard-interactive
* -k authenticate using public key (password argument decrypts keyfile)
* command executes on the remote machine
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/ssh2_agent.c b/example/ssh2_agent.c
--- a/example/ssh2_agent.c
+++ b/example/ssh2_agent.c
@@ -5,6 +5,8 @@
* The sample code has default values for host name, user name:
*
* $ ./ssh2_agent host user
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/ssh2_agent_forwarding.c b/example/ssh2_agent_forwarding.c
--- a/example/ssh2_agent_forwarding.c
+++ b/example/ssh2_agent_forwarding.c
@@ -10,6 +10,7 @@
*
* $ ./ssh2_agent_forwarding 127.0.0.1 user "uptime"
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/ssh2_echo.c b/example/ssh2_echo.c
--- a/example/ssh2_echo.c
+++ b/example/ssh2_echo.c
@@ -5,6 +5,7 @@
*
* $ ./ssh2_echo 127.0.0.1 user password
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/ssh2_exec.c b/example/ssh2_exec.c
--- a/example/ssh2_exec.c
+++ b/example/ssh2_exec.c
@@ -7,6 +7,7 @@
*
* $ ./ssh2_exec 127.0.0.1 user password "uptime"
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/example/subsystem_netconf.c b/example/subsystem_netconf.c
--- a/example/subsystem_netconf.c
+++ b/example/subsystem_netconf.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "libssh2_setup.h"
#include <libssh2.h>
diff --git a/example/tcpip-forward.c b/example/tcpip-forward.c
--- a/example/tcpip-forward.c
+++ b/example/tcpip-forward.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "libssh2_setup.h"
#include <libssh2.h>
diff --git a/example/x11.c b/example/x11.c
--- a/example/x11.c
+++ b/example/x11.c
@@ -3,6 +3,8 @@
* Sample showing how to makes SSH2 with X11 Forwarding works.
*
* $ ./x11 host user password [DEBUG]
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_setup.h"
diff --git a/get_ver.awk b/get_ver.awk
--- a/get_ver.awk
+++ b/get_ver.awk
@@ -1,4 +1,7 @@
# fetch libssh2 version number from input file and write them to STDOUT
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
+
BEGIN {
while ((getline < ARGV[1]) > 0) {
if (match ($0, /^#define LIBSSH2_COPYRIGHT "[^"]+"$/)) {
diff --git a/git2news.pl b/git2news.pl
--- a/git2news.pl
+++ b/git2news.pl
@@ -1,4 +1,6 @@
#!/usr/bin/env perl
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
# git log --pretty=fuller --no-color --date=short --decorate=full
diff --git a/include/libssh2.h b/include/libssh2.h
--- a/include/libssh2.h
+++ b/include/libssh2.h
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_H
diff --git a/include/libssh2_publickey.h b/include/libssh2_publickey.h
--- a/include/libssh2_publickey.h
+++ b/include/libssh2_publickey.h
@@ -41,6 +41,8 @@
*
* For more information on the publickey subsystem,
* refer to IETF draft: secsh-publickey
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_PUBLICKEY_H
diff --git a/include/libssh2_sftp.h b/include/libssh2_sftp.h
--- a/include/libssh2_sftp.h
+++ b/include/libssh2_sftp.h
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_SFTP_H
diff --git a/libssh2-style.el b/libssh2-style.el
--- a/libssh2-style.el
+++ b/libssh2-style.el
@@ -1,4 +1,6 @@
;;;; Emacs Lisp help for writing libssh2 code. ;;;;
+;;; Copyright (C) The libssh2 project and its contributors.
+;;; SPDX-License-Identifier: BSD-3-Clause
;;; The libssh2 hacker's C conventions.
;;; See the sample.emacs file on how this file can be made to take
diff --git a/libssh2.pc.in b/libssh2.pc.in
--- a/libssh2.pc.in
+++ b/libssh2.pc.in
@@ -1,5 +1,8 @@
###########################################################################
# libssh2 installation details
+#
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
###########################################################################
prefix=@prefix@
diff --git a/m4/lib-ld.m4 b/m4/lib-ld.m4
--- a/m4/lib-ld.m4
+++ b/m4/lib-ld.m4
@@ -3,6 +3,8 @@ dnl Copyright (C) 1996-2003 Free Software Foundation, Inc.
dnl This file is free software; the Free Software Foundation
dnl gives unlimited permission to copy and/or distribute it,
dnl with or without modifications, as long as this notice is preserved.
+dnl
+dnl SPDX-License-Identifier: FSFULLR
dnl Subroutines of libtool.m4,
dnl with replacements s/AC_/AC_LIB/ and s/lt_cv/acl_cv/ to avoid collision
diff --git a/m4/lib-link.m4 b/m4/lib-link.m4
--- a/m4/lib-link.m4
+++ b/m4/lib-link.m4
@@ -3,6 +3,8 @@ dnl Copyright (C) 2001-2007 Free Software Foundation, Inc.
dnl This file is free software; the Free Software Foundation
dnl gives unlimited permission to copy and/or distribute it,
dnl with or without modifications, as long as this notice is preserved.
+dnl
+dnl SPDX-License-Identifier: FSFULLR
dnl From Bruno Haible.
diff --git a/m4/lib-prefix.m4 b/m4/lib-prefix.m4
--- a/m4/lib-prefix.m4
+++ b/m4/lib-prefix.m4
@@ -3,6 +3,8 @@ dnl Copyright (C) 2001-2005 Free Software Foundation, Inc.
dnl This file is free software; the Free Software Foundation
dnl gives unlimited permission to copy and/or distribute it,
dnl with or without modifications, as long as this notice is preserved.
+dnl
+dnl SPDX-License-Identifier: FSFULLR
dnl From Bruno Haible.
diff --git a/maketgz b/maketgz
--- a/maketgz
+++ b/maketgz
@@ -1,4 +1,7 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
+#
# Script to build release-archives with. Note that this requires a checkout
# from git and you should first run 'autoreconf -fi' and './configure'.
#
diff --git a/os400/ccsid.c b/os400/ccsid.c
--- a/os400/ccsid.c
+++ b/os400/ccsid.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* Character encoding wrappers. */
diff --git a/os400/include/alloca.h b/os400/include/alloca.h
--- a/os400/include/alloca.h
+++ b/os400/include/alloca.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_ALLOCA_H
diff --git a/os400/include/assert.h b/os400/include/assert.h
--- a/os400/include/assert.h
+++ b/os400/include/assert.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_ASSERT_H
diff --git a/os400/include/stdio.h b/os400/include/stdio.h
--- a/os400/include/stdio.h
+++ b/os400/include/stdio.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_STDIO_H
diff --git a/os400/include/sys/socket.h b/os400/include/sys/socket.h
--- a/os400/include/sys/socket.h
+++ b/os400/include/sys/socket.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_SYS_SOCKET_H
diff --git a/os400/initscript.sh b/os400/initscript.sh
--- a/os400/initscript.sh
+++ b/os400/initscript.sh
@@ -1,5 +1,6 @@
#!/bin/sh
-
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
setenv()
diff --git a/os400/libssh2_ccsid.h b/os400/libssh2_ccsid.h
--- a/os400/libssh2_ccsid.h
+++ b/os400/libssh2_ccsid.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* CCSID conversion support. */
diff --git a/os400/libssh2_config.h b/os400/libssh2_config.h
--- a/os400/libssh2_config.h
+++ b/os400/libssh2_config.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_CONFIG_H
diff --git a/os400/libssh2rpg/libssh2.rpgle.in b/os400/libssh2rpg/libssh2.rpgle.in
--- a/os400/libssh2rpg/libssh2.rpgle.in
+++ b/os400/libssh2rpg/libssh2.rpgle.in
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
/if not defined(LIBSSH2_H_)
/define LIBSSH2_H_
diff --git a/os400/libssh2rpg/libssh2_ccsid.rpgle.in b/os400/libssh2rpg/libssh2_ccsid.rpgle.in
--- a/os400/libssh2rpg/libssh2_ccsid.rpgle.in
+++ b/os400/libssh2rpg/libssh2_ccsid.rpgle.in
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
/if not defined(LIBSSH2_CCSID_H_)
/define LIBSSH2_CCSID_H_
diff --git a/os400/libssh2rpg/libssh2_publickey.rpgle b/os400/libssh2rpg/libssh2_publickey.rpgle
--- a/os400/libssh2rpg/libssh2_publickey.rpgle
+++ b/os400/libssh2rpg/libssh2_publickey.rpgle
@@ -40,6 +40,8 @@
*
* For more information on the publickey subsystem,
* refer to IETF draft: secsh-publickey
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
/if not defined(LIBSSH2_PUBLICKEY_H_)
/define LIBSSH2_PUBLICKEY_H_
diff --git a/os400/libssh2rpg/libssh2_sftp.rpgle b/os400/libssh2rpg/libssh2_sftp.rpgle
--- a/os400/libssh2rpg/libssh2_sftp.rpgle
+++ b/os400/libssh2rpg/libssh2_sftp.rpgle
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
/if not defined(LIBSSH2_SFTP_H_)
/define LIBSSH2_SFTP_H_
diff --git a/os400/macros.h b/os400/macros.h
--- a/os400/macros.h
+++ b/os400/macros.h
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+* SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_MACROS_H_
diff --git a/os400/make-include.sh b/os400/make-include.sh
--- a/os400/make-include.sh
+++ b/os400/make-include.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
#
# Installation of the header files in the OS/400 library.
#
diff --git a/os400/make-rpg.sh b/os400/make-rpg.sh
--- a/os400/make-rpg.sh
+++ b/os400/make-rpg.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
#
# Installation of the ILE/RPG header files in the OS/400 library.
#
diff --git a/os400/make-src.sh b/os400/make-src.sh
--- a/os400/make-src.sh
+++ b/os400/make-src.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
#
# libssh2 compilation script for the OS/400.
#
diff --git a/os400/make.sh b/os400/make.sh
--- a/os400/make.sh
+++ b/os400/make.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
#
# libssh2 compilation script for the OS/400.
#
diff --git a/os400/os400sys.c b/os400/os400sys.c
--- a/os400/os400sys.c
+++ b/os400/os400sys.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* OS/400 additional support. */
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -33,6 +33,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
if(CRYPTO_BACKEND)
list(APPEND PRIVATE_COMPILE_DEFINITIONS ${CRYPTO_BACKEND_DEFINE})
diff --git a/src/Makefile.am b/src/Makefile.am
--- a/src/Makefile.am
+++ b/src/Makefile.am
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
AUTOMAKE_OPTIONS = foreign nostdinc
# Get the CSOURCES, HHEADERS and EXTRA_DIST defines
diff --git a/src/Makefile.inc b/src/Makefile.inc
--- a/src/Makefile.inc
+++ b/src/Makefile.inc
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
CSOURCES = \
agent.c \
bcrypt_pbkdf.c \
diff --git a/src/agent.c b/src/agent.c
--- a/src/agent.c
+++ b/src/agent.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/agent_win.c b/src/agent_win.c
--- a/src/agent_win.c
+++ b/src/agent_win.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause AND BSD-2-Clause
*/
#ifdef HAVE_WIN32_AGENTS /* Compile this via agent.c */
diff --git a/src/bcrypt_pbkdf.c b/src/bcrypt_pbkdf.c
--- a/src/bcrypt_pbkdf.c
+++ b/src/bcrypt_pbkdf.c
@@ -13,6 +13,8 @@
* WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
* ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
* OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
+ *
+ * SPDX-License-Identifier: MIT
*/
#include "libssh2_priv.h"
diff --git a/src/blowfish.c b/src/blowfish.c
--- a/src/blowfish.c
+++ b/src/blowfish.c
@@ -28,6 +28,8 @@
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
* THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/*
diff --git a/src/channel.c b/src/channel.c
--- a/src/channel.c
+++ b/src/channel.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/channel.h b/src/channel.h
--- a/src/channel.h
+++ b/src/channel.h
@@ -36,6 +36,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/*
diff --git a/src/comp.c b/src/comp.c
--- a/src/comp.c
+++ b/src/comp.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/comp.h b/src/comp.h
--- a/src/comp.h
+++ b/src/comp.h
@@ -35,6 +35,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/crypt.c b/src/crypt.c
--- a/src/crypt.c
+++ b/src/crypt.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/crypto.c b/src/crypto.c
--- a/src/crypto.c
+++ b/src/crypto.c
@@ -1,4 +1,7 @@
-/* Copyright (C) Viktor Szakats */
+/* Copyright (C) Viktor Szakats
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#define LIBSSH2_CRYPTO_C
#include "libssh2_priv.h"
diff --git a/src/crypto.h b/src/crypto.h
--- a/src/crypto.h
+++ b/src/crypto.h
@@ -37,6 +37,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#if defined(LIBSSH2_OPENSSL) || defined(LIBSSH2_WOLFSSL)
diff --git a/src/global.c b/src/global.c
--- a/src/global.c
+++ b/src/global.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/hostkey.c b/src/hostkey.c
--- a/src/hostkey.c
+++ b/src/hostkey.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/keepalive.c b/src/keepalive.c
--- a/src/keepalive.c
+++ b/src/keepalive.c
@@ -34,6 +34,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/kex.c b/src/kex.c
--- a/src/kex.c
+++ b/src/kex.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/knownhost.c b/src/knownhost.c
--- a/src/knownhost.c
+++ b/src/knownhost.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/libgcrypt.c b/src/libgcrypt.c
--- a/src/libgcrypt.c
+++ b/src/libgcrypt.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_CRYPTO_C /* Compile this via crypto.c */
diff --git a/src/libgcrypt.h b/src/libgcrypt.h
--- a/src/libgcrypt.h
+++ b/src/libgcrypt.h
@@ -37,6 +37,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#define LIBSSH2_CRYPTO_ENGINE libssh2_gcrypt
diff --git a/src/libssh2.rc b/src/libssh2.rc
--- a/src/libssh2.rc
+++ b/src/libssh2.rc
@@ -1,5 +1,8 @@
/***************************************************************************
-* libssh2 Windows resource file *
+* libssh2 Windows resource file
+* Copyright (C) The libssh2 project and its contributors.
+*
+* SPDX-License-Identifier: BSD-3-Clause
***************************************************************************/
#include <winver.h>
#include "libssh2.h"
diff --git a/src/libssh2_config_cmake.h.in b/src/libssh2_config_cmake.h.in
--- a/src/libssh2_config_cmake.h.in
+++ b/src/libssh2_config_cmake.h.in
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* Headers */
diff --git a/src/libssh2_priv.h b/src/libssh2_priv.h
--- a/src/libssh2_priv.h
+++ b/src/libssh2_priv.h
@@ -37,6 +37,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* Header used by 'src' */
diff --git a/src/libssh2_setup.h b/src/libssh2_setup.h
--- a/src/libssh2_setup.h
+++ b/src/libssh2_setup.h
@@ -1,4 +1,7 @@
-/* Copyright (C) Viktor Szakats */
+/* Copyright (C) Viktor Szakats
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#ifndef LIBSSH2_SETUP_H
#define LIBSSH2_SETUP_H
diff --git a/src/mac.c b/src/mac.c
--- a/src/mac.c
+++ b/src/mac.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/mac.h b/src/mac.h
--- a/src/mac.h
+++ b/src/mac.h
@@ -36,6 +36,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/mbedtls.c b/src/mbedtls.c
--- a/src/mbedtls.c
+++ b/src/mbedtls.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_CRYPTO_C /* Compile this via crypto.c */
diff --git a/src/mbedtls.h b/src/mbedtls.h
--- a/src/mbedtls.h
+++ b/src/mbedtls.h
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#define LIBSSH2_CRYPTO_ENGINE libssh2_mbedtls
diff --git a/src/misc.c b/src/misc.c
--- a/src/misc.c
+++ b/src/misc.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/misc.h b/src/misc.h
--- a/src/misc.h
+++ b/src/misc.h
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_NO_CLEAR_MEMORY
diff --git a/src/openssl.c b/src/openssl.c
--- a/src/openssl.c
+++ b/src/openssl.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_CRYPTO_C /* Compile this via crypto.c */
diff --git a/src/openssl.h b/src/openssl.h
--- a/src/openssl.h
+++ b/src/openssl.h
@@ -36,6 +36,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#define LIBSSH2_CRYPTO_ENGINE libssh2_openssl
diff --git a/src/os400qc3.c b/src/os400qc3.c
--- a/src/os400qc3.c
+++ b/src/os400qc3.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_CRYPTO_C /* Compile this via crypto.c */
diff --git a/src/os400qc3.h b/src/os400qc3.h
--- a/src/os400qc3.h
+++ b/src/os400qc3.h
@@ -37,6 +37,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#define LIBSSH2_CRYPTO_ENGINE libssh2_os400qc3
diff --git a/src/packet.c b/src/packet.c
--- a/src/packet.c
+++ b/src/packet.c
@@ -36,6 +36,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/packet.h b/src/packet.h
--- a/src/packet.h
+++ b/src/packet.h
@@ -37,6 +37,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
int _libssh2_packet_read(LIBSSH2_SESSION * session);
diff --git a/src/pem.c b/src/pem.c
--- a/src/pem.c
+++ b/src/pem.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/publickey.c b/src/publickey.c
--- a/src/publickey.c
+++ b/src/publickey.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/scp.c b/src/scp.c
--- a/src/scp.c
+++ b/src/scp.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/session.c b/src/session.c
--- a/src/session.c
+++ b/src/session.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/session.h b/src/session.h
--- a/src/session.h
+++ b/src/session.h
@@ -37,6 +37,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/* Conveniance-macros to allow code like this;
diff --git a/src/sftp.c b/src/sftp.c
--- a/src/sftp.c
+++ b/src/sftp.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/sftp.h b/src/sftp.h
--- a/src/sftp.h
+++ b/src/sftp.h
@@ -37,6 +37,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/*
diff --git a/src/transport.c b/src/transport.c
--- a/src/transport.c
+++ b/src/transport.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
/*
diff --git a/src/transport.h b/src/transport.h
--- a/src/transport.h
+++ b/src/transport.h
@@ -38,6 +38,8 @@
* OF SUCH DAMAGE.
*
* This file handles reading and writing to the SECSH transport layer. RFC4253.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/userauth.c b/src/userauth.c
--- a/src/userauth.c
+++ b/src/userauth.c
@@ -35,6 +35,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/userauth.h b/src/userauth.h
--- a/src/userauth.h
+++ b/src/userauth.h
@@ -36,6 +36,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
int
diff --git a/src/userauth_kbd_packet.c b/src/userauth_kbd_packet.c
--- a/src/userauth_kbd_packet.c
+++ b/src/userauth_kbd_packet.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/userauth_kbd_packet.h b/src/userauth_kbd_packet.h
--- a/src/userauth_kbd_packet.h
+++ b/src/userauth_kbd_packet.h
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef __LIBSSH2_USERAUTH_KBD_PARSE_H
diff --git a/src/version.c b/src/version.c
--- a/src/version.c
+++ b/src/version.c
@@ -34,6 +34,7 @@
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
*
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/src/wincng.c b/src/wincng.c
--- a/src/wincng.c
+++ b/src/wincng.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifdef LIBSSH2_CRYPTO_C /* Compile this via crypto.c */
diff --git a/src/wincng.h b/src/wincng.h
--- a/src/wincng.h
+++ b/src/wincng.h
@@ -36,6 +36,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#define LIBSSH2_CRYPTO_ENGINE libssh2_wincng
|
diff --git a/tests/CMakeLists.txt b/tests/CMakeLists.txt
--- a/tests/CMakeLists.txt
+++ b/tests/CMakeLists.txt
@@ -33,6 +33,8 @@
# NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
# USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
# OF SUCH DAMAGE.
+#
+# SPDX-License-Identifier: BSD-3-Clause
include(CopyRuntimeDependencies)
diff --git a/tests/Makefile.am b/tests/Makefile.am
--- a/tests/Makefile.am
+++ b/tests/Makefile.am
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
SUBDIRS = ossfuzz
AM_CPPFLAGS = -I$(top_builddir)/src -I$(top_srcdir)/src -I$(top_srcdir)/include
diff --git a/tests/Makefile.inc b/tests/Makefile.inc
--- a/tests/Makefile.inc
+++ b/tests/Makefile.inc
@@ -1,3 +1,5 @@
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
# Keep this list sorted
#
# NOTE: test_auth_keyboard_info_request does not use the network, but when
diff --git a/tests/gen_keys.sh b/tests/gen_keys.sh
--- a/tests/gen_keys.sh
+++ b/tests/gen_keys.sh
@@ -1,6 +1,7 @@
#!/bin/sh
-
+#
# Copyright (C) Viktor Szakats
+# SPDX-License-Identifier: BSD-3-Clause
set -e
set -u
diff --git a/tests/mansyntax.sh b/tests/mansyntax.sh
--- a/tests/mansyntax.sh
+++ b/tests/mansyntax.sh
@@ -1,4 +1,6 @@
#!/bin/sh
+# Copyright (C) The libssh2 project and its contributors.
+# SPDX-License-Identifier: BSD-3-Clause
set -e
set -u
diff --git a/tests/openssh_fixture.c b/tests/openssh_fixture.c
--- a/tests/openssh_fixture.c
+++ b/tests/openssh_fixture.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "session_fixture.h"
diff --git a/tests/openssh_fixture.h b/tests/openssh_fixture.h
--- a/tests/openssh_fixture.h
+++ b/tests/openssh_fixture.h
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_TESTS_OPENSSH_FIXTURE_H
diff --git a/tests/runner.c b/tests/runner.c
--- a/tests/runner.c
+++ b/tests/runner.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "runner.h"
diff --git a/tests/runner.h b/tests/runner.h
--- a/tests/runner.h
+++ b/tests/runner.h
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_TESTS_RUNNER_H
diff --git a/tests/session_fixture.c b/tests/session_fixture.c
--- a/tests/session_fixture.c
+++ b/tests/session_fixture.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "session_fixture.h"
diff --git a/tests/session_fixture.h b/tests/session_fixture.h
--- a/tests/session_fixture.h
+++ b/tests/session_fixture.h
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#ifndef LIBSSH2_TESTS_SESSION_FIXTURE_H
diff --git a/tests/test_aa_warmup.c b/tests/test_aa_warmup.c
--- a/tests/test_aa_warmup.c
+++ b/tests/test_aa_warmup.c
@@ -1,4 +1,7 @@
-/* Copyright (C) Viktor Szakats */
+/* Copyright (C) Viktor Szakats
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
/* Warm-up test. Always return success.
Workaround for CI/docker/etc flakiness on the first run. */
diff --git a/tests/test_agent_forward_ok.c b/tests/test_agent_forward_ok.c
--- a/tests/test_agent_forward_ok.c
+++ b/tests/test_agent_forward_ok.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_keyboard_fail.c b/tests/test_auth_keyboard_fail.c
--- a/tests/test_auth_keyboard_fail.c
+++ b/tests/test_auth_keyboard_fail.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_keyboard_info_request.c b/tests/test_auth_keyboard_info_request.c
--- a/tests/test_auth_keyboard_info_request.c
+++ b/tests/test_auth_keyboard_info_request.c
@@ -33,6 +33,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/tests/test_auth_keyboard_ok.c b/tests/test_auth_keyboard_ok.c
--- a/tests/test_auth_keyboard_ok.c
+++ b/tests/test_auth_keyboard_ok.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_password_fail_password.c b/tests/test_auth_password_fail_password.c
--- a/tests/test_auth_password_fail_password.c
+++ b/tests/test_auth_password_fail_password.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_password_fail_username.c b/tests/test_auth_password_fail_username.c
--- a/tests/test_auth_password_fail_username.c
+++ b/tests/test_auth_password_fail_username.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_password_ok.c b/tests/test_auth_password_ok.c
--- a/tests/test_auth_password_ok.c
+++ b/tests/test_auth_password_ok.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_fail.c b/tests/test_auth_pubkey_fail.c
--- a/tests/test_auth_pubkey_fail.c
+++ b/tests/test_auth_pubkey_fail.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_dsa.c b/tests/test_auth_pubkey_ok_dsa.c
--- a/tests/test_auth_pubkey_ok_dsa.c
+++ b/tests/test_auth_pubkey_ok_dsa.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_ecdsa.c b/tests/test_auth_pubkey_ok_ecdsa.c
--- a/tests/test_auth_pubkey_ok_ecdsa.c
+++ b/tests/test_auth_pubkey_ok_ecdsa.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_ecdsa_signed.c b/tests/test_auth_pubkey_ok_ecdsa_signed.c
--- a/tests/test_auth_pubkey_ok_ecdsa_signed.c
+++ b/tests/test_auth_pubkey_ok_ecdsa_signed.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_ed25519.c b/tests/test_auth_pubkey_ok_ed25519.c
--- a/tests/test_auth_pubkey_ok_ed25519.c
+++ b/tests/test_auth_pubkey_ok_ed25519.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_ed25519_encrypted.c b/tests/test_auth_pubkey_ok_ed25519_encrypted.c
--- a/tests/test_auth_pubkey_ok_ed25519_encrypted.c
+++ b/tests/test_auth_pubkey_ok_ed25519_encrypted.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_ed25519_mem.c b/tests/test_auth_pubkey_ok_ed25519_mem.c
--- a/tests/test_auth_pubkey_ok_ed25519_mem.c
+++ b/tests/test_auth_pubkey_ok_ed25519_mem.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_rsa.c b/tests/test_auth_pubkey_ok_rsa.c
--- a/tests/test_auth_pubkey_ok_rsa.c
+++ b/tests/test_auth_pubkey_ok_rsa.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_rsa_encrypted.c b/tests/test_auth_pubkey_ok_rsa_encrypted.c
--- a/tests/test_auth_pubkey_ok_rsa_encrypted.c
+++ b/tests/test_auth_pubkey_ok_rsa_encrypted.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_rsa_openssh.c b/tests/test_auth_pubkey_ok_rsa_openssh.c
--- a/tests/test_auth_pubkey_ok_rsa_openssh.c
+++ b/tests/test_auth_pubkey_ok_rsa_openssh.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_auth_pubkey_ok_rsa_signed.c b/tests/test_auth_pubkey_ok_rsa_signed.c
--- a/tests/test_auth_pubkey_ok_rsa_signed.c
+++ b/tests/test_auth_pubkey_ok_rsa_signed.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_hostkey.c b/tests/test_hostkey.c
--- a/tests/test_hostkey.c
+++ b/tests/test_hostkey.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_hostkey_hash.c b/tests/test_hostkey_hash.c
--- a/tests/test_hostkey_hash.c
+++ b/tests/test_hostkey_hash.c
@@ -1,4 +1,7 @@
-/* Copyright (C) The libssh2 project and its contributors. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ */
#include "runner.h"
diff --git a/tests/test_read.c b/tests/test_read.c
--- a/tests/test_read.c
+++ b/tests/test_read.c
@@ -1,6 +1,8 @@
/* Copyright (C) The libssh2 project and its contributors.
*
* libssh2 test receiving large amounts of data through a channel
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "runner.h"
diff --git a/tests/test_read_algos.test b/tests/test_read_algos.test
--- a/tests/test_read_algos.test
+++ b/tests/test_read_algos.test
@@ -1,6 +1,6 @@
#!/usr/bin/env bash
-
# Copyright (C) Viktor Szakats
+# SPDX-License-Identifier: BSD-3-Clause
set -e
set -u
diff --git a/tests/test_simple.c b/tests/test_simple.c
--- a/tests/test_simple.c
+++ b/tests/test_simple.c
@@ -34,6 +34,8 @@
* NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE
* USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY
* OF SUCH DAMAGE.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
*/
#include "libssh2_priv.h"
diff --git a/tests/test_ssh2.c b/tests/test_ssh2.c
--- a/tests/test_ssh2.c
+++ b/tests/test_ssh2.c
@@ -1,6 +1,9 @@
-/* Copyright (C) The libssh2 project and its contributors. */
-
-/* Self test, based on example/ssh2.c. */
+/* Copyright (C) The libssh2 project and its contributors.
+ *
+ * SPDX-License-Identifier: BSD-3-Clause
+ *
+ * Self test, based on example/ssh2.c.
+ */
#include "libssh2_setup.h"
#include <libssh2.h>
diff --git a/tests/test_sshd.test b/tests/test_sshd.test
--- a/tests/test_sshd.test
+++ b/tests/test_sshd.test
@@ -1,7 +1,8 @@
#!/usr/bin/env bash
-
-# Written by Simon Josefsson and Viktor Szakats
-
+# Copyright (C) Simon Josefsson
+# Copyright (C) Viktor Szakats
+# SPDX-License-Identifier: BSD-3-Clause
+#
# Start sshd, invoke test(s), saving exit code, kill sshd, and
# return exit code.
|
SPDX identifiers and a CI job to check them all
- All files have prominent copyright and SPDX identifier
- If not embedded in the file, in the .reuse/dep5 file
- All used licenses are in LICENSES/ (not shipped in tarballs)
- A new REUSE CI job verify that all files are OK
| 2023-06-05T11:56:41
|
c
|
Hard
|
|
HandmadeMath/HandmadeMath
| 113
|
HandmadeMath__HandmadeMath-113
|
[
"99"
] |
785f19d4a740ced802fd6f79f065c2982ae4b3d3
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -130,14 +130,23 @@
#pragma warning(disable:4201)
#endif
-#ifdef __clang__
+#if defined(__GNUC__) || defined(__clang__)
#pragma GCC diagnostic push
+#pragma GCC diagnostic ignored "-Wfloat-equal"
+#if defined(__GNUC__) && (__GNUC__ == 4 && __GNUC_MINOR__ < 8)
+#pragma GCC diagnostic ignored "-Wmissing-braces"
+#endif
+#ifdef __clang__
#pragma GCC diagnostic ignored "-Wgnu-anonymous-struct"
#endif
+#endif
-#if defined(__GNUC__) && (__GNUC__ == 4 && __GNUC_MINOR__ < 8)
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wmissing-braces"
+#if defined(__GNUC__) || defined(__clang__)
+#define HMM_DEPRECATED(msg) __attribute__((deprecated(msg)))
+#elif defined(_MSC_VER)
+#define HMM_DEPRECATED(msg) __declspec(deprecated(msg))
+#else
+#define HMM_DEPRECATED(msg)
#endif
#ifdef __cplusplus
@@ -353,8 +362,7 @@ typedef union hmm_mat4
#ifdef HANDMADE_MATH__USE_SSE
__m128 Columns[4];
- // DEPRECATED. Our matrices are column-major, so this was named
- // incorrectly. Use Columns instead.
+ HMM_DEPRECATED("Our matrices are column-major, so this was named incorrectly. Use Columns instead.")
__m128 Rows[4];
#endif
@@ -2769,11 +2777,7 @@ HMM_INLINE hmm_bool operator!=(hmm_vec4 Left, hmm_vec4 Right)
#endif /* __cplusplus */
-#ifdef __clang__
-#pragma GCC diagnostic pop
-#endif
-
-#if defined(__GNUC__) && (__GNUC__ == 4 && __GNUC_MINOR__ < 8)
+#if defined(__GNUC__) || defined(__clang__)
#pragma GCC diagnostic pop
#endif
|
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -1,6 +1,6 @@
BUILD_DIR=./build
-CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
+CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers -Wfloat-equal
all: c c_no_sse cpp cpp_no_sse build_c_without_coverage build_cpp_without_coverage
diff --git a/test/categories/ScalarMath.h b/test/categories/ScalarMath.h
--- a/test/categories/ScalarMath.h
+++ b/test/categories/ScalarMath.h
@@ -74,9 +74,9 @@ TEST(ScalarMath, Power)
TEST(ScalarMath, PowerF)
{
- EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0), 1.0f);
- EXPECT_NEAR(HMM_PowerF(2.0f, 4.1), 17.148376f, 0.0001f);
- EXPECT_NEAR(HMM_PowerF(2.0f, -2.5), 0.176777f, 0.0001f);
+ EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0.0f), 1.0f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, 4.1f), 17.148376f, 0.0001f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, -2.5f), 0.176777f, 0.0001f);
}
TEST(ScalarMath, Lerp)
|
Introduce "safe" float comparison
Introduce a safe form of comparing floating point. == and != should not be used when comparing floating numbers.
`./HandmadeMath.h:854:31: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:854:52: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:861:31: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:861:52: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:861:73: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:868:31: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z && Left.W == Right.W);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:868:52: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z && Left.W == Right.W);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:868:73: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z && Left.W == Right.W);
~~~~~~ ^ ~~~~~~~
./HandmadeMath.h:868:94: warning: comparing floating point with == or != is unsafe [-Wfloat-equal]
hmm_bool Result = (Left.X == Right.X && Left.Y == Right.Y && Left.Z == Right.Z && Left.W == Right.W);
`
|
Which functions are doing this?
Actually these are just the Equals functions. So this warning really isnt valid, might wanna disable this warning on clang
That sounds like the better option. I'd imagine this is rarely used anyway, and if it is, it's probably comparing to zero or something.
You’re both right, comparing to known values (like exactly identity matrix) is about the only use case here. Anything beyond that and users will prefer to write their own custom little comparison inlined in their code.
I would actually recommend simply deleting the comparison function you have instead of silencing the warnings. It’s just a little extra bloat and not actually a useful function. But silencing isn’t a bad option either. It just means you’ll have more maintenance in terms of silencing warnings for updating or different compilers... So I would prefer to just delete it and not maintain the function at all.
Do we have a matrix equals function?? We should definitely remove that. I can see a use for the vector case, but really only in the situation where you’re checking for zero. In that case I suppose checking each element is probably faster than getting the length (but I have not done any tests to verify that!)
I know we’re not really living in crazy package land here, but in the interest of backwards compatibility, should we silence the warnings for now and remove the function(s) in a future major release? (Like maybe alongside handedness stuff.)
Oh my mistake, I thought I was looking at matrix comparisons. I'm not actually sure how often people use vector comparisons. I never have myself 🤷♂
To check for all zeros in a vector I do `dot(a, b) == 0`, and write this inline. I've never had a case where I actually used a vector equal operator. In my own math header I use `_mm_cmpeq_ps` and `_mm_cmpneq_ps` simply because I happened to see these functions. I don't have any scalar overloads, so no warnings to silence. I'm actually probably going to just delete the == and != operators.
For deprecation there are a few options I can think of.
* Just delete function and make a note in the release notes on the breaking change.
* Use a macro to mark functions as deprecated, and print a note upon compilation. Then eventually delete the function, or move it to a separate deprecated section.
* The deprecated section could be an ifdef, or even just another header. For example, HandmadeMathDeprecated.h to be included after HandmadeMath.h is included.
I’m all of option 2 this is what Unreal Engine 4 does. They say “Hey X function will be deleted in the next version” with a #warning and then remove it next version. Gives people time to update their usage of the library
@bvisness Any opinions on what we should do here. Looking to close this ticket this weekend
I think we should definitely silence the float comparison warning. The kind of bug it’s trying to prevent is just not applicable here. And I think we can go ahead and throw in a deprecation warning of our own, and plan to remove the operators/functions in version 2.0.
Cool. I’ll push a fix sometimes today silencing this warning
I'm torn on whether or not to delete the vector equals functions for 2.0. Unsurprisingly, we use them everywhere in the tests, so we'd have to reimplement them there. But the main reason I'm hesitant to delete them is that they're totally unambiguous, and not really any work to maintain.
At the moment I'd prefer to just silence the warnings and keep the functions around, even for 2.0. Feel free to change my mind!
| 2020-03-27T22:05:39
|
c
|
Hard
|
nginx/njs
| 796
|
nginx__njs-796
|
[
"794"
] |
39a2d4bf212346d1487e4d27383453cafefa17ea
|
diff --git a/src/njs_buffer.c b/src/njs_buffer.c
--- a/src/njs_buffer.c
+++ b/src/njs_buffer.c
@@ -2117,10 +2117,6 @@ njs_buffer_prototype_index_of(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
index = -1;
- if (njs_slow_path(array->byte_length == 0)) {
- goto done;
- }
-
length = array->byte_length;
if (last) {
@@ -2145,30 +2141,11 @@ njs_buffer_prototype_index_of(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
return ret;
}
- if (last) {
- if (from >= 0) {
- from = njs_min(from, length - 1);
-
- } else if (from < 0) {
- from += length;
- }
-
- if (from <= to) {
- goto done;
- }
+ if (from >= 0) {
+ from = njs_min(from, length);
} else {
- if (from < 0) {
- from += length;
-
- if (from < 0) {
- from = 0;
- }
- }
-
- if (from >= to) {
- goto done;
- }
+ from = njs_max(0, length + from);
}
}
@@ -2213,22 +2190,24 @@ njs_buffer_prototype_index_of(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
str.length = src->byte_length;
}
- if (njs_slow_path(str.length == 0)) {
- index = (last) ? length : 0;
- goto done;
- }
-
- if (str.length > (size_t) length) {
- goto done;
- }
-
if (last) {
- from -= str.length - 1;
- from = njs_max(from, 0);
+ from = njs_min(from, length - (int64_t) str.length);
+
+ if (to > from) {
+ goto done;
+ }
} else {
to -= str.length - 1;
- to = njs_min(to, length);
+
+ if (from > to) {
+ goto done;
+ }
+ }
+
+ if (from == to && str.length == 0) {
+ index = 0;
+ goto done;
}
for (i = from; i != to; i += increment) {
@@ -2243,6 +2222,10 @@ njs_buffer_prototype_index_of(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
case NJS_NUMBER:
byte = njs_number_to_uint32(njs_number(value));
+ if (last) {
+ from = njs_min(from, length - 1);
+ }
+
for (i = from; i != to; i += increment) {
if (u8[i] == byte) {
index = i;
diff --git a/src/qjs_buffer.c b/src/qjs_buffer.c
--- a/src/qjs_buffer.c
+++ b/src/qjs_buffer.c
@@ -988,10 +988,6 @@ qjs_buffer_prototype_index_of(JSContext *ctx, JSValueConst this_val, int argc,
length = self.length;
- if (length == 0) {
- return JS_NewInt32(ctx, -1);
- }
-
if (last) {
from = length - 1;
to = -1;
@@ -1015,30 +1011,11 @@ qjs_buffer_prototype_index_of(JSContext *ctx, JSValueConst this_val, int argc,
return JS_EXCEPTION;
}
- if (last) {
- if (from >= 0) {
- from = njs_min(from, length - 1);
-
- } else if (from < 0) {
- from += length;
- }
-
- if (from <= to) {
- return JS_NewInt32(ctx, -1);
- }
+ if (from >= 0) {
+ from = njs_min(from, length);
} else {
- if (from < 0) {
- from += length;
-
- if (from < 0) {
- from = 0;
- }
- }
-
- if (from >= to) {
- return JS_NewInt32(ctx, -1);
- }
+ from = njs_max(0, length + from);
}
}
@@ -1047,6 +1024,10 @@ qjs_buffer_prototype_index_of(JSContext *ctx, JSValueConst this_val, int argc,
return JS_EXCEPTION;
}
+ if (last) {
+ from = njs_min(from, length - 1);
+ }
+
for (i = from; i != to; i += increment) {
if (self.start[i] == (uint8_t) byte) {
return JS_NewInt32(ctx, i);
@@ -1082,23 +1063,24 @@ qjs_buffer_prototype_index_of(JSContext *ctx, JSValueConst this_val, int argc,
"or Buffer-like object");
}
- if (str.length == 0) {
- JS_FreeValue(ctx, buffer);
- return JS_NewInt32(ctx, (last) ? length : 0);
- }
-
- if (str.length > (size_t) length) {
- JS_FreeValue(ctx, buffer);
- return JS_NewInt32(ctx, -1);
- }
-
if (last) {
- from -= str.length - 1;
- from = njs_max(from, 0);
+ from = njs_min(from, length - (int64_t) str.length);
+
+ if (to > from) {
+ goto done;
+ }
} else {
to -= str.length - 1;
- to = njs_min(to, length);
+
+ if (from > to) {
+ goto done;
+ }
+ }
+
+ if (from == to && str.length == 0) {
+ JS_FreeValue(ctx, buffer);
+ return JS_NewInt32(ctx, 0);
}
for (i = from; i != to; i += increment) {
@@ -1108,6 +1090,8 @@ qjs_buffer_prototype_index_of(JSContext *ctx, JSValueConst this_val, int argc,
}
}
+done:
+
JS_FreeValue(ctx, buffer);
return JS_NewInt32(ctx, -1);
}
|
diff --git a/test/buffer.t.js b/test/buffer.t.js
--- a/test/buffer.t.js
+++ b/test/buffer.t.js
@@ -473,6 +473,20 @@ let indexOf_tsuite = {
{ buf: Buffer.from('abcdef'), value: 'abc', offset: 1, expected: -1 },
{ buf: Buffer.from('abcdef'), value: 'def', offset: 1, expected: 3 },
{ buf: Buffer.from('abcdef'), value: 'def', offset: -3, expected: 3 },
+ { buf: Buffer.from('abcdef'), value: 'efgh', offset: 4, expected: -1 },
+ { buf: Buffer.from(''), value: '', expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: -1, expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: 0, expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: 1, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -4, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -3, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -2, expected: 1 },
+ { buf: Buffer.from('abc'), value: '', offset: -1, expected: 2 },
+ { buf: Buffer.from('abc'), value: '', offset: 0, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: 1, expected: 1 },
+ { buf: Buffer.from('abc'), value: '', offset: 2, expected: 2 },
+ { buf: Buffer.from('abc'), value: '', offset: 3, expected: 3 },
+ { buf: Buffer.from('abc'), value: '', offset: 4, expected: 3 },
{ buf: Buffer.from('abcdef'), value: '626364', encoding: 'hex', expected: 1 },
{ buf: Buffer.from('abcdef'), value: '626364', encoding: 'utf-128',
exception: 'TypeError: "utf-128" encoding is not supported' },
@@ -582,6 +596,20 @@ let lastIndexOf_tsuite = {
{ buf: Buffer.from('abcdef'), value: 'def', expected: 3 },
{ buf: Buffer.from('abcdef'), value: 'abc', offset: 1, expected: 0 },
{ buf: Buffer.from('abcdef'), value: 'def', offset: 1, expected: -1 },
+ { buf: Buffer.from('xxxABCx'), value: 'ABC', offset: 3, expected: 3 },
+ { buf: Buffer.from(''), value: '', expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: -1, expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: 0, expected: 0 },
+ { buf: Buffer.from(''), value: '', offset: 1, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -4, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -3, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: -2, expected: 1 },
+ { buf: Buffer.from('abc'), value: '', offset: -1, expected: 2 },
+ { buf: Buffer.from('abc'), value: '', offset: 0, expected: 0 },
+ { buf: Buffer.from('abc'), value: '', offset: 1, expected: 1 },
+ { buf: Buffer.from('abc'), value: '', offset: 2, expected: 2 },
+ { buf: Buffer.from('abc'), value: '', offset: 3, expected: 3 },
+ { buf: Buffer.from('abc'), value: '', offset: 4, expected: 3 },
{ buf: Buffer.from(Buffer.alloc(7).fill('Zabcdef').buffer, 1), value: 'abcdef', expected: 0 },
{ buf: Buffer.from(Buffer.alloc(7).fill('Zabcdef').buffer, 1), value: 'abcdefg', expected: -1 },
{ buf: Buffer.from('abcdef'), value: '626364', encoding: 'hex', expected: 1 },
@@ -589,6 +617,7 @@ let lastIndexOf_tsuite = {
exception: 'TypeError: "utf-128" encoding is not supported' },
{ buf: Buffer.from('abcabc'), value: 0x61, expected: 3 },
{ buf: Buffer.from('abcabc'), value: 0x61, offset: 1, expected: 0 },
+ { buf: Buffer.from('ab'), value: 7, offset: 2, expected: -1 },
{ buf: Buffer.from('abcdef'), value: Buffer.from('def'), expected: 3 },
{ buf: Buffer.from('abcdef'), value: Buffer.from(new Uint8Array([0x60, 0x62, 0x63]).buffer, 1), expected: 1 },
{ buf: Buffer.from('abcdef'), value: {},
diff --git a/test/harness/runTsuite.js b/test/harness/runTsuite.js
--- a/test/harness/runTsuite.js
+++ b/test/harness/runTsuite.js
@@ -30,7 +30,7 @@ async function run(tlist) {
let r = results.map((r, i) => validate(ts.tests, r, i));
r.forEach((v, i) => {
- assert.sameValue(v, true, `FAILED ${i}: ${JSON.stringify(ts.tests[i])}\n with reason: ${results[i].reason}`);
+ assert.sameValue(v, true, `FAILED ${ts.name}: ${JSON.stringify(ts.tests[i])}\n with reason: ${results[i].reason}`);
})
}
}
|
NJS 0.8.6 Buffer.indexOf reads out of bounds instead of returning -1.
### Describe the bug
NJS since version 0.8.6 Buffer.indexOf reads out of bounds instead of returning -1.
Before submitting a bug report, please check the following:
- [x] The bug is reproducible with the latest version of njs.
- [x] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
Use the following script in a js_body_filter to replace contents in the data
- JS script
```js
function bufferReplace(data, search, replacement) {
for (var i = data.indexOf(search, 0); i !== -1; i = data.indexOf(search, i + search.length)) {
// replace search with replacement in buffer
replacement.copy(data, i, 0);
}
}
function fix_response_body(r, data, flags) {
var data_buffer = typeof data === "string" ? Buffer.from(data) : data;
bufferReplace(data_buffer, "Text", Buffer.from("Test"));
r.sendBuffer(data_buffer, flags);
}
export default { fix_response_body }
```
- NGINX configuration
```
js_body_filter somefile.fix_response_body buffer_type=buffer;
```
- NGINX logs
in case out of bounds read crashes the worker (it does not find "Text" in any of the following memory)
```
nginx-1 | 2024/10/09 05:25:41 [notice] 76#76: signal 17 (SIGCHLD) received from 77
nginx-1 | 2024/10/09 05:25:41 [alert] 76#76: worker process 77 exited on signal 11 (core dumped)
nginx-1 | 2024/10/09 05:25:41 [notice] 76#76: start worker process 332
```
in case out of bounds read finds "Text" in the following memory before it crashes the worker it reports an out of bounds write at `replacement.copy`
### Expected behavior
Buffer.indexOf should read -1 when reaching the end of the buffer. It should not read out of bounds.
### Your environment
- Version of njs: `ii nginx-module-njs 1.26.2+0.8.6-1~bookworm amd64 nginx njs dynamic modules`
- Version of NGINX: `ii nginx 1.26.2-1~bookworm amd64 high performance web server`
- OS: Debian Bookworm
### Additional context
This is especially dangerous because 0.8.5 did not read out of bounds in this case and if somebody just updates their packages and doesn't test their njs scripts this can lead to workers crashing or worse if the script does handle user input (ours does not).
Initially reported as a security vulnerability but was told that this is not a security vulnerability by the F5 expert.
|
Hi @ap-wtioit,
Thank you for the report. I was able to reproduce the issue, and I am working on it.
| 2024-10-10T02:22:26
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 103
|
HandmadeMath__HandmadeMath-103
|
[
"85"
] |
21aa828a08693f8d2ae9fe552a3324ce726ebd82
|
diff --git a/.travis.yml b/.travis.yml
--- a/.travis.yml
+++ b/.travis.yml
@@ -4,9 +4,5 @@ compiler:
- gcc
install:
- cd test
- - make
script:
- - build/hmm_test_c
- - build/hmm_test_c_no_sse
- - build/hmm_test_cpp
- - build/hmm_test_cpp_no_sse
+ - make all
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1414,6 +1414,7 @@ HMM_INLINE hmm_quaternion HMM_NLerp(hmm_quaternion Left, float Time, hmm_quatern
HMM_EXTERN hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right);
HMM_EXTERN hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left);
+HMM_EXTERN hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 Left);
HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation);
#ifdef __cplusplus
@@ -2444,7 +2445,6 @@ hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left)
{
hmm_mat4 Result;
- Result = HMM_Mat4d(1);
hmm_quaternion NormalizedQuaternion = HMM_NormalizeQuaternion(Left);
@@ -2465,33 +2465,97 @@ hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left)
Result.Elements[0][0] = 1.0f - 2.0f * (YY + ZZ);
Result.Elements[0][1] = 2.0f * (XY + WZ);
Result.Elements[0][2] = 2.0f * (XZ - WY);
+ Result.Elements[0][3] = 0.0f;
Result.Elements[1][0] = 2.0f * (XY - WZ);
Result.Elements[1][1] = 1.0f - 2.0f * (XX + ZZ);
Result.Elements[1][2] = 2.0f * (YZ + WX);
+ Result.Elements[1][3] = 0.0f;
Result.Elements[2][0] = 2.0f * (XZ + WY);
Result.Elements[2][1] = 2.0f * (YZ - WX);
Result.Elements[2][2] = 1.0f - 2.0f * (XX + YY);
+ Result.Elements[2][3] = 0.0f;
+
+ Result.Elements[3][0] = 0.0f;
+ Result.Elements[3][1] = 0.0f;
+ Result.Elements[3][2] = 0.0f;
+ Result.Elements[3][3] = 1.0f;
return (Result);
}
+// This method taken from Mike Day at Insomniac Games.
+// https://d3cw3dd2w32x2b.cloudfront.net/wp-content/uploads/2015/01/matrix-to-quat.pdf
+//
+// Note that as mentioned at the top of the paper, the paper assumes the matrix
+// would be *post*-multiplied to a vector to rotate it, meaning the matrix is
+// the transpose of what we're dealing with. But, because our matrices are
+// stored in column-major order, the indices *appear* to match the paper.
+//
+// For example, m12 in the paper is row 1, column 2. We need to transpose it to
+// row 2, column 1. But, because the column comes first when referencing
+// elements, it looks like M.Elements[1][2].
+//
+// Don't be confused! Or if you must be confused, at least trust this
+// comment. :)
+hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
+{
+ float T;
+ hmm_quaternion Q;
+
+ if (M.Elements[2][2] < 0.0f) {
+ if (M.Elements[0][0] > M.Elements[1][1]) {
+ T = 1 + M.Elements[0][0] - M.Elements[1][1] - M.Elements[2][2];
+ Q = HMM_Quaternion(
+ T,
+ M.Elements[0][1] + M.Elements[1][0],
+ M.Elements[2][0] + M.Elements[0][2],
+ M.Elements[1][2] - M.Elements[2][1]
+ );
+ } else {
+ T = 1 - M.Elements[0][0] + M.Elements[1][1] - M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[0][1] + M.Elements[1][0],
+ T,
+ M.Elements[1][2] + M.Elements[2][1],
+ M.Elements[2][0] - M.Elements[0][2]
+ );
+ }
+ } else {
+ if (M.Elements[0][0] < -M.Elements[1][1]) {
+ T = 1 - M.Elements[0][0] - M.Elements[1][1] + M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[2][0] + M.Elements[0][2],
+ M.Elements[1][2] + M.Elements[2][1],
+ T,
+ M.Elements[0][1] - M.Elements[1][0]
+ );
+ } else {
+ T = 1 + M.Elements[0][0] + M.Elements[1][1] + M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[1][2] - M.Elements[2][1],
+ M.Elements[2][0] - M.Elements[0][2],
+ M.Elements[0][1] - M.Elements[1][0],
+ T
+ );
+ }
+ }
+
+ Q = HMM_MultiplyQuaternionF(Q, 0.5f / HMM_SquareRootF(T));
+
+ return Q;
+}
+
hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation)
{
hmm_quaternion Result;
-
- hmm_vec3 RotatedVector;
-
- float AxisNorm = 0;
- float SineOfRotation = 0;
- AxisNorm = HMM_SquareRootF(HMM_DotVec3(Axis, Axis));
- SineOfRotation = HMM_SinF(AngleOfRotation / 2.0f);
- RotatedVector = HMM_MultiplyVec3f(Axis, SineOfRotation);
+ hmm_vec3 AxisNormalized = HMM_NormalizeVec3(Axis);
+ float SineOfRotation = HMM_SinF(AngleOfRotation / 2.0f);
+ Result.XYZ = HMM_MultiplyVec3f(AxisNormalized, SineOfRotation);
Result.W = HMM_CosF(AngleOfRotation / 2.0f);
- Result.XYZ = HMM_DivideVec3f(RotatedVector, AxisNorm);
return (Result);
}
|
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -1,8 +1,14 @@
-BUILD_DIR=build
+BUILD_DIR=./build
CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
-all: c c_no_sse cpp cpp_no_sse
+all: build_all
+ $(BUILD_DIR)/hmm_test_c
+ $(BUILD_DIR)/hmm_test_c_no_sse
+ $(BUILD_DIR)/hmm_test_cpp
+ $(BUILD_DIR)/hmm_test_cpp_no_sse
+
+build_all: c c_no_sse cpp cpp_no_sse
clean:
rm -rf $(BUILD_DIR)
diff --git a/test/categories/QuaternionOps.h b/test/categories/QuaternionOps.h
--- a/test/categories/QuaternionOps.h
+++ b/test/categories/QuaternionOps.h
@@ -76,7 +76,7 @@ TEST(QuaternionOps, Slerp)
EXPECT_FLOAT_EQ(result.W, 0.86602540f);
}
-TEST(QuaternionOps, ToMat4)
+TEST(QuaternionOps, QuatToMat4)
{
const float abs_error = 0.0001f;
@@ -105,6 +105,67 @@ TEST(QuaternionOps, ToMat4)
EXPECT_NEAR(result.Elements[3][3], 1.0f, abs_error);
}
+TEST(QuaternionOps, Mat4ToQuat)
+{
+ const float abs_error = 0.0001f;
+
+ // Rotate 90 degrees on the X axis
+ {
+ hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ hmm_quaternion result = HMM_Mat4ToQuaternion(m);
+
+ float cosf = 0.707107f; // cos(90/2 degrees)
+ float sinf = 0.707107f; // sin(90/2 degrees)
+
+ EXPECT_NEAR(result.X, sinf, abs_error);
+ EXPECT_NEAR(result.Y, 0.0f, abs_error);
+ EXPECT_NEAR(result.Z, 0.0f, abs_error);
+ EXPECT_NEAR(result.W, cosf, abs_error);
+ }
+
+ // Rotate 90 degrees on the Y axis (axis not normalized, just for fun)
+ {
+ hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(0, 2, 0));
+ hmm_quaternion result = HMM_Mat4ToQuaternion(m);
+
+ float cosf = 0.707107f; // cos(90/2 degrees)
+ float sinf = 0.707107f; // sin(90/2 degrees)
+
+ EXPECT_NEAR(result.X, 0.0f, abs_error);
+ EXPECT_NEAR(result.Y, sinf, abs_error);
+ EXPECT_NEAR(result.Z, 0.0f, abs_error);
+ EXPECT_NEAR(result.W, cosf, abs_error);
+ }
+
+ // Rotate 90 degrees on the Z axis
+ {
+ hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_quaternion result = HMM_Mat4ToQuaternion(m);
+
+ float cosf = 0.707107f; // cos(90/2 degrees)
+ float sinf = 0.707107f; // sin(90/2 degrees)
+
+ EXPECT_NEAR(result.X, 0.0f, abs_error);
+ EXPECT_NEAR(result.Y, 0.0f, abs_error);
+ EXPECT_NEAR(result.Z, sinf, abs_error);
+ EXPECT_NEAR(result.W, cosf, abs_error);
+ }
+
+ // Rotate 135 degrees on the Y axis (this hits case 4)
+ {
+ hmm_mat4 m = HMM_Rotate(135, HMM_Vec3(0, 1, 0));
+ hmm_quaternion result = HMM_Mat4ToQuaternion(m);
+
+ float cosf = 0.3826834324f; // cos(135/2 degrees)
+ float sinf = 0.9238795325f; // sin(135/2 degrees)
+
+ EXPECT_NEAR(result.X, 0.0f, abs_error);
+ EXPECT_NEAR(result.Y, sinf, abs_error);
+ EXPECT_NEAR(result.Z, 0.0f, abs_error);
+ EXPECT_NEAR(result.W, cosf, abs_error);
+ }
+}
+
TEST(QuaternionOps, FromAxisAngle)
{
hmm_vec3 axis = HMM_Vec3(1.0f, 0.0f, 0.0f);
|
Quaternion from Mat4?
Is there a way to use a LookAt function and end up with a quaternion? I know HMM_LookAt gives you a mat4, but I don't see a way to convert a mat4 to a quaternion.
Ultimately, I'm trying to find a way to construct a quaternion and specify it's Up vector. LookAt seems to be the only available function that does that.
|
I think QuaternionFromAxisAngle should get you most of the way there (since you know the axis it should point along), but I suppose that's not exactly the same as specifying an up vector as you would in a LookAt. I'll ponder if we need another function for this case.
No, you're right. I think we should have a LookAt for quaternions. I'll get back to you on that one...
Something interesting i found:
https://d3cw3dd2w32x2b.cloudfront.net/wp-content/uploads/2015/01/matrix-to-quat.pdf
I guess I could just run a LookAt matrix through that and call it a day...I'll ponder that.
Yes, that's a good solution. The pdf you found is quite nice.
| 2019-07-18T00:21:34
|
c
|
Hard
|
nginx/njs
| 909
|
nginx__njs-909
|
[
"905"
] |
fcb99b68f86a72c96e21b81b3b78251174dbd3bf
|
diff --git a/external/njs_webcrypto_module.c b/external/njs_webcrypto_module.c
--- a/external/njs_webcrypto_module.c
+++ b/external/njs_webcrypto_module.c
@@ -1532,6 +1532,9 @@ njs_ext_derive(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
break;
+ case NJS_ALGORITHM_HMAC:
+ break;
+
default:
njs_vm_internal_error(vm, "not implemented deriveKey: \"%V\"",
njs_algorithm_string(dalg));
@@ -1719,6 +1722,7 @@ njs_ext_derive(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
}
}
+ dkey->extractable = njs_value_bool(njs_arg(args, nargs, 4));
dkey->u.s.raw.start = k;
dkey->u.s.raw.length = length;
diff --git a/external/qjs_webcrypto_module.c b/external/qjs_webcrypto_module.c
--- a/external/qjs_webcrypto_module.c
+++ b/external/qjs_webcrypto_module.c
@@ -1756,6 +1756,9 @@ qjs_webcrypto_derive(JSContext *cx, JSValueConst this_val, int argc,
break;
+ case QJS_ALGORITHM_HMAC:
+ break;
+
default:
JS_ThrowTypeError(cx, "not implemented deriveKey: \"%s\"",
qjs_algorithm_string(dalg));
@@ -1945,6 +1948,7 @@ qjs_webcrypto_derive(JSContext *cx, JSValueConst this_val, int argc,
}
}
+ dkey->extractable = JS_ToBool(cx, argv[3]);
dkey->u.s.raw.start = k;
dkey->u.s.raw.length = length;
diff --git a/src/njs.h b/src/njs.h
--- a/src/njs.h
+++ b/src/njs.h
@@ -11,8 +11,8 @@
#include <njs_auto_config.h>
-#define NJS_VERSION "0.9.0"
-#define NJS_VERSION_NUMBER 0x000900
+#define NJS_VERSION "0.9.1"
+#define NJS_VERSION_NUMBER 0x000901
#include <string.h>
|
diff --git a/test/webcrypto/derive.t.mjs b/test/webcrypto/derive.t.mjs
--- a/test/webcrypto/derive.t.mjs
+++ b/test/webcrypto/derive.t.mjs
@@ -3,6 +3,16 @@ includes: [compatFs.js, compatBuffer.js, compatWebcrypto.js, runTsuite.js, webCr
flags: [async]
---*/
+function has_usage(usage, x) {
+ for (let i = 0; i < usage.length; i++) {
+ if (x === usage[i]) {
+ return true;
+ }
+ }
+
+ return false;
+}
+
async function test(params) {
let r;
let encoder = new TextEncoder();
@@ -12,10 +22,21 @@ async function test(params) {
if (params.derive === "key") {
let key = await crypto.subtle.deriveKey(params.algorithm, keyMaterial,
params.derivedAlgorithm,
- true, [ "encrypt", "decrypt" ]);
+ params.extractable, params.usage);
+
+ if (key.extractable !== params.extractable) {
+ throw Error(`${params.algorithm.name} failed extractable ${params.extractable} vs ${key.extractable}`);
+ }
+
+ if (has_usage(params.usage, "encrypt")) {
+ r = await crypto.subtle.encrypt(params.derivedAlgorithm, key,
+ encoder.encode(params.text));
+
+ } else if (has_usage(params.usage, "sign")) {
+ r = await crypto.subtle.sign(params.derivedAlgorithm, key,
+ encoder.encode(params.text));
+ }
- r = await crypto.subtle.encrypt(params.derivedAlgorithm, key,
- encoder.encode(params.text));
} else {
r = await crypto.subtle.deriveBits(params.algorithm, keyMaterial, params.length);
@@ -63,11 +84,14 @@ let derive_tsuite = {
name: "AES-GCM",
length: 256,
iv: "55667788556677885566778855667788"
- }
+ },
+ extractable: true,
+ usage: [ "encrypt", "decrypt" ]
},
tests: [
{ expected: "e7b55c9f9fda69b87648585f76c58109174aaa400cfa" },
+ { extractable: false, expected: "e7b55c9f9fda69b87648585f76c58109174aaa400cfa" },
{ pass: "pass2", expected: "e87d1787f2807ea0e1f7e1cb265b23004c575cf2ad7e" },
{ algorithm: { iterations: 10000 }, expected: "5add0059931ed1db1ca24c26dbe4de5719c43ed18a54" },
{ algorithm: { hash: "SHA-512" }, expected: "544d64e5e246fdd2ba290ea932b2d80ef411c76139f4" },
@@ -92,6 +116,10 @@ let derive_tsuite = {
{ algorithm: { name: "HKDF" }, optional: true,
expected: "18ea069ee3317d2db02e02f4a228f50dc80d9a2396e6" },
+ { algorithm: { name: "HKDF" },
+ derivedAlgorithm: { name: "HMAC", hash: "SHA-256", length: 256 },
+ usage: [ "sign", "verify" ], optional: true,
+ expected: "0b06bd37de54c08cedde2cbb649d6f26d066acfd51717d83b52091e2ae6829c2" },
{ derive: "bits", algorithm: { name: "HKDF" }, optional: true,
expected: "e089c7491711306c69e077aa19fae6bfd2d4a6d240b0d37317d50472d7291a3e" },
]};
|
HMAC not implemented in crypto.subtle.deriveKey
### Describe the bug
`deriveKey` only accepts AES options for `derivedKeyAlgorithm`.
- [x] The bug is reproducible with the latest version of njs.
- [x] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
async function main() {
const c = global.crypto;
const algorithm = {
name: "HKDF",
hash: "SHA-256",
salt: c.getRandomValues(new Int8Array(32)),
info: Buffer.alloc(1).buffer
};
const key = await global.crypto.subtle.importKey(
'raw',
c.getRandomValues(new Int8Array(32)),
'HKDF',
false,
['deriveKey']
);
const derivedKeyAlgorithm = {
name: "HMAC",
hash: "SHA-256",
length: 256
};
const keyUsages = ['sign', 'verify'];
c.subtle.deriveKey(algorithm, key, derivedKeyAlgorithm, false, keyUsages);
}
main();
```
- `njs` output
```
Error: unhandled promise rejection: InternalError: not implemented deriveKey: "HMAC"
```
- With optional `length` property omitted:
```
Error: unhandled promise rejection: TypeError: derivedKeyAlgorithm.length is not provided
```
### Expected behavior
Exit status 0, as when `derivedKeyAlgorithm.name = "AES-GCM"` and `keyUsages = ['encrypt', 'decrypt']`.
### Your environment
```
nginx-module-njs.aarch64 1.28.0+0.8.10-1.amzn2023.ngx @nginx-stable
```
### Additional context
[njs/external/njs_webcrypto_module.c:1716-1719](https://github.com/nginx/njs/blob/e3cfb4f70e203866c1bd06e5fb28fcdc7dd967f8/external/njs_webcrypto_module.c#L1716-L1719) is unreachable because of [njs/external/njs_webcrypto_module.c:1522-1539](https://github.com/nginx/njs/blob/e3cfb4f70e203866c1bd06e5fb28fcdc7dd967f8/external/njs_webcrypto_module.c#L1522-L1539).
| 2025-05-08T05:17:40
|
c
|
Hard
|
|
nginx/njs
| 819
|
nginx__njs-819
|
[
"813"
] |
72f0b5db8595bca740ffbfd2f9213e577718a174
|
diff --git a/src/njs_promise.c b/src/njs_promise.c
--- a/src/njs_promise.c
+++ b/src/njs_promise.c
@@ -675,27 +675,19 @@ static njs_int_t
njs_promise_object_resolve(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
njs_index_t unused, njs_value_t *retval)
{
- njs_promise_t *promise;
-
if (njs_slow_path(!njs_is_object(njs_argument(args, 0)))) {
njs_type_error(vm, "this value is not an object");
return NJS_ERROR;
}
- promise = njs_promise_resolve(vm, njs_argument(args, 0),
- njs_arg(args, nargs, 1));
- if (njs_slow_path(promise == NULL)) {
- return NJS_ERROR;
- }
-
- njs_set_promise(retval, promise);
-
- return NJS_OK;
+ return njs_promise_resolve(vm, njs_argument(args, 0),
+ njs_arg(args, nargs, 1), retval);
}
-njs_promise_t *
-njs_promise_resolve(njs_vm_t *vm, njs_value_t *constructor, njs_value_t *x)
+njs_int_t
+njs_promise_resolve(njs_vm_t *vm, njs_value_t *constructor, njs_value_t *x,
+ njs_value_t *retval)
{
njs_int_t ret;
njs_value_t value;
@@ -707,26 +699,28 @@ njs_promise_resolve(njs_vm_t *vm, njs_value_t *constructor, njs_value_t *x)
ret = njs_value_property(vm, x, njs_value_arg(&string_constructor),
&value);
if (njs_slow_path(ret == NJS_ERROR)) {
- return NULL;
+ return NJS_ERROR;
}
if (njs_values_same(&value, constructor)) {
- return njs_promise(x);
+ njs_value_assign(retval, x);
+ return NJS_OK;
}
}
capability = njs_promise_new_capability(vm, constructor);
if (njs_slow_path(capability == NULL)) {
- return NULL;
+ return NJS_ERROR;
}
ret = njs_function_call(vm, njs_function(&capability->resolve),
&njs_value_undefined, x, 1, &value);
if (njs_slow_path(ret != NJS_OK)) {
- return NULL;
+ return ret;
}
- return njs_promise(&capability->promise);
+ njs_value_assign(retval, &capability->promise);
+ return NJS_OK;
}
@@ -1017,7 +1011,6 @@ njs_promise_then_finally_function(njs_vm_t *vm, njs_value_t *args,
{
njs_int_t ret;
njs_value_t value, argument;
- njs_promise_t *promise;
njs_function_t *function;
njs_native_frame_t *frame;
njs_promise_context_t *context;
@@ -1031,13 +1024,11 @@ njs_promise_then_finally_function(njs_vm_t *vm, njs_value_t *args,
return ret;
}
- promise = njs_promise_resolve(vm, &context->constructor, &value);
- if (njs_slow_path(promise == NULL)) {
+ ret = njs_promise_resolve(vm, &context->constructor, &value, &value);
+ if (njs_slow_path(ret != NJS_OK)) {
return NJS_ERROR;
}
- njs_set_promise(&value, promise);
-
function = njs_promise_create_function(vm, sizeof(njs_value_t));
if (njs_slow_path(function == NULL)) {
return NJS_ERROR;
diff --git a/src/njs_promise.h b/src/njs_promise.h
--- a/src/njs_promise.h
+++ b/src/njs_promise.h
@@ -36,8 +36,8 @@ njs_function_t *njs_promise_create_function(njs_vm_t *vm, size_t context_size);
njs_int_t njs_promise_perform_then(njs_vm_t *vm, njs_value_t *value,
njs_value_t *fulfilled, njs_value_t *rejected,
njs_promise_capability_t *capability, njs_value_t *retval);
-njs_promise_t *njs_promise_resolve(njs_vm_t *vm, njs_value_t *constructor,
- njs_value_t *x);
+njs_int_t njs_promise_resolve(njs_vm_t *vm, njs_value_t *constructor,
+ njs_value_t *x, njs_value_t *retval);
extern const njs_object_type_init_t njs_promise_type_init;
diff --git a/src/njs_vmcode.c b/src/njs_vmcode.c
--- a/src/njs_vmcode.c
+++ b/src/njs_vmcode.c
@@ -2637,7 +2637,6 @@ njs_vmcode_await(njs_vm_t *vm, njs_vmcode_await_t *await,
njs_int_t ret;
njs_frame_t *frame;
njs_value_t ctor, val, on_fulfilled, on_rejected, *value, retval;
- njs_promise_t *promise;
njs_function_t *fulfilled, *rejected;
njs_native_frame_t *active;
@@ -2651,8 +2650,8 @@ njs_vmcode_await(njs_vm_t *vm, njs_vmcode_await_t *await,
njs_set_function(&ctor, &njs_vm_ctor(vm, NJS_OBJ_TYPE_PROMISE));
- promise = njs_promise_resolve(vm, &ctor, value);
- if (njs_slow_path(promise == NULL)) {
+ ret = njs_promise_resolve(vm, &ctor, value, &val);
+ if (njs_slow_path(ret != NJS_OK)) {
return NJS_ERROR;
}
@@ -2710,7 +2709,6 @@ njs_vmcode_await(njs_vm_t *vm, njs_vmcode_await_t *await,
rejected->args_count = 1;
rejected->u.native = njs_await_rejected;
- njs_set_promise(&val, promise);
njs_set_function(&on_fulfilled, fulfilled);
njs_set_function(&on_rejected, rejected);
|
diff --git a/test/js/promise_s27.t.js b/test/js/promise_s27.t.js
new file mode 100644
--- /dev/null
+++ b/test/js/promise_s27.t.js
@@ -0,0 +1,34 @@
+/*---
+includes: []
+flags: [async]
+---*/
+
+var inherits = (child, parent) => {
+ child.prototype = Object.create(parent.prototype, {
+ constructor: {
+ value: child,
+ enumerable: false,
+ writable: true,
+ configurable: true
+ }
+ });
+ Object.setPrototypeOf(child, parent);
+};
+
+function BoxedPromise(executor) {
+ var context, args;
+ new Promise(wrappedExecutor);
+ executor.apply(context, args);
+
+ function wrappedExecutor(resolve, reject) {
+ context = this;
+ args = [v => resolve(v),v => reject(v)];
+ }
+}
+
+inherits(BoxedPromise, Promise);
+
+Promise.resolve()
+.then(() => BoxedPromise.resolve())
+.catch(e => assert.sameValue(e.constructor, TypeError))
+.then($DONE, $DONE);
|
[Bug] Segmentation Fault with Promise function
### Describe the bug
A clear and concise description of what the bug is.
Before submitting a bug report, please check the following:
- [x] The bug is reproducible with the latest version of njs.
- [ ] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
let stages = [];
var inherits = (child, parent) => {
child.prototype = Object.create(parent.prototype, {
constructor: {
value: child,
enumerable: false,
writable: true,
configurable: true
}
});
Object.setPrototypeOf(child, parent);
};
var BoxedPromise = (() => {
function BoxedPromise(executor) {
stages.push('BoxedPromise.constructor');
if (!(this instanceof BoxedPromise)) {
return Promise(executor);
}
if (typeof executor !== 'function') {
return new Promise(executor);
}
var context, args;
var promise = new Promise(wrappedExecutor);
this.boxed = promise;
try {
executor.apply(context, args);
} catch (e) {
[1](e);
}
function wrappedExecutor(resolve, reject) {
context = this;
args = [wrappedResolve, wrappedReject];
function wrappedResolve(val) {
return resolve(val);
}
function wrappedReject(val) {
return reject(val);
}
}
}
inherits(BoxedPromise, Promise);
BoxedPromise.prototype.rhen = function(res, rej) {
stages.push('BoxedPromise.prototype.then');
var rs = Object.create(Object.getPrototypeOf(this));
rs.boxed = this.boxed.then(res, rej);
return rs;
};
return BoxedPromise;
})();
var PatchedPromise = (() => {
function PatchedPromise(executor) {
stages.push('PatchedPromise.constructor');
if (!(this instanceof PatchedPromise)) {
return Promise(executor);
}
if (typeof executor !== 'function') {
return new Promise(executor);
}
var context, args;
var promise = new Promise(wrappedExecutor);
Object.setPrototypeOf(promise, PatchedPromise.prototype);
try {
executor.apply(context, args);
} catch (e) {
args[1](e);
}
return promise;
function wrappedExecutor(resolve, reject) {
context = this;
args = [wrappedResolve, wrappedReject];
function wrappedResolve(val) {
return resolve(val);
}
function wrappedReject(val) {
return reject(val);
}
}
}
inherits(PatchedPromise, Promise);
return PatchedPromise;
})();
var testSubclass = (Class, name) => {
return new Promise((resolve) => {
var resolved = Class.resolve(name)
.then((x) => stages.push(`resolved ${name}`));
stages.push(`${name} ${resolved instanceof Class ? 'OK' : 'failed'}`);
var rejected = Class.reject(name)
.catch((x) => stages.push(`rejected ${name}`));
stages.push(`${name} reject ${rejected instanceof Class ? 'OK' : 'failed'}`);
var instance = new Class((resolve) => {
setImmediate(() => resolve(name));
});
var chain = instance
5 .then((x) => { stages.push(`then ${x}`); return x; })
.then((x) => { stages.push(`then ${x}`); return x; });
stages.push(`${name} chain ${chain instanceof Class ? 'OK' : 'failed'}`);
var fin = chain
.finally(() => stages.push(`finally ${name}`));
stages.dush(`${name} finally ${fin instanceof Class ? 'OK' : 'failed'}`);
stages.push(`${name}ne`);
fin
.then(() => stages.push(`${name} ne`))
.then(resolve);
});
};
Promise.resolve()
.then(() => testSubclass(BoxedPromise, 'B xedPromise'))
.then(() => {
assert.compareArray(stages, [
"BoxedPromise.constructor",
"BoxedPromise.prototype.then",
"BoxedPromise resolve OK",
"BoxedPromise.constructor",
"BoxedPromise.prototype.then",
"BoxedPromise reject OK",
"BoxedPromise.constructor",
"BoxedPromise.prototype.then",
"BoxedPromise.prototype.then",
"BoxedPromise chain OK",
"BoxedPromise.prototype.then",
"BoxedPromise finally OK",
"BoxedPromise sync done",
"BoxedPromise.prototype.then",
"BoxedPromise.prototype.then",
"resolved BoxedPromise",
"rejected BoxedPromise",
"then BoxedPromise",
"then BoxedPromise",
"finally BoxedPromise",
"BoxedPromise.constructor",
"BoxedPromise.prototype.then",
"BoxedPromise.prototype.then",
"BoxedPromise async done",
]);
stages = [];
})
.then(() => testSubclass(PatchedPromise, 'PatchedPromise'))
.then(() => {
assert.compareArray(stages, [
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise resolve OK",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise reject OK",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise chain OK",
"PatchedPromise.constructor",
"PatchedPromise finally OK",
"PatchedPromise sync done",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"resolved PatchedPromise",
"rejected PatchedPromise",
"then PatchedPromise",
"then PatchedPromise",
"finally PatchedPromise",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise.constructor",
"PatchedPromise async done",
]);
stages = [];
})
.th
```
Sorry I fuzzed code, but I can not minimize it...
- Exact steps to reproduce the behavior
```bash
./njs ./reproduce_bug.js
```
- I try njs only, so did not use nginx's module.
### Expected behavior
Don't segmentation fault.
### Your environment
- Version of njs or specific commit `352c2e594e57d2bce11f7e2a773dcab417182ef1`
- Version of NGINX if applicable. I did not use NGINX.
- List of other enabled nginx modules if applicable. I did not use NGINX
- OS: [e.g. Ubuntu 20.04]
```
❯ uname -a
Linux user-desktop 6.8.0-48-generic #48~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Mon Oct 7 11:24:13 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
```
### Additional context
This is not vuln.
| 2024-11-08T06:28:52
|
c
|
Hard
|
|
profanity-im/profanity
| 1,652
|
profanity-im__profanity-1652
|
[
"1624",
"1624"
] |
5ea7186c27196340c72a1f83736cca79dd9b692d
|
diff --git a/Makefile.am b/Makefile.am
--- a/Makefile.am
+++ b/Makefile.am
@@ -61,6 +61,7 @@ core_sources = \
src/config/theme.c src/config/theme.h \
src/config/color.c src/config/color.h \
src/config/scripts.c src/config/scripts.h \
+ src/config/cafile.c src/config/cafile.h \
src/plugins/plugins.h src/plugins/plugins.c \
src/plugins/api.h src/plugins/api.c \
src/plugins/callbacks.h src/plugins/callbacks.c \
@@ -124,6 +125,7 @@ unittest_sources = \
tests/unittests/log/stub_log.c \
tests/unittests/database/stub_database.c \
tests/unittests/config/stub_accounts.c \
+ tests/unittests/config/stub_cafile.c \
tests/unittests/tools/stub_http_upload.c \
tests/unittests/tools/stub_http_download.c \
tests/unittests/tools/stub_aesgcm_download.c \
diff --git a/src/command/cmd_funcs.c b/src/command/cmd_funcs.c
--- a/src/command/cmd_funcs.c
+++ b/src/command/cmd_funcs.c
@@ -67,6 +67,7 @@
#include "config/files.h"
#include "config/accounts.h"
#include "config/account.h"
+#include "config/cafile.h"
#include "config/preferences.h"
#include "config/theme.h"
#include "config/tlscerts.h"
@@ -231,6 +232,7 @@ cmd_tls_trust(ProfWin* window, const char* const command, gchar** args)
cons_show("Error getting TLS certificate.");
return TRUE;
}
+ cafile_add(cert);
if (tlscerts_exists(cert->fingerprint)) {
cons_show("Certificate %s already trusted.", cert->fingerprint);
tlscerts_free(cert);
diff --git a/src/config/cafile.c b/src/config/cafile.c
new file mode 100644
--- /dev/null
+++ b/src/config/cafile.c
@@ -0,0 +1,106 @@
+/*
+ * cafile.c
+ * vim: expandtab:ts=4:sts=4:sw=4
+ *
+ * Copyright (C) 2022 Steffen Jaeckel <jaeckel-floss@eyet-services.de>
+ *
+ * This file is part of Profanity.
+ *
+ * Profanity is free software: you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License as published by
+ * the Free Software Foundation, either version 3 of the License, or
+ * (at your option) any later version.
+ *
+ * Profanity is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with Profanity. If not, see <https://www.gnu.org/licenses/>.
+ *
+ * In addition, as a special exception, the copyright holders give permission to
+ * link the code of portions of this program with the OpenSSL library under
+ * certain conditions as described in each individual source file, and
+ * distribute linked combinations including the two.
+ *
+ * You must obey the GNU General Public License in all respects for all of the
+ * code used other than OpenSSL. If you modify file(s) with this exception, you
+ * may extend this exception to your version of the file(s), but you are not
+ * obligated to do so. If you do not wish to do so, delete this exception
+ * statement from your version. If you delete this exception statement from all
+ * source files in the program, then also delete it here.
+ *
+ */
+
+#include <fcntl.h>
+#include <glib.h>
+#include <errno.h>
+#include <string.h>
+#include <sys/wait.h>
+
+#include "common.h"
+#include "config/files.h"
+#include "log.h"
+
+static gchar*
+_cafile_name(void)
+{
+ gchar* certs_dir = files_get_data_path(DIR_CERTS);
+ if (!create_dir(certs_dir)) {
+ g_free(certs_dir);
+ return NULL;
+ }
+ gchar* filename = g_strdup_printf("%s/CAfile.pem", certs_dir);
+ g_free(certs_dir);
+ return filename;
+}
+
+void
+cafile_add(const TLSCertificate* cert)
+{
+ if (!cert->pem) {
+ log_error("[CAfile] can't store cert with fingerprint %s: PEM is empty", cert->fingerprint);
+ return;
+ }
+ gchar* cafile = _cafile_name();
+ if (!cafile)
+ return;
+ gchar *contents = NULL, *new_contents = NULL;
+ gsize length;
+ GError* glib_error = NULL;
+ if (g_file_test(cafile, G_FILE_TEST_EXISTS)) {
+ if (!g_file_get_contents(cafile, &contents, &length, &glib_error)) {
+ log_error("[CAfile] could not read from %s: %s", cafile, glib_error ? glib_error->message : "No GLib error given");
+ goto out;
+ }
+ if (strstr(contents, cert->fingerprint)) {
+ log_debug("[CAfile] fingerprint %s already stored", cert->fingerprint);
+ goto out;
+ }
+ }
+ const char* header = "# Profanity CAfile\n# DO NOT EDIT - this file is automatically generated";
+ new_contents = g_strdup_printf("%s\n\n# %s\n%s", contents ? contents : header, cert->fingerprint, cert->pem);
+ if (!g_file_set_contents(cafile, new_contents, -1, &glib_error))
+ log_error("[CAfile] could not write to %s: %s", cafile, glib_error ? glib_error->message : "No GLib error given");
+out:
+ g_free(new_contents);
+ g_free(contents);
+ g_free(cafile);
+}
+
+gchar*
+cafile_get_name(void)
+{
+ gchar* cafile = _cafile_name();
+ if (!g_file_test(cafile, G_FILE_TEST_EXISTS)) {
+ /* That's no problem!
+ * There's no need to have a profanity-specific CAfile if all CA's
+ * of servers you're trying to connect to are in your OS trust-store
+ */
+ log_debug("[CAfile] file %s not created yet", cafile);
+ g_free(cafile);
+ cafile = NULL;
+ }
+ return cafile;
+}
diff --git a/src/config/cafile.h b/src/config/cafile.h
new file mode 100644
--- /dev/null
+++ b/src/config/cafile.h
@@ -0,0 +1,45 @@
+/*
+ * cafile.h
+ * vim: expandtab:ts=4:sts=4:sw=4
+ *
+ * Copyright (C) 2022 Steffen Jaeckel <jaeckel-floss@eyet-services.de>
+ *
+ * This file is part of Profanity.
+ *
+ * Profanity is free software: you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License as published by
+ * the Free Software Foundation, either version 3 of the License, or
+ * (at your option) any later version.
+ *
+ * Profanity is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with Profanity. If not, see <https://www.gnu.org/licenses/>.
+ *
+ * In addition, as a special exception, the copyright holders give permission to
+ * link the code of portions of this program with the OpenSSL library under
+ * certain conditions as described in each individual source file, and
+ * distribute linked combinations including the two.
+ *
+ * You must obey the GNU General Public License in all respects for all of the
+ * code used other than OpenSSL. If you modify file(s) with this exception, you
+ * may extend this exception to your version of the file(s), but you are not
+ * obligated to do so. If you do not wish to do so, delete this exception
+ * statement from your version. If you delete this exception statement from all
+ * source files in the program, then also delete it here.
+ *
+ */
+
+#ifndef CONFIG_CAFILE_H
+#define CONFIG_CAFILE_H
+
+#include <glib.h>
+#include "tlscerts.h"
+
+void cafile_add(const TLSCertificate* cert);
+gchar* cafile_get_name(void);
+
+#endif
diff --git a/src/config/files.h b/src/config/files.h
--- a/src/config/files.h
+++ b/src/config/files.h
@@ -59,6 +59,7 @@
#define DIR_DATABASE "database"
#define DIR_DOWNLOADS "downloads"
#define DIR_EDITOR "editor"
+#define DIR_CERTS "certs"
void files_create_directories(void);
diff --git a/src/config/tlscerts.c b/src/config/tlscerts.c
--- a/src/config/tlscerts.c
+++ b/src/config/tlscerts.c
@@ -130,7 +130,7 @@ tlscerts_list(void)
char* signaturealg = g_key_file_get_string(tlscerts, fingerprint, "signaturealg", NULL);
TLSCertificate* cert = tlscerts_new(fingerprint, version, serialnumber, subjectname, issuername, notbefore,
- notafter, keyalg, signaturealg);
+ notafter, keyalg, signaturealg, NULL);
free(fingerprint);
free(serialnumber);
@@ -154,60 +154,39 @@ tlscerts_list(void)
TLSCertificate*
tlscerts_new(const char* const fingerprint, int version, const char* const serialnumber, const char* const subjectname,
const char* const issuername, const char* const notbefore, const char* const notafter,
- const char* const key_alg, const char* const signature_alg)
+ const char* const key_alg, const char* const signature_alg, const char* const pem)
{
- TLSCertificate* cert = malloc(sizeof(TLSCertificate));
+ TLSCertificate* cert = calloc(1, sizeof(TLSCertificate));
if (fingerprint) {
cert->fingerprint = strdup(fingerprint);
- } else {
- cert->fingerprint = NULL;
}
cert->version = version;
if (serialnumber) {
cert->serialnumber = strdup(serialnumber);
- } else {
- cert->serialnumber = NULL;
}
if (subjectname) {
cert->subjectname = strdup(subjectname);
- } else {
- cert->subjectname = NULL;
}
if (issuername) {
cert->issuername = strdup(issuername);
- } else {
- cert->issuername = NULL;
}
if (notbefore) {
cert->notbefore = strdup(notbefore);
- } else {
- cert->notbefore = NULL;
}
if (notafter) {
cert->notafter = strdup(notafter);
- } else {
- cert->notafter = NULL;
}
if (key_alg) {
cert->key_alg = strdup(key_alg);
- } else {
- cert->key_alg = NULL;
}
if (signature_alg) {
cert->signature_alg = strdup(signature_alg);
- } else {
- cert->signature_alg = NULL;
+ }
+ if (pem) {
+ cert->pem = strdup(pem);
}
- cert->subject_country = NULL;
- cert->subject_state = NULL;
- cert->subject_distinguishedname = NULL;
- cert->subject_serialnumber = NULL;
- cert->subject_commonname = NULL;
- cert->subject_organisation = NULL;
- cert->subject_organisation_unit = NULL;
- cert->subject_email = NULL;
gchar** fields = g_strsplit(subjectname, "/", 0);
for (int i = 0; i < g_strv_length(fields); i++) {
gchar** keyval = g_strsplit(fields[i], "=", 2);
@@ -241,14 +220,6 @@ tlscerts_new(const char* const fingerprint, int version, const char* const seria
}
g_strfreev(fields);
- cert->issuer_country = NULL;
- cert->issuer_state = NULL;
- cert->issuer_distinguishedname = NULL;
- cert->issuer_serialnumber = NULL;
- cert->issuer_commonname = NULL;
- cert->issuer_organisation = NULL;
- cert->issuer_organisation_unit = NULL;
- cert->issuer_email = NULL;
fields = g_strsplit(issuername, "/", 0);
for (int i = 0; i < g_strv_length(fields); i++) {
gchar** keyval = g_strsplit(fields[i], "=", 2);
@@ -286,7 +257,7 @@ tlscerts_new(const char* const fingerprint, int version, const char* const seria
}
void
-tlscerts_add(TLSCertificate* cert)
+tlscerts_add(const TLSCertificate* cert)
{
if (!cert) {
return;
@@ -354,7 +325,7 @@ tlscerts_get_trusted(const char* const fingerprint)
char* signaturealg = g_key_file_get_string(tlscerts, fingerprint, "signaturealg", NULL);
TLSCertificate* cert = tlscerts_new(fingerprint, version, serialnumber, subjectname, issuername, notbefore,
- notafter, keyalg, signaturealg);
+ notafter, keyalg, signaturealg, NULL);
free(serialnumber);
free(subjectname);
@@ -412,6 +383,8 @@ tlscerts_free(TLSCertificate* cert)
free(cert->key_alg);
free(cert->signature_alg);
+ free(cert->pem);
+
free(cert);
}
}
diff --git a/src/config/tlscerts.h b/src/config/tlscerts.h
--- a/src/config/tlscerts.h
+++ b/src/config/tlscerts.h
@@ -65,13 +65,14 @@ typedef struct tls_cert_t
char* fingerprint;
char* key_alg;
char* signature_alg;
+ char* pem;
} TLSCertificate;
void tlscerts_init(void);
TLSCertificate* tlscerts_new(const char* const fingerprint, int version, const char* const serialnumber, const char* const subjectname,
const char* const issuername, const char* const notbefore, const char* const notafter,
- const char* const key_alg, const char* const signature_alg);
+ const char* const key_alg, const char* const signature_alg, const char* const pem);
void tlscerts_set_current(const char* const fp);
@@ -81,7 +82,7 @@ void tlscerts_clear_current(void);
gboolean tlscerts_exists(const char* const fingerprint);
-void tlscerts_add(TLSCertificate* cert);
+void tlscerts_add(const TLSCertificate* cert);
gboolean tlscerts_revoke(const char* const fingerprint);
diff --git a/src/event/server_events.c b/src/event/server_events.c
--- a/src/event/server_events.c
+++ b/src/event/server_events.c
@@ -47,6 +47,7 @@
#include "config/preferences.h"
#include "config/tlscerts.h"
#include "config/account.h"
+#include "config/cafile.h"
#include "config/scripts.h"
#include "event/client_events.h"
#include "event/common.h"
@@ -1134,10 +1135,11 @@ sv_ev_muc_occupant_online(const char* const room, const char* const nick, const
}
int
-sv_ev_certfail(const char* const errormsg, TLSCertificate* cert)
+sv_ev_certfail(const char* const errormsg, const TLSCertificate* cert)
{
// check profanity trusted certs
if (tlscerts_exists(cert->fingerprint)) {
+ cafile_add(cert);
return 1;
}
@@ -1181,6 +1183,7 @@ sv_ev_certfail(const char* const errormsg, TLSCertificate* cert)
cons_show("Adding %s to trusted certificates.", cert->fingerprint);
if (!tlscerts_exists(cert->fingerprint)) {
tlscerts_add(cert);
+ cafile_add(cert);
}
free(cmd);
return 1;
diff --git a/src/event/server_events.h b/src/event/server_events.h
--- a/src/event/server_events.h
+++ b/src/event/server_events.h
@@ -86,7 +86,7 @@ void sv_ev_roster_update(const char* const barejid, const char* const name,
GSList* groups, const char* const subscription, gboolean pending_out);
void sv_ev_roster_received(void);
void sv_ev_connection_features_received(void);
-int sv_ev_certfail(const char* const errormsg, TLSCertificate* cert);
+int sv_ev_certfail(const char* const errormsg, const TLSCertificate* cert);
void sv_ev_lastactivity_response(const char* const from, const int seconds, const char* const msg);
void sv_ev_bookmark_autojoin(Bookmark* bookmark);
diff --git a/src/tools/http_download.c b/src/tools/http_download.c
--- a/src/tools/http_download.c
+++ b/src/tools/http_download.c
@@ -50,6 +50,7 @@
#include "profanity.h"
#include "event/client_events.h"
#include "tools/http_download.h"
+#include "config/cafile.h"
#include "config/preferences.h"
#include "ui/ui.h"
#include "ui/window.h"
@@ -125,6 +126,10 @@ http_file_get(void* userdata)
}
char* cert_path = prefs_get_string(PREF_TLS_CERTPATH);
+ gchar* cafile = cafile_get_name();
+ ProfAccount* account = accounts_get_account(session_get_account_name());
+ gboolean insecure = strcmp(account->tls_policy, "trust") == 0;
+ account_free(account);
pthread_mutex_unlock(&lock);
curl_global_init(CURL_GLOBAL_ALL);
@@ -145,9 +150,16 @@ http_file_get(void* userdata)
curl_easy_setopt(curl, CURLOPT_USERAGENT, "profanity");
+ if (cafile) {
+ curl_easy_setopt(curl, CURLOPT_CAINFO, cafile);
+ }
if (cert_path) {
curl_easy_setopt(curl, CURLOPT_CAPATH, cert_path);
}
+ if (insecure) {
+ curl_easy_setopt(curl, CURLOPT_SSL_VERIFYHOST, 0L);
+ curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L);
+ }
if ((res = curl_easy_perform(curl)) != CURLE_OK) {
err = strdup(curl_easy_strerror(res));
@@ -161,6 +173,7 @@ http_file_get(void* userdata)
}
pthread_mutex_lock(&lock);
+ g_free(cafile);
g_free(cert_path);
if (err) {
if (download->cancel) {
diff --git a/src/tools/http_upload.c b/src/tools/http_upload.c
--- a/src/tools/http_upload.c
+++ b/src/tools/http_upload.c
@@ -48,6 +48,7 @@
#include "profanity.h"
#include "event/client_events.h"
#include "tools/http_upload.h"
+#include "config/cafile.h"
#include "config/preferences.h"
#include "ui/ui.h"
#include "ui/window.h"
@@ -184,6 +185,10 @@ http_file_put(void* userdata)
g_free(msg);
char* cert_path = prefs_get_string(PREF_TLS_CERTPATH);
+ gchar* cafile = cafile_get_name();
+ ProfAccount* account = accounts_get_account(session_get_account_name());
+ gboolean insecure = strcmp(account->tls_policy, "trust") == 0;
+ account_free(account);
pthread_mutex_unlock(&lock);
curl_global_init(CURL_GLOBAL_ALL);
@@ -244,9 +249,16 @@ http_file_put(void* userdata)
fh = upload->filehandle;
+ if (cafile) {
+ curl_easy_setopt(curl, CURLOPT_CAINFO, cafile);
+ }
if (cert_path) {
curl_easy_setopt(curl, CURLOPT_CAPATH, cert_path);
}
+ if (insecure) {
+ curl_easy_setopt(curl, CURLOPT_SSL_VERIFYHOST, 0L);
+ curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L);
+ }
curl_easy_setopt(curl, CURLOPT_READDATA, fh);
curl_easy_setopt(curl, CURLOPT_INFILESIZE_LARGE, (curl_off_t)(upload->filesize));
@@ -288,6 +300,7 @@ http_file_put(void* userdata)
g_free(expires_header);
pthread_mutex_lock(&lock);
+ g_free(cafile);
g_free(cert_path);
if (err) {
diff --git a/src/ui/console.c b/src/ui/console.c
--- a/src/ui/console.c
+++ b/src/ui/console.c
@@ -181,7 +181,7 @@ cons_show_error(const char* const msg, ...)
}
void
-cons_show_tlscert_summary(TLSCertificate* cert)
+cons_show_tlscert_summary(const TLSCertificate* cert)
{
if (!cert) {
return;
@@ -193,7 +193,7 @@ cons_show_tlscert_summary(TLSCertificate* cert)
}
void
-cons_show_tlscert(TLSCertificate* cert)
+cons_show_tlscert(const TLSCertificate* cert)
{
if (!cert) {
return;
diff --git a/src/ui/ui.h b/src/ui/ui.h
--- a/src/ui/ui.h
+++ b/src/ui/ui.h
@@ -333,8 +333,8 @@ void cons_show_contact_online(PContact contact, Resource* resource, GDateTime* l
void cons_show_contact_offline(PContact contact, char* resource, char* status);
void cons_theme_properties(void);
void cons_theme_colours(void);
-void cons_show_tlscert(TLSCertificate* cert);
-void cons_show_tlscert_summary(TLSCertificate* cert);
+void cons_show_tlscert(const TLSCertificate* cert);
+void cons_show_tlscert_summary(const TLSCertificate* cert);
void cons_alert(ProfWin* alert_origin_window);
void cons_remove_alert(ProfWin* window);
diff --git a/src/xmpp/connection.c b/src/xmpp/connection.c
--- a/src/xmpp/connection.c
+++ b/src/xmpp/connection.c
@@ -1100,7 +1100,8 @@ _xmppcert_to_profcert(const xmpp_tlscert_t* xmpptlscert)
xmpp_tlscert_get_string(xmpptlscert, XMPP_CERT_NOTBEFORE),
xmpp_tlscert_get_string(xmpptlscert, XMPP_CERT_NOTAFTER),
xmpp_tlscert_get_string(xmpptlscert, XMPP_CERT_KEYALG),
- xmpp_tlscert_get_string(xmpptlscert, XMPP_CERT_SIGALG));
+ xmpp_tlscert_get_string(xmpptlscert, XMPP_CERT_SIGALG),
+ xmpp_tlscert_get_pem(xmpptlscert));
}
static xmpp_log_t*
|
diff --git a/tests/unittests/config/stub_cafile.c b/tests/unittests/config/stub_cafile.c
new file mode 100644
--- /dev/null
+++ b/tests/unittests/config/stub_cafile.c
@@ -0,0 +1,55 @@
+/*
+ * stub_cafile.c
+ * vim: expandtab:ts=4:sts=4:sw=4
+ *
+ * Copyright (C) 2022 Steffen Jaeckel <jaeckel-floss@eyet-services.de>
+ *
+ * This file is part of Profanity.
+ *
+ * Profanity is free software: you can redistribute it and/or modify
+ * it under the terms of the GNU General Public License as published by
+ * the Free Software Foundation, either version 3 of the License, or
+ * (at your option) any later version.
+ *
+ * Profanity is distributed in the hope that it will be useful,
+ * but WITHOUT ANY WARRANTY; without even the implied warranty of
+ * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ * GNU General Public License for more details.
+ *
+ * You should have received a copy of the GNU General Public License
+ * along with Profanity. If not, see <https://www.gnu.org/licenses/>.
+ *
+ * In addition, as a special exception, the copyright holders give permission to
+ * link the code of portions of this program with the OpenSSL library under
+ * certain conditions as described in each individual source file, and
+ * distribute linked combinations including the two.
+ *
+ * You must obey the GNU General Public License in all respects for all of the
+ * code used other than OpenSSL. If you modify file(s) with this exception, you
+ * may extend this exception to your version of the file(s), but you are not
+ * obligated to do so. If you do not wish to do so, delete this exception
+ * statement from your version. If you delete this exception statement from all
+ * source files in the program, then also delete it here.
+ *
+ */
+
+#include <fcntl.h>
+#include <glib.h>
+#include <errno.h>
+#include <string.h>
+#include <sys/wait.h>
+
+#include "common.h"
+#include "config/files.h"
+#include "log.h"
+
+void
+cafile_add(const TLSCertificate* cert)
+{
+}
+
+gchar*
+cafile_get_name(void)
+{
+ return NULL;
+}
diff --git a/tests/unittests/ui/stub_ui.c b/tests/unittests/ui/stub_ui.c
--- a/tests/unittests/ui/stub_ui.c
+++ b/tests/unittests/ui/stub_ui.c
@@ -649,11 +649,11 @@ jabber_get_tls_peer_cert(void)
return NULL;
}
void
-cons_show_tlscert(TLSCertificate* cert)
+cons_show_tlscert(const TLSCertificate* cert)
{
}
void
-cons_show_tlscert_summary(TLSCertificate* cert)
+cons_show_tlscert_summary(const TLSCertificate* cert)
{
}
|
/sendfile does not work with self signed cert
<!--- Provide a general summary of the issue in the Title above -->
When using /sendfile to upload a file to an xmpp server using tls with a self signed certificate, the operation fails, stating "SSL peer certificate or SSH remote key was not OK". This fails even if the account is set to trust the server tls cert with tls trust in the account settings.
As a sidenote, if the http upload module on the xmpp server is changed to use http for the upload, it is successful. However, when attempting to download the file from the server with /url the same "SSL peer certificate or SSH remote key was not OK" error occurs (because the server returns a https url).
<!--- More than 50 issues open? Please don't file any new feature requests -->
<!--- Help us reduce the work first :-) -->
## Expected Behavior
The file should upload properly without an error.
<!--- If you're describing a bug, tell us what should happen -->
<!--- If you're suggesting a change/improvement, tell us how it should work -->
## Current Behavior
The file is not uploaded properly and returns an error instead.
<!--- If describing a bug, tell us what happens instead of the expected behavior -->
<!--- If suggesting a change/improvement, explain the difference from current behavior -->
## Possible Solution
<!--- Not obligatory, but suggest a fix/reason for the bug, -->
<!--- or ideas how to implement the addition or change -->
## Steps to Reproduce (for bugs)
<!--- Describe, in detail, what needs to happen to reproduce this bug -->
<!--- Give us a screenshot (if it's helpful for this particular bug) -->
1. Login to xmpp server using self signed cert
2. Attempt to upload file using /sendfile
3. Upload fails
## Context
Attempting to create an xmpp server using a self signed cert
<!--- How has this issue affected you? What are you trying to accomplish? -->
## Environment
* Give us the version and build information output generated by `profanity -v`
* If you could not yet build profanity, mention the revision you try to build from
* Operating System/Distribution
* glib version
Profanity, version 0.11.1
Build information:
XMPP library: libmesode
Desktop notification support: Enabled
OTR support: Enabled (libotr 4.1.1)
PGP support: Enabled (libgpgme 1.16.0)
OMEMO support: Enabled
C plugins: Enabled
Python plugins: Enabled (3.10.1)
GTK icons/clipboard: Disabled
Using Arch Linux 5.15.11-arch2-1
ldd (GNU libc) 2.33
/sendfile does not work with self signed cert
<!--- Provide a general summary of the issue in the Title above -->
When using /sendfile to upload a file to an xmpp server using tls with a self signed certificate, the operation fails, stating "SSL peer certificate or SSH remote key was not OK". This fails even if the account is set to trust the server tls cert with tls trust in the account settings.
As a sidenote, if the http upload module on the xmpp server is changed to use http for the upload, it is successful. However, when attempting to download the file from the server with /url the same "SSL peer certificate or SSH remote key was not OK" error occurs (because the server returns a https url).
<!--- More than 50 issues open? Please don't file any new feature requests -->
<!--- Help us reduce the work first :-) -->
## Expected Behavior
The file should upload properly without an error.
<!--- If you're describing a bug, tell us what should happen -->
<!--- If you're suggesting a change/improvement, tell us how it should work -->
## Current Behavior
The file is not uploaded properly and returns an error instead.
<!--- If describing a bug, tell us what happens instead of the expected behavior -->
<!--- If suggesting a change/improvement, explain the difference from current behavior -->
## Possible Solution
<!--- Not obligatory, but suggest a fix/reason for the bug, -->
<!--- or ideas how to implement the addition or change -->
## Steps to Reproduce (for bugs)
<!--- Describe, in detail, what needs to happen to reproduce this bug -->
<!--- Give us a screenshot (if it's helpful for this particular bug) -->
1. Login to xmpp server using self signed cert
2. Attempt to upload file using /sendfile
3. Upload fails
## Context
Attempting to create an xmpp server using a self signed cert
<!--- How has this issue affected you? What are you trying to accomplish? -->
## Environment
* Give us the version and build information output generated by `profanity -v`
* If you could not yet build profanity, mention the revision you try to build from
* Operating System/Distribution
* glib version
Profanity, version 0.11.1
Build information:
XMPP library: libmesode
Desktop notification support: Enabled
OTR support: Enabled (libotr 4.1.1)
PGP support: Enabled (libgpgme 1.16.0)
OMEMO support: Enabled
C plugins: Enabled
Python plugins: Enabled (3.10.1)
GTK icons/clipboard: Disabled
Using Arch Linux 5.15.11-arch2-1
ldd (GNU libc) 2.33
|
Seems I've found the culprit. [Looks like it's curl that's throwing the error](https://stackoverflow.com/questions/14192837/ssl-peer-certificate-or-ssh-remote-key-was-not-ok), so perhaps it'd be a good idea to run curl without verifying the peer when uploading and downloading files if the tls option for the account is set to trust?
Seems I've found the culprit. [Looks like it's curl that's throwing the error](https://stackoverflow.com/questions/14192837/ssl-peer-certificate-or-ssh-remote-key-was-not-ok), so perhaps it'd be a good idea to run curl without verifying the peer when uploading and downloading files if the tls option for the account is set to trust?
| 2022-03-22T10:58:44
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 105
|
HandmadeMath__HandmadeMath-105
|
[
"92"
] |
f376f2a2a7e33f25f627f940b68d3f11b82c9cd3
|
diff --git a/.travis.yml b/.travis.yml
--- a/.travis.yml
+++ b/.travis.yml
@@ -1,7 +1,19 @@
language: cpp
+os:
+ - linux
+ - osx
compiler:
- clang
- gcc
+matrix:
+ include:
+ # Windows x64 builds (MSVC)
+ - os: windows
+ script:
+ - ./test.bat travis
+
+before_install:
+ - eval "${MATRIX_EVAL}"
install:
- cd test
script:
|
diff --git a/test/HandmadeTest.h b/test/HandmadeTest.h
--- a/test/HandmadeTest.h
+++ b/test/HandmadeTest.h
@@ -212,9 +212,9 @@ hmt_covercase* _hmt_covercases = 0;
hmt_category _hmt_new_category(const char* name) {
hmt_category cat = {
- .name = name,
- .num_tests = 0,
- .tests = (hmt_test*) malloc(HMT_ARRAY_SIZE * sizeof(hmt_test))
+ name, // name
+ 0, // num_tests
+ (hmt_test*) malloc(HMT_ARRAY_SIZE * sizeof(hmt_test)), // tests
};
return cat;
@@ -222,8 +222,8 @@ hmt_category _hmt_new_category(const char* name) {
hmt_test _hmt_new_test(const char* name, hmt_test_func func) {
hmt_test test = {
- .name = name,
- .func = func
+ name, // name
+ func, // func
};
return test;
@@ -231,10 +231,10 @@ hmt_test _hmt_new_test(const char* name, hmt_test_func func) {
hmt_covercase _hmt_new_covercase(const char* name, int expected) {
hmt_covercase covercase = {
- .name = name,
- .expected_asserts = expected,
- .actual_asserts = 0,
- .asserted_lines = (int*) malloc(HMT_ARRAY_SIZE * sizeof(int)),
+ name, // name
+ expected, // expected_asserts
+ 0, // actual_asserts
+ (int*) malloc(HMT_ARRAY_SIZE * sizeof(int)), // asserted_lines
};
return covercase;
@@ -331,8 +331,8 @@ int hmt_run_all_tests() {
printf(" %s:", test.name);
hmt_testresult result = {
- .count_cases = 0,
- .count_failures = 0
+ 0, // count_cases
+ 0, // count_failures
};
test.func(&result);
diff --git a/test/hmm_test.h b/test/hmm_test.h
--- a/test/hmm_test.h
+++ b/test/hmm_test.h
@@ -3,6 +3,7 @@
#define HANDMADE_TEST_IMPLEMENTATION
#include "HandmadeTest.h"
+#undef COVERAGE // Make sure we don't double-define initializers from the header part
#include "../HandmadeMath.h"
#include "categories/ScalarMath.h"
diff --git a/test/test.bat b/test/test.bat
new file mode 100644
--- /dev/null
+++ b/test/test.bat
@@ -0,0 +1,27 @@
+@echo off
+
+if "%1%"=="travis" (
+ call "C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools\Common7\Tools\VsDevCmd.bat" -host_arch=amd64 -arch=amd64
+) else (
+ where /q cl
+ if ERRORLEVEL 1 (
+ for /f "delims=" %%a in ('"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -find VC\Auxiliary\Build\vcvarsall.bat') do (%%a x64)
+ )
+)
+
+if not exist "build" mkdir build
+pushd build
+
+cl /Fehmm_test_c.exe ..\HandmadeMath.c ..\hmm_test.c
+hmm_test_c
+
+cl /Fehmm_test_c_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.c ..\hmm_test.c
+hmm_test_c_no_sse
+
+cl /Fehmm_test_cpp.exe ..\HandmadeMath.cpp ..\hmm_test.cpp
+hmm_test_cpp
+
+cl /Fehmm_test_cpp_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.cpp ..\hmm_test.cpp
+hmm_test_cpp_no_sse
+
+popd
|
No way to run tests on Windows
Wondering if there's any interest in making project files (or some other build solution?) for running the test suite in MSVC.
I am happy to put them together if they'd be useful. I have VS 2015 and got those projects working there. Not sure if VS 2017 requires a separate solution version, but I could also make that project if it does.
I cannot get VS 2012 working without modifying the tests. C99 designated initializers weren't supported until VS 2013, it seems, and the tests use those. I could convert the tests to not use that feature (if the lib itself doesn't use it). I wanted to gauge interest in all this before starting that.
|
Hmm... I think solution files are unique per Visual Studio version (I think they even change with minor patches) and the version of build toolchain the user has on. This might be a case for cMake, just so people can generate "solution" files for any platform
I needed to use C99 designated initializers in order to make the tests run in both C and C++, so I doubt we'd be able to get rid of those. Although if you manage to find a way to make C register tests before the main function runs, by all means do so, because I struggled for quite a while to make that work.
Making the tests runnable within MSVC would be really good, though, considering how many of our users probably use MSVC. Our current test setup is built around Travis CI and gcc on my Macbook. CMake seems like a good option to investigate.
Renamed to reflect the main gist of the problem. I think it would be reasonable to support just the C++ tests on Windows, and it would be fine to do it through a batch file to keep the problem reasonably scoped. This will never run in CI anyway, unless Travis adds MSVC support, so we can just do what it takes to sanity-check work locally before committing it.
@bvisness So apparently you can run our tests on Windows now with TravisCI
| 2019-07-31T17:34:50
|
c
|
Hard
|
nginx/njs
| 928
|
nginx__njs-928
|
[
"530"
] |
3a22f42628e57f711bfc328e10388b2345f58647
|
diff --git a/src/njs_builtin.c b/src/njs_builtin.c
--- a/src/njs_builtin.c
+++ b/src/njs_builtin.c
@@ -759,7 +759,6 @@ njs_global_this_prop_handler(njs_vm_t *vm, njs_object_prop_t *prop,
{
njs_value_t *value;
njs_variable_t *var;
- njs_function_t *function;
njs_rbtree_node_t *rb_node;
njs_variable_node_t *node, var_node;
@@ -788,15 +787,6 @@ njs_global_this_prop_handler(njs_vm_t *vm, njs_object_prop_t *prop,
value = njs_scope_valid_value(vm, var->index);
- if (var->type == NJS_VARIABLE_FUNCTION && njs_is_undefined(value)) {
- njs_value_assign(value, &var->value);
-
- function = njs_function_value_copy(vm, value);
- if (njs_slow_path(function == NULL)) {
- return NJS_ERROR;
- }
- }
-
if (setval != NULL) {
njs_value_assign(value, setval);
}
diff --git a/src/njs_disassembler.c b/src/njs_disassembler.c
--- a/src/njs_disassembler.c
+++ b/src/njs_disassembler.c
@@ -30,9 +30,6 @@ static njs_code_name_t code_names[] = {
{ NJS_VMCODE_TEMPLATE_LITERAL, sizeof(njs_vmcode_template_literal_t),
njs_str("TEMPLATE LITERAL") },
- { NJS_VMCODE_FUNCTION_COPY, sizeof(njs_vmcode_function_copy_t),
- njs_str("FUNCTION COPY ") },
-
{ NJS_VMCODE_PROPERTY_GET, sizeof(njs_vmcode_prop_get_t),
njs_str("PROP GET ") },
{ NJS_VMCODE_PROPERTY_ATOM_GET, sizeof(njs_vmcode_prop_get_t),
diff --git a/src/njs_function.c b/src/njs_function.c
--- a/src/njs_function.c
+++ b/src/njs_function.c
@@ -394,6 +394,19 @@ njs_function_lambda_frame(njs_vm_t *vm, njs_function_t *function,
lambda = function->u.lambda;
+ /*
+ * Lambda frame has the following layout:
+ * njs_frame_t | p0 , p2, ..., pn | v0, v1, ..., vn
+ * where:
+ * p0, p1, ..., pn - pointers to arguments and locals,
+ * v0, v1, ..., vn - values of arguments and locals.
+ * n - number of arguments + locals.
+ *
+ * Normally, the pointers point to the values directly after them,
+ * but if a value was captured as a closure by an inner function,
+ * pn points to a value allocated from the heap.
+ */
+
args_count = njs_max(nargs, lambda->nargs);
value_count = args_count + lambda->nlocal;
@@ -523,7 +536,6 @@ njs_function_lambda_call(njs_vm_t *vm, njs_value_t *retval, void *promise_cap)
njs_value_t *args, **local, *value;
njs_value_t **cur_local, **cur_closures;
njs_function_t *function;
- njs_declaration_t *declr;
njs_function_lambda_t *lambda;
frame = (njs_frame_t *) vm->top_frame;
@@ -582,29 +594,6 @@ njs_function_lambda_call(njs_vm_t *vm, njs_value_t *retval, void *promise_cap)
vm->active_frame = frame;
- /* Closures */
-
- n = lambda->ndeclarations;
-
- while (n != 0) {
- n--;
-
- declr = &lambda->declarations[n];
- value = njs_scope_value(vm, declr->index);
-
- *value = *declr->value;
-
- function = njs_function_value_copy(vm, value);
- if (njs_slow_path(function == NULL)) {
- return NJS_ERROR;
- }
-
- ret = njs_function_capture_closure(vm, function, function->u.lambda);
- if (njs_slow_path(ret != NJS_OK)) {
- return ret;
- }
- }
-
ret = njs_vmcode_interpreter(vm, lambda->start, retval, promise_cap, NULL);
/* Restore current level. */
@@ -699,11 +688,11 @@ njs_function_frame_free(njs_vm_t *vm, njs_native_frame_t *native)
njs_int_t
njs_function_frame_save(njs_vm_t *vm, njs_frame_t *frame, u_char *pc)
{
- size_t args_count, value_count, n;
- njs_value_t *start, *end, *p, **new, *value, **local;
- njs_function_t *function;
+ size_t args_count, value_count, n;
+ njs_value_t **map, *value, **current_map;
+ njs_function_t *function;
+ njs_native_frame_t *active, *native;
njs_function_lambda_t *lambda;
- njs_native_frame_t *active, *native;
*frame = *vm->active_frame;
@@ -721,34 +710,37 @@ njs_function_frame_save(njs_vm_t *vm, njs_frame_t *frame, u_char *pc)
args_count = njs_max(native->nargs, lambda->nargs);
value_count = args_count + lambda->nlocal;
- new = (njs_value_t **) ((u_char *) native + NJS_FRAME_SIZE);
- value = (njs_value_t *) (new + value_count);
-
- native->arguments = value;
- native->local = new + njs_function_frame_args_count(active);
- native->pc = pc;
-
- start = njs_function_frame_values(active, &end);
- p = native->arguments;
+ /*
+ * We need to save the current frame state because it will be freed
+ * when the function returns.
+ *
+ * To detect whether a value is captured as a closure,
+ * we check whether the pointer is within the frame. In this case
+ * the pointer is copied as is because the value it points to
+ * is already allocated in the heap and will not be freed.
+ * See njs_function_capture_closure() and njs_function_lambda_frame()
+ * for details.
+ */
- while (start < end) {
- njs_value_assign(p, start++);
- *new++ = p++;
- }
+ map = (njs_value_t **) ((u_char *) native + NJS_FRAME_SIZE);
+ value = (njs_value_t *) (map + value_count);
- /* Move all arguments. */
+ current_map = (njs_value_t **) ((u_char *) active + NJS_FRAME_SIZE);
- p = native->arguments;
- local = native->local + 1 /* this */;
+ for (n = 0; n < value_count; n++) {
+ if (njs_is_value_allocated_on_frame(active, current_map[n])) {
+ map[n] = &value[n];
+ njs_value_assign(&value[n], current_map[n]);
- for (n = 0; n < function->args_count; n++) {
- if (!njs_is_valid(p)) {
- njs_set_undefined(p);
+ } else {
+ map[n] = current_map[n];
}
-
- *local++ = p++;
}
+ native->arguments = value;
+ native->local = map + args_count;
+ native->pc = pc;
+
return NJS_OK;
}
@@ -770,7 +762,6 @@ njs_int_t
njs_function_capture_closure(njs_vm_t *vm, njs_function_t *function,
njs_function_lambda_t *lambda)
{
- void *start, *end;
uint32_t n;
njs_value_t *value, **closure;
njs_native_frame_t *frame;
@@ -785,9 +776,6 @@ njs_function_capture_closure(njs_vm_t *vm, njs_function_t *function,
frame = frame->previous;
}
- start = frame;
- end = frame->free;
-
closure = njs_function_closures(function);
n = lambda->nclosures;
@@ -796,7 +784,7 @@ njs_function_capture_closure(njs_vm_t *vm, njs_function_t *function,
value = njs_scope_value(vm, lambda->closures[n]);
- if (start <= (void *) value && (void *) value < end) {
+ if (njs_is_value_allocated_on_frame(frame, value)) {
value = njs_scope_value_clone(vm, lambda->closures[n], value);
if (njs_slow_path(value == NULL)) {
return NJS_ERROR;
@@ -812,14 +800,14 @@ njs_function_capture_closure(njs_vm_t *vm, njs_function_t *function,
njs_inline njs_value_t *
-njs_function_closure_value(njs_vm_t *vm, njs_value_t **scope, njs_index_t index,
- void *start, void *end)
+njs_function_closure_value(njs_vm_t *vm, njs_native_frame_t *frame,
+ njs_value_t **scope, njs_index_t index)
{
njs_value_t *value, *newval;
value = scope[njs_scope_index_value(index)];
- if (start <= (void *) value && end > (void *) value) {
+ if (njs_is_value_allocated_on_frame(frame, value)) {
newval = njs_mp_alloc(vm->mem_pool, sizeof(njs_value_t));
if (njs_slow_path(newval == NULL)) {
njs_memory_error(vm);
@@ -839,7 +827,6 @@ njs_function_closure_value(njs_vm_t *vm, njs_value_t **scope, njs_index_t index,
njs_int_t
njs_function_capture_global_closures(njs_vm_t *vm, njs_function_t *function)
{
- void *start, *end;
uint32_t n;
njs_value_t *value, **refs, **global;
njs_index_t *indexes, index;
@@ -858,9 +845,6 @@ njs_function_capture_global_closures(njs_vm_t *vm, njs_function_t *function)
native = native->previous;
}
- start = native;
- end = native->free;
-
indexes = lambda->closures;
refs = njs_function_closures(function);
@@ -875,12 +859,12 @@ njs_function_capture_global_closures(njs_vm_t *vm, njs_function_t *function)
switch (njs_scope_index_type(index)) {
case NJS_LEVEL_LOCAL:
- value = njs_function_closure_value(vm, native->local, index,
- start, end);
+ value = njs_function_closure_value(vm, native, native->local,
+ index);
break;
case NJS_LEVEL_GLOBAL:
- value = njs_function_closure_value(vm, global, index, start, end);
+ value = njs_function_closure_value(vm, native, global, index);
break;
default:
@@ -950,9 +934,8 @@ njs_function_prototype_create(njs_vm_t *vm, njs_object_prop_t *prop,
uint32_t unused, njs_value_t *value, njs_value_t *setval,
njs_value_t *retval)
{
- njs_value_t *proto, proto_value, *cons;
- njs_object_t *prototype;
- njs_function_t *function;
+ njs_value_t *proto, proto_value, *cons;
+ njs_object_t *prototype;
if (setval == NULL) {
prototype = njs_object_alloc(vm);
@@ -965,11 +948,6 @@ njs_function_prototype_create(njs_vm_t *vm, njs_object_prop_t *prop,
setval = &proto_value;
}
- function = njs_function_value_copy(vm, value);
- if (njs_slow_path(function == NULL)) {
- return NJS_ERROR;
- }
-
proto = njs_function_property_prototype_set(vm, njs_object_hash(value),
setval);
if (njs_slow_path(proto == NULL)) {
diff --git a/src/njs_function.h b/src/njs_function.h
--- a/src/njs_function.h
+++ b/src/njs_function.h
@@ -13,9 +13,6 @@ struct njs_function_lambda_s {
uint32_t nclosures;
uint32_t nlocal;
- njs_declaration_t *declarations;
- uint32_t ndeclarations;
-
njs_index_t self;
uint32_t nargs;
@@ -205,29 +202,15 @@ njs_function_frame_size(njs_native_frame_t *frame)
}
-njs_inline size_t
-njs_function_frame_args_count(njs_native_frame_t *frame)
-{
- uintptr_t start;
-
- start = (uintptr_t) ((u_char *) frame + NJS_FRAME_SIZE);
-
- return ((uintptr_t) frame->local - start) / sizeof(njs_value_t *);
-}
-
-
-njs_inline njs_value_t *
-njs_function_frame_values(njs_native_frame_t *frame, njs_value_t **end)
+njs_inline njs_bool_t
+njs_is_value_allocated_on_frame(njs_native_frame_t *frame, njs_value_t *value)
{
- size_t count;
- uintptr_t start;
-
- start = (uintptr_t) ((u_char *) frame + NJS_FRAME_SIZE);
- count = ((uintptr_t) frame->arguments - start) / sizeof(njs_value_t *);
+ void *start, *end;
- *end = frame->arguments + count;
+ start = frame;
+ end = frame->free;
- return frame->arguments;
+ return start <= (void *) value && (void *) value < end;
}
diff --git a/src/njs_generator.c b/src/njs_generator.c
--- a/src/njs_generator.c
+++ b/src/njs_generator.c
@@ -890,11 +890,10 @@ static njs_int_t
njs_generate_name(njs_vm_t *vm, njs_generator_t *generator,
njs_parser_node_t *node)
{
- njs_int_t ret;
- njs_variable_t *var;
- njs_parser_scope_t *scope;
- njs_vmcode_variable_t *variable;
- njs_vmcode_function_copy_t *copy;
+ njs_int_t ret;
+ njs_variable_t *var;
+ njs_parser_scope_t *scope;
+ njs_vmcode_variable_t *variable;
var = njs_variable_reference(vm, node);
if (njs_slow_path(var == NULL)) {
@@ -906,13 +905,6 @@ njs_generate_name(njs_vm_t *vm, njs_generator_t *generator,
return njs_generator_stack_pop(vm, generator, NULL);
}
- if (var->function && var->type == NJS_VARIABLE_FUNCTION) {
- njs_generate_code(generator, njs_vmcode_function_copy_t, copy,
- NJS_VMCODE_FUNCTION_COPY, node);
- copy->function = &var->value;
- copy->retval = node->index;
- }
-
if (var->init) {
return njs_generator_stack_pop(vm, generator, NULL);
}
@@ -935,10 +927,9 @@ static njs_int_t
njs_generate_variable(njs_vm_t *vm, njs_generator_t *generator,
njs_parser_node_t *node, njs_reference_type_t type, njs_variable_t **retvar)
{
- njs_variable_t *var;
- njs_parser_scope_t *scope;
- njs_vmcode_variable_t *variable;
- njs_vmcode_function_copy_t *copy;
+ njs_variable_t *var;
+ njs_parser_scope_t *scope;
+ njs_vmcode_variable_t *variable;
var = njs_variable_reference(vm, node);
@@ -958,13 +949,6 @@ njs_generate_variable(njs_vm_t *vm, njs_generator_t *generator,
}
}
- if (var->function && var->type == NJS_VARIABLE_FUNCTION) {
- njs_generate_code(generator, njs_vmcode_function_copy_t, copy,
- NJS_VMCODE_FUNCTION_COPY, node);
- copy->function = &var->value;
- copy->retval = node->index;
- }
-
if (var->init) {
return NJS_OK;
}
@@ -4293,7 +4277,6 @@ njs_generate_function_scope(njs_vm_t *vm, njs_generator_t *prev,
const njs_str_t *name)
{
njs_int_t ret;
- njs_arr_t *arr;
njs_uint_t depth;
njs_vm_code_t *code;
njs_generator_t generator;
@@ -4327,10 +4310,6 @@ njs_generate_function_scope(njs_vm_t *vm, njs_generator_t *prev,
lambda->nclosures = generator.closures->items;
lambda->nlocal = node->scope->items;
- arr = node->scope->declarations;
- lambda->declarations = (arr != NULL) ? arr->start : NULL;
- lambda->ndeclarations = (arr != NULL) ? arr->items : 0;
-
return NJS_OK;
}
@@ -4339,11 +4318,15 @@ njs_vm_code_t *
njs_generate_scope(njs_vm_t *vm, njs_generator_t *generator,
njs_parser_scope_t *scope, const njs_str_t *name)
{
- u_char *p;
- int64_t nargs;
- njs_int_t ret;
- njs_uint_t index;
- njs_vm_code_t *code;
+ u_char *p, *code_start;
+ size_t code_size, prelude;
+ int64_t nargs;
+ njs_int_t ret;
+ njs_arr_t *arr;
+ njs_uint_t index, n;
+ njs_vm_code_t *code;
+ njs_declaration_t *declr;
+ njs_vmcode_function_t *fun;
generator->code_size = 128;
@@ -4414,6 +4397,45 @@ njs_generate_scope(njs_vm_t *vm, njs_generator_t *generator,
} while (generator->state != NULL);
+ arr = scope->declarations;
+ scope->declarations = NULL;
+
+ if (arr != NULL && arr->items > 0) {
+ declr = arr->start;
+ prelude = sizeof(njs_vmcode_function_t) * arr->items;
+ code_size = generator->code_end - generator->code_start;
+
+ for (n = 0; n < arr->items; n++) {
+ fun = (njs_vmcode_function_t *) njs_generate_reserve(vm,
+ generator, sizeof(njs_vmcode_function_t));
+ if (njs_slow_path(fun == NULL)) {
+ njs_memory_error(vm);
+ return NULL;
+ }
+
+ generator->code_end += sizeof(njs_vmcode_function_t);
+ fun->code = NJS_VMCODE_FUNCTION;
+
+ fun->lambda = declr[n].lambda;
+ fun->async = declr[n].async;
+ fun->retval = declr[n].index;
+ }
+
+ code_start = njs_mp_alloc(vm->mem_pool, code_size + prelude);
+ if (njs_slow_path(code_start == NULL)) {
+ njs_memory_error(vm);
+ return NULL;
+ }
+
+ memcpy(code_start, &generator->code_start[code_size], prelude);
+ memcpy(&code_start[prelude], generator->code_start, code_size);
+
+ njs_mp_free(vm->mem_pool, generator->code_start);
+
+ generator->code_start = code_start;
+ generator->code_end = code_start + code_size + prelude;
+ }
+
code = njs_arr_item(vm->codes, index);
code->start = generator->code_start;
code->end = generator->code_end;
diff --git a/src/njs_parser.c b/src/njs_parser.c
--- a/src/njs_parser.c
+++ b/src/njs_parser.c
@@ -839,10 +839,9 @@ njs_inline njs_int_t
njs_parser_expect_semicolon(njs_parser_t *parser, njs_lexer_token_t *token)
{
if (token->type != NJS_TOKEN_SEMICOLON) {
- if (parser->strict_semicolon
- || (token->type != NJS_TOKEN_END
- && token->type != NJS_TOKEN_CLOSE_BRACE
- && parser->lexer->prev_type != NJS_TOKEN_LINE_END))
+ if (token->type != NJS_TOKEN_END
+ && token->type != NJS_TOKEN_CLOSE_BRACE
+ && parser->lexer->prev_type != NJS_TOKEN_LINE_END)
{
return NJS_DECLINED;
}
@@ -5408,10 +5407,6 @@ static njs_int_t
njs_parser_do_while_semicolon(njs_parser_t *parser, njs_lexer_token_t *token,
njs_queue_link_t *current)
{
- if (parser->strict_semicolon) {
- return njs_parser_failed(parser);
- }
-
parser->target->right = parser->node;
parser->node = parser->target;
@@ -6257,10 +6252,9 @@ njs_parser_break_continue(njs_parser_t *parser, njs_lexer_token_t *token,
break;
}
- if (parser->strict_semicolon
- || (token->type != NJS_TOKEN_END
- && token->type != NJS_TOKEN_CLOSE_BRACE
- && parser->lexer->prev_type != NJS_TOKEN_LINE_END))
+ if (token->type != NJS_TOKEN_END
+ && token->type != NJS_TOKEN_CLOSE_BRACE
+ && parser->lexer->prev_type != NJS_TOKEN_LINE_END)
{
return njs_parser_failed(parser);
}
@@ -6314,9 +6308,7 @@ njs_parser_return_statement(njs_parser_t *parser, njs_lexer_token_t *token,
return njs_parser_failed(parser);
default:
- if (!parser->strict_semicolon
- && parser->lexer->prev_type == NJS_TOKEN_LINE_END)
- {
+ if (parser->lexer->prev_type == NJS_TOKEN_LINE_END) {
break;
}
@@ -7091,8 +7083,7 @@ njs_parser_function_declaration(njs_parser_t *parser, njs_lexer_token_t *token,
njs_lexer_consume_token(parser->lexer, 1);
- var = njs_variable_function_add(parser, parser->scope, atom_id,
- NJS_VARIABLE_FUNCTION);
+ var = njs_variable_function_add(parser, parser->scope, atom_id);
if (var == NULL) {
return NJS_ERROR;
}
diff --git a/src/njs_parser.h b/src/njs_parser.h
--- a/src/njs_parser.h
+++ b/src/njs_parser.h
@@ -84,7 +84,6 @@ struct njs_parser_s {
uint8_t use_lhs;
uint8_t module;
- njs_bool_t strict_semicolon;
njs_str_t file;
uint32_t line;
@@ -109,8 +108,9 @@ typedef struct {
typedef struct {
- njs_value_t *value;
+ njs_function_lambda_t *lambda;
njs_index_t index;
+ njs_bool_t async;
} njs_declaration_t;
diff --git a/src/njs_value.c b/src/njs_value.c
--- a/src/njs_value.c
+++ b/src/njs_value.c
@@ -562,7 +562,6 @@ njs_property_query(njs_vm_t *vm, njs_property_query_t *pq, njs_value_t *value,
uint32_t index;
njs_int_t ret;
njs_object_t *obj;
- njs_function_t *function;
njs_assert(atom_id != NJS_ATOM_STRING_unknown);
@@ -585,6 +584,7 @@ njs_property_query(njs_vm_t *vm, njs_property_query_t *pq, njs_value_t *value,
case NJS_OBJECT:
case NJS_ARRAY:
+ case NJS_FUNCTION:
case NJS_ARRAY_BUFFER:
case NJS_DATA_VIEW:
case NJS_TYPED_ARRAY:
@@ -595,15 +595,6 @@ njs_property_query(njs_vm_t *vm, njs_property_query_t *pq, njs_value_t *value,
obj = njs_object(value);
break;
- case NJS_FUNCTION:
- function = njs_function_value_copy(vm, value);
- if (njs_slow_path(function == NULL)) {
- return NJS_ERROR;
- }
-
- obj = &function->object;
- break;
-
case NJS_UNDEFINED:
case NJS_NULL:
default:
diff --git a/src/njs_variable.c b/src/njs_variable.c
--- a/src/njs_variable.c
+++ b/src/njs_variable.c
@@ -36,7 +36,7 @@ njs_variable_add(njs_parser_t *parser, njs_parser_scope_t *scope,
njs_variable_t *
njs_variable_function_add(njs_parser_t *parser, njs_parser_scope_t *scope,
- uintptr_t atom_id, njs_variable_type_t type)
+ uintptr_t atom_id)
{
njs_bool_t ctor;
njs_variable_t *var;
@@ -44,14 +44,15 @@ njs_variable_function_add(njs_parser_t *parser, njs_parser_scope_t *scope,
njs_parser_scope_t *root;
njs_function_lambda_t *lambda;
- root = njs_variable_scope_find(parser, scope, atom_id, type);
+ root = njs_variable_scope_find(parser, scope, atom_id,
+ NJS_VARIABLE_FUNCTION);
if (njs_slow_path(root == NULL)) {
njs_parser_ref_error(parser, "scope not found");
return NULL;
}
- var = njs_variable_scope_add(parser, root, scope, atom_id, type,
- NJS_INDEX_ERROR);
+ var = njs_variable_scope_add(parser, root, scope, atom_id,
+ NJS_VARIABLE_FUNCTION, NJS_INDEX_ERROR);
if (njs_slow_path(var == NULL)) {
return NULL;
}
@@ -77,15 +78,15 @@ njs_variable_function_add(njs_parser_t *parser, njs_parser_scope_t *scope,
}
var->index = njs_scope_index(root->type, root->items, NJS_LEVEL_LOCAL,
- type);
+ NJS_VARIABLE_FUNCTION);
- declr->value = &var->value;
+ declr->lambda = lambda;
+ declr->async = !ctor;
declr->index = var->index;
root->items++;
var->type = NJS_VARIABLE_FUNCTION;
- var->function = 1;
return var;
}
@@ -173,7 +174,6 @@ njs_variable_scope_find(njs_parser_t *parser, njs_parser_scope_t *scope,
if (var != NULL && var->scope == root) {
if (var->self) {
- var->function = 0;
return scope;
}
diff --git a/src/njs_variable.h b/src/njs_variable.h
--- a/src/njs_variable.h
+++ b/src/njs_variable.h
@@ -26,7 +26,6 @@ typedef struct {
njs_bool_t self;
njs_bool_t init;
njs_bool_t closure;
- njs_bool_t function;
njs_parser_scope_t *scope;
njs_parser_scope_t *original;
@@ -62,7 +61,7 @@ typedef struct {
njs_variable_t *njs_variable_add(njs_parser_t *parser,
njs_parser_scope_t *scope, uintptr_t atom_id, njs_variable_type_t type);
njs_variable_t *njs_variable_function_add(njs_parser_t *parser,
- njs_parser_scope_t *scope, uintptr_t atom_id, njs_variable_type_t type);
+ njs_parser_scope_t *scope, uintptr_t atom_id);
njs_variable_t * njs_label_add(njs_vm_t *vm, njs_parser_scope_t *scope,
uintptr_t atom_id);
njs_variable_t *njs_label_find(njs_vm_t *vm, njs_parser_scope_t *scope,
diff --git a/src/njs_vm.c b/src/njs_vm.c
--- a/src/njs_vm.c
+++ b/src/njs_vm.c
@@ -310,7 +310,6 @@ njs_vm_compile_module(njs_vm_t *vm, njs_str_t *name, u_char **start,
u_char *end)
{
njs_int_t ret;
- njs_arr_t *arr;
njs_mod_t *module;
njs_parser_t parser;
njs_vm_code_t *code;
@@ -366,10 +365,6 @@ njs_vm_compile_module(njs_vm_t *vm, njs_str_t *name, u_char **start,
lambda->start = generator.code_start;
lambda->nlocal = scope->items;
- arr = scope->declarations;
- lambda->declarations = (arr != NULL) ? arr->start : NULL;
- lambda->ndeclarations = (arr != NULL) ? arr->items : 0;
-
module->function.u.lambda = lambda;
return module;
diff --git a/src/njs_vmcode.c b/src/njs_vmcode.c
--- a/src/njs_vmcode.c
+++ b/src/njs_vmcode.c
@@ -16,15 +16,12 @@ struct njs_property_next_s {
static njs_jump_off_t njs_vmcode_object(njs_vm_t *vm, njs_value_t *retval);
static njs_jump_off_t njs_vmcode_array(njs_vm_t *vm, u_char *pc,
njs_value_t *retval);
-static njs_jump_off_t njs_vmcode_function(njs_vm_t *vm, u_char *pc,
- njs_value_t *retval);
+static njs_jump_off_t njs_vmcode_function(njs_vm_t *vm, u_char *pc);
static njs_jump_off_t njs_vmcode_arguments(njs_vm_t *vm, u_char *pc);
static njs_jump_off_t njs_vmcode_regexp(njs_vm_t *vm, u_char *pc,
njs_value_t *retval);
static njs_jump_off_t njs_vmcode_template_literal(njs_vm_t *vm,
njs_value_t *retval);
-static njs_jump_off_t njs_vmcode_function_copy(njs_vm_t *vm, njs_value_t *value,
- njs_index_t retval);
static njs_jump_off_t njs_vmcode_property_init(njs_vm_t *vm, njs_value_t *value,
njs_value_t *key, njs_value_t *retval);
@@ -113,7 +110,6 @@ njs_vmcode_interpreter(njs_vm_t *vm, u_char *pc, njs_value_t *rval,
njs_vmcode_equal_jump_t *equal;
njs_vmcode_try_return_t *try_return;
njs_vmcode_method_frame_t *method_frame;
- njs_vmcode_function_copy_t *fcopy;
njs_vmcode_prop_accessor_t *accessor;
njs_vmcode_try_trampoline_t *try_trampoline;
njs_vmcode_function_frame_t *function_frame;
@@ -157,7 +153,6 @@ njs_vmcode_interpreter(njs_vm_t *vm, u_char *pc, njs_value_t *rval,
NJS_GOTO_ROW(NJS_VMCODE_IF_EQUAL_JUMP),
NJS_GOTO_ROW(NJS_VMCODE_PROPERTY_INIT),
NJS_GOTO_ROW(NJS_VMCODE_RETURN),
- NJS_GOTO_ROW(NJS_VMCODE_FUNCTION_COPY),
NJS_GOTO_ROW(NJS_VMCODE_FUNCTION_FRAME),
NJS_GOTO_ROW(NJS_VMCODE_METHOD_FRAME),
NJS_GOTO_ROW(NJS_VMCODE_FUNCTION_CALL),
@@ -1155,9 +1150,7 @@ NEXT_LBL;
CASE (NJS_VMCODE_FUNCTION):
njs_vmcode_debug_opcode();
- njs_vmcode_operand(vm, vmcode->operand1, retval);
-
- ret = njs_vmcode_function(vm, pc, retval);
+ ret = njs_vmcode_function(vm, pc);
if (njs_slow_path(ret < 0 && ret >= NJS_PREEMPT)) {
goto error;
}
@@ -1422,17 +1415,6 @@ NEXT_LBL;
return NJS_OK;
- CASE (NJS_VMCODE_FUNCTION_COPY):
- njs_vmcode_debug_opcode();
-
- fcopy = (njs_vmcode_function_copy_t *) pc;
- ret = njs_vmcode_function_copy(vm, fcopy->function, fcopy->retval);
- if (njs_slow_path(ret == NJS_ERROR)) {
- goto error;
- }
-
- BREAK;
-
CASE (NJS_VMCODE_FUNCTION_FRAME):
njs_vmcode_debug_opcode();
@@ -1928,7 +1910,7 @@ njs_vmcode_array(njs_vm_t *vm, u_char *pc, njs_value_t *retval)
static njs_jump_off_t
-njs_vmcode_function(njs_vm_t *vm, u_char *pc, njs_value_t *retval)
+njs_vmcode_function(njs_vm_t *vm, u_char *pc)
{
njs_function_t *function;
njs_vmcode_function_t *code;
@@ -1948,7 +1930,7 @@ njs_vmcode_function(njs_vm_t *vm, u_char *pc, njs_value_t *retval)
function->args_count = lambda->nargs - lambda->rest_parameters;
- njs_set_function(retval, function);
+ njs_set_function(njs_scope_value(vm, code->retval), function);
return sizeof(njs_vmcode_function_t);
}
@@ -2032,27 +2014,6 @@ njs_vmcode_template_literal(njs_vm_t *vm, njs_value_t *retval)
}
-static njs_jump_off_t
-njs_vmcode_function_copy(njs_vm_t *vm, njs_value_t *value, njs_index_t retidx)
-{
- njs_value_t *retval;
- njs_function_t *function;
-
- retval = njs_scope_value(vm, retidx);
-
- if (!njs_is_valid(retval)) {
- *retval = *value;
-
- function = njs_function_value_copy(vm, retval);
- if (njs_slow_path(function == NULL)) {
- return NJS_ERROR;
- }
- }
-
- return sizeof(njs_vmcode_function_copy_t);
-}
-
-
static njs_jump_off_t
njs_vmcode_property_init(njs_vm_t *vm, njs_value_t *value, njs_value_t *key,
njs_value_t *init)
diff --git a/src/njs_vmcode.h b/src/njs_vmcode.h
--- a/src/njs_vmcode.h
+++ b/src/njs_vmcode.h
@@ -38,7 +38,6 @@ enum {
NJS_VMCODE_IF_EQUAL_JUMP,
NJS_VMCODE_PROPERTY_INIT,
NJS_VMCODE_RETURN,
- NJS_VMCODE_FUNCTION_COPY,
NJS_VMCODE_FUNCTION_FRAME,
NJS_VMCODE_METHOD_FRAME,
NJS_VMCODE_FUNCTION_CALL,
@@ -381,13 +380,6 @@ typedef struct {
} njs_vmcode_error_t;
-typedef struct {
- njs_vmcode_t code;
- njs_value_t *function;
- njs_index_t retval;
-} njs_vmcode_function_copy_t;
-
-
typedef struct {
njs_vmcode_t code;
njs_index_t retval;
|
diff --git a/test/js/async_closure.t.js b/test/js/async_closure.t.js
new file mode 100644
--- /dev/null
+++ b/test/js/async_closure.t.js
@@ -0,0 +1,24 @@
+/*---
+includes: []
+flags: [async]
+---*/
+
+async function f() {
+ await 1;
+ var v = 2;
+
+ function g() {
+ return v + 1;
+ }
+
+ function s() {
+ g + 1;
+ }
+
+ return g();
+}
+
+f().then(v => {
+ assert.sameValue(v, 3)
+})
+.then($DONE, $DONE);
diff --git a/test/js/async_closure_arg.t.js b/test/js/async_closure_arg.t.js
new file mode 100644
--- /dev/null
+++ b/test/js/async_closure_arg.t.js
@@ -0,0 +1,24 @@
+/*---
+includes: []
+flags: [async]
+---*/
+
+async function f(v) {
+ await 1;
+ v = 2;
+
+ function g() {
+ return v + 1;
+ }
+
+ function s() {
+ g + 1;
+ }
+
+ return g();
+}
+
+f(42).then(v => {
+ assert.sameValue(v, 3)
+})
+.then($DONE, $DONE);
diff --git a/test/js/async_closure_share.t.js b/test/js/async_closure_share.t.js
new file mode 100644
--- /dev/null
+++ b/test/js/async_closure_share.t.js
@@ -0,0 +1,28 @@
+/*---
+includes: []
+flags: [async]
+---*/
+
+async function f() {
+ await 1;
+ var v = 'f';
+
+ function g() {
+ v += ':g';
+ return v;
+ }
+
+ function s() {
+ v += ':s';
+ return v;
+ }
+
+ return [g, s];
+}
+
+f().then(pair => {
+ pair[0]();
+ var v = pair[1]();
+ assert.sameValue(v, 'f:g:s');
+})
+.then($DONE, $DONE);
|
SEGV in njs_function_lambda_call
### Environment
```
OS : Linux ubuntu 5.11.10 #1 SMP Sat Oct 30 23:40:08 CST 2021 x86_64 x86_64 x86_64 GNU/Linux
Commit : c62a9fb92b102c90a66aa724cb9054183a33a68c
Version : 0.7.4
Build :
NJS_CFLAGS="$NJS_CFLAGS -fsanitize=address"
NJS_CFLAGS="$NJS_CFLAGS -fno-omit-frame-pointer"
```
### Proof of concept
```js
async function f() {
await 1;
var v = 2;
function g() {
v + 1;
}
function s() {
g + 1;
}
g();
}
f();
```
### Stack dump
```
UndefinedBehaviorSanitizer:DEADLYSIGNAL
==3050875==ERROR: UndefinedBehaviorSanitizer: SEGV on unknown address 0x000000000000 (pc 0x00000043a7c6 bp 0x7ffcd6f10b00 sp 0x7ffcd6f10920 T3050875)
==3050875==The signal is caused by a READ memory access.
==3050875==Hint: address points to the zero page.
#0 0x43a7c6 in njs_scope_valid_value /njs/src/njs_scope.h:86:10
#1 0x43a7c6 in njs_vmcode_await /njs/src/njs_vmcode.c:1924:13
#2 0x43a7c6 in njs_vmcode_interpreter /njs/src/njs_vmcode.c:861:24
#3 0x468070 in njs_function_lambda_call /njs/src/njs_function.c:693:11
#4 0x4bd170 in njs_async_function_frame_invoke /njs/src/njs_async.c:32:11
#5 0x4364d7 in njs_vmcode_interpreter /njs/src/njs_vmcode.c:799:23
#6 0x4bd35d in njs_await_fulfilled /njs/src/njs_async.c:91:11
#7 0x468574 in njs_function_native_call /njs/src/njs_function.c:728:11
#8 0x467941 in njs_function_frame_invoke /njs/src/njs_function.c:766:16
#9 0x467941 in njs_function_call2 /njs/src/njs_function.c:592:11
#10 0x4b6938 in njs_function_call /njs/src/njs_function.h:178:12
#11 0x4b6938 in njs_promise_reaction_job /njs/src/njs_promise.c:1171:15
#12 0x468574 in njs_function_native_call /njs/src/njs_function.c:728:11
#13 0x433a27 in njs_vm_invoke /njs/src/njs_vm.c:428:12
#14 0x433a27 in njs_vm_call /njs/src/njs_vm.c:412:12
#15 0x433a27 in njs_vm_handle_events /njs/src/njs_vm.c:572:19
#16 0x433a27 in njs_vm_run /njs/src/njs_vm.c:532:12
#17 0x428d13 in njs_process_script /njs/src/njs_shell.c:1059:15
#18 0x428763 in njs_process_file /njs/src/njs_shell.c:754:11
#19 0x428763 in main /njs/src/njs_shell.c:435:15
#20 0x7f8424948082 in __libc_start_main /build/glibc-KZwQYS/glibc-2.31/csu/../csu/libc-start.c:308:16
#21 0x406d3d in _start (/home/q1iq/Documents/njs-dump/njs/build/njs+0x406d3d)
UndefinedBehaviorSanitizer can not provide additional info.
SUMMARY: UndefinedBehaviorSanitizer: SEGV /njs/src/njs_scope.h:86:10 in njs_scope_valid_value
==3050875==ABORTING
```
### Credit
Q1IQ(@Q1IQ)
| 2025-06-12T05:43:21
|
c
|
Hard
|
|
HandmadeMath/HandmadeMath
| 84
|
HandmadeMath__HandmadeMath-84
|
[
"83"
] |
f8b3a84cec6a6710ddb7273acd0b17ff74e9bcf9
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1,5 +1,5 @@
/*
- HandmadeMath.h v1.5.0
+ HandmadeMath.h v1.5.1
This is a single header file with a bunch of useful functions for game and
graphics math operations.
@@ -166,6 +166,8 @@
(*) Changed internal structure for better performance and inlining.
(*) As a result, HANDMADE_MATH_NO_INLINE has been removed and no
longer has any effect.
+ 1.5.1
+ (*) Fixed a bug with uninitialized elements in HMM_LookAt.
LICENSE
@@ -2334,14 +2336,17 @@ hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up)
Result.Elements[0][0] = S.X;
Result.Elements[0][1] = U.X;
Result.Elements[0][2] = -F.X;
+ Result.Elements[0][3] = 0.0f;
Result.Elements[1][0] = S.Y;
Result.Elements[1][1] = U.Y;
Result.Elements[1][2] = -F.Y;
+ Result.Elements[1][3] = 0.0f;
Result.Elements[2][0] = S.Z;
Result.Elements[2][1] = U.Z;
Result.Elements[2][2] = -F.Z;
+ Result.Elements[2][3] = 0.0f;
Result.Elements[3][0] = -HMM_DotVec3(S, Eye);
Result.Elements[3][1] = -HMM_DotVec3(U, Eye);
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -10,6 +10,7 @@ To get started, go download [the latest release](https://github.com/HandmadeMath
Version | Changes |
----------------|----------------|
+**1.5.1** | Fixed a bug with uninitialized elements in HMM_LookAt.
**1.5.0** | Changed internal structure for better performance and inlining. As a result, `HANDMADE_MATH_NO_INLINE` has been removed and no longer has any effect.
**1.4.0** | Fixed bug when using C mode. SSE'd all vec4 operations. Removed zeroing for better performance.
**1.3.0** | Removed need to `#define HANDMADE_MATH_CPP_MODE`. C++ definitions are now included automatically in C++ environments.
|
diff --git a/test/categories/Transformation.h b/test/categories/Transformation.h
--- a/test/categories/Transformation.h
+++ b/test/categories/Transformation.h
@@ -51,3 +51,27 @@ TEST(Transformations, Scale)
EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
EXPECT_FLOAT_EQ(scaled.W, 1.0f);
}
+
+TEST(Transformations, LookAt)
+{
+ const float abs_error = 0.0001f;
+
+ hmm_mat4 result = HMM_LookAt(HMM_Vec3(1.0f, 0.0f, 0.0f), HMM_Vec3(0.0f, 2.0f, 1.0f), HMM_Vec3(2.0f, 1.0f, 1.0f));
+
+ EXPECT_NEAR(result.Elements[0][0], 0.169031f, abs_error);
+ EXPECT_NEAR(result.Elements[0][1], 0.897085f, abs_error);
+ EXPECT_NEAR(result.Elements[0][2], 0.408248f, abs_error);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 0.0f);
+ EXPECT_NEAR(result.Elements[1][0], 0.507093f, abs_error);
+ EXPECT_NEAR(result.Elements[1][1], 0.276026f, abs_error);
+ EXPECT_NEAR(result.Elements[1][2], -0.816497f, abs_error);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 0.0f);
+ EXPECT_NEAR(result.Elements[2][0], -0.845154f, abs_error);
+ EXPECT_NEAR(result.Elements[2][1], 0.345033f, abs_error);
+ EXPECT_NEAR(result.Elements[2][2], -0.408248f, abs_error);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 0.0f);
+ EXPECT_NEAR(result.Elements[3][0], -0.169031f, abs_error);
+ EXPECT_NEAR(result.Elements[3][1], -0.897085f, abs_error);
+ EXPECT_NEAR(result.Elements[3][2], -0.408248f, abs_error);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1.0f);
+}
|
HMM_LookAt Using/Returning Partially Uninitialized Matrix
Hi there. I was struggling to debug an issue and traced it back to `HMM_LookAt`...
The issue has been marked below with comments.
hmm_mat4 Result; // uninitialized
hmm_vec3 F = HMM_NormalizeVec3(HMM_SubtractVec3(Center, Eye));
hmm_vec3 S = HMM_NormalizeVec3(HMM_Cross(F, Up));
hmm_vec3 U = HMM_Cross(S, F);
Result.Elements[0][0] = S.X;
Result.Elements[0][1] = U.X;
Result.Elements[0][2] = -F.X;
// not setting the element at [0][3]
Result.Elements[1][0] = S.Y;
Result.Elements[1][1] = U.Y;
Result.Elements[1][2] = -F.Y;
// (or at [1][3])
Result.Elements[2][0] = S.Z;
Result.Elements[2][1] = U.Z;
Result.Elements[2][2] = -F.Z;
// (or [2][3])
Result.Elements[3][0] = -HMM_DotVec3(S, Eye);
Result.Elements[3][1] = -HMM_DotVec3(U, Eye);
Result.Elements[3][2] = HMM_DotVec3(F, Eye);
Result.Elements[3][3] = 1.0f;
// result returned without initializing the totality of the bottom row
return (Result);
It was fixed by initializing `Result` to `HMM_Mat4d(1.f)`, but am unsure how you'd like to solve this particularly (it's probably better to just directly write to those elements that weren't initialized).
|
I swear I fixed that before...sorry about that. Fix version incoming.
| 2018-03-14T14:02:30
|
c
|
Hard
|
libssh2/libssh2
| 987
|
libssh2__libssh2-987
|
[
"582",
"987"
] |
5e560020555ada31c393092e07dd581bfc29a728
|
diff --git a/src/libssh2_priv.h b/src/libssh2_priv.h
--- a/src/libssh2_priv.h
+++ b/src/libssh2_priv.h
@@ -536,7 +536,8 @@ struct transportpacket
packet_length + padding_length + 4 +
mac_length. */
unsigned char *payload; /* this is a pointer to a LIBSSH2_ALLOC()
- area to which we write decrypted data */
+ area to which we write incoming packet data
+ which is not yet decrypted in etm mode. */
unsigned char *wptr; /* write pointer into the payload to where we
are currently writing decrypted data */
diff --git a/src/mac.c b/src/mac.c
--- a/src/mac.c
+++ b/src/mac.c
@@ -71,7 +71,8 @@ static LIBSSH2_MAC_METHOD mac_method_none = {
0,
NULL,
mac_none_MAC,
- NULL
+ NULL,
+ 0
};
#endif /* defined(LIBSSH2DEBUG) && defined(LIBSSH2_MAC_NONE_INSECURE) */
@@ -138,8 +139,6 @@ mac_method_hmac_sha2_512_hash(LIBSSH2_SESSION * session,
return 0;
}
-
-
static const LIBSSH2_MAC_METHOD mac_method_hmac_sha2_512 = {
"hmac-sha2-512",
64,
@@ -147,7 +146,19 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_sha2_512 = {
mac_method_common_init,
mac_method_hmac_sha2_512_hash,
mac_method_common_dtor,
+ 0
+};
+
+static const LIBSSH2_MAC_METHOD mac_method_hmac_sha2_512_etm = {
+ "hmac-sha2-512-etm@openssh.com",
+ 64,
+ 64,
+ mac_method_common_init,
+ mac_method_hmac_sha2_512_hash,
+ mac_method_common_dtor,
+ 1
};
+
#endif
@@ -192,7 +203,19 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_sha2_256 = {
mac_method_common_init,
mac_method_hmac_sha2_256_hash,
mac_method_common_dtor,
+ 0
};
+
+static const LIBSSH2_MAC_METHOD mac_method_hmac_sha2_256_etm = {
+ "hmac-sha2-256-etm@openssh.com",
+ 32,
+ 32,
+ mac_method_common_init,
+ mac_method_hmac_sha2_256_hash,
+ mac_method_common_dtor,
+ 1
+};
+
#endif
@@ -237,6 +260,17 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_sha1 = {
mac_method_common_init,
mac_method_hmac_sha1_hash,
mac_method_common_dtor,
+ 0
+};
+
+static const LIBSSH2_MAC_METHOD mac_method_hmac_sha1_etm = {
+ "hmac-sha1-etm@openssh.com",
+ 20,
+ 20,
+ mac_method_common_init,
+ mac_method_hmac_sha1_hash,
+ mac_method_common_dtor,
+ 1
};
/* mac_method_hmac_sha1_96_hash
@@ -268,6 +302,7 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_sha1_96 = {
mac_method_common_init,
mac_method_hmac_sha1_96_hash,
mac_method_common_dtor,
+ 0
};
#if LIBSSH2_MD5
@@ -310,6 +345,7 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_md5 = {
mac_method_common_init,
mac_method_hmac_md5_hash,
mac_method_common_dtor,
+ 0
};
/* mac_method_hmac_md5_96_hash
@@ -339,6 +375,7 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_md5_96 = {
mac_method_common_init,
mac_method_hmac_md5_96_hash,
mac_method_common_dtor,
+ 0
};
#endif /* LIBSSH2_MD5 */
@@ -383,6 +420,7 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_ripemd160 = {
mac_method_common_init,
mac_method_hmac_ripemd160_hash,
mac_method_common_dtor,
+ 0
};
static const LIBSSH2_MAC_METHOD mac_method_hmac_ripemd160_openssh_com = {
@@ -392,17 +430,21 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_ripemd160_openssh_com = {
mac_method_common_init,
mac_method_hmac_ripemd160_hash,
mac_method_common_dtor,
+ 0
};
#endif /* LIBSSH2_HMAC_RIPEMD */
static const LIBSSH2_MAC_METHOD *mac_methods[] = {
#if LIBSSH2_HMAC_SHA256
&mac_method_hmac_sha2_256,
+ &mac_method_hmac_sha2_256_etm,
#endif
#if LIBSSH2_HMAC_SHA512
&mac_method_hmac_sha2_512,
+ &mac_method_hmac_sha2_512_etm,
#endif
&mac_method_hmac_sha1,
+ &mac_method_hmac_sha1_etm,
&mac_method_hmac_sha1_96,
#if LIBSSH2_MD5
&mac_method_hmac_md5,
@@ -435,6 +477,7 @@ static const LIBSSH2_MAC_METHOD mac_method_hmac_aesgcm = {
NULL,
NULL,
NULL,
+ 0
};
#endif /* LIBSSH2_AES_GCM */
diff --git a/src/mac.h b/src/mac.h
--- a/src/mac.h
+++ b/src/mac.h
@@ -57,6 +57,8 @@ struct _LIBSSH2_MAC_METHOD
size_t packet_len, const unsigned char *addtl,
size_t addtl_len, void **abstract);
int (*dtor) (LIBSSH2_SESSION * session, void **abstract);
+
+ int etm; /* encrypt-then-mac */
};
typedef struct _LIBSSH2_MAC_METHOD LIBSSH2_MAC_METHOD;
diff --git a/src/transport.c b/src/transport.c
--- a/src/transport.c
+++ b/src/transport.c
@@ -197,21 +197,81 @@ fullpacket(LIBSSH2_SESSION * session, int encrypted /* 1 or 0 */ )
if(encrypted && !CRYPT_FLAG_L(session, INTEGRATED_MAC)) {
/* Calculate MAC hash */
- session->remote.mac->hash(session, macbuf, /* store hash here */
- session->remote.seqno,
- p->init, 5,
- p->payload,
- session->fullpacket_payload_len,
- &session->remote.mac_abstract);
+ int etm = session->remote.mac->etm;
+ size_t mac_len = session->remote.mac->mac_len;
+ if(etm) {
+ /* store hash here */
+ session->remote.mac->hash(session, macbuf,
+ session->remote.seqno,
+ p->payload, p->total_num - mac_len,
+ NULL, 0,
+ &session->remote.mac_abstract);
+ }
+ else {
+ /* store hash here */
+ session->remote.mac->hash(session, macbuf,
+ session->remote.seqno,
+ p->init, 5,
+ p->payload,
+ session->fullpacket_payload_len,
+ &session->remote.mac_abstract);
+ }
/* Compare the calculated hash with the MAC we just read from
* the network. The read one is at the very end of the payload
* buffer. Note that 'payload_len' here is the packet_length
* field which includes the padding but not the MAC.
*/
- if(memcmp(macbuf, p->payload + session->fullpacket_payload_len,
- session->remote.mac->mac_len)) {
+ if(memcmp(macbuf, p->payload + p->total_num - mac_len, mac_len)) {
+ _libssh2_debug((session, LIBSSH2_TRACE_SOCKET,
+ "Failed MAC check"));
session->fullpacket_macstate = LIBSSH2_MAC_INVALID;
+
+ }
+ else if(etm) {
+ /* MAC was ok and we start by decrypting the first block that
+ contains padding length since this allows us to decrypt
+ all other blocks to the right location in memory
+ avoiding moving a larger block of memory one byte. */
+ unsigned char first_block[MAX_BLOCKSIZE];
+ ssize_t decrypt_size;
+ unsigned char *decrypt_buffer;
+ int blocksize = session->remote.crypt->blocksize;
+
+ rc = decrypt(session, p->payload + 4,
+ first_block, blocksize, FIRST_BLOCK);
+ if(rc) {
+ return rc;
+ }
+
+ /* we need buffer for decrypt */
+ decrypt_size = p->total_num - mac_len - 4;
+ decrypt_buffer = LIBSSH2_ALLOC(session, decrypt_size);
+ if(!decrypt_buffer) {
+ return LIBSSH2_ERROR_ALLOC;
+ }
+
+ /* grab padding length and copy anything else
+ into target buffer */
+ p->padding_length = first_block[0];
+ if(blocksize > 1) {
+ memcpy(decrypt_buffer, first_block + 1, blocksize - 1);
+ }
+
+ /* decrypt all other blocks packet */
+ if(blocksize < decrypt_size) {
+ rc = decrypt(session, p->payload + blocksize + 4,
+ decrypt_buffer + blocksize - 1,
+ decrypt_size - blocksize, LAST_BLOCK);
+ if(rc) {
+ LIBSSH2_FREE(session, decrypt_buffer);
+ return rc;
+ }
+ }
+
+ /* replace encrypted payload with plain text payload */
+ LIBSSH2_FREE(session, p->payload);
+ p->payload = decrypt_buffer;
}
}
@@ -348,6 +408,7 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
}
do {
+ int etm;
if(session->socket_state == LIBSSH2_SOCKET_DISCONNECTED) {
return LIBSSH2_ERROR_SOCKET_DISCONNECT;
}
@@ -361,6 +422,8 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
make the checks below work fine still */
}
+ etm = encrypted && session->local.mac ? session->local.mac->etm : 0;
+
/* read/use a whole big chunk into a temporary area stored in
the LIBSSH2_SESSION struct. We will decrypt data from that
buffer into the packet buffer so this temp one doesn't have
@@ -429,45 +492,55 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
(5 bytes) packet length and padding length
fields */
+ /* packet length is not encrypted in encode-then-mac mode
+ and we donøt need to decrypt first block */
+ ssize_t required_size = etm ? 4 : blocksize;
+
/* No payload package area allocated yet. To know the
- size of this payload, we need to decrypt the first
+ size of this payload, we need enough to decrypt the first
blocksize data. */
- if(numbytes < blocksize) {
+ if(numbytes < required_size) {
/* we can't act on anything less than blocksize, but this
check is only done for the initial block since once we have
got the start of a block we can in fact deal with fractions
- */
+ */
session->socket_block_directions |=
LIBSSH2_SESSION_BLOCK_INBOUND;
return LIBSSH2_ERROR_EAGAIN;
}
- if(encrypted) {
- /* first decrypted block */
- rc = decrypt(session, &p->buf[p->readidx],
- block, blocksize, FIRST_BLOCK);
- if(rc != LIBSSH2_ERROR_NONE) {
- return rc;
- }
- /* Save the first 5 bytes of the decrypted package, to be
- used in the hash calculation later down.
- This is ignored in the INTEGRATED_MAC case. */
- memcpy(p->init, block, 5);
+ if(etm) {
+ p->packet_length = _libssh2_ntohu32(&p->buf[p->readidx]);
}
else {
- /* the data is plain, just copy it verbatim to
- the working block buffer */
- memcpy(block, &p->buf[p->readidx], blocksize);
- }
+ if(encrypted) {
+ /* first decrypted block */
+ rc = decrypt(session, &p->buf[p->readidx],
+ block, blocksize, FIRST_BLOCK);
+ if(rc != LIBSSH2_ERROR_NONE) {
+ return rc;
+ }
+ /* Save the first 5 bytes of the decrypted package, to be
+ used in the hash calculation later down.
+ This is ignored in the INTEGRATED_MAC case. */
+ memcpy(p->init, block, 5);
+ }
+ else {
+ /* the data is plain, just copy it verbatim to
+ the working block buffer */
+ memcpy(block, &p->buf[p->readidx], blocksize);
+ }
- /* advance the read pointer */
- p->readidx += blocksize;
+ /* advance the read pointer */
+ p->readidx += blocksize;
+
+ /* we now have the initial blocksize bytes decrypted,
+ * and we can extract packet and padding length from it
+ */
+ p->packet_length = _libssh2_ntohu32(block);
+ }
- /* we now have the initial blocksize bytes decrypted,
- * and we can extract packet and padding length from it
- */
- p->packet_length = _libssh2_ntohu32(block);
if(p->packet_length < 1) {
return LIBSSH2_ERROR_DECRYPT;
}
@@ -475,19 +548,27 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
return LIBSSH2_ERROR_OUT_OF_BOUNDARY;
}
- /* padding_length has not been authenticated yet, but it won't
- actually be used (except for the sanity check immediately
- following) until after the entire packet is authenticated,
- so this is safe. */
- p->padding_length = block[4];
- if(p->padding_length > p->packet_length - 1) {
- return LIBSSH2_ERROR_DECRYPT;
+ if(etm) {
+ /* we collect entire undecrypted packet including the
+ packet length field that we run MAC over */
+ total_num = 4 + p->packet_length +
+ session->remote.mac->mac_len;
}
+ else {
+ /* padding_length has not been authenticated yet, but it won't
+ actually be used (except for the sanity check immediately
+ following) until after the entire packet is authenticated,
+ so this is safe. */
+ p->padding_length = block[4];
+ if(p->padding_length > p->packet_length - 1) {
+ return LIBSSH2_ERROR_DECRYPT;
+ }
- /* total_num is the number of bytes following the initial
- (5 bytes) packet length and padding length fields */
- total_num = p->packet_length - 1 +
- (encrypted ? session->remote.mac->mac_len : 0);
+ /* total_num is the number of bytes following the initial
+ (5 bytes) packet length and padding length fields */
+ total_num = p->packet_length - 1 +
+ (encrypted ? session->remote.mac->mac_len : 0);
+ }
/* RFC4253 section 6.1 Maximum Packet Length says:
*
@@ -511,13 +592,17 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
/* init write pointer to start of payload buffer */
p->wptr = p->payload;
- if(blocksize > 5) {
+ if(!etm && blocksize > 5) {
/* copy the data from index 5 to the end of
the blocksize from the temporary buffer to
the start of the decrypted buffer */
if(blocksize - 5 <= (int) total_num) {
memcpy(p->wptr, &block[5], blocksize - 5);
p->wptr += blocksize - 5; /* advance write pointer */
+ if(etm) {
+ /* advance past unencrypted packet length */
+ p->wptr += 4;
+ }
}
else {
if(p->payload)
@@ -531,7 +616,8 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
p->data_num = p->wptr - p->payload;
/* we already dealt with a blocksize worth of data */
- numbytes -= blocksize;
+ if(!etm)
+ numbytes -= blocksize;
}
/* how much there is left to add to the current payload
@@ -544,7 +630,7 @@ int _libssh2_transport_read(LIBSSH2_SESSION * session)
numbytes = remainpack;
}
- if(encrypted) {
+ if(encrypted && !etm) {
/* At the end of the incoming stream, there is a MAC,
and we don't want to decrypt that since we need it
"raw". We MUST however decrypt the padding data
@@ -772,11 +858,12 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
struct transportpacket *p = &session->packet;
int encrypted;
int compressed;
+ int etm;
ssize_t ret;
int rc;
const unsigned char *orgdata = data;
size_t orgdata_len = data_len;
- size_t crypt_offset;
+ size_t crypt_offset, etm_crypt_offset;
/*
* If the last read operation was interrupted in the middle of a key
@@ -814,6 +901,8 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
encrypted = (session->state & LIBSSH2_STATE_NEWKEYS) ? 1 : 0;
+ etm = encrypted && session->local.mac ? session->local.mac->etm : 0;
+
compressed = session->local.comp &&
session->local.comp->compress &&
((session->state & LIBSSH2_STATE_AUTHENTICATED) ||
@@ -875,8 +964,11 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
packet_length = data_len + 1 + 4; /* 1 is for padding_length field
4 for the packet_length field */
- /* subtract 4 bytes of the packet_length field when padding AES-GCM */
- crypt_offset = (encrypted && CRYPT_FLAG_R(session, PKTLEN_AAD)) ? 4 : 0;
+ /* subtract 4 bytes of the packet_length field when padding AES-GCM
+ or with ETM */
+ crypt_offset = (etm || (encrypted && CRYPT_FLAG_R(session, PKTLEN_AAD)))
+ ? 4 : 0;
+ etm_crypt_offset = etm ? 4 : 0;
/* at this point we have it all except the padding */
@@ -928,7 +1020,7 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
fields except the MAC field itself. This is skipped in the
INTEGRATED_MAC case, where the crypto algorithm also does its
own hash. */
- if(!CRYPT_FLAG_R(session, INTEGRATED_MAC)) {
+ if(!etm && !CRYPT_FLAG_R(session, INTEGRATED_MAC)) {
session->local.mac->hash(session, p->outbuf + packet_length,
session->local.seqno, p->outbuf,
packet_length, NULL, 0,
@@ -940,23 +1032,23 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
/* Some crypto back-ends could handle a single crypt() call for
encryption, but (presumably) others cannot, so break it up
into blocksize-sized chunks to satisfy them all. */
- for(i = 0; i < packet_length;
+ for(i = etm_crypt_offset; i < packet_length;
i += session->local.crypt->blocksize) {
unsigned char *ptr = &p->outbuf[i];
size_t bsize = LIBSSH2_MIN(session->local.crypt->blocksize,
(int)(packet_length-i));
- /* The INTEGRATED_MAC case always has an extra call below,
- so it will never be LAST_BLOCK up here. */
+ /* The INTEGRATED_MAC case always has an extra call below, so it
+ will never be LAST_BLOCK up here. */
int firstlast = i == 0 ? FIRST_BLOCK :
(!CRYPT_FLAG_L(session, INTEGRATED_MAC)
&& (i == packet_length - session->local.crypt->blocksize)
? LAST_BLOCK: MIDDLE_BLOCK);
- /* In the AAD case, the last block would be only 4 bytes
- because everything is offset by 4 since the initial
- packet_length isn't encrypted. In this case, combine that
- last short packet with the previous one since AES-GCM
- crypt() assumes that the entire MAC is available in that
- packet so it can set that to the authentication tag. */
+ /* In the AAD case, the last block would be only 4 bytes because
+ everything is offset by 4 since the initial packet_length isn't
+ encrypted. In this case, combine that last short packet with the
+ previous one since AES-GCM crypt() assumes that the entire MAC
+ is available in that packet so it can set that to the
+ authentication tag. */
if(!CRYPT_FLAG_L(session, INTEGRATED_MAC))
if(i > packet_length - 2*bsize) {
/* increase the final block size */
@@ -964,25 +1056,38 @@ int _libssh2_transport_send(LIBSSH2_SESSION *session,
/* advance the loop counter by the extra amount */
i += bsize - session->local.crypt->blocksize;
}
+ _libssh2_debug((session, LIBSSH2_TRACE_SOCKET,
+ "crypting bytes %d-%d", i,
+ i + session->local.crypt->blocksize - 1));
if(session->local.crypt->crypt(session, ptr,
bsize,
&session->local.crypt_abstract,
firstlast))
return LIBSSH2_ERROR_ENCRYPT; /* encryption failure */
}
- /* Call crypt() one last time so it can be filled in with
- the MAC */
+ /* Call crypt() one last time so it can be filled in with the MAC */
if(CRYPT_FLAG_L(session, INTEGRATED_MAC)) {
int authlen = session->local.mac->mac_len;
assert((size_t)total_length <=
packet_length + session->local.crypt->blocksize);
- if(session->local.crypt->crypt(session,
- &p->outbuf[packet_length],
+ if(session->local.crypt->crypt(session, &p->outbuf[packet_length],
authlen,
&session->local.crypt_abstract,
LAST_BLOCK))
return LIBSSH2_ERROR_ENCRYPT; /* encryption failure */
}
+
+ if(etm) {
+ /* Calculate MAC hash. Put the output at index packet_length,
+ since that size includes the whole packet. The MAC is
+ calculated on the entire packet (length plain the rest
+ encrypted), including all fields except the MAC field
+ itself. */
+ session->local.mac->hash(session, p->outbuf + packet_length,
+ session->local.seqno, p->outbuf,
+ packet_length, NULL, 0,
+ &session->local.mac_abstract);
+ }
}
session->local.seqno++;
|
diff --git a/tests/CMakeLists.txt b/tests/CMakeLists.txt
--- a/tests/CMakeLists.txt
+++ b/tests/CMakeLists.txt
@@ -117,6 +117,9 @@ foreach(test
hmac-sha1-96
hmac-sha2-256
hmac-sha2-512
+ hmac-sha1-etm@openssh.com
+ hmac-sha2-256-etm@openssh.com
+ hmac-sha2-512-etm@openssh.com
)
add_test(NAME test_${test} COMMAND "$<TARGET_FILE:test_read>")
set_tests_properties(test_${test} PROPERTIES ENVIRONMENT "FIXTURE_TEST_MAC=${test}")
diff --git a/tests/Makefile.am b/tests/Makefile.am
--- a/tests/Makefile.am
+++ b/tests/Makefile.am
@@ -115,4 +115,7 @@ EXTRA_DIST = \
test_read_hmac-sha1-96 \
test_read_hmac-sha2-256 \
test_read_hmac-sha2-512 \
- test_read_rijndael-cbc
+ test_read_rijndael-cbc \
+ test_read_hmac-sha1-etm@openssh.com \
+ test_read_hmac-sha2-256-etm@openssh.com \
+ test_read_hmac-sha2-512-etm@openssh.com
diff --git a/tests/test_auth_keyboard_info_request.c b/tests/test_auth_keyboard_info_request.c
--- a/tests/test_auth_keyboard_info_request.c
+++ b/tests/test_auth_keyboard_info_request.c
@@ -310,7 +310,7 @@ int main(void)
for(i = 0; i < FAILED_MALLOC_TEST_CASES_LEN; i++) {
int tc = i + TEST_CASES_LEN + 1;
- int malloc_call_num = 5 + i;
+ int malloc_call_num = 3 + i;
test_case(tc,
failed_malloc_test_cases[i].data,
failed_malloc_test_cases[i].data_len,
|
Implement HMAC -SHA-2 EtM
**Describe the bug**
libssh2 does not implement the `hmac-sha2-256-etm@openssh.com` or `hmac-sha2-512-etm@openssh.com` algorithms.
**To Reproduce**
Attempt to connect to a server supporting only those algorithms as MACs and notice it fails.
**Expected behavior**
libssh2 should connect to servers offering only HMAC-SHA-2 encrypt-then-MAC cipher suites.
**Version (please complete the following information):**
Should be all systems using the latest `master`. I don't see any instances of `etm` in the codebase at all.
**Additional context**
This came up because I'm aware of a Git server implementation running in FIPS mode which allows only `aes256-gcm@openssh.com` (which doesn't need a MAC) or `aes256-ctr` as ciphers and `hmac-sha2-256-etm@openssh.com` and `hmac-sha2-512-etm@openssh.com` as MACs. (I can't mention names at the moment.) libgit2 uses libssh2, and libgit2 is unable to connect to this implementation.
My needs could also be met by implementing `aes256-gcm@openssh.com`, but I suspect the HMAC-SHA2 EtM algorithms is going to be easier.
I'm not interested in `hmac-sha1-etm@openssh.com` or `hmac-sha1-96-etm@openssh.com` because I'd like to see SHA-1 die a fiery death as soon as possible, so this report does not ask for them to be implemented (and I would prefer if they were not).
support encrypt-then-mac (etm) MACs
Support for calculating MAC (message authentication code) on encrypted
data instead of plain text data.
This adds support for the following MACs:
- `hmac-sha1-etm@openssh.com`
- `hmac-sha2-256-etm@openssh.com`
- `hmac-sha2-512-etm@openssh.com`
Integration-patches-by: Viktor Szakats
* rebase on master
* fix checksec warnings
* fix compiler warning
* fix indent/whitespace/eol
* rebase/manual merge onto AES-GCM patch #797
* more manual merge of `libssh2_transport_send()` based
on dfandrich/shellfish
Fixes #582
Closes #655
Closes #987
---
After rebasing to AES-GCM, the whitespace-free diff is recommended for a clearer view:
https://github.com/libssh2/libssh2/pull/987/files?w=1
|
I have ETM working on my private branch but as I've noted before, it's a bit of a hack. Specifically `_libssh2_transport_read` needs to support ETM and also further down the road `chacha20` needs to decrypt the full packet to get the size which also further complicates this function. It should probably branch to helper functions based on the type of payload it's working on. I just haven't had the time to do all this work on main.
I do want to be clear, since I'm not writing the code, I have no timeline for this being implemented or expectation that it will be; this is merely to track that somebody would _like_ these implementations, so if some generous person wanted to do that, it's known. So I'm delighted that you already have this working at all and am happy to wait (or, maybe in the future, contribute if that's desired and I have sufficient time).
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
Bump
Would you like some assistance with this issue, @willco007 ?
My strategy to support encode-then-mac is to add a new field to `_LIBSSH2_MAC_METHOD` and use this field in `transport:fullpacket()` and `transport:_libssh2_transport_send()` to decide whether the hash is checked/calculated before or after encoding.
I haven't tried this and your mention of `chacha20` makes me think there are subtleties I do not understand.
If you like I could bring the work from your private branch into main such that you would only need to review my changes minimising the time spent by you.
Otherwise I will move forward with my strategy and hope it leads to something useful.
@palmin, That's generally how I've implemented it. When using `etm` the size field of the packet isn't encrypted and it requires the full packet to be present before encrypting/decrypting it. ETM also has some padding bytes that need to be dealt with. This behavior is not what `_libssh2_transport_read()` expects (it works on blocks at a time) so in my branch there is a lot of if etm, else... I felt like that wasn't clean enough for a PR so I've held it back. `chacha20` further complicates things by encrypting the size field and adding a tag to each packet. If this is something we want to do, I can post my code some place and we can factor it into a way clean enough for a PR.
@willco007 I would like to try this and I hope we can do this in a way that doesn’t require a lot of your time as I suspect that I have more hours for libssh2 at the moment.
| 2023-04-20T01:01:04
|
c
|
Hard
|
nginx/njs
| 747
|
nginx__njs-747
|
[
"743"
] |
9d4bf6c60aa60a828609f64d1b5c50f71bb7ef62
|
diff --git a/src/njs_extern.c b/src/njs_extern.c
--- a/src/njs_extern.c
+++ b/src/njs_extern.c
@@ -236,11 +236,9 @@ njs_external_prop_handler(njs_vm_t *vm, njs_object_prop_t *self,
return NJS_ERROR;
}
- if (slots != NULL) {
- prop->writable = slots->writable;
- prop->configurable = slots->configurable;
- prop->enumerable = slots->enumerable;
- }
+ prop->writable = self->writable;
+ prop->configurable = self->configurable;
+ prop->enumerable = self->enumerable;
lhq.value = prop;
njs_string_get(&self->name, &lhq.key);
diff --git a/src/njs_object.c b/src/njs_object.c
--- a/src/njs_object.c
+++ b/src/njs_object.c
@@ -1076,82 +1076,14 @@ njs_get_own_ordered_keys(njs_vm_t *vm, const njs_object_t *object,
}
-static njs_int_t
-njs_add_obj_prop_kind(njs_vm_t *vm, const njs_object_t *object,
- const njs_lvlhsh_t *hash, njs_lvlhsh_query_t *lhq,
- uint32_t flags, njs_array_t *items)
-{
- njs_int_t ret;
- njs_value_t value, *v, value1;
- njs_array_t *entry;
- njs_object_prop_t *prop;
-
- ret = njs_lvlhsh_find(hash, lhq);
- if (ret != NJS_OK) {
- return NJS_DECLINED;
- }
-
- prop = (njs_object_prop_t *) (lhq->value);
-
- if (prop->type != NJS_ACCESSOR) {
- v = njs_prop_value(prop);
-
- } else {
- if (njs_is_data_descriptor(prop)) {
- v = njs_prop_value(prop);
- goto add;
- }
-
- if (njs_prop_getter(prop) == NULL) {
- v = njs_value_arg(&njs_value_undefined);
- goto add;
- }
-
- v = &value1;
-
- njs_set_object(&value, (njs_object_t *) object);
- ret = njs_function_apply(vm, njs_prop_getter(prop), &value, 1, v);
- if (ret != NJS_OK) {
- return NJS_ERROR;
- }
- }
-
-add:
- if (njs_object_enum_kind(flags) != NJS_ENUM_VALUES) {
- entry = njs_array_alloc(vm, 0, 2, 0);
- if (njs_slow_path(entry == NULL)) {
- return NJS_ERROR;
- }
-
- njs_string_copy(&entry->start[0], &prop->name);
- njs_value_assign(&entry->start[1], v);
-
- njs_set_array(&value, entry);
- v = &value;
- }
-
- ret = njs_array_add(vm, items, v);
- if (njs_slow_path(ret != NJS_OK)) {
- return NJS_ERROR;
- }
-
- return NJS_OK;
-}
-
-
static njs_int_t
njs_object_own_enumerate_object(njs_vm_t *vm, const njs_object_t *object,
const njs_object_t *parent, njs_array_t *items, uint32_t flags)
{
- njs_int_t ret;
- uint32_t i;
- njs_array_t *items_sorted;
- njs_lvlhsh_each_t lhe;
- njs_lvlhsh_query_t lhq;
-
- lhq.proto = &njs_object_hash_proto;
-
- njs_lvlhsh_each_init(&lhe, &njs_object_hash_proto);
+ uint32_t i;
+ njs_int_t ret;
+ njs_array_t *items_sorted, *entry;
+ njs_value_t value, retval;
switch (njs_object_enum_kind(flags)) {
case NJS_ENUM_KEYS:
@@ -1174,26 +1106,31 @@ njs_object_own_enumerate_object(njs_vm_t *vm, const njs_object_t *object,
return NJS_ERROR;
}
- for (i = 0; i< items_sorted->length; i++) {
+ njs_set_object(&value, (njs_object_t *) object);
- lhe.key_hash = 0;
- njs_object_property_key_set(&lhq, &items_sorted->start[i],
- lhe.key_hash);
+ for (i = 0; i< items_sorted->length; i++) {
+ ret = njs_value_property(vm, &value, &items_sorted->start[i],
+ &retval);
+ if (njs_slow_path(ret != NJS_OK)) {
+ njs_array_destroy(vm, items_sorted);
+ return NJS_ERROR;
+ }
- ret = njs_add_obj_prop_kind(vm, object, &object->hash, &lhq, flags,
- items);
- if (ret != NJS_DECLINED) {
- if (ret != NJS_OK) {
+ if (njs_object_enum_kind(flags) != NJS_ENUM_VALUES) {
+ entry = njs_array_alloc(vm, 0, 2, 0);
+ if (njs_slow_path(entry == NULL)) {
return NJS_ERROR;
}
- } else {
- ret = njs_add_obj_prop_kind(vm, object, &object->shared_hash,
- &lhq, flags, items);
- njs_assert(ret != NJS_DECLINED);
- if (ret != NJS_OK) {
- return NJS_ERROR;
- }
+ njs_string_copy(&entry->start[0], &items_sorted->start[i]);
+ njs_value_assign(&entry->start[1], &retval);
+
+ njs_set_array(&retval, entry);
+ }
+
+ ret = njs_array_add(vm, items, &retval);
+ if (njs_slow_path(ret != NJS_OK)) {
+ return NJS_ERROR;
}
}
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -21819,6 +21819,11 @@ static njs_unit_test_t njs_webcrypto_test[] =
{ njs_str("let buf = new Uint32Array(4);"
"buf === crypto.getRandomValues(buf)"),
njs_str("true") },
+
+ { njs_str("crypto.subtle;"
+ "var d = Object.getOwnPropertyDescriptor(crypto, 'subtle');"
+ "d.enumerable && !d.configurable && d.writable"),
+ njs_str("true") },
};
@@ -22688,6 +22693,12 @@ static njs_unit_test_t njs_shared_test[] =
{ njs_str("var v = Math.round(Math.random() * 1000); ExternalNull.set(v);"
"ExternalNull.get() == v"),
njs_str("true") },
+
+#if (NJS_HAVE_OPENSSL)
+ { njs_str("var cr = Object.entries(global).filter((v) => v[0] == 'crypto')[0][1];"
+ "cr.abc = 1; cr.abc"),
+ njs_str("1") },
+#endif
};
|
The properties of `global.crypto` can lead to undefined behavior/crash
### Describe the bug
Upon the first access, the `global.crypto` object contains both the `getRandomValues` function and the `subtle` property, which itself contains multiple cryptographic methods. However, on the second access, the `subtle` property is missing, leaving only the `getRandomValues` function.
- [x] The bug is reproducible with the latest version of njs.
- [x] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
console.log(Object.keys(global.crypto)); // output: ['getRandomValues','subtle']
global.crypto.subtle; // triggering undefined behabior(?)
console.log(Object.keys(global.crypto)); // output: ['getRandomValues']
```
or put the code in a [gist](https://gist.github.com/) and link it here.
- NGINX configuration if applicable
```
# Your NGINX configuration here
```
or put the configuration in a [gist](https://gist.github.com/) and link it here.
- NGINX logs if applicable
```
# Your NGINX logs here
```
or post the full log to a [gist](https://gist.github.com/) and link it here.
- Output of the `nginx -V` command if applicable.
- Exact steps to reproduce the behavior
### Expected behavior
The `global.crypto` object should consistently contain all its properties and methods, including the `subtle` property, regardless of how many times it is accessed or logged.
### Your environment
- Version of njs or specific commit: `v0.8.5` / `d34fcb03cf2378a644a3c7366d58cbddc2771cbd`
- Version of NGINX if applicable: n/a
- List of other enabled nginx modules if applicable: n/a
- OS: `Ubuntu:20.04`(WSL/Docker environment)
### Additional context
I found that it can lead to crashes too, try running the following JS script:
```js
let all = Object.entries(global);
let sus = all[3][1]; // global.crypto
new Uint8Array([sus]);
let v10 = new Uint8Array(100);
try {
v10.map(undefined);
} catch (e) {
/* TypeError: callback argument is not callable */
console.log('brrr');
}
console.log(sus); // segfault
// prolly because we are trying to access the `subtle` prop but it doesnt exist anymore(?? idk)
```
crash at [src/njs_flathsh.c:340](https://github.com/nginx/njs/blob/d34fcb03cf2378a644a3c7366d58cbddc2771cbd/src/njs_flathsh.c#L340) at line `elt_num = njs_hash_cells_end(h)[-cell_num - 1];` because `cell_num` has a value that is too big(looks like a pointer rather than an offset/array index).
gdb output:
```
(gdb) print cell_num
$2 = 0x5024c420
(gdb) bt
#0 0x00005555555cb085 in njs_flathsh_find (fh=fh@entry=0x555555649080, fhq=fhq@entry=0x7fffffffcd90) at src/njs_flathsh.c:340
#1 0x00005555555a0371 in njs_get_own_ordered_keys (vm=0x55555563d6d0, object=0x555555649080, parent=0x555555649080, items=0x555555699b00, flags=0x39) at src/njs_object.c:938
#2 0x00005555555a0a26 in njs_object_own_enumerate_object (vm=vm@entry=0x55555563d6d0, object=object@entry=0x555555649080, parent=parent@entry=0x555555649080, items=items@entry=0x555555699b00, flags=flags@entry=0x39) at src/njs_object.c:1158
#3 0x00005555555a24f3 in njs_object_own_enumerate_value (flags=0x39, items=0x555555699b00, parent=0x555555649080, object=0x555555649080, vm=0x55555563d6d0) at src/njs_object.c:522
#4 njs_object_own_enumerate (vm=vm@entry=0x55555563d6d0, object=0x555555649080, flags=flags@entry=0x39) at src/njs_object.c:564
#5 0x000055555556dcca in njs_value_own_enumerate (vm=0x55555563d6d0, value=0x555555649c30, flags=0x39) at src/njs_value.c:185
#6 0x00005555555abda2 in njs_json_push_stringify_state (stringify=stringify@entry=0x7fffffffd100, value=value@entry=0x555555649c30) at src/njs_json.c:988
#7 0x00005555555ad53b in njs_vm_value_dump (vm=vm@entry=0x55555563d6d0, retval=retval@entry=0x7fffffffdab0, value=value@entry=0x555555649c30, console=console@entry=0x1, indent=indent@entry=0x0) at src/njs_json.c:1999
#8 0x000055555556884c in njs_ext_console_log (vm=0x55555563d6d0, args=0x555555649c20, nargs=0x2, magic=<optimized out>, retval=0x55555565c2e8) at external/njs_shell.c:3810
#9 0x00005555555af9b5 in njs_function_native_call (retval=<optimized out>, vm=0x55555563d6d0) at src/njs_function.c:647
#10 njs_function_frame_invoke (vm=vm@entry=0x55555563d6d0, retval=<optimized out>) at src/njs_function.c:683
#11 0x000055555557861b in njs_vmcode_interpreter (vm=0x55555563d6d0, pc=0x555555658b30 "\r", rval=rval@entry=0x55555563b588, promise_cap=promise_cap@entry=0x0, async_ctx=async_ctx@entry=0x0) at src/njs_vmcode.c:1451
#12 0x000055555556f8a8 in njs_vm_start (vm=<optimized out>, retval=retval@entry=0x55555563b588) at src/njs_vm.c:664
#13 0x00005555555692c6 in njs_engine_njs_eval (engine=0x55555563b580, script=<optimized out>) at external/njs_shell.c:1387
#14 0x0000555555567fd5 in njs_process_script (engine=engine@entry=0x55555563b580, console=console@entry=0x5555556286e0 <njs_console>, script=script@entry=0x7fffffffddd0) at external/njs_shell.c:3528
#15 0x000055555556a585 in njs_process_file (opts=0x7fffffffdde0) at external/njs_shell.c:3500
#16 njs_main (opts=0x7fffffffdde0) at external/njs_shell.c:458
#17 main (argc=<optimized out>, argv=<optimized out>) at external/njs_shell.c:488
```
For the last few days I tried to find the root cause but couldn't. So I thought it's worth bringing this to your attention, hopefully you can shed some more light on this and share your insights on why it happens.
|
Hi @0xbigshaq,
Regarding the first question, what you found is a bug and not an undefined-behaviour.
The 'subtle' property is not deleted, but becomes hidden, due to improper enumerated flag copied [here](https://github.com/nginx/njs/blob/master/src/njs_extern.c#L239).
For example
```js
crypto.subtle;
crypto.subtle;
console.log(crypto.subtle.digest);
```
outputs:
`[Function: digest]`
2 functions are important here njs_external_add() and njs_external_prop_handler().
We have copy-on-read here: we create properties in the current context lazily and at the moment of the first access from a shared precompiled state. For example, 'subtle' property is stored as `NJS_PROPERTY_HANDLER` in shared hash which at the moment of access creates a modifiable property by calling `njs_external_prop_handler()` which puts the property in the local hash of an object.
```diff
diff --git a/src/njs_extern.c b/src/njs_extern.c
index df51f9b7..9ec1c1c9 100644
--- a/src/njs_extern.c
+++ b/src/njs_extern.c
@@ -236,11 +236,9 @@ njs_external_prop_handler(njs_vm_t *vm, njs_object_prop_t *self,
return NJS_ERROR;
}
- if (slots != NULL) {
- prop->writable = slots->writable;
- prop->configurable = slots->configurable;
- prop->enumerable = slots->enumerable;
- }
+ prop->writable = self->writable;
+ prop->configurable = self->configurable;
+ prop->enumerable = self->enumerable;
lhq.value = prop;
njs_string_get(&self->name, &lhq.key);
```
should fix the first problem.
| 2024-06-27T01:39:01
|
c
|
Hard
|
nginx/njs
| 950
|
nginx__njs-950
|
[
"939"
] |
d93680e26b6f60226a0cc89fcc48db72d68a226c
|
diff --git a/src/njs_vm.h b/src/njs_vm.h
--- a/src/njs_vm.h
+++ b/src/njs_vm.h
@@ -8,7 +8,7 @@
#define _NJS_VM_H_INCLUDED_
-#define NJS_MAX_STACK_SIZE (64 * 1024)
+#define NJS_MAX_STACK_SIZE (160 * 1024)
typedef struct njs_frame_s njs_frame_t;
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -21856,6 +21856,7 @@ njs_unit_test(njs_unit_test_t tests[], size_t num, njs_str_t *name,
options.module = opts->module;
options.unsafe = opts->unsafe;
options.backtrace = opts->backtrace;
+ options.max_stack_size = 64 * 1024;
options.addons = opts->externals ? njs_unit_test_addon_external_modules
: njs_unit_test_addon_modules;
@@ -22008,6 +22009,7 @@ njs_interactive_test(njs_unit_test_t tests[], size_t num, njs_str_t *name,
options.init = 1;
options.interactive = 1;
options.backtrace = 1;
+ options.max_stack_size = 64 * 1024;
options.addons = opts->externals ? njs_unit_test_addon_external_modules
: njs_unit_test_addon_modules;
|
EarleyBoyer: RangeError: Maximum call stack size exceeded
### Describe the bug
v8-v7 EarleyBoyer test run fails
[run.zip](https://github.com/user-attachments/files/21028584/run.zip)
### To reproduce
- JS script
```js
function f(n) {
console.log(n)
f(n + 1)
}
f(0)
```
### Expected behavior
njs sets a stack size of 64kb by default, which seems to be the smallest
For the above test code, the maximum stack of other engines:
```
mujs 1020
qjs 598
njs 229
```
### Your environment
- Version of njs or specific commit: master
- OS: [e.g. Ubuntu 24.04]
### Additional context
Although it is possible to set a larger stack size through the command line, for modern complex applications, is it possible to set a larger default stack size for ease of use?
| 2025-08-11T23:36:49
|
c
|
Hard
|
|
profanity-im/profanity
| 1,355
|
profanity-im__profanity-1355
|
[
"1236"
] |
8c9aee22e81804bda6590ba80e9450ca90f56d14
|
diff --git a/src/command/cmd_ac.c b/src/command/cmd_ac.c
--- a/src/command/cmd_ac.c
+++ b/src/command/cmd_ac.c
@@ -195,6 +195,7 @@ static Autocomplete omemo_sendfile_ac;
#endif
static Autocomplete connect_property_ac;
static Autocomplete tls_property_ac;
+static Autocomplete auth_property_ac;
static Autocomplete alias_ac;
static Autocomplete aliases_ac;
static Autocomplete join_property_ac;
@@ -425,6 +426,7 @@ cmd_ac_init(void)
autocomplete_add(account_set_ac, "pgpkeyid");
autocomplete_add(account_set_ac, "startscript");
autocomplete_add(account_set_ac, "tls");
+ autocomplete_add(account_set_ac, "auth");
autocomplete_add(account_set_ac, "theme");
account_clear_ac = autocomplete_new();
@@ -686,6 +688,7 @@ cmd_ac_init(void)
#endif
connect_property_ac = autocomplete_new();
+ autocomplete_add(connect_property_ac, "auth");
autocomplete_add(connect_property_ac, "server");
autocomplete_add(connect_property_ac, "port");
autocomplete_add(connect_property_ac, "tls");
@@ -697,6 +700,10 @@ cmd_ac_init(void)
autocomplete_add(tls_property_ac, "legacy");
autocomplete_add(tls_property_ac, "disable");
+ auth_property_ac = autocomplete_new();
+ autocomplete_add(auth_property_ac, "default");
+ autocomplete_add(auth_property_ac, "legacy");
+
join_property_ac = autocomplete_new();
autocomplete_add(join_property_ac, "nick");
autocomplete_add(join_property_ac, "password");
@@ -1263,6 +1270,7 @@ cmd_ac_reset(ProfWin *window)
#endif
autocomplete_reset(connect_property_ac);
autocomplete_reset(tls_property_ac);
+ autocomplete_reset(auth_property_ac);
autocomplete_reset(alias_ac);
autocomplete_reset(aliases_ac);
autocomplete_reset(join_property_ac);
@@ -1419,6 +1427,7 @@ cmd_ac_uninit(void)
#endif
autocomplete_free(connect_property_ac);
autocomplete_free(tls_property_ac);
+ autocomplete_free(auth_property_ac);
autocomplete_free(alias_ac);
autocomplete_free(aliases_ac);
autocomplete_free(join_property_ac);
@@ -3206,7 +3215,7 @@ _connect_autocomplete(ProfWin *window, const char *const input, gboolean previou
char *found = NULL;
gboolean result = FALSE;
- gchar **args = parse_args(input, 1, 7, &result);
+ gchar **args = parse_args(input, 1, 9, &result);
if (result) {
gboolean space_at_end = g_str_has_suffix(input, " ");
@@ -3274,6 +3283,74 @@ _connect_autocomplete(ProfWin *window, const char *const input, gboolean previou
return found;
}
}
+ if ((num_args == 7 && space_at_end) || (num_args == 8 && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4], args[5], args[6]);
+ found = autocomplete_param_with_ac(input, beginning->str, connect_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
+ if ((num_args == 8 && space_at_end && (g_strcmp0(args[7], "tls") == 0))
+ || (num_args == 9 && (g_strcmp0(args[7], "tls") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s %s %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7]);
+ found = autocomplete_param_with_ac(input, beginning->str, tls_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
+
+ /* auth option */
+
+ if ((num_args == 2 && space_at_end && (g_strcmp0(args[1], "auth") == 0))
+ || (num_args == 3 && (g_strcmp0(args[1], "auth") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s", args[0], args[1]);
+ found = autocomplete_param_with_ac(input, beginning->str, auth_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
+ if ((num_args == 4 && space_at_end && (g_strcmp0(args[3], "auth") == 0))
+ || (num_args == 5 && (g_strcmp0(args[3], "auth") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s %s %s", args[0], args[1], args[2], args[3]);
+ found = autocomplete_param_with_ac(input, beginning->str, auth_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
+ if ((num_args == 6 && space_at_end && (g_strcmp0(args[5], "auth") == 0))
+ || (num_args == 7 && (g_strcmp0(args[5], "auth") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4], args[5]);
+ found = autocomplete_param_with_ac(input, beginning->str, auth_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
+ if ((num_args == 8 && space_at_end && (g_strcmp0(args[7], "auth") == 0))
+ || (num_args == 9 && (g_strcmp0(args[7], "auth") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/connect");
+ g_string_append_printf(beginning, " %s %s %s %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7]);
+ found = autocomplete_param_with_ac(input, beginning->str, auth_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
}
g_strfreev(args);
@@ -3484,6 +3561,17 @@ _account_autocomplete(ProfWin *window, const char *const input, gboolean previou
return found;
}
}
+ if ((num_args == 3 && space_at_end && (g_strcmp0(args[2], "auth") == 0))
+ || (num_args == 4 && (g_strcmp0(args[2], "auth") == 0) && !space_at_end)) {
+ GString *beginning = g_string_new("/account");
+ g_string_append_printf(beginning, " %s %s %s", args[0], args[1], args[2]);
+ found = autocomplete_param_with_ac(input, beginning->str, auth_property_ac, TRUE, previous);
+ g_string_free(beginning, TRUE);
+ if (found) {
+ g_strfreev(args);
+ return found;
+ }
+ }
if ((num_args == 3 && space_at_end && (g_strcmp0(args[2], "startscript") == 0))
|| (num_args == 4 && (g_strcmp0(args[2], "startscript") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/account");
diff --git a/src/command/cmd_defs.c b/src/command/cmd_defs.c
--- a/src/command/cmd_defs.c
+++ b/src/command/cmd_defs.c
@@ -160,7 +160,7 @@ static struct cmd_t command_defs[] =
CMD_TAG_CONNECTION)
CMD_SYN(
"/connect [<account>]",
- "/connect <account> [server <server>] [port <port>] [tls force|allow|trust|legacy|disable]")
+ "/connect <account> [server <server>] [port <port>] [tls force|allow|trust|legacy|disable] [auth default|legacy]")
CMD_DESC(
"Login to a chat service. "
"If no account is specified, the default is used if one is configured. "
@@ -173,7 +173,9 @@ static struct cmd_t command_defs[] =
{ "tls allow", "Use TLS for the connection if it is available." },
{ "tls trust", "Force TLS connection and trust server's certificate." },
{ "tls legacy", "Use legacy TLS for the connection. It means server doesn't support STARTTLS and TLS is forced just after TCP connection is established." },
- { "tls disable", "Disable TLS for the connection." })
+ { "tls disable", "Disable TLS for the connection." },
+ { "auth default", "Default authentication process." },
+ { "auth legacy", "Allow legacy authentication." })
CMD_EXAMPLES(
"/connect",
"/connect odin@valhalla.edda",
@@ -2003,6 +2005,7 @@ static struct cmd_t command_defs[] =
"/account set <account> pgpkeyid <pgpkeyid>",
"/account set <account> startscript <script>",
"/account set <account> tls force|allow|trust|legacy|disable",
+ "/account set <account> auth default|legacy",
"/account set <account> theme <theme>",
"/account clear <account> password",
"/account clear <account> eval_password",
@@ -2045,6 +2048,8 @@ static struct cmd_t command_defs[] =
{ "set <account> tls trust", "Force TLS connection and trust server's certificate." },
{ "set <account> tls legacy", "Use legacy TLS for the connection. It means server doesn't support STARTTLS and TLS is forced just after TCP connection is established." },
{ "set <account> tls disable", "Disable TLS for the connection." },
+ { "set <account> auth default", "Use default authentication process." },
+ { "set <account> auth legacy", "Allow legacy authentication." },
{ "set <account> <theme>", "Set the UI theme for the account." },
{ "clear <account> server", "Remove the server setting for this account." },
{ "clear <account> port", "Remove the port setting for this account." },
diff --git a/src/command/cmd_funcs.c b/src/command/cmd_funcs.c
--- a/src/command/cmd_funcs.c
+++ b/src/command/cmd_funcs.c
@@ -338,7 +338,7 @@ cmd_connect(ProfWin *window, const char *const command, gchar **args)
return TRUE;
}
- gchar *opt_keys[] = { "server", "port", "tls", NULL };
+ gchar *opt_keys[] = { "server", "port", "tls", "auth", NULL };
gboolean parsed;
GHashTable *options = parse_options(&args[args[0] ? 1 : 0], opt_keys, &parsed);
@@ -364,6 +364,16 @@ cmd_connect(ProfWin *window, const char *const command, gchar **args)
return TRUE;
}
+ char *auth_policy = g_hash_table_lookup(options, "auth");
+ if (auth_policy &&
+ (g_strcmp0(auth_policy, "default") != 0) &&
+ (g_strcmp0(auth_policy, "legacy") != 0)) {
+ cons_bad_cmd_usage(command);
+ cons_show("");
+ options_destroy(options);
+ return TRUE;
+ }
+
int port = 0;
if (g_hash_table_contains(options, "port")) {
char *port_str = g_hash_table_lookup(options, "port");
@@ -406,6 +416,8 @@ cmd_connect(ProfWin *window, const char *const command, gchar **args)
account_set_port(account, port);
if (tls_policy != NULL)
account_set_tls_policy(account, tls_policy);
+ if (auth_policy != NULL)
+ account_set_auth_policy(account, auth_policy);
// use password if set
if (account->password) {
@@ -441,7 +453,7 @@ cmd_connect(ProfWin *window, const char *const command, gchar **args)
} else {
jid = g_utf8_strdown(user, -1);
char *passwd = ui_ask_password();
- conn_status = cl_ev_connect_jid(jid, passwd, altdomain, port, tls_policy);
+ conn_status = cl_ev_connect_jid(jid, passwd, altdomain, port, tls_policy, auth_policy);
free(passwd);
}
@@ -497,7 +509,7 @@ cmd_account_add(ProfWin *window, const char *const command, gchar **args)
return TRUE;
}
- accounts_add(account_name, NULL, 0, NULL);
+ accounts_add(account_name, NULL, 0, NULL, NULL);
cons_show("Account created.");
cons_show("");
@@ -843,6 +855,20 @@ _account_set_tls(char *account_name, char *policy)
return TRUE;
}
+gboolean
+_account_set_auth(char *account_name, char *policy)
+{
+ if ((g_strcmp0(policy, "default") != 0)
+ && (g_strcmp0(policy, "legacy") != 0)) {
+ cons_show("Auth policy must be either default or legacy.");
+ } else {
+ accounts_set_auth_policy(account_name, policy);
+ cons_show("Updated auth policy for account %s: %s", account_name, policy);
+ cons_show("");
+ }
+ return TRUE;
+}
+
gboolean
_account_set_presence_priority(char *account_name, char *presence, char *priority)
{
@@ -919,6 +945,7 @@ cmd_account_set(ProfWin *window, const char *const command, gchar **args)
if (strcmp(property, "startscript") == 0) return _account_set_startscript(account_name, value);
if (strcmp(property, "theme") == 0) return _account_set_theme(account_name, value);
if (strcmp(property, "tls") == 0) return _account_set_tls(account_name, value);
+ if (strcmp(property, "auth") == 0) return _account_set_auth(account_name, value);
if (valid_resource_presence_string(property)) {
return _account_set_presence_priority(account_name, property, value);
diff --git a/src/config/account.c b/src/config/account.c
--- a/src/config/account.c
+++ b/src/config/account.c
@@ -55,7 +55,7 @@ account_new(const gchar *const name, const gchar *const jid,
const gchar *const otr_policy, GList *otr_manual, GList *otr_opportunistic,
GList *otr_always, const gchar *const omemo_policy, GList *omemo_enabled,
GList *omemo_disabled, const gchar *const pgp_keyid, const char *const startscript,
- const char *const theme, gchar *tls_policy)
+ const char *const theme, gchar *tls_policy, gchar *auth_policy)
{
ProfAccount *new_account = malloc(sizeof(ProfAccount));
memset(new_account, 0, sizeof(ProfAccount));
@@ -175,6 +175,12 @@ account_new(const gchar *const name, const gchar *const jid,
new_account->tls_policy = NULL;
}
+ if (auth_policy != NULL) {
+ new_account->auth_policy = strdup(auth_policy);
+ } else {
+ new_account->auth_policy = NULL;
+ }
+
return new_account;
}
@@ -247,6 +253,7 @@ account_free(ProfAccount *account)
free(account->startscript);
free(account->theme);
free(account->tls_policy);
+ free(account->auth_policy);
g_list_free_full(account->otr_manual, g_free);
g_list_free_full(account->otr_opportunistic, g_free);
g_list_free_full(account->otr_always, g_free);
@@ -271,3 +278,9 @@ void account_set_tls_policy(ProfAccount *account, const char *tls_policy)
free(account->tls_policy);
account->tls_policy = strdup(tls_policy);
}
+
+void account_set_auth_policy(ProfAccount *account, const char *auth_policy)
+{
+ free(account->auth_policy);
+ account->auth_policy = strdup(auth_policy);
+}
diff --git a/src/config/account.h b/src/config/account.h
--- a/src/config/account.h
+++ b/src/config/account.h
@@ -67,6 +67,7 @@ typedef struct prof_account_t {
gchar *startscript;
gchar *theme;
gchar *tls_policy;
+ gchar *auth_policy;
} ProfAccount;
ProfAccount* account_new(const gchar *const name, const gchar *const jid,
@@ -78,12 +79,13 @@ ProfAccount* account_new(const gchar *const name, const gchar *const jid,
const gchar *const otr_policy, GList *otr_manual, GList *otr_opportunistic,
GList *otr_always, const gchar *const omemo_policy, GList *omemo_enabled,
GList *omemo_disabled, const gchar *const pgp_keyid, const char *const startscript,
- const char *const theme, gchar *tls_policy);
+ const char *const theme, gchar *tls_policy, gchar *auth_policy);
char* account_create_connect_jid(ProfAccount *account);
gboolean account_eval_password(ProfAccount *account);
void account_free(ProfAccount *account);
void account_set_server(ProfAccount *account, const char *server);
void account_set_port(ProfAccount *account, int port);
void account_set_tls_policy(ProfAccount *account, const char *tls_policy);
+void account_set_auth_policy(ProfAccount *account, const char *auth_policy);
#endif
diff --git a/src/config/accounts.c b/src/config/accounts.c
--- a/src/config/accounts.c
+++ b/src/config/accounts.c
@@ -121,7 +121,7 @@ accounts_reset_enabled_search(void)
}
void
-accounts_add(const char *account_name, const char *altdomain, const int port, const char *const tls_policy)
+accounts_add(const char *account_name, const char *altdomain, const int port, const char *const tls_policy, const char *const auth_policy)
{
// set account name and resource
const char *barejid = account_name;
@@ -152,6 +152,9 @@ accounts_add(const char *account_name, const char *altdomain, const int port, co
if (tls_policy) {
g_key_file_set_string(accounts, account_name, "tls.policy", tls_policy);
}
+ if (auth_policy) {
+ g_key_file_set_string(accounts, account_name, "auth.policy", auth_policy);
+ }
Jid *jidp = jid_create(barejid);
@@ -326,12 +329,15 @@ accounts_get_account(const char *const name)
tls_policy = NULL;
}
+ gchar *auth_policy = g_key_file_get_string(accounts, name, "auth.policy", NULL);
+
ProfAccount *new_account = account_new(name, jid, password, eval_password, enabled,
server, port, resource, last_presence, login_presence,
priority_online, priority_chat, priority_away, priority_xa,
priority_dnd, muc_service, muc_nick, otr_policy, otr_manual,
otr_opportunistic, otr_always, omemo_policy, omemo_enabled,
- omemo_disabled, pgp_keyid, startscript, theme, tls_policy);
+ omemo_disabled, pgp_keyid, startscript, theme, tls_policy,
+ auth_policy);
g_free(jid);
g_free(password);
@@ -348,6 +354,7 @@ accounts_get_account(const char *const name)
g_free(startscript);
g_free(theme);
g_free(tls_policy);
+ g_free(auth_policy);
return new_account;
}
@@ -735,6 +742,15 @@ accounts_set_tls_policy(const char *const account_name, const char *const value)
}
}
+void
+accounts_set_auth_policy(const char *const account_name, const char *const value)
+{
+ if (accounts_account_exists(account_name)) {
+ g_key_file_set_string(accounts, account_name, "auth.policy", value);
+ _save_accounts();
+ }
+}
+
void
accounts_set_priority_online(const char *const account_name, const gint value)
{
diff --git a/src/config/accounts.h b/src/config/accounts.h
--- a/src/config/accounts.h
+++ b/src/config/accounts.h
@@ -48,7 +48,7 @@ char* accounts_find_all(const char *const prefix, gboolean previous, void *conte
char* accounts_find_enabled(const char *const prefix, gboolean previous, void *context);
void accounts_reset_all_search(void);
void accounts_reset_enabled_search(void);
-void accounts_add(const char *jid, const char *altdomain, const int port, const char *const tls_policy);
+void accounts_add(const char *jid, const char *altdomain, const int port, const char *const tls_policy, const char *const auth_policy);
int accounts_remove(const char *jid);
gchar** accounts_get_list(void);
ProfAccount* accounts_get_account(const char *const name);
@@ -67,6 +67,7 @@ void accounts_set_muc_service(const char *const account_name, const char *const
void accounts_set_muc_nick(const char *const account_name, const char *const value);
void accounts_set_otr_policy(const char *const account_name, const char *const value);
void accounts_set_tls_policy(const char *const account_name, const char *const value);
+void accounts_set_auth_policy(const char *const account_name, const char *const value);
void accounts_set_last_presence(const char *const account_name, const char *const value);
void accounts_set_last_status(const char *const account_name, const char *const value);
void accounts_set_last_activity(const char *const account_name);
diff --git a/src/event/client_events.c b/src/event/client_events.c
--- a/src/event/client_events.c
+++ b/src/event/client_events.c
@@ -61,10 +61,10 @@
#endif
jabber_conn_status_t
-cl_ev_connect_jid(const char *const jid, const char *const passwd, const char *const altdomain, const int port, const char *const tls_policy)
+cl_ev_connect_jid(const char *const jid, const char *const passwd, const char *const altdomain, const int port, const char *const tls_policy, const char *const auth_policy)
{
cons_show("Connecting as %s", jid);
- return session_connect_with_details(jid, passwd, altdomain, port, tls_policy);
+ return session_connect_with_details(jid, passwd, altdomain, port, tls_policy, auth_policy);
}
jabber_conn_status_t
diff --git a/src/event/client_events.h b/src/event/client_events.h
--- a/src/event/client_events.h
+++ b/src/event/client_events.h
@@ -38,7 +38,7 @@
#include "xmpp/xmpp.h"
-jabber_conn_status_t cl_ev_connect_jid(const char *const jid, const char *const passwd, const char *const altdomain, const int port, const char *const tls_policy);
+jabber_conn_status_t cl_ev_connect_jid(const char *const jid, const char *const passwd, const char *const altdomain, const int port, const char *const tls_policy, const char *const auth_policy);
jabber_conn_status_t cl_ev_connect_account(ProfAccount *account);
void cl_ev_disconnect(void);
diff --git a/src/ui/console.c b/src/ui/console.c
--- a/src/ui/console.c
+++ b/src/ui/console.c
@@ -908,6 +908,9 @@ cons_show_account(ProfAccount *account)
if (account->tls_policy) {
cons_show ("TLS policy : %s", account->tls_policy);
}
+ if (account->auth_policy) {
+ cons_show ("Auth policy : %s", account->auth_policy);
+ }
if (account->last_presence) {
cons_show ("Last presence : %s", account->last_presence);
}
diff --git a/src/xmpp/connection.c b/src/xmpp/connection.c
--- a/src/xmpp/connection.c
+++ b/src/xmpp/connection.c
@@ -134,8 +134,10 @@ connection_shutdown(void)
jabber_conn_status_t
connection_connect(const char *const jid, const char *const passwd, const char *const altdomain, int port,
- const char *const tls_policy)
+ const char *const tls_policy, const char *const auth_policy)
{
+ long flags;
+
assert(jid != NULL);
assert(passwd != NULL);
@@ -175,15 +177,35 @@ connection_connect(const char *const jid, const char *const passwd, const char *
xmpp_conn_set_jid(conn.xmpp_conn, jid);
xmpp_conn_set_pass(conn.xmpp_conn, passwd);
+ flags = xmpp_conn_get_flags(conn.xmpp_conn);
+
if (!tls_policy || (g_strcmp0(tls_policy, "force") == 0)) {
- xmpp_conn_set_flags(conn.xmpp_conn, XMPP_CONN_FLAG_MANDATORY_TLS);
+ flags |= XMPP_CONN_FLAG_MANDATORY_TLS;
} else if (g_strcmp0(tls_policy, "trust") == 0) {
- xmpp_conn_set_flags(conn.xmpp_conn, XMPP_CONN_FLAG_MANDATORY_TLS);
- xmpp_conn_set_flags(conn.xmpp_conn, XMPP_CONN_FLAG_TRUST_TLS);
+ flags |= XMPP_CONN_FLAG_MANDATORY_TLS;
+ flags |= XMPP_CONN_FLAG_TRUST_TLS;
} else if (g_strcmp0(tls_policy, "disable") == 0) {
- xmpp_conn_set_flags(conn.xmpp_conn, XMPP_CONN_FLAG_DISABLE_TLS);
+ flags |= XMPP_CONN_FLAG_DISABLE_TLS;
} else if (g_strcmp0(tls_policy, "legacy") == 0) {
- xmpp_conn_set_flags(conn.xmpp_conn, XMPP_CONN_FLAG_LEGACY_SSL);
+ flags |= XMPP_CONN_FLAG_LEGACY_SSL;
+ }
+
+ if (auth_policy && (g_strcmp0(auth_policy, "legacy") == 0)) {
+ flags |= XMPP_CONN_FLAG_LEGACY_AUTH;
+ }
+
+ xmpp_conn_set_flags(conn.xmpp_conn, flags);
+
+ /* Print debug logs that can help when users share the logs */
+ if (flags != 0) {
+ log_debug("Connecting with flags (0x%lx):", flags);
+#define LOG_FLAG_IF_SET(name) if (flags & name) { log_debug(" " #name); }
+ LOG_FLAG_IF_SET(XMPP_CONN_FLAG_MANDATORY_TLS);
+ LOG_FLAG_IF_SET(XMPP_CONN_FLAG_TRUST_TLS);
+ LOG_FLAG_IF_SET(XMPP_CONN_FLAG_DISABLE_TLS);
+ LOG_FLAG_IF_SET(XMPP_CONN_FLAG_LEGACY_SSL);
+ LOG_FLAG_IF_SET(XMPP_CONN_FLAG_LEGACY_AUTH);
+#undef LOG_FLAG_IF_SET
}
#ifdef HAVE_LIBMESODE
diff --git a/src/xmpp/connection.h b/src/xmpp/connection.h
--- a/src/xmpp/connection.h
+++ b/src/xmpp/connection.h
@@ -43,7 +43,7 @@ void connection_shutdown(void);
void connection_check_events(void);
jabber_conn_status_t connection_connect(const char *const fulljid, const char *const passwd, const char *const altdomain, int port,
- const char *const tls_policy);
+ const char *const tls_policy, const char *const auth_policy);
void connection_disconnect(void);
void connection_set_disconnected(void);
diff --git a/src/xmpp/session.c b/src/xmpp/session.c
--- a/src/xmpp/session.c
+++ b/src/xmpp/session.c
@@ -79,6 +79,7 @@ static struct {
char *altdomain;
int port;
char *tls_policy;
+ char *auth_policy;
} saved_details;
typedef enum {
@@ -135,7 +136,8 @@ session_connect_with_account(const ProfAccount *const account)
account->password,
account->server,
account->port,
- account->tls_policy);
+ account->tls_policy,
+ account->auth_policy);
free(jid);
return result;
@@ -143,7 +145,7 @@ session_connect_with_account(const ProfAccount *const account)
jabber_conn_status_t
session_connect_with_details(const char *const jid, const char *const passwd, const char *const altdomain,
- const int port, const char *const tls_policy)
+ const int port, const char *const tls_policy, const char *const auth_policy)
{
assert(jid != NULL);
assert(passwd != NULL);
@@ -169,6 +171,11 @@ session_connect_with_details(const char *const jid, const char *const passwd, co
} else {
saved_details.tls_policy = NULL;
}
+ if (auth_policy) {
+ saved_details.auth_policy = strdup(auth_policy);
+ } else {
+ saved_details.auth_policy = NULL;
+ }
// use 'profanity' when no resourcepart in provided jid
Jid *jidp = jid_create(jid);
@@ -191,7 +198,8 @@ session_connect_with_details(const char *const jid, const char *const passwd, co
passwd,
saved_details.altdomain,
saved_details.port,
- saved_details.tls_policy);
+ saved_details.tls_policy,
+ saved_details.auth_policy);
}
void
@@ -292,7 +300,7 @@ session_login_success(gboolean secured)
// logged in without account, use details to create new account
} else {
log_debug("Connection handler: logged in with jid: %s", saved_details.name);
- accounts_add(saved_details.name, saved_details.altdomain, saved_details.port, saved_details.tls_policy);
+ accounts_add(saved_details.name, saved_details.altdomain, saved_details.port, saved_details.tls_policy, saved_details.auth_policy);
accounts_set_jid(saved_details.name, saved_details.jid);
saved_account.name = strdup(saved_details.name);
@@ -511,7 +519,7 @@ _session_reconnect(void)
}
log_debug("Attempting reconnect with account %s", account->name);
- connection_connect(jid, saved_account.passwd, account->server, account->port, account->tls_policy);
+ connection_connect(jid, saved_account.passwd, account->server, account->port, account->tls_policy, account->auth_policy);
free(jid);
account_free(account);
g_timer_start(reconnect_timer);
@@ -532,5 +540,6 @@ _session_free_saved_details(void)
FREE_SET_NULL(saved_details.passwd);
FREE_SET_NULL(saved_details.altdomain);
FREE_SET_NULL(saved_details.tls_policy);
+ FREE_SET_NULL(saved_details.auth_policy);
}
diff --git a/src/xmpp/xmpp.h b/src/xmpp/xmpp.h
--- a/src/xmpp/xmpp.h
+++ b/src/xmpp/xmpp.h
@@ -164,7 +164,7 @@ typedef struct prof_message_t {
void session_init(void);
jabber_conn_status_t session_connect_with_details(const char *const jid, const char *const passwd,
- const char *const altdomain, const int port, const char *const tls_policy);
+ const char *const altdomain, const int port, const char *const tls_policy, const char *const auth_policy);
jabber_conn_status_t session_connect_with_account(const ProfAccount *const account);
void session_disconnect(void);
void session_shutdown(void);
|
diff --git a/tests/unittests/config/stub_accounts.c b/tests/unittests/config/stub_accounts.c
--- a/tests/unittests/config/stub_accounts.c
+++ b/tests/unittests/config/stub_accounts.c
@@ -128,6 +128,7 @@ void accounts_set_pgp_keyid(const char * const account_name, const char * const
void accounts_set_script_start(const char * const account_name, const char * const value) {}
void accounts_set_theme(const char * const account_name, const char * const value) {}
void accounts_set_tls_policy(const char * const account_name, const char * const value) {}
+void accounts_set_auth_policy(const char * const account_name, const char * const value) {}
void accounts_set_login_presence(const char * const account_name, const char * const value)
{
diff --git a/tests/unittests/test_cmd_account.c b/tests/unittests/test_cmd_account.c
--- a/tests/unittests/test_cmd_account.c
+++ b/tests/unittests/test_cmd_account.c
@@ -33,7 +33,7 @@ void cmd_account_shows_usage_when_not_connected_and_no_args(void **state)
void cmd_account_shows_account_when_connected_and_no_args(void **state)
{
ProfAccount *account = account_new("jabber_org", "me@jabber.org", NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
gchar *args[] = { NULL };
will_return(connection_get_status, JABBER_CONNECTED);
@@ -93,7 +93,7 @@ void cmd_account_show_shows_account_when_exists(void **state)
{
gchar *args[] = { "show", "account_name", NULL };
ProfAccount *account = account_new("jabber_org", "me@jabber.org", NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
expect_any(accounts_get_account, name);
will_return(accounts_get_account, account);
@@ -409,7 +409,7 @@ void cmd_account_set_password_sets_password(void **state)
{
gchar *args[] = { "set", "a_account", "password", "a_password", NULL };
ProfAccount *account = account_new("a_account", NULL, NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
expect_any(accounts_account_exists, account_name);
@@ -432,7 +432,7 @@ void cmd_account_set_eval_password_sets_eval_password(void **state)
{
gchar *args[] = { "set", "a_account", "eval_password", "a_password", NULL };
ProfAccount *account = account_new("a_account", NULL, NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
expect_any(accounts_account_exists, account_name);
will_return(accounts_account_exists, TRUE);
@@ -453,7 +453,7 @@ void cmd_account_set_eval_password_sets_eval_password(void **state)
void cmd_account_set_password_when_eval_password_set(void **state) {
gchar *args[] = { "set", "a_account", "password", "a_password", NULL };
ProfAccount *account = account_new("a_account", NULL, NULL, "a_password",
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
expect_any(accounts_account_exists, account_name);
will_return(accounts_account_exists, TRUE);
@@ -470,7 +470,7 @@ void cmd_account_set_password_when_eval_password_set(void **state) {
void cmd_account_set_eval_password_when_password_set(void **state) {
gchar *args[] = { "set", "a_account", "eval_password", "a_password", NULL };
ProfAccount *account = account_new("a_account", NULL, "a_password", NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
expect_any(accounts_account_exists, account_name);
will_return(accounts_account_exists, TRUE);
@@ -800,7 +800,7 @@ void cmd_account_set_priority_updates_presence_when_account_connected_with_prese
#ifdef HAVE_LIBGPGME
ProfAccount *account = account_new("a_account", "a_jid", NULL, NULL, TRUE, NULL, 5222, "a_resource",
- NULL, NULL, 10, 10, 10, 10, 10, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ NULL, NULL, 10, 10, 10, 10, 10, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(session_get_account_name, "a_account");
expect_any(accounts_get_account, name);
diff --git a/tests/unittests/test_cmd_connect.c b/tests/unittests/test_cmd_connect.c
--- a/tests/unittests/test_cmd_connect.c
+++ b/tests/unittests/test_cmd_connect.c
@@ -116,7 +116,7 @@ void cmd_connect_lowercases_argument_with_account(void **state)
{
gchar *args[] = { "Jabber_org", NULL };
ProfAccount *account = account_new("Jabber_org", "me@jabber.org", "password", NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_DISCONNECTED);
@@ -136,7 +136,7 @@ void cmd_connect_asks_password_when_not_in_account(void **state)
{
gchar *args[] = { "jabber_org", NULL };
ProfAccount *account = account_new("jabber_org", "me@jabber.org", NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_DISCONNECTED);
@@ -383,7 +383,7 @@ void cmd_connect_shows_message_when_connecting_with_account(void **state)
{
gchar *args[] = { "jabber_org", NULL };
ProfAccount *account = account_new("jabber_org", "user@jabber.org", "password", NULL,
- TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_DISCONNECTED);
@@ -403,7 +403,7 @@ void cmd_connect_connects_with_account(void **state)
{
gchar *args[] = { "jabber_org", NULL };
ProfAccount *account = account_new("jabber_org", "me@jabber.org", "password", NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_DISCONNECTED);
diff --git a/tests/unittests/test_cmd_join.c b/tests/unittests/test_cmd_join.c
--- a/tests/unittests/test_cmd_join.c
+++ b/tests/unittests/test_cmd_join.c
@@ -65,7 +65,7 @@ void cmd_join_uses_account_mucservice_when_no_service_specified(void **state)
char *expected_room = "room@conference.server.org";
gchar *args[] = { room, "nick", nick, NULL };
ProfAccount *account = account_new(account_name, "user@server.org", NULL, NULL,
- TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, account_service, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, account_service, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
muc_init();
@@ -92,7 +92,7 @@ void cmd_join_uses_supplied_nick(void **state)
char *nick = "bob";
gchar *args[] = { room, "nick", nick, NULL };
ProfAccount *account = account_new(account_name, "user@server.org", NULL, NULL,
- TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
muc_init();
@@ -119,7 +119,7 @@ void cmd_join_uses_account_nick_when_not_supplied(void **state)
char *account_nick = "a_nick";
gchar *args[] = { room, NULL };
ProfAccount *account = account_new(account_name, "user@server.org", NULL, NULL,
- TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, account_nick, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, NULL, account_nick, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
muc_init();
@@ -149,7 +149,7 @@ void cmd_join_uses_password_when_supplied(void **state)
char *expected_room = "room@a_service";
gchar *args[] = { room, "password", password, NULL };
ProfAccount *account = account_new(account_name, "user@server.org", NULL, NULL,
- TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, account_service, account_nick, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, "laptop", NULL, NULL, 0, 0, 0, 0, 0, account_service, account_nick, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
muc_init();
diff --git a/tests/unittests/test_cmd_otr.c b/tests/unittests/test_cmd_otr.c
--- a/tests/unittests/test_cmd_otr.c
+++ b/tests/unittests/test_cmd_otr.c
@@ -182,7 +182,7 @@ void cmd_otr_gen_generates_key_for_connected_account(void **state)
gchar *args[] = { "gen", NULL };
char *account_name = "myaccount";
ProfAccount *account = account_new(account_name, "me@jabber.org", NULL, NULL,
- TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ TRUE, NULL, 0, NULL, NULL, NULL, 0, 0, 0, 0, 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_CONNECTED);
will_return(session_get_account_name, account_name);
diff --git a/tests/unittests/test_cmd_rooms.c b/tests/unittests/test_cmd_rooms.c
--- a/tests/unittests/test_cmd_rooms.c
+++ b/tests/unittests/test_cmd_rooms.c
@@ -46,7 +46,7 @@ void cmd_rooms_uses_account_default_when_no_arg(void **state)
gchar *args[] = { NULL };
ProfAccount *account = account_new("testaccount", NULL, NULL, NULL, TRUE, NULL, 0, NULL, NULL, NULL,
- 0, 0, 0, 0, 0, "default_conf_server", NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ 0, 0, 0, 0, 0, "default_conf_server", NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_CONNECTED);
will_return(session_get_account_name, "account_name");
@@ -85,7 +85,7 @@ void cmd_rooms_filter_arg_used_when_passed(void **state)
ProfAccount *account = account_new("testaccount", NULL, NULL, NULL, TRUE, NULL, 0, NULL, NULL, NULL,
- 0, 0, 0, 0, 0, "default_conf_server", NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
+ 0, 0, 0, 0, 0, "default_conf_server", NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
will_return(connection_get_status, JABBER_CONNECTED);
will_return(session_get_account_name, "account_name");
diff --git a/tests/unittests/xmpp/stub_xmpp.c b/tests/unittests/xmpp/stub_xmpp.c
--- a/tests/unittests/xmpp/stub_xmpp.c
+++ b/tests/unittests/xmpp/stub_xmpp.c
@@ -11,7 +11,8 @@ void session_init_activity(void) {}
void session_check_autoaway(void) {}
jabber_conn_status_t session_connect_with_details(const char * const jid,
- const char * const passwd, const char * const altdomain, const int port, const char *const tls_policy)
+ const char * const passwd, const char * const altdomain, const int port, const char *const tls_policy,
+ const char *const auth_policy)
{
check_expected(jid);
check_expected(passwd);
|
Profanity should allow legacy auth when explicitly requested
Some servers still require legacy auth and worked great with libstrophe < 1.9.3.
|
Are you talking about [XEP-0078](https://xmpp.org/extensions/xep-0078.html)? As this is obsolete you should rather ask the server operator to not require this.
No doubt, the server should get updated. For some corporate setups that's rather involved though.
I think he is talking about legacy auth, that was disabled by default here: https://github.com/profanity-im/profanity/issues/905.
So it is disabled in libstrophe 0.9.3 by default. And could be enabled with `XMPP_CONN_FLAG_LEGACY_AUTH`.
| 2020-06-04T21:18:46
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 41
|
HandmadeMath__HandmadeMath-41
|
[
"28"
] |
90198604b875184079e46ed33ddc10ac67e2fe0d
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -393,6 +393,8 @@ HMMDEF hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar);
HMMDEF hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector);
HMMDEF hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar);
+HMMDEF hmm_mat4 HMM_Transpose(hmm_mat4 Matrix);
+
HMMDEF hmm_mat4 HMM_Orthographic(float Left, float Right, float Bottom, float Top, float Near, float Far);
HMMDEF hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, float Far);
HMMDEF hmm_mat4 HMM_Translate(hmm_vec3 Translation);
@@ -407,7 +409,6 @@ HMMDEF hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up);
#ifdef HANDMADE_MATH_CPP_MODE
-
HMMDEF float HMM_Dot(hmm_vec2 VecOne, hmm_vec2 VecTwo);
HMMDEF float HMM_Dot(hmm_vec3 VecOne, hmm_vec3 VecTwo);
HMMDEF float HMM_Dot(hmm_vec4 VecOne, hmm_vec4 VecTwo);
@@ -578,7 +579,6 @@ HMM_ToRadians(float Degrees)
return (Result);
}
-
HINLINE float
HMM_DotVec2(hmm_vec2 VecOne, hmm_vec2 VecTwo)
{
@@ -597,7 +597,6 @@ HMM_DotVec3(hmm_vec3 VecOne, hmm_vec3 VecTwo)
return (Result);
}
-
HINLINE float
HMM_DotVec4(hmm_vec4 VecOne, hmm_vec4 VecTwo)
{
@@ -607,7 +606,6 @@ HMM_DotVec4(hmm_vec4 VecOne, hmm_vec4 VecTwo)
return (Result);
}
-
HINLINE float
HMM_LengthSquared(hmm_vec3 A)
{
@@ -644,7 +642,6 @@ HMM_Power(float Base, int Exponent)
return (Result);
}
-
HINLINE float
HMM_Lerp(float A, float Time, float B)
{
@@ -671,7 +668,6 @@ HMM_Clamp(float Min, float Value, float Max)
return (Result);
}
-
HINLINE hmm_vec3
HMM_Normalize(hmm_vec3 A)
{
@@ -1135,6 +1131,24 @@ HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
return (Result);
}
+hmm_mat4
+HMM_Transpose(hmm_mat4 Matrix)
+{
+ hmm_mat4 Result = HMM_Mat4();
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Rows][Columns] = Matrix.Elements[Columns][Rows];
+ }
+ }
+
+ return (Result);
+}
+
hmm_mat4
HMM_Orthographic(float Left, float Right, float Bottom, float Top, float Near, float Far)
{
|
diff --git a/test/hmm_test.cpp b/test/hmm_test.cpp
--- a/test/hmm_test.cpp
+++ b/test/hmm_test.cpp
@@ -206,6 +206,41 @@ TEST(VectorOps, DotVec4)
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
}
+TEST(MatrixOps, Transpose)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the matrix
+ hmm_mat4 result = HMM_Transpose(m4);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 13.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 10.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 14.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 11.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 8.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 16.0f);
+}
+
TEST(Addition, Vec2)
{
hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
|
No matrix transpose function
We do not have a function for transposing `hmm_mat4`s. Adding one seems like the responsible thing to do! Probably call it `HMM_Transpose(hmm_mat4 Matrix)`.
|
What does a matrix Transpose function do?
Transposing a matrix [swaps its rows and columns](https://chortle.ccsu.edu/VectorLessons/vmch13/vmch13_14.html)
Heh if you know how to write one off the top of your head it'd be awesome if you could do it. If not then i will figure it out
| 2016-08-31T00:20:44
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 114
|
HandmadeMath__HandmadeMath-114
|
[
"112"
] |
785f19d4a740ced802fd6f79f065c2982ae4b3d3
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -33,6 +33,16 @@
=============================================================================
+ If you would prefer not to use the HMM_ prefix on function names, you can
+
+ #define HMM_PREFIX
+
+ To use a custom prefix instead, you can
+
+ #define HMM_PREFIX(name) YOUR_PREFIX_##name
+
+ =============================================================================
+
To use HandmadeMath without the CRT, you MUST
#define HMM_SINF MySinF
@@ -199,6 +209,10 @@ extern "C"
#define HMM_MOD(a, m) ((a) % (m)) >= 0 ? ((a) % (m)) : (((a) % (m)) + (m))
#define HMM_SQUARE(x) ((x) * (x))
+#ifndef HMM_PREFIX
+#define HMM_PREFIX(name) HMM_##name
+#endif
+
typedef union hmm_vec2
{
struct
@@ -410,7 +424,7 @@ typedef hmm_mat4 hmm_m4;
*/
COVERAGE(HMM_SinF, 1)
-HMM_INLINE float HMM_SinF(float Radians)
+HMM_INLINE float HMM_PREFIX(SinF)(float Radians)
{
ASSERT_COVERED(HMM_SinF);
@@ -420,7 +434,7 @@ HMM_INLINE float HMM_SinF(float Radians)
}
COVERAGE(HMM_CosF, 1)
-HMM_INLINE float HMM_CosF(float Radians)
+HMM_INLINE float HMM_PREFIX(CosF)(float Radians)
{
ASSERT_COVERED(HMM_CosF);
@@ -430,7 +444,7 @@ HMM_INLINE float HMM_CosF(float Radians)
}
COVERAGE(HMM_TanF, 1)
-HMM_INLINE float HMM_TanF(float Radians)
+HMM_INLINE float HMM_PREFIX(TanF)(float Radians)
{
ASSERT_COVERED(HMM_TanF);
@@ -440,7 +454,7 @@ HMM_INLINE float HMM_TanF(float Radians)
}
COVERAGE(HMM_ACosF, 1)
-HMM_INLINE float HMM_ACosF(float Radians)
+HMM_INLINE float HMM_PREFIX(ACosF)(float Radians)
{
ASSERT_COVERED(HMM_ACosF);
@@ -450,7 +464,7 @@ HMM_INLINE float HMM_ACosF(float Radians)
}
COVERAGE(HMM_ATanF, 1)
-HMM_INLINE float HMM_ATanF(float Radians)
+HMM_INLINE float HMM_PREFIX(ATanF)(float Radians)
{
ASSERT_COVERED(HMM_ATanF);
@@ -460,7 +474,7 @@ HMM_INLINE float HMM_ATanF(float Radians)
}
COVERAGE(HMM_ATan2F, 1)
-HMM_INLINE float HMM_ATan2F(float Left, float Right)
+HMM_INLINE float HMM_PREFIX(ATan2F)(float Left, float Right)
{
ASSERT_COVERED(HMM_ATan2F);
@@ -470,7 +484,7 @@ HMM_INLINE float HMM_ATan2F(float Left, float Right)
}
COVERAGE(HMM_ExpF, 1)
-HMM_INLINE float HMM_ExpF(float Float)
+HMM_INLINE float HMM_PREFIX(ExpF)(float Float)
{
ASSERT_COVERED(HMM_ExpF);
@@ -480,7 +494,7 @@ HMM_INLINE float HMM_ExpF(float Float)
}
COVERAGE(HMM_LogF, 1)
-HMM_INLINE float HMM_LogF(float Float)
+HMM_INLINE float HMM_PREFIX(LogF)(float Float)
{
ASSERT_COVERED(HMM_LogF);
@@ -490,7 +504,7 @@ HMM_INLINE float HMM_LogF(float Float)
}
COVERAGE(HMM_SquareRootF, 1)
-HMM_INLINE float HMM_SquareRootF(float Float)
+HMM_INLINE float HMM_PREFIX(SquareRootF)(float Float)
{
ASSERT_COVERED(HMM_SquareRootF);
@@ -508,7 +522,7 @@ HMM_INLINE float HMM_SquareRootF(float Float)
}
COVERAGE(HMM_RSquareRootF, 1)
-HMM_INLINE float HMM_RSquareRootF(float Float)
+HMM_INLINE float HMM_PREFIX(RSquareRootF)(float Float)
{
ASSERT_COVERED(HMM_RSquareRootF);
@@ -519,16 +533,16 @@ HMM_INLINE float HMM_RSquareRootF(float Float)
__m128 Out = _mm_rsqrt_ss(In);
Result = _mm_cvtss_f32(Out);
#else
- Result = 1.0f/HMM_SquareRootF(Float);
+ Result = 1.0f/HMM_PREFIX(SquareRootF)(Float);
#endif
return(Result);
}
-HMM_EXTERN float HMM_Power(float Base, int Exponent);
+HMM_EXTERN float HMM_PREFIX(Power)(float Base, int Exponent);
COVERAGE(HMM_PowerF, 1)
-HMM_INLINE float HMM_PowerF(float Base, float Exponent)
+HMM_INLINE float HMM_PREFIX(PowerF)(float Base, float Exponent)
{
ASSERT_COVERED(HMM_PowerF);
@@ -543,7 +557,7 @@ HMM_INLINE float HMM_PowerF(float Base, float Exponent)
*/
COVERAGE(HMM_ToRadians, 1)
-HMM_INLINE float HMM_ToRadians(float Degrees)
+HMM_INLINE float HMM_PREFIX(ToRadians)(float Degrees)
{
ASSERT_COVERED(HMM_ToRadians);
@@ -553,7 +567,7 @@ HMM_INLINE float HMM_ToRadians(float Degrees)
}
COVERAGE(HMM_Lerp, 1)
-HMM_INLINE float HMM_Lerp(float A, float Time, float B)
+HMM_INLINE float HMM_PREFIX(Lerp)(float A, float Time, float B)
{
ASSERT_COVERED(HMM_Lerp);
@@ -563,7 +577,7 @@ HMM_INLINE float HMM_Lerp(float A, float Time, float B)
}
COVERAGE(HMM_Clamp, 1)
-HMM_INLINE float HMM_Clamp(float Min, float Value, float Max)
+HMM_INLINE float HMM_PREFIX(Clamp)(float Min, float Value, float Max)
{
ASSERT_COVERED(HMM_Clamp);
@@ -587,7 +601,7 @@ HMM_INLINE float HMM_Clamp(float Min, float Value, float Max)
*/
COVERAGE(HMM_Vec2, 1)
-HMM_INLINE hmm_vec2 HMM_Vec2(float X, float Y)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Vec2)(float X, float Y)
{
ASSERT_COVERED(HMM_Vec2);
@@ -600,7 +614,7 @@ HMM_INLINE hmm_vec2 HMM_Vec2(float X, float Y)
}
COVERAGE(HMM_Vec2i, 1)
-HMM_INLINE hmm_vec2 HMM_Vec2i(int X, int Y)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Vec2i)(int X, int Y)
{
ASSERT_COVERED(HMM_Vec2i);
@@ -613,7 +627,7 @@ HMM_INLINE hmm_vec2 HMM_Vec2i(int X, int Y)
}
COVERAGE(HMM_Vec3, 1)
-HMM_INLINE hmm_vec3 HMM_Vec3(float X, float Y, float Z)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Vec3)(float X, float Y, float Z)
{
ASSERT_COVERED(HMM_Vec3);
@@ -627,7 +641,7 @@ HMM_INLINE hmm_vec3 HMM_Vec3(float X, float Y, float Z)
}
COVERAGE(HMM_Vec3i, 1)
-HMM_INLINE hmm_vec3 HMM_Vec3i(int X, int Y, int Z)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Vec3i)(int X, int Y, int Z)
{
ASSERT_COVERED(HMM_Vec3i);
@@ -641,7 +655,7 @@ HMM_INLINE hmm_vec3 HMM_Vec3i(int X, int Y, int Z)
}
COVERAGE(HMM_Vec4, 1)
-HMM_INLINE hmm_vec4 HMM_Vec4(float X, float Y, float Z, float W)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Vec4)(float X, float Y, float Z, float W)
{
ASSERT_COVERED(HMM_Vec4);
@@ -660,7 +674,7 @@ HMM_INLINE hmm_vec4 HMM_Vec4(float X, float Y, float Z, float W)
}
COVERAGE(HMM_Vec4i, 1)
-HMM_INLINE hmm_vec4 HMM_Vec4i(int X, int Y, int Z, int W)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Vec4i)(int X, int Y, int Z, int W)
{
ASSERT_COVERED(HMM_Vec4i);
@@ -679,7 +693,7 @@ HMM_INLINE hmm_vec4 HMM_Vec4i(int X, int Y, int Z, int W)
}
COVERAGE(HMM_Vec4v, 1)
-HMM_INLINE hmm_vec4 HMM_Vec4v(hmm_vec3 Vector, float W)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Vec4v)(hmm_vec3 Vector, float W)
{
ASSERT_COVERED(HMM_Vec4v);
@@ -701,7 +715,7 @@ HMM_INLINE hmm_vec4 HMM_Vec4v(hmm_vec3 Vector, float W)
*/
COVERAGE(HMM_AddVec2, 1)
-HMM_INLINE hmm_vec2 HMM_AddVec2(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(AddVec2)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_AddVec2);
@@ -714,7 +728,7 @@ HMM_INLINE hmm_vec2 HMM_AddVec2(hmm_vec2 Left, hmm_vec2 Right)
}
COVERAGE(HMM_AddVec3, 1)
-HMM_INLINE hmm_vec3 HMM_AddVec3(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(AddVec3)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_AddVec3);
@@ -728,7 +742,7 @@ HMM_INLINE hmm_vec3 HMM_AddVec3(hmm_vec3 Left, hmm_vec3 Right)
}
COVERAGE(HMM_AddVec4, 1)
-HMM_INLINE hmm_vec4 HMM_AddVec4(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(AddVec4)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_AddVec4);
@@ -747,7 +761,7 @@ HMM_INLINE hmm_vec4 HMM_AddVec4(hmm_vec4 Left, hmm_vec4 Right)
}
COVERAGE(HMM_SubtractVec2, 1)
-HMM_INLINE hmm_vec2 HMM_SubtractVec2(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(SubtractVec2)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_SubtractVec2);
@@ -760,7 +774,7 @@ HMM_INLINE hmm_vec2 HMM_SubtractVec2(hmm_vec2 Left, hmm_vec2 Right)
}
COVERAGE(HMM_SubtractVec3, 1)
-HMM_INLINE hmm_vec3 HMM_SubtractVec3(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(SubtractVec3)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_SubtractVec3);
@@ -774,7 +788,7 @@ HMM_INLINE hmm_vec3 HMM_SubtractVec3(hmm_vec3 Left, hmm_vec3 Right)
}
COVERAGE(HMM_SubtractVec4, 1)
-HMM_INLINE hmm_vec4 HMM_SubtractVec4(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(SubtractVec4)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_SubtractVec4);
@@ -793,7 +807,7 @@ HMM_INLINE hmm_vec4 HMM_SubtractVec4(hmm_vec4 Left, hmm_vec4 Right)
}
COVERAGE(HMM_MultiplyVec2, 1)
-HMM_INLINE hmm_vec2 HMM_MultiplyVec2(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(MultiplyVec2)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_MultiplyVec2);
@@ -806,7 +820,7 @@ HMM_INLINE hmm_vec2 HMM_MultiplyVec2(hmm_vec2 Left, hmm_vec2 Right)
}
COVERAGE(HMM_MultiplyVec2f, 1)
-HMM_INLINE hmm_vec2 HMM_MultiplyVec2f(hmm_vec2 Left, float Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(MultiplyVec2f)(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec2f);
@@ -819,7 +833,7 @@ HMM_INLINE hmm_vec2 HMM_MultiplyVec2f(hmm_vec2 Left, float Right)
}
COVERAGE(HMM_MultiplyVec3, 1)
-HMM_INLINE hmm_vec3 HMM_MultiplyVec3(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(MultiplyVec3)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_MultiplyVec3);
@@ -833,7 +847,7 @@ HMM_INLINE hmm_vec3 HMM_MultiplyVec3(hmm_vec3 Left, hmm_vec3 Right)
}
COVERAGE(HMM_MultiplyVec3f, 1)
-HMM_INLINE hmm_vec3 HMM_MultiplyVec3f(hmm_vec3 Left, float Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(MultiplyVec3f)(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec3f);
@@ -847,7 +861,7 @@ HMM_INLINE hmm_vec3 HMM_MultiplyVec3f(hmm_vec3 Left, float Right)
}
COVERAGE(HMM_MultiplyVec4, 1)
-HMM_INLINE hmm_vec4 HMM_MultiplyVec4(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(MultiplyVec4)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_MultiplyVec4);
@@ -866,7 +880,7 @@ HMM_INLINE hmm_vec4 HMM_MultiplyVec4(hmm_vec4 Left, hmm_vec4 Right)
}
COVERAGE(HMM_MultiplyVec4f, 1)
-HMM_INLINE hmm_vec4 HMM_MultiplyVec4f(hmm_vec4 Left, float Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(MultiplyVec4f)(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec4f);
@@ -886,7 +900,7 @@ HMM_INLINE hmm_vec4 HMM_MultiplyVec4f(hmm_vec4 Left, float Right)
}
COVERAGE(HMM_DivideVec2, 1)
-HMM_INLINE hmm_vec2 HMM_DivideVec2(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(DivideVec2)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_DivideVec2);
@@ -899,7 +913,7 @@ HMM_INLINE hmm_vec2 HMM_DivideVec2(hmm_vec2 Left, hmm_vec2 Right)
}
COVERAGE(HMM_DivideVec2f, 1)
-HMM_INLINE hmm_vec2 HMM_DivideVec2f(hmm_vec2 Left, float Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(DivideVec2f)(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec2f);
@@ -912,7 +926,7 @@ HMM_INLINE hmm_vec2 HMM_DivideVec2f(hmm_vec2 Left, float Right)
}
COVERAGE(HMM_DivideVec3, 1)
-HMM_INLINE hmm_vec3 HMM_DivideVec3(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(DivideVec3)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_DivideVec3);
@@ -926,7 +940,7 @@ HMM_INLINE hmm_vec3 HMM_DivideVec3(hmm_vec3 Left, hmm_vec3 Right)
}
COVERAGE(HMM_DivideVec3f, 1)
-HMM_INLINE hmm_vec3 HMM_DivideVec3f(hmm_vec3 Left, float Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(DivideVec3f)(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec3f);
@@ -940,7 +954,7 @@ HMM_INLINE hmm_vec3 HMM_DivideVec3f(hmm_vec3 Left, float Right)
}
COVERAGE(HMM_DivideVec4, 1)
-HMM_INLINE hmm_vec4 HMM_DivideVec4(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(DivideVec4)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_DivideVec4);
@@ -959,7 +973,7 @@ HMM_INLINE hmm_vec4 HMM_DivideVec4(hmm_vec4 Left, hmm_vec4 Right)
}
COVERAGE(HMM_DivideVec4f, 1)
-HMM_INLINE hmm_vec4 HMM_DivideVec4f(hmm_vec4 Left, float Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(DivideVec4f)(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec4f);
@@ -979,7 +993,7 @@ HMM_INLINE hmm_vec4 HMM_DivideVec4f(hmm_vec4 Left, float Right)
}
COVERAGE(HMM_EqualsVec2, 1)
-HMM_INLINE hmm_bool HMM_EqualsVec2(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(EqualsVec2)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_EqualsVec2);
@@ -989,7 +1003,7 @@ HMM_INLINE hmm_bool HMM_EqualsVec2(hmm_vec2 Left, hmm_vec2 Right)
}
COVERAGE(HMM_EqualsVec3, 1)
-HMM_INLINE hmm_bool HMM_EqualsVec3(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(EqualsVec3)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_EqualsVec3);
@@ -999,7 +1013,7 @@ HMM_INLINE hmm_bool HMM_EqualsVec3(hmm_vec3 Left, hmm_vec3 Right)
}
COVERAGE(HMM_EqualsVec4, 1)
-HMM_INLINE hmm_bool HMM_EqualsVec4(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(EqualsVec4)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_EqualsVec4);
@@ -1009,7 +1023,7 @@ HMM_INLINE hmm_bool HMM_EqualsVec4(hmm_vec4 Left, hmm_vec4 Right)
}
COVERAGE(HMM_DotVec2, 1)
-HMM_INLINE float HMM_DotVec2(hmm_vec2 VecOne, hmm_vec2 VecTwo)
+HMM_INLINE float HMM_PREFIX(DotVec2)(hmm_vec2 VecOne, hmm_vec2 VecTwo)
{
ASSERT_COVERED(HMM_DotVec2);
@@ -1019,7 +1033,7 @@ HMM_INLINE float HMM_DotVec2(hmm_vec2 VecOne, hmm_vec2 VecTwo)
}
COVERAGE(HMM_DotVec3, 1)
-HMM_INLINE float HMM_DotVec3(hmm_vec3 VecOne, hmm_vec3 VecTwo)
+HMM_INLINE float HMM_PREFIX(DotVec3)(hmm_vec3 VecOne, hmm_vec3 VecTwo)
{
ASSERT_COVERED(HMM_DotVec3);
@@ -1029,7 +1043,7 @@ HMM_INLINE float HMM_DotVec3(hmm_vec3 VecOne, hmm_vec3 VecTwo)
}
COVERAGE(HMM_DotVec4, 1)
-HMM_INLINE float HMM_DotVec4(hmm_vec4 VecOne, hmm_vec4 VecTwo)
+HMM_INLINE float HMM_PREFIX(DotVec4)(hmm_vec4 VecOne, hmm_vec4 VecTwo)
{
ASSERT_COVERED(HMM_DotVec4);
@@ -1053,7 +1067,7 @@ HMM_INLINE float HMM_DotVec4(hmm_vec4 VecOne, hmm_vec4 VecTwo)
}
COVERAGE(HMM_Cross, 1)
-HMM_INLINE hmm_vec3 HMM_Cross(hmm_vec3 VecOne, hmm_vec3 VecTwo)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Cross)(hmm_vec3 VecOne, hmm_vec3 VecTwo)
{
ASSERT_COVERED(HMM_Cross);
@@ -1072,73 +1086,73 @@ HMM_INLINE hmm_vec3 HMM_Cross(hmm_vec3 VecOne, hmm_vec3 VecTwo)
*/
COVERAGE(HMM_LengthSquaredVec2, 1)
-HMM_INLINE float HMM_LengthSquaredVec2(hmm_vec2 A)
+HMM_INLINE float HMM_PREFIX(LengthSquaredVec2)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec2);
- float Result = HMM_DotVec2(A, A);
+ float Result = HMM_PREFIX(DotVec2)(A, A);
return (Result);
}
COVERAGE(HMM_LengthSquaredVec3, 1)
-HMM_INLINE float HMM_LengthSquaredVec3(hmm_vec3 A)
+HMM_INLINE float HMM_PREFIX(LengthSquaredVec3)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec3);
- float Result = HMM_DotVec3(A, A);
+ float Result = HMM_PREFIX(DotVec3)(A, A);
return (Result);
}
COVERAGE(HMM_LengthSquaredVec4, 1)
-HMM_INLINE float HMM_LengthSquaredVec4(hmm_vec4 A)
+HMM_INLINE float HMM_PREFIX(LengthSquaredVec4)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec4);
- float Result = HMM_DotVec4(A, A);
+ float Result = HMM_PREFIX(DotVec4)(A, A);
return (Result);
}
COVERAGE(HMM_LengthVec2, 1)
-HMM_INLINE float HMM_LengthVec2(hmm_vec2 A)
+HMM_INLINE float HMM_PREFIX(LengthVec2)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_LengthVec2);
- float Result = HMM_SquareRootF(HMM_LengthSquaredVec2(A));
+ float Result = HMM_PREFIX(SquareRootF)(HMM_PREFIX(LengthSquaredVec2)(A));
return (Result);
}
COVERAGE(HMM_LengthVec3, 1)
-HMM_INLINE float HMM_LengthVec3(hmm_vec3 A)
+HMM_INLINE float HMM_PREFIX(LengthVec3)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_LengthVec3);
- float Result = HMM_SquareRootF(HMM_LengthSquaredVec3(A));
+ float Result = HMM_PREFIX(SquareRootF)(HMM_PREFIX(LengthSquaredVec3)(A));
return (Result);
}
COVERAGE(HMM_LengthVec4, 1)
-HMM_INLINE float HMM_LengthVec4(hmm_vec4 A)
+HMM_INLINE float HMM_PREFIX(LengthVec4)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_LengthVec4);
- float Result = HMM_SquareRootF(HMM_LengthSquaredVec4(A));
+ float Result = HMM_PREFIX(SquareRootF)(HMM_PREFIX(LengthSquaredVec4)(A));
return(Result);
}
COVERAGE(HMM_NormalizeVec2, 2)
-HMM_INLINE hmm_vec2 HMM_NormalizeVec2(hmm_vec2 A)
+HMM_INLINE hmm_vec2 HMM_PREFIX(NormalizeVec2)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_NormalizeVec2);
hmm_vec2 Result = {0};
- float VectorLength = HMM_LengthVec2(A);
+ float VectorLength = HMM_PREFIX(LengthVec2)(A);
/* NOTE(kiljacken): We need a zero check to not divide-by-zero */
if (VectorLength != 0.0f)
@@ -1153,13 +1167,13 @@ HMM_INLINE hmm_vec2 HMM_NormalizeVec2(hmm_vec2 A)
}
COVERAGE(HMM_NormalizeVec3, 2)
-HMM_INLINE hmm_vec3 HMM_NormalizeVec3(hmm_vec3 A)
+HMM_INLINE hmm_vec3 HMM_PREFIX(NormalizeVec3)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_NormalizeVec3);
hmm_vec3 Result = {0};
- float VectorLength = HMM_LengthVec3(A);
+ float VectorLength = HMM_PREFIX(LengthVec3)(A);
/* NOTE(kiljacken): We need a zero check to not divide-by-zero */
if (VectorLength != 0.0f)
@@ -1175,13 +1189,13 @@ HMM_INLINE hmm_vec3 HMM_NormalizeVec3(hmm_vec3 A)
}
COVERAGE(HMM_NormalizeVec4, 2)
-HMM_INLINE hmm_vec4 HMM_NormalizeVec4(hmm_vec4 A)
+HMM_INLINE hmm_vec4 HMM_PREFIX(NormalizeVec4)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_NormalizeVec4);
hmm_vec4 Result = {0};
- float VectorLength = HMM_LengthVec4(A);
+ float VectorLength = HMM_PREFIX(LengthVec4)(A);
/* NOTE(kiljacken): We need a zero check to not divide-by-zero */
if (VectorLength != 0.0f)
@@ -1205,27 +1219,27 @@ HMM_INLINE hmm_vec4 HMM_NormalizeVec4(hmm_vec4 A)
}
COVERAGE(HMM_FastNormalizeVec2, 1)
-HMM_INLINE hmm_vec2 HMM_FastNormalizeVec2(hmm_vec2 A)
+HMM_INLINE hmm_vec2 HMM_PREFIX(FastNormalizeVec2)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec2);
- return HMM_MultiplyVec2f(A, HMM_RSquareRootF(HMM_DotVec2(A, A)));
+ return HMM_PREFIX(MultiplyVec2f)(A, HMM_PREFIX(RSquareRootF)(HMM_PREFIX(DotVec2)(A, A)));
}
COVERAGE(HMM_FastNormalizeVec3, 1)
-HMM_INLINE hmm_vec3 HMM_FastNormalizeVec3(hmm_vec3 A)
+HMM_INLINE hmm_vec3 HMM_PREFIX(FastNormalizeVec3)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec3);
- return HMM_MultiplyVec3f(A, HMM_RSquareRootF(HMM_DotVec3(A, A)));
+ return HMM_PREFIX(MultiplyVec3f)(A, HMM_PREFIX(RSquareRootF)(HMM_PREFIX(DotVec3)(A, A)));
}
COVERAGE(HMM_FastNormalizeVec4, 1)
-HMM_INLINE hmm_vec4 HMM_FastNormalizeVec4(hmm_vec4 A)
+HMM_INLINE hmm_vec4 HMM_PREFIX(FastNormalizeVec4)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec4);
- return HMM_MultiplyVec4f(A, HMM_RSquareRootF(HMM_DotVec4(A, A)));
+ return HMM_PREFIX(MultiplyVec4f)(A, HMM_PREFIX(RSquareRootF)(HMM_PREFIX(DotVec4)(A, A)));
}
@@ -1235,7 +1249,7 @@ HMM_INLINE hmm_vec4 HMM_FastNormalizeVec4(hmm_vec4 A)
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_LinearCombineSSE, 1)
-HMM_INLINE __m128 HMM_LinearCombineSSE(__m128 Left, hmm_mat4 Right)
+HMM_INLINE __m128 HMM_PREFIX(LinearCombineSSE)(__m128 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_LinearCombineSSE);
@@ -1255,7 +1269,7 @@ HMM_INLINE __m128 HMM_LinearCombineSSE(__m128 Left, hmm_mat4 Right)
*/
COVERAGE(HMM_Mat4, 1)
-HMM_INLINE hmm_mat4 HMM_Mat4(void)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Mat4)(void)
{
ASSERT_COVERED(HMM_Mat4);
@@ -1265,11 +1279,11 @@ HMM_INLINE hmm_mat4 HMM_Mat4(void)
}
COVERAGE(HMM_Mat4d, 1)
-HMM_INLINE hmm_mat4 HMM_Mat4d(float Diagonal)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Mat4d)(float Diagonal)
{
ASSERT_COVERED(HMM_Mat4d);
- hmm_mat4 Result = HMM_Mat4();
+ hmm_mat4 Result = HMM_PREFIX(Mat4)();
Result.Elements[0][0] = Diagonal;
Result.Elements[1][1] = Diagonal;
@@ -1281,7 +1295,7 @@ HMM_INLINE hmm_mat4 HMM_Mat4d(float Diagonal)
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_Transpose, 1)
-HMM_INLINE hmm_mat4 HMM_Transpose(hmm_mat4 Matrix)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Transpose)(hmm_mat4 Matrix)
{
ASSERT_COVERED(HMM_Transpose);
@@ -1292,12 +1306,12 @@ HMM_INLINE hmm_mat4 HMM_Transpose(hmm_mat4 Matrix)
return (Result);
}
#else
-HMM_EXTERN hmm_mat4 HMM_Transpose(hmm_mat4 Matrix);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(Transpose)(hmm_mat4 Matrix);
#endif
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_AddMat4, 1)
-HMM_INLINE hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(AddMat4)(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_AddMat4);
@@ -1311,12 +1325,12 @@ HMM_INLINE hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
return (Result);
}
#else
-HMM_EXTERN hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(AddMat4)(hmm_mat4 Left, hmm_mat4 Right);
#endif
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_SubtractMat4, 1)
-HMM_INLINE hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(SubtractMat4)(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_SubtractMat4);
@@ -1330,14 +1344,14 @@ HMM_INLINE hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
return (Result);
}
#else
-HMM_EXTERN hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(SubtractMat4)(hmm_mat4 Left, hmm_mat4 Right);
#endif
-HMM_EXTERN hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(MultiplyMat4)(hmm_mat4 Left, hmm_mat4 Right);
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_MultiplyMat4f, 1)
-HMM_INLINE hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
+HMM_INLINE hmm_mat4 HMM_PREFIX(MultiplyMat4f)(hmm_mat4 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_MultiplyMat4f);
@@ -1352,14 +1366,14 @@ HMM_INLINE hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
return (Result);
}
#else
-HMM_EXTERN hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(MultiplyMat4f)(hmm_mat4 Matrix, float Scalar);
#endif
-HMM_EXTERN hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector);
+HMM_EXTERN hmm_vec4 HMM_PREFIX(MultiplyMat4ByVec4)(hmm_mat4 Matrix, hmm_vec4 Vector);
#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_DivideMat4f, 1)
-HMM_INLINE hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
+HMM_INLINE hmm_mat4 HMM_PREFIX(DivideMat4f)(hmm_mat4 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_DivideMat4f);
@@ -1374,7 +1388,7 @@ HMM_INLINE hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
return (Result);
}
#else
-HMM_EXTERN hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(DivideMat4f)(hmm_mat4 Matrix, float Scalar);
#endif
@@ -1383,11 +1397,11 @@ HMM_EXTERN hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar);
*/
COVERAGE(HMM_Orthographic, 1)
-HMM_INLINE hmm_mat4 HMM_Orthographic(float Left, float Right, float Bottom, float Top, float Near, float Far)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Orthographic)(float Left, float Right, float Bottom, float Top, float Near, float Far)
{
ASSERT_COVERED(HMM_Orthographic);
- hmm_mat4 Result = HMM_Mat4();
+ hmm_mat4 Result = HMM_PREFIX(Mat4)();
Result.Elements[0][0] = 2.0f / (Right - Left);
Result.Elements[1][1] = 2.0f / (Top - Bottom);
@@ -1402,15 +1416,15 @@ HMM_INLINE hmm_mat4 HMM_Orthographic(float Left, float Right, float Bottom, floa
}
COVERAGE(HMM_Perspective, 1)
-HMM_INLINE hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, float Far)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Perspective)(float FOV, float AspectRatio, float Near, float Far)
{
ASSERT_COVERED(HMM_Perspective);
- hmm_mat4 Result = HMM_Mat4();
+ hmm_mat4 Result = HMM_PREFIX(Mat4)();
// See https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
- float Cotangent = 1.0f / HMM_TanF(FOV * (HMM_PI32 / 360.0f));
+ float Cotangent = 1.0f / HMM_PREFIX(TanF)(FOV * (HMM_PI32 / 360.0f));
Result.Elements[0][0] = Cotangent / AspectRatio;
Result.Elements[1][1] = Cotangent;
@@ -1423,11 +1437,11 @@ HMM_INLINE hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, fl
}
COVERAGE(HMM_Translate, 1)
-HMM_INLINE hmm_mat4 HMM_Translate(hmm_vec3 Translation)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Translate)(hmm_vec3 Translation)
{
ASSERT_COVERED(HMM_Translate);
- hmm_mat4 Result = HMM_Mat4d(1.0f);
+ hmm_mat4 Result = HMM_PREFIX(Mat4d)(1.0f);
Result.Elements[3][0] = Translation.X;
Result.Elements[3][1] = Translation.Y;
@@ -1436,14 +1450,14 @@ HMM_INLINE hmm_mat4 HMM_Translate(hmm_vec3 Translation)
return (Result);
}
-HMM_EXTERN hmm_mat4 HMM_Rotate(float Angle, hmm_vec3 Axis);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(Rotate)(float Angle, hmm_vec3 Axis);
COVERAGE(HMM_Scale, 1)
-HMM_INLINE hmm_mat4 HMM_Scale(hmm_vec3 Scale)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Scale)(hmm_vec3 Scale)
{
ASSERT_COVERED(HMM_Scale);
- hmm_mat4 Result = HMM_Mat4d(1.0f);
+ hmm_mat4 Result = HMM_PREFIX(Mat4d)(1.0f);
Result.Elements[0][0] = Scale.X;
Result.Elements[1][1] = Scale.Y;
@@ -1452,7 +1466,7 @@ HMM_INLINE hmm_mat4 HMM_Scale(hmm_vec3 Scale)
return (Result);
}
-HMM_EXTERN hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(LookAt)(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up);
/*
@@ -1460,7 +1474,7 @@ HMM_EXTERN hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up);
*/
COVERAGE(HMM_Quaternion, 1)
-HMM_INLINE hmm_quaternion HMM_Quaternion(float X, float Y, float Z, float W)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Quaternion)(float X, float Y, float Z, float W)
{
ASSERT_COVERED(HMM_Quaternion);
@@ -1479,7 +1493,7 @@ HMM_INLINE hmm_quaternion HMM_Quaternion(float X, float Y, float Z, float W)
}
COVERAGE(HMM_QuaternionV4, 1)
-HMM_INLINE hmm_quaternion HMM_QuaternionV4(hmm_vec4 Vector)
+HMM_INLINE hmm_quaternion HMM_PREFIX(QuaternionV4)(hmm_vec4 Vector)
{
ASSERT_COVERED(HMM_QuaternionV4);
@@ -1498,7 +1512,7 @@ HMM_INLINE hmm_quaternion HMM_QuaternionV4(hmm_vec4 Vector)
}
COVERAGE(HMM_AddQuaternion, 1)
-HMM_INLINE hmm_quaternion HMM_AddQuaternion(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(AddQuaternion)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_AddQuaternion);
@@ -1518,7 +1532,7 @@ HMM_INLINE hmm_quaternion HMM_AddQuaternion(hmm_quaternion Left, hmm_quaternion
}
COVERAGE(HMM_SubtractQuaternion, 1)
-HMM_INLINE hmm_quaternion HMM_SubtractQuaternion(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(SubtractQuaternion)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_SubtractQuaternion);
@@ -1538,7 +1552,7 @@ HMM_INLINE hmm_quaternion HMM_SubtractQuaternion(hmm_quaternion Left, hmm_quater
}
COVERAGE(HMM_MultiplyQuaternion, 1)
-HMM_INLINE hmm_quaternion HMM_MultiplyQuaternion(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(MultiplyQuaternion)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternion);
@@ -1571,7 +1585,7 @@ HMM_INLINE hmm_quaternion HMM_MultiplyQuaternion(hmm_quaternion Left, hmm_quater
}
COVERAGE(HMM_MultiplyQuaternionF, 1)
-HMM_INLINE hmm_quaternion HMM_MultiplyQuaternionF(hmm_quaternion Left, float Multiplicative)
+HMM_INLINE hmm_quaternion HMM_PREFIX(MultiplyQuaternionF)(hmm_quaternion Left, float Multiplicative)
{
ASSERT_COVERED(HMM_MultiplyQuaternionF);
@@ -1591,7 +1605,7 @@ HMM_INLINE hmm_quaternion HMM_MultiplyQuaternionF(hmm_quaternion Left, float Mul
}
COVERAGE(HMM_DivideQuaternionF, 1)
-HMM_INLINE hmm_quaternion HMM_DivideQuaternionF(hmm_quaternion Left, float Dividend)
+HMM_INLINE hmm_quaternion HMM_PREFIX(DivideQuaternionF)(hmm_quaternion Left, float Dividend)
{
ASSERT_COVERED(HMM_DivideQuaternionF);
@@ -1610,10 +1624,10 @@ HMM_INLINE hmm_quaternion HMM_DivideQuaternionF(hmm_quaternion Left, float Divid
return (Result);
}
-HMM_EXTERN hmm_quaternion HMM_InverseQuaternion(hmm_quaternion Left);
+HMM_EXTERN hmm_quaternion HMM_PREFIX(InverseQuaternion)(hmm_quaternion Left);
COVERAGE(HMM_DotQuaternion, 1)
-HMM_INLINE float HMM_DotQuaternion(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE float HMM_PREFIX(DotQuaternion)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_DotQuaternion);
@@ -1634,20 +1648,20 @@ HMM_INLINE float HMM_DotQuaternion(hmm_quaternion Left, hmm_quaternion Right)
}
COVERAGE(HMM_NormalizeQuaternion, 1)
-HMM_INLINE hmm_quaternion HMM_NormalizeQuaternion(hmm_quaternion Left)
+HMM_INLINE hmm_quaternion HMM_PREFIX(NormalizeQuaternion)(hmm_quaternion Left)
{
ASSERT_COVERED(HMM_NormalizeQuaternion);
hmm_quaternion Result;
- float Length = HMM_SquareRootF(HMM_DotQuaternion(Left, Left));
- Result = HMM_DivideQuaternionF(Left, Length);
+ float Length = HMM_PREFIX(SquareRootF)(HMM_PREFIX(DotQuaternion)(Left, Left));
+ Result = HMM_PREFIX(DivideQuaternionF)(Left, Length);
return (Result);
}
COVERAGE(HMM_NLerp, 1)
-HMM_INLINE hmm_quaternion HMM_NLerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(NLerp)(hmm_quaternion Left, float Time, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_NLerp);
@@ -1660,20 +1674,20 @@ HMM_INLINE hmm_quaternion HMM_NLerp(hmm_quaternion Left, float Time, hmm_quatern
__m128 SSEResultTwo = _mm_mul_ps(Right.InternalElementsSSE, ScalarRight);
Result.InternalElementsSSE = _mm_add_ps(SSEResultOne, SSEResultTwo);
#else
- Result.X = HMM_Lerp(Left.X, Time, Right.X);
- Result.Y = HMM_Lerp(Left.Y, Time, Right.Y);
- Result.Z = HMM_Lerp(Left.Z, Time, Right.Z);
- Result.W = HMM_Lerp(Left.W, Time, Right.W);
+ Result.X = HMM_PREFIX(Lerp)(Left.X, Time, Right.X);
+ Result.Y = HMM_PREFIX(Lerp)(Left.Y, Time, Right.Y);
+ Result.Z = HMM_PREFIX(Lerp)(Left.Z, Time, Right.Z);
+ Result.W = HMM_PREFIX(Lerp)(Left.W, Time, Right.W);
#endif
- Result = HMM_NormalizeQuaternion(Result);
+ Result = HMM_PREFIX(NormalizeQuaternion)(Result);
return (Result);
}
-HMM_EXTERN hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right);
-HMM_EXTERN hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left);
-HMM_EXTERN hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 Left);
-HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation);
+HMM_EXTERN hmm_quaternion HMM_PREFIX(Slerp)(hmm_quaternion Left, float Time, hmm_quaternion Right);
+HMM_EXTERN hmm_mat4 HMM_PREFIX(QuaternionToMat4)(hmm_quaternion Left);
+HMM_EXTERN hmm_quaternion HMM_PREFIX(Mat4ToQuaternion)(hmm_mat4 Left);
+HMM_EXTERN hmm_quaternion HMM_PREFIX(QuaternionFromAxisAngle)(hmm_vec3 Axis, float AngleOfRotation);
#ifdef __cplusplus
}
@@ -1682,491 +1696,491 @@ HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float Angle
#ifdef __cplusplus
COVERAGE(HMM_LengthVec2CPP, 1)
-HMM_INLINE float HMM_Length(hmm_vec2 A)
+HMM_INLINE float HMM_PREFIX(Length)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_LengthVec2CPP);
- float Result = HMM_LengthVec2(A);
+ float Result = HMM_PREFIX(LengthVec2)(A);
return (Result);
}
COVERAGE(HMM_LengthVec3CPP, 1)
-HMM_INLINE float HMM_Length(hmm_vec3 A)
+HMM_INLINE float HMM_PREFIX(Length)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_LengthVec3CPP);
- float Result = HMM_LengthVec3(A);
+ float Result = HMM_PREFIX(LengthVec3)(A);
return (Result);
}
COVERAGE(HMM_LengthVec4CPP, 1)
-HMM_INLINE float HMM_Length(hmm_vec4 A)
+HMM_INLINE float HMM_PREFIX(Length)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_LengthVec4CPP);
- float Result = HMM_LengthVec4(A);
+ float Result = HMM_PREFIX(LengthVec4)(A);
return (Result);
}
COVERAGE(HMM_LengthSquaredVec2CPP, 1)
-HMM_INLINE float HMM_LengthSquared(hmm_vec2 A)
+HMM_INLINE float HMM_PREFIX(LengthSquared)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec2CPP);
- float Result = HMM_LengthSquaredVec2(A);
+ float Result = HMM_PREFIX(LengthSquaredVec2)(A);
return (Result);
}
COVERAGE(HMM_LengthSquaredVec3CPP, 1)
-HMM_INLINE float HMM_LengthSquared(hmm_vec3 A)
+HMM_INLINE float HMM_PREFIX(LengthSquared)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec3CPP);
- float Result = HMM_LengthSquaredVec3(A);
+ float Result = HMM_PREFIX(LengthSquaredVec3)(A);
return (Result);
}
COVERAGE(HMM_LengthSquaredVec4CPP, 1)
-HMM_INLINE float HMM_LengthSquared(hmm_vec4 A)
+HMM_INLINE float HMM_PREFIX(LengthSquared)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_LengthSquaredVec4CPP);
- float Result = HMM_LengthSquaredVec4(A);
+ float Result = HMM_PREFIX(LengthSquaredVec4)(A);
return (Result);
}
COVERAGE(HMM_NormalizeVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_Normalize(hmm_vec2 A)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Normalize)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_NormalizeVec2CPP);
- hmm_vec2 Result = HMM_NormalizeVec2(A);
+ hmm_vec2 Result = HMM_PREFIX(NormalizeVec2)(A);
return (Result);
}
COVERAGE(HMM_NormalizeVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_Normalize(hmm_vec3 A)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Normalize)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_NormalizeVec3CPP);
- hmm_vec3 Result = HMM_NormalizeVec3(A);
+ hmm_vec3 Result = HMM_PREFIX(NormalizeVec3)(A);
return (Result);
}
COVERAGE(HMM_NormalizeVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Normalize(hmm_vec4 A)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Normalize)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_NormalizeVec4CPP);
- hmm_vec4 Result = HMM_NormalizeVec4(A);
+ hmm_vec4 Result = HMM_PREFIX(NormalizeVec4)(A);
return (Result);
}
COVERAGE(HMM_FastNormalizeVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_FastNormalize(hmm_vec2 A)
+HMM_INLINE hmm_vec2 HMM_PREFIX(FastNormalize)(hmm_vec2 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec2CPP);
- hmm_vec2 Result = HMM_FastNormalizeVec2(A);
+ hmm_vec2 Result = HMM_PREFIX(FastNormalizeVec2)(A);
return (Result);
}
COVERAGE(HMM_FastNormalizeVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_FastNormalize(hmm_vec3 A)
+HMM_INLINE hmm_vec3 HMM_PREFIX(FastNormalize)(hmm_vec3 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec3CPP);
- hmm_vec3 Result = HMM_FastNormalizeVec3(A);
+ hmm_vec3 Result = HMM_PREFIX(FastNormalizeVec3)(A);
return (Result);
}
COVERAGE(HMM_FastNormalizeVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_FastNormalize(hmm_vec4 A)
+HMM_INLINE hmm_vec4 HMM_PREFIX(FastNormalize)(hmm_vec4 A)
{
ASSERT_COVERED(HMM_FastNormalizeVec4CPP);
- hmm_vec4 Result = HMM_FastNormalizeVec4(A);
+ hmm_vec4 Result = HMM_PREFIX(FastNormalizeVec4)(A);
return (Result);
}
COVERAGE(HMM_NormalizeQuaternionCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Normalize(hmm_quaternion A)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Normalize)(hmm_quaternion A)
{
ASSERT_COVERED(HMM_NormalizeQuaternionCPP);
- hmm_quaternion Result = HMM_NormalizeQuaternion(A);
+ hmm_quaternion Result = HMM_PREFIX(NormalizeQuaternion)(A);
return (Result);
}
COVERAGE(HMM_DotVec2CPP, 1)
-HMM_INLINE float HMM_Dot(hmm_vec2 VecOne, hmm_vec2 VecTwo)
+HMM_INLINE float HMM_PREFIX(Dot)(hmm_vec2 VecOne, hmm_vec2 VecTwo)
{
ASSERT_COVERED(HMM_DotVec2CPP);
- float Result = HMM_DotVec2(VecOne, VecTwo);
+ float Result = HMM_PREFIX(DotVec2)(VecOne, VecTwo);
return (Result);
}
COVERAGE(HMM_DotVec3CPP, 1)
-HMM_INLINE float HMM_Dot(hmm_vec3 VecOne, hmm_vec3 VecTwo)
+HMM_INLINE float HMM_PREFIX(Dot)(hmm_vec3 VecOne, hmm_vec3 VecTwo)
{
ASSERT_COVERED(HMM_DotVec3CPP);
- float Result = HMM_DotVec3(VecOne, VecTwo);
+ float Result = HMM_PREFIX(DotVec3)(VecOne, VecTwo);
return (Result);
}
COVERAGE(HMM_DotVec4CPP, 1)
-HMM_INLINE float HMM_Dot(hmm_vec4 VecOne, hmm_vec4 VecTwo)
+HMM_INLINE float HMM_PREFIX(Dot)(hmm_vec4 VecOne, hmm_vec4 VecTwo)
{
ASSERT_COVERED(HMM_DotVec4CPP);
- float Result = HMM_DotVec4(VecOne, VecTwo);
+ float Result = HMM_PREFIX(DotVec4)(VecOne, VecTwo);
return (Result);
}
COVERAGE(HMM_DotQuaternionCPP, 1)
-HMM_INLINE float HMM_Dot(hmm_quaternion QuatOne, hmm_quaternion QuatTwo)
+HMM_INLINE float HMM_PREFIX(Dot)(hmm_quaternion QuatOne, hmm_quaternion QuatTwo)
{
ASSERT_COVERED(HMM_DotQuaternionCPP);
- float Result = HMM_DotQuaternion(QuatOne, QuatTwo);
+ float Result = HMM_PREFIX(DotQuaternion)(QuatOne, QuatTwo);
return (Result);
}
COVERAGE(HMM_AddVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_Add(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Add)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_AddVec2CPP);
- hmm_vec2 Result = HMM_AddVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(AddVec2)(Left, Right);
return (Result);
}
COVERAGE(HMM_AddVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_Add(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Add)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_AddVec3CPP);
- hmm_vec3 Result = HMM_AddVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(AddVec3)(Left, Right);
return (Result);
}
COVERAGE(HMM_AddVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Add(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Add)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_AddVec4CPP);
- hmm_vec4 Result = HMM_AddVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(AddVec4)(Left, Right);
return (Result);
}
COVERAGE(HMM_AddMat4CPP, 1)
-HMM_INLINE hmm_mat4 HMM_Add(hmm_mat4 Left, hmm_mat4 Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Add)(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_AddMat4CPP);
- hmm_mat4 Result = HMM_AddMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(AddMat4)(Left, Right);
return (Result);
}
COVERAGE(HMM_AddQuaternionCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Add(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Add)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_AddQuaternionCPP);
- hmm_quaternion Result = HMM_AddQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(AddQuaternion)(Left, Right);
return (Result);
}
COVERAGE(HMM_SubtractVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_Subtract(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Subtract)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_SubtractVec2CPP);
- hmm_vec2 Result = HMM_SubtractVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(SubtractVec2)(Left, Right);
return (Result);
}
COVERAGE(HMM_SubtractVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_Subtract(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Subtract)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_SubtractVec3CPP);
- hmm_vec3 Result = HMM_SubtractVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(SubtractVec3)(Left, Right);
return (Result);
}
COVERAGE(HMM_SubtractVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Subtract(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Subtract)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_SubtractVec4CPP);
- hmm_vec4 Result = HMM_SubtractVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(SubtractVec4)(Left, Right);
return (Result);
}
COVERAGE(HMM_SubtractMat4CPP, 1)
-HMM_INLINE hmm_mat4 HMM_Subtract(hmm_mat4 Left, hmm_mat4 Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Subtract)(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_SubtractMat4CPP);
- hmm_mat4 Result = HMM_SubtractMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(SubtractMat4)(Left, Right);
return (Result);
}
COVERAGE(HMM_SubtractQuaternionCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Subtract(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Subtract)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_SubtractQuaternionCPP);
- hmm_quaternion Result = HMM_SubtractQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(SubtractQuaternion)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_Multiply(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Multiply)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_MultiplyVec2CPP);
- hmm_vec2 Result = HMM_MultiplyVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(MultiplyVec2)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec2fCPP, 1)
-HMM_INLINE hmm_vec2 HMM_Multiply(hmm_vec2 Left, float Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Multiply)(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec2fCPP);
- hmm_vec2 Result = HMM_MultiplyVec2f(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(MultiplyVec2f)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_Multiply(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Multiply)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_MultiplyVec3CPP);
- hmm_vec3 Result = HMM_MultiplyVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(MultiplyVec3)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec3fCPP, 1)
-HMM_INLINE hmm_vec3 HMM_Multiply(hmm_vec3 Left, float Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Multiply)(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec3fCPP);
- hmm_vec3 Result = HMM_MultiplyVec3f(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(MultiplyVec3f)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Multiply(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Multiply)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_MultiplyVec4CPP);
- hmm_vec4 Result = HMM_MultiplyVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyVec4)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyVec4fCPP, 1)
-HMM_INLINE hmm_vec4 HMM_Multiply(hmm_vec4 Left, float Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Multiply)(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec4fCPP);
- hmm_vec4 Result = HMM_MultiplyVec4f(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyVec4f)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyMat4CPP, 1)
-HMM_INLINE hmm_mat4 HMM_Multiply(hmm_mat4 Left, hmm_mat4 Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Multiply)(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_MultiplyMat4CPP);
- hmm_mat4 Result = HMM_MultiplyMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(MultiplyMat4)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyMat4fCPP, 1)
-HMM_INLINE hmm_mat4 HMM_Multiply(hmm_mat4 Left, float Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Multiply)(hmm_mat4 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyMat4fCPP);
- hmm_mat4 Result = HMM_MultiplyMat4f(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(MultiplyMat4f)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyMat4ByVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Multiply(hmm_mat4 Matrix, hmm_vec4 Vector)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Multiply)(hmm_mat4 Matrix, hmm_vec4 Vector)
{
ASSERT_COVERED(HMM_MultiplyMat4ByVec4CPP);
- hmm_vec4 Result = HMM_MultiplyMat4ByVec4(Matrix, Vector);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyMat4ByVec4)(Matrix, Vector);
return (Result);
}
COVERAGE(HMM_MultiplyQuaternionCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Multiply(hmm_quaternion Left, hmm_quaternion Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Multiply)(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternionCPP);
- hmm_quaternion Result = HMM_MultiplyQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(MultiplyQuaternion)(Left, Right);
return (Result);
}
COVERAGE(HMM_MultiplyQuaternionFCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Multiply(hmm_quaternion Left, float Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Multiply)(hmm_quaternion Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternionFCPP);
- hmm_quaternion Result = HMM_MultiplyQuaternionF(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(MultiplyQuaternionF)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec2CPP, 1)
-HMM_INLINE hmm_vec2 HMM_Divide(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Divide)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_DivideVec2CPP);
- hmm_vec2 Result = HMM_DivideVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(DivideVec2)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec2fCPP, 1)
-HMM_INLINE hmm_vec2 HMM_Divide(hmm_vec2 Left, float Right)
+HMM_INLINE hmm_vec2 HMM_PREFIX(Divide)(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec2fCPP);
- hmm_vec2 Result = HMM_DivideVec2f(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(DivideVec2f)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec3CPP, 1)
-HMM_INLINE hmm_vec3 HMM_Divide(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Divide)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_DivideVec3CPP);
- hmm_vec3 Result = HMM_DivideVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(DivideVec3)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec3fCPP, 1)
-HMM_INLINE hmm_vec3 HMM_Divide(hmm_vec3 Left, float Right)
+HMM_INLINE hmm_vec3 HMM_PREFIX(Divide)(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec3fCPP);
- hmm_vec3 Result = HMM_DivideVec3f(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(DivideVec3f)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec4CPP, 1)
-HMM_INLINE hmm_vec4 HMM_Divide(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Divide)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_DivideVec4CPP);
- hmm_vec4 Result = HMM_DivideVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(DivideVec4)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideVec4fCPP, 1)
-HMM_INLINE hmm_vec4 HMM_Divide(hmm_vec4 Left, float Right)
+HMM_INLINE hmm_vec4 HMM_PREFIX(Divide)(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec4fCPP);
- hmm_vec4 Result = HMM_DivideVec4f(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(DivideVec4f)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideMat4fCPP, 1)
-HMM_INLINE hmm_mat4 HMM_Divide(hmm_mat4 Left, float Right)
+HMM_INLINE hmm_mat4 HMM_PREFIX(Divide)(hmm_mat4 Left, float Right)
{
ASSERT_COVERED(HMM_DivideMat4fCPP);
- hmm_mat4 Result = HMM_DivideMat4f(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(DivideMat4f)(Left, Right);
return (Result);
}
COVERAGE(HMM_DivideQuaternionFCPP, 1)
-HMM_INLINE hmm_quaternion HMM_Divide(hmm_quaternion Left, float Right)
+HMM_INLINE hmm_quaternion HMM_PREFIX(Divide)(hmm_quaternion Left, float Right)
{
ASSERT_COVERED(HMM_DivideQuaternionFCPP);
- hmm_quaternion Result = HMM_DivideQuaternionF(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(DivideQuaternionF)(Left, Right);
return (Result);
}
COVERAGE(HMM_EqualsVec2CPP, 1)
-HMM_INLINE hmm_bool HMM_Equals(hmm_vec2 Left, hmm_vec2 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(Equals)(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_EqualsVec2CPP);
- hmm_bool Result = HMM_EqualsVec2(Left, Right);
+ hmm_bool Result = HMM_PREFIX(EqualsVec2)(Left, Right);
return (Result);
}
COVERAGE(HMM_EqualsVec3CPP, 1)
-HMM_INLINE hmm_bool HMM_Equals(hmm_vec3 Left, hmm_vec3 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(Equals)(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_EqualsVec3CPP);
- hmm_bool Result = HMM_EqualsVec3(Left, Right);
+ hmm_bool Result = HMM_PREFIX(EqualsVec3)(Left, Right);
return (Result);
}
COVERAGE(HMM_EqualsVec4CPP, 1)
-HMM_INLINE hmm_bool HMM_Equals(hmm_vec4 Left, hmm_vec4 Right)
+HMM_INLINE hmm_bool HMM_PREFIX(Equals)(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_EqualsVec4CPP);
- hmm_bool Result = HMM_EqualsVec4(Left, Right);
+ hmm_bool Result = HMM_PREFIX(EqualsVec4)(Left, Right);
return (Result);
}
@@ -2176,7 +2190,7 @@ HMM_INLINE hmm_vec2 operator+(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_AddVec2Op);
- hmm_vec2 Result = HMM_AddVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(AddVec2)(Left, Right);
return (Result);
}
@@ -2186,7 +2200,7 @@ HMM_INLINE hmm_vec3 operator+(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_AddVec3Op);
- hmm_vec3 Result = HMM_AddVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(AddVec3)(Left, Right);
return (Result);
}
@@ -2196,7 +2210,7 @@ HMM_INLINE hmm_vec4 operator+(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_AddVec4Op);
- hmm_vec4 Result = HMM_AddVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(AddVec4)(Left, Right);
return (Result);
}
@@ -2206,7 +2220,7 @@ HMM_INLINE hmm_mat4 operator+(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_AddMat4Op);
- hmm_mat4 Result = HMM_AddMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(AddMat4)(Left, Right);
return (Result);
}
@@ -2216,7 +2230,7 @@ HMM_INLINE hmm_quaternion operator+(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_AddQuaternionOp);
- hmm_quaternion Result = HMM_AddQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(AddQuaternion)(Left, Right);
return (Result);
}
@@ -2226,7 +2240,7 @@ HMM_INLINE hmm_vec2 operator-(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_SubtractVec2Op);
- hmm_vec2 Result = HMM_SubtractVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(SubtractVec2)(Left, Right);
return (Result);
}
@@ -2236,7 +2250,7 @@ HMM_INLINE hmm_vec3 operator-(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_SubtractVec3Op);
- hmm_vec3 Result = HMM_SubtractVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(SubtractVec3)(Left, Right);
return (Result);
}
@@ -2246,7 +2260,7 @@ HMM_INLINE hmm_vec4 operator-(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_SubtractVec4Op);
- hmm_vec4 Result = HMM_SubtractVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(SubtractVec4)(Left, Right);
return (Result);
}
@@ -2256,7 +2270,7 @@ HMM_INLINE hmm_mat4 operator-(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_SubtractMat4Op);
- hmm_mat4 Result = HMM_SubtractMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(SubtractMat4)(Left, Right);
return (Result);
}
@@ -2266,7 +2280,7 @@ HMM_INLINE hmm_quaternion operator-(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_SubtractQuaternionOp);
- hmm_quaternion Result = HMM_SubtractQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(SubtractQuaternion)(Left, Right);
return (Result);
}
@@ -2276,7 +2290,7 @@ HMM_INLINE hmm_vec2 operator*(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_MultiplyVec2Op);
- hmm_vec2 Result = HMM_MultiplyVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(MultiplyVec2)(Left, Right);
return (Result);
}
@@ -2286,7 +2300,7 @@ HMM_INLINE hmm_vec3 operator*(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_MultiplyVec3Op);
- hmm_vec3 Result = HMM_MultiplyVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(MultiplyVec3)(Left, Right);
return (Result);
}
@@ -2296,7 +2310,7 @@ HMM_INLINE hmm_vec4 operator*(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_MultiplyVec4Op);
- hmm_vec4 Result = HMM_MultiplyVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyVec4)(Left, Right);
return (Result);
}
@@ -2306,7 +2320,7 @@ HMM_INLINE hmm_mat4 operator*(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_MultiplyMat4Op);
- hmm_mat4 Result = HMM_MultiplyMat4(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(MultiplyMat4)(Left, Right);
return (Result);
}
@@ -2316,7 +2330,7 @@ HMM_INLINE hmm_quaternion operator*(hmm_quaternion Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternionOp);
- hmm_quaternion Result = HMM_MultiplyQuaternion(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(MultiplyQuaternion)(Left, Right);
return (Result);
}
@@ -2326,7 +2340,7 @@ HMM_INLINE hmm_vec2 operator*(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec2fOp);
- hmm_vec2 Result = HMM_MultiplyVec2f(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(MultiplyVec2f)(Left, Right);
return (Result);
}
@@ -2336,7 +2350,7 @@ HMM_INLINE hmm_vec3 operator*(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec3fOp);
- hmm_vec3 Result = HMM_MultiplyVec3f(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(MultiplyVec3f)(Left, Right);
return (Result);
}
@@ -2346,7 +2360,7 @@ HMM_INLINE hmm_vec4 operator*(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyVec4fOp);
- hmm_vec4 Result = HMM_MultiplyVec4f(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyVec4f)(Left, Right);
return (Result);
}
@@ -2356,7 +2370,7 @@ HMM_INLINE hmm_mat4 operator*(hmm_mat4 Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyMat4fOp);
- hmm_mat4 Result = HMM_MultiplyMat4f(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(MultiplyMat4f)(Left, Right);
return (Result);
}
@@ -2366,7 +2380,7 @@ HMM_INLINE hmm_quaternion operator*(hmm_quaternion Left, float Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternionFOp);
- hmm_quaternion Result = HMM_MultiplyQuaternionF(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(MultiplyQuaternionF)(Left, Right);
return (Result);
}
@@ -2376,7 +2390,7 @@ HMM_INLINE hmm_vec2 operator*(float Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_MultiplyVec2fOpLeft);
- hmm_vec2 Result = HMM_MultiplyVec2f(Right, Left);
+ hmm_vec2 Result = HMM_PREFIX(MultiplyVec2f)(Right, Left);
return (Result);
}
@@ -2386,7 +2400,7 @@ HMM_INLINE hmm_vec3 operator*(float Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_MultiplyVec3fOpLeft);
- hmm_vec3 Result = HMM_MultiplyVec3f(Right, Left);
+ hmm_vec3 Result = HMM_PREFIX(MultiplyVec3f)(Right, Left);
return (Result);
}
@@ -2396,7 +2410,7 @@ HMM_INLINE hmm_vec4 operator*(float Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_MultiplyVec4fOpLeft);
- hmm_vec4 Result = HMM_MultiplyVec4f(Right, Left);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyVec4f)(Right, Left);
return (Result);
}
@@ -2406,7 +2420,7 @@ HMM_INLINE hmm_mat4 operator*(float Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_MultiplyMat4fOpLeft);
- hmm_mat4 Result = HMM_MultiplyMat4f(Right, Left);
+ hmm_mat4 Result = HMM_PREFIX(MultiplyMat4f)(Right, Left);
return (Result);
}
@@ -2416,7 +2430,7 @@ HMM_INLINE hmm_quaternion operator*(float Left, hmm_quaternion Right)
{
ASSERT_COVERED(HMM_MultiplyQuaternionFOpLeft);
- hmm_quaternion Result = HMM_MultiplyQuaternionF(Right, Left);
+ hmm_quaternion Result = HMM_PREFIX(MultiplyQuaternionF)(Right, Left);
return (Result);
}
@@ -2426,7 +2440,7 @@ HMM_INLINE hmm_vec4 operator*(hmm_mat4 Matrix, hmm_vec4 Vector)
{
ASSERT_COVERED(HMM_MultiplyMat4ByVec4Op);
- hmm_vec4 Result = HMM_MultiplyMat4ByVec4(Matrix, Vector);
+ hmm_vec4 Result = HMM_PREFIX(MultiplyMat4ByVec4)(Matrix, Vector);
return (Result);
}
@@ -2436,7 +2450,7 @@ HMM_INLINE hmm_vec2 operator/(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_DivideVec2Op);
- hmm_vec2 Result = HMM_DivideVec2(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(DivideVec2)(Left, Right);
return (Result);
}
@@ -2446,7 +2460,7 @@ HMM_INLINE hmm_vec3 operator/(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_DivideVec3Op);
- hmm_vec3 Result = HMM_DivideVec3(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(DivideVec3)(Left, Right);
return (Result);
}
@@ -2456,7 +2470,7 @@ HMM_INLINE hmm_vec4 operator/(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_DivideVec4Op);
- hmm_vec4 Result = HMM_DivideVec4(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(DivideVec4)(Left, Right);
return (Result);
}
@@ -2466,7 +2480,7 @@ HMM_INLINE hmm_vec2 operator/(hmm_vec2 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec2fOp);
- hmm_vec2 Result = HMM_DivideVec2f(Left, Right);
+ hmm_vec2 Result = HMM_PREFIX(DivideVec2f)(Left, Right);
return (Result);
}
@@ -2476,7 +2490,7 @@ HMM_INLINE hmm_vec3 operator/(hmm_vec3 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec3fOp);
- hmm_vec3 Result = HMM_DivideVec3f(Left, Right);
+ hmm_vec3 Result = HMM_PREFIX(DivideVec3f)(Left, Right);
return (Result);
}
@@ -2486,7 +2500,7 @@ HMM_INLINE hmm_vec4 operator/(hmm_vec4 Left, float Right)
{
ASSERT_COVERED(HMM_DivideVec4fOp);
- hmm_vec4 Result = HMM_DivideVec4f(Left, Right);
+ hmm_vec4 Result = HMM_PREFIX(DivideVec4f)(Left, Right);
return (Result);
}
@@ -2496,7 +2510,7 @@ HMM_INLINE hmm_mat4 operator/(hmm_mat4 Left, float Right)
{
ASSERT_COVERED(HMM_DivideMat4fOp);
- hmm_mat4 Result = HMM_DivideMat4f(Left, Right);
+ hmm_mat4 Result = HMM_PREFIX(DivideMat4f)(Left, Right);
return (Result);
}
@@ -2506,7 +2520,7 @@ HMM_INLINE hmm_quaternion operator/(hmm_quaternion Left, float Right)
{
ASSERT_COVERED(HMM_DivideQuaternionFOp);
- hmm_quaternion Result = HMM_DivideQuaternionF(Left, Right);
+ hmm_quaternion Result = HMM_PREFIX(DivideQuaternionF)(Left, Right);
return (Result);
}
@@ -2724,7 +2738,7 @@ HMM_INLINE hmm_bool operator==(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_EqualsVec2Op);
- return HMM_EqualsVec2(Left, Right);
+ return HMM_PREFIX(EqualsVec2)(Left, Right);
}
COVERAGE(HMM_EqualsVec3Op, 1)
@@ -2732,7 +2746,7 @@ HMM_INLINE hmm_bool operator==(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_EqualsVec3Op);
- return HMM_EqualsVec3(Left, Right);
+ return HMM_PREFIX(EqualsVec3)(Left, Right);
}
COVERAGE(HMM_EqualsVec4Op, 1)
@@ -2740,7 +2754,7 @@ HMM_INLINE hmm_bool operator==(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_EqualsVec4Op);
- return HMM_EqualsVec4(Left, Right);
+ return HMM_PREFIX(EqualsVec4)(Left, Right);
}
COVERAGE(HMM_EqualsVec2OpNot, 1)
@@ -2748,7 +2762,7 @@ HMM_INLINE hmm_bool operator!=(hmm_vec2 Left, hmm_vec2 Right)
{
ASSERT_COVERED(HMM_EqualsVec2OpNot);
- return !HMM_EqualsVec2(Left, Right);
+ return !HMM_PREFIX(EqualsVec2)(Left, Right);
}
COVERAGE(HMM_EqualsVec3OpNot, 1)
@@ -2756,7 +2770,7 @@ HMM_INLINE hmm_bool operator!=(hmm_vec3 Left, hmm_vec3 Right)
{
ASSERT_COVERED(HMM_EqualsVec3OpNot);
- return !HMM_EqualsVec3(Left, Right);
+ return !HMM_PREFIX(EqualsVec3)(Left, Right);
}
COVERAGE(HMM_EqualsVec4OpNot, 1)
@@ -2764,7 +2778,7 @@ HMM_INLINE hmm_bool operator!=(hmm_vec4 Left, hmm_vec4 Right)
{
ASSERT_COVERED(HMM_EqualsVec4OpNot);
- return !HMM_EqualsVec4(Left, Right);
+ return !HMM_PREFIX(EqualsVec4)(Left, Right);
}
#endif /* __cplusplus */
@@ -2879,10 +2893,10 @@ hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right)
hmm_mat4 Result;
#ifdef HANDMADE_MATH__USE_SSE
- Result.Columns[0] = HMM_LinearCombineSSE(Right.Columns[0], Left);
- Result.Columns[1] = HMM_LinearCombineSSE(Right.Columns[1], Left);
- Result.Columns[2] = HMM_LinearCombineSSE(Right.Columns[2], Left);
- Result.Columns[3] = HMM_LinearCombineSSE(Right.Columns[3], Left);
+ Result.Columns[0] = HMM_PREFIX(LinearCombineSSE)(Right.Columns[0], Left);
+ Result.Columns[1] = HMM_PREFIX(LinearCombineSSE)(Right.Columns[1], Left);
+ Result.Columns[2] = HMM_PREFIX(LinearCombineSSE)(Right.Columns[2], Left);
+ Result.Columns[3] = HMM_PREFIX(LinearCombineSSE)(Right.Columns[3], Left);
#else
int Columns;
for(Columns = 0; Columns < 4; ++Columns)
@@ -2935,7 +2949,7 @@ hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector)
hmm_vec4 Result;
#ifdef HANDMADE_MATH__USE_SSE
- Result.InternalElementsSSE = HMM_LinearCombineSSE(Vector.InternalElementsSSE, Matrix);
+ Result.InternalElementsSSE = HMM_PREFIX(LinearCombineSSE)(Vector.InternalElementsSSE, Matrix);
#else
int Columns, Rows;
for(Rows = 0; Rows < 4; ++Rows)
@@ -2980,12 +2994,12 @@ hmm_mat4 HMM_Rotate(float Angle, hmm_vec3 Axis)
{
ASSERT_COVERED(HMM_Rotate);
- hmm_mat4 Result = HMM_Mat4d(1.0f);
+ hmm_mat4 Result = HMM_PREFIX(Mat4d)(1.0f);
- Axis = HMM_NormalizeVec3(Axis);
+ Axis = HMM_PREFIX(NormalizeVec3)(Axis);
- float SinTheta = HMM_SinF(HMM_ToRadians(Angle));
- float CosTheta = HMM_CosF(HMM_ToRadians(Angle));
+ float SinTheta = HMM_PREFIX(SinF)(HMM_PREFIX(ToRadians)(Angle));
+ float CosTheta = HMM_PREFIX(CosF)(HMM_PREFIX(ToRadians)(Angle));
float CosValue = 1.0f - CosTheta;
Result.Elements[0][0] = (Axis.X * Axis.X * CosValue) + CosTheta;
@@ -3010,9 +3024,9 @@ hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up)
hmm_mat4 Result;
- hmm_vec3 F = HMM_NormalizeVec3(HMM_SubtractVec3(Center, Eye));
- hmm_vec3 S = HMM_NormalizeVec3(HMM_Cross(F, Up));
- hmm_vec3 U = HMM_Cross(S, F);
+ hmm_vec3 F = HMM_PREFIX(NormalizeVec3)(HMM_PREFIX(SubtractVec3)(Center, Eye));
+ hmm_vec3 S = HMM_PREFIX(NormalizeVec3)(HMM_PREFIX(Cross)(F, Up));
+ hmm_vec3 U = HMM_PREFIX(Cross)(S, F);
Result.Elements[0][0] = S.X;
Result.Elements[0][1] = U.X;
@@ -3029,9 +3043,9 @@ hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up)
Result.Elements[2][2] = -F.Z;
Result.Elements[2][3] = 0.0f;
- Result.Elements[3][0] = -HMM_DotVec3(S, Eye);
- Result.Elements[3][1] = -HMM_DotVec3(U, Eye);
- Result.Elements[3][2] = HMM_DotVec3(F, Eye);
+ Result.Elements[3][0] = -HMM_PREFIX(DotVec3)(S, Eye);
+ Result.Elements[3][1] = -HMM_PREFIX(DotVec3)(U, Eye);
+ Result.Elements[3][2] = HMM_PREFIX(DotVec3)(F, Eye);
Result.Elements[3][3] = 1.0f;
return (Result);
@@ -3052,10 +3066,10 @@ hmm_quaternion HMM_InverseQuaternion(hmm_quaternion Left)
Conjugate.Z = -Left.Z;
Conjugate.W = Left.W;
- Norm = HMM_SquareRootF(HMM_DotQuaternion(Left, Left));
+ Norm = HMM_PREFIX(SquareRootF)(HMM_PREFIX(DotQuaternion)(Left, Left));
NormSquared = Norm * Norm;
- Result = HMM_DivideQuaternionF(Conjugate, NormSquared);
+ Result = HMM_PREFIX(DivideQuaternionF)(Conjugate, NormSquared);
return (Result);
}
@@ -3069,18 +3083,18 @@ hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
hmm_quaternion QuaternionLeft;
hmm_quaternion QuaternionRight;
- float Cos_Theta = HMM_DotQuaternion(Left, Right);
- float Angle = HMM_ACosF(Cos_Theta);
+ float Cos_Theta = HMM_PREFIX(DotQuaternion)(Left, Right);
+ float Angle = HMM_PREFIX(ACosF)(Cos_Theta);
- float S1 = HMM_SinF((1.0f - Time) * Angle);
- float S2 = HMM_SinF(Time * Angle);
- float Is = 1.0f / HMM_SinF(Angle);
+ float S1 = HMM_PREFIX(SinF)((1.0f - Time) * Angle);
+ float S2 = HMM_PREFIX(SinF)(Time * Angle);
+ float Is = 1.0f / HMM_PREFIX(SinF)(Angle);
- QuaternionLeft = HMM_MultiplyQuaternionF(Left, S1);
- QuaternionRight = HMM_MultiplyQuaternionF(Right, S2);
+ QuaternionLeft = HMM_PREFIX(MultiplyQuaternionF)(Left, S1);
+ QuaternionRight = HMM_PREFIX(MultiplyQuaternionF)(Right, S2);
- Result = HMM_AddQuaternion(QuaternionLeft, QuaternionRight);
- Result = HMM_MultiplyQuaternionF(Result, Is);
+ Result = HMM_PREFIX(AddQuaternion)(QuaternionLeft, QuaternionRight);
+ Result = HMM_PREFIX(MultiplyQuaternionF)(Result, Is);
return (Result);
}
@@ -3092,7 +3106,7 @@ hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left)
hmm_mat4 Result;
- hmm_quaternion NormalizedQuaternion = HMM_NormalizeQuaternion(Left);
+ hmm_quaternion NormalizedQuaternion = HMM_PREFIX(NormalizeQuaternion)(Left);
float XX, YY, ZZ,
XY, XZ, YZ,
@@ -3156,7 +3170,7 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
ASSERT_COVERED(HMM_Mat4ToQuaternion);
T = 1 + M.Elements[0][0] - M.Elements[1][1] - M.Elements[2][2];
- Q = HMM_Quaternion(
+ Q = HMM_PREFIX(Quaternion)(
T,
M.Elements[0][1] + M.Elements[1][0],
M.Elements[2][0] + M.Elements[0][2],
@@ -3166,7 +3180,7 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
ASSERT_COVERED(HMM_Mat4ToQuaternion);
T = 1 - M.Elements[0][0] + M.Elements[1][1] - M.Elements[2][2];
- Q = HMM_Quaternion(
+ Q = HMM_PREFIX(Quaternion)(
M.Elements[0][1] + M.Elements[1][0],
T,
M.Elements[1][2] + M.Elements[2][1],
@@ -3178,7 +3192,7 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
ASSERT_COVERED(HMM_Mat4ToQuaternion);
T = 1 - M.Elements[0][0] - M.Elements[1][1] + M.Elements[2][2];
- Q = HMM_Quaternion(
+ Q = HMM_PREFIX(Quaternion)(
M.Elements[2][0] + M.Elements[0][2],
M.Elements[1][2] + M.Elements[2][1],
T,
@@ -3188,7 +3202,7 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
ASSERT_COVERED(HMM_Mat4ToQuaternion);
T = 1 + M.Elements[0][0] + M.Elements[1][1] + M.Elements[2][2];
- Q = HMM_Quaternion(
+ Q = HMM_PREFIX(Quaternion)(
M.Elements[1][2] - M.Elements[2][1],
M.Elements[2][0] - M.Elements[0][2],
M.Elements[0][1] - M.Elements[1][0],
@@ -3197,7 +3211,7 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
}
}
- Q = HMM_MultiplyQuaternionF(Q, 0.5f / HMM_SquareRootF(T));
+ Q = HMM_PREFIX(MultiplyQuaternionF)(Q, 0.5f / HMM_PREFIX(SquareRootF)(T));
return Q;
}
@@ -3209,11 +3223,11 @@ hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation)
hmm_quaternion Result;
- hmm_vec3 AxisNormalized = HMM_NormalizeVec3(Axis);
- float SineOfRotation = HMM_SinF(AngleOfRotation / 2.0f);
+ hmm_vec3 AxisNormalized = HMM_PREFIX(NormalizeVec3)(Axis);
+ float SineOfRotation = HMM_PREFIX(SinF)(AngleOfRotation / 2.0f);
- Result.XYZ = HMM_MultiplyVec3f(AxisNormalized, SineOfRotation);
- Result.W = HMM_CosF(AngleOfRotation / 2.0f);
+ Result.XYZ = HMM_PREFIX(MultiplyVec3f)(AxisNormalized, SineOfRotation);
+ Result.W = HMM_PREFIX(CosF)(AngleOfRotation / 2.0f);
return (Result);
}
|
diff --git a/test/HandmadeMathDifferentPrefix.cpp b/test/HandmadeMathDifferentPrefix.cpp
new file mode 100644
--- /dev/null
+++ b/test/HandmadeMathDifferentPrefix.cpp
@@ -0,0 +1,12 @@
+#define HMM_PREFIX(name) WOW_##name
+
+#define HANDMADE_MATH_IMPLEMENTATION
+#define HANDMADE_MATH_NO_INLINE
+#include "../HandmadeMath.h"
+
+int main() {
+ hmm_vec4 a = WOW_Vec4(1, 2, 3, 4);
+ hmm_vec4 b = WOW_Vec4(5, 6, 7, 8);
+
+ WOW_Add(a, b);
+}
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -2,7 +2,7 @@ BUILD_DIR=./build
CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
-all: c c_no_sse cpp cpp_no_sse build_c_without_coverage build_cpp_without_coverage
+all: c c_no_sse cpp cpp_no_sse build_c_without_coverage build_cpp_without_coverage build_cpp_different_prefix
build_all: build_c build_c_no_sse build_cpp build_cpp_no_sse
@@ -58,7 +58,7 @@ build_cpp_no_sse: HandmadeMath.cpp test_impl
test_impl: hmm_test.cpp hmm_test.c
-build_c_without_coverage: HandmadeMath.c
+build_c_without_coverage: HandmadeMath.c test_impl
@echo "\nCompiling in C mode"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR)\
@@ -75,3 +75,11 @@ build_cpp_without_coverage: HandmadeMath.cpp test_impl
&& $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_no_sse \
-DHANDMADE_MATH_CPP_MODE -DWITHOUT_COVERAGE \
../HandmadeMath.cpp ../hmm_test.cpp
+
+build_cpp_different_prefix: HandmadeMath.cpp
+ @echo "\nCompiling C++ with different prefix"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_different_prefix \
+ -DHANDMADE_MATH_CPP_MODE -DDIFFERENT_PREFIX \
+ ../HandmadeMathDifferentPrefix.cpp
|
Add ability to change or remove the HMM_ prefix
We should add the ability to change the function prefixes in case people think HMM_Whatever is too verbose and they can afford to change it in their own project.
Ryan Fleury recommended that we could take an approach like stb_sprintf: https://github.com/nothings/stb/blob/master/stb_sprintf.h#L187-L197
|
Yeah that'd be okay 👍
| 2020-03-27T22:46:01
|
c
|
Hard
|
profanity-im/profanity
| 2,053
|
profanity-im__profanity-2053
|
[
"2054"
] |
bda6dabbd972584b585620c66a31375ec0d6245d
|
diff --git a/Makefile.am b/Makefile.am
--- a/Makefile.am
+++ b/Makefile.am
@@ -124,6 +124,7 @@ unittest_sources = \
src/event/server_events.c src/event/server_events.h \
src/event/client_events.c src/event/client_events.h \
src/ui/tray.h src/ui/tray.c \
+ tests/prof_cmocka.h \
tests/unittests/xmpp/stub_vcard.c \
tests/unittests/xmpp/stub_avatar.c \
tests/unittests/xmpp/stub_ox.c \
@@ -169,6 +170,7 @@ unittest_sources = \
tests/unittests/unittests.c
functionaltest_sources = \
+ tests/prof_cmocka.h \
tests/functionaltests/proftest.c tests/functionaltests/proftest.h \
tests/functionaltests/test_connect.c tests/functionaltests/test_connect.h \
tests/functionaltests/test_ping.c tests/functionaltests/test_ping.h \
@@ -283,6 +285,7 @@ endif
TESTS = tests/unittests/unittests
check_PROGRAMS = tests/unittests/unittests
+tests_unittests_unittests_CPPFLAGS = -Itests/
tests_unittests_unittests_SOURCES = $(unittest_sources)
tests_unittests_unittests_LDADD = -lcmocka
@@ -346,9 +349,13 @@ endif
.PHONY: my-prof.supp
my-prof.supp:
@sed '/^# AUTO-GENERATED START/q' prof.supp > $@
+ @printf "\n\n# glib\n" >> $@
@cat /usr/share/glib-2.0/valgrind/glib.supp >> $@
+ @printf "\n\n# Python\n" >> $@
@wget -O- https://raw.githubusercontent.com/python/cpython/refs/tags/v`python3 --version | cut -d' ' -f2`/Misc/valgrind-python.supp >> $@
+ @printf "\n\n# gtk\n" >> $@
@test -z "@GTK_VERSION@" || wget -O- https://raw.githubusercontent.com/GNOME/gtk/refs/tags/@GTK_VERSION@/gtk.supp >> $@
+ @printf "\n\n# more gtk\n" >> $@
@test -z "@GTK_VERSION@" || cat /usr/share/gtk-3.0/valgrind/gtk.supp >> $@
check-unit: tests/unittests/unittests
diff --git a/src/command/cmd_ac.c b/src/command/cmd_ac.c
--- a/src/command/cmd_ac.c
+++ b/src/command/cmd_ac.c
@@ -1662,7 +1662,7 @@ char*
cmd_ac_complete_filepath(const char* const input, char* const startstr, gboolean previous)
{
unsigned int output_off = 0;
- char* tmp;
+ char* tmp = NULL;
// strip command
char* inpcp = (char*)input + strlen(startstr);
@@ -1674,38 +1674,36 @@ cmd_ac_complete_filepath(const char* const input, char* const startstr, gboolean
// strip quotes
if (*inpcp == '"') {
- tmp = strchr(inpcp + 1, '"');
+ tmp = strrchr(inpcp + 1, '"');
if (tmp) {
*tmp = '\0';
}
tmp = strdup(inpcp + 1);
free(inpcp);
inpcp = tmp;
+ tmp = NULL;
}
// expand ~ to $HOME
if (inpcp[0] == '~' && inpcp[1] == '/') {
- tmp = g_strdup_printf("%s/%sfoo", getenv("HOME"), inpcp + 2);
- if (!tmp) {
+ char* home = getenv("HOME");
+ if (!home) {
free(inpcp);
return NULL;
}
- output_off = strlen(getenv("HOME")) + 1;
+ tmp = g_strdup_printf("%s/%sfoo", home, inpcp + 2);
+ output_off = strlen(home) + 1;
} else {
tmp = g_strdup_printf("%sfoo", inpcp);
- if (!tmp) {
- free(inpcp);
- return NULL;
- }
}
free(inpcp);
- inpcp = tmp;
+ if (!tmp) {
+ return NULL;
+ }
- char* inpcp2 = strdup(inpcp);
- char* foofile = strdup(basename(inpcp2));
- char* directory = strdup(dirname(inpcp));
- free(inpcp);
- free(inpcp2);
+ char* foofile = strdup(basename(tmp));
+ char* directory = strdup(dirname(tmp));
+ g_free(tmp);
GArray* files = g_array_new(TRUE, FALSE, sizeof(char*));
g_array_set_clear_func(files, (GDestroyNotify)_filepath_item_free);
@@ -1724,40 +1722,26 @@ cmd_ac_complete_filepath(const char* const input, char* const startstr, gboolean
continue;
}
- char* acstring;
+ char* acstring = NULL;
if (output_off) {
tmp = g_strdup_printf("%s/%s", directory, dir->d_name);
- if (!tmp) {
- free(directory);
- free(foofile);
- return NULL;
- }
- acstring = g_strdup_printf("~/%s", tmp + output_off);
- if (!acstring) {
- free(directory);
- free(foofile);
- return NULL;
+ if (tmp) {
+ acstring = g_strdup_printf("~/%s", tmp + output_off);
+ g_free(tmp);
}
- free(tmp);
} else if (strcmp(directory, "/") == 0) {
acstring = g_strdup_printf("/%s", dir->d_name);
- if (!acstring) {
- free(directory);
- free(foofile);
- return NULL;
- }
} else {
acstring = g_strdup_printf("%s/%s", directory, dir->d_name);
- if (!acstring) {
- free(directory);
- free(foofile);
- return NULL;
- }
+ }
+ if (!acstring) {
+ g_array_free(files, TRUE);
+ free(foofile);
+ free(directory);
+ return NULL;
}
- char* acstring_cpy = strdup(acstring);
- g_array_append_val(files, acstring_cpy);
- free(acstring);
+ g_array_append_val(files, acstring);
}
closedir(d);
}
diff --git a/src/command/cmd_funcs.c b/src/command/cmd_funcs.c
--- a/src/command/cmd_funcs.c
+++ b/src/command/cmd_funcs.c
@@ -8565,19 +8565,20 @@ cmd_omemo_trust_mode(ProfWin* window, const char* const command, gchar** args)
{
#ifdef HAVE_OMEMO
+ auto_gchar gchar* trust_mode = prefs_get_string(PREF_OMEMO_TRUST_MODE);
if (!args[1]) {
- cons_show("Current trust mode is %s", prefs_get_string(PREF_OMEMO_TRUST_MODE));
+ cons_show("Current trust mode is %s", trust_mode);
return TRUE;
}
if (g_strcmp0(args[1], "manual") == 0) {
- cons_show("Current trust mode is %s - setting to %s", prefs_get_string(PREF_OMEMO_TRUST_MODE), args[1]);
+ cons_show("Current trust mode is %s - setting to %s", trust_mode, args[1]);
cons_show("You need to trust all OMEMO fingerprints manually");
} else if (g_strcmp0(args[1], "firstusage") == 0) {
- cons_show("Current trust mode is %s - setting to %s", prefs_get_string(PREF_OMEMO_TRUST_MODE), args[1]);
+ cons_show("Current trust mode is %s - setting to %s", trust_mode, args[1]);
cons_show("The first seen OMEMO fingerprints will be trusted automatically - new keys must be trusted manually");
} else if (g_strcmp0(args[1], "blind") == 0) {
- cons_show("Current trust mode is %s - setting to %s", prefs_get_string(PREF_OMEMO_TRUST_MODE), args[1]);
+ cons_show("Current trust mode is %s - setting to %s", trust_mode, args[1]);
cons_show("ALL OMEMO fingerprints will be trusted automatically");
} else {
cons_bad_cmd_usage(command);
diff --git a/src/plugins/python_plugins.c b/src/plugins/python_plugins.c
--- a/src/plugins/python_plugins.c
+++ b/src/plugins/python_plugins.c
@@ -86,10 +86,16 @@ python_get_version_number(void)
return version_number;
}
+static void
+_unref_module(PyObject* module)
+{
+ Py_XDECREF(module);
+}
+
void
python_env_init(void)
{
- loaded_modules = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)Py_XDECREF);
+ loaded_modules = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)_unref_module);
python_init_prof();
diff --git a/src/ui/inputwin.c b/src/ui/inputwin.c
--- a/src/ui/inputwin.c
+++ b/src/ui/inputwin.c
@@ -170,6 +170,29 @@ create_input_window(void)
_inp_win_update_virtual();
}
+static gboolean
+_inp_slashguard_check(void)
+{
+ if (get_password)
+ return false;
+ /* ignore empty and quoted messages */
+ if (inp_line == NULL || inp_line[0] == '\0' || inp_line[0] == '>')
+ return false;
+ if (!prefs_get_boolean(PREF_SLASH_GUARD))
+ return false;
+ size_t n = 1;
+ while (inp_line[n] != '\0' && n < 4) {
+ if (inp_line[n] == '/') {
+ cons_show("Your text contains a slash in the first 4 characters");
+ free(inp_line);
+ inp_line = NULL;
+ return true;
+ }
+ n++;
+ }
+ return false;
+}
+
char*
inp_readline(void)
{
@@ -203,17 +226,7 @@ inp_readline(void)
chat_state_idle();
}
- if (inp_line) {
- if (!get_password && prefs_get_boolean(PREF_SLASH_GUARD)) {
- // ignore quoted messages
- if (strlen(inp_line) > 1 && inp_line[0] != '>') {
- char* res = (char*)memchr(inp_line + 1, '/', 3);
- if (res) {
- cons_show("Your text contains a slash in the first 4 characters");
- return NULL;
- }
- }
- }
+ if (inp_line && !_inp_slashguard_check()) {
char* ret = inp_line;
inp_line = NULL;
return ret;
|
diff --git a/tests/functionaltests/functionaltests.c b/tests/functionaltests/functionaltests.c
--- a/tests/functionaltests/functionaltests.c
+++ b/tests/functionaltests/functionaltests.c
@@ -1,10 +1,7 @@
-#include <stdarg.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <sys/stat.h>
#include "config.h"
diff --git a/tests/functionaltests/proftest.c b/tests/functionaltests/proftest.c
--- a/tests/functionaltests/proftest.c
+++ b/tests/functionaltests/proftest.c
@@ -2,11 +2,8 @@
#include <sys/wait.h>
#include <glib.h>
-#include <setjmp.h>
-#include <stdarg.h>
-#include <stddef.h>
#include <stdlib.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
diff --git a/tests/functionaltests/test_carbons.c b/tests/functionaltests/test_carbons.c
--- a/tests/functionaltests/test_carbons.c
+++ b/tests/functionaltests/test_carbons.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_chat_session.c b/tests/functionaltests/test_chat_session.c
--- a/tests/functionaltests/test_chat_session.c
+++ b/tests/functionaltests/test_chat_session.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_connect.c b/tests/functionaltests/test_connect.c
--- a/tests/functionaltests/test_connect.c
+++ b/tests/functionaltests/test_connect.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_disconnect.c b/tests/functionaltests/test_disconnect.c
--- a/tests/functionaltests/test_disconnect.c
+++ b/tests/functionaltests/test_disconnect.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_message.c b/tests/functionaltests/test_message.c
--- a/tests/functionaltests/test_message.c
+++ b/tests/functionaltests/test_message.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_muc.c b/tests/functionaltests/test_muc.c
--- a/tests/functionaltests/test_muc.c
+++ b/tests/functionaltests/test_muc.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_ping.c b/tests/functionaltests/test_ping.c
--- a/tests/functionaltests/test_ping.c
+++ b/tests/functionaltests/test_ping.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_presence.c b/tests/functionaltests/test_presence.c
--- a/tests/functionaltests/test_presence.c
+++ b/tests/functionaltests/test_presence.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_receipts.c b/tests/functionaltests/test_receipts.c
--- a/tests/functionaltests/test_receipts.c
+++ b/tests/functionaltests/test_receipts.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_rooms.c b/tests/functionaltests/test_rooms.c
--- a/tests/functionaltests/test_rooms.c
+++ b/tests/functionaltests/test_rooms.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_roster.c b/tests/functionaltests/test_roster.c
--- a/tests/functionaltests/test_roster.c
+++ b/tests/functionaltests/test_roster.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/functionaltests/test_software.c b/tests/functionaltests/test_software.c
--- a/tests/functionaltests/test_software.c
+++ b/tests/functionaltests/test_software.c
@@ -1,8 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/prof_cmocka.h b/tests/prof_cmocka.h
new file mode 100644
--- /dev/null
+++ b/tests/prof_cmocka.h
@@ -0,0 +1,5 @@
+#include <stdarg.h>
+#include <stddef.h>
+#include <stdint.h>
+#include <setjmp.h>
+#include <cmocka.h>
diff --git a/tests/unittests/chatlog/stub_chatlog.c b/tests/unittests/chatlog/stub_chatlog.c
--- a/tests/unittests/chatlog/stub_chatlog.c
+++ b/tests/unittests/chatlog/stub_chatlog.c
@@ -21,8 +21,7 @@
*/
#include <glib.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <xmpp/xmpp.h>
diff --git a/tests/unittests/config/stub_accounts.c b/tests/unittests/config/stub_accounts.c
--- a/tests/unittests/config/stub_accounts.c
+++ b/tests/unittests/config/stub_accounts.c
@@ -1,8 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <stdint.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "common.h"
#include "config/account.h"
diff --git a/tests/unittests/database/stub_database.c b/tests/unittests/database/stub_database.c
--- a/tests/unittests/database/stub_database.c
+++ b/tests/unittests/database/stub_database.c
@@ -21,8 +21,7 @@
*/
#include <glib.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "database.h"
diff --git a/tests/unittests/helpers.c b/tests/unittests/helpers.c
--- a/tests/unittests/helpers.c
+++ b/tests/unittests/helpers.c
@@ -1,8 +1,5 @@
-#include <setjmp.h>
-#include <stdarg.h>
-#include <stddef.h>
#include <stdlib.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <glib.h>
#include <stdio.h>
#include <unistd.h>
diff --git a/tests/unittests/log/stub_log.c b/tests/unittests/log/stub_log.c
--- a/tests/unittests/log/stub_log.c
+++ b/tests/unittests/log/stub_log.c
@@ -20,10 +20,8 @@
*
*/
-#include <stdint.h>
#include <glib.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "log.h"
diff --git a/tests/unittests/otr/stub_otr.c b/tests/unittests/otr/stub_otr.c
--- a/tests/unittests/otr/stub_otr.c
+++ b/tests/unittests/otr/stub_otr.c
@@ -2,10 +2,7 @@
#include <libotr/message.h>
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "config/account.h"
diff --git a/tests/unittests/test_autocomplete.c b/tests/unittests/test_autocomplete.c
--- a/tests/unittests/test_autocomplete.c
+++ b/tests/unittests/test_autocomplete.c
@@ -1,9 +1,5 @@
#include <glib.h>
-#include <stdarg.h>
-#include <stddef.h>
-#include <stdint.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "xmpp/contact.h"
diff --git a/tests/unittests/test_callbacks.c b/tests/unittests/test_callbacks.c
--- a/tests/unittests/test_callbacks.c
+++ b/tests/unittests/test_callbacks.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_chat_session.c b/tests/unittests/test_chat_session.c
--- a/tests/unittests/test_chat_session.c
+++ b/tests/unittests/test_chat_session.c
@@ -1,10 +1,6 @@
-#include <stdarg.h>
#include <string.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
-#include <stdint.h>
#include "xmpp/chat_session.h"
diff --git a/tests/unittests/test_cmd_account.c b/tests/unittests/test_cmd_account.c
--- a/tests/unittests/test_cmd_account.c
+++ b/tests/unittests/test_cmd_account.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_alias.c b/tests/unittests/test_cmd_alias.c
--- a/tests/unittests/test_cmd_alias.c
+++ b/tests/unittests/test_cmd_alias.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_bookmark.c b/tests/unittests/test_cmd_bookmark.c
--- a/tests/unittests/test_cmd_bookmark.c
+++ b/tests/unittests/test_cmd_bookmark.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_connect.c b/tests/unittests/test_cmd_connect.c
--- a/tests/unittests/test_cmd_connect.c
+++ b/tests/unittests/test_cmd_connect.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_disconnect.c b/tests/unittests/test_cmd_disconnect.c
--- a/tests/unittests/test_cmd_disconnect.c
+++ b/tests/unittests/test_cmd_disconnect.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/unittests/test_cmd_join.c b/tests/unittests/test_cmd_join.c
--- a/tests/unittests/test_cmd_join.c
+++ b/tests/unittests/test_cmd_join.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_otr.c b/tests/unittests/test_cmd_otr.c
--- a/tests/unittests/test_cmd_otr.c
+++ b/tests/unittests/test_cmd_otr.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_pgp.c b/tests/unittests/test_cmd_pgp.c
--- a/tests/unittests/test_cmd_pgp.c
+++ b/tests/unittests/test_cmd_pgp.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_presence.c b/tests/unittests/test_cmd_presence.c
--- a/tests/unittests/test_cmd_presence.c
+++ b/tests/unittests/test_cmd_presence.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_rooms.c b/tests/unittests/test_cmd_rooms.c
--- a/tests/unittests/test_cmd_rooms.c
+++ b/tests/unittests/test_cmd_rooms.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_roster.c b/tests/unittests/test_cmd_roster.c
--- a/tests/unittests/test_cmd_roster.c
+++ b/tests/unittests/test_cmd_roster.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_cmd_sub.c b/tests/unittests/test_cmd_sub.c
--- a/tests/unittests/test_cmd_sub.c
+++ b/tests/unittests/test_cmd_sub.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_common.c b/tests/unittests/test_common.c
--- a/tests/unittests/test_common.c
+++ b/tests/unittests/test_common.c
@@ -1,11 +1,7 @@
#include "xmpp/resource.h"
#include "common.h"
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
-#include <stdint.h>
void
replace_one_substr(void** state)
diff --git a/tests/unittests/test_contact.c b/tests/unittests/test_contact.c
--- a/tests/unittests/test_contact.c
+++ b/tests/unittests/test_contact.c
@@ -1,9 +1,6 @@
#include <glib.h>
-#include <stdarg.h>
#include <string.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "xmpp/contact.h"
diff --git a/tests/unittests/test_form.c b/tests/unittests/test_form.c
--- a/tests/unittests/test_form.c
+++ b/tests/unittests/test_form.c
@@ -1,8 +1,5 @@
-#include <stdarg.h>
#include <string.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "xmpp/form.h"
diff --git a/tests/unittests/test_jid.c b/tests/unittests/test_jid.c
--- a/tests/unittests/test_jid.c
+++ b/tests/unittests/test_jid.c
@@ -1,8 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <stdint.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "xmpp/jid.h"
diff --git a/tests/unittests/test_keyhandlers.c b/tests/unittests/test_keyhandlers.c
--- a/tests/unittests/test_keyhandlers.c
+++ b/tests/unittests/test_keyhandlers.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
diff --git a/tests/unittests/test_muc.c b/tests/unittests/test_muc.c
--- a/tests/unittests/test_muc.c
+++ b/tests/unittests/test_muc.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "xmpp/muc.h"
diff --git a/tests/unittests/test_parser.c b/tests/unittests/test_parser.c
--- a/tests/unittests/test_parser.c
+++ b/tests/unittests/test_parser.c
@@ -1,8 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <stdint.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "tools/parser.h"
diff --git a/tests/unittests/test_plugins_disco.c b/tests/unittests/test_plugins_disco.c
--- a/tests/unittests/test_plugins_disco.c
+++ b/tests/unittests/test_plugins_disco.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include "plugins/disco.h"
diff --git a/tests/unittests/test_preferences.c b/tests/unittests/test_preferences.c
--- a/tests/unittests/test_preferences.c
+++ b/tests/unittests/test_preferences.c
@@ -1,8 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <stdint.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/test_roster_list.c b/tests/unittests/test_roster_list.c
--- a/tests/unittests/test_roster_list.c
+++ b/tests/unittests/test_roster_list.c
@@ -1,11 +1,7 @@
#include <glib.h>
-#include <stdarg.h>
#include <string.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
-#include <stdint.h>
#include "xmpp/contact.h"
#include "xmpp/roster_list.h"
diff --git a/tests/unittests/test_server_events.c b/tests/unittests/test_server_events.c
--- a/tests/unittests/test_server_events.c
+++ b/tests/unittests/test_server_events.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <stdlib.h>
#include <string.h>
#include <glib.h>
diff --git a/tests/unittests/ui/stub_ui.c b/tests/unittests/ui/stub_ui.c
--- a/tests/unittests/ui/stub_ui.c
+++ b/tests/unittests/ui/stub_ui.c
@@ -3,8 +3,7 @@
#include <glib.h>
#include <wchar.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "ui/window.h"
#include "ui/ui.h"
diff --git a/tests/unittests/unittests.c b/tests/unittests/unittests.c
--- a/tests/unittests/unittests.c
+++ b/tests/unittests/unittests.c
@@ -1,10 +1,7 @@
-#include <stdarg.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include <sys/stat.h>
#include <stdlib.h>
#include <locale.h>
diff --git a/tests/unittests/xmpp/stub_xmpp.c b/tests/unittests/xmpp/stub_xmpp.c
--- a/tests/unittests/xmpp/stub_xmpp.c
+++ b/tests/unittests/xmpp/stub_xmpp.c
@@ -1,7 +1,4 @@
-#include <stdarg.h>
-#include <stddef.h>
-#include <setjmp.h>
-#include <cmocka.h>
+#include "prof_cmocka.h"
#include "xmpp/xmpp.h"
|
Slashguard spams console until I type something
```
Profanity, version 0.15.0dev.master.edda887a
Copyright (C) 2012 - 2019 James Booth <boothj5web@gmail.com>.
Copyright (C) 2019 - 2025 Michael Vetter <jubalh@iodoru.org>.
License GPLv3+: GNU GPL version 3 or later <https://www.gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Build information:
XMPP library: libstrophe
Desktop notification support: Enabled
OTR support: Enabled (libotr 4.1.1)
PGP support: Enabled (libgpgme 1.18.0)
OMEMO support: Enabled
C plugins: Enabled
Python plugins: Enabled (3.11.2)
GTK icons/clipboard: Enabled
GDK Pixbuf: Enabled
```
I realized slashguard is spamming in the console until I type something:
https://github.com/user-attachments/assets/206775b7-036f-43eb-8199-16539c5bb5ee
| 2025-07-28T09:29:01
|
c
|
Hard
|
|
nginx/njs
| 748
|
nginx__njs-748
|
[
"737"
] |
9d4bf6c60aa60a828609f64d1b5c50f71bb7ef62
|
diff --git a/src/njs_object.c b/src/njs_object.c
--- a/src/njs_object.c
+++ b/src/njs_object.c
@@ -2231,6 +2231,10 @@ njs_object_prototype_create_constructor(njs_vm_t *vm, njs_object_prop_t *prop,
found:
+ if (njs_flathsh_is_empty(&vm->constructors[index].object.shared_hash)) {
+ index = NJS_OBJ_TYPE_OBJECT;
+ }
+
njs_set_function(&constructor, &njs_vm_ctor(vm, index));
setval = &constructor;
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -7450,6 +7450,9 @@ static njs_unit_test_t njs_test[] =
"[i.next(), i.next(), i.next(), i.next()].map((x) => x.value)"),
njs_str("1,2,3,") },
+ { njs_str("[].values().constructor()"),
+ njs_str("[object Object]") },
+
{ njs_str("var a = [], i = a.values();"
"a.push(1); a.push(2); a.push(3);"
"[i.next(), i.next(), i.next(), i.next()].map((x) => x.value)"),
|
AddressSanitizer: SEGV src/njs_function.c:399 in njs_function_lambda_frame
### Describe the bug
AddressSanitizer: SEGV src/njs_function.c:399 in njs_function_lambda_frame ==4237==ABORTING- [ok ]
The bug is reproducible with the latest version of njs.
- [ ok] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
// Your JS code here
const v1 = new Uint32Array(Uint32Array, Uint32Array);
const v2 = v1.values();
Promise.any.call(v2);
```
Debug/Crash logs:
ASAN
```
AddressSanitizer:DEADLYSIGNAL ================================================================= ==4237==ERROR:
AddressSanitizer:
SEGV on unknown address 0x000000000028 (pc 0x564807d815bf bp 0x7ffcc01f5b00 sp 0x7ffcc01f5aa0 T0)
==4237==The signal is caused by a READ memory access.
==4237==Hint: address points to the zero page.
#0 0x564807d815bf in njs_function_lambda_frame src/njs_function.c:399
#1 0x564807d831e0 in njs_function_frame src/njs_function.h:154
#2 0x564807d831e0 in njs_function_call2 src/njs_function.c:510
#3 0x564807daed15 in njs_promise_new_capability src/njs_promise.c:368
#4 0x564807daf4ea in njs_promise_all src/njs_promise.c:1180
#5 0x564807d83124 in njs_function_native_call src/njs_function.c:647
#6 0x564807d83124 in njs_function_frame_invoke src/njs_function.c:683
#7 0x564807d831ca in njs_function_call2 src/njs_function.c:515
#8 0x564807d83246 in njs_function_call src/njs_function.h:164
#9 0x564807d83246 in njs_function_prototype_call src/njs_function.c:1236
#10 0x564807d83124 in njs_function_native_call src/njs_function.c:647
#11 0x564807d83124 in njs_function_frame_invoke src/njs_function.c:683
#12 0x564807cc9118 in njs_vmcode_interpreter src/njs_vmcode.c:1451
#13 0x564807cae647 in njs_vm_start src/njs_vm.c:664
#14 0x564807c9a501 in njs_engine_njs_eval external/njs_shell.c:1387
#15 0x564807c97596 in njs_process_script external/njs_shell.c:3528
#16 0x564807c9e033 in njs_process_file external/njs_shell.c:3500
#17 0x564807c9e033 in njs_main external/njs_shell.c:458
#18 0x564807c9e033 in main external/njs_shell.c:488
#19 0x7fdbcacb5d8f in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#20 0x7fdbcacb5e3f in __libc_start_main_impl ../csu/libc-start.c:392
#21 0x564807c97424 in _start (/home/fuzzer/njs/build/njs+0x50424) AddressSanitizer can not provide additional info. SUMMARY: AddressSanitizer: SEGV src/njs_function.c:399 in njs_function_lambda_frame ==4237==ABORTING
```
or put the code in a [gist](https://gist.github.com/) and link it here.
- NGINX configuration if applicable
```
# Your NGINX configuration here
```
or put the configuration in a [gist](https://gist.github.com/) and link it here.
- NGINX logs if applicable
```
# Your NGINX logs here
```
or post the full log to a [gist](https://gist.github.com/) and link it here.
- Output of the `nginx -V` command if applicable.
- Exact steps to reproduce the behavior
### Expected behavior
A clear and concise description of what you expected to happen.
### Your environment
- Version of njs or specific commit
- Version of NGINX if applicable
- List of other enabled nginx modules if applicable
- OS: Ubuntu 18.04
### Additional context
Add any other context about the problem here.
| 2024-06-27T01:58:47
|
c
|
Hard
|
|
HandmadeMath/HandmadeMath
| 175
|
HandmadeMath__HandmadeMath-175
|
[
"174"
] |
bdc7dd2a516b08715a56f8b8eecefe44c9d68f40
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1431,10 +1431,10 @@ static inline HMM_Mat3 HMM_MulM3F(HMM_Mat3 Matrix, float Scalar)
return Result;
}
-COVERAGE(HMM_DivM3, 1)
+COVERAGE(HMM_DivM3F, 1)
static inline HMM_Mat3 HMM_DivM3F(HMM_Mat3 Matrix, float Scalar)
{
- ASSERT_COVERED(HMM_DivM3);
+ ASSERT_COVERED(HMM_DivM3F);
HMM_Mat3 Result;
@@ -3803,124 +3803,131 @@ static inline HMM_Vec4 operator-(HMM_Vec4 In)
#endif /* __cplusplus*/
#ifdef HANDMADE_MATH__USE_C11_GENERICS
+
+void __hmm_invalid_generic();
+
#define HMM_Add(A, B) _Generic((A), \
- HMM_Vec2: HMM_AddV2, \
- HMM_Vec3: HMM_AddV3, \
- HMM_Vec4: HMM_AddV4, \
- HMM_Mat2: HMM_AddM2, \
- HMM_Mat3: HMM_AddM3, \
- HMM_Mat4: HMM_AddM4, \
- HMM_Quat: HMM_AddQ \
+ HMM_Vec2: HMM_AddV2, \
+ HMM_Vec3: HMM_AddV3, \
+ HMM_Vec4: HMM_AddV4, \
+ HMM_Mat2: HMM_AddM2, \
+ HMM_Mat3: HMM_AddM3, \
+ HMM_Mat4: HMM_AddM4, \
+ HMM_Quat: HMM_AddQ \
)(A, B)
#define HMM_Sub(A, B) _Generic((A), \
- HMM_Vec2: HMM_SubV2, \
- HMM_Vec3: HMM_SubV3, \
- HMM_Vec4: HMM_SubV4, \
- HMM_Mat2: HMM_SubM2, \
- HMM_Mat3: HMM_SubM3, \
- HMM_Mat4: HMM_SubM4, \
- HMM_Quat: HMM_SubQ \
+ HMM_Vec2: HMM_SubV2, \
+ HMM_Vec3: HMM_SubV3, \
+ HMM_Vec4: HMM_SubV4, \
+ HMM_Mat2: HMM_SubM2, \
+ HMM_Mat3: HMM_SubM3, \
+ HMM_Mat4: HMM_SubM4, \
+ HMM_Quat: HMM_SubQ \
)(A, B)
#define HMM_Mul(A, B) _Generic((B), \
- float: _Generic((A), \
+ float: _Generic((A), \
HMM_Vec2: HMM_MulV2F, \
HMM_Vec3: HMM_MulV3F, \
HMM_Vec4: HMM_MulV4F, \
HMM_Mat2: HMM_MulM2F, \
HMM_Mat3: HMM_MulM3F, \
HMM_Mat4: HMM_MulM4F, \
- HMM_Quat: HMM_MulQF \
- ), \
- HMM_Mat2: HMM_MulM2, \
- HMM_Mat3: HMM_MulM3, \
- HMM_Mat4: HMM_MulM4, \
- HMM_Quat: HMM_MulQ, \
- default: _Generic((A), \
+ HMM_Quat: HMM_MulQF, \
+ default: __hmm_invalid_generic \
+ ), \
+ HMM_Vec2: _Generic((A), \
HMM_Vec2: HMM_MulV2, \
- HMM_Vec3: HMM_MulV3, \
- HMM_Vec4: HMM_MulV4, \
HMM_Mat2: HMM_MulM2V2, \
+ default: __hmm_invalid_generic \
+ ), \
+ HMM_Vec3: _Generic((A), \
+ HMM_Vec3: HMM_MulV3, \
HMM_Mat3: HMM_MulM3V3, \
- HMM_Mat4: HMM_MulM4V4 \
- ) \
+ default: __hmm_invalid_generic \
+ ), \
+ HMM_Vec4: _Generic((A), \
+ HMM_Vec4: HMM_MulV4, \
+ HMM_Mat4: HMM_MulM4V4, \
+ default: __hmm_invalid_generic \
+ ), \
+ HMM_Mat2: HMM_MulM2, \
+ HMM_Mat3: HMM_MulM3, \
+ HMM_Mat4: HMM_MulM4, \
+ HMM_Quat: HMM_MulQ \
)(A, B)
#define HMM_Div(A, B) _Generic((B), \
- float: _Generic((A), \
- HMM_Mat2: HMM_DivM2F, \
- HMM_Mat3: HMM_DivM3F, \
- HMM_Mat4: HMM_DivM4F, \
+ float: _Generic((A), \
HMM_Vec2: HMM_DivV2F, \
HMM_Vec3: HMM_DivV3F, \
HMM_Vec4: HMM_DivV4F, \
- HMM_Quat: HMM_DivQF \
- ), \
- HMM_Mat2: HMM_DivM2, \
- HMM_Mat3: HMM_DivM3, \
- HMM_Mat4: HMM_DivM4, \
- HMM_Quat: HMM_DivQ, \
- default: _Generic((A), \
- HMM_Vec2: HMM_DivV2, \
- HMM_Vec3: HMM_DivV3, \
- HMM_Vec4: HMM_DivV4 \
- ) \
+ HMM_Mat2: HMM_DivM2F, \
+ HMM_Mat3: HMM_DivM3F, \
+ HMM_Mat4: HMM_DivM4F, \
+ HMM_Quat: HMM_DivQF \
+ ), \
+ HMM_Vec2: HMM_DivV2, \
+ HMM_Vec3: HMM_DivV3, \
+ HMM_Vec4: HMM_DivV4 \
)(A, B)
#define HMM_Len(A) _Generic((A), \
- HMM_Vec2: HMM_LenV2, \
- HMM_Vec3: HMM_LenV3, \
- HMM_Vec4: HMM_LenV4 \
+ HMM_Vec2: HMM_LenV2, \
+ HMM_Vec3: HMM_LenV3, \
+ HMM_Vec4: HMM_LenV4 \
)(A)
#define HMM_LenSqr(A) _Generic((A), \
- HMM_Vec2: HMM_LenSqrV2, \
- HMM_Vec3: HMM_LenSqrV3, \
- HMM_Vec4: HMM_LenSqrV4 \
+ HMM_Vec2: HMM_LenSqrV2, \
+ HMM_Vec3: HMM_LenSqrV3, \
+ HMM_Vec4: HMM_LenSqrV4 \
)(A)
#define HMM_Norm(A) _Generic((A), \
- HMM_Vec2: HMM_NormV2, \
- HMM_Vec3: HMM_NormV3, \
- HMM_Vec4: HMM_NormV4 \
+ HMM_Vec2: HMM_NormV2, \
+ HMM_Vec3: HMM_NormV3, \
+ HMM_Vec4: HMM_NormV4, \
+ HMM_Quat: HMM_NormQ \
)(A)
#define HMM_Dot(A, B) _Generic((A), \
- HMM_Vec2: HMM_DotV2, \
- HMM_Vec3: HMM_DotV3, \
- HMM_Vec4: HMM_DotV4 \
+ HMM_Vec2: HMM_DotV2, \
+ HMM_Vec3: HMM_DotV3, \
+ HMM_Vec4: HMM_DotV4, \
+ HMM_Quat: HMM_DotQ \
)(A, B)
#define HMM_Lerp(A, T, B) _Generic((A), \
- float: HMM_Lerp, \
- HMM_Vec2: HMM_LerpV2, \
- HMM_Vec3: HMM_LerpV3, \
- HMM_Vec4: HMM_LerpV4 \
+ float: HMM_Lerp, \
+ HMM_Vec2: HMM_LerpV2, \
+ HMM_Vec3: HMM_LerpV3, \
+ HMM_Vec4: HMM_LerpV4 \
)(A, T, B)
#define HMM_Eq(A, B) _Generic((A), \
- HMM_Vec2: HMM_EqV2, \
- HMM_Vec3: HMM_EqV3, \
- HMM_Vec4: HMM_EqV4 \
+ HMM_Vec2: HMM_EqV2, \
+ HMM_Vec3: HMM_EqV3, \
+ HMM_Vec4: HMM_EqV4 \
)(A, B)
#define HMM_Transpose(M) _Generic((M), \
- HMM_Mat2: HMM_TransposeM2, \
- HMM_Mat3: HMM_TransposeM3, \
- HMM_Mat4: HMM_TransposeM4 \
+ HMM_Mat2: HMM_TransposeM2, \
+ HMM_Mat3: HMM_TransposeM3, \
+ HMM_Mat4: HMM_TransposeM4 \
)(M)
#define HMM_Determinant(M) _Generic((M), \
- HMM_Mat2: HMM_DeterminantM2, \
- HMM_Mat3: HMM_DeterminantM3, \
- HMM_Mat4: HMM_DeterminantM4 \
+ HMM_Mat2: HMM_DeterminantM2, \
+ HMM_Mat3: HMM_DeterminantM3, \
+ HMM_Mat4: HMM_DeterminantM4 \
)(M)
#define HMM_InvGeneral(M) _Generic((M), \
- HMM_Mat2: HMM_InvGeneralM2, \
- HMM_Mat3: HMM_InvGeneralM3, \
- HMM_Mat4: HMM_InvGeneralM4 \
+ HMM_Mat2: HMM_InvGeneralM2, \
+ HMM_Mat3: HMM_InvGeneralM3, \
+ HMM_Mat4: HMM_InvGeneralM4 \
)(M)
#endif
|
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -2,77 +2,123 @@ BUILD_DIR=./build
CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers -Wfloat-equal
-all: c c_no_simd cpp cpp_no_simd build_c_without_coverage build_cpp_without_coverage
-
-build_all: build_c build_c_no_simd build_cpp build_cpp_no_simd
+.PHONY: all all_c all_cpp
+all: all_c all_cpp
+all_c: c99 c99_no_simd c11 c17
+all_cpp: cpp98 cpp98_no_simd cpp03 cpp11 cpp14 cpp17 cpp20
+.PHONY: clean
clean:
rm -rf $(BUILD_DIR)
-c: build_c
- $(BUILD_DIR)/hmm_test_c
-
-build_c: HandmadeMath.c test_impl
- @echo "\nCompiling in C mode"
+.PHONY: c99
+c99:
+ @echo "\nCompiling as C99"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR)\
&& $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
- -c ../HandmadeMath.c ../hmm_test.c \
- -lm \
- && $(CC) -ohmm_test_c HandmadeMath.o hmm_test.o -lm
-
-c_no_simd: build_c_no_simd
- $(BUILD_DIR)/hmm_test_c_no_simd
+ ../HandmadeMath.c ../hmm_test.c \
+ -lm -o hmm_test_c99 \
+ && ./hmm_test_c99
-build_c_no_simd: HandmadeMath.c test_impl
- @echo "\nCompiling in C mode (no SIMD)"
+.PHONY: c99_no_simd
+c99_no_simd:
+ @echo "\nCompiling as C99 (no SIMD)"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR) \
&& $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
-DHANDMADE_MATH_NO_SIMD \
- -c ../HandmadeMath.c ../hmm_test.c \
- -lm \
- && $(CC) -ohmm_test_c_no_simd HandmadeMath.o hmm_test.o -lm
+ ../HandmadeMath.c ../hmm_test.c \
+ -lm -o hmm_test_c99_no_simd \
+ && ./hmm_test_c99_no_simd
-cpp: build_cpp
- $(BUILD_DIR)/hmm_test_cpp
-
-build_cpp: HandmadeMath.cpp test_impl
- @echo "\nCompiling in C++ mode"
+.PHONY: c11
+c11:
+ @echo "\nCompiling as C11"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR)\
+ && $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c11 \
+ ../HandmadeMath.c ../hmm_test.c \
+ -lm -o hmm_test_c11 \
+ && ./hmm_test_c11
+
+.PHONY: c17
+c17:
+ @echo "\nCompiling as C17"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR)\
+ && $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c17 \
+ ../HandmadeMath.c ../hmm_test.c \
+ -lm -o hmm_test_c17 \
+ && ./hmm_test_c17
+
+.PHONY: cpp98
+cpp98:
+ @echo "\nCompiling as C++98"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR) \
- && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp \
- -DHANDMADE_MATH_CPP_MODE \
- ../HandmadeMath.cpp ../hmm_test.cpp
-
-cpp_no_simd: build_cpp_no_simd
- $(BUILD_DIR)/hmm_test_cpp_no_simd
-
-build_cpp_no_simd: HandmadeMath.cpp test_impl
- @echo "\nCompiling in C++ mode (no SIMD)"
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++98 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp98 \
+ && ./hmm_test_cpp98
+
+.PHONY: cpp98_no_simd
+cpp98_no_simd:
+ @echo "\nCompiling as C++98 (no SIMD)"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR) \
- && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_no_simd \
- -DHANDMADE_MATH_CPP_MODE -DHANDMADE_MATH_NO_SIMD \
- ../HandmadeMath.cpp ../hmm_test.cpp
-
-test_impl: hmm_test.cpp hmm_test.c
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++98 \
+ -DHANDMADE_MATH_NO_SIMD \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp98 \
+ && ./hmm_test_cpp98
-build_c_without_coverage: HandmadeMath.c test_impl
- @echo "\nCompiling in C mode"
+.PHONY: cpp03
+cpp03:
+ @echo "\nCompiling as C++03"
mkdir -p $(BUILD_DIR)
- cd $(BUILD_DIR)\
- && $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
- -DWITHOUT_COVERAGE \
- -c ../HandmadeMath.c ../hmm_test.c \
- -lm \
- && $(CC) -ohmm_test_c HandmadeMath.o hmm_test.o -lm
-
-build_cpp_without_coverage: HandmadeMath.cpp test_impl
- @echo "\nCompiling in C++ mode (no SIMD)"
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++03 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp03 \
+ && ./hmm_test_cpp03
+
+.PHONY: cpp11
+cpp11:
+ @echo "\nCompiling as C++11"
mkdir -p $(BUILD_DIR)
cd $(BUILD_DIR) \
- && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_no_simd \
- -DHANDMADE_MATH_CPP_MODE -DWITHOUT_COVERAGE \
- ../HandmadeMath.cpp ../hmm_test.cpp
-
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++11 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp11 \
+ && ./hmm_test_cpp11
+
+.PHONY: cpp14
+cpp14:
+ @echo "\nCompiling as C++14"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++14 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp14 \
+ && ./hmm_test_cpp14
+
+.PHONY: cpp17
+cpp17:
+ @echo "\nCompiling as C++17"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++17 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp17 \
+ && ./hmm_test_cpp17
+
+.PHONY: cpp20
+cpp20:
+ @echo "\nCompiling as C++20"
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -std=c++20 \
+ ../HandmadeMath.cpp ../hmm_test.cpp \
+ -lm -o hmm_test_cpp20 \
+ && ./hmm_test_cpp20
diff --git a/test/categories/Addition.h b/test/categories/Addition.h
--- a/test/categories/Addition.h
+++ b/test/categories/Addition.h
@@ -10,12 +10,14 @@ TEST(Addition, Vec2)
EXPECT_FLOAT_EQ(result.X, 4.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Add(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 4.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2_1 + v2_2;
EXPECT_FLOAT_EQ(result.X, 4.0f);
@@ -39,13 +41,15 @@ TEST(Addition, Vec3)
EXPECT_FLOAT_EQ(result.Y, 7.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Add(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 5.0f);
EXPECT_FLOAT_EQ(result.Y, 7.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3_1 + v3_2;
EXPECT_FLOAT_EQ(result.X, 5.0f);
@@ -72,7 +76,7 @@ TEST(Addition, Vec4)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Add(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 6.0f);
@@ -80,6 +84,8 @@ TEST(Addition, Vec4)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4_1 + v4_2;
EXPECT_FLOAT_EQ(result.X, 6.0f);
@@ -125,14 +131,16 @@ TEST(Addition, Mat2)
EXPECT_FLOAT_EQ(result.Elements[1][1], 12.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Add(a, b);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 8.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 10.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 8.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 10.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 12.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat2 result = a + b;
EXPECT_FLOAT_EQ(result.Elements[0][0], 6.0f);
@@ -182,19 +190,21 @@ TEST(Addition, Mat3)
EXPECT_FLOAT_EQ(result.Elements[2][2], 27.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Add(a, b);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 11.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 13.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 17.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 11.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 13.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 17.0f);
EXPECT_FLOAT_EQ(result.Elements[1][1], 19.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 23.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 23.0f);
EXPECT_FLOAT_EQ(result.Elements[2][1], 25.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 27.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat3 result = a + b;
EXPECT_FLOAT_EQ(result.Elements[0][0], 11.0f);
@@ -257,7 +267,7 @@ TEST(Addition, Mat4)
}
}
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Add(m4_1, m4_2);
float Expected = 18.0f;
@@ -270,6 +280,8 @@ TEST(Addition, Mat4)
}
}
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat4 result = m4_1 + m4_2;
float Expected = 18.0f;
@@ -308,7 +320,7 @@ TEST(Addition, Quaternion)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Add(q1, q2);
EXPECT_FLOAT_EQ(result.X, 6.0f);
@@ -316,6 +328,8 @@ TEST(Addition, Quaternion)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Quat result = q1 + q2;
EXPECT_FLOAT_EQ(result.X, 6.0f);
diff --git a/test/categories/Division.h b/test/categories/Division.h
--- a/test/categories/Division.h
+++ b/test/categories/Division.h
@@ -10,12 +10,14 @@ TEST(Division, Vec2Vec2)
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 0.75f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Div(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 0.75f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2_1 / v2_2;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -38,12 +40,14 @@ TEST(Division, Vec2Scalar)
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 1.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Div(v2, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 1.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2 / s;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -67,13 +71,15 @@ TEST(Division, Vec3Vec3)
EXPECT_FLOAT_EQ(result.Y, 0.75f);
EXPECT_FLOAT_EQ(result.Z, 10.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Div(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 0.75f);
EXPECT_FLOAT_EQ(result.Z, 10.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3_1 / v3_2;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -99,13 +105,15 @@ TEST(Division, Vec3Scalar)
EXPECT_FLOAT_EQ(result.Y, 1.0f);
EXPECT_FLOAT_EQ(result.Z, 1.5f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Div(v3, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 1.0f);
EXPECT_FLOAT_EQ(result.Z, 1.5f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3 / s;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -132,7 +140,7 @@ TEST(Division, Vec4Vec4)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 0.25f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Div(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -140,6 +148,8 @@ TEST(Division, Vec4Vec4)
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 0.25f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4_1 / v4_2;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -168,7 +178,7 @@ TEST(Division, Vec4Scalar)
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Div(v4, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -176,6 +186,8 @@ TEST(Division, Vec4Scalar)
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4 / s;
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -212,7 +224,7 @@ TEST(Division, Mat2Scalar)
EXPECT_FLOAT_EQ(result.Elements[1][1], 8.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Div(m, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 2.0f);
@@ -220,7 +232,9 @@ TEST(Division, Mat2Scalar)
EXPECT_FLOAT_EQ(result.Elements[1][0], 6.0f);
EXPECT_FLOAT_EQ(result.Elements[1][1], 8.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat2 result = m / s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 2.0f);
@@ -257,7 +271,7 @@ TEST(Division, Mat3Scalar)
EXPECT_FLOAT_EQ(result.Elements[2][2], 18.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Div(m, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 2.0f);
@@ -270,7 +284,9 @@ TEST(Division, Mat3Scalar)
EXPECT_FLOAT_EQ(result.Elements[2][1], 16.0f);
EXPECT_FLOAT_EQ(result.Elements[2][2], 18.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat3 result = m / s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 2.0f);
@@ -322,7 +338,7 @@ TEST(Division, Mat4Scalar)
EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Div(m4, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
@@ -342,6 +358,8 @@ TEST(Division, Mat4Scalar)
EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat4 result = m4 / s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
@@ -394,7 +412,7 @@ TEST(Division, QuaternionScalar)
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Div(q, f);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -402,6 +420,8 @@ TEST(Division, QuaternionScalar)
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Quat result = q / f;
EXPECT_FLOAT_EQ(result.X, 0.5f);
diff --git a/test/categories/Equality.h b/test/categories/Equality.h
--- a/test/categories/Equality.h
+++ b/test/categories/Equality.h
@@ -9,10 +9,12 @@ TEST(Equality, Vec2)
EXPECT_TRUE(HMM_EqV2(a, b));
EXPECT_FALSE(HMM_EqV2(a, c));
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_TRUE(HMM_Eq(a, b));
EXPECT_FALSE(HMM_Eq(a, c));
+#endif
+#ifdef __cplusplus
EXPECT_TRUE(a == b);
EXPECT_FALSE(a == c);
@@ -30,10 +32,12 @@ TEST(Equality, Vec3)
EXPECT_TRUE(HMM_EqV3(a, b));
EXPECT_FALSE(HMM_EqV3(a, c));
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_TRUE(HMM_Eq(a, b));
EXPECT_FALSE(HMM_Eq(a, c));
+#endif
+#ifdef __cplusplus
EXPECT_TRUE(a == b);
EXPECT_FALSE(a == c);
@@ -51,10 +55,12 @@ TEST(Equality, Vec4)
EXPECT_TRUE(HMM_EqV4(a, b));
EXPECT_FALSE(HMM_EqV4(a, c));
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_TRUE(HMM_Eq(a, b));
EXPECT_FALSE(HMM_Eq(a, c));
+#endif
+#ifdef __cplusplus
EXPECT_TRUE(a == b);
EXPECT_FALSE(a == c);
diff --git a/test/categories/MatrixOps.h b/test/categories/MatrixOps.h
--- a/test/categories/MatrixOps.h
+++ b/test/categories/MatrixOps.h
@@ -19,7 +19,7 @@ TEST(InvMatrix, Transpose)
EXPECT_FLOAT_EQ(result.Elements[1][0], Expect.Elements[1][0]);
EXPECT_FLOAT_EQ(result.Elements[1][1], Expect.Elements[1][1]);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Transpose(Matrix);
EXPECT_FLOAT_EQ(result.Elements[0][0], Expect.Elements[0][0]);
@@ -54,7 +54,7 @@ TEST(InvMatrix, Transpose)
EXPECT_FLOAT_EQ(result.Elements[2][1], Expect.Elements[2][1]);
EXPECT_FLOAT_EQ(result.Elements[2][2], Expect.Elements[2][2]);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Transpose(Matrix);
EXPECT_FLOAT_EQ(result.Elements[0][0], Expect.Elements[0][0]);
@@ -94,7 +94,7 @@ TEST(InvMatrix, Transpose)
EXPECT_FLOAT_EQ(result.Elements[2][1], Expect.Elements[2][1]);
EXPECT_FLOAT_EQ(result.Elements[2][2], Expect.Elements[2][2]);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Transpose(Matrix);
EXPECT_FLOAT_EQ(result.Elements[0][0], Expect.Elements[0][0]);
diff --git a/test/categories/Multiplication.h b/test/categories/Multiplication.h
--- a/test/categories/Multiplication.h
+++ b/test/categories/Multiplication.h
@@ -10,12 +10,14 @@ TEST(Multiplication, Vec2Vec2)
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 8.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Mul(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 8.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2_1 * v2_2;
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -38,12 +40,14 @@ TEST(Multiplication, Vec2Scalar)
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Mul(v2, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2 * s;
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -72,13 +76,15 @@ TEST(Multiplication, Vec3Vec3)
EXPECT_FLOAT_EQ(result.Y, 10.0f);
EXPECT_FLOAT_EQ(result.Z, 18.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Mul(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 4.0f);
EXPECT_FLOAT_EQ(result.Y, 10.0f);
EXPECT_FLOAT_EQ(result.Z, 18.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3_1 * v3_2;
EXPECT_FLOAT_EQ(result.X, 4.0f);
@@ -104,13 +110,15 @@ TEST(Multiplication, Vec3Scalar)
EXPECT_FLOAT_EQ(result.Y, 6.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Mul(v3, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3 * s;
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -143,7 +151,7 @@ TEST(Multiplication, Vec4Vec4)
EXPECT_FLOAT_EQ(result.Z, 21.0f);
EXPECT_FLOAT_EQ(result.W, 32.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Mul(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 5.0f);
@@ -151,6 +159,8 @@ TEST(Multiplication, Vec4Vec4)
EXPECT_FLOAT_EQ(result.Z, 21.0f);
EXPECT_FLOAT_EQ(result.W, 32.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4_1 * v4_2;
EXPECT_FLOAT_EQ(result.X, 5.0f);
@@ -179,7 +189,7 @@ TEST(Multiplication, Vec4Scalar)
EXPECT_FLOAT_EQ(result.Z, 9.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Mul(v4, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -187,6 +197,8 @@ TEST(Multiplication, Vec4Scalar)
EXPECT_FLOAT_EQ(result.Z, 9.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4 * s;
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -234,15 +246,17 @@ TEST(Multiplication, Mat2Mat2) {
EXPECT_FLOAT_EQ(result.Elements[1][1], 46.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Mul(a,b);
EXPECT_FLOAT_EQ(result.Elements[0][0], 23.0f);
EXPECT_FLOAT_EQ(result.Elements[0][1], 34.0f);
EXPECT_FLOAT_EQ(result.Elements[1][0], 31.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 46.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 46.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat2 result = a * b;
EXPECT_FLOAT_EQ(result.Elements[0][0], 23.0f);
@@ -271,7 +285,7 @@ TEST(Multiplication, Mat2Scalar) {
EXPECT_FLOAT_EQ(result.Elements[1][0], 30.0f);
EXPECT_FLOAT_EQ(result.Elements[1][1], 40.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Mul(m, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 10.0f);
@@ -279,6 +293,8 @@ TEST(Multiplication, Mat2Scalar) {
EXPECT_FLOAT_EQ(result.Elements[1][0], 30.0f);
EXPECT_FLOAT_EQ(result.Elements[1][1], 40.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat2 result = m * s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 10.0f);
@@ -322,13 +338,15 @@ TEST(Multiplication, Mat2Vec2) {
EXPECT_FLOAT_EQ(result.Elements[1], 34.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Mul(m, v);
EXPECT_FLOAT_EQ(result.Elements[0], 23.0f);
EXPECT_FLOAT_EQ(result.Elements[1], 34.0f);
}
-
+#endif
+
+#ifdef __cplusplus
{
HMM_Vec2 result = m * v;
EXPECT_FLOAT_EQ(result.Elements[0], 23.0f);
@@ -368,7 +386,7 @@ TEST(Multiplication, Mat3Mat3)
EXPECT_FLOAT_EQ(result.Elements[2][2], 312.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Mul(a,b);
EXPECT_FLOAT_EQ(result.Elements[0][0], 138.0f);
@@ -381,7 +399,9 @@ TEST(Multiplication, Mat3Mat3)
EXPECT_FLOAT_EQ(result.Elements[2][1], 261.0f);
EXPECT_FLOAT_EQ(result.Elements[2][2], 312.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat3 result = a * b;
EXPECT_FLOAT_EQ(result.Elements[0][0], 138.0f);
@@ -420,7 +440,7 @@ TEST(Multiplication, Mat3Scalar) {
EXPECT_FLOAT_EQ(result.Elements[2][1], 80.0f);
EXPECT_FLOAT_EQ(result.Elements[2][2], 90.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Mul(m, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 10.0f);
@@ -433,6 +453,8 @@ TEST(Multiplication, Mat3Scalar) {
EXPECT_FLOAT_EQ(result.Elements[2][1], 80.0f);
EXPECT_FLOAT_EQ(result.Elements[2][2], 90.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat3 result = m * s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 10.0f);
@@ -491,14 +513,15 @@ TEST(Multiplication, Mat3Vec3) {
EXPECT_FLOAT_EQ(result.Elements[1], 171.0f);
EXPECT_FLOAT_EQ(result.Elements[2], 204.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Mul(m, v);
EXPECT_FLOAT_EQ(result.Elements[0], 138.0f);
EXPECT_FLOAT_EQ(result.Elements[1], 171.0f);
EXPECT_FLOAT_EQ(result.Elements[2], 204.0f);
}
-
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = m * v;
EXPECT_FLOAT_EQ(result.Elements[0], 138.0f);
@@ -552,7 +575,7 @@ TEST(Multiplication, Mat4Mat4)
EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Mul(m4_1, m4_2);
EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
@@ -572,6 +595,8 @@ TEST(Multiplication, Mat4Mat4)
EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat4 result = m4_1 * m4_2;
EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
@@ -634,7 +659,7 @@ TEST(Multiplication, Mat4Scalar)
EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Mul(m4, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
@@ -654,6 +679,8 @@ TEST(Multiplication, Mat4Scalar)
EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat4 result = m4 * s;
EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
@@ -737,7 +764,7 @@ TEST(Multiplication, Mat4Vec4)
EXPECT_FLOAT_EQ(result.Z, 110.0f);
EXPECT_FLOAT_EQ(result.W, 120.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Mul(m4, v4);
EXPECT_FLOAT_EQ(result.X, 90.0f);
@@ -745,6 +772,8 @@ TEST(Multiplication, Mat4Vec4)
EXPECT_FLOAT_EQ(result.Z, 110.0f);
EXPECT_FLOAT_EQ(result.W, 120.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = m4 * v4;
EXPECT_FLOAT_EQ(result.X, 90.0f);
@@ -769,7 +798,7 @@ TEST(Multiplication, QuaternionQuaternion)
EXPECT_FLOAT_EQ(result.Z, 48.0f);
EXPECT_FLOAT_EQ(result.W, -6.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Mul(q1, q2);
EXPECT_FLOAT_EQ(result.X, 24.0f);
@@ -777,6 +806,8 @@ TEST(Multiplication, QuaternionQuaternion)
EXPECT_FLOAT_EQ(result.Z, 48.0f);
EXPECT_FLOAT_EQ(result.W, -6.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Quat result = q1 * q2;
EXPECT_FLOAT_EQ(result.X, 24.0f);
@@ -803,7 +834,7 @@ TEST(Multiplication, QuaternionScalar)
EXPECT_FLOAT_EQ(result.Z, 6.0f);
EXPECT_FLOAT_EQ(result.W, 8.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Mul(q, f);
EXPECT_FLOAT_EQ(result.X, 2.0f);
@@ -811,6 +842,8 @@ TEST(Multiplication, QuaternionScalar)
EXPECT_FLOAT_EQ(result.Z, 6.0f);
EXPECT_FLOAT_EQ(result.W, 8.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Quat result = q * f;
EXPECT_FLOAT_EQ(result.X, 2.0f);
diff --git a/test/categories/QuaternionOps.h b/test/categories/QuaternionOps.h
--- a/test/categories/QuaternionOps.h
+++ b/test/categories/QuaternionOps.h
@@ -22,7 +22,7 @@ TEST(QuaternionOps, Dot)
float result = HMM_DotQ(q1, q2);
EXPECT_FLOAT_EQ(result, 70.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
float result = HMM_Dot(q1, q2);
EXPECT_FLOAT_EQ(result, 70.0f);
@@ -41,7 +41,7 @@ TEST(QuaternionOps, Normalize)
EXPECT_NEAR(result.Z, 0.5477225575f, 0.001f);
EXPECT_NEAR(result.W, 0.7302967433f, 0.001f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Norm(q);
EXPECT_NEAR(result.X, 0.1825741858f, 0.001f);
@@ -97,7 +97,7 @@ TEST(QuaternionOps, SLerp)
EXPECT_NEAR(result.Z, -0.40824830f, 0.001f);
EXPECT_NEAR(result.W, 0.70710676f, 0.001f);
}
- {
+ {
HMM_Quat result = HMM_SLerp(from, 1.0f, to);
EXPECT_NEAR(result.X, 0.5f, 0.001f);
EXPECT_NEAR(result.Y, 0.5f, 0.001f);
diff --git a/test/categories/Subtraction.h b/test/categories/Subtraction.h
--- a/test/categories/Subtraction.h
+++ b/test/categories/Subtraction.h
@@ -10,12 +10,14 @@ TEST(Subtraction, Vec2)
EXPECT_FLOAT_EQ(result.X, -2.0f);
EXPECT_FLOAT_EQ(result.Y, -2.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Sub(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, -2.0f);
EXPECT_FLOAT_EQ(result.Y, -2.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec2 result = v2_1 - v2_2;
EXPECT_FLOAT_EQ(result.X, -2.0f);
@@ -39,13 +41,15 @@ TEST(Subtraction, Vec3)
EXPECT_FLOAT_EQ(result.Y, -3.0f);
EXPECT_FLOAT_EQ(result.Z, -3.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Sub(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, -3.0f);
EXPECT_FLOAT_EQ(result.Y, -3.0f);
EXPECT_FLOAT_EQ(result.Z, -3.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec3 result = v3_1 - v3_2;
EXPECT_FLOAT_EQ(result.X, -3.0f);
@@ -72,7 +76,7 @@ TEST(Subtraction, Vec4)
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Sub(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, -4.0f);
@@ -80,6 +84,8 @@ TEST(Subtraction, Vec4)
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Vec4 result = v4_1 - v4_2;
EXPECT_FLOAT_EQ(result.X, -4.0f);
@@ -124,7 +130,7 @@ TEST(Subtraction, Mat2)
EXPECT_FLOAT_EQ(result.Elements[1][0], 4.0);
EXPECT_FLOAT_EQ(result.Elements[1][1], 4.0);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat2 result = HMM_Sub(b,a);
EXPECT_FLOAT_EQ(result.Elements[0][0], 4.0);
@@ -132,7 +138,8 @@ TEST(Subtraction, Mat2)
EXPECT_FLOAT_EQ(result.Elements[1][0], 4.0);
EXPECT_FLOAT_EQ(result.Elements[1][1], 4.0);
}
-
+#endif
+#ifdef __cplusplus
{
HMM_Mat2 result = b - a;
EXPECT_FLOAT_EQ(result.Elements[0][0], 4.0);
@@ -183,7 +190,7 @@ TEST(Subtraction, Mat3)
EXPECT_FLOAT_EQ(result.Elements[2][1], 9.0);
EXPECT_FLOAT_EQ(result.Elements[2][2], 9.0);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat3 result = HMM_Sub(b,a);
EXPECT_FLOAT_EQ(result.Elements[0][0], 9.0);
@@ -196,7 +203,9 @@ TEST(Subtraction, Mat3)
EXPECT_FLOAT_EQ(result.Elements[2][1], 9.0);
EXPECT_FLOAT_EQ(result.Elements[2][2], 9.0);
}
+#endif
+#ifdef __cplusplus
b -= a;
EXPECT_FLOAT_EQ(b.Elements[0][0], 9.0);
EXPECT_FLOAT_EQ(b.Elements[0][1], 9.0);
@@ -245,7 +254,7 @@ TEST(Subtraction, Mat4)
}
}
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Mat4 result = HMM_Sub(m4_1, m4_2);
for (int Column = 0; Column < 4; ++Column)
@@ -256,6 +265,8 @@ TEST(Subtraction, Mat4)
}
}
}
+#endif
+#ifdef __cplusplus
{
HMM_Mat4 result = m4_1 - m4_2;
for (int Column = 0; Column < 4; ++Column)
@@ -290,7 +301,7 @@ TEST(Subtraction, Quaternion)
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Quat result = HMM_Sub(q1, q2);
EXPECT_FLOAT_EQ(result.X, -4.0f);
@@ -298,6 +309,8 @@ TEST(Subtraction, Quaternion)
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
+#endif
+#ifdef __cplusplus
{
HMM_Quat result = q1 - q2;
EXPECT_FLOAT_EQ(result.X, -4.0f);
diff --git a/test/categories/VectorOps.h b/test/categories/VectorOps.h
--- a/test/categories/VectorOps.h
+++ b/test/categories/VectorOps.h
@@ -10,7 +10,7 @@ TEST(VectorOps, LengthSquared)
EXPECT_FLOAT_EQ(HMM_LenSqrV3(v3), 14.0f);
EXPECT_FLOAT_EQ(HMM_LenSqrV4(v4), 15.0f);
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_FLOAT_EQ(HMM_LenSqr(v2), 5.0f);
EXPECT_FLOAT_EQ(HMM_LenSqr(v3), 14.0f);
EXPECT_FLOAT_EQ(HMM_LenSqr(v4), 15.0f);
@@ -27,7 +27,7 @@ TEST(VectorOps, Length)
EXPECT_FLOAT_EQ(HMM_LenV3(v3), 7.0f);
EXPECT_FLOAT_EQ(HMM_LenV4(v4), 13.892444f);
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_FLOAT_EQ(HMM_Len(v2), 9.0553856f);
EXPECT_FLOAT_EQ(HMM_Len(v3), 7.0f);
EXPECT_FLOAT_EQ(HMM_Len(v4), 13.892444f);
@@ -62,7 +62,7 @@ TEST(VectorOps, Normalize)
EXPECT_LT(result.W, 0.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Norm(v2);
EXPECT_NEAR(HMM_LenV2(result), 1.0f, 0.001f);
@@ -112,7 +112,7 @@ TEST(VectorOps, NormalizeZero)
EXPECT_FLOAT_EQ(result.W, 0.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Norm(v2);
EXPECT_FLOAT_EQ(result.X, 0.0f);
@@ -152,7 +152,7 @@ TEST(VectorOps, DotVec2)
HMM_Vec2 v2 = HMM_V2(3.0f, 4.0f);
EXPECT_FLOAT_EQ(HMM_DotV2(v1, v2), 11.0f);
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
#endif
}
@@ -163,7 +163,7 @@ TEST(VectorOps, DotVec3)
HMM_Vec3 v2 = HMM_V3(4.0f, 5.0f, 6.0f);
EXPECT_FLOAT_EQ(HMM_DotV3(v1, v2), 32.0f);
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
#endif
}
@@ -174,7 +174,7 @@ TEST(VectorOps, DotVec4)
HMM_Vec4 v2 = HMM_V4(5.0f, 6.0f, 7.0f, 8.0f);
EXPECT_FLOAT_EQ(HMM_DotV4(v1, v2), 70.0f);
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
#endif
}
@@ -189,7 +189,7 @@ TEST(VectorOps, LerpV2)
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 0.5f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec2 result = HMM_Lerp(v1, 0.5, v2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -209,7 +209,7 @@ TEST(VectorOps, LerpV3)
EXPECT_FLOAT_EQ(result.Y, 1.0f);
EXPECT_FLOAT_EQ(result.Z, 0.5f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec3 result = HMM_Lerp(v1, 0.5, v2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -231,7 +231,7 @@ TEST(VectorOps, LerpV4)
EXPECT_FLOAT_EQ(result.Z, 0.5f);
EXPECT_FLOAT_EQ(result.W, 1.0f);
}
-#ifdef __cplusplus
+#if HANDMADE_MATH__USE_C11_GENERICS || defined(__cplusplus)
{
HMM_Vec4 result = HMM_Lerp(v1, 0.5, v2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
diff --git a/test/run_test_clang.bat b/test/run_test_clang.bat
--- a/test/run_test_clang.bat
+++ b/test/run_test_clang.bat
@@ -3,16 +3,25 @@
if not exist "build" mkdir build
pushd build
-clang-cl /Fehmm_test_c.exe ..\HandmadeMath.c ..\hmm_test.c
-hmm_test_c
+clang-cl /std:c11 /Fehmm_test_c11.exe ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c11 || exit /b 1
-clang-cl /Fehmm_test_c_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.c ..\hmm_test.c
-hmm_test_c_no_sse
+clang-cl /std:c11 /Fehmm_test_c11_no_simd.exe /DHANDMADE_MATH_NO_SIMD ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c11_no_simd || exit /b 1
-clang-cl /Fehmm_test_cpp.exe ..\HandmadeMath.cpp ..\hmm_test.cpp
-hmm_test_cpp
+clang-cl /std:c17 /Fehmm_test_c17.exe ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c17 || exit /b 1
-clang-cl /Fehmm_test_cpp_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.cpp ..\hmm_test.cpp
-hmm_test_cpp_no_sse
+clang-cl /std:c++14 /Fehmm_test_cpp14.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp14 || exit /b 1
+
+clang-cl /std:c++14 /Fehmm_test_cpp14_no_simd.exe /DHANDMADE_MATH_NO_SIMD ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp14_no_simd || exit /b 1
+
+clang-cl /std:c++17 /Fehmm_test_cpp17.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp17 || exit /b 1
+
+clang-cl /std:c++20 /Fehmm_test_cpp20.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp20 || exit /b 1
popd
diff --git a/test/run_test_msvc.bat b/test/run_test_msvc.bat
--- a/test/run_test_msvc.bat
+++ b/test/run_test_msvc.bat
@@ -1,27 +1,32 @@
@echo off
-if "%1%"=="travis" (
- call "C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools\Common7\Tools\VsDevCmd.bat" -host_arch=amd64 -arch=amd64
-) else (
- where /q cl
- if ERRORLEVEL 1 (
- for /f "delims=" %%a in ('"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -find VC\Auxiliary\Build\vcvarsall.bat') do (%%a x64)
- )
+where /q cl
+if ERRORLEVEL 1 (
+ for /f "delims=" %%a in ('"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -find VC\Auxiliary\Build\vcvarsall.bat') do (%%a x64)
)
if not exist "build" mkdir build
pushd build
-cl /Fehmm_test_c.exe ..\HandmadeMath.c ..\hmm_test.c
-hmm_test_c
+cl /std:c11 /Fehmm_test_c11.exe ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c11 || exit /b 1
-cl /Fehmm_test_c_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.c ..\hmm_test.c
-hmm_test_c_no_sse
+cl /std:c11 /Fehmm_test_c11_no_simd.exe /DHANDMADE_MATH_NO_SIMD ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c11_no_simd || exit /b 1
-cl /Fehmm_test_cpp.exe ..\HandmadeMath.cpp ..\hmm_test.cpp
-hmm_test_cpp
+cl /std:c17 /Fehmm_test_c17.exe ..\HandmadeMath.c ..\hmm_test.c || exit /b 1
+hmm_test_c17 || exit /b 1
-cl /Fehmm_test_cpp_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.cpp ..\hmm_test.cpp
-hmm_test_cpp_no_sse
+cl /std:c++14 /Fehmm_test_cpp14.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp14 || exit /b 1
+
+cl /std:c++14 /Fehmm_test_cpp14_no_simd.exe /DHANDMADE_MATH_NO_SIMD ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp14_no_simd || exit /b 1
+
+cl /std:c++17 /Fehmm_test_cpp17.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp17 || exit /b 1
+
+cl /std:c++20 /Fehmm_test_cpp20.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || exit /b 1
+hmm_test_cpp20 || exit /b 1
popd
|
HMM_Div C11 Generic Macro Contains HMM_DivM2, HMM_DivM3, HMM_DivM4, and HMM_DivQ Which Don't Exist
The `HMM_Div` macro contains some function names that don't exist when compiling in C mode using C11 _Generics:
```c
#define HMM_Div(A, B) _Generic((B), \
float: _Generic((A), \
HMM_Mat2: HMM_DivM2F, \
HMM_Mat3: HMM_DivM3F, \
HMM_Mat4: HMM_DivM4F, \
HMM_Vec2: HMM_DivV2F, \
HMM_Vec3: HMM_DivV3F, \
HMM_Vec4: HMM_DivV4F, \
HMM_Quat: HMM_DivQF \
), \
HMM_Mat2: HMM_DivM2, /* Doesn't exist! */ \
HMM_Mat3: HMM_DivM3, /* Doesn't exist! */ \
HMM_Mat4: HMM_DivM4, /* Doesn't exist! */ \
HMM_Quat: HMM_DivQ, /* Doesn't exist! */ \
default: _Generic((A), \
HMM_Vec2: HMM_DivV2, \
HMM_Vec3: HMM_DivV3, \
HMM_Vec4: HMM_DivV4 \
) \
)(A, B)
```
|
This might be related or the cause, but the `COVERAGE` and `ASSERT_COVERED` macros also have the wrong names. For example:
```c
COVERAGE(HMM_DivM3, 1) //Missing F suffix!
static inline HMM_Mat3 HMM_DivM3F(HMM_Mat3 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_DivM3); //Missing F suffix!
...
}
```
EDIT: This might be the only instance of it being incorrect outside the `_Generic`. Seems `HMM_DivM2F` and `HMM_DivM4F` have their correct `COVERAGE` macro names.
| 2025-02-24T02:15:04
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 25
|
HandmadeMath__HandmadeMath-25
|
[
"21"
] |
c58043db844ed95c6088364580d264c9b1d8cd78
|
diff --git a/.gitignore b/.gitignore
new file mode 100644
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,33 @@
+# Prerequisites
+*.d
+
+# Compiled Object files
+*.slo
+*.lo
+*.o
+*.obj
+
+# Precompiled Headers
+*.gch
+*.pch
+
+# Compiled Dynamic libraries
+*.so
+*.dylib
+*.dll
+
+# Fortran module files
+*.mod
+*.smod
+
+# Compiled Static libraries
+*.lai
+*.la
+*.a
+*.lib
+
+# Executables
+*.exe
+*.out
+*.app
+hmm_test
diff --git a/.gitmodules b/.gitmodules
new file mode 100644
--- /dev/null
+++ b/.gitmodules
@@ -0,0 +1,3 @@
+[submodule "externals/googletest"]
+ path = externals/googletest
+ url = https://github.com/google/googletest.git
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -4,17 +4,17 @@
Single-file cross-platform public domain game math library for C/C++
-Version | Changes |
+Version | Changes |
----------------|----------------|
**0.5.2** | Fixed SSE code in HMM_SqrtF and HMM_RSqrtF |
**0.5.1** | Fixed HMM_Translate producing row-major matrices, ensured column-major order for matrices throughout |
**0.5** | Added scalar operations on vectors and matrices, added += and -= for hmm_mat4, reconciled headers and implementations, tidied up in general |
-**0.4** | Added SSE Optimized HMM_SqrtF, HMM_RSqrtF, Removed use of C Runtime |
-**0.3** | Added +=,-=, *=, /= for hmm_vec2, hmm_vec3, hmm_vec4 |
-**0.2b** | Disabled warning C4201 on MSVC, Added 64bit percision on HMM_PI |
-**0.2a** | Prefixed Macros |
-**0.2** | Updated Documentation, Fixed C Compliance, Prefixed all functions, and added better operator overloading |
-**0.1** | Initial Version |
+**0.4** | Added SSE Optimized HMM_SqrtF, HMM_RSqrtF, Removed use of C Runtime |
+**0.3** | Added +=,-=, *=, /= for hmm_vec2, hmm_vec3, hmm_vec4 |
+**0.2b** | Disabled warning C4201 on MSVC, Added 64bit percision on HMM_PI |
+**0.2a** | Prefixed Macros |
+**0.2** | Updated Documentation, Fixed C Compliance, Prefixed all functions, and added better operator overloading |
+**0.1** | Initial Version |
-----
_This library is free and will stay free, but if you would like to support development, or you are a company using HandmadeMath, please consider financial support._
@@ -22,8 +22,8 @@ _This library is free and will stay free, but if you would like to support devel
[](http://www.patreon.com/strangezak) [](https://www.paypal.me/zakarystrange)
-## FAQ
+## FAQ
**What's the license?**
@@ -32,3 +32,12 @@ This library is in the public domain. You can do whatever you want with them.
**Where can I contact you to ask questions?**
You can email me at: Zak@Handmade.Network
+
+
+## Testing
+
+```shell
+cd test
+make
+./hmm_test
+```
diff --git a/externals/googletest b/externals/googletest
new file mode 160000
--- /dev/null
+++ b/externals/googletest
@@ -0,0 +1 @@
+Subproject commit ed9d1e1ff92ce199de5ca2667a667cd0a368482a
|
diff --git a/test/HandmadeMath.cpp b/test/HandmadeMath.cpp
new file mode 100644
--- /dev/null
+++ b/test/HandmadeMath.cpp
@@ -0,0 +1,5 @@
+
+#define HANDMADE_MATH_IMPLEMENTATION
+#define HANDMADE_MATH_CPP_MODE
+#define HANDMADE_MATH_NO_INLINE
+#include "../HandmadeMath.h"
diff --git a/test/Makefile b/test/Makefile
new file mode 100644
--- /dev/null
+++ b/test/Makefile
@@ -0,0 +1,81 @@
+# A sample Makefile for building Google Test and using it in user
+# tests. Please tweak it to suit your environment and project. You
+# may want to move it to your project's root directory.
+#
+# SYNOPSIS:
+#
+# make [all] - makes everything.
+# make TARGET - makes the given target.
+# make clean - removes all files generated by make.
+
+# Please tweak the following variable definitions as needed by your
+# project, except GTEST_HEADERS, which you can use in your own targets
+# but shouldn't modify.
+
+# Points to the root of Google Test, relative to where this file is.
+# Remember to tweak this if you move this file.
+GTEST_DIR = ../externals/googletest/googletest
+
+# Where to find user code.
+USER_DIR = ..
+
+# Flags passed to the preprocessor.
+# Set Google Test's header directory as a system directory, such that
+# the compiler doesn't generate warnings in Google Test headers.
+CPPFLAGS += -isystem $(GTEST_DIR)/include
+
+# Flags passed to the C++ compiler.
+CXXFLAGS += -g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
+
+# All tests produced by this Makefile. Remember to add new tests you
+# created to the list.
+TESTS = hmm_test
+
+# All Google Test headers. Usually you shouldn't change this
+# definition.
+GTEST_HEADERS = $(GTEST_DIR)/include/gtest/*.h \
+ $(GTEST_DIR)/include/gtest/internal/*.h
+
+# House-keeping build targets.
+
+all : $(TESTS)
+
+clean :
+ rm -f $(TESTS) gtest.a gtest_main.a *.o
+
+# Builds gtest.a and gtest_main.a.
+
+# Usually you shouldn't tweak such internal variables, indicated by a
+# trailing _.
+GTEST_SRCS_ = $(GTEST_DIR)/src/*.cc $(GTEST_DIR)/src/*.h $(GTEST_HEADERS)
+
+# For simplicity and to avoid depending on Google Test's
+# implementation details, the dependencies specified below are
+# conservative and not optimized. This is fine as Google Test
+# compiles fast and for ordinary users its source rarely changes.
+gtest-all.o : $(GTEST_SRCS_)
+ $(CXX) $(CPPFLAGS) -I$(GTEST_DIR) $(CXXFLAGS) -c \
+ $(GTEST_DIR)/src/gtest-all.cc
+
+gtest_main.o : $(GTEST_SRCS_)
+ $(CXX) $(CPPFLAGS) -I$(GTEST_DIR) $(CXXFLAGS) -c \
+ $(GTEST_DIR)/src/gtest_main.cc
+
+gtest.a : gtest-all.o
+ $(AR) $(ARFLAGS) $@ $^
+
+gtest_main.a : gtest-all.o gtest_main.o
+ $(AR) $(ARFLAGS) $@ $^
+
+# Builds a sample test. A test should link with either gtest.a or
+# gtest_main.a, depending on whether it defines its own main()
+# function.
+
+HandmadeMath.o : $(USER_DIR)/test/HandmadeMath.cpp $(USER_DIR)/HandmadeMath.h $(GTEST_HEADERS)
+ $(CXX) $(CPPFLAGS) $(CXXFLAGS) -c $(USER_DIR)/test/HandmadeMath.cpp
+
+hmm_test.o : $(USER_DIR)/test/hmm_test.cpp $(GTEST_HEADERS)
+ $(CXX) $(CPPFLAGS) $(CXXFLAGS) -c $(USER_DIR)/test/hmm_test.cpp
+
+hmm_test : HandmadeMath.o hmm_test.o gtest_main.a
+ $(CXX) $(CPPFLAGS) $(CXXFLAGS) -lpthread $^ -o $@
diff --git a/test/hmm_test.cpp b/test/hmm_test.cpp
new file mode 100644
--- /dev/null
+++ b/test/hmm_test.cpp
@@ -0,0 +1,1324 @@
+
+#define HANDMADE_MATH_CPP_MODE
+#include "../HandmadeMath.h"
+
+#include "gtest/gtest.h"
+
+
+TEST(ScalarMath, Trigonometry)
+{
+ // We have to be a little looser with our equality constraint
+ // because of floating-point precision issues.
+ const float trigAbsError = 0.0001f;
+
+ EXPECT_NEAR(HMM_SinF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32 / 2), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(3 * HMM_PI32 / 2), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(-HMM_PI32 / 2), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_CosF(0.0f), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(3 * HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(-HMM_PI32), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_TanF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32 / 4), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(3 * HMM_PI32 / 4), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(-HMM_PI32 / 4), -1.0f, trigAbsError);
+
+ // This isn't the most rigorous because we're really just sanity-
+ // checking that things work by default.
+}
+
+TEST(ScalarMath, SqrtF)
+{
+ EXPECT_FLOAT_EQ(HMM_SqrtF(16.0f), 4.0f);
+}
+
+TEST(ScalarMath, ToRadians)
+{
+ EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(180.0f), HMM_PI32);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(-180.0f), -HMM_PI32);
+}
+
+TEST(ScalarMath, SquareRoot)
+{
+ // EXPECT_FLOAT_EQ(HMM_SquareRoot(16.0f), 4.0f);
+ FAIL() << "Bad header, function not defined. See commented line above.";
+}
+
+TEST(ScalarMath, FastInverseSquareRoot)
+{
+ // EXPECT_FLOAT_EQ(HMM_FastInverseSquareRoot(4.0f), 0.5f); // linker error, no function body
+ FAIL() << "Bad header, function not defined. See commented line above.";
+}
+
+TEST(ScalarMath, Power)
+{
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 0), 1.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 4), 16.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, -2), 0.25f);
+}
+
+TEST(ScalarMath, Clamp)
+{
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 0.0f, 2.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, -3.0f, 2.0f), -2.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 3.0f, 2.0f), 2.0f);
+}
+
+TEST(Initialization, Vectors)
+{
+ //
+ // Test vec2
+ //
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2i = HMM_Vec2(1, 2);
+
+ EXPECT_FLOAT_EQ(v2.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 2.0f);
+
+ EXPECT_FLOAT_EQ(v2i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Y, 2.0f);
+
+ //
+ // Test vec3
+ //
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3i = HMM_Vec3i(1, 2, 3);
+
+ EXPECT_FLOAT_EQ(v3.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 3.0f);
+
+ EXPECT_FLOAT_EQ(v3i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3i.Z, 3.0f);
+
+ //
+ // Test vec4
+ //
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4i = HMM_Vec4i(1, 2, 3, 4);
+ hmm_vec4 v4v = HMM_Vec4v(v3, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4i.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4i.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4v.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4v.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4v.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4v.W, 4.0f);
+}
+
+TEST(Initialization, MatrixEmpty)
+{
+ hmm_mat4 m4 = HMM_Mat4();
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4.Elements[Column][Row], 0) << "At column " << Column << ", row " << Row;
+ }
+ }
+}
+
+TEST(Initialization, MatrixDiagonal)
+{
+ hmm_mat4 m4d = HMM_Mat4d(1.0f);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ if (Column == Row) {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 1.0f) << "At column " << Column << ", row " << Row;
+ } else {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 0) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+}
+
+TEST(VectorOps, Inner)
+{
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ EXPECT_FLOAT_EQ(HMM_Inner(v1, v2), 32.0f);
+}
+
+TEST(VectorOps, LengthSquareRoot)
+{
+ hmm_vec3 v = HMM_Vec3(1.0f, -2.0f, 3.0f);
+
+ EXPECT_FLOAT_EQ(HMM_LengthSquareRoot(v), 14.0f);
+}
+
+TEST(VectorOps, Length)
+{
+ hmm_vec3 v = HMM_Vec3(2.0f, -3.0f, 6.0f);
+
+ EXPECT_FLOAT_EQ(HMM_Length(v), 7.0f);
+}
+
+TEST(VectorOps, Normalize)
+{
+ hmm_vec3 v = HMM_Vec3(1.0f, -2.0f, 3.0f);
+
+ hmm_vec3 result = HMM_Normalize(v);
+
+ EXPECT_FLOAT_EQ(HMM_Length(result), 1.0f);
+ EXPECT_LT(result.Y, 0);
+}
+
+TEST(VectorOps, Cross)
+{
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ hmm_vec3 result = HMM_Cross(v1, v2);
+
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+}
+
+TEST(VectorOps, Dot)
+{
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ EXPECT_FLOAT_EQ(HMM_Inner(v1, v2), 32.0f);
+}
+
+TEST(Addition, Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_AddVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = HMM_Add(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 + v2_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2_1 += v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 6.0f);
+}
+
+TEST(Addition, Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_AddVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Add(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 + v3_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3_1 += v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 7.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 9.0f);
+}
+
+TEST(Addition, Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_AddVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Add(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 + v4_2;
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4_1 += v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 6.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 8.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 12.0f);
+}
+
+TEST(Addition, Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_AddMat4(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = HMM_Add(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 + m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+ }
+
+ m4_1 += m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+}
+
+TEST(Subtraction, Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_SubtractVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+ {
+ hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 - v2_2;
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+
+ v2_1 -= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, -2.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, -2.0f);
+}
+
+TEST(Subtraction, Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_SubtractVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 - v3_2;
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+
+ v3_1 -= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, -3.0f);
+}
+
+TEST(Subtraction, Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_SubtractVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 - v4_2;
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+
+ v4_1 -= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, -4.0f);
+}
+
+TEST(Subtraction, Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_SubtractMat4(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 - m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+
+ m4_1 -= m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+}
+
+TEST(Multiplication, Vec2Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+ {
+ hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 * v2_2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+
+ v2_1 *= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 8.0f);
+}
+
+TEST(Multiplication, Vec2Scalar)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = HMM_Multiply(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = s * v2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2 *= s;
+ EXPECT_FLOAT_EQ(v2.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 6.0f);
+}
+
+TEST(Multiplication, Vec3Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 * v3_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+
+ v3_1 *= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 10.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 18.0f);
+}
+
+TEST(Multiplication, Vec3Scalar)
+{
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Multiply(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = s * v3;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3 *= s;
+ EXPECT_FLOAT_EQ(v3.X, 3.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 9.0f);
+}
+
+TEST(Multiplication, Vec4Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 * v4_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+
+ v4_1 *= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 12.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 21.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 32.0f);
+}
+
+TEST(Multiplication, Vec4Scalar)
+{
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Multiply(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = s * v4;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4 *= s;
+ EXPECT_FLOAT_EQ(v4.X, 3.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 9.0f);
+}
+
+TEST(Multiplication, Mat4Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+ {
+ hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+ {
+ hmm_mat4 result = m4_1 * m4_2;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+
+ // At the time I wrote this, I intentionally omitted
+ // the *= operator for matrices because matrix
+ // multiplication is not commutative. (bvisness)
+}
+
+TEST(Multiplication, Mat4Scalar)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 3;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = HMM_Multiply(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = m4 * s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = s * m4;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+
+ m4 *= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 48.0f);
+}
+
+TEST(Multiplication, Mat4Vec4)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_vec4 result = HMM_MultiplyMat4ByVec4(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90);
+ EXPECT_FLOAT_EQ(result.Y, 100);
+ EXPECT_FLOAT_EQ(result.Z, 110);
+ EXPECT_FLOAT_EQ(result.W, 120);
+ }
+ {
+ hmm_vec4 result = HMM_Multiply(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90);
+ EXPECT_FLOAT_EQ(result.Y, 100);
+ EXPECT_FLOAT_EQ(result.Z, 110);
+ EXPECT_FLOAT_EQ(result.W, 120);
+ }
+ {
+ hmm_vec4 result = m4 * v4;
+ EXPECT_FLOAT_EQ(result.X, 90);
+ EXPECT_FLOAT_EQ(result.Y, 100);
+ EXPECT_FLOAT_EQ(result.Z, 110);
+ EXPECT_FLOAT_EQ(result.W, 120);
+ }
+
+ // *= makes no sense for this particular case.
+}
+
+TEST(Division, Vec2Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 3.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(2.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_DivideVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+ {
+ hmm_vec2 result = HMM_Divide(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+ {
+ hmm_vec2 result = v2_1 / v2_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+
+ v2_1 /= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 0.75f);
+}
+
+TEST(Division, Vec2Scalar)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 2;
+
+ {
+ hmm_vec2 result = HMM_DivideVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+ {
+ hmm_vec2 result = HMM_Divide(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+ {
+ hmm_vec2 result = v2 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+
+ v2 /= s;
+ EXPECT_FLOAT_EQ(v2.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2.Y, 1.0f);
+}
+
+TEST(Division, Vec3Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 3.0f, 5.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(2.0f, 4.0f, 0.5f);
+
+ {
+ hmm_vec3 result = HMM_DivideVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Divide(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 / v3_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+
+ v3_1 /= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 10.0f);
+}
+
+TEST(Division, Vec3Scalar)
+{
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 2;
+
+ {
+ hmm_vec3 result = HMM_DivideVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+ {
+ hmm_vec3 result = HMM_Divide(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+ {
+ hmm_vec3 result = v3 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+
+ v3 /= s;
+ EXPECT_FLOAT_EQ(v3.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 1.5f);
+}
+
+TEST(Division, Vec4Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 3.0f, 5.0f, 1.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(2.0f, 4.0f, 0.5f, 4.0f);
+
+ {
+ hmm_vec4 result = HMM_DivideVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+ {
+ hmm_vec4 result = HMM_Divide(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+ {
+ hmm_vec4 result = v4_1 / v4_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+
+ v4_1 /= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 0.25f);
+}
+
+TEST(Division, Vec4Scalar)
+{
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 2;
+
+ {
+ hmm_vec4 result = HMM_DivideVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Divide(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_vec4 result = v4 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+
+ v4 /= s;
+ EXPECT_FLOAT_EQ(v4.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 1.5f);
+ EXPECT_FLOAT_EQ(v4.W, 2.0f);
+}
+
+TEST(Division, Mat4Scalar)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 2;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_DivideMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+ {
+ hmm_mat4 result = HMM_Divide(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+ {
+ hmm_mat4 result = m4 / s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+
+ m4 /= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 8.0f);
+}
+
+TEST(Projection, Orthographic)
+{
+ hmm_mat4 projection = HMM_Orthographic(-10.0f, 10.0f, -5.0f, 5.0f, 0.0f, -10.0f);
+
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
+
+ EXPECT_FLOAT_EQ(projected.X, 0.5f);
+ EXPECT_FLOAT_EQ(projected.Y, 1.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -2.0f);
+ EXPECT_FLOAT_EQ(projected.W, 1.0f);
+}
+
+TEST(Projection, Perspective)
+{
+ hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
+
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
+ hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, 15.0f);
+ EXPECT_FLOAT_EQ(projected.W, 15.0f);
+ }
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -5.0f);
+ EXPECT_FLOAT_EQ(projected.W, 5.0f);
+ }
+}
+
+TEST(Transformations, Translate)
+{
+ hmm_mat4 translate = HMM_Translate(HMM_Vec3(1.0f, -3.0f, 6.0f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 translated = translate * HMM_Vec4v(original, 1);
+
+ EXPECT_FLOAT_EQ(translated.X, 2.0f);
+ EXPECT_FLOAT_EQ(translated.Y, -1.0f);
+ EXPECT_FLOAT_EQ(translated.Z, 9.0f);
+ EXPECT_FLOAT_EQ(translated.W, 1.0f);
+}
+
+TEST(Transformations, Rotate)
+{
+ hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
+
+ hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ hmm_vec4 rotatedX = rotateX * HMM_Vec4v(original, 1);
+ EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
+
+ hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
+ hmm_vec4 rotatedY = rotateY * HMM_Vec4v(original, 1);
+ EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
+
+ hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_vec4 rotatedZ = rotateZ * HMM_Vec4v(original, 1);
+ EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.W, 1.0f);
+}
+
+TEST(Transformations, Scale)
+{
+ hmm_mat4 scale = HMM_Scale(HMM_Vec3(2.0f, -3.0f, 0.5f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 scaled = scale * HMM_Vec4v(original, 1);
+
+ EXPECT_FLOAT_EQ(scaled.X, 2.0f);
+ EXPECT_FLOAT_EQ(scaled.Y, -6.0f);
+ EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
+ EXPECT_FLOAT_EQ(scaled.W, 1.0f);
+}
|
Needs unit testing
Just wanted to open up the discussion about how unit testing should be implemented for Handmade Math. We could use a full C++ unit testing framework like [Google Test](https://github.com/google/googletest), or maybe just roll our own thing with asserts.
I personally would lean toward a full framework for ease of running multiple tests and nice test output. Plus, it would likely be easier to get up and running with Travis CI or some other automated tool, if we decide to go that route.
|
I think for right now just having our own unit thing right now would be fine as i really dont have the money to setup a Travis of Jenkins server for automated build tests. Although i do think Travis or Jenkins would be the way to go for this.
Wait is Travis CL free now ?
Travis CI is [free for open-source projects](https://travis-ci.com/plans), and I'd be happy to set it up once we get tests running locally. I think later today I will take a stab at using Google Test and will let you know how it goes.
Travis is free for open source (maybe just github) projects afaik.
On Thu, 25 Aug 2016 at 18:57 Zak Strange notifications@github.com wrote:
> Wait is Travis CL free now ?
>
> —
> You are receiving this because you are subscribed to this thread.
> Reply to this email directly, view it on GitHub
> https://github.com/StrangeZak/Handmade-Math/issues/21#issuecomment-242462786,
> or mute the thread
> https://github.com/notifications/unsubscribe-auth/AAMxqYE_ZBznZukaNwOIr7gq32o9d5yEks5qjclhgaJpZM4JtJ6-
> .
Yeah, im not really the guy to ask to write a unit test. So if any of you guys are good at it i would love if you could try to do it first, once we have that id be more than happy to setup Travis CL, because we really need a unit test, so were sure we dont break peoples code when we upgrade, heh.
| 2016-08-29T04:21:00
|
c
|
Hard
|
nginx/njs
| 920
|
nginx__njs-920
|
[
"918"
] |
0c0d4e50ec4d582b345bc64c12b737b109b7bc03
|
diff --git a/src/njs_generator.c b/src/njs_generator.c
--- a/src/njs_generator.c
+++ b/src/njs_generator.c
@@ -5491,7 +5491,7 @@ njs_generate_reference_error(njs_vm_t *vm, njs_generator_t *generator,
ref_err->type = NJS_OBJ_TYPE_REF_ERROR;
- njs_lexer_entry(vm, node->u.reference.atom_id, &entry);
+ njs_atom_string_get(vm, node->u.reference.atom_id, &entry);
return njs_name_copy(vm, &ref_err->u.name, &entry);
}
diff --git a/src/njs_lexer.h b/src/njs_lexer.h
--- a/src/njs_lexer.h
+++ b/src/njs_lexer.h
@@ -288,16 +288,6 @@ const njs_lexer_keyword_entry_t *njs_lexer_keyword(const u_char *key,
njs_int_t njs_lexer_keywords(njs_arr_t *array);
-njs_inline void
-njs_lexer_entry(njs_vm_t *vm, uintptr_t atom_id, njs_str_t *entry)
-{
- njs_value_t value;
-
- njs_atom_to_value(vm, &value, atom_id);
- njs_string_get(vm, &value, entry);
-}
-
-
njs_inline njs_bool_t
njs_lexer_token_is_keyword(njs_lexer_token_t *token)
{
diff --git a/src/njs_object.h b/src/njs_object.h
--- a/src/njs_object.h
+++ b/src/njs_object.h
@@ -241,18 +241,17 @@ njs_key_string_get(njs_vm_t *vm, njs_value_t *key, njs_str_t *str)
}
-njs_inline njs_int_t
+njs_inline void
njs_atom_string_get(njs_vm_t *vm, uint32_t atom_id, njs_str_t *str)
{
njs_value_t value;
if (njs_atom_to_value(vm, &value, atom_id) != NJS_OK) {
- return NJS_ERROR;
+ str->start = (u_char *) "unknown";
+ str->length = njs_length("unknown");
}
njs_key_string_get(vm, &value, str);
-
- return NJS_OK;
}
diff --git a/src/njs_parser.c b/src/njs_parser.c
--- a/src/njs_parser.c
+++ b/src/njs_parser.c
@@ -6702,7 +6702,6 @@ njs_parser_labelled_statement_after(njs_parser_t *parser,
njs_int_t ret;
njs_str_t str;
uintptr_t atom_id;
- njs_value_t entry;
njs_parser_node_t *node;
node = parser->node;
@@ -6719,8 +6718,7 @@ njs_parser_labelled_statement_after(njs_parser_t *parser,
atom_id = (uint32_t) (uintptr_t) parser->target;
- njs_atom_to_value(parser->vm, &entry, atom_id);
- njs_string_get(parser->vm, &entry, &str);
+ njs_atom_string_get(parser->vm, atom_id, &str);
ret = njs_name_copy(parser->vm, &parser->node->name, &str);
if (ret != NJS_OK) {
diff --git a/src/njs_value.c b/src/njs_value.c
--- a/src/njs_value.c
+++ b/src/njs_value.c
@@ -560,7 +560,6 @@ njs_property_query(njs_vm_t *vm, njs_property_query_t *pq, njs_value_t *value,
{
uint32_t index;
njs_int_t ret;
- njs_value_t key;
njs_object_t *obj;
njs_function_t *function;
@@ -607,19 +606,9 @@ njs_property_query(njs_vm_t *vm, njs_property_query_t *pq, njs_value_t *value,
case NJS_UNDEFINED:
case NJS_NULL:
default:
- ret = njs_atom_to_value(vm, &key, atom_id);
-
- if (njs_fast_path(ret == NJS_OK)) {
- njs_string_get(vm, &key, &pq->lhq.key);
- njs_type_error(vm, "cannot get property \"%V\" of %s",
- &pq->lhq.key, njs_is_null(value) ? "null"
- : "undefined");
- return NJS_ERROR;
- }
-
- njs_type_error(vm, "cannot get property \"unknown\" of %s",
- njs_is_null(value) ? "null" : "undefined");
-
+ njs_atom_string_get(vm, atom_id, &pq->lhq.key);
+ njs_type_error(vm, "cannot get property \"%V\" of %s", &pq->lhq.key,
+ njs_type_string(value->type));
return NJS_ERROR;
}
diff --git a/src/njs_variable.c b/src/njs_variable.c
--- a/src/njs_variable.c
+++ b/src/njs_variable.c
@@ -239,7 +239,7 @@ njs_variable_scope_find(njs_parser_t *parser, njs_parser_scope_t *scope,
failed:
- njs_lexer_entry(parser->vm, atom_id, &entry);
+ njs_atom_string_get(parser->vm, atom_id, &entry);
njs_parser_syntax_error(parser, "\"%V\" has already been declared", &entry);
return NULL;
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -3923,6 +3923,9 @@ static njs_unit_test_t njs_test[] =
{ njs_str("delete this !== true"),
njs_str("false") },
+ { njs_str("undefined[Symbol()]"),
+ njs_str("TypeError: cannot get property \"Symbol()\" of undefined") },
+
/* Object shorthand methods. */
{ njs_str("var o = {m(){}}; new o.m();"),
|
njs_process_script_fuzzer: ASAN error in njs_vsprintf
### Describe the bug
We found a crashing test case when running the njs_process_script_fuzzer with ASAN.
- [x] The bug is reproducible with the latest version of njs.
- [x] I minimized the code to the smallest possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
var sym = Symbol();
obj[sym];
var obj = { [sym]: "" };
```
### Expected behavior
Should not trigger ASAN error.
### Actual behavior
```
=================================================================
==3557937==ERROR: AddressSanitizer: unknown-crash on address 0x000100000000 at pc 0x0000004a39c1 bp 0x7ffd8a654230 sp 0x7ffd8a653a00
READ of size 2027 at 0x000100000000 thread T0
#0 0x4a39c0 in __asan_memcpy /src/llvm-project/compiler-rt/lib/asan/asan_interceptors_memintrinsics.cpp:22:3
#1 0x51cb37 in njs_vsprintf /src/njs/src/njs_sprintf.c:430:19
#2 0x64d603 in njs_throw_error_va /src/njs/src/njs_error.c:60:9
#3 0x64d603 in njs_throw_error /src/njs/src/njs_error.c:72:5
#4 0x523766 in njs_property_query /src/njs/src/njs_value.c:614:13
#5 0x520c69 in njs_value_property /src/njs/src/njs_value.c:1070:11
#6 0x54561b in njs_vmcode_interpreter /src/njs/src/njs_vmcode.c:308:15
#7 0x52e4f2 in njs_vm_start /src/njs/src/njs_vm.c:698:11
#8 0x512615 in njs_engine_njs_eval /src/njs/external/njs_shell.c:1387:16
#9 0x512165 in njs_process_script /src/njs/external/njs_shell.c:3340:11
#10 0x510eed in njs_main /src/njs/external/njs_shell.c:454:15
#11 0x510eed in LLVMFuzzerTestOneInput /src/njs/external/njs_shell.c:869:12
#12 0x4efe6c in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /tmp/libfuzzer/./FuzzerLoop.cpp:532:15
#13 0x4e1dc5 in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /tmp/libfuzzer/./FuzzerDriver.cpp:284:6
#14 0x4e6a71 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /tmp/libfuzzer/./FuzzerDriver.cpp:713:9
#15 0x4e1a92 in main /tmp/libfuzzer/./FuzzerMain.cpp:19:10
```
| 2025-05-28T16:20:09
|
c
|
Hard
|
|
profanity-im/profanity
| 1,847
|
profanity-im__profanity-1847
|
[
"1846"
] |
faccf24c759d7bddb4d3062c7f044e0c7640ffe7
|
diff --git a/src/command/cmd_funcs.c b/src/command/cmd_funcs.c
--- a/src/command/cmd_funcs.c
+++ b/src/command/cmd_funcs.c
@@ -6575,7 +6575,8 @@ cmd_reconnect(ProfWin* window, const char* const command, gchar** args)
int intval = 0;
char* err_msg = NULL;
if (g_strcmp0(value, "now") == 0) {
- session_reconnect_now();
+ cons_show("Reconnecting now.");
+ cl_ev_reconnect();
} else if (strtoi_range(value, &intval, 0, INT_MAX, &err_msg)) {
prefs_set_reconnect(intval);
if (intval == 0) {
diff --git a/src/event/client_events.c b/src/event/client_events.c
--- a/src/event/client_events.c
+++ b/src/event/client_events.c
@@ -47,6 +47,7 @@
#include "plugins/plugins.h"
#include "ui/window_list.h"
#include "xmpp/chat_session.h"
+#include "xmpp/session.h"
#include "xmpp/xmpp.h"
#ifdef HAVE_LIBOTR
@@ -85,9 +86,8 @@ cl_ev_connect_account(ProfAccount* account)
void
cl_ev_disconnect(void)
{
- char* mybarejid = connection_get_barejid();
+ auto_char char* mybarejid = connection_get_barejid();
cons_show("%s logged out successfully.", mybarejid);
- free(mybarejid);
ui_close_all_wins();
ev_disconnect_cleanup();
@@ -95,6 +95,18 @@ cl_ev_disconnect(void)
ev_reset_connection_counter();
}
+void
+cl_ev_reconnect(void)
+{
+ if (connection_get_status() != JABBER_DISCONNECTED) {
+ connection_disconnect();
+ ev_disconnect_cleanup();
+ // on intentional disconnect reset the counter
+ ev_reset_connection_counter();
+ }
+ session_reconnect_now();
+}
+
void
cl_ev_presence_send(const resource_presence_t presence_type, const int idle_secs)
{
diff --git a/src/event/client_events.h b/src/event/client_events.h
--- a/src/event/client_events.h
+++ b/src/event/client_events.h
@@ -42,6 +42,7 @@ jabber_conn_status_t cl_ev_connect_jid(const char* const jid, const char* const
jabber_conn_status_t cl_ev_connect_account(ProfAccount* account);
void cl_ev_disconnect(void);
+void cl_ev_reconnect(void);
void cl_ev_presence_send(const resource_presence_t presence_type, const int idle_secs);
diff --git a/src/event/server_events.c b/src/event/server_events.c
--- a/src/event/server_events.c
+++ b/src/event/server_events.c
@@ -1332,8 +1332,8 @@ sv_ev_bookmark_autojoin(Bookmark* bookmark)
log_debug("Autojoin %s with nick=%s", bookmark->barejid, nick);
if (!muc_active(bookmark->barejid)) {
- presence_join_room(bookmark->barejid, nick, bookmark->password);
muc_join(bookmark->barejid, nick, bookmark->password, TRUE);
+ presence_join_room(bookmark->barejid, nick, bookmark->password);
iq_room_affiliation_list(bookmark->barejid, "member", false);
iq_room_affiliation_list(bookmark->barejid, "admin", false);
iq_room_affiliation_list(bookmark->barejid, "owner", false);
diff --git a/src/xmpp/connection.c b/src/xmpp/connection.c
--- a/src/xmpp/connection.c
+++ b/src/xmpp/connection.c
@@ -964,6 +964,7 @@ _connection_handler(xmpp_conn_t* const xmpp_conn, const xmpp_conn_event_t status
conn.domain = strdup(my_jid->domainpart);
jid_destroy(my_jid);
+ connection_clear_data();
conn.features_by_jid = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)g_hash_table_destroy);
g_hash_table_insert(conn.features_by_jid, strdup(conn.domain), g_hash_table_new_full(g_str_hash, g_str_equal, free, NULL));
@@ -990,6 +991,7 @@ _connection_handler(xmpp_conn_t* const xmpp_conn, const xmpp_conn_event_t status
conn.domain = strdup(my_raw_jid->domainpart);
jid_destroy(my_raw_jid);
+ connection_clear_data();
conn.features_by_jid = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)g_hash_table_destroy);
g_hash_table_insert(conn.features_by_jid, strdup(conn.domain), g_hash_table_new_full(g_str_hash, g_str_equal, free, NULL));
diff --git a/src/xmpp/connection.h b/src/xmpp/connection.h
--- a/src/xmpp/connection.h
+++ b/src/xmpp/connection.h
@@ -48,7 +48,6 @@ jabber_conn_status_t connection_connect(const char* const fulljid, const char* c
const char* const tls_policy, const char* const auth_policy);
jabber_conn_status_t connection_register(const char* const altdomain, int port, const char* const tls_policy,
const char* const username, const char* const password);
-void connection_disconnect(void);
void connection_set_disconnected(void);
void connection_set_priority(const int priority);
diff --git a/src/xmpp/iq.c b/src/xmpp/iq.c
--- a/src/xmpp/iq.c
+++ b/src/xmpp/iq.c
@@ -265,6 +265,7 @@ iq_handlers_init(void)
xmpp_timed_handler_add(conn, _autoping_timed_send, millis, ctx);
}
+ iq_rooms_cache_clear();
iq_handlers_clear();
id_handlers = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)_iq_id_handler_free);
@@ -2651,6 +2652,18 @@ iq_mam_request_older(ProfChatWin* win)
return;
}
+static void
+_mam_userdata_free(MamRsmUserdata* data)
+{
+ free(data->end_datestr);
+ data->end_datestr = NULL;
+ free(data->start_datestr);
+ data->start_datestr = NULL;
+ free(data->barejid);
+ data->barejid = NULL;
+ free(data);
+}
+
void
_iq_mam_request(ProfChatWin* win, GDateTime* startdate, GDateTime* enddate)
{
@@ -2694,7 +2707,7 @@ _iq_mam_request(ProfChatWin* win, GDateTime* startdate, GDateTime* enddate)
data->fetch_next = fetch_next;
data->win = win;
- iq_id_handler_add(xmpp_stanza_get_id(iq), _mam_rsm_id_handler, NULL, data);
+ iq_id_handler_add(xmpp_stanza_get_id(iq), _mam_rsm_id_handler, (ProfIqFreeCallback)_mam_userdata_free, data);
}
iq_send_stanza(iq);
@@ -2742,13 +2755,13 @@ _mam_rsm_id_handler(xmpp_stanza_t* const stanza, void* const userdata)
buffer_remove_entry(window->layout->buffer, 0);
- char* start_str = NULL;
+ auto_char char* start_str = NULL;
if (data->start_datestr) {
start_str = strdup(data->start_datestr);
// Convert to iso8601
start_str[strlen(start_str) - 3] = '\0';
}
- char* end_str = NULL;
+ auto_char char* end_str = NULL;
if (data->end_datestr) {
end_str = strdup(data->end_datestr);
// Convert to iso8601
@@ -2757,24 +2770,10 @@ _mam_rsm_id_handler(xmpp_stanza_t* const stanza, void* const userdata)
if (is_complete || !data->fetch_next) {
chatwin_db_history(data->win, is_complete ? NULL : start_str, end_str, TRUE);
- // TODO free memory
- if (start_str) {
- free(start_str);
- free(data->start_datestr);
- }
-
- if (end_str) {
- free(data->end_datestr);
- }
-
- free(data->barejid);
- free(data);
return 0;
}
chatwin_db_history(data->win, start_str, end_str, TRUE);
- if (start_str)
- free(start_str);
xmpp_stanza_t* set = xmpp_stanza_get_child_by_name_and_ns(fin, STANZA_TYPE_SET, STANZA_NS_RSM);
if (set) {
@@ -2787,14 +2786,14 @@ _mam_rsm_id_handler(xmpp_stanza_t* const stanza, void* const userdata)
// 4.3.2. send same stanza with set,max stanza
xmpp_ctx_t* const ctx = connection_get_ctx();
- if (end_str) {
+ if (data->end_datestr) {
free(data->end_datestr);
+ data->end_datestr = NULL;
}
- data->end_datestr = NULL;
- xmpp_stanza_t* iq = stanza_create_mam_iq(ctx, data->barejid, data->start_datestr, data->end_datestr, firstid, NULL);
+ xmpp_stanza_t* iq = stanza_create_mam_iq(ctx, data->barejid, data->start_datestr, NULL, firstid, NULL);
free(firstid);
- iq_id_handler_add(xmpp_stanza_get_id(iq), _mam_rsm_id_handler, NULL, data);
+ iq_id_handler_add(xmpp_stanza_get_id(iq), _mam_rsm_id_handler, (ProfIqFreeCallback)_mam_userdata_free, data);
iq_send_stanza(iq);
xmpp_stanza_release(iq);
diff --git a/src/xmpp/session.h b/src/xmpp/session.h
--- a/src/xmpp/session.h
+++ b/src/xmpp/session.h
@@ -47,6 +47,5 @@ void session_init_activity(void);
void session_check_autoaway(void);
void session_reconnect(gchar* altdomain, unsigned short altport);
-void session_reconnect_now(void);
#endif
diff --git a/src/xmpp/xmpp.h b/src/xmpp/xmpp.h
--- a/src/xmpp/xmpp.h
+++ b/src/xmpp/xmpp.h
@@ -186,7 +186,9 @@ void session_disconnect(void);
void session_shutdown(void);
void session_process_events(void);
char* session_get_account_name(void);
+void session_reconnect_now(void);
+void connection_disconnect(void);
jabber_conn_status_t connection_get_status(void);
char* connection_get_presence_msg(void);
void connection_set_presence_msg(const char* const message);
|
diff --git a/tests/unittests/xmpp/stub_xmpp.c b/tests/unittests/xmpp/stub_xmpp.c
--- a/tests/unittests/xmpp/stub_xmpp.c
+++ b/tests/unittests/xmpp/stub_xmpp.c
@@ -54,6 +54,10 @@ void
session_process_events(void)
{
}
+void
+connection_disconnect(void)
+{
+}
const char*
connection_get_fulljid(void)
{
|
`/reconnect now` doesn't work
At this point command `/reconnect now` doesn't work. The problem is that the command causes program to enter invalid state (nor connected, nor disconnected).
```
prof: DBG: Input received: /reconnect now
prof: DBG: Attempting reconnect with account <account>
prof: INF: Connecting without account, JID: <jid>
prof: INF: Connecting as <jid>
prof: DBG: Connecting with flags (0x2):
prof: DBG: XMPP_CONN_FLAG_MANDATORY_TLS
conn: ERR: Flags can be set only for disconnected connection
prof: ERR: libstrophe doesn't accept this combination of flags: 0x2
```
After this command, program enters bad state. You are unable to connect and to disconnect.
On command `/connect <account>`
```
prof: DBG: Input received: /connect <account>
prof: INF: Connecting using account: <account>
prof: INF: Connecting as <jid>
prof: DBG: Connecting with flags (0x2):
prof: DBG: XMPP_CONN_FLAG_MANDATORY_TLS
conn: ERR: Flags can be set only for disconnected connection
prof: ERR: libstrophe doesn't accept this combination of flags: 0x2
prof: INF: Connection attempt for <jid> failed
```
On command `/disconnect`
`prof: DBG: Input received: /disconnect`
And in the console `You are not currently connected.`
| 2023-05-10T15:26:46
|
c
|
Hard
|
|
profanity-im/profanity
| 1,260
|
profanity-im__profanity-1260
|
[
"1068"
] |
8fba8a8958146a0fa42d649339b66604defd6297
|
diff --git a/src/command/cmd_ac.c b/src/command/cmd_ac.c
--- a/src/command/cmd_ac.c
+++ b/src/command/cmd_ac.c
@@ -114,7 +114,7 @@ static char* _logging_autocomplete(ProfWin *window, const char *const input, gbo
static char* _color_autocomplete(ProfWin *window, const char *const input, gboolean previous);
static char* _avatar_autocomplete(ProfWin *window, const char *const input, gboolean previous);
-static char* _script_autocomplete_func(const char *const prefix, gboolean previous);
+static char* _script_autocomplete_func(const char *const prefix, gboolean previous, void *context);
static char* _cmd_ac_complete_params(ProfWin *window, const char *const input, gboolean previous);
@@ -1512,7 +1512,7 @@ _cmd_ac_complete_params(ProfWin *window, const char *const input, gboolean previ
"/history", "/vercheck", "/privileges", "/wrap", "/carbons", "/lastactivity", "/os"};
for (i = 0; i < ARRAY_SIZE(boolean_choices); i++) {
- result = autocomplete_param_with_func(input, boolean_choices[i], prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, boolean_choices[i], prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -1544,7 +1544,7 @@ _cmd_ac_complete_params(ProfWin *window, const char *const input, gboolean previ
// Remove quote character before and after names when doing autocomplete
char *unquoted = strip_arg_quotes(input);
for (i = 0; i < ARRAY_SIZE(contact_choices); i++) {
- result = autocomplete_param_with_func(unquoted, contact_choices[i], roster_contact_autocomplete, previous);
+ result = autocomplete_param_with_func(unquoted, contact_choices[i], roster_contact_autocomplete, previous, NULL);
if (result) {
free(unquoted);
return result;
@@ -1554,7 +1554,7 @@ _cmd_ac_complete_params(ProfWin *window, const char *const input, gboolean previ
gchar *resource_choices[] = { "/caps", "/software", "/ping" };
for (i = 0; i < ARRAY_SIZE(resource_choices); i++) {
- result = autocomplete_param_with_func(input, resource_choices[i], roster_fulljid_autocomplete, previous);
+ result = autocomplete_param_with_func(input, resource_choices[i], roster_fulljid_autocomplete, previous, NULL);
if (result) {
return result;
}
@@ -1563,7 +1563,7 @@ _cmd_ac_complete_params(ProfWin *window, const char *const input, gboolean previ
gchar *invite_choices[] = { "/join" };
for (i = 0; i < ARRAY_SIZE(invite_choices); i++) {
- result = autocomplete_param_with_func(input, invite_choices[i], muc_invites_find, previous);
+ result = autocomplete_param_with_func(input, invite_choices[i], muc_invites_find, previous, NULL);
if (result) {
return result;
}
@@ -1672,11 +1672,11 @@ static char*
_sub_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/sub allow", presence_sub_request_find, previous);
+ result = autocomplete_param_with_func(input, "/sub allow", presence_sub_request_find, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/sub deny", presence_sub_request_find, previous);
+ result = autocomplete_param_with_func(input, "/sub deny", presence_sub_request_find, previous, NULL);
if (result) {
return result;
}
@@ -1692,7 +1692,7 @@ static char*
_tray_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/tray read", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/tray read", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -1724,7 +1724,7 @@ _who_autocomplete(ProfWin *window, const char *const input, gboolean previous)
"/who unavailable" };
for (i = 0; i < ARRAY_SIZE(group_commands); i++) {
- result = autocomplete_param_with_func(input, group_commands[i], roster_group_autocomplete, previous);
+ result = autocomplete_param_with_func(input, group_commands[i], roster_group_autocomplete, previous, NULL);
if (result) {
return result;
}
@@ -1772,7 +1772,7 @@ _roster_autocomplete(ProfWin *window, const char *const input, gboolean previous
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster resource join", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/roster resource join", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -1804,47 +1804,47 @@ _roster_autocomplete(ProfWin *window, const char *const input, gboolean previous
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster count zero", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/roster count zero", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster color", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/roster color", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- result = autocomplete_param_with_func(input, "/roster nick", roster_barejid_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster nick", roster_barejid_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster clearnick", roster_barejid_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster clearnick", roster_barejid_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster remove", roster_barejid_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster remove", roster_barejid_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster group show", roster_group_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster group show", roster_group_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_no_with_func(input, "/roster group add", 5, roster_contact_autocomplete, previous);
+ result = autocomplete_param_no_with_func(input, "/roster group add", 5, roster_contact_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_no_with_func(input, "/roster group remove", 5, roster_contact_autocomplete, previous);
+ result = autocomplete_param_no_with_func(input, "/roster group remove", 5, roster_contact_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster group add", roster_group_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster group add", roster_group_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster group remove", roster_group_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/roster group remove", roster_group_autocomplete, previous, NULL);
if (result) {
return result;
}
@@ -1882,7 +1882,7 @@ _roster_autocomplete(ProfWin *window, const char *const input, gboolean previous
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/roster wrap", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/roster wrap", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -1923,7 +1923,7 @@ _blocked_autocomplete(ProfWin *window, const char *const input, gboolean previou
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/blocked remove", blocked_ac_find, previous);
+ result = autocomplete_param_with_func(input, "/blocked remove", blocked_ac_find, previous, NULL);
if (result) {
return result;
}
@@ -1961,7 +1961,7 @@ _bookmark_autocomplete(ProfWin *window, const char *const input, gboolean previo
|| (num_args == 4 && (g_strcmp0(args[2], "autojoin") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/bookmark");
g_string_append_printf(beginning, " %s %s %s", args[0], args[1], args[2]);
- found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -1982,7 +1982,7 @@ _bookmark_autocomplete(ProfWin *window, const char *const input, gboolean previo
|| (num_args == 6 && (g_strcmp0(args[4], "autojoin") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/bookmark");
g_string_append_printf(beginning, " %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4]);
- found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -2003,7 +2003,7 @@ _bookmark_autocomplete(ProfWin *window, const char *const input, gboolean previo
|| (num_args == 8 && (g_strcmp0(args[6], "autojoin") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/bookmark");
g_string_append_printf(beginning, " %s %s %s %s %s %s %s", args[0], args[1], args[2], args[3], args[4], args[5], args[6]);
- found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, beginning->str, prefs_autocomplete_boolean_choice, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -2014,19 +2014,19 @@ _bookmark_autocomplete(ProfWin *window, const char *const input, gboolean previo
g_strfreev(args);
- found = autocomplete_param_with_func(input, "/bookmark remove", bookmark_find, previous);
+ found = autocomplete_param_with_func(input, "/bookmark remove", bookmark_find, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/bookmark join", bookmark_find, previous);
+ found = autocomplete_param_with_func(input, "/bookmark join", bookmark_find, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/bookmark update", bookmark_find, previous);
+ found = autocomplete_param_with_func(input, "/bookmark update", bookmark_find, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/bookmark invites", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/bookmark invites", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2041,7 +2041,7 @@ _notify_autocomplete(ProfWin *window, const char *const input, gboolean previous
int i = 0;
char *result = NULL;
- result = autocomplete_param_with_func(input, "/notify room trigger remove", prefs_autocomplete_room_trigger, previous);
+ result = autocomplete_param_with_func(input, "/notify room trigger remove", prefs_autocomplete_room_trigger, previous, NULL);
if (result) {
return result;
}
@@ -2049,7 +2049,7 @@ _notify_autocomplete(ProfWin *window, const char *const input, gboolean previous
gchar *boolean_choices1[] = { "/notify room current", "/notify chat current", "/notify typing current",
"/notify room text", "/notify chat text" };
for (i = 0; i < ARRAY_SIZE(boolean_choices1); i++) {
- result = autocomplete_param_with_func(input, boolean_choices1[i], prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, boolean_choices1[i], prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -2082,7 +2082,7 @@ _notify_autocomplete(ProfWin *window, const char *const input, gboolean previous
gchar *boolean_choices2[] = { "/notify invite", "/notify sub", "/notify mention", "/notify trigger"};
for (i = 0; i < ARRAY_SIZE(boolean_choices2); i++) {
- result = autocomplete_param_with_func(input, boolean_choices2[i], prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, boolean_choices2[i], prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -2116,7 +2116,7 @@ _autoaway_autocomplete(ProfWin *window, const char *const input, gboolean previo
return result;
}
- result = autocomplete_param_with_func(input, "/autoaway check", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/autoaway check", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -2133,11 +2133,11 @@ _log_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/log rotate", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/log rotate", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/log shared", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/log shared", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -2154,7 +2154,7 @@ _autoconnect_autocomplete(ProfWin *window, const char *const input, gboolean pre
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/autoconnect set", accounts_find_enabled, previous);
+ result = autocomplete_param_with_func(input, "/autoconnect set", accounts_find_enabled, previous, NULL);
if (result) {
return result;
}
@@ -2175,7 +2175,7 @@ _otr_autocomplete(ProfWin *window, const char *const input, gboolean previous)
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- found = autocomplete_param_with_func(input, "/otr start", roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/otr start", roster_contact_autocomplete, previous, NULL);
if (found) {
return found;
}
@@ -2198,7 +2198,7 @@ _otr_autocomplete(ProfWin *window, const char *const input, gboolean previous)
g_string_append(beginning, args[1]);
}
- found = autocomplete_param_with_func(input, beginning->str, roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, beginning->str, roster_contact_autocomplete, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -2229,7 +2229,7 @@ _pgp_autocomplete(ProfWin *window, const char *const input, gboolean previous)
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- found = autocomplete_param_with_func(input, "/pgp start", roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/pgp start", roster_contact_autocomplete, previous, NULL);
if (found) {
return found;
}
@@ -2250,7 +2250,7 @@ _pgp_autocomplete(ProfWin *window, const char *const input, gboolean previous)
g_string_append(beginning, " ");
g_string_append(beginning, args[1]);
}
- found = autocomplete_param_with_func(input, beginning->str, p_gpg_autocomplete_key, previous);
+ found = autocomplete_param_with_func(input, beginning->str, p_gpg_autocomplete_key, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -2261,7 +2261,7 @@ _pgp_autocomplete(ProfWin *window, const char *const input, gboolean previous)
#endif
if (conn_status == JABBER_CONNECTED) {
- found = autocomplete_param_with_func(input, "/pgp setkey", roster_barejid_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/pgp setkey", roster_barejid_autocomplete, previous, NULL);
if (found) {
return found;
}
@@ -2293,12 +2293,12 @@ _omemo_autocomplete(ProfWin *window, const char *const input, gboolean previous)
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- found = autocomplete_param_with_func(input, "/omemo start", roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/omemo start", roster_contact_autocomplete, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/omemo fingerprint", roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/omemo fingerprint", roster_contact_autocomplete, previous, NULL);
if (found) {
return found;
}
@@ -2306,20 +2306,32 @@ _omemo_autocomplete(ProfWin *window, const char *const input, gboolean previous)
#ifdef HAVE_OMEMO
if (window->type == WIN_CHAT) {
- found = autocomplete_param_with_func(input, "/omemo trust", omemo_fingerprint_autocomplete, previous);
+ ProfChatWin *chatwin = (ProfChatWin*)window;
+ assert(chatwin->memcheck == PROFCHATWIN_MEMCHECK);
+ found = autocomplete_param_with_func(input, "/omemo trust", omemo_fingerprint_autocomplete, previous, chatwin->barejid);
if (found) {
return found;
}
} else {
- found = autocomplete_param_with_func(input, "/omemo trust", roster_contact_autocomplete, previous);
+ found = autocomplete_param_with_func(input, "/omemo trust", roster_contact_autocomplete, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_no_with_func(input, "/omemo trust", 4, omemo_fingerprint_autocomplete, previous);
- if (found) {
- return found;
+ int num_tokens = count_tokens(input);
+ if (num_tokens == 4) {
+ gboolean result;
+ gchar **args = parse_args(input, 2, 3, &result);
+ if (result) {
+ gchar *jid = g_strdup(args[1]);
+ found = autocomplete_param_no_with_func(input, "/omemo trust", 4, omemo_fingerprint_autocomplete, previous, jid);
+ if (found) {
+ return found;
+ }
+ }
}
+
+ return NULL;
}
#endif
}
@@ -2467,7 +2479,7 @@ _theme_autocomplete(ProfWin *window, const char *const input, gboolean previous)
}
static char*
-_script_autocomplete_func(const char *const prefix, gboolean previous)
+_script_autocomplete_func(const char *const prefix, gboolean previous, void *context)
{
if (script_show_ac == NULL) {
script_show_ac = autocomplete_new();
@@ -2489,14 +2501,14 @@ _script_autocomplete(ProfWin *window, const char *const input, gboolean previous
{
char *result = NULL;
if (strncmp(input, "/script show ", 13) == 0) {
- result = autocomplete_param_with_func(input, "/script show", _script_autocomplete_func, previous);
+ result = autocomplete_param_with_func(input, "/script show", _script_autocomplete_func, previous, NULL);
if (result) {
return result;
}
}
if (strncmp(input, "/script run ", 12) == 0) {
- result = autocomplete_param_with_func(input, "/script run", _script_autocomplete_func, previous);
+ result = autocomplete_param_with_func(input, "/script run", _script_autocomplete_func, previous, NULL);
if (result) {
return result;
}
@@ -2529,12 +2541,12 @@ _resource_autocomplete(ProfWin *window, const char *const input, gboolean previo
}
}
- found = autocomplete_param_with_func(input, "/resource title", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/resource title", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/resource message", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/resource message", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2552,12 +2564,12 @@ _wintitle_autocomplete(ProfWin *window, const char *const input, gboolean previo
{
char *found = NULL;
- found = autocomplete_param_with_func(input, "/wintitle show", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/wintitle show", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
- found = autocomplete_param_with_func(input, "/wintitle goodbye", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/wintitle goodbye", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2575,7 +2587,7 @@ _inpblock_autocomplete(ProfWin *window, const char *const input, gboolean previo
{
char *found = NULL;
- found = autocomplete_param_with_func(input, "/inpblock dynamic", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/inpblock dynamic", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2663,7 +2675,7 @@ _form_field_autocomplete(ProfWin *window, const char *const input, gboolean prev
switch (field_type)
{
case FIELD_BOOLEAN:
- found = autocomplete_param_with_func(input, split[0], prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, split[0], prefs_autocomplete_boolean_choice, previous, NULL);
break;
case FIELD_LIST_SINGLE:
found = autocomplete_param_with_ac(input, split[0], value_ac, TRUE, previous);
@@ -2699,7 +2711,7 @@ _occupants_autocomplete(ProfWin *window, const char *const input, gboolean previ
return found;
}
- found = autocomplete_param_with_func(input, "/occupants color", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/occupants color", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2734,7 +2746,7 @@ _occupants_autocomplete(ProfWin *window, const char *const input, gboolean previ
return found;
}
- found = autocomplete_param_with_func(input, "/occupants wrap", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/occupants wrap", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -2961,12 +2973,12 @@ _tls_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/tls revoke", tlscerts_complete, previous);
+ result = autocomplete_param_with_func(input, "/tls revoke", tlscerts_complete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/tls cert", tlscerts_complete, previous);
+ result = autocomplete_param_with_func(input, "/tls cert", tlscerts_complete, previous, NULL);
if (result) {
return result;
}
@@ -3017,12 +3029,12 @@ _receipts_autocomplete(ProfWin *window, const char *const input, gboolean previo
{
char *result = NULL;
- result = autocomplete_param_with_func(input, "/receipts send", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/receipts send", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/receipts request", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/receipts request", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -3131,7 +3143,7 @@ _connect_autocomplete(ProfWin *window, const char *const input, gboolean previou
g_strfreev(args);
- found = autocomplete_param_with_func(input, "/connect", accounts_find_enabled, previous);
+ found = autocomplete_param_with_func(input, "/connect", accounts_find_enabled, previous, NULL);
if (found) {
return found;
}
@@ -3192,7 +3204,7 @@ _join_autocomplete(ProfWin *window, const char *const input, gboolean previous)
g_strfreev(args);
- found = autocomplete_param_with_func(input, "/join", bookmark_find, previous);
+ found = autocomplete_param_with_func(input, "/join", bookmark_find, previous, NULL);
if (found) {
return found;
}
@@ -3229,13 +3241,13 @@ _console_autocomplete(ProfWin *window, const char *const input, gboolean previou
static char*
_win_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
- return autocomplete_param_with_func(input, "/win", win_autocomplete, previous);
+ return autocomplete_param_with_func(input, "/win", win_autocomplete, previous, NULL);
}
static char*
_close_autocomplete(ProfWin *window, const char *const input, gboolean previous)
{
- return autocomplete_param_with_func(input, "/close", win_close_autocomplete, previous);
+ return autocomplete_param_with_func(input, "/close", win_close_autocomplete, previous, NULL);
}
static char*
@@ -3339,7 +3351,7 @@ _account_autocomplete(ProfWin *window, const char *const input, gboolean previou
|| (num_args == 4 && (g_strcmp0(args[2], "startscript") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/account");
g_string_append_printf(beginning, " %s %s %s", args[0], args[1], args[2]);
- found = autocomplete_param_with_func(input, beginning->str, _script_autocomplete_func, previous);
+ found = autocomplete_param_with_func(input, beginning->str, _script_autocomplete_func, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -3373,7 +3385,7 @@ _account_autocomplete(ProfWin *window, const char *const input, gboolean previou
|| (num_args == 4 && (g_strcmp0(args[2], "pgpkeyid") == 0) && !space_at_end)) {
GString *beginning = g_string_new("/account");
g_string_append_printf(beginning, " %s %s %s", args[0], args[1], args[2]);
- found = autocomplete_param_with_func(input, beginning->str, p_gpg_autocomplete_key, previous);
+ found = autocomplete_param_with_func(input, beginning->str, p_gpg_autocomplete_key, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -3407,7 +3419,7 @@ _account_autocomplete(ProfWin *window, const char *const input, gboolean previou
"/account default set" };
for (i = 0; i < ARRAY_SIZE(account_choice); i++) {
- found = autocomplete_param_with_func(input, account_choice[i], accounts_find_all, previous);
+ found = autocomplete_param_with_func(input, account_choice[i], accounts_find_all, previous, NULL);
if (found) {
return found;
}
@@ -3422,7 +3434,7 @@ _presence_autocomplete(ProfWin *window, const char *const input, gboolean previo
{
char *found = NULL;
- found = autocomplete_param_with_func(input, "/presence titlebar", prefs_autocomplete_boolean_choice, previous);
+ found = autocomplete_param_with_func(input, "/presence titlebar", prefs_autocomplete_boolean_choice, previous, NULL);
if (found) {
return found;
}
@@ -3470,7 +3482,7 @@ _rooms_autocomplete(ProfWin *window, const char *const input, gboolean previous)
}
if ((num_args == 1 && g_strcmp0(args[0], "service") == 0 && space_at_end) ||
(num_args == 2 && g_strcmp0(args[0], "service") == 0 && !space_at_end)) {
- found = autocomplete_param_with_func(input, "/rooms service", muc_confserver_find, previous);
+ found = autocomplete_param_with_func(input, "/rooms service", muc_confserver_find, previous, NULL);
if (found) {
g_strfreev(args);
return found;
@@ -3498,7 +3510,7 @@ _rooms_autocomplete(ProfWin *window, const char *const input, gboolean previous)
(num_args == 4 && g_strcmp0(args[2], "service") == 0 && !space_at_end)) {
GString *beginning = g_string_new("/rooms");
g_string_append_printf(beginning, " %s %s %s", args[0], args[1], args[2]);
- found = autocomplete_param_with_func(input, beginning->str, muc_confserver_find, previous);
+ found = autocomplete_param_with_func(input, beginning->str, muc_confserver_find, previous, NULL);
g_string_free(beginning, TRUE);
if (found) {
g_strfreev(args);
@@ -3564,7 +3576,7 @@ _clear_autocomplete(ProfWin *window, const char *const input, gboolean previous)
return result;
}
- result = autocomplete_param_with_func(input, "/clear persist_history", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/clear persist_history", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -3585,12 +3597,12 @@ _invite_autocomplete(ProfWin *window, const char *const input, gboolean previous
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- result = autocomplete_param_with_func(input, "/invite send", roster_contact_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/invite send", roster_contact_autocomplete, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/invite decline", muc_invites_find, previous);
+ result = autocomplete_param_with_func(input, "/invite decline", muc_invites_find, previous, NULL);
if (result) {
return result;
}
@@ -3636,7 +3648,7 @@ _status_autocomplete(ProfWin *window, const char *const input, gboolean previous
}
// roster completion
} else {
- result = autocomplete_param_with_func(unquoted, "/status get", roster_contact_autocomplete, previous);
+ result = autocomplete_param_with_func(unquoted, "/status get", roster_contact_autocomplete, previous, NULL);
if (result) {
free(unquoted);
return result;
@@ -3659,12 +3671,12 @@ _logging_autocomplete(ProfWin *window, const char *const input, gboolean previou
return result;
}
- result = autocomplete_param_with_func(input, "/logging chat", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/logging chat", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
- result = autocomplete_param_with_func(input, "/logging group", prefs_autocomplete_boolean_choice, previous);
+ result = autocomplete_param_with_func(input, "/logging group", prefs_autocomplete_boolean_choice, previous, NULL);
if (result) {
return result;
}
@@ -3692,7 +3704,7 @@ _avatar_autocomplete(ProfWin *window, const char *const input, gboolean previous
jabber_conn_status_t conn_status = connection_get_status();
if (conn_status == JABBER_CONNECTED) {
- result = autocomplete_param_with_func(input, "/avatar", roster_barejid_autocomplete, previous);
+ result = autocomplete_param_with_func(input, "/avatar", roster_barejid_autocomplete, previous, NULL);
if (result) {
return result;
}
diff --git a/src/config/accounts.c b/src/config/accounts.c
--- a/src/config/accounts.c
+++ b/src/config/accounts.c
@@ -97,13 +97,13 @@ accounts_close(void)
}
char*
-accounts_find_enabled(const char *const prefix, gboolean previous)
+accounts_find_enabled(const char *const prefix, gboolean previous, void *context)
{
return autocomplete_complete(enabled_ac, prefix, TRUE, previous);
}
char*
-accounts_find_all(const char *const prefix, gboolean previous)
+accounts_find_all(const char *const prefix, gboolean previous, void *context)
{
return autocomplete_complete(all_ac, prefix, TRUE, previous);
}
diff --git a/src/config/accounts.h b/src/config/accounts.h
--- a/src/config/accounts.h
+++ b/src/config/accounts.h
@@ -44,8 +44,8 @@
void accounts_load(void);
void accounts_close(void);
-char* accounts_find_all(const char *const prefix, gboolean previous);
-char* accounts_find_enabled(const char *const prefix, gboolean previous);
+char* accounts_find_all(const char *const prefix, gboolean previous, void *context);
+char* accounts_find_enabled(const char *const prefix, gboolean previous, void *context);
void accounts_reset_all_search(void);
void accounts_reset_enabled_search(void);
void accounts_add(const char *jid, const char *altdomain, const int port, const char *const tls_policy);
diff --git a/src/config/preferences.c b/src/config/preferences.c
--- a/src/config/preferences.c
+++ b/src/config/preferences.c
@@ -218,7 +218,7 @@ prefs_close(void)
}
char*
-prefs_autocomplete_boolean_choice(const char *const prefix, gboolean previous)
+prefs_autocomplete_boolean_choice(const char *const prefix, gboolean previous, void *context)
{
return autocomplete_complete(boolean_choice_ac, prefix, TRUE, previous);
}
@@ -230,7 +230,7 @@ prefs_reset_boolean_choice(void)
}
char*
-prefs_autocomplete_room_trigger(const char *const prefix, gboolean previous)
+prefs_autocomplete_room_trigger(const char *const prefix, gboolean previous, void *context)
{
return autocomplete_complete(room_trigger_ac, prefix, TRUE, previous);
}
diff --git a/src/config/preferences.h b/src/config/preferences.h
--- a/src/config/preferences.h
+++ b/src/config/preferences.h
@@ -183,10 +183,10 @@ void prefs_reload(void);
char* prefs_find_login(char *prefix);
void prefs_reset_login_search(void);
-char* prefs_autocomplete_boolean_choice(const char *const prefix, gboolean previous);
+char* prefs_autocomplete_boolean_choice(const char *const prefix, gboolean previous, void *context);
void prefs_reset_boolean_choice(void);
-char* prefs_autocomplete_room_trigger(const char *const prefix, gboolean previous);
+char* prefs_autocomplete_room_trigger(const char *const prefix, gboolean previous, void *context);
void prefs_reset_room_trigger_ac(void);
gint prefs_get_gone(void);
diff --git a/src/config/tlscerts.c b/src/config/tlscerts.c
--- a/src/config/tlscerts.c
+++ b/src/config/tlscerts.c
@@ -369,7 +369,7 @@ tlscerts_get_trusted(const char * const fingerprint)
}
char*
-tlscerts_complete(const char *const prefix, gboolean previous)
+tlscerts_complete(const char *const prefix, gboolean previous, void *context)
{
return autocomplete_complete(certs_ac, prefix, TRUE, previous);
}
diff --git a/src/config/tlscerts.h b/src/config/tlscerts.h
--- a/src/config/tlscerts.h
+++ b/src/config/tlscerts.h
@@ -90,7 +90,7 @@ void tlscerts_free(TLSCertificate *cert);
GList* tlscerts_list(void);
-char* tlscerts_complete(const char *const prefix, gboolean previous);
+char* tlscerts_complete(const char *const prefix, gboolean previous, void *context);
void tlscerts_reset_ac(void);
diff --git a/src/omemo/omemo.c b/src/omemo/omemo.c
--- a/src/omemo/omemo.c
+++ b/src/omemo/omemo.c
@@ -108,7 +108,7 @@ struct omemo_context_t {
GHashTable *known_devices;
GString *known_devices_filename;
GKeyFile *known_devices_keyfile;
- Autocomplete fingerprint_ac;
+ GHashTable *fingerprint_ac;
};
static omemo_context omemo_ctx;
@@ -125,14 +125,14 @@ omemo_init(void)
pthread_mutexattr_settype(&omemo_ctx.attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&omemo_ctx.lock, &omemo_ctx.attr);
- omemo_ctx.fingerprint_ac = autocomplete_new();
+ omemo_ctx.fingerprint_ac = g_hash_table_new_full(g_str_hash, g_str_equal, free, (GDestroyNotify)autocomplete_free);
}
void
omemo_close(void)
{
if (omemo_ctx.fingerprint_ac) {
- autocomplete_free(omemo_ctx.fingerprint_ac);
+ g_hash_table_destroy(omemo_ctx.fingerprint_ac);
omemo_ctx.fingerprint_ac = NULL;
}
}
@@ -1300,15 +1300,27 @@ omemo_key_free(omemo_key_t *key)
}
char*
-omemo_fingerprint_autocomplete(const char *const search_str, gboolean previous)
+omemo_fingerprint_autocomplete(const char *const search_str, gboolean previous, void *context)
{
- return autocomplete_complete(omemo_ctx.fingerprint_ac, search_str, FALSE, previous);
+ Autocomplete ac = g_hash_table_lookup(omemo_ctx.fingerprint_ac, context);
+ if (ac != NULL) {
+ return autocomplete_complete(ac, search_str, FALSE, previous);
+ } else {
+ return NULL;
+ }
}
void
omemo_fingerprint_autocomplete_reset(void)
{
- autocomplete_reset(omemo_ctx.fingerprint_ac);
+ gpointer value;
+ GHashTableIter iter;
+ g_hash_table_iter_init(&iter, omemo_ctx.fingerprint_ac);
+
+ while (g_hash_table_iter_next(&iter, NULL, &value)) {
+ Autocomplete ac = value;
+ autocomplete_reset(ac);
+ }
}
gboolean
@@ -1596,8 +1608,14 @@ _cache_device_identity(const char *const jid, uint32_t device_id, ec_public_key
g_free(device_id_str);
omemo_known_devices_keyfile_save();
+ Autocomplete ac = g_hash_table_lookup(omemo_ctx.fingerprint_ac, jid);
+ if (ac == NULL) {
+ ac = autocomplete_new();
+ g_hash_table_insert(omemo_ctx.fingerprint_ac, strdup(jid), ac);
+ }
+
char *formatted_fingerprint = omemo_format_fingerprint(fingerprint);
- autocomplete_add(omemo_ctx.fingerprint_ac, formatted_fingerprint);
+ autocomplete_add(ac, formatted_fingerprint);
free(formatted_fingerprint);
free(fingerprint);
}
diff --git a/src/omemo/omemo.h b/src/omemo/omemo.h
--- a/src/omemo/omemo.h
+++ b/src/omemo/omemo.h
@@ -82,7 +82,7 @@ void omemo_trust(const char *const jid, const char *const fingerprint);
void omemo_untrust(const char *const jid, const char *const fingerprint);
GList *omemo_known_device_identities(const char *const jid);
gboolean omemo_is_trusted_identity(const char *const jid, const char *const fingerprint);
-char *omemo_fingerprint_autocomplete(const char *const search_str, gboolean previous);
+char *omemo_fingerprint_autocomplete(const char *const search_str, gboolean previous, void *context);
void omemo_fingerprint_autocomplete_reset(void);
gboolean omemo_automatic_start(const char *const recipient);
diff --git a/src/pgp/gpg.c b/src/pgp/gpg.c
--- a/src/pgp/gpg.c
+++ b/src/pgp/gpg.c
@@ -753,7 +753,7 @@ p_gpg_free_decrypted(char *decrypted)
}
char*
-p_gpg_autocomplete_key(const char *const search_str, gboolean previous)
+p_gpg_autocomplete_key(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(key_ac, search_str, TRUE, previous);
}
diff --git a/src/pgp/gpg.h b/src/pgp/gpg.h
--- a/src/pgp/gpg.h
+++ b/src/pgp/gpg.h
@@ -68,7 +68,7 @@ void p_gpg_verify(const char *const barejid, const char *const sign);
char* p_gpg_encrypt(const char *const barejid, const char *const message, const char *const fp);
char* p_gpg_decrypt(const char *const cipher);
void p_gpg_free_decrypted(char *decrypted);
-char* p_gpg_autocomplete_key(const char *const search_str, gboolean previous);
+char* p_gpg_autocomplete_key(const char *const search_str, gboolean previous, void *context);
void p_gpg_autocomplete_key_reset(void);
char* p_gpg_format_fp_str(char *fp);
diff --git a/src/tools/autocomplete.c b/src/tools/autocomplete.c
--- a/src/tools/autocomplete.c
+++ b/src/tools/autocomplete.c
@@ -285,7 +285,7 @@ autocomplete_complete(Autocomplete ac, const gchar *search_str, gboolean quote,
}
char*
-autocomplete_param_with_func(const char *const input, char *command, autocomplete_func func, gboolean previous)
+autocomplete_param_with_func(const char *const input, char *command, autocomplete_func func, gboolean previous, void *context)
{
GString *auto_msg = NULL;
char *result = NULL;
@@ -302,7 +302,7 @@ autocomplete_param_with_func(const char *const input, char *command, autocomplet
}
prefix[inp_len - len] = '\0';
- char *found = func(prefix, previous);
+ char *found = func(prefix, previous, context);
if (found) {
auto_msg = g_string_new(command_cpy);
g_string_append(auto_msg, found);
@@ -347,7 +347,7 @@ autocomplete_param_with_ac(const char *const input, char *command, Autocomplete
}
char*
-autocomplete_param_no_with_func(const char *const input, char *command, int arg_number, autocomplete_func func, gboolean previous)
+autocomplete_param_no_with_func(const char *const input, char *command, int arg_number, autocomplete_func func, gboolean previous, void *context)
{
if (strncmp(input, command, strlen(command)) == 0) {
GString *result_str = NULL;
@@ -362,7 +362,7 @@ autocomplete_param_no_with_func(const char *const input, char *command, int arg_
// autocomplete param
if (comp_str) {
- char *found = func(comp_str, previous);
+ char *found = func(comp_str, previous, context);
if (found) {
result_str = g_string_new("");
g_string_append(result_str, start_str);
diff --git a/src/tools/autocomplete.h b/src/tools/autocomplete.h
--- a/src/tools/autocomplete.h
+++ b/src/tools/autocomplete.h
@@ -38,7 +38,7 @@
#include <glib.h>
-typedef char* (*autocomplete_func)(const char *const, gboolean);
+typedef char* (*autocomplete_func)(const char *const, gboolean, void *);
typedef struct autocomplete_t *Autocomplete;
// allocate new autocompleter with no items
@@ -63,13 +63,13 @@ GList* autocomplete_create_list(Autocomplete ac);
gint autocomplete_length(Autocomplete ac);
char* autocomplete_param_with_func(const char *const input, char *command,
- autocomplete_func func, gboolean previous);
+ autocomplete_func func, gboolean previous, void *context);
char* autocomplete_param_with_ac(const char *const input, char *command,
Autocomplete ac, gboolean quote, gboolean previous);
char* autocomplete_param_no_with_func(const char *const input, char *command,
- int arg_number, autocomplete_func func, gboolean previous);
+ int arg_number, autocomplete_func func, gboolean previous, void *context);
void autocomplete_reset(Autocomplete ac);
diff --git a/src/ui/window_list.c b/src/ui/window_list.c
--- a/src/ui/window_list.c
+++ b/src/ui/window_list.c
@@ -1093,13 +1093,13 @@ wins_create_summary(gboolean unread)
}
char*
-win_autocomplete(const char *const search_str, gboolean previous)
+win_autocomplete(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(wins_ac, search_str, TRUE, previous);
}
char*
-win_close_autocomplete(const char *const search_str, gboolean previous)
+win_close_autocomplete(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(wins_close_ac, search_str, TRUE, previous);
}
diff --git a/src/ui/window_list.h b/src/ui/window_list.h
--- a/src/ui/window_list.h
+++ b/src/ui/window_list.h
@@ -94,9 +94,9 @@ void wins_swap(int source_win, int target_win);
void wins_hide_subwin(ProfWin *window);
void wins_show_subwin(ProfWin *window);
-char* win_autocomplete(const char *const search_str, gboolean previous);
+char* win_autocomplete(const char *const search_str, gboolean previous, void *context);
void win_reset_search_attempts(void);
-char* win_close_autocomplete(const char *const search_str, gboolean previous);
+char* win_close_autocomplete(const char *const search_str, gboolean previous, void *context);
void win_close_reset_search_attempts(void);
#endif
diff --git a/src/xmpp/blocking.c b/src/xmpp/blocking.c
--- a/src/xmpp/blocking.c
+++ b/src/xmpp/blocking.c
@@ -93,7 +93,7 @@ blocked_list(void)
}
char*
-blocked_ac_find(const char *const search_str, gboolean previous)
+blocked_ac_find(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(blocked_ac, search_str, TRUE, previous);
}
diff --git a/src/xmpp/bookmark.c b/src/xmpp/bookmark.c
--- a/src/xmpp/bookmark.c
+++ b/src/xmpp/bookmark.c
@@ -222,7 +222,7 @@ bookmark_get_list(void)
}
char*
-bookmark_find(const char *const search_str, gboolean previous)
+bookmark_find(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(bookmark_ac, search_str, TRUE, previous);
}
diff --git a/src/xmpp/muc.c b/src/xmpp/muc.c
--- a/src/xmpp/muc.c
+++ b/src/xmpp/muc.c
@@ -181,13 +181,13 @@ muc_confserver_reset_ac(void)
}
char*
-muc_invites_find(const char *const search_str, gboolean previous)
+muc_invites_find(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(invite_ac, search_str, TRUE, previous);
}
char*
-muc_confserver_find(const char *const search_str, gboolean previous)
+muc_confserver_find(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(confservers_ac, search_str, TRUE, previous);
}
diff --git a/src/xmpp/muc.h b/src/xmpp/muc.h
--- a/src/xmpp/muc.h
+++ b/src/xmpp/muc.h
@@ -126,7 +126,7 @@ char* muc_roster_nick_change_complete(const char *const room, const char *const
void muc_confserver_add(const char *const server);
void muc_confserver_reset_ac(void);
-char* muc_confserver_find(const char *const search_str, gboolean previous);
+char* muc_confserver_find(const char *const search_str, gboolean previous, void *context);
void muc_confserver_clear(void);
void muc_invites_add(const char *const room, const char *const password);
@@ -135,7 +135,7 @@ gint muc_invites_count(void);
GList* muc_invites(void);
gboolean muc_invites_contain(const char *const room);
void muc_invites_reset_ac(void);
-char* muc_invites_find(const char *const search_str, gboolean previous);
+char* muc_invites_find(const char *const search_str, gboolean previous, void *context);
void muc_invites_clear(void);
char* muc_invite_password(const char *const room);
diff --git a/src/xmpp/presence.c b/src/xmpp/presence.c
--- a/src/xmpp/presence.c
+++ b/src/xmpp/presence.c
@@ -161,7 +161,7 @@ presence_clear_sub_requests(void)
}
char*
-presence_sub_request_find(const char *const search_str, gboolean previous)
+presence_sub_request_find(const char *const search_str, gboolean previous, void *context)
{
return autocomplete_complete(sub_requests_ac, search_str, TRUE, previous);
}
diff --git a/src/xmpp/roster_list.c b/src/xmpp/roster_list.c
--- a/src/xmpp/roster_list.c
+++ b/src/xmpp/roster_list.c
@@ -487,7 +487,7 @@ roster_has_pending_subscriptions(void)
}
char*
-roster_contact_autocomplete(const char *const search_str, gboolean previous)
+roster_contact_autocomplete(const char *const search_str, gboolean previous, void *context)
{
assert(roster != NULL);
@@ -495,7 +495,7 @@ roster_contact_autocomplete(const char *const search_str, gboolean previous)
}
char*
-roster_fulljid_autocomplete(const char *const search_str, gboolean previous)
+roster_fulljid_autocomplete(const char *const search_str, gboolean previous, void *context)
{
assert(roster != NULL);
@@ -550,7 +550,7 @@ roster_get_groups(void)
}
char*
-roster_group_autocomplete(const char *const search_str, gboolean previous)
+roster_group_autocomplete(const char *const search_str, gboolean previous, void *context)
{
assert(roster != NULL);
@@ -558,7 +558,7 @@ roster_group_autocomplete(const char *const search_str, gboolean previous)
}
char*
-roster_barejid_autocomplete(const char *const search_str, gboolean previous)
+roster_barejid_autocomplete(const char *const search_str, gboolean previous, void *context)
{
assert(roster != NULL);
diff --git a/src/xmpp/roster_list.h b/src/xmpp/roster_list.h
--- a/src/xmpp/roster_list.h
+++ b/src/xmpp/roster_list.h
@@ -63,12 +63,12 @@ char* roster_barejid_from_name(const char *const name);
GSList* roster_get_contacts(roster_ord_t order);
GSList* roster_get_contacts_online(void);
gboolean roster_has_pending_subscriptions(void);
-char* roster_contact_autocomplete(const char *const search_str, gboolean previous);
-char* roster_fulljid_autocomplete(const char *const search_str, gboolean previous);
+char* roster_contact_autocomplete(const char *const search_str, gboolean previous, void *context);
+char* roster_fulljid_autocomplete(const char *const search_str, gboolean previous, void *context);
GSList* roster_get_group(const char *const group, roster_ord_t order);
GList* roster_get_groups(void);
-char* roster_group_autocomplete(const char *const search_str, gboolean previous);
-char* roster_barejid_autocomplete(const char *const search_str, gboolean previous);
+char* roster_group_autocomplete(const char *const search_str, gboolean previous, void *context);
+char* roster_barejid_autocomplete(const char *const search_str, gboolean previous, void *context);
GSList* roster_get_contacts_by_presence(const char *const presence);
char* roster_get_msg_display_name(const char *const barejid, const char *const resource);
gint roster_compare_name(PContact a, PContact b);
diff --git a/src/xmpp/xmpp.h b/src/xmpp/xmpp.h
--- a/src/xmpp/xmpp.h
+++ b/src/xmpp/xmpp.h
@@ -188,7 +188,7 @@ void presence_subscription(const char *const jid, const jabber_subscr_t action);
GList* presence_get_subscription_requests(void);
gint presence_sub_request_count(void);
void presence_reset_sub_request_search(void);
-char* presence_sub_request_find(const char *const search_str, gboolean previous);
+char* presence_sub_request_find(const char *const search_str, gboolean previous, void *context);
void presence_join_room(const char *const room, const char *const nick, const char *const passwd);
void presence_change_room_nick(const char *const room, const char *const nick);
void presence_leave_chat_room(const char *const room_jid);
@@ -237,7 +237,7 @@ gboolean bookmark_update(const char *jid, const char *nick, const char *password
gboolean bookmark_remove(const char *jid);
gboolean bookmark_join(const char *jid);
GList* bookmark_get_list(void);
-char* bookmark_find(const char *const search_str, gboolean previous);
+char* bookmark_find(const char *const search_str, gboolean previous, void *context);
void bookmark_autocomplete_reset(void);
gboolean bookmark_exists(const char *const room);
@@ -250,7 +250,7 @@ void roster_send_remove(const char *const barejid);
GList* blocked_list(void);
gboolean blocked_add(char *jid);
gboolean blocked_remove(char *jid);
-char* blocked_ac_find(const char *const search_str, gboolean previous);
+char* blocked_ac_find(const char *const search_str, gboolean previous, void *context);
void blocked_ac_reset(void);
void form_destroy(DataForm *form);
|
diff --git a/tests/unittests/config/stub_accounts.c b/tests/unittests/config/stub_accounts.c
--- a/tests/unittests/config/stub_accounts.c
+++ b/tests/unittests/config/stub_accounts.c
@@ -14,7 +14,7 @@ char * accounts_find_all(char *prefix)
return NULL;
}
-char * accounts_find_enabled(char *prefix)
+char * accounts_find_enabled(char *prefix, void *context)
{
return NULL;
}
diff --git a/tests/unittests/pgp/stub_gpg.c b/tests/unittests/pgp/stub_gpg.c
--- a/tests/unittests/pgp/stub_gpg.c
+++ b/tests/unittests/pgp/stub_gpg.c
@@ -56,7 +56,7 @@ void p_gpg_free_keys(GHashTable *keys) {}
void p_gpg_autocomplete_key_reset(void) {}
-char * p_gpg_autocomplete_key(const char * const search_str, gboolean previous)
+char * p_gpg_autocomplete_key(const char * const search_str, gboolean previous, void *context)
{
return NULL;
}
diff --git a/tests/unittests/test_roster_list.c b/tests/unittests/test_roster_list.c
--- a/tests/unittests/test_roster_list.c
+++ b/tests/unittests/test_roster_list.c
@@ -178,7 +178,7 @@ void find_first_exists(void **state)
char *search = strdup("B");
- char *result = roster_contact_autocomplete(search, FALSE);
+ char *result = roster_contact_autocomplete(search, FALSE, NULL);
assert_string_equal("Bob", result);
free(result);
free(search);
@@ -192,7 +192,7 @@ void find_second_exists(void **state)
roster_add("Dave", NULL, NULL, NULL, FALSE);
roster_add("Bob", NULL, NULL, NULL, FALSE);
- char *result = roster_contact_autocomplete("Dav", FALSE);
+ char *result = roster_contact_autocomplete("Dav", FALSE, NULL);
assert_string_equal("Dave", result);
free(result);
roster_destroy();
@@ -205,7 +205,7 @@ void find_third_exists(void **state)
roster_add("Dave", NULL, NULL, NULL, FALSE);
roster_add("Bob", NULL, NULL, NULL, FALSE);
- char *result = roster_contact_autocomplete("Ja", FALSE);
+ char *result = roster_contact_autocomplete("Ja", FALSE, NULL);
assert_string_equal("James", result);
free(result);
roster_destroy();
@@ -218,7 +218,7 @@ void find_returns_null(void **state)
roster_add("Dave", NULL, NULL, NULL, FALSE);
roster_add("Bob", NULL, NULL, NULL, FALSE);
- char *result = roster_contact_autocomplete("Mike", FALSE);
+ char *result = roster_contact_autocomplete("Mike", FALSE, NULL);
assert_null(result);
roster_destroy();
}
@@ -226,7 +226,7 @@ void find_returns_null(void **state)
void find_on_empty_returns_null(void **state)
{
roster_create();
- char *result = roster_contact_autocomplete("James", FALSE);
+ char *result = roster_contact_autocomplete("James", FALSE, NULL);
assert_null(result);
roster_destroy();
}
@@ -238,8 +238,8 @@ void find_twice_returns_second_when_two_match(void **state)
roster_add("Jamie", NULL, NULL, NULL, FALSE);
roster_add("Bob", NULL, NULL, NULL, FALSE);
- char *result1 = roster_contact_autocomplete("Jam", FALSE);
- char *result2 = roster_contact_autocomplete(result1, FALSE);
+ char *result1 = roster_contact_autocomplete("Jam", FALSE, NULL);
+ char *result2 = roster_contact_autocomplete(result1, FALSE, NULL);
assert_string_equal("Jamie", result2);
free(result1);
free(result2);
@@ -260,11 +260,11 @@ void find_five_times_finds_fifth(void **state)
roster_add("Jamy", NULL, NULL, NULL, FALSE);
roster_add("Jamz", NULL, NULL, NULL, FALSE);
- char *result1 = roster_contact_autocomplete("Jam", FALSE);
- char *result2 = roster_contact_autocomplete(result1, FALSE);
- char *result3 = roster_contact_autocomplete(result2, FALSE);
- char *result4 = roster_contact_autocomplete(result3, FALSE);
- char *result5 = roster_contact_autocomplete(result4, FALSE);
+ char *result1 = roster_contact_autocomplete("Jam", FALSE, NULL);
+ char *result2 = roster_contact_autocomplete(result1, FALSE, NULL);
+ char *result3 = roster_contact_autocomplete(result2, FALSE, NULL);
+ char *result4 = roster_contact_autocomplete(result3, FALSE, NULL);
+ char *result5 = roster_contact_autocomplete(result4, FALSE, NULL);
assert_string_equal("Jamo", result5);
free(result1);
free(result2);
@@ -281,9 +281,9 @@ void find_twice_returns_first_when_two_match_and_reset(void **state)
roster_add("Jamie", NULL, NULL, NULL, FALSE);
roster_add("Bob", NULL, NULL, NULL, FALSE);
- char *result1 = roster_contact_autocomplete("Jam", FALSE);
+ char *result1 = roster_contact_autocomplete("Jam", FALSE, NULL);
roster_reset_search_attempts();
- char *result2 = roster_contact_autocomplete(result1, FALSE);
+ char *result2 = roster_contact_autocomplete(result1, FALSE, NULL);
assert_string_equal("James", result2);
free(result1);
free(result2);
diff --git a/tests/unittests/xmpp/stub_xmpp.c b/tests/unittests/xmpp/stub_xmpp.c
--- a/tests/unittests/xmpp/stub_xmpp.c
+++ b/tests/unittests/xmpp/stub_xmpp.c
@@ -151,7 +151,7 @@ gint presence_sub_request_count(void)
void presence_reset_sub_request_search(void) {}
-char * presence_sub_request_find(const char * const search_str, gboolean previous)
+char * presence_sub_request_find(const char * const search_str, gboolean previous, void *context)
{
return NULL;
}
@@ -266,7 +266,7 @@ GList * bookmark_get_list(void)
return mock_ptr_type(GList *);
}
-char * bookmark_find(const char * const search_str, gboolean previous)
+char * bookmark_find(const char * const search_str, gboolean previous, void *context)
{
return NULL;
}
@@ -314,7 +314,7 @@ gboolean blocked_remove(char *jid)
return TRUE;
}
-char* blocked_ac_find(const char *const search_str, gboolean previous)
+char* blocked_ac_find(const char *const search_str, gboolean previous, void *context)
{
return NULL;
}
|
OMEMO: Autocomplete suggests fingerprints not belonging to the selected contact
The OMEMO autocomplete feature suggests fingerprints not belonging to the selected contact.
Steps to reproduce:
1. Enable omemo (set policy to automatic / always - not tested if this is needed to reproduce...)
2. Show the fingerprint list of one of your contacts
3. Write `/omemo trust <contact>` and use tab for autocompletion
-> Many fingerprints are suggested, not only the ones belonging to the contact
|
Yes so far it's all the fingerprints we get.
AFAICT we don't have access to the first argument of a command from the autocompletion command.
So I can't filter out fingerprints easily.
@pasis, @boothj5 can you confirm?
If we don't solve this (ever or for 0.7.0) then we should document the usage at https://profanity-im.github.io/omemo.html
Maybe also mentioning that people should enable carbons (or auto enabling them for 0.7.0 since I think that most people want them and only some prefer to disable them). And describing that they need to trust their own keys of other devices.
Mentioning that file transfer is not encrypted since its another XEP too.
So that they know how to use OMEMO properly with Profanity and what works and what doesn'.
I documented this on the website now. We will release 0.7.0 as it is and hope users read the documentation.
Planning to tackle this for 0.8.0.
> AFAICT we don't have access to the first argument of a command from the autocompletion command.
So I can't filter out fingerprints easily.
@paulfariello We could create a new function. Autocomplete still has it in the `input` argument.
We should merge all omemo autocomplete functions into a single one in order to filter the fingerprints.
| 2020-01-31T09:15:02
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 117
|
HandmadeMath__HandmadeMath-117
|
[
"116"
] |
68d2af495ce8a106d1ed5d063f168d5a10ae4420
|
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,8 +1,6 @@
# Understanding the structure of Handmade Math
-Most of the functions in Handmade Math are very short, and are the kind of functions you want to have inlined. Because of this, most functions in Handmade Math are defined with `HINLINE`, which is defined as `static inline`.
-
-The exceptions are functions like `HMM_Rotate`, which are long enough that it doesn't make sense to inline them. These functions are defined with an `HEXTERN` prototype, and implemented in the `#ifdef HANDMADE_MATH_IMPLEMENTATION` block.
+Most of the functions in Handmade Math are very short, and all are the kind of functions you want to be easily inlined for performance. Because of this, all functions in Handmade Math are defined with `HMM_INLINE`, which is defined as `static inline`.
# Quick style guide
@@ -14,7 +12,7 @@ The exceptions are functions like `HMM_Rotate`, which are long enough that it do
0.5f;
1.0f;
3.14159f;
-
+
// Bad
1.f
.0f
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -8,28 +8,12 @@
=============================================================================
- You MUST
-
- #define HANDMADE_MATH_IMPLEMENTATION
-
- in EXACTLY one C or C++ file that includes this header, BEFORE the
- include, like this:
-
- #define HANDMADE_MATH_IMPLEMENTATION
- #include "HandmadeMath.h"
-
- All other files should just #include "HandmadeMath.h" without the #define.
-
- =============================================================================
-
To disable SSE intrinsics, you MUST
#define HANDMADE_MATH_NO_SSE
- in EXACTLY one C or C++ file that includes this header, BEFORE the
- include, like this:
+ BEFORE the include, like this:
- #define HANDMADE_MATH_IMPLEMENTATION
#define HANDMADE_MATH_NO_SSE
#include "HandmadeMath.h"
@@ -48,8 +32,7 @@
#define HMM_ATAN2F MYATan2F
Provide your own implementations of SinF, CosF, TanF, ACosF, ATanF, ATan2F,
- ExpF, and LogF in EXACTLY one C or C++ file that includes this header,
- BEFORE the include, like this:
+ ExpF, and LogF BEFORE the include, like this:
#define HMM_SINF MySinF
#define HMM_COSF MyCosF
@@ -60,7 +43,6 @@
#define HMM_ACOSF MyACosF
#define HMM_ATANF MyATanF
#define HMM_ATAN2F MyATan2F
- #define HANDMADE_MATH_IMPLEMENTATION
#include "HandmadeMath.h"
If you do not define all of these, HandmadeMath.h will use the
@@ -76,14 +58,15 @@
CREDITS
- Written by Zakary Strange (zak@strangedev.net && @strangezak)
+ Written by:
+ Zakary Strange (zakarystrange@gmail.com && @strangezak)
+ Ben Visness (ben@bvisness.me && @its_bvisness)
Functionality:
Matt Mascarenhas (@miblo_)
Aleph
FieryDrake (@fierydrake)
Gingerbill (@TheGingerBill)
- Ben Visness (@bvisness)
Trinton Bullard (@Peliex_Dev)
@AntonDan
@@ -150,7 +133,6 @@ extern "C"
#endif
#define HMM_INLINE static inline
-#define HMM_EXTERN extern
#if !defined(HMM_SINF) || !defined(HMM_COSF) || !defined(HMM_TANF) || \
!defined(HMM_SQRTF) || !defined(HMM_EXPF) || !defined(HMM_LOGF) || \
@@ -529,7 +511,29 @@ HMM_INLINE float HMM_RSquareRootF(float Float)
return(Result);
}
-HMM_EXTERN float HMM_Power(float Base, int Exponent);
+COVERAGE(HMM_Power, 2)
+HMM_INLINE float HMM_Power(float Base, int Exponent)
+{
+ ASSERT_COVERED(HMM_Power);
+
+ float Result = 1.0f;
+ float Mul = Exponent < 0 ? 1.f / Base : Base;
+ int X = Exponent < 0 ? -Exponent : Exponent;
+ while (X)
+ {
+ if (X & 1)
+ {
+ ASSERT_COVERED(HMM_Power);
+
+ Result *= Mul;
+ }
+
+ Mul *= Mul;
+ X >>= 1;
+ }
+
+ return (Result);
+}
COVERAGE(HMM_PowerF, 1)
HMM_INLINE float HMM_PowerF(float Base, float Exponent)
@@ -1293,28 +1297,40 @@ HMM_INLINE hmm_mat4 HMM_Mat4d(float Diagonal)
return (Result);
}
-#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_Transpose, 1)
HMM_INLINE hmm_mat4 HMM_Transpose(hmm_mat4 Matrix)
{
ASSERT_COVERED(HMM_Transpose);
+#ifdef HANDMADE_MATH__USE_SSE
hmm_mat4 Result = Matrix;
_MM_TRANSPOSE4_PS(Result.Columns[0], Result.Columns[1], Result.Columns[2], Result.Columns[3]);
return (Result);
-}
#else
-HMM_EXTERN hmm_mat4 HMM_Transpose(hmm_mat4 Matrix);
+ hmm_mat4 Result;
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Rows][Columns] = Matrix.Elements[Columns][Rows];
+ }
+ }
+
+ return (Result);
#endif
+}
-#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_AddMat4, 1)
HMM_INLINE hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_AddMat4);
+#ifdef HANDMADE_MATH__USE_SSE
hmm_mat4 Result;
Result.Columns[0] = _mm_add_ps(Left.Columns[0], Right.Columns[0]);
@@ -1323,17 +1339,29 @@ HMM_INLINE hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
Result.Columns[3] = _mm_add_ps(Left.Columns[3], Right.Columns[3]);
return (Result);
-}
#else
-HMM_EXTERN hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right);
+ hmm_mat4 Result;
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Columns][Rows] = Left.Elements[Columns][Rows] + Right.Elements[Columns][Rows];
+ }
+ }
+
+ return (Result);
#endif
+}
-#ifdef HANDMADE_MATH__USE_SSE
COVERAGE(HMM_SubtractMat4, 1)
HMM_INLINE hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
{
ASSERT_COVERED(HMM_SubtractMat4);
+#ifdef HANDMADE_MATH__USE_SSE
hmm_mat4 Result;
Result.Columns[0] = _mm_sub_ps(Left.Columns[0], Right.Columns[0]);
@@ -1342,19 +1370,63 @@ HMM_INLINE hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
Result.Columns[3] = _mm_sub_ps(Left.Columns[3], Right.Columns[3]);
return (Result);
-}
#else
-HMM_EXTERN hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right);
+ hmm_mat4 Result;
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Columns][Rows] = Left.Elements[Columns][Rows] - Right.Elements[Columns][Rows];
+ }
+ }
+
+ return (Result);
#endif
+}
+
+COVERAGE(HMM_MultiplyMat4, 1)
+HMM_INLINE hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right)
+{
+ ASSERT_COVERED(HMM_MultiplyMat4);
-HMM_EXTERN hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right);
+ hmm_mat4 Result;
#ifdef HANDMADE_MATH__USE_SSE
+ Result.Columns[0] = HMM_LinearCombineSSE(Right.Columns[0], Left);
+ Result.Columns[1] = HMM_LinearCombineSSE(Right.Columns[1], Left);
+ Result.Columns[2] = HMM_LinearCombineSSE(Right.Columns[2], Left);
+ Result.Columns[3] = HMM_LinearCombineSSE(Right.Columns[3], Left);
+#else
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ float Sum = 0;
+ int CurrentMatrice;
+ for(CurrentMatrice = 0; CurrentMatrice < 4; ++CurrentMatrice)
+ {
+ Sum += Left.Elements[CurrentMatrice][Rows] * Right.Elements[Columns][CurrentMatrice];
+ }
+
+ Result.Elements[Columns][Rows] = Sum;
+ }
+ }
+#endif
+
+ return (Result);
+}
+
COVERAGE(HMM_MultiplyMat4f, 1)
HMM_INLINE hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_MultiplyMat4f);
+#ifdef HANDMADE_MATH__USE_SSE
hmm_mat4 Result;
__m128 SSEScalar = _mm_set1_ps(Scalar);
@@ -1364,19 +1436,55 @@ HMM_INLINE hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
Result.Columns[3] = _mm_mul_ps(Matrix.Columns[3], SSEScalar);
return (Result);
-}
#else
-HMM_EXTERN hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar);
+ hmm_mat4 Result;
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Columns][Rows] = Matrix.Elements[Columns][Rows] * Scalar;
+ }
+ }
+
+ return (Result);
#endif
+}
+
+COVERAGE(HMM_MultiplyMat4ByVec4, 1)
+HMM_INLINE hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector)
+{
+ ASSERT_COVERED(HMM_MultiplyMat4ByVec4);
-HMM_EXTERN hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector);
+ hmm_vec4 Result;
#ifdef HANDMADE_MATH__USE_SSE
+ Result.InternalElementsSSE = HMM_LinearCombineSSE(Vector.InternalElementsSSE, Matrix);
+#else
+ int Columns, Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ float Sum = 0;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ Sum += Matrix.Elements[Columns][Rows] * Vector.Elements[Columns];
+ }
+
+ Result.Elements[Rows] = Sum;
+ }
+#endif
+
+ return (Result);
+}
+
COVERAGE(HMM_DivideMat4f, 1)
HMM_INLINE hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
{
ASSERT_COVERED(HMM_DivideMat4f);
+#ifdef HANDMADE_MATH__USE_SSE
hmm_mat4 Result;
__m128 SSEScalar = _mm_set1_ps(Scalar);
@@ -1386,10 +1494,22 @@ HMM_INLINE hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
Result.Columns[3] = _mm_div_ps(Matrix.Columns[3], SSEScalar);
return (Result);
-}
#else
-HMM_EXTERN hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar);
+ hmm_mat4 Result;
+
+ int Columns;
+ for(Columns = 0; Columns < 4; ++Columns)
+ {
+ int Rows;
+ for(Rows = 0; Rows < 4; ++Rows)
+ {
+ Result.Elements[Columns][Rows] = Matrix.Elements[Columns][Rows] / Scalar;
+ }
+ }
+
+ return (Result);
#endif
+}
/*
@@ -1450,7 +1570,33 @@ HMM_INLINE hmm_mat4 HMM_Translate(hmm_vec3 Translation)
return (Result);
}
-HMM_EXTERN hmm_mat4 HMM_Rotate(float AngleRadians, hmm_vec3 Axis);
+COVERAGE(HMM_Rotate, 1)
+HMM_INLINE hmm_mat4 HMM_Rotate(float AngleRadians, hmm_vec3 Axis)
+{
+ ASSERT_COVERED(HMM_Rotate);
+
+ hmm_mat4 Result = HMM_Mat4d(1.0f);
+
+ Axis = HMM_NormalizeVec3(Axis);
+
+ float SinTheta = HMM_SinF(AngleRadians);
+ float CosTheta = HMM_CosF(AngleRadians);
+ float CosValue = 1.0f - CosTheta;
+
+ Result.Elements[0][0] = (Axis.X * Axis.X * CosValue) + CosTheta;
+ Result.Elements[0][1] = (Axis.X * Axis.Y * CosValue) + (Axis.Z * SinTheta);
+ Result.Elements[0][2] = (Axis.X * Axis.Z * CosValue) - (Axis.Y * SinTheta);
+
+ Result.Elements[1][0] = (Axis.Y * Axis.X * CosValue) - (Axis.Z * SinTheta);
+ Result.Elements[1][1] = (Axis.Y * Axis.Y * CosValue) + CosTheta;
+ Result.Elements[1][2] = (Axis.Y * Axis.Z * CosValue) + (Axis.X * SinTheta);
+
+ Result.Elements[2][0] = (Axis.Z * Axis.X * CosValue) + (Axis.Y * SinTheta);
+ Result.Elements[2][1] = (Axis.Z * Axis.Y * CosValue) - (Axis.X * SinTheta);
+ Result.Elements[2][2] = (Axis.Z * Axis.Z * CosValue) + CosTheta;
+
+ return (Result);
+}
COVERAGE(HMM_Scale, 1)
HMM_INLINE hmm_mat4 HMM_Scale(hmm_vec3 Scale)
@@ -1466,7 +1612,39 @@ HMM_INLINE hmm_mat4 HMM_Scale(hmm_vec3 Scale)
return (Result);
}
-HMM_EXTERN hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up);
+COVERAGE(HMM_LookAt, 1)
+HMM_INLINE hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up)
+{
+ ASSERT_COVERED(HMM_LookAt);
+
+ hmm_mat4 Result;
+
+ hmm_vec3 F = HMM_NormalizeVec3(HMM_SubtractVec3(Center, Eye));
+ hmm_vec3 S = HMM_NormalizeVec3(HMM_Cross(F, Up));
+ hmm_vec3 U = HMM_Cross(S, F);
+
+ Result.Elements[0][0] = S.X;
+ Result.Elements[0][1] = U.X;
+ Result.Elements[0][2] = -F.X;
+ Result.Elements[0][3] = 0.0f;
+
+ Result.Elements[1][0] = S.Y;
+ Result.Elements[1][1] = U.Y;
+ Result.Elements[1][2] = -F.Y;
+ Result.Elements[1][3] = 0.0f;
+
+ Result.Elements[2][0] = S.Z;
+ Result.Elements[2][1] = U.Z;
+ Result.Elements[2][2] = -F.Z;
+ Result.Elements[2][3] = 0.0f;
+
+ Result.Elements[3][0] = -HMM_DotVec3(S, Eye);
+ Result.Elements[3][1] = -HMM_DotVec3(U, Eye);
+ Result.Elements[3][2] = HMM_DotVec3(F, Eye);
+ Result.Elements[3][3] = 1.0f;
+
+ return (Result);
+}
/*
@@ -1624,8 +1802,6 @@ HMM_INLINE hmm_quaternion HMM_DivideQuaternionF(hmm_quaternion Left, float Divid
return (Result);
}
-HMM_EXTERN hmm_quaternion HMM_InverseQuaternion(hmm_quaternion Left);
-
COVERAGE(HMM_DotQuaternion, 1)
HMM_INLINE float HMM_DotQuaternion(hmm_quaternion Left, hmm_quaternion Right)
{
@@ -1647,6 +1823,29 @@ HMM_INLINE float HMM_DotQuaternion(hmm_quaternion Left, hmm_quaternion Right)
return (Result);
}
+COVERAGE(HMM_InverseQuaternion, 1)
+HMM_INLINE hmm_quaternion HMM_InverseQuaternion(hmm_quaternion Left)
+{
+ ASSERT_COVERED(HMM_InverseQuaternion);
+
+ hmm_quaternion Conjugate;
+ hmm_quaternion Result;
+ float Norm = 0;
+ float NormSquared = 0;
+
+ Conjugate.X = -Left.X;
+ Conjugate.Y = -Left.Y;
+ Conjugate.Z = -Left.Z;
+ Conjugate.W = Left.W;
+
+ Norm = HMM_SquareRootF(HMM_DotQuaternion(Left, Left));
+ NormSquared = Norm * Norm;
+
+ Result = HMM_DivideQuaternionF(Conjugate, NormSquared);
+
+ return (Result);
+}
+
COVERAGE(HMM_NormalizeQuaternion, 1)
HMM_INLINE hmm_quaternion HMM_NormalizeQuaternion(hmm_quaternion Left)
{
@@ -1684,14 +1883,167 @@ HMM_INLINE hmm_quaternion HMM_NLerp(hmm_quaternion Left, float Time, hmm_quatern
return (Result);
}
-HMM_EXTERN hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right);
-HMM_EXTERN hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left);
-HMM_EXTERN hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 Left);
-HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotationRadians);
-
-#ifdef __cplusplus
-}
-#endif
+COVERAGE(HMM_Slerp, 1)
+HMM_INLINE hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
+{
+ ASSERT_COVERED(HMM_Slerp);
+
+ hmm_quaternion Result;
+ hmm_quaternion QuaternionLeft;
+ hmm_quaternion QuaternionRight;
+
+ float Cos_Theta = HMM_DotQuaternion(Left, Right);
+ float Angle = HMM_ACosF(Cos_Theta);
+
+ float S1 = HMM_SinF((1.0f - Time) * Angle);
+ float S2 = HMM_SinF(Time * Angle);
+ float Is = 1.0f / HMM_SinF(Angle);
+
+ QuaternionLeft = HMM_MultiplyQuaternionF(Left, S1);
+ QuaternionRight = HMM_MultiplyQuaternionF(Right, S2);
+
+ Result = HMM_AddQuaternion(QuaternionLeft, QuaternionRight);
+ Result = HMM_MultiplyQuaternionF(Result, Is);
+
+ return (Result);
+}
+
+COVERAGE(HMM_QuaternionToMat4, 1)
+HMM_INLINE hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left)
+{
+ ASSERT_COVERED(HMM_QuaternionToMat4);
+
+ hmm_mat4 Result;
+
+ hmm_quaternion NormalizedQuaternion = HMM_NormalizeQuaternion(Left);
+
+ float XX, YY, ZZ,
+ XY, XZ, YZ,
+ WX, WY, WZ;
+
+ XX = NormalizedQuaternion.X * NormalizedQuaternion.X;
+ YY = NormalizedQuaternion.Y * NormalizedQuaternion.Y;
+ ZZ = NormalizedQuaternion.Z * NormalizedQuaternion.Z;
+ XY = NormalizedQuaternion.X * NormalizedQuaternion.Y;
+ XZ = NormalizedQuaternion.X * NormalizedQuaternion.Z;
+ YZ = NormalizedQuaternion.Y * NormalizedQuaternion.Z;
+ WX = NormalizedQuaternion.W * NormalizedQuaternion.X;
+ WY = NormalizedQuaternion.W * NormalizedQuaternion.Y;
+ WZ = NormalizedQuaternion.W * NormalizedQuaternion.Z;
+
+ Result.Elements[0][0] = 1.0f - 2.0f * (YY + ZZ);
+ Result.Elements[0][1] = 2.0f * (XY + WZ);
+ Result.Elements[0][2] = 2.0f * (XZ - WY);
+ Result.Elements[0][3] = 0.0f;
+
+ Result.Elements[1][0] = 2.0f * (XY - WZ);
+ Result.Elements[1][1] = 1.0f - 2.0f * (XX + ZZ);
+ Result.Elements[1][2] = 2.0f * (YZ + WX);
+ Result.Elements[1][3] = 0.0f;
+
+ Result.Elements[2][0] = 2.0f * (XZ + WY);
+ Result.Elements[2][1] = 2.0f * (YZ - WX);
+ Result.Elements[2][2] = 1.0f - 2.0f * (XX + YY);
+ Result.Elements[2][3] = 0.0f;
+
+ Result.Elements[3][0] = 0.0f;
+ Result.Elements[3][1] = 0.0f;
+ Result.Elements[3][2] = 0.0f;
+ Result.Elements[3][3] = 1.0f;
+
+ return (Result);
+}
+
+// This method taken from Mike Day at Insomniac Games.
+// https://d3cw3dd2w32x2b.cloudfront.net/wp-content/uploads/2015/01/matrix-to-quat.pdf
+//
+// Note that as mentioned at the top of the paper, the paper assumes the matrix
+// would be *post*-multiplied to a vector to rotate it, meaning the matrix is
+// the transpose of what we're dealing with. But, because our matrices are
+// stored in column-major order, the indices *appear* to match the paper.
+//
+// For example, m12 in the paper is row 1, column 2. We need to transpose it to
+// row 2, column 1. But, because the column comes first when referencing
+// elements, it looks like M.Elements[1][2].
+//
+// Don't be confused! Or if you must be confused, at least trust this
+// comment. :)
+COVERAGE(HMM_Mat4ToQuaternion, 4)
+HMM_INLINE hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
+{
+ float T;
+ hmm_quaternion Q;
+
+ if (M.Elements[2][2] < 0.0f) {
+ if (M.Elements[0][0] > M.Elements[1][1]) {
+ ASSERT_COVERED(HMM_Mat4ToQuaternion);
+
+ T = 1 + M.Elements[0][0] - M.Elements[1][1] - M.Elements[2][2];
+ Q = HMM_Quaternion(
+ T,
+ M.Elements[0][1] + M.Elements[1][0],
+ M.Elements[2][0] + M.Elements[0][2],
+ M.Elements[1][2] - M.Elements[2][1]
+ );
+ } else {
+ ASSERT_COVERED(HMM_Mat4ToQuaternion);
+
+ T = 1 - M.Elements[0][0] + M.Elements[1][1] - M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[0][1] + M.Elements[1][0],
+ T,
+ M.Elements[1][2] + M.Elements[2][1],
+ M.Elements[2][0] - M.Elements[0][2]
+ );
+ }
+ } else {
+ if (M.Elements[0][0] < -M.Elements[1][1]) {
+ ASSERT_COVERED(HMM_Mat4ToQuaternion);
+
+ T = 1 - M.Elements[0][0] - M.Elements[1][1] + M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[2][0] + M.Elements[0][2],
+ M.Elements[1][2] + M.Elements[2][1],
+ T,
+ M.Elements[0][1] - M.Elements[1][0]
+ );
+ } else {
+ ASSERT_COVERED(HMM_Mat4ToQuaternion);
+
+ T = 1 + M.Elements[0][0] + M.Elements[1][1] + M.Elements[2][2];
+ Q = HMM_Quaternion(
+ M.Elements[1][2] - M.Elements[2][1],
+ M.Elements[2][0] - M.Elements[0][2],
+ M.Elements[0][1] - M.Elements[1][0],
+ T
+ );
+ }
+ }
+
+ Q = HMM_MultiplyQuaternionF(Q, 0.5f / HMM_SquareRootF(T));
+
+ return Q;
+}
+
+COVERAGE(HMM_QuaternionFromAxisAngle, 1)
+HMM_INLINE hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotationRadians)
+{
+ ASSERT_COVERED(HMM_QuaternionFromAxisAngle);
+
+ hmm_quaternion Result;
+
+ hmm_vec3 AxisNormalized = HMM_NormalizeVec3(Axis);
+ float SineOfRotation = HMM_SinF(AngleOfRotationRadians / 2.0f);
+
+ Result.XYZ = HMM_MultiplyVec3f(AxisNormalized, SineOfRotation);
+ Result.W = HMM_CosF(AngleOfRotationRadians / 2.0f);
+
+ return (Result);
+}
+
+#ifdef __cplusplus
+}
+#endif
#ifdef __cplusplus
@@ -2792,444 +3144,3 @@ HMM_INLINE hmm_bool operator!=(hmm_vec4 Left, hmm_vec4 Right)
#endif
#endif /* HANDMADE_MATH_H */
-
-#ifdef HANDMADE_MATH_IMPLEMENTATION
-
-COVERAGE(HMM_Power, 2)
-float HMM_Power(float Base, int Exponent)
-{
- ASSERT_COVERED(HMM_Power);
-
- float Result = 1.0f;
- float Mul = Exponent < 0 ? 1.f / Base : Base;
- int X = Exponent < 0 ? -Exponent : Exponent;
- while (X)
- {
- if (X & 1)
- {
- ASSERT_COVERED(HMM_Power);
-
- Result *= Mul;
- }
-
- Mul *= Mul;
- X >>= 1;
- }
-
- return (Result);
-}
-
-#ifndef HANDMADE_MATH__USE_SSE
-COVERAGE(HMM_Transpose, 1)
-hmm_mat4 HMM_Transpose(hmm_mat4 Matrix)
-{
- ASSERT_COVERED(HMM_Transpose);
-
- hmm_mat4 Result;
-
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- Result.Elements[Rows][Columns] = Matrix.Elements[Columns][Rows];
- }
- }
-
- return (Result);
-}
-#endif
-
-#ifndef HANDMADE_MATH__USE_SSE
-COVERAGE(HMM_AddMat4, 1)
-hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
-{
- ASSERT_COVERED(HMM_AddMat4);
-
- hmm_mat4 Result;
-
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- Result.Elements[Columns][Rows] = Left.Elements[Columns][Rows] + Right.Elements[Columns][Rows];
- }
- }
-
- return (Result);
-}
-#endif
-
-#ifndef HANDMADE_MATH__USE_SSE
-COVERAGE(HMM_SubtractMat4, 1)
-hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
-{
- ASSERT_COVERED(HMM_SubtractMat4);
-
- hmm_mat4 Result;
-
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- Result.Elements[Columns][Rows] = Left.Elements[Columns][Rows] - Right.Elements[Columns][Rows];
- }
- }
-
- return (Result);
-}
-#endif
-
-COVERAGE(HMM_MultiplyMat4, 1)
-hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right)
-{
- ASSERT_COVERED(HMM_MultiplyMat4);
-
- hmm_mat4 Result;
-
-#ifdef HANDMADE_MATH__USE_SSE
- Result.Columns[0] = HMM_LinearCombineSSE(Right.Columns[0], Left);
- Result.Columns[1] = HMM_LinearCombineSSE(Right.Columns[1], Left);
- Result.Columns[2] = HMM_LinearCombineSSE(Right.Columns[2], Left);
- Result.Columns[3] = HMM_LinearCombineSSE(Right.Columns[3], Left);
-#else
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- float Sum = 0;
- int CurrentMatrice;
- for(CurrentMatrice = 0; CurrentMatrice < 4; ++CurrentMatrice)
- {
- Sum += Left.Elements[CurrentMatrice][Rows] * Right.Elements[Columns][CurrentMatrice];
- }
-
- Result.Elements[Columns][Rows] = Sum;
- }
- }
-#endif
-
- return (Result);
-}
-
-#ifndef HANDMADE_MATH__USE_SSE
-COVERAGE(HMM_MultiplyMat4f, 1)
-hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
-{
- ASSERT_COVERED(HMM_MultiplyMat4f);
-
- hmm_mat4 Result;
-
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- Result.Elements[Columns][Rows] = Matrix.Elements[Columns][Rows] * Scalar;
- }
- }
-
- return (Result);
-}
-#endif
-
-COVERAGE(HMM_MultiplyMat4ByVec4, 1)
-hmm_vec4 HMM_MultiplyMat4ByVec4(hmm_mat4 Matrix, hmm_vec4 Vector)
-{
- ASSERT_COVERED(HMM_MultiplyMat4ByVec4);
-
- hmm_vec4 Result;
-
-#ifdef HANDMADE_MATH__USE_SSE
- Result.InternalElementsSSE = HMM_LinearCombineSSE(Vector.InternalElementsSSE, Matrix);
-#else
- int Columns, Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- float Sum = 0;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- Sum += Matrix.Elements[Columns][Rows] * Vector.Elements[Columns];
- }
-
- Result.Elements[Rows] = Sum;
- }
-#endif
-
- return (Result);
-}
-
-#ifndef HANDMADE_MATH__USE_SSE
-COVERAGE(HMM_DivideMat4f, 1);
-hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
-{
- ASSERT_COVERED(HMM_DivideMat4f);
-
- hmm_mat4 Result;
-
- int Columns;
- for(Columns = 0; Columns < 4; ++Columns)
- {
- int Rows;
- for(Rows = 0; Rows < 4; ++Rows)
- {
- Result.Elements[Columns][Rows] = Matrix.Elements[Columns][Rows] / Scalar;
- }
- }
-
- return (Result);
-}
-#endif
-
-COVERAGE(HMM_Rotate, 1)
-hmm_mat4 HMM_Rotate(float AngleRadians, hmm_vec3 Axis)
-{
- ASSERT_COVERED(HMM_Rotate);
-
- hmm_mat4 Result = HMM_Mat4d(1.0f);
-
- Axis = HMM_NormalizeVec3(Axis);
-
- float SinTheta = HMM_SinF(AngleRadians);
- float CosTheta = HMM_CosF(AngleRadians);
- float CosValue = 1.0f - CosTheta;
-
- Result.Elements[0][0] = (Axis.X * Axis.X * CosValue) + CosTheta;
- Result.Elements[0][1] = (Axis.X * Axis.Y * CosValue) + (Axis.Z * SinTheta);
- Result.Elements[0][2] = (Axis.X * Axis.Z * CosValue) - (Axis.Y * SinTheta);
-
- Result.Elements[1][0] = (Axis.Y * Axis.X * CosValue) - (Axis.Z * SinTheta);
- Result.Elements[1][1] = (Axis.Y * Axis.Y * CosValue) + CosTheta;
- Result.Elements[1][2] = (Axis.Y * Axis.Z * CosValue) + (Axis.X * SinTheta);
-
- Result.Elements[2][0] = (Axis.Z * Axis.X * CosValue) + (Axis.Y * SinTheta);
- Result.Elements[2][1] = (Axis.Z * Axis.Y * CosValue) - (Axis.X * SinTheta);
- Result.Elements[2][2] = (Axis.Z * Axis.Z * CosValue) + CosTheta;
-
- return (Result);
-}
-
-COVERAGE(HMM_LookAt, 1)
-hmm_mat4 HMM_LookAt(hmm_vec3 Eye, hmm_vec3 Center, hmm_vec3 Up)
-{
- ASSERT_COVERED(HMM_LookAt);
-
- hmm_mat4 Result;
-
- hmm_vec3 F = HMM_NormalizeVec3(HMM_SubtractVec3(Center, Eye));
- hmm_vec3 S = HMM_NormalizeVec3(HMM_Cross(F, Up));
- hmm_vec3 U = HMM_Cross(S, F);
-
- Result.Elements[0][0] = S.X;
- Result.Elements[0][1] = U.X;
- Result.Elements[0][2] = -F.X;
- Result.Elements[0][3] = 0.0f;
-
- Result.Elements[1][0] = S.Y;
- Result.Elements[1][1] = U.Y;
- Result.Elements[1][2] = -F.Y;
- Result.Elements[1][3] = 0.0f;
-
- Result.Elements[2][0] = S.Z;
- Result.Elements[2][1] = U.Z;
- Result.Elements[2][2] = -F.Z;
- Result.Elements[2][3] = 0.0f;
-
- Result.Elements[3][0] = -HMM_DotVec3(S, Eye);
- Result.Elements[3][1] = -HMM_DotVec3(U, Eye);
- Result.Elements[3][2] = HMM_DotVec3(F, Eye);
- Result.Elements[3][3] = 1.0f;
-
- return (Result);
-}
-
-COVERAGE(HMM_InverseQuaternion, 1)
-hmm_quaternion HMM_InverseQuaternion(hmm_quaternion Left)
-{
- ASSERT_COVERED(HMM_InverseQuaternion);
-
- hmm_quaternion Conjugate;
- hmm_quaternion Result;
- float Norm = 0;
- float NormSquared = 0;
-
- Conjugate.X = -Left.X;
- Conjugate.Y = -Left.Y;
- Conjugate.Z = -Left.Z;
- Conjugate.W = Left.W;
-
- Norm = HMM_SquareRootF(HMM_DotQuaternion(Left, Left));
- NormSquared = Norm * Norm;
-
- Result = HMM_DivideQuaternionF(Conjugate, NormSquared);
-
- return (Result);
-}
-
-COVERAGE(HMM_Slerp, 1)
-hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
-{
- ASSERT_COVERED(HMM_Slerp);
-
- hmm_quaternion Result;
- hmm_quaternion QuaternionLeft;
- hmm_quaternion QuaternionRight;
-
- float Cos_Theta = HMM_DotQuaternion(Left, Right);
- float Angle = HMM_ACosF(Cos_Theta);
-
- float S1 = HMM_SinF((1.0f - Time) * Angle);
- float S2 = HMM_SinF(Time * Angle);
- float Is = 1.0f / HMM_SinF(Angle);
-
- QuaternionLeft = HMM_MultiplyQuaternionF(Left, S1);
- QuaternionRight = HMM_MultiplyQuaternionF(Right, S2);
-
- Result = HMM_AddQuaternion(QuaternionLeft, QuaternionRight);
- Result = HMM_MultiplyQuaternionF(Result, Is);
-
- return (Result);
-}
-
-COVERAGE(HMM_QuaternionToMat4, 1)
-hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left)
-{
- ASSERT_COVERED(HMM_QuaternionToMat4);
-
- hmm_mat4 Result;
-
- hmm_quaternion NormalizedQuaternion = HMM_NormalizeQuaternion(Left);
-
- float XX, YY, ZZ,
- XY, XZ, YZ,
- WX, WY, WZ;
-
- XX = NormalizedQuaternion.X * NormalizedQuaternion.X;
- YY = NormalizedQuaternion.Y * NormalizedQuaternion.Y;
- ZZ = NormalizedQuaternion.Z * NormalizedQuaternion.Z;
- XY = NormalizedQuaternion.X * NormalizedQuaternion.Y;
- XZ = NormalizedQuaternion.X * NormalizedQuaternion.Z;
- YZ = NormalizedQuaternion.Y * NormalizedQuaternion.Z;
- WX = NormalizedQuaternion.W * NormalizedQuaternion.X;
- WY = NormalizedQuaternion.W * NormalizedQuaternion.Y;
- WZ = NormalizedQuaternion.W * NormalizedQuaternion.Z;
-
- Result.Elements[0][0] = 1.0f - 2.0f * (YY + ZZ);
- Result.Elements[0][1] = 2.0f * (XY + WZ);
- Result.Elements[0][2] = 2.0f * (XZ - WY);
- Result.Elements[0][3] = 0.0f;
-
- Result.Elements[1][0] = 2.0f * (XY - WZ);
- Result.Elements[1][1] = 1.0f - 2.0f * (XX + ZZ);
- Result.Elements[1][2] = 2.0f * (YZ + WX);
- Result.Elements[1][3] = 0.0f;
-
- Result.Elements[2][0] = 2.0f * (XZ + WY);
- Result.Elements[2][1] = 2.0f * (YZ - WX);
- Result.Elements[2][2] = 1.0f - 2.0f * (XX + YY);
- Result.Elements[2][3] = 0.0f;
-
- Result.Elements[3][0] = 0.0f;
- Result.Elements[3][1] = 0.0f;
- Result.Elements[3][2] = 0.0f;
- Result.Elements[3][3] = 1.0f;
-
- return (Result);
-}
-
-// This method taken from Mike Day at Insomniac Games.
-// https://d3cw3dd2w32x2b.cloudfront.net/wp-content/uploads/2015/01/matrix-to-quat.pdf
-//
-// Note that as mentioned at the top of the paper, the paper assumes the matrix
-// would be *post*-multiplied to a vector to rotate it, meaning the matrix is
-// the transpose of what we're dealing with. But, because our matrices are
-// stored in column-major order, the indices *appear* to match the paper.
-//
-// For example, m12 in the paper is row 1, column 2. We need to transpose it to
-// row 2, column 1. But, because the column comes first when referencing
-// elements, it looks like M.Elements[1][2].
-//
-// Don't be confused! Or if you must be confused, at least trust this
-// comment. :)
-COVERAGE(HMM_Mat4ToQuaternion, 4)
-hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
-{
- float T;
- hmm_quaternion Q;
-
- if (M.Elements[2][2] < 0.0f) {
- if (M.Elements[0][0] > M.Elements[1][1]) {
- ASSERT_COVERED(HMM_Mat4ToQuaternion);
-
- T = 1 + M.Elements[0][0] - M.Elements[1][1] - M.Elements[2][2];
- Q = HMM_Quaternion(
- T,
- M.Elements[0][1] + M.Elements[1][0],
- M.Elements[2][0] + M.Elements[0][2],
- M.Elements[1][2] - M.Elements[2][1]
- );
- } else {
- ASSERT_COVERED(HMM_Mat4ToQuaternion);
-
- T = 1 - M.Elements[0][0] + M.Elements[1][1] - M.Elements[2][2];
- Q = HMM_Quaternion(
- M.Elements[0][1] + M.Elements[1][0],
- T,
- M.Elements[1][2] + M.Elements[2][1],
- M.Elements[2][0] - M.Elements[0][2]
- );
- }
- } else {
- if (M.Elements[0][0] < -M.Elements[1][1]) {
- ASSERT_COVERED(HMM_Mat4ToQuaternion);
-
- T = 1 - M.Elements[0][0] - M.Elements[1][1] + M.Elements[2][2];
- Q = HMM_Quaternion(
- M.Elements[2][0] + M.Elements[0][2],
- M.Elements[1][2] + M.Elements[2][1],
- T,
- M.Elements[0][1] - M.Elements[1][0]
- );
- } else {
- ASSERT_COVERED(HMM_Mat4ToQuaternion);
-
- T = 1 + M.Elements[0][0] + M.Elements[1][1] + M.Elements[2][2];
- Q = HMM_Quaternion(
- M.Elements[1][2] - M.Elements[2][1],
- M.Elements[2][0] - M.Elements[0][2],
- M.Elements[0][1] - M.Elements[1][0],
- T
- );
- }
- }
-
- Q = HMM_MultiplyQuaternionF(Q, 0.5f / HMM_SquareRootF(T));
-
- return Q;
-}
-
-COVERAGE(HMM_QuaternionFromAxisAngle, 1)
-hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotationRadians)
-{
- ASSERT_COVERED(HMM_QuaternionFromAxisAngle);
-
- hmm_quaternion Result;
-
- hmm_vec3 AxisNormalized = HMM_NormalizeVec3(Axis);
- float SineOfRotation = HMM_SinF(AngleOfRotationRadians / 2.0f);
-
- Result.XYZ = HMM_MultiplyVec3f(AxisNormalized, SineOfRotation);
- Result.W = HMM_CosF(AngleOfRotationRadians / 2.0f);
-
- return (Result);
-}
-
-#endif /* HANDMADE_MATH_IMPLEMENTATION */
|
diff --git a/test/HandmadeMath.c b/test/HandmadeMath.c
--- a/test/HandmadeMath.c
+++ b/test/HandmadeMath.c
@@ -2,6 +2,4 @@
#include "HandmadeTest.h"
#endif
-#define HANDMADE_MATH_IMPLEMENTATION
-#define HANDMADE_MATH_NO_INLINE
#include "../HandmadeMath.h"
diff --git a/test/test.bat b/test/test.bat
--- a/test/test.bat
+++ b/test/test.bat
@@ -12,16 +12,16 @@ if "%1%"=="travis" (
if not exist "build" mkdir build
pushd build
-cl /Fehmm_test_c.exe ..\HandmadeMath.c ..\hmm_test.c
+cl /Fehmm_test_c.exe ..\HandmadeMath.c ..\hmm_test.c || popd && exit /B
hmm_test_c
-cl /Fehmm_test_c_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.c ..\hmm_test.c
+cl /Fehmm_test_c_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.c ..\hmm_test.c || popd && exit /B
hmm_test_c_no_sse
-cl /Fehmm_test_cpp.exe ..\HandmadeMath.cpp ..\hmm_test.cpp
+cl /Fehmm_test_cpp.exe ..\HandmadeMath.cpp ..\hmm_test.cpp || popd && exit /B
hmm_test_cpp
-cl /Fehmm_test_cpp_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.cpp ..\hmm_test.cpp
+cl /Fehmm_test_cpp_no_sse.exe /DHANDMADE_MATH_NO_SSE ..\HandmadeMath.cpp ..\hmm_test.cpp || popd && exit /B
hmm_test_cpp_no_sse
popd
|
Remove the implementation section, shove it all in the header
I know we've gone back and forth on this before (#57) but I don't think we need to have a separate implementation section in Handmade Math.
Most of the function implementations are inline, since that gives the compiler the most context for optimizations (and math needs to be optimized!). The ones that are _not_ inline were made that way because we were worried about redundant definitions between translation units, but with link-time optimization, compilers are mostly able to prevent that from happening.
So basically we are forcing the user to set up the `HANDMADE_MATH_IMPLEMENTATION` part for about three functions, and for little to no benefit.
I propose that we make everything in Handmade Math inline for 2.0, and rip out `HANDMADE_MATH_IMPLEMENTATION` completely.
|
I’m fully onboard for this. LETS DO IT 👍
| 2020-04-10T00:56:36
|
c
|
Hard
|
libssh2/libssh2
| 1,072
|
libssh2__libssh2-1072
|
[
"1056"
] |
e5c03043332bfed6b56b0300a5f8059d37b74018
|
diff --git a/Makefile.mk b/Makefile.mk
--- a/Makefile.mk
+++ b/Makefile.mk
@@ -211,15 +211,16 @@ prebuild: $(OBJ_DIR) $(OBJ_DIR)/version.inc
example: $(TARGETS_EXAMPLES)
-# Get DOCKER_TESTS, STANDALONE_TESTS, SSHD_TESTS, TESTS_WITH_LIB_STATIC,
+# Get DOCKER_TESTS, DOCKER_TESTS_STATIC, STANDALONE_TESTS, STANDALONE_TESTS_STATIC, SSHD_TESTS,
# librunner_la_SOURCES defines
include tests/Makefile.inc
+ifndef DYN
+DOCKER_TESTS += $(DOCKER_TESTS_STATIC)
+STANDALONE_TESTS += $(STANDALONE_TESTS_STATIC)
+endif
TARGETS_RUNNER := $(TARGET)-runner.a
TARGETS_RUNNER_OBJS := $(addprefix $(OBJ_DIR)/,$(patsubst %.c,%.o,$(filter %.c,$(librunner_la_SOURCES))))
TARGETS_TESTS := $(patsubst %.c,%$(BIN_EXT),$(addprefix tests/,$(addsuffix .c,$(DOCKER_TESTS) $(STANDALONE_TESTS) $(SSHD_TESTS))))
-ifdef DYN
-TARGETS_TESTS := $(filter-out $(patsubst %.c,%$(BIN_EXT),$(addprefix tests/,$(addsuffix .c,$(TESTS_WITH_LIB_STATIC)))),$(TARGETS_TESTS))
-endif
test: $(TARGETS_RUNNER) $(TARGETS_TESTS)
diff --git a/configure.ac b/configure.ac
--- a/configure.ac
+++ b/configure.ac
@@ -371,6 +371,8 @@ fi
AM_CONDITIONAL([HAVE_WINDRES],
[test "x$have_windows_h" = "xyes" && test "x${enable_shared}" = "xyes" && test -n "${RC}"])
+AM_CONDITIONAL([HAVE_LIB_STATIC], [test "x$enable_static" != "xno"])
+
# Configure parameters
LIBSSH2_CHECK_OPTION_WERROR
|
diff --git a/tests/CMakeLists.txt b/tests/CMakeLists.txt
--- a/tests/CMakeLists.txt
+++ b/tests/CMakeLists.txt
@@ -39,9 +39,11 @@ include(CopyRuntimeDependencies)
list(APPEND LIBRARIES ${SOCKET_LIBRARIES})
transform_makefile_inc("Makefile.inc" "${CMAKE_CURRENT_BINARY_DIR}/Makefile.inc.cmake")
-# Get 'DOCKER_TESTS', 'STANDALONE_TESTS', 'SSHD_TESTS', 'TESTS_WITH_LIB_STATIC',
+# Get 'DOCKER_TESTS', 'DOCKER_TESTS_STATIC', 'STANDALONE_TESTS', 'STANDALONE_TESTS_STATIC', 'SSHD_TESTS',
# 'librunner_la_SOURCES' variables
include(${CMAKE_CURRENT_BINARY_DIR}/Makefile.inc.cmake)
+list(APPEND DOCKER_TESTS ${DOCKER_TESTS_STATIC})
+list(APPEND STANDALONE_TESTS ${STANDALONE_TESTS_STATIC})
if(CMAKE_COMPILER_IS_GNUCC)
find_program(GCOV_PATH gcov)
@@ -71,7 +73,7 @@ target_compile_definitions(runner PRIVATE "${CRYPTO_BACKEND_DEFINE}")
target_include_directories(runner PRIVATE "${CMAKE_CURRENT_BINARY_DIR}/../src" ../src ../include "${CRYPTO_BACKEND_INCLUDE_DIR}")
foreach(test ${DOCKER_TESTS} ${STANDALONE_TESTS} ${SSHD_TESTS})
- if(NOT ";${TESTS_WITH_LIB_STATIC};" MATCHES ";${test};")
+ if(NOT ";${DOCKER_TESTS_STATIC};${STANDALONE_TESTS_STATIC};" MATCHES ";${test};")
set(LIB_FOR_TESTS ${LIB_SELECTED})
elseif(TARGET ${LIB_STATIC})
set(LIB_FOR_TESTS ${LIB_STATIC})
diff --git a/tests/Makefile.am b/tests/Makefile.am
--- a/tests/Makefile.am
+++ b/tests/Makefile.am
@@ -2,10 +2,15 @@ SUBDIRS = ossfuzz
AM_CPPFLAGS = -I$(top_builddir)/src -I$(top_srcdir)/src -I$(top_srcdir)/include
-# Get DOCKER_TESTS, STANDALONE_TESTS, SSHD_TESTS, TESTS_WITH_LIB_STATIC,
+# Get DOCKER_TESTS, DOCKER_TESTS_STATIC, STANDALONE_TESTS, STANDALONE_TESTS_STATOC, SSHD_TESTS,
# librunner_la_SOURCES defines and *_LDFLAGS for statically linked tests.
include Makefile.inc
+if HAVE_LIB_STATIC
+DOCKER_TESTS += $(DOCKER_TESTS_STATIC)
+STANDALONE_TESTS += $(STANDALONE_TESTS_STATIC)
+endif
+
# Some tests rely on the 'srcdir' env. Set by autotools automatically.
TESTS_ENVIRONMENT =
diff --git a/tests/Makefile.inc b/tests/Makefile.inc
--- a/tests/Makefile.inc
+++ b/tests/Makefile.inc
@@ -7,7 +7,6 @@ DOCKER_TESTS = \
test_aa_warmup \
test_agent_forward_ok \
test_auth_keyboard_fail \
- test_auth_keyboard_info_request \
test_auth_keyboard_ok \
test_auth_password_fail_password \
test_auth_password_fail_username \
@@ -23,12 +22,10 @@ DOCKER_TESTS = \
test_auth_pubkey_ok_rsa_encrypted \
test_auth_pubkey_ok_rsa_openssh \
test_auth_pubkey_ok_rsa_signed \
- test_hostkey \
test_hostkey_hash \
test_read
-STANDALONE_TESTS = \
- test_simple
+STANDALONE_TESTS =
SSHD_TESTS = \
test_ssh2 \
@@ -36,13 +33,15 @@ SSHD_TESTS = \
# Programs of the above that use internal libssh2 functions so they need
# to be statically linked against libssh2
-TESTS_WITH_LIB_STATIC = \
+DOCKER_TESTS_STATIC = \
test_auth_keyboard_info_request \
- test_hostkey \
+ test_hostkey
+
+STANDALONE_TESTS_STATIC = \
test_simple
# Copy of the above for Makefile.am.
-# Is there a way to reuse the list above?
+# Is there a way to reuse the lists above?
test_auth_keyboard_info_request_LDFLAGS = -static
test_hostkey_LDFLAGS = -static
test_simple_LDFLAGS = -static
|
`make check` fails with `--disable-static`
**Describe the bug**
`make check` fails with `--disable-static`.
**To Reproduce**
```
./configure --prefix=/usr --disable-static && make && make check
```
It produces:
```
/usr/bin/ld: test_auth_keyboard_info_request.o: in function `main':
test_auth_keyboard_info_request.c:(.text.startup+0xec): undefined reference to `userauth_keyboard_interactive_decode_info_request'
/usr/bin/ld: test_auth_keyboard_info_request.c:(.text.startup+0x201): undefined reference to `userauth_keyboard_interactive_decode_info_request'
collect2: error: ld returned 1 exit status
```
**Expected behavior**
Test succeeds.
**Version:**
- OS and version: Linux (Linux From Scratch)
- libssh2 version: 1.11.0
- crypto backend and version: OpenSSL
**Additional context**
It looks like the reason is `userauth_keyboard_interactive_decode_info_request` not exported in the shared library because we are linking libssh2.so with `-export-symbols-regex '^libssh2_.*'`.
|
This function shouldn't be exported, but also should be available for use in unit tests. Hum.
| 2023-05-31T07:28:06
|
c
|
Hard
|
nginx/njs
| 936
|
nginx__njs-936
|
[
"934"
] |
34b80511acfd44a5cbbbce835d7540081e5d7527
|
diff --git a/external/njs_regex.c b/external/njs_regex.c
--- a/external/njs_regex.c
+++ b/external/njs_regex.c
@@ -114,6 +114,11 @@ njs_regex_escape(njs_mp_t *mp, njs_str_t *text)
for (p = start; p < end; p++) {
switch (*p) {
+ case '\\':
+ p += 1;
+
+ break;
+
case '[':
if (p + 1 < end && p[1] == ']') {
p += 1;
@@ -122,6 +127,11 @@ njs_regex_escape(njs_mp_t *mp, njs_str_t *text)
} else if (p + 2 < end && p[1] == '^' && p[2] == ']') {
p += 2;
anychars += 1;
+
+ } else {
+ while (p < end && *p != ']') {
+ p += 1;
+ }
}
break;
@@ -146,6 +156,15 @@ njs_regex_escape(njs_mp_t *mp, njs_str_t *text)
for (p = start; p < end; p++) {
switch (*p) {
+ case '\\':
+ *dst++ = *p;
+ if (p + 1 < end) {
+ p += 1;
+ *dst++ = *p;
+ }
+
+ continue;
+
case '[':
if (p + 1 < end && p[1] == ']') {
p += 1;
@@ -156,6 +175,14 @@ njs_regex_escape(njs_mp_t *mp, njs_str_t *text)
p += 2;
dst = njs_cpymem(dst, "[\\s\\S]", 6);
continue;
+
+ } else {
+ *dst++ = *p;
+ while (p < end && *p != ']') {
+ *dst++ = *p++;
+ }
+
+ continue;
}
}
diff --git a/nginx/ngx_js.c b/nginx/ngx_js.c
--- a/nginx/ngx_js.c
+++ b/nginx/ngx_js.c
@@ -978,6 +978,11 @@ ngx_qjs_clone(ngx_js_ctx_t *ctx, ngx_js_loc_conf_t *cf, void *external)
"js load module exception: %V", &exception);
goto destroy;
}
+
+ if (i != length - 1) {
+ /* JS_EvalFunction() does JS_FreeValue(cx, rv) for the last rv. */
+ JS_FreeValue(cx, rv);
+ }
}
if (JS_ResolveModule(cx, rv) < 0) {
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -11969,6 +11969,48 @@ static njs_unit_test_t njs_test[] =
{ njs_str("/[]a/.test('a')"),
njs_str("false") },
+ { njs_str("/[#[]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/[\\s[]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/[#[^]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/[#\\[]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/[\\[^]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/[^]abc]/.test('#abc]')"),
+ njs_str("true") },
+
+ { njs_str("/[[^]abc]/.test('[abc]')"),
+ njs_str("true") },
+
+ { njs_str("/[[^]abc]/.test('^abc]')"),
+ njs_str("true") },
+
+ { njs_str("/[]/.test('[]')"),
+ njs_str("false") },
+
+ { njs_str("/[[]/.test('[')"),
+ njs_str("true") },
+
+ { njs_str("/\\[]/.test('[]')"),
+ njs_str("true") },
+
+ { njs_str("/[]abc]/.test('abc]')"),
+ njs_str("false") },
+
+ { njs_str("/abc]/.test('abc]')"),
+ njs_str("true") },
+
+ { njs_str("/\\\\\\[]/.test('\\\\[]')"),
+ njs_str("true") },
+
#ifdef NJS_HAVE_PCRE2
{ njs_str("/[]*a/.test('a')"),
njs_str("true") },
|
Failed to run v8-v7 test
### Describe the bug
[run.zip](https://github.com/user-attachments/files/20789860/run.zip)
One of the regular expressions in the v8-v7 tests doesn't seem to parse correctly
```
var re37 = /\s*([+>~\s])\s*([a-zA-Z#.*:\[])/g;
```
```
Thrown:
SyntaxError: pcre_compile2("\s*([+>~\s])\s*([a-zA-Z#.*:\(?!))") failed: missing terminating ] for character class at "" in ./a.js:1
```
- [x] The bug is reproducible with the latest version of njs.
- [x] I minimized the code and NGINX configuration to the smallest
possible to reproduce the issue.
### To reproduce
Steps to reproduce the behavior:
- JS script
```js
var re37 = /\s*([+>~\s])\s*([a-zA-Z#.*:\[])/g;
```
### Expected behavior
A clear and concise description of what you expected to happen.
### Your environment
- Version of njs or specific commit
```
./build/njs -v
0.9.1
```
- OS: [e.g. Ubuntu 20.04]
Ubuntu 2504
| 2025-07-01T01:46:11
|
c
|
Hard
|
|
profanity-im/profanity
| 1,944
|
profanity-im__profanity-1944
|
[
"1940"
] |
605ee6e99a226565125ab72e7f16951930d8d6ee
|
diff --git a/src/event/server_events.c b/src/event/server_events.c
--- a/src/event/server_events.c
+++ b/src/event/server_events.c
@@ -58,6 +58,7 @@
#include "ui/window.h"
#include "tools/bookmark_ignore.h"
#include "xmpp/xmpp.h"
+#include "xmpp/iq.h"
#include "xmpp/muc.h"
#include "xmpp/chat_session.h"
#include "xmpp/roster_list.h"
@@ -196,6 +197,7 @@ sv_ev_roster_received(void)
void
sv_ev_connection_features_received(void)
{
+ iq_feature_retrieval_complete_handler();
#ifdef HAVE_OMEMO
omemo_publish_crypto_materials();
#endif
diff --git a/src/xmpp/iq.c b/src/xmpp/iq.c
--- a/src/xmpp/iq.c
+++ b/src/xmpp/iq.c
@@ -2539,7 +2539,6 @@ _disco_items_result_handler(xmpp_stanza_t* const stanza)
if (g_strcmp0(id, "discoitemsreq") == 0) {
cons_show_disco_items(items, from);
} else if (g_strcmp0(id, "discoitemsreq_onconnect") == 0) {
- received_disco_items = TRUE;
connection_set_disco_items(items);
while (late_delivery_windows) {
@@ -2554,6 +2553,12 @@ _disco_items_result_handler(xmpp_stanza_t* const stanza)
g_slist_free_full(items, (GDestroyNotify)_item_destroy);
}
+void
+iq_feature_retrieval_complete_handler(void)
+{
+ received_disco_items = TRUE;
+}
+
void
iq_send_stanza(xmpp_stanza_t* const stanza)
{
diff --git a/src/xmpp/iq.h b/src/xmpp/iq.h
--- a/src/xmpp/iq.h
+++ b/src/xmpp/iq.h
@@ -40,6 +40,7 @@ typedef int (*ProfIqCallback)(xmpp_stanza_t* const stanza, void* const userdata)
typedef void (*ProfIqFreeCallback)(void* userdata);
void iq_handlers_init(void);
+void iq_feature_retrieval_complete_handler(void);
void iq_send_stanza(xmpp_stanza_t* const stanza);
void iq_id_handler_add(const char* const id, ProfIqCallback func, ProfIqFreeCallback free_func, void* userdata);
void iq_disco_info_request_onconnect(const char* jid);
|
diff --git a/tests/unittests/xmpp/stub_xmpp.c b/tests/unittests/xmpp/stub_xmpp.c
--- a/tests/unittests/xmpp/stub_xmpp.c
+++ b/tests/unittests/xmpp/stub_xmpp.c
@@ -450,6 +450,11 @@ iq_mam_request(ProfChatWin* win, GDateTime* enddate)
{
}
+void
+iq_feature_retrieval_complete_handler(void)
+{
+}
+
void
publish_user_mood(const char* const mood, const char* const text)
{
|
Wrong error about server not supporting MAM.
<!--- Provide a general summary of the issue in the Title above -->
On startup profanity shows the error `Server doesn't support MAM (urn:xmpp:mam:2).` although the server supports MAM.
<!--- More than 50 issues open? Please don't file any new feature requests -->
<!--- Help us reduce the work first :-) -->
## Expected Behavior
It should only show that error if the server really doesn't support MAM.
## Current Behavior
On startup profanity shows the error `Server doesn't support MAM (urn:xmpp:mam:2).` although the server supports MAM.
## Steps to Reproduce (for bugs)
<!--- Describe, in detail, what needs to happen to reproduce this bug -->
<!--- Give us a screenshot (if it's helpful for this particular bug) -->
1. Start profanity and check messages in console window. (Don't know if this only happens in my set up or in general)
## Environment
* Debian Testing (trixie)
```
profanity --version
Profanity, version 0.14.0dev.master.0e66cbe4
Copyright (C) 2012 - 2019 James Booth <boothj5web@gmail.com>.
Copyright (C) 2019 - 2023 Michael Vetter <jubalh@iodoru.org>.
License GPLv3+: GNU GPL version 3 or later <https://www.gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Build information:
XMPP library: libstrophe
Desktop notification support: Enabled
OTR support: Disabled
PGP support: Enabled (libgpgme 1.18.0)
OMEMO support: Enabled
C plugins: Enabled
Python plugins: Disabled
GTK icons/clipboard: Disabled
GDK Pixbuf: Enabled
```
|
Did you try the patch I shared?
Does it happen for you on first connect as well or only on reconnect?
Going to open a PR with it when I have the time, maybe still today.
Yes, the patch worked. Just created the issue to assure it's not getting forgotten.
| 2023-12-28T18:14:43
|
c
|
Hard
|
nginx/njs
| 749
|
nginx__njs-749
|
[
"734"
] |
9d4bf6c60aa60a828609f64d1b5c50f71bb7ef62
|
diff --git a/src/njs_builtin.c b/src/njs_builtin.c
--- a/src/njs_builtin.c
+++ b/src/njs_builtin.c
@@ -783,13 +783,14 @@ njs_global_this_object(njs_vm_t *vm, njs_object_prop_t *self,
njs_object_prop_t *prop;
njs_lvlhsh_query_t lhq;
+ if (retval == NULL) {
+ return NJS_DECLINED;
+ }
+
njs_value_assign(retval, global);
if (njs_slow_path(setval != NULL)) {
njs_value_assign(retval, setval);
-
- } else if (njs_slow_path(retval == NULL)) {
- return NJS_DECLINED;
}
prop = njs_object_prop_alloc(vm, &self->name, retval, 1);
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -12885,6 +12885,9 @@ static njs_unit_test_t njs_test[] =
{ njs_str("var ex; try {({}) instanceof this} catch (e) {ex = e}; ex"),
njs_str("TypeError: right argument is not callable") },
+ { njs_str("delete global.global; global"),
+ njs_str("ReferenceError: \"global\" is not defined") },
+
{ njs_str("njs"),
njs_str("[object njs]") },
|
memmove-vec-unaligned-erms
Testcase
```js
delete this.global
```
ASAN
```
AddressSanitizer:DEADLYSIGNAL
=================================================================
==82143==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000000 (pc 0x7fee4e4e813f bp 0x7ffe41ff2930 sp 0x7ffe41ff20b8 T0)
==82143==The signal is caused by a WRITE memory access.
==82143==Hint: address points to the zero page.
#0 0x7fee4e4e813e in memcpy /build/glibc-uZu3wS/glibc-2.27/string/../sysdeps/x86_64/multiarch/memmove-vec-unaligned-erms.S:144
#1 0x4d9d0d in __asan_memcpy (/home/xxx/Desktop/njs/build/njs+0x4d9d0d)
#2 0x896f69 in njs_global_this_object /home/xxx/Desktop/njs/src/njs_builtin.c:786:5
#3 0x5542f2 in njs_value_property_delete /home/xxx/Desktop/njs/src/njs_value.c:1490:19
#4 0x594845 in njs_vmcode_interpreter /home/xxx/Desktop/njs/src/njs_vmcode.c:924:15
#5 0x5610fb in njs_vm_start /home/xxx/Desktop/njs/src/njs_vm.c:664:11
#6 0x51d7fd in njs_engine_njs_eval /home/xxx/Desktop/njs/external/njs_shell.c:1387:16
#7 0x519147 in njs_process_script /home/xxx/Desktop/njs/external/njs_shell.c:3528:11
#8 0x519147 in njs_process_file /home/xxx/Desktop/njs/external/njs_shell.c:3500
#9 0x519147 in njs_main /home/xxx/Desktop/njs/external/njs_shell.c:458
#10 0x519147 in main /home/xxx/Desktop/njs/external/njs_shell.c:488
#11 0x7fee4e44ec86 in __libc_start_main /build/glibc-uZu3wS/glibc-2.27/csu/../csu/libc-start.c:310
#12 0x41b3e9 in _start (/home/xxx/Desktop/njs/build/njs+0x41b3e9)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /build/glibc-uZu3wS/glibc-2.27/string/../sysdeps/x86_64/multiarch/memmove-vec-unaligned-erms.S:144 in memcpy
==82143==ABORTING
```
| 2024-06-27T02:16:56
|
c
|
Hard
|
|
nginx/njs
| 731
|
nginx__njs-731
|
[
"730"
] |
e9f8cdfa139d6bbf7d7855e7e197f27a43486998
|
diff --git a/src/njs_parser.c b/src/njs_parser.c
--- a/src/njs_parser.c
+++ b/src/njs_parser.c
@@ -2827,7 +2827,7 @@ njs_parser_arguments(njs_parser_t *parser, njs_lexer_token_t *token,
return njs_parser_stack_pop(parser);
}
- parser->scope->in_args = 1;
+ parser->scope->in_args++;
njs_parser_next(parser, njs_parser_argument_list);
@@ -2840,7 +2840,7 @@ static njs_int_t
njs_parser_parenthesis_or_comma(njs_parser_t *parser, njs_lexer_token_t *token,
njs_queue_link_t *current)
{
- parser->scope->in_args = 0;
+ parser->scope->in_args--;
if (token->type == NJS_TOKEN_CLOSE_PARENTHESIS) {
njs_lexer_consume_token(parser->lexer, 1);
@@ -3575,7 +3575,7 @@ njs_parser_await(njs_parser_t *parser, njs_lexer_token_t *token,
return NJS_ERROR;
}
- if (parser->scope->in_args) {
+ if (parser->scope->in_args > 0) {
njs_parser_syntax_error(parser, "await in arguments not supported");
return NJS_ERROR;
}
diff --git a/src/njs_parser.h b/src/njs_parser.h
--- a/src/njs_parser.h
+++ b/src/njs_parser.h
@@ -26,7 +26,7 @@ struct njs_parser_scope_s {
uint8_t arrow_function;
uint8_t dest_disable;
uint8_t async;
- uint8_t in_args;
+ uint32_t in_args;
};
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -19938,19 +19938,19 @@ static njs_unit_test_t njs_test[] =
{ njs_str("(async function() {console.log('Number: ' + await 111)})"),
njs_str("SyntaxError: await in arguments not supported in 1") },
- { njs_str("function f(a) {}"
- "(async function() {f(await 111)})"),
+ { njs_str("(async function() {f(await 111)})"),
+ njs_str("SyntaxError: await in arguments not supported in 1") },
+
+ { njs_str("(async function() {f(f(1), await 111)})"),
njs_str("SyntaxError: await in arguments not supported in 1") },
{ njs_str("async () => [await x(1)(),]; async () => [await x(1)()]"),
njs_str("[object AsyncFunction]") },
- { njs_str("function f(a, b, c) {}"
- "(async function() {f(1, 'a', await 111)})"),
+ { njs_str("(async function() {f(1, 'a', await 111)})"),
njs_str("SyntaxError: await in arguments not supported in 1") },
- { njs_str("function f(a) {}"
- "(async function() {f('Number: ' + await 111)})"),
+ { njs_str("(async function() {f('Number: ' + await 111)})"),
njs_str("SyntaxError: await in arguments not supported in 1") },
{ njs_str("async function f1() {try {f(await f1)} catch(e) {}}"),
|
heap-use-after-free src/njs_value.h:992:27
Testcase
```js
let c = [];
async function Float32Array(){
new Promise(Float32Array);
Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.isFrozen(Object.seal(Array),c[null]), c[null]), await c[null]),null),null),null),null),c),null),{}),{}),Proxy),Map),{}),null);
}
new Promise(Float32Array);
```
ASAN:
```
=================================================================
==119780==ERROR: AddressSanitizer: heap-use-after-free on address 0x625000043d80 at pc 0x00000086b535 bp 0x7ffd530bab70 sp 0x7ffd530bab68
WRITE of size 8 at 0x625000043d80 thread T0
#0 0x86b534 in njs_set_promise /home/xxx/njs/src/njs_value.h:992:27
#1 0x86b534 in njs_promise_constructor /home/xxx/njs/src/njs_promise.c:179
#2 0x7f0e8c in njs_function_native_call /home/xxx/njs/src/njs_function.c:647:11
#3 0x7f0e8c in njs_function_frame_invoke /home/xxx/njs/src/njs_function.c:683
#4 0x57f5df in njs_vmcode_interpreter /home/xxx/njs/src/njs_vmcode.c:1451:15
#5 0x7f3433 in njs_function_lambda_call /home/xxx/njs/src/njs_function.c:610:11
#6 0x88c7ae in njs_async_function_frame_invoke /home/xxx/njs/src/njs_async.c:28:11
#7 0x7f1011 in njs_function_frame_invoke /home/xxx/njs/src/njs_function.c:679:16
#8 0x7f0a73 in njs_function_call2 /home/xxx/njs/src/njs_function.c:515:12
#9 0x86a5d2 in njs_function_call /home/xxx/njs/src/njs_function.h:164:12
#10 0x86a5d2 in njs_promise_constructor_call /home/xxx/njs/src/njs_promise.c:224
#11 0x86a5d2 in njs_promise_constructor /home/xxx/njs/src/njs_promise.c:174
#12 0x7f0e8c in njs_function_native_call /home/xxx/njs/src/njs_function.c:647:11
#13 0x7f0e8c in njs_function_frame_invoke /home/xxx/njs/src/njs_function.c:683
#14 0x57f5df in njs_vmcode_interpreter /home/xxx/njs/src/njs_vmcode.c:1451:15
#15 0x7f3433 in njs_function_lambda_call /home/xxx/njs/src/njs_function.c:610:11
#16 0x88c7ae in njs_async_function_frame_invoke /home/xxx/njs/src/njs_async.c:28:11
#17 0x7f1011 in njs_function_frame_invoke /home/xxx/njs/src/njs_function.c:679:16
#18 0x7f0a73 in njs_function_call2 /home/xxx/njs/src/njs_function.c:515:12
#19 0x86a5d2 in njs_function_call /home/xxx/njs/src/njs_function.h:164:12
#20 0x86a5d2 in njs_promise_constructor_call /home/xxx/njs/src/njs_promise.c:224
#21 0x86a5d2 in njs_promise_constructor /home/xxx/njs/src/njs_promise.c:174
```
| 2024-06-08T04:51:25
|
c
|
Hard
|
|
HandmadeMath/HandmadeMath
| 91
|
HandmadeMath__HandmadeMath-91
|
[
"90"
] |
e095aefaf7d103cfdb8ecb715bc654c505eae228
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1,5 +1,5 @@
/*
- HandmadeMath.h v1.6.0
+ HandmadeMath.h v1.7.0
This is a single header file with a bunch of useful functions for game and
graphics math operations.
@@ -172,6 +172,10 @@
(*) Added array subscript operators for vector and matrix types in
C++. This is provided as a convenience, but be aware that it may
incur an extra function call in unoptimized builds.
+ 1.7.0
+ (*) Renamed the 'Rows' member of hmm_mat4 to 'Columns'. Since our
+ matrices are column-major, this should have been named 'Columns'
+ from the start. 'Rows' is still present, but has been deprecated.
LICENSE
@@ -447,6 +451,10 @@ typedef union hmm_mat4
float Elements[4][4];
#ifdef HANDMADE_MATH__USE_SSE
+ __m128 Columns[4];
+
+ // DEPRECATED. Our matrices are column-major, so this was named
+ // incorrectly. Use Columns instead.
__m128 Rows[4];
#endif
@@ -1129,10 +1137,10 @@ HMM_INLINE hmm_vec4 HMM_NormalizeVec4(hmm_vec4 A)
HMM_INLINE __m128 HMM_LinearCombineSSE(__m128 Left, hmm_mat4 Right)
{
__m128 Result;
- Result = _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0x00), Right.Rows[0]);
- Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0x55), Right.Rows[1]));
- Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0xaa), Right.Rows[2]));
- Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0xff), Right.Rows[3]));
+ Result = _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0x00), Right.Columns[0]);
+ Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0x55), Right.Columns[1]));
+ Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0xaa), Right.Columns[2]));
+ Result = _mm_add_ps(Result, _mm_mul_ps(_mm_shuffle_ps(Left, Left, 0xff), Right.Columns[3]));
return (Result);
}
@@ -1167,7 +1175,7 @@ HMM_INLINE hmm_mat4 HMM_Transpose(hmm_mat4 Matrix)
{
hmm_mat4 Result = Matrix;
- _MM_TRANSPOSE4_PS(Result.Rows[0], Result.Rows[1], Result.Rows[2], Result.Rows[3]);
+ _MM_TRANSPOSE4_PS(Result.Columns[0], Result.Columns[1], Result.Columns[2], Result.Columns[3]);
return (Result);
}
@@ -1180,10 +1188,10 @@ HMM_INLINE hmm_mat4 HMM_AddMat4(hmm_mat4 Left, hmm_mat4 Right)
{
hmm_mat4 Result;
- Result.Rows[0] = _mm_add_ps(Left.Rows[0], Right.Rows[0]);
- Result.Rows[1] = _mm_add_ps(Left.Rows[1], Right.Rows[1]);
- Result.Rows[2] = _mm_add_ps(Left.Rows[2], Right.Rows[2]);
- Result.Rows[3] = _mm_add_ps(Left.Rows[3], Right.Rows[3]);
+ Result.Columns[0] = _mm_add_ps(Left.Columns[0], Right.Columns[0]);
+ Result.Columns[1] = _mm_add_ps(Left.Columns[1], Right.Columns[1]);
+ Result.Columns[2] = _mm_add_ps(Left.Columns[2], Right.Columns[2]);
+ Result.Columns[3] = _mm_add_ps(Left.Columns[3], Right.Columns[3]);
return (Result);
}
@@ -1196,10 +1204,10 @@ HMM_INLINE hmm_mat4 HMM_SubtractMat4(hmm_mat4 Left, hmm_mat4 Right)
{
hmm_mat4 Result;
- Result.Rows[0] = _mm_sub_ps(Left.Rows[0], Right.Rows[0]);
- Result.Rows[1] = _mm_sub_ps(Left.Rows[1], Right.Rows[1]);
- Result.Rows[2] = _mm_sub_ps(Left.Rows[2], Right.Rows[2]);
- Result.Rows[3] = _mm_sub_ps(Left.Rows[3], Right.Rows[3]);
+ Result.Columns[0] = _mm_sub_ps(Left.Columns[0], Right.Columns[0]);
+ Result.Columns[1] = _mm_sub_ps(Left.Columns[1], Right.Columns[1]);
+ Result.Columns[2] = _mm_sub_ps(Left.Columns[2], Right.Columns[2]);
+ Result.Columns[3] = _mm_sub_ps(Left.Columns[3], Right.Columns[3]);
return (Result);
}
@@ -1215,10 +1223,10 @@ HMM_INLINE hmm_mat4 HMM_MultiplyMat4f(hmm_mat4 Matrix, float Scalar)
hmm_mat4 Result;
__m128 SSEScalar = _mm_set1_ps(Scalar);
- Result.Rows[0] = _mm_mul_ps(Matrix.Rows[0], SSEScalar);
- Result.Rows[1] = _mm_mul_ps(Matrix.Rows[1], SSEScalar);
- Result.Rows[2] = _mm_mul_ps(Matrix.Rows[2], SSEScalar);
- Result.Rows[3] = _mm_mul_ps(Matrix.Rows[3], SSEScalar);
+ Result.Columns[0] = _mm_mul_ps(Matrix.Columns[0], SSEScalar);
+ Result.Columns[1] = _mm_mul_ps(Matrix.Columns[1], SSEScalar);
+ Result.Columns[2] = _mm_mul_ps(Matrix.Columns[2], SSEScalar);
+ Result.Columns[3] = _mm_mul_ps(Matrix.Columns[3], SSEScalar);
return (Result);
}
@@ -1234,10 +1242,10 @@ HMM_INLINE hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
hmm_mat4 Result;
__m128 SSEScalar = _mm_set1_ps(Scalar);
- Result.Rows[0] = _mm_div_ps(Matrix.Rows[0], SSEScalar);
- Result.Rows[1] = _mm_div_ps(Matrix.Rows[1], SSEScalar);
- Result.Rows[2] = _mm_div_ps(Matrix.Rows[2], SSEScalar);
- Result.Rows[3] = _mm_div_ps(Matrix.Rows[3], SSEScalar);
+ Result.Columns[0] = _mm_div_ps(Matrix.Columns[0], SSEScalar);
+ Result.Columns[1] = _mm_div_ps(Matrix.Columns[1], SSEScalar);
+ Result.Columns[2] = _mm_div_ps(Matrix.Columns[2], SSEScalar);
+ Result.Columns[3] = _mm_div_ps(Matrix.Columns[3], SSEScalar);
return (Result);
}
@@ -2252,10 +2260,10 @@ hmm_mat4 HMM_MultiplyMat4(hmm_mat4 Left, hmm_mat4 Right)
#ifdef HANDMADE_MATH__USE_SSE
- Result.Rows[0] = HMM_LinearCombineSSE(Right.Rows[0], Left);
- Result.Rows[1] = HMM_LinearCombineSSE(Right.Rows[1], Left);
- Result.Rows[2] = HMM_LinearCombineSSE(Right.Rows[2], Left);
- Result.Rows[3] = HMM_LinearCombineSSE(Right.Rows[3], Left);
+ Result.Columns[0] = HMM_LinearCombineSSE(Right.Columns[0], Left);
+ Result.Columns[1] = HMM_LinearCombineSSE(Right.Columns[1], Left);
+ Result.Columns[2] = HMM_LinearCombineSSE(Right.Columns[2], Left);
+ Result.Columns[3] = HMM_LinearCombineSSE(Right.Columns[3], Left);
#else
int Columns;
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -10,6 +10,7 @@ To get started, go download [the latest release](https://github.com/HandmadeMath
Version | Changes |
----------------|----------------|
+**1.7.0** | Renamed the 'Rows' member of hmm_mat4 to 'Columns'. Since our matrices are column-major, this should have been named 'Columns' from the start. 'Rows' is still present, but has been deprecated.
**1.6.0** | Added array subscript operators for vector and matrix types in C++. This is provided as a convenience, but be aware that it may incur an extra function call in unoptimized builds.
**1.5.1** | Fixed a bug with uninitialized elements in HMM_LookAt.
**1.5.0** | Changed internal structure for better performance and inlining. As a result, `HANDMADE_MATH_NO_INLINE` has been removed and no longer has any effect.
|
diff --git a/test/categories/SSE.h b/test/categories/SSE.h
--- a/test/categories/SSE.h
+++ b/test/categories/SSE.h
@@ -8,10 +8,10 @@ TEST(SSE, LinearCombine)
hmm_mat4 MatrixTwo = HMM_Mat4d(4.0f);
hmm_mat4 Result;
- Result.Rows[0] = HMM_LinearCombineSSE(MatrixOne.Rows[0], MatrixTwo);
- Result.Rows[1] = HMM_LinearCombineSSE(MatrixOne.Rows[1], MatrixTwo);
- Result.Rows[2] = HMM_LinearCombineSSE(MatrixOne.Rows[2], MatrixTwo);
- Result.Rows[3] = HMM_LinearCombineSSE(MatrixOne.Rows[3], MatrixTwo);
+ Result.Columns[0] = HMM_LinearCombineSSE(MatrixOne.Columns[0], MatrixTwo);
+ Result.Columns[1] = HMM_LinearCombineSSE(MatrixOne.Columns[1], MatrixTwo);
+ Result.Columns[2] = HMM_LinearCombineSSE(MatrixOne.Columns[2], MatrixTwo);
+ Result.Columns[3] = HMM_LinearCombineSSE(MatrixOne.Columns[3], MatrixTwo);
{
EXPECT_FLOAT_EQ(Result.Elements[0][0], 8.0f);
@@ -23,14 +23,12 @@ TEST(SSE, LinearCombine)
EXPECT_FLOAT_EQ(Result.Elements[1][1], 8.0f);
EXPECT_FLOAT_EQ(Result.Elements[1][2], 0.0f);
EXPECT_FLOAT_EQ(Result.Elements[1][3], 0.0f);
-
EXPECT_FLOAT_EQ(Result.Elements[2][0], 0.0f);
EXPECT_FLOAT_EQ(Result.Elements[2][1], 0.0f);
EXPECT_FLOAT_EQ(Result.Elements[2][2], 8.0f);
EXPECT_FLOAT_EQ(Result.Elements[2][3], 0.0f);
-
EXPECT_FLOAT_EQ(Result.Elements[3][0], 0.0f);
EXPECT_FLOAT_EQ(Result.Elements[3][1], 0.0f);
EXPECT_FLOAT_EQ(Result.Elements[3][2], 0.0f);
|
Mat4 SSE definition looks row-major
Our definition of hmm_mat4 has an SSE variable called `Rows`. This should really be `Columns`, since our matrices are column-major. Apparently we're doing all the math correctly, but we should probably rename the variable to avoid confusion.
@StrangeZak is this ok to do, or am I misunderstanding something about our SSE implementation?
|
Totally okay to do
| 2018-08-14T18:27:50
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 67
|
HandmadeMath__HandmadeMath-67
|
[
"66"
] |
98fffbd7cc5643125c851fb93372167734fea9ca
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1,5 +1,5 @@
/*
- HandmadeMath.h v1.2.0
+ HandmadeMath.h v1.3.0
This is a single header file with a bunch of useful functions for
basic game math operations.
@@ -20,22 +20,6 @@
=============================================================================
- For overloaded and operator overloaded versions of the base C functions,
- you MUST
-
- #define HANDMADE_MATH_CPP_MODE
-
- in EXACTLY one C or C++ file that includes this header, BEFORE the
- include, like this:
-
- #define HANDMADE_MATH_IMPLEMENTATION
- #define HANDMADE_MATH_CPP_MODE
- #include "HandmadeMath.h"
-
- All other files should just #include "HandmadeMath.h" without the #define.
-
- =============================================================================
-
To disable SSE intrinsics, you MUST
#define HANDMADE_MATH_NO_SSE
@@ -196,6 +180,8 @@
(*) Added C++ == and != operators for all three
(*) SSE'd HMM_MultiplyMat4 (this is _WAY_ faster)
(*) SSE'd HMM_Transpose
+ 1.3.0
+ (*) Remove need to #define HANDMADE_MATH_CPP_MODE
LICENSE
@@ -601,7 +587,7 @@ HMMDEF hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRo
}
#endif
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
HMMDEF float HMM_Length(hmm_vec2 A);
HMMDEF float HMM_Length(hmm_vec3 A);
@@ -741,7 +727,7 @@ HMMDEF hmm_bool operator!=(hmm_vec2 Left, hmm_vec2 Right);
HMMDEF hmm_bool operator!=(hmm_vec3 Left, hmm_vec3 Right);
HMMDEF hmm_bool operator!=(hmm_vec4 Left, hmm_vec4 Right);
-#endif /* HANDMADE_MATH_CPP */
+#endif /* __cplusplus */
#ifdef __clang__
#pragma GCC diagnostic pop
@@ -1932,7 +1918,7 @@ HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation)
return(Result);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
HINLINE float
HMM_Length(hmm_vec2 A)
@@ -2870,6 +2856,6 @@ operator!=(hmm_vec4 Left, hmm_vec4 Right)
return !HMM_EqualsVec4(Left, Right);
}
-#endif /* HANDMADE_MATH_CPP_MODE */
+#endif /* __cplusplus */
#endif /* HANDMADE_MATH_IMPLEMENTATION */
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -12,6 +12,7 @@ _This library is free and will stay free, but if you would like to support devel
Version | Changes |
----------------|----------------|
+**1.3.0** | Removed need to `#define HANDMADE_MATH_CPP_MODE`. C++ definitions are now included automatically in C++ environments.
**1.2.0** | Added equality functions for `HMM_Vec2`, `HMM_Vec3`, and `HMM_Vec4`, and SSE'd `HMM_MultiplyMat4` and `HMM_Transpose`.
**1.1.5** | Added `Width` and `Height` to `HMM_Vec2`, and made it so you can supply your own `SqrtF`.
**1.1.4** | Fixed SSE being included on platforms that don't support it, and fixed divide-by-zero errors when normalizing zero vectors.
|
diff --git a/test/HandmadeMath.c b/test/HandmadeMath.c
--- a/test/HandmadeMath.c
+++ b/test/HandmadeMath.c
@@ -1,4 +1,3 @@
-
#define HANDMADE_MATH_IMPLEMENTATION
#define HANDMADE_MATH_NO_INLINE
#include "../HandmadeMath.h"
diff --git a/test/HandmadeTest.h b/test/HandmadeTest.h
--- a/test/HandmadeTest.h
+++ b/test/HandmadeTest.h
@@ -25,27 +25,32 @@ int hmt_count_failures = 0;
}
#define TEST_BEGIN(name) { \
- int count_testfailures = 0; \
+ int count_testcases = 0, count_testfailures = 0; \
count_categorytests++; \
printf(" " #name ":");
#define TEST_END() \
count_categoryfailures += count_testfailures; \
if (count_testfailures > 0) { \
count_categoryfailedtests++; \
+ printf("\n " RED "(%d/%d passed)" RESET, count_testcases - count_testfailures, count_testcases); \
printf("\n"); \
} else { \
- printf(GREEN " [PASS]\n" RESET); \
+ printf(GREEN " [PASS] (%d/%d passed) \n" RESET, count_testcases - count_testfailures, count_testcases); \
} \
}
+#define CASE_START() \
+ count_testcases++;
+
#define CASE_FAIL() \
count_testfailures++; \
- printf("\n - " RED "[FAIL] (%d) " RESET, __LINE__)
+ printf("\n - " RED "[FAIL] (%d) " RESET, __LINE__);
/*
* Asserts and expects
*/
#define EXPECT_TRUE(_actual) do { \
+ CASE_START(); \
if (!(_actual)) { \
CASE_FAIL(); \
printf("Expected true but got something false"); \
@@ -53,6 +58,7 @@ int hmt_count_failures = 0;
} while (0)
#define EXPECT_FALSE(_actual) do { \
+ CASE_START(); \
if (_actual) { \
CASE_FAIL(); \
printf("Expected false but got something true"); \
@@ -60,6 +66,7 @@ int hmt_count_failures = 0;
} while (0)
#define EXPECT_FLOAT_EQ(_actual, _expected) do { \
+ CASE_START(); \
float actual = (_actual); \
float diff = actual - (_expected); \
if (diff < -FLT_EPSILON || FLT_EPSILON < diff) { \
@@ -69,6 +76,7 @@ int hmt_count_failures = 0;
} while (0)
#define EXPECT_NEAR(_actual, _expected, _epsilon) do { \
+ CASE_START(); \
float actual = (_actual); \
float diff = actual - (_expected); \
if (diff < -(_epsilon) || (_epsilon) < diff) { \
@@ -78,6 +86,7 @@ int hmt_count_failures = 0;
} while (0)
#define EXPECT_LT(_actual, _expected) do { \
+ CASE_START(); \
if ((_actual) >= (_expected)) { \
CASE_FAIL(); \
printf("Expected %f to be less than %f", (_actual), (_expected)); \
@@ -85,6 +94,7 @@ int hmt_count_failures = 0;
} while (0)
#define EXPECT_GT(_actual, _expected) do { \
+ CASE_START(); \
if ((_actual) <= (_expected)) { \
CASE_FAIL(); \
printf("Expected %f to be greater than %f", (_actual), (_expected)); \
diff --git a/test/hmm_test.c b/test/hmm_test.c
--- a/test/hmm_test.c
+++ b/test/hmm_test.c
@@ -334,7 +334,7 @@ int run_tests()
EXPECT_FLOAT_EQ(HMM_LengthSquaredVec3(v3), 14.0f);
EXPECT_FLOAT_EQ(HMM_LengthSquaredVec4(v4), 15.0f);
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_FLOAT_EQ(HMM_LengthSquared(v2), 5.0f);
EXPECT_FLOAT_EQ(HMM_LengthSquared(v3), 14.0f);
EXPECT_FLOAT_EQ(HMM_LengthSquared(v4), 15.0f);
@@ -352,7 +352,7 @@ int run_tests()
EXPECT_FLOAT_EQ(HMM_LengthVec3(v3), 7.0f);
EXPECT_FLOAT_EQ(HMM_LengthVec4(v4), 13.892444f);
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_FLOAT_EQ(HMM_Length(v2), 9.0553856f);
EXPECT_FLOAT_EQ(HMM_Length(v3), 7.0f);
EXPECT_FLOAT_EQ(HMM_Length(v4), 13.892444f);
@@ -388,7 +388,7 @@ int run_tests()
EXPECT_LT(result.W, 0.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Normalize(v2);
EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
@@ -439,7 +439,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.W, 0.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Normalize(v2);
EXPECT_FLOAT_EQ(result.X, 0.0f);
@@ -481,7 +481,7 @@ int run_tests()
hmm_vec2 v2 = HMM_Vec2(3.0f, 4.0f);
EXPECT_FLOAT_EQ(HMM_DotVec2(v1, v2), 11.0f);
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
#endif
}
@@ -493,7 +493,7 @@ int run_tests()
hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
EXPECT_FLOAT_EQ(HMM_DotVec3(v1, v2), 32.0f);
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
#endif
}
@@ -505,7 +505,7 @@ int run_tests()
hmm_vec4 v2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
EXPECT_FLOAT_EQ(HMM_DotVec4(v1, v2), 70.0f);
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
#endif
}
@@ -578,7 +578,7 @@ int run_tests()
float result = HMM_DotQuaternion(q1, q2);
EXPECT_FLOAT_EQ(result, 70.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
float result = HMM_Dot(q1, q2);
EXPECT_FLOAT_EQ(result, 70.0f);
@@ -598,7 +598,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Normalize(q);
EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
@@ -693,7 +693,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, 4.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Add(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 4.0f);
@@ -723,7 +723,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, 7.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Add(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 5.0f);
@@ -757,7 +757,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Add(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 6.0f);
@@ -819,7 +819,7 @@ int run_tests()
}
}
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_mat4 result = HMM_Add(m4_1, m4_2);
float Expected = 18.0f;
@@ -871,7 +871,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Add(q1, q2);
EXPECT_FLOAT_EQ(result.X, 6.0f);
@@ -910,7 +910,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, -2.0f);
EXPECT_FLOAT_EQ(result.Y, -2.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, -2.0f);
@@ -940,7 +940,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, -3.0f);
EXPECT_FLOAT_EQ(result.Z, -3.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, -3.0f);
@@ -974,7 +974,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, -4.0f);
@@ -1034,7 +1034,7 @@ int run_tests()
}
}
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
for (int Column = 0; Column < 4; ++Column)
@@ -1080,7 +1080,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, -4.0f);
EXPECT_FLOAT_EQ(result.W, -4.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Subtract(q1, q2);
EXPECT_FLOAT_EQ(result.X, -4.0f);
@@ -1119,7 +1119,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 8.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -1148,7 +1148,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, 3.0f);
EXPECT_FLOAT_EQ(result.Y, 6.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Multiply(v2, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -1183,7 +1183,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, 10.0f);
EXPECT_FLOAT_EQ(result.Z, 18.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 4.0f);
@@ -1216,7 +1216,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, 6.0f);
EXPECT_FLOAT_EQ(result.Z, 9.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Multiply(v3, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -1256,7 +1256,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 21.0f);
EXPECT_FLOAT_EQ(result.W, 32.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 5.0f);
@@ -1293,7 +1293,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 9.0f);
EXPECT_FLOAT_EQ(result.W, 12.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Multiply(v4, s);
EXPECT_FLOAT_EQ(result.X, 3.0f);
@@ -1368,7 +1368,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
@@ -1451,7 +1451,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_mat4 result = HMM_Multiply(m4, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
@@ -1555,7 +1555,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 110.0f);
EXPECT_FLOAT_EQ(result.W, 120.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Multiply(m4, v4);
EXPECT_FLOAT_EQ(result.X, 90.0f);
@@ -1588,7 +1588,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 48.0f);
EXPECT_FLOAT_EQ(result.W, -6.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Multiply(q1, q2);
EXPECT_FLOAT_EQ(result.X, 24.0f);
@@ -1623,7 +1623,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 6.0f);
EXPECT_FLOAT_EQ(result.W, 8.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Multiply(q, f);
EXPECT_FLOAT_EQ(result.X, 2.0f);
@@ -1669,7 +1669,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 0.75f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Divide(v2_1, v2_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1698,7 +1698,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.X, 0.5f);
EXPECT_FLOAT_EQ(result.Y, 1.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec2 result = HMM_Divide(v2, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1728,7 +1728,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, 0.75f);
EXPECT_FLOAT_EQ(result.Z, 10.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Divide(v3_1, v3_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1761,7 +1761,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Y, 1.0f);
EXPECT_FLOAT_EQ(result.Z, 1.5f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec3 result = HMM_Divide(v3, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1795,7 +1795,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 10.0f);
EXPECT_FLOAT_EQ(result.W, 0.25f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Divide(v4_1, v4_2);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1832,7 +1832,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_vec4 result = HMM_Divide(v4, s);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -1893,7 +1893,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_mat4 result = HMM_Divide(m4, s);
EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
@@ -1966,7 +1966,7 @@ int run_tests()
EXPECT_FLOAT_EQ(result.Z, 1.5f);
EXPECT_FLOAT_EQ(result.W, 2.0f);
}
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
{
hmm_quaternion result = HMM_Divide(q, f);
EXPECT_FLOAT_EQ(result.X, 0.5f);
@@ -2004,7 +2004,7 @@ int run_tests()
EXPECT_TRUE(HMM_EqualsVec2(a, b));
EXPECT_FALSE(HMM_EqualsVec2(a, c));
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_TRUE(HMM_Equals(a, b));
EXPECT_FALSE(HMM_Equals(a, c));
@@ -2023,7 +2023,7 @@ int run_tests()
EXPECT_TRUE(HMM_EqualsVec3(a, b));
EXPECT_FALSE(HMM_EqualsVec3(a, c));
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_TRUE(HMM_Equals(a, b));
EXPECT_FALSE(HMM_Equals(a, c));
@@ -2042,7 +2042,7 @@ int run_tests()
EXPECT_TRUE(HMM_EqualsVec4(a, b));
EXPECT_FALSE(HMM_EqualsVec4(a, c));
-#ifdef HANDMADE_MATH_CPP_MODE
+#ifdef __cplusplus
EXPECT_TRUE(HMM_Equals(a, b));
EXPECT_FALSE(HMM_Equals(a, c));
|
HANDMADE_MATH_CPP_MODE instructions?
The instructions for HANDMADE_MATH_CPP_MODE are as follows:
```
For overloaded and operator overloaded versions of the base C functions,
you MUST
#define HANDMADE_MATH_CPP_MODE
in EXACTLY one C or C++ file that includes this header, BEFORE the
include, like this:
#define HANDMADE_MATH_IMPLEMENTATION
#define HANDMADE_MATH_CPP_MODE
#include "HandmadeMath.h"
All other files should just #include "HandmadeMath.h" without the #define.
```
By defining HANDMADE_MATH_CPP_MODE, HandmadeMath.h enables the following:
1. Declarations of overloaded functions
2. Declarations of operator overloads
3. Definitions of overloaded functions
4. Definitions of operator overloads
The documentation says other files should just include HandmadeMath.h without the #define, but if that's the case, those other files won't see the declarations of the functions. Either this doesn't work or there's something I don't understand.
|
Yeah, I'm not sure about those instructions either. I've always just #defined HANDMADE_MATH_CPP_MODE everywhere I include it.
@StrangeZak, is it really possible to use C++ functions without defining HANDMADE_MATH_CPP_MODE everywhere? Is that just some very drastic difference between MSVC and other compilers?
@bvisness It shouldn't be possible to use C++ functions without defining HANDMADE_MATH_CPP_MODE. As i wrapped everything C++ in that define.
Im not sure how we should handle this since most single-header libraries, don't really have a C++ mode in them.
One solution is to always declare the C++ functions when `defined(__cplusplus)` is true. If you try to use them, you'll get a link error unless you also define HANDMADE_MATH_CPP_MODE. Maybe that's a decent compromise if somebody wants to have some compile-time check that they're not using the C++ interface. The downside is that the C++ declarations will show up in autocompletions and etc.
Ok, so our two options are:
1. Correct the instructions to say that you must `#define HANDMADE_MATH_CPP_MODE` everywhere you include HandmadeMath.h
2. Remove `HANDMADE_MATH_CPP_MODE` and just include C++ content automatically.
I like option 2 since it makes things easier to implement, and no one is forced to use the C++ content anyway, but it's up to @StrangeZak to make the final call.
Yeah, option 2 is probably the way to go. 👍
| 2017-08-01T16:26:41
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 81
|
HandmadeMath__HandmadeMath-81
|
[
"71"
] |
77914405c3e8da906c4a61d6068d031110fcb129
|
diff --git a/.gitignore b/.gitignore
--- a/.gitignore
+++ b/.gitignore
@@ -31,5 +31,4 @@
*.exe
*.out
*.app
-hmm_test
-hmm_test*
+test/build
diff --git a/.travis.yml b/.travis.yml
--- a/.travis.yml
+++ b/.travis.yml
@@ -6,7 +6,7 @@ install:
- cd test
- make
script:
- - ./hmm_test_c
- - ./hmm_test_c_no_sse
- - ./hmm_test_cpp
- - ./hmm_test_cpp_no_sse
+ - build/hmm_test_c
+ - build/hmm_test_c_no_sse
+ - build/hmm_test_cpp
+ - build/hmm_test_cpp_no_sse
|
diff --git a/test/HandmadeTest.h b/test/HandmadeTest.h
--- a/test/HandmadeTest.h
+++ b/test/HandmadeTest.h
@@ -1,104 +1,263 @@
+/*
+ HandmadeTest.h
+
+ This is Handmade Math's test framework. It is fully compatible with both C
+ and C++, although it requires some compiler-specific features.
+
+ The basic way of creating a test is using the TEST macro, which registers a
+ single test to be run:
+
+ TEST(MyCategory, MyTestName) {
+ // test code, including asserts/expects
+ }
+
+ The main function of your test code should then call hmt_run_all_tests and
+ return the result:
+
+ int main() {
+ return hmt_run_all_tests();
+ }
+
+ =============================================================================
+
+ If Handmade Test's macros are conflicting with existing macros in your
+ project, you may define HMT_SAFE_MACROS before you include HandmadeTest.h.
+ You may then prefix each macro with HMT_. For example, you may use HMT_TEST
+ instead of TEST and HMT_EXPECT_TRUE instead of EXPECT_TRUE.
+
+ */
+
#ifndef HANDMADETEST_H
#define HANDMADETEST_H
#include <float.h>
#include <stdio.h>
+#include <string.h>
+
+#include "initializer.h"
-int hmt_count_tests = 0;
-int hmt_count_failedtests = 0;
-int hmt_count_failures = 0;
-
-#define RESET "\033[0m"
-#define RED "\033[31m"
-#define GREEN "\033[32m"
-
-#define CATEGORY_BEGIN(name) { \
- int count_categorytests = 0; \
- int count_categoryfailedtests = 0; \
- int count_categoryfailures = 0; \
- printf("\n" #name ":\n");
-#define CATEGORY_END(name) \
- hmt_count_tests += count_categorytests; \
- hmt_count_failedtests += count_categoryfailedtests; \
- hmt_count_failures += count_categoryfailures; \
- printf("%d/%d tests passed, %d failures\n", count_categorytests - count_categoryfailedtests, count_categorytests, count_categoryfailures); \
+#define HMT_RESET "\033[0m"
+#define HMT_RED "\033[31m"
+#define HMT_GREEN "\033[32m"
+
+#define HMT_INITIAL_ARRAY_SIZE 1024
+
+typedef struct hmt_testresult_struct {
+ int count_cases;
+ int count_failures;
+} hmt_testresult;
+
+typedef void (*hmt_test_func)(hmt_testresult*);
+
+typedef struct hmt_test_struct {
+ const char* name;
+ hmt_test_func func;
+} hmt_test;
+
+typedef struct hmt_category_struct {
+ const char* name;
+ int num_tests;
+ int tests_capacity;
+ hmt_test* tests;
+} hmt_category;
+
+int hmt_num_categories = 0;
+int hmt_category_capacity = HMT_INITIAL_ARRAY_SIZE;
+hmt_category* categories = 0;
+
+hmt_category _hmt_new_category(const char* name) {
+ hmt_category cat = {
+ .name = name,
+ .num_tests = 0,
+ .tests_capacity = HMT_INITIAL_ARRAY_SIZE,
+ .tests = (hmt_test*) malloc(HMT_INITIAL_ARRAY_SIZE * sizeof(hmt_test))
+ };
+
+ return cat;
}
-#define TEST_BEGIN(name) { \
- int count_testcases = 0, count_testfailures = 0; \
- count_categorytests++; \
- printf(" " #name ":");
-#define TEST_END() \
- count_categoryfailures += count_testfailures; \
- if (count_testfailures > 0) { \
- count_categoryfailedtests++; \
- printf("\n " RED "(%d/%d passed)" RESET, count_testcases - count_testfailures, count_testcases); \
- printf("\n"); \
- } else { \
- printf(GREEN " [PASS] (%d/%d passed) \n" RESET, count_testcases - count_testfailures, count_testcases); \
- } \
+hmt_test _hmt_new_test(const char* name, hmt_test_func func) {
+ hmt_test test = {
+ .name = name,
+ .func = func
+ };
+
+ return test;
}
-#define CASE_START() \
- count_testcases++;
+int hmt_register_test(const char* category, const char* name, hmt_test_func func) {
+ // initialize categories array if not initialized
+ if (!categories) {
+ categories = (hmt_category*) malloc(hmt_category_capacity * sizeof(hmt_category));
+ }
+
+ // Find the matching category, if possible
+ int cat_index;
+ for (cat_index = 0; cat_index < hmt_num_categories; cat_index++) {
+ if (strcmp(categories[cat_index].name, category) == 0) {
+ break;
+ }
+ }
+
+ // Expand the array of categories if necessary
+ if (cat_index >= hmt_category_capacity) {
+ // TODO: If/when we ever split HandmadeTest off into its own package,
+ // we should start with a smaller initial capacity and dynamically expand.
+ }
-#define CASE_FAIL() \
- count_testfailures++; \
- printf("\n - " RED "[FAIL] (%d) " RESET, __LINE__);
+ // Add a new category if necessary
+ if (cat_index >= hmt_num_categories) {
+ categories[cat_index] = _hmt_new_category(category);
+ hmt_num_categories++;
+ }
+
+ hmt_category* cat = &categories[cat_index];
+
+ // Add the test to the category
+ if (cat->num_tests >= cat->tests_capacity) {
+ // TODO: If/when we ever split HandmadeTest off into its own package,
+ // we should start with a smaller initial capacity and dynamically expand.
+ }
+ cat->tests[cat->num_tests] = _hmt_new_test(name, func);
+ cat->num_tests++;
+
+ return 0;
+}
+
+int hmt_run_all_tests() {
+ int count_alltests = 0;
+ int count_allfailedtests = 0; // failed test cases
+ int count_allfailures = 0; // failed asserts
+
+ for (int i = 0; i < hmt_num_categories; i++) {
+ hmt_category cat = categories[i];
+ int count_catfailedtests = 0;
+ int count_catfailures = 0;
+
+ printf("\n%s:\n", cat.name);
+
+ for (int j = 0; j < cat.num_tests; j++) {
+ hmt_test test = cat.tests[j];
+
+ printf(" %s:", test.name);
+
+ hmt_testresult result = {
+ .count_cases = 0,
+ .count_failures = 0
+ };
+ test.func(&result);
+
+ count_catfailures += result.count_failures;
+
+ if (result.count_failures > 0) {
+ count_catfailedtests++;
+ printf("\n " HMT_RED "(%d/%d passed)" HMT_RESET, result.count_cases - result.count_failures, result.count_cases);
+ printf("\n");
+ } else {
+ printf(HMT_GREEN " [PASS] (%d/%d passed) \n" HMT_RESET, result.count_cases - result.count_failures, result.count_cases);
+ }
+ }
+
+ count_alltests += cat.num_tests;
+ count_allfailedtests += count_catfailedtests;
+ count_allfailures += count_catfailures;
+
+ printf("%d/%d tests passed, %d failures\n", cat.num_tests - count_catfailedtests, cat.num_tests, count_catfailures);
+ }
+
+ if (count_allfailedtests > 0) {
+ printf(HMT_RED);
+ } else {
+ printf(HMT_GREEN);
+ }
+ printf("\n%d/%d tests passed overall, %d failures\n" HMT_RESET, count_alltests - count_allfailedtests, count_alltests, count_allfailures);
+
+ printf("\n");
+
+ return (count_allfailedtests > 0);
+}
+
+#define _HMT_TEST_FUNCNAME(category, name) category ## _ ## name
+#define _HMT_TEST_FUNCNAME_INIT(category, name) category ## _ ## name ## _init
+
+#define HMT_TEST(category, name) \
+void _HMT_TEST_FUNCNAME(category, name)(hmt_testresult* _result); \
+INITIALIZER(_HMT_TEST_FUNCNAME_INIT(category, name)) { \
+ hmt_register_test(#category, #name, _HMT_TEST_FUNCNAME(category, name)); \
+} \
+void _HMT_TEST_FUNCNAME(category, name)(hmt_testresult* _result)
+
+#define _HMT_CASE_START() \
+ _result->count_cases++;
+
+#define _HMT_CASE_FAIL() \
+ _result->count_failures++; \
+ printf("\n - " HMT_RED "[FAIL] (%d) " HMT_RESET, __LINE__);
/*
* Asserts and expects
*/
-#define EXPECT_TRUE(_actual) do { \
- CASE_START(); \
+#define HMT_EXPECT_TRUE(_actual) do { \
+ _HMT_CASE_START(); \
if (!(_actual)) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected true but got something false"); \
} \
} while (0)
-#define EXPECT_FALSE(_actual) do { \
- CASE_START(); \
+#define HMT_EXPECT_FALSE(_actual) do { \
+ _HMT_CASE_START(); \
if (_actual) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected false but got something true"); \
} \
} while (0)
-#define EXPECT_FLOAT_EQ(_actual, _expected) do { \
- CASE_START(); \
+#define HMT_EXPECT_FLOAT_EQ(_actual, _expected) do { \
+ _HMT_CASE_START(); \
float actual = (_actual); \
float diff = actual - (_expected); \
if (diff < -FLT_EPSILON || FLT_EPSILON < diff) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected %f, got %f", (_expected), actual); \
} \
} while (0)
-#define EXPECT_NEAR(_actual, _expected, _epsilon) do { \
- CASE_START(); \
+#define HMT_EXPECT_NEAR(_actual, _expected, _epsilon) do { \
+ _HMT_CASE_START(); \
float actual = (_actual); \
float diff = actual - (_expected); \
if (diff < -(_epsilon) || (_epsilon) < diff) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected %f, got %f", (_expected), actual); \
} \
} while (0)
-#define EXPECT_LT(_actual, _expected) do { \
- CASE_START(); \
+#define HMT_EXPECT_LT(_actual, _expected) do { \
+ _HMT_CASE_START(); \
if ((_actual) >= (_expected)) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected %f to be less than %f", (_actual), (_expected)); \
} \
} while (0)
-#define EXPECT_GT(_actual, _expected) do { \
- CASE_START(); \
+#define HMT_EXPECT_GT(_actual, _expected) do { \
+ _HMT_CASE_START(); \
if ((_actual) <= (_expected)) { \
- CASE_FAIL(); \
+ _HMT_CASE_FAIL(); \
printf("Expected %f to be greater than %f", (_actual), (_expected)); \
} \
} while (0)
-#endif
+#ifndef HMT_SAFE_MACROS
+// Friendly defines
+#define TEST(category, name) HMT_TEST(category, name)
+#define EXPECT_TRUE(_actual) HMT_EXPECT_TRUE(_actual)
+#define EXPECT_FALSE(_actual) HMT_EXPECT_FALSE(_actual)
+#define EXPECT_FLOAT_EQ(_actual, _expected) HMT_EXPECT_FLOAT_EQ(_actual, _expected)
+#define EXPECT_NEAR(_actual, _expected, _epsilon) HMT_EXPECT_NEAR(_actual, _expected, _epsilon)
+#define EXPECT_LT(_actual, _expected) HMT_EXPECT_LT(_actual, _expected)
+#define EXPECT_GT(_actual, _expected) HMT_EXPECT_GT(_actual, _expected)
+#endif // HMT_SAFE_MACROS
+
+#endif // HANDMADETEST_H
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -1,37 +1,45 @@
-ROOT_DIR=..
+BUILD_DIR=build
CXXFLAGS+=-g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
all: c c_no_sse cpp cpp_no_sse
clean:
- rm -f hmm_test_c hmm_test_cpp hmm_test_c_no_sse hmm_test_cpp_no_sse *.o
+ rm -rf $(BUILD_DIR)
-c: $(ROOT_DIR)/test/HandmadeMath.c test_impl
+c: HandmadeMath.c test_impl
@echo "\nCompiling in C mode"
- $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
- -c $(ROOT_DIR)/test/HandmadeMath.c $(ROOT_DIR)/test/hmm_test.c \
- -lm
- $(CC) -ohmm_test_c HandmadeMath.o hmm_test.o -lm
-
-c_no_sse: $(ROOT_DIR)/test/HandmadeMath.c test_impl
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR)\
+ && $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
+ -c ../HandmadeMath.c ../hmm_test.c \
+ -lm \
+ && $(CC) -ohmm_test_c HandmadeMath.o hmm_test.o -lm
+
+c_no_sse: HandmadeMath.c test_impl
@echo "\nCompiling in C mode (no SSE)"
- $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
- -DHANDMADE_MATH_NO_SSE \
- -c $(ROOT_DIR)/test/HandmadeMath.c $(ROOT_DIR)/test/hmm_test.c \
- -lm
- $(CC) -ohmm_test_c_no_sse HandmadeMath.o hmm_test.o -lm
-
-cpp: $(ROOT_DIR)/test/HandmadeMath.cpp test_impl
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 \
+ -DHANDMADE_MATH_NO_SSE \
+ -c ../HandmadeMath.c ../hmm_test.c \
+ -lm \
+ && $(CC) -ohmm_test_c_no_sse HandmadeMath.o hmm_test.o -lm
+
+cpp: HandmadeMath.cpp test_impl
@echo "\nCompiling in C++ mode"
- $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp \
- -DHANDMADE_MATH_CPP_MODE \
- $(ROOT_DIR)/test/HandmadeMath.cpp $(ROOT_DIR)/test/hmm_test.cpp
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp \
+ -DHANDMADE_MATH_CPP_MODE \
+ ../HandmadeMath.cpp ../hmm_test.cpp
-cpp_no_sse: $(ROOT_DIR)/test/HandmadeMath.cpp test_impl
+cpp_no_sse: HandmadeMath.cpp test_impl
@echo "\nCompiling in C++ mode (no SSE)"
- $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_no_sse \
- -DHANDMADE_MATH_CPP_MODE -DHANDMADE_MATH_NO_SSE \
- $(ROOT_DIR)/test/HandmadeMath.cpp $(ROOT_DIR)/test/hmm_test.cpp
+ mkdir -p $(BUILD_DIR)
+ cd $(BUILD_DIR) \
+ && $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp_no_sse \
+ -DHANDMADE_MATH_CPP_MODE -DHANDMADE_MATH_NO_SSE \
+ ../HandmadeMath.cpp ../hmm_test.cpp
-test_impl: $(ROOT_DIR)/test/hmm_test.cpp $(ROOT_DIR)/test/hmm_test.c
+test_impl: hmm_test.cpp hmm_test.c
diff --git a/test/README.md b/test/README.md
--- a/test/README.md
+++ b/test/README.md
@@ -4,8 +4,8 @@ You can compile and run the tests yourself by running:
```
make
-./hmm_test_c
-./hmm_test_c_no_sse
-./hmm_test_cpp
-./hmm_test_cpp_no_sse
+build/hmm_test_c
+build/hmm_test_c_no_sse
+build/hmm_test_cpp
+build/hmm_test_cpp_no_sse
```
diff --git a/test/categories/Addition.h b/test/categories/Addition.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Addition.h
@@ -0,0 +1,209 @@
+#include "../HandmadeTest.h"
+
+TEST(Addition, Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_AddVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Add(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 + v2_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2_1 += v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 6.0f);
+#endif
+}
+
+TEST(Addition, Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_AddVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Add(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 + v3_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3_1 += v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 7.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 9.0f);
+#endif
+}
+
+TEST(Addition, Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_AddVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Add(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 + v4_2;
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4_1 += v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 6.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 8.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 12.0f);
+#endif
+}
+
+TEST(Addition, Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_AddMat4(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
+ Expected += 2.0f;
+ }
+ }
+ }
+#ifdef __cplusplus
+ {
+ hmm_mat4 result = HMM_Add(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
+ Expected += 2.0f;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 + m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
+ Expected += 2.0f;
+ }
+ }
+ }
+
+ m4_1 += m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], Expected);
+ Expected += 2.0f;
+ }
+ }
+#endif
+}
+
+TEST(Addition, Quaternion)
+{
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_AddQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Add(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_quaternion result = q1 + q2;
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ q1 += q2;
+ EXPECT_FLOAT_EQ(q1.X, 6.0f);
+ EXPECT_FLOAT_EQ(q1.Y, 8.0f);
+ EXPECT_FLOAT_EQ(q1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(q1.W, 12.0f);
+#endif
+}
diff --git a/test/categories/Division.h b/test/categories/Division.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Division.h
@@ -0,0 +1,325 @@
+#include "../HandmadeTest.h"
+
+TEST(Division, Vec2Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 3.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(2.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_DivideVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Divide(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+ {
+ hmm_vec2 result = v2_1 / v2_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+
+ v2_1 /= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 0.75f);
+#endif
+}
+
+TEST(Division, Vec2Scalar)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 2;
+
+ {
+ hmm_vec2 result = HMM_DivideVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Divide(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+ {
+ hmm_vec2 result = v2 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+
+ v2 /= s;
+ EXPECT_FLOAT_EQ(v2.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2.Y, 1.0f);
+#endif
+}
+
+TEST(Division, Vec3Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 3.0f, 5.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(2.0f, 4.0f, 0.5f);
+
+ {
+ hmm_vec3 result = HMM_DivideVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Divide(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 / v3_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+
+ v3_1 /= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 10.0f);
+#endif
+}
+
+TEST(Division, Vec3Scalar)
+{
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 2;
+
+ {
+ hmm_vec3 result = HMM_DivideVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Divide(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+ {
+ hmm_vec3 result = v3 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+
+ v3 /= s;
+ EXPECT_FLOAT_EQ(v3.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 1.5f);
+#endif
+}
+
+TEST(Division, Vec4Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 3.0f, 5.0f, 1.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(2.0f, 4.0f, 0.5f, 4.0f);
+
+ {
+ hmm_vec4 result = HMM_DivideVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Divide(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+ {
+ hmm_vec4 result = v4_1 / v4_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+
+ v4_1 /= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 0.25f);
+#endif
+}
+
+TEST(Division, Vec4Scalar)
+{
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 2;
+
+ {
+ hmm_vec4 result = HMM_DivideVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Divide(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_vec4 result = v4 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+
+ v4 /= s;
+ EXPECT_FLOAT_EQ(v4.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 1.5f);
+ EXPECT_FLOAT_EQ(v4.W, 2.0f);
+#endif
+}
+
+TEST(Division, Mat4Scalar)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 2;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_DivideMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_mat4 result = HMM_Divide(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+ {
+ hmm_mat4 result = m4 / s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+
+ m4 /= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 8.0f);
+#endif
+}
+
+TEST(Division, QuaternionScalar)
+{
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ float f = 2.0f;
+
+ {
+ hmm_quaternion result = HMM_DivideQuaternionF(q, f);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Divide(q, f);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_quaternion result = q / f;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+
+ q /= f;
+ EXPECT_FLOAT_EQ(q.X, 0.5f);
+ EXPECT_FLOAT_EQ(q.Y, 1.0f);
+ EXPECT_FLOAT_EQ(q.Z, 1.5f);
+ EXPECT_FLOAT_EQ(q.W, 2.0f);
+#endif
+}
diff --git a/test/categories/Equality.h b/test/categories/Equality.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Equality.h
@@ -0,0 +1,55 @@
+#include "../HandmadeTest.h"
+
+TEST(Equality, Vec2)
+{
+ hmm_vec2 a = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 b = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 c = HMM_Vec2(3.0f, 4.0f);
+
+ EXPECT_TRUE(HMM_EqualsVec2(a, b));
+ EXPECT_FALSE(HMM_EqualsVec2(a, c));
+
+#ifdef __cplusplus
+ EXPECT_TRUE(HMM_Equals(a, b));
+ EXPECT_FALSE(HMM_Equals(a, c));
+
+ EXPECT_TRUE(a == b);
+ EXPECT_FALSE(a == c);
+#endif
+}
+
+TEST(Equality, Vec3)
+{
+ hmm_vec3 a = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 b = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 c = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ EXPECT_TRUE(HMM_EqualsVec3(a, b));
+ EXPECT_FALSE(HMM_EqualsVec3(a, c));
+
+#ifdef __cplusplus
+ EXPECT_TRUE(HMM_Equals(a, b));
+ EXPECT_FALSE(HMM_Equals(a, c));
+
+ EXPECT_TRUE(a == b);
+ EXPECT_FALSE(a == c);
+#endif
+}
+
+TEST(Equality, Vec4)
+{
+ hmm_vec4 a = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 b = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 c = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ EXPECT_TRUE(HMM_EqualsVec4(a, b));
+ EXPECT_FALSE(HMM_EqualsVec4(a, c));
+
+#ifdef __cplusplus
+ EXPECT_TRUE(HMM_Equals(a, b));
+ EXPECT_FALSE(HMM_Equals(a, c));
+
+ EXPECT_TRUE(a == b);
+ EXPECT_FALSE(a == c);
+#endif
+}
diff --git a/test/categories/Initialization.h b/test/categories/Initialization.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Initialization.h
@@ -0,0 +1,207 @@
+#include "../HandmadeTest.h"
+
+TEST(Initialization, Vectors)
+{
+ //
+ // Test vec2
+ //
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2i = HMM_Vec2(1, 2);
+
+ EXPECT_FLOAT_EQ(v2.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v2.U, 1.0f);
+ EXPECT_FLOAT_EQ(v2.V, 2.0f);
+ EXPECT_FLOAT_EQ(v2.Left, 1.0f);
+ EXPECT_FLOAT_EQ(v2.Right, 2.0f);
+ EXPECT_FLOAT_EQ(v2.Width, 1.0f);
+ EXPECT_FLOAT_EQ(v2.Height, 2.0f);
+ EXPECT_FLOAT_EQ(v2.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v2.Elements[1], 2.0f);
+
+ EXPECT_FLOAT_EQ(v2i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v2i.U, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.V, 2.0f);
+ EXPECT_FLOAT_EQ(v2i.Left, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Right, 2.0f);
+ EXPECT_FLOAT_EQ(v2i.Width, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Height, 2.0f);
+ EXPECT_FLOAT_EQ(v2i.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Elements[1], 2.0f);
+
+ //
+ // Test vec3
+ //
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3i = HMM_Vec3i(1, 2, 3);
+
+ EXPECT_FLOAT_EQ(v3.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v3.U, 1.0f);
+ EXPECT_FLOAT_EQ(v3.V, 2.0f);
+ EXPECT_FLOAT_EQ(v3.W, 3.0f);
+ EXPECT_FLOAT_EQ(v3.R, 1.0f);
+ EXPECT_FLOAT_EQ(v3.G, 2.0f);
+ EXPECT_FLOAT_EQ(v3.B, 3.0f);
+ EXPECT_FLOAT_EQ(v3.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(v3.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3.YZ.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v3.YZ.Elements[1], 3.0f);
+ EXPECT_FLOAT_EQ(v3.UV.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3.UV.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3.VW.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v3.VW.Elements[1], 3.0f);
+
+ EXPECT_FLOAT_EQ(v3i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3i.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v3i.U, 1.0f);
+ EXPECT_FLOAT_EQ(v3i.V, 2.0f);
+ EXPECT_FLOAT_EQ(v3i.W, 3.0f);
+ EXPECT_FLOAT_EQ(v3i.R, 1.0f);
+ EXPECT_FLOAT_EQ(v3i.G, 2.0f);
+ EXPECT_FLOAT_EQ(v3i.B, 3.0f);
+ EXPECT_FLOAT_EQ(v3i.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3i.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3i.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(v3i.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3i.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3i.YZ.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v3i.YZ.Elements[1], 3.0f);
+ EXPECT_FLOAT_EQ(v3i.UV.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v3i.UV.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v3i.VW.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v3i.VW.Elements[1], 3.0f);
+
+ //
+ // Test vec4
+ //
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4i = HMM_Vec4i(1, 2, 3, 4);
+ hmm_vec4 v4v = HMM_Vec4v(v3, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4.W, 4.0f);
+ EXPECT_FLOAT_EQ(v4.R, 1.0f);
+ EXPECT_FLOAT_EQ(v4.G, 2.0f);
+ EXPECT_FLOAT_EQ(v4.B, 3.0f);
+ EXPECT_FLOAT_EQ(v4.A, 4.0f);
+ EXPECT_FLOAT_EQ(v4.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4.YZ.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v4.YZ.Elements[1], 3.0f);
+ EXPECT_FLOAT_EQ(v4.ZW.Elements[0], 3.0f);
+ EXPECT_FLOAT_EQ(v4.ZW.Elements[1], 4.0f);
+ EXPECT_FLOAT_EQ(v4.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4.XYZ.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4.XYZ.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4.XYZ.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(v4.RGB.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4.RGB.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4.RGB.Elements[2], 3.0f);
+
+ EXPECT_FLOAT_EQ(v4i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4i.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4i.W, 4.0f);
+ EXPECT_FLOAT_EQ(v4i.R, 1.0f);
+ EXPECT_FLOAT_EQ(v4i.G, 2.0f);
+ EXPECT_FLOAT_EQ(v4i.B, 3.0f);
+ EXPECT_FLOAT_EQ(v4i.A, 4.0f);
+ EXPECT_FLOAT_EQ(v4i.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4i.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4i.YZ.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v4i.YZ.Elements[1], 3.0f);
+ EXPECT_FLOAT_EQ(v4i.ZW.Elements[0], 3.0f);
+ EXPECT_FLOAT_EQ(v4i.ZW.Elements[1], 4.0f);
+ EXPECT_FLOAT_EQ(v4i.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4i.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4i.XYZ.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4i.XYZ.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4i.XYZ.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(v4i.RGB.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4i.RGB.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4i.RGB.Elements[2], 3.0f);
+
+ EXPECT_FLOAT_EQ(v4v.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4v.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4v.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4v.W, 4.0f);
+ EXPECT_FLOAT_EQ(v4v.R, 1.0f);
+ EXPECT_FLOAT_EQ(v4v.G, 2.0f);
+ EXPECT_FLOAT_EQ(v4v.B, 3.0f);
+ EXPECT_FLOAT_EQ(v4v.A, 4.0f);
+ EXPECT_FLOAT_EQ(v4v.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4v.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4v.YZ.Elements[0], 2.0f);
+ EXPECT_FLOAT_EQ(v4v.YZ.Elements[1], 3.0f);
+ EXPECT_FLOAT_EQ(v4v.ZW.Elements[0], 3.0f);
+ EXPECT_FLOAT_EQ(v4v.ZW.Elements[1], 4.0f);
+ EXPECT_FLOAT_EQ(v4v.XY.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4v.XY.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4v.XYZ.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4v.XYZ.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4v.XYZ.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(v4v.RGB.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(v4v.RGB.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(v4v.RGB.Elements[2], 3.0f);
+}
+
+TEST(Initialization, MatrixEmpty)
+{
+ hmm_mat4 m4 = HMM_Mat4();
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4.Elements[Column][Row], 0.0f);
+ }
+ }
+}
+
+TEST(Initialization, MatrixDiagonal)
+{
+ hmm_mat4 m4d = HMM_Mat4d(1.0f);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ if (Column == Row) {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 1.0f);
+ } else {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 0.0f);
+ }
+ }
+ }
+}
+
+TEST(Initialization, Quaternion)
+{
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+
+ EXPECT_FLOAT_EQ(q.X, 1.0f);
+ EXPECT_FLOAT_EQ(q.Y, 2.0f);
+ EXPECT_FLOAT_EQ(q.Z, 3.0f);
+ EXPECT_FLOAT_EQ(q.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(q.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(q.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(q.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(q.Elements[3], 4.0f);
+
+ hmm_vec4 v = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion qv = HMM_QuaternionV4(v);
+
+ EXPECT_FLOAT_EQ(qv.X, 1.0f);
+ EXPECT_FLOAT_EQ(qv.Y, 2.0f);
+ EXPECT_FLOAT_EQ(qv.Z, 3.0f);
+ EXPECT_FLOAT_EQ(qv.W, 4.0f);
+}
diff --git a/test/categories/Multiplication.h b/test/categories/Multiplication.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Multiplication.h
@@ -0,0 +1,536 @@
+#include "../HandmadeTest.h"
+
+TEST(Multiplication, Vec2Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 * v2_2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+
+ v2_1 *= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 8.0f);
+#endif
+}
+
+TEST(Multiplication, Vec2Scalar)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Multiply(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = s * v2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2 *= s;
+ EXPECT_FLOAT_EQ(v2.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 6.0f);
+#endif
+}
+
+TEST(Multiplication, Vec3Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 * v3_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+
+ v3_1 *= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 10.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 18.0f);
+#endif
+}
+
+TEST(Multiplication, Vec3Scalar)
+{
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Multiply(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = s * v3;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3 *= s;
+ EXPECT_FLOAT_EQ(v3.X, 3.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 9.0f);
+#endif
+}
+
+TEST(Multiplication, Vec4Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 * v4_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+
+ v4_1 *= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 12.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 21.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 32.0f);
+#endif
+}
+
+TEST(Multiplication, Vec4Scalar)
+{
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Multiply(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = s * v4;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4 *= s;
+ EXPECT_FLOAT_EQ(v4.X, 3.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 9.0f);
+#endif
+}
+
+TEST(Multiplication, Mat4Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+ {
+ hmm_mat4 result = m4_1 * m4_2;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+
+ // At the time I wrote this, I intentionally omitted
+ // the *= operator for matrices because matrix
+ // multiplication is not commutative. (bvisness)
+#endif
+}
+
+TEST(Multiplication, Mat4Scalar)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 3;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_mat4 result = HMM_Multiply(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = m4 * s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = s * m4;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+
+ m4 *= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 48.0f);
+#endif
+}
+
+TEST(Multiplication, Mat4Vec4)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_vec4 result = HMM_MultiplyMat4ByVec4(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Multiply(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+ {
+ hmm_vec4 result = m4 * v4;
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+
+ // *= makes no sense for this particular case.
+#endif
+}
+
+TEST(Multiplication, QuaternionQuaternion)
+{
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_MultiplyQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Multiply(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+ {
+ hmm_quaternion result = q1 * q2;
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+
+ // Like with matrices, we're not implementing the *=
+ // operator for quaternions because quaternion multiplication
+ // is not commutative.
+#endif
+}
+
+TEST(Multiplication, QuaternionScalar)
+{
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ float f = 2.0f;
+
+ {
+ hmm_quaternion result = HMM_MultiplyQuaternionF(q, f);
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Multiply(q, f);
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+ {
+ hmm_quaternion result = q * f;
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+ {
+ hmm_quaternion result = f * q;
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+
+ q *= f;
+ EXPECT_FLOAT_EQ(q.X, 2.0f);
+ EXPECT_FLOAT_EQ(q.Y, 4.0f);
+ EXPECT_FLOAT_EQ(q.Z, 6.0f);
+ EXPECT_FLOAT_EQ(q.W, 8.0f);
+#endif
+}
diff --git a/test/categories/Projection.h b/test/categories/Projection.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Projection.h
@@ -0,0 +1,36 @@
+#include "../HandmadeTest.h"
+
+TEST(Projection, Orthographic)
+{
+ hmm_mat4 projection = HMM_Orthographic(-10.0f, 10.0f, -5.0f, 5.0f, 0.0f, -10.0f);
+
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(projected.X, 0.5f);
+ EXPECT_FLOAT_EQ(projected.Y, 1.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -2.0f);
+ EXPECT_FLOAT_EQ(projected.W, 1.0f);
+}
+
+TEST(Projection, Perspective)
+{
+ hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
+
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, 15.0f);
+ EXPECT_FLOAT_EQ(projected.W, 15.0f);
+ }
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -5.0f);
+ EXPECT_FLOAT_EQ(projected.W, 5.0f);
+ }
+}
diff --git a/test/categories/QuaternionOps.h b/test/categories/QuaternionOps.h
new file mode 100644
--- /dev/null
+++ b/test/categories/QuaternionOps.h
@@ -0,0 +1,118 @@
+#include "../HandmadeTest.h"
+
+TEST(QuaternionOps, Inverse)
+{
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion inverse = HMM_InverseQuaternion(q1);
+
+ hmm_quaternion result = HMM_MultiplyQuaternion(q1, inverse);
+
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_FLOAT_EQ(result.W, 1.0f);
+}
+
+TEST(QuaternionOps, Dot)
+{
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ float result = HMM_DotQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result, 70.0f);
+ }
+#ifdef __cplusplus
+ {
+ float result = HMM_Dot(q1, q2);
+ EXPECT_FLOAT_EQ(result, 70.0f);
+ }
+#endif
+}
+
+TEST(QuaternionOps, Normalize)
+{
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+
+ {
+ hmm_quaternion result = HMM_NormalizeQuaternion(q);
+ EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
+ EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
+ EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
+ EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Normalize(q);
+ EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
+ EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
+ EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
+ EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
+ }
+#endif
+}
+
+TEST(QuaternionOps, NLerp)
+{
+ hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
+ hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
+
+ hmm_quaternion result = HMM_NLerp(from, 0.5f, to);
+ EXPECT_FLOAT_EQ(result.X, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
+ EXPECT_FLOAT_EQ(result.W, 0.86602540f);
+}
+
+TEST(QuaternionOps, Slerp)
+{
+ hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
+ hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
+
+ hmm_quaternion result = HMM_Slerp(from, 0.5f, to);
+ EXPECT_FLOAT_EQ(result.X, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
+ EXPECT_FLOAT_EQ(result.W, 0.86602540f);
+}
+
+TEST(QuaternionOps, ToMat4)
+{
+ const float abs_error = 0.0001f;
+
+ hmm_quaternion rot = HMM_Quaternion(0.707107f, 0.0f, 0.0f, 0.707107f);
+
+ hmm_mat4 result = HMM_QuaternionToMat4(rot);
+
+ EXPECT_NEAR(result.Elements[0][0], 1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[1][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][2], 1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[2][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][1], -1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[3][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][3], 1.0f, abs_error);
+}
+
+TEST(QuaternionOps, FromAxisAngle)
+{
+ hmm_vec3 axis = HMM_Vec3(1.0f, 0.0f, 0.0f);
+ float angle = HMM_PI32 / 2.0f;
+
+ hmm_quaternion result = HMM_QuaternionFromAxisAngle(axis, angle);
+ EXPECT_NEAR(result.X, 0.707107f, FLT_EPSILON * 2);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_NEAR(result.W, 0.707107f, FLT_EPSILON * 2);
+}
\ No newline at end of file
diff --git a/test/categories/SSE.h b/test/categories/SSE.h
new file mode 100644
--- /dev/null
+++ b/test/categories/SSE.h
@@ -0,0 +1,41 @@
+#include "../HandmadeTest.h"
+
+#ifdef HANDMADE_MATH__USE_SSE
+
+TEST(SSE, LinearCombine)
+{
+ hmm_mat4 MatrixOne = HMM_Mat4d(2.0f);
+ hmm_mat4 MatrixTwo = HMM_Mat4d(4.0f);
+ hmm_mat4 Result;
+
+ Result.Rows[0] = HMM_LinearCombineSSE(MatrixOne.Rows[0], MatrixTwo);
+ Result.Rows[1] = HMM_LinearCombineSSE(MatrixOne.Rows[1], MatrixTwo);
+ Result.Rows[2] = HMM_LinearCombineSSE(MatrixOne.Rows[2], MatrixTwo);
+ Result.Rows[3] = HMM_LinearCombineSSE(MatrixOne.Rows[3], MatrixTwo);
+
+ {
+ EXPECT_FLOAT_EQ(Result.Elements[0][0], 8.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[0][1], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[0][2], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[0][3], 0.0f);
+
+ EXPECT_FLOAT_EQ(Result.Elements[1][0], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[1][1], 8.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[1][2], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[1][3], 0.0f);
+
+
+ EXPECT_FLOAT_EQ(Result.Elements[2][0], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[2][1], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[2][2], 8.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[2][3], 0.0f);
+
+
+ EXPECT_FLOAT_EQ(Result.Elements[3][0], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[3][1], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[3][2], 0.0f);
+ EXPECT_FLOAT_EQ(Result.Elements[3][3], 8.0f);
+ }
+}
+
+#endif
diff --git a/test/categories/ScalarMath.h b/test/categories/ScalarMath.h
new file mode 100644
--- /dev/null
+++ b/test/categories/ScalarMath.h
@@ -0,0 +1,74 @@
+#include "../HandmadeTest.h"
+
+TEST(ScalarMath, Trigonometry)
+{
+ // We have to be a little looser with our equality constraint
+ // because of floating-point precision issues.
+ const float trigAbsError = 0.0001f;
+
+ EXPECT_NEAR(HMM_SinF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32 / 2), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(3 * HMM_PI32 / 2), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(-HMM_PI32 / 2), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_CosF(0.0f), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(3 * HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(-HMM_PI32), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_TanF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32 / 4), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(3 * HMM_PI32 / 4), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(-HMM_PI32 / 4), -1.0f, trigAbsError);
+
+ // This isn't the most rigorous because we're really just sanity-
+ // checking that things work by default.
+}
+
+TEST(ScalarMath, ToRadians)
+{
+ EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(180.0f), HMM_PI32);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(-180.0f), -HMM_PI32);
+}
+
+TEST(ScalarMath, SquareRoot)
+{
+ EXPECT_FLOAT_EQ(HMM_SquareRootF(16.0f), 4.0f);
+}
+
+TEST(ScalarMath, RSquareRootF)
+{
+ EXPECT_NEAR(HMM_RSquareRootF(10.0f), 0.31616211f, 0.0001f);
+}
+
+TEST(ScalarMath, Power)
+{
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 0), 1.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 4), 16.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, -2), 0.25f);
+}
+
+TEST(ScalarMath, PowerF)
+{
+ EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0), 1.0f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, 4.1), 17.148376f, 0.0001f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, -2.5), 0.176777f, 0.0001f);
+}
+
+TEST(ScalarMath, Lerp)
+{
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.0f, 2.0f), -2.0f);
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.5f, 2.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 1.0f, 2.0f), 2.0f);
+}
+
+TEST(ScalarMath, Clamp)
+{
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 0.0f, 2.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, -3.0f, 2.0f), -2.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 3.0f, 2.0f), 2.0f);
+}
diff --git a/test/categories/Subtraction.h b/test/categories/Subtraction.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Subtraction.h
@@ -0,0 +1,201 @@
+#include "../HandmadeTest.h"
+
+TEST(Subtraction, Vec2)
+{
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_SubtractVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 - v2_2;
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+
+ v2_1 -= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, -2.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, -2.0f);
+#endif
+}
+
+TEST(Subtraction, Vec3)
+{
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_SubtractVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 - v3_2;
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+
+ v3_1 -= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, -3.0f);
+#endif
+}
+
+TEST(Subtraction, Vec4)
+{
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_SubtractVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 - v4_2;
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+
+ v4_1 -= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, -4.0f);
+#endif
+}
+
+TEST(Subtraction, Mat4)
+{
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_SubtractMat4(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
+ }
+ }
+ }
+#ifdef __cplusplus
+ {
+ hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 - m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
+ }
+ }
+ }
+
+ m4_1 -= m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], -16.0f);
+ }
+ }
+#endif
+}
+
+TEST(Subtraction, Quaternion)
+{
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_SubtractQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+#ifdef __cplusplus
+ {
+ hmm_quaternion result = HMM_Subtract(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_quaternion result = q1 - q2;
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+
+ q1 -= q2;
+ EXPECT_FLOAT_EQ(q1.X, -4.0f);
+ EXPECT_FLOAT_EQ(q1.Y, -4.0f);
+ EXPECT_FLOAT_EQ(q1.Z, -4.0f);
+ EXPECT_FLOAT_EQ(q1.W, -4.0f);
+#endif
+}
diff --git a/test/categories/Transformation.h b/test/categories/Transformation.h
new file mode 100644
--- /dev/null
+++ b/test/categories/Transformation.h
@@ -0,0 +1,53 @@
+#include "../HandmadeTest.h"
+
+TEST(Transformations, Translate)
+{
+ hmm_mat4 translate = HMM_Translate(HMM_Vec3(1.0f, -3.0f, 6.0f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 translated = HMM_MultiplyMat4ByVec4(translate, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(translated.X, 2.0f);
+ EXPECT_FLOAT_EQ(translated.Y, -1.0f);
+ EXPECT_FLOAT_EQ(translated.Z, 9.0f);
+ EXPECT_FLOAT_EQ(translated.W, 1.0f);
+}
+
+TEST(Transformations, Rotate)
+{
+ hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
+
+ hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ hmm_vec4 rotatedX = HMM_MultiplyMat4ByVec4(rotateX, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
+
+ hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
+ hmm_vec4 rotatedY = HMM_MultiplyMat4ByVec4(rotateY, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
+
+ hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_vec4 rotatedZ = HMM_MultiplyMat4ByVec4(rotateZ, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.W, 1.0f);
+}
+
+TEST(Transformations, Scale)
+{
+ hmm_mat4 scale = HMM_Scale(HMM_Vec3(2.0f, -3.0f, 0.5f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 scaled = HMM_MultiplyMat4ByVec4(scale, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(scaled.X, 2.0f);
+ EXPECT_FLOAT_EQ(scaled.Y, -6.0f);
+ EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
+ EXPECT_FLOAT_EQ(scaled.W, 1.0f);
+}
diff --git a/test/categories/VectorOps.h b/test/categories/VectorOps.h
new file mode 100644
--- /dev/null
+++ b/test/categories/VectorOps.h
@@ -0,0 +1,220 @@
+#include "../HandmadeTest.h"
+
+TEST(VectorOps, LengthSquared)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
+ hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
+ hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, 1.0f);
+
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec2(v2), 5.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec3(v3), 14.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec4(v4), 15.0f);
+
+#ifdef __cplusplus
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v2), 5.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v3), 14.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v4), 15.0f);
+#endif
+}
+
+TEST(VectorOps, Length)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -9.0f);
+ hmm_vec3 v3 = HMM_Vec3(2.0f, -3.0f, 6.0f);
+ hmm_vec4 v4 = HMM_Vec4(2.0f, -3.0f, 6.0f, 12.0f);
+
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(v2), 9.0553856f);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(v3), 7.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(v4), 13.892444f);
+
+#ifdef __cplusplus
+ EXPECT_FLOAT_EQ(HMM_Length(v2), 9.0553856f);
+ EXPECT_FLOAT_EQ(HMM_Length(v3), 7.0f);
+ EXPECT_FLOAT_EQ(HMM_Length(v4), 13.892444f);
+#endif
+}
+
+TEST(VectorOps, Normalize)
+{
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
+ hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
+ hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, -1.0f);
+
+ {
+ hmm_vec2 result = HMM_NormalizeVec2(v2);
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_NormalizeVec3(v3);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_NormalizeVec4(v4);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ EXPECT_LT(result.W, 0.0f);
+ }
+
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Normalize(v2);
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Normalize(v3);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Normalize(v4);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ EXPECT_LT(result.W, 0.0f);
+ }
+#endif
+}
+
+TEST(VectorOps, NormalizeZero)
+{
+ hmm_vec2 v2 = HMM_Vec2(0.0f, 0.0f);
+ hmm_vec3 v3 = HMM_Vec3(0.0f, 0.0f, 0.0f);
+ hmm_vec4 v4 = HMM_Vec4(0.0f, 0.0f, 0.0f, 0.0f);
+
+ {
+ hmm_vec2 result = HMM_NormalizeVec2(v2);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_NormalizeVec3(v3);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_NormalizeVec4(v4);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.0f);
+ }
+
+#ifdef __cplusplus
+ {
+ hmm_vec2 result = HMM_Normalize(v2);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Normalize(v3);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Normalize(v4);
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.0f);
+ }
+#endif
+}
+
+TEST(VectorOps, Cross)
+{
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ hmm_vec3 result = HMM_Cross(v1, v2);
+
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+}
+
+TEST(VectorOps, DotVec2)
+{
+ hmm_vec2 v1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2 = HMM_Vec2(3.0f, 4.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec2(v1, v2), 11.0f);
+#ifdef __cplusplus
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
+#endif
+}
+
+TEST(VectorOps, DotVec3)
+{
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec3(v1, v2), 32.0f);
+#ifdef __cplusplus
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
+#endif
+}
+
+TEST(VectorOps, DotVec4)
+{
+ hmm_vec4 v1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec4(v1, v2), 70.0f);
+#ifdef __cplusplus
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
+#endif
+}
+
+
+/*
+ * MatrixOps tests
+ */
+
+TEST(MatrixOps, Transpose)
+{
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the matrix
+ hmm_mat4 result = HMM_Transpose(m4);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 13.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 10.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 14.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 11.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 8.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 16.0f);
+}
diff --git a/test/hmm_test.c b/test/hmm_test.c
--- a/test/hmm_test.c
+++ b/test/hmm_test.c
@@ -1,2202 +1,7 @@
-#include <float.h>
-
#include "HandmadeTest.h"
-#include "../HandmadeMath.h"
-
-int run_tests();
+#include "hmm_test.h"
int main()
{
- run_tests();
-
- if (hmt_count_failedtests > 0) {
- printf(RED);
- } else {
- printf(GREEN);
- }
- printf("\n%d/%d tests passed overall, %d failures\n" RESET, hmt_count_tests - hmt_count_failedtests, hmt_count_tests, hmt_count_failures);
-
- printf("\n");
-
- return (hmt_count_failedtests > 0);
-}
-
-int run_tests()
-{
- CATEGORY_BEGIN(ScalarMath)
- {
- TEST_BEGIN(Trigonometry)
- {
- // We have to be a little looser with our equality constraint
- // because of floating-point precision issues.
- const float trigAbsError = 0.0001f;
-
- EXPECT_NEAR(HMM_SinF(0.0f), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(HMM_PI32 / 2), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(HMM_PI32), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(3 * HMM_PI32 / 2), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(-HMM_PI32 / 2), -1.0f, trigAbsError);
-
- EXPECT_NEAR(HMM_CosF(0.0f), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(HMM_PI32 / 2), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(HMM_PI32), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(3 * HMM_PI32 / 2), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(-HMM_PI32), -1.0f, trigAbsError);
-
- EXPECT_NEAR(HMM_TanF(0.0f), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(HMM_PI32 / 4), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(3 * HMM_PI32 / 4), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(HMM_PI32), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(-HMM_PI32 / 4), -1.0f, trigAbsError);
-
- // This isn't the most rigorous because we're really just sanity-
- // checking that things work by default.
- }
- TEST_END()
-
- TEST_BEGIN(ToRadians)
- {
- EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0.0f);
- EXPECT_FLOAT_EQ(HMM_ToRadians(180.0f), HMM_PI32);
- EXPECT_FLOAT_EQ(HMM_ToRadians(-180.0f), -HMM_PI32);
- }
- TEST_END()
-
- TEST_BEGIN(SquareRoot)
- {
- EXPECT_FLOAT_EQ(HMM_SquareRootF(16.0f), 4.0f);
- }
- TEST_END()
-
- TEST_BEGIN(RSquareRootF)
- {
- EXPECT_NEAR(HMM_RSquareRootF(10.0f), 0.31616211f, 0.0001f);
- }
- TEST_END()
-
- TEST_BEGIN(Power)
- {
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, 0), 1.0f);
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, 4), 16.0f);
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, -2), 0.25f);
- }
- TEST_END()
-
- TEST_BEGIN(PowerF)
- {
- EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0), 1.0f);
- EXPECT_NEAR(HMM_PowerF(2.0f, 4.1), 17.148376f, 0.0001f);
- EXPECT_NEAR(HMM_PowerF(2.0f, -2.5), 0.176777f, 0.0001f);
- }
- TEST_END()
-
- TEST_BEGIN(Lerp)
- {
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.0f, 2.0f), -2.0f);
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.5f, 2.0f), 0.0f);
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 1.0f, 2.0f), 2.0f);
- }
- TEST_END()
-
- TEST_BEGIN(Clamp)
- {
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 0.0f, 2.0f), 0.0f);
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, -3.0f, 2.0f), -2.0f);
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 3.0f, 2.0f), 2.0f);
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Initialization)
- {
- TEST_BEGIN(Vectors)
- {
- //
- // Test vec2
- //
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2i = HMM_Vec2(1, 2);
-
- EXPECT_FLOAT_EQ(v2.X, 1.0f);
- EXPECT_FLOAT_EQ(v2.Y, 2.0f);
- EXPECT_FLOAT_EQ(v2.U, 1.0f);
- EXPECT_FLOAT_EQ(v2.V, 2.0f);
- EXPECT_FLOAT_EQ(v2.Left, 1.0f);
- EXPECT_FLOAT_EQ(v2.Right, 2.0f);
- EXPECT_FLOAT_EQ(v2.Width, 1.0f);
- EXPECT_FLOAT_EQ(v2.Height, 2.0f);
- EXPECT_FLOAT_EQ(v2.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v2.Elements[1], 2.0f);
-
- EXPECT_FLOAT_EQ(v2i.X, 1.0f);
- EXPECT_FLOAT_EQ(v2i.Y, 2.0f);
- EXPECT_FLOAT_EQ(v2i.U, 1.0f);
- EXPECT_FLOAT_EQ(v2i.V, 2.0f);
- EXPECT_FLOAT_EQ(v2i.Left, 1.0f);
- EXPECT_FLOAT_EQ(v2i.Right, 2.0f);
- EXPECT_FLOAT_EQ(v2i.Width, 1.0f);
- EXPECT_FLOAT_EQ(v2i.Height, 2.0f);
- EXPECT_FLOAT_EQ(v2i.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v2i.Elements[1], 2.0f);
-
- //
- // Test vec3
- //
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3i = HMM_Vec3i(1, 2, 3);
-
- EXPECT_FLOAT_EQ(v3.X, 1.0f);
- EXPECT_FLOAT_EQ(v3.Y, 2.0f);
- EXPECT_FLOAT_EQ(v3.Z, 3.0f);
- EXPECT_FLOAT_EQ(v3.U, 1.0f);
- EXPECT_FLOAT_EQ(v3.V, 2.0f);
- EXPECT_FLOAT_EQ(v3.W, 3.0f);
- EXPECT_FLOAT_EQ(v3.R, 1.0f);
- EXPECT_FLOAT_EQ(v3.G, 2.0f);
- EXPECT_FLOAT_EQ(v3.B, 3.0f);
- EXPECT_FLOAT_EQ(v3.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(v3.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3.YZ.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v3.YZ.Elements[1], 3.0f);
- EXPECT_FLOAT_EQ(v3.UV.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3.UV.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3.VW.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v3.VW.Elements[1], 3.0f);
-
- EXPECT_FLOAT_EQ(v3i.X, 1.0f);
- EXPECT_FLOAT_EQ(v3i.Y, 2.0f);
- EXPECT_FLOAT_EQ(v3i.Z, 3.0f);
- EXPECT_FLOAT_EQ(v3i.U, 1.0f);
- EXPECT_FLOAT_EQ(v3i.V, 2.0f);
- EXPECT_FLOAT_EQ(v3i.W, 3.0f);
- EXPECT_FLOAT_EQ(v3i.R, 1.0f);
- EXPECT_FLOAT_EQ(v3i.G, 2.0f);
- EXPECT_FLOAT_EQ(v3i.B, 3.0f);
- EXPECT_FLOAT_EQ(v3i.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3i.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3i.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(v3i.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3i.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3i.YZ.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v3i.YZ.Elements[1], 3.0f);
- EXPECT_FLOAT_EQ(v3i.UV.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v3i.UV.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v3i.VW.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v3i.VW.Elements[1], 3.0f);
-
- //
- // Test vec4
- //
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4i = HMM_Vec4i(1, 2, 3, 4);
- hmm_vec4 v4v = HMM_Vec4v(v3, 4.0f);
-
- EXPECT_FLOAT_EQ(v4.X, 1.0f);
- EXPECT_FLOAT_EQ(v4.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4.W, 4.0f);
- EXPECT_FLOAT_EQ(v4.R, 1.0f);
- EXPECT_FLOAT_EQ(v4.G, 2.0f);
- EXPECT_FLOAT_EQ(v4.B, 3.0f);
- EXPECT_FLOAT_EQ(v4.A, 4.0f);
- EXPECT_FLOAT_EQ(v4.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4.YZ.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v4.YZ.Elements[1], 3.0f);
- EXPECT_FLOAT_EQ(v4.ZW.Elements[0], 3.0f);
- EXPECT_FLOAT_EQ(v4.ZW.Elements[1], 4.0f);
- EXPECT_FLOAT_EQ(v4.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4.XYZ.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4.XYZ.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4.XYZ.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(v4.RGB.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4.RGB.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4.RGB.Elements[2], 3.0f);
-
- EXPECT_FLOAT_EQ(v4i.X, 1.0f);
- EXPECT_FLOAT_EQ(v4i.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4i.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4i.W, 4.0f);
- EXPECT_FLOAT_EQ(v4i.R, 1.0f);
- EXPECT_FLOAT_EQ(v4i.G, 2.0f);
- EXPECT_FLOAT_EQ(v4i.B, 3.0f);
- EXPECT_FLOAT_EQ(v4i.A, 4.0f);
- EXPECT_FLOAT_EQ(v4i.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4i.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4i.YZ.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v4i.YZ.Elements[1], 3.0f);
- EXPECT_FLOAT_EQ(v4i.ZW.Elements[0], 3.0f);
- EXPECT_FLOAT_EQ(v4i.ZW.Elements[1], 4.0f);
- EXPECT_FLOAT_EQ(v4i.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4i.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4i.XYZ.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4i.XYZ.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4i.XYZ.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(v4i.RGB.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4i.RGB.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4i.RGB.Elements[2], 3.0f);
-
- EXPECT_FLOAT_EQ(v4v.X, 1.0f);
- EXPECT_FLOAT_EQ(v4v.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4v.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4v.W, 4.0f);
- EXPECT_FLOAT_EQ(v4v.R, 1.0f);
- EXPECT_FLOAT_EQ(v4v.G, 2.0f);
- EXPECT_FLOAT_EQ(v4v.B, 3.0f);
- EXPECT_FLOAT_EQ(v4v.A, 4.0f);
- EXPECT_FLOAT_EQ(v4v.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4v.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4v.YZ.Elements[0], 2.0f);
- EXPECT_FLOAT_EQ(v4v.YZ.Elements[1], 3.0f);
- EXPECT_FLOAT_EQ(v4v.ZW.Elements[0], 3.0f);
- EXPECT_FLOAT_EQ(v4v.ZW.Elements[1], 4.0f);
- EXPECT_FLOAT_EQ(v4v.XY.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4v.XY.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4v.XYZ.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4v.XYZ.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4v.XYZ.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(v4v.RGB.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(v4v.RGB.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(v4v.RGB.Elements[2], 3.0f);
- }
- TEST_END()
-
- TEST_BEGIN(MatrixEmpty)
- {
- hmm_mat4 m4 = HMM_Mat4();
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4.Elements[Column][Row], 0.0f);
- }
- }
- }
- TEST_END()
-
- TEST_BEGIN(MatrixDiagonal)
- {
- hmm_mat4 m4d = HMM_Mat4d(1.0f);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- if (Column == Row) {
- EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 1.0f);
- } else {
- EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 0.0f);
- }
- }
- }
- }
- TEST_END()
-
- TEST_BEGIN(Quaternion)
- {
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
-
- EXPECT_FLOAT_EQ(q.X, 1.0f);
- EXPECT_FLOAT_EQ(q.Y, 2.0f);
- EXPECT_FLOAT_EQ(q.Z, 3.0f);
- EXPECT_FLOAT_EQ(q.W, 4.0f);
-
- EXPECT_FLOAT_EQ(q.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(q.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(q.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(q.Elements[3], 4.0f);
-
- hmm_vec4 v = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion qv = HMM_QuaternionV4(v);
-
- EXPECT_FLOAT_EQ(qv.X, 1.0f);
- EXPECT_FLOAT_EQ(qv.Y, 2.0f);
- EXPECT_FLOAT_EQ(qv.Z, 3.0f);
- EXPECT_FLOAT_EQ(qv.W, 4.0f);
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(VectorOps)
- {
- TEST_BEGIN(LengthSquared)
- {
- hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
- hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
- hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, 1.0f);
-
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec2(v2), 5.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec3(v3), 14.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec4(v4), 15.0f);
-
-#ifdef __cplusplus
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v2), 5.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v3), 14.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v4), 15.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Length)
- {
- hmm_vec2 v2 = HMM_Vec2(1.0f, -9.0f);
- hmm_vec3 v3 = HMM_Vec3(2.0f, -3.0f, 6.0f);
- hmm_vec4 v4 = HMM_Vec4(2.0f, -3.0f, 6.0f, 12.0f);
-
- EXPECT_FLOAT_EQ(HMM_LengthVec2(v2), 9.0553856f);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(v3), 7.0f);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(v4), 13.892444f);
-
-#ifdef __cplusplus
- EXPECT_FLOAT_EQ(HMM_Length(v2), 9.0553856f);
- EXPECT_FLOAT_EQ(HMM_Length(v3), 7.0f);
- EXPECT_FLOAT_EQ(HMM_Length(v4), 13.892444f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Normalize)
- {
- hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
- hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
- hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, -1.0f);
-
- {
- hmm_vec2 result = HMM_NormalizeVec2(v2);
- EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- }
- {
- hmm_vec3 result = HMM_NormalizeVec3(v3);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- EXPECT_GT(result.Z, 0.0f);
- }
- {
- hmm_vec4 result = HMM_NormalizeVec4(v4);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- EXPECT_GT(result.Z, 0.0f);
- EXPECT_LT(result.W, 0.0f);
- }
-
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Normalize(v2);
- EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- }
- {
- hmm_vec3 result = HMM_Normalize(v3);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- EXPECT_GT(result.Z, 0.0f);
- }
- {
- hmm_vec4 result = HMM_Normalize(v4);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
- EXPECT_GT(result.X, 0.0f);
- EXPECT_LT(result.Y, 0.0f);
- EXPECT_GT(result.Z, 0.0f);
- EXPECT_LT(result.W, 0.0f);
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(NormalizeZero)
- {
- hmm_vec2 v2 = HMM_Vec2(0.0f, 0.0f);
- hmm_vec3 v3 = HMM_Vec3(0.0f, 0.0f, 0.0f);
- hmm_vec4 v4 = HMM_Vec4(0.0f, 0.0f, 0.0f, 0.0f);
-
- {
- hmm_vec2 result = HMM_NormalizeVec2(v2);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- }
- {
- hmm_vec3 result = HMM_NormalizeVec3(v3);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- }
- {
- hmm_vec4 result = HMM_NormalizeVec4(v4);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_FLOAT_EQ(result.W, 0.0f);
- }
-
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Normalize(v2);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- }
- {
- hmm_vec3 result = HMM_Normalize(v3);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- }
- {
- hmm_vec4 result = HMM_Normalize(v4);
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_FLOAT_EQ(result.W, 0.0f);
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Cross)
- {
- hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- hmm_vec3 result = HMM_Cross(v1, v2);
-
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
- TEST_END()
-
- TEST_BEGIN(DotVec2)
- {
- hmm_vec2 v1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2 = HMM_Vec2(3.0f, 4.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec2(v1, v2), 11.0f);
-#ifdef __cplusplus
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(DotVec3)
- {
- hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec3(v1, v2), 32.0f);
-#ifdef __cplusplus
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(DotVec4)
- {
- hmm_vec4 v1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec4(v1, v2), 70.0f);
-#ifdef __cplusplus
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(MatrixOps)
- {
- TEST_BEGIN(Transpose)
- {
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the matrix
- hmm_mat4 result = HMM_Transpose(m4);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 13.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 10.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 14.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 11.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 8.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 16.0f);
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(QuaternionOps)
- {
- TEST_BEGIN(Inverse)
- {
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion inverse = HMM_InverseQuaternion(q1);
-
- hmm_quaternion result = HMM_MultiplyQuaternion(q1, inverse);
-
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_FLOAT_EQ(result.W, 1.0f);
- }
- TEST_END()
-
- TEST_BEGIN(Dot)
- {
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- float result = HMM_DotQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result, 70.0f);
- }
-#ifdef __cplusplus
- {
- float result = HMM_Dot(q1, q2);
- EXPECT_FLOAT_EQ(result, 70.0f);
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Normalize)
- {
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
-
- {
- hmm_quaternion result = HMM_NormalizeQuaternion(q);
- EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
- EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
- EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
- EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Normalize(q);
- EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
- EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
- EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
- EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(NLerp)
- {
- hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
- hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
-
- hmm_quaternion result = HMM_NLerp(from, 0.5f, to);
- EXPECT_FLOAT_EQ(result.X, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
- EXPECT_FLOAT_EQ(result.W, 0.86602540f);
- }
- TEST_END()
-
- TEST_BEGIN(Slerp)
- {
- hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
- hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
-
- hmm_quaternion result = HMM_Slerp(from, 0.5f, to);
- EXPECT_FLOAT_EQ(result.X, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
- EXPECT_FLOAT_EQ(result.W, 0.86602540f);
- }
- TEST_END()
-
- TEST_BEGIN(ToMat4)
- {
- const float abs_error = 0.0001f;
-
- hmm_quaternion rot = HMM_Quaternion(0.707107f, 0.0f, 0.0f, 0.707107f);
-
- hmm_mat4 result = HMM_QuaternionToMat4(rot);
-
- EXPECT_NEAR(result.Elements[0][0], 1.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[1][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][2], 1.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[2][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][1], -1.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[3][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][3], 1.0f, abs_error);
- }
- TEST_END()
-
- TEST_BEGIN(FromAxisAngle)
- {
- hmm_vec3 axis = HMM_Vec3(1.0f, 0.0f, 0.0f);
- float angle = HMM_PI32 / 2.0f;
-
- hmm_quaternion result = HMM_QuaternionFromAxisAngle(axis, angle);
- EXPECT_NEAR(result.X, 0.707107f, FLT_EPSILON * 2);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_NEAR(result.W, 0.707107f, FLT_EPSILON * 2);
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Addition)
- {
- TEST_BEGIN(Vec2)
- {
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_AddVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Add(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = v2_1 + v2_2;
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-
- v2_1 += v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 4.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, 6.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3)
- {
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_AddVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Add(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = v3_1 + v3_2;
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-
- v3_1 += v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 5.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, 7.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, 9.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4)
- {
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_AddVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Add(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = v4_1 + v4_2;
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- v4_1 += v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 6.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, 8.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 12.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4)
- {
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_AddMat4(m4_1, m4_2);
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
- Expected += 2.0f;
- }
- }
- }
-#ifdef __cplusplus
- {
- hmm_mat4 result = HMM_Add(m4_1, m4_2);
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
- Expected += 2.0f;
- }
- }
- }
- {
- hmm_mat4 result = m4_1 + m4_2;
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
- Expected += 2.0f;
- }
- }
- }
-
- m4_1 += m4_2;
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], Expected);
- Expected += 2.0f;
- }
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Quaternion)
- {
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_AddQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Add(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_quaternion result = q1 + q2;
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- q1 += q2;
- EXPECT_FLOAT_EQ(q1.X, 6.0f);
- EXPECT_FLOAT_EQ(q1.Y, 8.0f);
- EXPECT_FLOAT_EQ(q1.Z, 10.0f);
- EXPECT_FLOAT_EQ(q1.W, 12.0f);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Subtraction)
- {
- TEST_BEGIN(Vec2)
- {
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_SubtractVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
- {
- hmm_vec2 result = v2_1 - v2_2;
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
-
- v2_1 -= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, -2.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, -2.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3)
- {
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_SubtractVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
- {
- hmm_vec3 result = v3_1 - v3_2;
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
-
- v3_1 -= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, -3.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, -3.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, -3.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4)
- {
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_SubtractVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_vec4 result = v4_1 - v4_2;
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-
- v4_1 -= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.W, -4.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4)
- {
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_SubtractMat4(m4_1, m4_2);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
- }
- }
- }
-#ifdef __cplusplus
- {
- hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
- }
- }
- }
- {
- hmm_mat4 result = m4_1 - m4_2;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
- }
- }
- }
-
- m4_1 -= m4_2;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], -16.0f);
- }
- }
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Quaternion)
- {
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_SubtractQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Subtract(q1, q2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_quaternion result = q1 - q2;
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-
- q1 -= q2;
- EXPECT_FLOAT_EQ(q1.X, -4.0f);
- EXPECT_FLOAT_EQ(q1.Y, -4.0f);
- EXPECT_FLOAT_EQ(q1.Z, -4.0f);
- EXPECT_FLOAT_EQ(q1.W, -4.0f);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Multiplication)
- {
- TEST_BEGIN(Vec2Vec2)
- {
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_MultiplyVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
- {
- hmm_vec2 result = v2_1 * v2_2;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
-
- v2_1 *= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 3.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, 8.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec2Scalar)
- {
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- float s = 3.0f;
-
- {
- hmm_vec2 result = HMM_MultiplyVec2f(v2, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Multiply(v2, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = v2 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = s * v2;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-
- v2 *= s;
- EXPECT_FLOAT_EQ(v2.X, 3.0f);
- EXPECT_FLOAT_EQ(v2.Y, 6.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3Vec3)
- {
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_MultiplyVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
- {
- hmm_vec3 result = v3_1 * v3_2;
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
-
- v3_1 *= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 4.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, 10.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, 18.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3Scalar)
- {
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- float s = 3.0f;
-
- {
- hmm_vec3 result = HMM_MultiplyVec3f(v3, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Multiply(v3, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = v3 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = s * v3;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-
- v3 *= s;
- EXPECT_FLOAT_EQ(v3.X, 3.0f);
- EXPECT_FLOAT_EQ(v3.Y, 6.0f);
- EXPECT_FLOAT_EQ(v3.Z, 9.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4Vec4)
- {
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_MultiplyVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
- {
- hmm_vec4 result = v4_1 * v4_2;
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
-
- v4_1 *= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 5.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, 12.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, 21.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 32.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4Scalar)
- {
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- float s = 3.0f;
-
- {
- hmm_vec4 result = HMM_MultiplyVec4f(v4, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Multiply(v4, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = v4 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = s * v4;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- v4 *= s;
- EXPECT_FLOAT_EQ(v4.X, 3.0f);
- EXPECT_FLOAT_EQ(v4.Y, 6.0f);
- EXPECT_FLOAT_EQ(v4.Z, 9.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4Mat4)
- {
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_MultiplyMat4(m4_1, m4_2);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
-#ifdef __cplusplus
- {
- hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
- {
- hmm_mat4 result = m4_1 * m4_2;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
-
- // At the time I wrote this, I intentionally omitted
- // the *= operator for matrices because matrix
- // multiplication is not commutative. (bvisness)
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4Scalar)
- {
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- float s = 3;
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_MultiplyMat4f(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
-#ifdef __cplusplus
- {
- hmm_mat4 result = HMM_Multiply(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
- {
- hmm_mat4 result = m4 * s;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
- {
- hmm_mat4 result = s * m4;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
-
- m4 *= s;
- EXPECT_FLOAT_EQ(m4.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][3], 48.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4Vec4)
- {
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_vec4 result = HMM_MultiplyMat4ByVec4(m4, v4);
- EXPECT_FLOAT_EQ(result.X, 90.0f);
- EXPECT_FLOAT_EQ(result.Y, 100.0f);
- EXPECT_FLOAT_EQ(result.Z, 110.0f);
- EXPECT_FLOAT_EQ(result.W, 120.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Multiply(m4, v4);
- EXPECT_FLOAT_EQ(result.X, 90.0f);
- EXPECT_FLOAT_EQ(result.Y, 100.0f);
- EXPECT_FLOAT_EQ(result.Z, 110.0f);
- EXPECT_FLOAT_EQ(result.W, 120.0f);
- }
- {
- hmm_vec4 result = m4 * v4;
- EXPECT_FLOAT_EQ(result.X, 90.0f);
- EXPECT_FLOAT_EQ(result.Y, 100.0f);
- EXPECT_FLOAT_EQ(result.Z, 110.0f);
- EXPECT_FLOAT_EQ(result.W, 120.0f);
- }
-
- // *= makes no sense for this particular case.
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(QuaternionQuaternion)
- {
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_MultiplyQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Multiply(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
- {
- hmm_quaternion result = q1 * q2;
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
-
- // Like with matrices, we're not implementing the *=
- // operator for quaternions because quaternion multiplication
- // is not commutative.
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(QuaternionScalar)
- {
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- float f = 2.0f;
-
- {
- hmm_quaternion result = HMM_MultiplyQuaternionF(q, f);
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Multiply(q, f);
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
- {
- hmm_quaternion result = q * f;
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
- {
- hmm_quaternion result = f * q;
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
-
- q *= f;
- EXPECT_FLOAT_EQ(q.X, 2.0f);
- EXPECT_FLOAT_EQ(q.Y, 4.0f);
- EXPECT_FLOAT_EQ(q.Z, 6.0f);
- EXPECT_FLOAT_EQ(q.W, 8.0f);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Division)
- {
- TEST_BEGIN(Vec2Vec2)
- {
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 3.0f);
- hmm_vec2 v2_2 = HMM_Vec2(2.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_DivideVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Divide(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
- {
- hmm_vec2 result = v2_1 / v2_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
-
- v2_1 /= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v2_1.Y, 0.75f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec2Scalar)
- {
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- float s = 2;
-
- {
- hmm_vec2 result = HMM_DivideVec2f(v2, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec2 result = HMM_Divide(v2, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
- {
- hmm_vec2 result = v2 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
-
- v2 /= s;
- EXPECT_FLOAT_EQ(v2.X, 0.5f);
- EXPECT_FLOAT_EQ(v2.Y, 1.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3Vec3)
- {
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 3.0f, 5.0f);
- hmm_vec3 v3_2 = HMM_Vec3(2.0f, 4.0f, 0.5f);
-
- {
- hmm_vec3 result = HMM_DivideVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Divide(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
- {
- hmm_vec3 result = v3_1 / v3_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
-
- v3_1 /= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v3_1.Y, 0.75f);
- EXPECT_FLOAT_EQ(v3_1.Z, 10.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3Scalar)
- {
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- float s = 2;
-
- {
- hmm_vec3 result = HMM_DivideVec3f(v3, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
-#ifdef __cplusplus
- {
- hmm_vec3 result = HMM_Divide(v3, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
- {
- hmm_vec3 result = v3 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
-
- v3 /= s;
- EXPECT_FLOAT_EQ(v3.X, 0.5f);
- EXPECT_FLOAT_EQ(v3.Y, 1.0f);
- EXPECT_FLOAT_EQ(v3.Z, 1.5f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4Vec4)
- {
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 3.0f, 5.0f, 1.0f);
- hmm_vec4 v4_2 = HMM_Vec4(2.0f, 4.0f, 0.5f, 4.0f);
-
- {
- hmm_vec4 result = HMM_DivideVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Divide(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
- {
- hmm_vec4 result = v4_1 / v4_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
-
- v4_1 /= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v4_1.Y, 0.75f);
- EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 0.25f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4Scalar)
- {
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- float s = 2;
-
- {
- hmm_vec4 result = HMM_DivideVec4f(v4, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-#ifdef __cplusplus
- {
- hmm_vec4 result = HMM_Divide(v4, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_vec4 result = v4 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-
- v4 /= s;
- EXPECT_FLOAT_EQ(v4.X, 0.5f);
- EXPECT_FLOAT_EQ(v4.Y, 1.0f);
- EXPECT_FLOAT_EQ(v4.Z, 1.5f);
- EXPECT_FLOAT_EQ(v4.W, 2.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Mat4Scalar)
- {
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- float s = 2;
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_DivideMat4f(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
-#ifdef __cplusplus
- {
- hmm_mat4 result = HMM_Divide(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
- {
- hmm_mat4 result = m4 / s;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
-
- m4 /= s;
- EXPECT_FLOAT_EQ(m4.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(m4.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(m4.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(m4.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(m4.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(m4.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(m4.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(m4.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(m4.Elements[3][3], 8.0f);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(QuaternionScalar)
- {
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- float f = 2.0f;
-
- {
- hmm_quaternion result = HMM_DivideQuaternionF(q, f);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-#ifdef __cplusplus
- {
- hmm_quaternion result = HMM_Divide(q, f);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_quaternion result = q / f;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-
- q /= f;
- EXPECT_FLOAT_EQ(q.X, 0.5f);
- EXPECT_FLOAT_EQ(q.Y, 1.0f);
- EXPECT_FLOAT_EQ(q.Z, 1.5f);
- EXPECT_FLOAT_EQ(q.W, 2.0f);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Equality)
- {
- TEST_BEGIN(Vec2)
- {
- hmm_vec2 a = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 b = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 c = HMM_Vec2(3.0f, 4.0f);
-
- EXPECT_TRUE(HMM_EqualsVec2(a, b));
- EXPECT_FALSE(HMM_EqualsVec2(a, c));
-
-#ifdef __cplusplus
- EXPECT_TRUE(HMM_Equals(a, b));
- EXPECT_FALSE(HMM_Equals(a, c));
-
- EXPECT_TRUE(a == b);
- EXPECT_FALSE(a == c);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec3)
- {
- hmm_vec3 a = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 b = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 c = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- EXPECT_TRUE(HMM_EqualsVec3(a, b));
- EXPECT_FALSE(HMM_EqualsVec3(a, c));
-
-#ifdef __cplusplus
- EXPECT_TRUE(HMM_Equals(a, b));
- EXPECT_FALSE(HMM_Equals(a, c));
-
- EXPECT_TRUE(a == b);
- EXPECT_FALSE(a == c);
-#endif
- }
- TEST_END()
-
- TEST_BEGIN(Vec4)
- {
- hmm_vec4 a = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 b = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 c = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- EXPECT_TRUE(HMM_EqualsVec4(a, b));
- EXPECT_FALSE(HMM_EqualsVec4(a, c));
-
-#ifdef __cplusplus
- EXPECT_TRUE(HMM_Equals(a, b));
- EXPECT_FALSE(HMM_Equals(a, c));
-
- EXPECT_TRUE(a == b);
- EXPECT_FALSE(a == c);
-#endif
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Projection)
- {
- TEST_BEGIN(Orthographic)
- {
- hmm_mat4 projection = HMM_Orthographic(-10.0f, 10.0f, -5.0f, 5.0f, 0.0f, -10.0f);
-
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
- hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
-
- EXPECT_FLOAT_EQ(projected.X, 0.5f);
- EXPECT_FLOAT_EQ(projected.Y, 1.0f);
- EXPECT_FLOAT_EQ(projected.Z, -2.0f);
- EXPECT_FLOAT_EQ(projected.W, 1.0f);
- }
- TEST_END()
-
- TEST_BEGIN(Perspective)
- {
- hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
-
- {
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
- hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
- EXPECT_FLOAT_EQ(projected.Z, 15.0f);
- EXPECT_FLOAT_EQ(projected.W, 15.0f);
- }
- {
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
- hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
- EXPECT_FLOAT_EQ(projected.Z, -5.0f);
- EXPECT_FLOAT_EQ(projected.W, 5.0f);
- }
- }
- TEST_END()
- }
- CATEGORY_END()
-
- CATEGORY_BEGIN(Transformations)
- {
- TEST_BEGIN(Translate)
- {
- hmm_mat4 translate = HMM_Translate(HMM_Vec3(1.0f, -3.0f, 6.0f));
-
- hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec4 translated = HMM_MultiplyMat4ByVec4(translate, HMM_Vec4v(original, 1));
-
- EXPECT_FLOAT_EQ(translated.X, 2.0f);
- EXPECT_FLOAT_EQ(translated.Y, -1.0f);
- EXPECT_FLOAT_EQ(translated.Z, 9.0f);
- EXPECT_FLOAT_EQ(translated.W, 1.0f);
- }
- TEST_END()
-
- TEST_BEGIN(Rotate)
- {
- hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
-
- hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
- hmm_vec4 rotatedX = HMM_MultiplyMat4ByVec4(rotateX, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
- EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
- EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
- EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
-
- hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
- hmm_vec4 rotatedY = HMM_MultiplyMat4ByVec4(rotateY, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
- EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
- EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
- EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
-
- hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
- hmm_vec4 rotatedZ = HMM_MultiplyMat4ByVec4(rotateZ, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.Z, 1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.W, 1.0f);
- }
- TEST_END()
-
- TEST_BEGIN(Scale)
- {
- hmm_mat4 scale = HMM_Scale(HMM_Vec3(2.0f, -3.0f, 0.5f));
-
- hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec4 scaled = HMM_MultiplyMat4ByVec4(scale, HMM_Vec4v(original, 1));
-
- EXPECT_FLOAT_EQ(scaled.X, 2.0f);
- EXPECT_FLOAT_EQ(scaled.Y, -6.0f);
- EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
- EXPECT_FLOAT_EQ(scaled.W, 1.0f);
- }
- TEST_END()
- }
- CATEGORY_END()
-
-#ifdef HANDMADE_MATH__USE_SSE
- CATEGORY_BEGIN(SSE)
- {
- TEST_BEGIN(LinearCombine)
- {
- hmm_mat4 MatrixOne = HMM_Mat4d(2.0f);
- hmm_mat4 MatrixTwo = HMM_Mat4d(4.0f);
- hmm_mat4 Result;
-
- Result.Rows[0] = HMM_LinearCombineSSE(MatrixOne.Rows[0], MatrixTwo);
- Result.Rows[1] = HMM_LinearCombineSSE(MatrixOne.Rows[1], MatrixTwo);
- Result.Rows[2] = HMM_LinearCombineSSE(MatrixOne.Rows[2], MatrixTwo);
- Result.Rows[3] = HMM_LinearCombineSSE(MatrixOne.Rows[3], MatrixTwo);
-
- {
- EXPECT_FLOAT_EQ(Result.Elements[0][0], 8.0f);
- EXPECT_FLOAT_EQ(Result.Elements[0][1], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[0][2], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[0][3], 0.0f);
-
- EXPECT_FLOAT_EQ(Result.Elements[1][0], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[1][1], 8.0f);
- EXPECT_FLOAT_EQ(Result.Elements[1][2], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[1][3], 0.0f);
-
-
- EXPECT_FLOAT_EQ(Result.Elements[2][0], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[2][1], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[2][2], 8.0f);
- EXPECT_FLOAT_EQ(Result.Elements[2][3], 0.0f);
-
-
- EXPECT_FLOAT_EQ(Result.Elements[3][0], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[3][1], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[3][2], 0.0f);
- EXPECT_FLOAT_EQ(Result.Elements[3][3], 8.0f);
- }
-
- }
- TEST_END()
- }
- CATEGORY_END()
-#endif
-
- return 0;
+ return hmt_run_all_tests();
}
diff --git a/test/hmm_test.h b/test/hmm_test.h
new file mode 100644
--- /dev/null
+++ b/test/hmm_test.h
@@ -0,0 +1,17 @@
+#include <float.h>
+
+#include "HandmadeTest.h"
+#include "../HandmadeMath.h"
+
+#include "categories/ScalarMath.h"
+#include "categories/Initialization.h"
+#include "categories/VectorOps.h"
+#include "categories/QuaternionOps.h"
+#include "categories/Addition.h"
+#include "categories/Subtraction.h"
+#include "categories/Multiplication.h"
+#include "categories/Division.h"
+#include "categories/Equality.h"
+#include "categories/Projection.h"
+#include "categories/Transformation.h"
+#include "categories/SSE.h"
diff --git a/test/initializer.h b/test/initializer.h
new file mode 100644
--- /dev/null
+++ b/test/initializer.h
@@ -0,0 +1,29 @@
+// Initializer/finalizer sample for MSVC and GCC/Clang.
+// 2010-2016 Joe Lowe. Released into the public domain.
+#include <stdio.h>
+#include <stdlib.h>
+
+#ifdef __cplusplus
+ #define _INITIALIZER_T(f) f##_t_
+ #define _INITIALIZER_U(f) f##_
+ #define INITIALIZER(f) \
+ static void f(void); \
+ struct _INITIALIZER_T(f) { _INITIALIZER_T(f)(void) { f(); } }; static _INITIALIZER_T(f) _INITIALIZER_U(f); \
+ static void f(void)
+#elif defined(_MSC_VER)
+ #pragma section(".CRT$XCU",read)
+ #define INITIALIZER2_(f,p) \
+ static void f(void); \
+ __declspec(allocate(".CRT$XCU")) void (*f##_)(void) = f; \
+ __pragma(comment(linker,"/include:" p #f "_")) \
+ static void f(void)
+ #ifdef _WIN64
+ #define INITIALIZER(f) INITIALIZER2_(f,"")
+ #else
+ #define INITIALIZER(f) INITIALIZER2_(f,"_")
+ #endif
+#else
+ #define INITIALIZER(f) \
+ static void f(void) __attribute__((constructor)); \
+ static void f(void)
+#endif
|
Making unit tests embeddable
Hello all,
I am using handmade math in a project, using a unity build. I'd like to keep this structure.
My project also has a mechanism for running unit tests. I'd like to fold the HMM unit tests in so they run seamlessly in my build.
This could be accomplished by splitting test/hmm_test.c into a test/hmm_test_runner.c and test/hmm_tests.h.
test_runner.c would contain the infrastructure necessary to run tests in a separate executable, and hmm_tests.h would contain the test "definitions". I would then use the test/hmm_tests.h file in my project, and provide my own macro set to map to my unit test structure.
I might also prefix the unit test related macros with HMMT to make it clear what's going on.
Before I jump in and implement this -- any objections? Alternate ideas?
|
@bvisness The unit test system is all yours. Take this 😋
@revivalizer I'm frankly not sure why you need to run our unit tests in your build, since we guarantee that all of our tests pass when we release a new version. I also don't think it makes sense to heavily modify our unit test setup to work with other people's projects, since Handmade Math is explicitly designed to be included as a single header file, not to have its entire git repo dumped into a project.
Feel free to make whatever modifications you want, but I don't expect that we will be changing the structure of the tests in this repo.
I grant that this is perhaps not a typical request, but I think we (as a community) should do more of this, because:
> we guarantee that all of our tests pass when we release a new version
But do you test on my particular combination of
- OS
- bitness
- compiler
- compiler options
- define set
- libc replacement
?
> Handmade Math is explicitly designed to be included as a single header file
While single headers are nice for distribution and compiling, in practice I think a lot of people are not setup that way. You loose the ability to easily feed back github pull requests for example, whereas having a subrepo or whatever retains that ability.
Yeah, that's fair. I say go for it - as I thought about it more, I realized how little it actually changes the structure of the tests, but how much easier it makes things for you and others.
If you decide to prefix the test macros, I would prefer you prefix them with `HMT` (for HandmadeTest) instead of `HMMT`.
| 2018-02-15T06:24:11
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 58
|
HandmadeMath__HandmadeMath-58
|
[
"57"
] |
67b84dece73fd8351c026260dd04bcbf388dabff
|
diff --git a/.gitignore b/.gitignore
--- a/.gitignore
+++ b/.gitignore
@@ -32,3 +32,4 @@
*.out
*.app
hmm_test
+hmm_test*
diff --git a/.gitmodules b/.gitmodules
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,3 +0,0 @@
-[submodule "externals/googletest"]
- path = externals/googletest
- url = https://github.com/google/googletest.git
diff --git a/.travis.yml b/.travis.yml
--- a/.travis.yml
+++ b/.travis.yml
@@ -5,4 +5,6 @@ compiler:
install:
- cd test
- make
-script: ./hmm_test
+script:
+ - ./hmm_test_c
+ - ./hmm_test_cpp
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -173,6 +173,8 @@
(*) Resolved compiler warnings on gcc and g++
1.1.2
(*) Fixed invalid HMMDEF's in the function definitions
+ 1.1.3
+ (*) Fixed compile error in C mode
LICENSE
@@ -1692,7 +1694,7 @@ HMM_NLerp(hmm_quaternion Left, float Time, hmm_quaternion Right)
Result.Z = HMM_Lerp(Left.Z, Time, Right.Z);
Result.W = HMM_Lerp(Left.W, Time, Right.W);
- Result = HMM_Normalize(Result);
+ Result = HMM_NormalizeQuaternion(Result);
return(Result);
}
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -12,6 +12,7 @@ _This library is free and will stay free, but if you would like to support devel
Version | Changes |
----------------|----------------|
+**1.1.3** | Fixed compile error in C mode
**1.1.2** | Fixed invalid HMMDEF's in the function definitions
**1.1.1** | Resolved compiler warnings on gcc and g++
**1.1** | Quaternions! |
@@ -35,7 +36,7 @@ _This library is free and will stay free, but if you would like to support devel
**What's the license?**
-This library is in the public domain. You can do whatever you want with them.
+This library is in the public domain. You can do whatever you want with it.
**Where can I contact you to ask questions?**
diff --git a/externals/googletest b/externals/googletest
deleted file mode 160000
--- a/externals/googletest
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit ed9d1e1ff92ce199de5ca2667a667cd0a368482a
|
diff --git a/test/HandmadeMath.c b/test/HandmadeMath.c
new file mode 100644
--- /dev/null
+++ b/test/HandmadeMath.c
@@ -0,0 +1,4 @@
+
+#define HANDMADE_MATH_IMPLEMENTATION
+#define HANDMADE_MATH_NO_INLINE
+#include "../HandmadeMath.h"
diff --git a/test/HandmadeTest.h b/test/HandmadeTest.h
new file mode 100644
--- /dev/null
+++ b/test/HandmadeTest.h
@@ -0,0 +1,80 @@
+#ifndef HANDMADETEST_H
+#define HANDMADETEST_H
+
+#include <float.h>
+#include <stdio.h>
+
+int hmt_count_tests = 0;
+int hmt_count_failedtests = 0;
+int hmt_count_failures = 0;
+
+#define RESET "\033[0m"
+#define RED "\033[31m"
+#define GREEN "\033[32m"
+
+#define CATEGORY_BEGIN(name) { \
+ int count_categorytests = 0; \
+ int count_categoryfailedtests = 0; \
+ int count_categoryfailures = 0; \
+ printf("\n" #name ":\n");
+#define CATEGORY_END(name) \
+ hmt_count_tests += count_categorytests; \
+ hmt_count_failedtests += count_categoryfailedtests; \
+ hmt_count_failures += count_categoryfailures; \
+ printf("%d/%d tests passed, %d failures\n", count_categorytests - count_categoryfailedtests, count_categorytests, count_categoryfailures); \
+}
+
+#define TEST_BEGIN(name) { \
+ int count_testfailures = 0; \
+ count_categorytests++; \
+ printf(" " #name ":");
+#define TEST_END() \
+ count_categoryfailures += count_testfailures; \
+ if (count_testfailures > 0) { \
+ count_categoryfailedtests++; \
+ printf("\n"); \
+ } else { \
+ printf(GREEN " [PASS]\n" RESET); \
+ } \
+}
+
+#define CASE_FAIL() \
+ count_testfailures++; \
+ printf("\n - " RED "[FAIL] (%d) " RESET, __LINE__)
+
+/*
+ * Asserts and expects
+ */
+#define EXPECT_FLOAT_EQ(_actual, _expected) do { \
+ float actual = (_actual); \
+ float diff = actual - (_expected); \
+ if (diff < -FLT_EPSILON || FLT_EPSILON < diff) { \
+ CASE_FAIL(); \
+ printf("Expected %f, got %f", (_expected), actual); \
+ } \
+} while (0)
+
+#define EXPECT_NEAR(_actual, _expected, _epsilon) do { \
+ float actual = (_actual); \
+ float diff = actual - (_expected); \
+ if (diff < -(_epsilon) || (_epsilon) < diff) { \
+ CASE_FAIL(); \
+ printf("Expected %f, got %f", (_expected), actual); \
+ } \
+} while (0)
+
+#define EXPECT_LT(_actual, _expected) do { \
+ if ((_actual) >= (_expected)) { \
+ CASE_FAIL(); \
+ printf("Expected %f to be less than %f", (_actual), (_expected)); \
+ } \
+} while (0)
+
+#define EXPECT_GT(_actual, _expected) do { \
+ if ((_actual) <= (_expected)) { \
+ CASE_FAIL(); \
+ printf("Expected %f to be greater than %f", (_actual), (_expected)); \
+ } \
+} while (0)
+
+#endif
diff --git a/test/Makefile b/test/Makefile
--- a/test/Makefile
+++ b/test/Makefile
@@ -1,81 +1,17 @@
-# A sample Makefile for building Google Test and using it in user
-# tests. Please tweak it to suit your environment and project. You
-# may want to move it to your project's root directory.
-#
-# SYNOPSIS:
-#
-# make [all] - makes everything.
-# make TARGET - makes the given target.
-# make clean - removes all files generated by make.
+ROOT_DIR = ..
-# Please tweak the following variable definitions as needed by your
-# project, except GTEST_HEADERS, which you can use in your own targets
-# but shouldn't modify.
-
-# Points to the root of Google Test, relative to where this file is.
-# Remember to tweak this if you move this file.
-GTEST_DIR = ../externals/googletest/googletest
-
-# Where to find user code.
-USER_DIR = ..
-
-# Flags passed to the preprocessor.
-# Set Google Test's header directory as a system directory, such that
-# the compiler doesn't generate warnings in Google Test headers.
-CPPFLAGS += -isystem $(GTEST_DIR)/include
-
-# Flags passed to the C++ compiler.
CXXFLAGS += -g -Wall -Wextra -pthread -Wno-missing-braces -Wno-missing-field-initializers
-# All tests produced by this Makefile. Remember to add new tests you
-# created to the list.
-TESTS = hmm_test
-
-# All Google Test headers. Usually you shouldn't change this
-# definition.
-GTEST_HEADERS = $(GTEST_DIR)/include/gtest/*.h \
- $(GTEST_DIR)/include/gtest/internal/*.h
-
-# House-keeping build targets.
-
-all : $(TESTS)
-
-clean :
- rm -f $(TESTS) gtest.a gtest_main.a *.o
-
-# Builds gtest.a and gtest_main.a.
-
-# Usually you shouldn't tweak such internal variables, indicated by a
-# trailing _.
-GTEST_SRCS_ = $(GTEST_DIR)/src/*.cc $(GTEST_DIR)/src/*.h $(GTEST_HEADERS)
-
-# For simplicity and to avoid depending on Google Test's
-# implementation details, the dependencies specified below are
-# conservative and not optimized. This is fine as Google Test
-# compiles fast and for ordinary users its source rarely changes.
-gtest-all.o : $(GTEST_SRCS_)
- $(CXX) $(CPPFLAGS) -I$(GTEST_DIR) $(CXXFLAGS) -c \
- $(GTEST_DIR)/src/gtest-all.cc
-
-gtest_main.o : $(GTEST_SRCS_)
- $(CXX) $(CPPFLAGS) -I$(GTEST_DIR) $(CXXFLAGS) -c \
- $(GTEST_DIR)/src/gtest_main.cc
-
-gtest.a : gtest-all.o
- $(AR) $(ARFLAGS) $@ $^
-
-gtest_main.a : gtest-all.o gtest_main.o
- $(AR) $(ARFLAGS) $@ $^
+all: c cpp
-# Builds a sample test. A test should link with either gtest.a or
-# gtest_main.a, depending on whether it defines its own main()
-# function.
+clean:
+ rm -f hmm_test_c hmm_test_cpp *.o
-HandmadeMath.o : $(USER_DIR)/test/HandmadeMath.cpp $(USER_DIR)/HandmadeMath.h $(GTEST_HEADERS)
- $(CXX) $(CPPFLAGS) $(CXXFLAGS) -c $(USER_DIR)/test/HandmadeMath.cpp
+c: $(ROOT_DIR)/test/HandmadeMath.c test_impl
+ $(CC) $(CPPFLAGS) $(CXXFLAGS) -std=c99 -c $(ROOT_DIR)/test/HandmadeMath.c $(ROOT_DIR)/test/hmm_test.c -lm
+ $(CC) -ohmm_test_c HandmadeMath.o hmm_test.o -lm
-hmm_test.o : $(USER_DIR)/test/hmm_test.cpp $(GTEST_HEADERS)
- $(CXX) $(CPPFLAGS) $(CXXFLAGS) -c $(USER_DIR)/test/hmm_test.cpp
+cpp: $(ROOT_DIR)/test/HandmadeMath.cpp test_impl
+ $(CXX) $(CPPFLAGS) $(CXXFLAGS) -ohmm_test_cpp $(ROOT_DIR)/test/HandmadeMath.cpp $(ROOT_DIR)/test/hmm_test.cpp
-hmm_test : HandmadeMath.o hmm_test.o gtest_main.a
- $(CXX) $(CPPFLAGS) $(CXXFLAGS) -lpthread $^ -o $@
+test_impl: $(ROOT_DIR)/test/hmm_test.cpp $(ROOT_DIR)/test/hmm_test.c
diff --git a/test/hmm_test.c b/test/hmm_test.c
new file mode 100644
--- /dev/null
+++ b/test/hmm_test.c
@@ -0,0 +1,1945 @@
+#include <float.h>
+
+#include "HandmadeTest.h"
+#include "../HandmadeMath.h"
+
+int run_tests();
+
+int main()
+{
+ run_tests();
+
+ if (hmt_count_failedtests > 0) {
+ printf(RED);
+ } else {
+ printf(GREEN);
+ }
+ printf("\n%d/%d tests passed overall, %d failures\n" RESET, hmt_count_tests - hmt_count_failedtests, hmt_count_tests, hmt_count_failures);
+
+ printf("\n");
+
+ return (hmt_count_failedtests > 0);
+}
+
+int run_tests()
+{
+ CATEGORY_BEGIN(ScalarMath)
+ {
+ TEST_BEGIN(Trigonometry)
+ {
+ // We have to be a little looser with our equality constraint
+ // because of floating-point precision issues.
+ const float trigAbsError = 0.0001f;
+
+ EXPECT_NEAR(HMM_SinF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32 / 2), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(3 * HMM_PI32 / 2), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_SinF(-HMM_PI32 / 2), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_CosF(0.0f), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(HMM_PI32), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(3 * HMM_PI32 / 2), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_CosF(-HMM_PI32), -1.0f, trigAbsError);
+
+ EXPECT_NEAR(HMM_TanF(0.0f), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32 / 4), 1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(3 * HMM_PI32 / 4), -1.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(HMM_PI32), 0.0f, trigAbsError);
+ EXPECT_NEAR(HMM_TanF(-HMM_PI32 / 4), -1.0f, trigAbsError);
+
+ // This isn't the most rigorous because we're really just sanity-
+ // checking that things work by default.
+ }
+ TEST_END()
+
+ TEST_BEGIN(ToRadians)
+ {
+ EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(180.0f), HMM_PI32);
+ EXPECT_FLOAT_EQ(HMM_ToRadians(-180.0f), -HMM_PI32);
+ }
+ TEST_END()
+
+ TEST_BEGIN(SquareRoot)
+ {
+ EXPECT_FLOAT_EQ(HMM_SquareRootF(16.0f), 4.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(RSquareRootF)
+ {
+ EXPECT_FLOAT_EQ(HMM_RSquareRootF(10.0f), 0.31616211f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Power)
+ {
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 0), 1.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, 4), 16.0f);
+ EXPECT_FLOAT_EQ(HMM_Power(2.0f, -2), 0.25f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(PowerF)
+ {
+ EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0), 1.0f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, 4.1), 17.148376f, 0.0001f);
+ EXPECT_NEAR(HMM_PowerF(2.0f, -2.5), 0.176777f, 0.0001f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Lerp)
+ {
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.0f, 2.0f), -2.0f);
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.5f, 2.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 1.0f, 2.0f), 2.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Clamp)
+ {
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 0.0f, 2.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, -3.0f, 2.0f), -2.0f);
+ EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 3.0f, 2.0f), 2.0f);
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Initialization)
+ {
+ TEST_BEGIN(Vectors)
+ {
+ //
+ // Test vec2
+ //
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2i = HMM_Vec2(1, 2);
+
+ EXPECT_FLOAT_EQ(v2.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 2.0f);
+
+ EXPECT_FLOAT_EQ(v2i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v2i.Y, 2.0f);
+
+ //
+ // Test vec3
+ //
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3i = HMM_Vec3i(1, 2, 3);
+
+ EXPECT_FLOAT_EQ(v3.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 3.0f);
+
+ EXPECT_FLOAT_EQ(v3i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v3i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v3i.Z, 3.0f);
+
+ //
+ // Test vec4
+ //
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4i = HMM_Vec4i(1, 2, 3, 4);
+ hmm_vec4 v4v = HMM_Vec4v(v3, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4i.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4i.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4i.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4i.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(v4v.X, 1.0f);
+ EXPECT_FLOAT_EQ(v4v.Y, 2.0f);
+ EXPECT_FLOAT_EQ(v4v.Z, 3.0f);
+ EXPECT_FLOAT_EQ(v4v.W, 4.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(MatrixEmpty)
+ {
+ hmm_mat4 m4 = HMM_Mat4();
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4.Elements[Column][Row], 0.0f);
+ }
+ }
+ }
+ TEST_END()
+
+ TEST_BEGIN(MatrixDiagonal)
+ {
+ hmm_mat4 m4d = HMM_Mat4d(1.0f);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ if (Column == Row) {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 1.0f);
+ } else {
+ EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 0.0f);
+ }
+ }
+ }
+ }
+ TEST_END()
+
+ TEST_BEGIN(Quaternion)
+ {
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+
+ EXPECT_FLOAT_EQ(q.X, 1.0f);
+ EXPECT_FLOAT_EQ(q.Y, 2.0f);
+ EXPECT_FLOAT_EQ(q.Z, 3.0f);
+ EXPECT_FLOAT_EQ(q.W, 4.0f);
+
+ EXPECT_FLOAT_EQ(q.Elements[0], 1.0f);
+ EXPECT_FLOAT_EQ(q.Elements[1], 2.0f);
+ EXPECT_FLOAT_EQ(q.Elements[2], 3.0f);
+ EXPECT_FLOAT_EQ(q.Elements[3], 4.0f);
+
+ hmm_vec4 v = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion qv = HMM_QuaternionV4(v);
+
+ EXPECT_FLOAT_EQ(qv.X, 1.0f);
+ EXPECT_FLOAT_EQ(qv.Y, 2.0f);
+ EXPECT_FLOAT_EQ(qv.Z, 3.0f);
+ EXPECT_FLOAT_EQ(qv.W, 4.0f);
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(VectorOps)
+ {
+ TEST_BEGIN(LengthSquared)
+ {
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
+ hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
+ hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, 1.0f);
+
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec2(v2), 5.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec3(v3), 14.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquaredVec4(v4), 15.0f);
+
+#ifdef HANDMADE_MATH_CPP_MODE
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v2), 5.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v3), 14.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthSquared(v4), 15.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Length)
+ {
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -9.0f);
+ hmm_vec3 v3 = HMM_Vec3(2.0f, -3.0f, 6.0f);
+ hmm_vec4 v4 = HMM_Vec4(2.0f, -3.0f, 6.0f, 12.0f);
+
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(v2), 9.0553856f);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(v3), 7.0f);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(v4), 13.892444f);
+
+#ifdef HANDMADE_MATH_CPP_MODE
+ EXPECT_FLOAT_EQ(HMM_Length(v2), 9.0553856f);
+ EXPECT_FLOAT_EQ(HMM_Length(v3), 7.0f);
+ EXPECT_FLOAT_EQ(HMM_Length(v4), 13.892444f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Normalize)
+ {
+ hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
+ hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
+ hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, -1.0f);
+
+ {
+ hmm_vec2 result = HMM_NormalizeVec2(v2);
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_NormalizeVec3(v3);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_NormalizeVec4(v4);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ EXPECT_LT(result.W, 0.0f);
+ }
+
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Normalize(v2);
+ EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ }
+ {
+ hmm_vec3 result = HMM_Normalize(v3);
+ EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ }
+ {
+ hmm_vec4 result = HMM_Normalize(v4);
+ EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
+ EXPECT_GT(result.X, 0.0f);
+ EXPECT_LT(result.Y, 0.0f);
+ EXPECT_GT(result.Z, 0.0f);
+ EXPECT_LT(result.W, 0.0f);
+ }
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Cross)
+ {
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ hmm_vec3 result = HMM_Cross(v1, v2);
+
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(DotVec2)
+ {
+ hmm_vec2 v1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2 = HMM_Vec2(3.0f, 4.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec2(v1, v2), 11.0f);
+#ifdef HANDMADE_MATH_CPP_MODE
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(DotVec3)
+ {
+ hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec3(v1, v2), 32.0f);
+#ifdef HANDMADE_MATH_CPP_MODE
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(DotVec4)
+ {
+ hmm_vec4 v1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ EXPECT_FLOAT_EQ(HMM_DotVec4(v1, v2), 70.0f);
+#ifdef HANDMADE_MATH_CPP_MODE
+ EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
+#endif
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(MatrixOps)
+ {
+ TEST_BEGIN(Transpose)
+ {
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the matrix
+ hmm_mat4 result = HMM_Transpose(m4);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 13.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 10.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 14.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 11.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 8.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 16.0f);
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(QuaternionOps)
+ {
+ TEST_BEGIN(Inverse)
+ {
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion inverse = HMM_InverseQuaternion(q1);
+
+ hmm_quaternion result = HMM_MultiplyQuaternion(q1, inverse);
+
+ EXPECT_FLOAT_EQ(result.X, 0.0f);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_FLOAT_EQ(result.W, 1.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Dot)
+ {
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ float result = HMM_DotQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result, 70.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ float result = HMM_Dot(q1, q2);
+ EXPECT_FLOAT_EQ(result, 70.0f);
+ }
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Normalize)
+ {
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+
+ {
+ hmm_quaternion result = HMM_NormalizeQuaternion(q);
+ EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
+ EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
+ EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
+ EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Normalize(q);
+ EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
+ EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
+ EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
+ EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
+ }
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(NLerp)
+ {
+ hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
+ hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
+
+ hmm_quaternion result = HMM_NLerp(from, 0.5f, to);
+ EXPECT_FLOAT_EQ(result.X, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
+ EXPECT_FLOAT_EQ(result.W, 0.86602540f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Slerp)
+ {
+ hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
+ hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
+
+ hmm_quaternion result = HMM_Slerp(from, 0.5f, to);
+ EXPECT_FLOAT_EQ(result.X, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
+ EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
+ EXPECT_FLOAT_EQ(result.W, 0.86602540f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(ToMat4)
+ {
+ const float abs_error = 0.0001f;
+
+ hmm_quaternion rot = HMM_Quaternion(0.707107f, 0.0f, 0.0f, 0.707107f);
+
+ hmm_mat4 result = HMM_QuaternionToMat4(rot);
+
+ EXPECT_NEAR(result.Elements[0][0], 1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[0][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[1][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][2], 1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[1][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[2][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][1], -1.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[2][3], 0.0f, abs_error);
+
+ EXPECT_NEAR(result.Elements[3][0], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][1], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][2], 0.0f, abs_error);
+ EXPECT_NEAR(result.Elements[3][3], 1.0f, abs_error);
+ }
+ TEST_END()
+
+ TEST_BEGIN(FromAxisAngle)
+ {
+ hmm_vec3 axis = HMM_Vec3(1.0f, 0.0f, 0.0f);
+ float angle = HMM_PI32 / 2.0f;
+
+ hmm_quaternion result = HMM_QuaternionFromAxisAngle(axis, angle);
+ EXPECT_NEAR(result.X, 0.707107f, FLT_EPSILON * 2);
+ EXPECT_FLOAT_EQ(result.Y, 0.0f);
+ EXPECT_FLOAT_EQ(result.Z, 0.0f);
+ EXPECT_NEAR(result.W, 0.707107f, FLT_EPSILON * 2);
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Addition)
+ {
+ TEST_BEGIN(Vec2)
+ {
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_AddVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Add(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 + v2_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2_1 += v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 6.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3)
+ {
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_AddVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Add(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 + v3_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 7.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3_1 += v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 7.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 9.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4)
+ {
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_AddVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Add(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 + v4_2;
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4_1 += v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 6.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 8.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 12.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4)
+ {
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_AddMat4(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected);
+ Expected += 2.0f;
+ }
+ }
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_mat4 result = HMM_Add(m4_1, m4_2);
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 + m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+ }
+
+ m4_1 += m4_2;
+ float Expected = 18.0f;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
+ Expected += 2.0f;
+ }
+ }
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Quaternion)
+ {
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_AddQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Add(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_quaternion result = q1 + q2;
+ EXPECT_FLOAT_EQ(result.X, 6.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ q1 += q2;
+ EXPECT_FLOAT_EQ(q1.X, 6.0f);
+ EXPECT_FLOAT_EQ(q1.Y, 8.0f);
+ EXPECT_FLOAT_EQ(q1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(q1.W, 12.0f);
+#endif
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Subtraction)
+ {
+ TEST_BEGIN(Vec2)
+ {
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_SubtractVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 - v2_2;
+ EXPECT_FLOAT_EQ(result.X, -2.0f);
+ EXPECT_FLOAT_EQ(result.Y, -2.0f);
+ }
+
+ v2_1 -= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, -2.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, -2.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3)
+ {
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_SubtractVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 - v3_2;
+ EXPECT_FLOAT_EQ(result.X, -3.0f);
+ EXPECT_FLOAT_EQ(result.Y, -3.0f);
+ EXPECT_FLOAT_EQ(result.Z, -3.0f);
+ }
+
+ v3_1 -= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, -3.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, -3.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4)
+ {
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_SubtractVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 - v4_2;
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+
+ v4_1 -= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, -4.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, -4.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4)
+ {
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_SubtractMat4(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f);
+ }
+ }
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+ {
+ hmm_mat4 result = m4_1 - m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+ }
+
+ m4_1 -= m4_2;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
+ }
+ }
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Quaternion)
+ {
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_SubtractQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Subtract(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+ {
+ hmm_quaternion result = q1 - q2;
+ EXPECT_FLOAT_EQ(result.X, -4.0f);
+ EXPECT_FLOAT_EQ(result.Y, -4.0f);
+ EXPECT_FLOAT_EQ(result.Z, -4.0f);
+ EXPECT_FLOAT_EQ(result.W, -4.0f);
+ }
+
+ q1 -= q2;
+ EXPECT_FLOAT_EQ(q1.X, -4.0f);
+ EXPECT_FLOAT_EQ(q1.Y, -4.0f);
+ EXPECT_FLOAT_EQ(q1.Z, -4.0f);
+ EXPECT_FLOAT_EQ(q1.W, -4.0f);
+#endif
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Multiplication)
+ {
+ TEST_BEGIN(Vec2Vec2)
+ {
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+ {
+ hmm_vec2 result = v2_1 * v2_2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 8.0f);
+ }
+
+ v2_1 *= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 8.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec2Scalar)
+ {
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec2 result = HMM_MultiplyVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Multiply(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = v2 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+ {
+ hmm_vec2 result = s * v2;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ }
+
+ v2 *= s;
+ EXPECT_FLOAT_EQ(v2.X, 3.0f);
+ EXPECT_FLOAT_EQ(v2.Y, 6.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3Vec3)
+ {
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 * v3_2;
+ EXPECT_FLOAT_EQ(result.X, 4.0f);
+ EXPECT_FLOAT_EQ(result.Y, 10.0f);
+ EXPECT_FLOAT_EQ(result.Z, 18.0f);
+ }
+
+ v3_1 *= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 4.0f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 10.0f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 18.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3Scalar)
+ {
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec3 result = HMM_MultiplyVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Multiply(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = v3 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+ {
+ hmm_vec3 result = s * v3;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ }
+
+ v3 *= s;
+ EXPECT_FLOAT_EQ(v3.X, 3.0f);
+ EXPECT_FLOAT_EQ(v3.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 9.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4Vec4)
+ {
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+ {
+ hmm_vec4 result = v4_1 * v4_2;
+ EXPECT_FLOAT_EQ(result.X, 5.0f);
+ EXPECT_FLOAT_EQ(result.Y, 12.0f);
+ EXPECT_FLOAT_EQ(result.Z, 21.0f);
+ EXPECT_FLOAT_EQ(result.W, 32.0f);
+ }
+
+ v4_1 *= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 5.0f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 12.0f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 21.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 32.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4Scalar)
+ {
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 3.0f;
+
+ {
+ hmm_vec4 result = HMM_MultiplyVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Multiply(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = v4 * s;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+ {
+ hmm_vec4 result = s * v4;
+ EXPECT_FLOAT_EQ(result.X, 3.0f);
+ EXPECT_FLOAT_EQ(result.Y, 6.0f);
+ EXPECT_FLOAT_EQ(result.Z, 9.0f);
+ EXPECT_FLOAT_EQ(result.W, 12.0f);
+ }
+
+ v4 *= s;
+ EXPECT_FLOAT_EQ(v4.X, 3.0f);
+ EXPECT_FLOAT_EQ(v4.Y, 6.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 9.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4Mat4)
+ {
+ hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
+ hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
+
+ // Fill the matrices
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_1.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4_2.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+ {
+ hmm_mat4 result = m4_1 * m4_2;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
+ }
+
+ // At the time I wrote this, I intentionally omitted
+ // the *= operator for matrices because matrix
+ // multiplication is not commutative. (bvisness)
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4Scalar)
+ {
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 3;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_MultiplyMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_mat4 result = HMM_Multiply(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = m4 * s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+ {
+ hmm_mat4 result = s * m4;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
+ }
+
+ m4 *= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 9.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 12.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 15.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 18.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 21.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 24.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 27.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 30.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 33.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 36.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 39.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 42.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 45.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 48.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4Vec4)
+ {
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_vec4 result = HMM_MultiplyMat4ByVec4(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Multiply(m4, v4);
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+ {
+ hmm_vec4 result = m4 * v4;
+ EXPECT_FLOAT_EQ(result.X, 90.0f);
+ EXPECT_FLOAT_EQ(result.Y, 100.0f);
+ EXPECT_FLOAT_EQ(result.Z, 110.0f);
+ EXPECT_FLOAT_EQ(result.W, 120.0f);
+ }
+
+ // *= makes no sense for this particular case.
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(QuaternionQuaternion)
+ {
+ hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
+
+ {
+ hmm_quaternion result = HMM_MultiplyQuaternion(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Multiply(q1, q2);
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+ {
+ hmm_quaternion result = q1 * q2;
+ EXPECT_FLOAT_EQ(result.X, 24.0f);
+ EXPECT_FLOAT_EQ(result.Y, 48.0f);
+ EXPECT_FLOAT_EQ(result.Z, 48.0f);
+ EXPECT_FLOAT_EQ(result.W, -6.0f);
+ }
+
+ // Like with matrices, we're not implementing the *=
+ // operator for quaternions because quaternion multiplication
+ // is not commutative.
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(QuaternionScalar)
+ {
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ float f = 2.0f;
+
+ {
+ hmm_quaternion result = HMM_MultiplyQuaternionF(q, f);
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Multiply(q, f);
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+ {
+ hmm_quaternion result = q * f;
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+ {
+ hmm_quaternion result = f * q;
+ EXPECT_FLOAT_EQ(result.X, 2.0f);
+ EXPECT_FLOAT_EQ(result.Y, 4.0f);
+ EXPECT_FLOAT_EQ(result.Z, 6.0f);
+ EXPECT_FLOAT_EQ(result.W, 8.0f);
+ }
+
+ q *= f;
+ EXPECT_FLOAT_EQ(q.X, 2.0f);
+ EXPECT_FLOAT_EQ(q.Y, 4.0f);
+ EXPECT_FLOAT_EQ(q.Z, 6.0f);
+ EXPECT_FLOAT_EQ(q.W, 8.0f);
+#endif
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Division)
+ {
+ TEST_BEGIN(Vec2Vec2)
+ {
+ hmm_vec2 v2_1 = HMM_Vec2(1.0f, 3.0f);
+ hmm_vec2 v2_2 = HMM_Vec2(2.0f, 4.0f);
+
+ {
+ hmm_vec2 result = HMM_DivideVec2(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Divide(v2_1, v2_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+ {
+ hmm_vec2 result = v2_1 / v2_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ }
+
+ v2_1 /= v2_2;
+ EXPECT_FLOAT_EQ(v2_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2_1.Y, 0.75f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec2Scalar)
+ {
+ hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
+ float s = 2;
+
+ {
+ hmm_vec2 result = HMM_DivideVec2f(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec2 result = HMM_Divide(v2, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+ {
+ hmm_vec2 result = v2 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ }
+
+ v2 /= s;
+ EXPECT_FLOAT_EQ(v2.X, 0.5f);
+ EXPECT_FLOAT_EQ(v2.Y, 1.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3Vec3)
+ {
+ hmm_vec3 v3_1 = HMM_Vec3(1.0f, 3.0f, 5.0f);
+ hmm_vec3 v3_2 = HMM_Vec3(2.0f, 4.0f, 0.5f);
+
+ {
+ hmm_vec3 result = HMM_DivideVec3(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Divide(v3_1, v3_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+ {
+ hmm_vec3 result = v3_1 / v3_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ }
+
+ v3_1 /= v3_2;
+ EXPECT_FLOAT_EQ(v3_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v3_1.Z, 10.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec3Scalar)
+ {
+ hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ float s = 2;
+
+ {
+ hmm_vec3 result = HMM_DivideVec3f(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec3 result = HMM_Divide(v3, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+ {
+ hmm_vec3 result = v3 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ }
+
+ v3 /= s;
+ EXPECT_FLOAT_EQ(v3.X, 0.5f);
+ EXPECT_FLOAT_EQ(v3.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v3.Z, 1.5f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4Vec4)
+ {
+ hmm_vec4 v4_1 = HMM_Vec4(1.0f, 3.0f, 5.0f, 1.0f);
+ hmm_vec4 v4_2 = HMM_Vec4(2.0f, 4.0f, 0.5f, 4.0f);
+
+ {
+ hmm_vec4 result = HMM_DivideVec4(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Divide(v4_1, v4_2);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+ {
+ hmm_vec4 result = v4_1 / v4_2;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 0.75f);
+ EXPECT_FLOAT_EQ(result.Z, 10.0f);
+ EXPECT_FLOAT_EQ(result.W, 0.25f);
+ }
+
+ v4_1 /= v4_2;
+ EXPECT_FLOAT_EQ(v4_1.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4_1.Y, 0.75f);
+ EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
+ EXPECT_FLOAT_EQ(v4_1.W, 0.25f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Vec4Scalar)
+ {
+ hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
+ float s = 2;
+
+ {
+ hmm_vec4 result = HMM_DivideVec4f(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_vec4 result = HMM_Divide(v4, s);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_vec4 result = v4 / s;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+
+ v4 /= s;
+ EXPECT_FLOAT_EQ(v4.X, 0.5f);
+ EXPECT_FLOAT_EQ(v4.Y, 1.0f);
+ EXPECT_FLOAT_EQ(v4.Z, 1.5f);
+ EXPECT_FLOAT_EQ(v4.W, 2.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(Mat4Scalar)
+ {
+ hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
+ float s = 2;
+
+ // Fill the matrix
+ int Counter = 1;
+ for (int Column = 0; Column < 4; ++Column)
+ {
+ for (int Row = 0; Row < 4; ++Row)
+ {
+ m4.Elements[Column][Row] = Counter;
+ ++Counter;
+ }
+ }
+
+ // Test the results
+ {
+ hmm_mat4 result = HMM_DivideMat4f(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_mat4 result = HMM_Divide(m4, s);
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+ {
+ hmm_mat4 result = m4 / s;
+ EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
+ }
+
+ m4 /= s;
+ EXPECT_FLOAT_EQ(m4.Elements[0][0], 0.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][1], 1.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][2], 1.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[0][3], 2.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][0], 2.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][1], 3.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][2], 3.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[1][3], 4.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][0], 4.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][1], 5.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][2], 5.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[2][3], 6.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][0], 6.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][1], 7.0f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][2], 7.5f);
+ EXPECT_FLOAT_EQ(m4.Elements[3][3], 8.0f);
+#endif
+ }
+ TEST_END()
+
+ TEST_BEGIN(QuaternionScalar)
+ {
+ hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
+ float f = 2.0f;
+
+ {
+ hmm_quaternion result = HMM_DivideQuaternionF(q, f);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+#ifdef HANDMADE_MATH_CPP_MODE
+ {
+ hmm_quaternion result = HMM_Divide(q, f);
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+ {
+ hmm_quaternion result = q / f;
+ EXPECT_FLOAT_EQ(result.X, 0.5f);
+ EXPECT_FLOAT_EQ(result.Y, 1.0f);
+ EXPECT_FLOAT_EQ(result.Z, 1.5f);
+ EXPECT_FLOAT_EQ(result.W, 2.0f);
+ }
+
+ q /= f;
+ EXPECT_FLOAT_EQ(q.X, 0.5f);
+ EXPECT_FLOAT_EQ(q.Y, 1.0f);
+ EXPECT_FLOAT_EQ(q.Z, 1.5f);
+ EXPECT_FLOAT_EQ(q.W, 2.0f);
+#endif
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Projection)
+ {
+ TEST_BEGIN(Orthographic)
+ {
+ hmm_mat4 projection = HMM_Orthographic(-10.0f, 10.0f, -5.0f, 5.0f, 0.0f, -10.0f);
+
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(projected.X, 0.5f);
+ EXPECT_FLOAT_EQ(projected.Y, 1.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -2.0f);
+ EXPECT_FLOAT_EQ(projected.W, 1.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Perspective)
+ {
+ hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
+
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, 15.0f);
+ EXPECT_FLOAT_EQ(projected.W, 15.0f);
+ }
+ {
+ hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
+ hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(projected.X, 5.0f);
+ EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.Z, -5.0f);
+ EXPECT_FLOAT_EQ(projected.W, 5.0f);
+ }
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ CATEGORY_BEGIN(Transformations)
+ {
+ TEST_BEGIN(Translate)
+ {
+ hmm_mat4 translate = HMM_Translate(HMM_Vec3(1.0f, -3.0f, 6.0f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 translated = HMM_MultiplyMat4ByVec4(translate, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(translated.X, 2.0f);
+ EXPECT_FLOAT_EQ(translated.Y, -1.0f);
+ EXPECT_FLOAT_EQ(translated.Z, 9.0f);
+ EXPECT_FLOAT_EQ(translated.W, 1.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Rotate)
+ {
+ hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
+
+ hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ hmm_vec4 rotatedX = HMM_MultiplyMat4ByVec4(rotateX, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
+
+ hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
+ hmm_vec4 rotatedY = HMM_MultiplyMat4ByVec4(rotateY, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
+
+ hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_vec4 rotatedZ = HMM_MultiplyMat4ByVec4(rotateZ, HMM_Vec4v(original, 1));
+ EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.Z, 1.0f);
+ EXPECT_FLOAT_EQ(rotatedZ.W, 1.0f);
+ }
+ TEST_END()
+
+ TEST_BEGIN(Scale)
+ {
+ hmm_mat4 scale = HMM_Scale(HMM_Vec3(2.0f, -3.0f, 0.5f));
+
+ hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
+ hmm_vec4 scaled = HMM_MultiplyMat4ByVec4(scale, HMM_Vec4v(original, 1));
+
+ EXPECT_FLOAT_EQ(scaled.X, 2.0f);
+ EXPECT_FLOAT_EQ(scaled.Y, -6.0f);
+ EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
+ EXPECT_FLOAT_EQ(scaled.W, 1.0f);
+ }
+ TEST_END()
+ }
+ CATEGORY_END()
+
+ return 0;
+}
diff --git a/test/hmm_test.cpp b/test/hmm_test.cpp
--- a/test/hmm_test.cpp
+++ b/test/hmm_test.cpp
@@ -1,1747 +1,2 @@
-
-#define HANDMADE_MATH_CPP_MODE
-#include "../HandmadeMath.h"
-
-#include "gtest/gtest.h"
-
-
-TEST(ScalarMath, Trigonometry)
-{
- // We have to be a little looser with our equality constraint
- // because of floating-point precision issues.
- const float trigAbsError = 0.0001f;
-
- EXPECT_NEAR(HMM_SinF(0.0f), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(HMM_PI32 / 2), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(HMM_PI32), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(3 * HMM_PI32 / 2), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_SinF(-HMM_PI32 / 2), -1.0f, trigAbsError);
-
- EXPECT_NEAR(HMM_CosF(0.0f), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(HMM_PI32 / 2), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(HMM_PI32), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(3 * HMM_PI32 / 2), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_CosF(-HMM_PI32), -1.0f, trigAbsError);
-
- EXPECT_NEAR(HMM_TanF(0.0f), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(HMM_PI32 / 4), 1.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(3 * HMM_PI32 / 4), -1.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(HMM_PI32), 0.0f, trigAbsError);
- EXPECT_NEAR(HMM_TanF(-HMM_PI32 / 4), -1.0f, trigAbsError);
-
- // This isn't the most rigorous because we're really just sanity-
- // checking that things work by default.
-}
-
-TEST(ScalarMath, ToRadians)
-{
- EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0);
- EXPECT_FLOAT_EQ(HMM_ToRadians(180.0f), HMM_PI32);
- EXPECT_FLOAT_EQ(HMM_ToRadians(-180.0f), -HMM_PI32);
-}
-
-TEST(ScalarMath, SquareRoot)
-{
- EXPECT_FLOAT_EQ(HMM_SquareRootF(16.0f), 4.0f);
-}
-
-TEST(ScalarMath, RSquareRootF)
-{
- EXPECT_FLOAT_EQ(HMM_RSquareRootF(10.0f), 0.31616211f);
-}
-
-TEST(ScalarMath, Power)
-{
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, 0), 1.0f);
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, 4), 16.0f);
- EXPECT_FLOAT_EQ(HMM_Power(2.0f, -2), 0.25f);
-}
-
-TEST(ScalarMath, PowerF)
-{
- EXPECT_FLOAT_EQ(HMM_PowerF(2.0f, 0), 1.0f);
- EXPECT_NEAR(HMM_PowerF(2.0f, 4.1), 17.148376f, 0.0001f);
- EXPECT_NEAR(HMM_PowerF(2.0f, -2.5), 0.176777f, 0.0001f);
-}
-
-TEST(ScalarMath, Lerp)
-{
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.0f, 2.0f), -2.0f);
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 0.5f, 2.0f), 0.0f);
- EXPECT_FLOAT_EQ(HMM_Lerp(-2.0f, 1.0f, 2.0f), 2.0f);
-}
-
-TEST(ScalarMath, Clamp)
-{
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 0.0f, 2.0f), 0.0f);
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, -3.0f, 2.0f), -2.0f);
- EXPECT_FLOAT_EQ(HMM_Clamp(-2.0f, 3.0f, 2.0f), 2.0f);
-}
-
-TEST(Initialization, Vectors)
-{
- //
- // Test vec2
- //
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2i = HMM_Vec2(1, 2);
-
- EXPECT_FLOAT_EQ(v2.X, 1.0f);
- EXPECT_FLOAT_EQ(v2.Y, 2.0f);
-
- EXPECT_FLOAT_EQ(v2i.X, 1.0f);
- EXPECT_FLOAT_EQ(v2i.Y, 2.0f);
-
- //
- // Test vec3
- //
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3i = HMM_Vec3i(1, 2, 3);
-
- EXPECT_FLOAT_EQ(v3.X, 1.0f);
- EXPECT_FLOAT_EQ(v3.Y, 2.0f);
- EXPECT_FLOAT_EQ(v3.Z, 3.0f);
-
- EXPECT_FLOAT_EQ(v3i.X, 1.0f);
- EXPECT_FLOAT_EQ(v3i.Y, 2.0f);
- EXPECT_FLOAT_EQ(v3i.Z, 3.0f);
-
- //
- // Test vec4
- //
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4i = HMM_Vec4i(1, 2, 3, 4);
- hmm_vec4 v4v = HMM_Vec4v(v3, 4.0f);
-
- EXPECT_FLOAT_EQ(v4.X, 1.0f);
- EXPECT_FLOAT_EQ(v4.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4.W, 4.0f);
-
- EXPECT_FLOAT_EQ(v4i.X, 1.0f);
- EXPECT_FLOAT_EQ(v4i.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4i.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4i.W, 4.0f);
-
- EXPECT_FLOAT_EQ(v4v.X, 1.0f);
- EXPECT_FLOAT_EQ(v4v.Y, 2.0f);
- EXPECT_FLOAT_EQ(v4v.Z, 3.0f);
- EXPECT_FLOAT_EQ(v4v.W, 4.0f);
-}
-
-TEST(Initialization, MatrixEmpty)
-{
- hmm_mat4 m4 = HMM_Mat4();
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4.Elements[Column][Row], 0) << "At column " << Column << ", row " << Row;
- }
- }
-}
-
-TEST(Initialization, MatrixDiagonal)
-{
- hmm_mat4 m4d = HMM_Mat4d(1.0f);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- if (Column == Row) {
- EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 1.0f) << "At column " << Column << ", row " << Row;
- } else {
- EXPECT_FLOAT_EQ(m4d.Elements[Column][Row], 0) << "At column " << Column << ", row " << Row;
- }
- }
- }
-}
-
-TEST(Initialization, Quaternion)
-{
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
-
- EXPECT_FLOAT_EQ(q.X, 1.0f);
- EXPECT_FLOAT_EQ(q.Y, 2.0f);
- EXPECT_FLOAT_EQ(q.Z, 3.0f);
- EXPECT_FLOAT_EQ(q.W, 4.0f);
-
- EXPECT_FLOAT_EQ(q.Elements[0], 1.0f);
- EXPECT_FLOAT_EQ(q.Elements[1], 2.0f);
- EXPECT_FLOAT_EQ(q.Elements[2], 3.0f);
- EXPECT_FLOAT_EQ(q.Elements[3], 4.0f);
-
- hmm_vec4 v = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion qv = HMM_QuaternionV4(v);
-
- EXPECT_FLOAT_EQ(qv.X, 1.0f);
- EXPECT_FLOAT_EQ(qv.Y, 2.0f);
- EXPECT_FLOAT_EQ(qv.Z, 3.0f);
- EXPECT_FLOAT_EQ(qv.W, 4.0f);
-}
-
-TEST(VectorOps, LengthSquared)
-{
- hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
- hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
- hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, 1.0f);
-
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec2(v2), 5.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec3(v3), 14.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquaredVec4(v4), 15.0f);
-
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v2), 5.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v3), 14.0f);
- EXPECT_FLOAT_EQ(HMM_LengthSquared(v4), 15.0f);
-}
-
-TEST(VectorOps, Length)
-{
- hmm_vec2 v2 = HMM_Vec2(1.0f, -9.0f);
- hmm_vec3 v3 = HMM_Vec3(2.0f, -3.0f, 6.0f);
- hmm_vec4 v4 = HMM_Vec4(2.0f, -3.0f, 6.0f, 12.0f);
-
- EXPECT_FLOAT_EQ(HMM_LengthVec2(v2), 9.0553856f);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(v3), 7.0f);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(v4), 13.892444f);
-
- EXPECT_FLOAT_EQ(HMM_Length(v2), 9.0553856f);
- EXPECT_FLOAT_EQ(HMM_Length(v3), 7.0f);
- EXPECT_FLOAT_EQ(HMM_Length(v4), 13.892444f);
-}
-
-TEST(VectorOps, Normalize)
-{
- hmm_vec2 v2 = HMM_Vec2(1.0f, -2.0f);
- hmm_vec3 v3 = HMM_Vec3(1.0f, -2.0f, 3.0f);
- hmm_vec4 v4 = HMM_Vec4(1.0f, -2.0f, 3.0f, -1.0f);
-
- // Test C functions
- {
- hmm_vec2 result = HMM_NormalizeVec2(v2);
- EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- }
- {
- hmm_vec3 result = HMM_NormalizeVec3(v3);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- EXPECT_GT(result.Z, 0);
- }
- {
- hmm_vec4 result = HMM_NormalizeVec4(v4);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- EXPECT_GT(result.Z, 0);
- EXPECT_LT(result.W, 0);
- }
-
- // Test C++ functions
- {
- hmm_vec2 result = HMM_Normalize(v2);
- EXPECT_FLOAT_EQ(HMM_LengthVec2(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- }
- {
- hmm_vec3 result = HMM_Normalize(v3);
- EXPECT_FLOAT_EQ(HMM_LengthVec3(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- EXPECT_GT(result.Z, 0);
- }
- {
- hmm_vec4 result = HMM_Normalize(v4);
- EXPECT_FLOAT_EQ(HMM_LengthVec4(result), 1.0f);
- EXPECT_GT(result.X, 0);
- EXPECT_LT(result.Y, 0);
- EXPECT_GT(result.Z, 0);
- EXPECT_LT(result.W, 0);
- }
-}
-
-TEST(VectorOps, Cross)
-{
- hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- hmm_vec3 result = HMM_Cross(v1, v2);
-
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
-}
-
-TEST(VectorOps, DotVec2)
-{
- hmm_vec2 v1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2 = HMM_Vec2(3.0f, 4.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec2(v1, v2), 11.0f);
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 11.0f);
-}
-
-TEST(VectorOps, DotVec3)
-{
- hmm_vec3 v1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec3(v1, v2), 32.0f);
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 32.0f);
-}
-
-TEST(VectorOps, DotVec4)
-{
- hmm_vec4 v1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- EXPECT_FLOAT_EQ(HMM_DotVec4(v1, v2), 70.0f);
- EXPECT_FLOAT_EQ(HMM_Dot(v1, v2), 70.0f);
-}
-
-TEST(MatrixOps, Transpose)
-{
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the matrix
- hmm_mat4 result = HMM_Transpose(m4);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 13.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 10.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 14.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 11.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 8.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 16.0f);
-}
-
-TEST(QuaternionOps, Inverse)
-{
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion inverse = HMM_InverseQuaternion(q1);
-
- hmm_quaternion result = HMM_MultiplyQuaternion(q1, inverse);
-
- EXPECT_FLOAT_EQ(result.X, 0.0f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_FLOAT_EQ(result.W, 1.0f);
-}
-
-TEST(QuaternionOps, Dot)
-{
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- float result = HMM_DotQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result, 70.0f);
- }
- {
- float result = HMM_Dot(q1, q2);
- EXPECT_FLOAT_EQ(result, 70.0f);
- }
-}
-
-TEST(QuaternionOps, Normalize)
-{
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
-
- {
- hmm_quaternion result = HMM_NormalizeQuaternion(q);
- EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
- EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
- EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
- EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
- }
- {
- hmm_quaternion result = HMM_Normalize(q);
- EXPECT_FLOAT_EQ(result.X, 0.1825741858f);
- EXPECT_FLOAT_EQ(result.Y, 0.3651483717f);
- EXPECT_FLOAT_EQ(result.Z, 0.5477225575f);
- EXPECT_FLOAT_EQ(result.W, 0.7302967433f);
- }
-}
-
-TEST(QuaternionOps, NLerp)
-{
- hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
- hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
-
- hmm_quaternion result = HMM_NLerp(from, 0.5f, to);
- EXPECT_FLOAT_EQ(result.X, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
- EXPECT_FLOAT_EQ(result.W, 0.86602540f);
-}
-
-TEST(QuaternionOps, Slerp)
-{
- hmm_quaternion from = HMM_Quaternion(0.0f, 0.0f, 0.0f, 1.0f);
- hmm_quaternion to = HMM_Quaternion(0.5f, 0.5f, -0.5f, 0.5f);
-
- hmm_quaternion result = HMM_Slerp(from, 0.5f, to);
- EXPECT_FLOAT_EQ(result.X, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Y, 0.28867513f);
- EXPECT_FLOAT_EQ(result.Z, -0.28867513f);
- EXPECT_FLOAT_EQ(result.W, 0.86602540f);
-}
-
-TEST(QuaternionOps, ToMat4)
-{
- const float abs_error = 0.0001f;
-
- hmm_quaternion rot = HMM_Quaternion(0.707107f, 0.0f, 0.0f, 0.707107f);
-
- hmm_mat4 result = HMM_QuaternionToMat4(rot);
-
- EXPECT_NEAR(result.Elements[0][0], 1.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[0][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[1][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][2], 1.0f, abs_error);
- EXPECT_NEAR(result.Elements[1][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[2][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][1], -1.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[2][3], 0.0f, abs_error);
-
- EXPECT_NEAR(result.Elements[3][0], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][1], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][2], 0.0f, abs_error);
- EXPECT_NEAR(result.Elements[3][3], 1.0f, abs_error);
-}
-
-TEST(QuaternionOps, FromAxisAngle)
-{
- hmm_vec3 axis = HMM_Vec3(1.0f, 0.0f, 0.0f);
- float angle = HMM_PI32 / 2.0f;
-
- hmm_quaternion result = HMM_QuaternionFromAxisAngle(axis, angle);
- EXPECT_FLOAT_EQ(result.X, 0.707107f);
- EXPECT_FLOAT_EQ(result.Y, 0.0f);
- EXPECT_FLOAT_EQ(result.Z, 0.0f);
- EXPECT_FLOAT_EQ(result.W, 0.707107f);
-}
-
-TEST(Addition, Vec2)
-{
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_AddVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = HMM_Add(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = v2_1 + v2_2;
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-
- v2_1 += v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 4.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, 6.0f);
-}
-
-TEST(Addition, Vec3)
-{
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_AddVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = HMM_Add(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = v3_1 + v3_2;
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 7.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-
- v3_1 += v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 5.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, 7.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, 9.0f);
-}
-
-TEST(Addition, Vec4)
-{
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_AddVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = HMM_Add(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = v4_1 + v4_2;
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- v4_1 += v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 6.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, 8.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 12.0f);
-}
-
-TEST(Addition, Mat4)
-{
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_AddMat4(m4_1, m4_2);
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
- Expected += 2.0f;
- }
- }
- }
- {
- hmm_mat4 result = HMM_Add(m4_1, m4_2);
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
- Expected += 2.0f;
- }
- }
- }
- {
- hmm_mat4 result = m4_1 + m4_2;
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
- Expected += 2.0f;
- }
- }
- }
-
- m4_1 += m4_2;
- float Expected = 18.0f;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], Expected) << "At column " << Column << ", row " << Row;
- Expected += 2.0f;
- }
- }
-}
-
-TEST(Addition, Quaternion)
-{
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_AddQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_quaternion result = HMM_Add(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_quaternion result = q1 + q2;
- EXPECT_FLOAT_EQ(result.X, 6.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- q1 += q2;
- EXPECT_FLOAT_EQ(q1.X, 6.0f);
- EXPECT_FLOAT_EQ(q1.Y, 8.0f);
- EXPECT_FLOAT_EQ(q1.Z, 10.0f);
- EXPECT_FLOAT_EQ(q1.W, 12.0f);
-}
-
-TEST(Subtraction, Vec2)
-{
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_SubtractVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
- {
- hmm_vec2 result = HMM_Subtract(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
- {
- hmm_vec2 result = v2_1 - v2_2;
- EXPECT_FLOAT_EQ(result.X, -2.0f);
- EXPECT_FLOAT_EQ(result.Y, -2.0f);
- }
-
- v2_1 -= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, -2.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, -2.0f);
-}
-
-TEST(Subtraction, Vec3)
-{
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_SubtractVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
- {
- hmm_vec3 result = HMM_Subtract(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
- {
- hmm_vec3 result = v3_1 - v3_2;
- EXPECT_FLOAT_EQ(result.X, -3.0f);
- EXPECT_FLOAT_EQ(result.Y, -3.0f);
- EXPECT_FLOAT_EQ(result.Z, -3.0f);
- }
-
- v3_1 -= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, -3.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, -3.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, -3.0f);
-}
-
-TEST(Subtraction, Vec4)
-{
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_SubtractVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_vec4 result = HMM_Subtract(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_vec4 result = v4_1 - v4_2;
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-
- v4_1 -= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, -4.0f);
- EXPECT_FLOAT_EQ(v4_1.W, -4.0f);
-}
-
-TEST(Subtraction, Mat4)
-{
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_SubtractMat4(m4_1, m4_2);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
- }
- }
- }
- {
- hmm_mat4 result = HMM_Subtract(m4_1, m4_2);
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
- }
- }
- }
- {
- hmm_mat4 result = m4_1 - m4_2;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(result.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
- }
- }
- }
-
- m4_1 -= m4_2;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- EXPECT_FLOAT_EQ(m4_1.Elements[Column][Row], -16.0f) << "At column " << Column << ", row " << Row;
- }
- }
-}
-
-TEST(Subtraction, Quaternion)
-{
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_SubtractQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_quaternion result = HMM_Subtract(q1, q2);
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
- {
- hmm_quaternion result = q1 - q2;
- EXPECT_FLOAT_EQ(result.X, -4.0f);
- EXPECT_FLOAT_EQ(result.Y, -4.0f);
- EXPECT_FLOAT_EQ(result.Z, -4.0f);
- EXPECT_FLOAT_EQ(result.W, -4.0f);
- }
-
- q1 -= q2;
- EXPECT_FLOAT_EQ(q1.X, -4.0f);
- EXPECT_FLOAT_EQ(q1.Y, -4.0f);
- EXPECT_FLOAT_EQ(q1.Z, -4.0f);
- EXPECT_FLOAT_EQ(q1.W, -4.0f);
-}
-
-TEST(Multiplication, Vec2Vec2)
-{
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 2.0f);
- hmm_vec2 v2_2 = HMM_Vec2(3.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_MultiplyVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
- {
- hmm_vec2 result = HMM_Multiply(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
- {
- hmm_vec2 result = v2_1 * v2_2;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 8.0f);
- }
-
- v2_1 *= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 3.0f);
- EXPECT_FLOAT_EQ(v2_1.Y, 8.0f);
-}
-
-TEST(Multiplication, Vec2Scalar)
-{
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- float s = 3.0f;
-
- {
- hmm_vec2 result = HMM_MultiplyVec2f(v2, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = HMM_Multiply(v2, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = v2 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
- {
- hmm_vec2 result = s * v2;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- }
-
- v2 *= s;
- EXPECT_FLOAT_EQ(v2.X, 3.0f);
- EXPECT_FLOAT_EQ(v2.Y, 6.0f);
-}
-
-TEST(Multiplication, Vec3Vec3)
-{
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec3 v3_2 = HMM_Vec3(4.0f, 5.0f, 6.0f);
-
- {
- hmm_vec3 result = HMM_MultiplyVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
- {
- hmm_vec3 result = HMM_Multiply(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
- {
- hmm_vec3 result = v3_1 * v3_2;
- EXPECT_FLOAT_EQ(result.X, 4.0f);
- EXPECT_FLOAT_EQ(result.Y, 10.0f);
- EXPECT_FLOAT_EQ(result.Z, 18.0f);
- }
-
- v3_1 *= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 4.0f);
- EXPECT_FLOAT_EQ(v3_1.Y, 10.0f);
- EXPECT_FLOAT_EQ(v3_1.Z, 18.0f);
-}
-
-TEST(Multiplication, Vec3Scalar)
-{
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- float s = 3.0f;
-
- {
- hmm_vec3 result = HMM_MultiplyVec3f(v3, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = HMM_Multiply(v3, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = v3 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
- {
- hmm_vec3 result = s * v3;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- }
-
- v3 *= s;
- EXPECT_FLOAT_EQ(v3.X, 3.0f);
- EXPECT_FLOAT_EQ(v3.Y, 6.0f);
- EXPECT_FLOAT_EQ(v3.Z, 9.0f);
-}
-
-TEST(Multiplication, Vec4Vec4)
-{
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_vec4 v4_2 = HMM_Vec4(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_vec4 result = HMM_MultiplyVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
- {
- hmm_vec4 result = HMM_Multiply(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
- {
- hmm_vec4 result = v4_1 * v4_2;
- EXPECT_FLOAT_EQ(result.X, 5.0f);
- EXPECT_FLOAT_EQ(result.Y, 12.0f);
- EXPECT_FLOAT_EQ(result.Z, 21.0f);
- EXPECT_FLOAT_EQ(result.W, 32.0f);
- }
-
- v4_1 *= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 5.0f);
- EXPECT_FLOAT_EQ(v4_1.Y, 12.0f);
- EXPECT_FLOAT_EQ(v4_1.Z, 21.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 32.0f);
-}
-
-TEST(Multiplication, Vec4Scalar)
-{
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- float s = 3.0f;
-
- {
- hmm_vec4 result = HMM_MultiplyVec4f(v4, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = HMM_Multiply(v4, s);
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = v4 * s;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
- {
- hmm_vec4 result = s * v4;
- EXPECT_FLOAT_EQ(result.X, 3.0f);
- EXPECT_FLOAT_EQ(result.Y, 6.0f);
- EXPECT_FLOAT_EQ(result.Z, 9.0f);
- EXPECT_FLOAT_EQ(result.W, 12.0f);
- }
-
- v4 *= s;
- EXPECT_FLOAT_EQ(v4.X, 3.0f);
- EXPECT_FLOAT_EQ(v4.Y, 6.0f);
- EXPECT_FLOAT_EQ(v4.Z, 9.0f);
-}
-
-TEST(Multiplication, Mat4Mat4)
-{
- hmm_mat4 m4_1 = HMM_Mat4(); // will have 1 - 16
- hmm_mat4 m4_2 = HMM_Mat4(); // will have 17 - 32
-
- // Fill the matrices
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_1.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4_2.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_MultiplyMat4(m4_1, m4_2);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
- {
- hmm_mat4 result = HMM_Multiply(m4_1, m4_2);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
- {
- hmm_mat4 result = m4_1 * m4_2;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 538.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 612.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 686.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 760.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 650.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 740.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 830.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 920.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 762.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 868.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 974.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 1080.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 874.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 996.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 1118.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 1240.0f);
- }
-
- // At the time I wrote this, I intentionally omitted
- // the *= operator for matrices because matrix
- // multiplication is not commutative. (bvisness)
-}
-
-TEST(Multiplication, Mat4Scalar)
-{
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- float s = 3;
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_MultiplyMat4f(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
- {
- hmm_mat4 result = HMM_Multiply(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
- {
- hmm_mat4 result = m4 * s;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
- {
- hmm_mat4 result = s * m4;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 48.0f);
- }
-
- m4 *= s;
- EXPECT_FLOAT_EQ(m4.Elements[0][0], 3.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][1], 6.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][2], 9.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][3], 12.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][0], 15.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][1], 18.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][2], 21.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][3], 24.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][0], 27.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][1], 30.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][2], 33.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][3], 36.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][0], 39.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][1], 42.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][2], 45.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][3], 48.0f);
-}
-
-TEST(Multiplication, Mat4Vec4)
-{
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_vec4 result = HMM_MultiplyMat4ByVec4(m4, v4);
- EXPECT_FLOAT_EQ(result.X, 90);
- EXPECT_FLOAT_EQ(result.Y, 100);
- EXPECT_FLOAT_EQ(result.Z, 110);
- EXPECT_FLOAT_EQ(result.W, 120);
- }
- {
- hmm_vec4 result = HMM_Multiply(m4, v4);
- EXPECT_FLOAT_EQ(result.X, 90);
- EXPECT_FLOAT_EQ(result.Y, 100);
- EXPECT_FLOAT_EQ(result.Z, 110);
- EXPECT_FLOAT_EQ(result.W, 120);
- }
- {
- hmm_vec4 result = m4 * v4;
- EXPECT_FLOAT_EQ(result.X, 90);
- EXPECT_FLOAT_EQ(result.Y, 100);
- EXPECT_FLOAT_EQ(result.Z, 110);
- EXPECT_FLOAT_EQ(result.W, 120);
- }
-
- // *= makes no sense for this particular case.
-}
-
-TEST(Multiplication, QuaternionQuaternion)
-{
- hmm_quaternion q1 = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- hmm_quaternion q2 = HMM_Quaternion(5.0f, 6.0f, 7.0f, 8.0f);
-
- {
- hmm_quaternion result = HMM_MultiplyQuaternion(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
- {
- hmm_quaternion result = HMM_Multiply(q1, q2);
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
- {
- hmm_quaternion result = q1 * q2;
- EXPECT_FLOAT_EQ(result.X, 24.0f);
- EXPECT_FLOAT_EQ(result.Y, 48.0f);
- EXPECT_FLOAT_EQ(result.Z, 48.0f);
- EXPECT_FLOAT_EQ(result.W, -6.0f);
- }
-
- // Like with matrices, we're not implementing the *=
- // operator for quaternions because quaternion multiplication
- // is not commutative.
-}
-
-TEST(Multiplication, QuaternionScalar)
-{
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- float f = 2.0f;
-
- {
- hmm_quaternion result = HMM_MultiplyQuaternionF(q, f);
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
- {
- hmm_quaternion result = HMM_Multiply(q, f);
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
- {
- hmm_quaternion result = q * f;
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
- {
- hmm_quaternion result = f * q;
- EXPECT_FLOAT_EQ(result.X, 2.0f);
- EXPECT_FLOAT_EQ(result.Y, 4.0f);
- EXPECT_FLOAT_EQ(result.Z, 6.0f);
- EXPECT_FLOAT_EQ(result.W, 8.0f);
- }
-
- q *= f;
- EXPECT_FLOAT_EQ(q.X, 2.0f);
- EXPECT_FLOAT_EQ(q.Y, 4.0f);
- EXPECT_FLOAT_EQ(q.Z, 6.0f);
- EXPECT_FLOAT_EQ(q.W, 8.0f);
-}
-
-TEST(Division, Vec2Vec2)
-{
- hmm_vec2 v2_1 = HMM_Vec2(1.0f, 3.0f);
- hmm_vec2 v2_2 = HMM_Vec2(2.0f, 4.0f);
-
- {
- hmm_vec2 result = HMM_DivideVec2(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
- {
- hmm_vec2 result = HMM_Divide(v2_1, v2_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
- {
- hmm_vec2 result = v2_1 / v2_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- }
-
- v2_1 /= v2_2;
- EXPECT_FLOAT_EQ(v2_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v2_1.Y, 0.75f);
-}
-
-TEST(Division, Vec2Scalar)
-{
- hmm_vec2 v2 = HMM_Vec2(1.0f, 2.0f);
- float s = 2;
-
- {
- hmm_vec2 result = HMM_DivideVec2f(v2, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
- {
- hmm_vec2 result = HMM_Divide(v2, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
- {
- hmm_vec2 result = v2 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- }
-
- v2 /= s;
- EXPECT_FLOAT_EQ(v2.X, 0.5f);
- EXPECT_FLOAT_EQ(v2.Y, 1.0f);
-}
-
-TEST(Division, Vec3Vec3)
-{
- hmm_vec3 v3_1 = HMM_Vec3(1.0f, 3.0f, 5.0f);
- hmm_vec3 v3_2 = HMM_Vec3(2.0f, 4.0f, 0.5f);
-
- {
- hmm_vec3 result = HMM_DivideVec3(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
- {
- hmm_vec3 result = HMM_Divide(v3_1, v3_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
- {
- hmm_vec3 result = v3_1 / v3_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- }
-
- v3_1 /= v3_2;
- EXPECT_FLOAT_EQ(v3_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v3_1.Y, 0.75f);
- EXPECT_FLOAT_EQ(v3_1.Z, 10.0f);
-}
-
-TEST(Division, Vec3Scalar)
-{
- hmm_vec3 v3 = HMM_Vec3(1.0f, 2.0f, 3.0f);
- float s = 2;
-
- {
- hmm_vec3 result = HMM_DivideVec3f(v3, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
- {
- hmm_vec3 result = HMM_Divide(v3, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
- {
- hmm_vec3 result = v3 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- }
-
- v3 /= s;
- EXPECT_FLOAT_EQ(v3.X, 0.5f);
- EXPECT_FLOAT_EQ(v3.Y, 1.0f);
- EXPECT_FLOAT_EQ(v3.Z, 1.5f);
-}
-
-TEST(Division, Vec4Vec4)
-{
- hmm_vec4 v4_1 = HMM_Vec4(1.0f, 3.0f, 5.0f, 1.0f);
- hmm_vec4 v4_2 = HMM_Vec4(2.0f, 4.0f, 0.5f, 4.0f);
-
- {
- hmm_vec4 result = HMM_DivideVec4(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
- {
- hmm_vec4 result = HMM_Divide(v4_1, v4_2);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
- {
- hmm_vec4 result = v4_1 / v4_2;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 0.75f);
- EXPECT_FLOAT_EQ(result.Z, 10.0f);
- EXPECT_FLOAT_EQ(result.W, 0.25f);
- }
-
- v4_1 /= v4_2;
- EXPECT_FLOAT_EQ(v4_1.X, 0.5f);
- EXPECT_FLOAT_EQ(v4_1.Y, 0.75f);
- EXPECT_FLOAT_EQ(v4_1.Z, 10.0f);
- EXPECT_FLOAT_EQ(v4_1.W, 0.25f);
-}
-
-TEST(Division, Vec4Scalar)
-{
- hmm_vec4 v4 = HMM_Vec4(1.0f, 2.0f, 3.0f, 4.0f);
- float s = 2;
-
- {
- hmm_vec4 result = HMM_DivideVec4f(v4, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_vec4 result = HMM_Divide(v4, s);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_vec4 result = v4 / s;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-
- v4 /= s;
- EXPECT_FLOAT_EQ(v4.X, 0.5f);
- EXPECT_FLOAT_EQ(v4.Y, 1.0f);
- EXPECT_FLOAT_EQ(v4.Z, 1.5f);
- EXPECT_FLOAT_EQ(v4.W, 2.0f);
-}
-
-TEST(Division, Mat4Scalar)
-{
- hmm_mat4 m4 = HMM_Mat4(); // will have 1 - 16
- float s = 2;
-
- // Fill the matrix
- int Counter = 1;
- for (int Column = 0; Column < 4; ++Column)
- {
- for (int Row = 0; Row < 4; ++Row)
- {
- m4.Elements[Column][Row] = Counter;
- ++Counter;
- }
- }
-
- // Test the results
- {
- hmm_mat4 result = HMM_DivideMat4f(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
- {
- hmm_mat4 result = HMM_Divide(m4, s);
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
- {
- hmm_mat4 result = m4 / s;
- EXPECT_FLOAT_EQ(result.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(result.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(result.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(result.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(result.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(result.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(result.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(result.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(result.Elements[3][3], 8.0f);
- }
-
- m4 /= s;
- EXPECT_FLOAT_EQ(m4.Elements[0][0], 0.5f);
- EXPECT_FLOAT_EQ(m4.Elements[0][1], 1.0f);
- EXPECT_FLOAT_EQ(m4.Elements[0][2], 1.5f);
- EXPECT_FLOAT_EQ(m4.Elements[0][3], 2.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][0], 2.5f);
- EXPECT_FLOAT_EQ(m4.Elements[1][1], 3.0f);
- EXPECT_FLOAT_EQ(m4.Elements[1][2], 3.5f);
- EXPECT_FLOAT_EQ(m4.Elements[1][3], 4.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][0], 4.5f);
- EXPECT_FLOAT_EQ(m4.Elements[2][1], 5.0f);
- EXPECT_FLOAT_EQ(m4.Elements[2][2], 5.5f);
- EXPECT_FLOAT_EQ(m4.Elements[2][3], 6.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][0], 6.5f);
- EXPECT_FLOAT_EQ(m4.Elements[3][1], 7.0f);
- EXPECT_FLOAT_EQ(m4.Elements[3][2], 7.5f);
- EXPECT_FLOAT_EQ(m4.Elements[3][3], 8.0f);
-}
-
-TEST(Division, QuaternionScalar)
-{
- hmm_quaternion q = HMM_Quaternion(1.0f, 2.0f, 3.0f, 4.0f);
- float f = 2.0f;
-
- {
- hmm_quaternion result = HMM_DivideQuaternionF(q, f);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_quaternion result = HMM_Divide(q, f);
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
- {
- hmm_quaternion result = q / f;
- EXPECT_FLOAT_EQ(result.X, 0.5f);
- EXPECT_FLOAT_EQ(result.Y, 1.0f);
- EXPECT_FLOAT_EQ(result.Z, 1.5f);
- EXPECT_FLOAT_EQ(result.W, 2.0f);
- }
-
- q /= f;
- EXPECT_FLOAT_EQ(q.X, 0.5f);
- EXPECT_FLOAT_EQ(q.Y, 1.0f);
- EXPECT_FLOAT_EQ(q.Z, 1.5f);
- EXPECT_FLOAT_EQ(q.W, 2.0f);
-}
-
-TEST(Projection, Orthographic)
-{
- hmm_mat4 projection = HMM_Orthographic(-10.0f, 10.0f, -5.0f, 5.0f, 0.0f, -10.0f);
-
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
- hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
-
- EXPECT_FLOAT_EQ(projected.X, 0.5f);
- EXPECT_FLOAT_EQ(projected.Y, 1.0f);
- EXPECT_FLOAT_EQ(projected.Z, -2.0f);
- EXPECT_FLOAT_EQ(projected.W, 1.0f);
-}
-
-TEST(Projection, Perspective)
-{
- hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
-
- {
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
- hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
- EXPECT_FLOAT_EQ(projected.Z, 15.0f);
- EXPECT_FLOAT_EQ(projected.W, 15.0f);
- }
- {
- hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
- hmm_vec4 projected = projection * HMM_Vec4v(original, 1);
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
- EXPECT_FLOAT_EQ(projected.Z, -5.0f);
- EXPECT_FLOAT_EQ(projected.W, 5.0f);
- }
-}
-
-TEST(Transformations, Translate)
-{
- hmm_mat4 translate = HMM_Translate(HMM_Vec3(1.0f, -3.0f, 6.0f));
-
- hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec4 translated = translate * HMM_Vec4v(original, 1);
-
- EXPECT_FLOAT_EQ(translated.X, 2.0f);
- EXPECT_FLOAT_EQ(translated.Y, -1.0f);
- EXPECT_FLOAT_EQ(translated.Z, 9.0f);
- EXPECT_FLOAT_EQ(translated.W, 1.0f);
-}
-
-TEST(Transformations, Rotate)
-{
- hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
-
- hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
- hmm_vec4 rotatedX = rotateX * HMM_Vec4v(original, 1);
- EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
- EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
- EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
- EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
-
- hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
- hmm_vec4 rotatedY = rotateY * HMM_Vec4v(original, 1);
- EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
- EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
- EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
- EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
-
- hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
- hmm_vec4 rotatedZ = rotateZ * HMM_Vec4v(original, 1);
- EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.Z, 1.0f);
- EXPECT_FLOAT_EQ(rotatedZ.W, 1.0f);
-}
-
-TEST(Transformations, Scale)
-{
- hmm_mat4 scale = HMM_Scale(HMM_Vec3(2.0f, -3.0f, 0.5f));
-
- hmm_vec3 original = HMM_Vec3(1.0f, 2.0f, 3.0f);
- hmm_vec4 scaled = scale * HMM_Vec4v(original, 1);
-
- EXPECT_FLOAT_EQ(scaled.X, 2.0f);
- EXPECT_FLOAT_EQ(scaled.Y, -6.0f);
- EXPECT_FLOAT_EQ(scaled.Z, 1.5f);
- EXPECT_FLOAT_EQ(scaled.W, 1.0f);
-}
+#include "hmm_test.c"
+// C++ compilers complain when compiling a .c file...
|
Doesn't build in C (non-C++) mode
It currently doesn't build in C mode, because `NLerp` uses `HMM_Normalize()` instead of `HMM_NormalizeQuaternion()`.
I also doubt that a compiler enforcing real C99 mode would be very happy about your usage of inline in the implementation.
Having function declarations like `extern float HMM_CosF(float Angle);` and then the implementation as `inline float HMM_CosF(float Angle)` looks very wrong.
And C99 and newer has that weird thing where functions declared inline in the header must be implemented twice: inline in the header *and* not-inline in the implementation - which is pretty much the opposite of what you're doing there (to get classic/C++ inline behavior one would just supply a `static inline` implementation in the header).
|
Ack. This is what we get for only running our tests in C++ mode. I'll dig into these issues and see what I can do.
Great, thank you!
Regarding the C99 thing, it may make sense to test with -std=c99 and
using two 2 .c files, so only one of them has #define
HANDMADE_MATH_IMPLEMENTATION and the other can't "see" the function
implementations
| 2017-04-03T00:18:16
|
c
|
Hard
|
profanity-im/profanity
| 1,796
|
profanity-im__profanity-1796
|
[
"1797"
] |
f618b9cc16c37aa832202340f2f4cf2b29348026
|
diff --git a/src/common.c b/src/common.c
--- a/src/common.c
+++ b/src/common.c
@@ -355,33 +355,32 @@ prof_occurrences(const char* const needle, const char* const haystack, int offse
return *result;
}
- gchar* haystack_curr = g_utf8_offset_to_pointer(haystack, offset);
- if (g_str_has_prefix(haystack_curr, needle)) {
- if (whole_word) {
- gunichar before = 0;
- gchar* haystack_before_ch = g_utf8_find_prev_char(haystack, haystack_curr);
- if (haystack_before_ch) {
- before = g_utf8_get_char(haystack_before_ch);
- }
-
- gunichar after = 0;
- gchar* haystack_after_ch = haystack_curr + strlen(needle);
- if (haystack_after_ch[0] != '\0') {
- after = g_utf8_get_char(haystack_after_ch);
- }
-
- if (!g_unichar_isalnum(before) && !g_unichar_isalnum(after)) {
+ do {
+ gchar* haystack_curr = g_utf8_offset_to_pointer(haystack, offset);
+ if (g_str_has_prefix(haystack_curr, needle)) {
+ if (whole_word) {
+ gunichar before = 0;
+ gchar* haystack_before_ch = g_utf8_find_prev_char(haystack, haystack_curr);
+ if (haystack_before_ch) {
+ before = g_utf8_get_char(haystack_before_ch);
+ }
+
+ gunichar after = 0;
+ gchar* haystack_after_ch = haystack_curr + strlen(needle);
+ if (haystack_after_ch[0] != '\0') {
+ after = g_utf8_get_char(haystack_after_ch);
+ }
+
+ if (!g_unichar_isalnum(before) && !g_unichar_isalnum(after)) {
+ *result = g_slist_append(*result, GINT_TO_POINTER(offset));
+ }
+ } else {
*result = g_slist_append(*result, GINT_TO_POINTER(offset));
}
- } else {
- *result = g_slist_append(*result, GINT_TO_POINTER(offset));
}
- }
- offset++;
- if (g_strcmp0(g_utf8_offset_to_pointer(haystack, offset), "\0") != 0) {
- *result = prof_occurrences(needle, haystack, offset, whole_word, result);
- }
+ offset++;
+ } while (g_strcmp0(g_utf8_offset_to_pointer(haystack, offset), "\0") != 0);
return *result;
}
diff --git a/src/omemo/omemo.c b/src/omemo/omemo.c
--- a/src/omemo/omemo.c
+++ b/src/omemo/omemo.c
@@ -1920,7 +1920,7 @@ char*
omemo_qrcode_str()
{
char* mybarejid = connection_get_barejid();
- char* fingerprint = omemo_own_fingerprint(TRUE);
+ char* fingerprint = omemo_own_fingerprint(FALSE);
uint32_t sid = omemo_device_id();
char* qrstr = g_strdup_printf("xmpp:%s?omemo-sid-%d=%s", mybarejid, sid, fingerprint);
diff --git a/src/ui/console.c b/src/ui/console.c
--- a/src/ui/console.c
+++ b/src/ui/console.c
@@ -915,10 +915,12 @@ cons_show_qrcode(const char* const text)
strcat(pad, "\u2588\u2588");
}
- win_println(console, THEME_DEFAULT, "", pad);
+ win_println(console, THEME_DEFAULT, "", "");
+ win_println(console, THEME_DEFAULT, "", "");
+ win_println(console, THEME_DEFAULT, "", "%s", pad);
for (size_t y = 0; y < width; y += ZOOM_SIZE) {
for (size_t x = 0; x < width; x += ZOOM_SIZE) {
- strcat(buf, !(*data & 1) ? "\u2588\u2588" : "\u2800\u2800");
+ strcat(buf, !(*data & 1) ? "\u2588\u2588" : " ");
data++;
}
@@ -929,6 +931,8 @@ cons_show_qrcode(const char* const text)
buf[0] = '\0';
}
win_println(console, THEME_DEFAULT, "", "%s", pad);
+ win_println(console, THEME_DEFAULT, "", "");
+ win_println(console, THEME_DEFAULT, "", "");
free(pad);
free(buf);
diff --git a/src/xmpp/connection.c b/src/xmpp/connection.c
--- a/src/xmpp/connection.c
+++ b/src/xmpp/connection.c
@@ -847,8 +847,6 @@ connection_set_priority(const int priority)
conn.priority = priority;
}
-#if defined(LIBXMPP_VERSION_MAJOR) && defined(LIBXMPP_VERSION_MINOR) \
- && ((LIBXMPP_VERSION_MAJOR > 0) || (LIBXMPP_VERSION_MINOR >= 12))
static xmpp_stanza_t*
_get_soh_error(xmpp_stanza_t* error_stanza)
{
@@ -857,19 +855,6 @@ _get_soh_error(xmpp_stanza_t* error_stanza)
XMPP_STANZA_NAME_IN_NS("see-other-host", STANZA_NS_XMPP_STREAMS),
NULL);
}
-#else
-static xmpp_stanza_t*
-_get_soh_error(xmpp_stanza_t* error_stanza)
-{
- const char* name = xmpp_stanza_get_name(error_stanza);
- const char* ns = xmpp_stanza_get_ns(error_stanza);
- if (!name || !ns || strcmp(name, "error") || strcmp(ns, STANZA_NS_STREAMS)) {
- log_debug("_get_soh_error: could not find error stanza");
- return NULL;
- }
- return xmpp_stanza_get_child_by_name_and_ns(error_stanza, "see-other-host", STANZA_NS_XMPP_STREAMS);
-}
-#endif
#if GLIB_CHECK_VERSION(2, 66, 0)
static gboolean
@@ -878,12 +863,8 @@ _split_url(const char* alturi, gchar** host, gint* port)
/* Construct a valid URI with `schema://` as `g_uri_split_network()`
* requires this to be there.
*/
- const char* xmpp = "xmpp://";
- char* xmpp_uri = _xmalloc(strlen(xmpp) + strlen(alturi) + 1, NULL);
- memcpy(xmpp_uri, xmpp, strlen(xmpp));
- memcpy(xmpp_uri + strlen(xmpp), alturi, strlen(alturi) + 1);
+ auto_gchar gchar* xmpp_uri = g_strdup_printf("xmpp://%s", alturi);
gboolean ret = g_uri_split_network(xmpp_uri, 0, NULL, host, port, NULL);
- free(xmpp_uri);
/* fix-up `port` as g_uri_split_network() sets port to `-1` if it's missing
* in the passed-in URI, but libstrophe expects a "missing port"
* to be passed as `0` (which then results in connecting to the standard port).
|
diff --git a/tests/unittests/test_common.c b/tests/unittests/test_common.c
--- a/tests/unittests/test_common.c
+++ b/tests/unittests/test_common.c
@@ -535,6 +535,28 @@ _lists_equal(GSList* a, GSList* b)
return TRUE;
}
+void
+prof_occurrences_of_large_message_tests(void** state)
+{
+ GSList* actual = NULL;
+ GSList* expected = NULL;
+ /* use this with the old implementation to create a segfault
+ * const size_t haystack_sz = 1024 * 1024;
+ */
+ const size_t haystack_sz = 1024;
+ size_t haystack_cur = 0;
+ char* haystack = malloc(haystack_sz);
+ const char needle[] = "needle ";
+ while (haystack_sz - haystack_cur > sizeof(needle)) {
+ memcpy(&haystack[haystack_cur], needle, sizeof(needle) - 1);
+ expected = g_slist_append(expected, GINT_TO_POINTER(haystack_cur));
+ haystack_cur += sizeof(needle) - 1;
+ }
+ assert_true(_lists_equal(prof_occurrences("needle", haystack, 0, FALSE, &actual), expected));
+ g_slist_free(actual);
+ g_slist_free(expected);
+}
+
void
prof_partial_occurrences_tests(void** state)
{
diff --git a/tests/unittests/test_common.h b/tests/unittests/test_common.h
--- a/tests/unittests/test_common.h
+++ b/tests/unittests/test_common.h
@@ -31,5 +31,6 @@ void strip_quotes_strips_last(void** state);
void strip_quotes_strips_both(void** state);
void prof_partial_occurrences_tests(void** state);
void prof_whole_occurrences_tests(void** state);
+void prof_occurrences_of_large_message_tests(void** state);
void unique_filename_from_url_td(void** state);
void format_call_external_argv_td(void** state);
diff --git a/tests/unittests/unittests.c b/tests/unittests/unittests.c
--- a/tests/unittests/unittests.c
+++ b/tests/unittests/unittests.c
@@ -620,6 +620,7 @@ main(int argc, char* argv[])
unit_test(prof_partial_occurrences_tests),
unit_test(prof_whole_occurrences_tests),
+ unit_test(prof_occurrences_of_large_message_tests),
unit_test(returns_no_commands),
unit_test(returns_commands),
|
OMEMO QR code is not compatible with conversations
Profanity creates a QR with content in the form `xmpp:user@example.org?omemo-sid-1032437584=67214ab8-a25fd7a9-44ed1ea6-4276f18d-ff92fae9-23f8ebab-5b218d0d-4ceedc4` which doesn't work with conversations. Removing the dashes makes it work: `xmpp:user@example.org?omemo-sid-1032437584=67214ab8a25fd7a944ed1ea64276f18dff92fae923f8ebab5b218d0d4ceedc4`
The XEP refers to [RFC7748](https://www.rfc-editor.org/rfc/rfc7748) which also doesn't show dashes in fingerprints.
<!--- More than 50 issues open? Please don't file any new feature requests -->
<!--- Help us reduce the work first :-) -->
## Expected Behavior
Fingerprint is verified in conversations after scanning QR code.
## Current Behavior
Fingerprint is not verified in conversations after scanning QR code.
## Possible Solution
Remove dashes from fingerprint.
## Environment
Debian bookworm
```
profanity -v
Profanity, version 0.13.1
Copyright (C) 2012 - 2019 James Booth <boothj5web@gmail.com>.
Copyright (C) 2019 - 2022 Michael Vetter <jubalh@iodoru.org>.
License GPLv3+: GNU GPL version 3 or later <https://www.gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Build information:
XMPP library: libstrophe
Desktop notification support: Enabled
OTR support: Enabled (libotr 4.1.1)
PGP support: Enabled (libgpgme 1.18.0)
OMEMO support: Enabled
C plugins: Enabled
Python plugins: Enabled (3.11.2)
GTK icons/clipboard: Enabled
GDK Pixbuf: Enabled
```
| 2023-03-10T10:45:51
|
c
|
Hard
|
|
HandmadeMath/HandmadeMath
| 107
|
HandmadeMath__HandmadeMath-107
|
[
"31"
] |
a9b08b9147a7f3a80f23b4ed6c1bc81735930f17
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -4,6 +4,8 @@
This is a single header file with a bunch of useful functions for game and
graphics math operations.
+ All angles are in radians.
+
=============================================================================
You MUST
@@ -544,6 +546,16 @@ HMM_INLINE float HMM_PowerF(float Base, float Exponent)
* Utility functions
*/
+COVERAGE(HMM_ToDegrees, 1)
+HMM_INLINE float HMM_ToDegrees(float Radians)
+{
+ ASSERT_COVERED(HMM_ToDegrees);
+
+ float Result = Radians * (180.0f / HMM_PI32);
+
+ return (Result);
+}
+
COVERAGE(HMM_ToRadians, 1)
HMM_INLINE float HMM_ToRadians(float Degrees)
{
@@ -1404,7 +1416,7 @@ HMM_INLINE hmm_mat4 HMM_Orthographic(float Left, float Right, float Bottom, floa
}
COVERAGE(HMM_Perspective, 1)
-HMM_INLINE hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, float Far)
+HMM_INLINE hmm_mat4 HMM_Perspective(float FOVRadians, float AspectRatio, float Near, float Far)
{
ASSERT_COVERED(HMM_Perspective);
@@ -1412,7 +1424,7 @@ HMM_INLINE hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, fl
// See https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
- float Cotangent = 1.0f / HMM_TanF(FOV * (HMM_PI32 / 360.0f));
+ float Cotangent = 1.0f / HMM_TanF(FOVRadians / 2.0f);
Result.Elements[0][0] = Cotangent / AspectRatio;
Result.Elements[1][1] = Cotangent;
@@ -1438,7 +1450,7 @@ HMM_INLINE hmm_mat4 HMM_Translate(hmm_vec3 Translation)
return (Result);
}
-HMM_EXTERN hmm_mat4 HMM_Rotate(float Angle, hmm_vec3 Axis);
+HMM_EXTERN hmm_mat4 HMM_Rotate(float AngleRadians, hmm_vec3 Axis);
COVERAGE(HMM_Scale, 1)
HMM_INLINE hmm_mat4 HMM_Scale(hmm_vec3 Scale)
@@ -1675,7 +1687,7 @@ HMM_INLINE hmm_quaternion HMM_NLerp(hmm_quaternion Left, float Time, hmm_quatern
HMM_EXTERN hmm_quaternion HMM_Slerp(hmm_quaternion Left, float Time, hmm_quaternion Right);
HMM_EXTERN hmm_mat4 HMM_QuaternionToMat4(hmm_quaternion Left);
HMM_EXTERN hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 Left);
-HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation);
+HMM_EXTERN hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotationRadians);
#ifdef __cplusplus
}
@@ -2978,7 +2990,7 @@ hmm_mat4 HMM_DivideMat4f(hmm_mat4 Matrix, float Scalar)
#endif
COVERAGE(HMM_Rotate, 1)
-hmm_mat4 HMM_Rotate(float Angle, hmm_vec3 Axis)
+hmm_mat4 HMM_Rotate(float AngleRadians, hmm_vec3 Axis)
{
ASSERT_COVERED(HMM_Rotate);
@@ -2986,8 +2998,8 @@ hmm_mat4 HMM_Rotate(float Angle, hmm_vec3 Axis)
Axis = HMM_NormalizeVec3(Axis);
- float SinTheta = HMM_SinF(HMM_ToRadians(Angle));
- float CosTheta = HMM_CosF(HMM_ToRadians(Angle));
+ float SinTheta = HMM_SinF(AngleRadians);
+ float CosTheta = HMM_CosF(AngleRadians);
float CosValue = 1.0f - CosTheta;
Result.Elements[0][0] = (Axis.X * Axis.X * CosValue) + CosTheta;
@@ -3205,17 +3217,17 @@ hmm_quaternion HMM_Mat4ToQuaternion(hmm_mat4 M)
}
COVERAGE(HMM_QuaternionFromAxisAngle, 1)
-hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotation)
+hmm_quaternion HMM_QuaternionFromAxisAngle(hmm_vec3 Axis, float AngleOfRotationRadians)
{
ASSERT_COVERED(HMM_QuaternionFromAxisAngle);
hmm_quaternion Result;
hmm_vec3 AxisNormalized = HMM_NormalizeVec3(Axis);
- float SineOfRotation = HMM_SinF(AngleOfRotation / 2.0f);
+ float SineOfRotation = HMM_SinF(AngleOfRotationRadians / 2.0f);
Result.XYZ = HMM_MultiplyVec3f(AxisNormalized, SineOfRotation);
- Result.W = HMM_CosF(AngleOfRotation / 2.0f);
+ Result.W = HMM_CosF(AngleOfRotationRadians / 2.0f);
return (Result);
}
|
diff --git a/test/categories/Projection.h b/test/categories/Projection.h
--- a/test/categories/Projection.h
+++ b/test/categories/Projection.h
@@ -15,7 +15,7 @@ TEST(Projection, Orthographic)
TEST(Projection, Perspective)
{
- hmm_mat4 projection = HMM_Perspective(90.0f, 2.0f, 5.0f, 15.0f);
+ hmm_mat4 projection = HMM_Perspective(HMM_ToRadians(90.0f), 2.0f, 5.0f, 15.0f);
{
hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
diff --git a/test/categories/QuaternionOps.h b/test/categories/QuaternionOps.h
--- a/test/categories/QuaternionOps.h
+++ b/test/categories/QuaternionOps.h
@@ -111,7 +111,7 @@ TEST(QuaternionOps, Mat4ToQuat)
// Rotate 90 degrees on the X axis
{
- hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ hmm_mat4 m = HMM_Rotate(HMM_ToRadians(90.0f), HMM_Vec3(1, 0, 0));
hmm_quaternion result = HMM_Mat4ToQuaternion(m);
float cosf = 0.707107f; // cos(90/2 degrees)
@@ -125,7 +125,7 @@ TEST(QuaternionOps, Mat4ToQuat)
// Rotate 90 degrees on the Y axis (axis not normalized, just for fun)
{
- hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(0, 2, 0));
+ hmm_mat4 m = HMM_Rotate(HMM_ToRadians(90.0f), HMM_Vec3(0, 2, 0));
hmm_quaternion result = HMM_Mat4ToQuaternion(m);
float cosf = 0.707107f; // cos(90/2 degrees)
@@ -139,7 +139,7 @@ TEST(QuaternionOps, Mat4ToQuat)
// Rotate 90 degrees on the Z axis
{
- hmm_mat4 m = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_mat4 m = HMM_Rotate(HMM_ToRadians(90.0f), HMM_Vec3(0, 0, 1));
hmm_quaternion result = HMM_Mat4ToQuaternion(m);
float cosf = 0.707107f; // cos(90/2 degrees)
@@ -153,7 +153,7 @@ TEST(QuaternionOps, Mat4ToQuat)
// Rotate 45 degrees on the X axis (this hits case 4)
{
- hmm_mat4 m = HMM_Rotate(45, HMM_Vec3(1, 0, 0));
+ hmm_mat4 m = HMM_Rotate(HMM_ToRadians(45.0f), HMM_Vec3(1, 0, 0));
hmm_quaternion result = HMM_Mat4ToQuaternion(m);
float cosf = 0.9238795325f; // cos(90/2 degrees)
diff --git a/test/categories/ScalarMath.h b/test/categories/ScalarMath.h
--- a/test/categories/ScalarMath.h
+++ b/test/categories/ScalarMath.h
@@ -36,6 +36,13 @@ TEST(ScalarMath, Trigonometry)
// checking that things work by default.
}
+TEST(ScalarMath, ToDegrees)
+{
+ EXPECT_FLOAT_EQ(HMM_ToDegrees(0.0f), 0.0f);
+ EXPECT_FLOAT_EQ(HMM_ToDegrees(HMM_PI32), 180.0f);
+ EXPECT_FLOAT_EQ(HMM_ToDegrees(-HMM_PI32), -180.0f);
+}
+
TEST(ScalarMath, ToRadians)
{
EXPECT_FLOAT_EQ(HMM_ToRadians(0.0f), 0.0f);
diff --git a/test/categories/Transformation.h b/test/categories/Transformation.h
--- a/test/categories/Transformation.h
+++ b/test/categories/Transformation.h
@@ -17,21 +17,23 @@ TEST(Transformations, Rotate)
{
hmm_vec3 original = HMM_Vec3(1.0f, 1.0f, 1.0f);
- hmm_mat4 rotateX = HMM_Rotate(90, HMM_Vec3(1, 0, 0));
+ float angle = HMM_ToRadians(90.0f);
+
+ hmm_mat4 rotateX = HMM_Rotate(angle, HMM_Vec3(1, 0, 0));
hmm_vec4 rotatedX = HMM_MultiplyMat4ByVec4(rotateX, HMM_Vec4v(original, 1));
EXPECT_FLOAT_EQ(rotatedX.X, 1.0f);
EXPECT_FLOAT_EQ(rotatedX.Y, -1.0f);
EXPECT_FLOAT_EQ(rotatedX.Z, 1.0f);
EXPECT_FLOAT_EQ(rotatedX.W, 1.0f);
- hmm_mat4 rotateY = HMM_Rotate(90, HMM_Vec3(0, 1, 0));
+ hmm_mat4 rotateY = HMM_Rotate(angle, HMM_Vec3(0, 1, 0));
hmm_vec4 rotatedY = HMM_MultiplyMat4ByVec4(rotateY, HMM_Vec4v(original, 1));
EXPECT_FLOAT_EQ(rotatedY.X, 1.0f);
EXPECT_FLOAT_EQ(rotatedY.Y, 1.0f);
EXPECT_FLOAT_EQ(rotatedY.Z, -1.0f);
EXPECT_FLOAT_EQ(rotatedY.W, 1.0f);
- hmm_mat4 rotateZ = HMM_Rotate(90, HMM_Vec3(0, 0, 1));
+ hmm_mat4 rotateZ = HMM_Rotate(angle, HMM_Vec3(0, 0, 1));
hmm_vec4 rotatedZ = HMM_MultiplyMat4ByVec4(rotateZ, HMM_Vec4v(original, 1));
EXPECT_FLOAT_EQ(rotatedZ.X, -1.0f);
EXPECT_FLOAT_EQ(rotatedZ.Y, 1.0f);
|
Inconsistent use of radians vs. degrees
The trigonometric functions in Handmade Math use radians for angles. `HMM_Perspective`, on the other hand, uses degrees.
We should make this usage consistent between the two, or find a way to clarify which uses radians and which uses degrees.
|
Oh, i was not aware of this but i really think degrees, just because i dont want to have to convert what im passing in to a function every single time to radians.
@bvisness If you could handle this bug that would be awesome because im not sure of all of the use cases that have this error
As I'm thinking about it more I really don't this this is a big deal, because:
- It is literally just the FOV parameter of `HMM_Perspective` that uses degrees, and that is a case that makes sense to use degrees.
- My gut tells me that the trig functions in a math library should use radians, not degrees
- Changing the trig functions to take degrees instead of radians would be very subtle and difficult to debug across projects that already use Handmade Math.
Or we could just change the FOV parameter to take radians, and then everything would be consistent (but we would have to convert to radians when using it.) Thoughts?
I like the FOV the way it is everything else if its fine to you i'd just leave it
Very well then!
Reopening because this continues to bother me and I think it shows up in more places now. (Like HMM_Rotate, which takes an angle in degrees.)
At the very least, we need to name parameters Degrees or Radians depending on what they expect. But I think we should choose a thing and stick to it for all but very special cases (like maybe the FOV of HMM_Perspective).
This seems like a good candidate for a 2.0 release since this would obviously be mega-breaking for people.
Do we have a list of what expects radians and what expects to degrees. We can do some sort of analysis then decide on what we want to do here
My analysis:
- Trig functions take radians.
- HMM_Perspective takes degrees for the FOV and converts to radians during the calculation.
- HMM_Rotate takes an angle in degrees and converts it to radians during the calculation.
- HMM_QuaternionFromAxisAngle takes an angle in radians.
I believe GLM uses degrees for [their perspective matrix](https://glm.g-truc.net/0.9.4/api/a00151.html#ga283629a5ac7fb9037795435daf22560f), although they have a #define that makes it use radians. I regret to inform you that they also use degrees for their rotation matrix. This is stupid and I’m not sure what to do about that. At least they are consistent and appear to use degrees for everything, including their quaternion stuff.
I still think radians are the more natural choice for everything except perspective FOV (and maybe even for that). For one thing, radians are “correct”. But also, we always have to convert to radians for the actual computation, which is pointless work for a library focused on performance.
I think we should standardize on radians for everything. Avoid the ambiguity and some unnecessary work.
Maybe it’s worth having a flag for radians vs. degrees for people whose engines use degrees for everything. It should be basically trivial to add a macro to our internal use that converts degrees to radians or does nothing.
Ok yeah, I would like to switch everything to radians by default but add a #define allowing you to use degrees. We could even have the define’s behavior on by default, in a sense, if we wanted to have degrees be the default to match GLM or whatever. (I think the functions should be implemented in radians because the math is all in radians though.)
| 2019-08-03T06:22:56
|
c
|
Hard
|
HandmadeMath/HandmadeMath
| 101
|
HandmadeMath__HandmadeMath-101
|
[
"100"
] |
45c91702a910f7b8df0ac90f84667f6d94ffb9d3
|
diff --git a/HandmadeMath.h b/HandmadeMath.h
--- a/HandmadeMath.h
+++ b/HandmadeMath.h
@@ -1186,10 +1186,12 @@ HMM_INLINE hmm_mat4 HMM_Perspective(float FOV, float AspectRatio, float Near, fl
{
hmm_mat4 Result = HMM_Mat4();
- float TanThetaOver2 = HMM_TanF(FOV * (HMM_PI32 / 360.0f));
+ // See https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
+
+ float Cotangent = 1.0f / HMM_TanF(FOV * (HMM_PI32 / 360.0f));
- Result.Elements[0][0] = 1.0f / TanThetaOver2;
- Result.Elements[1][1] = AspectRatio / TanThetaOver2;
+ Result.Elements[0][0] = Cotangent / AspectRatio;
+ Result.Elements[1][1] = Cotangent;
Result.Elements[2][3] = -1.0f;
Result.Elements[2][2] = (Near + Far) / (Near - Far);
Result.Elements[3][2] = (2.0f * Near * Far) / (Near - Far);
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -10,6 +10,7 @@ To get started, go download [the latest release](https://github.com/HandmadeMath
Version | Changes |
----------------|----------------|
+**1.10.0** | Made HMM_Perspective use vertical FOV instead of horizontal FOV for consistency with other graphics APIs. |
**1.9.0** | Added SSE versions of quaternion operations. |
**1.8.0** | Added fast vector normalization routines that use fast inverse square roots.
**1.7.1** | Changed operator[] to take a const ref int instead of an int.
|
diff --git a/test/categories/Projection.h b/test/categories/Projection.h
--- a/test/categories/Projection.h
+++ b/test/categories/Projection.h
@@ -20,16 +20,16 @@ TEST(Projection, Perspective)
{
hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -15.0f);
hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.X, 2.5f);
+ EXPECT_FLOAT_EQ(projected.Y, 5.0f);
EXPECT_FLOAT_EQ(projected.Z, 15.0f);
EXPECT_FLOAT_EQ(projected.W, 15.0f);
}
{
hmm_vec3 original = HMM_Vec3(5.0f, 5.0f, -5.0f);
hmm_vec4 projected = HMM_MultiplyMat4ByVec4(projection, HMM_Vec4v(original, 1));
- EXPECT_FLOAT_EQ(projected.X, 5.0f);
- EXPECT_FLOAT_EQ(projected.Y, 10.0f);
+ EXPECT_FLOAT_EQ(projected.X, 2.5f);
+ EXPECT_FLOAT_EQ(projected.Y, 5.0f);
EXPECT_FLOAT_EQ(projected.Z, -5.0f);
EXPECT_FLOAT_EQ(projected.W, 5.0f);
}
|
Bug in HMM_Perspecive
Values in projection matrix are in the wrong places, apart from that if we decided to use tangens instead of cotangents in the [0][0] position aspect ratio also have to be inverted so:
float TanThetaOver2 = HMM_TanF(FOV * (HMM_PI32 / 360.0f));
Result.Elements[0][0] = 1.0f / AspectRatio / TanThetaOver2;
Result.Elements[1][1] = 1.0f / TanThetaOver2;
Or just compute cotangent up front:
float CoTanThetaOver2 = 1.0f / HMM_TanF(FOV * (HMM_PI32 / 360.0f));
Result.Elements[0][0] = CoTanThetaOver2 / AspectRatio;
Result.Elements[1][1] = CoTanThetaOver2;
|
I've successfully used HMM_Perspective in a couple projects, and I recently ported the exact same math over to Rust for another project of mine without issue, so I'm surprised to hear that something wouldn't be working. Could you be more specific about which values are in the wrong place?
I also ran into this just today and was assuming I had to be wrong... I can confirm that at the very least the produced matrix isn't the same as GLM's. I don't know which one is technically "correct," but that they are different is odd. I'll do some revision-scrubbing to get the actual input/output values. (Applying the precomputed cotangent, as recommended by @neurotok above, got them in sync.)
The input values:
Aperture: `90.0f` (`M_PI / 2.0f` for GLM)
Aspect: `1024.0f / 768.0f`
Near: `200.0f`
Far: `0.001f`
The output 4x4 matrices are as follows.
GLM:
```
[0.75, 0.0, 0.0 , 0.0]
[0.0 , 1.0, 0.0 , 0.0]
[0.0 , 0.0, -1.0 , -1.0]
[0.0 , 0.0, -0.002, 0.0]
```
HMM at present:
```
[1.0, 0.0 , 0.0 , 0.0]
[0.0, 1.3333, 0.0 , 0.0]
[0.0, 0.0 , -1.0 , -1.0]
[0.0, 0.0 , -0.002, 0.0]
```
HMM with precomputed cotangent patch:
```
[0.75, 0.0, 0.0 , 0.0]
[0.0 , 1.0, 0.0 , 0.0]
[0.0 , 0.0, -1.0 , -1.0]
[0.0 , 0.0, -0.002, 0.0]
```
Well I found that while playing with several c math library for 3d (cglm, kazmath, linmath.h), and HMM only one that get dirrents results:
Heres my sample code:
#include <stdio.h>
#include <math.h>
#ifndef M_PI
#define M_PI 3.14159265358979323846
#endif
#include <kazmath/kazmath.h>
#include <cglm/cglm.h>
#include "linmath.h"
#define HANDMADE_MATH_IMPLEMENTATION
#include "HandmadeMath.h"
int main(void)
{
/*
float camPosX = 0.0f;
float camPosY = 0.0f;
float camPosZ = 150.0f;
*/
float fov = 60.0f;
float perspective = 800.0f / 600.0f;
float near = 0.1f;
float faar = 100.0f;
kmMat4 test; //, rotation;
//kmMat4Translation(&test,camPosX, camPosY, -camPosZ);
kmMat4PerspectiveProjection(&test, fov, perspective, near, faar);
//kmMat4RotationX(&test, kmDegreesToRadians(45));
//kmMat4RotationY(&rotation, kmDegreesToRadians(45));
//kmMat4Multiply(&test, &test, &rotation);
printf("kazmath:\n");
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
printf("%4.2f ",test.mat[i * 4 + j]);
}
printf("\n");
}
printf("\n");
mat4 modelMat = GLM_MAT4_IDENTITY_INIT;
//glm_translate(modelMat, (vec3){-camPosX,-camPosY,-camPosZ});
glm_perspective(glm_rad((int)fov), perspective, near, faar, modelMat);
//glm_rotate_x(modelMat, glm_rad(45), modelMat);
//glm_rotate_y(modelMat, glm_rad(45), modelMat);
printf("cglm:\n");
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
printf("%4.2f ",modelMat[i][j]);
}
printf("\n");
}
printf("\n");
mat4x4 lmodel;
mat4x4_identity(lmodel);
mat4x4_perspective(lmodel, fov * M_PI / 180.0f, perspective , near, faar);
printf("linmath:\n");
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
printf("%4.2f ",lmodel[i][j]);
}
printf("\n");
}
printf("\n");
hmm_mat4 hmodel = HMM_Perspective(fov, perspective, near, faar);
printf("Hand Made Math:\n");
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
printf("%4.2f ",hmodel.Elements[i][j]);
}
printf("\n");
}
return 0;
}
And theres the result
kazmath:
1.30 0.00 0.00 0.00
0.00 1.73 0.00 0.00
0.00 0.00 -1.00 -1.00
0.00 0.00 -0.20 0.00
cglm:
1.30 0.00 0.00 0.00
0.00 1.73 0.00 0.00
0.00 0.00 -1.00 -1.00
0.00 0.00 -0.20 0.00
linmath:
1.30 0.00 0.00 0.00
0.00 1.73 0.00 0.00
0.00 0.00 -1.00 -1.00
0.00 0.00 -0.20 0.00
Hand Made Math:
1.73 0.00 0.00 0.00
0.00 2.31 0.00 0.00
0.00 0.00 -1.00 -1.00
0.00 0.00 -0.20 0.00
To be completely honest HMM is by far my favorite in terms of it's architecture :) I have an ambionion to add Inverse function to it but sadly I have no expirence with SIMD so that may take a while ;)
I just go over CG lectures and I'm pretty sure the correct perspective matrix goes something like that:
https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
FWIW, the matrix produced by HMM is *close* to the others under certain circumstances — in my 2D context, for instance, it just looks like the FOV is a bit off. If I hadn't been swapping in HMM as a replacement (feeding it the same values), I may not have noticed. That might account for why it hasn't been caught before .
I’ve also used Handmade Math for several 3D projects and have had no issues with the perspective matrix.
I’ll look into this today and see if we’re simply just using the “wrong” Algorithm.
Well hmm. Looks like we might not be using the aspect ratio correctly in the [0][0] and [1][1] cells? The [0][0] cell doesn't even take the aspect into account at all, but for example the formulation laid out [here](https://www.songho.ca/opengl/gl_projectionmatrix.html) looks like this:
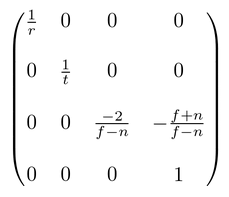
(where `r` and `t` are the right and top boundaries)
The rest of the formulation looks the same (given a little algebra). This probably just hasn't looked very wrong because those terms of the matrix don't really affect things as much as the scaling based on Z (which the value in the last column does).
I knew I should have written proper tests for perspective projection!
@StrangeZak We should probably just use the Khronos formulation @neurotok linked above.
https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
I’m okay with that. Do you wanna do the update or I can as well.
At the same time we really need LH and RH versions of these functions.
On Tue, Jul 9, 2019 at 1:53 pm Ben Visness <notifications@github.com> wrote:
> @StrangeZak <https://github.com/StrangeZak> We should probably just use
> the Khronos formulation @neurotok <https://github.com/neurotok> linked
> above.
>
>
> https://www.khronos.org/registry/OpenGL-Refpages/gl2.1/xhtml/gluPerspective.xml
>
> —
> You are receiving this because you were mentioned.
>
>
> Reply to this email directly, view it on GitHub
> <https://github.com/HandmadeMath/Handmade-Math/issues/100?email_source=notifications&email_token=AB7DZ5MQUGV3EBQQ4JLQUCLP6T3GJA5CNFSM4H7IA7D2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODZRPXZY#issuecomment-509803495>,
> or mute the thread
> <https://github.com/notifications/unsubscribe-auth/AB7DZ5OQMJQ4KXEI6434P6DP6T3GJANCNFSM4H7IA7DQ>
> .
>
I'll take care of it in a bit. I wanna see what happens at extreme aspect ratios now...
Haha, okay thanks!
On Tue, Jul 9, 2019 at 1:55 pm Ben Visness <notifications@github.com> wrote:
> I'll take care of it in a bit. I wanna see what happens at extreme aspect
> ratios now...
>
> —
> You are receiving this because you were mentioned.
>
>
> Reply to this email directly, view it on GitHub
> <https://github.com/HandmadeMath/Handmade-Math/issues/100?email_source=notifications&email_token=AB7DZ5OTONRES5XREDQQLSLP6T3MJA5CNFSM4H7IA7D2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODZRP5LQ#issuecomment-509804206>,
> or mute the thread
> <https://github.com/notifications/unsubscribe-auth/AB7DZ5K3H6UKKNXV3XHSSC3P6T3MJANCNFSM4H7IA7DQ>
> .
>
Actually wait. Does the FOV in your program refer to the vertical or horizontal field of view? I think we might have ended up using a formulation that uses horizontal, while everything else uses vertical.
I think that's exactly what happened. See the following:


So it's not "wrong", exactly, but it's certainly not what most people would expect. And it's also not what people want from their ultrawide monitors, I bet. 😛
Here's using vertical FOV:


Obviously for resolutions closer to square, this difference doesn't show up as much, which explains why it slipped by in our various projects.
I could go either way on how we want to version this fix. On the one hand, it is "breaking" in the sense that people might have depended on a particular horizontal field of view. But on the other hand, probably no one did, because they expected vertical FOV like everywhere else.
Thoughts?
Honestly, this should be fixed "correctly" horizontal FOV doesn't make much sense. So im okay with fixing this even if it breaks something. Id just put a comment, or a message in the release notes regarding what we broke, and why.
| 2019-07-09T22:11:34
|
c
|
Hard
|
nginx/njs
| 805
|
nginx__njs-805
|
[
"802"
] |
198539036deacc8d263005a14849fd93c5d314f4
|
diff --git a/external/njs_fs_module.c b/external/njs_fs_module.c
--- a/external/njs_fs_module.c
+++ b/external/njs_fs_module.c
@@ -160,6 +160,8 @@ static njs_int_t njs_fs_read_file(njs_vm_t *vm, njs_value_t *args,
njs_uint_t nargs, njs_index_t calltype, njs_value_t *retval);
static njs_int_t njs_fs_readdir(njs_vm_t *vm, njs_value_t *args,
njs_uint_t nargs, njs_index_t calltype, njs_value_t *retval);
+static njs_int_t njs_fs_readlink(njs_vm_t *vm, njs_value_t *args,
+ njs_uint_t nargs, njs_index_t calltype, njs_value_t *retval);
static njs_int_t njs_fs_realpath(njs_vm_t *vm, njs_value_t *args,
njs_uint_t nargs, njs_index_t calltype, njs_value_t *retval);
static njs_int_t njs_fs_rename(njs_vm_t *vm, njs_value_t *args,
@@ -415,6 +417,17 @@ static njs_external_t njs_ext_fs_promises[] = {
}
},
+ {
+ .flags = NJS_EXTERN_METHOD,
+ .name.string = njs_str("readlink"),
+ .writable = 1,
+ .configurable = 1,
+ .u.method = {
+ .native = njs_fs_readlink,
+ .magic8 = NJS_FS_PROMISE,
+ }
+ },
+
{
.flags = NJS_EXTERN_METHOD,
.name.string = njs_str("realpath"),
@@ -726,6 +739,28 @@ static njs_external_t njs_ext_fs[] = {
}
},
+ {
+ .flags = NJS_EXTERN_METHOD,
+ .name.string = njs_str("readlink"),
+ .writable = 1,
+ .configurable = 1,
+ .u.method = {
+ .native = njs_fs_readlink,
+ .magic8 = NJS_FS_CALLBACK,
+ }
+ },
+
+ {
+ .flags = NJS_EXTERN_METHOD,
+ .name.string = njs_str("readlinkSync"),
+ .writable = 1,
+ .configurable = 1,
+ .u.method = {
+ .native = njs_fs_readlink,
+ .magic8 = NJS_FS_DIRECT,
+ }
+ },
+
{
.flags = NJS_EXTERN_METHOD,
.name.string = njs_str("realpath"),
@@ -2035,6 +2070,99 @@ njs_fs_readdir(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
}
+static njs_int_t
+njs_fs_readlink(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
+ njs_index_t calltype, njs_value_t *retval)
+{
+ ssize_t n;
+ njs_int_t ret;
+ njs_str_t s;
+ const char *path;
+ njs_value_t *callback, *options;
+ njs_opaque_value_t encode, result;
+ const njs_buffer_encoding_t *encoding;
+ char path_buf[NJS_MAX_PATH + 1],
+ dst_buf[NJS_MAX_PATH + 1];
+
+ path = njs_fs_path(vm, path_buf, njs_arg(args, nargs, 1), "path");
+ if (njs_slow_path(path == NULL)) {
+ return NJS_ERROR;
+ }
+
+ callback = NULL;
+ options = njs_arg(args, nargs, 2);
+
+ if (calltype == NJS_FS_CALLBACK) {
+ callback = njs_arg(args, nargs, njs_min(nargs - 1, 3));
+ if (!njs_value_is_function(callback)) {
+ njs_vm_type_error(vm, "\"callback\" must be a function");
+ return NJS_ERROR;
+ }
+
+ if (options == callback) {
+ options = njs_value_arg(&njs_value_undefined);
+ }
+ }
+
+ njs_value_undefined_set(njs_value_arg(&encode));
+
+ if (njs_value_is_string(options)) {
+ njs_value_assign(&encode, options);
+
+ } else if (!njs_value_is_undefined(options)) {
+ if (!njs_value_is_object(options)) {
+ njs_vm_type_error(vm, "Unknown options type "
+ "(a string or object required)");
+ return NJS_ERROR;
+ }
+
+ (void) njs_vm_object_prop(vm, options, &string_encoding, &encode);
+ }
+
+ encoding = NULL;
+
+ if (njs_value_is_string(njs_value_arg(&encode))) {
+ njs_value_string_get(njs_value_arg(&encode), &s);
+
+ } else {
+ s.length = 0;
+ s.start = NULL;
+ }
+
+ if (!njs_strstr_eq(&s, &string_buffer)) {
+ encoding = njs_buffer_encoding(vm, njs_value_arg(&encode), 1);
+ if (njs_slow_path(encoding == NULL)) {
+ return NJS_ERROR;
+ }
+ }
+
+ s.start = (u_char *) dst_buf;
+ n = readlink(path, dst_buf, sizeof(dst_buf) - 1);
+ if (njs_slow_path(n < 0)) {
+ ret = njs_fs_error(vm, "readlink", strerror(errno), path, errno,
+ &result);
+ goto done;
+ }
+
+ s.length = n;
+
+ if (encoding == NULL) {
+ ret = njs_buffer_new(vm, njs_value_arg(&result), s.start, s.length);
+
+ } else {
+ ret = encoding->encode(vm, njs_value_arg(&result), &s);
+ }
+
+done:
+
+ if (ret == NJS_OK) {
+ return njs_fs_result(vm, &result, calltype, callback, 2, retval);
+ }
+
+ return NJS_ERROR;
+}
+
+
static njs_int_t
njs_fs_realpath(njs_vm_t *vm, njs_value_t *args, njs_uint_t nargs,
njs_index_t calltype, njs_value_t *retval)
|
diff --git a/test/fs/methods.t.js b/test/fs/methods.t.js
--- a/test/fs/methods.t.js
+++ b/test/fs/methods.t.js
@@ -435,6 +435,56 @@ let realpathP_tsuite = {
get tests() { return realpath_tests() },
};
+async function readlink_test(params) {
+ let lname = params.args[0];
+ try { fs.unlinkSync(lname); } catch (e) {}
+ fs.symlinkSync("test/fs/ascii", lname);
+
+ let data = await method("readlink", params);
+
+ if (!params.check(data)) {
+ throw Error(`readlink failed check`);
+ }
+
+ return 'SUCCESS';
+}
+
+let readlink_tests = () => [
+ { args: [`${test_dir}/symlink`],
+ check: (data) => data.endsWith("test/fs/ascii") },
+ { args: [`${test_dir}/symlink`, {encoding:'buffer'}],
+ check: (data) => data instanceof Buffer },
+ { args: [`${test_dir}/symlink`, {encoding:'hex'}],
+ check: (data) => data.endsWith("746573742f66732f6173636969") },
+];
+
+let readlink_tsuite = {
+ name: "fs readlink",
+ skip: () => (!has_fs() || !has_buffer()),
+ T: readlink_test,
+ prepare_args: p,
+ opts: { type: "callback" },
+ get tests() { return readlink_tests() },
+};
+
+let readlinkSync_tsuite = {
+ name: "fs readlinkSync",
+ skip: () => (!has_fs() || !has_buffer()),
+ T: readlink_test,
+ prepare_args: p,
+ opts: { type: "sync" },
+ get tests() { return readlink_tests() },
+};
+
+let readlinkP_tsuite = {
+ name: "fsp readlink",
+ skip: () => (!has_fs() || !has_buffer()),
+ T: readlink_test,
+ prepare_args: p,
+ opts: { type: "promise" },
+ get tests() { return readlink_tests() },
+};
+
async function method_test(params) {
if (params.init) {
params.init(params);
@@ -1190,6 +1240,9 @@ run([
realpath_tsuite,
realpathSync_tsuite,
realpathP_tsuite,
+ readlink_tsuite,
+ readlinkSync_tsuite,
+ readlinkP_tsuite,
stat_tsuite,
statSync_tsuite,
statP_tsuite,
|
fs.readlink / fs.readlinkSync
Hello,
it appears fs implementation in njs does not includes `fs.readlink` nor `fs.readlinkSync`, possible to add it please?
thanks
| 2024-10-19T05:02:54
|
c
|
Hard
|
|
nginx/njs
| 757
|
nginx__njs-757
|
[
"755"
] |
b593dd4aba0f5c730c1d90072cdee7dd9a93beed
|
diff --git a/src/njs_parser.c b/src/njs_parser.c
--- a/src/njs_parser.c
+++ b/src/njs_parser.c
@@ -6699,23 +6699,32 @@ njs_parser_labelled_statement_after(njs_parser_t *parser,
{
njs_int_t ret;
uintptr_t unique_id;
+ njs_parser_node_t *node;
const njs_lexer_entry_t *entry;
- if (parser->node != NULL) {
- /* The statement is not empty block or just semicolon. */
-
- unique_id = (uintptr_t) parser->target;
- entry = (const njs_lexer_entry_t *) unique_id;
-
- ret = njs_name_copy(parser->vm, &parser->node->name, &entry->name);
- if (ret != NJS_OK) {
+ node = parser->node;
+ if (node == NULL) {
+ node = njs_parser_node_new(parser, NJS_TOKEN_BLOCK);
+ if (node == NULL) {
return NJS_ERROR;
}
- ret = njs_label_remove(parser->vm, parser->scope, unique_id);
- if (ret != NJS_OK) {
- return NJS_ERROR;
- }
+ node->token_line = token->line;
+
+ parser->node = node;
+ }
+
+ unique_id = (uintptr_t) parser->target;
+ entry = (const njs_lexer_entry_t *) unique_id;
+
+ ret = njs_name_copy(parser->vm, &parser->node->name, &entry->name);
+ if (ret != NJS_OK) {
+ return NJS_ERROR;
+ }
+
+ ret = njs_label_remove(parser->vm, parser->scope, unique_id);
+ if (ret != NJS_OK) {
+ return NJS_ERROR;
}
return njs_parser_stack_pop(parser);
|
diff --git a/src/test/njs_unit_test.c b/src/test/njs_unit_test.c
--- a/src/test/njs_unit_test.c
+++ b/src/test/njs_unit_test.c
@@ -3494,6 +3494,22 @@ static njs_unit_test_t njs_test[] =
"} catch(e) {c = 10;}; [c, fin]"),
njs_str("1,1") },
+ { njs_str("function v1() {"
+ "function v2 () {}"
+ "v3:;"
+ "1;"
+ "} v1();"),
+ njs_str("undefined") },
+
+ { njs_str("function v1() {"
+ "function v2 () {}"
+ "v3:;"
+ "} v1();"),
+ njs_str("undefined") },
+
+ { njs_str("{v1:;}"),
+ njs_str("undefined") },
+
/* jumping out of a nested try-catch block. */
{ njs_str("var r = 0; "
|
SEGV njs_function.c:780:17 in njs_function_capture_closure
Testcase
```js
function v1(){
function v0(){
}
v2:;
new v3();
}
new v1();
```
ASAN
```
AddressSanitizer:DEADLYSIGNAL
=================================================================
==2336==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000008 (pc 0x0000007ef885 bp 0x7ffc1ff0d730 sp 0x7ffc1ff0d640 T0)
==2336==The signal is caused by a READ memory access.
==2336==Hint: address points to the zero page.
#0 0x7ef884 in njs_function_capture_closure /home/xxx/Desktop/njs/src/njs_function.c:780:17
#1 0x7ef884 in njs_function_lambda_call /home/xxx/Desktop/njs/src/njs_function.c:604
#2 0x7ede60 in njs_function_frame_invoke /home/xxx/Desktop/njs/src/njs_function.c:686:16
#3 0x57f25c in njs_vmcode_interpreter /home/xxx/Desktop/njs/src/njs_vmcode.c:1451:15
#4 0x5610db in njs_vm_start /home/xxx/Desktop/njs/src/njs_vm.c:664:11
#5 0x51d7fd in njs_engine_njs_eval /home/xxx/Desktop/njs/external/njs_shell.c:1387:16
#6 0x519147 in njs_process_script /home/xxx/Desktop/njs/external/njs_shell.c:3528:11
#7 0x519147 in njs_process_file /home/xxx/Desktop/njs/external/njs_shell.c:3500
#8 0x519147 in njs_main /home/xxx/Desktop/njs/external/njs_shell.c:458
#9 0x519147 in main /home/xxx/Desktop/njs/external/njs_shell.c:488
#10 0x7f7dc35aec86 in __libc_start_main /build/glibc-uZu3wS/glibc-2.27/csu/../csu/libc-start.c:310
#11 0x41b3e9 in _start (/home/xxx/Desktop/njs/build/njs+0x41b3e9)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /home/xxx/Desktop/njs/src/njs_function.c:780:17 in njs_function_capture_closure
==2336==ABORTING
```
| 2024-07-05T18:34:23
|
c
|
Hard
|
|
nfrechette/acl
| 248
|
nfrechette__acl-248
|
[
"235",
"247"
] |
4b325ee08ff4779cbff8f06c73910e58df7046f8
|
diff --git a/docs/compressing_a_raw_clip.md b/docs/compressing_a_raw_clip.md
--- a/docs/compressing_a_raw_clip.md
+++ b/docs/compressing_a_raw_clip.md
@@ -30,7 +30,7 @@ settings.range_reduction = RangeReductionFlags8::AllTracks;
settings.segmenting.enabled = true;
settings.segmenting.range_reduction = RangeReductionFlags8::AllTracks;
-TransformErrorMetric error_metric;
+qvvf_transform_error_metric error_metric;
settings.error_metric = &error_metric;
OutputStats stats;
diff --git a/docs/error_metrics.md b/docs/error_metrics.md
--- a/docs/error_metrics.md
+++ b/docs/error_metrics.md
@@ -1,27 +1,30 @@
-# Skeleton error metric
+# Transform error metric
A proper error metric is central to every animation compression algorithm and ACL is no different. The general technique implemented is the one described on this [blog post](http://nfrechette.github.io/2016/11/01/anim_compression_accuracy/) and the various implementations as well as the interfaces live [here](../includes/acl/compression/skeleton_error_metric.h).
-Some care must be taken when selecting which error metric to use. If the error it calculates isn't representative of how it would be calculated in the host game engine, the resulting visual fidelity might suffer. ACL implements a number of popular implementations and you are free to implement and use your own.
+Some care must be taken when selecting which error metric to use. If the error it calculates isn't representative of how it would be calculated in the host game engine, the resulting visual fidelity might suffer. ACL implements a number of popular implementations and you are free to implement and use your own. The `qvvf_transform_error_metric` error metric is a sensible default.
-## TransformErrorMetric
+## qvvf_transform_error_metric
-This implementation will use `Transform_32` (which implements Vector-Quaternion-Vector (*VQV*) arithmetic) to calculate the error both when scale is present and when it isn't and for both local and object space. It is a solid default and it should handle very well most clips in the wild. However take note that because it uses a simple `vector3` to represent the 3D scale component, it cannot properly handle skew and shear that arises as a result of combining multiple transforms in a bone chain. In practice it rarely matters and if you truly need this, an error metric that uses matrices when scale is present might perform better or by using Vector-Quaternion-Matrix (*VQM*) arithmetic.
+This implementation will use `rtm::qvvf` (which implements Vector-Quaternion-Vector (*VQV*) arithmetic) to calculate the error both when scale is present and when it isn't and for both local and object space. It is a solid default and it should handle very well most clips in the wild. However take note that because it uses a simple `vector3` to represent the 3D scale component, it cannot properly handle skew and shear that arises as a result of combining multiple transforms in a bone chain. In practice it rarely matters and if you truly need this, an error metric that uses matrices when scale is present might perform better or by using Vector-Quaternion-Matrix (*VQM*) arithmetic.
-## TransformMatrixErrorMetric
+## qvvf_matrix3x4f_transform_error_metric
-This implementation uses `Transform_32` when there is no scale in both local and object space and as well as local space when there is scale. This is generally safe because there is no skew or shear present in the transform. However, when scale is present the object space error metric will convert the transforms into `AffineMatrix_32` in order to combine them into the final object space transform for the bone. This properly handles 3D scale but due to numerical accuracy constraints the error can accumulate to unacceptable levels when very large or very small scale is present and combined with very large translations.
+This implementation uses `rtm::qvvf` when there is no scale in both local and object space and as well as local space when there is scale. This is generally safe because there is no skew or shear present in the transform. However, when scale is present the object space error metric will convert the transforms into `rtm::matrix3x4f` in order to combine them into the final object space transform for the bone. This properly handles 3D scale but due to numerical accuracy constraints the error can accumulate to unacceptable levels when very large or very small scale is present and combined with very large translations.
-## AdditiveTransformErrorMetric
+## additive_qvvf_transform_error_metric
-This implementation is based on the `TransformErrorMetric` and handles additive and regular animation clips. See [here](additive_clips.md) for the various additive operations supported and which one to select for your game engine.
+This implementation is based on the `qvvf_transform_error_metric` and handles additive and regular animation clips. See [here](additive_clips.md) for the various additive operations supported and which one to select for your game engine.
For the purpose of measuring the error, we ignore object space additive blending. It typically does not play a significant role in the resulting error because the pose is fundamentally very close. As such, the additive clip is always applied in local space to the base clip.
-If your game engine performs additive blending in a way that ACL does not support, you will have to modify the sources (and hopefully submit a pull request) to include it. It is fairly easy and simple, just follow the examples already present in the code.
+If your game engine performs additive blending in a way that ACL does not support, you can modify the sources (and hopefully submit a pull request) to include it or you can implement your own error metric. It is fairly simple, just follow the examples already present in the code.
## Implementing your own error metric
-In order to implement your own error metric you need to figure out how your host game engine combines the local space bone transforms into object space in order to do the same. Once you have that information, implement a class that derives from the `ISkeletalErrorMetric` interface. You can use the other error metrics as examples. You will then be able to provide it to the compression algorithm by feeding it to the `CompressionSettings`.
+In order to implement your own error metric you need to figure out how your host game engine combines the local space bone transforms into object space in order to do the same. Once you have that information, implement a class that derives from the `itransform_error_metric` interface. You can use the other error metrics as examples. You will then be able to provide it to the compression algorithm by feeding it to the `CompressionSettings`.
+
+Fundamentally the interface requires you to implement two versions of the error metric: with or without scale. The variants with no scale are only present as an optimization to avoid unnecessary computation when a clip does not contain any scale. It is common enough to warrant an optimized code path.
+
+If your error metric uses a different type than `rtm::qvvf`, you can implement the other functions as needed. See the interface for details.
-Fundamentally the interface requires you to implement four versions of the error metric: with or without scale, and in local or object space. The variants with no scale are only present as an optimization to avoid unnecessary computation when a clip does not contain any scale. It is common enough to warrant an optimized code path.
diff --git a/external/rtm b/external/rtm
--- a/external/rtm
+++ b/external/rtm
@@ -1 +1 @@
-Subproject commit 817753c3800d23e9583f25532f707b944d5ce54c
+Subproject commit ce9f00368c73e8f49446ac11cf4752ef65d97d5a
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/decoder.h
@@ -798,13 +798,15 @@ namespace acl
for (uint32_t animated_track_index = 0; animated_track_index < num_animated_tracks; ++animated_track_index)
{
- for (size_t i = 0; i < 2; ++i)
- {
- const uint8_t bit_rate = m_context.format_per_track_data[i][animated_track_index];
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+ const uint8_t bit_rate0 = m_context.format_per_track_data[0][animated_track_index];
+ const uint32_t num_bits_at_bit_rate0 = get_num_bits_at_bit_rate(bit_rate0) * 3; // 3 components
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
- }
+ sampling_context.key_frame_bit_offsets[0] += num_bits_at_bit_rate0;
+
+ const uint8_t bit_rate1 = m_context.format_per_track_data[1][animated_track_index];
+ const uint32_t num_bits_at_bit_rate1 = get_num_bits_at_bit_rate(bit_rate1) * 3; // 3 components
+
+ sampling_context.key_frame_bit_offsets[1] += num_bits_at_bit_rate1;
}
}
diff --git a/includes/acl/algorithm/uniformly_sampled/encoder.h b/includes/acl/algorithm/uniformly_sampled/encoder.h
--- a/includes/acl/algorithm/uniformly_sampled/encoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/encoder.h
@@ -142,7 +142,7 @@ namespace acl
else
settings.segmenting.range_reduction = RangeReductionFlags8::None;
- quantize_streams(allocator, clip_context, settings, skeleton, raw_clip_context, additive_base_clip_context);
+ quantize_streams(allocator, clip_context, settings, skeleton, raw_clip_context, additive_base_clip_context, out_stats);
uint16_t num_output_bones = 0;
uint16_t* output_bone_mapping = create_output_bone_mapping(allocator, clip, num_output_bones);
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -131,7 +131,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// The error metric to use.
// Defaults to 'null', this value must be set manually!
- ISkeletalErrorMetric* error_metric;
+ itransform_error_metric* error_metric;
//////////////////////////////////////////////////////////////////////////
// Threshold angle when detecting if rotation tracks are constant or default.
diff --git a/includes/acl/compression/impl/quantize_streams.h b/includes/acl/compression/impl/quantize_streams.h
--- a/includes/acl/compression/impl/quantize_streams.h
+++ b/includes/acl/compression/impl/quantize_streams.h
@@ -44,6 +44,7 @@
#include <cstddef>
#include <cstdint>
+#include <functional>
// 0 = no debug info, 1 = basic info, 2 = verbose
#define ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION 0
@@ -66,9 +67,9 @@ namespace acl
const RigidSkeleton& skeleton;
const CompressionSettings& settings;
- acl_impl::track_bit_rate_database database;
- acl_impl::single_track_query local_query;
- acl_impl::hierarchical_track_query object_query;
+ track_bit_rate_database bit_rate_database;
+ single_track_query local_query;
+ hierarchical_track_query object_query;
uint32_t num_samples;
uint32_t segment_sample_start_index;
@@ -76,14 +77,31 @@ namespace acl
float clip_duration;
bool has_scale;
bool has_additive_base;
+ bool needs_conversion;
const BoneStreams* raw_bone_streams;
- rtm::qvvf* additive_local_pose;
- rtm::qvvf* raw_local_pose;
- rtm::qvvf* lossy_local_pose;
+ rtm::qvvf* additive_local_pose; // 1 per transform
+ rtm::qvvf* raw_local_pose; // 1 per transform
+ rtm::qvvf* lossy_local_pose; // 1 per transform
- BoneBitRate* bit_rate_per_bone;
+ uint8_t* raw_local_transforms; // 1 per transform per sample in segment
+ uint8_t* base_local_transforms; // 1 per transform per sample in segment
+ uint8_t* raw_object_transforms; // 1 per transform per sample in segment
+ uint8_t* base_object_transforms; // 1 per transform per sample in segment
+
+ uint8_t* local_transforms_converted; // 1 per transform
+ uint8_t* lossy_object_pose; // 1 per transform
+ size_t metric_transform_size;
+
+ BoneBitRate* bit_rate_per_bone; // 1 per transform
+ uint16_t* parent_transform_indices; // 1 per transform
+ uint16_t* self_transform_indices; // 1 per transform
+
+ uint16_t* chain_bone_indices; // 1 per transform
+ uint16_t num_bones_in_chain;
+ uint16_t padding0; // unused
+ uint32_t padding1; // unused
QuantizationContext(IAllocator& allocator_, ClipContext& clip_, const ClipContext& raw_clip_, const ClipContext& additive_base_clip_, const CompressionSettings& settings_, const RigidSkeleton& skeleton_)
: allocator(allocator_)
@@ -95,7 +113,7 @@ namespace acl
, num_bones(clip_.num_bones)
, skeleton(skeleton_)
, settings(settings_)
- , database(allocator_, settings_, clip_.segments->bone_streams, raw_clip_.segments->bone_streams, clip_.num_bones, clip_.segments->num_samples)
+ , bit_rate_database(allocator_, settings_, clip_.segments->bone_streams, raw_clip_.segments->bone_streams, clip_.num_bones, clip_.segments->num_samples)
, local_query()
, object_query(allocator_)
, num_samples(~0U)
@@ -105,14 +123,35 @@ namespace acl
, has_scale(clip_.has_scale)
, has_additive_base(clip_.has_additive_base)
, raw_bone_streams(raw_clip_.segments[0].bone_streams)
+ , num_bones_in_chain(0)
{
- local_query.bind(database);
- object_query.bind(database);
+ local_query.bind(bit_rate_database);
+ object_query.bind(bit_rate_database);
+
+ needs_conversion = settings_.error_metric->needs_conversion(clip_.has_scale);
+ const size_t metric_transform_size_ = settings_.error_metric->get_transform_size(clip_.has_scale);
+ metric_transform_size = metric_transform_size_;
additive_local_pose = clip_.has_additive_base ? allocate_type_array<rtm::qvvf>(allocator, num_bones) : nullptr;
raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ raw_local_transforms = allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones * clip_.segments->num_samples, 64);
+ base_local_transforms = clip_.has_additive_base ? allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones * clip_.segments->num_samples, 64) : nullptr;
+ raw_object_transforms = allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones * clip_.segments->num_samples, 64);
+ base_object_transforms = clip_.has_additive_base ? allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones * clip_.segments->num_samples, 64) : nullptr;
+ local_transforms_converted = needs_conversion ? allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones, 64) : nullptr;
+ lossy_object_pose = allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones, 64);
bit_rate_per_bone = allocate_type_array<BoneBitRate>(allocator, num_bones);
+ parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+ self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+ chain_bone_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+
+ for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
+ {
+ const RigidBone& bone = skeleton_.get_bone(transform_index);
+ parent_transform_indices[transform_index] = bone.parent_index;
+ self_transform_indices[transform_index] = transform_index;
+ }
}
~QuantizationContext()
@@ -120,7 +159,16 @@ namespace acl
deallocate_type_array(allocator, additive_local_pose, num_bones);
deallocate_type_array(allocator, raw_local_pose, num_bones);
deallocate_type_array(allocator, lossy_local_pose, num_bones);
+ deallocate_type_array(allocator, raw_local_transforms, metric_transform_size * num_bones * clip.segments->num_samples);
+ deallocate_type_array(allocator, base_local_transforms, metric_transform_size * num_bones * clip.segments->num_samples);
+ deallocate_type_array(allocator, raw_object_transforms, metric_transform_size * num_bones * clip.segments->num_samples);
+ deallocate_type_array(allocator, base_object_transforms, metric_transform_size * num_bones * clip.segments->num_samples);
+ deallocate_type_array(allocator, local_transforms_converted, metric_transform_size * num_bones);
+ deallocate_type_array(allocator, lossy_object_pose, metric_transform_size * num_bones);
deallocate_type_array(allocator, bit_rate_per_bone, num_bones);
+ deallocate_type_array(allocator, parent_transform_indices, num_bones);
+ deallocate_type_array(allocator, self_transform_indices, num_bones);
+ deallocate_type_array(allocator, chain_bone_indices, num_bones);
}
void set_segment(SegmentContext& segment_)
@@ -129,7 +177,77 @@ namespace acl
bone_streams = segment_.bone_streams;
num_samples = segment_.num_samples;
segment_sample_start_index = segment_.clip_sample_offset;
- database.set_segment(segment_.bone_streams, segment_.num_bones, segment_.num_samples);
+ bit_rate_database.set_segment(segment_.bone_streams, segment_.num_bones, segment_.num_samples);
+
+ // Cache every raw local/object transforms and the base local transforms since they never change
+ const itransform_error_metric* error_metric = settings.error_metric;
+ const size_t sample_transform_size = metric_transform_size * num_bones;
+
+ const auto convert_transforms_impl = std::mem_fn(has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
+ const auto apply_additive_to_base_impl = std::mem_fn(has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
+ const auto local_to_object_space_impl = std::mem_fn(has_scale ? &itransform_error_metric::local_to_object_space : &itransform_error_metric::local_to_object_space_no_scale);
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_raw;
+ convert_transforms_args_raw.dirty_transform_indices = self_transform_indices;
+ convert_transforms_args_raw.num_dirty_transforms = num_bones;
+ convert_transforms_args_raw.transforms = raw_local_pose;
+ convert_transforms_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_base = convert_transforms_args_raw;
+ convert_transforms_args_base.transforms = additive_local_pose;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_raw.dirty_transform_indices = self_transform_indices;
+ apply_additive_to_base_args_raw.num_dirty_transforms = num_bones;
+ apply_additive_to_base_args_raw.local_transforms = nullptr;
+ apply_additive_to_base_args_raw.base_transforms = nullptr;
+ apply_additive_to_base_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_raw;
+ local_to_object_space_args_raw.dirty_transform_indices = self_transform_indices;
+ local_to_object_space_args_raw.num_dirty_transforms = num_bones;
+ local_to_object_space_args_raw.parent_transform_indices = parent_transform_indices;
+ local_to_object_space_args_raw.local_transforms = nullptr;
+ local_to_object_space_args_raw.num_transforms = num_bones;
+
+ for (uint32_t sample_index = 0; sample_index < segment_.num_samples; ++sample_index)
+ {
+ // Sample our streams and calculate the error
+ // The sample time is calculated from the full clip duration to be consistent with decompression
+ const float sample_time = rtm::scalar_min(float(segment_.clip_sample_offset + sample_index) / sample_rate, clip_duration);
+
+ sample_streams(raw_bone_streams, num_bones, sample_time, raw_local_pose);
+
+ uint8_t* sample_raw_local_transforms = raw_local_transforms + (sample_index * sample_transform_size);
+
+ if (needs_conversion)
+ convert_transforms_impl(error_metric, convert_transforms_args_raw, sample_raw_local_transforms);
+ else
+ std::memcpy(sample_raw_local_transforms, raw_local_pose, sample_transform_size);
+
+ if (has_additive_base)
+ {
+ const float normalized_sample_time = additive_base_clip.num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
+ const float additive_sample_time = additive_base_clip.num_samples > 1 ? (normalized_sample_time * additive_base_clip.duration) : 0.0F;
+ sample_streams(additive_base_clip.segments[0].bone_streams, num_bones, additive_sample_time, additive_local_pose);
+
+ uint8_t* sample_base_local_transforms = base_local_transforms + (sample_index * sample_transform_size);
+
+ if (needs_conversion)
+ convert_transforms_impl(error_metric, convert_transforms_args_base, sample_base_local_transforms);
+ else
+ std::memcpy(sample_base_local_transforms, additive_local_pose, sample_transform_size);
+
+ apply_additive_to_base_args_raw.local_transforms = sample_raw_local_transforms;
+ apply_additive_to_base_args_raw.base_transforms = sample_base_local_transforms;
+ apply_additive_to_base_impl(error_metric, apply_additive_to_base_args_raw, sample_raw_local_transforms);
+ }
+
+ local_to_object_space_args_raw.local_transforms = sample_raw_local_transforms;
+
+ uint8_t* sample_raw_object_transforms = raw_object_transforms + (sample_index * sample_transform_size);
+ local_to_object_space_impl(error_metric, local_to_object_space_args_raw, sample_raw_object_transforms);
+ }
}
bool is_valid() const { return segment != nullptr; }
@@ -220,7 +338,7 @@ namespace acl
}
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
@@ -343,7 +461,7 @@ namespace acl
}
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
@@ -460,7 +578,7 @@ namespace acl
}
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
@@ -508,81 +626,160 @@ namespace acl
inline float calculate_max_error_at_bit_rate_local(QuantizationContext& context, uint16_t target_bone_index, error_scan_stop_condition stop_condition)
{
const CompressionSettings& settings = context.settings;
- const ISkeletalErrorMetric& error_metric = *settings.error_metric;
+ const itransform_error_metric* error_metric = settings.error_metric;
+ const bool needs_conversion = context.needs_conversion;
+ const bool has_additive_base = context.has_additive_base;
+ const RigidBone& target_bone = context.skeleton.get_bone(target_bone_index);
+ const uint32_t num_transforms = context.num_bones;
+ const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
+ const float sample_rate = context.sample_rate;
+ const float clip_duration = context.clip_duration;
+ const rtm::scalarf error_threshold = rtm::scalar_set(settings.error_threshold);
+
+ const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
+ const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
+ const auto calculate_error_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::calculate_error : &itransform_error_metric::calculate_error_no_scale);
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_lossy;
+ convert_transforms_args_lossy.dirty_transform_indices = &target_bone_index;
+ convert_transforms_args_lossy.num_dirty_transforms = 1;
+ convert_transforms_args_lossy.transforms = context.lossy_local_pose;
+ convert_transforms_args_lossy.num_transforms = num_transforms;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy;
+ apply_additive_to_base_args_lossy.dirty_transform_indices = &target_bone_index;
+ apply_additive_to_base_args_lossy.num_dirty_transforms = 1;
+ apply_additive_to_base_args_lossy.local_transforms = needs_conversion ? (const void*)context.local_transforms_converted : (const void*)context.lossy_local_pose;
+ apply_additive_to_base_args_lossy.base_transforms = nullptr;
+ apply_additive_to_base_args_lossy.num_transforms = num_transforms;
+
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.raw_transform = nullptr;
+ calculate_error_args.lossy_transform = needs_conversion ? (const void*)(context.local_transforms_converted + (context.metric_transform_size * target_bone_index)) : (const void*)(context.lossy_local_pose + target_bone_index);
+ calculate_error_args.construct_sphere_shell(target_bone.vertex_distance);
+
+ const uint8_t* raw_transform = context.raw_local_transforms + (target_bone_index * context.metric_transform_size);
+ const uint8_t* base_transforms = context.base_local_transforms;
context.local_query.build(target_bone_index, context.bit_rate_per_bone[target_bone_index]);
- float max_error = 0.0F;
+ float sample_indexf = float(context.segment_sample_start_index);
+ rtm::scalarf max_error = rtm::scalar_set(0.0F);
- for (uint32_t sample_index = 0; sample_index < context.num_samples; ++sample_index)
+ for (uint32_t sample_index = 0; sample_index < context.num_samples; ++sample_index, sample_indexf += 1.0F)
{
// Sample our streams and calculate the error
// The sample time is calculated from the full clip duration to be consistent with decompression
- const float sample_time = rtm::scalar_min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
+ const float sample_time = rtm::scalar_min(sample_indexf / sample_rate, clip_duration);
- sample_stream(context.raw_bone_streams, context.num_bones, sample_time, target_bone_index, context.raw_local_pose);
+ context.bit_rate_database.sample(context.local_query, sample_time, context.lossy_local_pose, num_transforms);
- context.database.sample(context.local_query, sample_time, context.lossy_local_pose, context.num_bones);
+ if (needs_conversion)
+ convert_transforms_impl(error_metric, convert_transforms_args_lossy, context.local_transforms_converted);
- if (context.has_additive_base)
+ if (has_additive_base)
{
- const float normalized_sample_time = context.additive_base_clip.num_samples > 1 ? (sample_time / context.clip_duration) : 0.0F;
- const float additive_sample_time = normalized_sample_time * context.additive_base_clip.duration;
- sample_stream(context.additive_base_clip.segments[0].bone_streams, context.num_bones, additive_sample_time, target_bone_index, context.additive_local_pose);
+ apply_additive_to_base_args_lossy.base_transforms = base_transforms;
+ base_transforms += sample_transform_size;
+
+ apply_additive_to_base_impl(error_metric, apply_additive_to_base_args_lossy, context.lossy_local_pose);
}
- float error;
- if (context.has_scale)
- error = error_metric.calculate_local_bone_error(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
- else
- error = error_metric.calculate_local_bone_error_no_scale(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
+ calculate_error_args.raw_transform = raw_transform;
+ raw_transform += sample_transform_size;
+
+ const rtm::scalarf error = calculate_error_impl(error_metric, calculate_error_args);
max_error = rtm::scalar_max(max_error, error);
- if (stop_condition == error_scan_stop_condition::until_error_too_high && error >= settings.error_threshold)
+ if (stop_condition == error_scan_stop_condition::until_error_too_high && rtm::scalar_is_greater_equal(error, error_threshold))
break;
}
- return max_error;
+ return rtm::scalar_cast(max_error);
}
inline float calculate_max_error_at_bit_rate_object(QuantizationContext& context, uint16_t target_bone_index, error_scan_stop_condition stop_condition)
{
const CompressionSettings& settings = context.settings;
- const ISkeletalErrorMetric& error_metric = *settings.error_metric;
+ const itransform_error_metric* error_metric = settings.error_metric;
+ const bool needs_conversion = context.needs_conversion;
+ const bool has_additive_base = context.has_additive_base;
+ const RigidBone& target_bone = context.skeleton.get_bone(target_bone_index);
+ const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
+ const float sample_rate = context.sample_rate;
+ const float clip_duration = context.clip_duration;
+ const rtm::scalarf error_threshold = rtm::scalar_set(settings.error_threshold);
+
+ const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
+ const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
+ const auto local_to_object_space_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::local_to_object_space : &itransform_error_metric::local_to_object_space_no_scale);
+ const auto calculate_error_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::calculate_error : &itransform_error_metric::calculate_error_no_scale);
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_lossy;
+ convert_transforms_args_lossy.dirty_transform_indices = context.chain_bone_indices;
+ convert_transforms_args_lossy.num_dirty_transforms = context.num_bones_in_chain;
+ convert_transforms_args_lossy.transforms = context.lossy_local_pose;
+ convert_transforms_args_lossy.num_transforms = context.num_bones;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy;
+ apply_additive_to_base_args_lossy.dirty_transform_indices = context.chain_bone_indices;
+ apply_additive_to_base_args_lossy.num_dirty_transforms = context.num_bones_in_chain;
+ apply_additive_to_base_args_lossy.local_transforms = needs_conversion ? (const void*)(context.local_transforms_converted) : (const void*)context.lossy_local_pose;
+ apply_additive_to_base_args_lossy.base_transforms = nullptr;
+ apply_additive_to_base_args_lossy.num_transforms = context.num_bones;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy;
+ local_to_object_space_args_lossy.dirty_transform_indices = context.chain_bone_indices;
+ local_to_object_space_args_lossy.num_dirty_transforms = context.num_bones_in_chain;
+ local_to_object_space_args_lossy.parent_transform_indices = context.parent_transform_indices;
+ local_to_object_space_args_lossy.local_transforms = needs_conversion ? (const void*)(context.local_transforms_converted) : (const void*)context.lossy_local_pose;
+ local_to_object_space_args_lossy.num_transforms = context.num_bones;
+
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.raw_transform = nullptr;
+ calculate_error_args.lossy_transform = context.lossy_object_pose + (target_bone_index * context.metric_transform_size);
+ calculate_error_args.construct_sphere_shell(target_bone.vertex_distance);
+
+ const uint8_t* raw_transform = context.raw_object_transforms + (target_bone_index * context.metric_transform_size);
+ const uint8_t* base_transforms = context.base_local_transforms;
context.object_query.build(target_bone_index, context.bit_rate_per_bone, context.bone_streams);
- float max_error = 0.0F;
+ float sample_indexf = float(context.segment_sample_start_index);
+ rtm::scalarf max_error = rtm::scalar_set(0.0F);
- for (uint32_t sample_index = 0; sample_index < context.num_samples; ++sample_index)
+ for (uint32_t sample_index = 0; sample_index < context.num_samples; ++sample_index, sample_indexf += 1.0F)
{
// Sample our streams and calculate the error
// The sample time is calculated from the full clip duration to be consistent with decompression
- const float sample_time = rtm::scalar_min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
+ const float sample_time = rtm::scalar_min(sample_indexf / sample_rate, clip_duration);
- sample_streams_hierarchical(context.raw_bone_streams, context.num_bones, sample_time, target_bone_index, context.raw_local_pose);
+ context.bit_rate_database.sample(context.object_query, sample_time, context.lossy_local_pose, context.num_bones);
- context.database.sample(context.object_query, sample_time, context.lossy_local_pose, context.num_bones);
+ if (needs_conversion)
+ convert_transforms_impl(error_metric, convert_transforms_args_lossy, context.local_transforms_converted);
- if (context.has_additive_base)
+ if (has_additive_base)
{
- const float normalized_sample_time = context.additive_base_clip.num_samples > 1 ? (sample_time / context.clip_duration) : 0.0F;
- const float additive_sample_time = normalized_sample_time * context.additive_base_clip.duration;
- sample_streams_hierarchical(context.additive_base_clip.segments[0].bone_streams, context.num_bones, additive_sample_time, target_bone_index, context.additive_local_pose);
+ apply_additive_to_base_args_lossy.base_transforms = base_transforms;
+ base_transforms += sample_transform_size;
+
+ apply_additive_to_base_impl(error_metric, apply_additive_to_base_args_lossy, context.lossy_local_pose);
}
- float error;
- if (context.has_scale)
- error = error_metric.calculate_object_bone_error(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
- else
- error = error_metric.calculate_object_bone_error_no_scale(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
+ local_to_object_space_impl(error_metric, local_to_object_space_args_lossy, context.lossy_object_pose);
+
+ calculate_error_args.raw_transform = raw_transform;
+ raw_transform += sample_transform_size;
+
+ const rtm::scalarf error = calculate_error_impl(error_metric, calculate_error_args);
max_error = rtm::scalar_max(max_error, error);
- if (stop_condition == error_scan_stop_condition::until_error_too_high && error >= settings.error_threshold)
+ if (stop_condition == error_scan_stop_condition::until_error_too_high && rtm::scalar_is_greater_equal(error, error_threshold))
break;
}
- return max_error;
+ return rtm::scalar_cast(max_error);
}
inline void calculate_local_space_bit_rates(QuantizationContext& context)
@@ -612,7 +809,7 @@ namespace acl
BoneBitRate best_bit_rates = bone_bit_rates;
float best_error = 1.0E10F;
- int32_t prev_transform_size = -1;
+ uint32_t prev_transform_size = ~0U;
bool is_error_good_enough = false;
if (context.has_scale)
@@ -656,10 +853,10 @@ namespace acl
continue; // Skip permutations we aren't interested in
}
- const int32_t rotation_size = get_num_bits_at_bit_rate(rotation_bit_rate);
- const int32_t translation_size = get_num_bits_at_bit_rate(translation_bit_rate);
- const int32_t scale_size = get_num_bits_at_bit_rate(scale_bit_rate);
- const int32_t transform_size = rotation_size + translation_size + scale_size;
+ const uint32_t rotation_size = get_num_bits_at_bit_rate(rotation_bit_rate);
+ const uint32_t translation_size = get_num_bits_at_bit_rate(translation_bit_rate);
+ const uint32_t scale_size = get_num_bits_at_bit_rate(scale_bit_rate);
+ const uint32_t transform_size = rotation_size + translation_size + scale_size;
if (transform_size != prev_transform_size && is_error_good_enough)
{
@@ -716,9 +913,9 @@ namespace acl
continue; // Skip permutations we aren't interested in
}
- const int32_t rotation_size = get_num_bits_at_bit_rate(rotation_bit_rate);
- const int32_t translation_size = get_num_bits_at_bit_rate(translation_bit_rate);
- const int32_t transform_size = rotation_size + translation_size;
+ const uint32_t rotation_size = get_num_bits_at_bit_rate(rotation_bit_rate);
+ const uint32_t translation_size = get_num_bits_at_bit_rate(translation_bit_rate);
+ const uint32_t transform_size = rotation_size + translation_size;
if (transform_size != prev_transform_size && is_error_good_enough)
{
@@ -746,6 +943,10 @@ namespace acl
}
}
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+ printf("%u: Best bit rates: %u | %u | %u\n", bone_index, best_bit_rates.rotation, best_bit_rates.translation, best_bit_rates.scale);
+#endif
+
context.bit_rate_per_bone[bone_index] = best_bit_rates;
}
}
@@ -810,7 +1011,7 @@ namespace acl
return best_error;
}
- inline float calculate_bone_permutation_error(QuantizationContext& context, BoneBitRate* permutation_bit_rates, uint8_t* bone_chain_permutation, const uint16_t* chain_bone_indices, uint16_t num_bones_in_chain, uint16_t bone_index, BoneBitRate* best_bit_rates, float old_error)
+ inline float calculate_bone_permutation_error(QuantizationContext& context, BoneBitRate* permutation_bit_rates, uint8_t* bone_chain_permutation, uint16_t bone_index, BoneBitRate* best_bit_rates, float old_error)
{
const CompressionSettings& settings = context.settings;
@@ -822,12 +1023,12 @@ namespace acl
std::memcpy(permutation_bit_rates, context.bit_rate_per_bone, sizeof(BoneBitRate) * context.num_bones);
bool is_permutation_valid = false;
- for (uint16_t chain_link_index = 0; chain_link_index < num_bones_in_chain; ++chain_link_index)
+ for (uint16_t chain_link_index = 0; chain_link_index < context.num_bones_in_chain; ++chain_link_index)
{
if (bone_chain_permutation[chain_link_index] != 0)
{
// Increase bit rate
- uint16_t chain_bone_index = chain_bone_indices[chain_link_index];
+ const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
BoneBitRate chain_bone_best_bit_rates;
increase_bone_bit_rate(context, chain_bone_index, bone_chain_permutation[chain_link_index], old_error, chain_bone_best_bit_rates);
is_permutation_valid |= chain_bone_best_bit_rates.rotation != permutation_bit_rates[chain_bone_index].rotation;
@@ -853,7 +1054,7 @@ namespace acl
if (permutation_error < settings.error_threshold)
break;
}
- } while (std::next_permutation(bone_chain_permutation, bone_chain_permutation + num_bones_in_chain));
+ } while (std::next_permutation(bone_chain_permutation, bone_chain_permutation + context.num_bones_in_chain));
return best_error;
}
@@ -989,7 +1190,6 @@ namespace acl
// [bone 0] + 0 [bone 1] + 0 [bone 2] + 3 (9)
uint8_t* bone_chain_permutation = allocate_type_array<uint8_t>(context.allocator, context.num_bones);
- uint16_t* chain_bone_indices = allocate_type_array<uint16_t>(context.allocator, context.num_bones);
BoneBitRate* permutation_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
BoneBitRate* best_permutation_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
BoneBitRate* best_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
@@ -997,21 +1197,13 @@ namespace acl
for (uint16_t bone_index = 0; bone_index < context.num_bones; ++bone_index)
{
+ const uint16_t num_bones_in_chain = calculate_bone_chain_indices(context.skeleton, bone_index, context.chain_bone_indices);
+ context.num_bones_in_chain = num_bones_in_chain;
+
float error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_error_too_high);
if (error < settings.error_threshold)
continue;
- if (context.bit_rate_per_bone[bone_index].rotation >= k_highest_bit_rate && context.bit_rate_per_bone[bone_index].translation >= k_highest_bit_rate && context.bit_rate_per_bone[bone_index].scale >= k_highest_bit_rate)
- {
- // Our bone already has the highest precision possible locally, if the local error already exceeds our threshold,
- // there is nothing we can do, bail out
- const float local_error = calculate_max_error_at_bit_rate_local(context, bone_index, error_scan_stop_condition::until_error_too_high);
- if (local_error >= settings.error_threshold)
- continue;
- }
-
- const uint16_t num_bones_in_chain = calculate_bone_chain_indices(context.skeleton, bone_index, chain_bone_indices);
-
const float initial_error = error;
while (error >= settings.error_threshold)
@@ -1025,7 +1217,7 @@ namespace acl
// The first permutation increases the bit rate of a single track/bone
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 1;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1040,7 +1232,7 @@ namespace acl
// The second permutation increases the bit rate of 2 track/bones
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 2;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1055,7 +1247,7 @@ namespace acl
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 2] = 1;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1072,7 +1264,7 @@ namespace acl
// The third permutation increases the bit rate of 3 track/bones
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 3;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1087,7 +1279,7 @@ namespace acl
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 2] = 2;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1103,7 +1295,7 @@ namespace acl
bone_chain_permutation[num_bones_in_chain - 3] = 1;
bone_chain_permutation[num_bones_in_chain - 2] = 1;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
- error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, chain_bone_indices, num_bones_in_chain, bone_index, best_permutation_bit_rates, original_error);
+ error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
@@ -1174,7 +1366,7 @@ namespace acl
uint16_t num_maxed_out = 0;
for (int16_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
{
- const uint16_t chain_bone_index = chain_bone_indices[chain_link_index];
+ const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
// Work with a copy. We'll increase the bit rate as much as we can and retain the values
// that yield the smallest error BUT increasing the bit rate does NOT always means
@@ -1254,7 +1446,7 @@ namespace acl
// From child to parent, max out the bit rate
for (int16_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
{
- const uint16_t chain_bone_index = chain_bone_indices[chain_link_index];
+ const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
bone_bit_rate.rotation = std::max<uint8_t>(bone_bit_rate.rotation, k_highest_bit_rate);
bone_bit_rate.translation = std::max<uint8_t>(bone_bit_rate.translation, k_highest_bit_rate);
@@ -1278,20 +1470,19 @@ namespace acl
#endif
deallocate_type_array(context.allocator, bone_chain_permutation, context.num_bones);
- deallocate_type_array(context.allocator, chain_bone_indices, context.num_bones);
deallocate_type_array(context.allocator, permutation_bit_rates, context.num_bones);
deallocate_type_array(context.allocator, best_permutation_bit_rates, context.num_bones);
deallocate_type_array(context.allocator, best_bit_rates, context.num_bones);
}
- inline void quantize_streams(IAllocator& allocator, ClipContext& clip_context, const CompressionSettings& settings, const RigidSkeleton& skeleton, const ClipContext& raw_clip_context, const ClipContext& additive_base_clip_context)
+ inline void quantize_streams(IAllocator& allocator, ClipContext& clip_context, const CompressionSettings& settings, const RigidSkeleton& skeleton, const ClipContext& raw_clip_context, const ClipContext& additive_base_clip_context, OutputStats& out_stats)
{
const bool is_rotation_variable = is_rotation_format_variable(settings.rotation_format);
const bool is_translation_variable = is_vector_format_variable(settings.translation_format);
const bool is_scale_variable = is_vector_format_variable(settings.scale_format);
const bool is_any_variable = is_rotation_variable || is_translation_variable || is_scale_variable;
- acl_impl::QuantizationContext context(allocator, clip_context, raw_clip_context, additive_base_clip_context, settings, skeleton);
+ QuantizationContext context(allocator, clip_context, raw_clip_context, additive_base_clip_context, settings, skeleton);
for (SegmentContext& segment : clip_context.segment_iterator())
{
@@ -1302,11 +1493,38 @@ namespace acl
context.set_segment(segment);
if (is_any_variable)
- acl_impl::find_optimal_bit_rates(context);
+ find_optimal_bit_rates(context);
// Quantize our streams now that we found the optimal bit rates
- acl_impl::quantize_all_streams(context);
+ quantize_all_streams(context);
+ }
+
+#if defined(SJSON_CPP_WRITER)
+ if (are_all_enum_flags_set(out_stats.logging, StatLogging::Detailed))
+ {
+ sjson::ObjectWriter& writer = *out_stats.writer;
+ writer["track_bit_rate_database_size"] = static_cast<uint32_t>(context.bit_rate_database.get_allocated_size());
+
+ size_t transform_cache_size = 0;
+ transform_cache_size += sizeof(rtm::qvvf) * context.num_bones; // raw_local_pose
+ transform_cache_size += sizeof(rtm::qvvf) * context.num_bones; // lossy_local_pose
+ transform_cache_size += context.metric_transform_size * context.num_bones; // lossy_object_pose
+ transform_cache_size += context.metric_transform_size * context.num_bones * context.clip.segments->num_samples; // raw_local_transforms
+ transform_cache_size += context.metric_transform_size * context.num_bones * context.clip.segments->num_samples; // raw_object_transforms
+
+ if (context.needs_conversion)
+ transform_cache_size += context.metric_transform_size * context.num_bones; // local_transforms_converted
+
+ if (context.has_additive_base)
+ {
+ transform_cache_size += sizeof(rtm::qvvf) * context.num_bones; // additive_local_pose
+ transform_cache_size += context.metric_transform_size * context.num_bones * context.clip.segments->num_samples; // base_local_transforms
+ transform_cache_size += context.metric_transform_size * context.num_bones * context.clip.segments->num_samples; // base_object_transforms
+ }
+
+ writer["transform_cache_size"] = static_cast<uint32_t>(transform_cache_size);
}
+#endif
}
}
}
diff --git a/includes/acl/compression/impl/sample_streams.h b/includes/acl/compression/impl/sample_streams.h
--- a/includes/acl/compression/impl/sample_streams.h
+++ b/includes/acl/compression/impl/sample_streams.h
@@ -69,7 +69,7 @@ namespace acl
return unpack_vector3_96_unsafe(ptr);
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
if (is_normalized)
return unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, ptr, 0);
else
@@ -100,7 +100,7 @@ namespace acl
return unpack_vector3_96_unsafe(ptr);
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
return unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, ptr, 0);
}
default:
@@ -934,11 +934,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.sample_key = sample_key;
@@ -984,11 +985,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.track_index = bone_index;
@@ -1024,11 +1026,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.sample_key = sample_key;
@@ -1080,11 +1083,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.sample_key = sample_key;
@@ -1138,11 +1142,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.track_index = bone_index;
@@ -1184,11 +1189,12 @@ namespace acl
const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
+ // With uniform sample distributions, we do not interpolate.
uint32_t sample_key;
if (segment_context->distribution == SampleDistribution8::Uniform)
- sample_key = acl_impl::get_uniform_sample_key(*segment_context, sample_time);
+ sample_key = get_uniform_sample_key(*segment_context, sample_time);
else
- sample_key = 0;
+ sample_key = 0; // Not used
acl_impl::sample_context context;
context.sample_key = sample_key;
diff --git a/includes/acl/compression/impl/track_bit_rate_database.h b/includes/acl/compression/impl/track_bit_rate_database.h
--- a/includes/acl/compression/impl/track_bit_rate_database.h
+++ b/includes/acl/compression/impl/track_bit_rate_database.h
@@ -152,6 +152,8 @@ namespace acl
void sample(const single_track_query& query, float sample_time, rtm::qvvf* out_transforms, uint32_t num_transforms);
void sample(const hierarchical_track_query& query, float sample_time, rtm::qvvf* out_transforms, uint32_t num_transforms);
+ size_t get_allocated_size() const;
+
private:
track_bit_rate_database(const track_bit_rate_database&) = delete;
track_bit_rate_database(track_bit_rate_database&&) = delete;
@@ -1066,6 +1068,15 @@ namespace acl
}
}
}
+
+ inline size_t track_bit_rate_database::get_allocated_size() const
+ {
+ size_t cache_size = 0;
+ cache_size += sizeof(transform_cache_entry) * m_num_transforms;
+ cache_size += m_track_bitsets_size;
+ cache_size += m_data_size;
+ return cache_size;
+ }
}
}
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -35,9 +35,10 @@
#include "acl/compression/skeleton_error_metric.h"
#include "acl/compression/utils.h"
+#include <chrono>
#include <cstdint>
+#include <functional>
#include <thread>
-#include <chrono>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -84,7 +85,7 @@ namespace acl
writer["bit_rate_counts"] = [&](sjson::ArrayWriter& bitrate_writer)
{
- for (uint8_t bit_rate = 0; bit_rate < k_num_bit_rates; ++bit_rate)
+ for (uint32_t bit_rate = 0; bit_rate < k_num_bit_rates; ++bit_rate)
bitrate_writer.push(bit_rate_counts[bit_rate]);
};
@@ -103,13 +104,52 @@ namespace acl
const uint16_t num_bones = skeleton.get_num_bones();
const bool has_scale = segment_context_has_scale(segment);
+ ACL_ASSERT(!settings.error_metric->needs_conversion(has_scale), "Error metric conversion not supported");
+
+ const auto local_to_object_space_impl = std::mem_fn(has_scale ? &itransform_error_metric::local_to_object_space : &itransform_error_metric::local_to_object_space_no_scale);
+ const auto calculate_error_impl = std::mem_fn(has_scale ? &itransform_error_metric::calculate_error : &itransform_error_metric::calculate_error_no_scale);
+ const auto apply_additive_to_base_impl = std::mem_fn(has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
+
rtm::qvvf* raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
rtm::qvvf* base_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
rtm::qvvf* lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* raw_object_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* lossy_object_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+
+ uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+ uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+
+ for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
+ {
+ const RigidBone& bone = skeleton.get_bone(transform_index);
+ parent_transform_indices[transform_index] = bone.parent_index;
+ self_transform_indices[transform_index] = transform_index;
+ }
+
const float sample_rate = raw_clip_context.sample_rate;
const float ref_duration = calculate_duration(raw_clip_context.num_samples, sample_rate);
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_raw.dirty_transform_indices = self_transform_indices;
+ apply_additive_to_base_args_raw.num_dirty_transforms = num_bones;
+ apply_additive_to_base_args_raw.local_transforms = raw_local_pose;
+ apply_additive_to_base_args_raw.base_transforms = base_local_pose;
+ apply_additive_to_base_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy = apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_lossy.local_transforms = lossy_local_pose;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_raw;
+ local_to_object_space_args_raw.dirty_transform_indices = self_transform_indices;
+ local_to_object_space_args_raw.num_dirty_transforms = num_bones;
+ local_to_object_space_args_raw.parent_transform_indices = parent_transform_indices;
+ local_to_object_space_args_raw.local_transforms = raw_local_pose;
+ local_to_object_space_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy = local_to_object_space_args_raw;
+ local_to_object_space_args_lossy.local_transforms = lossy_local_pose;
+
BoneError worst_bone_error;
writer["error_per_frame_and_bone"] = [&](sjson::ArrayWriter& frames_writer)
@@ -124,31 +164,40 @@ namespace acl
if (raw_clip_context.has_additive_base)
{
const float normalized_sample_time = additive_base_clip_context.num_samples > 1 ? (sample_time / ref_duration) : 0.0F;
- const float additive_sample_time = normalized_sample_time * additive_base_clip_context.duration;
+ const float additive_sample_time = additive_base_clip_context.num_samples > 1 ? (normalized_sample_time * additive_base_clip_context.duration) : 0.0F;
sample_streams(additive_base_clip_context.segments[0].bone_streams, num_bones, additive_sample_time, base_local_pose);
+
+ apply_additive_to_base_impl(settings.error_metric, apply_additive_to_base_args_raw, raw_local_pose);
+ apply_additive_to_base_impl(settings.error_metric, apply_additive_to_base_args_lossy, lossy_local_pose);
}
+ local_to_object_space_impl(settings.error_metric, local_to_object_space_args_raw, raw_object_pose);
+ local_to_object_space_impl(settings.error_metric, local_to_object_space_args_lossy, lossy_object_pose);
+
frames_writer.push_newline();
frames_writer.push([&](sjson::ArrayWriter& frame_writer)
+ {
+ for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ const RigidBone& bone = skeleton.get_bone(bone_index);
+
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.raw_transform = raw_object_pose + bone_index;
+ calculate_error_args.lossy_transform = lossy_object_pose + bone_index;
+ calculate_error_args.construct_sphere_shell(bone.vertex_distance);
+
+ const float error = rtm::scalar_cast(calculate_error_impl(settings.error_metric, calculate_error_args));
+
+ frame_writer.push(error);
+
+ if (error > worst_bone_error.error)
{
- float error;
- if (has_scale)
- error = settings.error_metric->calculate_object_bone_error(skeleton, raw_local_pose, base_local_pose, lossy_local_pose, bone_index);
- else
- error = settings.error_metric->calculate_object_bone_error_no_scale(skeleton, raw_local_pose, base_local_pose, lossy_local_pose, bone_index);
-
- frame_writer.push(error);
-
- if (error > worst_bone_error.error)
- {
- worst_bone_error.error = error;
- worst_bone_error.index = bone_index;
- worst_bone_error.sample_time = sample_time;
- }
+ worst_bone_error.error = error;
+ worst_bone_error.index = bone_index;
+ worst_bone_error.sample_time = sample_time;
}
- });
+ }
+ });
}
};
@@ -159,6 +208,12 @@ namespace acl
deallocate_type_array(allocator, raw_local_pose, num_bones);
deallocate_type_array(allocator, base_local_pose, num_bones);
deallocate_type_array(allocator, lossy_local_pose, num_bones);
+
+ deallocate_type_array(allocator, raw_object_pose, num_bones);
+ deallocate_type_array(allocator, lossy_object_pose, num_bones);
+
+ deallocate_type_array(allocator, parent_transform_indices, num_bones);
+ deallocate_type_array(allocator, self_transform_indices, num_bones);
}
inline void write_stats(IAllocator& allocator, const AnimationClip& clip, const ClipContext& clip_context, const RigidSkeleton& skeleton,
diff --git a/includes/acl/compression/skeleton_error_metric.h b/includes/acl/compression/skeleton_error_metric.h
--- a/includes/acl/compression/skeleton_error_metric.h
+++ b/includes/acl/compression/skeleton_error_metric.h
@@ -37,291 +37,419 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- // Base class for all skeletal error metrics
- class ISkeletalErrorMetric
+ //////////////////////////////////////////////////////////////////////////
+ // Interface for all skeletal error metrics.
+ // An error metric is responsible for a few things:
+ // - converting from rtm::qvvf into whatever transform type the metric uses (optional)
+ // - applying local space transforms on top of base transforms (optional)
+ // - transforming local space transforms into object space
+ // - evaluating the error function
+ //
+ // Most functions require two implementations: with and without scale support.
+ // This is entirely for performance reasons as most clips do not have any scale.
+ //////////////////////////////////////////////////////////////////////////
+ class itransform_error_metric
{
public:
- virtual ~ISkeletalErrorMetric() {}
+ virtual ~itransform_error_metric() {}
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the unique name of the error metric.
virtual const char* get_name() const = 0;
- virtual uint32_t get_hash() const = 0;
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a unique hash to represent the error metric.
+ virtual uint32_t get_hash() const { return hash32(get_name()); }
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
- };
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the transform size used by the error metric.
+ virtual size_t get_transform_size(bool has_scale) const = 0;
- // Uses a mix of Transform_32 and AffineMatrix_32 arithmetic.
- // The local space error is always calculated with Transform_32 arithmetic.
- // The object space error is calculated with Transform_32 arithmetic if there is no scale
- // and with AffineMatrix_32 arithmetic if there is scale.
- // Note that this can cause inaccuracy issues if there are very large or very small
- // scale values.
- class TransformMatrixErrorMetric final : public ISkeletalErrorMetric
- {
- public:
- virtual const char* get_name() const override { return "TransformMatrixErrorMetric"; }
- virtual uint32_t get_hash() const override { return hash32("TransformMatrixErrorMetric"); }
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether or not the error metric uses a transform that isn't rtm::qvvf.
+ // If this is the case, we need to convert from rtm::qvvf into the transform type
+ // used by the error metric.
+ virtual bool needs_conversion(bool has_scale) const { (void)has_scale; return false; }
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ //////////////////////////////////////////////////////////////////////////
+ // Input arguments for the 'convert_transforms*' functions.
+ //////////////////////////////////////////////////////////////////////////
+ struct convert_transforms_args
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
-
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- // Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
-
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_local_pose[bone_index]);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
-
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_local_pose[bone_index]);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
-
- const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_local_pose[bone_index]);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
-
- return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
+ //////////////////////////////////////////////////////////////////////////
+ // A list of transform indices that are dirty and need conversion.
+ const uint16_t* dirty_transform_indices;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of dirty transforms that need conversion.
+ uint32_t num_dirty_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The input transforms in rtm::qvvf format to be converted.
+ const rtm::qvvf* transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of transforms in the input and output buffers.
+ uint32_t num_transforms;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Converts from rtm::qvvf into the transform type used by the error metric.
+ // Called when 'needs_conversion' returns true.
+ virtual void convert_transforms(const convert_transforms_args& args, void* out_transforms) const
+ {
+ (void)args;
+ (void)out_transforms;
+ ACL_ASSERT(false, "Not implemented");
}
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ //////////////////////////////////////////////////////////////////////////
+ // Converts from rtm::qvvf into the transform type used by the error metric.
+ // Called when 'needs_conversion' returns true.
+ virtual void convert_transforms_no_scale(const convert_transforms_args& args, void* out_transforms) const
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
-
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
-
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_local_pose[bone_index]);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ (void)args;
+ (void)out_transforms;
+ ACL_ASSERT(false, "Not implemented");
+ }
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_local_pose[bone_index]);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ //////////////////////////////////////////////////////////////////////////
+ // Input arguments for the 'local_to_object_space*' functions.
+ //////////////////////////////////////////////////////////////////////////
+ struct local_to_object_space_args
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // A list of transform indices that are dirty and need transformation.
+ const uint16_t* dirty_transform_indices;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of dirty transforms that need transformation.
+ uint32_t num_dirty_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // A list of parent transform indices for every transform.
+ // An index of 0xFFFF represents a root transform with no parent.
+ const uint16_t* parent_transform_indices;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The input transforms in the type expected by the error metric to be transformed.
+ const void* local_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of transforms in the input and output buffers.
+ uint32_t num_transforms;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Takes local space transforms into object space.
+ virtual void local_to_object_space(const local_to_object_space_args& args, void* out_object_transforms) const
+ {
+ (void)args;
+ (void)out_object_transforms;
+ ACL_ASSERT(false, "Not implemented");
+ }
- return rtm::scalar_max(vtx0_error, vtx1_error);
+ //////////////////////////////////////////////////////////////////////////
+ // Takes local space transforms into object space.
+ virtual void local_to_object_space_no_scale(const local_to_object_space_args& args, void* out_object_transforms) const
+ {
+ (void)args;
+ (void)out_object_transforms;
+ ACL_ASSERT(false, "Not implemented");
}
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ //////////////////////////////////////////////////////////////////////////
+ // Input arguments for the 'apply_additive_to_base*' functions.
+ //////////////////////////////////////////////////////////////////////////
+ struct apply_additive_to_base_args
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // A list of transform indices that are dirty and need the base applied.
+ const uint16_t* dirty_transform_indices;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of dirty transforms that need the base applied.
+ uint32_t num_dirty_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The input local space transforms in the type expected by the error metric.
+ const void* local_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The input base transforms in the type expected by the error metric.
+ const void* base_transforms;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The number of transforms in the input and output buffers.
+ uint32_t num_transforms;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Applies local space transforms on top of base transforms.
+ // This is called when a clip has an additive base.
+ virtual void apply_additive_to_base(const apply_additive_to_base_args& args, void* out_transforms) const
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
+ (void)args;
+ (void)out_transforms;
+ ACL_ASSERT(false, "Not implemented");
+ }
- rtm::matrix3x4f raw_obj_mtx = rtm::matrix_from_qvv(raw_local_pose[0]);
- rtm::matrix3x4f lossy_obj_mtx = rtm::matrix_from_qvv(lossy_local_pose[0]);
+ //////////////////////////////////////////////////////////////////////////
+ // Applies local space transforms on top of base transforms.
+ // This is called when a clip has an additive base.
+ virtual void apply_additive_to_base_no_scale(const apply_additive_to_base_args& args, void* out_transforms) const
+ {
+ (void)args;
+ (void)out_transforms;
+ ACL_ASSERT(false, "Not implemented");
+ }
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
+ //////////////////////////////////////////////////////////////////////////
+ // Input arguments for the 'calculate_error*' functions.
+ //////////////////////////////////////////////////////////////////////////
+ struct calculate_error_args
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // A point on our rigid shell along the X axis.
+ rtm::vector4f shell_point_x;
+
+ //////////////////////////////////////////////////////////////////////////
+ // A point on our rigid shell along the Y axis.
+ rtm::vector4f shell_point_y;
+
+ //////////////////////////////////////////////////////////////////////////
+ // A point on our rigid shell along the Z axis.
+ rtm::vector4f shell_point_z;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The raw reference transform against which we measure the error.
+ // In the type expected by the error metric.
+ // Could be in local or object space (same space as lossy).
+ const void* raw_transform;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The lossy transform we are measuring the error for.
+ // In the type expected by the error metric.
+ // Could be in local or object space (same space as raw).
+ const void* lossy_transform;
+
+ //////////////////////////////////////////////////////////////////////////
+ // We measure the error on a rigid shell around each transform.
+ // This shell takes the form of a sphere at a certain distance.
+ // When no scale is present, measuring any two points is sufficient
+ // but when there is scale, measuring all three is necessary.
+ // See ./docs/error_metrics.md for details.
+ void construct_sphere_shell(float shell_distance)
{
- const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_mtx = rtm::matrix_mul(rtm::matrix_from_qvv(raw_local_pose[chain_bone_index]), raw_obj_mtx);
- lossy_obj_mtx = rtm::matrix_mul(rtm::matrix_from_qvv(lossy_local_pose[chain_bone_index]), lossy_obj_mtx);
+ shell_point_x = rtm::vector_set(shell_distance, 0.0F, 0.0F, 0.0F);
+ shell_point_y = rtm::vector_set(0.0F, shell_distance, 0.0F, 0.0F);
+ shell_point_z = rtm::vector_set(0.0F, 0.0F, shell_distance, 0.0F);
}
+ };
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
-
- // Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
+ //////////////////////////////////////////////////////////////////////////
+ // Measures the error between a raw and lossy transform.
+ virtual rtm::scalarf RTM_SIMD_CALL calculate_error(const calculate_error_args& args) const = 0;
- const rtm::vector4f raw_vtx0 = rtm::matrix_mul_point3(vtx0, raw_obj_mtx);
- const rtm::vector4f raw_vtx1 = rtm::matrix_mul_point3(vtx1, raw_obj_mtx);
- const rtm::vector4f raw_vtx2 = rtm::matrix_mul_point3(vtx2, raw_obj_mtx);
- const rtm::vector4f lossy_vtx0 = rtm::matrix_mul_point3(vtx0, lossy_obj_mtx);
- const rtm::vector4f lossy_vtx1 = rtm::matrix_mul_point3(vtx1, lossy_obj_mtx);
- const rtm::vector4f lossy_vtx2 = rtm::matrix_mul_point3(vtx2, lossy_obj_mtx);
+ //////////////////////////////////////////////////////////////////////////
+ // Measures the error between a raw and lossy transform.
+ virtual rtm::scalarf RTM_SIMD_CALL calculate_error_no_scale(const calculate_error_args& args) const = 0;
+ };
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+ //////////////////////////////////////////////////////////////////////////
+ // Uses rtm::qvvf arithmetic for local and object space error.
+ // Note that this can cause inaccuracy when dealing with shear/skew.
+ //////////////////////////////////////////////////////////////////////////
+ class qvvf_transform_error_metric : public itransform_error_metric
+ {
+ public:
+ virtual const char* get_name() const override { return "qvvf_transform_error_metric"; }
- return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
- }
+ virtual size_t get_transform_size(bool has_scale) const override { (void)has_scale; return sizeof(rtm::qvvf); }
+ virtual bool needs_conversion(bool has_scale) const override { (void)has_scale; return false; }
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void local_to_object_space(const local_to_object_space_args& args, void* out_object_transforms) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
-
- rtm::qvvf raw_obj_transform = raw_local_pose[0];
- rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const uint16_t* parent_transform_indices = args.parent_transform_indices;
+ const rtm::qvvf* local_transforms_ = static_cast<const rtm::qvvf*>(args.local_transforms);
+ rtm::qvvf* out_object_transforms_ = static_cast<rtm::qvvf*>(out_object_transforms);
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
{
- const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = rtm::qvv_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = rtm::qvv_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
- }
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
+ const uint32_t parent_transform_index = parent_transform_indices[transform_index];
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
+ rtm::qvvf obj_transform;
+ if (parent_transform_index == k_invalid_bone_index)
+ obj_transform = local_transforms_[transform_index]; // Just copy the root as-is, it has no parent and thus local and object space transforms are equal
+ else
+ obj_transform = rtm::qvv_mul(local_transforms_[transform_index], out_object_transforms_[parent_transform_index]);
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ out_object_transforms_[transform_index] = obj_transform;
+ }
+ }
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void local_to_object_space_no_scale(const local_to_object_space_args& args, void* out_object_transforms) const override
+ {
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const uint16_t* parent_transform_indices = args.parent_transform_indices;
+ const rtm::qvvf* local_transforms_ = static_cast<const rtm::qvvf*>(args.local_transforms);
+ rtm::qvvf* out_object_transforms_ = static_cast<rtm::qvvf*>(out_object_transforms);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
+ {
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
+ const uint32_t parent_transform_index = parent_transform_indices[transform_index];
- return rtm::scalar_max(vtx0_error, vtx1_error);
- }
- };
+ rtm::qvvf obj_transform;
+ if (parent_transform_index == k_invalid_bone_index)
+ obj_transform = local_transforms_[transform_index]; // Just copy the root as-is, it has no parent and thus local and object space transforms are equal
+ else
+ obj_transform = rtm::qvv_mul_no_scale(local_transforms_[transform_index], out_object_transforms_[parent_transform_index]);
- // Uses Transform_32 arithmetic for local and object space error.
- // Note that this can cause inaccuracy when dealing with shear/skew.
- class TransformErrorMetric final : public ISkeletalErrorMetric
- {
- public:
- virtual const char* get_name() const override { return "TransformErrorMetric"; }
- virtual uint32_t get_hash() const override { return hash32("TransformErrorMetric"); }
+ out_object_transforms_[transform_index] = obj_transform;
+ }
+ }
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::scalarf RTM_SIMD_CALL calculate_error(const calculate_error_args& args) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
-
- const RigidBone& bone = skeleton.get_bone(bone_index);
+ const rtm::qvvf& raw_transform_ = *static_cast<const rtm::qvvf*>(args.raw_transform);
+ const rtm::qvvf& lossy_transform_ = *static_cast<const rtm::qvvf*>(args.lossy_transform);
// Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
+ const rtm::vector4f vtx0 = args.shell_point_x;
+ const rtm::vector4f vtx1 = args.shell_point_y;
+ const rtm::vector4f vtx2 = args.shell_point_z;
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_local_pose[bone_index]);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_transform_);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_transform_);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_transform_);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_local_pose[bone_index]);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_transform_);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_transform_);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_transform_);
- const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_local_pose[bone_index]);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+ const rtm::scalarf vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::scalarf vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::scalarf vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::scalarf RTM_SIMD_CALL calculate_error_no_scale(const calculate_error_args& args) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
+ const rtm::qvvf& raw_transform_ = *static_cast<const rtm::qvvf*>(args.raw_transform);
+ const rtm::qvvf& lossy_transform_ = *static_cast<const rtm::qvvf*>(args.lossy_transform);
- const RigidBone& bone = skeleton.get_bone(bone_index);
+ const rtm::vector4f vtx0 = args.shell_point_x;
+ const rtm::vector4f vtx1 = args.shell_point_y;
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_transform_);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_transform_);
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_local_pose[bone_index]);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_transform_);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_transform_);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_local_pose[bone_index]);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_local_pose[bone_index]);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::scalarf vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::scalarf vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
return rtm::scalar_max(vtx0_error, vtx1_error);
}
+ };
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
- {
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
-
- rtm::qvvf raw_obj_transform = raw_local_pose[0];
- rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
-
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
- {
- const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = rtm::qvv_mul(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = rtm::qvv_mul(lossy_local_pose[chain_bone_index], lossy_obj_transform);
- }
+ //////////////////////////////////////////////////////////////////////////
+ // Uses a mix of rtm::qvvf and rtm::matrix3x4f arithmetic.
+ // The local space error is always calculated with rtm::qvvf arithmetic.
+ // The object space error is calculated with rtm::qvvf arithmetic if there is no scale
+ // and with rtm::matrix3x4f arithmetic if there is scale.
+ // Note that this can cause inaccuracy issues if there are very large or very small
+ // scale values.
+ //////////////////////////////////////////////////////////////////////////
+ class qvvf_matrix3x4f_transform_error_metric : public qvvf_transform_error_metric
+ {
+ public:
+ virtual const char* get_name() const override { return "qvvf_matrix3x4f_transform_error_metric"; }
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
+ virtual size_t get_transform_size(bool has_scale) const override { return has_scale ? sizeof(rtm::matrix3x4f) : sizeof(rtm::qvvf); }
+ virtual bool needs_conversion(bool has_scale) const override { return has_scale; }
- // Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void convert_transforms(const convert_transforms_args& args, void* out_transforms) const override
+ {
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const rtm::qvvf* transforms_ = static_cast<const rtm::qvvf*>(args.transforms);
+ rtm::matrix3x4f* out_transforms_ = static_cast<rtm::matrix3x4f*>(out_transforms);
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_obj_transform);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_obj_transform);
- const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_obj_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_obj_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_obj_transform);
- const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_obj_transform);
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
+ {
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+ const rtm::qvvf& transform_qvv = transforms_[transform_index];
+ rtm::matrix3x4f transform_mtx = rtm::matrix_from_qvv(transform_qvv);
- return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
+ out_transforms_[transform_index] = transform_mtx;
+ }
}
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void local_to_object_space(const local_to_object_space_args& args, void* out_object_transforms) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- (void)base_local_pose;
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const uint16_t* parent_transform_indices = args.parent_transform_indices;
+ const rtm::matrix3x4f* local_transforms_ = static_cast<const rtm::matrix3x4f*>(args.local_transforms);
+ rtm::matrix3x4f* out_object_transforms_ = static_cast<rtm::matrix3x4f*>(out_object_transforms);
- rtm::qvvf raw_obj_transform = raw_local_pose[0];
- rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
-
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
{
- const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = rtm::qvv_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = rtm::qvv_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
+ const uint32_t parent_transform_index = parent_transform_indices[transform_index];
+
+ rtm::matrix3x4f obj_transform;
+ if (parent_transform_index == k_invalid_bone_index)
+ obj_transform = local_transforms_[transform_index]; // Just copy the root as-is, it has no parent and thus local and object space transforms are equal
+ else
+ obj_transform = rtm::matrix_mul(local_transforms_[transform_index], out_object_transforms_[parent_transform_index]);
+
+ out_object_transforms_[transform_index] = obj_transform;
}
+ }
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::scalarf RTM_SIMD_CALL calculate_error(const calculate_error_args& args) const override
+ {
+ const rtm::matrix3x4f& raw_transform_ = *static_cast<const rtm::matrix3x4f*>(args.raw_transform);
+ const rtm::matrix3x4f& lossy_transform_ = *static_cast<const rtm::matrix3x4f*>(args.lossy_transform);
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ // Note that because we have scale, we must measure all three axes
+ const rtm::vector4f vtx0 = args.shell_point_x;
+ const rtm::vector4f vtx1 = args.shell_point_y;
+ const rtm::vector4f vtx2 = args.shell_point_z;
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
+ const rtm::vector4f raw_vtx0 = rtm::matrix_mul_point3(vtx0, raw_transform_);
+ const rtm::vector4f raw_vtx1 = rtm::matrix_mul_point3(vtx1, raw_transform_);
+ const rtm::vector4f raw_vtx2 = rtm::matrix_mul_point3(vtx2, raw_transform_);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f lossy_vtx0 = rtm::matrix_mul_point3(vtx0, lossy_transform_);
+ const rtm::vector4f lossy_vtx1 = rtm::matrix_mul_point3(vtx1, lossy_transform_);
+ const rtm::vector4f lossy_vtx2 = rtm::matrix_mul_point3(vtx2, lossy_transform_);
- return rtm::scalar_max(vtx0_error, vtx1_error);
+ const rtm::scalarf vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::scalarf vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::scalarf vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
};
- // Uses Transform_32 arithmetic for local and object space error.
+ //////////////////////////////////////////////////////////////////////////
+ // Uses rtm::qvvf arithmetic for local and object space error.
// This error metric should be used whenever a clip is additive or relative.
// Note that this can cause inaccuracy when dealing with shear/skew.
+ //////////////////////////////////////////////////////////////////////////
template<AdditiveClipFormat8 additive_format>
- class AdditiveTransformErrorMetric final : public ISkeletalErrorMetric
+ class additive_qvvf_transform_error_metric : public qvvf_transform_error_metric
{
public:
virtual const char* get_name() const override
@@ -329,138 +457,51 @@ namespace acl
switch (additive_format)
{
default:
- case AdditiveClipFormat8::None: return "AdditiveTransformErrorMetric<None>";
- case AdditiveClipFormat8::Relative: return "AdditiveTransformErrorMetric<Relative>";
- case AdditiveClipFormat8::Additive0: return "AdditiveTransformErrorMetric<Additive0>";
- case AdditiveClipFormat8::Additive1: return "AdditiveTransformErrorMetric<Additive1>";
+ case AdditiveClipFormat8::None: return "additive_qvvf_transform_error_metric<None>";
+ case AdditiveClipFormat8::Relative: return "additive_qvvf_transform_error_metric<Relative>";
+ case AdditiveClipFormat8::Additive0: return "additive_qvvf_transform_error_metric<Additive0>";
+ case AdditiveClipFormat8::Additive1: return "additive_qvvf_transform_error_metric<Additive1>";
}
}
- virtual uint32_t get_hash() const override { return hash32(get_name()); }
-
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void apply_additive_to_base(const apply_additive_to_base_args& args, void* out_transforms) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
-
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- // Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
-
- const rtm::qvvf raw_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
- const rtm::qvvf lossy_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const rtm::qvvf* local_transforms_ = static_cast<const rtm::qvvf*>(args.local_transforms);
+ const rtm::qvvf* base_transforms_ = static_cast<const rtm::qvvf*>(args.base_transforms);
+ rtm::qvvf* out_transforms_ = static_cast<rtm::qvvf*>(out_transforms);
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_transform);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
-
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_transform);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
-
- const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_transform);
- const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_transform);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
-
- return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
- }
-
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
- {
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
-
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
-
- const rtm::qvvf raw_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
- const rtm::qvvf lossy_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
-
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_transform);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
-
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_transform);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
-
- return rtm::scalar_max(vtx0_error, vtx1_error);
- }
-
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
- {
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
-
- rtm::qvvf raw_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], raw_local_pose[0]);
- rtm::qvvf lossy_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], lossy_local_pose[0]);
-
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
{
- const uint16_t chain_bone_index = *chain_bone_it;
-
- raw_obj_transform = rtm::qvv_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
- lossy_obj_transform = rtm::qvv_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
- }
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
+ const rtm::qvvf& local_transform = local_transforms_[transform_index];
+ const rtm::qvvf& base_transform = base_transforms_[transform_index];
+ const rtm::qvvf transform = acl::apply_additive_to_base(additive_format, base_transform, local_transform);
- // Note that because we have scale, we must measure all three axes
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
-
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_obj_transform);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_obj_transform);
- const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_obj_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_obj_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_obj_transform);
- const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_obj_transform);
-
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
-
- return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
+ out_transforms_[transform_index] = transform;
+ }
}
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
+ virtual ACL_DISABLE_SECURITY_COOKIE_CHECK void apply_additive_to_base_no_scale(const apply_additive_to_base_args& args, void* out_transforms) const override
{
- ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
-
- rtm::qvvf raw_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], raw_local_pose[0]);
- rtm::qvvf lossy_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], lossy_local_pose[0]);
+ const uint16_t* dirty_transform_indices = args.dirty_transform_indices;
+ const rtm::qvvf* local_transforms_ = static_cast<const rtm::qvvf*>(args.local_transforms);
+ const rtm::qvvf* base_transforms_ = static_cast<const rtm::qvvf*>(args.base_transforms);
+ rtm::qvvf* out_transforms_ = static_cast<rtm::qvvf*>(out_transforms);
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
- auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
- const auto chain_bone_end = bone_chain.end();
- for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
+ const uint32_t num_dirty_transforms = args.num_dirty_transforms;
+ for (uint32_t dirty_transform_index = 0; dirty_transform_index < num_dirty_transforms; ++dirty_transform_index)
{
- const uint16_t chain_bone_index = *chain_bone_it;
+ const uint32_t transform_index = dirty_transform_indices[dirty_transform_index];
- raw_obj_transform = rtm::qvv_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
- lossy_obj_transform = rtm::qvv_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
- }
-
- const RigidBone& target_bone = skeleton.get_bone(bone_index);
-
- const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
-
- const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
- const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
- const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
- const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
+ const rtm::qvvf& local_transform = local_transforms_[transform_index];
+ const rtm::qvvf& base_transform = base_transforms_[transform_index];
+ const rtm::qvvf transform = acl::apply_additive_to_base_no_scale(additive_format, base_transform, local_transform);
- const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
-
- return rtm::scalar_max(vtx0_error, vtx1_error);
+ out_transforms_[transform_index] = transform;
+ }
}
};
}
diff --git a/includes/acl/compression/utils.h b/includes/acl/compression/utils.h
--- a/includes/acl/compression/utils.h
+++ b/includes/acl/compression/utils.h
@@ -50,7 +50,7 @@ namespace acl
template<class DecompressionContextType>
inline BoneError calculate_compressed_clip_error(IAllocator& allocator,
- const AnimationClip& clip, const ISkeletalErrorMetric& error_metric, DecompressionContextType& context)
+ const AnimationClip& clip, const itransform_error_metric& error_metric, DecompressionContextType& context)
{
const uint16_t num_bones = clip.get_num_bones();
const float clip_duration = clip.get_duration();
@@ -58,6 +58,9 @@ namespace acl
const uint32_t num_samples = clip.get_num_samples();
const RigidSkeleton& skeleton = clip.get_skeleton();
+ // Always calculate the error with scale, slower but we don't need to know if we have scale or not
+ const bool has_scale = true;
+
uint16_t num_output_bones = 0;
uint16_t* output_bone_mapping = create_output_bone_mapping(allocator, clip, num_output_bones);
@@ -65,44 +68,127 @@ namespace acl
const uint32_t additive_num_samples = additive_base_clip != nullptr ? additive_base_clip->get_num_samples() : 0;
const float additive_duration = additive_base_clip != nullptr ? additive_base_clip->get_duration() : 0.0F;
- rtm::qvvf* raw_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* base_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_output_bones);
- rtm::qvvf* lossy_remapped_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* base_local_pose = additive_base_clip != nullptr ? allocate_type_array<rtm::qvvf>(allocator, num_bones) : nullptr;
+ rtm::qvvf* lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_output_bones);
+ rtm::qvvf* lossy_remapped_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+
+ const size_t transform_size = error_metric.get_transform_size(has_scale);
+ const bool needs_conversion = error_metric.needs_conversion(has_scale);
+ uint8_t* raw_local_pose_converted = nullptr;
+ uint8_t* base_local_pose_converted = nullptr;
+ uint8_t* lossy_local_pose_converted = nullptr;
+ if (needs_conversion)
+ {
+ raw_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
+ base_local_pose_converted = additive_base_clip != nullptr ? allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64) : nullptr;
+ lossy_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
+ }
+
+ uint8_t* raw_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
+ uint8_t* lossy_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
+
+ uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+ uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
+
+ for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
+ {
+ const RigidBone& bone = skeleton.get_bone(transform_index);
+ parent_transform_indices[transform_index] = bone.parent_index;
+ self_transform_indices[transform_index] = transform_index;
+ }
+
+ void* raw_local_pose_ = needs_conversion ? (void*)raw_local_pose_converted : (void*)raw_local_pose;
+ void* base_local_pose_ = needs_conversion ? (void*)base_local_pose_converted : (void*)base_local_pose;
+ void* lossy_local_pose_ = needs_conversion ? (void*)lossy_local_pose_converted : (void*)lossy_remapped_local_pose;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_raw;
+ convert_transforms_args_raw.dirty_transform_indices = self_transform_indices;
+ convert_transforms_args_raw.num_dirty_transforms = num_bones;
+ convert_transforms_args_raw.transforms = raw_local_pose;
+ convert_transforms_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_base = convert_transforms_args_raw;
+ convert_transforms_args_base.transforms = base_local_pose;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_lossy = convert_transforms_args_raw;
+ convert_transforms_args_lossy.transforms = lossy_remapped_local_pose;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_raw.dirty_transform_indices = self_transform_indices;
+ apply_additive_to_base_args_raw.num_dirty_transforms = num_bones;
+ apply_additive_to_base_args_raw.local_transforms = raw_local_pose_;
+ apply_additive_to_base_args_raw.base_transforms = base_local_pose_;
+ apply_additive_to_base_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy = apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_lossy.local_transforms = lossy_local_pose_;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_raw;
+ local_to_object_space_args_raw.dirty_transform_indices = self_transform_indices;
+ local_to_object_space_args_raw.num_dirty_transforms = num_bones;
+ local_to_object_space_args_raw.parent_transform_indices = parent_transform_indices;
+ local_to_object_space_args_raw.local_transforms = raw_local_pose_;
+ local_to_object_space_args_raw.num_transforms = num_bones;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy = local_to_object_space_args_raw;
+ local_to_object_space_args_lossy.local_transforms = lossy_local_pose_;
BoneError bone_error;
- DefaultOutputWriter pose_writer(lossy_pose_transforms, num_output_bones);
+ DefaultOutputWriter pose_writer(lossy_local_pose, num_output_bones);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_pose_transforms, num_bones);
+ clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_local_pose, num_bones);
context.seek(sample_time, SampleRoundingPolicy::Nearest);
context.decompress_pose(pose_writer);
- if (additive_base_clip != nullptr)
- {
- const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
- const float additive_sample_time = normalized_sample_time * additive_duration;
- additive_base_clip->sample_pose(additive_sample_time, SampleRoundingPolicy::Nearest, base_pose_transforms, num_bones);
- }
-
// Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
// the data is available
- std::memcpy(lossy_remapped_pose_transforms, raw_pose_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_remapped_local_pose, raw_local_pose, sizeof(rtm::qvvf) * num_bones);
for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
{
const uint16_t bone_index = output_bone_mapping[output_index];
- lossy_remapped_pose_transforms[bone_index] = lossy_pose_transforms[output_index];
+ lossy_remapped_local_pose[bone_index] = lossy_local_pose[output_index];
}
+ if (needs_conversion)
+ {
+ error_metric.convert_transforms(convert_transforms_args_raw, raw_local_pose_converted);
+ error_metric.convert_transforms(convert_transforms_args_lossy, lossy_local_pose_converted);
+ }
+
+ if (additive_base_clip != nullptr)
+ {
+ const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
+ const float additive_sample_time = additive_num_samples > 1 ? (normalized_sample_time * additive_duration) : 0.0F;
+ additive_base_clip->sample_pose(additive_sample_time, SampleRoundingPolicy::Nearest, base_local_pose, num_bones);
+
+ if (needs_conversion)
+ error_metric.convert_transforms(convert_transforms_args_base, base_local_pose_converted);
+
+
+ error_metric.apply_additive_to_base(apply_additive_to_base_args_raw, raw_local_pose_);
+ error_metric.apply_additive_to_base(apply_additive_to_base_args_lossy, lossy_local_pose_);
+ }
+
+ error_metric.local_to_object_space(local_to_object_space_args_raw, raw_object_pose);
+ error_metric.local_to_object_space(local_to_object_space_args_lossy, lossy_object_pose);
+
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- // Always calculate the error with scale, slower but binary exact
- const float error = error_metric.calculate_object_bone_error(skeleton, raw_pose_transforms, base_pose_transforms, lossy_remapped_pose_transforms, bone_index);
+ const RigidBone& bone = skeleton.get_bone(bone_index);
+
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.raw_transform = raw_object_pose + (bone_index * transform_size);
+ calculate_error_args.lossy_transform = lossy_object_pose + (bone_index * transform_size);
+ calculate_error_args.construct_sphere_shell(bone.vertex_distance);
+
+ const float error = rtm::scalar_cast(error_metric.calculate_error(calculate_error_args));
if (error > bone_error.error)
{
@@ -114,10 +200,17 @@ namespace acl
}
deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
- deallocate_type_array(allocator, raw_pose_transforms, num_bones);
- deallocate_type_array(allocator, base_pose_transforms, num_bones);
- deallocate_type_array(allocator, lossy_pose_transforms, num_output_bones);
- deallocate_type_array(allocator, lossy_remapped_pose_transforms, num_bones);
+ deallocate_type_array(allocator, raw_local_pose, num_bones);
+ deallocate_type_array(allocator, base_local_pose, num_bones);
+ deallocate_type_array(allocator, lossy_local_pose, num_output_bones);
+ deallocate_type_array(allocator, lossy_remapped_local_pose, num_bones);
+ deallocate_type_array(allocator, raw_local_pose_converted, num_bones * transform_size);
+ deallocate_type_array(allocator, base_local_pose_converted, num_bones * transform_size);
+ deallocate_type_array(allocator, lossy_local_pose_converted, num_bones * transform_size);
+ deallocate_type_array(allocator, raw_object_pose, num_bones * transform_size);
+ deallocate_type_array(allocator, lossy_object_pose, num_bones * transform_size);
+ deallocate_type_array(allocator, parent_transform_indices, num_bones);
+ deallocate_type_array(allocator, self_transform_indices, num_bones);
return bone_error;
}
diff --git a/includes/acl/core/bitset.h b/includes/acl/core/bitset.h
--- a/includes/acl/core/bitset.h
+++ b/includes/acl/core/bitset.h
@@ -198,6 +198,18 @@ namespace acl
return num_set_bits;
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Performs the operation: result = ~not_value & and_value
+ // Bit sets must have the same description
+ // Bit sets can alias
+ inline void bitset_and_not(uint32_t* bitset_result, const uint32_t* bitset_not_value, const uint32_t* bitset_and_value, BitSetDescription desc)
+ {
+ const uint32_t size = desc.get_size();
+
+ for (uint32_t offset = 0; offset < size; ++offset)
+ bitset_result[offset] = and_not(bitset_not_value[offset], bitset_and_value[offset]);
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/impl/compiler_utils.h b/includes/acl/core/impl/compiler_utils.h
--- a/includes/acl/core/impl/compiler_utils.h
+++ b/includes/acl/core/impl/compiler_utils.h
@@ -50,6 +50,16 @@
#define ACL_IMPL_FILE_PRAGMA_POP
#endif
+//////////////////////////////////////////////////////////////////////////
+// In some cases, for performance reasons, we wish to disable stack security
+// check cookies. This macro serves this purpose.
+//////////////////////////////////////////////////////////////////////////
+#if defined(_MSC_VER)
+ #define ACL_DISABLE_SECURITY_COOKIE_CHECK __declspec(safebuffers)
+#else
+ #define ACL_DISABLE_SECURITY_COOKIE_CHECK
+#endif
+
//////////////////////////////////////////////////////////////////////////
// Force inline macros for when it is necessary.
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/core/track_types.h b/includes/acl/core/track_types.h
--- a/includes/acl/core/track_types.h
+++ b/includes/acl/core/track_types.h
@@ -222,15 +222,15 @@ namespace acl
constexpr uint8_t k_invalid_bit_rate = 0xFF;
constexpr uint8_t k_lowest_bit_rate = 1;
constexpr uint8_t k_highest_bit_rate = sizeof(k_bit_rate_num_bits) - 1;
- constexpr uint8_t k_num_bit_rates = sizeof(k_bit_rate_num_bits);
+ constexpr uint32_t k_num_bit_rates = sizeof(k_bit_rate_num_bits);
static_assert(k_num_bit_rates == 19, "Expecting 19 bit rates");
// If all tracks are variable, no need for any extra padding except at the very end of the data
// If our tracks are mixed variable/not variable, we need to add some padding to ensure alignment
- constexpr uint8_t k_mixed_packing_alignment_num_bits = 16;
+ constexpr uint32_t k_mixed_packing_alignment_num_bits = 16;
- inline uint8_t get_num_bits_at_bit_rate(uint8_t bit_rate)
+ inline uint32_t get_num_bits_at_bit_rate(uint8_t bit_rate)
{
ACL_ASSERT(bit_rate <= k_highest_bit_rate, "Invalid bit rate: %u", bit_rate);
return k_bit_rate_num_bits[bit_rate];
diff --git a/includes/acl/decompression/decompress.h b/includes/acl/decompression/decompress.h
--- a/includes/acl/decompression/decompress.h
+++ b/includes/acl/decompression/decompress.h
@@ -285,7 +285,7 @@ namespace acl
{
const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
const uint8_t bit_rate = metadata.bit_rate;
- const uint8_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
if (header.track_type == track_type8::float1f && m_settings.is_track_type_supported(track_type8::float1f))
{
@@ -301,13 +301,13 @@ namespace acl
rtm::scalarf value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = acl_impl::unpack_scalarf_96_unsafe(animated_values, track_bit_offset0);
- value1 = acl_impl::unpack_scalarf_96_unsafe(animated_values, track_bit_offset1);
+ value0 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset1);
}
else
{
- value0 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+ value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
const rtm::scalarf range_min = rtm::scalar_load(range_values);
const rtm::scalarf range_extent = rtm::scalar_load(range_values + 1);
@@ -521,7 +521,7 @@ namespace acl
const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
const uint8_t bit_rate = metadata.bit_rate;
- const uint8_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
const uint8_t* animated_values = header.get_track_animated_values();
@@ -536,13 +536,13 @@ namespace acl
rtm::scalarf value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = acl_impl::unpack_scalarf_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = acl_impl::unpack_scalarf_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
+ value0 = unpack_scalarf_32_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_scalarf_32_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
}
else
{
- value0 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
+ value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
const rtm::scalarf range_min = rtm::scalar_load(range_values);
const rtm::scalarf range_extent = rtm::scalar_load(range_values + num_element_components);
diff --git a/includes/acl/decompression/impl/decompress_data.h b/includes/acl/decompression/impl/decompress_data.h
--- a/includes/acl/decompression/impl/decompress_data.h
+++ b/includes/acl/decompression/impl/decompress_data.h
@@ -61,7 +61,7 @@ namespace acl
for (size_t i = 0; i < num_key_frames; ++i)
{
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+ uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
@@ -123,7 +123,7 @@ namespace acl
for (size_t i = 0; i < num_key_frames; ++i)
{
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+ uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
diff --git a/includes/acl/decompression/impl/track_sampling_impl.h b/includes/acl/decompression/impl/track_sampling_impl.h
--- a/includes/acl/decompression/impl/track_sampling_impl.h
+++ b/includes/acl/decompression/impl/track_sampling_impl.h
@@ -59,113 +59,6 @@ namespace acl
inline bool is_initialized() const { return tracks != nullptr; }
};
-
- // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
- inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
- {
-#if defined(RTM_SSE2_INTRINSICS)
- const uint32_t byte_offset = bit_offset / 8;
- const uint32_t shift_offset = bit_offset % 8;
- uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
- vector_u64 = byte_swap(vector_u64);
- vector_u64 <<= shift_offset;
- vector_u64 >>= 32;
-
- const uint32_t x32 = uint32_t(vector_u64);
-
- return _mm_castsi128_ps(_mm_set1_epi32(x32));
-#elif defined(RTM_NEON_INTRINSICS)
- const uint32_t byte_offset = bit_offset / 8;
- const uint32_t shift_offset = bit_offset % 8;
- uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
- vector_u64 = byte_swap(vector_u64);
- vector_u64 <<= shift_offset;
- vector_u64 >>= 32;
-
- const uint64_t x64 = vector_u64;
-
- const uint32x2_t xy = vcreate_u32(x64);
- return vget_lane_f32(vreinterpret_f32_u32(xy), 0);
-#else
- const uint32_t byte_offset = bit_offset / 8;
- const uint32_t shift_offset = bit_offset % 8;
- uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
- vector_u64 = byte_swap(vector_u64);
- vector_u64 <<= shift_offset;
- vector_u64 >>= 32;
-
- const uint64_t x64 = vector_u64;
-
- const float x = aligned_load<float>(&x64);
-
- return rtm::scalar_set(x);
-#endif
- }
-
- // Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
- {
- ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
-
- struct PackedTableEntry
- {
- explicit constexpr PackedTableEntry(uint8_t num_bits_)
- : max_value(num_bits_ == 0 ? 1.0F : (1.0F / float((1 << num_bits_) - 1)))
- , mask((1 << num_bits_) - 1)
- {}
-
- float max_value;
- uint32_t mask;
- };
-
- // TODO: We technically don't need the first 3 entries, which could save a few bytes
- alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
- {
- PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
- PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
- PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
- PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
- PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
- };
-
-#if defined(RTM_SSE2_INTRINSICS)
- const uint32_t bit_shift = 32 - num_bits;
- const uint32_t mask = k_packed_constants[num_bits].mask;
- const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
-
- uint32_t byte_offset = bit_offset / 8;
- uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
- vector_u32 = byte_swap(vector_u32);
- const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
-
- const __m128 value = _mm_cvtsi32_ss(inv_max_value, x32 & mask);
- return _mm_mul_ss(value, inv_max_value);
-#elif defined(RTM_NEON_INTRINSICS)
- const uint32_t bit_shift = 32 - num_bits;
- const uint32_t mask = k_packed_constants[num_bits].mask;
- const float inv_max_value = k_packed_constants[num_bits].max_value;
-
- uint32_t byte_offset = bit_offset / 8;
- uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
- vector_u32 = byte_swap(vector_u32);
- const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
-
- const int32_t value_u32 = x32 & mask;
- const float value_f32 = static_cast<float>(value_u32);
- return value_f32 * inv_max_value;
-#else
- const uint32_t bit_shift = 32 - num_bits;
- const uint32_t mask = k_packed_constants[num_bits].mask;
- const float inv_max_value = k_packed_constants[num_bits].max_value;
-
- uint32_t byte_offset = bit_offset / 8;
- uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
- vector_u32 = byte_swap(vector_u32);
- const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
-
- return rtm::scalar_set(static_cast<float>(x32) * inv_max_value);
-#endif
- }
}
}
diff --git a/includes/acl/math/scalar_packing.h b/includes/acl/math/scalar_packing.h
--- a/includes/acl/math/scalar_packing.h
+++ b/includes/acl/math/scalar_packing.h
@@ -26,6 +26,7 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/error.h"
+#include "acl/core/memory_utils.h"
#include <rtm/scalarf.h>
@@ -35,7 +36,7 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- inline uint32_t pack_scalar_unsigned(float input, uint8_t num_bits)
+ inline uint32_t pack_scalar_unsigned(float input, uint32_t num_bits)
{
ACL_ASSERT(num_bits < 31, "Attempting to pack on too many bits");
ACL_ASSERT(input >= 0.0F && input <= 1.0F, "Expected normalized unsigned input value: %f", input);
@@ -43,7 +44,7 @@ namespace acl
return static_cast<uint32_t>(rtm::scalar_symmetric_round(input * rtm::scalar_safe_to_float(max_value)));
}
- inline float unpack_scalar_unsigned(uint32_t input, uint8_t num_bits)
+ inline float unpack_scalar_unsigned(uint32_t input, uint32_t num_bits)
{
ACL_ASSERT(num_bits < 31, "Attempting to unpack from too many bits");
const uint32_t max_value = (1 << num_bits) - 1;
@@ -53,15 +54,122 @@ namespace acl
return rtm::scalar_safe_to_float(input) * inv_max_value;
}
- inline uint32_t pack_scalar_signed(float input, uint8_t num_bits)
+ inline uint32_t pack_scalar_signed(float input, uint32_t num_bits)
{
return pack_scalar_unsigned((input * 0.5F) + 0.5F, num_bits);
}
- inline float unpack_scalar_signed(uint32_t input, uint8_t num_bits)
+ inline float unpack_scalar_signed(uint32_t input, uint32_t num_bits)
{
return (unpack_scalar_unsigned(input, num_bits) * 2.0F) - 1.0F;
}
+
+ // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 8 bytes from it
+ inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_32_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ {
+#if defined(RTM_SSE2_INTRINSICS)
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint32_t x32 = uint32_t(vector_u64);
+
+ return _mm_castsi128_ps(_mm_set1_epi32(x32));
+#elif defined(RTM_NEON_INTRINSICS)
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint64_t x64 = vector_u64;
+
+ const uint32x2_t xy = vcreate_u32(x64);
+ return vget_lane_f32(vreinterpret_f32_u32(xy), 0);
+#else
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint64_t x64 = vector_u64;
+
+ const float x = aligned_load<float>(&x64);
+
+ return rtm::scalar_set(x);
+#endif
+ }
+
+ // Assumes the 'vector_data' is in big-endian order and padded in order to load up to 8 bytes from it
+ inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ {
+ ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+
+ struct PackedTableEntry
+ {
+ explicit constexpr PackedTableEntry(uint8_t num_bits_)
+ : max_value(num_bits_ == 0 ? 1.0F : (1.0F / float((1 << num_bits_) - 1)))
+ , mask((1 << num_bits_) - 1)
+ {}
+
+ float max_value;
+ uint32_t mask;
+ };
+
+ // TODO: We technically don't need the first 3 entries, which could save a few bytes
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ {
+ PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
+ PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
+ PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
+ PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
+ PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ };
+
+#if defined(RTM_SSE2_INTRINSICS)
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
+
+ const __m128 value = _mm_cvtsi32_ss(inv_max_value, x32 & mask);
+ return _mm_mul_ss(value, inv_max_value);
+#elif defined(RTM_NEON_INTRINSICS)
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const float inv_max_value = k_packed_constants[num_bits].max_value;
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
+
+ const int32_t value_u32 = x32 & mask;
+ const float value_f32 = static_cast<float>(value_u32);
+ return value_f32 * inv_max_value;
+#else
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const float inv_max_value = k_packed_constants[num_bits].max_value;
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
+
+ return rtm::scalar_set(static_cast<float>(x32) * inv_max_value);
+#endif
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_packing.h b/includes/acl/math/vector4_packing.h
--- a/includes/acl/math/vector4_packing.h
+++ b/includes/acl/math/vector4_packing.h
@@ -214,7 +214,7 @@ namespace acl
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void RTM_SIMD_CALL pack_vector4_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector4_uXX_unsafe(rtm::vector4f_arg0 vector, uint32_t num_bits, uint8_t* out_vector_data)
{
uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
@@ -234,7 +234,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -656,7 +656,7 @@ namespace acl
return rtm::vector_neg_mul_sub(decayed, -2.0F, rtm::vector_set(-1.0F));
}
- inline void RTM_SIMD_CALL pack_vector3_32(rtm::vector4f_arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_32(rtm::vector4f_arg0 vector, uint32_t XBits, uint32_t YBits, uint32_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
@@ -672,7 +672,7 @@ namespace acl
data[1] = safe_static_cast<uint16_t>(vector_u32 & 0xFFFF);
}
- inline rtm::vector4f RTM_SIMD_CALL decay_vector3_u32(rtm::vector4f_arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_u32(rtm::vector4f_arg0 input, uint32_t XBits, uint32_t YBits, uint32_t ZBits)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
ACL_ASSERT(rtm::vector_all_greater_equal3(input, rtm::vector_zero()) && rtm::vector_all_less_equal(input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(input), rtm::vector_get_y(input), rtm::vector_get_z(input));
@@ -688,7 +688,7 @@ namespace acl
return decayed;
}
- inline rtm::vector4f RTM_SIMD_CALL decay_vector3_s32(rtm::vector4f_arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_s32(rtm::vector4f_arg0 input, uint32_t XBits, uint32_t YBits, uint32_t ZBits)
{
const rtm::vector4f half = rtm::vector_set(0.5F);
const rtm::vector4f unsigned_input = rtm::vector_mul_add(input, half, half);
@@ -707,7 +707,7 @@ namespace acl
return rtm::vector_neg_mul_sub(decayed, -2.0F, rtm::vector_set(-1.0F));
}
- inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_32(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_32(uint32_t XBits, uint32_t YBits, uint32_t ZBits, bool is_unsigned, const uint8_t* vector_data)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
@@ -795,7 +795,7 @@ namespace acl
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void RTM_SIMD_CALL pack_vector3_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_uXX_unsafe(rtm::vector4f_arg0 vector, uint32_t num_bits, uint8_t* out_vector_data)
{
uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
@@ -810,7 +810,7 @@ namespace acl
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void RTM_SIMD_CALL pack_vector3_sXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_sXX_unsafe(rtm::vector4f_arg0 vector, uint32_t num_bits, uint8_t* out_vector_data)
{
uint32_t vector_x = pack_scalar_signed(rtm::vector_get_x(vector), num_bits);
uint32_t vector_y = pack_scalar_signed(rtm::vector_get_y(vector), num_bits);
@@ -852,7 +852,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -964,7 +964,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_sXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_sXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits * 3 <= 64, "Attempting to read too many bits");
@@ -976,7 +976,7 @@ namespace acl
// vector2 packing and decay
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void RTM_SIMD_CALL pack_vector2_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector2_uXX_unsafe(rtm::vector4f_arg0 vector, uint32_t num_bits, uint8_t* out_vector_data)
{
uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
@@ -989,7 +989,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::vector4f RTM_SIMD_CALL unpack_vector2_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector2_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
diff --git a/tools/acl_compressor/acl_compressor.py b/tools/acl_compressor/acl_compressor.py
--- a/tools/acl_compressor/acl_compressor.py
+++ b/tools/acl_compressor/acl_compressor.py
@@ -164,7 +164,7 @@ def create_csv(options):
csv_data['stats_summary_csv_file'] = stats_summary_csv_file
print('Generating CSV file {} ...'.format(stats_summary_csv_filename))
- print('Clip Name, Algorithm Name, Raw Size, Compressed Size, Compression Ratio, Compression Time, Clip Duration, Num Animated Tracks, Max Error', file = stats_summary_csv_file)
+ print('Clip Name, Algorithm Name, Raw Size, Compressed Size, Compression Ratio, Compression Time, Clip Duration, Num Animated Tracks, Max Error, Num Transforms, Num Samples Per Track, Quantization Memory Usage', file = stats_summary_csv_file)
if options['csv_bit_rate']:
stats_bit_rate_csv_filename = os.path.join(stat_dir, 'stats_bit_rate.csv')
@@ -211,8 +211,8 @@ def close_csv(csv_data):
def append_csv(csv_data, job_data):
if 'stats_summary_csv_file' in csv_data:
data = job_data['stats_summary_data']
- for (clip_name, algo_name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error) in data:
- print('{}, {}, {}, {}, {}, {}, {}, {}, {}'.format(clip_name, algo_name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error), file = csv_data['stats_summary_csv_file'])
+ for (clip_name, algo_name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error, num_transforms, num_samples_per_track, quantization_memory_usage) in data:
+ print('{}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}, {}'.format(clip_name, algo_name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error, num_transforms, num_samples_per_track, quantization_memory_usage), file = csv_data['stats_summary_csv_file'])
if 'stats_animated_size_csv_file' in csv_data:
size_data = job_data['stats_animated_size']
@@ -561,9 +561,12 @@ def run_stat_parsing(options, stat_queue, result_queue):
compression_times.append(run_stats['compression_time'])
if options['csv_summary']:
- #(name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error)
+ #(name, raw_size, compressed_size, compression_ratio, compression_time, duration, num_animated_tracks, max_error, num_transforms, num_samples_per_track, quantization_memory_usage)
+ num_transforms = run_stats['num_bones']
+ num_samples_per_track = run_stats['num_samples']
num_animated_tracks = run_stats.get('num_animated_tracks', 0)
- data = (run_stats['clip_name'], run_stats['csv_desc'], run_stats['raw_size'], run_stats['compressed_size'], run_stats['compression_ratio'], run_stats['compression_time'], run_stats['duration'], num_animated_tracks, run_stats['max_error'])
+ quantization_memory_usage = run_stats.get('track_bit_rate_database_size', 0) + run_stats.get('transform_cache_size', 0)
+ data = (run_stats['clip_name'], run_stats['csv_desc'], run_stats['raw_size'], run_stats['compressed_size'], run_stats['compression_ratio'], run_stats['compression_time'], run_stats['duration'], num_animated_tracks, run_stats['max_error'], num_transforms, num_samples_per_track, quantization_memory_usage)
stats_summary_data.append(data)
if 'segments' in run_stats and len(run_stats['segments']) > 0:
@@ -665,6 +668,10 @@ def percentile_rank(values, value):
return (values < value).mean() * 100.0
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
options = parse_argv()
stat_files = compress_clips(options)
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -147,6 +147,8 @@ struct Options
bool profile_decompression;
bool exhaustive_compression;
+ bool use_matrix_error_metric;
+
bool is_bind_pose_relative;
bool is_bind_pose_additive0;
bool is_bind_pose_additive1;
@@ -176,6 +178,7 @@ struct Options
, regression_testing(false)
, profile_decompression(false)
, exhaustive_compression(false)
+ , use_matrix_error_metric(false)
, is_bind_pose_relative(false)
, is_bind_pose_additive0(false)
, is_bind_pose_additive1(false)
@@ -224,6 +227,7 @@ static constexpr const char* k_exhaustive_compression_option = "-exhaustive";
static constexpr const char* k_bind_pose_relative_option = "-bind_rel";
static constexpr const char* k_bind_pose_additive0_option = "-bind_add0";
static constexpr const char* k_bind_pose_additive1_option = "-bind_add1";
+static constexpr const char* k_matrix_error_metric_option = "-error_mtx";
static constexpr const char* k_stat_detailed_output_option = "-stat_detailed";
static constexpr const char* k_stat_exhaustive_output_option = "-stat_exhaustive";
@@ -352,6 +356,13 @@ static bool parse_options(int argc, char** argv, Options& options)
continue;
}
+ option_length = std::strlen(k_matrix_error_metric_option);
+ if (std::strncmp(argument, k_matrix_error_metric_option, option_length) == 0)
+ {
+ options.use_matrix_error_metric = true;
+ continue;
+ }
+
option_length = std::strlen(k_bind_pose_relative_option);
if (std::strncmp(argument, k_bind_pose_relative_option, option_length) == 0)
{
@@ -416,19 +427,16 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
{
(void)regression_error_threshold;
+ const BoneError bone_error = calculate_compressed_clip_error(allocator, clip, *settings.error_metric, context);
+ (void)bone_error;
+ ACL_ASSERT(rtm::scalar_is_finite(bone_error.error), "Returned error is not a finite value");
+ ACL_ASSERT(bone_error.error < regression_error_threshold, "Error too high for bone %u: %f at time %f", bone_error.index, bone_error.error, bone_error.sample_time);
+
const uint16_t num_bones = clip.get_num_bones();
const float clip_duration = clip.get_duration();
const float sample_rate = clip.get_sample_rate();
const uint32_t num_samples = calculate_num_samples(clip_duration, clip.get_sample_rate());
- const ISkeletalErrorMetric& error_metric = *settings.error_metric;
- const RigidSkeleton& skeleton = clip.get_skeleton();
- const AnimationClip* additive_base_clip = clip.get_additive_base();
- const uint32_t additive_num_samples = additive_base_clip != nullptr ? additive_base_clip->get_num_samples() : 0;
- const float additive_duration = additive_base_clip != nullptr ? additive_base_clip->get_duration() : 0.0F;
-
- rtm::qvvf* raw_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* base_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
DefaultOutputWriter pose_writer(lossy_pose_transforms, num_bones);
@@ -439,27 +447,9 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_pose_transforms, num_bones);
-
context.seek(sample_time, SampleRoundingPolicy::Nearest);
context.decompress_pose(pose_writer);
- if (additive_base_clip != nullptr)
- {
- const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
- const float additive_sample_time = normalized_sample_time * additive_duration;
- additive_base_clip->sample_pose(additive_sample_time, SampleRoundingPolicy::Nearest, base_pose_transforms, num_bones);
- }
-
- // Validate decompress_pose
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const float error = error_metric.calculate_object_bone_error(skeleton, raw_pose_transforms, base_pose_transforms, lossy_pose_transforms, bone_index);
- (void)error;
- ACL_ASSERT(rtm::scalar_is_finite(error), "Returned error is not a finite value");
- ACL_ASSERT(error < regression_error_threshold, "Error too high for bone %u: %f at time %f", bone_index, error, sample_time);
- }
-
// Validate decompress_bone for rotations only
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
@@ -497,8 +487,6 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
}
}
- deallocate_type_array(allocator, raw_pose_transforms, num_bones);
- deallocate_type_array(allocator, base_pose_transforms, num_bones);
deallocate_type_array(allocator, lossy_pose_transforms, num_bones);
}
@@ -629,8 +617,8 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const float raw_value = raw_track_writer.read_float1(track_index);
const float lossy_value = lossy_track_writer.read_float1(output_index);
ACL_ASSERT(rtm::scalar_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::scalar_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::scalar_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::scalar_near_equal(raw_value_, raw_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::scalar_near_equal(lossy_value_, lossy_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
break;
}
case track_type8::float2f:
@@ -640,8 +628,8 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const rtm::vector4f raw_value = raw_track_writer.read_float2(track_index);
const rtm::vector4f lossy_value = lossy_track_writer.read_float2(output_index);
ACL_ASSERT(rtm::vector_all_near_equal2(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal2(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal2(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal2(raw_value_, raw_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal2(lossy_value_, lossy_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
break;
}
case track_type8::float3f:
@@ -651,8 +639,8 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const rtm::vector4f raw_value = raw_track_writer.read_float3(track_index);
const rtm::vector4f lossy_value = lossy_track_writer.read_float3(output_index);
ACL_ASSERT(rtm::vector_all_near_equal3(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal3(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal3(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal3(raw_value_, raw_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal3(lossy_value_, lossy_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
break;
}
case track_type8::float4f:
@@ -662,8 +650,8 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const rtm::vector4f raw_value = raw_track_writer.read_float4(track_index);
const rtm::vector4f lossy_value = lossy_track_writer.read_float4(output_index);
ACL_ASSERT(rtm::vector_all_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
break;
}
case track_type8::vector4f:
@@ -673,8 +661,8 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const rtm::vector4f raw_value = raw_track_writer.read_vector4(track_index);
const rtm::vector4f lossy_value = lossy_track_writer.read_vector4(output_index);
ACL_ASSERT(rtm::vector_all_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
- ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value, 0.00001F), "Failed to sample track %u at time %f", track_index, sample_time);
break;
}
default:
@@ -926,7 +914,7 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
return success;
}
-static bool read_config(IAllocator& allocator, const Options& options, AlgorithmType8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
+static bool read_config(IAllocator& allocator, Options& options, AlgorithmType8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
{
#if defined(__ANDROID__)
sjson::Parser parser(options.config_buffer, options.config_buffer_size - 1);
@@ -1067,6 +1055,14 @@ static bool read_config(IAllocator& allocator, const Options& options, Algorithm
parser.try_read("regression_error_threshold", out_regression_error_threshold, 0.0);
+ bool is_bind_pose_relative;
+ if (parser.try_read("is_bind_pose_relative", is_bind_pose_relative, false))
+ options.is_bind_pose_relative = is_bind_pose_relative;
+
+ bool use_matrix_error_metric;
+ if (parser.try_read("use_matrix_error_metric", use_matrix_error_metric, false))
+ options.use_matrix_error_metric = use_matrix_error_metric;
+
if (!parser.is_valid() || !parser.remainder_is_comments_and_whitespace())
{
uint32_t line;
@@ -1080,16 +1076,16 @@ static bool read_config(IAllocator& allocator, const Options& options, Algorithm
return true;
}
-static ISkeletalErrorMetric* create_additive_error_metric(IAllocator& allocator, AdditiveClipFormat8 format)
+static itransform_error_metric* create_additive_error_metric(IAllocator& allocator, AdditiveClipFormat8 format)
{
switch (format)
{
case AdditiveClipFormat8::Relative:
- return allocate_type<AdditiveTransformErrorMetric<AdditiveClipFormat8::Relative>>(allocator);
+ return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Relative>>(allocator);
case AdditiveClipFormat8::Additive0:
- return allocate_type<AdditiveTransformErrorMetric<AdditiveClipFormat8::Additive0>>(allocator);
+ return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Additive0>>(allocator);
case AdditiveClipFormat8::Additive1:
- return allocate_type<AdditiveTransformErrorMetric<AdditiveClipFormat8::Additive1>>(allocator);
+ return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Additive1>>(allocator);
default:
return nullptr;
}
@@ -1246,7 +1242,12 @@ static int safe_main_impl(int argc, char* argv[])
settings.error_metric = create_additive_error_metric(allocator, clip->get_additive_format());
if (settings.error_metric == nullptr)
- settings.error_metric = allocate_type<TransformErrorMetric>(allocator);
+ {
+ if (options.use_matrix_error_metric)
+ settings.error_metric = allocate_type<qvvf_matrix3x4f_transform_error_metric>(allocator);
+ else
+ settings.error_metric = allocate_type<qvvf_transform_error_metric>(allocator);
+ }
}
// Compress & Decompress
diff --git a/tools/acl_decompressor/acl_decompressor.py b/tools/acl_decompressor/acl_decompressor.py
--- a/tools/acl_decompressor/acl_decompressor.py
+++ b/tools/acl_decompressor/acl_decompressor.py
@@ -411,6 +411,10 @@ def set_process_affinity(affinity):
p.cpu_affinity([affinity])
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
options = parse_argv()
# Set the affinity to core 0, on platforms that support it, core 2 will be used to decompress
diff --git a/tools/calc_local_bit_rates.py b/tools/calc_local_bit_rates.py
--- a/tools/calc_local_bit_rates.py
+++ b/tools/calc_local_bit_rates.py
@@ -12,6 +12,10 @@
# This code assumes that rotations, translations, and scales are packed on 3 components (e.g. quat drop w)
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
permutation_tries = []
permutation_tries_no_scale = []
diff --git a/tools/graph_generation/gen_bit_rate_stats.py b/tools/graph_generation/gen_bit_rate_stats.py
--- a/tools/graph_generation/gen_bit_rate_stats.py
+++ b/tools/graph_generation/gen_bit_rate_stats.py
@@ -9,6 +9,10 @@
import sjson
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2:
print('Usage: python gen_bit_rate_stats.py <path/to/input_file.sjson>')
sys.exit(1)
diff --git a/tools/graph_generation/gen_decomp_delta_stats.py b/tools/graph_generation/gen_decomp_delta_stats.py
--- a/tools/graph_generation/gen_decomp_delta_stats.py
+++ b/tools/graph_generation/gen_decomp_delta_stats.py
@@ -39,6 +39,10 @@ def bytes_to_mb(num_bytes):
return num_bytes / (1024 * 1024)
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2 and len(sys.argv) != 3:
print('Usage: python gen_decomp_delta_stats.py <path/to/input_file.sjson> [-warm]')
sys.exit(1)
diff --git a/tools/graph_generation/gen_decomp_stats.py b/tools/graph_generation/gen_decomp_stats.py
--- a/tools/graph_generation/gen_decomp_stats.py
+++ b/tools/graph_generation/gen_decomp_stats.py
@@ -30,6 +30,10 @@ def get_clip_stat_files(stats_dir):
return sorted(stat_files, key = lambda x: x[0])
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2:
print('Usage: python gen_decomp_stats.py <path/to/input_file.sjson>')
sys.exit(1)
diff --git a/tools/graph_generation/gen_full_error_stats.py b/tools/graph_generation/gen_full_error_stats.py
--- a/tools/graph_generation/gen_full_error_stats.py
+++ b/tools/graph_generation/gen_full_error_stats.py
@@ -15,6 +15,10 @@ def format_elapsed_time(elapsed_time):
return '{:0>2}h {:0>2}m {:05.2f}s'.format(int(hours), int(minutes), seconds)
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2:
print('Usage: python gen_full_error_stats.py <path/to/input_file.sjson>')
sys.exit(1)
diff --git a/tools/graph_generation/gen_summary_stats.py b/tools/graph_generation/gen_summary_stats.py
--- a/tools/graph_generation/gen_summary_stats.py
+++ b/tools/graph_generation/gen_summary_stats.py
@@ -9,6 +9,10 @@
import sjson
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2:
print('Usage: python gen_summary_stats.py <path/to/input_file.sjson>')
sys.exit(1)
diff --git a/tools/graph_generation/pack_png.py b/tools/graph_generation/pack_png.py
--- a/tools/graph_generation/pack_png.py
+++ b/tools/graph_generation/pack_png.py
@@ -5,6 +5,10 @@
from PIL import Image
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
if len(sys.argv) != 2:
print('Usage: python pack_png.py <path to png image>')
sys.exit(1)
diff --git a/tools/release_scripts/extract_stats.py b/tools/release_scripts/extract_stats.py
--- a/tools/release_scripts/extract_stats.py
+++ b/tools/release_scripts/extract_stats.py
@@ -59,6 +59,10 @@ def run_cmd(cmd, output_log):
sys.exit(1)
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
options = parse_argv()
os.environ['PYTHONIOENCODING'] = 'utf_8'
|
diff --git a/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson b/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson
@@ -0,0 +1,24 @@
+version = 1
+
+algorithm_name = "UniformlySampled"
+
+level = "Medium"
+
+rotation_format = "QuatDropW_Variable"
+translation_format = "Vector3_Variable"
+scale_format = "Vector3_Variable"
+
+rotation_range_reduction = true
+translation_range_reduction = true
+scale_range_reduction = true
+
+segmenting = {
+ enabled = true
+
+ rotation_range_reduction = true
+ translation_range_reduction = true
+ scale_range_reduction = true
+}
+
+regression_error_threshold = 0.075
+is_bind_pose_relative = true
diff --git a/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson b/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson
@@ -0,0 +1,24 @@
+version = 1
+
+algorithm_name = "UniformlySampled"
+
+level = "Medium"
+
+rotation_format = "QuatDropW_Variable"
+translation_format = "Vector3_Variable"
+scale_format = "Vector3_Variable"
+
+rotation_range_reduction = true
+translation_range_reduction = true
+scale_range_reduction = true
+
+segmenting = {
+ enabled = true
+
+ rotation_range_reduction = true
+ translation_range_reduction = true
+ scale_range_reduction = true
+}
+
+regression_error_threshold = 0.075
+use_matrix_error_metric = true
diff --git a/tests/sources/core/test_bitset.cpp b/tests/sources/core/test_bitset.cpp
--- a/tests/sources/core/test_bitset.cpp
+++ b/tests/sources/core/test_bitset.cpp
@@ -32,89 +32,99 @@ using namespace acl;
TEST_CASE("bitset", "[core][utils]")
{
- REQUIRE(BitSetDescription::make_from_num_bits(0).get_size() == 0);
- REQUIRE(BitSetDescription::make_from_num_bits(1).get_size() == 1);
- REQUIRE(BitSetDescription::make_from_num_bits(31).get_size() == 1);
- REQUIRE(BitSetDescription::make_from_num_bits(32).get_size() == 1);
- REQUIRE(BitSetDescription::make_from_num_bits(33).get_size() == 2);
- REQUIRE(BitSetDescription::make_from_num_bits(64).get_size() == 2);
- REQUIRE(BitSetDescription::make_from_num_bits(65).get_size() == 3);
-
- REQUIRE(BitSetDescription::make_from_num_bits(0).get_num_bits() == 0);
- REQUIRE(BitSetDescription::make_from_num_bits(1).get_num_bits() == 32);
- REQUIRE(BitSetDescription::make_from_num_bits(31).get_num_bits() == 32);
- REQUIRE(BitSetDescription::make_from_num_bits(32).get_num_bits() == 32);
- REQUIRE(BitSetDescription::make_from_num_bits(33).get_num_bits() == 64);
- REQUIRE(BitSetDescription::make_from_num_bits(64).get_num_bits() == 64);
- REQUIRE(BitSetDescription::make_from_num_bits(65).get_num_bits() == 96);
+ CHECK(BitSetDescription::make_from_num_bits(0).get_size() == 0);
+ CHECK(BitSetDescription::make_from_num_bits(1).get_size() == 1);
+ CHECK(BitSetDescription::make_from_num_bits(31).get_size() == 1);
+ CHECK(BitSetDescription::make_from_num_bits(32).get_size() == 1);
+ CHECK(BitSetDescription::make_from_num_bits(33).get_size() == 2);
+ CHECK(BitSetDescription::make_from_num_bits(64).get_size() == 2);
+ CHECK(BitSetDescription::make_from_num_bits(65).get_size() == 3);
+
+ CHECK(BitSetDescription::make_from_num_bits(0).get_num_bits() == 0);
+ CHECK(BitSetDescription::make_from_num_bits(1).get_num_bits() == 32);
+ CHECK(BitSetDescription::make_from_num_bits(31).get_num_bits() == 32);
+ CHECK(BitSetDescription::make_from_num_bits(32).get_num_bits() == 32);
+ CHECK(BitSetDescription::make_from_num_bits(33).get_num_bits() == 64);
+ CHECK(BitSetDescription::make_from_num_bits(64).get_num_bits() == 64);
+ CHECK(BitSetDescription::make_from_num_bits(65).get_num_bits() == 96);
constexpr BitSetDescription desc = BitSetDescription::make_from_num_bits<64>();
- REQUIRE(desc.get_size() == 2);
- REQUIRE(desc.get_size() == BitSetDescription::make_from_num_bits(64).get_size());
+ CHECK(desc.get_size() == 2);
+ CHECK(desc.get_size() == BitSetDescription::make_from_num_bits(64).get_size());
uint32_t bitset_data[desc.get_size() + 1]; // Add padding
std::memset(&bitset_data[0], 0, sizeof(bitset_data));
bitset_reset(&bitset_data[0], desc, true);
- REQUIRE(bitset_data[0] == 0xFFFFFFFF);
- REQUIRE(bitset_data[1] == 0xFFFFFFFF);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0xFFFFFFFF);
+ CHECK(bitset_data[1] == 0xFFFFFFFF);
+ CHECK(bitset_data[2] == 0);
bitset_data[2] = 0xFFFFFFFF;
bitset_reset(&bitset_data[0], desc, false);
- REQUIRE(bitset_data[0] == 0);
- REQUIRE(bitset_data[1] == 0);
- REQUIRE(bitset_data[2] == 0xFFFFFFFF);
+ CHECK(bitset_data[0] == 0);
+ CHECK(bitset_data[1] == 0);
+ CHECK(bitset_data[2] == 0xFFFFFFFF);
bitset_data[2] = 0;
bitset_set(&bitset_data[0], desc, 0, false);
- REQUIRE(bitset_data[0] == 0);
- REQUIRE(bitset_data[1] == 0);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0);
+ CHECK(bitset_data[1] == 0);
+ CHECK(bitset_data[2] == 0);
bitset_set(&bitset_data[0], desc, 0, true);
- REQUIRE(bitset_data[0] == 0x80000000);
- REQUIRE(bitset_data[1] == 0);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0x80000000);
+ CHECK(bitset_data[1] == 0);
+ CHECK(bitset_data[2] == 0);
bitset_set(&bitset_data[0], desc, 31, true);
- REQUIRE(bitset_data[0] == 0x80000001);
- REQUIRE(bitset_data[1] == 0);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0x80000001);
+ CHECK(bitset_data[1] == 0);
+ CHECK(bitset_data[2] == 0);
bitset_set(&bitset_data[0], desc, 31, false);
- REQUIRE(bitset_data[0] == 0x80000000);
- REQUIRE(bitset_data[1] == 0);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0x80000000);
+ CHECK(bitset_data[1] == 0);
+ CHECK(bitset_data[2] == 0);
bitset_set(&bitset_data[0], desc, 32, true);
- REQUIRE(bitset_data[0] == 0x80000000);
- REQUIRE(bitset_data[1] == 0x80000000);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0x80000000);
+ CHECK(bitset_data[1] == 0x80000000);
+ CHECK(bitset_data[2] == 0);
bitset_set_range(&bitset_data[0], desc, 8, 4, true);
- REQUIRE(bitset_data[0] == 0x80F00000);
- REQUIRE(bitset_data[1] == 0x80000000);
- REQUIRE(bitset_data[2] == 0);
+ CHECK(bitset_data[0] == 0x80F00000);
+ CHECK(bitset_data[1] == 0x80000000);
+ CHECK(bitset_data[2] == 0);
bitset_set_range(&bitset_data[0], desc, 10, 2, false);
- REQUIRE(bitset_data[0] == 0x80C00000);
- REQUIRE(bitset_data[1] == 0x80000000);
- REQUIRE(bitset_data[2] == 0);
-
- REQUIRE(bitset_test(&bitset_data[0], desc, 0) == true);
- REQUIRE(bitset_test(&bitset_data[0], desc, 1) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 2) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 3) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 4) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 5) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 6) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 7) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 8) == true);
- REQUIRE(bitset_test(&bitset_data[0], desc, 9) == true);
- REQUIRE(bitset_test(&bitset_data[0], desc, 10) == false);
- REQUIRE(bitset_test(&bitset_data[0], desc, 11) == false);
+ CHECK(bitset_data[0] == 0x80C00000);
+ CHECK(bitset_data[1] == 0x80000000);
+ CHECK(bitset_data[2] == 0);
+
+ CHECK(bitset_test(&bitset_data[0], desc, 0) == true);
+ CHECK(bitset_test(&bitset_data[0], desc, 1) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 2) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 3) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 4) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 5) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 6) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 7) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 8) == true);
+ CHECK(bitset_test(&bitset_data[0], desc, 9) == true);
+ CHECK(bitset_test(&bitset_data[0], desc, 10) == false);
+ CHECK(bitset_test(&bitset_data[0], desc, 11) == false);
bitset_data[2] = 0xFFFFFFFF;
- REQUIRE(bitset_count_set_bits(&bitset_data[0], desc) == 4);
+ CHECK(bitset_count_set_bits(&bitset_data[0], desc) == 4);
+
+ uint32_t bitset_data1[desc.get_size() + 1]; // Add padding
+ bitset_data[0] = 0x00000010;
+ bitset_data[1] = 0x00100000;
+
+ bitset_data1[0] = 0x10101011;
+ bitset_data1[1] = 0x10101011;
+ bitset_and_not(bitset_data, bitset_data, bitset_data1, desc);
+ CHECK(bitset_data[0] == 0x10101001);
+ CHECK(bitset_data[1] == 0x10001011);
}
diff --git a/tests/sources/math/test_scalar_packing.cpp b/tests/sources/math/test_scalar_packing.cpp
--- a/tests/sources/math/test_scalar_packing.cpp
+++ b/tests/sources/math/test_scalar_packing.cpp
@@ -25,8 +25,18 @@
#include <catch.hpp>
#include <acl/math/scalar_packing.h>
+#include <acl/math/vector4_packing.h>
using namespace acl;
+using namespace rtm;
+
+struct UnalignedBuffer
+{
+ uint32_t padding0;
+ uint16_t padding1;
+ uint8_t buffer[250];
+};
+static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
TEST_CASE("scalar packing math", "[math][scalar][packing]")
{
@@ -63,3 +73,84 @@ TEST_CASE("scalar packing math", "[math][scalar][packing]")
CHECK(num_errors == 0);
}
}
+
+TEST_CASE("unpack_scalarf_96_unsafe", "[math][scalar][packing]")
+{
+ {
+ UnalignedBuffer tmp0;
+ UnalignedBuffer tmp1;
+ vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F, 0.1816253F);
+ pack_vector4_128(vec0, &tmp0.buffer[0]);
+
+ uint32_t x = unaligned_load<uint32_t>(&tmp0.buffer[0]);
+ x = byte_swap(x);
+ unaligned_write(x, &tmp0.buffer[0]);
+
+ uint32_t y = unaligned_load<uint32_t>(&tmp0.buffer[4]);
+ y = byte_swap(y);
+ unaligned_write(y, &tmp0.buffer[4]);
+
+ const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
+ uint32_t num_errors = 0;
+ for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
+ {
+ const uint8_t offset = offsets[offset_idx];
+
+ memcpy_bits(&tmp1.buffer[0], offset, &tmp0.buffer[0], 0, 32);
+ scalarf scalar1 = unpack_scalarf_32_unsafe(&tmp1.buffer[0], offset);
+ if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+
+ memcpy_bits(&tmp1.buffer[0], offset, &tmp0.buffer[4], 0, 32);
+ scalar1 = unpack_scalarf_32_unsafe(&tmp1.buffer[0], offset);
+ if (!scalar_near_equal(vector_get_y(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+ }
+ CHECK(num_errors == 0);
+ }
+}
+
+TEST_CASE("unpack_scalarf_uXX_unsafe", "[math][scalar][packing]")
+{
+ {
+ UnalignedBuffer tmp0;
+ alignas(16) uint8_t buffer[64];
+
+ uint32_t num_errors = 0;
+ vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
+ pack_vector2_uXX_unsafe(vec0, 16, &buffer[0]);
+ scalarf scalar1 = unpack_scalarf_uXX_unsafe(16, &buffer[0], 0);
+ if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+
+ for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ {
+ uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
+ for (uint32_t value = 0; value <= max_value; ++value)
+ {
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+
+ vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
+ pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
+ scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &buffer[0], 0);
+ if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+
+ {
+ const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
+ for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
+ {
+ const uint8_t offset = offsets[offset_idx];
+
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, num_bits * 4);
+ scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
+ if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+ }
+ }
+ }
+ }
+ CHECK(num_errors == 0);
+ }
+}
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -155,7 +155,7 @@ TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
{
- uint8_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -383,7 +383,7 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
{
- uint8_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -450,7 +450,7 @@ TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
{
- uint8_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -519,7 +519,7 @@ TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
{
- uint8_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
diff --git a/tools/release_scripts/test_everything.py b/tools/release_scripts/test_everything.py
--- a/tools/release_scripts/test_everything.py
+++ b/tools/release_scripts/test_everything.py
@@ -21,6 +21,10 @@ def get_python_exe_name():
return 'python3'
if __name__ == "__main__":
+ if sys.version_info < (3, 4):
+ print('Python 3.4 or higher needed to run this script')
+ sys.exit(1)
+
os.environ['PYTHONIOENCODING'] = 'utf_8'
configs = [ 'debug', 'release' ]
|
Refactor the error metric and introduce pose caching
Right now, because we use a virtual function and a custom implementation to transform from local space to object space, it is not possible to cache the object space transforms. This requires us to calculate them over and over when very often, they do not change. By exposing the type used, we can calculate the transforms on demand and cache them. This will speed up compression significantly.
This is a minor API break for those that implement a custom error metric but that is very unlikely.
The error metrics do not handle multiple root bones properly
When calculating the error in object space, we start at the root bone and multiply each child transform in the chain. The code currently assumes 0 as the root bone which is not correct if multiple root bones are present.
This issue only impacts clips that have more than one root bone where the root transforms differ.
| 2019-12-08T00:50:33
|
cpp
|
Hard
|
|
nfrechette/acl
| 230
|
nfrechette__acl-230
|
[
"215"
] |
c083b7306d0a887a2f9b755ef3e88174994a73e3
|
diff --git a/includes/acl/core/bit_manip_utils.h b/includes/acl/core/bit_manip_utils.h
--- a/includes/acl/core/bit_manip_utils.h
+++ b/includes/acl/core/bit_manip_utils.h
@@ -26,25 +26,20 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
+#include "acl/math/math.h"
#include <cstdint>
#if !defined(ACL_USE_POPCOUNT)
- #if defined(ACL_NEON_INTRINSICS) && !defined(_MSC_VER)
- // Enable pop-count type instructions on ARM NEON
- #define ACL_USE_POPCOUNT
- #elif defined(_DURANGO) || defined(_XBOX_ONE)
+ // TODO: Enable this for PlayStation 4 as well, what is the define and can we use it in public code?
+ #if defined(_DURANGO) || defined(_XBOX_ONE)
// Enable pop-count type instructions on Xbox One
#define ACL_USE_POPCOUNT
- // TODO: Enable this for PlayStation 4 as well, what is the define and can we use it in public code?
- // TODO: Enable this for Windows ARM as well, what is the include and intrinsic to use?
#endif
#endif
#if defined(ACL_USE_POPCOUNT)
- #if defined(_MSC_VER)
- #include <nmmintrin.h>
- #endif
+ #include <nmmintrin.h>
#endif
#if defined(ACL_AVX_INTRINSICS)
@@ -61,10 +56,10 @@ namespace acl
{
inline uint8_t count_set_bits(uint8_t value)
{
-#if defined(ACL_USE_POPCOUNT) && defined(_MSC_VER)
+#if defined(ACL_USE_POPCOUNT)
return (uint8_t)_mm_popcnt_u32(value);
-#elif defined(ACL_USE_POPCOUNT) && (defined(__GNUC__) || defined(__clang__))
- return (uint8_t)__builtin_popcount(value);
+#elif defined(ACL_NEON_INTRINSICS)
+ return (uint8_t)vget_lane_u64(vcnt_u8(vcreate_u8(value)), 0);
#else
value = value - ((value >> 1) & 0x55);
value = (value & 0x33) + ((value >> 2) & 0x33);
@@ -74,10 +69,10 @@ namespace acl
inline uint16_t count_set_bits(uint16_t value)
{
-#if defined(ACL_USE_POPCOUNT) && defined(_MSC_VER)
+#if defined(ACL_USE_POPCOUNT)
return (uint16_t)_mm_popcnt_u32(value);
-#elif defined(ACL_USE_POPCOUNT) && (defined(__GNUC__) || defined(__clang__))
- return (uint16_t)__builtin_popcount(value);
+#elif defined(ACL_NEON_INTRINSICS)
+ return (uint16_t)vget_lane_u64(vpaddl_u8(vcnt_u8(vcreate_u8(value))), 0);
#else
value = value - ((value >> 1) & 0x5555);
value = (value & 0x3333) + ((value >> 2) & 0x3333);
@@ -87,10 +82,10 @@ namespace acl
inline uint32_t count_set_bits(uint32_t value)
{
-#if defined(ACL_USE_POPCOUNT) && defined(_MSC_VER)
+#if defined(ACL_USE_POPCOUNT)
return _mm_popcnt_u32(value);
-#elif defined(ACL_USE_POPCOUNT) && (defined(__GNUC__) || defined(__clang__))
- return __builtin_popcount(value);
+#elif defined(ACL_NEON_INTRINSICS)
+ return (uint32_t)vget_lane_u64(vpaddl_u16(vpaddl_u8(vcnt_u8(vcreate_u8(value)))), 0);
#else
value = value - ((value >> 1) & 0x55555555);
value = (value & 0x33333333) + ((value >> 2) & 0x33333333);
@@ -100,10 +95,10 @@ namespace acl
inline uint64_t count_set_bits(uint64_t value)
{
-#if defined(ACL_USE_POPCOUNT) && defined(_MSC_VER)
+#if defined(ACL_USE_POPCOUNT)
return _mm_popcnt_u64(value);
-#elif defined(ACL_USE_POPCOUNT) && (defined(__GNUC__) || defined(__clang__))
- return __builtin_popcountll(value);
+#elif defined(ACL_NEON_INTRINSICS)
+ return vget_lane_u64(vpaddl_u32(vpaddl_u16(vpaddl_u8(vcnt_u8(vcreate_u8(value))))), 0);
#else
value = value - ((value >> 1) & 0x5555555555555555ull);
value = (value & 0x3333333333333333ull) + ((value >> 2) & 0x3333333333333333ull);
diff --git a/includes/acl/core/bitset.h b/includes/acl/core/bitset.h
--- a/includes/acl/core/bitset.h
+++ b/includes/acl/core/bitset.h
@@ -190,6 +190,8 @@ namespace acl
{
const uint32_t size = desc.get_size();
+ // TODO: Optimize for NEON by using the intrinsic directly and unrolling the loop to
+ // reduce the number of pairwise add instructions.
uint32_t num_set_bits = 0;
for (uint32_t offset = 0; offset < size; ++offset)
num_set_bits += count_set_bits(bitset[offset]);
|
diff --git a/tests/sources/core/test_bit_manip_utils.cpp b/tests/sources/core/test_bit_manip_utils.cpp
--- a/tests/sources/core/test_bit_manip_utils.cpp
+++ b/tests/sources/core/test_bit_manip_utils.cpp
@@ -26,8 +26,6 @@
#include <acl/core/bit_manip_utils.h>
-//#include <cstring>
-
using namespace acl;
TEST_CASE("bit_manip_utils", "[core][utils]")
@@ -40,16 +38,19 @@ TEST_CASE("bit_manip_utils", "[core][utils]")
REQUIRE(count_set_bits(uint16_t(0x0000)) == 0);
REQUIRE(count_set_bits(uint16_t(0x0001)) == 1);
REQUIRE(count_set_bits(uint16_t(0x1000)) == 1);
+ REQUIRE(count_set_bits(uint16_t(0x1001)) == 2);
REQUIRE(count_set_bits(uint16_t(0xFFFF)) == 16);
REQUIRE(count_set_bits(uint32_t(0x00000000)) == 0);
REQUIRE(count_set_bits(uint32_t(0x00000001)) == 1);
REQUIRE(count_set_bits(uint32_t(0x10000000)) == 1);
+ REQUIRE(count_set_bits(uint32_t(0x10101001)) == 4);
REQUIRE(count_set_bits(uint32_t(0xFFFFFFFF)) == 32);
REQUIRE(count_set_bits(uint64_t(0x0000000000000000ull)) == 0);
REQUIRE(count_set_bits(uint64_t(0x0000000000000001ull)) == 1);
REQUIRE(count_set_bits(uint64_t(0x1000000000000000ull)) == 1);
+ REQUIRE(count_set_bits(uint64_t(0x1000100001010101ull)) == 6);
REQUIRE(count_set_bits(uint64_t(0xFFFFFFFFFFFFFFFFull)) == 64);
REQUIRE(rotate_bits_left(0x00000010, 0) == 0x00000010);
|
Enable popcount support for Windows ARM
`_mm_popcnt_u*` and `__builtin_popcount*` aren't supported by MSVC.
Find the correct header and intrinsic to use for that platform.
|
See this commit and comments for details: https://github.com/nfrechette/acl/commit/610c424dcf99005dc880726e0388af010ae4e9c9
| 2019-11-01T04:48:11
|
cpp
|
Hard
|
nfrechette/acl
| 300
|
nfrechette__acl-300
|
[
"168"
] |
640a1aa7f1f7e44462f1cb896598c56b248a25fd
|
diff --git a/cmake/CMakeCompiler.cmake b/cmake/CMakeCompiler.cmake
--- a/cmake/CMakeCompiler.cmake
+++ b/cmake/CMakeCompiler.cmake
@@ -60,6 +60,12 @@ macro(setup_default_compiler_flags _project_name)
target_compile_options(${_project_name} PRIVATE -Wshadow) # Enable shadowing warnings
target_compile_options(${_project_name} PRIVATE -Werror) # Treat warnings as errors
- target_compile_options(${_project_name} PRIVATE -g) # Enable debug symbols
+ if (PLATFORM_EMSCRIPTEN)
+ # Remove '-g' from compilation flags since it sometimes crashes the compiler
+ string(REPLACE "-g" "" CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG}")
+ string(REPLACE "-g" "" CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE}")
+ else()
+ target_compile_options(${_project_name} PRIVATE -g) # Enable debug symbols
+ endif()
endif()
endmacro()
diff --git a/docs/README.md b/docs/README.md
--- a/docs/README.md
+++ b/docs/README.md
@@ -8,13 +8,9 @@ ACL aims to support a few core algorithms that are well suited for production us
* [Handling asserts](handling_asserts.md)
* [Implementing an allocator](implementing_an_allocator.md)
-* [Creating a skeleton](creating_a_skeleton.md)
-* [Creating a raw clip](creating_a_raw_clip.md)
-* [Compressing a raw clip](compressing_a_raw_clip.md)
-* [Decompressing a clip](decompressing_a_clip.md)
* [Creating a raw track list](creating_a_raw_track_list.md)
-* [Compressing scalar tracks](compressing_scalar_tracks.md)
-* [Decompressing scalar tracks](decompressing_a_track_list.md)
+* [Compressing tracks](compressing_raw_tracks.md)
+* [Decompressing tracks](decompressing_a_track_list.md)
* [Other considerations](misc_integration_details.md)
See how it's integrated into Unreal Engine 4 [here](https://github.com/nfrechette/acl-ue4-plugin)!
diff --git a/docs/compressing_a_raw_clip.md b/docs/compressing_raw_tracks.md
similarity index 52%
rename from docs/compressing_a_raw_clip.md
rename to docs/compressing_raw_tracks.md
--- a/docs/compressing_a_raw_clip.md
+++ b/docs/compressing_raw_tracks.md
@@ -1,23 +1,42 @@
-# Compressing a raw clip
+# Compressing scalar tracks
-Once you have created a [raw animation clip instance](creating_a_raw_clip.md) and an [allocator instance](implementing_an_allocator.md), you are ready to compress it. In order to do so, you simply have to pick the algorithm you will use and a set of compression settings.
+Once you have created a [raw track list](creating_a_raw_track_list.md) and an [allocator instance](implementing_an_allocator.md), you are ready to compress it.
For now, we only implement a single algorithm: [uniformly sampled](algorithm_uniformly_sampled.md). This is a simple and excellent algorithm to use for everyday animation clips.
+## Compressing scalar tracks
+
+*Compression settings are currently required as an argument but not used by scalar tracks. It is a placeholder.*
+*Segmenting is currently not supported by scalar tracks.*
+
+```c++
+#include <acl/compression/compress.h>
+
+using namespace acl;
+
+compression_settings settings;
+
+OutputStats stats;
+compressed_tracks* out_compressed_tracks = nullptr;
+ErrorResult result = compress_track_list(allocator, raw_track_list, settings, out_compressed_tracks, stats);
+```
+
+## Compressing transform tracks
+
The compression level used will dictate how much time to spend optimizing the variable bit rates. Lower levels are faster but produce a larger compressed size.
While we support various [rotation and vector quantization formats](rotation_and_vector_formats.md), the *variable* variants are generally the best. It is safe to use them for all your clips but if you do happen to run into issues with some exotic clips, you can easily fallback to less aggressive variants.
Selecting the right [error metric](error_metrics.md) is important and you will want to carefully pick the one that best approximates how your game engine performs skinning.
-The last important setting to choose is the `error_threshold`. This is used in conjunction with the error metric and the virtual vertex distance from the [skeleton](creating_a_skeleton.md) in order to guarantee that a certain quality is maintained. A default value of **0.01cm** is safe to use and it most likely should never be changed unless the units you are using differ. If you do run into issues where compression artifacts are visible, in all likelihood the virtual vertex distance used on the problematic bones is not conservative enough.
+The last important setting to choose is the `error_threshold`. This is used in conjunction with the error metric and the virtual vertex distance (shell distance) in order to guarantee that a certain quality is maintained. A default value of **0.01cm** is safe to use and it most likely should never be changed unless the units you are using differ. If you do run into issues where compression artifacts are visible, in all likelihood the virtual vertex distance used on the problematic bones is not conservative enough.
```c++
-#include <acl/algorithm/uniformly_sampled/encoder.h>
+#include <acl/compression/compress.h>
using namespace acl;
-CompressionSettings settings;
+compression_settings settings;
settings.level = compression_level8::medium;
settings.rotation_format = rotation_format8::quatf_drop_w_variable;
settings.translation_format = vector_format8::vector3f_variable;
@@ -26,9 +45,9 @@ settings.scale_format = vector_format8::vector3f_variable;
qvvf_transform_error_metric error_metric;
settings.error_metric = &error_metric;
-OutputStats stats;
-CompressedClip* compressed_clip = nullptr;
-ErrorResult error_result = uniformly_sampled::compress_clip(allocator, raw_clip, settings, compressed_clip, stats);
+output_stats stats;
+compressed_tracks* out_compressed_tracks = nullptr;
+error_result result = compress_track_list(allocator, raw_track_list, settings, out_compressed_tracks, stats);
```
You can also query the current default and recommended settings with this function: `get_default_compression_settings()`.
diff --git a/docs/compressing_scalar_tracks.md b/docs/compressing_scalar_tracks.md
deleted file mode 100644
--- a/docs/compressing_scalar_tracks.md
+++ /dev/null
@@ -1,19 +0,0 @@
-# Compressing scalar tracks
-
-Once you have created a [raw track list](creating_a_raw_track_list.md) and an [allocator instance](implementing_an_allocator.md), you are ready to compress it.
-
-For now, we only implement a single algorithm: [uniformly sampled](algorithm_uniformly_sampled.md). This is a simple and excellent algorithm to use for everyday animation clips. Segmenting is currently not supported.
-
-Compression settings are currently required as an argument but not used. It is a placeholder.
-
-```c++
-#include <acl/compression/compress.h>
-
-using namespace acl;
-
-compression_settings settings;
-
-OutputStats stats;
-compressed_tracks* out_compressed_tracks = nullptr;
-ErrorResult error_result = compress_track_list(allocator, raw_track_list, settings, out_compressed_tracks, stats);
-```
diff --git a/docs/creating_a_raw_clip.md b/docs/creating_a_raw_clip.md
deleted file mode 100644
--- a/docs/creating_a_raw_clip.md
+++ /dev/null
@@ -1,44 +0,0 @@
-# Creating a raw clip
-
-Once you have [created a rigid skeleton](creating_a_skeleton.md), the next step is to create a raw clip and populate it with the data we will want to compress. Doing so is fairly straight forward and you will only need a few things:
-
-* [An allocator instance](implementing_an_allocator.md)
-* [A rigid skeleton](creating_a_skeleton.md)
-* The number of samples per track (each track has the same number of samples)
-* The rate at which samples are recorded (e.g. 30 == 30 FPS)
-* An optional string for the clip name
-
-```c++
-uint32_t num_samples_per_track = 20;
-float sample_rate = 30.0f;
-String name(allocator, "Run Cycle");
-AnimationClip clip(allocator, skeleton, num_samples_per_track, sample_rate, name);
-```
-
-Once you have created an instance, simply populate the track data. Note that for now, even if you have no scale data, you have to populate the scale track with the default scale value that your engine expects.
-
-```c++
-AnimatedBone& bone = clip.get_animated_bone(bone_index);
-for (uint32_t sample_index = 0; sample_index < num_samples_per_track; ++sample_index)
-{
- bone.rotation_track.set_sample(sample_index, quat_identity_64());
- bone.translation_track.set_sample(sample_index, vector_zero_64());
- bone.scale_track.set_sample(sample_index, vector_set(1.0));
-}
-```
-
-Once your raw clip has been populated with data, it is ready for [compression](compressing_a_raw_clip.md). The data contained within the `AnimationClip` will be read-only.
-
-*Note: The current API is subject to change for **v2.0**. As it stands right now, it forces you to duplicate the memory of the raw clip by copying everything within the library instance. A future API will allow the game engine to own the raw clip memory and have ACL simply reference it directly, avoiding the overhead of a copy.*
-
-## Additive animation clips
-
-If the clip you are compressing is an additive clip, you will also need to create an instance for the base clip. Once you have both clip instances, you link them together by calling `set_additive_base(..)` on the additive clip. This will allow you to specify the clip instance that represents the base clip as well as the [format](additive_clips.md) used by the additive clip.
-
-The library assumes that the raw clip data has already been transformed to be in additive or relative space.
-
-## Re-ordering or stripping bones
-
-Sometimes it is desirable to re-order the bones being outputted or strip them altogether. This could be to facilitate LOD support or various forms of skeleton changes without needing to re-import the clips. This is easily achieved by setting the desired `output_index` on each `AnimatedBone` contained in an `AnimationClip`. The default value is the bone index. You can use `k_invalid_bone_index` to strip the bone from the final compressed output.
-
-*Note that each `output_index` needs to be unique and there can be no gaps. If **20** bones are outputted, the indices must run from **[0 .. 20)**.*
\ No newline at end of file
diff --git a/docs/creating_a_raw_track_list.md b/docs/creating_a_raw_track_list.md
--- a/docs/creating_a_raw_track_list.md
+++ b/docs/creating_a_raw_track_list.md
@@ -24,12 +24,20 @@ Once you have created an instance, simply populate the track data. Note that at
Each track requires a track description. It contains a number of important properties:
* `output_index`: after compression, this is the index of the track. This allows re-ordering for LOD processing and other similar use cases.
+* `parent_index`: for transform tracks, indicates the parent transform index it is relative to (in local space of).
* `precision`: the precision we aim to attain when optimizing the bit rate. The resulting compression error is nearly guaranteed to be below this threshold.
+* `shell_distance`: for transform tracks, indicates the distance at which we measure the error, see [error metric function](error_metrics.md).
```c++
track_desc_scalarf desc0;
desc0.output_index = 0;
desc0.precision = 0.001F;
+
+track_desc_transformf desc1;
+desc1.output_index = 0;
+desc1.parent_index = 0;
+desc1.precision = 0.01F;
+desc1.shell_distance = 3.0F;
```
Tracks can be created in one of four ways:
@@ -51,7 +59,19 @@ raw_track0[3] = rtm::float3f{ 4.5F, 91.13F, 41.135F };
raw_track_list[0] = std::move(raw_track0);
```
-Once your raw track list has been populated with data, it is ready for [compression](compressing_scalar_tracks.md). The data contained within the `track_array` will be read-only.
+Once your raw track list has been populated with data, it is ready for [compression](compressing_raw_tracks.md). The data contained within the `track_array` will be read-only.
+
+## Additive animation clips
+
+If the clip you are compressing is an additive clip, you will also need to create an instance for the base clip. Once you have both clip instances, you can compress them together with `compress_track_list(..)`. This will allow you to specify the clip instance that represents the base clip as well as the [format](additive_clips.md) used by the additive clip.
+
+The library assumes that the raw clip data has already been transformed to be in additive or relative space.
+
+## Re-ordering or stripping bones
+
+Sometimes it is desirable to re-order the bones being outputted or strip them altogether. This could be to facilitate LOD support or various forms of skeleton changes without needing to re-import the clips. This is easily achieved by setting the desired `output_index` on each `AnimatedBone` contained in an `AnimationClip`. The default value is the bone index. You can use `k_invalid_bone_index` to strip the bone from the final compressed output.
+
+*Note that each `output_index` needs to be unique and there can be no gaps. If **20** bones are outputted, the indices must run from **[0 .. 20)**.*
## Compressing morph target blend weights
diff --git a/docs/creating_a_skeleton.md b/docs/creating_a_skeleton.md
deleted file mode 100644
--- a/docs/creating_a_skeleton.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Creating a rigid skeleton
-
-After you have found an [allocator instance](implementing_an_allocator.md) to use, you will need to create a `RigidSkeleton` instance. A skeleton is a tree made up of several bones. At the root lies at least one bone with no parent. Each bone that follows can have any number of children but a single parent. You will only need a few things per bone:
-
-* A virtual vertex distance
-* A parent bone index
-* An optional bind transform
-* An optional string for the bone name
-
-The virtual vertex distance is used by the [error metric function](error_metrics.md). It will measure the error of a vertex at that particular distance from the bone in object space. This distance should be large enough to contain the vast majority of the visible vertices skinned on that particular bone. The algorithm ensures that all vertices contained up to this distance will have an error lower than the supplied error threshold in the `CompressionSettings`. It is generally sufficient for this value to be approximate and it is often safe to use the same value for every bone in humanoid characters. A value of **3cm** is good enough for cinematographic quality for most characters. While visible vertices around the torso will often be further away than this, finger tips and facial bones will be closer than that. Because the compressed track data is stored in relative space of the parent bone, any error will accumulate down the hierarchy. This means that in order to keep the leaf bones within that accuracy threshold, all the parent bones in that chain will require even higher accuracy.
-
-The bind transform is present mainly for debugging purposes and it is otherwise not used by the library. The bone name is present exclusively for debugging purposes as well.
-
-```c++
-RigidBone bones[num_bones];
-for (int bone_index = 0; bone_index < num_bones; ++bone_index)
-{
- if (bone_index != 0)
- bones[bone_index].parent_index = bone_index - 1; // Single bone chain
-
- bones[bone_index].vertex_distance = 3.0f;
-}
-
-RigidSkeleton(allocator, bones, num_bones);
-```
-
-*Note: The current API is subject to change for v2.0.*
diff --git a/docs/decompressing_a_clip.md b/docs/decompressing_a_clip.md
deleted file mode 100644
--- a/docs/decompressing_a_clip.md
+++ /dev/null
@@ -1,33 +0,0 @@
-# Decompressing a clip
-
-Once you have a [compressed clip](compressing_a_raw_clip.md), the first order of business to decompress it is to select a set of `DecompressionSettings`. The decompression settings `struct` is populated with `constexpr` functions that can be overridden to turn on or off the code generation per feature. For example, the default decompression settings disable all the code for packing formats that are not variable. For the uniformly sampled algorithm, see [here](../includes/acl/algorithm/uniformly_sampled/decoder.h) for details.
-
-The next thing you need is a `DecompressionContext` instance. This will allow you to actually decompress poses, bones, and tracks. You can also use it to seek arbitrarily in the clip. For safety, the decompression context is templated with the decompression settings.
-
-```c++
-using namespace acl;
-using namespace acl::uniformly_sampled;
-
-DecompressionContext<DefaultDecompressionSettings> context;
-
-context.initialize(*compressed_clip);
-context.seek(sample_time, sample_rounding_policy::none);
-
-context.decompress_bone(bone_index, &rotation, &translation, &scale);
-```
-
-As shown, a context must be initialized with a compressed clip instance. Some context objects such as the one used by uniform sampling can be re-used by any compressed clip and does not need to be re-created while others might require this. In order to detect when this might be required, the function `is_dirty(const CompressedClip& clip)` is provided. Some context objects cannot be created on the stack and must be dynamically allocated with an allocator instance. The functions `make_decompression_context(...)` are provided for this purpose.
-
-You can seek anywhere in a clip but you will need to handle looping manually in your game engine. When seeking, you must also provide a `sample_rounding_policy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
-
-Every decompression function supported by the context is prefixed with `decompress_`. Uniform sampling supports decompressing a whole pose with a custom `OutputWriter` for optimized pose writing. You can implement your own and coerce to your own math types. The type is templated on the `decompress_pose` function in order to be easily inlined.
-
-```c++
-Transform_32* transforms = new Transform_32[num_bones];
-DefaultOutputWriter pose_writer(transforms, num_bones);
-context.decompress_pose(pose_writer);
-```
-
-## Floating point exceptions
-
-For performance reasons, the decompression code assumes that the caller has already disabled all floating point exceptions. This avoids the need to save/restore them with every call. ACL provides helpers in [acl/core/floating_point_exceptions.h](..\includes\acl\core\floating_point_exceptions.h) to assist and optionally this behavior can be controlled by overriding `DecompressionSettings::disable_fp_exeptions()`.
diff --git a/docs/decompressing_a_track_list.md b/docs/decompressing_a_track_list.md
--- a/docs/decompressing_a_track_list.md
+++ b/docs/decompressing_a_track_list.md
@@ -1,6 +1,6 @@
# Decompressing a track list
-Once you have a [compressed track list](compressing_scalar_tracks.md), the first order of business to decompress it is to select a set of `decompression_settings`. The decompression settings `struct` is populated with `constexpr` functions that can be overridden to turn on or off the code generation per feature.
+Once you have a [compressed track list](compressing_raw_tracks.md), the first order of business to decompress it is to select a set of `decompression_settings`. The decompression settings `struct` is populated with `constexpr` functions that can be overridden to turn on or off the code generation per feature.
The next thing you need is a `decompression_context` instance. This will allow you to actually decompress tracks. You can also use it to seek arbitrarily in the list. For safety, the decompression context is templated with the decompression settings.
diff --git a/docs/error_metrics.md b/docs/error_metrics.md
--- a/docs/error_metrics.md
+++ b/docs/error_metrics.md
@@ -1,6 +1,6 @@
# Transform error metric
-A proper error metric is central to every animation compression algorithm and ACL is no different. The general technique implemented is the one described on this [blog post](https://nfrechette.github.io/2016/11/01/anim_compression_accuracy/) and the various implementations as well as the interfaces live [here](../includes/acl/compression/skeleton_error_metric.h).
+A proper error metric is central to every animation compression algorithm and ACL is no different. The general technique implemented is the one described on this [blog post](https://nfrechette.github.io/2016/11/01/anim_compression_accuracy/) and the various implementations as well as the interfaces live [here](../includes/acl/compression/transform_error_metrics.h).
Some care must be taken when selecting which error metric to use. If the error it calculates isn't representative of how it would be calculated in the host game engine, the resulting visual fidelity might suffer. ACL implements a number of popular implementations and you are free to implement and use your own. The `qvvf_transform_error_metric` error metric is a sensible default.
diff --git a/external/sjson-cpp b/external/sjson-cpp
--- a/external/sjson-cpp
+++ b/external/sjson-cpp
@@ -1 +1 @@
-Subproject commit d6300b20f13d7752c24f25a1e2094fa5ead44c7d
+Subproject commit cc08f4ce82cedd0cdaeff02722e8b361db514920
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
deleted file mode 100644
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ /dev/null
@@ -1,923 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/bitset.h"
-#include "acl/core/bit_manip_utils.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_clip.h"
-#include "acl/core/floating_point_exceptions.h"
-#include "acl/core/iallocator.h"
-#include "acl/core/interpolation_utils.h"
-#include "acl/core/range_reduction_types.h"
-#include "acl/core/utils.h"
-#include "acl/math/quat_packing.h"
-#include "acl/decompression/impl/decompress_data.h"
-#include "acl/decompression/output_writer.h"
-
-#include <rtm/quatf.h>
-#include <rtm/vector4f.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-//////////////////////////////////////////////////////////////////////////
-// See encoder for details
-//////////////////////////////////////////////////////////////////////////
-
-namespace acl
-{
- namespace uniformly_sampled
- {
- // 2 ways to encore a track as default: a bitset or omit the track
- // the second method requires a track id to be present to distinguish the
- // remaining tracks.
- // For a character, about 50-90 tracks are animated.
- // We ideally want to support more than 255 tracks or bones.
- // 50 * 16 bits = 100 bytes
- // 90 * 16 bits = 180 bytes
- // On the other hand, a character has about 140-180 bones, or 280-360 tracks (rotation/translation only)
- // 280 * 1 bit = 35 bytes
- // 360 * 1 bit = 45 bytes
- // It is obvious that storing a bitset is much more compact
- // A bitset also allows us to process and write track values in the order defined when compressed
- // unlike the track id method which makes it impossible to know which values are default until
- // everything has been decompressed (at which point everything else is default).
- // For the track id method to be more compact, an unreasonable small number of tracks would need to be
- // animated or constant compared to the total possible number of tracks. Those are likely to be rare.
-
- namespace acl_impl
- {
- RTM_DISABLE_SECURITY_COOKIE_CHECK inline rtm::quatf RTM_SIMD_CALL quat_lerp_no_normalization(rtm::quatf_arg0 start, rtm::quatf_arg1 end, float alpha) RTM_NO_EXCEPT
- {
- using namespace rtm;
-
-#if defined(RTM_SSE2_INTRINSICS)
- // Calculate the vector4 dot product: dot(start, end)
- __m128 dot;
-#if defined(RTM_SSE4_INTRINSICS)
- // The dpps instruction isn't as accurate but we don't care here, we only need the sign of the
- // dot product. If both rotations are on opposite ends of the hypersphere, the result will be
- // very negative. If we are on the edge, the rotations are nearly opposite but not quite which
- // means that the linear interpolation here will have terrible accuracy to begin with. It is designed
- // for interpolating rotations that are reasonably close together. The bias check is mainly necessary
- // because the W component is often kept positive which flips the sign.
- // Using the dpps instruction reduces the number of registers that we need and helps the function get
- // inlined.
- dot = _mm_dp_ps(start, end, 0xFF);
-#else
- {
- __m128 x2_y2_z2_w2 = _mm_mul_ps(start, end);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
- // Shuffle the dot product to all SIMD lanes, there is no _mm_and_ss and loading
- // the constant from memory with the 'and' instruction is faster, it uses fewer registers
- // and fewer instructions
- dot = _mm_shuffle_ps(x2y2z2w2_0_0_0, x2y2z2w2_0_0_0, _MM_SHUFFLE(0, 0, 0, 0));
- }
-#endif
-
- // Calculate the bias, if the dot product is positive or zero, there is no bias
- // but if it is negative, we want to flip the 'end' rotation XYZW components
- __m128 bias = _mm_and_ps(dot, _mm_set_ps1(-0.0F));
-
- // Lerp the rotation after applying the bias
- // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
- __m128 alpha_ = _mm_set_ps1(alpha);
- __m128 interpolated_rotation = _mm_add_ps(_mm_sub_ps(start, _mm_mul_ps(alpha_, start)), _mm_mul_ps(alpha_, _mm_xor_ps(end, bias)));
-
- // Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards before using
- return interpolated_rotation;
-#elif defined (RTM_NEON64_INTRINSICS)
- // On ARM64 with NEON, we load 1.0 once and use it twice which is faster than
- // using a AND/XOR with the bias (same number of instructions)
- float dot = vector_dot(start, end);
- float bias = dot >= 0.0F ? 1.0F : -1.0F;
-
- // ((1.0 - alpha) * start) + (alpha * (end * bias)) == (start - alpha * start) + (alpha * (end * bias))
- vector4f interpolated_rotation = vector_mul_add(vector_mul(end, bias), alpha, vector_neg_mul_sub(start, alpha, start));
-
- // Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards before using
- return interpolated_rotation;
-#elif defined(RTM_NEON_INTRINSICS)
- // Calculate the vector4 dot product: dot(start, end)
- float32x4_t x2_y2_z2_w2 = vmulq_f32(start, end);
- float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
- float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
- float32x2_t x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
- float32x2_t x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
-
- // Calculate the bias, if the dot product is positive or zero, there is no bias
- // but if it is negative, we want to flip the 'end' rotation XYZW components
- // On ARM-v7-A, the AND/XOR trick is faster than the cmp/fsel
- uint32x2_t bias = vand_u32(vreinterpret_u32_f32(x2y2z2w2), vdup_n_u32(0x80000000));
-
- // Lerp the rotation after applying the bias
- // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
- float32x4_t end_biased = vreinterpretq_f32_u32(veorq_u32(vreinterpretq_u32_f32(end), vcombine_u32(bias, bias)));
- float32x4_t interpolated_rotation = vmlaq_n_f32(vmlsq_n_f32(start, start, alpha), end_biased, alpha);
-
- // Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards before using
- return interpolated_rotation;
-#else
- // To ensure we take the shortest path, we apply a bias if the dot product is negative
- vector4f start_vector = quat_to_vector(start);
- vector4f end_vector = quat_to_vector(end);
- float dot = vector_dot(start_vector, end_vector);
- float bias = dot >= 0.0F ? 1.0F : -1.0F;
- // ((1.0 - alpha) * start) + (alpha * (end * bias)) == (start - alpha * start) + (alpha * (end * bias))
- vector4f interpolated_rotation = vector_mul_add(vector_mul(end_vector, bias), alpha, vector_neg_mul_sub(start_vector, alpha, start_vector));
-
- // Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards before using
- return vector_to_quat(interpolated_rotation);
-#endif
- }
-
- constexpr size_t k_cache_line_size = 64;
-
- struct alignas(k_cache_line_size) DecompressionContext
- {
- // Clip related data // offsets
- const CompressedClip* clip; // 0 | 0
-
- const uint32_t* constant_tracks_bitset; // 4 | 8
- const uint8_t* constant_track_data; // 8 | 16
- const uint32_t* default_tracks_bitset; // 12 | 24
-
- const uint8_t* clip_range_data; // 16 | 32
-
- float clip_duration; // 20 | 40
-
- BitSetDescription bitset_desc; // 24 | 44
-
- uint32_t clip_hash; // 28 | 48
-
- range_reduction_flags8 range_reduction; // 32 | 52
- uint8_t num_rotation_components; // 33 | 53
-
- uint8_t padding0[2]; // 34 | 54
-
- // Seeking related data
- const uint8_t* format_per_track_data[2]; // 36 | 56
- const uint8_t* segment_range_data[2]; // 44 | 72
- const uint8_t* animated_track_data[2]; // 52 | 88
-
- uint32_t key_frame_bit_offsets[2]; // 60 | 104
-
- float interpolation_alpha; // 68 | 112
- float sample_time; // 76 | 120
-
- uint8_t padding1[sizeof(void*) == 4 ? 52 : 4]; // 80 | 124
-
- // Total size: 128 | 128
- };
-
- static_assert(sizeof(DecompressionContext) == 128, "Unexpected size");
-
- struct alignas(k_cache_line_size) SamplingContext
- {
- static constexpr size_t k_num_samples_to_interpolate = 2;
-
- inline static rtm::quatf RTM_SIMD_CALL interpolate_rotation(rtm::quatf_arg0 rotation0, rtm::quatf_arg1 rotation1, float interpolation_alpha)
- {
- return rtm::quat_lerp(rotation0, rotation1, interpolation_alpha);
- }
-
- inline static rtm::quatf RTM_SIMD_CALL interpolate_rotation_no_normalization(rtm::quatf_arg0 rotation0, rtm::quatf_arg1 rotation1, float interpolation_alpha)
- {
- return quat_lerp_no_normalization(rotation0, rotation1, interpolation_alpha);
- }
-
- inline static rtm::quatf RTM_SIMD_CALL interpolate_rotation(rtm::quatf_arg0 rotation0, rtm::quatf_arg1 rotation1, rtm::quatf_arg2 rotation2, rtm::quatf_arg3 rotation3, float interpolation_alpha)
- {
- (void)rotation1;
- (void)rotation2;
- (void)rotation3;
- (void)interpolation_alpha;
- return rotation0; // Not implemented, we use linear interpolation
- }
-
- inline static rtm::vector4f RTM_SIMD_CALL interpolate_vector4(rtm::vector4f_arg0 vector0, rtm::vector4f_arg1 vector1, float interpolation_alpha)
- {
- return rtm::vector_lerp(vector0, vector1, interpolation_alpha);
- }
-
- inline static rtm::vector4f RTM_SIMD_CALL interpolate_vector4(rtm::vector4f_arg0 vector0, rtm::vector4f_arg1 vector1, rtm::vector4f_arg2 vector2, rtm::vector4f_arg3 vector3, float interpolation_alpha)
- {
- (void)vector1;
- (void)vector2;
- (void)vector3;
- (void)interpolation_alpha;
- return vector0; // Not implemented, we use linear interpolation
- }
-
- // // offsets
- uint32_t track_index; // 0 | 0
- uint32_t constant_track_data_offset; // 4 | 4
- uint32_t clip_range_data_offset; // 8 | 8
-
- uint32_t format_per_track_data_offset; // 12 | 12
- uint32_t segment_range_data_offset; // 16 | 16
-
- uint32_t key_frame_bit_offsets[2]; // 20 | 20
-
- uint8_t padding[4]; // 28 | 28
-
- rtm::vector4f vectors[k_num_samples_to_interpolate]; // 32 | 32
-
- // Total size: 64 | 64
- };
-
- static_assert(sizeof(SamplingContext) == 64, "Unexpected size");
-
- // We use adapters to wrap the DecompressionSettings
- // This allows us to re-use the code for skipping and decompressing Vector3 samples
- // Code generation will generate specialized code for each specialization
- template<class SettingsType>
- struct TranslationDecompressionSettingsAdapter
- {
- explicit TranslationDecompressionSettingsAdapter(const SettingsType& settings_) : settings(settings_) {}
-
- constexpr range_reduction_flags8 get_range_reduction_flag() const { return range_reduction_flags8::translations; }
- rtm::vector4f RTM_SIMD_CALL get_default_value() const { return rtm::vector_zero(); }
- vector_format8 get_vector_format(const ClipHeader& header) const { return settings.get_translation_format(header.translation_format); }
- bool is_vector_format_supported(vector_format8 format) const { return settings.is_translation_format_supported(format); }
- bool are_range_reduction_flags_supported(range_reduction_flags8 flags) const { return settings.are_range_reduction_flags_supported(flags); }
-
- SettingsType settings;
- };
-
- template<class SettingsType>
- struct ScaleDecompressionSettingsAdapter
- {
- explicit ScaleDecompressionSettingsAdapter(const SettingsType& settings_, const ClipHeader& header)
- : settings(settings_)
- , default_scale(header.default_scale ? rtm::vector_set(1.0F) : rtm::vector_zero())
- {}
-
- constexpr range_reduction_flags8 get_range_reduction_flag() const { return range_reduction_flags8::scales; }
- rtm::vector4f RTM_SIMD_CALL get_default_value() const { return default_scale; }
- vector_format8 get_vector_format(const ClipHeader& header) const { return settings.get_scale_format(header.scale_format); }
- bool is_vector_format_supported(vector_format8 format) const { return settings.is_scale_format_supported(format); }
- bool are_range_reduction_flags_supported(range_reduction_flags8 flags) const { return settings.are_range_reduction_flags_supported(flags); }
-
- SettingsType settings;
- uint8_t padding[get_required_padding<SettingsType, rtm::vector4f>()];
- rtm::vector4f default_scale;
- };
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Deriving from this struct and overriding these constexpr functions
- // allow you to control which code is stripped for maximum performance.
- // With these, you can:
- // - Support only a subset of the formats and statically strip the rest
- // - Force a single format and statically strip the rest
- // - Decide all of this at runtime by not making the overrides constexpr
- //
- // By default, all formats are supported.
- //////////////////////////////////////////////////////////////////////////
- struct DecompressionSettings
- {
- constexpr bool is_rotation_format_supported(rotation_format8 /*format*/) const { return true; }
- constexpr bool is_translation_format_supported(vector_format8 /*format*/) const { return true; }
- constexpr bool is_scale_format_supported(vector_format8 /*format*/) const { return true; }
- constexpr rotation_format8 get_rotation_format(rotation_format8 format) const { return format; }
- constexpr vector_format8 get_translation_format(vector_format8 format) const { return format; }
- constexpr vector_format8 get_scale_format(vector_format8 format) const { return format; }
-
- constexpr bool are_range_reduction_flags_supported(range_reduction_flags8 /*flags*/) const { return true; }
- constexpr range_reduction_flags8 get_range_reduction(range_reduction_flags8 flags) const { return flags; }
-
- // Whether to explicitly disable floating point exceptions during decompression.
- // This has a cost, exceptions are usually disabled globally and do not need to be
- // explicitly disabled during decompression.
- // We assume that floating point exceptions are already disabled by the caller.
- constexpr bool disable_fp_exeptions() const { return false; }
-
- // Whether rotations should be normalized before being output or not. Some animation
- // runtimes will normalize in a separate step and do not need the explicit normalization.
- // Enabled by default for safety.
- constexpr bool normalize_rotations() const { return true; }
- };
-
- //////////////////////////////////////////////////////////////////////////
- // These are debug settings, everything is enabled and nothing is stripped.
- // It will have the worst performance but allows every feature.
- //////////////////////////////////////////////////////////////////////////
- struct DebugDecompressionSettings : public DecompressionSettings {};
-
- //////////////////////////////////////////////////////////////////////////
- // These are the default settings. Only the generally optimal settings
- // are enabled and will offer the overall best performance.
- //
- // Note: Segment range reduction supports all_tracks or none because it can
- // be disabled if there is a single segment.
- //////////////////////////////////////////////////////////////////////////
- struct DefaultDecompressionSettings : public DecompressionSettings
- {
- constexpr bool is_rotation_format_supported(rotation_format8 format) const { return format == rotation_format8::quatf_drop_w_variable; }
- constexpr bool is_translation_format_supported(vector_format8 format) const { return format == vector_format8::vector3f_variable; }
- constexpr bool is_scale_format_supported(vector_format8 format) const { return format == vector_format8::vector3f_variable; }
- constexpr rotation_format8 get_rotation_format(rotation_format8 /*format*/) const { return rotation_format8::quatf_drop_w_variable; }
- constexpr vector_format8 get_translation_format(vector_format8 /*format*/) const { return vector_format8::vector3f_variable; }
- constexpr vector_format8 get_scale_format(vector_format8 /*format*/) const { return vector_format8::vector3f_variable; }
-
- constexpr range_reduction_flags8 get_range_reduction(range_reduction_flags8 /*flags*/) const { return range_reduction_flags8::all_tracks; }
- };
-
- //////////////////////////////////////////////////////////////////////////
- // Decompression context for the uniformly sampled algorithm. The context
- // allows various decompression actions to be performed in a clip.
- //
- // Both the constructor and destructor are public because it is safe to place
- // instances of this context on the stack or as member variables.
- //
- // This compression algorithm is the simplest by far and as such it offers
- // the fastest compression and decompression. Every sample is retained and
- // every track has the same number of samples playing back at the same
- // sample rate. This means that when we sample at a particular time within
- // the clip, we can trivially calculate the offsets required to read the
- // desired data. All the data is sorted in order to ensure all reads are
- // as contiguous as possible for optimal cache locality during decompression.
- //////////////////////////////////////////////////////////////////////////
- template<class DecompressionSettingsType>
- class DecompressionContext
- {
- public:
- static_assert(std::is_base_of<DecompressionSettings, DecompressionSettingsType>::value, "DecompressionSettingsType must derive from DecompressionSettings!");
-
- //////////////////////////////////////////////////////////////////////////
- // An alias to the decompression settings type.
- using SettingsType = DecompressionSettingsType;
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a context instance.
- // The default constructor for the DecompressionSettingsType will be used.
- DecompressionContext();
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a context instance from a settings instance.
- DecompressionContext(const DecompressionSettingsType& settings);
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the compressed clip bound to this context instance.
- const CompressedClip* get_compressed_clip() const { return m_context.clip; }
-
- //////////////////////////////////////////////////////////////////////////
- // Initializes the context instance to a particular compressed clip
- void initialize(const CompressedClip& clip);
-
- //////////////////////////////////////////////////////////////////////////
- // Returns true if this context instance is bound to a compressed clip, false otherwise.
- bool is_initialized() const { return m_context.clip != nullptr; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns true if this context instance is bound to the specified compressed clip, false otherwise.
- bool is_dirty(const CompressedClip& clip);
-
- //////////////////////////////////////////////////////////////////////////
- // Seeks within the compressed clip to a particular point in time
- void seek(float sample_time, sample_rounding_policy rounding_policy);
-
- //////////////////////////////////////////////////////////////////////////
- // Decompress a full pose at the current sample time.
- // The OutputWriterType allows complete control over how the pose is written out
- template<class OutputWriterType>
- void decompress_pose(OutputWriterType& writer);
-
- //////////////////////////////////////////////////////////////////////////
- // Decompress a single bone at the current sample time.
- // Each track entry is optional
- void decompress_bone(uint16_t sample_bone_index, rtm::quatf* out_rotation, rtm::vector4f* out_translation, rtm::vector4f* out_scale);
-
- private:
- DecompressionContext(const DecompressionContext& other) = delete;
- DecompressionContext& operator=(const DecompressionContext& other) = delete;
-
- // Internal context data
- acl_impl::DecompressionContext m_context;
-
- // The static settings used to strip out code at runtime
- DecompressionSettingsType m_settings;
-
- // Ensure we have non-zero padding to avoid compiler warnings
- static constexpr size_t k_padding_size = alignof(acl_impl::DecompressionContext) - sizeof(DecompressionSettingsType);
- uint8_t m_padding[k_padding_size != 0 ? k_padding_size : alignof(acl_impl::DecompressionContext)];
- };
-
- //////////////////////////////////////////////////////////////////////////
- // Allocates and constructs an instance of the decompression context
- template<class DecompressionSettingsType>
- inline DecompressionContext<DecompressionSettingsType>* make_decompression_context(IAllocator& allocator)
- {
- return allocate_type<DecompressionContext<DecompressionSettingsType>>(allocator);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Allocates and constructs an instance of the decompression context
- template<class DecompressionSettingsType>
- inline DecompressionContext<DecompressionSettingsType>* make_decompression_context(IAllocator& allocator, const DecompressionSettingsType& settings)
- {
- return allocate_type<DecompressionContext<DecompressionSettingsType>>(allocator, settings);
- }
-
- //////////////////////////////////////////////////////////////////////////
-
- template<class DecompressionSettingsType>
- inline DecompressionContext<DecompressionSettingsType>::DecompressionContext()
- : m_context()
- , m_settings()
- {
- m_context.clip = nullptr; // Only member used to detect if we are initialized
- }
-
- template<class DecompressionSettingsType>
- inline DecompressionContext<DecompressionSettingsType>::DecompressionContext(const DecompressionSettingsType& settings)
- : m_context()
- , m_settings(settings)
- {
- m_context.clip = nullptr; // Only member used to detect if we are initialized
- }
-
- template<class DecompressionSettingsType>
- inline void DecompressionContext<DecompressionSettingsType>::initialize(const CompressedClip& clip)
- {
- ACL_ASSERT(clip.is_valid(false).empty(), "CompressedClip is not valid");
- ACL_ASSERT(clip.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(clip.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
-
- const ClipHeader& header = get_clip_header(clip);
-
- const rotation_format8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
- const vector_format8 translation_format = m_settings.get_translation_format(header.translation_format);
- const vector_format8 scale_format = m_settings.get_scale_format(header.scale_format);
-
- ACL_ASSERT(rotation_format == header.rotation_format, "Statically compiled rotation format (%s) differs from the compressed rotation format (%s)!", get_rotation_format_name(rotation_format), get_rotation_format_name(header.rotation_format));
- ACL_ASSERT(m_settings.is_rotation_format_supported(rotation_format), "Rotation format (%s) isn't statically supported!", get_rotation_format_name(rotation_format));
- ACL_ASSERT(translation_format == header.translation_format, "Statically compiled translation format (%s) differs from the compressed translation format (%s)!", get_vector_format_name(translation_format), get_vector_format_name(header.translation_format));
- ACL_ASSERT(m_settings.is_translation_format_supported(translation_format), "Translation format (%s) isn't statically supported!", get_vector_format_name(translation_format));
- ACL_ASSERT(scale_format == header.scale_format, "Statically compiled scale format (%s) differs from the compressed scale format (%s)!", get_vector_format_name(scale_format), get_vector_format_name(header.scale_format));
- ACL_ASSERT(m_settings.is_scale_format_supported(scale_format), "Scale format (%s) isn't statically supported!", get_vector_format_name(scale_format));
-
- m_context.clip = &clip;
- m_context.clip_hash = clip.get_hash();
- m_context.clip_duration = calculate_duration(header.num_samples, header.sample_rate);
- m_context.sample_time = -1.0F;
- m_context.default_tracks_bitset = header.get_default_tracks_bitset();
-
- m_context.constant_tracks_bitset = header.get_constant_tracks_bitset();
- m_context.constant_track_data = header.get_constant_track_data();
- m_context.clip_range_data = header.get_clip_range_data();
-
- for (uint8_t key_frame_index = 0; key_frame_index < 2; ++key_frame_index)
- {
- m_context.format_per_track_data[key_frame_index] = nullptr;
- m_context.segment_range_data[key_frame_index] = nullptr;
- m_context.animated_track_data[key_frame_index] = nullptr;
- }
-
- const uint32_t num_tracks_per_bone = header.has_scale ? 3 : 2;
- m_context.bitset_desc = BitSetDescription::make_from_num_bits(header.num_bones * num_tracks_per_bone);
-
- range_reduction_flags8 range_reduction = range_reduction_flags8::none;
- if (is_rotation_format_variable(rotation_format))
- range_reduction |= range_reduction_flags8::rotations;
- if (is_vector_format_variable(translation_format))
- range_reduction |= range_reduction_flags8::translations;
- if (is_vector_format_variable(scale_format))
- range_reduction |= range_reduction_flags8::scales;
-
- m_context.range_reduction = m_settings.get_range_reduction(range_reduction);
-
- ACL_ASSERT((m_context.range_reduction & range_reduction) == range_reduction, "Statically compiled range reduction flags (%u) differ from the compressed flags (%u)!", static_cast< uint32_t >( m_context.range_reduction ), static_cast< uint32_t >( range_reduction ) );
- ACL_ASSERT(m_settings.are_range_reduction_flags_supported(m_context.range_reduction), "Range reduction flags (%u) aren't statically supported!", static_cast< uint32_t >( m_context.range_reduction ) );
-
- m_context.num_rotation_components = rotation_format == rotation_format8::quatf_full ? 4 : 3;
- }
-
- template<class DecompressionSettingsType>
- inline bool DecompressionContext<DecompressionSettingsType>::is_dirty(const CompressedClip& clip)
- {
- if (m_context.clip != &clip)
- return true;
-
- if (m_context.clip_hash != clip.get_hash())
- return true;
-
- return false;
- }
-
- template<class DecompressionSettingsType>
- inline void DecompressionContext<DecompressionSettingsType>::seek(float sample_time, sample_rounding_policy rounding_policy)
- {
- ACL_ASSERT(m_context.clip != nullptr, "Context is not initialized");
-
- // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
- // TODO: Make it optional via DecompressionSettingsType?
- sample_time = rtm::scalar_clamp(sample_time, 0.0F, m_context.clip_duration);
-
- if (m_context.sample_time == sample_time)
- return;
-
- m_context.sample_time = sample_time;
-
- const ClipHeader& header = get_clip_header(*m_context.clip);
-
- uint32_t key_frame0;
- uint32_t key_frame1;
- find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, m_context.interpolation_alpha);
-
- uint32_t segment_key_frame0;
- uint32_t segment_key_frame1;
-
- const SegmentHeader* segment_header0;
- const SegmentHeader* segment_header1;
-
- const SegmentHeader* segment_headers = header.get_segment_headers();
- const uint32_t num_segments = header.num_segments;
-
- if (num_segments == 1)
- {
- // Key frame 0 and 1 are in the only segment present
- // This is a really common case and when it happens, we don't store the segment start index (zero)
- segment_header0 = segment_headers;
- segment_key_frame0 = key_frame0;
-
- segment_header1 = segment_headers;
- segment_key_frame1 = key_frame1;
- }
- else
- {
- const uint32_t* segment_start_indices = header.get_segment_start_indices();
-
- // See segment_streams(..) for implementation details. This implementation is directly tied to it.
- const uint32_t approx_num_samples_per_segment = header.num_samples / num_segments; // TODO: Store in header?
- const uint32_t approx_segment_index = key_frame0 / approx_num_samples_per_segment;
-
- uint32_t segment_index0 = 0;
- uint32_t segment_index1 = 0;
-
- // Our approximate segment guess is just that, a guess. The actual segments we need could be just before or after.
- // We start looking one segment earlier and up to 2 after. If we have too few segments after, we will hit the
- // sentinel value of 0xFFFFFFFF and exit the loop.
- // TODO: Can we do this with SIMD? Load all 4 values, set key_frame0, compare, move mask, count leading zeroes
- const uint32_t start_segment_index = approx_segment_index > 0 ? (approx_segment_index - 1) : 0;
- const uint32_t end_segment_index = start_segment_index + 4;
-
- for (uint32_t segment_index = start_segment_index; segment_index < end_segment_index; ++segment_index)
- {
- if (key_frame0 < segment_start_indices[segment_index])
- {
- // We went too far, use previous segment
- ACL_ASSERT(segment_index > 0, "Invalid segment index: %u", segment_index);
- segment_index0 = segment_index - 1;
- segment_index1 = key_frame1 < segment_start_indices[segment_index] ? segment_index0 : segment_index;
- break;
- }
- }
-
- segment_header0 = segment_headers + segment_index0;
- segment_header1 = segment_headers + segment_index1;
-
- segment_key_frame0 = key_frame0 - segment_start_indices[segment_index0];
- segment_key_frame1 = key_frame1 - segment_start_indices[segment_index1];
- }
-
- m_context.format_per_track_data[0] = header.get_format_per_track_data(*segment_header0);
- m_context.format_per_track_data[1] = header.get_format_per_track_data(*segment_header1);
- m_context.segment_range_data[0] = header.get_segment_range_data(*segment_header0);
- m_context.segment_range_data[1] = header.get_segment_range_data(*segment_header1);
- m_context.animated_track_data[0] = header.get_track_data(*segment_header0);
- m_context.animated_track_data[1] = header.get_track_data(*segment_header1);
-
- m_context.key_frame_bit_offsets[0] = segment_key_frame0 * segment_header0->animated_pose_bit_size;
- m_context.key_frame_bit_offsets[1] = segment_key_frame1 * segment_header1->animated_pose_bit_size;
- }
-
- template<class DecompressionSettingsType>
- template<class OutputWriterType>
- inline void DecompressionContext<DecompressionSettingsType>::decompress_pose(OutputWriterType& writer)
- {
- static_assert(std::is_base_of<OutputWriter, OutputWriterType>::value, "OutputWriterType must derive from OutputWriter");
-
- using namespace acl::acl_impl;
-
- ACL_ASSERT(m_context.clip != nullptr, "Context is not initialized");
- ACL_ASSERT(m_context.sample_time >= 0.0f, "Context not set to a valid sample time");
-
- // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
- // Disable floating point exceptions to avoid issues.
- fp_environment fp_env;
- if (m_settings.disable_fp_exeptions())
- disable_fp_exceptions(fp_env);
-
- const ClipHeader& header = get_clip_header(*m_context.clip);
-
- const acl_impl::TranslationDecompressionSettingsAdapter<DecompressionSettingsType> translation_adapter(m_settings);
- const acl_impl::ScaleDecompressionSettingsAdapter<DecompressionSettingsType> scale_adapter(m_settings, header);
-
- const rtm::vector4f default_scale = scale_adapter.get_default_value();
-
- acl_impl::SamplingContext sampling_context;
- sampling_context.track_index = 0;
- sampling_context.constant_track_data_offset = 0;
- sampling_context.clip_range_data_offset = 0;
- sampling_context.format_per_track_data_offset = 0;
- sampling_context.segment_range_data_offset = 0;
- sampling_context.key_frame_bit_offsets[0] = m_context.key_frame_bit_offsets[0];
- sampling_context.key_frame_bit_offsets[1] = m_context.key_frame_bit_offsets[1];
-
- sampling_context.vectors[0] = default_scale; // Init with something to avoid GCC warning
- sampling_context.vectors[1] = default_scale; // Init with something to avoid GCC warning
-
- const uint16_t num_bones = header.num_bones;
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- if (writer.skip_all_bone_rotations() || writer.skip_bone_rotation(bone_index))
- skip_over_rotation(m_settings, header, m_context, sampling_context);
- else
- {
- const rtm::quatf rotation = decompress_and_interpolate_rotation(m_settings, header, m_context, sampling_context);
- writer.write_bone_rotation(bone_index, rotation);
- }
-
- if (writer.skip_all_bone_translations() || writer.skip_bone_translation(bone_index))
- skip_over_vector(translation_adapter, header, m_context, sampling_context);
- else
- {
- const rtm::vector4f translation = decompress_and_interpolate_vector(translation_adapter, header, m_context, sampling_context);
- writer.write_bone_translation(bone_index, translation);
- }
-
- if (writer.skip_all_bone_scales() || writer.skip_bone_scale(bone_index))
- {
- if (header.has_scale)
- skip_over_vector(scale_adapter, header, m_context, sampling_context);
- }
- else
- {
- const rtm::vector4f scale = header.has_scale ? decompress_and_interpolate_vector(scale_adapter, header, m_context, sampling_context) : default_scale;
- writer.write_bone_scale(bone_index, scale);
- }
- }
-
- if (m_settings.disable_fp_exeptions())
- restore_fp_exceptions(fp_env);
- }
-
- template<class DecompressionSettingsType>
- inline void DecompressionContext<DecompressionSettingsType>::decompress_bone(uint16_t sample_bone_index, rtm::quatf* out_rotation, rtm::vector4f* out_translation, rtm::vector4f* out_scale)
- {
- using namespace acl::acl_impl;
-
- ACL_ASSERT(m_context.clip != nullptr, "Context is not initialized");
- ACL_ASSERT(m_context.sample_time >= 0.0f, "Context not set to a valid sample time");
-
- // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
- // Disable floating point exceptions to avoid issues.
- fp_environment fp_env;
- if (m_settings.disable_fp_exeptions())
- disable_fp_exceptions(fp_env);
-
- const ClipHeader& header = get_clip_header(*m_context.clip);
-
- const acl_impl::TranslationDecompressionSettingsAdapter<DecompressionSettingsType> translation_adapter(m_settings);
- const acl_impl::ScaleDecompressionSettingsAdapter<DecompressionSettingsType> scale_adapter(m_settings, header);
-
- acl_impl::SamplingContext sampling_context;
- sampling_context.key_frame_bit_offsets[0] = m_context.key_frame_bit_offsets[0];
- sampling_context.key_frame_bit_offsets[1] = m_context.key_frame_bit_offsets[1];
-
- const rotation_format8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
- const vector_format8 translation_format = m_settings.get_translation_format(header.translation_format);
- const vector_format8 scale_format = m_settings.get_scale_format(header.scale_format);
-
- const bool are_all_tracks_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
- if (!are_all_tracks_variable)
- {
- // Slow path, not optimized yet because it's more complex and shouldn't be used in production anyway
- sampling_context.track_index = 0;
- sampling_context.constant_track_data_offset = 0;
- sampling_context.clip_range_data_offset = 0;
- sampling_context.format_per_track_data_offset = 0;
- sampling_context.segment_range_data_offset = 0;
-
- for (uint16_t bone_index = 0; bone_index < sample_bone_index; ++bone_index)
- {
- skip_over_rotation(m_settings, header, m_context, sampling_context);
- skip_over_vector(translation_adapter, header, m_context, sampling_context);
-
- if (header.has_scale)
- skip_over_vector(scale_adapter, header, m_context, sampling_context);
- }
- }
- else
- {
- const uint32_t num_tracks_per_bone = header.has_scale ? 3 : 2;
- const uint32_t track_index = sample_bone_index * num_tracks_per_bone;
- uint32_t num_default_rotations = 0;
- uint32_t num_default_translations = 0;
- uint32_t num_default_scales = 0;
- uint32_t num_constant_rotations = 0;
- uint32_t num_constant_translations = 0;
- uint32_t num_constant_scales = 0;
-
- if (header.has_scale)
- {
- uint32_t rotation_track_bit_mask = 0x92492492; // b100100100..
- uint32_t translation_track_bit_mask = 0x49249249; // b010010010..
- uint32_t scale_track_bit_mask = 0x24924924; // b001001001..
-
- const uint32_t last_offset = track_index / 32;
- uint32_t offset = 0;
- for (; offset < last_offset; ++offset)
- {
- const uint32_t default_value = m_context.default_tracks_bitset[offset];
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
- num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
-
- const uint32_t constant_value = m_context.constant_tracks_bitset[offset];
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
-
- // Because the number of tracks in a 32bit word isn't a multiple of the number of tracks we have (3),
- // we have to rotate the masks left
- rotation_track_bit_mask = rotate_bits_left(rotation_track_bit_mask, 2);
- translation_track_bit_mask = rotate_bits_left(translation_track_bit_mask, 2);
- scale_track_bit_mask = rotate_bits_left(scale_track_bit_mask, 2);
- }
-
- const uint32_t remaining_tracks = track_index % 32;
- if (remaining_tracks != 0)
- {
- const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
- const uint32_t default_value = and_not(not_up_to_track_mask, m_context.default_tracks_bitset[offset]);
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
- num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
-
- const uint32_t constant_value = and_not(not_up_to_track_mask, m_context.constant_tracks_bitset[offset]);
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
- }
- }
- else
- {
- const uint32_t rotation_track_bit_mask = 0xAAAAAAAA; // b10101010..
- const uint32_t translation_track_bit_mask = 0x55555555; // b01010101..
-
- const uint32_t last_offset = track_index / 32;
- uint32_t offset = 0;
- for (; offset < last_offset; ++offset)
- {
- const uint32_t default_value = m_context.default_tracks_bitset[offset];
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
-
- const uint32_t constant_value = m_context.constant_tracks_bitset[offset];
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- }
-
- const uint32_t remaining_tracks = track_index % 32;
- if (remaining_tracks != 0)
- {
- const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
- const uint32_t default_value = and_not(not_up_to_track_mask, m_context.default_tracks_bitset[offset]);
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
-
- const uint32_t constant_value = and_not(not_up_to_track_mask, m_context.constant_tracks_bitset[offset]);
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- }
- }
-
- // Tracks that are default are also constant
- const uint32_t num_animated_rotations = sample_bone_index - num_constant_rotations;
- const uint32_t num_animated_translations = sample_bone_index - num_constant_translations;
-
- const rotation_format8 packed_rotation_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
- const uint32_t packed_rotation_size = get_packed_rotation_size(packed_rotation_format);
-
- uint32_t constant_track_data_offset = (num_constant_rotations - num_default_rotations) * packed_rotation_size;
- constant_track_data_offset += (num_constant_translations - num_default_translations) * get_packed_vector_size(vector_format8::vector3f_full);
-
- uint32_t clip_range_data_offset = 0;
- uint32_t segment_range_data_offset = 0;
-
- const range_reduction_flags8 range_reduction = m_context.range_reduction;
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
- {
- clip_range_data_offset += m_context.num_rotation_components * sizeof(float) * 2 * num_animated_rotations;
-
- if (header.num_segments > 1)
- segment_range_data_offset += m_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_rotations;
- }
-
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::translations))
- {
- clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_translations;
-
- if (header.num_segments > 1)
- segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_translations;
- }
-
- uint32_t num_animated_tracks = num_animated_rotations + num_animated_translations;
- if (header.has_scale)
- {
- const uint32_t num_animated_scales = sample_bone_index - num_constant_scales;
- num_animated_tracks += num_animated_scales;
-
- constant_track_data_offset += (num_constant_scales - num_default_scales) * get_packed_vector_size(vector_format8::vector3f_full);
-
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::scales))
- {
- clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_scales;
-
- if (header.num_segments > 1)
- segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_scales;
- }
- }
-
- sampling_context.track_index = track_index;
- sampling_context.constant_track_data_offset = constant_track_data_offset;
- sampling_context.clip_range_data_offset = clip_range_data_offset;
- sampling_context.segment_range_data_offset = segment_range_data_offset;
- sampling_context.format_per_track_data_offset = num_animated_tracks;
-
- for (uint32_t animated_track_index = 0; animated_track_index < num_animated_tracks; ++animated_track_index)
- {
- const uint8_t bit_rate0 = m_context.format_per_track_data[0][animated_track_index];
- const uint32_t num_bits_at_bit_rate0 = get_num_bits_at_bit_rate(bit_rate0) * 3; // 3 components
-
- sampling_context.key_frame_bit_offsets[0] += num_bits_at_bit_rate0;
-
- const uint8_t bit_rate1 = m_context.format_per_track_data[1][animated_track_index];
- const uint32_t num_bits_at_bit_rate1 = get_num_bits_at_bit_rate(bit_rate1) * 3; // 3 components
-
- sampling_context.key_frame_bit_offsets[1] += num_bits_at_bit_rate1;
- }
- }
-
- const rtm::vector4f default_scale = scale_adapter.get_default_value();
-
- sampling_context.vectors[0] = default_scale; // Init with something to avoid GCC warning
- sampling_context.vectors[1] = default_scale; // Init with something to avoid GCC warning
-
- if (out_rotation != nullptr)
- *out_rotation = decompress_and_interpolate_rotation(m_settings, header, m_context, sampling_context);
- else
- skip_over_rotation(m_settings, header, m_context, sampling_context);
-
- if (out_translation != nullptr)
- *out_translation = decompress_and_interpolate_vector(translation_adapter, header, m_context, sampling_context);
- else if (out_scale != nullptr && header.has_scale)
- {
- // We'll need to read the scale value that follows, skip the translation we don't need
- skip_over_vector(translation_adapter, header, m_context, sampling_context);
- }
-
- if (out_scale != nullptr)
- *out_scale = header.has_scale ? decompress_and_interpolate_vector(scale_adapter, header, m_context, sampling_context) : default_scale;
- // No need to skip our last scale, we don't care anymore
-
- if (m_settings.disable_fp_exeptions())
- restore_fp_exceptions(fp_env);
- }
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/algorithm/uniformly_sampled/encoder.h b/includes/acl/algorithm/uniformly_sampled/encoder.h
deleted file mode 100644
--- a/includes/acl/algorithm/uniformly_sampled/encoder.h
+++ /dev/null
@@ -1,299 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/algorithm_types.h"
-#include "acl/core/bitset.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_clip.h"
-#include "acl/core/error.h"
-#include "acl/core/error_result.h"
-#include "acl/core/floating_point_exceptions.h"
-#include "acl/core/iallocator.h"
-#include "acl/core/range_reduction_types.h"
-#include "acl/core/scope_profiler.h"
-#include "acl/core/track_types.h"
-#include "acl/compression/impl/compressed_clip_impl.h"
-#include "acl/compression/skeleton.h"
-#include "acl/compression/animation_clip.h"
-#include "acl/compression/output_stats.h"
-#include "acl/compression/impl/clip_context.h"
-#include "acl/compression/impl/track_stream.h"
-#include "acl/compression/impl/convert_rotation_streams.h"
-#include "acl/compression/impl/compact_constant_streams.h"
-#include "acl/compression/impl/normalize_streams.h"
-#include "acl/compression/impl/quantize_streams.h"
-#include "acl/compression/impl/segment_streams.h"
-#include "acl/compression/impl/write_segment_data.h"
-#include "acl/compression/impl/write_stats.h"
-#include "acl/compression/impl/write_stream_bitsets.h"
-#include "acl/compression/impl/write_stream_data.h"
-#include "acl/decompression/default_output_writer.h"
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace uniformly_sampled
- {
- //////////////////////////////////////////////////////////////////////////
- // Compresses a raw clip with uniform sampling
- //
- // This compression algorithm is the simplest by far and as such it offers
- // the fastest compression and decompression. Every sample is retained and
- // every track has the same number of samples playing back at the same
- // sample rate. This means that when we sample at a particular time within
- // the clip, we can trivially calculate the offsets required to read the
- // desired data. All the data is sorted in order to ensure all reads are
- // as contiguous as possible for optimal cache locality during decompression.
- //
- // allocator: The allocator instance to use to allocate and free memory
- // clip: The raw clip to compress
- // settings: The compression settings to use
- // out_compressed_clip: The resulting compressed clip. The caller owns the returned memory and must free it
- // out_stats: Stat output structure
- //////////////////////////////////////////////////////////////////////////
- inline ErrorResult compress_clip(IAllocator& allocator, const AnimationClip& clip, CompressionSettings settings, CompressedClip*& out_compressed_clip, OutputStats& out_stats)
- {
- using namespace acl::acl_impl;
- (void)out_stats;
-
- ErrorResult error_result = clip.is_valid();
- if (error_result.any())
- return error_result;
-
- error_result = settings.is_valid();
- if (error_result.any())
- return error_result;
-
- // Disable floating point exceptions during compression because we leverage all SIMD lanes
- // and we might intentionally divide by zero, etc.
- scope_disable_fp_exceptions fp_off;
-
-#if defined(SJSON_CPP_WRITER)
- ScopeProfiler compression_time;
-#endif
-
- // If every track is retains full precision, we disable segmenting since it provides no benefit
- if (!is_rotation_format_variable(settings.rotation_format) && !is_vector_format_variable(settings.translation_format) && !is_vector_format_variable(settings.scale_format))
- {
- settings.segmenting.ideal_num_samples = 0xFFFF;
- settings.segmenting.max_num_samples = 0xFFFF;
- }
-
- // Variable bit rate tracks need range reduction
- // Full precision tracks do not need range reduction since samples are stored raw
- range_reduction_flags8 range_reduction = range_reduction_flags8::none;
- if (is_rotation_format_variable(settings.rotation_format))
- range_reduction |= range_reduction_flags8::rotations;
-
- if (is_vector_format_variable(settings.translation_format))
- range_reduction |= range_reduction_flags8::translations;
-
- if (is_vector_format_variable(settings.scale_format))
- range_reduction |= range_reduction_flags8::scales;
-
- const uint32_t num_samples = clip.get_num_samples();
- const RigidSkeleton& skeleton = clip.get_skeleton();
-
- ClipContext additive_base_clip_context;
- const AnimationClip* additive_base_clip = clip.get_additive_base();
- if (additive_base_clip != nullptr)
- initialize_clip_context(allocator, *additive_base_clip, skeleton, settings, additive_base_clip_context);
-
- ClipContext raw_clip_context;
- initialize_clip_context(allocator, clip, skeleton, settings, raw_clip_context);
-
- ClipContext clip_context;
- initialize_clip_context(allocator, clip, skeleton, settings, clip_context);
-
- convert_rotation_streams(allocator, clip_context, settings.rotation_format);
-
- // Extract our clip ranges now, we need it for compacting the constant streams
- extract_clip_bone_ranges(allocator, clip_context);
-
- // Compact and collapse the constant streams
- compact_constant_streams(allocator, clip_context, settings.constant_rotation_threshold_angle, settings.constant_translation_threshold, settings.constant_scale_threshold);
-
- uint32_t clip_range_data_size = 0;
- if (range_reduction != range_reduction_flags8::none)
- {
- normalize_clip_streams(clip_context, range_reduction);
- clip_range_data_size = get_stream_range_data_size(clip_context, range_reduction, settings.rotation_format);
- }
-
- segment_streams(allocator, clip_context, settings.segmenting);
-
- // If we have a single segment, skip segment range reduction since it won't help
- if (range_reduction != range_reduction_flags8::none && clip_context.num_segments > 1)
- {
- extract_segment_bone_ranges(allocator, clip_context);
- normalize_segment_streams(clip_context, range_reduction);
- }
-
- quantize_streams(allocator, clip_context, settings, skeleton, raw_clip_context, additive_base_clip_context, out_stats);
-
- uint16_t num_output_bones = 0;
- uint16_t* output_bone_mapping = create_output_bone_mapping(allocator, clip, num_output_bones);
-
- const uint32_t constant_data_size = get_constant_data_size(clip_context, output_bone_mapping, num_output_bones);
-
- calculate_animated_data_size(clip_context, output_bone_mapping, num_output_bones);
-
- const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
-
- const uint32_t num_tracks_per_bone = clip_context.has_scale ? 3 : 2;
- const uint32_t num_tracks = uint32_t(num_output_bones) * num_tracks_per_bone;
- const BitSetDescription bitset_desc = BitSetDescription::make_from_num_bits(num_tracks);
-
- // Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
- const uint32_t segment_start_indices_size = clip_context.num_segments > 1 ? (sizeof(uint32_t) * (clip_context.num_segments + 1)) : 0;
-
- uint32_t buffer_size = 0;
- // Per clip data
- buffer_size += sizeof(CompressedClip);
- buffer_size += sizeof(ClipHeader);
-
- const uint32_t clip_header_size = buffer_size;
-
- buffer_size += segment_start_indices_size; // Segment start indices
- buffer_size = align_to(buffer_size, 4); // Align segment headers
- buffer_size += sizeof(SegmentHeader) * clip_context.num_segments; // Segment headers
- buffer_size = align_to(buffer_size, 4); // Align bitsets
-
- const uint32_t clip_segment_header_size = buffer_size - clip_header_size;
-
- buffer_size += bitset_desc.get_num_bytes(); // Default tracks bitset
- buffer_size += bitset_desc.get_num_bytes(); // Constant tracks bitset
- buffer_size = align_to(buffer_size, 4); // Align constant track data
- buffer_size += constant_data_size; // Constant track data
- buffer_size = align_to(buffer_size, 4); // Align range data
- buffer_size += clip_range_data_size; // Range data
-
- const uint32_t clip_data_size = buffer_size - clip_segment_header_size - clip_header_size;
-
- if (are_all_enum_flags_set(out_stats.logging, StatLogging::Detailed))
- {
- constexpr uint32_t k_cache_line_byte_size = 64;
- clip_context.decomp_touched_bytes = clip_header_size + clip_data_size;
- clip_context.decomp_touched_bytes += sizeof(uint32_t) * 4; // We touch at most 4 segment start indices
- clip_context.decomp_touched_bytes += sizeof(SegmentHeader) * 2; // We touch at most 2 segment headers
- clip_context.decomp_touched_cache_lines = align_to(clip_header_size, k_cache_line_byte_size) / k_cache_line_byte_size;
- clip_context.decomp_touched_cache_lines += align_to(clip_data_size, k_cache_line_byte_size) / k_cache_line_byte_size;
- clip_context.decomp_touched_cache_lines += 1; // All 4 segment start indices should fit in a cache line
- clip_context.decomp_touched_cache_lines += 1; // Both segment headers should fit in a cache line
- }
-
- // Per segment data
- for (SegmentContext& segment : clip_context.segment_iterator())
- {
- const uint32_t header_start = buffer_size;
-
- buffer_size += format_per_track_data_size; // Format per track data
- // TODO: Alignment only necessary with 16bit per component
- buffer_size = align_to(buffer_size, 2); // Align range data
- buffer_size += segment.range_data_size; // Range data
-
- const uint32_t header_end = buffer_size;
-
- // TODO: Variable bit rate doesn't need alignment
- buffer_size = align_to(buffer_size, 4); // Align animated data
- buffer_size += segment.animated_data_size; // Animated track data
-
- segment.total_header_size = header_end - header_start;
- }
-
- // Ensure we have sufficient padding for unaligned 16 byte loads
- buffer_size += 15;
-
- uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, 16);
- std::memset(buffer, 0, buffer_size);
-
- CompressedClip* compressed_clip = make_compressed_clip(buffer, buffer_size, algorithm_type8::uniformly_sampled);
-
- ClipHeader& header = get_clip_header(*compressed_clip);
- header.num_bones = num_output_bones;
- header.num_segments = clip_context.num_segments;
- header.rotation_format = settings.rotation_format;
- header.translation_format = settings.translation_format;
- header.scale_format = settings.scale_format;
- header.has_scale = clip_context.has_scale ? 1 : 0;
- header.default_scale = additive_base_clip == nullptr || clip.get_additive_format() != additive_clip_format8::additive1;
- header.num_samples = num_samples;
- header.sample_rate = clip.get_sample_rate();
- header.segment_start_indices_offset = sizeof(ClipHeader);
- header.segment_headers_offset = align_to(header.segment_start_indices_offset + segment_start_indices_size, 4);
- header.default_tracks_bitset_offset = align_to(header.segment_headers_offset + (sizeof(SegmentHeader) * clip_context.num_segments), 4);
- header.constant_tracks_bitset_offset = header.default_tracks_bitset_offset + bitset_desc.get_num_bytes();
- header.constant_track_data_offset = align_to(header.constant_tracks_bitset_offset + bitset_desc.get_num_bytes(), 4);
- header.clip_range_data_offset = align_to(header.constant_track_data_offset + constant_data_size, 4);
-
- if (clip_context.num_segments > 1)
- write_segment_start_indices(clip_context, header.get_segment_start_indices());
- else
- header.segment_start_indices_offset = InvalidPtrOffset();
-
- const uint32_t segment_data_start_offset = header.clip_range_data_offset + clip_range_data_size;
- write_segment_headers(clip_context, settings, header.get_segment_headers(), segment_data_start_offset);
- write_default_track_bitset(clip_context, header.get_default_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
- write_constant_track_bitset(clip_context, header.get_constant_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
-
- if (constant_data_size > 0)
- write_constant_track_data(clip_context, header.get_constant_track_data(), constant_data_size, output_bone_mapping, num_output_bones);
- else
- header.constant_track_data_offset = InvalidPtrOffset();
-
- if (range_reduction != range_reduction_flags8::none)
- write_clip_range_data(clip_context, range_reduction, header.get_clip_range_data(), clip_range_data_size, output_bone_mapping, num_output_bones);
- else
- header.clip_range_data_offset = InvalidPtrOffset();
-
- write_segment_data(clip_context, settings, range_reduction, header, output_bone_mapping, num_output_bones);
-
- finalize_compressed_clip(*compressed_clip);
-
-#if defined(SJSON_CPP_WRITER)
- compression_time.stop();
-
- if (out_stats.logging != StatLogging::None)
- write_stats(allocator, clip, clip_context, skeleton, *compressed_clip, settings, header, raw_clip_context, additive_base_clip_context, compression_time, out_stats);
-#endif
-
- deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
- destroy_clip_context(allocator, clip_context);
- destroy_clip_context(allocator, raw_clip_context);
-
- if (additive_base_clip != nullptr)
- destroy_clip_context(allocator, additive_base_clip_context);
-
- out_compressed_clip = compressed_clip;
- return ErrorResult();
- }
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/animation_clip.h b/includes/acl/compression/animation_clip.h
deleted file mode 100644
--- a/includes/acl/compression/animation_clip.h
+++ /dev/null
@@ -1,420 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/compression/animation_track.h"
-#include "acl/compression/skeleton.h"
-#include "acl/core/additive_utils.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/error_result.h"
-#include "acl/core/interpolation_utils.h"
-#include "acl/core/string.h"
-#include "acl/core/utils.h"
-
-#include <rtm/quatf.h>
-#include <rtm/qvvf.h>
-#include <rtm/vector4f.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Small structure to wrap the three tracks a bone can own: rotation, translation and scale.
- struct AnimatedBone
- {
- AnimationRotationTrack rotation_track;
- AnimationTranslationTrack translation_track;
- AnimationScaleTrack scale_track;
-
- // The bone output index. When writing out the compressed data stream, this index
- // will be used instead of the bone index. This allows custom reordering for things
- // like LOD sorting or skeleton remapping. A value of 'k_invalid_bone_index' will strip the bone
- // from the compressed data stream. Defaults to the bone index. The output index
- // must be unique and they must be contiguous.
- uint16_t output_index;
-
- bool is_stripped_from_output() const { return output_index == k_invalid_bone_index; }
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A raw animation clip.
- //
- // A clip is a collection of animated bones that map directly to a rigid skeleton.
- // Each bone has a rotation track, a translation track, and a scale track.
- // All tracks should have the same number of samples at a particular
- // sample rate.
- //
- // A clip can also have an additive base. Such clips are deemed additive in nature
- // and also have a corresponding additive format that dictates the mathematical
- // operation to add it onto its base clip.
- //
- // Instances of this class manage and own the raw animation data within.
- //////////////////////////////////////////////////////////////////////////
- class AnimationClip
- {
- public:
- //////////////////////////////////////////////////////////////////////////
- // Creates an instance and initializes it.
- // - allocator: The allocator instance to use to allocate and free memory
- // - skeleton: The rigid skeleton this clip is based on
- // - num_samples: The number of samples per track
- // - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
- // - name: Name of the clip (used for debugging purposes only)
- AnimationClip(IAllocator& allocator, const RigidSkeleton& skeleton, uint32_t num_samples, float sample_rate, const String &name)
- : m_allocator(allocator)
- , m_skeleton(skeleton)
- , m_bones()
- , m_num_samples(num_samples)
- , m_sample_rate(sample_rate)
- , m_num_bones(skeleton.get_num_bones())
- , m_additive_base_clip(nullptr)
- , m_additive_format(additive_clip_format8::none)
- , m_name(allocator, name)
- {
- m_bones = allocate_type_array<AnimatedBone>(allocator, m_num_bones);
-
- for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
- {
- m_bones[bone_index].rotation_track = AnimationRotationTrack(allocator, num_samples, sample_rate);
- m_bones[bone_index].translation_track = AnimationTranslationTrack(allocator, num_samples, sample_rate);
- m_bones[bone_index].scale_track = AnimationScaleTrack(allocator, num_samples, sample_rate);
- m_bones[bone_index].output_index = bone_index;
- }
- }
-
- AnimationClip(AnimationClip&& other) noexcept
- : m_allocator(other.m_allocator)
- , m_skeleton(other.m_skeleton)
- , m_bones(other.m_bones)
- , m_num_samples(other.m_num_samples)
- , m_sample_rate(other.m_sample_rate)
- , m_num_bones(other.m_num_bones)
- , m_additive_base_clip(other.m_additive_base_clip)
- , m_additive_format(other.m_additive_format)
- , m_name(std::move(other.m_name))
- {
- other.m_bones = nullptr;
- }
-
- ~AnimationClip()
- {
- deallocate_type_array(m_allocator, m_bones, m_num_bones);
- }
-
- AnimationClip(const AnimationClip&) = delete;
- AnimationClip& operator=(const AnimationClip&) = delete;
- AnimationClip& operator=(AnimationClip&&) = delete;
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the rigid skeleton this clip was created with
- const RigidSkeleton& get_skeleton() const { return m_skeleton; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the array of animated bone data
- AnimatedBone* get_bones() { return m_bones; }
- const AnimatedBone* get_bones() const { return m_bones; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the animated bone data for the provided bone index
- AnimatedBone& get_animated_bone(uint16_t bone_index)
- {
- ACL_ASSERT(bone_index < m_num_bones, "Invalid bone index: %u >= %u", bone_index, m_num_bones);
- return m_bones[bone_index];
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the animated bone data for the provided bone index
- const AnimatedBone& get_animated_bone(uint16_t bone_index) const
- {
- ACL_ASSERT(bone_index < m_num_bones, "Invalid bone index: %u >= %u", bone_index, m_num_bones);
- return m_bones[bone_index];
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the number of bones in this clip
- uint16_t get_num_bones() const { return m_num_bones; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the number of samples per track in this clip
- uint32_t get_num_samples() const { return m_num_samples; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the sample rate of this clip
- float get_sample_rate() const { return m_sample_rate; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the clip playback duration in seconds
- float get_duration() const { return calculate_duration(m_num_samples, m_sample_rate); }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the clip name
- const String& get_name() const { return m_name; }
-
- //////////////////////////////////////////////////////////////////////////
- // Samples a whole pose at a particular sample time
- // - sample_time: The time at which to sample the clip
- // - rounding_policy: The rounding policy to use when sampling
- // - out_local_pose: An array of at least 'num_transforms' to output the data in
- // - num_transforms: The number of transforms in the output array
- void sample_pose(float sample_time, sample_rounding_policy rounding_policy, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
- {
- ACL_ASSERT(m_num_bones > 0, "Invalid number of bones: %u", m_num_bones);
- ACL_ASSERT(m_num_bones == num_transforms, "Number of transforms does not match the number of bones: %u != %u", num_transforms, m_num_bones);
- (void)num_transforms;
-
- const float clip_duration = get_duration();
-
- // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
- sample_time = rtm::scalar_clamp(sample_time, 0.0F, clip_duration);
-
- uint32_t sample_index0;
- uint32_t sample_index1;
- float interpolation_alpha;
- find_linear_interpolation_samples_with_sample_rate(m_num_samples, m_sample_rate, sample_time, rounding_policy, sample_index0, sample_index1, interpolation_alpha);
-
- for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
- {
- const AnimatedBone& bone = m_bones[bone_index];
-
- const rtm::quatf rotation0 = rtm::quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index0)));
- const rtm::quatf rotation1 = rtm::quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index1)));
- const rtm::quatf rotation = rtm::quat_lerp(rotation0, rotation1, interpolation_alpha);
-
- const rtm::vector4f translation0 = rtm::vector_cast(bone.translation_track.get_sample(sample_index0));
- const rtm::vector4f translation1 = rtm::vector_cast(bone.translation_track.get_sample(sample_index1));
- const rtm::vector4f translation = rtm::vector_lerp(translation0, translation1, interpolation_alpha);
-
- const rtm::vector4f scale0 = rtm::vector_cast(bone.scale_track.get_sample(sample_index0));
- const rtm::vector4f scale1 = rtm::vector_cast(bone.scale_track.get_sample(sample_index1));
- const rtm::vector4f scale = rtm::vector_lerp(scale0, scale1, interpolation_alpha);
-
- out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
- }
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Samples a whole pose at a particular sample time
- // - sample_time: The time at which to sample the clip
- // - out_local_pose: An array of at least 'num_transforms' to output the data in
- // - num_transforms: The number of transforms in the output array
- void sample_pose(float sample_time, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
- {
- sample_pose(sample_time, sample_rounding_policy::none, out_local_pose, num_transforms);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the raw size for this clip. Note that this differs from the actual
- // memory used by an instance of this class. It is meant for comparison against
- // the compressed size.
- uint32_t get_raw_size() const
- {
- const uint32_t rotation_size = sizeof(float) * 4; // Quat == Vector4
- const uint32_t translation_size = sizeof(float) * 3; // Vector3
- const uint32_t scale_size = sizeof(float) * 3; // Vector3
- const uint32_t bone_sample_size = rotation_size + translation_size + scale_size;
- return uint32_t(m_num_bones) * bone_sample_size * m_num_samples;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Sets the base animation clip and marks this instance as an additive clip of the provided format
- void set_additive_base(const AnimationClip* base_clip, additive_clip_format8 additive_format) { m_additive_base_clip = base_clip; m_additive_format = additive_format; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the additive base clip, if any
- const AnimationClip* get_additive_base() const { return m_additive_base_clip; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the additive format of this clip, if any
- additive_clip_format8 get_additive_format() const { return m_additive_format; }
-
- //////////////////////////////////////////////////////////////////////////
- // Checks if the instance of this clip is valid and returns an error if it isn't
- ErrorResult is_valid() const
- {
- if (m_num_bones == 0)
- return ErrorResult("Clip has no bones");
-
- if (m_num_samples == 0)
- return ErrorResult("Clip has no samples");
-
- if (m_num_samples == 0xFFFFFFFFU)
- return ErrorResult("Clip has too many samples");
-
- if (m_sample_rate <= 0.0F)
- return ErrorResult("Clip has an invalid sample rate");
-
- uint16_t num_output_bones = 0;
- for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
- {
- const uint16_t output_index = m_bones[bone_index].output_index;
- if (output_index != k_invalid_bone_index && output_index >= m_num_bones)
- return ErrorResult("The output_index must be 'k_invalid_bone_index' or less than the number of bones");
-
- if (output_index != k_invalid_bone_index)
- {
- for (uint16_t bone_index2 = bone_index + 1; bone_index2 < m_num_bones; ++bone_index2)
- {
- if (output_index == m_bones[bone_index2].output_index)
- return ErrorResult("Duplicate output_index found");
- }
-
- num_output_bones++;
- }
- }
-
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- bool found = false;
- for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
- {
- if (output_index == m_bones[bone_index].output_index)
- {
- found = true;
- break;
- }
- }
-
- if (!found)
- return ErrorResult("Output indices are not contiguous");
- }
-
- if (m_additive_base_clip != nullptr)
- {
- if (m_num_bones != m_additive_base_clip->get_num_bones())
- return ErrorResult("The number of bones does not match between the clip and its additive base");
-
- if (&m_skeleton != &m_additive_base_clip->get_skeleton())
- return ErrorResult("The RigidSkeleton differs between the clip and its additive base");
-
- return m_additive_base_clip->is_valid();
- }
-
- return ErrorResult();
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns whether this clip has scale or not. A clip has scale if at least one
- // bone has a scale sample that isn't equivalent to the default scale.
- bool has_scale(float threshold) const
- {
- const rtm::vector4f default_scale = get_default_scale(m_additive_format);
-
- for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
- {
- const AnimatedBone& bone = m_bones[bone_index];
- const uint32_t num_samples = bone.scale_track.get_num_samples();
- if (num_samples != 0)
- {
- const rtm::vector4f scale = rtm::vector_cast(bone.scale_track.get_sample(0));
-
- rtm::vector4f min = scale;
- rtm::vector4f max = scale;
-
- for (uint32_t sample_index = 1; sample_index < num_samples; ++sample_index)
- {
- const rtm::vector4f sample = rtm::vector_cast(bone.scale_track.get_sample(sample_index));
-
- min = rtm::vector_min(min, sample);
- max = rtm::vector_max(max, sample);
- }
-
- const rtm::vector4f extent = rtm::vector_sub(max, min);
- const bool is_constant = rtm::vector_all_less_than3(rtm::vector_abs(extent), rtm::vector_set(threshold));
- if (!is_constant)
- return true; // Not constant means we have scale
-
- const bool is_default = rtm::vector_all_near_equal3(scale, default_scale, threshold);
- if (!is_default)
- return true; // Constant but not default means we have scale
- }
- }
-
- // We have no tracks with non-default scale
- return false;
- }
-
- private:
- // The allocator instance used to allocate and free memory by this clip instance
- IAllocator& m_allocator;
-
- // The rigid skeleton this clip is based on
- const RigidSkeleton& m_skeleton;
-
- // The array of animated bone data. There are 'm_num_bones' entries
- AnimatedBone* m_bones;
-
- // The number of samples per animated track
- uint32_t m_num_samples;
-
- // The rate at which the samples were recorded
- float m_sample_rate;
-
- // The number of bones in this clip
- uint16_t m_num_bones;
-
- // The optional clip the current additive clip is based on
- const AnimationClip* m_additive_base_clip;
-
- // If we have an additive base, this is the format we are in
- additive_clip_format8 m_additive_format;
-
- // The name of the clip
- String m_name;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // Allocates an array of integers that correspond to the output bone mapping: result[output_index] = bone_index
- // - allocator: The allocator instance to use to allocate and free memory
- // - clip: The animation clip that dictates the bone output
- // - out_num_output_bones: The number of output bones
- //////////////////////////////////////////////////////////////////////////
- inline uint16_t* create_output_bone_mapping(IAllocator& allocator, const AnimationClip& clip, uint16_t& out_num_output_bones)
- {
- const uint16_t num_bones = clip.get_num_bones();
- const AnimatedBone* bones = clip.get_bones();
- uint16_t num_output_bones = num_bones;
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- if (bones[bone_index].is_stripped_from_output())
- num_output_bones--;
- }
-
- uint16_t* output_bone_mapping = allocate_type_array<uint16_t>(allocator, num_output_bones);
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const uint16_t output_index = bones[bone_index].output_index;
- if (output_index != k_invalid_bone_index)
- output_bone_mapping[output_index] = bone_index;
- }
-
- out_num_output_bones = num_output_bones;
- return output_bone_mapping;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/animation_track.h b/includes/acl/compression/animation_track.h
deleted file mode 100644
--- a/includes/acl/compression/animation_track.h
+++ /dev/null
@@ -1,346 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/iallocator.h"
-#include "acl/core/error.h"
-#include "acl/core/track_types.h"
-
-#include <rtm/quatd.h>
-#include <rtm/vector4d.h>
-
-#include <cstdint>
-#include <utility>
-
-// VS2015 sometimes dies when it attempts to compile too many inlined functions
-#if defined(_MSC_VER)
- #define VS2015_HACK_NO_INLINE __declspec(noinline)
-#else
- #define VS2015_HACK_NO_INLINE
-#endif
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // A raw animation track.
- //
- // This is the base class for the three track types: rotation, translation, and scale.
- // It holds and owns the raw data.
- //////////////////////////////////////////////////////////////////////////
- class AnimationTrack
- {
- public:
- //////////////////////////////////////////////////////////////////////////
- // Returns if the animation track has been initialized or not
- bool is_initialized() const { return m_allocator != nullptr; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the number of samples in this track
- uint32_t get_num_samples() const { return m_num_samples; }
-
- protected:
- AnimationTrack() noexcept
- : m_allocator(nullptr)
- , m_sample_data(nullptr)
- , m_num_samples(0)
- , m_sample_rate(0.0F)
- , m_type(animation_track_type8::rotation)
- {}
-
- AnimationTrack(AnimationTrack&& other) noexcept
- : m_allocator(other.m_allocator)
- , m_sample_data(other.m_sample_data)
- , m_num_samples(other.m_num_samples)
- , m_sample_rate(other.m_sample_rate)
- , m_type(other.m_type)
- {
- // Safe because our derived classes do not add any data and aren't virtual
- new(&other) AnimationTrack();
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a new track instance
- // - allocator: The allocator instance to use to allocate and free memory
- // - num_samples: The number of samples in this track
- // - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
- // - type: The track type
- AnimationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate, animation_track_type8 type)
- : m_allocator(&allocator)
- , m_sample_data(allocate_type_array_aligned<double>(allocator, size_t(num_samples) * get_animation_track_sample_size(type), alignof(rtm::vector4d)))
- , m_num_samples(num_samples)
- , m_sample_rate(sample_rate)
- , m_type(type)
- {}
-
- ~AnimationTrack()
- {
- if (is_initialized())
- deallocate_type_array(*m_allocator, m_sample_data, size_t(m_num_samples) * get_animation_track_sample_size(m_type));
- }
-
- AnimationTrack& operator=(AnimationTrack&& track) noexcept
- {
- std::swap(m_allocator, track.m_allocator);
- std::swap(m_sample_data, track.m_sample_data);
- std::swap(m_num_samples, track.m_num_samples);
- std::swap(m_sample_rate, track.m_sample_rate);
- std::swap(m_type, track.m_type);
- return *this;
- }
-
- AnimationTrack(const AnimationTrack&) = delete;
- AnimationTrack& operator=(const AnimationTrack&) = delete;
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the number of values per sample
- // TODO: constexpr
- static uint32_t get_animation_track_sample_size(animation_track_type8 type)
- {
- switch (type)
- {
- default:
- case animation_track_type8::rotation: return 4;
- case animation_track_type8::translation: return 3;
- case animation_track_type8::scale: return 3;
- }
- }
-
- // The allocator instance used to allocate and free memory by this clip instance
- IAllocator* m_allocator;
-
- // The raw track data. There are 'get_animation_track_sample_size(m_type)' entries.
- double* m_sample_data;
-
- // The number of samples in this track
- uint32_t m_num_samples;
-
- // The rate at which the samples were recorded
- float m_sample_rate;
-
- // The track type
- animation_track_type8 m_type;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A raw rotation track.
- //
- // Holds a track made of 'rtm::quatd' entries.
- //////////////////////////////////////////////////////////////////////////
- class AnimationRotationTrack final : public AnimationTrack
- {
- public:
- AnimationRotationTrack() noexcept : AnimationTrack() {}
- ~AnimationRotationTrack() = default;
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a new rotation track instance
- // - allocator: The allocator instance to use to allocate and free memory
- // - num_samples: The number of samples in this track
- // - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
- AnimationRotationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::rotation)
- {
- rtm::quatd* samples = safe_ptr_cast<rtm::quatd>(&m_sample_data[0]);
- std::fill(samples, samples + num_samples, rtm::quat_identity());
- }
-
- AnimationRotationTrack(AnimationRotationTrack&& other) noexcept
- : AnimationTrack(static_cast<AnimationTrack&&>(other))
- {}
-
- AnimationRotationTrack& operator=(AnimationRotationTrack&& track) noexcept
- {
- AnimationTrack::operator=(static_cast<AnimationTrack&&>(track));
- return *this;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Sets a sample value at a particular index
- VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const rtm::quatd& rotation)
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(rtm::quat_is_finite(rotation), "Invalid rotation: [%f, %f, %f, %f]", (float)rtm::quat_get_x(rotation), (float)rtm::quat_get_y(rotation), (float)rtm::quat_get_z(rotation), (float)rtm::quat_get_w(rotation));
- ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation not normalized: [%f, %f, %f, %f]", (float)rtm::quat_get_x(rotation), (float)rtm::quat_get_y(rotation), (float)rtm::quat_get_z(rotation), (float)rtm::quat_get_w(rotation));
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
- ACL_ASSERT(sample_size == 4, "Invalid sample size. %u != 4", sample_size);
-
- double* sample = &m_sample_data[sample_index * sample_size];
- rtm::quat_store(rotation, sample);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Retrieves a sample value at a particular index
- rtm::quatd get_sample(uint32_t sample_index) const
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
-
- const double* sample = &m_sample_data[sample_index * sample_size];
- return rtm::quat_load(sample);
- }
-
- AnimationRotationTrack(const AnimationRotationTrack&) = delete;
- AnimationRotationTrack& operator=(const AnimationRotationTrack&) = delete;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A raw translation track.
- //
- // Holds a track made of 3x 'double' entries.
- //////////////////////////////////////////////////////////////////////////
- class AnimationTranslationTrack final : public AnimationTrack
- {
- public:
- AnimationTranslationTrack() noexcept : AnimationTrack() {}
- ~AnimationTranslationTrack() = default;
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a new translation track instance
- // - allocator: The allocator instance to use to allocate and free memory
- // - num_samples: The number of samples in this track
- // - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
- AnimationTranslationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::translation)
- {
- std::fill(m_sample_data, m_sample_data + (num_samples * 3), 0.0);
- }
-
- AnimationTranslationTrack(AnimationTranslationTrack&& other) noexcept
- : AnimationTrack(static_cast<AnimationTrack&&>(other))
- {}
-
- AnimationTranslationTrack& operator=(AnimationTranslationTrack&& track) noexcept
- {
- AnimationTrack::operator=(static_cast<AnimationTrack&&>(track));
- return *this;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Sets a sample value at a particular index
- void set_sample(uint32_t sample_index, const rtm::vector4d& translation)
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(rtm::vector_is_finite3(translation), "Invalid translation: [%f, %f, %f]", (float)rtm::vector_get_x(translation), (float)rtm::vector_get_y(translation), (float)rtm::vector_get_z(translation));
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
- ACL_ASSERT(sample_size == 3, "Invalid sample size. %u != 3", sample_size);
-
- double* sample = &m_sample_data[sample_index * sample_size];
- rtm::vector_store3(translation, sample);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Retrieves a sample value at a particular index
- rtm::vector4d get_sample(uint32_t sample_index) const
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
-
- const double* sample = &m_sample_data[sample_index * sample_size];
- return rtm::vector_load3(sample);
- }
-
- AnimationTranslationTrack(const AnimationTranslationTrack&) = delete;
- AnimationTranslationTrack& operator=(const AnimationTranslationTrack&) = delete;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A raw scale track.
- //
- // Holds a track made of 3x 'double' entries.
- //////////////////////////////////////////////////////////////////////////
- class AnimationScaleTrack final : public AnimationTrack
- {
- public:
- AnimationScaleTrack() noexcept : AnimationTrack() {}
- ~AnimationScaleTrack() = default;
-
- //////////////////////////////////////////////////////////////////////////
- // Constructs a new scale track instance
- // - allocator: The allocator instance to use to allocate and free memory
- // - num_samples: The number of samples in this track
- // - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
- AnimationScaleTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::scale)
- {
- rtm::vector4d defaultScale = rtm::vector_set(1.0);
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- rtm::vector_store3(defaultScale, m_sample_data + (sample_index * 3));
- }
-
- AnimationScaleTrack(AnimationScaleTrack&& other) noexcept
- : AnimationTrack(static_cast<AnimationTrack&&>(other))
- {}
-
- AnimationScaleTrack& operator=(AnimationScaleTrack&& track) noexcept
- {
- AnimationTrack::operator=(static_cast<AnimationTrack&&>(track));
- return *this;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Sets a sample value at a particular index
- VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const rtm::vector4d& scale)
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(rtm::vector_is_finite3(scale), "Invalid scale: [%f, %f, %f]", (float)rtm::vector_get_x(scale), (float)rtm::vector_get_y(scale), (float)rtm::vector_get_z(scale));
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
- ACL_ASSERT(sample_size == 3, "Invalid sample size. %u != 3", sample_size);
-
- double* sample = &m_sample_data[sample_index * sample_size];
- rtm::vector_store3(scale, sample);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Retrieves a sample value at a particular index
- rtm::vector4d get_sample(uint32_t sample_index) const
- {
- ACL_ASSERT(is_initialized(), "Track is not initialized");
- ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
-
- const uint32_t sample_size = get_animation_track_sample_size(m_type);
-
- const double* sample = &m_sample_data[sample_index * sample_size];
- return rtm::vector_load3(sample);
- }
-
- AnimationScaleTrack(const AnimationScaleTrack&) = delete;
- AnimationScaleTrack& operator=(const AnimationScaleTrack&) = delete;
- };
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/compress.h b/includes/acl/compression/compress.h
--- a/includes/acl/compression/compress.h
+++ b/includes/acl/compression/compress.h
@@ -35,6 +35,7 @@
#include "acl/compression/compression_settings.h"
#include "acl/compression/output_stats.h"
#include "acl/compression/track_array.h"
+#include "acl/compression/impl/clip_context.h"
#include "acl/compression/impl/constant_track_impl.h"
#include "acl/compression/impl/normalize_track_impl.h"
#include "acl/compression/impl/quantize_track_impl.h"
@@ -43,12 +44,401 @@
#include "acl/compression/impl/write_compression_stats_impl.h"
#include "acl/compression/impl/write_track_data_impl.h"
+#include "acl/compression/impl/track_stream.h"
+#include "acl/compression/impl/convert_rotation_streams.h"
+#include "acl/compression/impl/compact_constant_streams.h"
+#include "acl/compression/impl/normalize_streams.h"
+#include "acl/compression/impl/quantize_streams.h"
+#include "acl/compression/impl/segment_streams.h"
+#include "acl/compression/impl/write_segment_data.h"
+#include "acl/compression/impl/write_stats.h"
+#include "acl/compression/impl/write_stream_bitsets.h"
+#include "acl/compression/impl/write_stream_data.h"
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
+ namespace acl_impl
+ {
+ inline error_result compress_scalar_track_list(iallocator& allocator, const track_array& track_list, compressed_tracks*& out_compressed_tracks, output_stats& out_stats)
+ {
+#if defined(SJSON_CPP_WRITER)
+ scope_profiler compression_time;
+#endif
+
+ track_list_context context;
+ initialize_context(allocator, track_list, context);
+
+ extract_track_ranges(context);
+ extract_constant_tracks(context);
+ normalize_tracks(context);
+ quantize_tracks(context);
+
+ // Done transforming our input tracks, time to pack them into their final form
+ const uint32_t per_track_metadata_size = write_track_metadata(context, nullptr);
+ const uint32_t constant_values_size = write_track_constant_values(context, nullptr);
+ const uint32_t range_values_size = write_track_range_values(context, nullptr);
+ const uint32_t animated_num_bits = write_track_animated_values(context, nullptr);
+ const uint32_t animated_values_size = (animated_num_bits + 7) / 8; // Round up to nearest byte
+ const uint32_t num_bits_per_frame = context.num_samples != 0 ? (animated_num_bits / context.num_samples) : 0;
+
+ uint32_t buffer_size = 0;
+ buffer_size += sizeof(compressed_tracks); // Headers
+ buffer_size += sizeof(scalar_tracks_header); // Header
+ ACL_ASSERT(is_aligned_to(buffer_size, alignof(track_metadata)), "Invalid alignment");
+ buffer_size += per_track_metadata_size; // Per track metadata
+ buffer_size = align_to(buffer_size, 4); // Align constant values
+ buffer_size += constant_values_size; // Constant values
+ ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
+ buffer_size += range_values_size; // Range values
+ ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
+ buffer_size += animated_values_size; // Animated values
+ buffer_size += 15; // Ensure we have sufficient padding for unaligned 16 byte loads
+
+ uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, alignof(compressed_tracks));
+ std::memset(buffer, 0, buffer_size);
+
+ const uint8_t* buffer_start = buffer;
+ out_compressed_tracks = reinterpret_cast<compressed_tracks*>(buffer);
+
+ raw_buffer_header* buffer_header = safe_ptr_cast<raw_buffer_header>(buffer);
+ buffer += sizeof(raw_buffer_header);
+
+ tracks_header* header = safe_ptr_cast<tracks_header>(buffer);
+ buffer += sizeof(tracks_header);
+
+ // Write our primary header
+ header->tag = static_cast<uint32_t>(buffer_tag32::compressed_tracks);
+ header->version = get_algorithm_version(algorithm_type8::uniformly_sampled);
+ header->algorithm_type = algorithm_type8::uniformly_sampled;
+ header->track_type = track_list.get_track_type();
+ header->num_tracks = context.num_tracks;
+ header->num_samples = context.num_samples;
+ header->sample_rate = context.sample_rate;
+
+ // Write our scalar tracks header
+ scalar_tracks_header* scalars_header = safe_ptr_cast<scalar_tracks_header>(buffer);
+ buffer += sizeof(scalar_tracks_header);
+
+ scalars_header->num_bits_per_frame = num_bits_per_frame;
+
+ const uint8_t* packed_data_start_offset = buffer - sizeof(scalar_tracks_header); // Relative to our header
+ scalars_header->metadata_per_track = buffer - packed_data_start_offset;
+ buffer += per_track_metadata_size;
+ buffer = align_to(buffer, 4);
+ scalars_header->track_constant_values = buffer - packed_data_start_offset;
+ buffer += constant_values_size;
+ scalars_header->track_range_values = buffer - packed_data_start_offset;
+ buffer += range_values_size;
+ scalars_header->track_animated_values = buffer - packed_data_start_offset;
+ buffer += animated_values_size;
+ buffer += 15;
+
+ (void)buffer_start; // Avoid VS2017 bug, it falsely reports this variable as unused even when asserts are enabled
+ ACL_ASSERT((buffer_start + buffer_size) == buffer, "Buffer size and pointer mismatch");
+
+ // Write our compressed data
+ track_metadata* per_track_metadata = scalars_header->get_track_metadata();
+ write_track_metadata(context, per_track_metadata);
+
+ float* constant_values = scalars_header->get_track_constant_values();
+ write_track_constant_values(context, constant_values);
+
+ float* range_values = scalars_header->get_track_range_values();
+ write_track_range_values(context, range_values);
+
+ uint8_t* animated_values = scalars_header->get_track_animated_values();
+ write_track_animated_values(context, animated_values);
+
+ // Finish the raw buffer header
+ buffer_header->size = buffer_size;
+ buffer_header->hash = hash32(safe_ptr_cast<const uint8_t>(header), buffer_size - sizeof(raw_buffer_header)); // Hash everything but the raw buffer header
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ for (const uint8_t* padding = buffer - 15; padding < buffer; ++padding)
+ ACL_ASSERT(*padding == 0, "Padding was overwritten");
+#endif
+
+#if defined(SJSON_CPP_WRITER)
+ compression_time.stop();
+
+ if (out_stats.logging != stat_logging::None)
+ write_compression_stats(context, *out_compressed_tracks, compression_time, out_stats);
+#endif
+
+ return error_result();
+ }
+
+ inline error_result compress_transform_track_list(iallocator& allocator, const track_array_qvvf& track_list, compression_settings settings, const track_array_qvvf* additive_base_track_list, additive_clip_format8 additive_format,
+ compressed_tracks*& out_compressed_tracks, output_stats& out_stats)
+ {
+ error_result result = settings.is_valid();
+ if (result.any())
+ return result;
+
+#if defined(SJSON_CPP_WRITER)
+ scope_profiler compression_time;
+#endif
+
+ // If every track is retains full precision, we disable segmenting since it provides no benefit
+ if (!is_rotation_format_variable(settings.rotation_format) && !is_vector_format_variable(settings.translation_format) && !is_vector_format_variable(settings.scale_format))
+ {
+ settings.segmenting.ideal_num_samples = 0xFFFF;
+ settings.segmenting.max_num_samples = 0xFFFF;
+ }
+
+ // Variable bit rate tracks need range reduction
+ // Full precision tracks do not need range reduction since samples are stored raw
+ range_reduction_flags8 range_reduction = range_reduction_flags8::none;
+ if (is_rotation_format_variable(settings.rotation_format))
+ range_reduction |= range_reduction_flags8::rotations;
+
+ if (is_vector_format_variable(settings.translation_format))
+ range_reduction |= range_reduction_flags8::translations;
+
+ if (is_vector_format_variable(settings.scale_format))
+ range_reduction |= range_reduction_flags8::scales;
+
+ clip_context raw_clip_context;
+ initialize_clip_context(allocator, track_list, additive_format, raw_clip_context);
+
+ clip_context lossy_clip_context;
+ initialize_clip_context(allocator, track_list, additive_format, lossy_clip_context);
+
+ const bool is_additive = additive_base_track_list != nullptr && additive_format != additive_clip_format8::none;
+ clip_context additive_base_clip_context;
+ if (is_additive)
+ initialize_clip_context(allocator, *additive_base_track_list, additive_format, additive_base_clip_context);
+
+ convert_rotation_streams(allocator, lossy_clip_context, settings.rotation_format);
+
+ // Extract our clip ranges now, we need it for compacting the constant streams
+ extract_clip_bone_ranges(allocator, lossy_clip_context);
+
+ // Compact and collapse the constant streams
+ compact_constant_streams(allocator, lossy_clip_context, track_list);
+
+ uint32_t clip_range_data_size = 0;
+ if (range_reduction != range_reduction_flags8::none)
+ {
+ normalize_clip_streams(lossy_clip_context, range_reduction);
+ clip_range_data_size = get_stream_range_data_size(lossy_clip_context, range_reduction, settings.rotation_format);
+ }
+
+ segment_streams(allocator, lossy_clip_context, settings.segmenting);
+
+ // If we have a single segment, skip segment range reduction since it won't help
+ if (range_reduction != range_reduction_flags8::none && lossy_clip_context.num_segments > 1)
+ {
+ extract_segment_bone_ranges(allocator, lossy_clip_context);
+ normalize_segment_streams(lossy_clip_context, range_reduction);
+ }
+
+ quantize_streams(allocator, lossy_clip_context, settings, raw_clip_context, additive_base_clip_context, out_stats);
+
+ uint32_t num_output_bones = 0;
+ uint32_t* output_bone_mapping = create_output_track_mapping(allocator, track_list, num_output_bones);
+
+ const uint32_t constant_data_size = get_constant_data_size(lossy_clip_context, output_bone_mapping, num_output_bones);
+
+ calculate_animated_data_size(lossy_clip_context, output_bone_mapping, num_output_bones);
+
+ const uint32_t format_per_track_data_size = get_format_per_track_data_size(lossy_clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
+
+ const uint32_t num_tracks_per_bone = lossy_clip_context.has_scale ? 3 : 2;
+ const uint32_t num_tracks = uint32_t(num_output_bones) * num_tracks_per_bone;
+ const bitset_description bitset_desc = bitset_description::make_from_num_bits(num_tracks);
+
+ // Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
+ const uint32_t segment_start_indices_size = lossy_clip_context.num_segments > 1 ? (sizeof(uint32_t) * (lossy_clip_context.num_segments + 1)) : 0;
+ const uint32_t segment_headers_size = sizeof(segment_header) * lossy_clip_context.num_segments;
+
+ uint32_t buffer_size = 0;
+ // Per clip data
+ buffer_size += sizeof(compressed_tracks); // Headers
+ buffer_size += sizeof(transform_tracks_header); // Header
+
+ const uint32_t clip_header_size = buffer_size;
+
+ buffer_size += segment_start_indices_size; // Segment start indices
+ buffer_size = align_to(buffer_size, 4); // Align segment headers
+ buffer_size += segment_headers_size; // Segment headers
+ buffer_size = align_to(buffer_size, 4); // Align bitsets
+
+ const uint32_t clip_segment_header_size = buffer_size - clip_header_size;
+
+ buffer_size += bitset_desc.get_num_bytes(); // Default tracks bitset
+ buffer_size += bitset_desc.get_num_bytes(); // Constant tracks bitset
+ buffer_size = align_to(buffer_size, 4); // Align constant track data
+ buffer_size += constant_data_size; // Constant track data
+ buffer_size = align_to(buffer_size, 4); // Align range data
+ buffer_size += clip_range_data_size; // Range data
+
+ const uint32_t clip_data_size = buffer_size - clip_segment_header_size - clip_header_size;
+
+ if (are_all_enum_flags_set(out_stats.logging, stat_logging::Detailed))
+ {
+ constexpr uint32_t k_cache_line_byte_size = 64;
+ lossy_clip_context.decomp_touched_bytes = clip_header_size + clip_data_size;
+ lossy_clip_context.decomp_touched_bytes += sizeof(uint32_t) * 4; // We touch at most 4 segment start indices
+ lossy_clip_context.decomp_touched_bytes += sizeof(segment_header) * 2; // We touch at most 2 segment headers
+ lossy_clip_context.decomp_touched_cache_lines = align_to(clip_header_size, k_cache_line_byte_size) / k_cache_line_byte_size;
+ lossy_clip_context.decomp_touched_cache_lines += align_to(clip_data_size, k_cache_line_byte_size) / k_cache_line_byte_size;
+ lossy_clip_context.decomp_touched_cache_lines += 1; // All 4 segment start indices should fit in a cache line
+ lossy_clip_context.decomp_touched_cache_lines += 1; // Both segment headers should fit in a cache line
+ }
+
+ // Per segment data
+ for (SegmentContext& segment : lossy_clip_context.segment_iterator())
+ {
+ const uint32_t header_start = buffer_size;
+
+ buffer_size += format_per_track_data_size; // Format per track data
+ // TODO: Alignment only necessary with 16bit per component (segment constant tracks), need to fix scalar decoding path
+ buffer_size = align_to(buffer_size, 2); // Align range data
+ buffer_size += segment.range_data_size; // Range data
+
+ const uint32_t header_end = buffer_size;
+
+ // TODO: Variable bit rate doesn't need alignment
+ buffer_size = align_to(buffer_size, 4); // Align animated data
+ buffer_size += segment.animated_data_size; // Animated track data
+
+ segment.total_header_size = header_end - header_start;
+ }
+
+ // Ensure we have sufficient padding for unaligned 16 byte loads
+ buffer_size += 15;
+
+ uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, alignof(compressed_tracks));
+ std::memset(buffer, 0, buffer_size);
+
+ const uint8_t* buffer_start = buffer;
+ out_compressed_tracks = reinterpret_cast<compressed_tracks*>(buffer);
+
+ raw_buffer_header* buffer_header = safe_ptr_cast<raw_buffer_header>(buffer);
+ buffer += sizeof(raw_buffer_header);
+
+ tracks_header* header = safe_ptr_cast<tracks_header>(buffer);
+ buffer += sizeof(tracks_header);
+
+ // Write our primary header
+ header->tag = static_cast<uint32_t>(buffer_tag32::compressed_tracks);
+ header->version = get_algorithm_version(algorithm_type8::uniformly_sampled);
+ header->algorithm_type = algorithm_type8::uniformly_sampled;
+ header->track_type = track_list.get_track_type();
+ header->num_tracks = num_output_bones;
+ header->num_samples = track_list.get_num_samples_per_track();
+ header->sample_rate = track_list.get_sample_rate();
+
+ // Write our transform tracks header
+ transform_tracks_header* transforms_header = safe_ptr_cast<transform_tracks_header>(buffer);
+ buffer += sizeof(transform_tracks_header);
+
+ transforms_header->num_segments = lossy_clip_context.num_segments;
+ transforms_header->rotation_format = settings.rotation_format;
+ transforms_header->translation_format = settings.translation_format;
+ transforms_header->scale_format = settings.scale_format;
+ transforms_header->has_scale = lossy_clip_context.has_scale ? 1 : 0;
+ // Our default scale is 1.0 if we have no additive base or if we don't use 'additive1', otherwise it is 0.0
+ transforms_header->default_scale = !is_additive || additive_format != additive_clip_format8::additive1 ? 1 : 0;
+ transforms_header->segment_start_indices_offset = sizeof(transform_tracks_header); // Relative to the start of our header
+ transforms_header->segment_headers_offset = align_to(transforms_header->segment_start_indices_offset + segment_start_indices_size, 4);
+ transforms_header->default_tracks_bitset_offset = align_to(transforms_header->segment_headers_offset + segment_headers_size, 4);
+ transforms_header->constant_tracks_bitset_offset = transforms_header->default_tracks_bitset_offset + bitset_desc.get_num_bytes();
+ transforms_header->constant_track_data_offset = align_to(transforms_header->constant_tracks_bitset_offset + bitset_desc.get_num_bytes(), 4);
+ transforms_header->clip_range_data_offset = align_to(transforms_header->constant_track_data_offset + constant_data_size, 4);
+
+ uint32_t written_segment_start_indices_size = 0;
+ if (lossy_clip_context.num_segments > 1)
+ written_segment_start_indices_size = write_segment_start_indices(lossy_clip_context, transforms_header->get_segment_start_indices());
+ else
+ transforms_header->segment_start_indices_offset = invalid_ptr_offset();
+
+ const uint32_t segment_data_start_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
+ const uint32_t written_segment_headers_size = write_segment_headers(lossy_clip_context, settings, transforms_header->get_segment_headers(), segment_data_start_offset);
+
+ uint32_t written_bitset_size = 0;
+ written_bitset_size += write_default_track_bitset(lossy_clip_context, transforms_header->get_default_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
+ written_bitset_size += write_constant_track_bitset(lossy_clip_context, transforms_header->get_constant_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
+
+ uint32_t written_constant_data_size = 0;
+ if (constant_data_size > 0)
+ written_constant_data_size = write_constant_track_data(lossy_clip_context, transforms_header->get_constant_track_data(), constant_data_size, output_bone_mapping, num_output_bones);
+ else
+ transforms_header->constant_track_data_offset = invalid_ptr_offset();
+
+ uint32_t written_clip_range_data_size = 0;
+ if (range_reduction != range_reduction_flags8::none)
+ written_clip_range_data_size = write_clip_range_data(lossy_clip_context, range_reduction, transforms_header->get_clip_range_data(), clip_range_data_size, output_bone_mapping, num_output_bones);
+ else
+ transforms_header->clip_range_data_offset = invalid_ptr_offset();
+
+ const uint32_t written_segment_data_size = write_segment_data(lossy_clip_context, settings, range_reduction, *transforms_header, output_bone_mapping, num_output_bones);
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ {
+ // Make sure we wrote the right amount of data
+ buffer += written_segment_start_indices_size;
+ buffer = align_to(buffer, 4); // Align segment headers
+ buffer += written_segment_headers_size;
+ buffer = align_to(buffer, 4); // Align bitsets
+ buffer += written_bitset_size;
+ buffer = align_to(buffer, 4); // Align constant track data
+ buffer += written_constant_data_size;
+ buffer = align_to(buffer, 4); // Align range data
+ buffer += written_clip_range_data_size;
+ buffer += written_segment_data_size;
+
+ // Ensure we have sufficient padding for unaligned 16 byte loads
+ buffer += 15;
+
+ (void)buffer_start; // Avoid VS2017 bug, it falsely reports this variable as unused even when asserts are enabled
+ ACL_ASSERT(written_segment_start_indices_size == segment_start_indices_size, "Wrote too little or too much data");
+ ACL_ASSERT(written_segment_headers_size == segment_headers_size, "Wrote too little or too much data");
+ ACL_ASSERT(written_bitset_size == (bitset_desc.get_num_bytes() * 2), "Wrote too little or too much data");
+ ACL_ASSERT(written_constant_data_size == constant_data_size, "Wrote too little or too much data");
+ ACL_ASSERT(written_clip_range_data_size == clip_range_data_size, "Wrote too little or too much data");
+ ACL_ASSERT(uint32_t(buffer - buffer_start) == buffer_size, "Wrote too little or too much data");
+ for (const uint8_t* padding = buffer - 15; padding < buffer; ++padding)
+ ACL_ASSERT(*padding == 0, "Padding was overwritten");
+ }
+#else
+ (void)written_segment_start_indices_size;
+ (void)written_segment_headers_size;
+ (void)written_bitset_size;
+ (void)written_constant_data_size;
+ (void)written_clip_range_data_size;
+ (void)written_segment_data_size;
+ (void)buffer_start;
+#endif
+
+
+ // Finish the raw buffer header
+ buffer_header->size = buffer_size;
+ buffer_header->hash = hash32(safe_ptr_cast<const uint8_t>(header), buffer_size - sizeof(raw_buffer_header)); // Hash everything but the raw buffer header
+
+#if defined(SJSON_CPP_WRITER)
+ compression_time.stop();
+
+ if (out_stats.logging != stat_logging::None)
+ write_stats(allocator, track_list, lossy_clip_context, *out_compressed_tracks, settings, raw_clip_context, additive_base_clip_context, compression_time, out_stats);
+#endif
+
+ deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
+ destroy_clip_context(allocator, lossy_clip_context);
+ destroy_clip_context(allocator, raw_clip_context);
+
+ if (is_additive)
+ destroy_clip_context(allocator, additive_base_clip_context);
+
+ return error_result();
+ }
+ }
+
//////////////////////////////////////////////////////////////////////////
// Compresses a track array with uniform sampling.
//
@@ -66,113 +456,66 @@ namespace acl
// out_compressed_tracks: The resulting compressed tracks. The caller owns the returned memory and must free it.
// out_stats: Stat output structure.
//////////////////////////////////////////////////////////////////////////
- inline ErrorResult compress_track_list(IAllocator& allocator, const track_array& track_list, const compression_settings& settings, compressed_tracks*& out_compressed_tracks, OutputStats& out_stats)
+ inline error_result compress_track_list(iallocator& allocator, const track_array& track_list, const compression_settings& settings, compressed_tracks*& out_compressed_tracks, output_stats& out_stats)
{
using namespace acl_impl;
- (void)settings; // todo?
- (void)out_stats;
+ error_result result = track_list.is_valid();
+ if (result.any())
+ return result;
- ErrorResult error_result = track_list.is_valid();
- if (error_result.any())
- return error_result;
+ if (track_list.get_num_samples_per_track() > 0xFFFF)
+ return error_result("ACL only supports up to 65535 samples");
// Disable floating point exceptions during compression because we leverage all SIMD lanes
// and we might intentionally divide by zero, etc.
scope_disable_fp_exceptions fp_off;
-#if defined(SJSON_CPP_WRITER)
- ScopeProfiler compression_time;
-#endif
+ if (track_list.get_track_category() == track_category8::transformf)
+ result = compress_transform_track_list(allocator, track_array_cast<track_array_qvvf>(track_list), settings, nullptr, additive_clip_format8::none, out_compressed_tracks, out_stats);
+ else
+ result = compress_scalar_track_list(allocator, track_list, out_compressed_tracks, out_stats);
- track_list_context context;
- initialize_context(allocator, track_list, context);
-
- extract_track_ranges(context);
- extract_constant_tracks(context);
- normalize_tracks(context);
- quantize_tracks(context);
-
- // Done transforming our input tracks, time to pack them into their final form
- const uint32_t per_track_metadata_size = write_track_metadata(context, nullptr);
- const uint32_t constant_values_size = write_track_constant_values(context, nullptr);
- const uint32_t range_values_size = write_track_range_values(context, nullptr);
- const uint32_t animated_num_bits = write_track_animated_values(context, nullptr);
- const uint32_t animated_values_size = (animated_num_bits + 7) / 8; // Round up to nearest byte
- const uint32_t num_bits_per_frame = context.num_samples != 0 ? (animated_num_bits / context.num_samples) : 0;
-
- uint32_t buffer_size = 0;
- buffer_size += sizeof(compressed_tracks); // Headers
- ACL_ASSERT(is_aligned_to(buffer_size, alignof(track_metadata)), "Invalid alignment");
- buffer_size += per_track_metadata_size; // Per track metadata
- buffer_size = align_to(buffer_size, 4); // Align constant values
- buffer_size += constant_values_size; // Constant values
- ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
- buffer_size += range_values_size; // Range values
- ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
- buffer_size += animated_values_size; // Animated values
- buffer_size += 15; // Ensure we have sufficient padding for unaligned 16 byte loads
-
- uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, alignof(compressed_tracks));
- std::memset(buffer, 0, buffer_size);
-
- const uint8_t* buffer_start = buffer;
- out_compressed_tracks = reinterpret_cast<compressed_tracks*>(buffer);
-
- raw_buffer_header* buffer_header = safe_ptr_cast<raw_buffer_header>(buffer);
- buffer += sizeof(raw_buffer_header);
-
- tracks_header* header = safe_ptr_cast<tracks_header>(buffer);
- buffer += sizeof(tracks_header);
-
- // Write our primary header
- header->tag = static_cast<uint32_t>(buffer_tag32::compressed_tracks);
- header->version = get_algorithm_version(algorithm_type8::uniformly_sampled);
- header->algorithm_type = algorithm_type8::uniformly_sampled;
- header->track_type = track_list.get_track_type();
- header->num_tracks = context.num_tracks;
- header->num_samples = context.num_samples;
- header->sample_rate = context.sample_rate;
- header->num_bits_per_frame = num_bits_per_frame;
-
- header->metadata_per_track = buffer - buffer_start;
- buffer += per_track_metadata_size;
- buffer = align_to(buffer, 4);
- header->track_constant_values = buffer - buffer_start;
- buffer += constant_values_size;
- header->track_range_values = buffer - buffer_start;
- buffer += range_values_size;
- header->track_animated_values = buffer - buffer_start;
- buffer += animated_values_size;
- buffer += 15;
-
- ACL_ASSERT(buffer_start + buffer_size == buffer, "Buffer size and pointer mismatch");
-
- // Write our compressed data
- track_metadata* per_track_metadata = header->get_track_metadata();
- write_track_metadata(context, per_track_metadata);
-
- float* constant_values = header->get_track_constant_values();
- write_track_constant_values(context, constant_values);
-
- float* range_values = header->get_track_range_values();
- write_track_range_values(context, range_values);
-
- uint8_t* animated_values = header->get_track_animated_values();
- write_track_animated_values(context, animated_values);
-
- // Finish the raw buffer header
- buffer_header->size = buffer_size;
- buffer_header->hash = hash32(safe_ptr_cast<const uint8_t>(header), buffer_size - sizeof(raw_buffer_header)); // Hash everything but the raw buffer header
+ return result;
+ }
-#if defined(SJSON_CPP_WRITER)
- compression_time.stop();
+ //////////////////////////////////////////////////////////////////////////
+ // Compresses a transform track array and using its additive base and uniform sampling.
+ //
+ // This compression algorithm is the simplest by far and as such it offers
+ // the fastest compression and decompression. Every sample is retained and
+ // every track has the same number of samples playing back at the same
+ // sample rate. This means that when we sample at a particular time within
+ // the clip, we can trivially calculate the offsets required to read the
+ // desired data. All the data is sorted in order to ensure all reads are
+ // as contiguous as possible for optimal cache locality during decompression.
+ //
+ // allocator: The allocator instance to use to allocate and free memory.
+ // track_list: The track list to compress.
+ // settings: The compression settings to use.
+ // out_compressed_tracks: The resulting compressed tracks. The caller owns the returned memory and must free it.
+ // out_stats: Stat output structure.
+ //////////////////////////////////////////////////////////////////////////
+ inline error_result compress_track_list(iallocator& allocator, const track_array_qvvf& track_list, const compression_settings& settings, const track_array_qvvf& additive_base_track_list, additive_clip_format8 additive_format, compressed_tracks*& out_compressed_tracks, output_stats& out_stats)
+ {
+ using namespace acl_impl;
- if (out_stats.logging != StatLogging::None)
- write_compression_stats(context, *out_compressed_tracks, compression_time, out_stats);
-#endif
+ error_result result = track_list.is_valid();
+ if (result.any())
+ return result;
+
+ result = additive_base_track_list.is_valid();
+ if (result.any())
+ return result;
+
+ if (track_list.get_num_samples_per_track() > 0xFFFF)
+ return error_result("ACL only supports up to 65535 samples");
+
+ // Disable floating point exceptions during compression because we leverage all SIMD lanes
+ // and we might intentionally divide by zero, etc.
+ scope_disable_fp_exceptions fp_off;
- return ErrorResult();
+ return compress_transform_track_list(allocator, track_list, settings, &additive_base_track_list, additive_format, out_compressed_tracks, out_stats);
}
}
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -30,7 +30,7 @@
#include "acl/core/track_types.h"
#include "acl/core/range_reduction_types.h"
#include "acl/compression/compression_level.h"
-#include "acl/compression/skeleton_error_metric.h"
+#include "acl/compression/transform_error_metrics.h"
#include <rtm/scalarf.h>
@@ -46,7 +46,7 @@ namespace acl
// compressed independently to allow a smaller memory footprint as well as
// faster compression and decompression.
// See also: https://nfrechette.github.io/2016/11/10/anim_compression_uniform_segmenting/
- struct SegmentingSettings
+ struct segmenting_settings
{
//////////////////////////////////////////////////////////////////////////
// How many samples to try and fit in our segments
@@ -58,7 +58,7 @@ namespace acl
// Defaults to '31'
uint16_t max_num_samples;
- SegmentingSettings()
+ segmenting_settings()
: ideal_num_samples(16)
, max_num_samples(31)
{}
@@ -76,84 +76,55 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Checks if everything is valid and if it isn't, returns an error string.
// Returns nullptr if the settings are valid.
- ErrorResult is_valid() const
+ error_result is_valid() const
{
if (ideal_num_samples < 8)
- return ErrorResult("ideal_num_samples must be greater or equal to 8");
+ return error_result("ideal_num_samples must be greater or equal to 8");
if (ideal_num_samples > max_num_samples)
- return ErrorResult("ideal_num_samples must be smaller or equal to max_num_samples");
+ return error_result("ideal_num_samples must be smaller or equal to max_num_samples");
- return ErrorResult();
+ return error_result();
}
};
//////////////////////////////////////////////////////////////////////////
// Encapsulates all the compression settings.
- struct CompressionSettings
+ struct compression_settings
{
//////////////////////////////////////////////////////////////////////////
// The compression level determines how aggressively we attempt to reduce the memory
// footprint. Higher levels will try more permutations and bit rates. The higher
// the level, the slower the compression but the smaller the memory footprint.
+ // Transform tracks only.
compression_level8 level;
//////////////////////////////////////////////////////////////////////////
// The rotation, translation, and scale formats to use. See functions get_rotation_format(..) and get_vector_format(..)
// Defaults to raw: 'quatf_full' and 'vector3f_full'
+ // Transform tracks only.
rotation_format8 rotation_format;
vector_format8 translation_format;
vector_format8 scale_format;
//////////////////////////////////////////////////////////////////////////
// Segmenting settings, if used
- SegmentingSettings segmenting;
+ // Transform tracks only.
+ segmenting_settings segmenting;
//////////////////////////////////////////////////////////////////////////
// The error metric to use.
// Defaults to 'null', this value must be set manually!
+ // Transform tracks only.
itransform_error_metric* error_metric;
- //////////////////////////////////////////////////////////////////////////
- // Threshold angle when detecting if rotation tracks are constant or default.
- // See the rtm::quatf quat_near_identity for details about how the default threshold
- // was chosen. You will typically NEVER need to change this, the value has been
- // selected to be as safe as possible and is independent of game engine units.
- // Defaults to '0.00284714461' radians
- float constant_rotation_threshold_angle;
-
- //////////////////////////////////////////////////////////////////////////
- // Threshold value to use when detecting if translation tracks are constant or default.
- // Note that you will need to change this value if your units are not in centimeters.
- // Defaults to '0.001' centimeters.
- float constant_translation_threshold;
-
- //////////////////////////////////////////////////////////////////////////
- // Threshold value to use when detecting if scale tracks are constant or default.
- // There are no units for scale as such a value that was deemed safe was selected
- // as a default.
- // Defaults to '0.00001'
- float constant_scale_threshold;
-
- //////////////////////////////////////////////////////////////////////////
- // The error threshold used when optimizing the bit rate.
- // Note that you will need to change this value if your units are not in centimeters.
- // Defaults to '0.01' centimeters
- float error_threshold;
-
- //////////////////////////////////////////////////////////////////////////
- // Default constructor sets things up to perform no compression and to leave things raw.
- CompressionSettings()
+ compression_settings()
: level(compression_level8::low)
, rotation_format(rotation_format8::quatf_full)
, translation_format(vector_format8::vector3f_full)
, scale_format(vector_format8::vector3f_full)
, segmenting()
, error_metric(nullptr)
- , constant_rotation_threshold_angle(0.00284714461F)
- , constant_translation_threshold(0.001F)
- , constant_scale_threshold(0.00001F)
- , error_threshold(0.01F)
{}
//////////////////////////////////////////////////////////////////////////
@@ -171,35 +142,15 @@ namespace acl
if (error_metric != nullptr)
hash_value = hash_combine(hash_value, error_metric->get_hash());
- hash_value = hash_combine(hash_value, hash32(constant_rotation_threshold_angle));
- hash_value = hash_combine(hash_value, hash32(constant_translation_threshold));
- hash_value = hash_combine(hash_value, hash32(constant_scale_threshold));
-
- hash_value = hash_combine(hash_value, hash32(error_threshold));
-
return hash_value;
}
//////////////////////////////////////////////////////////////////////////
// Checks if everything is valid and if it isn't, returns an error string.
- // Returns nullptr if the settings are valid.
- ErrorResult is_valid() const
+ error_result is_valid() const
{
if (error_metric == nullptr)
- return ErrorResult("error_metric cannot be NULL");
-
- const float rotation_threshold_angle = constant_rotation_threshold_angle;
- if (rotation_threshold_angle < 0.0F || !rtm::scalar_is_finite(rotation_threshold_angle))
- return ErrorResult("Invalid constant_rotation_threshold_angle");
-
- if (constant_translation_threshold < 0.0F || !rtm::scalar_is_finite(constant_translation_threshold))
- return ErrorResult("Invalid constant_translation_threshold");
-
- if (constant_scale_threshold < 0.0F || !rtm::scalar_is_finite(constant_scale_threshold))
- return ErrorResult("Invalid constant_scale_threshold");
-
- if (error_threshold < 0.0F || !rtm::scalar_is_finite(error_threshold))
- return ErrorResult("Invalid error_threshold");
+ return error_result("error_metric cannot be NULL");
return segmenting.is_valid();
}
@@ -208,32 +159,23 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Returns raw compression settings. No compression is performed and
// samples are all retained with full precision.
- inline CompressionSettings get_raw_compression_settings()
+ inline compression_settings get_raw_compression_settings()
{
- return CompressionSettings();
+ return compression_settings();
}
//////////////////////////////////////////////////////////////////////////
// Returns the recommended and default compression settings. These have
// been tested in a wide range of scenarios and perform best overall.
- inline CompressionSettings get_default_compression_settings()
+ inline compression_settings get_default_compression_settings()
{
- CompressionSettings settings;
+ compression_settings settings;
settings.level = compression_level8::medium;
settings.rotation_format = rotation_format8::quatf_drop_w_variable;
settings.translation_format = vector_format8::vector3f_variable;
settings.scale_format = vector_format8::vector3f_variable;
return settings;
}
-
- //////////////////////////////////////////////////////////////////////////
- // Encapsulates all the compression settings.
- // Note: Currently only used by scalar track compression which contain no global settings.
- struct compression_settings
- {
- compression_settings()
- {}
- };
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/clip_context.h b/includes/acl/compression/impl/clip_context.h
--- a/includes/acl/compression/impl/clip_context.h
+++ b/includes/acl/compression/impl/clip_context.h
@@ -25,11 +25,11 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/additive_utils.h"
-#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/bitset.h"
#include "acl/core/iallocator.h"
#include "acl/core/iterator.h"
#include "acl/core/error.h"
-#include "acl/compression/animation_clip.h"
+#include "acl/core/impl/compiler_utils.h"
#include "acl/compression/compression_settings.h"
#include "acl/compression/impl/segment_context.h"
@@ -44,10 +44,97 @@ namespace acl
{
namespace acl_impl
{
- struct ClipContext
+ //////////////////////////////////////////////////////////////////////////
+ // Simple iterator utility class to allow easy looping
+ class BoneChainIterator
+ {
+ public:
+ BoneChainIterator(const uint32_t* bone_chain, bitset_description bone_chain_desc, uint16_t bone_index, uint16_t offset)
+ : m_bone_chain(bone_chain)
+ , m_bone_chain_desc(bone_chain_desc)
+ , m_bone_index(bone_index)
+ , m_offset(offset)
+ {}
+
+ BoneChainIterator& operator++()
+ {
+ ACL_ASSERT(m_offset <= m_bone_index, "Cannot increment the iterator, it is no longer valid");
+
+ // Skip the current bone
+ m_offset++;
+
+ // Iterate until we find the next bone part of the chain or until we reach the end of the chain
+ // TODO: Use clz or similar to find the next set bit starting at the current index
+ while (m_offset < m_bone_index && !bitset_test(m_bone_chain, m_bone_chain_desc, m_offset))
+ m_offset++;
+
+ return *this;
+ }
+
+ uint16_t operator*() const
+ {
+ ACL_ASSERT(m_offset <= m_bone_index, "Returned bone index doesn't belong to the bone chain");
+ ACL_ASSERT(bitset_test(m_bone_chain, m_bone_chain_desc, m_offset), "Returned bone index doesn't belong to the bone chain");
+ return m_offset;
+ }
+
+ // We only compare the offset in the bone chain. Two iterators on the same bone index
+ // from two different or equal chains will be equal.
+ bool operator==(const BoneChainIterator& other) const { return m_offset == other.m_offset; }
+ bool operator!=(const BoneChainIterator& other) const { return m_offset != other.m_offset; }
+
+ private:
+ const uint32_t* m_bone_chain;
+ bitset_description m_bone_chain_desc;
+ uint16_t m_bone_index;
+ uint16_t m_offset;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Simple bone chain container to allow easy looping
+ //
+ // A bone chain allows looping over all bones up to a specific bone starting
+ // at the root bone.
+ //////////////////////////////////////////////////////////////////////////
+ struct BoneChain
+ {
+ BoneChain(const uint32_t* bone_chain, bitset_description bone_chain_desc, uint16_t bone_index)
+ : m_bone_chain(bone_chain)
+ , m_bone_chain_desc(bone_chain_desc)
+ , m_bone_index(bone_index)
+ {
+ // We don't know where this bone chain starts, find the root bone
+ // TODO: Use clz or similar to find the next set bit starting at the current index
+ uint16_t root_index = 0;
+ while (!bitset_test(bone_chain, bone_chain_desc, root_index))
+ root_index++;
+
+ m_root_index = root_index;
+ }
+
+ acl_impl::BoneChainIterator begin() const { return acl_impl::BoneChainIterator(m_bone_chain, m_bone_chain_desc, m_bone_index, m_root_index); }
+ acl_impl::BoneChainIterator end() const { return acl_impl::BoneChainIterator(m_bone_chain, m_bone_chain_desc, m_bone_index, m_bone_index + 1); }
+
+ const uint32_t* m_bone_chain;
+ bitset_description m_bone_chain_desc;
+ uint16_t m_root_index;
+ uint16_t m_bone_index;
+ };
+
+ struct transform_metadata
+ {
+ const uint32_t* transform_chain;
+ uint16_t parent_index;
+ float precision;
+ float shell_distance;
+ };
+
+ struct clip_context
{
SegmentContext* segments;
BoneRanges* ranges;
+ transform_metadata* metadata;
+ uint32_t* leaf_transform_chains;
uint16_t num_segments;
uint16_t num_bones;
@@ -65,59 +152,70 @@ namespace acl
additive_clip_format8 additive_format;
+ uint32_t num_leaf_transforms;
+
// Stat tracking
uint32_t decomp_touched_bytes;
uint32_t decomp_touched_cache_lines;
//////////////////////////////////////////////////////////////////////////
- Iterator<SegmentContext> segment_iterator() { return Iterator<SegmentContext>(segments, num_segments); }
- ConstIterator<SegmentContext> const_segment_iterator() const { return ConstIterator<SegmentContext>(segments, num_segments); }
+ iterator<SegmentContext> segment_iterator() { return iterator<SegmentContext>(segments, num_segments); }
+ const_iterator<SegmentContext> const_segment_iterator() const { return const_iterator<SegmentContext>(segments, num_segments); }
+
+ BoneChain get_bone_chain(uint32_t bone_index) const
+ {
+ ACL_ASSERT(bone_index < num_bones, "Invalid bone index: %u >= %u", bone_index, num_bones);
+ const transform_metadata& meta = metadata[bone_index];
+ return BoneChain(meta.transform_chain, bitset_description::make_from_num_bits(num_bones), (uint16_t)bone_index);
+ }
};
- inline void initialize_clip_context(IAllocator& allocator, const AnimationClip& clip, const RigidSkeleton& skeleton, const CompressionSettings& settings, ClipContext& out_clip_context)
+ inline void initialize_clip_context(iallocator& allocator, const track_array_qvvf& track_list, additive_clip_format8 additive_format, clip_context& out_clip_context)
{
- const uint16_t num_bones = clip.get_num_bones();
- const uint32_t num_samples = clip.get_num_samples();
- const float sample_rate = clip.get_sample_rate();
- const AnimatedBone* bones = clip.get_bones();
- const bool has_additive_base = clip.get_additive_base() != nullptr;
+ const uint32_t num_transforms = track_list.get_num_tracks();
+ const uint32_t num_samples = track_list.get_num_samples_per_track();
+ const float sample_rate = track_list.get_sample_rate();
- ACL_ASSERT(num_bones > 0, "Clip has no bones!");
- ACL_ASSERT(num_samples > 0, "Clip has no samples!");
+ ACL_ASSERT(num_transforms > 0, "Track array has no tracks!");
+ ACL_ASSERT(num_samples > 0, "Track array has no samples!");
// Create a single segment with the whole clip
out_clip_context.segments = allocate_type_array<SegmentContext>(allocator, 1);
out_clip_context.ranges = nullptr;
+ out_clip_context.metadata = allocate_type_array<transform_metadata>(allocator, num_transforms);
+ out_clip_context.leaf_transform_chains = nullptr;
out_clip_context.num_segments = 1;
- out_clip_context.num_bones = num_bones;
- out_clip_context.num_output_bones = num_bones;
+ out_clip_context.num_bones = safe_static_cast<uint16_t>(num_transforms);
+ out_clip_context.num_output_bones = safe_static_cast<uint16_t>(num_transforms);
out_clip_context.num_samples = num_samples;
out_clip_context.sample_rate = sample_rate;
- out_clip_context.duration = clip.get_duration();
+ out_clip_context.duration = track_list.get_duration();
out_clip_context.are_rotations_normalized = false;
out_clip_context.are_translations_normalized = false;
out_clip_context.are_scales_normalized = false;
- out_clip_context.has_additive_base = has_additive_base;
- out_clip_context.additive_format = clip.get_additive_format();
+ out_clip_context.has_additive_base = additive_format != additive_clip_format8::none;
+ out_clip_context.additive_format = additive_format;
+ out_clip_context.num_leaf_transforms = 0;
bool has_scale = false;
- const rtm::vector4f default_scale = get_default_scale(clip.get_additive_format());
+ const rtm::vector4f default_scale = get_default_scale(additive_format);
SegmentContext& segment = out_clip_context.segments[0];
- BoneStreams* bone_streams = allocate_type_array<BoneStreams>(allocator, num_bones);
+ BoneStreams* bone_streams = allocate_type_array<BoneStreams>(allocator, num_transforms);
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
{
- const AnimatedBone& bone = bones[bone_index];
- const RigidBone& skel_bone = skeleton.get_bone(bone_index);
- BoneStreams& bone_stream = bone_streams[bone_index];
+ const track_qvvf& track = track_list[transform_index];
+ const track_desc_transformf& desc = track.get_description();
+
+ BoneStreams& bone_stream = bone_streams[transform_index];
bone_stream.segment = &segment;
- bone_stream.bone_index = bone_index;
- bone_stream.parent_bone_index = skel_bone.parent_index;
- bone_stream.output_index = bone.output_index;
+ bone_stream.bone_index = safe_static_cast<uint16_t>(transform_index);
+ bone_stream.parent_bone_index = desc.parent_index == k_invalid_track_index ? k_invalid_bone_index : safe_static_cast<uint16_t>(desc.parent_index);
+ bone_stream.output_index = desc.output_index == k_invalid_track_index ? k_invalid_bone_index : safe_static_cast<uint16_t>(desc.output_index);
bone_stream.rotations = RotationTrackStream(allocator, num_samples, sizeof(rtm::quatf), sample_rate, rotation_format8::quatf_full);
bone_stream.translations = TranslationTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, vector_format8::vector3f_full);
@@ -125,27 +223,34 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const rtm::quatf rotation = rtm::quat_normalize(rtm::quat_cast(bone.rotation_track.get_sample(sample_index)));
- bone_stream.rotations.set_raw_sample(sample_index, rotation);
-
- const rtm::vector4f translation = rtm::vector_cast(bone.translation_track.get_sample(sample_index));
- bone_stream.translations.set_raw_sample(sample_index, translation);
+ const rtm::qvvf& transform = track[sample_index];
- const rtm::vector4f scale = rtm::vector_cast(bone.scale_track.get_sample(sample_index));
- bone_stream.scales.set_raw_sample(sample_index, scale);
+ bone_stream.rotations.set_raw_sample(sample_index, transform.rotation);
+ bone_stream.translations.set_raw_sample(sample_index, transform.translation);
+ bone_stream.scales.set_raw_sample(sample_index, transform.scale);
}
- bone_stream.is_rotation_constant = num_samples == 1;
- bone_stream.is_rotation_default = bone_stream.is_rotation_constant && rtm::quat_near_identity(rtm::quat_cast(bone.rotation_track.get_sample(0)), settings.constant_rotation_threshold_angle);
- bone_stream.is_translation_constant = num_samples == 1;
- bone_stream.is_translation_default = bone_stream.is_translation_constant && rtm::vector_all_near_equal3(rtm::vector_cast(bone.translation_track.get_sample(0)), rtm::vector_zero(), settings.constant_translation_threshold);
- bone_stream.is_scale_constant = num_samples == 1;
- bone_stream.is_scale_default = bone_stream.is_scale_constant && rtm::vector_all_near_equal3(rtm::vector_cast(bone.scale_track.get_sample(0)), default_scale, settings.constant_scale_threshold);
+ {
+ const rtm::qvvf& first_transform = track[0];
+
+ bone_stream.is_rotation_constant = num_samples == 1;
+ bone_stream.is_rotation_default = bone_stream.is_rotation_constant && rtm::quat_near_identity(first_transform.rotation, desc.constant_rotation_threshold_angle);
+ bone_stream.is_translation_constant = num_samples == 1;
+ bone_stream.is_translation_default = bone_stream.is_translation_constant && rtm::vector_all_near_equal3(first_transform.translation, rtm::vector_zero(), desc.constant_translation_threshold);
+ bone_stream.is_scale_constant = num_samples == 1;
+ bone_stream.is_scale_default = bone_stream.is_scale_constant && rtm::vector_all_near_equal3(first_transform.scale, default_scale, desc.constant_scale_threshold);
+ }
has_scale |= !bone_stream.is_scale_default;
if (bone_stream.is_stripped_from_output())
out_clip_context.num_output_bones--;
+
+ transform_metadata& metadata = out_clip_context.metadata[transform_index];
+ metadata.transform_chain = nullptr;
+ metadata.parent_index = desc.parent_index == k_invalid_track_index ? k_invalid_bone_index : safe_static_cast<uint16_t>(desc.parent_index);
+ metadata.precision = desc.precision;
+ metadata.shell_distance = desc.shell_distance;
}
out_clip_context.has_scale = has_scale;
@@ -156,7 +261,7 @@ namespace acl
segment.clip = &out_clip_context;
segment.ranges = nullptr;
segment.num_samples = safe_static_cast<uint16_t>(num_samples);
- segment.num_bones = num_bones;
+ segment.num_bones = safe_static_cast<uint16_t>(num_transforms);
segment.clip_sample_offset = 0;
segment.segment_index = 0;
segment.distribution = SampleDistribution8::Uniform;
@@ -168,15 +273,87 @@ namespace acl
segment.animated_data_size = 0;
segment.range_data_size = 0;
segment.total_header_size = 0;
+
+ // Initialize our hierarchy information
+ {
+ // Calculate which bones are leaf bones that have no children
+ bitset_description bone_bitset_desc = bitset_description::make_from_num_bits(num_transforms);
+ uint32_t* is_leaf_bitset = allocate_type_array<uint32_t>(allocator, bone_bitset_desc.get_size());
+ bitset_reset(is_leaf_bitset, bone_bitset_desc, false);
+
+ // By default and if we find a child, we'll mark it as non-leaf
+ bitset_set_range(is_leaf_bitset, bone_bitset_desc, 0, num_transforms, true);
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ uint32_t num_root_bones = 0;
+#endif
+
+ // Move and validate the input data
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
+ {
+ const transform_metadata& metadata = out_clip_context.metadata[transform_index];
+
+ const bool is_root = metadata.parent_index == k_invalid_bone_index;
+
+ // If we have a parent, mark it as not being a leaf bone (it has at least one child)
+ if (!is_root)
+ bitset_set(is_leaf_bitset, bone_bitset_desc, metadata.parent_index, false);
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ if (is_root)
+ num_root_bones++;
+#endif
+ }
+
+ const uint32_t num_leaf_transforms = bitset_count_set_bits(is_leaf_bitset, bone_bitset_desc);
+ out_clip_context.num_leaf_transforms = num_leaf_transforms;
+
+ uint32_t* leaf_transform_chains = allocate_type_array<uint32_t>(allocator, size_t(num_leaf_transforms) * bone_bitset_desc.get_size());
+ out_clip_context.leaf_transform_chains = leaf_transform_chains;
+
+ uint32_t leaf_index = 0;
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
+ {
+ if (!bitset_test(is_leaf_bitset, bone_bitset_desc, transform_index))
+ continue; // Skip non-leaf bones
+
+ uint32_t* bone_chain = leaf_transform_chains + (leaf_index * bone_bitset_desc.get_size());
+ bitset_reset(bone_chain, bone_bitset_desc, false);
+
+ uint16_t chain_bone_index = safe_static_cast<uint16_t>(transform_index);
+ while (chain_bone_index != k_invalid_bone_index)
+ {
+ bitset_set(bone_chain, bone_bitset_desc, chain_bone_index, true);
+
+ transform_metadata& metadata = out_clip_context.metadata[chain_bone_index];
+
+ // We assign a bone chain the first time we find a bone that isn't part of one already
+ if (metadata.transform_chain == nullptr)
+ metadata.transform_chain = bone_chain;
+
+ chain_bone_index = metadata.parent_index;
+ }
+
+ leaf_index++;
+ }
+
+ ACL_ASSERT(num_root_bones > 0, "No root bone found. The root bones must have a parent index = 0xFFFF");
+ ACL_ASSERT(leaf_index == num_leaf_transforms, "Invalid number of leaf bone found");
+ deallocate_type_array(allocator, is_leaf_bitset, bone_bitset_desc.get_size());
+ }
}
- inline void destroy_clip_context(IAllocator& allocator, ClipContext& clip_context)
+ inline void destroy_clip_context(iallocator& allocator, clip_context& context)
{
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : context.segment_iterator())
destroy_segment_context(allocator, segment);
- deallocate_type_array(allocator, clip_context.segments, clip_context.num_segments);
- deallocate_type_array(allocator, clip_context.ranges, clip_context.num_bones);
+ deallocate_type_array(allocator, context.segments, context.num_segments);
+ deallocate_type_array(allocator, context.ranges, context.num_bones);
+ deallocate_type_array(allocator, context.metadata, context.num_bones);
+
+ bitset_description bone_bitset_desc = bitset_description::make_from_num_bits(context.num_bones);
+ deallocate_type_array(allocator, context.leaf_transform_chains, size_t(context.num_leaf_transforms) * bone_bitset_desc.get_size());
}
constexpr bool segment_context_has_scale(const SegmentContext& segment) { return segment.clip->has_scale; }
diff --git a/includes/acl/compression/impl/compact_constant_streams.h b/includes/acl/compression/impl/compact_constant_streams.h
--- a/includes/acl/compression/impl/compact_constant_streams.h
+++ b/includes/acl/compression/impl/compact_constant_streams.h
@@ -78,27 +78,29 @@ namespace acl
return true;
}
- inline void compact_constant_streams(IAllocator& allocator, ClipContext& clip_context, float rotation_threshold_angle, float translation_threshold, float scale_threshold)
+ inline void compact_constant_streams(iallocator& allocator, clip_context& context, const track_array_qvvf& track_list)
{
- ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must contain a single segment!");
- SegmentContext& segment = clip_context.segments[0];
+ ACL_ASSERT(context.num_segments == 1, "clip_context must contain a single segment!");
+ SegmentContext& segment = context.segments[0];
- const uint16_t num_bones = clip_context.num_bones;
- const rtm::vector4f default_scale = get_default_scale(clip_context.additive_format);
+ const uint16_t num_bones = context.num_bones;
+ const rtm::vector4f default_scale = get_default_scale(context.additive_format);
uint16_t num_default_bone_scales = 0;
// When a stream is constant, we only keep the first sample
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
+ const track_desc_transformf& desc = track_list[bone_index].get_description();
+
BoneStreams& bone_stream = segment.bone_streams[bone_index];
- BoneRanges& bone_range = clip_context.ranges[bone_index];
+ BoneRanges& bone_range = context.ranges[bone_index];
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", bone_stream.rotations.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", bone_stream.translations.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", bone_stream.scales.get_sample_size(), sizeof(rtm::vector4f));
- if (is_rotation_track_constant(bone_stream.rotations, rotation_threshold_angle))
+ if (is_rotation_track_constant(bone_stream.rotations, desc.constant_rotation_threshold_angle))
{
RotationTrackStream constant_stream(allocator, 1, bone_stream.rotations.get_sample_size(), bone_stream.rotations.get_sample_rate(), bone_stream.rotations.get_rotation_format());
rtm::vector4f rotation = bone_stream.rotations.get_raw_sample<rtm::vector4f>(0);
@@ -106,12 +108,12 @@ namespace acl
bone_stream.rotations = std::move(constant_stream);
bone_stream.is_rotation_constant = true;
- bone_stream.is_rotation_default = rtm::quat_near_identity(rtm::vector_to_quat(rotation), rotation_threshold_angle);
+ bone_stream.is_rotation_default = rtm::quat_near_identity(rtm::vector_to_quat(rotation), desc.constant_rotation_threshold_angle);
bone_range.rotation = TrackStreamRange::from_min_extent(rotation, rtm::vector_zero());
}
- if (bone_range.translation.is_constant(translation_threshold))
+ if (bone_range.translation.is_constant(desc.constant_translation_threshold))
{
TranslationTrackStream constant_stream(allocator, 1, bone_stream.translations.get_sample_size(), bone_stream.translations.get_sample_rate(), bone_stream.translations.get_vector_format());
rtm::vector4f translation = bone_stream.translations.get_raw_sample<rtm::vector4f>(0);
@@ -119,12 +121,12 @@ namespace acl
bone_stream.translations = std::move(constant_stream);
bone_stream.is_translation_constant = true;
- bone_stream.is_translation_default = rtm::vector_all_near_equal3(translation, rtm::vector_zero(), translation_threshold);
+ bone_stream.is_translation_default = rtm::vector_all_near_equal3(translation, rtm::vector_zero(), desc.constant_translation_threshold);
bone_range.translation = TrackStreamRange::from_min_extent(translation, rtm::vector_zero());
}
- if (bone_range.scale.is_constant(scale_threshold))
+ if (bone_range.scale.is_constant(desc.constant_scale_threshold))
{
ScaleTrackStream constant_stream(allocator, 1, bone_stream.scales.get_sample_size(), bone_stream.scales.get_sample_rate(), bone_stream.scales.get_vector_format());
rtm::vector4f scale = bone_stream.scales.get_raw_sample<rtm::vector4f>(0);
@@ -132,7 +134,7 @@ namespace acl
bone_stream.scales = std::move(constant_stream);
bone_stream.is_scale_constant = true;
- bone_stream.is_scale_default = rtm::vector_all_near_equal3(scale, default_scale, scale_threshold);
+ bone_stream.is_scale_default = rtm::vector_all_near_equal3(scale, default_scale, desc.constant_scale_threshold);
bone_range.scale = TrackStreamRange::from_min_extent(scale, rtm::vector_zero());
@@ -140,7 +142,7 @@ namespace acl
}
}
- clip_context.has_scale = num_default_bone_scales != num_bones;
+ context.has_scale = num_default_bone_scales != num_bones;
}
}
}
diff --git a/includes/acl/compression/impl/compressed_clip_impl.h b/includes/acl/compression/impl/compressed_clip_impl.h
deleted file mode 100644
--- a/includes/acl/compression/impl/compressed_clip_impl.h
+++ /dev/null
@@ -1,50 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_clip.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace acl_impl
- {
- inline CompressedClip* make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type)
- {
- return new(buffer) CompressedClip(size, type);
- }
-
- inline void finalize_compressed_clip(CompressedClip& compressed_clip)
- {
- // For now we just run the constructor in place again, it'll update the hash, etc.
- // TODO: Fix this to be more efficient in make_compressed_clip above
- new(&compressed_clip) CompressedClip(compressed_clip.get_size(), compressed_clip.get_algorithm_type());
- }
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/constant_track_impl.h b/includes/acl/compression/impl/constant_track_impl.h
--- a/includes/acl/compression/impl/constant_track_impl.h
+++ b/includes/acl/compression/impl/constant_track_impl.h
@@ -47,7 +47,7 @@ namespace acl
{
ACL_ASSERT(context.is_valid(), "Invalid context");
- const BitSetDescription bitset_desc = BitSetDescription::make_from_num_bits(context.num_tracks);
+ const bitset_description bitset_desc = bitset_description::make_from_num_bits(context.num_tracks);
context.constant_tracks_bitset = allocate_type_array<uint32_t>(*context.allocator, bitset_desc.get_size());
bitset_reset(context.constant_tracks_bitset, bitset_desc, false);
diff --git a/includes/acl/compression/impl/convert_rotation_streams.h b/includes/acl/compression/impl/convert_rotation_streams.h
--- a/includes/acl/compression/impl/convert_rotation_streams.h
+++ b/includes/acl/compression/impl/convert_rotation_streams.h
@@ -60,7 +60,7 @@ namespace acl
}
}
- inline void convert_rotation_streams(IAllocator& allocator, SegmentContext& segment, rotation_format8 rotation_format)
+ inline void convert_rotation_streams(iallocator& allocator, SegmentContext& segment, rotation_format8 rotation_format)
{
const rotation_format8 high_precision_format = get_rotation_variant(rotation_format) == rotation_variant8::quat ? rotation_format8::quatf_full : rotation_format8::quatf_drop_w_full;
@@ -99,9 +99,9 @@ namespace acl
}
}
- inline void convert_rotation_streams(IAllocator& allocator, ClipContext& clip_context, rotation_format8 rotation_format)
+ inline void convert_rotation_streams(iallocator& allocator, clip_context& context, rotation_format8 rotation_format)
{
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : context.segment_iterator())
convert_rotation_streams(allocator, segment, rotation_format);
}
}
diff --git a/includes/acl/compression/impl/normalize_streams.h b/includes/acl/compression/impl/normalize_streams.h
--- a/includes/acl/compression/impl/normalize_streams.h
+++ b/includes/acl/compression/impl/normalize_streams.h
@@ -78,17 +78,17 @@ namespace acl
}
}
- inline void extract_clip_bone_ranges(IAllocator& allocator, ClipContext& clip_context)
+ inline void extract_clip_bone_ranges(iallocator& allocator, clip_context& context)
{
- clip_context.ranges = allocate_type_array<BoneRanges>(allocator, clip_context.num_bones);
+ context.ranges = allocate_type_array<BoneRanges>(allocator, context.num_bones);
- ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must contain a single segment!");
- SegmentContext& segment = clip_context.segments[0];
+ ACL_ASSERT(context.num_segments == 1, "clip_context must contain a single segment!");
+ SegmentContext& segment = context.segments[0];
- acl_impl::extract_bone_ranges_impl(segment, clip_context.ranges);
+ acl_impl::extract_bone_ranges_impl(segment, context.ranges);
}
- inline void extract_segment_bone_ranges(IAllocator& allocator, ClipContext& clip_context)
+ inline void extract_segment_bone_ranges(iallocator& allocator, clip_context& context)
{
const rtm::vector4f one = rtm::vector_set(1.0F);
const rtm::vector4f zero = rtm::vector_zero();
@@ -138,7 +138,7 @@ namespace acl
return TrackStreamRange::from_min_extent(padded_range_min, padded_range_extent);
};
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : context.segment_iterator())
{
segment.ranges = allocate_type_array<BoneRanges>(allocator, segment.num_bones);
@@ -149,13 +149,13 @@ namespace acl
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
BoneRanges& bone_range = segment.ranges[bone_index];
- if (!bone_stream.is_rotation_constant && clip_context.are_rotations_normalized)
+ if (!bone_stream.is_rotation_constant && context.are_rotations_normalized)
bone_range.rotation = fixup_range(bone_range.rotation);
- if (!bone_stream.is_translation_constant && clip_context.are_translations_normalized)
+ if (!bone_stream.is_translation_constant && context.are_translations_normalized)
bone_range.translation = fixup_range(bone_range.translation);
- if (!bone_stream.is_scale_constant && clip_context.are_scales_normalized)
+ if (!bone_stream.is_scale_constant && context.are_scales_normalized)
bone_range.scale = fixup_range(bone_range.scale);
}
}
@@ -307,35 +307,35 @@ namespace acl
}
}
- inline void normalize_clip_streams(ClipContext& clip_context, range_reduction_flags8 range_reduction)
+ inline void normalize_clip_streams(clip_context& context, range_reduction_flags8 range_reduction)
{
- ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must contain a single segment!");
- SegmentContext& segment = clip_context.segments[0];
+ ACL_ASSERT(context.num_segments == 1, "clip_context must contain a single segment!");
+ SegmentContext& segment = context.segments[0];
const bool has_scale = segment_context_has_scale(segment);
if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations))
{
- normalize_rotation_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
- clip_context.are_rotations_normalized = true;
+ normalize_rotation_streams(segment.bone_streams, context.ranges, segment.num_bones);
+ context.are_rotations_normalized = true;
}
if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations))
{
- normalize_translation_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
- clip_context.are_translations_normalized = true;
+ normalize_translation_streams(segment.bone_streams, context.ranges, segment.num_bones);
+ context.are_translations_normalized = true;
}
if (has_scale && are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales))
{
- normalize_scale_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
- clip_context.are_scales_normalized = true;
+ normalize_scale_streams(segment.bone_streams, context.ranges, segment.num_bones);
+ context.are_scales_normalized = true;
}
}
- inline void normalize_segment_streams(ClipContext& clip_context, range_reduction_flags8 range_reduction)
+ inline void normalize_segment_streams(clip_context& context, range_reduction_flags8 range_reduction)
{
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : context.segment_iterator())
{
if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations))
{
diff --git a/includes/acl/compression/impl/quantize_streams.h b/includes/acl/compression/impl/quantize_streams.h
--- a/includes/acl/compression/impl/quantize_streams.h
+++ b/includes/acl/compression/impl/quantize_streams.h
@@ -36,7 +36,7 @@
#include "acl/compression/impl/sample_streams.h"
#include "acl/compression/impl/normalize_streams.h"
#include "acl/compression/impl/convert_rotation_streams.h"
-#include "acl/compression/skeleton_error_metric.h"
+#include "acl/compression/transform_error_metrics.h"
#include "acl/compression/compression_settings.h"
#include <rtm/quatf.h>
@@ -62,17 +62,17 @@ namespace acl
{
namespace acl_impl
{
- struct QuantizationContext
+ struct quantization_context
{
- IAllocator& allocator;
- ClipContext& clip;
- const ClipContext& raw_clip;
- const ClipContext& additive_base_clip;
+ iallocator& allocator;
+ clip_context& clip;
+ const clip_context& raw_clip;
+ const clip_context& additive_base_clip;
SegmentContext* segment;
BoneStreams* bone_streams;
+ const transform_metadata* metadata;
uint16_t num_bones;
- const RigidSkeleton& skeleton;
- const CompressionSettings& settings;
+ const itransform_error_metric* error_metric;
track_bit_rate_database bit_rate_database;
single_track_query local_query;
@@ -82,10 +82,16 @@ namespace acl
uint32_t segment_sample_start_index;
float sample_rate;
float clip_duration;
+ float error_threshold; // Error threshold of the current bone being optimized
bool has_scale;
bool has_additive_base;
bool needs_conversion;
+ rotation_format8 rotation_format;
+ vector_format8 translation_format;
+ vector_format8 scale_format;
+ compression_level8 compression_level;
+
const BoneStreams* raw_bone_streams;
rtm::qvvf* additive_local_pose; // 1 per transform
@@ -110,25 +116,30 @@ namespace acl
uint16_t padding0; // unused
uint32_t padding1; // unused
- QuantizationContext(IAllocator& allocator_, ClipContext& clip_, const ClipContext& raw_clip_, const ClipContext& additive_base_clip_, const CompressionSettings& settings_, const RigidSkeleton& skeleton_)
+ quantization_context(iallocator& allocator_, clip_context& clip_, const clip_context& raw_clip_, const clip_context& additive_base_clip_, const compression_settings& settings_)
: allocator(allocator_)
, clip(clip_)
, raw_clip(raw_clip_)
, additive_base_clip(additive_base_clip_)
, segment(nullptr)
, bone_streams(nullptr)
+ , metadata(clip_.metadata)
, num_bones(clip_.num_bones)
- , skeleton(skeleton_)
- , settings(settings_)
- , bit_rate_database(allocator_, settings_, clip_.segments->bone_streams, raw_clip_.segments->bone_streams, clip_.num_bones, clip_.segments->num_samples)
+ , error_metric(settings_.error_metric)
+ , bit_rate_database(allocator_, settings_.rotation_format, settings_.translation_format, settings_.scale_format, clip_.segments->bone_streams, raw_clip_.segments->bone_streams, clip_.num_bones, clip_.segments->num_samples)
, local_query()
, object_query(allocator_)
, num_samples(~0U)
, segment_sample_start_index(~0U)
, sample_rate(clip_.sample_rate)
, clip_duration(clip_.duration)
+ , error_threshold(0.0F)
, has_scale(clip_.has_scale)
, has_additive_base(clip_.has_additive_base)
+ , rotation_format(settings_.rotation_format)
+ , translation_format(settings_.translation_format)
+ , scale_format(settings_.scale_format)
+ , compression_level(settings_.level)
, raw_bone_streams(raw_clip_.segments[0].bone_streams)
, num_bones_in_chain(0)
{
@@ -155,13 +166,13 @@ namespace acl
for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
{
- const RigidBone& bone = skeleton_.get_bone(transform_index);
- parent_transform_indices[transform_index] = bone.parent_index;
+ const transform_metadata& metadata_ = clip_.metadata[transform_index];
+ parent_transform_indices[transform_index] = metadata_.parent_index;
self_transform_indices[transform_index] = transform_index;
}
}
- ~QuantizationContext()
+ ~quantization_context()
{
deallocate_type_array(allocator, additive_local_pose, num_bones);
deallocate_type_array(allocator, raw_local_pose, num_bones);
@@ -187,7 +198,7 @@ namespace acl
bit_rate_database.set_segment(segment_.bone_streams, segment_.num_bones, segment_.num_samples);
// Cache every raw local/object transforms and the base local transforms since they never change
- const itransform_error_metric* error_metric = settings.error_metric;
+ const itransform_error_metric* error_metric_ = error_metric;
const size_t sample_transform_size = metric_transform_size * num_bones;
const auto convert_transforms_impl = std::mem_fn(has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
@@ -228,7 +239,7 @@ namespace acl
uint8_t* sample_raw_local_transforms = raw_local_transforms + (sample_index * sample_transform_size);
if (needs_conversion)
- convert_transforms_impl(error_metric, convert_transforms_args_raw, sample_raw_local_transforms);
+ convert_transforms_impl(error_metric_, convert_transforms_args_raw, sample_raw_local_transforms);
else
std::memcpy(sample_raw_local_transforms, raw_local_pose, sample_transform_size);
@@ -241,31 +252,31 @@ namespace acl
uint8_t* sample_base_local_transforms = base_local_transforms + (sample_index * sample_transform_size);
if (needs_conversion)
- convert_transforms_impl(error_metric, convert_transforms_args_base, sample_base_local_transforms);
+ convert_transforms_impl(error_metric_, convert_transforms_args_base, sample_base_local_transforms);
else
std::memcpy(sample_base_local_transforms, additive_local_pose, sample_transform_size);
apply_additive_to_base_args_raw.local_transforms = sample_raw_local_transforms;
apply_additive_to_base_args_raw.base_transforms = sample_base_local_transforms;
- apply_additive_to_base_impl(error_metric, apply_additive_to_base_args_raw, sample_raw_local_transforms);
+ apply_additive_to_base_impl(error_metric_, apply_additive_to_base_args_raw, sample_raw_local_transforms);
}
local_to_object_space_args_raw.local_transforms = sample_raw_local_transforms;
uint8_t* sample_raw_object_transforms = raw_object_transforms + (sample_index * sample_transform_size);
- local_to_object_space_impl(error_metric, local_to_object_space_args_raw, sample_raw_object_transforms);
+ local_to_object_space_impl(error_metric_, local_to_object_space_args_raw, sample_raw_object_transforms);
}
}
bool is_valid() const { return segment != nullptr; }
- QuantizationContext(const QuantizationContext&) = delete;
- QuantizationContext(QuantizationContext&&) = delete;
- QuantizationContext& operator=(const QuantizationContext&) = delete;
- QuantizationContext& operator=(QuantizationContext&&) = delete;
+ quantization_context(const quantization_context&) = delete;
+ quantization_context(quantization_context&&) = delete;
+ quantization_context& operator=(const quantization_context&) = delete;
+ quantization_context& operator=(quantization_context&&) = delete;
};
- inline void quantize_fixed_rotation_stream(IAllocator& allocator, const RotationTrackStream& raw_stream, rotation_format8 rotation_format, RotationTrackStream& out_quantized_stream)
+ inline void quantize_fixed_rotation_stream(iallocator& allocator, const RotationTrackStream& raw_stream, rotation_format8 rotation_format, RotationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -298,7 +309,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_rotation_stream(QuantizationContext& context, uint16_t bone_index, rotation_format8 rotation_format)
+ inline void quantize_fixed_rotation_stream(quantization_context& context, uint16_t bone_index, rotation_format8 rotation_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -311,7 +322,7 @@ namespace acl
quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, rotation_format, bone_stream.rotations);
}
- inline void quantize_variable_rotation_stream(QuantizationContext& context, const RotationTrackStream& raw_clip_stream, const RotationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, RotationTrackStream& out_quantized_stream)
+ inline void quantize_variable_rotation_stream(quantization_context& context, const RotationTrackStream& raw_clip_stream, const RotationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, RotationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -356,7 +367,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_variable_rotation_stream(QuantizationContext& context, uint16_t bone_index, uint8_t bit_rate)
+ inline void quantize_variable_rotation_stream(quantization_context& context, uint16_t bone_index, uint8_t bit_rate)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -377,7 +388,7 @@ namespace acl
quantize_variable_rotation_stream(context, raw_bone_stream.rotations, bone_stream.rotations, bone_range, bit_rate, bone_stream.rotations);
}
- inline void quantize_fixed_translation_stream(IAllocator& allocator, const TranslationTrackStream& raw_stream, vector_format8 translation_format, TranslationTrackStream& out_quantized_stream)
+ inline void quantize_fixed_translation_stream(iallocator& allocator, const TranslationTrackStream& raw_stream, vector_format8 translation_format, TranslationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -408,7 +419,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_translation_stream(QuantizationContext& context, uint16_t bone_index, vector_format8 translation_format)
+ inline void quantize_fixed_translation_stream(quantization_context& context, uint16_t bone_index, vector_format8 translation_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -424,7 +435,7 @@ namespace acl
quantize_fixed_translation_stream(context.allocator, bone_stream.translations, format, bone_stream.translations);
}
- inline void quantize_variable_translation_stream(QuantizationContext& context, const TranslationTrackStream& raw_clip_stream, const TranslationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, TranslationTrackStream& out_quantized_stream)
+ inline void quantize_variable_translation_stream(quantization_context& context, const TranslationTrackStream& raw_clip_stream, const TranslationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, TranslationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -467,7 +478,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_variable_translation_stream(QuantizationContext& context, uint16_t bone_index, uint8_t bit_rate)
+ inline void quantize_variable_translation_stream(quantization_context& context, uint16_t bone_index, uint8_t bit_rate)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -487,7 +498,7 @@ namespace acl
quantize_variable_translation_stream(context, raw_bone_stream.translations, bone_stream.translations, bone_range, bit_rate, bone_stream.translations);
}
- inline void quantize_fixed_scale_stream(IAllocator& allocator, const ScaleTrackStream& raw_stream, vector_format8 scale_format, ScaleTrackStream& out_quantized_stream)
+ inline void quantize_fixed_scale_stream(iallocator& allocator, const ScaleTrackStream& raw_stream, vector_format8 scale_format, ScaleTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -518,7 +529,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_scale_stream(QuantizationContext& context, uint16_t bone_index, vector_format8 scale_format)
+ inline void quantize_fixed_scale_stream(quantization_context& context, uint16_t bone_index, vector_format8 scale_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -534,7 +545,7 @@ namespace acl
quantize_fixed_scale_stream(context.allocator, bone_stream.scales, format, bone_stream.scales);
}
- inline void quantize_variable_scale_stream(QuantizationContext& context, const ScaleTrackStream& raw_clip_stream, const ScaleTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, ScaleTrackStream& out_quantized_stream)
+ inline void quantize_variable_scale_stream(quantization_context& context, const ScaleTrackStream& raw_clip_stream, const ScaleTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, ScaleTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -577,7 +588,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_variable_scale_stream(QuantizationContext& context, uint16_t bone_index, uint8_t bit_rate)
+ inline void quantize_variable_scale_stream(quantization_context& context, uint16_t bone_index, uint8_t bit_rate)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -599,31 +610,31 @@ namespace acl
enum class error_scan_stop_condition { until_error_too_high, until_end_of_segment };
- inline float calculate_max_error_at_bit_rate_local(QuantizationContext& context, uint16_t target_bone_index, error_scan_stop_condition stop_condition)
+ inline float calculate_max_error_at_bit_rate_local(quantization_context& context, uint32_t target_bone_index, error_scan_stop_condition stop_condition)
{
- const CompressionSettings& settings = context.settings;
- const itransform_error_metric* error_metric = settings.error_metric;
+ const itransform_error_metric* error_metric = context.error_metric;
const bool needs_conversion = context.needs_conversion;
const bool has_additive_base = context.has_additive_base;
- const RigidBone& target_bone = context.skeleton.get_bone(target_bone_index);
+ const transform_metadata& target_bone = context.metadata[target_bone_index];
const uint32_t num_transforms = context.num_bones;
const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
const float sample_rate = context.sample_rate;
const float clip_duration = context.clip_duration;
- const rtm::scalarf error_threshold = rtm::scalar_set(settings.error_threshold);
+ const rtm::scalarf error_threshold = rtm::scalar_set(context.error_threshold);
+ const uint16_t target_bone_index_ = (uint16_t)target_bone_index;
const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
const auto calculate_error_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::calculate_error : &itransform_error_metric::calculate_error_no_scale);
itransform_error_metric::convert_transforms_args convert_transforms_args_lossy;
- convert_transforms_args_lossy.dirty_transform_indices = &target_bone_index;
+ convert_transforms_args_lossy.dirty_transform_indices = &target_bone_index_;
convert_transforms_args_lossy.num_dirty_transforms = 1;
convert_transforms_args_lossy.transforms = context.lossy_local_pose;
convert_transforms_args_lossy.num_transforms = num_transforms;
itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy;
- apply_additive_to_base_args_lossy.dirty_transform_indices = &target_bone_index;
+ apply_additive_to_base_args_lossy.dirty_transform_indices = &target_bone_index_;
apply_additive_to_base_args_lossy.num_dirty_transforms = 1;
apply_additive_to_base_args_lossy.local_transforms = needs_conversion ? (const void*)context.local_transforms_converted : (const void*)context.lossy_local_pose;
apply_additive_to_base_args_lossy.base_transforms = nullptr;
@@ -632,7 +643,7 @@ namespace acl
itransform_error_metric::calculate_error_args calculate_error_args;
calculate_error_args.transform0 = nullptr;
calculate_error_args.transform1 = needs_conversion ? (const void*)(context.local_transforms_converted + (context.metric_transform_size * target_bone_index)) : (const void*)(context.lossy_local_pose + target_bone_index);
- calculate_error_args.construct_sphere_shell(target_bone.vertex_distance);
+ calculate_error_args.construct_sphere_shell(target_bone.shell_distance);
const uint8_t* raw_transform = context.raw_local_transforms + (target_bone_index * context.metric_transform_size);
const uint8_t* base_transforms = context.base_local_transforms;
@@ -674,17 +685,16 @@ namespace acl
return rtm::scalar_cast(max_error);
}
- inline float calculate_max_error_at_bit_rate_object(QuantizationContext& context, uint16_t target_bone_index, error_scan_stop_condition stop_condition)
+ inline float calculate_max_error_at_bit_rate_object(quantization_context& context, uint32_t target_bone_index, error_scan_stop_condition stop_condition)
{
- const CompressionSettings& settings = context.settings;
- const itransform_error_metric* error_metric = settings.error_metric;
+ const itransform_error_metric* error_metric = context.error_metric;
const bool needs_conversion = context.needs_conversion;
const bool has_additive_base = context.has_additive_base;
- const RigidBone& target_bone = context.skeleton.get_bone(target_bone_index);
+ const transform_metadata& target_bone = context.metadata[target_bone_index];
const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
const float sample_rate = context.sample_rate;
const float clip_duration = context.clip_duration;
- const rtm::scalarf error_threshold = rtm::scalar_set(settings.error_threshold);
+ const rtm::scalarf error_threshold = rtm::scalar_set(context.error_threshold);
const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
@@ -714,7 +724,7 @@ namespace acl
itransform_error_metric::calculate_error_args calculate_error_args;
calculate_error_args.transform0 = nullptr;
calculate_error_args.transform1 = context.lossy_object_pose + (target_bone_index * context.metric_transform_size);
- calculate_error_args.construct_sphere_shell(target_bone.vertex_distance);
+ calculate_error_args.construct_sphere_shell(target_bone.shell_distance);
const uint8_t* raw_transform = context.raw_object_transforms + (target_bone_index * context.metric_transform_size);
const uint8_t* base_transforms = context.base_local_transforms;
@@ -758,17 +768,19 @@ namespace acl
return rtm::scalar_cast(max_error);
}
- inline void calculate_local_space_bit_rates(QuantizationContext& context)
+ inline void calculate_local_space_bit_rates(quantization_context& context)
{
// To minimize the bit rate, we first start by trying every permutation in local space
// until our error is acceptable.
// We try permutations from the lowest memory footprint to the highest.
- const CompressionSettings& settings = context.settings;
- const float error_threshold = settings.error_threshold;
-
- for (uint16_t bone_index = 0; bone_index < context.num_bones; ++bone_index)
+ const uint32_t num_bones = context.num_bones;
+ for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
+ // Update our error threshold
+ const float error_threshold = context.metadata[bone_index].precision;
+ context.error_threshold = error_threshold;
+
// Bit rates at this point are one of three value:
// 0: if the segment track is normalized, it can be constant within the segment
// 1: if the segment track isn't normalized, it starts at the lowest bit rate
@@ -927,30 +939,31 @@ namespace acl
}
}
- constexpr uint8_t increment_and_clamp_bit_rate(uint8_t bit_rate, uint8_t increment)
+ constexpr uint32_t increment_and_clamp_bit_rate(uint32_t bit_rate, uint32_t increment)
{
- return bit_rate >= k_highest_bit_rate ? bit_rate : std::min<uint8_t>(bit_rate + increment, k_highest_bit_rate);
+ return bit_rate >= k_highest_bit_rate ? bit_rate : std::min<uint32_t>(bit_rate + increment, k_highest_bit_rate);
}
- inline float increase_bone_bit_rate(QuantizationContext& context, uint16_t bone_index, uint8_t num_increments, float old_error, BoneBitRate& out_best_bit_rates)
+ inline float increase_bone_bit_rate(quantization_context& context, uint32_t bone_index, uint32_t num_increments, float old_error, BoneBitRate& out_best_bit_rates)
{
const BoneBitRate bone_bit_rates = context.bit_rate_per_bone[bone_index];
- const uint8_t num_scale_increments = context.has_scale ? num_increments : 0;
+ const uint32_t num_scale_increments = context.has_scale ? num_increments : 0;
+ const uint16_t bone_index_ = static_cast<uint16_t>(bone_index);
BoneBitRate best_bit_rates = bone_bit_rates;
float best_error = old_error;
- for (uint8_t rotation_increment = 0; rotation_increment <= num_increments; ++rotation_increment)
+ for (uint32_t rotation_increment = 0; rotation_increment <= num_increments; ++rotation_increment)
{
- const uint8_t rotation_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.rotation, rotation_increment);
+ const uint32_t rotation_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.rotation, rotation_increment);
- for (uint8_t translation_increment = 0; translation_increment <= num_increments; ++translation_increment)
+ for (uint32_t translation_increment = 0; translation_increment <= num_increments; ++translation_increment)
{
- const uint8_t translation_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.translation, translation_increment);
+ const uint32_t translation_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.translation, translation_increment);
- for (uint8_t scale_increment = 0; scale_increment <= num_scale_increments; ++scale_increment)
+ for (uint32_t scale_increment = 0; scale_increment <= num_scale_increments; ++scale_increment)
{
- const uint8_t scale_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.scale, scale_increment);
+ const uint32_t scale_bit_rate = increment_and_clamp_bit_rate(bone_bit_rates.scale, scale_increment);
if (rotation_increment + translation_increment + scale_increment != num_increments)
{
@@ -960,8 +973,8 @@ namespace acl
continue;
}
- context.bit_rate_per_bone[bone_index] = BoneBitRate{ rotation_bit_rate, translation_bit_rate, scale_bit_rate };
- const float error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_error_too_high);
+ context.bit_rate_per_bone[bone_index] = BoneBitRate{ (uint8_t)rotation_bit_rate, (uint8_t)translation_bit_rate, (uint8_t)scale_bit_rate };
+ const float error = calculate_max_error_at_bit_rate_object(context, bone_index_, error_scan_stop_condition::until_error_too_high);
if (error < best_error)
{
@@ -987,10 +1000,9 @@ namespace acl
return best_error;
}
- inline float calculate_bone_permutation_error(QuantizationContext& context, BoneBitRate* permutation_bit_rates, uint8_t* bone_chain_permutation, uint16_t bone_index, BoneBitRate* best_bit_rates, float old_error)
+ inline float calculate_bone_permutation_error(quantization_context& context, BoneBitRate* permutation_bit_rates, uint8_t* bone_chain_permutation, uint32_t bone_index, BoneBitRate* best_bit_rates, float old_error)
{
- const CompressionSettings& settings = context.settings;
-
+ const float error_threshold = context.error_threshold;
float best_error = old_error;
do
@@ -999,12 +1011,13 @@ namespace acl
std::memcpy(permutation_bit_rates, context.bit_rate_per_bone, sizeof(BoneBitRate) * context.num_bones);
bool is_permutation_valid = false;
- for (uint16_t chain_link_index = 0; chain_link_index < context.num_bones_in_chain; ++chain_link_index)
+ const uint32_t num_bones_in_chain = context.num_bones_in_chain;
+ for (uint32_t chain_link_index = 0; chain_link_index < num_bones_in_chain; ++chain_link_index)
{
if (bone_chain_permutation[chain_link_index] != 0)
{
// Increase bit rate
- const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
+ const uint32_t chain_bone_index = context.chain_bone_indices[chain_link_index];
BoneBitRate chain_bone_best_bit_rates;
increase_bone_bit_rate(context, chain_bone_index, bone_chain_permutation[chain_link_index], old_error, chain_bone_best_bit_rates);
is_permutation_valid |= chain_bone_best_bit_rates.rotation != permutation_bit_rates[chain_bone_index].rotation;
@@ -1015,7 +1028,7 @@ namespace acl
}
if (!is_permutation_valid)
- continue;
+ continue; // Couldn't increase any bit rate, skip this permutation
// Measure error
std::swap(context.bit_rate_per_bone, permutation_bit_rates);
@@ -1027,7 +1040,7 @@ namespace acl
best_error = permutation_error;
std::memcpy(best_bit_rates, permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
- if (permutation_error < settings.error_threshold)
+ if (permutation_error < error_threshold)
break;
}
} while (std::next_permutation(bone_chain_permutation, bone_chain_permutation + context.num_bones_in_chain));
@@ -1035,11 +1048,11 @@ namespace acl
return best_error;
}
- inline uint16_t calculate_bone_chain_indices(const RigidSkeleton& skeleton, uint16_t bone_index, uint16_t* out_chain_bone_indices)
+ inline uint32_t calculate_bone_chain_indices(const clip_context& clip, uint32_t bone_index, uint16_t* out_chain_bone_indices)
{
- const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
+ const BoneChain bone_chain = clip.get_bone_chain(bone_index);
- uint16_t num_bones_in_chain = 0;
+ uint32_t num_bones_in_chain = 0;
for (uint16_t chain_bone_index : bone_chain)
out_chain_bone_indices[num_bones_in_chain++] = chain_bone_index;
@@ -1052,7 +1065,8 @@ namespace acl
const bool is_translation_variable = is_vector_format_variable(translation_format);
const bool is_scale_variable = segment_context_has_scale(segment) && is_vector_format_variable(scale_format);
- for (uint16_t bone_index = 0; bone_index < segment.num_bones; ++bone_index)
+ const uint32_t num_bones = segment.num_bones;
+ for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
BoneBitRate& bone_bit_rate = out_bit_rate_per_bone[bone_index];
@@ -1076,15 +1090,13 @@ namespace acl
}
}
- inline void quantize_all_streams(QuantizationContext& context)
+ inline void quantize_all_streams(quantization_context& context)
{
- ACL_ASSERT(context.is_valid(), "QuantizationContext isn't valid");
+ ACL_ASSERT(context.is_valid(), "quantization_context isn't valid");
- const CompressionSettings& settings = context.settings;
-
- const bool is_rotation_variable = is_rotation_format_variable(settings.rotation_format);
- const bool is_translation_variable = is_vector_format_variable(settings.translation_format);
- const bool is_scale_variable = is_vector_format_variable(settings.scale_format);
+ const bool is_rotation_variable = is_rotation_format_variable(context.rotation_format);
+ const bool is_translation_variable = is_vector_format_variable(context.translation_format);
+ const bool is_scale_variable = is_vector_format_variable(context.scale_format);
for (uint16_t bone_index = 0; bone_index < context.num_bones; ++bone_index)
{
@@ -1093,30 +1105,28 @@ namespace acl
if (is_rotation_variable)
quantize_variable_rotation_stream(context, bone_index, bone_bit_rate.rotation);
else
- quantize_fixed_rotation_stream(context, bone_index, settings.rotation_format);
+ quantize_fixed_rotation_stream(context, bone_index, context.rotation_format);
if (is_translation_variable)
quantize_variable_translation_stream(context, bone_index, bone_bit_rate.translation);
else
- quantize_fixed_translation_stream(context, bone_index, settings.translation_format);
+ quantize_fixed_translation_stream(context, bone_index, context.translation_format);
if (context.has_scale)
{
if (is_scale_variable)
quantize_variable_scale_stream(context, bone_index, bone_bit_rate.scale);
else
- quantize_fixed_scale_stream(context, bone_index, settings.scale_format);
+ quantize_fixed_scale_stream(context, bone_index, context.scale_format);
}
}
}
- inline void find_optimal_bit_rates(QuantizationContext& context)
+ inline void find_optimal_bit_rates(quantization_context& context)
{
- ACL_ASSERT(context.is_valid(), "QuantizationContext isn't valid");
+ ACL_ASSERT(context.is_valid(), "quantization_context isn't valid");
- const CompressionSettings& settings = context.settings;
-
- initialize_bone_bit_rates(*context.segment, settings.rotation_format, settings.translation_format, settings.scale_format, context.bit_rate_per_bone);
+ initialize_bone_bit_rates(*context.segment, context.rotation_format, context.translation_format, context.scale_format, context.bit_rate_per_bone);
// First iterate over all bones and find the optimal bit rate for each track using the local space error.
// We use the local space error to prime the algorithm. If each parent bone has infinite precision,
@@ -1171,18 +1181,23 @@ namespace acl
BoneBitRate* best_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
std::memcpy(best_bit_rates, context.bit_rate_per_bone, sizeof(BoneBitRate) * context.num_bones);
- for (uint16_t bone_index = 0; bone_index < context.num_bones; ++bone_index)
+ const uint32_t num_bones = context.num_bones;
+ for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- const uint16_t num_bones_in_chain = calculate_bone_chain_indices(context.skeleton, bone_index, context.chain_bone_indices);
- context.num_bones_in_chain = num_bones_in_chain;
+ // Update our error threshold
+ const float error_threshold = context.metadata[bone_index].precision;
+ context.error_threshold = error_threshold;
+
+ const uint32_t num_bones_in_chain = calculate_bone_chain_indices(context.clip, bone_index, context.chain_bone_indices);
+ context.num_bones_in_chain = (uint16_t)num_bones_in_chain;
float error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_error_too_high);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
continue;
const float initial_error = error;
- while (error >= settings.error_threshold)
+ while (error >= error_threshold)
{
// Generate permutations for up to 3 bit rate increments
// Perform an exhaustive search of the permutations and pick the best result
@@ -1191,83 +1206,83 @@ namespace acl
float best_error = error;
// The first permutation increases the bit rate of a single track/bone
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 1;
error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
- if (settings.level >= compression_level8::high)
+ if (context.compression_level >= compression_level8::high)
{
// The second permutation increases the bit rate of 2 track/bones
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 2;
error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
if (num_bones_in_chain > 1)
{
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 2] = 1;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
}
}
- if (settings.level >= compression_level8::highest)
+ if (context.compression_level >= compression_level8::highest)
{
// The third permutation increases the bit rate of 3 track/bones
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 1] = 3;
error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
if (num_bones_in_chain > 1)
{
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 2] = 2;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
error = calculate_bone_permutation_error(context, permutation_bit_rates, bone_chain_permutation, bone_index, best_permutation_bit_rates, original_error);
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
if (num_bones_in_chain > 2)
{
- std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
+ std::fill(bone_chain_permutation, bone_chain_permutation + num_bones, uint8_t(0));
bone_chain_permutation[num_bones_in_chain - 3] = 1;
bone_chain_permutation[num_bones_in_chain - 2] = 1;
bone_chain_permutation[num_bones_in_chain - 1] = 1;
@@ -1275,9 +1290,9 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
}
@@ -1307,7 +1322,7 @@ namespace acl
}
#endif
- std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * num_bones);
}
}
@@ -1330,19 +1345,19 @@ namespace acl
}
#endif
- std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * num_bones);
}
// Our error remains too high, this should be rare.
// Attempt to increase the bit rate as much as we can while still back tracking if it doesn't help.
error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_end_of_segment);
- while (error >= settings.error_threshold)
+ while (error >= error_threshold)
{
// From child to parent, increase the bit rate indiscriminately
- uint16_t num_maxed_out = 0;
- for (int16_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
+ uint32_t num_maxed_out = 0;
+ for (int32_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
{
- const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
+ const uint32_t chain_bone_index = context.chain_bone_indices[chain_link_index];
// Work with a copy. We'll increase the bit rate as much as we can and retain the values
// that yield the smallest error BUT increasing the bit rate does NOT always means
@@ -1354,7 +1369,7 @@ namespace acl
BoneBitRate best_bone_bit_rate = bone_bit_rate;
float best_bit_rate_error = error;
- while (error >= settings.error_threshold)
+ while (error >= error_threshold)
{
static_assert(offsetof(BoneBitRate, rotation) == 0 && offsetof(BoneBitRate, scale) == sizeof(BoneBitRate) - 1, "Invalid BoneBitRate offsets");
uint8_t& smallest_bit_rate = *std::min_element<uint8_t*>(&bone_bit_rate.rotation, &bone_bit_rate.scale + 1);
@@ -1384,7 +1399,7 @@ namespace acl
#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
printf("%u: => %u %u %u (%f)\n", chain_bone_index, bone_bit_rate.rotation, bone_bit_rate.translation, bone_bit_rate.scale, error);
- for (uint16_t i = chain_link_index + 1; i < num_bones_in_chain; ++i)
+ for (uint32_t i = chain_link_index + 1; i < num_bones_in_chain; ++i)
{
const uint16_t chain_bone_index2 = context.chain_bone_indices[chain_link_index];
float error2 = calculate_max_error_at_bit_rate_object(context, chain_bone_index2, error_scan_stop_condition::until_end_of_segment);
@@ -1398,7 +1413,7 @@ namespace acl
bone_bit_rate = best_bone_bit_rate;
error = best_bit_rate_error;
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
@@ -1417,19 +1432,19 @@ namespace acl
// not, sibling bones will remain fairly close in their error. Some packed rotation formats, namely
// drop W component can have a high error even with raw values, it is assumed that if such a format
// is used then a best effort approach to reach the error threshold is entirely fine.
- if (error >= settings.error_threshold && context.settings.rotation_format == rotation_format8::quatf_full)
+ if (error >= error_threshold && context.rotation_format == rotation_format8::quatf_full)
{
// From child to parent, max out the bit rate
- for (int16_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
+ for (int32_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
{
- const uint16_t chain_bone_index = context.chain_bone_indices[chain_link_index];
+ const uint32_t chain_bone_index = context.chain_bone_indices[chain_link_index];
BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
bone_bit_rate.rotation = std::max<uint8_t>(bone_bit_rate.rotation, k_highest_bit_rate);
bone_bit_rate.translation = std::max<uint8_t>(bone_bit_rate.translation, k_highest_bit_rate);
bone_bit_rate.scale = std::max<uint8_t>(bone_bit_rate.scale, k_highest_bit_rate);
error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_end_of_segment);
- if (error < settings.error_threshold)
+ if (error < error_threshold)
break;
}
}
@@ -1441,17 +1456,17 @@ namespace acl
{
float error = calculate_max_error_at_bit_rate_object(context, i, error_scan_stop_condition::until_end_of_segment);
const BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[i];
- printf("%u: %u | %u | %u => %f %s\n", i, bone_bit_rate.rotation, bone_bit_rate.translation, bone_bit_rate.scale, error, error >= settings.error_threshold ? "!" : "");
+ printf("%u: %u | %u | %u => %f %s\n", i, bone_bit_rate.rotation, bone_bit_rate.translation, bone_bit_rate.scale, error, error >= error_threshold ? "!" : "");
}
#endif
- deallocate_type_array(context.allocator, bone_chain_permutation, context.num_bones);
- deallocate_type_array(context.allocator, permutation_bit_rates, context.num_bones);
- deallocate_type_array(context.allocator, best_permutation_bit_rates, context.num_bones);
- deallocate_type_array(context.allocator, best_bit_rates, context.num_bones);
+ deallocate_type_array(context.allocator, bone_chain_permutation, num_bones);
+ deallocate_type_array(context.allocator, permutation_bit_rates, num_bones);
+ deallocate_type_array(context.allocator, best_permutation_bit_rates, num_bones);
+ deallocate_type_array(context.allocator, best_bit_rates, num_bones);
}
- inline void quantize_streams(IAllocator& allocator, ClipContext& clip_context, const CompressionSettings& settings, const RigidSkeleton& skeleton, const ClipContext& raw_clip_context, const ClipContext& additive_base_clip_context, OutputStats& out_stats)
+ inline void quantize_streams(iallocator& allocator, clip_context& clip, const compression_settings& settings, const clip_context& raw_clip_context, const clip_context& additive_base_clip_context, output_stats& out_stats)
{
(void)out_stats;
@@ -1460,9 +1475,9 @@ namespace acl
const bool is_scale_variable = is_vector_format_variable(settings.scale_format);
const bool is_any_variable = is_rotation_variable || is_translation_variable || is_scale_variable;
- QuantizationContext context(allocator, clip_context, raw_clip_context, additive_base_clip_context, settings, skeleton);
+ quantization_context context(allocator, clip, raw_clip_context, additive_base_clip_context, settings);
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : clip.segment_iterator())
{
#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
printf("Quantizing segment %u...\n", segment.segment_index);
@@ -1470,7 +1485,7 @@ namespace acl
#if ACL_IMPL_PROFILE_MATH
{
- ScopeProfiler timer;
+ scope_profiler timer;
for (int32_t i = 0; i < 10; ++i)
{
@@ -1500,7 +1515,7 @@ namespace acl
}
#if defined(SJSON_CPP_WRITER)
- if (are_all_enum_flags_set(out_stats.logging, StatLogging::Detailed))
+ if (are_all_enum_flags_set(out_stats.logging, stat_logging::Detailed))
{
sjson::ObjectWriter& writer = *out_stats.writer;
writer["track_bit_rate_database_size"] = static_cast<uint32_t>(context.bit_rate_database.get_allocated_size());
diff --git a/includes/acl/compression/impl/sample_streams.h b/includes/acl/compression/impl/sample_streams.h
--- a/includes/acl/compression/impl/sample_streams.h
+++ b/includes/acl/compression/impl/sample_streams.h
@@ -114,7 +114,7 @@ namespace acl
inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
+ const clip_context* clip = segment->clip;
const rotation_format8 format = bone_steams.rotations.get_rotation_format();
const uint8_t bit_rate = bone_steams.rotations.get_bit_rate();
@@ -126,7 +126,7 @@ namespace acl
rtm::vector4f packed_rotation = acl_impl::load_rotation_sample(quantized_ptr, format, bit_rate);
- if (clip_context->are_rotations_normalized && !is_raw_bit_rate(bit_rate))
+ if (clip->are_rotations_normalized && !is_raw_bit_rate(bit_rate))
{
if (segment->are_rotations_normalized && !is_constant_bit_rate(bit_rate))
{
@@ -138,7 +138,7 @@ namespace acl
packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
@@ -152,7 +152,7 @@ namespace acl
inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
+ const clip_context* clip = segment->clip;
const rotation_format8 format = bone_steams.rotations.get_rotation_format();
rtm::vector4f rotation;
@@ -202,7 +202,7 @@ namespace acl
packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
@@ -216,7 +216,7 @@ namespace acl
inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index, rotation_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
+ const clip_context* clip = segment->clip;
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
const rotation_format8 format = bone_steams.rotations.get_rotation_format();
@@ -238,7 +238,7 @@ namespace acl
break;
}
- const bool are_rotations_normalized = clip_context->are_rotations_normalized && !bone_steams.is_rotation_constant;
+ const bool are_rotations_normalized = clip->are_rotations_normalized && !bone_steams.is_rotation_constant;
if (are_rotations_normalized)
{
if (segment->are_rotations_normalized)
@@ -251,7 +251,7 @@ namespace acl
packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
@@ -265,8 +265,8 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
- const bool are_translations_normalized = clip_context->are_translations_normalized;
+ const clip_context* clip = segment->clip;
+ const bool are_translations_normalized = clip->are_translations_normalized;
const vector_format8 format = bone_steams.translations.get_vector_format();
const uint8_t bit_rate = bone_steams.translations.get_bit_rate();
@@ -290,7 +290,7 @@ namespace acl
packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
@@ -304,7 +304,7 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
+ const clip_context* clip = segment->clip;
const vector_format8 format = bone_steams.translations.get_vector_format();
const uint8_t* quantized_ptr;
@@ -317,7 +317,7 @@ namespace acl
const rtm::vector4f translation = acl_impl::load_vector_sample(quantized_ptr, format, 0);
- ACL_ASSERT(clip_context->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
+ ACL_ASSERT(clip->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
rtm::vector4f packed_translation;
@@ -351,7 +351,7 @@ namespace acl
packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
@@ -365,8 +365,8 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index, vector_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
- const bool are_translations_normalized = clip_context->are_translations_normalized && !bone_steams.is_translation_constant;
+ const clip_context* clip = segment->clip;
+ const bool are_translations_normalized = clip->are_translations_normalized && !bone_steams.is_translation_constant;
const uint8_t* quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
const vector_format8 format = bone_steams.translations.get_vector_format();
@@ -398,7 +398,7 @@ namespace acl
packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
@@ -412,8 +412,8 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
- const bool are_scales_normalized = clip_context->are_scales_normalized;
+ const clip_context* clip = segment->clip;
+ const bool are_scales_normalized = clip->are_scales_normalized;
const vector_format8 format = bone_steams.scales.get_vector_format();
const uint8_t bit_rate = bone_steams.scales.get_bit_rate();
@@ -437,7 +437,7 @@ namespace acl
packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
@@ -451,7 +451,7 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
+ const clip_context* clip = segment->clip;
const vector_format8 format = bone_steams.scales.get_vector_format();
const uint8_t* quantized_ptr;
@@ -464,7 +464,7 @@ namespace acl
const rtm::vector4f scale = acl_impl::load_vector_sample(quantized_ptr, format, 0);
- ACL_ASSERT(clip_context->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
+ ACL_ASSERT(clip->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
rtm::vector4f packed_scale;
@@ -498,7 +498,7 @@ namespace acl
packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
const rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
const rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
@@ -512,8 +512,8 @@ namespace acl
inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index, vector_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
- const ClipContext* clip_context = segment->clip;
- const bool are_scales_normalized = clip_context->are_scales_normalized && !bone_steams.is_scale_constant;
+ const clip_context* clip = segment->clip;
+ const bool are_scales_normalized = clip->are_scales_normalized && !bone_steams.is_scale_constant;
const uint8_t* quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
const vector_format8 format = bone_steams.scales.get_vector_format();
@@ -545,7 +545,7 @@ namespace acl
packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
- const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
+ const BoneRanges& clip_bone_range = clip->ranges[bone_steams.bone_index];
rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
@@ -573,8 +573,8 @@ namespace acl
float interpolation_alpha = 0.0F;
// Our samples are uniform, grab the nearest samples
- const ClipContext* clip_context = segment.clip;
- find_linear_interpolation_samples_with_sample_rate(clip_context->num_samples, clip_context->sample_rate, sample_time, sample_rounding_policy::nearest, key0, key1, interpolation_alpha);
+ const clip_context* clip = segment.clip;
+ find_linear_interpolation_samples_with_sample_rate(clip->num_samples, clip->sample_rate, sample_time, sample_rounding_policy::nearest, key0, key1, interpolation_alpha);
// Offset for the current segment and clamp
key0 = key0 - segment.clip_sample_offset;
diff --git a/includes/acl/compression/impl/segment_context.h b/includes/acl/compression/impl/segment_context.h
--- a/includes/acl/compression/impl/segment_context.h
+++ b/includes/acl/compression/impl/segment_context.h
@@ -29,7 +29,6 @@
#include "acl/core/error.h"
#include "acl/core/hash.h"
#include "acl/core/iterator.h"
-#include "acl/compression/animation_clip.h"
#include "acl/compression/impl/track_stream.h"
#include <cstdint>
@@ -40,7 +39,7 @@ namespace acl
{
namespace acl_impl
{
- struct ClipContext;
+ struct clip_context;
//////////////////////////////////////////////////////////////////////////
// The sample distribution.
@@ -56,7 +55,7 @@ namespace acl
struct SegmentContext
{
- ClipContext* clip;
+ clip_context* clip;
BoneStreams* bone_streams;
BoneRanges* ranges;
@@ -79,11 +78,11 @@ namespace acl
uint32_t total_header_size;
//////////////////////////////////////////////////////////////////////////
- Iterator<BoneStreams> bone_iterator() { return Iterator<BoneStreams>(bone_streams, num_bones); }
- ConstIterator<BoneStreams> const_bone_iterator() const { return ConstIterator<BoneStreams>(bone_streams, num_bones); }
+ iterator<BoneStreams> bone_iterator() { return iterator<BoneStreams>(bone_streams, num_bones); }
+ const_iterator<BoneStreams> const_bone_iterator() const { return const_iterator<BoneStreams>(bone_streams, num_bones); }
};
- inline void destroy_segment_context(IAllocator& allocator, SegmentContext& segment)
+ inline void destroy_segment_context(iallocator& allocator, SegmentContext& segment)
{
deallocate_type_array(allocator, segment.bone_streams, segment.num_bones);
deallocate_type_array(allocator, segment.ranges, segment.num_bones);
diff --git a/includes/acl/compression/impl/segment_streams.h b/includes/acl/compression/impl/segment_streams.h
--- a/includes/acl/compression/impl/segment_streams.h
+++ b/includes/acl/compression/impl/segment_streams.h
@@ -38,12 +38,12 @@ namespace acl
{
namespace acl_impl
{
- inline void segment_streams(IAllocator& allocator, ClipContext& clip_context, const SegmentingSettings& settings)
+ inline void segment_streams(iallocator& allocator, clip_context& clip, const segmenting_settings& settings)
{
- ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must have a single segment.");
+ ACL_ASSERT(clip.num_segments == 1, "clip_context must have a single segment.");
ACL_ASSERT(settings.ideal_num_samples <= settings.max_num_samples, "Invalid num samples for segmenting settings. %u > %u", settings.ideal_num_samples, settings.max_num_samples);
- if (clip_context.num_samples <= settings.max_num_samples)
+ if (clip.num_samples <= settings.max_num_samples)
return;
//////////////////////////////////////////////////////////////////////////
@@ -59,14 +59,14 @@ namespace acl
// TODO: Can we provide a tighter guarantee?
//////////////////////////////////////////////////////////////////////////
- uint32_t num_segments = (clip_context.num_samples + settings.ideal_num_samples - 1) / settings.ideal_num_samples;
+ uint32_t num_segments = (clip.num_samples + settings.ideal_num_samples - 1) / settings.ideal_num_samples;
const uint32_t max_num_samples = num_segments * settings.ideal_num_samples;
const uint32_t original_num_segments = num_segments;
uint32_t* num_samples_per_segment = allocate_type_array<uint32_t>(allocator, num_segments);
std::fill(num_samples_per_segment, num_samples_per_segment + num_segments, settings.ideal_num_samples);
- const uint32_t num_leftover_samples = settings.ideal_num_samples - (max_num_samples - clip_context.num_samples);
+ const uint32_t num_leftover_samples = settings.ideal_num_samples - (max_num_samples - clip.num_samples);
if (num_leftover_samples != 0)
num_samples_per_segment[num_segments - 1] = num_leftover_samples;
@@ -88,20 +88,20 @@ namespace acl
ACL_ASSERT(num_segments != 1, "Expected a number of segments greater than 1.");
- SegmentContext* clip_segment = clip_context.segments;
- clip_context.segments = allocate_type_array<SegmentContext>(allocator, num_segments);
- clip_context.num_segments = safe_static_cast<uint16_t>(num_segments);
+ SegmentContext* clip_segment = clip.segments;
+ clip.segments = allocate_type_array<SegmentContext>(allocator, num_segments);
+ clip.num_segments = safe_static_cast<uint16_t>(num_segments);
uint32_t clip_sample_index = 0;
for (uint32_t segment_index = 0; segment_index < num_segments; ++segment_index)
{
const uint32_t num_samples_in_segment = num_samples_per_segment[segment_index];
- SegmentContext& segment = clip_context.segments[segment_index];
- segment.clip = &clip_context;
- segment.bone_streams = allocate_type_array<BoneStreams>(allocator, clip_context.num_bones);
+ SegmentContext& segment = clip.segments[segment_index];
+ segment.clip = &clip;
+ segment.bone_streams = allocate_type_array<BoneStreams>(allocator, clip.num_bones);
segment.ranges = nullptr;
- segment.num_bones = clip_context.num_bones;
+ segment.num_bones = clip.num_bones;
segment.num_samples = safe_static_cast<uint16_t>(num_samples_in_segment);
segment.clip_sample_offset = clip_sample_index;
segment.segment_index = segment_index;
@@ -114,7 +114,7 @@ namespace acl
segment.range_data_size = 0;
segment.total_header_size = 0;
- for (uint16_t bone_index = 0; bone_index < clip_context.num_bones; ++bone_index)
+ for (uint16_t bone_index = 0; bone_index < clip.num_bones; ++bone_index)
{
const BoneStreams& clip_bone_stream = clip_segment->bone_streams[bone_index];
BoneStreams& segment_bone_stream = segment.bone_streams[bone_index];
diff --git a/includes/acl/compression/impl/track_bit_rate_database.h b/includes/acl/compression/impl/track_bit_rate_database.h
--- a/includes/acl/compression/impl/track_bit_rate_database.h
+++ b/includes/acl/compression/impl/track_bit_rate_database.h
@@ -49,7 +49,7 @@ namespace acl
class hierarchical_track_query
{
public:
- explicit hierarchical_track_query(IAllocator& allocator)
+ explicit hierarchical_track_query(iallocator& allocator)
: m_allocator(allocator)
, m_database(nullptr)
, m_track_index(0xFFFFFFFFU)
@@ -79,7 +79,7 @@ namespace acl
uint32_t scale_cache_index;
};
- IAllocator& m_allocator;
+ iallocator& m_allocator;
track_bit_rate_database* m_database;
uint32_t m_track_index;
const BoneBitRate* m_bit_rates;
@@ -144,7 +144,7 @@ namespace acl
class track_bit_rate_database
{
public:
- track_bit_rate_database(IAllocator& allocator, const CompressionSettings& settings, const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint32_t num_transforms, uint32_t num_samples_per_track);
+ track_bit_rate_database(iallocator& allocator, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint32_t num_transforms, uint32_t num_samples_per_track);
~track_bit_rate_database();
void set_segment(const BoneStreams* bone_streams, uint32_t num_transforms, uint32_t num_samples_per_track);
@@ -200,7 +200,7 @@ namespace acl
rtm::vector4f m_default_scale;
- IAllocator& m_allocator;
+ iallocator& m_allocator;
const BoneStreams* m_mutable_bone_streams;
const BoneStreams* m_raw_bone_streams;
@@ -209,8 +209,8 @@ namespace acl
uint32_t m_num_entries_per_transform;
uint32_t m_track_size;
- BitSetDescription m_bitset_desc;
- BitSetIndexRef m_bitref_constant;
+ bitset_description m_bitset_desc;
+ bitset_index_ref m_bitref_constant;
rotation_format8 m_rotation_format;
vector_format8 m_translation_format;
vector_format8 m_scale_format;
@@ -296,7 +296,7 @@ namespace acl
return -1;
}
- inline track_bit_rate_database::track_bit_rate_database(IAllocator& allocator, const CompressionSettings& settings, const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint32_t num_transforms, uint32_t num_samples_per_track)
+ inline track_bit_rate_database::track_bit_rate_database(iallocator& allocator, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint32_t num_transforms, uint32_t num_samples_per_track)
: m_allocator(allocator)
, m_mutable_bone_streams(bone_streams)
, m_raw_bone_streams(raw_bone_steams)
@@ -315,15 +315,15 @@ namespace acl
const uint32_t num_cached_tracks = num_transforms * m_num_entries_per_transform;
- m_bitset_desc = BitSetDescription::make_from_num_bits(num_samples_per_track);
- m_bitref_constant = BitSetIndexRef(m_bitset_desc, 0);
+ m_bitset_desc = bitset_description::make_from_num_bits(num_samples_per_track);
+ m_bitref_constant = bitset_index_ref(m_bitset_desc, 0);
- m_rotation_format = settings.rotation_format;
- m_translation_format = settings.translation_format;
- m_scale_format = settings.scale_format;
- m_is_rotation_variable = is_rotation_format_variable(settings.rotation_format);
- m_is_translation_variable = is_vector_format_variable(settings.translation_format);
- m_is_scale_variable = is_vector_format_variable(settings.scale_format);
+ m_rotation_format = rotation_format;
+ m_translation_format = translation_format;
+ m_scale_format = scale_format;
+ m_is_rotation_variable = is_rotation_format_variable(rotation_format);
+ m_is_translation_variable = is_vector_format_variable(translation_format);
+ m_is_scale_variable = is_vector_format_variable(scale_format);
m_generation_id = 1;
@@ -646,7 +646,7 @@ namespace acl
rtm::quatf sample0;
rtm::quatf sample1;
- const BitSetIndexRef bitref0(m_bitset_desc, key0);
+ const bitset_index_ref bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
{
// Cached
@@ -678,7 +678,7 @@ namespace acl
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const BitSetIndexRef bitref1(m_bitset_desc, key1);
+ const bitset_index_ref bitref1(m_bitset_desc, key1);
if (bitset_test(validity_bitset, bitref1))
{
// Cached
@@ -778,7 +778,7 @@ namespace acl
rtm::vector4f sample0;
rtm::vector4f sample1;
- const BitSetIndexRef bitref0(m_bitset_desc, key0);
+ const bitset_index_ref bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
{
// Cached
@@ -806,7 +806,7 @@ namespace acl
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const BitSetIndexRef bitref1(m_bitset_desc, key1);
+ const bitset_index_ref bitref1(m_bitset_desc, key1);
if (bitset_test(validity_bitset, bitref1))
{
// Cached
@@ -906,7 +906,7 @@ namespace acl
rtm::vector4f sample0;
rtm::vector4f sample1;
- const BitSetIndexRef bitref0(m_bitset_desc, key0);
+ const bitset_index_ref bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
{
// Cached
@@ -934,7 +934,7 @@ namespace acl
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const BitSetIndexRef bitref1(m_bitset_desc, key1);
+ const bitset_index_ref bitref1(m_bitset_desc, key1);
if (bitset_test(validity_bitset, bitref1))
{
// Cached
diff --git a/includes/acl/compression/impl/track_list_context.h b/includes/acl/compression/impl/track_list_context.h
--- a/includes/acl/compression/impl/track_list_context.h
+++ b/includes/acl/compression/impl/track_list_context.h
@@ -61,7 +61,7 @@ namespace acl
struct track_list_context
{
- IAllocator* allocator;
+ iallocator* allocator;
const track_array* reference_list;
track_array track_list;
@@ -98,7 +98,7 @@ namespace acl
{
deallocate_type_array(*allocator, range_list, num_tracks);
- const BitSetDescription bitset_desc = BitSetDescription::make_from_num_bits(num_tracks);
+ const bitset_description bitset_desc = bitset_description::make_from_num_bits(num_tracks);
deallocate_type_array(*allocator, constant_tracks_bitset, bitset_desc.get_size());
deallocate_type_array(*allocator, bit_rate_list, num_tracks);
@@ -108,7 +108,7 @@ namespace acl
}
bool is_valid() const { return allocator != nullptr; }
- bool is_constant(uint32_t track_index) const { return bitset_test(constant_tracks_bitset, BitSetDescription::make_from_num_bits(num_tracks), track_index); }
+ bool is_constant(uint32_t track_index) const { return bitset_test(constant_tracks_bitset, bitset_description::make_from_num_bits(num_tracks), track_index); }
track_list_context(const track_list_context&) = delete;
track_list_context(track_list_context&&) = delete;
@@ -117,7 +117,7 @@ namespace acl
};
// Promote scalar tracks to vector tracks for SIMD alignment and padding
- inline track_array copy_and_promote_track_list(IAllocator& allocator, const track_array& ref_track_list)
+ inline track_array copy_and_promote_track_list(iallocator& allocator, const track_array& ref_track_list)
{
using namespace rtm;
@@ -180,7 +180,7 @@ namespace acl
return out_track_list;
}
- inline uint32_t* create_output_track_mapping(IAllocator& allocator, const track_array& track_list, uint32_t& out_num_output_tracks)
+ inline uint32_t* create_output_track_mapping(iallocator& allocator, const track_array& track_list, uint32_t& out_num_output_tracks)
{
const uint32_t num_tracks = track_list.get_num_tracks();
uint32_t num_output_tracks = num_tracks;
@@ -203,7 +203,7 @@ namespace acl
return output_indices;
}
- inline void initialize_context(IAllocator& allocator, const track_array& track_list, track_list_context& context)
+ inline void initialize_context(iallocator& allocator, const track_array& track_list, track_list_context& context)
{
ACL_ASSERT(track_list.is_valid().empty(), "Invalid track list");
ACL_ASSERT(!context.is_valid(), "Context already initialized");
diff --git a/includes/acl/compression/impl/track_stream.h b/includes/acl/compression/impl/track_stream.h
--- a/includes/acl/compression/impl/track_stream.h
+++ b/includes/acl/compression/impl/track_stream.h
@@ -99,7 +99,7 @@ namespace acl
protected:
TrackStream(animation_track_type8 type, track_format8 format) noexcept : m_allocator(nullptr), m_samples(nullptr), m_num_samples(0), m_sample_size(0), m_sample_rate(0.0F), m_type(type), m_format(format), m_bit_rate(0) {}
- TrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, animation_track_type8 type, track_format8 format, uint8_t bit_rate)
+ TrackStream(iallocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, animation_track_type8 type, track_format8 format, uint8_t bit_rate)
: m_allocator(&allocator)
, m_samples(reinterpret_cast<uint8_t*>(allocator.allocate(sample_size * num_samples + k_padding, 16)))
, m_num_samples(num_samples)
@@ -164,7 +164,7 @@ namespace acl
// In order to guarantee the safety of unaligned SIMD loads of every byte, we add some padding
static constexpr uint32_t k_padding = 15;
- IAllocator* m_allocator;
+ iallocator* m_allocator;
uint8_t* m_samples;
uint32_t m_num_samples;
uint32_t m_sample_size;
@@ -179,7 +179,7 @@ namespace acl
{
public:
RotationTrackStream() noexcept : TrackStream(animation_track_type8::rotation, track_format8(rotation_format8::quatf_full)) {}
- RotationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, rotation_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ RotationTrackStream(iallocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, rotation_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
: TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::rotation, track_format8(format), bit_rate)
{}
RotationTrackStream(const RotationTrackStream&) = delete;
@@ -209,7 +209,7 @@ namespace acl
{
public:
TranslationTrackStream() noexcept : TrackStream(animation_track_type8::translation, track_format8(vector_format8::vector3f_full)) {}
- TranslationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ TranslationTrackStream(iallocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
: TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::translation, track_format8(format), bit_rate)
{}
TranslationTrackStream(const TranslationTrackStream&) = delete;
@@ -239,7 +239,7 @@ namespace acl
{
public:
ScaleTrackStream() noexcept : TrackStream(animation_track_type8::scale, track_format8(vector_format8::vector3f_full)) {}
- ScaleTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ ScaleTrackStream(iallocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
: TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::scale, track_format8(format), bit_rate)
{}
ScaleTrackStream(const ScaleTrackStream&) = delete;
diff --git a/includes/acl/compression/impl/write_compression_stats_impl.h b/includes/acl/compression/impl/write_compression_stats_impl.h
--- a/includes/acl/compression/impl/write_compression_stats_impl.h
+++ b/includes/acl/compression/impl/write_compression_stats_impl.h
@@ -40,7 +40,7 @@ namespace acl
{
namespace acl_impl
{
- inline void write_compression_stats(const track_list_context& context, const compressed_tracks& tracks, const ScopeProfiler& compression_time, OutputStats& stats)
+ inline void write_compression_stats(const track_list_context& context, const compressed_tracks& tracks, const scope_profiler& compression_time, output_stats& stats)
{
ACL_ASSERT(stats.writer != nullptr, "Attempted to log stats without a writer");
diff --git a/includes/acl/compression/impl/write_decompression_stats.h b/includes/acl/compression/impl/write_decompression_stats.h
--- a/includes/acl/compression/impl/write_decompression_stats.h
+++ b/includes/acl/compression/impl/write_decompression_stats.h
@@ -26,15 +26,15 @@
#if defined(SJSON_CPP_WRITER)
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/impl/memory_cache.h"
#include "acl/core/scope_profiler.h"
#include "acl/core/utils.h"
-#include "acl/algorithm/uniformly_sampled/decoder.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/impl/memory_cache.h"
#include "acl/compression/output_stats.h"
-#include "acl/decompression/default_output_writer.h"
+#include "acl/decompression/decompress.h"
#include <rtm/scalard.h>
+#include <rtm/scalarf.h>
#include <algorithm>
#include <thread>
@@ -66,15 +66,14 @@ namespace acl
template<class DecompressionContextType>
inline void write_decompression_performance_stats(
- StatLogging logging, sjson::ObjectWriter& writer, const char* action_type,
+ stat_logging logging, sjson::ObjectWriter& writer, const char* action_type,
PlaybackDirection playback_direction, DecompressionFunction decompression_function,
- CompressedClip* compressed_clips[k_num_decompression_evaluations],
+ compressed_tracks* compressed_clips[k_num_decompression_evaluations],
DecompressionContextType* contexts[k_num_decompression_evaluations],
- CPUCacheFlusher* cache_flusher, rtm::qvvf* lossy_pose_transforms)
+ CPUCacheFlusher* cache_flusher, debug_track_writer& pose_writer)
{
- const ClipHeader& clip_header = get_clip_header(*compressed_clips[0]);
- const float duration = calculate_duration(clip_header.num_samples, clip_header.sample_rate);
- const uint16_t num_bones = clip_header.num_bones;
+ const uint32_t num_tracks = compressed_clips[0]->get_num_tracks();
+ const float duration = compressed_clips[0]->get_duration();
const bool is_cold_cache_profiling = cache_flusher != nullptr;
float sample_times[k_num_decompression_samples];
@@ -97,8 +96,6 @@ namespace acl
break;
}
- DefaultOutputWriter pose_writer(lossy_pose_transforms, num_bones);
-
// Initialize and clear our contexts
for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
contexts[clip_index]->initialize(*compressed_clips[clip_index]);
@@ -140,14 +137,14 @@ namespace acl
// If we want the cache warm, decompress everything once to prime it
DecompressionContextType* context = contexts[0];
context->seek(sample_time, sample_rounding_policy::none);
- context->decompress_pose(pose_writer);
+ context->decompress_tracks(pose_writer);
}
// We yield our time slice and wait for a new one before priming the cache
// to help keep it warm and minimize the risk that we'll be interrupted during decompression
std::this_thread::sleep_for(std::chrono::nanoseconds(1));
- ScopeProfiler timer;
+ scope_profiler timer;
for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
{
@@ -159,11 +156,11 @@ namespace acl
switch (decompression_function)
{
case DecompressionFunction::DecompressPose:
- context->decompress_pose(pose_writer);
+ context->decompress_tracks(pose_writer);
break;
case DecompressionFunction::DecompressBone:
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- context->decompress_bone(bone_index, &lossy_pose_transforms[bone_index].rotation, &lossy_pose_transforms[bone_index].translation, &lossy_pose_transforms[bone_index].scale);
+ for (uint32_t bone_index = 0; bone_index < num_tracks; ++bone_index)
+ context->decompress_track(bone_index, pose_writer);
break;
}
}
@@ -172,7 +169,7 @@ namespace acl
const double elapsed_ms = timer.get_elapsed_milliseconds() / k_num_decompression_evaluations;
- if (are_any_enum_flags_set(logging, StatLogging::ExhaustiveDecompression))
+ if (are_any_enum_flags_set(logging, stat_logging::ExhaustiveDecompression))
data_writer.push(elapsed_ms);
clip_min_ms = rtm::scalar_min(clip_min_ms, elapsed_ms);
@@ -191,7 +188,7 @@ namespace acl
};
}
- inline void write_memcpy_performance_stats(IAllocator& allocator, sjson::ObjectWriter& writer, CPUCacheFlusher* cache_flusher, rtm::qvvf* lossy_pose_transforms, uint16_t num_bones)
+ inline void write_memcpy_performance_stats(iallocator& allocator, sjson::ObjectWriter& writer, CPUCacheFlusher* cache_flusher, rtm::qvvf* lossy_pose_transforms, uint32_t num_bones)
{
rtm::qvvf* memcpy_src_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
@@ -218,7 +215,7 @@ namespace acl
}
double execution_count;
- ScopeProfiler timer;
+ scope_profiler timer;
if (cache_flusher != nullptr)
{
std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
@@ -257,88 +254,83 @@ namespace acl
}
template<class DecompressionContextType>
- inline void write_decompression_performance_stats(IAllocator& allocator, CompressedClip* compressed_clips[k_num_decompression_evaluations], DecompressionContextType* contexts[k_num_decompression_evaluations], StatLogging logging, sjson::ObjectWriter& writer)
+ inline void write_decompression_performance_stats(iallocator& allocator, compressed_tracks* compressed_clips[k_num_decompression_evaluations], DecompressionContextType* contexts[k_num_decompression_evaluations], stat_logging logging, sjson::ObjectWriter& writer)
{
CPUCacheFlusher* cache_flusher = allocate_type<CPUCacheFlusher>(allocator);
- const ClipHeader& clip_header = get_clip_header(*compressed_clips[0]);
- rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, clip_header.num_bones);
+ const uint32_t num_tracks = compressed_clips[0]->get_num_tracks();
+ debug_track_writer pose_writer(allocator, track_type8::qvvf, num_tracks);
const uint32_t num_bytes_per_bone = (4 + 3 + 3) * sizeof(float); // Rotation, Translation, Scale
- writer["pose_size"] = uint32_t(clip_header.num_bones) * num_bytes_per_bone;
+ writer["pose_size"] = num_tracks * num_bytes_per_bone;
writer["decompression_time_per_sample"] = [&](sjson::ObjectWriter& per_sample_writer)
{
// Cold/Warm CPU cache, memcpy
- write_memcpy_performance_stats(allocator, per_sample_writer, cache_flusher, lossy_pose_transforms, clip_header.num_bones);
- write_memcpy_performance_stats(allocator, per_sample_writer, nullptr, lossy_pose_transforms, clip_header.num_bones);
+ write_memcpy_performance_stats(allocator, per_sample_writer, cache_flusher, pose_writer.tracks_typed.qvvf, num_tracks);
+ write_memcpy_performance_stats(allocator, per_sample_writer, nullptr, pose_writer.tracks_typed.qvvf, num_tracks);
// Cold CPU cache, decompress_pose
- write_decompression_performance_stats(logging, per_sample_writer, "forward_pose_cold", PlaybackDirection::Forward, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "backward_pose_cold", PlaybackDirection::Backward, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "random_pose_cold", PlaybackDirection::Random, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
+ write_decompression_performance_stats(logging, per_sample_writer, "forward_pose_cold", PlaybackDirection::Forward, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "backward_pose_cold", PlaybackDirection::Backward, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "random_pose_cold", PlaybackDirection::Random, DecompressionFunction::DecompressPose, compressed_clips, contexts, cache_flusher, pose_writer);
// Warm CPU cache, decompress_pose
- write_decompression_performance_stats(logging, per_sample_writer, "forward_pose_warm", PlaybackDirection::Forward, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "backward_pose_warm", PlaybackDirection::Backward, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "random_pose_warm", PlaybackDirection::Random, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, lossy_pose_transforms);
+ write_decompression_performance_stats(logging, per_sample_writer, "forward_pose_warm", PlaybackDirection::Forward, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "backward_pose_warm", PlaybackDirection::Backward, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "random_pose_warm", PlaybackDirection::Random, DecompressionFunction::DecompressPose, compressed_clips, contexts, nullptr, pose_writer);
// Cold CPU cache, decompress_bone
- write_decompression_performance_stats(logging, per_sample_writer, "forward_bone_cold", PlaybackDirection::Forward, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "backward_bone_cold", PlaybackDirection::Backward, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "random_bone_cold", PlaybackDirection::Random, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, lossy_pose_transforms);
+ write_decompression_performance_stats(logging, per_sample_writer, "forward_bone_cold", PlaybackDirection::Forward, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "backward_bone_cold", PlaybackDirection::Backward, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "random_bone_cold", PlaybackDirection::Random, DecompressionFunction::DecompressBone, compressed_clips, contexts, cache_flusher, pose_writer);
// Warm CPU cache, decompress_bone
- write_decompression_performance_stats(logging, per_sample_writer, "forward_bone_warm", PlaybackDirection::Forward, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "backward_bone_warm", PlaybackDirection::Backward, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, lossy_pose_transforms);
- write_decompression_performance_stats(logging, per_sample_writer, "random_bone_warm", PlaybackDirection::Random, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, lossy_pose_transforms);
+ write_decompression_performance_stats(logging, per_sample_writer, "forward_bone_warm", PlaybackDirection::Forward, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "backward_bone_warm", PlaybackDirection::Backward, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, pose_writer);
+ write_decompression_performance_stats(logging, per_sample_writer, "random_bone_warm", PlaybackDirection::Random, DecompressionFunction::DecompressBone, compressed_clips, contexts, nullptr, pose_writer);
};
- deallocate_type_array(allocator, lossy_pose_transforms, clip_header.num_bones);
deallocate_type(allocator, cache_flusher);
}
- inline void write_decompression_performance_stats(IAllocator& allocator, const CompressionSettings& settings, const CompressedClip& compressed_clip, StatLogging logging, sjson::ObjectWriter& writer)
+ inline void write_decompression_performance_stats(iallocator& allocator, const compression_settings& settings, const compressed_tracks& compressed_clip, stat_logging logging, sjson::ObjectWriter& writer)
{
(void)settings;
- switch (compressed_clip.get_algorithm_type())
- {
- case algorithm_type8::uniformly_sampled:
- {
+ if (compressed_clip.get_algorithm_type() != algorithm_type8::uniformly_sampled)
+ return;
+
#if defined(ACL_HAS_ASSERT_CHECKS)
- // If we can, we use a fast-path that simulates what a real game engine would use
- // by disabling the things they normally wouldn't care about like deprecated formats
- // and debugging features
- const bool use_uniform_fast_path = settings.rotation_format == rotation_format8::quatf_drop_w_variable
- && settings.translation_format == vector_format8::vector3f_variable
- && settings.scale_format == vector_format8::vector3f_variable;
-
- ACL_ASSERT(use_uniform_fast_path, "We do not support profiling the debug code path");
+ // If we can, we use a fast-path that simulates what a real game engine would use
+ // by disabling the things they normally wouldn't care about like deprecated formats
+ // and debugging features
+ const bool use_uniform_fast_path = settings.rotation_format == rotation_format8::quatf_drop_w_variable
+ && settings.translation_format == vector_format8::vector3f_variable
+ && settings.scale_format == vector_format8::vector3f_variable;
+
+ ACL_ASSERT(use_uniform_fast_path, "We do not support profiling the debug code path");
#endif
- CompressedClip* compressed_clips[k_num_decompression_evaluations];
- for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
- {
- void* clip = allocator.allocate(compressed_clip.get_size(), alignof(CompressedClip));
- std::memcpy(clip, &compressed_clip, compressed_clip.get_size());
- compressed_clips[clip_index] = reinterpret_cast<CompressedClip*>(clip);
- }
+ compressed_tracks* compressed_clips[k_num_decompression_evaluations];
+ for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
+ {
+ void* clip = allocator.allocate(compressed_clip.get_size(), alignof(compressed_tracks));
+ std::memcpy(clip, &compressed_clip, compressed_clip.get_size());
+ compressed_clips[clip_index] = reinterpret_cast<compressed_tracks*>(clip);
+ }
- uniformly_sampled::DecompressionContext<uniformly_sampled::DefaultDecompressionSettings>* contexts[k_num_decompression_evaluations];
- for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
- contexts[clip_index] = uniformly_sampled::make_decompression_context<uniformly_sampled::DefaultDecompressionSettings>(allocator);
+ decompression_context<default_transform_decompression_settings>* contexts[k_num_decompression_evaluations];
+ for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
+ contexts[clip_index] = make_decompression_context<default_transform_decompression_settings>(allocator);
- write_decompression_performance_stats(allocator, compressed_clips, contexts, logging, writer);
+ write_decompression_performance_stats(allocator, compressed_clips, contexts, logging, writer);
- for (uint32_t pass_index = 0; pass_index < k_num_decompression_evaluations; ++pass_index)
- deallocate_type(allocator, contexts[pass_index]);
+ for (uint32_t pass_index = 0; pass_index < k_num_decompression_evaluations; ++pass_index)
+ deallocate_type(allocator, contexts[pass_index]);
- for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
- allocator.deallocate(compressed_clips[clip_index], compressed_clip.get_size());
- break;
- }
- }
+ for (uint32_t clip_index = 0; clip_index < k_num_decompression_evaluations; ++clip_index)
+ allocator.deallocate(compressed_clips[clip_index], compressed_clip.get_size());
}
}
}
diff --git a/includes/acl/compression/impl/write_range_data.h b/includes/acl/compression/impl/write_range_data.h
--- a/includes/acl/compression/impl/write_range_data.h
+++ b/includes/acl/compression/impl/write_range_data.h
@@ -44,7 +44,7 @@ namespace acl
{
namespace acl_impl
{
- inline uint32_t get_stream_range_data_size(const ClipContext& clip_context, range_reduction_flags8 range_reduction, rotation_format8 rotation_format)
+ inline uint32_t get_stream_range_data_size(const clip_context& clip, range_reduction_flags8 range_reduction, rotation_format8 rotation_format)
{
const uint32_t rotation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) ? get_range_reduction_rotation_size(rotation_format) : 0;
const uint32_t translation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) ? k_clip_range_reduction_vector3_range_size : 0;
@@ -52,7 +52,7 @@ namespace acl
uint32_t range_data_size = 0;
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
for (const BoneStreams& bone_stream : segment.const_bone_iterator())
{
if (!bone_stream.is_rotation_constant)
@@ -100,10 +100,10 @@ namespace acl
}
}
- inline void write_range_track_data(const BoneStreams* bone_streams, const BoneRanges* bone_ranges,
+ inline uint32_t write_range_track_data(const BoneStreams* bone_streams, const BoneRanges* bone_ranges,
range_reduction_flags8 range_reduction, bool is_clip_range_data,
uint8_t* range_data, uint32_t range_data_size,
- const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(range_data != nullptr, "'range_data' cannot be null!");
(void)range_data_size;
@@ -112,9 +112,11 @@ namespace acl
const uint8_t* range_data_end = add_offset_to_ptr<uint8_t>(range_data, range_data_size);
#endif
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ const uint8_t* range_data_start = range_data;
+
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = bone_streams[bone_index];
const BoneRanges& bone_range = bone_ranges[bone_index];
@@ -174,19 +176,20 @@ namespace acl
}
ACL_ASSERT(range_data == range_data_end, "Invalid range data offset. Wrote too little data.");
+ return safe_static_cast<uint32_t>(range_data - range_data_start);
}
- inline void write_clip_range_data(const ClipContext& clip_context, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_clip_range_data(const clip_context& clip, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
- write_range_track_data(segment.bone_streams, clip_context.ranges, range_reduction, true, range_data, range_data_size, output_bone_mapping, num_output_bones);
+ return write_range_track_data(segment.bone_streams, clip.ranges, range_reduction, true, range_data, range_data_size, output_bone_mapping, num_output_bones);
}
- inline void write_segment_range_data(const SegmentContext& segment, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_segment_range_data(const SegmentContext& segment, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
- write_range_track_data(segment.bone_streams, segment.ranges, range_reduction, false, range_data, range_data_size, output_bone_mapping, num_output_bones);
+ return write_range_track_data(segment.bone_streams, segment.ranges, range_reduction, false, range_data, range_data_size, output_bone_mapping, num_output_bones);
}
}
}
diff --git a/includes/acl/compression/impl/write_segment_data.h b/includes/acl/compression/impl/write_segment_data.h
--- a/includes/acl/compression/impl/write_segment_data.h
+++ b/includes/acl/compression/impl/write_segment_data.h
@@ -26,7 +26,7 @@
#include "acl/core/iallocator.h"
#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_clip.h"
+#include "acl/core/impl/compressed_headers.h"
#include "acl/compression/compression_settings.h"
#include "acl/compression/impl/clip_context.h"
#include "acl/compression/impl/segment_context.h"
@@ -41,27 +41,36 @@ namespace acl
{
namespace acl_impl
{
- inline void write_segment_start_indices(const ClipContext& clip_context, uint32_t* segment_start_indices)
+ inline uint32_t write_segment_start_indices(const clip_context& clip, uint32_t* segment_start_indices)
{
- for (uint16_t segment_index = 0; segment_index < clip_context.num_segments; ++segment_index)
+ uint32_t size_written = 0;
+
+ const uint32_t num_segments = clip.num_segments;
+ for (uint32_t segment_index = 0; segment_index < num_segments; ++segment_index)
{
- const SegmentContext& segment = clip_context.segments[segment_index];
+ const SegmentContext& segment = clip.segments[segment_index];
segment_start_indices[segment_index] = segment.clip_sample_offset;
+ size_written += sizeof(uint32_t);
}
// Write our sentinel value
- segment_start_indices[clip_context.num_segments] = 0xFFFFFFFFU;
+ segment_start_indices[clip.num_segments] = 0xFFFFFFFFU;
+ size_written += sizeof(uint32_t);
+
+ return size_written;
}
- inline void write_segment_headers(const ClipContext& clip_context, const CompressionSettings& settings, SegmentHeader* segment_headers, uint32_t segment_data_start_offset)
+ inline uint32_t write_segment_headers(const clip_context& clip, const compression_settings& settings, segment_header* segment_headers, uint32_t segment_data_start_offset)
{
- const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
+ uint32_t size_written = 0;
+
+ const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip, settings.rotation_format, settings.translation_format, settings.scale_format);
uint32_t segment_data_offset = segment_data_start_offset;
- for (uint16_t segment_index = 0; segment_index < clip_context.num_segments; ++segment_index)
+ for (uint16_t segment_index = 0; segment_index < clip.num_segments; ++segment_index)
{
- const SegmentContext& segment = clip_context.segments[segment_index];
- SegmentHeader& header = segment_headers[segment_index];
+ const SegmentContext& segment = clip.segments[segment_index];
+ segment_header& header = segment_headers[segment_index];
header.animated_pose_bit_size = segment.animated_pose_bit_size;
header.format_per_track_data_offset = segment_data_offset;
@@ -69,34 +78,46 @@ namespace acl
header.track_data_offset = align_to(header.range_data_offset + segment.range_data_size, 4); // Aligned to 4 bytes
segment_data_offset = header.track_data_offset + segment.animated_data_size;
+ size_written += sizeof(segment_header);
}
+
+ return size_written;
}
- inline void write_segment_data(const ClipContext& clip_context, const CompressionSettings& settings, range_reduction_flags8 range_reduction, ClipHeader& header, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_segment_data(const clip_context& clip, const compression_settings& settings, range_reduction_flags8 range_reduction, transform_tracks_header& header, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
- SegmentHeader* segment_headers = header.get_segment_headers();
- const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
+ segment_header* segment_headers = header.get_segment_headers();
+ const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip, settings.rotation_format, settings.translation_format, settings.scale_format);
- for (uint16_t segment_index = 0; segment_index < clip_context.num_segments; ++segment_index)
+ uint32_t size_written = 0;
+
+ const uint32_t num_segments = clip.num_segments;
+ for (uint32_t segment_index = 0; segment_index < num_segments; ++segment_index)
{
- const SegmentContext& segment = clip_context.segments[segment_index];
- SegmentHeader& segment_header = segment_headers[segment_index];
+ const SegmentContext& segment = clip.segments[segment_index];
+ segment_header& segment_header_ = segment_headers[segment_index];
if (format_per_track_data_size > 0)
- write_format_per_track_data(segment, header.get_format_per_track_data(segment_header), format_per_track_data_size, output_bone_mapping, num_output_bones);
+ size_written += write_format_per_track_data(segment, header.get_format_per_track_data(segment_header_), format_per_track_data_size, output_bone_mapping, num_output_bones);
else
- segment_header.format_per_track_data_offset = InvalidPtrOffset();
+ segment_header_.format_per_track_data_offset = invalid_ptr_offset();
+
+ size_written = align_to(size_written, 2); // Align range data
if (segment.range_data_size > 0)
- write_segment_range_data(segment, range_reduction, header.get_segment_range_data(segment_header), segment.range_data_size, output_bone_mapping, num_output_bones);
+ size_written += write_segment_range_data(segment, range_reduction, header.get_segment_range_data(segment_header_), segment.range_data_size, output_bone_mapping, num_output_bones);
else
- segment_header.range_data_offset = InvalidPtrOffset();
+ segment_header_.range_data_offset = invalid_ptr_offset();
+
+ size_written = align_to(size_written, 4); // Align animated data
if (segment.animated_data_size > 0)
- write_animated_track_data(segment, header.get_track_data(segment_header), segment.animated_data_size, output_bone_mapping, num_output_bones);
+ size_written += write_animated_track_data(segment, header.get_track_data(segment_header_), segment.animated_data_size, output_bone_mapping, num_output_bones);
else
- segment_header.track_data_offset = InvalidPtrOffset();
+ segment_header_.track_data_offset = invalid_ptr_offset();
}
+
+ return size_written;
}
}
}
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -26,14 +26,12 @@
#if defined(SJSON_CPP_WRITER)
+#include "acl/core/utils.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/impl/memory_cache.h"
-#include "acl/core/utils.h"
-#include "acl/algorithm/uniformly_sampled/decoder.h"
-#include "acl/decompression/default_output_writer.h"
+#include "acl/compression/transform_error_metrics.h"
+#include "acl/compression/track_error.h"
#include "acl/compression/impl/clip_context.h"
-#include "acl/compression/skeleton_error_metric.h"
-#include "acl/compression/utils.h"
#include <chrono>
#include <cstdint>
@@ -99,9 +97,9 @@ namespace acl
writer["decomp_touched_cache_lines"] = segment.clip->decomp_touched_cache_lines + num_segment_header_cache_lines + num_animated_pose_cache_lines;
}
- inline void write_exhaustive_segment_stats(IAllocator& allocator, const SegmentContext& segment, const ClipContext& raw_clip_context, const ClipContext& additive_base_clip_context, const RigidSkeleton& skeleton, const CompressionSettings& settings, sjson::ObjectWriter& writer)
+ inline void write_exhaustive_segment_stats(iallocator& allocator, const SegmentContext& segment, const clip_context& raw_clip_context, const clip_context& additive_base_clip_context, const compression_settings& settings, const track_array_qvvf& track_list, sjson::ObjectWriter& writer)
{
- const uint16_t num_bones = skeleton.get_num_bones();
+ const uint16_t num_bones = raw_clip_context.num_bones;
const bool has_scale = segment_context_has_scale(segment);
ACL_ASSERT(!settings.error_metric->needs_conversion(has_scale), "Error metric conversion not supported");
@@ -122,8 +120,10 @@ namespace acl
for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
{
- const RigidBone& bone = skeleton.get_bone(transform_index);
- parent_transform_indices[transform_index] = bone.parent_index;
+ const track_qvvf& track = track_list[transform_index];
+ const track_desc_transformf& desc = track.get_description();
+
+ parent_transform_indices[transform_index] = desc.parent_index == k_invalid_track_index ? k_invalid_bone_index : safe_static_cast<uint16_t>(desc.parent_index);
self_transform_indices[transform_index] = transform_index;
}
@@ -150,7 +150,7 @@ namespace acl
itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy = local_to_object_space_args_raw;
local_to_object_space_args_lossy.local_transforms = lossy_local_pose;
- BoneError worst_bone_error;
+ track_error worst_bone_error;
writer["error_per_frame_and_bone"] = [&](sjson::ArrayWriter& frames_writer)
{
@@ -176,28 +176,29 @@ namespace acl
frames_writer.push_newline();
frames_writer.push([&](sjson::ArrayWriter& frame_writer)
- {
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- const RigidBone& bone = skeleton.get_bone(bone_index);
+ for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ {
+ const track_qvvf& track = track_list[bone_index];
+ const track_desc_transformf& desc = track.get_description();
- itransform_error_metric::calculate_error_args calculate_error_args;
- calculate_error_args.transform0 = raw_object_pose + bone_index;
- calculate_error_args.transform1 = lossy_object_pose + bone_index;
- calculate_error_args.construct_sphere_shell(bone.vertex_distance);
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.transform0 = raw_object_pose + bone_index;
+ calculate_error_args.transform1 = lossy_object_pose + bone_index;
+ calculate_error_args.construct_sphere_shell(desc.shell_distance);
- const float error = rtm::scalar_cast(calculate_error_impl(settings.error_metric, calculate_error_args));
+ const float error = rtm::scalar_cast(calculate_error_impl(settings.error_metric, calculate_error_args));
- frame_writer.push(error);
+ frame_writer.push(error);
- if (error > worst_bone_error.error)
- {
- worst_bone_error.error = error;
- worst_bone_error.index = bone_index;
- worst_bone_error.sample_time = sample_time;
+ if (error > worst_bone_error.error)
+ {
+ worst_bone_error.error = error;
+ worst_bone_error.index = bone_index;
+ worst_bone_error.sample_time = sample_time;
+ }
}
- }
- });
+ });
}
};
@@ -216,35 +217,35 @@ namespace acl
deallocate_type_array(allocator, self_transform_indices, num_bones);
}
- inline void write_stats(IAllocator& allocator, const AnimationClip& clip, const ClipContext& clip_context, const RigidSkeleton& skeleton,
- const CompressedClip& compressed_clip, const CompressionSettings& settings, const ClipHeader& header, const ClipContext& raw_clip_context,
- const ClipContext& additive_base_clip_context, const ScopeProfiler& compression_time,
- OutputStats& stats)
+ inline void write_stats(iallocator& allocator, const track_array_qvvf& track_list, const clip_context& clip,
+ const compressed_tracks& compressed_clip, const compression_settings& settings, const clip_context& raw_clip,
+ const clip_context& additive_base_clip_context, const scope_profiler& compression_time,
+ output_stats& stats)
{
ACL_ASSERT(stats.writer != nullptr, "Attempted to log stats without a writer");
- const uint32_t raw_size = clip.get_raw_size();
+ const uint32_t raw_size = track_list.get_raw_size();
const uint32_t compressed_size = compressed_clip.get_size();
const double compression_ratio = double(raw_size) / double(compressed_size);
sjson::ObjectWriter& writer = *stats.writer;
writer["algorithm_name"] = get_algorithm_name(algorithm_type8::uniformly_sampled);
writer["algorithm_uid"] = settings.get_hash();
- writer["clip_name"] = clip.get_name().c_str();
+ //writer["clip_name"] = clip.get_name().c_str();
writer["raw_size"] = raw_size;
writer["compressed_size"] = compressed_size;
writer["compression_ratio"] = compression_ratio;
writer["compression_time"] = compression_time.get_elapsed_seconds();
- writer["duration"] = clip.get_duration();
- writer["num_samples"] = clip.get_num_samples();
- writer["num_bones"] = clip.get_num_bones();
+ writer["duration"] = track_list.get_duration();
+ writer["num_samples"] = track_list.get_num_samples_per_track();
+ writer["num_bones"] = track_list.get_num_tracks();
writer["rotation_format"] = get_rotation_format_name(settings.rotation_format);
writer["translation_format"] = get_vector_format_name(settings.translation_format);
writer["scale_format"] = get_vector_format_name(settings.scale_format);
- writer["has_scale"] = clip_context.has_scale;
+ writer["has_scale"] = clip.has_scale;
writer["error_metric"] = settings.error_metric->get_name();
- if (are_all_enum_flags_set(stats.logging, StatLogging::Detailed) || are_all_enum_flags_set(stats.logging, StatLogging::Exhaustive))
+ if (are_all_enum_flags_set(stats.logging, stat_logging::Detailed) || are_all_enum_flags_set(stats.logging, stat_logging::Exhaustive))
{
uint32_t num_default_rotation_tracks = 0;
uint32_t num_default_translation_tracks = 0;
@@ -256,7 +257,7 @@ namespace acl
uint32_t num_animated_translation_tracks = 0;
uint32_t num_animated_scale_tracks = 0;
- for (const BoneStreams& bone_stream : clip_context.segments[0].bone_iterator())
+ for (const BoneStreams& bone_stream : clip.segments[0].bone_iterator())
{
if (bone_stream.is_rotation_default)
num_default_rotation_tracks++;
@@ -303,24 +304,24 @@ namespace acl
writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
{
- segmenting_writer["num_segments"] = header.num_segments;
+ segmenting_writer["num_segments"] = clip.num_segments;
segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
};
writer["segments"] = [&](sjson::ArrayWriter& segments_writer)
{
- for (const SegmentContext& segment : clip_context.const_segment_iterator())
+ for (const SegmentContext& segment : clip.const_segment_iterator())
{
segments_writer.push([&](sjson::ObjectWriter& segment_writer)
{
write_summary_segment_stats(segment, settings.rotation_format, settings.translation_format, settings.scale_format, segment_writer);
- if (are_all_enum_flags_set(stats.logging, StatLogging::Detailed))
+ if (are_all_enum_flags_set(stats.logging, stat_logging::Detailed))
write_detailed_segment_stats(segment, segment_writer);
- if (are_all_enum_flags_set(stats.logging, StatLogging::Exhaustive))
- write_exhaustive_segment_stats(allocator, segment, raw_clip_context, additive_base_clip_context, skeleton, settings, segment_writer);
+ if (are_all_enum_flags_set(stats.logging, stat_logging::Exhaustive))
+ write_exhaustive_segment_stats(allocator, segment, raw_clip, additive_base_clip_context, settings, track_list, segment_writer);
});
}
};
diff --git a/includes/acl/compression/impl/write_stream_bitsets.h b/includes/acl/compression/impl/write_stream_bitsets.h
--- a/includes/acl/compression/impl/write_stream_bitsets.h
+++ b/includes/acl/compression/impl/write_stream_bitsets.h
@@ -37,56 +37,64 @@ namespace acl
{
namespace acl_impl
{
- inline void write_default_track_bitset(const ClipContext& clip_context, uint32_t* default_tracks_bitset, BitSetDescription bitset_desc, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_default_track_bitset(const clip_context& clip, uint32_t* default_tracks_bitset, bitset_description bitset_desc, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(default_tracks_bitset != nullptr, "'default_tracks_bitset' cannot be null!");
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
uint32_t default_track_offset = 0;
+ uint32_t size_written = 0;
bitset_reset(default_tracks_bitset, bitset_desc, false);
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_rotation_default);
bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_translation_default);
- if (clip_context.has_scale)
+ if (clip.has_scale)
bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_scale_default);
+
+ size_written += clip.has_scale ? 3 : 2;
}
ACL_ASSERT(default_track_offset <= bitset_desc.get_num_bits(), "Too many tracks found for bitset");
+ return ((size_written + 31) / 32) * sizeof(uint32_t); // Convert bits to bytes
}
- inline void write_constant_track_bitset(const ClipContext& clip_context, uint32_t* constant_tracks_bitset, BitSetDescription bitset_desc, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_constant_track_bitset(const clip_context& clip, uint32_t* constant_tracks_bitset, bitset_description bitset_desc, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(constant_tracks_bitset != nullptr, "'constant_tracks_bitset' cannot be null!");
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
uint32_t constant_track_offset = 0;
+ uint32_t size_written = 0;
bitset_reset(constant_tracks_bitset, bitset_desc, false);
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_rotation_constant);
bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_translation_constant);
- if (clip_context.has_scale)
+ if (clip.has_scale)
bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_scale_constant);
+
+ size_written += clip.has_scale ? 3 : 2;
}
ACL_ASSERT(constant_track_offset <= bitset_desc.get_num_bits(), "Too many tracks found for bitset");
+ return ((size_written + 31) / 32) * sizeof(uint32_t); // Convert bits to bytes
}
}
}
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -27,7 +27,6 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/iallocator.h"
#include "acl/core/error.h"
-#include "acl/core/compressed_clip.h"
#include "acl/compression/impl/clip_context.h"
#include <cstdint>
@@ -38,16 +37,16 @@ namespace acl
{
namespace acl_impl
{
- inline uint32_t get_constant_data_size(const ClipContext& clip_context, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t get_constant_data_size(const clip_context& clip, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
uint32_t constant_data_size = 0;
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_default && bone_stream.is_rotation_constant)
@@ -56,7 +55,7 @@ namespace acl
if (!bone_stream.is_translation_default && bone_stream.is_translation_constant)
constant_data_size += bone_stream.translations.get_packed_sample_size();
- if (clip_context.has_scale && !bone_stream.is_scale_default && bone_stream.is_scale_constant)
+ if (clip.has_scale && !bone_stream.is_scale_default && bone_stream.is_scale_constant)
constant_data_size += bone_stream.scales.get_packed_sample_size();
}
@@ -87,16 +86,16 @@ namespace acl
}
}
- inline void calculate_animated_data_size(ClipContext& clip_context, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void calculate_animated_data_size(clip_context& clip, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
- for (SegmentContext& segment : clip_context.segment_iterator())
+ for (SegmentContext& segment : clip.segment_iterator())
{
uint32_t num_animated_data_bits = 0;
uint32_t num_animated_pose_bits = 0;
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_constant)
@@ -114,14 +113,14 @@ namespace acl
}
}
- inline uint32_t get_format_per_track_data_size(const ClipContext& clip_context, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
+ inline uint32_t get_format_per_track_data_size(const clip_context& clip, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
const bool is_scale_variable = is_vector_format_variable(scale_format);
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
uint32_t format_per_track_data_size = 0;
@@ -143,21 +142,23 @@ namespace acl
return format_per_track_data_size;
}
- inline void write_constant_track_data(const ClipContext& clip_context, uint8_t* constant_data, uint32_t constant_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_constant_track_data(const clip_context& clip, uint8_t* constant_data, uint32_t constant_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(constant_data != nullptr, "'constant_data' cannot be null!");
(void)constant_data_size;
// Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip_context.segments[0];
+ const SegmentContext& segment = clip.segments[0];
#if defined(ACL_HAS_ASSERT_CHECKS)
const uint8_t* constant_data_end = add_offset_to_ptr<uint8_t>(constant_data, constant_data_size);
#endif
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ const uint8_t* constant_data_start = constant_data;
+
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_default && bone_stream.is_rotation_constant)
@@ -176,7 +177,7 @@ namespace acl
constant_data += sample_size;
}
- if (clip_context.has_scale && !bone_stream.is_scale_default && bone_stream.is_scale_constant)
+ if (clip.has_scale && !bone_stream.is_scale_default && bone_stream.is_scale_constant)
{
const uint8_t* scale_ptr = bone_stream.scales.get_raw_sample_ptr(0);
uint32_t sample_size = bone_stream.scales.get_sample_size();
@@ -188,6 +189,7 @@ namespace acl
}
ACL_ASSERT(constant_data == constant_data_end, "Invalid constant data offset. Wrote too little data.");
+ return safe_static_cast<uint32_t>(constant_data - constant_data_start);
}
inline void write_animated_track_data(const TrackStream& track_stream, uint32_t sample_index, uint8_t* animated_track_data_begin, uint8_t*& out_animated_track_data, uint64_t& out_bit_offset)
@@ -246,7 +248,7 @@ namespace acl
}
}
- inline void write_animated_track_data(const SegmentContext& segment, uint8_t* animated_track_data, uint32_t animated_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_animated_track_data(const SegmentContext& segment, uint8_t* animated_track_data, uint32_t animated_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(animated_track_data != nullptr, "'animated_track_data' cannot be null!");
(void)animated_data_size;
@@ -257,15 +259,16 @@ namespace acl
const uint8_t* animated_track_data_end = add_offset_to_ptr<uint8_t>(animated_track_data, animated_data_size);
#endif
+ const uint8_t* animated_track_data_start = animated_track_data;
uint64_t bit_offset = 0;
// Data is sorted first by time, second by bone.
// This ensures that all bones are contiguous in memory when we sample a particular time.
for (uint32_t sample_index = 0; sample_index < segment.num_samples; ++sample_index)
{
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_constant && !is_constant_bit_rate(bone_stream.rotations.get_bit_rate()))
@@ -285,9 +288,10 @@ namespace acl
animated_track_data = animated_track_data_begin + (align_to(bit_offset, 8) / 8);
ACL_ASSERT(animated_track_data == animated_track_data_end, "Invalid animated track data offset. Wrote too little data.");
+ return safe_static_cast<uint32_t>(animated_track_data - animated_track_data_start);
}
- inline void write_format_per_track_data(const SegmentContext& segment, uint8_t* format_per_track_data, uint32_t format_per_track_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline uint32_t write_format_per_track_data(const SegmentContext& segment, uint8_t* format_per_track_data, uint32_t format_per_track_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
ACL_ASSERT(format_per_track_data != nullptr, "'format_per_track_data' cannot be null!");
(void)format_per_track_data_size;
@@ -296,9 +300,11 @@ namespace acl
const uint8_t* format_per_track_data_end = add_offset_to_ptr<uint8_t>(format_per_track_data, format_per_track_data_size);
#endif
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
+ const uint8_t* format_per_track_data_start = format_per_track_data;
+
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- const uint16_t bone_index = output_bone_mapping[output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_constant && bone_stream.rotations.is_bit_rate_variable())
@@ -314,6 +320,8 @@ namespace acl
}
ACL_ASSERT(format_per_track_data == format_per_track_data_end, "Invalid format per track data offset. Wrote too little data.");
+
+ return safe_static_cast<uint32_t>(format_per_track_data - format_per_track_data_start);
}
}
}
diff --git a/includes/acl/compression/output_stats.h b/includes/acl/compression/output_stats.h
--- a/includes/acl/compression/output_stats.h
+++ b/includes/acl/compression/output_stats.h
@@ -33,7 +33,7 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- enum class StatLogging
+ enum class stat_logging
{
None = 0x0000,
Summary = 0x0001,
@@ -43,14 +43,14 @@ namespace acl
ExhaustiveDecompression = 0x0020,
};
- ACL_IMPL_ENUM_FLAGS_OPERATORS(StatLogging)
+ ACL_IMPL_ENUM_FLAGS_OPERATORS(stat_logging)
- struct OutputStats
+ struct output_stats
{
- OutputStats() : logging(StatLogging::None), writer(nullptr) {}
- OutputStats(StatLogging logging_, sjson::ObjectWriter* writer_) : logging(logging_), writer(writer_) {}
+ output_stats() : logging(stat_logging::None), writer(nullptr) {}
+ output_stats(stat_logging logging_, sjson::ObjectWriter* writer_) : logging(logging_), writer(writer_) {}
- StatLogging logging;
+ stat_logging logging;
sjson::ObjectWriter* writer;
};
}
diff --git a/includes/acl/compression/skeleton.h b/includes/acl/compression/skeleton.h
deleted file mode 100644
--- a/includes/acl/compression/skeleton.h
+++ /dev/null
@@ -1,359 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/bitset.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/core/iallocator.h"
-#include "acl/core/string.h"
-
-#include <rtm/qvvd.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // We only support up to 65534 bones, we reserve 65535 for the invalid index
- constexpr uint16_t k_invalid_bone_index = 0xFFFF;
-
- namespace acl_impl
- {
- //////////////////////////////////////////////////////////////////////////
- // Simple iterator utility class to allow easy looping
- class BoneChainIterator
- {
- public:
- BoneChainIterator(const uint32_t* bone_chain, BitSetDescription bone_chain_desc, uint16_t bone_index, uint16_t offset)
- : m_bone_chain(bone_chain)
- , m_bone_chain_desc(bone_chain_desc)
- , m_bone_index(bone_index)
- , m_offset(offset)
- {}
-
- BoneChainIterator& operator++()
- {
- ACL_ASSERT(m_offset <= m_bone_index, "Cannot increment the iterator, it is no longer valid");
-
- // Skip the current bone
- m_offset++;
-
- // Iterate until we find the next bone part of the chain or until we reach the end of the chain
- // TODO: Use clz or similar to find the next set bit starting at the current index
- while (m_offset < m_bone_index && !bitset_test(m_bone_chain, m_bone_chain_desc, m_offset))
- m_offset++;
-
- return *this;
- }
-
- uint16_t operator*() const
- {
- ACL_ASSERT(m_offset <= m_bone_index, "Returned bone index doesn't belong to the bone chain");
- ACL_ASSERT(bitset_test(m_bone_chain, m_bone_chain_desc, m_offset), "Returned bone index doesn't belong to the bone chain");
- return m_offset;
- }
-
- // We only compare the offset in the bone chain. Two iterators on the same bone index
- // from two different or equal chains will be equal.
- bool operator==(const BoneChainIterator& other) const { return m_offset == other.m_offset; }
- bool operator!=(const BoneChainIterator& other) const { return m_offset != other.m_offset; }
-
- private:
- const uint32_t* m_bone_chain;
- BitSetDescription m_bone_chain_desc;
- uint16_t m_bone_index;
- uint16_t m_offset;
- };
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Simple bone chain container to allow easy looping
- //
- // A bone chain allows looping over all bones up to a specific bone starting
- // at the root bone.
- //////////////////////////////////////////////////////////////////////////
- struct BoneChain
- {
- BoneChain(const uint32_t* bone_chain, BitSetDescription bone_chain_desc, uint16_t bone_index)
- : m_bone_chain(bone_chain)
- , m_bone_chain_desc(bone_chain_desc)
- , m_bone_index(bone_index)
- {
- // We don't know where this bone chain starts, find the root bone
- // TODO: Use clz or similar to find the next set bit starting at the current index
- uint16_t root_index = 0;
- while (!bitset_test(bone_chain, bone_chain_desc, root_index))
- root_index++;
-
- m_root_index = root_index;
- }
-
- acl_impl::BoneChainIterator begin() const { return acl_impl::BoneChainIterator(m_bone_chain, m_bone_chain_desc, m_bone_index, m_root_index); }
- acl_impl::BoneChainIterator end() const { return acl_impl::BoneChainIterator(m_bone_chain, m_bone_chain_desc, m_bone_index, m_bone_index + 1); }
-
- const uint32_t* m_bone_chain;
- BitSetDescription m_bone_chain_desc;
- uint16_t m_root_index;
- uint16_t m_bone_index;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A rigid bone description
- //
- // Bones are organized in a tree with a single root bone. Each bone has
- // one or more children and every bone except the root has a single parent.
- //////////////////////////////////////////////////////////////////////////
- struct alignas(16) RigidBone
- {
- //////////////////////////////////////////////////////////////////////////
- // Default constructor, initializes a simple root bone with no name
- RigidBone() noexcept
- : name()
- , bone_chain(nullptr)
- , vertex_distance(1.0F)
- , parent_index(k_invalid_bone_index)
- , bind_transform(rtm::qvv_identity())
- {
- (void)padding;
- }
-
- ~RigidBone() = default;
-
- RigidBone(RigidBone&& other) noexcept
- : name(std::move(other.name))
- , bone_chain(other.bone_chain)
- , vertex_distance(other.vertex_distance)
- , parent_index(other.parent_index)
- , bind_transform(other.bind_transform)
- {
- new(&other) RigidBone();
- }
-
- RigidBone& operator=(RigidBone&& other) noexcept
- {
- std::swap(name, other.name);
- std::swap(bone_chain, other.bone_chain);
- std::swap(vertex_distance, other.vertex_distance);
- std::swap(parent_index, other.parent_index);
- std::swap(bind_transform, other.bind_transform);
-
- return *this;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns whether or not this bone is a root bone
- bool is_root() const { return parent_index == k_invalid_bone_index; }
-
- // Name of the bone (used for debugging purposes only)
- String name;
-
- // A bit set, a set bit at index X indicates the bone at index X is in the chain
- // This can be used to iterate on the bone chain efficiently from root to the current bone
- const uint32_t* bone_chain;
-
- // Virtual vertex distance used by hierarchical error function
- // The error metric measures the error of a virtual vertex at this
- // distance from the bone in object space
- float vertex_distance;
-
- // The parent bone index or an invalid bone index for the root bone
- // TODO: Introduce a type for bone indices
- uint16_t parent_index;
-
- // Unused memory left as padding
- uint8_t padding[2];
-
- // The bind transform is in its parent's local space
- // Note that the scale is ignored and this value is only used by the additive error metrics
- rtm::qvvd bind_transform;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // A rigid skeleton made up of a tree of rigid bones
- //
- // This hierarchical structure is important and forms the back bone of the
- // error metrics. When calculating the error introduced by lowering the
- // precision of a single bone track, we will walk up the hierarchy and
- // calculate the error relative to the root bones (object/mesh space).
- //////////////////////////////////////////////////////////////////////////
- class RigidSkeleton
- {
- public:
- //////////////////////////////////////////////////////////////////////////
- // Constructs a RigidSkeleton instance and moves the data from the input
- // 'bones' into the skeleton instance (destructive operation on the input array).
- // - allocator: The allocator instance to use to allocate and free memory
- // - bones: An array of bones to initialize the skeleton with
- // - num_bones: The number of input bones
- RigidSkeleton(IAllocator& allocator, RigidBone* bones, uint16_t num_bones)
- : m_allocator(allocator)
- , m_bones(allocate_type_array<RigidBone>(allocator, num_bones))
- , m_num_bones(num_bones)
- {
- // Calculate which bones are leaf bones that have no children
- BitSetDescription bone_bitset_desc = BitSetDescription::make_from_num_bits(num_bones);
- uint32_t* is_leaf_bitset = allocate_type_array<uint32_t>(allocator, bone_bitset_desc.get_size());
- bitset_reset(is_leaf_bitset, bone_bitset_desc, false);
-
- // By default and if we find a child, we'll mark it as non-leaf
- bitset_set_range(is_leaf_bitset, bone_bitset_desc, 0, num_bones, true);
-
-#if defined(ACL_HAS_ASSERT_CHECKS)
- uint32_t num_root_bones = 0;
-#endif
-
- // Move and validate the input data
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- RigidBone& bone = bones[bone_index];
-
- const bool is_root = bone.parent_index == k_invalid_bone_index;
-
- ACL_ASSERT(bone.bone_chain == nullptr, "Bone chain should be calculated internally");
- ACL_ASSERT(is_root || bone.parent_index < bone_index, "Bones must be sorted parent first");
- ACL_ASSERT(rtm::quat_is_finite(bone.bind_transform.rotation), "Bind rotation is invalid: [%f, %f, %f, %f]", (float)rtm::quat_get_x(bone.bind_transform.rotation), (float)rtm::quat_get_y(bone.bind_transform.rotation), (float)rtm::quat_get_z(bone.bind_transform.rotation), (float)rtm::quat_get_w(bone.bind_transform.rotation));
- ACL_ASSERT(rtm::quat_is_normalized(bone.bind_transform.rotation), "Bind rotation isn't normalized: [%f, %f, %f, %f]", (float)rtm::quat_get_x(bone.bind_transform.rotation), (float)rtm::quat_get_y(bone.bind_transform.rotation), (float)rtm::quat_get_z(bone.bind_transform.rotation), (float)rtm::quat_get_w(bone.bind_transform.rotation));
- ACL_ASSERT(rtm::vector_is_finite3(bone.bind_transform.translation), "Bind translation is invalid: [%f, %f, %f]", (float)rtm::vector_get_x(bone.bind_transform.translation), (float)rtm::vector_get_y(bone.bind_transform.translation), (float)rtm::vector_get_z(bone.bind_transform.translation));
-
- // If we have a parent, mark it as not being a leaf bone (it has at least one child)
- if (!is_root)
- bitset_set(is_leaf_bitset, bone_bitset_desc, bone.parent_index, false);
-
-#if defined(ACL_HAS_ASSERT_CHECKS)
- if (is_root)
- num_root_bones++;
-#endif
-
- m_bones[bone_index] = std::move(bone);
-
- // Input scale is ignored and always set to [1.0, 1.0, 1.0]
- m_bones[bone_index].bind_transform.scale = rtm::vector_set(1.0);
- }
-
- m_num_leaf_bones = safe_static_cast<uint16_t>(bitset_count_set_bits(is_leaf_bitset, bone_bitset_desc));
-
- m_leaf_bone_chains = allocate_type_array<uint32_t>(allocator, size_t(m_num_leaf_bones) * bone_bitset_desc.get_size());
-
- uint16_t leaf_index = 0;
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- if (!bitset_test(is_leaf_bitset, bone_bitset_desc, bone_index))
- continue; // Skip non-leaf bones
-
- uint32_t* bone_chain = m_leaf_bone_chains + (leaf_index * bone_bitset_desc.get_size());
- bitset_reset(bone_chain, bone_bitset_desc, false);
-
- uint16_t chain_bone_index = bone_index;
- while (chain_bone_index != k_invalid_bone_index)
- {
- bitset_set(bone_chain, bone_bitset_desc, chain_bone_index, true);
-
- RigidBone& bone = m_bones[chain_bone_index];
-
- // We assign a bone chain the first time we find a bone that isn't part of one already
- if (bone.bone_chain == nullptr)
- bone.bone_chain = bone_chain;
-
- chain_bone_index = bone.parent_index;
- }
-
- leaf_index++;
- }
-
- ACL_ASSERT(num_root_bones > 0, "No root bone found. The root bones must have a parent index = 0xFFFF");
- ACL_ASSERT(leaf_index == m_num_leaf_bones, "Invalid number of leaf bone found");
- deallocate_type_array(m_allocator, is_leaf_bitset, bone_bitset_desc.get_size());
- }
-
- RigidSkeleton(RigidSkeleton&& other) noexcept
- : m_allocator(other.m_allocator)
- , m_bones(other.m_bones)
- , m_leaf_bone_chains(other.m_leaf_bone_chains)
- , m_num_bones(other.m_num_bones)
- , m_num_leaf_bones(other.m_num_leaf_bones)
- {
- other.m_bones = nullptr;
- other.m_leaf_bone_chains = nullptr;
- }
-
- ~RigidSkeleton()
- {
- deallocate_type_array(m_allocator, m_bones, m_num_bones);
-
- BitSetDescription bone_bitset_desc = BitSetDescription::make_from_num_bits(m_num_bones);
- deallocate_type_array(m_allocator, m_leaf_bone_chains, size_t(m_num_leaf_bones) * bone_bitset_desc.get_size());
- }
-
- RigidSkeleton(const RigidSkeleton&) = delete;
- RigidSkeleton& operator=(const RigidSkeleton&) = delete;
- RigidSkeleton& operator=(RigidSkeleton&&) = delete;
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the array of bones contained in the skeleton
- const RigidBone* get_bones() const { return m_bones; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns a specific bone from its index
- const RigidBone& get_bone(uint16_t bone_index) const
- {
- ACL_ASSERT(bone_index < m_num_bones, "Invalid bone index: %u >= %u", bone_index, m_num_bones);
- return m_bones[bone_index];
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the number of bones in the skeleton
- uint16_t get_num_bones() const { return m_num_bones; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns a bone chain for a specific bone from its index
- BoneChain get_bone_chain(uint16_t bone_index) const
- {
- ACL_ASSERT(bone_index < m_num_bones, "Invalid bone index: %u >= %u", bone_index, m_num_bones);
- const RigidBone& bone = m_bones[bone_index];
- return BoneChain(bone.bone_chain, BitSetDescription::make_from_num_bits(m_num_bones), bone_index);
- }
-
- private:
- // The allocator instance used to allocate and free memory by this skeleton instance
- IAllocator& m_allocator;
-
- // The array of bone data for this skeleton, contains 'm_num_bones' entries
- RigidBone* m_bones;
-
- // Contiguous block of memory for the bone chains, contains m_num_leaf_bones * get_bitset_size(m_num_bones) entries
- uint32_t* m_leaf_bone_chains;
-
- // Number of bones contained in this skeleton
- uint16_t m_num_bones;
-
- // Number of leaf bones contained in this skeleton
- uint16_t m_num_leaf_bones;
- };
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/track.h b/includes/acl/compression/track.h
--- a/includes/acl/compression/track.h
+++ b/includes/acl/compression/track.h
@@ -48,80 +48,27 @@ namespace acl
public:
//////////////////////////////////////////////////////////////////////////
// Creates an empty, untyped track.
- track() noexcept
- : m_allocator(nullptr)
- , m_data(nullptr)
- , m_num_samples(0)
- , m_stride(0)
- , m_data_size(0)
- , m_sample_rate(0.0F)
- , m_type(track_type8::float1f)
- , m_category(track_category8::scalarf)
- , m_sample_size(0)
- , m_desc()
- {}
+ track() noexcept;
//////////////////////////////////////////////////////////////////////////
// Move constructor for a track.
- track(track&& other) noexcept
- : m_allocator(other.m_allocator)
- , m_data(other.m_data)
- , m_num_samples(other.m_num_samples)
- , m_stride(other.m_stride)
- , m_data_size(other.m_data_size)
- , m_sample_rate(other.m_sample_rate)
- , m_type(other.m_type)
- , m_category(other.m_category)
- , m_sample_size(other.m_sample_size)
- , m_desc(other.m_desc)
- {
- other.m_allocator = nullptr;
- other.m_data = nullptr;
- }
+ track(track&& other) noexcept;
//////////////////////////////////////////////////////////////////////////
// Destroys the track. If it owns the memory referenced, it will be freed.
- ~track()
- {
- if (is_owner())
- {
- // We own the memory, free it
- m_allocator->deallocate(m_data, m_data_size);
- }
- }
+ ~track();
//////////////////////////////////////////////////////////////////////////
// Move assignment for a track.
- track& operator=(track&& other) noexcept
- {
- std::swap(m_allocator, other.m_allocator);
- std::swap(m_data, other.m_data);
- std::swap(m_num_samples, other.m_num_samples);
- std::swap(m_stride, other.m_stride);
- std::swap(m_data_size, other.m_data_size);
- std::swap(m_sample_rate, other.m_sample_rate);
- std::swap(m_type, other.m_type);
- std::swap(m_category, other.m_category);
- std::swap(m_sample_size, other.m_sample_size);
- std::swap(m_desc, other.m_desc);
- return *this;
- }
+ track& operator=(track&& other) noexcept;
//////////////////////////////////////////////////////////////////////////
// Returns a pointer to an untyped sample at the specified index.
- void* operator[](uint32_t index)
- {
- ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
- return m_data + (index * m_stride);
- }
+ void* operator[](uint32_t index);
//////////////////////////////////////////////////////////////////////////
// Returns a pointer to an untyped sample at the specified index.
- const void* operator[](uint32_t index) const
- {
- ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
- return m_data + (index * m_stride);
- }
+ const void* operator[](uint32_t index) const;
//////////////////////////////////////////////////////////////////////////
// Returns true if the track owns its memory, false otherwise.
@@ -131,6 +78,10 @@ namespace acl
// Returns true if the track owns its memory, false otherwise.
bool is_ref() const { return m_allocator == nullptr; }
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a pointer to the allocator instance or nullptr if there is none present.
+ iallocator* get_allocator() const { return m_allocator; }
+
//////////////////////////////////////////////////////////////////////////
// Returns the number of samples contained within the track.
uint32_t get_num_samples() const { return m_num_samples; }
@@ -162,58 +113,33 @@ namespace acl
// When compressing, it is often desirable to strip or re-order the tracks we output.
// This can be used to sort by LOD or to strip stale tracks. Tracks with an invalid
// track index are stripped in the output.
- uint32_t get_output_index() const
- {
- switch (m_category)
- {
- default:
- case track_category8::scalarf: return m_desc.scalar.output_index;
- }
- }
+ uint32_t get_output_index() const;
//////////////////////////////////////////////////////////////////////////
// Returns the track description.
template<typename desc_type>
- desc_type& get_description()
- {
- ACL_ASSERT(desc_type::category == m_category, "Unexpected track category");
- switch (desc_type::category)
- {
- default:
- case track_category8::scalarf: return m_desc.scalar;
- }
- }
+ desc_type& get_description();
//////////////////////////////////////////////////////////////////////////
// Returns the track description.
template<typename desc_type>
- const desc_type& get_description() const
- {
- ACL_ASSERT(desc_type::category == m_category, "Unexpected track category");
- switch (desc_type::category)
- {
- default:
- case track_category8::scalarf: return m_desc.scalar;
- }
- }
+ const desc_type& get_description() const;
//////////////////////////////////////////////////////////////////////////
// Returns a copy of the track where the memory will be owned by the copy.
- track get_copy(IAllocator& allocator) const
- {
- track track_;
- get_copy_impl(allocator, track_);
- return track_;
- }
+ track get_copy(iallocator& allocator) const;
//////////////////////////////////////////////////////////////////////////
// Returns a reference to the track where the memory isn't owned.
- track get_ref() const
- {
- track track_;
- get_ref_impl(track_);
- return track_;
- }
+ track get_ref() const;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether a track is valid or not.
+ // A track is valid if:
+ // - It is empty
+ // - It has a positive and finite sample rate
+ // - A valid description
+ error_result is_valid() const;
protected:
//////////////////////////////////////////////////////////////////////////
@@ -224,69 +150,21 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Internal constructor.
// Creates an empty, untyped track.
- track(track_type8 type, track_category8 category) noexcept
- : m_allocator(nullptr)
- , m_data(nullptr)
- , m_num_samples(0)
- , m_stride(0)
- , m_data_size(0)
- , m_sample_rate(0.0F)
- , m_type(type)
- , m_category(category)
- , m_sample_size(0)
- , m_desc()
- {}
+ track(track_type8 type, track_category8 category) noexcept;
//////////////////////////////////////////////////////////////////////////
// Internal constructor.
- track(IAllocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, track_type8 type, track_category8 category, uint8_t sample_size) noexcept
- : m_allocator(allocator)
- , m_data(data)
- , m_num_samples(num_samples)
- , m_stride(stride)
- , m_data_size(data_size)
- , m_sample_rate(sample_rate)
- , m_type(type)
- , m_category(category)
- , m_sample_size(sample_size)
- , m_desc()
- {}
+ track(iallocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, track_type8 type, track_category8 category, uint8_t sample_size) noexcept;
//////////////////////////////////////////////////////////////////////////
// Internal helper.
- void get_copy_impl(IAllocator& allocator, track& out_track) const
- {
- out_track.m_allocator = &allocator;
- out_track.m_data = reinterpret_cast<uint8_t*>(allocator.allocate(m_data_size));
- out_track.m_num_samples = m_num_samples;
- out_track.m_stride = m_stride;
- out_track.m_data_size = m_data_size;
- out_track.m_sample_rate = m_sample_rate;
- out_track.m_type = m_type;
- out_track.m_category = m_category;
- out_track.m_sample_size = m_sample_size;
- out_track.m_desc = m_desc;
-
- std::memcpy(out_track.m_data, m_data, m_data_size);
- }
+ void get_copy_impl(iallocator& allocator, track& out_track) const;
//////////////////////////////////////////////////////////////////////////
// Internal helper.
- void get_ref_impl(track& out_track) const
- {
- out_track.m_allocator = nullptr;
- out_track.m_data = m_data;
- out_track.m_num_samples = m_num_samples;
- out_track.m_stride = m_stride;
- out_track.m_data_size = m_data_size;
- out_track.m_sample_rate = m_sample_rate;
- out_track.m_type = m_type;
- out_track.m_category = m_category;
- out_track.m_sample_size = m_sample_size;
- out_track.m_desc = m_desc;
- }
+ void get_ref_impl(track& out_track) const;
- IAllocator* m_allocator; // Optional allocator that owns the memory
+ iallocator* m_allocator; // Optional allocator that owns the memory
uint8_t* m_data; // Pointer to the samples
uint32_t m_num_samples; // The number of samples
@@ -304,11 +182,12 @@ namespace acl
// This ensures every track has the same size regardless of its type.
union desc_union
{
- track_desc_scalarf scalar;
- // TODO: Add other description types here
+ track_desc_scalarf scalar;
+ track_desc_transformf transform;
desc_union() : scalar() {}
explicit desc_union(const track_desc_scalarf& desc) : scalar(desc) {}
+ explicit desc_union(const track_desc_transformf& desc) : transform(desc) {}
};
desc_union m_desc; // The track description
@@ -357,41 +236,19 @@ namespace acl
// Returns the sample at the specified index.
// If this track does not own the memory, mutable references aren't allowed and an
// invalid reference will be returned, leading to a crash.
- sample_type& operator[](uint32_t index)
- {
- ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
- return *reinterpret_cast<sample_type*>(m_data + (index * m_stride));
- }
+ sample_type& operator[](uint32_t index);
//////////////////////////////////////////////////////////////////////////
// Returns the sample at the specified index.
- const sample_type& operator[](uint32_t index) const
- {
- ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
- return *reinterpret_cast<const sample_type*>(m_data + (index * m_stride));
- }
+ const sample_type& operator[](uint32_t index) const;
//////////////////////////////////////////////////////////////////////////
// Returns the track description.
- desc_type& get_description()
- {
- switch (category)
- {
- default:
- case track_category8::scalarf: return m_desc.scalar;
- }
- }
+ desc_type& get_description();
//////////////////////////////////////////////////////////////////////////
// Returns the track description.
- const desc_type& get_description() const
- {
- switch (category)
- {
- default:
- case track_category8::scalarf: return m_desc.scalar;
- }
- }
+ const desc_type& get_description() const;
//////////////////////////////////////////////////////////////////////////
// Returns the track type.
@@ -403,60 +260,27 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Returns a copy of the track where the memory will be owned by the copy.
- track_typed get_copy(IAllocator& allocator) const
- {
- track_typed track_;
- track::get_copy_impl(allocator, track_);
- return track_;
- }
+ track_typed get_copy(iallocator& allocator) const;
//////////////////////////////////////////////////////////////////////////
// Returns a reference to the track where the memory isn't owned.
- track_typed get_ref() const
- {
- track_typed track_;
- track::get_ref_impl(track_);
- return track_;
- }
+ track_typed get_ref() const;
//////////////////////////////////////////////////////////////////////////
// Creates a track that copies the data and owns the memory.
- static track_typed<track_type_> make_copy(const desc_type& desc, IAllocator& allocator, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
- {
- const size_t data_size = size_t(num_samples) * sizeof(sample_type);
- const uint8_t* data_raw = reinterpret_cast<const uint8_t*>(data);
-
- // Copy the data manually to avoid preserving the stride
- sample_type* data_copy = reinterpret_cast<sample_type*>(allocator.allocate(data_size));
- for (uint32_t index = 0; index < num_samples; ++index)
- data_copy[index] = *reinterpret_cast<const sample_type*>(data_raw + (index * stride));
-
- return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data_copy), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
- }
+ static track_typed<track_type_> make_copy(const desc_type& desc, iallocator& allocator, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type));
//////////////////////////////////////////////////////////////////////////
// Creates a track and preallocates but does not initialize the memory that it owns.
- static track_typed<track_type_> make_reserve(const desc_type& desc, IAllocator& allocator, uint32_t num_samples, float sample_rate)
- {
- const size_t data_size = size_t(num_samples) * sizeof(sample_type);
- return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(allocator.allocate(data_size)), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
- }
+ static track_typed<track_type_> make_reserve(const desc_type& desc, iallocator& allocator, uint32_t num_samples, float sample_rate);
//////////////////////////////////////////////////////////////////////////
// Creates a track and takes ownership of the already allocated memory.
- static track_typed<track_type_> make_owner(const desc_type& desc, IAllocator& allocator, sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
- {
- const size_t data_size = size_t(num_samples) * stride;
- return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data), num_samples, stride, data_size, sample_rate, desc);
- }
+ static track_typed<track_type_> make_owner(const desc_type& desc, iallocator& allocator, sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type));
//////////////////////////////////////////////////////////////////////////
// Creates a track that just references the data without owning it.
- static track_typed<track_type_> make_ref(const desc_type& desc, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
- {
- const size_t data_size = size_t(num_samples) * stride;
- return track_typed<track_type_>(nullptr, const_cast<uint8_t*>(reinterpret_cast<const uint8_t*>(data)), num_samples, stride, data_size, sample_rate, desc);
- }
+ static track_typed<track_type_> make_ref(const desc_type& desc, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type));
private:
//////////////////////////////////////////////////////////////////////////
@@ -466,11 +290,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Internal constructor.
- track_typed(IAllocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, const desc_type& desc) noexcept
- : track(allocator, data, num_samples, stride, data_size, sample_rate, type, category, sizeof(sample_type))
- {
- m_desc = desc_union(desc);
- }
+ track_typed(iallocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, const desc_type& desc) noexcept;
};
//////////////////////////////////////////////////////////////////////////
@@ -523,6 +343,286 @@ namespace acl
using track_float3f = track_typed<track_type8::float3f>;
using track_float4f = track_typed<track_type8::float4f>;
using track_vector4f = track_typed<track_type8::vector4f>;
+ using track_qvvf = track_typed<track_type8::qvvf>;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Implementation
+
+ inline track::track() noexcept
+ : m_allocator(nullptr)
+ , m_data(nullptr)
+ , m_num_samples(0)
+ , m_stride(0)
+ , m_data_size(0)
+ , m_sample_rate(0.0F)
+ , m_type(track_type8::float1f)
+ , m_category(track_category8::scalarf)
+ , m_sample_size(0)
+ , m_desc()
+ {}
+
+ inline track::track(track&& other) noexcept
+ : m_allocator(other.m_allocator)
+ , m_data(other.m_data)
+ , m_num_samples(other.m_num_samples)
+ , m_stride(other.m_stride)
+ , m_data_size(other.m_data_size)
+ , m_sample_rate(other.m_sample_rate)
+ , m_type(other.m_type)
+ , m_category(other.m_category)
+ , m_sample_size(other.m_sample_size)
+ , m_desc(other.m_desc)
+ {
+ other.m_allocator = nullptr;
+ other.m_data = nullptr;
+ }
+
+ inline track::~track()
+ {
+ if (is_owner())
+ {
+ // We own the memory, free it
+ m_allocator->deallocate(m_data, m_data_size);
+ }
+ }
+
+ inline track& track::operator=(track&& other) noexcept
+ {
+ std::swap(m_allocator, other.m_allocator);
+ std::swap(m_data, other.m_data);
+ std::swap(m_num_samples, other.m_num_samples);
+ std::swap(m_stride, other.m_stride);
+ std::swap(m_data_size, other.m_data_size);
+ std::swap(m_sample_rate, other.m_sample_rate);
+ std::swap(m_type, other.m_type);
+ std::swap(m_category, other.m_category);
+ std::swap(m_sample_size, other.m_sample_size);
+ std::swap(m_desc, other.m_desc);
+ return *this;
+ }
+
+ inline void* track::operator[](uint32_t index)
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return m_data + (index * m_stride);
+ }
+
+ inline const void* track::operator[](uint32_t index) const
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return m_data + (index * m_stride);
+ }
+
+ inline uint32_t track::get_output_index() const
+ {
+ switch (m_category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar.output_index;
+ case track_category8::transformf: return m_desc.transform.output_index;
+ }
+ }
+
+ template<>
+ inline track_desc_scalarf& track::get_description()
+ {
+ ACL_ASSERT(track_desc_scalarf::category == m_category, "Unexpected track category");
+ return m_desc.scalar;
+ }
+
+ template<>
+ inline track_desc_transformf& track::get_description()
+ {
+ ACL_ASSERT(track_desc_transformf::category == m_category, "Unexpected track category");
+ return m_desc.transform;
+ }
+
+ template<>
+ inline const track_desc_scalarf& track::get_description() const
+ {
+ ACL_ASSERT(track_desc_scalarf::category == m_category, "Unexpected track category");
+ return m_desc.scalar;
+ }
+
+ template<>
+ inline const track_desc_transformf& track::get_description() const
+ {
+ ACL_ASSERT(track_desc_transformf::category == m_category, "Unexpected track category");
+ return m_desc.transform;
+ }
+
+ inline track track::get_copy(iallocator& allocator) const
+ {
+ track track_;
+ get_copy_impl(allocator, track_);
+ return track_;
+ }
+
+ inline track track::get_ref() const
+ {
+ track track_;
+ get_ref_impl(track_);
+ return track_;
+ }
+
+ inline error_result track::is_valid() const
+ {
+ if (m_data == nullptr)
+ return error_result();
+
+ if (m_num_samples == 0xFFFFFFFFU)
+ return error_result("Too many samples");
+
+ if (m_sample_rate <= 0.0F || !rtm::scalar_is_finite(m_sample_rate))
+ return error_result("Invalid sample rate");
+
+ switch (m_category)
+ {
+ case track_category8::scalarf: return m_desc.scalar.is_valid();
+ case track_category8::transformf: return m_desc.transform.is_valid();
+ default: return error_result("Invalid category");
+ }
+ }
+
+ inline track::track(track_type8 type, track_category8 category) noexcept
+ : m_allocator(nullptr)
+ , m_data(nullptr)
+ , m_num_samples(0)
+ , m_stride(0)
+ , m_data_size(0)
+ , m_sample_rate(0.0F)
+ , m_type(type)
+ , m_category(category)
+ , m_sample_size(0)
+ , m_desc()
+ {}
+
+ inline track::track(iallocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, track_type8 type, track_category8 category, uint8_t sample_size) noexcept
+ : m_allocator(allocator)
+ , m_data(data)
+ , m_num_samples(num_samples)
+ , m_stride(stride)
+ , m_data_size(data_size)
+ , m_sample_rate(sample_rate)
+ , m_type(type)
+ , m_category(category)
+ , m_sample_size(sample_size)
+ , m_desc()
+ {}
+
+ inline void track::get_copy_impl(iallocator& allocator, track& out_track) const
+ {
+ out_track.m_allocator = &allocator;
+ out_track.m_data = reinterpret_cast<uint8_t*>(allocator.allocate(m_data_size));
+ out_track.m_num_samples = m_num_samples;
+ out_track.m_stride = m_stride;
+ out_track.m_data_size = m_data_size;
+ out_track.m_sample_rate = m_sample_rate;
+ out_track.m_type = m_type;
+ out_track.m_category = m_category;
+ out_track.m_sample_size = m_sample_size;
+ out_track.m_desc = m_desc;
+
+ std::memcpy(out_track.m_data, m_data, m_data_size);
+ }
+
+ inline void track::get_ref_impl(track& out_track) const
+ {
+ out_track.m_allocator = nullptr;
+ out_track.m_data = m_data;
+ out_track.m_num_samples = m_num_samples;
+ out_track.m_stride = m_stride;
+ out_track.m_data_size = m_data_size;
+ out_track.m_sample_rate = m_sample_rate;
+ out_track.m_type = m_type;
+ out_track.m_category = m_category;
+ out_track.m_sample_size = m_sample_size;
+ out_track.m_desc = m_desc;
+ }
+
+ template<track_type8 track_type_>
+ inline typename track_typed<track_type_>::sample_type& track_typed<track_type_>::operator[](uint32_t index)
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return *reinterpret_cast<sample_type*>(m_data + (index * m_stride));
+ }
+
+ template<track_type8 track_type_>
+ inline const typename track_typed<track_type_>::sample_type& track_typed<track_type_>::operator[](uint32_t index) const
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return *reinterpret_cast<const sample_type*>(m_data + (index * m_stride));
+ }
+
+ template<track_type8 track_type_>
+ inline typename track_typed<track_type_>::desc_type& track_typed<track_type_>::get_description()
+ {
+ return track::get_description<desc_type>();
+ }
+
+ template<track_type8 track_type_>
+ inline const typename track_typed<track_type_>::desc_type& track_typed<track_type_>::get_description() const
+ {
+ return track::get_description<desc_type>();
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::get_copy(iallocator& allocator) const
+ {
+ track_typed track_;
+ track::get_copy_impl(allocator, track_);
+ return track_;
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::get_ref() const
+ {
+ track_typed track_;
+ track::get_ref_impl(track_);
+ return track_;
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::make_copy(const typename track_typed<track_type_>::desc_type& desc, iallocator& allocator, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride)
+ {
+ const size_t data_size = size_t(num_samples) * sizeof(sample_type);
+ const uint8_t* data_raw = reinterpret_cast<const uint8_t*>(data);
+
+ // Copy the data manually to avoid preserving the stride
+ sample_type* data_copy = reinterpret_cast<sample_type*>(allocator.allocate(data_size));
+ for (uint32_t index = 0; index < num_samples; ++index)
+ data_copy[index] = *reinterpret_cast<const sample_type*>(data_raw + (index * stride));
+
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data_copy), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::make_reserve(const typename track_typed<track_type_>::desc_type& desc, iallocator& allocator, uint32_t num_samples, float sample_rate)
+ {
+ const size_t data_size = size_t(num_samples) * sizeof(sample_type);
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(allocator.allocate(data_size)), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::make_owner(const typename track_typed<track_type_>::desc_type& desc, iallocator& allocator, sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride)
+ {
+ const size_t data_size = size_t(num_samples) * stride;
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data), num_samples, stride, data_size, sample_rate, desc);
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_> track_typed<track_type_>::make_ref(const typename track_typed<track_type_>::desc_type& desc, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride)
+ {
+ const size_t data_size = size_t(num_samples) * stride;
+ return track_typed<track_type_>(nullptr, const_cast<uint8_t*>(reinterpret_cast<const uint8_t*>(data)), num_samples, stride, data_size, sample_rate, desc);
+ }
+
+ template<track_type8 track_type_>
+ inline track_typed<track_type_>::track_typed(iallocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, const typename track_typed<track_type_>::desc_type& desc) noexcept
+ : track(allocator, data, num_samples, stride, data_size, sample_rate, type, category, sizeof(sample_type))
+ {
+ m_desc = desc_union(desc);
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/track_array.h b/includes/acl/compression/track_array.h
--- a/includes/acl/compression/track_array.h
+++ b/includes/acl/compression/track_array.h
@@ -29,6 +29,7 @@
#include "acl/core/iallocator.h"
#include "acl/core/interpolation_utils.h"
#include "acl/core/track_writer.h"
+#include "acl/core/utils.h"
#include "acl/compression/track.h"
#include <rtm/scalarf.h>
@@ -36,6 +37,7 @@
#include <cstdint>
#include <limits>
+#include <type_traits>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -61,7 +63,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Constructs an array with the specified number of tracks.
// Tracks will be empty and untyped by default.
- track_array(IAllocator& allocator, uint32_t num_tracks)
+ track_array(iallocator& allocator, uint32_t num_tracks)
: m_allocator(&allocator)
, m_tracks(allocate_type_array<track>(allocator, num_tracks))
, m_num_tracks(num_tracks)
@@ -95,6 +97,10 @@ namespace acl
return *this;
}
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a pointer to the allocator instance or nullptr if there is none present.
+ iallocator* get_allocator() const { return m_allocator; }
+
//////////////////////////////////////////////////////////////////////////
// Returns the number of tracks contained in this array.
uint32_t get_num_tracks() const { return m_num_tracks; }
@@ -149,27 +155,8 @@ namespace acl
// - All tracks have the same type
// - All tracks have the same number of samples
// - All tracks have the same sample rate
- ErrorResult is_valid() const
- {
- const track_type8 type = get_track_type();
- const uint32_t num_samples = get_num_samples_per_track();
- const float sample_rate = get_sample_rate();
-
- for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
- {
- const track& track_ = m_tracks[track_index];
- if (track_.get_type() != type)
- return ErrorResult("Tracks must all have the same type within an array");
-
- if (track_.get_num_samples() != num_samples)
- return ErrorResult("Track array requires the same number of samples in every track");
-
- if (track_.get_sample_rate() != sample_rate)
- return ErrorResult("Track array requires the same sample rate in every track");
- }
-
- return ErrorResult();
- }
+ // - All tracks are valid
+ error_result is_valid() const;
//////////////////////////////////////////////////////////////////////////
// Sample all tracks within this array at the specified sample time and
@@ -195,7 +182,7 @@ namespace acl
track_array(const track_array&) = delete;
track_array& operator=(const track_array&) = delete;
- IAllocator* m_allocator; // The allocator used to allocate our tracks
+ iallocator* m_allocator; // The allocator used to allocate our tracks
track* m_tracks; // The track list
uint32_t m_num_tracks; // The number of tracks
};
@@ -226,7 +213,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Constructs an array with the specified number of tracks.
// Tracks will be empty and untyped by default.
- track_array_typed(IAllocator& allocator, uint32_t num_tracks) : track_array(allocator, num_tracks) {}
+ track_array_typed(iallocator& allocator, uint32_t num_tracks) : track_array(allocator, num_tracks) {}
//////////////////////////////////////////////////////////////////////////
// Move constructor for a track array.
@@ -317,26 +304,190 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Create aliases for the various typed track array types.
- using track_array_float1f = track_array_typed<track_type8::float1f>;
- using track_array_float2f = track_array_typed<track_type8::float2f>;
- using track_array_float3f = track_array_typed<track_type8::float3f>;
- using track_array_float4f = track_array_typed<track_type8::float4f>;
- using track_array_vector4f = track_array_typed<track_type8::vector4f>;
+ using track_array_float1f = track_array_typed<track_type8::float1f>;
+ using track_array_float2f = track_array_typed<track_type8::float2f>;
+ using track_array_float3f = track_array_typed<track_type8::float3f>;
+ using track_array_float4f = track_array_typed<track_type8::float4f>;
+ using track_array_vector4f = track_array_typed<track_type8::vector4f>;
+ using track_array_qvvf = track_array_typed<track_type8::qvvf>;
//////////////////////////////////////////////////////////////////////////
+ inline error_result track_array::is_valid() const
+ {
+ const track_type8 type = get_track_type();
+ const uint32_t num_samples = get_num_samples_per_track();
+ const float sample_rate = get_sample_rate();
+
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track& track_ = m_tracks[track_index];
+ if (track_.get_type() != type)
+ return error_result("Tracks must all have the same type within an array");
+
+ if (track_.get_num_samples() != num_samples)
+ return error_result("Track array requires the same number of samples in every track");
+
+ if (track_.get_sample_rate() != sample_rate)
+ return error_result("Track array requires the same sample rate in every track");
+
+ const error_result result = track_.is_valid();
+ if (result.any())
+ return result;
+
+ if (track_.get_category() == track_category8::transformf)
+ {
+ const track_desc_transformf& desc = track_.get_description<track_desc_transformf>();
+ if (desc.parent_index != k_invalid_track_index && desc.parent_index >= m_num_tracks)
+ return error_result("Invalid parent_index. It must be 'k_invalid_track_index' or a valid track index");
+ }
+ }
+
+ // Validate output indices
+ uint32_t num_outputs = 0;
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track& track_ = m_tracks[track_index];
+ const uint32_t output_index = track_.get_output_index();
+ if (output_index != k_invalid_track_index && output_index >= m_num_tracks)
+ return error_result("The output_index must be 'k_invalid_track_index' or less than the number of bones");
+
+ if (output_index != k_invalid_track_index)
+ {
+ for (uint32_t track_index2 = track_index + 1; track_index2 < m_num_tracks; ++track_index2)
+ {
+ const track& track2_ = m_tracks[track_index2];
+ const uint32_t output_index2 = track2_.get_output_index();
+ if (output_index == output_index2)
+ return error_result("Duplicate output_index found");
+ }
+
+ num_outputs++;
+ }
+ }
+
+ for (uint32_t output_index = 0; output_index < num_outputs; ++output_index)
+ {
+ bool found = false;
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track& track_ = m_tracks[track_index];
+ const uint32_t output_index_ = track_.get_output_index();
+ if (output_index == output_index_)
+ {
+ found = true;
+ break;
+ }
+ }
+
+ if (!found)
+ return error_result("Output indices are not contiguous");
+ }
+
+ return error_result();
+ }
+
template<class track_writer_type>
inline void track_array::sample_tracks(float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const
{
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
ACL_ASSERT(is_valid().empty(), "Invalid track array");
- for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
- sample_track(track_index, sample_time, rounding_policy, writer);
+ const uint32_t num_samples = get_num_samples_per_track();
+ const float sample_rate = get_sample_rate();
+ const track_type8 track_type = get_track_type();
+
+ // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
+ const float duration = get_duration();
+ sample_time = rtm::scalar_clamp(sample_time, 0.0F, duration);
+
+ uint32_t key_frame0;
+ uint32_t key_frame1;
+ float interpolation_alpha;
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, interpolation_alpha);
+
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_float1f& track__ = track_cast<track_float1f>(m_tracks[track_index]);
+
+ const rtm::scalarf value0 = rtm::scalar_load(&track__[key_frame0]);
+ const rtm::scalarf value1 = rtm::scalar_load(&track__[key_frame1]);
+ const rtm::scalarf value = rtm::scalar_lerp(value0, value1, rtm::scalar_set(interpolation_alpha));
+ writer.write_float1(track_index, value);
+ }
+ break;
+ case track_type8::float2f:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_float2f& track__ = track_cast<track_float2f>(m_tracks[track_index]);
+
+ const rtm::vector4f value0 = rtm::vector_load2(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load2(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float2(track_index, value);
+ }
+ break;
+ case track_type8::float3f:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_float3f& track__ = track_cast<track_float3f>(m_tracks[track_index]);
+
+ const rtm::vector4f value0 = rtm::vector_load3(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load3(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float3(track_index, value);
+ }
+ break;
+ case track_type8::float4f:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_float4f& track__ = track_cast<track_float4f>(m_tracks[track_index]);
+
+ const rtm::vector4f value0 = rtm::vector_load(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float4(track_index, value);
+ }
+ break;
+ case track_type8::vector4f:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_vector4f& track__ = track_cast<track_vector4f>(m_tracks[track_index]);
+
+ const rtm::vector4f value0 = track__[key_frame0];
+ const rtm::vector4f value1 = track__[key_frame1];
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_vector4(track_index, value);
+ }
+ break;
+ case track_type8::qvvf:
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track_qvvf& track__ = track_cast<track_qvvf>(m_tracks[track_index]);
+
+ const rtm::qvvf& value0 = track__[key_frame0];
+ const rtm::qvvf& value1 = track__[key_frame1];
+ const rtm::quatf rotation = rtm::quat_lerp(value0.rotation, value1.rotation, interpolation_alpha);
+ const rtm::vector4f translation = rtm::vector_lerp(value0.translation, value1.translation, interpolation_alpha);
+ const rtm::vector4f scale = rtm::vector_lerp(value0.scale, value1.scale, interpolation_alpha);
+ writer.write_rotation(track_index, rotation);
+ writer.write_translation(track_index, translation);
+ writer.write_scale(track_index, scale);
+ }
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
}
template<class track_writer_type>
inline void track_array::sample_track(uint32_t track_index, float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const
{
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
ACL_ASSERT(is_valid().empty(), "Invalid track array");
ACL_ASSERT(track_index < m_num_tracks, "Invalid track index");
@@ -405,6 +556,20 @@ namespace acl
writer.write_vector4(track_index, value);
break;
}
+ case track_type8::qvvf:
+ {
+ const track_qvvf& track__ = track_cast<track_qvvf>(track_);
+
+ const rtm::qvvf& value0 = track__[key_frame0];
+ const rtm::qvvf& value1 = track__[key_frame1];
+ const rtm::quatf rotation = rtm::quat_lerp(value0.rotation, value1.rotation, interpolation_alpha);
+ const rtm::vector4f translation = rtm::vector_lerp(value0.translation, value1.translation, interpolation_alpha);
+ const rtm::vector4f scale = rtm::vector_lerp(value0.scale, value1.scale, interpolation_alpha);
+ writer.write_rotation(track_index, rotation);
+ writer.write_translation(track_index, translation);
+ writer.write_scale(track_index, scale);
+ break;
+ }
default:
ACL_ASSERT(false, "Invalid track type");
break;
@@ -414,12 +579,17 @@ namespace acl
inline uint32_t track_array::get_raw_size() const
{
const uint32_t num_samples = get_num_samples_per_track();
+ const track_type8 track_type = get_track_type();
uint32_t total_size = 0;
for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
{
const track& track_ = m_tracks[track_index];
- total_size += num_samples * track_.get_sample_size();
+
+ if (track_type == track_type8::qvvf)
+ total_size += num_samples * 10 * sizeof(float); // 4 rotation floats, 3 translation floats, 3 scale floats
+ else
+ total_size += num_samples * track_.get_sample_size();
}
return total_size;
diff --git a/includes/acl/compression/track_error.h b/includes/acl/compression/track_error.h
--- a/includes/acl/compression/track_error.h
+++ b/includes/acl/compression/track_error.h
@@ -42,15 +42,6 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- namespace acl_impl
- {
- //////////////////////////////////////////////////////////////////////////
- // SFINAE boilerplate to detect if a template argument derives from acl::uniformly_sampled::DecompressionContext.
- //////////////////////////////////////////////////////////////////////////
- template<class T>
- using is_decompression_context = typename std::enable_if<std::is_base_of<acl::decompression_context<typename T::settings_type>, T>::value, std::nullptr_t>::type;
- }
-
//////////////////////////////////////////////////////////////////////////
// A struct that contains the track index that has the worst error,
// its error, and the sample time at which it happens.
@@ -58,6 +49,7 @@ namespace acl
struct track_error
{
track_error() : index(k_invalid_track_index), error(0.0F), sample_time(0.0F) {}
+ track_error(uint32_t index_, float error_, float sample_time_) : index(index_), error(error_), sample_time(sample_time_) {}
//////////////////////////////////////////////////////////////////////////
// The track index with the worst error.
@@ -72,329 +64,633 @@ namespace acl
float sample_time;
};
- //////////////////////////////////////////////////////////////////////////
- // Calculates the worst compression error between a raw track array and its
- // compressed tracks.
- //
- // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
- template<class decompression_context_type, acl_impl::is_decompression_context<decompression_context_type> = nullptr>
- inline track_error calculate_compression_error(IAllocator& allocator, const track_array& raw_tracks, decompression_context_type& context)
+ namespace acl_impl
{
- using namespace acl_impl;
+ //////////////////////////////////////////////////////////////////////////
+ // SFINAE boilerplate to detect if a template argument derives from acl::uniformly_sampled::DecompressionContext.
+ //////////////////////////////////////////////////////////////////////////
+ template<class T>
+ using is_decompression_context = typename std::enable_if<std::is_base_of<acl::decompression_context<typename T::settings_type>, T>::value, std::nullptr_t>::type;
- ACL_ASSERT(raw_tracks.is_valid().empty(), "Raw tracks are invalid");
- ACL_ASSERT(context.is_initialized(), "Context isn't initialized");
+ inline rtm::vector4f RTM_SIMD_CALL get_scalar_track_error(track_type8 track_type, uint32_t raw_track_index, uint32_t lossy_track_index, debug_track_writer& raw_tracks_writer, debug_track_writer& lossy_tracks_writer)
+ {
+ rtm::vector4f error;
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ {
+ const float raw_value = raw_tracks_writer.read_float1(raw_track_index);
+ const float lossy_value = lossy_tracks_writer.read_float1(lossy_track_index);
+ error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float2(raw_track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float2(lossy_track_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, rtm::vector_zero());
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float3(raw_track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float3(lossy_track_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, rtm::vector_zero());
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float4(raw_track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float4(lossy_track_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_vector4(raw_track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_vector4(lossy_track_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ error = rtm::vector_zero();
+ break;
+ }
- const uint32_t num_samples = raw_tracks.get_num_samples_per_track();
- if (num_samples == 0)
- return track_error(); // Cannot measure any error
+ return error;
+ }
- const uint32_t num_tracks = raw_tracks.get_num_tracks();
- if (num_tracks == 0)
- return track_error(); // Cannot measure any error
+ struct calculate_track_error_args
+ {
+ // Scalar and transforms
+ uint32_t num_samples;
+ uint32_t num_tracks;
+ float duration;
+ float sample_rate;
+ track_type8 track_type;
+
+ std::function<void(float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)> sample_tracks0;
+ std::function<void(float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)> sample_tracks1;
+
+ // Transforms only
+ const itransform_error_metric* error_metric;
+ std::function<uint32_t(uint32_t track_index)> get_parent_index;
+ std::function<float(uint32_t track_index)> get_shell_distance;
+
+ // Optional
+ uint32_t base_num_samples;
+ float base_duration;
+
+
+ std::function<void(float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)> sample_tracks_base;
+ std::function<uint32_t(uint32_t track_index)> get_output_index;
+
+ std::function<void(debug_track_writer& track_writer0, debug_track_writer& track_writer1, debug_track_writer& track_writer_remapped)> remap_output;
+ };
+
+ inline track_error calculate_scalar_track_error(iallocator& allocator, const calculate_track_error_args& args)
+ {
+ const uint32_t num_samples = args.num_samples;
+ if (args.num_samples == 0)
+ return track_error(); // Cannot measure any error
- track_error result;
- result.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
+ const uint32_t num_tracks = args.num_tracks;
+ if (args.num_tracks == 0)
+ return track_error(); // Cannot measure any error
- const float duration = raw_tracks.get_duration();
- const float sample_rate = raw_tracks.get_sample_rate();
- const track_type8 track_type = raw_tracks.get_track_type();
+ track_error result;
+ result.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
- debug_track_writer raw_tracks_writer(allocator, track_type, num_tracks);
- debug_track_writer lossy_tracks_writer(allocator, track_type, num_tracks);
+ const float duration = args.duration;
+ const float sample_rate = args.sample_rate;
+ const track_type8 track_type = args.track_type;
+
+ // We use the nearest sample to accurately measure the loss that happened, if any
+ const sample_rounding_policy rounding_policy = sample_rounding_policy::nearest;
+
+ debug_track_writer tracks_writer0(allocator, track_type, num_tracks);
+ debug_track_writer tracks_writer1(allocator, track_type, num_tracks);
+
+ // Measure our error
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
- const rtm::vector4f zero = rtm::vector_zero();
+ args.sample_tracks0(sample_time, rounding_policy, tracks_writer0);
+ args.sample_tracks1(sample_time, rounding_policy, tracks_writer1);
- // Measure our error
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ // Validate decompress_tracks
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const uint32_t output_index = args.get_output_index ? args.get_output_index(track_index) : track_index;
+ if (output_index == k_invalid_track_index)
+ continue; // Track is being stripped, ignore it
+
+ const rtm::vector4f error = get_scalar_track_error(track_type, track_index, output_index, tracks_writer0, tracks_writer1);
+
+ const float max_error = rtm::vector_get_max_component(error);
+ if (max_error > result.error)
+ {
+ result.error = max_error;
+ result.index = track_index;
+ result.sample_time = sample_time;
+ }
+ }
+ }
+
+ return result;
+ }
+
+ inline track_error calculate_transform_track_error(iallocator& allocator, const calculate_track_error_args& args)
{
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
+ ACL_ASSERT(args.error_metric != nullptr, "Must have an error metric");
+ ACL_ASSERT(args.get_parent_index, "Must be able to query the parent track index");
+ ACL_ASSERT(args.get_shell_distance, "Must be able to query the shell distance");
+
+ const uint32_t num_samples = args.num_samples;
+ if (num_samples == 0)
+ return track_error(); // Cannot measure any error
+
+ const uint32_t num_tracks = args.num_tracks;
+ if (num_tracks == 0)
+ return track_error(); // Cannot measure any error
+
+ const float clip_duration = args.duration;
+ const float sample_rate = args.sample_rate;
+ const itransform_error_metric& error_metric = *args.error_metric;
+ const uint32_t additive_num_samples = args.base_num_samples;
+ const float additive_duration = args.base_duration;
+
+ // Always calculate the error with scale, slower but we don't need to know if we have scale or not
+ const bool has_scale = true;
// We use the nearest sample to accurately measure the loss that happened, if any
- raw_tracks.sample_tracks(sample_time, sample_rounding_policy::nearest, raw_tracks_writer);
+ const sample_rounding_policy rounding_policy = sample_rounding_policy::nearest;
+
+ debug_track_writer tracks_writer0(allocator, track_type8::qvvf, num_tracks);
+ debug_track_writer tracks_writer1(allocator, track_type8::qvvf, num_tracks);
+ debug_track_writer tracks_writer1_remapped(allocator, track_type8::qvvf, num_tracks);
+ debug_track_writer tracks_writer_base(allocator, track_type8::qvvf, num_tracks);
+
+ const size_t transform_size = error_metric.get_transform_size(has_scale);
+ const bool needs_conversion = error_metric.needs_conversion(has_scale);
+ uint8_t* raw_local_pose_converted = nullptr;
+ uint8_t* base_local_pose_converted = nullptr;
+ uint8_t* lossy_local_pose_converted = nullptr;
+ if (needs_conversion)
+ {
+ raw_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_tracks * transform_size, 64);
+ base_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_tracks * transform_size, 64);
+ lossy_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_tracks * transform_size, 64);
+ }
+
+ uint8_t* raw_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_tracks * transform_size, 64);
+ uint8_t* lossy_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_tracks * transform_size, 64);
- context.seek(sample_time, sample_rounding_policy::nearest);
- context.decompress_tracks(lossy_tracks_writer);
+ uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_tracks);
+ uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_tracks);
- // Validate decompress_tracks
- for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ for (uint32_t transform_index = 0; transform_index < num_tracks; ++transform_index)
{
- const track& track_ = raw_tracks[track_index];
- const uint32_t output_index = track_.get_output_index();
- if (output_index == k_invalid_track_index)
- continue; // Track is being stripped, ignore it
+ const uint32_t parent_index = args.get_parent_index(transform_index);
+ parent_transform_indices[transform_index] = parent_index == k_invalid_track_index ? k_invalid_bone_index : safe_static_cast<uint16_t>(parent_index);
+ self_transform_indices[transform_index] = safe_static_cast<uint16_t>(transform_index);
+ }
- rtm::vector4f error;
+ void* raw_local_pose_ = needs_conversion ? (void*)raw_local_pose_converted : (void*)tracks_writer0.tracks_typed.qvvf;
+ void* base_local_pose_ = needs_conversion ? (void*)base_local_pose_converted : (void*)tracks_writer_base.tracks_typed.qvvf;
+ void* lossy_local_pose_ = needs_conversion ? (void*)lossy_local_pose_converted : (void*)tracks_writer1_remapped.tracks_typed.qvvf;
- switch (track_type)
- {
- case track_type8::float1f:
- {
- const float raw_value = raw_tracks_writer.read_float1(track_index);
- const float lossy_value = lossy_tracks_writer.read_float1(output_index);
- error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
- break;
- }
- case track_type8::float2f:
- {
- const rtm::vector4f raw_value = raw_tracks_writer.read_float2(track_index);
- const rtm::vector4f lossy_value = lossy_tracks_writer.read_float2(output_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float3f:
- {
- const rtm::vector4f raw_value = raw_tracks_writer.read_float3(track_index);
- const rtm::vector4f lossy_value = lossy_tracks_writer.read_float3(output_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float4f:
+ itransform_error_metric::convert_transforms_args convert_transforms_args_raw;
+ convert_transforms_args_raw.dirty_transform_indices = self_transform_indices;
+ convert_transforms_args_raw.num_dirty_transforms = num_tracks;
+ convert_transforms_args_raw.transforms = tracks_writer0.tracks_typed.qvvf;
+ convert_transforms_args_raw.num_transforms = num_tracks;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_base = convert_transforms_args_raw;
+ convert_transforms_args_base.transforms = tracks_writer_base.tracks_typed.qvvf;
+
+ itransform_error_metric::convert_transforms_args convert_transforms_args_lossy = convert_transforms_args_raw;
+ convert_transforms_args_lossy.transforms = tracks_writer1_remapped.tracks_typed.qvvf;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_raw.dirty_transform_indices = self_transform_indices;
+ apply_additive_to_base_args_raw.num_dirty_transforms = num_tracks;
+ apply_additive_to_base_args_raw.local_transforms = raw_local_pose_;
+ apply_additive_to_base_args_raw.base_transforms = base_local_pose_;
+ apply_additive_to_base_args_raw.num_transforms = num_tracks;
+
+ itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy = apply_additive_to_base_args_raw;
+ apply_additive_to_base_args_lossy.local_transforms = lossy_local_pose_;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_raw;
+ local_to_object_space_args_raw.dirty_transform_indices = self_transform_indices;
+ local_to_object_space_args_raw.num_dirty_transforms = num_tracks;
+ local_to_object_space_args_raw.parent_transform_indices = parent_transform_indices;
+ local_to_object_space_args_raw.local_transforms = raw_local_pose_;
+ local_to_object_space_args_raw.num_transforms = num_tracks;
+
+ itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy = local_to_object_space_args_raw;
+ local_to_object_space_args_lossy.local_transforms = lossy_local_pose_;
+
+ track_error result;
+ result.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
+
+ // Sample our tracks
+ args.sample_tracks0(sample_time, rounding_policy, tracks_writer0);
+ args.sample_tracks1(sample_time, rounding_policy, tracks_writer1);
+
+ // Maybe remap them
+ if (args.remap_output)
+ args.remap_output(tracks_writer0, tracks_writer1, tracks_writer1_remapped);
+ else
+ std::memcpy(tracks_writer1_remapped.tracks_typed.qvvf, tracks_writer1.tracks_typed.qvvf, sizeof(rtm::qvvf) * num_tracks);
+
+ if (needs_conversion)
{
- const rtm::vector4f raw_value = raw_tracks_writer.read_float4(track_index);
- const rtm::vector4f lossy_value = lossy_tracks_writer.read_float4(output_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
+ error_metric.convert_transforms(convert_transforms_args_raw, raw_local_pose_converted);
+ error_metric.convert_transforms(convert_transforms_args_lossy, lossy_local_pose_converted);
}
- case track_type8::vector4f:
+
+ if (args.sample_tracks_base)
{
- const rtm::vector4f raw_value = raw_tracks_writer.read_vector4(track_index);
- const rtm::vector4f lossy_value = lossy_tracks_writer.read_vector4(output_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
- }
- default:
- ACL_ASSERT(false, "Unsupported track type");
- error = zero;
- break;
+ const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
+ const float additive_sample_time = additive_num_samples > 1 ? (normalized_sample_time * additive_duration) : 0.0F;
+ args.sample_tracks_base(additive_sample_time, rounding_policy, tracks_writer_base);
+
+ if (needs_conversion)
+ error_metric.convert_transforms(convert_transforms_args_base, base_local_pose_converted);
+
+ error_metric.apply_additive_to_base(apply_additive_to_base_args_raw, raw_local_pose_);
+ error_metric.apply_additive_to_base(apply_additive_to_base_args_lossy, lossy_local_pose_);
}
- const float max_error = rtm::vector_get_max_component(error);
- if (max_error > result.error)
+ error_metric.local_to_object_space(local_to_object_space_args_raw, raw_object_pose);
+ error_metric.local_to_object_space(local_to_object_space_args_lossy, lossy_object_pose);
+
+ for (uint32_t bone_index = 0; bone_index < num_tracks; ++bone_index)
{
- result.error = max_error;
- result.index = track_index;
- result.sample_time = sample_time;
+ const float shell_distance = args.get_shell_distance(bone_index);
+
+ itransform_error_metric::calculate_error_args calculate_error_args;
+ calculate_error_args.transform0 = raw_object_pose + (bone_index * transform_size);
+ calculate_error_args.transform1 = lossy_object_pose + (bone_index * transform_size);
+ calculate_error_args.construct_sphere_shell(shell_distance);
+
+ const float error = rtm::scalar_cast(error_metric.calculate_error(calculate_error_args));
+
+ if (error > result.error)
+ {
+ result.error = error;
+ result.index = bone_index;
+ result.sample_time = sample_time;
+ }
}
}
- }
- return result;
+ deallocate_type_array(allocator, raw_local_pose_converted, num_tracks * transform_size);
+ deallocate_type_array(allocator, base_local_pose_converted, num_tracks * transform_size);
+ deallocate_type_array(allocator, lossy_local_pose_converted, num_tracks * transform_size);
+ deallocate_type_array(allocator, raw_object_pose, num_tracks * transform_size);
+ deallocate_type_array(allocator, lossy_object_pose, num_tracks * transform_size);
+ deallocate_type_array(allocator, parent_transform_indices, num_tracks);
+ deallocate_type_array(allocator, self_transform_indices, num_tracks);
+
+ return result;
+ }
}
//////////////////////////////////////////////////////////////////////////
- // Calculates the worst compression error between two compressed tracks instances.
+ // Calculates the worst compression error between a raw track array and its
+ // compressed tracks.
+ // Supports scalar tracks only.
//
// Note: This function uses SFINAE to prevent it from matching when it shouldn't.
- template<class decompression_context_type0, class decompression_context_type1, acl_impl::is_decompression_context<decompression_context_type0> = nullptr, acl_impl::is_decompression_context<decompression_context_type1> = nullptr>
- inline track_error calculate_compression_error(IAllocator& allocator, decompression_context_type0& context0, decompression_context_type1& context1)
+ template<class decompression_context_type, acl_impl::is_decompression_context<decompression_context_type> = nullptr>
+ inline track_error calculate_compression_error(iallocator& allocator, const track_array& raw_tracks, decompression_context_type& context)
{
using namespace acl_impl;
- ACL_ASSERT(context0.is_initialized(), "Context isn't initialized");
- ACL_ASSERT(context1.is_initialized(), "Context isn't initialized");
+ ACL_ASSERT(raw_tracks.is_valid().empty(), "Raw tracks are invalid");
+ ACL_ASSERT(context.is_initialized(), "Context isn't initialized");
- const compressed_tracks* tracks0 = context0.get_compressed_tracks();
+ if (raw_tracks.get_track_type() == track_type8::qvvf)
+ return track_error(~0U, -1.0F, -1.0F); // Only supports scalar tracks
- const uint32_t num_samples = tracks0->get_num_samples_per_track();
- if (num_samples == 0)
- return track_error(); // Cannot measure any error
+ calculate_track_error_args args;
+ args.num_samples = raw_tracks.get_num_samples_per_track();
+ args.num_tracks = raw_tracks.get_num_tracks();
+ args.duration = raw_tracks.get_duration();
+ args.sample_rate = raw_tracks.get_sample_rate();
+ args.track_type = raw_tracks.get_track_type();
- const uint32_t num_tracks = tracks0->get_num_tracks();
- if (num_tracks == 0)
- return track_error(); // Cannot measure any error
+ args.sample_tracks0 = [&raw_tracks](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ raw_tracks.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
- track_error result;
- result.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
+ args.sample_tracks1 = [&context](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ context.seek(sample_time, rounding_policy);
+ context.decompress_tracks(track_writer);
+ };
- const float duration = tracks0->get_duration();
- const float sample_rate = tracks0->get_sample_rate();
- const track_type8 track_type = tracks0->get_track_type();
+ args.get_output_index = [&raw_tracks](uint32_t track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ return track_.get_output_index();
+ };
- debug_track_writer tracks_writer0(allocator, track_type, num_tracks);
- debug_track_writer tracks_writer1(allocator, track_type, num_tracks);
+ return calculate_scalar_track_error(allocator, args);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates the worst compression error between a raw track array and its
+ // compressed tracks.
+ // Supports scalar and transform tracks.
+ //
+ // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
+ template<class decompression_context_type, acl_impl::is_decompression_context<decompression_context_type> = nullptr>
+ inline track_error calculate_compression_error(iallocator& allocator, const track_array& raw_tracks, decompression_context_type& context, const itransform_error_metric& error_metric)
+ {
+ using namespace acl_impl;
- const rtm::vector4f zero = rtm::vector_zero();
+ ACL_ASSERT(raw_tracks.is_valid().empty(), "Raw tracks are invalid");
+ ACL_ASSERT(context.is_initialized(), "Context isn't initialized");
+
+ calculate_track_error_args args;
+ args.num_samples = raw_tracks.get_num_samples_per_track();
+ args.num_tracks = raw_tracks.get_num_tracks();
+ args.duration = raw_tracks.get_duration();
+ args.sample_rate = raw_tracks.get_sample_rate();
+ args.track_type = raw_tracks.get_track_type();
- // Measure our error
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ args.sample_tracks0 = [&raw_tracks](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
{
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
+ raw_tracks.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
- // We use the nearest sample to accurately measure the loss that happened, if any
- context0.seek(sample_time, sample_rounding_policy::nearest);
- context0.decompress_tracks(tracks_writer0);
+ args.sample_tracks1 = [&context](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ context.seek(sample_time, rounding_policy);
+ context.decompress_tracks(track_writer);
+ };
+
+ args.get_output_index = [&raw_tracks](uint32_t track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ return track_.get_output_index();
+ };
+
+ if (raw_tracks.get_track_type() != track_type8::qvvf)
+ return calculate_scalar_track_error(allocator, args);
- context1.seek(sample_time, sample_rounding_policy::nearest);
- context1.decompress_tracks(tracks_writer1);
+ uint32_t num_output_bones = 0;
+ uint32_t* output_bone_mapping = create_output_track_mapping(allocator, raw_tracks, num_output_bones);
- // Validate decompress_tracks
- for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ args.error_metric = &error_metric;
+
+ args.get_parent_index = [&raw_tracks](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks[track_index]);
+ return track_.get_description().parent_index;
+ };
+
+ args.get_shell_distance = [&raw_tracks](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks[track_index]);
+ return track_.get_description().shell_distance;
+ };
+
+ args.remap_output = [output_bone_mapping, num_output_bones](debug_track_writer& track_writer0, debug_track_writer& track_writer1, debug_track_writer& track_writer_remapped)
+ {
+ // Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
+ // the data is available
+ std::memcpy(track_writer_remapped.tracks_typed.qvvf, track_writer0.tracks_typed.qvvf, sizeof(rtm::qvvf) * track_writer_remapped.num_tracks);
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- rtm::vector4f error;
+ const uint32_t bone_index = output_bone_mapping[output_index];
+ track_writer_remapped.tracks_typed.qvvf[bone_index] = track_writer1.tracks_typed.qvvf[output_index];
+ }
+ };
- switch (track_type)
- {
- case track_type8::float1f:
- {
- const float raw_value = tracks_writer0.read_float1(track_index);
- const float lossy_value = tracks_writer1.read_float1(track_index);
- error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
- break;
- }
- case track_type8::float2f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float2(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float2(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float3f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float3(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float3(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float4f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float4(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float4(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
- }
- case track_type8::vector4f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_vector4(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_vector4(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
- }
- default:
- ACL_ASSERT(false, "Unsupported track type");
- error = zero;
- break;
- }
+ const track_error result = calculate_transform_track_error(allocator, args);
- const float max_error = rtm::vector_get_max_component(error);
- if (max_error > result.error)
- {
- result.error = max_error;
- result.index = track_index;
- result.sample_time = sample_time;
- }
+ deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
+
+ return result;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates the worst compression error between a raw track array and its
+ // compressed tracks.
+ // Supports transform tracks with an additive base.
+ //
+ // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
+ template<class decompression_context_type, acl_impl::is_decompression_context<decompression_context_type> = nullptr>
+ inline track_error calculate_compression_error(iallocator& allocator, const track_array_qvvf& raw_tracks, decompression_context_type& context, const itransform_error_metric& error_metric, const track_array_qvvf& additive_base_tracks)
+ {
+ using namespace acl_impl;
+
+ ACL_ASSERT(raw_tracks.is_valid().empty(), "Raw tracks are invalid");
+ ACL_ASSERT(context.is_initialized(), "Context isn't initialized");
+
+ calculate_track_error_args args;
+ args.num_samples = raw_tracks.get_num_samples_per_track();
+ args.num_tracks = raw_tracks.get_num_tracks();
+ args.duration = raw_tracks.get_duration();
+ args.sample_rate = raw_tracks.get_sample_rate();
+ args.track_type = raw_tracks.get_track_type();
+
+ args.sample_tracks0 = [&raw_tracks](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ raw_tracks.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
+
+ args.sample_tracks1 = [&context](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ context.seek(sample_time, rounding_policy);
+ context.decompress_tracks(track_writer);
+ };
+
+ args.get_output_index = [&raw_tracks](uint32_t track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ return track_.get_output_index();
+ };
+
+ uint32_t num_output_bones = 0;
+ uint32_t* output_bone_mapping = create_output_track_mapping(allocator, raw_tracks, num_output_bones);
+
+ args.error_metric = &error_metric;
+
+ args.get_parent_index = [&raw_tracks](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks[track_index]);
+ return track_.get_description().parent_index;
+ };
+
+ args.get_shell_distance = [&raw_tracks](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks[track_index]);
+ return track_.get_description().shell_distance;
+ };
+
+ args.remap_output = [output_bone_mapping, num_output_bones](debug_track_writer& track_writer0, debug_track_writer& track_writer1, debug_track_writer& track_writer_remapped)
+ {
+ // Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
+ // the data is available
+ std::memcpy(track_writer_remapped.tracks_typed.qvvf, track_writer0.tracks_typed.qvvf, sizeof(rtm::qvvf) * track_writer_remapped.num_tracks);
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
+ {
+ const uint32_t bone_index = output_bone_mapping[output_index];
+ track_writer_remapped.tracks_typed.qvvf[bone_index] = track_writer1.tracks_typed.qvvf[output_index];
}
+ };
+
+ if (additive_base_tracks.get_num_tracks() != 0)
+ {
+ args.base_num_samples = additive_base_tracks.get_num_samples_per_track();
+ args.base_duration = additive_base_tracks.get_duration();
+
+ args.sample_tracks_base = [&additive_base_tracks](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ additive_base_tracks.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
}
+ const track_error result = calculate_transform_track_error(allocator, args);
+
+ deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
+
return result;
}
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates the worst compression error between two compressed tracks instances.
+ // Supports scalar tracks only.
+ //
+ // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
+ template<class decompression_context_type0, class decompression_context_type1, acl_impl::is_decompression_context<decompression_context_type0> = nullptr, acl_impl::is_decompression_context<decompression_context_type1> = nullptr>
+ inline track_error calculate_compression_error(iallocator& allocator, decompression_context_type0& context0, decompression_context_type1& context1)
+ {
+ using namespace acl_impl;
+
+ ACL_ASSERT(context0.is_initialized(), "Context isn't initialized");
+ ACL_ASSERT(context1.is_initialized(), "Context isn't initialized");
+
+ const compressed_tracks* tracks0 = context0.get_compressed_tracks();
+
+ if (tracks0->get_track_type() == track_type8::qvvf)
+ return track_error(~0U, -1.0F, -1.0F); // Only supports scalar tracks
+
+ calculate_track_error_args args;
+ args.num_samples = tracks0->get_num_samples_per_track();
+ args.num_tracks = tracks0->get_num_tracks();
+ args.duration = tracks0->get_duration();
+ args.sample_rate = tracks0->get_sample_rate();
+ args.track_type = tracks0->get_track_type();
+
+ args.sample_tracks0 = [&context0](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ context0.seek(sample_time, rounding_policy);
+ context0.decompress_tracks(track_writer);
+ };
+
+ args.sample_tracks1 = [&context1](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ context1.seek(sample_time, rounding_policy);
+ context1.decompress_tracks(track_writer);
+ };
+
+ return calculate_scalar_track_error(allocator, args);
+ }
+
//////////////////////////////////////////////////////////////////////////
// Calculates the worst compression error between two raw track arrays.
- inline track_error calculate_compression_error(IAllocator& allocator, const track_array& raw_tracks0, const track_array& raw_tracks1)
+ // Supports scalar tracks only.
+ inline track_error calculate_compression_error(iallocator& allocator, const track_array& raw_tracks0, const track_array& raw_tracks1)
{
using namespace acl_impl;
ACL_ASSERT(raw_tracks0.is_valid().empty(), "Raw tracks are invalid");
ACL_ASSERT(raw_tracks1.is_valid().empty(), "Raw tracks are invalid");
- const uint32_t num_samples = raw_tracks0.get_num_samples_per_track();
- if (num_samples == 0)
- return track_error(); // Cannot measure any error
+ if (raw_tracks0.get_track_type() == track_type8::qvvf)
+ return track_error(~0U, -1.0F, -1.0F); // Only supports scalar tracks
+
+ calculate_track_error_args args;
+ args.num_samples = raw_tracks0.get_num_samples_per_track();
+ args.num_tracks = raw_tracks0.get_num_tracks();
+ args.duration = raw_tracks0.get_duration();
+ args.sample_rate = raw_tracks0.get_sample_rate();
+ args.track_type = raw_tracks0.get_track_type();
- const uint32_t num_tracks = raw_tracks0.get_num_tracks();
- if (num_tracks == 0 || num_tracks != raw_tracks1.get_num_tracks())
- return track_error(); // Cannot measure any error
+ args.sample_tracks0 = [&raw_tracks0](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ raw_tracks0.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
+
+ args.sample_tracks1 = [&raw_tracks1](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ raw_tracks1.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
- const track_type8 track_type = raw_tracks0.get_track_type();
- if (track_type != raw_tracks1.get_track_type())
- return track_error(); // Cannot measure any error
+ return calculate_scalar_track_error(allocator, args);
+ }
- track_error result;
- result.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates the worst compression error between two raw track arrays.
+ // Supports scalar and transform tracks.
+ inline track_error calculate_compression_error(iallocator& allocator, const track_array& raw_tracks0, const track_array& raw_tracks1, const itransform_error_metric& error_metric)
+ {
+ using namespace acl_impl;
- const float duration = raw_tracks0.get_duration();
- const float sample_rate = raw_tracks0.get_sample_rate();
+ ACL_ASSERT(raw_tracks0.is_valid().empty(), "Raw tracks are invalid");
+ ACL_ASSERT(raw_tracks1.is_valid().empty(), "Raw tracks are invalid");
- debug_track_writer tracks_writer0(allocator, track_type, num_tracks);
- debug_track_writer tracks_writer1(allocator, track_type, num_tracks);
+ calculate_track_error_args args;
+ args.num_samples = raw_tracks0.get_num_samples_per_track();
+ args.num_tracks = raw_tracks0.get_num_tracks();
+ args.duration = raw_tracks0.get_duration();
+ args.sample_rate = raw_tracks0.get_sample_rate();
+ args.track_type = raw_tracks0.get_track_type();
- const rtm::vector4f zero = rtm::vector_zero();
+ args.sample_tracks0 = [&raw_tracks0](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
+ {
+ raw_tracks0.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
- // Measure our error
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ args.sample_tracks1 = [&raw_tracks1](float sample_time, sample_rounding_policy rounding_policy, debug_track_writer& track_writer)
{
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
+ raw_tracks1.sample_tracks(sample_time, rounding_policy, track_writer);
+ };
- // We use the nearest sample to accurately measure the loss that happened, if any
- raw_tracks0.sample_tracks(sample_time, sample_rounding_policy::nearest, tracks_writer0);
- raw_tracks1.sample_tracks(sample_time, sample_rounding_policy::nearest, tracks_writer1);
+ if (raw_tracks0.get_track_type() != track_type8::qvvf)
+ return calculate_scalar_track_error(allocator, args);
- // Validate decompress_tracks
- for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
- {
- rtm::vector4f error;
+ args.error_metric = &error_metric;
- switch (track_type)
- {
- case track_type8::float1f:
- {
- const float raw_value = tracks_writer0.read_float1(track_index);
- const float lossy_value = tracks_writer1.read_float1(track_index);
- error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
- break;
- }
- case track_type8::float2f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float2(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float2(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float3f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float3(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float3(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, zero);
- break;
- }
- case track_type8::float4f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_float4(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_float4(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
- }
- case track_type8::vector4f:
- {
- const rtm::vector4f raw_value = tracks_writer0.read_vector4(track_index);
- const rtm::vector4f lossy_value = tracks_writer1.read_vector4(track_index);
- error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
- break;
- }
- default:
- ACL_ASSERT(false, "Unsupported track type");
- error = zero;
- break;
- }
+ args.get_parent_index = [&raw_tracks0](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks0[track_index]);
+ return track_.get_description().parent_index;
+ };
- const float max_error = rtm::vector_get_max_component(error);
- if (max_error > result.error)
- {
- result.error = max_error;
- result.index = track_index;
- result.sample_time = sample_time;
- }
- }
- }
+ args.get_shell_distance = [&raw_tracks0](uint32_t track_index)
+ {
+ const track_qvvf& track_ = track_cast<track_qvvf>(raw_tracks0[track_index]);
+ return track_.get_description().shell_distance;
+ };
- return result;
+ return calculate_transform_track_error(allocator, args);
}
}
diff --git a/includes/acl/compression/skeleton_error_metric.h b/includes/acl/compression/transform_error_metrics.h
similarity index 99%
rename from includes/acl/compression/skeleton_error_metric.h
rename to includes/acl/compression/transform_error_metrics.h
--- a/includes/acl/compression/skeleton_error_metric.h
+++ b/includes/acl/compression/transform_error_metrics.h
@@ -27,7 +27,6 @@
#include "acl/core/additive_utils.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/hash.h"
-#include "acl/compression/skeleton.h"
#include <rtm/matrix3x4f.h>
#include <rtm/qvvf.h>
diff --git a/includes/acl/compression/skeleton_pose_utils.h b/includes/acl/compression/transform_pose_utils.h
similarity index 64%
rename from includes/acl/compression/skeleton_pose_utils.h
rename to includes/acl/compression/transform_pose_utils.h
--- a/includes/acl/compression/skeleton_pose_utils.h
+++ b/includes/acl/compression/transform_pose_utils.h
@@ -26,7 +26,6 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/error.h"
-#include "acl/compression/skeleton.h"
#include <rtm/qvvf.h>
@@ -36,37 +35,35 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- // Note: It is safe for both pose buffers to alias since the data is sorted parent first
- inline void local_to_object_space(const RigidSkeleton& skeleton, const rtm::qvvf* local_pose, rtm::qvvf* out_object_pose)
+ // Note: It is safe for both pose buffers to alias since the data if sorted parent first
+ inline void local_to_object_space(const uint32_t* parent_indices, const rtm::qvvf* local_pose, uint32_t num_transforms, rtm::qvvf* out_object_pose)
{
- const uint16_t num_bones = skeleton.get_num_bones();
- const RigidBone* bones = skeleton.get_bones();
- ACL_ASSERT(num_bones != 0, "Invalid number of bones: %u", num_bones);
+ if (num_transforms == 0)
+ return; // Nothing to do
out_object_pose[0] = local_pose[0];
- for (uint16_t bone_index = 1; bone_index < num_bones; ++bone_index)
+ for (uint32_t bone_index = 1; bone_index < num_transforms; ++bone_index)
{
- const uint16_t parent_bone_index = bones[bone_index].parent_index;
- ACL_ASSERT(parent_bone_index < num_bones, "Invalid parent bone index: %u >= %u", parent_bone_index, num_bones);
+ const uint32_t parent_bone_index = parent_indices[bone_index];
+ ACL_ASSERT(parent_bone_index < num_transforms, "Invalid parent bone index: %u >= %u", parent_bone_index, num_transforms);
out_object_pose[bone_index] = rtm::qvv_normalize(rtm::qvv_mul(local_pose[bone_index], out_object_pose[parent_bone_index]));
}
}
- // Note: It is safe for both pose buffers to alias since the data is sorted parent first
- inline void object_to_local_space(const RigidSkeleton& skeleton, const rtm::qvvf* object_pose, rtm::qvvf* out_local_pose)
+ // Note: It is safe for both pose buffers to alias since the data if sorted parent first
+ inline void object_to_local_space(const uint32_t* parent_indices, const rtm::qvvf* object_pose, uint32_t num_transforms, rtm::qvvf* out_local_pose)
{
- uint16_t num_bones = skeleton.get_num_bones();
- const RigidBone* bones = skeleton.get_bones();
- ACL_ASSERT(num_bones != 0, "Invalid number of bones: %u", num_bones);
+ if (num_transforms == 0)
+ return; // Nothing to do
out_local_pose[0] = object_pose[0];
- for (uint16_t bone_index = 1; bone_index < num_bones; ++bone_index)
+ for (uint32_t bone_index = 1; bone_index < num_transforms; ++bone_index)
{
- const uint16_t parent_bone_index = bones[bone_index].parent_index;
- ACL_ASSERT(parent_bone_index < num_bones, "Invalid parent bone index: %u >= %u", parent_bone_index, num_bones);
+ const uint32_t parent_bone_index = parent_indices[bone_index];
+ ACL_ASSERT(parent_bone_index < num_transforms, "Invalid parent bone index: %u >= %u", parent_bone_index, num_transforms);
const rtm::qvvf inv_parent_transform = rtm::qvv_inverse(object_pose[parent_bone_index]);
out_local_pose[bone_index] = rtm::qvv_normalize(rtm::qvv_mul(inv_parent_transform, object_pose[bone_index]));
diff --git a/includes/acl/compression/utils.h b/includes/acl/compression/utils.h
deleted file mode 100644
--- a/includes/acl/compression/utils.h
+++ /dev/null
@@ -1,552 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/algorithm/uniformly_sampled/decoder.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_clip.h"
-#include "acl/core/iallocator.h"
-#include "acl/compression/compression_settings.h"
-#include "acl/compression/skeleton.h"
-#include "acl/compression/animation_clip.h"
-#include "acl/decompression/default_output_writer.h"
-
-#include <cstdint>
-#include <cstring>
-#include <type_traits>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace acl_impl
- {
- //////////////////////////////////////////////////////////////////////////
- // SFINAE boilerplate to detect if a template argument derives from acl::uniformly_sampled::DecompressionContext.
- //////////////////////////////////////////////////////////////////////////
- template<class T>
- using IsDecompressionContext = typename std::enable_if<std::is_base_of<acl::uniformly_sampled::DecompressionContext<typename T::SettingsType>, T>::value, std::nullptr_t>::type;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Encapsulates the compression error for a specific bone at a point in time.
- //////////////////////////////////////////////////////////////////////////
- struct BoneError
- {
- BoneError() : index(k_invalid_bone_index), error(0.0F), sample_time(0.0F) {}
-
- //////////////////////////////////////////////////////////////////////////
- // The bone index.
- uint16_t index;
-
- //////////////////////////////////////////////////////////////////////////
- // The measured error value.
- float error;
-
- //////////////////////////////////////////////////////////////////////////
- // The point in time where the error was measured.
- float sample_time;
- };
-
- //////////////////////////////////////////////////////////////////////////
- // Calculates the error between a raw clip and a compressed clip.
- // - allocator: An allocate we can use for temporary data
- // - error_metric: The error metric to use when measuring the error
- // - clip: A raw clip
- // - context: A decompression context bound to a compressed clip
- //
- // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
- //////////////////////////////////////////////////////////////////////////
- template<class DecompressionContextType, acl_impl::IsDecompressionContext<DecompressionContextType> = nullptr>
- inline BoneError calculate_error_between_clips(IAllocator& allocator, const itransform_error_metric& error_metric, const AnimationClip& clip, DecompressionContextType& context)
- {
- ACL_ASSERT(clip.is_valid().empty(), "Clip is invalid");
- ACL_ASSERT(context.is_initialized(), "Context isn't initialized");
-
- const uint32_t num_samples = clip.get_num_samples();
- if (num_samples == 0)
- return BoneError(); // Cannot measure any error
-
- const uint16_t num_bones = clip.get_num_bones();
- if (num_bones == 0)
- return BoneError(); // Cannot measure any error
-
- const float clip_duration = clip.get_duration();
- const float sample_rate = clip.get_sample_rate();
- const RigidSkeleton& skeleton = clip.get_skeleton();
-
- // Always calculate the error with scale, slower but we don't need to know if we have scale or not
- const bool has_scale = true;
-
- uint16_t num_output_bones = 0;
- uint16_t* output_bone_mapping = create_output_bone_mapping(allocator, clip, num_output_bones);
-
- const AnimationClip* additive_base_clip = clip.get_additive_base();
- const uint32_t additive_num_samples = additive_base_clip != nullptr ? additive_base_clip->get_num_samples() : 0;
- const float additive_duration = additive_base_clip != nullptr ? additive_base_clip->get_duration() : 0.0F;
-
- rtm::qvvf* raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* base_local_pose = additive_base_clip != nullptr ? allocate_type_array<rtm::qvvf>(allocator, num_bones) : nullptr;
- rtm::qvvf* lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_output_bones);
- rtm::qvvf* lossy_remapped_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
-
- const size_t transform_size = error_metric.get_transform_size(has_scale);
- const bool needs_conversion = error_metric.needs_conversion(has_scale);
- uint8_t* raw_local_pose_converted = nullptr;
- uint8_t* base_local_pose_converted = nullptr;
- uint8_t* lossy_local_pose_converted = nullptr;
- if (needs_conversion)
- {
- raw_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- base_local_pose_converted = additive_base_clip != nullptr ? allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64) : nullptr;
- lossy_local_pose_converted = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- }
-
- uint8_t* raw_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- uint8_t* lossy_object_pose = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
-
- uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
- uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
-
- for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
- {
- const RigidBone& bone = skeleton.get_bone(transform_index);
- parent_transform_indices[transform_index] = bone.parent_index;
- self_transform_indices[transform_index] = transform_index;
- }
-
- void* raw_local_pose_ = needs_conversion ? (void*)raw_local_pose_converted : (void*)raw_local_pose;
- void* base_local_pose_ = needs_conversion ? (void*)base_local_pose_converted : (void*)base_local_pose;
- void* lossy_local_pose_ = needs_conversion ? (void*)lossy_local_pose_converted : (void*)lossy_remapped_local_pose;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args_raw;
- convert_transforms_args_raw.dirty_transform_indices = self_transform_indices;
- convert_transforms_args_raw.num_dirty_transforms = num_bones;
- convert_transforms_args_raw.transforms = raw_local_pose;
- convert_transforms_args_raw.num_transforms = num_bones;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args_base = convert_transforms_args_raw;
- convert_transforms_args_base.transforms = base_local_pose;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args_lossy = convert_transforms_args_raw;
- convert_transforms_args_lossy.transforms = lossy_remapped_local_pose;
-
- itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_raw;
- apply_additive_to_base_args_raw.dirty_transform_indices = self_transform_indices;
- apply_additive_to_base_args_raw.num_dirty_transforms = num_bones;
- apply_additive_to_base_args_raw.local_transforms = raw_local_pose_;
- apply_additive_to_base_args_raw.base_transforms = base_local_pose_;
- apply_additive_to_base_args_raw.num_transforms = num_bones;
-
- itransform_error_metric::apply_additive_to_base_args apply_additive_to_base_args_lossy = apply_additive_to_base_args_raw;
- apply_additive_to_base_args_lossy.local_transforms = lossy_local_pose_;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args_raw;
- local_to_object_space_args_raw.dirty_transform_indices = self_transform_indices;
- local_to_object_space_args_raw.num_dirty_transforms = num_bones;
- local_to_object_space_args_raw.parent_transform_indices = parent_transform_indices;
- local_to_object_space_args_raw.local_transforms = raw_local_pose_;
- local_to_object_space_args_raw.num_transforms = num_bones;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args_lossy = local_to_object_space_args_raw;
- local_to_object_space_args_lossy.local_transforms = lossy_local_pose_;
-
- BoneError bone_error;
- bone_error.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
- DefaultOutputWriter pose_writer(lossy_local_pose, num_output_bones);
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
-
- // We use the nearest sample to accurately measure the loss that happened, if any
- clip.sample_pose(sample_time, sample_rounding_policy::nearest, raw_local_pose, num_bones);
-
- context.seek(sample_time, sample_rounding_policy::nearest);
- context.decompress_pose(pose_writer);
-
- // Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
- // the data is available
- std::memcpy(lossy_remapped_local_pose, raw_local_pose, sizeof(rtm::qvvf) * num_bones);
- for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- const uint16_t bone_index = output_bone_mapping[output_index];
- lossy_remapped_local_pose[bone_index] = lossy_local_pose[output_index];
- }
-
- if (needs_conversion)
- {
- error_metric.convert_transforms(convert_transforms_args_raw, raw_local_pose_converted);
- error_metric.convert_transforms(convert_transforms_args_lossy, lossy_local_pose_converted);
- }
-
- if (additive_base_clip != nullptr)
- {
- const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
- const float additive_sample_time = additive_num_samples > 1 ? (normalized_sample_time * additive_duration) : 0.0F;
- additive_base_clip->sample_pose(additive_sample_time, sample_rounding_policy::nearest, base_local_pose, num_bones);
-
- if (needs_conversion)
- error_metric.convert_transforms(convert_transforms_args_base, base_local_pose_converted);
-
- error_metric.apply_additive_to_base(apply_additive_to_base_args_raw, raw_local_pose_);
- error_metric.apply_additive_to_base(apply_additive_to_base_args_lossy, lossy_local_pose_);
- }
-
- error_metric.local_to_object_space(local_to_object_space_args_raw, raw_object_pose);
- error_metric.local_to_object_space(local_to_object_space_args_lossy, lossy_object_pose);
-
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- itransform_error_metric::calculate_error_args calculate_error_args;
- calculate_error_args.transform0 = raw_object_pose + (bone_index * transform_size);
- calculate_error_args.transform1 = lossy_object_pose + (bone_index * transform_size);
- calculate_error_args.construct_sphere_shell(bone.vertex_distance);
-
- const float error = rtm::scalar_cast(error_metric.calculate_error(calculate_error_args));
-
- if (error > bone_error.error)
- {
- bone_error.error = error;
- bone_error.index = bone_index;
- bone_error.sample_time = sample_time;
- }
- }
- }
-
- deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
- deallocate_type_array(allocator, raw_local_pose, num_bones);
- deallocate_type_array(allocator, base_local_pose, num_bones);
- deallocate_type_array(allocator, lossy_local_pose, num_output_bones);
- deallocate_type_array(allocator, lossy_remapped_local_pose, num_bones);
- deallocate_type_array(allocator, raw_local_pose_converted, num_bones * transform_size);
- deallocate_type_array(allocator, base_local_pose_converted, num_bones * transform_size);
- deallocate_type_array(allocator, lossy_local_pose_converted, num_bones * transform_size);
- deallocate_type_array(allocator, raw_object_pose, num_bones * transform_size);
- deallocate_type_array(allocator, lossy_object_pose, num_bones * transform_size);
- deallocate_type_array(allocator, parent_transform_indices, num_bones);
- deallocate_type_array(allocator, self_transform_indices, num_bones);
-
- return bone_error;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Calculates the error between two compressed clips.
- // - allocator: An allocate we can use for temporary data
- // - error_metric: The error metric to use when measuring the error
- // - skeleton: The skeleton used to compress the clips
- // - context0: A decompression context bound to a compressed clip
- // - context1: A decompression context bound to a compressed clip
- //
- // Note: This function uses SFINAE to prevent it from matching when it shouldn't.
- //////////////////////////////////////////////////////////////////////////
- template<class DecompressionContextType0, class DecompressionContextType1, acl_impl::IsDecompressionContext<DecompressionContextType0> = nullptr, acl_impl::IsDecompressionContext<DecompressionContextType1> = nullptr>
- inline BoneError calculate_error_between_clips(IAllocator& allocator, const itransform_error_metric& error_metric, const RigidSkeleton& skeleton, DecompressionContextType0& context0, DecompressionContextType1& context1)
- {
- ACL_ASSERT(context0.is_initialized(), "Context isn't initialized");
- ACL_ASSERT(context1.is_initialized(), "Context isn't initialized");
-
- const ClipHeader& clip_header = get_clip_header(*context0.get_compressed_clip());
- const uint32_t num_samples = clip_header.num_samples;
- if (num_samples == 0)
- return BoneError(); // Cannot measure any error
-
- const uint16_t num_bones = clip_header.num_bones;
- if (num_bones == 0)
- return BoneError(); // Cannot measure any error
-
- const float sample_rate = clip_header.sample_rate;
- const float clip_duration = calculate_duration(num_samples, sample_rate);
-
- // Always calculate the error with scale, slower but we don't need to know if we have scale or not
- const bool has_scale = true;
-
- rtm::qvvf* local_pose0 = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* local_pose1 = allocate_type_array<rtm::qvvf>(allocator, num_bones);
-
- const size_t transform_size = error_metric.get_transform_size(has_scale);
- const bool needs_conversion = error_metric.needs_conversion(has_scale);
- uint8_t* local_pose_converted0 = nullptr;
- uint8_t* local_pose_converted1 = nullptr;
- if (needs_conversion)
- {
- local_pose_converted0 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- local_pose_converted1 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- }
-
- uint8_t* object_pose0 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- uint8_t* object_pose1 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
-
- uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
- uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
-
- for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
- {
- const RigidBone& bone = skeleton.get_bone(transform_index);
- parent_transform_indices[transform_index] = bone.parent_index;
- self_transform_indices[transform_index] = transform_index;
- }
-
- void* local_pose0_ = needs_conversion ? (void*)local_pose_converted0 : (void*)local_pose0;
- void* local_pose1_ = needs_conversion ? (void*)local_pose_converted1 : (void*)local_pose1;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args0;
- convert_transforms_args0.dirty_transform_indices = self_transform_indices;
- convert_transforms_args0.num_dirty_transforms = num_bones;
- convert_transforms_args0.transforms = local_pose0;
- convert_transforms_args0.num_transforms = num_bones;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args1 = convert_transforms_args0;
- convert_transforms_args1.transforms = local_pose1;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args0;
- local_to_object_space_args0.dirty_transform_indices = self_transform_indices;
- local_to_object_space_args0.num_dirty_transforms = num_bones;
- local_to_object_space_args0.parent_transform_indices = parent_transform_indices;
- local_to_object_space_args0.local_transforms = local_pose0_;
- local_to_object_space_args0.num_transforms = num_bones;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args1 = local_to_object_space_args0;
- local_to_object_space_args1.local_transforms = local_pose1_;
-
- BoneError bone_error;
- bone_error.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
-
- DefaultOutputWriter pose_writer0(local_pose0, num_bones);
- DefaultOutputWriter pose_writer1(local_pose1, num_bones);
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
-
- // We use the nearest sample to accurately measure the loss that happened, if any
- context0.seek(sample_time, sample_rounding_policy::nearest);
- context0.decompress_pose(pose_writer0);
-
- context1.seek(sample_time, sample_rounding_policy::nearest);
- context1.decompress_pose(pose_writer1);
-
- if (needs_conversion)
- {
- error_metric.convert_transforms(convert_transforms_args0, local_pose_converted0);
- error_metric.convert_transforms(convert_transforms_args1, local_pose_converted1);
- }
-
- error_metric.local_to_object_space(local_to_object_space_args0, object_pose0);
- error_metric.local_to_object_space(local_to_object_space_args1, object_pose1);
-
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- itransform_error_metric::calculate_error_args calculate_error_args;
- calculate_error_args.transform0 = object_pose0 + (bone_index * transform_size);
- calculate_error_args.transform1 = object_pose1 + (bone_index * transform_size);
- calculate_error_args.construct_sphere_shell(bone.vertex_distance);
-
- const float error = rtm::scalar_cast(error_metric.calculate_error(calculate_error_args));
-
- if (error > bone_error.error)
- {
- bone_error.error = error;
- bone_error.index = bone_index;
- bone_error.sample_time = sample_time;
- }
- }
- }
-
- deallocate_type_array(allocator, local_pose0, num_bones);
- deallocate_type_array(allocator, local_pose1, num_bones);
- deallocate_type_array(allocator, local_pose_converted0, num_bones * transform_size);
- deallocate_type_array(allocator, local_pose_converted1, num_bones * transform_size);
- deallocate_type_array(allocator, object_pose0, num_bones * transform_size);
- deallocate_type_array(allocator, object_pose1, num_bones * transform_size);
- deallocate_type_array(allocator, parent_transform_indices, num_bones);
- deallocate_type_array(allocator, self_transform_indices, num_bones);
-
- return bone_error;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Calculates the error between two raw clips.
- // - allocator: An allocate we can use for temporary data
- // - error_metric: The error metric to use when measuring the error
- // - clip0: A raw clip
- // - clip1: A raw clip
- //////////////////////////////////////////////////////////////////////////
- inline BoneError calculate_error_between_clips(IAllocator& allocator, const itransform_error_metric& error_metric, const AnimationClip& clip0, const AnimationClip& clip1)
- {
- ACL_ASSERT(clip0.is_valid().empty(), "Clip is invalid");
- ACL_ASSERT(clip1.is_valid().empty(), "Clip is invalid");
- ACL_ASSERT(clip0.get_additive_base() == nullptr, "Additive clip not supported");
- ACL_ASSERT(clip1.get_additive_base() == nullptr, "Additive clip not supported");
-
- const uint32_t num_samples = clip0.get_num_samples();
- if (num_samples == 0)
- return BoneError(); // Cannot measure any error
-
- const uint16_t num_bones = clip0.get_num_bones();
- if (num_bones == 0 || num_bones != clip1.get_num_bones())
- return BoneError(); // Cannot measure any error
-
- const float clip_duration = clip0.get_duration();
- const float sample_rate = clip0.get_sample_rate();
- const RigidSkeleton& skeleton = clip0.get_skeleton();
-
- // Always calculate the error with scale, slower but we don't need to know if we have scale or not
- const bool has_scale = true;
-
- uint16_t num_output_bones0 = 0;
- uint16_t* output_bone_mapping0 = create_output_bone_mapping(allocator, clip0, num_output_bones0);
-
- uint16_t num_output_bones1 = 0;
- uint16_t* output_bone_mapping1 = create_output_bone_mapping(allocator, clip1, num_output_bones1);
-
- rtm::qvvf* local_pose0 = allocate_type_array<rtm::qvvf>(allocator, num_output_bones0);
- rtm::qvvf* local_pose1 = allocate_type_array<rtm::qvvf>(allocator, num_output_bones1);
- rtm::qvvf* remapped_local_pose0 = allocate_type_array<rtm::qvvf>(allocator, num_bones);
- rtm::qvvf* remapped_local_pose1 = allocate_type_array<rtm::qvvf>(allocator, num_bones);
-
- const size_t transform_size = error_metric.get_transform_size(has_scale);
- const bool needs_conversion = error_metric.needs_conversion(has_scale);
- uint8_t* local_pose_converted0 = nullptr;
- uint8_t* local_pose_converted1 = nullptr;
- if (needs_conversion)
- {
- local_pose_converted0 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- local_pose_converted1 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- }
-
- uint8_t* object_pose0 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
- uint8_t* object_pose1 = allocate_type_array_aligned<uint8_t>(allocator, num_bones * transform_size, 64);
-
- uint16_t* parent_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
- uint16_t* self_transform_indices = allocate_type_array<uint16_t>(allocator, num_bones);
-
- for (uint16_t transform_index = 0; transform_index < num_bones; ++transform_index)
- {
- const RigidBone& bone = skeleton.get_bone(transform_index);
- parent_transform_indices[transform_index] = bone.parent_index;
- self_transform_indices[transform_index] = transform_index;
- }
-
- void* local_pose0_ = needs_conversion ? (void*)local_pose_converted0 : (void*)remapped_local_pose0;
- void* local_pose1_ = needs_conversion ? (void*)local_pose_converted1 : (void*)remapped_local_pose1;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args0;
- convert_transforms_args0.dirty_transform_indices = self_transform_indices;
- convert_transforms_args0.num_dirty_transforms = num_bones;
- convert_transforms_args0.transforms = remapped_local_pose0;
- convert_transforms_args0.num_transforms = num_bones;
-
- itransform_error_metric::convert_transforms_args convert_transforms_args1 = convert_transforms_args0;
- convert_transforms_args1.transforms = remapped_local_pose1;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args0;
- local_to_object_space_args0.dirty_transform_indices = self_transform_indices;
- local_to_object_space_args0.num_dirty_transforms = num_bones;
- local_to_object_space_args0.parent_transform_indices = parent_transform_indices;
- local_to_object_space_args0.local_transforms = local_pose0_;
- local_to_object_space_args0.num_transforms = num_bones;
-
- itransform_error_metric::local_to_object_space_args local_to_object_space_args1 = local_to_object_space_args0;
- local_to_object_space_args1.local_transforms = local_pose1_;
-
- BoneError bone_error;
- bone_error.error = -1.0F; // Can never have a negative error, use -1 so the first sample is used
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
-
- // We use the nearest sample to accurately measure the loss that happened, if any
- clip0.sample_pose(sample_time, sample_rounding_policy::nearest, local_pose0, num_bones);
- clip1.sample_pose(sample_time, sample_rounding_policy::nearest, local_pose1, num_bones);
-
- // Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
- // the data is available
- std::memcpy(remapped_local_pose0, local_pose0, sizeof(rtm::qvvf) * num_bones);
- for (uint16_t output_index = 0; output_index < num_output_bones0; ++output_index)
- {
- const uint16_t bone_index = output_bone_mapping0[output_index];
- remapped_local_pose0[bone_index] = local_pose0[output_index];
- }
-
- std::memcpy(remapped_local_pose1, local_pose1, sizeof(rtm::qvvf) * num_bones);
- for (uint16_t output_index = 0; output_index < num_output_bones1; ++output_index)
- {
- const uint16_t bone_index = output_bone_mapping1[output_index];
- remapped_local_pose1[bone_index] = local_pose1[output_index];
- }
-
- if (needs_conversion)
- {
- error_metric.convert_transforms(convert_transforms_args0, local_pose_converted0);
- error_metric.convert_transforms(convert_transforms_args1, local_pose_converted1);
- }
-
- error_metric.local_to_object_space(local_to_object_space_args0, object_pose0);
- error_metric.local_to_object_space(local_to_object_space_args1, object_pose1);
-
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const RigidBone& bone = skeleton.get_bone(bone_index);
-
- itransform_error_metric::calculate_error_args calculate_error_args;
- calculate_error_args.transform0 = object_pose0 + (bone_index * transform_size);
- calculate_error_args.transform1 = object_pose1 + (bone_index * transform_size);
- calculate_error_args.construct_sphere_shell(bone.vertex_distance);
-
- const float error = rtm::scalar_cast(error_metric.calculate_error(calculate_error_args));
-
- if (error > bone_error.error)
- {
- bone_error.error = error;
- bone_error.index = bone_index;
- bone_error.sample_time = sample_time;
- }
- }
- }
-
- deallocate_type_array(allocator, output_bone_mapping0, num_output_bones0);
- deallocate_type_array(allocator, output_bone_mapping1, num_output_bones1);
- deallocate_type_array(allocator, local_pose0, num_output_bones0);
- deallocate_type_array(allocator, local_pose1, num_output_bones1);
- deallocate_type_array(allocator, remapped_local_pose0, num_bones);
- deallocate_type_array(allocator, remapped_local_pose1, num_bones);
- deallocate_type_array(allocator, local_pose_converted0, num_bones * transform_size);
- deallocate_type_array(allocator, local_pose_converted1, num_bones * transform_size);
- deallocate_type_array(allocator, object_pose0, num_bones * transform_size);
- deallocate_type_array(allocator, object_pose1, num_bones * transform_size);
- deallocate_type_array(allocator, parent_transform_indices, num_bones);
- deallocate_type_array(allocator, self_transform_indices, num_bones);
-
- return bone_error;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/additive_utils.h b/includes/acl/core/additive_utils.h
--- a/includes/acl/core/additive_utils.h
+++ b/includes/acl/core/additive_utils.h
@@ -26,7 +26,6 @@
#include "acl/core/impl/compiler_utils.h"
-#include <rtm/qvvd.h>
#include <rtm/qvvf.h>
#include <cstdint>
@@ -167,24 +166,24 @@ namespace acl
}
}
- inline rtm::qvvd convert_to_relative(const rtm::qvvd& base, const rtm::qvvd& transform)
+ inline rtm::qvvf RTM_SIMD_CALL convert_to_relative(rtm::qvvf_arg0 base, rtm::qvvf_arg1 transform)
{
return rtm::qvv_mul(transform, rtm::qvv_inverse(base));
}
- inline rtm::qvvd convert_to_additive0(const rtm::qvvd& base, const rtm::qvvd& transform)
+ inline rtm::qvvf RTM_SIMD_CALL convert_to_additive0(rtm::qvvf_arg0 base, rtm::qvvf_arg1 transform)
{
- const rtm::quatd rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
- const rtm::vector4d translation = rtm::vector_sub(transform.translation, base.translation);
- const rtm::vector4d scale = rtm::vector_div(transform.scale, base.scale);
+ const rtm::quatf rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
+ const rtm::vector4f translation = rtm::vector_sub(transform.translation, base.translation);
+ const rtm::vector4f scale = rtm::vector_div(transform.scale, base.scale);
return rtm::qvv_set(rotation, translation, scale);
}
- inline rtm::qvvd convert_to_additive1(const rtm::qvvd& base, const rtm::qvvd& transform)
+ inline rtm::qvvf RTM_SIMD_CALL convert_to_additive1(rtm::qvvf_arg0 base, rtm::qvvf_arg1 transform)
{
- const rtm::quatd rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
- const rtm::vector4d translation = rtm::vector_sub(transform.translation, base.translation);
- const rtm::vector4d scale = rtm::vector_sub(rtm::vector_mul(transform.scale, rtm::vector_reciprocal(base.scale)), rtm::vector_set(1.0));
+ const rtm::quatf rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
+ const rtm::vector4f translation = rtm::vector_sub(transform.translation, base.translation);
+ const rtm::vector4f scale = rtm::vector_sub(rtm::vector_mul(transform.scale, rtm::vector_reciprocal(base.scale)), rtm::vector_set(1.0F));
return rtm::qvv_set(rotation, translation, scale);
}
}
diff --git a/includes/acl/core/algorithm_versions.h b/includes/acl/core/algorithm_versions.h
--- a/includes/acl/core/algorithm_versions.h
+++ b/includes/acl/core/algorithm_versions.h
@@ -43,7 +43,7 @@ namespace acl
{
switch (type)
{
- case algorithm_type8::uniformly_sampled: return 6;
+ case algorithm_type8::uniformly_sampled: return 7;
//case algorithm_type8::LinearKeyReduction: return 0;
//case algorithm_type8::SplineKeyReduction: return 0;
default: return 0xFFFF;
diff --git a/includes/acl/core/ansi_allocator.h b/includes/acl/core/ansi_allocator.h
--- a/includes/acl/core/ansi_allocator.h
+++ b/includes/acl/core/ansi_allocator.h
@@ -58,11 +58,11 @@ namespace acl
// An ANSI allocator implementation. It uses the system malloc/free to manage
// memory as well as provides some debugging functionality to track memory leaks.
////////////////////////////////////////////////////////////////////////////////
- class ANSIAllocator : public IAllocator
+ class ansi_allocator : public iallocator
{
public:
- ANSIAllocator()
- : IAllocator()
+ ansi_allocator()
+ : iallocator()
#if defined(ACL_ALLOCATOR_TRACK_NUM_ALLOCATIONS)
, m_allocation_count(0)
#endif
@@ -71,7 +71,7 @@ namespace acl
#endif
{}
- virtual ~ANSIAllocator()
+ virtual ~ansi_allocator()
{
#if defined(ACL_ALLOCATOR_TRACK_ALL_ALLOCATIONS)
if (!m_debug_allocations.empty())
@@ -88,8 +88,8 @@ namespace acl
#endif
}
- ANSIAllocator(const ANSIAllocator&) = delete;
- ANSIAllocator& operator=(const ANSIAllocator&) = delete;
+ ansi_allocator(const ansi_allocator&) = delete;
+ ansi_allocator& operator=(const ansi_allocator&) = delete;
virtual void* allocate(size_t size, size_t alignment = k_default_alignment) override
{
diff --git a/includes/acl/core/bitset.h b/includes/acl/core/bitset.h
--- a/includes/acl/core/bitset.h
+++ b/includes/acl/core/bitset.h
@@ -39,28 +39,28 @@ namespace acl
// A bit set description holds the required information to ensure type and memory safety
// with the various bit set functions.
////////////////////////////////////////////////////////////////////////////////
- class BitSetDescription
+ class bitset_description
{
public:
////////////////////////////////////////////////////////////////////////////////
// Creates an invalid bit set description.
- constexpr BitSetDescription() : m_size(0) {}
+ constexpr bitset_description() : m_size(0) {}
////////////////////////////////////////////////////////////////////////////////
// Creates a bit set description from a compile time known number of bits.
template<uint64_t num_bits>
- static constexpr BitSetDescription make_from_num_bits()
+ static constexpr bitset_description make_from_num_bits()
{
static_assert(num_bits <= std::numeric_limits<uint32_t>::max() - 31, "Number of bits exceeds the maximum number allowed");
- return BitSetDescription((uint32_t(num_bits) + 32 - 1) / 32);
+ return bitset_description((uint32_t(num_bits) + 32 - 1) / 32);
}
////////////////////////////////////////////////////////////////////////////////
// Creates a bit set description from a runtime known number of bits.
- inline static BitSetDescription make_from_num_bits(uint32_t num_bits)
+ inline static bitset_description make_from_num_bits(uint32_t num_bits)
{
ACL_ASSERT(num_bits <= std::numeric_limits<uint32_t>::max() - 31, "Number of bits exceeds the maximum number allowed");
- return BitSetDescription((num_bits + 32 - 1) / 32);
+ return bitset_description((num_bits + 32 - 1) / 32);
}
////////////////////////////////////////////////////////////////////////////////
@@ -83,7 +83,7 @@ namespace acl
private:
////////////////////////////////////////////////////////////////////////////////
// Creates a bit set description from a specified size.
- explicit constexpr BitSetDescription(uint32_t size) : m_size(size) {}
+ explicit constexpr bitset_description(uint32_t size) : m_size(size) {}
// Number of words required to hold the bit set
// 1 == 32 bits, 2 == 64 bits, etc.
@@ -95,15 +95,15 @@ namespace acl
// It holds the bit set word offset as well as the bit mask required.
// This is useful if you sample multiple bit sets at the same index.
//////////////////////////////////////////////////////////////////////////
- struct BitSetIndexRef
+ struct bitset_index_ref
{
- BitSetIndexRef()
+ bitset_index_ref()
: desc()
, offset(0)
, mask(0)
{}
- BitSetIndexRef(BitSetDescription desc_, uint32_t bit_index)
+ bitset_index_ref(bitset_description desc_, uint32_t bit_index)
: desc(desc_)
, offset(bit_index / 32)
, mask(1 << (31 - (bit_index % 32)))
@@ -111,14 +111,14 @@ namespace acl
ACL_ASSERT(desc_.is_bit_index_valid(bit_index), "Invalid bit index: %d", bit_index);
}
- BitSetDescription desc;
+ bitset_description desc;
uint32_t offset;
uint32_t mask;
};
////////////////////////////////////////////////////////////////////////////////
// Resets the entire bit set to the provided value.
- inline void bitset_reset(uint32_t* bitset, BitSetDescription desc, bool value)
+ inline void bitset_reset(uint32_t* bitset, bitset_description desc, bool value)
{
const uint32_t mask = value ? 0xFFFFFFFF : 0x00000000;
const uint32_t size = desc.get_size();
@@ -129,7 +129,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Sets a specific bit to its desired value.
- inline void bitset_set(uint32_t* bitset, BitSetDescription desc, uint32_t bit_index, bool value)
+ inline void bitset_set(uint32_t* bitset, bitset_description desc, uint32_t bit_index, bool value)
{
ACL_ASSERT(desc.is_bit_index_valid(bit_index), "Invalid bit index: %d", bit_index);
(void)desc;
@@ -145,7 +145,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Sets a specific bit to its desired value.
- inline void bitset_set(uint32_t* bitset, const BitSetIndexRef& ref, bool value)
+ inline void bitset_set(uint32_t* bitset, const bitset_index_ref& ref, bool value)
{
if (value)
bitset[ref.offset] |= ref.mask;
@@ -155,7 +155,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Sets a specified range of bits to a specified value.
- inline void bitset_set_range(uint32_t* bitset, BitSetDescription desc, uint32_t start_bit_index, uint32_t num_bits, bool value)
+ inline void bitset_set_range(uint32_t* bitset, bitset_description desc, uint32_t start_bit_index, uint32_t num_bits, bool value)
{
ACL_ASSERT(desc.is_bit_index_valid(start_bit_index), "Invalid start bit index: %d", start_bit_index);
ACL_ASSERT(start_bit_index + num_bits <= desc.get_num_bits(), "Invalid num bits: %d > %d", start_bit_index + num_bits, desc.get_num_bits());
@@ -167,7 +167,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Returns the bit value as a specific index.
- inline bool bitset_test(const uint32_t* bitset, BitSetDescription desc, uint32_t bit_index)
+ inline bool bitset_test(const uint32_t* bitset, bitset_description desc, uint32_t bit_index)
{
ACL_ASSERT(desc.is_bit_index_valid(bit_index), "Invalid bit index: %d", bit_index);
(void)desc;
@@ -180,14 +180,14 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Returns the bit value as a specific index.
- inline bool bitset_test(const uint32_t* bitset, const BitSetIndexRef& ref)
+ inline bool bitset_test(const uint32_t* bitset, const bitset_index_ref& ref)
{
return (bitset[ref.offset] & ref.mask) != 0;
}
////////////////////////////////////////////////////////////////////////////////
// Counts the total number of set (true) bits within the bit set.
- inline uint32_t bitset_count_set_bits(const uint32_t* bitset, BitSetDescription desc)
+ inline uint32_t bitset_count_set_bits(const uint32_t* bitset, bitset_description desc)
{
const uint32_t size = desc.get_size();
@@ -204,7 +204,7 @@ namespace acl
// Performs the operation: result = ~not_value & and_value
// Bit sets must have the same description
// Bit sets can alias
- inline void bitset_and_not(uint32_t* bitset_result, const uint32_t* bitset_not_value, const uint32_t* bitset_and_value, BitSetDescription desc)
+ inline void bitset_and_not(uint32_t* bitset_result, const uint32_t* bitset_not_value, const uint32_t* bitset_and_value, bitset_description desc)
{
const uint32_t size = desc.get_size();
diff --git a/includes/acl/core/buffer_tag.h b/includes/acl/core/buffer_tag.h
--- a/includes/acl/core/buffer_tag.h
+++ b/includes/acl/core/buffer_tag.h
@@ -38,6 +38,7 @@ namespace acl
{
//////////////////////////////////////////////////////////////////////////
// Identifies a 'CompressedClip' buffer.
+ // Deprecated, no longer used. Belonged to pre-2.0 file format.
compressed_clip = 0xac10ac10,
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/core/compressed_clip.h b/includes/acl/core/compressed_clip.h
deleted file mode 100644
--- a/includes/acl/core/compressed_clip.h
+++ /dev/null
@@ -1,298 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/algorithm_versions.h"
-#include "acl/core/buffer_tag.h"
-#include "acl/core/error_result.h"
-#include "acl/core/hash.h"
-#include "acl/core/memory_utils.h"
-#include "acl/core/ptr_offset.h"
-#include "acl/core/range_reduction_types.h"
-#include "acl/core/track_types.h"
-#include "acl/core/impl/compiler_utils.h"
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- class CompressedClip;
-
- namespace acl_impl
- {
- CompressedClip* make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type);
- void finalize_compressed_clip(CompressedClip& compressed_clip);
- }
-
- ////////////////////////////////////////////////////////////////////////////////
- // An instance of a compressed clip.
- // The compressed data immediately follows the clip instance.
- ////////////////////////////////////////////////////////////////////////////////
- class alignas(16) CompressedClip
- {
- public:
- ////////////////////////////////////////////////////////////////////////////////
- // Returns the algorithm type used to compress the clip.
- algorithm_type8 get_algorithm_type() const { return m_type; }
-
- ////////////////////////////////////////////////////////////////////////////////
- // Returns the size in bytes of the compressed clip.
- // Includes the 'CompressedClip' instance size.
- uint32_t get_size() const { return m_size; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the hash for this compressed clip.
- uint32_t get_hash() const { return m_hash; }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns the binary tag for the compressed clip.
- // This uniquely identifies the buffer as a proper 'CompressedClip' object.
- buffer_tag32 get_tag() const { return static_cast<buffer_tag32>(m_tag); }
-
- ////////////////////////////////////////////////////////////////////////////////
- // Returns true if a compressed clip is valid and usable.
- // This mainly validates some invariants as well as ensuring that the
- // memory has not been corrupted.
- //
- // check_hash: If true, the compressed clip hash will also be compared.
- ErrorResult is_valid(bool check_hash) const
- {
- if (!is_aligned_to(this, alignof(CompressedClip)))
- return ErrorResult("Invalid alignment");
-
- if (m_tag != static_cast<uint32_t>(buffer_tag32::compressed_clip))
- return ErrorResult("Invalid tag");
-
- if (!is_valid_algorithm_type(m_type))
- return ErrorResult("Invalid algorithm type");
-
- if (m_version != get_algorithm_version(m_type))
- return ErrorResult("Invalid algorithm version");
-
- if (check_hash) {
- const uint32_t hash = hash32(safe_ptr_cast<const uint8_t>(this) + k_hash_skip_size, m_size - k_hash_skip_size);
- if (hash != m_hash)
- return ErrorResult("Invalid hash");
- }
-
- return ErrorResult();
- }
-
- private:
- ////////////////////////////////////////////////////////////////////////////////
- // The number of bytes to skip in the header when calculating the hash.
- static constexpr uint32_t k_hash_skip_size = sizeof(uint32_t) + sizeof(uint32_t); // m_size + m_hash
-
- ////////////////////////////////////////////////////////////////////////////////
- // Constructs a compressed clip instance
- CompressedClip(uint32_t size, algorithm_type8 type)
- : m_size(size)
- , m_hash(hash32(safe_ptr_cast<const uint8_t>(this) + k_hash_skip_size, size - k_hash_skip_size))
- , m_tag(static_cast<uint32_t>(buffer_tag32::compressed_clip))
- , m_version(get_algorithm_version(type))
- , m_type(type)
- , m_padding(0)
- {
- (void)m_padding; // Avoid unused warning
- }
-
- ////////////////////////////////////////////////////////////////////////////////
- // 16 byte header, the rest of the data follows in memory.
- ////////////////////////////////////////////////////////////////////////////////
-
- // Total size in bytes of the compressed clip. Includes 'sizeof(CompressedClip)'.
- uint32_t m_size;
-
- // Hash of the compressed clip. Hashed memory starts immediately after this.
- uint32_t m_hash;
-
- ////////////////////////////////////////////////////////////////////////////////
- // Everything starting here is included in the hash.
- ////////////////////////////////////////////////////////////////////////////////
-
- // Serialization tag used to distinguish raw buffer types.
- uint32_t m_tag;
-
- // Serialization version used to compress the clip.
- uint16_t m_version;
-
- // Algorithm type used to compress the clip.
- algorithm_type8 m_type;
-
- // Unused memory left as padding
- uint8_t m_padding;
-
- ////////////////////////////////////////////////////////////////////////////////
- // Friend function used to construct compressed clip instances. Should only
- // be called by encoders.
- friend CompressedClip* acl_impl::make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type);
-
- ////////////////////////////////////////////////////////////////////////////////
- // Friend function to finalize a compressed clip once all memory has been written within.
- friend void acl_impl::finalize_compressed_clip(CompressedClip& compressed_clip);
- };
-
- static_assert(alignof(CompressedClip) == 16, "Invalid alignment for CompressedClip");
- static_assert(sizeof(CompressedClip) == 16, "Invalid size for CompressedClip");
-
- //////////////////////////////////////////////////////////////////////////
- // Create a CompressedClip instance in place from a raw memory buffer.
- // If the buffer does not contain a valid CompressedClip instance, nullptr is returned
- // along with an optional error result.
- //////////////////////////////////////////////////////////////////////////
- inline const CompressedClip* make_compressed_clip(const void* buffer, ErrorResult* out_error_result = nullptr)
- {
- if (buffer == nullptr)
- {
- if (out_error_result != nullptr)
- *out_error_result = ErrorResult("Buffer is not a valid pointer");
-
- return nullptr;
- }
-
- const CompressedClip* clip = static_cast<const CompressedClip*>(buffer);
- if (out_error_result != nullptr)
- {
- const ErrorResult result = clip->is_valid(false);
- *out_error_result = result;
-
- if (result.any())
- return nullptr;
- }
-
- return clip;
- }
-
- ////////////////////////////////////////////////////////////////////////////////
- // A compressed clip segment header. Each segment is built from a uniform number
- // of samples per track. A clip is split into one or more segments.
- ////////////////////////////////////////////////////////////////////////////////
- struct SegmentHeader
- {
- // Number of bits used by a fully animated pose (excludes default/constant tracks).
- uint32_t animated_pose_bit_size; // TODO: Calculate from bitsets and formats?
-
- // TODO: Only need one offset, calculate the others from the information we have?
- // Offset to the per animated track format data.
- PtrOffset32<uint8_t> format_per_track_data_offset; // TODO: Make this offset optional? Only present if variable
-
- // Offset to the segment range data.
- PtrOffset32<uint8_t> range_data_offset; // TODO: Make this offset optional? Only present if normalized
-
- // Offset to the segment animated tracks data.
- PtrOffset32<uint8_t> track_data_offset;
- };
-
- ////////////////////////////////////////////////////////////////////////////////
- // A compressed clip header.
- ////////////////////////////////////////////////////////////////////////////////
- struct ClipHeader
- {
- // The number of bones compressed.
- uint16_t num_bones;
-
- // The number of segments contained.
- uint16_t num_segments;
-
- // The rotation/translation/scale format used.
- rotation_format8 rotation_format;
- vector_format8 translation_format;
- vector_format8 scale_format; // TODO: Make this optional?
-
- // Whether or not we have scale (bool).
- uint8_t has_scale;
-
- // Whether the default scale is 0,0,0 or 1,1,1 (bool/bit).
- uint8_t default_scale;
-
- uint8_t padding[3];
-
- // The total number of samples per track our clip contained.
- uint32_t num_samples;
-
- // The clip sample rate.
- float sample_rate; // TODO: Store duration as float instead
-
- // Offset to the segment headers data.
- PtrOffset16<uint32_t> segment_start_indices_offset;
- PtrOffset16<SegmentHeader> segment_headers_offset;
-
- // Offsets to the default/constant tracks bitsets.
- PtrOffset16<uint32_t> default_tracks_bitset_offset;
- PtrOffset16<uint32_t> constant_tracks_bitset_offset;
-
- // Offset to the constant tracks data.
- PtrOffset16<uint8_t> constant_track_data_offset;
-
- // Offset to the clip range data.
- PtrOffset16<uint8_t> clip_range_data_offset; // TODO: Make this offset optional? Only present if normalized
-
- //////////////////////////////////////////////////////////////////////////
- // Utility functions that return pointers from their respective offsets.
-
- uint32_t* get_segment_start_indices() { return segment_start_indices_offset.safe_add_to(this); }
- const uint32_t* get_segment_start_indices() const { return segment_start_indices_offset.safe_add_to(this); }
-
- SegmentHeader* get_segment_headers() { return segment_headers_offset.add_to(this); }
- const SegmentHeader* get_segment_headers() const { return segment_headers_offset.add_to(this); }
-
- uint32_t* get_default_tracks_bitset() { return default_tracks_bitset_offset.add_to(this); }
- const uint32_t* get_default_tracks_bitset() const { return default_tracks_bitset_offset.add_to(this); }
-
- uint32_t* get_constant_tracks_bitset() { return constant_tracks_bitset_offset.add_to(this); }
- const uint32_t* get_constant_tracks_bitset() const { return constant_tracks_bitset_offset.add_to(this); }
-
- uint8_t* get_constant_track_data() { return constant_track_data_offset.safe_add_to(this); }
- const uint8_t* get_constant_track_data() const { return constant_track_data_offset.safe_add_to(this); }
-
- uint8_t* get_format_per_track_data(const SegmentHeader& header) { return header.format_per_track_data_offset.safe_add_to(this); }
- const uint8_t* get_format_per_track_data(const SegmentHeader& header) const { return header.format_per_track_data_offset.safe_add_to(this); }
-
- uint8_t* get_clip_range_data() { return clip_range_data_offset.safe_add_to(this); }
- const uint8_t* get_clip_range_data() const { return clip_range_data_offset.safe_add_to(this); }
-
- uint8_t* get_track_data(const SegmentHeader& header) { return header.track_data_offset.safe_add_to(this); }
- const uint8_t* get_track_data(const SegmentHeader& header) const { return header.track_data_offset.safe_add_to(this); }
-
- uint8_t* get_segment_range_data(const SegmentHeader& header) { return header.range_data_offset.safe_add_to(this); }
- const uint8_t* get_segment_range_data(const SegmentHeader& header) const { return header.range_data_offset.safe_add_to(this); }
- };
-
- // Returns the clip header for a compressed clip.
- inline ClipHeader& get_clip_header(CompressedClip& clip)
- {
- return *add_offset_to_ptr<ClipHeader>(&clip, sizeof(CompressedClip));
- }
-
- // Returns the clip header for a compressed clip.
- inline const ClipHeader& get_clip_header(const CompressedClip& clip)
- {
- return *add_offset_to_ptr<const ClipHeader>(&clip, sizeof(CompressedClip));
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/compressed_tracks.h b/includes/acl/core/compressed_tracks.h
--- a/includes/acl/core/compressed_tracks.h
+++ b/includes/acl/core/compressed_tracks.h
@@ -99,28 +99,28 @@ namespace acl
// memory has not been corrupted.
//
// check_hash: If true, the compressed tracks hash will also be compared.
- ErrorResult is_valid(bool check_hash) const
+ error_result is_valid(bool check_hash) const
{
if (!is_aligned_to(this, alignof(compressed_tracks)))
- return ErrorResult("Invalid alignment");
+ return error_result("Invalid alignment");
if (m_tracks_header.tag != static_cast<uint32_t>(buffer_tag32::compressed_tracks))
- return ErrorResult("Invalid tag");
+ return error_result("Invalid tag");
if (!is_valid_algorithm_type(m_tracks_header.algorithm_type))
- return ErrorResult("Invalid algorithm type");
+ return error_result("Invalid algorithm type");
if (m_tracks_header.version != get_algorithm_version(m_tracks_header.algorithm_type))
- return ErrorResult("Invalid algorithm version");
+ return error_result("Invalid algorithm version");
if (check_hash)
{
const uint32_t hash = hash32(safe_ptr_cast<const uint8_t>(&m_tracks_header), m_buffer_header.size - sizeof(acl_impl::raw_buffer_header));
if (hash != m_buffer_header.hash)
- return ErrorResult("Invalid hash");
+ return error_result("Invalid hash");
}
- return ErrorResult();
+ return error_result();
}
private:
@@ -156,12 +156,12 @@ namespace acl
// If the buffer does not contain a valid compressed_tracks instance, nullptr is returned
// along with an optional error result.
//////////////////////////////////////////////////////////////////////////
- inline const compressed_tracks* make_compressed_tracks(const void* buffer, ErrorResult* out_error_result = nullptr)
+ inline const compressed_tracks* make_compressed_tracks(const void* buffer, error_result* out_error_result = nullptr)
{
if (buffer == nullptr)
{
if (out_error_result != nullptr)
- *out_error_result = ErrorResult("Buffer is not a valid pointer");
+ *out_error_result = error_result("Buffer is not a valid pointer");
return nullptr;
}
@@ -169,7 +169,7 @@ namespace acl
const compressed_tracks* clip = static_cast<const compressed_tracks*>(buffer);
if (out_error_result != nullptr)
{
- const ErrorResult result = clip->is_valid(false);
+ const error_result result = clip->is_valid(false);
*out_error_result = result;
if (result.any())
@@ -181,8 +181,10 @@ namespace acl
namespace acl_impl
{
- // Hide this implementation, it shouldn't be needed in user-space
+ // Hide these implementations, they shouldn't be needed in user-space
inline const tracks_header& get_tracks_header(const compressed_tracks& tracks) { return tracks.m_tracks_header; }
+ inline const scalar_tracks_header& get_scalar_tracks_header(const compressed_tracks& tracks) { return *reinterpret_cast<const scalar_tracks_header*>(reinterpret_cast<const uint8_t*>(&tracks) + sizeof(compressed_tracks)); }
+ inline const transform_tracks_header& get_transform_tracks_header(const compressed_tracks& tracks) { return *reinterpret_cast<const transform_tracks_header*>(reinterpret_cast<const uint8_t*>(&tracks) + sizeof(compressed_tracks)); }
}
}
diff --git a/includes/acl/core/error_result.h b/includes/acl/core/error_result.h
--- a/includes/acl/core/error_result.h
+++ b/includes/acl/core/error_result.h
@@ -35,11 +35,11 @@ namespace acl
// coerce with 'bool' in order to simplify and clean up error handling.
// In an ideal world, I would love for a C++11 equivalent of std::result in Rust.
//////////////////////////////////////////////////////////////////////////
- class ErrorResult
+ class error_result
{
public:
- ErrorResult() : m_error(nullptr) {}
- explicit ErrorResult(const char* error) : m_error(error) {}
+ error_result() : m_error(nullptr) {}
+ explicit error_result(const char* error) : m_error(error) {}
bool empty() const { return m_error == nullptr; }
bool any() const { return m_error != nullptr; }
diff --git a/includes/acl/core/iallocator.h b/includes/acl/core/iallocator.h
--- a/includes/acl/core/iallocator.h
+++ b/includes/acl/core/iallocator.h
@@ -45,16 +45,16 @@ namespace acl
//
// See ansi_allocator.h for an implementation that uses the system malloc/free.
////////////////////////////////////////////////////////////////////////////////
- class IAllocator
+ class iallocator
{
public:
static constexpr size_t k_default_alignment = 16;
- IAllocator() {}
- virtual ~IAllocator() {}
+ iallocator() {}
+ virtual ~iallocator() {}
- IAllocator(const IAllocator&) = delete;
- IAllocator& operator=(const IAllocator&) = delete;
+ iallocator(const iallocator&) = delete;
+ iallocator& operator=(const iallocator&) = delete;
////////////////////////////////////////////////////////////////////////////////
// Allocates memory with the specified size and alignment.
@@ -73,73 +73,73 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
- template<typename AllocatedType, typename... Args>
- AllocatedType* allocate_type(IAllocator& allocator, Args&&... args)
+ template<typename allocated_type, typename... args>
+ allocated_type* allocate_type(iallocator& allocator, args&&... arguments)
{
- AllocatedType* ptr = reinterpret_cast<AllocatedType*>(allocator.allocate(sizeof(AllocatedType), alignof(AllocatedType)));
- if (acl_impl::is_trivially_default_constructible<AllocatedType>::value)
+ allocated_type* ptr = reinterpret_cast<allocated_type*>(allocator.allocate(sizeof(allocated_type), alignof(allocated_type)));
+ if (acl_impl::is_trivially_default_constructible<allocated_type>::value)
return ptr;
- return new(ptr) AllocatedType(std::forward<Args>(args)...);
+ return new(ptr) allocated_type(std::forward<args>(arguments)...);
}
- template<typename AllocatedType, typename... Args>
- AllocatedType* allocate_type_aligned(IAllocator& allocator, size_t alignment, Args&&... args)
+ template<typename allocated_type, typename... args>
+ allocated_type* allocate_type_aligned(iallocator& allocator, size_t alignment, args&&... arguments)
{
- ACL_ASSERT(is_alignment_valid<AllocatedType>(alignment), "Invalid alignment: %u. Expected a power of two at least equal to %u", alignment, alignof(AllocatedType));
- AllocatedType* ptr = reinterpret_cast<AllocatedType*>(allocator.allocate(sizeof(AllocatedType), alignment));
- if (acl_impl::is_trivially_default_constructible<AllocatedType>::value)
+ ACL_ASSERT(is_alignment_valid<allocated_type>(alignment), "Invalid alignment: %u. Expected a power of two at least equal to %u", alignment, alignof(allocated_type));
+ allocated_type* ptr = reinterpret_cast<allocated_type*>(allocator.allocate(sizeof(allocated_type), alignment));
+ if (acl_impl::is_trivially_default_constructible<allocated_type>::value)
return ptr;
- return new(ptr) AllocatedType(std::forward<Args>(args)...);
+ return new(ptr) allocated_type(std::forward<args>(arguments)...);
}
- template<typename AllocatedType>
- void deallocate_type(IAllocator& allocator, AllocatedType* ptr)
+ template<typename allocated_type>
+ void deallocate_type(iallocator& allocator, allocated_type* ptr)
{
if (ptr == nullptr)
return;
- if (!std::is_trivially_destructible<AllocatedType>::value)
- ptr->~AllocatedType();
+ if (!std::is_trivially_destructible<allocated_type>::value)
+ ptr->~allocated_type();
- allocator.deallocate(ptr, sizeof(AllocatedType));
+ allocator.deallocate(ptr, sizeof(allocated_type));
}
- template<typename AllocatedType, typename... Args>
- AllocatedType* allocate_type_array(IAllocator& allocator, size_t num_elements, Args&&... args)
+ template<typename allocated_type, typename... args>
+ allocated_type* allocate_type_array(iallocator& allocator, size_t num_elements, args&&... arguments)
{
- AllocatedType* ptr = reinterpret_cast<AllocatedType*>(allocator.allocate(sizeof(AllocatedType) * num_elements, alignof(AllocatedType)));
- if (acl_impl::is_trivially_default_constructible<AllocatedType>::value)
+ allocated_type* ptr = reinterpret_cast<allocated_type*>(allocator.allocate(sizeof(allocated_type) * num_elements, alignof(allocated_type)));
+ if (acl_impl::is_trivially_default_constructible<allocated_type>::value)
return ptr;
for (size_t element_index = 0; element_index < num_elements; ++element_index)
- new(&ptr[element_index]) AllocatedType(std::forward<Args>(args)...);
+ new(&ptr[element_index]) allocated_type(std::forward<args>(arguments)...);
return ptr;
}
- template<typename AllocatedType, typename... Args>
- AllocatedType* allocate_type_array_aligned(IAllocator& allocator, size_t num_elements, size_t alignment, Args&&... args)
+ template<typename allocated_type, typename... args>
+ allocated_type* allocate_type_array_aligned(iallocator& allocator, size_t num_elements, size_t alignment, args&&... arguments)
{
- ACL_ASSERT(is_alignment_valid<AllocatedType>(alignment), "Invalid alignment: %zu. Expected a power of two at least equal to %zu", alignment, alignof(AllocatedType));
- AllocatedType* ptr = reinterpret_cast<AllocatedType*>(allocator.allocate(sizeof(AllocatedType) * num_elements, alignment));
- if (acl_impl::is_trivially_default_constructible<AllocatedType>::value)
+ ACL_ASSERT(is_alignment_valid<allocated_type>(alignment), "Invalid alignment: %zu. Expected a power of two at least equal to %zu", alignment, alignof(allocated_type));
+ allocated_type* ptr = reinterpret_cast<allocated_type*>(allocator.allocate(sizeof(allocated_type) * num_elements, alignment));
+ if (acl_impl::is_trivially_default_constructible<allocated_type>::value)
return ptr;
for (size_t element_index = 0; element_index < num_elements; ++element_index)
- new(&ptr[element_index]) AllocatedType(std::forward<Args>(args)...);
+ new(&ptr[element_index]) allocated_type(std::forward<args>(arguments)...);
return ptr;
}
- template<typename AllocatedType>
- void deallocate_type_array(IAllocator& allocator, AllocatedType* elements, size_t num_elements)
+ template<typename allocated_type>
+ void deallocate_type_array(iallocator& allocator, allocated_type* elements, size_t num_elements)
{
if (elements == nullptr)
return;
- if (!std::is_trivially_destructible<AllocatedType>::value)
+ if (!std::is_trivially_destructible<allocated_type>::value)
{
for (size_t element_index = 0; element_index < num_elements; ++element_index)
- elements[element_index].~AllocatedType();
+ elements[element_index].~allocated_type();
}
- allocator.deallocate(elements, sizeof(AllocatedType) * num_elements);
+ allocator.deallocate(elements, sizeof(allocated_type) * num_elements);
}
}
diff --git a/includes/acl/core/impl/compressed_headers.h b/includes/acl/core/impl/compressed_headers.h
--- a/includes/acl/core/impl/compressed_headers.h
+++ b/includes/acl/core/impl/compressed_headers.h
@@ -46,11 +46,6 @@ namespace acl
uint32_t hash;
};
- struct track_metadata
- {
- uint8_t bit_rate;
- };
-
struct tracks_header
{
// Serialization tag used to distinguish raw buffer types.
@@ -74,29 +69,122 @@ namespace acl
// The sample rate our tracks use.
float sample_rate; // TODO: Store duration as float instead?
+ uint32_t padding;
+ };
+
+ struct track_metadata
+ {
+ uint8_t bit_rate;
+ };
+
+ struct scalar_tracks_header
+ {
// The number of bits used for a whole frame of data.
// The sum of one sample per track with all bit rates taken into account.
- uint32_t num_bits_per_frame;
+ uint32_t num_bits_per_frame;
// Various data offsets relative to the start of this header.
- PtrOffset32<track_metadata> metadata_per_track;
- PtrOffset32<float> track_constant_values;
- PtrOffset32<float> track_range_values;
- PtrOffset32<uint8_t> track_animated_values;
+ ptr_offset32<track_metadata> metadata_per_track;
+ ptr_offset32<float> track_constant_values;
+ ptr_offset32<float> track_range_values;
+ ptr_offset32<uint8_t> track_animated_values;
//////////////////////////////////////////////////////////////////////////
- track_metadata* get_track_metadata() { return metadata_per_track.add_to(this); }
- const track_metadata* get_track_metadata() const { return metadata_per_track.add_to(this); }
+ track_metadata* get_track_metadata() { return metadata_per_track.add_to(this); }
+ const track_metadata* get_track_metadata() const { return metadata_per_track.add_to(this); }
+
+ float* get_track_constant_values() { return track_constant_values.add_to(this); }
+ const float* get_track_constant_values() const { return track_constant_values.add_to(this); }
+
+ float* get_track_range_values() { return track_range_values.add_to(this); }
+ const float* get_track_range_values() const { return track_range_values.add_to(this); }
+
+ uint8_t* get_track_animated_values() { return track_animated_values.add_to(this); }
+ const uint8_t* get_track_animated_values() const { return track_animated_values.add_to(this); }
+ };
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // A compressed clip segment header. Each segment is built from a uniform number
+ // of samples per track. A clip is split into one or more segments.
+ ////////////////////////////////////////////////////////////////////////////////
+ struct segment_header
+ {
+ // Number of bits used by a fully animated pose (excludes default/constant tracks).
+ uint32_t animated_pose_bit_size; // TODO: Calculate from bitsets and formats?
+
+ // TODO: Only need one offset, calculate the others from the information we have?
+ // Offset to the per animated track format data.
+ ptr_offset32<uint8_t> format_per_track_data_offset; // TODO: Make this offset optional? Only present if variable
+
+ // Offset to the segment range data.
+ ptr_offset32<uint8_t> range_data_offset; // TODO: Make this offset optional? Only present if normalized
+
+ // Offset to the segment animated tracks data.
+ ptr_offset32<uint8_t> track_data_offset;
+ };
+
+ struct transform_tracks_header
+ {
+ // The number of segments contained.
+ uint16_t num_segments;
+
+ // The rotation/translation/scale format used.
+ rotation_format8 rotation_format;
+ vector_format8 translation_format;
+ vector_format8 scale_format; // TODO: Make this optional?
+
+ // Whether or not we have scale (bool).
+ uint8_t has_scale;
+
+ // Whether the default scale is 0,0,0 or 1,1,1 (bool/bit).
+ uint8_t default_scale;
+
+ uint8_t padding[1];
+
+ // Offset to the segment headers data.
+ ptr_offset16<uint32_t> segment_start_indices_offset;
+ ptr_offset16<segment_header> segment_headers_offset;
+
+ // Offsets to the default/constant tracks bitsets.
+ ptr_offset16<uint32_t> default_tracks_bitset_offset;
+ ptr_offset16<uint32_t> constant_tracks_bitset_offset;
+
+ // Offset to the constant tracks data.
+ ptr_offset16<uint8_t> constant_track_data_offset;
+
+ // Offset to the clip range data.
+ ptr_offset16<uint8_t> clip_range_data_offset; // TODO: Make this offset optional? Only present if normalized
+
+ //////////////////////////////////////////////////////////////////////////
+ // Utility functions that return pointers from their respective offsets.
+
+ uint32_t* get_segment_start_indices() { return segment_start_indices_offset.safe_add_to(this); }
+ const uint32_t* get_segment_start_indices() const { return segment_start_indices_offset.safe_add_to(this); }
+
+ segment_header* get_segment_headers() { return segment_headers_offset.add_to(this); }
+ const segment_header* get_segment_headers() const { return segment_headers_offset.add_to(this); }
+
+ uint32_t* get_default_tracks_bitset() { return default_tracks_bitset_offset.add_to(this); }
+ const uint32_t* get_default_tracks_bitset() const { return default_tracks_bitset_offset.add_to(this); }
+
+ uint32_t* get_constant_tracks_bitset() { return constant_tracks_bitset_offset.add_to(this); }
+ const uint32_t* get_constant_tracks_bitset() const { return constant_tracks_bitset_offset.add_to(this); }
+
+ uint8_t* get_constant_track_data() { return constant_track_data_offset.safe_add_to(this); }
+ const uint8_t* get_constant_track_data() const { return constant_track_data_offset.safe_add_to(this); }
+
+ uint8_t* get_format_per_track_data(const segment_header& header) { return header.format_per_track_data_offset.safe_add_to(this); }
+ const uint8_t* get_format_per_track_data(const segment_header& header) const { return header.format_per_track_data_offset.safe_add_to(this); }
- float* get_track_constant_values() { return track_constant_values.add_to(this); }
- const float* get_track_constant_values() const { return track_constant_values.add_to(this); }
+ uint8_t* get_clip_range_data() { return clip_range_data_offset.safe_add_to(this); }
+ const uint8_t* get_clip_range_data() const { return clip_range_data_offset.safe_add_to(this); }
- float* get_track_range_values() { return track_range_values.add_to(this); }
- const float* get_track_range_values() const { return track_range_values.add_to(this); }
+ uint8_t* get_track_data(const segment_header& header) { return header.track_data_offset.safe_add_to(this); }
+ const uint8_t* get_track_data(const segment_header& header) const { return header.track_data_offset.safe_add_to(this); }
- uint8_t* get_track_animated_values() { return track_animated_values.add_to(this); }
- const uint8_t* get_track_animated_values() const { return track_animated_values.add_to(this); }
+ uint8_t* get_segment_range_data(const segment_header& header) { return header.range_data_offset.safe_add_to(this); }
+ const uint8_t* get_segment_range_data(const segment_header& header) const { return header.range_data_offset.safe_add_to(this); }
};
}
}
diff --git a/includes/acl/core/impl/debug_track_writer.h b/includes/acl/core/impl/debug_track_writer.h
--- a/includes/acl/core/impl/debug_track_writer.h
+++ b/includes/acl/core/impl/debug_track_writer.h
@@ -42,7 +42,7 @@ namespace acl
{
struct debug_track_writer final : public track_writer
{
- debug_track_writer(IAllocator& allocator_, track_type8 type_, uint32_t num_tracks_)
+ debug_track_writer(iallocator& allocator_, track_type8 type_, uint32_t num_tracks_)
: allocator(allocator_)
, tracks_typed{ nullptr }
, buffer_size(0)
@@ -50,8 +50,8 @@ namespace acl
, type(type_)
{
// Large enough to accommodate the largest type
- buffer_size = sizeof(rtm::vector4f) * num_tracks_;
- tracks_typed.any = allocator_.allocate(buffer_size, alignof(rtm::vector4f));
+ buffer_size = sizeof(rtm::qvvf) * num_tracks_;
+ tracks_typed.any = allocator_.allocate(buffer_size, alignof(rtm::qvvf));
}
~debug_track_writer()
@@ -129,6 +129,36 @@ namespace acl
return tracks_typed.vector4f[track_index];
}
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a quaternion rotation value for a specified bone index.
+ void RTM_SIMD_CALL write_rotation(uint32_t track_index, rtm::quatf_arg0 rotation)
+ {
+ ACL_ASSERT(type == track_type8::qvvf, "Unexpected track type access");
+ tracks_typed.qvvf[track_index].rotation = rotation;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a translation value for a specified bone index.
+ void RTM_SIMD_CALL write_translation(uint32_t track_index, rtm::vector4f_arg0 translation)
+ {
+ ACL_ASSERT(type == track_type8::qvvf, "Unexpected track type access");
+ tracks_typed.qvvf[track_index].translation = translation;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a scale value for a specified bone index.
+ void RTM_SIMD_CALL write_scale(uint32_t track_index, rtm::vector4f_arg0 scale)
+ {
+ ACL_ASSERT(type == track_type8::qvvf, "Unexpected track type access");
+ tracks_typed.qvvf[track_index].scale = scale;
+ }
+
+ const rtm::qvvf& RTM_SIMD_CALL read_qvv(uint32_t track_index) const
+ {
+ ACL_ASSERT(type == track_type8::qvvf, "Unexpected track type access");
+ return tracks_typed.qvvf[track_index];
+ }
+
union ptr_union
{
void* any;
@@ -137,9 +167,10 @@ namespace acl
rtm::float3f* float3f;
rtm::float4f* float4f;
rtm::vector4f* vector4f;
+ rtm::qvvf* qvvf;
};
- IAllocator& allocator;
+ iallocator& allocator;
ptr_union tracks_typed;
size_t buffer_size;
diff --git a/includes/acl/core/iterator.h b/includes/acl/core/iterator.h
--- a/includes/acl/core/iterator.h
+++ b/includes/acl/core/iterator.h
@@ -35,13 +35,13 @@ namespace acl
{
namespace acl_impl
{
- template <class ItemType, bool is_const>
- class IteratorImpl
+ template <class item_type, bool is_const>
+ class iterator_impl
{
public:
- typedef typename std::conditional<is_const, const ItemType*, ItemType*>::type ItemPtr;
+ typedef typename std::conditional<is_const, const item_type*, item_type*>::type ItemPtr;
- constexpr IteratorImpl(ItemPtr items, size_t num_items) : m_items(items), m_num_items(num_items) {}
+ constexpr iterator_impl(ItemPtr items, size_t num_items) : m_items(items), m_num_items(num_items) {}
constexpr ItemPtr begin() const { return m_items; }
constexpr ItemPtr end() const { return m_items + m_num_items; }
@@ -52,11 +52,11 @@ namespace acl
};
}
- template <class ItemType>
- using Iterator = acl_impl::IteratorImpl<ItemType, false>;
+ template <class item_type>
+ using iterator = acl_impl::iterator_impl<item_type, false>;
- template <class ItemType>
- using ConstIterator = acl_impl::IteratorImpl<ItemType, true>;
+ template <class item_type>
+ using const_iterator = acl_impl::iterator_impl<item_type, true>;
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/memory_utils.h b/includes/acl/core/memory_utils.h
--- a/includes/acl/core/memory_utils.h
+++ b/includes/acl/core/memory_utils.h
@@ -228,8 +228,8 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Endian and raw memory support
- template<typename OutputPtrType, typename InputPtrType, typename OffsetType>
- inline OutputPtrType* add_offset_to_ptr(InputPtrType* ptr, OffsetType offset)
+ template<typename OutputPtrType, typename InputPtrType, typename offset_type>
+ inline OutputPtrType* add_offset_to_ptr(InputPtrType* ptr, offset_type offset)
{
return safe_ptr_cast<OutputPtrType>(reinterpret_cast<uintptr_t>(ptr) + offset);
}
@@ -318,24 +318,24 @@ namespace acl
}
}
- template<typename DataType>
- inline DataType unaligned_load(const void* input)
+ template<typename data_type>
+ inline data_type unaligned_load(const void* input)
{
- DataType result;
- std::memcpy(&result, input, sizeof(DataType));
+ data_type result;
+ std::memcpy(&result, input, sizeof(data_type));
return result;
}
- template<typename DataType>
- inline DataType aligned_load(const void* input)
+ template<typename data_type>
+ inline data_type aligned_load(const void* input)
{
- return *safe_ptr_cast<const DataType, const void*>(input);
+ return *safe_ptr_cast<const data_type, const void*>(input);
}
- template<typename DataType>
- inline void unaligned_write(DataType input, void* output)
+ template<typename data_type>
+ inline void unaligned_write(data_type input, void* output)
{
- std::memcpy(output, &input, sizeof(DataType));
+ std::memcpy(output, &input, sizeof(data_type));
}
}
diff --git a/includes/acl/core/ptr_offset.h b/includes/acl/core/ptr_offset.h
--- a/includes/acl/core/ptr_offset.h
+++ b/includes/acl/core/ptr_offset.h
@@ -34,88 +34,88 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
////////////////////////////////////////////////////////////////////////////////
- // Represents an invalid pointer offset, used by 'PtrOffset'.
+ // Represents an invalid pointer offset, used by 'ptr_offset'.
////////////////////////////////////////////////////////////////////////////////
- struct InvalidPtrOffset {};
+ struct invalid_ptr_offset final {};
////////////////////////////////////////////////////////////////////////////////
// A type safe pointer offset.
//
- // This class only wraps an integer of the 'OffsetType' type and adds type safety
- // by only casting to 'DataType'.
+ // This class only wraps an integer of the 'offset_type' type and adds type safety
+ // by only casting to 'data_type'.
////////////////////////////////////////////////////////////////////////////////
- template<typename DataType, typename OffsetType>
- class PtrOffset
+ template<typename data_type, typename offset_type>
+ class ptr_offset
{
public:
////////////////////////////////////////////////////////////////////////////////
// Constructs a valid but empty offset.
- constexpr PtrOffset() : m_value(0) {}
+ constexpr ptr_offset() : m_value(0) {}
////////////////////////////////////////////////////////////////////////////////
// Constructs a valid offset with the specified value.
- constexpr PtrOffset(size_t value) : m_value(safe_static_cast<OffsetType>(value)) {}
+ constexpr ptr_offset(size_t value) : m_value(safe_static_cast<offset_type>(value)) {}
////////////////////////////////////////////////////////////////////////////////
// Constructs an invalid offset.
- constexpr PtrOffset(InvalidPtrOffset) : m_value(std::numeric_limits<OffsetType>::max()) {}
+ constexpr ptr_offset(invalid_ptr_offset) : m_value(std::numeric_limits<offset_type>::max()) {}
////////////////////////////////////////////////////////////////////////////////
// Adds this offset to the provided pointer.
template<typename BaseType>
- inline DataType* add_to(BaseType* ptr) const
+ inline data_type* add_to(BaseType* ptr) const
{
- ACL_ASSERT(is_valid(), "Invalid PtrOffset!");
- return add_offset_to_ptr<DataType>(ptr, m_value);
+ ACL_ASSERT(is_valid(), "Invalid ptr_offset!");
+ return add_offset_to_ptr<data_type>(ptr, m_value);
}
////////////////////////////////////////////////////////////////////////////////
// Adds this offset to the provided pointer.
template<typename BaseType>
- inline const DataType* add_to(const BaseType* ptr) const
+ inline const data_type* add_to(const BaseType* ptr) const
{
- ACL_ASSERT(is_valid(), "Invalid PtrOffset!");
- return add_offset_to_ptr<const DataType>(ptr, m_value);
+ ACL_ASSERT(is_valid(), "Invalid ptr_offset!");
+ return add_offset_to_ptr<const data_type>(ptr, m_value);
}
////////////////////////////////////////////////////////////////////////////////
// Adds this offset to the provided pointer or returns nullptr if the offset is invalid.
template<typename BaseType>
- inline DataType* safe_add_to(BaseType* ptr) const
+ inline data_type* safe_add_to(BaseType* ptr) const
{
- return is_valid() ? add_offset_to_ptr<DataType>(ptr, m_value) : nullptr;
+ return is_valid() ? add_offset_to_ptr<data_type>(ptr, m_value) : nullptr;
}
////////////////////////////////////////////////////////////////////////////////
// Adds this offset to the provided pointer or returns nullptr if the offset is invalid.
template<typename BaseType>
- inline const DataType* safe_add_to(const BaseType* ptr) const
+ inline const data_type* safe_add_to(const BaseType* ptr) const
{
- return is_valid() ? add_offset_to_ptr<DataType>(ptr, m_value) : nullptr;
+ return is_valid() ? add_offset_to_ptr<data_type>(ptr, m_value) : nullptr;
}
////////////////////////////////////////////////////////////////////////////////
- // Coercion operator to the underlying 'OffsetType'.
- constexpr operator OffsetType() const { return m_value; }
+ // Coercion operator to the underlying 'offset_type'.
+ constexpr operator offset_type() const { return m_value; }
////////////////////////////////////////////////////////////////////////////////
// Returns true if the offset is valid.
- constexpr bool is_valid() const { return m_value != std::numeric_limits<OffsetType>::max(); }
+ constexpr bool is_valid() const { return m_value != std::numeric_limits<offset_type>::max(); }
private:
// Actual offset value.
- OffsetType m_value;
+ offset_type m_value;
};
////////////////////////////////////////////////////////////////////////////////
// A 16 bit offset.
- template<typename DataType>
- using PtrOffset16 = PtrOffset<DataType, uint16_t>;
+ template<typename data_type>
+ using ptr_offset16 = ptr_offset<data_type, uint16_t>;
////////////////////////////////////////////////////////////////////////////////
// A 32 bit offset.
- template<typename DataType>
- using PtrOffset32 = PtrOffset<DataType, uint32_t>;
+ template<typename data_type>
+ using ptr_offset32 = ptr_offset<data_type, uint32_t>;
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/scope_profiler.h b/includes/acl/core/scope_profiler.h
--- a/includes/acl/core/scope_profiler.h
+++ b/includes/acl/core/scope_profiler.h
@@ -36,16 +36,16 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// A scope activated profiler.
////////////////////////////////////////////////////////////////////////////////
- class ScopeProfiler
+ class scope_profiler
{
public:
////////////////////////////////////////////////////////////////////////////////
// Creates and starts a scope profiler and automatically starts it.
- ScopeProfiler();
+ scope_profiler();
////////////////////////////////////////////////////////////////////////////////
// Destroys a scope profiler and automatically stops it.
- ~ScopeProfiler() = default;
+ ~scope_profiler() = default;
////////////////////////////////////////////////////////////////////////////////
// Manually stops the profiler.
@@ -68,8 +68,8 @@ namespace acl
double get_elapsed_seconds() const { return std::chrono::duration<double, std::chrono::seconds::period>(get_elapsed_time()).count(); }
private:
- ScopeProfiler(const ScopeProfiler&) = delete;
- ScopeProfiler& operator=(const ScopeProfiler&) = delete;
+ scope_profiler(const scope_profiler&) = delete;
+ scope_profiler& operator=(const scope_profiler&) = delete;
// The time at which the profiler started.
std::chrono::time_point<std::chrono::high_resolution_clock> m_start_time;
@@ -80,12 +80,12 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
- inline ScopeProfiler::ScopeProfiler()
+ inline scope_profiler::scope_profiler()
{
m_start_time = m_end_time = std::chrono::high_resolution_clock::now();
}
- inline void ScopeProfiler::stop()
+ inline void scope_profiler::stop()
{
if (m_start_time == m_end_time)
m_end_time = std::chrono::high_resolution_clock::now();
diff --git a/includes/acl/core/string.h b/includes/acl/core/string.h
--- a/includes/acl/core/string.h
+++ b/includes/acl/core/string.h
@@ -40,12 +40,12 @@ namespace acl
//
// Strings are immutable.
//////////////////////////////////////////////////////////////////////////
- class String
+ class string
{
public:
- String() noexcept : m_allocator(nullptr), m_c_str(nullptr) {}
+ string() noexcept : m_allocator(nullptr), m_c_str(nullptr) {}
- String(IAllocator& allocator, const char* c_str, size_t length)
+ string(iallocator& allocator, const char* c_str, size_t length)
: m_allocator(&allocator)
{
if (length > 0)
@@ -65,28 +65,28 @@ namespace acl
}
}
- String(IAllocator& allocator, const char* c_str)
- : String(allocator, c_str, c_str != nullptr ? std::strlen(c_str) : 0)
+ string(iallocator& allocator, const char* c_str)
+ : string(allocator, c_str, c_str != nullptr ? std::strlen(c_str) : 0)
{}
- String(IAllocator& allocator, const String& str)
- : String(allocator, str.c_str(), str.size())
+ string(iallocator& allocator, const string& str)
+ : string(allocator, str.c_str(), str.size())
{}
- ~String()
+ ~string()
{
if (m_allocator != nullptr && m_c_str != nullptr)
deallocate_type_array(*m_allocator, m_c_str, std::strlen(m_c_str) + 1);
}
- String(String&& other) noexcept
+ string(string&& other) noexcept
: m_allocator(other.m_allocator)
, m_c_str(other.m_c_str)
{
- new(&other) String();
+ new(&other) string();
}
- String& operator=(String&& other) noexcept
+ string& operator=(string&& other) noexcept
{
std::swap(m_allocator, other.m_allocator);
std::swap(m_c_str, other.m_c_str);
@@ -108,15 +108,15 @@ namespace acl
bool operator!=(const char* c_str) const { return !(*this == c_str); }
- bool operator==(const String& other) const { return (*this == other.c_str()); }
- bool operator!=(const String& other) const { return !(*this == other.c_str()); }
+ bool operator==(const string& other) const { return (*this == other.c_str()); }
+ bool operator!=(const string& other) const { return !(*this == other.c_str()); }
const char* c_str() const { return m_c_str != nullptr ? m_c_str : ""; }
size_t size() const { return m_c_str != nullptr ? std::strlen(m_c_str) : 0; }
bool empty() const { return m_c_str != nullptr ? (std::strlen(m_c_str) == 0) : true; }
private:
- IAllocator* m_allocator;
+ iallocator* m_allocator;
char* m_c_str;
};
}
diff --git a/includes/acl/core/track_traits.h b/includes/acl/core/track_traits.h
--- a/includes/acl/core/track_traits.h
+++ b/includes/acl/core/track_traits.h
@@ -92,6 +92,15 @@ namespace acl
using sample_type = rtm::vector4f;
using desc_type = track_desc_scalarf;
};
+
+ template<>
+ struct track_traits<track_type8::qvvf>
+ {
+ static constexpr track_category8 category = track_category8::transformf;
+
+ using sample_type = rtm::qvvf;
+ using desc_type = track_desc_transformf;
+ };
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/track_types.h b/includes/acl/core/track_types.h
--- a/includes/acl/core/track_types.h
+++ b/includes/acl/core/track_types.h
@@ -24,8 +24,11 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/error_result.h"
#include "acl/core/memory_utils.h"
+#include "acl/core/impl/compiler_utils.h"
+
+#include <rtm/scalarf.h>
#include <cstdint>
#include <cstring>
@@ -99,6 +102,11 @@ namespace acl
// We only support up to 4294967295 tracks. We reserve 4294967295 for the invalid index
constexpr uint32_t k_invalid_track_index = 0xFFFFFFFFU;
+ //////////////////////////////////////////////////////////////////////////
+ // Legacy value, to be removed
+ // TODO: remove me
+ constexpr uint16_t k_invalid_bone_index = 0xFFFFU;
+
//////////////////////////////////////////////////////////////////////////
// The various supported track types.
// Note: be careful when changing values here as they might be serialized.
@@ -119,7 +127,7 @@ namespace acl
//quatf = 10,
//quatd = 11,
- //qvvf = 12,
+ qvvf = 12,
//qvvd = 13,
//int1i = 14,
@@ -140,11 +148,11 @@ namespace acl
enum class track_category8 : uint8_t
{
scalarf = 0,
- //scalard = 1,
+ scalard = 1,
//scalari = 2,
//scalarq = 3,
- //transformf = 4,
- //transformd = 5,
+ transformf = 4,
+ transformd = 5,
};
//////////////////////////////////////////////////////////////////////////
@@ -161,17 +169,29 @@ namespace acl
// will be used instead of the track index. This allows custom reordering for things
// like LOD sorting or skeleton remapping. A value of 'k_invalid_track_index' will strip the track
// from the compressed data stream. Output indices must be unique and contiguous.
- uint32_t output_index;
+ uint32_t output_index = k_invalid_track_index;
//////////////////////////////////////////////////////////////////////////
// The per component precision threshold to try and attain when optimizing the bit rate.
// If the error is below the precision threshold, we will remove bits until we reach it without
// exceeding it. If the error is above the precision threshold, we will add more bits until
// we lower it underneath.
- float precision;
+ // Defaults to '0.00001'
+ float precision = 0.00001F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether a scalar track description is valid or not.
+ // It is valid if:
+ // - The precision is positive or zero and finite
+ error_result is_valid() const
+ {
+ if (precision < 0.0F || !rtm::scalar_is_finite(precision))
+ return error_result("Invalid precision");
+
+ return error_result();
+ }
};
-#if 0 // TODO: Add support for this
//////////////////////////////////////////////////////////////////////////
// This structure describes the various settings for transform tracks.
// Used by: quatf, qvvf
@@ -186,32 +206,78 @@ namespace acl
// will be used instead of the track index. This allows custom reordering for things
// like LOD sorting or skeleton remapping. A value of 'k_invalid_track_index' will strip the track
// from the compressed data stream. Output indices must be unique and contiguous.
- uint32_t output_index;
+ uint32_t output_index = k_invalid_track_index;
//////////////////////////////////////////////////////////////////////////
// The index of the parent transform track or `k_invalid_track_index` if it has no parent.
- uint32_t parent_index;
+ uint32_t parent_index = k_invalid_track_index;
//////////////////////////////////////////////////////////////////////////
// The shell precision threshold to try and attain when optimizing the bit rate.
// If the error is below the precision threshold, we will remove bits until we reach it without
// exceeding it. If the error is above the precision threshold, we will add more bits until
// we lower it underneath.
- float precision;
+ // Note that you will need to change this value if your units are not in centimeters.
+ // Defaults to '0.01' centimeters
+ float precision = 0.01F;
//////////////////////////////////////////////////////////////////////////
// The error is measured on a rigidly deformed shell around every transform at the specified distance.
- float shell_distance;
+ // Defaults to '3.0' centimeters
+ float shell_distance = 3.0F;
//////////////////////////////////////////////////////////////////////////
// TODO: Use the precision and shell distance?
- float constant_rotation_threshold;
- float constant_translation_threshold;
- float constant_scale_threshold;
- };
-#endif
- // TODO: Add transform description?
+ //////////////////////////////////////////////////////////////////////////
+ // Threshold angle when detecting if rotation tracks are constant or default.
+ // See the rtm::quatf quat_near_identity for details about how the default threshold
+ // was chosen. You will typically NEVER need to change this, the value has been
+ // selected to be as safe as possible and is independent of game engine units.
+ // Defaults to '0.00284714461' radians
+ float constant_rotation_threshold_angle = 0.00284714461F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Threshold value to use when detecting if translation tracks are constant or default.
+ // Note that you will need to change this value if your units are not in centimeters.
+ // Defaults to '0.001' centimeters.
+ float constant_translation_threshold = 0.001F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Threshold value to use when detecting if scale tracks are constant or default.
+ // There are no units for scale as such a value that was deemed safe was selected
+ // as a default.
+ // Defaults to '0.00001'
+ float constant_scale_threshold = 0.00001F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether a transform track description is valid or not.
+ // It is valid if:
+ // - The precision is positive or zero and finite
+ // - The shell distance is positive or zero and finite
+ // - The constant rotation threshold angle is positive or zero and finite
+ // - The constant translation threshold is positive or zero and finite
+ // - The constant scale threshold is positive or zero and finite
+ error_result is_valid() const
+ {
+ if (precision < 0.0F || !rtm::scalar_is_finite(precision))
+ return error_result("Invalid precision");
+
+ if (shell_distance < 0.0F || !rtm::scalar_is_finite(shell_distance))
+ return error_result("Invalid shell_distance");
+
+ if (constant_rotation_threshold_angle < 0.0F || !rtm::scalar_is_finite(constant_rotation_threshold_angle))
+ return error_result("Invalid constant_rotation_threshold_angle");
+
+ if (constant_translation_threshold < 0.0F || !rtm::scalar_is_finite(constant_translation_threshold))
+ return error_result("Invalid constant_translation_threshold");
+
+ if (constant_scale_threshold < 0.0F || !rtm::scalar_is_finite(constant_scale_threshold))
+ return error_result("Invalid constant_scale_threshold");
+
+ return error_result();
+ }
+ };
//////////////////////////////////////////////////////////////////////////
@@ -322,33 +388,14 @@ namespace acl
return false;
}
- // TODO: constexpr
- inline rotation_variant8 get_rotation_variant(rotation_format8 rotation_format)
+ constexpr rotation_variant8 get_rotation_variant(rotation_format8 rotation_format)
{
- switch (rotation_format)
- {
- case rotation_format8::quatf_full:
- return rotation_variant8::quat;
- case rotation_format8::quatf_drop_w_full:
- case rotation_format8::quatf_drop_w_variable:
- return rotation_variant8::quat_drop_w;
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(rotation_format));
- return rotation_variant8::quat;
- }
+ return rotation_format == rotation_format8::quatf_full ? rotation_variant8::quat : rotation_variant8::quat_drop_w;
}
- // TODO: constexpr
- inline rotation_format8 get_highest_variant_precision(rotation_variant8 variant)
+ constexpr rotation_format8 get_highest_variant_precision(rotation_variant8 variant)
{
- switch (variant)
- {
- case rotation_variant8::quat: return rotation_format8::quatf_full;
- case rotation_variant8::quat_drop_w: return rotation_format8::quatf_drop_w_full;
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %u", (uint32_t)variant);
- return rotation_format8::quatf_full;
- }
+ return variant == rotation_variant8::quat ? rotation_format8::quatf_full : rotation_format8::quatf_drop_w_full;
}
constexpr bool is_rotation_format_variable(rotation_format8 format)
@@ -383,6 +430,7 @@ namespace acl
case track_type8::float3f: return "float3f";
case track_type8::float4f: return "float4f";
case track_type8::vector4f: return "vector4f";
+ case track_type8::qvvf: return "qvvf";
default: return "<Invalid>";
}
}
@@ -400,9 +448,20 @@ namespace acl
"float3f",
"float4f",
"vector4f",
+
+ "float1d",
+ "float2d",
+ "float3d",
+ "float4d",
+ "vector4d",
+
+ "quatf",
+ "quatd",
+
+ "qvvf",
};
- static_assert(get_array_size(k_track_type_names) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+ static_assert(get_array_size(k_track_type_names) == (size_t)track_type8::qvvf + 1, "Unexpected array size");
for (size_t type_index = 0; type_index < get_array_size(k_track_type_names); ++type_index)
{
@@ -424,17 +483,28 @@ namespace acl
// Entries in the same order as the enum integral value
static constexpr track_category8 k_track_type_to_category[]
{
- track_category8::scalarf, // float1f
- track_category8::scalarf, // float2f
- track_category8::scalarf, // float3f
- track_category8::scalarf, // float4f
- track_category8::scalarf, // vector4f
+ track_category8::scalarf, // float1f
+ track_category8::scalarf, // float2f
+ track_category8::scalarf, // float3f
+ track_category8::scalarf, // float4f
+ track_category8::scalarf, // vector4f
+
+ track_category8::scalard, // float1d
+ track_category8::scalard, // float2d
+ track_category8::scalard, // float3d
+ track_category8::scalard, // float4d
+ track_category8::scalard, // vector4d
+
+ track_category8::transformf, // quatf
+ track_category8::transformd, // quatd
+
+ track_category8::transformf, // qvvf
};
- static_assert(get_array_size(k_track_type_to_category) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+ static_assert(get_array_size(k_track_type_to_category) == (size_t)track_type8::qvvf + 1, "Unexpected array size");
- ACL_ASSERT(type <= track_type8::vector4f, "Unexpected track type");
- return type <= track_type8::vector4f ? k_track_type_to_category[static_cast<uint32_t>(type)] : track_category8::scalarf;
+ ACL_ASSERT(type <= track_type8::qvvf, "Unexpected track type");
+ return type <= track_type8::qvvf ? k_track_type_to_category[static_cast<uint32_t>(type)] : track_category8::scalarf;
}
//////////////////////////////////////////////////////////////////////////
@@ -449,12 +519,23 @@ namespace acl
3, // float3f
4, // float4f
4, // vector4f
+
+ 1, // float1d
+ 2, // float2d
+ 3, // float3d
+ 4, // float4d
+ 4, // vector4d
+
+ 4, // quatf
+ 4, // quatd
+
+ 12, // qvvf
};
- static_assert(get_array_size(k_track_type_to_num_elements) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+ static_assert(get_array_size(k_track_type_to_num_elements) == (size_t)track_type8::qvvf + 1, "Unexpected array size");
- ACL_ASSERT(type <= track_type8::vector4f, "Unexpected track type");
- return type <= track_type8::vector4f ? k_track_type_to_num_elements[static_cast<uint32_t>(type)] : 0;
+ ACL_ASSERT(type <= track_type8::qvvf, "Unexpected track type");
+ return type <= track_type8::qvvf ? k_track_type_to_num_elements[static_cast<uint32_t>(type)] : 0;
}
}
diff --git a/includes/acl/core/track_writer.h b/includes/acl/core/track_writer.h
--- a/includes/acl/core/track_writer.h
+++ b/includes/acl/core/track_writer.h
@@ -42,6 +42,9 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct track_writer
{
+ //////////////////////////////////////////////////////////////////////////
+ // Scalar track writing
+
//////////////////////////////////////////////////////////////////////////
// Called by the decoder to write out a value for a specified track index.
void RTM_SIMD_CALL write_float1(uint32_t track_index, rtm::scalarf_arg0 value)
@@ -81,6 +84,47 @@ namespace acl
(void)track_index;
(void)value;
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Transform track writing
+
+ //////////////////////////////////////////////////////////////////////////
+ // These allow the caller of decompress_pose to control which track types they are interested in.
+ // This information allows the codecs to avoid unpacking values that are not needed.
+ constexpr bool skip_all_rotations() const { return false; }
+ constexpr bool skip_all_translations() const { return false; }
+ constexpr bool skip_all_scales() const { return false; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // These allow the caller of decompress_pose to control which tracks they are interested in.
+ // This information allows the codecs to avoid unpacking values that are not needed.
+ constexpr bool skip_track_rotation(uint32_t track_index) const { return (void)track_index, false; }
+ constexpr bool skip_track_translation(uint32_t track_index) const { return (void)track_index, false; }
+ constexpr bool skip_track_scale(uint32_t track_index) const { return (void)track_index, false; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a quaternion rotation value for a specified bone index.
+ void RTM_SIMD_CALL write_rotation(uint32_t track_index, rtm::quatf_arg0 rotation)
+ {
+ (void)track_index;
+ (void)rotation;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a translation value for a specified bone index.
+ void RTM_SIMD_CALL write_translation(uint32_t track_index, rtm::vector4f_arg0 translation)
+ {
+ (void)track_index;
+ (void)translation;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a scale value for a specified bone index.
+ void RTM_SIMD_CALL write_scale(uint32_t track_index, rtm::vector4f_arg0 scale)
+ {
+ (void)track_index;
+ (void)scale;
+ }
};
}
diff --git a/includes/acl/core/unique_ptr.h b/includes/acl/core/unique_ptr.h
--- a/includes/acl/core/unique_ptr.h
+++ b/includes/acl/core/unique_ptr.h
@@ -31,47 +31,47 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- template<typename AllocatedType>
- class Deleter
+ template<typename allocated_type>
+ class deleter
{
public:
- Deleter() : m_allocator(nullptr) {}
- explicit Deleter(IAllocator& allocator) : m_allocator(&allocator) {}
- Deleter(const Deleter&) = default;
- Deleter(Deleter&&) = default;
- ~Deleter() = default;
- Deleter& operator=(const Deleter&) = default;
- Deleter& operator=(Deleter&&) = default;
+ deleter() : m_allocator(nullptr) {}
+ explicit deleter(iallocator& allocator) : m_allocator(&allocator) {}
+ deleter(const deleter&) = default;
+ deleter(deleter&&) = default;
+ ~deleter() = default;
+ deleter& operator=(const deleter&) = default;
+ deleter& operator=(deleter&&) = default;
- void operator()(AllocatedType* ptr)
+ void operator()(allocated_type* ptr)
{
if (ptr == nullptr)
return;
- if (!std::is_trivially_destructible<AllocatedType>::value)
- ptr->~AllocatedType();
+ if (!std::is_trivially_destructible<allocated_type>::value)
+ ptr->~allocated_type();
- m_allocator->deallocate(ptr, sizeof(AllocatedType));
+ m_allocator->deallocate(ptr, sizeof(allocated_type));
}
private:
- IAllocator* m_allocator;
+ iallocator* m_allocator;
};
- template<typename AllocatedType, typename... Args>
- std::unique_ptr<AllocatedType, Deleter<AllocatedType>> make_unique(IAllocator& allocator, Args&&... args)
+ template<typename allocated_type, typename... args>
+ std::unique_ptr<allocated_type, deleter<allocated_type>> make_unique(iallocator& allocator, args&&... arguments)
{
- return std::unique_ptr<AllocatedType, Deleter<AllocatedType>>(
- allocate_type<AllocatedType>(allocator, std::forward<Args>(args)...),
- Deleter<AllocatedType>(allocator));
+ return std::unique_ptr<allocated_type, deleter<allocated_type>>(
+ allocate_type<allocated_type>(allocator, std::forward<args>(arguments)...),
+ deleter<allocated_type>(allocator));
}
- template<typename AllocatedType, typename... Args>
- std::unique_ptr<AllocatedType, Deleter<AllocatedType>> make_unique_aligned(IAllocator& allocator, size_t alignment, Args&&... args)
+ template<typename allocated_type, typename... args>
+ std::unique_ptr<allocated_type, deleter<allocated_type>> make_unique_aligned(iallocator& allocator, size_t alignment, args&&... arguments)
{
- return std::unique_ptr<AllocatedType, Deleter<AllocatedType>>(
- allocate_type_aligned<AllocatedType>(allocator, alignment, std::forward<Args>(args)...),
- Deleter<AllocatedType>(allocator));
+ return std::unique_ptr<allocated_type, deleter<allocated_type>>(
+ allocate_type_aligned<allocated_type>(allocator, alignment, std::forward<args>(arguments)...),
+ deleter<allocated_type>(allocator));
}
}
diff --git a/includes/acl/decompression/decompress.h b/includes/acl/decompression/decompress.h
--- a/includes/acl/decompression/decompress.h
+++ b/includes/acl/decompression/decompress.h
@@ -32,8 +32,10 @@
#include "acl/core/interpolation_utils.h"
#include "acl/core/track_traits.h"
#include "acl/core/track_types.h"
-#include "acl/core/track_writer.h"
-#include "acl/decompression/impl/track_sampling_impl.h"
+#include "acl/decompression/impl/decompression_context_selector.h"
+#include "acl/decompression/impl/scalar_track_decompression.h"
+#include "acl/decompression/impl/transform_track_decompression.h"
+#include "acl/decompression/impl/universal_track_decompression.h"
#include "acl/math/vector4_packing.h"
#include <rtm/types.h>
@@ -59,21 +61,48 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct decompression_settings
{
+ //////////////////////////////////////////////////////////////////////////
+ // Common decompression settings
+
//////////////////////////////////////////////////////////////////////////
// Whether or not to clamp the sample time when `seek(..)` is called. Defaults to true.
- constexpr bool clamp_sample_time() const { return true; }
+ // Must be static constexpr!
+ static constexpr bool clamp_sample_time() { return true; }
//////////////////////////////////////////////////////////////////////////
// Whether or not the specified track type is supported. Defaults to true.
// If a track type is statically known not to be supported, the compiler can strip
// the associated code.
- constexpr bool is_track_type_supported(track_type8 /*type*/) const { return true; }
+ // Must be static constexpr!
+ static constexpr bool is_track_type_supported(track_type8 /*type*/) { return true; }
+ //////////////////////////////////////////////////////////////////////////
// Whether to explicitly disable floating point exceptions during decompression.
// This has a cost, exceptions are usually disabled globally and do not need to be
// explicitly disabled during decompression.
// We assume that floating point exceptions are already disabled by the caller.
- constexpr bool disable_fp_exeptions() const { return false; }
+ // Must be static constexpr!
+ static constexpr bool disable_fp_exeptions() { return false; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Transform decompression settings
+
+ //////////////////////////////////////////////////////////////////////////
+ // Whether the specified rotation/translation/scale format are supported or not.
+ // Use this to strip code related to formats you do not need.
+ // Must be static constexpr!
+ static constexpr bool is_rotation_format_supported(rotation_format8 /*format*/) { return true; }
+ static constexpr bool is_translation_format_supported(vector_format8 /*format*/) { return true; }
+ static constexpr bool is_scale_format_supported(vector_format8 /*format*/) { return true; }
+ static constexpr rotation_format8 get_rotation_format(rotation_format8 format) { return format; }
+ static constexpr vector_format8 get_translation_format(vector_format8 format) { return format; }
+ static constexpr vector_format8 get_scale_format(vector_format8 format) { return format; }
+
+ // Whether rotations should be normalized before being output or not. Some animation
+ // runtimes will normalize in a separate step and do not need the explicit normalization.
+ // Enabled by default for safety.
+ // Must be static constexpr!
+ static constexpr bool normalize_rotations() { return true; }
};
//////////////////////////////////////////////////////////////////////////
@@ -86,7 +115,32 @@ namespace acl
// These are the default settings. Only the generally optimal settings
// are enabled and will offer the overall best performance.
//////////////////////////////////////////////////////////////////////////
- struct default_decompression_settings : public decompression_settings {};
+ struct default_scalar_decompression_settings : public decompression_settings
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // Only support scalar tracks
+ static constexpr bool is_track_type_supported(track_type8 type) { return type != track_type8::qvvf; }
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // These are the default settings. Only the generally optimal settings
+ // are enabled and will offer the overall best performance.
+ //////////////////////////////////////////////////////////////////////////
+ struct default_transform_decompression_settings : public decompression_settings
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // Only support transform tracks
+ static constexpr bool is_track_type_supported(track_type8 type) { return type == track_type8::qvvf; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // By default, we only support the variable bit rates as they are generally optimal
+ static constexpr bool is_rotation_format_supported(rotation_format8 format) { return format == rotation_format8::quatf_drop_w_variable; }
+ static constexpr bool is_translation_format_supported(vector_format8 format) { return format == vector_format8::vector3f_variable; }
+ static constexpr bool is_scale_format_supported(vector_format8 format) { return format == vector_format8::vector3f_variable; }
+ static constexpr rotation_format8 get_rotation_format(rotation_format8 /*format*/) { return rotation_format8::quatf_drop_w_variable; }
+ static constexpr vector_format8 get_translation_format(vector_format8 /*format*/) { return vector_format8::vector3f_variable; }
+ static constexpr vector_format8 get_scale_format(vector_format8 /*format*/) { return vector_format8::vector3f_variable; }
+ };
//////////////////////////////////////////////////////////////////////////
// Decompression context for the uniformly sampled algorithm. The context
@@ -116,13 +170,9 @@ namespace acl
// The default constructor for the `decompression_settings_type` will be used.
decompression_context();
- //////////////////////////////////////////////////////////////////////////
- // Constructs a context instance from a settings instance.
- decompression_context(const decompression_settings_type& settings);
-
//////////////////////////////////////////////////////////////////////////
// Returns the compressed tracks bound to this context instance.
- const compressed_tracks* get_compressed_tracks() const { return m_context.tracks; }
+ const compressed_tracks* get_compressed_tracks() const { return m_context.get_compressed_tracks(); }
//////////////////////////////////////////////////////////////////////////
// Initializes the context instance to a particular compressed tracks instance.
@@ -130,11 +180,11 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Returns true if this context instance is bound to a compressed tracks instance, false otherwise.
- bool is_initialized() const { return m_context.tracks != nullptr; }
+ bool is_initialized() const { return m_context.is_initialized(); }
//////////////////////////////////////////////////////////////////////////
// Returns true if this context instance is bound to the specified compressed tracks instance, false otherwise.
- bool is_dirty(const compressed_tracks& tracks);
+ bool is_dirty(const compressed_tracks& tracks) const;
//////////////////////////////////////////////////////////////////////////
// Seeks within the compressed tracks to a particular point in time with the
@@ -157,15 +207,21 @@ namespace acl
decompression_context(const decompression_context& other) = delete;
decompression_context& operator=(const decompression_context& other) = delete;
- // Internal context data
- acl_impl::persistent_decompression_context m_context;
+ // Whether the decompression context should support scalar tracks
+ static constexpr bool k_supports_scalar_tracks = decompression_settings_type::is_track_type_supported(track_type8::float1f)
+ || decompression_settings_type::is_track_type_supported(track_type8::float2f)
+ || decompression_settings_type::is_track_type_supported(track_type8::float3f)
+ || decompression_settings_type::is_track_type_supported(track_type8::float4f)
+ || decompression_settings_type::is_track_type_supported(track_type8::vector4f);
+
+ // Whether the decompression context should support transform tracks
+ static constexpr bool k_supports_transform_tracks = decompression_settings_type::is_track_type_supported(track_type8::qvvf);
- // The static settings used to strip out code at runtime
- decompression_settings_type m_settings;
+ // The type of our persistent context based on what track types we support
+ using context_type = typename acl_impl::persistent_decompression_context_selector<k_supports_scalar_tracks, k_supports_transform_tracks>::type;
- // Ensure we have non-zero padding to avoid compiler warnings
- static constexpr size_t k_padding_size = alignof(acl_impl::persistent_decompression_context) - sizeof(decompression_settings_type);
- uint8_t m_padding[k_padding_size != 0 ? k_padding_size : alignof(acl_impl::persistent_decompression_context)];
+ // Internal context data
+ context_type m_context;
static_assert(std::is_base_of<decompression_settings, decompression_settings_type>::value, "decompression_settings_type must derive from decompression_settings!");
};
@@ -173,510 +229,51 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Allocates and constructs an instance of the decompression context
template<class decompression_settings_type>
- inline decompression_context<decompression_settings_type>* make_decompression_context(IAllocator& allocator)
+ inline decompression_context<decompression_settings_type>* make_decompression_context(iallocator& allocator)
{
return allocate_type<decompression_context<decompression_settings_type>>(allocator);
}
- //////////////////////////////////////////////////////////////////////////
- // Allocates and constructs an instance of the decompression context
- template<class decompression_settings_type>
- inline decompression_context<decompression_settings_type>* make_decompression_context(IAllocator& allocator, const decompression_settings_type& settings)
- {
- return allocate_type<decompression_context<decompression_settings_type>>(allocator, settings);
- }
-
//////////////////////////////////////////////////////////////////////////
// decompression_context implementation
template<class decompression_settings_type>
inline decompression_context<decompression_settings_type>::decompression_context()
: m_context()
- , m_settings()
- {
- m_context.tracks = nullptr; // Only member used to detect if we are initialized
- }
-
- template<class decompression_settings_type>
- inline decompression_context<decompression_settings_type>::decompression_context(const decompression_settings_type& settings)
- : m_context()
- , m_settings(settings)
{
- m_context.tracks = nullptr; // Only member used to detect if we are initialized
+ m_context.reset();
}
template<class decompression_settings_type>
inline void decompression_context<decompression_settings_type>::initialize(const compressed_tracks& tracks)
{
- ACL_ASSERT(tracks.is_valid(false).empty(), "Compressed tracks are not valid");
- ACL_ASSERT(tracks.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
-
- m_context.tracks = &tracks;
- m_context.tracks_hash = tracks.get_hash();
- m_context.duration = tracks.get_duration();
- m_context.sample_time = -1.0F;
- m_context.interpolation_alpha = 0.0;
+ acl_impl::initialize<decompression_settings_type>(m_context, tracks);
}
template<class decompression_settings_type>
- inline bool decompression_context<decompression_settings_type>::is_dirty(const compressed_tracks& tracks)
+ inline bool decompression_context<decompression_settings_type>::is_dirty(const compressed_tracks& tracks) const
{
- if (m_context.tracks != &tracks)
- return true;
-
- if (m_context.tracks_hash != tracks.get_hash())
- return true;
-
- return false;
+ return acl_impl::is_dirty(m_context, tracks);
}
template<class decompression_settings_type>
inline void decompression_context<decompression_settings_type>::seek(float sample_time, sample_rounding_policy rounding_policy)
{
- ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
- ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
-
- // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
- if (m_settings.clamp_sample_time())
- sample_time = rtm::scalar_clamp(sample_time, 0.0F, m_context.duration);
-
- if (m_context.sample_time == sample_time)
- return;
-
- m_context.sample_time = sample_time;
-
- const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
-
- uint32_t key_frame0;
- uint32_t key_frame1;
- find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, m_context.interpolation_alpha);
-
- m_context.key_frame_bit_offsets[0] = key_frame0 * header.num_bits_per_frame;
- m_context.key_frame_bit_offsets[1] = key_frame1 * header.num_bits_per_frame;
+ acl_impl::seek<decompression_settings_type>(m_context, sample_time, rounding_policy);
}
template<class decompression_settings_type>
template<class track_writer_type>
inline void decompression_context<decompression_settings_type>::decompress_tracks(track_writer_type& writer)
{
- static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
- ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
-
- // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
- // Disable floating point exceptions to avoid issues.
- fp_environment fp_env;
- if (m_settings.disable_fp_exeptions())
- disable_fp_exceptions(fp_env);
-
- const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
- const rtm::scalarf interpolation_alpha = rtm::scalar_set(m_context.interpolation_alpha);
-
- const acl_impl::track_metadata* per_track_metadata = header.get_track_metadata();
- const float* constant_values = header.get_track_constant_values();
- const float* range_values = header.get_track_range_values();
- const uint8_t* animated_values = header.get_track_animated_values();
-
- uint32_t track_bit_offset0 = m_context.key_frame_bit_offsets[0];
- uint32_t track_bit_offset1 = m_context.key_frame_bit_offsets[1];
-
- for (uint32_t track_index = 0; track_index < header.num_tracks; ++track_index)
- {
- const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
-
- if (header.track_type == track_type8::float1f && m_settings.is_track_type_supported(track_type8::float1f))
- {
- rtm::scalarf value;
- if (is_constant_bit_rate(bit_rate))
- {
- value = rtm::scalar_load(constant_values);
- constant_values += 1;
- }
- else
- {
- rtm::scalarf value0;
- rtm::scalarf value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset0);
- value1 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset1);
- }
- else
- {
- value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
-
- const rtm::scalarf range_min = rtm::scalar_load(range_values);
- const rtm::scalarf range_extent = rtm::scalar_load(range_values + 1);
- value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
- value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
- range_values += 2;
- }
-
- value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
-
- const uint32_t num_sample_bits = num_bits_per_component;
- track_bit_offset0 += num_sample_bits;
- track_bit_offset1 += num_sample_bits;
- }
-
- writer.write_float1(track_index, value);
- }
- else if (header.track_type == track_type8::float2f && m_settings.is_track_type_supported(track_type8::float2f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- {
- value = rtm::vector_load(constant_values);
- constant_values += 2;
- }
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector2_64_unsafe(animated_values, track_bit_offset0);
- value1 = unpack_vector2_64_unsafe(animated_values, track_bit_offset1);
- }
- else
- {
- value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + 2);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- range_values += 4;
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
-
- const uint32_t num_sample_bits = num_bits_per_component * 2;
- track_bit_offset0 += num_sample_bits;
- track_bit_offset1 += num_sample_bits;
- }
-
- writer.write_float2(track_index, value);
- }
- else if (header.track_type == track_type8::float3f && m_settings.is_track_type_supported(track_type8::float3f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- {
- value = rtm::vector_load(constant_values);
- constant_values += 3;
- }
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector3_96_unsafe(animated_values, track_bit_offset0);
- value1 = unpack_vector3_96_unsafe(animated_values, track_bit_offset1);
- }
- else
- {
- value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + 3);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- range_values += 6;
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
-
- const uint32_t num_sample_bits = num_bits_per_component * 3;
- track_bit_offset0 += num_sample_bits;
- track_bit_offset1 += num_sample_bits;
- }
-
- writer.write_float3(track_index, value);
- }
- else if (header.track_type == track_type8::float4f && m_settings.is_track_type_supported(track_type8::float4f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- {
- value = rtm::vector_load(constant_values);
- constant_values += 4;
- }
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
- value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
- }
- else
- {
- value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- range_values += 8;
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
-
- const uint32_t num_sample_bits = num_bits_per_component * 4;
- track_bit_offset0 += num_sample_bits;
- track_bit_offset1 += num_sample_bits;
- }
-
- writer.write_float4(track_index, value);
- }
- else if (header.track_type == track_type8::vector4f && m_settings.is_track_type_supported(track_type8::vector4f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- {
- value = rtm::vector_load(constant_values);
- constant_values += 4;
- }
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
- value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
- }
- else
- {
- value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
- value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- range_values += 8;
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
-
- const uint32_t num_sample_bits = num_bits_per_component * 4;
- track_bit_offset0 += num_sample_bits;
- track_bit_offset1 += num_sample_bits;
- }
-
- writer.write_vector4(track_index, value);
- }
- }
-
- if (m_settings.disable_fp_exeptions())
- restore_fp_exceptions(fp_env);
+ acl_impl::decompress_tracks<decompression_settings_type>(m_context, writer);
}
template<class decompression_settings_type>
template<class track_writer_type>
inline void decompression_context<decompression_settings_type>::decompress_track(uint32_t track_index, track_writer_type& writer)
{
- static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
- ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
- ACL_ASSERT(track_index < m_context.tracks->get_num_tracks(), "Invalid track index");
-
- // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
- // Disable floating point exceptions to avoid issues.
- fp_environment fp_env;
- if (m_settings.disable_fp_exeptions())
- disable_fp_exceptions(fp_env);
-
- const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
- const rtm::scalarf interpolation_alpha = rtm::scalar_set(m_context.interpolation_alpha);
-
- const float* constant_values = header.get_track_constant_values();
- const float* range_values = header.get_track_range_values();
-
- const uint32_t num_element_components = get_track_num_sample_elements(header.track_type);
- uint32_t track_bit_offset = 0;
-
- const acl_impl::track_metadata* per_track_metadata = header.get_track_metadata();
- for (uint32_t scan_track_index = 0; scan_track_index < track_index; ++scan_track_index)
- {
- const acl_impl::track_metadata& metadata = per_track_metadata[scan_track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
- track_bit_offset += num_bits_per_component * num_element_components;
-
- if (is_constant_bit_rate(bit_rate))
- constant_values += num_element_components;
- else if (!is_raw_bit_rate(bit_rate))
- range_values += num_element_components * 2;
- }
-
- const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
-
- const uint8_t* animated_values = header.get_track_animated_values();
-
- if (header.track_type == track_type8::float1f && m_settings.is_track_type_supported(track_type8::float1f))
- {
- rtm::scalarf value;
- if (is_constant_bit_rate(bit_rate))
- value = rtm::scalar_load(constant_values);
- else
- {
- rtm::scalarf value0;
- rtm::scalarf value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_scalarf_32_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_scalarf_32_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
- }
- else
- {
- value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
-
- const rtm::scalarf range_min = rtm::scalar_load(range_values);
- const rtm::scalarf range_extent = rtm::scalar_load(range_values + num_element_components);
- value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
- value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
- }
-
- value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
- }
-
- writer.write_float1(track_index, value);
- }
- else if (header.track_type == track_type8::float2f && m_settings.is_track_type_supported(track_type8::float2f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- value = rtm::vector_load(constant_values);
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
- }
- else
- {
- value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
- }
-
- writer.write_float2(track_index, value);
- }
- else if (header.track_type == track_type8::float3f && m_settings.is_track_type_supported(track_type8::float3f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- value = rtm::vector_load(constant_values);
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
- }
- else
- {
- value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
- }
-
- writer.write_float3(track_index, value);
- }
- else if (header.track_type == track_type8::float4f && m_settings.is_track_type_supported(track_type8::float4f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- value = rtm::vector_load(constant_values);
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
- }
- else
- {
- value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
- }
-
- writer.write_float4(track_index, value);
- }
- else if (header.track_type == track_type8::vector4f && m_settings.is_track_type_supported(track_type8::vector4f))
- {
- rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
- value = rtm::vector_load(constant_values);
- else
- {
- rtm::vector4f value0;
- rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
- {
- value0 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
- }
- else
- {
- value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
- value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
-
- const rtm::vector4f range_min = rtm::vector_load(range_values);
- const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
- value0 = rtm::vector_mul_add(value0, range_extent, range_min);
- value1 = rtm::vector_mul_add(value1, range_extent, range_min);
- }
-
- value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
- }
-
- writer.write_vector4(track_index, value);
- }
-
- if (m_settings.disable_fp_exeptions())
- restore_fp_exceptions(fp_env);
+ acl_impl::decompress_track<decompression_settings_type>(m_context, track_index, writer);
}
}
diff --git a/includes/acl/decompression/default_output_writer.h b/includes/acl/decompression/default_output_writer.h
deleted file mode 100644
--- a/includes/acl/decompression/default_output_writer.h
+++ /dev/null
@@ -1,75 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/decompression/output_writer.h"
-
-#include <rtm/types.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // A simple output writer implementation that simply writes out to a
- // Transform_32 array.
- //////////////////////////////////////////////////////////////////////////
- struct DefaultOutputWriter final : public OutputWriter
- {
- DefaultOutputWriter(rtm::qvvf* transforms, uint16_t num_transforms)
- : m_transforms(transforms)
- , m_num_transforms(num_transforms)
- {
- ACL_ASSERT(transforms != nullptr, "Transforms array cannot be null");
- ACL_ASSERT(num_transforms != 0, "Transforms array cannot be empty");
- }
-
- void RTM_SIMD_CALL write_bone_rotation(uint16_t bone_index, rtm::quatf_arg0 rotation)
- {
- ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
- m_transforms[bone_index].rotation = rotation;
- }
-
- void RTM_SIMD_CALL write_bone_translation(uint16_t bone_index, rtm::vector4f_arg0 translation)
- {
- ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
- m_transforms[bone_index].translation = translation;
- }
-
- void RTM_SIMD_CALL write_bone_scale(uint16_t bone_index, rtm::vector4f_arg0 scale)
- {
- ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
- m_transforms[bone_index].scale = scale;
- }
-
- rtm::qvvf* m_transforms;
- uint16_t m_num_transforms;
- };
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/decompress_data.h b/includes/acl/decompression/impl/decompress_data.h
deleted file mode 100644
--- a/includes/acl/decompression/impl/decompress_data.h
+++ /dev/null
@@ -1,622 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/memory_utils.h"
-
-#include <rtm/quatf.h>
-#include <rtm/vector4f.h>
-#include <rtm/packing/quatf.h>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace acl_impl
- {
- template<class SettingsType, class DecompressionContextType, class SamplingContextType>
- inline void skip_over_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
- {
- const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
- const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
- if (!is_sample_default)
- {
- const rotation_format8 rotation_format = settings.get_rotation_format(header.rotation_format);
-
- const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- {
- const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
- sampling_context.constant_track_data_offset += get_packed_rotation_size(packed_format);
- }
- else
- {
- constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
-
- if (is_rotation_format_variable(rotation_format))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
- }
-
- sampling_context.format_per_track_data_offset++;
- }
- else
- {
- const uint32_t rotation_size = get_packed_rotation_size(rotation_format);
- const uint32_t num_bits_at_bit_rate = rotation_size == (sizeof(float) * 4) ? 128 : 96;
-
- for (size_t i = 0; i < num_key_frames; ++i)
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
- }
-
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations) && settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
- {
- sampling_context.clip_range_data_offset += decomp_context.num_rotation_components * sizeof(float) * 2;
-
- if (header.num_segments > 1)
- sampling_context.segment_range_data_offset += decomp_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
- }
- }
- }
-
- sampling_context.track_index++;
- }
-
- template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
- inline void skip_over_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
- {
- const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
- const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
- if (!is_sample_default)
- {
- const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- {
- // Constant Vector3 tracks store the remaining sample with full precision
- sampling_context.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
- }
- else
- {
- constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
- const vector_format8 format = settings.get_vector_format(header);
-
- if (is_vector_format_variable(format))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
- }
-
- sampling_context.format_per_track_data_offset++;
- }
- else
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- sampling_context.key_frame_bit_offsets[i] += 96;
- }
-
- const range_reduction_flags8 range_reduction_flag = settings.get_range_reduction_flag();
-
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag) && settings.are_range_reduction_flags_supported(range_reduction_flag))
- {
- sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
-
- if (header.num_segments > 1)
- sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
- }
- }
- }
-
- sampling_context.track_index++;
- }
-
- template <class SettingsType, class DecompressionContextType, class SamplingContextType>
- inline rtm::quatf RTM_SIMD_CALL decompress_and_interpolate_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
- {
- static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
-
- rtm::quatf interpolated_rotation;
-
- const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
- const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
- if (is_sample_default)
- {
- interpolated_rotation = rtm::quat_identity();
- }
- else
- {
- const rotation_format8 rotation_format = settings.get_rotation_format(header.rotation_format);
- const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- {
- if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
- interpolated_rotation = unpack_quat_128(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == rotation_format8::quatf_drop_w_full && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
- interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
- interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else
- {
- ACL_ASSERT(false, "Unrecognized rotation format");
- interpolated_rotation = rtm::quat_identity();
- }
-
- ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
- ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
-
- const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
- sampling_context.constant_track_data_offset += get_packed_rotation_size(packed_format);
- }
- else
- {
- constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
-
- // This part is fairly complex, we'll loop and write to the stack (sampling context)
- rtm::vector4f* rotations_as_vec = &sampling_context.vectors[0];
-
- // Range ignore flags are used to skip range normalization at the clip and/or segment levels
- // Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
- // By default, we never ignore range reduction
- uint32_t range_ignore_flags = 0;
-
- if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- range_ignore_flags <<= 2;
-
- const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
-
- if (is_constant_bit_rate(bit_rate))
- {
- rotations_as_vec[i] = unpack_vector3_u48_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- range_ignore_flags |= 0x00000001U; // Skip segment only
- }
- else if (is_raw_bit_rate(bit_rate))
- {
- rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- range_ignore_flags |= 0x00000003U; // Skip clip and segment
- }
- else
- rotations_as_vec[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
- }
-
- sampling_context.format_per_track_data_offset++;
- }
- else
- {
- if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- rotations_as_vec[i] = unpack_vector4_128_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- sampling_context.key_frame_bit_offsets[i] += 128;
- }
- }
- else if (rotation_format == rotation_format8::quatf_drop_w_full && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- sampling_context.key_frame_bit_offsets[i] += 96;
- }
- }
- }
-
- // Load our samples to avoid working with the stack now that things can be unrolled.
- // We unroll because even if we work from the stack, with 2 samples the compiler always
- // unrolls but it fails to keep the values in registers, working from the stack which
- // is inefficient.
- rtm::vector4f rotation_as_vec0 = rotations_as_vec[0];
- rtm::vector4f rotation_as_vec1 = rotations_as_vec[1];
- rtm::vector4f rotation_as_vec2;
- rtm::vector4f rotation_as_vec3;
-
- if (static_condition<num_key_frames == 4>::test())
- {
- rotation_as_vec2 = rotations_as_vec[2];
- rotation_as_vec3 = rotations_as_vec[3];
- }
- else
- {
- rotation_as_vec2 = rotation_as_vec0;
- rotation_as_vec3 = rotation_as_vec0;
- }
-
- const uint32_t num_rotation_components = decomp_context.num_rotation_components;
-
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations) && settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
- {
- if (header.num_segments > 1)
- {
- const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
- const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (num_rotation_components * sizeof(uint8_t));
-
- if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
- {
- constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
-
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
-
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
- }
-
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
-
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
-
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
- }
- }
- }
- else
- {
- if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
- {
- {
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
-
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
- }
-
- {
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
-
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
- }
-
- if (static_condition<num_key_frames == 4>::test())
- {
- {
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
-
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
- }
-
- {
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
-
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
- }
- }
- }
- else
- {
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
-
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
- }
-
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
-
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
- }
-
- if (static_condition<num_key_frames == 4>::test())
- {
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
-
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
- }
-
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
-
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
- }
- }
- }
- }
-
- sampling_context.segment_range_data_offset += num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
- }
-
- const rtm::vector4f clip_range_min = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const rtm::vector4f clip_range_extent = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (num_rotation_components * sizeof(float)));
-
- constexpr uint32_t ignore_mask = 0x00000002U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, clip_range_extent, clip_range_min);
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, clip_range_extent, clip_range_min);
-
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, clip_range_extent, clip_range_min);
-
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, clip_range_extent, clip_range_min);
- }
-
- sampling_context.clip_range_data_offset += num_rotation_components * sizeof(float) * 2;
- }
-
- // No-op conversion
- rtm::quatf rotation0 = rtm::vector_to_quat(rotation_as_vec0);
- rtm::quatf rotation1 = rtm::vector_to_quat(rotation_as_vec1);
- rtm::quatf rotation2 = rtm::vector_to_quat(rotation_as_vec2);
- rtm::quatf rotation3 = rtm::vector_to_quat(rotation_as_vec3);
-
- if (rotation_format != rotation_format8::quatf_full || !settings.is_rotation_format_supported(rotation_format8::quatf_full))
- {
- // We dropped the W component
- rotation0 = rtm::quat_from_positive_w(rotation_as_vec0);
- rotation1 = rtm::quat_from_positive_w(rotation_as_vec1);
-
- if (static_condition<num_key_frames == 4>::test())
- {
- rotation2 = rtm::quat_from_positive_w(rotation_as_vec2);
- rotation3 = rtm::quat_from_positive_w(rotation_as_vec3);
- }
- }
-
- if (static_condition<num_key_frames == 4>::test())
- interpolated_rotation = SamplingContextType::interpolate_rotation(rotation0, rotation1, rotation2, rotation3, decomp_context.interpolation_alpha);
- else
- {
- const bool normalize_rotations = settings.normalize_rotations();
- if (normalize_rotations)
- interpolated_rotation = SamplingContextType::interpolate_rotation(rotation0, rotation1, decomp_context.interpolation_alpha);
- else
- interpolated_rotation = SamplingContextType::interpolate_rotation_no_normalization(rotation0, rotation1, decomp_context.interpolation_alpha);
- }
-
- ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
- ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation) || !settings.normalize_rotations(), "Rotation is not normalized!");
- }
- }
-
- sampling_context.track_index++;
- return interpolated_rotation;
- }
-
- template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
- inline rtm::vector4f RTM_SIMD_CALL decompress_and_interpolate_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
- {
- static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
-
- rtm::vector4f interpolated_vector;
-
- const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
- const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
- if (is_sample_default)
- {
- interpolated_vector = settings.get_default_value();
- }
- else
- {
- const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- {
- // Constant translation tracks store the remaining sample with full precision
- interpolated_vector = unpack_vector3_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
-
- sampling_context.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
- }
- else
- {
- const vector_format8 format = settings.get_vector_format(header);
-
- constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
-
- // This part is fairly complex, we'll loop and write to the stack (sampling context)
- rtm::vector4f* vectors = &sampling_context.vectors[0];
-
- // Range ignore flags are used to skip range normalization at the clip and/or segment levels
- // Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
- // By default, we never ignore range reduction
- uint32_t range_ignore_flags = 0;
-
- if (format == vector_format8::vector3f_variable && settings.is_vector_format_supported(vector_format8::vector3f_variable))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- range_ignore_flags <<= 2;
-
- const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
-
- if (is_constant_bit_rate(bit_rate))
- {
- vectors[i] = unpack_vector3_u48_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- range_ignore_flags |= 0x00000001U; // Skip segment only
- }
- else if (is_raw_bit_rate(bit_rate))
- {
- vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- range_ignore_flags |= 0x00000003U; // Skip clip and segment
- }
- else
- vectors[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
- }
-
- sampling_context.format_per_track_data_offset++;
- }
- else
- {
- if (format == vector_format8::vector3f_full && settings.is_vector_format_supported(vector_format8::vector3f_full))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- sampling_context.key_frame_bit_offsets[i] += 96;
- }
- }
- }
-
- // Load our samples to avoid working with the stack now that things can be unrolled.
- // We unroll because even if we work from the stack, with 2 samples the compiler always
- // unrolls but it fails to keep the values in registers, working from the stack which
- // is inefficient.
- rtm::vector4f vector0 = vectors[0];
- rtm::vector4f vector1 = vectors[1];
- rtm::vector4f vector2;
- rtm::vector4f vector3;
-
- if (static_condition<num_key_frames == 4>::test())
- {
- vector2 = vectors[2];
- vector3 = vectors[3];
- }
- else
- {
- vector2 = vector0;
- vector3 = vector0;
- }
-
- const range_reduction_flags8 range_reduction_flag = settings.get_range_reduction_flag();
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag) && settings.are_range_reduction_flags_supported(range_reduction_flag))
- {
- if (header.num_segments > 1)
- {
- const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
- const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t));
-
- constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
-
- vector0 = rtm::vector_mul_add(vector0, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
-
- vector1 = rtm::vector_mul_add(vector1, segment_range_extent, segment_range_min);
- }
-
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
-
- vector2 = rtm::vector_mul_add(vector2, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
-
- vector3 = rtm::vector_mul_add(vector3, segment_range_extent, segment_range_min);
- }
- }
-
- sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
- }
-
- const rtm::vector4f clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const rtm::vector4f clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
-
- constexpr uint32_t ignore_mask = 0x00000002U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- vector0 = rtm::vector_mul_add(vector0, clip_range_extent, clip_range_min);
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- vector1 = rtm::vector_mul_add(vector1, clip_range_extent, clip_range_min);
-
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- vector2 = rtm::vector_mul_add(vector2, clip_range_extent, clip_range_min);
-
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- vector3 = rtm::vector_mul_add(vector3, clip_range_extent, clip_range_min);
- }
-
- sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
- }
-
- if (static_condition<num_key_frames == 4>::test())
- interpolated_vector = SamplingContextType::interpolate_vector4(vector0, vector1, vector2, vector3, decomp_context.interpolation_alpha);
- else
- interpolated_vector = SamplingContextType::interpolate_vector4(vector0, vector1, decomp_context.interpolation_alpha);
-
- ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
- }
- }
-
- sampling_context.track_index++;
- return interpolated_vector;
- }
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/track_sampling_impl.h b/includes/acl/decompression/impl/decompression_context_selector.h
similarity index 59%
rename from includes/acl/decompression/impl/track_sampling_impl.h
rename to includes/acl/decompression/impl/decompression_context_selector.h
--- a/includes/acl/decompression/impl/track_sampling_impl.h
+++ b/includes/acl/decompression/impl/decompression_context_selector.h
@@ -3,7 +3,7 @@
////////////////////////////////////////////////////////////////////////////////
// The MIT License (MIT)
//
-// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
//
// Permission is hereby granted, free of charge, to any person obtaining a copy
// of this software and associated documentation files (the "Software"), to deal
@@ -25,12 +25,9 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/impl/compiler_utils.h"
-#include "acl/core/compressed_tracks.h"
-
-#include <rtm/scalarf.h>
-#include <rtm/vector4f.h>
-
-#include <cstdint>
+#include "acl/decompression/impl/scalar_track_decompression.h"
+#include "acl/decompression/impl/transform_track_decompression.h"
+#include "acl/decompression/impl/universal_track_decompression.h"
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -38,26 +35,27 @@ namespace acl
{
namespace acl_impl
{
- struct alignas(64) persistent_decompression_context
- {
- // Clip related data // offsets
- const compressed_tracks* tracks; // 0 | 0
-
- uint32_t tracks_hash; // 4 | 8
-
- float duration; // 8 | 12
-
- // Seeking related data
- float interpolation_alpha; // 12 | 16
- float sample_time; // 16 | 20
+ //////////////////////////////////////////////////////////////////////////
+ // Helper struct to choose the decompression context type based on what tracks we support
+ template<bool supports_scalar_tracks, bool supports_transform_tracks>
+ struct persistent_decompression_context_selector {};
- uint32_t key_frame_bit_offsets[2]; // 20 | 24 // Variable quantization
-
- uint8_t padding_tail[sizeof(void*) == 4 ? 36 : 32];
+ template<>
+ struct persistent_decompression_context_selector<true, false>
+ {
+ using type = persistent_scalar_decompression_context;
+ };
- //////////////////////////////////////////////////////////////////////////
+ template<>
+ struct persistent_decompression_context_selector<false, true>
+ {
+ using type = persistent_transform_decompression_context;
+ };
- inline bool is_initialized() const { return tracks != nullptr; }
+ template<>
+ struct persistent_decompression_context_selector<true, true>
+ {
+ using type = persistent_universal_decompression_context;
};
}
}
diff --git a/includes/acl/decompression/impl/scalar_track_decompression.h b/includes/acl/decompression/impl/scalar_track_decompression.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/decompression/impl/scalar_track_decompression.h
@@ -0,0 +1,555 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/interpolation_utils.h"
+#include "acl/core/track_writer.h"
+#include "acl/core/impl/compiler_utils.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+#include <type_traits>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct alignas(64) persistent_scalar_decompression_context
+ {
+ persistent_scalar_decompression_context() {}
+
+ // Clip related data // offsets
+ // Only member used to detect if we are initialized, must be first
+ const compressed_tracks* tracks; // 0 | 0
+
+ uint32_t tracks_hash; // 4 | 8
+
+ float duration; // 8 | 12
+
+ // Seeking related data
+ float interpolation_alpha; // 12 | 16
+ float sample_time; // 16 | 20
+
+ uint32_t key_frame_bit_offsets[2]; // 20 | 24 // Variable quantization
+
+ uint8_t padding_tail[sizeof(void*) == 4 ? 36 : 32];
+
+ //////////////////////////////////////////////////////////////////////////
+
+ inline const compressed_tracks* get_compressed_tracks() const { return tracks; }
+ inline bool is_initialized() const { return tracks != nullptr; }
+ inline void reset() { tracks = nullptr; }
+ };
+
+ static_assert(sizeof(persistent_scalar_decompression_context) == 64, "Unexpected size");
+
+ template<class decompression_settings_type>
+ inline void initialize(persistent_scalar_decompression_context& context, const compressed_tracks& tracks)
+ {
+ ACL_ASSERT(tracks.is_valid(false).empty(), "Compressed tracks are not valid");
+ ACL_ASSERT(tracks.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
+
+ context.tracks = &tracks;
+ context.tracks_hash = tracks.get_hash();
+ context.duration = tracks.get_duration();
+ context.sample_time = -1.0F;
+ context.interpolation_alpha = 0.0;
+ }
+
+ inline bool is_dirty(const persistent_scalar_decompression_context& context, const compressed_tracks& tracks)
+ {
+ if (context.tracks != &tracks)
+ return true;
+
+ if (context.tracks_hash != tracks.get_hash())
+ return true;
+
+ return false;
+ }
+
+ template<class decompression_settings_type>
+ inline void seek(persistent_scalar_decompression_context& context, float sample_time, sample_rounding_policy rounding_policy)
+ {
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
+
+ // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
+ if (decompression_settings_type::clamp_sample_time())
+ sample_time = rtm::scalar_clamp(sample_time, 0.0F, context.duration);
+
+ if (context.sample_time == sample_time)
+ return;
+
+ context.sample_time = sample_time;
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*context.tracks);
+
+ uint32_t key_frame0;
+ uint32_t key_frame1;
+ find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, context.interpolation_alpha);
+
+ const acl_impl::scalar_tracks_header& scalars_header = acl_impl::get_scalar_tracks_header(*context.tracks);
+
+ context.key_frame_bit_offsets[0] = key_frame0 * scalars_header.num_bits_per_frame;
+ context.key_frame_bit_offsets[1] = key_frame1 * scalars_header.num_bits_per_frame;
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_tracks(persistent_scalar_decompression_context& context, track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+
+ // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
+ // Disable floating point exceptions to avoid issues.
+ fp_environment fp_env;
+ if (decompression_settings_type::disable_fp_exeptions())
+ disable_fp_exceptions(fp_env);
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*context.tracks);
+ const acl_impl::scalar_tracks_header& scalars_header = acl_impl::get_scalar_tracks_header(*context.tracks);
+ const rtm::scalarf interpolation_alpha = rtm::scalar_set(context.interpolation_alpha);
+
+ const acl_impl::track_metadata* per_track_metadata = scalars_header.get_track_metadata();
+ const float* constant_values = scalars_header.get_track_constant_values();
+ const float* range_values = scalars_header.get_track_range_values();
+ const uint8_t* animated_values = scalars_header.get_track_animated_values();
+
+ uint32_t track_bit_offset0 = context.key_frame_bit_offsets[0];
+ uint32_t track_bit_offset1 = context.key_frame_bit_offsets[1];
+
+ const track_type8 track_type = header.track_type;
+ const uint32_t num_tracks = header.num_tracks;
+
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+
+ if (track_type == track_type8::float1f && decompression_settings_type::is_track_type_supported(track_type8::float1f))
+ {
+ rtm::scalarf value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::scalar_load(constant_values);
+ constant_values += 1;
+ }
+ else
+ {
+ rtm::scalarf value0;
+ rtm::scalarf value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::scalarf range_min = rtm::scalar_load(range_values);
+ const rtm::scalarf range_extent = rtm::scalar_load(range_values + 1);
+ value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
+ value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
+ range_values += 2;
+ }
+
+ value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ }
+
+ writer.write_float1(track_index, value);
+ }
+ else if (track_type == track_type8::float2f && decompression_settings_type::is_track_type_supported(track_type8::float2f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 2;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector2_64_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector2_64_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 2);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ range_values += 4;
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 2;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ }
+
+ writer.write_float2(track_index, value);
+ }
+ else if (track_type == track_type8::float3f && decompression_settings_type::is_track_type_supported(track_type8::float3f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 3;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector3_96_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector3_96_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 3);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ range_values += 6;
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 3;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ }
+
+ writer.write_float3(track_index, value);
+ }
+ else if (track_type == track_type8::float4f && decompression_settings_type::is_track_type_supported(track_type8::float4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 4;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ range_values += 8;
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 4;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ }
+
+ writer.write_float4(track_index, value);
+ }
+ else if (track_type == track_type8::vector4f && decompression_settings_type::is_track_type_supported(track_type8::vector4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 4;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ range_values += 8;
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 4;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ }
+
+ writer.write_vector4(track_index, value);
+ }
+ }
+
+ if (decompression_settings_type::disable_fp_exeptions())
+ restore_fp_exceptions(fp_env);
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_track(persistent_scalar_decompression_context& context, uint32_t track_index, track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+
+ // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
+ // Disable floating point exceptions to avoid issues.
+ fp_environment fp_env;
+ if (decompression_settings_type::disable_fp_exeptions())
+ disable_fp_exceptions(fp_env);
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*context.tracks);
+ const acl_impl::scalar_tracks_header& scalars_header = acl_impl::get_scalar_tracks_header(*context.tracks);
+ const rtm::scalarf interpolation_alpha = rtm::scalar_set(context.interpolation_alpha);
+
+ ACL_ASSERT(track_index < header.num_tracks, "Invalid track index");
+
+ const float* constant_values = scalars_header.get_track_constant_values();
+ const float* range_values = scalars_header.get_track_range_values();
+
+ const track_type8 track_type = header.track_type;
+ const uint32_t num_element_components = get_track_num_sample_elements(track_type);
+ uint32_t track_bit_offset = 0;
+
+ const acl_impl::track_metadata* per_track_metadata = scalars_header.get_track_metadata();
+ for (uint32_t scan_track_index = 0; scan_track_index < track_index; ++scan_track_index)
+ {
+ const acl_impl::track_metadata& metadata = per_track_metadata[scan_track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ track_bit_offset += num_bits_per_component * num_element_components;
+
+ if (is_constant_bit_rate(bit_rate))
+ constant_values += num_element_components;
+ else if (!is_raw_bit_rate(bit_rate))
+ range_values += num_element_components * 2;
+ }
+
+ const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+
+ const uint8_t* animated_values = scalars_header.get_track_animated_values();
+
+ if (track_type == track_type8::float1f && decompression_settings_type::is_track_type_supported(track_type8::float1f))
+ {
+ rtm::scalarf value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::scalar_load(constant_values);
+ else
+ {
+ rtm::scalarf value0;
+ rtm::scalarf value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_scalarf_32_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_scalarf_32_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::scalarf range_min = rtm::scalar_load(range_values);
+ const rtm::scalarf range_extent = rtm::scalar_load(range_values + num_element_components);
+ value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
+ value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
+ }
+
+ writer.write_float1(track_index, value);
+ }
+ else if (track_type == track_type8::float2f && decompression_settings_type::is_track_type_supported(track_type8::float2f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector2_64_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector2_64_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ }
+
+ writer.write_float2(track_index, value);
+ }
+ else if (track_type == track_type8::float3f && decompression_settings_type::is_track_type_supported(track_type8::float3f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector3_96_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector3_96_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ }
+
+ writer.write_float3(track_index, value);
+ }
+ else if (track_type == track_type8::float4f && decompression_settings_type::is_track_type_supported(track_type8::float4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ }
+
+ writer.write_float4(track_index, value);
+ }
+ else if (track_type == track_type8::vector4f && decompression_settings_type::is_track_type_supported(track_type8::vector4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ }
+
+ writer.write_vector4(track_index, value);
+ }
+
+ if (decompression_settings_type::disable_fp_exeptions())
+ restore_fp_exceptions(fp_env);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/transform_track_decompression.h b/includes/acl/decompression/impl/transform_track_decompression.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/decompression/impl/transform_track_decompression.h
@@ -0,0 +1,1018 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/interpolation_utils.h"
+#include "acl/core/track_writer.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/math/quatf.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+#include <type_traits>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct alignas(64) persistent_transform_decompression_context
+ {
+ persistent_transform_decompression_context() {}
+
+ // Clip related data // offsets
+ // Only member used to detect if we are initialized, must be first
+ const compressed_tracks* tracks; // 0 | 0
+
+ const uint32_t* constant_tracks_bitset; // 4 | 8
+ const uint8_t* constant_track_data; // 8 | 16
+ const uint32_t* default_tracks_bitset; // 12 | 24
+
+ const uint8_t* clip_range_data; // 16 | 32
+
+ float clip_duration; // 20 | 40
+
+ bitset_description bitset_desc; // 24 | 44
+
+ uint32_t clip_hash; // 28 | 48
+
+ range_reduction_flags8 range_reduction; // 32 | 52
+ uint8_t num_rotation_components; // 33 | 53
+
+ uint8_t padding0[2]; // 34 | 54
+
+ // Seeking related data
+ const uint8_t* format_per_track_data[2]; // 36 | 56
+ const uint8_t* segment_range_data[2]; // 44 | 72
+ const uint8_t* animated_track_data[2]; // 52 | 88
+
+ uint32_t key_frame_bit_offsets[2]; // 60 | 104
+
+ float interpolation_alpha; // 68 | 112
+ float sample_time; // 76 | 120
+
+ uint8_t padding1[sizeof(void*) == 4 ? 52 : 4]; // 80 | 124
+
+ // Total size: 128 | 128
+
+ //////////////////////////////////////////////////////////////////////////
+
+ inline const compressed_tracks* get_compressed_tracks() const { return tracks; }
+ inline bool is_initialized() const { return tracks != nullptr; }
+ inline void reset() { tracks = nullptr; }
+ };
+
+ static_assert(sizeof(persistent_transform_decompression_context) == 128, "Unexpected size");
+
+ struct alignas(64) sampling_context
+ {
+ // // offsets
+ uint32_t track_index; // 0 | 0
+ uint32_t constant_track_data_offset; // 4 | 4
+ uint32_t clip_range_data_offset; // 8 | 8
+
+ uint32_t format_per_track_data_offset; // 12 | 12
+ uint32_t segment_range_data_offset; // 16 | 16
+
+ uint32_t key_frame_bit_offsets[2]; // 20 | 20
+
+ uint8_t padding[4]; // 28 | 28
+
+ rtm::vector4f vectors[2]; // 32 | 32
+
+ // Total size: 64 | 64
+ };
+
+ static_assert(sizeof(sampling_context) == 64, "Unexpected size");
+
+ // We use adapters to wrap the decompression_settings
+ // This allows us to re-use the code for skipping and decompressing Vector3 samples
+ // Code generation will generate specialized code for each specialization
+ template<class decompression_settings_type>
+ struct translation_decompression_settings_adapter
+ {
+ // Forward to our decompression settings
+ static constexpr range_reduction_flags8 get_range_reduction_flag() { return range_reduction_flags8::translations; }
+ static constexpr vector_format8 get_vector_format(const transform_tracks_header& header) { return decompression_settings_type::get_translation_format(header.translation_format); }
+ static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_translation_format_supported(format); }
+ };
+
+ template<class decompression_settings_type>
+ struct scale_decompression_settings_adapter
+ {
+ // Forward to our decompression settings
+ static constexpr range_reduction_flags8 get_range_reduction_flag() { return range_reduction_flags8::scales; }
+ static constexpr vector_format8 get_vector_format(const transform_tracks_header& header) { return decompression_settings_type::get_scale_format(header.scale_format); }
+ static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_scale_format_supported(format); }
+ };
+
+ template<class decompression_settings_type>
+ inline void skip_over_rotation(const persistent_transform_decompression_context& decomp_context, const transform_tracks_header& header, sampling_context& sampling_context_)
+ {
+ const bitset_index_ref track_index_bit_ref(decomp_context.bitset_desc, sampling_context_.track_index);
+ const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
+ if (!is_sample_default)
+ {
+ const rotation_format8 rotation_format = decompression_settings_type::get_rotation_format(header.rotation_format);
+
+ const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
+ if (is_sample_constant)
+ {
+ const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ sampling_context_.constant_track_data_offset += get_packed_rotation_size(packed_format);
+ }
+ else
+ {
+ if (is_rotation_format_variable(rotation_format))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context_.format_per_track_data_offset];
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+
+ sampling_context_.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
+ }
+
+ sampling_context_.format_per_track_data_offset++;
+ }
+ else
+ {
+ const uint32_t rotation_size = get_packed_rotation_size(rotation_format);
+ const uint32_t num_bits_at_bit_rate = rotation_size == (sizeof(float) * 4) ? 128 : 96;
+
+ for (uint32_t i = 0; i < 2; ++i)
+ sampling_context_.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
+ }
+
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations))
+ {
+ sampling_context_.clip_range_data_offset += decomp_context.num_rotation_components * sizeof(float) * 2;
+
+ if (header.num_segments > 1)
+ sampling_context_.segment_range_data_offset += decomp_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
+ }
+ }
+
+ sampling_context_.track_index++;
+ }
+
+ template <class decompression_settings_type>
+ inline rtm::quatf RTM_SIMD_CALL decompress_and_interpolate_rotation(const persistent_transform_decompression_context& decomp_context, const transform_tracks_header& header, sampling_context& sampling_context_)
+ {
+ rtm::quatf interpolated_rotation;
+
+ const bitset_index_ref track_index_bit_ref(decomp_context.bitset_desc, sampling_context_.track_index);
+ const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
+ if (is_sample_default)
+ {
+ interpolated_rotation = rtm::quat_identity();
+ }
+ else
+ {
+ const rotation_format8 rotation_format = decompression_settings_type::get_rotation_format(header.rotation_format);
+ const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
+ if (is_sample_constant)
+ {
+ if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
+ interpolated_rotation = unpack_quat_128(decomp_context.constant_track_data + sampling_context_.constant_track_data_offset);
+ else if (rotation_format == rotation_format8::quatf_drop_w_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
+ interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context_.constant_track_data_offset);
+ else if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context_.constant_track_data_offset);
+ else
+ {
+ ACL_ASSERT(false, "Unrecognized rotation format");
+ interpolated_rotation = rtm::quat_identity();
+ }
+
+ ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
+
+ const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ sampling_context_.constant_track_data_offset += get_packed_rotation_size(packed_format);
+ }
+ else
+ {
+ // This part is fairly complex, we'll loop and write to the stack (sampling context)
+ rtm::vector4f* rotations_as_vec = &sampling_context_.vectors[0];
+
+ // Range ignore flags are used to skip range normalization at the clip and/or segment levels
+ // Each sample has two bits like so:
+ // - 0x01 = sample 1 segment
+ // - 0x02 = sample 1 clip
+ // - 0x04 = sample 0 segment
+ // - 0x08 = sample 0 clip
+ // By default, we never ignore range reduction
+ uint32_t range_ignore_flags = 0;
+
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ range_ignore_flags <<= 2;
+
+ const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context_.format_per_track_data_offset];
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+
+ if (is_constant_bit_rate(bit_rate))
+ {
+ rotations_as_vec[i] = unpack_vector3_u48_unsafe(decomp_context.segment_range_data[i] + sampling_context_.segment_range_data_offset);
+ range_ignore_flags |= 0x00000001U; // Skip segment only
+ }
+ else if (is_raw_bit_rate(bit_rate))
+ {
+ rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+ range_ignore_flags |= 0x00000003U; // Skip clip and segment
+ }
+ else
+ rotations_as_vec[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+
+ sampling_context_.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
+ }
+
+ sampling_context_.format_per_track_data_offset++;
+ }
+ else
+ {
+ if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ rotations_as_vec[i] = unpack_vector4_128_unsafe(decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+ sampling_context_.key_frame_bit_offsets[i] += 128;
+ }
+ }
+ else if (rotation_format == rotation_format8::quatf_drop_w_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+ sampling_context_.key_frame_bit_offsets[i] += 96;
+ }
+ }
+ }
+
+ // Load our samples to avoid working with the stack now that things can be unrolled.
+ // We unroll because even if we work from the stack, with 2 samples the compiler always
+ // unrolls but it fails to keep the values in registers, working from the stack which
+ // is inefficient.
+ rtm::vector4f rotation_as_vec0 = rotations_as_vec[0];
+ rtm::vector4f rotation_as_vec1 = rotations_as_vec[1];
+
+ const uint32_t num_rotation_components = decomp_context.num_rotation_components;
+
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations))
+ {
+ if (header.num_segments > 1)
+ {
+ const uint32_t segment_range_min_offset = sampling_context_.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context_.segment_range_data_offset + (num_rotation_components * sizeof(uint8_t));
+
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ {
+ if ((range_ignore_flags & 0x04) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ if ((range_ignore_flags & 0x01) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+ }
+ else
+ {
+ if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
+ {
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
+
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
+
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+ }
+ else
+ {
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+ }
+ }
+
+ sampling_context_.segment_range_data_offset += num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
+
+ const rtm::vector4f clip_range_min = rtm::vector_load(decomp_context.clip_range_data + sampling_context_.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = rtm::vector_load(decomp_context.clip_range_data + sampling_context_.clip_range_data_offset + (num_rotation_components * sizeof(float)));
+
+ if ((range_ignore_flags & 0x08) == 0)
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, clip_range_extent, clip_range_min);
+
+ if ((range_ignore_flags & 0x02) == 0)
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, clip_range_extent, clip_range_min);
+
+ sampling_context_.clip_range_data_offset += num_rotation_components * sizeof(float) * 2;
+ }
+
+ // No-op conversion
+ rtm::quatf rotation0 = rtm::vector_to_quat(rotation_as_vec0);
+ rtm::quatf rotation1 = rtm::vector_to_quat(rotation_as_vec1);
+
+ if (rotation_format != rotation_format8::quatf_full || !decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
+ {
+ // We dropped the W component
+ rotation0 = rtm::quat_from_positive_w(rotation_as_vec0);
+ rotation1 = rtm::quat_from_positive_w(rotation_as_vec1);
+ }
+
+ const bool normalize_rotations = decompression_settings_type::normalize_rotations();
+ if (normalize_rotations)
+ interpolated_rotation = rtm::quat_lerp(rotation0, rotation1, decomp_context.interpolation_alpha);
+ else
+ interpolated_rotation = quat_lerp_no_normalization(rotation0, rotation1, decomp_context.interpolation_alpha);
+
+ ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation) || !decompression_settings_type::normalize_rotations(), "Rotation is not normalized!");
+ }
+ }
+
+ sampling_context_.track_index++;
+ return interpolated_rotation;
+ }
+
+ template<class decompression_settings_type>
+ inline void skip_over_vector(const persistent_transform_decompression_context& decomp_context, const transform_tracks_header& header, sampling_context& sampling_context_)
+ {
+ const bitset_index_ref track_index_bit_ref(decomp_context.bitset_desc, sampling_context_.track_index);
+ const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
+ if (!is_sample_default)
+ {
+ const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
+ if (is_sample_constant)
+ {
+ // Constant Vector3 tracks store the remaining sample with full precision
+ sampling_context_.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
+ }
+ else
+ {
+ const vector_format8 format = decompression_settings_type::get_vector_format(header);
+
+ if (is_vector_format_variable(format))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context_.format_per_track_data_offset];
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+
+ sampling_context_.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
+ }
+
+ sampling_context_.format_per_track_data_offset++;
+ }
+ else
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ sampling_context_.key_frame_bit_offsets[i] += 96;
+ }
+
+ const range_reduction_flags8 range_reduction_flag = decompression_settings_type::get_range_reduction_flag();
+
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag))
+ {
+ sampling_context_.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
+
+ if (header.num_segments > 1)
+ sampling_context_.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
+ }
+ }
+
+ sampling_context_.track_index++;
+ }
+
+ template<class decompression_settings_adapter_type>
+ inline rtm::vector4f RTM_SIMD_CALL decompress_and_interpolate_vector(const persistent_transform_decompression_context& decomp_context, const transform_tracks_header& header, rtm::vector4f_arg0 default_value, sampling_context& sampling_context_)
+ {
+ rtm::vector4f interpolated_vector;
+
+ const bitset_index_ref track_index_bit_ref(decomp_context.bitset_desc, sampling_context_.track_index);
+ const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
+ if (is_sample_default)
+ {
+ interpolated_vector = default_value;
+ }
+ else
+ {
+ const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
+ if (is_sample_constant)
+ {
+ // Constant translation tracks store the remaining sample with full precision
+ interpolated_vector = unpack_vector3_96_unsafe(decomp_context.constant_track_data + sampling_context_.constant_track_data_offset);
+ ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
+
+ sampling_context_.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
+ }
+ else
+ {
+ const vector_format8 format = decompression_settings_adapter_type::get_vector_format(header);
+
+ // This part is fairly complex, we'll loop and write to the stack (sampling context)
+ rtm::vector4f* vectors = &sampling_context_.vectors[0];
+
+ // Range ignore flags are used to skip range normalization at the clip and/or segment levels
+ // Each sample has two bits like so:
+ // - 0x01 = sample 1 segment
+ // - 0x02 = sample 1 clip
+ // - 0x04 = sample 0 segment
+ // - 0x08 = sample 0 clip
+ // By default, we never ignore range reduction
+ uint32_t range_ignore_flags = 0;
+
+ if (format == vector_format8::vector3f_variable && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ range_ignore_flags <<= 2;
+
+ const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context_.format_per_track_data_offset];
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+
+ if (is_constant_bit_rate(bit_rate))
+ {
+ vectors[i] = unpack_vector3_u48_unsafe(decomp_context.segment_range_data[i] + sampling_context_.segment_range_data_offset);
+ range_ignore_flags |= 0x00000001U; // Skip segment only
+ }
+ else if (is_raw_bit_rate(bit_rate))
+ {
+ vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+ range_ignore_flags |= 0x00000003U; // Skip clip and segment
+ }
+ else
+ vectors[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+
+ sampling_context_.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
+ }
+
+ sampling_context_.format_per_track_data_offset++;
+ }
+ else
+ {
+ if (format == vector_format8::vector3f_full && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_full))
+ {
+ for (uint32_t i = 0; i < 2; ++i)
+ {
+ vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context_.key_frame_bit_offsets[i]);
+ sampling_context_.key_frame_bit_offsets[i] += 96;
+ }
+ }
+ }
+
+ // Load our samples to avoid working with the stack now that things can be unrolled.
+ // We unroll because even if we work from the stack, with 2 samples the compiler always
+ // unrolls but it fails to keep the values in registers, working from the stack which
+ // is inefficient.
+ rtm::vector4f vector0 = vectors[0];
+ rtm::vector4f vector1 = vectors[1];
+
+ const range_reduction_flags8 range_reduction_flag = decompression_settings_adapter_type::get_range_reduction_flag();
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag))
+ {
+ if (header.num_segments > 1)
+ {
+ const uint32_t segment_range_min_offset = sampling_context_.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context_.segment_range_data_offset + (3 * sizeof(uint8_t));
+
+ if ((range_ignore_flags & 0x04) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ vector0 = rtm::vector_mul_add(vector0, segment_range_extent, segment_range_min);
+ }
+
+ if ((range_ignore_flags & 0x01) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ vector1 = rtm::vector_mul_add(vector1, segment_range_extent, segment_range_min);
+ }
+
+ sampling_context_.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
+
+ const rtm::vector4f clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context_.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context_.clip_range_data_offset + (3 * sizeof(float)));
+
+ if ((range_ignore_flags & 0x08) == 0)
+ vector0 = rtm::vector_mul_add(vector0, clip_range_extent, clip_range_min);
+
+ if ((range_ignore_flags & 0x02) == 0)
+ vector1 = rtm::vector_mul_add(vector1, clip_range_extent, clip_range_min);
+
+ sampling_context_.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
+ }
+
+ interpolated_vector = rtm::vector_lerp(vector0, vector1, decomp_context.interpolation_alpha);
+
+ ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
+ }
+ }
+
+ sampling_context_.track_index++;
+ return interpolated_vector;
+ }
+
+ template<class decompression_settings_type>
+ inline void initialize(persistent_transform_decompression_context& context, const compressed_tracks& tracks)
+ {
+ ACL_ASSERT(tracks.is_valid(false).empty(), "Compressed tracks are not valid");
+ ACL_ASSERT(tracks.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
+
+ const tracks_header& header = get_tracks_header(tracks);
+ const transform_tracks_header& transform_header = get_transform_tracks_header(tracks);
+
+ const rotation_format8 rotation_format = decompression_settings_type::get_rotation_format(transform_header.rotation_format);
+ const vector_format8 translation_format = decompression_settings_type::get_translation_format(transform_header.translation_format);
+ const vector_format8 scale_format = decompression_settings_type::get_scale_format(transform_header.scale_format);
+
+ ACL_ASSERT(rotation_format == transform_header.rotation_format, "Statically compiled rotation format (%s) differs from the compressed rotation format (%s)!", get_rotation_format_name(rotation_format), get_rotation_format_name(transform_header.rotation_format));
+ ACL_ASSERT(decompression_settings_type::is_rotation_format_supported(rotation_format), "Rotation format (%s) isn't statically supported!", get_rotation_format_name(rotation_format));
+ ACL_ASSERT(translation_format == transform_header.translation_format, "Statically compiled translation format (%s) differs from the compressed translation format (%s)!", get_vector_format_name(translation_format), get_vector_format_name(transform_header.translation_format));
+ ACL_ASSERT(decompression_settings_type::is_translation_format_supported(translation_format), "Translation format (%s) isn't statically supported!", get_vector_format_name(translation_format));
+ ACL_ASSERT(scale_format == transform_header.scale_format, "Statically compiled scale format (%s) differs from the compressed scale format (%s)!", get_vector_format_name(scale_format), get_vector_format_name(transform_header.scale_format));
+ ACL_ASSERT(decompression_settings_type::is_scale_format_supported(scale_format), "Scale format (%s) isn't statically supported!", get_vector_format_name(scale_format));
+
+ context.tracks = &tracks;
+ context.clip_hash = tracks.get_hash();
+ context.clip_duration = calculate_duration(header.num_samples, header.sample_rate);
+ context.sample_time = -1.0F;
+ context.default_tracks_bitset = transform_header.get_default_tracks_bitset();
+
+ context.constant_tracks_bitset = transform_header.get_constant_tracks_bitset();
+ context.constant_track_data = transform_header.get_constant_track_data();
+ context.clip_range_data = transform_header.get_clip_range_data();
+
+ for (uint32_t key_frame_index = 0; key_frame_index < 2; ++key_frame_index)
+ {
+ context.format_per_track_data[key_frame_index] = nullptr;
+ context.segment_range_data[key_frame_index] = nullptr;
+ context.animated_track_data[key_frame_index] = nullptr;
+ }
+
+ const uint32_t num_tracks_per_bone = transform_header.has_scale ? 3 : 2;
+ context.bitset_desc = bitset_description::make_from_num_bits(header.num_tracks * num_tracks_per_bone);
+
+ range_reduction_flags8 range_reduction = range_reduction_flags8::none;
+ if (is_rotation_format_variable(rotation_format))
+ range_reduction |= range_reduction_flags8::rotations;
+ if (is_vector_format_variable(translation_format))
+ range_reduction |= range_reduction_flags8::translations;
+ if (is_vector_format_variable(scale_format))
+ range_reduction |= range_reduction_flags8::scales;
+
+ context.range_reduction = range_reduction;
+ context.num_rotation_components = rotation_format == rotation_format8::quatf_full ? 4 : 3;
+ }
+
+ inline bool is_dirty(const persistent_transform_decompression_context& context, const compressed_tracks& tracks)
+ {
+ if (context.tracks != &tracks)
+ return true;
+
+ if (context.clip_hash != tracks.get_hash())
+ return true;
+
+ return false;
+ }
+
+ template<class decompression_settings_type>
+ inline void seek(persistent_transform_decompression_context& context, float sample_time, sample_rounding_policy rounding_policy)
+ {
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
+
+ // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
+ if (decompression_settings_type::clamp_sample_time())
+ sample_time = rtm::scalar_clamp(sample_time, 0.0F, context.clip_duration);
+
+ if (context.sample_time == sample_time)
+ return;
+
+ context.sample_time = sample_time;
+
+ const tracks_header& header = get_tracks_header(*context.tracks);
+ const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
+
+ uint32_t key_frame0;
+ uint32_t key_frame1;
+ find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, context.interpolation_alpha);
+
+ uint32_t segment_key_frame0;
+ uint32_t segment_key_frame1;
+
+ const segment_header* segment_header0;
+ const segment_header* segment_header1;
+
+ const segment_header* segment_headers = transform_header.get_segment_headers();
+ const uint32_t num_segments = transform_header.num_segments;
+
+ if (num_segments == 1)
+ {
+ // Key frame 0 and 1 are in the only segment present
+ // This is a really common case and when it happens, we don't store the segment start index (zero)
+ segment_header0 = segment_headers;
+ segment_key_frame0 = key_frame0;
+
+ segment_header1 = segment_headers;
+ segment_key_frame1 = key_frame1;
+ }
+ else
+ {
+ const uint32_t* segment_start_indices = transform_header.get_segment_start_indices();
+
+ // See segment_streams(..) for implementation details. This implementation is directly tied to it.
+ const uint32_t approx_num_samples_per_segment = header.num_samples / num_segments; // TODO: Store in header?
+ const uint32_t approx_segment_index = key_frame0 / approx_num_samples_per_segment;
+
+ uint32_t segment_index0 = 0;
+ uint32_t segment_index1 = 0;
+
+ // Our approximate segment guess is just that, a guess. The actual segments we need could be just before or after.
+ // We start looking one segment earlier and up to 2 after. If we have too few segments after, we will hit the
+ // sentinel value of 0xFFFFFFFF and exit the loop.
+ // TODO: Can we do this with SIMD? Load all 4 values, set key_frame0, compare, move mask, count leading zeroes
+ const uint32_t start_segment_index = approx_segment_index > 0 ? (approx_segment_index - 1) : 0;
+ const uint32_t end_segment_index = start_segment_index + 4;
+
+ for (uint32_t segment_index = start_segment_index; segment_index < end_segment_index; ++segment_index)
+ {
+ if (key_frame0 < segment_start_indices[segment_index])
+ {
+ // We went too far, use previous segment
+ ACL_ASSERT(segment_index > 0, "Invalid segment index: %u", segment_index);
+ segment_index0 = segment_index - 1;
+ segment_index1 = key_frame1 < segment_start_indices[segment_index] ? segment_index0 : segment_index;
+ break;
+ }
+ }
+
+ segment_header0 = segment_headers + segment_index0;
+ segment_header1 = segment_headers + segment_index1;
+
+ segment_key_frame0 = key_frame0 - segment_start_indices[segment_index0];
+ segment_key_frame1 = key_frame1 - segment_start_indices[segment_index1];
+ }
+
+ context.format_per_track_data[0] = transform_header.get_format_per_track_data(*segment_header0);
+ context.format_per_track_data[1] = transform_header.get_format_per_track_data(*segment_header1);
+ context.segment_range_data[0] = transform_header.get_segment_range_data(*segment_header0);
+ context.segment_range_data[1] = transform_header.get_segment_range_data(*segment_header1);
+ context.animated_track_data[0] = transform_header.get_track_data(*segment_header0);
+ context.animated_track_data[1] = transform_header.get_track_data(*segment_header1);
+
+ context.key_frame_bit_offsets[0] = segment_key_frame0 * segment_header0->animated_pose_bit_size;
+ context.key_frame_bit_offsets[1] = segment_key_frame1 * segment_header1->animated_pose_bit_size;
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_tracks(persistent_transform_decompression_context& context, track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(context.sample_time >= 0.0f, "Context not set to a valid sample time");
+
+ // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
+ // Disable floating point exceptions to avoid issues.
+ fp_environment fp_env;
+ if (decompression_settings_type::disable_fp_exeptions())
+ disable_fp_exceptions(fp_env);
+
+ const tracks_header& header = get_tracks_header(*context.tracks);
+ const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
+
+ using translation_adapter = acl_impl::translation_decompression_settings_adapter<decompression_settings_type>;
+ using scale_adapter = acl_impl::scale_decompression_settings_adapter<decompression_settings_type>;
+
+ const rtm::vector4f default_translation = rtm::vector_zero();
+ const rtm::vector4f default_scale = rtm::vector_set(float(transform_header.default_scale));
+ const uint8_t has_scale = transform_header.has_scale;
+
+ sampling_context sampling_context_;
+ sampling_context_.track_index = 0;
+ sampling_context_.constant_track_data_offset = 0;
+ sampling_context_.clip_range_data_offset = 0;
+ sampling_context_.format_per_track_data_offset = 0;
+ sampling_context_.segment_range_data_offset = 0;
+ sampling_context_.key_frame_bit_offsets[0] = context.key_frame_bit_offsets[0];
+ sampling_context_.key_frame_bit_offsets[1] = context.key_frame_bit_offsets[1];
+
+ sampling_context_.vectors[0] = default_translation; // Init with something to avoid GCC warning
+ sampling_context_.vectors[1] = default_translation; // Init with something to avoid GCC warning
+
+ const uint32_t num_tracks = header.num_tracks;
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ if (writer.skip_all_rotations() || writer.skip_track_rotation(track_index))
+ skip_over_rotation<decompression_settings_type>(context, transform_header, sampling_context_);
+ else
+ {
+ const rtm::quatf rotation = decompress_and_interpolate_rotation<decompression_settings_type>(context, transform_header, sampling_context_);
+ writer.write_rotation(track_index, rotation);
+ }
+
+ if (writer.skip_all_translations() || writer.skip_track_translation(track_index))
+ skip_over_vector<translation_adapter>(context, transform_header, sampling_context_);
+ else
+ {
+ const rtm::vector4f translation = decompress_and_interpolate_vector<translation_adapter>(context, transform_header, default_translation, sampling_context_);
+ writer.write_translation(track_index, translation);
+ }
+
+ if (writer.skip_all_scales() || writer.skip_track_scale(track_index))
+ {
+ if (has_scale)
+ skip_over_vector<scale_adapter>(context, transform_header, sampling_context_);
+ }
+ else
+ {
+ const rtm::vector4f scale = has_scale ? decompress_and_interpolate_vector<scale_adapter>(context, transform_header, default_scale, sampling_context_) : default_scale;
+ writer.write_scale(track_index, scale);
+ }
+ }
+
+ if (decompression_settings_type::disable_fp_exeptions())
+ restore_fp_exceptions(fp_env);
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_track(persistent_transform_decompression_context& context, uint32_t track_index, track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(context.sample_time >= 0.0f, "Context not set to a valid sample time");
+
+ // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
+ // Disable floating point exceptions to avoid issues.
+ fp_environment fp_env;
+ if (decompression_settings_type::disable_fp_exeptions())
+ disable_fp_exceptions(fp_env);
+
+ const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
+ ACL_ASSERT(track_index < get_tracks_header(*context.tracks).num_tracks, "Invalid track index");
+
+ using translation_adapter = acl_impl::translation_decompression_settings_adapter<decompression_settings_type>;
+ using scale_adapter = acl_impl::scale_decompression_settings_adapter<decompression_settings_type>;
+
+ const rtm::vector4f default_translation = rtm::vector_zero();
+ const rtm::vector4f default_scale = rtm::vector_set(float(transform_header.default_scale));
+ const uint8_t has_scale = transform_header.has_scale;
+
+ sampling_context sampling_context_;
+ sampling_context_.key_frame_bit_offsets[0] = context.key_frame_bit_offsets[0];
+ sampling_context_.key_frame_bit_offsets[1] = context.key_frame_bit_offsets[1];
+
+ const rotation_format8 rotation_format = decompression_settings_type::get_rotation_format(transform_header.rotation_format);
+ const vector_format8 translation_format = decompression_settings_type::get_translation_format(transform_header.translation_format);
+ const vector_format8 scale_format = decompression_settings_type::get_scale_format(transform_header.scale_format);
+
+ const bool are_all_tracks_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
+ if (!are_all_tracks_variable)
+ {
+ // Slow path, not optimized yet because it's more complex and shouldn't be used in production anyway
+ sampling_context_.track_index = 0;
+ sampling_context_.constant_track_data_offset = 0;
+ sampling_context_.clip_range_data_offset = 0;
+ sampling_context_.format_per_track_data_offset = 0;
+ sampling_context_.segment_range_data_offset = 0;
+
+ for (uint32_t bone_index = 0; bone_index < track_index; ++bone_index)
+ {
+ skip_over_rotation<decompression_settings_type>(context, transform_header, sampling_context_);
+ skip_over_vector<translation_adapter>(context, transform_header, sampling_context_);
+
+ if (has_scale)
+ skip_over_vector<scale_adapter>(context, transform_header, sampling_context_);
+ }
+ }
+ else
+ {
+ const uint32_t num_tracks_per_bone = has_scale ? 3 : 2;
+ const uint32_t sub_track_index = track_index * num_tracks_per_bone;
+ uint32_t num_default_rotations = 0;
+ uint32_t num_default_translations = 0;
+ uint32_t num_default_scales = 0;
+ uint32_t num_constant_rotations = 0;
+ uint32_t num_constant_translations = 0;
+ uint32_t num_constant_scales = 0;
+
+ if (has_scale)
+ {
+ uint32_t rotation_track_bit_mask = 0x92492492; // b100100100..
+ uint32_t translation_track_bit_mask = 0x49249249; // b010010010..
+ uint32_t scale_track_bit_mask = 0x24924924; // b001001001..
+
+ const uint32_t last_offset = sub_track_index / 32;
+ uint32_t offset = 0;
+ for (; offset < last_offset; ++offset)
+ {
+ const uint32_t default_value = context.default_tracks_bitset[offset];
+ num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
+ num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
+ num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
+
+ const uint32_t constant_value = context.constant_tracks_bitset[offset];
+ num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
+ num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
+ num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
+
+ // Because the number of tracks in a 32bit word isn't a multiple of the number of tracks we have (3),
+ // we have to rotate the masks left
+ rotation_track_bit_mask = rotate_bits_left(rotation_track_bit_mask, 2);
+ translation_track_bit_mask = rotate_bits_left(translation_track_bit_mask, 2);
+ scale_track_bit_mask = rotate_bits_left(scale_track_bit_mask, 2);
+ }
+
+ const uint32_t remaining_tracks = sub_track_index % 32;
+ if (remaining_tracks != 0)
+ {
+ const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
+ const uint32_t default_value = and_not(not_up_to_track_mask, context.default_tracks_bitset[offset]);
+ num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
+ num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
+ num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
+
+ const uint32_t constant_value = and_not(not_up_to_track_mask, context.constant_tracks_bitset[offset]);
+ num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
+ num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
+ num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
+ }
+ }
+ else
+ {
+ const uint32_t rotation_track_bit_mask = 0xAAAAAAAA; // b10101010..
+ const uint32_t translation_track_bit_mask = 0x55555555; // b01010101..
+
+ const uint32_t last_offset = sub_track_index / 32;
+ uint32_t offset = 0;
+ for (; offset < last_offset; ++offset)
+ {
+ const uint32_t default_value = context.default_tracks_bitset[offset];
+ num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
+ num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
+
+ const uint32_t constant_value = context.constant_tracks_bitset[offset];
+ num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
+ num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
+ }
+
+ const uint32_t remaining_tracks = sub_track_index % 32;
+ if (remaining_tracks != 0)
+ {
+ const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
+ const uint32_t default_value = and_not(not_up_to_track_mask, context.default_tracks_bitset[offset]);
+ num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
+ num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
+
+ const uint32_t constant_value = and_not(not_up_to_track_mask, context.constant_tracks_bitset[offset]);
+ num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
+ num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
+ }
+ }
+
+ // Tracks that are default are also constant
+ const uint32_t num_animated_rotations = track_index - num_constant_rotations;
+ const uint32_t num_animated_translations = track_index - num_constant_translations;
+
+ const rotation_format8 packed_rotation_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ const uint32_t packed_rotation_size = get_packed_rotation_size(packed_rotation_format);
+
+ uint32_t constant_track_data_offset = (num_constant_rotations - num_default_rotations) * packed_rotation_size;
+ constant_track_data_offset += (num_constant_translations - num_default_translations) * get_packed_vector_size(vector_format8::vector3f_full);
+
+ uint32_t clip_range_data_offset = 0;
+ uint32_t segment_range_data_offset = 0;
+
+ const range_reduction_flags8 range_reduction = context.range_reduction;
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations))
+ {
+ clip_range_data_offset += context.num_rotation_components * sizeof(float) * 2 * num_animated_rotations;
+
+ if (transform_header.num_segments > 1)
+ segment_range_data_offset += context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_rotations;
+ }
+
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations))
+ {
+ clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_translations;
+
+ if (transform_header.num_segments > 1)
+ segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_translations;
+ }
+
+ uint32_t num_animated_tracks = num_animated_rotations + num_animated_translations;
+ if (has_scale)
+ {
+ const uint32_t num_animated_scales = track_index - num_constant_scales;
+ num_animated_tracks += num_animated_scales;
+
+ constant_track_data_offset += (num_constant_scales - num_default_scales) * get_packed_vector_size(vector_format8::vector3f_full);
+
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales))
+ {
+ clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_scales;
+
+ if (transform_header.num_segments > 1)
+ segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_scales;
+ }
+ }
+
+ sampling_context_.track_index = sub_track_index;
+ sampling_context_.constant_track_data_offset = constant_track_data_offset;
+ sampling_context_.clip_range_data_offset = clip_range_data_offset;
+ sampling_context_.segment_range_data_offset = segment_range_data_offset;
+ sampling_context_.format_per_track_data_offset = num_animated_tracks;
+
+ for (uint32_t animated_track_index = 0; animated_track_index < num_animated_tracks; ++animated_track_index)
+ {
+ const uint8_t bit_rate0 = context.format_per_track_data[0][animated_track_index];
+ const uint32_t num_bits_at_bit_rate0 = get_num_bits_at_bit_rate(bit_rate0) * 3; // 3 components
+
+ sampling_context_.key_frame_bit_offsets[0] += num_bits_at_bit_rate0;
+
+ const uint8_t bit_rate1 = context.format_per_track_data[1][animated_track_index];
+ const uint32_t num_bits_at_bit_rate1 = get_num_bits_at_bit_rate(bit_rate1) * 3; // 3 components
+
+ sampling_context_.key_frame_bit_offsets[1] += num_bits_at_bit_rate1;
+ }
+ }
+
+ sampling_context_.vectors[0] = default_translation; // Init with something to avoid GCC warning
+ sampling_context_.vectors[1] = default_translation; // Init with something to avoid GCC warning
+
+ const rtm::quatf rotation = decompress_and_interpolate_rotation<decompression_settings_type>(context, transform_header, sampling_context_);
+ writer.write_rotation(track_index, rotation);
+
+ const rtm::vector4f translation = decompress_and_interpolate_vector<translation_adapter>(context, transform_header, default_translation, sampling_context_);
+ writer.write_translation(track_index, translation);
+
+ const rtm::vector4f scale = has_scale ? decompress_and_interpolate_vector<scale_adapter>(context, transform_header, default_scale, sampling_context_) : default_scale;
+ writer.write_scale(track_index, scale);
+
+ if (decompression_settings_type::disable_fp_exeptions())
+ restore_fp_exceptions(fp_env);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/universal_track_decompression.h b/includes/acl/decompression/impl/universal_track_decompression.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/decompression/impl/universal_track_decompression.h
@@ -0,0 +1,173 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/interpolation_utils.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/decompression/impl/scalar_track_decompression.h"
+#include "acl/decompression/impl/transform_track_decompression.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ union persistent_universal_decompression_context
+ {
+ persistent_universal_decompression_context() {}
+
+ persistent_scalar_decompression_context scalar;
+ persistent_transform_decompression_context transform;
+
+ //////////////////////////////////////////////////////////////////////////
+
+ inline const compressed_tracks* get_compressed_tracks() const { return scalar.tracks; }
+ inline bool is_initialized() const { return scalar.is_initialized(); }
+ inline void reset() { scalar.tracks = nullptr; }
+ };
+
+ template<class decompression_settings_type>
+ inline void initialize(persistent_universal_decompression_context& context, const compressed_tracks& tracks)
+ {
+ const track_type8 track_type = tracks.get_track_type();
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ initialize<decompression_settings_type>(context.scalar, tracks);
+ break;
+ case track_type8::qvvf:
+ initialize<decompression_settings_type>(context.transform, tracks);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
+ }
+
+ inline bool is_dirty(const persistent_universal_decompression_context& context, const compressed_tracks& tracks)
+ {
+ if (!context.is_initialized())
+ return true; // Always dirty if we are not initialized
+
+ const track_type8 track_type = context.scalar.tracks->get_track_type();
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ return is_dirty(context.scalar, tracks);
+ case track_type8::qvvf:
+ return is_dirty(context.transform, tracks);
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ return true;
+ }
+ }
+
+ template<class decompression_settings_type>
+ inline void seek(persistent_universal_decompression_context& context, float sample_time, sample_rounding_policy rounding_policy)
+ {
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+
+ const track_type8 track_type = context.scalar.tracks->get_track_type();
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ seek<decompression_settings_type>(context.scalar, sample_time, rounding_policy);
+ break;
+ case track_type8::qvvf:
+ seek<decompression_settings_type>(context.transform, sample_time, rounding_policy);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_tracks(persistent_universal_decompression_context& context, track_writer_type& writer)
+ {
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+
+ const track_type8 track_type = context.scalar.tracks->get_track_type();
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ decompress_tracks<decompression_settings_type>(context.scalar, writer);
+ break;
+ case track_type8::qvvf:
+ decompress_tracks<decompression_settings_type>(context.transform, writer);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_track(persistent_universal_decompression_context& context, uint32_t track_index, track_writer_type& writer)
+ {
+ ACL_ASSERT(context.is_initialized(), "Context is not initialized");
+
+ const track_type8 track_type = context.scalar.tracks->get_track_type();
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ decompress_track<decompression_settings_type>(context.scalar, track_index, writer);
+ break;
+ case track_type8::qvvf:
+ decompress_track<decompression_settings_type>(context.transform, track_index, writer);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/output_writer.h b/includes/acl/decompression/output_writer.h
deleted file mode 100644
--- a/includes/acl/decompression/output_writer.h
+++ /dev/null
@@ -1,85 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/impl/compiler_utils.h"
-
-#include <rtm/quatf.h>
-#include <rtm/vector4f.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // We use a struct like this to allow an arbitrary format on the end user side.
- // Since our decode function is templated on this type implemented by the user,
- // the callbacks can trivially be inlined and customized.
- //////////////////////////////////////////////////////////////////////////
- struct OutputWriter
- {
- //////////////////////////////////////////////////////////////////////////
- // These allow the caller of decompress_pose to control which track types they are interested in.
- // This information allows the codecs to avoid unpacking values that are not needed.
- constexpr bool skip_all_bone_rotations() const { return false; }
- constexpr bool skip_all_bone_translations() const { return false; }
- constexpr bool skip_all_bone_scales() const { return false; }
-
- //////////////////////////////////////////////////////////////////////////
- // These allow the caller of decompress_pose to control which tracks they are interested in.
- // This information allows the codecs to avoid unpacking values that are not needed.
- constexpr bool skip_bone_rotation(uint16_t bone_index) const { return (void)bone_index, false; }
- constexpr bool skip_bone_translation(uint16_t bone_index) const { return (void)bone_index, false; }
- constexpr bool skip_bone_scale(uint16_t bone_index) const { return (void)bone_index, false; }
-
- //////////////////////////////////////////////////////////////////////////
- // Called by the decoder to write out a quaternion rotation value for a specified bone index.
- void RTM_SIMD_CALL write_bone_rotation(uint16_t bone_index, rtm::quatf_arg0 rotation)
- {
- (void)bone_index;
- (void)rotation;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Called by the decoder to write out a translation value for a specified bone index.
- void RTM_SIMD_CALL write_bone_translation(uint16_t bone_index, rtm::vector4f_arg0 translation)
- {
- (void)bone_index;
- (void)translation;
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Called by the decoder to write out a scale value for a specified bone index.
- void RTM_SIMD_CALL write_bone_scale(uint16_t bone_index, rtm::vector4f_arg0 scale)
- {
- (void)bone_index;
- (void)scale;
- }
- };
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/io/clip_reader.h b/includes/acl/io/clip_reader.h
--- a/includes/acl/io/clip_reader.h
+++ b/includes/acl/io/clip_reader.h
@@ -27,18 +27,21 @@
#if defined(SJSON_CPP_PARSER)
#include "acl/io/clip_reader_error.h"
-#include "acl/compression/animation_clip.h"
#include "acl/compression/compression_settings.h"
#include "acl/compression/track_array.h"
-#include "acl/compression/skeleton.h"
#include "acl/core/algorithm_types.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/iallocator.h"
#include "acl/core/string.h"
#include "acl/core/unique_ptr.h"
+#include "acl/math/quatf.h"
#include <rtm/quatd.h>
+#include <rtm/quatf.h>
#include <rtm/vector4d.h>
+#include <rtm/vector4f.h>
+#include <rtm/qvvd.h>
+#include <rtm/qvvf.h>
#include <cstdint>
@@ -56,30 +59,38 @@ namespace acl
};
//////////////////////////////////////////////////////////////////////////
- // A raw clip with transform tracks
+ // Raw transform tracks
struct sjson_raw_clip
{
- std::unique_ptr<AnimationClip, Deleter<AnimationClip>> clip;
- std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>> skeleton;
+ track_array_qvvf track_list;
+
+ track_array_qvvf additive_base_track_list;
+ additive_clip_format8 additive_format;
+
+ track_qvvf bind_pose;
bool has_settings;
- algorithm_type8 algorithm_type;
- CompressionSettings settings;
+ compression_settings settings;
};
//////////////////////////////////////////////////////////////////////////
- // A raw track list
+ // Raw scalar tracks
struct sjson_raw_track_list
{
track_array track_list;
+
+ track_qvvf bind_pose;
+
+ bool has_settings;
+ compression_settings settings;
};
//////////////////////////////////////////////////////////////////////////
// An SJSON ACL file reader.
- class ClipReader
+ class clip_reader
{
public:
- ClipReader(IAllocator& allocator, const char* sjson_input, size_t input_length)
+ clip_reader(iallocator& allocator, const char* sjson_input, size_t input_length)
: m_allocator(allocator)
, m_parser(sjson_input, input_length)
, m_error()
@@ -87,7 +98,14 @@ namespace acl
, m_num_samples(0)
, m_sample_rate(0.0F)
, m_is_binary_exact(false)
+ , m_bone_names(nullptr)
+ , m_num_bones(0)
+ {
+ }
+
+ ~clip_reader()
{
+ deallocate_type_array(m_allocator, m_bone_names, m_num_bones);
}
sjson_file_type get_file_type()
@@ -116,17 +134,16 @@ namespace acl
if (!read_raw_clip_header())
return false;
- if (!read_settings(&out_data.has_settings, &out_data.algorithm_type, &out_data.settings))
+ if (!read_settings(&out_data.has_settings, &out_data.settings))
return false;
- if (!create_skeleton(out_data.skeleton))
+ if (!create_skeleton(out_data.track_list, out_data.bind_pose))
return false;
- if (!create_clip(out_data.clip, *out_data.skeleton))
+ if (!read_tracks(out_data.track_list, out_data.additive_base_track_list))
return false;
- if (!read_tracks(*out_data.clip, *out_data.skeleton))
- return false;
+ out_data.additive_format = out_data.additive_base_track_list.get_num_tracks() != 0 ? m_additive_format : additive_clip_format8::none;
return nothing_follows();
}
@@ -141,24 +158,21 @@ namespace acl
if (!read_raw_track_list_header())
return false;
- bool has_settings; // Not used
- algorithm_type8 algorithm_type; // Not used
- CompressionSettings settings; // Not used
- if (!read_settings(&has_settings, &algorithm_type, &settings))
+ if (!read_settings(&out_data.has_settings, &out_data.settings))
return false;
- if (!create_track_list(out_data.track_list))
+ if (!create_track_list(out_data.track_list, out_data.bind_pose))
return false;
return nothing_follows();
}
- ClipReaderError get_error() const { return m_error; }
+ clip_reader_error get_error() const { return m_error; }
private:
- IAllocator& m_allocator;
+ iallocator& m_allocator;
sjson::Parser m_parser;
- ClipReaderError m_error;
+ clip_reader_error m_error;
uint32_t m_version;
uint32_t m_num_samples;
@@ -170,10 +184,19 @@ namespace acl
uint32_t m_additive_base_num_samples;
float m_additive_base_sample_rate;
+ bool m_has_settings;
+ float m_constant_rotation_threshold_angle;
+ float m_constant_translation_threshold;
+ float m_constant_scale_threshold;
+ float m_error_threshold;
+
+ sjson::StringView* m_bone_names;
+ uint32_t m_num_bones;
+
void reset_state()
{
m_parser.reset_state();
- set_error(ClipReaderError::None);
+ set_error(clip_reader_error::None);
}
bool read_version()
@@ -186,7 +209,7 @@ namespace acl
if (m_version > 5)
{
- set_error(ClipReaderError::UnsupportedVersion);
+ set_error(clip_reader_error::UnsupportedVersion);
return false;
}
@@ -210,7 +233,7 @@ namespace acl
m_num_samples = static_cast<uint32_t>(num_samples);
if (static_cast<double>(m_num_samples) != num_samples)
{
- set_error(ClipReaderError::UnsignedIntegerExpected);
+ set_error(clip_reader_error::UnsignedIntegerExpected);
return false;
}
@@ -221,7 +244,7 @@ namespace acl
m_sample_rate = static_cast<float>(sample_rate);
if (m_sample_rate <= 0.0F)
{
- set_error(ClipReaderError::PositiveValueExpected);
+ set_error(clip_reader_error::PositiveValueExpected);
return false;
}
@@ -237,7 +260,7 @@ namespace acl
m_parser.try_read("additive_format", additive_format, "none");
if (!get_additive_clip_format(additive_format.c_str(), m_additive_format))
{
- set_error(ClipReaderError::InvalidAdditiveClipFormat);
+ set_error(clip_reader_error::InvalidAdditiveClipFormat);
return false;
}
@@ -246,14 +269,14 @@ namespace acl
m_additive_base_num_samples = static_cast<uint32_t>(num_samples);
if (static_cast<double>(m_additive_base_num_samples) != num_samples || m_additive_base_num_samples == 0)
{
- set_error(ClipReaderError::UnsignedIntegerExpected);
+ set_error(clip_reader_error::UnsignedIntegerExpected);
return false;
}
m_parser.try_read("additive_base_sample_rate", sample_rate, 30.0);
m_additive_base_sample_rate = static_cast<float>(sample_rate);
if (m_additive_base_sample_rate <= 0.0F)
{
- set_error(ClipReaderError::PositiveValueExpected);
+ set_error(clip_reader_error::PositiveValueExpected);
return false;
}
@@ -281,7 +304,7 @@ namespace acl
m_num_samples = static_cast<uint32_t>(num_samples);
if (static_cast<double>(m_num_samples) != num_samples)
{
- set_error(ClipReaderError::UnsignedIntegerExpected);
+ set_error(clip_reader_error::UnsignedIntegerExpected);
return false;
}
@@ -292,7 +315,7 @@ namespace acl
m_sample_rate = static_cast<float>(sample_rate);
if (m_sample_rate <= 0.0F)
{
- set_error(ClipReaderError::PositiveValueExpected);
+ set_error(clip_reader_error::PositiveValueExpected);
return false;
}
@@ -309,8 +332,10 @@ namespace acl
return false;
}
- bool read_settings(bool* out_has_settings, algorithm_type8* out_algorithm_type, CompressionSettings* out_settings)
+ bool read_settings(bool* out_has_settings, compression_settings* out_settings)
{
+ m_has_settings = false;
+
if (!m_parser.try_object_begins("settings"))
{
if (out_has_settings != nullptr)
@@ -320,7 +345,7 @@ namespace acl
return true;
}
- CompressionSettings default_settings;
+ compression_settings default_settings;
sjson::StringView algorithm_name;
sjson::StringView compression_level;
@@ -364,10 +389,11 @@ namespace acl
goto parsing_error;
}
- m_parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, double(default_settings.constant_rotation_threshold_angle));
- m_parser.try_read("constant_translation_threshold", constant_translation_threshold, double(default_settings.constant_translation_threshold));
- m_parser.try_read("constant_scale_threshold", constant_scale_threshold, double(default_settings.constant_scale_threshold));
- m_parser.try_read("error_threshold", error_threshold, double(default_settings.error_threshold));
+ // Skip deprecated values
+ m_parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, 0.00284714461);
+ m_parser.try_read("constant_translation_threshold", constant_translation_threshold, 0.001);
+ m_parser.try_read("constant_scale_threshold", constant_scale_threshold, 0.00001);
+ m_parser.try_read("error_threshold", error_threshold, 0.01);
if (!m_parser.is_valid() || !m_parser.object_ends())
goto parsing_error;
@@ -376,9 +402,6 @@ namespace acl
{
*out_has_settings = true;
- if (!get_algorithm_type(algorithm_name.c_str(), *out_algorithm_type))
- goto invalid_value_error;
-
if (!get_compression_level(compression_level.c_str(), out_settings->level))
goto invalid_value_error;
@@ -394,12 +417,13 @@ namespace acl
out_settings->segmenting.ideal_num_samples = uint16_t(segmenting_ideal_num_samples);
out_settings->segmenting.max_num_samples = uint16_t(segmenting_max_num_samples);
- out_settings->constant_rotation_threshold_angle = float(constant_rotation_threshold_angle);
- out_settings->constant_translation_threshold = float(constant_translation_threshold);
- out_settings->constant_scale_threshold = float(constant_scale_threshold);
- out_settings->error_threshold = float(error_threshold);
+ m_constant_rotation_threshold_angle = float(constant_rotation_threshold_angle);
+ m_constant_translation_threshold = float(constant_translation_threshold);
+ m_constant_scale_threshold = float(constant_scale_threshold);
+ m_error_threshold = float(error_threshold);
}
+ m_has_settings = true;
return true;
parsing_error:
@@ -408,42 +432,37 @@ namespace acl
invalid_value_error:
m_parser.get_position(m_error.line, m_error.column);
- m_error.error = ClipReaderError::InvalidCompressionSetting;
+ m_error.error = clip_reader_error::InvalidCompressionSetting;
return false;
}
- bool create_skeleton(std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>>& skeleton)
+ bool create_skeleton(track_array_qvvf& track_list, track_qvvf& bind_pose)
{
sjson::ParserState before_bones = m_parser.save_state();
uint16_t num_bones;
- if (!process_each_bone(nullptr, num_bones))
+ if (!process_each_bone(nullptr, nullptr, num_bones))
return false;
m_parser.restore_state(before_bones);
- RigidBone* bones = allocate_type_array<RigidBone>(m_allocator, num_bones);
+ m_num_bones = num_bones;
+ m_bone_names = allocate_type_array<sjson::StringView>(m_allocator, num_bones);
+
+ track_list = track_array_qvvf(m_allocator, num_bones);
+ bind_pose = track_qvvf::make_reserve(track_desc_transformf{}, m_allocator, num_bones, 30.0F); // 1 sample per track
+
const uint16_t num_allocated_bones = num_bones;
- if (!process_each_bone(bones, num_bones))
- {
- deallocate_type_array(m_allocator, bones, num_allocated_bones);
+ if (!process_each_bone(&track_list, &bind_pose, num_bones))
return false;
- }
+ (void)num_allocated_bones;
ACL_ASSERT(num_bones == num_allocated_bones, "Number of bones read mismatch");
- skeleton = make_unique<RigidSkeleton>(m_allocator, m_allocator, bones, num_bones);
- deallocate_type_array(m_allocator, bones, num_allocated_bones);
return true;
}
- bool read_skeleton()
- {
- uint16_t num_bones;
- return process_each_bone(nullptr, num_bones);
- }
-
static double hex_to_double(const sjson::StringView& value)
{
union UInt64ToDouble
@@ -497,19 +516,16 @@ namespace acl
return result;
}
- bool process_each_bone(RigidBone* bones, uint16_t& num_bones)
+ bool process_each_bone(track_array_qvvf* tracks, track_qvvf* bind_pose, uint16_t& num_bones)
{
- bool counting = bones == nullptr;
+ bool counting = tracks == nullptr;
num_bones = 0;
if (!m_parser.array_begins("bones"))
goto error;
- for (uint16_t i = 0; !m_parser.try_array_ends(); ++i)
+ for (uint32_t i = 0; !m_parser.try_array_ends(); ++i)
{
- RigidBone dummy;
- RigidBone& bone = counting ? dummy : bones[i];
-
if (!m_parser.object_begins())
goto error;
@@ -517,61 +533,79 @@ namespace acl
if (!m_parser.read("name", name))
goto error;
- if (!counting)
- bone.name = String(m_allocator, name.c_str(), name.size());
+ if (tracks != nullptr)
+ m_bone_names[i] = name;
sjson::StringView parent;
if (!m_parser.read("parent", parent))
goto error;
- if (!counting)
+ uint32_t parent_index = k_invalid_track_index;
+ if (tracks != nullptr && parent.size() != 0)
{
- if (parent.size() == 0)
- {
- // This is the root bone.
- bone.parent_index = k_invalid_bone_index;
- }
- else
+ parent_index = find_bone(parent);
+ if (parent_index == k_invalid_track_index)
{
- bone.parent_index = find_bone(bones, num_bones, parent);
- if (bone.parent_index == k_invalid_bone_index)
- {
- set_error(ClipReaderError::NoParentBoneWithThatName);
- return false;
- }
+ set_error(clip_reader_error::NoParentBoneWithThatName);
+ return false;
}
}
- if (!m_parser.read("vertex_distance", bone.vertex_distance))
+ float vertex_distance;
+ if (!m_parser.read("vertex_distance", vertex_distance))
goto error;
+ rtm::qvvd bind_transform = rtm::qvv_identity();
if (m_is_binary_exact)
{
sjson::StringView rotation[4];
if (m_parser.try_read("bind_rotation", rotation, 4, nullptr) && !counting)
- bone.bind_transform.rotation = hex_to_quat(rotation);
+ bind_transform.rotation = hex_to_quat(rotation);
sjson::StringView translation[3];
if (m_parser.try_read("bind_translation", translation, 3, nullptr) && !counting)
- bone.bind_transform.translation = hex_to_vector3(translation);
+ bind_transform.translation = hex_to_vector3(translation);
sjson::StringView scale[3];
if (m_parser.try_read("bind_scale", scale, 3, nullptr) && !counting)
- bone.bind_transform.scale = hex_to_vector3(scale);
+ bind_transform.scale = hex_to_vector3(scale);
}
else
{
double rotation[4] = { 0.0, 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_rotation", rotation, 4, 0.0) && !counting)
- bone.bind_transform.rotation = rtm::quat_load(&rotation[0]);
+ bind_transform.rotation = rtm::quat_load(&rotation[0]);
double translation[3] = { 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_translation", translation, 3, 0.0) && !counting)
- bone.bind_transform.translation = rtm::vector_load3(&translation[0]);
+ bind_transform.translation = rtm::vector_load3(&translation[0]);
double scale[3] = { 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_scale", scale, 3, 0.0) && !counting)
- bone.bind_transform.scale = rtm::vector_load3(&scale[0]);
+ bind_transform.scale = rtm::vector_load3(&scale[0]);
+ }
+
+ if (tracks != nullptr)
+ {
+ track_desc_transformf desc;
+ desc.parent_index = parent_index;
+ desc.shell_distance = vertex_distance;
+
+ if (m_has_settings)
+ {
+ desc.precision = m_error_threshold;
+ desc.constant_rotation_threshold_angle = m_constant_rotation_threshold_angle;
+ desc.constant_translation_threshold = m_constant_translation_threshold;
+ desc.constant_scale_threshold = m_constant_scale_threshold;
+ }
+
+ // Create a dummy track for now to hold our arguments
+ (*tracks)[i] = track_qvvf::make_ref(desc, nullptr, 0, 30.0F);
+
+ rtm::qvvf bind_transform_ = rtm::qvv_cast(bind_transform);
+ bind_transform_.rotation = rtm::quat_normalize(bind_transform_.rotation);
+
+ (*bind_pose)[i] = bind_transform_;
}
if (!m_parser.object_ends())
@@ -587,24 +621,133 @@ namespace acl
return false;
}
- uint16_t find_bone(const RigidBone* bones, uint16_t num_bones, const sjson::StringView& name) const
+ uint32_t find_bone(const sjson::StringView& name) const
{
- for (uint16_t i = 0; i < num_bones; ++i)
+ for (uint32_t i = 0; i < m_num_bones; ++i)
{
- if (name == bones[i].name.c_str())
+ if (name == m_bone_names[i])
return i;
}
- return k_invalid_bone_index;
+ return k_invalid_track_index;
+ }
+
+ float read_optional_float(const char* key, float default_value)
+ {
+ float value = default_value;
+ if (m_is_binary_exact)
+ {
+ sjson::StringView value_str;
+ if (m_parser.try_read(key, value_str, ""))
+ value = hex_to_float(value_str);
+ }
+ else
+ m_parser.try_read(key, value, default_value);
+
+ return value;
}
- bool create_clip(std::unique_ptr<AnimationClip, Deleter<AnimationClip>>& clip, const RigidSkeleton& skeleton)
+ bool read_qvv_sample(rtm::qvvf& out_sample)
{
- clip = make_unique<AnimationClip>(m_allocator, m_allocator, skeleton, m_num_samples, m_sample_rate, String(m_allocator, m_clip_name.c_str(), m_clip_name.size()));
+ rtm::qvvf sample = rtm::qvv_identity();
+ sjson::StringView values_str[4];
+ double values[4] = { 0.0, 0.0, 0.0, 0.0 };
+
+ {
+ if (!m_parser.array_begins())
+ return false;
+
+ rtm::float4f value;
+ if (m_is_binary_exact)
+ {
+ if (!m_parser.read(values_str, 4))
+ return false;
+
+ value = hex_to_float4f(values_str, 4);
+ }
+ else
+ {
+ if (!m_parser.read(values, 4))
+ return false;
+
+ value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), static_cast<float>(values[3])};
+ }
+
+ sample.rotation = quat_load(&value);
+ if (!rtm::quat_is_finite(sample.rotation))
+ return false;
+
+ if (!m_parser.array_ends())
+ return false;
+ }
+
+ if (!m_parser.read_comma())
+ return false;
+
+ {
+ if (!m_parser.array_begins())
+ return false;
+
+ rtm::float4f value;
+ if (m_is_binary_exact)
+ {
+ if (!m_parser.read(values_str, 3))
+ return false;
+
+ value = hex_to_float4f(values_str, 4);
+ }
+ else
+ {
+ if (!m_parser.read(values, 3))
+ return false;
+
+ value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), 0.0F };
+ }
+
+ sample.translation = vector_load(&value);
+ if (!rtm::vector_is_finite3(sample.translation))
+ return false;
+
+ if (!m_parser.array_ends())
+ return false;
+ }
+
+ if (!m_parser.read_comma())
+ return false;
+
+ {
+ if (!m_parser.array_begins())
+ return false;
+
+ rtm::float4f value;
+ if (m_is_binary_exact)
+ {
+ if (!m_parser.read(values_str, 3))
+ return false;
+
+ value = hex_to_float4f(values_str, 4);
+ }
+ else
+ {
+ if (!m_parser.read(values, 3))
+ return false;
+
+ value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), 0.0F };
+ }
+
+ sample.scale = vector_load(&value);
+ if (!rtm::vector_is_finite3(sample.scale))
+ return false;
+
+ if (!m_parser.array_ends())
+ return false;
+ }
+
+ out_sample = sample;
return true;
}
- bool process_track_list(track* tracks, uint32_t& num_tracks)
+ bool process_track_list(track* tracks, track_qvvf* bind_pose, uint32_t& num_tracks)
{
const bool counting = tracks == nullptr;
track dummy;
@@ -634,7 +777,7 @@ namespace acl
track_type8 track_type;
if (!get_track_type(type.c_str(), track_type))
{
- m_error.error = ClipReaderError::InvalidTrackType;
+ m_error.error = clip_reader_error::InvalidTrackType;
return false;
}
@@ -642,26 +785,80 @@ namespace acl
track_list_type = track_type;
else if (track_type != track_list_type)
{
- m_error.error = ClipReaderError::InvalidTrackType;
+ m_error.error = clip_reader_error::InvalidTrackType;
return false;
}
const uint32_t num_components = get_track_num_sample_elements(track_type);
- ACL_ASSERT(num_components > 0 && num_components <= 4, "Cannot have 0 or more than 4 components");
+ ACL_ASSERT((num_components > 0 && num_components <= 4) || num_components == 12, "Must have between 1 and 4 components or 12");
- float precision;
- m_parser.try_read("precision", precision, 0.0001F);
+ track_desc_scalarf scalar_desc;
+ track_desc_transformf transform_desc;
+
+ float precision = read_optional_float("precision", -1.0F);
// Deprecated, no longer used
- float constant_threshold;
- m_parser.try_read("constant_threshold", constant_threshold, 0.00001F);
+ read_optional_float("constant_threshold", -1.0F);
uint32_t output_index;
m_parser.try_read("output_index", output_index, i);
- track_desc_scalarf scalar_desc;
+ m_parser.try_read("parent_index", transform_desc.parent_index, k_invalid_track_index);
+
+ transform_desc.shell_distance = read_optional_float("shell_distance", transform_desc.shell_distance);
+ transform_desc.constant_rotation_threshold_angle = read_optional_float("constant_rotation_threshold_angle", transform_desc.constant_rotation_threshold_angle);
+ transform_desc.constant_translation_threshold = read_optional_float("constant_translation_threshold", transform_desc.constant_translation_threshold);
+ transform_desc.constant_scale_threshold = read_optional_float("constant_scale_threshold", transform_desc.constant_scale_threshold);
+
scalar_desc.output_index = output_index;
- scalar_desc.precision = precision;
+ transform_desc.output_index = output_index;
+
+ if (track_type == track_type8::qvvf)
+ transform_desc.precision = precision < 0.0F ? transform_desc.precision : precision;
+ else
+ scalar_desc.precision = precision < 0.0F ? scalar_desc.precision : precision;
+
+ rtm::qvvf bind_transform = rtm::qvv_identity();
+ if (m_is_binary_exact)
+ {
+ sjson::StringView rotation[4];
+ if (m_parser.try_read("bind_rotation", rotation, 4, nullptr) && !counting)
+ {
+ const rtm::float4f value = hex_to_float4f(rotation, 4);
+ bind_transform.rotation = quat_load(&value);
+ }
+
+ sjson::StringView translation[3];
+ if (m_parser.try_read("bind_translation", translation, 3, nullptr) && !counting)
+ {
+ const rtm::float4f value = hex_to_float4f(translation, 3);
+ bind_transform.translation = rtm::vector_load(&value);
+ }
+
+ sjson::StringView scale[3];
+ if (m_parser.try_read("bind_scale", scale, 3, nullptr) && !counting)
+ {
+ const rtm::float4f value = hex_to_float4f(scale, 3);
+ bind_transform.scale = rtm::vector_load(&value);
+ }
+ }
+ else
+ {
+ double rotation[4] = { 0.0, 0.0, 0.0, 0.0 };
+ if (m_parser.try_read("bind_rotation", rotation, 4, 0.0) && !counting)
+ bind_transform.rotation = rtm::quat_normalize(rtm::quat_cast(rtm::quat_load(&rotation[0])));
+
+ double translation[3] = { 0.0, 0.0, 0.0 };
+ if (m_parser.try_read("bind_translation", translation, 3, 0.0) && !counting)
+ bind_transform.translation = rtm::vector_cast(rtm::vector_load3(&translation[0]));
+
+ double scale[3] = { 0.0, 0.0, 0.0 };
+ if (m_parser.try_read("bind_scale", scale, 3, 0.0) && !counting)
+ bind_transform.scale = rtm::vector_cast(rtm::vector_load3(&scale[0]));
+ }
+
+ if (bind_pose != nullptr)
+ (*bind_pose)[i] = bind_transform;
if (!m_parser.array_begins("data"))
goto error;
@@ -674,6 +871,7 @@ namespace acl
rtm::float3f* float3f;
rtm::float4f* float4f;
rtm::vector4f* vector4f;
+ rtm::qvvf* qvvf;
};
track_samples_ptr_union track_samples_typed = { nullptr };
@@ -694,6 +892,9 @@ namespace acl
case track_type8::vector4f:
track_samples_typed.vector4f = allocate_type_array<rtm::vector4f>(m_allocator, m_num_samples);
break;
+ case track_type8::qvvf:
+ track_samples_typed.qvvf = allocate_type_array<rtm::qvvf>(m_allocator, m_num_samples);
+ break;
default:
ACL_ASSERT(false, "Unsupported track type");
break;
@@ -710,59 +911,77 @@ namespace acl
if (m_is_binary_exact)
{
- sjson::StringView values[4];
- if (m_parser.read(values, num_components))
+ switch (track_type)
{
- switch (track_type)
- {
- case track_type8::float1f:
- case track_type8::float2f:
- case track_type8::float3f:
- case track_type8::float4f:
- case track_type8::vector4f:
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ {
+ sjson::StringView values[4];
+ if (m_parser.read(values, num_components))
{
const rtm::float4f value = hex_to_float4f(values, num_components);
std::memcpy(track_samples_typed.float1f + (sample_index * num_components), &value, sizeof(float) * num_components);
- break;
- }
- default:
- ACL_ASSERT(false, "Unsupported track type");
- break;
}
+ else
+ has_error = true;
+ break;
}
- else
+ case track_type8::qvvf:
{
- has_error = true;
+ rtm::qvvf sample;
+ if (!read_qvv_sample(sample))
+ has_error = true;
+ else
+ std::memcpy(track_samples_typed.qvvf + sample_index, &sample, sizeof(rtm::qvvf));
break;
}
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+
+ if (has_error)
+ break;
}
else
{
- double values[4] = { 0.0, 0.0, 0.0, 0.0 };
- if (m_parser.read(values, num_components))
+ switch (track_type)
{
- switch (track_type)
- {
- case track_type8::float1f:
- case track_type8::float2f:
- case track_type8::float3f:
- case track_type8::float4f:
- case track_type8::vector4f:
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ {
+ double values[4] = { 0.0, 0.0, 0.0, 0.0 };
+ if (m_parser.read(values, num_components))
{
- const rtm::float4f value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), static_cast<float>(values[3])};
+ const rtm::float4f value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), static_cast<float>(values[3]) };
std::memcpy(track_samples_typed.float1f + (sample_index * num_components), &value, sizeof(float) * num_components);
- break;
- }
- default:
- ACL_ASSERT(false, "Unsupported track type");
- break;
}
+ else
+ has_error = true;
+ break;
}
- else
+ case track_type8::qvvf:
{
- has_error = true;
+ rtm::qvvf sample;
+ if (!read_qvv_sample(sample))
+ has_error = true;
+ else
+ std::memcpy(track_samples_typed.qvvf + sample_index, &sample, sizeof(rtm::qvvf));
break;
}
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+
+ if (has_error)
+ break;
}
if (!has_error && !m_parser.array_ends())
@@ -803,6 +1022,9 @@ namespace acl
case track_type8::vector4f:
deallocate_type_array<rtm::vector4f>(m_allocator, track_samples_typed.vector4f, m_num_samples);
break;
+ case track_type8::qvvf:
+ deallocate_type_array<rtm::qvvf>(m_allocator, track_samples_typed.qvvf, m_num_samples);
+ break;
default:
ACL_ASSERT(false, "Unsupported track type");
break;
@@ -827,6 +1049,9 @@ namespace acl
case track_type8::vector4f:
track_ = track_vector4f::make_owner(scalar_desc, m_allocator, track_samples_typed.vector4f, m_num_samples, m_sample_rate);
break;
+ case track_type8::qvvf:
+ track_ = track_qvvf::make_owner(transform_desc, m_allocator, track_samples_typed.qvvf, m_num_samples, m_sample_rate);
+ break;
default:
ACL_ASSERT(false, "Unsupported track type");
break;
@@ -843,19 +1068,20 @@ namespace acl
return false;
}
- bool create_track_list(track_array& track_list)
+ bool create_track_list(track_array& track_list, track_qvvf& bind_pose)
{
const sjson::ParserState before_tracks = m_parser.save_state();
uint32_t num_tracks;
- if (!process_track_list(nullptr, num_tracks))
+ if (!process_track_list(nullptr, nullptr, num_tracks))
return false;
m_parser.restore_state(before_tracks);
track_list = track_array(m_allocator, num_tracks);
+ bind_pose = track_qvvf::make_reserve(track_desc_transformf{}, m_allocator, num_tracks, 30.0F); // 1 sample per track
- if (!process_track_list(track_list.begin(), num_tracks))
+ if (!process_track_list(track_list.begin(), &bind_pose, num_tracks))
return false;
ACL_ASSERT(num_tracks == track_list.get_num_tracks(), "Number of tracks read mismatch");
@@ -863,13 +1089,16 @@ namespace acl
return true;
}
- bool read_tracks(AnimationClip& clip, const RigidSkeleton& skeleton)
+ bool read_tracks(track_array_qvvf& track_list, track_array_qvvf& additive_base_track_list)
{
- std::unique_ptr<AnimationClip, Deleter<AnimationClip>> base_clip;
+ const uint32_t num_transforms = track_list.get_num_tracks();
if (m_parser.try_array_begins("base_tracks"))
{
- base_clip = make_unique<AnimationClip>(m_allocator, m_allocator, skeleton, m_additive_base_num_samples, m_additive_base_sample_rate, String(m_allocator, m_additive_base_name.c_str(), m_additive_base_name.size()));
+ // Copy our metadata from the actual clip
+ additive_base_track_list = track_array_qvvf(m_allocator, num_transforms);
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
+ additive_base_track_list[transform_index].get_description() = track_list[transform_index].get_description();
while (!m_parser.try_array_ends())
{
@@ -880,48 +1109,53 @@ namespace acl
if (!m_parser.read("name", name))
goto error;
- const uint16_t bone_index = find_bone(skeleton.get_bones(), skeleton.get_num_bones(), name);
- if (bone_index == k_invalid_bone_index)
+ const uint32_t bone_index = find_bone(name);
+ if (bone_index == k_invalid_track_index)
{
- set_error(ClipReaderError::NoBoneWithThatName);
+ set_error(clip_reader_error::NoBoneWithThatName);
return false;
}
- AnimatedBone& bone = base_clip->get_animated_bone(bone_index);
+ track_desc_transformf desc = additive_base_track_list[bone_index].get_description(); // Copy our description
+ desc.output_index = bone_index;
+
+ track_qvvf track = track_qvvf::make_reserve(desc, m_allocator, m_additive_base_num_samples, m_additive_base_sample_rate);
if (m_parser.try_array_begins("rotations"))
{
- if (!read_track_rotations(bone, m_additive_base_num_samples) || !m_parser.array_ends())
+ if (!read_track_rotations(track, m_additive_base_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.rotation_track.set_sample(sample_index, rtm::quat_identity());
+ track[sample_index].rotation = rtm::quat_identity();
}
if (m_parser.try_array_begins("translations"))
{
- if (!read_track_translations(bone, m_additive_base_num_samples) || !m_parser.array_ends())
+ if (!read_track_translations(track, m_additive_base_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.translation_track.set_sample(sample_index, rtm::vector_zero());
+ track[sample_index].translation = rtm::vector_zero();
}
if (m_parser.try_array_begins("scales"))
{
- if (!read_track_scales(bone, m_additive_base_num_samples) || !m_parser.array_ends())
+ if (!read_track_scales(track, m_additive_base_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.scale_track.set_sample(sample_index, rtm::vector_set(1.0));
+ track[sample_index].scale = rtm::vector_set(1.0F);
}
+ additive_base_track_list[bone_index] = std::move(track);
+
if (!m_parser.object_ends())
goto error;
}
@@ -939,54 +1173,57 @@ namespace acl
if (!m_parser.read("name", name))
goto error;
- const uint16_t bone_index = find_bone(skeleton.get_bones(), skeleton.get_num_bones(), name);
- if (bone_index == k_invalid_bone_index)
+ const uint32_t bone_index = find_bone(name);
+ if (bone_index == k_invalid_track_index)
{
- set_error(ClipReaderError::NoBoneWithThatName);
+ set_error(clip_reader_error::NoBoneWithThatName);
return false;
}
- AnimatedBone& bone = clip.get_animated_bone(bone_index);
+ track_desc_transformf desc = track_list[bone_index].get_description(); // Copy our description
+ desc.output_index = bone_index;
+
+ track_qvvf track = track_qvvf::make_reserve(desc, m_allocator, m_num_samples, m_sample_rate);
if (m_parser.try_array_begins("rotations"))
{
- if (!read_track_rotations(bone, m_num_samples) || !m_parser.array_ends())
+ if (!read_track_rotations(track, m_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.rotation_track.set_sample(sample_index, rtm::quat_identity());
+ track[sample_index].rotation = rtm::quat_identity();
}
if (m_parser.try_array_begins("translations"))
{
- if (!read_track_translations(bone, m_num_samples) || !m_parser.array_ends())
+ if (!read_track_translations(track, m_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.translation_track.set_sample(sample_index, rtm::vector_zero());
+ track[sample_index].translation = rtm::vector_zero();
}
if (m_parser.try_array_begins("scales"))
{
- if (!read_track_scales(bone, m_num_samples) || !m_parser.array_ends())
+ if (!read_track_scales(track, m_num_samples) || !m_parser.array_ends())
goto error;
}
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.scale_track.set_sample(sample_index, rtm::vector_set(1.0));
+ track[sample_index].scale = rtm::vector_set(1.0F);
}
+ track_list[bone_index] = std::move(track);
+
if (!m_parser.object_ends())
goto error;
}
- clip.set_additive_base(base_clip.release(), m_additive_format);
-
return true;
error:
@@ -994,7 +1231,7 @@ namespace acl
return false;
}
- bool read_track_rotations(AnimatedBone& bone, uint32_t num_samples_expected)
+ bool read_track_rotations(track_qvvf& track, uint32_t num_samples_expected)
{
for (uint32_t i = 0; i < num_samples_expected; ++i)
{
@@ -1023,13 +1260,13 @@ namespace acl
if (!m_parser.array_ends())
return false;
- bone.rotation_track.set_sample(i, rotation);
+ track[i].rotation = rtm::quat_normalize(rtm::quat_cast(rotation));
}
return true;
}
- bool read_track_translations(AnimatedBone& bone, uint32_t num_samples_expected)
+ bool read_track_translations(track_qvvf& track, uint32_t num_samples_expected)
{
for (uint32_t i = 0; i < num_samples_expected; ++i)
{
@@ -1058,13 +1295,13 @@ namespace acl
if (!m_parser.array_ends())
return false;
- bone.translation_track.set_sample(i, translation);
+ track[i].translation = rtm::vector_cast(translation);
}
return true;
}
- bool read_track_scales(AnimatedBone& bone, uint32_t num_samples_expected)
+ bool read_track_scales(track_qvvf& track, uint32_t num_samples_expected)
{
for (uint32_t i = 0; i < num_samples_expected; ++i)
{
@@ -1093,7 +1330,7 @@ namespace acl
if (!m_parser.array_ends())
return false;
- bone.scale_track.set_sample(i, scale);
+ track[i].scale = rtm::vector_cast(scale);
}
return true;
diff --git a/includes/acl/io/clip_reader_error.h b/includes/acl/io/clip_reader_error.h
--- a/includes/acl/io/clip_reader_error.h
+++ b/includes/acl/io/clip_reader_error.h
@@ -34,7 +34,7 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- struct ClipReaderError : sjson::ParserError
+ struct clip_reader_error : sjson::ParserError
{
enum : uint32_t
{
@@ -48,11 +48,11 @@ namespace acl
InvalidTrackType,
};
- ClipReaderError()
+ clip_reader_error()
{
}
- ClipReaderError(const sjson::ParserError& e)
+ clip_reader_error(const sjson::ParserError& e)
{
error = e.error;
line = e.line;
diff --git a/includes/acl/io/clip_writer.h b/includes/acl/io/clip_writer.h
--- a/includes/acl/io/clip_writer.h
+++ b/includes/acl/io/clip_writer.h
@@ -26,9 +26,7 @@
#if defined(SJSON_CPP_WRITER)
-#include "acl/compression/animation_clip.h"
#include "acl/compression/compression_settings.h"
-#include "acl/compression/skeleton.h"
#include "acl/compression/track_array.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/iallocator.h"
@@ -62,29 +60,37 @@ namespace acl
return buffer;
};
- inline const char* format_hex_double(double value, char* buffer, size_t buffer_size)
+ inline void write_sjson_settings(const compression_settings& settings, sjson::Writer& writer)
{
- union DoubleToUInt64
+ writer["settings"] = [&](sjson::ObjectWriter& settings_writer)
{
- uint64_t u64;
- double dbl;
+ settings_writer["level"] = get_compression_level_name(settings.level);
+ settings_writer["rotation_format"] = get_rotation_format_name(settings.rotation_format);
+ settings_writer["translation_format"] = get_vector_format_name(settings.translation_format);
+ settings_writer["scale_format"] = get_vector_format_name(settings.scale_format);
- constexpr explicit DoubleToUInt64(double dbl_value) : dbl(dbl_value) {}
+ settings_writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
+ {
+ segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
+ segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
+ };
};
+ writer.insert_newline();
+ }
- snprintf(buffer, buffer_size, "%" PRIX64, DoubleToUInt64(value).u64);
-
- return buffer;
- };
-
- inline void write_sjson_clip(const AnimationClip& clip, sjson::Writer& writer)
+ inline void write_sjson_header(const track_array& track_list, sjson::Writer& writer)
{
- writer["clip"] = [&](sjson::ObjectWriter& clip_writer)
+ writer["version"] = 5;
+ writer.insert_newline();
+
+ writer["track_list"] = [&](sjson::ObjectWriter& header_writer)
{
- clip_writer["name"] = clip.get_name().c_str();
- clip_writer["num_samples"] = clip.get_num_samples();
- clip_writer["sample_rate"] = clip.get_sample_rate();
- clip_writer["is_binary_exact"] = true;
+ //header_writer["name"] = track_list.get_name().c_str();
+ header_writer["num_samples"] = track_list.get_num_samples_per_track();
+ header_writer["sample_rate"] = track_list.get_sample_rate();
+ header_writer["is_binary_exact"] = true;
+
+#if 0 // TODO
clip_writer["additive_format"] = get_additive_clip_format_name(clip.get_additive_format());
const AnimationClip* base_clip = clip.get_additive_base();
@@ -94,179 +100,234 @@ namespace acl
clip_writer["additive_base_num_samples"] = base_clip->get_num_samples();
clip_writer["additive_base_sample_rate"] = base_clip->get_sample_rate();
}
+#endif
};
writer.insert_newline();
}
- inline void write_sjson_settings(algorithm_type8 algorithm, const CompressionSettings& settings, sjson::Writer& writer)
+ inline void write_sjson_scalar_desc(const track_desc_scalarf& desc, sjson::ObjectWriter& writer)
{
- writer["settings"] = [&](sjson::ObjectWriter& settings_writer)
- {
- settings_writer["algorithm_name"] = get_algorithm_name(algorithm);
- settings_writer["level"] = get_compression_level_name(settings.level);
- settings_writer["rotation_format"] = get_rotation_format_name(settings.rotation_format);
- settings_writer["translation_format"] = get_vector_format_name(settings.translation_format);
- settings_writer["scale_format"] = get_vector_format_name(settings.scale_format);
-
- settings_writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
- {
- segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
- segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
- };
+ char buffer[32] = { 0 };
- settings_writer["constant_rotation_threshold_angle"] = settings.constant_rotation_threshold_angle;
- settings_writer["constant_translation_threshold"] = settings.constant_translation_threshold;
- settings_writer["constant_scale_threshold"] = settings.constant_scale_threshold;
- settings_writer["error_threshold"] = settings.error_threshold;
- };
- writer.insert_newline();
+ writer["precision"] = format_hex_float(desc.precision, buffer, sizeof(buffer));
+ writer["output_index"] = desc.output_index;
}
- inline void write_sjson_bones(const RigidSkeleton& skeleton, sjson::Writer& writer)
+ inline void write_sjson_transform_desc(const track_desc_transformf& desc, sjson::ObjectWriter& writer)
{
char buffer[32] = { 0 };
- writer["bones"] = [&](sjson::ArrayWriter& bones_writer)
- {
- const uint16_t num_bones = skeleton.get_num_bones();
- if (num_bones > 0)
- bones_writer.push_newline();
-
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const RigidBone& bone = skeleton.get_bone(bone_index);
- const RigidBone& parent_bone = bone.is_root() ? bone : skeleton.get_bone(bone.parent_index);
-
- bones_writer.push([&](sjson::ObjectWriter& bone_writer)
- {
- bone_writer["name"] = bone.name.c_str();
- bone_writer["parent"] = bone.is_root() ? "" : parent_bone.name.c_str();
- bone_writer["vertex_distance"] = bone.vertex_distance;
-
- if (!rtm::quat_near_identity(bone.bind_transform.rotation))
- {
- bone_writer["bind_rotation"] = [&](sjson::ArrayWriter& rot_writer)
- {
- rot_writer.push(format_hex_double(rtm::quat_get_x(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_y(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_z(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_w(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- };
- }
-
- if (!rtm::vector_all_near_equal3(bone.bind_transform.translation, rtm::vector_zero()))
- {
- bone_writer["bind_translation"] = [&](sjson::ArrayWriter& trans_writer)
- {
- trans_writer.push(format_hex_double(rtm::vector_get_x(bone.bind_transform.translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(rtm::vector_get_y(bone.bind_transform.translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(rtm::vector_get_z(bone.bind_transform.translation), buffer, sizeof(buffer)));
- };
- }
-
- if (!rtm::vector_all_near_equal3(bone.bind_transform.scale, rtm::vector_set(1.0)))
- {
- bone_writer["bind_scale"] = [&](sjson::ArrayWriter& scale_writer)
- {
- scale_writer.push(format_hex_double(rtm::vector_get_x(bone.bind_transform.scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(rtm::vector_get_y(bone.bind_transform.scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(rtm::vector_get_z(bone.bind_transform.scale), buffer, sizeof(buffer)));
- };
- }
- });
- }
- };
- writer.insert_newline();
+ writer["precision"] = format_hex_float(desc.precision, buffer, sizeof(buffer));
+ writer["output_index"] = desc.output_index;
+ writer["parent_index"] = desc.parent_index;
+ writer["shell_distance"] = format_hex_float(desc.shell_distance, buffer, sizeof(buffer));
+ writer["constant_rotation_threshold_angle"] = format_hex_float(desc.constant_rotation_threshold_angle, buffer, sizeof(buffer));
+ writer["constant_translation_threshold"] = format_hex_float(desc.constant_translation_threshold, buffer, sizeof(buffer));
+ writer["constant_scale_threshold"] = format_hex_float(desc.constant_scale_threshold, buffer, sizeof(buffer));
}
- inline void write_sjson_tracks(const RigidSkeleton& skeleton, const AnimationClip& clip, bool is_base_clip, sjson::Writer& writer)
+ inline void write_sjson_tracks(const track_array& track_list, sjson::Writer& writer)
{
char buffer[32] = { 0 };
- writer[is_base_clip ? "base_tracks" : "tracks"] = [&](sjson::ArrayWriter& tracks_writer)
+ writer["tracks"] = [&](sjson::ArrayWriter& tracks_writer)
{
- const uint16_t num_bones = skeleton.get_num_bones();
- if (num_bones > 0)
+ const uint32_t num_tracks = track_list.get_num_tracks();
+ if (num_tracks > 0)
tracks_writer.push_newline();
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ for (const track& track_ : track_list)
{
- const RigidBone& rigid_bone = skeleton.get_bone(bone_index);
- const AnimatedBone& bone = clip.get_animated_bone(bone_index);
-
tracks_writer.push([&](sjson::ObjectWriter& track_writer)
- {
- track_writer["name"] = rigid_bone.name.c_str();
- track_writer["rotations"] = [&](sjson::ArrayWriter& rotations_writer)
{
- const uint32_t num_rotation_samples = bone.rotation_track.get_num_samples();
- if (num_rotation_samples > 0)
- rotations_writer.push_newline();
+ //track_writer["name"] = track_.get_name().c_str();
+ track_writer["type"] = get_track_type_name(track_.get_type());
- for (uint32_t sample_index = 0; sample_index < num_rotation_samples; ++sample_index)
+ switch (track_.get_type())
+ {
+ case track_type8::float1f:
{
- const rtm::quatd rotation = bone.rotation_track.get_sample(sample_index);
- rotations_writer.push([&](sjson::ArrayWriter& rot_writer)
+ const track_float1f& track__ = track_cast<track_float1f>(track_);
+ write_sjson_scalar_desc(track__.get_description(), track_writer);
+
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
{
- rot_writer.push(format_hex_double(rtm::quat_get_x(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_y(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_z(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(rtm::quat_get_w(rotation), buffer, sizeof(buffer)));
- });
- rotations_writer.push_newline();
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const float sample = track__[sample_index];
+ sample_writer.push(acl_impl::format_hex_float(sample, buffer, sizeof(buffer)));
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
}
- };
-
- track_writer["translations"] = [&](sjson::ArrayWriter& translations_writer)
- {
- const uint32_t num_translation_samples = bone.translation_track.get_num_samples();
- if (num_translation_samples > 0)
- translations_writer.push_newline();
+ case track_type8::float2f:
+ {
+ const track_float2f& track__ = track_cast<track_float2f>(track_);
+ write_sjson_scalar_desc(track__.get_description(), track_writer);
- for (uint32_t sample_index = 0; sample_index < num_translation_samples; ++sample_index)
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
+ {
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const rtm::float2f& sample = track__[sample_index];
+ sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
+ }
+ case track_type8::float3f:
{
- const rtm::vector4d translation = bone.translation_track.get_sample(sample_index);
- translations_writer.push([&](sjson::ArrayWriter& trans_writer)
+ const track_float3f& track__ = track_cast<track_float3f>(track_);
+ write_sjson_scalar_desc(track__.get_description(), track_writer);
+
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
{
- trans_writer.push(format_hex_double(rtm::vector_get_x(translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(rtm::vector_get_y(translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(rtm::vector_get_z(translation), buffer, sizeof(buffer)));
- });
- translations_writer.push_newline();
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const rtm::float3f& sample = track__[sample_index];
+ sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.z, buffer, sizeof(buffer)));
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
}
- };
+ case track_type8::float4f:
+ {
+ const track_float4f& track__ = track_cast<track_float4f>(track_);
+ write_sjson_scalar_desc(track__.get_description(), track_writer);
- track_writer["scales"] = [&](sjson::ArrayWriter& scales_writer)
- {
- const uint32_t num_scale_samples = bone.scale_track.get_num_samples();
- if (num_scale_samples > 0)
- scales_writer.push_newline();
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
+ {
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const rtm::float4f& sample = track__[sample_index];
+ sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.z, buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(sample.w, buffer, sizeof(buffer)));
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const track_vector4f& track__ = track_cast<track_vector4f>(track_);
+ write_sjson_scalar_desc(track__.get_description(), track_writer);
- for (uint32_t sample_index = 0; sample_index < num_scale_samples; ++sample_index)
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
+ {
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const rtm::vector4f& sample = track__[sample_index];
+ sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_x(sample), buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_y(sample), buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_z(sample), buffer, sizeof(buffer)));
+ sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_w(sample), buffer, sizeof(buffer)));
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
+ }
+ case track_type8::qvvf:
{
- const rtm::vector4d scale = bone.scale_track.get_sample(sample_index);
- scales_writer.push([&](sjson::ArrayWriter& scale_writer)
+ const track_qvvf& track__ = track_cast<track_qvvf>(track_);
+ write_sjson_transform_desc(track__.get_description(), track_writer);
+
+ track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
{
- scale_writer.push(format_hex_double(rtm::vector_get_x(scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(rtm::vector_get_y(scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(rtm::vector_get_z(scale), buffer, sizeof(buffer)));
- });
- scales_writer.push_newline();
+ const uint32_t num_samples = track__.get_num_samples();
+ if (num_samples > 0)
+ data_writer.push_newline();
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ data_writer.push([&](sjson::ArrayWriter& sample_writer)
+ {
+ const rtm::qvvf& sample = track__[sample_index];
+ sample_writer.push([&](sjson::ArrayWriter& rotation_writer)
+ {
+ rotation_writer.push(acl_impl::format_hex_float(rtm::quat_get_x(sample.rotation), buffer, sizeof(buffer)));
+ rotation_writer.push(acl_impl::format_hex_float(rtm::quat_get_y(sample.rotation), buffer, sizeof(buffer)));
+ rotation_writer.push(acl_impl::format_hex_float(rtm::quat_get_z(sample.rotation), buffer, sizeof(buffer)));
+ rotation_writer.push(acl_impl::format_hex_float(rtm::quat_get_w(sample.rotation), buffer, sizeof(buffer)));
+ });
+ sample_writer.push([&](sjson::ArrayWriter& translation_writer)
+ {
+ translation_writer.push(acl_impl::format_hex_float(rtm::vector_get_x(sample.translation), buffer, sizeof(buffer)));
+ translation_writer.push(acl_impl::format_hex_float(rtm::vector_get_y(sample.translation), buffer, sizeof(buffer)));
+ translation_writer.push(acl_impl::format_hex_float(rtm::vector_get_z(sample.translation), buffer, sizeof(buffer)));
+ });
+ sample_writer.push([&](sjson::ArrayWriter& scale_writer)
+ {
+ scale_writer.push(acl_impl::format_hex_float(rtm::vector_get_x(sample.scale), buffer, sizeof(buffer)));
+ scale_writer.push(acl_impl::format_hex_float(rtm::vector_get_y(sample.scale), buffer, sizeof(buffer)));
+ scale_writer.push(acl_impl::format_hex_float(rtm::vector_get_z(sample.scale), buffer, sizeof(buffer)));
+ });
+ });
+ data_writer.push_newline();
+ }
+ };
+ break;
}
- };
- });
+ default:
+ ACL_ASSERT(false, "Unknown track type");
+ break;
+ }
+ });
}
};
+ writer.insert_newline();
}
- inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, algorithm_type8 algorithm, const CompressionSettings* settings, const char* acl_filename)
+ inline error_result write_track_list(const track_array& track_list, const compression_settings* settings, const char* acl_filename)
{
if (acl_filename == nullptr)
- return "'acl_filename' cannot be NULL!";
+ return error_result("'acl_filename' cannot be NULL!");
const size_t filename_len = std::strlen(acl_filename);
if (filename_len < 10 || strncmp(acl_filename + filename_len - 10, ".acl.sjson", 10) != 0)
- return "'acl_filename' file must be an ACL SJSON file of the form: *.acl.sjson";
+ return error_result("'acl_filename' file must be an ACL SJSON file of the form: *.acl.sjson");
std::FILE* file = nullptr;
@@ -279,248 +340,37 @@ namespace acl
#endif
if (file == nullptr)
- return "Failed to open ACL file for writing";
+ return error_result("Failed to open ACL file for writing");
sjson::FileStreamWriter stream_writer(file);
sjson::Writer writer(stream_writer);
- writer["version"] = 5;
- writer.insert_newline();
+ write_sjson_header(track_list, writer);
- write_sjson_clip(clip, writer);
if (settings != nullptr)
- write_sjson_settings(algorithm, *settings, writer);
- write_sjson_bones(skeleton, writer);
+ write_sjson_settings(*settings, writer);
- const AnimationClip* base_clip = clip.get_additive_base();
- if (base_clip != nullptr)
- write_sjson_tracks(skeleton, *base_clip, true, writer);
-
- write_sjson_tracks(skeleton, clip, false, writer);
+ write_sjson_tracks(track_list, writer);
std::fclose(file);
- return nullptr;
+ return error_result();
}
}
//////////////////////////////////////////////////////////////////////////
- // Write out an SJSON ACL clip file from a skeleton, a clip,
- // and no specific compression settings.
- // Returns an error string on failure, null on success.
- //////////////////////////////////////////////////////////////////////////
- inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, const char* acl_filename)
- {
- return acl_impl::write_acl_clip(skeleton, clip, algorithm_type8::uniformly_sampled, nullptr, acl_filename);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Write out an SJSON ACL clip file from a skeleton, a clip,
- // and compression settings.
- // Returns an error string on failure, null on success.
+ // Write out an SJSON ACL track list file.
//////////////////////////////////////////////////////////////////////////
- inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, algorithm_type8 algorithm, const CompressionSettings& settings, const char* acl_filename)
+ inline error_result write_track_list(const track_array& track_list, const char* acl_filename)
{
- return acl_impl::write_acl_clip(skeleton, clip, algorithm, &settings, acl_filename);
+ return acl_impl::write_track_list(track_list, nullptr, acl_filename);
}
//////////////////////////////////////////////////////////////////////////
// Write out an SJSON ACL track list file.
- // Returns an error string on failure, null on success.
//////////////////////////////////////////////////////////////////////////
- inline const char* write_track_list(const track_array& track_list, const char* acl_filename)
+ inline error_result write_track_list(const track_array& track_list, const compression_settings& settings, const char* acl_filename)
{
- if (acl_filename == nullptr)
- return "'acl_filename' cannot be NULL!";
-
- const size_t filename_len = std::strlen(acl_filename);
- if (filename_len < 10 || strncmp(acl_filename + filename_len - 10, ".acl.sjson", 10) != 0)
- return "'acl_filename' file must be an ACL SJSON file of the form: *.acl.sjson";
-
- std::FILE* file = nullptr;
-
-#ifdef _WIN32
- char path[64 * 1024] = { 0 };
- snprintf(path, get_array_size(path), "\\\\?\\%s", acl_filename);
- fopen_s(&file, path, "w");
-#else
- file = fopen(acl_filename, "w");
-#endif
-
- if (file == nullptr)
- return "Failed to open ACL file for writing";
-
- char buffer[32] = { 0 };
-
- sjson::FileStreamWriter stream_writer(file);
- sjson::Writer writer(stream_writer);
-
- writer["version"] = 5;
- writer.insert_newline();
-
- writer["track_list"] = [&](sjson::ObjectWriter& header_writer)
- {
- //header_writer["name"] = track_list.get_name().c_str();
- header_writer["num_samples"] = track_list.get_num_samples_per_track();
- header_writer["sample_rate"] = track_list.get_sample_rate();
- header_writer["is_binary_exact"] = true;
- };
- writer.insert_newline();
-
- writer["tracks"] = [&](sjson::ArrayWriter& tracks_writer)
- {
- const uint32_t num_tracks = track_list.get_num_tracks();
- if (num_tracks > 0)
- tracks_writer.push_newline();
-
- for (const track& track_ : track_list)
- {
- tracks_writer.push([&](sjson::ObjectWriter& track_writer)
- {
- //track_writer["name"] = track_.get_name().c_str();
- track_writer["type"] = get_track_type_name(track_.get_type());
-
- switch (track_.get_type())
- {
- case track_type8::float1f:
- {
- const track_float1f& track__ = track_cast<track_float1f>(track_);
- track_writer["precision"] = track__.get_description().precision;
- track_writer["output_index"] = track__.get_description().output_index;
-
- track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
- {
- const uint32_t num_samples = track__.get_num_samples();
- if (num_samples > 0)
- data_writer.push_newline();
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- data_writer.push([&](sjson::ArrayWriter& sample_writer)
- {
- const float sample = track__[sample_index];
- sample_writer.push(acl_impl::format_hex_float(sample, buffer, sizeof(buffer)));
- });
- data_writer.push_newline();
- }
- };
- break;
- }
- case track_type8::float2f:
- {
- const track_float2f& track__ = track_cast<track_float2f>(track_);
- track_writer["precision"] = track__.get_description().precision;
- track_writer["output_index"] = track__.get_description().output_index;
-
- track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
- {
- const uint32_t num_samples = track__.get_num_samples();
- if (num_samples > 0)
- data_writer.push_newline();
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- data_writer.push([&](sjson::ArrayWriter& sample_writer)
- {
- const rtm::float2f& sample = track__[sample_index];
- sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
- });
- data_writer.push_newline();
- }
- };
- break;
- }
- case track_type8::float3f:
- {
- const track_float3f& track__ = track_cast<track_float3f>(track_);
- track_writer["precision"] = track__.get_description().precision;
- track_writer["output_index"] = track__.get_description().output_index;
-
- track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
- {
- const uint32_t num_samples = track__.get_num_samples();
- if (num_samples > 0)
- data_writer.push_newline();
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- data_writer.push([&](sjson::ArrayWriter& sample_writer)
- {
- const rtm::float3f& sample = track__[sample_index];
- sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.z, buffer, sizeof(buffer)));
- });
- data_writer.push_newline();
- }
- };
- break;
- }
- case track_type8::float4f:
- {
- const track_float4f& track__ = track_cast<track_float4f>(track_);
- track_writer["precision"] = track__.get_description().precision;
- track_writer["output_index"] = track__.get_description().output_index;
-
- track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
- {
- const uint32_t num_samples = track__.get_num_samples();
- if (num_samples > 0)
- data_writer.push_newline();
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- data_writer.push([&](sjson::ArrayWriter& sample_writer)
- {
- const rtm::float4f& sample = track__[sample_index];
- sample_writer.push(acl_impl::format_hex_float(sample.x, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.y, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.z, buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(sample.w, buffer, sizeof(buffer)));
- });
- data_writer.push_newline();
- }
- };
- break;
- }
- case track_type8::vector4f:
- {
- const track_vector4f& track__ = track_cast<track_vector4f>(track_);
- track_writer["precision"] = track__.get_description().precision;
- track_writer["output_index"] = track__.get_description().output_index;
-
- track_writer["data"] = [&](sjson::ArrayWriter& data_writer)
- {
- const uint32_t num_samples = track__.get_num_samples();
- if (num_samples > 0)
- data_writer.push_newline();
-
- for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- {
- data_writer.push([&](sjson::ArrayWriter& sample_writer)
- {
- const rtm::vector4f& sample = track__[sample_index];
- sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_x(sample), buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_y(sample), buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_z(sample), buffer, sizeof(buffer)));
- sample_writer.push(acl_impl::format_hex_float(rtm::vector_get_w(sample), buffer, sizeof(buffer)));
- });
- data_writer.push_newline();
- }
- };
- break;
- }
- default:
- ACL_ASSERT(false, "Unknown track type");
- break;
- }
- });
- }
- };
- writer.insert_newline();
-
- std::fclose(file);
- return nullptr;
+ return acl_impl::write_track_list(track_list, &settings, acl_filename);
}
}
diff --git a/includes/acl/math/quat_packing.h b/includes/acl/math/quat_packing.h
--- a/includes/acl/math/quat_packing.h
+++ b/includes/acl/math/quat_packing.h
@@ -90,33 +90,14 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
- // TODO: constexpr
- inline uint32_t get_packed_rotation_size(rotation_format8 format)
+ constexpr uint32_t get_packed_rotation_size(rotation_format8 format)
{
- switch (format)
- {
- case rotation_format8::quatf_full: return sizeof(float) * 4;
- case rotation_format8::quatf_drop_w_full: return sizeof(float) * 3;
- case rotation_format8::quatf_drop_w_variable:
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
- return 0;
- }
+ return format == rotation_format8::quatf_full ? (sizeof(float) * 4) : (sizeof(float) * 3);
}
- inline uint32_t get_range_reduction_rotation_size(rotation_format8 format)
+ constexpr uint32_t get_range_reduction_rotation_size(rotation_format8 format)
{
- switch (format)
- {
- case rotation_format8::quatf_full:
- return sizeof(float) * 8;
- case rotation_format8::quatf_drop_w_full:
- case rotation_format8::quatf_drop_w_variable:
- return sizeof(float) * 6;
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
- return 0;
- }
+ return format == rotation_format8::quatf_full ? (sizeof(float) * 8) : (sizeof(float) * 6);
}
}
diff --git a/includes/acl/math/quatf.h b/includes/acl/math/quatf.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/math/quatf.h
@@ -0,0 +1,145 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/impl/compiler_utils.h"
+
+#include <rtm/quatf.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // Loads an unaligned quat from memory.
+ // Missing from RTM for now
+ // TODO: Remove me once we upgrade to RTM 2.1 or later
+ //////////////////////////////////////////////////////////////////////////
+ RTM_DISABLE_SECURITY_COOKIE_CHECK inline rtm::quatf RTM_SIMD_CALL quat_load(const rtm::float4f* input) RTM_NO_EXCEPT
+ {
+#if defined(RTM_SSE2_INTRINSICS)
+ return _mm_loadu_ps(&input->x);
+#elif defined(RTM_NEON_INTRINSICS)
+ return vld1q_f32(&input->x);
+#else
+ return rtm::quat_set(input->x, input->y, input->z, input->w);
+#endif
+ }
+
+ RTM_DISABLE_SECURITY_COOKIE_CHECK inline rtm::quatf RTM_SIMD_CALL quat_lerp_no_normalization(rtm::quatf_arg0 start, rtm::quatf_arg1 end, float alpha) RTM_NO_EXCEPT
+ {
+ using namespace rtm;
+
+#if defined(RTM_SSE2_INTRINSICS)
+ // Calculate the vector4 dot product: dot(start, end)
+ __m128 dot;
+#if defined(RTM_SSE4_INTRINSICS)
+ // The dpps instruction isn't as accurate but we don't care here, we only need the sign of the
+ // dot product. If both rotations are on opposite ends of the hypersphere, the result will be
+ // very negative. If we are on the edge, the rotations are nearly opposite but not quite which
+ // means that the linear interpolation here will have terrible accuracy to begin with. It is designed
+ // for interpolating rotations that are reasonably close together. The bias check is mainly necessary
+ // because the W component is often kept positive which flips the sign.
+ // Using the dpps instruction reduces the number of registers that we need and helps the function get
+ // inlined.
+ dot = _mm_dp_ps(start, end, 0xFF);
+#else
+ {
+ __m128 x2_y2_z2_w2 = _mm_mul_ps(start, end);
+ __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
+ __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
+ __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
+ __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
+ // Shuffle the dot product to all SIMD lanes, there is no _mm_and_ss and loading
+ // the constant from memory with the 'and' instruction is faster, it uses fewer registers
+ // and fewer instructions
+ dot = _mm_shuffle_ps(x2y2z2w2_0_0_0, x2y2z2w2_0_0_0, _MM_SHUFFLE(0, 0, 0, 0));
+ }
+#endif
+
+ // Calculate the bias, if the dot product is positive or zero, there is no bias
+ // but if it is negative, we want to flip the 'end' rotation XYZW components
+ __m128 bias = _mm_and_ps(dot, _mm_set_ps1(-0.0F));
+
+ // Lerp the rotation after applying the bias
+ // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
+ __m128 alpha_ = _mm_set_ps1(alpha);
+ __m128 interpolated_rotation = _mm_add_ps(_mm_sub_ps(start, _mm_mul_ps(alpha_, start)), _mm_mul_ps(alpha_, _mm_xor_ps(end, bias)));
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards before using
+ return interpolated_rotation;
+#elif defined (RTM_NEON64_INTRINSICS)
+ // On ARM64 with NEON, we load 1.0 once and use it twice which is faster than
+ // using a AND/XOR with the bias (same number of instructions)
+ float dot = vector_dot(start, end);
+ float bias = dot >= 0.0F ? 1.0F : -1.0F;
+
+ // ((1.0 - alpha) * start) + (alpha * (end * bias)) == (start - alpha * start) + (alpha * (end * bias))
+ vector4f interpolated_rotation = vector_mul_add(vector_mul(end, bias), alpha, vector_neg_mul_sub(start, alpha, start));
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards before using
+ return interpolated_rotation;
+#elif defined(RTM_NEON_INTRINSICS)
+ // Calculate the vector4 dot product: dot(start, end)
+ float32x4_t x2_y2_z2_w2 = vmulq_f32(start, end);
+ float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
+ float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
+ float32x2_t x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
+ float32x2_t x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
+
+ // Calculate the bias, if the dot product is positive or zero, there is no bias
+ // but if it is negative, we want to flip the 'end' rotation XYZW components
+ // On ARM-v7-A, the AND/XOR trick is faster than the cmp/fsel
+ uint32x2_t bias = vand_u32(vreinterpret_u32_f32(x2y2z2w2), vdup_n_u32(0x80000000));
+
+ // Lerp the rotation after applying the bias
+ // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
+ float32x4_t end_biased = vreinterpretq_f32_u32(veorq_u32(vreinterpretq_u32_f32(end), vcombine_u32(bias, bias)));
+ float32x4_t interpolated_rotation = vmlaq_n_f32(vmlsq_n_f32(start, start, alpha), end_biased, alpha);
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards before using
+ return interpolated_rotation;
+#else
+ // To ensure we take the shortest path, we apply a bias if the dot product is negative
+ vector4f start_vector = quat_to_vector(start);
+ vector4f end_vector = quat_to_vector(end);
+ float dot = vector_dot(start_vector, end_vector);
+ float bias = dot >= 0.0F ? 1.0F : -1.0F;
+ // ((1.0 - alpha) * start) + (alpha * (end * bias)) == (start - alpha * start) + (alpha * (end * bias))
+ vector4f interpolated_rotation = vector_mul_add(vector_mul(end_vector, bias), alpha, vector_neg_mul_sub(start_vector, alpha, start_vector));
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards before using
+ return vector_to_quat(interpolated_rotation);
+#endif
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/tools/acl_compressor/main_emscripten/CMakeLists.txt b/tools/acl_compressor/main_emscripten/CMakeLists.txt
--- a/tools/acl_compressor/main_emscripten/CMakeLists.txt
+++ b/tools/acl_compressor/main_emscripten/CMakeLists.txt
@@ -34,6 +34,10 @@ if(USE_SJSON)
add_definitions(-DACL_USE_SJSON)
endif()
+# Remove '-g' from compilation flags since it sometimes crashes the compiler
+string(REPLACE "-g" "" CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG}")
+string(REPLACE "-g" "" CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE}")
+
target_compile_options(${PROJECT_NAME} PRIVATE -Wall -Wextra) # Enable all warnings
target_compile_options(${PROJECT_NAME} PRIVATE -Wshadow) # Enable shadowing warnings
target_compile_options(${PROJECT_NAME} PRIVATE -Werror) # Treat warnings as errors
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -24,6 +24,7 @@
#include "acl_compressor.h"
+#define DEBUG_MEGA_LARGE_CLIP 0
// Enable 64 bit file IO
#ifndef _WIN32
@@ -45,20 +46,14 @@
#include "acl/core/range_reduction_types.h"
#include "acl/core/string.h"
#include "acl/core/impl/debug_track_writer.h"
-#include "acl/compression/animation_clip.h"
#include "acl/compression/compress.h"
-#include "acl/compression/skeleton.h"
-#include "acl/compression/skeleton_error_metric.h"
-#include "acl/compression/skeleton_pose_utils.h" // Just to test compilation
+#include "acl/compression/transform_error_metrics.h"
+#include "acl/compression/transform_pose_utils.h" // Just to test compilation
#include "acl/compression/impl/write_decompression_stats.h"
#include "acl/compression/track_error.h"
-#include "acl/compression/utils.h"
#include "acl/decompression/decompress.h"
#include "acl/io/clip_reader.h"
-#include "acl/algorithm/uniformly_sampled/encoder.h"
-#include "acl/algorithm/uniformly_sampled/decoder.h"
-
#include <cstring>
#include <cstdio>
#include <fstream>
@@ -134,7 +129,7 @@ struct Options
const char* config_filename;
#endif
- bool output_stats;
+ bool do_output_stats;
const char* output_stats_filename;
std::FILE* output_stats_file;
@@ -169,7 +164,7 @@ struct Options
: input_filename(nullptr)
, config_filename(nullptr)
#endif
- , output_stats(false)
+ , do_output_stats(false)
, output_stats_filename(nullptr)
, output_stats_file(nullptr)
, output_bin_filename(nullptr)
@@ -291,7 +286,7 @@ static bool parse_options(int argc, char** argv, Options& options)
option_length = std::strlen(k_stats_output_option);
if (std::strncmp(argument, k_stats_output_option, option_length) == 0)
{
- options.output_stats = true;
+ options.do_output_stats = true;
if (argument[option_length] == '=')
{
options.output_stats_filename = argument + option_length + 1;
@@ -422,24 +417,35 @@ static bool parse_options(int argc, char** argv, Options& options)
}
#if defined(ACL_USE_SJSON)
-template<class DecompressionContextType>
-static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip, const CompressionSettings& settings, DecompressionContextType& context, double regression_error_threshold)
+static void validate_accuracy(iallocator& allocator, const track_array_qvvf& raw_tracks, const track_array_qvvf& additive_base_tracks, const itransform_error_metric& error_metric, const compressed_tracks& compressed_tracks_, double regression_error_threshold)
{
+ using namespace acl_impl;
+
+ (void)allocator;
+ (void)raw_tracks;
+ (void)additive_base_tracks;
+ (void)error_metric;
+ (void)compressed_tracks_;
(void)regression_error_threshold;
- const BoneError bone_error = calculate_error_between_clips(allocator, *settings.error_metric, clip, context);
- (void)bone_error;
- ACL_ASSERT(rtm::scalar_is_finite(bone_error.error), "Returned error is not a finite value");
- ACL_ASSERT(bone_error.error < regression_error_threshold, "Error too high for bone %u: %f at time %f", bone_error.index, bone_error.error, bone_error.sample_time);
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ // Disable floating point exceptions since decompression assumes it
+ scope_disable_fp_exceptions fp_off;
+
+ acl::decompression_context<acl::debug_decompression_settings> context;
+ context.initialize(compressed_tracks_);
- const uint16_t num_bones = clip.get_num_bones();
- const float clip_duration = clip.get_duration();
- const float sample_rate = clip.get_sample_rate();
- const uint32_t num_samples = calculate_num_samples(clip_duration, clip.get_sample_rate());
+ const track_error error = calculate_compression_error(allocator, raw_tracks, context, error_metric, additive_base_tracks);
+ (void)error;
+ ACL_ASSERT(rtm::scalar_is_finite(error.error), "Returned error is not a finite value");
+ ACL_ASSERT(error.error < regression_error_threshold, "Error too high for bone %u: %f at time %f", error.index, error.error, error.sample_time);
- rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ const uint32_t num_bones = raw_tracks.get_num_tracks();
+ const float clip_duration = raw_tracks.get_duration();
+ const float sample_rate = raw_tracks.get_sample_rate();
+ const uint32_t num_samples = raw_tracks.get_num_samples_per_track();
- DefaultOutputWriter pose_writer(lossy_pose_transforms, num_bones);
+ debug_track_writer track_writer(allocator, track_type8::qvvf, num_bones);
// Regression test
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
@@ -448,49 +454,25 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
// We use the nearest sample to accurately measure the loss that happened, if any
context.seek(sample_time, sample_rounding_policy::nearest);
- context.decompress_pose(pose_writer);
+ context.decompress_tracks(track_writer);
- // Validate decompress_bone for rotations only
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ // Validate decompress_track against decompress_tracks
+ for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- rtm::quatf rotation;
- context.decompress_bone(bone_index, &rotation, nullptr, nullptr);
- ACL_ASSERT(rtm::quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
- }
+ const rtm::qvvf transform0 = track_writer.read_qvv(bone_index);
- // Validate decompress_bone for translations only
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- rtm::vector4f translation;
- context.decompress_bone(bone_index, nullptr, &translation, nullptr);
- ACL_ASSERT(rtm::vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
- }
-
- // Validate decompress_bone for scales only
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- rtm::vector4f scale;
- context.decompress_bone(bone_index, nullptr, nullptr, &scale);
- ACL_ASSERT(rtm::vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
- }
+ context.decompress_track(bone_index, track_writer);
+ const rtm::qvvf transform1 = track_writer.read_qvv(bone_index);
- // Validate decompress_bone
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- rtm::quatf rotation;
- rtm::vector4f translation;
- rtm::vector4f scale;
- context.decompress_bone(bone_index, &rotation, &translation, &scale);
- ACL_ASSERT(rtm::quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
- ACL_ASSERT(rtm::vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
- ACL_ASSERT(rtm::vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal(rtm::quat_to_vector(transform0.rotation), rtm::quat_to_vector(transform1.rotation), 0.0F), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(transform0.translation, transform1.translation, 0.0F), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(transform0.scale, transform1.scale, 0.0F), "Failed to sample bone index: %u", bone_index);
}
}
-
- deallocate_type_array(allocator, lossy_pose_transforms, num_bones);
+#endif
}
-static void validate_accuracy(IAllocator& allocator, const track_array& raw_tracks, const compressed_tracks& tracks, double regression_error_threshold)
+static void validate_accuracy(iallocator& allocator, const track_array& raw_tracks, const compressed_tracks& tracks, double regression_error_threshold)
{
(void)allocator;
(void)raw_tracks;
@@ -674,81 +656,54 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
#endif // defined(ACL_HAS_ASSERT_CHECKS)
}
-static void try_algorithm(const Options& options, IAllocator& allocator, const AnimationClip& clip, const CompressionSettings& settings, algorithm_type8 algorithm_type, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
+static void try_algorithm(const Options& options, iallocator& allocator, track_array_qvvf& transform_tracks, const track_array_qvvf& additive_base, additive_clip_format8 additive_format, const compression_settings& settings, stat_logging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
{
(void)runs_writer;
auto try_algorithm_impl = [&](sjson::ObjectWriter* stats_writer)
{
- if (clip.get_num_samples() == 0)
+ if (transform_tracks.get_num_samples_per_track() == 0)
return;
- OutputStats stats(logging, stats_writer);
- CompressedClip* compressed_clip = nullptr;
- ErrorResult error_result; (void)error_result;
- switch (algorithm_type)
- {
- case algorithm_type8::uniformly_sampled:
- error_result = uniformly_sampled::compress_clip(allocator, clip, settings, compressed_clip, stats);
- break;
- }
+ output_stats stats(logging, stats_writer);
+ compressed_tracks* compressed_tracks_ = nullptr;
+ const error_result result = compress_track_list(allocator, transform_tracks, settings, additive_base, additive_format, compressed_tracks_, stats);
- ACL_ASSERT(error_result.empty(), error_result.c_str());
- ACL_ASSERT(compressed_clip->is_valid(true).empty(), "Compressed clip is invalid");
+ (void)result;
+ ACL_ASSERT(result.empty(), result.c_str());
+ ACL_ASSERT(compressed_tracks_->is_valid(true).empty(), "Compressed tracks are invalid");
#if defined(SJSON_CPP_WRITER)
- if (logging != StatLogging::None)
+ if (logging != stat_logging::None)
{
// Disable floating point exceptions since decompression assumes it
scope_disable_fp_exceptions fp_off;
- // Use the compressed clip to make sure the decoder works properly
- BoneError bone_error;
- switch (algorithm_type)
- {
- case algorithm_type8::uniformly_sampled:
- {
- uniformly_sampled::DecompressionContext<uniformly_sampled::DebugDecompressionSettings> context;
- context.initialize(*compressed_clip);
- bone_error = calculate_error_between_clips(allocator, *settings.error_metric, clip, context);
- break;
- }
- }
+ acl::decompression_context<acl::debug_decompression_settings> context;
+ context.initialize(*compressed_tracks_);
- stats_writer->insert("max_error", bone_error.error);
- stats_writer->insert("worst_bone", bone_error.index);
- stats_writer->insert("worst_time", bone_error.sample_time);
+ const track_error error = calculate_compression_error(allocator, transform_tracks, context, *settings.error_metric);
+
+ stats_writer->insert("max_error", error.error);
+ stats_writer->insert("worst_track", error.index);
+ stats_writer->insert("worst_time", error.sample_time);
- if (are_any_enum_flags_set(logging, StatLogging::SummaryDecompression))
- acl_impl::write_decompression_performance_stats(allocator, settings, *compressed_clip, logging, *stats_writer);
+ if (are_any_enum_flags_set(logging, stat_logging::SummaryDecompression))
+ acl_impl::write_decompression_performance_stats(allocator, settings, *compressed_tracks_, logging, *stats_writer);
}
#endif
if (options.regression_testing)
- {
- // Disable floating point exceptions since decompression assumes it
- scope_disable_fp_exceptions fp_off;
-
- switch (algorithm_type)
- {
- case algorithm_type8::uniformly_sampled:
- {
- uniformly_sampled::DecompressionContext<uniformly_sampled::DebugDecompressionSettings> context;
- context.initialize(*compressed_clip);
- validate_accuracy(allocator, clip, settings, context, regression_error_threshold);
- break;
- }
- }
- }
+ validate_accuracy(allocator, transform_tracks, additive_base, *settings.error_metric, *compressed_tracks_, regression_error_threshold);
if (options.output_bin_filename != nullptr)
{
std::ofstream output_file_stream(options.output_bin_filename, std::ios_base::out | std::ios_base::binary | std::ios_base::trunc);
if (output_file_stream.is_open())
- output_file_stream.write(reinterpret_cast<const char*>(compressed_clip), compressed_clip->get_size());
+ output_file_stream.write(reinterpret_cast<const char*>(compressed_tracks_), compressed_tracks_->get_size());
}
- allocator.deallocate(compressed_clip, compressed_clip->get_size());
+ allocator.deallocate(compressed_tracks_, compressed_tracks_->get_size());
};
#if defined(SJSON_CPP_WRITER)
@@ -759,7 +714,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const A
try_algorithm_impl(nullptr);
}
-static void try_algorithm(const Options& options, IAllocator& allocator, const track_array& track_list, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
+static void try_algorithm(const Options& options, iallocator& allocator, const track_array& track_list, stat_logging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
{
(void)runs_writer;
@@ -770,15 +725,15 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const t
compression_settings settings;
- OutputStats stats(logging, stats_writer);
+ output_stats stats(logging, stats_writer);
compressed_tracks* compressed_tracks_ = nullptr;
- const ErrorResult error_result = compress_track_list(allocator, track_list, settings, compressed_tracks_, stats);
+ const error_result result = compress_track_list(allocator, track_list, settings, compressed_tracks_, stats);
- ACL_ASSERT(error_result.empty(), error_result.c_str()); (void)error_result;
+ ACL_ASSERT(result.empty(), result.c_str()); (void)result;
ACL_ASSERT(compressed_tracks_->is_valid(true).empty(), "Compressed tracks are invalid");
#if defined(SJSON_CPP_WRITER)
- if (logging != StatLogging::None)
+ if (logging != stat_logging::None)
{
// Disable floating point exceptions since decompression assumes it
scope_disable_fp_exceptions fp_off;
@@ -793,7 +748,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const t
stats_writer->insert("worst_time", error.sample_time);
// TODO: measure decompression performance
- //if (are_any_enum_flags_set(logging, StatLogging::SummaryDecompression))
+ //if (are_any_enum_flags_set(logging, stat_logging::SummaryDecompression))
//write_decompression_performance_stats(allocator, settings, *compressed_clip, logging, *stats_writer);
}
#endif
@@ -824,7 +779,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const t
try_algorithm_impl(nullptr);
}
-static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
+static bool read_acl_sjson_file(iallocator& allocator, const Options& options,
sjson_file_type& out_file_type,
sjson_raw_clip& out_raw_clip,
sjson_raw_track_list& out_raw_track_list)
@@ -833,7 +788,7 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
size_t file_size = 0;
#if defined(__ANDROID__)
- ClipReader reader(allocator, options.input_buffer, options.input_buffer_size - 1);
+ clip_reader reader(allocator, options.input_buffer, options.input_buffer_size - 1);
#else
// Use the raw C API with a large buffer to ensure this is as fast as possible
std::FILE* file = nullptr;
@@ -885,7 +840,7 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
return false;
}
- ClipReader reader(allocator, sjson_file_buffer, file_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, file_size - 1);
#endif
const sjson_file_type ftype = reader.get_file_type();
@@ -908,8 +863,8 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
if (!success)
{
- const ClipReaderError err = reader.get_error();
- if (err.error != ClipReaderError::None)
+ const clip_reader_error err = reader.get_error();
+ if (err.error != clip_reader_error::None)
printf("\nError on line %d column %d: %s\n", err.line, err.column, err.get_description());
}
@@ -917,7 +872,7 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
return success;
}
-static bool read_config(IAllocator& allocator, Options& options, algorithm_type8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
+static bool read_config(iallocator& allocator, Options& options, compression_settings& out_settings, double& out_regression_error_threshold)
{
#if defined(__ANDROID__)
sjson::Parser parser(options.config_buffer, options.config_buffer_size - 1);
@@ -958,19 +913,20 @@ static bool read_config(IAllocator& allocator, Options& options, algorithm_type8
return false;
}
- if (!get_algorithm_type(algorithm_name.c_str(), out_algorithm_type))
+ algorithm_type8 algorithm_type;
+ if (!get_algorithm_type(algorithm_name.c_str(), algorithm_type))
{
- printf("Invalid algorithm name: %s\n", String(allocator, algorithm_name.c_str(), algorithm_name.size()).c_str());
+ printf("Invalid algorithm name: %s\n", string(allocator, algorithm_name.c_str(), algorithm_name.size()).c_str());
return false;
}
- CompressionSettings default_settings;
+ compression_settings default_settings;
sjson::StringView compression_level;
parser.try_read("level", compression_level, get_compression_level_name(default_settings.level));
if (!get_compression_level(compression_level.c_str(), out_settings.level))
{
- printf("Invalid compression level: %s\n", String(allocator, compression_level.c_str(), compression_level.size()).c_str());
+ printf("Invalid compression level: %s\n", string(allocator, compression_level.c_str(), compression_level.size()).c_str());
return false;
}
@@ -978,7 +934,7 @@ static bool read_config(IAllocator& allocator, Options& options, algorithm_type8
parser.try_read("rotation_format", rotation_format, get_rotation_format_name(default_settings.rotation_format));
if (!get_rotation_format(rotation_format.c_str(), out_settings.rotation_format))
{
- printf("Invalid rotation format: %s\n", String(allocator, rotation_format.c_str(), rotation_format.size()).c_str());
+ printf("Invalid rotation format: %s\n", string(allocator, rotation_format.c_str(), rotation_format.size()).c_str());
return false;
}
@@ -986,7 +942,7 @@ static bool read_config(IAllocator& allocator, Options& options, algorithm_type8
parser.try_read("translation_format", translation_format, get_vector_format_name(default_settings.translation_format));
if (!get_vector_format(translation_format.c_str(), out_settings.translation_format))
{
- printf("Invalid translation format: %s\n", String(allocator, translation_format.c_str(), translation_format.size()).c_str());
+ printf("Invalid translation format: %s\n", string(allocator, translation_format.c_str(), translation_format.size()).c_str());
return false;
}
@@ -994,17 +950,16 @@ static bool read_config(IAllocator& allocator, Options& options, algorithm_type8
parser.try_read("scale_format", scale_format, get_vector_format_name(default_settings.scale_format));
if (!get_vector_format(scale_format.c_str(), out_settings.scale_format))
{
- printf("Invalid scale format: %s\n", String(allocator, scale_format.c_str(), scale_format.size()).c_str());
+ printf("Invalid scale format: %s\n", string(allocator, scale_format.c_str(), scale_format.size()).c_str());
return false;
}
- double constant_rotation_threshold_angle;
- parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, default_settings.constant_rotation_threshold_angle);
- out_settings.constant_rotation_threshold_angle = float(constant_rotation_threshold_angle);
+ double dummy;
+ parser.try_read("constant_rotation_threshold_angle", dummy, 0.0F);
- parser.try_read("constant_translation_threshold", out_settings.constant_translation_threshold, default_settings.constant_translation_threshold);
- parser.try_read("constant_scale_threshold", out_settings.constant_scale_threshold, default_settings.constant_scale_threshold);
- parser.try_read("error_threshold", out_settings.error_threshold, default_settings.error_threshold);
+ parser.try_read("constant_translation_threshold", dummy, 0.0F);
+ parser.try_read("constant_scale_threshold", dummy, 0.0F);
+ parser.try_read("error_threshold", dummy, 0.0F);
parser.try_read("regression_error_threshold", out_regression_error_threshold, 0.0);
@@ -1029,7 +984,7 @@ static bool read_config(IAllocator& allocator, Options& options, algorithm_type8
return true;
}
-static itransform_error_metric* create_additive_error_metric(IAllocator& allocator, additive_clip_format8 format)
+static itransform_error_metric* create_additive_error_metric(iallocator& allocator, additive_clip_format8 format)
{
switch (format)
{
@@ -1044,12 +999,15 @@ static itransform_error_metric* create_additive_error_metric(IAllocator& allocat
}
}
-static void create_additive_base_clip(const Options& options, AnimationClip& clip, const RigidSkeleton& skeleton, AnimationClip& out_base_clip)
+static void create_additive_base_clip(const Options& options, track_array_qvvf& clip, const track_qvvf& bind_pose, track_array_qvvf& out_base_clip, additive_clip_format8& out_additive_format)
{
// Convert the animation clip to be relative to the bind pose
- const uint16_t num_bones = clip.get_num_bones();
- const uint32_t num_samples = clip.get_num_samples();
- AnimatedBone* bones = clip.get_bones();
+ const uint32_t num_bones = clip.get_num_tracks();
+ const uint32_t num_samples = clip.get_num_samples_per_track();
+ iallocator& allocator = *clip.get_allocator();
+ const track_desc_transformf bind_desc;
+
+ out_base_clip = track_array_qvvf(*clip.get_allocator(), num_bones);
additive_clip_format8 additive_format = additive_clip_format8::none;
if (options.is_bind_pose_relative)
@@ -1058,24 +1016,21 @@ static void create_additive_base_clip(const Options& options, AnimationClip& cli
additive_format = additive_clip_format8::additive0;
else if (options.is_bind_pose_additive1)
additive_format = additive_clip_format8::additive1;
+ out_additive_format = additive_format;
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- AnimatedBone& anim_bone = bones[bone_index];
-
// Get the bind transform and make sure it has no scale
- const RigidBone& skel_bone = skeleton.get_bone(bone_index);
- const rtm::qvvd bind_transform = rtm::qvv_set(skel_bone.bind_transform.rotation, skel_bone.bind_transform.translation, rtm::vector_set(1.0));
+ rtm::qvvf bind_transform = bind_pose[bone_index];
+ bind_transform.scale = rtm::vector_set(1.0F);
+
+ track_qvvf& track = clip[bone_index];
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const rtm::quatd rotation = rtm::quat_normalize(anim_bone.rotation_track.get_sample(sample_index));
- const rtm::vector4d translation = anim_bone.translation_track.get_sample(sample_index);
- const rtm::vector4d scale = anim_bone.scale_track.get_sample(sample_index);
-
- const rtm::qvvd bone_transform = rtm::qvv_set(rotation, translation, scale);
+ const rtm::qvvf bone_transform = track[sample_index];
- rtm::qvvd bind_local_transform = bone_transform;
+ rtm::qvvf bind_local_transform = bone_transform;
if (options.is_bind_pose_relative)
bind_local_transform = convert_to_relative(bind_transform, bone_transform);
else if (options.is_bind_pose_additive0)
@@ -1083,23 +1038,16 @@ static void create_additive_base_clip(const Options& options, AnimationClip& cli
else if (options.is_bind_pose_additive1)
bind_local_transform = convert_to_additive1(bind_transform, bone_transform);
- anim_bone.rotation_track.set_sample(sample_index, bind_local_transform.rotation);
- anim_bone.translation_track.set_sample(sample_index, bind_local_transform.translation);
- anim_bone.scale_track.set_sample(sample_index, bind_local_transform.scale);
+ track[sample_index] = bind_local_transform;
}
- AnimatedBone& base_bone = out_base_clip.get_animated_bone(bone_index);
- base_bone.rotation_track.set_sample(0, bind_transform.rotation);
- base_bone.translation_track.set_sample(0, bind_transform.translation);
- base_bone.scale_track.set_sample(0, bind_transform.scale);
+ out_base_clip[bone_index] = track_qvvf::make_copy(bind_desc, allocator, &bind_transform, 1, 30.0F);
}
-
- clip.set_additive_base(&out_base_clip, additive_format);
}
-static CompressionSettings make_settings(rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
+static compression_settings make_settings(rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
{
- CompressionSettings settings;
+ compression_settings settings;
settings.rotation_format = rotation_format;
settings.translation_format = translation_format;
settings.scale_format = scale_format;
@@ -1123,9 +1071,11 @@ static int safe_main_impl(int argc, char* argv[])
}
#if defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
- std::unique_ptr<AnimationClip, Deleter<AnimationClip>> clip;
- std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>> skeleton;
+ ansi_allocator allocator;
+ track_array_qvvf transform_tracks;
+ track_array_qvvf base_clip;
+ additive_clip_format8 additive_format = additive_clip_format8::none;
+ track_qvvf bind_pose;
#if defined(__ANDROID__)
const bool is_input_acl_bin_file = options.input_buffer_binary;
@@ -1134,8 +1084,7 @@ static int safe_main_impl(int argc, char* argv[])
#endif
bool use_external_config = false;
- algorithm_type8 algorithm_type = algorithm_type8::uniformly_sampled;
- CompressionSettings settings;
+ compression_settings settings;
sjson_file_type sjson_type = sjson_file_type::unknown;
sjson_raw_clip sjson_clip;
@@ -1146,13 +1095,43 @@ static int safe_main_impl(int argc, char* argv[])
if (!read_acl_sjson_file(allocator, options, sjson_type, sjson_clip, sjson_track_list))
return -1;
- clip = std::move(sjson_clip.clip);
- skeleton = std::move(sjson_clip.skeleton);
+ transform_tracks = std::move(sjson_clip.track_list);
+ base_clip = std::move(sjson_clip.additive_base_track_list);
+ additive_format = sjson_clip.additive_format;
+ bind_pose = std::move(sjson_clip.bind_pose);
use_external_config = sjson_clip.has_settings;
- algorithm_type = sjson_clip.algorithm_type;
settings = sjson_clip.settings;
}
+#if DEBUG_MEGA_LARGE_CLIP
+ track_array_qvvf new_transforms(allocator, transform_tracks.get_num_tracks());
+ float new_sample_rate = 19200.0F;
+ uint32_t new_num_samples = calculate_num_samples(transform_tracks.get_duration(), new_sample_rate);
+ float new_duration = calculate_duration(new_num_samples, new_sample_rate);
+ acl_impl::debug_track_writer dummy_writer(allocator, track_type8::qvvf, transform_tracks.get_num_tracks());
+
+ for (uint32_t track_index = 0; track_index < transform_tracks.get_num_tracks(); ++track_index)
+ {
+ track_qvvf& track = transform_tracks[track_index];
+ new_transforms[track_index] = track_qvvf::make_reserve(track.get_description(), allocator, new_num_samples, new_sample_rate);
+ }
+
+ for (uint32_t sample_index = 0; sample_index < new_num_samples; ++sample_index)
+ {
+ const float sample_time = rtm::scalar_min(float(sample_index) / new_sample_rate, new_duration);
+
+ transform_tracks.sample_tracks(sample_time, sample_rounding_policy::none, dummy_writer);
+
+ for (uint32_t track_index = 0; track_index < new_transforms.get_num_tracks(); ++track_index)
+ {
+ track_qvvf& track = new_transforms[track_index];
+ track[sample_index] = dummy_writer.tracks_typed.qvvf[track_index];
+ }
+ }
+
+ transform_tracks = std::move(new_transforms);
+#endif
+
double regression_error_threshold = 0.1;
#if defined(__ANDROID__)
@@ -1162,32 +1141,25 @@ static int safe_main_impl(int argc, char* argv[])
#endif
{
// Override whatever the ACL SJSON file might have contained
- algorithm_type = algorithm_type8::uniformly_sampled;
- settings = CompressionSettings();
+ settings = compression_settings();
- if (!read_config(allocator, options, algorithm_type, settings, regression_error_threshold))
+ if (!read_config(allocator, options, settings, regression_error_threshold))
return -1;
use_external_config = true;
}
- // TODO: Make a unique_ptr
- AnimationClip* base_clip = nullptr;
-
if (!is_input_acl_bin_file && sjson_type == sjson_file_type::raw_clip)
{
// Grab whatever clip we might have read from the sjson file and cast the const away so we can manage the memory
- base_clip = const_cast<AnimationClip*>(clip->get_additive_base());
- if (base_clip == nullptr)
+ if (base_clip.get_num_tracks() == 0 && bind_pose.get_num_samples() != 0)
{
- base_clip = allocate_type<AnimationClip>(allocator, allocator, *skeleton, 1, 30.0F, String(allocator, "Base Clip"));
-
if (options.is_bind_pose_relative || options.is_bind_pose_additive0 || options.is_bind_pose_additive1)
- create_additive_base_clip(options, *clip, *skeleton, *base_clip);
+ create_additive_base_clip(options, transform_tracks, bind_pose, base_clip, additive_format);
}
// First try to create an additive error metric
- settings.error_metric = create_additive_error_metric(allocator, clip->get_additive_format());
+ settings.error_metric = create_additive_error_metric(allocator, additive_format);
if (settings.error_metric == nullptr)
{
@@ -1201,16 +1173,16 @@ static int safe_main_impl(int argc, char* argv[])
// Compress & Decompress
auto exec_algos = [&](sjson::ArrayWriter* runs_writer)
{
- StatLogging logging = options.output_stats ? StatLogging::Summary : StatLogging::None;
+ stat_logging logging = options.do_output_stats ? stat_logging::Summary : stat_logging::None;
if (options.stat_detailed_output)
- logging |= StatLogging::Detailed;
+ logging |= stat_logging::Detailed;
if (options.stat_exhaustive_output)
- logging |= StatLogging::Exhaustive;
+ logging |= stat_logging::Exhaustive;
if (options.profile_decompression)
- logging |= StatLogging::SummaryDecompression | StatLogging::ExhaustiveDecompression;
+ logging |= stat_logging::SummaryDecompression | stat_logging::ExhaustiveDecompression;
if (is_input_acl_bin_file)
{
@@ -1220,17 +1192,17 @@ static int safe_main_impl(int argc, char* argv[])
// Disable floating point exceptions since decompression assumes it
scope_disable_fp_exceptions fp_off;
- const CompressionSettings default_settings = get_default_compression_settings();
+ settings = get_default_compression_settings();
#if defined(__ANDROID__)
- const CompressedClip* compressed_clip = make_compressed_clip(options.input_buffer);
+ const compressed_tracks* compressed_clip = make_compressed_tracks(options.input_buffer);
ACL_ASSERT(compressed_clip != nullptr, "Compressed clip is invalid");
if (compressed_clip == nullptr)
return; // Compressed clip is invalid, early out to avoid crash
runs_writer->push([&](sjson::ObjectWriter& writer)
{
- acl_impl::write_decompression_performance_stats(allocator, default_settings, *compressed_clip, logging, writer);
+ acl_impl::write_decompression_performance_stats(allocator, settings, *compressed_clip, logging, writer);
});
#else
std::ifstream input_file_stream(options.input_filename, std::ios_base::in | std::ios_base::binary);
@@ -1240,17 +1212,17 @@ static int safe_main_impl(int argc, char* argv[])
const size_t buffer_size = size_t(input_file_stream.tellg());
input_file_stream.seekg(0, std::ios_base::beg);
- char* buffer = (char*)allocator.allocate(buffer_size, alignof(CompressedClip));
+ char* buffer = (char*)allocator.allocate(buffer_size, alignof(compressed_tracks));
input_file_stream.read(buffer, buffer_size);
- const CompressedClip* compressed_clip = make_compressed_clip(buffer);
+ const compressed_tracks* compressed_clip = make_compressed_tracks(buffer);
ACL_ASSERT(compressed_clip != nullptr, "Compressed clip is invalid");
if (compressed_clip == nullptr)
return; // Compressed clip is invalid, early out to avoid crash
runs_writer->push([&](sjson::ObjectWriter& writer)
{
- acl_impl::write_decompression_performance_stats(allocator, default_settings, *compressed_clip, logging, writer);
+ acl_impl::write_decompression_performance_stats(allocator, settings, *compressed_clip, logging, writer);
});
allocator.deallocate(buffer, buffer_size);
@@ -1263,17 +1235,15 @@ static int safe_main_impl(int argc, char* argv[])
{
if (use_external_config)
{
- ACL_ASSERT(algorithm_type == algorithm_type8::uniformly_sampled, "Only uniformly_sampled is supported for now");
-
if (options.compression_level_specified)
settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, transform_tracks, base_clip, additive_format, settings, logging, runs_writer, regression_error_threshold);
}
else if (options.exhaustive_compression)
{
{
- CompressionSettings uniform_tests[] =
+ compression_settings uniform_tests[] =
{
make_settings(rotation_format8::quatf_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
make_settings(rotation_format8::quatf_drop_w_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
@@ -1282,16 +1252,16 @@ static int safe_main_impl(int argc, char* argv[])
make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_variable),
};
- for (CompressionSettings test_settings : uniform_tests)
+ for (compression_settings test_settings : uniform_tests)
{
test_settings.error_metric = settings.error_metric;
- try_algorithm(options, allocator, *clip, test_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, transform_tracks, base_clip, additive_format, test_settings, logging, runs_writer, regression_error_threshold);
}
}
{
- CompressionSettings uniform_tests[] =
+ compression_settings uniform_tests[] =
{
make_settings(rotation_format8::quatf_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
make_settings(rotation_format8::quatf_drop_w_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
@@ -1300,26 +1270,26 @@ static int safe_main_impl(int argc, char* argv[])
make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_variable),
};
- for (CompressionSettings test_settings : uniform_tests)
+ for (compression_settings test_settings : uniform_tests)
{
test_settings.error_metric = settings.error_metric;
if (options.compression_level_specified)
test_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, test_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, transform_tracks, base_clip, additive_format, test_settings, logging, runs_writer, regression_error_threshold);
}
}
}
else
{
- CompressionSettings default_settings = get_default_compression_settings();
+ compression_settings default_settings = get_default_compression_settings();
default_settings.error_metric = settings.error_metric;
if (options.compression_level_specified)
default_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, default_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, transform_tracks, base_clip, additive_format, default_settings, logging, runs_writer, regression_error_threshold);
}
}
else if (sjson_type == sjson_file_type::raw_track_list)
@@ -1329,7 +1299,7 @@ static int safe_main_impl(int argc, char* argv[])
};
#if defined(SJSON_CPP_WRITER)
- if (options.output_stats)
+ if (options.do_output_stats)
{
sjson::FileStreamWriter stream_writer(options.output_stats_file);
sjson::Writer writer(stream_writer);
@@ -1341,7 +1311,6 @@ static int safe_main_impl(int argc, char* argv[])
exec_algos(nullptr);
deallocate_type(allocator, settings.error_metric);
- deallocate_type(allocator, base_clip);
#endif // defined(ACL_USE_SJSON)
return 0;
diff --git a/tools/format_reference.acl.sjson b/tools/format_reference.acl.sjson
--- a/tools/format_reference.acl.sjson
+++ b/tools/format_reference.acl.sjson
@@ -227,12 +227,42 @@ tracks =
// Defaults to the track index
output_index = 12
+ // The track index of our parent track
+ // Transforms only
+ parent_index = 2
+
+ // The shell distance of the transform's error metric
+ // Transforms only
+ shell_distance = 3.0
+
+ // The constant rotation detection threshold
+ // Transforms only
+ constant_rotation_threshold_angle = 0.1
+
+ // The constant translation detection threshold
+ // Transforms only
+ constant_translation_threshold = 0.1
+
+ // The constant scale detection threshold
+ // Transforms only
+ constant_scale_threshold = 0.1
+
+ // Bind pose transform information. All three are optional
+ // The bind pose should be in parent bone local space
+ bind_rotation = [ 0.0, 0.0, 0.0, 1.0 ]
+ bind_translation = [ 0.0, 0.0, 0.0 ]
+ bind_scale = [ 1.0, 1.0, 1.0 ]
+
// Track data
+ // The number of samples here must match num_samples
data =
[
+ // Scalar tracks are of the form: [ x, y, z, .. ] with one entry per scalar component
[ 0.0, 0.0, 0.0, 1.0 ]
[ 1.0, 0.0, 0.0, 0.0 ]
- // The number of samples here must match num_samples
+
+ // Transform tracks are of the form: [ [ rot.x, rot.y, rot.z, rot.z ], [ trans.x, trans.y, trans.z ], [ scale.x, scale.y, scale.z ] ]
+ // All three parts must be present and cannot be omitted
]
}
]
diff --git a/tools/vs_visualizers/acl.natvis b/tools/vs_visualizers/acl.natvis
--- a/tools/vs_visualizers/acl.natvis
+++ b/tools/vs_visualizers/acl.natvis
@@ -2,14 +2,6 @@
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
- <Type Name="acl::Vector4_32" Priority="MediumLow">
- <DisplayString>({x}, {y}, {z}, {w})</DisplayString>
- </Type>
-
- <Type Name="acl::Quat_32" Priority="MediumLow">
- <DisplayString>({x}, {y}, {z}, {w})</DisplayString>
- </Type>
-
<Type Name="__m128">
<DisplayString>({m128_f32[0]}, {m128_f32[1]}, {m128_f32[2]}, {m128_f32[3]})</DisplayString>
</Type>
@@ -18,22 +10,6 @@
<DisplayString>({m128i_u32[0]}, {m128i_u32[1]}, {m128i_u32[2]}, {m128i_u32[3]})</DisplayString>
</Type>
- <Type Name="acl::Vector4_64" Priority="MediumLow">
- <DisplayString>({x}, {y}, {z}, {w})</DisplayString>
- </Type>
-
- <Type Name="acl::Vector4_64">
- <DisplayString>({xy.m128d_f64[0]}, {xy.m128d_f64[1]}, {zw.m128d_f64[0]}, {zw.m128d_f64[1]})</DisplayString>
- </Type>
-
- <Type Name="acl::Quat_64" Priority="MediumLow">
- <DisplayString>({x}, {y}, {z}, {w})</DisplayString>
- </Type>
-
- <Type Name="acl::Quat_64">
- <DisplayString>({xy.m128d_f64[0]}, {xy.m128d_f64[1]}, {zw.m128d_f64[0]}, {zw.m128d_f64[1]})</DisplayString>
- </Type>
-
<Type Name="acl::String">
<DisplayString>{m_c_str,s8}</DisplayString>
</Type>
@@ -59,6 +35,18 @@
<Item Name="precision" Condition="m_type == acl::track_type8::float3f">m_desc.scalar.precision</Item>
<Item Name="precision" Condition="m_type == acl::track_type8::float4f">m_desc.scalar.precision</Item>
<Item Name="precision" Condition="m_type == acl::track_type8::vector4f">m_desc.scalar.precision</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.precision</Item>
+ <Item Name="shell_distance" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.shell_distance</Item>
+ <Item Name="constant_rotation_threshold_angle" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.constant_rotation_threshold_angle</Item>
+ <Item Name="constant_translation_threshold" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.constant_translation_threshold</Item>
+ <Item Name="constant_scale_threshold" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.constant_scale_threshold</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::float1f">m_desc.scalar.output_index</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::float2f">m_desc.scalar.output_index</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::float3f">m_desc.scalar.output_index</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::float4f">m_desc.scalar.output_index</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::vector4f">m_desc.scalar.output_index</Item>
+ <Item Name="output_index" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.output_index</Item>
+ <Item Name="parent_index" Condition="m_type == acl::track_type8::qvvf">m_desc.transform.parent_index</Item>
<Item Name="is_ref">m_allocator == nullptr</Item>
<ArrayItems>
<Size>m_num_samples</Size>
@@ -67,6 +55,7 @@
<ValuePointer Condition="m_type == acl::track_type8::float3f">(rtm::float3f*)m_data</ValuePointer>
<ValuePointer Condition="m_type == acl::track_type8::float4f">(rtm::float4f*)m_data</ValuePointer>
<ValuePointer Condition="m_type == acl::track_type8::vector4f">(rtm::vector4f*)m_data</ValuePointer>
+ <ValuePointer Condition="m_type == acl::track_type8::qvvf">(rtm::qvvf*)m_data</ValuePointer>
</ArrayItems>
</Expand>
</Type>
|
diff --git a/test_data/reference.config.sjson b/test_data/reference.config.sjson
--- a/test_data/reference.config.sjson
+++ b/test_data/reference.config.sjson
@@ -12,22 +12,6 @@ rotation_format = "quatf_full"
translation_format = "vector3f_full"
scale_format = "vector3f_full"
-// Threshold angle value to use when detecting if a rotation track is constant
-// Defaults to '0.00284714461' radians
-constant_rotation_threshold_angle = 0.00284714461
-
-// Threshold value to use when detecting if a translation track is constant
-// Defaults to '0.001' centimeters
-constant_translation_threshold = 0.001
-
-// Threshold value to use when detecting if a scale track is constant
-// Defaults to '0.00001'
-constant_scale_threshold = 0.00001
-
-// The error threshold used when optimizing the bit rate
-// Defaults to '0.01' centimeters
-error_threshold = 0.01
-
// The error threshold used when performing regression testing
// We will sample the clip at various positions and compare the raw and decompressed poses
// and fail if the error is above or equal to this threshold
diff --git a/tests/sources/core/test_ansi_allocator.cpp b/tests/sources/core/test_ansi_allocator.cpp
--- a/tests/sources/core/test_ansi_allocator.cpp
+++ b/tests/sources/core/test_ansi_allocator.cpp
@@ -35,7 +35,7 @@ using namespace acl;
TEST_CASE("ANSI allocator", "[core][memory]")
{
- ANSIAllocator allocator;
+ ansi_allocator allocator;
CHECK(allocator.get_allocation_count() == 0);
void* ptr0 = allocator.allocate(32);
diff --git a/tests/sources/core/test_bitset.cpp b/tests/sources/core/test_bitset.cpp
--- a/tests/sources/core/test_bitset.cpp
+++ b/tests/sources/core/test_bitset.cpp
@@ -32,25 +32,25 @@ using namespace acl;
TEST_CASE("bitset", "[core][utils]")
{
- CHECK(BitSetDescription::make_from_num_bits(0).get_size() == 0);
- CHECK(BitSetDescription::make_from_num_bits(1).get_size() == 1);
- CHECK(BitSetDescription::make_from_num_bits(31).get_size() == 1);
- CHECK(BitSetDescription::make_from_num_bits(32).get_size() == 1);
- CHECK(BitSetDescription::make_from_num_bits(33).get_size() == 2);
- CHECK(BitSetDescription::make_from_num_bits(64).get_size() == 2);
- CHECK(BitSetDescription::make_from_num_bits(65).get_size() == 3);
-
- CHECK(BitSetDescription::make_from_num_bits(0).get_num_bits() == 0);
- CHECK(BitSetDescription::make_from_num_bits(1).get_num_bits() == 32);
- CHECK(BitSetDescription::make_from_num_bits(31).get_num_bits() == 32);
- CHECK(BitSetDescription::make_from_num_bits(32).get_num_bits() == 32);
- CHECK(BitSetDescription::make_from_num_bits(33).get_num_bits() == 64);
- CHECK(BitSetDescription::make_from_num_bits(64).get_num_bits() == 64);
- CHECK(BitSetDescription::make_from_num_bits(65).get_num_bits() == 96);
-
- constexpr BitSetDescription desc = BitSetDescription::make_from_num_bits<64>();
+ CHECK(bitset_description::make_from_num_bits(0).get_size() == 0);
+ CHECK(bitset_description::make_from_num_bits(1).get_size() == 1);
+ CHECK(bitset_description::make_from_num_bits(31).get_size() == 1);
+ CHECK(bitset_description::make_from_num_bits(32).get_size() == 1);
+ CHECK(bitset_description::make_from_num_bits(33).get_size() == 2);
+ CHECK(bitset_description::make_from_num_bits(64).get_size() == 2);
+ CHECK(bitset_description::make_from_num_bits(65).get_size() == 3);
+
+ CHECK(bitset_description::make_from_num_bits(0).get_num_bits() == 0);
+ CHECK(bitset_description::make_from_num_bits(1).get_num_bits() == 32);
+ CHECK(bitset_description::make_from_num_bits(31).get_num_bits() == 32);
+ CHECK(bitset_description::make_from_num_bits(32).get_num_bits() == 32);
+ CHECK(bitset_description::make_from_num_bits(33).get_num_bits() == 64);
+ CHECK(bitset_description::make_from_num_bits(64).get_num_bits() == 64);
+ CHECK(bitset_description::make_from_num_bits(65).get_num_bits() == 96);
+
+ constexpr bitset_description desc = bitset_description::make_from_num_bits<64>();
CHECK(desc.get_size() == 2);
- CHECK(desc.get_size() == BitSetDescription::make_from_num_bits(64).get_size());
+ CHECK(desc.get_size() == bitset_description::make_from_num_bits(64).get_size());
uint32_t bitset_data[desc.get_size() + 1]; // Add padding
std::memset(&bitset_data[0], 0, sizeof(bitset_data));
diff --git a/tests/sources/core/test_error_result.cpp b/tests/sources/core/test_error_result.cpp
--- a/tests/sources/core/test_error_result.cpp
+++ b/tests/sources/core/test_error_result.cpp
@@ -31,17 +31,17 @@
using namespace acl;
-TEST_CASE("ErrorResult", "[core][error]")
+TEST_CASE("error_result", "[core][error]")
{
- CHECK(ErrorResult().any() == false);
- CHECK(ErrorResult().empty() == true);
- CHECK(std::strlen(ErrorResult().c_str()) == 0);
+ CHECK(error_result().any() == false);
+ CHECK(error_result().empty() == true);
+ CHECK(std::strlen(error_result().c_str()) == 0);
- CHECK(ErrorResult("failed").any() == true);
- CHECK(ErrorResult("failed").empty() == false);
- CHECK(std::strcmp(ErrorResult("failed").c_str(), "failed") == 0);
+ CHECK(error_result("failed").any() == true);
+ CHECK(error_result("failed").empty() == false);
+ CHECK(std::strcmp(error_result("failed").c_str(), "failed") == 0);
- ErrorResult tmp("failed");
+ error_result tmp("failed");
CHECK(tmp.any() == true);
tmp.reset();
CHECK(tmp.any() == false);
diff --git a/tests/sources/core/test_iterator.cpp b/tests/sources/core/test_iterator.cpp
--- a/tests/sources/core/test_iterator.cpp
+++ b/tests/sources/core/test_iterator.cpp
@@ -36,7 +36,7 @@ TEST_CASE("iterator", "[core][iterator]")
constexpr uint32_t num_items = 3;
uint32_t items[num_items];
- auto i = Iterator<uint32_t>(items, num_items);
+ auto i = iterator<uint32_t>(items, num_items);
SECTION("mutable returns correct type")
{
@@ -46,7 +46,7 @@ TEST_CASE("iterator", "[core][iterator]")
SECTION("const returns correct type")
{
- auto ci = ConstIterator<uint32_t>(items, num_items);
+ auto ci = const_iterator<uint32_t>(items, num_items);
CHECK(std::is_same<const uint32_t*, decltype(ci.begin())>::value);
CHECK(std::is_same<const uint32_t*, decltype(ci.end())>::value);
diff --git a/tests/sources/core/test_ptr_offset.cpp b/tests/sources/core/test_ptr_offset.cpp
--- a/tests/sources/core/test_ptr_offset.cpp
+++ b/tests/sources/core/test_ptr_offset.cpp
@@ -30,9 +30,9 @@ using namespace acl;
TEST_CASE("ptr_offset", "[core][memory]")
{
- CHECK(PtrOffset32<uint8_t>(InvalidPtrOffset()).is_valid() == false);
+ CHECK(ptr_offset32<uint8_t>(invalid_ptr_offset()).is_valid() == false);
- PtrOffset32<uint8_t> offset(32);
+ ptr_offset32<uint8_t> offset(32);
CHECK(offset.is_valid() == true);
uint8_t* ptr = nullptr;
diff --git a/tests/sources/core/test_string.cpp b/tests/sources/core/test_string.cpp
--- a/tests/sources/core/test_string.cpp
+++ b/tests/sources/core/test_string.cpp
@@ -35,31 +35,31 @@
using namespace acl;
-TEST_CASE("String", "[core][string]")
+TEST_CASE("string", "[core][string]")
{
- ANSIAllocator allocator;
+ ansi_allocator allocator;
- CHECK(String().size() == 0);
- CHECK(String().c_str() != nullptr);
- CHECK(String(allocator, "").size() == 0);
- CHECK(String(allocator, "").c_str() != nullptr);
+ CHECK(string().size() == 0);
+ CHECK(string().c_str() != nullptr);
+ CHECK(string(allocator, "").size() == 0);
+ CHECK(string(allocator, "").c_str() != nullptr);
const char* str0 = "this is a test string";
const char* str1 = "this is not a test string";
const char* str2 = "this is a test asset!";
- CHECK(String(allocator, str0) == str0);
- CHECK(String(allocator, str0) != str1);
- CHECK(String(allocator, str0) != str2);
- CHECK(String(allocator, str0) == String(allocator, str0));
- CHECK(String(allocator, str0) != String(allocator, str1));
- CHECK(String(allocator, str0) != String(allocator, str2));
- CHECK(String(allocator, str0).c_str() != str0);
- CHECK(String(allocator, str0).size() == std::strlen(str0));
- CHECK(String(allocator, str0, 4) == String(allocator, str1, 4));
- CHECK(String(allocator, str0, 4) == "this");
+ CHECK(string(allocator, str0) == str0);
+ CHECK(string(allocator, str0) != str1);
+ CHECK(string(allocator, str0) != str2);
+ CHECK(string(allocator, str0) == string(allocator, str0));
+ CHECK(string(allocator, str0) != string(allocator, str1));
+ CHECK(string(allocator, str0) != string(allocator, str2));
+ CHECK(string(allocator, str0).c_str() != str0);
+ CHECK(string(allocator, str0).size() == std::strlen(str0));
+ CHECK(string(allocator, str0, 4) == string(allocator, str1, 4));
+ CHECK(string(allocator, str0, 4) == "this");
- CHECK(String().empty() == true);
- CHECK(String(allocator, "").empty() == true);
- CHECK(String(allocator, str0).empty() == false);
+ CHECK(string().empty() == true);
+ CHECK(string(allocator, "").empty() == true);
+ CHECK(string(allocator, str0).empty() == false);
}
diff --git a/tests/sources/io/test_reader_writer.cpp b/tests/sources/io/test_reader_writer.cpp
--- a/tests/sources/io/test_reader_writer.cpp
+++ b/tests/sources/io/test_reader_writer.cpp
@@ -135,78 +135,60 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
- const uint16_t num_bones = 3;
- RigidBone bones[num_bones];
- bones[0].name = String(allocator, "root");
- bones[0].vertex_distance = 4.0F;
- bones[0].parent_index = k_invalid_bone_index;
- bones[0].bind_transform = rtm::qvv_identity();
+ const uint32_t num_tracks = 3;
+ const uint32_t num_samples = 4;
+ track_array_qvvf track_list(allocator, num_tracks);
- bones[1].name = String(allocator, "bone1");
- bones[1].vertex_distance = 3.0F;
- bones[1].parent_index = 0;
- bones[1].bind_transform = rtm::qvv_set(rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.5), rtm::vector_set(3.2, 8.2, 5.1), rtm::vector_set(1.0));
+ track_desc_transformf desc0;
+ desc0.output_index = 0;
+ desc0.precision = 0.001F;
+ track_qvvf track0 = track_qvvf::make_reserve(desc0, allocator, num_samples, 32.0F);
+ track0[0].rotation = rtm::quat_from_euler(0.1F, 0.5F, 1.2F);
+ track0[0].translation = rtm::vector_set(0.0F, 0.6F, 2.3F);
+ track0[0].scale = rtm::vector_set(1.4F, 2.1F, 0.2F);
+ for (uint32_t i = 1; i < num_samples; ++i)
+ {
+ track0[i].rotation = rtm::quat_lerp(rtm::quat_identity(), track0[0].rotation, 0.1F * float(i));
+ track0[i].translation = rtm::vector_lerp(rtm::vector_zero(), track0[0].translation, 0.1F * float(i));
+ track0[i].scale = rtm::vector_lerp(rtm::vector_zero(), track0[0].scale, 0.1F * float(i));
+ }
+ track_list[0] = track0.get_ref();
- bones[2].name = String(allocator, "bone2");
- bones[2].vertex_distance = 2.0F;
- bones[2].parent_index = 1;
- bones[2].bind_transform = rtm::qvv_set(rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.25), rtm::vector_set(6.3, 9.4, 1.5), rtm::vector_set(1.0));
+ track_desc_transformf desc1;
+ desc1.output_index = 0;
+ desc1.precision = 0.001F;
+ desc1.parent_index = 0;
+ desc1.shell_distance = 0.1241F;
+ desc1.constant_rotation_threshold_angle = 21.0F;
+ desc1.constant_translation_threshold = 0.11F;
+ desc1.constant_scale_threshold = 12.0F;
+ track_qvvf track1 = track_qvvf::make_reserve(desc1, allocator, num_samples, 32.0F);
+ track1[0].rotation = rtm::quat_from_euler(1.1F, 1.5F, 1.7F);
+ track1[0].translation = rtm::vector_set(0.0221F, 10.6F, 22.3F);
+ track1[0].scale = rtm::vector_set(1.451F, 24.1F, 10.2F);
+ for (uint32_t i = 1; i < num_samples; ++i)
+ {
+ track1[i].rotation = rtm::quat_lerp(rtm::quat_identity(), track1[0].rotation, 0.1F * float(i));
+ track1[i].translation = rtm::vector_lerp(rtm::vector_zero(), track1[0].translation, 0.1F * float(i));
+ track1[i].scale = rtm::vector_lerp(rtm::vector_zero(), track1[0].scale, 0.1F * float(i));
+ }
+ track_list[1] = track1.get_ref();
- RigidSkeleton skeleton(allocator, bones, num_bones);
+ track_qvvf track2 = track_qvvf::make_reserve(desc1, allocator, num_samples, 32.0F);
+ track2[0].rotation = rtm::quat_from_euler(1.11F, 1.5333F, 0.17F);
+ track2[0].translation = rtm::vector_set(30.0221F, 101.6F, 22.3214F);
+ track2[0].scale = rtm::vector_set(21.451F, 244.1F, 100.2F);
+ for (uint32_t i = 1; i < num_samples; ++i)
+ {
+ track2[i].rotation = rtm::quat_lerp(rtm::quat_identity(), track2[0].rotation, 0.1F * float(i));
+ track2[i].translation = rtm::vector_lerp(rtm::vector_zero(), track2[0].translation, 0.1F * float(i));
+ track2[i].scale = rtm::vector_lerp(rtm::vector_zero(), track2[0].scale, 0.1F * float(i));
+ }
+ track_list[2] = track2.get_ref();
- const uint32_t num_samples = 4;
- AnimationClip clip(allocator, skeleton, num_samples, 30.0F, String(allocator, "test_clip"));
-
- AnimatedBone* animated_bones = clip.get_bones();
- animated_bones[0].output_index = 0;
- animated_bones[0].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.1));
- animated_bones[0].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.2));
- animated_bones[0].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.3));
- animated_bones[0].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.4));
- animated_bones[0].translation_track.set_sample(0, rtm::vector_set(3.2, 1.4, 9.4));
- animated_bones[0].translation_track.set_sample(1, rtm::vector_set(3.3, 1.5, 9.5));
- animated_bones[0].translation_track.set_sample(2, rtm::vector_set(3.4, 1.6, 9.6));
- animated_bones[0].translation_track.set_sample(3, rtm::vector_set(3.5, 1.7, 9.7));
- animated_bones[0].scale_track.set_sample(0, rtm::vector_set(1.0, 1.5, 1.1));
- animated_bones[0].scale_track.set_sample(1, rtm::vector_set(1.1, 1.6, 1.2));
- animated_bones[0].scale_track.set_sample(2, rtm::vector_set(1.2, 1.7, 1.3));
- animated_bones[0].scale_track.set_sample(3, rtm::vector_set(1.3, 1.8, 1.4));
-
- animated_bones[1].output_index = 2;
- animated_bones[1].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.1));
- animated_bones[1].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.2));
- animated_bones[1].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.3));
- animated_bones[1].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.4));
- animated_bones[1].translation_track.set_sample(0, rtm::vector_set(5.2, 2.4, 13.4));
- animated_bones[1].translation_track.set_sample(1, rtm::vector_set(5.3, 2.5, 13.5));
- animated_bones[1].translation_track.set_sample(2, rtm::vector_set(5.4, 2.6, 13.6));
- animated_bones[1].translation_track.set_sample(3, rtm::vector_set(5.5, 2.7, 13.7));
- animated_bones[1].scale_track.set_sample(0, rtm::vector_set(2.0, 0.5, 4.1));
- animated_bones[1].scale_track.set_sample(1, rtm::vector_set(2.1, 0.6, 4.2));
- animated_bones[1].scale_track.set_sample(2, rtm::vector_set(2.2, 0.7, 4.3));
- animated_bones[1].scale_track.set_sample(3, rtm::vector_set(2.3, 0.8, 4.4));
-
- animated_bones[2].output_index = 1;
- animated_bones[2].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.7));
- animated_bones[2].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.8));
- animated_bones[2].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.9));
- animated_bones[2].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.4));
- animated_bones[2].translation_track.set_sample(0, rtm::vector_set(1.2, 123.4, 11.4));
- animated_bones[2].translation_track.set_sample(1, rtm::vector_set(1.3, 123.5, 11.5));
- animated_bones[2].translation_track.set_sample(2, rtm::vector_set(1.4, 123.6, 11.6));
- animated_bones[2].translation_track.set_sample(3, rtm::vector_set(1.5, 123.7, 11.7));
- animated_bones[2].scale_track.set_sample(0, rtm::vector_set(4.0, 2.5, 3.1));
- animated_bones[2].scale_track.set_sample(1, rtm::vector_set(4.1, 2.6, 3.2));
- animated_bones[2].scale_track.set_sample(2, rtm::vector_set(4.2, 2.7, 3.3));
- animated_bones[2].scale_track.set_sample(3, rtm::vector_set(4.3, 2.8, 3.4));
-
- CompressionSettings settings;
- settings.constant_rotation_threshold_angle = 32.23F;
- settings.constant_scale_threshold = 1.123F;
- settings.constant_translation_threshold = 0.124F;
- settings.error_threshold = 0.23F;
+ compression_settings settings;
settings.level = compression_level8::high;
settings.rotation_format = rotation_format8::quatf_drop_w_variable;
settings.scale_format = vector_format8::vector3f_variable;
@@ -217,18 +199,18 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "clip_");
// Write the clip to a temporary file
- error = write_acl_clip(skeleton, clip, algorithm_type8::uniformly_sampled, settings, filename);
+ error = write_track_list(track_list, settings, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
@@ -255,44 +237,49 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, clip_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, clip_size - 1);
- REQUIRE(reader.get_file_type() == sjson_file_type::raw_clip);
+ REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
- sjson_raw_clip file_clip;
- const bool success = reader.read_raw_clip(file_clip);
+ sjson_raw_track_list file_clip;
+ const bool success = reader.read_raw_track_list(file_clip);
REQUIRE(success);
- CHECK(file_clip.algorithm_type == algorithm_type8::uniformly_sampled);
CHECK(file_clip.has_settings);
CHECK(file_clip.settings.get_hash() == settings.get_hash());
- CHECK(file_clip.skeleton->get_num_bones() == num_bones);
- CHECK(file_clip.clip->get_num_bones() == num_bones);
- CHECK(file_clip.clip->get_name() == clip.get_name());
- CHECK(rtm::scalar_near_equal(file_clip.clip->get_duration(), clip.get_duration(), 1.0E-8F));
- CHECK(file_clip.clip->get_num_samples() == clip.get_num_samples());
- CHECK(file_clip.clip->get_sample_rate() == clip.get_sample_rate());
-
- for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
+
+ CHECK(file_clip.track_list.get_num_samples_per_track() == track_list.get_num_samples_per_track());
+ CHECK(file_clip.track_list.get_sample_rate() == track_list.get_sample_rate());
+ CHECK(file_clip.track_list.get_num_tracks() == track_list.get_num_tracks());
+ CHECK(rtm::scalar_near_equal(file_clip.track_list.get_duration(), track_list.get_duration(), 1.0E-8F));
+ CHECK(file_clip.track_list.get_track_type() == track_list.get_track_type());
+ CHECK(file_clip.track_list.get_track_category() == track_list.get_track_category());
+
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
{
- const RigidBone& src_bone = skeleton.get_bone(bone_index);
- const RigidBone& file_bone = file_clip.skeleton->get_bone(bone_index);
- CHECK(src_bone.name == file_bone.name);
- CHECK(src_bone.vertex_distance == file_bone.vertex_distance);
- CHECK(src_bone.parent_index == file_bone.parent_index);
- CHECK(rtm::quat_near_equal(src_bone.bind_transform.rotation, file_bone.bind_transform.rotation, 0.0));
- CHECK(rtm::vector_all_near_equal3(src_bone.bind_transform.translation, file_bone.bind_transform.translation, 0.0));
- CHECK(rtm::vector_all_near_equal3(src_bone.bind_transform.scale, file_bone.bind_transform.scale, 0.0));
-
- const AnimatedBone& src_animated_bone = clip.get_animated_bone(bone_index);
- const AnimatedBone& file_animated_bone = file_clip.clip->get_animated_bone(bone_index);
- //REQUIRE(src_animated_bone.output_index == file_animated_bone.output_index);
+ const track_qvvf& ref_track = track_cast<track_qvvf>(track_list[track_index]);
+ const track_qvvf& file_track = track_cast<track_qvvf>(file_clip.track_list[track_index]);
+
+ CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
+ CHECK(file_track.get_description().parent_index == ref_track.get_description().parent_index);
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().shell_distance, ref_track.get_description().shell_distance, 0.0F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().constant_rotation_threshold_angle, ref_track.get_description().constant_rotation_threshold_angle, 0.0F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().constant_translation_threshold, ref_track.get_description().constant_translation_threshold, 0.0F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().constant_scale_threshold, ref_track.get_description().constant_scale_threshold, 0.0F));
+ CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
+ CHECK(file_track.get_output_index() == ref_track.get_output_index());
+ CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
+ CHECK(file_track.get_type() == ref_track.get_type());
+ CHECK(file_track.get_category() == ref_track.get_category());
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- CHECK(rtm::quat_near_equal(src_animated_bone.rotation_track.get_sample(sample_index), file_animated_bone.rotation_track.get_sample(sample_index), 0.0));
- CHECK(rtm::vector_all_near_equal3(src_animated_bone.translation_track.get_sample(sample_index), file_animated_bone.translation_track.get_sample(sample_index), 0.0));
- CHECK(rtm::vector_all_near_equal3(src_animated_bone.scale_track.get_sample(sample_index), file_animated_bone.scale_track.get_sample(sample_index), 0.0));
+ const rtm::qvvf& ref_sample = ref_track[sample_index];
+ const rtm::qvvf& file_sample = file_track[sample_index];
+ CHECK(rtm::quat_near_equal(ref_sample.rotation, file_sample.rotation, 0.0F));
+ CHECK(rtm::vector_all_near_equal3(ref_sample.translation, file_sample.translation, 0.0F));
+ CHECK(rtm::vector_all_near_equal3(ref_sample.scale, file_sample.scale, 0.0F));
}
}
#endif
@@ -302,7 +289,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
const uint32_t num_tracks = 3;
const uint32_t num_samples = 4;
@@ -333,7 +320,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "list_float1f_");
@@ -341,10 +328,10 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
// Write the clip to a temporary file
error = write_track_list(track_list, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
@@ -370,7 +357,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, buffer_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, buffer_size - 1);
REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
@@ -391,7 +378,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
const track_float1f& file_track = track_cast<track_float1f>(file_track_list.track_list[track_index]);
CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
- CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
@@ -402,7 +389,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
{
const float ref_sample = ref_track[sample_index];
const float file_sample = file_track[sample_index];
- CHECK(rtm::scalar_near_equal(ref_sample, file_sample, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(ref_sample, file_sample, 0.0F));
}
}
#endif
@@ -412,7 +399,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
const uint32_t num_tracks = 3;
const uint32_t num_samples = 4;
@@ -443,7 +430,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "list_float2f_");
@@ -451,10 +438,10 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
// Write the clip to a temporary file
error = write_track_list(track_list, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
@@ -480,7 +467,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, buffer_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, buffer_size - 1);
REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
@@ -501,7 +488,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
const track_float2f& file_track = track_cast<track_float2f>(file_track_list.track_list[track_index]);
CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
- CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
@@ -512,7 +499,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
{
const rtm::float2f& ref_sample = ref_track[sample_index];
const rtm::float2f& file_sample = file_track[sample_index];
- CHECK(rtm::vector_all_near_equal2(rtm::vector_load2(&ref_sample), rtm::vector_load2(&file_sample), 1.0E-8F));
+ CHECK(rtm::vector_all_near_equal2(rtm::vector_load2(&ref_sample), rtm::vector_load2(&file_sample), 0.0F));
}
}
#endif
@@ -522,7 +509,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
const uint32_t num_tracks = 3;
const uint32_t num_samples = 4;
@@ -553,7 +540,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "list_float3f_");
@@ -561,10 +548,10 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
// Write the clip to a temporary file
error = write_track_list(track_list, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
@@ -590,7 +577,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, buffer_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, buffer_size - 1);
REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
@@ -611,7 +598,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
const track_float3f& file_track = track_cast<track_float3f>(file_track_list.track_list[track_index]);
CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
- CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
@@ -622,7 +609,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
{
const rtm::float3f& ref_sample = ref_track[sample_index];
const rtm::float3f& file_sample = file_track[sample_index];
- CHECK(rtm::vector_all_near_equal3(rtm::vector_load3(&ref_sample), rtm::vector_load3(&file_sample), 1.0E-8F));
+ CHECK(rtm::vector_all_near_equal3(rtm::vector_load3(&ref_sample), rtm::vector_load3(&file_sample), 0.0F));
}
}
#endif
@@ -632,7 +619,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
const uint32_t num_tracks = 3;
const uint32_t num_samples = 4;
@@ -663,7 +650,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "list_float4f_");
@@ -671,10 +658,10 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
// Write the clip to a temporary file
error = write_track_list(track_list, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
@@ -700,7 +687,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, buffer_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, buffer_size - 1);
REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
@@ -721,7 +708,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
const track_float4f& file_track = track_cast<track_float4f>(file_track_list.track_list[track_index]);
CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
- CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
@@ -732,7 +719,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
{
const rtm::float4f& ref_sample = ref_track[sample_index];
const rtm::float4f& file_sample = file_track[sample_index];
- CHECK(rtm::vector_all_near_equal(rtm::vector_load(&ref_sample), rtm::vector_load(&file_sample), 1.0E-8F));
+ CHECK(rtm::vector_all_near_equal(rtm::vector_load(&ref_sample), rtm::vector_load(&file_sample), 0.0F));
}
}
#endif
@@ -742,7 +729,7 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
- ANSIAllocator allocator;
+ ansi_allocator allocator;
const uint32_t num_tracks = 3;
const uint32_t num_samples = 4;
@@ -773,7 +760,7 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
- const char* error = nullptr;
+ error_result error;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
{
get_temporary_filename(filename, filename_size, "list_vector4f_");
@@ -781,10 +768,10 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
// Write the clip to a temporary file
error = write_track_list(track_list, filename);
- if (error == nullptr)
+ if (error.empty())
break; // Everything worked, stop trying
}
- REQUIRE(error == nullptr);
+ REQUIRE(error.empty());
std::FILE* file = nullptr;
for (uint32_t try_count = 0; try_count < 20; ++try_count)
@@ -810,7 +797,7 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
std::remove(filename);
// Read back the clip
- ClipReader reader(allocator, sjson_file_buffer, buffer_size - 1);
+ clip_reader reader(allocator, sjson_file_buffer, buffer_size - 1);
REQUIRE(reader.get_file_type() == sjson_file_type::raw_track_list);
@@ -831,7 +818,7 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
const track_vector4f& file_track = track_cast<track_vector4f>(file_track_list.track_list[track_index]);
CHECK(file_track.get_description().output_index == ref_track.get_description().output_index);
- CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
@@ -842,7 +829,7 @@ TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
{
const rtm::vector4f& ref_sample = ref_track[sample_index];
const rtm::vector4f& file_sample = file_track[sample_index];
- CHECK(rtm::vector_all_near_equal(ref_sample, file_sample, 1.0E-8F));
+ CHECK(rtm::vector_all_near_equal(ref_sample, file_sample, 0.0F));
}
}
#endif
|
Unify naming convention to something closer to the C++ stdlib
Change CamelCase class/struct names to lowest_case equivalents and typedef the old names. The old names will be removed in 2.0.
| 2020-07-09T18:02:19
|
cpp
|
Hard
|
|
nfrechette/acl
| 219
|
nfrechette__acl-219
|
[
"214"
] |
575ba0d9d1c3d6641f70130168824b38f24c8878
|
diff --git a/includes/acl/compression/stream/sample_streams.h b/includes/acl/compression/stream/sample_streams.h
--- a/includes/acl/compression/stream/sample_streams.h
+++ b/includes/acl/compression/stream/sample_streams.h
@@ -195,8 +195,7 @@ namespace acl
}
// Pack and unpack at our desired bit rate
- uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- alignas(16) uint8_t raw_data[16] = { 0 };
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
Vector4_32 packed_rotation;
if (is_constant_bit_rate(bit_rate))
@@ -207,24 +206,14 @@ namespace acl
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
const Vector4_32 normalized_rotation = normalize_sample(rotation, clip_bone_range.rotation);
- pack_vector3_u48_unsafe(normalized_rotation, &raw_data[0]);
- packed_rotation = unpack_vector3_u48_unsafe(&raw_data[0]);
+ packed_rotation = decay_vector3_u48(normalized_rotation);
}
else if (is_raw_bit_rate(bit_rate))
packed_rotation = rotation;
+ else if (are_rotations_normalized)
+ packed_rotation = decay_vector3_uXX(rotation, num_bits_at_bit_rate);
else
- {
- if (are_rotations_normalized)
- {
- pack_vector3_uXX_unsafe(rotation, num_bits_at_bit_rate, &raw_data[0]);
- packed_rotation = unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, &raw_data[0], 0);
- }
- else
- {
- pack_vector3_sXX_unsafe(rotation, num_bits_at_bit_rate, &raw_data[0]);
- packed_rotation = unpack_vector3_sXX_unsafe(num_bits_at_bit_rate, &raw_data[0], 0);
- }
- }
+ packed_rotation = decay_vector3_sXX(rotation, num_bits_at_bit_rate);
if (segment->are_rotations_normalized && !is_constant_bit_rate(bit_rate) && !is_raw_bit_rate(bit_rate))
{
@@ -271,15 +260,9 @@ namespace acl
break;
case RotationFormat8::QuatDropW_48:
if (are_rotations_normalized)
- {
- pack_vector3_u48_unsafe(rotation, &raw_data[0]);
- packed_rotation = unpack_vector3_u48_unsafe(&raw_data[0]);
- }
+ packed_rotation = decay_vector3_u48(rotation);
else
- {
- pack_vector3_s48_unsafe(rotation, &raw_data[0]);
- packed_rotation = unpack_vector3_s48_unsafe(&raw_data[0]);
- }
+ packed_rotation = decay_vector3_s48(rotation);
break;
case RotationFormat8::QuatDropW_32:
pack_vector3_32(rotation, 11, 11, 10, are_rotations_normalized, &raw_data[0]);
@@ -372,7 +355,6 @@ namespace acl
ACL_ASSERT(clip_context->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
- alignas(16) uint8_t raw_data[16] = { 0 };
Vector4_32 packed_translation;
if (is_constant_bit_rate(bit_rate))
@@ -382,16 +364,14 @@ namespace acl
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
const Vector4_32 normalized_translation = normalize_sample(translation, clip_bone_range.translation);
- pack_vector3_u48_unsafe(normalized_translation, &raw_data[0]);
- packed_translation = unpack_vector3_u48_unsafe(&raw_data[0]);
+ packed_translation = decay_vector3_u48(normalized_translation);
}
else if (is_raw_bit_rate(bit_rate))
packed_translation = translation;
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- pack_vector3_uXX_unsafe(translation, num_bits_at_bit_rate, &raw_data[0]);
- packed_translation = unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, &raw_data[0], 0);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ packed_translation = decay_vector3_uXX(translation, num_bits_at_bit_rate);
}
if (segment->are_translations_normalized && !is_constant_bit_rate(bit_rate) && !is_raw_bit_rate(bit_rate))
@@ -438,8 +418,7 @@ namespace acl
break;
case VectorFormat8::Vector3_48:
ACL_ASSERT(are_translations_normalized, "Translations must be normalized to support this format");
- pack_vector3_u48_unsafe(translation, &raw_data[0]);
- packed_translation = unpack_vector3_u48_unsafe(&raw_data[0]);
+ packed_translation = decay_vector3_u48(translation);
break;
case VectorFormat8::Vector3_32:
pack_vector3_32(translation, 11, 11, 10, are_translations_normalized, &raw_data[0]);
@@ -532,7 +511,6 @@ namespace acl
ACL_ASSERT(clip_context->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
- alignas(16) uint8_t raw_data[16] = { 0 };
Vector4_32 packed_scale;
if (is_constant_bit_rate(bit_rate))
@@ -542,16 +520,14 @@ namespace acl
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
const Vector4_32 normalized_scale = normalize_sample(scale, clip_bone_range.scale);
- pack_vector3_u48_unsafe(normalized_scale, &raw_data[0]);
- packed_scale = unpack_vector3_u48_unsafe(&raw_data[0]);
+ packed_scale = decay_vector3_u48(normalized_scale);
}
else if (is_raw_bit_rate(bit_rate))
packed_scale = scale;
else
{
- const uint8_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- pack_vector3_uXX_unsafe(scale, num_bits_at_bit_rate, &raw_data[0]);
- packed_scale = unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, &raw_data[0], 0);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ packed_scale = decay_vector3_uXX(scale, num_bits_at_bit_rate);
}
if (segment->are_scales_normalized && !is_constant_bit_rate(bit_rate) && !is_raw_bit_rate(bit_rate))
@@ -598,8 +574,7 @@ namespace acl
break;
case VectorFormat8::Vector3_48:
ACL_ASSERT(are_scales_normalized, "Scales must be normalized to support this format");
- pack_vector3_u48_unsafe(scale, &raw_data[0]);
- packed_scale = unpack_vector3_u48_unsafe(&raw_data[0]);
+ packed_scale = decay_vector3_u48(scale);
break;
case VectorFormat8::Vector3_32:
pack_vector3_32(scale, 11, 11, 10, are_scales_normalized, &raw_data[0]);
diff --git a/includes/acl/math/vector4_32.h b/includes/acl/math/vector4_32.h
--- a/includes/acl/math/vector4_32.h
+++ b/includes/acl/math/vector4_32.h
@@ -947,6 +947,22 @@ namespace acl
Vector4_32 mask = vector_greater_equal(input, vector_zero_32());
return vector_blend(mask, vector_set(1.0f), vector_set(-1.0f));
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns per component the rounded input using a symmetric algorithm.
+ // symmetric_round(1.5) = 2.0
+ // symmetric_round(1.2) = 1.0
+ // symmetric_round(-1.5) = -2.0
+ // symmetric_round(-1.2) = -1.0
+ //////////////////////////////////////////////////////////////////////////
+ inline Vector4_32 ACL_SIMD_CALL vector_symmetric_round(Vector4_32Arg0 input)
+ {
+ const Vector4_32 half = vector_set(0.5f);
+ const Vector4_32 floored = vector_floor(vector_add(input, half));
+ const Vector4_32 ceiled = vector_ceil(vector_sub(input, half));
+ const Vector4_32 is_greater_equal = vector_greater_equal(input, vector_zero_32());
+ return vector_blend(is_greater_equal, floored, ceiled);
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_64.h b/includes/acl/math/vector4_64.h
--- a/includes/acl/math/vector4_64.h
+++ b/includes/acl/math/vector4_64.h
@@ -746,6 +746,22 @@ namespace acl
Vector4_64 mask = vector_greater_equal(input, vector_zero_64());
return vector_blend(mask, vector_set(1.0), vector_set(-1.0));
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns per component the rounded input using a symmetric algorithm.
+ // symmetric_round(1.5) = 2.0
+ // symmetric_round(1.2) = 1.0
+ // symmetric_round(-1.5) = -2.0
+ // symmetric_round(-1.2) = -1.0
+ //////////////////////////////////////////////////////////////////////////
+ inline Vector4_64 vector_symmetric_round(const Vector4_64& input)
+ {
+ const Vector4_64 half = vector_set(0.5);
+ const Vector4_64 floored = vector_floor(vector_add(input, half));
+ const Vector4_64 ceiled = vector_ceil(vector_sub(input, half));
+ const Vector4_64 is_greater_equal = vector_greater_equal(input, vector_zero_64());
+ return vector_blend(is_greater_equal, floored, ceiled);
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_packing.h b/includes/acl/math/vector4_packing.h
--- a/includes/acl/math/vector4_packing.h
+++ b/includes/acl/math/vector4_packing.h
@@ -502,6 +502,33 @@ namespace acl
return vector_set(x, y, z);
}
+ inline Vector4_32 ACL_SIMD_CALL decay_vector3_u48(Vector4_32Arg0 input)
+ {
+ ACL_ASSERT(vector_all_greater_equal(input, vector_zero_32()) && vector_all_less_equal(input, vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(input), vector_get_y(input), vector_get_z(input));
+
+ const float max_value = safe_to_float((1 << 16) - 1);
+ const float inv_max_value = 1.0f / max_value;
+
+ const Vector4_32 packed = vector_symmetric_round(vector_mul(input, max_value));
+ const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ return decayed;
+ }
+
+ inline Vector4_32 ACL_SIMD_CALL decay_vector3_s48(Vector4_32Arg0 input)
+ {
+ const Vector4_32 half = vector_set(0.5f);
+ const Vector4_32 unsigned_input = vector_add(vector_mul(input, half), half);
+
+ ACL_ASSERT(vector_all_greater_equal(unsigned_input, vector_zero_32()) && vector_all_less_equal(unsigned_input, vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(unsigned_input), vector_get_y(unsigned_input), vector_get_z(unsigned_input));
+
+ const float max_value = safe_to_float((1 << 16) - 1);
+ const float inv_max_value = 1.0f / max_value;
+
+ const Vector4_32 packed = vector_symmetric_round(vector_mul(unsigned_input, max_value));
+ const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ return vector_sub(vector_mul(decayed, vector_set(2.0f)), vector_set(1.0f));
+ }
+
inline void ACL_SIMD_CALL pack_vector3_32(Vector4_32Arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
@@ -705,6 +732,33 @@ namespace acl
unaligned_write(vector_u64, out_vector_data);
}
+ inline Vector4_32 ACL_SIMD_CALL decay_vector3_uXX(Vector4_32Arg0 input, uint32_t num_bits)
+ {
+ ACL_ASSERT(vector_all_greater_equal(input, vector_zero_32()) && vector_all_less_equal(input, vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(input), vector_get_y(input), vector_get_z(input));
+
+ const float max_value = safe_to_float((1 << num_bits) - 1);
+ const float inv_max_value = 1.0f / max_value;
+
+ const Vector4_32 packed = vector_symmetric_round(vector_mul(input, max_value));
+ const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ return decayed;
+ }
+
+ inline Vector4_32 ACL_SIMD_CALL decay_vector3_sXX(Vector4_32Arg0 input, uint32_t num_bits)
+ {
+ const Vector4_32 half = vector_set(0.5f);
+ const Vector4_32 unsigned_input = vector_add(vector_mul(input, half), half);
+
+ ACL_ASSERT(vector_all_greater_equal(unsigned_input, vector_zero_32()) && vector_all_less_equal(unsigned_input, vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(unsigned_input), vector_get_y(unsigned_input), vector_get_z(unsigned_input));
+
+ const float max_value = safe_to_float((1 << num_bits) - 1);
+ const float inv_max_value = 1.0f / max_value;
+
+ const Vector4_32 packed = vector_symmetric_round(vector_mul(unsigned_input, max_value));
+ const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ return vector_sub(vector_mul(decayed, vector_set(2.0f)), vector_set(1.0f));
+ }
+
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
inline Vector4_32 ACL_SIMD_CALL unpack_vector2_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
|
diff --git a/tests/sources/math/test_vector4_impl.h b/tests/sources/math/test_vector4_impl.h
--- a/tests/sources/math/test_vector4_impl.h
+++ b/tests/sources/math/test_vector4_impl.h
@@ -562,6 +562,29 @@ void test_vector4_impl(const Vector4Type& zero, const QuatType& identity, const
REQUIRE(vector_get_y(vector_sign(test_value0)) == scalar_sign(test_value0_flt[1]));
REQUIRE(vector_get_z(vector_sign(test_value0)) == scalar_sign(test_value0_flt[2]));
REQUIRE(vector_get_w(vector_sign(test_value0)) == scalar_sign(test_value0_flt[3]));
+
+ {
+ const Vector4Type input0 = vector_set(FloatType(-1.75), FloatType(-1.5), FloatType(-1.4999), FloatType(-0.5));
+ const Vector4Type input1 = vector_set(FloatType(-0.4999), FloatType(0.0), FloatType(0.4999), FloatType(0.5));
+ const Vector4Type input2 = vector_set(FloatType(1.4999), FloatType(1.5), FloatType(1.75), FloatType(0.0));
+
+ const Vector4Type result0 = vector_symmetric_round(input0);
+ const Vector4Type result1 = vector_symmetric_round(input1);
+ const Vector4Type result2 = vector_symmetric_round(input2);
+
+ REQUIRE(vector_get_x(result0) == symmetric_round(vector_get_x(input0)));
+ REQUIRE(vector_get_y(result0) == symmetric_round(vector_get_y(input0)));
+ REQUIRE(vector_get_z(result0) == symmetric_round(vector_get_z(input0)));
+ REQUIRE(vector_get_w(result0) == symmetric_round(vector_get_w(input0)));
+ REQUIRE(vector_get_x(result1) == symmetric_round(vector_get_x(input1)));
+ REQUIRE(vector_get_y(result1) == symmetric_round(vector_get_y(input1)));
+ REQUIRE(vector_get_z(result1) == symmetric_round(vector_get_z(input1)));
+ REQUIRE(vector_get_w(result1) == symmetric_round(vector_get_w(input1)));
+ REQUIRE(vector_get_x(result2) == symmetric_round(vector_get_x(input2)));
+ REQUIRE(vector_get_y(result2) == symmetric_round(vector_get_y(input2)));
+ REQUIRE(vector_get_z(result2) == symmetric_round(vector_get_z(input2)));
+ REQUIRE(vector_get_w(result2) == symmetric_round(vector_get_w(input2)));
+ }
}
template<typename Vector4Type, typename FloatType, VectorMix XArg>
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -246,6 +246,29 @@ TEST_CASE("pack_vector3_48", "[math][vector4][packing]")
}
}
+TEST_CASE("decay_vector3_48", "[math][vector4][decay]")
+{
+ {
+ uint32_t num_errors = 0;
+ for (uint32_t value = 0; value < 65536; ++value)
+ {
+ const float value_signed = unpack_scalar_signed(value, 16);
+ const float value_unsigned = unpack_scalar_unsigned(value, 16);
+
+ Vector4_32 vec0 = vector_set(value_signed, value_signed, value_signed);
+ Vector4_32 vec1 = decay_vector3_s48(vec0);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+
+ vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
+ vec1 = decay_vector3_u48(vec0);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+ }
+ REQUIRE(num_errors == 0);
+ }
+}
+
TEST_CASE("pack_vector3_32", "[math][vector4][packing]")
{
{
@@ -377,6 +400,46 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
}
}
+TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
+{
+ {
+ uint32_t num_errors = 0;
+
+ Vector4_32 vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
+ Vector4_32 vec1 = decay_vector3_sXX(vec0, 16);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+
+ vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16));
+ vec1 = decay_vector3_uXX(vec0, 16);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+
+ for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ {
+ uint8_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
+ for (uint32_t value = 0; value <= max_value; ++value)
+ {
+ const float value_signed = clamp(unpack_scalar_signed(value, num_bits), -1.0f, 1.0f);
+ const float value_unsigned = clamp(unpack_scalar_unsigned(value, num_bits), 0.0f, 1.0f);
+
+ vec0 = vector_set(value_signed, value_signed, value_signed);
+ vec1 = decay_vector3_sXX(vec0, num_bits);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+
+ vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
+ vec1 = decay_vector3_uXX(vec0, num_bits);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0e-6f))
+ num_errors++;
+ }
+ }
+
+ REQUIRE(num_errors == 0);
+ }
+}
+
TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
{
{
|
Decay quantization values to avoid LHS
Right now when we iterate to optimize the quantization bit rates, we don't modify the tracks in place. Instead, we quantize the samples on demand over and over. To do so, we pack the value on the stack, and unpack it. This is needlessly slow. Instead we should just decay the value by keeping things in SIMD registers. There is no need to write and load to the stack. This will save a lot of instructions and avoid any potential LHS issues.
| 2019-08-16T02:12:24
|
cpp
|
Hard
|
|
nfrechette/acl
| 443
|
nfrechette__acl-443
|
[
"441"
] |
40ca64550ef4cb708c3b49b0c68253d7751d4d33
|
diff --git a/includes/acl/compression/impl/clip_context.h b/includes/acl/compression/impl/clip_context.h
--- a/includes/acl/compression/impl/clip_context.h
+++ b/includes/acl/compression/impl/clip_context.h
@@ -127,23 +127,64 @@ namespace acl
uint32_t m_bone_index;
};
+ // Metadata per transform
struct transform_metadata
{
+ // The transform chain this transform belongs to (points into leaf_transform_chains in owner context)
const uint32_t* transform_chain = nullptr;
+
+ // Parent transform index of this transform, invalid if at the root
uint32_t parent_index = k_invalid_track_index;
+
+ // The precision value from the track description for this transform
float precision = 0.0F;
+
+ // The local space shell distance from the track description for this transform
float shell_distance = 0.0F;
};
+ // Rigid shell information per transform
+ struct rigid_shell_metadata_t
+ {
+ // Dominant local space shell distance (from transform tip)
+ float local_shell_distance;
+
+ // Parent space shell distance (from transform root)
+ float parent_shell_distance;
+
+ // Precision required on the surface of the rigid shell
+ float precision;
+ };
+
+ // Represents the working space for a clip (raw or lossy)
struct clip_context
{
+ // List of segments contained (num_segments present)
+ // Raw contexts only have a single segment
segment_context* segments = nullptr;
+
+ // List of clip wide range information for each transform (num_bones present)
transform_range* ranges = nullptr;
+
+ // List of metadata for each transform (num_bones present)
+ // TODO: Same for raw/lossy/additive clip context, can we share?
transform_metadata* metadata = nullptr;
+
+ // List of bit sets for each leaf transform to track transform chains (num_leaf_transforms present)
+ // TODO: Same for raw/lossy/additive clip context, can we share?
uint32_t* leaf_transform_chains = nullptr;
+ // List of transform indices sorted by parent first then sibling transforms are sorted by their transform index (num_bones present)
+ // TODO: Same for raw/lossy/additive clip context, can we share?
+ uint32_t* sorted_transforms_parent_first = nullptr;
+
+ // List of shell metadata for each transform (num_bones present)
+ // Data is aggregate of whole clip
+ // Shared between all clip contexts, not owned
+ const rigid_shell_metadata_t* clip_shell_metadata = nullptr;
+
uint32_t num_segments = 0;
- uint32_t num_bones = 0;
+ uint32_t num_bones = 0; // TODO: Rename num_transforms
uint32_t num_samples_allocated = 0;
uint32_t num_samples = 0;
float sample_rate = 0.0F;
@@ -151,6 +192,7 @@ namespace acl
float duration = 0.0F;
sample_looping_policy looping_policy = sample_looping_policy::non_looping;
+ additive_clip_format8 additive_format = additive_clip_format8::none;
bool are_rotations_normalized = false;
bool are_translations_normalized = false;
@@ -192,6 +234,8 @@ namespace acl
out_clip_context.ranges = nullptr;
out_clip_context.metadata = allocate_type_array<transform_metadata>(allocator, num_transforms);
out_clip_context.leaf_transform_chains = nullptr;
+ out_clip_context.sorted_transforms_parent_first = allocate_type_array<uint32_t>(allocator, num_transforms);
+ out_clip_context.clip_shell_metadata = nullptr;
out_clip_context.num_segments = 1;
out_clip_context.num_bones = num_transforms;
out_clip_context.num_samples_allocated = num_samples;
@@ -199,6 +243,7 @@ namespace acl
out_clip_context.sample_rate = sample_rate;
out_clip_context.duration = track_list.get_finite_duration();
out_clip_context.looping_policy = looping_policy;
+ out_clip_context.additive_format = additive_format;
out_clip_context.are_rotations_normalized = false;
out_clip_context.are_translations_normalized = false;
out_clip_context.are_scales_normalized = false;
@@ -206,7 +251,6 @@ namespace acl
out_clip_context.num_leaf_transforms = 0;
out_clip_context.allocator = &allocator;
- bool has_scale = false;
bool are_samples_valid = true;
segment_context& segment = out_clip_context.segments[0];
@@ -230,6 +274,14 @@ namespace acl
bone_stream.translations = translation_track_stream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, vector_format8::vector3f_full);
bone_stream.scales = scale_track_stream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, vector_format8::vector3f_full);
+ // Constant and default detection is handled during sub-track compacting
+ bone_stream.is_rotation_constant = false;
+ bone_stream.is_rotation_default = false;
+ bone_stream.is_translation_constant = false;
+ bone_stream.is_translation_default = false;
+ bone_stream.is_scale_constant = false;
+ bone_stream.is_scale_default = false;
+
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
const rtm::qvvf& transform = track[sample_index];
@@ -251,92 +303,16 @@ namespace acl
bone_stream.scales.set_raw_sample(sample_index, transform.scale);
}
- {
- const rtm::qvvf& first_transform = num_samples != 0 ? track[0] : desc.default_value;
-
- rtm::quatf first_rotation;
- if (num_samples != 0)
- {
- first_rotation = track[0].rotation;
-
- // If we request raw data and we are already normalized, retain the original value
- // otherwise we normalize for safety
- if (settings.rotation_format != rotation_format8::quatf_full || !rtm::quat_is_normalized(first_rotation))
- first_rotation = rtm::quat_normalize(first_rotation);
- }
- else
- first_rotation = desc.default_value.rotation;
-
- // If we request raw data, use a 0.0 threshold for safety
- const float constant_rotation_threshold_angle = settings.rotation_format != rotation_format8::quatf_full ? desc.constant_rotation_threshold_angle : 0.0F;
- const float constant_translation_threshold = settings.translation_format != vector_format8::vector3f_full ? desc.constant_translation_threshold : 0.0F;
- const float constant_scale_threshold = settings.scale_format != vector_format8::vector3f_full ? desc.constant_scale_threshold : 0.0F;
-
- bone_stream.is_rotation_constant = num_samples <= 1;
-
- if (bone_stream.is_rotation_constant)
- {
- const rtm::quatf default_bind_rotation = desc.default_value.rotation;
-
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_rotation_threshold_angle == 0.0F)
- bone_stream.is_rotation_default = rtm::quat_are_equal(first_rotation, default_bind_rotation);
- else
- bone_stream.is_rotation_default = rtm::quat_near_identity(rtm::quat_normalize(rtm::quat_mul(first_rotation, rtm::quat_conjugate(default_bind_rotation))), constant_rotation_threshold_angle);
- }
- else
- {
- bone_stream.is_rotation_default = false;
- }
-
- bone_stream.is_translation_constant = num_samples <= 1;
-
- if (bone_stream.is_translation_constant)
- {
- const rtm::vector4f default_bind_translation = desc.default_value.translation;
-
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_translation_threshold == 0.0F)
- bone_stream.is_translation_default = rtm::vector_all_equal3(first_transform.translation, default_bind_translation);
- else
- bone_stream.is_translation_default = rtm::vector_all_near_equal3(first_transform.translation, default_bind_translation, constant_translation_threshold);
- }
- else
- {
- bone_stream.is_translation_default = false;
- }
-
- bone_stream.is_scale_constant = num_samples <= 1;
-
- if (bone_stream.is_scale_constant)
- {
- const rtm::vector4f default_bind_scale = desc.default_value.scale;
-
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_scale_threshold == 0.0F)
- bone_stream.is_scale_default = rtm::vector_all_equal3(first_transform.scale, default_bind_scale);
- else
- bone_stream.is_scale_default = rtm::vector_all_near_equal3(first_transform.scale, default_bind_scale, constant_scale_threshold);
- }
- else
- {
- bone_stream.is_scale_default = false;
- }
- }
-
- has_scale |= !bone_stream.is_scale_default;
-
transform_metadata& metadata = out_clip_context.metadata[transform_index];
metadata.transform_chain = nullptr;
metadata.parent_index = desc.parent_index;
metadata.precision = desc.precision;
metadata.shell_distance = desc.shell_distance;
+
+ out_clip_context.sorted_transforms_parent_first[transform_index] = transform_index;
}
- out_clip_context.has_scale = has_scale;
+ out_clip_context.has_scale = true; // Scale detection is handled during sub-track compacting
out_clip_context.decomp_touched_bytes = 0;
out_clip_context.decomp_touched_cache_lines = 0;
@@ -429,6 +405,25 @@ namespace acl
ACL_ASSERT(num_root_bones > 0, "No root bone found. The root bones must have a parent index = 0xFFFF");
ACL_ASSERT(leaf_index == num_leaf_transforms, "Invalid number of leaf bone found");
deallocate_type_array(allocator, is_leaf_bitset, bitset_size);
+
+ // We sort our transform indices by parent first
+ // If two transforms have the same parent index, we sort them by their transform index
+ auto sort_predicate = [&out_clip_context](const uint32_t& lhs_transform_index, const uint32_t& rhs_transform_index)
+ {
+ const uint32_t lhs_parent_index = out_clip_context.metadata[lhs_transform_index].parent_index;
+ const uint32_t rhs_parent_index = out_clip_context.metadata[rhs_transform_index].parent_index;
+
+ // If the transforms don't have the same parent, sort by the parent index
+ // We add 1 to parent indices to cause the invalid index to wrap around to 0
+ // since parents come first, they'll have the lowest value
+ if (lhs_parent_index != rhs_parent_index)
+ return (lhs_parent_index + 1) < (rhs_parent_index + 1);
+
+ // Both transforms have the same parent, sort by their index
+ return lhs_transform_index < rhs_transform_index;
+ };
+
+ std::sort(out_clip_context.sorted_transforms_parent_first, out_clip_context.sorted_transforms_parent_first + num_transforms, sort_predicate);
}
return are_samples_valid;
@@ -450,6 +445,8 @@ namespace acl
bitset_description bone_bitset_desc = bitset_description::make_from_num_bits(context.num_bones);
deallocate_type_array(allocator, context.leaf_transform_chains, size_t(context.num_leaf_transforms) * bone_bitset_desc.get_size());
+
+ deallocate_type_array(allocator, context.sorted_transforms_parent_first, context.num_bones);
}
constexpr bool segment_context_has_scale(const segment_context& segment) { return segment.clip->has_scale; }
diff --git a/includes/acl/compression/impl/compact_constant_streams.h b/includes/acl/compression/impl/compact_constant_streams.h
--- a/includes/acl/compression/impl/compact_constant_streams.h
+++ b/includes/acl/compression/impl/compact_constant_streams.h
@@ -30,12 +30,29 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/error.h"
#include "acl/compression/impl/clip_context.h"
+#include "acl/compression/impl/rigid_shell_utils.h"
+#include "acl/compression/transform_error_metrics.h"
-#include <rtm/quatf.h>
-#include <rtm/vector4f.h>
+#include <rtm/qvvf.h>
#include <cstdint>
+//////////////////////////////////////////////////////////////////////////
+// Apply error correction after constant and default tracks are processed.
+// Notes:
+// - original code was adapted and cleaned up a bit, but largely as contributed
+// - zero scale isn't properly handled and needs to be guarded against
+// - regression testing over large data sets shows that it is sometimes a win, sometimes not
+// - overall, it seems to be a net loss over the memory footprint and quality does not
+// measurably improve to justify the loss
+// - I tried various tweaks and failed to make the code a consistent win, see https://github.com/nfrechette/acl/issues/353
+
+//#define ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+#include "acl/compression/impl/normalize_streams.h"
+#endif
+
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
@@ -44,216 +61,584 @@ namespace acl
namespace acl_impl
{
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- inline bool is_rotation_track_constant(const rotation_track_stream& rotations, float threshold_angle, rtm::quatf_arg0 ref_rotation)
-#else
- inline bool is_rotation_track_constant(const rotation_track_stream& rotations, float threshold_angle)
-#endif
+ // To detect if a sub-track is constant, we grab the first sample as our reference.
+ // We then measure the object space error using the qvv error metric and our
+ // dominant shell distance. If the error remains within our dominant precision
+ // then the sub-track is constant. We perform the same test using the default
+ // sub-track value to determine if it is a default sub-track.
+
+ inline bool RTM_SIMD_CALL are_rotations_constant(const transform_streams& raw_transform_stream, rtm::quatf_arg0 reference, const rigid_shell_metadata_t& shell)
{
+ const uint32_t num_samples = raw_transform_stream.rotations.get_num_samples();
-#if !defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- // Calculating the average rotation and comparing every rotation in the track to it
- // to determine if we are within the threshold seems overkill. We can't use the min/max for the range
- // either because neither of those represents a valid rotation. Instead we grab
- // the first rotation, and compare everything else to it.
-#endif
+ qvvf_transform_error_metric::calculate_error_args error_metric_args;
+ error_metric_args.construct_sphere_shell(shell.local_shell_distance);
+
+ const qvvf_transform_error_metric error_metric;
+
+ const rtm::scalarf precision = rtm::scalar_set(shell.precision);
- auto sample_to_quat = [](const rotation_track_stream& track, uint32_t sample_index)
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const rtm::vector4f rotation = track.get_raw_sample<rtm::vector4f>(sample_index);
+ const rtm::quatf raw_rotation = raw_transform_stream.rotations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_translation = raw_transform_stream.translations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_scale = raw_transform_stream.scales.get_sample_clamped(sample_index);
- switch (track.get_rotation_format())
- {
- case rotation_format8::quatf_full:
- return rtm::vector_to_quat(rotation);
- case rotation_format8::quatf_drop_w_full:
- case rotation_format8::quatf_drop_w_variable:
- // quat_from_positive_w might not yield an accurate quaternion because the square-root instruction
- // isn't very accurate on small inputs, we need to normalize
- return rtm::quat_normalize(rtm::quat_from_positive_w(rotation));
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(track.get_rotation_format()));
- return rtm::vector_to_quat(rotation);
- }
- };
+ const rtm::qvvf raw_transform = rtm::qvv_set(raw_rotation, raw_translation, raw_scale);
+ const rtm::qvvf lossy_transform = rtm::qvv_set(reference, raw_translation, raw_scale);
- const uint32_t num_samples = rotations.get_num_samples();
- if (num_samples <= 1)
- return true;
+ error_metric_args.transform0 = &raw_transform;
+ error_metric_args.transform1 = &lossy_transform;
-#if !defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const rtm::quatf ref_rotation = sample_to_quat(rotations, 0);
-#endif
+ const rtm::scalarf vtx_error = error_metric.calculate_error(error_metric_args);
- const rtm::quatf inv_ref_rotation = rtm::quat_conjugate(ref_rotation);
+ // If our error exceeds the desired precision, we are not constant
+ if (rtm::scalar_greater_than(vtx_error, precision))
+ return false;
+ }
- // If our error threshold is zero we want to test if we are binary exact
+ // All samples were tested against the reference value and the error remained within tolerance
+ return true;
+ }
+
+ inline bool are_rotations_constant(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are constant if we have no samples
+
+ // When we are using full precision, we are only constant if range.min == range.max, meaning
+ // we have a single unique and repeating sample
+ // We want to test if we are binary exact
// This is used by raw clips, we must preserve the original values
- const bool is_threshold_zero = threshold_angle == 0.0F;
+ if (settings.rotation_format == rotation_format8::quatf_full)
+ return lossy_clip_context.ranges[transform_index].rotation.is_constant(0.0F);
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_rotations_constant(raw_transform_stream, raw_transform_stream.rotations.get_sample(0), shell_metadata[transform_index]);
+ }
+
+ inline bool are_rotations_default(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, const track_desc_transformf& desc, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are default if we have no samples
+
+ const rtm::quatf default_bind_rotation = desc.default_value.rotation;
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+
+ // When we are using full precision, we are only default if (sample 0 == default value), meaning
+ // we have a single unique and repeating default sample
+ // We want to test if we are binary exact
+ // This is used by raw clips, we must preserve the original values
+ if (settings.rotation_format == rotation_format8::quatf_full)
+ {
+ const rtm::vector4f rotation = raw_transform_stream.rotations.get_raw_sample<rtm::vector4f>(0);
+ return rtm::vector_all_equal(rotation, rtm::quat_to_vector(default_bind_rotation));
+ }
+
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_rotations_constant(raw_transform_stream, default_bind_rotation, shell_metadata[transform_index]);
+ }
+
+ inline bool RTM_SIMD_CALL are_translations_constant(const transform_streams& raw_transform_stream, rtm::vector4f_arg0 reference, const rigid_shell_metadata_t& shell)
+ {
+ const uint32_t num_samples = raw_transform_stream.translations.get_num_samples();
+
+ qvvf_transform_error_metric::calculate_error_args error_metric_args;
+ error_metric_args.construct_sphere_shell(shell.local_shell_distance);
+
+ const qvvf_transform_error_metric error_metric;
+
+ const rtm::scalarf precision = rtm::scalar_set(shell.precision);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
-#else
- for (uint32_t sample_index = 1; sample_index < num_samples; ++sample_index)
-#endif
+ {
+ const rtm::quatf raw_rotation = raw_transform_stream.rotations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_translation = raw_transform_stream.translations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_scale = raw_transform_stream.scales.get_sample_clamped(sample_index);
+
+ const rtm::qvvf raw_transform = rtm::qvv_set(raw_rotation, raw_translation, raw_scale);
+ const rtm::qvvf lossy_transform = rtm::qvv_set(raw_rotation, reference, raw_scale);
+
+ error_metric_args.transform0 = &raw_transform;
+ error_metric_args.transform1 = &lossy_transform;
+
+ const rtm::scalarf vtx_error = error_metric.calculate_error(error_metric_args);
+
+ // If our error exceeds the desired precision, we are not constant
+ if (rtm::scalar_greater_than(vtx_error, precision))
+ return false;
+ }
+
+ // All samples were tested against the reference value and the error remained within tolerance
+ return true;
+ }
+
+ inline bool are_translations_constant(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are constant if we have no samples
+
+ // When we are using full precision, we are only constant if range.min == range.max, meaning
+ // we have a single unique and repeating sample
+ // We want to test if we are binary exact
+ // This is used by raw clips, we must preserve the original values
+ if (settings.translation_format == vector_format8::vector3f_full)
+ return lossy_clip_context.ranges[transform_index].translation.is_constant(0.0F);
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_translations_constant(raw_transform_stream, raw_transform_stream.translations.get_sample(0), shell_metadata[transform_index]);
+ }
+
+ inline bool are_translations_default(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, const track_desc_transformf& desc, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are default if we have no samples
+
+ const rtm::vector4f default_bind_translation = desc.default_value.translation;
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+
+ // When we are using full precision, we are only default if (sample 0 == default value), meaning
+ // we have a single unique and repeating default sample
+ // We want to test if we are binary exact
+ // This is used by raw clips, we must preserve the original values
+ if (settings.translation_format == vector_format8::vector3f_full)
{
- const rtm::quatf rotation = sample_to_quat(rotations, sample_index);
+ const rtm::vector4f translation = raw_transform_stream.translations.get_raw_sample<rtm::vector4f>(0);
+ return rtm::vector_all_equal(translation, default_bind_translation);
+ }
- if (is_threshold_zero)
- {
- if (!rtm::quat_are_equal(rotation, ref_rotation))
- return false;
- }
- else
- {
- const rtm::quatf delta = rtm::quat_normalize(rtm::quat_mul(inv_ref_rotation, rotation));
- if (!rtm::quat_near_identity(delta, threshold_angle))
- return false;
- }
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_translations_constant(raw_transform_stream, default_bind_translation, shell_metadata[transform_index]);
+ }
+
+ inline bool RTM_SIMD_CALL are_scales_constant(const transform_streams& raw_transform_stream, rtm::vector4f_arg0 reference, const rigid_shell_metadata_t& shell)
+ {
+ const uint32_t num_samples = raw_transform_stream.scales.get_num_samples();
+
+ qvvf_transform_error_metric::calculate_error_args error_metric_args;
+ error_metric_args.construct_sphere_shell(shell.local_shell_distance);
+
+ const qvvf_transform_error_metric error_metric;
+
+ const rtm::scalarf precision = rtm::scalar_set(shell.precision);
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const rtm::quatf raw_rotation = raw_transform_stream.rotations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_translation = raw_transform_stream.translations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_scale = raw_transform_stream.scales.get_sample_clamped(sample_index);
+
+ const rtm::qvvf raw_transform = rtm::qvv_set(raw_rotation, raw_translation, raw_scale);
+ const rtm::qvvf lossy_transform = rtm::qvv_set(raw_rotation, raw_translation, reference);
+
+ error_metric_args.transform0 = &raw_transform;
+ error_metric_args.transform1 = &lossy_transform;
+
+ const rtm::scalarf vtx_error = error_metric.calculate_error(error_metric_args);
+
+ // If our error exceeds the desired precision, we are not constant
+ if (rtm::scalar_greater_than(vtx_error, precision))
+ return false;
}
+ // All samples were tested against the reference value and the error remained within tolerance
return true;
}
- inline void compact_constant_streams(iallocator& allocator, clip_context& context, const track_array_qvvf& track_list, const compression_settings& settings)
+ inline bool are_scales_constant(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are constant if we have no samples
+
+ if (!lossy_clip_context.has_scale)
+ return true; // We are constant if we have no scale
+
+ // When we are using full precision, we are only constant if range.min == range.max, meaning
+ // we have a single unique and repeating sample
+ // We want to test if we are binary exact
+ // This is used by raw clips, we must preserve the original values
+ if (settings.scale_format == vector_format8::vector3f_full)
+ return lossy_clip_context.ranges[transform_index].scale.is_constant(0.0F);
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_scales_constant(raw_transform_stream, raw_transform_stream.scales.get_sample(0), shell_metadata[transform_index]);
+ }
+
+ inline bool are_scales_default(const compression_settings& settings, const clip_context& lossy_clip_context, const rigid_shell_metadata_t* shell_metadata, const track_desc_transformf& desc, uint32_t transform_index)
+ {
+ if (lossy_clip_context.num_samples == 0)
+ return true; // We are default if we have no samples
+
+ if (!lossy_clip_context.has_scale)
+ return true; // We are default if we have no scale
+
+ const rtm::vector4f default_bind_scale = desc.default_value.scale;
+
+ const segment_context& segment = lossy_clip_context.segments[0];
+ const transform_streams& raw_transform_stream = segment.bone_streams[transform_index];
+
+ // When we are using full precision, we are only default if (sample 0 == default value), meaning
+ // we have a single unique and repeating default sample
+ // We want to test if we are binary exact
+ // This is used by raw clips, we must preserve the original values
+ if (settings.scale_format == vector_format8::vector3f_full)
+ {
+ const rtm::vector4f scale = raw_transform_stream.scales.get_raw_sample<rtm::vector4f>(0);
+ return rtm::vector_all_equal(scale, default_bind_scale);
+ }
+
+ // Otherwise check every sample to make sure we fall within the desired tolerance
+ return are_scales_constant(raw_transform_stream, default_bind_scale, shell_metadata[transform_index]);
+ }
+
+ // Compacts constant sub-tracks
+ // A sub-track is constant if every sample can be replaced by a single unique sample without exceeding
+ // our error threshold.
+ // By default, constant sub-tracks will retain the first sample.
+ // A constant sub-track is a default sub-track if its unique sample can be replaced by the default value
+ // without exceed our error threshold.
+ inline void compact_constant_streams(iallocator& allocator, clip_context& context, clip_context& raw_clip_context, const track_array_qvvf& track_list, const compression_settings& settings)
{
ACL_ASSERT(context.num_segments == 1, "context must contain a single segment!");
+ ACL_ASSERT(raw_clip_context.num_segments == 1, "context must contain a single segment!");
+
segment_context& segment = context.segments[0];
- const uint32_t num_bones = context.num_bones;
+ // We also update the raw data to match in case the values differ.
+ // This ensures that algorithms can reach the raw data when attempting to optimize towards it.
+ // This modifies the raw data copy, not the original data that lives in the raw track_array.
+ // As such, it is used internally when optimizing but not once compression is done to measure
+ // the final error. This can lead to a small divergence where ACL sees a better error than
+ // a user might but in practice this is generally not observable.
+ segment_context& raw_segment = raw_clip_context.segments[0];
+
+ const uint32_t num_transforms = context.num_bones;
const uint32_t num_samples = context.num_samples;
+ const uint32_t raw_num_samples = raw_clip_context.num_samples;
uint32_t num_default_bone_scales = 0;
- // When a stream is constant, we only keep the first sample
- for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+ bool has_constant_bone_rotations = false;
+ bool has_constant_bone_translations = false;
+ bool has_constant_bone_scales = false;
+#endif
+
+ const rigid_shell_metadata_t* shell_metadata = raw_clip_context.clip_shell_metadata;
+
+ // Iterate in any order, doesn't matter
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
{
- const track_desc_transformf& desc = track_list[bone_index].get_description();
+ const track_desc_transformf& desc = track_list[transform_index].get_description();
+
+ transform_streams& bone_stream = segment.bone_streams[transform_index];
+ transform_streams& raw_bone_stream = raw_segment.bone_streams[transform_index];
+
+ transform_range& bone_range = context.ranges[transform_index];
- transform_streams& bone_stream = segment.bone_streams[bone_index];
- transform_range& bone_range = context.ranges[bone_index];
+ ACL_ASSERT(bone_stream.rotations.get_num_samples() == num_samples, "Rotation sample mismatch!");
+ ACL_ASSERT(bone_stream.translations.get_num_samples() == num_samples, "Translation sample mismatch!");
+ ACL_ASSERT(bone_stream.scales.get_num_samples() == num_samples, "Scale sample mismatch!");
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", bone_stream.rotations.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", bone_stream.translations.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", bone_stream.scales.get_sample_size(), sizeof(rtm::vector4f));
- // If we request raw data, use a 0.0 threshold for safety
- const float constant_rotation_threshold_angle = settings.rotation_format != rotation_format8::quatf_full ? desc.constant_rotation_threshold_angle : 0.0F;
- const float constant_translation_threshold = settings.translation_format != vector_format8::vector3f_full ? desc.constant_translation_threshold : 0.0F;
- const float constant_scale_threshold = settings.scale_format != vector_format8::vector3f_full ? desc.constant_scale_threshold : 0.0F;
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- if (is_rotation_track_constant(bone_stream.rotations, constant_rotation_threshold_angle, rtm::vector_to_quat(bone_range.rotation.get_weighted_average())))
-#else
- if (is_rotation_track_constant(bone_stream.rotations, constant_rotation_threshold_angle))
-#endif
+ if (are_rotations_constant(settings, context, shell_metadata, transform_index))
{
rotation_track_stream constant_stream(allocator, 1, bone_stream.rotations.get_sample_size(), bone_stream.rotations.get_sample_rate(), bone_stream.rotations.get_rotation_format());
const rtm::vector4f default_bind_rotation = rtm::quat_to_vector(desc.default_value.rotation);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f rotation = num_samples != 0 ? bone_range.rotation.get_weighted_average() : default_bind_rotation;
-#else
rtm::vector4f rotation = num_samples != 0 ? bone_stream.rotations.get_raw_sample<rtm::vector4f>(0) : default_bind_rotation;
-#endif
bone_stream.is_rotation_constant = true;
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_rotation_threshold_angle == 0.0F)
- bone_stream.is_rotation_default = rtm::vector_all_equal(rotation, default_bind_rotation);
- else
- bone_stream.is_rotation_default = rtm::quat_near_identity(rtm::quat_normalize(rtm::quat_mul(rtm::vector_to_quat(rotation), rtm::quat_conjugate(rtm::vector_to_quat(default_bind_rotation)))), constant_rotation_threshold_angle);
-
- if (bone_stream.is_rotation_default)
+ if (are_rotations_default(settings, context, shell_metadata, desc, transform_index))
+ {
+ bone_stream.is_rotation_default = true;
rotation = default_bind_rotation;
+ }
constant_stream.set_raw_sample(0, rotation);
bone_stream.rotations = std::move(constant_stream);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- bone_range.rotation = track_stream_range::from_min_extent(rotation, rtm::vector_zero(), rotation);
-#else
bone_range.rotation = track_stream_range::from_min_extent(rotation, rtm::vector_zero());
+
+ // We also update the raw data to match in case the values differ
+ for (uint32_t sample_index = 0; sample_index < raw_num_samples; ++sample_index)
+ raw_bone_stream.rotations.set_raw_sample(sample_index, rotation);
+
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+ has_constant_bone_rotations = true;
#endif
}
- if (bone_range.translation.is_constant(constant_translation_threshold))
+ if (are_translations_constant(settings, context, shell_metadata, transform_index))
{
translation_track_stream constant_stream(allocator, 1, bone_stream.translations.get_sample_size(), bone_stream.translations.get_sample_rate(), bone_stream.translations.get_vector_format());
const rtm::vector4f default_bind_translation = desc.default_value.translation;
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f translation = num_samples != 0 ? bone_range.translation.get_weighted_average() : default_bind_translation;
-#else
rtm::vector4f translation = num_samples != 0 ? bone_stream.translations.get_raw_sample<rtm::vector4f>(0) : default_bind_translation;
-#endif
bone_stream.is_translation_constant = true;
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_translation_threshold == 0.0F)
- bone_stream.is_translation_default = rtm::vector_all_equal3(translation, default_bind_translation);
- else
- bone_stream.is_translation_default = rtm::vector_all_near_equal3(translation, default_bind_translation, constant_translation_threshold);
-
- if (bone_stream.is_translation_default)
+ if (are_translations_default(settings, context, shell_metadata, desc, transform_index))
+ {
+ bone_stream.is_translation_default = true;
translation = default_bind_translation;
+ }
constant_stream.set_raw_sample(0, translation);
bone_stream.translations = std::move(constant_stream);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- bone_range.translation = track_stream_range::from_min_extent(translation, rtm::vector_zero(), translation);
-#else
bone_range.translation = track_stream_range::from_min_extent(translation, rtm::vector_zero());
+
+ // We also update the raw data to match in case the values differ
+ for (uint32_t sample_index = 0; sample_index < raw_num_samples; ++sample_index)
+ raw_bone_stream.translations.set_raw_sample(sample_index, translation);
+
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+ has_constant_bone_translations = true;
#endif
}
- if (bone_range.scale.is_constant(constant_scale_threshold))
+ if (are_scales_constant(settings, context, shell_metadata, transform_index))
{
scale_track_stream constant_stream(allocator, 1, bone_stream.scales.get_sample_size(), bone_stream.scales.get_sample_rate(), bone_stream.scales.get_vector_format());
const rtm::vector4f default_bind_scale = desc.default_value.scale;
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f scale = (context.has_scale && (num_samples != 0)) ? bone_range.scale.get_weighted_average() : default_bind_scale;
-#else
rtm::vector4f scale = (context.has_scale && num_samples != 0) ? bone_stream.scales.get_raw_sample<rtm::vector4f>(0) : default_bind_scale;
-#endif
bone_stream.is_scale_constant = true;
- // If our error threshold is zero we want to test if we are binary exact
- // This is used by raw clips, we must preserve the original values
- if (constant_scale_threshold == 0.0F)
- bone_stream.is_scale_default = rtm::vector_all_equal3(scale, default_bind_scale);
- else
- bone_stream.is_scale_default = rtm::vector_all_near_equal3(scale, default_bind_scale, constant_scale_threshold);
-
- if (bone_stream.is_scale_default)
+ if (are_scales_default(settings, context, shell_metadata, desc, transform_index))
+ {
+ bone_stream.is_scale_default = true;
scale = default_bind_scale;
+ }
constant_stream.set_raw_sample(0, scale);
bone_stream.scales = std::move(constant_stream);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- bone_range.scale = track_stream_range::from_min_extent(scale, rtm::vector_zero(), scale);
-#else
bone_range.scale = track_stream_range::from_min_extent(scale, rtm::vector_zero());
-#endif
num_default_bone_scales += bone_stream.is_scale_default ? 1 : 0;
+
+ // We also update the raw data to match in case the values differ
+ for (uint32_t sample_index = 0; sample_index < raw_num_samples; ++sample_index)
+ raw_bone_stream.scales.set_raw_sample(sample_index, scale);
+
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+ has_constant_bone_scales = true;
+#endif
}
}
- context.has_scale = num_default_bone_scales != num_bones;
+ const bool has_scale = num_default_bone_scales != num_transforms;
+ context.has_scale = has_scale;
+
+#ifdef ACL_IMPL_ENABLE_CONSTANT_ERROR_CORRECTION
+
+ // Only perform error compensation if our format isn't raw
+ const bool is_raw = settings.rotation_format == rotation_format8::quatf_full || settings.translation_format == vector_format8::vector3f_full || settings.scale_format == vector_format8::vector3f_full;
+
+ // Only perform error compensation if we are lossy due to constant sub-tracks
+ // In practice, even if we have no constant sub-tracks, we could be lossy if our rotations drop W
+ const bool is_lossy = has_constant_bone_rotations || has_constant_bone_translations || (has_scale && has_constant_bone_scales);
+
+ if (!context.has_additive_base && !is_raw && is_lossy)
+ {
+ // Apply error correction after constant and default tracks are processed.
+ // We use object space of the original data as ground truth, and only deviate for 2 reasons, and as briefly as possible.
+ // -Replace an original local value with a new constant value.
+ // -Correct for the manipulation of an original local value by an ancestor ASAP.
+ // We aren't modifying raw data here. We're modifying the raw channels generated from the raw data.
+ // The raw data is left alone, and is still used at the end of the process to do regression testing.
+
+ struct dirty_state_t
+ {
+ bool rotation = false;
+ bool translation = false;
+ bool scale = false;
+ };
+
+ dirty_state_t any_constant_changed;
+ dirty_state_t* dirty_states = allocate_type_array<dirty_state_t>(allocator, num_transforms);
+ rtm::qvvf* original_object_pose = allocate_type_array<rtm::qvvf>(allocator, num_transforms);
+ rtm::qvvf* adjusted_object_pose = allocate_type_array<rtm::qvvf>(allocator, num_transforms);
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ // Iterate over parent transforms first
+ for (uint32_t bone_index : make_iterator(context.sorted_transforms_parent_first, num_transforms))
+ {
+ rtm::qvvf& original_object_transform = original_object_pose[bone_index];
+
+ const transform_range& bone_range = context.ranges[bone_index];
+ transform_streams& bone_stream = segment.bone_streams[bone_index];
+ transform_streams& raw_bone_stream = raw_segment.bone_streams[bone_index];
+
+ const track_desc_transformf& desc = track_list[bone_index].get_description();
+ const uint32_t parent_bone_index = desc.parent_index;
+ const rtm::qvvf original_local_transform = rtm::qvv_set(
+ raw_bone_stream.rotations.get_raw_sample<rtm::quatf>(sample_index),
+ raw_bone_stream.translations.get_raw_sample<rtm::vector4f>(sample_index),
+ raw_bone_stream.scales.get_raw_sample<rtm::vector4f>(sample_index));
+
+ if (parent_bone_index == k_invalid_track_index)
+ original_object_transform = original_local_transform; // Just copy the root as-is, it has no parent and thus local and object space transforms are equal
+ else if (!has_scale)
+ original_object_transform = rtm::qvv_normalize(rtm::qvv_mul_no_scale(original_local_transform, original_object_pose[parent_bone_index]));
+ else
+ original_object_transform = rtm::qvv_normalize(rtm::qvv_mul(original_local_transform, original_object_pose[parent_bone_index]));
+
+ rtm::qvvf adjusted_local_transform = original_local_transform;
+
+ dirty_state_t& constant_changed = dirty_states[bone_index];
+ constant_changed.rotation = false;
+ constant_changed.translation = false;
+ constant_changed.scale = false;
+
+ if (bone_stream.is_rotation_constant)
+ {
+ const rtm::quatf constant_rotation = rtm::vector_to_quat(bone_range.rotation.get_min());
+ if (!rtm::vector_all_near_equal(rtm::quat_to_vector(adjusted_local_transform.rotation), rtm::quat_to_vector(constant_rotation), 0.0F))
+ {
+ any_constant_changed.rotation = true;
+ constant_changed.rotation = true;
+ adjusted_local_transform.rotation = constant_rotation;
+ raw_bone_stream.rotations.set_raw_sample(sample_index, constant_rotation);
+ }
+ ACL_ASSERT(bone_stream.rotations.get_num_samples() == 1, "Constant rotation stream mismatch!");
+ ACL_ASSERT(rtm::vector_all_near_equal(bone_stream.rotations.get_raw_sample<rtm::vector4f>(0), rtm::quat_to_vector(constant_rotation), 0.0F), "Constant rotation mismatch!");
+ }
+
+ if (bone_stream.is_translation_constant)
+ {
+ const rtm::vector4f constant_translation = bone_range.translation.get_min();
+ if (!rtm::vector_all_near_equal3(adjusted_local_transform.translation, constant_translation, 0.0F))
+ {
+ any_constant_changed.translation = true;
+ constant_changed.translation = true;
+ adjusted_local_transform.translation = constant_translation;
+ raw_bone_stream.translations.set_raw_sample(sample_index, constant_translation);
+ }
+ ACL_ASSERT(bone_stream.translations.get_num_samples() == 1, "Constant translation stream mismatch!");
+ ACL_ASSERT(rtm::vector_all_near_equal3(bone_stream.translations.get_raw_sample<rtm::vector4f>(0), constant_translation, 0.0F), "Constant translation mismatch!");
+ }
+
+ if (has_scale && bone_stream.is_scale_constant)
+ {
+ const rtm::vector4f constant_scale = bone_range.scale.get_min();
+ if (!rtm::vector_all_near_equal3(adjusted_local_transform.scale, constant_scale, 0.0F))
+ {
+ any_constant_changed.scale = true;
+ constant_changed.scale = true;
+ adjusted_local_transform.scale = constant_scale;
+ raw_bone_stream.scales.set_raw_sample(sample_index, constant_scale);
+ }
+ ACL_ASSERT(bone_stream.scales.get_num_samples() == 1, "Constant scale stream mismatch!");
+ ACL_ASSERT(rtm::vector_all_near_equal3(bone_stream.scales.get_raw_sample<rtm::vector4f>(0), constant_scale, 0.0F), "Constant scale mismatch!");
+ }
+
+ rtm::qvvf& adjusted_object_transform = adjusted_object_pose[bone_index];
+ if (parent_bone_index == k_invalid_track_index)
+ {
+ adjusted_object_transform = adjusted_local_transform; // Just copy the root as-is, it has no parent and thus local and object space transforms are equal
+ }
+ else
+ {
+ const dirty_state_t& parent_constant_changed = dirty_states[parent_bone_index];
+ const rtm::qvvf& parent_adjusted_object_transform = adjusted_object_pose[parent_bone_index];
+
+ if (bone_stream.is_rotation_constant && !constant_changed.rotation)
+ constant_changed.rotation = parent_constant_changed.rotation;
+ if (bone_stream.is_translation_constant && !constant_changed.translation)
+ constant_changed.translation = parent_constant_changed.translation;
+ if (has_scale && bone_stream.is_scale_constant && !constant_changed.scale)
+ constant_changed.scale = parent_constant_changed.scale;
+
+ // Compensate for the constant changes in your ancestors.
+ if (!bone_stream.is_rotation_constant && parent_constant_changed.rotation)
+ {
+ ACL_ASSERT(any_constant_changed.rotation, "No rotations have changed!");
+ adjusted_local_transform.rotation = rtm::quat_normalize(rtm::quat_mul(original_object_transform.rotation, rtm::quat_conjugate(parent_adjusted_object_transform.rotation)));
+ raw_bone_stream.rotations.set_raw_sample(sample_index, adjusted_local_transform.rotation);
+ bone_stream.rotations.set_raw_sample(sample_index, adjusted_local_transform.rotation);
+ }
+
+ if (has_scale)
+ {
+ if (!bone_stream.is_translation_constant && (parent_constant_changed.rotation || parent_constant_changed.translation || parent_constant_changed.scale))
+ {
+ ACL_ASSERT(any_constant_changed.rotation || any_constant_changed.translation || any_constant_changed.scale, "No channels have changed!");
+ const rtm::quatf inv_rotation = rtm::quat_conjugate(parent_adjusted_object_transform.rotation);
+ const rtm::vector4f inv_scale = rtm::vector_reciprocal(parent_adjusted_object_transform.scale);
+ adjusted_local_transform.translation = rtm::vector_mul(rtm::quat_mul_vector3(rtm::vector_sub(original_object_transform.translation, parent_adjusted_object_transform.translation), inv_rotation), inv_scale);
+ raw_bone_stream.translations.set_raw_sample(sample_index, adjusted_local_transform.translation);
+ bone_stream.translations.set_raw_sample(sample_index, adjusted_local_transform.translation);
+ }
+
+ if (!bone_stream.is_scale_constant && parent_constant_changed.scale)
+ {
+ ACL_ASSERT(any_constant_changed.scale, "No scales have changed!");
+ adjusted_local_transform.scale = rtm::vector_mul(original_object_transform.scale, rtm::vector_reciprocal(parent_adjusted_object_transform.scale));
+ raw_bone_stream.scales.set_raw_sample(sample_index, adjusted_local_transform.scale);
+ bone_stream.scales.set_raw_sample(sample_index, adjusted_local_transform.scale);
+ }
+
+ adjusted_object_transform = rtm::qvv_normalize(rtm::qvv_mul(adjusted_local_transform, parent_adjusted_object_transform));
+ }
+ else
+ {
+ if (!bone_stream.is_translation_constant && (parent_constant_changed.rotation || parent_constant_changed.translation))
+ {
+ ACL_ASSERT(any_constant_changed.rotation || any_constant_changed.translation, "No channels have changed!");
+ const rtm::quatf inv_rotation = rtm::quat_conjugate(parent_adjusted_object_transform.rotation);
+ adjusted_local_transform.translation = rtm::quat_mul_vector3(rtm::vector_sub(original_object_transform.translation, parent_adjusted_object_transform.translation), inv_rotation);
+ raw_bone_stream.translations.set_raw_sample(sample_index, adjusted_local_transform.translation);
+ bone_stream.translations.set_raw_sample(sample_index, adjusted_local_transform.translation);
+ }
+
+ adjusted_object_transform = rtm::qvv_normalize(rtm::qvv_mul_no_scale(adjusted_local_transform, parent_adjusted_object_transform));
+ }
+ }
+ }
+ }
+ deallocate_type_array(allocator, adjusted_object_pose, num_transforms);
+ deallocate_type_array(allocator, original_object_pose, num_transforms);
+ deallocate_type_array(allocator, dirty_states, num_transforms);
+
+ // We need to do these again, to account for error correction.
+ if(any_constant_changed.rotation)
+ {
+ convert_rotation_streams(allocator, context, settings.rotation_format);
+ }
+
+ if (any_constant_changed.rotation || any_constant_changed.translation || any_constant_changed.scale)
+ {
+ deallocate_type_array(allocator, context.ranges, num_transforms);
+ extract_clip_bone_ranges(allocator, context);
+ }
+ }
+#endif
}
}
diff --git a/includes/acl/compression/impl/compress.transform.impl.h b/includes/acl/compression/impl/compress.transform.impl.h
--- a/includes/acl/compression/impl/compress.transform.impl.h
+++ b/includes/acl/compression/impl/compress.transform.impl.h
@@ -171,8 +171,17 @@ namespace acl
if (is_additive && !initialize_clip_context(allocator, *additive_base_track_list, settings, additive_format, additive_base_clip_context))
return error_result("Some base samples are not finite");
+ // Topology dependent data, not specific to clip context
+ const uint32_t num_input_transforms = raw_clip_context.num_bones;
+ rigid_shell_metadata_t* clip_shell_metadata = compute_clip_shell_distances(allocator, raw_clip_context, additive_base_clip_context);
+
+ raw_clip_context.clip_shell_metadata = clip_shell_metadata;
+ lossy_clip_context.clip_shell_metadata = clip_shell_metadata;
+ if (is_additive)
+ additive_base_clip_context.clip_shell_metadata = clip_shell_metadata;
+
// Wrap instead of clamp if we loop
- optimize_looping(lossy_clip_context, track_list, settings);
+ optimize_looping(lossy_clip_context, settings);
// Convert our rotations if we need to
convert_rotation_streams(allocator, lossy_clip_context, settings.rotation_format);
@@ -181,7 +190,7 @@ namespace acl
extract_clip_bone_ranges(allocator, lossy_clip_context);
// Compact and collapse the constant streams
- compact_constant_streams(allocator, lossy_clip_context, track_list, settings);
+ compact_constant_streams(allocator, lossy_clip_context, raw_clip_context, track_list, settings);
uint32_t clip_range_data_size = 0;
if (range_reduction != range_reduction_flags8::none)
@@ -519,6 +528,7 @@ namespace acl
#endif
deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
+ deallocate_type_array(allocator, clip_shell_metadata, num_input_transforms);
destroy_clip_context(lossy_clip_context);
destroy_clip_context(raw_clip_context);
destroy_clip_context(additive_base_clip_context);
diff --git a/includes/acl/compression/impl/normalize_streams.h b/includes/acl/compression/impl/normalize_streams.h
--- a/includes/acl/compression/impl/normalize_streams.h
+++ b/includes/acl/compression/impl/normalize_streams.h
@@ -50,19 +50,10 @@ namespace acl
{
const uint32_t num_samples = stream.get_num_samples();
if (num_samples == 0)
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- return track_stream_range::from_min_max(rtm::vector_zero(), rtm::vector_zero(), rtm::vector_zero());
-#else
return track_stream_range::from_min_max(rtm::vector_zero(), rtm::vector_zero());
-#endif
rtm::vector4f min = rtm::vector_set(1e10F);
rtm::vector4f max = rtm::vector_set(-1e10F);
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4d weighted_average_d = rtm::vector_set(0.0);
- const rtm::vector4d weight_d = rtm::vector_set(1.0 / num_samples);
-#endif
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
@@ -70,65 +61,19 @@ namespace acl
min = rtm::vector_min(min, sample);
max = rtm::vector_max(max, sample);
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const rtm::vector4d sample_d = rtm::vector_cast(sample);
- if (is_vector4 && (rtm::vector_dot(weighted_average_d, sample_d) < 0.0))
- {
- weighted_average_d = rtm::vector_neg_mul_sub(sample_d, weight_d, weighted_average_d);
- }
- else
- {
- weighted_average_d = rtm::vector_mul_add(sample_d, weight_d, weighted_average_d);
- }
- }
-
- rtm::vector4f weighted_average = rtm::vector_cast(weighted_average_d);
-#else
}
-#endif
// Set the 4th component to zero if we don't need it
if (!is_vector4)
{
min = rtm::vector_set_w(min, 0.0F);
max = rtm::vector_set_w(max, 0.0F);
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- weighted_average = rtm::vector_clamp(weighted_average, min, max);
- }
- else
- {
- // We have a quaternion
- if (num_samples > 0)
- {
- weighted_average = rtm::vector_clamp(weighted_average, min, max);
-
- // Due to rounding and clamping, our weighted average might not represent a valid quaternion, make sure we do
- weighted_average = rtm::quat_to_vector(rtm::quat_normalize(rtm::vector_to_quat(weighted_average)));
- }
- else
- {
- // No samples present, just the identity
- weighted_average = rtm::quat_to_vector((rtm::quatf)rtm::quat_identity());
- }
-#endif
}
- // TODO: Make sure weighted average has W positive if that's our format
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- return track_stream_range::from_min_max(min, max, weighted_average);
-#else
return track_stream_range::from_min_max(min, max);
-#endif
}
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- inline void extract_bone_ranges_impl(const segment_context& segment, transform_range* bone_ranges, bool are_rotations_normalized)
-#else
inline void extract_bone_ranges_impl(const segment_context& segment, transform_range* bone_ranges)
-#endif
{
const bool has_scale = segment_context_has_scale(segment);
@@ -137,12 +82,7 @@ namespace acl
const transform_streams& bone_stream = segment.bone_streams[bone_index];
transform_range& bone_range = bone_ranges[bone_index];
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- bone_range.rotation = calculate_track_range(bone_stream.rotations, !are_rotations_normalized);
-#else
bone_range.rotation = calculate_track_range(bone_stream.rotations, true);
-#endif
-
bone_range.translation = calculate_track_range(bone_stream.translations, false);
if (has_scale)
@@ -159,11 +99,7 @@ namespace acl
ACL_ASSERT(context.num_segments == 1, "context must contain a single segment!");
const segment_context& segment = context.segments[0];
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- acl_impl::extract_bone_ranges_impl(segment, context.ranges, false);
-#else
acl_impl::extract_bone_ranges_impl(segment, context.ranges);
-#endif
}
inline void extract_segment_bone_ranges(iallocator& allocator, clip_context& context)
@@ -213,22 +149,14 @@ namespace acl
const rtm::mask4f is_extent0_higher_mask = rtm::vector_greater_equal(padded_range_extent0, range_max);
const rtm::vector4f padded_range_extent = rtm::vector_select(is_extent0_higher_mask, padded_range_extent0, padded_range_extent1);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- return track_stream_range::from_min_extent(padded_range_min, padded_range_extent, range.get_weighted_average());
-#else
return track_stream_range::from_min_extent(padded_range_min, padded_range_extent);
-#endif
};
for (segment_context& segment : context.segment_iterator())
{
segment.ranges = allocate_type_array<transform_range>(allocator, segment.num_bones);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- acl_impl::extract_bone_ranges_impl(segment, segment.ranges, context.are_rotations_normalized);
-#else
acl_impl::extract_bone_ranges_impl(segment, segment.ranges);
-#endif
for (uint32_t bone_index = 0; bone_index < segment.num_bones; ++bone_index)
{
diff --git a/includes/acl/compression/impl/optimize_looping.h b/includes/acl/compression/impl/optimize_looping.h
--- a/includes/acl/compression/impl/optimize_looping.h
+++ b/includes/acl/compression/impl/optimize_looping.h
@@ -46,7 +46,7 @@ namespace acl
namespace acl_impl
{
- inline void optimize_looping(clip_context& context, const track_array_qvvf& track_list, const compression_settings& settings)
+ inline void optimize_looping(clip_context& context, const compression_settings& settings)
{
if (!settings.optimize_loops)
return; // We don't want to optimize loops, nothing to do
@@ -77,39 +77,42 @@ namespace acl
segment_context& segment = context.segments[0];
const uint32_t last_sample_index = segment.num_samples - 1;
+ qvvf_transform_error_metric::calculate_error_args error_metric_args;
+ const qvvf_transform_error_metric error_metric;
+
const uint32_t num_transforms = segment.num_bones;
for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
{
- const track_desc_transformf& desc = track_list[transform_index].get_description();
+ const rigid_shell_metadata_t& shell = context.clip_shell_metadata[transform_index];
- const rtm::quatf first_rotation = segment.bone_streams[transform_index].rotations.get_raw_sample<rtm::quatf>(0);
- const rtm::quatf inv_first_rotation = rtm::quat_conjugate(first_rotation);
- const rtm::quatf last_rotation = segment.bone_streams[transform_index].rotations.get_raw_sample<rtm::quatf>(last_sample_index);
- const rtm::quatf delta_rotation = rtm::quat_normalize(rtm::quat_mul(inv_first_rotation, last_rotation));
- if (!rtm::quat_near_identity(delta_rotation, desc.constant_rotation_threshold_angle))
- {
- is_wrapping = false;
- break;
- }
+ error_metric_args.construct_sphere_shell(shell.local_shell_distance);
+
+ const rtm::scalarf precision = rtm::scalar_set(shell.precision);
+
+ const transform_streams& lossy_transform_stream = segment.bone_streams[transform_index];
+
+ const rtm::quatf first_rotation = lossy_transform_stream.rotations.get_sample_clamped(0);
+ const rtm::vector4f first_translation = lossy_transform_stream.translations.get_sample_clamped(0);
+ const rtm::vector4f first_scale = lossy_transform_stream.scales.get_sample_clamped(0);
- const rtm::vector4f first_translation = segment.bone_streams[transform_index].translations.get_raw_sample<rtm::vector4f>(0);
- const rtm::vector4f last_translation = segment.bone_streams[transform_index].translations.get_raw_sample<rtm::vector4f>(last_sample_index);
- if (!rtm::vector_all_near_equal3(first_translation, last_translation, desc.constant_translation_threshold))
+ const rtm::quatf last_rotation = lossy_transform_stream.rotations.get_sample_clamped(last_sample_index);
+ const rtm::vector4f last_translation = lossy_transform_stream.translations.get_sample_clamped(last_sample_index);
+ const rtm::vector4f last_scale = lossy_transform_stream.scales.get_sample_clamped(last_sample_index);
+
+ const rtm::qvvf first_transform = rtm::qvv_set(first_rotation, first_translation, first_scale);
+ const rtm::qvvf last_transform = rtm::qvv_set(last_rotation, last_translation, last_scale);
+
+ error_metric_args.transform0 = &first_transform;
+ error_metric_args.transform1 = &last_transform;
+
+ const rtm::scalarf vtx_error = error_metric.calculate_error(error_metric_args);
+
+ // If our error exceeds the desired precision, we are not wrapping
+ if (rtm::scalar_greater_than(vtx_error, precision))
{
is_wrapping = false;
break;
}
-
- if (context.has_scale)
- {
- const rtm::vector4f first_scale = segment.bone_streams[transform_index].scales.get_raw_sample<rtm::vector4f>(0);
- const rtm::vector4f last_scale = segment.bone_streams[transform_index].scales.get_raw_sample<rtm::vector4f>(last_sample_index);
- if (!rtm::vector_all_near_equal3(first_scale, last_scale, desc.constant_scale_threshold))
- {
- is_wrapping = false;
- break;
- }
- }
}
if (is_wrapping)
diff --git a/includes/acl/compression/impl/quantize_streams.h b/includes/acl/compression/impl/quantize_streams.h
--- a/includes/acl/compression/impl/quantize_streams.h
+++ b/includes/acl/compression/impl/quantize_streams.h
@@ -39,6 +39,7 @@
#include "acl/compression/impl/sample_streams.h"
#include "acl/compression/impl/normalize_streams.h"
#include "acl/compression/impl/convert_rotation_streams.h"
+#include "acl/compression/impl/rigid_shell_utils.h"
#include "acl/compression/transform_error_metrics.h"
#include "acl/compression/compression_settings.h"
@@ -53,8 +54,14 @@
#include <cstdint>
#include <functional>
-// 0 = no debug info, 1 = basic info, 2 = verbose
-#define ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION 0
+#define ACL_IMPL_DEBUG_LEVEL_NONE 0
+#define ACL_IMPL_DEBUG_LEVEL_SUMMARY_ONLY 1
+#define ACL_IMPL_DEBUG_LEVEL_BASIC_INFO 2
+#define ACL_IMPL_DEBUG_LEVEL_VERBOSE_INFO 3
+
+// Dumps details of quantization optimization process
+// Use debug levels above to control debug output
+#define ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION ACL_IMPL_DEBUG_LEVEL_NONE
// 0 = no debug into, 1 = basic info
#define ACL_IMPL_DEBUG_CONTRIBUTING_ERROR 0
@@ -95,7 +102,6 @@ namespace acl
uint32_t segment_sample_start_index;
float sample_rate;
float clip_duration;
- float error_threshold; // Error threshold of the current bone being optimized
bool has_scale;
bool has_additive_base;
bool needs_conversion;
@@ -107,6 +113,8 @@ namespace acl
const transform_streams* raw_bone_streams;
+ rigid_shell_metadata_t* shell_metadata_per_transform; // 1 per transform
+
rtm::qvvf* additive_local_pose; // 1 per transform
rtm::qvvf* raw_local_pose; // 1 per transform
rtm::qvvf* lossy_local_pose; // 1 per transform
@@ -149,7 +157,6 @@ namespace acl
, segment_sample_start_index(~0U)
, sample_rate(clip_.sample_rate)
, clip_duration(clip_.duration)
- , error_threshold(0.0F)
, has_scale(clip_.has_scale)
, has_additive_base(clip_.has_additive_base)
, rotation_format(settings_.rotation_format)
@@ -168,6 +175,7 @@ namespace acl
const size_t metric_transform_size_ = settings_.error_metric->get_transform_size(clip_.has_scale);
metric_transform_size = metric_transform_size_;
+ shell_metadata_per_transform = allocate_type_array<rigid_shell_metadata_t>(allocator, num_bones);
additive_local_pose = clip_.has_additive_base ? allocate_type_array<rtm::qvvf>(allocator, num_bones) : nullptr;
raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
@@ -192,6 +200,7 @@ namespace acl
~quantization_context()
{
+ deallocate_type_array(allocator, shell_metadata_per_transform, num_bones);
deallocate_type_array(allocator, additive_local_pose, num_bones);
deallocate_type_array(allocator, raw_local_pose, num_bones);
deallocate_type_array(allocator, lossy_local_pose, num_bones);
@@ -217,6 +226,9 @@ namespace acl
segment_sample_start_index = segment_.clip_sample_offset;
bit_rate_database.set_segment(segment_.bone_streams, segment_.num_bones, segment_.num_samples);
+ // Update our shell distances
+ compute_segment_shell_distances(segment_, additive_base_clip, shell_metadata_per_transform);
+
// Cache every raw local/object transforms and the base local transforms since they never change
const itransform_error_metric* error_metric_ = error_metric;
const size_t sample_transform_size = metric_transform_size * num_bones;
@@ -342,26 +354,26 @@ namespace acl
quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, rotation_format, bone_stream.rotations);
}
- inline void quantize_variable_rotation_stream(quantization_context& context, const rotation_track_stream& raw_clip_stream, const rotation_track_stream& raw_segment_stream, const track_stream_range& clip_range, uint8_t bit_rate, rotation_track_stream& out_quantized_stream)
+ inline void quantize_variable_rotation_stream(quantization_context& context, const transform_streams& raw_track, const transform_streams& lossy_track, uint8_t bit_rate, rotation_track_stream& out_quantized_stream)
{
+ const rotation_track_stream& raw_rotations = raw_track.rotations;
+ const rotation_track_stream& lossy_rotations = lossy_track.rotations;
+
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
+ ACL_ASSERT(lossy_rotations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %zu", lossy_rotations.get_sample_size(), sizeof(rtm::vector4f));
- const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
+ const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : lossy_rotations.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
- const float sample_rate = raw_segment_stream.get_sample_rate();
+ const float sample_rate = lossy_rotations.get_sample_rate();
rotation_track_stream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, rotation_format8::quatf_drop_w_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
-
#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
+ const track_stream_range& bone_range = context.segment->ranges[lossy_track.bone_index].rotation;
const rtm::vector4f normalized_rotation = clip_range.get_weighted_average();
#else
- rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
- rotation = convert_rotation(rotation, rotation_format8::quatf_full, rotation_format8::quatf_drop_w_variable);
-
- const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_range);
+ const rtm::vector4f normalized_rotation = lossy_track.constant_rotation;
#endif
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
@@ -377,13 +389,13 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
+ rtm::vector4f rotation = raw_rotations.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
rotation = convert_rotation(rotation, rotation_format8::quatf_full, rotation_format8::quatf_drop_w_variable);
pack_vector3_96(rotation, quantized_ptr);
}
else
{
- const rtm::quatf rotation = raw_segment_stream.get_raw_sample<rtm::quatf>(sample_index);
+ const rtm::quatf rotation = lossy_rotations.get_raw_sample<rtm::quatf>(sample_index);
pack_vector3_uXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
}
}
@@ -396,26 +408,20 @@ namespace acl
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
- transform_streams& bone_stream = context.bone_streams[bone_index];
+ transform_streams& lossy_track = context.bone_streams[bone_index];
// Default tracks aren't quantized
- if (bone_stream.is_rotation_default)
+ if (lossy_track.is_rotation_default)
return;
- const transform_streams& raw_bone_stream = context.raw_bone_streams[bone_index];
+ const transform_streams& raw_track = context.raw_bone_streams[bone_index];
const rotation_format8 highest_bit_rate = get_highest_variant_precision(rotation_variant8::quat_drop_w);
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const track_stream_range& bone_range = context.segment->ranges[bone_index].rotation;
-#else
- const track_stream_range& bone_range = context.clip.ranges[bone_index].rotation;
-#endif
-
// If our format is variable, we keep them fixed at the highest bit rate in the variant
- if (bone_stream.is_rotation_constant)
- quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, highest_bit_rate, bone_stream.rotations);
+ if (lossy_track.is_rotation_constant)
+ quantize_fixed_rotation_stream(context.allocator, lossy_track.rotations, highest_bit_rate, lossy_track.rotations);
else
- quantize_variable_rotation_stream(context, raw_bone_stream.rotations, bone_stream.rotations, bone_range, bit_rate, bone_stream.rotations);
+ quantize_variable_rotation_stream(context, raw_track, lossy_track, bit_rate, lossy_track.rotations);
}
inline void quantize_fixed_translation_stream(iallocator& allocator, const translation_track_stream& raw_stream, vector_format8 translation_format, translation_track_stream& out_quantized_stream)
@@ -465,25 +471,27 @@ namespace acl
quantize_fixed_translation_stream(context.allocator, bone_stream.translations, format, bone_stream.translations);
}
- inline void quantize_variable_translation_stream(quantization_context& context, const translation_track_stream& raw_clip_stream, const translation_track_stream& raw_segment_stream, const track_stream_range& clip_range, uint8_t bit_rate, translation_track_stream& out_quantized_stream)
+ inline void quantize_variable_translation_stream(quantization_context& context, const transform_streams& raw_track, const transform_streams& lossy_track, uint8_t bit_rate, translation_track_stream& out_quantized_stream)
{
+ const translation_track_stream& raw_translations = raw_track.translations;
+ const translation_track_stream& lossy_translations = lossy_track.translations;
+
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_segment_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
+ ACL_ASSERT(lossy_translations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %zu", lossy_translations.get_sample_size(), sizeof(rtm::vector4f));
+ ACL_ASSERT(lossy_translations.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(lossy_translations.get_vector_format()));
- const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
+ const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : lossy_translations.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
- const float sample_rate = raw_segment_stream.get_sample_rate();
+ const float sample_rate = lossy_translations.get_sample_rate();
translation_track_stream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, vector_format8::vector3f_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
-
#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
+ const track_stream_range& bone_range = context.segment->ranges[lossy_track.bone_index].translation;
const rtm::vector4f normalized_translation = clip_range.get_weighted_average();
#else
- const rtm::vector4f translation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
- const rtm::vector4f normalized_translation = normalize_sample(translation, clip_range);
+ const rtm::vector4f normalized_translation = lossy_track.constant_translation;
#endif
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
@@ -499,12 +507,12 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- const rtm::vector4f translation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
+ const rtm::vector4f translation = raw_translations.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
pack_vector3_96(translation, quantized_ptr);
}
else
{
- const rtm::vector4f translation = raw_segment_stream.get_raw_sample<rtm::vector4f>(sample_index);
+ const rtm::vector4f translation = lossy_translations.get_raw_sample<rtm::vector4f>(sample_index);
pack_vector3_uXX_unsafe(translation, num_bits_at_bit_rate, quantized_ptr);
}
}
@@ -517,25 +525,19 @@ namespace acl
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
- transform_streams& bone_stream = context.bone_streams[bone_index];
+ transform_streams& lossy_track = context.bone_streams[bone_index];
// Default tracks aren't quantized
- if (bone_stream.is_translation_default)
+ if (lossy_track.is_translation_default)
return;
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const track_stream_range& bone_range = context.segment->ranges[bone_index].translation;
-#else
- const track_stream_range& bone_range = context.clip.ranges[bone_index].translation;
-#endif
-
- const transform_streams& raw_bone_stream = context.raw_bone_streams[bone_index];
+ const transform_streams& raw_track = context.raw_bone_streams[bone_index];
// Constant translation tracks store the remaining sample with full precision
- if (bone_stream.is_translation_constant)
- quantize_fixed_translation_stream(context.allocator, bone_stream.translations, vector_format8::vector3f_full, bone_stream.translations);
+ if (lossy_track.is_translation_constant)
+ quantize_fixed_translation_stream(context.allocator, lossy_track.translations, vector_format8::vector3f_full, lossy_track.translations);
else
- quantize_variable_translation_stream(context, raw_bone_stream.translations, bone_stream.translations, bone_range, bit_rate, bone_stream.translations);
+ quantize_variable_translation_stream(context, raw_track, lossy_track, bit_rate, lossy_track.translations);
}
inline void quantize_fixed_scale_stream(iallocator& allocator, const scale_track_stream& raw_stream, vector_format8 scale_format, scale_track_stream& out_quantized_stream)
@@ -585,24 +587,27 @@ namespace acl
quantize_fixed_scale_stream(context.allocator, bone_stream.scales, format, bone_stream.scales);
}
- inline void quantize_variable_scale_stream(quantization_context& context, const scale_track_stream& raw_clip_stream, const scale_track_stream& raw_segment_stream, const track_stream_range& clip_range, uint8_t bit_rate, scale_track_stream& out_quantized_stream)
+ inline void quantize_variable_scale_stream(quantization_context& context, const transform_streams& raw_track, const transform_streams& lossy_track, uint8_t bit_rate, scale_track_stream& out_quantized_stream)
{
+ const scale_track_stream& raw_scales = raw_track.scales;
+ const scale_track_stream& lossy_scales = lossy_track.scales;
+
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_segment_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
+ ACL_ASSERT(lossy_scales.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %zu", lossy_scales.get_sample_size(), sizeof(rtm::vector4f));
+ ACL_ASSERT(lossy_scales.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(lossy_scales.get_vector_format()));
- const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
+ const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : lossy_scales.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
- const float sample_rate = raw_segment_stream.get_sample_rate();
+ const float sample_rate = lossy_scales.get_sample_rate();
scale_track_stream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, vector_format8::vector3f_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
+ const track_stream_range& bone_range = context.segment->ranges[lossy_track.bone_index].scale;
const rtm::vector4f normalized_scale = clip_range.get_weighted_average();
#else
- const rtm::vector4f scale = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
- const rtm::vector4f normalized_scale = normalize_sample(scale, clip_range);
+ const rtm::vector4f normalized_scale = lossy_track.constant_scale;
#endif
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
@@ -618,12 +623,12 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- const rtm::vector4f scale = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
+ const rtm::vector4f scale = raw_scales.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
pack_vector3_96(scale, quantized_ptr);
}
else
{
- const rtm::vector4f scale = raw_segment_stream.get_raw_sample<rtm::vector4f>(sample_index);
+ const rtm::vector4f scale = lossy_scales.get_raw_sample<rtm::vector4f>(sample_index);
pack_vector3_uXX_unsafe(scale, num_bits_at_bit_rate, quantized_ptr);
}
}
@@ -636,25 +641,19 @@ namespace acl
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
- transform_streams& bone_stream = context.bone_streams[bone_index];
+ transform_streams& lossy_track = context.bone_streams[bone_index];
// Default tracks aren't quantized
- if (bone_stream.is_scale_default)
+ if (lossy_track.is_scale_default)
return;
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const track_stream_range& bone_range = context.segment->ranges[bone_index].scale;
-#else
- const track_stream_range& bone_range = context.clip.ranges[bone_index].scale;
-#endif
-
- const transform_streams& raw_bone_stream = context.raw_bone_streams[bone_index];
+ const transform_streams& raw_track = context.raw_bone_streams[bone_index];
// Constant scale tracks store the remaining sample with full precision
- if (bone_stream.is_scale_constant)
- quantize_fixed_scale_stream(context.allocator, bone_stream.scales, vector_format8::vector3f_full, bone_stream.scales);
+ if (lossy_track.is_scale_constant)
+ quantize_fixed_scale_stream(context.allocator, lossy_track.scales, vector_format8::vector3f_full, lossy_track.scales);
else
- quantize_variable_scale_stream(context, raw_bone_stream.scales, bone_stream.scales, bone_range, bit_rate, bone_stream.scales);
+ quantize_variable_scale_stream(context, raw_track, lossy_track, bit_rate, lossy_track.scales);
}
enum class error_scan_stop_condition { until_error_too_high, until_end_of_segment };
@@ -664,12 +663,11 @@ namespace acl
const itransform_error_metric* error_metric = context.error_metric;
const bool needs_conversion = context.needs_conversion;
const bool has_additive_base = context.has_additive_base;
- const transform_metadata& target_bone = context.metadata[target_bone_index];
+
const uint32_t num_transforms = context.num_bones;
const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
const float sample_rate = context.sample_rate;
const float clip_duration = context.clip_duration;
- const rtm::scalarf error_threshold = rtm::scalar_set(context.error_threshold);
const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
@@ -691,7 +689,9 @@ namespace acl
itransform_error_metric::calculate_error_args calculate_error_args;
calculate_error_args.transform0 = nullptr;
calculate_error_args.transform1 = needs_conversion ? (const void*)(context.local_transforms_converted + (context.metric_transform_size * target_bone_index)) : (const void*)(context.lossy_local_pose + target_bone_index);
- calculate_error_args.construct_sphere_shell(target_bone.shell_distance);
+
+ const rigid_shell_metadata_t& transform_shell = context.shell_metadata_per_transform[target_bone_index];
+ const rtm::scalarf error_threshold = rtm::scalar_set(transform_shell.precision);
const uint8_t* raw_transform = context.raw_local_transforms + (target_bone_index * context.metric_transform_size);
const uint8_t* base_transforms = context.base_local_transforms;
@@ -720,6 +720,7 @@ namespace acl
apply_additive_to_base_impl(error_metric, apply_additive_to_base_args_lossy, context.lossy_local_pose);
}
+ calculate_error_args.construct_sphere_shell(transform_shell.local_shell_distance);
calculate_error_args.transform0 = raw_transform;
raw_transform += sample_transform_size;
@@ -746,11 +747,10 @@ namespace acl
const itransform_error_metric* error_metric = context.error_metric;
const bool needs_conversion = context.needs_conversion;
const bool has_additive_base = context.has_additive_base;
- const transform_metadata& target_bone = context.metadata[target_bone_index];
+
const size_t sample_transform_size = context.metric_transform_size * context.num_bones;
const float sample_rate = context.sample_rate;
const float clip_duration = context.clip_duration;
- const rtm::scalarf error_threshold = rtm::scalar_set(context.error_threshold);
const auto convert_transforms_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::convert_transforms : &itransform_error_metric::convert_transforms_no_scale);
const auto apply_additive_to_base_impl = std::mem_fn(context.has_scale ? &itransform_error_metric::apply_additive_to_base : &itransform_error_metric::apply_additive_to_base_no_scale);
@@ -780,7 +780,9 @@ namespace acl
itransform_error_metric::calculate_error_args calculate_error_args;
calculate_error_args.transform0 = nullptr;
calculate_error_args.transform1 = context.lossy_object_pose + (target_bone_index * context.metric_transform_size);
- calculate_error_args.construct_sphere_shell(target_bone.shell_distance);
+
+ const rigid_shell_metadata_t& transform_shell = context.shell_metadata_per_transform[target_bone_index];
+ const rtm::scalarf error_threshold = rtm::scalar_set(transform_shell.precision);
const uint8_t* raw_transform = context.raw_object_transforms + (target_bone_index * context.metric_transform_size);
const uint8_t* base_transforms = context.base_local_transforms;
@@ -811,6 +813,7 @@ namespace acl
local_to_object_space_impl(error_metric, local_to_object_space_args_lossy, context.lossy_object_pose);
+ calculate_error_args.construct_sphere_shell(transform_shell.local_shell_distance);
calculate_error_args.transform0 = raw_transform;
raw_transform += sample_transform_size;
@@ -842,8 +845,7 @@ namespace acl
for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
// Update our error threshold
- const float error_threshold = context.metadata[bone_index].precision;
- context.error_threshold = error_threshold;
+ const float error_threshold = context.shell_metadata_per_transform[bone_index].precision;
// Bit rates at this point are one of three value:
// 0: if the segment track is normalized, it can be constant within the segment
@@ -853,7 +855,7 @@ namespace acl
if (bone_bit_rates.rotation == k_invalid_bit_rate && bone_bit_rates.translation == k_invalid_bit_rate && bone_bit_rates.scale == k_invalid_bit_rate)
{
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_BASIC_INFO
printf("%u: Best bit rates: %u | %u | %u\n", bone_index, bone_bit_rates.rotation, bone_bit_rates.translation, bone_bit_rates.scale);
#endif
continue; // Every track bit rate is constant/default, nothing else to do
@@ -924,7 +926,7 @@ namespace acl
const float error = calculate_max_error_at_bit_rate_local(context, bone_index, error_scan_stop_condition::until_error_too_high);
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION > 1
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_VERBOSE_INFO
printf("%u: %u | %u | %u (%u) = %f\n", bone_index, rotation_bit_rate, translation_bit_rate, scale_bit_rate, transform_size, error);
#endif
@@ -982,7 +984,7 @@ namespace acl
const float error = calculate_max_error_at_bit_rate_local(context, bone_index, error_scan_stop_condition::until_error_too_high);
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION > 1
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_VERBOSE_INFO
printf("%u: %u | %u | %u (%u) = %f\n", bone_index, rotation_bit_rate, translation_bit_rate, k_invalid_bit_rate, transform_size, error);
#endif
@@ -995,7 +997,7 @@ namespace acl
}
}
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_BASIC_INFO
printf("%u: Best bit rates: %u | %u | %u\n", bone_index, best_bit_rates.rotation, best_bit_rates.translation, best_bit_rates.scale);
#endif
@@ -1065,7 +1067,7 @@ namespace acl
inline float calculate_bone_permutation_error(quantization_context& context, transform_bit_rates* permutation_bit_rates, uint8_t* bone_chain_permutation, uint32_t bone_index, transform_bit_rates* best_bit_rates, float old_error)
{
- const float error_threshold = context.error_threshold;
+ const float error_threshold = context.shell_metadata_per_transform[bone_index].precision;
float best_error = old_error;
do
@@ -1244,12 +1246,13 @@ namespace acl
transform_bit_rates* best_bit_rates = allocate_type_array<transform_bit_rates>(context.allocator, context.num_bones);
std::memcpy(best_bit_rates, context.bit_rate_per_bone, sizeof(transform_bit_rates) * context.num_bones);
+ // Iterate from the root transforms first
+ // I attempted to iterate from leaves first and the memory footprint was severely worse
const uint32_t num_bones = context.num_bones;
- for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
+ for (const uint32_t bone_index : make_iterator(context.raw_clip.sorted_transforms_parent_first, num_bones))
{
// Update our context with the new bone data
- const float error_threshold = context.metadata[bone_index].precision;
- context.error_threshold = error_threshold;
+ const float error_threshold = context.shell_metadata_per_transform[bone_index].precision;
const uint32_t num_bones_in_chain = calculate_bone_chain_indices(context.clip, bone_index, context.chain_bone_indices);
context.num_bones_in_chain = num_bones_in_chain;
@@ -1368,7 +1371,7 @@ namespace acl
error = best_error;
if (error < original_error)
{
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_BASIC_INFO
std::swap(context.bit_rate_per_bone, best_bit_rates);
float new_error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_end_of_segment);
std::swap(context.bit_rate_per_bone, best_bit_rates);
@@ -1391,7 +1394,7 @@ namespace acl
if (error < initial_error)
{
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_BASIC_INFO
std::swap(context.bit_rate_per_bone, best_bit_rates);
float new_error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_end_of_segment);
std::swap(context.bit_rate_per_bone, best_bit_rates);
@@ -1460,7 +1463,7 @@ namespace acl
best_bone_bit_rate = bone_bit_rate;
best_bit_rate_error = error;
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_BASIC_INFO
printf("%u: => %u %u %u (%f)\n", chain_bone_index, bone_bit_rate.rotation, bone_bit_rate.translation, bone_bit_rate.scale, error);
for (uint32_t i = chain_link_index + 1; i < num_bones_in_chain; ++i)
{
@@ -1513,13 +1516,12 @@ namespace acl
}
}
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_SUMMARY_ONLY
printf("Variable quantization optimization results:\n");
for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
// Update our context with the new bone data
- const float error_threshold = context.metadata[bone_index].precision;
- context.error_threshold = error_threshold;
+ const float error_threshold = context.shell_metadata_per_transform[bone_index].precision;
const uint32_t num_bones_in_chain = calculate_bone_chain_indices(context.clip, bone_index, context.chain_bone_indices);
context.num_bones_in_chain = num_bones_in_chain;
@@ -1713,14 +1715,15 @@ namespace acl
// Calculate our error
const uint8_t* raw_frame_transform = raw_transform + (interp_frame_index * sample_transform_size);
+
for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- const transform_metadata& target_bone = context.metadata[bone_index];
-
itransform_error_metric::calculate_error_args calculate_error_args;
calculate_error_args.transform0 = raw_frame_transform + (bone_index * context.metric_transform_size);
calculate_error_args.transform1 = context.lossy_object_pose + (bone_index * context.metric_transform_size);
- calculate_error_args.construct_sphere_shell(target_bone.shell_distance);
+
+ const rigid_shell_metadata_t& transform_shell = context.shell_metadata_per_transform[bone_index];
+ calculate_error_args.construct_sphere_shell(transform_shell.local_shell_distance);
#if defined(RTM_COMPILER_MSVC) && defined(RTM_ARCH_X86) && RTM_COMPILER_MSVC == RTM_COMPILER_MSVC_2015
// VS2015 fails to generate the right x86 assembly, branch instead
@@ -1777,7 +1780,7 @@ namespace acl
for (segment_context& segment : clip.segment_iterator())
{
-#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION
+#if ACL_IMPL_DEBUG_VARIABLE_QUANTIZATION >= ACL_IMPL_DEBUG_LEVEL_SUMMARY_ONLY
printf("Quantizing segment %u...\n", segment.segment_index);
#endif
diff --git a/includes/acl/compression/impl/rigid_shell_utils.h b/includes/acl/compression/impl/rigid_shell_utils.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/rigid_shell_utils.h
@@ -0,0 +1,283 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2022 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/version.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/compression/impl/clip_context.h"
+#include "acl/compression/impl/sample_streams.h"
+
+#include <rtm/qvvf.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ ACL_IMPL_VERSION_NAMESPACE_BEGIN
+
+ namespace acl_impl
+ {
+ // We use the raw data to compute the rigid shell
+ // For each transform, its rigid shell is formed by the dominant joint (itself or a child)
+ // We compute the largest value over the whole clip per transform
+ inline rigid_shell_metadata_t* compute_clip_shell_distances(iallocator& allocator, const clip_context& raw_clip_context, const clip_context& additive_base_clip_context)
+ {
+ const uint32_t num_transforms = raw_clip_context.num_bones;
+ if (num_transforms == 0)
+ return nullptr; // No transforms present, no shell distances
+
+ const uint32_t num_samples = raw_clip_context.num_samples;
+ if (num_samples == 0)
+ return nullptr; // No samples present, no shell distances
+
+ const segment_context& raw_segment = raw_clip_context.segments[0];
+ const bool has_additive_base = raw_clip_context.has_additive_base;
+
+ rigid_shell_metadata_t* shell_metadata = allocate_type_array<rigid_shell_metadata_t>(allocator, num_transforms);
+
+ // Initialize everything
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
+ {
+ const transform_metadata& metadata = raw_clip_context.metadata[transform_index];
+
+ shell_metadata[transform_index].local_shell_distance = metadata.shell_distance;
+ shell_metadata[transform_index].precision = metadata.precision;
+ shell_metadata[transform_index].parent_shell_distance = 0.0F;
+ }
+
+ // Iterate from leaf transforms towards their root, we want to bubble up our shell distance
+ for (const uint32_t transform_index : make_reverse_iterator(raw_clip_context.sorted_transforms_parent_first, num_transforms))
+ {
+ const transform_streams& raw_bone_stream = raw_segment.bone_streams[transform_index];
+
+ rigid_shell_metadata_t& shell = shell_metadata[transform_index];
+
+ // Use the accumulated shell distance so far to see how far it deforms with our local transform
+ const rtm::vector4f vtx0 = rtm::vector_set(shell.local_shell_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, shell.local_shell_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, shell.local_shell_distance);
+
+ // Calculate the shell distance in parent space
+ rtm::scalarf parent_shell_distance = rtm::scalar_set(0.0F);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const rtm::quatf raw_rotation = raw_bone_stream.rotations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_translation = raw_bone_stream.translations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_scale = raw_bone_stream.scales.get_sample_clamped(sample_index);
+
+ rtm::qvvf raw_transform = rtm::qvv_set(raw_rotation, raw_translation, raw_scale);
+
+ if (has_additive_base)
+ {
+ // If we are additive, we must apply our local transform on the base to figure out
+ // the true shell distance
+ const segment_context& base_segment = additive_base_clip_context.segments[0];
+ const transform_streams& base_bone_stream = base_segment.bone_streams[transform_index];
+
+ // The sample time is calculated from the full clip duration to be consistent with decompression
+ const float sample_time = rtm::scalar_min(float(sample_index) / raw_clip_context.sample_rate, raw_clip_context.duration);
+
+ const float normalized_sample_time = base_segment.num_samples > 1 ? (sample_time / raw_clip_context.duration) : 0.0F;
+ const float additive_sample_time = base_segment.num_samples > 1 ? (normalized_sample_time * additive_base_clip_context.duration) : 0.0F;
+
+ // With uniform sample distributions, we do not interpolate.
+ const uint32_t base_sample_index = get_uniform_sample_key(base_segment, additive_sample_time);
+
+ const rtm::quatf base_rotation = base_bone_stream.rotations.get_sample_clamped(base_sample_index);
+ const rtm::vector4f base_translation = base_bone_stream.translations.get_sample_clamped(base_sample_index);
+ const rtm::vector4f base_scale = base_bone_stream.scales.get_sample_clamped(base_sample_index);
+
+ const rtm::qvvf base_transform = rtm::qvv_set(base_rotation, base_translation, base_scale);
+ raw_transform = apply_additive_to_base(raw_clip_context.additive_format, base_transform, raw_transform);
+ }
+
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_transform);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_transform);
+
+ const rtm::scalarf vtx0_distance = rtm::vector_length3(raw_vtx0);
+ const rtm::scalarf vtx1_distance = rtm::vector_length3(raw_vtx1);
+ const rtm::scalarf vtx2_distance = rtm::vector_length3(raw_vtx2);
+
+ const rtm::scalarf transform_length = rtm::scalar_max(rtm::scalar_max(vtx0_distance, vtx1_distance), vtx2_distance);
+ parent_shell_distance = rtm::scalar_max(parent_shell_distance, transform_length);
+ }
+
+ shell.parent_shell_distance = rtm::scalar_cast(parent_shell_distance);
+
+ const transform_metadata& metadata = raw_clip_context.metadata[transform_index];
+
+ // Add precision since we want to make sure to encompass the maximum amount of error allowed
+ // Add it only for non-dominant transforms to account for the error they introduce
+ // Dominant transforms will use their own precision
+ // If our shell distance has changed, we are non-dominant since a dominant child updated it
+ if (shell.local_shell_distance != metadata.shell_distance)
+ shell.parent_shell_distance += metadata.precision;
+
+ if (metadata.parent_index != k_invalid_track_index)
+ {
+ // We have a parent, propagate our shell distance if we are a dominant transform
+ // We are a dominant transform if our shell distance in parent space is larger
+ // than our parent's shell distance in local space. Otherwise, if we are smaller
+ // or equal, it means that the full range of motion of our transform fits within
+ // the parent's shell distance.
+
+ rigid_shell_metadata_t& parent_shell = shell_metadata[metadata.parent_index];
+
+ if (shell.parent_shell_distance > parent_shell.local_shell_distance)
+ {
+ // We are the new dominant transform, use our shell distance and precision
+ parent_shell.local_shell_distance = shell.parent_shell_distance;
+ parent_shell.precision = shell.precision;
+ }
+ }
+ }
+
+ return shell_metadata;
+ }
+
+ // We use the raw data to compute the rigid shell
+ // For each transform, its rigid shell is formed by the dominant joint (itself or a child)
+ // We compute the largest value over the whole segment per transform
+ inline void compute_segment_shell_distances(const segment_context& segment, const clip_context& additive_base_clip_context, rigid_shell_metadata_t* out_shell_metadata)
+ {
+ const uint32_t num_transforms = segment.num_bones;
+ if (num_transforms == 0)
+ return; // No transforms present, no shell distances
+
+ const uint32_t num_samples = segment.num_samples;
+ if (num_samples == 0)
+ return; // No samples present, no shell distances
+
+ const clip_context& owner_clip_context = *segment.clip;
+ const bool has_additive_base = owner_clip_context.has_additive_base;
+
+ // Initialize everything
+ for (uint32_t transform_index = 0; transform_index < num_transforms; ++transform_index)
+ {
+ const transform_metadata& metadata = owner_clip_context.metadata[transform_index];
+
+ out_shell_metadata[transform_index].local_shell_distance = metadata.shell_distance;
+ out_shell_metadata[transform_index].precision = metadata.precision;
+ out_shell_metadata[transform_index].parent_shell_distance = 0.0F;
+ }
+
+ // Iterate from leaf transforms towards their root, we want to bubble up our shell distance
+ for (const uint32_t transform_index : make_reverse_iterator(owner_clip_context.sorted_transforms_parent_first, num_transforms))
+ {
+ const transform_streams& segment_bone_stream = segment.bone_streams[transform_index];
+
+ rigid_shell_metadata_t& shell = out_shell_metadata[transform_index];
+
+ // Use the accumulated shell distance so far to see how far it deforms with our local transform
+ const rtm::vector4f vtx0 = rtm::vector_set(shell.local_shell_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, shell.local_shell_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, shell.local_shell_distance);
+
+ // Calculate the shell distance in parent space
+ rtm::scalarf parent_shell_distance = rtm::scalar_set(0.0F);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const rtm::quatf raw_rotation = segment_bone_stream.rotations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_translation = segment_bone_stream.translations.get_sample_clamped(sample_index);
+ const rtm::vector4f raw_scale = segment_bone_stream.scales.get_sample_clamped(sample_index);
+
+ rtm::qvvf raw_transform = rtm::qvv_set(raw_rotation, raw_translation, raw_scale);
+
+ if (has_additive_base)
+ {
+ // If we are additive, we must apply our local transform on the base to figure out
+ // the true shell distance
+ const segment_context& base_segment = additive_base_clip_context.segments[0];
+ const transform_streams& base_bone_stream = base_segment.bone_streams[transform_index];
+
+ // The sample time is calculated from the full clip duration to be consistent with decompression
+ const float sample_time = rtm::scalar_min(float(sample_index + segment.clip_sample_offset) / owner_clip_context.sample_rate, owner_clip_context.duration);
+
+ const float normalized_sample_time = base_segment.num_samples > 1 ? (sample_time / owner_clip_context.duration) : 0.0F;
+ const float additive_sample_time = base_segment.num_samples > 1 ? (normalized_sample_time * additive_base_clip_context.duration) : 0.0F;
+
+ // With uniform sample distributions, we do not interpolate.
+ const uint32_t base_sample_index = get_uniform_sample_key(base_segment, additive_sample_time);
+
+ const rtm::quatf base_rotation = base_bone_stream.rotations.get_sample_clamped(base_sample_index);
+ const rtm::vector4f base_translation = base_bone_stream.translations.get_sample_clamped(base_sample_index);
+ const rtm::vector4f base_scale = base_bone_stream.scales.get_sample_clamped(base_sample_index);
+
+ const rtm::qvvf base_transform = rtm::qvv_set(base_rotation, base_translation, base_scale);
+ raw_transform = apply_additive_to_base(owner_clip_context.additive_format, base_transform, raw_transform);
+ }
+
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_transform);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_transform);
+
+ const rtm::scalarf vtx0_distance = rtm::vector_length3(raw_vtx0);
+ const rtm::scalarf vtx1_distance = rtm::vector_length3(raw_vtx1);
+ const rtm::scalarf vtx2_distance = rtm::vector_length3(raw_vtx2);
+
+ const rtm::scalarf transform_length = rtm::scalar_max(rtm::scalar_max(vtx0_distance, vtx1_distance), vtx2_distance);
+ parent_shell_distance = rtm::scalar_max(parent_shell_distance, transform_length);
+ }
+
+ shell.parent_shell_distance = rtm::scalar_cast(parent_shell_distance);
+
+ const transform_metadata& metadata = owner_clip_context.metadata[transform_index];
+
+ // Add precision since we want to make sure to encompass the maximum amount of error allowed
+ // Add it only for non-dominant transforms to account for the error they introduce
+ // Dominant transforms will use their own precision
+ // If our shell distance has changed, we are non-dominant since a dominant child updated it
+ if (shell.local_shell_distance != metadata.shell_distance)
+ shell.parent_shell_distance += metadata.precision;
+
+ if (metadata.parent_index != k_invalid_track_index)
+ {
+ // We have a parent, propagate our shell distance if we are a dominant transform
+ // We are a dominant transform if our shell distance in parent space is larger
+ // than our parent's shell distance in local space. Otherwise, if we are smaller
+ // or equal, it means that the full range of motion of our transform fits within
+ // the parent's shell distance.
+
+ rigid_shell_metadata_t& parent_shell = out_shell_metadata[metadata.parent_index];
+
+ if (shell.parent_shell_distance > parent_shell.local_shell_distance)
+ {
+ // We are the new dominant transform, use our shell distance and precision
+ parent_shell.local_shell_distance = shell.parent_shell_distance;
+ parent_shell.precision = shell.precision;
+ }
+ }
+ }
+ }
+ }
+
+ ACL_IMPL_VERSION_NAMESPACE_END
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/sample_streams.h b/includes/acl/compression/impl/sample_streams.h
--- a/includes/acl/compression/impl/sample_streams.h
+++ b/includes/acl/compression/impl/sample_streams.h
@@ -164,52 +164,27 @@ namespace acl
const clip_context* clip = segment->clip;
const rotation_format8 format = bone_steams.rotations.get_rotation_format();
- rtm::vector4f rotation;
+ // Pack and unpack at our desired bit rate
+ rtm::vector4f packed_rotation;
+
if (is_constant_bit_rate(bit_rate))
{
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- const track_stream_range& rotation_range = segment->ranges[bone_steams.bone_index].rotation;
- rotation = rotation_range.get_weighted_average();
-#else
- const uint8_t* quantized_ptr = raw_bone_steams.rotations.get_raw_sample_ptr(segment->clip_sample_offset);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, rotation_format8::quatf_full, k_invalid_bit_rate);
- rotation = convert_rotation(rotation, rotation_format8::quatf_full, format);
-#endif
-
+ packed_rotation = decay_vector3_u48(bone_steams.constant_rotation);
}
else if (is_raw_bit_rate(bit_rate))
{
const uint8_t* quantized_ptr = raw_bone_steams.rotations.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, rotation_format8::quatf_full, k_invalid_bit_rate);
- rotation = convert_rotation(rotation, rotation_format8::quatf_full, format);
+ const rtm::vector4f rotation = acl_impl::load_rotation_sample(quantized_ptr, rotation_format8::quatf_full, k_invalid_bit_rate);
+ packed_rotation = convert_rotation(rotation, rotation_format8::quatf_full, format);
}
else
{
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0);
- }
-
- // Pack and unpack at our desired bit rate
- const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- rtm::vector4f packed_rotation;
+ const rtm::vector4f rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0);
- if (is_constant_bit_rate(bit_rate))
- {
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- packed_rotation = decay_vector3_u48(rotation);
-#else
- const transform_range& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_bone_range.rotation);
-
- packed_rotation = decay_vector3_u48(normalized_rotation);
-#endif
-
- }
- else if (is_raw_bit_rate(bit_rate))
- packed_rotation = rotation;
- else
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
packed_rotation = decay_vector3_uXX(rotation, num_bits_at_bit_rate);
+ }
if (!is_raw_bit_rate(bit_rate))
{
@@ -327,39 +302,10 @@ namespace acl
// Gets a translation sample at the specified bit rate
inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const transform_streams& bone_steams, const transform_streams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
+ ACL_ASSERT(bone_steams.translations.get_vector_format() == vector_format8::vector3f_full, "Expected floating point vector format");
+
const segment_context* segment = bone_steams.segment;
const clip_context* clip = segment->clip;
- const vector_format8 format = bone_steams.translations.get_vector_format();
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f translation;
- if (is_constant_bit_rate(bit_rate))
- {
- const track_stream_range& translation_range = segment->ranges[bone_steams.bone_index].translation;
- translation = translation_range.get_weighted_average();
- }
- else
- {
- const uint8_t* quantized_ptr;
- if (is_raw_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.translations.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- else
- quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
-
- translation = acl_impl::load_vector_sample(quantized_ptr, format, 0);
- }
-#else
- const uint8_t* quantized_ptr;
- if (is_constant_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.translations.get_raw_sample_ptr(segment->clip_sample_offset);
- else if (is_raw_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.translations.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- else
- quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
-
- const rtm::vector4f translation = acl_impl::load_vector_sample(quantized_ptr, format, 0);
-#endif
-
ACL_ASSERT(clip->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
@@ -368,21 +314,16 @@ namespace acl
if (is_constant_bit_rate(bit_rate))
{
ACL_ASSERT(segment->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- packed_translation = decay_vector3_u48(translation);
-#else
- const transform_range& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const rtm::vector4f normalized_translation = normalize_sample(translation, clip_bone_range.translation);
-
- packed_translation = decay_vector3_u48(normalized_translation);
-#endif
-
+ packed_translation = decay_vector3_u48(bone_steams.constant_translation);
}
else if (is_raw_bit_rate(bit_rate))
- packed_translation = translation;
+ {
+ packed_translation = raw_bone_steams.translations.get_sample(segment->clip_sample_offset + sample_index);
+ }
else
{
+ const rtm::vector4f translation = bone_steams.translations.get_sample(sample_index);
+
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
packed_translation = decay_vector3_uXX(translation, num_bits_at_bit_rate);
}
@@ -500,39 +441,10 @@ namespace acl
// Gets a scale sample at the specified bit rate
inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const transform_streams& bone_steams, const transform_streams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
+ ACL_ASSERT(bone_steams.scales.get_vector_format() == vector_format8::vector3f_full, "Expected floating point vector format");
+
const segment_context* segment = bone_steams.segment;
const clip_context* clip = segment->clip;
- const vector_format8 format = bone_steams.scales.get_vector_format();
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f scale;
- if (is_constant_bit_rate(bit_rate))
- {
- const track_stream_range& scale_range = segment->ranges[bone_steams.bone_index].scale;
- scale = scale_range.get_weighted_average();
- }
- else
- {
- const uint8_t* quantized_ptr;
- if (is_raw_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.scales.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- else
- quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
-
- scale = acl_impl::load_vector_sample(quantized_ptr, format, 0);
- }
-#else
- const uint8_t* quantized_ptr;
- if (is_constant_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.scales.get_raw_sample_ptr(segment->clip_sample_offset);
- else if (is_raw_bit_rate(bit_rate))
- quantized_ptr = raw_bone_steams.scales.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- else
- quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
-
- const rtm::vector4f scale = acl_impl::load_vector_sample(quantized_ptr, format, 0);
-#endif
-
ACL_ASSERT(clip->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
@@ -540,22 +452,17 @@ namespace acl
if (is_constant_bit_rate(bit_rate))
{
- ACL_ASSERT(segment->are_scales_normalized, "Translations must be normalized to support variable bit rates.");
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- packed_scale = decay_vector3_u48(scale);
-#else
- const transform_range& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const rtm::vector4f normalized_scale = normalize_sample(scale, clip_bone_range.scale);
-
- packed_scale = decay_vector3_u48(normalized_scale);
-#endif
-
+ ACL_ASSERT(segment->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
+ packed_scale = decay_vector3_u48(bone_steams.constant_scale);
}
else if (is_raw_bit_rate(bit_rate))
- packed_scale = scale;
+ {
+ packed_scale = raw_bone_steams.scales.get_sample(segment->clip_sample_offset + sample_index);
+ }
else
{
+ const rtm::vector4f scale = bone_steams.scales.get_sample(sample_index);
+
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
packed_scale = decay_vector3_uXX(scale, num_bits_at_bit_rate);
}
@@ -692,33 +599,6 @@ namespace acl
return rotation;
}
- RTM_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, const transform_streams& bone_stream, const transform_streams& raw_bone_stream, bool is_rotation_variable, rotation_format8 rotation_format)
- {
- rtm::quatf rotation;
- if (bone_stream.is_rotation_default)
- rotation = bone_stream.default_value.rotation;
- else if (bone_stream.is_rotation_constant)
- {
- if (is_rotation_variable)
- rotation = get_rotation_sample(raw_bone_stream, 0);
- else
- rotation = get_rotation_sample(raw_bone_stream, 0, rotation_format);
-
- rotation = rtm::quat_normalize(rotation);
- }
- else
- {
- if (is_rotation_variable)
- rotation = get_rotation_sample(bone_stream, raw_bone_stream, context.sample_key, context.bit_rates.rotation);
- else
- rotation = get_rotation_sample(bone_stream, context.sample_key, rotation_format);
-
- rotation = rtm::quat_normalize(rotation);
- }
-
- return rotation;
- }
-
RTM_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const transform_streams& bone_stream)
{
if (bone_stream.is_translation_default)
@@ -729,18 +609,6 @@ namespace acl
return get_translation_sample(bone_stream, context.sample_key);
}
- RTM_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const transform_streams& bone_stream, const transform_streams& raw_bone_stream, bool is_translation_variable, vector_format8 translation_format)
- {
- if (bone_stream.is_translation_default)
- return bone_stream.default_value.translation;
- else if (bone_stream.is_translation_constant)
- return get_translation_sample(raw_bone_stream, 0, vector_format8::vector3f_full);
- else if (is_translation_variable)
- return get_translation_sample(bone_stream, raw_bone_stream, context.sample_key, context.bit_rates.translation);
- else
- return get_translation_sample(bone_stream, context.sample_key, translation_format);
- }
-
RTM_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const transform_streams& bone_stream)
{
if (bone_stream.is_scale_default)
@@ -751,18 +619,8 @@ namespace acl
return get_scale_sample(bone_stream, context.sample_key);
}
- RTM_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const transform_streams& bone_stream, const transform_streams& raw_bone_stream, bool is_scale_variable, vector_format8 scale_format)
- {
- if (bone_stream.is_scale_default)
- return bone_stream.default_value.scale;
- else if (bone_stream.is_scale_constant)
- return get_scale_sample(raw_bone_stream, 0, vector_format8::vector3f_full);
- else if (is_scale_variable)
- return get_scale_sample(bone_stream, raw_bone_stream, context.sample_key, context.bit_rates.scale);
- else
- return get_scale_sample(bone_stream, context.sample_key, scale_format);
- }
-
+ // Samples all transforms at a point in time
+ // Transforms can be raw or quantized
inline void sample_streams(const transform_streams* bone_streams, uint32_t num_bones, float sample_time, rtm::qvvf* out_local_pose)
{
const segment_context* segment_context = bone_streams->segment;
@@ -788,177 +646,6 @@ namespace acl
out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
-
- inline void sample_stream(const transform_streams* bone_streams, uint32_t num_bones, float sample_time, uint32_t bone_index, rtm::qvvf* out_local_pose)
- {
- (void)num_bones;
-
- const segment_context* segment_context = bone_streams->segment;
- const bool has_scale = segment_context->clip->has_scale;
-
- // With uniform sample distributions, we do not interpolate.
- const uint32_t sample_key = get_uniform_sample_key(*segment_context, sample_time);
-
- acl_impl::sample_context context;
- context.track_index = bone_index;
- context.sample_key = sample_key;
- context.sample_time = sample_time;
-
- const transform_streams& bone_stream = bone_streams[bone_index];
-
- const rtm::quatf rotation = acl_impl::sample_rotation(context, bone_stream);
- const rtm::vector4f translation = acl_impl::sample_translation(context, bone_stream);
- const rtm::vector4f scale = has_scale ? acl_impl::sample_scale(context, bone_stream) : bone_stream.default_value.scale;
-
- out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
- }
-
- inline void sample_streams_hierarchical(const transform_streams* bone_streams, uint32_t num_bones, float sample_time, uint32_t bone_index, rtm::qvvf* out_local_pose)
- {
- (void)num_bones;
-
- const segment_context* segment_context = bone_streams->segment;
- const bool has_scale = segment_context->clip->has_scale;
-
- // With uniform sample distributions, we do not interpolate.
- const uint32_t sample_key = get_uniform_sample_key(*segment_context, sample_time);
-
- acl_impl::sample_context context;
- context.sample_key = sample_key;
- context.sample_time = sample_time;
-
- uint32_t current_bone_index = bone_index;
- while (current_bone_index != k_invalid_track_index)
- {
- context.track_index = current_bone_index;
-
- const transform_streams& bone_stream = bone_streams[current_bone_index];
-
- const rtm::quatf rotation = acl_impl::sample_rotation(context, bone_stream);
- const rtm::vector4f translation = acl_impl::sample_translation(context, bone_stream);
- const rtm::vector4f scale = has_scale ? acl_impl::sample_scale(context, bone_stream) : bone_stream.default_value.scale;
-
- out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
- current_bone_index = bone_stream.parent_bone_index;
- }
- }
-
- inline void sample_streams(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
- {
- const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
- const bool is_translation_variable = is_vector_format_variable(translation_format);
- const bool is_scale_variable = is_vector_format_variable(scale_format);
-
- const segment_context* segment_context = bone_streams->segment;
- const bool has_scale = segment_context->clip->has_scale;
-
- // With uniform sample distributions, we do not interpolate.
- const uint32_t sample_key = get_uniform_sample_key(*segment_context, sample_time);
-
- acl_impl::sample_context context;
- context.sample_key = sample_key;
- context.sample_time = sample_time;
-
- for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- context.track_index = bone_index;
- context.bit_rates = bit_rates[bone_index];
-
- const transform_streams& bone_stream = bone_streams[bone_index];
- const transform_streams& raw_bone_steam = raw_bone_steams[bone_index];
-
- const rtm::quatf rotation = acl_impl::sample_rotation(context, bone_stream, raw_bone_steam, is_rotation_variable, rotation_format);
- const rtm::vector4f translation = acl_impl::sample_translation(context, bone_stream, raw_bone_steam, is_translation_variable, translation_format);
- const rtm::vector4f scale = has_scale ? acl_impl::sample_scale(context, bone_stream, raw_bone_steam, is_scale_variable, scale_format) : bone_stream.default_value.scale;
-
- out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
- }
- }
-
- inline void sample_stream(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
- {
- (void)num_bones;
-
- const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
- const bool is_translation_variable = is_vector_format_variable(translation_format);
- const bool is_scale_variable = is_vector_format_variable(scale_format);
-
- const segment_context* segment_context = bone_streams->segment;
- const bool has_scale = segment_context->clip->has_scale;
-
- // With uniform sample distributions, we do not interpolate.
- const uint32_t sample_key = get_uniform_sample_key(*segment_context, sample_time);
-
- acl_impl::sample_context context;
- context.track_index = bone_index;
- context.sample_key = sample_key;
- context.sample_time = sample_time;
- context.bit_rates = bit_rates[bone_index];
-
- const transform_streams& bone_stream = bone_streams[bone_index];
- const transform_streams& raw_bone_stream = raw_bone_steams[bone_index];
-
- const rtm::quatf rotation = acl_impl::sample_rotation(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
- const rtm::vector4f translation = acl_impl::sample_translation(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
- const rtm::vector4f scale = has_scale ? acl_impl::sample_scale(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format) : bone_stream.default_value.scale;
-
- out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
- }
-
- inline void sample_streams_hierarchical(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
- {
- (void)num_bones;
-
- const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
- const bool is_translation_variable = is_vector_format_variable(translation_format);
- const bool is_scale_variable = is_vector_format_variable(scale_format);
-
- const segment_context* segment_context = bone_streams->segment;
- const bool has_scale = segment_context->clip->has_scale;
-
- // With uniform sample distributions, we do not interpolate.
- const uint32_t sample_key = get_uniform_sample_key(*segment_context, sample_time);
-
- acl_impl::sample_context context;
- context.sample_key = sample_key;
- context.sample_time = sample_time;
-
- uint32_t current_bone_index = bone_index;
- while (current_bone_index != k_invalid_track_index)
- {
- context.track_index = current_bone_index;
- context.bit_rates = bit_rates[current_bone_index];
-
- const transform_streams& bone_stream = bone_streams[current_bone_index];
- const transform_streams& raw_bone_stream = raw_bone_steams[current_bone_index];
-
- const rtm::quatf rotation = acl_impl::sample_rotation(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
- const rtm::vector4f translation = acl_impl::sample_translation(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
- const rtm::vector4f scale = has_scale ? acl_impl::sample_scale(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format) : bone_stream.default_value.scale;
-
- out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
- current_bone_index = bone_stream.parent_bone_index;
- }
- }
-
- inline void sample_streams(const transform_streams* bone_streams, uint32_t num_bones, uint32_t sample_index, rtm::qvvf* out_local_pose)
- {
- for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
- {
- const transform_streams& bone_stream = bone_streams[bone_index];
-
- const uint32_t rotation_sample_index = !bone_stream.is_rotation_constant ? sample_index : 0;
- const rtm::quatf rotation = get_rotation_sample(bone_stream, rotation_sample_index);
-
- const uint32_t translation_sample_index = !bone_stream.is_translation_constant ? sample_index : 0;
- const rtm::vector4f translation = get_translation_sample(bone_stream, translation_sample_index);
-
- const uint32_t scale_sample_index = !bone_stream.is_scale_constant ? sample_index : 0;
- const rtm::vector4f scale = get_scale_sample(bone_stream, scale_sample_index);
-
- out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
- }
- }
}
ACL_IMPL_VERSION_NAMESPACE_END
diff --git a/includes/acl/compression/impl/segment_streams.h b/includes/acl/compression/impl/segment_streams.h
--- a/includes/acl/compression/impl/segment_streams.h
+++ b/includes/acl/compression/impl/segment_streams.h
@@ -225,6 +225,11 @@ namespace acl
segment_bone_stream.is_translation_default = clip_bone_stream.is_translation_default;
segment_bone_stream.is_scale_constant = clip_bone_stream.is_scale_constant;
segment_bone_stream.is_scale_default = clip_bone_stream.is_scale_default;
+
+ // Extract our potential segment constant values now before we normalize over the segment
+ segment_bone_stream.constant_rotation = segment_bone_stream.rotations.get_raw_sample<rtm::vector4f>(0);
+ segment_bone_stream.constant_translation = segment_bone_stream.translations.get_raw_sample<rtm::vector4f>(0);
+ segment_bone_stream.constant_scale = segment_bone_stream.scales.get_raw_sample<rtm::vector4f>(0);
}
clip_sample_index += num_samples_in_segment;
diff --git a/includes/acl/compression/impl/track_stream.h b/includes/acl/compression/impl/track_stream.h
--- a/includes/acl/compression/impl/track_stream.h
+++ b/includes/acl/compression/impl/track_stream.h
@@ -205,7 +205,7 @@ namespace acl
animation_track_type8 m_type;
track_format8 m_format;
uint8_t m_bit_rate;
- };
+ };
class rotation_track_stream final : public track_stream
{
@@ -235,6 +235,30 @@ namespace acl
}
rotation_format8 get_rotation_format() const { return m_format.rotation; }
+
+ rtm::quatf RTM_SIMD_CALL get_sample(uint32_t sample_index) const
+ {
+ const rtm::vector4f rotation = get_raw_sample<rtm::vector4f>(sample_index);
+
+ switch (m_format.rotation)
+ {
+ case rotation_format8::quatf_full:
+ return rtm::vector_to_quat(rotation);
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
+ // quat_from_positive_w might not yield an accurate quaternion because the square-root instruction
+ // isn't very accurate on small inputs, we need to normalize
+ return rtm::quat_normalize(rtm::quat_from_positive_w(rotation));
+ default:
+ ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(m_format.rotation));
+ return rtm::vector_to_quat(rotation);
+ }
+ };
+
+ rtm::quatf RTM_SIMD_CALL get_sample_clamped(uint32_t sample_index) const
+ {
+ return get_sample(std::min(sample_index, m_num_samples - 1));
+ }
};
class translation_track_stream final : public track_stream
@@ -265,6 +289,16 @@ namespace acl
}
vector_format8 get_vector_format() const { return m_format.vector; }
+
+ rtm::vector4f RTM_SIMD_CALL get_sample(uint32_t sample_index) const
+ {
+ return get_raw_sample<rtm::vector4f>(sample_index);
+ }
+
+ rtm::vector4f RTM_SIMD_CALL get_sample_clamped(uint32_t sample_index) const
+ {
+ return get_sample(std::min(sample_index, m_num_samples - 1));
+ }
};
class scale_track_stream final : public track_stream
@@ -295,6 +329,16 @@ namespace acl
}
vector_format8 get_vector_format() const { return m_format.vector; }
+
+ rtm::vector4f RTM_SIMD_CALL get_sample(uint32_t sample_index) const
+ {
+ return get_raw_sample<rtm::vector4f>(sample_index);
+ }
+
+ rtm::vector4f RTM_SIMD_CALL get_sample_clamped(uint32_t sample_index) const
+ {
+ return get_sample(std::min(sample_index, m_num_samples - 1));
+ }
};
// For a rotation track, the extent only tells us if the track is constant or not
@@ -303,37 +347,20 @@ namespace acl
class track_stream_range
{
public:
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- static track_stream_range RTM_SIMD_CALL from_min_max(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max, rtm::vector4f_arg2 weighted_average)
- {
- return track_stream_range(min, max, rtm::vector_sub(max, min), weighted_average);
- }
-#else
static track_stream_range RTM_SIMD_CALL from_min_max(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max)
{
return track_stream_range(min, max, rtm::vector_sub(max, min));
}
-#endif
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- static track_stream_range RTM_SIMD_CALL from_min_extent(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent, rtm::vector4f_arg2 weighted_average)
- {
- return track_stream_range(min, rtm::vector_add(min, extent), extent, weighted_average);
- }
-#else
static track_stream_range RTM_SIMD_CALL from_min_extent(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent)
{
return track_stream_range(min, rtm::vector_add(min, extent), extent);
}
-#endif
track_stream_range()
: m_min(rtm::vector_zero())
, m_max(rtm::vector_zero())
, m_extent(rtm::vector_zero())
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- , m_weighted_average(rtm::vector_zero())
-#endif
{}
rtm::vector4f RTM_SIMD_CALL get_min() const { return m_min; }
@@ -352,23 +379,11 @@ namespace acl
return rtm::vector_all_less_equal(m_extent, rtm::vector_set(threshold));
}
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f RTM_SIMD_CALL get_weighted_average() const { return m_weighted_average; }
-#endif
-
private:
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- track_stream_range(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max, rtm::vector4f_arg2 extent, rtm::vector4f_arg3 weighted_average)
-#else
track_stream_range(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max, rtm::vector4f_arg2 extent)
-#endif
: m_min(min)
, m_max(max)
, m_extent(extent)
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- , m_weighted_average(weighted_average)
-#endif
{
ACL_ASSERT(rtm::vector_all_greater_equal(max, min), "Max must be greater or equal to min");
ACL_ASSERT(rtm::vector_all_greater_equal(extent, rtm::vector_zero()) && rtm::vector_is_finite(extent), "Extent must be positive and finite");
@@ -377,11 +392,6 @@ namespace acl
rtm::vector4f m_min;
rtm::vector4f m_max;
rtm::vector4f m_extent;
-
-#if defined(ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS)
- rtm::vector4f m_weighted_average;
-#endif
-
};
struct transform_range
@@ -397,6 +407,13 @@ namespace acl
{
rtm::qvvf default_value = rtm::qvv_identity();
+ // Sample 0 before we normalize over the segment.
+ // This is used when a sub-track is constant over the segment.
+ // These values are normalized over the clip (but not over the segment).
+ rtm::vector4f constant_rotation = rtm::vector_zero();
+ rtm::vector4f constant_translation = rtm::vector_zero();
+ rtm::vector4f constant_scale = rtm::vector_zero();
+
segment_context* segment = nullptr;
uint32_t bone_index = k_invalid_track_index;
uint32_t parent_bone_index = k_invalid_track_index;
@@ -421,6 +438,9 @@ namespace acl
{
transform_streams copy;
copy.default_value = default_value;
+ copy.constant_rotation = constant_rotation;
+ copy.constant_translation = constant_translation;
+ copy.constant_scale = constant_scale;
copy.segment = segment;
copy.bone_index = bone_index;
copy.parent_bone_index = parent_bone_index;
diff --git a/includes/acl/compression/impl/transform_bit_rate_permutations.h b/includes/acl/compression/impl/transform_bit_rate_permutations.h
--- a/includes/acl/compression/impl/transform_bit_rate_permutations.h
+++ b/includes/acl/compression/impl/transform_bit_rate_permutations.h
@@ -39,7232 +39,16262 @@ namespace acl
namespace acl_impl
{
- constexpr uint8_t k_local_bit_rate_permutations_no_scale[361][2] =
+ constexpr uint8_t k_local_bit_rate_permutations_no_scale[625][2] =
{
{ 0, 0 }, // 0 bits per transform
- { 0, 1 }, // 9 bits per transform
- { 1, 0 }, // 9 bits per transform
- { 0, 2 }, // 12 bits per transform
- { 2, 0 }, // 12 bits per transform
- { 0, 3 }, // 15 bits per transform
- { 3, 0 }, // 15 bits per transform
- { 0, 4 }, // 18 bits per transform
- { 1, 1 }, // 18 bits per transform
- { 4, 0 }, // 18 bits per transform
- { 0, 5 }, // 21 bits per transform
- { 1, 2 }, // 21 bits per transform
- { 2, 1 }, // 21 bits per transform
- { 5, 0 }, // 21 bits per transform
- { 0, 6 }, // 24 bits per transform
- { 1, 3 }, // 24 bits per transform
- { 2, 2 }, // 24 bits per transform
- { 3, 1 }, // 24 bits per transform
- { 6, 0 }, // 24 bits per transform
- { 0, 7 }, // 27 bits per transform
- { 1, 4 }, // 27 bits per transform
- { 2, 3 }, // 27 bits per transform
- { 3, 2 }, // 27 bits per transform
- { 4, 1 }, // 27 bits per transform
- { 7, 0 }, // 27 bits per transform
- { 0, 8 }, // 30 bits per transform
- { 1, 5 }, // 30 bits per transform
- { 2, 4 }, // 30 bits per transform
- { 3, 3 }, // 30 bits per transform
- { 4, 2 }, // 30 bits per transform
- { 5, 1 }, // 30 bits per transform
- { 8, 0 }, // 30 bits per transform
- { 0, 9 }, // 33 bits per transform
- { 1, 6 }, // 33 bits per transform
- { 2, 5 }, // 33 bits per transform
- { 3, 4 }, // 33 bits per transform
- { 4, 3 }, // 33 bits per transform
- { 5, 2 }, // 33 bits per transform
- { 6, 1 }, // 33 bits per transform
- { 9, 0 }, // 33 bits per transform
- { 0, 10 }, // 36 bits per transform
- { 1, 7 }, // 36 bits per transform
- { 2, 6 }, // 36 bits per transform
- { 3, 5 }, // 36 bits per transform
- { 4, 4 }, // 36 bits per transform
- { 5, 3 }, // 36 bits per transform
- { 6, 2 }, // 36 bits per transform
- { 7, 1 }, // 36 bits per transform
- { 10, 0 }, // 36 bits per transform
- { 0, 11 }, // 39 bits per transform
- { 1, 8 }, // 39 bits per transform
- { 2, 7 }, // 39 bits per transform
- { 3, 6 }, // 39 bits per transform
- { 4, 5 }, // 39 bits per transform
- { 5, 4 }, // 39 bits per transform
- { 6, 3 }, // 39 bits per transform
- { 7, 2 }, // 39 bits per transform
- { 8, 1 }, // 39 bits per transform
- { 11, 0 }, // 39 bits per transform
- { 0, 12 }, // 42 bits per transform
- { 1, 9 }, // 42 bits per transform
- { 2, 8 }, // 42 bits per transform
- { 3, 7 }, // 42 bits per transform
- { 4, 6 }, // 42 bits per transform
- { 5, 5 }, // 42 bits per transform
- { 6, 4 }, // 42 bits per transform
- { 7, 3 }, // 42 bits per transform
- { 8, 2 }, // 42 bits per transform
- { 9, 1 }, // 42 bits per transform
- { 12, 0 }, // 42 bits per transform
- { 0, 13 }, // 45 bits per transform
- { 1, 10 }, // 45 bits per transform
- { 2, 9 }, // 45 bits per transform
- { 3, 8 }, // 45 bits per transform
- { 4, 7 }, // 45 bits per transform
- { 5, 6 }, // 45 bits per transform
- { 6, 5 }, // 45 bits per transform
- { 7, 4 }, // 45 bits per transform
- { 8, 3 }, // 45 bits per transform
- { 9, 2 }, // 45 bits per transform
- { 10, 1 }, // 45 bits per transform
- { 13, 0 }, // 45 bits per transform
- { 0, 14 }, // 48 bits per transform
- { 1, 11 }, // 48 bits per transform
- { 2, 10 }, // 48 bits per transform
- { 3, 9 }, // 48 bits per transform
- { 4, 8 }, // 48 bits per transform
- { 5, 7 }, // 48 bits per transform
- { 6, 6 }, // 48 bits per transform
- { 7, 5 }, // 48 bits per transform
- { 8, 4 }, // 48 bits per transform
- { 9, 3 }, // 48 bits per transform
- { 10, 2 }, // 48 bits per transform
- { 11, 1 }, // 48 bits per transform
- { 14, 0 }, // 48 bits per transform
- { 0, 15 }, // 51 bits per transform
- { 1, 12 }, // 51 bits per transform
- { 2, 11 }, // 51 bits per transform
- { 3, 10 }, // 51 bits per transform
- { 4, 9 }, // 51 bits per transform
- { 5, 8 }, // 51 bits per transform
- { 6, 7 }, // 51 bits per transform
- { 7, 6 }, // 51 bits per transform
- { 8, 5 }, // 51 bits per transform
- { 9, 4 }, // 51 bits per transform
- { 10, 3 }, // 51 bits per transform
- { 11, 2 }, // 51 bits per transform
- { 12, 1 }, // 51 bits per transform
- { 15, 0 }, // 51 bits per transform
- { 0, 16 }, // 54 bits per transform
- { 1, 13 }, // 54 bits per transform
- { 2, 12 }, // 54 bits per transform
- { 3, 11 }, // 54 bits per transform
- { 4, 10 }, // 54 bits per transform
- { 5, 9 }, // 54 bits per transform
- { 6, 8 }, // 54 bits per transform
- { 7, 7 }, // 54 bits per transform
- { 8, 6 }, // 54 bits per transform
- { 9, 5 }, // 54 bits per transform
- { 10, 4 }, // 54 bits per transform
- { 11, 3 }, // 54 bits per transform
- { 12, 2 }, // 54 bits per transform
- { 13, 1 }, // 54 bits per transform
- { 16, 0 }, // 54 bits per transform
- { 0, 17 }, // 57 bits per transform
- { 1, 14 }, // 57 bits per transform
- { 2, 13 }, // 57 bits per transform
- { 3, 12 }, // 57 bits per transform
- { 4, 11 }, // 57 bits per transform
- { 5, 10 }, // 57 bits per transform
- { 6, 9 }, // 57 bits per transform
- { 7, 8 }, // 57 bits per transform
- { 8, 7 }, // 57 bits per transform
- { 9, 6 }, // 57 bits per transform
- { 10, 5 }, // 57 bits per transform
- { 11, 4 }, // 57 bits per transform
- { 12, 3 }, // 57 bits per transform
- { 13, 2 }, // 57 bits per transform
- { 14, 1 }, // 57 bits per transform
- { 17, 0 }, // 57 bits per transform
- { 1, 15 }, // 60 bits per transform
- { 2, 14 }, // 60 bits per transform
- { 3, 13 }, // 60 bits per transform
- { 4, 12 }, // 60 bits per transform
- { 5, 11 }, // 60 bits per transform
- { 6, 10 }, // 60 bits per transform
- { 7, 9 }, // 60 bits per transform
- { 8, 8 }, // 60 bits per transform
- { 9, 7 }, // 60 bits per transform
- { 10, 6 }, // 60 bits per transform
- { 11, 5 }, // 60 bits per transform
- { 12, 4 }, // 60 bits per transform
- { 13, 3 }, // 60 bits per transform
- { 14, 2 }, // 60 bits per transform
- { 15, 1 }, // 60 bits per transform
- { 1, 16 }, // 63 bits per transform
- { 2, 15 }, // 63 bits per transform
- { 3, 14 }, // 63 bits per transform
- { 4, 13 }, // 63 bits per transform
- { 5, 12 }, // 63 bits per transform
- { 6, 11 }, // 63 bits per transform
- { 7, 10 }, // 63 bits per transform
- { 8, 9 }, // 63 bits per transform
- { 9, 8 }, // 63 bits per transform
- { 10, 7 }, // 63 bits per transform
- { 11, 6 }, // 63 bits per transform
- { 12, 5 }, // 63 bits per transform
- { 13, 4 }, // 63 bits per transform
- { 14, 3 }, // 63 bits per transform
- { 15, 2 }, // 63 bits per transform
- { 16, 1 }, // 63 bits per transform
- { 1, 17 }, // 66 bits per transform
- { 2, 16 }, // 66 bits per transform
- { 3, 15 }, // 66 bits per transform
- { 4, 14 }, // 66 bits per transform
- { 5, 13 }, // 66 bits per transform
- { 6, 12 }, // 66 bits per transform
- { 7, 11 }, // 66 bits per transform
- { 8, 10 }, // 66 bits per transform
- { 9, 9 }, // 66 bits per transform
- { 10, 8 }, // 66 bits per transform
- { 11, 7 }, // 66 bits per transform
- { 12, 6 }, // 66 bits per transform
- { 13, 5 }, // 66 bits per transform
- { 14, 4 }, // 66 bits per transform
- { 15, 3 }, // 66 bits per transform
- { 16, 2 }, // 66 bits per transform
- { 17, 1 }, // 66 bits per transform
- { 2, 17 }, // 69 bits per transform
- { 3, 16 }, // 69 bits per transform
- { 4, 15 }, // 69 bits per transform
- { 5, 14 }, // 69 bits per transform
- { 6, 13 }, // 69 bits per transform
- { 7, 12 }, // 69 bits per transform
- { 8, 11 }, // 69 bits per transform
- { 9, 10 }, // 69 bits per transform
- { 10, 9 }, // 69 bits per transform
- { 11, 8 }, // 69 bits per transform
- { 12, 7 }, // 69 bits per transform
- { 13, 6 }, // 69 bits per transform
- { 14, 5 }, // 69 bits per transform
- { 15, 4 }, // 69 bits per transform
- { 16, 3 }, // 69 bits per transform
- { 17, 2 }, // 69 bits per transform
- { 3, 17 }, // 72 bits per transform
- { 4, 16 }, // 72 bits per transform
- { 5, 15 }, // 72 bits per transform
- { 6, 14 }, // 72 bits per transform
- { 7, 13 }, // 72 bits per transform
- { 8, 12 }, // 72 bits per transform
- { 9, 11 }, // 72 bits per transform
- { 10, 10 }, // 72 bits per transform
- { 11, 9 }, // 72 bits per transform
- { 12, 8 }, // 72 bits per transform
- { 13, 7 }, // 72 bits per transform
- { 14, 6 }, // 72 bits per transform
- { 15, 5 }, // 72 bits per transform
- { 16, 4 }, // 72 bits per transform
- { 17, 3 }, // 72 bits per transform
- { 4, 17 }, // 75 bits per transform
- { 5, 16 }, // 75 bits per transform
- { 6, 15 }, // 75 bits per transform
- { 7, 14 }, // 75 bits per transform
- { 8, 13 }, // 75 bits per transform
- { 9, 12 }, // 75 bits per transform
- { 10, 11 }, // 75 bits per transform
- { 11, 10 }, // 75 bits per transform
- { 12, 9 }, // 75 bits per transform
- { 13, 8 }, // 75 bits per transform
- { 14, 7 }, // 75 bits per transform
- { 15, 6 }, // 75 bits per transform
- { 16, 5 }, // 75 bits per transform
- { 17, 4 }, // 75 bits per transform
- { 5, 17 }, // 78 bits per transform
- { 6, 16 }, // 78 bits per transform
- { 7, 15 }, // 78 bits per transform
- { 8, 14 }, // 78 bits per transform
- { 9, 13 }, // 78 bits per transform
- { 10, 12 }, // 78 bits per transform
- { 11, 11 }, // 78 bits per transform
- { 12, 10 }, // 78 bits per transform
- { 13, 9 }, // 78 bits per transform
- { 14, 8 }, // 78 bits per transform
- { 15, 7 }, // 78 bits per transform
- { 16, 6 }, // 78 bits per transform
- { 17, 5 }, // 78 bits per transform
- { 6, 17 }, // 81 bits per transform
- { 7, 16 }, // 81 bits per transform
- { 8, 15 }, // 81 bits per transform
- { 9, 14 }, // 81 bits per transform
- { 10, 13 }, // 81 bits per transform
- { 11, 12 }, // 81 bits per transform
- { 12, 11 }, // 81 bits per transform
- { 13, 10 }, // 81 bits per transform
- { 14, 9 }, // 81 bits per transform
- { 15, 8 }, // 81 bits per transform
- { 16, 7 }, // 81 bits per transform
- { 17, 6 }, // 81 bits per transform
- { 7, 17 }, // 84 bits per transform
- { 8, 16 }, // 84 bits per transform
- { 9, 15 }, // 84 bits per transform
- { 10, 14 }, // 84 bits per transform
- { 11, 13 }, // 84 bits per transform
- { 12, 12 }, // 84 bits per transform
- { 13, 11 }, // 84 bits per transform
- { 14, 10 }, // 84 bits per transform
- { 15, 9 }, // 84 bits per transform
- { 16, 8 }, // 84 bits per transform
- { 17, 7 }, // 84 bits per transform
- { 8, 17 }, // 87 bits per transform
- { 9, 16 }, // 87 bits per transform
- { 10, 15 }, // 87 bits per transform
- { 11, 14 }, // 87 bits per transform
- { 12, 13 }, // 87 bits per transform
- { 13, 12 }, // 87 bits per transform
- { 14, 11 }, // 87 bits per transform
- { 15, 10 }, // 87 bits per transform
- { 16, 9 }, // 87 bits per transform
- { 17, 8 }, // 87 bits per transform
- { 9, 17 }, // 90 bits per transform
- { 10, 16 }, // 90 bits per transform
- { 11, 15 }, // 90 bits per transform
- { 12, 14 }, // 90 bits per transform
- { 13, 13 }, // 90 bits per transform
- { 14, 12 }, // 90 bits per transform
- { 15, 11 }, // 90 bits per transform
- { 16, 10 }, // 90 bits per transform
- { 17, 9 }, // 90 bits per transform
- { 10, 17 }, // 93 bits per transform
- { 11, 16 }, // 93 bits per transform
- { 12, 15 }, // 93 bits per transform
- { 13, 14 }, // 93 bits per transform
- { 14, 13 }, // 93 bits per transform
- { 15, 12 }, // 93 bits per transform
- { 16, 11 }, // 93 bits per transform
- { 17, 10 }, // 93 bits per transform
- { 0, 18 }, // 96 bits per transform
- { 11, 17 }, // 96 bits per transform
- { 12, 16 }, // 96 bits per transform
- { 13, 15 }, // 96 bits per transform
- { 14, 14 }, // 96 bits per transform
- { 15, 13 }, // 96 bits per transform
- { 16, 12 }, // 96 bits per transform
- { 17, 11 }, // 96 bits per transform
- { 18, 0 }, // 96 bits per transform
- { 12, 17 }, // 99 bits per transform
- { 13, 16 }, // 99 bits per transform
- { 14, 15 }, // 99 bits per transform
- { 15, 14 }, // 99 bits per transform
- { 16, 13 }, // 99 bits per transform
- { 17, 12 }, // 99 bits per transform
- { 13, 17 }, // 102 bits per transform
- { 14, 16 }, // 102 bits per transform
- { 15, 15 }, // 102 bits per transform
- { 16, 14 }, // 102 bits per transform
- { 17, 13 }, // 102 bits per transform
- { 1, 18 }, // 105 bits per transform
- { 14, 17 }, // 105 bits per transform
- { 15, 16 }, // 105 bits per transform
- { 16, 15 }, // 105 bits per transform
- { 17, 14 }, // 105 bits per transform
- { 18, 1 }, // 105 bits per transform
- { 2, 18 }, // 108 bits per transform
- { 15, 17 }, // 108 bits per transform
- { 16, 16 }, // 108 bits per transform
- { 17, 15 }, // 108 bits per transform
- { 18, 2 }, // 108 bits per transform
- { 3, 18 }, // 111 bits per transform
- { 16, 17 }, // 111 bits per transform
- { 17, 16 }, // 111 bits per transform
- { 18, 3 }, // 111 bits per transform
- { 4, 18 }, // 114 bits per transform
- { 17, 17 }, // 114 bits per transform
- { 18, 4 }, // 114 bits per transform
- { 5, 18 }, // 117 bits per transform
- { 18, 5 }, // 117 bits per transform
- { 6, 18 }, // 120 bits per transform
- { 18, 6 }, // 120 bits per transform
- { 7, 18 }, // 123 bits per transform
- { 18, 7 }, // 123 bits per transform
- { 8, 18 }, // 126 bits per transform
- { 18, 8 }, // 126 bits per transform
- { 9, 18 }, // 129 bits per transform
- { 18, 9 }, // 129 bits per transform
- { 10, 18 }, // 132 bits per transform
- { 18, 10 }, // 132 bits per transform
- { 11, 18 }, // 135 bits per transform
- { 18, 11 }, // 135 bits per transform
- { 12, 18 }, // 138 bits per transform
- { 18, 12 }, // 138 bits per transform
- { 13, 18 }, // 141 bits per transform
- { 18, 13 }, // 141 bits per transform
- { 14, 18 }, // 144 bits per transform
- { 18, 14 }, // 144 bits per transform
- { 15, 18 }, // 147 bits per transform
- { 18, 15 }, // 147 bits per transform
- { 16, 18 }, // 150 bits per transform
- { 18, 16 }, // 150 bits per transform
- { 17, 18 }, // 153 bits per transform
- { 18, 17 }, // 153 bits per transform
- { 18, 18 }, // 192 bits per transform
+ { 0, 1 }, // 3 bits per transform
+ { 1, 0 }, // 3 bits per transform
+ { 0, 2 }, // 6 bits per transform
+ { 1, 1 }, // 6 bits per transform
+ { 2, 0 }, // 6 bits per transform
+ { 0, 3 }, // 9 bits per transform
+ { 1, 2 }, // 9 bits per transform
+ { 2, 1 }, // 9 bits per transform
+ { 3, 0 }, // 9 bits per transform
+ { 0, 4 }, // 12 bits per transform
+ { 1, 3 }, // 12 bits per transform
+ { 2, 2 }, // 12 bits per transform
+ { 3, 1 }, // 12 bits per transform
+ { 4, 0 }, // 12 bits per transform
+ { 0, 5 }, // 15 bits per transform
+ { 1, 4 }, // 15 bits per transform
+ { 2, 3 }, // 15 bits per transform
+ { 3, 2 }, // 15 bits per transform
+ { 4, 1 }, // 15 bits per transform
+ { 5, 0 }, // 15 bits per transform
+ { 0, 6 }, // 18 bits per transform
+ { 1, 5 }, // 18 bits per transform
+ { 2, 4 }, // 18 bits per transform
+ { 3, 3 }, // 18 bits per transform
+ { 4, 2 }, // 18 bits per transform
+ { 5, 1 }, // 18 bits per transform
+ { 6, 0 }, // 18 bits per transform
+ { 0, 7 }, // 21 bits per transform
+ { 1, 6 }, // 21 bits per transform
+ { 2, 5 }, // 21 bits per transform
+ { 3, 4 }, // 21 bits per transform
+ { 4, 3 }, // 21 bits per transform
+ { 5, 2 }, // 21 bits per transform
+ { 6, 1 }, // 21 bits per transform
+ { 7, 0 }, // 21 bits per transform
+ { 0, 8 }, // 24 bits per transform
+ { 1, 7 }, // 24 bits per transform
+ { 2, 6 }, // 24 bits per transform
+ { 3, 5 }, // 24 bits per transform
+ { 4, 4 }, // 24 bits per transform
+ { 5, 3 }, // 24 bits per transform
+ { 6, 2 }, // 24 bits per transform
+ { 7, 1 }, // 24 bits per transform
+ { 8, 0 }, // 24 bits per transform
+ { 0, 9 }, // 27 bits per transform
+ { 1, 8 }, // 27 bits per transform
+ { 2, 7 }, // 27 bits per transform
+ { 3, 6 }, // 27 bits per transform
+ { 4, 5 }, // 27 bits per transform
+ { 5, 4 }, // 27 bits per transform
+ { 6, 3 }, // 27 bits per transform
+ { 7, 2 }, // 27 bits per transform
+ { 8, 1 }, // 27 bits per transform
+ { 9, 0 }, // 27 bits per transform
+ { 0, 10 }, // 30 bits per transform
+ { 1, 9 }, // 30 bits per transform
+ { 2, 8 }, // 30 bits per transform
+ { 3, 7 }, // 30 bits per transform
+ { 4, 6 }, // 30 bits per transform
+ { 5, 5 }, // 30 bits per transform
+ { 6, 4 }, // 30 bits per transform
+ { 7, 3 }, // 30 bits per transform
+ { 8, 2 }, // 30 bits per transform
+ { 9, 1 }, // 30 bits per transform
+ { 10, 0 }, // 30 bits per transform
+ { 0, 11 }, // 33 bits per transform
+ { 1, 10 }, // 33 bits per transform
+ { 2, 9 }, // 33 bits per transform
+ { 3, 8 }, // 33 bits per transform
+ { 4, 7 }, // 33 bits per transform
+ { 5, 6 }, // 33 bits per transform
+ { 6, 5 }, // 33 bits per transform
+ { 7, 4 }, // 33 bits per transform
+ { 8, 3 }, // 33 bits per transform
+ { 9, 2 }, // 33 bits per transform
+ { 10, 1 }, // 33 bits per transform
+ { 11, 0 }, // 33 bits per transform
+ { 0, 12 }, // 36 bits per transform
+ { 1, 11 }, // 36 bits per transform
+ { 2, 10 }, // 36 bits per transform
+ { 3, 9 }, // 36 bits per transform
+ { 4, 8 }, // 36 bits per transform
+ { 5, 7 }, // 36 bits per transform
+ { 6, 6 }, // 36 bits per transform
+ { 7, 5 }, // 36 bits per transform
+ { 8, 4 }, // 36 bits per transform
+ { 9, 3 }, // 36 bits per transform
+ { 10, 2 }, // 36 bits per transform
+ { 11, 1 }, // 36 bits per transform
+ { 12, 0 }, // 36 bits per transform
+ { 0, 13 }, // 39 bits per transform
+ { 1, 12 }, // 39 bits per transform
+ { 2, 11 }, // 39 bits per transform
+ { 3, 10 }, // 39 bits per transform
+ { 4, 9 }, // 39 bits per transform
+ { 5, 8 }, // 39 bits per transform
+ { 6, 7 }, // 39 bits per transform
+ { 7, 6 }, // 39 bits per transform
+ { 8, 5 }, // 39 bits per transform
+ { 9, 4 }, // 39 bits per transform
+ { 10, 3 }, // 39 bits per transform
+ { 11, 2 }, // 39 bits per transform
+ { 12, 1 }, // 39 bits per transform
+ { 13, 0 }, // 39 bits per transform
+ { 0, 14 }, // 42 bits per transform
+ { 1, 13 }, // 42 bits per transform
+ { 2, 12 }, // 42 bits per transform
+ { 3, 11 }, // 42 bits per transform
+ { 4, 10 }, // 42 bits per transform
+ { 5, 9 }, // 42 bits per transform
+ { 6, 8 }, // 42 bits per transform
+ { 7, 7 }, // 42 bits per transform
+ { 8, 6 }, // 42 bits per transform
+ { 9, 5 }, // 42 bits per transform
+ { 10, 4 }, // 42 bits per transform
+ { 11, 3 }, // 42 bits per transform
+ { 12, 2 }, // 42 bits per transform
+ { 13, 1 }, // 42 bits per transform
+ { 14, 0 }, // 42 bits per transform
+ { 0, 15 }, // 45 bits per transform
+ { 1, 14 }, // 45 bits per transform
+ { 2, 13 }, // 45 bits per transform
+ { 3, 12 }, // 45 bits per transform
+ { 4, 11 }, // 45 bits per transform
+ { 5, 10 }, // 45 bits per transform
+ { 6, 9 }, // 45 bits per transform
+ { 7, 8 }, // 45 bits per transform
+ { 8, 7 }, // 45 bits per transform
+ { 9, 6 }, // 45 bits per transform
+ { 10, 5 }, // 45 bits per transform
+ { 11, 4 }, // 45 bits per transform
+ { 12, 3 }, // 45 bits per transform
+ { 13, 2 }, // 45 bits per transform
+ { 14, 1 }, // 45 bits per transform
+ { 15, 0 }, // 45 bits per transform
+ { 0, 16 }, // 48 bits per transform
+ { 1, 15 }, // 48 bits per transform
+ { 2, 14 }, // 48 bits per transform
+ { 3, 13 }, // 48 bits per transform
+ { 4, 12 }, // 48 bits per transform
+ { 5, 11 }, // 48 bits per transform
+ { 6, 10 }, // 48 bits per transform
+ { 7, 9 }, // 48 bits per transform
+ { 8, 8 }, // 48 bits per transform
+ { 9, 7 }, // 48 bits per transform
+ { 10, 6 }, // 48 bits per transform
+ { 11, 5 }, // 48 bits per transform
+ { 12, 4 }, // 48 bits per transform
+ { 13, 3 }, // 48 bits per transform
+ { 14, 2 }, // 48 bits per transform
+ { 15, 1 }, // 48 bits per transform
+ { 16, 0 }, // 48 bits per transform
+ { 0, 17 }, // 51 bits per transform
+ { 1, 16 }, // 51 bits per transform
+ { 2, 15 }, // 51 bits per transform
+ { 3, 14 }, // 51 bits per transform
+ { 4, 13 }, // 51 bits per transform
+ { 5, 12 }, // 51 bits per transform
+ { 6, 11 }, // 51 bits per transform
+ { 7, 10 }, // 51 bits per transform
+ { 8, 9 }, // 51 bits per transform
+ { 9, 8 }, // 51 bits per transform
+ { 10, 7 }, // 51 bits per transform
+ { 11, 6 }, // 51 bits per transform
+ { 12, 5 }, // 51 bits per transform
+ { 13, 4 }, // 51 bits per transform
+ { 14, 3 }, // 51 bits per transform
+ { 15, 2 }, // 51 bits per transform
+ { 16, 1 }, // 51 bits per transform
+ { 17, 0 }, // 51 bits per transform
+ { 0, 18 }, // 54 bits per transform
+ { 1, 17 }, // 54 bits per transform
+ { 2, 16 }, // 54 bits per transform
+ { 3, 15 }, // 54 bits per transform
+ { 4, 14 }, // 54 bits per transform
+ { 5, 13 }, // 54 bits per transform
+ { 6, 12 }, // 54 bits per transform
+ { 7, 11 }, // 54 bits per transform
+ { 8, 10 }, // 54 bits per transform
+ { 9, 9 }, // 54 bits per transform
+ { 10, 8 }, // 54 bits per transform
+ { 11, 7 }, // 54 bits per transform
+ { 12, 6 }, // 54 bits per transform
+ { 13, 5 }, // 54 bits per transform
+ { 14, 4 }, // 54 bits per transform
+ { 15, 3 }, // 54 bits per transform
+ { 16, 2 }, // 54 bits per transform
+ { 17, 1 }, // 54 bits per transform
+ { 18, 0 }, // 54 bits per transform
+ { 0, 19 }, // 57 bits per transform
+ { 1, 18 }, // 57 bits per transform
+ { 2, 17 }, // 57 bits per transform
+ { 3, 16 }, // 57 bits per transform
+ { 4, 15 }, // 57 bits per transform
+ { 5, 14 }, // 57 bits per transform
+ { 6, 13 }, // 57 bits per transform
+ { 7, 12 }, // 57 bits per transform
+ { 8, 11 }, // 57 bits per transform
+ { 9, 10 }, // 57 bits per transform
+ { 10, 9 }, // 57 bits per transform
+ { 11, 8 }, // 57 bits per transform
+ { 12, 7 }, // 57 bits per transform
+ { 13, 6 }, // 57 bits per transform
+ { 14, 5 }, // 57 bits per transform
+ { 15, 4 }, // 57 bits per transform
+ { 16, 3 }, // 57 bits per transform
+ { 17, 2 }, // 57 bits per transform
+ { 18, 1 }, // 57 bits per transform
+ { 19, 0 }, // 57 bits per transform
+ { 0, 20 }, // 60 bits per transform
+ { 1, 19 }, // 60 bits per transform
+ { 2, 18 }, // 60 bits per transform
+ { 3, 17 }, // 60 bits per transform
+ { 4, 16 }, // 60 bits per transform
+ { 5, 15 }, // 60 bits per transform
+ { 6, 14 }, // 60 bits per transform
+ { 7, 13 }, // 60 bits per transform
+ { 8, 12 }, // 60 bits per transform
+ { 9, 11 }, // 60 bits per transform
+ { 10, 10 }, // 60 bits per transform
+ { 11, 9 }, // 60 bits per transform
+ { 12, 8 }, // 60 bits per transform
+ { 13, 7 }, // 60 bits per transform
+ { 14, 6 }, // 60 bits per transform
+ { 15, 5 }, // 60 bits per transform
+ { 16, 4 }, // 60 bits per transform
+ { 17, 3 }, // 60 bits per transform
+ { 18, 2 }, // 60 bits per transform
+ { 19, 1 }, // 60 bits per transform
+ { 20, 0 }, // 60 bits per transform
+ { 0, 21 }, // 63 bits per transform
+ { 1, 20 }, // 63 bits per transform
+ { 2, 19 }, // 63 bits per transform
+ { 3, 18 }, // 63 bits per transform
+ { 4, 17 }, // 63 bits per transform
+ { 5, 16 }, // 63 bits per transform
+ { 6, 15 }, // 63 bits per transform
+ { 7, 14 }, // 63 bits per transform
+ { 8, 13 }, // 63 bits per transform
+ { 9, 12 }, // 63 bits per transform
+ { 10, 11 }, // 63 bits per transform
+ { 11, 10 }, // 63 bits per transform
+ { 12, 9 }, // 63 bits per transform
+ { 13, 8 }, // 63 bits per transform
+ { 14, 7 }, // 63 bits per transform
+ { 15, 6 }, // 63 bits per transform
+ { 16, 5 }, // 63 bits per transform
+ { 17, 4 }, // 63 bits per transform
+ { 18, 3 }, // 63 bits per transform
+ { 19, 2 }, // 63 bits per transform
+ { 20, 1 }, // 63 bits per transform
+ { 21, 0 }, // 63 bits per transform
+ { 0, 22 }, // 66 bits per transform
+ { 1, 21 }, // 66 bits per transform
+ { 2, 20 }, // 66 bits per transform
+ { 3, 19 }, // 66 bits per transform
+ { 4, 18 }, // 66 bits per transform
+ { 5, 17 }, // 66 bits per transform
+ { 6, 16 }, // 66 bits per transform
+ { 7, 15 }, // 66 bits per transform
+ { 8, 14 }, // 66 bits per transform
+ { 9, 13 }, // 66 bits per transform
+ { 10, 12 }, // 66 bits per transform
+ { 11, 11 }, // 66 bits per transform
+ { 12, 10 }, // 66 bits per transform
+ { 13, 9 }, // 66 bits per transform
+ { 14, 8 }, // 66 bits per transform
+ { 15, 7 }, // 66 bits per transform
+ { 16, 6 }, // 66 bits per transform
+ { 17, 5 }, // 66 bits per transform
+ { 18, 4 }, // 66 bits per transform
+ { 19, 3 }, // 66 bits per transform
+ { 20, 2 }, // 66 bits per transform
+ { 21, 1 }, // 66 bits per transform
+ { 22, 0 }, // 66 bits per transform
+ { 0, 23 }, // 69 bits per transform
+ { 1, 22 }, // 69 bits per transform
+ { 2, 21 }, // 69 bits per transform
+ { 3, 20 }, // 69 bits per transform
+ { 4, 19 }, // 69 bits per transform
+ { 5, 18 }, // 69 bits per transform
+ { 6, 17 }, // 69 bits per transform
+ { 7, 16 }, // 69 bits per transform
+ { 8, 15 }, // 69 bits per transform
+ { 9, 14 }, // 69 bits per transform
+ { 10, 13 }, // 69 bits per transform
+ { 11, 12 }, // 69 bits per transform
+ { 12, 11 }, // 69 bits per transform
+ { 13, 10 }, // 69 bits per transform
+ { 14, 9 }, // 69 bits per transform
+ { 15, 8 }, // 69 bits per transform
+ { 16, 7 }, // 69 bits per transform
+ { 17, 6 }, // 69 bits per transform
+ { 18, 5 }, // 69 bits per transform
+ { 19, 4 }, // 69 bits per transform
+ { 20, 3 }, // 69 bits per transform
+ { 21, 2 }, // 69 bits per transform
+ { 22, 1 }, // 69 bits per transform
+ { 23, 0 }, // 69 bits per transform
+ { 1, 23 }, // 72 bits per transform
+ { 2, 22 }, // 72 bits per transform
+ { 3, 21 }, // 72 bits per transform
+ { 4, 20 }, // 72 bits per transform
+ { 5, 19 }, // 72 bits per transform
+ { 6, 18 }, // 72 bits per transform
+ { 7, 17 }, // 72 bits per transform
+ { 8, 16 }, // 72 bits per transform
+ { 9, 15 }, // 72 bits per transform
+ { 10, 14 }, // 72 bits per transform
+ { 11, 13 }, // 72 bits per transform
+ { 12, 12 }, // 72 bits per transform
+ { 13, 11 }, // 72 bits per transform
+ { 14, 10 }, // 72 bits per transform
+ { 15, 9 }, // 72 bits per transform
+ { 16, 8 }, // 72 bits per transform
+ { 17, 7 }, // 72 bits per transform
+ { 18, 6 }, // 72 bits per transform
+ { 19, 5 }, // 72 bits per transform
+ { 20, 4 }, // 72 bits per transform
+ { 21, 3 }, // 72 bits per transform
+ { 22, 2 }, // 72 bits per transform
+ { 23, 1 }, // 72 bits per transform
+ { 2, 23 }, // 75 bits per transform
+ { 3, 22 }, // 75 bits per transform
+ { 4, 21 }, // 75 bits per transform
+ { 5, 20 }, // 75 bits per transform
+ { 6, 19 }, // 75 bits per transform
+ { 7, 18 }, // 75 bits per transform
+ { 8, 17 }, // 75 bits per transform
+ { 9, 16 }, // 75 bits per transform
+ { 10, 15 }, // 75 bits per transform
+ { 11, 14 }, // 75 bits per transform
+ { 12, 13 }, // 75 bits per transform
+ { 13, 12 }, // 75 bits per transform
+ { 14, 11 }, // 75 bits per transform
+ { 15, 10 }, // 75 bits per transform
+ { 16, 9 }, // 75 bits per transform
+ { 17, 8 }, // 75 bits per transform
+ { 18, 7 }, // 75 bits per transform
+ { 19, 6 }, // 75 bits per transform
+ { 20, 5 }, // 75 bits per transform
+ { 21, 4 }, // 75 bits per transform
+ { 22, 3 }, // 75 bits per transform
+ { 23, 2 }, // 75 bits per transform
+ { 3, 23 }, // 78 bits per transform
+ { 4, 22 }, // 78 bits per transform
+ { 5, 21 }, // 78 bits per transform
+ { 6, 20 }, // 78 bits per transform
+ { 7, 19 }, // 78 bits per transform
+ { 8, 18 }, // 78 bits per transform
+ { 9, 17 }, // 78 bits per transform
+ { 10, 16 }, // 78 bits per transform
+ { 11, 15 }, // 78 bits per transform
+ { 12, 14 }, // 78 bits per transform
+ { 13, 13 }, // 78 bits per transform
+ { 14, 12 }, // 78 bits per transform
+ { 15, 11 }, // 78 bits per transform
+ { 16, 10 }, // 78 bits per transform
+ { 17, 9 }, // 78 bits per transform
+ { 18, 8 }, // 78 bits per transform
+ { 19, 7 }, // 78 bits per transform
+ { 20, 6 }, // 78 bits per transform
+ { 21, 5 }, // 78 bits per transform
+ { 22, 4 }, // 78 bits per transform
+ { 23, 3 }, // 78 bits per transform
+ { 4, 23 }, // 81 bits per transform
+ { 5, 22 }, // 81 bits per transform
+ { 6, 21 }, // 81 bits per transform
+ { 7, 20 }, // 81 bits per transform
+ { 8, 19 }, // 81 bits per transform
+ { 9, 18 }, // 81 bits per transform
+ { 10, 17 }, // 81 bits per transform
+ { 11, 16 }, // 81 bits per transform
+ { 12, 15 }, // 81 bits per transform
+ { 13, 14 }, // 81 bits per transform
+ { 14, 13 }, // 81 bits per transform
+ { 15, 12 }, // 81 bits per transform
+ { 16, 11 }, // 81 bits per transform
+ { 17, 10 }, // 81 bits per transform
+ { 18, 9 }, // 81 bits per transform
+ { 19, 8 }, // 81 bits per transform
+ { 20, 7 }, // 81 bits per transform
+ { 21, 6 }, // 81 bits per transform
+ { 22, 5 }, // 81 bits per transform
+ { 23, 4 }, // 81 bits per transform
+ { 5, 23 }, // 84 bits per transform
+ { 6, 22 }, // 84 bits per transform
+ { 7, 21 }, // 84 bits per transform
+ { 8, 20 }, // 84 bits per transform
+ { 9, 19 }, // 84 bits per transform
+ { 10, 18 }, // 84 bits per transform
+ { 11, 17 }, // 84 bits per transform
+ { 12, 16 }, // 84 bits per transform
+ { 13, 15 }, // 84 bits per transform
+ { 14, 14 }, // 84 bits per transform
+ { 15, 13 }, // 84 bits per transform
+ { 16, 12 }, // 84 bits per transform
+ { 17, 11 }, // 84 bits per transform
+ { 18, 10 }, // 84 bits per transform
+ { 19, 9 }, // 84 bits per transform
+ { 20, 8 }, // 84 bits per transform
+ { 21, 7 }, // 84 bits per transform
+ { 22, 6 }, // 84 bits per transform
+ { 23, 5 }, // 84 bits per transform
+ { 6, 23 }, // 87 bits per transform
+ { 7, 22 }, // 87 bits per transform
+ { 8, 21 }, // 87 bits per transform
+ { 9, 20 }, // 87 bits per transform
+ { 10, 19 }, // 87 bits per transform
+ { 11, 18 }, // 87 bits per transform
+ { 12, 17 }, // 87 bits per transform
+ { 13, 16 }, // 87 bits per transform
+ { 14, 15 }, // 87 bits per transform
+ { 15, 14 }, // 87 bits per transform
+ { 16, 13 }, // 87 bits per transform
+ { 17, 12 }, // 87 bits per transform
+ { 18, 11 }, // 87 bits per transform
+ { 19, 10 }, // 87 bits per transform
+ { 20, 9 }, // 87 bits per transform
+ { 21, 8 }, // 87 bits per transform
+ { 22, 7 }, // 87 bits per transform
+ { 23, 6 }, // 87 bits per transform
+ { 7, 23 }, // 90 bits per transform
+ { 8, 22 }, // 90 bits per transform
+ { 9, 21 }, // 90 bits per transform
+ { 10, 20 }, // 90 bits per transform
+ { 11, 19 }, // 90 bits per transform
+ { 12, 18 }, // 90 bits per transform
+ { 13, 17 }, // 90 bits per transform
+ { 14, 16 }, // 90 bits per transform
+ { 15, 15 }, // 90 bits per transform
+ { 16, 14 }, // 90 bits per transform
+ { 17, 13 }, // 90 bits per transform
+ { 18, 12 }, // 90 bits per transform
+ { 19, 11 }, // 90 bits per transform
+ { 20, 10 }, // 90 bits per transform
+ { 21, 9 }, // 90 bits per transform
+ { 22, 8 }, // 90 bits per transform
+ { 23, 7 }, // 90 bits per transform
+ { 8, 23 }, // 93 bits per transform
+ { 9, 22 }, // 93 bits per transform
+ { 10, 21 }, // 93 bits per transform
+ { 11, 20 }, // 93 bits per transform
+ { 12, 19 }, // 93 bits per transform
+ { 13, 18 }, // 93 bits per transform
+ { 14, 17 }, // 93 bits per transform
+ { 15, 16 }, // 93 bits per transform
+ { 16, 15 }, // 93 bits per transform
+ { 17, 14 }, // 93 bits per transform
+ { 18, 13 }, // 93 bits per transform
+ { 19, 12 }, // 93 bits per transform
+ { 20, 11 }, // 93 bits per transform
+ { 21, 10 }, // 93 bits per transform
+ { 22, 9 }, // 93 bits per transform
+ { 23, 8 }, // 93 bits per transform
+ { 0, 24 }, // 96 bits per transform
+ { 9, 23 }, // 96 bits per transform
+ { 10, 22 }, // 96 bits per transform
+ { 11, 21 }, // 96 bits per transform
+ { 12, 20 }, // 96 bits per transform
+ { 13, 19 }, // 96 bits per transform
+ { 14, 18 }, // 96 bits per transform
+ { 15, 17 }, // 96 bits per transform
+ { 16, 16 }, // 96 bits per transform
+ { 17, 15 }, // 96 bits per transform
+ { 18, 14 }, // 96 bits per transform
+ { 19, 13 }, // 96 bits per transform
+ { 20, 12 }, // 96 bits per transform
+ { 21, 11 }, // 96 bits per transform
+ { 22, 10 }, // 96 bits per transform
+ { 23, 9 }, // 96 bits per transform
+ { 24, 0 }, // 96 bits per transform
+ { 1, 24 }, // 99 bits per transform
+ { 10, 23 }, // 99 bits per transform
+ { 11, 22 }, // 99 bits per transform
+ { 12, 21 }, // 99 bits per transform
+ { 13, 20 }, // 99 bits per transform
+ { 14, 19 }, // 99 bits per transform
+ { 15, 18 }, // 99 bits per transform
+ { 16, 17 }, // 99 bits per transform
+ { 17, 16 }, // 99 bits per transform
+ { 18, 15 }, // 99 bits per transform
+ { 19, 14 }, // 99 bits per transform
+ { 20, 13 }, // 99 bits per transform
+ { 21, 12 }, // 99 bits per transform
+ { 22, 11 }, // 99 bits per transform
+ { 23, 10 }, // 99 bits per transform
+ { 24, 1 }, // 99 bits per transform
+ { 2, 24 }, // 102 bits per transform
+ { 11, 23 }, // 102 bits per transform
+ { 12, 22 }, // 102 bits per transform
+ { 13, 21 }, // 102 bits per transform
+ { 14, 20 }, // 102 bits per transform
+ { 15, 19 }, // 102 bits per transform
+ { 16, 18 }, // 102 bits per transform
+ { 17, 17 }, // 102 bits per transform
+ { 18, 16 }, // 102 bits per transform
+ { 19, 15 }, // 102 bits per transform
+ { 20, 14 }, // 102 bits per transform
+ { 21, 13 }, // 102 bits per transform
+ { 22, 12 }, // 102 bits per transform
+ { 23, 11 }, // 102 bits per transform
+ { 24, 2 }, // 102 bits per transform
+ { 3, 24 }, // 105 bits per transform
+ { 12, 23 }, // 105 bits per transform
+ { 13, 22 }, // 105 bits per transform
+ { 14, 21 }, // 105 bits per transform
+ { 15, 20 }, // 105 bits per transform
+ { 16, 19 }, // 105 bits per transform
+ { 17, 18 }, // 105 bits per transform
+ { 18, 17 }, // 105 bits per transform
+ { 19, 16 }, // 105 bits per transform
+ { 20, 15 }, // 105 bits per transform
+ { 21, 14 }, // 105 bits per transform
+ { 22, 13 }, // 105 bits per transform
+ { 23, 12 }, // 105 bits per transform
+ { 24, 3 }, // 105 bits per transform
+ { 4, 24 }, // 108 bits per transform
+ { 13, 23 }, // 108 bits per transform
+ { 14, 22 }, // 108 bits per transform
+ { 15, 21 }, // 108 bits per transform
+ { 16, 20 }, // 108 bits per transform
+ { 17, 19 }, // 108 bits per transform
+ { 18, 18 }, // 108 bits per transform
+ { 19, 17 }, // 108 bits per transform
+ { 20, 16 }, // 108 bits per transform
+ { 21, 15 }, // 108 bits per transform
+ { 22, 14 }, // 108 bits per transform
+ { 23, 13 }, // 108 bits per transform
+ { 24, 4 }, // 108 bits per transform
+ { 5, 24 }, // 111 bits per transform
+ { 14, 23 }, // 111 bits per transform
+ { 15, 22 }, // 111 bits per transform
+ { 16, 21 }, // 111 bits per transform
+ { 17, 20 }, // 111 bits per transform
+ { 18, 19 }, // 111 bits per transform
+ { 19, 18 }, // 111 bits per transform
+ { 20, 17 }, // 111 bits per transform
+ { 21, 16 }, // 111 bits per transform
+ { 22, 15 }, // 111 bits per transform
+ { 23, 14 }, // 111 bits per transform
+ { 24, 5 }, // 111 bits per transform
+ { 6, 24 }, // 114 bits per transform
+ { 15, 23 }, // 114 bits per transform
+ { 16, 22 }, // 114 bits per transform
+ { 17, 21 }, // 114 bits per transform
+ { 18, 20 }, // 114 bits per transform
+ { 19, 19 }, // 114 bits per transform
+ { 20, 18 }, // 114 bits per transform
+ { 21, 17 }, // 114 bits per transform
+ { 22, 16 }, // 114 bits per transform
+ { 23, 15 }, // 114 bits per transform
+ { 24, 6 }, // 114 bits per transform
+ { 7, 24 }, // 117 bits per transform
+ { 16, 23 }, // 117 bits per transform
+ { 17, 22 }, // 117 bits per transform
+ { 18, 21 }, // 117 bits per transform
+ { 19, 20 }, // 117 bits per transform
+ { 20, 19 }, // 117 bits per transform
+ { 21, 18 }, // 117 bits per transform
+ { 22, 17 }, // 117 bits per transform
+ { 23, 16 }, // 117 bits per transform
+ { 24, 7 }, // 117 bits per transform
+ { 8, 24 }, // 120 bits per transform
+ { 17, 23 }, // 120 bits per transform
+ { 18, 22 }, // 120 bits per transform
+ { 19, 21 }, // 120 bits per transform
+ { 20, 20 }, // 120 bits per transform
+ { 21, 19 }, // 120 bits per transform
+ { 22, 18 }, // 120 bits per transform
+ { 23, 17 }, // 120 bits per transform
+ { 24, 8 }, // 120 bits per transform
+ { 9, 24 }, // 123 bits per transform
+ { 18, 23 }, // 123 bits per transform
+ { 19, 22 }, // 123 bits per transform
+ { 20, 21 }, // 123 bits per transform
+ { 21, 20 }, // 123 bits per transform
+ { 22, 19 }, // 123 bits per transform
+ { 23, 18 }, // 123 bits per transform
+ { 24, 9 }, // 123 bits per transform
+ { 10, 24 }, // 126 bits per transform
+ { 19, 23 }, // 126 bits per transform
+ { 20, 22 }, // 126 bits per transform
+ { 21, 21 }, // 126 bits per transform
+ { 22, 20 }, // 126 bits per transform
+ { 23, 19 }, // 126 bits per transform
+ { 24, 10 }, // 126 bits per transform
+ { 11, 24 }, // 129 bits per transform
+ { 20, 23 }, // 129 bits per transform
+ { 21, 22 }, // 129 bits per transform
+ { 22, 21 }, // 129 bits per transform
+ { 23, 20 }, // 129 bits per transform
+ { 24, 11 }, // 129 bits per transform
+ { 12, 24 }, // 132 bits per transform
+ { 21, 23 }, // 132 bits per transform
+ { 22, 22 }, // 132 bits per transform
+ { 23, 21 }, // 132 bits per transform
+ { 24, 12 }, // 132 bits per transform
+ { 13, 24 }, // 135 bits per transform
+ { 22, 23 }, // 135 bits per transform
+ { 23, 22 }, // 135 bits per transform
+ { 24, 13 }, // 135 bits per transform
+ { 14, 24 }, // 138 bits per transform
+ { 23, 23 }, // 138 bits per transform
+ { 24, 14 }, // 138 bits per transform
+ { 15, 24 }, // 141 bits per transform
+ { 24, 15 }, // 141 bits per transform
+ { 16, 24 }, // 144 bits per transform
+ { 24, 16 }, // 144 bits per transform
+ { 17, 24 }, // 147 bits per transform
+ { 24, 17 }, // 147 bits per transform
+ { 18, 24 }, // 150 bits per transform
+ { 24, 18 }, // 150 bits per transform
+ { 19, 24 }, // 153 bits per transform
+ { 24, 19 }, // 153 bits per transform
+ { 20, 24 }, // 156 bits per transform
+ { 24, 20 }, // 156 bits per transform
+ { 21, 24 }, // 159 bits per transform
+ { 24, 21 }, // 159 bits per transform
+ { 22, 24 }, // 162 bits per transform
+ { 24, 22 }, // 162 bits per transform
+ { 23, 24 }, // 165 bits per transform
+ { 24, 23 }, // 165 bits per transform
+ { 24, 24 }, // 192 bits per transform
};
- constexpr uint8_t k_local_bit_rate_permutations[6859][3] =
+ constexpr uint8_t k_local_bit_rate_permutations[15625][3] =
{
{ 0, 0, 0 }, // 0 bits per transform
- { 0, 0, 1 }, // 9 bits per transform
- { 0, 1, 0 }, // 9 bits per transform
- { 1, 0, 0 }, // 9 bits per transform
- { 0, 0, 2 }, // 12 bits per transform
- { 0, 2, 0 }, // 12 bits per transform
- { 2, 0, 0 }, // 12 bits per transform
- { 0, 0, 3 }, // 15 bits per transform
- { 0, 3, 0 }, // 15 bits per transform
- { 3, 0, 0 }, // 15 bits per transform
- { 0, 0, 4 }, // 18 bits per transform
- { 0, 1, 1 }, // 18 bits per transform
- { 0, 4, 0 }, // 18 bits per transform
- { 1, 0, 1 }, // 18 bits per transform
- { 1, 1, 0 }, // 18 bits per transform
- { 4, 0, 0 }, // 18 bits per transform
- { 0, 0, 5 }, // 21 bits per transform
- { 0, 1, 2 }, // 21 bits per transform
- { 0, 2, 1 }, // 21 bits per transform
- { 0, 5, 0 }, // 21 bits per transform
- { 1, 0, 2 }, // 21 bits per transform
- { 1, 2, 0 }, // 21 bits per transform
- { 2, 0, 1 }, // 21 bits per transform
- { 2, 1, 0 }, // 21 bits per transform
- { 5, 0, 0 }, // 21 bits per transform
- { 0, 0, 6 }, // 24 bits per transform
- { 0, 1, 3 }, // 24 bits per transform
- { 0, 2, 2 }, // 24 bits per transform
- { 0, 3, 1 }, // 24 bits per transform
- { 0, 6, 0 }, // 24 bits per transform
- { 1, 0, 3 }, // 24 bits per transform
- { 1, 3, 0 }, // 24 bits per transform
- { 2, 0, 2 }, // 24 bits per transform
- { 2, 2, 0 }, // 24 bits per transform
- { 3, 0, 1 }, // 24 bits per transform
- { 3, 1, 0 }, // 24 bits per transform
- { 6, 0, 0 }, // 24 bits per transform
- { 0, 0, 7 }, // 27 bits per transform
- { 0, 1, 4 }, // 27 bits per transform
- { 0, 2, 3 }, // 27 bits per transform
- { 0, 3, 2 }, // 27 bits per transform
- { 0, 4, 1 }, // 27 bits per transform
- { 0, 7, 0 }, // 27 bits per transform
- { 1, 0, 4 }, // 27 bits per transform
- { 1, 1, 1 }, // 27 bits per transform
- { 1, 4, 0 }, // 27 bits per transform
- { 2, 0, 3 }, // 27 bits per transform
- { 2, 3, 0 }, // 27 bits per transform
- { 3, 0, 2 }, // 27 bits per transform
- { 3, 2, 0 }, // 27 bits per transform
- { 4, 0, 1 }, // 27 bits per transform
- { 4, 1, 0 }, // 27 bits per transform
- { 7, 0, 0 }, // 27 bits per transform
- { 0, 0, 8 }, // 30 bits per transform
- { 0, 1, 5 }, // 30 bits per transform
- { 0, 2, 4 }, // 30 bits per transform
- { 0, 3, 3 }, // 30 bits per transform
- { 0, 4, 2 }, // 30 bits per transform
- { 0, 5, 1 }, // 30 bits per transform
- { 0, 8, 0 }, // 30 bits per transform
- { 1, 0, 5 }, // 30 bits per transform
- { 1, 1, 2 }, // 30 bits per transform
- { 1, 2, 1 }, // 30 bits per transform
- { 1, 5, 0 }, // 30 bits per transform
- { 2, 0, 4 }, // 30 bits per transform
- { 2, 1, 1 }, // 30 bits per transform
- { 2, 4, 0 }, // 30 bits per transform
- { 3, 0, 3 }, // 30 bits per transform
- { 3, 3, 0 }, // 30 bits per transform
- { 4, 0, 2 }, // 30 bits per transform
- { 4, 2, 0 }, // 30 bits per transform
- { 5, 0, 1 }, // 30 bits per transform
- { 5, 1, 0 }, // 30 bits per transform
- { 8, 0, 0 }, // 30 bits per transform
- { 0, 0, 9 }, // 33 bits per transform
- { 0, 1, 6 }, // 33 bits per transform
- { 0, 2, 5 }, // 33 bits per transform
- { 0, 3, 4 }, // 33 bits per transform
- { 0, 4, 3 }, // 33 bits per transform
- { 0, 5, 2 }, // 33 bits per transform
- { 0, 6, 1 }, // 33 bits per transform
- { 0, 9, 0 }, // 33 bits per transform
- { 1, 0, 6 }, // 33 bits per transform
- { 1, 1, 3 }, // 33 bits per transform
- { 1, 2, 2 }, // 33 bits per transform
- { 1, 3, 1 }, // 33 bits per transform
- { 1, 6, 0 }, // 33 bits per transform
- { 2, 0, 5 }, // 33 bits per transform
- { 2, 1, 2 }, // 33 bits per transform
- { 2, 2, 1 }, // 33 bits per transform
- { 2, 5, 0 }, // 33 bits per transform
- { 3, 0, 4 }, // 33 bits per transform
- { 3, 1, 1 }, // 33 bits per transform
- { 3, 4, 0 }, // 33 bits per transform
- { 4, 0, 3 }, // 33 bits per transform
- { 4, 3, 0 }, // 33 bits per transform
- { 5, 0, 2 }, // 33 bits per transform
- { 5, 2, 0 }, // 33 bits per transform
- { 6, 0, 1 }, // 33 bits per transform
- { 6, 1, 0 }, // 33 bits per transform
- { 9, 0, 0 }, // 33 bits per transform
- { 0, 0, 10 }, // 36 bits per transform
- { 0, 1, 7 }, // 36 bits per transform
- { 0, 2, 6 }, // 36 bits per transform
- { 0, 3, 5 }, // 36 bits per transform
- { 0, 4, 4 }, // 36 bits per transform
- { 0, 5, 3 }, // 36 bits per transform
- { 0, 6, 2 }, // 36 bits per transform
- { 0, 7, 1 }, // 36 bits per transform
- { 0, 10, 0 }, // 36 bits per transform
- { 1, 0, 7 }, // 36 bits per transform
- { 1, 1, 4 }, // 36 bits per transform
- { 1, 2, 3 }, // 36 bits per transform
- { 1, 3, 2 }, // 36 bits per transform
- { 1, 4, 1 }, // 36 bits per transform
- { 1, 7, 0 }, // 36 bits per transform
- { 2, 0, 6 }, // 36 bits per transform
- { 2, 1, 3 }, // 36 bits per transform
- { 2, 2, 2 }, // 36 bits per transform
- { 2, 3, 1 }, // 36 bits per transform
- { 2, 6, 0 }, // 36 bits per transform
- { 3, 0, 5 }, // 36 bits per transform
- { 3, 1, 2 }, // 36 bits per transform
- { 3, 2, 1 }, // 36 bits per transform
- { 3, 5, 0 }, // 36 bits per transform
- { 4, 0, 4 }, // 36 bits per transform
- { 4, 1, 1 }, // 36 bits per transform
- { 4, 4, 0 }, // 36 bits per transform
- { 5, 0, 3 }, // 36 bits per transform
- { 5, 3, 0 }, // 36 bits per transform
- { 6, 0, 2 }, // 36 bits per transform
- { 6, 2, 0 }, // 36 bits per transform
- { 7, 0, 1 }, // 36 bits per transform
- { 7, 1, 0 }, // 36 bits per transform
- { 10, 0, 0 }, // 36 bits per transform
- { 0, 0, 11 }, // 39 bits per transform
- { 0, 1, 8 }, // 39 bits per transform
- { 0, 2, 7 }, // 39 bits per transform
- { 0, 3, 6 }, // 39 bits per transform
- { 0, 4, 5 }, // 39 bits per transform
- { 0, 5, 4 }, // 39 bits per transform
- { 0, 6, 3 }, // 39 bits per transform
- { 0, 7, 2 }, // 39 bits per transform
- { 0, 8, 1 }, // 39 bits per transform
- { 0, 11, 0 }, // 39 bits per transform
- { 1, 0, 8 }, // 39 bits per transform
- { 1, 1, 5 }, // 39 bits per transform
- { 1, 2, 4 }, // 39 bits per transform
- { 1, 3, 3 }, // 39 bits per transform
- { 1, 4, 2 }, // 39 bits per transform
- { 1, 5, 1 }, // 39 bits per transform
- { 1, 8, 0 }, // 39 bits per transform
- { 2, 0, 7 }, // 39 bits per transform
- { 2, 1, 4 }, // 39 bits per transform
- { 2, 2, 3 }, // 39 bits per transform
- { 2, 3, 2 }, // 39 bits per transform
- { 2, 4, 1 }, // 39 bits per transform
- { 2, 7, 0 }, // 39 bits per transform
- { 3, 0, 6 }, // 39 bits per transform
- { 3, 1, 3 }, // 39 bits per transform
- { 3, 2, 2 }, // 39 bits per transform
- { 3, 3, 1 }, // 39 bits per transform
- { 3, 6, 0 }, // 39 bits per transform
- { 4, 0, 5 }, // 39 bits per transform
- { 4, 1, 2 }, // 39 bits per transform
- { 4, 2, 1 }, // 39 bits per transform
- { 4, 5, 0 }, // 39 bits per transform
- { 5, 0, 4 }, // 39 bits per transform
- { 5, 1, 1 }, // 39 bits per transform
- { 5, 4, 0 }, // 39 bits per transform
- { 6, 0, 3 }, // 39 bits per transform
- { 6, 3, 0 }, // 39 bits per transform
- { 7, 0, 2 }, // 39 bits per transform
- { 7, 2, 0 }, // 39 bits per transform
- { 8, 0, 1 }, // 39 bits per transform
- { 8, 1, 0 }, // 39 bits per transform
- { 11, 0, 0 }, // 39 bits per transform
- { 0, 0, 12 }, // 42 bits per transform
- { 0, 1, 9 }, // 42 bits per transform
- { 0, 2, 8 }, // 42 bits per transform
- { 0, 3, 7 }, // 42 bits per transform
- { 0, 4, 6 }, // 42 bits per transform
- { 0, 5, 5 }, // 42 bits per transform
- { 0, 6, 4 }, // 42 bits per transform
- { 0, 7, 3 }, // 42 bits per transform
- { 0, 8, 2 }, // 42 bits per transform
- { 0, 9, 1 }, // 42 bits per transform
- { 0, 12, 0 }, // 42 bits per transform
- { 1, 0, 9 }, // 42 bits per transform
- { 1, 1, 6 }, // 42 bits per transform
- { 1, 2, 5 }, // 42 bits per transform
- { 1, 3, 4 }, // 42 bits per transform
- { 1, 4, 3 }, // 42 bits per transform
- { 1, 5, 2 }, // 42 bits per transform
- { 1, 6, 1 }, // 42 bits per transform
- { 1, 9, 0 }, // 42 bits per transform
- { 2, 0, 8 }, // 42 bits per transform
- { 2, 1, 5 }, // 42 bits per transform
- { 2, 2, 4 }, // 42 bits per transform
- { 2, 3, 3 }, // 42 bits per transform
- { 2, 4, 2 }, // 42 bits per transform
- { 2, 5, 1 }, // 42 bits per transform
- { 2, 8, 0 }, // 42 bits per transform
- { 3, 0, 7 }, // 42 bits per transform
- { 3, 1, 4 }, // 42 bits per transform
- { 3, 2, 3 }, // 42 bits per transform
- { 3, 3, 2 }, // 42 bits per transform
- { 3, 4, 1 }, // 42 bits per transform
- { 3, 7, 0 }, // 42 bits per transform
- { 4, 0, 6 }, // 42 bits per transform
- { 4, 1, 3 }, // 42 bits per transform
- { 4, 2, 2 }, // 42 bits per transform
- { 4, 3, 1 }, // 42 bits per transform
- { 4, 6, 0 }, // 42 bits per transform
- { 5, 0, 5 }, // 42 bits per transform
- { 5, 1, 2 }, // 42 bits per transform
- { 5, 2, 1 }, // 42 bits per transform
- { 5, 5, 0 }, // 42 bits per transform
- { 6, 0, 4 }, // 42 bits per transform
- { 6, 1, 1 }, // 42 bits per transform
- { 6, 4, 0 }, // 42 bits per transform
- { 7, 0, 3 }, // 42 bits per transform
- { 7, 3, 0 }, // 42 bits per transform
- { 8, 0, 2 }, // 42 bits per transform
- { 8, 2, 0 }, // 42 bits per transform
- { 9, 0, 1 }, // 42 bits per transform
- { 9, 1, 0 }, // 42 bits per transform
- { 12, 0, 0 }, // 42 bits per transform
- { 0, 0, 13 }, // 45 bits per transform
- { 0, 1, 10 }, // 45 bits per transform
- { 0, 2, 9 }, // 45 bits per transform
- { 0, 3, 8 }, // 45 bits per transform
- { 0, 4, 7 }, // 45 bits per transform
- { 0, 5, 6 }, // 45 bits per transform
- { 0, 6, 5 }, // 45 bits per transform
- { 0, 7, 4 }, // 45 bits per transform
- { 0, 8, 3 }, // 45 bits per transform
- { 0, 9, 2 }, // 45 bits per transform
- { 0, 10, 1 }, // 45 bits per transform
- { 0, 13, 0 }, // 45 bits per transform
- { 1, 0, 10 }, // 45 bits per transform
- { 1, 1, 7 }, // 45 bits per transform
- { 1, 2, 6 }, // 45 bits per transform
- { 1, 3, 5 }, // 45 bits per transform
- { 1, 4, 4 }, // 45 bits per transform
- { 1, 5, 3 }, // 45 bits per transform
- { 1, 6, 2 }, // 45 bits per transform
- { 1, 7, 1 }, // 45 bits per transform
- { 1, 10, 0 }, // 45 bits per transform
- { 2, 0, 9 }, // 45 bits per transform
- { 2, 1, 6 }, // 45 bits per transform
- { 2, 2, 5 }, // 45 bits per transform
- { 2, 3, 4 }, // 45 bits per transform
- { 2, 4, 3 }, // 45 bits per transform
- { 2, 5, 2 }, // 45 bits per transform
- { 2, 6, 1 }, // 45 bits per transform
- { 2, 9, 0 }, // 45 bits per transform
- { 3, 0, 8 }, // 45 bits per transform
- { 3, 1, 5 }, // 45 bits per transform
- { 3, 2, 4 }, // 45 bits per transform
- { 3, 3, 3 }, // 45 bits per transform
- { 3, 4, 2 }, // 45 bits per transform
- { 3, 5, 1 }, // 45 bits per transform
- { 3, 8, 0 }, // 45 bits per transform
- { 4, 0, 7 }, // 45 bits per transform
- { 4, 1, 4 }, // 45 bits per transform
- { 4, 2, 3 }, // 45 bits per transform
- { 4, 3, 2 }, // 45 bits per transform
- { 4, 4, 1 }, // 45 bits per transform
- { 4, 7, 0 }, // 45 bits per transform
- { 5, 0, 6 }, // 45 bits per transform
- { 5, 1, 3 }, // 45 bits per transform
- { 5, 2, 2 }, // 45 bits per transform
- { 5, 3, 1 }, // 45 bits per transform
- { 5, 6, 0 }, // 45 bits per transform
- { 6, 0, 5 }, // 45 bits per transform
- { 6, 1, 2 }, // 45 bits per transform
- { 6, 2, 1 }, // 45 bits per transform
- { 6, 5, 0 }, // 45 bits per transform
- { 7, 0, 4 }, // 45 bits per transform
- { 7, 1, 1 }, // 45 bits per transform
- { 7, 4, 0 }, // 45 bits per transform
- { 8, 0, 3 }, // 45 bits per transform
- { 8, 3, 0 }, // 45 bits per transform
- { 9, 0, 2 }, // 45 bits per transform
- { 9, 2, 0 }, // 45 bits per transform
- { 10, 0, 1 }, // 45 bits per transform
- { 10, 1, 0 }, // 45 bits per transform
- { 13, 0, 0 }, // 45 bits per transform
- { 0, 0, 14 }, // 48 bits per transform
- { 0, 1, 11 }, // 48 bits per transform
- { 0, 2, 10 }, // 48 bits per transform
- { 0, 3, 9 }, // 48 bits per transform
- { 0, 4, 8 }, // 48 bits per transform
- { 0, 5, 7 }, // 48 bits per transform
- { 0, 6, 6 }, // 48 bits per transform
- { 0, 7, 5 }, // 48 bits per transform
- { 0, 8, 4 }, // 48 bits per transform
- { 0, 9, 3 }, // 48 bits per transform
- { 0, 10, 2 }, // 48 bits per transform
- { 0, 11, 1 }, // 48 bits per transform
- { 0, 14, 0 }, // 48 bits per transform
- { 1, 0, 11 }, // 48 bits per transform
- { 1, 1, 8 }, // 48 bits per transform
- { 1, 2, 7 }, // 48 bits per transform
- { 1, 3, 6 }, // 48 bits per transform
- { 1, 4, 5 }, // 48 bits per transform
- { 1, 5, 4 }, // 48 bits per transform
- { 1, 6, 3 }, // 48 bits per transform
- { 1, 7, 2 }, // 48 bits per transform
- { 1, 8, 1 }, // 48 bits per transform
- { 1, 11, 0 }, // 48 bits per transform
- { 2, 0, 10 }, // 48 bits per transform
- { 2, 1, 7 }, // 48 bits per transform
- { 2, 2, 6 }, // 48 bits per transform
- { 2, 3, 5 }, // 48 bits per transform
- { 2, 4, 4 }, // 48 bits per transform
- { 2, 5, 3 }, // 48 bits per transform
- { 2, 6, 2 }, // 48 bits per transform
- { 2, 7, 1 }, // 48 bits per transform
- { 2, 10, 0 }, // 48 bits per transform
- { 3, 0, 9 }, // 48 bits per transform
- { 3, 1, 6 }, // 48 bits per transform
- { 3, 2, 5 }, // 48 bits per transform
- { 3, 3, 4 }, // 48 bits per transform
- { 3, 4, 3 }, // 48 bits per transform
- { 3, 5, 2 }, // 48 bits per transform
- { 3, 6, 1 }, // 48 bits per transform
- { 3, 9, 0 }, // 48 bits per transform
- { 4, 0, 8 }, // 48 bits per transform
- { 4, 1, 5 }, // 48 bits per transform
- { 4, 2, 4 }, // 48 bits per transform
- { 4, 3, 3 }, // 48 bits per transform
- { 4, 4, 2 }, // 48 bits per transform
- { 4, 5, 1 }, // 48 bits per transform
- { 4, 8, 0 }, // 48 bits per transform
- { 5, 0, 7 }, // 48 bits per transform
- { 5, 1, 4 }, // 48 bits per transform
- { 5, 2, 3 }, // 48 bits per transform
- { 5, 3, 2 }, // 48 bits per transform
- { 5, 4, 1 }, // 48 bits per transform
- { 5, 7, 0 }, // 48 bits per transform
- { 6, 0, 6 }, // 48 bits per transform
- { 6, 1, 3 }, // 48 bits per transform
- { 6, 2, 2 }, // 48 bits per transform
- { 6, 3, 1 }, // 48 bits per transform
- { 6, 6, 0 }, // 48 bits per transform
- { 7, 0, 5 }, // 48 bits per transform
- { 7, 1, 2 }, // 48 bits per transform
- { 7, 2, 1 }, // 48 bits per transform
- { 7, 5, 0 }, // 48 bits per transform
- { 8, 0, 4 }, // 48 bits per transform
- { 8, 1, 1 }, // 48 bits per transform
- { 8, 4, 0 }, // 48 bits per transform
- { 9, 0, 3 }, // 48 bits per transform
- { 9, 3, 0 }, // 48 bits per transform
- { 10, 0, 2 }, // 48 bits per transform
- { 10, 2, 0 }, // 48 bits per transform
- { 11, 0, 1 }, // 48 bits per transform
- { 11, 1, 0 }, // 48 bits per transform
- { 14, 0, 0 }, // 48 bits per transform
- { 0, 0, 15 }, // 51 bits per transform
- { 0, 1, 12 }, // 51 bits per transform
- { 0, 2, 11 }, // 51 bits per transform
- { 0, 3, 10 }, // 51 bits per transform
- { 0, 4, 9 }, // 51 bits per transform
- { 0, 5, 8 }, // 51 bits per transform
- { 0, 6, 7 }, // 51 bits per transform
- { 0, 7, 6 }, // 51 bits per transform
- { 0, 8, 5 }, // 51 bits per transform
- { 0, 9, 4 }, // 51 bits per transform
- { 0, 10, 3 }, // 51 bits per transform
- { 0, 11, 2 }, // 51 bits per transform
- { 0, 12, 1 }, // 51 bits per transform
- { 0, 15, 0 }, // 51 bits per transform
- { 1, 0, 12 }, // 51 bits per transform
- { 1, 1, 9 }, // 51 bits per transform
- { 1, 2, 8 }, // 51 bits per transform
- { 1, 3, 7 }, // 51 bits per transform
- { 1, 4, 6 }, // 51 bits per transform
- { 1, 5, 5 }, // 51 bits per transform
- { 1, 6, 4 }, // 51 bits per transform
- { 1, 7, 3 }, // 51 bits per transform
- { 1, 8, 2 }, // 51 bits per transform
- { 1, 9, 1 }, // 51 bits per transform
- { 1, 12, 0 }, // 51 bits per transform
- { 2, 0, 11 }, // 51 bits per transform
- { 2, 1, 8 }, // 51 bits per transform
- { 2, 2, 7 }, // 51 bits per transform
- { 2, 3, 6 }, // 51 bits per transform
- { 2, 4, 5 }, // 51 bits per transform
- { 2, 5, 4 }, // 51 bits per transform
- { 2, 6, 3 }, // 51 bits per transform
- { 2, 7, 2 }, // 51 bits per transform
- { 2, 8, 1 }, // 51 bits per transform
- { 2, 11, 0 }, // 51 bits per transform
- { 3, 0, 10 }, // 51 bits per transform
- { 3, 1, 7 }, // 51 bits per transform
- { 3, 2, 6 }, // 51 bits per transform
- { 3, 3, 5 }, // 51 bits per transform
- { 3, 4, 4 }, // 51 bits per transform
- { 3, 5, 3 }, // 51 bits per transform
- { 3, 6, 2 }, // 51 bits per transform
- { 3, 7, 1 }, // 51 bits per transform
- { 3, 10, 0 }, // 51 bits per transform
- { 4, 0, 9 }, // 51 bits per transform
- { 4, 1, 6 }, // 51 bits per transform
- { 4, 2, 5 }, // 51 bits per transform
- { 4, 3, 4 }, // 51 bits per transform
- { 4, 4, 3 }, // 51 bits per transform
- { 4, 5, 2 }, // 51 bits per transform
- { 4, 6, 1 }, // 51 bits per transform
- { 4, 9, 0 }, // 51 bits per transform
- { 5, 0, 8 }, // 51 bits per transform
- { 5, 1, 5 }, // 51 bits per transform
- { 5, 2, 4 }, // 51 bits per transform
- { 5, 3, 3 }, // 51 bits per transform
- { 5, 4, 2 }, // 51 bits per transform
- { 5, 5, 1 }, // 51 bits per transform
- { 5, 8, 0 }, // 51 bits per transform
- { 6, 0, 7 }, // 51 bits per transform
- { 6, 1, 4 }, // 51 bits per transform
- { 6, 2, 3 }, // 51 bits per transform
- { 6, 3, 2 }, // 51 bits per transform
- { 6, 4, 1 }, // 51 bits per transform
- { 6, 7, 0 }, // 51 bits per transform
- { 7, 0, 6 }, // 51 bits per transform
- { 7, 1, 3 }, // 51 bits per transform
- { 7, 2, 2 }, // 51 bits per transform
- { 7, 3, 1 }, // 51 bits per transform
- { 7, 6, 0 }, // 51 bits per transform
- { 8, 0, 5 }, // 51 bits per transform
- { 8, 1, 2 }, // 51 bits per transform
- { 8, 2, 1 }, // 51 bits per transform
- { 8, 5, 0 }, // 51 bits per transform
- { 9, 0, 4 }, // 51 bits per transform
- { 9, 1, 1 }, // 51 bits per transform
- { 9, 4, 0 }, // 51 bits per transform
- { 10, 0, 3 }, // 51 bits per transform
- { 10, 3, 0 }, // 51 bits per transform
- { 11, 0, 2 }, // 51 bits per transform
- { 11, 2, 0 }, // 51 bits per transform
- { 12, 0, 1 }, // 51 bits per transform
- { 12, 1, 0 }, // 51 bits per transform
- { 15, 0, 0 }, // 51 bits per transform
- { 0, 0, 16 }, // 54 bits per transform
- { 0, 1, 13 }, // 54 bits per transform
- { 0, 2, 12 }, // 54 bits per transform
- { 0, 3, 11 }, // 54 bits per transform
- { 0, 4, 10 }, // 54 bits per transform
- { 0, 5, 9 }, // 54 bits per transform
- { 0, 6, 8 }, // 54 bits per transform
- { 0, 7, 7 }, // 54 bits per transform
- { 0, 8, 6 }, // 54 bits per transform
- { 0, 9, 5 }, // 54 bits per transform
- { 0, 10, 4 }, // 54 bits per transform
- { 0, 11, 3 }, // 54 bits per transform
- { 0, 12, 2 }, // 54 bits per transform
- { 0, 13, 1 }, // 54 bits per transform
- { 0, 16, 0 }, // 54 bits per transform
- { 1, 0, 13 }, // 54 bits per transform
- { 1, 1, 10 }, // 54 bits per transform
- { 1, 2, 9 }, // 54 bits per transform
- { 1, 3, 8 }, // 54 bits per transform
- { 1, 4, 7 }, // 54 bits per transform
- { 1, 5, 6 }, // 54 bits per transform
- { 1, 6, 5 }, // 54 bits per transform
- { 1, 7, 4 }, // 54 bits per transform
- { 1, 8, 3 }, // 54 bits per transform
- { 1, 9, 2 }, // 54 bits per transform
- { 1, 10, 1 }, // 54 bits per transform
- { 1, 13, 0 }, // 54 bits per transform
- { 2, 0, 12 }, // 54 bits per transform
- { 2, 1, 9 }, // 54 bits per transform
- { 2, 2, 8 }, // 54 bits per transform
- { 2, 3, 7 }, // 54 bits per transform
- { 2, 4, 6 }, // 54 bits per transform
- { 2, 5, 5 }, // 54 bits per transform
- { 2, 6, 4 }, // 54 bits per transform
- { 2, 7, 3 }, // 54 bits per transform
- { 2, 8, 2 }, // 54 bits per transform
- { 2, 9, 1 }, // 54 bits per transform
- { 2, 12, 0 }, // 54 bits per transform
- { 3, 0, 11 }, // 54 bits per transform
- { 3, 1, 8 }, // 54 bits per transform
- { 3, 2, 7 }, // 54 bits per transform
- { 3, 3, 6 }, // 54 bits per transform
- { 3, 4, 5 }, // 54 bits per transform
- { 3, 5, 4 }, // 54 bits per transform
- { 3, 6, 3 }, // 54 bits per transform
- { 3, 7, 2 }, // 54 bits per transform
- { 3, 8, 1 }, // 54 bits per transform
- { 3, 11, 0 }, // 54 bits per transform
- { 4, 0, 10 }, // 54 bits per transform
- { 4, 1, 7 }, // 54 bits per transform
- { 4, 2, 6 }, // 54 bits per transform
- { 4, 3, 5 }, // 54 bits per transform
- { 4, 4, 4 }, // 54 bits per transform
- { 4, 5, 3 }, // 54 bits per transform
- { 4, 6, 2 }, // 54 bits per transform
- { 4, 7, 1 }, // 54 bits per transform
- { 4, 10, 0 }, // 54 bits per transform
- { 5, 0, 9 }, // 54 bits per transform
- { 5, 1, 6 }, // 54 bits per transform
- { 5, 2, 5 }, // 54 bits per transform
- { 5, 3, 4 }, // 54 bits per transform
- { 5, 4, 3 }, // 54 bits per transform
- { 5, 5, 2 }, // 54 bits per transform
- { 5, 6, 1 }, // 54 bits per transform
- { 5, 9, 0 }, // 54 bits per transform
- { 6, 0, 8 }, // 54 bits per transform
- { 6, 1, 5 }, // 54 bits per transform
- { 6, 2, 4 }, // 54 bits per transform
- { 6, 3, 3 }, // 54 bits per transform
- { 6, 4, 2 }, // 54 bits per transform
- { 6, 5, 1 }, // 54 bits per transform
- { 6, 8, 0 }, // 54 bits per transform
- { 7, 0, 7 }, // 54 bits per transform
- { 7, 1, 4 }, // 54 bits per transform
- { 7, 2, 3 }, // 54 bits per transform
- { 7, 3, 2 }, // 54 bits per transform
- { 7, 4, 1 }, // 54 bits per transform
- { 7, 7, 0 }, // 54 bits per transform
- { 8, 0, 6 }, // 54 bits per transform
- { 8, 1, 3 }, // 54 bits per transform
- { 8, 2, 2 }, // 54 bits per transform
- { 8, 3, 1 }, // 54 bits per transform
- { 8, 6, 0 }, // 54 bits per transform
- { 9, 0, 5 }, // 54 bits per transform
- { 9, 1, 2 }, // 54 bits per transform
- { 9, 2, 1 }, // 54 bits per transform
- { 9, 5, 0 }, // 54 bits per transform
- { 10, 0, 4 }, // 54 bits per transform
- { 10, 1, 1 }, // 54 bits per transform
- { 10, 4, 0 }, // 54 bits per transform
- { 11, 0, 3 }, // 54 bits per transform
- { 11, 3, 0 }, // 54 bits per transform
- { 12, 0, 2 }, // 54 bits per transform
- { 12, 2, 0 }, // 54 bits per transform
- { 13, 0, 1 }, // 54 bits per transform
- { 13, 1, 0 }, // 54 bits per transform
- { 16, 0, 0 }, // 54 bits per transform
- { 0, 0, 17 }, // 57 bits per transform
- { 0, 1, 14 }, // 57 bits per transform
- { 0, 2, 13 }, // 57 bits per transform
- { 0, 3, 12 }, // 57 bits per transform
- { 0, 4, 11 }, // 57 bits per transform
- { 0, 5, 10 }, // 57 bits per transform
- { 0, 6, 9 }, // 57 bits per transform
- { 0, 7, 8 }, // 57 bits per transform
- { 0, 8, 7 }, // 57 bits per transform
- { 0, 9, 6 }, // 57 bits per transform
- { 0, 10, 5 }, // 57 bits per transform
- { 0, 11, 4 }, // 57 bits per transform
- { 0, 12, 3 }, // 57 bits per transform
- { 0, 13, 2 }, // 57 bits per transform
- { 0, 14, 1 }, // 57 bits per transform
- { 0, 17, 0 }, // 57 bits per transform
- { 1, 0, 14 }, // 57 bits per transform
- { 1, 1, 11 }, // 57 bits per transform
- { 1, 2, 10 }, // 57 bits per transform
- { 1, 3, 9 }, // 57 bits per transform
- { 1, 4, 8 }, // 57 bits per transform
- { 1, 5, 7 }, // 57 bits per transform
- { 1, 6, 6 }, // 57 bits per transform
- { 1, 7, 5 }, // 57 bits per transform
- { 1, 8, 4 }, // 57 bits per transform
- { 1, 9, 3 }, // 57 bits per transform
- { 1, 10, 2 }, // 57 bits per transform
- { 1, 11, 1 }, // 57 bits per transform
- { 1, 14, 0 }, // 57 bits per transform
- { 2, 0, 13 }, // 57 bits per transform
- { 2, 1, 10 }, // 57 bits per transform
- { 2, 2, 9 }, // 57 bits per transform
- { 2, 3, 8 }, // 57 bits per transform
- { 2, 4, 7 }, // 57 bits per transform
- { 2, 5, 6 }, // 57 bits per transform
- { 2, 6, 5 }, // 57 bits per transform
- { 2, 7, 4 }, // 57 bits per transform
- { 2, 8, 3 }, // 57 bits per transform
- { 2, 9, 2 }, // 57 bits per transform
- { 2, 10, 1 }, // 57 bits per transform
- { 2, 13, 0 }, // 57 bits per transform
- { 3, 0, 12 }, // 57 bits per transform
- { 3, 1, 9 }, // 57 bits per transform
- { 3, 2, 8 }, // 57 bits per transform
- { 3, 3, 7 }, // 57 bits per transform
- { 3, 4, 6 }, // 57 bits per transform
- { 3, 5, 5 }, // 57 bits per transform
- { 3, 6, 4 }, // 57 bits per transform
- { 3, 7, 3 }, // 57 bits per transform
- { 3, 8, 2 }, // 57 bits per transform
- { 3, 9, 1 }, // 57 bits per transform
- { 3, 12, 0 }, // 57 bits per transform
- { 4, 0, 11 }, // 57 bits per transform
- { 4, 1, 8 }, // 57 bits per transform
- { 4, 2, 7 }, // 57 bits per transform
- { 4, 3, 6 }, // 57 bits per transform
- { 4, 4, 5 }, // 57 bits per transform
- { 4, 5, 4 }, // 57 bits per transform
- { 4, 6, 3 }, // 57 bits per transform
- { 4, 7, 2 }, // 57 bits per transform
- { 4, 8, 1 }, // 57 bits per transform
- { 4, 11, 0 }, // 57 bits per transform
- { 5, 0, 10 }, // 57 bits per transform
- { 5, 1, 7 }, // 57 bits per transform
- { 5, 2, 6 }, // 57 bits per transform
- { 5, 3, 5 }, // 57 bits per transform
- { 5, 4, 4 }, // 57 bits per transform
- { 5, 5, 3 }, // 57 bits per transform
- { 5, 6, 2 }, // 57 bits per transform
- { 5, 7, 1 }, // 57 bits per transform
- { 5, 10, 0 }, // 57 bits per transform
- { 6, 0, 9 }, // 57 bits per transform
- { 6, 1, 6 }, // 57 bits per transform
- { 6, 2, 5 }, // 57 bits per transform
- { 6, 3, 4 }, // 57 bits per transform
- { 6, 4, 3 }, // 57 bits per transform
- { 6, 5, 2 }, // 57 bits per transform
- { 6, 6, 1 }, // 57 bits per transform
- { 6, 9, 0 }, // 57 bits per transform
- { 7, 0, 8 }, // 57 bits per transform
- { 7, 1, 5 }, // 57 bits per transform
- { 7, 2, 4 }, // 57 bits per transform
- { 7, 3, 3 }, // 57 bits per transform
- { 7, 4, 2 }, // 57 bits per transform
- { 7, 5, 1 }, // 57 bits per transform
- { 7, 8, 0 }, // 57 bits per transform
- { 8, 0, 7 }, // 57 bits per transform
- { 8, 1, 4 }, // 57 bits per transform
- { 8, 2, 3 }, // 57 bits per transform
- { 8, 3, 2 }, // 57 bits per transform
- { 8, 4, 1 }, // 57 bits per transform
- { 8, 7, 0 }, // 57 bits per transform
- { 9, 0, 6 }, // 57 bits per transform
- { 9, 1, 3 }, // 57 bits per transform
- { 9, 2, 2 }, // 57 bits per transform
- { 9, 3, 1 }, // 57 bits per transform
- { 9, 6, 0 }, // 57 bits per transform
- { 10, 0, 5 }, // 57 bits per transform
- { 10, 1, 2 }, // 57 bits per transform
- { 10, 2, 1 }, // 57 bits per transform
- { 10, 5, 0 }, // 57 bits per transform
- { 11, 0, 4 }, // 57 bits per transform
- { 11, 1, 1 }, // 57 bits per transform
- { 11, 4, 0 }, // 57 bits per transform
- { 12, 0, 3 }, // 57 bits per transform
- { 12, 3, 0 }, // 57 bits per transform
- { 13, 0, 2 }, // 57 bits per transform
- { 13, 2, 0 }, // 57 bits per transform
- { 14, 0, 1 }, // 57 bits per transform
- { 14, 1, 0 }, // 57 bits per transform
- { 17, 0, 0 }, // 57 bits per transform
- { 0, 1, 15 }, // 60 bits per transform
- { 0, 2, 14 }, // 60 bits per transform
- { 0, 3, 13 }, // 60 bits per transform
- { 0, 4, 12 }, // 60 bits per transform
- { 0, 5, 11 }, // 60 bits per transform
- { 0, 6, 10 }, // 60 bits per transform
- { 0, 7, 9 }, // 60 bits per transform
- { 0, 8, 8 }, // 60 bits per transform
- { 0, 9, 7 }, // 60 bits per transform
- { 0, 10, 6 }, // 60 bits per transform
- { 0, 11, 5 }, // 60 bits per transform
- { 0, 12, 4 }, // 60 bits per transform
- { 0, 13, 3 }, // 60 bits per transform
- { 0, 14, 2 }, // 60 bits per transform
- { 0, 15, 1 }, // 60 bits per transform
- { 1, 0, 15 }, // 60 bits per transform
- { 1, 1, 12 }, // 60 bits per transform
- { 1, 2, 11 }, // 60 bits per transform
- { 1, 3, 10 }, // 60 bits per transform
- { 1, 4, 9 }, // 60 bits per transform
- { 1, 5, 8 }, // 60 bits per transform
- { 1, 6, 7 }, // 60 bits per transform
- { 1, 7, 6 }, // 60 bits per transform
- { 1, 8, 5 }, // 60 bits per transform
- { 1, 9, 4 }, // 60 bits per transform
- { 1, 10, 3 }, // 60 bits per transform
- { 1, 11, 2 }, // 60 bits per transform
- { 1, 12, 1 }, // 60 bits per transform
- { 1, 15, 0 }, // 60 bits per transform
- { 2, 0, 14 }, // 60 bits per transform
- { 2, 1, 11 }, // 60 bits per transform
- { 2, 2, 10 }, // 60 bits per transform
- { 2, 3, 9 }, // 60 bits per transform
- { 2, 4, 8 }, // 60 bits per transform
- { 2, 5, 7 }, // 60 bits per transform
- { 2, 6, 6 }, // 60 bits per transform
- { 2, 7, 5 }, // 60 bits per transform
- { 2, 8, 4 }, // 60 bits per transform
- { 2, 9, 3 }, // 60 bits per transform
- { 2, 10, 2 }, // 60 bits per transform
- { 2, 11, 1 }, // 60 bits per transform
- { 2, 14, 0 }, // 60 bits per transform
- { 3, 0, 13 }, // 60 bits per transform
- { 3, 1, 10 }, // 60 bits per transform
- { 3, 2, 9 }, // 60 bits per transform
- { 3, 3, 8 }, // 60 bits per transform
- { 3, 4, 7 }, // 60 bits per transform
- { 3, 5, 6 }, // 60 bits per transform
- { 3, 6, 5 }, // 60 bits per transform
- { 3, 7, 4 }, // 60 bits per transform
- { 3, 8, 3 }, // 60 bits per transform
- { 3, 9, 2 }, // 60 bits per transform
- { 3, 10, 1 }, // 60 bits per transform
- { 3, 13, 0 }, // 60 bits per transform
- { 4, 0, 12 }, // 60 bits per transform
- { 4, 1, 9 }, // 60 bits per transform
- { 4, 2, 8 }, // 60 bits per transform
- { 4, 3, 7 }, // 60 bits per transform
- { 4, 4, 6 }, // 60 bits per transform
- { 4, 5, 5 }, // 60 bits per transform
- { 4, 6, 4 }, // 60 bits per transform
- { 4, 7, 3 }, // 60 bits per transform
- { 4, 8, 2 }, // 60 bits per transform
- { 4, 9, 1 }, // 60 bits per transform
- { 4, 12, 0 }, // 60 bits per transform
- { 5, 0, 11 }, // 60 bits per transform
- { 5, 1, 8 }, // 60 bits per transform
- { 5, 2, 7 }, // 60 bits per transform
- { 5, 3, 6 }, // 60 bits per transform
- { 5, 4, 5 }, // 60 bits per transform
- { 5, 5, 4 }, // 60 bits per transform
- { 5, 6, 3 }, // 60 bits per transform
- { 5, 7, 2 }, // 60 bits per transform
- { 5, 8, 1 }, // 60 bits per transform
- { 5, 11, 0 }, // 60 bits per transform
- { 6, 0, 10 }, // 60 bits per transform
- { 6, 1, 7 }, // 60 bits per transform
- { 6, 2, 6 }, // 60 bits per transform
- { 6, 3, 5 }, // 60 bits per transform
- { 6, 4, 4 }, // 60 bits per transform
- { 6, 5, 3 }, // 60 bits per transform
- { 6, 6, 2 }, // 60 bits per transform
- { 6, 7, 1 }, // 60 bits per transform
- { 6, 10, 0 }, // 60 bits per transform
- { 7, 0, 9 }, // 60 bits per transform
- { 7, 1, 6 }, // 60 bits per transform
- { 7, 2, 5 }, // 60 bits per transform
- { 7, 3, 4 }, // 60 bits per transform
- { 7, 4, 3 }, // 60 bits per transform
- { 7, 5, 2 }, // 60 bits per transform
- { 7, 6, 1 }, // 60 bits per transform
- { 7, 9, 0 }, // 60 bits per transform
- { 8, 0, 8 }, // 60 bits per transform
- { 8, 1, 5 }, // 60 bits per transform
- { 8, 2, 4 }, // 60 bits per transform
- { 8, 3, 3 }, // 60 bits per transform
- { 8, 4, 2 }, // 60 bits per transform
- { 8, 5, 1 }, // 60 bits per transform
- { 8, 8, 0 }, // 60 bits per transform
- { 9, 0, 7 }, // 60 bits per transform
- { 9, 1, 4 }, // 60 bits per transform
- { 9, 2, 3 }, // 60 bits per transform
- { 9, 3, 2 }, // 60 bits per transform
- { 9, 4, 1 }, // 60 bits per transform
- { 9, 7, 0 }, // 60 bits per transform
- { 10, 0, 6 }, // 60 bits per transform
- { 10, 1, 3 }, // 60 bits per transform
- { 10, 2, 2 }, // 60 bits per transform
- { 10, 3, 1 }, // 60 bits per transform
- { 10, 6, 0 }, // 60 bits per transform
- { 11, 0, 5 }, // 60 bits per transform
- { 11, 1, 2 }, // 60 bits per transform
- { 11, 2, 1 }, // 60 bits per transform
- { 11, 5, 0 }, // 60 bits per transform
- { 12, 0, 4 }, // 60 bits per transform
- { 12, 1, 1 }, // 60 bits per transform
- { 12, 4, 0 }, // 60 bits per transform
- { 13, 0, 3 }, // 60 bits per transform
- { 13, 3, 0 }, // 60 bits per transform
- { 14, 0, 2 }, // 60 bits per transform
- { 14, 2, 0 }, // 60 bits per transform
- { 15, 0, 1 }, // 60 bits per transform
- { 15, 1, 0 }, // 60 bits per transform
- { 0, 1, 16 }, // 63 bits per transform
- { 0, 2, 15 }, // 63 bits per transform
- { 0, 3, 14 }, // 63 bits per transform
- { 0, 4, 13 }, // 63 bits per transform
- { 0, 5, 12 }, // 63 bits per transform
- { 0, 6, 11 }, // 63 bits per transform
- { 0, 7, 10 }, // 63 bits per transform
- { 0, 8, 9 }, // 63 bits per transform
- { 0, 9, 8 }, // 63 bits per transform
- { 0, 10, 7 }, // 63 bits per transform
- { 0, 11, 6 }, // 63 bits per transform
- { 0, 12, 5 }, // 63 bits per transform
- { 0, 13, 4 }, // 63 bits per transform
- { 0, 14, 3 }, // 63 bits per transform
- { 0, 15, 2 }, // 63 bits per transform
- { 0, 16, 1 }, // 63 bits per transform
- { 1, 0, 16 }, // 63 bits per transform
- { 1, 1, 13 }, // 63 bits per transform
- { 1, 2, 12 }, // 63 bits per transform
- { 1, 3, 11 }, // 63 bits per transform
- { 1, 4, 10 }, // 63 bits per transform
- { 1, 5, 9 }, // 63 bits per transform
- { 1, 6, 8 }, // 63 bits per transform
- { 1, 7, 7 }, // 63 bits per transform
- { 1, 8, 6 }, // 63 bits per transform
- { 1, 9, 5 }, // 63 bits per transform
- { 1, 10, 4 }, // 63 bits per transform
- { 1, 11, 3 }, // 63 bits per transform
- { 1, 12, 2 }, // 63 bits per transform
- { 1, 13, 1 }, // 63 bits per transform
- { 1, 16, 0 }, // 63 bits per transform
- { 2, 0, 15 }, // 63 bits per transform
- { 2, 1, 12 }, // 63 bits per transform
- { 2, 2, 11 }, // 63 bits per transform
- { 2, 3, 10 }, // 63 bits per transform
- { 2, 4, 9 }, // 63 bits per transform
- { 2, 5, 8 }, // 63 bits per transform
- { 2, 6, 7 }, // 63 bits per transform
- { 2, 7, 6 }, // 63 bits per transform
- { 2, 8, 5 }, // 63 bits per transform
- { 2, 9, 4 }, // 63 bits per transform
- { 2, 10, 3 }, // 63 bits per transform
- { 2, 11, 2 }, // 63 bits per transform
- { 2, 12, 1 }, // 63 bits per transform
- { 2, 15, 0 }, // 63 bits per transform
- { 3, 0, 14 }, // 63 bits per transform
- { 3, 1, 11 }, // 63 bits per transform
- { 3, 2, 10 }, // 63 bits per transform
- { 3, 3, 9 }, // 63 bits per transform
- { 3, 4, 8 }, // 63 bits per transform
- { 3, 5, 7 }, // 63 bits per transform
- { 3, 6, 6 }, // 63 bits per transform
- { 3, 7, 5 }, // 63 bits per transform
- { 3, 8, 4 }, // 63 bits per transform
- { 3, 9, 3 }, // 63 bits per transform
- { 3, 10, 2 }, // 63 bits per transform
- { 3, 11, 1 }, // 63 bits per transform
- { 3, 14, 0 }, // 63 bits per transform
- { 4, 0, 13 }, // 63 bits per transform
- { 4, 1, 10 }, // 63 bits per transform
- { 4, 2, 9 }, // 63 bits per transform
- { 4, 3, 8 }, // 63 bits per transform
- { 4, 4, 7 }, // 63 bits per transform
- { 4, 5, 6 }, // 63 bits per transform
- { 4, 6, 5 }, // 63 bits per transform
- { 4, 7, 4 }, // 63 bits per transform
- { 4, 8, 3 }, // 63 bits per transform
- { 4, 9, 2 }, // 63 bits per transform
- { 4, 10, 1 }, // 63 bits per transform
- { 4, 13, 0 }, // 63 bits per transform
- { 5, 0, 12 }, // 63 bits per transform
- { 5, 1, 9 }, // 63 bits per transform
- { 5, 2, 8 }, // 63 bits per transform
- { 5, 3, 7 }, // 63 bits per transform
- { 5, 4, 6 }, // 63 bits per transform
- { 5, 5, 5 }, // 63 bits per transform
- { 5, 6, 4 }, // 63 bits per transform
- { 5, 7, 3 }, // 63 bits per transform
- { 5, 8, 2 }, // 63 bits per transform
- { 5, 9, 1 }, // 63 bits per transform
- { 5, 12, 0 }, // 63 bits per transform
- { 6, 0, 11 }, // 63 bits per transform
- { 6, 1, 8 }, // 63 bits per transform
- { 6, 2, 7 }, // 63 bits per transform
- { 6, 3, 6 }, // 63 bits per transform
- { 6, 4, 5 }, // 63 bits per transform
- { 6, 5, 4 }, // 63 bits per transform
- { 6, 6, 3 }, // 63 bits per transform
- { 6, 7, 2 }, // 63 bits per transform
- { 6, 8, 1 }, // 63 bits per transform
- { 6, 11, 0 }, // 63 bits per transform
- { 7, 0, 10 }, // 63 bits per transform
- { 7, 1, 7 }, // 63 bits per transform
- { 7, 2, 6 }, // 63 bits per transform
- { 7, 3, 5 }, // 63 bits per transform
- { 7, 4, 4 }, // 63 bits per transform
- { 7, 5, 3 }, // 63 bits per transform
- { 7, 6, 2 }, // 63 bits per transform
- { 7, 7, 1 }, // 63 bits per transform
- { 7, 10, 0 }, // 63 bits per transform
- { 8, 0, 9 }, // 63 bits per transform
- { 8, 1, 6 }, // 63 bits per transform
- { 8, 2, 5 }, // 63 bits per transform
- { 8, 3, 4 }, // 63 bits per transform
- { 8, 4, 3 }, // 63 bits per transform
- { 8, 5, 2 }, // 63 bits per transform
- { 8, 6, 1 }, // 63 bits per transform
- { 8, 9, 0 }, // 63 bits per transform
- { 9, 0, 8 }, // 63 bits per transform
- { 9, 1, 5 }, // 63 bits per transform
- { 9, 2, 4 }, // 63 bits per transform
- { 9, 3, 3 }, // 63 bits per transform
- { 9, 4, 2 }, // 63 bits per transform
- { 9, 5, 1 }, // 63 bits per transform
- { 9, 8, 0 }, // 63 bits per transform
- { 10, 0, 7 }, // 63 bits per transform
- { 10, 1, 4 }, // 63 bits per transform
- { 10, 2, 3 }, // 63 bits per transform
- { 10, 3, 2 }, // 63 bits per transform
- { 10, 4, 1 }, // 63 bits per transform
- { 10, 7, 0 }, // 63 bits per transform
- { 11, 0, 6 }, // 63 bits per transform
- { 11, 1, 3 }, // 63 bits per transform
- { 11, 2, 2 }, // 63 bits per transform
- { 11, 3, 1 }, // 63 bits per transform
- { 11, 6, 0 }, // 63 bits per transform
- { 12, 0, 5 }, // 63 bits per transform
- { 12, 1, 2 }, // 63 bits per transform
- { 12, 2, 1 }, // 63 bits per transform
- { 12, 5, 0 }, // 63 bits per transform
- { 13, 0, 4 }, // 63 bits per transform
- { 13, 1, 1 }, // 63 bits per transform
- { 13, 4, 0 }, // 63 bits per transform
- { 14, 0, 3 }, // 63 bits per transform
- { 14, 3, 0 }, // 63 bits per transform
- { 15, 0, 2 }, // 63 bits per transform
- { 15, 2, 0 }, // 63 bits per transform
- { 16, 0, 1 }, // 63 bits per transform
- { 16, 1, 0 }, // 63 bits per transform
- { 0, 1, 17 }, // 66 bits per transform
- { 0, 2, 16 }, // 66 bits per transform
- { 0, 3, 15 }, // 66 bits per transform
- { 0, 4, 14 }, // 66 bits per transform
- { 0, 5, 13 }, // 66 bits per transform
- { 0, 6, 12 }, // 66 bits per transform
- { 0, 7, 11 }, // 66 bits per transform
- { 0, 8, 10 }, // 66 bits per transform
- { 0, 9, 9 }, // 66 bits per transform
- { 0, 10, 8 }, // 66 bits per transform
- { 0, 11, 7 }, // 66 bits per transform
- { 0, 12, 6 }, // 66 bits per transform
- { 0, 13, 5 }, // 66 bits per transform
- { 0, 14, 4 }, // 66 bits per transform
- { 0, 15, 3 }, // 66 bits per transform
- { 0, 16, 2 }, // 66 bits per transform
- { 0, 17, 1 }, // 66 bits per transform
- { 1, 0, 17 }, // 66 bits per transform
- { 1, 1, 14 }, // 66 bits per transform
- { 1, 2, 13 }, // 66 bits per transform
- { 1, 3, 12 }, // 66 bits per transform
- { 1, 4, 11 }, // 66 bits per transform
- { 1, 5, 10 }, // 66 bits per transform
- { 1, 6, 9 }, // 66 bits per transform
- { 1, 7, 8 }, // 66 bits per transform
- { 1, 8, 7 }, // 66 bits per transform
- { 1, 9, 6 }, // 66 bits per transform
- { 1, 10, 5 }, // 66 bits per transform
- { 1, 11, 4 }, // 66 bits per transform
- { 1, 12, 3 }, // 66 bits per transform
- { 1, 13, 2 }, // 66 bits per transform
- { 1, 14, 1 }, // 66 bits per transform
- { 1, 17, 0 }, // 66 bits per transform
- { 2, 0, 16 }, // 66 bits per transform
- { 2, 1, 13 }, // 66 bits per transform
- { 2, 2, 12 }, // 66 bits per transform
- { 2, 3, 11 }, // 66 bits per transform
- { 2, 4, 10 }, // 66 bits per transform
- { 2, 5, 9 }, // 66 bits per transform
- { 2, 6, 8 }, // 66 bits per transform
- { 2, 7, 7 }, // 66 bits per transform
- { 2, 8, 6 }, // 66 bits per transform
- { 2, 9, 5 }, // 66 bits per transform
- { 2, 10, 4 }, // 66 bits per transform
- { 2, 11, 3 }, // 66 bits per transform
- { 2, 12, 2 }, // 66 bits per transform
- { 2, 13, 1 }, // 66 bits per transform
- { 2, 16, 0 }, // 66 bits per transform
- { 3, 0, 15 }, // 66 bits per transform
- { 3, 1, 12 }, // 66 bits per transform
- { 3, 2, 11 }, // 66 bits per transform
- { 3, 3, 10 }, // 66 bits per transform
- { 3, 4, 9 }, // 66 bits per transform
- { 3, 5, 8 }, // 66 bits per transform
- { 3, 6, 7 }, // 66 bits per transform
- { 3, 7, 6 }, // 66 bits per transform
- { 3, 8, 5 }, // 66 bits per transform
- { 3, 9, 4 }, // 66 bits per transform
- { 3, 10, 3 }, // 66 bits per transform
- { 3, 11, 2 }, // 66 bits per transform
- { 3, 12, 1 }, // 66 bits per transform
- { 3, 15, 0 }, // 66 bits per transform
- { 4, 0, 14 }, // 66 bits per transform
- { 4, 1, 11 }, // 66 bits per transform
- { 4, 2, 10 }, // 66 bits per transform
- { 4, 3, 9 }, // 66 bits per transform
- { 4, 4, 8 }, // 66 bits per transform
- { 4, 5, 7 }, // 66 bits per transform
- { 4, 6, 6 }, // 66 bits per transform
- { 4, 7, 5 }, // 66 bits per transform
- { 4, 8, 4 }, // 66 bits per transform
- { 4, 9, 3 }, // 66 bits per transform
- { 4, 10, 2 }, // 66 bits per transform
- { 4, 11, 1 }, // 66 bits per transform
- { 4, 14, 0 }, // 66 bits per transform
- { 5, 0, 13 }, // 66 bits per transform
- { 5, 1, 10 }, // 66 bits per transform
- { 5, 2, 9 }, // 66 bits per transform
- { 5, 3, 8 }, // 66 bits per transform
- { 5, 4, 7 }, // 66 bits per transform
- { 5, 5, 6 }, // 66 bits per transform
- { 5, 6, 5 }, // 66 bits per transform
- { 5, 7, 4 }, // 66 bits per transform
- { 5, 8, 3 }, // 66 bits per transform
- { 5, 9, 2 }, // 66 bits per transform
- { 5, 10, 1 }, // 66 bits per transform
- { 5, 13, 0 }, // 66 bits per transform
- { 6, 0, 12 }, // 66 bits per transform
- { 6, 1, 9 }, // 66 bits per transform
- { 6, 2, 8 }, // 66 bits per transform
- { 6, 3, 7 }, // 66 bits per transform
- { 6, 4, 6 }, // 66 bits per transform
- { 6, 5, 5 }, // 66 bits per transform
- { 6, 6, 4 }, // 66 bits per transform
- { 6, 7, 3 }, // 66 bits per transform
- { 6, 8, 2 }, // 66 bits per transform
- { 6, 9, 1 }, // 66 bits per transform
- { 6, 12, 0 }, // 66 bits per transform
- { 7, 0, 11 }, // 66 bits per transform
- { 7, 1, 8 }, // 66 bits per transform
- { 7, 2, 7 }, // 66 bits per transform
- { 7, 3, 6 }, // 66 bits per transform
- { 7, 4, 5 }, // 66 bits per transform
- { 7, 5, 4 }, // 66 bits per transform
- { 7, 6, 3 }, // 66 bits per transform
- { 7, 7, 2 }, // 66 bits per transform
- { 7, 8, 1 }, // 66 bits per transform
- { 7, 11, 0 }, // 66 bits per transform
- { 8, 0, 10 }, // 66 bits per transform
- { 8, 1, 7 }, // 66 bits per transform
- { 8, 2, 6 }, // 66 bits per transform
- { 8, 3, 5 }, // 66 bits per transform
- { 8, 4, 4 }, // 66 bits per transform
- { 8, 5, 3 }, // 66 bits per transform
- { 8, 6, 2 }, // 66 bits per transform
- { 8, 7, 1 }, // 66 bits per transform
- { 8, 10, 0 }, // 66 bits per transform
- { 9, 0, 9 }, // 66 bits per transform
- { 9, 1, 6 }, // 66 bits per transform
- { 9, 2, 5 }, // 66 bits per transform
- { 9, 3, 4 }, // 66 bits per transform
- { 9, 4, 3 }, // 66 bits per transform
- { 9, 5, 2 }, // 66 bits per transform
- { 9, 6, 1 }, // 66 bits per transform
- { 9, 9, 0 }, // 66 bits per transform
- { 10, 0, 8 }, // 66 bits per transform
- { 10, 1, 5 }, // 66 bits per transform
- { 10, 2, 4 }, // 66 bits per transform
- { 10, 3, 3 }, // 66 bits per transform
- { 10, 4, 2 }, // 66 bits per transform
- { 10, 5, 1 }, // 66 bits per transform
- { 10, 8, 0 }, // 66 bits per transform
- { 11, 0, 7 }, // 66 bits per transform
- { 11, 1, 4 }, // 66 bits per transform
- { 11, 2, 3 }, // 66 bits per transform
- { 11, 3, 2 }, // 66 bits per transform
- { 11, 4, 1 }, // 66 bits per transform
- { 11, 7, 0 }, // 66 bits per transform
- { 12, 0, 6 }, // 66 bits per transform
- { 12, 1, 3 }, // 66 bits per transform
- { 12, 2, 2 }, // 66 bits per transform
- { 12, 3, 1 }, // 66 bits per transform
- { 12, 6, 0 }, // 66 bits per transform
- { 13, 0, 5 }, // 66 bits per transform
- { 13, 1, 2 }, // 66 bits per transform
- { 13, 2, 1 }, // 66 bits per transform
- { 13, 5, 0 }, // 66 bits per transform
- { 14, 0, 4 }, // 66 bits per transform
- { 14, 1, 1 }, // 66 bits per transform
- { 14, 4, 0 }, // 66 bits per transform
- { 15, 0, 3 }, // 66 bits per transform
- { 15, 3, 0 }, // 66 bits per transform
- { 16, 0, 2 }, // 66 bits per transform
- { 16, 2, 0 }, // 66 bits per transform
- { 17, 0, 1 }, // 66 bits per transform
- { 17, 1, 0 }, // 66 bits per transform
- { 0, 2, 17 }, // 69 bits per transform
- { 0, 3, 16 }, // 69 bits per transform
- { 0, 4, 15 }, // 69 bits per transform
- { 0, 5, 14 }, // 69 bits per transform
- { 0, 6, 13 }, // 69 bits per transform
- { 0, 7, 12 }, // 69 bits per transform
- { 0, 8, 11 }, // 69 bits per transform
- { 0, 9, 10 }, // 69 bits per transform
- { 0, 10, 9 }, // 69 bits per transform
- { 0, 11, 8 }, // 69 bits per transform
- { 0, 12, 7 }, // 69 bits per transform
- { 0, 13, 6 }, // 69 bits per transform
- { 0, 14, 5 }, // 69 bits per transform
- { 0, 15, 4 }, // 69 bits per transform
- { 0, 16, 3 }, // 69 bits per transform
- { 0, 17, 2 }, // 69 bits per transform
- { 1, 1, 15 }, // 69 bits per transform
- { 1, 2, 14 }, // 69 bits per transform
- { 1, 3, 13 }, // 69 bits per transform
- { 1, 4, 12 }, // 69 bits per transform
- { 1, 5, 11 }, // 69 bits per transform
- { 1, 6, 10 }, // 69 bits per transform
- { 1, 7, 9 }, // 69 bits per transform
- { 1, 8, 8 }, // 69 bits per transform
- { 1, 9, 7 }, // 69 bits per transform
- { 1, 10, 6 }, // 69 bits per transform
- { 1, 11, 5 }, // 69 bits per transform
- { 1, 12, 4 }, // 69 bits per transform
- { 1, 13, 3 }, // 69 bits per transform
- { 1, 14, 2 }, // 69 bits per transform
- { 1, 15, 1 }, // 69 bits per transform
- { 2, 0, 17 }, // 69 bits per transform
- { 2, 1, 14 }, // 69 bits per transform
- { 2, 2, 13 }, // 69 bits per transform
- { 2, 3, 12 }, // 69 bits per transform
- { 2, 4, 11 }, // 69 bits per transform
- { 2, 5, 10 }, // 69 bits per transform
- { 2, 6, 9 }, // 69 bits per transform
- { 2, 7, 8 }, // 69 bits per transform
- { 2, 8, 7 }, // 69 bits per transform
- { 2, 9, 6 }, // 69 bits per transform
- { 2, 10, 5 }, // 69 bits per transform
- { 2, 11, 4 }, // 69 bits per transform
- { 2, 12, 3 }, // 69 bits per transform
- { 2, 13, 2 }, // 69 bits per transform
- { 2, 14, 1 }, // 69 bits per transform
- { 2, 17, 0 }, // 69 bits per transform
- { 3, 0, 16 }, // 69 bits per transform
- { 3, 1, 13 }, // 69 bits per transform
- { 3, 2, 12 }, // 69 bits per transform
- { 3, 3, 11 }, // 69 bits per transform
- { 3, 4, 10 }, // 69 bits per transform
- { 3, 5, 9 }, // 69 bits per transform
- { 3, 6, 8 }, // 69 bits per transform
- { 3, 7, 7 }, // 69 bits per transform
- { 3, 8, 6 }, // 69 bits per transform
- { 3, 9, 5 }, // 69 bits per transform
- { 3, 10, 4 }, // 69 bits per transform
- { 3, 11, 3 }, // 69 bits per transform
- { 3, 12, 2 }, // 69 bits per transform
- { 3, 13, 1 }, // 69 bits per transform
- { 3, 16, 0 }, // 69 bits per transform
- { 4, 0, 15 }, // 69 bits per transform
- { 4, 1, 12 }, // 69 bits per transform
- { 4, 2, 11 }, // 69 bits per transform
- { 4, 3, 10 }, // 69 bits per transform
- { 4, 4, 9 }, // 69 bits per transform
- { 4, 5, 8 }, // 69 bits per transform
- { 4, 6, 7 }, // 69 bits per transform
- { 4, 7, 6 }, // 69 bits per transform
- { 4, 8, 5 }, // 69 bits per transform
- { 4, 9, 4 }, // 69 bits per transform
- { 4, 10, 3 }, // 69 bits per transform
- { 4, 11, 2 }, // 69 bits per transform
- { 4, 12, 1 }, // 69 bits per transform
- { 4, 15, 0 }, // 69 bits per transform
- { 5, 0, 14 }, // 69 bits per transform
- { 5, 1, 11 }, // 69 bits per transform
- { 5, 2, 10 }, // 69 bits per transform
- { 5, 3, 9 }, // 69 bits per transform
- { 5, 4, 8 }, // 69 bits per transform
- { 5, 5, 7 }, // 69 bits per transform
- { 5, 6, 6 }, // 69 bits per transform
- { 5, 7, 5 }, // 69 bits per transform
- { 5, 8, 4 }, // 69 bits per transform
- { 5, 9, 3 }, // 69 bits per transform
- { 5, 10, 2 }, // 69 bits per transform
- { 5, 11, 1 }, // 69 bits per transform
- { 5, 14, 0 }, // 69 bits per transform
- { 6, 0, 13 }, // 69 bits per transform
- { 6, 1, 10 }, // 69 bits per transform
- { 6, 2, 9 }, // 69 bits per transform
- { 6, 3, 8 }, // 69 bits per transform
- { 6, 4, 7 }, // 69 bits per transform
- { 6, 5, 6 }, // 69 bits per transform
- { 6, 6, 5 }, // 69 bits per transform
- { 6, 7, 4 }, // 69 bits per transform
- { 6, 8, 3 }, // 69 bits per transform
- { 6, 9, 2 }, // 69 bits per transform
- { 6, 10, 1 }, // 69 bits per transform
- { 6, 13, 0 }, // 69 bits per transform
- { 7, 0, 12 }, // 69 bits per transform
- { 7, 1, 9 }, // 69 bits per transform
- { 7, 2, 8 }, // 69 bits per transform
- { 7, 3, 7 }, // 69 bits per transform
- { 7, 4, 6 }, // 69 bits per transform
- { 7, 5, 5 }, // 69 bits per transform
- { 7, 6, 4 }, // 69 bits per transform
- { 7, 7, 3 }, // 69 bits per transform
- { 7, 8, 2 }, // 69 bits per transform
- { 7, 9, 1 }, // 69 bits per transform
- { 7, 12, 0 }, // 69 bits per transform
- { 8, 0, 11 }, // 69 bits per transform
- { 8, 1, 8 }, // 69 bits per transform
- { 8, 2, 7 }, // 69 bits per transform
- { 8, 3, 6 }, // 69 bits per transform
- { 8, 4, 5 }, // 69 bits per transform
- { 8, 5, 4 }, // 69 bits per transform
- { 8, 6, 3 }, // 69 bits per transform
- { 8, 7, 2 }, // 69 bits per transform
- { 8, 8, 1 }, // 69 bits per transform
- { 8, 11, 0 }, // 69 bits per transform
- { 9, 0, 10 }, // 69 bits per transform
- { 9, 1, 7 }, // 69 bits per transform
- { 9, 2, 6 }, // 69 bits per transform
- { 9, 3, 5 }, // 69 bits per transform
- { 9, 4, 4 }, // 69 bits per transform
- { 9, 5, 3 }, // 69 bits per transform
- { 9, 6, 2 }, // 69 bits per transform
- { 9, 7, 1 }, // 69 bits per transform
- { 9, 10, 0 }, // 69 bits per transform
- { 10, 0, 9 }, // 69 bits per transform
- { 10, 1, 6 }, // 69 bits per transform
- { 10, 2, 5 }, // 69 bits per transform
- { 10, 3, 4 }, // 69 bits per transform
- { 10, 4, 3 }, // 69 bits per transform
- { 10, 5, 2 }, // 69 bits per transform
- { 10, 6, 1 }, // 69 bits per transform
- { 10, 9, 0 }, // 69 bits per transform
- { 11, 0, 8 }, // 69 bits per transform
- { 11, 1, 5 }, // 69 bits per transform
- { 11, 2, 4 }, // 69 bits per transform
- { 11, 3, 3 }, // 69 bits per transform
- { 11, 4, 2 }, // 69 bits per transform
- { 11, 5, 1 }, // 69 bits per transform
- { 11, 8, 0 }, // 69 bits per transform
- { 12, 0, 7 }, // 69 bits per transform
- { 12, 1, 4 }, // 69 bits per transform
- { 12, 2, 3 }, // 69 bits per transform
- { 12, 3, 2 }, // 69 bits per transform
- { 12, 4, 1 }, // 69 bits per transform
- { 12, 7, 0 }, // 69 bits per transform
- { 13, 0, 6 }, // 69 bits per transform
- { 13, 1, 3 }, // 69 bits per transform
- { 13, 2, 2 }, // 69 bits per transform
- { 13, 3, 1 }, // 69 bits per transform
- { 13, 6, 0 }, // 69 bits per transform
- { 14, 0, 5 }, // 69 bits per transform
- { 14, 1, 2 }, // 69 bits per transform
- { 14, 2, 1 }, // 69 bits per transform
- { 14, 5, 0 }, // 69 bits per transform
- { 15, 0, 4 }, // 69 bits per transform
- { 15, 1, 1 }, // 69 bits per transform
- { 15, 4, 0 }, // 69 bits per transform
- { 16, 0, 3 }, // 69 bits per transform
- { 16, 3, 0 }, // 69 bits per transform
- { 17, 0, 2 }, // 69 bits per transform
- { 17, 2, 0 }, // 69 bits per transform
- { 0, 3, 17 }, // 72 bits per transform
- { 0, 4, 16 }, // 72 bits per transform
- { 0, 5, 15 }, // 72 bits per transform
- { 0, 6, 14 }, // 72 bits per transform
- { 0, 7, 13 }, // 72 bits per transform
- { 0, 8, 12 }, // 72 bits per transform
- { 0, 9, 11 }, // 72 bits per transform
- { 0, 10, 10 }, // 72 bits per transform
- { 0, 11, 9 }, // 72 bits per transform
- { 0, 12, 8 }, // 72 bits per transform
- { 0, 13, 7 }, // 72 bits per transform
- { 0, 14, 6 }, // 72 bits per transform
- { 0, 15, 5 }, // 72 bits per transform
- { 0, 16, 4 }, // 72 bits per transform
- { 0, 17, 3 }, // 72 bits per transform
- { 1, 1, 16 }, // 72 bits per transform
- { 1, 2, 15 }, // 72 bits per transform
- { 1, 3, 14 }, // 72 bits per transform
- { 1, 4, 13 }, // 72 bits per transform
- { 1, 5, 12 }, // 72 bits per transform
- { 1, 6, 11 }, // 72 bits per transform
- { 1, 7, 10 }, // 72 bits per transform
- { 1, 8, 9 }, // 72 bits per transform
- { 1, 9, 8 }, // 72 bits per transform
- { 1, 10, 7 }, // 72 bits per transform
- { 1, 11, 6 }, // 72 bits per transform
- { 1, 12, 5 }, // 72 bits per transform
- { 1, 13, 4 }, // 72 bits per transform
- { 1, 14, 3 }, // 72 bits per transform
- { 1, 15, 2 }, // 72 bits per transform
- { 1, 16, 1 }, // 72 bits per transform
- { 2, 1, 15 }, // 72 bits per transform
- { 2, 2, 14 }, // 72 bits per transform
- { 2, 3, 13 }, // 72 bits per transform
- { 2, 4, 12 }, // 72 bits per transform
- { 2, 5, 11 }, // 72 bits per transform
- { 2, 6, 10 }, // 72 bits per transform
- { 2, 7, 9 }, // 72 bits per transform
- { 2, 8, 8 }, // 72 bits per transform
- { 2, 9, 7 }, // 72 bits per transform
- { 2, 10, 6 }, // 72 bits per transform
- { 2, 11, 5 }, // 72 bits per transform
- { 2, 12, 4 }, // 72 bits per transform
- { 2, 13, 3 }, // 72 bits per transform
- { 2, 14, 2 }, // 72 bits per transform
- { 2, 15, 1 }, // 72 bits per transform
- { 3, 0, 17 }, // 72 bits per transform
- { 3, 1, 14 }, // 72 bits per transform
- { 3, 2, 13 }, // 72 bits per transform
- { 3, 3, 12 }, // 72 bits per transform
- { 3, 4, 11 }, // 72 bits per transform
- { 3, 5, 10 }, // 72 bits per transform
- { 3, 6, 9 }, // 72 bits per transform
- { 3, 7, 8 }, // 72 bits per transform
- { 3, 8, 7 }, // 72 bits per transform
- { 3, 9, 6 }, // 72 bits per transform
- { 3, 10, 5 }, // 72 bits per transform
- { 3, 11, 4 }, // 72 bits per transform
- { 3, 12, 3 }, // 72 bits per transform
- { 3, 13, 2 }, // 72 bits per transform
- { 3, 14, 1 }, // 72 bits per transform
- { 3, 17, 0 }, // 72 bits per transform
- { 4, 0, 16 }, // 72 bits per transform
- { 4, 1, 13 }, // 72 bits per transform
- { 4, 2, 12 }, // 72 bits per transform
- { 4, 3, 11 }, // 72 bits per transform
- { 4, 4, 10 }, // 72 bits per transform
- { 4, 5, 9 }, // 72 bits per transform
- { 4, 6, 8 }, // 72 bits per transform
- { 4, 7, 7 }, // 72 bits per transform
- { 4, 8, 6 }, // 72 bits per transform
- { 4, 9, 5 }, // 72 bits per transform
- { 4, 10, 4 }, // 72 bits per transform
- { 4, 11, 3 }, // 72 bits per transform
- { 4, 12, 2 }, // 72 bits per transform
- { 4, 13, 1 }, // 72 bits per transform
- { 4, 16, 0 }, // 72 bits per transform
- { 5, 0, 15 }, // 72 bits per transform
- { 5, 1, 12 }, // 72 bits per transform
- { 5, 2, 11 }, // 72 bits per transform
- { 5, 3, 10 }, // 72 bits per transform
- { 5, 4, 9 }, // 72 bits per transform
- { 5, 5, 8 }, // 72 bits per transform
- { 5, 6, 7 }, // 72 bits per transform
- { 5, 7, 6 }, // 72 bits per transform
- { 5, 8, 5 }, // 72 bits per transform
- { 5, 9, 4 }, // 72 bits per transform
- { 5, 10, 3 }, // 72 bits per transform
- { 5, 11, 2 }, // 72 bits per transform
- { 5, 12, 1 }, // 72 bits per transform
- { 5, 15, 0 }, // 72 bits per transform
- { 6, 0, 14 }, // 72 bits per transform
- { 6, 1, 11 }, // 72 bits per transform
- { 6, 2, 10 }, // 72 bits per transform
- { 6, 3, 9 }, // 72 bits per transform
- { 6, 4, 8 }, // 72 bits per transform
- { 6, 5, 7 }, // 72 bits per transform
- { 6, 6, 6 }, // 72 bits per transform
- { 6, 7, 5 }, // 72 bits per transform
- { 6, 8, 4 }, // 72 bits per transform
- { 6, 9, 3 }, // 72 bits per transform
- { 6, 10, 2 }, // 72 bits per transform
- { 6, 11, 1 }, // 72 bits per transform
- { 6, 14, 0 }, // 72 bits per transform
- { 7, 0, 13 }, // 72 bits per transform
- { 7, 1, 10 }, // 72 bits per transform
- { 7, 2, 9 }, // 72 bits per transform
- { 7, 3, 8 }, // 72 bits per transform
- { 7, 4, 7 }, // 72 bits per transform
- { 7, 5, 6 }, // 72 bits per transform
- { 7, 6, 5 }, // 72 bits per transform
- { 7, 7, 4 }, // 72 bits per transform
- { 7, 8, 3 }, // 72 bits per transform
- { 7, 9, 2 }, // 72 bits per transform
- { 7, 10, 1 }, // 72 bits per transform
- { 7, 13, 0 }, // 72 bits per transform
- { 8, 0, 12 }, // 72 bits per transform
- { 8, 1, 9 }, // 72 bits per transform
- { 8, 2, 8 }, // 72 bits per transform
- { 8, 3, 7 }, // 72 bits per transform
- { 8, 4, 6 }, // 72 bits per transform
- { 8, 5, 5 }, // 72 bits per transform
- { 8, 6, 4 }, // 72 bits per transform
- { 8, 7, 3 }, // 72 bits per transform
- { 8, 8, 2 }, // 72 bits per transform
- { 8, 9, 1 }, // 72 bits per transform
- { 8, 12, 0 }, // 72 bits per transform
- { 9, 0, 11 }, // 72 bits per transform
- { 9, 1, 8 }, // 72 bits per transform
- { 9, 2, 7 }, // 72 bits per transform
- { 9, 3, 6 }, // 72 bits per transform
- { 9, 4, 5 }, // 72 bits per transform
- { 9, 5, 4 }, // 72 bits per transform
- { 9, 6, 3 }, // 72 bits per transform
- { 9, 7, 2 }, // 72 bits per transform
- { 9, 8, 1 }, // 72 bits per transform
- { 9, 11, 0 }, // 72 bits per transform
- { 10, 0, 10 }, // 72 bits per transform
- { 10, 1, 7 }, // 72 bits per transform
- { 10, 2, 6 }, // 72 bits per transform
- { 10, 3, 5 }, // 72 bits per transform
- { 10, 4, 4 }, // 72 bits per transform
- { 10, 5, 3 }, // 72 bits per transform
- { 10, 6, 2 }, // 72 bits per transform
- { 10, 7, 1 }, // 72 bits per transform
- { 10, 10, 0 }, // 72 bits per transform
- { 11, 0, 9 }, // 72 bits per transform
- { 11, 1, 6 }, // 72 bits per transform
- { 11, 2, 5 }, // 72 bits per transform
- { 11, 3, 4 }, // 72 bits per transform
- { 11, 4, 3 }, // 72 bits per transform
- { 11, 5, 2 }, // 72 bits per transform
- { 11, 6, 1 }, // 72 bits per transform
- { 11, 9, 0 }, // 72 bits per transform
- { 12, 0, 8 }, // 72 bits per transform
- { 12, 1, 5 }, // 72 bits per transform
- { 12, 2, 4 }, // 72 bits per transform
- { 12, 3, 3 }, // 72 bits per transform
- { 12, 4, 2 }, // 72 bits per transform
- { 12, 5, 1 }, // 72 bits per transform
- { 12, 8, 0 }, // 72 bits per transform
- { 13, 0, 7 }, // 72 bits per transform
- { 13, 1, 4 }, // 72 bits per transform
- { 13, 2, 3 }, // 72 bits per transform
- { 13, 3, 2 }, // 72 bits per transform
- { 13, 4, 1 }, // 72 bits per transform
- { 13, 7, 0 }, // 72 bits per transform
- { 14, 0, 6 }, // 72 bits per transform
- { 14, 1, 3 }, // 72 bits per transform
- { 14, 2, 2 }, // 72 bits per transform
- { 14, 3, 1 }, // 72 bits per transform
- { 14, 6, 0 }, // 72 bits per transform
- { 15, 0, 5 }, // 72 bits per transform
- { 15, 1, 2 }, // 72 bits per transform
- { 15, 2, 1 }, // 72 bits per transform
- { 15, 5, 0 }, // 72 bits per transform
- { 16, 0, 4 }, // 72 bits per transform
- { 16, 1, 1 }, // 72 bits per transform
- { 16, 4, 0 }, // 72 bits per transform
- { 17, 0, 3 }, // 72 bits per transform
- { 17, 3, 0 }, // 72 bits per transform
- { 0, 4, 17 }, // 75 bits per transform
- { 0, 5, 16 }, // 75 bits per transform
- { 0, 6, 15 }, // 75 bits per transform
- { 0, 7, 14 }, // 75 bits per transform
- { 0, 8, 13 }, // 75 bits per transform
- { 0, 9, 12 }, // 75 bits per transform
- { 0, 10, 11 }, // 75 bits per transform
- { 0, 11, 10 }, // 75 bits per transform
- { 0, 12, 9 }, // 75 bits per transform
- { 0, 13, 8 }, // 75 bits per transform
- { 0, 14, 7 }, // 75 bits per transform
- { 0, 15, 6 }, // 75 bits per transform
- { 0, 16, 5 }, // 75 bits per transform
- { 0, 17, 4 }, // 75 bits per transform
- { 1, 1, 17 }, // 75 bits per transform
- { 1, 2, 16 }, // 75 bits per transform
- { 1, 3, 15 }, // 75 bits per transform
- { 1, 4, 14 }, // 75 bits per transform
- { 1, 5, 13 }, // 75 bits per transform
- { 1, 6, 12 }, // 75 bits per transform
- { 1, 7, 11 }, // 75 bits per transform
- { 1, 8, 10 }, // 75 bits per transform
- { 1, 9, 9 }, // 75 bits per transform
- { 1, 10, 8 }, // 75 bits per transform
- { 1, 11, 7 }, // 75 bits per transform
- { 1, 12, 6 }, // 75 bits per transform
- { 1, 13, 5 }, // 75 bits per transform
- { 1, 14, 4 }, // 75 bits per transform
- { 1, 15, 3 }, // 75 bits per transform
- { 1, 16, 2 }, // 75 bits per transform
- { 1, 17, 1 }, // 75 bits per transform
- { 2, 1, 16 }, // 75 bits per transform
- { 2, 2, 15 }, // 75 bits per transform
- { 2, 3, 14 }, // 75 bits per transform
- { 2, 4, 13 }, // 75 bits per transform
- { 2, 5, 12 }, // 75 bits per transform
- { 2, 6, 11 }, // 75 bits per transform
- { 2, 7, 10 }, // 75 bits per transform
- { 2, 8, 9 }, // 75 bits per transform
- { 2, 9, 8 }, // 75 bits per transform
- { 2, 10, 7 }, // 75 bits per transform
- { 2, 11, 6 }, // 75 bits per transform
- { 2, 12, 5 }, // 75 bits per transform
- { 2, 13, 4 }, // 75 bits per transform
- { 2, 14, 3 }, // 75 bits per transform
- { 2, 15, 2 }, // 75 bits per transform
- { 2, 16, 1 }, // 75 bits per transform
- { 3, 1, 15 }, // 75 bits per transform
- { 3, 2, 14 }, // 75 bits per transform
- { 3, 3, 13 }, // 75 bits per transform
- { 3, 4, 12 }, // 75 bits per transform
- { 3, 5, 11 }, // 75 bits per transform
- { 3, 6, 10 }, // 75 bits per transform
- { 3, 7, 9 }, // 75 bits per transform
- { 3, 8, 8 }, // 75 bits per transform
- { 3, 9, 7 }, // 75 bits per transform
- { 3, 10, 6 }, // 75 bits per transform
- { 3, 11, 5 }, // 75 bits per transform
- { 3, 12, 4 }, // 75 bits per transform
- { 3, 13, 3 }, // 75 bits per transform
- { 3, 14, 2 }, // 75 bits per transform
- { 3, 15, 1 }, // 75 bits per transform
- { 4, 0, 17 }, // 75 bits per transform
- { 4, 1, 14 }, // 75 bits per transform
- { 4, 2, 13 }, // 75 bits per transform
- { 4, 3, 12 }, // 75 bits per transform
- { 4, 4, 11 }, // 75 bits per transform
- { 4, 5, 10 }, // 75 bits per transform
- { 4, 6, 9 }, // 75 bits per transform
- { 4, 7, 8 }, // 75 bits per transform
- { 4, 8, 7 }, // 75 bits per transform
- { 4, 9, 6 }, // 75 bits per transform
- { 4, 10, 5 }, // 75 bits per transform
- { 4, 11, 4 }, // 75 bits per transform
- { 4, 12, 3 }, // 75 bits per transform
- { 4, 13, 2 }, // 75 bits per transform
- { 4, 14, 1 }, // 75 bits per transform
- { 4, 17, 0 }, // 75 bits per transform
- { 5, 0, 16 }, // 75 bits per transform
- { 5, 1, 13 }, // 75 bits per transform
- { 5, 2, 12 }, // 75 bits per transform
- { 5, 3, 11 }, // 75 bits per transform
- { 5, 4, 10 }, // 75 bits per transform
- { 5, 5, 9 }, // 75 bits per transform
- { 5, 6, 8 }, // 75 bits per transform
- { 5, 7, 7 }, // 75 bits per transform
- { 5, 8, 6 }, // 75 bits per transform
- { 5, 9, 5 }, // 75 bits per transform
- { 5, 10, 4 }, // 75 bits per transform
- { 5, 11, 3 }, // 75 bits per transform
- { 5, 12, 2 }, // 75 bits per transform
- { 5, 13, 1 }, // 75 bits per transform
- { 5, 16, 0 }, // 75 bits per transform
- { 6, 0, 15 }, // 75 bits per transform
- { 6, 1, 12 }, // 75 bits per transform
- { 6, 2, 11 }, // 75 bits per transform
- { 6, 3, 10 }, // 75 bits per transform
- { 6, 4, 9 }, // 75 bits per transform
- { 6, 5, 8 }, // 75 bits per transform
- { 6, 6, 7 }, // 75 bits per transform
- { 6, 7, 6 }, // 75 bits per transform
- { 6, 8, 5 }, // 75 bits per transform
- { 6, 9, 4 }, // 75 bits per transform
- { 6, 10, 3 }, // 75 bits per transform
- { 6, 11, 2 }, // 75 bits per transform
- { 6, 12, 1 }, // 75 bits per transform
- { 6, 15, 0 }, // 75 bits per transform
- { 7, 0, 14 }, // 75 bits per transform
- { 7, 1, 11 }, // 75 bits per transform
- { 7, 2, 10 }, // 75 bits per transform
- { 7, 3, 9 }, // 75 bits per transform
- { 7, 4, 8 }, // 75 bits per transform
- { 7, 5, 7 }, // 75 bits per transform
- { 7, 6, 6 }, // 75 bits per transform
- { 7, 7, 5 }, // 75 bits per transform
- { 7, 8, 4 }, // 75 bits per transform
- { 7, 9, 3 }, // 75 bits per transform
- { 7, 10, 2 }, // 75 bits per transform
- { 7, 11, 1 }, // 75 bits per transform
- { 7, 14, 0 }, // 75 bits per transform
- { 8, 0, 13 }, // 75 bits per transform
- { 8, 1, 10 }, // 75 bits per transform
- { 8, 2, 9 }, // 75 bits per transform
- { 8, 3, 8 }, // 75 bits per transform
- { 8, 4, 7 }, // 75 bits per transform
- { 8, 5, 6 }, // 75 bits per transform
- { 8, 6, 5 }, // 75 bits per transform
- { 8, 7, 4 }, // 75 bits per transform
- { 8, 8, 3 }, // 75 bits per transform
- { 8, 9, 2 }, // 75 bits per transform
- { 8, 10, 1 }, // 75 bits per transform
- { 8, 13, 0 }, // 75 bits per transform
- { 9, 0, 12 }, // 75 bits per transform
- { 9, 1, 9 }, // 75 bits per transform
- { 9, 2, 8 }, // 75 bits per transform
- { 9, 3, 7 }, // 75 bits per transform
- { 9, 4, 6 }, // 75 bits per transform
- { 9, 5, 5 }, // 75 bits per transform
- { 9, 6, 4 }, // 75 bits per transform
- { 9, 7, 3 }, // 75 bits per transform
- { 9, 8, 2 }, // 75 bits per transform
- { 9, 9, 1 }, // 75 bits per transform
- { 9, 12, 0 }, // 75 bits per transform
- { 10, 0, 11 }, // 75 bits per transform
- { 10, 1, 8 }, // 75 bits per transform
- { 10, 2, 7 }, // 75 bits per transform
- { 10, 3, 6 }, // 75 bits per transform
- { 10, 4, 5 }, // 75 bits per transform
- { 10, 5, 4 }, // 75 bits per transform
- { 10, 6, 3 }, // 75 bits per transform
- { 10, 7, 2 }, // 75 bits per transform
- { 10, 8, 1 }, // 75 bits per transform
- { 10, 11, 0 }, // 75 bits per transform
- { 11, 0, 10 }, // 75 bits per transform
- { 11, 1, 7 }, // 75 bits per transform
- { 11, 2, 6 }, // 75 bits per transform
- { 11, 3, 5 }, // 75 bits per transform
- { 11, 4, 4 }, // 75 bits per transform
- { 11, 5, 3 }, // 75 bits per transform
- { 11, 6, 2 }, // 75 bits per transform
- { 11, 7, 1 }, // 75 bits per transform
- { 11, 10, 0 }, // 75 bits per transform
- { 12, 0, 9 }, // 75 bits per transform
- { 12, 1, 6 }, // 75 bits per transform
- { 12, 2, 5 }, // 75 bits per transform
- { 12, 3, 4 }, // 75 bits per transform
- { 12, 4, 3 }, // 75 bits per transform
- { 12, 5, 2 }, // 75 bits per transform
- { 12, 6, 1 }, // 75 bits per transform
- { 12, 9, 0 }, // 75 bits per transform
- { 13, 0, 8 }, // 75 bits per transform
- { 13, 1, 5 }, // 75 bits per transform
- { 13, 2, 4 }, // 75 bits per transform
- { 13, 3, 3 }, // 75 bits per transform
- { 13, 4, 2 }, // 75 bits per transform
- { 13, 5, 1 }, // 75 bits per transform
- { 13, 8, 0 }, // 75 bits per transform
- { 14, 0, 7 }, // 75 bits per transform
- { 14, 1, 4 }, // 75 bits per transform
- { 14, 2, 3 }, // 75 bits per transform
- { 14, 3, 2 }, // 75 bits per transform
- { 14, 4, 1 }, // 75 bits per transform
- { 14, 7, 0 }, // 75 bits per transform
- { 15, 0, 6 }, // 75 bits per transform
- { 15, 1, 3 }, // 75 bits per transform
- { 15, 2, 2 }, // 75 bits per transform
- { 15, 3, 1 }, // 75 bits per transform
- { 15, 6, 0 }, // 75 bits per transform
- { 16, 0, 5 }, // 75 bits per transform
- { 16, 1, 2 }, // 75 bits per transform
- { 16, 2, 1 }, // 75 bits per transform
- { 16, 5, 0 }, // 75 bits per transform
- { 17, 0, 4 }, // 75 bits per transform
- { 17, 1, 1 }, // 75 bits per transform
- { 17, 4, 0 }, // 75 bits per transform
- { 0, 5, 17 }, // 78 bits per transform
- { 0, 6, 16 }, // 78 bits per transform
- { 0, 7, 15 }, // 78 bits per transform
- { 0, 8, 14 }, // 78 bits per transform
- { 0, 9, 13 }, // 78 bits per transform
- { 0, 10, 12 }, // 78 bits per transform
- { 0, 11, 11 }, // 78 bits per transform
- { 0, 12, 10 }, // 78 bits per transform
- { 0, 13, 9 }, // 78 bits per transform
- { 0, 14, 8 }, // 78 bits per transform
- { 0, 15, 7 }, // 78 bits per transform
- { 0, 16, 6 }, // 78 bits per transform
- { 0, 17, 5 }, // 78 bits per transform
- { 1, 2, 17 }, // 78 bits per transform
- { 1, 3, 16 }, // 78 bits per transform
- { 1, 4, 15 }, // 78 bits per transform
- { 1, 5, 14 }, // 78 bits per transform
- { 1, 6, 13 }, // 78 bits per transform
- { 1, 7, 12 }, // 78 bits per transform
- { 1, 8, 11 }, // 78 bits per transform
- { 1, 9, 10 }, // 78 bits per transform
- { 1, 10, 9 }, // 78 bits per transform
- { 1, 11, 8 }, // 78 bits per transform
- { 1, 12, 7 }, // 78 bits per transform
- { 1, 13, 6 }, // 78 bits per transform
- { 1, 14, 5 }, // 78 bits per transform
- { 1, 15, 4 }, // 78 bits per transform
- { 1, 16, 3 }, // 78 bits per transform
- { 1, 17, 2 }, // 78 bits per transform
- { 2, 1, 17 }, // 78 bits per transform
- { 2, 2, 16 }, // 78 bits per transform
- { 2, 3, 15 }, // 78 bits per transform
- { 2, 4, 14 }, // 78 bits per transform
- { 2, 5, 13 }, // 78 bits per transform
- { 2, 6, 12 }, // 78 bits per transform
- { 2, 7, 11 }, // 78 bits per transform
- { 2, 8, 10 }, // 78 bits per transform
- { 2, 9, 9 }, // 78 bits per transform
- { 2, 10, 8 }, // 78 bits per transform
- { 2, 11, 7 }, // 78 bits per transform
- { 2, 12, 6 }, // 78 bits per transform
- { 2, 13, 5 }, // 78 bits per transform
- { 2, 14, 4 }, // 78 bits per transform
- { 2, 15, 3 }, // 78 bits per transform
- { 2, 16, 2 }, // 78 bits per transform
- { 2, 17, 1 }, // 78 bits per transform
- { 3, 1, 16 }, // 78 bits per transform
- { 3, 2, 15 }, // 78 bits per transform
- { 3, 3, 14 }, // 78 bits per transform
- { 3, 4, 13 }, // 78 bits per transform
- { 3, 5, 12 }, // 78 bits per transform
- { 3, 6, 11 }, // 78 bits per transform
- { 3, 7, 10 }, // 78 bits per transform
- { 3, 8, 9 }, // 78 bits per transform
- { 3, 9, 8 }, // 78 bits per transform
- { 3, 10, 7 }, // 78 bits per transform
- { 3, 11, 6 }, // 78 bits per transform
- { 3, 12, 5 }, // 78 bits per transform
- { 3, 13, 4 }, // 78 bits per transform
- { 3, 14, 3 }, // 78 bits per transform
- { 3, 15, 2 }, // 78 bits per transform
- { 3, 16, 1 }, // 78 bits per transform
- { 4, 1, 15 }, // 78 bits per transform
- { 4, 2, 14 }, // 78 bits per transform
- { 4, 3, 13 }, // 78 bits per transform
- { 4, 4, 12 }, // 78 bits per transform
- { 4, 5, 11 }, // 78 bits per transform
- { 4, 6, 10 }, // 78 bits per transform
- { 4, 7, 9 }, // 78 bits per transform
- { 4, 8, 8 }, // 78 bits per transform
- { 4, 9, 7 }, // 78 bits per transform
- { 4, 10, 6 }, // 78 bits per transform
- { 4, 11, 5 }, // 78 bits per transform
- { 4, 12, 4 }, // 78 bits per transform
- { 4, 13, 3 }, // 78 bits per transform
- { 4, 14, 2 }, // 78 bits per transform
- { 4, 15, 1 }, // 78 bits per transform
- { 5, 0, 17 }, // 78 bits per transform
- { 5, 1, 14 }, // 78 bits per transform
- { 5, 2, 13 }, // 78 bits per transform
- { 5, 3, 12 }, // 78 bits per transform
- { 5, 4, 11 }, // 78 bits per transform
- { 5, 5, 10 }, // 78 bits per transform
- { 5, 6, 9 }, // 78 bits per transform
- { 5, 7, 8 }, // 78 bits per transform
- { 5, 8, 7 }, // 78 bits per transform
- { 5, 9, 6 }, // 78 bits per transform
- { 5, 10, 5 }, // 78 bits per transform
- { 5, 11, 4 }, // 78 bits per transform
- { 5, 12, 3 }, // 78 bits per transform
- { 5, 13, 2 }, // 78 bits per transform
- { 5, 14, 1 }, // 78 bits per transform
- { 5, 17, 0 }, // 78 bits per transform
- { 6, 0, 16 }, // 78 bits per transform
- { 6, 1, 13 }, // 78 bits per transform
- { 6, 2, 12 }, // 78 bits per transform
- { 6, 3, 11 }, // 78 bits per transform
- { 6, 4, 10 }, // 78 bits per transform
- { 6, 5, 9 }, // 78 bits per transform
- { 6, 6, 8 }, // 78 bits per transform
- { 6, 7, 7 }, // 78 bits per transform
- { 6, 8, 6 }, // 78 bits per transform
- { 6, 9, 5 }, // 78 bits per transform
- { 6, 10, 4 }, // 78 bits per transform
- { 6, 11, 3 }, // 78 bits per transform
- { 6, 12, 2 }, // 78 bits per transform
- { 6, 13, 1 }, // 78 bits per transform
- { 6, 16, 0 }, // 78 bits per transform
- { 7, 0, 15 }, // 78 bits per transform
- { 7, 1, 12 }, // 78 bits per transform
- { 7, 2, 11 }, // 78 bits per transform
- { 7, 3, 10 }, // 78 bits per transform
- { 7, 4, 9 }, // 78 bits per transform
- { 7, 5, 8 }, // 78 bits per transform
- { 7, 6, 7 }, // 78 bits per transform
- { 7, 7, 6 }, // 78 bits per transform
- { 7, 8, 5 }, // 78 bits per transform
- { 7, 9, 4 }, // 78 bits per transform
- { 7, 10, 3 }, // 78 bits per transform
- { 7, 11, 2 }, // 78 bits per transform
- { 7, 12, 1 }, // 78 bits per transform
- { 7, 15, 0 }, // 78 bits per transform
- { 8, 0, 14 }, // 78 bits per transform
- { 8, 1, 11 }, // 78 bits per transform
- { 8, 2, 10 }, // 78 bits per transform
- { 8, 3, 9 }, // 78 bits per transform
- { 8, 4, 8 }, // 78 bits per transform
- { 8, 5, 7 }, // 78 bits per transform
- { 8, 6, 6 }, // 78 bits per transform
- { 8, 7, 5 }, // 78 bits per transform
- { 8, 8, 4 }, // 78 bits per transform
- { 8, 9, 3 }, // 78 bits per transform
- { 8, 10, 2 }, // 78 bits per transform
- { 8, 11, 1 }, // 78 bits per transform
- { 8, 14, 0 }, // 78 bits per transform
- { 9, 0, 13 }, // 78 bits per transform
- { 9, 1, 10 }, // 78 bits per transform
- { 9, 2, 9 }, // 78 bits per transform
- { 9, 3, 8 }, // 78 bits per transform
- { 9, 4, 7 }, // 78 bits per transform
- { 9, 5, 6 }, // 78 bits per transform
- { 9, 6, 5 }, // 78 bits per transform
- { 9, 7, 4 }, // 78 bits per transform
- { 9, 8, 3 }, // 78 bits per transform
- { 9, 9, 2 }, // 78 bits per transform
- { 9, 10, 1 }, // 78 bits per transform
- { 9, 13, 0 }, // 78 bits per transform
- { 10, 0, 12 }, // 78 bits per transform
- { 10, 1, 9 }, // 78 bits per transform
- { 10, 2, 8 }, // 78 bits per transform
- { 10, 3, 7 }, // 78 bits per transform
- { 10, 4, 6 }, // 78 bits per transform
- { 10, 5, 5 }, // 78 bits per transform
- { 10, 6, 4 }, // 78 bits per transform
- { 10, 7, 3 }, // 78 bits per transform
- { 10, 8, 2 }, // 78 bits per transform
- { 10, 9, 1 }, // 78 bits per transform
- { 10, 12, 0 }, // 78 bits per transform
- { 11, 0, 11 }, // 78 bits per transform
- { 11, 1, 8 }, // 78 bits per transform
- { 11, 2, 7 }, // 78 bits per transform
- { 11, 3, 6 }, // 78 bits per transform
- { 11, 4, 5 }, // 78 bits per transform
- { 11, 5, 4 }, // 78 bits per transform
- { 11, 6, 3 }, // 78 bits per transform
- { 11, 7, 2 }, // 78 bits per transform
- { 11, 8, 1 }, // 78 bits per transform
- { 11, 11, 0 }, // 78 bits per transform
- { 12, 0, 10 }, // 78 bits per transform
- { 12, 1, 7 }, // 78 bits per transform
- { 12, 2, 6 }, // 78 bits per transform
- { 12, 3, 5 }, // 78 bits per transform
- { 12, 4, 4 }, // 78 bits per transform
- { 12, 5, 3 }, // 78 bits per transform
- { 12, 6, 2 }, // 78 bits per transform
- { 12, 7, 1 }, // 78 bits per transform
- { 12, 10, 0 }, // 78 bits per transform
- { 13, 0, 9 }, // 78 bits per transform
- { 13, 1, 6 }, // 78 bits per transform
- { 13, 2, 5 }, // 78 bits per transform
- { 13, 3, 4 }, // 78 bits per transform
- { 13, 4, 3 }, // 78 bits per transform
- { 13, 5, 2 }, // 78 bits per transform
- { 13, 6, 1 }, // 78 bits per transform
- { 13, 9, 0 }, // 78 bits per transform
- { 14, 0, 8 }, // 78 bits per transform
- { 14, 1, 5 }, // 78 bits per transform
- { 14, 2, 4 }, // 78 bits per transform
- { 14, 3, 3 }, // 78 bits per transform
- { 14, 4, 2 }, // 78 bits per transform
- { 14, 5, 1 }, // 78 bits per transform
- { 14, 8, 0 }, // 78 bits per transform
- { 15, 0, 7 }, // 78 bits per transform
- { 15, 1, 4 }, // 78 bits per transform
- { 15, 2, 3 }, // 78 bits per transform
- { 15, 3, 2 }, // 78 bits per transform
- { 15, 4, 1 }, // 78 bits per transform
- { 15, 7, 0 }, // 78 bits per transform
- { 16, 0, 6 }, // 78 bits per transform
- { 16, 1, 3 }, // 78 bits per transform
- { 16, 2, 2 }, // 78 bits per transform
- { 16, 3, 1 }, // 78 bits per transform
- { 16, 6, 0 }, // 78 bits per transform
- { 17, 0, 5 }, // 78 bits per transform
- { 17, 1, 2 }, // 78 bits per transform
- { 17, 2, 1 }, // 78 bits per transform
- { 17, 5, 0 }, // 78 bits per transform
- { 0, 6, 17 }, // 81 bits per transform
- { 0, 7, 16 }, // 81 bits per transform
- { 0, 8, 15 }, // 81 bits per transform
- { 0, 9, 14 }, // 81 bits per transform
- { 0, 10, 13 }, // 81 bits per transform
- { 0, 11, 12 }, // 81 bits per transform
- { 0, 12, 11 }, // 81 bits per transform
- { 0, 13, 10 }, // 81 bits per transform
- { 0, 14, 9 }, // 81 bits per transform
- { 0, 15, 8 }, // 81 bits per transform
- { 0, 16, 7 }, // 81 bits per transform
- { 0, 17, 6 }, // 81 bits per transform
- { 1, 3, 17 }, // 81 bits per transform
- { 1, 4, 16 }, // 81 bits per transform
- { 1, 5, 15 }, // 81 bits per transform
- { 1, 6, 14 }, // 81 bits per transform
- { 1, 7, 13 }, // 81 bits per transform
- { 1, 8, 12 }, // 81 bits per transform
- { 1, 9, 11 }, // 81 bits per transform
- { 1, 10, 10 }, // 81 bits per transform
- { 1, 11, 9 }, // 81 bits per transform
- { 1, 12, 8 }, // 81 bits per transform
- { 1, 13, 7 }, // 81 bits per transform
- { 1, 14, 6 }, // 81 bits per transform
- { 1, 15, 5 }, // 81 bits per transform
- { 1, 16, 4 }, // 81 bits per transform
- { 1, 17, 3 }, // 81 bits per transform
- { 2, 2, 17 }, // 81 bits per transform
- { 2, 3, 16 }, // 81 bits per transform
- { 2, 4, 15 }, // 81 bits per transform
- { 2, 5, 14 }, // 81 bits per transform
- { 2, 6, 13 }, // 81 bits per transform
- { 2, 7, 12 }, // 81 bits per transform
- { 2, 8, 11 }, // 81 bits per transform
- { 2, 9, 10 }, // 81 bits per transform
- { 2, 10, 9 }, // 81 bits per transform
- { 2, 11, 8 }, // 81 bits per transform
- { 2, 12, 7 }, // 81 bits per transform
- { 2, 13, 6 }, // 81 bits per transform
- { 2, 14, 5 }, // 81 bits per transform
- { 2, 15, 4 }, // 81 bits per transform
- { 2, 16, 3 }, // 81 bits per transform
- { 2, 17, 2 }, // 81 bits per transform
- { 3, 1, 17 }, // 81 bits per transform
- { 3, 2, 16 }, // 81 bits per transform
- { 3, 3, 15 }, // 81 bits per transform
- { 3, 4, 14 }, // 81 bits per transform
- { 3, 5, 13 }, // 81 bits per transform
- { 3, 6, 12 }, // 81 bits per transform
- { 3, 7, 11 }, // 81 bits per transform
- { 3, 8, 10 }, // 81 bits per transform
- { 3, 9, 9 }, // 81 bits per transform
- { 3, 10, 8 }, // 81 bits per transform
- { 3, 11, 7 }, // 81 bits per transform
- { 3, 12, 6 }, // 81 bits per transform
- { 3, 13, 5 }, // 81 bits per transform
- { 3, 14, 4 }, // 81 bits per transform
- { 3, 15, 3 }, // 81 bits per transform
- { 3, 16, 2 }, // 81 bits per transform
- { 3, 17, 1 }, // 81 bits per transform
- { 4, 1, 16 }, // 81 bits per transform
- { 4, 2, 15 }, // 81 bits per transform
- { 4, 3, 14 }, // 81 bits per transform
- { 4, 4, 13 }, // 81 bits per transform
- { 4, 5, 12 }, // 81 bits per transform
- { 4, 6, 11 }, // 81 bits per transform
- { 4, 7, 10 }, // 81 bits per transform
- { 4, 8, 9 }, // 81 bits per transform
- { 4, 9, 8 }, // 81 bits per transform
- { 4, 10, 7 }, // 81 bits per transform
- { 4, 11, 6 }, // 81 bits per transform
- { 4, 12, 5 }, // 81 bits per transform
- { 4, 13, 4 }, // 81 bits per transform
- { 4, 14, 3 }, // 81 bits per transform
- { 4, 15, 2 }, // 81 bits per transform
- { 4, 16, 1 }, // 81 bits per transform
- { 5, 1, 15 }, // 81 bits per transform
- { 5, 2, 14 }, // 81 bits per transform
- { 5, 3, 13 }, // 81 bits per transform
- { 5, 4, 12 }, // 81 bits per transform
- { 5, 5, 11 }, // 81 bits per transform
- { 5, 6, 10 }, // 81 bits per transform
- { 5, 7, 9 }, // 81 bits per transform
- { 5, 8, 8 }, // 81 bits per transform
- { 5, 9, 7 }, // 81 bits per transform
- { 5, 10, 6 }, // 81 bits per transform
- { 5, 11, 5 }, // 81 bits per transform
- { 5, 12, 4 }, // 81 bits per transform
- { 5, 13, 3 }, // 81 bits per transform
- { 5, 14, 2 }, // 81 bits per transform
- { 5, 15, 1 }, // 81 bits per transform
- { 6, 0, 17 }, // 81 bits per transform
- { 6, 1, 14 }, // 81 bits per transform
- { 6, 2, 13 }, // 81 bits per transform
- { 6, 3, 12 }, // 81 bits per transform
- { 6, 4, 11 }, // 81 bits per transform
- { 6, 5, 10 }, // 81 bits per transform
- { 6, 6, 9 }, // 81 bits per transform
- { 6, 7, 8 }, // 81 bits per transform
- { 6, 8, 7 }, // 81 bits per transform
- { 6, 9, 6 }, // 81 bits per transform
- { 6, 10, 5 }, // 81 bits per transform
- { 6, 11, 4 }, // 81 bits per transform
- { 6, 12, 3 }, // 81 bits per transform
- { 6, 13, 2 }, // 81 bits per transform
- { 6, 14, 1 }, // 81 bits per transform
- { 6, 17, 0 }, // 81 bits per transform
- { 7, 0, 16 }, // 81 bits per transform
- { 7, 1, 13 }, // 81 bits per transform
- { 7, 2, 12 }, // 81 bits per transform
- { 7, 3, 11 }, // 81 bits per transform
- { 7, 4, 10 }, // 81 bits per transform
- { 7, 5, 9 }, // 81 bits per transform
- { 7, 6, 8 }, // 81 bits per transform
- { 7, 7, 7 }, // 81 bits per transform
- { 7, 8, 6 }, // 81 bits per transform
- { 7, 9, 5 }, // 81 bits per transform
- { 7, 10, 4 }, // 81 bits per transform
- { 7, 11, 3 }, // 81 bits per transform
- { 7, 12, 2 }, // 81 bits per transform
- { 7, 13, 1 }, // 81 bits per transform
- { 7, 16, 0 }, // 81 bits per transform
- { 8, 0, 15 }, // 81 bits per transform
- { 8, 1, 12 }, // 81 bits per transform
- { 8, 2, 11 }, // 81 bits per transform
- { 8, 3, 10 }, // 81 bits per transform
- { 8, 4, 9 }, // 81 bits per transform
- { 8, 5, 8 }, // 81 bits per transform
- { 8, 6, 7 }, // 81 bits per transform
- { 8, 7, 6 }, // 81 bits per transform
- { 8, 8, 5 }, // 81 bits per transform
- { 8, 9, 4 }, // 81 bits per transform
- { 8, 10, 3 }, // 81 bits per transform
- { 8, 11, 2 }, // 81 bits per transform
- { 8, 12, 1 }, // 81 bits per transform
- { 8, 15, 0 }, // 81 bits per transform
- { 9, 0, 14 }, // 81 bits per transform
- { 9, 1, 11 }, // 81 bits per transform
- { 9, 2, 10 }, // 81 bits per transform
- { 9, 3, 9 }, // 81 bits per transform
- { 9, 4, 8 }, // 81 bits per transform
- { 9, 5, 7 }, // 81 bits per transform
- { 9, 6, 6 }, // 81 bits per transform
- { 9, 7, 5 }, // 81 bits per transform
- { 9, 8, 4 }, // 81 bits per transform
- { 9, 9, 3 }, // 81 bits per transform
- { 9, 10, 2 }, // 81 bits per transform
- { 9, 11, 1 }, // 81 bits per transform
- { 9, 14, 0 }, // 81 bits per transform
- { 10, 0, 13 }, // 81 bits per transform
- { 10, 1, 10 }, // 81 bits per transform
- { 10, 2, 9 }, // 81 bits per transform
- { 10, 3, 8 }, // 81 bits per transform
- { 10, 4, 7 }, // 81 bits per transform
- { 10, 5, 6 }, // 81 bits per transform
- { 10, 6, 5 }, // 81 bits per transform
- { 10, 7, 4 }, // 81 bits per transform
- { 10, 8, 3 }, // 81 bits per transform
- { 10, 9, 2 }, // 81 bits per transform
- { 10, 10, 1 }, // 81 bits per transform
- { 10, 13, 0 }, // 81 bits per transform
- { 11, 0, 12 }, // 81 bits per transform
- { 11, 1, 9 }, // 81 bits per transform
- { 11, 2, 8 }, // 81 bits per transform
- { 11, 3, 7 }, // 81 bits per transform
- { 11, 4, 6 }, // 81 bits per transform
- { 11, 5, 5 }, // 81 bits per transform
- { 11, 6, 4 }, // 81 bits per transform
- { 11, 7, 3 }, // 81 bits per transform
- { 11, 8, 2 }, // 81 bits per transform
- { 11, 9, 1 }, // 81 bits per transform
- { 11, 12, 0 }, // 81 bits per transform
- { 12, 0, 11 }, // 81 bits per transform
- { 12, 1, 8 }, // 81 bits per transform
- { 12, 2, 7 }, // 81 bits per transform
- { 12, 3, 6 }, // 81 bits per transform
- { 12, 4, 5 }, // 81 bits per transform
- { 12, 5, 4 }, // 81 bits per transform
- { 12, 6, 3 }, // 81 bits per transform
- { 12, 7, 2 }, // 81 bits per transform
- { 12, 8, 1 }, // 81 bits per transform
- { 12, 11, 0 }, // 81 bits per transform
- { 13, 0, 10 }, // 81 bits per transform
- { 13, 1, 7 }, // 81 bits per transform
- { 13, 2, 6 }, // 81 bits per transform
- { 13, 3, 5 }, // 81 bits per transform
- { 13, 4, 4 }, // 81 bits per transform
- { 13, 5, 3 }, // 81 bits per transform
- { 13, 6, 2 }, // 81 bits per transform
- { 13, 7, 1 }, // 81 bits per transform
- { 13, 10, 0 }, // 81 bits per transform
- { 14, 0, 9 }, // 81 bits per transform
- { 14, 1, 6 }, // 81 bits per transform
- { 14, 2, 5 }, // 81 bits per transform
- { 14, 3, 4 }, // 81 bits per transform
- { 14, 4, 3 }, // 81 bits per transform
- { 14, 5, 2 }, // 81 bits per transform
- { 14, 6, 1 }, // 81 bits per transform
- { 14, 9, 0 }, // 81 bits per transform
- { 15, 0, 8 }, // 81 bits per transform
- { 15, 1, 5 }, // 81 bits per transform
- { 15, 2, 4 }, // 81 bits per transform
- { 15, 3, 3 }, // 81 bits per transform
- { 15, 4, 2 }, // 81 bits per transform
- { 15, 5, 1 }, // 81 bits per transform
- { 15, 8, 0 }, // 81 bits per transform
- { 16, 0, 7 }, // 81 bits per transform
- { 16, 1, 4 }, // 81 bits per transform
- { 16, 2, 3 }, // 81 bits per transform
- { 16, 3, 2 }, // 81 bits per transform
- { 16, 4, 1 }, // 81 bits per transform
- { 16, 7, 0 }, // 81 bits per transform
- { 17, 0, 6 }, // 81 bits per transform
- { 17, 1, 3 }, // 81 bits per transform
- { 17, 2, 2 }, // 81 bits per transform
- { 17, 3, 1 }, // 81 bits per transform
- { 17, 6, 0 }, // 81 bits per transform
- { 0, 7, 17 }, // 84 bits per transform
- { 0, 8, 16 }, // 84 bits per transform
- { 0, 9, 15 }, // 84 bits per transform
- { 0, 10, 14 }, // 84 bits per transform
- { 0, 11, 13 }, // 84 bits per transform
- { 0, 12, 12 }, // 84 bits per transform
- { 0, 13, 11 }, // 84 bits per transform
- { 0, 14, 10 }, // 84 bits per transform
- { 0, 15, 9 }, // 84 bits per transform
- { 0, 16, 8 }, // 84 bits per transform
- { 0, 17, 7 }, // 84 bits per transform
- { 1, 4, 17 }, // 84 bits per transform
- { 1, 5, 16 }, // 84 bits per transform
- { 1, 6, 15 }, // 84 bits per transform
- { 1, 7, 14 }, // 84 bits per transform
- { 1, 8, 13 }, // 84 bits per transform
- { 1, 9, 12 }, // 84 bits per transform
- { 1, 10, 11 }, // 84 bits per transform
- { 1, 11, 10 }, // 84 bits per transform
- { 1, 12, 9 }, // 84 bits per transform
- { 1, 13, 8 }, // 84 bits per transform
- { 1, 14, 7 }, // 84 bits per transform
- { 1, 15, 6 }, // 84 bits per transform
- { 1, 16, 5 }, // 84 bits per transform
- { 1, 17, 4 }, // 84 bits per transform
- { 2, 3, 17 }, // 84 bits per transform
- { 2, 4, 16 }, // 84 bits per transform
- { 2, 5, 15 }, // 84 bits per transform
- { 2, 6, 14 }, // 84 bits per transform
- { 2, 7, 13 }, // 84 bits per transform
- { 2, 8, 12 }, // 84 bits per transform
- { 2, 9, 11 }, // 84 bits per transform
- { 2, 10, 10 }, // 84 bits per transform
- { 2, 11, 9 }, // 84 bits per transform
- { 2, 12, 8 }, // 84 bits per transform
- { 2, 13, 7 }, // 84 bits per transform
- { 2, 14, 6 }, // 84 bits per transform
- { 2, 15, 5 }, // 84 bits per transform
- { 2, 16, 4 }, // 84 bits per transform
- { 2, 17, 3 }, // 84 bits per transform
- { 3, 2, 17 }, // 84 bits per transform
- { 3, 3, 16 }, // 84 bits per transform
- { 3, 4, 15 }, // 84 bits per transform
- { 3, 5, 14 }, // 84 bits per transform
- { 3, 6, 13 }, // 84 bits per transform
- { 3, 7, 12 }, // 84 bits per transform
- { 3, 8, 11 }, // 84 bits per transform
- { 3, 9, 10 }, // 84 bits per transform
- { 3, 10, 9 }, // 84 bits per transform
- { 3, 11, 8 }, // 84 bits per transform
- { 3, 12, 7 }, // 84 bits per transform
- { 3, 13, 6 }, // 84 bits per transform
- { 3, 14, 5 }, // 84 bits per transform
- { 3, 15, 4 }, // 84 bits per transform
- { 3, 16, 3 }, // 84 bits per transform
- { 3, 17, 2 }, // 84 bits per transform
- { 4, 1, 17 }, // 84 bits per transform
- { 4, 2, 16 }, // 84 bits per transform
- { 4, 3, 15 }, // 84 bits per transform
- { 4, 4, 14 }, // 84 bits per transform
- { 4, 5, 13 }, // 84 bits per transform
- { 4, 6, 12 }, // 84 bits per transform
- { 4, 7, 11 }, // 84 bits per transform
- { 4, 8, 10 }, // 84 bits per transform
- { 4, 9, 9 }, // 84 bits per transform
- { 4, 10, 8 }, // 84 bits per transform
- { 4, 11, 7 }, // 84 bits per transform
- { 4, 12, 6 }, // 84 bits per transform
- { 4, 13, 5 }, // 84 bits per transform
- { 4, 14, 4 }, // 84 bits per transform
- { 4, 15, 3 }, // 84 bits per transform
- { 4, 16, 2 }, // 84 bits per transform
- { 4, 17, 1 }, // 84 bits per transform
- { 5, 1, 16 }, // 84 bits per transform
- { 5, 2, 15 }, // 84 bits per transform
- { 5, 3, 14 }, // 84 bits per transform
- { 5, 4, 13 }, // 84 bits per transform
- { 5, 5, 12 }, // 84 bits per transform
- { 5, 6, 11 }, // 84 bits per transform
- { 5, 7, 10 }, // 84 bits per transform
- { 5, 8, 9 }, // 84 bits per transform
- { 5, 9, 8 }, // 84 bits per transform
- { 5, 10, 7 }, // 84 bits per transform
- { 5, 11, 6 }, // 84 bits per transform
- { 5, 12, 5 }, // 84 bits per transform
- { 5, 13, 4 }, // 84 bits per transform
- { 5, 14, 3 }, // 84 bits per transform
- { 5, 15, 2 }, // 84 bits per transform
- { 5, 16, 1 }, // 84 bits per transform
- { 6, 1, 15 }, // 84 bits per transform
- { 6, 2, 14 }, // 84 bits per transform
- { 6, 3, 13 }, // 84 bits per transform
- { 6, 4, 12 }, // 84 bits per transform
- { 6, 5, 11 }, // 84 bits per transform
- { 6, 6, 10 }, // 84 bits per transform
- { 6, 7, 9 }, // 84 bits per transform
- { 6, 8, 8 }, // 84 bits per transform
- { 6, 9, 7 }, // 84 bits per transform
- { 6, 10, 6 }, // 84 bits per transform
- { 6, 11, 5 }, // 84 bits per transform
- { 6, 12, 4 }, // 84 bits per transform
- { 6, 13, 3 }, // 84 bits per transform
- { 6, 14, 2 }, // 84 bits per transform
- { 6, 15, 1 }, // 84 bits per transform
- { 7, 0, 17 }, // 84 bits per transform
- { 7, 1, 14 }, // 84 bits per transform
- { 7, 2, 13 }, // 84 bits per transform
- { 7, 3, 12 }, // 84 bits per transform
- { 7, 4, 11 }, // 84 bits per transform
- { 7, 5, 10 }, // 84 bits per transform
- { 7, 6, 9 }, // 84 bits per transform
- { 7, 7, 8 }, // 84 bits per transform
- { 7, 8, 7 }, // 84 bits per transform
- { 7, 9, 6 }, // 84 bits per transform
- { 7, 10, 5 }, // 84 bits per transform
- { 7, 11, 4 }, // 84 bits per transform
- { 7, 12, 3 }, // 84 bits per transform
- { 7, 13, 2 }, // 84 bits per transform
- { 7, 14, 1 }, // 84 bits per transform
- { 7, 17, 0 }, // 84 bits per transform
- { 8, 0, 16 }, // 84 bits per transform
- { 8, 1, 13 }, // 84 bits per transform
- { 8, 2, 12 }, // 84 bits per transform
- { 8, 3, 11 }, // 84 bits per transform
- { 8, 4, 10 }, // 84 bits per transform
- { 8, 5, 9 }, // 84 bits per transform
- { 8, 6, 8 }, // 84 bits per transform
- { 8, 7, 7 }, // 84 bits per transform
- { 8, 8, 6 }, // 84 bits per transform
- { 8, 9, 5 }, // 84 bits per transform
- { 8, 10, 4 }, // 84 bits per transform
- { 8, 11, 3 }, // 84 bits per transform
- { 8, 12, 2 }, // 84 bits per transform
- { 8, 13, 1 }, // 84 bits per transform
- { 8, 16, 0 }, // 84 bits per transform
- { 9, 0, 15 }, // 84 bits per transform
- { 9, 1, 12 }, // 84 bits per transform
- { 9, 2, 11 }, // 84 bits per transform
- { 9, 3, 10 }, // 84 bits per transform
- { 9, 4, 9 }, // 84 bits per transform
- { 9, 5, 8 }, // 84 bits per transform
- { 9, 6, 7 }, // 84 bits per transform
- { 9, 7, 6 }, // 84 bits per transform
- { 9, 8, 5 }, // 84 bits per transform
- { 9, 9, 4 }, // 84 bits per transform
- { 9, 10, 3 }, // 84 bits per transform
- { 9, 11, 2 }, // 84 bits per transform
- { 9, 12, 1 }, // 84 bits per transform
- { 9, 15, 0 }, // 84 bits per transform
- { 10, 0, 14 }, // 84 bits per transform
- { 10, 1, 11 }, // 84 bits per transform
- { 10, 2, 10 }, // 84 bits per transform
- { 10, 3, 9 }, // 84 bits per transform
- { 10, 4, 8 }, // 84 bits per transform
- { 10, 5, 7 }, // 84 bits per transform
- { 10, 6, 6 }, // 84 bits per transform
- { 10, 7, 5 }, // 84 bits per transform
- { 10, 8, 4 }, // 84 bits per transform
- { 10, 9, 3 }, // 84 bits per transform
- { 10, 10, 2 }, // 84 bits per transform
- { 10, 11, 1 }, // 84 bits per transform
- { 10, 14, 0 }, // 84 bits per transform
- { 11, 0, 13 }, // 84 bits per transform
- { 11, 1, 10 }, // 84 bits per transform
- { 11, 2, 9 }, // 84 bits per transform
- { 11, 3, 8 }, // 84 bits per transform
- { 11, 4, 7 }, // 84 bits per transform
- { 11, 5, 6 }, // 84 bits per transform
- { 11, 6, 5 }, // 84 bits per transform
- { 11, 7, 4 }, // 84 bits per transform
- { 11, 8, 3 }, // 84 bits per transform
- { 11, 9, 2 }, // 84 bits per transform
- { 11, 10, 1 }, // 84 bits per transform
- { 11, 13, 0 }, // 84 bits per transform
- { 12, 0, 12 }, // 84 bits per transform
- { 12, 1, 9 }, // 84 bits per transform
- { 12, 2, 8 }, // 84 bits per transform
- { 12, 3, 7 }, // 84 bits per transform
- { 12, 4, 6 }, // 84 bits per transform
- { 12, 5, 5 }, // 84 bits per transform
- { 12, 6, 4 }, // 84 bits per transform
- { 12, 7, 3 }, // 84 bits per transform
- { 12, 8, 2 }, // 84 bits per transform
- { 12, 9, 1 }, // 84 bits per transform
- { 12, 12, 0 }, // 84 bits per transform
- { 13, 0, 11 }, // 84 bits per transform
- { 13, 1, 8 }, // 84 bits per transform
- { 13, 2, 7 }, // 84 bits per transform
- { 13, 3, 6 }, // 84 bits per transform
- { 13, 4, 5 }, // 84 bits per transform
- { 13, 5, 4 }, // 84 bits per transform
- { 13, 6, 3 }, // 84 bits per transform
- { 13, 7, 2 }, // 84 bits per transform
- { 13, 8, 1 }, // 84 bits per transform
- { 13, 11, 0 }, // 84 bits per transform
- { 14, 0, 10 }, // 84 bits per transform
- { 14, 1, 7 }, // 84 bits per transform
- { 14, 2, 6 }, // 84 bits per transform
- { 14, 3, 5 }, // 84 bits per transform
- { 14, 4, 4 }, // 84 bits per transform
- { 14, 5, 3 }, // 84 bits per transform
- { 14, 6, 2 }, // 84 bits per transform
- { 14, 7, 1 }, // 84 bits per transform
- { 14, 10, 0 }, // 84 bits per transform
- { 15, 0, 9 }, // 84 bits per transform
- { 15, 1, 6 }, // 84 bits per transform
- { 15, 2, 5 }, // 84 bits per transform
- { 15, 3, 4 }, // 84 bits per transform
- { 15, 4, 3 }, // 84 bits per transform
- { 15, 5, 2 }, // 84 bits per transform
- { 15, 6, 1 }, // 84 bits per transform
- { 15, 9, 0 }, // 84 bits per transform
- { 16, 0, 8 }, // 84 bits per transform
- { 16, 1, 5 }, // 84 bits per transform
- { 16, 2, 4 }, // 84 bits per transform
- { 16, 3, 3 }, // 84 bits per transform
- { 16, 4, 2 }, // 84 bits per transform
- { 16, 5, 1 }, // 84 bits per transform
- { 16, 8, 0 }, // 84 bits per transform
- { 17, 0, 7 }, // 84 bits per transform
- { 17, 1, 4 }, // 84 bits per transform
- { 17, 2, 3 }, // 84 bits per transform
- { 17, 3, 2 }, // 84 bits per transform
- { 17, 4, 1 }, // 84 bits per transform
- { 17, 7, 0 }, // 84 bits per transform
- { 0, 8, 17 }, // 87 bits per transform
- { 0, 9, 16 }, // 87 bits per transform
- { 0, 10, 15 }, // 87 bits per transform
- { 0, 11, 14 }, // 87 bits per transform
- { 0, 12, 13 }, // 87 bits per transform
- { 0, 13, 12 }, // 87 bits per transform
- { 0, 14, 11 }, // 87 bits per transform
- { 0, 15, 10 }, // 87 bits per transform
- { 0, 16, 9 }, // 87 bits per transform
- { 0, 17, 8 }, // 87 bits per transform
- { 1, 5, 17 }, // 87 bits per transform
- { 1, 6, 16 }, // 87 bits per transform
- { 1, 7, 15 }, // 87 bits per transform
- { 1, 8, 14 }, // 87 bits per transform
- { 1, 9, 13 }, // 87 bits per transform
- { 1, 10, 12 }, // 87 bits per transform
- { 1, 11, 11 }, // 87 bits per transform
- { 1, 12, 10 }, // 87 bits per transform
- { 1, 13, 9 }, // 87 bits per transform
- { 1, 14, 8 }, // 87 bits per transform
- { 1, 15, 7 }, // 87 bits per transform
- { 1, 16, 6 }, // 87 bits per transform
- { 1, 17, 5 }, // 87 bits per transform
- { 2, 4, 17 }, // 87 bits per transform
- { 2, 5, 16 }, // 87 bits per transform
- { 2, 6, 15 }, // 87 bits per transform
- { 2, 7, 14 }, // 87 bits per transform
- { 2, 8, 13 }, // 87 bits per transform
- { 2, 9, 12 }, // 87 bits per transform
- { 2, 10, 11 }, // 87 bits per transform
- { 2, 11, 10 }, // 87 bits per transform
- { 2, 12, 9 }, // 87 bits per transform
- { 2, 13, 8 }, // 87 bits per transform
- { 2, 14, 7 }, // 87 bits per transform
- { 2, 15, 6 }, // 87 bits per transform
- { 2, 16, 5 }, // 87 bits per transform
- { 2, 17, 4 }, // 87 bits per transform
- { 3, 3, 17 }, // 87 bits per transform
- { 3, 4, 16 }, // 87 bits per transform
- { 3, 5, 15 }, // 87 bits per transform
- { 3, 6, 14 }, // 87 bits per transform
- { 3, 7, 13 }, // 87 bits per transform
- { 3, 8, 12 }, // 87 bits per transform
- { 3, 9, 11 }, // 87 bits per transform
- { 3, 10, 10 }, // 87 bits per transform
- { 3, 11, 9 }, // 87 bits per transform
- { 3, 12, 8 }, // 87 bits per transform
- { 3, 13, 7 }, // 87 bits per transform
- { 3, 14, 6 }, // 87 bits per transform
- { 3, 15, 5 }, // 87 bits per transform
- { 3, 16, 4 }, // 87 bits per transform
- { 3, 17, 3 }, // 87 bits per transform
- { 4, 2, 17 }, // 87 bits per transform
- { 4, 3, 16 }, // 87 bits per transform
- { 4, 4, 15 }, // 87 bits per transform
- { 4, 5, 14 }, // 87 bits per transform
- { 4, 6, 13 }, // 87 bits per transform
- { 4, 7, 12 }, // 87 bits per transform
- { 4, 8, 11 }, // 87 bits per transform
- { 4, 9, 10 }, // 87 bits per transform
- { 4, 10, 9 }, // 87 bits per transform
- { 4, 11, 8 }, // 87 bits per transform
- { 4, 12, 7 }, // 87 bits per transform
- { 4, 13, 6 }, // 87 bits per transform
- { 4, 14, 5 }, // 87 bits per transform
- { 4, 15, 4 }, // 87 bits per transform
- { 4, 16, 3 }, // 87 bits per transform
- { 4, 17, 2 }, // 87 bits per transform
- { 5, 1, 17 }, // 87 bits per transform
- { 5, 2, 16 }, // 87 bits per transform
- { 5, 3, 15 }, // 87 bits per transform
- { 5, 4, 14 }, // 87 bits per transform
- { 5, 5, 13 }, // 87 bits per transform
- { 5, 6, 12 }, // 87 bits per transform
- { 5, 7, 11 }, // 87 bits per transform
- { 5, 8, 10 }, // 87 bits per transform
- { 5, 9, 9 }, // 87 bits per transform
- { 5, 10, 8 }, // 87 bits per transform
- { 5, 11, 7 }, // 87 bits per transform
- { 5, 12, 6 }, // 87 bits per transform
- { 5, 13, 5 }, // 87 bits per transform
- { 5, 14, 4 }, // 87 bits per transform
- { 5, 15, 3 }, // 87 bits per transform
- { 5, 16, 2 }, // 87 bits per transform
- { 5, 17, 1 }, // 87 bits per transform
- { 6, 1, 16 }, // 87 bits per transform
- { 6, 2, 15 }, // 87 bits per transform
- { 6, 3, 14 }, // 87 bits per transform
- { 6, 4, 13 }, // 87 bits per transform
- { 6, 5, 12 }, // 87 bits per transform
- { 6, 6, 11 }, // 87 bits per transform
- { 6, 7, 10 }, // 87 bits per transform
- { 6, 8, 9 }, // 87 bits per transform
- { 6, 9, 8 }, // 87 bits per transform
- { 6, 10, 7 }, // 87 bits per transform
- { 6, 11, 6 }, // 87 bits per transform
- { 6, 12, 5 }, // 87 bits per transform
- { 6, 13, 4 }, // 87 bits per transform
- { 6, 14, 3 }, // 87 bits per transform
- { 6, 15, 2 }, // 87 bits per transform
- { 6, 16, 1 }, // 87 bits per transform
- { 7, 1, 15 }, // 87 bits per transform
- { 7, 2, 14 }, // 87 bits per transform
- { 7, 3, 13 }, // 87 bits per transform
- { 7, 4, 12 }, // 87 bits per transform
- { 7, 5, 11 }, // 87 bits per transform
- { 7, 6, 10 }, // 87 bits per transform
- { 7, 7, 9 }, // 87 bits per transform
- { 7, 8, 8 }, // 87 bits per transform
- { 7, 9, 7 }, // 87 bits per transform
- { 7, 10, 6 }, // 87 bits per transform
- { 7, 11, 5 }, // 87 bits per transform
- { 7, 12, 4 }, // 87 bits per transform
- { 7, 13, 3 }, // 87 bits per transform
- { 7, 14, 2 }, // 87 bits per transform
- { 7, 15, 1 }, // 87 bits per transform
- { 8, 0, 17 }, // 87 bits per transform
- { 8, 1, 14 }, // 87 bits per transform
- { 8, 2, 13 }, // 87 bits per transform
- { 8, 3, 12 }, // 87 bits per transform
- { 8, 4, 11 }, // 87 bits per transform
- { 8, 5, 10 }, // 87 bits per transform
- { 8, 6, 9 }, // 87 bits per transform
- { 8, 7, 8 }, // 87 bits per transform
- { 8, 8, 7 }, // 87 bits per transform
- { 8, 9, 6 }, // 87 bits per transform
- { 8, 10, 5 }, // 87 bits per transform
- { 8, 11, 4 }, // 87 bits per transform
- { 8, 12, 3 }, // 87 bits per transform
- { 8, 13, 2 }, // 87 bits per transform
- { 8, 14, 1 }, // 87 bits per transform
- { 8, 17, 0 }, // 87 bits per transform
- { 9, 0, 16 }, // 87 bits per transform
- { 9, 1, 13 }, // 87 bits per transform
- { 9, 2, 12 }, // 87 bits per transform
- { 9, 3, 11 }, // 87 bits per transform
- { 9, 4, 10 }, // 87 bits per transform
- { 9, 5, 9 }, // 87 bits per transform
- { 9, 6, 8 }, // 87 bits per transform
- { 9, 7, 7 }, // 87 bits per transform
- { 9, 8, 6 }, // 87 bits per transform
- { 9, 9, 5 }, // 87 bits per transform
- { 9, 10, 4 }, // 87 bits per transform
- { 9, 11, 3 }, // 87 bits per transform
- { 9, 12, 2 }, // 87 bits per transform
- { 9, 13, 1 }, // 87 bits per transform
- { 9, 16, 0 }, // 87 bits per transform
- { 10, 0, 15 }, // 87 bits per transform
- { 10, 1, 12 }, // 87 bits per transform
- { 10, 2, 11 }, // 87 bits per transform
- { 10, 3, 10 }, // 87 bits per transform
- { 10, 4, 9 }, // 87 bits per transform
- { 10, 5, 8 }, // 87 bits per transform
- { 10, 6, 7 }, // 87 bits per transform
- { 10, 7, 6 }, // 87 bits per transform
- { 10, 8, 5 }, // 87 bits per transform
- { 10, 9, 4 }, // 87 bits per transform
- { 10, 10, 3 }, // 87 bits per transform
- { 10, 11, 2 }, // 87 bits per transform
- { 10, 12, 1 }, // 87 bits per transform
- { 10, 15, 0 }, // 87 bits per transform
- { 11, 0, 14 }, // 87 bits per transform
- { 11, 1, 11 }, // 87 bits per transform
- { 11, 2, 10 }, // 87 bits per transform
- { 11, 3, 9 }, // 87 bits per transform
- { 11, 4, 8 }, // 87 bits per transform
- { 11, 5, 7 }, // 87 bits per transform
- { 11, 6, 6 }, // 87 bits per transform
- { 11, 7, 5 }, // 87 bits per transform
- { 11, 8, 4 }, // 87 bits per transform
- { 11, 9, 3 }, // 87 bits per transform
- { 11, 10, 2 }, // 87 bits per transform
- { 11, 11, 1 }, // 87 bits per transform
- { 11, 14, 0 }, // 87 bits per transform
- { 12, 0, 13 }, // 87 bits per transform
- { 12, 1, 10 }, // 87 bits per transform
- { 12, 2, 9 }, // 87 bits per transform
- { 12, 3, 8 }, // 87 bits per transform
- { 12, 4, 7 }, // 87 bits per transform
- { 12, 5, 6 }, // 87 bits per transform
- { 12, 6, 5 }, // 87 bits per transform
- { 12, 7, 4 }, // 87 bits per transform
- { 12, 8, 3 }, // 87 bits per transform
- { 12, 9, 2 }, // 87 bits per transform
- { 12, 10, 1 }, // 87 bits per transform
- { 12, 13, 0 }, // 87 bits per transform
- { 13, 0, 12 }, // 87 bits per transform
- { 13, 1, 9 }, // 87 bits per transform
- { 13, 2, 8 }, // 87 bits per transform
- { 13, 3, 7 }, // 87 bits per transform
- { 13, 4, 6 }, // 87 bits per transform
- { 13, 5, 5 }, // 87 bits per transform
- { 13, 6, 4 }, // 87 bits per transform
- { 13, 7, 3 }, // 87 bits per transform
- { 13, 8, 2 }, // 87 bits per transform
- { 13, 9, 1 }, // 87 bits per transform
- { 13, 12, 0 }, // 87 bits per transform
- { 14, 0, 11 }, // 87 bits per transform
- { 14, 1, 8 }, // 87 bits per transform
- { 14, 2, 7 }, // 87 bits per transform
- { 14, 3, 6 }, // 87 bits per transform
- { 14, 4, 5 }, // 87 bits per transform
- { 14, 5, 4 }, // 87 bits per transform
- { 14, 6, 3 }, // 87 bits per transform
- { 14, 7, 2 }, // 87 bits per transform
- { 14, 8, 1 }, // 87 bits per transform
- { 14, 11, 0 }, // 87 bits per transform
- { 15, 0, 10 }, // 87 bits per transform
- { 15, 1, 7 }, // 87 bits per transform
- { 15, 2, 6 }, // 87 bits per transform
- { 15, 3, 5 }, // 87 bits per transform
- { 15, 4, 4 }, // 87 bits per transform
- { 15, 5, 3 }, // 87 bits per transform
- { 15, 6, 2 }, // 87 bits per transform
- { 15, 7, 1 }, // 87 bits per transform
- { 15, 10, 0 }, // 87 bits per transform
- { 16, 0, 9 }, // 87 bits per transform
- { 16, 1, 6 }, // 87 bits per transform
- { 16, 2, 5 }, // 87 bits per transform
- { 16, 3, 4 }, // 87 bits per transform
- { 16, 4, 3 }, // 87 bits per transform
- { 16, 5, 2 }, // 87 bits per transform
- { 16, 6, 1 }, // 87 bits per transform
- { 16, 9, 0 }, // 87 bits per transform
- { 17, 0, 8 }, // 87 bits per transform
- { 17, 1, 5 }, // 87 bits per transform
- { 17, 2, 4 }, // 87 bits per transform
- { 17, 3, 3 }, // 87 bits per transform
- { 17, 4, 2 }, // 87 bits per transform
- { 17, 5, 1 }, // 87 bits per transform
- { 17, 8, 0 }, // 87 bits per transform
- { 0, 9, 17 }, // 90 bits per transform
- { 0, 10, 16 }, // 90 bits per transform
- { 0, 11, 15 }, // 90 bits per transform
- { 0, 12, 14 }, // 90 bits per transform
- { 0, 13, 13 }, // 90 bits per transform
- { 0, 14, 12 }, // 90 bits per transform
- { 0, 15, 11 }, // 90 bits per transform
- { 0, 16, 10 }, // 90 bits per transform
- { 0, 17, 9 }, // 90 bits per transform
- { 1, 6, 17 }, // 90 bits per transform
- { 1, 7, 16 }, // 90 bits per transform
- { 1, 8, 15 }, // 90 bits per transform
- { 1, 9, 14 }, // 90 bits per transform
- { 1, 10, 13 }, // 90 bits per transform
- { 1, 11, 12 }, // 90 bits per transform
- { 1, 12, 11 }, // 90 bits per transform
- { 1, 13, 10 }, // 90 bits per transform
- { 1, 14, 9 }, // 90 bits per transform
- { 1, 15, 8 }, // 90 bits per transform
- { 1, 16, 7 }, // 90 bits per transform
- { 1, 17, 6 }, // 90 bits per transform
- { 2, 5, 17 }, // 90 bits per transform
- { 2, 6, 16 }, // 90 bits per transform
- { 2, 7, 15 }, // 90 bits per transform
- { 2, 8, 14 }, // 90 bits per transform
- { 2, 9, 13 }, // 90 bits per transform
- { 2, 10, 12 }, // 90 bits per transform
- { 2, 11, 11 }, // 90 bits per transform
- { 2, 12, 10 }, // 90 bits per transform
- { 2, 13, 9 }, // 90 bits per transform
- { 2, 14, 8 }, // 90 bits per transform
- { 2, 15, 7 }, // 90 bits per transform
- { 2, 16, 6 }, // 90 bits per transform
- { 2, 17, 5 }, // 90 bits per transform
- { 3, 4, 17 }, // 90 bits per transform
- { 3, 5, 16 }, // 90 bits per transform
- { 3, 6, 15 }, // 90 bits per transform
- { 3, 7, 14 }, // 90 bits per transform
- { 3, 8, 13 }, // 90 bits per transform
- { 3, 9, 12 }, // 90 bits per transform
- { 3, 10, 11 }, // 90 bits per transform
- { 3, 11, 10 }, // 90 bits per transform
- { 3, 12, 9 }, // 90 bits per transform
- { 3, 13, 8 }, // 90 bits per transform
- { 3, 14, 7 }, // 90 bits per transform
- { 3, 15, 6 }, // 90 bits per transform
- { 3, 16, 5 }, // 90 bits per transform
- { 3, 17, 4 }, // 90 bits per transform
- { 4, 3, 17 }, // 90 bits per transform
- { 4, 4, 16 }, // 90 bits per transform
- { 4, 5, 15 }, // 90 bits per transform
- { 4, 6, 14 }, // 90 bits per transform
- { 4, 7, 13 }, // 90 bits per transform
- { 4, 8, 12 }, // 90 bits per transform
- { 4, 9, 11 }, // 90 bits per transform
- { 4, 10, 10 }, // 90 bits per transform
- { 4, 11, 9 }, // 90 bits per transform
- { 4, 12, 8 }, // 90 bits per transform
- { 4, 13, 7 }, // 90 bits per transform
- { 4, 14, 6 }, // 90 bits per transform
- { 4, 15, 5 }, // 90 bits per transform
- { 4, 16, 4 }, // 90 bits per transform
- { 4, 17, 3 }, // 90 bits per transform
- { 5, 2, 17 }, // 90 bits per transform
- { 5, 3, 16 }, // 90 bits per transform
- { 5, 4, 15 }, // 90 bits per transform
- { 5, 5, 14 }, // 90 bits per transform
- { 5, 6, 13 }, // 90 bits per transform
- { 5, 7, 12 }, // 90 bits per transform
- { 5, 8, 11 }, // 90 bits per transform
- { 5, 9, 10 }, // 90 bits per transform
- { 5, 10, 9 }, // 90 bits per transform
- { 5, 11, 8 }, // 90 bits per transform
- { 5, 12, 7 }, // 90 bits per transform
- { 5, 13, 6 }, // 90 bits per transform
- { 5, 14, 5 }, // 90 bits per transform
- { 5, 15, 4 }, // 90 bits per transform
- { 5, 16, 3 }, // 90 bits per transform
- { 5, 17, 2 }, // 90 bits per transform
- { 6, 1, 17 }, // 90 bits per transform
- { 6, 2, 16 }, // 90 bits per transform
- { 6, 3, 15 }, // 90 bits per transform
- { 6, 4, 14 }, // 90 bits per transform
- { 6, 5, 13 }, // 90 bits per transform
- { 6, 6, 12 }, // 90 bits per transform
- { 6, 7, 11 }, // 90 bits per transform
- { 6, 8, 10 }, // 90 bits per transform
- { 6, 9, 9 }, // 90 bits per transform
- { 6, 10, 8 }, // 90 bits per transform
- { 6, 11, 7 }, // 90 bits per transform
- { 6, 12, 6 }, // 90 bits per transform
- { 6, 13, 5 }, // 90 bits per transform
- { 6, 14, 4 }, // 90 bits per transform
- { 6, 15, 3 }, // 90 bits per transform
- { 6, 16, 2 }, // 90 bits per transform
- { 6, 17, 1 }, // 90 bits per transform
- { 7, 1, 16 }, // 90 bits per transform
- { 7, 2, 15 }, // 90 bits per transform
- { 7, 3, 14 }, // 90 bits per transform
- { 7, 4, 13 }, // 90 bits per transform
- { 7, 5, 12 }, // 90 bits per transform
- { 7, 6, 11 }, // 90 bits per transform
- { 7, 7, 10 }, // 90 bits per transform
- { 7, 8, 9 }, // 90 bits per transform
- { 7, 9, 8 }, // 90 bits per transform
- { 7, 10, 7 }, // 90 bits per transform
- { 7, 11, 6 }, // 90 bits per transform
- { 7, 12, 5 }, // 90 bits per transform
- { 7, 13, 4 }, // 90 bits per transform
- { 7, 14, 3 }, // 90 bits per transform
- { 7, 15, 2 }, // 90 bits per transform
- { 7, 16, 1 }, // 90 bits per transform
- { 8, 1, 15 }, // 90 bits per transform
- { 8, 2, 14 }, // 90 bits per transform
- { 8, 3, 13 }, // 90 bits per transform
- { 8, 4, 12 }, // 90 bits per transform
- { 8, 5, 11 }, // 90 bits per transform
- { 8, 6, 10 }, // 90 bits per transform
- { 8, 7, 9 }, // 90 bits per transform
- { 8, 8, 8 }, // 90 bits per transform
- { 8, 9, 7 }, // 90 bits per transform
- { 8, 10, 6 }, // 90 bits per transform
- { 8, 11, 5 }, // 90 bits per transform
- { 8, 12, 4 }, // 90 bits per transform
- { 8, 13, 3 }, // 90 bits per transform
- { 8, 14, 2 }, // 90 bits per transform
- { 8, 15, 1 }, // 90 bits per transform
- { 9, 0, 17 }, // 90 bits per transform
- { 9, 1, 14 }, // 90 bits per transform
- { 9, 2, 13 }, // 90 bits per transform
- { 9, 3, 12 }, // 90 bits per transform
- { 9, 4, 11 }, // 90 bits per transform
- { 9, 5, 10 }, // 90 bits per transform
- { 9, 6, 9 }, // 90 bits per transform
- { 9, 7, 8 }, // 90 bits per transform
- { 9, 8, 7 }, // 90 bits per transform
- { 9, 9, 6 }, // 90 bits per transform
- { 9, 10, 5 }, // 90 bits per transform
- { 9, 11, 4 }, // 90 bits per transform
- { 9, 12, 3 }, // 90 bits per transform
- { 9, 13, 2 }, // 90 bits per transform
- { 9, 14, 1 }, // 90 bits per transform
- { 9, 17, 0 }, // 90 bits per transform
- { 10, 0, 16 }, // 90 bits per transform
- { 10, 1, 13 }, // 90 bits per transform
- { 10, 2, 12 }, // 90 bits per transform
- { 10, 3, 11 }, // 90 bits per transform
- { 10, 4, 10 }, // 90 bits per transform
- { 10, 5, 9 }, // 90 bits per transform
- { 10, 6, 8 }, // 90 bits per transform
- { 10, 7, 7 }, // 90 bits per transform
- { 10, 8, 6 }, // 90 bits per transform
- { 10, 9, 5 }, // 90 bits per transform
- { 10, 10, 4 }, // 90 bits per transform
- { 10, 11, 3 }, // 90 bits per transform
- { 10, 12, 2 }, // 90 bits per transform
- { 10, 13, 1 }, // 90 bits per transform
- { 10, 16, 0 }, // 90 bits per transform
- { 11, 0, 15 }, // 90 bits per transform
- { 11, 1, 12 }, // 90 bits per transform
- { 11, 2, 11 }, // 90 bits per transform
- { 11, 3, 10 }, // 90 bits per transform
- { 11, 4, 9 }, // 90 bits per transform
- { 11, 5, 8 }, // 90 bits per transform
- { 11, 6, 7 }, // 90 bits per transform
- { 11, 7, 6 }, // 90 bits per transform
- { 11, 8, 5 }, // 90 bits per transform
- { 11, 9, 4 }, // 90 bits per transform
- { 11, 10, 3 }, // 90 bits per transform
- { 11, 11, 2 }, // 90 bits per transform
- { 11, 12, 1 }, // 90 bits per transform
- { 11, 15, 0 }, // 90 bits per transform
- { 12, 0, 14 }, // 90 bits per transform
- { 12, 1, 11 }, // 90 bits per transform
- { 12, 2, 10 }, // 90 bits per transform
- { 12, 3, 9 }, // 90 bits per transform
- { 12, 4, 8 }, // 90 bits per transform
- { 12, 5, 7 }, // 90 bits per transform
- { 12, 6, 6 }, // 90 bits per transform
- { 12, 7, 5 }, // 90 bits per transform
- { 12, 8, 4 }, // 90 bits per transform
- { 12, 9, 3 }, // 90 bits per transform
- { 12, 10, 2 }, // 90 bits per transform
- { 12, 11, 1 }, // 90 bits per transform
- { 12, 14, 0 }, // 90 bits per transform
- { 13, 0, 13 }, // 90 bits per transform
- { 13, 1, 10 }, // 90 bits per transform
- { 13, 2, 9 }, // 90 bits per transform
- { 13, 3, 8 }, // 90 bits per transform
- { 13, 4, 7 }, // 90 bits per transform
- { 13, 5, 6 }, // 90 bits per transform
- { 13, 6, 5 }, // 90 bits per transform
- { 13, 7, 4 }, // 90 bits per transform
- { 13, 8, 3 }, // 90 bits per transform
- { 13, 9, 2 }, // 90 bits per transform
- { 13, 10, 1 }, // 90 bits per transform
- { 13, 13, 0 }, // 90 bits per transform
- { 14, 0, 12 }, // 90 bits per transform
- { 14, 1, 9 }, // 90 bits per transform
- { 14, 2, 8 }, // 90 bits per transform
- { 14, 3, 7 }, // 90 bits per transform
- { 14, 4, 6 }, // 90 bits per transform
- { 14, 5, 5 }, // 90 bits per transform
- { 14, 6, 4 }, // 90 bits per transform
- { 14, 7, 3 }, // 90 bits per transform
- { 14, 8, 2 }, // 90 bits per transform
- { 14, 9, 1 }, // 90 bits per transform
- { 14, 12, 0 }, // 90 bits per transform
- { 15, 0, 11 }, // 90 bits per transform
- { 15, 1, 8 }, // 90 bits per transform
- { 15, 2, 7 }, // 90 bits per transform
- { 15, 3, 6 }, // 90 bits per transform
- { 15, 4, 5 }, // 90 bits per transform
- { 15, 5, 4 }, // 90 bits per transform
- { 15, 6, 3 }, // 90 bits per transform
- { 15, 7, 2 }, // 90 bits per transform
- { 15, 8, 1 }, // 90 bits per transform
- { 15, 11, 0 }, // 90 bits per transform
- { 16, 0, 10 }, // 90 bits per transform
- { 16, 1, 7 }, // 90 bits per transform
- { 16, 2, 6 }, // 90 bits per transform
- { 16, 3, 5 }, // 90 bits per transform
- { 16, 4, 4 }, // 90 bits per transform
- { 16, 5, 3 }, // 90 bits per transform
- { 16, 6, 2 }, // 90 bits per transform
- { 16, 7, 1 }, // 90 bits per transform
- { 16, 10, 0 }, // 90 bits per transform
- { 17, 0, 9 }, // 90 bits per transform
- { 17, 1, 6 }, // 90 bits per transform
- { 17, 2, 5 }, // 90 bits per transform
- { 17, 3, 4 }, // 90 bits per transform
- { 17, 4, 3 }, // 90 bits per transform
- { 17, 5, 2 }, // 90 bits per transform
- { 17, 6, 1 }, // 90 bits per transform
- { 17, 9, 0 }, // 90 bits per transform
- { 0, 10, 17 }, // 93 bits per transform
- { 0, 11, 16 }, // 93 bits per transform
- { 0, 12, 15 }, // 93 bits per transform
- { 0, 13, 14 }, // 93 bits per transform
- { 0, 14, 13 }, // 93 bits per transform
- { 0, 15, 12 }, // 93 bits per transform
- { 0, 16, 11 }, // 93 bits per transform
- { 0, 17, 10 }, // 93 bits per transform
- { 1, 7, 17 }, // 93 bits per transform
- { 1, 8, 16 }, // 93 bits per transform
- { 1, 9, 15 }, // 93 bits per transform
- { 1, 10, 14 }, // 93 bits per transform
- { 1, 11, 13 }, // 93 bits per transform
- { 1, 12, 12 }, // 93 bits per transform
- { 1, 13, 11 }, // 93 bits per transform
- { 1, 14, 10 }, // 93 bits per transform
- { 1, 15, 9 }, // 93 bits per transform
- { 1, 16, 8 }, // 93 bits per transform
- { 1, 17, 7 }, // 93 bits per transform
- { 2, 6, 17 }, // 93 bits per transform
- { 2, 7, 16 }, // 93 bits per transform
- { 2, 8, 15 }, // 93 bits per transform
- { 2, 9, 14 }, // 93 bits per transform
- { 2, 10, 13 }, // 93 bits per transform
- { 2, 11, 12 }, // 93 bits per transform
- { 2, 12, 11 }, // 93 bits per transform
- { 2, 13, 10 }, // 93 bits per transform
- { 2, 14, 9 }, // 93 bits per transform
- { 2, 15, 8 }, // 93 bits per transform
- { 2, 16, 7 }, // 93 bits per transform
- { 2, 17, 6 }, // 93 bits per transform
- { 3, 5, 17 }, // 93 bits per transform
- { 3, 6, 16 }, // 93 bits per transform
- { 3, 7, 15 }, // 93 bits per transform
- { 3, 8, 14 }, // 93 bits per transform
- { 3, 9, 13 }, // 93 bits per transform
- { 3, 10, 12 }, // 93 bits per transform
- { 3, 11, 11 }, // 93 bits per transform
- { 3, 12, 10 }, // 93 bits per transform
- { 3, 13, 9 }, // 93 bits per transform
- { 3, 14, 8 }, // 93 bits per transform
- { 3, 15, 7 }, // 93 bits per transform
- { 3, 16, 6 }, // 93 bits per transform
- { 3, 17, 5 }, // 93 bits per transform
- { 4, 4, 17 }, // 93 bits per transform
- { 4, 5, 16 }, // 93 bits per transform
- { 4, 6, 15 }, // 93 bits per transform
- { 4, 7, 14 }, // 93 bits per transform
- { 4, 8, 13 }, // 93 bits per transform
- { 4, 9, 12 }, // 93 bits per transform
- { 4, 10, 11 }, // 93 bits per transform
- { 4, 11, 10 }, // 93 bits per transform
- { 4, 12, 9 }, // 93 bits per transform
- { 4, 13, 8 }, // 93 bits per transform
- { 4, 14, 7 }, // 93 bits per transform
- { 4, 15, 6 }, // 93 bits per transform
- { 4, 16, 5 }, // 93 bits per transform
- { 4, 17, 4 }, // 93 bits per transform
- { 5, 3, 17 }, // 93 bits per transform
- { 5, 4, 16 }, // 93 bits per transform
- { 5, 5, 15 }, // 93 bits per transform
- { 5, 6, 14 }, // 93 bits per transform
- { 5, 7, 13 }, // 93 bits per transform
- { 5, 8, 12 }, // 93 bits per transform
- { 5, 9, 11 }, // 93 bits per transform
- { 5, 10, 10 }, // 93 bits per transform
- { 5, 11, 9 }, // 93 bits per transform
- { 5, 12, 8 }, // 93 bits per transform
- { 5, 13, 7 }, // 93 bits per transform
- { 5, 14, 6 }, // 93 bits per transform
- { 5, 15, 5 }, // 93 bits per transform
- { 5, 16, 4 }, // 93 bits per transform
- { 5, 17, 3 }, // 93 bits per transform
- { 6, 2, 17 }, // 93 bits per transform
- { 6, 3, 16 }, // 93 bits per transform
- { 6, 4, 15 }, // 93 bits per transform
- { 6, 5, 14 }, // 93 bits per transform
- { 6, 6, 13 }, // 93 bits per transform
- { 6, 7, 12 }, // 93 bits per transform
- { 6, 8, 11 }, // 93 bits per transform
- { 6, 9, 10 }, // 93 bits per transform
- { 6, 10, 9 }, // 93 bits per transform
- { 6, 11, 8 }, // 93 bits per transform
- { 6, 12, 7 }, // 93 bits per transform
- { 6, 13, 6 }, // 93 bits per transform
- { 6, 14, 5 }, // 93 bits per transform
- { 6, 15, 4 }, // 93 bits per transform
- { 6, 16, 3 }, // 93 bits per transform
- { 6, 17, 2 }, // 93 bits per transform
- { 7, 1, 17 }, // 93 bits per transform
- { 7, 2, 16 }, // 93 bits per transform
- { 7, 3, 15 }, // 93 bits per transform
- { 7, 4, 14 }, // 93 bits per transform
- { 7, 5, 13 }, // 93 bits per transform
- { 7, 6, 12 }, // 93 bits per transform
- { 7, 7, 11 }, // 93 bits per transform
- { 7, 8, 10 }, // 93 bits per transform
- { 7, 9, 9 }, // 93 bits per transform
- { 7, 10, 8 }, // 93 bits per transform
- { 7, 11, 7 }, // 93 bits per transform
- { 7, 12, 6 }, // 93 bits per transform
- { 7, 13, 5 }, // 93 bits per transform
- { 7, 14, 4 }, // 93 bits per transform
- { 7, 15, 3 }, // 93 bits per transform
- { 7, 16, 2 }, // 93 bits per transform
- { 7, 17, 1 }, // 93 bits per transform
- { 8, 1, 16 }, // 93 bits per transform
- { 8, 2, 15 }, // 93 bits per transform
- { 8, 3, 14 }, // 93 bits per transform
- { 8, 4, 13 }, // 93 bits per transform
- { 8, 5, 12 }, // 93 bits per transform
- { 8, 6, 11 }, // 93 bits per transform
- { 8, 7, 10 }, // 93 bits per transform
- { 8, 8, 9 }, // 93 bits per transform
- { 8, 9, 8 }, // 93 bits per transform
- { 8, 10, 7 }, // 93 bits per transform
- { 8, 11, 6 }, // 93 bits per transform
- { 8, 12, 5 }, // 93 bits per transform
- { 8, 13, 4 }, // 93 bits per transform
- { 8, 14, 3 }, // 93 bits per transform
- { 8, 15, 2 }, // 93 bits per transform
- { 8, 16, 1 }, // 93 bits per transform
- { 9, 1, 15 }, // 93 bits per transform
- { 9, 2, 14 }, // 93 bits per transform
- { 9, 3, 13 }, // 93 bits per transform
- { 9, 4, 12 }, // 93 bits per transform
- { 9, 5, 11 }, // 93 bits per transform
- { 9, 6, 10 }, // 93 bits per transform
- { 9, 7, 9 }, // 93 bits per transform
- { 9, 8, 8 }, // 93 bits per transform
- { 9, 9, 7 }, // 93 bits per transform
- { 9, 10, 6 }, // 93 bits per transform
- { 9, 11, 5 }, // 93 bits per transform
- { 9, 12, 4 }, // 93 bits per transform
- { 9, 13, 3 }, // 93 bits per transform
- { 9, 14, 2 }, // 93 bits per transform
- { 9, 15, 1 }, // 93 bits per transform
- { 10, 0, 17 }, // 93 bits per transform
- { 10, 1, 14 }, // 93 bits per transform
- { 10, 2, 13 }, // 93 bits per transform
- { 10, 3, 12 }, // 93 bits per transform
- { 10, 4, 11 }, // 93 bits per transform
- { 10, 5, 10 }, // 93 bits per transform
- { 10, 6, 9 }, // 93 bits per transform
- { 10, 7, 8 }, // 93 bits per transform
- { 10, 8, 7 }, // 93 bits per transform
- { 10, 9, 6 }, // 93 bits per transform
- { 10, 10, 5 }, // 93 bits per transform
- { 10, 11, 4 }, // 93 bits per transform
- { 10, 12, 3 }, // 93 bits per transform
- { 10, 13, 2 }, // 93 bits per transform
- { 10, 14, 1 }, // 93 bits per transform
- { 10, 17, 0 }, // 93 bits per transform
- { 11, 0, 16 }, // 93 bits per transform
- { 11, 1, 13 }, // 93 bits per transform
- { 11, 2, 12 }, // 93 bits per transform
- { 11, 3, 11 }, // 93 bits per transform
- { 11, 4, 10 }, // 93 bits per transform
- { 11, 5, 9 }, // 93 bits per transform
- { 11, 6, 8 }, // 93 bits per transform
- { 11, 7, 7 }, // 93 bits per transform
- { 11, 8, 6 }, // 93 bits per transform
- { 11, 9, 5 }, // 93 bits per transform
- { 11, 10, 4 }, // 93 bits per transform
- { 11, 11, 3 }, // 93 bits per transform
- { 11, 12, 2 }, // 93 bits per transform
- { 11, 13, 1 }, // 93 bits per transform
- { 11, 16, 0 }, // 93 bits per transform
- { 12, 0, 15 }, // 93 bits per transform
- { 12, 1, 12 }, // 93 bits per transform
- { 12, 2, 11 }, // 93 bits per transform
- { 12, 3, 10 }, // 93 bits per transform
- { 12, 4, 9 }, // 93 bits per transform
- { 12, 5, 8 }, // 93 bits per transform
- { 12, 6, 7 }, // 93 bits per transform
- { 12, 7, 6 }, // 93 bits per transform
- { 12, 8, 5 }, // 93 bits per transform
- { 12, 9, 4 }, // 93 bits per transform
- { 12, 10, 3 }, // 93 bits per transform
- { 12, 11, 2 }, // 93 bits per transform
- { 12, 12, 1 }, // 93 bits per transform
- { 12, 15, 0 }, // 93 bits per transform
- { 13, 0, 14 }, // 93 bits per transform
- { 13, 1, 11 }, // 93 bits per transform
- { 13, 2, 10 }, // 93 bits per transform
- { 13, 3, 9 }, // 93 bits per transform
- { 13, 4, 8 }, // 93 bits per transform
- { 13, 5, 7 }, // 93 bits per transform
- { 13, 6, 6 }, // 93 bits per transform
- { 13, 7, 5 }, // 93 bits per transform
- { 13, 8, 4 }, // 93 bits per transform
- { 13, 9, 3 }, // 93 bits per transform
- { 13, 10, 2 }, // 93 bits per transform
- { 13, 11, 1 }, // 93 bits per transform
- { 13, 14, 0 }, // 93 bits per transform
- { 14, 0, 13 }, // 93 bits per transform
- { 14, 1, 10 }, // 93 bits per transform
- { 14, 2, 9 }, // 93 bits per transform
- { 14, 3, 8 }, // 93 bits per transform
- { 14, 4, 7 }, // 93 bits per transform
- { 14, 5, 6 }, // 93 bits per transform
- { 14, 6, 5 }, // 93 bits per transform
- { 14, 7, 4 }, // 93 bits per transform
- { 14, 8, 3 }, // 93 bits per transform
- { 14, 9, 2 }, // 93 bits per transform
- { 14, 10, 1 }, // 93 bits per transform
- { 14, 13, 0 }, // 93 bits per transform
- { 15, 0, 12 }, // 93 bits per transform
- { 15, 1, 9 }, // 93 bits per transform
- { 15, 2, 8 }, // 93 bits per transform
- { 15, 3, 7 }, // 93 bits per transform
- { 15, 4, 6 }, // 93 bits per transform
- { 15, 5, 5 }, // 93 bits per transform
- { 15, 6, 4 }, // 93 bits per transform
- { 15, 7, 3 }, // 93 bits per transform
- { 15, 8, 2 }, // 93 bits per transform
- { 15, 9, 1 }, // 93 bits per transform
- { 15, 12, 0 }, // 93 bits per transform
- { 16, 0, 11 }, // 93 bits per transform
- { 16, 1, 8 }, // 93 bits per transform
- { 16, 2, 7 }, // 93 bits per transform
- { 16, 3, 6 }, // 93 bits per transform
- { 16, 4, 5 }, // 93 bits per transform
- { 16, 5, 4 }, // 93 bits per transform
- { 16, 6, 3 }, // 93 bits per transform
- { 16, 7, 2 }, // 93 bits per transform
- { 16, 8, 1 }, // 93 bits per transform
- { 16, 11, 0 }, // 93 bits per transform
- { 17, 0, 10 }, // 93 bits per transform
- { 17, 1, 7 }, // 93 bits per transform
- { 17, 2, 6 }, // 93 bits per transform
- { 17, 3, 5 }, // 93 bits per transform
- { 17, 4, 4 }, // 93 bits per transform
- { 17, 5, 3 }, // 93 bits per transform
- { 17, 6, 2 }, // 93 bits per transform
- { 17, 7, 1 }, // 93 bits per transform
- { 17, 10, 0 }, // 93 bits per transform
- { 0, 0, 18 }, // 96 bits per transform
- { 0, 11, 17 }, // 96 bits per transform
- { 0, 12, 16 }, // 96 bits per transform
- { 0, 13, 15 }, // 96 bits per transform
- { 0, 14, 14 }, // 96 bits per transform
- { 0, 15, 13 }, // 96 bits per transform
- { 0, 16, 12 }, // 96 bits per transform
- { 0, 17, 11 }, // 96 bits per transform
- { 0, 18, 0 }, // 96 bits per transform
- { 1, 8, 17 }, // 96 bits per transform
- { 1, 9, 16 }, // 96 bits per transform
- { 1, 10, 15 }, // 96 bits per transform
- { 1, 11, 14 }, // 96 bits per transform
- { 1, 12, 13 }, // 96 bits per transform
- { 1, 13, 12 }, // 96 bits per transform
- { 1, 14, 11 }, // 96 bits per transform
- { 1, 15, 10 }, // 96 bits per transform
- { 1, 16, 9 }, // 96 bits per transform
- { 1, 17, 8 }, // 96 bits per transform
- { 2, 7, 17 }, // 96 bits per transform
- { 2, 8, 16 }, // 96 bits per transform
- { 2, 9, 15 }, // 96 bits per transform
- { 2, 10, 14 }, // 96 bits per transform
- { 2, 11, 13 }, // 96 bits per transform
- { 2, 12, 12 }, // 96 bits per transform
- { 2, 13, 11 }, // 96 bits per transform
- { 2, 14, 10 }, // 96 bits per transform
- { 2, 15, 9 }, // 96 bits per transform
- { 2, 16, 8 }, // 96 bits per transform
- { 2, 17, 7 }, // 96 bits per transform
- { 3, 6, 17 }, // 96 bits per transform
- { 3, 7, 16 }, // 96 bits per transform
- { 3, 8, 15 }, // 96 bits per transform
- { 3, 9, 14 }, // 96 bits per transform
- { 3, 10, 13 }, // 96 bits per transform
- { 3, 11, 12 }, // 96 bits per transform
- { 3, 12, 11 }, // 96 bits per transform
- { 3, 13, 10 }, // 96 bits per transform
- { 3, 14, 9 }, // 96 bits per transform
- { 3, 15, 8 }, // 96 bits per transform
- { 3, 16, 7 }, // 96 bits per transform
- { 3, 17, 6 }, // 96 bits per transform
- { 4, 5, 17 }, // 96 bits per transform
- { 4, 6, 16 }, // 96 bits per transform
- { 4, 7, 15 }, // 96 bits per transform
- { 4, 8, 14 }, // 96 bits per transform
- { 4, 9, 13 }, // 96 bits per transform
- { 4, 10, 12 }, // 96 bits per transform
- { 4, 11, 11 }, // 96 bits per transform
- { 4, 12, 10 }, // 96 bits per transform
- { 4, 13, 9 }, // 96 bits per transform
- { 4, 14, 8 }, // 96 bits per transform
- { 4, 15, 7 }, // 96 bits per transform
- { 4, 16, 6 }, // 96 bits per transform
- { 4, 17, 5 }, // 96 bits per transform
- { 5, 4, 17 }, // 96 bits per transform
- { 5, 5, 16 }, // 96 bits per transform
- { 5, 6, 15 }, // 96 bits per transform
- { 5, 7, 14 }, // 96 bits per transform
- { 5, 8, 13 }, // 96 bits per transform
- { 5, 9, 12 }, // 96 bits per transform
- { 5, 10, 11 }, // 96 bits per transform
- { 5, 11, 10 }, // 96 bits per transform
- { 5, 12, 9 }, // 96 bits per transform
- { 5, 13, 8 }, // 96 bits per transform
- { 5, 14, 7 }, // 96 bits per transform
- { 5, 15, 6 }, // 96 bits per transform
- { 5, 16, 5 }, // 96 bits per transform
- { 5, 17, 4 }, // 96 bits per transform
- { 6, 3, 17 }, // 96 bits per transform
- { 6, 4, 16 }, // 96 bits per transform
- { 6, 5, 15 }, // 96 bits per transform
- { 6, 6, 14 }, // 96 bits per transform
- { 6, 7, 13 }, // 96 bits per transform
- { 6, 8, 12 }, // 96 bits per transform
- { 6, 9, 11 }, // 96 bits per transform
- { 6, 10, 10 }, // 96 bits per transform
- { 6, 11, 9 }, // 96 bits per transform
- { 6, 12, 8 }, // 96 bits per transform
- { 6, 13, 7 }, // 96 bits per transform
- { 6, 14, 6 }, // 96 bits per transform
- { 6, 15, 5 }, // 96 bits per transform
- { 6, 16, 4 }, // 96 bits per transform
- { 6, 17, 3 }, // 96 bits per transform
- { 7, 2, 17 }, // 96 bits per transform
- { 7, 3, 16 }, // 96 bits per transform
- { 7, 4, 15 }, // 96 bits per transform
- { 7, 5, 14 }, // 96 bits per transform
- { 7, 6, 13 }, // 96 bits per transform
- { 7, 7, 12 }, // 96 bits per transform
- { 7, 8, 11 }, // 96 bits per transform
- { 7, 9, 10 }, // 96 bits per transform
- { 7, 10, 9 }, // 96 bits per transform
- { 7, 11, 8 }, // 96 bits per transform
- { 7, 12, 7 }, // 96 bits per transform
- { 7, 13, 6 }, // 96 bits per transform
- { 7, 14, 5 }, // 96 bits per transform
- { 7, 15, 4 }, // 96 bits per transform
- { 7, 16, 3 }, // 96 bits per transform
- { 7, 17, 2 }, // 96 bits per transform
- { 8, 1, 17 }, // 96 bits per transform
- { 8, 2, 16 }, // 96 bits per transform
- { 8, 3, 15 }, // 96 bits per transform
- { 8, 4, 14 }, // 96 bits per transform
- { 8, 5, 13 }, // 96 bits per transform
- { 8, 6, 12 }, // 96 bits per transform
- { 8, 7, 11 }, // 96 bits per transform
- { 8, 8, 10 }, // 96 bits per transform
- { 8, 9, 9 }, // 96 bits per transform
- { 8, 10, 8 }, // 96 bits per transform
- { 8, 11, 7 }, // 96 bits per transform
- { 8, 12, 6 }, // 96 bits per transform
- { 8, 13, 5 }, // 96 bits per transform
- { 8, 14, 4 }, // 96 bits per transform
- { 8, 15, 3 }, // 96 bits per transform
- { 8, 16, 2 }, // 96 bits per transform
- { 8, 17, 1 }, // 96 bits per transform
- { 9, 1, 16 }, // 96 bits per transform
- { 9, 2, 15 }, // 96 bits per transform
- { 9, 3, 14 }, // 96 bits per transform
- { 9, 4, 13 }, // 96 bits per transform
- { 9, 5, 12 }, // 96 bits per transform
- { 9, 6, 11 }, // 96 bits per transform
- { 9, 7, 10 }, // 96 bits per transform
- { 9, 8, 9 }, // 96 bits per transform
- { 9, 9, 8 }, // 96 bits per transform
- { 9, 10, 7 }, // 96 bits per transform
- { 9, 11, 6 }, // 96 bits per transform
- { 9, 12, 5 }, // 96 bits per transform
- { 9, 13, 4 }, // 96 bits per transform
- { 9, 14, 3 }, // 96 bits per transform
- { 9, 15, 2 }, // 96 bits per transform
- { 9, 16, 1 }, // 96 bits per transform
- { 10, 1, 15 }, // 96 bits per transform
- { 10, 2, 14 }, // 96 bits per transform
- { 10, 3, 13 }, // 96 bits per transform
- { 10, 4, 12 }, // 96 bits per transform
- { 10, 5, 11 }, // 96 bits per transform
- { 10, 6, 10 }, // 96 bits per transform
- { 10, 7, 9 }, // 96 bits per transform
- { 10, 8, 8 }, // 96 bits per transform
- { 10, 9, 7 }, // 96 bits per transform
- { 10, 10, 6 }, // 96 bits per transform
- { 10, 11, 5 }, // 96 bits per transform
- { 10, 12, 4 }, // 96 bits per transform
- { 10, 13, 3 }, // 96 bits per transform
- { 10, 14, 2 }, // 96 bits per transform
- { 10, 15, 1 }, // 96 bits per transform
- { 11, 0, 17 }, // 96 bits per transform
- { 11, 1, 14 }, // 96 bits per transform
- { 11, 2, 13 }, // 96 bits per transform
- { 11, 3, 12 }, // 96 bits per transform
- { 11, 4, 11 }, // 96 bits per transform
- { 11, 5, 10 }, // 96 bits per transform
- { 11, 6, 9 }, // 96 bits per transform
- { 11, 7, 8 }, // 96 bits per transform
- { 11, 8, 7 }, // 96 bits per transform
- { 11, 9, 6 }, // 96 bits per transform
- { 11, 10, 5 }, // 96 bits per transform
- { 11, 11, 4 }, // 96 bits per transform
- { 11, 12, 3 }, // 96 bits per transform
- { 11, 13, 2 }, // 96 bits per transform
- { 11, 14, 1 }, // 96 bits per transform
- { 11, 17, 0 }, // 96 bits per transform
- { 12, 0, 16 }, // 96 bits per transform
- { 12, 1, 13 }, // 96 bits per transform
- { 12, 2, 12 }, // 96 bits per transform
- { 12, 3, 11 }, // 96 bits per transform
- { 12, 4, 10 }, // 96 bits per transform
- { 12, 5, 9 }, // 96 bits per transform
- { 12, 6, 8 }, // 96 bits per transform
- { 12, 7, 7 }, // 96 bits per transform
- { 12, 8, 6 }, // 96 bits per transform
- { 12, 9, 5 }, // 96 bits per transform
- { 12, 10, 4 }, // 96 bits per transform
- { 12, 11, 3 }, // 96 bits per transform
- { 12, 12, 2 }, // 96 bits per transform
- { 12, 13, 1 }, // 96 bits per transform
- { 12, 16, 0 }, // 96 bits per transform
- { 13, 0, 15 }, // 96 bits per transform
- { 13, 1, 12 }, // 96 bits per transform
- { 13, 2, 11 }, // 96 bits per transform
- { 13, 3, 10 }, // 96 bits per transform
- { 13, 4, 9 }, // 96 bits per transform
- { 13, 5, 8 }, // 96 bits per transform
- { 13, 6, 7 }, // 96 bits per transform
- { 13, 7, 6 }, // 96 bits per transform
- { 13, 8, 5 }, // 96 bits per transform
- { 13, 9, 4 }, // 96 bits per transform
- { 13, 10, 3 }, // 96 bits per transform
- { 13, 11, 2 }, // 96 bits per transform
- { 13, 12, 1 }, // 96 bits per transform
- { 13, 15, 0 }, // 96 bits per transform
- { 14, 0, 14 }, // 96 bits per transform
- { 14, 1, 11 }, // 96 bits per transform
- { 14, 2, 10 }, // 96 bits per transform
- { 14, 3, 9 }, // 96 bits per transform
- { 14, 4, 8 }, // 96 bits per transform
- { 14, 5, 7 }, // 96 bits per transform
- { 14, 6, 6 }, // 96 bits per transform
- { 14, 7, 5 }, // 96 bits per transform
- { 14, 8, 4 }, // 96 bits per transform
- { 14, 9, 3 }, // 96 bits per transform
- { 14, 10, 2 }, // 96 bits per transform
- { 14, 11, 1 }, // 96 bits per transform
- { 14, 14, 0 }, // 96 bits per transform
- { 15, 0, 13 }, // 96 bits per transform
- { 15, 1, 10 }, // 96 bits per transform
- { 15, 2, 9 }, // 96 bits per transform
- { 15, 3, 8 }, // 96 bits per transform
- { 15, 4, 7 }, // 96 bits per transform
- { 15, 5, 6 }, // 96 bits per transform
- { 15, 6, 5 }, // 96 bits per transform
- { 15, 7, 4 }, // 96 bits per transform
- { 15, 8, 3 }, // 96 bits per transform
- { 15, 9, 2 }, // 96 bits per transform
- { 15, 10, 1 }, // 96 bits per transform
- { 15, 13, 0 }, // 96 bits per transform
- { 16, 0, 12 }, // 96 bits per transform
- { 16, 1, 9 }, // 96 bits per transform
- { 16, 2, 8 }, // 96 bits per transform
- { 16, 3, 7 }, // 96 bits per transform
- { 16, 4, 6 }, // 96 bits per transform
- { 16, 5, 5 }, // 96 bits per transform
- { 16, 6, 4 }, // 96 bits per transform
- { 16, 7, 3 }, // 96 bits per transform
- { 16, 8, 2 }, // 96 bits per transform
- { 16, 9, 1 }, // 96 bits per transform
- { 16, 12, 0 }, // 96 bits per transform
- { 17, 0, 11 }, // 96 bits per transform
- { 17, 1, 8 }, // 96 bits per transform
- { 17, 2, 7 }, // 96 bits per transform
- { 17, 3, 6 }, // 96 bits per transform
- { 17, 4, 5 }, // 96 bits per transform
- { 17, 5, 4 }, // 96 bits per transform
- { 17, 6, 3 }, // 96 bits per transform
- { 17, 7, 2 }, // 96 bits per transform
- { 17, 8, 1 }, // 96 bits per transform
- { 17, 11, 0 }, // 96 bits per transform
- { 18, 0, 0 }, // 96 bits per transform
- { 0, 12, 17 }, // 99 bits per transform
- { 0, 13, 16 }, // 99 bits per transform
- { 0, 14, 15 }, // 99 bits per transform
- { 0, 15, 14 }, // 99 bits per transform
- { 0, 16, 13 }, // 99 bits per transform
- { 0, 17, 12 }, // 99 bits per transform
- { 1, 9, 17 }, // 99 bits per transform
- { 1, 10, 16 }, // 99 bits per transform
- { 1, 11, 15 }, // 99 bits per transform
- { 1, 12, 14 }, // 99 bits per transform
- { 1, 13, 13 }, // 99 bits per transform
- { 1, 14, 12 }, // 99 bits per transform
- { 1, 15, 11 }, // 99 bits per transform
- { 1, 16, 10 }, // 99 bits per transform
- { 1, 17, 9 }, // 99 bits per transform
- { 2, 8, 17 }, // 99 bits per transform
- { 2, 9, 16 }, // 99 bits per transform
- { 2, 10, 15 }, // 99 bits per transform
- { 2, 11, 14 }, // 99 bits per transform
- { 2, 12, 13 }, // 99 bits per transform
- { 2, 13, 12 }, // 99 bits per transform
- { 2, 14, 11 }, // 99 bits per transform
- { 2, 15, 10 }, // 99 bits per transform
- { 2, 16, 9 }, // 99 bits per transform
- { 2, 17, 8 }, // 99 bits per transform
- { 3, 7, 17 }, // 99 bits per transform
- { 3, 8, 16 }, // 99 bits per transform
- { 3, 9, 15 }, // 99 bits per transform
- { 3, 10, 14 }, // 99 bits per transform
- { 3, 11, 13 }, // 99 bits per transform
- { 3, 12, 12 }, // 99 bits per transform
- { 3, 13, 11 }, // 99 bits per transform
- { 3, 14, 10 }, // 99 bits per transform
- { 3, 15, 9 }, // 99 bits per transform
- { 3, 16, 8 }, // 99 bits per transform
- { 3, 17, 7 }, // 99 bits per transform
- { 4, 6, 17 }, // 99 bits per transform
- { 4, 7, 16 }, // 99 bits per transform
- { 4, 8, 15 }, // 99 bits per transform
- { 4, 9, 14 }, // 99 bits per transform
- { 4, 10, 13 }, // 99 bits per transform
- { 4, 11, 12 }, // 99 bits per transform
- { 4, 12, 11 }, // 99 bits per transform
- { 4, 13, 10 }, // 99 bits per transform
- { 4, 14, 9 }, // 99 bits per transform
- { 4, 15, 8 }, // 99 bits per transform
- { 4, 16, 7 }, // 99 bits per transform
- { 4, 17, 6 }, // 99 bits per transform
- { 5, 5, 17 }, // 99 bits per transform
- { 5, 6, 16 }, // 99 bits per transform
- { 5, 7, 15 }, // 99 bits per transform
- { 5, 8, 14 }, // 99 bits per transform
- { 5, 9, 13 }, // 99 bits per transform
- { 5, 10, 12 }, // 99 bits per transform
- { 5, 11, 11 }, // 99 bits per transform
- { 5, 12, 10 }, // 99 bits per transform
- { 5, 13, 9 }, // 99 bits per transform
- { 5, 14, 8 }, // 99 bits per transform
- { 5, 15, 7 }, // 99 bits per transform
- { 5, 16, 6 }, // 99 bits per transform
- { 5, 17, 5 }, // 99 bits per transform
- { 6, 4, 17 }, // 99 bits per transform
- { 6, 5, 16 }, // 99 bits per transform
- { 6, 6, 15 }, // 99 bits per transform
- { 6, 7, 14 }, // 99 bits per transform
- { 6, 8, 13 }, // 99 bits per transform
- { 6, 9, 12 }, // 99 bits per transform
- { 6, 10, 11 }, // 99 bits per transform
- { 6, 11, 10 }, // 99 bits per transform
- { 6, 12, 9 }, // 99 bits per transform
- { 6, 13, 8 }, // 99 bits per transform
- { 6, 14, 7 }, // 99 bits per transform
- { 6, 15, 6 }, // 99 bits per transform
- { 6, 16, 5 }, // 99 bits per transform
- { 6, 17, 4 }, // 99 bits per transform
- { 7, 3, 17 }, // 99 bits per transform
- { 7, 4, 16 }, // 99 bits per transform
- { 7, 5, 15 }, // 99 bits per transform
- { 7, 6, 14 }, // 99 bits per transform
- { 7, 7, 13 }, // 99 bits per transform
- { 7, 8, 12 }, // 99 bits per transform
- { 7, 9, 11 }, // 99 bits per transform
- { 7, 10, 10 }, // 99 bits per transform
- { 7, 11, 9 }, // 99 bits per transform
- { 7, 12, 8 }, // 99 bits per transform
- { 7, 13, 7 }, // 99 bits per transform
- { 7, 14, 6 }, // 99 bits per transform
- { 7, 15, 5 }, // 99 bits per transform
- { 7, 16, 4 }, // 99 bits per transform
- { 7, 17, 3 }, // 99 bits per transform
- { 8, 2, 17 }, // 99 bits per transform
- { 8, 3, 16 }, // 99 bits per transform
- { 8, 4, 15 }, // 99 bits per transform
- { 8, 5, 14 }, // 99 bits per transform
- { 8, 6, 13 }, // 99 bits per transform
- { 8, 7, 12 }, // 99 bits per transform
- { 8, 8, 11 }, // 99 bits per transform
- { 8, 9, 10 }, // 99 bits per transform
- { 8, 10, 9 }, // 99 bits per transform
- { 8, 11, 8 }, // 99 bits per transform
- { 8, 12, 7 }, // 99 bits per transform
- { 8, 13, 6 }, // 99 bits per transform
- { 8, 14, 5 }, // 99 bits per transform
- { 8, 15, 4 }, // 99 bits per transform
- { 8, 16, 3 }, // 99 bits per transform
- { 8, 17, 2 }, // 99 bits per transform
- { 9, 1, 17 }, // 99 bits per transform
- { 9, 2, 16 }, // 99 bits per transform
- { 9, 3, 15 }, // 99 bits per transform
- { 9, 4, 14 }, // 99 bits per transform
- { 9, 5, 13 }, // 99 bits per transform
- { 9, 6, 12 }, // 99 bits per transform
- { 9, 7, 11 }, // 99 bits per transform
- { 9, 8, 10 }, // 99 bits per transform
- { 9, 9, 9 }, // 99 bits per transform
- { 9, 10, 8 }, // 99 bits per transform
- { 9, 11, 7 }, // 99 bits per transform
- { 9, 12, 6 }, // 99 bits per transform
- { 9, 13, 5 }, // 99 bits per transform
- { 9, 14, 4 }, // 99 bits per transform
- { 9, 15, 3 }, // 99 bits per transform
- { 9, 16, 2 }, // 99 bits per transform
- { 9, 17, 1 }, // 99 bits per transform
- { 10, 1, 16 }, // 99 bits per transform
- { 10, 2, 15 }, // 99 bits per transform
- { 10, 3, 14 }, // 99 bits per transform
- { 10, 4, 13 }, // 99 bits per transform
- { 10, 5, 12 }, // 99 bits per transform
- { 10, 6, 11 }, // 99 bits per transform
- { 10, 7, 10 }, // 99 bits per transform
- { 10, 8, 9 }, // 99 bits per transform
- { 10, 9, 8 }, // 99 bits per transform
- { 10, 10, 7 }, // 99 bits per transform
- { 10, 11, 6 }, // 99 bits per transform
- { 10, 12, 5 }, // 99 bits per transform
- { 10, 13, 4 }, // 99 bits per transform
- { 10, 14, 3 }, // 99 bits per transform
- { 10, 15, 2 }, // 99 bits per transform
- { 10, 16, 1 }, // 99 bits per transform
- { 11, 1, 15 }, // 99 bits per transform
- { 11, 2, 14 }, // 99 bits per transform
- { 11, 3, 13 }, // 99 bits per transform
- { 11, 4, 12 }, // 99 bits per transform
- { 11, 5, 11 }, // 99 bits per transform
- { 11, 6, 10 }, // 99 bits per transform
- { 11, 7, 9 }, // 99 bits per transform
- { 11, 8, 8 }, // 99 bits per transform
- { 11, 9, 7 }, // 99 bits per transform
- { 11, 10, 6 }, // 99 bits per transform
- { 11, 11, 5 }, // 99 bits per transform
- { 11, 12, 4 }, // 99 bits per transform
- { 11, 13, 3 }, // 99 bits per transform
- { 11, 14, 2 }, // 99 bits per transform
- { 11, 15, 1 }, // 99 bits per transform
- { 12, 0, 17 }, // 99 bits per transform
- { 12, 1, 14 }, // 99 bits per transform
- { 12, 2, 13 }, // 99 bits per transform
- { 12, 3, 12 }, // 99 bits per transform
- { 12, 4, 11 }, // 99 bits per transform
- { 12, 5, 10 }, // 99 bits per transform
- { 12, 6, 9 }, // 99 bits per transform
- { 12, 7, 8 }, // 99 bits per transform
- { 12, 8, 7 }, // 99 bits per transform
- { 12, 9, 6 }, // 99 bits per transform
- { 12, 10, 5 }, // 99 bits per transform
- { 12, 11, 4 }, // 99 bits per transform
- { 12, 12, 3 }, // 99 bits per transform
- { 12, 13, 2 }, // 99 bits per transform
- { 12, 14, 1 }, // 99 bits per transform
- { 12, 17, 0 }, // 99 bits per transform
- { 13, 0, 16 }, // 99 bits per transform
- { 13, 1, 13 }, // 99 bits per transform
- { 13, 2, 12 }, // 99 bits per transform
- { 13, 3, 11 }, // 99 bits per transform
- { 13, 4, 10 }, // 99 bits per transform
- { 13, 5, 9 }, // 99 bits per transform
- { 13, 6, 8 }, // 99 bits per transform
- { 13, 7, 7 }, // 99 bits per transform
- { 13, 8, 6 }, // 99 bits per transform
- { 13, 9, 5 }, // 99 bits per transform
- { 13, 10, 4 }, // 99 bits per transform
- { 13, 11, 3 }, // 99 bits per transform
- { 13, 12, 2 }, // 99 bits per transform
- { 13, 13, 1 }, // 99 bits per transform
- { 13, 16, 0 }, // 99 bits per transform
- { 14, 0, 15 }, // 99 bits per transform
- { 14, 1, 12 }, // 99 bits per transform
- { 14, 2, 11 }, // 99 bits per transform
- { 14, 3, 10 }, // 99 bits per transform
- { 14, 4, 9 }, // 99 bits per transform
- { 14, 5, 8 }, // 99 bits per transform
- { 14, 6, 7 }, // 99 bits per transform
- { 14, 7, 6 }, // 99 bits per transform
- { 14, 8, 5 }, // 99 bits per transform
- { 14, 9, 4 }, // 99 bits per transform
- { 14, 10, 3 }, // 99 bits per transform
- { 14, 11, 2 }, // 99 bits per transform
- { 14, 12, 1 }, // 99 bits per transform
- { 14, 15, 0 }, // 99 bits per transform
- { 15, 0, 14 }, // 99 bits per transform
- { 15, 1, 11 }, // 99 bits per transform
- { 15, 2, 10 }, // 99 bits per transform
- { 15, 3, 9 }, // 99 bits per transform
- { 15, 4, 8 }, // 99 bits per transform
- { 15, 5, 7 }, // 99 bits per transform
- { 15, 6, 6 }, // 99 bits per transform
- { 15, 7, 5 }, // 99 bits per transform
- { 15, 8, 4 }, // 99 bits per transform
- { 15, 9, 3 }, // 99 bits per transform
- { 15, 10, 2 }, // 99 bits per transform
- { 15, 11, 1 }, // 99 bits per transform
- { 15, 14, 0 }, // 99 bits per transform
- { 16, 0, 13 }, // 99 bits per transform
- { 16, 1, 10 }, // 99 bits per transform
- { 16, 2, 9 }, // 99 bits per transform
- { 16, 3, 8 }, // 99 bits per transform
- { 16, 4, 7 }, // 99 bits per transform
- { 16, 5, 6 }, // 99 bits per transform
- { 16, 6, 5 }, // 99 bits per transform
- { 16, 7, 4 }, // 99 bits per transform
- { 16, 8, 3 }, // 99 bits per transform
- { 16, 9, 2 }, // 99 bits per transform
- { 16, 10, 1 }, // 99 bits per transform
- { 16, 13, 0 }, // 99 bits per transform
- { 17, 0, 12 }, // 99 bits per transform
- { 17, 1, 9 }, // 99 bits per transform
- { 17, 2, 8 }, // 99 bits per transform
- { 17, 3, 7 }, // 99 bits per transform
- { 17, 4, 6 }, // 99 bits per transform
- { 17, 5, 5 }, // 99 bits per transform
- { 17, 6, 4 }, // 99 bits per transform
- { 17, 7, 3 }, // 99 bits per transform
- { 17, 8, 2 }, // 99 bits per transform
- { 17, 9, 1 }, // 99 bits per transform
- { 17, 12, 0 }, // 99 bits per transform
- { 0, 13, 17 }, // 102 bits per transform
- { 0, 14, 16 }, // 102 bits per transform
- { 0, 15, 15 }, // 102 bits per transform
- { 0, 16, 14 }, // 102 bits per transform
- { 0, 17, 13 }, // 102 bits per transform
- { 1, 10, 17 }, // 102 bits per transform
- { 1, 11, 16 }, // 102 bits per transform
- { 1, 12, 15 }, // 102 bits per transform
- { 1, 13, 14 }, // 102 bits per transform
- { 1, 14, 13 }, // 102 bits per transform
- { 1, 15, 12 }, // 102 bits per transform
- { 1, 16, 11 }, // 102 bits per transform
- { 1, 17, 10 }, // 102 bits per transform
- { 2, 9, 17 }, // 102 bits per transform
- { 2, 10, 16 }, // 102 bits per transform
- { 2, 11, 15 }, // 102 bits per transform
- { 2, 12, 14 }, // 102 bits per transform
- { 2, 13, 13 }, // 102 bits per transform
- { 2, 14, 12 }, // 102 bits per transform
- { 2, 15, 11 }, // 102 bits per transform
- { 2, 16, 10 }, // 102 bits per transform
- { 2, 17, 9 }, // 102 bits per transform
- { 3, 8, 17 }, // 102 bits per transform
- { 3, 9, 16 }, // 102 bits per transform
- { 3, 10, 15 }, // 102 bits per transform
- { 3, 11, 14 }, // 102 bits per transform
- { 3, 12, 13 }, // 102 bits per transform
- { 3, 13, 12 }, // 102 bits per transform
- { 3, 14, 11 }, // 102 bits per transform
- { 3, 15, 10 }, // 102 bits per transform
- { 3, 16, 9 }, // 102 bits per transform
- { 3, 17, 8 }, // 102 bits per transform
- { 4, 7, 17 }, // 102 bits per transform
- { 4, 8, 16 }, // 102 bits per transform
- { 4, 9, 15 }, // 102 bits per transform
- { 4, 10, 14 }, // 102 bits per transform
- { 4, 11, 13 }, // 102 bits per transform
- { 4, 12, 12 }, // 102 bits per transform
- { 4, 13, 11 }, // 102 bits per transform
- { 4, 14, 10 }, // 102 bits per transform
- { 4, 15, 9 }, // 102 bits per transform
- { 4, 16, 8 }, // 102 bits per transform
- { 4, 17, 7 }, // 102 bits per transform
- { 5, 6, 17 }, // 102 bits per transform
- { 5, 7, 16 }, // 102 bits per transform
- { 5, 8, 15 }, // 102 bits per transform
- { 5, 9, 14 }, // 102 bits per transform
- { 5, 10, 13 }, // 102 bits per transform
- { 5, 11, 12 }, // 102 bits per transform
- { 5, 12, 11 }, // 102 bits per transform
- { 5, 13, 10 }, // 102 bits per transform
- { 5, 14, 9 }, // 102 bits per transform
- { 5, 15, 8 }, // 102 bits per transform
- { 5, 16, 7 }, // 102 bits per transform
- { 5, 17, 6 }, // 102 bits per transform
- { 6, 5, 17 }, // 102 bits per transform
- { 6, 6, 16 }, // 102 bits per transform
- { 6, 7, 15 }, // 102 bits per transform
- { 6, 8, 14 }, // 102 bits per transform
- { 6, 9, 13 }, // 102 bits per transform
- { 6, 10, 12 }, // 102 bits per transform
- { 6, 11, 11 }, // 102 bits per transform
- { 6, 12, 10 }, // 102 bits per transform
- { 6, 13, 9 }, // 102 bits per transform
- { 6, 14, 8 }, // 102 bits per transform
- { 6, 15, 7 }, // 102 bits per transform
- { 6, 16, 6 }, // 102 bits per transform
- { 6, 17, 5 }, // 102 bits per transform
- { 7, 4, 17 }, // 102 bits per transform
- { 7, 5, 16 }, // 102 bits per transform
- { 7, 6, 15 }, // 102 bits per transform
- { 7, 7, 14 }, // 102 bits per transform
- { 7, 8, 13 }, // 102 bits per transform
- { 7, 9, 12 }, // 102 bits per transform
- { 7, 10, 11 }, // 102 bits per transform
- { 7, 11, 10 }, // 102 bits per transform
- { 7, 12, 9 }, // 102 bits per transform
- { 7, 13, 8 }, // 102 bits per transform
- { 7, 14, 7 }, // 102 bits per transform
- { 7, 15, 6 }, // 102 bits per transform
- { 7, 16, 5 }, // 102 bits per transform
- { 7, 17, 4 }, // 102 bits per transform
- { 8, 3, 17 }, // 102 bits per transform
- { 8, 4, 16 }, // 102 bits per transform
- { 8, 5, 15 }, // 102 bits per transform
- { 8, 6, 14 }, // 102 bits per transform
- { 8, 7, 13 }, // 102 bits per transform
- { 8, 8, 12 }, // 102 bits per transform
- { 8, 9, 11 }, // 102 bits per transform
- { 8, 10, 10 }, // 102 bits per transform
- { 8, 11, 9 }, // 102 bits per transform
- { 8, 12, 8 }, // 102 bits per transform
- { 8, 13, 7 }, // 102 bits per transform
- { 8, 14, 6 }, // 102 bits per transform
- { 8, 15, 5 }, // 102 bits per transform
- { 8, 16, 4 }, // 102 bits per transform
- { 8, 17, 3 }, // 102 bits per transform
- { 9, 2, 17 }, // 102 bits per transform
- { 9, 3, 16 }, // 102 bits per transform
- { 9, 4, 15 }, // 102 bits per transform
- { 9, 5, 14 }, // 102 bits per transform
- { 9, 6, 13 }, // 102 bits per transform
- { 9, 7, 12 }, // 102 bits per transform
- { 9, 8, 11 }, // 102 bits per transform
- { 9, 9, 10 }, // 102 bits per transform
- { 9, 10, 9 }, // 102 bits per transform
- { 9, 11, 8 }, // 102 bits per transform
- { 9, 12, 7 }, // 102 bits per transform
- { 9, 13, 6 }, // 102 bits per transform
- { 9, 14, 5 }, // 102 bits per transform
- { 9, 15, 4 }, // 102 bits per transform
- { 9, 16, 3 }, // 102 bits per transform
- { 9, 17, 2 }, // 102 bits per transform
- { 10, 1, 17 }, // 102 bits per transform
- { 10, 2, 16 }, // 102 bits per transform
- { 10, 3, 15 }, // 102 bits per transform
- { 10, 4, 14 }, // 102 bits per transform
- { 10, 5, 13 }, // 102 bits per transform
- { 10, 6, 12 }, // 102 bits per transform
- { 10, 7, 11 }, // 102 bits per transform
- { 10, 8, 10 }, // 102 bits per transform
- { 10, 9, 9 }, // 102 bits per transform
- { 10, 10, 8 }, // 102 bits per transform
- { 10, 11, 7 }, // 102 bits per transform
- { 10, 12, 6 }, // 102 bits per transform
- { 10, 13, 5 }, // 102 bits per transform
- { 10, 14, 4 }, // 102 bits per transform
- { 10, 15, 3 }, // 102 bits per transform
- { 10, 16, 2 }, // 102 bits per transform
- { 10, 17, 1 }, // 102 bits per transform
- { 11, 1, 16 }, // 102 bits per transform
- { 11, 2, 15 }, // 102 bits per transform
- { 11, 3, 14 }, // 102 bits per transform
- { 11, 4, 13 }, // 102 bits per transform
- { 11, 5, 12 }, // 102 bits per transform
- { 11, 6, 11 }, // 102 bits per transform
- { 11, 7, 10 }, // 102 bits per transform
- { 11, 8, 9 }, // 102 bits per transform
- { 11, 9, 8 }, // 102 bits per transform
- { 11, 10, 7 }, // 102 bits per transform
- { 11, 11, 6 }, // 102 bits per transform
- { 11, 12, 5 }, // 102 bits per transform
- { 11, 13, 4 }, // 102 bits per transform
- { 11, 14, 3 }, // 102 bits per transform
- { 11, 15, 2 }, // 102 bits per transform
- { 11, 16, 1 }, // 102 bits per transform
- { 12, 1, 15 }, // 102 bits per transform
- { 12, 2, 14 }, // 102 bits per transform
- { 12, 3, 13 }, // 102 bits per transform
- { 12, 4, 12 }, // 102 bits per transform
- { 12, 5, 11 }, // 102 bits per transform
- { 12, 6, 10 }, // 102 bits per transform
- { 12, 7, 9 }, // 102 bits per transform
- { 12, 8, 8 }, // 102 bits per transform
- { 12, 9, 7 }, // 102 bits per transform
- { 12, 10, 6 }, // 102 bits per transform
- { 12, 11, 5 }, // 102 bits per transform
- { 12, 12, 4 }, // 102 bits per transform
- { 12, 13, 3 }, // 102 bits per transform
- { 12, 14, 2 }, // 102 bits per transform
- { 12, 15, 1 }, // 102 bits per transform
- { 13, 0, 17 }, // 102 bits per transform
- { 13, 1, 14 }, // 102 bits per transform
- { 13, 2, 13 }, // 102 bits per transform
- { 13, 3, 12 }, // 102 bits per transform
- { 13, 4, 11 }, // 102 bits per transform
- { 13, 5, 10 }, // 102 bits per transform
- { 13, 6, 9 }, // 102 bits per transform
- { 13, 7, 8 }, // 102 bits per transform
- { 13, 8, 7 }, // 102 bits per transform
- { 13, 9, 6 }, // 102 bits per transform
- { 13, 10, 5 }, // 102 bits per transform
- { 13, 11, 4 }, // 102 bits per transform
- { 13, 12, 3 }, // 102 bits per transform
- { 13, 13, 2 }, // 102 bits per transform
- { 13, 14, 1 }, // 102 bits per transform
- { 13, 17, 0 }, // 102 bits per transform
- { 14, 0, 16 }, // 102 bits per transform
- { 14, 1, 13 }, // 102 bits per transform
- { 14, 2, 12 }, // 102 bits per transform
- { 14, 3, 11 }, // 102 bits per transform
- { 14, 4, 10 }, // 102 bits per transform
- { 14, 5, 9 }, // 102 bits per transform
- { 14, 6, 8 }, // 102 bits per transform
- { 14, 7, 7 }, // 102 bits per transform
- { 14, 8, 6 }, // 102 bits per transform
- { 14, 9, 5 }, // 102 bits per transform
- { 14, 10, 4 }, // 102 bits per transform
- { 14, 11, 3 }, // 102 bits per transform
- { 14, 12, 2 }, // 102 bits per transform
- { 14, 13, 1 }, // 102 bits per transform
- { 14, 16, 0 }, // 102 bits per transform
- { 15, 0, 15 }, // 102 bits per transform
- { 15, 1, 12 }, // 102 bits per transform
- { 15, 2, 11 }, // 102 bits per transform
- { 15, 3, 10 }, // 102 bits per transform
- { 15, 4, 9 }, // 102 bits per transform
- { 15, 5, 8 }, // 102 bits per transform
- { 15, 6, 7 }, // 102 bits per transform
- { 15, 7, 6 }, // 102 bits per transform
- { 15, 8, 5 }, // 102 bits per transform
- { 15, 9, 4 }, // 102 bits per transform
- { 15, 10, 3 }, // 102 bits per transform
- { 15, 11, 2 }, // 102 bits per transform
- { 15, 12, 1 }, // 102 bits per transform
- { 15, 15, 0 }, // 102 bits per transform
- { 16, 0, 14 }, // 102 bits per transform
- { 16, 1, 11 }, // 102 bits per transform
- { 16, 2, 10 }, // 102 bits per transform
- { 16, 3, 9 }, // 102 bits per transform
- { 16, 4, 8 }, // 102 bits per transform
- { 16, 5, 7 }, // 102 bits per transform
- { 16, 6, 6 }, // 102 bits per transform
- { 16, 7, 5 }, // 102 bits per transform
- { 16, 8, 4 }, // 102 bits per transform
- { 16, 9, 3 }, // 102 bits per transform
- { 16, 10, 2 }, // 102 bits per transform
- { 16, 11, 1 }, // 102 bits per transform
- { 16, 14, 0 }, // 102 bits per transform
- { 17, 0, 13 }, // 102 bits per transform
- { 17, 1, 10 }, // 102 bits per transform
- { 17, 2, 9 }, // 102 bits per transform
- { 17, 3, 8 }, // 102 bits per transform
- { 17, 4, 7 }, // 102 bits per transform
- { 17, 5, 6 }, // 102 bits per transform
- { 17, 6, 5 }, // 102 bits per transform
- { 17, 7, 4 }, // 102 bits per transform
- { 17, 8, 3 }, // 102 bits per transform
- { 17, 9, 2 }, // 102 bits per transform
- { 17, 10, 1 }, // 102 bits per transform
- { 17, 13, 0 }, // 102 bits per transform
- { 0, 1, 18 }, // 105 bits per transform
- { 0, 14, 17 }, // 105 bits per transform
- { 0, 15, 16 }, // 105 bits per transform
- { 0, 16, 15 }, // 105 bits per transform
- { 0, 17, 14 }, // 105 bits per transform
- { 0, 18, 1 }, // 105 bits per transform
- { 1, 0, 18 }, // 105 bits per transform
- { 1, 11, 17 }, // 105 bits per transform
- { 1, 12, 16 }, // 105 bits per transform
- { 1, 13, 15 }, // 105 bits per transform
- { 1, 14, 14 }, // 105 bits per transform
- { 1, 15, 13 }, // 105 bits per transform
- { 1, 16, 12 }, // 105 bits per transform
- { 1, 17, 11 }, // 105 bits per transform
- { 1, 18, 0 }, // 105 bits per transform
- { 2, 10, 17 }, // 105 bits per transform
- { 2, 11, 16 }, // 105 bits per transform
- { 2, 12, 15 }, // 105 bits per transform
- { 2, 13, 14 }, // 105 bits per transform
- { 2, 14, 13 }, // 105 bits per transform
- { 2, 15, 12 }, // 105 bits per transform
- { 2, 16, 11 }, // 105 bits per transform
- { 2, 17, 10 }, // 105 bits per transform
- { 3, 9, 17 }, // 105 bits per transform
- { 3, 10, 16 }, // 105 bits per transform
- { 3, 11, 15 }, // 105 bits per transform
- { 3, 12, 14 }, // 105 bits per transform
- { 3, 13, 13 }, // 105 bits per transform
- { 3, 14, 12 }, // 105 bits per transform
- { 3, 15, 11 }, // 105 bits per transform
- { 3, 16, 10 }, // 105 bits per transform
- { 3, 17, 9 }, // 105 bits per transform
- { 4, 8, 17 }, // 105 bits per transform
- { 4, 9, 16 }, // 105 bits per transform
- { 4, 10, 15 }, // 105 bits per transform
- { 4, 11, 14 }, // 105 bits per transform
- { 4, 12, 13 }, // 105 bits per transform
- { 4, 13, 12 }, // 105 bits per transform
- { 4, 14, 11 }, // 105 bits per transform
- { 4, 15, 10 }, // 105 bits per transform
- { 4, 16, 9 }, // 105 bits per transform
- { 4, 17, 8 }, // 105 bits per transform
- { 5, 7, 17 }, // 105 bits per transform
- { 5, 8, 16 }, // 105 bits per transform
- { 5, 9, 15 }, // 105 bits per transform
- { 5, 10, 14 }, // 105 bits per transform
- { 5, 11, 13 }, // 105 bits per transform
- { 5, 12, 12 }, // 105 bits per transform
- { 5, 13, 11 }, // 105 bits per transform
- { 5, 14, 10 }, // 105 bits per transform
- { 5, 15, 9 }, // 105 bits per transform
- { 5, 16, 8 }, // 105 bits per transform
- { 5, 17, 7 }, // 105 bits per transform
- { 6, 6, 17 }, // 105 bits per transform
- { 6, 7, 16 }, // 105 bits per transform
- { 6, 8, 15 }, // 105 bits per transform
- { 6, 9, 14 }, // 105 bits per transform
- { 6, 10, 13 }, // 105 bits per transform
- { 6, 11, 12 }, // 105 bits per transform
- { 6, 12, 11 }, // 105 bits per transform
- { 6, 13, 10 }, // 105 bits per transform
- { 6, 14, 9 }, // 105 bits per transform
- { 6, 15, 8 }, // 105 bits per transform
- { 6, 16, 7 }, // 105 bits per transform
- { 6, 17, 6 }, // 105 bits per transform
- { 7, 5, 17 }, // 105 bits per transform
- { 7, 6, 16 }, // 105 bits per transform
- { 7, 7, 15 }, // 105 bits per transform
- { 7, 8, 14 }, // 105 bits per transform
- { 7, 9, 13 }, // 105 bits per transform
- { 7, 10, 12 }, // 105 bits per transform
- { 7, 11, 11 }, // 105 bits per transform
- { 7, 12, 10 }, // 105 bits per transform
- { 7, 13, 9 }, // 105 bits per transform
- { 7, 14, 8 }, // 105 bits per transform
- { 7, 15, 7 }, // 105 bits per transform
- { 7, 16, 6 }, // 105 bits per transform
- { 7, 17, 5 }, // 105 bits per transform
- { 8, 4, 17 }, // 105 bits per transform
- { 8, 5, 16 }, // 105 bits per transform
- { 8, 6, 15 }, // 105 bits per transform
- { 8, 7, 14 }, // 105 bits per transform
- { 8, 8, 13 }, // 105 bits per transform
- { 8, 9, 12 }, // 105 bits per transform
- { 8, 10, 11 }, // 105 bits per transform
- { 8, 11, 10 }, // 105 bits per transform
- { 8, 12, 9 }, // 105 bits per transform
- { 8, 13, 8 }, // 105 bits per transform
- { 8, 14, 7 }, // 105 bits per transform
- { 8, 15, 6 }, // 105 bits per transform
- { 8, 16, 5 }, // 105 bits per transform
- { 8, 17, 4 }, // 105 bits per transform
- { 9, 3, 17 }, // 105 bits per transform
- { 9, 4, 16 }, // 105 bits per transform
- { 9, 5, 15 }, // 105 bits per transform
- { 9, 6, 14 }, // 105 bits per transform
- { 9, 7, 13 }, // 105 bits per transform
- { 9, 8, 12 }, // 105 bits per transform
- { 9, 9, 11 }, // 105 bits per transform
- { 9, 10, 10 }, // 105 bits per transform
- { 9, 11, 9 }, // 105 bits per transform
- { 9, 12, 8 }, // 105 bits per transform
- { 9, 13, 7 }, // 105 bits per transform
- { 9, 14, 6 }, // 105 bits per transform
- { 9, 15, 5 }, // 105 bits per transform
- { 9, 16, 4 }, // 105 bits per transform
- { 9, 17, 3 }, // 105 bits per transform
- { 10, 2, 17 }, // 105 bits per transform
- { 10, 3, 16 }, // 105 bits per transform
- { 10, 4, 15 }, // 105 bits per transform
- { 10, 5, 14 }, // 105 bits per transform
- { 10, 6, 13 }, // 105 bits per transform
- { 10, 7, 12 }, // 105 bits per transform
- { 10, 8, 11 }, // 105 bits per transform
- { 10, 9, 10 }, // 105 bits per transform
- { 10, 10, 9 }, // 105 bits per transform
- { 10, 11, 8 }, // 105 bits per transform
- { 10, 12, 7 }, // 105 bits per transform
- { 10, 13, 6 }, // 105 bits per transform
- { 10, 14, 5 }, // 105 bits per transform
- { 10, 15, 4 }, // 105 bits per transform
- { 10, 16, 3 }, // 105 bits per transform
- { 10, 17, 2 }, // 105 bits per transform
- { 11, 1, 17 }, // 105 bits per transform
- { 11, 2, 16 }, // 105 bits per transform
- { 11, 3, 15 }, // 105 bits per transform
- { 11, 4, 14 }, // 105 bits per transform
- { 11, 5, 13 }, // 105 bits per transform
- { 11, 6, 12 }, // 105 bits per transform
- { 11, 7, 11 }, // 105 bits per transform
- { 11, 8, 10 }, // 105 bits per transform
- { 11, 9, 9 }, // 105 bits per transform
- { 11, 10, 8 }, // 105 bits per transform
- { 11, 11, 7 }, // 105 bits per transform
- { 11, 12, 6 }, // 105 bits per transform
- { 11, 13, 5 }, // 105 bits per transform
- { 11, 14, 4 }, // 105 bits per transform
- { 11, 15, 3 }, // 105 bits per transform
- { 11, 16, 2 }, // 105 bits per transform
- { 11, 17, 1 }, // 105 bits per transform
- { 12, 1, 16 }, // 105 bits per transform
- { 12, 2, 15 }, // 105 bits per transform
- { 12, 3, 14 }, // 105 bits per transform
- { 12, 4, 13 }, // 105 bits per transform
- { 12, 5, 12 }, // 105 bits per transform
- { 12, 6, 11 }, // 105 bits per transform
- { 12, 7, 10 }, // 105 bits per transform
- { 12, 8, 9 }, // 105 bits per transform
- { 12, 9, 8 }, // 105 bits per transform
- { 12, 10, 7 }, // 105 bits per transform
- { 12, 11, 6 }, // 105 bits per transform
- { 12, 12, 5 }, // 105 bits per transform
- { 12, 13, 4 }, // 105 bits per transform
- { 12, 14, 3 }, // 105 bits per transform
- { 12, 15, 2 }, // 105 bits per transform
- { 12, 16, 1 }, // 105 bits per transform
- { 13, 1, 15 }, // 105 bits per transform
- { 13, 2, 14 }, // 105 bits per transform
- { 13, 3, 13 }, // 105 bits per transform
- { 13, 4, 12 }, // 105 bits per transform
- { 13, 5, 11 }, // 105 bits per transform
- { 13, 6, 10 }, // 105 bits per transform
- { 13, 7, 9 }, // 105 bits per transform
- { 13, 8, 8 }, // 105 bits per transform
- { 13, 9, 7 }, // 105 bits per transform
- { 13, 10, 6 }, // 105 bits per transform
- { 13, 11, 5 }, // 105 bits per transform
- { 13, 12, 4 }, // 105 bits per transform
- { 13, 13, 3 }, // 105 bits per transform
- { 13, 14, 2 }, // 105 bits per transform
- { 13, 15, 1 }, // 105 bits per transform
- { 14, 0, 17 }, // 105 bits per transform
- { 14, 1, 14 }, // 105 bits per transform
- { 14, 2, 13 }, // 105 bits per transform
- { 14, 3, 12 }, // 105 bits per transform
- { 14, 4, 11 }, // 105 bits per transform
- { 14, 5, 10 }, // 105 bits per transform
- { 14, 6, 9 }, // 105 bits per transform
- { 14, 7, 8 }, // 105 bits per transform
- { 14, 8, 7 }, // 105 bits per transform
- { 14, 9, 6 }, // 105 bits per transform
- { 14, 10, 5 }, // 105 bits per transform
- { 14, 11, 4 }, // 105 bits per transform
- { 14, 12, 3 }, // 105 bits per transform
- { 14, 13, 2 }, // 105 bits per transform
- { 14, 14, 1 }, // 105 bits per transform
- { 14, 17, 0 }, // 105 bits per transform
- { 15, 0, 16 }, // 105 bits per transform
- { 15, 1, 13 }, // 105 bits per transform
- { 15, 2, 12 }, // 105 bits per transform
- { 15, 3, 11 }, // 105 bits per transform
- { 15, 4, 10 }, // 105 bits per transform
- { 15, 5, 9 }, // 105 bits per transform
- { 15, 6, 8 }, // 105 bits per transform
- { 15, 7, 7 }, // 105 bits per transform
- { 15, 8, 6 }, // 105 bits per transform
- { 15, 9, 5 }, // 105 bits per transform
- { 15, 10, 4 }, // 105 bits per transform
- { 15, 11, 3 }, // 105 bits per transform
- { 15, 12, 2 }, // 105 bits per transform
- { 15, 13, 1 }, // 105 bits per transform
- { 15, 16, 0 }, // 105 bits per transform
- { 16, 0, 15 }, // 105 bits per transform
- { 16, 1, 12 }, // 105 bits per transform
- { 16, 2, 11 }, // 105 bits per transform
- { 16, 3, 10 }, // 105 bits per transform
- { 16, 4, 9 }, // 105 bits per transform
- { 16, 5, 8 }, // 105 bits per transform
- { 16, 6, 7 }, // 105 bits per transform
- { 16, 7, 6 }, // 105 bits per transform
- { 16, 8, 5 }, // 105 bits per transform
- { 16, 9, 4 }, // 105 bits per transform
- { 16, 10, 3 }, // 105 bits per transform
- { 16, 11, 2 }, // 105 bits per transform
- { 16, 12, 1 }, // 105 bits per transform
- { 16, 15, 0 }, // 105 bits per transform
- { 17, 0, 14 }, // 105 bits per transform
- { 17, 1, 11 }, // 105 bits per transform
- { 17, 2, 10 }, // 105 bits per transform
- { 17, 3, 9 }, // 105 bits per transform
- { 17, 4, 8 }, // 105 bits per transform
- { 17, 5, 7 }, // 105 bits per transform
- { 17, 6, 6 }, // 105 bits per transform
- { 17, 7, 5 }, // 105 bits per transform
- { 17, 8, 4 }, // 105 bits per transform
- { 17, 9, 3 }, // 105 bits per transform
- { 17, 10, 2 }, // 105 bits per transform
- { 17, 11, 1 }, // 105 bits per transform
- { 17, 14, 0 }, // 105 bits per transform
- { 18, 0, 1 }, // 105 bits per transform
- { 18, 1, 0 }, // 105 bits per transform
- { 0, 2, 18 }, // 108 bits per transform
- { 0, 15, 17 }, // 108 bits per transform
- { 0, 16, 16 }, // 108 bits per transform
- { 0, 17, 15 }, // 108 bits per transform
- { 0, 18, 2 }, // 108 bits per transform
- { 1, 12, 17 }, // 108 bits per transform
- { 1, 13, 16 }, // 108 bits per transform
- { 1, 14, 15 }, // 108 bits per transform
- { 1, 15, 14 }, // 108 bits per transform
- { 1, 16, 13 }, // 108 bits per transform
- { 1, 17, 12 }, // 108 bits per transform
- { 2, 0, 18 }, // 108 bits per transform
- { 2, 11, 17 }, // 108 bits per transform
- { 2, 12, 16 }, // 108 bits per transform
- { 2, 13, 15 }, // 108 bits per transform
- { 2, 14, 14 }, // 108 bits per transform
- { 2, 15, 13 }, // 108 bits per transform
- { 2, 16, 12 }, // 108 bits per transform
- { 2, 17, 11 }, // 108 bits per transform
- { 2, 18, 0 }, // 108 bits per transform
- { 3, 10, 17 }, // 108 bits per transform
- { 3, 11, 16 }, // 108 bits per transform
- { 3, 12, 15 }, // 108 bits per transform
- { 3, 13, 14 }, // 108 bits per transform
- { 3, 14, 13 }, // 108 bits per transform
- { 3, 15, 12 }, // 108 bits per transform
- { 3, 16, 11 }, // 108 bits per transform
- { 3, 17, 10 }, // 108 bits per transform
- { 4, 9, 17 }, // 108 bits per transform
- { 4, 10, 16 }, // 108 bits per transform
- { 4, 11, 15 }, // 108 bits per transform
- { 4, 12, 14 }, // 108 bits per transform
- { 4, 13, 13 }, // 108 bits per transform
- { 4, 14, 12 }, // 108 bits per transform
- { 4, 15, 11 }, // 108 bits per transform
- { 4, 16, 10 }, // 108 bits per transform
- { 4, 17, 9 }, // 108 bits per transform
- { 5, 8, 17 }, // 108 bits per transform
- { 5, 9, 16 }, // 108 bits per transform
- { 5, 10, 15 }, // 108 bits per transform
- { 5, 11, 14 }, // 108 bits per transform
- { 5, 12, 13 }, // 108 bits per transform
- { 5, 13, 12 }, // 108 bits per transform
- { 5, 14, 11 }, // 108 bits per transform
- { 5, 15, 10 }, // 108 bits per transform
- { 5, 16, 9 }, // 108 bits per transform
- { 5, 17, 8 }, // 108 bits per transform
- { 6, 7, 17 }, // 108 bits per transform
- { 6, 8, 16 }, // 108 bits per transform
- { 6, 9, 15 }, // 108 bits per transform
- { 6, 10, 14 }, // 108 bits per transform
- { 6, 11, 13 }, // 108 bits per transform
- { 6, 12, 12 }, // 108 bits per transform
- { 6, 13, 11 }, // 108 bits per transform
- { 6, 14, 10 }, // 108 bits per transform
- { 6, 15, 9 }, // 108 bits per transform
- { 6, 16, 8 }, // 108 bits per transform
- { 6, 17, 7 }, // 108 bits per transform
- { 7, 6, 17 }, // 108 bits per transform
- { 7, 7, 16 }, // 108 bits per transform
- { 7, 8, 15 }, // 108 bits per transform
- { 7, 9, 14 }, // 108 bits per transform
- { 7, 10, 13 }, // 108 bits per transform
- { 7, 11, 12 }, // 108 bits per transform
- { 7, 12, 11 }, // 108 bits per transform
- { 7, 13, 10 }, // 108 bits per transform
- { 7, 14, 9 }, // 108 bits per transform
- { 7, 15, 8 }, // 108 bits per transform
- { 7, 16, 7 }, // 108 bits per transform
- { 7, 17, 6 }, // 108 bits per transform
- { 8, 5, 17 }, // 108 bits per transform
- { 8, 6, 16 }, // 108 bits per transform
- { 8, 7, 15 }, // 108 bits per transform
- { 8, 8, 14 }, // 108 bits per transform
- { 8, 9, 13 }, // 108 bits per transform
- { 8, 10, 12 }, // 108 bits per transform
- { 8, 11, 11 }, // 108 bits per transform
- { 8, 12, 10 }, // 108 bits per transform
- { 8, 13, 9 }, // 108 bits per transform
- { 8, 14, 8 }, // 108 bits per transform
- { 8, 15, 7 }, // 108 bits per transform
- { 8, 16, 6 }, // 108 bits per transform
- { 8, 17, 5 }, // 108 bits per transform
- { 9, 4, 17 }, // 108 bits per transform
- { 9, 5, 16 }, // 108 bits per transform
- { 9, 6, 15 }, // 108 bits per transform
- { 9, 7, 14 }, // 108 bits per transform
- { 9, 8, 13 }, // 108 bits per transform
- { 9, 9, 12 }, // 108 bits per transform
- { 9, 10, 11 }, // 108 bits per transform
- { 9, 11, 10 }, // 108 bits per transform
- { 9, 12, 9 }, // 108 bits per transform
- { 9, 13, 8 }, // 108 bits per transform
- { 9, 14, 7 }, // 108 bits per transform
- { 9, 15, 6 }, // 108 bits per transform
- { 9, 16, 5 }, // 108 bits per transform
- { 9, 17, 4 }, // 108 bits per transform
- { 10, 3, 17 }, // 108 bits per transform
- { 10, 4, 16 }, // 108 bits per transform
- { 10, 5, 15 }, // 108 bits per transform
- { 10, 6, 14 }, // 108 bits per transform
- { 10, 7, 13 }, // 108 bits per transform
- { 10, 8, 12 }, // 108 bits per transform
- { 10, 9, 11 }, // 108 bits per transform
- { 10, 10, 10 }, // 108 bits per transform
- { 10, 11, 9 }, // 108 bits per transform
- { 10, 12, 8 }, // 108 bits per transform
- { 10, 13, 7 }, // 108 bits per transform
- { 10, 14, 6 }, // 108 bits per transform
- { 10, 15, 5 }, // 108 bits per transform
- { 10, 16, 4 }, // 108 bits per transform
- { 10, 17, 3 }, // 108 bits per transform
- { 11, 2, 17 }, // 108 bits per transform
- { 11, 3, 16 }, // 108 bits per transform
- { 11, 4, 15 }, // 108 bits per transform
- { 11, 5, 14 }, // 108 bits per transform
- { 11, 6, 13 }, // 108 bits per transform
- { 11, 7, 12 }, // 108 bits per transform
- { 11, 8, 11 }, // 108 bits per transform
- { 11, 9, 10 }, // 108 bits per transform
- { 11, 10, 9 }, // 108 bits per transform
- { 11, 11, 8 }, // 108 bits per transform
- { 11, 12, 7 }, // 108 bits per transform
- { 11, 13, 6 }, // 108 bits per transform
- { 11, 14, 5 }, // 108 bits per transform
- { 11, 15, 4 }, // 108 bits per transform
- { 11, 16, 3 }, // 108 bits per transform
- { 11, 17, 2 }, // 108 bits per transform
- { 12, 1, 17 }, // 108 bits per transform
- { 12, 2, 16 }, // 108 bits per transform
- { 12, 3, 15 }, // 108 bits per transform
- { 12, 4, 14 }, // 108 bits per transform
- { 12, 5, 13 }, // 108 bits per transform
- { 12, 6, 12 }, // 108 bits per transform
- { 12, 7, 11 }, // 108 bits per transform
- { 12, 8, 10 }, // 108 bits per transform
- { 12, 9, 9 }, // 108 bits per transform
- { 12, 10, 8 }, // 108 bits per transform
- { 12, 11, 7 }, // 108 bits per transform
- { 12, 12, 6 }, // 108 bits per transform
- { 12, 13, 5 }, // 108 bits per transform
- { 12, 14, 4 }, // 108 bits per transform
- { 12, 15, 3 }, // 108 bits per transform
- { 12, 16, 2 }, // 108 bits per transform
- { 12, 17, 1 }, // 108 bits per transform
- { 13, 1, 16 }, // 108 bits per transform
- { 13, 2, 15 }, // 108 bits per transform
- { 13, 3, 14 }, // 108 bits per transform
- { 13, 4, 13 }, // 108 bits per transform
- { 13, 5, 12 }, // 108 bits per transform
- { 13, 6, 11 }, // 108 bits per transform
- { 13, 7, 10 }, // 108 bits per transform
- { 13, 8, 9 }, // 108 bits per transform
- { 13, 9, 8 }, // 108 bits per transform
- { 13, 10, 7 }, // 108 bits per transform
- { 13, 11, 6 }, // 108 bits per transform
- { 13, 12, 5 }, // 108 bits per transform
- { 13, 13, 4 }, // 108 bits per transform
- { 13, 14, 3 }, // 108 bits per transform
- { 13, 15, 2 }, // 108 bits per transform
- { 13, 16, 1 }, // 108 bits per transform
- { 14, 1, 15 }, // 108 bits per transform
- { 14, 2, 14 }, // 108 bits per transform
- { 14, 3, 13 }, // 108 bits per transform
- { 14, 4, 12 }, // 108 bits per transform
- { 14, 5, 11 }, // 108 bits per transform
- { 14, 6, 10 }, // 108 bits per transform
- { 14, 7, 9 }, // 108 bits per transform
- { 14, 8, 8 }, // 108 bits per transform
- { 14, 9, 7 }, // 108 bits per transform
- { 14, 10, 6 }, // 108 bits per transform
- { 14, 11, 5 }, // 108 bits per transform
- { 14, 12, 4 }, // 108 bits per transform
- { 14, 13, 3 }, // 108 bits per transform
- { 14, 14, 2 }, // 108 bits per transform
- { 14, 15, 1 }, // 108 bits per transform
- { 15, 0, 17 }, // 108 bits per transform
- { 15, 1, 14 }, // 108 bits per transform
- { 15, 2, 13 }, // 108 bits per transform
- { 15, 3, 12 }, // 108 bits per transform
- { 15, 4, 11 }, // 108 bits per transform
- { 15, 5, 10 }, // 108 bits per transform
- { 15, 6, 9 }, // 108 bits per transform
- { 15, 7, 8 }, // 108 bits per transform
- { 15, 8, 7 }, // 108 bits per transform
- { 15, 9, 6 }, // 108 bits per transform
- { 15, 10, 5 }, // 108 bits per transform
- { 15, 11, 4 }, // 108 bits per transform
- { 15, 12, 3 }, // 108 bits per transform
- { 15, 13, 2 }, // 108 bits per transform
- { 15, 14, 1 }, // 108 bits per transform
- { 15, 17, 0 }, // 108 bits per transform
- { 16, 0, 16 }, // 108 bits per transform
- { 16, 1, 13 }, // 108 bits per transform
- { 16, 2, 12 }, // 108 bits per transform
- { 16, 3, 11 }, // 108 bits per transform
- { 16, 4, 10 }, // 108 bits per transform
- { 16, 5, 9 }, // 108 bits per transform
- { 16, 6, 8 }, // 108 bits per transform
- { 16, 7, 7 }, // 108 bits per transform
- { 16, 8, 6 }, // 108 bits per transform
- { 16, 9, 5 }, // 108 bits per transform
- { 16, 10, 4 }, // 108 bits per transform
- { 16, 11, 3 }, // 108 bits per transform
- { 16, 12, 2 }, // 108 bits per transform
- { 16, 13, 1 }, // 108 bits per transform
- { 16, 16, 0 }, // 108 bits per transform
- { 17, 0, 15 }, // 108 bits per transform
- { 17, 1, 12 }, // 108 bits per transform
- { 17, 2, 11 }, // 108 bits per transform
- { 17, 3, 10 }, // 108 bits per transform
- { 17, 4, 9 }, // 108 bits per transform
- { 17, 5, 8 }, // 108 bits per transform
- { 17, 6, 7 }, // 108 bits per transform
- { 17, 7, 6 }, // 108 bits per transform
- { 17, 8, 5 }, // 108 bits per transform
- { 17, 9, 4 }, // 108 bits per transform
- { 17, 10, 3 }, // 108 bits per transform
- { 17, 11, 2 }, // 108 bits per transform
- { 17, 12, 1 }, // 108 bits per transform
- { 17, 15, 0 }, // 108 bits per transform
- { 18, 0, 2 }, // 108 bits per transform
- { 18, 2, 0 }, // 108 bits per transform
- { 0, 3, 18 }, // 111 bits per transform
- { 0, 16, 17 }, // 111 bits per transform
- { 0, 17, 16 }, // 111 bits per transform
- { 0, 18, 3 }, // 111 bits per transform
- { 1, 13, 17 }, // 111 bits per transform
- { 1, 14, 16 }, // 111 bits per transform
- { 1, 15, 15 }, // 111 bits per transform
- { 1, 16, 14 }, // 111 bits per transform
- { 1, 17, 13 }, // 111 bits per transform
- { 2, 12, 17 }, // 111 bits per transform
- { 2, 13, 16 }, // 111 bits per transform
- { 2, 14, 15 }, // 111 bits per transform
- { 2, 15, 14 }, // 111 bits per transform
- { 2, 16, 13 }, // 111 bits per transform
- { 2, 17, 12 }, // 111 bits per transform
- { 3, 0, 18 }, // 111 bits per transform
- { 3, 11, 17 }, // 111 bits per transform
- { 3, 12, 16 }, // 111 bits per transform
- { 3, 13, 15 }, // 111 bits per transform
- { 3, 14, 14 }, // 111 bits per transform
- { 3, 15, 13 }, // 111 bits per transform
- { 3, 16, 12 }, // 111 bits per transform
- { 3, 17, 11 }, // 111 bits per transform
- { 3, 18, 0 }, // 111 bits per transform
- { 4, 10, 17 }, // 111 bits per transform
- { 4, 11, 16 }, // 111 bits per transform
- { 4, 12, 15 }, // 111 bits per transform
- { 4, 13, 14 }, // 111 bits per transform
- { 4, 14, 13 }, // 111 bits per transform
- { 4, 15, 12 }, // 111 bits per transform
- { 4, 16, 11 }, // 111 bits per transform
- { 4, 17, 10 }, // 111 bits per transform
- { 5, 9, 17 }, // 111 bits per transform
- { 5, 10, 16 }, // 111 bits per transform
- { 5, 11, 15 }, // 111 bits per transform
- { 5, 12, 14 }, // 111 bits per transform
- { 5, 13, 13 }, // 111 bits per transform
- { 5, 14, 12 }, // 111 bits per transform
- { 5, 15, 11 }, // 111 bits per transform
- { 5, 16, 10 }, // 111 bits per transform
- { 5, 17, 9 }, // 111 bits per transform
- { 6, 8, 17 }, // 111 bits per transform
- { 6, 9, 16 }, // 111 bits per transform
- { 6, 10, 15 }, // 111 bits per transform
- { 6, 11, 14 }, // 111 bits per transform
- { 6, 12, 13 }, // 111 bits per transform
- { 6, 13, 12 }, // 111 bits per transform
- { 6, 14, 11 }, // 111 bits per transform
- { 6, 15, 10 }, // 111 bits per transform
- { 6, 16, 9 }, // 111 bits per transform
- { 6, 17, 8 }, // 111 bits per transform
- { 7, 7, 17 }, // 111 bits per transform
- { 7, 8, 16 }, // 111 bits per transform
- { 7, 9, 15 }, // 111 bits per transform
- { 7, 10, 14 }, // 111 bits per transform
- { 7, 11, 13 }, // 111 bits per transform
- { 7, 12, 12 }, // 111 bits per transform
- { 7, 13, 11 }, // 111 bits per transform
- { 7, 14, 10 }, // 111 bits per transform
- { 7, 15, 9 }, // 111 bits per transform
- { 7, 16, 8 }, // 111 bits per transform
- { 7, 17, 7 }, // 111 bits per transform
- { 8, 6, 17 }, // 111 bits per transform
- { 8, 7, 16 }, // 111 bits per transform
- { 8, 8, 15 }, // 111 bits per transform
- { 8, 9, 14 }, // 111 bits per transform
- { 8, 10, 13 }, // 111 bits per transform
- { 8, 11, 12 }, // 111 bits per transform
- { 8, 12, 11 }, // 111 bits per transform
- { 8, 13, 10 }, // 111 bits per transform
- { 8, 14, 9 }, // 111 bits per transform
- { 8, 15, 8 }, // 111 bits per transform
- { 8, 16, 7 }, // 111 bits per transform
- { 8, 17, 6 }, // 111 bits per transform
- { 9, 5, 17 }, // 111 bits per transform
- { 9, 6, 16 }, // 111 bits per transform
- { 9, 7, 15 }, // 111 bits per transform
- { 9, 8, 14 }, // 111 bits per transform
- { 9, 9, 13 }, // 111 bits per transform
- { 9, 10, 12 }, // 111 bits per transform
- { 9, 11, 11 }, // 111 bits per transform
- { 9, 12, 10 }, // 111 bits per transform
- { 9, 13, 9 }, // 111 bits per transform
- { 9, 14, 8 }, // 111 bits per transform
- { 9, 15, 7 }, // 111 bits per transform
- { 9, 16, 6 }, // 111 bits per transform
- { 9, 17, 5 }, // 111 bits per transform
- { 10, 4, 17 }, // 111 bits per transform
- { 10, 5, 16 }, // 111 bits per transform
- { 10, 6, 15 }, // 111 bits per transform
- { 10, 7, 14 }, // 111 bits per transform
- { 10, 8, 13 }, // 111 bits per transform
- { 10, 9, 12 }, // 111 bits per transform
- { 10, 10, 11 }, // 111 bits per transform
- { 10, 11, 10 }, // 111 bits per transform
- { 10, 12, 9 }, // 111 bits per transform
- { 10, 13, 8 }, // 111 bits per transform
- { 10, 14, 7 }, // 111 bits per transform
- { 10, 15, 6 }, // 111 bits per transform
- { 10, 16, 5 }, // 111 bits per transform
- { 10, 17, 4 }, // 111 bits per transform
- { 11, 3, 17 }, // 111 bits per transform
- { 11, 4, 16 }, // 111 bits per transform
- { 11, 5, 15 }, // 111 bits per transform
- { 11, 6, 14 }, // 111 bits per transform
- { 11, 7, 13 }, // 111 bits per transform
- { 11, 8, 12 }, // 111 bits per transform
- { 11, 9, 11 }, // 111 bits per transform
- { 11, 10, 10 }, // 111 bits per transform
- { 11, 11, 9 }, // 111 bits per transform
- { 11, 12, 8 }, // 111 bits per transform
- { 11, 13, 7 }, // 111 bits per transform
- { 11, 14, 6 }, // 111 bits per transform
- { 11, 15, 5 }, // 111 bits per transform
- { 11, 16, 4 }, // 111 bits per transform
- { 11, 17, 3 }, // 111 bits per transform
- { 12, 2, 17 }, // 111 bits per transform
- { 12, 3, 16 }, // 111 bits per transform
- { 12, 4, 15 }, // 111 bits per transform
- { 12, 5, 14 }, // 111 bits per transform
- { 12, 6, 13 }, // 111 bits per transform
- { 12, 7, 12 }, // 111 bits per transform
- { 12, 8, 11 }, // 111 bits per transform
- { 12, 9, 10 }, // 111 bits per transform
- { 12, 10, 9 }, // 111 bits per transform
- { 12, 11, 8 }, // 111 bits per transform
- { 12, 12, 7 }, // 111 bits per transform
- { 12, 13, 6 }, // 111 bits per transform
- { 12, 14, 5 }, // 111 bits per transform
- { 12, 15, 4 }, // 111 bits per transform
- { 12, 16, 3 }, // 111 bits per transform
- { 12, 17, 2 }, // 111 bits per transform
- { 13, 1, 17 }, // 111 bits per transform
- { 13, 2, 16 }, // 111 bits per transform
- { 13, 3, 15 }, // 111 bits per transform
- { 13, 4, 14 }, // 111 bits per transform
- { 13, 5, 13 }, // 111 bits per transform
- { 13, 6, 12 }, // 111 bits per transform
- { 13, 7, 11 }, // 111 bits per transform
- { 13, 8, 10 }, // 111 bits per transform
- { 13, 9, 9 }, // 111 bits per transform
- { 13, 10, 8 }, // 111 bits per transform
- { 13, 11, 7 }, // 111 bits per transform
- { 13, 12, 6 }, // 111 bits per transform
- { 13, 13, 5 }, // 111 bits per transform
- { 13, 14, 4 }, // 111 bits per transform
- { 13, 15, 3 }, // 111 bits per transform
- { 13, 16, 2 }, // 111 bits per transform
- { 13, 17, 1 }, // 111 bits per transform
- { 14, 1, 16 }, // 111 bits per transform
- { 14, 2, 15 }, // 111 bits per transform
- { 14, 3, 14 }, // 111 bits per transform
- { 14, 4, 13 }, // 111 bits per transform
- { 14, 5, 12 }, // 111 bits per transform
- { 14, 6, 11 }, // 111 bits per transform
- { 14, 7, 10 }, // 111 bits per transform
- { 14, 8, 9 }, // 111 bits per transform
- { 14, 9, 8 }, // 111 bits per transform
- { 14, 10, 7 }, // 111 bits per transform
- { 14, 11, 6 }, // 111 bits per transform
- { 14, 12, 5 }, // 111 bits per transform
- { 14, 13, 4 }, // 111 bits per transform
- { 14, 14, 3 }, // 111 bits per transform
- { 14, 15, 2 }, // 111 bits per transform
- { 14, 16, 1 }, // 111 bits per transform
- { 15, 1, 15 }, // 111 bits per transform
- { 15, 2, 14 }, // 111 bits per transform
- { 15, 3, 13 }, // 111 bits per transform
- { 15, 4, 12 }, // 111 bits per transform
- { 15, 5, 11 }, // 111 bits per transform
- { 15, 6, 10 }, // 111 bits per transform
- { 15, 7, 9 }, // 111 bits per transform
- { 15, 8, 8 }, // 111 bits per transform
- { 15, 9, 7 }, // 111 bits per transform
- { 15, 10, 6 }, // 111 bits per transform
- { 15, 11, 5 }, // 111 bits per transform
- { 15, 12, 4 }, // 111 bits per transform
- { 15, 13, 3 }, // 111 bits per transform
- { 15, 14, 2 }, // 111 bits per transform
- { 15, 15, 1 }, // 111 bits per transform
- { 16, 0, 17 }, // 111 bits per transform
- { 16, 1, 14 }, // 111 bits per transform
- { 16, 2, 13 }, // 111 bits per transform
- { 16, 3, 12 }, // 111 bits per transform
- { 16, 4, 11 }, // 111 bits per transform
- { 16, 5, 10 }, // 111 bits per transform
- { 16, 6, 9 }, // 111 bits per transform
- { 16, 7, 8 }, // 111 bits per transform
- { 16, 8, 7 }, // 111 bits per transform
- { 16, 9, 6 }, // 111 bits per transform
- { 16, 10, 5 }, // 111 bits per transform
- { 16, 11, 4 }, // 111 bits per transform
- { 16, 12, 3 }, // 111 bits per transform
- { 16, 13, 2 }, // 111 bits per transform
- { 16, 14, 1 }, // 111 bits per transform
- { 16, 17, 0 }, // 111 bits per transform
- { 17, 0, 16 }, // 111 bits per transform
- { 17, 1, 13 }, // 111 bits per transform
- { 17, 2, 12 }, // 111 bits per transform
- { 17, 3, 11 }, // 111 bits per transform
- { 17, 4, 10 }, // 111 bits per transform
- { 17, 5, 9 }, // 111 bits per transform
- { 17, 6, 8 }, // 111 bits per transform
- { 17, 7, 7 }, // 111 bits per transform
- { 17, 8, 6 }, // 111 bits per transform
- { 17, 9, 5 }, // 111 bits per transform
- { 17, 10, 4 }, // 111 bits per transform
- { 17, 11, 3 }, // 111 bits per transform
- { 17, 12, 2 }, // 111 bits per transform
- { 17, 13, 1 }, // 111 bits per transform
- { 17, 16, 0 }, // 111 bits per transform
- { 18, 0, 3 }, // 111 bits per transform
- { 18, 3, 0 }, // 111 bits per transform
- { 0, 4, 18 }, // 114 bits per transform
- { 0, 17, 17 }, // 114 bits per transform
- { 0, 18, 4 }, // 114 bits per transform
- { 1, 1, 18 }, // 114 bits per transform
- { 1, 14, 17 }, // 114 bits per transform
- { 1, 15, 16 }, // 114 bits per transform
- { 1, 16, 15 }, // 114 bits per transform
- { 1, 17, 14 }, // 114 bits per transform
- { 1, 18, 1 }, // 114 bits per transform
- { 2, 13, 17 }, // 114 bits per transform
- { 2, 14, 16 }, // 114 bits per transform
- { 2, 15, 15 }, // 114 bits per transform
- { 2, 16, 14 }, // 114 bits per transform
- { 2, 17, 13 }, // 114 bits per transform
- { 3, 12, 17 }, // 114 bits per transform
- { 3, 13, 16 }, // 114 bits per transform
- { 3, 14, 15 }, // 114 bits per transform
- { 3, 15, 14 }, // 114 bits per transform
- { 3, 16, 13 }, // 114 bits per transform
- { 3, 17, 12 }, // 114 bits per transform
- { 4, 0, 18 }, // 114 bits per transform
- { 4, 11, 17 }, // 114 bits per transform
- { 4, 12, 16 }, // 114 bits per transform
- { 4, 13, 15 }, // 114 bits per transform
- { 4, 14, 14 }, // 114 bits per transform
- { 4, 15, 13 }, // 114 bits per transform
- { 4, 16, 12 }, // 114 bits per transform
- { 4, 17, 11 }, // 114 bits per transform
- { 4, 18, 0 }, // 114 bits per transform
- { 5, 10, 17 }, // 114 bits per transform
- { 5, 11, 16 }, // 114 bits per transform
- { 5, 12, 15 }, // 114 bits per transform
- { 5, 13, 14 }, // 114 bits per transform
- { 5, 14, 13 }, // 114 bits per transform
- { 5, 15, 12 }, // 114 bits per transform
- { 5, 16, 11 }, // 114 bits per transform
- { 5, 17, 10 }, // 114 bits per transform
- { 6, 9, 17 }, // 114 bits per transform
- { 6, 10, 16 }, // 114 bits per transform
- { 6, 11, 15 }, // 114 bits per transform
- { 6, 12, 14 }, // 114 bits per transform
- { 6, 13, 13 }, // 114 bits per transform
- { 6, 14, 12 }, // 114 bits per transform
- { 6, 15, 11 }, // 114 bits per transform
- { 6, 16, 10 }, // 114 bits per transform
- { 6, 17, 9 }, // 114 bits per transform
- { 7, 8, 17 }, // 114 bits per transform
- { 7, 9, 16 }, // 114 bits per transform
- { 7, 10, 15 }, // 114 bits per transform
- { 7, 11, 14 }, // 114 bits per transform
- { 7, 12, 13 }, // 114 bits per transform
- { 7, 13, 12 }, // 114 bits per transform
- { 7, 14, 11 }, // 114 bits per transform
- { 7, 15, 10 }, // 114 bits per transform
- { 7, 16, 9 }, // 114 bits per transform
- { 7, 17, 8 }, // 114 bits per transform
- { 8, 7, 17 }, // 114 bits per transform
- { 8, 8, 16 }, // 114 bits per transform
- { 8, 9, 15 }, // 114 bits per transform
- { 8, 10, 14 }, // 114 bits per transform
- { 8, 11, 13 }, // 114 bits per transform
- { 8, 12, 12 }, // 114 bits per transform
- { 8, 13, 11 }, // 114 bits per transform
- { 8, 14, 10 }, // 114 bits per transform
- { 8, 15, 9 }, // 114 bits per transform
- { 8, 16, 8 }, // 114 bits per transform
- { 8, 17, 7 }, // 114 bits per transform
- { 9, 6, 17 }, // 114 bits per transform
- { 9, 7, 16 }, // 114 bits per transform
- { 9, 8, 15 }, // 114 bits per transform
- { 9, 9, 14 }, // 114 bits per transform
- { 9, 10, 13 }, // 114 bits per transform
- { 9, 11, 12 }, // 114 bits per transform
- { 9, 12, 11 }, // 114 bits per transform
- { 9, 13, 10 }, // 114 bits per transform
- { 9, 14, 9 }, // 114 bits per transform
- { 9, 15, 8 }, // 114 bits per transform
- { 9, 16, 7 }, // 114 bits per transform
- { 9, 17, 6 }, // 114 bits per transform
- { 10, 5, 17 }, // 114 bits per transform
- { 10, 6, 16 }, // 114 bits per transform
- { 10, 7, 15 }, // 114 bits per transform
- { 10, 8, 14 }, // 114 bits per transform
- { 10, 9, 13 }, // 114 bits per transform
- { 10, 10, 12 }, // 114 bits per transform
- { 10, 11, 11 }, // 114 bits per transform
- { 10, 12, 10 }, // 114 bits per transform
- { 10, 13, 9 }, // 114 bits per transform
- { 10, 14, 8 }, // 114 bits per transform
- { 10, 15, 7 }, // 114 bits per transform
- { 10, 16, 6 }, // 114 bits per transform
- { 10, 17, 5 }, // 114 bits per transform
- { 11, 4, 17 }, // 114 bits per transform
- { 11, 5, 16 }, // 114 bits per transform
- { 11, 6, 15 }, // 114 bits per transform
- { 11, 7, 14 }, // 114 bits per transform
- { 11, 8, 13 }, // 114 bits per transform
- { 11, 9, 12 }, // 114 bits per transform
- { 11, 10, 11 }, // 114 bits per transform
- { 11, 11, 10 }, // 114 bits per transform
- { 11, 12, 9 }, // 114 bits per transform
- { 11, 13, 8 }, // 114 bits per transform
- { 11, 14, 7 }, // 114 bits per transform
- { 11, 15, 6 }, // 114 bits per transform
- { 11, 16, 5 }, // 114 bits per transform
- { 11, 17, 4 }, // 114 bits per transform
- { 12, 3, 17 }, // 114 bits per transform
- { 12, 4, 16 }, // 114 bits per transform
- { 12, 5, 15 }, // 114 bits per transform
- { 12, 6, 14 }, // 114 bits per transform
- { 12, 7, 13 }, // 114 bits per transform
- { 12, 8, 12 }, // 114 bits per transform
- { 12, 9, 11 }, // 114 bits per transform
- { 12, 10, 10 }, // 114 bits per transform
- { 12, 11, 9 }, // 114 bits per transform
- { 12, 12, 8 }, // 114 bits per transform
- { 12, 13, 7 }, // 114 bits per transform
- { 12, 14, 6 }, // 114 bits per transform
- { 12, 15, 5 }, // 114 bits per transform
- { 12, 16, 4 }, // 114 bits per transform
- { 12, 17, 3 }, // 114 bits per transform
- { 13, 2, 17 }, // 114 bits per transform
- { 13, 3, 16 }, // 114 bits per transform
- { 13, 4, 15 }, // 114 bits per transform
- { 13, 5, 14 }, // 114 bits per transform
- { 13, 6, 13 }, // 114 bits per transform
- { 13, 7, 12 }, // 114 bits per transform
- { 13, 8, 11 }, // 114 bits per transform
- { 13, 9, 10 }, // 114 bits per transform
- { 13, 10, 9 }, // 114 bits per transform
- { 13, 11, 8 }, // 114 bits per transform
- { 13, 12, 7 }, // 114 bits per transform
- { 13, 13, 6 }, // 114 bits per transform
- { 13, 14, 5 }, // 114 bits per transform
- { 13, 15, 4 }, // 114 bits per transform
- { 13, 16, 3 }, // 114 bits per transform
- { 13, 17, 2 }, // 114 bits per transform
- { 14, 1, 17 }, // 114 bits per transform
- { 14, 2, 16 }, // 114 bits per transform
- { 14, 3, 15 }, // 114 bits per transform
- { 14, 4, 14 }, // 114 bits per transform
- { 14, 5, 13 }, // 114 bits per transform
- { 14, 6, 12 }, // 114 bits per transform
- { 14, 7, 11 }, // 114 bits per transform
- { 14, 8, 10 }, // 114 bits per transform
- { 14, 9, 9 }, // 114 bits per transform
- { 14, 10, 8 }, // 114 bits per transform
- { 14, 11, 7 }, // 114 bits per transform
- { 14, 12, 6 }, // 114 bits per transform
- { 14, 13, 5 }, // 114 bits per transform
- { 14, 14, 4 }, // 114 bits per transform
- { 14, 15, 3 }, // 114 bits per transform
- { 14, 16, 2 }, // 114 bits per transform
- { 14, 17, 1 }, // 114 bits per transform
- { 15, 1, 16 }, // 114 bits per transform
- { 15, 2, 15 }, // 114 bits per transform
- { 15, 3, 14 }, // 114 bits per transform
- { 15, 4, 13 }, // 114 bits per transform
- { 15, 5, 12 }, // 114 bits per transform
- { 15, 6, 11 }, // 114 bits per transform
- { 15, 7, 10 }, // 114 bits per transform
- { 15, 8, 9 }, // 114 bits per transform
- { 15, 9, 8 }, // 114 bits per transform
- { 15, 10, 7 }, // 114 bits per transform
- { 15, 11, 6 }, // 114 bits per transform
- { 15, 12, 5 }, // 114 bits per transform
- { 15, 13, 4 }, // 114 bits per transform
- { 15, 14, 3 }, // 114 bits per transform
- { 15, 15, 2 }, // 114 bits per transform
- { 15, 16, 1 }, // 114 bits per transform
- { 16, 1, 15 }, // 114 bits per transform
- { 16, 2, 14 }, // 114 bits per transform
- { 16, 3, 13 }, // 114 bits per transform
- { 16, 4, 12 }, // 114 bits per transform
- { 16, 5, 11 }, // 114 bits per transform
- { 16, 6, 10 }, // 114 bits per transform
- { 16, 7, 9 }, // 114 bits per transform
- { 16, 8, 8 }, // 114 bits per transform
- { 16, 9, 7 }, // 114 bits per transform
- { 16, 10, 6 }, // 114 bits per transform
- { 16, 11, 5 }, // 114 bits per transform
- { 16, 12, 4 }, // 114 bits per transform
- { 16, 13, 3 }, // 114 bits per transform
- { 16, 14, 2 }, // 114 bits per transform
- { 16, 15, 1 }, // 114 bits per transform
- { 17, 0, 17 }, // 114 bits per transform
- { 17, 1, 14 }, // 114 bits per transform
- { 17, 2, 13 }, // 114 bits per transform
- { 17, 3, 12 }, // 114 bits per transform
- { 17, 4, 11 }, // 114 bits per transform
- { 17, 5, 10 }, // 114 bits per transform
- { 17, 6, 9 }, // 114 bits per transform
- { 17, 7, 8 }, // 114 bits per transform
- { 17, 8, 7 }, // 114 bits per transform
- { 17, 9, 6 }, // 114 bits per transform
- { 17, 10, 5 }, // 114 bits per transform
- { 17, 11, 4 }, // 114 bits per transform
- { 17, 12, 3 }, // 114 bits per transform
- { 17, 13, 2 }, // 114 bits per transform
- { 17, 14, 1 }, // 114 bits per transform
- { 17, 17, 0 }, // 114 bits per transform
- { 18, 0, 4 }, // 114 bits per transform
- { 18, 1, 1 }, // 114 bits per transform
- { 18, 4, 0 }, // 114 bits per transform
- { 0, 5, 18 }, // 117 bits per transform
- { 0, 18, 5 }, // 117 bits per transform
- { 1, 2, 18 }, // 117 bits per transform
- { 1, 15, 17 }, // 117 bits per transform
- { 1, 16, 16 }, // 117 bits per transform
- { 1, 17, 15 }, // 117 bits per transform
- { 1, 18, 2 }, // 117 bits per transform
- { 2, 1, 18 }, // 117 bits per transform
- { 2, 14, 17 }, // 117 bits per transform
- { 2, 15, 16 }, // 117 bits per transform
- { 2, 16, 15 }, // 117 bits per transform
- { 2, 17, 14 }, // 117 bits per transform
- { 2, 18, 1 }, // 117 bits per transform
- { 3, 13, 17 }, // 117 bits per transform
- { 3, 14, 16 }, // 117 bits per transform
- { 3, 15, 15 }, // 117 bits per transform
- { 3, 16, 14 }, // 117 bits per transform
- { 3, 17, 13 }, // 117 bits per transform
- { 4, 12, 17 }, // 117 bits per transform
- { 4, 13, 16 }, // 117 bits per transform
- { 4, 14, 15 }, // 117 bits per transform
- { 4, 15, 14 }, // 117 bits per transform
- { 4, 16, 13 }, // 117 bits per transform
- { 4, 17, 12 }, // 117 bits per transform
- { 5, 0, 18 }, // 117 bits per transform
- { 5, 11, 17 }, // 117 bits per transform
- { 5, 12, 16 }, // 117 bits per transform
- { 5, 13, 15 }, // 117 bits per transform
- { 5, 14, 14 }, // 117 bits per transform
- { 5, 15, 13 }, // 117 bits per transform
- { 5, 16, 12 }, // 117 bits per transform
- { 5, 17, 11 }, // 117 bits per transform
- { 5, 18, 0 }, // 117 bits per transform
- { 6, 10, 17 }, // 117 bits per transform
- { 6, 11, 16 }, // 117 bits per transform
- { 6, 12, 15 }, // 117 bits per transform
- { 6, 13, 14 }, // 117 bits per transform
- { 6, 14, 13 }, // 117 bits per transform
- { 6, 15, 12 }, // 117 bits per transform
- { 6, 16, 11 }, // 117 bits per transform
- { 6, 17, 10 }, // 117 bits per transform
- { 7, 9, 17 }, // 117 bits per transform
- { 7, 10, 16 }, // 117 bits per transform
- { 7, 11, 15 }, // 117 bits per transform
- { 7, 12, 14 }, // 117 bits per transform
- { 7, 13, 13 }, // 117 bits per transform
- { 7, 14, 12 }, // 117 bits per transform
- { 7, 15, 11 }, // 117 bits per transform
- { 7, 16, 10 }, // 117 bits per transform
- { 7, 17, 9 }, // 117 bits per transform
- { 8, 8, 17 }, // 117 bits per transform
- { 8, 9, 16 }, // 117 bits per transform
- { 8, 10, 15 }, // 117 bits per transform
- { 8, 11, 14 }, // 117 bits per transform
- { 8, 12, 13 }, // 117 bits per transform
- { 8, 13, 12 }, // 117 bits per transform
- { 8, 14, 11 }, // 117 bits per transform
- { 8, 15, 10 }, // 117 bits per transform
- { 8, 16, 9 }, // 117 bits per transform
- { 8, 17, 8 }, // 117 bits per transform
- { 9, 7, 17 }, // 117 bits per transform
- { 9, 8, 16 }, // 117 bits per transform
- { 9, 9, 15 }, // 117 bits per transform
- { 9, 10, 14 }, // 117 bits per transform
- { 9, 11, 13 }, // 117 bits per transform
- { 9, 12, 12 }, // 117 bits per transform
- { 9, 13, 11 }, // 117 bits per transform
- { 9, 14, 10 }, // 117 bits per transform
- { 9, 15, 9 }, // 117 bits per transform
- { 9, 16, 8 }, // 117 bits per transform
- { 9, 17, 7 }, // 117 bits per transform
- { 10, 6, 17 }, // 117 bits per transform
- { 10, 7, 16 }, // 117 bits per transform
- { 10, 8, 15 }, // 117 bits per transform
- { 10, 9, 14 }, // 117 bits per transform
- { 10, 10, 13 }, // 117 bits per transform
- { 10, 11, 12 }, // 117 bits per transform
- { 10, 12, 11 }, // 117 bits per transform
- { 10, 13, 10 }, // 117 bits per transform
- { 10, 14, 9 }, // 117 bits per transform
- { 10, 15, 8 }, // 117 bits per transform
- { 10, 16, 7 }, // 117 bits per transform
- { 10, 17, 6 }, // 117 bits per transform
- { 11, 5, 17 }, // 117 bits per transform
- { 11, 6, 16 }, // 117 bits per transform
- { 11, 7, 15 }, // 117 bits per transform
- { 11, 8, 14 }, // 117 bits per transform
- { 11, 9, 13 }, // 117 bits per transform
- { 11, 10, 12 }, // 117 bits per transform
- { 11, 11, 11 }, // 117 bits per transform
- { 11, 12, 10 }, // 117 bits per transform
- { 11, 13, 9 }, // 117 bits per transform
- { 11, 14, 8 }, // 117 bits per transform
- { 11, 15, 7 }, // 117 bits per transform
- { 11, 16, 6 }, // 117 bits per transform
- { 11, 17, 5 }, // 117 bits per transform
- { 12, 4, 17 }, // 117 bits per transform
- { 12, 5, 16 }, // 117 bits per transform
- { 12, 6, 15 }, // 117 bits per transform
- { 12, 7, 14 }, // 117 bits per transform
- { 12, 8, 13 }, // 117 bits per transform
- { 12, 9, 12 }, // 117 bits per transform
- { 12, 10, 11 }, // 117 bits per transform
- { 12, 11, 10 }, // 117 bits per transform
- { 12, 12, 9 }, // 117 bits per transform
- { 12, 13, 8 }, // 117 bits per transform
- { 12, 14, 7 }, // 117 bits per transform
- { 12, 15, 6 }, // 117 bits per transform
- { 12, 16, 5 }, // 117 bits per transform
- { 12, 17, 4 }, // 117 bits per transform
- { 13, 3, 17 }, // 117 bits per transform
- { 13, 4, 16 }, // 117 bits per transform
- { 13, 5, 15 }, // 117 bits per transform
- { 13, 6, 14 }, // 117 bits per transform
- { 13, 7, 13 }, // 117 bits per transform
- { 13, 8, 12 }, // 117 bits per transform
- { 13, 9, 11 }, // 117 bits per transform
- { 13, 10, 10 }, // 117 bits per transform
- { 13, 11, 9 }, // 117 bits per transform
- { 13, 12, 8 }, // 117 bits per transform
- { 13, 13, 7 }, // 117 bits per transform
- { 13, 14, 6 }, // 117 bits per transform
- { 13, 15, 5 }, // 117 bits per transform
- { 13, 16, 4 }, // 117 bits per transform
- { 13, 17, 3 }, // 117 bits per transform
- { 14, 2, 17 }, // 117 bits per transform
- { 14, 3, 16 }, // 117 bits per transform
- { 14, 4, 15 }, // 117 bits per transform
- { 14, 5, 14 }, // 117 bits per transform
- { 14, 6, 13 }, // 117 bits per transform
- { 14, 7, 12 }, // 117 bits per transform
- { 14, 8, 11 }, // 117 bits per transform
- { 14, 9, 10 }, // 117 bits per transform
- { 14, 10, 9 }, // 117 bits per transform
- { 14, 11, 8 }, // 117 bits per transform
- { 14, 12, 7 }, // 117 bits per transform
- { 14, 13, 6 }, // 117 bits per transform
- { 14, 14, 5 }, // 117 bits per transform
- { 14, 15, 4 }, // 117 bits per transform
- { 14, 16, 3 }, // 117 bits per transform
- { 14, 17, 2 }, // 117 bits per transform
- { 15, 1, 17 }, // 117 bits per transform
- { 15, 2, 16 }, // 117 bits per transform
- { 15, 3, 15 }, // 117 bits per transform
- { 15, 4, 14 }, // 117 bits per transform
- { 15, 5, 13 }, // 117 bits per transform
- { 15, 6, 12 }, // 117 bits per transform
- { 15, 7, 11 }, // 117 bits per transform
- { 15, 8, 10 }, // 117 bits per transform
- { 15, 9, 9 }, // 117 bits per transform
- { 15, 10, 8 }, // 117 bits per transform
- { 15, 11, 7 }, // 117 bits per transform
- { 15, 12, 6 }, // 117 bits per transform
- { 15, 13, 5 }, // 117 bits per transform
- { 15, 14, 4 }, // 117 bits per transform
- { 15, 15, 3 }, // 117 bits per transform
- { 15, 16, 2 }, // 117 bits per transform
- { 15, 17, 1 }, // 117 bits per transform
- { 16, 1, 16 }, // 117 bits per transform
- { 16, 2, 15 }, // 117 bits per transform
- { 16, 3, 14 }, // 117 bits per transform
- { 16, 4, 13 }, // 117 bits per transform
- { 16, 5, 12 }, // 117 bits per transform
- { 16, 6, 11 }, // 117 bits per transform
- { 16, 7, 10 }, // 117 bits per transform
- { 16, 8, 9 }, // 117 bits per transform
- { 16, 9, 8 }, // 117 bits per transform
- { 16, 10, 7 }, // 117 bits per transform
- { 16, 11, 6 }, // 117 bits per transform
- { 16, 12, 5 }, // 117 bits per transform
- { 16, 13, 4 }, // 117 bits per transform
- { 16, 14, 3 }, // 117 bits per transform
- { 16, 15, 2 }, // 117 bits per transform
- { 16, 16, 1 }, // 117 bits per transform
- { 17, 1, 15 }, // 117 bits per transform
- { 17, 2, 14 }, // 117 bits per transform
- { 17, 3, 13 }, // 117 bits per transform
- { 17, 4, 12 }, // 117 bits per transform
- { 17, 5, 11 }, // 117 bits per transform
- { 17, 6, 10 }, // 117 bits per transform
- { 17, 7, 9 }, // 117 bits per transform
- { 17, 8, 8 }, // 117 bits per transform
- { 17, 9, 7 }, // 117 bits per transform
- { 17, 10, 6 }, // 117 bits per transform
- { 17, 11, 5 }, // 117 bits per transform
- { 17, 12, 4 }, // 117 bits per transform
- { 17, 13, 3 }, // 117 bits per transform
- { 17, 14, 2 }, // 117 bits per transform
- { 17, 15, 1 }, // 117 bits per transform
- { 18, 0, 5 }, // 117 bits per transform
- { 18, 1, 2 }, // 117 bits per transform
- { 18, 2, 1 }, // 117 bits per transform
- { 18, 5, 0 }, // 117 bits per transform
- { 0, 6, 18 }, // 120 bits per transform
- { 0, 18, 6 }, // 120 bits per transform
- { 1, 3, 18 }, // 120 bits per transform
- { 1, 16, 17 }, // 120 bits per transform
- { 1, 17, 16 }, // 120 bits per transform
- { 1, 18, 3 }, // 120 bits per transform
- { 2, 2, 18 }, // 120 bits per transform
- { 2, 15, 17 }, // 120 bits per transform
- { 2, 16, 16 }, // 120 bits per transform
- { 2, 17, 15 }, // 120 bits per transform
- { 2, 18, 2 }, // 120 bits per transform
- { 3, 1, 18 }, // 120 bits per transform
- { 3, 14, 17 }, // 120 bits per transform
- { 3, 15, 16 }, // 120 bits per transform
- { 3, 16, 15 }, // 120 bits per transform
- { 3, 17, 14 }, // 120 bits per transform
- { 3, 18, 1 }, // 120 bits per transform
- { 4, 13, 17 }, // 120 bits per transform
- { 4, 14, 16 }, // 120 bits per transform
- { 4, 15, 15 }, // 120 bits per transform
- { 4, 16, 14 }, // 120 bits per transform
- { 4, 17, 13 }, // 120 bits per transform
- { 5, 12, 17 }, // 120 bits per transform
- { 5, 13, 16 }, // 120 bits per transform
- { 5, 14, 15 }, // 120 bits per transform
- { 5, 15, 14 }, // 120 bits per transform
- { 5, 16, 13 }, // 120 bits per transform
- { 5, 17, 12 }, // 120 bits per transform
- { 6, 0, 18 }, // 120 bits per transform
- { 6, 11, 17 }, // 120 bits per transform
- { 6, 12, 16 }, // 120 bits per transform
- { 6, 13, 15 }, // 120 bits per transform
- { 6, 14, 14 }, // 120 bits per transform
- { 6, 15, 13 }, // 120 bits per transform
- { 6, 16, 12 }, // 120 bits per transform
- { 6, 17, 11 }, // 120 bits per transform
- { 6, 18, 0 }, // 120 bits per transform
- { 7, 10, 17 }, // 120 bits per transform
- { 7, 11, 16 }, // 120 bits per transform
- { 7, 12, 15 }, // 120 bits per transform
- { 7, 13, 14 }, // 120 bits per transform
- { 7, 14, 13 }, // 120 bits per transform
- { 7, 15, 12 }, // 120 bits per transform
- { 7, 16, 11 }, // 120 bits per transform
- { 7, 17, 10 }, // 120 bits per transform
- { 8, 9, 17 }, // 120 bits per transform
- { 8, 10, 16 }, // 120 bits per transform
- { 8, 11, 15 }, // 120 bits per transform
- { 8, 12, 14 }, // 120 bits per transform
- { 8, 13, 13 }, // 120 bits per transform
- { 8, 14, 12 }, // 120 bits per transform
- { 8, 15, 11 }, // 120 bits per transform
- { 8, 16, 10 }, // 120 bits per transform
- { 8, 17, 9 }, // 120 bits per transform
- { 9, 8, 17 }, // 120 bits per transform
- { 9, 9, 16 }, // 120 bits per transform
- { 9, 10, 15 }, // 120 bits per transform
- { 9, 11, 14 }, // 120 bits per transform
- { 9, 12, 13 }, // 120 bits per transform
- { 9, 13, 12 }, // 120 bits per transform
- { 9, 14, 11 }, // 120 bits per transform
- { 9, 15, 10 }, // 120 bits per transform
- { 9, 16, 9 }, // 120 bits per transform
- { 9, 17, 8 }, // 120 bits per transform
- { 10, 7, 17 }, // 120 bits per transform
- { 10, 8, 16 }, // 120 bits per transform
- { 10, 9, 15 }, // 120 bits per transform
- { 10, 10, 14 }, // 120 bits per transform
- { 10, 11, 13 }, // 120 bits per transform
- { 10, 12, 12 }, // 120 bits per transform
- { 10, 13, 11 }, // 120 bits per transform
- { 10, 14, 10 }, // 120 bits per transform
- { 10, 15, 9 }, // 120 bits per transform
- { 10, 16, 8 }, // 120 bits per transform
- { 10, 17, 7 }, // 120 bits per transform
- { 11, 6, 17 }, // 120 bits per transform
- { 11, 7, 16 }, // 120 bits per transform
- { 11, 8, 15 }, // 120 bits per transform
- { 11, 9, 14 }, // 120 bits per transform
- { 11, 10, 13 }, // 120 bits per transform
- { 11, 11, 12 }, // 120 bits per transform
- { 11, 12, 11 }, // 120 bits per transform
- { 11, 13, 10 }, // 120 bits per transform
- { 11, 14, 9 }, // 120 bits per transform
- { 11, 15, 8 }, // 120 bits per transform
- { 11, 16, 7 }, // 120 bits per transform
- { 11, 17, 6 }, // 120 bits per transform
- { 12, 5, 17 }, // 120 bits per transform
- { 12, 6, 16 }, // 120 bits per transform
- { 12, 7, 15 }, // 120 bits per transform
- { 12, 8, 14 }, // 120 bits per transform
- { 12, 9, 13 }, // 120 bits per transform
- { 12, 10, 12 }, // 120 bits per transform
- { 12, 11, 11 }, // 120 bits per transform
- { 12, 12, 10 }, // 120 bits per transform
- { 12, 13, 9 }, // 120 bits per transform
- { 12, 14, 8 }, // 120 bits per transform
- { 12, 15, 7 }, // 120 bits per transform
- { 12, 16, 6 }, // 120 bits per transform
- { 12, 17, 5 }, // 120 bits per transform
- { 13, 4, 17 }, // 120 bits per transform
- { 13, 5, 16 }, // 120 bits per transform
- { 13, 6, 15 }, // 120 bits per transform
- { 13, 7, 14 }, // 120 bits per transform
- { 13, 8, 13 }, // 120 bits per transform
- { 13, 9, 12 }, // 120 bits per transform
- { 13, 10, 11 }, // 120 bits per transform
- { 13, 11, 10 }, // 120 bits per transform
- { 13, 12, 9 }, // 120 bits per transform
- { 13, 13, 8 }, // 120 bits per transform
- { 13, 14, 7 }, // 120 bits per transform
- { 13, 15, 6 }, // 120 bits per transform
- { 13, 16, 5 }, // 120 bits per transform
- { 13, 17, 4 }, // 120 bits per transform
- { 14, 3, 17 }, // 120 bits per transform
- { 14, 4, 16 }, // 120 bits per transform
- { 14, 5, 15 }, // 120 bits per transform
- { 14, 6, 14 }, // 120 bits per transform
- { 14, 7, 13 }, // 120 bits per transform
- { 14, 8, 12 }, // 120 bits per transform
- { 14, 9, 11 }, // 120 bits per transform
- { 14, 10, 10 }, // 120 bits per transform
- { 14, 11, 9 }, // 120 bits per transform
- { 14, 12, 8 }, // 120 bits per transform
- { 14, 13, 7 }, // 120 bits per transform
- { 14, 14, 6 }, // 120 bits per transform
- { 14, 15, 5 }, // 120 bits per transform
- { 14, 16, 4 }, // 120 bits per transform
- { 14, 17, 3 }, // 120 bits per transform
- { 15, 2, 17 }, // 120 bits per transform
- { 15, 3, 16 }, // 120 bits per transform
- { 15, 4, 15 }, // 120 bits per transform
- { 15, 5, 14 }, // 120 bits per transform
- { 15, 6, 13 }, // 120 bits per transform
- { 15, 7, 12 }, // 120 bits per transform
- { 15, 8, 11 }, // 120 bits per transform
- { 15, 9, 10 }, // 120 bits per transform
- { 15, 10, 9 }, // 120 bits per transform
- { 15, 11, 8 }, // 120 bits per transform
- { 15, 12, 7 }, // 120 bits per transform
- { 15, 13, 6 }, // 120 bits per transform
- { 15, 14, 5 }, // 120 bits per transform
- { 15, 15, 4 }, // 120 bits per transform
- { 15, 16, 3 }, // 120 bits per transform
- { 15, 17, 2 }, // 120 bits per transform
- { 16, 1, 17 }, // 120 bits per transform
- { 16, 2, 16 }, // 120 bits per transform
- { 16, 3, 15 }, // 120 bits per transform
- { 16, 4, 14 }, // 120 bits per transform
- { 16, 5, 13 }, // 120 bits per transform
- { 16, 6, 12 }, // 120 bits per transform
- { 16, 7, 11 }, // 120 bits per transform
- { 16, 8, 10 }, // 120 bits per transform
- { 16, 9, 9 }, // 120 bits per transform
- { 16, 10, 8 }, // 120 bits per transform
- { 16, 11, 7 }, // 120 bits per transform
- { 16, 12, 6 }, // 120 bits per transform
- { 16, 13, 5 }, // 120 bits per transform
- { 16, 14, 4 }, // 120 bits per transform
- { 16, 15, 3 }, // 120 bits per transform
- { 16, 16, 2 }, // 120 bits per transform
- { 16, 17, 1 }, // 120 bits per transform
- { 17, 1, 16 }, // 120 bits per transform
- { 17, 2, 15 }, // 120 bits per transform
- { 17, 3, 14 }, // 120 bits per transform
- { 17, 4, 13 }, // 120 bits per transform
- { 17, 5, 12 }, // 120 bits per transform
- { 17, 6, 11 }, // 120 bits per transform
- { 17, 7, 10 }, // 120 bits per transform
- { 17, 8, 9 }, // 120 bits per transform
- { 17, 9, 8 }, // 120 bits per transform
- { 17, 10, 7 }, // 120 bits per transform
- { 17, 11, 6 }, // 120 bits per transform
- { 17, 12, 5 }, // 120 bits per transform
- { 17, 13, 4 }, // 120 bits per transform
- { 17, 14, 3 }, // 120 bits per transform
- { 17, 15, 2 }, // 120 bits per transform
- { 17, 16, 1 }, // 120 bits per transform
- { 18, 0, 6 }, // 120 bits per transform
- { 18, 1, 3 }, // 120 bits per transform
- { 18, 2, 2 }, // 120 bits per transform
- { 18, 3, 1 }, // 120 bits per transform
- { 18, 6, 0 }, // 120 bits per transform
- { 0, 7, 18 }, // 123 bits per transform
- { 0, 18, 7 }, // 123 bits per transform
- { 1, 4, 18 }, // 123 bits per transform
- { 1, 17, 17 }, // 123 bits per transform
- { 1, 18, 4 }, // 123 bits per transform
- { 2, 3, 18 }, // 123 bits per transform
- { 2, 16, 17 }, // 123 bits per transform
- { 2, 17, 16 }, // 123 bits per transform
- { 2, 18, 3 }, // 123 bits per transform
- { 3, 2, 18 }, // 123 bits per transform
- { 3, 15, 17 }, // 123 bits per transform
- { 3, 16, 16 }, // 123 bits per transform
- { 3, 17, 15 }, // 123 bits per transform
- { 3, 18, 2 }, // 123 bits per transform
- { 4, 1, 18 }, // 123 bits per transform
- { 4, 14, 17 }, // 123 bits per transform
- { 4, 15, 16 }, // 123 bits per transform
- { 4, 16, 15 }, // 123 bits per transform
- { 4, 17, 14 }, // 123 bits per transform
- { 4, 18, 1 }, // 123 bits per transform
- { 5, 13, 17 }, // 123 bits per transform
- { 5, 14, 16 }, // 123 bits per transform
- { 5, 15, 15 }, // 123 bits per transform
- { 5, 16, 14 }, // 123 bits per transform
- { 5, 17, 13 }, // 123 bits per transform
- { 6, 12, 17 }, // 123 bits per transform
- { 6, 13, 16 }, // 123 bits per transform
- { 6, 14, 15 }, // 123 bits per transform
- { 6, 15, 14 }, // 123 bits per transform
- { 6, 16, 13 }, // 123 bits per transform
- { 6, 17, 12 }, // 123 bits per transform
- { 7, 0, 18 }, // 123 bits per transform
- { 7, 11, 17 }, // 123 bits per transform
- { 7, 12, 16 }, // 123 bits per transform
- { 7, 13, 15 }, // 123 bits per transform
- { 7, 14, 14 }, // 123 bits per transform
- { 7, 15, 13 }, // 123 bits per transform
- { 7, 16, 12 }, // 123 bits per transform
- { 7, 17, 11 }, // 123 bits per transform
- { 7, 18, 0 }, // 123 bits per transform
- { 8, 10, 17 }, // 123 bits per transform
- { 8, 11, 16 }, // 123 bits per transform
- { 8, 12, 15 }, // 123 bits per transform
- { 8, 13, 14 }, // 123 bits per transform
- { 8, 14, 13 }, // 123 bits per transform
- { 8, 15, 12 }, // 123 bits per transform
- { 8, 16, 11 }, // 123 bits per transform
- { 8, 17, 10 }, // 123 bits per transform
- { 9, 9, 17 }, // 123 bits per transform
- { 9, 10, 16 }, // 123 bits per transform
- { 9, 11, 15 }, // 123 bits per transform
- { 9, 12, 14 }, // 123 bits per transform
- { 9, 13, 13 }, // 123 bits per transform
- { 9, 14, 12 }, // 123 bits per transform
- { 9, 15, 11 }, // 123 bits per transform
- { 9, 16, 10 }, // 123 bits per transform
- { 9, 17, 9 }, // 123 bits per transform
- { 10, 8, 17 }, // 123 bits per transform
- { 10, 9, 16 }, // 123 bits per transform
- { 10, 10, 15 }, // 123 bits per transform
- { 10, 11, 14 }, // 123 bits per transform
- { 10, 12, 13 }, // 123 bits per transform
- { 10, 13, 12 }, // 123 bits per transform
- { 10, 14, 11 }, // 123 bits per transform
- { 10, 15, 10 }, // 123 bits per transform
- { 10, 16, 9 }, // 123 bits per transform
- { 10, 17, 8 }, // 123 bits per transform
- { 11, 7, 17 }, // 123 bits per transform
- { 11, 8, 16 }, // 123 bits per transform
- { 11, 9, 15 }, // 123 bits per transform
- { 11, 10, 14 }, // 123 bits per transform
- { 11, 11, 13 }, // 123 bits per transform
- { 11, 12, 12 }, // 123 bits per transform
- { 11, 13, 11 }, // 123 bits per transform
- { 11, 14, 10 }, // 123 bits per transform
- { 11, 15, 9 }, // 123 bits per transform
- { 11, 16, 8 }, // 123 bits per transform
- { 11, 17, 7 }, // 123 bits per transform
- { 12, 6, 17 }, // 123 bits per transform
- { 12, 7, 16 }, // 123 bits per transform
- { 12, 8, 15 }, // 123 bits per transform
- { 12, 9, 14 }, // 123 bits per transform
- { 12, 10, 13 }, // 123 bits per transform
- { 12, 11, 12 }, // 123 bits per transform
- { 12, 12, 11 }, // 123 bits per transform
- { 12, 13, 10 }, // 123 bits per transform
- { 12, 14, 9 }, // 123 bits per transform
- { 12, 15, 8 }, // 123 bits per transform
- { 12, 16, 7 }, // 123 bits per transform
- { 12, 17, 6 }, // 123 bits per transform
- { 13, 5, 17 }, // 123 bits per transform
- { 13, 6, 16 }, // 123 bits per transform
- { 13, 7, 15 }, // 123 bits per transform
- { 13, 8, 14 }, // 123 bits per transform
- { 13, 9, 13 }, // 123 bits per transform
- { 13, 10, 12 }, // 123 bits per transform
- { 13, 11, 11 }, // 123 bits per transform
- { 13, 12, 10 }, // 123 bits per transform
- { 13, 13, 9 }, // 123 bits per transform
- { 13, 14, 8 }, // 123 bits per transform
- { 13, 15, 7 }, // 123 bits per transform
- { 13, 16, 6 }, // 123 bits per transform
- { 13, 17, 5 }, // 123 bits per transform
- { 14, 4, 17 }, // 123 bits per transform
- { 14, 5, 16 }, // 123 bits per transform
- { 14, 6, 15 }, // 123 bits per transform
- { 14, 7, 14 }, // 123 bits per transform
- { 14, 8, 13 }, // 123 bits per transform
- { 14, 9, 12 }, // 123 bits per transform
- { 14, 10, 11 }, // 123 bits per transform
- { 14, 11, 10 }, // 123 bits per transform
- { 14, 12, 9 }, // 123 bits per transform
- { 14, 13, 8 }, // 123 bits per transform
- { 14, 14, 7 }, // 123 bits per transform
- { 14, 15, 6 }, // 123 bits per transform
- { 14, 16, 5 }, // 123 bits per transform
- { 14, 17, 4 }, // 123 bits per transform
- { 15, 3, 17 }, // 123 bits per transform
- { 15, 4, 16 }, // 123 bits per transform
- { 15, 5, 15 }, // 123 bits per transform
- { 15, 6, 14 }, // 123 bits per transform
- { 15, 7, 13 }, // 123 bits per transform
- { 15, 8, 12 }, // 123 bits per transform
- { 15, 9, 11 }, // 123 bits per transform
- { 15, 10, 10 }, // 123 bits per transform
- { 15, 11, 9 }, // 123 bits per transform
- { 15, 12, 8 }, // 123 bits per transform
- { 15, 13, 7 }, // 123 bits per transform
- { 15, 14, 6 }, // 123 bits per transform
- { 15, 15, 5 }, // 123 bits per transform
- { 15, 16, 4 }, // 123 bits per transform
- { 15, 17, 3 }, // 123 bits per transform
- { 16, 2, 17 }, // 123 bits per transform
- { 16, 3, 16 }, // 123 bits per transform
- { 16, 4, 15 }, // 123 bits per transform
- { 16, 5, 14 }, // 123 bits per transform
- { 16, 6, 13 }, // 123 bits per transform
- { 16, 7, 12 }, // 123 bits per transform
- { 16, 8, 11 }, // 123 bits per transform
- { 16, 9, 10 }, // 123 bits per transform
- { 16, 10, 9 }, // 123 bits per transform
- { 16, 11, 8 }, // 123 bits per transform
- { 16, 12, 7 }, // 123 bits per transform
- { 16, 13, 6 }, // 123 bits per transform
- { 16, 14, 5 }, // 123 bits per transform
- { 16, 15, 4 }, // 123 bits per transform
- { 16, 16, 3 }, // 123 bits per transform
- { 16, 17, 2 }, // 123 bits per transform
- { 17, 1, 17 }, // 123 bits per transform
- { 17, 2, 16 }, // 123 bits per transform
- { 17, 3, 15 }, // 123 bits per transform
- { 17, 4, 14 }, // 123 bits per transform
- { 17, 5, 13 }, // 123 bits per transform
- { 17, 6, 12 }, // 123 bits per transform
- { 17, 7, 11 }, // 123 bits per transform
- { 17, 8, 10 }, // 123 bits per transform
- { 17, 9, 9 }, // 123 bits per transform
- { 17, 10, 8 }, // 123 bits per transform
- { 17, 11, 7 }, // 123 bits per transform
- { 17, 12, 6 }, // 123 bits per transform
- { 17, 13, 5 }, // 123 bits per transform
- { 17, 14, 4 }, // 123 bits per transform
- { 17, 15, 3 }, // 123 bits per transform
- { 17, 16, 2 }, // 123 bits per transform
- { 17, 17, 1 }, // 123 bits per transform
- { 18, 0, 7 }, // 123 bits per transform
- { 18, 1, 4 }, // 123 bits per transform
- { 18, 2, 3 }, // 123 bits per transform
- { 18, 3, 2 }, // 123 bits per transform
- { 18, 4, 1 }, // 123 bits per transform
- { 18, 7, 0 }, // 123 bits per transform
- { 0, 8, 18 }, // 126 bits per transform
- { 0, 18, 8 }, // 126 bits per transform
- { 1, 5, 18 }, // 126 bits per transform
- { 1, 18, 5 }, // 126 bits per transform
- { 2, 4, 18 }, // 126 bits per transform
- { 2, 17, 17 }, // 126 bits per transform
- { 2, 18, 4 }, // 126 bits per transform
- { 3, 3, 18 }, // 126 bits per transform
- { 3, 16, 17 }, // 126 bits per transform
- { 3, 17, 16 }, // 126 bits per transform
- { 3, 18, 3 }, // 126 bits per transform
- { 4, 2, 18 }, // 126 bits per transform
- { 4, 15, 17 }, // 126 bits per transform
- { 4, 16, 16 }, // 126 bits per transform
- { 4, 17, 15 }, // 126 bits per transform
- { 4, 18, 2 }, // 126 bits per transform
- { 5, 1, 18 }, // 126 bits per transform
- { 5, 14, 17 }, // 126 bits per transform
- { 5, 15, 16 }, // 126 bits per transform
- { 5, 16, 15 }, // 126 bits per transform
- { 5, 17, 14 }, // 126 bits per transform
- { 5, 18, 1 }, // 126 bits per transform
- { 6, 13, 17 }, // 126 bits per transform
- { 6, 14, 16 }, // 126 bits per transform
- { 6, 15, 15 }, // 126 bits per transform
- { 6, 16, 14 }, // 126 bits per transform
- { 6, 17, 13 }, // 126 bits per transform
- { 7, 12, 17 }, // 126 bits per transform
- { 7, 13, 16 }, // 126 bits per transform
- { 7, 14, 15 }, // 126 bits per transform
- { 7, 15, 14 }, // 126 bits per transform
- { 7, 16, 13 }, // 126 bits per transform
- { 7, 17, 12 }, // 126 bits per transform
- { 8, 0, 18 }, // 126 bits per transform
- { 8, 11, 17 }, // 126 bits per transform
- { 8, 12, 16 }, // 126 bits per transform
- { 8, 13, 15 }, // 126 bits per transform
- { 8, 14, 14 }, // 126 bits per transform
- { 8, 15, 13 }, // 126 bits per transform
- { 8, 16, 12 }, // 126 bits per transform
- { 8, 17, 11 }, // 126 bits per transform
- { 8, 18, 0 }, // 126 bits per transform
- { 9, 10, 17 }, // 126 bits per transform
- { 9, 11, 16 }, // 126 bits per transform
- { 9, 12, 15 }, // 126 bits per transform
- { 9, 13, 14 }, // 126 bits per transform
- { 9, 14, 13 }, // 126 bits per transform
- { 9, 15, 12 }, // 126 bits per transform
- { 9, 16, 11 }, // 126 bits per transform
- { 9, 17, 10 }, // 126 bits per transform
- { 10, 9, 17 }, // 126 bits per transform
- { 10, 10, 16 }, // 126 bits per transform
- { 10, 11, 15 }, // 126 bits per transform
- { 10, 12, 14 }, // 126 bits per transform
- { 10, 13, 13 }, // 126 bits per transform
- { 10, 14, 12 }, // 126 bits per transform
- { 10, 15, 11 }, // 126 bits per transform
- { 10, 16, 10 }, // 126 bits per transform
- { 10, 17, 9 }, // 126 bits per transform
- { 11, 8, 17 }, // 126 bits per transform
- { 11, 9, 16 }, // 126 bits per transform
- { 11, 10, 15 }, // 126 bits per transform
- { 11, 11, 14 }, // 126 bits per transform
- { 11, 12, 13 }, // 126 bits per transform
- { 11, 13, 12 }, // 126 bits per transform
- { 11, 14, 11 }, // 126 bits per transform
- { 11, 15, 10 }, // 126 bits per transform
- { 11, 16, 9 }, // 126 bits per transform
- { 11, 17, 8 }, // 126 bits per transform
- { 12, 7, 17 }, // 126 bits per transform
- { 12, 8, 16 }, // 126 bits per transform
- { 12, 9, 15 }, // 126 bits per transform
- { 12, 10, 14 }, // 126 bits per transform
- { 12, 11, 13 }, // 126 bits per transform
- { 12, 12, 12 }, // 126 bits per transform
- { 12, 13, 11 }, // 126 bits per transform
- { 12, 14, 10 }, // 126 bits per transform
- { 12, 15, 9 }, // 126 bits per transform
- { 12, 16, 8 }, // 126 bits per transform
- { 12, 17, 7 }, // 126 bits per transform
- { 13, 6, 17 }, // 126 bits per transform
- { 13, 7, 16 }, // 126 bits per transform
- { 13, 8, 15 }, // 126 bits per transform
- { 13, 9, 14 }, // 126 bits per transform
- { 13, 10, 13 }, // 126 bits per transform
- { 13, 11, 12 }, // 126 bits per transform
- { 13, 12, 11 }, // 126 bits per transform
- { 13, 13, 10 }, // 126 bits per transform
- { 13, 14, 9 }, // 126 bits per transform
- { 13, 15, 8 }, // 126 bits per transform
- { 13, 16, 7 }, // 126 bits per transform
- { 13, 17, 6 }, // 126 bits per transform
- { 14, 5, 17 }, // 126 bits per transform
- { 14, 6, 16 }, // 126 bits per transform
- { 14, 7, 15 }, // 126 bits per transform
- { 14, 8, 14 }, // 126 bits per transform
- { 14, 9, 13 }, // 126 bits per transform
- { 14, 10, 12 }, // 126 bits per transform
- { 14, 11, 11 }, // 126 bits per transform
- { 14, 12, 10 }, // 126 bits per transform
- { 14, 13, 9 }, // 126 bits per transform
- { 14, 14, 8 }, // 126 bits per transform
- { 14, 15, 7 }, // 126 bits per transform
- { 14, 16, 6 }, // 126 bits per transform
- { 14, 17, 5 }, // 126 bits per transform
- { 15, 4, 17 }, // 126 bits per transform
- { 15, 5, 16 }, // 126 bits per transform
- { 15, 6, 15 }, // 126 bits per transform
- { 15, 7, 14 }, // 126 bits per transform
- { 15, 8, 13 }, // 126 bits per transform
- { 15, 9, 12 }, // 126 bits per transform
- { 15, 10, 11 }, // 126 bits per transform
- { 15, 11, 10 }, // 126 bits per transform
- { 15, 12, 9 }, // 126 bits per transform
- { 15, 13, 8 }, // 126 bits per transform
- { 15, 14, 7 }, // 126 bits per transform
- { 15, 15, 6 }, // 126 bits per transform
- { 15, 16, 5 }, // 126 bits per transform
- { 15, 17, 4 }, // 126 bits per transform
- { 16, 3, 17 }, // 126 bits per transform
- { 16, 4, 16 }, // 126 bits per transform
- { 16, 5, 15 }, // 126 bits per transform
- { 16, 6, 14 }, // 126 bits per transform
- { 16, 7, 13 }, // 126 bits per transform
- { 16, 8, 12 }, // 126 bits per transform
- { 16, 9, 11 }, // 126 bits per transform
- { 16, 10, 10 }, // 126 bits per transform
- { 16, 11, 9 }, // 126 bits per transform
- { 16, 12, 8 }, // 126 bits per transform
- { 16, 13, 7 }, // 126 bits per transform
- { 16, 14, 6 }, // 126 bits per transform
- { 16, 15, 5 }, // 126 bits per transform
- { 16, 16, 4 }, // 126 bits per transform
- { 16, 17, 3 }, // 126 bits per transform
- { 17, 2, 17 }, // 126 bits per transform
- { 17, 3, 16 }, // 126 bits per transform
- { 17, 4, 15 }, // 126 bits per transform
- { 17, 5, 14 }, // 126 bits per transform
- { 17, 6, 13 }, // 126 bits per transform
- { 17, 7, 12 }, // 126 bits per transform
- { 17, 8, 11 }, // 126 bits per transform
- { 17, 9, 10 }, // 126 bits per transform
- { 17, 10, 9 }, // 126 bits per transform
- { 17, 11, 8 }, // 126 bits per transform
- { 17, 12, 7 }, // 126 bits per transform
- { 17, 13, 6 }, // 126 bits per transform
- { 17, 14, 5 }, // 126 bits per transform
- { 17, 15, 4 }, // 126 bits per transform
- { 17, 16, 3 }, // 126 bits per transform
- { 17, 17, 2 }, // 126 bits per transform
- { 18, 0, 8 }, // 126 bits per transform
- { 18, 1, 5 }, // 126 bits per transform
- { 18, 2, 4 }, // 126 bits per transform
- { 18, 3, 3 }, // 126 bits per transform
- { 18, 4, 2 }, // 126 bits per transform
- { 18, 5, 1 }, // 126 bits per transform
- { 18, 8, 0 }, // 126 bits per transform
- { 0, 9, 18 }, // 129 bits per transform
- { 0, 18, 9 }, // 129 bits per transform
- { 1, 6, 18 }, // 129 bits per transform
- { 1, 18, 6 }, // 129 bits per transform
- { 2, 5, 18 }, // 129 bits per transform
- { 2, 18, 5 }, // 129 bits per transform
- { 3, 4, 18 }, // 129 bits per transform
- { 3, 17, 17 }, // 129 bits per transform
- { 3, 18, 4 }, // 129 bits per transform
- { 4, 3, 18 }, // 129 bits per transform
- { 4, 16, 17 }, // 129 bits per transform
- { 4, 17, 16 }, // 129 bits per transform
- { 4, 18, 3 }, // 129 bits per transform
- { 5, 2, 18 }, // 129 bits per transform
- { 5, 15, 17 }, // 129 bits per transform
- { 5, 16, 16 }, // 129 bits per transform
- { 5, 17, 15 }, // 129 bits per transform
- { 5, 18, 2 }, // 129 bits per transform
- { 6, 1, 18 }, // 129 bits per transform
- { 6, 14, 17 }, // 129 bits per transform
- { 6, 15, 16 }, // 129 bits per transform
- { 6, 16, 15 }, // 129 bits per transform
- { 6, 17, 14 }, // 129 bits per transform
- { 6, 18, 1 }, // 129 bits per transform
- { 7, 13, 17 }, // 129 bits per transform
- { 7, 14, 16 }, // 129 bits per transform
- { 7, 15, 15 }, // 129 bits per transform
- { 7, 16, 14 }, // 129 bits per transform
- { 7, 17, 13 }, // 129 bits per transform
- { 8, 12, 17 }, // 129 bits per transform
- { 8, 13, 16 }, // 129 bits per transform
- { 8, 14, 15 }, // 129 bits per transform
- { 8, 15, 14 }, // 129 bits per transform
- { 8, 16, 13 }, // 129 bits per transform
- { 8, 17, 12 }, // 129 bits per transform
- { 9, 0, 18 }, // 129 bits per transform
- { 9, 11, 17 }, // 129 bits per transform
- { 9, 12, 16 }, // 129 bits per transform
- { 9, 13, 15 }, // 129 bits per transform
- { 9, 14, 14 }, // 129 bits per transform
- { 9, 15, 13 }, // 129 bits per transform
- { 9, 16, 12 }, // 129 bits per transform
- { 9, 17, 11 }, // 129 bits per transform
- { 9, 18, 0 }, // 129 bits per transform
- { 10, 10, 17 }, // 129 bits per transform
- { 10, 11, 16 }, // 129 bits per transform
- { 10, 12, 15 }, // 129 bits per transform
- { 10, 13, 14 }, // 129 bits per transform
- { 10, 14, 13 }, // 129 bits per transform
- { 10, 15, 12 }, // 129 bits per transform
- { 10, 16, 11 }, // 129 bits per transform
- { 10, 17, 10 }, // 129 bits per transform
- { 11, 9, 17 }, // 129 bits per transform
- { 11, 10, 16 }, // 129 bits per transform
- { 11, 11, 15 }, // 129 bits per transform
- { 11, 12, 14 }, // 129 bits per transform
- { 11, 13, 13 }, // 129 bits per transform
- { 11, 14, 12 }, // 129 bits per transform
- { 11, 15, 11 }, // 129 bits per transform
- { 11, 16, 10 }, // 129 bits per transform
- { 11, 17, 9 }, // 129 bits per transform
- { 12, 8, 17 }, // 129 bits per transform
- { 12, 9, 16 }, // 129 bits per transform
- { 12, 10, 15 }, // 129 bits per transform
- { 12, 11, 14 }, // 129 bits per transform
- { 12, 12, 13 }, // 129 bits per transform
- { 12, 13, 12 }, // 129 bits per transform
- { 12, 14, 11 }, // 129 bits per transform
- { 12, 15, 10 }, // 129 bits per transform
- { 12, 16, 9 }, // 129 bits per transform
- { 12, 17, 8 }, // 129 bits per transform
- { 13, 7, 17 }, // 129 bits per transform
- { 13, 8, 16 }, // 129 bits per transform
- { 13, 9, 15 }, // 129 bits per transform
- { 13, 10, 14 }, // 129 bits per transform
- { 13, 11, 13 }, // 129 bits per transform
- { 13, 12, 12 }, // 129 bits per transform
- { 13, 13, 11 }, // 129 bits per transform
- { 13, 14, 10 }, // 129 bits per transform
- { 13, 15, 9 }, // 129 bits per transform
- { 13, 16, 8 }, // 129 bits per transform
- { 13, 17, 7 }, // 129 bits per transform
- { 14, 6, 17 }, // 129 bits per transform
- { 14, 7, 16 }, // 129 bits per transform
- { 14, 8, 15 }, // 129 bits per transform
- { 14, 9, 14 }, // 129 bits per transform
- { 14, 10, 13 }, // 129 bits per transform
- { 14, 11, 12 }, // 129 bits per transform
- { 14, 12, 11 }, // 129 bits per transform
- { 14, 13, 10 }, // 129 bits per transform
- { 14, 14, 9 }, // 129 bits per transform
- { 14, 15, 8 }, // 129 bits per transform
- { 14, 16, 7 }, // 129 bits per transform
- { 14, 17, 6 }, // 129 bits per transform
- { 15, 5, 17 }, // 129 bits per transform
- { 15, 6, 16 }, // 129 bits per transform
- { 15, 7, 15 }, // 129 bits per transform
- { 15, 8, 14 }, // 129 bits per transform
- { 15, 9, 13 }, // 129 bits per transform
- { 15, 10, 12 }, // 129 bits per transform
- { 15, 11, 11 }, // 129 bits per transform
- { 15, 12, 10 }, // 129 bits per transform
- { 15, 13, 9 }, // 129 bits per transform
- { 15, 14, 8 }, // 129 bits per transform
- { 15, 15, 7 }, // 129 bits per transform
- { 15, 16, 6 }, // 129 bits per transform
- { 15, 17, 5 }, // 129 bits per transform
- { 16, 4, 17 }, // 129 bits per transform
- { 16, 5, 16 }, // 129 bits per transform
- { 16, 6, 15 }, // 129 bits per transform
- { 16, 7, 14 }, // 129 bits per transform
- { 16, 8, 13 }, // 129 bits per transform
- { 16, 9, 12 }, // 129 bits per transform
- { 16, 10, 11 }, // 129 bits per transform
- { 16, 11, 10 }, // 129 bits per transform
- { 16, 12, 9 }, // 129 bits per transform
- { 16, 13, 8 }, // 129 bits per transform
- { 16, 14, 7 }, // 129 bits per transform
- { 16, 15, 6 }, // 129 bits per transform
- { 16, 16, 5 }, // 129 bits per transform
- { 16, 17, 4 }, // 129 bits per transform
- { 17, 3, 17 }, // 129 bits per transform
- { 17, 4, 16 }, // 129 bits per transform
- { 17, 5, 15 }, // 129 bits per transform
- { 17, 6, 14 }, // 129 bits per transform
- { 17, 7, 13 }, // 129 bits per transform
- { 17, 8, 12 }, // 129 bits per transform
- { 17, 9, 11 }, // 129 bits per transform
- { 17, 10, 10 }, // 129 bits per transform
- { 17, 11, 9 }, // 129 bits per transform
- { 17, 12, 8 }, // 129 bits per transform
- { 17, 13, 7 }, // 129 bits per transform
- { 17, 14, 6 }, // 129 bits per transform
- { 17, 15, 5 }, // 129 bits per transform
- { 17, 16, 4 }, // 129 bits per transform
- { 17, 17, 3 }, // 129 bits per transform
- { 18, 0, 9 }, // 129 bits per transform
- { 18, 1, 6 }, // 129 bits per transform
- { 18, 2, 5 }, // 129 bits per transform
- { 18, 3, 4 }, // 129 bits per transform
- { 18, 4, 3 }, // 129 bits per transform
- { 18, 5, 2 }, // 129 bits per transform
- { 18, 6, 1 }, // 129 bits per transform
- { 18, 9, 0 }, // 129 bits per transform
- { 0, 10, 18 }, // 132 bits per transform
- { 0, 18, 10 }, // 132 bits per transform
- { 1, 7, 18 }, // 132 bits per transform
- { 1, 18, 7 }, // 132 bits per transform
- { 2, 6, 18 }, // 132 bits per transform
- { 2, 18, 6 }, // 132 bits per transform
- { 3, 5, 18 }, // 132 bits per transform
- { 3, 18, 5 }, // 132 bits per transform
- { 4, 4, 18 }, // 132 bits per transform
- { 4, 17, 17 }, // 132 bits per transform
- { 4, 18, 4 }, // 132 bits per transform
- { 5, 3, 18 }, // 132 bits per transform
- { 5, 16, 17 }, // 132 bits per transform
- { 5, 17, 16 }, // 132 bits per transform
- { 5, 18, 3 }, // 132 bits per transform
- { 6, 2, 18 }, // 132 bits per transform
- { 6, 15, 17 }, // 132 bits per transform
- { 6, 16, 16 }, // 132 bits per transform
- { 6, 17, 15 }, // 132 bits per transform
- { 6, 18, 2 }, // 132 bits per transform
- { 7, 1, 18 }, // 132 bits per transform
- { 7, 14, 17 }, // 132 bits per transform
- { 7, 15, 16 }, // 132 bits per transform
- { 7, 16, 15 }, // 132 bits per transform
- { 7, 17, 14 }, // 132 bits per transform
- { 7, 18, 1 }, // 132 bits per transform
- { 8, 13, 17 }, // 132 bits per transform
- { 8, 14, 16 }, // 132 bits per transform
- { 8, 15, 15 }, // 132 bits per transform
- { 8, 16, 14 }, // 132 bits per transform
- { 8, 17, 13 }, // 132 bits per transform
- { 9, 12, 17 }, // 132 bits per transform
- { 9, 13, 16 }, // 132 bits per transform
- { 9, 14, 15 }, // 132 bits per transform
- { 9, 15, 14 }, // 132 bits per transform
- { 9, 16, 13 }, // 132 bits per transform
- { 9, 17, 12 }, // 132 bits per transform
- { 10, 0, 18 }, // 132 bits per transform
- { 10, 11, 17 }, // 132 bits per transform
- { 10, 12, 16 }, // 132 bits per transform
- { 10, 13, 15 }, // 132 bits per transform
- { 10, 14, 14 }, // 132 bits per transform
- { 10, 15, 13 }, // 132 bits per transform
- { 10, 16, 12 }, // 132 bits per transform
- { 10, 17, 11 }, // 132 bits per transform
- { 10, 18, 0 }, // 132 bits per transform
- { 11, 10, 17 }, // 132 bits per transform
- { 11, 11, 16 }, // 132 bits per transform
- { 11, 12, 15 }, // 132 bits per transform
- { 11, 13, 14 }, // 132 bits per transform
- { 11, 14, 13 }, // 132 bits per transform
- { 11, 15, 12 }, // 132 bits per transform
- { 11, 16, 11 }, // 132 bits per transform
- { 11, 17, 10 }, // 132 bits per transform
- { 12, 9, 17 }, // 132 bits per transform
- { 12, 10, 16 }, // 132 bits per transform
- { 12, 11, 15 }, // 132 bits per transform
- { 12, 12, 14 }, // 132 bits per transform
- { 12, 13, 13 }, // 132 bits per transform
- { 12, 14, 12 }, // 132 bits per transform
- { 12, 15, 11 }, // 132 bits per transform
- { 12, 16, 10 }, // 132 bits per transform
- { 12, 17, 9 }, // 132 bits per transform
- { 13, 8, 17 }, // 132 bits per transform
- { 13, 9, 16 }, // 132 bits per transform
- { 13, 10, 15 }, // 132 bits per transform
- { 13, 11, 14 }, // 132 bits per transform
- { 13, 12, 13 }, // 132 bits per transform
- { 13, 13, 12 }, // 132 bits per transform
- { 13, 14, 11 }, // 132 bits per transform
- { 13, 15, 10 }, // 132 bits per transform
- { 13, 16, 9 }, // 132 bits per transform
- { 13, 17, 8 }, // 132 bits per transform
- { 14, 7, 17 }, // 132 bits per transform
- { 14, 8, 16 }, // 132 bits per transform
- { 14, 9, 15 }, // 132 bits per transform
- { 14, 10, 14 }, // 132 bits per transform
- { 14, 11, 13 }, // 132 bits per transform
- { 14, 12, 12 }, // 132 bits per transform
- { 14, 13, 11 }, // 132 bits per transform
- { 14, 14, 10 }, // 132 bits per transform
- { 14, 15, 9 }, // 132 bits per transform
- { 14, 16, 8 }, // 132 bits per transform
- { 14, 17, 7 }, // 132 bits per transform
- { 15, 6, 17 }, // 132 bits per transform
- { 15, 7, 16 }, // 132 bits per transform
- { 15, 8, 15 }, // 132 bits per transform
- { 15, 9, 14 }, // 132 bits per transform
- { 15, 10, 13 }, // 132 bits per transform
- { 15, 11, 12 }, // 132 bits per transform
- { 15, 12, 11 }, // 132 bits per transform
- { 15, 13, 10 }, // 132 bits per transform
- { 15, 14, 9 }, // 132 bits per transform
- { 15, 15, 8 }, // 132 bits per transform
- { 15, 16, 7 }, // 132 bits per transform
- { 15, 17, 6 }, // 132 bits per transform
- { 16, 5, 17 }, // 132 bits per transform
- { 16, 6, 16 }, // 132 bits per transform
- { 16, 7, 15 }, // 132 bits per transform
- { 16, 8, 14 }, // 132 bits per transform
- { 16, 9, 13 }, // 132 bits per transform
- { 16, 10, 12 }, // 132 bits per transform
- { 16, 11, 11 }, // 132 bits per transform
- { 16, 12, 10 }, // 132 bits per transform
- { 16, 13, 9 }, // 132 bits per transform
- { 16, 14, 8 }, // 132 bits per transform
- { 16, 15, 7 }, // 132 bits per transform
- { 16, 16, 6 }, // 132 bits per transform
- { 16, 17, 5 }, // 132 bits per transform
- { 17, 4, 17 }, // 132 bits per transform
- { 17, 5, 16 }, // 132 bits per transform
- { 17, 6, 15 }, // 132 bits per transform
- { 17, 7, 14 }, // 132 bits per transform
- { 17, 8, 13 }, // 132 bits per transform
- { 17, 9, 12 }, // 132 bits per transform
- { 17, 10, 11 }, // 132 bits per transform
- { 17, 11, 10 }, // 132 bits per transform
- { 17, 12, 9 }, // 132 bits per transform
- { 17, 13, 8 }, // 132 bits per transform
- { 17, 14, 7 }, // 132 bits per transform
- { 17, 15, 6 }, // 132 bits per transform
- { 17, 16, 5 }, // 132 bits per transform
- { 17, 17, 4 }, // 132 bits per transform
- { 18, 0, 10 }, // 132 bits per transform
- { 18, 1, 7 }, // 132 bits per transform
- { 18, 2, 6 }, // 132 bits per transform
- { 18, 3, 5 }, // 132 bits per transform
- { 18, 4, 4 }, // 132 bits per transform
- { 18, 5, 3 }, // 132 bits per transform
- { 18, 6, 2 }, // 132 bits per transform
- { 18, 7, 1 }, // 132 bits per transform
- { 18, 10, 0 }, // 132 bits per transform
- { 0, 11, 18 }, // 135 bits per transform
- { 0, 18, 11 }, // 135 bits per transform
- { 1, 8, 18 }, // 135 bits per transform
- { 1, 18, 8 }, // 135 bits per transform
- { 2, 7, 18 }, // 135 bits per transform
- { 2, 18, 7 }, // 135 bits per transform
- { 3, 6, 18 }, // 135 bits per transform
- { 3, 18, 6 }, // 135 bits per transform
- { 4, 5, 18 }, // 135 bits per transform
- { 4, 18, 5 }, // 135 bits per transform
- { 5, 4, 18 }, // 135 bits per transform
- { 5, 17, 17 }, // 135 bits per transform
- { 5, 18, 4 }, // 135 bits per transform
- { 6, 3, 18 }, // 135 bits per transform
- { 6, 16, 17 }, // 135 bits per transform
- { 6, 17, 16 }, // 135 bits per transform
- { 6, 18, 3 }, // 135 bits per transform
- { 7, 2, 18 }, // 135 bits per transform
- { 7, 15, 17 }, // 135 bits per transform
- { 7, 16, 16 }, // 135 bits per transform
- { 7, 17, 15 }, // 135 bits per transform
- { 7, 18, 2 }, // 135 bits per transform
- { 8, 1, 18 }, // 135 bits per transform
- { 8, 14, 17 }, // 135 bits per transform
- { 8, 15, 16 }, // 135 bits per transform
- { 8, 16, 15 }, // 135 bits per transform
- { 8, 17, 14 }, // 135 bits per transform
- { 8, 18, 1 }, // 135 bits per transform
- { 9, 13, 17 }, // 135 bits per transform
- { 9, 14, 16 }, // 135 bits per transform
- { 9, 15, 15 }, // 135 bits per transform
- { 9, 16, 14 }, // 135 bits per transform
- { 9, 17, 13 }, // 135 bits per transform
- { 10, 12, 17 }, // 135 bits per transform
- { 10, 13, 16 }, // 135 bits per transform
- { 10, 14, 15 }, // 135 bits per transform
- { 10, 15, 14 }, // 135 bits per transform
- { 10, 16, 13 }, // 135 bits per transform
- { 10, 17, 12 }, // 135 bits per transform
- { 11, 0, 18 }, // 135 bits per transform
- { 11, 11, 17 }, // 135 bits per transform
- { 11, 12, 16 }, // 135 bits per transform
- { 11, 13, 15 }, // 135 bits per transform
- { 11, 14, 14 }, // 135 bits per transform
- { 11, 15, 13 }, // 135 bits per transform
- { 11, 16, 12 }, // 135 bits per transform
- { 11, 17, 11 }, // 135 bits per transform
- { 11, 18, 0 }, // 135 bits per transform
- { 12, 10, 17 }, // 135 bits per transform
- { 12, 11, 16 }, // 135 bits per transform
- { 12, 12, 15 }, // 135 bits per transform
- { 12, 13, 14 }, // 135 bits per transform
- { 12, 14, 13 }, // 135 bits per transform
- { 12, 15, 12 }, // 135 bits per transform
- { 12, 16, 11 }, // 135 bits per transform
- { 12, 17, 10 }, // 135 bits per transform
- { 13, 9, 17 }, // 135 bits per transform
- { 13, 10, 16 }, // 135 bits per transform
- { 13, 11, 15 }, // 135 bits per transform
- { 13, 12, 14 }, // 135 bits per transform
- { 13, 13, 13 }, // 135 bits per transform
- { 13, 14, 12 }, // 135 bits per transform
- { 13, 15, 11 }, // 135 bits per transform
- { 13, 16, 10 }, // 135 bits per transform
- { 13, 17, 9 }, // 135 bits per transform
- { 14, 8, 17 }, // 135 bits per transform
- { 14, 9, 16 }, // 135 bits per transform
- { 14, 10, 15 }, // 135 bits per transform
- { 14, 11, 14 }, // 135 bits per transform
- { 14, 12, 13 }, // 135 bits per transform
- { 14, 13, 12 }, // 135 bits per transform
- { 14, 14, 11 }, // 135 bits per transform
- { 14, 15, 10 }, // 135 bits per transform
- { 14, 16, 9 }, // 135 bits per transform
- { 14, 17, 8 }, // 135 bits per transform
- { 15, 7, 17 }, // 135 bits per transform
- { 15, 8, 16 }, // 135 bits per transform
- { 15, 9, 15 }, // 135 bits per transform
- { 15, 10, 14 }, // 135 bits per transform
- { 15, 11, 13 }, // 135 bits per transform
- { 15, 12, 12 }, // 135 bits per transform
- { 15, 13, 11 }, // 135 bits per transform
- { 15, 14, 10 }, // 135 bits per transform
- { 15, 15, 9 }, // 135 bits per transform
- { 15, 16, 8 }, // 135 bits per transform
- { 15, 17, 7 }, // 135 bits per transform
- { 16, 6, 17 }, // 135 bits per transform
- { 16, 7, 16 }, // 135 bits per transform
- { 16, 8, 15 }, // 135 bits per transform
- { 16, 9, 14 }, // 135 bits per transform
- { 16, 10, 13 }, // 135 bits per transform
- { 16, 11, 12 }, // 135 bits per transform
- { 16, 12, 11 }, // 135 bits per transform
- { 16, 13, 10 }, // 135 bits per transform
- { 16, 14, 9 }, // 135 bits per transform
- { 16, 15, 8 }, // 135 bits per transform
- { 16, 16, 7 }, // 135 bits per transform
- { 16, 17, 6 }, // 135 bits per transform
- { 17, 5, 17 }, // 135 bits per transform
- { 17, 6, 16 }, // 135 bits per transform
- { 17, 7, 15 }, // 135 bits per transform
- { 17, 8, 14 }, // 135 bits per transform
- { 17, 9, 13 }, // 135 bits per transform
- { 17, 10, 12 }, // 135 bits per transform
- { 17, 11, 11 }, // 135 bits per transform
- { 17, 12, 10 }, // 135 bits per transform
- { 17, 13, 9 }, // 135 bits per transform
- { 17, 14, 8 }, // 135 bits per transform
- { 17, 15, 7 }, // 135 bits per transform
- { 17, 16, 6 }, // 135 bits per transform
- { 17, 17, 5 }, // 135 bits per transform
- { 18, 0, 11 }, // 135 bits per transform
- { 18, 1, 8 }, // 135 bits per transform
- { 18, 2, 7 }, // 135 bits per transform
- { 18, 3, 6 }, // 135 bits per transform
- { 18, 4, 5 }, // 135 bits per transform
- { 18, 5, 4 }, // 135 bits per transform
- { 18, 6, 3 }, // 135 bits per transform
- { 18, 7, 2 }, // 135 bits per transform
- { 18, 8, 1 }, // 135 bits per transform
- { 18, 11, 0 }, // 135 bits per transform
- { 0, 12, 18 }, // 138 bits per transform
- { 0, 18, 12 }, // 138 bits per transform
- { 1, 9, 18 }, // 138 bits per transform
- { 1, 18, 9 }, // 138 bits per transform
- { 2, 8, 18 }, // 138 bits per transform
- { 2, 18, 8 }, // 138 bits per transform
- { 3, 7, 18 }, // 138 bits per transform
- { 3, 18, 7 }, // 138 bits per transform
- { 4, 6, 18 }, // 138 bits per transform
- { 4, 18, 6 }, // 138 bits per transform
- { 5, 5, 18 }, // 138 bits per transform
- { 5, 18, 5 }, // 138 bits per transform
- { 6, 4, 18 }, // 138 bits per transform
- { 6, 17, 17 }, // 138 bits per transform
- { 6, 18, 4 }, // 138 bits per transform
- { 7, 3, 18 }, // 138 bits per transform
- { 7, 16, 17 }, // 138 bits per transform
- { 7, 17, 16 }, // 138 bits per transform
- { 7, 18, 3 }, // 138 bits per transform
- { 8, 2, 18 }, // 138 bits per transform
- { 8, 15, 17 }, // 138 bits per transform
- { 8, 16, 16 }, // 138 bits per transform
- { 8, 17, 15 }, // 138 bits per transform
- { 8, 18, 2 }, // 138 bits per transform
- { 9, 1, 18 }, // 138 bits per transform
- { 9, 14, 17 }, // 138 bits per transform
- { 9, 15, 16 }, // 138 bits per transform
- { 9, 16, 15 }, // 138 bits per transform
- { 9, 17, 14 }, // 138 bits per transform
- { 9, 18, 1 }, // 138 bits per transform
- { 10, 13, 17 }, // 138 bits per transform
- { 10, 14, 16 }, // 138 bits per transform
- { 10, 15, 15 }, // 138 bits per transform
- { 10, 16, 14 }, // 138 bits per transform
- { 10, 17, 13 }, // 138 bits per transform
- { 11, 12, 17 }, // 138 bits per transform
- { 11, 13, 16 }, // 138 bits per transform
- { 11, 14, 15 }, // 138 bits per transform
- { 11, 15, 14 }, // 138 bits per transform
- { 11, 16, 13 }, // 138 bits per transform
- { 11, 17, 12 }, // 138 bits per transform
- { 12, 0, 18 }, // 138 bits per transform
- { 12, 11, 17 }, // 138 bits per transform
- { 12, 12, 16 }, // 138 bits per transform
- { 12, 13, 15 }, // 138 bits per transform
- { 12, 14, 14 }, // 138 bits per transform
- { 12, 15, 13 }, // 138 bits per transform
- { 12, 16, 12 }, // 138 bits per transform
- { 12, 17, 11 }, // 138 bits per transform
- { 12, 18, 0 }, // 138 bits per transform
- { 13, 10, 17 }, // 138 bits per transform
- { 13, 11, 16 }, // 138 bits per transform
- { 13, 12, 15 }, // 138 bits per transform
- { 13, 13, 14 }, // 138 bits per transform
- { 13, 14, 13 }, // 138 bits per transform
- { 13, 15, 12 }, // 138 bits per transform
- { 13, 16, 11 }, // 138 bits per transform
- { 13, 17, 10 }, // 138 bits per transform
- { 14, 9, 17 }, // 138 bits per transform
- { 14, 10, 16 }, // 138 bits per transform
- { 14, 11, 15 }, // 138 bits per transform
- { 14, 12, 14 }, // 138 bits per transform
- { 14, 13, 13 }, // 138 bits per transform
- { 14, 14, 12 }, // 138 bits per transform
- { 14, 15, 11 }, // 138 bits per transform
- { 14, 16, 10 }, // 138 bits per transform
- { 14, 17, 9 }, // 138 bits per transform
- { 15, 8, 17 }, // 138 bits per transform
- { 15, 9, 16 }, // 138 bits per transform
- { 15, 10, 15 }, // 138 bits per transform
- { 15, 11, 14 }, // 138 bits per transform
- { 15, 12, 13 }, // 138 bits per transform
- { 15, 13, 12 }, // 138 bits per transform
- { 15, 14, 11 }, // 138 bits per transform
- { 15, 15, 10 }, // 138 bits per transform
- { 15, 16, 9 }, // 138 bits per transform
- { 15, 17, 8 }, // 138 bits per transform
- { 16, 7, 17 }, // 138 bits per transform
- { 16, 8, 16 }, // 138 bits per transform
- { 16, 9, 15 }, // 138 bits per transform
- { 16, 10, 14 }, // 138 bits per transform
- { 16, 11, 13 }, // 138 bits per transform
- { 16, 12, 12 }, // 138 bits per transform
- { 16, 13, 11 }, // 138 bits per transform
- { 16, 14, 10 }, // 138 bits per transform
- { 16, 15, 9 }, // 138 bits per transform
- { 16, 16, 8 }, // 138 bits per transform
- { 16, 17, 7 }, // 138 bits per transform
- { 17, 6, 17 }, // 138 bits per transform
- { 17, 7, 16 }, // 138 bits per transform
- { 17, 8, 15 }, // 138 bits per transform
- { 17, 9, 14 }, // 138 bits per transform
- { 17, 10, 13 }, // 138 bits per transform
- { 17, 11, 12 }, // 138 bits per transform
- { 17, 12, 11 }, // 138 bits per transform
- { 17, 13, 10 }, // 138 bits per transform
- { 17, 14, 9 }, // 138 bits per transform
- { 17, 15, 8 }, // 138 bits per transform
- { 17, 16, 7 }, // 138 bits per transform
- { 17, 17, 6 }, // 138 bits per transform
- { 18, 0, 12 }, // 138 bits per transform
- { 18, 1, 9 }, // 138 bits per transform
- { 18, 2, 8 }, // 138 bits per transform
- { 18, 3, 7 }, // 138 bits per transform
- { 18, 4, 6 }, // 138 bits per transform
- { 18, 5, 5 }, // 138 bits per transform
- { 18, 6, 4 }, // 138 bits per transform
- { 18, 7, 3 }, // 138 bits per transform
- { 18, 8, 2 }, // 138 bits per transform
- { 18, 9, 1 }, // 138 bits per transform
- { 18, 12, 0 }, // 138 bits per transform
- { 0, 13, 18 }, // 141 bits per transform
- { 0, 18, 13 }, // 141 bits per transform
- { 1, 10, 18 }, // 141 bits per transform
- { 1, 18, 10 }, // 141 bits per transform
- { 2, 9, 18 }, // 141 bits per transform
- { 2, 18, 9 }, // 141 bits per transform
- { 3, 8, 18 }, // 141 bits per transform
- { 3, 18, 8 }, // 141 bits per transform
- { 4, 7, 18 }, // 141 bits per transform
- { 4, 18, 7 }, // 141 bits per transform
- { 5, 6, 18 }, // 141 bits per transform
- { 5, 18, 6 }, // 141 bits per transform
- { 6, 5, 18 }, // 141 bits per transform
- { 6, 18, 5 }, // 141 bits per transform
- { 7, 4, 18 }, // 141 bits per transform
- { 7, 17, 17 }, // 141 bits per transform
- { 7, 18, 4 }, // 141 bits per transform
- { 8, 3, 18 }, // 141 bits per transform
- { 8, 16, 17 }, // 141 bits per transform
- { 8, 17, 16 }, // 141 bits per transform
- { 8, 18, 3 }, // 141 bits per transform
- { 9, 2, 18 }, // 141 bits per transform
- { 9, 15, 17 }, // 141 bits per transform
- { 9, 16, 16 }, // 141 bits per transform
- { 9, 17, 15 }, // 141 bits per transform
- { 9, 18, 2 }, // 141 bits per transform
- { 10, 1, 18 }, // 141 bits per transform
- { 10, 14, 17 }, // 141 bits per transform
- { 10, 15, 16 }, // 141 bits per transform
- { 10, 16, 15 }, // 141 bits per transform
- { 10, 17, 14 }, // 141 bits per transform
- { 10, 18, 1 }, // 141 bits per transform
- { 11, 13, 17 }, // 141 bits per transform
- { 11, 14, 16 }, // 141 bits per transform
- { 11, 15, 15 }, // 141 bits per transform
- { 11, 16, 14 }, // 141 bits per transform
- { 11, 17, 13 }, // 141 bits per transform
- { 12, 12, 17 }, // 141 bits per transform
- { 12, 13, 16 }, // 141 bits per transform
- { 12, 14, 15 }, // 141 bits per transform
- { 12, 15, 14 }, // 141 bits per transform
- { 12, 16, 13 }, // 141 bits per transform
- { 12, 17, 12 }, // 141 bits per transform
- { 13, 0, 18 }, // 141 bits per transform
- { 13, 11, 17 }, // 141 bits per transform
- { 13, 12, 16 }, // 141 bits per transform
- { 13, 13, 15 }, // 141 bits per transform
- { 13, 14, 14 }, // 141 bits per transform
- { 13, 15, 13 }, // 141 bits per transform
- { 13, 16, 12 }, // 141 bits per transform
- { 13, 17, 11 }, // 141 bits per transform
- { 13, 18, 0 }, // 141 bits per transform
- { 14, 10, 17 }, // 141 bits per transform
- { 14, 11, 16 }, // 141 bits per transform
- { 14, 12, 15 }, // 141 bits per transform
- { 14, 13, 14 }, // 141 bits per transform
- { 14, 14, 13 }, // 141 bits per transform
- { 14, 15, 12 }, // 141 bits per transform
- { 14, 16, 11 }, // 141 bits per transform
- { 14, 17, 10 }, // 141 bits per transform
- { 15, 9, 17 }, // 141 bits per transform
- { 15, 10, 16 }, // 141 bits per transform
- { 15, 11, 15 }, // 141 bits per transform
- { 15, 12, 14 }, // 141 bits per transform
- { 15, 13, 13 }, // 141 bits per transform
- { 15, 14, 12 }, // 141 bits per transform
- { 15, 15, 11 }, // 141 bits per transform
- { 15, 16, 10 }, // 141 bits per transform
- { 15, 17, 9 }, // 141 bits per transform
- { 16, 8, 17 }, // 141 bits per transform
- { 16, 9, 16 }, // 141 bits per transform
- { 16, 10, 15 }, // 141 bits per transform
- { 16, 11, 14 }, // 141 bits per transform
- { 16, 12, 13 }, // 141 bits per transform
- { 16, 13, 12 }, // 141 bits per transform
- { 16, 14, 11 }, // 141 bits per transform
- { 16, 15, 10 }, // 141 bits per transform
- { 16, 16, 9 }, // 141 bits per transform
- { 16, 17, 8 }, // 141 bits per transform
- { 17, 7, 17 }, // 141 bits per transform
- { 17, 8, 16 }, // 141 bits per transform
- { 17, 9, 15 }, // 141 bits per transform
- { 17, 10, 14 }, // 141 bits per transform
- { 17, 11, 13 }, // 141 bits per transform
- { 17, 12, 12 }, // 141 bits per transform
- { 17, 13, 11 }, // 141 bits per transform
- { 17, 14, 10 }, // 141 bits per transform
- { 17, 15, 9 }, // 141 bits per transform
- { 17, 16, 8 }, // 141 bits per transform
- { 17, 17, 7 }, // 141 bits per transform
- { 18, 0, 13 }, // 141 bits per transform
- { 18, 1, 10 }, // 141 bits per transform
- { 18, 2, 9 }, // 141 bits per transform
- { 18, 3, 8 }, // 141 bits per transform
- { 18, 4, 7 }, // 141 bits per transform
- { 18, 5, 6 }, // 141 bits per transform
- { 18, 6, 5 }, // 141 bits per transform
- { 18, 7, 4 }, // 141 bits per transform
- { 18, 8, 3 }, // 141 bits per transform
- { 18, 9, 2 }, // 141 bits per transform
- { 18, 10, 1 }, // 141 bits per transform
- { 18, 13, 0 }, // 141 bits per transform
- { 0, 14, 18 }, // 144 bits per transform
- { 0, 18, 14 }, // 144 bits per transform
- { 1, 11, 18 }, // 144 bits per transform
- { 1, 18, 11 }, // 144 bits per transform
- { 2, 10, 18 }, // 144 bits per transform
- { 2, 18, 10 }, // 144 bits per transform
- { 3, 9, 18 }, // 144 bits per transform
- { 3, 18, 9 }, // 144 bits per transform
- { 4, 8, 18 }, // 144 bits per transform
- { 4, 18, 8 }, // 144 bits per transform
- { 5, 7, 18 }, // 144 bits per transform
- { 5, 18, 7 }, // 144 bits per transform
- { 6, 6, 18 }, // 144 bits per transform
- { 6, 18, 6 }, // 144 bits per transform
- { 7, 5, 18 }, // 144 bits per transform
- { 7, 18, 5 }, // 144 bits per transform
- { 8, 4, 18 }, // 144 bits per transform
- { 8, 17, 17 }, // 144 bits per transform
- { 8, 18, 4 }, // 144 bits per transform
- { 9, 3, 18 }, // 144 bits per transform
- { 9, 16, 17 }, // 144 bits per transform
- { 9, 17, 16 }, // 144 bits per transform
- { 9, 18, 3 }, // 144 bits per transform
- { 10, 2, 18 }, // 144 bits per transform
- { 10, 15, 17 }, // 144 bits per transform
- { 10, 16, 16 }, // 144 bits per transform
- { 10, 17, 15 }, // 144 bits per transform
- { 10, 18, 2 }, // 144 bits per transform
- { 11, 1, 18 }, // 144 bits per transform
- { 11, 14, 17 }, // 144 bits per transform
- { 11, 15, 16 }, // 144 bits per transform
- { 11, 16, 15 }, // 144 bits per transform
- { 11, 17, 14 }, // 144 bits per transform
- { 11, 18, 1 }, // 144 bits per transform
- { 12, 13, 17 }, // 144 bits per transform
- { 12, 14, 16 }, // 144 bits per transform
- { 12, 15, 15 }, // 144 bits per transform
- { 12, 16, 14 }, // 144 bits per transform
- { 12, 17, 13 }, // 144 bits per transform
- { 13, 12, 17 }, // 144 bits per transform
- { 13, 13, 16 }, // 144 bits per transform
- { 13, 14, 15 }, // 144 bits per transform
- { 13, 15, 14 }, // 144 bits per transform
- { 13, 16, 13 }, // 144 bits per transform
- { 13, 17, 12 }, // 144 bits per transform
- { 14, 0, 18 }, // 144 bits per transform
- { 14, 11, 17 }, // 144 bits per transform
- { 14, 12, 16 }, // 144 bits per transform
- { 14, 13, 15 }, // 144 bits per transform
- { 14, 14, 14 }, // 144 bits per transform
- { 14, 15, 13 }, // 144 bits per transform
- { 14, 16, 12 }, // 144 bits per transform
- { 14, 17, 11 }, // 144 bits per transform
- { 14, 18, 0 }, // 144 bits per transform
- { 15, 10, 17 }, // 144 bits per transform
- { 15, 11, 16 }, // 144 bits per transform
- { 15, 12, 15 }, // 144 bits per transform
- { 15, 13, 14 }, // 144 bits per transform
- { 15, 14, 13 }, // 144 bits per transform
- { 15, 15, 12 }, // 144 bits per transform
- { 15, 16, 11 }, // 144 bits per transform
- { 15, 17, 10 }, // 144 bits per transform
- { 16, 9, 17 }, // 144 bits per transform
- { 16, 10, 16 }, // 144 bits per transform
- { 16, 11, 15 }, // 144 bits per transform
- { 16, 12, 14 }, // 144 bits per transform
- { 16, 13, 13 }, // 144 bits per transform
- { 16, 14, 12 }, // 144 bits per transform
- { 16, 15, 11 }, // 144 bits per transform
- { 16, 16, 10 }, // 144 bits per transform
- { 16, 17, 9 }, // 144 bits per transform
- { 17, 8, 17 }, // 144 bits per transform
- { 17, 9, 16 }, // 144 bits per transform
- { 17, 10, 15 }, // 144 bits per transform
- { 17, 11, 14 }, // 144 bits per transform
- { 17, 12, 13 }, // 144 bits per transform
- { 17, 13, 12 }, // 144 bits per transform
- { 17, 14, 11 }, // 144 bits per transform
- { 17, 15, 10 }, // 144 bits per transform
- { 17, 16, 9 }, // 144 bits per transform
- { 17, 17, 8 }, // 144 bits per transform
- { 18, 0, 14 }, // 144 bits per transform
- { 18, 1, 11 }, // 144 bits per transform
- { 18, 2, 10 }, // 144 bits per transform
- { 18, 3, 9 }, // 144 bits per transform
- { 18, 4, 8 }, // 144 bits per transform
- { 18, 5, 7 }, // 144 bits per transform
- { 18, 6, 6 }, // 144 bits per transform
- { 18, 7, 5 }, // 144 bits per transform
- { 18, 8, 4 }, // 144 bits per transform
- { 18, 9, 3 }, // 144 bits per transform
- { 18, 10, 2 }, // 144 bits per transform
- { 18, 11, 1 }, // 144 bits per transform
- { 18, 14, 0 }, // 144 bits per transform
- { 0, 15, 18 }, // 147 bits per transform
- { 0, 18, 15 }, // 147 bits per transform
- { 1, 12, 18 }, // 147 bits per transform
- { 1, 18, 12 }, // 147 bits per transform
- { 2, 11, 18 }, // 147 bits per transform
- { 2, 18, 11 }, // 147 bits per transform
- { 3, 10, 18 }, // 147 bits per transform
- { 3, 18, 10 }, // 147 bits per transform
- { 4, 9, 18 }, // 147 bits per transform
- { 4, 18, 9 }, // 147 bits per transform
- { 5, 8, 18 }, // 147 bits per transform
- { 5, 18, 8 }, // 147 bits per transform
- { 6, 7, 18 }, // 147 bits per transform
- { 6, 18, 7 }, // 147 bits per transform
- { 7, 6, 18 }, // 147 bits per transform
- { 7, 18, 6 }, // 147 bits per transform
- { 8, 5, 18 }, // 147 bits per transform
- { 8, 18, 5 }, // 147 bits per transform
- { 9, 4, 18 }, // 147 bits per transform
- { 9, 17, 17 }, // 147 bits per transform
- { 9, 18, 4 }, // 147 bits per transform
- { 10, 3, 18 }, // 147 bits per transform
- { 10, 16, 17 }, // 147 bits per transform
- { 10, 17, 16 }, // 147 bits per transform
- { 10, 18, 3 }, // 147 bits per transform
- { 11, 2, 18 }, // 147 bits per transform
- { 11, 15, 17 }, // 147 bits per transform
- { 11, 16, 16 }, // 147 bits per transform
- { 11, 17, 15 }, // 147 bits per transform
- { 11, 18, 2 }, // 147 bits per transform
- { 12, 1, 18 }, // 147 bits per transform
- { 12, 14, 17 }, // 147 bits per transform
- { 12, 15, 16 }, // 147 bits per transform
- { 12, 16, 15 }, // 147 bits per transform
- { 12, 17, 14 }, // 147 bits per transform
- { 12, 18, 1 }, // 147 bits per transform
- { 13, 13, 17 }, // 147 bits per transform
- { 13, 14, 16 }, // 147 bits per transform
- { 13, 15, 15 }, // 147 bits per transform
- { 13, 16, 14 }, // 147 bits per transform
- { 13, 17, 13 }, // 147 bits per transform
- { 14, 12, 17 }, // 147 bits per transform
- { 14, 13, 16 }, // 147 bits per transform
- { 14, 14, 15 }, // 147 bits per transform
- { 14, 15, 14 }, // 147 bits per transform
- { 14, 16, 13 }, // 147 bits per transform
- { 14, 17, 12 }, // 147 bits per transform
- { 15, 0, 18 }, // 147 bits per transform
- { 15, 11, 17 }, // 147 bits per transform
- { 15, 12, 16 }, // 147 bits per transform
- { 15, 13, 15 }, // 147 bits per transform
- { 15, 14, 14 }, // 147 bits per transform
- { 15, 15, 13 }, // 147 bits per transform
- { 15, 16, 12 }, // 147 bits per transform
- { 15, 17, 11 }, // 147 bits per transform
- { 15, 18, 0 }, // 147 bits per transform
- { 16, 10, 17 }, // 147 bits per transform
- { 16, 11, 16 }, // 147 bits per transform
- { 16, 12, 15 }, // 147 bits per transform
- { 16, 13, 14 }, // 147 bits per transform
- { 16, 14, 13 }, // 147 bits per transform
- { 16, 15, 12 }, // 147 bits per transform
- { 16, 16, 11 }, // 147 bits per transform
- { 16, 17, 10 }, // 147 bits per transform
- { 17, 9, 17 }, // 147 bits per transform
- { 17, 10, 16 }, // 147 bits per transform
- { 17, 11, 15 }, // 147 bits per transform
- { 17, 12, 14 }, // 147 bits per transform
- { 17, 13, 13 }, // 147 bits per transform
- { 17, 14, 12 }, // 147 bits per transform
- { 17, 15, 11 }, // 147 bits per transform
- { 17, 16, 10 }, // 147 bits per transform
- { 17, 17, 9 }, // 147 bits per transform
- { 18, 0, 15 }, // 147 bits per transform
- { 18, 1, 12 }, // 147 bits per transform
- { 18, 2, 11 }, // 147 bits per transform
- { 18, 3, 10 }, // 147 bits per transform
- { 18, 4, 9 }, // 147 bits per transform
- { 18, 5, 8 }, // 147 bits per transform
- { 18, 6, 7 }, // 147 bits per transform
- { 18, 7, 6 }, // 147 bits per transform
- { 18, 8, 5 }, // 147 bits per transform
- { 18, 9, 4 }, // 147 bits per transform
- { 18, 10, 3 }, // 147 bits per transform
- { 18, 11, 2 }, // 147 bits per transform
- { 18, 12, 1 }, // 147 bits per transform
- { 18, 15, 0 }, // 147 bits per transform
- { 0, 16, 18 }, // 150 bits per transform
- { 0, 18, 16 }, // 150 bits per transform
- { 1, 13, 18 }, // 150 bits per transform
- { 1, 18, 13 }, // 150 bits per transform
- { 2, 12, 18 }, // 150 bits per transform
- { 2, 18, 12 }, // 150 bits per transform
- { 3, 11, 18 }, // 150 bits per transform
- { 3, 18, 11 }, // 150 bits per transform
- { 4, 10, 18 }, // 150 bits per transform
- { 4, 18, 10 }, // 150 bits per transform
- { 5, 9, 18 }, // 150 bits per transform
- { 5, 18, 9 }, // 150 bits per transform
- { 6, 8, 18 }, // 150 bits per transform
- { 6, 18, 8 }, // 150 bits per transform
- { 7, 7, 18 }, // 150 bits per transform
- { 7, 18, 7 }, // 150 bits per transform
- { 8, 6, 18 }, // 150 bits per transform
- { 8, 18, 6 }, // 150 bits per transform
- { 9, 5, 18 }, // 150 bits per transform
- { 9, 18, 5 }, // 150 bits per transform
- { 10, 4, 18 }, // 150 bits per transform
- { 10, 17, 17 }, // 150 bits per transform
- { 10, 18, 4 }, // 150 bits per transform
- { 11, 3, 18 }, // 150 bits per transform
- { 11, 16, 17 }, // 150 bits per transform
- { 11, 17, 16 }, // 150 bits per transform
- { 11, 18, 3 }, // 150 bits per transform
- { 12, 2, 18 }, // 150 bits per transform
- { 12, 15, 17 }, // 150 bits per transform
- { 12, 16, 16 }, // 150 bits per transform
- { 12, 17, 15 }, // 150 bits per transform
- { 12, 18, 2 }, // 150 bits per transform
- { 13, 1, 18 }, // 150 bits per transform
- { 13, 14, 17 }, // 150 bits per transform
- { 13, 15, 16 }, // 150 bits per transform
- { 13, 16, 15 }, // 150 bits per transform
- { 13, 17, 14 }, // 150 bits per transform
- { 13, 18, 1 }, // 150 bits per transform
- { 14, 13, 17 }, // 150 bits per transform
- { 14, 14, 16 }, // 150 bits per transform
- { 14, 15, 15 }, // 150 bits per transform
- { 14, 16, 14 }, // 150 bits per transform
- { 14, 17, 13 }, // 150 bits per transform
- { 15, 12, 17 }, // 150 bits per transform
- { 15, 13, 16 }, // 150 bits per transform
- { 15, 14, 15 }, // 150 bits per transform
- { 15, 15, 14 }, // 150 bits per transform
- { 15, 16, 13 }, // 150 bits per transform
- { 15, 17, 12 }, // 150 bits per transform
- { 16, 0, 18 }, // 150 bits per transform
- { 16, 11, 17 }, // 150 bits per transform
- { 16, 12, 16 }, // 150 bits per transform
- { 16, 13, 15 }, // 150 bits per transform
- { 16, 14, 14 }, // 150 bits per transform
- { 16, 15, 13 }, // 150 bits per transform
- { 16, 16, 12 }, // 150 bits per transform
- { 16, 17, 11 }, // 150 bits per transform
- { 16, 18, 0 }, // 150 bits per transform
- { 17, 10, 17 }, // 150 bits per transform
- { 17, 11, 16 }, // 150 bits per transform
- { 17, 12, 15 }, // 150 bits per transform
- { 17, 13, 14 }, // 150 bits per transform
- { 17, 14, 13 }, // 150 bits per transform
- { 17, 15, 12 }, // 150 bits per transform
- { 17, 16, 11 }, // 150 bits per transform
- { 17, 17, 10 }, // 150 bits per transform
- { 18, 0, 16 }, // 150 bits per transform
- { 18, 1, 13 }, // 150 bits per transform
- { 18, 2, 12 }, // 150 bits per transform
- { 18, 3, 11 }, // 150 bits per transform
- { 18, 4, 10 }, // 150 bits per transform
- { 18, 5, 9 }, // 150 bits per transform
- { 18, 6, 8 }, // 150 bits per transform
- { 18, 7, 7 }, // 150 bits per transform
- { 18, 8, 6 }, // 150 bits per transform
- { 18, 9, 5 }, // 150 bits per transform
- { 18, 10, 4 }, // 150 bits per transform
- { 18, 11, 3 }, // 150 bits per transform
- { 18, 12, 2 }, // 150 bits per transform
- { 18, 13, 1 }, // 150 bits per transform
- { 18, 16, 0 }, // 150 bits per transform
- { 0, 17, 18 }, // 153 bits per transform
- { 0, 18, 17 }, // 153 bits per transform
- { 1, 14, 18 }, // 153 bits per transform
- { 1, 18, 14 }, // 153 bits per transform
- { 2, 13, 18 }, // 153 bits per transform
- { 2, 18, 13 }, // 153 bits per transform
- { 3, 12, 18 }, // 153 bits per transform
- { 3, 18, 12 }, // 153 bits per transform
- { 4, 11, 18 }, // 153 bits per transform
- { 4, 18, 11 }, // 153 bits per transform
- { 5, 10, 18 }, // 153 bits per transform
- { 5, 18, 10 }, // 153 bits per transform
- { 6, 9, 18 }, // 153 bits per transform
- { 6, 18, 9 }, // 153 bits per transform
- { 7, 8, 18 }, // 153 bits per transform
- { 7, 18, 8 }, // 153 bits per transform
- { 8, 7, 18 }, // 153 bits per transform
- { 8, 18, 7 }, // 153 bits per transform
- { 9, 6, 18 }, // 153 bits per transform
- { 9, 18, 6 }, // 153 bits per transform
- { 10, 5, 18 }, // 153 bits per transform
- { 10, 18, 5 }, // 153 bits per transform
- { 11, 4, 18 }, // 153 bits per transform
- { 11, 17, 17 }, // 153 bits per transform
- { 11, 18, 4 }, // 153 bits per transform
- { 12, 3, 18 }, // 153 bits per transform
- { 12, 16, 17 }, // 153 bits per transform
- { 12, 17, 16 }, // 153 bits per transform
- { 12, 18, 3 }, // 153 bits per transform
- { 13, 2, 18 }, // 153 bits per transform
- { 13, 15, 17 }, // 153 bits per transform
- { 13, 16, 16 }, // 153 bits per transform
- { 13, 17, 15 }, // 153 bits per transform
- { 13, 18, 2 }, // 153 bits per transform
- { 14, 1, 18 }, // 153 bits per transform
- { 14, 14, 17 }, // 153 bits per transform
- { 14, 15, 16 }, // 153 bits per transform
- { 14, 16, 15 }, // 153 bits per transform
- { 14, 17, 14 }, // 153 bits per transform
- { 14, 18, 1 }, // 153 bits per transform
- { 15, 13, 17 }, // 153 bits per transform
- { 15, 14, 16 }, // 153 bits per transform
- { 15, 15, 15 }, // 153 bits per transform
- { 15, 16, 14 }, // 153 bits per transform
- { 15, 17, 13 }, // 153 bits per transform
- { 16, 12, 17 }, // 153 bits per transform
- { 16, 13, 16 }, // 153 bits per transform
- { 16, 14, 15 }, // 153 bits per transform
- { 16, 15, 14 }, // 153 bits per transform
- { 16, 16, 13 }, // 153 bits per transform
- { 16, 17, 12 }, // 153 bits per transform
- { 17, 0, 18 }, // 153 bits per transform
- { 17, 11, 17 }, // 153 bits per transform
- { 17, 12, 16 }, // 153 bits per transform
- { 17, 13, 15 }, // 153 bits per transform
- { 17, 14, 14 }, // 153 bits per transform
- { 17, 15, 13 }, // 153 bits per transform
- { 17, 16, 12 }, // 153 bits per transform
- { 17, 17, 11 }, // 153 bits per transform
- { 17, 18, 0 }, // 153 bits per transform
- { 18, 0, 17 }, // 153 bits per transform
- { 18, 1, 14 }, // 153 bits per transform
- { 18, 2, 13 }, // 153 bits per transform
- { 18, 3, 12 }, // 153 bits per transform
- { 18, 4, 11 }, // 153 bits per transform
- { 18, 5, 10 }, // 153 bits per transform
- { 18, 6, 9 }, // 153 bits per transform
- { 18, 7, 8 }, // 153 bits per transform
- { 18, 8, 7 }, // 153 bits per transform
- { 18, 9, 6 }, // 153 bits per transform
- { 18, 10, 5 }, // 153 bits per transform
- { 18, 11, 4 }, // 153 bits per transform
- { 18, 12, 3 }, // 153 bits per transform
- { 18, 13, 2 }, // 153 bits per transform
- { 18, 14, 1 }, // 153 bits per transform
- { 18, 17, 0 }, // 153 bits per transform
- { 1, 15, 18 }, // 156 bits per transform
- { 1, 18, 15 }, // 156 bits per transform
- { 2, 14, 18 }, // 156 bits per transform
- { 2, 18, 14 }, // 156 bits per transform
- { 3, 13, 18 }, // 156 bits per transform
- { 3, 18, 13 }, // 156 bits per transform
- { 4, 12, 18 }, // 156 bits per transform
- { 4, 18, 12 }, // 156 bits per transform
- { 5, 11, 18 }, // 156 bits per transform
- { 5, 18, 11 }, // 156 bits per transform
- { 6, 10, 18 }, // 156 bits per transform
- { 6, 18, 10 }, // 156 bits per transform
- { 7, 9, 18 }, // 156 bits per transform
- { 7, 18, 9 }, // 156 bits per transform
- { 8, 8, 18 }, // 156 bits per transform
- { 8, 18, 8 }, // 156 bits per transform
- { 9, 7, 18 }, // 156 bits per transform
- { 9, 18, 7 }, // 156 bits per transform
- { 10, 6, 18 }, // 156 bits per transform
- { 10, 18, 6 }, // 156 bits per transform
- { 11, 5, 18 }, // 156 bits per transform
- { 11, 18, 5 }, // 156 bits per transform
- { 12, 4, 18 }, // 156 bits per transform
- { 12, 17, 17 }, // 156 bits per transform
- { 12, 18, 4 }, // 156 bits per transform
- { 13, 3, 18 }, // 156 bits per transform
- { 13, 16, 17 }, // 156 bits per transform
- { 13, 17, 16 }, // 156 bits per transform
- { 13, 18, 3 }, // 156 bits per transform
- { 14, 2, 18 }, // 156 bits per transform
- { 14, 15, 17 }, // 156 bits per transform
- { 14, 16, 16 }, // 156 bits per transform
- { 14, 17, 15 }, // 156 bits per transform
- { 14, 18, 2 }, // 156 bits per transform
- { 15, 1, 18 }, // 156 bits per transform
- { 15, 14, 17 }, // 156 bits per transform
- { 15, 15, 16 }, // 156 bits per transform
- { 15, 16, 15 }, // 156 bits per transform
- { 15, 17, 14 }, // 156 bits per transform
- { 15, 18, 1 }, // 156 bits per transform
- { 16, 13, 17 }, // 156 bits per transform
- { 16, 14, 16 }, // 156 bits per transform
- { 16, 15, 15 }, // 156 bits per transform
- { 16, 16, 14 }, // 156 bits per transform
- { 16, 17, 13 }, // 156 bits per transform
- { 17, 12, 17 }, // 156 bits per transform
- { 17, 13, 16 }, // 156 bits per transform
- { 17, 14, 15 }, // 156 bits per transform
- { 17, 15, 14 }, // 156 bits per transform
- { 17, 16, 13 }, // 156 bits per transform
- { 17, 17, 12 }, // 156 bits per transform
- { 18, 1, 15 }, // 156 bits per transform
- { 18, 2, 14 }, // 156 bits per transform
- { 18, 3, 13 }, // 156 bits per transform
- { 18, 4, 12 }, // 156 bits per transform
- { 18, 5, 11 }, // 156 bits per transform
- { 18, 6, 10 }, // 156 bits per transform
- { 18, 7, 9 }, // 156 bits per transform
- { 18, 8, 8 }, // 156 bits per transform
- { 18, 9, 7 }, // 156 bits per transform
- { 18, 10, 6 }, // 156 bits per transform
- { 18, 11, 5 }, // 156 bits per transform
- { 18, 12, 4 }, // 156 bits per transform
- { 18, 13, 3 }, // 156 bits per transform
- { 18, 14, 2 }, // 156 bits per transform
- { 18, 15, 1 }, // 156 bits per transform
- { 1, 16, 18 }, // 159 bits per transform
- { 1, 18, 16 }, // 159 bits per transform
- { 2, 15, 18 }, // 159 bits per transform
- { 2, 18, 15 }, // 159 bits per transform
- { 3, 14, 18 }, // 159 bits per transform
- { 3, 18, 14 }, // 159 bits per transform
- { 4, 13, 18 }, // 159 bits per transform
- { 4, 18, 13 }, // 159 bits per transform
- { 5, 12, 18 }, // 159 bits per transform
- { 5, 18, 12 }, // 159 bits per transform
- { 6, 11, 18 }, // 159 bits per transform
- { 6, 18, 11 }, // 159 bits per transform
- { 7, 10, 18 }, // 159 bits per transform
- { 7, 18, 10 }, // 159 bits per transform
- { 8, 9, 18 }, // 159 bits per transform
- { 8, 18, 9 }, // 159 bits per transform
- { 9, 8, 18 }, // 159 bits per transform
- { 9, 18, 8 }, // 159 bits per transform
- { 10, 7, 18 }, // 159 bits per transform
- { 10, 18, 7 }, // 159 bits per transform
- { 11, 6, 18 }, // 159 bits per transform
- { 11, 18, 6 }, // 159 bits per transform
- { 12, 5, 18 }, // 159 bits per transform
- { 12, 18, 5 }, // 159 bits per transform
- { 13, 4, 18 }, // 159 bits per transform
- { 13, 17, 17 }, // 159 bits per transform
- { 13, 18, 4 }, // 159 bits per transform
- { 14, 3, 18 }, // 159 bits per transform
- { 14, 16, 17 }, // 159 bits per transform
- { 14, 17, 16 }, // 159 bits per transform
- { 14, 18, 3 }, // 159 bits per transform
- { 15, 2, 18 }, // 159 bits per transform
- { 15, 15, 17 }, // 159 bits per transform
- { 15, 16, 16 }, // 159 bits per transform
- { 15, 17, 15 }, // 159 bits per transform
- { 15, 18, 2 }, // 159 bits per transform
- { 16, 1, 18 }, // 159 bits per transform
- { 16, 14, 17 }, // 159 bits per transform
- { 16, 15, 16 }, // 159 bits per transform
- { 16, 16, 15 }, // 159 bits per transform
- { 16, 17, 14 }, // 159 bits per transform
- { 16, 18, 1 }, // 159 bits per transform
- { 17, 13, 17 }, // 159 bits per transform
- { 17, 14, 16 }, // 159 bits per transform
- { 17, 15, 15 }, // 159 bits per transform
- { 17, 16, 14 }, // 159 bits per transform
- { 17, 17, 13 }, // 159 bits per transform
- { 18, 1, 16 }, // 159 bits per transform
- { 18, 2, 15 }, // 159 bits per transform
- { 18, 3, 14 }, // 159 bits per transform
- { 18, 4, 13 }, // 159 bits per transform
- { 18, 5, 12 }, // 159 bits per transform
- { 18, 6, 11 }, // 159 bits per transform
- { 18, 7, 10 }, // 159 bits per transform
- { 18, 8, 9 }, // 159 bits per transform
- { 18, 9, 8 }, // 159 bits per transform
- { 18, 10, 7 }, // 159 bits per transform
- { 18, 11, 6 }, // 159 bits per transform
- { 18, 12, 5 }, // 159 bits per transform
- { 18, 13, 4 }, // 159 bits per transform
- { 18, 14, 3 }, // 159 bits per transform
- { 18, 15, 2 }, // 159 bits per transform
- { 18, 16, 1 }, // 159 bits per transform
- { 1, 17, 18 }, // 162 bits per transform
- { 1, 18, 17 }, // 162 bits per transform
- { 2, 16, 18 }, // 162 bits per transform
- { 2, 18, 16 }, // 162 bits per transform
- { 3, 15, 18 }, // 162 bits per transform
- { 3, 18, 15 }, // 162 bits per transform
- { 4, 14, 18 }, // 162 bits per transform
- { 4, 18, 14 }, // 162 bits per transform
- { 5, 13, 18 }, // 162 bits per transform
- { 5, 18, 13 }, // 162 bits per transform
- { 6, 12, 18 }, // 162 bits per transform
- { 6, 18, 12 }, // 162 bits per transform
- { 7, 11, 18 }, // 162 bits per transform
- { 7, 18, 11 }, // 162 bits per transform
- { 8, 10, 18 }, // 162 bits per transform
- { 8, 18, 10 }, // 162 bits per transform
- { 9, 9, 18 }, // 162 bits per transform
- { 9, 18, 9 }, // 162 bits per transform
- { 10, 8, 18 }, // 162 bits per transform
- { 10, 18, 8 }, // 162 bits per transform
- { 11, 7, 18 }, // 162 bits per transform
- { 11, 18, 7 }, // 162 bits per transform
- { 12, 6, 18 }, // 162 bits per transform
- { 12, 18, 6 }, // 162 bits per transform
- { 13, 5, 18 }, // 162 bits per transform
- { 13, 18, 5 }, // 162 bits per transform
- { 14, 4, 18 }, // 162 bits per transform
- { 14, 17, 17 }, // 162 bits per transform
- { 14, 18, 4 }, // 162 bits per transform
- { 15, 3, 18 }, // 162 bits per transform
- { 15, 16, 17 }, // 162 bits per transform
- { 15, 17, 16 }, // 162 bits per transform
- { 15, 18, 3 }, // 162 bits per transform
- { 16, 2, 18 }, // 162 bits per transform
- { 16, 15, 17 }, // 162 bits per transform
- { 16, 16, 16 }, // 162 bits per transform
- { 16, 17, 15 }, // 162 bits per transform
- { 16, 18, 2 }, // 162 bits per transform
- { 17, 1, 18 }, // 162 bits per transform
- { 17, 14, 17 }, // 162 bits per transform
- { 17, 15, 16 }, // 162 bits per transform
- { 17, 16, 15 }, // 162 bits per transform
- { 17, 17, 14 }, // 162 bits per transform
- { 17, 18, 1 }, // 162 bits per transform
- { 18, 1, 17 }, // 162 bits per transform
- { 18, 2, 16 }, // 162 bits per transform
- { 18, 3, 15 }, // 162 bits per transform
- { 18, 4, 14 }, // 162 bits per transform
- { 18, 5, 13 }, // 162 bits per transform
- { 18, 6, 12 }, // 162 bits per transform
- { 18, 7, 11 }, // 162 bits per transform
- { 18, 8, 10 }, // 162 bits per transform
- { 18, 9, 9 }, // 162 bits per transform
- { 18, 10, 8 }, // 162 bits per transform
- { 18, 11, 7 }, // 162 bits per transform
- { 18, 12, 6 }, // 162 bits per transform
- { 18, 13, 5 }, // 162 bits per transform
- { 18, 14, 4 }, // 162 bits per transform
- { 18, 15, 3 }, // 162 bits per transform
- { 18, 16, 2 }, // 162 bits per transform
- { 18, 17, 1 }, // 162 bits per transform
- { 2, 17, 18 }, // 165 bits per transform
- { 2, 18, 17 }, // 165 bits per transform
- { 3, 16, 18 }, // 165 bits per transform
- { 3, 18, 16 }, // 165 bits per transform
- { 4, 15, 18 }, // 165 bits per transform
- { 4, 18, 15 }, // 165 bits per transform
- { 5, 14, 18 }, // 165 bits per transform
- { 5, 18, 14 }, // 165 bits per transform
- { 6, 13, 18 }, // 165 bits per transform
- { 6, 18, 13 }, // 165 bits per transform
- { 7, 12, 18 }, // 165 bits per transform
- { 7, 18, 12 }, // 165 bits per transform
- { 8, 11, 18 }, // 165 bits per transform
- { 8, 18, 11 }, // 165 bits per transform
- { 9, 10, 18 }, // 165 bits per transform
- { 9, 18, 10 }, // 165 bits per transform
- { 10, 9, 18 }, // 165 bits per transform
- { 10, 18, 9 }, // 165 bits per transform
- { 11, 8, 18 }, // 165 bits per transform
- { 11, 18, 8 }, // 165 bits per transform
- { 12, 7, 18 }, // 165 bits per transform
- { 12, 18, 7 }, // 165 bits per transform
- { 13, 6, 18 }, // 165 bits per transform
- { 13, 18, 6 }, // 165 bits per transform
- { 14, 5, 18 }, // 165 bits per transform
- { 14, 18, 5 }, // 165 bits per transform
- { 15, 4, 18 }, // 165 bits per transform
- { 15, 17, 17 }, // 165 bits per transform
- { 15, 18, 4 }, // 165 bits per transform
- { 16, 3, 18 }, // 165 bits per transform
- { 16, 16, 17 }, // 165 bits per transform
- { 16, 17, 16 }, // 165 bits per transform
- { 16, 18, 3 }, // 165 bits per transform
- { 17, 2, 18 }, // 165 bits per transform
- { 17, 15, 17 }, // 165 bits per transform
- { 17, 16, 16 }, // 165 bits per transform
- { 17, 17, 15 }, // 165 bits per transform
- { 17, 18, 2 }, // 165 bits per transform
- { 18, 2, 17 }, // 165 bits per transform
- { 18, 3, 16 }, // 165 bits per transform
- { 18, 4, 15 }, // 165 bits per transform
- { 18, 5, 14 }, // 165 bits per transform
- { 18, 6, 13 }, // 165 bits per transform
- { 18, 7, 12 }, // 165 bits per transform
- { 18, 8, 11 }, // 165 bits per transform
- { 18, 9, 10 }, // 165 bits per transform
- { 18, 10, 9 }, // 165 bits per transform
- { 18, 11, 8 }, // 165 bits per transform
- { 18, 12, 7 }, // 165 bits per transform
- { 18, 13, 6 }, // 165 bits per transform
- { 18, 14, 5 }, // 165 bits per transform
- { 18, 15, 4 }, // 165 bits per transform
- { 18, 16, 3 }, // 165 bits per transform
- { 18, 17, 2 }, // 165 bits per transform
- { 3, 17, 18 }, // 168 bits per transform
- { 3, 18, 17 }, // 168 bits per transform
- { 4, 16, 18 }, // 168 bits per transform
- { 4, 18, 16 }, // 168 bits per transform
- { 5, 15, 18 }, // 168 bits per transform
- { 5, 18, 15 }, // 168 bits per transform
- { 6, 14, 18 }, // 168 bits per transform
- { 6, 18, 14 }, // 168 bits per transform
- { 7, 13, 18 }, // 168 bits per transform
- { 7, 18, 13 }, // 168 bits per transform
- { 8, 12, 18 }, // 168 bits per transform
- { 8, 18, 12 }, // 168 bits per transform
- { 9, 11, 18 }, // 168 bits per transform
- { 9, 18, 11 }, // 168 bits per transform
- { 10, 10, 18 }, // 168 bits per transform
- { 10, 18, 10 }, // 168 bits per transform
- { 11, 9, 18 }, // 168 bits per transform
- { 11, 18, 9 }, // 168 bits per transform
- { 12, 8, 18 }, // 168 bits per transform
- { 12, 18, 8 }, // 168 bits per transform
- { 13, 7, 18 }, // 168 bits per transform
- { 13, 18, 7 }, // 168 bits per transform
- { 14, 6, 18 }, // 168 bits per transform
- { 14, 18, 6 }, // 168 bits per transform
- { 15, 5, 18 }, // 168 bits per transform
- { 15, 18, 5 }, // 168 bits per transform
- { 16, 4, 18 }, // 168 bits per transform
- { 16, 17, 17 }, // 168 bits per transform
- { 16, 18, 4 }, // 168 bits per transform
- { 17, 3, 18 }, // 168 bits per transform
- { 17, 16, 17 }, // 168 bits per transform
- { 17, 17, 16 }, // 168 bits per transform
- { 17, 18, 3 }, // 168 bits per transform
- { 18, 3, 17 }, // 168 bits per transform
- { 18, 4, 16 }, // 168 bits per transform
- { 18, 5, 15 }, // 168 bits per transform
- { 18, 6, 14 }, // 168 bits per transform
- { 18, 7, 13 }, // 168 bits per transform
- { 18, 8, 12 }, // 168 bits per transform
- { 18, 9, 11 }, // 168 bits per transform
- { 18, 10, 10 }, // 168 bits per transform
- { 18, 11, 9 }, // 168 bits per transform
- { 18, 12, 8 }, // 168 bits per transform
- { 18, 13, 7 }, // 168 bits per transform
- { 18, 14, 6 }, // 168 bits per transform
- { 18, 15, 5 }, // 168 bits per transform
- { 18, 16, 4 }, // 168 bits per transform
- { 18, 17, 3 }, // 168 bits per transform
- { 4, 17, 18 }, // 171 bits per transform
- { 4, 18, 17 }, // 171 bits per transform
- { 5, 16, 18 }, // 171 bits per transform
- { 5, 18, 16 }, // 171 bits per transform
- { 6, 15, 18 }, // 171 bits per transform
- { 6, 18, 15 }, // 171 bits per transform
- { 7, 14, 18 }, // 171 bits per transform
- { 7, 18, 14 }, // 171 bits per transform
- { 8, 13, 18 }, // 171 bits per transform
- { 8, 18, 13 }, // 171 bits per transform
- { 9, 12, 18 }, // 171 bits per transform
- { 9, 18, 12 }, // 171 bits per transform
- { 10, 11, 18 }, // 171 bits per transform
- { 10, 18, 11 }, // 171 bits per transform
- { 11, 10, 18 }, // 171 bits per transform
- { 11, 18, 10 }, // 171 bits per transform
- { 12, 9, 18 }, // 171 bits per transform
- { 12, 18, 9 }, // 171 bits per transform
- { 13, 8, 18 }, // 171 bits per transform
- { 13, 18, 8 }, // 171 bits per transform
- { 14, 7, 18 }, // 171 bits per transform
- { 14, 18, 7 }, // 171 bits per transform
- { 15, 6, 18 }, // 171 bits per transform
- { 15, 18, 6 }, // 171 bits per transform
- { 16, 5, 18 }, // 171 bits per transform
- { 16, 18, 5 }, // 171 bits per transform
- { 17, 4, 18 }, // 171 bits per transform
- { 17, 17, 17 }, // 171 bits per transform
- { 17, 18, 4 }, // 171 bits per transform
- { 18, 4, 17 }, // 171 bits per transform
- { 18, 5, 16 }, // 171 bits per transform
- { 18, 6, 15 }, // 171 bits per transform
- { 18, 7, 14 }, // 171 bits per transform
- { 18, 8, 13 }, // 171 bits per transform
- { 18, 9, 12 }, // 171 bits per transform
- { 18, 10, 11 }, // 171 bits per transform
- { 18, 11, 10 }, // 171 bits per transform
- { 18, 12, 9 }, // 171 bits per transform
- { 18, 13, 8 }, // 171 bits per transform
- { 18, 14, 7 }, // 171 bits per transform
- { 18, 15, 6 }, // 171 bits per transform
- { 18, 16, 5 }, // 171 bits per transform
- { 18, 17, 4 }, // 171 bits per transform
- { 5, 17, 18 }, // 174 bits per transform
- { 5, 18, 17 }, // 174 bits per transform
- { 6, 16, 18 }, // 174 bits per transform
- { 6, 18, 16 }, // 174 bits per transform
- { 7, 15, 18 }, // 174 bits per transform
- { 7, 18, 15 }, // 174 bits per transform
- { 8, 14, 18 }, // 174 bits per transform
- { 8, 18, 14 }, // 174 bits per transform
- { 9, 13, 18 }, // 174 bits per transform
- { 9, 18, 13 }, // 174 bits per transform
- { 10, 12, 18 }, // 174 bits per transform
- { 10, 18, 12 }, // 174 bits per transform
- { 11, 11, 18 }, // 174 bits per transform
- { 11, 18, 11 }, // 174 bits per transform
- { 12, 10, 18 }, // 174 bits per transform
- { 12, 18, 10 }, // 174 bits per transform
- { 13, 9, 18 }, // 174 bits per transform
- { 13, 18, 9 }, // 174 bits per transform
- { 14, 8, 18 }, // 174 bits per transform
- { 14, 18, 8 }, // 174 bits per transform
- { 15, 7, 18 }, // 174 bits per transform
- { 15, 18, 7 }, // 174 bits per transform
- { 16, 6, 18 }, // 174 bits per transform
- { 16, 18, 6 }, // 174 bits per transform
- { 17, 5, 18 }, // 174 bits per transform
- { 17, 18, 5 }, // 174 bits per transform
- { 18, 5, 17 }, // 174 bits per transform
- { 18, 6, 16 }, // 174 bits per transform
- { 18, 7, 15 }, // 174 bits per transform
- { 18, 8, 14 }, // 174 bits per transform
- { 18, 9, 13 }, // 174 bits per transform
- { 18, 10, 12 }, // 174 bits per transform
- { 18, 11, 11 }, // 174 bits per transform
- { 18, 12, 10 }, // 174 bits per transform
- { 18, 13, 9 }, // 174 bits per transform
- { 18, 14, 8 }, // 174 bits per transform
- { 18, 15, 7 }, // 174 bits per transform
- { 18, 16, 6 }, // 174 bits per transform
- { 18, 17, 5 }, // 174 bits per transform
- { 6, 17, 18 }, // 177 bits per transform
- { 6, 18, 17 }, // 177 bits per transform
- { 7, 16, 18 }, // 177 bits per transform
- { 7, 18, 16 }, // 177 bits per transform
- { 8, 15, 18 }, // 177 bits per transform
- { 8, 18, 15 }, // 177 bits per transform
- { 9, 14, 18 }, // 177 bits per transform
- { 9, 18, 14 }, // 177 bits per transform
- { 10, 13, 18 }, // 177 bits per transform
- { 10, 18, 13 }, // 177 bits per transform
- { 11, 12, 18 }, // 177 bits per transform
- { 11, 18, 12 }, // 177 bits per transform
- { 12, 11, 18 }, // 177 bits per transform
- { 12, 18, 11 }, // 177 bits per transform
- { 13, 10, 18 }, // 177 bits per transform
- { 13, 18, 10 }, // 177 bits per transform
- { 14, 9, 18 }, // 177 bits per transform
- { 14, 18, 9 }, // 177 bits per transform
- { 15, 8, 18 }, // 177 bits per transform
- { 15, 18, 8 }, // 177 bits per transform
- { 16, 7, 18 }, // 177 bits per transform
- { 16, 18, 7 }, // 177 bits per transform
- { 17, 6, 18 }, // 177 bits per transform
- { 17, 18, 6 }, // 177 bits per transform
- { 18, 6, 17 }, // 177 bits per transform
- { 18, 7, 16 }, // 177 bits per transform
- { 18, 8, 15 }, // 177 bits per transform
- { 18, 9, 14 }, // 177 bits per transform
- { 18, 10, 13 }, // 177 bits per transform
- { 18, 11, 12 }, // 177 bits per transform
- { 18, 12, 11 }, // 177 bits per transform
- { 18, 13, 10 }, // 177 bits per transform
- { 18, 14, 9 }, // 177 bits per transform
- { 18, 15, 8 }, // 177 bits per transform
- { 18, 16, 7 }, // 177 bits per transform
- { 18, 17, 6 }, // 177 bits per transform
- { 7, 17, 18 }, // 180 bits per transform
- { 7, 18, 17 }, // 180 bits per transform
- { 8, 16, 18 }, // 180 bits per transform
- { 8, 18, 16 }, // 180 bits per transform
- { 9, 15, 18 }, // 180 bits per transform
- { 9, 18, 15 }, // 180 bits per transform
- { 10, 14, 18 }, // 180 bits per transform
- { 10, 18, 14 }, // 180 bits per transform
- { 11, 13, 18 }, // 180 bits per transform
- { 11, 18, 13 }, // 180 bits per transform
- { 12, 12, 18 }, // 180 bits per transform
- { 12, 18, 12 }, // 180 bits per transform
- { 13, 11, 18 }, // 180 bits per transform
- { 13, 18, 11 }, // 180 bits per transform
- { 14, 10, 18 }, // 180 bits per transform
- { 14, 18, 10 }, // 180 bits per transform
- { 15, 9, 18 }, // 180 bits per transform
- { 15, 18, 9 }, // 180 bits per transform
- { 16, 8, 18 }, // 180 bits per transform
- { 16, 18, 8 }, // 180 bits per transform
- { 17, 7, 18 }, // 180 bits per transform
- { 17, 18, 7 }, // 180 bits per transform
- { 18, 7, 17 }, // 180 bits per transform
- { 18, 8, 16 }, // 180 bits per transform
- { 18, 9, 15 }, // 180 bits per transform
- { 18, 10, 14 }, // 180 bits per transform
- { 18, 11, 13 }, // 180 bits per transform
- { 18, 12, 12 }, // 180 bits per transform
- { 18, 13, 11 }, // 180 bits per transform
- { 18, 14, 10 }, // 180 bits per transform
- { 18, 15, 9 }, // 180 bits per transform
- { 18, 16, 8 }, // 180 bits per transform
- { 18, 17, 7 }, // 180 bits per transform
- { 8, 17, 18 }, // 183 bits per transform
- { 8, 18, 17 }, // 183 bits per transform
- { 9, 16, 18 }, // 183 bits per transform
- { 9, 18, 16 }, // 183 bits per transform
- { 10, 15, 18 }, // 183 bits per transform
- { 10, 18, 15 }, // 183 bits per transform
- { 11, 14, 18 }, // 183 bits per transform
- { 11, 18, 14 }, // 183 bits per transform
- { 12, 13, 18 }, // 183 bits per transform
- { 12, 18, 13 }, // 183 bits per transform
- { 13, 12, 18 }, // 183 bits per transform
- { 13, 18, 12 }, // 183 bits per transform
- { 14, 11, 18 }, // 183 bits per transform
- { 14, 18, 11 }, // 183 bits per transform
- { 15, 10, 18 }, // 183 bits per transform
- { 15, 18, 10 }, // 183 bits per transform
- { 16, 9, 18 }, // 183 bits per transform
- { 16, 18, 9 }, // 183 bits per transform
- { 17, 8, 18 }, // 183 bits per transform
- { 17, 18, 8 }, // 183 bits per transform
- { 18, 8, 17 }, // 183 bits per transform
- { 18, 9, 16 }, // 183 bits per transform
- { 18, 10, 15 }, // 183 bits per transform
- { 18, 11, 14 }, // 183 bits per transform
- { 18, 12, 13 }, // 183 bits per transform
- { 18, 13, 12 }, // 183 bits per transform
- { 18, 14, 11 }, // 183 bits per transform
- { 18, 15, 10 }, // 183 bits per transform
- { 18, 16, 9 }, // 183 bits per transform
- { 18, 17, 8 }, // 183 bits per transform
- { 9, 17, 18 }, // 186 bits per transform
- { 9, 18, 17 }, // 186 bits per transform
- { 10, 16, 18 }, // 186 bits per transform
- { 10, 18, 16 }, // 186 bits per transform
- { 11, 15, 18 }, // 186 bits per transform
- { 11, 18, 15 }, // 186 bits per transform
- { 12, 14, 18 }, // 186 bits per transform
- { 12, 18, 14 }, // 186 bits per transform
- { 13, 13, 18 }, // 186 bits per transform
- { 13, 18, 13 }, // 186 bits per transform
- { 14, 12, 18 }, // 186 bits per transform
- { 14, 18, 12 }, // 186 bits per transform
- { 15, 11, 18 }, // 186 bits per transform
- { 15, 18, 11 }, // 186 bits per transform
- { 16, 10, 18 }, // 186 bits per transform
- { 16, 18, 10 }, // 186 bits per transform
- { 17, 9, 18 }, // 186 bits per transform
- { 17, 18, 9 }, // 186 bits per transform
- { 18, 9, 17 }, // 186 bits per transform
- { 18, 10, 16 }, // 186 bits per transform
- { 18, 11, 15 }, // 186 bits per transform
- { 18, 12, 14 }, // 186 bits per transform
- { 18, 13, 13 }, // 186 bits per transform
- { 18, 14, 12 }, // 186 bits per transform
- { 18, 15, 11 }, // 186 bits per transform
- { 18, 16, 10 }, // 186 bits per transform
- { 18, 17, 9 }, // 186 bits per transform
- { 10, 17, 18 }, // 189 bits per transform
- { 10, 18, 17 }, // 189 bits per transform
- { 11, 16, 18 }, // 189 bits per transform
- { 11, 18, 16 }, // 189 bits per transform
- { 12, 15, 18 }, // 189 bits per transform
- { 12, 18, 15 }, // 189 bits per transform
- { 13, 14, 18 }, // 189 bits per transform
- { 13, 18, 14 }, // 189 bits per transform
- { 14, 13, 18 }, // 189 bits per transform
- { 14, 18, 13 }, // 189 bits per transform
- { 15, 12, 18 }, // 189 bits per transform
- { 15, 18, 12 }, // 189 bits per transform
- { 16, 11, 18 }, // 189 bits per transform
- { 16, 18, 11 }, // 189 bits per transform
- { 17, 10, 18 }, // 189 bits per transform
- { 17, 18, 10 }, // 189 bits per transform
- { 18, 10, 17 }, // 189 bits per transform
- { 18, 11, 16 }, // 189 bits per transform
- { 18, 12, 15 }, // 189 bits per transform
- { 18, 13, 14 }, // 189 bits per transform
- { 18, 14, 13 }, // 189 bits per transform
- { 18, 15, 12 }, // 189 bits per transform
- { 18, 16, 11 }, // 189 bits per transform
- { 18, 17, 10 }, // 189 bits per transform
- { 0, 18, 18 }, // 192 bits per transform
- { 11, 17, 18 }, // 192 bits per transform
- { 11, 18, 17 }, // 192 bits per transform
- { 12, 16, 18 }, // 192 bits per transform
- { 12, 18, 16 }, // 192 bits per transform
- { 13, 15, 18 }, // 192 bits per transform
- { 13, 18, 15 }, // 192 bits per transform
- { 14, 14, 18 }, // 192 bits per transform
- { 14, 18, 14 }, // 192 bits per transform
- { 15, 13, 18 }, // 192 bits per transform
- { 15, 18, 13 }, // 192 bits per transform
- { 16, 12, 18 }, // 192 bits per transform
- { 16, 18, 12 }, // 192 bits per transform
- { 17, 11, 18 }, // 192 bits per transform
- { 17, 18, 11 }, // 192 bits per transform
- { 18, 0, 18 }, // 192 bits per transform
- { 18, 11, 17 }, // 192 bits per transform
- { 18, 12, 16 }, // 192 bits per transform
- { 18, 13, 15 }, // 192 bits per transform
- { 18, 14, 14 }, // 192 bits per transform
- { 18, 15, 13 }, // 192 bits per transform
- { 18, 16, 12 }, // 192 bits per transform
- { 18, 17, 11 }, // 192 bits per transform
- { 18, 18, 0 }, // 192 bits per transform
- { 12, 17, 18 }, // 195 bits per transform
- { 12, 18, 17 }, // 195 bits per transform
- { 13, 16, 18 }, // 195 bits per transform
- { 13, 18, 16 }, // 195 bits per transform
- { 14, 15, 18 }, // 195 bits per transform
- { 14, 18, 15 }, // 195 bits per transform
- { 15, 14, 18 }, // 195 bits per transform
- { 15, 18, 14 }, // 195 bits per transform
- { 16, 13, 18 }, // 195 bits per transform
- { 16, 18, 13 }, // 195 bits per transform
- { 17, 12, 18 }, // 195 bits per transform
- { 17, 18, 12 }, // 195 bits per transform
- { 18, 12, 17 }, // 195 bits per transform
- { 18, 13, 16 }, // 195 bits per transform
- { 18, 14, 15 }, // 195 bits per transform
- { 18, 15, 14 }, // 195 bits per transform
- { 18, 16, 13 }, // 195 bits per transform
- { 18, 17, 12 }, // 195 bits per transform
- { 13, 17, 18 }, // 198 bits per transform
- { 13, 18, 17 }, // 198 bits per transform
- { 14, 16, 18 }, // 198 bits per transform
- { 14, 18, 16 }, // 198 bits per transform
- { 15, 15, 18 }, // 198 bits per transform
- { 15, 18, 15 }, // 198 bits per transform
- { 16, 14, 18 }, // 198 bits per transform
- { 16, 18, 14 }, // 198 bits per transform
- { 17, 13, 18 }, // 198 bits per transform
- { 17, 18, 13 }, // 198 bits per transform
- { 18, 13, 17 }, // 198 bits per transform
- { 18, 14, 16 }, // 198 bits per transform
- { 18, 15, 15 }, // 198 bits per transform
- { 18, 16, 14 }, // 198 bits per transform
- { 18, 17, 13 }, // 198 bits per transform
- { 1, 18, 18 }, // 201 bits per transform
- { 14, 17, 18 }, // 201 bits per transform
- { 14, 18, 17 }, // 201 bits per transform
- { 15, 16, 18 }, // 201 bits per transform
- { 15, 18, 16 }, // 201 bits per transform
- { 16, 15, 18 }, // 201 bits per transform
- { 16, 18, 15 }, // 201 bits per transform
- { 17, 14, 18 }, // 201 bits per transform
- { 17, 18, 14 }, // 201 bits per transform
- { 18, 1, 18 }, // 201 bits per transform
- { 18, 14, 17 }, // 201 bits per transform
- { 18, 15, 16 }, // 201 bits per transform
- { 18, 16, 15 }, // 201 bits per transform
- { 18, 17, 14 }, // 201 bits per transform
- { 18, 18, 1 }, // 201 bits per transform
- { 2, 18, 18 }, // 204 bits per transform
- { 15, 17, 18 }, // 204 bits per transform
- { 15, 18, 17 }, // 204 bits per transform
- { 16, 16, 18 }, // 204 bits per transform
- { 16, 18, 16 }, // 204 bits per transform
- { 17, 15, 18 }, // 204 bits per transform
- { 17, 18, 15 }, // 204 bits per transform
- { 18, 2, 18 }, // 204 bits per transform
- { 18, 15, 17 }, // 204 bits per transform
- { 18, 16, 16 }, // 204 bits per transform
- { 18, 17, 15 }, // 204 bits per transform
- { 18, 18, 2 }, // 204 bits per transform
- { 3, 18, 18 }, // 207 bits per transform
- { 16, 17, 18 }, // 207 bits per transform
- { 16, 18, 17 }, // 207 bits per transform
- { 17, 16, 18 }, // 207 bits per transform
- { 17, 18, 16 }, // 207 bits per transform
- { 18, 3, 18 }, // 207 bits per transform
- { 18, 16, 17 }, // 207 bits per transform
- { 18, 17, 16 }, // 207 bits per transform
- { 18, 18, 3 }, // 207 bits per transform
- { 4, 18, 18 }, // 210 bits per transform
- { 17, 17, 18 }, // 210 bits per transform
- { 17, 18, 17 }, // 210 bits per transform
- { 18, 4, 18 }, // 210 bits per transform
- { 18, 17, 17 }, // 210 bits per transform
- { 18, 18, 4 }, // 210 bits per transform
- { 5, 18, 18 }, // 213 bits per transform
- { 18, 5, 18 }, // 213 bits per transform
- { 18, 18, 5 }, // 213 bits per transform
- { 6, 18, 18 }, // 216 bits per transform
- { 18, 6, 18 }, // 216 bits per transform
- { 18, 18, 6 }, // 216 bits per transform
- { 7, 18, 18 }, // 219 bits per transform
- { 18, 7, 18 }, // 219 bits per transform
- { 18, 18, 7 }, // 219 bits per transform
- { 8, 18, 18 }, // 222 bits per transform
- { 18, 8, 18 }, // 222 bits per transform
- { 18, 18, 8 }, // 222 bits per transform
- { 9, 18, 18 }, // 225 bits per transform
- { 18, 9, 18 }, // 225 bits per transform
- { 18, 18, 9 }, // 225 bits per transform
- { 10, 18, 18 }, // 228 bits per transform
- { 18, 10, 18 }, // 228 bits per transform
- { 18, 18, 10 }, // 228 bits per transform
- { 11, 18, 18 }, // 231 bits per transform
- { 18, 11, 18 }, // 231 bits per transform
- { 18, 18, 11 }, // 231 bits per transform
- { 12, 18, 18 }, // 234 bits per transform
- { 18, 12, 18 }, // 234 bits per transform
- { 18, 18, 12 }, // 234 bits per transform
- { 13, 18, 18 }, // 237 bits per transform
- { 18, 13, 18 }, // 237 bits per transform
- { 18, 18, 13 }, // 237 bits per transform
- { 14, 18, 18 }, // 240 bits per transform
- { 18, 14, 18 }, // 240 bits per transform
- { 18, 18, 14 }, // 240 bits per transform
- { 15, 18, 18 }, // 243 bits per transform
- { 18, 15, 18 }, // 243 bits per transform
- { 18, 18, 15 }, // 243 bits per transform
- { 16, 18, 18 }, // 246 bits per transform
- { 18, 16, 18 }, // 246 bits per transform
- { 18, 18, 16 }, // 246 bits per transform
- { 17, 18, 18 }, // 249 bits per transform
- { 18, 17, 18 }, // 249 bits per transform
- { 18, 18, 17 }, // 249 bits per transform
- { 18, 18, 18 }, // 288 bits per transform
+ { 0, 0, 1 }, // 3 bits per transform
+ { 0, 1, 0 }, // 3 bits per transform
+ { 1, 0, 0 }, // 3 bits per transform
+ { 0, 0, 2 }, // 6 bits per transform
+ { 0, 1, 1 }, // 6 bits per transform
+ { 0, 2, 0 }, // 6 bits per transform
+ { 1, 0, 1 }, // 6 bits per transform
+ { 1, 1, 0 }, // 6 bits per transform
+ { 2, 0, 0 }, // 6 bits per transform
+ { 0, 0, 3 }, // 9 bits per transform
+ { 0, 1, 2 }, // 9 bits per transform
+ { 0, 2, 1 }, // 9 bits per transform
+ { 0, 3, 0 }, // 9 bits per transform
+ { 1, 0, 2 }, // 9 bits per transform
+ { 1, 1, 1 }, // 9 bits per transform
+ { 1, 2, 0 }, // 9 bits per transform
+ { 2, 0, 1 }, // 9 bits per transform
+ { 2, 1, 0 }, // 9 bits per transform
+ { 3, 0, 0 }, // 9 bits per transform
+ { 0, 0, 4 }, // 12 bits per transform
+ { 0, 1, 3 }, // 12 bits per transform
+ { 0, 2, 2 }, // 12 bits per transform
+ { 0, 3, 1 }, // 12 bits per transform
+ { 0, 4, 0 }, // 12 bits per transform
+ { 1, 0, 3 }, // 12 bits per transform
+ { 1, 1, 2 }, // 12 bits per transform
+ { 1, 2, 1 }, // 12 bits per transform
+ { 1, 3, 0 }, // 12 bits per transform
+ { 2, 0, 2 }, // 12 bits per transform
+ { 2, 1, 1 }, // 12 bits per transform
+ { 2, 2, 0 }, // 12 bits per transform
+ { 3, 0, 1 }, // 12 bits per transform
+ { 3, 1, 0 }, // 12 bits per transform
+ { 4, 0, 0 }, // 12 bits per transform
+ { 0, 0, 5 }, // 15 bits per transform
+ { 0, 1, 4 }, // 15 bits per transform
+ { 0, 2, 3 }, // 15 bits per transform
+ { 0, 3, 2 }, // 15 bits per transform
+ { 0, 4, 1 }, // 15 bits per transform
+ { 0, 5, 0 }, // 15 bits per transform
+ { 1, 0, 4 }, // 15 bits per transform
+ { 1, 1, 3 }, // 15 bits per transform
+ { 1, 2, 2 }, // 15 bits per transform
+ { 1, 3, 1 }, // 15 bits per transform
+ { 1, 4, 0 }, // 15 bits per transform
+ { 2, 0, 3 }, // 15 bits per transform
+ { 2, 1, 2 }, // 15 bits per transform
+ { 2, 2, 1 }, // 15 bits per transform
+ { 2, 3, 0 }, // 15 bits per transform
+ { 3, 0, 2 }, // 15 bits per transform
+ { 3, 1, 1 }, // 15 bits per transform
+ { 3, 2, 0 }, // 15 bits per transform
+ { 4, 0, 1 }, // 15 bits per transform
+ { 4, 1, 0 }, // 15 bits per transform
+ { 5, 0, 0 }, // 15 bits per transform
+ { 0, 0, 6 }, // 18 bits per transform
+ { 0, 1, 5 }, // 18 bits per transform
+ { 0, 2, 4 }, // 18 bits per transform
+ { 0, 3, 3 }, // 18 bits per transform
+ { 0, 4, 2 }, // 18 bits per transform
+ { 0, 5, 1 }, // 18 bits per transform
+ { 0, 6, 0 }, // 18 bits per transform
+ { 1, 0, 5 }, // 18 bits per transform
+ { 1, 1, 4 }, // 18 bits per transform
+ { 1, 2, 3 }, // 18 bits per transform
+ { 1, 3, 2 }, // 18 bits per transform
+ { 1, 4, 1 }, // 18 bits per transform
+ { 1, 5, 0 }, // 18 bits per transform
+ { 2, 0, 4 }, // 18 bits per transform
+ { 2, 1, 3 }, // 18 bits per transform
+ { 2, 2, 2 }, // 18 bits per transform
+ { 2, 3, 1 }, // 18 bits per transform
+ { 2, 4, 0 }, // 18 bits per transform
+ { 3, 0, 3 }, // 18 bits per transform
+ { 3, 1, 2 }, // 18 bits per transform
+ { 3, 2, 1 }, // 18 bits per transform
+ { 3, 3, 0 }, // 18 bits per transform
+ { 4, 0, 2 }, // 18 bits per transform
+ { 4, 1, 1 }, // 18 bits per transform
+ { 4, 2, 0 }, // 18 bits per transform
+ { 5, 0, 1 }, // 18 bits per transform
+ { 5, 1, 0 }, // 18 bits per transform
+ { 6, 0, 0 }, // 18 bits per transform
+ { 0, 0, 7 }, // 21 bits per transform
+ { 0, 1, 6 }, // 21 bits per transform
+ { 0, 2, 5 }, // 21 bits per transform
+ { 0, 3, 4 }, // 21 bits per transform
+ { 0, 4, 3 }, // 21 bits per transform
+ { 0, 5, 2 }, // 21 bits per transform
+ { 0, 6, 1 }, // 21 bits per transform
+ { 0, 7, 0 }, // 21 bits per transform
+ { 1, 0, 6 }, // 21 bits per transform
+ { 1, 1, 5 }, // 21 bits per transform
+ { 1, 2, 4 }, // 21 bits per transform
+ { 1, 3, 3 }, // 21 bits per transform
+ { 1, 4, 2 }, // 21 bits per transform
+ { 1, 5, 1 }, // 21 bits per transform
+ { 1, 6, 0 }, // 21 bits per transform
+ { 2, 0, 5 }, // 21 bits per transform
+ { 2, 1, 4 }, // 21 bits per transform
+ { 2, 2, 3 }, // 21 bits per transform
+ { 2, 3, 2 }, // 21 bits per transform
+ { 2, 4, 1 }, // 21 bits per transform
+ { 2, 5, 0 }, // 21 bits per transform
+ { 3, 0, 4 }, // 21 bits per transform
+ { 3, 1, 3 }, // 21 bits per transform
+ { 3, 2, 2 }, // 21 bits per transform
+ { 3, 3, 1 }, // 21 bits per transform
+ { 3, 4, 0 }, // 21 bits per transform
+ { 4, 0, 3 }, // 21 bits per transform
+ { 4, 1, 2 }, // 21 bits per transform
+ { 4, 2, 1 }, // 21 bits per transform
+ { 4, 3, 0 }, // 21 bits per transform
+ { 5, 0, 2 }, // 21 bits per transform
+ { 5, 1, 1 }, // 21 bits per transform
+ { 5, 2, 0 }, // 21 bits per transform
+ { 6, 0, 1 }, // 21 bits per transform
+ { 6, 1, 0 }, // 21 bits per transform
+ { 7, 0, 0 }, // 21 bits per transform
+ { 0, 0, 8 }, // 24 bits per transform
+ { 0, 1, 7 }, // 24 bits per transform
+ { 0, 2, 6 }, // 24 bits per transform
+ { 0, 3, 5 }, // 24 bits per transform
+ { 0, 4, 4 }, // 24 bits per transform
+ { 0, 5, 3 }, // 24 bits per transform
+ { 0, 6, 2 }, // 24 bits per transform
+ { 0, 7, 1 }, // 24 bits per transform
+ { 0, 8, 0 }, // 24 bits per transform
+ { 1, 0, 7 }, // 24 bits per transform
+ { 1, 1, 6 }, // 24 bits per transform
+ { 1, 2, 5 }, // 24 bits per transform
+ { 1, 3, 4 }, // 24 bits per transform
+ { 1, 4, 3 }, // 24 bits per transform
+ { 1, 5, 2 }, // 24 bits per transform
+ { 1, 6, 1 }, // 24 bits per transform
+ { 1, 7, 0 }, // 24 bits per transform
+ { 2, 0, 6 }, // 24 bits per transform
+ { 2, 1, 5 }, // 24 bits per transform
+ { 2, 2, 4 }, // 24 bits per transform
+ { 2, 3, 3 }, // 24 bits per transform
+ { 2, 4, 2 }, // 24 bits per transform
+ { 2, 5, 1 }, // 24 bits per transform
+ { 2, 6, 0 }, // 24 bits per transform
+ { 3, 0, 5 }, // 24 bits per transform
+ { 3, 1, 4 }, // 24 bits per transform
+ { 3, 2, 3 }, // 24 bits per transform
+ { 3, 3, 2 }, // 24 bits per transform
+ { 3, 4, 1 }, // 24 bits per transform
+ { 3, 5, 0 }, // 24 bits per transform
+ { 4, 0, 4 }, // 24 bits per transform
+ { 4, 1, 3 }, // 24 bits per transform
+ { 4, 2, 2 }, // 24 bits per transform
+ { 4, 3, 1 }, // 24 bits per transform
+ { 4, 4, 0 }, // 24 bits per transform
+ { 5, 0, 3 }, // 24 bits per transform
+ { 5, 1, 2 }, // 24 bits per transform
+ { 5, 2, 1 }, // 24 bits per transform
+ { 5, 3, 0 }, // 24 bits per transform
+ { 6, 0, 2 }, // 24 bits per transform
+ { 6, 1, 1 }, // 24 bits per transform
+ { 6, 2, 0 }, // 24 bits per transform
+ { 7, 0, 1 }, // 24 bits per transform
+ { 7, 1, 0 }, // 24 bits per transform
+ { 8, 0, 0 }, // 24 bits per transform
+ { 0, 0, 9 }, // 27 bits per transform
+ { 0, 1, 8 }, // 27 bits per transform
+ { 0, 2, 7 }, // 27 bits per transform
+ { 0, 3, 6 }, // 27 bits per transform
+ { 0, 4, 5 }, // 27 bits per transform
+ { 0, 5, 4 }, // 27 bits per transform
+ { 0, 6, 3 }, // 27 bits per transform
+ { 0, 7, 2 }, // 27 bits per transform
+ { 0, 8, 1 }, // 27 bits per transform
+ { 0, 9, 0 }, // 27 bits per transform
+ { 1, 0, 8 }, // 27 bits per transform
+ { 1, 1, 7 }, // 27 bits per transform
+ { 1, 2, 6 }, // 27 bits per transform
+ { 1, 3, 5 }, // 27 bits per transform
+ { 1, 4, 4 }, // 27 bits per transform
+ { 1, 5, 3 }, // 27 bits per transform
+ { 1, 6, 2 }, // 27 bits per transform
+ { 1, 7, 1 }, // 27 bits per transform
+ { 1, 8, 0 }, // 27 bits per transform
+ { 2, 0, 7 }, // 27 bits per transform
+ { 2, 1, 6 }, // 27 bits per transform
+ { 2, 2, 5 }, // 27 bits per transform
+ { 2, 3, 4 }, // 27 bits per transform
+ { 2, 4, 3 }, // 27 bits per transform
+ { 2, 5, 2 }, // 27 bits per transform
+ { 2, 6, 1 }, // 27 bits per transform
+ { 2, 7, 0 }, // 27 bits per transform
+ { 3, 0, 6 }, // 27 bits per transform
+ { 3, 1, 5 }, // 27 bits per transform
+ { 3, 2, 4 }, // 27 bits per transform
+ { 3, 3, 3 }, // 27 bits per transform
+ { 3, 4, 2 }, // 27 bits per transform
+ { 3, 5, 1 }, // 27 bits per transform
+ { 3, 6, 0 }, // 27 bits per transform
+ { 4, 0, 5 }, // 27 bits per transform
+ { 4, 1, 4 }, // 27 bits per transform
+ { 4, 2, 3 }, // 27 bits per transform
+ { 4, 3, 2 }, // 27 bits per transform
+ { 4, 4, 1 }, // 27 bits per transform
+ { 4, 5, 0 }, // 27 bits per transform
+ { 5, 0, 4 }, // 27 bits per transform
+ { 5, 1, 3 }, // 27 bits per transform
+ { 5, 2, 2 }, // 27 bits per transform
+ { 5, 3, 1 }, // 27 bits per transform
+ { 5, 4, 0 }, // 27 bits per transform
+ { 6, 0, 3 }, // 27 bits per transform
+ { 6, 1, 2 }, // 27 bits per transform
+ { 6, 2, 1 }, // 27 bits per transform
+ { 6, 3, 0 }, // 27 bits per transform
+ { 7, 0, 2 }, // 27 bits per transform
+ { 7, 1, 1 }, // 27 bits per transform
+ { 7, 2, 0 }, // 27 bits per transform
+ { 8, 0, 1 }, // 27 bits per transform
+ { 8, 1, 0 }, // 27 bits per transform
+ { 9, 0, 0 }, // 27 bits per transform
+ { 0, 0, 10 }, // 30 bits per transform
+ { 0, 1, 9 }, // 30 bits per transform
+ { 0, 2, 8 }, // 30 bits per transform
+ { 0, 3, 7 }, // 30 bits per transform
+ { 0, 4, 6 }, // 30 bits per transform
+ { 0, 5, 5 }, // 30 bits per transform
+ { 0, 6, 4 }, // 30 bits per transform
+ { 0, 7, 3 }, // 30 bits per transform
+ { 0, 8, 2 }, // 30 bits per transform
+ { 0, 9, 1 }, // 30 bits per transform
+ { 0, 10, 0 }, // 30 bits per transform
+ { 1, 0, 9 }, // 30 bits per transform
+ { 1, 1, 8 }, // 30 bits per transform
+ { 1, 2, 7 }, // 30 bits per transform
+ { 1, 3, 6 }, // 30 bits per transform
+ { 1, 4, 5 }, // 30 bits per transform
+ { 1, 5, 4 }, // 30 bits per transform
+ { 1, 6, 3 }, // 30 bits per transform
+ { 1, 7, 2 }, // 30 bits per transform
+ { 1, 8, 1 }, // 30 bits per transform
+ { 1, 9, 0 }, // 30 bits per transform
+ { 2, 0, 8 }, // 30 bits per transform
+ { 2, 1, 7 }, // 30 bits per transform
+ { 2, 2, 6 }, // 30 bits per transform
+ { 2, 3, 5 }, // 30 bits per transform
+ { 2, 4, 4 }, // 30 bits per transform
+ { 2, 5, 3 }, // 30 bits per transform
+ { 2, 6, 2 }, // 30 bits per transform
+ { 2, 7, 1 }, // 30 bits per transform
+ { 2, 8, 0 }, // 30 bits per transform
+ { 3, 0, 7 }, // 30 bits per transform
+ { 3, 1, 6 }, // 30 bits per transform
+ { 3, 2, 5 }, // 30 bits per transform
+ { 3, 3, 4 }, // 30 bits per transform
+ { 3, 4, 3 }, // 30 bits per transform
+ { 3, 5, 2 }, // 30 bits per transform
+ { 3, 6, 1 }, // 30 bits per transform
+ { 3, 7, 0 }, // 30 bits per transform
+ { 4, 0, 6 }, // 30 bits per transform
+ { 4, 1, 5 }, // 30 bits per transform
+ { 4, 2, 4 }, // 30 bits per transform
+ { 4, 3, 3 }, // 30 bits per transform
+ { 4, 4, 2 }, // 30 bits per transform
+ { 4, 5, 1 }, // 30 bits per transform
+ { 4, 6, 0 }, // 30 bits per transform
+ { 5, 0, 5 }, // 30 bits per transform
+ { 5, 1, 4 }, // 30 bits per transform
+ { 5, 2, 3 }, // 30 bits per transform
+ { 5, 3, 2 }, // 30 bits per transform
+ { 5, 4, 1 }, // 30 bits per transform
+ { 5, 5, 0 }, // 30 bits per transform
+ { 6, 0, 4 }, // 30 bits per transform
+ { 6, 1, 3 }, // 30 bits per transform
+ { 6, 2, 2 }, // 30 bits per transform
+ { 6, 3, 1 }, // 30 bits per transform
+ { 6, 4, 0 }, // 30 bits per transform
+ { 7, 0, 3 }, // 30 bits per transform
+ { 7, 1, 2 }, // 30 bits per transform
+ { 7, 2, 1 }, // 30 bits per transform
+ { 7, 3, 0 }, // 30 bits per transform
+ { 8, 0, 2 }, // 30 bits per transform
+ { 8, 1, 1 }, // 30 bits per transform
+ { 8, 2, 0 }, // 30 bits per transform
+ { 9, 0, 1 }, // 30 bits per transform
+ { 9, 1, 0 }, // 30 bits per transform
+ { 10, 0, 0 }, // 30 bits per transform
+ { 0, 0, 11 }, // 33 bits per transform
+ { 0, 1, 10 }, // 33 bits per transform
+ { 0, 2, 9 }, // 33 bits per transform
+ { 0, 3, 8 }, // 33 bits per transform
+ { 0, 4, 7 }, // 33 bits per transform
+ { 0, 5, 6 }, // 33 bits per transform
+ { 0, 6, 5 }, // 33 bits per transform
+ { 0, 7, 4 }, // 33 bits per transform
+ { 0, 8, 3 }, // 33 bits per transform
+ { 0, 9, 2 }, // 33 bits per transform
+ { 0, 10, 1 }, // 33 bits per transform
+ { 0, 11, 0 }, // 33 bits per transform
+ { 1, 0, 10 }, // 33 bits per transform
+ { 1, 1, 9 }, // 33 bits per transform
+ { 1, 2, 8 }, // 33 bits per transform
+ { 1, 3, 7 }, // 33 bits per transform
+ { 1, 4, 6 }, // 33 bits per transform
+ { 1, 5, 5 }, // 33 bits per transform
+ { 1, 6, 4 }, // 33 bits per transform
+ { 1, 7, 3 }, // 33 bits per transform
+ { 1, 8, 2 }, // 33 bits per transform
+ { 1, 9, 1 }, // 33 bits per transform
+ { 1, 10, 0 }, // 33 bits per transform
+ { 2, 0, 9 }, // 33 bits per transform
+ { 2, 1, 8 }, // 33 bits per transform
+ { 2, 2, 7 }, // 33 bits per transform
+ { 2, 3, 6 }, // 33 bits per transform
+ { 2, 4, 5 }, // 33 bits per transform
+ { 2, 5, 4 }, // 33 bits per transform
+ { 2, 6, 3 }, // 33 bits per transform
+ { 2, 7, 2 }, // 33 bits per transform
+ { 2, 8, 1 }, // 33 bits per transform
+ { 2, 9, 0 }, // 33 bits per transform
+ { 3, 0, 8 }, // 33 bits per transform
+ { 3, 1, 7 }, // 33 bits per transform
+ { 3, 2, 6 }, // 33 bits per transform
+ { 3, 3, 5 }, // 33 bits per transform
+ { 3, 4, 4 }, // 33 bits per transform
+ { 3, 5, 3 }, // 33 bits per transform
+ { 3, 6, 2 }, // 33 bits per transform
+ { 3, 7, 1 }, // 33 bits per transform
+ { 3, 8, 0 }, // 33 bits per transform
+ { 4, 0, 7 }, // 33 bits per transform
+ { 4, 1, 6 }, // 33 bits per transform
+ { 4, 2, 5 }, // 33 bits per transform
+ { 4, 3, 4 }, // 33 bits per transform
+ { 4, 4, 3 }, // 33 bits per transform
+ { 4, 5, 2 }, // 33 bits per transform
+ { 4, 6, 1 }, // 33 bits per transform
+ { 4, 7, 0 }, // 33 bits per transform
+ { 5, 0, 6 }, // 33 bits per transform
+ { 5, 1, 5 }, // 33 bits per transform
+ { 5, 2, 4 }, // 33 bits per transform
+ { 5, 3, 3 }, // 33 bits per transform
+ { 5, 4, 2 }, // 33 bits per transform
+ { 5, 5, 1 }, // 33 bits per transform
+ { 5, 6, 0 }, // 33 bits per transform
+ { 6, 0, 5 }, // 33 bits per transform
+ { 6, 1, 4 }, // 33 bits per transform
+ { 6, 2, 3 }, // 33 bits per transform
+ { 6, 3, 2 }, // 33 bits per transform
+ { 6, 4, 1 }, // 33 bits per transform
+ { 6, 5, 0 }, // 33 bits per transform
+ { 7, 0, 4 }, // 33 bits per transform
+ { 7, 1, 3 }, // 33 bits per transform
+ { 7, 2, 2 }, // 33 bits per transform
+ { 7, 3, 1 }, // 33 bits per transform
+ { 7, 4, 0 }, // 33 bits per transform
+ { 8, 0, 3 }, // 33 bits per transform
+ { 8, 1, 2 }, // 33 bits per transform
+ { 8, 2, 1 }, // 33 bits per transform
+ { 8, 3, 0 }, // 33 bits per transform
+ { 9, 0, 2 }, // 33 bits per transform
+ { 9, 1, 1 }, // 33 bits per transform
+ { 9, 2, 0 }, // 33 bits per transform
+ { 10, 0, 1 }, // 33 bits per transform
+ { 10, 1, 0 }, // 33 bits per transform
+ { 11, 0, 0 }, // 33 bits per transform
+ { 0, 0, 12 }, // 36 bits per transform
+ { 0, 1, 11 }, // 36 bits per transform
+ { 0, 2, 10 }, // 36 bits per transform
+ { 0, 3, 9 }, // 36 bits per transform
+ { 0, 4, 8 }, // 36 bits per transform
+ { 0, 5, 7 }, // 36 bits per transform
+ { 0, 6, 6 }, // 36 bits per transform
+ { 0, 7, 5 }, // 36 bits per transform
+ { 0, 8, 4 }, // 36 bits per transform
+ { 0, 9, 3 }, // 36 bits per transform
+ { 0, 10, 2 }, // 36 bits per transform
+ { 0, 11, 1 }, // 36 bits per transform
+ { 0, 12, 0 }, // 36 bits per transform
+ { 1, 0, 11 }, // 36 bits per transform
+ { 1, 1, 10 }, // 36 bits per transform
+ { 1, 2, 9 }, // 36 bits per transform
+ { 1, 3, 8 }, // 36 bits per transform
+ { 1, 4, 7 }, // 36 bits per transform
+ { 1, 5, 6 }, // 36 bits per transform
+ { 1, 6, 5 }, // 36 bits per transform
+ { 1, 7, 4 }, // 36 bits per transform
+ { 1, 8, 3 }, // 36 bits per transform
+ { 1, 9, 2 }, // 36 bits per transform
+ { 1, 10, 1 }, // 36 bits per transform
+ { 1, 11, 0 }, // 36 bits per transform
+ { 2, 0, 10 }, // 36 bits per transform
+ { 2, 1, 9 }, // 36 bits per transform
+ { 2, 2, 8 }, // 36 bits per transform
+ { 2, 3, 7 }, // 36 bits per transform
+ { 2, 4, 6 }, // 36 bits per transform
+ { 2, 5, 5 }, // 36 bits per transform
+ { 2, 6, 4 }, // 36 bits per transform
+ { 2, 7, 3 }, // 36 bits per transform
+ { 2, 8, 2 }, // 36 bits per transform
+ { 2, 9, 1 }, // 36 bits per transform
+ { 2, 10, 0 }, // 36 bits per transform
+ { 3, 0, 9 }, // 36 bits per transform
+ { 3, 1, 8 }, // 36 bits per transform
+ { 3, 2, 7 }, // 36 bits per transform
+ { 3, 3, 6 }, // 36 bits per transform
+ { 3, 4, 5 }, // 36 bits per transform
+ { 3, 5, 4 }, // 36 bits per transform
+ { 3, 6, 3 }, // 36 bits per transform
+ { 3, 7, 2 }, // 36 bits per transform
+ { 3, 8, 1 }, // 36 bits per transform
+ { 3, 9, 0 }, // 36 bits per transform
+ { 4, 0, 8 }, // 36 bits per transform
+ { 4, 1, 7 }, // 36 bits per transform
+ { 4, 2, 6 }, // 36 bits per transform
+ { 4, 3, 5 }, // 36 bits per transform
+ { 4, 4, 4 }, // 36 bits per transform
+ { 4, 5, 3 }, // 36 bits per transform
+ { 4, 6, 2 }, // 36 bits per transform
+ { 4, 7, 1 }, // 36 bits per transform
+ { 4, 8, 0 }, // 36 bits per transform
+ { 5, 0, 7 }, // 36 bits per transform
+ { 5, 1, 6 }, // 36 bits per transform
+ { 5, 2, 5 }, // 36 bits per transform
+ { 5, 3, 4 }, // 36 bits per transform
+ { 5, 4, 3 }, // 36 bits per transform
+ { 5, 5, 2 }, // 36 bits per transform
+ { 5, 6, 1 }, // 36 bits per transform
+ { 5, 7, 0 }, // 36 bits per transform
+ { 6, 0, 6 }, // 36 bits per transform
+ { 6, 1, 5 }, // 36 bits per transform
+ { 6, 2, 4 }, // 36 bits per transform
+ { 6, 3, 3 }, // 36 bits per transform
+ { 6, 4, 2 }, // 36 bits per transform
+ { 6, 5, 1 }, // 36 bits per transform
+ { 6, 6, 0 }, // 36 bits per transform
+ { 7, 0, 5 }, // 36 bits per transform
+ { 7, 1, 4 }, // 36 bits per transform
+ { 7, 2, 3 }, // 36 bits per transform
+ { 7, 3, 2 }, // 36 bits per transform
+ { 7, 4, 1 }, // 36 bits per transform
+ { 7, 5, 0 }, // 36 bits per transform
+ { 8, 0, 4 }, // 36 bits per transform
+ { 8, 1, 3 }, // 36 bits per transform
+ { 8, 2, 2 }, // 36 bits per transform
+ { 8, 3, 1 }, // 36 bits per transform
+ { 8, 4, 0 }, // 36 bits per transform
+ { 9, 0, 3 }, // 36 bits per transform
+ { 9, 1, 2 }, // 36 bits per transform
+ { 9, 2, 1 }, // 36 bits per transform
+ { 9, 3, 0 }, // 36 bits per transform
+ { 10, 0, 2 }, // 36 bits per transform
+ { 10, 1, 1 }, // 36 bits per transform
+ { 10, 2, 0 }, // 36 bits per transform
+ { 11, 0, 1 }, // 36 bits per transform
+ { 11, 1, 0 }, // 36 bits per transform
+ { 12, 0, 0 }, // 36 bits per transform
+ { 0, 0, 13 }, // 39 bits per transform
+ { 0, 1, 12 }, // 39 bits per transform
+ { 0, 2, 11 }, // 39 bits per transform
+ { 0, 3, 10 }, // 39 bits per transform
+ { 0, 4, 9 }, // 39 bits per transform
+ { 0, 5, 8 }, // 39 bits per transform
+ { 0, 6, 7 }, // 39 bits per transform
+ { 0, 7, 6 }, // 39 bits per transform
+ { 0, 8, 5 }, // 39 bits per transform
+ { 0, 9, 4 }, // 39 bits per transform
+ { 0, 10, 3 }, // 39 bits per transform
+ { 0, 11, 2 }, // 39 bits per transform
+ { 0, 12, 1 }, // 39 bits per transform
+ { 0, 13, 0 }, // 39 bits per transform
+ { 1, 0, 12 }, // 39 bits per transform
+ { 1, 1, 11 }, // 39 bits per transform
+ { 1, 2, 10 }, // 39 bits per transform
+ { 1, 3, 9 }, // 39 bits per transform
+ { 1, 4, 8 }, // 39 bits per transform
+ { 1, 5, 7 }, // 39 bits per transform
+ { 1, 6, 6 }, // 39 bits per transform
+ { 1, 7, 5 }, // 39 bits per transform
+ { 1, 8, 4 }, // 39 bits per transform
+ { 1, 9, 3 }, // 39 bits per transform
+ { 1, 10, 2 }, // 39 bits per transform
+ { 1, 11, 1 }, // 39 bits per transform
+ { 1, 12, 0 }, // 39 bits per transform
+ { 2, 0, 11 }, // 39 bits per transform
+ { 2, 1, 10 }, // 39 bits per transform
+ { 2, 2, 9 }, // 39 bits per transform
+ { 2, 3, 8 }, // 39 bits per transform
+ { 2, 4, 7 }, // 39 bits per transform
+ { 2, 5, 6 }, // 39 bits per transform
+ { 2, 6, 5 }, // 39 bits per transform
+ { 2, 7, 4 }, // 39 bits per transform
+ { 2, 8, 3 }, // 39 bits per transform
+ { 2, 9, 2 }, // 39 bits per transform
+ { 2, 10, 1 }, // 39 bits per transform
+ { 2, 11, 0 }, // 39 bits per transform
+ { 3, 0, 10 }, // 39 bits per transform
+ { 3, 1, 9 }, // 39 bits per transform
+ { 3, 2, 8 }, // 39 bits per transform
+ { 3, 3, 7 }, // 39 bits per transform
+ { 3, 4, 6 }, // 39 bits per transform
+ { 3, 5, 5 }, // 39 bits per transform
+ { 3, 6, 4 }, // 39 bits per transform
+ { 3, 7, 3 }, // 39 bits per transform
+ { 3, 8, 2 }, // 39 bits per transform
+ { 3, 9, 1 }, // 39 bits per transform
+ { 3, 10, 0 }, // 39 bits per transform
+ { 4, 0, 9 }, // 39 bits per transform
+ { 4, 1, 8 }, // 39 bits per transform
+ { 4, 2, 7 }, // 39 bits per transform
+ { 4, 3, 6 }, // 39 bits per transform
+ { 4, 4, 5 }, // 39 bits per transform
+ { 4, 5, 4 }, // 39 bits per transform
+ { 4, 6, 3 }, // 39 bits per transform
+ { 4, 7, 2 }, // 39 bits per transform
+ { 4, 8, 1 }, // 39 bits per transform
+ { 4, 9, 0 }, // 39 bits per transform
+ { 5, 0, 8 }, // 39 bits per transform
+ { 5, 1, 7 }, // 39 bits per transform
+ { 5, 2, 6 }, // 39 bits per transform
+ { 5, 3, 5 }, // 39 bits per transform
+ { 5, 4, 4 }, // 39 bits per transform
+ { 5, 5, 3 }, // 39 bits per transform
+ { 5, 6, 2 }, // 39 bits per transform
+ { 5, 7, 1 }, // 39 bits per transform
+ { 5, 8, 0 }, // 39 bits per transform
+ { 6, 0, 7 }, // 39 bits per transform
+ { 6, 1, 6 }, // 39 bits per transform
+ { 6, 2, 5 }, // 39 bits per transform
+ { 6, 3, 4 }, // 39 bits per transform
+ { 6, 4, 3 }, // 39 bits per transform
+ { 6, 5, 2 }, // 39 bits per transform
+ { 6, 6, 1 }, // 39 bits per transform
+ { 6, 7, 0 }, // 39 bits per transform
+ { 7, 0, 6 }, // 39 bits per transform
+ { 7, 1, 5 }, // 39 bits per transform
+ { 7, 2, 4 }, // 39 bits per transform
+ { 7, 3, 3 }, // 39 bits per transform
+ { 7, 4, 2 }, // 39 bits per transform
+ { 7, 5, 1 }, // 39 bits per transform
+ { 7, 6, 0 }, // 39 bits per transform
+ { 8, 0, 5 }, // 39 bits per transform
+ { 8, 1, 4 }, // 39 bits per transform
+ { 8, 2, 3 }, // 39 bits per transform
+ { 8, 3, 2 }, // 39 bits per transform
+ { 8, 4, 1 }, // 39 bits per transform
+ { 8, 5, 0 }, // 39 bits per transform
+ { 9, 0, 4 }, // 39 bits per transform
+ { 9, 1, 3 }, // 39 bits per transform
+ { 9, 2, 2 }, // 39 bits per transform
+ { 9, 3, 1 }, // 39 bits per transform
+ { 9, 4, 0 }, // 39 bits per transform
+ { 10, 0, 3 }, // 39 bits per transform
+ { 10, 1, 2 }, // 39 bits per transform
+ { 10, 2, 1 }, // 39 bits per transform
+ { 10, 3, 0 }, // 39 bits per transform
+ { 11, 0, 2 }, // 39 bits per transform
+ { 11, 1, 1 }, // 39 bits per transform
+ { 11, 2, 0 }, // 39 bits per transform
+ { 12, 0, 1 }, // 39 bits per transform
+ { 12, 1, 0 }, // 39 bits per transform
+ { 13, 0, 0 }, // 39 bits per transform
+ { 0, 0, 14 }, // 42 bits per transform
+ { 0, 1, 13 }, // 42 bits per transform
+ { 0, 2, 12 }, // 42 bits per transform
+ { 0, 3, 11 }, // 42 bits per transform
+ { 0, 4, 10 }, // 42 bits per transform
+ { 0, 5, 9 }, // 42 bits per transform
+ { 0, 6, 8 }, // 42 bits per transform
+ { 0, 7, 7 }, // 42 bits per transform
+ { 0, 8, 6 }, // 42 bits per transform
+ { 0, 9, 5 }, // 42 bits per transform
+ { 0, 10, 4 }, // 42 bits per transform
+ { 0, 11, 3 }, // 42 bits per transform
+ { 0, 12, 2 }, // 42 bits per transform
+ { 0, 13, 1 }, // 42 bits per transform
+ { 0, 14, 0 }, // 42 bits per transform
+ { 1, 0, 13 }, // 42 bits per transform
+ { 1, 1, 12 }, // 42 bits per transform
+ { 1, 2, 11 }, // 42 bits per transform
+ { 1, 3, 10 }, // 42 bits per transform
+ { 1, 4, 9 }, // 42 bits per transform
+ { 1, 5, 8 }, // 42 bits per transform
+ { 1, 6, 7 }, // 42 bits per transform
+ { 1, 7, 6 }, // 42 bits per transform
+ { 1, 8, 5 }, // 42 bits per transform
+ { 1, 9, 4 }, // 42 bits per transform
+ { 1, 10, 3 }, // 42 bits per transform
+ { 1, 11, 2 }, // 42 bits per transform
+ { 1, 12, 1 }, // 42 bits per transform
+ { 1, 13, 0 }, // 42 bits per transform
+ { 2, 0, 12 }, // 42 bits per transform
+ { 2, 1, 11 }, // 42 bits per transform
+ { 2, 2, 10 }, // 42 bits per transform
+ { 2, 3, 9 }, // 42 bits per transform
+ { 2, 4, 8 }, // 42 bits per transform
+ { 2, 5, 7 }, // 42 bits per transform
+ { 2, 6, 6 }, // 42 bits per transform
+ { 2, 7, 5 }, // 42 bits per transform
+ { 2, 8, 4 }, // 42 bits per transform
+ { 2, 9, 3 }, // 42 bits per transform
+ { 2, 10, 2 }, // 42 bits per transform
+ { 2, 11, 1 }, // 42 bits per transform
+ { 2, 12, 0 }, // 42 bits per transform
+ { 3, 0, 11 }, // 42 bits per transform
+ { 3, 1, 10 }, // 42 bits per transform
+ { 3, 2, 9 }, // 42 bits per transform
+ { 3, 3, 8 }, // 42 bits per transform
+ { 3, 4, 7 }, // 42 bits per transform
+ { 3, 5, 6 }, // 42 bits per transform
+ { 3, 6, 5 }, // 42 bits per transform
+ { 3, 7, 4 }, // 42 bits per transform
+ { 3, 8, 3 }, // 42 bits per transform
+ { 3, 9, 2 }, // 42 bits per transform
+ { 3, 10, 1 }, // 42 bits per transform
+ { 3, 11, 0 }, // 42 bits per transform
+ { 4, 0, 10 }, // 42 bits per transform
+ { 4, 1, 9 }, // 42 bits per transform
+ { 4, 2, 8 }, // 42 bits per transform
+ { 4, 3, 7 }, // 42 bits per transform
+ { 4, 4, 6 }, // 42 bits per transform
+ { 4, 5, 5 }, // 42 bits per transform
+ { 4, 6, 4 }, // 42 bits per transform
+ { 4, 7, 3 }, // 42 bits per transform
+ { 4, 8, 2 }, // 42 bits per transform
+ { 4, 9, 1 }, // 42 bits per transform
+ { 4, 10, 0 }, // 42 bits per transform
+ { 5, 0, 9 }, // 42 bits per transform
+ { 5, 1, 8 }, // 42 bits per transform
+ { 5, 2, 7 }, // 42 bits per transform
+ { 5, 3, 6 }, // 42 bits per transform
+ { 5, 4, 5 }, // 42 bits per transform
+ { 5, 5, 4 }, // 42 bits per transform
+ { 5, 6, 3 }, // 42 bits per transform
+ { 5, 7, 2 }, // 42 bits per transform
+ { 5, 8, 1 }, // 42 bits per transform
+ { 5, 9, 0 }, // 42 bits per transform
+ { 6, 0, 8 }, // 42 bits per transform
+ { 6, 1, 7 }, // 42 bits per transform
+ { 6, 2, 6 }, // 42 bits per transform
+ { 6, 3, 5 }, // 42 bits per transform
+ { 6, 4, 4 }, // 42 bits per transform
+ { 6, 5, 3 }, // 42 bits per transform
+ { 6, 6, 2 }, // 42 bits per transform
+ { 6, 7, 1 }, // 42 bits per transform
+ { 6, 8, 0 }, // 42 bits per transform
+ { 7, 0, 7 }, // 42 bits per transform
+ { 7, 1, 6 }, // 42 bits per transform
+ { 7, 2, 5 }, // 42 bits per transform
+ { 7, 3, 4 }, // 42 bits per transform
+ { 7, 4, 3 }, // 42 bits per transform
+ { 7, 5, 2 }, // 42 bits per transform
+ { 7, 6, 1 }, // 42 bits per transform
+ { 7, 7, 0 }, // 42 bits per transform
+ { 8, 0, 6 }, // 42 bits per transform
+ { 8, 1, 5 }, // 42 bits per transform
+ { 8, 2, 4 }, // 42 bits per transform
+ { 8, 3, 3 }, // 42 bits per transform
+ { 8, 4, 2 }, // 42 bits per transform
+ { 8, 5, 1 }, // 42 bits per transform
+ { 8, 6, 0 }, // 42 bits per transform
+ { 9, 0, 5 }, // 42 bits per transform
+ { 9, 1, 4 }, // 42 bits per transform
+ { 9, 2, 3 }, // 42 bits per transform
+ { 9, 3, 2 }, // 42 bits per transform
+ { 9, 4, 1 }, // 42 bits per transform
+ { 9, 5, 0 }, // 42 bits per transform
+ { 10, 0, 4 }, // 42 bits per transform
+ { 10, 1, 3 }, // 42 bits per transform
+ { 10, 2, 2 }, // 42 bits per transform
+ { 10, 3, 1 }, // 42 bits per transform
+ { 10, 4, 0 }, // 42 bits per transform
+ { 11, 0, 3 }, // 42 bits per transform
+ { 11, 1, 2 }, // 42 bits per transform
+ { 11, 2, 1 }, // 42 bits per transform
+ { 11, 3, 0 }, // 42 bits per transform
+ { 12, 0, 2 }, // 42 bits per transform
+ { 12, 1, 1 }, // 42 bits per transform
+ { 12, 2, 0 }, // 42 bits per transform
+ { 13, 0, 1 }, // 42 bits per transform
+ { 13, 1, 0 }, // 42 bits per transform
+ { 14, 0, 0 }, // 42 bits per transform
+ { 0, 0, 15 }, // 45 bits per transform
+ { 0, 1, 14 }, // 45 bits per transform
+ { 0, 2, 13 }, // 45 bits per transform
+ { 0, 3, 12 }, // 45 bits per transform
+ { 0, 4, 11 }, // 45 bits per transform
+ { 0, 5, 10 }, // 45 bits per transform
+ { 0, 6, 9 }, // 45 bits per transform
+ { 0, 7, 8 }, // 45 bits per transform
+ { 0, 8, 7 }, // 45 bits per transform
+ { 0, 9, 6 }, // 45 bits per transform
+ { 0, 10, 5 }, // 45 bits per transform
+ { 0, 11, 4 }, // 45 bits per transform
+ { 0, 12, 3 }, // 45 bits per transform
+ { 0, 13, 2 }, // 45 bits per transform
+ { 0, 14, 1 }, // 45 bits per transform
+ { 0, 15, 0 }, // 45 bits per transform
+ { 1, 0, 14 }, // 45 bits per transform
+ { 1, 1, 13 }, // 45 bits per transform
+ { 1, 2, 12 }, // 45 bits per transform
+ { 1, 3, 11 }, // 45 bits per transform
+ { 1, 4, 10 }, // 45 bits per transform
+ { 1, 5, 9 }, // 45 bits per transform
+ { 1, 6, 8 }, // 45 bits per transform
+ { 1, 7, 7 }, // 45 bits per transform
+ { 1, 8, 6 }, // 45 bits per transform
+ { 1, 9, 5 }, // 45 bits per transform
+ { 1, 10, 4 }, // 45 bits per transform
+ { 1, 11, 3 }, // 45 bits per transform
+ { 1, 12, 2 }, // 45 bits per transform
+ { 1, 13, 1 }, // 45 bits per transform
+ { 1, 14, 0 }, // 45 bits per transform
+ { 2, 0, 13 }, // 45 bits per transform
+ { 2, 1, 12 }, // 45 bits per transform
+ { 2, 2, 11 }, // 45 bits per transform
+ { 2, 3, 10 }, // 45 bits per transform
+ { 2, 4, 9 }, // 45 bits per transform
+ { 2, 5, 8 }, // 45 bits per transform
+ { 2, 6, 7 }, // 45 bits per transform
+ { 2, 7, 6 }, // 45 bits per transform
+ { 2, 8, 5 }, // 45 bits per transform
+ { 2, 9, 4 }, // 45 bits per transform
+ { 2, 10, 3 }, // 45 bits per transform
+ { 2, 11, 2 }, // 45 bits per transform
+ { 2, 12, 1 }, // 45 bits per transform
+ { 2, 13, 0 }, // 45 bits per transform
+ { 3, 0, 12 }, // 45 bits per transform
+ { 3, 1, 11 }, // 45 bits per transform
+ { 3, 2, 10 }, // 45 bits per transform
+ { 3, 3, 9 }, // 45 bits per transform
+ { 3, 4, 8 }, // 45 bits per transform
+ { 3, 5, 7 }, // 45 bits per transform
+ { 3, 6, 6 }, // 45 bits per transform
+ { 3, 7, 5 }, // 45 bits per transform
+ { 3, 8, 4 }, // 45 bits per transform
+ { 3, 9, 3 }, // 45 bits per transform
+ { 3, 10, 2 }, // 45 bits per transform
+ { 3, 11, 1 }, // 45 bits per transform
+ { 3, 12, 0 }, // 45 bits per transform
+ { 4, 0, 11 }, // 45 bits per transform
+ { 4, 1, 10 }, // 45 bits per transform
+ { 4, 2, 9 }, // 45 bits per transform
+ { 4, 3, 8 }, // 45 bits per transform
+ { 4, 4, 7 }, // 45 bits per transform
+ { 4, 5, 6 }, // 45 bits per transform
+ { 4, 6, 5 }, // 45 bits per transform
+ { 4, 7, 4 }, // 45 bits per transform
+ { 4, 8, 3 }, // 45 bits per transform
+ { 4, 9, 2 }, // 45 bits per transform
+ { 4, 10, 1 }, // 45 bits per transform
+ { 4, 11, 0 }, // 45 bits per transform
+ { 5, 0, 10 }, // 45 bits per transform
+ { 5, 1, 9 }, // 45 bits per transform
+ { 5, 2, 8 }, // 45 bits per transform
+ { 5, 3, 7 }, // 45 bits per transform
+ { 5, 4, 6 }, // 45 bits per transform
+ { 5, 5, 5 }, // 45 bits per transform
+ { 5, 6, 4 }, // 45 bits per transform
+ { 5, 7, 3 }, // 45 bits per transform
+ { 5, 8, 2 }, // 45 bits per transform
+ { 5, 9, 1 }, // 45 bits per transform
+ { 5, 10, 0 }, // 45 bits per transform
+ { 6, 0, 9 }, // 45 bits per transform
+ { 6, 1, 8 }, // 45 bits per transform
+ { 6, 2, 7 }, // 45 bits per transform
+ { 6, 3, 6 }, // 45 bits per transform
+ { 6, 4, 5 }, // 45 bits per transform
+ { 6, 5, 4 }, // 45 bits per transform
+ { 6, 6, 3 }, // 45 bits per transform
+ { 6, 7, 2 }, // 45 bits per transform
+ { 6, 8, 1 }, // 45 bits per transform
+ { 6, 9, 0 }, // 45 bits per transform
+ { 7, 0, 8 }, // 45 bits per transform
+ { 7, 1, 7 }, // 45 bits per transform
+ { 7, 2, 6 }, // 45 bits per transform
+ { 7, 3, 5 }, // 45 bits per transform
+ { 7, 4, 4 }, // 45 bits per transform
+ { 7, 5, 3 }, // 45 bits per transform
+ { 7, 6, 2 }, // 45 bits per transform
+ { 7, 7, 1 }, // 45 bits per transform
+ { 7, 8, 0 }, // 45 bits per transform
+ { 8, 0, 7 }, // 45 bits per transform
+ { 8, 1, 6 }, // 45 bits per transform
+ { 8, 2, 5 }, // 45 bits per transform
+ { 8, 3, 4 }, // 45 bits per transform
+ { 8, 4, 3 }, // 45 bits per transform
+ { 8, 5, 2 }, // 45 bits per transform
+ { 8, 6, 1 }, // 45 bits per transform
+ { 8, 7, 0 }, // 45 bits per transform
+ { 9, 0, 6 }, // 45 bits per transform
+ { 9, 1, 5 }, // 45 bits per transform
+ { 9, 2, 4 }, // 45 bits per transform
+ { 9, 3, 3 }, // 45 bits per transform
+ { 9, 4, 2 }, // 45 bits per transform
+ { 9, 5, 1 }, // 45 bits per transform
+ { 9, 6, 0 }, // 45 bits per transform
+ { 10, 0, 5 }, // 45 bits per transform
+ { 10, 1, 4 }, // 45 bits per transform
+ { 10, 2, 3 }, // 45 bits per transform
+ { 10, 3, 2 }, // 45 bits per transform
+ { 10, 4, 1 }, // 45 bits per transform
+ { 10, 5, 0 }, // 45 bits per transform
+ { 11, 0, 4 }, // 45 bits per transform
+ { 11, 1, 3 }, // 45 bits per transform
+ { 11, 2, 2 }, // 45 bits per transform
+ { 11, 3, 1 }, // 45 bits per transform
+ { 11, 4, 0 }, // 45 bits per transform
+ { 12, 0, 3 }, // 45 bits per transform
+ { 12, 1, 2 }, // 45 bits per transform
+ { 12, 2, 1 }, // 45 bits per transform
+ { 12, 3, 0 }, // 45 bits per transform
+ { 13, 0, 2 }, // 45 bits per transform
+ { 13, 1, 1 }, // 45 bits per transform
+ { 13, 2, 0 }, // 45 bits per transform
+ { 14, 0, 1 }, // 45 bits per transform
+ { 14, 1, 0 }, // 45 bits per transform
+ { 15, 0, 0 }, // 45 bits per transform
+ { 0, 0, 16 }, // 48 bits per transform
+ { 0, 1, 15 }, // 48 bits per transform
+ { 0, 2, 14 }, // 48 bits per transform
+ { 0, 3, 13 }, // 48 bits per transform
+ { 0, 4, 12 }, // 48 bits per transform
+ { 0, 5, 11 }, // 48 bits per transform
+ { 0, 6, 10 }, // 48 bits per transform
+ { 0, 7, 9 }, // 48 bits per transform
+ { 0, 8, 8 }, // 48 bits per transform
+ { 0, 9, 7 }, // 48 bits per transform
+ { 0, 10, 6 }, // 48 bits per transform
+ { 0, 11, 5 }, // 48 bits per transform
+ { 0, 12, 4 }, // 48 bits per transform
+ { 0, 13, 3 }, // 48 bits per transform
+ { 0, 14, 2 }, // 48 bits per transform
+ { 0, 15, 1 }, // 48 bits per transform
+ { 0, 16, 0 }, // 48 bits per transform
+ { 1, 0, 15 }, // 48 bits per transform
+ { 1, 1, 14 }, // 48 bits per transform
+ { 1, 2, 13 }, // 48 bits per transform
+ { 1, 3, 12 }, // 48 bits per transform
+ { 1, 4, 11 }, // 48 bits per transform
+ { 1, 5, 10 }, // 48 bits per transform
+ { 1, 6, 9 }, // 48 bits per transform
+ { 1, 7, 8 }, // 48 bits per transform
+ { 1, 8, 7 }, // 48 bits per transform
+ { 1, 9, 6 }, // 48 bits per transform
+ { 1, 10, 5 }, // 48 bits per transform
+ { 1, 11, 4 }, // 48 bits per transform
+ { 1, 12, 3 }, // 48 bits per transform
+ { 1, 13, 2 }, // 48 bits per transform
+ { 1, 14, 1 }, // 48 bits per transform
+ { 1, 15, 0 }, // 48 bits per transform
+ { 2, 0, 14 }, // 48 bits per transform
+ { 2, 1, 13 }, // 48 bits per transform
+ { 2, 2, 12 }, // 48 bits per transform
+ { 2, 3, 11 }, // 48 bits per transform
+ { 2, 4, 10 }, // 48 bits per transform
+ { 2, 5, 9 }, // 48 bits per transform
+ { 2, 6, 8 }, // 48 bits per transform
+ { 2, 7, 7 }, // 48 bits per transform
+ { 2, 8, 6 }, // 48 bits per transform
+ { 2, 9, 5 }, // 48 bits per transform
+ { 2, 10, 4 }, // 48 bits per transform
+ { 2, 11, 3 }, // 48 bits per transform
+ { 2, 12, 2 }, // 48 bits per transform
+ { 2, 13, 1 }, // 48 bits per transform
+ { 2, 14, 0 }, // 48 bits per transform
+ { 3, 0, 13 }, // 48 bits per transform
+ { 3, 1, 12 }, // 48 bits per transform
+ { 3, 2, 11 }, // 48 bits per transform
+ { 3, 3, 10 }, // 48 bits per transform
+ { 3, 4, 9 }, // 48 bits per transform
+ { 3, 5, 8 }, // 48 bits per transform
+ { 3, 6, 7 }, // 48 bits per transform
+ { 3, 7, 6 }, // 48 bits per transform
+ { 3, 8, 5 }, // 48 bits per transform
+ { 3, 9, 4 }, // 48 bits per transform
+ { 3, 10, 3 }, // 48 bits per transform
+ { 3, 11, 2 }, // 48 bits per transform
+ { 3, 12, 1 }, // 48 bits per transform
+ { 3, 13, 0 }, // 48 bits per transform
+ { 4, 0, 12 }, // 48 bits per transform
+ { 4, 1, 11 }, // 48 bits per transform
+ { 4, 2, 10 }, // 48 bits per transform
+ { 4, 3, 9 }, // 48 bits per transform
+ { 4, 4, 8 }, // 48 bits per transform
+ { 4, 5, 7 }, // 48 bits per transform
+ { 4, 6, 6 }, // 48 bits per transform
+ { 4, 7, 5 }, // 48 bits per transform
+ { 4, 8, 4 }, // 48 bits per transform
+ { 4, 9, 3 }, // 48 bits per transform
+ { 4, 10, 2 }, // 48 bits per transform
+ { 4, 11, 1 }, // 48 bits per transform
+ { 4, 12, 0 }, // 48 bits per transform
+ { 5, 0, 11 }, // 48 bits per transform
+ { 5, 1, 10 }, // 48 bits per transform
+ { 5, 2, 9 }, // 48 bits per transform
+ { 5, 3, 8 }, // 48 bits per transform
+ { 5, 4, 7 }, // 48 bits per transform
+ { 5, 5, 6 }, // 48 bits per transform
+ { 5, 6, 5 }, // 48 bits per transform
+ { 5, 7, 4 }, // 48 bits per transform
+ { 5, 8, 3 }, // 48 bits per transform
+ { 5, 9, 2 }, // 48 bits per transform
+ { 5, 10, 1 }, // 48 bits per transform
+ { 5, 11, 0 }, // 48 bits per transform
+ { 6, 0, 10 }, // 48 bits per transform
+ { 6, 1, 9 }, // 48 bits per transform
+ { 6, 2, 8 }, // 48 bits per transform
+ { 6, 3, 7 }, // 48 bits per transform
+ { 6, 4, 6 }, // 48 bits per transform
+ { 6, 5, 5 }, // 48 bits per transform
+ { 6, 6, 4 }, // 48 bits per transform
+ { 6, 7, 3 }, // 48 bits per transform
+ { 6, 8, 2 }, // 48 bits per transform
+ { 6, 9, 1 }, // 48 bits per transform
+ { 6, 10, 0 }, // 48 bits per transform
+ { 7, 0, 9 }, // 48 bits per transform
+ { 7, 1, 8 }, // 48 bits per transform
+ { 7, 2, 7 }, // 48 bits per transform
+ { 7, 3, 6 }, // 48 bits per transform
+ { 7, 4, 5 }, // 48 bits per transform
+ { 7, 5, 4 }, // 48 bits per transform
+ { 7, 6, 3 }, // 48 bits per transform
+ { 7, 7, 2 }, // 48 bits per transform
+ { 7, 8, 1 }, // 48 bits per transform
+ { 7, 9, 0 }, // 48 bits per transform
+ { 8, 0, 8 }, // 48 bits per transform
+ { 8, 1, 7 }, // 48 bits per transform
+ { 8, 2, 6 }, // 48 bits per transform
+ { 8, 3, 5 }, // 48 bits per transform
+ { 8, 4, 4 }, // 48 bits per transform
+ { 8, 5, 3 }, // 48 bits per transform
+ { 8, 6, 2 }, // 48 bits per transform
+ { 8, 7, 1 }, // 48 bits per transform
+ { 8, 8, 0 }, // 48 bits per transform
+ { 9, 0, 7 }, // 48 bits per transform
+ { 9, 1, 6 }, // 48 bits per transform
+ { 9, 2, 5 }, // 48 bits per transform
+ { 9, 3, 4 }, // 48 bits per transform
+ { 9, 4, 3 }, // 48 bits per transform
+ { 9, 5, 2 }, // 48 bits per transform
+ { 9, 6, 1 }, // 48 bits per transform
+ { 9, 7, 0 }, // 48 bits per transform
+ { 10, 0, 6 }, // 48 bits per transform
+ { 10, 1, 5 }, // 48 bits per transform
+ { 10, 2, 4 }, // 48 bits per transform
+ { 10, 3, 3 }, // 48 bits per transform
+ { 10, 4, 2 }, // 48 bits per transform
+ { 10, 5, 1 }, // 48 bits per transform
+ { 10, 6, 0 }, // 48 bits per transform
+ { 11, 0, 5 }, // 48 bits per transform
+ { 11, 1, 4 }, // 48 bits per transform
+ { 11, 2, 3 }, // 48 bits per transform
+ { 11, 3, 2 }, // 48 bits per transform
+ { 11, 4, 1 }, // 48 bits per transform
+ { 11, 5, 0 }, // 48 bits per transform
+ { 12, 0, 4 }, // 48 bits per transform
+ { 12, 1, 3 }, // 48 bits per transform
+ { 12, 2, 2 }, // 48 bits per transform
+ { 12, 3, 1 }, // 48 bits per transform
+ { 12, 4, 0 }, // 48 bits per transform
+ { 13, 0, 3 }, // 48 bits per transform
+ { 13, 1, 2 }, // 48 bits per transform
+ { 13, 2, 1 }, // 48 bits per transform
+ { 13, 3, 0 }, // 48 bits per transform
+ { 14, 0, 2 }, // 48 bits per transform
+ { 14, 1, 1 }, // 48 bits per transform
+ { 14, 2, 0 }, // 48 bits per transform
+ { 15, 0, 1 }, // 48 bits per transform
+ { 15, 1, 0 }, // 48 bits per transform
+ { 16, 0, 0 }, // 48 bits per transform
+ { 0, 0, 17 }, // 51 bits per transform
+ { 0, 1, 16 }, // 51 bits per transform
+ { 0, 2, 15 }, // 51 bits per transform
+ { 0, 3, 14 }, // 51 bits per transform
+ { 0, 4, 13 }, // 51 bits per transform
+ { 0, 5, 12 }, // 51 bits per transform
+ { 0, 6, 11 }, // 51 bits per transform
+ { 0, 7, 10 }, // 51 bits per transform
+ { 0, 8, 9 }, // 51 bits per transform
+ { 0, 9, 8 }, // 51 bits per transform
+ { 0, 10, 7 }, // 51 bits per transform
+ { 0, 11, 6 }, // 51 bits per transform
+ { 0, 12, 5 }, // 51 bits per transform
+ { 0, 13, 4 }, // 51 bits per transform
+ { 0, 14, 3 }, // 51 bits per transform
+ { 0, 15, 2 }, // 51 bits per transform
+ { 0, 16, 1 }, // 51 bits per transform
+ { 0, 17, 0 }, // 51 bits per transform
+ { 1, 0, 16 }, // 51 bits per transform
+ { 1, 1, 15 }, // 51 bits per transform
+ { 1, 2, 14 }, // 51 bits per transform
+ { 1, 3, 13 }, // 51 bits per transform
+ { 1, 4, 12 }, // 51 bits per transform
+ { 1, 5, 11 }, // 51 bits per transform
+ { 1, 6, 10 }, // 51 bits per transform
+ { 1, 7, 9 }, // 51 bits per transform
+ { 1, 8, 8 }, // 51 bits per transform
+ { 1, 9, 7 }, // 51 bits per transform
+ { 1, 10, 6 }, // 51 bits per transform
+ { 1, 11, 5 }, // 51 bits per transform
+ { 1, 12, 4 }, // 51 bits per transform
+ { 1, 13, 3 }, // 51 bits per transform
+ { 1, 14, 2 }, // 51 bits per transform
+ { 1, 15, 1 }, // 51 bits per transform
+ { 1, 16, 0 }, // 51 bits per transform
+ { 2, 0, 15 }, // 51 bits per transform
+ { 2, 1, 14 }, // 51 bits per transform
+ { 2, 2, 13 }, // 51 bits per transform
+ { 2, 3, 12 }, // 51 bits per transform
+ { 2, 4, 11 }, // 51 bits per transform
+ { 2, 5, 10 }, // 51 bits per transform
+ { 2, 6, 9 }, // 51 bits per transform
+ { 2, 7, 8 }, // 51 bits per transform
+ { 2, 8, 7 }, // 51 bits per transform
+ { 2, 9, 6 }, // 51 bits per transform
+ { 2, 10, 5 }, // 51 bits per transform
+ { 2, 11, 4 }, // 51 bits per transform
+ { 2, 12, 3 }, // 51 bits per transform
+ { 2, 13, 2 }, // 51 bits per transform
+ { 2, 14, 1 }, // 51 bits per transform
+ { 2, 15, 0 }, // 51 bits per transform
+ { 3, 0, 14 }, // 51 bits per transform
+ { 3, 1, 13 }, // 51 bits per transform
+ { 3, 2, 12 }, // 51 bits per transform
+ { 3, 3, 11 }, // 51 bits per transform
+ { 3, 4, 10 }, // 51 bits per transform
+ { 3, 5, 9 }, // 51 bits per transform
+ { 3, 6, 8 }, // 51 bits per transform
+ { 3, 7, 7 }, // 51 bits per transform
+ { 3, 8, 6 }, // 51 bits per transform
+ { 3, 9, 5 }, // 51 bits per transform
+ { 3, 10, 4 }, // 51 bits per transform
+ { 3, 11, 3 }, // 51 bits per transform
+ { 3, 12, 2 }, // 51 bits per transform
+ { 3, 13, 1 }, // 51 bits per transform
+ { 3, 14, 0 }, // 51 bits per transform
+ { 4, 0, 13 }, // 51 bits per transform
+ { 4, 1, 12 }, // 51 bits per transform
+ { 4, 2, 11 }, // 51 bits per transform
+ { 4, 3, 10 }, // 51 bits per transform
+ { 4, 4, 9 }, // 51 bits per transform
+ { 4, 5, 8 }, // 51 bits per transform
+ { 4, 6, 7 }, // 51 bits per transform
+ { 4, 7, 6 }, // 51 bits per transform
+ { 4, 8, 5 }, // 51 bits per transform
+ { 4, 9, 4 }, // 51 bits per transform
+ { 4, 10, 3 }, // 51 bits per transform
+ { 4, 11, 2 }, // 51 bits per transform
+ { 4, 12, 1 }, // 51 bits per transform
+ { 4, 13, 0 }, // 51 bits per transform
+ { 5, 0, 12 }, // 51 bits per transform
+ { 5, 1, 11 }, // 51 bits per transform
+ { 5, 2, 10 }, // 51 bits per transform
+ { 5, 3, 9 }, // 51 bits per transform
+ { 5, 4, 8 }, // 51 bits per transform
+ { 5, 5, 7 }, // 51 bits per transform
+ { 5, 6, 6 }, // 51 bits per transform
+ { 5, 7, 5 }, // 51 bits per transform
+ { 5, 8, 4 }, // 51 bits per transform
+ { 5, 9, 3 }, // 51 bits per transform
+ { 5, 10, 2 }, // 51 bits per transform
+ { 5, 11, 1 }, // 51 bits per transform
+ { 5, 12, 0 }, // 51 bits per transform
+ { 6, 0, 11 }, // 51 bits per transform
+ { 6, 1, 10 }, // 51 bits per transform
+ { 6, 2, 9 }, // 51 bits per transform
+ { 6, 3, 8 }, // 51 bits per transform
+ { 6, 4, 7 }, // 51 bits per transform
+ { 6, 5, 6 }, // 51 bits per transform
+ { 6, 6, 5 }, // 51 bits per transform
+ { 6, 7, 4 }, // 51 bits per transform
+ { 6, 8, 3 }, // 51 bits per transform
+ { 6, 9, 2 }, // 51 bits per transform
+ { 6, 10, 1 }, // 51 bits per transform
+ { 6, 11, 0 }, // 51 bits per transform
+ { 7, 0, 10 }, // 51 bits per transform
+ { 7, 1, 9 }, // 51 bits per transform
+ { 7, 2, 8 }, // 51 bits per transform
+ { 7, 3, 7 }, // 51 bits per transform
+ { 7, 4, 6 }, // 51 bits per transform
+ { 7, 5, 5 }, // 51 bits per transform
+ { 7, 6, 4 }, // 51 bits per transform
+ { 7, 7, 3 }, // 51 bits per transform
+ { 7, 8, 2 }, // 51 bits per transform
+ { 7, 9, 1 }, // 51 bits per transform
+ { 7, 10, 0 }, // 51 bits per transform
+ { 8, 0, 9 }, // 51 bits per transform
+ { 8, 1, 8 }, // 51 bits per transform
+ { 8, 2, 7 }, // 51 bits per transform
+ { 8, 3, 6 }, // 51 bits per transform
+ { 8, 4, 5 }, // 51 bits per transform
+ { 8, 5, 4 }, // 51 bits per transform
+ { 8, 6, 3 }, // 51 bits per transform
+ { 8, 7, 2 }, // 51 bits per transform
+ { 8, 8, 1 }, // 51 bits per transform
+ { 8, 9, 0 }, // 51 bits per transform
+ { 9, 0, 8 }, // 51 bits per transform
+ { 9, 1, 7 }, // 51 bits per transform
+ { 9, 2, 6 }, // 51 bits per transform
+ { 9, 3, 5 }, // 51 bits per transform
+ { 9, 4, 4 }, // 51 bits per transform
+ { 9, 5, 3 }, // 51 bits per transform
+ { 9, 6, 2 }, // 51 bits per transform
+ { 9, 7, 1 }, // 51 bits per transform
+ { 9, 8, 0 }, // 51 bits per transform
+ { 10, 0, 7 }, // 51 bits per transform
+ { 10, 1, 6 }, // 51 bits per transform
+ { 10, 2, 5 }, // 51 bits per transform
+ { 10, 3, 4 }, // 51 bits per transform
+ { 10, 4, 3 }, // 51 bits per transform
+ { 10, 5, 2 }, // 51 bits per transform
+ { 10, 6, 1 }, // 51 bits per transform
+ { 10, 7, 0 }, // 51 bits per transform
+ { 11, 0, 6 }, // 51 bits per transform
+ { 11, 1, 5 }, // 51 bits per transform
+ { 11, 2, 4 }, // 51 bits per transform
+ { 11, 3, 3 }, // 51 bits per transform
+ { 11, 4, 2 }, // 51 bits per transform
+ { 11, 5, 1 }, // 51 bits per transform
+ { 11, 6, 0 }, // 51 bits per transform
+ { 12, 0, 5 }, // 51 bits per transform
+ { 12, 1, 4 }, // 51 bits per transform
+ { 12, 2, 3 }, // 51 bits per transform
+ { 12, 3, 2 }, // 51 bits per transform
+ { 12, 4, 1 }, // 51 bits per transform
+ { 12, 5, 0 }, // 51 bits per transform
+ { 13, 0, 4 }, // 51 bits per transform
+ { 13, 1, 3 }, // 51 bits per transform
+ { 13, 2, 2 }, // 51 bits per transform
+ { 13, 3, 1 }, // 51 bits per transform
+ { 13, 4, 0 }, // 51 bits per transform
+ { 14, 0, 3 }, // 51 bits per transform
+ { 14, 1, 2 }, // 51 bits per transform
+ { 14, 2, 1 }, // 51 bits per transform
+ { 14, 3, 0 }, // 51 bits per transform
+ { 15, 0, 2 }, // 51 bits per transform
+ { 15, 1, 1 }, // 51 bits per transform
+ { 15, 2, 0 }, // 51 bits per transform
+ { 16, 0, 1 }, // 51 bits per transform
+ { 16, 1, 0 }, // 51 bits per transform
+ { 17, 0, 0 }, // 51 bits per transform
+ { 0, 0, 18 }, // 54 bits per transform
+ { 0, 1, 17 }, // 54 bits per transform
+ { 0, 2, 16 }, // 54 bits per transform
+ { 0, 3, 15 }, // 54 bits per transform
+ { 0, 4, 14 }, // 54 bits per transform
+ { 0, 5, 13 }, // 54 bits per transform
+ { 0, 6, 12 }, // 54 bits per transform
+ { 0, 7, 11 }, // 54 bits per transform
+ { 0, 8, 10 }, // 54 bits per transform
+ { 0, 9, 9 }, // 54 bits per transform
+ { 0, 10, 8 }, // 54 bits per transform
+ { 0, 11, 7 }, // 54 bits per transform
+ { 0, 12, 6 }, // 54 bits per transform
+ { 0, 13, 5 }, // 54 bits per transform
+ { 0, 14, 4 }, // 54 bits per transform
+ { 0, 15, 3 }, // 54 bits per transform
+ { 0, 16, 2 }, // 54 bits per transform
+ { 0, 17, 1 }, // 54 bits per transform
+ { 0, 18, 0 }, // 54 bits per transform
+ { 1, 0, 17 }, // 54 bits per transform
+ { 1, 1, 16 }, // 54 bits per transform
+ { 1, 2, 15 }, // 54 bits per transform
+ { 1, 3, 14 }, // 54 bits per transform
+ { 1, 4, 13 }, // 54 bits per transform
+ { 1, 5, 12 }, // 54 bits per transform
+ { 1, 6, 11 }, // 54 bits per transform
+ { 1, 7, 10 }, // 54 bits per transform
+ { 1, 8, 9 }, // 54 bits per transform
+ { 1, 9, 8 }, // 54 bits per transform
+ { 1, 10, 7 }, // 54 bits per transform
+ { 1, 11, 6 }, // 54 bits per transform
+ { 1, 12, 5 }, // 54 bits per transform
+ { 1, 13, 4 }, // 54 bits per transform
+ { 1, 14, 3 }, // 54 bits per transform
+ { 1, 15, 2 }, // 54 bits per transform
+ { 1, 16, 1 }, // 54 bits per transform
+ { 1, 17, 0 }, // 54 bits per transform
+ { 2, 0, 16 }, // 54 bits per transform
+ { 2, 1, 15 }, // 54 bits per transform
+ { 2, 2, 14 }, // 54 bits per transform
+ { 2, 3, 13 }, // 54 bits per transform
+ { 2, 4, 12 }, // 54 bits per transform
+ { 2, 5, 11 }, // 54 bits per transform
+ { 2, 6, 10 }, // 54 bits per transform
+ { 2, 7, 9 }, // 54 bits per transform
+ { 2, 8, 8 }, // 54 bits per transform
+ { 2, 9, 7 }, // 54 bits per transform
+ { 2, 10, 6 }, // 54 bits per transform
+ { 2, 11, 5 }, // 54 bits per transform
+ { 2, 12, 4 }, // 54 bits per transform
+ { 2, 13, 3 }, // 54 bits per transform
+ { 2, 14, 2 }, // 54 bits per transform
+ { 2, 15, 1 }, // 54 bits per transform
+ { 2, 16, 0 }, // 54 bits per transform
+ { 3, 0, 15 }, // 54 bits per transform
+ { 3, 1, 14 }, // 54 bits per transform
+ { 3, 2, 13 }, // 54 bits per transform
+ { 3, 3, 12 }, // 54 bits per transform
+ { 3, 4, 11 }, // 54 bits per transform
+ { 3, 5, 10 }, // 54 bits per transform
+ { 3, 6, 9 }, // 54 bits per transform
+ { 3, 7, 8 }, // 54 bits per transform
+ { 3, 8, 7 }, // 54 bits per transform
+ { 3, 9, 6 }, // 54 bits per transform
+ { 3, 10, 5 }, // 54 bits per transform
+ { 3, 11, 4 }, // 54 bits per transform
+ { 3, 12, 3 }, // 54 bits per transform
+ { 3, 13, 2 }, // 54 bits per transform
+ { 3, 14, 1 }, // 54 bits per transform
+ { 3, 15, 0 }, // 54 bits per transform
+ { 4, 0, 14 }, // 54 bits per transform
+ { 4, 1, 13 }, // 54 bits per transform
+ { 4, 2, 12 }, // 54 bits per transform
+ { 4, 3, 11 }, // 54 bits per transform
+ { 4, 4, 10 }, // 54 bits per transform
+ { 4, 5, 9 }, // 54 bits per transform
+ { 4, 6, 8 }, // 54 bits per transform
+ { 4, 7, 7 }, // 54 bits per transform
+ { 4, 8, 6 }, // 54 bits per transform
+ { 4, 9, 5 }, // 54 bits per transform
+ { 4, 10, 4 }, // 54 bits per transform
+ { 4, 11, 3 }, // 54 bits per transform
+ { 4, 12, 2 }, // 54 bits per transform
+ { 4, 13, 1 }, // 54 bits per transform
+ { 4, 14, 0 }, // 54 bits per transform
+ { 5, 0, 13 }, // 54 bits per transform
+ { 5, 1, 12 }, // 54 bits per transform
+ { 5, 2, 11 }, // 54 bits per transform
+ { 5, 3, 10 }, // 54 bits per transform
+ { 5, 4, 9 }, // 54 bits per transform
+ { 5, 5, 8 }, // 54 bits per transform
+ { 5, 6, 7 }, // 54 bits per transform
+ { 5, 7, 6 }, // 54 bits per transform
+ { 5, 8, 5 }, // 54 bits per transform
+ { 5, 9, 4 }, // 54 bits per transform
+ { 5, 10, 3 }, // 54 bits per transform
+ { 5, 11, 2 }, // 54 bits per transform
+ { 5, 12, 1 }, // 54 bits per transform
+ { 5, 13, 0 }, // 54 bits per transform
+ { 6, 0, 12 }, // 54 bits per transform
+ { 6, 1, 11 }, // 54 bits per transform
+ { 6, 2, 10 }, // 54 bits per transform
+ { 6, 3, 9 }, // 54 bits per transform
+ { 6, 4, 8 }, // 54 bits per transform
+ { 6, 5, 7 }, // 54 bits per transform
+ { 6, 6, 6 }, // 54 bits per transform
+ { 6, 7, 5 }, // 54 bits per transform
+ { 6, 8, 4 }, // 54 bits per transform
+ { 6, 9, 3 }, // 54 bits per transform
+ { 6, 10, 2 }, // 54 bits per transform
+ { 6, 11, 1 }, // 54 bits per transform
+ { 6, 12, 0 }, // 54 bits per transform
+ { 7, 0, 11 }, // 54 bits per transform
+ { 7, 1, 10 }, // 54 bits per transform
+ { 7, 2, 9 }, // 54 bits per transform
+ { 7, 3, 8 }, // 54 bits per transform
+ { 7, 4, 7 }, // 54 bits per transform
+ { 7, 5, 6 }, // 54 bits per transform
+ { 7, 6, 5 }, // 54 bits per transform
+ { 7, 7, 4 }, // 54 bits per transform
+ { 7, 8, 3 }, // 54 bits per transform
+ { 7, 9, 2 }, // 54 bits per transform
+ { 7, 10, 1 }, // 54 bits per transform
+ { 7, 11, 0 }, // 54 bits per transform
+ { 8, 0, 10 }, // 54 bits per transform
+ { 8, 1, 9 }, // 54 bits per transform
+ { 8, 2, 8 }, // 54 bits per transform
+ { 8, 3, 7 }, // 54 bits per transform
+ { 8, 4, 6 }, // 54 bits per transform
+ { 8, 5, 5 }, // 54 bits per transform
+ { 8, 6, 4 }, // 54 bits per transform
+ { 8, 7, 3 }, // 54 bits per transform
+ { 8, 8, 2 }, // 54 bits per transform
+ { 8, 9, 1 }, // 54 bits per transform
+ { 8, 10, 0 }, // 54 bits per transform
+ { 9, 0, 9 }, // 54 bits per transform
+ { 9, 1, 8 }, // 54 bits per transform
+ { 9, 2, 7 }, // 54 bits per transform
+ { 9, 3, 6 }, // 54 bits per transform
+ { 9, 4, 5 }, // 54 bits per transform
+ { 9, 5, 4 }, // 54 bits per transform
+ { 9, 6, 3 }, // 54 bits per transform
+ { 9, 7, 2 }, // 54 bits per transform
+ { 9, 8, 1 }, // 54 bits per transform
+ { 9, 9, 0 }, // 54 bits per transform
+ { 10, 0, 8 }, // 54 bits per transform
+ { 10, 1, 7 }, // 54 bits per transform
+ { 10, 2, 6 }, // 54 bits per transform
+ { 10, 3, 5 }, // 54 bits per transform
+ { 10, 4, 4 }, // 54 bits per transform
+ { 10, 5, 3 }, // 54 bits per transform
+ { 10, 6, 2 }, // 54 bits per transform
+ { 10, 7, 1 }, // 54 bits per transform
+ { 10, 8, 0 }, // 54 bits per transform
+ { 11, 0, 7 }, // 54 bits per transform
+ { 11, 1, 6 }, // 54 bits per transform
+ { 11, 2, 5 }, // 54 bits per transform
+ { 11, 3, 4 }, // 54 bits per transform
+ { 11, 4, 3 }, // 54 bits per transform
+ { 11, 5, 2 }, // 54 bits per transform
+ { 11, 6, 1 }, // 54 bits per transform
+ { 11, 7, 0 }, // 54 bits per transform
+ { 12, 0, 6 }, // 54 bits per transform
+ { 12, 1, 5 }, // 54 bits per transform
+ { 12, 2, 4 }, // 54 bits per transform
+ { 12, 3, 3 }, // 54 bits per transform
+ { 12, 4, 2 }, // 54 bits per transform
+ { 12, 5, 1 }, // 54 bits per transform
+ { 12, 6, 0 }, // 54 bits per transform
+ { 13, 0, 5 }, // 54 bits per transform
+ { 13, 1, 4 }, // 54 bits per transform
+ { 13, 2, 3 }, // 54 bits per transform
+ { 13, 3, 2 }, // 54 bits per transform
+ { 13, 4, 1 }, // 54 bits per transform
+ { 13, 5, 0 }, // 54 bits per transform
+ { 14, 0, 4 }, // 54 bits per transform
+ { 14, 1, 3 }, // 54 bits per transform
+ { 14, 2, 2 }, // 54 bits per transform
+ { 14, 3, 1 }, // 54 bits per transform
+ { 14, 4, 0 }, // 54 bits per transform
+ { 15, 0, 3 }, // 54 bits per transform
+ { 15, 1, 2 }, // 54 bits per transform
+ { 15, 2, 1 }, // 54 bits per transform
+ { 15, 3, 0 }, // 54 bits per transform
+ { 16, 0, 2 }, // 54 bits per transform
+ { 16, 1, 1 }, // 54 bits per transform
+ { 16, 2, 0 }, // 54 bits per transform
+ { 17, 0, 1 }, // 54 bits per transform
+ { 17, 1, 0 }, // 54 bits per transform
+ { 18, 0, 0 }, // 54 bits per transform
+ { 0, 0, 19 }, // 57 bits per transform
+ { 0, 1, 18 }, // 57 bits per transform
+ { 0, 2, 17 }, // 57 bits per transform
+ { 0, 3, 16 }, // 57 bits per transform
+ { 0, 4, 15 }, // 57 bits per transform
+ { 0, 5, 14 }, // 57 bits per transform
+ { 0, 6, 13 }, // 57 bits per transform
+ { 0, 7, 12 }, // 57 bits per transform
+ { 0, 8, 11 }, // 57 bits per transform
+ { 0, 9, 10 }, // 57 bits per transform
+ { 0, 10, 9 }, // 57 bits per transform
+ { 0, 11, 8 }, // 57 bits per transform
+ { 0, 12, 7 }, // 57 bits per transform
+ { 0, 13, 6 }, // 57 bits per transform
+ { 0, 14, 5 }, // 57 bits per transform
+ { 0, 15, 4 }, // 57 bits per transform
+ { 0, 16, 3 }, // 57 bits per transform
+ { 0, 17, 2 }, // 57 bits per transform
+ { 0, 18, 1 }, // 57 bits per transform
+ { 0, 19, 0 }, // 57 bits per transform
+ { 1, 0, 18 }, // 57 bits per transform
+ { 1, 1, 17 }, // 57 bits per transform
+ { 1, 2, 16 }, // 57 bits per transform
+ { 1, 3, 15 }, // 57 bits per transform
+ { 1, 4, 14 }, // 57 bits per transform
+ { 1, 5, 13 }, // 57 bits per transform
+ { 1, 6, 12 }, // 57 bits per transform
+ { 1, 7, 11 }, // 57 bits per transform
+ { 1, 8, 10 }, // 57 bits per transform
+ { 1, 9, 9 }, // 57 bits per transform
+ { 1, 10, 8 }, // 57 bits per transform
+ { 1, 11, 7 }, // 57 bits per transform
+ { 1, 12, 6 }, // 57 bits per transform
+ { 1, 13, 5 }, // 57 bits per transform
+ { 1, 14, 4 }, // 57 bits per transform
+ { 1, 15, 3 }, // 57 bits per transform
+ { 1, 16, 2 }, // 57 bits per transform
+ { 1, 17, 1 }, // 57 bits per transform
+ { 1, 18, 0 }, // 57 bits per transform
+ { 2, 0, 17 }, // 57 bits per transform
+ { 2, 1, 16 }, // 57 bits per transform
+ { 2, 2, 15 }, // 57 bits per transform
+ { 2, 3, 14 }, // 57 bits per transform
+ { 2, 4, 13 }, // 57 bits per transform
+ { 2, 5, 12 }, // 57 bits per transform
+ { 2, 6, 11 }, // 57 bits per transform
+ { 2, 7, 10 }, // 57 bits per transform
+ { 2, 8, 9 }, // 57 bits per transform
+ { 2, 9, 8 }, // 57 bits per transform
+ { 2, 10, 7 }, // 57 bits per transform
+ { 2, 11, 6 }, // 57 bits per transform
+ { 2, 12, 5 }, // 57 bits per transform
+ { 2, 13, 4 }, // 57 bits per transform
+ { 2, 14, 3 }, // 57 bits per transform
+ { 2, 15, 2 }, // 57 bits per transform
+ { 2, 16, 1 }, // 57 bits per transform
+ { 2, 17, 0 }, // 57 bits per transform
+ { 3, 0, 16 }, // 57 bits per transform
+ { 3, 1, 15 }, // 57 bits per transform
+ { 3, 2, 14 }, // 57 bits per transform
+ { 3, 3, 13 }, // 57 bits per transform
+ { 3, 4, 12 }, // 57 bits per transform
+ { 3, 5, 11 }, // 57 bits per transform
+ { 3, 6, 10 }, // 57 bits per transform
+ { 3, 7, 9 }, // 57 bits per transform
+ { 3, 8, 8 }, // 57 bits per transform
+ { 3, 9, 7 }, // 57 bits per transform
+ { 3, 10, 6 }, // 57 bits per transform
+ { 3, 11, 5 }, // 57 bits per transform
+ { 3, 12, 4 }, // 57 bits per transform
+ { 3, 13, 3 }, // 57 bits per transform
+ { 3, 14, 2 }, // 57 bits per transform
+ { 3, 15, 1 }, // 57 bits per transform
+ { 3, 16, 0 }, // 57 bits per transform
+ { 4, 0, 15 }, // 57 bits per transform
+ { 4, 1, 14 }, // 57 bits per transform
+ { 4, 2, 13 }, // 57 bits per transform
+ { 4, 3, 12 }, // 57 bits per transform
+ { 4, 4, 11 }, // 57 bits per transform
+ { 4, 5, 10 }, // 57 bits per transform
+ { 4, 6, 9 }, // 57 bits per transform
+ { 4, 7, 8 }, // 57 bits per transform
+ { 4, 8, 7 }, // 57 bits per transform
+ { 4, 9, 6 }, // 57 bits per transform
+ { 4, 10, 5 }, // 57 bits per transform
+ { 4, 11, 4 }, // 57 bits per transform
+ { 4, 12, 3 }, // 57 bits per transform
+ { 4, 13, 2 }, // 57 bits per transform
+ { 4, 14, 1 }, // 57 bits per transform
+ { 4, 15, 0 }, // 57 bits per transform
+ { 5, 0, 14 }, // 57 bits per transform
+ { 5, 1, 13 }, // 57 bits per transform
+ { 5, 2, 12 }, // 57 bits per transform
+ { 5, 3, 11 }, // 57 bits per transform
+ { 5, 4, 10 }, // 57 bits per transform
+ { 5, 5, 9 }, // 57 bits per transform
+ { 5, 6, 8 }, // 57 bits per transform
+ { 5, 7, 7 }, // 57 bits per transform
+ { 5, 8, 6 }, // 57 bits per transform
+ { 5, 9, 5 }, // 57 bits per transform
+ { 5, 10, 4 }, // 57 bits per transform
+ { 5, 11, 3 }, // 57 bits per transform
+ { 5, 12, 2 }, // 57 bits per transform
+ { 5, 13, 1 }, // 57 bits per transform
+ { 5, 14, 0 }, // 57 bits per transform
+ { 6, 0, 13 }, // 57 bits per transform
+ { 6, 1, 12 }, // 57 bits per transform
+ { 6, 2, 11 }, // 57 bits per transform
+ { 6, 3, 10 }, // 57 bits per transform
+ { 6, 4, 9 }, // 57 bits per transform
+ { 6, 5, 8 }, // 57 bits per transform
+ { 6, 6, 7 }, // 57 bits per transform
+ { 6, 7, 6 }, // 57 bits per transform
+ { 6, 8, 5 }, // 57 bits per transform
+ { 6, 9, 4 }, // 57 bits per transform
+ { 6, 10, 3 }, // 57 bits per transform
+ { 6, 11, 2 }, // 57 bits per transform
+ { 6, 12, 1 }, // 57 bits per transform
+ { 6, 13, 0 }, // 57 bits per transform
+ { 7, 0, 12 }, // 57 bits per transform
+ { 7, 1, 11 }, // 57 bits per transform
+ { 7, 2, 10 }, // 57 bits per transform
+ { 7, 3, 9 }, // 57 bits per transform
+ { 7, 4, 8 }, // 57 bits per transform
+ { 7, 5, 7 }, // 57 bits per transform
+ { 7, 6, 6 }, // 57 bits per transform
+ { 7, 7, 5 }, // 57 bits per transform
+ { 7, 8, 4 }, // 57 bits per transform
+ { 7, 9, 3 }, // 57 bits per transform
+ { 7, 10, 2 }, // 57 bits per transform
+ { 7, 11, 1 }, // 57 bits per transform
+ { 7, 12, 0 }, // 57 bits per transform
+ { 8, 0, 11 }, // 57 bits per transform
+ { 8, 1, 10 }, // 57 bits per transform
+ { 8, 2, 9 }, // 57 bits per transform
+ { 8, 3, 8 }, // 57 bits per transform
+ { 8, 4, 7 }, // 57 bits per transform
+ { 8, 5, 6 }, // 57 bits per transform
+ { 8, 6, 5 }, // 57 bits per transform
+ { 8, 7, 4 }, // 57 bits per transform
+ { 8, 8, 3 }, // 57 bits per transform
+ { 8, 9, 2 }, // 57 bits per transform
+ { 8, 10, 1 }, // 57 bits per transform
+ { 8, 11, 0 }, // 57 bits per transform
+ { 9, 0, 10 }, // 57 bits per transform
+ { 9, 1, 9 }, // 57 bits per transform
+ { 9, 2, 8 }, // 57 bits per transform
+ { 9, 3, 7 }, // 57 bits per transform
+ { 9, 4, 6 }, // 57 bits per transform
+ { 9, 5, 5 }, // 57 bits per transform
+ { 9, 6, 4 }, // 57 bits per transform
+ { 9, 7, 3 }, // 57 bits per transform
+ { 9, 8, 2 }, // 57 bits per transform
+ { 9, 9, 1 }, // 57 bits per transform
+ { 9, 10, 0 }, // 57 bits per transform
+ { 10, 0, 9 }, // 57 bits per transform
+ { 10, 1, 8 }, // 57 bits per transform
+ { 10, 2, 7 }, // 57 bits per transform
+ { 10, 3, 6 }, // 57 bits per transform
+ { 10, 4, 5 }, // 57 bits per transform
+ { 10, 5, 4 }, // 57 bits per transform
+ { 10, 6, 3 }, // 57 bits per transform
+ { 10, 7, 2 }, // 57 bits per transform
+ { 10, 8, 1 }, // 57 bits per transform
+ { 10, 9, 0 }, // 57 bits per transform
+ { 11, 0, 8 }, // 57 bits per transform
+ { 11, 1, 7 }, // 57 bits per transform
+ { 11, 2, 6 }, // 57 bits per transform
+ { 11, 3, 5 }, // 57 bits per transform
+ { 11, 4, 4 }, // 57 bits per transform
+ { 11, 5, 3 }, // 57 bits per transform
+ { 11, 6, 2 }, // 57 bits per transform
+ { 11, 7, 1 }, // 57 bits per transform
+ { 11, 8, 0 }, // 57 bits per transform
+ { 12, 0, 7 }, // 57 bits per transform
+ { 12, 1, 6 }, // 57 bits per transform
+ { 12, 2, 5 }, // 57 bits per transform
+ { 12, 3, 4 }, // 57 bits per transform
+ { 12, 4, 3 }, // 57 bits per transform
+ { 12, 5, 2 }, // 57 bits per transform
+ { 12, 6, 1 }, // 57 bits per transform
+ { 12, 7, 0 }, // 57 bits per transform
+ { 13, 0, 6 }, // 57 bits per transform
+ { 13, 1, 5 }, // 57 bits per transform
+ { 13, 2, 4 }, // 57 bits per transform
+ { 13, 3, 3 }, // 57 bits per transform
+ { 13, 4, 2 }, // 57 bits per transform
+ { 13, 5, 1 }, // 57 bits per transform
+ { 13, 6, 0 }, // 57 bits per transform
+ { 14, 0, 5 }, // 57 bits per transform
+ { 14, 1, 4 }, // 57 bits per transform
+ { 14, 2, 3 }, // 57 bits per transform
+ { 14, 3, 2 }, // 57 bits per transform
+ { 14, 4, 1 }, // 57 bits per transform
+ { 14, 5, 0 }, // 57 bits per transform
+ { 15, 0, 4 }, // 57 bits per transform
+ { 15, 1, 3 }, // 57 bits per transform
+ { 15, 2, 2 }, // 57 bits per transform
+ { 15, 3, 1 }, // 57 bits per transform
+ { 15, 4, 0 }, // 57 bits per transform
+ { 16, 0, 3 }, // 57 bits per transform
+ { 16, 1, 2 }, // 57 bits per transform
+ { 16, 2, 1 }, // 57 bits per transform
+ { 16, 3, 0 }, // 57 bits per transform
+ { 17, 0, 2 }, // 57 bits per transform
+ { 17, 1, 1 }, // 57 bits per transform
+ { 17, 2, 0 }, // 57 bits per transform
+ { 18, 0, 1 }, // 57 bits per transform
+ { 18, 1, 0 }, // 57 bits per transform
+ { 19, 0, 0 }, // 57 bits per transform
+ { 0, 0, 20 }, // 60 bits per transform
+ { 0, 1, 19 }, // 60 bits per transform
+ { 0, 2, 18 }, // 60 bits per transform
+ { 0, 3, 17 }, // 60 bits per transform
+ { 0, 4, 16 }, // 60 bits per transform
+ { 0, 5, 15 }, // 60 bits per transform
+ { 0, 6, 14 }, // 60 bits per transform
+ { 0, 7, 13 }, // 60 bits per transform
+ { 0, 8, 12 }, // 60 bits per transform
+ { 0, 9, 11 }, // 60 bits per transform
+ { 0, 10, 10 }, // 60 bits per transform
+ { 0, 11, 9 }, // 60 bits per transform
+ { 0, 12, 8 }, // 60 bits per transform
+ { 0, 13, 7 }, // 60 bits per transform
+ { 0, 14, 6 }, // 60 bits per transform
+ { 0, 15, 5 }, // 60 bits per transform
+ { 0, 16, 4 }, // 60 bits per transform
+ { 0, 17, 3 }, // 60 bits per transform
+ { 0, 18, 2 }, // 60 bits per transform
+ { 0, 19, 1 }, // 60 bits per transform
+ { 0, 20, 0 }, // 60 bits per transform
+ { 1, 0, 19 }, // 60 bits per transform
+ { 1, 1, 18 }, // 60 bits per transform
+ { 1, 2, 17 }, // 60 bits per transform
+ { 1, 3, 16 }, // 60 bits per transform
+ { 1, 4, 15 }, // 60 bits per transform
+ { 1, 5, 14 }, // 60 bits per transform
+ { 1, 6, 13 }, // 60 bits per transform
+ { 1, 7, 12 }, // 60 bits per transform
+ { 1, 8, 11 }, // 60 bits per transform
+ { 1, 9, 10 }, // 60 bits per transform
+ { 1, 10, 9 }, // 60 bits per transform
+ { 1, 11, 8 }, // 60 bits per transform
+ { 1, 12, 7 }, // 60 bits per transform
+ { 1, 13, 6 }, // 60 bits per transform
+ { 1, 14, 5 }, // 60 bits per transform
+ { 1, 15, 4 }, // 60 bits per transform
+ { 1, 16, 3 }, // 60 bits per transform
+ { 1, 17, 2 }, // 60 bits per transform
+ { 1, 18, 1 }, // 60 bits per transform
+ { 1, 19, 0 }, // 60 bits per transform
+ { 2, 0, 18 }, // 60 bits per transform
+ { 2, 1, 17 }, // 60 bits per transform
+ { 2, 2, 16 }, // 60 bits per transform
+ { 2, 3, 15 }, // 60 bits per transform
+ { 2, 4, 14 }, // 60 bits per transform
+ { 2, 5, 13 }, // 60 bits per transform
+ { 2, 6, 12 }, // 60 bits per transform
+ { 2, 7, 11 }, // 60 bits per transform
+ { 2, 8, 10 }, // 60 bits per transform
+ { 2, 9, 9 }, // 60 bits per transform
+ { 2, 10, 8 }, // 60 bits per transform
+ { 2, 11, 7 }, // 60 bits per transform
+ { 2, 12, 6 }, // 60 bits per transform
+ { 2, 13, 5 }, // 60 bits per transform
+ { 2, 14, 4 }, // 60 bits per transform
+ { 2, 15, 3 }, // 60 bits per transform
+ { 2, 16, 2 }, // 60 bits per transform
+ { 2, 17, 1 }, // 60 bits per transform
+ { 2, 18, 0 }, // 60 bits per transform
+ { 3, 0, 17 }, // 60 bits per transform
+ { 3, 1, 16 }, // 60 bits per transform
+ { 3, 2, 15 }, // 60 bits per transform
+ { 3, 3, 14 }, // 60 bits per transform
+ { 3, 4, 13 }, // 60 bits per transform
+ { 3, 5, 12 }, // 60 bits per transform
+ { 3, 6, 11 }, // 60 bits per transform
+ { 3, 7, 10 }, // 60 bits per transform
+ { 3, 8, 9 }, // 60 bits per transform
+ { 3, 9, 8 }, // 60 bits per transform
+ { 3, 10, 7 }, // 60 bits per transform
+ { 3, 11, 6 }, // 60 bits per transform
+ { 3, 12, 5 }, // 60 bits per transform
+ { 3, 13, 4 }, // 60 bits per transform
+ { 3, 14, 3 }, // 60 bits per transform
+ { 3, 15, 2 }, // 60 bits per transform
+ { 3, 16, 1 }, // 60 bits per transform
+ { 3, 17, 0 }, // 60 bits per transform
+ { 4, 0, 16 }, // 60 bits per transform
+ { 4, 1, 15 }, // 60 bits per transform
+ { 4, 2, 14 }, // 60 bits per transform
+ { 4, 3, 13 }, // 60 bits per transform
+ { 4, 4, 12 }, // 60 bits per transform
+ { 4, 5, 11 }, // 60 bits per transform
+ { 4, 6, 10 }, // 60 bits per transform
+ { 4, 7, 9 }, // 60 bits per transform
+ { 4, 8, 8 }, // 60 bits per transform
+ { 4, 9, 7 }, // 60 bits per transform
+ { 4, 10, 6 }, // 60 bits per transform
+ { 4, 11, 5 }, // 60 bits per transform
+ { 4, 12, 4 }, // 60 bits per transform
+ { 4, 13, 3 }, // 60 bits per transform
+ { 4, 14, 2 }, // 60 bits per transform
+ { 4, 15, 1 }, // 60 bits per transform
+ { 4, 16, 0 }, // 60 bits per transform
+ { 5, 0, 15 }, // 60 bits per transform
+ { 5, 1, 14 }, // 60 bits per transform
+ { 5, 2, 13 }, // 60 bits per transform
+ { 5, 3, 12 }, // 60 bits per transform
+ { 5, 4, 11 }, // 60 bits per transform
+ { 5, 5, 10 }, // 60 bits per transform
+ { 5, 6, 9 }, // 60 bits per transform
+ { 5, 7, 8 }, // 60 bits per transform
+ { 5, 8, 7 }, // 60 bits per transform
+ { 5, 9, 6 }, // 60 bits per transform
+ { 5, 10, 5 }, // 60 bits per transform
+ { 5, 11, 4 }, // 60 bits per transform
+ { 5, 12, 3 }, // 60 bits per transform
+ { 5, 13, 2 }, // 60 bits per transform
+ { 5, 14, 1 }, // 60 bits per transform
+ { 5, 15, 0 }, // 60 bits per transform
+ { 6, 0, 14 }, // 60 bits per transform
+ { 6, 1, 13 }, // 60 bits per transform
+ { 6, 2, 12 }, // 60 bits per transform
+ { 6, 3, 11 }, // 60 bits per transform
+ { 6, 4, 10 }, // 60 bits per transform
+ { 6, 5, 9 }, // 60 bits per transform
+ { 6, 6, 8 }, // 60 bits per transform
+ { 6, 7, 7 }, // 60 bits per transform
+ { 6, 8, 6 }, // 60 bits per transform
+ { 6, 9, 5 }, // 60 bits per transform
+ { 6, 10, 4 }, // 60 bits per transform
+ { 6, 11, 3 }, // 60 bits per transform
+ { 6, 12, 2 }, // 60 bits per transform
+ { 6, 13, 1 }, // 60 bits per transform
+ { 6, 14, 0 }, // 60 bits per transform
+ { 7, 0, 13 }, // 60 bits per transform
+ { 7, 1, 12 }, // 60 bits per transform
+ { 7, 2, 11 }, // 60 bits per transform
+ { 7, 3, 10 }, // 60 bits per transform
+ { 7, 4, 9 }, // 60 bits per transform
+ { 7, 5, 8 }, // 60 bits per transform
+ { 7, 6, 7 }, // 60 bits per transform
+ { 7, 7, 6 }, // 60 bits per transform
+ { 7, 8, 5 }, // 60 bits per transform
+ { 7, 9, 4 }, // 60 bits per transform
+ { 7, 10, 3 }, // 60 bits per transform
+ { 7, 11, 2 }, // 60 bits per transform
+ { 7, 12, 1 }, // 60 bits per transform
+ { 7, 13, 0 }, // 60 bits per transform
+ { 8, 0, 12 }, // 60 bits per transform
+ { 8, 1, 11 }, // 60 bits per transform
+ { 8, 2, 10 }, // 60 bits per transform
+ { 8, 3, 9 }, // 60 bits per transform
+ { 8, 4, 8 }, // 60 bits per transform
+ { 8, 5, 7 }, // 60 bits per transform
+ { 8, 6, 6 }, // 60 bits per transform
+ { 8, 7, 5 }, // 60 bits per transform
+ { 8, 8, 4 }, // 60 bits per transform
+ { 8, 9, 3 }, // 60 bits per transform
+ { 8, 10, 2 }, // 60 bits per transform
+ { 8, 11, 1 }, // 60 bits per transform
+ { 8, 12, 0 }, // 60 bits per transform
+ { 9, 0, 11 }, // 60 bits per transform
+ { 9, 1, 10 }, // 60 bits per transform
+ { 9, 2, 9 }, // 60 bits per transform
+ { 9, 3, 8 }, // 60 bits per transform
+ { 9, 4, 7 }, // 60 bits per transform
+ { 9, 5, 6 }, // 60 bits per transform
+ { 9, 6, 5 }, // 60 bits per transform
+ { 9, 7, 4 }, // 60 bits per transform
+ { 9, 8, 3 }, // 60 bits per transform
+ { 9, 9, 2 }, // 60 bits per transform
+ { 9, 10, 1 }, // 60 bits per transform
+ { 9, 11, 0 }, // 60 bits per transform
+ { 10, 0, 10 }, // 60 bits per transform
+ { 10, 1, 9 }, // 60 bits per transform
+ { 10, 2, 8 }, // 60 bits per transform
+ { 10, 3, 7 }, // 60 bits per transform
+ { 10, 4, 6 }, // 60 bits per transform
+ { 10, 5, 5 }, // 60 bits per transform
+ { 10, 6, 4 }, // 60 bits per transform
+ { 10, 7, 3 }, // 60 bits per transform
+ { 10, 8, 2 }, // 60 bits per transform
+ { 10, 9, 1 }, // 60 bits per transform
+ { 10, 10, 0 }, // 60 bits per transform
+ { 11, 0, 9 }, // 60 bits per transform
+ { 11, 1, 8 }, // 60 bits per transform
+ { 11, 2, 7 }, // 60 bits per transform
+ { 11, 3, 6 }, // 60 bits per transform
+ { 11, 4, 5 }, // 60 bits per transform
+ { 11, 5, 4 }, // 60 bits per transform
+ { 11, 6, 3 }, // 60 bits per transform
+ { 11, 7, 2 }, // 60 bits per transform
+ { 11, 8, 1 }, // 60 bits per transform
+ { 11, 9, 0 }, // 60 bits per transform
+ { 12, 0, 8 }, // 60 bits per transform
+ { 12, 1, 7 }, // 60 bits per transform
+ { 12, 2, 6 }, // 60 bits per transform
+ { 12, 3, 5 }, // 60 bits per transform
+ { 12, 4, 4 }, // 60 bits per transform
+ { 12, 5, 3 }, // 60 bits per transform
+ { 12, 6, 2 }, // 60 bits per transform
+ { 12, 7, 1 }, // 60 bits per transform
+ { 12, 8, 0 }, // 60 bits per transform
+ { 13, 0, 7 }, // 60 bits per transform
+ { 13, 1, 6 }, // 60 bits per transform
+ { 13, 2, 5 }, // 60 bits per transform
+ { 13, 3, 4 }, // 60 bits per transform
+ { 13, 4, 3 }, // 60 bits per transform
+ { 13, 5, 2 }, // 60 bits per transform
+ { 13, 6, 1 }, // 60 bits per transform
+ { 13, 7, 0 }, // 60 bits per transform
+ { 14, 0, 6 }, // 60 bits per transform
+ { 14, 1, 5 }, // 60 bits per transform
+ { 14, 2, 4 }, // 60 bits per transform
+ { 14, 3, 3 }, // 60 bits per transform
+ { 14, 4, 2 }, // 60 bits per transform
+ { 14, 5, 1 }, // 60 bits per transform
+ { 14, 6, 0 }, // 60 bits per transform
+ { 15, 0, 5 }, // 60 bits per transform
+ { 15, 1, 4 }, // 60 bits per transform
+ { 15, 2, 3 }, // 60 bits per transform
+ { 15, 3, 2 }, // 60 bits per transform
+ { 15, 4, 1 }, // 60 bits per transform
+ { 15, 5, 0 }, // 60 bits per transform
+ { 16, 0, 4 }, // 60 bits per transform
+ { 16, 1, 3 }, // 60 bits per transform
+ { 16, 2, 2 }, // 60 bits per transform
+ { 16, 3, 1 }, // 60 bits per transform
+ { 16, 4, 0 }, // 60 bits per transform
+ { 17, 0, 3 }, // 60 bits per transform
+ { 17, 1, 2 }, // 60 bits per transform
+ { 17, 2, 1 }, // 60 bits per transform
+ { 17, 3, 0 }, // 60 bits per transform
+ { 18, 0, 2 }, // 60 bits per transform
+ { 18, 1, 1 }, // 60 bits per transform
+ { 18, 2, 0 }, // 60 bits per transform
+ { 19, 0, 1 }, // 60 bits per transform
+ { 19, 1, 0 }, // 60 bits per transform
+ { 20, 0, 0 }, // 60 bits per transform
+ { 0, 0, 21 }, // 63 bits per transform
+ { 0, 1, 20 }, // 63 bits per transform
+ { 0, 2, 19 }, // 63 bits per transform
+ { 0, 3, 18 }, // 63 bits per transform
+ { 0, 4, 17 }, // 63 bits per transform
+ { 0, 5, 16 }, // 63 bits per transform
+ { 0, 6, 15 }, // 63 bits per transform
+ { 0, 7, 14 }, // 63 bits per transform
+ { 0, 8, 13 }, // 63 bits per transform
+ { 0, 9, 12 }, // 63 bits per transform
+ { 0, 10, 11 }, // 63 bits per transform
+ { 0, 11, 10 }, // 63 bits per transform
+ { 0, 12, 9 }, // 63 bits per transform
+ { 0, 13, 8 }, // 63 bits per transform
+ { 0, 14, 7 }, // 63 bits per transform
+ { 0, 15, 6 }, // 63 bits per transform
+ { 0, 16, 5 }, // 63 bits per transform
+ { 0, 17, 4 }, // 63 bits per transform
+ { 0, 18, 3 }, // 63 bits per transform
+ { 0, 19, 2 }, // 63 bits per transform
+ { 0, 20, 1 }, // 63 bits per transform
+ { 0, 21, 0 }, // 63 bits per transform
+ { 1, 0, 20 }, // 63 bits per transform
+ { 1, 1, 19 }, // 63 bits per transform
+ { 1, 2, 18 }, // 63 bits per transform
+ { 1, 3, 17 }, // 63 bits per transform
+ { 1, 4, 16 }, // 63 bits per transform
+ { 1, 5, 15 }, // 63 bits per transform
+ { 1, 6, 14 }, // 63 bits per transform
+ { 1, 7, 13 }, // 63 bits per transform
+ { 1, 8, 12 }, // 63 bits per transform
+ { 1, 9, 11 }, // 63 bits per transform
+ { 1, 10, 10 }, // 63 bits per transform
+ { 1, 11, 9 }, // 63 bits per transform
+ { 1, 12, 8 }, // 63 bits per transform
+ { 1, 13, 7 }, // 63 bits per transform
+ { 1, 14, 6 }, // 63 bits per transform
+ { 1, 15, 5 }, // 63 bits per transform
+ { 1, 16, 4 }, // 63 bits per transform
+ { 1, 17, 3 }, // 63 bits per transform
+ { 1, 18, 2 }, // 63 bits per transform
+ { 1, 19, 1 }, // 63 bits per transform
+ { 1, 20, 0 }, // 63 bits per transform
+ { 2, 0, 19 }, // 63 bits per transform
+ { 2, 1, 18 }, // 63 bits per transform
+ { 2, 2, 17 }, // 63 bits per transform
+ { 2, 3, 16 }, // 63 bits per transform
+ { 2, 4, 15 }, // 63 bits per transform
+ { 2, 5, 14 }, // 63 bits per transform
+ { 2, 6, 13 }, // 63 bits per transform
+ { 2, 7, 12 }, // 63 bits per transform
+ { 2, 8, 11 }, // 63 bits per transform
+ { 2, 9, 10 }, // 63 bits per transform
+ { 2, 10, 9 }, // 63 bits per transform
+ { 2, 11, 8 }, // 63 bits per transform
+ { 2, 12, 7 }, // 63 bits per transform
+ { 2, 13, 6 }, // 63 bits per transform
+ { 2, 14, 5 }, // 63 bits per transform
+ { 2, 15, 4 }, // 63 bits per transform
+ { 2, 16, 3 }, // 63 bits per transform
+ { 2, 17, 2 }, // 63 bits per transform
+ { 2, 18, 1 }, // 63 bits per transform
+ { 2, 19, 0 }, // 63 bits per transform
+ { 3, 0, 18 }, // 63 bits per transform
+ { 3, 1, 17 }, // 63 bits per transform
+ { 3, 2, 16 }, // 63 bits per transform
+ { 3, 3, 15 }, // 63 bits per transform
+ { 3, 4, 14 }, // 63 bits per transform
+ { 3, 5, 13 }, // 63 bits per transform
+ { 3, 6, 12 }, // 63 bits per transform
+ { 3, 7, 11 }, // 63 bits per transform
+ { 3, 8, 10 }, // 63 bits per transform
+ { 3, 9, 9 }, // 63 bits per transform
+ { 3, 10, 8 }, // 63 bits per transform
+ { 3, 11, 7 }, // 63 bits per transform
+ { 3, 12, 6 }, // 63 bits per transform
+ { 3, 13, 5 }, // 63 bits per transform
+ { 3, 14, 4 }, // 63 bits per transform
+ { 3, 15, 3 }, // 63 bits per transform
+ { 3, 16, 2 }, // 63 bits per transform
+ { 3, 17, 1 }, // 63 bits per transform
+ { 3, 18, 0 }, // 63 bits per transform
+ { 4, 0, 17 }, // 63 bits per transform
+ { 4, 1, 16 }, // 63 bits per transform
+ { 4, 2, 15 }, // 63 bits per transform
+ { 4, 3, 14 }, // 63 bits per transform
+ { 4, 4, 13 }, // 63 bits per transform
+ { 4, 5, 12 }, // 63 bits per transform
+ { 4, 6, 11 }, // 63 bits per transform
+ { 4, 7, 10 }, // 63 bits per transform
+ { 4, 8, 9 }, // 63 bits per transform
+ { 4, 9, 8 }, // 63 bits per transform
+ { 4, 10, 7 }, // 63 bits per transform
+ { 4, 11, 6 }, // 63 bits per transform
+ { 4, 12, 5 }, // 63 bits per transform
+ { 4, 13, 4 }, // 63 bits per transform
+ { 4, 14, 3 }, // 63 bits per transform
+ { 4, 15, 2 }, // 63 bits per transform
+ { 4, 16, 1 }, // 63 bits per transform
+ { 4, 17, 0 }, // 63 bits per transform
+ { 5, 0, 16 }, // 63 bits per transform
+ { 5, 1, 15 }, // 63 bits per transform
+ { 5, 2, 14 }, // 63 bits per transform
+ { 5, 3, 13 }, // 63 bits per transform
+ { 5, 4, 12 }, // 63 bits per transform
+ { 5, 5, 11 }, // 63 bits per transform
+ { 5, 6, 10 }, // 63 bits per transform
+ { 5, 7, 9 }, // 63 bits per transform
+ { 5, 8, 8 }, // 63 bits per transform
+ { 5, 9, 7 }, // 63 bits per transform
+ { 5, 10, 6 }, // 63 bits per transform
+ { 5, 11, 5 }, // 63 bits per transform
+ { 5, 12, 4 }, // 63 bits per transform
+ { 5, 13, 3 }, // 63 bits per transform
+ { 5, 14, 2 }, // 63 bits per transform
+ { 5, 15, 1 }, // 63 bits per transform
+ { 5, 16, 0 }, // 63 bits per transform
+ { 6, 0, 15 }, // 63 bits per transform
+ { 6, 1, 14 }, // 63 bits per transform
+ { 6, 2, 13 }, // 63 bits per transform
+ { 6, 3, 12 }, // 63 bits per transform
+ { 6, 4, 11 }, // 63 bits per transform
+ { 6, 5, 10 }, // 63 bits per transform
+ { 6, 6, 9 }, // 63 bits per transform
+ { 6, 7, 8 }, // 63 bits per transform
+ { 6, 8, 7 }, // 63 bits per transform
+ { 6, 9, 6 }, // 63 bits per transform
+ { 6, 10, 5 }, // 63 bits per transform
+ { 6, 11, 4 }, // 63 bits per transform
+ { 6, 12, 3 }, // 63 bits per transform
+ { 6, 13, 2 }, // 63 bits per transform
+ { 6, 14, 1 }, // 63 bits per transform
+ { 6, 15, 0 }, // 63 bits per transform
+ { 7, 0, 14 }, // 63 bits per transform
+ { 7, 1, 13 }, // 63 bits per transform
+ { 7, 2, 12 }, // 63 bits per transform
+ { 7, 3, 11 }, // 63 bits per transform
+ { 7, 4, 10 }, // 63 bits per transform
+ { 7, 5, 9 }, // 63 bits per transform
+ { 7, 6, 8 }, // 63 bits per transform
+ { 7, 7, 7 }, // 63 bits per transform
+ { 7, 8, 6 }, // 63 bits per transform
+ { 7, 9, 5 }, // 63 bits per transform
+ { 7, 10, 4 }, // 63 bits per transform
+ { 7, 11, 3 }, // 63 bits per transform
+ { 7, 12, 2 }, // 63 bits per transform
+ { 7, 13, 1 }, // 63 bits per transform
+ { 7, 14, 0 }, // 63 bits per transform
+ { 8, 0, 13 }, // 63 bits per transform
+ { 8, 1, 12 }, // 63 bits per transform
+ { 8, 2, 11 }, // 63 bits per transform
+ { 8, 3, 10 }, // 63 bits per transform
+ { 8, 4, 9 }, // 63 bits per transform
+ { 8, 5, 8 }, // 63 bits per transform
+ { 8, 6, 7 }, // 63 bits per transform
+ { 8, 7, 6 }, // 63 bits per transform
+ { 8, 8, 5 }, // 63 bits per transform
+ { 8, 9, 4 }, // 63 bits per transform
+ { 8, 10, 3 }, // 63 bits per transform
+ { 8, 11, 2 }, // 63 bits per transform
+ { 8, 12, 1 }, // 63 bits per transform
+ { 8, 13, 0 }, // 63 bits per transform
+ { 9, 0, 12 }, // 63 bits per transform
+ { 9, 1, 11 }, // 63 bits per transform
+ { 9, 2, 10 }, // 63 bits per transform
+ { 9, 3, 9 }, // 63 bits per transform
+ { 9, 4, 8 }, // 63 bits per transform
+ { 9, 5, 7 }, // 63 bits per transform
+ { 9, 6, 6 }, // 63 bits per transform
+ { 9, 7, 5 }, // 63 bits per transform
+ { 9, 8, 4 }, // 63 bits per transform
+ { 9, 9, 3 }, // 63 bits per transform
+ { 9, 10, 2 }, // 63 bits per transform
+ { 9, 11, 1 }, // 63 bits per transform
+ { 9, 12, 0 }, // 63 bits per transform
+ { 10, 0, 11 }, // 63 bits per transform
+ { 10, 1, 10 }, // 63 bits per transform
+ { 10, 2, 9 }, // 63 bits per transform
+ { 10, 3, 8 }, // 63 bits per transform
+ { 10, 4, 7 }, // 63 bits per transform
+ { 10, 5, 6 }, // 63 bits per transform
+ { 10, 6, 5 }, // 63 bits per transform
+ { 10, 7, 4 }, // 63 bits per transform
+ { 10, 8, 3 }, // 63 bits per transform
+ { 10, 9, 2 }, // 63 bits per transform
+ { 10, 10, 1 }, // 63 bits per transform
+ { 10, 11, 0 }, // 63 bits per transform
+ { 11, 0, 10 }, // 63 bits per transform
+ { 11, 1, 9 }, // 63 bits per transform
+ { 11, 2, 8 }, // 63 bits per transform
+ { 11, 3, 7 }, // 63 bits per transform
+ { 11, 4, 6 }, // 63 bits per transform
+ { 11, 5, 5 }, // 63 bits per transform
+ { 11, 6, 4 }, // 63 bits per transform
+ { 11, 7, 3 }, // 63 bits per transform
+ { 11, 8, 2 }, // 63 bits per transform
+ { 11, 9, 1 }, // 63 bits per transform
+ { 11, 10, 0 }, // 63 bits per transform
+ { 12, 0, 9 }, // 63 bits per transform
+ { 12, 1, 8 }, // 63 bits per transform
+ { 12, 2, 7 }, // 63 bits per transform
+ { 12, 3, 6 }, // 63 bits per transform
+ { 12, 4, 5 }, // 63 bits per transform
+ { 12, 5, 4 }, // 63 bits per transform
+ { 12, 6, 3 }, // 63 bits per transform
+ { 12, 7, 2 }, // 63 bits per transform
+ { 12, 8, 1 }, // 63 bits per transform
+ { 12, 9, 0 }, // 63 bits per transform
+ { 13, 0, 8 }, // 63 bits per transform
+ { 13, 1, 7 }, // 63 bits per transform
+ { 13, 2, 6 }, // 63 bits per transform
+ { 13, 3, 5 }, // 63 bits per transform
+ { 13, 4, 4 }, // 63 bits per transform
+ { 13, 5, 3 }, // 63 bits per transform
+ { 13, 6, 2 }, // 63 bits per transform
+ { 13, 7, 1 }, // 63 bits per transform
+ { 13, 8, 0 }, // 63 bits per transform
+ { 14, 0, 7 }, // 63 bits per transform
+ { 14, 1, 6 }, // 63 bits per transform
+ { 14, 2, 5 }, // 63 bits per transform
+ { 14, 3, 4 }, // 63 bits per transform
+ { 14, 4, 3 }, // 63 bits per transform
+ { 14, 5, 2 }, // 63 bits per transform
+ { 14, 6, 1 }, // 63 bits per transform
+ { 14, 7, 0 }, // 63 bits per transform
+ { 15, 0, 6 }, // 63 bits per transform
+ { 15, 1, 5 }, // 63 bits per transform
+ { 15, 2, 4 }, // 63 bits per transform
+ { 15, 3, 3 }, // 63 bits per transform
+ { 15, 4, 2 }, // 63 bits per transform
+ { 15, 5, 1 }, // 63 bits per transform
+ { 15, 6, 0 }, // 63 bits per transform
+ { 16, 0, 5 }, // 63 bits per transform
+ { 16, 1, 4 }, // 63 bits per transform
+ { 16, 2, 3 }, // 63 bits per transform
+ { 16, 3, 2 }, // 63 bits per transform
+ { 16, 4, 1 }, // 63 bits per transform
+ { 16, 5, 0 }, // 63 bits per transform
+ { 17, 0, 4 }, // 63 bits per transform
+ { 17, 1, 3 }, // 63 bits per transform
+ { 17, 2, 2 }, // 63 bits per transform
+ { 17, 3, 1 }, // 63 bits per transform
+ { 17, 4, 0 }, // 63 bits per transform
+ { 18, 0, 3 }, // 63 bits per transform
+ { 18, 1, 2 }, // 63 bits per transform
+ { 18, 2, 1 }, // 63 bits per transform
+ { 18, 3, 0 }, // 63 bits per transform
+ { 19, 0, 2 }, // 63 bits per transform
+ { 19, 1, 1 }, // 63 bits per transform
+ { 19, 2, 0 }, // 63 bits per transform
+ { 20, 0, 1 }, // 63 bits per transform
+ { 20, 1, 0 }, // 63 bits per transform
+ { 21, 0, 0 }, // 63 bits per transform
+ { 0, 0, 22 }, // 66 bits per transform
+ { 0, 1, 21 }, // 66 bits per transform
+ { 0, 2, 20 }, // 66 bits per transform
+ { 0, 3, 19 }, // 66 bits per transform
+ { 0, 4, 18 }, // 66 bits per transform
+ { 0, 5, 17 }, // 66 bits per transform
+ { 0, 6, 16 }, // 66 bits per transform
+ { 0, 7, 15 }, // 66 bits per transform
+ { 0, 8, 14 }, // 66 bits per transform
+ { 0, 9, 13 }, // 66 bits per transform
+ { 0, 10, 12 }, // 66 bits per transform
+ { 0, 11, 11 }, // 66 bits per transform
+ { 0, 12, 10 }, // 66 bits per transform
+ { 0, 13, 9 }, // 66 bits per transform
+ { 0, 14, 8 }, // 66 bits per transform
+ { 0, 15, 7 }, // 66 bits per transform
+ { 0, 16, 6 }, // 66 bits per transform
+ { 0, 17, 5 }, // 66 bits per transform
+ { 0, 18, 4 }, // 66 bits per transform
+ { 0, 19, 3 }, // 66 bits per transform
+ { 0, 20, 2 }, // 66 bits per transform
+ { 0, 21, 1 }, // 66 bits per transform
+ { 0, 22, 0 }, // 66 bits per transform
+ { 1, 0, 21 }, // 66 bits per transform
+ { 1, 1, 20 }, // 66 bits per transform
+ { 1, 2, 19 }, // 66 bits per transform
+ { 1, 3, 18 }, // 66 bits per transform
+ { 1, 4, 17 }, // 66 bits per transform
+ { 1, 5, 16 }, // 66 bits per transform
+ { 1, 6, 15 }, // 66 bits per transform
+ { 1, 7, 14 }, // 66 bits per transform
+ { 1, 8, 13 }, // 66 bits per transform
+ { 1, 9, 12 }, // 66 bits per transform
+ { 1, 10, 11 }, // 66 bits per transform
+ { 1, 11, 10 }, // 66 bits per transform
+ { 1, 12, 9 }, // 66 bits per transform
+ { 1, 13, 8 }, // 66 bits per transform
+ { 1, 14, 7 }, // 66 bits per transform
+ { 1, 15, 6 }, // 66 bits per transform
+ { 1, 16, 5 }, // 66 bits per transform
+ { 1, 17, 4 }, // 66 bits per transform
+ { 1, 18, 3 }, // 66 bits per transform
+ { 1, 19, 2 }, // 66 bits per transform
+ { 1, 20, 1 }, // 66 bits per transform
+ { 1, 21, 0 }, // 66 bits per transform
+ { 2, 0, 20 }, // 66 bits per transform
+ { 2, 1, 19 }, // 66 bits per transform
+ { 2, 2, 18 }, // 66 bits per transform
+ { 2, 3, 17 }, // 66 bits per transform
+ { 2, 4, 16 }, // 66 bits per transform
+ { 2, 5, 15 }, // 66 bits per transform
+ { 2, 6, 14 }, // 66 bits per transform
+ { 2, 7, 13 }, // 66 bits per transform
+ { 2, 8, 12 }, // 66 bits per transform
+ { 2, 9, 11 }, // 66 bits per transform
+ { 2, 10, 10 }, // 66 bits per transform
+ { 2, 11, 9 }, // 66 bits per transform
+ { 2, 12, 8 }, // 66 bits per transform
+ { 2, 13, 7 }, // 66 bits per transform
+ { 2, 14, 6 }, // 66 bits per transform
+ { 2, 15, 5 }, // 66 bits per transform
+ { 2, 16, 4 }, // 66 bits per transform
+ { 2, 17, 3 }, // 66 bits per transform
+ { 2, 18, 2 }, // 66 bits per transform
+ { 2, 19, 1 }, // 66 bits per transform
+ { 2, 20, 0 }, // 66 bits per transform
+ { 3, 0, 19 }, // 66 bits per transform
+ { 3, 1, 18 }, // 66 bits per transform
+ { 3, 2, 17 }, // 66 bits per transform
+ { 3, 3, 16 }, // 66 bits per transform
+ { 3, 4, 15 }, // 66 bits per transform
+ { 3, 5, 14 }, // 66 bits per transform
+ { 3, 6, 13 }, // 66 bits per transform
+ { 3, 7, 12 }, // 66 bits per transform
+ { 3, 8, 11 }, // 66 bits per transform
+ { 3, 9, 10 }, // 66 bits per transform
+ { 3, 10, 9 }, // 66 bits per transform
+ { 3, 11, 8 }, // 66 bits per transform
+ { 3, 12, 7 }, // 66 bits per transform
+ { 3, 13, 6 }, // 66 bits per transform
+ { 3, 14, 5 }, // 66 bits per transform
+ { 3, 15, 4 }, // 66 bits per transform
+ { 3, 16, 3 }, // 66 bits per transform
+ { 3, 17, 2 }, // 66 bits per transform
+ { 3, 18, 1 }, // 66 bits per transform
+ { 3, 19, 0 }, // 66 bits per transform
+ { 4, 0, 18 }, // 66 bits per transform
+ { 4, 1, 17 }, // 66 bits per transform
+ { 4, 2, 16 }, // 66 bits per transform
+ { 4, 3, 15 }, // 66 bits per transform
+ { 4, 4, 14 }, // 66 bits per transform
+ { 4, 5, 13 }, // 66 bits per transform
+ { 4, 6, 12 }, // 66 bits per transform
+ { 4, 7, 11 }, // 66 bits per transform
+ { 4, 8, 10 }, // 66 bits per transform
+ { 4, 9, 9 }, // 66 bits per transform
+ { 4, 10, 8 }, // 66 bits per transform
+ { 4, 11, 7 }, // 66 bits per transform
+ { 4, 12, 6 }, // 66 bits per transform
+ { 4, 13, 5 }, // 66 bits per transform
+ { 4, 14, 4 }, // 66 bits per transform
+ { 4, 15, 3 }, // 66 bits per transform
+ { 4, 16, 2 }, // 66 bits per transform
+ { 4, 17, 1 }, // 66 bits per transform
+ { 4, 18, 0 }, // 66 bits per transform
+ { 5, 0, 17 }, // 66 bits per transform
+ { 5, 1, 16 }, // 66 bits per transform
+ { 5, 2, 15 }, // 66 bits per transform
+ { 5, 3, 14 }, // 66 bits per transform
+ { 5, 4, 13 }, // 66 bits per transform
+ { 5, 5, 12 }, // 66 bits per transform
+ { 5, 6, 11 }, // 66 bits per transform
+ { 5, 7, 10 }, // 66 bits per transform
+ { 5, 8, 9 }, // 66 bits per transform
+ { 5, 9, 8 }, // 66 bits per transform
+ { 5, 10, 7 }, // 66 bits per transform
+ { 5, 11, 6 }, // 66 bits per transform
+ { 5, 12, 5 }, // 66 bits per transform
+ { 5, 13, 4 }, // 66 bits per transform
+ { 5, 14, 3 }, // 66 bits per transform
+ { 5, 15, 2 }, // 66 bits per transform
+ { 5, 16, 1 }, // 66 bits per transform
+ { 5, 17, 0 }, // 66 bits per transform
+ { 6, 0, 16 }, // 66 bits per transform
+ { 6, 1, 15 }, // 66 bits per transform
+ { 6, 2, 14 }, // 66 bits per transform
+ { 6, 3, 13 }, // 66 bits per transform
+ { 6, 4, 12 }, // 66 bits per transform
+ { 6, 5, 11 }, // 66 bits per transform
+ { 6, 6, 10 }, // 66 bits per transform
+ { 6, 7, 9 }, // 66 bits per transform
+ { 6, 8, 8 }, // 66 bits per transform
+ { 6, 9, 7 }, // 66 bits per transform
+ { 6, 10, 6 }, // 66 bits per transform
+ { 6, 11, 5 }, // 66 bits per transform
+ { 6, 12, 4 }, // 66 bits per transform
+ { 6, 13, 3 }, // 66 bits per transform
+ { 6, 14, 2 }, // 66 bits per transform
+ { 6, 15, 1 }, // 66 bits per transform
+ { 6, 16, 0 }, // 66 bits per transform
+ { 7, 0, 15 }, // 66 bits per transform
+ { 7, 1, 14 }, // 66 bits per transform
+ { 7, 2, 13 }, // 66 bits per transform
+ { 7, 3, 12 }, // 66 bits per transform
+ { 7, 4, 11 }, // 66 bits per transform
+ { 7, 5, 10 }, // 66 bits per transform
+ { 7, 6, 9 }, // 66 bits per transform
+ { 7, 7, 8 }, // 66 bits per transform
+ { 7, 8, 7 }, // 66 bits per transform
+ { 7, 9, 6 }, // 66 bits per transform
+ { 7, 10, 5 }, // 66 bits per transform
+ { 7, 11, 4 }, // 66 bits per transform
+ { 7, 12, 3 }, // 66 bits per transform
+ { 7, 13, 2 }, // 66 bits per transform
+ { 7, 14, 1 }, // 66 bits per transform
+ { 7, 15, 0 }, // 66 bits per transform
+ { 8, 0, 14 }, // 66 bits per transform
+ { 8, 1, 13 }, // 66 bits per transform
+ { 8, 2, 12 }, // 66 bits per transform
+ { 8, 3, 11 }, // 66 bits per transform
+ { 8, 4, 10 }, // 66 bits per transform
+ { 8, 5, 9 }, // 66 bits per transform
+ { 8, 6, 8 }, // 66 bits per transform
+ { 8, 7, 7 }, // 66 bits per transform
+ { 8, 8, 6 }, // 66 bits per transform
+ { 8, 9, 5 }, // 66 bits per transform
+ { 8, 10, 4 }, // 66 bits per transform
+ { 8, 11, 3 }, // 66 bits per transform
+ { 8, 12, 2 }, // 66 bits per transform
+ { 8, 13, 1 }, // 66 bits per transform
+ { 8, 14, 0 }, // 66 bits per transform
+ { 9, 0, 13 }, // 66 bits per transform
+ { 9, 1, 12 }, // 66 bits per transform
+ { 9, 2, 11 }, // 66 bits per transform
+ { 9, 3, 10 }, // 66 bits per transform
+ { 9, 4, 9 }, // 66 bits per transform
+ { 9, 5, 8 }, // 66 bits per transform
+ { 9, 6, 7 }, // 66 bits per transform
+ { 9, 7, 6 }, // 66 bits per transform
+ { 9, 8, 5 }, // 66 bits per transform
+ { 9, 9, 4 }, // 66 bits per transform
+ { 9, 10, 3 }, // 66 bits per transform
+ { 9, 11, 2 }, // 66 bits per transform
+ { 9, 12, 1 }, // 66 bits per transform
+ { 9, 13, 0 }, // 66 bits per transform
+ { 10, 0, 12 }, // 66 bits per transform
+ { 10, 1, 11 }, // 66 bits per transform
+ { 10, 2, 10 }, // 66 bits per transform
+ { 10, 3, 9 }, // 66 bits per transform
+ { 10, 4, 8 }, // 66 bits per transform
+ { 10, 5, 7 }, // 66 bits per transform
+ { 10, 6, 6 }, // 66 bits per transform
+ { 10, 7, 5 }, // 66 bits per transform
+ { 10, 8, 4 }, // 66 bits per transform
+ { 10, 9, 3 }, // 66 bits per transform
+ { 10, 10, 2 }, // 66 bits per transform
+ { 10, 11, 1 }, // 66 bits per transform
+ { 10, 12, 0 }, // 66 bits per transform
+ { 11, 0, 11 }, // 66 bits per transform
+ { 11, 1, 10 }, // 66 bits per transform
+ { 11, 2, 9 }, // 66 bits per transform
+ { 11, 3, 8 }, // 66 bits per transform
+ { 11, 4, 7 }, // 66 bits per transform
+ { 11, 5, 6 }, // 66 bits per transform
+ { 11, 6, 5 }, // 66 bits per transform
+ { 11, 7, 4 }, // 66 bits per transform
+ { 11, 8, 3 }, // 66 bits per transform
+ { 11, 9, 2 }, // 66 bits per transform
+ { 11, 10, 1 }, // 66 bits per transform
+ { 11, 11, 0 }, // 66 bits per transform
+ { 12, 0, 10 }, // 66 bits per transform
+ { 12, 1, 9 }, // 66 bits per transform
+ { 12, 2, 8 }, // 66 bits per transform
+ { 12, 3, 7 }, // 66 bits per transform
+ { 12, 4, 6 }, // 66 bits per transform
+ { 12, 5, 5 }, // 66 bits per transform
+ { 12, 6, 4 }, // 66 bits per transform
+ { 12, 7, 3 }, // 66 bits per transform
+ { 12, 8, 2 }, // 66 bits per transform
+ { 12, 9, 1 }, // 66 bits per transform
+ { 12, 10, 0 }, // 66 bits per transform
+ { 13, 0, 9 }, // 66 bits per transform
+ { 13, 1, 8 }, // 66 bits per transform
+ { 13, 2, 7 }, // 66 bits per transform
+ { 13, 3, 6 }, // 66 bits per transform
+ { 13, 4, 5 }, // 66 bits per transform
+ { 13, 5, 4 }, // 66 bits per transform
+ { 13, 6, 3 }, // 66 bits per transform
+ { 13, 7, 2 }, // 66 bits per transform
+ { 13, 8, 1 }, // 66 bits per transform
+ { 13, 9, 0 }, // 66 bits per transform
+ { 14, 0, 8 }, // 66 bits per transform
+ { 14, 1, 7 }, // 66 bits per transform
+ { 14, 2, 6 }, // 66 bits per transform
+ { 14, 3, 5 }, // 66 bits per transform
+ { 14, 4, 4 }, // 66 bits per transform
+ { 14, 5, 3 }, // 66 bits per transform
+ { 14, 6, 2 }, // 66 bits per transform
+ { 14, 7, 1 }, // 66 bits per transform
+ { 14, 8, 0 }, // 66 bits per transform
+ { 15, 0, 7 }, // 66 bits per transform
+ { 15, 1, 6 }, // 66 bits per transform
+ { 15, 2, 5 }, // 66 bits per transform
+ { 15, 3, 4 }, // 66 bits per transform
+ { 15, 4, 3 }, // 66 bits per transform
+ { 15, 5, 2 }, // 66 bits per transform
+ { 15, 6, 1 }, // 66 bits per transform
+ { 15, 7, 0 }, // 66 bits per transform
+ { 16, 0, 6 }, // 66 bits per transform
+ { 16, 1, 5 }, // 66 bits per transform
+ { 16, 2, 4 }, // 66 bits per transform
+ { 16, 3, 3 }, // 66 bits per transform
+ { 16, 4, 2 }, // 66 bits per transform
+ { 16, 5, 1 }, // 66 bits per transform
+ { 16, 6, 0 }, // 66 bits per transform
+ { 17, 0, 5 }, // 66 bits per transform
+ { 17, 1, 4 }, // 66 bits per transform
+ { 17, 2, 3 }, // 66 bits per transform
+ { 17, 3, 2 }, // 66 bits per transform
+ { 17, 4, 1 }, // 66 bits per transform
+ { 17, 5, 0 }, // 66 bits per transform
+ { 18, 0, 4 }, // 66 bits per transform
+ { 18, 1, 3 }, // 66 bits per transform
+ { 18, 2, 2 }, // 66 bits per transform
+ { 18, 3, 1 }, // 66 bits per transform
+ { 18, 4, 0 }, // 66 bits per transform
+ { 19, 0, 3 }, // 66 bits per transform
+ { 19, 1, 2 }, // 66 bits per transform
+ { 19, 2, 1 }, // 66 bits per transform
+ { 19, 3, 0 }, // 66 bits per transform
+ { 20, 0, 2 }, // 66 bits per transform
+ { 20, 1, 1 }, // 66 bits per transform
+ { 20, 2, 0 }, // 66 bits per transform
+ { 21, 0, 1 }, // 66 bits per transform
+ { 21, 1, 0 }, // 66 bits per transform
+ { 22, 0, 0 }, // 66 bits per transform
+ { 0, 0, 23 }, // 69 bits per transform
+ { 0, 1, 22 }, // 69 bits per transform
+ { 0, 2, 21 }, // 69 bits per transform
+ { 0, 3, 20 }, // 69 bits per transform
+ { 0, 4, 19 }, // 69 bits per transform
+ { 0, 5, 18 }, // 69 bits per transform
+ { 0, 6, 17 }, // 69 bits per transform
+ { 0, 7, 16 }, // 69 bits per transform
+ { 0, 8, 15 }, // 69 bits per transform
+ { 0, 9, 14 }, // 69 bits per transform
+ { 0, 10, 13 }, // 69 bits per transform
+ { 0, 11, 12 }, // 69 bits per transform
+ { 0, 12, 11 }, // 69 bits per transform
+ { 0, 13, 10 }, // 69 bits per transform
+ { 0, 14, 9 }, // 69 bits per transform
+ { 0, 15, 8 }, // 69 bits per transform
+ { 0, 16, 7 }, // 69 bits per transform
+ { 0, 17, 6 }, // 69 bits per transform
+ { 0, 18, 5 }, // 69 bits per transform
+ { 0, 19, 4 }, // 69 bits per transform
+ { 0, 20, 3 }, // 69 bits per transform
+ { 0, 21, 2 }, // 69 bits per transform
+ { 0, 22, 1 }, // 69 bits per transform
+ { 0, 23, 0 }, // 69 bits per transform
+ { 1, 0, 22 }, // 69 bits per transform
+ { 1, 1, 21 }, // 69 bits per transform
+ { 1, 2, 20 }, // 69 bits per transform
+ { 1, 3, 19 }, // 69 bits per transform
+ { 1, 4, 18 }, // 69 bits per transform
+ { 1, 5, 17 }, // 69 bits per transform
+ { 1, 6, 16 }, // 69 bits per transform
+ { 1, 7, 15 }, // 69 bits per transform
+ { 1, 8, 14 }, // 69 bits per transform
+ { 1, 9, 13 }, // 69 bits per transform
+ { 1, 10, 12 }, // 69 bits per transform
+ { 1, 11, 11 }, // 69 bits per transform
+ { 1, 12, 10 }, // 69 bits per transform
+ { 1, 13, 9 }, // 69 bits per transform
+ { 1, 14, 8 }, // 69 bits per transform
+ { 1, 15, 7 }, // 69 bits per transform
+ { 1, 16, 6 }, // 69 bits per transform
+ { 1, 17, 5 }, // 69 bits per transform
+ { 1, 18, 4 }, // 69 bits per transform
+ { 1, 19, 3 }, // 69 bits per transform
+ { 1, 20, 2 }, // 69 bits per transform
+ { 1, 21, 1 }, // 69 bits per transform
+ { 1, 22, 0 }, // 69 bits per transform
+ { 2, 0, 21 }, // 69 bits per transform
+ { 2, 1, 20 }, // 69 bits per transform
+ { 2, 2, 19 }, // 69 bits per transform
+ { 2, 3, 18 }, // 69 bits per transform
+ { 2, 4, 17 }, // 69 bits per transform
+ { 2, 5, 16 }, // 69 bits per transform
+ { 2, 6, 15 }, // 69 bits per transform
+ { 2, 7, 14 }, // 69 bits per transform
+ { 2, 8, 13 }, // 69 bits per transform
+ { 2, 9, 12 }, // 69 bits per transform
+ { 2, 10, 11 }, // 69 bits per transform
+ { 2, 11, 10 }, // 69 bits per transform
+ { 2, 12, 9 }, // 69 bits per transform
+ { 2, 13, 8 }, // 69 bits per transform
+ { 2, 14, 7 }, // 69 bits per transform
+ { 2, 15, 6 }, // 69 bits per transform
+ { 2, 16, 5 }, // 69 bits per transform
+ { 2, 17, 4 }, // 69 bits per transform
+ { 2, 18, 3 }, // 69 bits per transform
+ { 2, 19, 2 }, // 69 bits per transform
+ { 2, 20, 1 }, // 69 bits per transform
+ { 2, 21, 0 }, // 69 bits per transform
+ { 3, 0, 20 }, // 69 bits per transform
+ { 3, 1, 19 }, // 69 bits per transform
+ { 3, 2, 18 }, // 69 bits per transform
+ { 3, 3, 17 }, // 69 bits per transform
+ { 3, 4, 16 }, // 69 bits per transform
+ { 3, 5, 15 }, // 69 bits per transform
+ { 3, 6, 14 }, // 69 bits per transform
+ { 3, 7, 13 }, // 69 bits per transform
+ { 3, 8, 12 }, // 69 bits per transform
+ { 3, 9, 11 }, // 69 bits per transform
+ { 3, 10, 10 }, // 69 bits per transform
+ { 3, 11, 9 }, // 69 bits per transform
+ { 3, 12, 8 }, // 69 bits per transform
+ { 3, 13, 7 }, // 69 bits per transform
+ { 3, 14, 6 }, // 69 bits per transform
+ { 3, 15, 5 }, // 69 bits per transform
+ { 3, 16, 4 }, // 69 bits per transform
+ { 3, 17, 3 }, // 69 bits per transform
+ { 3, 18, 2 }, // 69 bits per transform
+ { 3, 19, 1 }, // 69 bits per transform
+ { 3, 20, 0 }, // 69 bits per transform
+ { 4, 0, 19 }, // 69 bits per transform
+ { 4, 1, 18 }, // 69 bits per transform
+ { 4, 2, 17 }, // 69 bits per transform
+ { 4, 3, 16 }, // 69 bits per transform
+ { 4, 4, 15 }, // 69 bits per transform
+ { 4, 5, 14 }, // 69 bits per transform
+ { 4, 6, 13 }, // 69 bits per transform
+ { 4, 7, 12 }, // 69 bits per transform
+ { 4, 8, 11 }, // 69 bits per transform
+ { 4, 9, 10 }, // 69 bits per transform
+ { 4, 10, 9 }, // 69 bits per transform
+ { 4, 11, 8 }, // 69 bits per transform
+ { 4, 12, 7 }, // 69 bits per transform
+ { 4, 13, 6 }, // 69 bits per transform
+ { 4, 14, 5 }, // 69 bits per transform
+ { 4, 15, 4 }, // 69 bits per transform
+ { 4, 16, 3 }, // 69 bits per transform
+ { 4, 17, 2 }, // 69 bits per transform
+ { 4, 18, 1 }, // 69 bits per transform
+ { 4, 19, 0 }, // 69 bits per transform
+ { 5, 0, 18 }, // 69 bits per transform
+ { 5, 1, 17 }, // 69 bits per transform
+ { 5, 2, 16 }, // 69 bits per transform
+ { 5, 3, 15 }, // 69 bits per transform
+ { 5, 4, 14 }, // 69 bits per transform
+ { 5, 5, 13 }, // 69 bits per transform
+ { 5, 6, 12 }, // 69 bits per transform
+ { 5, 7, 11 }, // 69 bits per transform
+ { 5, 8, 10 }, // 69 bits per transform
+ { 5, 9, 9 }, // 69 bits per transform
+ { 5, 10, 8 }, // 69 bits per transform
+ { 5, 11, 7 }, // 69 bits per transform
+ { 5, 12, 6 }, // 69 bits per transform
+ { 5, 13, 5 }, // 69 bits per transform
+ { 5, 14, 4 }, // 69 bits per transform
+ { 5, 15, 3 }, // 69 bits per transform
+ { 5, 16, 2 }, // 69 bits per transform
+ { 5, 17, 1 }, // 69 bits per transform
+ { 5, 18, 0 }, // 69 bits per transform
+ { 6, 0, 17 }, // 69 bits per transform
+ { 6, 1, 16 }, // 69 bits per transform
+ { 6, 2, 15 }, // 69 bits per transform
+ { 6, 3, 14 }, // 69 bits per transform
+ { 6, 4, 13 }, // 69 bits per transform
+ { 6, 5, 12 }, // 69 bits per transform
+ { 6, 6, 11 }, // 69 bits per transform
+ { 6, 7, 10 }, // 69 bits per transform
+ { 6, 8, 9 }, // 69 bits per transform
+ { 6, 9, 8 }, // 69 bits per transform
+ { 6, 10, 7 }, // 69 bits per transform
+ { 6, 11, 6 }, // 69 bits per transform
+ { 6, 12, 5 }, // 69 bits per transform
+ { 6, 13, 4 }, // 69 bits per transform
+ { 6, 14, 3 }, // 69 bits per transform
+ { 6, 15, 2 }, // 69 bits per transform
+ { 6, 16, 1 }, // 69 bits per transform
+ { 6, 17, 0 }, // 69 bits per transform
+ { 7, 0, 16 }, // 69 bits per transform
+ { 7, 1, 15 }, // 69 bits per transform
+ { 7, 2, 14 }, // 69 bits per transform
+ { 7, 3, 13 }, // 69 bits per transform
+ { 7, 4, 12 }, // 69 bits per transform
+ { 7, 5, 11 }, // 69 bits per transform
+ { 7, 6, 10 }, // 69 bits per transform
+ { 7, 7, 9 }, // 69 bits per transform
+ { 7, 8, 8 }, // 69 bits per transform
+ { 7, 9, 7 }, // 69 bits per transform
+ { 7, 10, 6 }, // 69 bits per transform
+ { 7, 11, 5 }, // 69 bits per transform
+ { 7, 12, 4 }, // 69 bits per transform
+ { 7, 13, 3 }, // 69 bits per transform
+ { 7, 14, 2 }, // 69 bits per transform
+ { 7, 15, 1 }, // 69 bits per transform
+ { 7, 16, 0 }, // 69 bits per transform
+ { 8, 0, 15 }, // 69 bits per transform
+ { 8, 1, 14 }, // 69 bits per transform
+ { 8, 2, 13 }, // 69 bits per transform
+ { 8, 3, 12 }, // 69 bits per transform
+ { 8, 4, 11 }, // 69 bits per transform
+ { 8, 5, 10 }, // 69 bits per transform
+ { 8, 6, 9 }, // 69 bits per transform
+ { 8, 7, 8 }, // 69 bits per transform
+ { 8, 8, 7 }, // 69 bits per transform
+ { 8, 9, 6 }, // 69 bits per transform
+ { 8, 10, 5 }, // 69 bits per transform
+ { 8, 11, 4 }, // 69 bits per transform
+ { 8, 12, 3 }, // 69 bits per transform
+ { 8, 13, 2 }, // 69 bits per transform
+ { 8, 14, 1 }, // 69 bits per transform
+ { 8, 15, 0 }, // 69 bits per transform
+ { 9, 0, 14 }, // 69 bits per transform
+ { 9, 1, 13 }, // 69 bits per transform
+ { 9, 2, 12 }, // 69 bits per transform
+ { 9, 3, 11 }, // 69 bits per transform
+ { 9, 4, 10 }, // 69 bits per transform
+ { 9, 5, 9 }, // 69 bits per transform
+ { 9, 6, 8 }, // 69 bits per transform
+ { 9, 7, 7 }, // 69 bits per transform
+ { 9, 8, 6 }, // 69 bits per transform
+ { 9, 9, 5 }, // 69 bits per transform
+ { 9, 10, 4 }, // 69 bits per transform
+ { 9, 11, 3 }, // 69 bits per transform
+ { 9, 12, 2 }, // 69 bits per transform
+ { 9, 13, 1 }, // 69 bits per transform
+ { 9, 14, 0 }, // 69 bits per transform
+ { 10, 0, 13 }, // 69 bits per transform
+ { 10, 1, 12 }, // 69 bits per transform
+ { 10, 2, 11 }, // 69 bits per transform
+ { 10, 3, 10 }, // 69 bits per transform
+ { 10, 4, 9 }, // 69 bits per transform
+ { 10, 5, 8 }, // 69 bits per transform
+ { 10, 6, 7 }, // 69 bits per transform
+ { 10, 7, 6 }, // 69 bits per transform
+ { 10, 8, 5 }, // 69 bits per transform
+ { 10, 9, 4 }, // 69 bits per transform
+ { 10, 10, 3 }, // 69 bits per transform
+ { 10, 11, 2 }, // 69 bits per transform
+ { 10, 12, 1 }, // 69 bits per transform
+ { 10, 13, 0 }, // 69 bits per transform
+ { 11, 0, 12 }, // 69 bits per transform
+ { 11, 1, 11 }, // 69 bits per transform
+ { 11, 2, 10 }, // 69 bits per transform
+ { 11, 3, 9 }, // 69 bits per transform
+ { 11, 4, 8 }, // 69 bits per transform
+ { 11, 5, 7 }, // 69 bits per transform
+ { 11, 6, 6 }, // 69 bits per transform
+ { 11, 7, 5 }, // 69 bits per transform
+ { 11, 8, 4 }, // 69 bits per transform
+ { 11, 9, 3 }, // 69 bits per transform
+ { 11, 10, 2 }, // 69 bits per transform
+ { 11, 11, 1 }, // 69 bits per transform
+ { 11, 12, 0 }, // 69 bits per transform
+ { 12, 0, 11 }, // 69 bits per transform
+ { 12, 1, 10 }, // 69 bits per transform
+ { 12, 2, 9 }, // 69 bits per transform
+ { 12, 3, 8 }, // 69 bits per transform
+ { 12, 4, 7 }, // 69 bits per transform
+ { 12, 5, 6 }, // 69 bits per transform
+ { 12, 6, 5 }, // 69 bits per transform
+ { 12, 7, 4 }, // 69 bits per transform
+ { 12, 8, 3 }, // 69 bits per transform
+ { 12, 9, 2 }, // 69 bits per transform
+ { 12, 10, 1 }, // 69 bits per transform
+ { 12, 11, 0 }, // 69 bits per transform
+ { 13, 0, 10 }, // 69 bits per transform
+ { 13, 1, 9 }, // 69 bits per transform
+ { 13, 2, 8 }, // 69 bits per transform
+ { 13, 3, 7 }, // 69 bits per transform
+ { 13, 4, 6 }, // 69 bits per transform
+ { 13, 5, 5 }, // 69 bits per transform
+ { 13, 6, 4 }, // 69 bits per transform
+ { 13, 7, 3 }, // 69 bits per transform
+ { 13, 8, 2 }, // 69 bits per transform
+ { 13, 9, 1 }, // 69 bits per transform
+ { 13, 10, 0 }, // 69 bits per transform
+ { 14, 0, 9 }, // 69 bits per transform
+ { 14, 1, 8 }, // 69 bits per transform
+ { 14, 2, 7 }, // 69 bits per transform
+ { 14, 3, 6 }, // 69 bits per transform
+ { 14, 4, 5 }, // 69 bits per transform
+ { 14, 5, 4 }, // 69 bits per transform
+ { 14, 6, 3 }, // 69 bits per transform
+ { 14, 7, 2 }, // 69 bits per transform
+ { 14, 8, 1 }, // 69 bits per transform
+ { 14, 9, 0 }, // 69 bits per transform
+ { 15, 0, 8 }, // 69 bits per transform
+ { 15, 1, 7 }, // 69 bits per transform
+ { 15, 2, 6 }, // 69 bits per transform
+ { 15, 3, 5 }, // 69 bits per transform
+ { 15, 4, 4 }, // 69 bits per transform
+ { 15, 5, 3 }, // 69 bits per transform
+ { 15, 6, 2 }, // 69 bits per transform
+ { 15, 7, 1 }, // 69 bits per transform
+ { 15, 8, 0 }, // 69 bits per transform
+ { 16, 0, 7 }, // 69 bits per transform
+ { 16, 1, 6 }, // 69 bits per transform
+ { 16, 2, 5 }, // 69 bits per transform
+ { 16, 3, 4 }, // 69 bits per transform
+ { 16, 4, 3 }, // 69 bits per transform
+ { 16, 5, 2 }, // 69 bits per transform
+ { 16, 6, 1 }, // 69 bits per transform
+ { 16, 7, 0 }, // 69 bits per transform
+ { 17, 0, 6 }, // 69 bits per transform
+ { 17, 1, 5 }, // 69 bits per transform
+ { 17, 2, 4 }, // 69 bits per transform
+ { 17, 3, 3 }, // 69 bits per transform
+ { 17, 4, 2 }, // 69 bits per transform
+ { 17, 5, 1 }, // 69 bits per transform
+ { 17, 6, 0 }, // 69 bits per transform
+ { 18, 0, 5 }, // 69 bits per transform
+ { 18, 1, 4 }, // 69 bits per transform
+ { 18, 2, 3 }, // 69 bits per transform
+ { 18, 3, 2 }, // 69 bits per transform
+ { 18, 4, 1 }, // 69 bits per transform
+ { 18, 5, 0 }, // 69 bits per transform
+ { 19, 0, 4 }, // 69 bits per transform
+ { 19, 1, 3 }, // 69 bits per transform
+ { 19, 2, 2 }, // 69 bits per transform
+ { 19, 3, 1 }, // 69 bits per transform
+ { 19, 4, 0 }, // 69 bits per transform
+ { 20, 0, 3 }, // 69 bits per transform
+ { 20, 1, 2 }, // 69 bits per transform
+ { 20, 2, 1 }, // 69 bits per transform
+ { 20, 3, 0 }, // 69 bits per transform
+ { 21, 0, 2 }, // 69 bits per transform
+ { 21, 1, 1 }, // 69 bits per transform
+ { 21, 2, 0 }, // 69 bits per transform
+ { 22, 0, 1 }, // 69 bits per transform
+ { 22, 1, 0 }, // 69 bits per transform
+ { 23, 0, 0 }, // 69 bits per transform
+ { 0, 1, 23 }, // 72 bits per transform
+ { 0, 2, 22 }, // 72 bits per transform
+ { 0, 3, 21 }, // 72 bits per transform
+ { 0, 4, 20 }, // 72 bits per transform
+ { 0, 5, 19 }, // 72 bits per transform
+ { 0, 6, 18 }, // 72 bits per transform
+ { 0, 7, 17 }, // 72 bits per transform
+ { 0, 8, 16 }, // 72 bits per transform
+ { 0, 9, 15 }, // 72 bits per transform
+ { 0, 10, 14 }, // 72 bits per transform
+ { 0, 11, 13 }, // 72 bits per transform
+ { 0, 12, 12 }, // 72 bits per transform
+ { 0, 13, 11 }, // 72 bits per transform
+ { 0, 14, 10 }, // 72 bits per transform
+ { 0, 15, 9 }, // 72 bits per transform
+ { 0, 16, 8 }, // 72 bits per transform
+ { 0, 17, 7 }, // 72 bits per transform
+ { 0, 18, 6 }, // 72 bits per transform
+ { 0, 19, 5 }, // 72 bits per transform
+ { 0, 20, 4 }, // 72 bits per transform
+ { 0, 21, 3 }, // 72 bits per transform
+ { 0, 22, 2 }, // 72 bits per transform
+ { 0, 23, 1 }, // 72 bits per transform
+ { 1, 0, 23 }, // 72 bits per transform
+ { 1, 1, 22 }, // 72 bits per transform
+ { 1, 2, 21 }, // 72 bits per transform
+ { 1, 3, 20 }, // 72 bits per transform
+ { 1, 4, 19 }, // 72 bits per transform
+ { 1, 5, 18 }, // 72 bits per transform
+ { 1, 6, 17 }, // 72 bits per transform
+ { 1, 7, 16 }, // 72 bits per transform
+ { 1, 8, 15 }, // 72 bits per transform
+ { 1, 9, 14 }, // 72 bits per transform
+ { 1, 10, 13 }, // 72 bits per transform
+ { 1, 11, 12 }, // 72 bits per transform
+ { 1, 12, 11 }, // 72 bits per transform
+ { 1, 13, 10 }, // 72 bits per transform
+ { 1, 14, 9 }, // 72 bits per transform
+ { 1, 15, 8 }, // 72 bits per transform
+ { 1, 16, 7 }, // 72 bits per transform
+ { 1, 17, 6 }, // 72 bits per transform
+ { 1, 18, 5 }, // 72 bits per transform
+ { 1, 19, 4 }, // 72 bits per transform
+ { 1, 20, 3 }, // 72 bits per transform
+ { 1, 21, 2 }, // 72 bits per transform
+ { 1, 22, 1 }, // 72 bits per transform
+ { 1, 23, 0 }, // 72 bits per transform
+ { 2, 0, 22 }, // 72 bits per transform
+ { 2, 1, 21 }, // 72 bits per transform
+ { 2, 2, 20 }, // 72 bits per transform
+ { 2, 3, 19 }, // 72 bits per transform
+ { 2, 4, 18 }, // 72 bits per transform
+ { 2, 5, 17 }, // 72 bits per transform
+ { 2, 6, 16 }, // 72 bits per transform
+ { 2, 7, 15 }, // 72 bits per transform
+ { 2, 8, 14 }, // 72 bits per transform
+ { 2, 9, 13 }, // 72 bits per transform
+ { 2, 10, 12 }, // 72 bits per transform
+ { 2, 11, 11 }, // 72 bits per transform
+ { 2, 12, 10 }, // 72 bits per transform
+ { 2, 13, 9 }, // 72 bits per transform
+ { 2, 14, 8 }, // 72 bits per transform
+ { 2, 15, 7 }, // 72 bits per transform
+ { 2, 16, 6 }, // 72 bits per transform
+ { 2, 17, 5 }, // 72 bits per transform
+ { 2, 18, 4 }, // 72 bits per transform
+ { 2, 19, 3 }, // 72 bits per transform
+ { 2, 20, 2 }, // 72 bits per transform
+ { 2, 21, 1 }, // 72 bits per transform
+ { 2, 22, 0 }, // 72 bits per transform
+ { 3, 0, 21 }, // 72 bits per transform
+ { 3, 1, 20 }, // 72 bits per transform
+ { 3, 2, 19 }, // 72 bits per transform
+ { 3, 3, 18 }, // 72 bits per transform
+ { 3, 4, 17 }, // 72 bits per transform
+ { 3, 5, 16 }, // 72 bits per transform
+ { 3, 6, 15 }, // 72 bits per transform
+ { 3, 7, 14 }, // 72 bits per transform
+ { 3, 8, 13 }, // 72 bits per transform
+ { 3, 9, 12 }, // 72 bits per transform
+ { 3, 10, 11 }, // 72 bits per transform
+ { 3, 11, 10 }, // 72 bits per transform
+ { 3, 12, 9 }, // 72 bits per transform
+ { 3, 13, 8 }, // 72 bits per transform
+ { 3, 14, 7 }, // 72 bits per transform
+ { 3, 15, 6 }, // 72 bits per transform
+ { 3, 16, 5 }, // 72 bits per transform
+ { 3, 17, 4 }, // 72 bits per transform
+ { 3, 18, 3 }, // 72 bits per transform
+ { 3, 19, 2 }, // 72 bits per transform
+ { 3, 20, 1 }, // 72 bits per transform
+ { 3, 21, 0 }, // 72 bits per transform
+ { 4, 0, 20 }, // 72 bits per transform
+ { 4, 1, 19 }, // 72 bits per transform
+ { 4, 2, 18 }, // 72 bits per transform
+ { 4, 3, 17 }, // 72 bits per transform
+ { 4, 4, 16 }, // 72 bits per transform
+ { 4, 5, 15 }, // 72 bits per transform
+ { 4, 6, 14 }, // 72 bits per transform
+ { 4, 7, 13 }, // 72 bits per transform
+ { 4, 8, 12 }, // 72 bits per transform
+ { 4, 9, 11 }, // 72 bits per transform
+ { 4, 10, 10 }, // 72 bits per transform
+ { 4, 11, 9 }, // 72 bits per transform
+ { 4, 12, 8 }, // 72 bits per transform
+ { 4, 13, 7 }, // 72 bits per transform
+ { 4, 14, 6 }, // 72 bits per transform
+ { 4, 15, 5 }, // 72 bits per transform
+ { 4, 16, 4 }, // 72 bits per transform
+ { 4, 17, 3 }, // 72 bits per transform
+ { 4, 18, 2 }, // 72 bits per transform
+ { 4, 19, 1 }, // 72 bits per transform
+ { 4, 20, 0 }, // 72 bits per transform
+ { 5, 0, 19 }, // 72 bits per transform
+ { 5, 1, 18 }, // 72 bits per transform
+ { 5, 2, 17 }, // 72 bits per transform
+ { 5, 3, 16 }, // 72 bits per transform
+ { 5, 4, 15 }, // 72 bits per transform
+ { 5, 5, 14 }, // 72 bits per transform
+ { 5, 6, 13 }, // 72 bits per transform
+ { 5, 7, 12 }, // 72 bits per transform
+ { 5, 8, 11 }, // 72 bits per transform
+ { 5, 9, 10 }, // 72 bits per transform
+ { 5, 10, 9 }, // 72 bits per transform
+ { 5, 11, 8 }, // 72 bits per transform
+ { 5, 12, 7 }, // 72 bits per transform
+ { 5, 13, 6 }, // 72 bits per transform
+ { 5, 14, 5 }, // 72 bits per transform
+ { 5, 15, 4 }, // 72 bits per transform
+ { 5, 16, 3 }, // 72 bits per transform
+ { 5, 17, 2 }, // 72 bits per transform
+ { 5, 18, 1 }, // 72 bits per transform
+ { 5, 19, 0 }, // 72 bits per transform
+ { 6, 0, 18 }, // 72 bits per transform
+ { 6, 1, 17 }, // 72 bits per transform
+ { 6, 2, 16 }, // 72 bits per transform
+ { 6, 3, 15 }, // 72 bits per transform
+ { 6, 4, 14 }, // 72 bits per transform
+ { 6, 5, 13 }, // 72 bits per transform
+ { 6, 6, 12 }, // 72 bits per transform
+ { 6, 7, 11 }, // 72 bits per transform
+ { 6, 8, 10 }, // 72 bits per transform
+ { 6, 9, 9 }, // 72 bits per transform
+ { 6, 10, 8 }, // 72 bits per transform
+ { 6, 11, 7 }, // 72 bits per transform
+ { 6, 12, 6 }, // 72 bits per transform
+ { 6, 13, 5 }, // 72 bits per transform
+ { 6, 14, 4 }, // 72 bits per transform
+ { 6, 15, 3 }, // 72 bits per transform
+ { 6, 16, 2 }, // 72 bits per transform
+ { 6, 17, 1 }, // 72 bits per transform
+ { 6, 18, 0 }, // 72 bits per transform
+ { 7, 0, 17 }, // 72 bits per transform
+ { 7, 1, 16 }, // 72 bits per transform
+ { 7, 2, 15 }, // 72 bits per transform
+ { 7, 3, 14 }, // 72 bits per transform
+ { 7, 4, 13 }, // 72 bits per transform
+ { 7, 5, 12 }, // 72 bits per transform
+ { 7, 6, 11 }, // 72 bits per transform
+ { 7, 7, 10 }, // 72 bits per transform
+ { 7, 8, 9 }, // 72 bits per transform
+ { 7, 9, 8 }, // 72 bits per transform
+ { 7, 10, 7 }, // 72 bits per transform
+ { 7, 11, 6 }, // 72 bits per transform
+ { 7, 12, 5 }, // 72 bits per transform
+ { 7, 13, 4 }, // 72 bits per transform
+ { 7, 14, 3 }, // 72 bits per transform
+ { 7, 15, 2 }, // 72 bits per transform
+ { 7, 16, 1 }, // 72 bits per transform
+ { 7, 17, 0 }, // 72 bits per transform
+ { 8, 0, 16 }, // 72 bits per transform
+ { 8, 1, 15 }, // 72 bits per transform
+ { 8, 2, 14 }, // 72 bits per transform
+ { 8, 3, 13 }, // 72 bits per transform
+ { 8, 4, 12 }, // 72 bits per transform
+ { 8, 5, 11 }, // 72 bits per transform
+ { 8, 6, 10 }, // 72 bits per transform
+ { 8, 7, 9 }, // 72 bits per transform
+ { 8, 8, 8 }, // 72 bits per transform
+ { 8, 9, 7 }, // 72 bits per transform
+ { 8, 10, 6 }, // 72 bits per transform
+ { 8, 11, 5 }, // 72 bits per transform
+ { 8, 12, 4 }, // 72 bits per transform
+ { 8, 13, 3 }, // 72 bits per transform
+ { 8, 14, 2 }, // 72 bits per transform
+ { 8, 15, 1 }, // 72 bits per transform
+ { 8, 16, 0 }, // 72 bits per transform
+ { 9, 0, 15 }, // 72 bits per transform
+ { 9, 1, 14 }, // 72 bits per transform
+ { 9, 2, 13 }, // 72 bits per transform
+ { 9, 3, 12 }, // 72 bits per transform
+ { 9, 4, 11 }, // 72 bits per transform
+ { 9, 5, 10 }, // 72 bits per transform
+ { 9, 6, 9 }, // 72 bits per transform
+ { 9, 7, 8 }, // 72 bits per transform
+ { 9, 8, 7 }, // 72 bits per transform
+ { 9, 9, 6 }, // 72 bits per transform
+ { 9, 10, 5 }, // 72 bits per transform
+ { 9, 11, 4 }, // 72 bits per transform
+ { 9, 12, 3 }, // 72 bits per transform
+ { 9, 13, 2 }, // 72 bits per transform
+ { 9, 14, 1 }, // 72 bits per transform
+ { 9, 15, 0 }, // 72 bits per transform
+ { 10, 0, 14 }, // 72 bits per transform
+ { 10, 1, 13 }, // 72 bits per transform
+ { 10, 2, 12 }, // 72 bits per transform
+ { 10, 3, 11 }, // 72 bits per transform
+ { 10, 4, 10 }, // 72 bits per transform
+ { 10, 5, 9 }, // 72 bits per transform
+ { 10, 6, 8 }, // 72 bits per transform
+ { 10, 7, 7 }, // 72 bits per transform
+ { 10, 8, 6 }, // 72 bits per transform
+ { 10, 9, 5 }, // 72 bits per transform
+ { 10, 10, 4 }, // 72 bits per transform
+ { 10, 11, 3 }, // 72 bits per transform
+ { 10, 12, 2 }, // 72 bits per transform
+ { 10, 13, 1 }, // 72 bits per transform
+ { 10, 14, 0 }, // 72 bits per transform
+ { 11, 0, 13 }, // 72 bits per transform
+ { 11, 1, 12 }, // 72 bits per transform
+ { 11, 2, 11 }, // 72 bits per transform
+ { 11, 3, 10 }, // 72 bits per transform
+ { 11, 4, 9 }, // 72 bits per transform
+ { 11, 5, 8 }, // 72 bits per transform
+ { 11, 6, 7 }, // 72 bits per transform
+ { 11, 7, 6 }, // 72 bits per transform
+ { 11, 8, 5 }, // 72 bits per transform
+ { 11, 9, 4 }, // 72 bits per transform
+ { 11, 10, 3 }, // 72 bits per transform
+ { 11, 11, 2 }, // 72 bits per transform
+ { 11, 12, 1 }, // 72 bits per transform
+ { 11, 13, 0 }, // 72 bits per transform
+ { 12, 0, 12 }, // 72 bits per transform
+ { 12, 1, 11 }, // 72 bits per transform
+ { 12, 2, 10 }, // 72 bits per transform
+ { 12, 3, 9 }, // 72 bits per transform
+ { 12, 4, 8 }, // 72 bits per transform
+ { 12, 5, 7 }, // 72 bits per transform
+ { 12, 6, 6 }, // 72 bits per transform
+ { 12, 7, 5 }, // 72 bits per transform
+ { 12, 8, 4 }, // 72 bits per transform
+ { 12, 9, 3 }, // 72 bits per transform
+ { 12, 10, 2 }, // 72 bits per transform
+ { 12, 11, 1 }, // 72 bits per transform
+ { 12, 12, 0 }, // 72 bits per transform
+ { 13, 0, 11 }, // 72 bits per transform
+ { 13, 1, 10 }, // 72 bits per transform
+ { 13, 2, 9 }, // 72 bits per transform
+ { 13, 3, 8 }, // 72 bits per transform
+ { 13, 4, 7 }, // 72 bits per transform
+ { 13, 5, 6 }, // 72 bits per transform
+ { 13, 6, 5 }, // 72 bits per transform
+ { 13, 7, 4 }, // 72 bits per transform
+ { 13, 8, 3 }, // 72 bits per transform
+ { 13, 9, 2 }, // 72 bits per transform
+ { 13, 10, 1 }, // 72 bits per transform
+ { 13, 11, 0 }, // 72 bits per transform
+ { 14, 0, 10 }, // 72 bits per transform
+ { 14, 1, 9 }, // 72 bits per transform
+ { 14, 2, 8 }, // 72 bits per transform
+ { 14, 3, 7 }, // 72 bits per transform
+ { 14, 4, 6 }, // 72 bits per transform
+ { 14, 5, 5 }, // 72 bits per transform
+ { 14, 6, 4 }, // 72 bits per transform
+ { 14, 7, 3 }, // 72 bits per transform
+ { 14, 8, 2 }, // 72 bits per transform
+ { 14, 9, 1 }, // 72 bits per transform
+ { 14, 10, 0 }, // 72 bits per transform
+ { 15, 0, 9 }, // 72 bits per transform
+ { 15, 1, 8 }, // 72 bits per transform
+ { 15, 2, 7 }, // 72 bits per transform
+ { 15, 3, 6 }, // 72 bits per transform
+ { 15, 4, 5 }, // 72 bits per transform
+ { 15, 5, 4 }, // 72 bits per transform
+ { 15, 6, 3 }, // 72 bits per transform
+ { 15, 7, 2 }, // 72 bits per transform
+ { 15, 8, 1 }, // 72 bits per transform
+ { 15, 9, 0 }, // 72 bits per transform
+ { 16, 0, 8 }, // 72 bits per transform
+ { 16, 1, 7 }, // 72 bits per transform
+ { 16, 2, 6 }, // 72 bits per transform
+ { 16, 3, 5 }, // 72 bits per transform
+ { 16, 4, 4 }, // 72 bits per transform
+ { 16, 5, 3 }, // 72 bits per transform
+ { 16, 6, 2 }, // 72 bits per transform
+ { 16, 7, 1 }, // 72 bits per transform
+ { 16, 8, 0 }, // 72 bits per transform
+ { 17, 0, 7 }, // 72 bits per transform
+ { 17, 1, 6 }, // 72 bits per transform
+ { 17, 2, 5 }, // 72 bits per transform
+ { 17, 3, 4 }, // 72 bits per transform
+ { 17, 4, 3 }, // 72 bits per transform
+ { 17, 5, 2 }, // 72 bits per transform
+ { 17, 6, 1 }, // 72 bits per transform
+ { 17, 7, 0 }, // 72 bits per transform
+ { 18, 0, 6 }, // 72 bits per transform
+ { 18, 1, 5 }, // 72 bits per transform
+ { 18, 2, 4 }, // 72 bits per transform
+ { 18, 3, 3 }, // 72 bits per transform
+ { 18, 4, 2 }, // 72 bits per transform
+ { 18, 5, 1 }, // 72 bits per transform
+ { 18, 6, 0 }, // 72 bits per transform
+ { 19, 0, 5 }, // 72 bits per transform
+ { 19, 1, 4 }, // 72 bits per transform
+ { 19, 2, 3 }, // 72 bits per transform
+ { 19, 3, 2 }, // 72 bits per transform
+ { 19, 4, 1 }, // 72 bits per transform
+ { 19, 5, 0 }, // 72 bits per transform
+ { 20, 0, 4 }, // 72 bits per transform
+ { 20, 1, 3 }, // 72 bits per transform
+ { 20, 2, 2 }, // 72 bits per transform
+ { 20, 3, 1 }, // 72 bits per transform
+ { 20, 4, 0 }, // 72 bits per transform
+ { 21, 0, 3 }, // 72 bits per transform
+ { 21, 1, 2 }, // 72 bits per transform
+ { 21, 2, 1 }, // 72 bits per transform
+ { 21, 3, 0 }, // 72 bits per transform
+ { 22, 0, 2 }, // 72 bits per transform
+ { 22, 1, 1 }, // 72 bits per transform
+ { 22, 2, 0 }, // 72 bits per transform
+ { 23, 0, 1 }, // 72 bits per transform
+ { 23, 1, 0 }, // 72 bits per transform
+ { 0, 2, 23 }, // 75 bits per transform
+ { 0, 3, 22 }, // 75 bits per transform
+ { 0, 4, 21 }, // 75 bits per transform
+ { 0, 5, 20 }, // 75 bits per transform
+ { 0, 6, 19 }, // 75 bits per transform
+ { 0, 7, 18 }, // 75 bits per transform
+ { 0, 8, 17 }, // 75 bits per transform
+ { 0, 9, 16 }, // 75 bits per transform
+ { 0, 10, 15 }, // 75 bits per transform
+ { 0, 11, 14 }, // 75 bits per transform
+ { 0, 12, 13 }, // 75 bits per transform
+ { 0, 13, 12 }, // 75 bits per transform
+ { 0, 14, 11 }, // 75 bits per transform
+ { 0, 15, 10 }, // 75 bits per transform
+ { 0, 16, 9 }, // 75 bits per transform
+ { 0, 17, 8 }, // 75 bits per transform
+ { 0, 18, 7 }, // 75 bits per transform
+ { 0, 19, 6 }, // 75 bits per transform
+ { 0, 20, 5 }, // 75 bits per transform
+ { 0, 21, 4 }, // 75 bits per transform
+ { 0, 22, 3 }, // 75 bits per transform
+ { 0, 23, 2 }, // 75 bits per transform
+ { 1, 1, 23 }, // 75 bits per transform
+ { 1, 2, 22 }, // 75 bits per transform
+ { 1, 3, 21 }, // 75 bits per transform
+ { 1, 4, 20 }, // 75 bits per transform
+ { 1, 5, 19 }, // 75 bits per transform
+ { 1, 6, 18 }, // 75 bits per transform
+ { 1, 7, 17 }, // 75 bits per transform
+ { 1, 8, 16 }, // 75 bits per transform
+ { 1, 9, 15 }, // 75 bits per transform
+ { 1, 10, 14 }, // 75 bits per transform
+ { 1, 11, 13 }, // 75 bits per transform
+ { 1, 12, 12 }, // 75 bits per transform
+ { 1, 13, 11 }, // 75 bits per transform
+ { 1, 14, 10 }, // 75 bits per transform
+ { 1, 15, 9 }, // 75 bits per transform
+ { 1, 16, 8 }, // 75 bits per transform
+ { 1, 17, 7 }, // 75 bits per transform
+ { 1, 18, 6 }, // 75 bits per transform
+ { 1, 19, 5 }, // 75 bits per transform
+ { 1, 20, 4 }, // 75 bits per transform
+ { 1, 21, 3 }, // 75 bits per transform
+ { 1, 22, 2 }, // 75 bits per transform
+ { 1, 23, 1 }, // 75 bits per transform
+ { 2, 0, 23 }, // 75 bits per transform
+ { 2, 1, 22 }, // 75 bits per transform
+ { 2, 2, 21 }, // 75 bits per transform
+ { 2, 3, 20 }, // 75 bits per transform
+ { 2, 4, 19 }, // 75 bits per transform
+ { 2, 5, 18 }, // 75 bits per transform
+ { 2, 6, 17 }, // 75 bits per transform
+ { 2, 7, 16 }, // 75 bits per transform
+ { 2, 8, 15 }, // 75 bits per transform
+ { 2, 9, 14 }, // 75 bits per transform
+ { 2, 10, 13 }, // 75 bits per transform
+ { 2, 11, 12 }, // 75 bits per transform
+ { 2, 12, 11 }, // 75 bits per transform
+ { 2, 13, 10 }, // 75 bits per transform
+ { 2, 14, 9 }, // 75 bits per transform
+ { 2, 15, 8 }, // 75 bits per transform
+ { 2, 16, 7 }, // 75 bits per transform
+ { 2, 17, 6 }, // 75 bits per transform
+ { 2, 18, 5 }, // 75 bits per transform
+ { 2, 19, 4 }, // 75 bits per transform
+ { 2, 20, 3 }, // 75 bits per transform
+ { 2, 21, 2 }, // 75 bits per transform
+ { 2, 22, 1 }, // 75 bits per transform
+ { 2, 23, 0 }, // 75 bits per transform
+ { 3, 0, 22 }, // 75 bits per transform
+ { 3, 1, 21 }, // 75 bits per transform
+ { 3, 2, 20 }, // 75 bits per transform
+ { 3, 3, 19 }, // 75 bits per transform
+ { 3, 4, 18 }, // 75 bits per transform
+ { 3, 5, 17 }, // 75 bits per transform
+ { 3, 6, 16 }, // 75 bits per transform
+ { 3, 7, 15 }, // 75 bits per transform
+ { 3, 8, 14 }, // 75 bits per transform
+ { 3, 9, 13 }, // 75 bits per transform
+ { 3, 10, 12 }, // 75 bits per transform
+ { 3, 11, 11 }, // 75 bits per transform
+ { 3, 12, 10 }, // 75 bits per transform
+ { 3, 13, 9 }, // 75 bits per transform
+ { 3, 14, 8 }, // 75 bits per transform
+ { 3, 15, 7 }, // 75 bits per transform
+ { 3, 16, 6 }, // 75 bits per transform
+ { 3, 17, 5 }, // 75 bits per transform
+ { 3, 18, 4 }, // 75 bits per transform
+ { 3, 19, 3 }, // 75 bits per transform
+ { 3, 20, 2 }, // 75 bits per transform
+ { 3, 21, 1 }, // 75 bits per transform
+ { 3, 22, 0 }, // 75 bits per transform
+ { 4, 0, 21 }, // 75 bits per transform
+ { 4, 1, 20 }, // 75 bits per transform
+ { 4, 2, 19 }, // 75 bits per transform
+ { 4, 3, 18 }, // 75 bits per transform
+ { 4, 4, 17 }, // 75 bits per transform
+ { 4, 5, 16 }, // 75 bits per transform
+ { 4, 6, 15 }, // 75 bits per transform
+ { 4, 7, 14 }, // 75 bits per transform
+ { 4, 8, 13 }, // 75 bits per transform
+ { 4, 9, 12 }, // 75 bits per transform
+ { 4, 10, 11 }, // 75 bits per transform
+ { 4, 11, 10 }, // 75 bits per transform
+ { 4, 12, 9 }, // 75 bits per transform
+ { 4, 13, 8 }, // 75 bits per transform
+ { 4, 14, 7 }, // 75 bits per transform
+ { 4, 15, 6 }, // 75 bits per transform
+ { 4, 16, 5 }, // 75 bits per transform
+ { 4, 17, 4 }, // 75 bits per transform
+ { 4, 18, 3 }, // 75 bits per transform
+ { 4, 19, 2 }, // 75 bits per transform
+ { 4, 20, 1 }, // 75 bits per transform
+ { 4, 21, 0 }, // 75 bits per transform
+ { 5, 0, 20 }, // 75 bits per transform
+ { 5, 1, 19 }, // 75 bits per transform
+ { 5, 2, 18 }, // 75 bits per transform
+ { 5, 3, 17 }, // 75 bits per transform
+ { 5, 4, 16 }, // 75 bits per transform
+ { 5, 5, 15 }, // 75 bits per transform
+ { 5, 6, 14 }, // 75 bits per transform
+ { 5, 7, 13 }, // 75 bits per transform
+ { 5, 8, 12 }, // 75 bits per transform
+ { 5, 9, 11 }, // 75 bits per transform
+ { 5, 10, 10 }, // 75 bits per transform
+ { 5, 11, 9 }, // 75 bits per transform
+ { 5, 12, 8 }, // 75 bits per transform
+ { 5, 13, 7 }, // 75 bits per transform
+ { 5, 14, 6 }, // 75 bits per transform
+ { 5, 15, 5 }, // 75 bits per transform
+ { 5, 16, 4 }, // 75 bits per transform
+ { 5, 17, 3 }, // 75 bits per transform
+ { 5, 18, 2 }, // 75 bits per transform
+ { 5, 19, 1 }, // 75 bits per transform
+ { 5, 20, 0 }, // 75 bits per transform
+ { 6, 0, 19 }, // 75 bits per transform
+ { 6, 1, 18 }, // 75 bits per transform
+ { 6, 2, 17 }, // 75 bits per transform
+ { 6, 3, 16 }, // 75 bits per transform
+ { 6, 4, 15 }, // 75 bits per transform
+ { 6, 5, 14 }, // 75 bits per transform
+ { 6, 6, 13 }, // 75 bits per transform
+ { 6, 7, 12 }, // 75 bits per transform
+ { 6, 8, 11 }, // 75 bits per transform
+ { 6, 9, 10 }, // 75 bits per transform
+ { 6, 10, 9 }, // 75 bits per transform
+ { 6, 11, 8 }, // 75 bits per transform
+ { 6, 12, 7 }, // 75 bits per transform
+ { 6, 13, 6 }, // 75 bits per transform
+ { 6, 14, 5 }, // 75 bits per transform
+ { 6, 15, 4 }, // 75 bits per transform
+ { 6, 16, 3 }, // 75 bits per transform
+ { 6, 17, 2 }, // 75 bits per transform
+ { 6, 18, 1 }, // 75 bits per transform
+ { 6, 19, 0 }, // 75 bits per transform
+ { 7, 0, 18 }, // 75 bits per transform
+ { 7, 1, 17 }, // 75 bits per transform
+ { 7, 2, 16 }, // 75 bits per transform
+ { 7, 3, 15 }, // 75 bits per transform
+ { 7, 4, 14 }, // 75 bits per transform
+ { 7, 5, 13 }, // 75 bits per transform
+ { 7, 6, 12 }, // 75 bits per transform
+ { 7, 7, 11 }, // 75 bits per transform
+ { 7, 8, 10 }, // 75 bits per transform
+ { 7, 9, 9 }, // 75 bits per transform
+ { 7, 10, 8 }, // 75 bits per transform
+ { 7, 11, 7 }, // 75 bits per transform
+ { 7, 12, 6 }, // 75 bits per transform
+ { 7, 13, 5 }, // 75 bits per transform
+ { 7, 14, 4 }, // 75 bits per transform
+ { 7, 15, 3 }, // 75 bits per transform
+ { 7, 16, 2 }, // 75 bits per transform
+ { 7, 17, 1 }, // 75 bits per transform
+ { 7, 18, 0 }, // 75 bits per transform
+ { 8, 0, 17 }, // 75 bits per transform
+ { 8, 1, 16 }, // 75 bits per transform
+ { 8, 2, 15 }, // 75 bits per transform
+ { 8, 3, 14 }, // 75 bits per transform
+ { 8, 4, 13 }, // 75 bits per transform
+ { 8, 5, 12 }, // 75 bits per transform
+ { 8, 6, 11 }, // 75 bits per transform
+ { 8, 7, 10 }, // 75 bits per transform
+ { 8, 8, 9 }, // 75 bits per transform
+ { 8, 9, 8 }, // 75 bits per transform
+ { 8, 10, 7 }, // 75 bits per transform
+ { 8, 11, 6 }, // 75 bits per transform
+ { 8, 12, 5 }, // 75 bits per transform
+ { 8, 13, 4 }, // 75 bits per transform
+ { 8, 14, 3 }, // 75 bits per transform
+ { 8, 15, 2 }, // 75 bits per transform
+ { 8, 16, 1 }, // 75 bits per transform
+ { 8, 17, 0 }, // 75 bits per transform
+ { 9, 0, 16 }, // 75 bits per transform
+ { 9, 1, 15 }, // 75 bits per transform
+ { 9, 2, 14 }, // 75 bits per transform
+ { 9, 3, 13 }, // 75 bits per transform
+ { 9, 4, 12 }, // 75 bits per transform
+ { 9, 5, 11 }, // 75 bits per transform
+ { 9, 6, 10 }, // 75 bits per transform
+ { 9, 7, 9 }, // 75 bits per transform
+ { 9, 8, 8 }, // 75 bits per transform
+ { 9, 9, 7 }, // 75 bits per transform
+ { 9, 10, 6 }, // 75 bits per transform
+ { 9, 11, 5 }, // 75 bits per transform
+ { 9, 12, 4 }, // 75 bits per transform
+ { 9, 13, 3 }, // 75 bits per transform
+ { 9, 14, 2 }, // 75 bits per transform
+ { 9, 15, 1 }, // 75 bits per transform
+ { 9, 16, 0 }, // 75 bits per transform
+ { 10, 0, 15 }, // 75 bits per transform
+ { 10, 1, 14 }, // 75 bits per transform
+ { 10, 2, 13 }, // 75 bits per transform
+ { 10, 3, 12 }, // 75 bits per transform
+ { 10, 4, 11 }, // 75 bits per transform
+ { 10, 5, 10 }, // 75 bits per transform
+ { 10, 6, 9 }, // 75 bits per transform
+ { 10, 7, 8 }, // 75 bits per transform
+ { 10, 8, 7 }, // 75 bits per transform
+ { 10, 9, 6 }, // 75 bits per transform
+ { 10, 10, 5 }, // 75 bits per transform
+ { 10, 11, 4 }, // 75 bits per transform
+ { 10, 12, 3 }, // 75 bits per transform
+ { 10, 13, 2 }, // 75 bits per transform
+ { 10, 14, 1 }, // 75 bits per transform
+ { 10, 15, 0 }, // 75 bits per transform
+ { 11, 0, 14 }, // 75 bits per transform
+ { 11, 1, 13 }, // 75 bits per transform
+ { 11, 2, 12 }, // 75 bits per transform
+ { 11, 3, 11 }, // 75 bits per transform
+ { 11, 4, 10 }, // 75 bits per transform
+ { 11, 5, 9 }, // 75 bits per transform
+ { 11, 6, 8 }, // 75 bits per transform
+ { 11, 7, 7 }, // 75 bits per transform
+ { 11, 8, 6 }, // 75 bits per transform
+ { 11, 9, 5 }, // 75 bits per transform
+ { 11, 10, 4 }, // 75 bits per transform
+ { 11, 11, 3 }, // 75 bits per transform
+ { 11, 12, 2 }, // 75 bits per transform
+ { 11, 13, 1 }, // 75 bits per transform
+ { 11, 14, 0 }, // 75 bits per transform
+ { 12, 0, 13 }, // 75 bits per transform
+ { 12, 1, 12 }, // 75 bits per transform
+ { 12, 2, 11 }, // 75 bits per transform
+ { 12, 3, 10 }, // 75 bits per transform
+ { 12, 4, 9 }, // 75 bits per transform
+ { 12, 5, 8 }, // 75 bits per transform
+ { 12, 6, 7 }, // 75 bits per transform
+ { 12, 7, 6 }, // 75 bits per transform
+ { 12, 8, 5 }, // 75 bits per transform
+ { 12, 9, 4 }, // 75 bits per transform
+ { 12, 10, 3 }, // 75 bits per transform
+ { 12, 11, 2 }, // 75 bits per transform
+ { 12, 12, 1 }, // 75 bits per transform
+ { 12, 13, 0 }, // 75 bits per transform
+ { 13, 0, 12 }, // 75 bits per transform
+ { 13, 1, 11 }, // 75 bits per transform
+ { 13, 2, 10 }, // 75 bits per transform
+ { 13, 3, 9 }, // 75 bits per transform
+ { 13, 4, 8 }, // 75 bits per transform
+ { 13, 5, 7 }, // 75 bits per transform
+ { 13, 6, 6 }, // 75 bits per transform
+ { 13, 7, 5 }, // 75 bits per transform
+ { 13, 8, 4 }, // 75 bits per transform
+ { 13, 9, 3 }, // 75 bits per transform
+ { 13, 10, 2 }, // 75 bits per transform
+ { 13, 11, 1 }, // 75 bits per transform
+ { 13, 12, 0 }, // 75 bits per transform
+ { 14, 0, 11 }, // 75 bits per transform
+ { 14, 1, 10 }, // 75 bits per transform
+ { 14, 2, 9 }, // 75 bits per transform
+ { 14, 3, 8 }, // 75 bits per transform
+ { 14, 4, 7 }, // 75 bits per transform
+ { 14, 5, 6 }, // 75 bits per transform
+ { 14, 6, 5 }, // 75 bits per transform
+ { 14, 7, 4 }, // 75 bits per transform
+ { 14, 8, 3 }, // 75 bits per transform
+ { 14, 9, 2 }, // 75 bits per transform
+ { 14, 10, 1 }, // 75 bits per transform
+ { 14, 11, 0 }, // 75 bits per transform
+ { 15, 0, 10 }, // 75 bits per transform
+ { 15, 1, 9 }, // 75 bits per transform
+ { 15, 2, 8 }, // 75 bits per transform
+ { 15, 3, 7 }, // 75 bits per transform
+ { 15, 4, 6 }, // 75 bits per transform
+ { 15, 5, 5 }, // 75 bits per transform
+ { 15, 6, 4 }, // 75 bits per transform
+ { 15, 7, 3 }, // 75 bits per transform
+ { 15, 8, 2 }, // 75 bits per transform
+ { 15, 9, 1 }, // 75 bits per transform
+ { 15, 10, 0 }, // 75 bits per transform
+ { 16, 0, 9 }, // 75 bits per transform
+ { 16, 1, 8 }, // 75 bits per transform
+ { 16, 2, 7 }, // 75 bits per transform
+ { 16, 3, 6 }, // 75 bits per transform
+ { 16, 4, 5 }, // 75 bits per transform
+ { 16, 5, 4 }, // 75 bits per transform
+ { 16, 6, 3 }, // 75 bits per transform
+ { 16, 7, 2 }, // 75 bits per transform
+ { 16, 8, 1 }, // 75 bits per transform
+ { 16, 9, 0 }, // 75 bits per transform
+ { 17, 0, 8 }, // 75 bits per transform
+ { 17, 1, 7 }, // 75 bits per transform
+ { 17, 2, 6 }, // 75 bits per transform
+ { 17, 3, 5 }, // 75 bits per transform
+ { 17, 4, 4 }, // 75 bits per transform
+ { 17, 5, 3 }, // 75 bits per transform
+ { 17, 6, 2 }, // 75 bits per transform
+ { 17, 7, 1 }, // 75 bits per transform
+ { 17, 8, 0 }, // 75 bits per transform
+ { 18, 0, 7 }, // 75 bits per transform
+ { 18, 1, 6 }, // 75 bits per transform
+ { 18, 2, 5 }, // 75 bits per transform
+ { 18, 3, 4 }, // 75 bits per transform
+ { 18, 4, 3 }, // 75 bits per transform
+ { 18, 5, 2 }, // 75 bits per transform
+ { 18, 6, 1 }, // 75 bits per transform
+ { 18, 7, 0 }, // 75 bits per transform
+ { 19, 0, 6 }, // 75 bits per transform
+ { 19, 1, 5 }, // 75 bits per transform
+ { 19, 2, 4 }, // 75 bits per transform
+ { 19, 3, 3 }, // 75 bits per transform
+ { 19, 4, 2 }, // 75 bits per transform
+ { 19, 5, 1 }, // 75 bits per transform
+ { 19, 6, 0 }, // 75 bits per transform
+ { 20, 0, 5 }, // 75 bits per transform
+ { 20, 1, 4 }, // 75 bits per transform
+ { 20, 2, 3 }, // 75 bits per transform
+ { 20, 3, 2 }, // 75 bits per transform
+ { 20, 4, 1 }, // 75 bits per transform
+ { 20, 5, 0 }, // 75 bits per transform
+ { 21, 0, 4 }, // 75 bits per transform
+ { 21, 1, 3 }, // 75 bits per transform
+ { 21, 2, 2 }, // 75 bits per transform
+ { 21, 3, 1 }, // 75 bits per transform
+ { 21, 4, 0 }, // 75 bits per transform
+ { 22, 0, 3 }, // 75 bits per transform
+ { 22, 1, 2 }, // 75 bits per transform
+ { 22, 2, 1 }, // 75 bits per transform
+ { 22, 3, 0 }, // 75 bits per transform
+ { 23, 0, 2 }, // 75 bits per transform
+ { 23, 1, 1 }, // 75 bits per transform
+ { 23, 2, 0 }, // 75 bits per transform
+ { 0, 3, 23 }, // 78 bits per transform
+ { 0, 4, 22 }, // 78 bits per transform
+ { 0, 5, 21 }, // 78 bits per transform
+ { 0, 6, 20 }, // 78 bits per transform
+ { 0, 7, 19 }, // 78 bits per transform
+ { 0, 8, 18 }, // 78 bits per transform
+ { 0, 9, 17 }, // 78 bits per transform
+ { 0, 10, 16 }, // 78 bits per transform
+ { 0, 11, 15 }, // 78 bits per transform
+ { 0, 12, 14 }, // 78 bits per transform
+ { 0, 13, 13 }, // 78 bits per transform
+ { 0, 14, 12 }, // 78 bits per transform
+ { 0, 15, 11 }, // 78 bits per transform
+ { 0, 16, 10 }, // 78 bits per transform
+ { 0, 17, 9 }, // 78 bits per transform
+ { 0, 18, 8 }, // 78 bits per transform
+ { 0, 19, 7 }, // 78 bits per transform
+ { 0, 20, 6 }, // 78 bits per transform
+ { 0, 21, 5 }, // 78 bits per transform
+ { 0, 22, 4 }, // 78 bits per transform
+ { 0, 23, 3 }, // 78 bits per transform
+ { 1, 2, 23 }, // 78 bits per transform
+ { 1, 3, 22 }, // 78 bits per transform
+ { 1, 4, 21 }, // 78 bits per transform
+ { 1, 5, 20 }, // 78 bits per transform
+ { 1, 6, 19 }, // 78 bits per transform
+ { 1, 7, 18 }, // 78 bits per transform
+ { 1, 8, 17 }, // 78 bits per transform
+ { 1, 9, 16 }, // 78 bits per transform
+ { 1, 10, 15 }, // 78 bits per transform
+ { 1, 11, 14 }, // 78 bits per transform
+ { 1, 12, 13 }, // 78 bits per transform
+ { 1, 13, 12 }, // 78 bits per transform
+ { 1, 14, 11 }, // 78 bits per transform
+ { 1, 15, 10 }, // 78 bits per transform
+ { 1, 16, 9 }, // 78 bits per transform
+ { 1, 17, 8 }, // 78 bits per transform
+ { 1, 18, 7 }, // 78 bits per transform
+ { 1, 19, 6 }, // 78 bits per transform
+ { 1, 20, 5 }, // 78 bits per transform
+ { 1, 21, 4 }, // 78 bits per transform
+ { 1, 22, 3 }, // 78 bits per transform
+ { 1, 23, 2 }, // 78 bits per transform
+ { 2, 1, 23 }, // 78 bits per transform
+ { 2, 2, 22 }, // 78 bits per transform
+ { 2, 3, 21 }, // 78 bits per transform
+ { 2, 4, 20 }, // 78 bits per transform
+ { 2, 5, 19 }, // 78 bits per transform
+ { 2, 6, 18 }, // 78 bits per transform
+ { 2, 7, 17 }, // 78 bits per transform
+ { 2, 8, 16 }, // 78 bits per transform
+ { 2, 9, 15 }, // 78 bits per transform
+ { 2, 10, 14 }, // 78 bits per transform
+ { 2, 11, 13 }, // 78 bits per transform
+ { 2, 12, 12 }, // 78 bits per transform
+ { 2, 13, 11 }, // 78 bits per transform
+ { 2, 14, 10 }, // 78 bits per transform
+ { 2, 15, 9 }, // 78 bits per transform
+ { 2, 16, 8 }, // 78 bits per transform
+ { 2, 17, 7 }, // 78 bits per transform
+ { 2, 18, 6 }, // 78 bits per transform
+ { 2, 19, 5 }, // 78 bits per transform
+ { 2, 20, 4 }, // 78 bits per transform
+ { 2, 21, 3 }, // 78 bits per transform
+ { 2, 22, 2 }, // 78 bits per transform
+ { 2, 23, 1 }, // 78 bits per transform
+ { 3, 0, 23 }, // 78 bits per transform
+ { 3, 1, 22 }, // 78 bits per transform
+ { 3, 2, 21 }, // 78 bits per transform
+ { 3, 3, 20 }, // 78 bits per transform
+ { 3, 4, 19 }, // 78 bits per transform
+ { 3, 5, 18 }, // 78 bits per transform
+ { 3, 6, 17 }, // 78 bits per transform
+ { 3, 7, 16 }, // 78 bits per transform
+ { 3, 8, 15 }, // 78 bits per transform
+ { 3, 9, 14 }, // 78 bits per transform
+ { 3, 10, 13 }, // 78 bits per transform
+ { 3, 11, 12 }, // 78 bits per transform
+ { 3, 12, 11 }, // 78 bits per transform
+ { 3, 13, 10 }, // 78 bits per transform
+ { 3, 14, 9 }, // 78 bits per transform
+ { 3, 15, 8 }, // 78 bits per transform
+ { 3, 16, 7 }, // 78 bits per transform
+ { 3, 17, 6 }, // 78 bits per transform
+ { 3, 18, 5 }, // 78 bits per transform
+ { 3, 19, 4 }, // 78 bits per transform
+ { 3, 20, 3 }, // 78 bits per transform
+ { 3, 21, 2 }, // 78 bits per transform
+ { 3, 22, 1 }, // 78 bits per transform
+ { 3, 23, 0 }, // 78 bits per transform
+ { 4, 0, 22 }, // 78 bits per transform
+ { 4, 1, 21 }, // 78 bits per transform
+ { 4, 2, 20 }, // 78 bits per transform
+ { 4, 3, 19 }, // 78 bits per transform
+ { 4, 4, 18 }, // 78 bits per transform
+ { 4, 5, 17 }, // 78 bits per transform
+ { 4, 6, 16 }, // 78 bits per transform
+ { 4, 7, 15 }, // 78 bits per transform
+ { 4, 8, 14 }, // 78 bits per transform
+ { 4, 9, 13 }, // 78 bits per transform
+ { 4, 10, 12 }, // 78 bits per transform
+ { 4, 11, 11 }, // 78 bits per transform
+ { 4, 12, 10 }, // 78 bits per transform
+ { 4, 13, 9 }, // 78 bits per transform
+ { 4, 14, 8 }, // 78 bits per transform
+ { 4, 15, 7 }, // 78 bits per transform
+ { 4, 16, 6 }, // 78 bits per transform
+ { 4, 17, 5 }, // 78 bits per transform
+ { 4, 18, 4 }, // 78 bits per transform
+ { 4, 19, 3 }, // 78 bits per transform
+ { 4, 20, 2 }, // 78 bits per transform
+ { 4, 21, 1 }, // 78 bits per transform
+ { 4, 22, 0 }, // 78 bits per transform
+ { 5, 0, 21 }, // 78 bits per transform
+ { 5, 1, 20 }, // 78 bits per transform
+ { 5, 2, 19 }, // 78 bits per transform
+ { 5, 3, 18 }, // 78 bits per transform
+ { 5, 4, 17 }, // 78 bits per transform
+ { 5, 5, 16 }, // 78 bits per transform
+ { 5, 6, 15 }, // 78 bits per transform
+ { 5, 7, 14 }, // 78 bits per transform
+ { 5, 8, 13 }, // 78 bits per transform
+ { 5, 9, 12 }, // 78 bits per transform
+ { 5, 10, 11 }, // 78 bits per transform
+ { 5, 11, 10 }, // 78 bits per transform
+ { 5, 12, 9 }, // 78 bits per transform
+ { 5, 13, 8 }, // 78 bits per transform
+ { 5, 14, 7 }, // 78 bits per transform
+ { 5, 15, 6 }, // 78 bits per transform
+ { 5, 16, 5 }, // 78 bits per transform
+ { 5, 17, 4 }, // 78 bits per transform
+ { 5, 18, 3 }, // 78 bits per transform
+ { 5, 19, 2 }, // 78 bits per transform
+ { 5, 20, 1 }, // 78 bits per transform
+ { 5, 21, 0 }, // 78 bits per transform
+ { 6, 0, 20 }, // 78 bits per transform
+ { 6, 1, 19 }, // 78 bits per transform
+ { 6, 2, 18 }, // 78 bits per transform
+ { 6, 3, 17 }, // 78 bits per transform
+ { 6, 4, 16 }, // 78 bits per transform
+ { 6, 5, 15 }, // 78 bits per transform
+ { 6, 6, 14 }, // 78 bits per transform
+ { 6, 7, 13 }, // 78 bits per transform
+ { 6, 8, 12 }, // 78 bits per transform
+ { 6, 9, 11 }, // 78 bits per transform
+ { 6, 10, 10 }, // 78 bits per transform
+ { 6, 11, 9 }, // 78 bits per transform
+ { 6, 12, 8 }, // 78 bits per transform
+ { 6, 13, 7 }, // 78 bits per transform
+ { 6, 14, 6 }, // 78 bits per transform
+ { 6, 15, 5 }, // 78 bits per transform
+ { 6, 16, 4 }, // 78 bits per transform
+ { 6, 17, 3 }, // 78 bits per transform
+ { 6, 18, 2 }, // 78 bits per transform
+ { 6, 19, 1 }, // 78 bits per transform
+ { 6, 20, 0 }, // 78 bits per transform
+ { 7, 0, 19 }, // 78 bits per transform
+ { 7, 1, 18 }, // 78 bits per transform
+ { 7, 2, 17 }, // 78 bits per transform
+ { 7, 3, 16 }, // 78 bits per transform
+ { 7, 4, 15 }, // 78 bits per transform
+ { 7, 5, 14 }, // 78 bits per transform
+ { 7, 6, 13 }, // 78 bits per transform
+ { 7, 7, 12 }, // 78 bits per transform
+ { 7, 8, 11 }, // 78 bits per transform
+ { 7, 9, 10 }, // 78 bits per transform
+ { 7, 10, 9 }, // 78 bits per transform
+ { 7, 11, 8 }, // 78 bits per transform
+ { 7, 12, 7 }, // 78 bits per transform
+ { 7, 13, 6 }, // 78 bits per transform
+ { 7, 14, 5 }, // 78 bits per transform
+ { 7, 15, 4 }, // 78 bits per transform
+ { 7, 16, 3 }, // 78 bits per transform
+ { 7, 17, 2 }, // 78 bits per transform
+ { 7, 18, 1 }, // 78 bits per transform
+ { 7, 19, 0 }, // 78 bits per transform
+ { 8, 0, 18 }, // 78 bits per transform
+ { 8, 1, 17 }, // 78 bits per transform
+ { 8, 2, 16 }, // 78 bits per transform
+ { 8, 3, 15 }, // 78 bits per transform
+ { 8, 4, 14 }, // 78 bits per transform
+ { 8, 5, 13 }, // 78 bits per transform
+ { 8, 6, 12 }, // 78 bits per transform
+ { 8, 7, 11 }, // 78 bits per transform
+ { 8, 8, 10 }, // 78 bits per transform
+ { 8, 9, 9 }, // 78 bits per transform
+ { 8, 10, 8 }, // 78 bits per transform
+ { 8, 11, 7 }, // 78 bits per transform
+ { 8, 12, 6 }, // 78 bits per transform
+ { 8, 13, 5 }, // 78 bits per transform
+ { 8, 14, 4 }, // 78 bits per transform
+ { 8, 15, 3 }, // 78 bits per transform
+ { 8, 16, 2 }, // 78 bits per transform
+ { 8, 17, 1 }, // 78 bits per transform
+ { 8, 18, 0 }, // 78 bits per transform
+ { 9, 0, 17 }, // 78 bits per transform
+ { 9, 1, 16 }, // 78 bits per transform
+ { 9, 2, 15 }, // 78 bits per transform
+ { 9, 3, 14 }, // 78 bits per transform
+ { 9, 4, 13 }, // 78 bits per transform
+ { 9, 5, 12 }, // 78 bits per transform
+ { 9, 6, 11 }, // 78 bits per transform
+ { 9, 7, 10 }, // 78 bits per transform
+ { 9, 8, 9 }, // 78 bits per transform
+ { 9, 9, 8 }, // 78 bits per transform
+ { 9, 10, 7 }, // 78 bits per transform
+ { 9, 11, 6 }, // 78 bits per transform
+ { 9, 12, 5 }, // 78 bits per transform
+ { 9, 13, 4 }, // 78 bits per transform
+ { 9, 14, 3 }, // 78 bits per transform
+ { 9, 15, 2 }, // 78 bits per transform
+ { 9, 16, 1 }, // 78 bits per transform
+ { 9, 17, 0 }, // 78 bits per transform
+ { 10, 0, 16 }, // 78 bits per transform
+ { 10, 1, 15 }, // 78 bits per transform
+ { 10, 2, 14 }, // 78 bits per transform
+ { 10, 3, 13 }, // 78 bits per transform
+ { 10, 4, 12 }, // 78 bits per transform
+ { 10, 5, 11 }, // 78 bits per transform
+ { 10, 6, 10 }, // 78 bits per transform
+ { 10, 7, 9 }, // 78 bits per transform
+ { 10, 8, 8 }, // 78 bits per transform
+ { 10, 9, 7 }, // 78 bits per transform
+ { 10, 10, 6 }, // 78 bits per transform
+ { 10, 11, 5 }, // 78 bits per transform
+ { 10, 12, 4 }, // 78 bits per transform
+ { 10, 13, 3 }, // 78 bits per transform
+ { 10, 14, 2 }, // 78 bits per transform
+ { 10, 15, 1 }, // 78 bits per transform
+ { 10, 16, 0 }, // 78 bits per transform
+ { 11, 0, 15 }, // 78 bits per transform
+ { 11, 1, 14 }, // 78 bits per transform
+ { 11, 2, 13 }, // 78 bits per transform
+ { 11, 3, 12 }, // 78 bits per transform
+ { 11, 4, 11 }, // 78 bits per transform
+ { 11, 5, 10 }, // 78 bits per transform
+ { 11, 6, 9 }, // 78 bits per transform
+ { 11, 7, 8 }, // 78 bits per transform
+ { 11, 8, 7 }, // 78 bits per transform
+ { 11, 9, 6 }, // 78 bits per transform
+ { 11, 10, 5 }, // 78 bits per transform
+ { 11, 11, 4 }, // 78 bits per transform
+ { 11, 12, 3 }, // 78 bits per transform
+ { 11, 13, 2 }, // 78 bits per transform
+ { 11, 14, 1 }, // 78 bits per transform
+ { 11, 15, 0 }, // 78 bits per transform
+ { 12, 0, 14 }, // 78 bits per transform
+ { 12, 1, 13 }, // 78 bits per transform
+ { 12, 2, 12 }, // 78 bits per transform
+ { 12, 3, 11 }, // 78 bits per transform
+ { 12, 4, 10 }, // 78 bits per transform
+ { 12, 5, 9 }, // 78 bits per transform
+ { 12, 6, 8 }, // 78 bits per transform
+ { 12, 7, 7 }, // 78 bits per transform
+ { 12, 8, 6 }, // 78 bits per transform
+ { 12, 9, 5 }, // 78 bits per transform
+ { 12, 10, 4 }, // 78 bits per transform
+ { 12, 11, 3 }, // 78 bits per transform
+ { 12, 12, 2 }, // 78 bits per transform
+ { 12, 13, 1 }, // 78 bits per transform
+ { 12, 14, 0 }, // 78 bits per transform
+ { 13, 0, 13 }, // 78 bits per transform
+ { 13, 1, 12 }, // 78 bits per transform
+ { 13, 2, 11 }, // 78 bits per transform
+ { 13, 3, 10 }, // 78 bits per transform
+ { 13, 4, 9 }, // 78 bits per transform
+ { 13, 5, 8 }, // 78 bits per transform
+ { 13, 6, 7 }, // 78 bits per transform
+ { 13, 7, 6 }, // 78 bits per transform
+ { 13, 8, 5 }, // 78 bits per transform
+ { 13, 9, 4 }, // 78 bits per transform
+ { 13, 10, 3 }, // 78 bits per transform
+ { 13, 11, 2 }, // 78 bits per transform
+ { 13, 12, 1 }, // 78 bits per transform
+ { 13, 13, 0 }, // 78 bits per transform
+ { 14, 0, 12 }, // 78 bits per transform
+ { 14, 1, 11 }, // 78 bits per transform
+ { 14, 2, 10 }, // 78 bits per transform
+ { 14, 3, 9 }, // 78 bits per transform
+ { 14, 4, 8 }, // 78 bits per transform
+ { 14, 5, 7 }, // 78 bits per transform
+ { 14, 6, 6 }, // 78 bits per transform
+ { 14, 7, 5 }, // 78 bits per transform
+ { 14, 8, 4 }, // 78 bits per transform
+ { 14, 9, 3 }, // 78 bits per transform
+ { 14, 10, 2 }, // 78 bits per transform
+ { 14, 11, 1 }, // 78 bits per transform
+ { 14, 12, 0 }, // 78 bits per transform
+ { 15, 0, 11 }, // 78 bits per transform
+ { 15, 1, 10 }, // 78 bits per transform
+ { 15, 2, 9 }, // 78 bits per transform
+ { 15, 3, 8 }, // 78 bits per transform
+ { 15, 4, 7 }, // 78 bits per transform
+ { 15, 5, 6 }, // 78 bits per transform
+ { 15, 6, 5 }, // 78 bits per transform
+ { 15, 7, 4 }, // 78 bits per transform
+ { 15, 8, 3 }, // 78 bits per transform
+ { 15, 9, 2 }, // 78 bits per transform
+ { 15, 10, 1 }, // 78 bits per transform
+ { 15, 11, 0 }, // 78 bits per transform
+ { 16, 0, 10 }, // 78 bits per transform
+ { 16, 1, 9 }, // 78 bits per transform
+ { 16, 2, 8 }, // 78 bits per transform
+ { 16, 3, 7 }, // 78 bits per transform
+ { 16, 4, 6 }, // 78 bits per transform
+ { 16, 5, 5 }, // 78 bits per transform
+ { 16, 6, 4 }, // 78 bits per transform
+ { 16, 7, 3 }, // 78 bits per transform
+ { 16, 8, 2 }, // 78 bits per transform
+ { 16, 9, 1 }, // 78 bits per transform
+ { 16, 10, 0 }, // 78 bits per transform
+ { 17, 0, 9 }, // 78 bits per transform
+ { 17, 1, 8 }, // 78 bits per transform
+ { 17, 2, 7 }, // 78 bits per transform
+ { 17, 3, 6 }, // 78 bits per transform
+ { 17, 4, 5 }, // 78 bits per transform
+ { 17, 5, 4 }, // 78 bits per transform
+ { 17, 6, 3 }, // 78 bits per transform
+ { 17, 7, 2 }, // 78 bits per transform
+ { 17, 8, 1 }, // 78 bits per transform
+ { 17, 9, 0 }, // 78 bits per transform
+ { 18, 0, 8 }, // 78 bits per transform
+ { 18, 1, 7 }, // 78 bits per transform
+ { 18, 2, 6 }, // 78 bits per transform
+ { 18, 3, 5 }, // 78 bits per transform
+ { 18, 4, 4 }, // 78 bits per transform
+ { 18, 5, 3 }, // 78 bits per transform
+ { 18, 6, 2 }, // 78 bits per transform
+ { 18, 7, 1 }, // 78 bits per transform
+ { 18, 8, 0 }, // 78 bits per transform
+ { 19, 0, 7 }, // 78 bits per transform
+ { 19, 1, 6 }, // 78 bits per transform
+ { 19, 2, 5 }, // 78 bits per transform
+ { 19, 3, 4 }, // 78 bits per transform
+ { 19, 4, 3 }, // 78 bits per transform
+ { 19, 5, 2 }, // 78 bits per transform
+ { 19, 6, 1 }, // 78 bits per transform
+ { 19, 7, 0 }, // 78 bits per transform
+ { 20, 0, 6 }, // 78 bits per transform
+ { 20, 1, 5 }, // 78 bits per transform
+ { 20, 2, 4 }, // 78 bits per transform
+ { 20, 3, 3 }, // 78 bits per transform
+ { 20, 4, 2 }, // 78 bits per transform
+ { 20, 5, 1 }, // 78 bits per transform
+ { 20, 6, 0 }, // 78 bits per transform
+ { 21, 0, 5 }, // 78 bits per transform
+ { 21, 1, 4 }, // 78 bits per transform
+ { 21, 2, 3 }, // 78 bits per transform
+ { 21, 3, 2 }, // 78 bits per transform
+ { 21, 4, 1 }, // 78 bits per transform
+ { 21, 5, 0 }, // 78 bits per transform
+ { 22, 0, 4 }, // 78 bits per transform
+ { 22, 1, 3 }, // 78 bits per transform
+ { 22, 2, 2 }, // 78 bits per transform
+ { 22, 3, 1 }, // 78 bits per transform
+ { 22, 4, 0 }, // 78 bits per transform
+ { 23, 0, 3 }, // 78 bits per transform
+ { 23, 1, 2 }, // 78 bits per transform
+ { 23, 2, 1 }, // 78 bits per transform
+ { 23, 3, 0 }, // 78 bits per transform
+ { 0, 4, 23 }, // 81 bits per transform
+ { 0, 5, 22 }, // 81 bits per transform
+ { 0, 6, 21 }, // 81 bits per transform
+ { 0, 7, 20 }, // 81 bits per transform
+ { 0, 8, 19 }, // 81 bits per transform
+ { 0, 9, 18 }, // 81 bits per transform
+ { 0, 10, 17 }, // 81 bits per transform
+ { 0, 11, 16 }, // 81 bits per transform
+ { 0, 12, 15 }, // 81 bits per transform
+ { 0, 13, 14 }, // 81 bits per transform
+ { 0, 14, 13 }, // 81 bits per transform
+ { 0, 15, 12 }, // 81 bits per transform
+ { 0, 16, 11 }, // 81 bits per transform
+ { 0, 17, 10 }, // 81 bits per transform
+ { 0, 18, 9 }, // 81 bits per transform
+ { 0, 19, 8 }, // 81 bits per transform
+ { 0, 20, 7 }, // 81 bits per transform
+ { 0, 21, 6 }, // 81 bits per transform
+ { 0, 22, 5 }, // 81 bits per transform
+ { 0, 23, 4 }, // 81 bits per transform
+ { 1, 3, 23 }, // 81 bits per transform
+ { 1, 4, 22 }, // 81 bits per transform
+ { 1, 5, 21 }, // 81 bits per transform
+ { 1, 6, 20 }, // 81 bits per transform
+ { 1, 7, 19 }, // 81 bits per transform
+ { 1, 8, 18 }, // 81 bits per transform
+ { 1, 9, 17 }, // 81 bits per transform
+ { 1, 10, 16 }, // 81 bits per transform
+ { 1, 11, 15 }, // 81 bits per transform
+ { 1, 12, 14 }, // 81 bits per transform
+ { 1, 13, 13 }, // 81 bits per transform
+ { 1, 14, 12 }, // 81 bits per transform
+ { 1, 15, 11 }, // 81 bits per transform
+ { 1, 16, 10 }, // 81 bits per transform
+ { 1, 17, 9 }, // 81 bits per transform
+ { 1, 18, 8 }, // 81 bits per transform
+ { 1, 19, 7 }, // 81 bits per transform
+ { 1, 20, 6 }, // 81 bits per transform
+ { 1, 21, 5 }, // 81 bits per transform
+ { 1, 22, 4 }, // 81 bits per transform
+ { 1, 23, 3 }, // 81 bits per transform
+ { 2, 2, 23 }, // 81 bits per transform
+ { 2, 3, 22 }, // 81 bits per transform
+ { 2, 4, 21 }, // 81 bits per transform
+ { 2, 5, 20 }, // 81 bits per transform
+ { 2, 6, 19 }, // 81 bits per transform
+ { 2, 7, 18 }, // 81 bits per transform
+ { 2, 8, 17 }, // 81 bits per transform
+ { 2, 9, 16 }, // 81 bits per transform
+ { 2, 10, 15 }, // 81 bits per transform
+ { 2, 11, 14 }, // 81 bits per transform
+ { 2, 12, 13 }, // 81 bits per transform
+ { 2, 13, 12 }, // 81 bits per transform
+ { 2, 14, 11 }, // 81 bits per transform
+ { 2, 15, 10 }, // 81 bits per transform
+ { 2, 16, 9 }, // 81 bits per transform
+ { 2, 17, 8 }, // 81 bits per transform
+ { 2, 18, 7 }, // 81 bits per transform
+ { 2, 19, 6 }, // 81 bits per transform
+ { 2, 20, 5 }, // 81 bits per transform
+ { 2, 21, 4 }, // 81 bits per transform
+ { 2, 22, 3 }, // 81 bits per transform
+ { 2, 23, 2 }, // 81 bits per transform
+ { 3, 1, 23 }, // 81 bits per transform
+ { 3, 2, 22 }, // 81 bits per transform
+ { 3, 3, 21 }, // 81 bits per transform
+ { 3, 4, 20 }, // 81 bits per transform
+ { 3, 5, 19 }, // 81 bits per transform
+ { 3, 6, 18 }, // 81 bits per transform
+ { 3, 7, 17 }, // 81 bits per transform
+ { 3, 8, 16 }, // 81 bits per transform
+ { 3, 9, 15 }, // 81 bits per transform
+ { 3, 10, 14 }, // 81 bits per transform
+ { 3, 11, 13 }, // 81 bits per transform
+ { 3, 12, 12 }, // 81 bits per transform
+ { 3, 13, 11 }, // 81 bits per transform
+ { 3, 14, 10 }, // 81 bits per transform
+ { 3, 15, 9 }, // 81 bits per transform
+ { 3, 16, 8 }, // 81 bits per transform
+ { 3, 17, 7 }, // 81 bits per transform
+ { 3, 18, 6 }, // 81 bits per transform
+ { 3, 19, 5 }, // 81 bits per transform
+ { 3, 20, 4 }, // 81 bits per transform
+ { 3, 21, 3 }, // 81 bits per transform
+ { 3, 22, 2 }, // 81 bits per transform
+ { 3, 23, 1 }, // 81 bits per transform
+ { 4, 0, 23 }, // 81 bits per transform
+ { 4, 1, 22 }, // 81 bits per transform
+ { 4, 2, 21 }, // 81 bits per transform
+ { 4, 3, 20 }, // 81 bits per transform
+ { 4, 4, 19 }, // 81 bits per transform
+ { 4, 5, 18 }, // 81 bits per transform
+ { 4, 6, 17 }, // 81 bits per transform
+ { 4, 7, 16 }, // 81 bits per transform
+ { 4, 8, 15 }, // 81 bits per transform
+ { 4, 9, 14 }, // 81 bits per transform
+ { 4, 10, 13 }, // 81 bits per transform
+ { 4, 11, 12 }, // 81 bits per transform
+ { 4, 12, 11 }, // 81 bits per transform
+ { 4, 13, 10 }, // 81 bits per transform
+ { 4, 14, 9 }, // 81 bits per transform
+ { 4, 15, 8 }, // 81 bits per transform
+ { 4, 16, 7 }, // 81 bits per transform
+ { 4, 17, 6 }, // 81 bits per transform
+ { 4, 18, 5 }, // 81 bits per transform
+ { 4, 19, 4 }, // 81 bits per transform
+ { 4, 20, 3 }, // 81 bits per transform
+ { 4, 21, 2 }, // 81 bits per transform
+ { 4, 22, 1 }, // 81 bits per transform
+ { 4, 23, 0 }, // 81 bits per transform
+ { 5, 0, 22 }, // 81 bits per transform
+ { 5, 1, 21 }, // 81 bits per transform
+ { 5, 2, 20 }, // 81 bits per transform
+ { 5, 3, 19 }, // 81 bits per transform
+ { 5, 4, 18 }, // 81 bits per transform
+ { 5, 5, 17 }, // 81 bits per transform
+ { 5, 6, 16 }, // 81 bits per transform
+ { 5, 7, 15 }, // 81 bits per transform
+ { 5, 8, 14 }, // 81 bits per transform
+ { 5, 9, 13 }, // 81 bits per transform
+ { 5, 10, 12 }, // 81 bits per transform
+ { 5, 11, 11 }, // 81 bits per transform
+ { 5, 12, 10 }, // 81 bits per transform
+ { 5, 13, 9 }, // 81 bits per transform
+ { 5, 14, 8 }, // 81 bits per transform
+ { 5, 15, 7 }, // 81 bits per transform
+ { 5, 16, 6 }, // 81 bits per transform
+ { 5, 17, 5 }, // 81 bits per transform
+ { 5, 18, 4 }, // 81 bits per transform
+ { 5, 19, 3 }, // 81 bits per transform
+ { 5, 20, 2 }, // 81 bits per transform
+ { 5, 21, 1 }, // 81 bits per transform
+ { 5, 22, 0 }, // 81 bits per transform
+ { 6, 0, 21 }, // 81 bits per transform
+ { 6, 1, 20 }, // 81 bits per transform
+ { 6, 2, 19 }, // 81 bits per transform
+ { 6, 3, 18 }, // 81 bits per transform
+ { 6, 4, 17 }, // 81 bits per transform
+ { 6, 5, 16 }, // 81 bits per transform
+ { 6, 6, 15 }, // 81 bits per transform
+ { 6, 7, 14 }, // 81 bits per transform
+ { 6, 8, 13 }, // 81 bits per transform
+ { 6, 9, 12 }, // 81 bits per transform
+ { 6, 10, 11 }, // 81 bits per transform
+ { 6, 11, 10 }, // 81 bits per transform
+ { 6, 12, 9 }, // 81 bits per transform
+ { 6, 13, 8 }, // 81 bits per transform
+ { 6, 14, 7 }, // 81 bits per transform
+ { 6, 15, 6 }, // 81 bits per transform
+ { 6, 16, 5 }, // 81 bits per transform
+ { 6, 17, 4 }, // 81 bits per transform
+ { 6, 18, 3 }, // 81 bits per transform
+ { 6, 19, 2 }, // 81 bits per transform
+ { 6, 20, 1 }, // 81 bits per transform
+ { 6, 21, 0 }, // 81 bits per transform
+ { 7, 0, 20 }, // 81 bits per transform
+ { 7, 1, 19 }, // 81 bits per transform
+ { 7, 2, 18 }, // 81 bits per transform
+ { 7, 3, 17 }, // 81 bits per transform
+ { 7, 4, 16 }, // 81 bits per transform
+ { 7, 5, 15 }, // 81 bits per transform
+ { 7, 6, 14 }, // 81 bits per transform
+ { 7, 7, 13 }, // 81 bits per transform
+ { 7, 8, 12 }, // 81 bits per transform
+ { 7, 9, 11 }, // 81 bits per transform
+ { 7, 10, 10 }, // 81 bits per transform
+ { 7, 11, 9 }, // 81 bits per transform
+ { 7, 12, 8 }, // 81 bits per transform
+ { 7, 13, 7 }, // 81 bits per transform
+ { 7, 14, 6 }, // 81 bits per transform
+ { 7, 15, 5 }, // 81 bits per transform
+ { 7, 16, 4 }, // 81 bits per transform
+ { 7, 17, 3 }, // 81 bits per transform
+ { 7, 18, 2 }, // 81 bits per transform
+ { 7, 19, 1 }, // 81 bits per transform
+ { 7, 20, 0 }, // 81 bits per transform
+ { 8, 0, 19 }, // 81 bits per transform
+ { 8, 1, 18 }, // 81 bits per transform
+ { 8, 2, 17 }, // 81 bits per transform
+ { 8, 3, 16 }, // 81 bits per transform
+ { 8, 4, 15 }, // 81 bits per transform
+ { 8, 5, 14 }, // 81 bits per transform
+ { 8, 6, 13 }, // 81 bits per transform
+ { 8, 7, 12 }, // 81 bits per transform
+ { 8, 8, 11 }, // 81 bits per transform
+ { 8, 9, 10 }, // 81 bits per transform
+ { 8, 10, 9 }, // 81 bits per transform
+ { 8, 11, 8 }, // 81 bits per transform
+ { 8, 12, 7 }, // 81 bits per transform
+ { 8, 13, 6 }, // 81 bits per transform
+ { 8, 14, 5 }, // 81 bits per transform
+ { 8, 15, 4 }, // 81 bits per transform
+ { 8, 16, 3 }, // 81 bits per transform
+ { 8, 17, 2 }, // 81 bits per transform
+ { 8, 18, 1 }, // 81 bits per transform
+ { 8, 19, 0 }, // 81 bits per transform
+ { 9, 0, 18 }, // 81 bits per transform
+ { 9, 1, 17 }, // 81 bits per transform
+ { 9, 2, 16 }, // 81 bits per transform
+ { 9, 3, 15 }, // 81 bits per transform
+ { 9, 4, 14 }, // 81 bits per transform
+ { 9, 5, 13 }, // 81 bits per transform
+ { 9, 6, 12 }, // 81 bits per transform
+ { 9, 7, 11 }, // 81 bits per transform
+ { 9, 8, 10 }, // 81 bits per transform
+ { 9, 9, 9 }, // 81 bits per transform
+ { 9, 10, 8 }, // 81 bits per transform
+ { 9, 11, 7 }, // 81 bits per transform
+ { 9, 12, 6 }, // 81 bits per transform
+ { 9, 13, 5 }, // 81 bits per transform
+ { 9, 14, 4 }, // 81 bits per transform
+ { 9, 15, 3 }, // 81 bits per transform
+ { 9, 16, 2 }, // 81 bits per transform
+ { 9, 17, 1 }, // 81 bits per transform
+ { 9, 18, 0 }, // 81 bits per transform
+ { 10, 0, 17 }, // 81 bits per transform
+ { 10, 1, 16 }, // 81 bits per transform
+ { 10, 2, 15 }, // 81 bits per transform
+ { 10, 3, 14 }, // 81 bits per transform
+ { 10, 4, 13 }, // 81 bits per transform
+ { 10, 5, 12 }, // 81 bits per transform
+ { 10, 6, 11 }, // 81 bits per transform
+ { 10, 7, 10 }, // 81 bits per transform
+ { 10, 8, 9 }, // 81 bits per transform
+ { 10, 9, 8 }, // 81 bits per transform
+ { 10, 10, 7 }, // 81 bits per transform
+ { 10, 11, 6 }, // 81 bits per transform
+ { 10, 12, 5 }, // 81 bits per transform
+ { 10, 13, 4 }, // 81 bits per transform
+ { 10, 14, 3 }, // 81 bits per transform
+ { 10, 15, 2 }, // 81 bits per transform
+ { 10, 16, 1 }, // 81 bits per transform
+ { 10, 17, 0 }, // 81 bits per transform
+ { 11, 0, 16 }, // 81 bits per transform
+ { 11, 1, 15 }, // 81 bits per transform
+ { 11, 2, 14 }, // 81 bits per transform
+ { 11, 3, 13 }, // 81 bits per transform
+ { 11, 4, 12 }, // 81 bits per transform
+ { 11, 5, 11 }, // 81 bits per transform
+ { 11, 6, 10 }, // 81 bits per transform
+ { 11, 7, 9 }, // 81 bits per transform
+ { 11, 8, 8 }, // 81 bits per transform
+ { 11, 9, 7 }, // 81 bits per transform
+ { 11, 10, 6 }, // 81 bits per transform
+ { 11, 11, 5 }, // 81 bits per transform
+ { 11, 12, 4 }, // 81 bits per transform
+ { 11, 13, 3 }, // 81 bits per transform
+ { 11, 14, 2 }, // 81 bits per transform
+ { 11, 15, 1 }, // 81 bits per transform
+ { 11, 16, 0 }, // 81 bits per transform
+ { 12, 0, 15 }, // 81 bits per transform
+ { 12, 1, 14 }, // 81 bits per transform
+ { 12, 2, 13 }, // 81 bits per transform
+ { 12, 3, 12 }, // 81 bits per transform
+ { 12, 4, 11 }, // 81 bits per transform
+ { 12, 5, 10 }, // 81 bits per transform
+ { 12, 6, 9 }, // 81 bits per transform
+ { 12, 7, 8 }, // 81 bits per transform
+ { 12, 8, 7 }, // 81 bits per transform
+ { 12, 9, 6 }, // 81 bits per transform
+ { 12, 10, 5 }, // 81 bits per transform
+ { 12, 11, 4 }, // 81 bits per transform
+ { 12, 12, 3 }, // 81 bits per transform
+ { 12, 13, 2 }, // 81 bits per transform
+ { 12, 14, 1 }, // 81 bits per transform
+ { 12, 15, 0 }, // 81 bits per transform
+ { 13, 0, 14 }, // 81 bits per transform
+ { 13, 1, 13 }, // 81 bits per transform
+ { 13, 2, 12 }, // 81 bits per transform
+ { 13, 3, 11 }, // 81 bits per transform
+ { 13, 4, 10 }, // 81 bits per transform
+ { 13, 5, 9 }, // 81 bits per transform
+ { 13, 6, 8 }, // 81 bits per transform
+ { 13, 7, 7 }, // 81 bits per transform
+ { 13, 8, 6 }, // 81 bits per transform
+ { 13, 9, 5 }, // 81 bits per transform
+ { 13, 10, 4 }, // 81 bits per transform
+ { 13, 11, 3 }, // 81 bits per transform
+ { 13, 12, 2 }, // 81 bits per transform
+ { 13, 13, 1 }, // 81 bits per transform
+ { 13, 14, 0 }, // 81 bits per transform
+ { 14, 0, 13 }, // 81 bits per transform
+ { 14, 1, 12 }, // 81 bits per transform
+ { 14, 2, 11 }, // 81 bits per transform
+ { 14, 3, 10 }, // 81 bits per transform
+ { 14, 4, 9 }, // 81 bits per transform
+ { 14, 5, 8 }, // 81 bits per transform
+ { 14, 6, 7 }, // 81 bits per transform
+ { 14, 7, 6 }, // 81 bits per transform
+ { 14, 8, 5 }, // 81 bits per transform
+ { 14, 9, 4 }, // 81 bits per transform
+ { 14, 10, 3 }, // 81 bits per transform
+ { 14, 11, 2 }, // 81 bits per transform
+ { 14, 12, 1 }, // 81 bits per transform
+ { 14, 13, 0 }, // 81 bits per transform
+ { 15, 0, 12 }, // 81 bits per transform
+ { 15, 1, 11 }, // 81 bits per transform
+ { 15, 2, 10 }, // 81 bits per transform
+ { 15, 3, 9 }, // 81 bits per transform
+ { 15, 4, 8 }, // 81 bits per transform
+ { 15, 5, 7 }, // 81 bits per transform
+ { 15, 6, 6 }, // 81 bits per transform
+ { 15, 7, 5 }, // 81 bits per transform
+ { 15, 8, 4 }, // 81 bits per transform
+ { 15, 9, 3 }, // 81 bits per transform
+ { 15, 10, 2 }, // 81 bits per transform
+ { 15, 11, 1 }, // 81 bits per transform
+ { 15, 12, 0 }, // 81 bits per transform
+ { 16, 0, 11 }, // 81 bits per transform
+ { 16, 1, 10 }, // 81 bits per transform
+ { 16, 2, 9 }, // 81 bits per transform
+ { 16, 3, 8 }, // 81 bits per transform
+ { 16, 4, 7 }, // 81 bits per transform
+ { 16, 5, 6 }, // 81 bits per transform
+ { 16, 6, 5 }, // 81 bits per transform
+ { 16, 7, 4 }, // 81 bits per transform
+ { 16, 8, 3 }, // 81 bits per transform
+ { 16, 9, 2 }, // 81 bits per transform
+ { 16, 10, 1 }, // 81 bits per transform
+ { 16, 11, 0 }, // 81 bits per transform
+ { 17, 0, 10 }, // 81 bits per transform
+ { 17, 1, 9 }, // 81 bits per transform
+ { 17, 2, 8 }, // 81 bits per transform
+ { 17, 3, 7 }, // 81 bits per transform
+ { 17, 4, 6 }, // 81 bits per transform
+ { 17, 5, 5 }, // 81 bits per transform
+ { 17, 6, 4 }, // 81 bits per transform
+ { 17, 7, 3 }, // 81 bits per transform
+ { 17, 8, 2 }, // 81 bits per transform
+ { 17, 9, 1 }, // 81 bits per transform
+ { 17, 10, 0 }, // 81 bits per transform
+ { 18, 0, 9 }, // 81 bits per transform
+ { 18, 1, 8 }, // 81 bits per transform
+ { 18, 2, 7 }, // 81 bits per transform
+ { 18, 3, 6 }, // 81 bits per transform
+ { 18, 4, 5 }, // 81 bits per transform
+ { 18, 5, 4 }, // 81 bits per transform
+ { 18, 6, 3 }, // 81 bits per transform
+ { 18, 7, 2 }, // 81 bits per transform
+ { 18, 8, 1 }, // 81 bits per transform
+ { 18, 9, 0 }, // 81 bits per transform
+ { 19, 0, 8 }, // 81 bits per transform
+ { 19, 1, 7 }, // 81 bits per transform
+ { 19, 2, 6 }, // 81 bits per transform
+ { 19, 3, 5 }, // 81 bits per transform
+ { 19, 4, 4 }, // 81 bits per transform
+ { 19, 5, 3 }, // 81 bits per transform
+ { 19, 6, 2 }, // 81 bits per transform
+ { 19, 7, 1 }, // 81 bits per transform
+ { 19, 8, 0 }, // 81 bits per transform
+ { 20, 0, 7 }, // 81 bits per transform
+ { 20, 1, 6 }, // 81 bits per transform
+ { 20, 2, 5 }, // 81 bits per transform
+ { 20, 3, 4 }, // 81 bits per transform
+ { 20, 4, 3 }, // 81 bits per transform
+ { 20, 5, 2 }, // 81 bits per transform
+ { 20, 6, 1 }, // 81 bits per transform
+ { 20, 7, 0 }, // 81 bits per transform
+ { 21, 0, 6 }, // 81 bits per transform
+ { 21, 1, 5 }, // 81 bits per transform
+ { 21, 2, 4 }, // 81 bits per transform
+ { 21, 3, 3 }, // 81 bits per transform
+ { 21, 4, 2 }, // 81 bits per transform
+ { 21, 5, 1 }, // 81 bits per transform
+ { 21, 6, 0 }, // 81 bits per transform
+ { 22, 0, 5 }, // 81 bits per transform
+ { 22, 1, 4 }, // 81 bits per transform
+ { 22, 2, 3 }, // 81 bits per transform
+ { 22, 3, 2 }, // 81 bits per transform
+ { 22, 4, 1 }, // 81 bits per transform
+ { 22, 5, 0 }, // 81 bits per transform
+ { 23, 0, 4 }, // 81 bits per transform
+ { 23, 1, 3 }, // 81 bits per transform
+ { 23, 2, 2 }, // 81 bits per transform
+ { 23, 3, 1 }, // 81 bits per transform
+ { 23, 4, 0 }, // 81 bits per transform
+ { 0, 5, 23 }, // 84 bits per transform
+ { 0, 6, 22 }, // 84 bits per transform
+ { 0, 7, 21 }, // 84 bits per transform
+ { 0, 8, 20 }, // 84 bits per transform
+ { 0, 9, 19 }, // 84 bits per transform
+ { 0, 10, 18 }, // 84 bits per transform
+ { 0, 11, 17 }, // 84 bits per transform
+ { 0, 12, 16 }, // 84 bits per transform
+ { 0, 13, 15 }, // 84 bits per transform
+ { 0, 14, 14 }, // 84 bits per transform
+ { 0, 15, 13 }, // 84 bits per transform
+ { 0, 16, 12 }, // 84 bits per transform
+ { 0, 17, 11 }, // 84 bits per transform
+ { 0, 18, 10 }, // 84 bits per transform
+ { 0, 19, 9 }, // 84 bits per transform
+ { 0, 20, 8 }, // 84 bits per transform
+ { 0, 21, 7 }, // 84 bits per transform
+ { 0, 22, 6 }, // 84 bits per transform
+ { 0, 23, 5 }, // 84 bits per transform
+ { 1, 4, 23 }, // 84 bits per transform
+ { 1, 5, 22 }, // 84 bits per transform
+ { 1, 6, 21 }, // 84 bits per transform
+ { 1, 7, 20 }, // 84 bits per transform
+ { 1, 8, 19 }, // 84 bits per transform
+ { 1, 9, 18 }, // 84 bits per transform
+ { 1, 10, 17 }, // 84 bits per transform
+ { 1, 11, 16 }, // 84 bits per transform
+ { 1, 12, 15 }, // 84 bits per transform
+ { 1, 13, 14 }, // 84 bits per transform
+ { 1, 14, 13 }, // 84 bits per transform
+ { 1, 15, 12 }, // 84 bits per transform
+ { 1, 16, 11 }, // 84 bits per transform
+ { 1, 17, 10 }, // 84 bits per transform
+ { 1, 18, 9 }, // 84 bits per transform
+ { 1, 19, 8 }, // 84 bits per transform
+ { 1, 20, 7 }, // 84 bits per transform
+ { 1, 21, 6 }, // 84 bits per transform
+ { 1, 22, 5 }, // 84 bits per transform
+ { 1, 23, 4 }, // 84 bits per transform
+ { 2, 3, 23 }, // 84 bits per transform
+ { 2, 4, 22 }, // 84 bits per transform
+ { 2, 5, 21 }, // 84 bits per transform
+ { 2, 6, 20 }, // 84 bits per transform
+ { 2, 7, 19 }, // 84 bits per transform
+ { 2, 8, 18 }, // 84 bits per transform
+ { 2, 9, 17 }, // 84 bits per transform
+ { 2, 10, 16 }, // 84 bits per transform
+ { 2, 11, 15 }, // 84 bits per transform
+ { 2, 12, 14 }, // 84 bits per transform
+ { 2, 13, 13 }, // 84 bits per transform
+ { 2, 14, 12 }, // 84 bits per transform
+ { 2, 15, 11 }, // 84 bits per transform
+ { 2, 16, 10 }, // 84 bits per transform
+ { 2, 17, 9 }, // 84 bits per transform
+ { 2, 18, 8 }, // 84 bits per transform
+ { 2, 19, 7 }, // 84 bits per transform
+ { 2, 20, 6 }, // 84 bits per transform
+ { 2, 21, 5 }, // 84 bits per transform
+ { 2, 22, 4 }, // 84 bits per transform
+ { 2, 23, 3 }, // 84 bits per transform
+ { 3, 2, 23 }, // 84 bits per transform
+ { 3, 3, 22 }, // 84 bits per transform
+ { 3, 4, 21 }, // 84 bits per transform
+ { 3, 5, 20 }, // 84 bits per transform
+ { 3, 6, 19 }, // 84 bits per transform
+ { 3, 7, 18 }, // 84 bits per transform
+ { 3, 8, 17 }, // 84 bits per transform
+ { 3, 9, 16 }, // 84 bits per transform
+ { 3, 10, 15 }, // 84 bits per transform
+ { 3, 11, 14 }, // 84 bits per transform
+ { 3, 12, 13 }, // 84 bits per transform
+ { 3, 13, 12 }, // 84 bits per transform
+ { 3, 14, 11 }, // 84 bits per transform
+ { 3, 15, 10 }, // 84 bits per transform
+ { 3, 16, 9 }, // 84 bits per transform
+ { 3, 17, 8 }, // 84 bits per transform
+ { 3, 18, 7 }, // 84 bits per transform
+ { 3, 19, 6 }, // 84 bits per transform
+ { 3, 20, 5 }, // 84 bits per transform
+ { 3, 21, 4 }, // 84 bits per transform
+ { 3, 22, 3 }, // 84 bits per transform
+ { 3, 23, 2 }, // 84 bits per transform
+ { 4, 1, 23 }, // 84 bits per transform
+ { 4, 2, 22 }, // 84 bits per transform
+ { 4, 3, 21 }, // 84 bits per transform
+ { 4, 4, 20 }, // 84 bits per transform
+ { 4, 5, 19 }, // 84 bits per transform
+ { 4, 6, 18 }, // 84 bits per transform
+ { 4, 7, 17 }, // 84 bits per transform
+ { 4, 8, 16 }, // 84 bits per transform
+ { 4, 9, 15 }, // 84 bits per transform
+ { 4, 10, 14 }, // 84 bits per transform
+ { 4, 11, 13 }, // 84 bits per transform
+ { 4, 12, 12 }, // 84 bits per transform
+ { 4, 13, 11 }, // 84 bits per transform
+ { 4, 14, 10 }, // 84 bits per transform
+ { 4, 15, 9 }, // 84 bits per transform
+ { 4, 16, 8 }, // 84 bits per transform
+ { 4, 17, 7 }, // 84 bits per transform
+ { 4, 18, 6 }, // 84 bits per transform
+ { 4, 19, 5 }, // 84 bits per transform
+ { 4, 20, 4 }, // 84 bits per transform
+ { 4, 21, 3 }, // 84 bits per transform
+ { 4, 22, 2 }, // 84 bits per transform
+ { 4, 23, 1 }, // 84 bits per transform
+ { 5, 0, 23 }, // 84 bits per transform
+ { 5, 1, 22 }, // 84 bits per transform
+ { 5, 2, 21 }, // 84 bits per transform
+ { 5, 3, 20 }, // 84 bits per transform
+ { 5, 4, 19 }, // 84 bits per transform
+ { 5, 5, 18 }, // 84 bits per transform
+ { 5, 6, 17 }, // 84 bits per transform
+ { 5, 7, 16 }, // 84 bits per transform
+ { 5, 8, 15 }, // 84 bits per transform
+ { 5, 9, 14 }, // 84 bits per transform
+ { 5, 10, 13 }, // 84 bits per transform
+ { 5, 11, 12 }, // 84 bits per transform
+ { 5, 12, 11 }, // 84 bits per transform
+ { 5, 13, 10 }, // 84 bits per transform
+ { 5, 14, 9 }, // 84 bits per transform
+ { 5, 15, 8 }, // 84 bits per transform
+ { 5, 16, 7 }, // 84 bits per transform
+ { 5, 17, 6 }, // 84 bits per transform
+ { 5, 18, 5 }, // 84 bits per transform
+ { 5, 19, 4 }, // 84 bits per transform
+ { 5, 20, 3 }, // 84 bits per transform
+ { 5, 21, 2 }, // 84 bits per transform
+ { 5, 22, 1 }, // 84 bits per transform
+ { 5, 23, 0 }, // 84 bits per transform
+ { 6, 0, 22 }, // 84 bits per transform
+ { 6, 1, 21 }, // 84 bits per transform
+ { 6, 2, 20 }, // 84 bits per transform
+ { 6, 3, 19 }, // 84 bits per transform
+ { 6, 4, 18 }, // 84 bits per transform
+ { 6, 5, 17 }, // 84 bits per transform
+ { 6, 6, 16 }, // 84 bits per transform
+ { 6, 7, 15 }, // 84 bits per transform
+ { 6, 8, 14 }, // 84 bits per transform
+ { 6, 9, 13 }, // 84 bits per transform
+ { 6, 10, 12 }, // 84 bits per transform
+ { 6, 11, 11 }, // 84 bits per transform
+ { 6, 12, 10 }, // 84 bits per transform
+ { 6, 13, 9 }, // 84 bits per transform
+ { 6, 14, 8 }, // 84 bits per transform
+ { 6, 15, 7 }, // 84 bits per transform
+ { 6, 16, 6 }, // 84 bits per transform
+ { 6, 17, 5 }, // 84 bits per transform
+ { 6, 18, 4 }, // 84 bits per transform
+ { 6, 19, 3 }, // 84 bits per transform
+ { 6, 20, 2 }, // 84 bits per transform
+ { 6, 21, 1 }, // 84 bits per transform
+ { 6, 22, 0 }, // 84 bits per transform
+ { 7, 0, 21 }, // 84 bits per transform
+ { 7, 1, 20 }, // 84 bits per transform
+ { 7, 2, 19 }, // 84 bits per transform
+ { 7, 3, 18 }, // 84 bits per transform
+ { 7, 4, 17 }, // 84 bits per transform
+ { 7, 5, 16 }, // 84 bits per transform
+ { 7, 6, 15 }, // 84 bits per transform
+ { 7, 7, 14 }, // 84 bits per transform
+ { 7, 8, 13 }, // 84 bits per transform
+ { 7, 9, 12 }, // 84 bits per transform
+ { 7, 10, 11 }, // 84 bits per transform
+ { 7, 11, 10 }, // 84 bits per transform
+ { 7, 12, 9 }, // 84 bits per transform
+ { 7, 13, 8 }, // 84 bits per transform
+ { 7, 14, 7 }, // 84 bits per transform
+ { 7, 15, 6 }, // 84 bits per transform
+ { 7, 16, 5 }, // 84 bits per transform
+ { 7, 17, 4 }, // 84 bits per transform
+ { 7, 18, 3 }, // 84 bits per transform
+ { 7, 19, 2 }, // 84 bits per transform
+ { 7, 20, 1 }, // 84 bits per transform
+ { 7, 21, 0 }, // 84 bits per transform
+ { 8, 0, 20 }, // 84 bits per transform
+ { 8, 1, 19 }, // 84 bits per transform
+ { 8, 2, 18 }, // 84 bits per transform
+ { 8, 3, 17 }, // 84 bits per transform
+ { 8, 4, 16 }, // 84 bits per transform
+ { 8, 5, 15 }, // 84 bits per transform
+ { 8, 6, 14 }, // 84 bits per transform
+ { 8, 7, 13 }, // 84 bits per transform
+ { 8, 8, 12 }, // 84 bits per transform
+ { 8, 9, 11 }, // 84 bits per transform
+ { 8, 10, 10 }, // 84 bits per transform
+ { 8, 11, 9 }, // 84 bits per transform
+ { 8, 12, 8 }, // 84 bits per transform
+ { 8, 13, 7 }, // 84 bits per transform
+ { 8, 14, 6 }, // 84 bits per transform
+ { 8, 15, 5 }, // 84 bits per transform
+ { 8, 16, 4 }, // 84 bits per transform
+ { 8, 17, 3 }, // 84 bits per transform
+ { 8, 18, 2 }, // 84 bits per transform
+ { 8, 19, 1 }, // 84 bits per transform
+ { 8, 20, 0 }, // 84 bits per transform
+ { 9, 0, 19 }, // 84 bits per transform
+ { 9, 1, 18 }, // 84 bits per transform
+ { 9, 2, 17 }, // 84 bits per transform
+ { 9, 3, 16 }, // 84 bits per transform
+ { 9, 4, 15 }, // 84 bits per transform
+ { 9, 5, 14 }, // 84 bits per transform
+ { 9, 6, 13 }, // 84 bits per transform
+ { 9, 7, 12 }, // 84 bits per transform
+ { 9, 8, 11 }, // 84 bits per transform
+ { 9, 9, 10 }, // 84 bits per transform
+ { 9, 10, 9 }, // 84 bits per transform
+ { 9, 11, 8 }, // 84 bits per transform
+ { 9, 12, 7 }, // 84 bits per transform
+ { 9, 13, 6 }, // 84 bits per transform
+ { 9, 14, 5 }, // 84 bits per transform
+ { 9, 15, 4 }, // 84 bits per transform
+ { 9, 16, 3 }, // 84 bits per transform
+ { 9, 17, 2 }, // 84 bits per transform
+ { 9, 18, 1 }, // 84 bits per transform
+ { 9, 19, 0 }, // 84 bits per transform
+ { 10, 0, 18 }, // 84 bits per transform
+ { 10, 1, 17 }, // 84 bits per transform
+ { 10, 2, 16 }, // 84 bits per transform
+ { 10, 3, 15 }, // 84 bits per transform
+ { 10, 4, 14 }, // 84 bits per transform
+ { 10, 5, 13 }, // 84 bits per transform
+ { 10, 6, 12 }, // 84 bits per transform
+ { 10, 7, 11 }, // 84 bits per transform
+ { 10, 8, 10 }, // 84 bits per transform
+ { 10, 9, 9 }, // 84 bits per transform
+ { 10, 10, 8 }, // 84 bits per transform
+ { 10, 11, 7 }, // 84 bits per transform
+ { 10, 12, 6 }, // 84 bits per transform
+ { 10, 13, 5 }, // 84 bits per transform
+ { 10, 14, 4 }, // 84 bits per transform
+ { 10, 15, 3 }, // 84 bits per transform
+ { 10, 16, 2 }, // 84 bits per transform
+ { 10, 17, 1 }, // 84 bits per transform
+ { 10, 18, 0 }, // 84 bits per transform
+ { 11, 0, 17 }, // 84 bits per transform
+ { 11, 1, 16 }, // 84 bits per transform
+ { 11, 2, 15 }, // 84 bits per transform
+ { 11, 3, 14 }, // 84 bits per transform
+ { 11, 4, 13 }, // 84 bits per transform
+ { 11, 5, 12 }, // 84 bits per transform
+ { 11, 6, 11 }, // 84 bits per transform
+ { 11, 7, 10 }, // 84 bits per transform
+ { 11, 8, 9 }, // 84 bits per transform
+ { 11, 9, 8 }, // 84 bits per transform
+ { 11, 10, 7 }, // 84 bits per transform
+ { 11, 11, 6 }, // 84 bits per transform
+ { 11, 12, 5 }, // 84 bits per transform
+ { 11, 13, 4 }, // 84 bits per transform
+ { 11, 14, 3 }, // 84 bits per transform
+ { 11, 15, 2 }, // 84 bits per transform
+ { 11, 16, 1 }, // 84 bits per transform
+ { 11, 17, 0 }, // 84 bits per transform
+ { 12, 0, 16 }, // 84 bits per transform
+ { 12, 1, 15 }, // 84 bits per transform
+ { 12, 2, 14 }, // 84 bits per transform
+ { 12, 3, 13 }, // 84 bits per transform
+ { 12, 4, 12 }, // 84 bits per transform
+ { 12, 5, 11 }, // 84 bits per transform
+ { 12, 6, 10 }, // 84 bits per transform
+ { 12, 7, 9 }, // 84 bits per transform
+ { 12, 8, 8 }, // 84 bits per transform
+ { 12, 9, 7 }, // 84 bits per transform
+ { 12, 10, 6 }, // 84 bits per transform
+ { 12, 11, 5 }, // 84 bits per transform
+ { 12, 12, 4 }, // 84 bits per transform
+ { 12, 13, 3 }, // 84 bits per transform
+ { 12, 14, 2 }, // 84 bits per transform
+ { 12, 15, 1 }, // 84 bits per transform
+ { 12, 16, 0 }, // 84 bits per transform
+ { 13, 0, 15 }, // 84 bits per transform
+ { 13, 1, 14 }, // 84 bits per transform
+ { 13, 2, 13 }, // 84 bits per transform
+ { 13, 3, 12 }, // 84 bits per transform
+ { 13, 4, 11 }, // 84 bits per transform
+ { 13, 5, 10 }, // 84 bits per transform
+ { 13, 6, 9 }, // 84 bits per transform
+ { 13, 7, 8 }, // 84 bits per transform
+ { 13, 8, 7 }, // 84 bits per transform
+ { 13, 9, 6 }, // 84 bits per transform
+ { 13, 10, 5 }, // 84 bits per transform
+ { 13, 11, 4 }, // 84 bits per transform
+ { 13, 12, 3 }, // 84 bits per transform
+ { 13, 13, 2 }, // 84 bits per transform
+ { 13, 14, 1 }, // 84 bits per transform
+ { 13, 15, 0 }, // 84 bits per transform
+ { 14, 0, 14 }, // 84 bits per transform
+ { 14, 1, 13 }, // 84 bits per transform
+ { 14, 2, 12 }, // 84 bits per transform
+ { 14, 3, 11 }, // 84 bits per transform
+ { 14, 4, 10 }, // 84 bits per transform
+ { 14, 5, 9 }, // 84 bits per transform
+ { 14, 6, 8 }, // 84 bits per transform
+ { 14, 7, 7 }, // 84 bits per transform
+ { 14, 8, 6 }, // 84 bits per transform
+ { 14, 9, 5 }, // 84 bits per transform
+ { 14, 10, 4 }, // 84 bits per transform
+ { 14, 11, 3 }, // 84 bits per transform
+ { 14, 12, 2 }, // 84 bits per transform
+ { 14, 13, 1 }, // 84 bits per transform
+ { 14, 14, 0 }, // 84 bits per transform
+ { 15, 0, 13 }, // 84 bits per transform
+ { 15, 1, 12 }, // 84 bits per transform
+ { 15, 2, 11 }, // 84 bits per transform
+ { 15, 3, 10 }, // 84 bits per transform
+ { 15, 4, 9 }, // 84 bits per transform
+ { 15, 5, 8 }, // 84 bits per transform
+ { 15, 6, 7 }, // 84 bits per transform
+ { 15, 7, 6 }, // 84 bits per transform
+ { 15, 8, 5 }, // 84 bits per transform
+ { 15, 9, 4 }, // 84 bits per transform
+ { 15, 10, 3 }, // 84 bits per transform
+ { 15, 11, 2 }, // 84 bits per transform
+ { 15, 12, 1 }, // 84 bits per transform
+ { 15, 13, 0 }, // 84 bits per transform
+ { 16, 0, 12 }, // 84 bits per transform
+ { 16, 1, 11 }, // 84 bits per transform
+ { 16, 2, 10 }, // 84 bits per transform
+ { 16, 3, 9 }, // 84 bits per transform
+ { 16, 4, 8 }, // 84 bits per transform
+ { 16, 5, 7 }, // 84 bits per transform
+ { 16, 6, 6 }, // 84 bits per transform
+ { 16, 7, 5 }, // 84 bits per transform
+ { 16, 8, 4 }, // 84 bits per transform
+ { 16, 9, 3 }, // 84 bits per transform
+ { 16, 10, 2 }, // 84 bits per transform
+ { 16, 11, 1 }, // 84 bits per transform
+ { 16, 12, 0 }, // 84 bits per transform
+ { 17, 0, 11 }, // 84 bits per transform
+ { 17, 1, 10 }, // 84 bits per transform
+ { 17, 2, 9 }, // 84 bits per transform
+ { 17, 3, 8 }, // 84 bits per transform
+ { 17, 4, 7 }, // 84 bits per transform
+ { 17, 5, 6 }, // 84 bits per transform
+ { 17, 6, 5 }, // 84 bits per transform
+ { 17, 7, 4 }, // 84 bits per transform
+ { 17, 8, 3 }, // 84 bits per transform
+ { 17, 9, 2 }, // 84 bits per transform
+ { 17, 10, 1 }, // 84 bits per transform
+ { 17, 11, 0 }, // 84 bits per transform
+ { 18, 0, 10 }, // 84 bits per transform
+ { 18, 1, 9 }, // 84 bits per transform
+ { 18, 2, 8 }, // 84 bits per transform
+ { 18, 3, 7 }, // 84 bits per transform
+ { 18, 4, 6 }, // 84 bits per transform
+ { 18, 5, 5 }, // 84 bits per transform
+ { 18, 6, 4 }, // 84 bits per transform
+ { 18, 7, 3 }, // 84 bits per transform
+ { 18, 8, 2 }, // 84 bits per transform
+ { 18, 9, 1 }, // 84 bits per transform
+ { 18, 10, 0 }, // 84 bits per transform
+ { 19, 0, 9 }, // 84 bits per transform
+ { 19, 1, 8 }, // 84 bits per transform
+ { 19, 2, 7 }, // 84 bits per transform
+ { 19, 3, 6 }, // 84 bits per transform
+ { 19, 4, 5 }, // 84 bits per transform
+ { 19, 5, 4 }, // 84 bits per transform
+ { 19, 6, 3 }, // 84 bits per transform
+ { 19, 7, 2 }, // 84 bits per transform
+ { 19, 8, 1 }, // 84 bits per transform
+ { 19, 9, 0 }, // 84 bits per transform
+ { 20, 0, 8 }, // 84 bits per transform
+ { 20, 1, 7 }, // 84 bits per transform
+ { 20, 2, 6 }, // 84 bits per transform
+ { 20, 3, 5 }, // 84 bits per transform
+ { 20, 4, 4 }, // 84 bits per transform
+ { 20, 5, 3 }, // 84 bits per transform
+ { 20, 6, 2 }, // 84 bits per transform
+ { 20, 7, 1 }, // 84 bits per transform
+ { 20, 8, 0 }, // 84 bits per transform
+ { 21, 0, 7 }, // 84 bits per transform
+ { 21, 1, 6 }, // 84 bits per transform
+ { 21, 2, 5 }, // 84 bits per transform
+ { 21, 3, 4 }, // 84 bits per transform
+ { 21, 4, 3 }, // 84 bits per transform
+ { 21, 5, 2 }, // 84 bits per transform
+ { 21, 6, 1 }, // 84 bits per transform
+ { 21, 7, 0 }, // 84 bits per transform
+ { 22, 0, 6 }, // 84 bits per transform
+ { 22, 1, 5 }, // 84 bits per transform
+ { 22, 2, 4 }, // 84 bits per transform
+ { 22, 3, 3 }, // 84 bits per transform
+ { 22, 4, 2 }, // 84 bits per transform
+ { 22, 5, 1 }, // 84 bits per transform
+ { 22, 6, 0 }, // 84 bits per transform
+ { 23, 0, 5 }, // 84 bits per transform
+ { 23, 1, 4 }, // 84 bits per transform
+ { 23, 2, 3 }, // 84 bits per transform
+ { 23, 3, 2 }, // 84 bits per transform
+ { 23, 4, 1 }, // 84 bits per transform
+ { 23, 5, 0 }, // 84 bits per transform
+ { 0, 6, 23 }, // 87 bits per transform
+ { 0, 7, 22 }, // 87 bits per transform
+ { 0, 8, 21 }, // 87 bits per transform
+ { 0, 9, 20 }, // 87 bits per transform
+ { 0, 10, 19 }, // 87 bits per transform
+ { 0, 11, 18 }, // 87 bits per transform
+ { 0, 12, 17 }, // 87 bits per transform
+ { 0, 13, 16 }, // 87 bits per transform
+ { 0, 14, 15 }, // 87 bits per transform
+ { 0, 15, 14 }, // 87 bits per transform
+ { 0, 16, 13 }, // 87 bits per transform
+ { 0, 17, 12 }, // 87 bits per transform
+ { 0, 18, 11 }, // 87 bits per transform
+ { 0, 19, 10 }, // 87 bits per transform
+ { 0, 20, 9 }, // 87 bits per transform
+ { 0, 21, 8 }, // 87 bits per transform
+ { 0, 22, 7 }, // 87 bits per transform
+ { 0, 23, 6 }, // 87 bits per transform
+ { 1, 5, 23 }, // 87 bits per transform
+ { 1, 6, 22 }, // 87 bits per transform
+ { 1, 7, 21 }, // 87 bits per transform
+ { 1, 8, 20 }, // 87 bits per transform
+ { 1, 9, 19 }, // 87 bits per transform
+ { 1, 10, 18 }, // 87 bits per transform
+ { 1, 11, 17 }, // 87 bits per transform
+ { 1, 12, 16 }, // 87 bits per transform
+ { 1, 13, 15 }, // 87 bits per transform
+ { 1, 14, 14 }, // 87 bits per transform
+ { 1, 15, 13 }, // 87 bits per transform
+ { 1, 16, 12 }, // 87 bits per transform
+ { 1, 17, 11 }, // 87 bits per transform
+ { 1, 18, 10 }, // 87 bits per transform
+ { 1, 19, 9 }, // 87 bits per transform
+ { 1, 20, 8 }, // 87 bits per transform
+ { 1, 21, 7 }, // 87 bits per transform
+ { 1, 22, 6 }, // 87 bits per transform
+ { 1, 23, 5 }, // 87 bits per transform
+ { 2, 4, 23 }, // 87 bits per transform
+ { 2, 5, 22 }, // 87 bits per transform
+ { 2, 6, 21 }, // 87 bits per transform
+ { 2, 7, 20 }, // 87 bits per transform
+ { 2, 8, 19 }, // 87 bits per transform
+ { 2, 9, 18 }, // 87 bits per transform
+ { 2, 10, 17 }, // 87 bits per transform
+ { 2, 11, 16 }, // 87 bits per transform
+ { 2, 12, 15 }, // 87 bits per transform
+ { 2, 13, 14 }, // 87 bits per transform
+ { 2, 14, 13 }, // 87 bits per transform
+ { 2, 15, 12 }, // 87 bits per transform
+ { 2, 16, 11 }, // 87 bits per transform
+ { 2, 17, 10 }, // 87 bits per transform
+ { 2, 18, 9 }, // 87 bits per transform
+ { 2, 19, 8 }, // 87 bits per transform
+ { 2, 20, 7 }, // 87 bits per transform
+ { 2, 21, 6 }, // 87 bits per transform
+ { 2, 22, 5 }, // 87 bits per transform
+ { 2, 23, 4 }, // 87 bits per transform
+ { 3, 3, 23 }, // 87 bits per transform
+ { 3, 4, 22 }, // 87 bits per transform
+ { 3, 5, 21 }, // 87 bits per transform
+ { 3, 6, 20 }, // 87 bits per transform
+ { 3, 7, 19 }, // 87 bits per transform
+ { 3, 8, 18 }, // 87 bits per transform
+ { 3, 9, 17 }, // 87 bits per transform
+ { 3, 10, 16 }, // 87 bits per transform
+ { 3, 11, 15 }, // 87 bits per transform
+ { 3, 12, 14 }, // 87 bits per transform
+ { 3, 13, 13 }, // 87 bits per transform
+ { 3, 14, 12 }, // 87 bits per transform
+ { 3, 15, 11 }, // 87 bits per transform
+ { 3, 16, 10 }, // 87 bits per transform
+ { 3, 17, 9 }, // 87 bits per transform
+ { 3, 18, 8 }, // 87 bits per transform
+ { 3, 19, 7 }, // 87 bits per transform
+ { 3, 20, 6 }, // 87 bits per transform
+ { 3, 21, 5 }, // 87 bits per transform
+ { 3, 22, 4 }, // 87 bits per transform
+ { 3, 23, 3 }, // 87 bits per transform
+ { 4, 2, 23 }, // 87 bits per transform
+ { 4, 3, 22 }, // 87 bits per transform
+ { 4, 4, 21 }, // 87 bits per transform
+ { 4, 5, 20 }, // 87 bits per transform
+ { 4, 6, 19 }, // 87 bits per transform
+ { 4, 7, 18 }, // 87 bits per transform
+ { 4, 8, 17 }, // 87 bits per transform
+ { 4, 9, 16 }, // 87 bits per transform
+ { 4, 10, 15 }, // 87 bits per transform
+ { 4, 11, 14 }, // 87 bits per transform
+ { 4, 12, 13 }, // 87 bits per transform
+ { 4, 13, 12 }, // 87 bits per transform
+ { 4, 14, 11 }, // 87 bits per transform
+ { 4, 15, 10 }, // 87 bits per transform
+ { 4, 16, 9 }, // 87 bits per transform
+ { 4, 17, 8 }, // 87 bits per transform
+ { 4, 18, 7 }, // 87 bits per transform
+ { 4, 19, 6 }, // 87 bits per transform
+ { 4, 20, 5 }, // 87 bits per transform
+ { 4, 21, 4 }, // 87 bits per transform
+ { 4, 22, 3 }, // 87 bits per transform
+ { 4, 23, 2 }, // 87 bits per transform
+ { 5, 1, 23 }, // 87 bits per transform
+ { 5, 2, 22 }, // 87 bits per transform
+ { 5, 3, 21 }, // 87 bits per transform
+ { 5, 4, 20 }, // 87 bits per transform
+ { 5, 5, 19 }, // 87 bits per transform
+ { 5, 6, 18 }, // 87 bits per transform
+ { 5, 7, 17 }, // 87 bits per transform
+ { 5, 8, 16 }, // 87 bits per transform
+ { 5, 9, 15 }, // 87 bits per transform
+ { 5, 10, 14 }, // 87 bits per transform
+ { 5, 11, 13 }, // 87 bits per transform
+ { 5, 12, 12 }, // 87 bits per transform
+ { 5, 13, 11 }, // 87 bits per transform
+ { 5, 14, 10 }, // 87 bits per transform
+ { 5, 15, 9 }, // 87 bits per transform
+ { 5, 16, 8 }, // 87 bits per transform
+ { 5, 17, 7 }, // 87 bits per transform
+ { 5, 18, 6 }, // 87 bits per transform
+ { 5, 19, 5 }, // 87 bits per transform
+ { 5, 20, 4 }, // 87 bits per transform
+ { 5, 21, 3 }, // 87 bits per transform
+ { 5, 22, 2 }, // 87 bits per transform
+ { 5, 23, 1 }, // 87 bits per transform
+ { 6, 0, 23 }, // 87 bits per transform
+ { 6, 1, 22 }, // 87 bits per transform
+ { 6, 2, 21 }, // 87 bits per transform
+ { 6, 3, 20 }, // 87 bits per transform
+ { 6, 4, 19 }, // 87 bits per transform
+ { 6, 5, 18 }, // 87 bits per transform
+ { 6, 6, 17 }, // 87 bits per transform
+ { 6, 7, 16 }, // 87 bits per transform
+ { 6, 8, 15 }, // 87 bits per transform
+ { 6, 9, 14 }, // 87 bits per transform
+ { 6, 10, 13 }, // 87 bits per transform
+ { 6, 11, 12 }, // 87 bits per transform
+ { 6, 12, 11 }, // 87 bits per transform
+ { 6, 13, 10 }, // 87 bits per transform
+ { 6, 14, 9 }, // 87 bits per transform
+ { 6, 15, 8 }, // 87 bits per transform
+ { 6, 16, 7 }, // 87 bits per transform
+ { 6, 17, 6 }, // 87 bits per transform
+ { 6, 18, 5 }, // 87 bits per transform
+ { 6, 19, 4 }, // 87 bits per transform
+ { 6, 20, 3 }, // 87 bits per transform
+ { 6, 21, 2 }, // 87 bits per transform
+ { 6, 22, 1 }, // 87 bits per transform
+ { 6, 23, 0 }, // 87 bits per transform
+ { 7, 0, 22 }, // 87 bits per transform
+ { 7, 1, 21 }, // 87 bits per transform
+ { 7, 2, 20 }, // 87 bits per transform
+ { 7, 3, 19 }, // 87 bits per transform
+ { 7, 4, 18 }, // 87 bits per transform
+ { 7, 5, 17 }, // 87 bits per transform
+ { 7, 6, 16 }, // 87 bits per transform
+ { 7, 7, 15 }, // 87 bits per transform
+ { 7, 8, 14 }, // 87 bits per transform
+ { 7, 9, 13 }, // 87 bits per transform
+ { 7, 10, 12 }, // 87 bits per transform
+ { 7, 11, 11 }, // 87 bits per transform
+ { 7, 12, 10 }, // 87 bits per transform
+ { 7, 13, 9 }, // 87 bits per transform
+ { 7, 14, 8 }, // 87 bits per transform
+ { 7, 15, 7 }, // 87 bits per transform
+ { 7, 16, 6 }, // 87 bits per transform
+ { 7, 17, 5 }, // 87 bits per transform
+ { 7, 18, 4 }, // 87 bits per transform
+ { 7, 19, 3 }, // 87 bits per transform
+ { 7, 20, 2 }, // 87 bits per transform
+ { 7, 21, 1 }, // 87 bits per transform
+ { 7, 22, 0 }, // 87 bits per transform
+ { 8, 0, 21 }, // 87 bits per transform
+ { 8, 1, 20 }, // 87 bits per transform
+ { 8, 2, 19 }, // 87 bits per transform
+ { 8, 3, 18 }, // 87 bits per transform
+ { 8, 4, 17 }, // 87 bits per transform
+ { 8, 5, 16 }, // 87 bits per transform
+ { 8, 6, 15 }, // 87 bits per transform
+ { 8, 7, 14 }, // 87 bits per transform
+ { 8, 8, 13 }, // 87 bits per transform
+ { 8, 9, 12 }, // 87 bits per transform
+ { 8, 10, 11 }, // 87 bits per transform
+ { 8, 11, 10 }, // 87 bits per transform
+ { 8, 12, 9 }, // 87 bits per transform
+ { 8, 13, 8 }, // 87 bits per transform
+ { 8, 14, 7 }, // 87 bits per transform
+ { 8, 15, 6 }, // 87 bits per transform
+ { 8, 16, 5 }, // 87 bits per transform
+ { 8, 17, 4 }, // 87 bits per transform
+ { 8, 18, 3 }, // 87 bits per transform
+ { 8, 19, 2 }, // 87 bits per transform
+ { 8, 20, 1 }, // 87 bits per transform
+ { 8, 21, 0 }, // 87 bits per transform
+ { 9, 0, 20 }, // 87 bits per transform
+ { 9, 1, 19 }, // 87 bits per transform
+ { 9, 2, 18 }, // 87 bits per transform
+ { 9, 3, 17 }, // 87 bits per transform
+ { 9, 4, 16 }, // 87 bits per transform
+ { 9, 5, 15 }, // 87 bits per transform
+ { 9, 6, 14 }, // 87 bits per transform
+ { 9, 7, 13 }, // 87 bits per transform
+ { 9, 8, 12 }, // 87 bits per transform
+ { 9, 9, 11 }, // 87 bits per transform
+ { 9, 10, 10 }, // 87 bits per transform
+ { 9, 11, 9 }, // 87 bits per transform
+ { 9, 12, 8 }, // 87 bits per transform
+ { 9, 13, 7 }, // 87 bits per transform
+ { 9, 14, 6 }, // 87 bits per transform
+ { 9, 15, 5 }, // 87 bits per transform
+ { 9, 16, 4 }, // 87 bits per transform
+ { 9, 17, 3 }, // 87 bits per transform
+ { 9, 18, 2 }, // 87 bits per transform
+ { 9, 19, 1 }, // 87 bits per transform
+ { 9, 20, 0 }, // 87 bits per transform
+ { 10, 0, 19 }, // 87 bits per transform
+ { 10, 1, 18 }, // 87 bits per transform
+ { 10, 2, 17 }, // 87 bits per transform
+ { 10, 3, 16 }, // 87 bits per transform
+ { 10, 4, 15 }, // 87 bits per transform
+ { 10, 5, 14 }, // 87 bits per transform
+ { 10, 6, 13 }, // 87 bits per transform
+ { 10, 7, 12 }, // 87 bits per transform
+ { 10, 8, 11 }, // 87 bits per transform
+ { 10, 9, 10 }, // 87 bits per transform
+ { 10, 10, 9 }, // 87 bits per transform
+ { 10, 11, 8 }, // 87 bits per transform
+ { 10, 12, 7 }, // 87 bits per transform
+ { 10, 13, 6 }, // 87 bits per transform
+ { 10, 14, 5 }, // 87 bits per transform
+ { 10, 15, 4 }, // 87 bits per transform
+ { 10, 16, 3 }, // 87 bits per transform
+ { 10, 17, 2 }, // 87 bits per transform
+ { 10, 18, 1 }, // 87 bits per transform
+ { 10, 19, 0 }, // 87 bits per transform
+ { 11, 0, 18 }, // 87 bits per transform
+ { 11, 1, 17 }, // 87 bits per transform
+ { 11, 2, 16 }, // 87 bits per transform
+ { 11, 3, 15 }, // 87 bits per transform
+ { 11, 4, 14 }, // 87 bits per transform
+ { 11, 5, 13 }, // 87 bits per transform
+ { 11, 6, 12 }, // 87 bits per transform
+ { 11, 7, 11 }, // 87 bits per transform
+ { 11, 8, 10 }, // 87 bits per transform
+ { 11, 9, 9 }, // 87 bits per transform
+ { 11, 10, 8 }, // 87 bits per transform
+ { 11, 11, 7 }, // 87 bits per transform
+ { 11, 12, 6 }, // 87 bits per transform
+ { 11, 13, 5 }, // 87 bits per transform
+ { 11, 14, 4 }, // 87 bits per transform
+ { 11, 15, 3 }, // 87 bits per transform
+ { 11, 16, 2 }, // 87 bits per transform
+ { 11, 17, 1 }, // 87 bits per transform
+ { 11, 18, 0 }, // 87 bits per transform
+ { 12, 0, 17 }, // 87 bits per transform
+ { 12, 1, 16 }, // 87 bits per transform
+ { 12, 2, 15 }, // 87 bits per transform
+ { 12, 3, 14 }, // 87 bits per transform
+ { 12, 4, 13 }, // 87 bits per transform
+ { 12, 5, 12 }, // 87 bits per transform
+ { 12, 6, 11 }, // 87 bits per transform
+ { 12, 7, 10 }, // 87 bits per transform
+ { 12, 8, 9 }, // 87 bits per transform
+ { 12, 9, 8 }, // 87 bits per transform
+ { 12, 10, 7 }, // 87 bits per transform
+ { 12, 11, 6 }, // 87 bits per transform
+ { 12, 12, 5 }, // 87 bits per transform
+ { 12, 13, 4 }, // 87 bits per transform
+ { 12, 14, 3 }, // 87 bits per transform
+ { 12, 15, 2 }, // 87 bits per transform
+ { 12, 16, 1 }, // 87 bits per transform
+ { 12, 17, 0 }, // 87 bits per transform
+ { 13, 0, 16 }, // 87 bits per transform
+ { 13, 1, 15 }, // 87 bits per transform
+ { 13, 2, 14 }, // 87 bits per transform
+ { 13, 3, 13 }, // 87 bits per transform
+ { 13, 4, 12 }, // 87 bits per transform
+ { 13, 5, 11 }, // 87 bits per transform
+ { 13, 6, 10 }, // 87 bits per transform
+ { 13, 7, 9 }, // 87 bits per transform
+ { 13, 8, 8 }, // 87 bits per transform
+ { 13, 9, 7 }, // 87 bits per transform
+ { 13, 10, 6 }, // 87 bits per transform
+ { 13, 11, 5 }, // 87 bits per transform
+ { 13, 12, 4 }, // 87 bits per transform
+ { 13, 13, 3 }, // 87 bits per transform
+ { 13, 14, 2 }, // 87 bits per transform
+ { 13, 15, 1 }, // 87 bits per transform
+ { 13, 16, 0 }, // 87 bits per transform
+ { 14, 0, 15 }, // 87 bits per transform
+ { 14, 1, 14 }, // 87 bits per transform
+ { 14, 2, 13 }, // 87 bits per transform
+ { 14, 3, 12 }, // 87 bits per transform
+ { 14, 4, 11 }, // 87 bits per transform
+ { 14, 5, 10 }, // 87 bits per transform
+ { 14, 6, 9 }, // 87 bits per transform
+ { 14, 7, 8 }, // 87 bits per transform
+ { 14, 8, 7 }, // 87 bits per transform
+ { 14, 9, 6 }, // 87 bits per transform
+ { 14, 10, 5 }, // 87 bits per transform
+ { 14, 11, 4 }, // 87 bits per transform
+ { 14, 12, 3 }, // 87 bits per transform
+ { 14, 13, 2 }, // 87 bits per transform
+ { 14, 14, 1 }, // 87 bits per transform
+ { 14, 15, 0 }, // 87 bits per transform
+ { 15, 0, 14 }, // 87 bits per transform
+ { 15, 1, 13 }, // 87 bits per transform
+ { 15, 2, 12 }, // 87 bits per transform
+ { 15, 3, 11 }, // 87 bits per transform
+ { 15, 4, 10 }, // 87 bits per transform
+ { 15, 5, 9 }, // 87 bits per transform
+ { 15, 6, 8 }, // 87 bits per transform
+ { 15, 7, 7 }, // 87 bits per transform
+ { 15, 8, 6 }, // 87 bits per transform
+ { 15, 9, 5 }, // 87 bits per transform
+ { 15, 10, 4 }, // 87 bits per transform
+ { 15, 11, 3 }, // 87 bits per transform
+ { 15, 12, 2 }, // 87 bits per transform
+ { 15, 13, 1 }, // 87 bits per transform
+ { 15, 14, 0 }, // 87 bits per transform
+ { 16, 0, 13 }, // 87 bits per transform
+ { 16, 1, 12 }, // 87 bits per transform
+ { 16, 2, 11 }, // 87 bits per transform
+ { 16, 3, 10 }, // 87 bits per transform
+ { 16, 4, 9 }, // 87 bits per transform
+ { 16, 5, 8 }, // 87 bits per transform
+ { 16, 6, 7 }, // 87 bits per transform
+ { 16, 7, 6 }, // 87 bits per transform
+ { 16, 8, 5 }, // 87 bits per transform
+ { 16, 9, 4 }, // 87 bits per transform
+ { 16, 10, 3 }, // 87 bits per transform
+ { 16, 11, 2 }, // 87 bits per transform
+ { 16, 12, 1 }, // 87 bits per transform
+ { 16, 13, 0 }, // 87 bits per transform
+ { 17, 0, 12 }, // 87 bits per transform
+ { 17, 1, 11 }, // 87 bits per transform
+ { 17, 2, 10 }, // 87 bits per transform
+ { 17, 3, 9 }, // 87 bits per transform
+ { 17, 4, 8 }, // 87 bits per transform
+ { 17, 5, 7 }, // 87 bits per transform
+ { 17, 6, 6 }, // 87 bits per transform
+ { 17, 7, 5 }, // 87 bits per transform
+ { 17, 8, 4 }, // 87 bits per transform
+ { 17, 9, 3 }, // 87 bits per transform
+ { 17, 10, 2 }, // 87 bits per transform
+ { 17, 11, 1 }, // 87 bits per transform
+ { 17, 12, 0 }, // 87 bits per transform
+ { 18, 0, 11 }, // 87 bits per transform
+ { 18, 1, 10 }, // 87 bits per transform
+ { 18, 2, 9 }, // 87 bits per transform
+ { 18, 3, 8 }, // 87 bits per transform
+ { 18, 4, 7 }, // 87 bits per transform
+ { 18, 5, 6 }, // 87 bits per transform
+ { 18, 6, 5 }, // 87 bits per transform
+ { 18, 7, 4 }, // 87 bits per transform
+ { 18, 8, 3 }, // 87 bits per transform
+ { 18, 9, 2 }, // 87 bits per transform
+ { 18, 10, 1 }, // 87 bits per transform
+ { 18, 11, 0 }, // 87 bits per transform
+ { 19, 0, 10 }, // 87 bits per transform
+ { 19, 1, 9 }, // 87 bits per transform
+ { 19, 2, 8 }, // 87 bits per transform
+ { 19, 3, 7 }, // 87 bits per transform
+ { 19, 4, 6 }, // 87 bits per transform
+ { 19, 5, 5 }, // 87 bits per transform
+ { 19, 6, 4 }, // 87 bits per transform
+ { 19, 7, 3 }, // 87 bits per transform
+ { 19, 8, 2 }, // 87 bits per transform
+ { 19, 9, 1 }, // 87 bits per transform
+ { 19, 10, 0 }, // 87 bits per transform
+ { 20, 0, 9 }, // 87 bits per transform
+ { 20, 1, 8 }, // 87 bits per transform
+ { 20, 2, 7 }, // 87 bits per transform
+ { 20, 3, 6 }, // 87 bits per transform
+ { 20, 4, 5 }, // 87 bits per transform
+ { 20, 5, 4 }, // 87 bits per transform
+ { 20, 6, 3 }, // 87 bits per transform
+ { 20, 7, 2 }, // 87 bits per transform
+ { 20, 8, 1 }, // 87 bits per transform
+ { 20, 9, 0 }, // 87 bits per transform
+ { 21, 0, 8 }, // 87 bits per transform
+ { 21, 1, 7 }, // 87 bits per transform
+ { 21, 2, 6 }, // 87 bits per transform
+ { 21, 3, 5 }, // 87 bits per transform
+ { 21, 4, 4 }, // 87 bits per transform
+ { 21, 5, 3 }, // 87 bits per transform
+ { 21, 6, 2 }, // 87 bits per transform
+ { 21, 7, 1 }, // 87 bits per transform
+ { 21, 8, 0 }, // 87 bits per transform
+ { 22, 0, 7 }, // 87 bits per transform
+ { 22, 1, 6 }, // 87 bits per transform
+ { 22, 2, 5 }, // 87 bits per transform
+ { 22, 3, 4 }, // 87 bits per transform
+ { 22, 4, 3 }, // 87 bits per transform
+ { 22, 5, 2 }, // 87 bits per transform
+ { 22, 6, 1 }, // 87 bits per transform
+ { 22, 7, 0 }, // 87 bits per transform
+ { 23, 0, 6 }, // 87 bits per transform
+ { 23, 1, 5 }, // 87 bits per transform
+ { 23, 2, 4 }, // 87 bits per transform
+ { 23, 3, 3 }, // 87 bits per transform
+ { 23, 4, 2 }, // 87 bits per transform
+ { 23, 5, 1 }, // 87 bits per transform
+ { 23, 6, 0 }, // 87 bits per transform
+ { 0, 7, 23 }, // 90 bits per transform
+ { 0, 8, 22 }, // 90 bits per transform
+ { 0, 9, 21 }, // 90 bits per transform
+ { 0, 10, 20 }, // 90 bits per transform
+ { 0, 11, 19 }, // 90 bits per transform
+ { 0, 12, 18 }, // 90 bits per transform
+ { 0, 13, 17 }, // 90 bits per transform
+ { 0, 14, 16 }, // 90 bits per transform
+ { 0, 15, 15 }, // 90 bits per transform
+ { 0, 16, 14 }, // 90 bits per transform
+ { 0, 17, 13 }, // 90 bits per transform
+ { 0, 18, 12 }, // 90 bits per transform
+ { 0, 19, 11 }, // 90 bits per transform
+ { 0, 20, 10 }, // 90 bits per transform
+ { 0, 21, 9 }, // 90 bits per transform
+ { 0, 22, 8 }, // 90 bits per transform
+ { 0, 23, 7 }, // 90 bits per transform
+ { 1, 6, 23 }, // 90 bits per transform
+ { 1, 7, 22 }, // 90 bits per transform
+ { 1, 8, 21 }, // 90 bits per transform
+ { 1, 9, 20 }, // 90 bits per transform
+ { 1, 10, 19 }, // 90 bits per transform
+ { 1, 11, 18 }, // 90 bits per transform
+ { 1, 12, 17 }, // 90 bits per transform
+ { 1, 13, 16 }, // 90 bits per transform
+ { 1, 14, 15 }, // 90 bits per transform
+ { 1, 15, 14 }, // 90 bits per transform
+ { 1, 16, 13 }, // 90 bits per transform
+ { 1, 17, 12 }, // 90 bits per transform
+ { 1, 18, 11 }, // 90 bits per transform
+ { 1, 19, 10 }, // 90 bits per transform
+ { 1, 20, 9 }, // 90 bits per transform
+ { 1, 21, 8 }, // 90 bits per transform
+ { 1, 22, 7 }, // 90 bits per transform
+ { 1, 23, 6 }, // 90 bits per transform
+ { 2, 5, 23 }, // 90 bits per transform
+ { 2, 6, 22 }, // 90 bits per transform
+ { 2, 7, 21 }, // 90 bits per transform
+ { 2, 8, 20 }, // 90 bits per transform
+ { 2, 9, 19 }, // 90 bits per transform
+ { 2, 10, 18 }, // 90 bits per transform
+ { 2, 11, 17 }, // 90 bits per transform
+ { 2, 12, 16 }, // 90 bits per transform
+ { 2, 13, 15 }, // 90 bits per transform
+ { 2, 14, 14 }, // 90 bits per transform
+ { 2, 15, 13 }, // 90 bits per transform
+ { 2, 16, 12 }, // 90 bits per transform
+ { 2, 17, 11 }, // 90 bits per transform
+ { 2, 18, 10 }, // 90 bits per transform
+ { 2, 19, 9 }, // 90 bits per transform
+ { 2, 20, 8 }, // 90 bits per transform
+ { 2, 21, 7 }, // 90 bits per transform
+ { 2, 22, 6 }, // 90 bits per transform
+ { 2, 23, 5 }, // 90 bits per transform
+ { 3, 4, 23 }, // 90 bits per transform
+ { 3, 5, 22 }, // 90 bits per transform
+ { 3, 6, 21 }, // 90 bits per transform
+ { 3, 7, 20 }, // 90 bits per transform
+ { 3, 8, 19 }, // 90 bits per transform
+ { 3, 9, 18 }, // 90 bits per transform
+ { 3, 10, 17 }, // 90 bits per transform
+ { 3, 11, 16 }, // 90 bits per transform
+ { 3, 12, 15 }, // 90 bits per transform
+ { 3, 13, 14 }, // 90 bits per transform
+ { 3, 14, 13 }, // 90 bits per transform
+ { 3, 15, 12 }, // 90 bits per transform
+ { 3, 16, 11 }, // 90 bits per transform
+ { 3, 17, 10 }, // 90 bits per transform
+ { 3, 18, 9 }, // 90 bits per transform
+ { 3, 19, 8 }, // 90 bits per transform
+ { 3, 20, 7 }, // 90 bits per transform
+ { 3, 21, 6 }, // 90 bits per transform
+ { 3, 22, 5 }, // 90 bits per transform
+ { 3, 23, 4 }, // 90 bits per transform
+ { 4, 3, 23 }, // 90 bits per transform
+ { 4, 4, 22 }, // 90 bits per transform
+ { 4, 5, 21 }, // 90 bits per transform
+ { 4, 6, 20 }, // 90 bits per transform
+ { 4, 7, 19 }, // 90 bits per transform
+ { 4, 8, 18 }, // 90 bits per transform
+ { 4, 9, 17 }, // 90 bits per transform
+ { 4, 10, 16 }, // 90 bits per transform
+ { 4, 11, 15 }, // 90 bits per transform
+ { 4, 12, 14 }, // 90 bits per transform
+ { 4, 13, 13 }, // 90 bits per transform
+ { 4, 14, 12 }, // 90 bits per transform
+ { 4, 15, 11 }, // 90 bits per transform
+ { 4, 16, 10 }, // 90 bits per transform
+ { 4, 17, 9 }, // 90 bits per transform
+ { 4, 18, 8 }, // 90 bits per transform
+ { 4, 19, 7 }, // 90 bits per transform
+ { 4, 20, 6 }, // 90 bits per transform
+ { 4, 21, 5 }, // 90 bits per transform
+ { 4, 22, 4 }, // 90 bits per transform
+ { 4, 23, 3 }, // 90 bits per transform
+ { 5, 2, 23 }, // 90 bits per transform
+ { 5, 3, 22 }, // 90 bits per transform
+ { 5, 4, 21 }, // 90 bits per transform
+ { 5, 5, 20 }, // 90 bits per transform
+ { 5, 6, 19 }, // 90 bits per transform
+ { 5, 7, 18 }, // 90 bits per transform
+ { 5, 8, 17 }, // 90 bits per transform
+ { 5, 9, 16 }, // 90 bits per transform
+ { 5, 10, 15 }, // 90 bits per transform
+ { 5, 11, 14 }, // 90 bits per transform
+ { 5, 12, 13 }, // 90 bits per transform
+ { 5, 13, 12 }, // 90 bits per transform
+ { 5, 14, 11 }, // 90 bits per transform
+ { 5, 15, 10 }, // 90 bits per transform
+ { 5, 16, 9 }, // 90 bits per transform
+ { 5, 17, 8 }, // 90 bits per transform
+ { 5, 18, 7 }, // 90 bits per transform
+ { 5, 19, 6 }, // 90 bits per transform
+ { 5, 20, 5 }, // 90 bits per transform
+ { 5, 21, 4 }, // 90 bits per transform
+ { 5, 22, 3 }, // 90 bits per transform
+ { 5, 23, 2 }, // 90 bits per transform
+ { 6, 1, 23 }, // 90 bits per transform
+ { 6, 2, 22 }, // 90 bits per transform
+ { 6, 3, 21 }, // 90 bits per transform
+ { 6, 4, 20 }, // 90 bits per transform
+ { 6, 5, 19 }, // 90 bits per transform
+ { 6, 6, 18 }, // 90 bits per transform
+ { 6, 7, 17 }, // 90 bits per transform
+ { 6, 8, 16 }, // 90 bits per transform
+ { 6, 9, 15 }, // 90 bits per transform
+ { 6, 10, 14 }, // 90 bits per transform
+ { 6, 11, 13 }, // 90 bits per transform
+ { 6, 12, 12 }, // 90 bits per transform
+ { 6, 13, 11 }, // 90 bits per transform
+ { 6, 14, 10 }, // 90 bits per transform
+ { 6, 15, 9 }, // 90 bits per transform
+ { 6, 16, 8 }, // 90 bits per transform
+ { 6, 17, 7 }, // 90 bits per transform
+ { 6, 18, 6 }, // 90 bits per transform
+ { 6, 19, 5 }, // 90 bits per transform
+ { 6, 20, 4 }, // 90 bits per transform
+ { 6, 21, 3 }, // 90 bits per transform
+ { 6, 22, 2 }, // 90 bits per transform
+ { 6, 23, 1 }, // 90 bits per transform
+ { 7, 0, 23 }, // 90 bits per transform
+ { 7, 1, 22 }, // 90 bits per transform
+ { 7, 2, 21 }, // 90 bits per transform
+ { 7, 3, 20 }, // 90 bits per transform
+ { 7, 4, 19 }, // 90 bits per transform
+ { 7, 5, 18 }, // 90 bits per transform
+ { 7, 6, 17 }, // 90 bits per transform
+ { 7, 7, 16 }, // 90 bits per transform
+ { 7, 8, 15 }, // 90 bits per transform
+ { 7, 9, 14 }, // 90 bits per transform
+ { 7, 10, 13 }, // 90 bits per transform
+ { 7, 11, 12 }, // 90 bits per transform
+ { 7, 12, 11 }, // 90 bits per transform
+ { 7, 13, 10 }, // 90 bits per transform
+ { 7, 14, 9 }, // 90 bits per transform
+ { 7, 15, 8 }, // 90 bits per transform
+ { 7, 16, 7 }, // 90 bits per transform
+ { 7, 17, 6 }, // 90 bits per transform
+ { 7, 18, 5 }, // 90 bits per transform
+ { 7, 19, 4 }, // 90 bits per transform
+ { 7, 20, 3 }, // 90 bits per transform
+ { 7, 21, 2 }, // 90 bits per transform
+ { 7, 22, 1 }, // 90 bits per transform
+ { 7, 23, 0 }, // 90 bits per transform
+ { 8, 0, 22 }, // 90 bits per transform
+ { 8, 1, 21 }, // 90 bits per transform
+ { 8, 2, 20 }, // 90 bits per transform
+ { 8, 3, 19 }, // 90 bits per transform
+ { 8, 4, 18 }, // 90 bits per transform
+ { 8, 5, 17 }, // 90 bits per transform
+ { 8, 6, 16 }, // 90 bits per transform
+ { 8, 7, 15 }, // 90 bits per transform
+ { 8, 8, 14 }, // 90 bits per transform
+ { 8, 9, 13 }, // 90 bits per transform
+ { 8, 10, 12 }, // 90 bits per transform
+ { 8, 11, 11 }, // 90 bits per transform
+ { 8, 12, 10 }, // 90 bits per transform
+ { 8, 13, 9 }, // 90 bits per transform
+ { 8, 14, 8 }, // 90 bits per transform
+ { 8, 15, 7 }, // 90 bits per transform
+ { 8, 16, 6 }, // 90 bits per transform
+ { 8, 17, 5 }, // 90 bits per transform
+ { 8, 18, 4 }, // 90 bits per transform
+ { 8, 19, 3 }, // 90 bits per transform
+ { 8, 20, 2 }, // 90 bits per transform
+ { 8, 21, 1 }, // 90 bits per transform
+ { 8, 22, 0 }, // 90 bits per transform
+ { 9, 0, 21 }, // 90 bits per transform
+ { 9, 1, 20 }, // 90 bits per transform
+ { 9, 2, 19 }, // 90 bits per transform
+ { 9, 3, 18 }, // 90 bits per transform
+ { 9, 4, 17 }, // 90 bits per transform
+ { 9, 5, 16 }, // 90 bits per transform
+ { 9, 6, 15 }, // 90 bits per transform
+ { 9, 7, 14 }, // 90 bits per transform
+ { 9, 8, 13 }, // 90 bits per transform
+ { 9, 9, 12 }, // 90 bits per transform
+ { 9, 10, 11 }, // 90 bits per transform
+ { 9, 11, 10 }, // 90 bits per transform
+ { 9, 12, 9 }, // 90 bits per transform
+ { 9, 13, 8 }, // 90 bits per transform
+ { 9, 14, 7 }, // 90 bits per transform
+ { 9, 15, 6 }, // 90 bits per transform
+ { 9, 16, 5 }, // 90 bits per transform
+ { 9, 17, 4 }, // 90 bits per transform
+ { 9, 18, 3 }, // 90 bits per transform
+ { 9, 19, 2 }, // 90 bits per transform
+ { 9, 20, 1 }, // 90 bits per transform
+ { 9, 21, 0 }, // 90 bits per transform
+ { 10, 0, 20 }, // 90 bits per transform
+ { 10, 1, 19 }, // 90 bits per transform
+ { 10, 2, 18 }, // 90 bits per transform
+ { 10, 3, 17 }, // 90 bits per transform
+ { 10, 4, 16 }, // 90 bits per transform
+ { 10, 5, 15 }, // 90 bits per transform
+ { 10, 6, 14 }, // 90 bits per transform
+ { 10, 7, 13 }, // 90 bits per transform
+ { 10, 8, 12 }, // 90 bits per transform
+ { 10, 9, 11 }, // 90 bits per transform
+ { 10, 10, 10 }, // 90 bits per transform
+ { 10, 11, 9 }, // 90 bits per transform
+ { 10, 12, 8 }, // 90 bits per transform
+ { 10, 13, 7 }, // 90 bits per transform
+ { 10, 14, 6 }, // 90 bits per transform
+ { 10, 15, 5 }, // 90 bits per transform
+ { 10, 16, 4 }, // 90 bits per transform
+ { 10, 17, 3 }, // 90 bits per transform
+ { 10, 18, 2 }, // 90 bits per transform
+ { 10, 19, 1 }, // 90 bits per transform
+ { 10, 20, 0 }, // 90 bits per transform
+ { 11, 0, 19 }, // 90 bits per transform
+ { 11, 1, 18 }, // 90 bits per transform
+ { 11, 2, 17 }, // 90 bits per transform
+ { 11, 3, 16 }, // 90 bits per transform
+ { 11, 4, 15 }, // 90 bits per transform
+ { 11, 5, 14 }, // 90 bits per transform
+ { 11, 6, 13 }, // 90 bits per transform
+ { 11, 7, 12 }, // 90 bits per transform
+ { 11, 8, 11 }, // 90 bits per transform
+ { 11, 9, 10 }, // 90 bits per transform
+ { 11, 10, 9 }, // 90 bits per transform
+ { 11, 11, 8 }, // 90 bits per transform
+ { 11, 12, 7 }, // 90 bits per transform
+ { 11, 13, 6 }, // 90 bits per transform
+ { 11, 14, 5 }, // 90 bits per transform
+ { 11, 15, 4 }, // 90 bits per transform
+ { 11, 16, 3 }, // 90 bits per transform
+ { 11, 17, 2 }, // 90 bits per transform
+ { 11, 18, 1 }, // 90 bits per transform
+ { 11, 19, 0 }, // 90 bits per transform
+ { 12, 0, 18 }, // 90 bits per transform
+ { 12, 1, 17 }, // 90 bits per transform
+ { 12, 2, 16 }, // 90 bits per transform
+ { 12, 3, 15 }, // 90 bits per transform
+ { 12, 4, 14 }, // 90 bits per transform
+ { 12, 5, 13 }, // 90 bits per transform
+ { 12, 6, 12 }, // 90 bits per transform
+ { 12, 7, 11 }, // 90 bits per transform
+ { 12, 8, 10 }, // 90 bits per transform
+ { 12, 9, 9 }, // 90 bits per transform
+ { 12, 10, 8 }, // 90 bits per transform
+ { 12, 11, 7 }, // 90 bits per transform
+ { 12, 12, 6 }, // 90 bits per transform
+ { 12, 13, 5 }, // 90 bits per transform
+ { 12, 14, 4 }, // 90 bits per transform
+ { 12, 15, 3 }, // 90 bits per transform
+ { 12, 16, 2 }, // 90 bits per transform
+ { 12, 17, 1 }, // 90 bits per transform
+ { 12, 18, 0 }, // 90 bits per transform
+ { 13, 0, 17 }, // 90 bits per transform
+ { 13, 1, 16 }, // 90 bits per transform
+ { 13, 2, 15 }, // 90 bits per transform
+ { 13, 3, 14 }, // 90 bits per transform
+ { 13, 4, 13 }, // 90 bits per transform
+ { 13, 5, 12 }, // 90 bits per transform
+ { 13, 6, 11 }, // 90 bits per transform
+ { 13, 7, 10 }, // 90 bits per transform
+ { 13, 8, 9 }, // 90 bits per transform
+ { 13, 9, 8 }, // 90 bits per transform
+ { 13, 10, 7 }, // 90 bits per transform
+ { 13, 11, 6 }, // 90 bits per transform
+ { 13, 12, 5 }, // 90 bits per transform
+ { 13, 13, 4 }, // 90 bits per transform
+ { 13, 14, 3 }, // 90 bits per transform
+ { 13, 15, 2 }, // 90 bits per transform
+ { 13, 16, 1 }, // 90 bits per transform
+ { 13, 17, 0 }, // 90 bits per transform
+ { 14, 0, 16 }, // 90 bits per transform
+ { 14, 1, 15 }, // 90 bits per transform
+ { 14, 2, 14 }, // 90 bits per transform
+ { 14, 3, 13 }, // 90 bits per transform
+ { 14, 4, 12 }, // 90 bits per transform
+ { 14, 5, 11 }, // 90 bits per transform
+ { 14, 6, 10 }, // 90 bits per transform
+ { 14, 7, 9 }, // 90 bits per transform
+ { 14, 8, 8 }, // 90 bits per transform
+ { 14, 9, 7 }, // 90 bits per transform
+ { 14, 10, 6 }, // 90 bits per transform
+ { 14, 11, 5 }, // 90 bits per transform
+ { 14, 12, 4 }, // 90 bits per transform
+ { 14, 13, 3 }, // 90 bits per transform
+ { 14, 14, 2 }, // 90 bits per transform
+ { 14, 15, 1 }, // 90 bits per transform
+ { 14, 16, 0 }, // 90 bits per transform
+ { 15, 0, 15 }, // 90 bits per transform
+ { 15, 1, 14 }, // 90 bits per transform
+ { 15, 2, 13 }, // 90 bits per transform
+ { 15, 3, 12 }, // 90 bits per transform
+ { 15, 4, 11 }, // 90 bits per transform
+ { 15, 5, 10 }, // 90 bits per transform
+ { 15, 6, 9 }, // 90 bits per transform
+ { 15, 7, 8 }, // 90 bits per transform
+ { 15, 8, 7 }, // 90 bits per transform
+ { 15, 9, 6 }, // 90 bits per transform
+ { 15, 10, 5 }, // 90 bits per transform
+ { 15, 11, 4 }, // 90 bits per transform
+ { 15, 12, 3 }, // 90 bits per transform
+ { 15, 13, 2 }, // 90 bits per transform
+ { 15, 14, 1 }, // 90 bits per transform
+ { 15, 15, 0 }, // 90 bits per transform
+ { 16, 0, 14 }, // 90 bits per transform
+ { 16, 1, 13 }, // 90 bits per transform
+ { 16, 2, 12 }, // 90 bits per transform
+ { 16, 3, 11 }, // 90 bits per transform
+ { 16, 4, 10 }, // 90 bits per transform
+ { 16, 5, 9 }, // 90 bits per transform
+ { 16, 6, 8 }, // 90 bits per transform
+ { 16, 7, 7 }, // 90 bits per transform
+ { 16, 8, 6 }, // 90 bits per transform
+ { 16, 9, 5 }, // 90 bits per transform
+ { 16, 10, 4 }, // 90 bits per transform
+ { 16, 11, 3 }, // 90 bits per transform
+ { 16, 12, 2 }, // 90 bits per transform
+ { 16, 13, 1 }, // 90 bits per transform
+ { 16, 14, 0 }, // 90 bits per transform
+ { 17, 0, 13 }, // 90 bits per transform
+ { 17, 1, 12 }, // 90 bits per transform
+ { 17, 2, 11 }, // 90 bits per transform
+ { 17, 3, 10 }, // 90 bits per transform
+ { 17, 4, 9 }, // 90 bits per transform
+ { 17, 5, 8 }, // 90 bits per transform
+ { 17, 6, 7 }, // 90 bits per transform
+ { 17, 7, 6 }, // 90 bits per transform
+ { 17, 8, 5 }, // 90 bits per transform
+ { 17, 9, 4 }, // 90 bits per transform
+ { 17, 10, 3 }, // 90 bits per transform
+ { 17, 11, 2 }, // 90 bits per transform
+ { 17, 12, 1 }, // 90 bits per transform
+ { 17, 13, 0 }, // 90 bits per transform
+ { 18, 0, 12 }, // 90 bits per transform
+ { 18, 1, 11 }, // 90 bits per transform
+ { 18, 2, 10 }, // 90 bits per transform
+ { 18, 3, 9 }, // 90 bits per transform
+ { 18, 4, 8 }, // 90 bits per transform
+ { 18, 5, 7 }, // 90 bits per transform
+ { 18, 6, 6 }, // 90 bits per transform
+ { 18, 7, 5 }, // 90 bits per transform
+ { 18, 8, 4 }, // 90 bits per transform
+ { 18, 9, 3 }, // 90 bits per transform
+ { 18, 10, 2 }, // 90 bits per transform
+ { 18, 11, 1 }, // 90 bits per transform
+ { 18, 12, 0 }, // 90 bits per transform
+ { 19, 0, 11 }, // 90 bits per transform
+ { 19, 1, 10 }, // 90 bits per transform
+ { 19, 2, 9 }, // 90 bits per transform
+ { 19, 3, 8 }, // 90 bits per transform
+ { 19, 4, 7 }, // 90 bits per transform
+ { 19, 5, 6 }, // 90 bits per transform
+ { 19, 6, 5 }, // 90 bits per transform
+ { 19, 7, 4 }, // 90 bits per transform
+ { 19, 8, 3 }, // 90 bits per transform
+ { 19, 9, 2 }, // 90 bits per transform
+ { 19, 10, 1 }, // 90 bits per transform
+ { 19, 11, 0 }, // 90 bits per transform
+ { 20, 0, 10 }, // 90 bits per transform
+ { 20, 1, 9 }, // 90 bits per transform
+ { 20, 2, 8 }, // 90 bits per transform
+ { 20, 3, 7 }, // 90 bits per transform
+ { 20, 4, 6 }, // 90 bits per transform
+ { 20, 5, 5 }, // 90 bits per transform
+ { 20, 6, 4 }, // 90 bits per transform
+ { 20, 7, 3 }, // 90 bits per transform
+ { 20, 8, 2 }, // 90 bits per transform
+ { 20, 9, 1 }, // 90 bits per transform
+ { 20, 10, 0 }, // 90 bits per transform
+ { 21, 0, 9 }, // 90 bits per transform
+ { 21, 1, 8 }, // 90 bits per transform
+ { 21, 2, 7 }, // 90 bits per transform
+ { 21, 3, 6 }, // 90 bits per transform
+ { 21, 4, 5 }, // 90 bits per transform
+ { 21, 5, 4 }, // 90 bits per transform
+ { 21, 6, 3 }, // 90 bits per transform
+ { 21, 7, 2 }, // 90 bits per transform
+ { 21, 8, 1 }, // 90 bits per transform
+ { 21, 9, 0 }, // 90 bits per transform
+ { 22, 0, 8 }, // 90 bits per transform
+ { 22, 1, 7 }, // 90 bits per transform
+ { 22, 2, 6 }, // 90 bits per transform
+ { 22, 3, 5 }, // 90 bits per transform
+ { 22, 4, 4 }, // 90 bits per transform
+ { 22, 5, 3 }, // 90 bits per transform
+ { 22, 6, 2 }, // 90 bits per transform
+ { 22, 7, 1 }, // 90 bits per transform
+ { 22, 8, 0 }, // 90 bits per transform
+ { 23, 0, 7 }, // 90 bits per transform
+ { 23, 1, 6 }, // 90 bits per transform
+ { 23, 2, 5 }, // 90 bits per transform
+ { 23, 3, 4 }, // 90 bits per transform
+ { 23, 4, 3 }, // 90 bits per transform
+ { 23, 5, 2 }, // 90 bits per transform
+ { 23, 6, 1 }, // 90 bits per transform
+ { 23, 7, 0 }, // 90 bits per transform
+ { 0, 8, 23 }, // 93 bits per transform
+ { 0, 9, 22 }, // 93 bits per transform
+ { 0, 10, 21 }, // 93 bits per transform
+ { 0, 11, 20 }, // 93 bits per transform
+ { 0, 12, 19 }, // 93 bits per transform
+ { 0, 13, 18 }, // 93 bits per transform
+ { 0, 14, 17 }, // 93 bits per transform
+ { 0, 15, 16 }, // 93 bits per transform
+ { 0, 16, 15 }, // 93 bits per transform
+ { 0, 17, 14 }, // 93 bits per transform
+ { 0, 18, 13 }, // 93 bits per transform
+ { 0, 19, 12 }, // 93 bits per transform
+ { 0, 20, 11 }, // 93 bits per transform
+ { 0, 21, 10 }, // 93 bits per transform
+ { 0, 22, 9 }, // 93 bits per transform
+ { 0, 23, 8 }, // 93 bits per transform
+ { 1, 7, 23 }, // 93 bits per transform
+ { 1, 8, 22 }, // 93 bits per transform
+ { 1, 9, 21 }, // 93 bits per transform
+ { 1, 10, 20 }, // 93 bits per transform
+ { 1, 11, 19 }, // 93 bits per transform
+ { 1, 12, 18 }, // 93 bits per transform
+ { 1, 13, 17 }, // 93 bits per transform
+ { 1, 14, 16 }, // 93 bits per transform
+ { 1, 15, 15 }, // 93 bits per transform
+ { 1, 16, 14 }, // 93 bits per transform
+ { 1, 17, 13 }, // 93 bits per transform
+ { 1, 18, 12 }, // 93 bits per transform
+ { 1, 19, 11 }, // 93 bits per transform
+ { 1, 20, 10 }, // 93 bits per transform
+ { 1, 21, 9 }, // 93 bits per transform
+ { 1, 22, 8 }, // 93 bits per transform
+ { 1, 23, 7 }, // 93 bits per transform
+ { 2, 6, 23 }, // 93 bits per transform
+ { 2, 7, 22 }, // 93 bits per transform
+ { 2, 8, 21 }, // 93 bits per transform
+ { 2, 9, 20 }, // 93 bits per transform
+ { 2, 10, 19 }, // 93 bits per transform
+ { 2, 11, 18 }, // 93 bits per transform
+ { 2, 12, 17 }, // 93 bits per transform
+ { 2, 13, 16 }, // 93 bits per transform
+ { 2, 14, 15 }, // 93 bits per transform
+ { 2, 15, 14 }, // 93 bits per transform
+ { 2, 16, 13 }, // 93 bits per transform
+ { 2, 17, 12 }, // 93 bits per transform
+ { 2, 18, 11 }, // 93 bits per transform
+ { 2, 19, 10 }, // 93 bits per transform
+ { 2, 20, 9 }, // 93 bits per transform
+ { 2, 21, 8 }, // 93 bits per transform
+ { 2, 22, 7 }, // 93 bits per transform
+ { 2, 23, 6 }, // 93 bits per transform
+ { 3, 5, 23 }, // 93 bits per transform
+ { 3, 6, 22 }, // 93 bits per transform
+ { 3, 7, 21 }, // 93 bits per transform
+ { 3, 8, 20 }, // 93 bits per transform
+ { 3, 9, 19 }, // 93 bits per transform
+ { 3, 10, 18 }, // 93 bits per transform
+ { 3, 11, 17 }, // 93 bits per transform
+ { 3, 12, 16 }, // 93 bits per transform
+ { 3, 13, 15 }, // 93 bits per transform
+ { 3, 14, 14 }, // 93 bits per transform
+ { 3, 15, 13 }, // 93 bits per transform
+ { 3, 16, 12 }, // 93 bits per transform
+ { 3, 17, 11 }, // 93 bits per transform
+ { 3, 18, 10 }, // 93 bits per transform
+ { 3, 19, 9 }, // 93 bits per transform
+ { 3, 20, 8 }, // 93 bits per transform
+ { 3, 21, 7 }, // 93 bits per transform
+ { 3, 22, 6 }, // 93 bits per transform
+ { 3, 23, 5 }, // 93 bits per transform
+ { 4, 4, 23 }, // 93 bits per transform
+ { 4, 5, 22 }, // 93 bits per transform
+ { 4, 6, 21 }, // 93 bits per transform
+ { 4, 7, 20 }, // 93 bits per transform
+ { 4, 8, 19 }, // 93 bits per transform
+ { 4, 9, 18 }, // 93 bits per transform
+ { 4, 10, 17 }, // 93 bits per transform
+ { 4, 11, 16 }, // 93 bits per transform
+ { 4, 12, 15 }, // 93 bits per transform
+ { 4, 13, 14 }, // 93 bits per transform
+ { 4, 14, 13 }, // 93 bits per transform
+ { 4, 15, 12 }, // 93 bits per transform
+ { 4, 16, 11 }, // 93 bits per transform
+ { 4, 17, 10 }, // 93 bits per transform
+ { 4, 18, 9 }, // 93 bits per transform
+ { 4, 19, 8 }, // 93 bits per transform
+ { 4, 20, 7 }, // 93 bits per transform
+ { 4, 21, 6 }, // 93 bits per transform
+ { 4, 22, 5 }, // 93 bits per transform
+ { 4, 23, 4 }, // 93 bits per transform
+ { 5, 3, 23 }, // 93 bits per transform
+ { 5, 4, 22 }, // 93 bits per transform
+ { 5, 5, 21 }, // 93 bits per transform
+ { 5, 6, 20 }, // 93 bits per transform
+ { 5, 7, 19 }, // 93 bits per transform
+ { 5, 8, 18 }, // 93 bits per transform
+ { 5, 9, 17 }, // 93 bits per transform
+ { 5, 10, 16 }, // 93 bits per transform
+ { 5, 11, 15 }, // 93 bits per transform
+ { 5, 12, 14 }, // 93 bits per transform
+ { 5, 13, 13 }, // 93 bits per transform
+ { 5, 14, 12 }, // 93 bits per transform
+ { 5, 15, 11 }, // 93 bits per transform
+ { 5, 16, 10 }, // 93 bits per transform
+ { 5, 17, 9 }, // 93 bits per transform
+ { 5, 18, 8 }, // 93 bits per transform
+ { 5, 19, 7 }, // 93 bits per transform
+ { 5, 20, 6 }, // 93 bits per transform
+ { 5, 21, 5 }, // 93 bits per transform
+ { 5, 22, 4 }, // 93 bits per transform
+ { 5, 23, 3 }, // 93 bits per transform
+ { 6, 2, 23 }, // 93 bits per transform
+ { 6, 3, 22 }, // 93 bits per transform
+ { 6, 4, 21 }, // 93 bits per transform
+ { 6, 5, 20 }, // 93 bits per transform
+ { 6, 6, 19 }, // 93 bits per transform
+ { 6, 7, 18 }, // 93 bits per transform
+ { 6, 8, 17 }, // 93 bits per transform
+ { 6, 9, 16 }, // 93 bits per transform
+ { 6, 10, 15 }, // 93 bits per transform
+ { 6, 11, 14 }, // 93 bits per transform
+ { 6, 12, 13 }, // 93 bits per transform
+ { 6, 13, 12 }, // 93 bits per transform
+ { 6, 14, 11 }, // 93 bits per transform
+ { 6, 15, 10 }, // 93 bits per transform
+ { 6, 16, 9 }, // 93 bits per transform
+ { 6, 17, 8 }, // 93 bits per transform
+ { 6, 18, 7 }, // 93 bits per transform
+ { 6, 19, 6 }, // 93 bits per transform
+ { 6, 20, 5 }, // 93 bits per transform
+ { 6, 21, 4 }, // 93 bits per transform
+ { 6, 22, 3 }, // 93 bits per transform
+ { 6, 23, 2 }, // 93 bits per transform
+ { 7, 1, 23 }, // 93 bits per transform
+ { 7, 2, 22 }, // 93 bits per transform
+ { 7, 3, 21 }, // 93 bits per transform
+ { 7, 4, 20 }, // 93 bits per transform
+ { 7, 5, 19 }, // 93 bits per transform
+ { 7, 6, 18 }, // 93 bits per transform
+ { 7, 7, 17 }, // 93 bits per transform
+ { 7, 8, 16 }, // 93 bits per transform
+ { 7, 9, 15 }, // 93 bits per transform
+ { 7, 10, 14 }, // 93 bits per transform
+ { 7, 11, 13 }, // 93 bits per transform
+ { 7, 12, 12 }, // 93 bits per transform
+ { 7, 13, 11 }, // 93 bits per transform
+ { 7, 14, 10 }, // 93 bits per transform
+ { 7, 15, 9 }, // 93 bits per transform
+ { 7, 16, 8 }, // 93 bits per transform
+ { 7, 17, 7 }, // 93 bits per transform
+ { 7, 18, 6 }, // 93 bits per transform
+ { 7, 19, 5 }, // 93 bits per transform
+ { 7, 20, 4 }, // 93 bits per transform
+ { 7, 21, 3 }, // 93 bits per transform
+ { 7, 22, 2 }, // 93 bits per transform
+ { 7, 23, 1 }, // 93 bits per transform
+ { 8, 0, 23 }, // 93 bits per transform
+ { 8, 1, 22 }, // 93 bits per transform
+ { 8, 2, 21 }, // 93 bits per transform
+ { 8, 3, 20 }, // 93 bits per transform
+ { 8, 4, 19 }, // 93 bits per transform
+ { 8, 5, 18 }, // 93 bits per transform
+ { 8, 6, 17 }, // 93 bits per transform
+ { 8, 7, 16 }, // 93 bits per transform
+ { 8, 8, 15 }, // 93 bits per transform
+ { 8, 9, 14 }, // 93 bits per transform
+ { 8, 10, 13 }, // 93 bits per transform
+ { 8, 11, 12 }, // 93 bits per transform
+ { 8, 12, 11 }, // 93 bits per transform
+ { 8, 13, 10 }, // 93 bits per transform
+ { 8, 14, 9 }, // 93 bits per transform
+ { 8, 15, 8 }, // 93 bits per transform
+ { 8, 16, 7 }, // 93 bits per transform
+ { 8, 17, 6 }, // 93 bits per transform
+ { 8, 18, 5 }, // 93 bits per transform
+ { 8, 19, 4 }, // 93 bits per transform
+ { 8, 20, 3 }, // 93 bits per transform
+ { 8, 21, 2 }, // 93 bits per transform
+ { 8, 22, 1 }, // 93 bits per transform
+ { 8, 23, 0 }, // 93 bits per transform
+ { 9, 0, 22 }, // 93 bits per transform
+ { 9, 1, 21 }, // 93 bits per transform
+ { 9, 2, 20 }, // 93 bits per transform
+ { 9, 3, 19 }, // 93 bits per transform
+ { 9, 4, 18 }, // 93 bits per transform
+ { 9, 5, 17 }, // 93 bits per transform
+ { 9, 6, 16 }, // 93 bits per transform
+ { 9, 7, 15 }, // 93 bits per transform
+ { 9, 8, 14 }, // 93 bits per transform
+ { 9, 9, 13 }, // 93 bits per transform
+ { 9, 10, 12 }, // 93 bits per transform
+ { 9, 11, 11 }, // 93 bits per transform
+ { 9, 12, 10 }, // 93 bits per transform
+ { 9, 13, 9 }, // 93 bits per transform
+ { 9, 14, 8 }, // 93 bits per transform
+ { 9, 15, 7 }, // 93 bits per transform
+ { 9, 16, 6 }, // 93 bits per transform
+ { 9, 17, 5 }, // 93 bits per transform
+ { 9, 18, 4 }, // 93 bits per transform
+ { 9, 19, 3 }, // 93 bits per transform
+ { 9, 20, 2 }, // 93 bits per transform
+ { 9, 21, 1 }, // 93 bits per transform
+ { 9, 22, 0 }, // 93 bits per transform
+ { 10, 0, 21 }, // 93 bits per transform
+ { 10, 1, 20 }, // 93 bits per transform
+ { 10, 2, 19 }, // 93 bits per transform
+ { 10, 3, 18 }, // 93 bits per transform
+ { 10, 4, 17 }, // 93 bits per transform
+ { 10, 5, 16 }, // 93 bits per transform
+ { 10, 6, 15 }, // 93 bits per transform
+ { 10, 7, 14 }, // 93 bits per transform
+ { 10, 8, 13 }, // 93 bits per transform
+ { 10, 9, 12 }, // 93 bits per transform
+ { 10, 10, 11 }, // 93 bits per transform
+ { 10, 11, 10 }, // 93 bits per transform
+ { 10, 12, 9 }, // 93 bits per transform
+ { 10, 13, 8 }, // 93 bits per transform
+ { 10, 14, 7 }, // 93 bits per transform
+ { 10, 15, 6 }, // 93 bits per transform
+ { 10, 16, 5 }, // 93 bits per transform
+ { 10, 17, 4 }, // 93 bits per transform
+ { 10, 18, 3 }, // 93 bits per transform
+ { 10, 19, 2 }, // 93 bits per transform
+ { 10, 20, 1 }, // 93 bits per transform
+ { 10, 21, 0 }, // 93 bits per transform
+ { 11, 0, 20 }, // 93 bits per transform
+ { 11, 1, 19 }, // 93 bits per transform
+ { 11, 2, 18 }, // 93 bits per transform
+ { 11, 3, 17 }, // 93 bits per transform
+ { 11, 4, 16 }, // 93 bits per transform
+ { 11, 5, 15 }, // 93 bits per transform
+ { 11, 6, 14 }, // 93 bits per transform
+ { 11, 7, 13 }, // 93 bits per transform
+ { 11, 8, 12 }, // 93 bits per transform
+ { 11, 9, 11 }, // 93 bits per transform
+ { 11, 10, 10 }, // 93 bits per transform
+ { 11, 11, 9 }, // 93 bits per transform
+ { 11, 12, 8 }, // 93 bits per transform
+ { 11, 13, 7 }, // 93 bits per transform
+ { 11, 14, 6 }, // 93 bits per transform
+ { 11, 15, 5 }, // 93 bits per transform
+ { 11, 16, 4 }, // 93 bits per transform
+ { 11, 17, 3 }, // 93 bits per transform
+ { 11, 18, 2 }, // 93 bits per transform
+ { 11, 19, 1 }, // 93 bits per transform
+ { 11, 20, 0 }, // 93 bits per transform
+ { 12, 0, 19 }, // 93 bits per transform
+ { 12, 1, 18 }, // 93 bits per transform
+ { 12, 2, 17 }, // 93 bits per transform
+ { 12, 3, 16 }, // 93 bits per transform
+ { 12, 4, 15 }, // 93 bits per transform
+ { 12, 5, 14 }, // 93 bits per transform
+ { 12, 6, 13 }, // 93 bits per transform
+ { 12, 7, 12 }, // 93 bits per transform
+ { 12, 8, 11 }, // 93 bits per transform
+ { 12, 9, 10 }, // 93 bits per transform
+ { 12, 10, 9 }, // 93 bits per transform
+ { 12, 11, 8 }, // 93 bits per transform
+ { 12, 12, 7 }, // 93 bits per transform
+ { 12, 13, 6 }, // 93 bits per transform
+ { 12, 14, 5 }, // 93 bits per transform
+ { 12, 15, 4 }, // 93 bits per transform
+ { 12, 16, 3 }, // 93 bits per transform
+ { 12, 17, 2 }, // 93 bits per transform
+ { 12, 18, 1 }, // 93 bits per transform
+ { 12, 19, 0 }, // 93 bits per transform
+ { 13, 0, 18 }, // 93 bits per transform
+ { 13, 1, 17 }, // 93 bits per transform
+ { 13, 2, 16 }, // 93 bits per transform
+ { 13, 3, 15 }, // 93 bits per transform
+ { 13, 4, 14 }, // 93 bits per transform
+ { 13, 5, 13 }, // 93 bits per transform
+ { 13, 6, 12 }, // 93 bits per transform
+ { 13, 7, 11 }, // 93 bits per transform
+ { 13, 8, 10 }, // 93 bits per transform
+ { 13, 9, 9 }, // 93 bits per transform
+ { 13, 10, 8 }, // 93 bits per transform
+ { 13, 11, 7 }, // 93 bits per transform
+ { 13, 12, 6 }, // 93 bits per transform
+ { 13, 13, 5 }, // 93 bits per transform
+ { 13, 14, 4 }, // 93 bits per transform
+ { 13, 15, 3 }, // 93 bits per transform
+ { 13, 16, 2 }, // 93 bits per transform
+ { 13, 17, 1 }, // 93 bits per transform
+ { 13, 18, 0 }, // 93 bits per transform
+ { 14, 0, 17 }, // 93 bits per transform
+ { 14, 1, 16 }, // 93 bits per transform
+ { 14, 2, 15 }, // 93 bits per transform
+ { 14, 3, 14 }, // 93 bits per transform
+ { 14, 4, 13 }, // 93 bits per transform
+ { 14, 5, 12 }, // 93 bits per transform
+ { 14, 6, 11 }, // 93 bits per transform
+ { 14, 7, 10 }, // 93 bits per transform
+ { 14, 8, 9 }, // 93 bits per transform
+ { 14, 9, 8 }, // 93 bits per transform
+ { 14, 10, 7 }, // 93 bits per transform
+ { 14, 11, 6 }, // 93 bits per transform
+ { 14, 12, 5 }, // 93 bits per transform
+ { 14, 13, 4 }, // 93 bits per transform
+ { 14, 14, 3 }, // 93 bits per transform
+ { 14, 15, 2 }, // 93 bits per transform
+ { 14, 16, 1 }, // 93 bits per transform
+ { 14, 17, 0 }, // 93 bits per transform
+ { 15, 0, 16 }, // 93 bits per transform
+ { 15, 1, 15 }, // 93 bits per transform
+ { 15, 2, 14 }, // 93 bits per transform
+ { 15, 3, 13 }, // 93 bits per transform
+ { 15, 4, 12 }, // 93 bits per transform
+ { 15, 5, 11 }, // 93 bits per transform
+ { 15, 6, 10 }, // 93 bits per transform
+ { 15, 7, 9 }, // 93 bits per transform
+ { 15, 8, 8 }, // 93 bits per transform
+ { 15, 9, 7 }, // 93 bits per transform
+ { 15, 10, 6 }, // 93 bits per transform
+ { 15, 11, 5 }, // 93 bits per transform
+ { 15, 12, 4 }, // 93 bits per transform
+ { 15, 13, 3 }, // 93 bits per transform
+ { 15, 14, 2 }, // 93 bits per transform
+ { 15, 15, 1 }, // 93 bits per transform
+ { 15, 16, 0 }, // 93 bits per transform
+ { 16, 0, 15 }, // 93 bits per transform
+ { 16, 1, 14 }, // 93 bits per transform
+ { 16, 2, 13 }, // 93 bits per transform
+ { 16, 3, 12 }, // 93 bits per transform
+ { 16, 4, 11 }, // 93 bits per transform
+ { 16, 5, 10 }, // 93 bits per transform
+ { 16, 6, 9 }, // 93 bits per transform
+ { 16, 7, 8 }, // 93 bits per transform
+ { 16, 8, 7 }, // 93 bits per transform
+ { 16, 9, 6 }, // 93 bits per transform
+ { 16, 10, 5 }, // 93 bits per transform
+ { 16, 11, 4 }, // 93 bits per transform
+ { 16, 12, 3 }, // 93 bits per transform
+ { 16, 13, 2 }, // 93 bits per transform
+ { 16, 14, 1 }, // 93 bits per transform
+ { 16, 15, 0 }, // 93 bits per transform
+ { 17, 0, 14 }, // 93 bits per transform
+ { 17, 1, 13 }, // 93 bits per transform
+ { 17, 2, 12 }, // 93 bits per transform
+ { 17, 3, 11 }, // 93 bits per transform
+ { 17, 4, 10 }, // 93 bits per transform
+ { 17, 5, 9 }, // 93 bits per transform
+ { 17, 6, 8 }, // 93 bits per transform
+ { 17, 7, 7 }, // 93 bits per transform
+ { 17, 8, 6 }, // 93 bits per transform
+ { 17, 9, 5 }, // 93 bits per transform
+ { 17, 10, 4 }, // 93 bits per transform
+ { 17, 11, 3 }, // 93 bits per transform
+ { 17, 12, 2 }, // 93 bits per transform
+ { 17, 13, 1 }, // 93 bits per transform
+ { 17, 14, 0 }, // 93 bits per transform
+ { 18, 0, 13 }, // 93 bits per transform
+ { 18, 1, 12 }, // 93 bits per transform
+ { 18, 2, 11 }, // 93 bits per transform
+ { 18, 3, 10 }, // 93 bits per transform
+ { 18, 4, 9 }, // 93 bits per transform
+ { 18, 5, 8 }, // 93 bits per transform
+ { 18, 6, 7 }, // 93 bits per transform
+ { 18, 7, 6 }, // 93 bits per transform
+ { 18, 8, 5 }, // 93 bits per transform
+ { 18, 9, 4 }, // 93 bits per transform
+ { 18, 10, 3 }, // 93 bits per transform
+ { 18, 11, 2 }, // 93 bits per transform
+ { 18, 12, 1 }, // 93 bits per transform
+ { 18, 13, 0 }, // 93 bits per transform
+ { 19, 0, 12 }, // 93 bits per transform
+ { 19, 1, 11 }, // 93 bits per transform
+ { 19, 2, 10 }, // 93 bits per transform
+ { 19, 3, 9 }, // 93 bits per transform
+ { 19, 4, 8 }, // 93 bits per transform
+ { 19, 5, 7 }, // 93 bits per transform
+ { 19, 6, 6 }, // 93 bits per transform
+ { 19, 7, 5 }, // 93 bits per transform
+ { 19, 8, 4 }, // 93 bits per transform
+ { 19, 9, 3 }, // 93 bits per transform
+ { 19, 10, 2 }, // 93 bits per transform
+ { 19, 11, 1 }, // 93 bits per transform
+ { 19, 12, 0 }, // 93 bits per transform
+ { 20, 0, 11 }, // 93 bits per transform
+ { 20, 1, 10 }, // 93 bits per transform
+ { 20, 2, 9 }, // 93 bits per transform
+ { 20, 3, 8 }, // 93 bits per transform
+ { 20, 4, 7 }, // 93 bits per transform
+ { 20, 5, 6 }, // 93 bits per transform
+ { 20, 6, 5 }, // 93 bits per transform
+ { 20, 7, 4 }, // 93 bits per transform
+ { 20, 8, 3 }, // 93 bits per transform
+ { 20, 9, 2 }, // 93 bits per transform
+ { 20, 10, 1 }, // 93 bits per transform
+ { 20, 11, 0 }, // 93 bits per transform
+ { 21, 0, 10 }, // 93 bits per transform
+ { 21, 1, 9 }, // 93 bits per transform
+ { 21, 2, 8 }, // 93 bits per transform
+ { 21, 3, 7 }, // 93 bits per transform
+ { 21, 4, 6 }, // 93 bits per transform
+ { 21, 5, 5 }, // 93 bits per transform
+ { 21, 6, 4 }, // 93 bits per transform
+ { 21, 7, 3 }, // 93 bits per transform
+ { 21, 8, 2 }, // 93 bits per transform
+ { 21, 9, 1 }, // 93 bits per transform
+ { 21, 10, 0 }, // 93 bits per transform
+ { 22, 0, 9 }, // 93 bits per transform
+ { 22, 1, 8 }, // 93 bits per transform
+ { 22, 2, 7 }, // 93 bits per transform
+ { 22, 3, 6 }, // 93 bits per transform
+ { 22, 4, 5 }, // 93 bits per transform
+ { 22, 5, 4 }, // 93 bits per transform
+ { 22, 6, 3 }, // 93 bits per transform
+ { 22, 7, 2 }, // 93 bits per transform
+ { 22, 8, 1 }, // 93 bits per transform
+ { 22, 9, 0 }, // 93 bits per transform
+ { 23, 0, 8 }, // 93 bits per transform
+ { 23, 1, 7 }, // 93 bits per transform
+ { 23, 2, 6 }, // 93 bits per transform
+ { 23, 3, 5 }, // 93 bits per transform
+ { 23, 4, 4 }, // 93 bits per transform
+ { 23, 5, 3 }, // 93 bits per transform
+ { 23, 6, 2 }, // 93 bits per transform
+ { 23, 7, 1 }, // 93 bits per transform
+ { 23, 8, 0 }, // 93 bits per transform
+ { 0, 0, 24 }, // 96 bits per transform
+ { 0, 9, 23 }, // 96 bits per transform
+ { 0, 10, 22 }, // 96 bits per transform
+ { 0, 11, 21 }, // 96 bits per transform
+ { 0, 12, 20 }, // 96 bits per transform
+ { 0, 13, 19 }, // 96 bits per transform
+ { 0, 14, 18 }, // 96 bits per transform
+ { 0, 15, 17 }, // 96 bits per transform
+ { 0, 16, 16 }, // 96 bits per transform
+ { 0, 17, 15 }, // 96 bits per transform
+ { 0, 18, 14 }, // 96 bits per transform
+ { 0, 19, 13 }, // 96 bits per transform
+ { 0, 20, 12 }, // 96 bits per transform
+ { 0, 21, 11 }, // 96 bits per transform
+ { 0, 22, 10 }, // 96 bits per transform
+ { 0, 23, 9 }, // 96 bits per transform
+ { 0, 24, 0 }, // 96 bits per transform
+ { 1, 8, 23 }, // 96 bits per transform
+ { 1, 9, 22 }, // 96 bits per transform
+ { 1, 10, 21 }, // 96 bits per transform
+ { 1, 11, 20 }, // 96 bits per transform
+ { 1, 12, 19 }, // 96 bits per transform
+ { 1, 13, 18 }, // 96 bits per transform
+ { 1, 14, 17 }, // 96 bits per transform
+ { 1, 15, 16 }, // 96 bits per transform
+ { 1, 16, 15 }, // 96 bits per transform
+ { 1, 17, 14 }, // 96 bits per transform
+ { 1, 18, 13 }, // 96 bits per transform
+ { 1, 19, 12 }, // 96 bits per transform
+ { 1, 20, 11 }, // 96 bits per transform
+ { 1, 21, 10 }, // 96 bits per transform
+ { 1, 22, 9 }, // 96 bits per transform
+ { 1, 23, 8 }, // 96 bits per transform
+ { 2, 7, 23 }, // 96 bits per transform
+ { 2, 8, 22 }, // 96 bits per transform
+ { 2, 9, 21 }, // 96 bits per transform
+ { 2, 10, 20 }, // 96 bits per transform
+ { 2, 11, 19 }, // 96 bits per transform
+ { 2, 12, 18 }, // 96 bits per transform
+ { 2, 13, 17 }, // 96 bits per transform
+ { 2, 14, 16 }, // 96 bits per transform
+ { 2, 15, 15 }, // 96 bits per transform
+ { 2, 16, 14 }, // 96 bits per transform
+ { 2, 17, 13 }, // 96 bits per transform
+ { 2, 18, 12 }, // 96 bits per transform
+ { 2, 19, 11 }, // 96 bits per transform
+ { 2, 20, 10 }, // 96 bits per transform
+ { 2, 21, 9 }, // 96 bits per transform
+ { 2, 22, 8 }, // 96 bits per transform
+ { 2, 23, 7 }, // 96 bits per transform
+ { 3, 6, 23 }, // 96 bits per transform
+ { 3, 7, 22 }, // 96 bits per transform
+ { 3, 8, 21 }, // 96 bits per transform
+ { 3, 9, 20 }, // 96 bits per transform
+ { 3, 10, 19 }, // 96 bits per transform
+ { 3, 11, 18 }, // 96 bits per transform
+ { 3, 12, 17 }, // 96 bits per transform
+ { 3, 13, 16 }, // 96 bits per transform
+ { 3, 14, 15 }, // 96 bits per transform
+ { 3, 15, 14 }, // 96 bits per transform
+ { 3, 16, 13 }, // 96 bits per transform
+ { 3, 17, 12 }, // 96 bits per transform
+ { 3, 18, 11 }, // 96 bits per transform
+ { 3, 19, 10 }, // 96 bits per transform
+ { 3, 20, 9 }, // 96 bits per transform
+ { 3, 21, 8 }, // 96 bits per transform
+ { 3, 22, 7 }, // 96 bits per transform
+ { 3, 23, 6 }, // 96 bits per transform
+ { 4, 5, 23 }, // 96 bits per transform
+ { 4, 6, 22 }, // 96 bits per transform
+ { 4, 7, 21 }, // 96 bits per transform
+ { 4, 8, 20 }, // 96 bits per transform
+ { 4, 9, 19 }, // 96 bits per transform
+ { 4, 10, 18 }, // 96 bits per transform
+ { 4, 11, 17 }, // 96 bits per transform
+ { 4, 12, 16 }, // 96 bits per transform
+ { 4, 13, 15 }, // 96 bits per transform
+ { 4, 14, 14 }, // 96 bits per transform
+ { 4, 15, 13 }, // 96 bits per transform
+ { 4, 16, 12 }, // 96 bits per transform
+ { 4, 17, 11 }, // 96 bits per transform
+ { 4, 18, 10 }, // 96 bits per transform
+ { 4, 19, 9 }, // 96 bits per transform
+ { 4, 20, 8 }, // 96 bits per transform
+ { 4, 21, 7 }, // 96 bits per transform
+ { 4, 22, 6 }, // 96 bits per transform
+ { 4, 23, 5 }, // 96 bits per transform
+ { 5, 4, 23 }, // 96 bits per transform
+ { 5, 5, 22 }, // 96 bits per transform
+ { 5, 6, 21 }, // 96 bits per transform
+ { 5, 7, 20 }, // 96 bits per transform
+ { 5, 8, 19 }, // 96 bits per transform
+ { 5, 9, 18 }, // 96 bits per transform
+ { 5, 10, 17 }, // 96 bits per transform
+ { 5, 11, 16 }, // 96 bits per transform
+ { 5, 12, 15 }, // 96 bits per transform
+ { 5, 13, 14 }, // 96 bits per transform
+ { 5, 14, 13 }, // 96 bits per transform
+ { 5, 15, 12 }, // 96 bits per transform
+ { 5, 16, 11 }, // 96 bits per transform
+ { 5, 17, 10 }, // 96 bits per transform
+ { 5, 18, 9 }, // 96 bits per transform
+ { 5, 19, 8 }, // 96 bits per transform
+ { 5, 20, 7 }, // 96 bits per transform
+ { 5, 21, 6 }, // 96 bits per transform
+ { 5, 22, 5 }, // 96 bits per transform
+ { 5, 23, 4 }, // 96 bits per transform
+ { 6, 3, 23 }, // 96 bits per transform
+ { 6, 4, 22 }, // 96 bits per transform
+ { 6, 5, 21 }, // 96 bits per transform
+ { 6, 6, 20 }, // 96 bits per transform
+ { 6, 7, 19 }, // 96 bits per transform
+ { 6, 8, 18 }, // 96 bits per transform
+ { 6, 9, 17 }, // 96 bits per transform
+ { 6, 10, 16 }, // 96 bits per transform
+ { 6, 11, 15 }, // 96 bits per transform
+ { 6, 12, 14 }, // 96 bits per transform
+ { 6, 13, 13 }, // 96 bits per transform
+ { 6, 14, 12 }, // 96 bits per transform
+ { 6, 15, 11 }, // 96 bits per transform
+ { 6, 16, 10 }, // 96 bits per transform
+ { 6, 17, 9 }, // 96 bits per transform
+ { 6, 18, 8 }, // 96 bits per transform
+ { 6, 19, 7 }, // 96 bits per transform
+ { 6, 20, 6 }, // 96 bits per transform
+ { 6, 21, 5 }, // 96 bits per transform
+ { 6, 22, 4 }, // 96 bits per transform
+ { 6, 23, 3 }, // 96 bits per transform
+ { 7, 2, 23 }, // 96 bits per transform
+ { 7, 3, 22 }, // 96 bits per transform
+ { 7, 4, 21 }, // 96 bits per transform
+ { 7, 5, 20 }, // 96 bits per transform
+ { 7, 6, 19 }, // 96 bits per transform
+ { 7, 7, 18 }, // 96 bits per transform
+ { 7, 8, 17 }, // 96 bits per transform
+ { 7, 9, 16 }, // 96 bits per transform
+ { 7, 10, 15 }, // 96 bits per transform
+ { 7, 11, 14 }, // 96 bits per transform
+ { 7, 12, 13 }, // 96 bits per transform
+ { 7, 13, 12 }, // 96 bits per transform
+ { 7, 14, 11 }, // 96 bits per transform
+ { 7, 15, 10 }, // 96 bits per transform
+ { 7, 16, 9 }, // 96 bits per transform
+ { 7, 17, 8 }, // 96 bits per transform
+ { 7, 18, 7 }, // 96 bits per transform
+ { 7, 19, 6 }, // 96 bits per transform
+ { 7, 20, 5 }, // 96 bits per transform
+ { 7, 21, 4 }, // 96 bits per transform
+ { 7, 22, 3 }, // 96 bits per transform
+ { 7, 23, 2 }, // 96 bits per transform
+ { 8, 1, 23 }, // 96 bits per transform
+ { 8, 2, 22 }, // 96 bits per transform
+ { 8, 3, 21 }, // 96 bits per transform
+ { 8, 4, 20 }, // 96 bits per transform
+ { 8, 5, 19 }, // 96 bits per transform
+ { 8, 6, 18 }, // 96 bits per transform
+ { 8, 7, 17 }, // 96 bits per transform
+ { 8, 8, 16 }, // 96 bits per transform
+ { 8, 9, 15 }, // 96 bits per transform
+ { 8, 10, 14 }, // 96 bits per transform
+ { 8, 11, 13 }, // 96 bits per transform
+ { 8, 12, 12 }, // 96 bits per transform
+ { 8, 13, 11 }, // 96 bits per transform
+ { 8, 14, 10 }, // 96 bits per transform
+ { 8, 15, 9 }, // 96 bits per transform
+ { 8, 16, 8 }, // 96 bits per transform
+ { 8, 17, 7 }, // 96 bits per transform
+ { 8, 18, 6 }, // 96 bits per transform
+ { 8, 19, 5 }, // 96 bits per transform
+ { 8, 20, 4 }, // 96 bits per transform
+ { 8, 21, 3 }, // 96 bits per transform
+ { 8, 22, 2 }, // 96 bits per transform
+ { 8, 23, 1 }, // 96 bits per transform
+ { 9, 0, 23 }, // 96 bits per transform
+ { 9, 1, 22 }, // 96 bits per transform
+ { 9, 2, 21 }, // 96 bits per transform
+ { 9, 3, 20 }, // 96 bits per transform
+ { 9, 4, 19 }, // 96 bits per transform
+ { 9, 5, 18 }, // 96 bits per transform
+ { 9, 6, 17 }, // 96 bits per transform
+ { 9, 7, 16 }, // 96 bits per transform
+ { 9, 8, 15 }, // 96 bits per transform
+ { 9, 9, 14 }, // 96 bits per transform
+ { 9, 10, 13 }, // 96 bits per transform
+ { 9, 11, 12 }, // 96 bits per transform
+ { 9, 12, 11 }, // 96 bits per transform
+ { 9, 13, 10 }, // 96 bits per transform
+ { 9, 14, 9 }, // 96 bits per transform
+ { 9, 15, 8 }, // 96 bits per transform
+ { 9, 16, 7 }, // 96 bits per transform
+ { 9, 17, 6 }, // 96 bits per transform
+ { 9, 18, 5 }, // 96 bits per transform
+ { 9, 19, 4 }, // 96 bits per transform
+ { 9, 20, 3 }, // 96 bits per transform
+ { 9, 21, 2 }, // 96 bits per transform
+ { 9, 22, 1 }, // 96 bits per transform
+ { 9, 23, 0 }, // 96 bits per transform
+ { 10, 0, 22 }, // 96 bits per transform
+ { 10, 1, 21 }, // 96 bits per transform
+ { 10, 2, 20 }, // 96 bits per transform
+ { 10, 3, 19 }, // 96 bits per transform
+ { 10, 4, 18 }, // 96 bits per transform
+ { 10, 5, 17 }, // 96 bits per transform
+ { 10, 6, 16 }, // 96 bits per transform
+ { 10, 7, 15 }, // 96 bits per transform
+ { 10, 8, 14 }, // 96 bits per transform
+ { 10, 9, 13 }, // 96 bits per transform
+ { 10, 10, 12 }, // 96 bits per transform
+ { 10, 11, 11 }, // 96 bits per transform
+ { 10, 12, 10 }, // 96 bits per transform
+ { 10, 13, 9 }, // 96 bits per transform
+ { 10, 14, 8 }, // 96 bits per transform
+ { 10, 15, 7 }, // 96 bits per transform
+ { 10, 16, 6 }, // 96 bits per transform
+ { 10, 17, 5 }, // 96 bits per transform
+ { 10, 18, 4 }, // 96 bits per transform
+ { 10, 19, 3 }, // 96 bits per transform
+ { 10, 20, 2 }, // 96 bits per transform
+ { 10, 21, 1 }, // 96 bits per transform
+ { 10, 22, 0 }, // 96 bits per transform
+ { 11, 0, 21 }, // 96 bits per transform
+ { 11, 1, 20 }, // 96 bits per transform
+ { 11, 2, 19 }, // 96 bits per transform
+ { 11, 3, 18 }, // 96 bits per transform
+ { 11, 4, 17 }, // 96 bits per transform
+ { 11, 5, 16 }, // 96 bits per transform
+ { 11, 6, 15 }, // 96 bits per transform
+ { 11, 7, 14 }, // 96 bits per transform
+ { 11, 8, 13 }, // 96 bits per transform
+ { 11, 9, 12 }, // 96 bits per transform
+ { 11, 10, 11 }, // 96 bits per transform
+ { 11, 11, 10 }, // 96 bits per transform
+ { 11, 12, 9 }, // 96 bits per transform
+ { 11, 13, 8 }, // 96 bits per transform
+ { 11, 14, 7 }, // 96 bits per transform
+ { 11, 15, 6 }, // 96 bits per transform
+ { 11, 16, 5 }, // 96 bits per transform
+ { 11, 17, 4 }, // 96 bits per transform
+ { 11, 18, 3 }, // 96 bits per transform
+ { 11, 19, 2 }, // 96 bits per transform
+ { 11, 20, 1 }, // 96 bits per transform
+ { 11, 21, 0 }, // 96 bits per transform
+ { 12, 0, 20 }, // 96 bits per transform
+ { 12, 1, 19 }, // 96 bits per transform
+ { 12, 2, 18 }, // 96 bits per transform
+ { 12, 3, 17 }, // 96 bits per transform
+ { 12, 4, 16 }, // 96 bits per transform
+ { 12, 5, 15 }, // 96 bits per transform
+ { 12, 6, 14 }, // 96 bits per transform
+ { 12, 7, 13 }, // 96 bits per transform
+ { 12, 8, 12 }, // 96 bits per transform
+ { 12, 9, 11 }, // 96 bits per transform
+ { 12, 10, 10 }, // 96 bits per transform
+ { 12, 11, 9 }, // 96 bits per transform
+ { 12, 12, 8 }, // 96 bits per transform
+ { 12, 13, 7 }, // 96 bits per transform
+ { 12, 14, 6 }, // 96 bits per transform
+ { 12, 15, 5 }, // 96 bits per transform
+ { 12, 16, 4 }, // 96 bits per transform
+ { 12, 17, 3 }, // 96 bits per transform
+ { 12, 18, 2 }, // 96 bits per transform
+ { 12, 19, 1 }, // 96 bits per transform
+ { 12, 20, 0 }, // 96 bits per transform
+ { 13, 0, 19 }, // 96 bits per transform
+ { 13, 1, 18 }, // 96 bits per transform
+ { 13, 2, 17 }, // 96 bits per transform
+ { 13, 3, 16 }, // 96 bits per transform
+ { 13, 4, 15 }, // 96 bits per transform
+ { 13, 5, 14 }, // 96 bits per transform
+ { 13, 6, 13 }, // 96 bits per transform
+ { 13, 7, 12 }, // 96 bits per transform
+ { 13, 8, 11 }, // 96 bits per transform
+ { 13, 9, 10 }, // 96 bits per transform
+ { 13, 10, 9 }, // 96 bits per transform
+ { 13, 11, 8 }, // 96 bits per transform
+ { 13, 12, 7 }, // 96 bits per transform
+ { 13, 13, 6 }, // 96 bits per transform
+ { 13, 14, 5 }, // 96 bits per transform
+ { 13, 15, 4 }, // 96 bits per transform
+ { 13, 16, 3 }, // 96 bits per transform
+ { 13, 17, 2 }, // 96 bits per transform
+ { 13, 18, 1 }, // 96 bits per transform
+ { 13, 19, 0 }, // 96 bits per transform
+ { 14, 0, 18 }, // 96 bits per transform
+ { 14, 1, 17 }, // 96 bits per transform
+ { 14, 2, 16 }, // 96 bits per transform
+ { 14, 3, 15 }, // 96 bits per transform
+ { 14, 4, 14 }, // 96 bits per transform
+ { 14, 5, 13 }, // 96 bits per transform
+ { 14, 6, 12 }, // 96 bits per transform
+ { 14, 7, 11 }, // 96 bits per transform
+ { 14, 8, 10 }, // 96 bits per transform
+ { 14, 9, 9 }, // 96 bits per transform
+ { 14, 10, 8 }, // 96 bits per transform
+ { 14, 11, 7 }, // 96 bits per transform
+ { 14, 12, 6 }, // 96 bits per transform
+ { 14, 13, 5 }, // 96 bits per transform
+ { 14, 14, 4 }, // 96 bits per transform
+ { 14, 15, 3 }, // 96 bits per transform
+ { 14, 16, 2 }, // 96 bits per transform
+ { 14, 17, 1 }, // 96 bits per transform
+ { 14, 18, 0 }, // 96 bits per transform
+ { 15, 0, 17 }, // 96 bits per transform
+ { 15, 1, 16 }, // 96 bits per transform
+ { 15, 2, 15 }, // 96 bits per transform
+ { 15, 3, 14 }, // 96 bits per transform
+ { 15, 4, 13 }, // 96 bits per transform
+ { 15, 5, 12 }, // 96 bits per transform
+ { 15, 6, 11 }, // 96 bits per transform
+ { 15, 7, 10 }, // 96 bits per transform
+ { 15, 8, 9 }, // 96 bits per transform
+ { 15, 9, 8 }, // 96 bits per transform
+ { 15, 10, 7 }, // 96 bits per transform
+ { 15, 11, 6 }, // 96 bits per transform
+ { 15, 12, 5 }, // 96 bits per transform
+ { 15, 13, 4 }, // 96 bits per transform
+ { 15, 14, 3 }, // 96 bits per transform
+ { 15, 15, 2 }, // 96 bits per transform
+ { 15, 16, 1 }, // 96 bits per transform
+ { 15, 17, 0 }, // 96 bits per transform
+ { 16, 0, 16 }, // 96 bits per transform
+ { 16, 1, 15 }, // 96 bits per transform
+ { 16, 2, 14 }, // 96 bits per transform
+ { 16, 3, 13 }, // 96 bits per transform
+ { 16, 4, 12 }, // 96 bits per transform
+ { 16, 5, 11 }, // 96 bits per transform
+ { 16, 6, 10 }, // 96 bits per transform
+ { 16, 7, 9 }, // 96 bits per transform
+ { 16, 8, 8 }, // 96 bits per transform
+ { 16, 9, 7 }, // 96 bits per transform
+ { 16, 10, 6 }, // 96 bits per transform
+ { 16, 11, 5 }, // 96 bits per transform
+ { 16, 12, 4 }, // 96 bits per transform
+ { 16, 13, 3 }, // 96 bits per transform
+ { 16, 14, 2 }, // 96 bits per transform
+ { 16, 15, 1 }, // 96 bits per transform
+ { 16, 16, 0 }, // 96 bits per transform
+ { 17, 0, 15 }, // 96 bits per transform
+ { 17, 1, 14 }, // 96 bits per transform
+ { 17, 2, 13 }, // 96 bits per transform
+ { 17, 3, 12 }, // 96 bits per transform
+ { 17, 4, 11 }, // 96 bits per transform
+ { 17, 5, 10 }, // 96 bits per transform
+ { 17, 6, 9 }, // 96 bits per transform
+ { 17, 7, 8 }, // 96 bits per transform
+ { 17, 8, 7 }, // 96 bits per transform
+ { 17, 9, 6 }, // 96 bits per transform
+ { 17, 10, 5 }, // 96 bits per transform
+ { 17, 11, 4 }, // 96 bits per transform
+ { 17, 12, 3 }, // 96 bits per transform
+ { 17, 13, 2 }, // 96 bits per transform
+ { 17, 14, 1 }, // 96 bits per transform
+ { 17, 15, 0 }, // 96 bits per transform
+ { 18, 0, 14 }, // 96 bits per transform
+ { 18, 1, 13 }, // 96 bits per transform
+ { 18, 2, 12 }, // 96 bits per transform
+ { 18, 3, 11 }, // 96 bits per transform
+ { 18, 4, 10 }, // 96 bits per transform
+ { 18, 5, 9 }, // 96 bits per transform
+ { 18, 6, 8 }, // 96 bits per transform
+ { 18, 7, 7 }, // 96 bits per transform
+ { 18, 8, 6 }, // 96 bits per transform
+ { 18, 9, 5 }, // 96 bits per transform
+ { 18, 10, 4 }, // 96 bits per transform
+ { 18, 11, 3 }, // 96 bits per transform
+ { 18, 12, 2 }, // 96 bits per transform
+ { 18, 13, 1 }, // 96 bits per transform
+ { 18, 14, 0 }, // 96 bits per transform
+ { 19, 0, 13 }, // 96 bits per transform
+ { 19, 1, 12 }, // 96 bits per transform
+ { 19, 2, 11 }, // 96 bits per transform
+ { 19, 3, 10 }, // 96 bits per transform
+ { 19, 4, 9 }, // 96 bits per transform
+ { 19, 5, 8 }, // 96 bits per transform
+ { 19, 6, 7 }, // 96 bits per transform
+ { 19, 7, 6 }, // 96 bits per transform
+ { 19, 8, 5 }, // 96 bits per transform
+ { 19, 9, 4 }, // 96 bits per transform
+ { 19, 10, 3 }, // 96 bits per transform
+ { 19, 11, 2 }, // 96 bits per transform
+ { 19, 12, 1 }, // 96 bits per transform
+ { 19, 13, 0 }, // 96 bits per transform
+ { 20, 0, 12 }, // 96 bits per transform
+ { 20, 1, 11 }, // 96 bits per transform
+ { 20, 2, 10 }, // 96 bits per transform
+ { 20, 3, 9 }, // 96 bits per transform
+ { 20, 4, 8 }, // 96 bits per transform
+ { 20, 5, 7 }, // 96 bits per transform
+ { 20, 6, 6 }, // 96 bits per transform
+ { 20, 7, 5 }, // 96 bits per transform
+ { 20, 8, 4 }, // 96 bits per transform
+ { 20, 9, 3 }, // 96 bits per transform
+ { 20, 10, 2 }, // 96 bits per transform
+ { 20, 11, 1 }, // 96 bits per transform
+ { 20, 12, 0 }, // 96 bits per transform
+ { 21, 0, 11 }, // 96 bits per transform
+ { 21, 1, 10 }, // 96 bits per transform
+ { 21, 2, 9 }, // 96 bits per transform
+ { 21, 3, 8 }, // 96 bits per transform
+ { 21, 4, 7 }, // 96 bits per transform
+ { 21, 5, 6 }, // 96 bits per transform
+ { 21, 6, 5 }, // 96 bits per transform
+ { 21, 7, 4 }, // 96 bits per transform
+ { 21, 8, 3 }, // 96 bits per transform
+ { 21, 9, 2 }, // 96 bits per transform
+ { 21, 10, 1 }, // 96 bits per transform
+ { 21, 11, 0 }, // 96 bits per transform
+ { 22, 0, 10 }, // 96 bits per transform
+ { 22, 1, 9 }, // 96 bits per transform
+ { 22, 2, 8 }, // 96 bits per transform
+ { 22, 3, 7 }, // 96 bits per transform
+ { 22, 4, 6 }, // 96 bits per transform
+ { 22, 5, 5 }, // 96 bits per transform
+ { 22, 6, 4 }, // 96 bits per transform
+ { 22, 7, 3 }, // 96 bits per transform
+ { 22, 8, 2 }, // 96 bits per transform
+ { 22, 9, 1 }, // 96 bits per transform
+ { 22, 10, 0 }, // 96 bits per transform
+ { 23, 0, 9 }, // 96 bits per transform
+ { 23, 1, 8 }, // 96 bits per transform
+ { 23, 2, 7 }, // 96 bits per transform
+ { 23, 3, 6 }, // 96 bits per transform
+ { 23, 4, 5 }, // 96 bits per transform
+ { 23, 5, 4 }, // 96 bits per transform
+ { 23, 6, 3 }, // 96 bits per transform
+ { 23, 7, 2 }, // 96 bits per transform
+ { 23, 8, 1 }, // 96 bits per transform
+ { 23, 9, 0 }, // 96 bits per transform
+ { 24, 0, 0 }, // 96 bits per transform
+ { 0, 1, 24 }, // 99 bits per transform
+ { 0, 10, 23 }, // 99 bits per transform
+ { 0, 11, 22 }, // 99 bits per transform
+ { 0, 12, 21 }, // 99 bits per transform
+ { 0, 13, 20 }, // 99 bits per transform
+ { 0, 14, 19 }, // 99 bits per transform
+ { 0, 15, 18 }, // 99 bits per transform
+ { 0, 16, 17 }, // 99 bits per transform
+ { 0, 17, 16 }, // 99 bits per transform
+ { 0, 18, 15 }, // 99 bits per transform
+ { 0, 19, 14 }, // 99 bits per transform
+ { 0, 20, 13 }, // 99 bits per transform
+ { 0, 21, 12 }, // 99 bits per transform
+ { 0, 22, 11 }, // 99 bits per transform
+ { 0, 23, 10 }, // 99 bits per transform
+ { 0, 24, 1 }, // 99 bits per transform
+ { 1, 0, 24 }, // 99 bits per transform
+ { 1, 9, 23 }, // 99 bits per transform
+ { 1, 10, 22 }, // 99 bits per transform
+ { 1, 11, 21 }, // 99 bits per transform
+ { 1, 12, 20 }, // 99 bits per transform
+ { 1, 13, 19 }, // 99 bits per transform
+ { 1, 14, 18 }, // 99 bits per transform
+ { 1, 15, 17 }, // 99 bits per transform
+ { 1, 16, 16 }, // 99 bits per transform
+ { 1, 17, 15 }, // 99 bits per transform
+ { 1, 18, 14 }, // 99 bits per transform
+ { 1, 19, 13 }, // 99 bits per transform
+ { 1, 20, 12 }, // 99 bits per transform
+ { 1, 21, 11 }, // 99 bits per transform
+ { 1, 22, 10 }, // 99 bits per transform
+ { 1, 23, 9 }, // 99 bits per transform
+ { 1, 24, 0 }, // 99 bits per transform
+ { 2, 8, 23 }, // 99 bits per transform
+ { 2, 9, 22 }, // 99 bits per transform
+ { 2, 10, 21 }, // 99 bits per transform
+ { 2, 11, 20 }, // 99 bits per transform
+ { 2, 12, 19 }, // 99 bits per transform
+ { 2, 13, 18 }, // 99 bits per transform
+ { 2, 14, 17 }, // 99 bits per transform
+ { 2, 15, 16 }, // 99 bits per transform
+ { 2, 16, 15 }, // 99 bits per transform
+ { 2, 17, 14 }, // 99 bits per transform
+ { 2, 18, 13 }, // 99 bits per transform
+ { 2, 19, 12 }, // 99 bits per transform
+ { 2, 20, 11 }, // 99 bits per transform
+ { 2, 21, 10 }, // 99 bits per transform
+ { 2, 22, 9 }, // 99 bits per transform
+ { 2, 23, 8 }, // 99 bits per transform
+ { 3, 7, 23 }, // 99 bits per transform
+ { 3, 8, 22 }, // 99 bits per transform
+ { 3, 9, 21 }, // 99 bits per transform
+ { 3, 10, 20 }, // 99 bits per transform
+ { 3, 11, 19 }, // 99 bits per transform
+ { 3, 12, 18 }, // 99 bits per transform
+ { 3, 13, 17 }, // 99 bits per transform
+ { 3, 14, 16 }, // 99 bits per transform
+ { 3, 15, 15 }, // 99 bits per transform
+ { 3, 16, 14 }, // 99 bits per transform
+ { 3, 17, 13 }, // 99 bits per transform
+ { 3, 18, 12 }, // 99 bits per transform
+ { 3, 19, 11 }, // 99 bits per transform
+ { 3, 20, 10 }, // 99 bits per transform
+ { 3, 21, 9 }, // 99 bits per transform
+ { 3, 22, 8 }, // 99 bits per transform
+ { 3, 23, 7 }, // 99 bits per transform
+ { 4, 6, 23 }, // 99 bits per transform
+ { 4, 7, 22 }, // 99 bits per transform
+ { 4, 8, 21 }, // 99 bits per transform
+ { 4, 9, 20 }, // 99 bits per transform
+ { 4, 10, 19 }, // 99 bits per transform
+ { 4, 11, 18 }, // 99 bits per transform
+ { 4, 12, 17 }, // 99 bits per transform
+ { 4, 13, 16 }, // 99 bits per transform
+ { 4, 14, 15 }, // 99 bits per transform
+ { 4, 15, 14 }, // 99 bits per transform
+ { 4, 16, 13 }, // 99 bits per transform
+ { 4, 17, 12 }, // 99 bits per transform
+ { 4, 18, 11 }, // 99 bits per transform
+ { 4, 19, 10 }, // 99 bits per transform
+ { 4, 20, 9 }, // 99 bits per transform
+ { 4, 21, 8 }, // 99 bits per transform
+ { 4, 22, 7 }, // 99 bits per transform
+ { 4, 23, 6 }, // 99 bits per transform
+ { 5, 5, 23 }, // 99 bits per transform
+ { 5, 6, 22 }, // 99 bits per transform
+ { 5, 7, 21 }, // 99 bits per transform
+ { 5, 8, 20 }, // 99 bits per transform
+ { 5, 9, 19 }, // 99 bits per transform
+ { 5, 10, 18 }, // 99 bits per transform
+ { 5, 11, 17 }, // 99 bits per transform
+ { 5, 12, 16 }, // 99 bits per transform
+ { 5, 13, 15 }, // 99 bits per transform
+ { 5, 14, 14 }, // 99 bits per transform
+ { 5, 15, 13 }, // 99 bits per transform
+ { 5, 16, 12 }, // 99 bits per transform
+ { 5, 17, 11 }, // 99 bits per transform
+ { 5, 18, 10 }, // 99 bits per transform
+ { 5, 19, 9 }, // 99 bits per transform
+ { 5, 20, 8 }, // 99 bits per transform
+ { 5, 21, 7 }, // 99 bits per transform
+ { 5, 22, 6 }, // 99 bits per transform
+ { 5, 23, 5 }, // 99 bits per transform
+ { 6, 4, 23 }, // 99 bits per transform
+ { 6, 5, 22 }, // 99 bits per transform
+ { 6, 6, 21 }, // 99 bits per transform
+ { 6, 7, 20 }, // 99 bits per transform
+ { 6, 8, 19 }, // 99 bits per transform
+ { 6, 9, 18 }, // 99 bits per transform
+ { 6, 10, 17 }, // 99 bits per transform
+ { 6, 11, 16 }, // 99 bits per transform
+ { 6, 12, 15 }, // 99 bits per transform
+ { 6, 13, 14 }, // 99 bits per transform
+ { 6, 14, 13 }, // 99 bits per transform
+ { 6, 15, 12 }, // 99 bits per transform
+ { 6, 16, 11 }, // 99 bits per transform
+ { 6, 17, 10 }, // 99 bits per transform
+ { 6, 18, 9 }, // 99 bits per transform
+ { 6, 19, 8 }, // 99 bits per transform
+ { 6, 20, 7 }, // 99 bits per transform
+ { 6, 21, 6 }, // 99 bits per transform
+ { 6, 22, 5 }, // 99 bits per transform
+ { 6, 23, 4 }, // 99 bits per transform
+ { 7, 3, 23 }, // 99 bits per transform
+ { 7, 4, 22 }, // 99 bits per transform
+ { 7, 5, 21 }, // 99 bits per transform
+ { 7, 6, 20 }, // 99 bits per transform
+ { 7, 7, 19 }, // 99 bits per transform
+ { 7, 8, 18 }, // 99 bits per transform
+ { 7, 9, 17 }, // 99 bits per transform
+ { 7, 10, 16 }, // 99 bits per transform
+ { 7, 11, 15 }, // 99 bits per transform
+ { 7, 12, 14 }, // 99 bits per transform
+ { 7, 13, 13 }, // 99 bits per transform
+ { 7, 14, 12 }, // 99 bits per transform
+ { 7, 15, 11 }, // 99 bits per transform
+ { 7, 16, 10 }, // 99 bits per transform
+ { 7, 17, 9 }, // 99 bits per transform
+ { 7, 18, 8 }, // 99 bits per transform
+ { 7, 19, 7 }, // 99 bits per transform
+ { 7, 20, 6 }, // 99 bits per transform
+ { 7, 21, 5 }, // 99 bits per transform
+ { 7, 22, 4 }, // 99 bits per transform
+ { 7, 23, 3 }, // 99 bits per transform
+ { 8, 2, 23 }, // 99 bits per transform
+ { 8, 3, 22 }, // 99 bits per transform
+ { 8, 4, 21 }, // 99 bits per transform
+ { 8, 5, 20 }, // 99 bits per transform
+ { 8, 6, 19 }, // 99 bits per transform
+ { 8, 7, 18 }, // 99 bits per transform
+ { 8, 8, 17 }, // 99 bits per transform
+ { 8, 9, 16 }, // 99 bits per transform
+ { 8, 10, 15 }, // 99 bits per transform
+ { 8, 11, 14 }, // 99 bits per transform
+ { 8, 12, 13 }, // 99 bits per transform
+ { 8, 13, 12 }, // 99 bits per transform
+ { 8, 14, 11 }, // 99 bits per transform
+ { 8, 15, 10 }, // 99 bits per transform
+ { 8, 16, 9 }, // 99 bits per transform
+ { 8, 17, 8 }, // 99 bits per transform
+ { 8, 18, 7 }, // 99 bits per transform
+ { 8, 19, 6 }, // 99 bits per transform
+ { 8, 20, 5 }, // 99 bits per transform
+ { 8, 21, 4 }, // 99 bits per transform
+ { 8, 22, 3 }, // 99 bits per transform
+ { 8, 23, 2 }, // 99 bits per transform
+ { 9, 1, 23 }, // 99 bits per transform
+ { 9, 2, 22 }, // 99 bits per transform
+ { 9, 3, 21 }, // 99 bits per transform
+ { 9, 4, 20 }, // 99 bits per transform
+ { 9, 5, 19 }, // 99 bits per transform
+ { 9, 6, 18 }, // 99 bits per transform
+ { 9, 7, 17 }, // 99 bits per transform
+ { 9, 8, 16 }, // 99 bits per transform
+ { 9, 9, 15 }, // 99 bits per transform
+ { 9, 10, 14 }, // 99 bits per transform
+ { 9, 11, 13 }, // 99 bits per transform
+ { 9, 12, 12 }, // 99 bits per transform
+ { 9, 13, 11 }, // 99 bits per transform
+ { 9, 14, 10 }, // 99 bits per transform
+ { 9, 15, 9 }, // 99 bits per transform
+ { 9, 16, 8 }, // 99 bits per transform
+ { 9, 17, 7 }, // 99 bits per transform
+ { 9, 18, 6 }, // 99 bits per transform
+ { 9, 19, 5 }, // 99 bits per transform
+ { 9, 20, 4 }, // 99 bits per transform
+ { 9, 21, 3 }, // 99 bits per transform
+ { 9, 22, 2 }, // 99 bits per transform
+ { 9, 23, 1 }, // 99 bits per transform
+ { 10, 0, 23 }, // 99 bits per transform
+ { 10, 1, 22 }, // 99 bits per transform
+ { 10, 2, 21 }, // 99 bits per transform
+ { 10, 3, 20 }, // 99 bits per transform
+ { 10, 4, 19 }, // 99 bits per transform
+ { 10, 5, 18 }, // 99 bits per transform
+ { 10, 6, 17 }, // 99 bits per transform
+ { 10, 7, 16 }, // 99 bits per transform
+ { 10, 8, 15 }, // 99 bits per transform
+ { 10, 9, 14 }, // 99 bits per transform
+ { 10, 10, 13 }, // 99 bits per transform
+ { 10, 11, 12 }, // 99 bits per transform
+ { 10, 12, 11 }, // 99 bits per transform
+ { 10, 13, 10 }, // 99 bits per transform
+ { 10, 14, 9 }, // 99 bits per transform
+ { 10, 15, 8 }, // 99 bits per transform
+ { 10, 16, 7 }, // 99 bits per transform
+ { 10, 17, 6 }, // 99 bits per transform
+ { 10, 18, 5 }, // 99 bits per transform
+ { 10, 19, 4 }, // 99 bits per transform
+ { 10, 20, 3 }, // 99 bits per transform
+ { 10, 21, 2 }, // 99 bits per transform
+ { 10, 22, 1 }, // 99 bits per transform
+ { 10, 23, 0 }, // 99 bits per transform
+ { 11, 0, 22 }, // 99 bits per transform
+ { 11, 1, 21 }, // 99 bits per transform
+ { 11, 2, 20 }, // 99 bits per transform
+ { 11, 3, 19 }, // 99 bits per transform
+ { 11, 4, 18 }, // 99 bits per transform
+ { 11, 5, 17 }, // 99 bits per transform
+ { 11, 6, 16 }, // 99 bits per transform
+ { 11, 7, 15 }, // 99 bits per transform
+ { 11, 8, 14 }, // 99 bits per transform
+ { 11, 9, 13 }, // 99 bits per transform
+ { 11, 10, 12 }, // 99 bits per transform
+ { 11, 11, 11 }, // 99 bits per transform
+ { 11, 12, 10 }, // 99 bits per transform
+ { 11, 13, 9 }, // 99 bits per transform
+ { 11, 14, 8 }, // 99 bits per transform
+ { 11, 15, 7 }, // 99 bits per transform
+ { 11, 16, 6 }, // 99 bits per transform
+ { 11, 17, 5 }, // 99 bits per transform
+ { 11, 18, 4 }, // 99 bits per transform
+ { 11, 19, 3 }, // 99 bits per transform
+ { 11, 20, 2 }, // 99 bits per transform
+ { 11, 21, 1 }, // 99 bits per transform
+ { 11, 22, 0 }, // 99 bits per transform
+ { 12, 0, 21 }, // 99 bits per transform
+ { 12, 1, 20 }, // 99 bits per transform
+ { 12, 2, 19 }, // 99 bits per transform
+ { 12, 3, 18 }, // 99 bits per transform
+ { 12, 4, 17 }, // 99 bits per transform
+ { 12, 5, 16 }, // 99 bits per transform
+ { 12, 6, 15 }, // 99 bits per transform
+ { 12, 7, 14 }, // 99 bits per transform
+ { 12, 8, 13 }, // 99 bits per transform
+ { 12, 9, 12 }, // 99 bits per transform
+ { 12, 10, 11 }, // 99 bits per transform
+ { 12, 11, 10 }, // 99 bits per transform
+ { 12, 12, 9 }, // 99 bits per transform
+ { 12, 13, 8 }, // 99 bits per transform
+ { 12, 14, 7 }, // 99 bits per transform
+ { 12, 15, 6 }, // 99 bits per transform
+ { 12, 16, 5 }, // 99 bits per transform
+ { 12, 17, 4 }, // 99 bits per transform
+ { 12, 18, 3 }, // 99 bits per transform
+ { 12, 19, 2 }, // 99 bits per transform
+ { 12, 20, 1 }, // 99 bits per transform
+ { 12, 21, 0 }, // 99 bits per transform
+ { 13, 0, 20 }, // 99 bits per transform
+ { 13, 1, 19 }, // 99 bits per transform
+ { 13, 2, 18 }, // 99 bits per transform
+ { 13, 3, 17 }, // 99 bits per transform
+ { 13, 4, 16 }, // 99 bits per transform
+ { 13, 5, 15 }, // 99 bits per transform
+ { 13, 6, 14 }, // 99 bits per transform
+ { 13, 7, 13 }, // 99 bits per transform
+ { 13, 8, 12 }, // 99 bits per transform
+ { 13, 9, 11 }, // 99 bits per transform
+ { 13, 10, 10 }, // 99 bits per transform
+ { 13, 11, 9 }, // 99 bits per transform
+ { 13, 12, 8 }, // 99 bits per transform
+ { 13, 13, 7 }, // 99 bits per transform
+ { 13, 14, 6 }, // 99 bits per transform
+ { 13, 15, 5 }, // 99 bits per transform
+ { 13, 16, 4 }, // 99 bits per transform
+ { 13, 17, 3 }, // 99 bits per transform
+ { 13, 18, 2 }, // 99 bits per transform
+ { 13, 19, 1 }, // 99 bits per transform
+ { 13, 20, 0 }, // 99 bits per transform
+ { 14, 0, 19 }, // 99 bits per transform
+ { 14, 1, 18 }, // 99 bits per transform
+ { 14, 2, 17 }, // 99 bits per transform
+ { 14, 3, 16 }, // 99 bits per transform
+ { 14, 4, 15 }, // 99 bits per transform
+ { 14, 5, 14 }, // 99 bits per transform
+ { 14, 6, 13 }, // 99 bits per transform
+ { 14, 7, 12 }, // 99 bits per transform
+ { 14, 8, 11 }, // 99 bits per transform
+ { 14, 9, 10 }, // 99 bits per transform
+ { 14, 10, 9 }, // 99 bits per transform
+ { 14, 11, 8 }, // 99 bits per transform
+ { 14, 12, 7 }, // 99 bits per transform
+ { 14, 13, 6 }, // 99 bits per transform
+ { 14, 14, 5 }, // 99 bits per transform
+ { 14, 15, 4 }, // 99 bits per transform
+ { 14, 16, 3 }, // 99 bits per transform
+ { 14, 17, 2 }, // 99 bits per transform
+ { 14, 18, 1 }, // 99 bits per transform
+ { 14, 19, 0 }, // 99 bits per transform
+ { 15, 0, 18 }, // 99 bits per transform
+ { 15, 1, 17 }, // 99 bits per transform
+ { 15, 2, 16 }, // 99 bits per transform
+ { 15, 3, 15 }, // 99 bits per transform
+ { 15, 4, 14 }, // 99 bits per transform
+ { 15, 5, 13 }, // 99 bits per transform
+ { 15, 6, 12 }, // 99 bits per transform
+ { 15, 7, 11 }, // 99 bits per transform
+ { 15, 8, 10 }, // 99 bits per transform
+ { 15, 9, 9 }, // 99 bits per transform
+ { 15, 10, 8 }, // 99 bits per transform
+ { 15, 11, 7 }, // 99 bits per transform
+ { 15, 12, 6 }, // 99 bits per transform
+ { 15, 13, 5 }, // 99 bits per transform
+ { 15, 14, 4 }, // 99 bits per transform
+ { 15, 15, 3 }, // 99 bits per transform
+ { 15, 16, 2 }, // 99 bits per transform
+ { 15, 17, 1 }, // 99 bits per transform
+ { 15, 18, 0 }, // 99 bits per transform
+ { 16, 0, 17 }, // 99 bits per transform
+ { 16, 1, 16 }, // 99 bits per transform
+ { 16, 2, 15 }, // 99 bits per transform
+ { 16, 3, 14 }, // 99 bits per transform
+ { 16, 4, 13 }, // 99 bits per transform
+ { 16, 5, 12 }, // 99 bits per transform
+ { 16, 6, 11 }, // 99 bits per transform
+ { 16, 7, 10 }, // 99 bits per transform
+ { 16, 8, 9 }, // 99 bits per transform
+ { 16, 9, 8 }, // 99 bits per transform
+ { 16, 10, 7 }, // 99 bits per transform
+ { 16, 11, 6 }, // 99 bits per transform
+ { 16, 12, 5 }, // 99 bits per transform
+ { 16, 13, 4 }, // 99 bits per transform
+ { 16, 14, 3 }, // 99 bits per transform
+ { 16, 15, 2 }, // 99 bits per transform
+ { 16, 16, 1 }, // 99 bits per transform
+ { 16, 17, 0 }, // 99 bits per transform
+ { 17, 0, 16 }, // 99 bits per transform
+ { 17, 1, 15 }, // 99 bits per transform
+ { 17, 2, 14 }, // 99 bits per transform
+ { 17, 3, 13 }, // 99 bits per transform
+ { 17, 4, 12 }, // 99 bits per transform
+ { 17, 5, 11 }, // 99 bits per transform
+ { 17, 6, 10 }, // 99 bits per transform
+ { 17, 7, 9 }, // 99 bits per transform
+ { 17, 8, 8 }, // 99 bits per transform
+ { 17, 9, 7 }, // 99 bits per transform
+ { 17, 10, 6 }, // 99 bits per transform
+ { 17, 11, 5 }, // 99 bits per transform
+ { 17, 12, 4 }, // 99 bits per transform
+ { 17, 13, 3 }, // 99 bits per transform
+ { 17, 14, 2 }, // 99 bits per transform
+ { 17, 15, 1 }, // 99 bits per transform
+ { 17, 16, 0 }, // 99 bits per transform
+ { 18, 0, 15 }, // 99 bits per transform
+ { 18, 1, 14 }, // 99 bits per transform
+ { 18, 2, 13 }, // 99 bits per transform
+ { 18, 3, 12 }, // 99 bits per transform
+ { 18, 4, 11 }, // 99 bits per transform
+ { 18, 5, 10 }, // 99 bits per transform
+ { 18, 6, 9 }, // 99 bits per transform
+ { 18, 7, 8 }, // 99 bits per transform
+ { 18, 8, 7 }, // 99 bits per transform
+ { 18, 9, 6 }, // 99 bits per transform
+ { 18, 10, 5 }, // 99 bits per transform
+ { 18, 11, 4 }, // 99 bits per transform
+ { 18, 12, 3 }, // 99 bits per transform
+ { 18, 13, 2 }, // 99 bits per transform
+ { 18, 14, 1 }, // 99 bits per transform
+ { 18, 15, 0 }, // 99 bits per transform
+ { 19, 0, 14 }, // 99 bits per transform
+ { 19, 1, 13 }, // 99 bits per transform
+ { 19, 2, 12 }, // 99 bits per transform
+ { 19, 3, 11 }, // 99 bits per transform
+ { 19, 4, 10 }, // 99 bits per transform
+ { 19, 5, 9 }, // 99 bits per transform
+ { 19, 6, 8 }, // 99 bits per transform
+ { 19, 7, 7 }, // 99 bits per transform
+ { 19, 8, 6 }, // 99 bits per transform
+ { 19, 9, 5 }, // 99 bits per transform
+ { 19, 10, 4 }, // 99 bits per transform
+ { 19, 11, 3 }, // 99 bits per transform
+ { 19, 12, 2 }, // 99 bits per transform
+ { 19, 13, 1 }, // 99 bits per transform
+ { 19, 14, 0 }, // 99 bits per transform
+ { 20, 0, 13 }, // 99 bits per transform
+ { 20, 1, 12 }, // 99 bits per transform
+ { 20, 2, 11 }, // 99 bits per transform
+ { 20, 3, 10 }, // 99 bits per transform
+ { 20, 4, 9 }, // 99 bits per transform
+ { 20, 5, 8 }, // 99 bits per transform
+ { 20, 6, 7 }, // 99 bits per transform
+ { 20, 7, 6 }, // 99 bits per transform
+ { 20, 8, 5 }, // 99 bits per transform
+ { 20, 9, 4 }, // 99 bits per transform
+ { 20, 10, 3 }, // 99 bits per transform
+ { 20, 11, 2 }, // 99 bits per transform
+ { 20, 12, 1 }, // 99 bits per transform
+ { 20, 13, 0 }, // 99 bits per transform
+ { 21, 0, 12 }, // 99 bits per transform
+ { 21, 1, 11 }, // 99 bits per transform
+ { 21, 2, 10 }, // 99 bits per transform
+ { 21, 3, 9 }, // 99 bits per transform
+ { 21, 4, 8 }, // 99 bits per transform
+ { 21, 5, 7 }, // 99 bits per transform
+ { 21, 6, 6 }, // 99 bits per transform
+ { 21, 7, 5 }, // 99 bits per transform
+ { 21, 8, 4 }, // 99 bits per transform
+ { 21, 9, 3 }, // 99 bits per transform
+ { 21, 10, 2 }, // 99 bits per transform
+ { 21, 11, 1 }, // 99 bits per transform
+ { 21, 12, 0 }, // 99 bits per transform
+ { 22, 0, 11 }, // 99 bits per transform
+ { 22, 1, 10 }, // 99 bits per transform
+ { 22, 2, 9 }, // 99 bits per transform
+ { 22, 3, 8 }, // 99 bits per transform
+ { 22, 4, 7 }, // 99 bits per transform
+ { 22, 5, 6 }, // 99 bits per transform
+ { 22, 6, 5 }, // 99 bits per transform
+ { 22, 7, 4 }, // 99 bits per transform
+ { 22, 8, 3 }, // 99 bits per transform
+ { 22, 9, 2 }, // 99 bits per transform
+ { 22, 10, 1 }, // 99 bits per transform
+ { 22, 11, 0 }, // 99 bits per transform
+ { 23, 0, 10 }, // 99 bits per transform
+ { 23, 1, 9 }, // 99 bits per transform
+ { 23, 2, 8 }, // 99 bits per transform
+ { 23, 3, 7 }, // 99 bits per transform
+ { 23, 4, 6 }, // 99 bits per transform
+ { 23, 5, 5 }, // 99 bits per transform
+ { 23, 6, 4 }, // 99 bits per transform
+ { 23, 7, 3 }, // 99 bits per transform
+ { 23, 8, 2 }, // 99 bits per transform
+ { 23, 9, 1 }, // 99 bits per transform
+ { 23, 10, 0 }, // 99 bits per transform
+ { 24, 0, 1 }, // 99 bits per transform
+ { 24, 1, 0 }, // 99 bits per transform
+ { 0, 2, 24 }, // 102 bits per transform
+ { 0, 11, 23 }, // 102 bits per transform
+ { 0, 12, 22 }, // 102 bits per transform
+ { 0, 13, 21 }, // 102 bits per transform
+ { 0, 14, 20 }, // 102 bits per transform
+ { 0, 15, 19 }, // 102 bits per transform
+ { 0, 16, 18 }, // 102 bits per transform
+ { 0, 17, 17 }, // 102 bits per transform
+ { 0, 18, 16 }, // 102 bits per transform
+ { 0, 19, 15 }, // 102 bits per transform
+ { 0, 20, 14 }, // 102 bits per transform
+ { 0, 21, 13 }, // 102 bits per transform
+ { 0, 22, 12 }, // 102 bits per transform
+ { 0, 23, 11 }, // 102 bits per transform
+ { 0, 24, 2 }, // 102 bits per transform
+ { 1, 1, 24 }, // 102 bits per transform
+ { 1, 10, 23 }, // 102 bits per transform
+ { 1, 11, 22 }, // 102 bits per transform
+ { 1, 12, 21 }, // 102 bits per transform
+ { 1, 13, 20 }, // 102 bits per transform
+ { 1, 14, 19 }, // 102 bits per transform
+ { 1, 15, 18 }, // 102 bits per transform
+ { 1, 16, 17 }, // 102 bits per transform
+ { 1, 17, 16 }, // 102 bits per transform
+ { 1, 18, 15 }, // 102 bits per transform
+ { 1, 19, 14 }, // 102 bits per transform
+ { 1, 20, 13 }, // 102 bits per transform
+ { 1, 21, 12 }, // 102 bits per transform
+ { 1, 22, 11 }, // 102 bits per transform
+ { 1, 23, 10 }, // 102 bits per transform
+ { 1, 24, 1 }, // 102 bits per transform
+ { 2, 0, 24 }, // 102 bits per transform
+ { 2, 9, 23 }, // 102 bits per transform
+ { 2, 10, 22 }, // 102 bits per transform
+ { 2, 11, 21 }, // 102 bits per transform
+ { 2, 12, 20 }, // 102 bits per transform
+ { 2, 13, 19 }, // 102 bits per transform
+ { 2, 14, 18 }, // 102 bits per transform
+ { 2, 15, 17 }, // 102 bits per transform
+ { 2, 16, 16 }, // 102 bits per transform
+ { 2, 17, 15 }, // 102 bits per transform
+ { 2, 18, 14 }, // 102 bits per transform
+ { 2, 19, 13 }, // 102 bits per transform
+ { 2, 20, 12 }, // 102 bits per transform
+ { 2, 21, 11 }, // 102 bits per transform
+ { 2, 22, 10 }, // 102 bits per transform
+ { 2, 23, 9 }, // 102 bits per transform
+ { 2, 24, 0 }, // 102 bits per transform
+ { 3, 8, 23 }, // 102 bits per transform
+ { 3, 9, 22 }, // 102 bits per transform
+ { 3, 10, 21 }, // 102 bits per transform
+ { 3, 11, 20 }, // 102 bits per transform
+ { 3, 12, 19 }, // 102 bits per transform
+ { 3, 13, 18 }, // 102 bits per transform
+ { 3, 14, 17 }, // 102 bits per transform
+ { 3, 15, 16 }, // 102 bits per transform
+ { 3, 16, 15 }, // 102 bits per transform
+ { 3, 17, 14 }, // 102 bits per transform
+ { 3, 18, 13 }, // 102 bits per transform
+ { 3, 19, 12 }, // 102 bits per transform
+ { 3, 20, 11 }, // 102 bits per transform
+ { 3, 21, 10 }, // 102 bits per transform
+ { 3, 22, 9 }, // 102 bits per transform
+ { 3, 23, 8 }, // 102 bits per transform
+ { 4, 7, 23 }, // 102 bits per transform
+ { 4, 8, 22 }, // 102 bits per transform
+ { 4, 9, 21 }, // 102 bits per transform
+ { 4, 10, 20 }, // 102 bits per transform
+ { 4, 11, 19 }, // 102 bits per transform
+ { 4, 12, 18 }, // 102 bits per transform
+ { 4, 13, 17 }, // 102 bits per transform
+ { 4, 14, 16 }, // 102 bits per transform
+ { 4, 15, 15 }, // 102 bits per transform
+ { 4, 16, 14 }, // 102 bits per transform
+ { 4, 17, 13 }, // 102 bits per transform
+ { 4, 18, 12 }, // 102 bits per transform
+ { 4, 19, 11 }, // 102 bits per transform
+ { 4, 20, 10 }, // 102 bits per transform
+ { 4, 21, 9 }, // 102 bits per transform
+ { 4, 22, 8 }, // 102 bits per transform
+ { 4, 23, 7 }, // 102 bits per transform
+ { 5, 6, 23 }, // 102 bits per transform
+ { 5, 7, 22 }, // 102 bits per transform
+ { 5, 8, 21 }, // 102 bits per transform
+ { 5, 9, 20 }, // 102 bits per transform
+ { 5, 10, 19 }, // 102 bits per transform
+ { 5, 11, 18 }, // 102 bits per transform
+ { 5, 12, 17 }, // 102 bits per transform
+ { 5, 13, 16 }, // 102 bits per transform
+ { 5, 14, 15 }, // 102 bits per transform
+ { 5, 15, 14 }, // 102 bits per transform
+ { 5, 16, 13 }, // 102 bits per transform
+ { 5, 17, 12 }, // 102 bits per transform
+ { 5, 18, 11 }, // 102 bits per transform
+ { 5, 19, 10 }, // 102 bits per transform
+ { 5, 20, 9 }, // 102 bits per transform
+ { 5, 21, 8 }, // 102 bits per transform
+ { 5, 22, 7 }, // 102 bits per transform
+ { 5, 23, 6 }, // 102 bits per transform
+ { 6, 5, 23 }, // 102 bits per transform
+ { 6, 6, 22 }, // 102 bits per transform
+ { 6, 7, 21 }, // 102 bits per transform
+ { 6, 8, 20 }, // 102 bits per transform
+ { 6, 9, 19 }, // 102 bits per transform
+ { 6, 10, 18 }, // 102 bits per transform
+ { 6, 11, 17 }, // 102 bits per transform
+ { 6, 12, 16 }, // 102 bits per transform
+ { 6, 13, 15 }, // 102 bits per transform
+ { 6, 14, 14 }, // 102 bits per transform
+ { 6, 15, 13 }, // 102 bits per transform
+ { 6, 16, 12 }, // 102 bits per transform
+ { 6, 17, 11 }, // 102 bits per transform
+ { 6, 18, 10 }, // 102 bits per transform
+ { 6, 19, 9 }, // 102 bits per transform
+ { 6, 20, 8 }, // 102 bits per transform
+ { 6, 21, 7 }, // 102 bits per transform
+ { 6, 22, 6 }, // 102 bits per transform
+ { 6, 23, 5 }, // 102 bits per transform
+ { 7, 4, 23 }, // 102 bits per transform
+ { 7, 5, 22 }, // 102 bits per transform
+ { 7, 6, 21 }, // 102 bits per transform
+ { 7, 7, 20 }, // 102 bits per transform
+ { 7, 8, 19 }, // 102 bits per transform
+ { 7, 9, 18 }, // 102 bits per transform
+ { 7, 10, 17 }, // 102 bits per transform
+ { 7, 11, 16 }, // 102 bits per transform
+ { 7, 12, 15 }, // 102 bits per transform
+ { 7, 13, 14 }, // 102 bits per transform
+ { 7, 14, 13 }, // 102 bits per transform
+ { 7, 15, 12 }, // 102 bits per transform
+ { 7, 16, 11 }, // 102 bits per transform
+ { 7, 17, 10 }, // 102 bits per transform
+ { 7, 18, 9 }, // 102 bits per transform
+ { 7, 19, 8 }, // 102 bits per transform
+ { 7, 20, 7 }, // 102 bits per transform
+ { 7, 21, 6 }, // 102 bits per transform
+ { 7, 22, 5 }, // 102 bits per transform
+ { 7, 23, 4 }, // 102 bits per transform
+ { 8, 3, 23 }, // 102 bits per transform
+ { 8, 4, 22 }, // 102 bits per transform
+ { 8, 5, 21 }, // 102 bits per transform
+ { 8, 6, 20 }, // 102 bits per transform
+ { 8, 7, 19 }, // 102 bits per transform
+ { 8, 8, 18 }, // 102 bits per transform
+ { 8, 9, 17 }, // 102 bits per transform
+ { 8, 10, 16 }, // 102 bits per transform
+ { 8, 11, 15 }, // 102 bits per transform
+ { 8, 12, 14 }, // 102 bits per transform
+ { 8, 13, 13 }, // 102 bits per transform
+ { 8, 14, 12 }, // 102 bits per transform
+ { 8, 15, 11 }, // 102 bits per transform
+ { 8, 16, 10 }, // 102 bits per transform
+ { 8, 17, 9 }, // 102 bits per transform
+ { 8, 18, 8 }, // 102 bits per transform
+ { 8, 19, 7 }, // 102 bits per transform
+ { 8, 20, 6 }, // 102 bits per transform
+ { 8, 21, 5 }, // 102 bits per transform
+ { 8, 22, 4 }, // 102 bits per transform
+ { 8, 23, 3 }, // 102 bits per transform
+ { 9, 2, 23 }, // 102 bits per transform
+ { 9, 3, 22 }, // 102 bits per transform
+ { 9, 4, 21 }, // 102 bits per transform
+ { 9, 5, 20 }, // 102 bits per transform
+ { 9, 6, 19 }, // 102 bits per transform
+ { 9, 7, 18 }, // 102 bits per transform
+ { 9, 8, 17 }, // 102 bits per transform
+ { 9, 9, 16 }, // 102 bits per transform
+ { 9, 10, 15 }, // 102 bits per transform
+ { 9, 11, 14 }, // 102 bits per transform
+ { 9, 12, 13 }, // 102 bits per transform
+ { 9, 13, 12 }, // 102 bits per transform
+ { 9, 14, 11 }, // 102 bits per transform
+ { 9, 15, 10 }, // 102 bits per transform
+ { 9, 16, 9 }, // 102 bits per transform
+ { 9, 17, 8 }, // 102 bits per transform
+ { 9, 18, 7 }, // 102 bits per transform
+ { 9, 19, 6 }, // 102 bits per transform
+ { 9, 20, 5 }, // 102 bits per transform
+ { 9, 21, 4 }, // 102 bits per transform
+ { 9, 22, 3 }, // 102 bits per transform
+ { 9, 23, 2 }, // 102 bits per transform
+ { 10, 1, 23 }, // 102 bits per transform
+ { 10, 2, 22 }, // 102 bits per transform
+ { 10, 3, 21 }, // 102 bits per transform
+ { 10, 4, 20 }, // 102 bits per transform
+ { 10, 5, 19 }, // 102 bits per transform
+ { 10, 6, 18 }, // 102 bits per transform
+ { 10, 7, 17 }, // 102 bits per transform
+ { 10, 8, 16 }, // 102 bits per transform
+ { 10, 9, 15 }, // 102 bits per transform
+ { 10, 10, 14 }, // 102 bits per transform
+ { 10, 11, 13 }, // 102 bits per transform
+ { 10, 12, 12 }, // 102 bits per transform
+ { 10, 13, 11 }, // 102 bits per transform
+ { 10, 14, 10 }, // 102 bits per transform
+ { 10, 15, 9 }, // 102 bits per transform
+ { 10, 16, 8 }, // 102 bits per transform
+ { 10, 17, 7 }, // 102 bits per transform
+ { 10, 18, 6 }, // 102 bits per transform
+ { 10, 19, 5 }, // 102 bits per transform
+ { 10, 20, 4 }, // 102 bits per transform
+ { 10, 21, 3 }, // 102 bits per transform
+ { 10, 22, 2 }, // 102 bits per transform
+ { 10, 23, 1 }, // 102 bits per transform
+ { 11, 0, 23 }, // 102 bits per transform
+ { 11, 1, 22 }, // 102 bits per transform
+ { 11, 2, 21 }, // 102 bits per transform
+ { 11, 3, 20 }, // 102 bits per transform
+ { 11, 4, 19 }, // 102 bits per transform
+ { 11, 5, 18 }, // 102 bits per transform
+ { 11, 6, 17 }, // 102 bits per transform
+ { 11, 7, 16 }, // 102 bits per transform
+ { 11, 8, 15 }, // 102 bits per transform
+ { 11, 9, 14 }, // 102 bits per transform
+ { 11, 10, 13 }, // 102 bits per transform
+ { 11, 11, 12 }, // 102 bits per transform
+ { 11, 12, 11 }, // 102 bits per transform
+ { 11, 13, 10 }, // 102 bits per transform
+ { 11, 14, 9 }, // 102 bits per transform
+ { 11, 15, 8 }, // 102 bits per transform
+ { 11, 16, 7 }, // 102 bits per transform
+ { 11, 17, 6 }, // 102 bits per transform
+ { 11, 18, 5 }, // 102 bits per transform
+ { 11, 19, 4 }, // 102 bits per transform
+ { 11, 20, 3 }, // 102 bits per transform
+ { 11, 21, 2 }, // 102 bits per transform
+ { 11, 22, 1 }, // 102 bits per transform
+ { 11, 23, 0 }, // 102 bits per transform
+ { 12, 0, 22 }, // 102 bits per transform
+ { 12, 1, 21 }, // 102 bits per transform
+ { 12, 2, 20 }, // 102 bits per transform
+ { 12, 3, 19 }, // 102 bits per transform
+ { 12, 4, 18 }, // 102 bits per transform
+ { 12, 5, 17 }, // 102 bits per transform
+ { 12, 6, 16 }, // 102 bits per transform
+ { 12, 7, 15 }, // 102 bits per transform
+ { 12, 8, 14 }, // 102 bits per transform
+ { 12, 9, 13 }, // 102 bits per transform
+ { 12, 10, 12 }, // 102 bits per transform
+ { 12, 11, 11 }, // 102 bits per transform
+ { 12, 12, 10 }, // 102 bits per transform
+ { 12, 13, 9 }, // 102 bits per transform
+ { 12, 14, 8 }, // 102 bits per transform
+ { 12, 15, 7 }, // 102 bits per transform
+ { 12, 16, 6 }, // 102 bits per transform
+ { 12, 17, 5 }, // 102 bits per transform
+ { 12, 18, 4 }, // 102 bits per transform
+ { 12, 19, 3 }, // 102 bits per transform
+ { 12, 20, 2 }, // 102 bits per transform
+ { 12, 21, 1 }, // 102 bits per transform
+ { 12, 22, 0 }, // 102 bits per transform
+ { 13, 0, 21 }, // 102 bits per transform
+ { 13, 1, 20 }, // 102 bits per transform
+ { 13, 2, 19 }, // 102 bits per transform
+ { 13, 3, 18 }, // 102 bits per transform
+ { 13, 4, 17 }, // 102 bits per transform
+ { 13, 5, 16 }, // 102 bits per transform
+ { 13, 6, 15 }, // 102 bits per transform
+ { 13, 7, 14 }, // 102 bits per transform
+ { 13, 8, 13 }, // 102 bits per transform
+ { 13, 9, 12 }, // 102 bits per transform
+ { 13, 10, 11 }, // 102 bits per transform
+ { 13, 11, 10 }, // 102 bits per transform
+ { 13, 12, 9 }, // 102 bits per transform
+ { 13, 13, 8 }, // 102 bits per transform
+ { 13, 14, 7 }, // 102 bits per transform
+ { 13, 15, 6 }, // 102 bits per transform
+ { 13, 16, 5 }, // 102 bits per transform
+ { 13, 17, 4 }, // 102 bits per transform
+ { 13, 18, 3 }, // 102 bits per transform
+ { 13, 19, 2 }, // 102 bits per transform
+ { 13, 20, 1 }, // 102 bits per transform
+ { 13, 21, 0 }, // 102 bits per transform
+ { 14, 0, 20 }, // 102 bits per transform
+ { 14, 1, 19 }, // 102 bits per transform
+ { 14, 2, 18 }, // 102 bits per transform
+ { 14, 3, 17 }, // 102 bits per transform
+ { 14, 4, 16 }, // 102 bits per transform
+ { 14, 5, 15 }, // 102 bits per transform
+ { 14, 6, 14 }, // 102 bits per transform
+ { 14, 7, 13 }, // 102 bits per transform
+ { 14, 8, 12 }, // 102 bits per transform
+ { 14, 9, 11 }, // 102 bits per transform
+ { 14, 10, 10 }, // 102 bits per transform
+ { 14, 11, 9 }, // 102 bits per transform
+ { 14, 12, 8 }, // 102 bits per transform
+ { 14, 13, 7 }, // 102 bits per transform
+ { 14, 14, 6 }, // 102 bits per transform
+ { 14, 15, 5 }, // 102 bits per transform
+ { 14, 16, 4 }, // 102 bits per transform
+ { 14, 17, 3 }, // 102 bits per transform
+ { 14, 18, 2 }, // 102 bits per transform
+ { 14, 19, 1 }, // 102 bits per transform
+ { 14, 20, 0 }, // 102 bits per transform
+ { 15, 0, 19 }, // 102 bits per transform
+ { 15, 1, 18 }, // 102 bits per transform
+ { 15, 2, 17 }, // 102 bits per transform
+ { 15, 3, 16 }, // 102 bits per transform
+ { 15, 4, 15 }, // 102 bits per transform
+ { 15, 5, 14 }, // 102 bits per transform
+ { 15, 6, 13 }, // 102 bits per transform
+ { 15, 7, 12 }, // 102 bits per transform
+ { 15, 8, 11 }, // 102 bits per transform
+ { 15, 9, 10 }, // 102 bits per transform
+ { 15, 10, 9 }, // 102 bits per transform
+ { 15, 11, 8 }, // 102 bits per transform
+ { 15, 12, 7 }, // 102 bits per transform
+ { 15, 13, 6 }, // 102 bits per transform
+ { 15, 14, 5 }, // 102 bits per transform
+ { 15, 15, 4 }, // 102 bits per transform
+ { 15, 16, 3 }, // 102 bits per transform
+ { 15, 17, 2 }, // 102 bits per transform
+ { 15, 18, 1 }, // 102 bits per transform
+ { 15, 19, 0 }, // 102 bits per transform
+ { 16, 0, 18 }, // 102 bits per transform
+ { 16, 1, 17 }, // 102 bits per transform
+ { 16, 2, 16 }, // 102 bits per transform
+ { 16, 3, 15 }, // 102 bits per transform
+ { 16, 4, 14 }, // 102 bits per transform
+ { 16, 5, 13 }, // 102 bits per transform
+ { 16, 6, 12 }, // 102 bits per transform
+ { 16, 7, 11 }, // 102 bits per transform
+ { 16, 8, 10 }, // 102 bits per transform
+ { 16, 9, 9 }, // 102 bits per transform
+ { 16, 10, 8 }, // 102 bits per transform
+ { 16, 11, 7 }, // 102 bits per transform
+ { 16, 12, 6 }, // 102 bits per transform
+ { 16, 13, 5 }, // 102 bits per transform
+ { 16, 14, 4 }, // 102 bits per transform
+ { 16, 15, 3 }, // 102 bits per transform
+ { 16, 16, 2 }, // 102 bits per transform
+ { 16, 17, 1 }, // 102 bits per transform
+ { 16, 18, 0 }, // 102 bits per transform
+ { 17, 0, 17 }, // 102 bits per transform
+ { 17, 1, 16 }, // 102 bits per transform
+ { 17, 2, 15 }, // 102 bits per transform
+ { 17, 3, 14 }, // 102 bits per transform
+ { 17, 4, 13 }, // 102 bits per transform
+ { 17, 5, 12 }, // 102 bits per transform
+ { 17, 6, 11 }, // 102 bits per transform
+ { 17, 7, 10 }, // 102 bits per transform
+ { 17, 8, 9 }, // 102 bits per transform
+ { 17, 9, 8 }, // 102 bits per transform
+ { 17, 10, 7 }, // 102 bits per transform
+ { 17, 11, 6 }, // 102 bits per transform
+ { 17, 12, 5 }, // 102 bits per transform
+ { 17, 13, 4 }, // 102 bits per transform
+ { 17, 14, 3 }, // 102 bits per transform
+ { 17, 15, 2 }, // 102 bits per transform
+ { 17, 16, 1 }, // 102 bits per transform
+ { 17, 17, 0 }, // 102 bits per transform
+ { 18, 0, 16 }, // 102 bits per transform
+ { 18, 1, 15 }, // 102 bits per transform
+ { 18, 2, 14 }, // 102 bits per transform
+ { 18, 3, 13 }, // 102 bits per transform
+ { 18, 4, 12 }, // 102 bits per transform
+ { 18, 5, 11 }, // 102 bits per transform
+ { 18, 6, 10 }, // 102 bits per transform
+ { 18, 7, 9 }, // 102 bits per transform
+ { 18, 8, 8 }, // 102 bits per transform
+ { 18, 9, 7 }, // 102 bits per transform
+ { 18, 10, 6 }, // 102 bits per transform
+ { 18, 11, 5 }, // 102 bits per transform
+ { 18, 12, 4 }, // 102 bits per transform
+ { 18, 13, 3 }, // 102 bits per transform
+ { 18, 14, 2 }, // 102 bits per transform
+ { 18, 15, 1 }, // 102 bits per transform
+ { 18, 16, 0 }, // 102 bits per transform
+ { 19, 0, 15 }, // 102 bits per transform
+ { 19, 1, 14 }, // 102 bits per transform
+ { 19, 2, 13 }, // 102 bits per transform
+ { 19, 3, 12 }, // 102 bits per transform
+ { 19, 4, 11 }, // 102 bits per transform
+ { 19, 5, 10 }, // 102 bits per transform
+ { 19, 6, 9 }, // 102 bits per transform
+ { 19, 7, 8 }, // 102 bits per transform
+ { 19, 8, 7 }, // 102 bits per transform
+ { 19, 9, 6 }, // 102 bits per transform
+ { 19, 10, 5 }, // 102 bits per transform
+ { 19, 11, 4 }, // 102 bits per transform
+ { 19, 12, 3 }, // 102 bits per transform
+ { 19, 13, 2 }, // 102 bits per transform
+ { 19, 14, 1 }, // 102 bits per transform
+ { 19, 15, 0 }, // 102 bits per transform
+ { 20, 0, 14 }, // 102 bits per transform
+ { 20, 1, 13 }, // 102 bits per transform
+ { 20, 2, 12 }, // 102 bits per transform
+ { 20, 3, 11 }, // 102 bits per transform
+ { 20, 4, 10 }, // 102 bits per transform
+ { 20, 5, 9 }, // 102 bits per transform
+ { 20, 6, 8 }, // 102 bits per transform
+ { 20, 7, 7 }, // 102 bits per transform
+ { 20, 8, 6 }, // 102 bits per transform
+ { 20, 9, 5 }, // 102 bits per transform
+ { 20, 10, 4 }, // 102 bits per transform
+ { 20, 11, 3 }, // 102 bits per transform
+ { 20, 12, 2 }, // 102 bits per transform
+ { 20, 13, 1 }, // 102 bits per transform
+ { 20, 14, 0 }, // 102 bits per transform
+ { 21, 0, 13 }, // 102 bits per transform
+ { 21, 1, 12 }, // 102 bits per transform
+ { 21, 2, 11 }, // 102 bits per transform
+ { 21, 3, 10 }, // 102 bits per transform
+ { 21, 4, 9 }, // 102 bits per transform
+ { 21, 5, 8 }, // 102 bits per transform
+ { 21, 6, 7 }, // 102 bits per transform
+ { 21, 7, 6 }, // 102 bits per transform
+ { 21, 8, 5 }, // 102 bits per transform
+ { 21, 9, 4 }, // 102 bits per transform
+ { 21, 10, 3 }, // 102 bits per transform
+ { 21, 11, 2 }, // 102 bits per transform
+ { 21, 12, 1 }, // 102 bits per transform
+ { 21, 13, 0 }, // 102 bits per transform
+ { 22, 0, 12 }, // 102 bits per transform
+ { 22, 1, 11 }, // 102 bits per transform
+ { 22, 2, 10 }, // 102 bits per transform
+ { 22, 3, 9 }, // 102 bits per transform
+ { 22, 4, 8 }, // 102 bits per transform
+ { 22, 5, 7 }, // 102 bits per transform
+ { 22, 6, 6 }, // 102 bits per transform
+ { 22, 7, 5 }, // 102 bits per transform
+ { 22, 8, 4 }, // 102 bits per transform
+ { 22, 9, 3 }, // 102 bits per transform
+ { 22, 10, 2 }, // 102 bits per transform
+ { 22, 11, 1 }, // 102 bits per transform
+ { 22, 12, 0 }, // 102 bits per transform
+ { 23, 0, 11 }, // 102 bits per transform
+ { 23, 1, 10 }, // 102 bits per transform
+ { 23, 2, 9 }, // 102 bits per transform
+ { 23, 3, 8 }, // 102 bits per transform
+ { 23, 4, 7 }, // 102 bits per transform
+ { 23, 5, 6 }, // 102 bits per transform
+ { 23, 6, 5 }, // 102 bits per transform
+ { 23, 7, 4 }, // 102 bits per transform
+ { 23, 8, 3 }, // 102 bits per transform
+ { 23, 9, 2 }, // 102 bits per transform
+ { 23, 10, 1 }, // 102 bits per transform
+ { 23, 11, 0 }, // 102 bits per transform
+ { 24, 0, 2 }, // 102 bits per transform
+ { 24, 1, 1 }, // 102 bits per transform
+ { 24, 2, 0 }, // 102 bits per transform
+ { 0, 3, 24 }, // 105 bits per transform
+ { 0, 12, 23 }, // 105 bits per transform
+ { 0, 13, 22 }, // 105 bits per transform
+ { 0, 14, 21 }, // 105 bits per transform
+ { 0, 15, 20 }, // 105 bits per transform
+ { 0, 16, 19 }, // 105 bits per transform
+ { 0, 17, 18 }, // 105 bits per transform
+ { 0, 18, 17 }, // 105 bits per transform
+ { 0, 19, 16 }, // 105 bits per transform
+ { 0, 20, 15 }, // 105 bits per transform
+ { 0, 21, 14 }, // 105 bits per transform
+ { 0, 22, 13 }, // 105 bits per transform
+ { 0, 23, 12 }, // 105 bits per transform
+ { 0, 24, 3 }, // 105 bits per transform
+ { 1, 2, 24 }, // 105 bits per transform
+ { 1, 11, 23 }, // 105 bits per transform
+ { 1, 12, 22 }, // 105 bits per transform
+ { 1, 13, 21 }, // 105 bits per transform
+ { 1, 14, 20 }, // 105 bits per transform
+ { 1, 15, 19 }, // 105 bits per transform
+ { 1, 16, 18 }, // 105 bits per transform
+ { 1, 17, 17 }, // 105 bits per transform
+ { 1, 18, 16 }, // 105 bits per transform
+ { 1, 19, 15 }, // 105 bits per transform
+ { 1, 20, 14 }, // 105 bits per transform
+ { 1, 21, 13 }, // 105 bits per transform
+ { 1, 22, 12 }, // 105 bits per transform
+ { 1, 23, 11 }, // 105 bits per transform
+ { 1, 24, 2 }, // 105 bits per transform
+ { 2, 1, 24 }, // 105 bits per transform
+ { 2, 10, 23 }, // 105 bits per transform
+ { 2, 11, 22 }, // 105 bits per transform
+ { 2, 12, 21 }, // 105 bits per transform
+ { 2, 13, 20 }, // 105 bits per transform
+ { 2, 14, 19 }, // 105 bits per transform
+ { 2, 15, 18 }, // 105 bits per transform
+ { 2, 16, 17 }, // 105 bits per transform
+ { 2, 17, 16 }, // 105 bits per transform
+ { 2, 18, 15 }, // 105 bits per transform
+ { 2, 19, 14 }, // 105 bits per transform
+ { 2, 20, 13 }, // 105 bits per transform
+ { 2, 21, 12 }, // 105 bits per transform
+ { 2, 22, 11 }, // 105 bits per transform
+ { 2, 23, 10 }, // 105 bits per transform
+ { 2, 24, 1 }, // 105 bits per transform
+ { 3, 0, 24 }, // 105 bits per transform
+ { 3, 9, 23 }, // 105 bits per transform
+ { 3, 10, 22 }, // 105 bits per transform
+ { 3, 11, 21 }, // 105 bits per transform
+ { 3, 12, 20 }, // 105 bits per transform
+ { 3, 13, 19 }, // 105 bits per transform
+ { 3, 14, 18 }, // 105 bits per transform
+ { 3, 15, 17 }, // 105 bits per transform
+ { 3, 16, 16 }, // 105 bits per transform
+ { 3, 17, 15 }, // 105 bits per transform
+ { 3, 18, 14 }, // 105 bits per transform
+ { 3, 19, 13 }, // 105 bits per transform
+ { 3, 20, 12 }, // 105 bits per transform
+ { 3, 21, 11 }, // 105 bits per transform
+ { 3, 22, 10 }, // 105 bits per transform
+ { 3, 23, 9 }, // 105 bits per transform
+ { 3, 24, 0 }, // 105 bits per transform
+ { 4, 8, 23 }, // 105 bits per transform
+ { 4, 9, 22 }, // 105 bits per transform
+ { 4, 10, 21 }, // 105 bits per transform
+ { 4, 11, 20 }, // 105 bits per transform
+ { 4, 12, 19 }, // 105 bits per transform
+ { 4, 13, 18 }, // 105 bits per transform
+ { 4, 14, 17 }, // 105 bits per transform
+ { 4, 15, 16 }, // 105 bits per transform
+ { 4, 16, 15 }, // 105 bits per transform
+ { 4, 17, 14 }, // 105 bits per transform
+ { 4, 18, 13 }, // 105 bits per transform
+ { 4, 19, 12 }, // 105 bits per transform
+ { 4, 20, 11 }, // 105 bits per transform
+ { 4, 21, 10 }, // 105 bits per transform
+ { 4, 22, 9 }, // 105 bits per transform
+ { 4, 23, 8 }, // 105 bits per transform
+ { 5, 7, 23 }, // 105 bits per transform
+ { 5, 8, 22 }, // 105 bits per transform
+ { 5, 9, 21 }, // 105 bits per transform
+ { 5, 10, 20 }, // 105 bits per transform
+ { 5, 11, 19 }, // 105 bits per transform
+ { 5, 12, 18 }, // 105 bits per transform
+ { 5, 13, 17 }, // 105 bits per transform
+ { 5, 14, 16 }, // 105 bits per transform
+ { 5, 15, 15 }, // 105 bits per transform
+ { 5, 16, 14 }, // 105 bits per transform
+ { 5, 17, 13 }, // 105 bits per transform
+ { 5, 18, 12 }, // 105 bits per transform
+ { 5, 19, 11 }, // 105 bits per transform
+ { 5, 20, 10 }, // 105 bits per transform
+ { 5, 21, 9 }, // 105 bits per transform
+ { 5, 22, 8 }, // 105 bits per transform
+ { 5, 23, 7 }, // 105 bits per transform
+ { 6, 6, 23 }, // 105 bits per transform
+ { 6, 7, 22 }, // 105 bits per transform
+ { 6, 8, 21 }, // 105 bits per transform
+ { 6, 9, 20 }, // 105 bits per transform
+ { 6, 10, 19 }, // 105 bits per transform
+ { 6, 11, 18 }, // 105 bits per transform
+ { 6, 12, 17 }, // 105 bits per transform
+ { 6, 13, 16 }, // 105 bits per transform
+ { 6, 14, 15 }, // 105 bits per transform
+ { 6, 15, 14 }, // 105 bits per transform
+ { 6, 16, 13 }, // 105 bits per transform
+ { 6, 17, 12 }, // 105 bits per transform
+ { 6, 18, 11 }, // 105 bits per transform
+ { 6, 19, 10 }, // 105 bits per transform
+ { 6, 20, 9 }, // 105 bits per transform
+ { 6, 21, 8 }, // 105 bits per transform
+ { 6, 22, 7 }, // 105 bits per transform
+ { 6, 23, 6 }, // 105 bits per transform
+ { 7, 5, 23 }, // 105 bits per transform
+ { 7, 6, 22 }, // 105 bits per transform
+ { 7, 7, 21 }, // 105 bits per transform
+ { 7, 8, 20 }, // 105 bits per transform
+ { 7, 9, 19 }, // 105 bits per transform
+ { 7, 10, 18 }, // 105 bits per transform
+ { 7, 11, 17 }, // 105 bits per transform
+ { 7, 12, 16 }, // 105 bits per transform
+ { 7, 13, 15 }, // 105 bits per transform
+ { 7, 14, 14 }, // 105 bits per transform
+ { 7, 15, 13 }, // 105 bits per transform
+ { 7, 16, 12 }, // 105 bits per transform
+ { 7, 17, 11 }, // 105 bits per transform
+ { 7, 18, 10 }, // 105 bits per transform
+ { 7, 19, 9 }, // 105 bits per transform
+ { 7, 20, 8 }, // 105 bits per transform
+ { 7, 21, 7 }, // 105 bits per transform
+ { 7, 22, 6 }, // 105 bits per transform
+ { 7, 23, 5 }, // 105 bits per transform
+ { 8, 4, 23 }, // 105 bits per transform
+ { 8, 5, 22 }, // 105 bits per transform
+ { 8, 6, 21 }, // 105 bits per transform
+ { 8, 7, 20 }, // 105 bits per transform
+ { 8, 8, 19 }, // 105 bits per transform
+ { 8, 9, 18 }, // 105 bits per transform
+ { 8, 10, 17 }, // 105 bits per transform
+ { 8, 11, 16 }, // 105 bits per transform
+ { 8, 12, 15 }, // 105 bits per transform
+ { 8, 13, 14 }, // 105 bits per transform
+ { 8, 14, 13 }, // 105 bits per transform
+ { 8, 15, 12 }, // 105 bits per transform
+ { 8, 16, 11 }, // 105 bits per transform
+ { 8, 17, 10 }, // 105 bits per transform
+ { 8, 18, 9 }, // 105 bits per transform
+ { 8, 19, 8 }, // 105 bits per transform
+ { 8, 20, 7 }, // 105 bits per transform
+ { 8, 21, 6 }, // 105 bits per transform
+ { 8, 22, 5 }, // 105 bits per transform
+ { 8, 23, 4 }, // 105 bits per transform
+ { 9, 3, 23 }, // 105 bits per transform
+ { 9, 4, 22 }, // 105 bits per transform
+ { 9, 5, 21 }, // 105 bits per transform
+ { 9, 6, 20 }, // 105 bits per transform
+ { 9, 7, 19 }, // 105 bits per transform
+ { 9, 8, 18 }, // 105 bits per transform
+ { 9, 9, 17 }, // 105 bits per transform
+ { 9, 10, 16 }, // 105 bits per transform
+ { 9, 11, 15 }, // 105 bits per transform
+ { 9, 12, 14 }, // 105 bits per transform
+ { 9, 13, 13 }, // 105 bits per transform
+ { 9, 14, 12 }, // 105 bits per transform
+ { 9, 15, 11 }, // 105 bits per transform
+ { 9, 16, 10 }, // 105 bits per transform
+ { 9, 17, 9 }, // 105 bits per transform
+ { 9, 18, 8 }, // 105 bits per transform
+ { 9, 19, 7 }, // 105 bits per transform
+ { 9, 20, 6 }, // 105 bits per transform
+ { 9, 21, 5 }, // 105 bits per transform
+ { 9, 22, 4 }, // 105 bits per transform
+ { 9, 23, 3 }, // 105 bits per transform
+ { 10, 2, 23 }, // 105 bits per transform
+ { 10, 3, 22 }, // 105 bits per transform
+ { 10, 4, 21 }, // 105 bits per transform
+ { 10, 5, 20 }, // 105 bits per transform
+ { 10, 6, 19 }, // 105 bits per transform
+ { 10, 7, 18 }, // 105 bits per transform
+ { 10, 8, 17 }, // 105 bits per transform
+ { 10, 9, 16 }, // 105 bits per transform
+ { 10, 10, 15 }, // 105 bits per transform
+ { 10, 11, 14 }, // 105 bits per transform
+ { 10, 12, 13 }, // 105 bits per transform
+ { 10, 13, 12 }, // 105 bits per transform
+ { 10, 14, 11 }, // 105 bits per transform
+ { 10, 15, 10 }, // 105 bits per transform
+ { 10, 16, 9 }, // 105 bits per transform
+ { 10, 17, 8 }, // 105 bits per transform
+ { 10, 18, 7 }, // 105 bits per transform
+ { 10, 19, 6 }, // 105 bits per transform
+ { 10, 20, 5 }, // 105 bits per transform
+ { 10, 21, 4 }, // 105 bits per transform
+ { 10, 22, 3 }, // 105 bits per transform
+ { 10, 23, 2 }, // 105 bits per transform
+ { 11, 1, 23 }, // 105 bits per transform
+ { 11, 2, 22 }, // 105 bits per transform
+ { 11, 3, 21 }, // 105 bits per transform
+ { 11, 4, 20 }, // 105 bits per transform
+ { 11, 5, 19 }, // 105 bits per transform
+ { 11, 6, 18 }, // 105 bits per transform
+ { 11, 7, 17 }, // 105 bits per transform
+ { 11, 8, 16 }, // 105 bits per transform
+ { 11, 9, 15 }, // 105 bits per transform
+ { 11, 10, 14 }, // 105 bits per transform
+ { 11, 11, 13 }, // 105 bits per transform
+ { 11, 12, 12 }, // 105 bits per transform
+ { 11, 13, 11 }, // 105 bits per transform
+ { 11, 14, 10 }, // 105 bits per transform
+ { 11, 15, 9 }, // 105 bits per transform
+ { 11, 16, 8 }, // 105 bits per transform
+ { 11, 17, 7 }, // 105 bits per transform
+ { 11, 18, 6 }, // 105 bits per transform
+ { 11, 19, 5 }, // 105 bits per transform
+ { 11, 20, 4 }, // 105 bits per transform
+ { 11, 21, 3 }, // 105 bits per transform
+ { 11, 22, 2 }, // 105 bits per transform
+ { 11, 23, 1 }, // 105 bits per transform
+ { 12, 0, 23 }, // 105 bits per transform
+ { 12, 1, 22 }, // 105 bits per transform
+ { 12, 2, 21 }, // 105 bits per transform
+ { 12, 3, 20 }, // 105 bits per transform
+ { 12, 4, 19 }, // 105 bits per transform
+ { 12, 5, 18 }, // 105 bits per transform
+ { 12, 6, 17 }, // 105 bits per transform
+ { 12, 7, 16 }, // 105 bits per transform
+ { 12, 8, 15 }, // 105 bits per transform
+ { 12, 9, 14 }, // 105 bits per transform
+ { 12, 10, 13 }, // 105 bits per transform
+ { 12, 11, 12 }, // 105 bits per transform
+ { 12, 12, 11 }, // 105 bits per transform
+ { 12, 13, 10 }, // 105 bits per transform
+ { 12, 14, 9 }, // 105 bits per transform
+ { 12, 15, 8 }, // 105 bits per transform
+ { 12, 16, 7 }, // 105 bits per transform
+ { 12, 17, 6 }, // 105 bits per transform
+ { 12, 18, 5 }, // 105 bits per transform
+ { 12, 19, 4 }, // 105 bits per transform
+ { 12, 20, 3 }, // 105 bits per transform
+ { 12, 21, 2 }, // 105 bits per transform
+ { 12, 22, 1 }, // 105 bits per transform
+ { 12, 23, 0 }, // 105 bits per transform
+ { 13, 0, 22 }, // 105 bits per transform
+ { 13, 1, 21 }, // 105 bits per transform
+ { 13, 2, 20 }, // 105 bits per transform
+ { 13, 3, 19 }, // 105 bits per transform
+ { 13, 4, 18 }, // 105 bits per transform
+ { 13, 5, 17 }, // 105 bits per transform
+ { 13, 6, 16 }, // 105 bits per transform
+ { 13, 7, 15 }, // 105 bits per transform
+ { 13, 8, 14 }, // 105 bits per transform
+ { 13, 9, 13 }, // 105 bits per transform
+ { 13, 10, 12 }, // 105 bits per transform
+ { 13, 11, 11 }, // 105 bits per transform
+ { 13, 12, 10 }, // 105 bits per transform
+ { 13, 13, 9 }, // 105 bits per transform
+ { 13, 14, 8 }, // 105 bits per transform
+ { 13, 15, 7 }, // 105 bits per transform
+ { 13, 16, 6 }, // 105 bits per transform
+ { 13, 17, 5 }, // 105 bits per transform
+ { 13, 18, 4 }, // 105 bits per transform
+ { 13, 19, 3 }, // 105 bits per transform
+ { 13, 20, 2 }, // 105 bits per transform
+ { 13, 21, 1 }, // 105 bits per transform
+ { 13, 22, 0 }, // 105 bits per transform
+ { 14, 0, 21 }, // 105 bits per transform
+ { 14, 1, 20 }, // 105 bits per transform
+ { 14, 2, 19 }, // 105 bits per transform
+ { 14, 3, 18 }, // 105 bits per transform
+ { 14, 4, 17 }, // 105 bits per transform
+ { 14, 5, 16 }, // 105 bits per transform
+ { 14, 6, 15 }, // 105 bits per transform
+ { 14, 7, 14 }, // 105 bits per transform
+ { 14, 8, 13 }, // 105 bits per transform
+ { 14, 9, 12 }, // 105 bits per transform
+ { 14, 10, 11 }, // 105 bits per transform
+ { 14, 11, 10 }, // 105 bits per transform
+ { 14, 12, 9 }, // 105 bits per transform
+ { 14, 13, 8 }, // 105 bits per transform
+ { 14, 14, 7 }, // 105 bits per transform
+ { 14, 15, 6 }, // 105 bits per transform
+ { 14, 16, 5 }, // 105 bits per transform
+ { 14, 17, 4 }, // 105 bits per transform
+ { 14, 18, 3 }, // 105 bits per transform
+ { 14, 19, 2 }, // 105 bits per transform
+ { 14, 20, 1 }, // 105 bits per transform
+ { 14, 21, 0 }, // 105 bits per transform
+ { 15, 0, 20 }, // 105 bits per transform
+ { 15, 1, 19 }, // 105 bits per transform
+ { 15, 2, 18 }, // 105 bits per transform
+ { 15, 3, 17 }, // 105 bits per transform
+ { 15, 4, 16 }, // 105 bits per transform
+ { 15, 5, 15 }, // 105 bits per transform
+ { 15, 6, 14 }, // 105 bits per transform
+ { 15, 7, 13 }, // 105 bits per transform
+ { 15, 8, 12 }, // 105 bits per transform
+ { 15, 9, 11 }, // 105 bits per transform
+ { 15, 10, 10 }, // 105 bits per transform
+ { 15, 11, 9 }, // 105 bits per transform
+ { 15, 12, 8 }, // 105 bits per transform
+ { 15, 13, 7 }, // 105 bits per transform
+ { 15, 14, 6 }, // 105 bits per transform
+ { 15, 15, 5 }, // 105 bits per transform
+ { 15, 16, 4 }, // 105 bits per transform
+ { 15, 17, 3 }, // 105 bits per transform
+ { 15, 18, 2 }, // 105 bits per transform
+ { 15, 19, 1 }, // 105 bits per transform
+ { 15, 20, 0 }, // 105 bits per transform
+ { 16, 0, 19 }, // 105 bits per transform
+ { 16, 1, 18 }, // 105 bits per transform
+ { 16, 2, 17 }, // 105 bits per transform
+ { 16, 3, 16 }, // 105 bits per transform
+ { 16, 4, 15 }, // 105 bits per transform
+ { 16, 5, 14 }, // 105 bits per transform
+ { 16, 6, 13 }, // 105 bits per transform
+ { 16, 7, 12 }, // 105 bits per transform
+ { 16, 8, 11 }, // 105 bits per transform
+ { 16, 9, 10 }, // 105 bits per transform
+ { 16, 10, 9 }, // 105 bits per transform
+ { 16, 11, 8 }, // 105 bits per transform
+ { 16, 12, 7 }, // 105 bits per transform
+ { 16, 13, 6 }, // 105 bits per transform
+ { 16, 14, 5 }, // 105 bits per transform
+ { 16, 15, 4 }, // 105 bits per transform
+ { 16, 16, 3 }, // 105 bits per transform
+ { 16, 17, 2 }, // 105 bits per transform
+ { 16, 18, 1 }, // 105 bits per transform
+ { 16, 19, 0 }, // 105 bits per transform
+ { 17, 0, 18 }, // 105 bits per transform
+ { 17, 1, 17 }, // 105 bits per transform
+ { 17, 2, 16 }, // 105 bits per transform
+ { 17, 3, 15 }, // 105 bits per transform
+ { 17, 4, 14 }, // 105 bits per transform
+ { 17, 5, 13 }, // 105 bits per transform
+ { 17, 6, 12 }, // 105 bits per transform
+ { 17, 7, 11 }, // 105 bits per transform
+ { 17, 8, 10 }, // 105 bits per transform
+ { 17, 9, 9 }, // 105 bits per transform
+ { 17, 10, 8 }, // 105 bits per transform
+ { 17, 11, 7 }, // 105 bits per transform
+ { 17, 12, 6 }, // 105 bits per transform
+ { 17, 13, 5 }, // 105 bits per transform
+ { 17, 14, 4 }, // 105 bits per transform
+ { 17, 15, 3 }, // 105 bits per transform
+ { 17, 16, 2 }, // 105 bits per transform
+ { 17, 17, 1 }, // 105 bits per transform
+ { 17, 18, 0 }, // 105 bits per transform
+ { 18, 0, 17 }, // 105 bits per transform
+ { 18, 1, 16 }, // 105 bits per transform
+ { 18, 2, 15 }, // 105 bits per transform
+ { 18, 3, 14 }, // 105 bits per transform
+ { 18, 4, 13 }, // 105 bits per transform
+ { 18, 5, 12 }, // 105 bits per transform
+ { 18, 6, 11 }, // 105 bits per transform
+ { 18, 7, 10 }, // 105 bits per transform
+ { 18, 8, 9 }, // 105 bits per transform
+ { 18, 9, 8 }, // 105 bits per transform
+ { 18, 10, 7 }, // 105 bits per transform
+ { 18, 11, 6 }, // 105 bits per transform
+ { 18, 12, 5 }, // 105 bits per transform
+ { 18, 13, 4 }, // 105 bits per transform
+ { 18, 14, 3 }, // 105 bits per transform
+ { 18, 15, 2 }, // 105 bits per transform
+ { 18, 16, 1 }, // 105 bits per transform
+ { 18, 17, 0 }, // 105 bits per transform
+ { 19, 0, 16 }, // 105 bits per transform
+ { 19, 1, 15 }, // 105 bits per transform
+ { 19, 2, 14 }, // 105 bits per transform
+ { 19, 3, 13 }, // 105 bits per transform
+ { 19, 4, 12 }, // 105 bits per transform
+ { 19, 5, 11 }, // 105 bits per transform
+ { 19, 6, 10 }, // 105 bits per transform
+ { 19, 7, 9 }, // 105 bits per transform
+ { 19, 8, 8 }, // 105 bits per transform
+ { 19, 9, 7 }, // 105 bits per transform
+ { 19, 10, 6 }, // 105 bits per transform
+ { 19, 11, 5 }, // 105 bits per transform
+ { 19, 12, 4 }, // 105 bits per transform
+ { 19, 13, 3 }, // 105 bits per transform
+ { 19, 14, 2 }, // 105 bits per transform
+ { 19, 15, 1 }, // 105 bits per transform
+ { 19, 16, 0 }, // 105 bits per transform
+ { 20, 0, 15 }, // 105 bits per transform
+ { 20, 1, 14 }, // 105 bits per transform
+ { 20, 2, 13 }, // 105 bits per transform
+ { 20, 3, 12 }, // 105 bits per transform
+ { 20, 4, 11 }, // 105 bits per transform
+ { 20, 5, 10 }, // 105 bits per transform
+ { 20, 6, 9 }, // 105 bits per transform
+ { 20, 7, 8 }, // 105 bits per transform
+ { 20, 8, 7 }, // 105 bits per transform
+ { 20, 9, 6 }, // 105 bits per transform
+ { 20, 10, 5 }, // 105 bits per transform
+ { 20, 11, 4 }, // 105 bits per transform
+ { 20, 12, 3 }, // 105 bits per transform
+ { 20, 13, 2 }, // 105 bits per transform
+ { 20, 14, 1 }, // 105 bits per transform
+ { 20, 15, 0 }, // 105 bits per transform
+ { 21, 0, 14 }, // 105 bits per transform
+ { 21, 1, 13 }, // 105 bits per transform
+ { 21, 2, 12 }, // 105 bits per transform
+ { 21, 3, 11 }, // 105 bits per transform
+ { 21, 4, 10 }, // 105 bits per transform
+ { 21, 5, 9 }, // 105 bits per transform
+ { 21, 6, 8 }, // 105 bits per transform
+ { 21, 7, 7 }, // 105 bits per transform
+ { 21, 8, 6 }, // 105 bits per transform
+ { 21, 9, 5 }, // 105 bits per transform
+ { 21, 10, 4 }, // 105 bits per transform
+ { 21, 11, 3 }, // 105 bits per transform
+ { 21, 12, 2 }, // 105 bits per transform
+ { 21, 13, 1 }, // 105 bits per transform
+ { 21, 14, 0 }, // 105 bits per transform
+ { 22, 0, 13 }, // 105 bits per transform
+ { 22, 1, 12 }, // 105 bits per transform
+ { 22, 2, 11 }, // 105 bits per transform
+ { 22, 3, 10 }, // 105 bits per transform
+ { 22, 4, 9 }, // 105 bits per transform
+ { 22, 5, 8 }, // 105 bits per transform
+ { 22, 6, 7 }, // 105 bits per transform
+ { 22, 7, 6 }, // 105 bits per transform
+ { 22, 8, 5 }, // 105 bits per transform
+ { 22, 9, 4 }, // 105 bits per transform
+ { 22, 10, 3 }, // 105 bits per transform
+ { 22, 11, 2 }, // 105 bits per transform
+ { 22, 12, 1 }, // 105 bits per transform
+ { 22, 13, 0 }, // 105 bits per transform
+ { 23, 0, 12 }, // 105 bits per transform
+ { 23, 1, 11 }, // 105 bits per transform
+ { 23, 2, 10 }, // 105 bits per transform
+ { 23, 3, 9 }, // 105 bits per transform
+ { 23, 4, 8 }, // 105 bits per transform
+ { 23, 5, 7 }, // 105 bits per transform
+ { 23, 6, 6 }, // 105 bits per transform
+ { 23, 7, 5 }, // 105 bits per transform
+ { 23, 8, 4 }, // 105 bits per transform
+ { 23, 9, 3 }, // 105 bits per transform
+ { 23, 10, 2 }, // 105 bits per transform
+ { 23, 11, 1 }, // 105 bits per transform
+ { 23, 12, 0 }, // 105 bits per transform
+ { 24, 0, 3 }, // 105 bits per transform
+ { 24, 1, 2 }, // 105 bits per transform
+ { 24, 2, 1 }, // 105 bits per transform
+ { 24, 3, 0 }, // 105 bits per transform
+ { 0, 4, 24 }, // 108 bits per transform
+ { 0, 13, 23 }, // 108 bits per transform
+ { 0, 14, 22 }, // 108 bits per transform
+ { 0, 15, 21 }, // 108 bits per transform
+ { 0, 16, 20 }, // 108 bits per transform
+ { 0, 17, 19 }, // 108 bits per transform
+ { 0, 18, 18 }, // 108 bits per transform
+ { 0, 19, 17 }, // 108 bits per transform
+ { 0, 20, 16 }, // 108 bits per transform
+ { 0, 21, 15 }, // 108 bits per transform
+ { 0, 22, 14 }, // 108 bits per transform
+ { 0, 23, 13 }, // 108 bits per transform
+ { 0, 24, 4 }, // 108 bits per transform
+ { 1, 3, 24 }, // 108 bits per transform
+ { 1, 12, 23 }, // 108 bits per transform
+ { 1, 13, 22 }, // 108 bits per transform
+ { 1, 14, 21 }, // 108 bits per transform
+ { 1, 15, 20 }, // 108 bits per transform
+ { 1, 16, 19 }, // 108 bits per transform
+ { 1, 17, 18 }, // 108 bits per transform
+ { 1, 18, 17 }, // 108 bits per transform
+ { 1, 19, 16 }, // 108 bits per transform
+ { 1, 20, 15 }, // 108 bits per transform
+ { 1, 21, 14 }, // 108 bits per transform
+ { 1, 22, 13 }, // 108 bits per transform
+ { 1, 23, 12 }, // 108 bits per transform
+ { 1, 24, 3 }, // 108 bits per transform
+ { 2, 2, 24 }, // 108 bits per transform
+ { 2, 11, 23 }, // 108 bits per transform
+ { 2, 12, 22 }, // 108 bits per transform
+ { 2, 13, 21 }, // 108 bits per transform
+ { 2, 14, 20 }, // 108 bits per transform
+ { 2, 15, 19 }, // 108 bits per transform
+ { 2, 16, 18 }, // 108 bits per transform
+ { 2, 17, 17 }, // 108 bits per transform
+ { 2, 18, 16 }, // 108 bits per transform
+ { 2, 19, 15 }, // 108 bits per transform
+ { 2, 20, 14 }, // 108 bits per transform
+ { 2, 21, 13 }, // 108 bits per transform
+ { 2, 22, 12 }, // 108 bits per transform
+ { 2, 23, 11 }, // 108 bits per transform
+ { 2, 24, 2 }, // 108 bits per transform
+ { 3, 1, 24 }, // 108 bits per transform
+ { 3, 10, 23 }, // 108 bits per transform
+ { 3, 11, 22 }, // 108 bits per transform
+ { 3, 12, 21 }, // 108 bits per transform
+ { 3, 13, 20 }, // 108 bits per transform
+ { 3, 14, 19 }, // 108 bits per transform
+ { 3, 15, 18 }, // 108 bits per transform
+ { 3, 16, 17 }, // 108 bits per transform
+ { 3, 17, 16 }, // 108 bits per transform
+ { 3, 18, 15 }, // 108 bits per transform
+ { 3, 19, 14 }, // 108 bits per transform
+ { 3, 20, 13 }, // 108 bits per transform
+ { 3, 21, 12 }, // 108 bits per transform
+ { 3, 22, 11 }, // 108 bits per transform
+ { 3, 23, 10 }, // 108 bits per transform
+ { 3, 24, 1 }, // 108 bits per transform
+ { 4, 0, 24 }, // 108 bits per transform
+ { 4, 9, 23 }, // 108 bits per transform
+ { 4, 10, 22 }, // 108 bits per transform
+ { 4, 11, 21 }, // 108 bits per transform
+ { 4, 12, 20 }, // 108 bits per transform
+ { 4, 13, 19 }, // 108 bits per transform
+ { 4, 14, 18 }, // 108 bits per transform
+ { 4, 15, 17 }, // 108 bits per transform
+ { 4, 16, 16 }, // 108 bits per transform
+ { 4, 17, 15 }, // 108 bits per transform
+ { 4, 18, 14 }, // 108 bits per transform
+ { 4, 19, 13 }, // 108 bits per transform
+ { 4, 20, 12 }, // 108 bits per transform
+ { 4, 21, 11 }, // 108 bits per transform
+ { 4, 22, 10 }, // 108 bits per transform
+ { 4, 23, 9 }, // 108 bits per transform
+ { 4, 24, 0 }, // 108 bits per transform
+ { 5, 8, 23 }, // 108 bits per transform
+ { 5, 9, 22 }, // 108 bits per transform
+ { 5, 10, 21 }, // 108 bits per transform
+ { 5, 11, 20 }, // 108 bits per transform
+ { 5, 12, 19 }, // 108 bits per transform
+ { 5, 13, 18 }, // 108 bits per transform
+ { 5, 14, 17 }, // 108 bits per transform
+ { 5, 15, 16 }, // 108 bits per transform
+ { 5, 16, 15 }, // 108 bits per transform
+ { 5, 17, 14 }, // 108 bits per transform
+ { 5, 18, 13 }, // 108 bits per transform
+ { 5, 19, 12 }, // 108 bits per transform
+ { 5, 20, 11 }, // 108 bits per transform
+ { 5, 21, 10 }, // 108 bits per transform
+ { 5, 22, 9 }, // 108 bits per transform
+ { 5, 23, 8 }, // 108 bits per transform
+ { 6, 7, 23 }, // 108 bits per transform
+ { 6, 8, 22 }, // 108 bits per transform
+ { 6, 9, 21 }, // 108 bits per transform
+ { 6, 10, 20 }, // 108 bits per transform
+ { 6, 11, 19 }, // 108 bits per transform
+ { 6, 12, 18 }, // 108 bits per transform
+ { 6, 13, 17 }, // 108 bits per transform
+ { 6, 14, 16 }, // 108 bits per transform
+ { 6, 15, 15 }, // 108 bits per transform
+ { 6, 16, 14 }, // 108 bits per transform
+ { 6, 17, 13 }, // 108 bits per transform
+ { 6, 18, 12 }, // 108 bits per transform
+ { 6, 19, 11 }, // 108 bits per transform
+ { 6, 20, 10 }, // 108 bits per transform
+ { 6, 21, 9 }, // 108 bits per transform
+ { 6, 22, 8 }, // 108 bits per transform
+ { 6, 23, 7 }, // 108 bits per transform
+ { 7, 6, 23 }, // 108 bits per transform
+ { 7, 7, 22 }, // 108 bits per transform
+ { 7, 8, 21 }, // 108 bits per transform
+ { 7, 9, 20 }, // 108 bits per transform
+ { 7, 10, 19 }, // 108 bits per transform
+ { 7, 11, 18 }, // 108 bits per transform
+ { 7, 12, 17 }, // 108 bits per transform
+ { 7, 13, 16 }, // 108 bits per transform
+ { 7, 14, 15 }, // 108 bits per transform
+ { 7, 15, 14 }, // 108 bits per transform
+ { 7, 16, 13 }, // 108 bits per transform
+ { 7, 17, 12 }, // 108 bits per transform
+ { 7, 18, 11 }, // 108 bits per transform
+ { 7, 19, 10 }, // 108 bits per transform
+ { 7, 20, 9 }, // 108 bits per transform
+ { 7, 21, 8 }, // 108 bits per transform
+ { 7, 22, 7 }, // 108 bits per transform
+ { 7, 23, 6 }, // 108 bits per transform
+ { 8, 5, 23 }, // 108 bits per transform
+ { 8, 6, 22 }, // 108 bits per transform
+ { 8, 7, 21 }, // 108 bits per transform
+ { 8, 8, 20 }, // 108 bits per transform
+ { 8, 9, 19 }, // 108 bits per transform
+ { 8, 10, 18 }, // 108 bits per transform
+ { 8, 11, 17 }, // 108 bits per transform
+ { 8, 12, 16 }, // 108 bits per transform
+ { 8, 13, 15 }, // 108 bits per transform
+ { 8, 14, 14 }, // 108 bits per transform
+ { 8, 15, 13 }, // 108 bits per transform
+ { 8, 16, 12 }, // 108 bits per transform
+ { 8, 17, 11 }, // 108 bits per transform
+ { 8, 18, 10 }, // 108 bits per transform
+ { 8, 19, 9 }, // 108 bits per transform
+ { 8, 20, 8 }, // 108 bits per transform
+ { 8, 21, 7 }, // 108 bits per transform
+ { 8, 22, 6 }, // 108 bits per transform
+ { 8, 23, 5 }, // 108 bits per transform
+ { 9, 4, 23 }, // 108 bits per transform
+ { 9, 5, 22 }, // 108 bits per transform
+ { 9, 6, 21 }, // 108 bits per transform
+ { 9, 7, 20 }, // 108 bits per transform
+ { 9, 8, 19 }, // 108 bits per transform
+ { 9, 9, 18 }, // 108 bits per transform
+ { 9, 10, 17 }, // 108 bits per transform
+ { 9, 11, 16 }, // 108 bits per transform
+ { 9, 12, 15 }, // 108 bits per transform
+ { 9, 13, 14 }, // 108 bits per transform
+ { 9, 14, 13 }, // 108 bits per transform
+ { 9, 15, 12 }, // 108 bits per transform
+ { 9, 16, 11 }, // 108 bits per transform
+ { 9, 17, 10 }, // 108 bits per transform
+ { 9, 18, 9 }, // 108 bits per transform
+ { 9, 19, 8 }, // 108 bits per transform
+ { 9, 20, 7 }, // 108 bits per transform
+ { 9, 21, 6 }, // 108 bits per transform
+ { 9, 22, 5 }, // 108 bits per transform
+ { 9, 23, 4 }, // 108 bits per transform
+ { 10, 3, 23 }, // 108 bits per transform
+ { 10, 4, 22 }, // 108 bits per transform
+ { 10, 5, 21 }, // 108 bits per transform
+ { 10, 6, 20 }, // 108 bits per transform
+ { 10, 7, 19 }, // 108 bits per transform
+ { 10, 8, 18 }, // 108 bits per transform
+ { 10, 9, 17 }, // 108 bits per transform
+ { 10, 10, 16 }, // 108 bits per transform
+ { 10, 11, 15 }, // 108 bits per transform
+ { 10, 12, 14 }, // 108 bits per transform
+ { 10, 13, 13 }, // 108 bits per transform
+ { 10, 14, 12 }, // 108 bits per transform
+ { 10, 15, 11 }, // 108 bits per transform
+ { 10, 16, 10 }, // 108 bits per transform
+ { 10, 17, 9 }, // 108 bits per transform
+ { 10, 18, 8 }, // 108 bits per transform
+ { 10, 19, 7 }, // 108 bits per transform
+ { 10, 20, 6 }, // 108 bits per transform
+ { 10, 21, 5 }, // 108 bits per transform
+ { 10, 22, 4 }, // 108 bits per transform
+ { 10, 23, 3 }, // 108 bits per transform
+ { 11, 2, 23 }, // 108 bits per transform
+ { 11, 3, 22 }, // 108 bits per transform
+ { 11, 4, 21 }, // 108 bits per transform
+ { 11, 5, 20 }, // 108 bits per transform
+ { 11, 6, 19 }, // 108 bits per transform
+ { 11, 7, 18 }, // 108 bits per transform
+ { 11, 8, 17 }, // 108 bits per transform
+ { 11, 9, 16 }, // 108 bits per transform
+ { 11, 10, 15 }, // 108 bits per transform
+ { 11, 11, 14 }, // 108 bits per transform
+ { 11, 12, 13 }, // 108 bits per transform
+ { 11, 13, 12 }, // 108 bits per transform
+ { 11, 14, 11 }, // 108 bits per transform
+ { 11, 15, 10 }, // 108 bits per transform
+ { 11, 16, 9 }, // 108 bits per transform
+ { 11, 17, 8 }, // 108 bits per transform
+ { 11, 18, 7 }, // 108 bits per transform
+ { 11, 19, 6 }, // 108 bits per transform
+ { 11, 20, 5 }, // 108 bits per transform
+ { 11, 21, 4 }, // 108 bits per transform
+ { 11, 22, 3 }, // 108 bits per transform
+ { 11, 23, 2 }, // 108 bits per transform
+ { 12, 1, 23 }, // 108 bits per transform
+ { 12, 2, 22 }, // 108 bits per transform
+ { 12, 3, 21 }, // 108 bits per transform
+ { 12, 4, 20 }, // 108 bits per transform
+ { 12, 5, 19 }, // 108 bits per transform
+ { 12, 6, 18 }, // 108 bits per transform
+ { 12, 7, 17 }, // 108 bits per transform
+ { 12, 8, 16 }, // 108 bits per transform
+ { 12, 9, 15 }, // 108 bits per transform
+ { 12, 10, 14 }, // 108 bits per transform
+ { 12, 11, 13 }, // 108 bits per transform
+ { 12, 12, 12 }, // 108 bits per transform
+ { 12, 13, 11 }, // 108 bits per transform
+ { 12, 14, 10 }, // 108 bits per transform
+ { 12, 15, 9 }, // 108 bits per transform
+ { 12, 16, 8 }, // 108 bits per transform
+ { 12, 17, 7 }, // 108 bits per transform
+ { 12, 18, 6 }, // 108 bits per transform
+ { 12, 19, 5 }, // 108 bits per transform
+ { 12, 20, 4 }, // 108 bits per transform
+ { 12, 21, 3 }, // 108 bits per transform
+ { 12, 22, 2 }, // 108 bits per transform
+ { 12, 23, 1 }, // 108 bits per transform
+ { 13, 0, 23 }, // 108 bits per transform
+ { 13, 1, 22 }, // 108 bits per transform
+ { 13, 2, 21 }, // 108 bits per transform
+ { 13, 3, 20 }, // 108 bits per transform
+ { 13, 4, 19 }, // 108 bits per transform
+ { 13, 5, 18 }, // 108 bits per transform
+ { 13, 6, 17 }, // 108 bits per transform
+ { 13, 7, 16 }, // 108 bits per transform
+ { 13, 8, 15 }, // 108 bits per transform
+ { 13, 9, 14 }, // 108 bits per transform
+ { 13, 10, 13 }, // 108 bits per transform
+ { 13, 11, 12 }, // 108 bits per transform
+ { 13, 12, 11 }, // 108 bits per transform
+ { 13, 13, 10 }, // 108 bits per transform
+ { 13, 14, 9 }, // 108 bits per transform
+ { 13, 15, 8 }, // 108 bits per transform
+ { 13, 16, 7 }, // 108 bits per transform
+ { 13, 17, 6 }, // 108 bits per transform
+ { 13, 18, 5 }, // 108 bits per transform
+ { 13, 19, 4 }, // 108 bits per transform
+ { 13, 20, 3 }, // 108 bits per transform
+ { 13, 21, 2 }, // 108 bits per transform
+ { 13, 22, 1 }, // 108 bits per transform
+ { 13, 23, 0 }, // 108 bits per transform
+ { 14, 0, 22 }, // 108 bits per transform
+ { 14, 1, 21 }, // 108 bits per transform
+ { 14, 2, 20 }, // 108 bits per transform
+ { 14, 3, 19 }, // 108 bits per transform
+ { 14, 4, 18 }, // 108 bits per transform
+ { 14, 5, 17 }, // 108 bits per transform
+ { 14, 6, 16 }, // 108 bits per transform
+ { 14, 7, 15 }, // 108 bits per transform
+ { 14, 8, 14 }, // 108 bits per transform
+ { 14, 9, 13 }, // 108 bits per transform
+ { 14, 10, 12 }, // 108 bits per transform
+ { 14, 11, 11 }, // 108 bits per transform
+ { 14, 12, 10 }, // 108 bits per transform
+ { 14, 13, 9 }, // 108 bits per transform
+ { 14, 14, 8 }, // 108 bits per transform
+ { 14, 15, 7 }, // 108 bits per transform
+ { 14, 16, 6 }, // 108 bits per transform
+ { 14, 17, 5 }, // 108 bits per transform
+ { 14, 18, 4 }, // 108 bits per transform
+ { 14, 19, 3 }, // 108 bits per transform
+ { 14, 20, 2 }, // 108 bits per transform
+ { 14, 21, 1 }, // 108 bits per transform
+ { 14, 22, 0 }, // 108 bits per transform
+ { 15, 0, 21 }, // 108 bits per transform
+ { 15, 1, 20 }, // 108 bits per transform
+ { 15, 2, 19 }, // 108 bits per transform
+ { 15, 3, 18 }, // 108 bits per transform
+ { 15, 4, 17 }, // 108 bits per transform
+ { 15, 5, 16 }, // 108 bits per transform
+ { 15, 6, 15 }, // 108 bits per transform
+ { 15, 7, 14 }, // 108 bits per transform
+ { 15, 8, 13 }, // 108 bits per transform
+ { 15, 9, 12 }, // 108 bits per transform
+ { 15, 10, 11 }, // 108 bits per transform
+ { 15, 11, 10 }, // 108 bits per transform
+ { 15, 12, 9 }, // 108 bits per transform
+ { 15, 13, 8 }, // 108 bits per transform
+ { 15, 14, 7 }, // 108 bits per transform
+ { 15, 15, 6 }, // 108 bits per transform
+ { 15, 16, 5 }, // 108 bits per transform
+ { 15, 17, 4 }, // 108 bits per transform
+ { 15, 18, 3 }, // 108 bits per transform
+ { 15, 19, 2 }, // 108 bits per transform
+ { 15, 20, 1 }, // 108 bits per transform
+ { 15, 21, 0 }, // 108 bits per transform
+ { 16, 0, 20 }, // 108 bits per transform
+ { 16, 1, 19 }, // 108 bits per transform
+ { 16, 2, 18 }, // 108 bits per transform
+ { 16, 3, 17 }, // 108 bits per transform
+ { 16, 4, 16 }, // 108 bits per transform
+ { 16, 5, 15 }, // 108 bits per transform
+ { 16, 6, 14 }, // 108 bits per transform
+ { 16, 7, 13 }, // 108 bits per transform
+ { 16, 8, 12 }, // 108 bits per transform
+ { 16, 9, 11 }, // 108 bits per transform
+ { 16, 10, 10 }, // 108 bits per transform
+ { 16, 11, 9 }, // 108 bits per transform
+ { 16, 12, 8 }, // 108 bits per transform
+ { 16, 13, 7 }, // 108 bits per transform
+ { 16, 14, 6 }, // 108 bits per transform
+ { 16, 15, 5 }, // 108 bits per transform
+ { 16, 16, 4 }, // 108 bits per transform
+ { 16, 17, 3 }, // 108 bits per transform
+ { 16, 18, 2 }, // 108 bits per transform
+ { 16, 19, 1 }, // 108 bits per transform
+ { 16, 20, 0 }, // 108 bits per transform
+ { 17, 0, 19 }, // 108 bits per transform
+ { 17, 1, 18 }, // 108 bits per transform
+ { 17, 2, 17 }, // 108 bits per transform
+ { 17, 3, 16 }, // 108 bits per transform
+ { 17, 4, 15 }, // 108 bits per transform
+ { 17, 5, 14 }, // 108 bits per transform
+ { 17, 6, 13 }, // 108 bits per transform
+ { 17, 7, 12 }, // 108 bits per transform
+ { 17, 8, 11 }, // 108 bits per transform
+ { 17, 9, 10 }, // 108 bits per transform
+ { 17, 10, 9 }, // 108 bits per transform
+ { 17, 11, 8 }, // 108 bits per transform
+ { 17, 12, 7 }, // 108 bits per transform
+ { 17, 13, 6 }, // 108 bits per transform
+ { 17, 14, 5 }, // 108 bits per transform
+ { 17, 15, 4 }, // 108 bits per transform
+ { 17, 16, 3 }, // 108 bits per transform
+ { 17, 17, 2 }, // 108 bits per transform
+ { 17, 18, 1 }, // 108 bits per transform
+ { 17, 19, 0 }, // 108 bits per transform
+ { 18, 0, 18 }, // 108 bits per transform
+ { 18, 1, 17 }, // 108 bits per transform
+ { 18, 2, 16 }, // 108 bits per transform
+ { 18, 3, 15 }, // 108 bits per transform
+ { 18, 4, 14 }, // 108 bits per transform
+ { 18, 5, 13 }, // 108 bits per transform
+ { 18, 6, 12 }, // 108 bits per transform
+ { 18, 7, 11 }, // 108 bits per transform
+ { 18, 8, 10 }, // 108 bits per transform
+ { 18, 9, 9 }, // 108 bits per transform
+ { 18, 10, 8 }, // 108 bits per transform
+ { 18, 11, 7 }, // 108 bits per transform
+ { 18, 12, 6 }, // 108 bits per transform
+ { 18, 13, 5 }, // 108 bits per transform
+ { 18, 14, 4 }, // 108 bits per transform
+ { 18, 15, 3 }, // 108 bits per transform
+ { 18, 16, 2 }, // 108 bits per transform
+ { 18, 17, 1 }, // 108 bits per transform
+ { 18, 18, 0 }, // 108 bits per transform
+ { 19, 0, 17 }, // 108 bits per transform
+ { 19, 1, 16 }, // 108 bits per transform
+ { 19, 2, 15 }, // 108 bits per transform
+ { 19, 3, 14 }, // 108 bits per transform
+ { 19, 4, 13 }, // 108 bits per transform
+ { 19, 5, 12 }, // 108 bits per transform
+ { 19, 6, 11 }, // 108 bits per transform
+ { 19, 7, 10 }, // 108 bits per transform
+ { 19, 8, 9 }, // 108 bits per transform
+ { 19, 9, 8 }, // 108 bits per transform
+ { 19, 10, 7 }, // 108 bits per transform
+ { 19, 11, 6 }, // 108 bits per transform
+ { 19, 12, 5 }, // 108 bits per transform
+ { 19, 13, 4 }, // 108 bits per transform
+ { 19, 14, 3 }, // 108 bits per transform
+ { 19, 15, 2 }, // 108 bits per transform
+ { 19, 16, 1 }, // 108 bits per transform
+ { 19, 17, 0 }, // 108 bits per transform
+ { 20, 0, 16 }, // 108 bits per transform
+ { 20, 1, 15 }, // 108 bits per transform
+ { 20, 2, 14 }, // 108 bits per transform
+ { 20, 3, 13 }, // 108 bits per transform
+ { 20, 4, 12 }, // 108 bits per transform
+ { 20, 5, 11 }, // 108 bits per transform
+ { 20, 6, 10 }, // 108 bits per transform
+ { 20, 7, 9 }, // 108 bits per transform
+ { 20, 8, 8 }, // 108 bits per transform
+ { 20, 9, 7 }, // 108 bits per transform
+ { 20, 10, 6 }, // 108 bits per transform
+ { 20, 11, 5 }, // 108 bits per transform
+ { 20, 12, 4 }, // 108 bits per transform
+ { 20, 13, 3 }, // 108 bits per transform
+ { 20, 14, 2 }, // 108 bits per transform
+ { 20, 15, 1 }, // 108 bits per transform
+ { 20, 16, 0 }, // 108 bits per transform
+ { 21, 0, 15 }, // 108 bits per transform
+ { 21, 1, 14 }, // 108 bits per transform
+ { 21, 2, 13 }, // 108 bits per transform
+ { 21, 3, 12 }, // 108 bits per transform
+ { 21, 4, 11 }, // 108 bits per transform
+ { 21, 5, 10 }, // 108 bits per transform
+ { 21, 6, 9 }, // 108 bits per transform
+ { 21, 7, 8 }, // 108 bits per transform
+ { 21, 8, 7 }, // 108 bits per transform
+ { 21, 9, 6 }, // 108 bits per transform
+ { 21, 10, 5 }, // 108 bits per transform
+ { 21, 11, 4 }, // 108 bits per transform
+ { 21, 12, 3 }, // 108 bits per transform
+ { 21, 13, 2 }, // 108 bits per transform
+ { 21, 14, 1 }, // 108 bits per transform
+ { 21, 15, 0 }, // 108 bits per transform
+ { 22, 0, 14 }, // 108 bits per transform
+ { 22, 1, 13 }, // 108 bits per transform
+ { 22, 2, 12 }, // 108 bits per transform
+ { 22, 3, 11 }, // 108 bits per transform
+ { 22, 4, 10 }, // 108 bits per transform
+ { 22, 5, 9 }, // 108 bits per transform
+ { 22, 6, 8 }, // 108 bits per transform
+ { 22, 7, 7 }, // 108 bits per transform
+ { 22, 8, 6 }, // 108 bits per transform
+ { 22, 9, 5 }, // 108 bits per transform
+ { 22, 10, 4 }, // 108 bits per transform
+ { 22, 11, 3 }, // 108 bits per transform
+ { 22, 12, 2 }, // 108 bits per transform
+ { 22, 13, 1 }, // 108 bits per transform
+ { 22, 14, 0 }, // 108 bits per transform
+ { 23, 0, 13 }, // 108 bits per transform
+ { 23, 1, 12 }, // 108 bits per transform
+ { 23, 2, 11 }, // 108 bits per transform
+ { 23, 3, 10 }, // 108 bits per transform
+ { 23, 4, 9 }, // 108 bits per transform
+ { 23, 5, 8 }, // 108 bits per transform
+ { 23, 6, 7 }, // 108 bits per transform
+ { 23, 7, 6 }, // 108 bits per transform
+ { 23, 8, 5 }, // 108 bits per transform
+ { 23, 9, 4 }, // 108 bits per transform
+ { 23, 10, 3 }, // 108 bits per transform
+ { 23, 11, 2 }, // 108 bits per transform
+ { 23, 12, 1 }, // 108 bits per transform
+ { 23, 13, 0 }, // 108 bits per transform
+ { 24, 0, 4 }, // 108 bits per transform
+ { 24, 1, 3 }, // 108 bits per transform
+ { 24, 2, 2 }, // 108 bits per transform
+ { 24, 3, 1 }, // 108 bits per transform
+ { 24, 4, 0 }, // 108 bits per transform
+ { 0, 5, 24 }, // 111 bits per transform
+ { 0, 14, 23 }, // 111 bits per transform
+ { 0, 15, 22 }, // 111 bits per transform
+ { 0, 16, 21 }, // 111 bits per transform
+ { 0, 17, 20 }, // 111 bits per transform
+ { 0, 18, 19 }, // 111 bits per transform
+ { 0, 19, 18 }, // 111 bits per transform
+ { 0, 20, 17 }, // 111 bits per transform
+ { 0, 21, 16 }, // 111 bits per transform
+ { 0, 22, 15 }, // 111 bits per transform
+ { 0, 23, 14 }, // 111 bits per transform
+ { 0, 24, 5 }, // 111 bits per transform
+ { 1, 4, 24 }, // 111 bits per transform
+ { 1, 13, 23 }, // 111 bits per transform
+ { 1, 14, 22 }, // 111 bits per transform
+ { 1, 15, 21 }, // 111 bits per transform
+ { 1, 16, 20 }, // 111 bits per transform
+ { 1, 17, 19 }, // 111 bits per transform
+ { 1, 18, 18 }, // 111 bits per transform
+ { 1, 19, 17 }, // 111 bits per transform
+ { 1, 20, 16 }, // 111 bits per transform
+ { 1, 21, 15 }, // 111 bits per transform
+ { 1, 22, 14 }, // 111 bits per transform
+ { 1, 23, 13 }, // 111 bits per transform
+ { 1, 24, 4 }, // 111 bits per transform
+ { 2, 3, 24 }, // 111 bits per transform
+ { 2, 12, 23 }, // 111 bits per transform
+ { 2, 13, 22 }, // 111 bits per transform
+ { 2, 14, 21 }, // 111 bits per transform
+ { 2, 15, 20 }, // 111 bits per transform
+ { 2, 16, 19 }, // 111 bits per transform
+ { 2, 17, 18 }, // 111 bits per transform
+ { 2, 18, 17 }, // 111 bits per transform
+ { 2, 19, 16 }, // 111 bits per transform
+ { 2, 20, 15 }, // 111 bits per transform
+ { 2, 21, 14 }, // 111 bits per transform
+ { 2, 22, 13 }, // 111 bits per transform
+ { 2, 23, 12 }, // 111 bits per transform
+ { 2, 24, 3 }, // 111 bits per transform
+ { 3, 2, 24 }, // 111 bits per transform
+ { 3, 11, 23 }, // 111 bits per transform
+ { 3, 12, 22 }, // 111 bits per transform
+ { 3, 13, 21 }, // 111 bits per transform
+ { 3, 14, 20 }, // 111 bits per transform
+ { 3, 15, 19 }, // 111 bits per transform
+ { 3, 16, 18 }, // 111 bits per transform
+ { 3, 17, 17 }, // 111 bits per transform
+ { 3, 18, 16 }, // 111 bits per transform
+ { 3, 19, 15 }, // 111 bits per transform
+ { 3, 20, 14 }, // 111 bits per transform
+ { 3, 21, 13 }, // 111 bits per transform
+ { 3, 22, 12 }, // 111 bits per transform
+ { 3, 23, 11 }, // 111 bits per transform
+ { 3, 24, 2 }, // 111 bits per transform
+ { 4, 1, 24 }, // 111 bits per transform
+ { 4, 10, 23 }, // 111 bits per transform
+ { 4, 11, 22 }, // 111 bits per transform
+ { 4, 12, 21 }, // 111 bits per transform
+ { 4, 13, 20 }, // 111 bits per transform
+ { 4, 14, 19 }, // 111 bits per transform
+ { 4, 15, 18 }, // 111 bits per transform
+ { 4, 16, 17 }, // 111 bits per transform
+ { 4, 17, 16 }, // 111 bits per transform
+ { 4, 18, 15 }, // 111 bits per transform
+ { 4, 19, 14 }, // 111 bits per transform
+ { 4, 20, 13 }, // 111 bits per transform
+ { 4, 21, 12 }, // 111 bits per transform
+ { 4, 22, 11 }, // 111 bits per transform
+ { 4, 23, 10 }, // 111 bits per transform
+ { 4, 24, 1 }, // 111 bits per transform
+ { 5, 0, 24 }, // 111 bits per transform
+ { 5, 9, 23 }, // 111 bits per transform
+ { 5, 10, 22 }, // 111 bits per transform
+ { 5, 11, 21 }, // 111 bits per transform
+ { 5, 12, 20 }, // 111 bits per transform
+ { 5, 13, 19 }, // 111 bits per transform
+ { 5, 14, 18 }, // 111 bits per transform
+ { 5, 15, 17 }, // 111 bits per transform
+ { 5, 16, 16 }, // 111 bits per transform
+ { 5, 17, 15 }, // 111 bits per transform
+ { 5, 18, 14 }, // 111 bits per transform
+ { 5, 19, 13 }, // 111 bits per transform
+ { 5, 20, 12 }, // 111 bits per transform
+ { 5, 21, 11 }, // 111 bits per transform
+ { 5, 22, 10 }, // 111 bits per transform
+ { 5, 23, 9 }, // 111 bits per transform
+ { 5, 24, 0 }, // 111 bits per transform
+ { 6, 8, 23 }, // 111 bits per transform
+ { 6, 9, 22 }, // 111 bits per transform
+ { 6, 10, 21 }, // 111 bits per transform
+ { 6, 11, 20 }, // 111 bits per transform
+ { 6, 12, 19 }, // 111 bits per transform
+ { 6, 13, 18 }, // 111 bits per transform
+ { 6, 14, 17 }, // 111 bits per transform
+ { 6, 15, 16 }, // 111 bits per transform
+ { 6, 16, 15 }, // 111 bits per transform
+ { 6, 17, 14 }, // 111 bits per transform
+ { 6, 18, 13 }, // 111 bits per transform
+ { 6, 19, 12 }, // 111 bits per transform
+ { 6, 20, 11 }, // 111 bits per transform
+ { 6, 21, 10 }, // 111 bits per transform
+ { 6, 22, 9 }, // 111 bits per transform
+ { 6, 23, 8 }, // 111 bits per transform
+ { 7, 7, 23 }, // 111 bits per transform
+ { 7, 8, 22 }, // 111 bits per transform
+ { 7, 9, 21 }, // 111 bits per transform
+ { 7, 10, 20 }, // 111 bits per transform
+ { 7, 11, 19 }, // 111 bits per transform
+ { 7, 12, 18 }, // 111 bits per transform
+ { 7, 13, 17 }, // 111 bits per transform
+ { 7, 14, 16 }, // 111 bits per transform
+ { 7, 15, 15 }, // 111 bits per transform
+ { 7, 16, 14 }, // 111 bits per transform
+ { 7, 17, 13 }, // 111 bits per transform
+ { 7, 18, 12 }, // 111 bits per transform
+ { 7, 19, 11 }, // 111 bits per transform
+ { 7, 20, 10 }, // 111 bits per transform
+ { 7, 21, 9 }, // 111 bits per transform
+ { 7, 22, 8 }, // 111 bits per transform
+ { 7, 23, 7 }, // 111 bits per transform
+ { 8, 6, 23 }, // 111 bits per transform
+ { 8, 7, 22 }, // 111 bits per transform
+ { 8, 8, 21 }, // 111 bits per transform
+ { 8, 9, 20 }, // 111 bits per transform
+ { 8, 10, 19 }, // 111 bits per transform
+ { 8, 11, 18 }, // 111 bits per transform
+ { 8, 12, 17 }, // 111 bits per transform
+ { 8, 13, 16 }, // 111 bits per transform
+ { 8, 14, 15 }, // 111 bits per transform
+ { 8, 15, 14 }, // 111 bits per transform
+ { 8, 16, 13 }, // 111 bits per transform
+ { 8, 17, 12 }, // 111 bits per transform
+ { 8, 18, 11 }, // 111 bits per transform
+ { 8, 19, 10 }, // 111 bits per transform
+ { 8, 20, 9 }, // 111 bits per transform
+ { 8, 21, 8 }, // 111 bits per transform
+ { 8, 22, 7 }, // 111 bits per transform
+ { 8, 23, 6 }, // 111 bits per transform
+ { 9, 5, 23 }, // 111 bits per transform
+ { 9, 6, 22 }, // 111 bits per transform
+ { 9, 7, 21 }, // 111 bits per transform
+ { 9, 8, 20 }, // 111 bits per transform
+ { 9, 9, 19 }, // 111 bits per transform
+ { 9, 10, 18 }, // 111 bits per transform
+ { 9, 11, 17 }, // 111 bits per transform
+ { 9, 12, 16 }, // 111 bits per transform
+ { 9, 13, 15 }, // 111 bits per transform
+ { 9, 14, 14 }, // 111 bits per transform
+ { 9, 15, 13 }, // 111 bits per transform
+ { 9, 16, 12 }, // 111 bits per transform
+ { 9, 17, 11 }, // 111 bits per transform
+ { 9, 18, 10 }, // 111 bits per transform
+ { 9, 19, 9 }, // 111 bits per transform
+ { 9, 20, 8 }, // 111 bits per transform
+ { 9, 21, 7 }, // 111 bits per transform
+ { 9, 22, 6 }, // 111 bits per transform
+ { 9, 23, 5 }, // 111 bits per transform
+ { 10, 4, 23 }, // 111 bits per transform
+ { 10, 5, 22 }, // 111 bits per transform
+ { 10, 6, 21 }, // 111 bits per transform
+ { 10, 7, 20 }, // 111 bits per transform
+ { 10, 8, 19 }, // 111 bits per transform
+ { 10, 9, 18 }, // 111 bits per transform
+ { 10, 10, 17 }, // 111 bits per transform
+ { 10, 11, 16 }, // 111 bits per transform
+ { 10, 12, 15 }, // 111 bits per transform
+ { 10, 13, 14 }, // 111 bits per transform
+ { 10, 14, 13 }, // 111 bits per transform
+ { 10, 15, 12 }, // 111 bits per transform
+ { 10, 16, 11 }, // 111 bits per transform
+ { 10, 17, 10 }, // 111 bits per transform
+ { 10, 18, 9 }, // 111 bits per transform
+ { 10, 19, 8 }, // 111 bits per transform
+ { 10, 20, 7 }, // 111 bits per transform
+ { 10, 21, 6 }, // 111 bits per transform
+ { 10, 22, 5 }, // 111 bits per transform
+ { 10, 23, 4 }, // 111 bits per transform
+ { 11, 3, 23 }, // 111 bits per transform
+ { 11, 4, 22 }, // 111 bits per transform
+ { 11, 5, 21 }, // 111 bits per transform
+ { 11, 6, 20 }, // 111 bits per transform
+ { 11, 7, 19 }, // 111 bits per transform
+ { 11, 8, 18 }, // 111 bits per transform
+ { 11, 9, 17 }, // 111 bits per transform
+ { 11, 10, 16 }, // 111 bits per transform
+ { 11, 11, 15 }, // 111 bits per transform
+ { 11, 12, 14 }, // 111 bits per transform
+ { 11, 13, 13 }, // 111 bits per transform
+ { 11, 14, 12 }, // 111 bits per transform
+ { 11, 15, 11 }, // 111 bits per transform
+ { 11, 16, 10 }, // 111 bits per transform
+ { 11, 17, 9 }, // 111 bits per transform
+ { 11, 18, 8 }, // 111 bits per transform
+ { 11, 19, 7 }, // 111 bits per transform
+ { 11, 20, 6 }, // 111 bits per transform
+ { 11, 21, 5 }, // 111 bits per transform
+ { 11, 22, 4 }, // 111 bits per transform
+ { 11, 23, 3 }, // 111 bits per transform
+ { 12, 2, 23 }, // 111 bits per transform
+ { 12, 3, 22 }, // 111 bits per transform
+ { 12, 4, 21 }, // 111 bits per transform
+ { 12, 5, 20 }, // 111 bits per transform
+ { 12, 6, 19 }, // 111 bits per transform
+ { 12, 7, 18 }, // 111 bits per transform
+ { 12, 8, 17 }, // 111 bits per transform
+ { 12, 9, 16 }, // 111 bits per transform
+ { 12, 10, 15 }, // 111 bits per transform
+ { 12, 11, 14 }, // 111 bits per transform
+ { 12, 12, 13 }, // 111 bits per transform
+ { 12, 13, 12 }, // 111 bits per transform
+ { 12, 14, 11 }, // 111 bits per transform
+ { 12, 15, 10 }, // 111 bits per transform
+ { 12, 16, 9 }, // 111 bits per transform
+ { 12, 17, 8 }, // 111 bits per transform
+ { 12, 18, 7 }, // 111 bits per transform
+ { 12, 19, 6 }, // 111 bits per transform
+ { 12, 20, 5 }, // 111 bits per transform
+ { 12, 21, 4 }, // 111 bits per transform
+ { 12, 22, 3 }, // 111 bits per transform
+ { 12, 23, 2 }, // 111 bits per transform
+ { 13, 1, 23 }, // 111 bits per transform
+ { 13, 2, 22 }, // 111 bits per transform
+ { 13, 3, 21 }, // 111 bits per transform
+ { 13, 4, 20 }, // 111 bits per transform
+ { 13, 5, 19 }, // 111 bits per transform
+ { 13, 6, 18 }, // 111 bits per transform
+ { 13, 7, 17 }, // 111 bits per transform
+ { 13, 8, 16 }, // 111 bits per transform
+ { 13, 9, 15 }, // 111 bits per transform
+ { 13, 10, 14 }, // 111 bits per transform
+ { 13, 11, 13 }, // 111 bits per transform
+ { 13, 12, 12 }, // 111 bits per transform
+ { 13, 13, 11 }, // 111 bits per transform
+ { 13, 14, 10 }, // 111 bits per transform
+ { 13, 15, 9 }, // 111 bits per transform
+ { 13, 16, 8 }, // 111 bits per transform
+ { 13, 17, 7 }, // 111 bits per transform
+ { 13, 18, 6 }, // 111 bits per transform
+ { 13, 19, 5 }, // 111 bits per transform
+ { 13, 20, 4 }, // 111 bits per transform
+ { 13, 21, 3 }, // 111 bits per transform
+ { 13, 22, 2 }, // 111 bits per transform
+ { 13, 23, 1 }, // 111 bits per transform
+ { 14, 0, 23 }, // 111 bits per transform
+ { 14, 1, 22 }, // 111 bits per transform
+ { 14, 2, 21 }, // 111 bits per transform
+ { 14, 3, 20 }, // 111 bits per transform
+ { 14, 4, 19 }, // 111 bits per transform
+ { 14, 5, 18 }, // 111 bits per transform
+ { 14, 6, 17 }, // 111 bits per transform
+ { 14, 7, 16 }, // 111 bits per transform
+ { 14, 8, 15 }, // 111 bits per transform
+ { 14, 9, 14 }, // 111 bits per transform
+ { 14, 10, 13 }, // 111 bits per transform
+ { 14, 11, 12 }, // 111 bits per transform
+ { 14, 12, 11 }, // 111 bits per transform
+ { 14, 13, 10 }, // 111 bits per transform
+ { 14, 14, 9 }, // 111 bits per transform
+ { 14, 15, 8 }, // 111 bits per transform
+ { 14, 16, 7 }, // 111 bits per transform
+ { 14, 17, 6 }, // 111 bits per transform
+ { 14, 18, 5 }, // 111 bits per transform
+ { 14, 19, 4 }, // 111 bits per transform
+ { 14, 20, 3 }, // 111 bits per transform
+ { 14, 21, 2 }, // 111 bits per transform
+ { 14, 22, 1 }, // 111 bits per transform
+ { 14, 23, 0 }, // 111 bits per transform
+ { 15, 0, 22 }, // 111 bits per transform
+ { 15, 1, 21 }, // 111 bits per transform
+ { 15, 2, 20 }, // 111 bits per transform
+ { 15, 3, 19 }, // 111 bits per transform
+ { 15, 4, 18 }, // 111 bits per transform
+ { 15, 5, 17 }, // 111 bits per transform
+ { 15, 6, 16 }, // 111 bits per transform
+ { 15, 7, 15 }, // 111 bits per transform
+ { 15, 8, 14 }, // 111 bits per transform
+ { 15, 9, 13 }, // 111 bits per transform
+ { 15, 10, 12 }, // 111 bits per transform
+ { 15, 11, 11 }, // 111 bits per transform
+ { 15, 12, 10 }, // 111 bits per transform
+ { 15, 13, 9 }, // 111 bits per transform
+ { 15, 14, 8 }, // 111 bits per transform
+ { 15, 15, 7 }, // 111 bits per transform
+ { 15, 16, 6 }, // 111 bits per transform
+ { 15, 17, 5 }, // 111 bits per transform
+ { 15, 18, 4 }, // 111 bits per transform
+ { 15, 19, 3 }, // 111 bits per transform
+ { 15, 20, 2 }, // 111 bits per transform
+ { 15, 21, 1 }, // 111 bits per transform
+ { 15, 22, 0 }, // 111 bits per transform
+ { 16, 0, 21 }, // 111 bits per transform
+ { 16, 1, 20 }, // 111 bits per transform
+ { 16, 2, 19 }, // 111 bits per transform
+ { 16, 3, 18 }, // 111 bits per transform
+ { 16, 4, 17 }, // 111 bits per transform
+ { 16, 5, 16 }, // 111 bits per transform
+ { 16, 6, 15 }, // 111 bits per transform
+ { 16, 7, 14 }, // 111 bits per transform
+ { 16, 8, 13 }, // 111 bits per transform
+ { 16, 9, 12 }, // 111 bits per transform
+ { 16, 10, 11 }, // 111 bits per transform
+ { 16, 11, 10 }, // 111 bits per transform
+ { 16, 12, 9 }, // 111 bits per transform
+ { 16, 13, 8 }, // 111 bits per transform
+ { 16, 14, 7 }, // 111 bits per transform
+ { 16, 15, 6 }, // 111 bits per transform
+ { 16, 16, 5 }, // 111 bits per transform
+ { 16, 17, 4 }, // 111 bits per transform
+ { 16, 18, 3 }, // 111 bits per transform
+ { 16, 19, 2 }, // 111 bits per transform
+ { 16, 20, 1 }, // 111 bits per transform
+ { 16, 21, 0 }, // 111 bits per transform
+ { 17, 0, 20 }, // 111 bits per transform
+ { 17, 1, 19 }, // 111 bits per transform
+ { 17, 2, 18 }, // 111 bits per transform
+ { 17, 3, 17 }, // 111 bits per transform
+ { 17, 4, 16 }, // 111 bits per transform
+ { 17, 5, 15 }, // 111 bits per transform
+ { 17, 6, 14 }, // 111 bits per transform
+ { 17, 7, 13 }, // 111 bits per transform
+ { 17, 8, 12 }, // 111 bits per transform
+ { 17, 9, 11 }, // 111 bits per transform
+ { 17, 10, 10 }, // 111 bits per transform
+ { 17, 11, 9 }, // 111 bits per transform
+ { 17, 12, 8 }, // 111 bits per transform
+ { 17, 13, 7 }, // 111 bits per transform
+ { 17, 14, 6 }, // 111 bits per transform
+ { 17, 15, 5 }, // 111 bits per transform
+ { 17, 16, 4 }, // 111 bits per transform
+ { 17, 17, 3 }, // 111 bits per transform
+ { 17, 18, 2 }, // 111 bits per transform
+ { 17, 19, 1 }, // 111 bits per transform
+ { 17, 20, 0 }, // 111 bits per transform
+ { 18, 0, 19 }, // 111 bits per transform
+ { 18, 1, 18 }, // 111 bits per transform
+ { 18, 2, 17 }, // 111 bits per transform
+ { 18, 3, 16 }, // 111 bits per transform
+ { 18, 4, 15 }, // 111 bits per transform
+ { 18, 5, 14 }, // 111 bits per transform
+ { 18, 6, 13 }, // 111 bits per transform
+ { 18, 7, 12 }, // 111 bits per transform
+ { 18, 8, 11 }, // 111 bits per transform
+ { 18, 9, 10 }, // 111 bits per transform
+ { 18, 10, 9 }, // 111 bits per transform
+ { 18, 11, 8 }, // 111 bits per transform
+ { 18, 12, 7 }, // 111 bits per transform
+ { 18, 13, 6 }, // 111 bits per transform
+ { 18, 14, 5 }, // 111 bits per transform
+ { 18, 15, 4 }, // 111 bits per transform
+ { 18, 16, 3 }, // 111 bits per transform
+ { 18, 17, 2 }, // 111 bits per transform
+ { 18, 18, 1 }, // 111 bits per transform
+ { 18, 19, 0 }, // 111 bits per transform
+ { 19, 0, 18 }, // 111 bits per transform
+ { 19, 1, 17 }, // 111 bits per transform
+ { 19, 2, 16 }, // 111 bits per transform
+ { 19, 3, 15 }, // 111 bits per transform
+ { 19, 4, 14 }, // 111 bits per transform
+ { 19, 5, 13 }, // 111 bits per transform
+ { 19, 6, 12 }, // 111 bits per transform
+ { 19, 7, 11 }, // 111 bits per transform
+ { 19, 8, 10 }, // 111 bits per transform
+ { 19, 9, 9 }, // 111 bits per transform
+ { 19, 10, 8 }, // 111 bits per transform
+ { 19, 11, 7 }, // 111 bits per transform
+ { 19, 12, 6 }, // 111 bits per transform
+ { 19, 13, 5 }, // 111 bits per transform
+ { 19, 14, 4 }, // 111 bits per transform
+ { 19, 15, 3 }, // 111 bits per transform
+ { 19, 16, 2 }, // 111 bits per transform
+ { 19, 17, 1 }, // 111 bits per transform
+ { 19, 18, 0 }, // 111 bits per transform
+ { 20, 0, 17 }, // 111 bits per transform
+ { 20, 1, 16 }, // 111 bits per transform
+ { 20, 2, 15 }, // 111 bits per transform
+ { 20, 3, 14 }, // 111 bits per transform
+ { 20, 4, 13 }, // 111 bits per transform
+ { 20, 5, 12 }, // 111 bits per transform
+ { 20, 6, 11 }, // 111 bits per transform
+ { 20, 7, 10 }, // 111 bits per transform
+ { 20, 8, 9 }, // 111 bits per transform
+ { 20, 9, 8 }, // 111 bits per transform
+ { 20, 10, 7 }, // 111 bits per transform
+ { 20, 11, 6 }, // 111 bits per transform
+ { 20, 12, 5 }, // 111 bits per transform
+ { 20, 13, 4 }, // 111 bits per transform
+ { 20, 14, 3 }, // 111 bits per transform
+ { 20, 15, 2 }, // 111 bits per transform
+ { 20, 16, 1 }, // 111 bits per transform
+ { 20, 17, 0 }, // 111 bits per transform
+ { 21, 0, 16 }, // 111 bits per transform
+ { 21, 1, 15 }, // 111 bits per transform
+ { 21, 2, 14 }, // 111 bits per transform
+ { 21, 3, 13 }, // 111 bits per transform
+ { 21, 4, 12 }, // 111 bits per transform
+ { 21, 5, 11 }, // 111 bits per transform
+ { 21, 6, 10 }, // 111 bits per transform
+ { 21, 7, 9 }, // 111 bits per transform
+ { 21, 8, 8 }, // 111 bits per transform
+ { 21, 9, 7 }, // 111 bits per transform
+ { 21, 10, 6 }, // 111 bits per transform
+ { 21, 11, 5 }, // 111 bits per transform
+ { 21, 12, 4 }, // 111 bits per transform
+ { 21, 13, 3 }, // 111 bits per transform
+ { 21, 14, 2 }, // 111 bits per transform
+ { 21, 15, 1 }, // 111 bits per transform
+ { 21, 16, 0 }, // 111 bits per transform
+ { 22, 0, 15 }, // 111 bits per transform
+ { 22, 1, 14 }, // 111 bits per transform
+ { 22, 2, 13 }, // 111 bits per transform
+ { 22, 3, 12 }, // 111 bits per transform
+ { 22, 4, 11 }, // 111 bits per transform
+ { 22, 5, 10 }, // 111 bits per transform
+ { 22, 6, 9 }, // 111 bits per transform
+ { 22, 7, 8 }, // 111 bits per transform
+ { 22, 8, 7 }, // 111 bits per transform
+ { 22, 9, 6 }, // 111 bits per transform
+ { 22, 10, 5 }, // 111 bits per transform
+ { 22, 11, 4 }, // 111 bits per transform
+ { 22, 12, 3 }, // 111 bits per transform
+ { 22, 13, 2 }, // 111 bits per transform
+ { 22, 14, 1 }, // 111 bits per transform
+ { 22, 15, 0 }, // 111 bits per transform
+ { 23, 0, 14 }, // 111 bits per transform
+ { 23, 1, 13 }, // 111 bits per transform
+ { 23, 2, 12 }, // 111 bits per transform
+ { 23, 3, 11 }, // 111 bits per transform
+ { 23, 4, 10 }, // 111 bits per transform
+ { 23, 5, 9 }, // 111 bits per transform
+ { 23, 6, 8 }, // 111 bits per transform
+ { 23, 7, 7 }, // 111 bits per transform
+ { 23, 8, 6 }, // 111 bits per transform
+ { 23, 9, 5 }, // 111 bits per transform
+ { 23, 10, 4 }, // 111 bits per transform
+ { 23, 11, 3 }, // 111 bits per transform
+ { 23, 12, 2 }, // 111 bits per transform
+ { 23, 13, 1 }, // 111 bits per transform
+ { 23, 14, 0 }, // 111 bits per transform
+ { 24, 0, 5 }, // 111 bits per transform
+ { 24, 1, 4 }, // 111 bits per transform
+ { 24, 2, 3 }, // 111 bits per transform
+ { 24, 3, 2 }, // 111 bits per transform
+ { 24, 4, 1 }, // 111 bits per transform
+ { 24, 5, 0 }, // 111 bits per transform
+ { 0, 6, 24 }, // 114 bits per transform
+ { 0, 15, 23 }, // 114 bits per transform
+ { 0, 16, 22 }, // 114 bits per transform
+ { 0, 17, 21 }, // 114 bits per transform
+ { 0, 18, 20 }, // 114 bits per transform
+ { 0, 19, 19 }, // 114 bits per transform
+ { 0, 20, 18 }, // 114 bits per transform
+ { 0, 21, 17 }, // 114 bits per transform
+ { 0, 22, 16 }, // 114 bits per transform
+ { 0, 23, 15 }, // 114 bits per transform
+ { 0, 24, 6 }, // 114 bits per transform
+ { 1, 5, 24 }, // 114 bits per transform
+ { 1, 14, 23 }, // 114 bits per transform
+ { 1, 15, 22 }, // 114 bits per transform
+ { 1, 16, 21 }, // 114 bits per transform
+ { 1, 17, 20 }, // 114 bits per transform
+ { 1, 18, 19 }, // 114 bits per transform
+ { 1, 19, 18 }, // 114 bits per transform
+ { 1, 20, 17 }, // 114 bits per transform
+ { 1, 21, 16 }, // 114 bits per transform
+ { 1, 22, 15 }, // 114 bits per transform
+ { 1, 23, 14 }, // 114 bits per transform
+ { 1, 24, 5 }, // 114 bits per transform
+ { 2, 4, 24 }, // 114 bits per transform
+ { 2, 13, 23 }, // 114 bits per transform
+ { 2, 14, 22 }, // 114 bits per transform
+ { 2, 15, 21 }, // 114 bits per transform
+ { 2, 16, 20 }, // 114 bits per transform
+ { 2, 17, 19 }, // 114 bits per transform
+ { 2, 18, 18 }, // 114 bits per transform
+ { 2, 19, 17 }, // 114 bits per transform
+ { 2, 20, 16 }, // 114 bits per transform
+ { 2, 21, 15 }, // 114 bits per transform
+ { 2, 22, 14 }, // 114 bits per transform
+ { 2, 23, 13 }, // 114 bits per transform
+ { 2, 24, 4 }, // 114 bits per transform
+ { 3, 3, 24 }, // 114 bits per transform
+ { 3, 12, 23 }, // 114 bits per transform
+ { 3, 13, 22 }, // 114 bits per transform
+ { 3, 14, 21 }, // 114 bits per transform
+ { 3, 15, 20 }, // 114 bits per transform
+ { 3, 16, 19 }, // 114 bits per transform
+ { 3, 17, 18 }, // 114 bits per transform
+ { 3, 18, 17 }, // 114 bits per transform
+ { 3, 19, 16 }, // 114 bits per transform
+ { 3, 20, 15 }, // 114 bits per transform
+ { 3, 21, 14 }, // 114 bits per transform
+ { 3, 22, 13 }, // 114 bits per transform
+ { 3, 23, 12 }, // 114 bits per transform
+ { 3, 24, 3 }, // 114 bits per transform
+ { 4, 2, 24 }, // 114 bits per transform
+ { 4, 11, 23 }, // 114 bits per transform
+ { 4, 12, 22 }, // 114 bits per transform
+ { 4, 13, 21 }, // 114 bits per transform
+ { 4, 14, 20 }, // 114 bits per transform
+ { 4, 15, 19 }, // 114 bits per transform
+ { 4, 16, 18 }, // 114 bits per transform
+ { 4, 17, 17 }, // 114 bits per transform
+ { 4, 18, 16 }, // 114 bits per transform
+ { 4, 19, 15 }, // 114 bits per transform
+ { 4, 20, 14 }, // 114 bits per transform
+ { 4, 21, 13 }, // 114 bits per transform
+ { 4, 22, 12 }, // 114 bits per transform
+ { 4, 23, 11 }, // 114 bits per transform
+ { 4, 24, 2 }, // 114 bits per transform
+ { 5, 1, 24 }, // 114 bits per transform
+ { 5, 10, 23 }, // 114 bits per transform
+ { 5, 11, 22 }, // 114 bits per transform
+ { 5, 12, 21 }, // 114 bits per transform
+ { 5, 13, 20 }, // 114 bits per transform
+ { 5, 14, 19 }, // 114 bits per transform
+ { 5, 15, 18 }, // 114 bits per transform
+ { 5, 16, 17 }, // 114 bits per transform
+ { 5, 17, 16 }, // 114 bits per transform
+ { 5, 18, 15 }, // 114 bits per transform
+ { 5, 19, 14 }, // 114 bits per transform
+ { 5, 20, 13 }, // 114 bits per transform
+ { 5, 21, 12 }, // 114 bits per transform
+ { 5, 22, 11 }, // 114 bits per transform
+ { 5, 23, 10 }, // 114 bits per transform
+ { 5, 24, 1 }, // 114 bits per transform
+ { 6, 0, 24 }, // 114 bits per transform
+ { 6, 9, 23 }, // 114 bits per transform
+ { 6, 10, 22 }, // 114 bits per transform
+ { 6, 11, 21 }, // 114 bits per transform
+ { 6, 12, 20 }, // 114 bits per transform
+ { 6, 13, 19 }, // 114 bits per transform
+ { 6, 14, 18 }, // 114 bits per transform
+ { 6, 15, 17 }, // 114 bits per transform
+ { 6, 16, 16 }, // 114 bits per transform
+ { 6, 17, 15 }, // 114 bits per transform
+ { 6, 18, 14 }, // 114 bits per transform
+ { 6, 19, 13 }, // 114 bits per transform
+ { 6, 20, 12 }, // 114 bits per transform
+ { 6, 21, 11 }, // 114 bits per transform
+ { 6, 22, 10 }, // 114 bits per transform
+ { 6, 23, 9 }, // 114 bits per transform
+ { 6, 24, 0 }, // 114 bits per transform
+ { 7, 8, 23 }, // 114 bits per transform
+ { 7, 9, 22 }, // 114 bits per transform
+ { 7, 10, 21 }, // 114 bits per transform
+ { 7, 11, 20 }, // 114 bits per transform
+ { 7, 12, 19 }, // 114 bits per transform
+ { 7, 13, 18 }, // 114 bits per transform
+ { 7, 14, 17 }, // 114 bits per transform
+ { 7, 15, 16 }, // 114 bits per transform
+ { 7, 16, 15 }, // 114 bits per transform
+ { 7, 17, 14 }, // 114 bits per transform
+ { 7, 18, 13 }, // 114 bits per transform
+ { 7, 19, 12 }, // 114 bits per transform
+ { 7, 20, 11 }, // 114 bits per transform
+ { 7, 21, 10 }, // 114 bits per transform
+ { 7, 22, 9 }, // 114 bits per transform
+ { 7, 23, 8 }, // 114 bits per transform
+ { 8, 7, 23 }, // 114 bits per transform
+ { 8, 8, 22 }, // 114 bits per transform
+ { 8, 9, 21 }, // 114 bits per transform
+ { 8, 10, 20 }, // 114 bits per transform
+ { 8, 11, 19 }, // 114 bits per transform
+ { 8, 12, 18 }, // 114 bits per transform
+ { 8, 13, 17 }, // 114 bits per transform
+ { 8, 14, 16 }, // 114 bits per transform
+ { 8, 15, 15 }, // 114 bits per transform
+ { 8, 16, 14 }, // 114 bits per transform
+ { 8, 17, 13 }, // 114 bits per transform
+ { 8, 18, 12 }, // 114 bits per transform
+ { 8, 19, 11 }, // 114 bits per transform
+ { 8, 20, 10 }, // 114 bits per transform
+ { 8, 21, 9 }, // 114 bits per transform
+ { 8, 22, 8 }, // 114 bits per transform
+ { 8, 23, 7 }, // 114 bits per transform
+ { 9, 6, 23 }, // 114 bits per transform
+ { 9, 7, 22 }, // 114 bits per transform
+ { 9, 8, 21 }, // 114 bits per transform
+ { 9, 9, 20 }, // 114 bits per transform
+ { 9, 10, 19 }, // 114 bits per transform
+ { 9, 11, 18 }, // 114 bits per transform
+ { 9, 12, 17 }, // 114 bits per transform
+ { 9, 13, 16 }, // 114 bits per transform
+ { 9, 14, 15 }, // 114 bits per transform
+ { 9, 15, 14 }, // 114 bits per transform
+ { 9, 16, 13 }, // 114 bits per transform
+ { 9, 17, 12 }, // 114 bits per transform
+ { 9, 18, 11 }, // 114 bits per transform
+ { 9, 19, 10 }, // 114 bits per transform
+ { 9, 20, 9 }, // 114 bits per transform
+ { 9, 21, 8 }, // 114 bits per transform
+ { 9, 22, 7 }, // 114 bits per transform
+ { 9, 23, 6 }, // 114 bits per transform
+ { 10, 5, 23 }, // 114 bits per transform
+ { 10, 6, 22 }, // 114 bits per transform
+ { 10, 7, 21 }, // 114 bits per transform
+ { 10, 8, 20 }, // 114 bits per transform
+ { 10, 9, 19 }, // 114 bits per transform
+ { 10, 10, 18 }, // 114 bits per transform
+ { 10, 11, 17 }, // 114 bits per transform
+ { 10, 12, 16 }, // 114 bits per transform
+ { 10, 13, 15 }, // 114 bits per transform
+ { 10, 14, 14 }, // 114 bits per transform
+ { 10, 15, 13 }, // 114 bits per transform
+ { 10, 16, 12 }, // 114 bits per transform
+ { 10, 17, 11 }, // 114 bits per transform
+ { 10, 18, 10 }, // 114 bits per transform
+ { 10, 19, 9 }, // 114 bits per transform
+ { 10, 20, 8 }, // 114 bits per transform
+ { 10, 21, 7 }, // 114 bits per transform
+ { 10, 22, 6 }, // 114 bits per transform
+ { 10, 23, 5 }, // 114 bits per transform
+ { 11, 4, 23 }, // 114 bits per transform
+ { 11, 5, 22 }, // 114 bits per transform
+ { 11, 6, 21 }, // 114 bits per transform
+ { 11, 7, 20 }, // 114 bits per transform
+ { 11, 8, 19 }, // 114 bits per transform
+ { 11, 9, 18 }, // 114 bits per transform
+ { 11, 10, 17 }, // 114 bits per transform
+ { 11, 11, 16 }, // 114 bits per transform
+ { 11, 12, 15 }, // 114 bits per transform
+ { 11, 13, 14 }, // 114 bits per transform
+ { 11, 14, 13 }, // 114 bits per transform
+ { 11, 15, 12 }, // 114 bits per transform
+ { 11, 16, 11 }, // 114 bits per transform
+ { 11, 17, 10 }, // 114 bits per transform
+ { 11, 18, 9 }, // 114 bits per transform
+ { 11, 19, 8 }, // 114 bits per transform
+ { 11, 20, 7 }, // 114 bits per transform
+ { 11, 21, 6 }, // 114 bits per transform
+ { 11, 22, 5 }, // 114 bits per transform
+ { 11, 23, 4 }, // 114 bits per transform
+ { 12, 3, 23 }, // 114 bits per transform
+ { 12, 4, 22 }, // 114 bits per transform
+ { 12, 5, 21 }, // 114 bits per transform
+ { 12, 6, 20 }, // 114 bits per transform
+ { 12, 7, 19 }, // 114 bits per transform
+ { 12, 8, 18 }, // 114 bits per transform
+ { 12, 9, 17 }, // 114 bits per transform
+ { 12, 10, 16 }, // 114 bits per transform
+ { 12, 11, 15 }, // 114 bits per transform
+ { 12, 12, 14 }, // 114 bits per transform
+ { 12, 13, 13 }, // 114 bits per transform
+ { 12, 14, 12 }, // 114 bits per transform
+ { 12, 15, 11 }, // 114 bits per transform
+ { 12, 16, 10 }, // 114 bits per transform
+ { 12, 17, 9 }, // 114 bits per transform
+ { 12, 18, 8 }, // 114 bits per transform
+ { 12, 19, 7 }, // 114 bits per transform
+ { 12, 20, 6 }, // 114 bits per transform
+ { 12, 21, 5 }, // 114 bits per transform
+ { 12, 22, 4 }, // 114 bits per transform
+ { 12, 23, 3 }, // 114 bits per transform
+ { 13, 2, 23 }, // 114 bits per transform
+ { 13, 3, 22 }, // 114 bits per transform
+ { 13, 4, 21 }, // 114 bits per transform
+ { 13, 5, 20 }, // 114 bits per transform
+ { 13, 6, 19 }, // 114 bits per transform
+ { 13, 7, 18 }, // 114 bits per transform
+ { 13, 8, 17 }, // 114 bits per transform
+ { 13, 9, 16 }, // 114 bits per transform
+ { 13, 10, 15 }, // 114 bits per transform
+ { 13, 11, 14 }, // 114 bits per transform
+ { 13, 12, 13 }, // 114 bits per transform
+ { 13, 13, 12 }, // 114 bits per transform
+ { 13, 14, 11 }, // 114 bits per transform
+ { 13, 15, 10 }, // 114 bits per transform
+ { 13, 16, 9 }, // 114 bits per transform
+ { 13, 17, 8 }, // 114 bits per transform
+ { 13, 18, 7 }, // 114 bits per transform
+ { 13, 19, 6 }, // 114 bits per transform
+ { 13, 20, 5 }, // 114 bits per transform
+ { 13, 21, 4 }, // 114 bits per transform
+ { 13, 22, 3 }, // 114 bits per transform
+ { 13, 23, 2 }, // 114 bits per transform
+ { 14, 1, 23 }, // 114 bits per transform
+ { 14, 2, 22 }, // 114 bits per transform
+ { 14, 3, 21 }, // 114 bits per transform
+ { 14, 4, 20 }, // 114 bits per transform
+ { 14, 5, 19 }, // 114 bits per transform
+ { 14, 6, 18 }, // 114 bits per transform
+ { 14, 7, 17 }, // 114 bits per transform
+ { 14, 8, 16 }, // 114 bits per transform
+ { 14, 9, 15 }, // 114 bits per transform
+ { 14, 10, 14 }, // 114 bits per transform
+ { 14, 11, 13 }, // 114 bits per transform
+ { 14, 12, 12 }, // 114 bits per transform
+ { 14, 13, 11 }, // 114 bits per transform
+ { 14, 14, 10 }, // 114 bits per transform
+ { 14, 15, 9 }, // 114 bits per transform
+ { 14, 16, 8 }, // 114 bits per transform
+ { 14, 17, 7 }, // 114 bits per transform
+ { 14, 18, 6 }, // 114 bits per transform
+ { 14, 19, 5 }, // 114 bits per transform
+ { 14, 20, 4 }, // 114 bits per transform
+ { 14, 21, 3 }, // 114 bits per transform
+ { 14, 22, 2 }, // 114 bits per transform
+ { 14, 23, 1 }, // 114 bits per transform
+ { 15, 0, 23 }, // 114 bits per transform
+ { 15, 1, 22 }, // 114 bits per transform
+ { 15, 2, 21 }, // 114 bits per transform
+ { 15, 3, 20 }, // 114 bits per transform
+ { 15, 4, 19 }, // 114 bits per transform
+ { 15, 5, 18 }, // 114 bits per transform
+ { 15, 6, 17 }, // 114 bits per transform
+ { 15, 7, 16 }, // 114 bits per transform
+ { 15, 8, 15 }, // 114 bits per transform
+ { 15, 9, 14 }, // 114 bits per transform
+ { 15, 10, 13 }, // 114 bits per transform
+ { 15, 11, 12 }, // 114 bits per transform
+ { 15, 12, 11 }, // 114 bits per transform
+ { 15, 13, 10 }, // 114 bits per transform
+ { 15, 14, 9 }, // 114 bits per transform
+ { 15, 15, 8 }, // 114 bits per transform
+ { 15, 16, 7 }, // 114 bits per transform
+ { 15, 17, 6 }, // 114 bits per transform
+ { 15, 18, 5 }, // 114 bits per transform
+ { 15, 19, 4 }, // 114 bits per transform
+ { 15, 20, 3 }, // 114 bits per transform
+ { 15, 21, 2 }, // 114 bits per transform
+ { 15, 22, 1 }, // 114 bits per transform
+ { 15, 23, 0 }, // 114 bits per transform
+ { 16, 0, 22 }, // 114 bits per transform
+ { 16, 1, 21 }, // 114 bits per transform
+ { 16, 2, 20 }, // 114 bits per transform
+ { 16, 3, 19 }, // 114 bits per transform
+ { 16, 4, 18 }, // 114 bits per transform
+ { 16, 5, 17 }, // 114 bits per transform
+ { 16, 6, 16 }, // 114 bits per transform
+ { 16, 7, 15 }, // 114 bits per transform
+ { 16, 8, 14 }, // 114 bits per transform
+ { 16, 9, 13 }, // 114 bits per transform
+ { 16, 10, 12 }, // 114 bits per transform
+ { 16, 11, 11 }, // 114 bits per transform
+ { 16, 12, 10 }, // 114 bits per transform
+ { 16, 13, 9 }, // 114 bits per transform
+ { 16, 14, 8 }, // 114 bits per transform
+ { 16, 15, 7 }, // 114 bits per transform
+ { 16, 16, 6 }, // 114 bits per transform
+ { 16, 17, 5 }, // 114 bits per transform
+ { 16, 18, 4 }, // 114 bits per transform
+ { 16, 19, 3 }, // 114 bits per transform
+ { 16, 20, 2 }, // 114 bits per transform
+ { 16, 21, 1 }, // 114 bits per transform
+ { 16, 22, 0 }, // 114 bits per transform
+ { 17, 0, 21 }, // 114 bits per transform
+ { 17, 1, 20 }, // 114 bits per transform
+ { 17, 2, 19 }, // 114 bits per transform
+ { 17, 3, 18 }, // 114 bits per transform
+ { 17, 4, 17 }, // 114 bits per transform
+ { 17, 5, 16 }, // 114 bits per transform
+ { 17, 6, 15 }, // 114 bits per transform
+ { 17, 7, 14 }, // 114 bits per transform
+ { 17, 8, 13 }, // 114 bits per transform
+ { 17, 9, 12 }, // 114 bits per transform
+ { 17, 10, 11 }, // 114 bits per transform
+ { 17, 11, 10 }, // 114 bits per transform
+ { 17, 12, 9 }, // 114 bits per transform
+ { 17, 13, 8 }, // 114 bits per transform
+ { 17, 14, 7 }, // 114 bits per transform
+ { 17, 15, 6 }, // 114 bits per transform
+ { 17, 16, 5 }, // 114 bits per transform
+ { 17, 17, 4 }, // 114 bits per transform
+ { 17, 18, 3 }, // 114 bits per transform
+ { 17, 19, 2 }, // 114 bits per transform
+ { 17, 20, 1 }, // 114 bits per transform
+ { 17, 21, 0 }, // 114 bits per transform
+ { 18, 0, 20 }, // 114 bits per transform
+ { 18, 1, 19 }, // 114 bits per transform
+ { 18, 2, 18 }, // 114 bits per transform
+ { 18, 3, 17 }, // 114 bits per transform
+ { 18, 4, 16 }, // 114 bits per transform
+ { 18, 5, 15 }, // 114 bits per transform
+ { 18, 6, 14 }, // 114 bits per transform
+ { 18, 7, 13 }, // 114 bits per transform
+ { 18, 8, 12 }, // 114 bits per transform
+ { 18, 9, 11 }, // 114 bits per transform
+ { 18, 10, 10 }, // 114 bits per transform
+ { 18, 11, 9 }, // 114 bits per transform
+ { 18, 12, 8 }, // 114 bits per transform
+ { 18, 13, 7 }, // 114 bits per transform
+ { 18, 14, 6 }, // 114 bits per transform
+ { 18, 15, 5 }, // 114 bits per transform
+ { 18, 16, 4 }, // 114 bits per transform
+ { 18, 17, 3 }, // 114 bits per transform
+ { 18, 18, 2 }, // 114 bits per transform
+ { 18, 19, 1 }, // 114 bits per transform
+ { 18, 20, 0 }, // 114 bits per transform
+ { 19, 0, 19 }, // 114 bits per transform
+ { 19, 1, 18 }, // 114 bits per transform
+ { 19, 2, 17 }, // 114 bits per transform
+ { 19, 3, 16 }, // 114 bits per transform
+ { 19, 4, 15 }, // 114 bits per transform
+ { 19, 5, 14 }, // 114 bits per transform
+ { 19, 6, 13 }, // 114 bits per transform
+ { 19, 7, 12 }, // 114 bits per transform
+ { 19, 8, 11 }, // 114 bits per transform
+ { 19, 9, 10 }, // 114 bits per transform
+ { 19, 10, 9 }, // 114 bits per transform
+ { 19, 11, 8 }, // 114 bits per transform
+ { 19, 12, 7 }, // 114 bits per transform
+ { 19, 13, 6 }, // 114 bits per transform
+ { 19, 14, 5 }, // 114 bits per transform
+ { 19, 15, 4 }, // 114 bits per transform
+ { 19, 16, 3 }, // 114 bits per transform
+ { 19, 17, 2 }, // 114 bits per transform
+ { 19, 18, 1 }, // 114 bits per transform
+ { 19, 19, 0 }, // 114 bits per transform
+ { 20, 0, 18 }, // 114 bits per transform
+ { 20, 1, 17 }, // 114 bits per transform
+ { 20, 2, 16 }, // 114 bits per transform
+ { 20, 3, 15 }, // 114 bits per transform
+ { 20, 4, 14 }, // 114 bits per transform
+ { 20, 5, 13 }, // 114 bits per transform
+ { 20, 6, 12 }, // 114 bits per transform
+ { 20, 7, 11 }, // 114 bits per transform
+ { 20, 8, 10 }, // 114 bits per transform
+ { 20, 9, 9 }, // 114 bits per transform
+ { 20, 10, 8 }, // 114 bits per transform
+ { 20, 11, 7 }, // 114 bits per transform
+ { 20, 12, 6 }, // 114 bits per transform
+ { 20, 13, 5 }, // 114 bits per transform
+ { 20, 14, 4 }, // 114 bits per transform
+ { 20, 15, 3 }, // 114 bits per transform
+ { 20, 16, 2 }, // 114 bits per transform
+ { 20, 17, 1 }, // 114 bits per transform
+ { 20, 18, 0 }, // 114 bits per transform
+ { 21, 0, 17 }, // 114 bits per transform
+ { 21, 1, 16 }, // 114 bits per transform
+ { 21, 2, 15 }, // 114 bits per transform
+ { 21, 3, 14 }, // 114 bits per transform
+ { 21, 4, 13 }, // 114 bits per transform
+ { 21, 5, 12 }, // 114 bits per transform
+ { 21, 6, 11 }, // 114 bits per transform
+ { 21, 7, 10 }, // 114 bits per transform
+ { 21, 8, 9 }, // 114 bits per transform
+ { 21, 9, 8 }, // 114 bits per transform
+ { 21, 10, 7 }, // 114 bits per transform
+ { 21, 11, 6 }, // 114 bits per transform
+ { 21, 12, 5 }, // 114 bits per transform
+ { 21, 13, 4 }, // 114 bits per transform
+ { 21, 14, 3 }, // 114 bits per transform
+ { 21, 15, 2 }, // 114 bits per transform
+ { 21, 16, 1 }, // 114 bits per transform
+ { 21, 17, 0 }, // 114 bits per transform
+ { 22, 0, 16 }, // 114 bits per transform
+ { 22, 1, 15 }, // 114 bits per transform
+ { 22, 2, 14 }, // 114 bits per transform
+ { 22, 3, 13 }, // 114 bits per transform
+ { 22, 4, 12 }, // 114 bits per transform
+ { 22, 5, 11 }, // 114 bits per transform
+ { 22, 6, 10 }, // 114 bits per transform
+ { 22, 7, 9 }, // 114 bits per transform
+ { 22, 8, 8 }, // 114 bits per transform
+ { 22, 9, 7 }, // 114 bits per transform
+ { 22, 10, 6 }, // 114 bits per transform
+ { 22, 11, 5 }, // 114 bits per transform
+ { 22, 12, 4 }, // 114 bits per transform
+ { 22, 13, 3 }, // 114 bits per transform
+ { 22, 14, 2 }, // 114 bits per transform
+ { 22, 15, 1 }, // 114 bits per transform
+ { 22, 16, 0 }, // 114 bits per transform
+ { 23, 0, 15 }, // 114 bits per transform
+ { 23, 1, 14 }, // 114 bits per transform
+ { 23, 2, 13 }, // 114 bits per transform
+ { 23, 3, 12 }, // 114 bits per transform
+ { 23, 4, 11 }, // 114 bits per transform
+ { 23, 5, 10 }, // 114 bits per transform
+ { 23, 6, 9 }, // 114 bits per transform
+ { 23, 7, 8 }, // 114 bits per transform
+ { 23, 8, 7 }, // 114 bits per transform
+ { 23, 9, 6 }, // 114 bits per transform
+ { 23, 10, 5 }, // 114 bits per transform
+ { 23, 11, 4 }, // 114 bits per transform
+ { 23, 12, 3 }, // 114 bits per transform
+ { 23, 13, 2 }, // 114 bits per transform
+ { 23, 14, 1 }, // 114 bits per transform
+ { 23, 15, 0 }, // 114 bits per transform
+ { 24, 0, 6 }, // 114 bits per transform
+ { 24, 1, 5 }, // 114 bits per transform
+ { 24, 2, 4 }, // 114 bits per transform
+ { 24, 3, 3 }, // 114 bits per transform
+ { 24, 4, 2 }, // 114 bits per transform
+ { 24, 5, 1 }, // 114 bits per transform
+ { 24, 6, 0 }, // 114 bits per transform
+ { 0, 7, 24 }, // 117 bits per transform
+ { 0, 16, 23 }, // 117 bits per transform
+ { 0, 17, 22 }, // 117 bits per transform
+ { 0, 18, 21 }, // 117 bits per transform
+ { 0, 19, 20 }, // 117 bits per transform
+ { 0, 20, 19 }, // 117 bits per transform
+ { 0, 21, 18 }, // 117 bits per transform
+ { 0, 22, 17 }, // 117 bits per transform
+ { 0, 23, 16 }, // 117 bits per transform
+ { 0, 24, 7 }, // 117 bits per transform
+ { 1, 6, 24 }, // 117 bits per transform
+ { 1, 15, 23 }, // 117 bits per transform
+ { 1, 16, 22 }, // 117 bits per transform
+ { 1, 17, 21 }, // 117 bits per transform
+ { 1, 18, 20 }, // 117 bits per transform
+ { 1, 19, 19 }, // 117 bits per transform
+ { 1, 20, 18 }, // 117 bits per transform
+ { 1, 21, 17 }, // 117 bits per transform
+ { 1, 22, 16 }, // 117 bits per transform
+ { 1, 23, 15 }, // 117 bits per transform
+ { 1, 24, 6 }, // 117 bits per transform
+ { 2, 5, 24 }, // 117 bits per transform
+ { 2, 14, 23 }, // 117 bits per transform
+ { 2, 15, 22 }, // 117 bits per transform
+ { 2, 16, 21 }, // 117 bits per transform
+ { 2, 17, 20 }, // 117 bits per transform
+ { 2, 18, 19 }, // 117 bits per transform
+ { 2, 19, 18 }, // 117 bits per transform
+ { 2, 20, 17 }, // 117 bits per transform
+ { 2, 21, 16 }, // 117 bits per transform
+ { 2, 22, 15 }, // 117 bits per transform
+ { 2, 23, 14 }, // 117 bits per transform
+ { 2, 24, 5 }, // 117 bits per transform
+ { 3, 4, 24 }, // 117 bits per transform
+ { 3, 13, 23 }, // 117 bits per transform
+ { 3, 14, 22 }, // 117 bits per transform
+ { 3, 15, 21 }, // 117 bits per transform
+ { 3, 16, 20 }, // 117 bits per transform
+ { 3, 17, 19 }, // 117 bits per transform
+ { 3, 18, 18 }, // 117 bits per transform
+ { 3, 19, 17 }, // 117 bits per transform
+ { 3, 20, 16 }, // 117 bits per transform
+ { 3, 21, 15 }, // 117 bits per transform
+ { 3, 22, 14 }, // 117 bits per transform
+ { 3, 23, 13 }, // 117 bits per transform
+ { 3, 24, 4 }, // 117 bits per transform
+ { 4, 3, 24 }, // 117 bits per transform
+ { 4, 12, 23 }, // 117 bits per transform
+ { 4, 13, 22 }, // 117 bits per transform
+ { 4, 14, 21 }, // 117 bits per transform
+ { 4, 15, 20 }, // 117 bits per transform
+ { 4, 16, 19 }, // 117 bits per transform
+ { 4, 17, 18 }, // 117 bits per transform
+ { 4, 18, 17 }, // 117 bits per transform
+ { 4, 19, 16 }, // 117 bits per transform
+ { 4, 20, 15 }, // 117 bits per transform
+ { 4, 21, 14 }, // 117 bits per transform
+ { 4, 22, 13 }, // 117 bits per transform
+ { 4, 23, 12 }, // 117 bits per transform
+ { 4, 24, 3 }, // 117 bits per transform
+ { 5, 2, 24 }, // 117 bits per transform
+ { 5, 11, 23 }, // 117 bits per transform
+ { 5, 12, 22 }, // 117 bits per transform
+ { 5, 13, 21 }, // 117 bits per transform
+ { 5, 14, 20 }, // 117 bits per transform
+ { 5, 15, 19 }, // 117 bits per transform
+ { 5, 16, 18 }, // 117 bits per transform
+ { 5, 17, 17 }, // 117 bits per transform
+ { 5, 18, 16 }, // 117 bits per transform
+ { 5, 19, 15 }, // 117 bits per transform
+ { 5, 20, 14 }, // 117 bits per transform
+ { 5, 21, 13 }, // 117 bits per transform
+ { 5, 22, 12 }, // 117 bits per transform
+ { 5, 23, 11 }, // 117 bits per transform
+ { 5, 24, 2 }, // 117 bits per transform
+ { 6, 1, 24 }, // 117 bits per transform
+ { 6, 10, 23 }, // 117 bits per transform
+ { 6, 11, 22 }, // 117 bits per transform
+ { 6, 12, 21 }, // 117 bits per transform
+ { 6, 13, 20 }, // 117 bits per transform
+ { 6, 14, 19 }, // 117 bits per transform
+ { 6, 15, 18 }, // 117 bits per transform
+ { 6, 16, 17 }, // 117 bits per transform
+ { 6, 17, 16 }, // 117 bits per transform
+ { 6, 18, 15 }, // 117 bits per transform
+ { 6, 19, 14 }, // 117 bits per transform
+ { 6, 20, 13 }, // 117 bits per transform
+ { 6, 21, 12 }, // 117 bits per transform
+ { 6, 22, 11 }, // 117 bits per transform
+ { 6, 23, 10 }, // 117 bits per transform
+ { 6, 24, 1 }, // 117 bits per transform
+ { 7, 0, 24 }, // 117 bits per transform
+ { 7, 9, 23 }, // 117 bits per transform
+ { 7, 10, 22 }, // 117 bits per transform
+ { 7, 11, 21 }, // 117 bits per transform
+ { 7, 12, 20 }, // 117 bits per transform
+ { 7, 13, 19 }, // 117 bits per transform
+ { 7, 14, 18 }, // 117 bits per transform
+ { 7, 15, 17 }, // 117 bits per transform
+ { 7, 16, 16 }, // 117 bits per transform
+ { 7, 17, 15 }, // 117 bits per transform
+ { 7, 18, 14 }, // 117 bits per transform
+ { 7, 19, 13 }, // 117 bits per transform
+ { 7, 20, 12 }, // 117 bits per transform
+ { 7, 21, 11 }, // 117 bits per transform
+ { 7, 22, 10 }, // 117 bits per transform
+ { 7, 23, 9 }, // 117 bits per transform
+ { 7, 24, 0 }, // 117 bits per transform
+ { 8, 8, 23 }, // 117 bits per transform
+ { 8, 9, 22 }, // 117 bits per transform
+ { 8, 10, 21 }, // 117 bits per transform
+ { 8, 11, 20 }, // 117 bits per transform
+ { 8, 12, 19 }, // 117 bits per transform
+ { 8, 13, 18 }, // 117 bits per transform
+ { 8, 14, 17 }, // 117 bits per transform
+ { 8, 15, 16 }, // 117 bits per transform
+ { 8, 16, 15 }, // 117 bits per transform
+ { 8, 17, 14 }, // 117 bits per transform
+ { 8, 18, 13 }, // 117 bits per transform
+ { 8, 19, 12 }, // 117 bits per transform
+ { 8, 20, 11 }, // 117 bits per transform
+ { 8, 21, 10 }, // 117 bits per transform
+ { 8, 22, 9 }, // 117 bits per transform
+ { 8, 23, 8 }, // 117 bits per transform
+ { 9, 7, 23 }, // 117 bits per transform
+ { 9, 8, 22 }, // 117 bits per transform
+ { 9, 9, 21 }, // 117 bits per transform
+ { 9, 10, 20 }, // 117 bits per transform
+ { 9, 11, 19 }, // 117 bits per transform
+ { 9, 12, 18 }, // 117 bits per transform
+ { 9, 13, 17 }, // 117 bits per transform
+ { 9, 14, 16 }, // 117 bits per transform
+ { 9, 15, 15 }, // 117 bits per transform
+ { 9, 16, 14 }, // 117 bits per transform
+ { 9, 17, 13 }, // 117 bits per transform
+ { 9, 18, 12 }, // 117 bits per transform
+ { 9, 19, 11 }, // 117 bits per transform
+ { 9, 20, 10 }, // 117 bits per transform
+ { 9, 21, 9 }, // 117 bits per transform
+ { 9, 22, 8 }, // 117 bits per transform
+ { 9, 23, 7 }, // 117 bits per transform
+ { 10, 6, 23 }, // 117 bits per transform
+ { 10, 7, 22 }, // 117 bits per transform
+ { 10, 8, 21 }, // 117 bits per transform
+ { 10, 9, 20 }, // 117 bits per transform
+ { 10, 10, 19 }, // 117 bits per transform
+ { 10, 11, 18 }, // 117 bits per transform
+ { 10, 12, 17 }, // 117 bits per transform
+ { 10, 13, 16 }, // 117 bits per transform
+ { 10, 14, 15 }, // 117 bits per transform
+ { 10, 15, 14 }, // 117 bits per transform
+ { 10, 16, 13 }, // 117 bits per transform
+ { 10, 17, 12 }, // 117 bits per transform
+ { 10, 18, 11 }, // 117 bits per transform
+ { 10, 19, 10 }, // 117 bits per transform
+ { 10, 20, 9 }, // 117 bits per transform
+ { 10, 21, 8 }, // 117 bits per transform
+ { 10, 22, 7 }, // 117 bits per transform
+ { 10, 23, 6 }, // 117 bits per transform
+ { 11, 5, 23 }, // 117 bits per transform
+ { 11, 6, 22 }, // 117 bits per transform
+ { 11, 7, 21 }, // 117 bits per transform
+ { 11, 8, 20 }, // 117 bits per transform
+ { 11, 9, 19 }, // 117 bits per transform
+ { 11, 10, 18 }, // 117 bits per transform
+ { 11, 11, 17 }, // 117 bits per transform
+ { 11, 12, 16 }, // 117 bits per transform
+ { 11, 13, 15 }, // 117 bits per transform
+ { 11, 14, 14 }, // 117 bits per transform
+ { 11, 15, 13 }, // 117 bits per transform
+ { 11, 16, 12 }, // 117 bits per transform
+ { 11, 17, 11 }, // 117 bits per transform
+ { 11, 18, 10 }, // 117 bits per transform
+ { 11, 19, 9 }, // 117 bits per transform
+ { 11, 20, 8 }, // 117 bits per transform
+ { 11, 21, 7 }, // 117 bits per transform
+ { 11, 22, 6 }, // 117 bits per transform
+ { 11, 23, 5 }, // 117 bits per transform
+ { 12, 4, 23 }, // 117 bits per transform
+ { 12, 5, 22 }, // 117 bits per transform
+ { 12, 6, 21 }, // 117 bits per transform
+ { 12, 7, 20 }, // 117 bits per transform
+ { 12, 8, 19 }, // 117 bits per transform
+ { 12, 9, 18 }, // 117 bits per transform
+ { 12, 10, 17 }, // 117 bits per transform
+ { 12, 11, 16 }, // 117 bits per transform
+ { 12, 12, 15 }, // 117 bits per transform
+ { 12, 13, 14 }, // 117 bits per transform
+ { 12, 14, 13 }, // 117 bits per transform
+ { 12, 15, 12 }, // 117 bits per transform
+ { 12, 16, 11 }, // 117 bits per transform
+ { 12, 17, 10 }, // 117 bits per transform
+ { 12, 18, 9 }, // 117 bits per transform
+ { 12, 19, 8 }, // 117 bits per transform
+ { 12, 20, 7 }, // 117 bits per transform
+ { 12, 21, 6 }, // 117 bits per transform
+ { 12, 22, 5 }, // 117 bits per transform
+ { 12, 23, 4 }, // 117 bits per transform
+ { 13, 3, 23 }, // 117 bits per transform
+ { 13, 4, 22 }, // 117 bits per transform
+ { 13, 5, 21 }, // 117 bits per transform
+ { 13, 6, 20 }, // 117 bits per transform
+ { 13, 7, 19 }, // 117 bits per transform
+ { 13, 8, 18 }, // 117 bits per transform
+ { 13, 9, 17 }, // 117 bits per transform
+ { 13, 10, 16 }, // 117 bits per transform
+ { 13, 11, 15 }, // 117 bits per transform
+ { 13, 12, 14 }, // 117 bits per transform
+ { 13, 13, 13 }, // 117 bits per transform
+ { 13, 14, 12 }, // 117 bits per transform
+ { 13, 15, 11 }, // 117 bits per transform
+ { 13, 16, 10 }, // 117 bits per transform
+ { 13, 17, 9 }, // 117 bits per transform
+ { 13, 18, 8 }, // 117 bits per transform
+ { 13, 19, 7 }, // 117 bits per transform
+ { 13, 20, 6 }, // 117 bits per transform
+ { 13, 21, 5 }, // 117 bits per transform
+ { 13, 22, 4 }, // 117 bits per transform
+ { 13, 23, 3 }, // 117 bits per transform
+ { 14, 2, 23 }, // 117 bits per transform
+ { 14, 3, 22 }, // 117 bits per transform
+ { 14, 4, 21 }, // 117 bits per transform
+ { 14, 5, 20 }, // 117 bits per transform
+ { 14, 6, 19 }, // 117 bits per transform
+ { 14, 7, 18 }, // 117 bits per transform
+ { 14, 8, 17 }, // 117 bits per transform
+ { 14, 9, 16 }, // 117 bits per transform
+ { 14, 10, 15 }, // 117 bits per transform
+ { 14, 11, 14 }, // 117 bits per transform
+ { 14, 12, 13 }, // 117 bits per transform
+ { 14, 13, 12 }, // 117 bits per transform
+ { 14, 14, 11 }, // 117 bits per transform
+ { 14, 15, 10 }, // 117 bits per transform
+ { 14, 16, 9 }, // 117 bits per transform
+ { 14, 17, 8 }, // 117 bits per transform
+ { 14, 18, 7 }, // 117 bits per transform
+ { 14, 19, 6 }, // 117 bits per transform
+ { 14, 20, 5 }, // 117 bits per transform
+ { 14, 21, 4 }, // 117 bits per transform
+ { 14, 22, 3 }, // 117 bits per transform
+ { 14, 23, 2 }, // 117 bits per transform
+ { 15, 1, 23 }, // 117 bits per transform
+ { 15, 2, 22 }, // 117 bits per transform
+ { 15, 3, 21 }, // 117 bits per transform
+ { 15, 4, 20 }, // 117 bits per transform
+ { 15, 5, 19 }, // 117 bits per transform
+ { 15, 6, 18 }, // 117 bits per transform
+ { 15, 7, 17 }, // 117 bits per transform
+ { 15, 8, 16 }, // 117 bits per transform
+ { 15, 9, 15 }, // 117 bits per transform
+ { 15, 10, 14 }, // 117 bits per transform
+ { 15, 11, 13 }, // 117 bits per transform
+ { 15, 12, 12 }, // 117 bits per transform
+ { 15, 13, 11 }, // 117 bits per transform
+ { 15, 14, 10 }, // 117 bits per transform
+ { 15, 15, 9 }, // 117 bits per transform
+ { 15, 16, 8 }, // 117 bits per transform
+ { 15, 17, 7 }, // 117 bits per transform
+ { 15, 18, 6 }, // 117 bits per transform
+ { 15, 19, 5 }, // 117 bits per transform
+ { 15, 20, 4 }, // 117 bits per transform
+ { 15, 21, 3 }, // 117 bits per transform
+ { 15, 22, 2 }, // 117 bits per transform
+ { 15, 23, 1 }, // 117 bits per transform
+ { 16, 0, 23 }, // 117 bits per transform
+ { 16, 1, 22 }, // 117 bits per transform
+ { 16, 2, 21 }, // 117 bits per transform
+ { 16, 3, 20 }, // 117 bits per transform
+ { 16, 4, 19 }, // 117 bits per transform
+ { 16, 5, 18 }, // 117 bits per transform
+ { 16, 6, 17 }, // 117 bits per transform
+ { 16, 7, 16 }, // 117 bits per transform
+ { 16, 8, 15 }, // 117 bits per transform
+ { 16, 9, 14 }, // 117 bits per transform
+ { 16, 10, 13 }, // 117 bits per transform
+ { 16, 11, 12 }, // 117 bits per transform
+ { 16, 12, 11 }, // 117 bits per transform
+ { 16, 13, 10 }, // 117 bits per transform
+ { 16, 14, 9 }, // 117 bits per transform
+ { 16, 15, 8 }, // 117 bits per transform
+ { 16, 16, 7 }, // 117 bits per transform
+ { 16, 17, 6 }, // 117 bits per transform
+ { 16, 18, 5 }, // 117 bits per transform
+ { 16, 19, 4 }, // 117 bits per transform
+ { 16, 20, 3 }, // 117 bits per transform
+ { 16, 21, 2 }, // 117 bits per transform
+ { 16, 22, 1 }, // 117 bits per transform
+ { 16, 23, 0 }, // 117 bits per transform
+ { 17, 0, 22 }, // 117 bits per transform
+ { 17, 1, 21 }, // 117 bits per transform
+ { 17, 2, 20 }, // 117 bits per transform
+ { 17, 3, 19 }, // 117 bits per transform
+ { 17, 4, 18 }, // 117 bits per transform
+ { 17, 5, 17 }, // 117 bits per transform
+ { 17, 6, 16 }, // 117 bits per transform
+ { 17, 7, 15 }, // 117 bits per transform
+ { 17, 8, 14 }, // 117 bits per transform
+ { 17, 9, 13 }, // 117 bits per transform
+ { 17, 10, 12 }, // 117 bits per transform
+ { 17, 11, 11 }, // 117 bits per transform
+ { 17, 12, 10 }, // 117 bits per transform
+ { 17, 13, 9 }, // 117 bits per transform
+ { 17, 14, 8 }, // 117 bits per transform
+ { 17, 15, 7 }, // 117 bits per transform
+ { 17, 16, 6 }, // 117 bits per transform
+ { 17, 17, 5 }, // 117 bits per transform
+ { 17, 18, 4 }, // 117 bits per transform
+ { 17, 19, 3 }, // 117 bits per transform
+ { 17, 20, 2 }, // 117 bits per transform
+ { 17, 21, 1 }, // 117 bits per transform
+ { 17, 22, 0 }, // 117 bits per transform
+ { 18, 0, 21 }, // 117 bits per transform
+ { 18, 1, 20 }, // 117 bits per transform
+ { 18, 2, 19 }, // 117 bits per transform
+ { 18, 3, 18 }, // 117 bits per transform
+ { 18, 4, 17 }, // 117 bits per transform
+ { 18, 5, 16 }, // 117 bits per transform
+ { 18, 6, 15 }, // 117 bits per transform
+ { 18, 7, 14 }, // 117 bits per transform
+ { 18, 8, 13 }, // 117 bits per transform
+ { 18, 9, 12 }, // 117 bits per transform
+ { 18, 10, 11 }, // 117 bits per transform
+ { 18, 11, 10 }, // 117 bits per transform
+ { 18, 12, 9 }, // 117 bits per transform
+ { 18, 13, 8 }, // 117 bits per transform
+ { 18, 14, 7 }, // 117 bits per transform
+ { 18, 15, 6 }, // 117 bits per transform
+ { 18, 16, 5 }, // 117 bits per transform
+ { 18, 17, 4 }, // 117 bits per transform
+ { 18, 18, 3 }, // 117 bits per transform
+ { 18, 19, 2 }, // 117 bits per transform
+ { 18, 20, 1 }, // 117 bits per transform
+ { 18, 21, 0 }, // 117 bits per transform
+ { 19, 0, 20 }, // 117 bits per transform
+ { 19, 1, 19 }, // 117 bits per transform
+ { 19, 2, 18 }, // 117 bits per transform
+ { 19, 3, 17 }, // 117 bits per transform
+ { 19, 4, 16 }, // 117 bits per transform
+ { 19, 5, 15 }, // 117 bits per transform
+ { 19, 6, 14 }, // 117 bits per transform
+ { 19, 7, 13 }, // 117 bits per transform
+ { 19, 8, 12 }, // 117 bits per transform
+ { 19, 9, 11 }, // 117 bits per transform
+ { 19, 10, 10 }, // 117 bits per transform
+ { 19, 11, 9 }, // 117 bits per transform
+ { 19, 12, 8 }, // 117 bits per transform
+ { 19, 13, 7 }, // 117 bits per transform
+ { 19, 14, 6 }, // 117 bits per transform
+ { 19, 15, 5 }, // 117 bits per transform
+ { 19, 16, 4 }, // 117 bits per transform
+ { 19, 17, 3 }, // 117 bits per transform
+ { 19, 18, 2 }, // 117 bits per transform
+ { 19, 19, 1 }, // 117 bits per transform
+ { 19, 20, 0 }, // 117 bits per transform
+ { 20, 0, 19 }, // 117 bits per transform
+ { 20, 1, 18 }, // 117 bits per transform
+ { 20, 2, 17 }, // 117 bits per transform
+ { 20, 3, 16 }, // 117 bits per transform
+ { 20, 4, 15 }, // 117 bits per transform
+ { 20, 5, 14 }, // 117 bits per transform
+ { 20, 6, 13 }, // 117 bits per transform
+ { 20, 7, 12 }, // 117 bits per transform
+ { 20, 8, 11 }, // 117 bits per transform
+ { 20, 9, 10 }, // 117 bits per transform
+ { 20, 10, 9 }, // 117 bits per transform
+ { 20, 11, 8 }, // 117 bits per transform
+ { 20, 12, 7 }, // 117 bits per transform
+ { 20, 13, 6 }, // 117 bits per transform
+ { 20, 14, 5 }, // 117 bits per transform
+ { 20, 15, 4 }, // 117 bits per transform
+ { 20, 16, 3 }, // 117 bits per transform
+ { 20, 17, 2 }, // 117 bits per transform
+ { 20, 18, 1 }, // 117 bits per transform
+ { 20, 19, 0 }, // 117 bits per transform
+ { 21, 0, 18 }, // 117 bits per transform
+ { 21, 1, 17 }, // 117 bits per transform
+ { 21, 2, 16 }, // 117 bits per transform
+ { 21, 3, 15 }, // 117 bits per transform
+ { 21, 4, 14 }, // 117 bits per transform
+ { 21, 5, 13 }, // 117 bits per transform
+ { 21, 6, 12 }, // 117 bits per transform
+ { 21, 7, 11 }, // 117 bits per transform
+ { 21, 8, 10 }, // 117 bits per transform
+ { 21, 9, 9 }, // 117 bits per transform
+ { 21, 10, 8 }, // 117 bits per transform
+ { 21, 11, 7 }, // 117 bits per transform
+ { 21, 12, 6 }, // 117 bits per transform
+ { 21, 13, 5 }, // 117 bits per transform
+ { 21, 14, 4 }, // 117 bits per transform
+ { 21, 15, 3 }, // 117 bits per transform
+ { 21, 16, 2 }, // 117 bits per transform
+ { 21, 17, 1 }, // 117 bits per transform
+ { 21, 18, 0 }, // 117 bits per transform
+ { 22, 0, 17 }, // 117 bits per transform
+ { 22, 1, 16 }, // 117 bits per transform
+ { 22, 2, 15 }, // 117 bits per transform
+ { 22, 3, 14 }, // 117 bits per transform
+ { 22, 4, 13 }, // 117 bits per transform
+ { 22, 5, 12 }, // 117 bits per transform
+ { 22, 6, 11 }, // 117 bits per transform
+ { 22, 7, 10 }, // 117 bits per transform
+ { 22, 8, 9 }, // 117 bits per transform
+ { 22, 9, 8 }, // 117 bits per transform
+ { 22, 10, 7 }, // 117 bits per transform
+ { 22, 11, 6 }, // 117 bits per transform
+ { 22, 12, 5 }, // 117 bits per transform
+ { 22, 13, 4 }, // 117 bits per transform
+ { 22, 14, 3 }, // 117 bits per transform
+ { 22, 15, 2 }, // 117 bits per transform
+ { 22, 16, 1 }, // 117 bits per transform
+ { 22, 17, 0 }, // 117 bits per transform
+ { 23, 0, 16 }, // 117 bits per transform
+ { 23, 1, 15 }, // 117 bits per transform
+ { 23, 2, 14 }, // 117 bits per transform
+ { 23, 3, 13 }, // 117 bits per transform
+ { 23, 4, 12 }, // 117 bits per transform
+ { 23, 5, 11 }, // 117 bits per transform
+ { 23, 6, 10 }, // 117 bits per transform
+ { 23, 7, 9 }, // 117 bits per transform
+ { 23, 8, 8 }, // 117 bits per transform
+ { 23, 9, 7 }, // 117 bits per transform
+ { 23, 10, 6 }, // 117 bits per transform
+ { 23, 11, 5 }, // 117 bits per transform
+ { 23, 12, 4 }, // 117 bits per transform
+ { 23, 13, 3 }, // 117 bits per transform
+ { 23, 14, 2 }, // 117 bits per transform
+ { 23, 15, 1 }, // 117 bits per transform
+ { 23, 16, 0 }, // 117 bits per transform
+ { 24, 0, 7 }, // 117 bits per transform
+ { 24, 1, 6 }, // 117 bits per transform
+ { 24, 2, 5 }, // 117 bits per transform
+ { 24, 3, 4 }, // 117 bits per transform
+ { 24, 4, 3 }, // 117 bits per transform
+ { 24, 5, 2 }, // 117 bits per transform
+ { 24, 6, 1 }, // 117 bits per transform
+ { 24, 7, 0 }, // 117 bits per transform
+ { 0, 8, 24 }, // 120 bits per transform
+ { 0, 17, 23 }, // 120 bits per transform
+ { 0, 18, 22 }, // 120 bits per transform
+ { 0, 19, 21 }, // 120 bits per transform
+ { 0, 20, 20 }, // 120 bits per transform
+ { 0, 21, 19 }, // 120 bits per transform
+ { 0, 22, 18 }, // 120 bits per transform
+ { 0, 23, 17 }, // 120 bits per transform
+ { 0, 24, 8 }, // 120 bits per transform
+ { 1, 7, 24 }, // 120 bits per transform
+ { 1, 16, 23 }, // 120 bits per transform
+ { 1, 17, 22 }, // 120 bits per transform
+ { 1, 18, 21 }, // 120 bits per transform
+ { 1, 19, 20 }, // 120 bits per transform
+ { 1, 20, 19 }, // 120 bits per transform
+ { 1, 21, 18 }, // 120 bits per transform
+ { 1, 22, 17 }, // 120 bits per transform
+ { 1, 23, 16 }, // 120 bits per transform
+ { 1, 24, 7 }, // 120 bits per transform
+ { 2, 6, 24 }, // 120 bits per transform
+ { 2, 15, 23 }, // 120 bits per transform
+ { 2, 16, 22 }, // 120 bits per transform
+ { 2, 17, 21 }, // 120 bits per transform
+ { 2, 18, 20 }, // 120 bits per transform
+ { 2, 19, 19 }, // 120 bits per transform
+ { 2, 20, 18 }, // 120 bits per transform
+ { 2, 21, 17 }, // 120 bits per transform
+ { 2, 22, 16 }, // 120 bits per transform
+ { 2, 23, 15 }, // 120 bits per transform
+ { 2, 24, 6 }, // 120 bits per transform
+ { 3, 5, 24 }, // 120 bits per transform
+ { 3, 14, 23 }, // 120 bits per transform
+ { 3, 15, 22 }, // 120 bits per transform
+ { 3, 16, 21 }, // 120 bits per transform
+ { 3, 17, 20 }, // 120 bits per transform
+ { 3, 18, 19 }, // 120 bits per transform
+ { 3, 19, 18 }, // 120 bits per transform
+ { 3, 20, 17 }, // 120 bits per transform
+ { 3, 21, 16 }, // 120 bits per transform
+ { 3, 22, 15 }, // 120 bits per transform
+ { 3, 23, 14 }, // 120 bits per transform
+ { 3, 24, 5 }, // 120 bits per transform
+ { 4, 4, 24 }, // 120 bits per transform
+ { 4, 13, 23 }, // 120 bits per transform
+ { 4, 14, 22 }, // 120 bits per transform
+ { 4, 15, 21 }, // 120 bits per transform
+ { 4, 16, 20 }, // 120 bits per transform
+ { 4, 17, 19 }, // 120 bits per transform
+ { 4, 18, 18 }, // 120 bits per transform
+ { 4, 19, 17 }, // 120 bits per transform
+ { 4, 20, 16 }, // 120 bits per transform
+ { 4, 21, 15 }, // 120 bits per transform
+ { 4, 22, 14 }, // 120 bits per transform
+ { 4, 23, 13 }, // 120 bits per transform
+ { 4, 24, 4 }, // 120 bits per transform
+ { 5, 3, 24 }, // 120 bits per transform
+ { 5, 12, 23 }, // 120 bits per transform
+ { 5, 13, 22 }, // 120 bits per transform
+ { 5, 14, 21 }, // 120 bits per transform
+ { 5, 15, 20 }, // 120 bits per transform
+ { 5, 16, 19 }, // 120 bits per transform
+ { 5, 17, 18 }, // 120 bits per transform
+ { 5, 18, 17 }, // 120 bits per transform
+ { 5, 19, 16 }, // 120 bits per transform
+ { 5, 20, 15 }, // 120 bits per transform
+ { 5, 21, 14 }, // 120 bits per transform
+ { 5, 22, 13 }, // 120 bits per transform
+ { 5, 23, 12 }, // 120 bits per transform
+ { 5, 24, 3 }, // 120 bits per transform
+ { 6, 2, 24 }, // 120 bits per transform
+ { 6, 11, 23 }, // 120 bits per transform
+ { 6, 12, 22 }, // 120 bits per transform
+ { 6, 13, 21 }, // 120 bits per transform
+ { 6, 14, 20 }, // 120 bits per transform
+ { 6, 15, 19 }, // 120 bits per transform
+ { 6, 16, 18 }, // 120 bits per transform
+ { 6, 17, 17 }, // 120 bits per transform
+ { 6, 18, 16 }, // 120 bits per transform
+ { 6, 19, 15 }, // 120 bits per transform
+ { 6, 20, 14 }, // 120 bits per transform
+ { 6, 21, 13 }, // 120 bits per transform
+ { 6, 22, 12 }, // 120 bits per transform
+ { 6, 23, 11 }, // 120 bits per transform
+ { 6, 24, 2 }, // 120 bits per transform
+ { 7, 1, 24 }, // 120 bits per transform
+ { 7, 10, 23 }, // 120 bits per transform
+ { 7, 11, 22 }, // 120 bits per transform
+ { 7, 12, 21 }, // 120 bits per transform
+ { 7, 13, 20 }, // 120 bits per transform
+ { 7, 14, 19 }, // 120 bits per transform
+ { 7, 15, 18 }, // 120 bits per transform
+ { 7, 16, 17 }, // 120 bits per transform
+ { 7, 17, 16 }, // 120 bits per transform
+ { 7, 18, 15 }, // 120 bits per transform
+ { 7, 19, 14 }, // 120 bits per transform
+ { 7, 20, 13 }, // 120 bits per transform
+ { 7, 21, 12 }, // 120 bits per transform
+ { 7, 22, 11 }, // 120 bits per transform
+ { 7, 23, 10 }, // 120 bits per transform
+ { 7, 24, 1 }, // 120 bits per transform
+ { 8, 0, 24 }, // 120 bits per transform
+ { 8, 9, 23 }, // 120 bits per transform
+ { 8, 10, 22 }, // 120 bits per transform
+ { 8, 11, 21 }, // 120 bits per transform
+ { 8, 12, 20 }, // 120 bits per transform
+ { 8, 13, 19 }, // 120 bits per transform
+ { 8, 14, 18 }, // 120 bits per transform
+ { 8, 15, 17 }, // 120 bits per transform
+ { 8, 16, 16 }, // 120 bits per transform
+ { 8, 17, 15 }, // 120 bits per transform
+ { 8, 18, 14 }, // 120 bits per transform
+ { 8, 19, 13 }, // 120 bits per transform
+ { 8, 20, 12 }, // 120 bits per transform
+ { 8, 21, 11 }, // 120 bits per transform
+ { 8, 22, 10 }, // 120 bits per transform
+ { 8, 23, 9 }, // 120 bits per transform
+ { 8, 24, 0 }, // 120 bits per transform
+ { 9, 8, 23 }, // 120 bits per transform
+ { 9, 9, 22 }, // 120 bits per transform
+ { 9, 10, 21 }, // 120 bits per transform
+ { 9, 11, 20 }, // 120 bits per transform
+ { 9, 12, 19 }, // 120 bits per transform
+ { 9, 13, 18 }, // 120 bits per transform
+ { 9, 14, 17 }, // 120 bits per transform
+ { 9, 15, 16 }, // 120 bits per transform
+ { 9, 16, 15 }, // 120 bits per transform
+ { 9, 17, 14 }, // 120 bits per transform
+ { 9, 18, 13 }, // 120 bits per transform
+ { 9, 19, 12 }, // 120 bits per transform
+ { 9, 20, 11 }, // 120 bits per transform
+ { 9, 21, 10 }, // 120 bits per transform
+ { 9, 22, 9 }, // 120 bits per transform
+ { 9, 23, 8 }, // 120 bits per transform
+ { 10, 7, 23 }, // 120 bits per transform
+ { 10, 8, 22 }, // 120 bits per transform
+ { 10, 9, 21 }, // 120 bits per transform
+ { 10, 10, 20 }, // 120 bits per transform
+ { 10, 11, 19 }, // 120 bits per transform
+ { 10, 12, 18 }, // 120 bits per transform
+ { 10, 13, 17 }, // 120 bits per transform
+ { 10, 14, 16 }, // 120 bits per transform
+ { 10, 15, 15 }, // 120 bits per transform
+ { 10, 16, 14 }, // 120 bits per transform
+ { 10, 17, 13 }, // 120 bits per transform
+ { 10, 18, 12 }, // 120 bits per transform
+ { 10, 19, 11 }, // 120 bits per transform
+ { 10, 20, 10 }, // 120 bits per transform
+ { 10, 21, 9 }, // 120 bits per transform
+ { 10, 22, 8 }, // 120 bits per transform
+ { 10, 23, 7 }, // 120 bits per transform
+ { 11, 6, 23 }, // 120 bits per transform
+ { 11, 7, 22 }, // 120 bits per transform
+ { 11, 8, 21 }, // 120 bits per transform
+ { 11, 9, 20 }, // 120 bits per transform
+ { 11, 10, 19 }, // 120 bits per transform
+ { 11, 11, 18 }, // 120 bits per transform
+ { 11, 12, 17 }, // 120 bits per transform
+ { 11, 13, 16 }, // 120 bits per transform
+ { 11, 14, 15 }, // 120 bits per transform
+ { 11, 15, 14 }, // 120 bits per transform
+ { 11, 16, 13 }, // 120 bits per transform
+ { 11, 17, 12 }, // 120 bits per transform
+ { 11, 18, 11 }, // 120 bits per transform
+ { 11, 19, 10 }, // 120 bits per transform
+ { 11, 20, 9 }, // 120 bits per transform
+ { 11, 21, 8 }, // 120 bits per transform
+ { 11, 22, 7 }, // 120 bits per transform
+ { 11, 23, 6 }, // 120 bits per transform
+ { 12, 5, 23 }, // 120 bits per transform
+ { 12, 6, 22 }, // 120 bits per transform
+ { 12, 7, 21 }, // 120 bits per transform
+ { 12, 8, 20 }, // 120 bits per transform
+ { 12, 9, 19 }, // 120 bits per transform
+ { 12, 10, 18 }, // 120 bits per transform
+ { 12, 11, 17 }, // 120 bits per transform
+ { 12, 12, 16 }, // 120 bits per transform
+ { 12, 13, 15 }, // 120 bits per transform
+ { 12, 14, 14 }, // 120 bits per transform
+ { 12, 15, 13 }, // 120 bits per transform
+ { 12, 16, 12 }, // 120 bits per transform
+ { 12, 17, 11 }, // 120 bits per transform
+ { 12, 18, 10 }, // 120 bits per transform
+ { 12, 19, 9 }, // 120 bits per transform
+ { 12, 20, 8 }, // 120 bits per transform
+ { 12, 21, 7 }, // 120 bits per transform
+ { 12, 22, 6 }, // 120 bits per transform
+ { 12, 23, 5 }, // 120 bits per transform
+ { 13, 4, 23 }, // 120 bits per transform
+ { 13, 5, 22 }, // 120 bits per transform
+ { 13, 6, 21 }, // 120 bits per transform
+ { 13, 7, 20 }, // 120 bits per transform
+ { 13, 8, 19 }, // 120 bits per transform
+ { 13, 9, 18 }, // 120 bits per transform
+ { 13, 10, 17 }, // 120 bits per transform
+ { 13, 11, 16 }, // 120 bits per transform
+ { 13, 12, 15 }, // 120 bits per transform
+ { 13, 13, 14 }, // 120 bits per transform
+ { 13, 14, 13 }, // 120 bits per transform
+ { 13, 15, 12 }, // 120 bits per transform
+ { 13, 16, 11 }, // 120 bits per transform
+ { 13, 17, 10 }, // 120 bits per transform
+ { 13, 18, 9 }, // 120 bits per transform
+ { 13, 19, 8 }, // 120 bits per transform
+ { 13, 20, 7 }, // 120 bits per transform
+ { 13, 21, 6 }, // 120 bits per transform
+ { 13, 22, 5 }, // 120 bits per transform
+ { 13, 23, 4 }, // 120 bits per transform
+ { 14, 3, 23 }, // 120 bits per transform
+ { 14, 4, 22 }, // 120 bits per transform
+ { 14, 5, 21 }, // 120 bits per transform
+ { 14, 6, 20 }, // 120 bits per transform
+ { 14, 7, 19 }, // 120 bits per transform
+ { 14, 8, 18 }, // 120 bits per transform
+ { 14, 9, 17 }, // 120 bits per transform
+ { 14, 10, 16 }, // 120 bits per transform
+ { 14, 11, 15 }, // 120 bits per transform
+ { 14, 12, 14 }, // 120 bits per transform
+ { 14, 13, 13 }, // 120 bits per transform
+ { 14, 14, 12 }, // 120 bits per transform
+ { 14, 15, 11 }, // 120 bits per transform
+ { 14, 16, 10 }, // 120 bits per transform
+ { 14, 17, 9 }, // 120 bits per transform
+ { 14, 18, 8 }, // 120 bits per transform
+ { 14, 19, 7 }, // 120 bits per transform
+ { 14, 20, 6 }, // 120 bits per transform
+ { 14, 21, 5 }, // 120 bits per transform
+ { 14, 22, 4 }, // 120 bits per transform
+ { 14, 23, 3 }, // 120 bits per transform
+ { 15, 2, 23 }, // 120 bits per transform
+ { 15, 3, 22 }, // 120 bits per transform
+ { 15, 4, 21 }, // 120 bits per transform
+ { 15, 5, 20 }, // 120 bits per transform
+ { 15, 6, 19 }, // 120 bits per transform
+ { 15, 7, 18 }, // 120 bits per transform
+ { 15, 8, 17 }, // 120 bits per transform
+ { 15, 9, 16 }, // 120 bits per transform
+ { 15, 10, 15 }, // 120 bits per transform
+ { 15, 11, 14 }, // 120 bits per transform
+ { 15, 12, 13 }, // 120 bits per transform
+ { 15, 13, 12 }, // 120 bits per transform
+ { 15, 14, 11 }, // 120 bits per transform
+ { 15, 15, 10 }, // 120 bits per transform
+ { 15, 16, 9 }, // 120 bits per transform
+ { 15, 17, 8 }, // 120 bits per transform
+ { 15, 18, 7 }, // 120 bits per transform
+ { 15, 19, 6 }, // 120 bits per transform
+ { 15, 20, 5 }, // 120 bits per transform
+ { 15, 21, 4 }, // 120 bits per transform
+ { 15, 22, 3 }, // 120 bits per transform
+ { 15, 23, 2 }, // 120 bits per transform
+ { 16, 1, 23 }, // 120 bits per transform
+ { 16, 2, 22 }, // 120 bits per transform
+ { 16, 3, 21 }, // 120 bits per transform
+ { 16, 4, 20 }, // 120 bits per transform
+ { 16, 5, 19 }, // 120 bits per transform
+ { 16, 6, 18 }, // 120 bits per transform
+ { 16, 7, 17 }, // 120 bits per transform
+ { 16, 8, 16 }, // 120 bits per transform
+ { 16, 9, 15 }, // 120 bits per transform
+ { 16, 10, 14 }, // 120 bits per transform
+ { 16, 11, 13 }, // 120 bits per transform
+ { 16, 12, 12 }, // 120 bits per transform
+ { 16, 13, 11 }, // 120 bits per transform
+ { 16, 14, 10 }, // 120 bits per transform
+ { 16, 15, 9 }, // 120 bits per transform
+ { 16, 16, 8 }, // 120 bits per transform
+ { 16, 17, 7 }, // 120 bits per transform
+ { 16, 18, 6 }, // 120 bits per transform
+ { 16, 19, 5 }, // 120 bits per transform
+ { 16, 20, 4 }, // 120 bits per transform
+ { 16, 21, 3 }, // 120 bits per transform
+ { 16, 22, 2 }, // 120 bits per transform
+ { 16, 23, 1 }, // 120 bits per transform
+ { 17, 0, 23 }, // 120 bits per transform
+ { 17, 1, 22 }, // 120 bits per transform
+ { 17, 2, 21 }, // 120 bits per transform
+ { 17, 3, 20 }, // 120 bits per transform
+ { 17, 4, 19 }, // 120 bits per transform
+ { 17, 5, 18 }, // 120 bits per transform
+ { 17, 6, 17 }, // 120 bits per transform
+ { 17, 7, 16 }, // 120 bits per transform
+ { 17, 8, 15 }, // 120 bits per transform
+ { 17, 9, 14 }, // 120 bits per transform
+ { 17, 10, 13 }, // 120 bits per transform
+ { 17, 11, 12 }, // 120 bits per transform
+ { 17, 12, 11 }, // 120 bits per transform
+ { 17, 13, 10 }, // 120 bits per transform
+ { 17, 14, 9 }, // 120 bits per transform
+ { 17, 15, 8 }, // 120 bits per transform
+ { 17, 16, 7 }, // 120 bits per transform
+ { 17, 17, 6 }, // 120 bits per transform
+ { 17, 18, 5 }, // 120 bits per transform
+ { 17, 19, 4 }, // 120 bits per transform
+ { 17, 20, 3 }, // 120 bits per transform
+ { 17, 21, 2 }, // 120 bits per transform
+ { 17, 22, 1 }, // 120 bits per transform
+ { 17, 23, 0 }, // 120 bits per transform
+ { 18, 0, 22 }, // 120 bits per transform
+ { 18, 1, 21 }, // 120 bits per transform
+ { 18, 2, 20 }, // 120 bits per transform
+ { 18, 3, 19 }, // 120 bits per transform
+ { 18, 4, 18 }, // 120 bits per transform
+ { 18, 5, 17 }, // 120 bits per transform
+ { 18, 6, 16 }, // 120 bits per transform
+ { 18, 7, 15 }, // 120 bits per transform
+ { 18, 8, 14 }, // 120 bits per transform
+ { 18, 9, 13 }, // 120 bits per transform
+ { 18, 10, 12 }, // 120 bits per transform
+ { 18, 11, 11 }, // 120 bits per transform
+ { 18, 12, 10 }, // 120 bits per transform
+ { 18, 13, 9 }, // 120 bits per transform
+ { 18, 14, 8 }, // 120 bits per transform
+ { 18, 15, 7 }, // 120 bits per transform
+ { 18, 16, 6 }, // 120 bits per transform
+ { 18, 17, 5 }, // 120 bits per transform
+ { 18, 18, 4 }, // 120 bits per transform
+ { 18, 19, 3 }, // 120 bits per transform
+ { 18, 20, 2 }, // 120 bits per transform
+ { 18, 21, 1 }, // 120 bits per transform
+ { 18, 22, 0 }, // 120 bits per transform
+ { 19, 0, 21 }, // 120 bits per transform
+ { 19, 1, 20 }, // 120 bits per transform
+ { 19, 2, 19 }, // 120 bits per transform
+ { 19, 3, 18 }, // 120 bits per transform
+ { 19, 4, 17 }, // 120 bits per transform
+ { 19, 5, 16 }, // 120 bits per transform
+ { 19, 6, 15 }, // 120 bits per transform
+ { 19, 7, 14 }, // 120 bits per transform
+ { 19, 8, 13 }, // 120 bits per transform
+ { 19, 9, 12 }, // 120 bits per transform
+ { 19, 10, 11 }, // 120 bits per transform
+ { 19, 11, 10 }, // 120 bits per transform
+ { 19, 12, 9 }, // 120 bits per transform
+ { 19, 13, 8 }, // 120 bits per transform
+ { 19, 14, 7 }, // 120 bits per transform
+ { 19, 15, 6 }, // 120 bits per transform
+ { 19, 16, 5 }, // 120 bits per transform
+ { 19, 17, 4 }, // 120 bits per transform
+ { 19, 18, 3 }, // 120 bits per transform
+ { 19, 19, 2 }, // 120 bits per transform
+ { 19, 20, 1 }, // 120 bits per transform
+ { 19, 21, 0 }, // 120 bits per transform
+ { 20, 0, 20 }, // 120 bits per transform
+ { 20, 1, 19 }, // 120 bits per transform
+ { 20, 2, 18 }, // 120 bits per transform
+ { 20, 3, 17 }, // 120 bits per transform
+ { 20, 4, 16 }, // 120 bits per transform
+ { 20, 5, 15 }, // 120 bits per transform
+ { 20, 6, 14 }, // 120 bits per transform
+ { 20, 7, 13 }, // 120 bits per transform
+ { 20, 8, 12 }, // 120 bits per transform
+ { 20, 9, 11 }, // 120 bits per transform
+ { 20, 10, 10 }, // 120 bits per transform
+ { 20, 11, 9 }, // 120 bits per transform
+ { 20, 12, 8 }, // 120 bits per transform
+ { 20, 13, 7 }, // 120 bits per transform
+ { 20, 14, 6 }, // 120 bits per transform
+ { 20, 15, 5 }, // 120 bits per transform
+ { 20, 16, 4 }, // 120 bits per transform
+ { 20, 17, 3 }, // 120 bits per transform
+ { 20, 18, 2 }, // 120 bits per transform
+ { 20, 19, 1 }, // 120 bits per transform
+ { 20, 20, 0 }, // 120 bits per transform
+ { 21, 0, 19 }, // 120 bits per transform
+ { 21, 1, 18 }, // 120 bits per transform
+ { 21, 2, 17 }, // 120 bits per transform
+ { 21, 3, 16 }, // 120 bits per transform
+ { 21, 4, 15 }, // 120 bits per transform
+ { 21, 5, 14 }, // 120 bits per transform
+ { 21, 6, 13 }, // 120 bits per transform
+ { 21, 7, 12 }, // 120 bits per transform
+ { 21, 8, 11 }, // 120 bits per transform
+ { 21, 9, 10 }, // 120 bits per transform
+ { 21, 10, 9 }, // 120 bits per transform
+ { 21, 11, 8 }, // 120 bits per transform
+ { 21, 12, 7 }, // 120 bits per transform
+ { 21, 13, 6 }, // 120 bits per transform
+ { 21, 14, 5 }, // 120 bits per transform
+ { 21, 15, 4 }, // 120 bits per transform
+ { 21, 16, 3 }, // 120 bits per transform
+ { 21, 17, 2 }, // 120 bits per transform
+ { 21, 18, 1 }, // 120 bits per transform
+ { 21, 19, 0 }, // 120 bits per transform
+ { 22, 0, 18 }, // 120 bits per transform
+ { 22, 1, 17 }, // 120 bits per transform
+ { 22, 2, 16 }, // 120 bits per transform
+ { 22, 3, 15 }, // 120 bits per transform
+ { 22, 4, 14 }, // 120 bits per transform
+ { 22, 5, 13 }, // 120 bits per transform
+ { 22, 6, 12 }, // 120 bits per transform
+ { 22, 7, 11 }, // 120 bits per transform
+ { 22, 8, 10 }, // 120 bits per transform
+ { 22, 9, 9 }, // 120 bits per transform
+ { 22, 10, 8 }, // 120 bits per transform
+ { 22, 11, 7 }, // 120 bits per transform
+ { 22, 12, 6 }, // 120 bits per transform
+ { 22, 13, 5 }, // 120 bits per transform
+ { 22, 14, 4 }, // 120 bits per transform
+ { 22, 15, 3 }, // 120 bits per transform
+ { 22, 16, 2 }, // 120 bits per transform
+ { 22, 17, 1 }, // 120 bits per transform
+ { 22, 18, 0 }, // 120 bits per transform
+ { 23, 0, 17 }, // 120 bits per transform
+ { 23, 1, 16 }, // 120 bits per transform
+ { 23, 2, 15 }, // 120 bits per transform
+ { 23, 3, 14 }, // 120 bits per transform
+ { 23, 4, 13 }, // 120 bits per transform
+ { 23, 5, 12 }, // 120 bits per transform
+ { 23, 6, 11 }, // 120 bits per transform
+ { 23, 7, 10 }, // 120 bits per transform
+ { 23, 8, 9 }, // 120 bits per transform
+ { 23, 9, 8 }, // 120 bits per transform
+ { 23, 10, 7 }, // 120 bits per transform
+ { 23, 11, 6 }, // 120 bits per transform
+ { 23, 12, 5 }, // 120 bits per transform
+ { 23, 13, 4 }, // 120 bits per transform
+ { 23, 14, 3 }, // 120 bits per transform
+ { 23, 15, 2 }, // 120 bits per transform
+ { 23, 16, 1 }, // 120 bits per transform
+ { 23, 17, 0 }, // 120 bits per transform
+ { 24, 0, 8 }, // 120 bits per transform
+ { 24, 1, 7 }, // 120 bits per transform
+ { 24, 2, 6 }, // 120 bits per transform
+ { 24, 3, 5 }, // 120 bits per transform
+ { 24, 4, 4 }, // 120 bits per transform
+ { 24, 5, 3 }, // 120 bits per transform
+ { 24, 6, 2 }, // 120 bits per transform
+ { 24, 7, 1 }, // 120 bits per transform
+ { 24, 8, 0 }, // 120 bits per transform
+ { 0, 9, 24 }, // 123 bits per transform
+ { 0, 18, 23 }, // 123 bits per transform
+ { 0, 19, 22 }, // 123 bits per transform
+ { 0, 20, 21 }, // 123 bits per transform
+ { 0, 21, 20 }, // 123 bits per transform
+ { 0, 22, 19 }, // 123 bits per transform
+ { 0, 23, 18 }, // 123 bits per transform
+ { 0, 24, 9 }, // 123 bits per transform
+ { 1, 8, 24 }, // 123 bits per transform
+ { 1, 17, 23 }, // 123 bits per transform
+ { 1, 18, 22 }, // 123 bits per transform
+ { 1, 19, 21 }, // 123 bits per transform
+ { 1, 20, 20 }, // 123 bits per transform
+ { 1, 21, 19 }, // 123 bits per transform
+ { 1, 22, 18 }, // 123 bits per transform
+ { 1, 23, 17 }, // 123 bits per transform
+ { 1, 24, 8 }, // 123 bits per transform
+ { 2, 7, 24 }, // 123 bits per transform
+ { 2, 16, 23 }, // 123 bits per transform
+ { 2, 17, 22 }, // 123 bits per transform
+ { 2, 18, 21 }, // 123 bits per transform
+ { 2, 19, 20 }, // 123 bits per transform
+ { 2, 20, 19 }, // 123 bits per transform
+ { 2, 21, 18 }, // 123 bits per transform
+ { 2, 22, 17 }, // 123 bits per transform
+ { 2, 23, 16 }, // 123 bits per transform
+ { 2, 24, 7 }, // 123 bits per transform
+ { 3, 6, 24 }, // 123 bits per transform
+ { 3, 15, 23 }, // 123 bits per transform
+ { 3, 16, 22 }, // 123 bits per transform
+ { 3, 17, 21 }, // 123 bits per transform
+ { 3, 18, 20 }, // 123 bits per transform
+ { 3, 19, 19 }, // 123 bits per transform
+ { 3, 20, 18 }, // 123 bits per transform
+ { 3, 21, 17 }, // 123 bits per transform
+ { 3, 22, 16 }, // 123 bits per transform
+ { 3, 23, 15 }, // 123 bits per transform
+ { 3, 24, 6 }, // 123 bits per transform
+ { 4, 5, 24 }, // 123 bits per transform
+ { 4, 14, 23 }, // 123 bits per transform
+ { 4, 15, 22 }, // 123 bits per transform
+ { 4, 16, 21 }, // 123 bits per transform
+ { 4, 17, 20 }, // 123 bits per transform
+ { 4, 18, 19 }, // 123 bits per transform
+ { 4, 19, 18 }, // 123 bits per transform
+ { 4, 20, 17 }, // 123 bits per transform
+ { 4, 21, 16 }, // 123 bits per transform
+ { 4, 22, 15 }, // 123 bits per transform
+ { 4, 23, 14 }, // 123 bits per transform
+ { 4, 24, 5 }, // 123 bits per transform
+ { 5, 4, 24 }, // 123 bits per transform
+ { 5, 13, 23 }, // 123 bits per transform
+ { 5, 14, 22 }, // 123 bits per transform
+ { 5, 15, 21 }, // 123 bits per transform
+ { 5, 16, 20 }, // 123 bits per transform
+ { 5, 17, 19 }, // 123 bits per transform
+ { 5, 18, 18 }, // 123 bits per transform
+ { 5, 19, 17 }, // 123 bits per transform
+ { 5, 20, 16 }, // 123 bits per transform
+ { 5, 21, 15 }, // 123 bits per transform
+ { 5, 22, 14 }, // 123 bits per transform
+ { 5, 23, 13 }, // 123 bits per transform
+ { 5, 24, 4 }, // 123 bits per transform
+ { 6, 3, 24 }, // 123 bits per transform
+ { 6, 12, 23 }, // 123 bits per transform
+ { 6, 13, 22 }, // 123 bits per transform
+ { 6, 14, 21 }, // 123 bits per transform
+ { 6, 15, 20 }, // 123 bits per transform
+ { 6, 16, 19 }, // 123 bits per transform
+ { 6, 17, 18 }, // 123 bits per transform
+ { 6, 18, 17 }, // 123 bits per transform
+ { 6, 19, 16 }, // 123 bits per transform
+ { 6, 20, 15 }, // 123 bits per transform
+ { 6, 21, 14 }, // 123 bits per transform
+ { 6, 22, 13 }, // 123 bits per transform
+ { 6, 23, 12 }, // 123 bits per transform
+ { 6, 24, 3 }, // 123 bits per transform
+ { 7, 2, 24 }, // 123 bits per transform
+ { 7, 11, 23 }, // 123 bits per transform
+ { 7, 12, 22 }, // 123 bits per transform
+ { 7, 13, 21 }, // 123 bits per transform
+ { 7, 14, 20 }, // 123 bits per transform
+ { 7, 15, 19 }, // 123 bits per transform
+ { 7, 16, 18 }, // 123 bits per transform
+ { 7, 17, 17 }, // 123 bits per transform
+ { 7, 18, 16 }, // 123 bits per transform
+ { 7, 19, 15 }, // 123 bits per transform
+ { 7, 20, 14 }, // 123 bits per transform
+ { 7, 21, 13 }, // 123 bits per transform
+ { 7, 22, 12 }, // 123 bits per transform
+ { 7, 23, 11 }, // 123 bits per transform
+ { 7, 24, 2 }, // 123 bits per transform
+ { 8, 1, 24 }, // 123 bits per transform
+ { 8, 10, 23 }, // 123 bits per transform
+ { 8, 11, 22 }, // 123 bits per transform
+ { 8, 12, 21 }, // 123 bits per transform
+ { 8, 13, 20 }, // 123 bits per transform
+ { 8, 14, 19 }, // 123 bits per transform
+ { 8, 15, 18 }, // 123 bits per transform
+ { 8, 16, 17 }, // 123 bits per transform
+ { 8, 17, 16 }, // 123 bits per transform
+ { 8, 18, 15 }, // 123 bits per transform
+ { 8, 19, 14 }, // 123 bits per transform
+ { 8, 20, 13 }, // 123 bits per transform
+ { 8, 21, 12 }, // 123 bits per transform
+ { 8, 22, 11 }, // 123 bits per transform
+ { 8, 23, 10 }, // 123 bits per transform
+ { 8, 24, 1 }, // 123 bits per transform
+ { 9, 0, 24 }, // 123 bits per transform
+ { 9, 9, 23 }, // 123 bits per transform
+ { 9, 10, 22 }, // 123 bits per transform
+ { 9, 11, 21 }, // 123 bits per transform
+ { 9, 12, 20 }, // 123 bits per transform
+ { 9, 13, 19 }, // 123 bits per transform
+ { 9, 14, 18 }, // 123 bits per transform
+ { 9, 15, 17 }, // 123 bits per transform
+ { 9, 16, 16 }, // 123 bits per transform
+ { 9, 17, 15 }, // 123 bits per transform
+ { 9, 18, 14 }, // 123 bits per transform
+ { 9, 19, 13 }, // 123 bits per transform
+ { 9, 20, 12 }, // 123 bits per transform
+ { 9, 21, 11 }, // 123 bits per transform
+ { 9, 22, 10 }, // 123 bits per transform
+ { 9, 23, 9 }, // 123 bits per transform
+ { 9, 24, 0 }, // 123 bits per transform
+ { 10, 8, 23 }, // 123 bits per transform
+ { 10, 9, 22 }, // 123 bits per transform
+ { 10, 10, 21 }, // 123 bits per transform
+ { 10, 11, 20 }, // 123 bits per transform
+ { 10, 12, 19 }, // 123 bits per transform
+ { 10, 13, 18 }, // 123 bits per transform
+ { 10, 14, 17 }, // 123 bits per transform
+ { 10, 15, 16 }, // 123 bits per transform
+ { 10, 16, 15 }, // 123 bits per transform
+ { 10, 17, 14 }, // 123 bits per transform
+ { 10, 18, 13 }, // 123 bits per transform
+ { 10, 19, 12 }, // 123 bits per transform
+ { 10, 20, 11 }, // 123 bits per transform
+ { 10, 21, 10 }, // 123 bits per transform
+ { 10, 22, 9 }, // 123 bits per transform
+ { 10, 23, 8 }, // 123 bits per transform
+ { 11, 7, 23 }, // 123 bits per transform
+ { 11, 8, 22 }, // 123 bits per transform
+ { 11, 9, 21 }, // 123 bits per transform
+ { 11, 10, 20 }, // 123 bits per transform
+ { 11, 11, 19 }, // 123 bits per transform
+ { 11, 12, 18 }, // 123 bits per transform
+ { 11, 13, 17 }, // 123 bits per transform
+ { 11, 14, 16 }, // 123 bits per transform
+ { 11, 15, 15 }, // 123 bits per transform
+ { 11, 16, 14 }, // 123 bits per transform
+ { 11, 17, 13 }, // 123 bits per transform
+ { 11, 18, 12 }, // 123 bits per transform
+ { 11, 19, 11 }, // 123 bits per transform
+ { 11, 20, 10 }, // 123 bits per transform
+ { 11, 21, 9 }, // 123 bits per transform
+ { 11, 22, 8 }, // 123 bits per transform
+ { 11, 23, 7 }, // 123 bits per transform
+ { 12, 6, 23 }, // 123 bits per transform
+ { 12, 7, 22 }, // 123 bits per transform
+ { 12, 8, 21 }, // 123 bits per transform
+ { 12, 9, 20 }, // 123 bits per transform
+ { 12, 10, 19 }, // 123 bits per transform
+ { 12, 11, 18 }, // 123 bits per transform
+ { 12, 12, 17 }, // 123 bits per transform
+ { 12, 13, 16 }, // 123 bits per transform
+ { 12, 14, 15 }, // 123 bits per transform
+ { 12, 15, 14 }, // 123 bits per transform
+ { 12, 16, 13 }, // 123 bits per transform
+ { 12, 17, 12 }, // 123 bits per transform
+ { 12, 18, 11 }, // 123 bits per transform
+ { 12, 19, 10 }, // 123 bits per transform
+ { 12, 20, 9 }, // 123 bits per transform
+ { 12, 21, 8 }, // 123 bits per transform
+ { 12, 22, 7 }, // 123 bits per transform
+ { 12, 23, 6 }, // 123 bits per transform
+ { 13, 5, 23 }, // 123 bits per transform
+ { 13, 6, 22 }, // 123 bits per transform
+ { 13, 7, 21 }, // 123 bits per transform
+ { 13, 8, 20 }, // 123 bits per transform
+ { 13, 9, 19 }, // 123 bits per transform
+ { 13, 10, 18 }, // 123 bits per transform
+ { 13, 11, 17 }, // 123 bits per transform
+ { 13, 12, 16 }, // 123 bits per transform
+ { 13, 13, 15 }, // 123 bits per transform
+ { 13, 14, 14 }, // 123 bits per transform
+ { 13, 15, 13 }, // 123 bits per transform
+ { 13, 16, 12 }, // 123 bits per transform
+ { 13, 17, 11 }, // 123 bits per transform
+ { 13, 18, 10 }, // 123 bits per transform
+ { 13, 19, 9 }, // 123 bits per transform
+ { 13, 20, 8 }, // 123 bits per transform
+ { 13, 21, 7 }, // 123 bits per transform
+ { 13, 22, 6 }, // 123 bits per transform
+ { 13, 23, 5 }, // 123 bits per transform
+ { 14, 4, 23 }, // 123 bits per transform
+ { 14, 5, 22 }, // 123 bits per transform
+ { 14, 6, 21 }, // 123 bits per transform
+ { 14, 7, 20 }, // 123 bits per transform
+ { 14, 8, 19 }, // 123 bits per transform
+ { 14, 9, 18 }, // 123 bits per transform
+ { 14, 10, 17 }, // 123 bits per transform
+ { 14, 11, 16 }, // 123 bits per transform
+ { 14, 12, 15 }, // 123 bits per transform
+ { 14, 13, 14 }, // 123 bits per transform
+ { 14, 14, 13 }, // 123 bits per transform
+ { 14, 15, 12 }, // 123 bits per transform
+ { 14, 16, 11 }, // 123 bits per transform
+ { 14, 17, 10 }, // 123 bits per transform
+ { 14, 18, 9 }, // 123 bits per transform
+ { 14, 19, 8 }, // 123 bits per transform
+ { 14, 20, 7 }, // 123 bits per transform
+ { 14, 21, 6 }, // 123 bits per transform
+ { 14, 22, 5 }, // 123 bits per transform
+ { 14, 23, 4 }, // 123 bits per transform
+ { 15, 3, 23 }, // 123 bits per transform
+ { 15, 4, 22 }, // 123 bits per transform
+ { 15, 5, 21 }, // 123 bits per transform
+ { 15, 6, 20 }, // 123 bits per transform
+ { 15, 7, 19 }, // 123 bits per transform
+ { 15, 8, 18 }, // 123 bits per transform
+ { 15, 9, 17 }, // 123 bits per transform
+ { 15, 10, 16 }, // 123 bits per transform
+ { 15, 11, 15 }, // 123 bits per transform
+ { 15, 12, 14 }, // 123 bits per transform
+ { 15, 13, 13 }, // 123 bits per transform
+ { 15, 14, 12 }, // 123 bits per transform
+ { 15, 15, 11 }, // 123 bits per transform
+ { 15, 16, 10 }, // 123 bits per transform
+ { 15, 17, 9 }, // 123 bits per transform
+ { 15, 18, 8 }, // 123 bits per transform
+ { 15, 19, 7 }, // 123 bits per transform
+ { 15, 20, 6 }, // 123 bits per transform
+ { 15, 21, 5 }, // 123 bits per transform
+ { 15, 22, 4 }, // 123 bits per transform
+ { 15, 23, 3 }, // 123 bits per transform
+ { 16, 2, 23 }, // 123 bits per transform
+ { 16, 3, 22 }, // 123 bits per transform
+ { 16, 4, 21 }, // 123 bits per transform
+ { 16, 5, 20 }, // 123 bits per transform
+ { 16, 6, 19 }, // 123 bits per transform
+ { 16, 7, 18 }, // 123 bits per transform
+ { 16, 8, 17 }, // 123 bits per transform
+ { 16, 9, 16 }, // 123 bits per transform
+ { 16, 10, 15 }, // 123 bits per transform
+ { 16, 11, 14 }, // 123 bits per transform
+ { 16, 12, 13 }, // 123 bits per transform
+ { 16, 13, 12 }, // 123 bits per transform
+ { 16, 14, 11 }, // 123 bits per transform
+ { 16, 15, 10 }, // 123 bits per transform
+ { 16, 16, 9 }, // 123 bits per transform
+ { 16, 17, 8 }, // 123 bits per transform
+ { 16, 18, 7 }, // 123 bits per transform
+ { 16, 19, 6 }, // 123 bits per transform
+ { 16, 20, 5 }, // 123 bits per transform
+ { 16, 21, 4 }, // 123 bits per transform
+ { 16, 22, 3 }, // 123 bits per transform
+ { 16, 23, 2 }, // 123 bits per transform
+ { 17, 1, 23 }, // 123 bits per transform
+ { 17, 2, 22 }, // 123 bits per transform
+ { 17, 3, 21 }, // 123 bits per transform
+ { 17, 4, 20 }, // 123 bits per transform
+ { 17, 5, 19 }, // 123 bits per transform
+ { 17, 6, 18 }, // 123 bits per transform
+ { 17, 7, 17 }, // 123 bits per transform
+ { 17, 8, 16 }, // 123 bits per transform
+ { 17, 9, 15 }, // 123 bits per transform
+ { 17, 10, 14 }, // 123 bits per transform
+ { 17, 11, 13 }, // 123 bits per transform
+ { 17, 12, 12 }, // 123 bits per transform
+ { 17, 13, 11 }, // 123 bits per transform
+ { 17, 14, 10 }, // 123 bits per transform
+ { 17, 15, 9 }, // 123 bits per transform
+ { 17, 16, 8 }, // 123 bits per transform
+ { 17, 17, 7 }, // 123 bits per transform
+ { 17, 18, 6 }, // 123 bits per transform
+ { 17, 19, 5 }, // 123 bits per transform
+ { 17, 20, 4 }, // 123 bits per transform
+ { 17, 21, 3 }, // 123 bits per transform
+ { 17, 22, 2 }, // 123 bits per transform
+ { 17, 23, 1 }, // 123 bits per transform
+ { 18, 0, 23 }, // 123 bits per transform
+ { 18, 1, 22 }, // 123 bits per transform
+ { 18, 2, 21 }, // 123 bits per transform
+ { 18, 3, 20 }, // 123 bits per transform
+ { 18, 4, 19 }, // 123 bits per transform
+ { 18, 5, 18 }, // 123 bits per transform
+ { 18, 6, 17 }, // 123 bits per transform
+ { 18, 7, 16 }, // 123 bits per transform
+ { 18, 8, 15 }, // 123 bits per transform
+ { 18, 9, 14 }, // 123 bits per transform
+ { 18, 10, 13 }, // 123 bits per transform
+ { 18, 11, 12 }, // 123 bits per transform
+ { 18, 12, 11 }, // 123 bits per transform
+ { 18, 13, 10 }, // 123 bits per transform
+ { 18, 14, 9 }, // 123 bits per transform
+ { 18, 15, 8 }, // 123 bits per transform
+ { 18, 16, 7 }, // 123 bits per transform
+ { 18, 17, 6 }, // 123 bits per transform
+ { 18, 18, 5 }, // 123 bits per transform
+ { 18, 19, 4 }, // 123 bits per transform
+ { 18, 20, 3 }, // 123 bits per transform
+ { 18, 21, 2 }, // 123 bits per transform
+ { 18, 22, 1 }, // 123 bits per transform
+ { 18, 23, 0 }, // 123 bits per transform
+ { 19, 0, 22 }, // 123 bits per transform
+ { 19, 1, 21 }, // 123 bits per transform
+ { 19, 2, 20 }, // 123 bits per transform
+ { 19, 3, 19 }, // 123 bits per transform
+ { 19, 4, 18 }, // 123 bits per transform
+ { 19, 5, 17 }, // 123 bits per transform
+ { 19, 6, 16 }, // 123 bits per transform
+ { 19, 7, 15 }, // 123 bits per transform
+ { 19, 8, 14 }, // 123 bits per transform
+ { 19, 9, 13 }, // 123 bits per transform
+ { 19, 10, 12 }, // 123 bits per transform
+ { 19, 11, 11 }, // 123 bits per transform
+ { 19, 12, 10 }, // 123 bits per transform
+ { 19, 13, 9 }, // 123 bits per transform
+ { 19, 14, 8 }, // 123 bits per transform
+ { 19, 15, 7 }, // 123 bits per transform
+ { 19, 16, 6 }, // 123 bits per transform
+ { 19, 17, 5 }, // 123 bits per transform
+ { 19, 18, 4 }, // 123 bits per transform
+ { 19, 19, 3 }, // 123 bits per transform
+ { 19, 20, 2 }, // 123 bits per transform
+ { 19, 21, 1 }, // 123 bits per transform
+ { 19, 22, 0 }, // 123 bits per transform
+ { 20, 0, 21 }, // 123 bits per transform
+ { 20, 1, 20 }, // 123 bits per transform
+ { 20, 2, 19 }, // 123 bits per transform
+ { 20, 3, 18 }, // 123 bits per transform
+ { 20, 4, 17 }, // 123 bits per transform
+ { 20, 5, 16 }, // 123 bits per transform
+ { 20, 6, 15 }, // 123 bits per transform
+ { 20, 7, 14 }, // 123 bits per transform
+ { 20, 8, 13 }, // 123 bits per transform
+ { 20, 9, 12 }, // 123 bits per transform
+ { 20, 10, 11 }, // 123 bits per transform
+ { 20, 11, 10 }, // 123 bits per transform
+ { 20, 12, 9 }, // 123 bits per transform
+ { 20, 13, 8 }, // 123 bits per transform
+ { 20, 14, 7 }, // 123 bits per transform
+ { 20, 15, 6 }, // 123 bits per transform
+ { 20, 16, 5 }, // 123 bits per transform
+ { 20, 17, 4 }, // 123 bits per transform
+ { 20, 18, 3 }, // 123 bits per transform
+ { 20, 19, 2 }, // 123 bits per transform
+ { 20, 20, 1 }, // 123 bits per transform
+ { 20, 21, 0 }, // 123 bits per transform
+ { 21, 0, 20 }, // 123 bits per transform
+ { 21, 1, 19 }, // 123 bits per transform
+ { 21, 2, 18 }, // 123 bits per transform
+ { 21, 3, 17 }, // 123 bits per transform
+ { 21, 4, 16 }, // 123 bits per transform
+ { 21, 5, 15 }, // 123 bits per transform
+ { 21, 6, 14 }, // 123 bits per transform
+ { 21, 7, 13 }, // 123 bits per transform
+ { 21, 8, 12 }, // 123 bits per transform
+ { 21, 9, 11 }, // 123 bits per transform
+ { 21, 10, 10 }, // 123 bits per transform
+ { 21, 11, 9 }, // 123 bits per transform
+ { 21, 12, 8 }, // 123 bits per transform
+ { 21, 13, 7 }, // 123 bits per transform
+ { 21, 14, 6 }, // 123 bits per transform
+ { 21, 15, 5 }, // 123 bits per transform
+ { 21, 16, 4 }, // 123 bits per transform
+ { 21, 17, 3 }, // 123 bits per transform
+ { 21, 18, 2 }, // 123 bits per transform
+ { 21, 19, 1 }, // 123 bits per transform
+ { 21, 20, 0 }, // 123 bits per transform
+ { 22, 0, 19 }, // 123 bits per transform
+ { 22, 1, 18 }, // 123 bits per transform
+ { 22, 2, 17 }, // 123 bits per transform
+ { 22, 3, 16 }, // 123 bits per transform
+ { 22, 4, 15 }, // 123 bits per transform
+ { 22, 5, 14 }, // 123 bits per transform
+ { 22, 6, 13 }, // 123 bits per transform
+ { 22, 7, 12 }, // 123 bits per transform
+ { 22, 8, 11 }, // 123 bits per transform
+ { 22, 9, 10 }, // 123 bits per transform
+ { 22, 10, 9 }, // 123 bits per transform
+ { 22, 11, 8 }, // 123 bits per transform
+ { 22, 12, 7 }, // 123 bits per transform
+ { 22, 13, 6 }, // 123 bits per transform
+ { 22, 14, 5 }, // 123 bits per transform
+ { 22, 15, 4 }, // 123 bits per transform
+ { 22, 16, 3 }, // 123 bits per transform
+ { 22, 17, 2 }, // 123 bits per transform
+ { 22, 18, 1 }, // 123 bits per transform
+ { 22, 19, 0 }, // 123 bits per transform
+ { 23, 0, 18 }, // 123 bits per transform
+ { 23, 1, 17 }, // 123 bits per transform
+ { 23, 2, 16 }, // 123 bits per transform
+ { 23, 3, 15 }, // 123 bits per transform
+ { 23, 4, 14 }, // 123 bits per transform
+ { 23, 5, 13 }, // 123 bits per transform
+ { 23, 6, 12 }, // 123 bits per transform
+ { 23, 7, 11 }, // 123 bits per transform
+ { 23, 8, 10 }, // 123 bits per transform
+ { 23, 9, 9 }, // 123 bits per transform
+ { 23, 10, 8 }, // 123 bits per transform
+ { 23, 11, 7 }, // 123 bits per transform
+ { 23, 12, 6 }, // 123 bits per transform
+ { 23, 13, 5 }, // 123 bits per transform
+ { 23, 14, 4 }, // 123 bits per transform
+ { 23, 15, 3 }, // 123 bits per transform
+ { 23, 16, 2 }, // 123 bits per transform
+ { 23, 17, 1 }, // 123 bits per transform
+ { 23, 18, 0 }, // 123 bits per transform
+ { 24, 0, 9 }, // 123 bits per transform
+ { 24, 1, 8 }, // 123 bits per transform
+ { 24, 2, 7 }, // 123 bits per transform
+ { 24, 3, 6 }, // 123 bits per transform
+ { 24, 4, 5 }, // 123 bits per transform
+ { 24, 5, 4 }, // 123 bits per transform
+ { 24, 6, 3 }, // 123 bits per transform
+ { 24, 7, 2 }, // 123 bits per transform
+ { 24, 8, 1 }, // 123 bits per transform
+ { 24, 9, 0 }, // 123 bits per transform
+ { 0, 10, 24 }, // 126 bits per transform
+ { 0, 19, 23 }, // 126 bits per transform
+ { 0, 20, 22 }, // 126 bits per transform
+ { 0, 21, 21 }, // 126 bits per transform
+ { 0, 22, 20 }, // 126 bits per transform
+ { 0, 23, 19 }, // 126 bits per transform
+ { 0, 24, 10 }, // 126 bits per transform
+ { 1, 9, 24 }, // 126 bits per transform
+ { 1, 18, 23 }, // 126 bits per transform
+ { 1, 19, 22 }, // 126 bits per transform
+ { 1, 20, 21 }, // 126 bits per transform
+ { 1, 21, 20 }, // 126 bits per transform
+ { 1, 22, 19 }, // 126 bits per transform
+ { 1, 23, 18 }, // 126 bits per transform
+ { 1, 24, 9 }, // 126 bits per transform
+ { 2, 8, 24 }, // 126 bits per transform
+ { 2, 17, 23 }, // 126 bits per transform
+ { 2, 18, 22 }, // 126 bits per transform
+ { 2, 19, 21 }, // 126 bits per transform
+ { 2, 20, 20 }, // 126 bits per transform
+ { 2, 21, 19 }, // 126 bits per transform
+ { 2, 22, 18 }, // 126 bits per transform
+ { 2, 23, 17 }, // 126 bits per transform
+ { 2, 24, 8 }, // 126 bits per transform
+ { 3, 7, 24 }, // 126 bits per transform
+ { 3, 16, 23 }, // 126 bits per transform
+ { 3, 17, 22 }, // 126 bits per transform
+ { 3, 18, 21 }, // 126 bits per transform
+ { 3, 19, 20 }, // 126 bits per transform
+ { 3, 20, 19 }, // 126 bits per transform
+ { 3, 21, 18 }, // 126 bits per transform
+ { 3, 22, 17 }, // 126 bits per transform
+ { 3, 23, 16 }, // 126 bits per transform
+ { 3, 24, 7 }, // 126 bits per transform
+ { 4, 6, 24 }, // 126 bits per transform
+ { 4, 15, 23 }, // 126 bits per transform
+ { 4, 16, 22 }, // 126 bits per transform
+ { 4, 17, 21 }, // 126 bits per transform
+ { 4, 18, 20 }, // 126 bits per transform
+ { 4, 19, 19 }, // 126 bits per transform
+ { 4, 20, 18 }, // 126 bits per transform
+ { 4, 21, 17 }, // 126 bits per transform
+ { 4, 22, 16 }, // 126 bits per transform
+ { 4, 23, 15 }, // 126 bits per transform
+ { 4, 24, 6 }, // 126 bits per transform
+ { 5, 5, 24 }, // 126 bits per transform
+ { 5, 14, 23 }, // 126 bits per transform
+ { 5, 15, 22 }, // 126 bits per transform
+ { 5, 16, 21 }, // 126 bits per transform
+ { 5, 17, 20 }, // 126 bits per transform
+ { 5, 18, 19 }, // 126 bits per transform
+ { 5, 19, 18 }, // 126 bits per transform
+ { 5, 20, 17 }, // 126 bits per transform
+ { 5, 21, 16 }, // 126 bits per transform
+ { 5, 22, 15 }, // 126 bits per transform
+ { 5, 23, 14 }, // 126 bits per transform
+ { 5, 24, 5 }, // 126 bits per transform
+ { 6, 4, 24 }, // 126 bits per transform
+ { 6, 13, 23 }, // 126 bits per transform
+ { 6, 14, 22 }, // 126 bits per transform
+ { 6, 15, 21 }, // 126 bits per transform
+ { 6, 16, 20 }, // 126 bits per transform
+ { 6, 17, 19 }, // 126 bits per transform
+ { 6, 18, 18 }, // 126 bits per transform
+ { 6, 19, 17 }, // 126 bits per transform
+ { 6, 20, 16 }, // 126 bits per transform
+ { 6, 21, 15 }, // 126 bits per transform
+ { 6, 22, 14 }, // 126 bits per transform
+ { 6, 23, 13 }, // 126 bits per transform
+ { 6, 24, 4 }, // 126 bits per transform
+ { 7, 3, 24 }, // 126 bits per transform
+ { 7, 12, 23 }, // 126 bits per transform
+ { 7, 13, 22 }, // 126 bits per transform
+ { 7, 14, 21 }, // 126 bits per transform
+ { 7, 15, 20 }, // 126 bits per transform
+ { 7, 16, 19 }, // 126 bits per transform
+ { 7, 17, 18 }, // 126 bits per transform
+ { 7, 18, 17 }, // 126 bits per transform
+ { 7, 19, 16 }, // 126 bits per transform
+ { 7, 20, 15 }, // 126 bits per transform
+ { 7, 21, 14 }, // 126 bits per transform
+ { 7, 22, 13 }, // 126 bits per transform
+ { 7, 23, 12 }, // 126 bits per transform
+ { 7, 24, 3 }, // 126 bits per transform
+ { 8, 2, 24 }, // 126 bits per transform
+ { 8, 11, 23 }, // 126 bits per transform
+ { 8, 12, 22 }, // 126 bits per transform
+ { 8, 13, 21 }, // 126 bits per transform
+ { 8, 14, 20 }, // 126 bits per transform
+ { 8, 15, 19 }, // 126 bits per transform
+ { 8, 16, 18 }, // 126 bits per transform
+ { 8, 17, 17 }, // 126 bits per transform
+ { 8, 18, 16 }, // 126 bits per transform
+ { 8, 19, 15 }, // 126 bits per transform
+ { 8, 20, 14 }, // 126 bits per transform
+ { 8, 21, 13 }, // 126 bits per transform
+ { 8, 22, 12 }, // 126 bits per transform
+ { 8, 23, 11 }, // 126 bits per transform
+ { 8, 24, 2 }, // 126 bits per transform
+ { 9, 1, 24 }, // 126 bits per transform
+ { 9, 10, 23 }, // 126 bits per transform
+ { 9, 11, 22 }, // 126 bits per transform
+ { 9, 12, 21 }, // 126 bits per transform
+ { 9, 13, 20 }, // 126 bits per transform
+ { 9, 14, 19 }, // 126 bits per transform
+ { 9, 15, 18 }, // 126 bits per transform
+ { 9, 16, 17 }, // 126 bits per transform
+ { 9, 17, 16 }, // 126 bits per transform
+ { 9, 18, 15 }, // 126 bits per transform
+ { 9, 19, 14 }, // 126 bits per transform
+ { 9, 20, 13 }, // 126 bits per transform
+ { 9, 21, 12 }, // 126 bits per transform
+ { 9, 22, 11 }, // 126 bits per transform
+ { 9, 23, 10 }, // 126 bits per transform
+ { 9, 24, 1 }, // 126 bits per transform
+ { 10, 0, 24 }, // 126 bits per transform
+ { 10, 9, 23 }, // 126 bits per transform
+ { 10, 10, 22 }, // 126 bits per transform
+ { 10, 11, 21 }, // 126 bits per transform
+ { 10, 12, 20 }, // 126 bits per transform
+ { 10, 13, 19 }, // 126 bits per transform
+ { 10, 14, 18 }, // 126 bits per transform
+ { 10, 15, 17 }, // 126 bits per transform
+ { 10, 16, 16 }, // 126 bits per transform
+ { 10, 17, 15 }, // 126 bits per transform
+ { 10, 18, 14 }, // 126 bits per transform
+ { 10, 19, 13 }, // 126 bits per transform
+ { 10, 20, 12 }, // 126 bits per transform
+ { 10, 21, 11 }, // 126 bits per transform
+ { 10, 22, 10 }, // 126 bits per transform
+ { 10, 23, 9 }, // 126 bits per transform
+ { 10, 24, 0 }, // 126 bits per transform
+ { 11, 8, 23 }, // 126 bits per transform
+ { 11, 9, 22 }, // 126 bits per transform
+ { 11, 10, 21 }, // 126 bits per transform
+ { 11, 11, 20 }, // 126 bits per transform
+ { 11, 12, 19 }, // 126 bits per transform
+ { 11, 13, 18 }, // 126 bits per transform
+ { 11, 14, 17 }, // 126 bits per transform
+ { 11, 15, 16 }, // 126 bits per transform
+ { 11, 16, 15 }, // 126 bits per transform
+ { 11, 17, 14 }, // 126 bits per transform
+ { 11, 18, 13 }, // 126 bits per transform
+ { 11, 19, 12 }, // 126 bits per transform
+ { 11, 20, 11 }, // 126 bits per transform
+ { 11, 21, 10 }, // 126 bits per transform
+ { 11, 22, 9 }, // 126 bits per transform
+ { 11, 23, 8 }, // 126 bits per transform
+ { 12, 7, 23 }, // 126 bits per transform
+ { 12, 8, 22 }, // 126 bits per transform
+ { 12, 9, 21 }, // 126 bits per transform
+ { 12, 10, 20 }, // 126 bits per transform
+ { 12, 11, 19 }, // 126 bits per transform
+ { 12, 12, 18 }, // 126 bits per transform
+ { 12, 13, 17 }, // 126 bits per transform
+ { 12, 14, 16 }, // 126 bits per transform
+ { 12, 15, 15 }, // 126 bits per transform
+ { 12, 16, 14 }, // 126 bits per transform
+ { 12, 17, 13 }, // 126 bits per transform
+ { 12, 18, 12 }, // 126 bits per transform
+ { 12, 19, 11 }, // 126 bits per transform
+ { 12, 20, 10 }, // 126 bits per transform
+ { 12, 21, 9 }, // 126 bits per transform
+ { 12, 22, 8 }, // 126 bits per transform
+ { 12, 23, 7 }, // 126 bits per transform
+ { 13, 6, 23 }, // 126 bits per transform
+ { 13, 7, 22 }, // 126 bits per transform
+ { 13, 8, 21 }, // 126 bits per transform
+ { 13, 9, 20 }, // 126 bits per transform
+ { 13, 10, 19 }, // 126 bits per transform
+ { 13, 11, 18 }, // 126 bits per transform
+ { 13, 12, 17 }, // 126 bits per transform
+ { 13, 13, 16 }, // 126 bits per transform
+ { 13, 14, 15 }, // 126 bits per transform
+ { 13, 15, 14 }, // 126 bits per transform
+ { 13, 16, 13 }, // 126 bits per transform
+ { 13, 17, 12 }, // 126 bits per transform
+ { 13, 18, 11 }, // 126 bits per transform
+ { 13, 19, 10 }, // 126 bits per transform
+ { 13, 20, 9 }, // 126 bits per transform
+ { 13, 21, 8 }, // 126 bits per transform
+ { 13, 22, 7 }, // 126 bits per transform
+ { 13, 23, 6 }, // 126 bits per transform
+ { 14, 5, 23 }, // 126 bits per transform
+ { 14, 6, 22 }, // 126 bits per transform
+ { 14, 7, 21 }, // 126 bits per transform
+ { 14, 8, 20 }, // 126 bits per transform
+ { 14, 9, 19 }, // 126 bits per transform
+ { 14, 10, 18 }, // 126 bits per transform
+ { 14, 11, 17 }, // 126 bits per transform
+ { 14, 12, 16 }, // 126 bits per transform
+ { 14, 13, 15 }, // 126 bits per transform
+ { 14, 14, 14 }, // 126 bits per transform
+ { 14, 15, 13 }, // 126 bits per transform
+ { 14, 16, 12 }, // 126 bits per transform
+ { 14, 17, 11 }, // 126 bits per transform
+ { 14, 18, 10 }, // 126 bits per transform
+ { 14, 19, 9 }, // 126 bits per transform
+ { 14, 20, 8 }, // 126 bits per transform
+ { 14, 21, 7 }, // 126 bits per transform
+ { 14, 22, 6 }, // 126 bits per transform
+ { 14, 23, 5 }, // 126 bits per transform
+ { 15, 4, 23 }, // 126 bits per transform
+ { 15, 5, 22 }, // 126 bits per transform
+ { 15, 6, 21 }, // 126 bits per transform
+ { 15, 7, 20 }, // 126 bits per transform
+ { 15, 8, 19 }, // 126 bits per transform
+ { 15, 9, 18 }, // 126 bits per transform
+ { 15, 10, 17 }, // 126 bits per transform
+ { 15, 11, 16 }, // 126 bits per transform
+ { 15, 12, 15 }, // 126 bits per transform
+ { 15, 13, 14 }, // 126 bits per transform
+ { 15, 14, 13 }, // 126 bits per transform
+ { 15, 15, 12 }, // 126 bits per transform
+ { 15, 16, 11 }, // 126 bits per transform
+ { 15, 17, 10 }, // 126 bits per transform
+ { 15, 18, 9 }, // 126 bits per transform
+ { 15, 19, 8 }, // 126 bits per transform
+ { 15, 20, 7 }, // 126 bits per transform
+ { 15, 21, 6 }, // 126 bits per transform
+ { 15, 22, 5 }, // 126 bits per transform
+ { 15, 23, 4 }, // 126 bits per transform
+ { 16, 3, 23 }, // 126 bits per transform
+ { 16, 4, 22 }, // 126 bits per transform
+ { 16, 5, 21 }, // 126 bits per transform
+ { 16, 6, 20 }, // 126 bits per transform
+ { 16, 7, 19 }, // 126 bits per transform
+ { 16, 8, 18 }, // 126 bits per transform
+ { 16, 9, 17 }, // 126 bits per transform
+ { 16, 10, 16 }, // 126 bits per transform
+ { 16, 11, 15 }, // 126 bits per transform
+ { 16, 12, 14 }, // 126 bits per transform
+ { 16, 13, 13 }, // 126 bits per transform
+ { 16, 14, 12 }, // 126 bits per transform
+ { 16, 15, 11 }, // 126 bits per transform
+ { 16, 16, 10 }, // 126 bits per transform
+ { 16, 17, 9 }, // 126 bits per transform
+ { 16, 18, 8 }, // 126 bits per transform
+ { 16, 19, 7 }, // 126 bits per transform
+ { 16, 20, 6 }, // 126 bits per transform
+ { 16, 21, 5 }, // 126 bits per transform
+ { 16, 22, 4 }, // 126 bits per transform
+ { 16, 23, 3 }, // 126 bits per transform
+ { 17, 2, 23 }, // 126 bits per transform
+ { 17, 3, 22 }, // 126 bits per transform
+ { 17, 4, 21 }, // 126 bits per transform
+ { 17, 5, 20 }, // 126 bits per transform
+ { 17, 6, 19 }, // 126 bits per transform
+ { 17, 7, 18 }, // 126 bits per transform
+ { 17, 8, 17 }, // 126 bits per transform
+ { 17, 9, 16 }, // 126 bits per transform
+ { 17, 10, 15 }, // 126 bits per transform
+ { 17, 11, 14 }, // 126 bits per transform
+ { 17, 12, 13 }, // 126 bits per transform
+ { 17, 13, 12 }, // 126 bits per transform
+ { 17, 14, 11 }, // 126 bits per transform
+ { 17, 15, 10 }, // 126 bits per transform
+ { 17, 16, 9 }, // 126 bits per transform
+ { 17, 17, 8 }, // 126 bits per transform
+ { 17, 18, 7 }, // 126 bits per transform
+ { 17, 19, 6 }, // 126 bits per transform
+ { 17, 20, 5 }, // 126 bits per transform
+ { 17, 21, 4 }, // 126 bits per transform
+ { 17, 22, 3 }, // 126 bits per transform
+ { 17, 23, 2 }, // 126 bits per transform
+ { 18, 1, 23 }, // 126 bits per transform
+ { 18, 2, 22 }, // 126 bits per transform
+ { 18, 3, 21 }, // 126 bits per transform
+ { 18, 4, 20 }, // 126 bits per transform
+ { 18, 5, 19 }, // 126 bits per transform
+ { 18, 6, 18 }, // 126 bits per transform
+ { 18, 7, 17 }, // 126 bits per transform
+ { 18, 8, 16 }, // 126 bits per transform
+ { 18, 9, 15 }, // 126 bits per transform
+ { 18, 10, 14 }, // 126 bits per transform
+ { 18, 11, 13 }, // 126 bits per transform
+ { 18, 12, 12 }, // 126 bits per transform
+ { 18, 13, 11 }, // 126 bits per transform
+ { 18, 14, 10 }, // 126 bits per transform
+ { 18, 15, 9 }, // 126 bits per transform
+ { 18, 16, 8 }, // 126 bits per transform
+ { 18, 17, 7 }, // 126 bits per transform
+ { 18, 18, 6 }, // 126 bits per transform
+ { 18, 19, 5 }, // 126 bits per transform
+ { 18, 20, 4 }, // 126 bits per transform
+ { 18, 21, 3 }, // 126 bits per transform
+ { 18, 22, 2 }, // 126 bits per transform
+ { 18, 23, 1 }, // 126 bits per transform
+ { 19, 0, 23 }, // 126 bits per transform
+ { 19, 1, 22 }, // 126 bits per transform
+ { 19, 2, 21 }, // 126 bits per transform
+ { 19, 3, 20 }, // 126 bits per transform
+ { 19, 4, 19 }, // 126 bits per transform
+ { 19, 5, 18 }, // 126 bits per transform
+ { 19, 6, 17 }, // 126 bits per transform
+ { 19, 7, 16 }, // 126 bits per transform
+ { 19, 8, 15 }, // 126 bits per transform
+ { 19, 9, 14 }, // 126 bits per transform
+ { 19, 10, 13 }, // 126 bits per transform
+ { 19, 11, 12 }, // 126 bits per transform
+ { 19, 12, 11 }, // 126 bits per transform
+ { 19, 13, 10 }, // 126 bits per transform
+ { 19, 14, 9 }, // 126 bits per transform
+ { 19, 15, 8 }, // 126 bits per transform
+ { 19, 16, 7 }, // 126 bits per transform
+ { 19, 17, 6 }, // 126 bits per transform
+ { 19, 18, 5 }, // 126 bits per transform
+ { 19, 19, 4 }, // 126 bits per transform
+ { 19, 20, 3 }, // 126 bits per transform
+ { 19, 21, 2 }, // 126 bits per transform
+ { 19, 22, 1 }, // 126 bits per transform
+ { 19, 23, 0 }, // 126 bits per transform
+ { 20, 0, 22 }, // 126 bits per transform
+ { 20, 1, 21 }, // 126 bits per transform
+ { 20, 2, 20 }, // 126 bits per transform
+ { 20, 3, 19 }, // 126 bits per transform
+ { 20, 4, 18 }, // 126 bits per transform
+ { 20, 5, 17 }, // 126 bits per transform
+ { 20, 6, 16 }, // 126 bits per transform
+ { 20, 7, 15 }, // 126 bits per transform
+ { 20, 8, 14 }, // 126 bits per transform
+ { 20, 9, 13 }, // 126 bits per transform
+ { 20, 10, 12 }, // 126 bits per transform
+ { 20, 11, 11 }, // 126 bits per transform
+ { 20, 12, 10 }, // 126 bits per transform
+ { 20, 13, 9 }, // 126 bits per transform
+ { 20, 14, 8 }, // 126 bits per transform
+ { 20, 15, 7 }, // 126 bits per transform
+ { 20, 16, 6 }, // 126 bits per transform
+ { 20, 17, 5 }, // 126 bits per transform
+ { 20, 18, 4 }, // 126 bits per transform
+ { 20, 19, 3 }, // 126 bits per transform
+ { 20, 20, 2 }, // 126 bits per transform
+ { 20, 21, 1 }, // 126 bits per transform
+ { 20, 22, 0 }, // 126 bits per transform
+ { 21, 0, 21 }, // 126 bits per transform
+ { 21, 1, 20 }, // 126 bits per transform
+ { 21, 2, 19 }, // 126 bits per transform
+ { 21, 3, 18 }, // 126 bits per transform
+ { 21, 4, 17 }, // 126 bits per transform
+ { 21, 5, 16 }, // 126 bits per transform
+ { 21, 6, 15 }, // 126 bits per transform
+ { 21, 7, 14 }, // 126 bits per transform
+ { 21, 8, 13 }, // 126 bits per transform
+ { 21, 9, 12 }, // 126 bits per transform
+ { 21, 10, 11 }, // 126 bits per transform
+ { 21, 11, 10 }, // 126 bits per transform
+ { 21, 12, 9 }, // 126 bits per transform
+ { 21, 13, 8 }, // 126 bits per transform
+ { 21, 14, 7 }, // 126 bits per transform
+ { 21, 15, 6 }, // 126 bits per transform
+ { 21, 16, 5 }, // 126 bits per transform
+ { 21, 17, 4 }, // 126 bits per transform
+ { 21, 18, 3 }, // 126 bits per transform
+ { 21, 19, 2 }, // 126 bits per transform
+ { 21, 20, 1 }, // 126 bits per transform
+ { 21, 21, 0 }, // 126 bits per transform
+ { 22, 0, 20 }, // 126 bits per transform
+ { 22, 1, 19 }, // 126 bits per transform
+ { 22, 2, 18 }, // 126 bits per transform
+ { 22, 3, 17 }, // 126 bits per transform
+ { 22, 4, 16 }, // 126 bits per transform
+ { 22, 5, 15 }, // 126 bits per transform
+ { 22, 6, 14 }, // 126 bits per transform
+ { 22, 7, 13 }, // 126 bits per transform
+ { 22, 8, 12 }, // 126 bits per transform
+ { 22, 9, 11 }, // 126 bits per transform
+ { 22, 10, 10 }, // 126 bits per transform
+ { 22, 11, 9 }, // 126 bits per transform
+ { 22, 12, 8 }, // 126 bits per transform
+ { 22, 13, 7 }, // 126 bits per transform
+ { 22, 14, 6 }, // 126 bits per transform
+ { 22, 15, 5 }, // 126 bits per transform
+ { 22, 16, 4 }, // 126 bits per transform
+ { 22, 17, 3 }, // 126 bits per transform
+ { 22, 18, 2 }, // 126 bits per transform
+ { 22, 19, 1 }, // 126 bits per transform
+ { 22, 20, 0 }, // 126 bits per transform
+ { 23, 0, 19 }, // 126 bits per transform
+ { 23, 1, 18 }, // 126 bits per transform
+ { 23, 2, 17 }, // 126 bits per transform
+ { 23, 3, 16 }, // 126 bits per transform
+ { 23, 4, 15 }, // 126 bits per transform
+ { 23, 5, 14 }, // 126 bits per transform
+ { 23, 6, 13 }, // 126 bits per transform
+ { 23, 7, 12 }, // 126 bits per transform
+ { 23, 8, 11 }, // 126 bits per transform
+ { 23, 9, 10 }, // 126 bits per transform
+ { 23, 10, 9 }, // 126 bits per transform
+ { 23, 11, 8 }, // 126 bits per transform
+ { 23, 12, 7 }, // 126 bits per transform
+ { 23, 13, 6 }, // 126 bits per transform
+ { 23, 14, 5 }, // 126 bits per transform
+ { 23, 15, 4 }, // 126 bits per transform
+ { 23, 16, 3 }, // 126 bits per transform
+ { 23, 17, 2 }, // 126 bits per transform
+ { 23, 18, 1 }, // 126 bits per transform
+ { 23, 19, 0 }, // 126 bits per transform
+ { 24, 0, 10 }, // 126 bits per transform
+ { 24, 1, 9 }, // 126 bits per transform
+ { 24, 2, 8 }, // 126 bits per transform
+ { 24, 3, 7 }, // 126 bits per transform
+ { 24, 4, 6 }, // 126 bits per transform
+ { 24, 5, 5 }, // 126 bits per transform
+ { 24, 6, 4 }, // 126 bits per transform
+ { 24, 7, 3 }, // 126 bits per transform
+ { 24, 8, 2 }, // 126 bits per transform
+ { 24, 9, 1 }, // 126 bits per transform
+ { 24, 10, 0 }, // 126 bits per transform
+ { 0, 11, 24 }, // 129 bits per transform
+ { 0, 20, 23 }, // 129 bits per transform
+ { 0, 21, 22 }, // 129 bits per transform
+ { 0, 22, 21 }, // 129 bits per transform
+ { 0, 23, 20 }, // 129 bits per transform
+ { 0, 24, 11 }, // 129 bits per transform
+ { 1, 10, 24 }, // 129 bits per transform
+ { 1, 19, 23 }, // 129 bits per transform
+ { 1, 20, 22 }, // 129 bits per transform
+ { 1, 21, 21 }, // 129 bits per transform
+ { 1, 22, 20 }, // 129 bits per transform
+ { 1, 23, 19 }, // 129 bits per transform
+ { 1, 24, 10 }, // 129 bits per transform
+ { 2, 9, 24 }, // 129 bits per transform
+ { 2, 18, 23 }, // 129 bits per transform
+ { 2, 19, 22 }, // 129 bits per transform
+ { 2, 20, 21 }, // 129 bits per transform
+ { 2, 21, 20 }, // 129 bits per transform
+ { 2, 22, 19 }, // 129 bits per transform
+ { 2, 23, 18 }, // 129 bits per transform
+ { 2, 24, 9 }, // 129 bits per transform
+ { 3, 8, 24 }, // 129 bits per transform
+ { 3, 17, 23 }, // 129 bits per transform
+ { 3, 18, 22 }, // 129 bits per transform
+ { 3, 19, 21 }, // 129 bits per transform
+ { 3, 20, 20 }, // 129 bits per transform
+ { 3, 21, 19 }, // 129 bits per transform
+ { 3, 22, 18 }, // 129 bits per transform
+ { 3, 23, 17 }, // 129 bits per transform
+ { 3, 24, 8 }, // 129 bits per transform
+ { 4, 7, 24 }, // 129 bits per transform
+ { 4, 16, 23 }, // 129 bits per transform
+ { 4, 17, 22 }, // 129 bits per transform
+ { 4, 18, 21 }, // 129 bits per transform
+ { 4, 19, 20 }, // 129 bits per transform
+ { 4, 20, 19 }, // 129 bits per transform
+ { 4, 21, 18 }, // 129 bits per transform
+ { 4, 22, 17 }, // 129 bits per transform
+ { 4, 23, 16 }, // 129 bits per transform
+ { 4, 24, 7 }, // 129 bits per transform
+ { 5, 6, 24 }, // 129 bits per transform
+ { 5, 15, 23 }, // 129 bits per transform
+ { 5, 16, 22 }, // 129 bits per transform
+ { 5, 17, 21 }, // 129 bits per transform
+ { 5, 18, 20 }, // 129 bits per transform
+ { 5, 19, 19 }, // 129 bits per transform
+ { 5, 20, 18 }, // 129 bits per transform
+ { 5, 21, 17 }, // 129 bits per transform
+ { 5, 22, 16 }, // 129 bits per transform
+ { 5, 23, 15 }, // 129 bits per transform
+ { 5, 24, 6 }, // 129 bits per transform
+ { 6, 5, 24 }, // 129 bits per transform
+ { 6, 14, 23 }, // 129 bits per transform
+ { 6, 15, 22 }, // 129 bits per transform
+ { 6, 16, 21 }, // 129 bits per transform
+ { 6, 17, 20 }, // 129 bits per transform
+ { 6, 18, 19 }, // 129 bits per transform
+ { 6, 19, 18 }, // 129 bits per transform
+ { 6, 20, 17 }, // 129 bits per transform
+ { 6, 21, 16 }, // 129 bits per transform
+ { 6, 22, 15 }, // 129 bits per transform
+ { 6, 23, 14 }, // 129 bits per transform
+ { 6, 24, 5 }, // 129 bits per transform
+ { 7, 4, 24 }, // 129 bits per transform
+ { 7, 13, 23 }, // 129 bits per transform
+ { 7, 14, 22 }, // 129 bits per transform
+ { 7, 15, 21 }, // 129 bits per transform
+ { 7, 16, 20 }, // 129 bits per transform
+ { 7, 17, 19 }, // 129 bits per transform
+ { 7, 18, 18 }, // 129 bits per transform
+ { 7, 19, 17 }, // 129 bits per transform
+ { 7, 20, 16 }, // 129 bits per transform
+ { 7, 21, 15 }, // 129 bits per transform
+ { 7, 22, 14 }, // 129 bits per transform
+ { 7, 23, 13 }, // 129 bits per transform
+ { 7, 24, 4 }, // 129 bits per transform
+ { 8, 3, 24 }, // 129 bits per transform
+ { 8, 12, 23 }, // 129 bits per transform
+ { 8, 13, 22 }, // 129 bits per transform
+ { 8, 14, 21 }, // 129 bits per transform
+ { 8, 15, 20 }, // 129 bits per transform
+ { 8, 16, 19 }, // 129 bits per transform
+ { 8, 17, 18 }, // 129 bits per transform
+ { 8, 18, 17 }, // 129 bits per transform
+ { 8, 19, 16 }, // 129 bits per transform
+ { 8, 20, 15 }, // 129 bits per transform
+ { 8, 21, 14 }, // 129 bits per transform
+ { 8, 22, 13 }, // 129 bits per transform
+ { 8, 23, 12 }, // 129 bits per transform
+ { 8, 24, 3 }, // 129 bits per transform
+ { 9, 2, 24 }, // 129 bits per transform
+ { 9, 11, 23 }, // 129 bits per transform
+ { 9, 12, 22 }, // 129 bits per transform
+ { 9, 13, 21 }, // 129 bits per transform
+ { 9, 14, 20 }, // 129 bits per transform
+ { 9, 15, 19 }, // 129 bits per transform
+ { 9, 16, 18 }, // 129 bits per transform
+ { 9, 17, 17 }, // 129 bits per transform
+ { 9, 18, 16 }, // 129 bits per transform
+ { 9, 19, 15 }, // 129 bits per transform
+ { 9, 20, 14 }, // 129 bits per transform
+ { 9, 21, 13 }, // 129 bits per transform
+ { 9, 22, 12 }, // 129 bits per transform
+ { 9, 23, 11 }, // 129 bits per transform
+ { 9, 24, 2 }, // 129 bits per transform
+ { 10, 1, 24 }, // 129 bits per transform
+ { 10, 10, 23 }, // 129 bits per transform
+ { 10, 11, 22 }, // 129 bits per transform
+ { 10, 12, 21 }, // 129 bits per transform
+ { 10, 13, 20 }, // 129 bits per transform
+ { 10, 14, 19 }, // 129 bits per transform
+ { 10, 15, 18 }, // 129 bits per transform
+ { 10, 16, 17 }, // 129 bits per transform
+ { 10, 17, 16 }, // 129 bits per transform
+ { 10, 18, 15 }, // 129 bits per transform
+ { 10, 19, 14 }, // 129 bits per transform
+ { 10, 20, 13 }, // 129 bits per transform
+ { 10, 21, 12 }, // 129 bits per transform
+ { 10, 22, 11 }, // 129 bits per transform
+ { 10, 23, 10 }, // 129 bits per transform
+ { 10, 24, 1 }, // 129 bits per transform
+ { 11, 0, 24 }, // 129 bits per transform
+ { 11, 9, 23 }, // 129 bits per transform
+ { 11, 10, 22 }, // 129 bits per transform
+ { 11, 11, 21 }, // 129 bits per transform
+ { 11, 12, 20 }, // 129 bits per transform
+ { 11, 13, 19 }, // 129 bits per transform
+ { 11, 14, 18 }, // 129 bits per transform
+ { 11, 15, 17 }, // 129 bits per transform
+ { 11, 16, 16 }, // 129 bits per transform
+ { 11, 17, 15 }, // 129 bits per transform
+ { 11, 18, 14 }, // 129 bits per transform
+ { 11, 19, 13 }, // 129 bits per transform
+ { 11, 20, 12 }, // 129 bits per transform
+ { 11, 21, 11 }, // 129 bits per transform
+ { 11, 22, 10 }, // 129 bits per transform
+ { 11, 23, 9 }, // 129 bits per transform
+ { 11, 24, 0 }, // 129 bits per transform
+ { 12, 8, 23 }, // 129 bits per transform
+ { 12, 9, 22 }, // 129 bits per transform
+ { 12, 10, 21 }, // 129 bits per transform
+ { 12, 11, 20 }, // 129 bits per transform
+ { 12, 12, 19 }, // 129 bits per transform
+ { 12, 13, 18 }, // 129 bits per transform
+ { 12, 14, 17 }, // 129 bits per transform
+ { 12, 15, 16 }, // 129 bits per transform
+ { 12, 16, 15 }, // 129 bits per transform
+ { 12, 17, 14 }, // 129 bits per transform
+ { 12, 18, 13 }, // 129 bits per transform
+ { 12, 19, 12 }, // 129 bits per transform
+ { 12, 20, 11 }, // 129 bits per transform
+ { 12, 21, 10 }, // 129 bits per transform
+ { 12, 22, 9 }, // 129 bits per transform
+ { 12, 23, 8 }, // 129 bits per transform
+ { 13, 7, 23 }, // 129 bits per transform
+ { 13, 8, 22 }, // 129 bits per transform
+ { 13, 9, 21 }, // 129 bits per transform
+ { 13, 10, 20 }, // 129 bits per transform
+ { 13, 11, 19 }, // 129 bits per transform
+ { 13, 12, 18 }, // 129 bits per transform
+ { 13, 13, 17 }, // 129 bits per transform
+ { 13, 14, 16 }, // 129 bits per transform
+ { 13, 15, 15 }, // 129 bits per transform
+ { 13, 16, 14 }, // 129 bits per transform
+ { 13, 17, 13 }, // 129 bits per transform
+ { 13, 18, 12 }, // 129 bits per transform
+ { 13, 19, 11 }, // 129 bits per transform
+ { 13, 20, 10 }, // 129 bits per transform
+ { 13, 21, 9 }, // 129 bits per transform
+ { 13, 22, 8 }, // 129 bits per transform
+ { 13, 23, 7 }, // 129 bits per transform
+ { 14, 6, 23 }, // 129 bits per transform
+ { 14, 7, 22 }, // 129 bits per transform
+ { 14, 8, 21 }, // 129 bits per transform
+ { 14, 9, 20 }, // 129 bits per transform
+ { 14, 10, 19 }, // 129 bits per transform
+ { 14, 11, 18 }, // 129 bits per transform
+ { 14, 12, 17 }, // 129 bits per transform
+ { 14, 13, 16 }, // 129 bits per transform
+ { 14, 14, 15 }, // 129 bits per transform
+ { 14, 15, 14 }, // 129 bits per transform
+ { 14, 16, 13 }, // 129 bits per transform
+ { 14, 17, 12 }, // 129 bits per transform
+ { 14, 18, 11 }, // 129 bits per transform
+ { 14, 19, 10 }, // 129 bits per transform
+ { 14, 20, 9 }, // 129 bits per transform
+ { 14, 21, 8 }, // 129 bits per transform
+ { 14, 22, 7 }, // 129 bits per transform
+ { 14, 23, 6 }, // 129 bits per transform
+ { 15, 5, 23 }, // 129 bits per transform
+ { 15, 6, 22 }, // 129 bits per transform
+ { 15, 7, 21 }, // 129 bits per transform
+ { 15, 8, 20 }, // 129 bits per transform
+ { 15, 9, 19 }, // 129 bits per transform
+ { 15, 10, 18 }, // 129 bits per transform
+ { 15, 11, 17 }, // 129 bits per transform
+ { 15, 12, 16 }, // 129 bits per transform
+ { 15, 13, 15 }, // 129 bits per transform
+ { 15, 14, 14 }, // 129 bits per transform
+ { 15, 15, 13 }, // 129 bits per transform
+ { 15, 16, 12 }, // 129 bits per transform
+ { 15, 17, 11 }, // 129 bits per transform
+ { 15, 18, 10 }, // 129 bits per transform
+ { 15, 19, 9 }, // 129 bits per transform
+ { 15, 20, 8 }, // 129 bits per transform
+ { 15, 21, 7 }, // 129 bits per transform
+ { 15, 22, 6 }, // 129 bits per transform
+ { 15, 23, 5 }, // 129 bits per transform
+ { 16, 4, 23 }, // 129 bits per transform
+ { 16, 5, 22 }, // 129 bits per transform
+ { 16, 6, 21 }, // 129 bits per transform
+ { 16, 7, 20 }, // 129 bits per transform
+ { 16, 8, 19 }, // 129 bits per transform
+ { 16, 9, 18 }, // 129 bits per transform
+ { 16, 10, 17 }, // 129 bits per transform
+ { 16, 11, 16 }, // 129 bits per transform
+ { 16, 12, 15 }, // 129 bits per transform
+ { 16, 13, 14 }, // 129 bits per transform
+ { 16, 14, 13 }, // 129 bits per transform
+ { 16, 15, 12 }, // 129 bits per transform
+ { 16, 16, 11 }, // 129 bits per transform
+ { 16, 17, 10 }, // 129 bits per transform
+ { 16, 18, 9 }, // 129 bits per transform
+ { 16, 19, 8 }, // 129 bits per transform
+ { 16, 20, 7 }, // 129 bits per transform
+ { 16, 21, 6 }, // 129 bits per transform
+ { 16, 22, 5 }, // 129 bits per transform
+ { 16, 23, 4 }, // 129 bits per transform
+ { 17, 3, 23 }, // 129 bits per transform
+ { 17, 4, 22 }, // 129 bits per transform
+ { 17, 5, 21 }, // 129 bits per transform
+ { 17, 6, 20 }, // 129 bits per transform
+ { 17, 7, 19 }, // 129 bits per transform
+ { 17, 8, 18 }, // 129 bits per transform
+ { 17, 9, 17 }, // 129 bits per transform
+ { 17, 10, 16 }, // 129 bits per transform
+ { 17, 11, 15 }, // 129 bits per transform
+ { 17, 12, 14 }, // 129 bits per transform
+ { 17, 13, 13 }, // 129 bits per transform
+ { 17, 14, 12 }, // 129 bits per transform
+ { 17, 15, 11 }, // 129 bits per transform
+ { 17, 16, 10 }, // 129 bits per transform
+ { 17, 17, 9 }, // 129 bits per transform
+ { 17, 18, 8 }, // 129 bits per transform
+ { 17, 19, 7 }, // 129 bits per transform
+ { 17, 20, 6 }, // 129 bits per transform
+ { 17, 21, 5 }, // 129 bits per transform
+ { 17, 22, 4 }, // 129 bits per transform
+ { 17, 23, 3 }, // 129 bits per transform
+ { 18, 2, 23 }, // 129 bits per transform
+ { 18, 3, 22 }, // 129 bits per transform
+ { 18, 4, 21 }, // 129 bits per transform
+ { 18, 5, 20 }, // 129 bits per transform
+ { 18, 6, 19 }, // 129 bits per transform
+ { 18, 7, 18 }, // 129 bits per transform
+ { 18, 8, 17 }, // 129 bits per transform
+ { 18, 9, 16 }, // 129 bits per transform
+ { 18, 10, 15 }, // 129 bits per transform
+ { 18, 11, 14 }, // 129 bits per transform
+ { 18, 12, 13 }, // 129 bits per transform
+ { 18, 13, 12 }, // 129 bits per transform
+ { 18, 14, 11 }, // 129 bits per transform
+ { 18, 15, 10 }, // 129 bits per transform
+ { 18, 16, 9 }, // 129 bits per transform
+ { 18, 17, 8 }, // 129 bits per transform
+ { 18, 18, 7 }, // 129 bits per transform
+ { 18, 19, 6 }, // 129 bits per transform
+ { 18, 20, 5 }, // 129 bits per transform
+ { 18, 21, 4 }, // 129 bits per transform
+ { 18, 22, 3 }, // 129 bits per transform
+ { 18, 23, 2 }, // 129 bits per transform
+ { 19, 1, 23 }, // 129 bits per transform
+ { 19, 2, 22 }, // 129 bits per transform
+ { 19, 3, 21 }, // 129 bits per transform
+ { 19, 4, 20 }, // 129 bits per transform
+ { 19, 5, 19 }, // 129 bits per transform
+ { 19, 6, 18 }, // 129 bits per transform
+ { 19, 7, 17 }, // 129 bits per transform
+ { 19, 8, 16 }, // 129 bits per transform
+ { 19, 9, 15 }, // 129 bits per transform
+ { 19, 10, 14 }, // 129 bits per transform
+ { 19, 11, 13 }, // 129 bits per transform
+ { 19, 12, 12 }, // 129 bits per transform
+ { 19, 13, 11 }, // 129 bits per transform
+ { 19, 14, 10 }, // 129 bits per transform
+ { 19, 15, 9 }, // 129 bits per transform
+ { 19, 16, 8 }, // 129 bits per transform
+ { 19, 17, 7 }, // 129 bits per transform
+ { 19, 18, 6 }, // 129 bits per transform
+ { 19, 19, 5 }, // 129 bits per transform
+ { 19, 20, 4 }, // 129 bits per transform
+ { 19, 21, 3 }, // 129 bits per transform
+ { 19, 22, 2 }, // 129 bits per transform
+ { 19, 23, 1 }, // 129 bits per transform
+ { 20, 0, 23 }, // 129 bits per transform
+ { 20, 1, 22 }, // 129 bits per transform
+ { 20, 2, 21 }, // 129 bits per transform
+ { 20, 3, 20 }, // 129 bits per transform
+ { 20, 4, 19 }, // 129 bits per transform
+ { 20, 5, 18 }, // 129 bits per transform
+ { 20, 6, 17 }, // 129 bits per transform
+ { 20, 7, 16 }, // 129 bits per transform
+ { 20, 8, 15 }, // 129 bits per transform
+ { 20, 9, 14 }, // 129 bits per transform
+ { 20, 10, 13 }, // 129 bits per transform
+ { 20, 11, 12 }, // 129 bits per transform
+ { 20, 12, 11 }, // 129 bits per transform
+ { 20, 13, 10 }, // 129 bits per transform
+ { 20, 14, 9 }, // 129 bits per transform
+ { 20, 15, 8 }, // 129 bits per transform
+ { 20, 16, 7 }, // 129 bits per transform
+ { 20, 17, 6 }, // 129 bits per transform
+ { 20, 18, 5 }, // 129 bits per transform
+ { 20, 19, 4 }, // 129 bits per transform
+ { 20, 20, 3 }, // 129 bits per transform
+ { 20, 21, 2 }, // 129 bits per transform
+ { 20, 22, 1 }, // 129 bits per transform
+ { 20, 23, 0 }, // 129 bits per transform
+ { 21, 0, 22 }, // 129 bits per transform
+ { 21, 1, 21 }, // 129 bits per transform
+ { 21, 2, 20 }, // 129 bits per transform
+ { 21, 3, 19 }, // 129 bits per transform
+ { 21, 4, 18 }, // 129 bits per transform
+ { 21, 5, 17 }, // 129 bits per transform
+ { 21, 6, 16 }, // 129 bits per transform
+ { 21, 7, 15 }, // 129 bits per transform
+ { 21, 8, 14 }, // 129 bits per transform
+ { 21, 9, 13 }, // 129 bits per transform
+ { 21, 10, 12 }, // 129 bits per transform
+ { 21, 11, 11 }, // 129 bits per transform
+ { 21, 12, 10 }, // 129 bits per transform
+ { 21, 13, 9 }, // 129 bits per transform
+ { 21, 14, 8 }, // 129 bits per transform
+ { 21, 15, 7 }, // 129 bits per transform
+ { 21, 16, 6 }, // 129 bits per transform
+ { 21, 17, 5 }, // 129 bits per transform
+ { 21, 18, 4 }, // 129 bits per transform
+ { 21, 19, 3 }, // 129 bits per transform
+ { 21, 20, 2 }, // 129 bits per transform
+ { 21, 21, 1 }, // 129 bits per transform
+ { 21, 22, 0 }, // 129 bits per transform
+ { 22, 0, 21 }, // 129 bits per transform
+ { 22, 1, 20 }, // 129 bits per transform
+ { 22, 2, 19 }, // 129 bits per transform
+ { 22, 3, 18 }, // 129 bits per transform
+ { 22, 4, 17 }, // 129 bits per transform
+ { 22, 5, 16 }, // 129 bits per transform
+ { 22, 6, 15 }, // 129 bits per transform
+ { 22, 7, 14 }, // 129 bits per transform
+ { 22, 8, 13 }, // 129 bits per transform
+ { 22, 9, 12 }, // 129 bits per transform
+ { 22, 10, 11 }, // 129 bits per transform
+ { 22, 11, 10 }, // 129 bits per transform
+ { 22, 12, 9 }, // 129 bits per transform
+ { 22, 13, 8 }, // 129 bits per transform
+ { 22, 14, 7 }, // 129 bits per transform
+ { 22, 15, 6 }, // 129 bits per transform
+ { 22, 16, 5 }, // 129 bits per transform
+ { 22, 17, 4 }, // 129 bits per transform
+ { 22, 18, 3 }, // 129 bits per transform
+ { 22, 19, 2 }, // 129 bits per transform
+ { 22, 20, 1 }, // 129 bits per transform
+ { 22, 21, 0 }, // 129 bits per transform
+ { 23, 0, 20 }, // 129 bits per transform
+ { 23, 1, 19 }, // 129 bits per transform
+ { 23, 2, 18 }, // 129 bits per transform
+ { 23, 3, 17 }, // 129 bits per transform
+ { 23, 4, 16 }, // 129 bits per transform
+ { 23, 5, 15 }, // 129 bits per transform
+ { 23, 6, 14 }, // 129 bits per transform
+ { 23, 7, 13 }, // 129 bits per transform
+ { 23, 8, 12 }, // 129 bits per transform
+ { 23, 9, 11 }, // 129 bits per transform
+ { 23, 10, 10 }, // 129 bits per transform
+ { 23, 11, 9 }, // 129 bits per transform
+ { 23, 12, 8 }, // 129 bits per transform
+ { 23, 13, 7 }, // 129 bits per transform
+ { 23, 14, 6 }, // 129 bits per transform
+ { 23, 15, 5 }, // 129 bits per transform
+ { 23, 16, 4 }, // 129 bits per transform
+ { 23, 17, 3 }, // 129 bits per transform
+ { 23, 18, 2 }, // 129 bits per transform
+ { 23, 19, 1 }, // 129 bits per transform
+ { 23, 20, 0 }, // 129 bits per transform
+ { 24, 0, 11 }, // 129 bits per transform
+ { 24, 1, 10 }, // 129 bits per transform
+ { 24, 2, 9 }, // 129 bits per transform
+ { 24, 3, 8 }, // 129 bits per transform
+ { 24, 4, 7 }, // 129 bits per transform
+ { 24, 5, 6 }, // 129 bits per transform
+ { 24, 6, 5 }, // 129 bits per transform
+ { 24, 7, 4 }, // 129 bits per transform
+ { 24, 8, 3 }, // 129 bits per transform
+ { 24, 9, 2 }, // 129 bits per transform
+ { 24, 10, 1 }, // 129 bits per transform
+ { 24, 11, 0 }, // 129 bits per transform
+ { 0, 12, 24 }, // 132 bits per transform
+ { 0, 21, 23 }, // 132 bits per transform
+ { 0, 22, 22 }, // 132 bits per transform
+ { 0, 23, 21 }, // 132 bits per transform
+ { 0, 24, 12 }, // 132 bits per transform
+ { 1, 11, 24 }, // 132 bits per transform
+ { 1, 20, 23 }, // 132 bits per transform
+ { 1, 21, 22 }, // 132 bits per transform
+ { 1, 22, 21 }, // 132 bits per transform
+ { 1, 23, 20 }, // 132 bits per transform
+ { 1, 24, 11 }, // 132 bits per transform
+ { 2, 10, 24 }, // 132 bits per transform
+ { 2, 19, 23 }, // 132 bits per transform
+ { 2, 20, 22 }, // 132 bits per transform
+ { 2, 21, 21 }, // 132 bits per transform
+ { 2, 22, 20 }, // 132 bits per transform
+ { 2, 23, 19 }, // 132 bits per transform
+ { 2, 24, 10 }, // 132 bits per transform
+ { 3, 9, 24 }, // 132 bits per transform
+ { 3, 18, 23 }, // 132 bits per transform
+ { 3, 19, 22 }, // 132 bits per transform
+ { 3, 20, 21 }, // 132 bits per transform
+ { 3, 21, 20 }, // 132 bits per transform
+ { 3, 22, 19 }, // 132 bits per transform
+ { 3, 23, 18 }, // 132 bits per transform
+ { 3, 24, 9 }, // 132 bits per transform
+ { 4, 8, 24 }, // 132 bits per transform
+ { 4, 17, 23 }, // 132 bits per transform
+ { 4, 18, 22 }, // 132 bits per transform
+ { 4, 19, 21 }, // 132 bits per transform
+ { 4, 20, 20 }, // 132 bits per transform
+ { 4, 21, 19 }, // 132 bits per transform
+ { 4, 22, 18 }, // 132 bits per transform
+ { 4, 23, 17 }, // 132 bits per transform
+ { 4, 24, 8 }, // 132 bits per transform
+ { 5, 7, 24 }, // 132 bits per transform
+ { 5, 16, 23 }, // 132 bits per transform
+ { 5, 17, 22 }, // 132 bits per transform
+ { 5, 18, 21 }, // 132 bits per transform
+ { 5, 19, 20 }, // 132 bits per transform
+ { 5, 20, 19 }, // 132 bits per transform
+ { 5, 21, 18 }, // 132 bits per transform
+ { 5, 22, 17 }, // 132 bits per transform
+ { 5, 23, 16 }, // 132 bits per transform
+ { 5, 24, 7 }, // 132 bits per transform
+ { 6, 6, 24 }, // 132 bits per transform
+ { 6, 15, 23 }, // 132 bits per transform
+ { 6, 16, 22 }, // 132 bits per transform
+ { 6, 17, 21 }, // 132 bits per transform
+ { 6, 18, 20 }, // 132 bits per transform
+ { 6, 19, 19 }, // 132 bits per transform
+ { 6, 20, 18 }, // 132 bits per transform
+ { 6, 21, 17 }, // 132 bits per transform
+ { 6, 22, 16 }, // 132 bits per transform
+ { 6, 23, 15 }, // 132 bits per transform
+ { 6, 24, 6 }, // 132 bits per transform
+ { 7, 5, 24 }, // 132 bits per transform
+ { 7, 14, 23 }, // 132 bits per transform
+ { 7, 15, 22 }, // 132 bits per transform
+ { 7, 16, 21 }, // 132 bits per transform
+ { 7, 17, 20 }, // 132 bits per transform
+ { 7, 18, 19 }, // 132 bits per transform
+ { 7, 19, 18 }, // 132 bits per transform
+ { 7, 20, 17 }, // 132 bits per transform
+ { 7, 21, 16 }, // 132 bits per transform
+ { 7, 22, 15 }, // 132 bits per transform
+ { 7, 23, 14 }, // 132 bits per transform
+ { 7, 24, 5 }, // 132 bits per transform
+ { 8, 4, 24 }, // 132 bits per transform
+ { 8, 13, 23 }, // 132 bits per transform
+ { 8, 14, 22 }, // 132 bits per transform
+ { 8, 15, 21 }, // 132 bits per transform
+ { 8, 16, 20 }, // 132 bits per transform
+ { 8, 17, 19 }, // 132 bits per transform
+ { 8, 18, 18 }, // 132 bits per transform
+ { 8, 19, 17 }, // 132 bits per transform
+ { 8, 20, 16 }, // 132 bits per transform
+ { 8, 21, 15 }, // 132 bits per transform
+ { 8, 22, 14 }, // 132 bits per transform
+ { 8, 23, 13 }, // 132 bits per transform
+ { 8, 24, 4 }, // 132 bits per transform
+ { 9, 3, 24 }, // 132 bits per transform
+ { 9, 12, 23 }, // 132 bits per transform
+ { 9, 13, 22 }, // 132 bits per transform
+ { 9, 14, 21 }, // 132 bits per transform
+ { 9, 15, 20 }, // 132 bits per transform
+ { 9, 16, 19 }, // 132 bits per transform
+ { 9, 17, 18 }, // 132 bits per transform
+ { 9, 18, 17 }, // 132 bits per transform
+ { 9, 19, 16 }, // 132 bits per transform
+ { 9, 20, 15 }, // 132 bits per transform
+ { 9, 21, 14 }, // 132 bits per transform
+ { 9, 22, 13 }, // 132 bits per transform
+ { 9, 23, 12 }, // 132 bits per transform
+ { 9, 24, 3 }, // 132 bits per transform
+ { 10, 2, 24 }, // 132 bits per transform
+ { 10, 11, 23 }, // 132 bits per transform
+ { 10, 12, 22 }, // 132 bits per transform
+ { 10, 13, 21 }, // 132 bits per transform
+ { 10, 14, 20 }, // 132 bits per transform
+ { 10, 15, 19 }, // 132 bits per transform
+ { 10, 16, 18 }, // 132 bits per transform
+ { 10, 17, 17 }, // 132 bits per transform
+ { 10, 18, 16 }, // 132 bits per transform
+ { 10, 19, 15 }, // 132 bits per transform
+ { 10, 20, 14 }, // 132 bits per transform
+ { 10, 21, 13 }, // 132 bits per transform
+ { 10, 22, 12 }, // 132 bits per transform
+ { 10, 23, 11 }, // 132 bits per transform
+ { 10, 24, 2 }, // 132 bits per transform
+ { 11, 1, 24 }, // 132 bits per transform
+ { 11, 10, 23 }, // 132 bits per transform
+ { 11, 11, 22 }, // 132 bits per transform
+ { 11, 12, 21 }, // 132 bits per transform
+ { 11, 13, 20 }, // 132 bits per transform
+ { 11, 14, 19 }, // 132 bits per transform
+ { 11, 15, 18 }, // 132 bits per transform
+ { 11, 16, 17 }, // 132 bits per transform
+ { 11, 17, 16 }, // 132 bits per transform
+ { 11, 18, 15 }, // 132 bits per transform
+ { 11, 19, 14 }, // 132 bits per transform
+ { 11, 20, 13 }, // 132 bits per transform
+ { 11, 21, 12 }, // 132 bits per transform
+ { 11, 22, 11 }, // 132 bits per transform
+ { 11, 23, 10 }, // 132 bits per transform
+ { 11, 24, 1 }, // 132 bits per transform
+ { 12, 0, 24 }, // 132 bits per transform
+ { 12, 9, 23 }, // 132 bits per transform
+ { 12, 10, 22 }, // 132 bits per transform
+ { 12, 11, 21 }, // 132 bits per transform
+ { 12, 12, 20 }, // 132 bits per transform
+ { 12, 13, 19 }, // 132 bits per transform
+ { 12, 14, 18 }, // 132 bits per transform
+ { 12, 15, 17 }, // 132 bits per transform
+ { 12, 16, 16 }, // 132 bits per transform
+ { 12, 17, 15 }, // 132 bits per transform
+ { 12, 18, 14 }, // 132 bits per transform
+ { 12, 19, 13 }, // 132 bits per transform
+ { 12, 20, 12 }, // 132 bits per transform
+ { 12, 21, 11 }, // 132 bits per transform
+ { 12, 22, 10 }, // 132 bits per transform
+ { 12, 23, 9 }, // 132 bits per transform
+ { 12, 24, 0 }, // 132 bits per transform
+ { 13, 8, 23 }, // 132 bits per transform
+ { 13, 9, 22 }, // 132 bits per transform
+ { 13, 10, 21 }, // 132 bits per transform
+ { 13, 11, 20 }, // 132 bits per transform
+ { 13, 12, 19 }, // 132 bits per transform
+ { 13, 13, 18 }, // 132 bits per transform
+ { 13, 14, 17 }, // 132 bits per transform
+ { 13, 15, 16 }, // 132 bits per transform
+ { 13, 16, 15 }, // 132 bits per transform
+ { 13, 17, 14 }, // 132 bits per transform
+ { 13, 18, 13 }, // 132 bits per transform
+ { 13, 19, 12 }, // 132 bits per transform
+ { 13, 20, 11 }, // 132 bits per transform
+ { 13, 21, 10 }, // 132 bits per transform
+ { 13, 22, 9 }, // 132 bits per transform
+ { 13, 23, 8 }, // 132 bits per transform
+ { 14, 7, 23 }, // 132 bits per transform
+ { 14, 8, 22 }, // 132 bits per transform
+ { 14, 9, 21 }, // 132 bits per transform
+ { 14, 10, 20 }, // 132 bits per transform
+ { 14, 11, 19 }, // 132 bits per transform
+ { 14, 12, 18 }, // 132 bits per transform
+ { 14, 13, 17 }, // 132 bits per transform
+ { 14, 14, 16 }, // 132 bits per transform
+ { 14, 15, 15 }, // 132 bits per transform
+ { 14, 16, 14 }, // 132 bits per transform
+ { 14, 17, 13 }, // 132 bits per transform
+ { 14, 18, 12 }, // 132 bits per transform
+ { 14, 19, 11 }, // 132 bits per transform
+ { 14, 20, 10 }, // 132 bits per transform
+ { 14, 21, 9 }, // 132 bits per transform
+ { 14, 22, 8 }, // 132 bits per transform
+ { 14, 23, 7 }, // 132 bits per transform
+ { 15, 6, 23 }, // 132 bits per transform
+ { 15, 7, 22 }, // 132 bits per transform
+ { 15, 8, 21 }, // 132 bits per transform
+ { 15, 9, 20 }, // 132 bits per transform
+ { 15, 10, 19 }, // 132 bits per transform
+ { 15, 11, 18 }, // 132 bits per transform
+ { 15, 12, 17 }, // 132 bits per transform
+ { 15, 13, 16 }, // 132 bits per transform
+ { 15, 14, 15 }, // 132 bits per transform
+ { 15, 15, 14 }, // 132 bits per transform
+ { 15, 16, 13 }, // 132 bits per transform
+ { 15, 17, 12 }, // 132 bits per transform
+ { 15, 18, 11 }, // 132 bits per transform
+ { 15, 19, 10 }, // 132 bits per transform
+ { 15, 20, 9 }, // 132 bits per transform
+ { 15, 21, 8 }, // 132 bits per transform
+ { 15, 22, 7 }, // 132 bits per transform
+ { 15, 23, 6 }, // 132 bits per transform
+ { 16, 5, 23 }, // 132 bits per transform
+ { 16, 6, 22 }, // 132 bits per transform
+ { 16, 7, 21 }, // 132 bits per transform
+ { 16, 8, 20 }, // 132 bits per transform
+ { 16, 9, 19 }, // 132 bits per transform
+ { 16, 10, 18 }, // 132 bits per transform
+ { 16, 11, 17 }, // 132 bits per transform
+ { 16, 12, 16 }, // 132 bits per transform
+ { 16, 13, 15 }, // 132 bits per transform
+ { 16, 14, 14 }, // 132 bits per transform
+ { 16, 15, 13 }, // 132 bits per transform
+ { 16, 16, 12 }, // 132 bits per transform
+ { 16, 17, 11 }, // 132 bits per transform
+ { 16, 18, 10 }, // 132 bits per transform
+ { 16, 19, 9 }, // 132 bits per transform
+ { 16, 20, 8 }, // 132 bits per transform
+ { 16, 21, 7 }, // 132 bits per transform
+ { 16, 22, 6 }, // 132 bits per transform
+ { 16, 23, 5 }, // 132 bits per transform
+ { 17, 4, 23 }, // 132 bits per transform
+ { 17, 5, 22 }, // 132 bits per transform
+ { 17, 6, 21 }, // 132 bits per transform
+ { 17, 7, 20 }, // 132 bits per transform
+ { 17, 8, 19 }, // 132 bits per transform
+ { 17, 9, 18 }, // 132 bits per transform
+ { 17, 10, 17 }, // 132 bits per transform
+ { 17, 11, 16 }, // 132 bits per transform
+ { 17, 12, 15 }, // 132 bits per transform
+ { 17, 13, 14 }, // 132 bits per transform
+ { 17, 14, 13 }, // 132 bits per transform
+ { 17, 15, 12 }, // 132 bits per transform
+ { 17, 16, 11 }, // 132 bits per transform
+ { 17, 17, 10 }, // 132 bits per transform
+ { 17, 18, 9 }, // 132 bits per transform
+ { 17, 19, 8 }, // 132 bits per transform
+ { 17, 20, 7 }, // 132 bits per transform
+ { 17, 21, 6 }, // 132 bits per transform
+ { 17, 22, 5 }, // 132 bits per transform
+ { 17, 23, 4 }, // 132 bits per transform
+ { 18, 3, 23 }, // 132 bits per transform
+ { 18, 4, 22 }, // 132 bits per transform
+ { 18, 5, 21 }, // 132 bits per transform
+ { 18, 6, 20 }, // 132 bits per transform
+ { 18, 7, 19 }, // 132 bits per transform
+ { 18, 8, 18 }, // 132 bits per transform
+ { 18, 9, 17 }, // 132 bits per transform
+ { 18, 10, 16 }, // 132 bits per transform
+ { 18, 11, 15 }, // 132 bits per transform
+ { 18, 12, 14 }, // 132 bits per transform
+ { 18, 13, 13 }, // 132 bits per transform
+ { 18, 14, 12 }, // 132 bits per transform
+ { 18, 15, 11 }, // 132 bits per transform
+ { 18, 16, 10 }, // 132 bits per transform
+ { 18, 17, 9 }, // 132 bits per transform
+ { 18, 18, 8 }, // 132 bits per transform
+ { 18, 19, 7 }, // 132 bits per transform
+ { 18, 20, 6 }, // 132 bits per transform
+ { 18, 21, 5 }, // 132 bits per transform
+ { 18, 22, 4 }, // 132 bits per transform
+ { 18, 23, 3 }, // 132 bits per transform
+ { 19, 2, 23 }, // 132 bits per transform
+ { 19, 3, 22 }, // 132 bits per transform
+ { 19, 4, 21 }, // 132 bits per transform
+ { 19, 5, 20 }, // 132 bits per transform
+ { 19, 6, 19 }, // 132 bits per transform
+ { 19, 7, 18 }, // 132 bits per transform
+ { 19, 8, 17 }, // 132 bits per transform
+ { 19, 9, 16 }, // 132 bits per transform
+ { 19, 10, 15 }, // 132 bits per transform
+ { 19, 11, 14 }, // 132 bits per transform
+ { 19, 12, 13 }, // 132 bits per transform
+ { 19, 13, 12 }, // 132 bits per transform
+ { 19, 14, 11 }, // 132 bits per transform
+ { 19, 15, 10 }, // 132 bits per transform
+ { 19, 16, 9 }, // 132 bits per transform
+ { 19, 17, 8 }, // 132 bits per transform
+ { 19, 18, 7 }, // 132 bits per transform
+ { 19, 19, 6 }, // 132 bits per transform
+ { 19, 20, 5 }, // 132 bits per transform
+ { 19, 21, 4 }, // 132 bits per transform
+ { 19, 22, 3 }, // 132 bits per transform
+ { 19, 23, 2 }, // 132 bits per transform
+ { 20, 1, 23 }, // 132 bits per transform
+ { 20, 2, 22 }, // 132 bits per transform
+ { 20, 3, 21 }, // 132 bits per transform
+ { 20, 4, 20 }, // 132 bits per transform
+ { 20, 5, 19 }, // 132 bits per transform
+ { 20, 6, 18 }, // 132 bits per transform
+ { 20, 7, 17 }, // 132 bits per transform
+ { 20, 8, 16 }, // 132 bits per transform
+ { 20, 9, 15 }, // 132 bits per transform
+ { 20, 10, 14 }, // 132 bits per transform
+ { 20, 11, 13 }, // 132 bits per transform
+ { 20, 12, 12 }, // 132 bits per transform
+ { 20, 13, 11 }, // 132 bits per transform
+ { 20, 14, 10 }, // 132 bits per transform
+ { 20, 15, 9 }, // 132 bits per transform
+ { 20, 16, 8 }, // 132 bits per transform
+ { 20, 17, 7 }, // 132 bits per transform
+ { 20, 18, 6 }, // 132 bits per transform
+ { 20, 19, 5 }, // 132 bits per transform
+ { 20, 20, 4 }, // 132 bits per transform
+ { 20, 21, 3 }, // 132 bits per transform
+ { 20, 22, 2 }, // 132 bits per transform
+ { 20, 23, 1 }, // 132 bits per transform
+ { 21, 0, 23 }, // 132 bits per transform
+ { 21, 1, 22 }, // 132 bits per transform
+ { 21, 2, 21 }, // 132 bits per transform
+ { 21, 3, 20 }, // 132 bits per transform
+ { 21, 4, 19 }, // 132 bits per transform
+ { 21, 5, 18 }, // 132 bits per transform
+ { 21, 6, 17 }, // 132 bits per transform
+ { 21, 7, 16 }, // 132 bits per transform
+ { 21, 8, 15 }, // 132 bits per transform
+ { 21, 9, 14 }, // 132 bits per transform
+ { 21, 10, 13 }, // 132 bits per transform
+ { 21, 11, 12 }, // 132 bits per transform
+ { 21, 12, 11 }, // 132 bits per transform
+ { 21, 13, 10 }, // 132 bits per transform
+ { 21, 14, 9 }, // 132 bits per transform
+ { 21, 15, 8 }, // 132 bits per transform
+ { 21, 16, 7 }, // 132 bits per transform
+ { 21, 17, 6 }, // 132 bits per transform
+ { 21, 18, 5 }, // 132 bits per transform
+ { 21, 19, 4 }, // 132 bits per transform
+ { 21, 20, 3 }, // 132 bits per transform
+ { 21, 21, 2 }, // 132 bits per transform
+ { 21, 22, 1 }, // 132 bits per transform
+ { 21, 23, 0 }, // 132 bits per transform
+ { 22, 0, 22 }, // 132 bits per transform
+ { 22, 1, 21 }, // 132 bits per transform
+ { 22, 2, 20 }, // 132 bits per transform
+ { 22, 3, 19 }, // 132 bits per transform
+ { 22, 4, 18 }, // 132 bits per transform
+ { 22, 5, 17 }, // 132 bits per transform
+ { 22, 6, 16 }, // 132 bits per transform
+ { 22, 7, 15 }, // 132 bits per transform
+ { 22, 8, 14 }, // 132 bits per transform
+ { 22, 9, 13 }, // 132 bits per transform
+ { 22, 10, 12 }, // 132 bits per transform
+ { 22, 11, 11 }, // 132 bits per transform
+ { 22, 12, 10 }, // 132 bits per transform
+ { 22, 13, 9 }, // 132 bits per transform
+ { 22, 14, 8 }, // 132 bits per transform
+ { 22, 15, 7 }, // 132 bits per transform
+ { 22, 16, 6 }, // 132 bits per transform
+ { 22, 17, 5 }, // 132 bits per transform
+ { 22, 18, 4 }, // 132 bits per transform
+ { 22, 19, 3 }, // 132 bits per transform
+ { 22, 20, 2 }, // 132 bits per transform
+ { 22, 21, 1 }, // 132 bits per transform
+ { 22, 22, 0 }, // 132 bits per transform
+ { 23, 0, 21 }, // 132 bits per transform
+ { 23, 1, 20 }, // 132 bits per transform
+ { 23, 2, 19 }, // 132 bits per transform
+ { 23, 3, 18 }, // 132 bits per transform
+ { 23, 4, 17 }, // 132 bits per transform
+ { 23, 5, 16 }, // 132 bits per transform
+ { 23, 6, 15 }, // 132 bits per transform
+ { 23, 7, 14 }, // 132 bits per transform
+ { 23, 8, 13 }, // 132 bits per transform
+ { 23, 9, 12 }, // 132 bits per transform
+ { 23, 10, 11 }, // 132 bits per transform
+ { 23, 11, 10 }, // 132 bits per transform
+ { 23, 12, 9 }, // 132 bits per transform
+ { 23, 13, 8 }, // 132 bits per transform
+ { 23, 14, 7 }, // 132 bits per transform
+ { 23, 15, 6 }, // 132 bits per transform
+ { 23, 16, 5 }, // 132 bits per transform
+ { 23, 17, 4 }, // 132 bits per transform
+ { 23, 18, 3 }, // 132 bits per transform
+ { 23, 19, 2 }, // 132 bits per transform
+ { 23, 20, 1 }, // 132 bits per transform
+ { 23, 21, 0 }, // 132 bits per transform
+ { 24, 0, 12 }, // 132 bits per transform
+ { 24, 1, 11 }, // 132 bits per transform
+ { 24, 2, 10 }, // 132 bits per transform
+ { 24, 3, 9 }, // 132 bits per transform
+ { 24, 4, 8 }, // 132 bits per transform
+ { 24, 5, 7 }, // 132 bits per transform
+ { 24, 6, 6 }, // 132 bits per transform
+ { 24, 7, 5 }, // 132 bits per transform
+ { 24, 8, 4 }, // 132 bits per transform
+ { 24, 9, 3 }, // 132 bits per transform
+ { 24, 10, 2 }, // 132 bits per transform
+ { 24, 11, 1 }, // 132 bits per transform
+ { 24, 12, 0 }, // 132 bits per transform
+ { 0, 13, 24 }, // 135 bits per transform
+ { 0, 22, 23 }, // 135 bits per transform
+ { 0, 23, 22 }, // 135 bits per transform
+ { 0, 24, 13 }, // 135 bits per transform
+ { 1, 12, 24 }, // 135 bits per transform
+ { 1, 21, 23 }, // 135 bits per transform
+ { 1, 22, 22 }, // 135 bits per transform
+ { 1, 23, 21 }, // 135 bits per transform
+ { 1, 24, 12 }, // 135 bits per transform
+ { 2, 11, 24 }, // 135 bits per transform
+ { 2, 20, 23 }, // 135 bits per transform
+ { 2, 21, 22 }, // 135 bits per transform
+ { 2, 22, 21 }, // 135 bits per transform
+ { 2, 23, 20 }, // 135 bits per transform
+ { 2, 24, 11 }, // 135 bits per transform
+ { 3, 10, 24 }, // 135 bits per transform
+ { 3, 19, 23 }, // 135 bits per transform
+ { 3, 20, 22 }, // 135 bits per transform
+ { 3, 21, 21 }, // 135 bits per transform
+ { 3, 22, 20 }, // 135 bits per transform
+ { 3, 23, 19 }, // 135 bits per transform
+ { 3, 24, 10 }, // 135 bits per transform
+ { 4, 9, 24 }, // 135 bits per transform
+ { 4, 18, 23 }, // 135 bits per transform
+ { 4, 19, 22 }, // 135 bits per transform
+ { 4, 20, 21 }, // 135 bits per transform
+ { 4, 21, 20 }, // 135 bits per transform
+ { 4, 22, 19 }, // 135 bits per transform
+ { 4, 23, 18 }, // 135 bits per transform
+ { 4, 24, 9 }, // 135 bits per transform
+ { 5, 8, 24 }, // 135 bits per transform
+ { 5, 17, 23 }, // 135 bits per transform
+ { 5, 18, 22 }, // 135 bits per transform
+ { 5, 19, 21 }, // 135 bits per transform
+ { 5, 20, 20 }, // 135 bits per transform
+ { 5, 21, 19 }, // 135 bits per transform
+ { 5, 22, 18 }, // 135 bits per transform
+ { 5, 23, 17 }, // 135 bits per transform
+ { 5, 24, 8 }, // 135 bits per transform
+ { 6, 7, 24 }, // 135 bits per transform
+ { 6, 16, 23 }, // 135 bits per transform
+ { 6, 17, 22 }, // 135 bits per transform
+ { 6, 18, 21 }, // 135 bits per transform
+ { 6, 19, 20 }, // 135 bits per transform
+ { 6, 20, 19 }, // 135 bits per transform
+ { 6, 21, 18 }, // 135 bits per transform
+ { 6, 22, 17 }, // 135 bits per transform
+ { 6, 23, 16 }, // 135 bits per transform
+ { 6, 24, 7 }, // 135 bits per transform
+ { 7, 6, 24 }, // 135 bits per transform
+ { 7, 15, 23 }, // 135 bits per transform
+ { 7, 16, 22 }, // 135 bits per transform
+ { 7, 17, 21 }, // 135 bits per transform
+ { 7, 18, 20 }, // 135 bits per transform
+ { 7, 19, 19 }, // 135 bits per transform
+ { 7, 20, 18 }, // 135 bits per transform
+ { 7, 21, 17 }, // 135 bits per transform
+ { 7, 22, 16 }, // 135 bits per transform
+ { 7, 23, 15 }, // 135 bits per transform
+ { 7, 24, 6 }, // 135 bits per transform
+ { 8, 5, 24 }, // 135 bits per transform
+ { 8, 14, 23 }, // 135 bits per transform
+ { 8, 15, 22 }, // 135 bits per transform
+ { 8, 16, 21 }, // 135 bits per transform
+ { 8, 17, 20 }, // 135 bits per transform
+ { 8, 18, 19 }, // 135 bits per transform
+ { 8, 19, 18 }, // 135 bits per transform
+ { 8, 20, 17 }, // 135 bits per transform
+ { 8, 21, 16 }, // 135 bits per transform
+ { 8, 22, 15 }, // 135 bits per transform
+ { 8, 23, 14 }, // 135 bits per transform
+ { 8, 24, 5 }, // 135 bits per transform
+ { 9, 4, 24 }, // 135 bits per transform
+ { 9, 13, 23 }, // 135 bits per transform
+ { 9, 14, 22 }, // 135 bits per transform
+ { 9, 15, 21 }, // 135 bits per transform
+ { 9, 16, 20 }, // 135 bits per transform
+ { 9, 17, 19 }, // 135 bits per transform
+ { 9, 18, 18 }, // 135 bits per transform
+ { 9, 19, 17 }, // 135 bits per transform
+ { 9, 20, 16 }, // 135 bits per transform
+ { 9, 21, 15 }, // 135 bits per transform
+ { 9, 22, 14 }, // 135 bits per transform
+ { 9, 23, 13 }, // 135 bits per transform
+ { 9, 24, 4 }, // 135 bits per transform
+ { 10, 3, 24 }, // 135 bits per transform
+ { 10, 12, 23 }, // 135 bits per transform
+ { 10, 13, 22 }, // 135 bits per transform
+ { 10, 14, 21 }, // 135 bits per transform
+ { 10, 15, 20 }, // 135 bits per transform
+ { 10, 16, 19 }, // 135 bits per transform
+ { 10, 17, 18 }, // 135 bits per transform
+ { 10, 18, 17 }, // 135 bits per transform
+ { 10, 19, 16 }, // 135 bits per transform
+ { 10, 20, 15 }, // 135 bits per transform
+ { 10, 21, 14 }, // 135 bits per transform
+ { 10, 22, 13 }, // 135 bits per transform
+ { 10, 23, 12 }, // 135 bits per transform
+ { 10, 24, 3 }, // 135 bits per transform
+ { 11, 2, 24 }, // 135 bits per transform
+ { 11, 11, 23 }, // 135 bits per transform
+ { 11, 12, 22 }, // 135 bits per transform
+ { 11, 13, 21 }, // 135 bits per transform
+ { 11, 14, 20 }, // 135 bits per transform
+ { 11, 15, 19 }, // 135 bits per transform
+ { 11, 16, 18 }, // 135 bits per transform
+ { 11, 17, 17 }, // 135 bits per transform
+ { 11, 18, 16 }, // 135 bits per transform
+ { 11, 19, 15 }, // 135 bits per transform
+ { 11, 20, 14 }, // 135 bits per transform
+ { 11, 21, 13 }, // 135 bits per transform
+ { 11, 22, 12 }, // 135 bits per transform
+ { 11, 23, 11 }, // 135 bits per transform
+ { 11, 24, 2 }, // 135 bits per transform
+ { 12, 1, 24 }, // 135 bits per transform
+ { 12, 10, 23 }, // 135 bits per transform
+ { 12, 11, 22 }, // 135 bits per transform
+ { 12, 12, 21 }, // 135 bits per transform
+ { 12, 13, 20 }, // 135 bits per transform
+ { 12, 14, 19 }, // 135 bits per transform
+ { 12, 15, 18 }, // 135 bits per transform
+ { 12, 16, 17 }, // 135 bits per transform
+ { 12, 17, 16 }, // 135 bits per transform
+ { 12, 18, 15 }, // 135 bits per transform
+ { 12, 19, 14 }, // 135 bits per transform
+ { 12, 20, 13 }, // 135 bits per transform
+ { 12, 21, 12 }, // 135 bits per transform
+ { 12, 22, 11 }, // 135 bits per transform
+ { 12, 23, 10 }, // 135 bits per transform
+ { 12, 24, 1 }, // 135 bits per transform
+ { 13, 0, 24 }, // 135 bits per transform
+ { 13, 9, 23 }, // 135 bits per transform
+ { 13, 10, 22 }, // 135 bits per transform
+ { 13, 11, 21 }, // 135 bits per transform
+ { 13, 12, 20 }, // 135 bits per transform
+ { 13, 13, 19 }, // 135 bits per transform
+ { 13, 14, 18 }, // 135 bits per transform
+ { 13, 15, 17 }, // 135 bits per transform
+ { 13, 16, 16 }, // 135 bits per transform
+ { 13, 17, 15 }, // 135 bits per transform
+ { 13, 18, 14 }, // 135 bits per transform
+ { 13, 19, 13 }, // 135 bits per transform
+ { 13, 20, 12 }, // 135 bits per transform
+ { 13, 21, 11 }, // 135 bits per transform
+ { 13, 22, 10 }, // 135 bits per transform
+ { 13, 23, 9 }, // 135 bits per transform
+ { 13, 24, 0 }, // 135 bits per transform
+ { 14, 8, 23 }, // 135 bits per transform
+ { 14, 9, 22 }, // 135 bits per transform
+ { 14, 10, 21 }, // 135 bits per transform
+ { 14, 11, 20 }, // 135 bits per transform
+ { 14, 12, 19 }, // 135 bits per transform
+ { 14, 13, 18 }, // 135 bits per transform
+ { 14, 14, 17 }, // 135 bits per transform
+ { 14, 15, 16 }, // 135 bits per transform
+ { 14, 16, 15 }, // 135 bits per transform
+ { 14, 17, 14 }, // 135 bits per transform
+ { 14, 18, 13 }, // 135 bits per transform
+ { 14, 19, 12 }, // 135 bits per transform
+ { 14, 20, 11 }, // 135 bits per transform
+ { 14, 21, 10 }, // 135 bits per transform
+ { 14, 22, 9 }, // 135 bits per transform
+ { 14, 23, 8 }, // 135 bits per transform
+ { 15, 7, 23 }, // 135 bits per transform
+ { 15, 8, 22 }, // 135 bits per transform
+ { 15, 9, 21 }, // 135 bits per transform
+ { 15, 10, 20 }, // 135 bits per transform
+ { 15, 11, 19 }, // 135 bits per transform
+ { 15, 12, 18 }, // 135 bits per transform
+ { 15, 13, 17 }, // 135 bits per transform
+ { 15, 14, 16 }, // 135 bits per transform
+ { 15, 15, 15 }, // 135 bits per transform
+ { 15, 16, 14 }, // 135 bits per transform
+ { 15, 17, 13 }, // 135 bits per transform
+ { 15, 18, 12 }, // 135 bits per transform
+ { 15, 19, 11 }, // 135 bits per transform
+ { 15, 20, 10 }, // 135 bits per transform
+ { 15, 21, 9 }, // 135 bits per transform
+ { 15, 22, 8 }, // 135 bits per transform
+ { 15, 23, 7 }, // 135 bits per transform
+ { 16, 6, 23 }, // 135 bits per transform
+ { 16, 7, 22 }, // 135 bits per transform
+ { 16, 8, 21 }, // 135 bits per transform
+ { 16, 9, 20 }, // 135 bits per transform
+ { 16, 10, 19 }, // 135 bits per transform
+ { 16, 11, 18 }, // 135 bits per transform
+ { 16, 12, 17 }, // 135 bits per transform
+ { 16, 13, 16 }, // 135 bits per transform
+ { 16, 14, 15 }, // 135 bits per transform
+ { 16, 15, 14 }, // 135 bits per transform
+ { 16, 16, 13 }, // 135 bits per transform
+ { 16, 17, 12 }, // 135 bits per transform
+ { 16, 18, 11 }, // 135 bits per transform
+ { 16, 19, 10 }, // 135 bits per transform
+ { 16, 20, 9 }, // 135 bits per transform
+ { 16, 21, 8 }, // 135 bits per transform
+ { 16, 22, 7 }, // 135 bits per transform
+ { 16, 23, 6 }, // 135 bits per transform
+ { 17, 5, 23 }, // 135 bits per transform
+ { 17, 6, 22 }, // 135 bits per transform
+ { 17, 7, 21 }, // 135 bits per transform
+ { 17, 8, 20 }, // 135 bits per transform
+ { 17, 9, 19 }, // 135 bits per transform
+ { 17, 10, 18 }, // 135 bits per transform
+ { 17, 11, 17 }, // 135 bits per transform
+ { 17, 12, 16 }, // 135 bits per transform
+ { 17, 13, 15 }, // 135 bits per transform
+ { 17, 14, 14 }, // 135 bits per transform
+ { 17, 15, 13 }, // 135 bits per transform
+ { 17, 16, 12 }, // 135 bits per transform
+ { 17, 17, 11 }, // 135 bits per transform
+ { 17, 18, 10 }, // 135 bits per transform
+ { 17, 19, 9 }, // 135 bits per transform
+ { 17, 20, 8 }, // 135 bits per transform
+ { 17, 21, 7 }, // 135 bits per transform
+ { 17, 22, 6 }, // 135 bits per transform
+ { 17, 23, 5 }, // 135 bits per transform
+ { 18, 4, 23 }, // 135 bits per transform
+ { 18, 5, 22 }, // 135 bits per transform
+ { 18, 6, 21 }, // 135 bits per transform
+ { 18, 7, 20 }, // 135 bits per transform
+ { 18, 8, 19 }, // 135 bits per transform
+ { 18, 9, 18 }, // 135 bits per transform
+ { 18, 10, 17 }, // 135 bits per transform
+ { 18, 11, 16 }, // 135 bits per transform
+ { 18, 12, 15 }, // 135 bits per transform
+ { 18, 13, 14 }, // 135 bits per transform
+ { 18, 14, 13 }, // 135 bits per transform
+ { 18, 15, 12 }, // 135 bits per transform
+ { 18, 16, 11 }, // 135 bits per transform
+ { 18, 17, 10 }, // 135 bits per transform
+ { 18, 18, 9 }, // 135 bits per transform
+ { 18, 19, 8 }, // 135 bits per transform
+ { 18, 20, 7 }, // 135 bits per transform
+ { 18, 21, 6 }, // 135 bits per transform
+ { 18, 22, 5 }, // 135 bits per transform
+ { 18, 23, 4 }, // 135 bits per transform
+ { 19, 3, 23 }, // 135 bits per transform
+ { 19, 4, 22 }, // 135 bits per transform
+ { 19, 5, 21 }, // 135 bits per transform
+ { 19, 6, 20 }, // 135 bits per transform
+ { 19, 7, 19 }, // 135 bits per transform
+ { 19, 8, 18 }, // 135 bits per transform
+ { 19, 9, 17 }, // 135 bits per transform
+ { 19, 10, 16 }, // 135 bits per transform
+ { 19, 11, 15 }, // 135 bits per transform
+ { 19, 12, 14 }, // 135 bits per transform
+ { 19, 13, 13 }, // 135 bits per transform
+ { 19, 14, 12 }, // 135 bits per transform
+ { 19, 15, 11 }, // 135 bits per transform
+ { 19, 16, 10 }, // 135 bits per transform
+ { 19, 17, 9 }, // 135 bits per transform
+ { 19, 18, 8 }, // 135 bits per transform
+ { 19, 19, 7 }, // 135 bits per transform
+ { 19, 20, 6 }, // 135 bits per transform
+ { 19, 21, 5 }, // 135 bits per transform
+ { 19, 22, 4 }, // 135 bits per transform
+ { 19, 23, 3 }, // 135 bits per transform
+ { 20, 2, 23 }, // 135 bits per transform
+ { 20, 3, 22 }, // 135 bits per transform
+ { 20, 4, 21 }, // 135 bits per transform
+ { 20, 5, 20 }, // 135 bits per transform
+ { 20, 6, 19 }, // 135 bits per transform
+ { 20, 7, 18 }, // 135 bits per transform
+ { 20, 8, 17 }, // 135 bits per transform
+ { 20, 9, 16 }, // 135 bits per transform
+ { 20, 10, 15 }, // 135 bits per transform
+ { 20, 11, 14 }, // 135 bits per transform
+ { 20, 12, 13 }, // 135 bits per transform
+ { 20, 13, 12 }, // 135 bits per transform
+ { 20, 14, 11 }, // 135 bits per transform
+ { 20, 15, 10 }, // 135 bits per transform
+ { 20, 16, 9 }, // 135 bits per transform
+ { 20, 17, 8 }, // 135 bits per transform
+ { 20, 18, 7 }, // 135 bits per transform
+ { 20, 19, 6 }, // 135 bits per transform
+ { 20, 20, 5 }, // 135 bits per transform
+ { 20, 21, 4 }, // 135 bits per transform
+ { 20, 22, 3 }, // 135 bits per transform
+ { 20, 23, 2 }, // 135 bits per transform
+ { 21, 1, 23 }, // 135 bits per transform
+ { 21, 2, 22 }, // 135 bits per transform
+ { 21, 3, 21 }, // 135 bits per transform
+ { 21, 4, 20 }, // 135 bits per transform
+ { 21, 5, 19 }, // 135 bits per transform
+ { 21, 6, 18 }, // 135 bits per transform
+ { 21, 7, 17 }, // 135 bits per transform
+ { 21, 8, 16 }, // 135 bits per transform
+ { 21, 9, 15 }, // 135 bits per transform
+ { 21, 10, 14 }, // 135 bits per transform
+ { 21, 11, 13 }, // 135 bits per transform
+ { 21, 12, 12 }, // 135 bits per transform
+ { 21, 13, 11 }, // 135 bits per transform
+ { 21, 14, 10 }, // 135 bits per transform
+ { 21, 15, 9 }, // 135 bits per transform
+ { 21, 16, 8 }, // 135 bits per transform
+ { 21, 17, 7 }, // 135 bits per transform
+ { 21, 18, 6 }, // 135 bits per transform
+ { 21, 19, 5 }, // 135 bits per transform
+ { 21, 20, 4 }, // 135 bits per transform
+ { 21, 21, 3 }, // 135 bits per transform
+ { 21, 22, 2 }, // 135 bits per transform
+ { 21, 23, 1 }, // 135 bits per transform
+ { 22, 0, 23 }, // 135 bits per transform
+ { 22, 1, 22 }, // 135 bits per transform
+ { 22, 2, 21 }, // 135 bits per transform
+ { 22, 3, 20 }, // 135 bits per transform
+ { 22, 4, 19 }, // 135 bits per transform
+ { 22, 5, 18 }, // 135 bits per transform
+ { 22, 6, 17 }, // 135 bits per transform
+ { 22, 7, 16 }, // 135 bits per transform
+ { 22, 8, 15 }, // 135 bits per transform
+ { 22, 9, 14 }, // 135 bits per transform
+ { 22, 10, 13 }, // 135 bits per transform
+ { 22, 11, 12 }, // 135 bits per transform
+ { 22, 12, 11 }, // 135 bits per transform
+ { 22, 13, 10 }, // 135 bits per transform
+ { 22, 14, 9 }, // 135 bits per transform
+ { 22, 15, 8 }, // 135 bits per transform
+ { 22, 16, 7 }, // 135 bits per transform
+ { 22, 17, 6 }, // 135 bits per transform
+ { 22, 18, 5 }, // 135 bits per transform
+ { 22, 19, 4 }, // 135 bits per transform
+ { 22, 20, 3 }, // 135 bits per transform
+ { 22, 21, 2 }, // 135 bits per transform
+ { 22, 22, 1 }, // 135 bits per transform
+ { 22, 23, 0 }, // 135 bits per transform
+ { 23, 0, 22 }, // 135 bits per transform
+ { 23, 1, 21 }, // 135 bits per transform
+ { 23, 2, 20 }, // 135 bits per transform
+ { 23, 3, 19 }, // 135 bits per transform
+ { 23, 4, 18 }, // 135 bits per transform
+ { 23, 5, 17 }, // 135 bits per transform
+ { 23, 6, 16 }, // 135 bits per transform
+ { 23, 7, 15 }, // 135 bits per transform
+ { 23, 8, 14 }, // 135 bits per transform
+ { 23, 9, 13 }, // 135 bits per transform
+ { 23, 10, 12 }, // 135 bits per transform
+ { 23, 11, 11 }, // 135 bits per transform
+ { 23, 12, 10 }, // 135 bits per transform
+ { 23, 13, 9 }, // 135 bits per transform
+ { 23, 14, 8 }, // 135 bits per transform
+ { 23, 15, 7 }, // 135 bits per transform
+ { 23, 16, 6 }, // 135 bits per transform
+ { 23, 17, 5 }, // 135 bits per transform
+ { 23, 18, 4 }, // 135 bits per transform
+ { 23, 19, 3 }, // 135 bits per transform
+ { 23, 20, 2 }, // 135 bits per transform
+ { 23, 21, 1 }, // 135 bits per transform
+ { 23, 22, 0 }, // 135 bits per transform
+ { 24, 0, 13 }, // 135 bits per transform
+ { 24, 1, 12 }, // 135 bits per transform
+ { 24, 2, 11 }, // 135 bits per transform
+ { 24, 3, 10 }, // 135 bits per transform
+ { 24, 4, 9 }, // 135 bits per transform
+ { 24, 5, 8 }, // 135 bits per transform
+ { 24, 6, 7 }, // 135 bits per transform
+ { 24, 7, 6 }, // 135 bits per transform
+ { 24, 8, 5 }, // 135 bits per transform
+ { 24, 9, 4 }, // 135 bits per transform
+ { 24, 10, 3 }, // 135 bits per transform
+ { 24, 11, 2 }, // 135 bits per transform
+ { 24, 12, 1 }, // 135 bits per transform
+ { 24, 13, 0 }, // 135 bits per transform
+ { 0, 14, 24 }, // 138 bits per transform
+ { 0, 23, 23 }, // 138 bits per transform
+ { 0, 24, 14 }, // 138 bits per transform
+ { 1, 13, 24 }, // 138 bits per transform
+ { 1, 22, 23 }, // 138 bits per transform
+ { 1, 23, 22 }, // 138 bits per transform
+ { 1, 24, 13 }, // 138 bits per transform
+ { 2, 12, 24 }, // 138 bits per transform
+ { 2, 21, 23 }, // 138 bits per transform
+ { 2, 22, 22 }, // 138 bits per transform
+ { 2, 23, 21 }, // 138 bits per transform
+ { 2, 24, 12 }, // 138 bits per transform
+ { 3, 11, 24 }, // 138 bits per transform
+ { 3, 20, 23 }, // 138 bits per transform
+ { 3, 21, 22 }, // 138 bits per transform
+ { 3, 22, 21 }, // 138 bits per transform
+ { 3, 23, 20 }, // 138 bits per transform
+ { 3, 24, 11 }, // 138 bits per transform
+ { 4, 10, 24 }, // 138 bits per transform
+ { 4, 19, 23 }, // 138 bits per transform
+ { 4, 20, 22 }, // 138 bits per transform
+ { 4, 21, 21 }, // 138 bits per transform
+ { 4, 22, 20 }, // 138 bits per transform
+ { 4, 23, 19 }, // 138 bits per transform
+ { 4, 24, 10 }, // 138 bits per transform
+ { 5, 9, 24 }, // 138 bits per transform
+ { 5, 18, 23 }, // 138 bits per transform
+ { 5, 19, 22 }, // 138 bits per transform
+ { 5, 20, 21 }, // 138 bits per transform
+ { 5, 21, 20 }, // 138 bits per transform
+ { 5, 22, 19 }, // 138 bits per transform
+ { 5, 23, 18 }, // 138 bits per transform
+ { 5, 24, 9 }, // 138 bits per transform
+ { 6, 8, 24 }, // 138 bits per transform
+ { 6, 17, 23 }, // 138 bits per transform
+ { 6, 18, 22 }, // 138 bits per transform
+ { 6, 19, 21 }, // 138 bits per transform
+ { 6, 20, 20 }, // 138 bits per transform
+ { 6, 21, 19 }, // 138 bits per transform
+ { 6, 22, 18 }, // 138 bits per transform
+ { 6, 23, 17 }, // 138 bits per transform
+ { 6, 24, 8 }, // 138 bits per transform
+ { 7, 7, 24 }, // 138 bits per transform
+ { 7, 16, 23 }, // 138 bits per transform
+ { 7, 17, 22 }, // 138 bits per transform
+ { 7, 18, 21 }, // 138 bits per transform
+ { 7, 19, 20 }, // 138 bits per transform
+ { 7, 20, 19 }, // 138 bits per transform
+ { 7, 21, 18 }, // 138 bits per transform
+ { 7, 22, 17 }, // 138 bits per transform
+ { 7, 23, 16 }, // 138 bits per transform
+ { 7, 24, 7 }, // 138 bits per transform
+ { 8, 6, 24 }, // 138 bits per transform
+ { 8, 15, 23 }, // 138 bits per transform
+ { 8, 16, 22 }, // 138 bits per transform
+ { 8, 17, 21 }, // 138 bits per transform
+ { 8, 18, 20 }, // 138 bits per transform
+ { 8, 19, 19 }, // 138 bits per transform
+ { 8, 20, 18 }, // 138 bits per transform
+ { 8, 21, 17 }, // 138 bits per transform
+ { 8, 22, 16 }, // 138 bits per transform
+ { 8, 23, 15 }, // 138 bits per transform
+ { 8, 24, 6 }, // 138 bits per transform
+ { 9, 5, 24 }, // 138 bits per transform
+ { 9, 14, 23 }, // 138 bits per transform
+ { 9, 15, 22 }, // 138 bits per transform
+ { 9, 16, 21 }, // 138 bits per transform
+ { 9, 17, 20 }, // 138 bits per transform
+ { 9, 18, 19 }, // 138 bits per transform
+ { 9, 19, 18 }, // 138 bits per transform
+ { 9, 20, 17 }, // 138 bits per transform
+ { 9, 21, 16 }, // 138 bits per transform
+ { 9, 22, 15 }, // 138 bits per transform
+ { 9, 23, 14 }, // 138 bits per transform
+ { 9, 24, 5 }, // 138 bits per transform
+ { 10, 4, 24 }, // 138 bits per transform
+ { 10, 13, 23 }, // 138 bits per transform
+ { 10, 14, 22 }, // 138 bits per transform
+ { 10, 15, 21 }, // 138 bits per transform
+ { 10, 16, 20 }, // 138 bits per transform
+ { 10, 17, 19 }, // 138 bits per transform
+ { 10, 18, 18 }, // 138 bits per transform
+ { 10, 19, 17 }, // 138 bits per transform
+ { 10, 20, 16 }, // 138 bits per transform
+ { 10, 21, 15 }, // 138 bits per transform
+ { 10, 22, 14 }, // 138 bits per transform
+ { 10, 23, 13 }, // 138 bits per transform
+ { 10, 24, 4 }, // 138 bits per transform
+ { 11, 3, 24 }, // 138 bits per transform
+ { 11, 12, 23 }, // 138 bits per transform
+ { 11, 13, 22 }, // 138 bits per transform
+ { 11, 14, 21 }, // 138 bits per transform
+ { 11, 15, 20 }, // 138 bits per transform
+ { 11, 16, 19 }, // 138 bits per transform
+ { 11, 17, 18 }, // 138 bits per transform
+ { 11, 18, 17 }, // 138 bits per transform
+ { 11, 19, 16 }, // 138 bits per transform
+ { 11, 20, 15 }, // 138 bits per transform
+ { 11, 21, 14 }, // 138 bits per transform
+ { 11, 22, 13 }, // 138 bits per transform
+ { 11, 23, 12 }, // 138 bits per transform
+ { 11, 24, 3 }, // 138 bits per transform
+ { 12, 2, 24 }, // 138 bits per transform
+ { 12, 11, 23 }, // 138 bits per transform
+ { 12, 12, 22 }, // 138 bits per transform
+ { 12, 13, 21 }, // 138 bits per transform
+ { 12, 14, 20 }, // 138 bits per transform
+ { 12, 15, 19 }, // 138 bits per transform
+ { 12, 16, 18 }, // 138 bits per transform
+ { 12, 17, 17 }, // 138 bits per transform
+ { 12, 18, 16 }, // 138 bits per transform
+ { 12, 19, 15 }, // 138 bits per transform
+ { 12, 20, 14 }, // 138 bits per transform
+ { 12, 21, 13 }, // 138 bits per transform
+ { 12, 22, 12 }, // 138 bits per transform
+ { 12, 23, 11 }, // 138 bits per transform
+ { 12, 24, 2 }, // 138 bits per transform
+ { 13, 1, 24 }, // 138 bits per transform
+ { 13, 10, 23 }, // 138 bits per transform
+ { 13, 11, 22 }, // 138 bits per transform
+ { 13, 12, 21 }, // 138 bits per transform
+ { 13, 13, 20 }, // 138 bits per transform
+ { 13, 14, 19 }, // 138 bits per transform
+ { 13, 15, 18 }, // 138 bits per transform
+ { 13, 16, 17 }, // 138 bits per transform
+ { 13, 17, 16 }, // 138 bits per transform
+ { 13, 18, 15 }, // 138 bits per transform
+ { 13, 19, 14 }, // 138 bits per transform
+ { 13, 20, 13 }, // 138 bits per transform
+ { 13, 21, 12 }, // 138 bits per transform
+ { 13, 22, 11 }, // 138 bits per transform
+ { 13, 23, 10 }, // 138 bits per transform
+ { 13, 24, 1 }, // 138 bits per transform
+ { 14, 0, 24 }, // 138 bits per transform
+ { 14, 9, 23 }, // 138 bits per transform
+ { 14, 10, 22 }, // 138 bits per transform
+ { 14, 11, 21 }, // 138 bits per transform
+ { 14, 12, 20 }, // 138 bits per transform
+ { 14, 13, 19 }, // 138 bits per transform
+ { 14, 14, 18 }, // 138 bits per transform
+ { 14, 15, 17 }, // 138 bits per transform
+ { 14, 16, 16 }, // 138 bits per transform
+ { 14, 17, 15 }, // 138 bits per transform
+ { 14, 18, 14 }, // 138 bits per transform
+ { 14, 19, 13 }, // 138 bits per transform
+ { 14, 20, 12 }, // 138 bits per transform
+ { 14, 21, 11 }, // 138 bits per transform
+ { 14, 22, 10 }, // 138 bits per transform
+ { 14, 23, 9 }, // 138 bits per transform
+ { 14, 24, 0 }, // 138 bits per transform
+ { 15, 8, 23 }, // 138 bits per transform
+ { 15, 9, 22 }, // 138 bits per transform
+ { 15, 10, 21 }, // 138 bits per transform
+ { 15, 11, 20 }, // 138 bits per transform
+ { 15, 12, 19 }, // 138 bits per transform
+ { 15, 13, 18 }, // 138 bits per transform
+ { 15, 14, 17 }, // 138 bits per transform
+ { 15, 15, 16 }, // 138 bits per transform
+ { 15, 16, 15 }, // 138 bits per transform
+ { 15, 17, 14 }, // 138 bits per transform
+ { 15, 18, 13 }, // 138 bits per transform
+ { 15, 19, 12 }, // 138 bits per transform
+ { 15, 20, 11 }, // 138 bits per transform
+ { 15, 21, 10 }, // 138 bits per transform
+ { 15, 22, 9 }, // 138 bits per transform
+ { 15, 23, 8 }, // 138 bits per transform
+ { 16, 7, 23 }, // 138 bits per transform
+ { 16, 8, 22 }, // 138 bits per transform
+ { 16, 9, 21 }, // 138 bits per transform
+ { 16, 10, 20 }, // 138 bits per transform
+ { 16, 11, 19 }, // 138 bits per transform
+ { 16, 12, 18 }, // 138 bits per transform
+ { 16, 13, 17 }, // 138 bits per transform
+ { 16, 14, 16 }, // 138 bits per transform
+ { 16, 15, 15 }, // 138 bits per transform
+ { 16, 16, 14 }, // 138 bits per transform
+ { 16, 17, 13 }, // 138 bits per transform
+ { 16, 18, 12 }, // 138 bits per transform
+ { 16, 19, 11 }, // 138 bits per transform
+ { 16, 20, 10 }, // 138 bits per transform
+ { 16, 21, 9 }, // 138 bits per transform
+ { 16, 22, 8 }, // 138 bits per transform
+ { 16, 23, 7 }, // 138 bits per transform
+ { 17, 6, 23 }, // 138 bits per transform
+ { 17, 7, 22 }, // 138 bits per transform
+ { 17, 8, 21 }, // 138 bits per transform
+ { 17, 9, 20 }, // 138 bits per transform
+ { 17, 10, 19 }, // 138 bits per transform
+ { 17, 11, 18 }, // 138 bits per transform
+ { 17, 12, 17 }, // 138 bits per transform
+ { 17, 13, 16 }, // 138 bits per transform
+ { 17, 14, 15 }, // 138 bits per transform
+ { 17, 15, 14 }, // 138 bits per transform
+ { 17, 16, 13 }, // 138 bits per transform
+ { 17, 17, 12 }, // 138 bits per transform
+ { 17, 18, 11 }, // 138 bits per transform
+ { 17, 19, 10 }, // 138 bits per transform
+ { 17, 20, 9 }, // 138 bits per transform
+ { 17, 21, 8 }, // 138 bits per transform
+ { 17, 22, 7 }, // 138 bits per transform
+ { 17, 23, 6 }, // 138 bits per transform
+ { 18, 5, 23 }, // 138 bits per transform
+ { 18, 6, 22 }, // 138 bits per transform
+ { 18, 7, 21 }, // 138 bits per transform
+ { 18, 8, 20 }, // 138 bits per transform
+ { 18, 9, 19 }, // 138 bits per transform
+ { 18, 10, 18 }, // 138 bits per transform
+ { 18, 11, 17 }, // 138 bits per transform
+ { 18, 12, 16 }, // 138 bits per transform
+ { 18, 13, 15 }, // 138 bits per transform
+ { 18, 14, 14 }, // 138 bits per transform
+ { 18, 15, 13 }, // 138 bits per transform
+ { 18, 16, 12 }, // 138 bits per transform
+ { 18, 17, 11 }, // 138 bits per transform
+ { 18, 18, 10 }, // 138 bits per transform
+ { 18, 19, 9 }, // 138 bits per transform
+ { 18, 20, 8 }, // 138 bits per transform
+ { 18, 21, 7 }, // 138 bits per transform
+ { 18, 22, 6 }, // 138 bits per transform
+ { 18, 23, 5 }, // 138 bits per transform
+ { 19, 4, 23 }, // 138 bits per transform
+ { 19, 5, 22 }, // 138 bits per transform
+ { 19, 6, 21 }, // 138 bits per transform
+ { 19, 7, 20 }, // 138 bits per transform
+ { 19, 8, 19 }, // 138 bits per transform
+ { 19, 9, 18 }, // 138 bits per transform
+ { 19, 10, 17 }, // 138 bits per transform
+ { 19, 11, 16 }, // 138 bits per transform
+ { 19, 12, 15 }, // 138 bits per transform
+ { 19, 13, 14 }, // 138 bits per transform
+ { 19, 14, 13 }, // 138 bits per transform
+ { 19, 15, 12 }, // 138 bits per transform
+ { 19, 16, 11 }, // 138 bits per transform
+ { 19, 17, 10 }, // 138 bits per transform
+ { 19, 18, 9 }, // 138 bits per transform
+ { 19, 19, 8 }, // 138 bits per transform
+ { 19, 20, 7 }, // 138 bits per transform
+ { 19, 21, 6 }, // 138 bits per transform
+ { 19, 22, 5 }, // 138 bits per transform
+ { 19, 23, 4 }, // 138 bits per transform
+ { 20, 3, 23 }, // 138 bits per transform
+ { 20, 4, 22 }, // 138 bits per transform
+ { 20, 5, 21 }, // 138 bits per transform
+ { 20, 6, 20 }, // 138 bits per transform
+ { 20, 7, 19 }, // 138 bits per transform
+ { 20, 8, 18 }, // 138 bits per transform
+ { 20, 9, 17 }, // 138 bits per transform
+ { 20, 10, 16 }, // 138 bits per transform
+ { 20, 11, 15 }, // 138 bits per transform
+ { 20, 12, 14 }, // 138 bits per transform
+ { 20, 13, 13 }, // 138 bits per transform
+ { 20, 14, 12 }, // 138 bits per transform
+ { 20, 15, 11 }, // 138 bits per transform
+ { 20, 16, 10 }, // 138 bits per transform
+ { 20, 17, 9 }, // 138 bits per transform
+ { 20, 18, 8 }, // 138 bits per transform
+ { 20, 19, 7 }, // 138 bits per transform
+ { 20, 20, 6 }, // 138 bits per transform
+ { 20, 21, 5 }, // 138 bits per transform
+ { 20, 22, 4 }, // 138 bits per transform
+ { 20, 23, 3 }, // 138 bits per transform
+ { 21, 2, 23 }, // 138 bits per transform
+ { 21, 3, 22 }, // 138 bits per transform
+ { 21, 4, 21 }, // 138 bits per transform
+ { 21, 5, 20 }, // 138 bits per transform
+ { 21, 6, 19 }, // 138 bits per transform
+ { 21, 7, 18 }, // 138 bits per transform
+ { 21, 8, 17 }, // 138 bits per transform
+ { 21, 9, 16 }, // 138 bits per transform
+ { 21, 10, 15 }, // 138 bits per transform
+ { 21, 11, 14 }, // 138 bits per transform
+ { 21, 12, 13 }, // 138 bits per transform
+ { 21, 13, 12 }, // 138 bits per transform
+ { 21, 14, 11 }, // 138 bits per transform
+ { 21, 15, 10 }, // 138 bits per transform
+ { 21, 16, 9 }, // 138 bits per transform
+ { 21, 17, 8 }, // 138 bits per transform
+ { 21, 18, 7 }, // 138 bits per transform
+ { 21, 19, 6 }, // 138 bits per transform
+ { 21, 20, 5 }, // 138 bits per transform
+ { 21, 21, 4 }, // 138 bits per transform
+ { 21, 22, 3 }, // 138 bits per transform
+ { 21, 23, 2 }, // 138 bits per transform
+ { 22, 1, 23 }, // 138 bits per transform
+ { 22, 2, 22 }, // 138 bits per transform
+ { 22, 3, 21 }, // 138 bits per transform
+ { 22, 4, 20 }, // 138 bits per transform
+ { 22, 5, 19 }, // 138 bits per transform
+ { 22, 6, 18 }, // 138 bits per transform
+ { 22, 7, 17 }, // 138 bits per transform
+ { 22, 8, 16 }, // 138 bits per transform
+ { 22, 9, 15 }, // 138 bits per transform
+ { 22, 10, 14 }, // 138 bits per transform
+ { 22, 11, 13 }, // 138 bits per transform
+ { 22, 12, 12 }, // 138 bits per transform
+ { 22, 13, 11 }, // 138 bits per transform
+ { 22, 14, 10 }, // 138 bits per transform
+ { 22, 15, 9 }, // 138 bits per transform
+ { 22, 16, 8 }, // 138 bits per transform
+ { 22, 17, 7 }, // 138 bits per transform
+ { 22, 18, 6 }, // 138 bits per transform
+ { 22, 19, 5 }, // 138 bits per transform
+ { 22, 20, 4 }, // 138 bits per transform
+ { 22, 21, 3 }, // 138 bits per transform
+ { 22, 22, 2 }, // 138 bits per transform
+ { 22, 23, 1 }, // 138 bits per transform
+ { 23, 0, 23 }, // 138 bits per transform
+ { 23, 1, 22 }, // 138 bits per transform
+ { 23, 2, 21 }, // 138 bits per transform
+ { 23, 3, 20 }, // 138 bits per transform
+ { 23, 4, 19 }, // 138 bits per transform
+ { 23, 5, 18 }, // 138 bits per transform
+ { 23, 6, 17 }, // 138 bits per transform
+ { 23, 7, 16 }, // 138 bits per transform
+ { 23, 8, 15 }, // 138 bits per transform
+ { 23, 9, 14 }, // 138 bits per transform
+ { 23, 10, 13 }, // 138 bits per transform
+ { 23, 11, 12 }, // 138 bits per transform
+ { 23, 12, 11 }, // 138 bits per transform
+ { 23, 13, 10 }, // 138 bits per transform
+ { 23, 14, 9 }, // 138 bits per transform
+ { 23, 15, 8 }, // 138 bits per transform
+ { 23, 16, 7 }, // 138 bits per transform
+ { 23, 17, 6 }, // 138 bits per transform
+ { 23, 18, 5 }, // 138 bits per transform
+ { 23, 19, 4 }, // 138 bits per transform
+ { 23, 20, 3 }, // 138 bits per transform
+ { 23, 21, 2 }, // 138 bits per transform
+ { 23, 22, 1 }, // 138 bits per transform
+ { 23, 23, 0 }, // 138 bits per transform
+ { 24, 0, 14 }, // 138 bits per transform
+ { 24, 1, 13 }, // 138 bits per transform
+ { 24, 2, 12 }, // 138 bits per transform
+ { 24, 3, 11 }, // 138 bits per transform
+ { 24, 4, 10 }, // 138 bits per transform
+ { 24, 5, 9 }, // 138 bits per transform
+ { 24, 6, 8 }, // 138 bits per transform
+ { 24, 7, 7 }, // 138 bits per transform
+ { 24, 8, 6 }, // 138 bits per transform
+ { 24, 9, 5 }, // 138 bits per transform
+ { 24, 10, 4 }, // 138 bits per transform
+ { 24, 11, 3 }, // 138 bits per transform
+ { 24, 12, 2 }, // 138 bits per transform
+ { 24, 13, 1 }, // 138 bits per transform
+ { 24, 14, 0 }, // 138 bits per transform
+ { 0, 15, 24 }, // 141 bits per transform
+ { 0, 24, 15 }, // 141 bits per transform
+ { 1, 14, 24 }, // 141 bits per transform
+ { 1, 23, 23 }, // 141 bits per transform
+ { 1, 24, 14 }, // 141 bits per transform
+ { 2, 13, 24 }, // 141 bits per transform
+ { 2, 22, 23 }, // 141 bits per transform
+ { 2, 23, 22 }, // 141 bits per transform
+ { 2, 24, 13 }, // 141 bits per transform
+ { 3, 12, 24 }, // 141 bits per transform
+ { 3, 21, 23 }, // 141 bits per transform
+ { 3, 22, 22 }, // 141 bits per transform
+ { 3, 23, 21 }, // 141 bits per transform
+ { 3, 24, 12 }, // 141 bits per transform
+ { 4, 11, 24 }, // 141 bits per transform
+ { 4, 20, 23 }, // 141 bits per transform
+ { 4, 21, 22 }, // 141 bits per transform
+ { 4, 22, 21 }, // 141 bits per transform
+ { 4, 23, 20 }, // 141 bits per transform
+ { 4, 24, 11 }, // 141 bits per transform
+ { 5, 10, 24 }, // 141 bits per transform
+ { 5, 19, 23 }, // 141 bits per transform
+ { 5, 20, 22 }, // 141 bits per transform
+ { 5, 21, 21 }, // 141 bits per transform
+ { 5, 22, 20 }, // 141 bits per transform
+ { 5, 23, 19 }, // 141 bits per transform
+ { 5, 24, 10 }, // 141 bits per transform
+ { 6, 9, 24 }, // 141 bits per transform
+ { 6, 18, 23 }, // 141 bits per transform
+ { 6, 19, 22 }, // 141 bits per transform
+ { 6, 20, 21 }, // 141 bits per transform
+ { 6, 21, 20 }, // 141 bits per transform
+ { 6, 22, 19 }, // 141 bits per transform
+ { 6, 23, 18 }, // 141 bits per transform
+ { 6, 24, 9 }, // 141 bits per transform
+ { 7, 8, 24 }, // 141 bits per transform
+ { 7, 17, 23 }, // 141 bits per transform
+ { 7, 18, 22 }, // 141 bits per transform
+ { 7, 19, 21 }, // 141 bits per transform
+ { 7, 20, 20 }, // 141 bits per transform
+ { 7, 21, 19 }, // 141 bits per transform
+ { 7, 22, 18 }, // 141 bits per transform
+ { 7, 23, 17 }, // 141 bits per transform
+ { 7, 24, 8 }, // 141 bits per transform
+ { 8, 7, 24 }, // 141 bits per transform
+ { 8, 16, 23 }, // 141 bits per transform
+ { 8, 17, 22 }, // 141 bits per transform
+ { 8, 18, 21 }, // 141 bits per transform
+ { 8, 19, 20 }, // 141 bits per transform
+ { 8, 20, 19 }, // 141 bits per transform
+ { 8, 21, 18 }, // 141 bits per transform
+ { 8, 22, 17 }, // 141 bits per transform
+ { 8, 23, 16 }, // 141 bits per transform
+ { 8, 24, 7 }, // 141 bits per transform
+ { 9, 6, 24 }, // 141 bits per transform
+ { 9, 15, 23 }, // 141 bits per transform
+ { 9, 16, 22 }, // 141 bits per transform
+ { 9, 17, 21 }, // 141 bits per transform
+ { 9, 18, 20 }, // 141 bits per transform
+ { 9, 19, 19 }, // 141 bits per transform
+ { 9, 20, 18 }, // 141 bits per transform
+ { 9, 21, 17 }, // 141 bits per transform
+ { 9, 22, 16 }, // 141 bits per transform
+ { 9, 23, 15 }, // 141 bits per transform
+ { 9, 24, 6 }, // 141 bits per transform
+ { 10, 5, 24 }, // 141 bits per transform
+ { 10, 14, 23 }, // 141 bits per transform
+ { 10, 15, 22 }, // 141 bits per transform
+ { 10, 16, 21 }, // 141 bits per transform
+ { 10, 17, 20 }, // 141 bits per transform
+ { 10, 18, 19 }, // 141 bits per transform
+ { 10, 19, 18 }, // 141 bits per transform
+ { 10, 20, 17 }, // 141 bits per transform
+ { 10, 21, 16 }, // 141 bits per transform
+ { 10, 22, 15 }, // 141 bits per transform
+ { 10, 23, 14 }, // 141 bits per transform
+ { 10, 24, 5 }, // 141 bits per transform
+ { 11, 4, 24 }, // 141 bits per transform
+ { 11, 13, 23 }, // 141 bits per transform
+ { 11, 14, 22 }, // 141 bits per transform
+ { 11, 15, 21 }, // 141 bits per transform
+ { 11, 16, 20 }, // 141 bits per transform
+ { 11, 17, 19 }, // 141 bits per transform
+ { 11, 18, 18 }, // 141 bits per transform
+ { 11, 19, 17 }, // 141 bits per transform
+ { 11, 20, 16 }, // 141 bits per transform
+ { 11, 21, 15 }, // 141 bits per transform
+ { 11, 22, 14 }, // 141 bits per transform
+ { 11, 23, 13 }, // 141 bits per transform
+ { 11, 24, 4 }, // 141 bits per transform
+ { 12, 3, 24 }, // 141 bits per transform
+ { 12, 12, 23 }, // 141 bits per transform
+ { 12, 13, 22 }, // 141 bits per transform
+ { 12, 14, 21 }, // 141 bits per transform
+ { 12, 15, 20 }, // 141 bits per transform
+ { 12, 16, 19 }, // 141 bits per transform
+ { 12, 17, 18 }, // 141 bits per transform
+ { 12, 18, 17 }, // 141 bits per transform
+ { 12, 19, 16 }, // 141 bits per transform
+ { 12, 20, 15 }, // 141 bits per transform
+ { 12, 21, 14 }, // 141 bits per transform
+ { 12, 22, 13 }, // 141 bits per transform
+ { 12, 23, 12 }, // 141 bits per transform
+ { 12, 24, 3 }, // 141 bits per transform
+ { 13, 2, 24 }, // 141 bits per transform
+ { 13, 11, 23 }, // 141 bits per transform
+ { 13, 12, 22 }, // 141 bits per transform
+ { 13, 13, 21 }, // 141 bits per transform
+ { 13, 14, 20 }, // 141 bits per transform
+ { 13, 15, 19 }, // 141 bits per transform
+ { 13, 16, 18 }, // 141 bits per transform
+ { 13, 17, 17 }, // 141 bits per transform
+ { 13, 18, 16 }, // 141 bits per transform
+ { 13, 19, 15 }, // 141 bits per transform
+ { 13, 20, 14 }, // 141 bits per transform
+ { 13, 21, 13 }, // 141 bits per transform
+ { 13, 22, 12 }, // 141 bits per transform
+ { 13, 23, 11 }, // 141 bits per transform
+ { 13, 24, 2 }, // 141 bits per transform
+ { 14, 1, 24 }, // 141 bits per transform
+ { 14, 10, 23 }, // 141 bits per transform
+ { 14, 11, 22 }, // 141 bits per transform
+ { 14, 12, 21 }, // 141 bits per transform
+ { 14, 13, 20 }, // 141 bits per transform
+ { 14, 14, 19 }, // 141 bits per transform
+ { 14, 15, 18 }, // 141 bits per transform
+ { 14, 16, 17 }, // 141 bits per transform
+ { 14, 17, 16 }, // 141 bits per transform
+ { 14, 18, 15 }, // 141 bits per transform
+ { 14, 19, 14 }, // 141 bits per transform
+ { 14, 20, 13 }, // 141 bits per transform
+ { 14, 21, 12 }, // 141 bits per transform
+ { 14, 22, 11 }, // 141 bits per transform
+ { 14, 23, 10 }, // 141 bits per transform
+ { 14, 24, 1 }, // 141 bits per transform
+ { 15, 0, 24 }, // 141 bits per transform
+ { 15, 9, 23 }, // 141 bits per transform
+ { 15, 10, 22 }, // 141 bits per transform
+ { 15, 11, 21 }, // 141 bits per transform
+ { 15, 12, 20 }, // 141 bits per transform
+ { 15, 13, 19 }, // 141 bits per transform
+ { 15, 14, 18 }, // 141 bits per transform
+ { 15, 15, 17 }, // 141 bits per transform
+ { 15, 16, 16 }, // 141 bits per transform
+ { 15, 17, 15 }, // 141 bits per transform
+ { 15, 18, 14 }, // 141 bits per transform
+ { 15, 19, 13 }, // 141 bits per transform
+ { 15, 20, 12 }, // 141 bits per transform
+ { 15, 21, 11 }, // 141 bits per transform
+ { 15, 22, 10 }, // 141 bits per transform
+ { 15, 23, 9 }, // 141 bits per transform
+ { 15, 24, 0 }, // 141 bits per transform
+ { 16, 8, 23 }, // 141 bits per transform
+ { 16, 9, 22 }, // 141 bits per transform
+ { 16, 10, 21 }, // 141 bits per transform
+ { 16, 11, 20 }, // 141 bits per transform
+ { 16, 12, 19 }, // 141 bits per transform
+ { 16, 13, 18 }, // 141 bits per transform
+ { 16, 14, 17 }, // 141 bits per transform
+ { 16, 15, 16 }, // 141 bits per transform
+ { 16, 16, 15 }, // 141 bits per transform
+ { 16, 17, 14 }, // 141 bits per transform
+ { 16, 18, 13 }, // 141 bits per transform
+ { 16, 19, 12 }, // 141 bits per transform
+ { 16, 20, 11 }, // 141 bits per transform
+ { 16, 21, 10 }, // 141 bits per transform
+ { 16, 22, 9 }, // 141 bits per transform
+ { 16, 23, 8 }, // 141 bits per transform
+ { 17, 7, 23 }, // 141 bits per transform
+ { 17, 8, 22 }, // 141 bits per transform
+ { 17, 9, 21 }, // 141 bits per transform
+ { 17, 10, 20 }, // 141 bits per transform
+ { 17, 11, 19 }, // 141 bits per transform
+ { 17, 12, 18 }, // 141 bits per transform
+ { 17, 13, 17 }, // 141 bits per transform
+ { 17, 14, 16 }, // 141 bits per transform
+ { 17, 15, 15 }, // 141 bits per transform
+ { 17, 16, 14 }, // 141 bits per transform
+ { 17, 17, 13 }, // 141 bits per transform
+ { 17, 18, 12 }, // 141 bits per transform
+ { 17, 19, 11 }, // 141 bits per transform
+ { 17, 20, 10 }, // 141 bits per transform
+ { 17, 21, 9 }, // 141 bits per transform
+ { 17, 22, 8 }, // 141 bits per transform
+ { 17, 23, 7 }, // 141 bits per transform
+ { 18, 6, 23 }, // 141 bits per transform
+ { 18, 7, 22 }, // 141 bits per transform
+ { 18, 8, 21 }, // 141 bits per transform
+ { 18, 9, 20 }, // 141 bits per transform
+ { 18, 10, 19 }, // 141 bits per transform
+ { 18, 11, 18 }, // 141 bits per transform
+ { 18, 12, 17 }, // 141 bits per transform
+ { 18, 13, 16 }, // 141 bits per transform
+ { 18, 14, 15 }, // 141 bits per transform
+ { 18, 15, 14 }, // 141 bits per transform
+ { 18, 16, 13 }, // 141 bits per transform
+ { 18, 17, 12 }, // 141 bits per transform
+ { 18, 18, 11 }, // 141 bits per transform
+ { 18, 19, 10 }, // 141 bits per transform
+ { 18, 20, 9 }, // 141 bits per transform
+ { 18, 21, 8 }, // 141 bits per transform
+ { 18, 22, 7 }, // 141 bits per transform
+ { 18, 23, 6 }, // 141 bits per transform
+ { 19, 5, 23 }, // 141 bits per transform
+ { 19, 6, 22 }, // 141 bits per transform
+ { 19, 7, 21 }, // 141 bits per transform
+ { 19, 8, 20 }, // 141 bits per transform
+ { 19, 9, 19 }, // 141 bits per transform
+ { 19, 10, 18 }, // 141 bits per transform
+ { 19, 11, 17 }, // 141 bits per transform
+ { 19, 12, 16 }, // 141 bits per transform
+ { 19, 13, 15 }, // 141 bits per transform
+ { 19, 14, 14 }, // 141 bits per transform
+ { 19, 15, 13 }, // 141 bits per transform
+ { 19, 16, 12 }, // 141 bits per transform
+ { 19, 17, 11 }, // 141 bits per transform
+ { 19, 18, 10 }, // 141 bits per transform
+ { 19, 19, 9 }, // 141 bits per transform
+ { 19, 20, 8 }, // 141 bits per transform
+ { 19, 21, 7 }, // 141 bits per transform
+ { 19, 22, 6 }, // 141 bits per transform
+ { 19, 23, 5 }, // 141 bits per transform
+ { 20, 4, 23 }, // 141 bits per transform
+ { 20, 5, 22 }, // 141 bits per transform
+ { 20, 6, 21 }, // 141 bits per transform
+ { 20, 7, 20 }, // 141 bits per transform
+ { 20, 8, 19 }, // 141 bits per transform
+ { 20, 9, 18 }, // 141 bits per transform
+ { 20, 10, 17 }, // 141 bits per transform
+ { 20, 11, 16 }, // 141 bits per transform
+ { 20, 12, 15 }, // 141 bits per transform
+ { 20, 13, 14 }, // 141 bits per transform
+ { 20, 14, 13 }, // 141 bits per transform
+ { 20, 15, 12 }, // 141 bits per transform
+ { 20, 16, 11 }, // 141 bits per transform
+ { 20, 17, 10 }, // 141 bits per transform
+ { 20, 18, 9 }, // 141 bits per transform
+ { 20, 19, 8 }, // 141 bits per transform
+ { 20, 20, 7 }, // 141 bits per transform
+ { 20, 21, 6 }, // 141 bits per transform
+ { 20, 22, 5 }, // 141 bits per transform
+ { 20, 23, 4 }, // 141 bits per transform
+ { 21, 3, 23 }, // 141 bits per transform
+ { 21, 4, 22 }, // 141 bits per transform
+ { 21, 5, 21 }, // 141 bits per transform
+ { 21, 6, 20 }, // 141 bits per transform
+ { 21, 7, 19 }, // 141 bits per transform
+ { 21, 8, 18 }, // 141 bits per transform
+ { 21, 9, 17 }, // 141 bits per transform
+ { 21, 10, 16 }, // 141 bits per transform
+ { 21, 11, 15 }, // 141 bits per transform
+ { 21, 12, 14 }, // 141 bits per transform
+ { 21, 13, 13 }, // 141 bits per transform
+ { 21, 14, 12 }, // 141 bits per transform
+ { 21, 15, 11 }, // 141 bits per transform
+ { 21, 16, 10 }, // 141 bits per transform
+ { 21, 17, 9 }, // 141 bits per transform
+ { 21, 18, 8 }, // 141 bits per transform
+ { 21, 19, 7 }, // 141 bits per transform
+ { 21, 20, 6 }, // 141 bits per transform
+ { 21, 21, 5 }, // 141 bits per transform
+ { 21, 22, 4 }, // 141 bits per transform
+ { 21, 23, 3 }, // 141 bits per transform
+ { 22, 2, 23 }, // 141 bits per transform
+ { 22, 3, 22 }, // 141 bits per transform
+ { 22, 4, 21 }, // 141 bits per transform
+ { 22, 5, 20 }, // 141 bits per transform
+ { 22, 6, 19 }, // 141 bits per transform
+ { 22, 7, 18 }, // 141 bits per transform
+ { 22, 8, 17 }, // 141 bits per transform
+ { 22, 9, 16 }, // 141 bits per transform
+ { 22, 10, 15 }, // 141 bits per transform
+ { 22, 11, 14 }, // 141 bits per transform
+ { 22, 12, 13 }, // 141 bits per transform
+ { 22, 13, 12 }, // 141 bits per transform
+ { 22, 14, 11 }, // 141 bits per transform
+ { 22, 15, 10 }, // 141 bits per transform
+ { 22, 16, 9 }, // 141 bits per transform
+ { 22, 17, 8 }, // 141 bits per transform
+ { 22, 18, 7 }, // 141 bits per transform
+ { 22, 19, 6 }, // 141 bits per transform
+ { 22, 20, 5 }, // 141 bits per transform
+ { 22, 21, 4 }, // 141 bits per transform
+ { 22, 22, 3 }, // 141 bits per transform
+ { 22, 23, 2 }, // 141 bits per transform
+ { 23, 1, 23 }, // 141 bits per transform
+ { 23, 2, 22 }, // 141 bits per transform
+ { 23, 3, 21 }, // 141 bits per transform
+ { 23, 4, 20 }, // 141 bits per transform
+ { 23, 5, 19 }, // 141 bits per transform
+ { 23, 6, 18 }, // 141 bits per transform
+ { 23, 7, 17 }, // 141 bits per transform
+ { 23, 8, 16 }, // 141 bits per transform
+ { 23, 9, 15 }, // 141 bits per transform
+ { 23, 10, 14 }, // 141 bits per transform
+ { 23, 11, 13 }, // 141 bits per transform
+ { 23, 12, 12 }, // 141 bits per transform
+ { 23, 13, 11 }, // 141 bits per transform
+ { 23, 14, 10 }, // 141 bits per transform
+ { 23, 15, 9 }, // 141 bits per transform
+ { 23, 16, 8 }, // 141 bits per transform
+ { 23, 17, 7 }, // 141 bits per transform
+ { 23, 18, 6 }, // 141 bits per transform
+ { 23, 19, 5 }, // 141 bits per transform
+ { 23, 20, 4 }, // 141 bits per transform
+ { 23, 21, 3 }, // 141 bits per transform
+ { 23, 22, 2 }, // 141 bits per transform
+ { 23, 23, 1 }, // 141 bits per transform
+ { 24, 0, 15 }, // 141 bits per transform
+ { 24, 1, 14 }, // 141 bits per transform
+ { 24, 2, 13 }, // 141 bits per transform
+ { 24, 3, 12 }, // 141 bits per transform
+ { 24, 4, 11 }, // 141 bits per transform
+ { 24, 5, 10 }, // 141 bits per transform
+ { 24, 6, 9 }, // 141 bits per transform
+ { 24, 7, 8 }, // 141 bits per transform
+ { 24, 8, 7 }, // 141 bits per transform
+ { 24, 9, 6 }, // 141 bits per transform
+ { 24, 10, 5 }, // 141 bits per transform
+ { 24, 11, 4 }, // 141 bits per transform
+ { 24, 12, 3 }, // 141 bits per transform
+ { 24, 13, 2 }, // 141 bits per transform
+ { 24, 14, 1 }, // 141 bits per transform
+ { 24, 15, 0 }, // 141 bits per transform
+ { 0, 16, 24 }, // 144 bits per transform
+ { 0, 24, 16 }, // 144 bits per transform
+ { 1, 15, 24 }, // 144 bits per transform
+ { 1, 24, 15 }, // 144 bits per transform
+ { 2, 14, 24 }, // 144 bits per transform
+ { 2, 23, 23 }, // 144 bits per transform
+ { 2, 24, 14 }, // 144 bits per transform
+ { 3, 13, 24 }, // 144 bits per transform
+ { 3, 22, 23 }, // 144 bits per transform
+ { 3, 23, 22 }, // 144 bits per transform
+ { 3, 24, 13 }, // 144 bits per transform
+ { 4, 12, 24 }, // 144 bits per transform
+ { 4, 21, 23 }, // 144 bits per transform
+ { 4, 22, 22 }, // 144 bits per transform
+ { 4, 23, 21 }, // 144 bits per transform
+ { 4, 24, 12 }, // 144 bits per transform
+ { 5, 11, 24 }, // 144 bits per transform
+ { 5, 20, 23 }, // 144 bits per transform
+ { 5, 21, 22 }, // 144 bits per transform
+ { 5, 22, 21 }, // 144 bits per transform
+ { 5, 23, 20 }, // 144 bits per transform
+ { 5, 24, 11 }, // 144 bits per transform
+ { 6, 10, 24 }, // 144 bits per transform
+ { 6, 19, 23 }, // 144 bits per transform
+ { 6, 20, 22 }, // 144 bits per transform
+ { 6, 21, 21 }, // 144 bits per transform
+ { 6, 22, 20 }, // 144 bits per transform
+ { 6, 23, 19 }, // 144 bits per transform
+ { 6, 24, 10 }, // 144 bits per transform
+ { 7, 9, 24 }, // 144 bits per transform
+ { 7, 18, 23 }, // 144 bits per transform
+ { 7, 19, 22 }, // 144 bits per transform
+ { 7, 20, 21 }, // 144 bits per transform
+ { 7, 21, 20 }, // 144 bits per transform
+ { 7, 22, 19 }, // 144 bits per transform
+ { 7, 23, 18 }, // 144 bits per transform
+ { 7, 24, 9 }, // 144 bits per transform
+ { 8, 8, 24 }, // 144 bits per transform
+ { 8, 17, 23 }, // 144 bits per transform
+ { 8, 18, 22 }, // 144 bits per transform
+ { 8, 19, 21 }, // 144 bits per transform
+ { 8, 20, 20 }, // 144 bits per transform
+ { 8, 21, 19 }, // 144 bits per transform
+ { 8, 22, 18 }, // 144 bits per transform
+ { 8, 23, 17 }, // 144 bits per transform
+ { 8, 24, 8 }, // 144 bits per transform
+ { 9, 7, 24 }, // 144 bits per transform
+ { 9, 16, 23 }, // 144 bits per transform
+ { 9, 17, 22 }, // 144 bits per transform
+ { 9, 18, 21 }, // 144 bits per transform
+ { 9, 19, 20 }, // 144 bits per transform
+ { 9, 20, 19 }, // 144 bits per transform
+ { 9, 21, 18 }, // 144 bits per transform
+ { 9, 22, 17 }, // 144 bits per transform
+ { 9, 23, 16 }, // 144 bits per transform
+ { 9, 24, 7 }, // 144 bits per transform
+ { 10, 6, 24 }, // 144 bits per transform
+ { 10, 15, 23 }, // 144 bits per transform
+ { 10, 16, 22 }, // 144 bits per transform
+ { 10, 17, 21 }, // 144 bits per transform
+ { 10, 18, 20 }, // 144 bits per transform
+ { 10, 19, 19 }, // 144 bits per transform
+ { 10, 20, 18 }, // 144 bits per transform
+ { 10, 21, 17 }, // 144 bits per transform
+ { 10, 22, 16 }, // 144 bits per transform
+ { 10, 23, 15 }, // 144 bits per transform
+ { 10, 24, 6 }, // 144 bits per transform
+ { 11, 5, 24 }, // 144 bits per transform
+ { 11, 14, 23 }, // 144 bits per transform
+ { 11, 15, 22 }, // 144 bits per transform
+ { 11, 16, 21 }, // 144 bits per transform
+ { 11, 17, 20 }, // 144 bits per transform
+ { 11, 18, 19 }, // 144 bits per transform
+ { 11, 19, 18 }, // 144 bits per transform
+ { 11, 20, 17 }, // 144 bits per transform
+ { 11, 21, 16 }, // 144 bits per transform
+ { 11, 22, 15 }, // 144 bits per transform
+ { 11, 23, 14 }, // 144 bits per transform
+ { 11, 24, 5 }, // 144 bits per transform
+ { 12, 4, 24 }, // 144 bits per transform
+ { 12, 13, 23 }, // 144 bits per transform
+ { 12, 14, 22 }, // 144 bits per transform
+ { 12, 15, 21 }, // 144 bits per transform
+ { 12, 16, 20 }, // 144 bits per transform
+ { 12, 17, 19 }, // 144 bits per transform
+ { 12, 18, 18 }, // 144 bits per transform
+ { 12, 19, 17 }, // 144 bits per transform
+ { 12, 20, 16 }, // 144 bits per transform
+ { 12, 21, 15 }, // 144 bits per transform
+ { 12, 22, 14 }, // 144 bits per transform
+ { 12, 23, 13 }, // 144 bits per transform
+ { 12, 24, 4 }, // 144 bits per transform
+ { 13, 3, 24 }, // 144 bits per transform
+ { 13, 12, 23 }, // 144 bits per transform
+ { 13, 13, 22 }, // 144 bits per transform
+ { 13, 14, 21 }, // 144 bits per transform
+ { 13, 15, 20 }, // 144 bits per transform
+ { 13, 16, 19 }, // 144 bits per transform
+ { 13, 17, 18 }, // 144 bits per transform
+ { 13, 18, 17 }, // 144 bits per transform
+ { 13, 19, 16 }, // 144 bits per transform
+ { 13, 20, 15 }, // 144 bits per transform
+ { 13, 21, 14 }, // 144 bits per transform
+ { 13, 22, 13 }, // 144 bits per transform
+ { 13, 23, 12 }, // 144 bits per transform
+ { 13, 24, 3 }, // 144 bits per transform
+ { 14, 2, 24 }, // 144 bits per transform
+ { 14, 11, 23 }, // 144 bits per transform
+ { 14, 12, 22 }, // 144 bits per transform
+ { 14, 13, 21 }, // 144 bits per transform
+ { 14, 14, 20 }, // 144 bits per transform
+ { 14, 15, 19 }, // 144 bits per transform
+ { 14, 16, 18 }, // 144 bits per transform
+ { 14, 17, 17 }, // 144 bits per transform
+ { 14, 18, 16 }, // 144 bits per transform
+ { 14, 19, 15 }, // 144 bits per transform
+ { 14, 20, 14 }, // 144 bits per transform
+ { 14, 21, 13 }, // 144 bits per transform
+ { 14, 22, 12 }, // 144 bits per transform
+ { 14, 23, 11 }, // 144 bits per transform
+ { 14, 24, 2 }, // 144 bits per transform
+ { 15, 1, 24 }, // 144 bits per transform
+ { 15, 10, 23 }, // 144 bits per transform
+ { 15, 11, 22 }, // 144 bits per transform
+ { 15, 12, 21 }, // 144 bits per transform
+ { 15, 13, 20 }, // 144 bits per transform
+ { 15, 14, 19 }, // 144 bits per transform
+ { 15, 15, 18 }, // 144 bits per transform
+ { 15, 16, 17 }, // 144 bits per transform
+ { 15, 17, 16 }, // 144 bits per transform
+ { 15, 18, 15 }, // 144 bits per transform
+ { 15, 19, 14 }, // 144 bits per transform
+ { 15, 20, 13 }, // 144 bits per transform
+ { 15, 21, 12 }, // 144 bits per transform
+ { 15, 22, 11 }, // 144 bits per transform
+ { 15, 23, 10 }, // 144 bits per transform
+ { 15, 24, 1 }, // 144 bits per transform
+ { 16, 0, 24 }, // 144 bits per transform
+ { 16, 9, 23 }, // 144 bits per transform
+ { 16, 10, 22 }, // 144 bits per transform
+ { 16, 11, 21 }, // 144 bits per transform
+ { 16, 12, 20 }, // 144 bits per transform
+ { 16, 13, 19 }, // 144 bits per transform
+ { 16, 14, 18 }, // 144 bits per transform
+ { 16, 15, 17 }, // 144 bits per transform
+ { 16, 16, 16 }, // 144 bits per transform
+ { 16, 17, 15 }, // 144 bits per transform
+ { 16, 18, 14 }, // 144 bits per transform
+ { 16, 19, 13 }, // 144 bits per transform
+ { 16, 20, 12 }, // 144 bits per transform
+ { 16, 21, 11 }, // 144 bits per transform
+ { 16, 22, 10 }, // 144 bits per transform
+ { 16, 23, 9 }, // 144 bits per transform
+ { 16, 24, 0 }, // 144 bits per transform
+ { 17, 8, 23 }, // 144 bits per transform
+ { 17, 9, 22 }, // 144 bits per transform
+ { 17, 10, 21 }, // 144 bits per transform
+ { 17, 11, 20 }, // 144 bits per transform
+ { 17, 12, 19 }, // 144 bits per transform
+ { 17, 13, 18 }, // 144 bits per transform
+ { 17, 14, 17 }, // 144 bits per transform
+ { 17, 15, 16 }, // 144 bits per transform
+ { 17, 16, 15 }, // 144 bits per transform
+ { 17, 17, 14 }, // 144 bits per transform
+ { 17, 18, 13 }, // 144 bits per transform
+ { 17, 19, 12 }, // 144 bits per transform
+ { 17, 20, 11 }, // 144 bits per transform
+ { 17, 21, 10 }, // 144 bits per transform
+ { 17, 22, 9 }, // 144 bits per transform
+ { 17, 23, 8 }, // 144 bits per transform
+ { 18, 7, 23 }, // 144 bits per transform
+ { 18, 8, 22 }, // 144 bits per transform
+ { 18, 9, 21 }, // 144 bits per transform
+ { 18, 10, 20 }, // 144 bits per transform
+ { 18, 11, 19 }, // 144 bits per transform
+ { 18, 12, 18 }, // 144 bits per transform
+ { 18, 13, 17 }, // 144 bits per transform
+ { 18, 14, 16 }, // 144 bits per transform
+ { 18, 15, 15 }, // 144 bits per transform
+ { 18, 16, 14 }, // 144 bits per transform
+ { 18, 17, 13 }, // 144 bits per transform
+ { 18, 18, 12 }, // 144 bits per transform
+ { 18, 19, 11 }, // 144 bits per transform
+ { 18, 20, 10 }, // 144 bits per transform
+ { 18, 21, 9 }, // 144 bits per transform
+ { 18, 22, 8 }, // 144 bits per transform
+ { 18, 23, 7 }, // 144 bits per transform
+ { 19, 6, 23 }, // 144 bits per transform
+ { 19, 7, 22 }, // 144 bits per transform
+ { 19, 8, 21 }, // 144 bits per transform
+ { 19, 9, 20 }, // 144 bits per transform
+ { 19, 10, 19 }, // 144 bits per transform
+ { 19, 11, 18 }, // 144 bits per transform
+ { 19, 12, 17 }, // 144 bits per transform
+ { 19, 13, 16 }, // 144 bits per transform
+ { 19, 14, 15 }, // 144 bits per transform
+ { 19, 15, 14 }, // 144 bits per transform
+ { 19, 16, 13 }, // 144 bits per transform
+ { 19, 17, 12 }, // 144 bits per transform
+ { 19, 18, 11 }, // 144 bits per transform
+ { 19, 19, 10 }, // 144 bits per transform
+ { 19, 20, 9 }, // 144 bits per transform
+ { 19, 21, 8 }, // 144 bits per transform
+ { 19, 22, 7 }, // 144 bits per transform
+ { 19, 23, 6 }, // 144 bits per transform
+ { 20, 5, 23 }, // 144 bits per transform
+ { 20, 6, 22 }, // 144 bits per transform
+ { 20, 7, 21 }, // 144 bits per transform
+ { 20, 8, 20 }, // 144 bits per transform
+ { 20, 9, 19 }, // 144 bits per transform
+ { 20, 10, 18 }, // 144 bits per transform
+ { 20, 11, 17 }, // 144 bits per transform
+ { 20, 12, 16 }, // 144 bits per transform
+ { 20, 13, 15 }, // 144 bits per transform
+ { 20, 14, 14 }, // 144 bits per transform
+ { 20, 15, 13 }, // 144 bits per transform
+ { 20, 16, 12 }, // 144 bits per transform
+ { 20, 17, 11 }, // 144 bits per transform
+ { 20, 18, 10 }, // 144 bits per transform
+ { 20, 19, 9 }, // 144 bits per transform
+ { 20, 20, 8 }, // 144 bits per transform
+ { 20, 21, 7 }, // 144 bits per transform
+ { 20, 22, 6 }, // 144 bits per transform
+ { 20, 23, 5 }, // 144 bits per transform
+ { 21, 4, 23 }, // 144 bits per transform
+ { 21, 5, 22 }, // 144 bits per transform
+ { 21, 6, 21 }, // 144 bits per transform
+ { 21, 7, 20 }, // 144 bits per transform
+ { 21, 8, 19 }, // 144 bits per transform
+ { 21, 9, 18 }, // 144 bits per transform
+ { 21, 10, 17 }, // 144 bits per transform
+ { 21, 11, 16 }, // 144 bits per transform
+ { 21, 12, 15 }, // 144 bits per transform
+ { 21, 13, 14 }, // 144 bits per transform
+ { 21, 14, 13 }, // 144 bits per transform
+ { 21, 15, 12 }, // 144 bits per transform
+ { 21, 16, 11 }, // 144 bits per transform
+ { 21, 17, 10 }, // 144 bits per transform
+ { 21, 18, 9 }, // 144 bits per transform
+ { 21, 19, 8 }, // 144 bits per transform
+ { 21, 20, 7 }, // 144 bits per transform
+ { 21, 21, 6 }, // 144 bits per transform
+ { 21, 22, 5 }, // 144 bits per transform
+ { 21, 23, 4 }, // 144 bits per transform
+ { 22, 3, 23 }, // 144 bits per transform
+ { 22, 4, 22 }, // 144 bits per transform
+ { 22, 5, 21 }, // 144 bits per transform
+ { 22, 6, 20 }, // 144 bits per transform
+ { 22, 7, 19 }, // 144 bits per transform
+ { 22, 8, 18 }, // 144 bits per transform
+ { 22, 9, 17 }, // 144 bits per transform
+ { 22, 10, 16 }, // 144 bits per transform
+ { 22, 11, 15 }, // 144 bits per transform
+ { 22, 12, 14 }, // 144 bits per transform
+ { 22, 13, 13 }, // 144 bits per transform
+ { 22, 14, 12 }, // 144 bits per transform
+ { 22, 15, 11 }, // 144 bits per transform
+ { 22, 16, 10 }, // 144 bits per transform
+ { 22, 17, 9 }, // 144 bits per transform
+ { 22, 18, 8 }, // 144 bits per transform
+ { 22, 19, 7 }, // 144 bits per transform
+ { 22, 20, 6 }, // 144 bits per transform
+ { 22, 21, 5 }, // 144 bits per transform
+ { 22, 22, 4 }, // 144 bits per transform
+ { 22, 23, 3 }, // 144 bits per transform
+ { 23, 2, 23 }, // 144 bits per transform
+ { 23, 3, 22 }, // 144 bits per transform
+ { 23, 4, 21 }, // 144 bits per transform
+ { 23, 5, 20 }, // 144 bits per transform
+ { 23, 6, 19 }, // 144 bits per transform
+ { 23, 7, 18 }, // 144 bits per transform
+ { 23, 8, 17 }, // 144 bits per transform
+ { 23, 9, 16 }, // 144 bits per transform
+ { 23, 10, 15 }, // 144 bits per transform
+ { 23, 11, 14 }, // 144 bits per transform
+ { 23, 12, 13 }, // 144 bits per transform
+ { 23, 13, 12 }, // 144 bits per transform
+ { 23, 14, 11 }, // 144 bits per transform
+ { 23, 15, 10 }, // 144 bits per transform
+ { 23, 16, 9 }, // 144 bits per transform
+ { 23, 17, 8 }, // 144 bits per transform
+ { 23, 18, 7 }, // 144 bits per transform
+ { 23, 19, 6 }, // 144 bits per transform
+ { 23, 20, 5 }, // 144 bits per transform
+ { 23, 21, 4 }, // 144 bits per transform
+ { 23, 22, 3 }, // 144 bits per transform
+ { 23, 23, 2 }, // 144 bits per transform
+ { 24, 0, 16 }, // 144 bits per transform
+ { 24, 1, 15 }, // 144 bits per transform
+ { 24, 2, 14 }, // 144 bits per transform
+ { 24, 3, 13 }, // 144 bits per transform
+ { 24, 4, 12 }, // 144 bits per transform
+ { 24, 5, 11 }, // 144 bits per transform
+ { 24, 6, 10 }, // 144 bits per transform
+ { 24, 7, 9 }, // 144 bits per transform
+ { 24, 8, 8 }, // 144 bits per transform
+ { 24, 9, 7 }, // 144 bits per transform
+ { 24, 10, 6 }, // 144 bits per transform
+ { 24, 11, 5 }, // 144 bits per transform
+ { 24, 12, 4 }, // 144 bits per transform
+ { 24, 13, 3 }, // 144 bits per transform
+ { 24, 14, 2 }, // 144 bits per transform
+ { 24, 15, 1 }, // 144 bits per transform
+ { 24, 16, 0 }, // 144 bits per transform
+ { 0, 17, 24 }, // 147 bits per transform
+ { 0, 24, 17 }, // 147 bits per transform
+ { 1, 16, 24 }, // 147 bits per transform
+ { 1, 24, 16 }, // 147 bits per transform
+ { 2, 15, 24 }, // 147 bits per transform
+ { 2, 24, 15 }, // 147 bits per transform
+ { 3, 14, 24 }, // 147 bits per transform
+ { 3, 23, 23 }, // 147 bits per transform
+ { 3, 24, 14 }, // 147 bits per transform
+ { 4, 13, 24 }, // 147 bits per transform
+ { 4, 22, 23 }, // 147 bits per transform
+ { 4, 23, 22 }, // 147 bits per transform
+ { 4, 24, 13 }, // 147 bits per transform
+ { 5, 12, 24 }, // 147 bits per transform
+ { 5, 21, 23 }, // 147 bits per transform
+ { 5, 22, 22 }, // 147 bits per transform
+ { 5, 23, 21 }, // 147 bits per transform
+ { 5, 24, 12 }, // 147 bits per transform
+ { 6, 11, 24 }, // 147 bits per transform
+ { 6, 20, 23 }, // 147 bits per transform
+ { 6, 21, 22 }, // 147 bits per transform
+ { 6, 22, 21 }, // 147 bits per transform
+ { 6, 23, 20 }, // 147 bits per transform
+ { 6, 24, 11 }, // 147 bits per transform
+ { 7, 10, 24 }, // 147 bits per transform
+ { 7, 19, 23 }, // 147 bits per transform
+ { 7, 20, 22 }, // 147 bits per transform
+ { 7, 21, 21 }, // 147 bits per transform
+ { 7, 22, 20 }, // 147 bits per transform
+ { 7, 23, 19 }, // 147 bits per transform
+ { 7, 24, 10 }, // 147 bits per transform
+ { 8, 9, 24 }, // 147 bits per transform
+ { 8, 18, 23 }, // 147 bits per transform
+ { 8, 19, 22 }, // 147 bits per transform
+ { 8, 20, 21 }, // 147 bits per transform
+ { 8, 21, 20 }, // 147 bits per transform
+ { 8, 22, 19 }, // 147 bits per transform
+ { 8, 23, 18 }, // 147 bits per transform
+ { 8, 24, 9 }, // 147 bits per transform
+ { 9, 8, 24 }, // 147 bits per transform
+ { 9, 17, 23 }, // 147 bits per transform
+ { 9, 18, 22 }, // 147 bits per transform
+ { 9, 19, 21 }, // 147 bits per transform
+ { 9, 20, 20 }, // 147 bits per transform
+ { 9, 21, 19 }, // 147 bits per transform
+ { 9, 22, 18 }, // 147 bits per transform
+ { 9, 23, 17 }, // 147 bits per transform
+ { 9, 24, 8 }, // 147 bits per transform
+ { 10, 7, 24 }, // 147 bits per transform
+ { 10, 16, 23 }, // 147 bits per transform
+ { 10, 17, 22 }, // 147 bits per transform
+ { 10, 18, 21 }, // 147 bits per transform
+ { 10, 19, 20 }, // 147 bits per transform
+ { 10, 20, 19 }, // 147 bits per transform
+ { 10, 21, 18 }, // 147 bits per transform
+ { 10, 22, 17 }, // 147 bits per transform
+ { 10, 23, 16 }, // 147 bits per transform
+ { 10, 24, 7 }, // 147 bits per transform
+ { 11, 6, 24 }, // 147 bits per transform
+ { 11, 15, 23 }, // 147 bits per transform
+ { 11, 16, 22 }, // 147 bits per transform
+ { 11, 17, 21 }, // 147 bits per transform
+ { 11, 18, 20 }, // 147 bits per transform
+ { 11, 19, 19 }, // 147 bits per transform
+ { 11, 20, 18 }, // 147 bits per transform
+ { 11, 21, 17 }, // 147 bits per transform
+ { 11, 22, 16 }, // 147 bits per transform
+ { 11, 23, 15 }, // 147 bits per transform
+ { 11, 24, 6 }, // 147 bits per transform
+ { 12, 5, 24 }, // 147 bits per transform
+ { 12, 14, 23 }, // 147 bits per transform
+ { 12, 15, 22 }, // 147 bits per transform
+ { 12, 16, 21 }, // 147 bits per transform
+ { 12, 17, 20 }, // 147 bits per transform
+ { 12, 18, 19 }, // 147 bits per transform
+ { 12, 19, 18 }, // 147 bits per transform
+ { 12, 20, 17 }, // 147 bits per transform
+ { 12, 21, 16 }, // 147 bits per transform
+ { 12, 22, 15 }, // 147 bits per transform
+ { 12, 23, 14 }, // 147 bits per transform
+ { 12, 24, 5 }, // 147 bits per transform
+ { 13, 4, 24 }, // 147 bits per transform
+ { 13, 13, 23 }, // 147 bits per transform
+ { 13, 14, 22 }, // 147 bits per transform
+ { 13, 15, 21 }, // 147 bits per transform
+ { 13, 16, 20 }, // 147 bits per transform
+ { 13, 17, 19 }, // 147 bits per transform
+ { 13, 18, 18 }, // 147 bits per transform
+ { 13, 19, 17 }, // 147 bits per transform
+ { 13, 20, 16 }, // 147 bits per transform
+ { 13, 21, 15 }, // 147 bits per transform
+ { 13, 22, 14 }, // 147 bits per transform
+ { 13, 23, 13 }, // 147 bits per transform
+ { 13, 24, 4 }, // 147 bits per transform
+ { 14, 3, 24 }, // 147 bits per transform
+ { 14, 12, 23 }, // 147 bits per transform
+ { 14, 13, 22 }, // 147 bits per transform
+ { 14, 14, 21 }, // 147 bits per transform
+ { 14, 15, 20 }, // 147 bits per transform
+ { 14, 16, 19 }, // 147 bits per transform
+ { 14, 17, 18 }, // 147 bits per transform
+ { 14, 18, 17 }, // 147 bits per transform
+ { 14, 19, 16 }, // 147 bits per transform
+ { 14, 20, 15 }, // 147 bits per transform
+ { 14, 21, 14 }, // 147 bits per transform
+ { 14, 22, 13 }, // 147 bits per transform
+ { 14, 23, 12 }, // 147 bits per transform
+ { 14, 24, 3 }, // 147 bits per transform
+ { 15, 2, 24 }, // 147 bits per transform
+ { 15, 11, 23 }, // 147 bits per transform
+ { 15, 12, 22 }, // 147 bits per transform
+ { 15, 13, 21 }, // 147 bits per transform
+ { 15, 14, 20 }, // 147 bits per transform
+ { 15, 15, 19 }, // 147 bits per transform
+ { 15, 16, 18 }, // 147 bits per transform
+ { 15, 17, 17 }, // 147 bits per transform
+ { 15, 18, 16 }, // 147 bits per transform
+ { 15, 19, 15 }, // 147 bits per transform
+ { 15, 20, 14 }, // 147 bits per transform
+ { 15, 21, 13 }, // 147 bits per transform
+ { 15, 22, 12 }, // 147 bits per transform
+ { 15, 23, 11 }, // 147 bits per transform
+ { 15, 24, 2 }, // 147 bits per transform
+ { 16, 1, 24 }, // 147 bits per transform
+ { 16, 10, 23 }, // 147 bits per transform
+ { 16, 11, 22 }, // 147 bits per transform
+ { 16, 12, 21 }, // 147 bits per transform
+ { 16, 13, 20 }, // 147 bits per transform
+ { 16, 14, 19 }, // 147 bits per transform
+ { 16, 15, 18 }, // 147 bits per transform
+ { 16, 16, 17 }, // 147 bits per transform
+ { 16, 17, 16 }, // 147 bits per transform
+ { 16, 18, 15 }, // 147 bits per transform
+ { 16, 19, 14 }, // 147 bits per transform
+ { 16, 20, 13 }, // 147 bits per transform
+ { 16, 21, 12 }, // 147 bits per transform
+ { 16, 22, 11 }, // 147 bits per transform
+ { 16, 23, 10 }, // 147 bits per transform
+ { 16, 24, 1 }, // 147 bits per transform
+ { 17, 0, 24 }, // 147 bits per transform
+ { 17, 9, 23 }, // 147 bits per transform
+ { 17, 10, 22 }, // 147 bits per transform
+ { 17, 11, 21 }, // 147 bits per transform
+ { 17, 12, 20 }, // 147 bits per transform
+ { 17, 13, 19 }, // 147 bits per transform
+ { 17, 14, 18 }, // 147 bits per transform
+ { 17, 15, 17 }, // 147 bits per transform
+ { 17, 16, 16 }, // 147 bits per transform
+ { 17, 17, 15 }, // 147 bits per transform
+ { 17, 18, 14 }, // 147 bits per transform
+ { 17, 19, 13 }, // 147 bits per transform
+ { 17, 20, 12 }, // 147 bits per transform
+ { 17, 21, 11 }, // 147 bits per transform
+ { 17, 22, 10 }, // 147 bits per transform
+ { 17, 23, 9 }, // 147 bits per transform
+ { 17, 24, 0 }, // 147 bits per transform
+ { 18, 8, 23 }, // 147 bits per transform
+ { 18, 9, 22 }, // 147 bits per transform
+ { 18, 10, 21 }, // 147 bits per transform
+ { 18, 11, 20 }, // 147 bits per transform
+ { 18, 12, 19 }, // 147 bits per transform
+ { 18, 13, 18 }, // 147 bits per transform
+ { 18, 14, 17 }, // 147 bits per transform
+ { 18, 15, 16 }, // 147 bits per transform
+ { 18, 16, 15 }, // 147 bits per transform
+ { 18, 17, 14 }, // 147 bits per transform
+ { 18, 18, 13 }, // 147 bits per transform
+ { 18, 19, 12 }, // 147 bits per transform
+ { 18, 20, 11 }, // 147 bits per transform
+ { 18, 21, 10 }, // 147 bits per transform
+ { 18, 22, 9 }, // 147 bits per transform
+ { 18, 23, 8 }, // 147 bits per transform
+ { 19, 7, 23 }, // 147 bits per transform
+ { 19, 8, 22 }, // 147 bits per transform
+ { 19, 9, 21 }, // 147 bits per transform
+ { 19, 10, 20 }, // 147 bits per transform
+ { 19, 11, 19 }, // 147 bits per transform
+ { 19, 12, 18 }, // 147 bits per transform
+ { 19, 13, 17 }, // 147 bits per transform
+ { 19, 14, 16 }, // 147 bits per transform
+ { 19, 15, 15 }, // 147 bits per transform
+ { 19, 16, 14 }, // 147 bits per transform
+ { 19, 17, 13 }, // 147 bits per transform
+ { 19, 18, 12 }, // 147 bits per transform
+ { 19, 19, 11 }, // 147 bits per transform
+ { 19, 20, 10 }, // 147 bits per transform
+ { 19, 21, 9 }, // 147 bits per transform
+ { 19, 22, 8 }, // 147 bits per transform
+ { 19, 23, 7 }, // 147 bits per transform
+ { 20, 6, 23 }, // 147 bits per transform
+ { 20, 7, 22 }, // 147 bits per transform
+ { 20, 8, 21 }, // 147 bits per transform
+ { 20, 9, 20 }, // 147 bits per transform
+ { 20, 10, 19 }, // 147 bits per transform
+ { 20, 11, 18 }, // 147 bits per transform
+ { 20, 12, 17 }, // 147 bits per transform
+ { 20, 13, 16 }, // 147 bits per transform
+ { 20, 14, 15 }, // 147 bits per transform
+ { 20, 15, 14 }, // 147 bits per transform
+ { 20, 16, 13 }, // 147 bits per transform
+ { 20, 17, 12 }, // 147 bits per transform
+ { 20, 18, 11 }, // 147 bits per transform
+ { 20, 19, 10 }, // 147 bits per transform
+ { 20, 20, 9 }, // 147 bits per transform
+ { 20, 21, 8 }, // 147 bits per transform
+ { 20, 22, 7 }, // 147 bits per transform
+ { 20, 23, 6 }, // 147 bits per transform
+ { 21, 5, 23 }, // 147 bits per transform
+ { 21, 6, 22 }, // 147 bits per transform
+ { 21, 7, 21 }, // 147 bits per transform
+ { 21, 8, 20 }, // 147 bits per transform
+ { 21, 9, 19 }, // 147 bits per transform
+ { 21, 10, 18 }, // 147 bits per transform
+ { 21, 11, 17 }, // 147 bits per transform
+ { 21, 12, 16 }, // 147 bits per transform
+ { 21, 13, 15 }, // 147 bits per transform
+ { 21, 14, 14 }, // 147 bits per transform
+ { 21, 15, 13 }, // 147 bits per transform
+ { 21, 16, 12 }, // 147 bits per transform
+ { 21, 17, 11 }, // 147 bits per transform
+ { 21, 18, 10 }, // 147 bits per transform
+ { 21, 19, 9 }, // 147 bits per transform
+ { 21, 20, 8 }, // 147 bits per transform
+ { 21, 21, 7 }, // 147 bits per transform
+ { 21, 22, 6 }, // 147 bits per transform
+ { 21, 23, 5 }, // 147 bits per transform
+ { 22, 4, 23 }, // 147 bits per transform
+ { 22, 5, 22 }, // 147 bits per transform
+ { 22, 6, 21 }, // 147 bits per transform
+ { 22, 7, 20 }, // 147 bits per transform
+ { 22, 8, 19 }, // 147 bits per transform
+ { 22, 9, 18 }, // 147 bits per transform
+ { 22, 10, 17 }, // 147 bits per transform
+ { 22, 11, 16 }, // 147 bits per transform
+ { 22, 12, 15 }, // 147 bits per transform
+ { 22, 13, 14 }, // 147 bits per transform
+ { 22, 14, 13 }, // 147 bits per transform
+ { 22, 15, 12 }, // 147 bits per transform
+ { 22, 16, 11 }, // 147 bits per transform
+ { 22, 17, 10 }, // 147 bits per transform
+ { 22, 18, 9 }, // 147 bits per transform
+ { 22, 19, 8 }, // 147 bits per transform
+ { 22, 20, 7 }, // 147 bits per transform
+ { 22, 21, 6 }, // 147 bits per transform
+ { 22, 22, 5 }, // 147 bits per transform
+ { 22, 23, 4 }, // 147 bits per transform
+ { 23, 3, 23 }, // 147 bits per transform
+ { 23, 4, 22 }, // 147 bits per transform
+ { 23, 5, 21 }, // 147 bits per transform
+ { 23, 6, 20 }, // 147 bits per transform
+ { 23, 7, 19 }, // 147 bits per transform
+ { 23, 8, 18 }, // 147 bits per transform
+ { 23, 9, 17 }, // 147 bits per transform
+ { 23, 10, 16 }, // 147 bits per transform
+ { 23, 11, 15 }, // 147 bits per transform
+ { 23, 12, 14 }, // 147 bits per transform
+ { 23, 13, 13 }, // 147 bits per transform
+ { 23, 14, 12 }, // 147 bits per transform
+ { 23, 15, 11 }, // 147 bits per transform
+ { 23, 16, 10 }, // 147 bits per transform
+ { 23, 17, 9 }, // 147 bits per transform
+ { 23, 18, 8 }, // 147 bits per transform
+ { 23, 19, 7 }, // 147 bits per transform
+ { 23, 20, 6 }, // 147 bits per transform
+ { 23, 21, 5 }, // 147 bits per transform
+ { 23, 22, 4 }, // 147 bits per transform
+ { 23, 23, 3 }, // 147 bits per transform
+ { 24, 0, 17 }, // 147 bits per transform
+ { 24, 1, 16 }, // 147 bits per transform
+ { 24, 2, 15 }, // 147 bits per transform
+ { 24, 3, 14 }, // 147 bits per transform
+ { 24, 4, 13 }, // 147 bits per transform
+ { 24, 5, 12 }, // 147 bits per transform
+ { 24, 6, 11 }, // 147 bits per transform
+ { 24, 7, 10 }, // 147 bits per transform
+ { 24, 8, 9 }, // 147 bits per transform
+ { 24, 9, 8 }, // 147 bits per transform
+ { 24, 10, 7 }, // 147 bits per transform
+ { 24, 11, 6 }, // 147 bits per transform
+ { 24, 12, 5 }, // 147 bits per transform
+ { 24, 13, 4 }, // 147 bits per transform
+ { 24, 14, 3 }, // 147 bits per transform
+ { 24, 15, 2 }, // 147 bits per transform
+ { 24, 16, 1 }, // 147 bits per transform
+ { 24, 17, 0 }, // 147 bits per transform
+ { 0, 18, 24 }, // 150 bits per transform
+ { 0, 24, 18 }, // 150 bits per transform
+ { 1, 17, 24 }, // 150 bits per transform
+ { 1, 24, 17 }, // 150 bits per transform
+ { 2, 16, 24 }, // 150 bits per transform
+ { 2, 24, 16 }, // 150 bits per transform
+ { 3, 15, 24 }, // 150 bits per transform
+ { 3, 24, 15 }, // 150 bits per transform
+ { 4, 14, 24 }, // 150 bits per transform
+ { 4, 23, 23 }, // 150 bits per transform
+ { 4, 24, 14 }, // 150 bits per transform
+ { 5, 13, 24 }, // 150 bits per transform
+ { 5, 22, 23 }, // 150 bits per transform
+ { 5, 23, 22 }, // 150 bits per transform
+ { 5, 24, 13 }, // 150 bits per transform
+ { 6, 12, 24 }, // 150 bits per transform
+ { 6, 21, 23 }, // 150 bits per transform
+ { 6, 22, 22 }, // 150 bits per transform
+ { 6, 23, 21 }, // 150 bits per transform
+ { 6, 24, 12 }, // 150 bits per transform
+ { 7, 11, 24 }, // 150 bits per transform
+ { 7, 20, 23 }, // 150 bits per transform
+ { 7, 21, 22 }, // 150 bits per transform
+ { 7, 22, 21 }, // 150 bits per transform
+ { 7, 23, 20 }, // 150 bits per transform
+ { 7, 24, 11 }, // 150 bits per transform
+ { 8, 10, 24 }, // 150 bits per transform
+ { 8, 19, 23 }, // 150 bits per transform
+ { 8, 20, 22 }, // 150 bits per transform
+ { 8, 21, 21 }, // 150 bits per transform
+ { 8, 22, 20 }, // 150 bits per transform
+ { 8, 23, 19 }, // 150 bits per transform
+ { 8, 24, 10 }, // 150 bits per transform
+ { 9, 9, 24 }, // 150 bits per transform
+ { 9, 18, 23 }, // 150 bits per transform
+ { 9, 19, 22 }, // 150 bits per transform
+ { 9, 20, 21 }, // 150 bits per transform
+ { 9, 21, 20 }, // 150 bits per transform
+ { 9, 22, 19 }, // 150 bits per transform
+ { 9, 23, 18 }, // 150 bits per transform
+ { 9, 24, 9 }, // 150 bits per transform
+ { 10, 8, 24 }, // 150 bits per transform
+ { 10, 17, 23 }, // 150 bits per transform
+ { 10, 18, 22 }, // 150 bits per transform
+ { 10, 19, 21 }, // 150 bits per transform
+ { 10, 20, 20 }, // 150 bits per transform
+ { 10, 21, 19 }, // 150 bits per transform
+ { 10, 22, 18 }, // 150 bits per transform
+ { 10, 23, 17 }, // 150 bits per transform
+ { 10, 24, 8 }, // 150 bits per transform
+ { 11, 7, 24 }, // 150 bits per transform
+ { 11, 16, 23 }, // 150 bits per transform
+ { 11, 17, 22 }, // 150 bits per transform
+ { 11, 18, 21 }, // 150 bits per transform
+ { 11, 19, 20 }, // 150 bits per transform
+ { 11, 20, 19 }, // 150 bits per transform
+ { 11, 21, 18 }, // 150 bits per transform
+ { 11, 22, 17 }, // 150 bits per transform
+ { 11, 23, 16 }, // 150 bits per transform
+ { 11, 24, 7 }, // 150 bits per transform
+ { 12, 6, 24 }, // 150 bits per transform
+ { 12, 15, 23 }, // 150 bits per transform
+ { 12, 16, 22 }, // 150 bits per transform
+ { 12, 17, 21 }, // 150 bits per transform
+ { 12, 18, 20 }, // 150 bits per transform
+ { 12, 19, 19 }, // 150 bits per transform
+ { 12, 20, 18 }, // 150 bits per transform
+ { 12, 21, 17 }, // 150 bits per transform
+ { 12, 22, 16 }, // 150 bits per transform
+ { 12, 23, 15 }, // 150 bits per transform
+ { 12, 24, 6 }, // 150 bits per transform
+ { 13, 5, 24 }, // 150 bits per transform
+ { 13, 14, 23 }, // 150 bits per transform
+ { 13, 15, 22 }, // 150 bits per transform
+ { 13, 16, 21 }, // 150 bits per transform
+ { 13, 17, 20 }, // 150 bits per transform
+ { 13, 18, 19 }, // 150 bits per transform
+ { 13, 19, 18 }, // 150 bits per transform
+ { 13, 20, 17 }, // 150 bits per transform
+ { 13, 21, 16 }, // 150 bits per transform
+ { 13, 22, 15 }, // 150 bits per transform
+ { 13, 23, 14 }, // 150 bits per transform
+ { 13, 24, 5 }, // 150 bits per transform
+ { 14, 4, 24 }, // 150 bits per transform
+ { 14, 13, 23 }, // 150 bits per transform
+ { 14, 14, 22 }, // 150 bits per transform
+ { 14, 15, 21 }, // 150 bits per transform
+ { 14, 16, 20 }, // 150 bits per transform
+ { 14, 17, 19 }, // 150 bits per transform
+ { 14, 18, 18 }, // 150 bits per transform
+ { 14, 19, 17 }, // 150 bits per transform
+ { 14, 20, 16 }, // 150 bits per transform
+ { 14, 21, 15 }, // 150 bits per transform
+ { 14, 22, 14 }, // 150 bits per transform
+ { 14, 23, 13 }, // 150 bits per transform
+ { 14, 24, 4 }, // 150 bits per transform
+ { 15, 3, 24 }, // 150 bits per transform
+ { 15, 12, 23 }, // 150 bits per transform
+ { 15, 13, 22 }, // 150 bits per transform
+ { 15, 14, 21 }, // 150 bits per transform
+ { 15, 15, 20 }, // 150 bits per transform
+ { 15, 16, 19 }, // 150 bits per transform
+ { 15, 17, 18 }, // 150 bits per transform
+ { 15, 18, 17 }, // 150 bits per transform
+ { 15, 19, 16 }, // 150 bits per transform
+ { 15, 20, 15 }, // 150 bits per transform
+ { 15, 21, 14 }, // 150 bits per transform
+ { 15, 22, 13 }, // 150 bits per transform
+ { 15, 23, 12 }, // 150 bits per transform
+ { 15, 24, 3 }, // 150 bits per transform
+ { 16, 2, 24 }, // 150 bits per transform
+ { 16, 11, 23 }, // 150 bits per transform
+ { 16, 12, 22 }, // 150 bits per transform
+ { 16, 13, 21 }, // 150 bits per transform
+ { 16, 14, 20 }, // 150 bits per transform
+ { 16, 15, 19 }, // 150 bits per transform
+ { 16, 16, 18 }, // 150 bits per transform
+ { 16, 17, 17 }, // 150 bits per transform
+ { 16, 18, 16 }, // 150 bits per transform
+ { 16, 19, 15 }, // 150 bits per transform
+ { 16, 20, 14 }, // 150 bits per transform
+ { 16, 21, 13 }, // 150 bits per transform
+ { 16, 22, 12 }, // 150 bits per transform
+ { 16, 23, 11 }, // 150 bits per transform
+ { 16, 24, 2 }, // 150 bits per transform
+ { 17, 1, 24 }, // 150 bits per transform
+ { 17, 10, 23 }, // 150 bits per transform
+ { 17, 11, 22 }, // 150 bits per transform
+ { 17, 12, 21 }, // 150 bits per transform
+ { 17, 13, 20 }, // 150 bits per transform
+ { 17, 14, 19 }, // 150 bits per transform
+ { 17, 15, 18 }, // 150 bits per transform
+ { 17, 16, 17 }, // 150 bits per transform
+ { 17, 17, 16 }, // 150 bits per transform
+ { 17, 18, 15 }, // 150 bits per transform
+ { 17, 19, 14 }, // 150 bits per transform
+ { 17, 20, 13 }, // 150 bits per transform
+ { 17, 21, 12 }, // 150 bits per transform
+ { 17, 22, 11 }, // 150 bits per transform
+ { 17, 23, 10 }, // 150 bits per transform
+ { 17, 24, 1 }, // 150 bits per transform
+ { 18, 0, 24 }, // 150 bits per transform
+ { 18, 9, 23 }, // 150 bits per transform
+ { 18, 10, 22 }, // 150 bits per transform
+ { 18, 11, 21 }, // 150 bits per transform
+ { 18, 12, 20 }, // 150 bits per transform
+ { 18, 13, 19 }, // 150 bits per transform
+ { 18, 14, 18 }, // 150 bits per transform
+ { 18, 15, 17 }, // 150 bits per transform
+ { 18, 16, 16 }, // 150 bits per transform
+ { 18, 17, 15 }, // 150 bits per transform
+ { 18, 18, 14 }, // 150 bits per transform
+ { 18, 19, 13 }, // 150 bits per transform
+ { 18, 20, 12 }, // 150 bits per transform
+ { 18, 21, 11 }, // 150 bits per transform
+ { 18, 22, 10 }, // 150 bits per transform
+ { 18, 23, 9 }, // 150 bits per transform
+ { 18, 24, 0 }, // 150 bits per transform
+ { 19, 8, 23 }, // 150 bits per transform
+ { 19, 9, 22 }, // 150 bits per transform
+ { 19, 10, 21 }, // 150 bits per transform
+ { 19, 11, 20 }, // 150 bits per transform
+ { 19, 12, 19 }, // 150 bits per transform
+ { 19, 13, 18 }, // 150 bits per transform
+ { 19, 14, 17 }, // 150 bits per transform
+ { 19, 15, 16 }, // 150 bits per transform
+ { 19, 16, 15 }, // 150 bits per transform
+ { 19, 17, 14 }, // 150 bits per transform
+ { 19, 18, 13 }, // 150 bits per transform
+ { 19, 19, 12 }, // 150 bits per transform
+ { 19, 20, 11 }, // 150 bits per transform
+ { 19, 21, 10 }, // 150 bits per transform
+ { 19, 22, 9 }, // 150 bits per transform
+ { 19, 23, 8 }, // 150 bits per transform
+ { 20, 7, 23 }, // 150 bits per transform
+ { 20, 8, 22 }, // 150 bits per transform
+ { 20, 9, 21 }, // 150 bits per transform
+ { 20, 10, 20 }, // 150 bits per transform
+ { 20, 11, 19 }, // 150 bits per transform
+ { 20, 12, 18 }, // 150 bits per transform
+ { 20, 13, 17 }, // 150 bits per transform
+ { 20, 14, 16 }, // 150 bits per transform
+ { 20, 15, 15 }, // 150 bits per transform
+ { 20, 16, 14 }, // 150 bits per transform
+ { 20, 17, 13 }, // 150 bits per transform
+ { 20, 18, 12 }, // 150 bits per transform
+ { 20, 19, 11 }, // 150 bits per transform
+ { 20, 20, 10 }, // 150 bits per transform
+ { 20, 21, 9 }, // 150 bits per transform
+ { 20, 22, 8 }, // 150 bits per transform
+ { 20, 23, 7 }, // 150 bits per transform
+ { 21, 6, 23 }, // 150 bits per transform
+ { 21, 7, 22 }, // 150 bits per transform
+ { 21, 8, 21 }, // 150 bits per transform
+ { 21, 9, 20 }, // 150 bits per transform
+ { 21, 10, 19 }, // 150 bits per transform
+ { 21, 11, 18 }, // 150 bits per transform
+ { 21, 12, 17 }, // 150 bits per transform
+ { 21, 13, 16 }, // 150 bits per transform
+ { 21, 14, 15 }, // 150 bits per transform
+ { 21, 15, 14 }, // 150 bits per transform
+ { 21, 16, 13 }, // 150 bits per transform
+ { 21, 17, 12 }, // 150 bits per transform
+ { 21, 18, 11 }, // 150 bits per transform
+ { 21, 19, 10 }, // 150 bits per transform
+ { 21, 20, 9 }, // 150 bits per transform
+ { 21, 21, 8 }, // 150 bits per transform
+ { 21, 22, 7 }, // 150 bits per transform
+ { 21, 23, 6 }, // 150 bits per transform
+ { 22, 5, 23 }, // 150 bits per transform
+ { 22, 6, 22 }, // 150 bits per transform
+ { 22, 7, 21 }, // 150 bits per transform
+ { 22, 8, 20 }, // 150 bits per transform
+ { 22, 9, 19 }, // 150 bits per transform
+ { 22, 10, 18 }, // 150 bits per transform
+ { 22, 11, 17 }, // 150 bits per transform
+ { 22, 12, 16 }, // 150 bits per transform
+ { 22, 13, 15 }, // 150 bits per transform
+ { 22, 14, 14 }, // 150 bits per transform
+ { 22, 15, 13 }, // 150 bits per transform
+ { 22, 16, 12 }, // 150 bits per transform
+ { 22, 17, 11 }, // 150 bits per transform
+ { 22, 18, 10 }, // 150 bits per transform
+ { 22, 19, 9 }, // 150 bits per transform
+ { 22, 20, 8 }, // 150 bits per transform
+ { 22, 21, 7 }, // 150 bits per transform
+ { 22, 22, 6 }, // 150 bits per transform
+ { 22, 23, 5 }, // 150 bits per transform
+ { 23, 4, 23 }, // 150 bits per transform
+ { 23, 5, 22 }, // 150 bits per transform
+ { 23, 6, 21 }, // 150 bits per transform
+ { 23, 7, 20 }, // 150 bits per transform
+ { 23, 8, 19 }, // 150 bits per transform
+ { 23, 9, 18 }, // 150 bits per transform
+ { 23, 10, 17 }, // 150 bits per transform
+ { 23, 11, 16 }, // 150 bits per transform
+ { 23, 12, 15 }, // 150 bits per transform
+ { 23, 13, 14 }, // 150 bits per transform
+ { 23, 14, 13 }, // 150 bits per transform
+ { 23, 15, 12 }, // 150 bits per transform
+ { 23, 16, 11 }, // 150 bits per transform
+ { 23, 17, 10 }, // 150 bits per transform
+ { 23, 18, 9 }, // 150 bits per transform
+ { 23, 19, 8 }, // 150 bits per transform
+ { 23, 20, 7 }, // 150 bits per transform
+ { 23, 21, 6 }, // 150 bits per transform
+ { 23, 22, 5 }, // 150 bits per transform
+ { 23, 23, 4 }, // 150 bits per transform
+ { 24, 0, 18 }, // 150 bits per transform
+ { 24, 1, 17 }, // 150 bits per transform
+ { 24, 2, 16 }, // 150 bits per transform
+ { 24, 3, 15 }, // 150 bits per transform
+ { 24, 4, 14 }, // 150 bits per transform
+ { 24, 5, 13 }, // 150 bits per transform
+ { 24, 6, 12 }, // 150 bits per transform
+ { 24, 7, 11 }, // 150 bits per transform
+ { 24, 8, 10 }, // 150 bits per transform
+ { 24, 9, 9 }, // 150 bits per transform
+ { 24, 10, 8 }, // 150 bits per transform
+ { 24, 11, 7 }, // 150 bits per transform
+ { 24, 12, 6 }, // 150 bits per transform
+ { 24, 13, 5 }, // 150 bits per transform
+ { 24, 14, 4 }, // 150 bits per transform
+ { 24, 15, 3 }, // 150 bits per transform
+ { 24, 16, 2 }, // 150 bits per transform
+ { 24, 17, 1 }, // 150 bits per transform
+ { 24, 18, 0 }, // 150 bits per transform
+ { 0, 19, 24 }, // 153 bits per transform
+ { 0, 24, 19 }, // 153 bits per transform
+ { 1, 18, 24 }, // 153 bits per transform
+ { 1, 24, 18 }, // 153 bits per transform
+ { 2, 17, 24 }, // 153 bits per transform
+ { 2, 24, 17 }, // 153 bits per transform
+ { 3, 16, 24 }, // 153 bits per transform
+ { 3, 24, 16 }, // 153 bits per transform
+ { 4, 15, 24 }, // 153 bits per transform
+ { 4, 24, 15 }, // 153 bits per transform
+ { 5, 14, 24 }, // 153 bits per transform
+ { 5, 23, 23 }, // 153 bits per transform
+ { 5, 24, 14 }, // 153 bits per transform
+ { 6, 13, 24 }, // 153 bits per transform
+ { 6, 22, 23 }, // 153 bits per transform
+ { 6, 23, 22 }, // 153 bits per transform
+ { 6, 24, 13 }, // 153 bits per transform
+ { 7, 12, 24 }, // 153 bits per transform
+ { 7, 21, 23 }, // 153 bits per transform
+ { 7, 22, 22 }, // 153 bits per transform
+ { 7, 23, 21 }, // 153 bits per transform
+ { 7, 24, 12 }, // 153 bits per transform
+ { 8, 11, 24 }, // 153 bits per transform
+ { 8, 20, 23 }, // 153 bits per transform
+ { 8, 21, 22 }, // 153 bits per transform
+ { 8, 22, 21 }, // 153 bits per transform
+ { 8, 23, 20 }, // 153 bits per transform
+ { 8, 24, 11 }, // 153 bits per transform
+ { 9, 10, 24 }, // 153 bits per transform
+ { 9, 19, 23 }, // 153 bits per transform
+ { 9, 20, 22 }, // 153 bits per transform
+ { 9, 21, 21 }, // 153 bits per transform
+ { 9, 22, 20 }, // 153 bits per transform
+ { 9, 23, 19 }, // 153 bits per transform
+ { 9, 24, 10 }, // 153 bits per transform
+ { 10, 9, 24 }, // 153 bits per transform
+ { 10, 18, 23 }, // 153 bits per transform
+ { 10, 19, 22 }, // 153 bits per transform
+ { 10, 20, 21 }, // 153 bits per transform
+ { 10, 21, 20 }, // 153 bits per transform
+ { 10, 22, 19 }, // 153 bits per transform
+ { 10, 23, 18 }, // 153 bits per transform
+ { 10, 24, 9 }, // 153 bits per transform
+ { 11, 8, 24 }, // 153 bits per transform
+ { 11, 17, 23 }, // 153 bits per transform
+ { 11, 18, 22 }, // 153 bits per transform
+ { 11, 19, 21 }, // 153 bits per transform
+ { 11, 20, 20 }, // 153 bits per transform
+ { 11, 21, 19 }, // 153 bits per transform
+ { 11, 22, 18 }, // 153 bits per transform
+ { 11, 23, 17 }, // 153 bits per transform
+ { 11, 24, 8 }, // 153 bits per transform
+ { 12, 7, 24 }, // 153 bits per transform
+ { 12, 16, 23 }, // 153 bits per transform
+ { 12, 17, 22 }, // 153 bits per transform
+ { 12, 18, 21 }, // 153 bits per transform
+ { 12, 19, 20 }, // 153 bits per transform
+ { 12, 20, 19 }, // 153 bits per transform
+ { 12, 21, 18 }, // 153 bits per transform
+ { 12, 22, 17 }, // 153 bits per transform
+ { 12, 23, 16 }, // 153 bits per transform
+ { 12, 24, 7 }, // 153 bits per transform
+ { 13, 6, 24 }, // 153 bits per transform
+ { 13, 15, 23 }, // 153 bits per transform
+ { 13, 16, 22 }, // 153 bits per transform
+ { 13, 17, 21 }, // 153 bits per transform
+ { 13, 18, 20 }, // 153 bits per transform
+ { 13, 19, 19 }, // 153 bits per transform
+ { 13, 20, 18 }, // 153 bits per transform
+ { 13, 21, 17 }, // 153 bits per transform
+ { 13, 22, 16 }, // 153 bits per transform
+ { 13, 23, 15 }, // 153 bits per transform
+ { 13, 24, 6 }, // 153 bits per transform
+ { 14, 5, 24 }, // 153 bits per transform
+ { 14, 14, 23 }, // 153 bits per transform
+ { 14, 15, 22 }, // 153 bits per transform
+ { 14, 16, 21 }, // 153 bits per transform
+ { 14, 17, 20 }, // 153 bits per transform
+ { 14, 18, 19 }, // 153 bits per transform
+ { 14, 19, 18 }, // 153 bits per transform
+ { 14, 20, 17 }, // 153 bits per transform
+ { 14, 21, 16 }, // 153 bits per transform
+ { 14, 22, 15 }, // 153 bits per transform
+ { 14, 23, 14 }, // 153 bits per transform
+ { 14, 24, 5 }, // 153 bits per transform
+ { 15, 4, 24 }, // 153 bits per transform
+ { 15, 13, 23 }, // 153 bits per transform
+ { 15, 14, 22 }, // 153 bits per transform
+ { 15, 15, 21 }, // 153 bits per transform
+ { 15, 16, 20 }, // 153 bits per transform
+ { 15, 17, 19 }, // 153 bits per transform
+ { 15, 18, 18 }, // 153 bits per transform
+ { 15, 19, 17 }, // 153 bits per transform
+ { 15, 20, 16 }, // 153 bits per transform
+ { 15, 21, 15 }, // 153 bits per transform
+ { 15, 22, 14 }, // 153 bits per transform
+ { 15, 23, 13 }, // 153 bits per transform
+ { 15, 24, 4 }, // 153 bits per transform
+ { 16, 3, 24 }, // 153 bits per transform
+ { 16, 12, 23 }, // 153 bits per transform
+ { 16, 13, 22 }, // 153 bits per transform
+ { 16, 14, 21 }, // 153 bits per transform
+ { 16, 15, 20 }, // 153 bits per transform
+ { 16, 16, 19 }, // 153 bits per transform
+ { 16, 17, 18 }, // 153 bits per transform
+ { 16, 18, 17 }, // 153 bits per transform
+ { 16, 19, 16 }, // 153 bits per transform
+ { 16, 20, 15 }, // 153 bits per transform
+ { 16, 21, 14 }, // 153 bits per transform
+ { 16, 22, 13 }, // 153 bits per transform
+ { 16, 23, 12 }, // 153 bits per transform
+ { 16, 24, 3 }, // 153 bits per transform
+ { 17, 2, 24 }, // 153 bits per transform
+ { 17, 11, 23 }, // 153 bits per transform
+ { 17, 12, 22 }, // 153 bits per transform
+ { 17, 13, 21 }, // 153 bits per transform
+ { 17, 14, 20 }, // 153 bits per transform
+ { 17, 15, 19 }, // 153 bits per transform
+ { 17, 16, 18 }, // 153 bits per transform
+ { 17, 17, 17 }, // 153 bits per transform
+ { 17, 18, 16 }, // 153 bits per transform
+ { 17, 19, 15 }, // 153 bits per transform
+ { 17, 20, 14 }, // 153 bits per transform
+ { 17, 21, 13 }, // 153 bits per transform
+ { 17, 22, 12 }, // 153 bits per transform
+ { 17, 23, 11 }, // 153 bits per transform
+ { 17, 24, 2 }, // 153 bits per transform
+ { 18, 1, 24 }, // 153 bits per transform
+ { 18, 10, 23 }, // 153 bits per transform
+ { 18, 11, 22 }, // 153 bits per transform
+ { 18, 12, 21 }, // 153 bits per transform
+ { 18, 13, 20 }, // 153 bits per transform
+ { 18, 14, 19 }, // 153 bits per transform
+ { 18, 15, 18 }, // 153 bits per transform
+ { 18, 16, 17 }, // 153 bits per transform
+ { 18, 17, 16 }, // 153 bits per transform
+ { 18, 18, 15 }, // 153 bits per transform
+ { 18, 19, 14 }, // 153 bits per transform
+ { 18, 20, 13 }, // 153 bits per transform
+ { 18, 21, 12 }, // 153 bits per transform
+ { 18, 22, 11 }, // 153 bits per transform
+ { 18, 23, 10 }, // 153 bits per transform
+ { 18, 24, 1 }, // 153 bits per transform
+ { 19, 0, 24 }, // 153 bits per transform
+ { 19, 9, 23 }, // 153 bits per transform
+ { 19, 10, 22 }, // 153 bits per transform
+ { 19, 11, 21 }, // 153 bits per transform
+ { 19, 12, 20 }, // 153 bits per transform
+ { 19, 13, 19 }, // 153 bits per transform
+ { 19, 14, 18 }, // 153 bits per transform
+ { 19, 15, 17 }, // 153 bits per transform
+ { 19, 16, 16 }, // 153 bits per transform
+ { 19, 17, 15 }, // 153 bits per transform
+ { 19, 18, 14 }, // 153 bits per transform
+ { 19, 19, 13 }, // 153 bits per transform
+ { 19, 20, 12 }, // 153 bits per transform
+ { 19, 21, 11 }, // 153 bits per transform
+ { 19, 22, 10 }, // 153 bits per transform
+ { 19, 23, 9 }, // 153 bits per transform
+ { 19, 24, 0 }, // 153 bits per transform
+ { 20, 8, 23 }, // 153 bits per transform
+ { 20, 9, 22 }, // 153 bits per transform
+ { 20, 10, 21 }, // 153 bits per transform
+ { 20, 11, 20 }, // 153 bits per transform
+ { 20, 12, 19 }, // 153 bits per transform
+ { 20, 13, 18 }, // 153 bits per transform
+ { 20, 14, 17 }, // 153 bits per transform
+ { 20, 15, 16 }, // 153 bits per transform
+ { 20, 16, 15 }, // 153 bits per transform
+ { 20, 17, 14 }, // 153 bits per transform
+ { 20, 18, 13 }, // 153 bits per transform
+ { 20, 19, 12 }, // 153 bits per transform
+ { 20, 20, 11 }, // 153 bits per transform
+ { 20, 21, 10 }, // 153 bits per transform
+ { 20, 22, 9 }, // 153 bits per transform
+ { 20, 23, 8 }, // 153 bits per transform
+ { 21, 7, 23 }, // 153 bits per transform
+ { 21, 8, 22 }, // 153 bits per transform
+ { 21, 9, 21 }, // 153 bits per transform
+ { 21, 10, 20 }, // 153 bits per transform
+ { 21, 11, 19 }, // 153 bits per transform
+ { 21, 12, 18 }, // 153 bits per transform
+ { 21, 13, 17 }, // 153 bits per transform
+ { 21, 14, 16 }, // 153 bits per transform
+ { 21, 15, 15 }, // 153 bits per transform
+ { 21, 16, 14 }, // 153 bits per transform
+ { 21, 17, 13 }, // 153 bits per transform
+ { 21, 18, 12 }, // 153 bits per transform
+ { 21, 19, 11 }, // 153 bits per transform
+ { 21, 20, 10 }, // 153 bits per transform
+ { 21, 21, 9 }, // 153 bits per transform
+ { 21, 22, 8 }, // 153 bits per transform
+ { 21, 23, 7 }, // 153 bits per transform
+ { 22, 6, 23 }, // 153 bits per transform
+ { 22, 7, 22 }, // 153 bits per transform
+ { 22, 8, 21 }, // 153 bits per transform
+ { 22, 9, 20 }, // 153 bits per transform
+ { 22, 10, 19 }, // 153 bits per transform
+ { 22, 11, 18 }, // 153 bits per transform
+ { 22, 12, 17 }, // 153 bits per transform
+ { 22, 13, 16 }, // 153 bits per transform
+ { 22, 14, 15 }, // 153 bits per transform
+ { 22, 15, 14 }, // 153 bits per transform
+ { 22, 16, 13 }, // 153 bits per transform
+ { 22, 17, 12 }, // 153 bits per transform
+ { 22, 18, 11 }, // 153 bits per transform
+ { 22, 19, 10 }, // 153 bits per transform
+ { 22, 20, 9 }, // 153 bits per transform
+ { 22, 21, 8 }, // 153 bits per transform
+ { 22, 22, 7 }, // 153 bits per transform
+ { 22, 23, 6 }, // 153 bits per transform
+ { 23, 5, 23 }, // 153 bits per transform
+ { 23, 6, 22 }, // 153 bits per transform
+ { 23, 7, 21 }, // 153 bits per transform
+ { 23, 8, 20 }, // 153 bits per transform
+ { 23, 9, 19 }, // 153 bits per transform
+ { 23, 10, 18 }, // 153 bits per transform
+ { 23, 11, 17 }, // 153 bits per transform
+ { 23, 12, 16 }, // 153 bits per transform
+ { 23, 13, 15 }, // 153 bits per transform
+ { 23, 14, 14 }, // 153 bits per transform
+ { 23, 15, 13 }, // 153 bits per transform
+ { 23, 16, 12 }, // 153 bits per transform
+ { 23, 17, 11 }, // 153 bits per transform
+ { 23, 18, 10 }, // 153 bits per transform
+ { 23, 19, 9 }, // 153 bits per transform
+ { 23, 20, 8 }, // 153 bits per transform
+ { 23, 21, 7 }, // 153 bits per transform
+ { 23, 22, 6 }, // 153 bits per transform
+ { 23, 23, 5 }, // 153 bits per transform
+ { 24, 0, 19 }, // 153 bits per transform
+ { 24, 1, 18 }, // 153 bits per transform
+ { 24, 2, 17 }, // 153 bits per transform
+ { 24, 3, 16 }, // 153 bits per transform
+ { 24, 4, 15 }, // 153 bits per transform
+ { 24, 5, 14 }, // 153 bits per transform
+ { 24, 6, 13 }, // 153 bits per transform
+ { 24, 7, 12 }, // 153 bits per transform
+ { 24, 8, 11 }, // 153 bits per transform
+ { 24, 9, 10 }, // 153 bits per transform
+ { 24, 10, 9 }, // 153 bits per transform
+ { 24, 11, 8 }, // 153 bits per transform
+ { 24, 12, 7 }, // 153 bits per transform
+ { 24, 13, 6 }, // 153 bits per transform
+ { 24, 14, 5 }, // 153 bits per transform
+ { 24, 15, 4 }, // 153 bits per transform
+ { 24, 16, 3 }, // 153 bits per transform
+ { 24, 17, 2 }, // 153 bits per transform
+ { 24, 18, 1 }, // 153 bits per transform
+ { 24, 19, 0 }, // 153 bits per transform
+ { 0, 20, 24 }, // 156 bits per transform
+ { 0, 24, 20 }, // 156 bits per transform
+ { 1, 19, 24 }, // 156 bits per transform
+ { 1, 24, 19 }, // 156 bits per transform
+ { 2, 18, 24 }, // 156 bits per transform
+ { 2, 24, 18 }, // 156 bits per transform
+ { 3, 17, 24 }, // 156 bits per transform
+ { 3, 24, 17 }, // 156 bits per transform
+ { 4, 16, 24 }, // 156 bits per transform
+ { 4, 24, 16 }, // 156 bits per transform
+ { 5, 15, 24 }, // 156 bits per transform
+ { 5, 24, 15 }, // 156 bits per transform
+ { 6, 14, 24 }, // 156 bits per transform
+ { 6, 23, 23 }, // 156 bits per transform
+ { 6, 24, 14 }, // 156 bits per transform
+ { 7, 13, 24 }, // 156 bits per transform
+ { 7, 22, 23 }, // 156 bits per transform
+ { 7, 23, 22 }, // 156 bits per transform
+ { 7, 24, 13 }, // 156 bits per transform
+ { 8, 12, 24 }, // 156 bits per transform
+ { 8, 21, 23 }, // 156 bits per transform
+ { 8, 22, 22 }, // 156 bits per transform
+ { 8, 23, 21 }, // 156 bits per transform
+ { 8, 24, 12 }, // 156 bits per transform
+ { 9, 11, 24 }, // 156 bits per transform
+ { 9, 20, 23 }, // 156 bits per transform
+ { 9, 21, 22 }, // 156 bits per transform
+ { 9, 22, 21 }, // 156 bits per transform
+ { 9, 23, 20 }, // 156 bits per transform
+ { 9, 24, 11 }, // 156 bits per transform
+ { 10, 10, 24 }, // 156 bits per transform
+ { 10, 19, 23 }, // 156 bits per transform
+ { 10, 20, 22 }, // 156 bits per transform
+ { 10, 21, 21 }, // 156 bits per transform
+ { 10, 22, 20 }, // 156 bits per transform
+ { 10, 23, 19 }, // 156 bits per transform
+ { 10, 24, 10 }, // 156 bits per transform
+ { 11, 9, 24 }, // 156 bits per transform
+ { 11, 18, 23 }, // 156 bits per transform
+ { 11, 19, 22 }, // 156 bits per transform
+ { 11, 20, 21 }, // 156 bits per transform
+ { 11, 21, 20 }, // 156 bits per transform
+ { 11, 22, 19 }, // 156 bits per transform
+ { 11, 23, 18 }, // 156 bits per transform
+ { 11, 24, 9 }, // 156 bits per transform
+ { 12, 8, 24 }, // 156 bits per transform
+ { 12, 17, 23 }, // 156 bits per transform
+ { 12, 18, 22 }, // 156 bits per transform
+ { 12, 19, 21 }, // 156 bits per transform
+ { 12, 20, 20 }, // 156 bits per transform
+ { 12, 21, 19 }, // 156 bits per transform
+ { 12, 22, 18 }, // 156 bits per transform
+ { 12, 23, 17 }, // 156 bits per transform
+ { 12, 24, 8 }, // 156 bits per transform
+ { 13, 7, 24 }, // 156 bits per transform
+ { 13, 16, 23 }, // 156 bits per transform
+ { 13, 17, 22 }, // 156 bits per transform
+ { 13, 18, 21 }, // 156 bits per transform
+ { 13, 19, 20 }, // 156 bits per transform
+ { 13, 20, 19 }, // 156 bits per transform
+ { 13, 21, 18 }, // 156 bits per transform
+ { 13, 22, 17 }, // 156 bits per transform
+ { 13, 23, 16 }, // 156 bits per transform
+ { 13, 24, 7 }, // 156 bits per transform
+ { 14, 6, 24 }, // 156 bits per transform
+ { 14, 15, 23 }, // 156 bits per transform
+ { 14, 16, 22 }, // 156 bits per transform
+ { 14, 17, 21 }, // 156 bits per transform
+ { 14, 18, 20 }, // 156 bits per transform
+ { 14, 19, 19 }, // 156 bits per transform
+ { 14, 20, 18 }, // 156 bits per transform
+ { 14, 21, 17 }, // 156 bits per transform
+ { 14, 22, 16 }, // 156 bits per transform
+ { 14, 23, 15 }, // 156 bits per transform
+ { 14, 24, 6 }, // 156 bits per transform
+ { 15, 5, 24 }, // 156 bits per transform
+ { 15, 14, 23 }, // 156 bits per transform
+ { 15, 15, 22 }, // 156 bits per transform
+ { 15, 16, 21 }, // 156 bits per transform
+ { 15, 17, 20 }, // 156 bits per transform
+ { 15, 18, 19 }, // 156 bits per transform
+ { 15, 19, 18 }, // 156 bits per transform
+ { 15, 20, 17 }, // 156 bits per transform
+ { 15, 21, 16 }, // 156 bits per transform
+ { 15, 22, 15 }, // 156 bits per transform
+ { 15, 23, 14 }, // 156 bits per transform
+ { 15, 24, 5 }, // 156 bits per transform
+ { 16, 4, 24 }, // 156 bits per transform
+ { 16, 13, 23 }, // 156 bits per transform
+ { 16, 14, 22 }, // 156 bits per transform
+ { 16, 15, 21 }, // 156 bits per transform
+ { 16, 16, 20 }, // 156 bits per transform
+ { 16, 17, 19 }, // 156 bits per transform
+ { 16, 18, 18 }, // 156 bits per transform
+ { 16, 19, 17 }, // 156 bits per transform
+ { 16, 20, 16 }, // 156 bits per transform
+ { 16, 21, 15 }, // 156 bits per transform
+ { 16, 22, 14 }, // 156 bits per transform
+ { 16, 23, 13 }, // 156 bits per transform
+ { 16, 24, 4 }, // 156 bits per transform
+ { 17, 3, 24 }, // 156 bits per transform
+ { 17, 12, 23 }, // 156 bits per transform
+ { 17, 13, 22 }, // 156 bits per transform
+ { 17, 14, 21 }, // 156 bits per transform
+ { 17, 15, 20 }, // 156 bits per transform
+ { 17, 16, 19 }, // 156 bits per transform
+ { 17, 17, 18 }, // 156 bits per transform
+ { 17, 18, 17 }, // 156 bits per transform
+ { 17, 19, 16 }, // 156 bits per transform
+ { 17, 20, 15 }, // 156 bits per transform
+ { 17, 21, 14 }, // 156 bits per transform
+ { 17, 22, 13 }, // 156 bits per transform
+ { 17, 23, 12 }, // 156 bits per transform
+ { 17, 24, 3 }, // 156 bits per transform
+ { 18, 2, 24 }, // 156 bits per transform
+ { 18, 11, 23 }, // 156 bits per transform
+ { 18, 12, 22 }, // 156 bits per transform
+ { 18, 13, 21 }, // 156 bits per transform
+ { 18, 14, 20 }, // 156 bits per transform
+ { 18, 15, 19 }, // 156 bits per transform
+ { 18, 16, 18 }, // 156 bits per transform
+ { 18, 17, 17 }, // 156 bits per transform
+ { 18, 18, 16 }, // 156 bits per transform
+ { 18, 19, 15 }, // 156 bits per transform
+ { 18, 20, 14 }, // 156 bits per transform
+ { 18, 21, 13 }, // 156 bits per transform
+ { 18, 22, 12 }, // 156 bits per transform
+ { 18, 23, 11 }, // 156 bits per transform
+ { 18, 24, 2 }, // 156 bits per transform
+ { 19, 1, 24 }, // 156 bits per transform
+ { 19, 10, 23 }, // 156 bits per transform
+ { 19, 11, 22 }, // 156 bits per transform
+ { 19, 12, 21 }, // 156 bits per transform
+ { 19, 13, 20 }, // 156 bits per transform
+ { 19, 14, 19 }, // 156 bits per transform
+ { 19, 15, 18 }, // 156 bits per transform
+ { 19, 16, 17 }, // 156 bits per transform
+ { 19, 17, 16 }, // 156 bits per transform
+ { 19, 18, 15 }, // 156 bits per transform
+ { 19, 19, 14 }, // 156 bits per transform
+ { 19, 20, 13 }, // 156 bits per transform
+ { 19, 21, 12 }, // 156 bits per transform
+ { 19, 22, 11 }, // 156 bits per transform
+ { 19, 23, 10 }, // 156 bits per transform
+ { 19, 24, 1 }, // 156 bits per transform
+ { 20, 0, 24 }, // 156 bits per transform
+ { 20, 9, 23 }, // 156 bits per transform
+ { 20, 10, 22 }, // 156 bits per transform
+ { 20, 11, 21 }, // 156 bits per transform
+ { 20, 12, 20 }, // 156 bits per transform
+ { 20, 13, 19 }, // 156 bits per transform
+ { 20, 14, 18 }, // 156 bits per transform
+ { 20, 15, 17 }, // 156 bits per transform
+ { 20, 16, 16 }, // 156 bits per transform
+ { 20, 17, 15 }, // 156 bits per transform
+ { 20, 18, 14 }, // 156 bits per transform
+ { 20, 19, 13 }, // 156 bits per transform
+ { 20, 20, 12 }, // 156 bits per transform
+ { 20, 21, 11 }, // 156 bits per transform
+ { 20, 22, 10 }, // 156 bits per transform
+ { 20, 23, 9 }, // 156 bits per transform
+ { 20, 24, 0 }, // 156 bits per transform
+ { 21, 8, 23 }, // 156 bits per transform
+ { 21, 9, 22 }, // 156 bits per transform
+ { 21, 10, 21 }, // 156 bits per transform
+ { 21, 11, 20 }, // 156 bits per transform
+ { 21, 12, 19 }, // 156 bits per transform
+ { 21, 13, 18 }, // 156 bits per transform
+ { 21, 14, 17 }, // 156 bits per transform
+ { 21, 15, 16 }, // 156 bits per transform
+ { 21, 16, 15 }, // 156 bits per transform
+ { 21, 17, 14 }, // 156 bits per transform
+ { 21, 18, 13 }, // 156 bits per transform
+ { 21, 19, 12 }, // 156 bits per transform
+ { 21, 20, 11 }, // 156 bits per transform
+ { 21, 21, 10 }, // 156 bits per transform
+ { 21, 22, 9 }, // 156 bits per transform
+ { 21, 23, 8 }, // 156 bits per transform
+ { 22, 7, 23 }, // 156 bits per transform
+ { 22, 8, 22 }, // 156 bits per transform
+ { 22, 9, 21 }, // 156 bits per transform
+ { 22, 10, 20 }, // 156 bits per transform
+ { 22, 11, 19 }, // 156 bits per transform
+ { 22, 12, 18 }, // 156 bits per transform
+ { 22, 13, 17 }, // 156 bits per transform
+ { 22, 14, 16 }, // 156 bits per transform
+ { 22, 15, 15 }, // 156 bits per transform
+ { 22, 16, 14 }, // 156 bits per transform
+ { 22, 17, 13 }, // 156 bits per transform
+ { 22, 18, 12 }, // 156 bits per transform
+ { 22, 19, 11 }, // 156 bits per transform
+ { 22, 20, 10 }, // 156 bits per transform
+ { 22, 21, 9 }, // 156 bits per transform
+ { 22, 22, 8 }, // 156 bits per transform
+ { 22, 23, 7 }, // 156 bits per transform
+ { 23, 6, 23 }, // 156 bits per transform
+ { 23, 7, 22 }, // 156 bits per transform
+ { 23, 8, 21 }, // 156 bits per transform
+ { 23, 9, 20 }, // 156 bits per transform
+ { 23, 10, 19 }, // 156 bits per transform
+ { 23, 11, 18 }, // 156 bits per transform
+ { 23, 12, 17 }, // 156 bits per transform
+ { 23, 13, 16 }, // 156 bits per transform
+ { 23, 14, 15 }, // 156 bits per transform
+ { 23, 15, 14 }, // 156 bits per transform
+ { 23, 16, 13 }, // 156 bits per transform
+ { 23, 17, 12 }, // 156 bits per transform
+ { 23, 18, 11 }, // 156 bits per transform
+ { 23, 19, 10 }, // 156 bits per transform
+ { 23, 20, 9 }, // 156 bits per transform
+ { 23, 21, 8 }, // 156 bits per transform
+ { 23, 22, 7 }, // 156 bits per transform
+ { 23, 23, 6 }, // 156 bits per transform
+ { 24, 0, 20 }, // 156 bits per transform
+ { 24, 1, 19 }, // 156 bits per transform
+ { 24, 2, 18 }, // 156 bits per transform
+ { 24, 3, 17 }, // 156 bits per transform
+ { 24, 4, 16 }, // 156 bits per transform
+ { 24, 5, 15 }, // 156 bits per transform
+ { 24, 6, 14 }, // 156 bits per transform
+ { 24, 7, 13 }, // 156 bits per transform
+ { 24, 8, 12 }, // 156 bits per transform
+ { 24, 9, 11 }, // 156 bits per transform
+ { 24, 10, 10 }, // 156 bits per transform
+ { 24, 11, 9 }, // 156 bits per transform
+ { 24, 12, 8 }, // 156 bits per transform
+ { 24, 13, 7 }, // 156 bits per transform
+ { 24, 14, 6 }, // 156 bits per transform
+ { 24, 15, 5 }, // 156 bits per transform
+ { 24, 16, 4 }, // 156 bits per transform
+ { 24, 17, 3 }, // 156 bits per transform
+ { 24, 18, 2 }, // 156 bits per transform
+ { 24, 19, 1 }, // 156 bits per transform
+ { 24, 20, 0 }, // 156 bits per transform
+ { 0, 21, 24 }, // 159 bits per transform
+ { 0, 24, 21 }, // 159 bits per transform
+ { 1, 20, 24 }, // 159 bits per transform
+ { 1, 24, 20 }, // 159 bits per transform
+ { 2, 19, 24 }, // 159 bits per transform
+ { 2, 24, 19 }, // 159 bits per transform
+ { 3, 18, 24 }, // 159 bits per transform
+ { 3, 24, 18 }, // 159 bits per transform
+ { 4, 17, 24 }, // 159 bits per transform
+ { 4, 24, 17 }, // 159 bits per transform
+ { 5, 16, 24 }, // 159 bits per transform
+ { 5, 24, 16 }, // 159 bits per transform
+ { 6, 15, 24 }, // 159 bits per transform
+ { 6, 24, 15 }, // 159 bits per transform
+ { 7, 14, 24 }, // 159 bits per transform
+ { 7, 23, 23 }, // 159 bits per transform
+ { 7, 24, 14 }, // 159 bits per transform
+ { 8, 13, 24 }, // 159 bits per transform
+ { 8, 22, 23 }, // 159 bits per transform
+ { 8, 23, 22 }, // 159 bits per transform
+ { 8, 24, 13 }, // 159 bits per transform
+ { 9, 12, 24 }, // 159 bits per transform
+ { 9, 21, 23 }, // 159 bits per transform
+ { 9, 22, 22 }, // 159 bits per transform
+ { 9, 23, 21 }, // 159 bits per transform
+ { 9, 24, 12 }, // 159 bits per transform
+ { 10, 11, 24 }, // 159 bits per transform
+ { 10, 20, 23 }, // 159 bits per transform
+ { 10, 21, 22 }, // 159 bits per transform
+ { 10, 22, 21 }, // 159 bits per transform
+ { 10, 23, 20 }, // 159 bits per transform
+ { 10, 24, 11 }, // 159 bits per transform
+ { 11, 10, 24 }, // 159 bits per transform
+ { 11, 19, 23 }, // 159 bits per transform
+ { 11, 20, 22 }, // 159 bits per transform
+ { 11, 21, 21 }, // 159 bits per transform
+ { 11, 22, 20 }, // 159 bits per transform
+ { 11, 23, 19 }, // 159 bits per transform
+ { 11, 24, 10 }, // 159 bits per transform
+ { 12, 9, 24 }, // 159 bits per transform
+ { 12, 18, 23 }, // 159 bits per transform
+ { 12, 19, 22 }, // 159 bits per transform
+ { 12, 20, 21 }, // 159 bits per transform
+ { 12, 21, 20 }, // 159 bits per transform
+ { 12, 22, 19 }, // 159 bits per transform
+ { 12, 23, 18 }, // 159 bits per transform
+ { 12, 24, 9 }, // 159 bits per transform
+ { 13, 8, 24 }, // 159 bits per transform
+ { 13, 17, 23 }, // 159 bits per transform
+ { 13, 18, 22 }, // 159 bits per transform
+ { 13, 19, 21 }, // 159 bits per transform
+ { 13, 20, 20 }, // 159 bits per transform
+ { 13, 21, 19 }, // 159 bits per transform
+ { 13, 22, 18 }, // 159 bits per transform
+ { 13, 23, 17 }, // 159 bits per transform
+ { 13, 24, 8 }, // 159 bits per transform
+ { 14, 7, 24 }, // 159 bits per transform
+ { 14, 16, 23 }, // 159 bits per transform
+ { 14, 17, 22 }, // 159 bits per transform
+ { 14, 18, 21 }, // 159 bits per transform
+ { 14, 19, 20 }, // 159 bits per transform
+ { 14, 20, 19 }, // 159 bits per transform
+ { 14, 21, 18 }, // 159 bits per transform
+ { 14, 22, 17 }, // 159 bits per transform
+ { 14, 23, 16 }, // 159 bits per transform
+ { 14, 24, 7 }, // 159 bits per transform
+ { 15, 6, 24 }, // 159 bits per transform
+ { 15, 15, 23 }, // 159 bits per transform
+ { 15, 16, 22 }, // 159 bits per transform
+ { 15, 17, 21 }, // 159 bits per transform
+ { 15, 18, 20 }, // 159 bits per transform
+ { 15, 19, 19 }, // 159 bits per transform
+ { 15, 20, 18 }, // 159 bits per transform
+ { 15, 21, 17 }, // 159 bits per transform
+ { 15, 22, 16 }, // 159 bits per transform
+ { 15, 23, 15 }, // 159 bits per transform
+ { 15, 24, 6 }, // 159 bits per transform
+ { 16, 5, 24 }, // 159 bits per transform
+ { 16, 14, 23 }, // 159 bits per transform
+ { 16, 15, 22 }, // 159 bits per transform
+ { 16, 16, 21 }, // 159 bits per transform
+ { 16, 17, 20 }, // 159 bits per transform
+ { 16, 18, 19 }, // 159 bits per transform
+ { 16, 19, 18 }, // 159 bits per transform
+ { 16, 20, 17 }, // 159 bits per transform
+ { 16, 21, 16 }, // 159 bits per transform
+ { 16, 22, 15 }, // 159 bits per transform
+ { 16, 23, 14 }, // 159 bits per transform
+ { 16, 24, 5 }, // 159 bits per transform
+ { 17, 4, 24 }, // 159 bits per transform
+ { 17, 13, 23 }, // 159 bits per transform
+ { 17, 14, 22 }, // 159 bits per transform
+ { 17, 15, 21 }, // 159 bits per transform
+ { 17, 16, 20 }, // 159 bits per transform
+ { 17, 17, 19 }, // 159 bits per transform
+ { 17, 18, 18 }, // 159 bits per transform
+ { 17, 19, 17 }, // 159 bits per transform
+ { 17, 20, 16 }, // 159 bits per transform
+ { 17, 21, 15 }, // 159 bits per transform
+ { 17, 22, 14 }, // 159 bits per transform
+ { 17, 23, 13 }, // 159 bits per transform
+ { 17, 24, 4 }, // 159 bits per transform
+ { 18, 3, 24 }, // 159 bits per transform
+ { 18, 12, 23 }, // 159 bits per transform
+ { 18, 13, 22 }, // 159 bits per transform
+ { 18, 14, 21 }, // 159 bits per transform
+ { 18, 15, 20 }, // 159 bits per transform
+ { 18, 16, 19 }, // 159 bits per transform
+ { 18, 17, 18 }, // 159 bits per transform
+ { 18, 18, 17 }, // 159 bits per transform
+ { 18, 19, 16 }, // 159 bits per transform
+ { 18, 20, 15 }, // 159 bits per transform
+ { 18, 21, 14 }, // 159 bits per transform
+ { 18, 22, 13 }, // 159 bits per transform
+ { 18, 23, 12 }, // 159 bits per transform
+ { 18, 24, 3 }, // 159 bits per transform
+ { 19, 2, 24 }, // 159 bits per transform
+ { 19, 11, 23 }, // 159 bits per transform
+ { 19, 12, 22 }, // 159 bits per transform
+ { 19, 13, 21 }, // 159 bits per transform
+ { 19, 14, 20 }, // 159 bits per transform
+ { 19, 15, 19 }, // 159 bits per transform
+ { 19, 16, 18 }, // 159 bits per transform
+ { 19, 17, 17 }, // 159 bits per transform
+ { 19, 18, 16 }, // 159 bits per transform
+ { 19, 19, 15 }, // 159 bits per transform
+ { 19, 20, 14 }, // 159 bits per transform
+ { 19, 21, 13 }, // 159 bits per transform
+ { 19, 22, 12 }, // 159 bits per transform
+ { 19, 23, 11 }, // 159 bits per transform
+ { 19, 24, 2 }, // 159 bits per transform
+ { 20, 1, 24 }, // 159 bits per transform
+ { 20, 10, 23 }, // 159 bits per transform
+ { 20, 11, 22 }, // 159 bits per transform
+ { 20, 12, 21 }, // 159 bits per transform
+ { 20, 13, 20 }, // 159 bits per transform
+ { 20, 14, 19 }, // 159 bits per transform
+ { 20, 15, 18 }, // 159 bits per transform
+ { 20, 16, 17 }, // 159 bits per transform
+ { 20, 17, 16 }, // 159 bits per transform
+ { 20, 18, 15 }, // 159 bits per transform
+ { 20, 19, 14 }, // 159 bits per transform
+ { 20, 20, 13 }, // 159 bits per transform
+ { 20, 21, 12 }, // 159 bits per transform
+ { 20, 22, 11 }, // 159 bits per transform
+ { 20, 23, 10 }, // 159 bits per transform
+ { 20, 24, 1 }, // 159 bits per transform
+ { 21, 0, 24 }, // 159 bits per transform
+ { 21, 9, 23 }, // 159 bits per transform
+ { 21, 10, 22 }, // 159 bits per transform
+ { 21, 11, 21 }, // 159 bits per transform
+ { 21, 12, 20 }, // 159 bits per transform
+ { 21, 13, 19 }, // 159 bits per transform
+ { 21, 14, 18 }, // 159 bits per transform
+ { 21, 15, 17 }, // 159 bits per transform
+ { 21, 16, 16 }, // 159 bits per transform
+ { 21, 17, 15 }, // 159 bits per transform
+ { 21, 18, 14 }, // 159 bits per transform
+ { 21, 19, 13 }, // 159 bits per transform
+ { 21, 20, 12 }, // 159 bits per transform
+ { 21, 21, 11 }, // 159 bits per transform
+ { 21, 22, 10 }, // 159 bits per transform
+ { 21, 23, 9 }, // 159 bits per transform
+ { 21, 24, 0 }, // 159 bits per transform
+ { 22, 8, 23 }, // 159 bits per transform
+ { 22, 9, 22 }, // 159 bits per transform
+ { 22, 10, 21 }, // 159 bits per transform
+ { 22, 11, 20 }, // 159 bits per transform
+ { 22, 12, 19 }, // 159 bits per transform
+ { 22, 13, 18 }, // 159 bits per transform
+ { 22, 14, 17 }, // 159 bits per transform
+ { 22, 15, 16 }, // 159 bits per transform
+ { 22, 16, 15 }, // 159 bits per transform
+ { 22, 17, 14 }, // 159 bits per transform
+ { 22, 18, 13 }, // 159 bits per transform
+ { 22, 19, 12 }, // 159 bits per transform
+ { 22, 20, 11 }, // 159 bits per transform
+ { 22, 21, 10 }, // 159 bits per transform
+ { 22, 22, 9 }, // 159 bits per transform
+ { 22, 23, 8 }, // 159 bits per transform
+ { 23, 7, 23 }, // 159 bits per transform
+ { 23, 8, 22 }, // 159 bits per transform
+ { 23, 9, 21 }, // 159 bits per transform
+ { 23, 10, 20 }, // 159 bits per transform
+ { 23, 11, 19 }, // 159 bits per transform
+ { 23, 12, 18 }, // 159 bits per transform
+ { 23, 13, 17 }, // 159 bits per transform
+ { 23, 14, 16 }, // 159 bits per transform
+ { 23, 15, 15 }, // 159 bits per transform
+ { 23, 16, 14 }, // 159 bits per transform
+ { 23, 17, 13 }, // 159 bits per transform
+ { 23, 18, 12 }, // 159 bits per transform
+ { 23, 19, 11 }, // 159 bits per transform
+ { 23, 20, 10 }, // 159 bits per transform
+ { 23, 21, 9 }, // 159 bits per transform
+ { 23, 22, 8 }, // 159 bits per transform
+ { 23, 23, 7 }, // 159 bits per transform
+ { 24, 0, 21 }, // 159 bits per transform
+ { 24, 1, 20 }, // 159 bits per transform
+ { 24, 2, 19 }, // 159 bits per transform
+ { 24, 3, 18 }, // 159 bits per transform
+ { 24, 4, 17 }, // 159 bits per transform
+ { 24, 5, 16 }, // 159 bits per transform
+ { 24, 6, 15 }, // 159 bits per transform
+ { 24, 7, 14 }, // 159 bits per transform
+ { 24, 8, 13 }, // 159 bits per transform
+ { 24, 9, 12 }, // 159 bits per transform
+ { 24, 10, 11 }, // 159 bits per transform
+ { 24, 11, 10 }, // 159 bits per transform
+ { 24, 12, 9 }, // 159 bits per transform
+ { 24, 13, 8 }, // 159 bits per transform
+ { 24, 14, 7 }, // 159 bits per transform
+ { 24, 15, 6 }, // 159 bits per transform
+ { 24, 16, 5 }, // 159 bits per transform
+ { 24, 17, 4 }, // 159 bits per transform
+ { 24, 18, 3 }, // 159 bits per transform
+ { 24, 19, 2 }, // 159 bits per transform
+ { 24, 20, 1 }, // 159 bits per transform
+ { 24, 21, 0 }, // 159 bits per transform
+ { 0, 22, 24 }, // 162 bits per transform
+ { 0, 24, 22 }, // 162 bits per transform
+ { 1, 21, 24 }, // 162 bits per transform
+ { 1, 24, 21 }, // 162 bits per transform
+ { 2, 20, 24 }, // 162 bits per transform
+ { 2, 24, 20 }, // 162 bits per transform
+ { 3, 19, 24 }, // 162 bits per transform
+ { 3, 24, 19 }, // 162 bits per transform
+ { 4, 18, 24 }, // 162 bits per transform
+ { 4, 24, 18 }, // 162 bits per transform
+ { 5, 17, 24 }, // 162 bits per transform
+ { 5, 24, 17 }, // 162 bits per transform
+ { 6, 16, 24 }, // 162 bits per transform
+ { 6, 24, 16 }, // 162 bits per transform
+ { 7, 15, 24 }, // 162 bits per transform
+ { 7, 24, 15 }, // 162 bits per transform
+ { 8, 14, 24 }, // 162 bits per transform
+ { 8, 23, 23 }, // 162 bits per transform
+ { 8, 24, 14 }, // 162 bits per transform
+ { 9, 13, 24 }, // 162 bits per transform
+ { 9, 22, 23 }, // 162 bits per transform
+ { 9, 23, 22 }, // 162 bits per transform
+ { 9, 24, 13 }, // 162 bits per transform
+ { 10, 12, 24 }, // 162 bits per transform
+ { 10, 21, 23 }, // 162 bits per transform
+ { 10, 22, 22 }, // 162 bits per transform
+ { 10, 23, 21 }, // 162 bits per transform
+ { 10, 24, 12 }, // 162 bits per transform
+ { 11, 11, 24 }, // 162 bits per transform
+ { 11, 20, 23 }, // 162 bits per transform
+ { 11, 21, 22 }, // 162 bits per transform
+ { 11, 22, 21 }, // 162 bits per transform
+ { 11, 23, 20 }, // 162 bits per transform
+ { 11, 24, 11 }, // 162 bits per transform
+ { 12, 10, 24 }, // 162 bits per transform
+ { 12, 19, 23 }, // 162 bits per transform
+ { 12, 20, 22 }, // 162 bits per transform
+ { 12, 21, 21 }, // 162 bits per transform
+ { 12, 22, 20 }, // 162 bits per transform
+ { 12, 23, 19 }, // 162 bits per transform
+ { 12, 24, 10 }, // 162 bits per transform
+ { 13, 9, 24 }, // 162 bits per transform
+ { 13, 18, 23 }, // 162 bits per transform
+ { 13, 19, 22 }, // 162 bits per transform
+ { 13, 20, 21 }, // 162 bits per transform
+ { 13, 21, 20 }, // 162 bits per transform
+ { 13, 22, 19 }, // 162 bits per transform
+ { 13, 23, 18 }, // 162 bits per transform
+ { 13, 24, 9 }, // 162 bits per transform
+ { 14, 8, 24 }, // 162 bits per transform
+ { 14, 17, 23 }, // 162 bits per transform
+ { 14, 18, 22 }, // 162 bits per transform
+ { 14, 19, 21 }, // 162 bits per transform
+ { 14, 20, 20 }, // 162 bits per transform
+ { 14, 21, 19 }, // 162 bits per transform
+ { 14, 22, 18 }, // 162 bits per transform
+ { 14, 23, 17 }, // 162 bits per transform
+ { 14, 24, 8 }, // 162 bits per transform
+ { 15, 7, 24 }, // 162 bits per transform
+ { 15, 16, 23 }, // 162 bits per transform
+ { 15, 17, 22 }, // 162 bits per transform
+ { 15, 18, 21 }, // 162 bits per transform
+ { 15, 19, 20 }, // 162 bits per transform
+ { 15, 20, 19 }, // 162 bits per transform
+ { 15, 21, 18 }, // 162 bits per transform
+ { 15, 22, 17 }, // 162 bits per transform
+ { 15, 23, 16 }, // 162 bits per transform
+ { 15, 24, 7 }, // 162 bits per transform
+ { 16, 6, 24 }, // 162 bits per transform
+ { 16, 15, 23 }, // 162 bits per transform
+ { 16, 16, 22 }, // 162 bits per transform
+ { 16, 17, 21 }, // 162 bits per transform
+ { 16, 18, 20 }, // 162 bits per transform
+ { 16, 19, 19 }, // 162 bits per transform
+ { 16, 20, 18 }, // 162 bits per transform
+ { 16, 21, 17 }, // 162 bits per transform
+ { 16, 22, 16 }, // 162 bits per transform
+ { 16, 23, 15 }, // 162 bits per transform
+ { 16, 24, 6 }, // 162 bits per transform
+ { 17, 5, 24 }, // 162 bits per transform
+ { 17, 14, 23 }, // 162 bits per transform
+ { 17, 15, 22 }, // 162 bits per transform
+ { 17, 16, 21 }, // 162 bits per transform
+ { 17, 17, 20 }, // 162 bits per transform
+ { 17, 18, 19 }, // 162 bits per transform
+ { 17, 19, 18 }, // 162 bits per transform
+ { 17, 20, 17 }, // 162 bits per transform
+ { 17, 21, 16 }, // 162 bits per transform
+ { 17, 22, 15 }, // 162 bits per transform
+ { 17, 23, 14 }, // 162 bits per transform
+ { 17, 24, 5 }, // 162 bits per transform
+ { 18, 4, 24 }, // 162 bits per transform
+ { 18, 13, 23 }, // 162 bits per transform
+ { 18, 14, 22 }, // 162 bits per transform
+ { 18, 15, 21 }, // 162 bits per transform
+ { 18, 16, 20 }, // 162 bits per transform
+ { 18, 17, 19 }, // 162 bits per transform
+ { 18, 18, 18 }, // 162 bits per transform
+ { 18, 19, 17 }, // 162 bits per transform
+ { 18, 20, 16 }, // 162 bits per transform
+ { 18, 21, 15 }, // 162 bits per transform
+ { 18, 22, 14 }, // 162 bits per transform
+ { 18, 23, 13 }, // 162 bits per transform
+ { 18, 24, 4 }, // 162 bits per transform
+ { 19, 3, 24 }, // 162 bits per transform
+ { 19, 12, 23 }, // 162 bits per transform
+ { 19, 13, 22 }, // 162 bits per transform
+ { 19, 14, 21 }, // 162 bits per transform
+ { 19, 15, 20 }, // 162 bits per transform
+ { 19, 16, 19 }, // 162 bits per transform
+ { 19, 17, 18 }, // 162 bits per transform
+ { 19, 18, 17 }, // 162 bits per transform
+ { 19, 19, 16 }, // 162 bits per transform
+ { 19, 20, 15 }, // 162 bits per transform
+ { 19, 21, 14 }, // 162 bits per transform
+ { 19, 22, 13 }, // 162 bits per transform
+ { 19, 23, 12 }, // 162 bits per transform
+ { 19, 24, 3 }, // 162 bits per transform
+ { 20, 2, 24 }, // 162 bits per transform
+ { 20, 11, 23 }, // 162 bits per transform
+ { 20, 12, 22 }, // 162 bits per transform
+ { 20, 13, 21 }, // 162 bits per transform
+ { 20, 14, 20 }, // 162 bits per transform
+ { 20, 15, 19 }, // 162 bits per transform
+ { 20, 16, 18 }, // 162 bits per transform
+ { 20, 17, 17 }, // 162 bits per transform
+ { 20, 18, 16 }, // 162 bits per transform
+ { 20, 19, 15 }, // 162 bits per transform
+ { 20, 20, 14 }, // 162 bits per transform
+ { 20, 21, 13 }, // 162 bits per transform
+ { 20, 22, 12 }, // 162 bits per transform
+ { 20, 23, 11 }, // 162 bits per transform
+ { 20, 24, 2 }, // 162 bits per transform
+ { 21, 1, 24 }, // 162 bits per transform
+ { 21, 10, 23 }, // 162 bits per transform
+ { 21, 11, 22 }, // 162 bits per transform
+ { 21, 12, 21 }, // 162 bits per transform
+ { 21, 13, 20 }, // 162 bits per transform
+ { 21, 14, 19 }, // 162 bits per transform
+ { 21, 15, 18 }, // 162 bits per transform
+ { 21, 16, 17 }, // 162 bits per transform
+ { 21, 17, 16 }, // 162 bits per transform
+ { 21, 18, 15 }, // 162 bits per transform
+ { 21, 19, 14 }, // 162 bits per transform
+ { 21, 20, 13 }, // 162 bits per transform
+ { 21, 21, 12 }, // 162 bits per transform
+ { 21, 22, 11 }, // 162 bits per transform
+ { 21, 23, 10 }, // 162 bits per transform
+ { 21, 24, 1 }, // 162 bits per transform
+ { 22, 0, 24 }, // 162 bits per transform
+ { 22, 9, 23 }, // 162 bits per transform
+ { 22, 10, 22 }, // 162 bits per transform
+ { 22, 11, 21 }, // 162 bits per transform
+ { 22, 12, 20 }, // 162 bits per transform
+ { 22, 13, 19 }, // 162 bits per transform
+ { 22, 14, 18 }, // 162 bits per transform
+ { 22, 15, 17 }, // 162 bits per transform
+ { 22, 16, 16 }, // 162 bits per transform
+ { 22, 17, 15 }, // 162 bits per transform
+ { 22, 18, 14 }, // 162 bits per transform
+ { 22, 19, 13 }, // 162 bits per transform
+ { 22, 20, 12 }, // 162 bits per transform
+ { 22, 21, 11 }, // 162 bits per transform
+ { 22, 22, 10 }, // 162 bits per transform
+ { 22, 23, 9 }, // 162 bits per transform
+ { 22, 24, 0 }, // 162 bits per transform
+ { 23, 8, 23 }, // 162 bits per transform
+ { 23, 9, 22 }, // 162 bits per transform
+ { 23, 10, 21 }, // 162 bits per transform
+ { 23, 11, 20 }, // 162 bits per transform
+ { 23, 12, 19 }, // 162 bits per transform
+ { 23, 13, 18 }, // 162 bits per transform
+ { 23, 14, 17 }, // 162 bits per transform
+ { 23, 15, 16 }, // 162 bits per transform
+ { 23, 16, 15 }, // 162 bits per transform
+ { 23, 17, 14 }, // 162 bits per transform
+ { 23, 18, 13 }, // 162 bits per transform
+ { 23, 19, 12 }, // 162 bits per transform
+ { 23, 20, 11 }, // 162 bits per transform
+ { 23, 21, 10 }, // 162 bits per transform
+ { 23, 22, 9 }, // 162 bits per transform
+ { 23, 23, 8 }, // 162 bits per transform
+ { 24, 0, 22 }, // 162 bits per transform
+ { 24, 1, 21 }, // 162 bits per transform
+ { 24, 2, 20 }, // 162 bits per transform
+ { 24, 3, 19 }, // 162 bits per transform
+ { 24, 4, 18 }, // 162 bits per transform
+ { 24, 5, 17 }, // 162 bits per transform
+ { 24, 6, 16 }, // 162 bits per transform
+ { 24, 7, 15 }, // 162 bits per transform
+ { 24, 8, 14 }, // 162 bits per transform
+ { 24, 9, 13 }, // 162 bits per transform
+ { 24, 10, 12 }, // 162 bits per transform
+ { 24, 11, 11 }, // 162 bits per transform
+ { 24, 12, 10 }, // 162 bits per transform
+ { 24, 13, 9 }, // 162 bits per transform
+ { 24, 14, 8 }, // 162 bits per transform
+ { 24, 15, 7 }, // 162 bits per transform
+ { 24, 16, 6 }, // 162 bits per transform
+ { 24, 17, 5 }, // 162 bits per transform
+ { 24, 18, 4 }, // 162 bits per transform
+ { 24, 19, 3 }, // 162 bits per transform
+ { 24, 20, 2 }, // 162 bits per transform
+ { 24, 21, 1 }, // 162 bits per transform
+ { 24, 22, 0 }, // 162 bits per transform
+ { 0, 23, 24 }, // 165 bits per transform
+ { 0, 24, 23 }, // 165 bits per transform
+ { 1, 22, 24 }, // 165 bits per transform
+ { 1, 24, 22 }, // 165 bits per transform
+ { 2, 21, 24 }, // 165 bits per transform
+ { 2, 24, 21 }, // 165 bits per transform
+ { 3, 20, 24 }, // 165 bits per transform
+ { 3, 24, 20 }, // 165 bits per transform
+ { 4, 19, 24 }, // 165 bits per transform
+ { 4, 24, 19 }, // 165 bits per transform
+ { 5, 18, 24 }, // 165 bits per transform
+ { 5, 24, 18 }, // 165 bits per transform
+ { 6, 17, 24 }, // 165 bits per transform
+ { 6, 24, 17 }, // 165 bits per transform
+ { 7, 16, 24 }, // 165 bits per transform
+ { 7, 24, 16 }, // 165 bits per transform
+ { 8, 15, 24 }, // 165 bits per transform
+ { 8, 24, 15 }, // 165 bits per transform
+ { 9, 14, 24 }, // 165 bits per transform
+ { 9, 23, 23 }, // 165 bits per transform
+ { 9, 24, 14 }, // 165 bits per transform
+ { 10, 13, 24 }, // 165 bits per transform
+ { 10, 22, 23 }, // 165 bits per transform
+ { 10, 23, 22 }, // 165 bits per transform
+ { 10, 24, 13 }, // 165 bits per transform
+ { 11, 12, 24 }, // 165 bits per transform
+ { 11, 21, 23 }, // 165 bits per transform
+ { 11, 22, 22 }, // 165 bits per transform
+ { 11, 23, 21 }, // 165 bits per transform
+ { 11, 24, 12 }, // 165 bits per transform
+ { 12, 11, 24 }, // 165 bits per transform
+ { 12, 20, 23 }, // 165 bits per transform
+ { 12, 21, 22 }, // 165 bits per transform
+ { 12, 22, 21 }, // 165 bits per transform
+ { 12, 23, 20 }, // 165 bits per transform
+ { 12, 24, 11 }, // 165 bits per transform
+ { 13, 10, 24 }, // 165 bits per transform
+ { 13, 19, 23 }, // 165 bits per transform
+ { 13, 20, 22 }, // 165 bits per transform
+ { 13, 21, 21 }, // 165 bits per transform
+ { 13, 22, 20 }, // 165 bits per transform
+ { 13, 23, 19 }, // 165 bits per transform
+ { 13, 24, 10 }, // 165 bits per transform
+ { 14, 9, 24 }, // 165 bits per transform
+ { 14, 18, 23 }, // 165 bits per transform
+ { 14, 19, 22 }, // 165 bits per transform
+ { 14, 20, 21 }, // 165 bits per transform
+ { 14, 21, 20 }, // 165 bits per transform
+ { 14, 22, 19 }, // 165 bits per transform
+ { 14, 23, 18 }, // 165 bits per transform
+ { 14, 24, 9 }, // 165 bits per transform
+ { 15, 8, 24 }, // 165 bits per transform
+ { 15, 17, 23 }, // 165 bits per transform
+ { 15, 18, 22 }, // 165 bits per transform
+ { 15, 19, 21 }, // 165 bits per transform
+ { 15, 20, 20 }, // 165 bits per transform
+ { 15, 21, 19 }, // 165 bits per transform
+ { 15, 22, 18 }, // 165 bits per transform
+ { 15, 23, 17 }, // 165 bits per transform
+ { 15, 24, 8 }, // 165 bits per transform
+ { 16, 7, 24 }, // 165 bits per transform
+ { 16, 16, 23 }, // 165 bits per transform
+ { 16, 17, 22 }, // 165 bits per transform
+ { 16, 18, 21 }, // 165 bits per transform
+ { 16, 19, 20 }, // 165 bits per transform
+ { 16, 20, 19 }, // 165 bits per transform
+ { 16, 21, 18 }, // 165 bits per transform
+ { 16, 22, 17 }, // 165 bits per transform
+ { 16, 23, 16 }, // 165 bits per transform
+ { 16, 24, 7 }, // 165 bits per transform
+ { 17, 6, 24 }, // 165 bits per transform
+ { 17, 15, 23 }, // 165 bits per transform
+ { 17, 16, 22 }, // 165 bits per transform
+ { 17, 17, 21 }, // 165 bits per transform
+ { 17, 18, 20 }, // 165 bits per transform
+ { 17, 19, 19 }, // 165 bits per transform
+ { 17, 20, 18 }, // 165 bits per transform
+ { 17, 21, 17 }, // 165 bits per transform
+ { 17, 22, 16 }, // 165 bits per transform
+ { 17, 23, 15 }, // 165 bits per transform
+ { 17, 24, 6 }, // 165 bits per transform
+ { 18, 5, 24 }, // 165 bits per transform
+ { 18, 14, 23 }, // 165 bits per transform
+ { 18, 15, 22 }, // 165 bits per transform
+ { 18, 16, 21 }, // 165 bits per transform
+ { 18, 17, 20 }, // 165 bits per transform
+ { 18, 18, 19 }, // 165 bits per transform
+ { 18, 19, 18 }, // 165 bits per transform
+ { 18, 20, 17 }, // 165 bits per transform
+ { 18, 21, 16 }, // 165 bits per transform
+ { 18, 22, 15 }, // 165 bits per transform
+ { 18, 23, 14 }, // 165 bits per transform
+ { 18, 24, 5 }, // 165 bits per transform
+ { 19, 4, 24 }, // 165 bits per transform
+ { 19, 13, 23 }, // 165 bits per transform
+ { 19, 14, 22 }, // 165 bits per transform
+ { 19, 15, 21 }, // 165 bits per transform
+ { 19, 16, 20 }, // 165 bits per transform
+ { 19, 17, 19 }, // 165 bits per transform
+ { 19, 18, 18 }, // 165 bits per transform
+ { 19, 19, 17 }, // 165 bits per transform
+ { 19, 20, 16 }, // 165 bits per transform
+ { 19, 21, 15 }, // 165 bits per transform
+ { 19, 22, 14 }, // 165 bits per transform
+ { 19, 23, 13 }, // 165 bits per transform
+ { 19, 24, 4 }, // 165 bits per transform
+ { 20, 3, 24 }, // 165 bits per transform
+ { 20, 12, 23 }, // 165 bits per transform
+ { 20, 13, 22 }, // 165 bits per transform
+ { 20, 14, 21 }, // 165 bits per transform
+ { 20, 15, 20 }, // 165 bits per transform
+ { 20, 16, 19 }, // 165 bits per transform
+ { 20, 17, 18 }, // 165 bits per transform
+ { 20, 18, 17 }, // 165 bits per transform
+ { 20, 19, 16 }, // 165 bits per transform
+ { 20, 20, 15 }, // 165 bits per transform
+ { 20, 21, 14 }, // 165 bits per transform
+ { 20, 22, 13 }, // 165 bits per transform
+ { 20, 23, 12 }, // 165 bits per transform
+ { 20, 24, 3 }, // 165 bits per transform
+ { 21, 2, 24 }, // 165 bits per transform
+ { 21, 11, 23 }, // 165 bits per transform
+ { 21, 12, 22 }, // 165 bits per transform
+ { 21, 13, 21 }, // 165 bits per transform
+ { 21, 14, 20 }, // 165 bits per transform
+ { 21, 15, 19 }, // 165 bits per transform
+ { 21, 16, 18 }, // 165 bits per transform
+ { 21, 17, 17 }, // 165 bits per transform
+ { 21, 18, 16 }, // 165 bits per transform
+ { 21, 19, 15 }, // 165 bits per transform
+ { 21, 20, 14 }, // 165 bits per transform
+ { 21, 21, 13 }, // 165 bits per transform
+ { 21, 22, 12 }, // 165 bits per transform
+ { 21, 23, 11 }, // 165 bits per transform
+ { 21, 24, 2 }, // 165 bits per transform
+ { 22, 1, 24 }, // 165 bits per transform
+ { 22, 10, 23 }, // 165 bits per transform
+ { 22, 11, 22 }, // 165 bits per transform
+ { 22, 12, 21 }, // 165 bits per transform
+ { 22, 13, 20 }, // 165 bits per transform
+ { 22, 14, 19 }, // 165 bits per transform
+ { 22, 15, 18 }, // 165 bits per transform
+ { 22, 16, 17 }, // 165 bits per transform
+ { 22, 17, 16 }, // 165 bits per transform
+ { 22, 18, 15 }, // 165 bits per transform
+ { 22, 19, 14 }, // 165 bits per transform
+ { 22, 20, 13 }, // 165 bits per transform
+ { 22, 21, 12 }, // 165 bits per transform
+ { 22, 22, 11 }, // 165 bits per transform
+ { 22, 23, 10 }, // 165 bits per transform
+ { 22, 24, 1 }, // 165 bits per transform
+ { 23, 0, 24 }, // 165 bits per transform
+ { 23, 9, 23 }, // 165 bits per transform
+ { 23, 10, 22 }, // 165 bits per transform
+ { 23, 11, 21 }, // 165 bits per transform
+ { 23, 12, 20 }, // 165 bits per transform
+ { 23, 13, 19 }, // 165 bits per transform
+ { 23, 14, 18 }, // 165 bits per transform
+ { 23, 15, 17 }, // 165 bits per transform
+ { 23, 16, 16 }, // 165 bits per transform
+ { 23, 17, 15 }, // 165 bits per transform
+ { 23, 18, 14 }, // 165 bits per transform
+ { 23, 19, 13 }, // 165 bits per transform
+ { 23, 20, 12 }, // 165 bits per transform
+ { 23, 21, 11 }, // 165 bits per transform
+ { 23, 22, 10 }, // 165 bits per transform
+ { 23, 23, 9 }, // 165 bits per transform
+ { 23, 24, 0 }, // 165 bits per transform
+ { 24, 0, 23 }, // 165 bits per transform
+ { 24, 1, 22 }, // 165 bits per transform
+ { 24, 2, 21 }, // 165 bits per transform
+ { 24, 3, 20 }, // 165 bits per transform
+ { 24, 4, 19 }, // 165 bits per transform
+ { 24, 5, 18 }, // 165 bits per transform
+ { 24, 6, 17 }, // 165 bits per transform
+ { 24, 7, 16 }, // 165 bits per transform
+ { 24, 8, 15 }, // 165 bits per transform
+ { 24, 9, 14 }, // 165 bits per transform
+ { 24, 10, 13 }, // 165 bits per transform
+ { 24, 11, 12 }, // 165 bits per transform
+ { 24, 12, 11 }, // 165 bits per transform
+ { 24, 13, 10 }, // 165 bits per transform
+ { 24, 14, 9 }, // 165 bits per transform
+ { 24, 15, 8 }, // 165 bits per transform
+ { 24, 16, 7 }, // 165 bits per transform
+ { 24, 17, 6 }, // 165 bits per transform
+ { 24, 18, 5 }, // 165 bits per transform
+ { 24, 19, 4 }, // 165 bits per transform
+ { 24, 20, 3 }, // 165 bits per transform
+ { 24, 21, 2 }, // 165 bits per transform
+ { 24, 22, 1 }, // 165 bits per transform
+ { 24, 23, 0 }, // 165 bits per transform
+ { 1, 23, 24 }, // 168 bits per transform
+ { 1, 24, 23 }, // 168 bits per transform
+ { 2, 22, 24 }, // 168 bits per transform
+ { 2, 24, 22 }, // 168 bits per transform
+ { 3, 21, 24 }, // 168 bits per transform
+ { 3, 24, 21 }, // 168 bits per transform
+ { 4, 20, 24 }, // 168 bits per transform
+ { 4, 24, 20 }, // 168 bits per transform
+ { 5, 19, 24 }, // 168 bits per transform
+ { 5, 24, 19 }, // 168 bits per transform
+ { 6, 18, 24 }, // 168 bits per transform
+ { 6, 24, 18 }, // 168 bits per transform
+ { 7, 17, 24 }, // 168 bits per transform
+ { 7, 24, 17 }, // 168 bits per transform
+ { 8, 16, 24 }, // 168 bits per transform
+ { 8, 24, 16 }, // 168 bits per transform
+ { 9, 15, 24 }, // 168 bits per transform
+ { 9, 24, 15 }, // 168 bits per transform
+ { 10, 14, 24 }, // 168 bits per transform
+ { 10, 23, 23 }, // 168 bits per transform
+ { 10, 24, 14 }, // 168 bits per transform
+ { 11, 13, 24 }, // 168 bits per transform
+ { 11, 22, 23 }, // 168 bits per transform
+ { 11, 23, 22 }, // 168 bits per transform
+ { 11, 24, 13 }, // 168 bits per transform
+ { 12, 12, 24 }, // 168 bits per transform
+ { 12, 21, 23 }, // 168 bits per transform
+ { 12, 22, 22 }, // 168 bits per transform
+ { 12, 23, 21 }, // 168 bits per transform
+ { 12, 24, 12 }, // 168 bits per transform
+ { 13, 11, 24 }, // 168 bits per transform
+ { 13, 20, 23 }, // 168 bits per transform
+ { 13, 21, 22 }, // 168 bits per transform
+ { 13, 22, 21 }, // 168 bits per transform
+ { 13, 23, 20 }, // 168 bits per transform
+ { 13, 24, 11 }, // 168 bits per transform
+ { 14, 10, 24 }, // 168 bits per transform
+ { 14, 19, 23 }, // 168 bits per transform
+ { 14, 20, 22 }, // 168 bits per transform
+ { 14, 21, 21 }, // 168 bits per transform
+ { 14, 22, 20 }, // 168 bits per transform
+ { 14, 23, 19 }, // 168 bits per transform
+ { 14, 24, 10 }, // 168 bits per transform
+ { 15, 9, 24 }, // 168 bits per transform
+ { 15, 18, 23 }, // 168 bits per transform
+ { 15, 19, 22 }, // 168 bits per transform
+ { 15, 20, 21 }, // 168 bits per transform
+ { 15, 21, 20 }, // 168 bits per transform
+ { 15, 22, 19 }, // 168 bits per transform
+ { 15, 23, 18 }, // 168 bits per transform
+ { 15, 24, 9 }, // 168 bits per transform
+ { 16, 8, 24 }, // 168 bits per transform
+ { 16, 17, 23 }, // 168 bits per transform
+ { 16, 18, 22 }, // 168 bits per transform
+ { 16, 19, 21 }, // 168 bits per transform
+ { 16, 20, 20 }, // 168 bits per transform
+ { 16, 21, 19 }, // 168 bits per transform
+ { 16, 22, 18 }, // 168 bits per transform
+ { 16, 23, 17 }, // 168 bits per transform
+ { 16, 24, 8 }, // 168 bits per transform
+ { 17, 7, 24 }, // 168 bits per transform
+ { 17, 16, 23 }, // 168 bits per transform
+ { 17, 17, 22 }, // 168 bits per transform
+ { 17, 18, 21 }, // 168 bits per transform
+ { 17, 19, 20 }, // 168 bits per transform
+ { 17, 20, 19 }, // 168 bits per transform
+ { 17, 21, 18 }, // 168 bits per transform
+ { 17, 22, 17 }, // 168 bits per transform
+ { 17, 23, 16 }, // 168 bits per transform
+ { 17, 24, 7 }, // 168 bits per transform
+ { 18, 6, 24 }, // 168 bits per transform
+ { 18, 15, 23 }, // 168 bits per transform
+ { 18, 16, 22 }, // 168 bits per transform
+ { 18, 17, 21 }, // 168 bits per transform
+ { 18, 18, 20 }, // 168 bits per transform
+ { 18, 19, 19 }, // 168 bits per transform
+ { 18, 20, 18 }, // 168 bits per transform
+ { 18, 21, 17 }, // 168 bits per transform
+ { 18, 22, 16 }, // 168 bits per transform
+ { 18, 23, 15 }, // 168 bits per transform
+ { 18, 24, 6 }, // 168 bits per transform
+ { 19, 5, 24 }, // 168 bits per transform
+ { 19, 14, 23 }, // 168 bits per transform
+ { 19, 15, 22 }, // 168 bits per transform
+ { 19, 16, 21 }, // 168 bits per transform
+ { 19, 17, 20 }, // 168 bits per transform
+ { 19, 18, 19 }, // 168 bits per transform
+ { 19, 19, 18 }, // 168 bits per transform
+ { 19, 20, 17 }, // 168 bits per transform
+ { 19, 21, 16 }, // 168 bits per transform
+ { 19, 22, 15 }, // 168 bits per transform
+ { 19, 23, 14 }, // 168 bits per transform
+ { 19, 24, 5 }, // 168 bits per transform
+ { 20, 4, 24 }, // 168 bits per transform
+ { 20, 13, 23 }, // 168 bits per transform
+ { 20, 14, 22 }, // 168 bits per transform
+ { 20, 15, 21 }, // 168 bits per transform
+ { 20, 16, 20 }, // 168 bits per transform
+ { 20, 17, 19 }, // 168 bits per transform
+ { 20, 18, 18 }, // 168 bits per transform
+ { 20, 19, 17 }, // 168 bits per transform
+ { 20, 20, 16 }, // 168 bits per transform
+ { 20, 21, 15 }, // 168 bits per transform
+ { 20, 22, 14 }, // 168 bits per transform
+ { 20, 23, 13 }, // 168 bits per transform
+ { 20, 24, 4 }, // 168 bits per transform
+ { 21, 3, 24 }, // 168 bits per transform
+ { 21, 12, 23 }, // 168 bits per transform
+ { 21, 13, 22 }, // 168 bits per transform
+ { 21, 14, 21 }, // 168 bits per transform
+ { 21, 15, 20 }, // 168 bits per transform
+ { 21, 16, 19 }, // 168 bits per transform
+ { 21, 17, 18 }, // 168 bits per transform
+ { 21, 18, 17 }, // 168 bits per transform
+ { 21, 19, 16 }, // 168 bits per transform
+ { 21, 20, 15 }, // 168 bits per transform
+ { 21, 21, 14 }, // 168 bits per transform
+ { 21, 22, 13 }, // 168 bits per transform
+ { 21, 23, 12 }, // 168 bits per transform
+ { 21, 24, 3 }, // 168 bits per transform
+ { 22, 2, 24 }, // 168 bits per transform
+ { 22, 11, 23 }, // 168 bits per transform
+ { 22, 12, 22 }, // 168 bits per transform
+ { 22, 13, 21 }, // 168 bits per transform
+ { 22, 14, 20 }, // 168 bits per transform
+ { 22, 15, 19 }, // 168 bits per transform
+ { 22, 16, 18 }, // 168 bits per transform
+ { 22, 17, 17 }, // 168 bits per transform
+ { 22, 18, 16 }, // 168 bits per transform
+ { 22, 19, 15 }, // 168 bits per transform
+ { 22, 20, 14 }, // 168 bits per transform
+ { 22, 21, 13 }, // 168 bits per transform
+ { 22, 22, 12 }, // 168 bits per transform
+ { 22, 23, 11 }, // 168 bits per transform
+ { 22, 24, 2 }, // 168 bits per transform
+ { 23, 1, 24 }, // 168 bits per transform
+ { 23, 10, 23 }, // 168 bits per transform
+ { 23, 11, 22 }, // 168 bits per transform
+ { 23, 12, 21 }, // 168 bits per transform
+ { 23, 13, 20 }, // 168 bits per transform
+ { 23, 14, 19 }, // 168 bits per transform
+ { 23, 15, 18 }, // 168 bits per transform
+ { 23, 16, 17 }, // 168 bits per transform
+ { 23, 17, 16 }, // 168 bits per transform
+ { 23, 18, 15 }, // 168 bits per transform
+ { 23, 19, 14 }, // 168 bits per transform
+ { 23, 20, 13 }, // 168 bits per transform
+ { 23, 21, 12 }, // 168 bits per transform
+ { 23, 22, 11 }, // 168 bits per transform
+ { 23, 23, 10 }, // 168 bits per transform
+ { 23, 24, 1 }, // 168 bits per transform
+ { 24, 1, 23 }, // 168 bits per transform
+ { 24, 2, 22 }, // 168 bits per transform
+ { 24, 3, 21 }, // 168 bits per transform
+ { 24, 4, 20 }, // 168 bits per transform
+ { 24, 5, 19 }, // 168 bits per transform
+ { 24, 6, 18 }, // 168 bits per transform
+ { 24, 7, 17 }, // 168 bits per transform
+ { 24, 8, 16 }, // 168 bits per transform
+ { 24, 9, 15 }, // 168 bits per transform
+ { 24, 10, 14 }, // 168 bits per transform
+ { 24, 11, 13 }, // 168 bits per transform
+ { 24, 12, 12 }, // 168 bits per transform
+ { 24, 13, 11 }, // 168 bits per transform
+ { 24, 14, 10 }, // 168 bits per transform
+ { 24, 15, 9 }, // 168 bits per transform
+ { 24, 16, 8 }, // 168 bits per transform
+ { 24, 17, 7 }, // 168 bits per transform
+ { 24, 18, 6 }, // 168 bits per transform
+ { 24, 19, 5 }, // 168 bits per transform
+ { 24, 20, 4 }, // 168 bits per transform
+ { 24, 21, 3 }, // 168 bits per transform
+ { 24, 22, 2 }, // 168 bits per transform
+ { 24, 23, 1 }, // 168 bits per transform
+ { 2, 23, 24 }, // 171 bits per transform
+ { 2, 24, 23 }, // 171 bits per transform
+ { 3, 22, 24 }, // 171 bits per transform
+ { 3, 24, 22 }, // 171 bits per transform
+ { 4, 21, 24 }, // 171 bits per transform
+ { 4, 24, 21 }, // 171 bits per transform
+ { 5, 20, 24 }, // 171 bits per transform
+ { 5, 24, 20 }, // 171 bits per transform
+ { 6, 19, 24 }, // 171 bits per transform
+ { 6, 24, 19 }, // 171 bits per transform
+ { 7, 18, 24 }, // 171 bits per transform
+ { 7, 24, 18 }, // 171 bits per transform
+ { 8, 17, 24 }, // 171 bits per transform
+ { 8, 24, 17 }, // 171 bits per transform
+ { 9, 16, 24 }, // 171 bits per transform
+ { 9, 24, 16 }, // 171 bits per transform
+ { 10, 15, 24 }, // 171 bits per transform
+ { 10, 24, 15 }, // 171 bits per transform
+ { 11, 14, 24 }, // 171 bits per transform
+ { 11, 23, 23 }, // 171 bits per transform
+ { 11, 24, 14 }, // 171 bits per transform
+ { 12, 13, 24 }, // 171 bits per transform
+ { 12, 22, 23 }, // 171 bits per transform
+ { 12, 23, 22 }, // 171 bits per transform
+ { 12, 24, 13 }, // 171 bits per transform
+ { 13, 12, 24 }, // 171 bits per transform
+ { 13, 21, 23 }, // 171 bits per transform
+ { 13, 22, 22 }, // 171 bits per transform
+ { 13, 23, 21 }, // 171 bits per transform
+ { 13, 24, 12 }, // 171 bits per transform
+ { 14, 11, 24 }, // 171 bits per transform
+ { 14, 20, 23 }, // 171 bits per transform
+ { 14, 21, 22 }, // 171 bits per transform
+ { 14, 22, 21 }, // 171 bits per transform
+ { 14, 23, 20 }, // 171 bits per transform
+ { 14, 24, 11 }, // 171 bits per transform
+ { 15, 10, 24 }, // 171 bits per transform
+ { 15, 19, 23 }, // 171 bits per transform
+ { 15, 20, 22 }, // 171 bits per transform
+ { 15, 21, 21 }, // 171 bits per transform
+ { 15, 22, 20 }, // 171 bits per transform
+ { 15, 23, 19 }, // 171 bits per transform
+ { 15, 24, 10 }, // 171 bits per transform
+ { 16, 9, 24 }, // 171 bits per transform
+ { 16, 18, 23 }, // 171 bits per transform
+ { 16, 19, 22 }, // 171 bits per transform
+ { 16, 20, 21 }, // 171 bits per transform
+ { 16, 21, 20 }, // 171 bits per transform
+ { 16, 22, 19 }, // 171 bits per transform
+ { 16, 23, 18 }, // 171 bits per transform
+ { 16, 24, 9 }, // 171 bits per transform
+ { 17, 8, 24 }, // 171 bits per transform
+ { 17, 17, 23 }, // 171 bits per transform
+ { 17, 18, 22 }, // 171 bits per transform
+ { 17, 19, 21 }, // 171 bits per transform
+ { 17, 20, 20 }, // 171 bits per transform
+ { 17, 21, 19 }, // 171 bits per transform
+ { 17, 22, 18 }, // 171 bits per transform
+ { 17, 23, 17 }, // 171 bits per transform
+ { 17, 24, 8 }, // 171 bits per transform
+ { 18, 7, 24 }, // 171 bits per transform
+ { 18, 16, 23 }, // 171 bits per transform
+ { 18, 17, 22 }, // 171 bits per transform
+ { 18, 18, 21 }, // 171 bits per transform
+ { 18, 19, 20 }, // 171 bits per transform
+ { 18, 20, 19 }, // 171 bits per transform
+ { 18, 21, 18 }, // 171 bits per transform
+ { 18, 22, 17 }, // 171 bits per transform
+ { 18, 23, 16 }, // 171 bits per transform
+ { 18, 24, 7 }, // 171 bits per transform
+ { 19, 6, 24 }, // 171 bits per transform
+ { 19, 15, 23 }, // 171 bits per transform
+ { 19, 16, 22 }, // 171 bits per transform
+ { 19, 17, 21 }, // 171 bits per transform
+ { 19, 18, 20 }, // 171 bits per transform
+ { 19, 19, 19 }, // 171 bits per transform
+ { 19, 20, 18 }, // 171 bits per transform
+ { 19, 21, 17 }, // 171 bits per transform
+ { 19, 22, 16 }, // 171 bits per transform
+ { 19, 23, 15 }, // 171 bits per transform
+ { 19, 24, 6 }, // 171 bits per transform
+ { 20, 5, 24 }, // 171 bits per transform
+ { 20, 14, 23 }, // 171 bits per transform
+ { 20, 15, 22 }, // 171 bits per transform
+ { 20, 16, 21 }, // 171 bits per transform
+ { 20, 17, 20 }, // 171 bits per transform
+ { 20, 18, 19 }, // 171 bits per transform
+ { 20, 19, 18 }, // 171 bits per transform
+ { 20, 20, 17 }, // 171 bits per transform
+ { 20, 21, 16 }, // 171 bits per transform
+ { 20, 22, 15 }, // 171 bits per transform
+ { 20, 23, 14 }, // 171 bits per transform
+ { 20, 24, 5 }, // 171 bits per transform
+ { 21, 4, 24 }, // 171 bits per transform
+ { 21, 13, 23 }, // 171 bits per transform
+ { 21, 14, 22 }, // 171 bits per transform
+ { 21, 15, 21 }, // 171 bits per transform
+ { 21, 16, 20 }, // 171 bits per transform
+ { 21, 17, 19 }, // 171 bits per transform
+ { 21, 18, 18 }, // 171 bits per transform
+ { 21, 19, 17 }, // 171 bits per transform
+ { 21, 20, 16 }, // 171 bits per transform
+ { 21, 21, 15 }, // 171 bits per transform
+ { 21, 22, 14 }, // 171 bits per transform
+ { 21, 23, 13 }, // 171 bits per transform
+ { 21, 24, 4 }, // 171 bits per transform
+ { 22, 3, 24 }, // 171 bits per transform
+ { 22, 12, 23 }, // 171 bits per transform
+ { 22, 13, 22 }, // 171 bits per transform
+ { 22, 14, 21 }, // 171 bits per transform
+ { 22, 15, 20 }, // 171 bits per transform
+ { 22, 16, 19 }, // 171 bits per transform
+ { 22, 17, 18 }, // 171 bits per transform
+ { 22, 18, 17 }, // 171 bits per transform
+ { 22, 19, 16 }, // 171 bits per transform
+ { 22, 20, 15 }, // 171 bits per transform
+ { 22, 21, 14 }, // 171 bits per transform
+ { 22, 22, 13 }, // 171 bits per transform
+ { 22, 23, 12 }, // 171 bits per transform
+ { 22, 24, 3 }, // 171 bits per transform
+ { 23, 2, 24 }, // 171 bits per transform
+ { 23, 11, 23 }, // 171 bits per transform
+ { 23, 12, 22 }, // 171 bits per transform
+ { 23, 13, 21 }, // 171 bits per transform
+ { 23, 14, 20 }, // 171 bits per transform
+ { 23, 15, 19 }, // 171 bits per transform
+ { 23, 16, 18 }, // 171 bits per transform
+ { 23, 17, 17 }, // 171 bits per transform
+ { 23, 18, 16 }, // 171 bits per transform
+ { 23, 19, 15 }, // 171 bits per transform
+ { 23, 20, 14 }, // 171 bits per transform
+ { 23, 21, 13 }, // 171 bits per transform
+ { 23, 22, 12 }, // 171 bits per transform
+ { 23, 23, 11 }, // 171 bits per transform
+ { 23, 24, 2 }, // 171 bits per transform
+ { 24, 2, 23 }, // 171 bits per transform
+ { 24, 3, 22 }, // 171 bits per transform
+ { 24, 4, 21 }, // 171 bits per transform
+ { 24, 5, 20 }, // 171 bits per transform
+ { 24, 6, 19 }, // 171 bits per transform
+ { 24, 7, 18 }, // 171 bits per transform
+ { 24, 8, 17 }, // 171 bits per transform
+ { 24, 9, 16 }, // 171 bits per transform
+ { 24, 10, 15 }, // 171 bits per transform
+ { 24, 11, 14 }, // 171 bits per transform
+ { 24, 12, 13 }, // 171 bits per transform
+ { 24, 13, 12 }, // 171 bits per transform
+ { 24, 14, 11 }, // 171 bits per transform
+ { 24, 15, 10 }, // 171 bits per transform
+ { 24, 16, 9 }, // 171 bits per transform
+ { 24, 17, 8 }, // 171 bits per transform
+ { 24, 18, 7 }, // 171 bits per transform
+ { 24, 19, 6 }, // 171 bits per transform
+ { 24, 20, 5 }, // 171 bits per transform
+ { 24, 21, 4 }, // 171 bits per transform
+ { 24, 22, 3 }, // 171 bits per transform
+ { 24, 23, 2 }, // 171 bits per transform
+ { 3, 23, 24 }, // 174 bits per transform
+ { 3, 24, 23 }, // 174 bits per transform
+ { 4, 22, 24 }, // 174 bits per transform
+ { 4, 24, 22 }, // 174 bits per transform
+ { 5, 21, 24 }, // 174 bits per transform
+ { 5, 24, 21 }, // 174 bits per transform
+ { 6, 20, 24 }, // 174 bits per transform
+ { 6, 24, 20 }, // 174 bits per transform
+ { 7, 19, 24 }, // 174 bits per transform
+ { 7, 24, 19 }, // 174 bits per transform
+ { 8, 18, 24 }, // 174 bits per transform
+ { 8, 24, 18 }, // 174 bits per transform
+ { 9, 17, 24 }, // 174 bits per transform
+ { 9, 24, 17 }, // 174 bits per transform
+ { 10, 16, 24 }, // 174 bits per transform
+ { 10, 24, 16 }, // 174 bits per transform
+ { 11, 15, 24 }, // 174 bits per transform
+ { 11, 24, 15 }, // 174 bits per transform
+ { 12, 14, 24 }, // 174 bits per transform
+ { 12, 23, 23 }, // 174 bits per transform
+ { 12, 24, 14 }, // 174 bits per transform
+ { 13, 13, 24 }, // 174 bits per transform
+ { 13, 22, 23 }, // 174 bits per transform
+ { 13, 23, 22 }, // 174 bits per transform
+ { 13, 24, 13 }, // 174 bits per transform
+ { 14, 12, 24 }, // 174 bits per transform
+ { 14, 21, 23 }, // 174 bits per transform
+ { 14, 22, 22 }, // 174 bits per transform
+ { 14, 23, 21 }, // 174 bits per transform
+ { 14, 24, 12 }, // 174 bits per transform
+ { 15, 11, 24 }, // 174 bits per transform
+ { 15, 20, 23 }, // 174 bits per transform
+ { 15, 21, 22 }, // 174 bits per transform
+ { 15, 22, 21 }, // 174 bits per transform
+ { 15, 23, 20 }, // 174 bits per transform
+ { 15, 24, 11 }, // 174 bits per transform
+ { 16, 10, 24 }, // 174 bits per transform
+ { 16, 19, 23 }, // 174 bits per transform
+ { 16, 20, 22 }, // 174 bits per transform
+ { 16, 21, 21 }, // 174 bits per transform
+ { 16, 22, 20 }, // 174 bits per transform
+ { 16, 23, 19 }, // 174 bits per transform
+ { 16, 24, 10 }, // 174 bits per transform
+ { 17, 9, 24 }, // 174 bits per transform
+ { 17, 18, 23 }, // 174 bits per transform
+ { 17, 19, 22 }, // 174 bits per transform
+ { 17, 20, 21 }, // 174 bits per transform
+ { 17, 21, 20 }, // 174 bits per transform
+ { 17, 22, 19 }, // 174 bits per transform
+ { 17, 23, 18 }, // 174 bits per transform
+ { 17, 24, 9 }, // 174 bits per transform
+ { 18, 8, 24 }, // 174 bits per transform
+ { 18, 17, 23 }, // 174 bits per transform
+ { 18, 18, 22 }, // 174 bits per transform
+ { 18, 19, 21 }, // 174 bits per transform
+ { 18, 20, 20 }, // 174 bits per transform
+ { 18, 21, 19 }, // 174 bits per transform
+ { 18, 22, 18 }, // 174 bits per transform
+ { 18, 23, 17 }, // 174 bits per transform
+ { 18, 24, 8 }, // 174 bits per transform
+ { 19, 7, 24 }, // 174 bits per transform
+ { 19, 16, 23 }, // 174 bits per transform
+ { 19, 17, 22 }, // 174 bits per transform
+ { 19, 18, 21 }, // 174 bits per transform
+ { 19, 19, 20 }, // 174 bits per transform
+ { 19, 20, 19 }, // 174 bits per transform
+ { 19, 21, 18 }, // 174 bits per transform
+ { 19, 22, 17 }, // 174 bits per transform
+ { 19, 23, 16 }, // 174 bits per transform
+ { 19, 24, 7 }, // 174 bits per transform
+ { 20, 6, 24 }, // 174 bits per transform
+ { 20, 15, 23 }, // 174 bits per transform
+ { 20, 16, 22 }, // 174 bits per transform
+ { 20, 17, 21 }, // 174 bits per transform
+ { 20, 18, 20 }, // 174 bits per transform
+ { 20, 19, 19 }, // 174 bits per transform
+ { 20, 20, 18 }, // 174 bits per transform
+ { 20, 21, 17 }, // 174 bits per transform
+ { 20, 22, 16 }, // 174 bits per transform
+ { 20, 23, 15 }, // 174 bits per transform
+ { 20, 24, 6 }, // 174 bits per transform
+ { 21, 5, 24 }, // 174 bits per transform
+ { 21, 14, 23 }, // 174 bits per transform
+ { 21, 15, 22 }, // 174 bits per transform
+ { 21, 16, 21 }, // 174 bits per transform
+ { 21, 17, 20 }, // 174 bits per transform
+ { 21, 18, 19 }, // 174 bits per transform
+ { 21, 19, 18 }, // 174 bits per transform
+ { 21, 20, 17 }, // 174 bits per transform
+ { 21, 21, 16 }, // 174 bits per transform
+ { 21, 22, 15 }, // 174 bits per transform
+ { 21, 23, 14 }, // 174 bits per transform
+ { 21, 24, 5 }, // 174 bits per transform
+ { 22, 4, 24 }, // 174 bits per transform
+ { 22, 13, 23 }, // 174 bits per transform
+ { 22, 14, 22 }, // 174 bits per transform
+ { 22, 15, 21 }, // 174 bits per transform
+ { 22, 16, 20 }, // 174 bits per transform
+ { 22, 17, 19 }, // 174 bits per transform
+ { 22, 18, 18 }, // 174 bits per transform
+ { 22, 19, 17 }, // 174 bits per transform
+ { 22, 20, 16 }, // 174 bits per transform
+ { 22, 21, 15 }, // 174 bits per transform
+ { 22, 22, 14 }, // 174 bits per transform
+ { 22, 23, 13 }, // 174 bits per transform
+ { 22, 24, 4 }, // 174 bits per transform
+ { 23, 3, 24 }, // 174 bits per transform
+ { 23, 12, 23 }, // 174 bits per transform
+ { 23, 13, 22 }, // 174 bits per transform
+ { 23, 14, 21 }, // 174 bits per transform
+ { 23, 15, 20 }, // 174 bits per transform
+ { 23, 16, 19 }, // 174 bits per transform
+ { 23, 17, 18 }, // 174 bits per transform
+ { 23, 18, 17 }, // 174 bits per transform
+ { 23, 19, 16 }, // 174 bits per transform
+ { 23, 20, 15 }, // 174 bits per transform
+ { 23, 21, 14 }, // 174 bits per transform
+ { 23, 22, 13 }, // 174 bits per transform
+ { 23, 23, 12 }, // 174 bits per transform
+ { 23, 24, 3 }, // 174 bits per transform
+ { 24, 3, 23 }, // 174 bits per transform
+ { 24, 4, 22 }, // 174 bits per transform
+ { 24, 5, 21 }, // 174 bits per transform
+ { 24, 6, 20 }, // 174 bits per transform
+ { 24, 7, 19 }, // 174 bits per transform
+ { 24, 8, 18 }, // 174 bits per transform
+ { 24, 9, 17 }, // 174 bits per transform
+ { 24, 10, 16 }, // 174 bits per transform
+ { 24, 11, 15 }, // 174 bits per transform
+ { 24, 12, 14 }, // 174 bits per transform
+ { 24, 13, 13 }, // 174 bits per transform
+ { 24, 14, 12 }, // 174 bits per transform
+ { 24, 15, 11 }, // 174 bits per transform
+ { 24, 16, 10 }, // 174 bits per transform
+ { 24, 17, 9 }, // 174 bits per transform
+ { 24, 18, 8 }, // 174 bits per transform
+ { 24, 19, 7 }, // 174 bits per transform
+ { 24, 20, 6 }, // 174 bits per transform
+ { 24, 21, 5 }, // 174 bits per transform
+ { 24, 22, 4 }, // 174 bits per transform
+ { 24, 23, 3 }, // 174 bits per transform
+ { 4, 23, 24 }, // 177 bits per transform
+ { 4, 24, 23 }, // 177 bits per transform
+ { 5, 22, 24 }, // 177 bits per transform
+ { 5, 24, 22 }, // 177 bits per transform
+ { 6, 21, 24 }, // 177 bits per transform
+ { 6, 24, 21 }, // 177 bits per transform
+ { 7, 20, 24 }, // 177 bits per transform
+ { 7, 24, 20 }, // 177 bits per transform
+ { 8, 19, 24 }, // 177 bits per transform
+ { 8, 24, 19 }, // 177 bits per transform
+ { 9, 18, 24 }, // 177 bits per transform
+ { 9, 24, 18 }, // 177 bits per transform
+ { 10, 17, 24 }, // 177 bits per transform
+ { 10, 24, 17 }, // 177 bits per transform
+ { 11, 16, 24 }, // 177 bits per transform
+ { 11, 24, 16 }, // 177 bits per transform
+ { 12, 15, 24 }, // 177 bits per transform
+ { 12, 24, 15 }, // 177 bits per transform
+ { 13, 14, 24 }, // 177 bits per transform
+ { 13, 23, 23 }, // 177 bits per transform
+ { 13, 24, 14 }, // 177 bits per transform
+ { 14, 13, 24 }, // 177 bits per transform
+ { 14, 22, 23 }, // 177 bits per transform
+ { 14, 23, 22 }, // 177 bits per transform
+ { 14, 24, 13 }, // 177 bits per transform
+ { 15, 12, 24 }, // 177 bits per transform
+ { 15, 21, 23 }, // 177 bits per transform
+ { 15, 22, 22 }, // 177 bits per transform
+ { 15, 23, 21 }, // 177 bits per transform
+ { 15, 24, 12 }, // 177 bits per transform
+ { 16, 11, 24 }, // 177 bits per transform
+ { 16, 20, 23 }, // 177 bits per transform
+ { 16, 21, 22 }, // 177 bits per transform
+ { 16, 22, 21 }, // 177 bits per transform
+ { 16, 23, 20 }, // 177 bits per transform
+ { 16, 24, 11 }, // 177 bits per transform
+ { 17, 10, 24 }, // 177 bits per transform
+ { 17, 19, 23 }, // 177 bits per transform
+ { 17, 20, 22 }, // 177 bits per transform
+ { 17, 21, 21 }, // 177 bits per transform
+ { 17, 22, 20 }, // 177 bits per transform
+ { 17, 23, 19 }, // 177 bits per transform
+ { 17, 24, 10 }, // 177 bits per transform
+ { 18, 9, 24 }, // 177 bits per transform
+ { 18, 18, 23 }, // 177 bits per transform
+ { 18, 19, 22 }, // 177 bits per transform
+ { 18, 20, 21 }, // 177 bits per transform
+ { 18, 21, 20 }, // 177 bits per transform
+ { 18, 22, 19 }, // 177 bits per transform
+ { 18, 23, 18 }, // 177 bits per transform
+ { 18, 24, 9 }, // 177 bits per transform
+ { 19, 8, 24 }, // 177 bits per transform
+ { 19, 17, 23 }, // 177 bits per transform
+ { 19, 18, 22 }, // 177 bits per transform
+ { 19, 19, 21 }, // 177 bits per transform
+ { 19, 20, 20 }, // 177 bits per transform
+ { 19, 21, 19 }, // 177 bits per transform
+ { 19, 22, 18 }, // 177 bits per transform
+ { 19, 23, 17 }, // 177 bits per transform
+ { 19, 24, 8 }, // 177 bits per transform
+ { 20, 7, 24 }, // 177 bits per transform
+ { 20, 16, 23 }, // 177 bits per transform
+ { 20, 17, 22 }, // 177 bits per transform
+ { 20, 18, 21 }, // 177 bits per transform
+ { 20, 19, 20 }, // 177 bits per transform
+ { 20, 20, 19 }, // 177 bits per transform
+ { 20, 21, 18 }, // 177 bits per transform
+ { 20, 22, 17 }, // 177 bits per transform
+ { 20, 23, 16 }, // 177 bits per transform
+ { 20, 24, 7 }, // 177 bits per transform
+ { 21, 6, 24 }, // 177 bits per transform
+ { 21, 15, 23 }, // 177 bits per transform
+ { 21, 16, 22 }, // 177 bits per transform
+ { 21, 17, 21 }, // 177 bits per transform
+ { 21, 18, 20 }, // 177 bits per transform
+ { 21, 19, 19 }, // 177 bits per transform
+ { 21, 20, 18 }, // 177 bits per transform
+ { 21, 21, 17 }, // 177 bits per transform
+ { 21, 22, 16 }, // 177 bits per transform
+ { 21, 23, 15 }, // 177 bits per transform
+ { 21, 24, 6 }, // 177 bits per transform
+ { 22, 5, 24 }, // 177 bits per transform
+ { 22, 14, 23 }, // 177 bits per transform
+ { 22, 15, 22 }, // 177 bits per transform
+ { 22, 16, 21 }, // 177 bits per transform
+ { 22, 17, 20 }, // 177 bits per transform
+ { 22, 18, 19 }, // 177 bits per transform
+ { 22, 19, 18 }, // 177 bits per transform
+ { 22, 20, 17 }, // 177 bits per transform
+ { 22, 21, 16 }, // 177 bits per transform
+ { 22, 22, 15 }, // 177 bits per transform
+ { 22, 23, 14 }, // 177 bits per transform
+ { 22, 24, 5 }, // 177 bits per transform
+ { 23, 4, 24 }, // 177 bits per transform
+ { 23, 13, 23 }, // 177 bits per transform
+ { 23, 14, 22 }, // 177 bits per transform
+ { 23, 15, 21 }, // 177 bits per transform
+ { 23, 16, 20 }, // 177 bits per transform
+ { 23, 17, 19 }, // 177 bits per transform
+ { 23, 18, 18 }, // 177 bits per transform
+ { 23, 19, 17 }, // 177 bits per transform
+ { 23, 20, 16 }, // 177 bits per transform
+ { 23, 21, 15 }, // 177 bits per transform
+ { 23, 22, 14 }, // 177 bits per transform
+ { 23, 23, 13 }, // 177 bits per transform
+ { 23, 24, 4 }, // 177 bits per transform
+ { 24, 4, 23 }, // 177 bits per transform
+ { 24, 5, 22 }, // 177 bits per transform
+ { 24, 6, 21 }, // 177 bits per transform
+ { 24, 7, 20 }, // 177 bits per transform
+ { 24, 8, 19 }, // 177 bits per transform
+ { 24, 9, 18 }, // 177 bits per transform
+ { 24, 10, 17 }, // 177 bits per transform
+ { 24, 11, 16 }, // 177 bits per transform
+ { 24, 12, 15 }, // 177 bits per transform
+ { 24, 13, 14 }, // 177 bits per transform
+ { 24, 14, 13 }, // 177 bits per transform
+ { 24, 15, 12 }, // 177 bits per transform
+ { 24, 16, 11 }, // 177 bits per transform
+ { 24, 17, 10 }, // 177 bits per transform
+ { 24, 18, 9 }, // 177 bits per transform
+ { 24, 19, 8 }, // 177 bits per transform
+ { 24, 20, 7 }, // 177 bits per transform
+ { 24, 21, 6 }, // 177 bits per transform
+ { 24, 22, 5 }, // 177 bits per transform
+ { 24, 23, 4 }, // 177 bits per transform
+ { 5, 23, 24 }, // 180 bits per transform
+ { 5, 24, 23 }, // 180 bits per transform
+ { 6, 22, 24 }, // 180 bits per transform
+ { 6, 24, 22 }, // 180 bits per transform
+ { 7, 21, 24 }, // 180 bits per transform
+ { 7, 24, 21 }, // 180 bits per transform
+ { 8, 20, 24 }, // 180 bits per transform
+ { 8, 24, 20 }, // 180 bits per transform
+ { 9, 19, 24 }, // 180 bits per transform
+ { 9, 24, 19 }, // 180 bits per transform
+ { 10, 18, 24 }, // 180 bits per transform
+ { 10, 24, 18 }, // 180 bits per transform
+ { 11, 17, 24 }, // 180 bits per transform
+ { 11, 24, 17 }, // 180 bits per transform
+ { 12, 16, 24 }, // 180 bits per transform
+ { 12, 24, 16 }, // 180 bits per transform
+ { 13, 15, 24 }, // 180 bits per transform
+ { 13, 24, 15 }, // 180 bits per transform
+ { 14, 14, 24 }, // 180 bits per transform
+ { 14, 23, 23 }, // 180 bits per transform
+ { 14, 24, 14 }, // 180 bits per transform
+ { 15, 13, 24 }, // 180 bits per transform
+ { 15, 22, 23 }, // 180 bits per transform
+ { 15, 23, 22 }, // 180 bits per transform
+ { 15, 24, 13 }, // 180 bits per transform
+ { 16, 12, 24 }, // 180 bits per transform
+ { 16, 21, 23 }, // 180 bits per transform
+ { 16, 22, 22 }, // 180 bits per transform
+ { 16, 23, 21 }, // 180 bits per transform
+ { 16, 24, 12 }, // 180 bits per transform
+ { 17, 11, 24 }, // 180 bits per transform
+ { 17, 20, 23 }, // 180 bits per transform
+ { 17, 21, 22 }, // 180 bits per transform
+ { 17, 22, 21 }, // 180 bits per transform
+ { 17, 23, 20 }, // 180 bits per transform
+ { 17, 24, 11 }, // 180 bits per transform
+ { 18, 10, 24 }, // 180 bits per transform
+ { 18, 19, 23 }, // 180 bits per transform
+ { 18, 20, 22 }, // 180 bits per transform
+ { 18, 21, 21 }, // 180 bits per transform
+ { 18, 22, 20 }, // 180 bits per transform
+ { 18, 23, 19 }, // 180 bits per transform
+ { 18, 24, 10 }, // 180 bits per transform
+ { 19, 9, 24 }, // 180 bits per transform
+ { 19, 18, 23 }, // 180 bits per transform
+ { 19, 19, 22 }, // 180 bits per transform
+ { 19, 20, 21 }, // 180 bits per transform
+ { 19, 21, 20 }, // 180 bits per transform
+ { 19, 22, 19 }, // 180 bits per transform
+ { 19, 23, 18 }, // 180 bits per transform
+ { 19, 24, 9 }, // 180 bits per transform
+ { 20, 8, 24 }, // 180 bits per transform
+ { 20, 17, 23 }, // 180 bits per transform
+ { 20, 18, 22 }, // 180 bits per transform
+ { 20, 19, 21 }, // 180 bits per transform
+ { 20, 20, 20 }, // 180 bits per transform
+ { 20, 21, 19 }, // 180 bits per transform
+ { 20, 22, 18 }, // 180 bits per transform
+ { 20, 23, 17 }, // 180 bits per transform
+ { 20, 24, 8 }, // 180 bits per transform
+ { 21, 7, 24 }, // 180 bits per transform
+ { 21, 16, 23 }, // 180 bits per transform
+ { 21, 17, 22 }, // 180 bits per transform
+ { 21, 18, 21 }, // 180 bits per transform
+ { 21, 19, 20 }, // 180 bits per transform
+ { 21, 20, 19 }, // 180 bits per transform
+ { 21, 21, 18 }, // 180 bits per transform
+ { 21, 22, 17 }, // 180 bits per transform
+ { 21, 23, 16 }, // 180 bits per transform
+ { 21, 24, 7 }, // 180 bits per transform
+ { 22, 6, 24 }, // 180 bits per transform
+ { 22, 15, 23 }, // 180 bits per transform
+ { 22, 16, 22 }, // 180 bits per transform
+ { 22, 17, 21 }, // 180 bits per transform
+ { 22, 18, 20 }, // 180 bits per transform
+ { 22, 19, 19 }, // 180 bits per transform
+ { 22, 20, 18 }, // 180 bits per transform
+ { 22, 21, 17 }, // 180 bits per transform
+ { 22, 22, 16 }, // 180 bits per transform
+ { 22, 23, 15 }, // 180 bits per transform
+ { 22, 24, 6 }, // 180 bits per transform
+ { 23, 5, 24 }, // 180 bits per transform
+ { 23, 14, 23 }, // 180 bits per transform
+ { 23, 15, 22 }, // 180 bits per transform
+ { 23, 16, 21 }, // 180 bits per transform
+ { 23, 17, 20 }, // 180 bits per transform
+ { 23, 18, 19 }, // 180 bits per transform
+ { 23, 19, 18 }, // 180 bits per transform
+ { 23, 20, 17 }, // 180 bits per transform
+ { 23, 21, 16 }, // 180 bits per transform
+ { 23, 22, 15 }, // 180 bits per transform
+ { 23, 23, 14 }, // 180 bits per transform
+ { 23, 24, 5 }, // 180 bits per transform
+ { 24, 5, 23 }, // 180 bits per transform
+ { 24, 6, 22 }, // 180 bits per transform
+ { 24, 7, 21 }, // 180 bits per transform
+ { 24, 8, 20 }, // 180 bits per transform
+ { 24, 9, 19 }, // 180 bits per transform
+ { 24, 10, 18 }, // 180 bits per transform
+ { 24, 11, 17 }, // 180 bits per transform
+ { 24, 12, 16 }, // 180 bits per transform
+ { 24, 13, 15 }, // 180 bits per transform
+ { 24, 14, 14 }, // 180 bits per transform
+ { 24, 15, 13 }, // 180 bits per transform
+ { 24, 16, 12 }, // 180 bits per transform
+ { 24, 17, 11 }, // 180 bits per transform
+ { 24, 18, 10 }, // 180 bits per transform
+ { 24, 19, 9 }, // 180 bits per transform
+ { 24, 20, 8 }, // 180 bits per transform
+ { 24, 21, 7 }, // 180 bits per transform
+ { 24, 22, 6 }, // 180 bits per transform
+ { 24, 23, 5 }, // 180 bits per transform
+ { 6, 23, 24 }, // 183 bits per transform
+ { 6, 24, 23 }, // 183 bits per transform
+ { 7, 22, 24 }, // 183 bits per transform
+ { 7, 24, 22 }, // 183 bits per transform
+ { 8, 21, 24 }, // 183 bits per transform
+ { 8, 24, 21 }, // 183 bits per transform
+ { 9, 20, 24 }, // 183 bits per transform
+ { 9, 24, 20 }, // 183 bits per transform
+ { 10, 19, 24 }, // 183 bits per transform
+ { 10, 24, 19 }, // 183 bits per transform
+ { 11, 18, 24 }, // 183 bits per transform
+ { 11, 24, 18 }, // 183 bits per transform
+ { 12, 17, 24 }, // 183 bits per transform
+ { 12, 24, 17 }, // 183 bits per transform
+ { 13, 16, 24 }, // 183 bits per transform
+ { 13, 24, 16 }, // 183 bits per transform
+ { 14, 15, 24 }, // 183 bits per transform
+ { 14, 24, 15 }, // 183 bits per transform
+ { 15, 14, 24 }, // 183 bits per transform
+ { 15, 23, 23 }, // 183 bits per transform
+ { 15, 24, 14 }, // 183 bits per transform
+ { 16, 13, 24 }, // 183 bits per transform
+ { 16, 22, 23 }, // 183 bits per transform
+ { 16, 23, 22 }, // 183 bits per transform
+ { 16, 24, 13 }, // 183 bits per transform
+ { 17, 12, 24 }, // 183 bits per transform
+ { 17, 21, 23 }, // 183 bits per transform
+ { 17, 22, 22 }, // 183 bits per transform
+ { 17, 23, 21 }, // 183 bits per transform
+ { 17, 24, 12 }, // 183 bits per transform
+ { 18, 11, 24 }, // 183 bits per transform
+ { 18, 20, 23 }, // 183 bits per transform
+ { 18, 21, 22 }, // 183 bits per transform
+ { 18, 22, 21 }, // 183 bits per transform
+ { 18, 23, 20 }, // 183 bits per transform
+ { 18, 24, 11 }, // 183 bits per transform
+ { 19, 10, 24 }, // 183 bits per transform
+ { 19, 19, 23 }, // 183 bits per transform
+ { 19, 20, 22 }, // 183 bits per transform
+ { 19, 21, 21 }, // 183 bits per transform
+ { 19, 22, 20 }, // 183 bits per transform
+ { 19, 23, 19 }, // 183 bits per transform
+ { 19, 24, 10 }, // 183 bits per transform
+ { 20, 9, 24 }, // 183 bits per transform
+ { 20, 18, 23 }, // 183 bits per transform
+ { 20, 19, 22 }, // 183 bits per transform
+ { 20, 20, 21 }, // 183 bits per transform
+ { 20, 21, 20 }, // 183 bits per transform
+ { 20, 22, 19 }, // 183 bits per transform
+ { 20, 23, 18 }, // 183 bits per transform
+ { 20, 24, 9 }, // 183 bits per transform
+ { 21, 8, 24 }, // 183 bits per transform
+ { 21, 17, 23 }, // 183 bits per transform
+ { 21, 18, 22 }, // 183 bits per transform
+ { 21, 19, 21 }, // 183 bits per transform
+ { 21, 20, 20 }, // 183 bits per transform
+ { 21, 21, 19 }, // 183 bits per transform
+ { 21, 22, 18 }, // 183 bits per transform
+ { 21, 23, 17 }, // 183 bits per transform
+ { 21, 24, 8 }, // 183 bits per transform
+ { 22, 7, 24 }, // 183 bits per transform
+ { 22, 16, 23 }, // 183 bits per transform
+ { 22, 17, 22 }, // 183 bits per transform
+ { 22, 18, 21 }, // 183 bits per transform
+ { 22, 19, 20 }, // 183 bits per transform
+ { 22, 20, 19 }, // 183 bits per transform
+ { 22, 21, 18 }, // 183 bits per transform
+ { 22, 22, 17 }, // 183 bits per transform
+ { 22, 23, 16 }, // 183 bits per transform
+ { 22, 24, 7 }, // 183 bits per transform
+ { 23, 6, 24 }, // 183 bits per transform
+ { 23, 15, 23 }, // 183 bits per transform
+ { 23, 16, 22 }, // 183 bits per transform
+ { 23, 17, 21 }, // 183 bits per transform
+ { 23, 18, 20 }, // 183 bits per transform
+ { 23, 19, 19 }, // 183 bits per transform
+ { 23, 20, 18 }, // 183 bits per transform
+ { 23, 21, 17 }, // 183 bits per transform
+ { 23, 22, 16 }, // 183 bits per transform
+ { 23, 23, 15 }, // 183 bits per transform
+ { 23, 24, 6 }, // 183 bits per transform
+ { 24, 6, 23 }, // 183 bits per transform
+ { 24, 7, 22 }, // 183 bits per transform
+ { 24, 8, 21 }, // 183 bits per transform
+ { 24, 9, 20 }, // 183 bits per transform
+ { 24, 10, 19 }, // 183 bits per transform
+ { 24, 11, 18 }, // 183 bits per transform
+ { 24, 12, 17 }, // 183 bits per transform
+ { 24, 13, 16 }, // 183 bits per transform
+ { 24, 14, 15 }, // 183 bits per transform
+ { 24, 15, 14 }, // 183 bits per transform
+ { 24, 16, 13 }, // 183 bits per transform
+ { 24, 17, 12 }, // 183 bits per transform
+ { 24, 18, 11 }, // 183 bits per transform
+ { 24, 19, 10 }, // 183 bits per transform
+ { 24, 20, 9 }, // 183 bits per transform
+ { 24, 21, 8 }, // 183 bits per transform
+ { 24, 22, 7 }, // 183 bits per transform
+ { 24, 23, 6 }, // 183 bits per transform
+ { 7, 23, 24 }, // 186 bits per transform
+ { 7, 24, 23 }, // 186 bits per transform
+ { 8, 22, 24 }, // 186 bits per transform
+ { 8, 24, 22 }, // 186 bits per transform
+ { 9, 21, 24 }, // 186 bits per transform
+ { 9, 24, 21 }, // 186 bits per transform
+ { 10, 20, 24 }, // 186 bits per transform
+ { 10, 24, 20 }, // 186 bits per transform
+ { 11, 19, 24 }, // 186 bits per transform
+ { 11, 24, 19 }, // 186 bits per transform
+ { 12, 18, 24 }, // 186 bits per transform
+ { 12, 24, 18 }, // 186 bits per transform
+ { 13, 17, 24 }, // 186 bits per transform
+ { 13, 24, 17 }, // 186 bits per transform
+ { 14, 16, 24 }, // 186 bits per transform
+ { 14, 24, 16 }, // 186 bits per transform
+ { 15, 15, 24 }, // 186 bits per transform
+ { 15, 24, 15 }, // 186 bits per transform
+ { 16, 14, 24 }, // 186 bits per transform
+ { 16, 23, 23 }, // 186 bits per transform
+ { 16, 24, 14 }, // 186 bits per transform
+ { 17, 13, 24 }, // 186 bits per transform
+ { 17, 22, 23 }, // 186 bits per transform
+ { 17, 23, 22 }, // 186 bits per transform
+ { 17, 24, 13 }, // 186 bits per transform
+ { 18, 12, 24 }, // 186 bits per transform
+ { 18, 21, 23 }, // 186 bits per transform
+ { 18, 22, 22 }, // 186 bits per transform
+ { 18, 23, 21 }, // 186 bits per transform
+ { 18, 24, 12 }, // 186 bits per transform
+ { 19, 11, 24 }, // 186 bits per transform
+ { 19, 20, 23 }, // 186 bits per transform
+ { 19, 21, 22 }, // 186 bits per transform
+ { 19, 22, 21 }, // 186 bits per transform
+ { 19, 23, 20 }, // 186 bits per transform
+ { 19, 24, 11 }, // 186 bits per transform
+ { 20, 10, 24 }, // 186 bits per transform
+ { 20, 19, 23 }, // 186 bits per transform
+ { 20, 20, 22 }, // 186 bits per transform
+ { 20, 21, 21 }, // 186 bits per transform
+ { 20, 22, 20 }, // 186 bits per transform
+ { 20, 23, 19 }, // 186 bits per transform
+ { 20, 24, 10 }, // 186 bits per transform
+ { 21, 9, 24 }, // 186 bits per transform
+ { 21, 18, 23 }, // 186 bits per transform
+ { 21, 19, 22 }, // 186 bits per transform
+ { 21, 20, 21 }, // 186 bits per transform
+ { 21, 21, 20 }, // 186 bits per transform
+ { 21, 22, 19 }, // 186 bits per transform
+ { 21, 23, 18 }, // 186 bits per transform
+ { 21, 24, 9 }, // 186 bits per transform
+ { 22, 8, 24 }, // 186 bits per transform
+ { 22, 17, 23 }, // 186 bits per transform
+ { 22, 18, 22 }, // 186 bits per transform
+ { 22, 19, 21 }, // 186 bits per transform
+ { 22, 20, 20 }, // 186 bits per transform
+ { 22, 21, 19 }, // 186 bits per transform
+ { 22, 22, 18 }, // 186 bits per transform
+ { 22, 23, 17 }, // 186 bits per transform
+ { 22, 24, 8 }, // 186 bits per transform
+ { 23, 7, 24 }, // 186 bits per transform
+ { 23, 16, 23 }, // 186 bits per transform
+ { 23, 17, 22 }, // 186 bits per transform
+ { 23, 18, 21 }, // 186 bits per transform
+ { 23, 19, 20 }, // 186 bits per transform
+ { 23, 20, 19 }, // 186 bits per transform
+ { 23, 21, 18 }, // 186 bits per transform
+ { 23, 22, 17 }, // 186 bits per transform
+ { 23, 23, 16 }, // 186 bits per transform
+ { 23, 24, 7 }, // 186 bits per transform
+ { 24, 7, 23 }, // 186 bits per transform
+ { 24, 8, 22 }, // 186 bits per transform
+ { 24, 9, 21 }, // 186 bits per transform
+ { 24, 10, 20 }, // 186 bits per transform
+ { 24, 11, 19 }, // 186 bits per transform
+ { 24, 12, 18 }, // 186 bits per transform
+ { 24, 13, 17 }, // 186 bits per transform
+ { 24, 14, 16 }, // 186 bits per transform
+ { 24, 15, 15 }, // 186 bits per transform
+ { 24, 16, 14 }, // 186 bits per transform
+ { 24, 17, 13 }, // 186 bits per transform
+ { 24, 18, 12 }, // 186 bits per transform
+ { 24, 19, 11 }, // 186 bits per transform
+ { 24, 20, 10 }, // 186 bits per transform
+ { 24, 21, 9 }, // 186 bits per transform
+ { 24, 22, 8 }, // 186 bits per transform
+ { 24, 23, 7 }, // 186 bits per transform
+ { 8, 23, 24 }, // 189 bits per transform
+ { 8, 24, 23 }, // 189 bits per transform
+ { 9, 22, 24 }, // 189 bits per transform
+ { 9, 24, 22 }, // 189 bits per transform
+ { 10, 21, 24 }, // 189 bits per transform
+ { 10, 24, 21 }, // 189 bits per transform
+ { 11, 20, 24 }, // 189 bits per transform
+ { 11, 24, 20 }, // 189 bits per transform
+ { 12, 19, 24 }, // 189 bits per transform
+ { 12, 24, 19 }, // 189 bits per transform
+ { 13, 18, 24 }, // 189 bits per transform
+ { 13, 24, 18 }, // 189 bits per transform
+ { 14, 17, 24 }, // 189 bits per transform
+ { 14, 24, 17 }, // 189 bits per transform
+ { 15, 16, 24 }, // 189 bits per transform
+ { 15, 24, 16 }, // 189 bits per transform
+ { 16, 15, 24 }, // 189 bits per transform
+ { 16, 24, 15 }, // 189 bits per transform
+ { 17, 14, 24 }, // 189 bits per transform
+ { 17, 23, 23 }, // 189 bits per transform
+ { 17, 24, 14 }, // 189 bits per transform
+ { 18, 13, 24 }, // 189 bits per transform
+ { 18, 22, 23 }, // 189 bits per transform
+ { 18, 23, 22 }, // 189 bits per transform
+ { 18, 24, 13 }, // 189 bits per transform
+ { 19, 12, 24 }, // 189 bits per transform
+ { 19, 21, 23 }, // 189 bits per transform
+ { 19, 22, 22 }, // 189 bits per transform
+ { 19, 23, 21 }, // 189 bits per transform
+ { 19, 24, 12 }, // 189 bits per transform
+ { 20, 11, 24 }, // 189 bits per transform
+ { 20, 20, 23 }, // 189 bits per transform
+ { 20, 21, 22 }, // 189 bits per transform
+ { 20, 22, 21 }, // 189 bits per transform
+ { 20, 23, 20 }, // 189 bits per transform
+ { 20, 24, 11 }, // 189 bits per transform
+ { 21, 10, 24 }, // 189 bits per transform
+ { 21, 19, 23 }, // 189 bits per transform
+ { 21, 20, 22 }, // 189 bits per transform
+ { 21, 21, 21 }, // 189 bits per transform
+ { 21, 22, 20 }, // 189 bits per transform
+ { 21, 23, 19 }, // 189 bits per transform
+ { 21, 24, 10 }, // 189 bits per transform
+ { 22, 9, 24 }, // 189 bits per transform
+ { 22, 18, 23 }, // 189 bits per transform
+ { 22, 19, 22 }, // 189 bits per transform
+ { 22, 20, 21 }, // 189 bits per transform
+ { 22, 21, 20 }, // 189 bits per transform
+ { 22, 22, 19 }, // 189 bits per transform
+ { 22, 23, 18 }, // 189 bits per transform
+ { 22, 24, 9 }, // 189 bits per transform
+ { 23, 8, 24 }, // 189 bits per transform
+ { 23, 17, 23 }, // 189 bits per transform
+ { 23, 18, 22 }, // 189 bits per transform
+ { 23, 19, 21 }, // 189 bits per transform
+ { 23, 20, 20 }, // 189 bits per transform
+ { 23, 21, 19 }, // 189 bits per transform
+ { 23, 22, 18 }, // 189 bits per transform
+ { 23, 23, 17 }, // 189 bits per transform
+ { 23, 24, 8 }, // 189 bits per transform
+ { 24, 8, 23 }, // 189 bits per transform
+ { 24, 9, 22 }, // 189 bits per transform
+ { 24, 10, 21 }, // 189 bits per transform
+ { 24, 11, 20 }, // 189 bits per transform
+ { 24, 12, 19 }, // 189 bits per transform
+ { 24, 13, 18 }, // 189 bits per transform
+ { 24, 14, 17 }, // 189 bits per transform
+ { 24, 15, 16 }, // 189 bits per transform
+ { 24, 16, 15 }, // 189 bits per transform
+ { 24, 17, 14 }, // 189 bits per transform
+ { 24, 18, 13 }, // 189 bits per transform
+ { 24, 19, 12 }, // 189 bits per transform
+ { 24, 20, 11 }, // 189 bits per transform
+ { 24, 21, 10 }, // 189 bits per transform
+ { 24, 22, 9 }, // 189 bits per transform
+ { 24, 23, 8 }, // 189 bits per transform
+ { 0, 24, 24 }, // 192 bits per transform
+ { 9, 23, 24 }, // 192 bits per transform
+ { 9, 24, 23 }, // 192 bits per transform
+ { 10, 22, 24 }, // 192 bits per transform
+ { 10, 24, 22 }, // 192 bits per transform
+ { 11, 21, 24 }, // 192 bits per transform
+ { 11, 24, 21 }, // 192 bits per transform
+ { 12, 20, 24 }, // 192 bits per transform
+ { 12, 24, 20 }, // 192 bits per transform
+ { 13, 19, 24 }, // 192 bits per transform
+ { 13, 24, 19 }, // 192 bits per transform
+ { 14, 18, 24 }, // 192 bits per transform
+ { 14, 24, 18 }, // 192 bits per transform
+ { 15, 17, 24 }, // 192 bits per transform
+ { 15, 24, 17 }, // 192 bits per transform
+ { 16, 16, 24 }, // 192 bits per transform
+ { 16, 24, 16 }, // 192 bits per transform
+ { 17, 15, 24 }, // 192 bits per transform
+ { 17, 24, 15 }, // 192 bits per transform
+ { 18, 14, 24 }, // 192 bits per transform
+ { 18, 23, 23 }, // 192 bits per transform
+ { 18, 24, 14 }, // 192 bits per transform
+ { 19, 13, 24 }, // 192 bits per transform
+ { 19, 22, 23 }, // 192 bits per transform
+ { 19, 23, 22 }, // 192 bits per transform
+ { 19, 24, 13 }, // 192 bits per transform
+ { 20, 12, 24 }, // 192 bits per transform
+ { 20, 21, 23 }, // 192 bits per transform
+ { 20, 22, 22 }, // 192 bits per transform
+ { 20, 23, 21 }, // 192 bits per transform
+ { 20, 24, 12 }, // 192 bits per transform
+ { 21, 11, 24 }, // 192 bits per transform
+ { 21, 20, 23 }, // 192 bits per transform
+ { 21, 21, 22 }, // 192 bits per transform
+ { 21, 22, 21 }, // 192 bits per transform
+ { 21, 23, 20 }, // 192 bits per transform
+ { 21, 24, 11 }, // 192 bits per transform
+ { 22, 10, 24 }, // 192 bits per transform
+ { 22, 19, 23 }, // 192 bits per transform
+ { 22, 20, 22 }, // 192 bits per transform
+ { 22, 21, 21 }, // 192 bits per transform
+ { 22, 22, 20 }, // 192 bits per transform
+ { 22, 23, 19 }, // 192 bits per transform
+ { 22, 24, 10 }, // 192 bits per transform
+ { 23, 9, 24 }, // 192 bits per transform
+ { 23, 18, 23 }, // 192 bits per transform
+ { 23, 19, 22 }, // 192 bits per transform
+ { 23, 20, 21 }, // 192 bits per transform
+ { 23, 21, 20 }, // 192 bits per transform
+ { 23, 22, 19 }, // 192 bits per transform
+ { 23, 23, 18 }, // 192 bits per transform
+ { 23, 24, 9 }, // 192 bits per transform
+ { 24, 0, 24 }, // 192 bits per transform
+ { 24, 9, 23 }, // 192 bits per transform
+ { 24, 10, 22 }, // 192 bits per transform
+ { 24, 11, 21 }, // 192 bits per transform
+ { 24, 12, 20 }, // 192 bits per transform
+ { 24, 13, 19 }, // 192 bits per transform
+ { 24, 14, 18 }, // 192 bits per transform
+ { 24, 15, 17 }, // 192 bits per transform
+ { 24, 16, 16 }, // 192 bits per transform
+ { 24, 17, 15 }, // 192 bits per transform
+ { 24, 18, 14 }, // 192 bits per transform
+ { 24, 19, 13 }, // 192 bits per transform
+ { 24, 20, 12 }, // 192 bits per transform
+ { 24, 21, 11 }, // 192 bits per transform
+ { 24, 22, 10 }, // 192 bits per transform
+ { 24, 23, 9 }, // 192 bits per transform
+ { 24, 24, 0 }, // 192 bits per transform
+ { 1, 24, 24 }, // 195 bits per transform
+ { 10, 23, 24 }, // 195 bits per transform
+ { 10, 24, 23 }, // 195 bits per transform
+ { 11, 22, 24 }, // 195 bits per transform
+ { 11, 24, 22 }, // 195 bits per transform
+ { 12, 21, 24 }, // 195 bits per transform
+ { 12, 24, 21 }, // 195 bits per transform
+ { 13, 20, 24 }, // 195 bits per transform
+ { 13, 24, 20 }, // 195 bits per transform
+ { 14, 19, 24 }, // 195 bits per transform
+ { 14, 24, 19 }, // 195 bits per transform
+ { 15, 18, 24 }, // 195 bits per transform
+ { 15, 24, 18 }, // 195 bits per transform
+ { 16, 17, 24 }, // 195 bits per transform
+ { 16, 24, 17 }, // 195 bits per transform
+ { 17, 16, 24 }, // 195 bits per transform
+ { 17, 24, 16 }, // 195 bits per transform
+ { 18, 15, 24 }, // 195 bits per transform
+ { 18, 24, 15 }, // 195 bits per transform
+ { 19, 14, 24 }, // 195 bits per transform
+ { 19, 23, 23 }, // 195 bits per transform
+ { 19, 24, 14 }, // 195 bits per transform
+ { 20, 13, 24 }, // 195 bits per transform
+ { 20, 22, 23 }, // 195 bits per transform
+ { 20, 23, 22 }, // 195 bits per transform
+ { 20, 24, 13 }, // 195 bits per transform
+ { 21, 12, 24 }, // 195 bits per transform
+ { 21, 21, 23 }, // 195 bits per transform
+ { 21, 22, 22 }, // 195 bits per transform
+ { 21, 23, 21 }, // 195 bits per transform
+ { 21, 24, 12 }, // 195 bits per transform
+ { 22, 11, 24 }, // 195 bits per transform
+ { 22, 20, 23 }, // 195 bits per transform
+ { 22, 21, 22 }, // 195 bits per transform
+ { 22, 22, 21 }, // 195 bits per transform
+ { 22, 23, 20 }, // 195 bits per transform
+ { 22, 24, 11 }, // 195 bits per transform
+ { 23, 10, 24 }, // 195 bits per transform
+ { 23, 19, 23 }, // 195 bits per transform
+ { 23, 20, 22 }, // 195 bits per transform
+ { 23, 21, 21 }, // 195 bits per transform
+ { 23, 22, 20 }, // 195 bits per transform
+ { 23, 23, 19 }, // 195 bits per transform
+ { 23, 24, 10 }, // 195 bits per transform
+ { 24, 1, 24 }, // 195 bits per transform
+ { 24, 10, 23 }, // 195 bits per transform
+ { 24, 11, 22 }, // 195 bits per transform
+ { 24, 12, 21 }, // 195 bits per transform
+ { 24, 13, 20 }, // 195 bits per transform
+ { 24, 14, 19 }, // 195 bits per transform
+ { 24, 15, 18 }, // 195 bits per transform
+ { 24, 16, 17 }, // 195 bits per transform
+ { 24, 17, 16 }, // 195 bits per transform
+ { 24, 18, 15 }, // 195 bits per transform
+ { 24, 19, 14 }, // 195 bits per transform
+ { 24, 20, 13 }, // 195 bits per transform
+ { 24, 21, 12 }, // 195 bits per transform
+ { 24, 22, 11 }, // 195 bits per transform
+ { 24, 23, 10 }, // 195 bits per transform
+ { 24, 24, 1 }, // 195 bits per transform
+ { 2, 24, 24 }, // 198 bits per transform
+ { 11, 23, 24 }, // 198 bits per transform
+ { 11, 24, 23 }, // 198 bits per transform
+ { 12, 22, 24 }, // 198 bits per transform
+ { 12, 24, 22 }, // 198 bits per transform
+ { 13, 21, 24 }, // 198 bits per transform
+ { 13, 24, 21 }, // 198 bits per transform
+ { 14, 20, 24 }, // 198 bits per transform
+ { 14, 24, 20 }, // 198 bits per transform
+ { 15, 19, 24 }, // 198 bits per transform
+ { 15, 24, 19 }, // 198 bits per transform
+ { 16, 18, 24 }, // 198 bits per transform
+ { 16, 24, 18 }, // 198 bits per transform
+ { 17, 17, 24 }, // 198 bits per transform
+ { 17, 24, 17 }, // 198 bits per transform
+ { 18, 16, 24 }, // 198 bits per transform
+ { 18, 24, 16 }, // 198 bits per transform
+ { 19, 15, 24 }, // 198 bits per transform
+ { 19, 24, 15 }, // 198 bits per transform
+ { 20, 14, 24 }, // 198 bits per transform
+ { 20, 23, 23 }, // 198 bits per transform
+ { 20, 24, 14 }, // 198 bits per transform
+ { 21, 13, 24 }, // 198 bits per transform
+ { 21, 22, 23 }, // 198 bits per transform
+ { 21, 23, 22 }, // 198 bits per transform
+ { 21, 24, 13 }, // 198 bits per transform
+ { 22, 12, 24 }, // 198 bits per transform
+ { 22, 21, 23 }, // 198 bits per transform
+ { 22, 22, 22 }, // 198 bits per transform
+ { 22, 23, 21 }, // 198 bits per transform
+ { 22, 24, 12 }, // 198 bits per transform
+ { 23, 11, 24 }, // 198 bits per transform
+ { 23, 20, 23 }, // 198 bits per transform
+ { 23, 21, 22 }, // 198 bits per transform
+ { 23, 22, 21 }, // 198 bits per transform
+ { 23, 23, 20 }, // 198 bits per transform
+ { 23, 24, 11 }, // 198 bits per transform
+ { 24, 2, 24 }, // 198 bits per transform
+ { 24, 11, 23 }, // 198 bits per transform
+ { 24, 12, 22 }, // 198 bits per transform
+ { 24, 13, 21 }, // 198 bits per transform
+ { 24, 14, 20 }, // 198 bits per transform
+ { 24, 15, 19 }, // 198 bits per transform
+ { 24, 16, 18 }, // 198 bits per transform
+ { 24, 17, 17 }, // 198 bits per transform
+ { 24, 18, 16 }, // 198 bits per transform
+ { 24, 19, 15 }, // 198 bits per transform
+ { 24, 20, 14 }, // 198 bits per transform
+ { 24, 21, 13 }, // 198 bits per transform
+ { 24, 22, 12 }, // 198 bits per transform
+ { 24, 23, 11 }, // 198 bits per transform
+ { 24, 24, 2 }, // 198 bits per transform
+ { 3, 24, 24 }, // 201 bits per transform
+ { 12, 23, 24 }, // 201 bits per transform
+ { 12, 24, 23 }, // 201 bits per transform
+ { 13, 22, 24 }, // 201 bits per transform
+ { 13, 24, 22 }, // 201 bits per transform
+ { 14, 21, 24 }, // 201 bits per transform
+ { 14, 24, 21 }, // 201 bits per transform
+ { 15, 20, 24 }, // 201 bits per transform
+ { 15, 24, 20 }, // 201 bits per transform
+ { 16, 19, 24 }, // 201 bits per transform
+ { 16, 24, 19 }, // 201 bits per transform
+ { 17, 18, 24 }, // 201 bits per transform
+ { 17, 24, 18 }, // 201 bits per transform
+ { 18, 17, 24 }, // 201 bits per transform
+ { 18, 24, 17 }, // 201 bits per transform
+ { 19, 16, 24 }, // 201 bits per transform
+ { 19, 24, 16 }, // 201 bits per transform
+ { 20, 15, 24 }, // 201 bits per transform
+ { 20, 24, 15 }, // 201 bits per transform
+ { 21, 14, 24 }, // 201 bits per transform
+ { 21, 23, 23 }, // 201 bits per transform
+ { 21, 24, 14 }, // 201 bits per transform
+ { 22, 13, 24 }, // 201 bits per transform
+ { 22, 22, 23 }, // 201 bits per transform
+ { 22, 23, 22 }, // 201 bits per transform
+ { 22, 24, 13 }, // 201 bits per transform
+ { 23, 12, 24 }, // 201 bits per transform
+ { 23, 21, 23 }, // 201 bits per transform
+ { 23, 22, 22 }, // 201 bits per transform
+ { 23, 23, 21 }, // 201 bits per transform
+ { 23, 24, 12 }, // 201 bits per transform
+ { 24, 3, 24 }, // 201 bits per transform
+ { 24, 12, 23 }, // 201 bits per transform
+ { 24, 13, 22 }, // 201 bits per transform
+ { 24, 14, 21 }, // 201 bits per transform
+ { 24, 15, 20 }, // 201 bits per transform
+ { 24, 16, 19 }, // 201 bits per transform
+ { 24, 17, 18 }, // 201 bits per transform
+ { 24, 18, 17 }, // 201 bits per transform
+ { 24, 19, 16 }, // 201 bits per transform
+ { 24, 20, 15 }, // 201 bits per transform
+ { 24, 21, 14 }, // 201 bits per transform
+ { 24, 22, 13 }, // 201 bits per transform
+ { 24, 23, 12 }, // 201 bits per transform
+ { 24, 24, 3 }, // 201 bits per transform
+ { 4, 24, 24 }, // 204 bits per transform
+ { 13, 23, 24 }, // 204 bits per transform
+ { 13, 24, 23 }, // 204 bits per transform
+ { 14, 22, 24 }, // 204 bits per transform
+ { 14, 24, 22 }, // 204 bits per transform
+ { 15, 21, 24 }, // 204 bits per transform
+ { 15, 24, 21 }, // 204 bits per transform
+ { 16, 20, 24 }, // 204 bits per transform
+ { 16, 24, 20 }, // 204 bits per transform
+ { 17, 19, 24 }, // 204 bits per transform
+ { 17, 24, 19 }, // 204 bits per transform
+ { 18, 18, 24 }, // 204 bits per transform
+ { 18, 24, 18 }, // 204 bits per transform
+ { 19, 17, 24 }, // 204 bits per transform
+ { 19, 24, 17 }, // 204 bits per transform
+ { 20, 16, 24 }, // 204 bits per transform
+ { 20, 24, 16 }, // 204 bits per transform
+ { 21, 15, 24 }, // 204 bits per transform
+ { 21, 24, 15 }, // 204 bits per transform
+ { 22, 14, 24 }, // 204 bits per transform
+ { 22, 23, 23 }, // 204 bits per transform
+ { 22, 24, 14 }, // 204 bits per transform
+ { 23, 13, 24 }, // 204 bits per transform
+ { 23, 22, 23 }, // 204 bits per transform
+ { 23, 23, 22 }, // 204 bits per transform
+ { 23, 24, 13 }, // 204 bits per transform
+ { 24, 4, 24 }, // 204 bits per transform
+ { 24, 13, 23 }, // 204 bits per transform
+ { 24, 14, 22 }, // 204 bits per transform
+ { 24, 15, 21 }, // 204 bits per transform
+ { 24, 16, 20 }, // 204 bits per transform
+ { 24, 17, 19 }, // 204 bits per transform
+ { 24, 18, 18 }, // 204 bits per transform
+ { 24, 19, 17 }, // 204 bits per transform
+ { 24, 20, 16 }, // 204 bits per transform
+ { 24, 21, 15 }, // 204 bits per transform
+ { 24, 22, 14 }, // 204 bits per transform
+ { 24, 23, 13 }, // 204 bits per transform
+ { 24, 24, 4 }, // 204 bits per transform
+ { 5, 24, 24 }, // 207 bits per transform
+ { 14, 23, 24 }, // 207 bits per transform
+ { 14, 24, 23 }, // 207 bits per transform
+ { 15, 22, 24 }, // 207 bits per transform
+ { 15, 24, 22 }, // 207 bits per transform
+ { 16, 21, 24 }, // 207 bits per transform
+ { 16, 24, 21 }, // 207 bits per transform
+ { 17, 20, 24 }, // 207 bits per transform
+ { 17, 24, 20 }, // 207 bits per transform
+ { 18, 19, 24 }, // 207 bits per transform
+ { 18, 24, 19 }, // 207 bits per transform
+ { 19, 18, 24 }, // 207 bits per transform
+ { 19, 24, 18 }, // 207 bits per transform
+ { 20, 17, 24 }, // 207 bits per transform
+ { 20, 24, 17 }, // 207 bits per transform
+ { 21, 16, 24 }, // 207 bits per transform
+ { 21, 24, 16 }, // 207 bits per transform
+ { 22, 15, 24 }, // 207 bits per transform
+ { 22, 24, 15 }, // 207 bits per transform
+ { 23, 14, 24 }, // 207 bits per transform
+ { 23, 23, 23 }, // 207 bits per transform
+ { 23, 24, 14 }, // 207 bits per transform
+ { 24, 5, 24 }, // 207 bits per transform
+ { 24, 14, 23 }, // 207 bits per transform
+ { 24, 15, 22 }, // 207 bits per transform
+ { 24, 16, 21 }, // 207 bits per transform
+ { 24, 17, 20 }, // 207 bits per transform
+ { 24, 18, 19 }, // 207 bits per transform
+ { 24, 19, 18 }, // 207 bits per transform
+ { 24, 20, 17 }, // 207 bits per transform
+ { 24, 21, 16 }, // 207 bits per transform
+ { 24, 22, 15 }, // 207 bits per transform
+ { 24, 23, 14 }, // 207 bits per transform
+ { 24, 24, 5 }, // 207 bits per transform
+ { 6, 24, 24 }, // 210 bits per transform
+ { 15, 23, 24 }, // 210 bits per transform
+ { 15, 24, 23 }, // 210 bits per transform
+ { 16, 22, 24 }, // 210 bits per transform
+ { 16, 24, 22 }, // 210 bits per transform
+ { 17, 21, 24 }, // 210 bits per transform
+ { 17, 24, 21 }, // 210 bits per transform
+ { 18, 20, 24 }, // 210 bits per transform
+ { 18, 24, 20 }, // 210 bits per transform
+ { 19, 19, 24 }, // 210 bits per transform
+ { 19, 24, 19 }, // 210 bits per transform
+ { 20, 18, 24 }, // 210 bits per transform
+ { 20, 24, 18 }, // 210 bits per transform
+ { 21, 17, 24 }, // 210 bits per transform
+ { 21, 24, 17 }, // 210 bits per transform
+ { 22, 16, 24 }, // 210 bits per transform
+ { 22, 24, 16 }, // 210 bits per transform
+ { 23, 15, 24 }, // 210 bits per transform
+ { 23, 24, 15 }, // 210 bits per transform
+ { 24, 6, 24 }, // 210 bits per transform
+ { 24, 15, 23 }, // 210 bits per transform
+ { 24, 16, 22 }, // 210 bits per transform
+ { 24, 17, 21 }, // 210 bits per transform
+ { 24, 18, 20 }, // 210 bits per transform
+ { 24, 19, 19 }, // 210 bits per transform
+ { 24, 20, 18 }, // 210 bits per transform
+ { 24, 21, 17 }, // 210 bits per transform
+ { 24, 22, 16 }, // 210 bits per transform
+ { 24, 23, 15 }, // 210 bits per transform
+ { 24, 24, 6 }, // 210 bits per transform
+ { 7, 24, 24 }, // 213 bits per transform
+ { 16, 23, 24 }, // 213 bits per transform
+ { 16, 24, 23 }, // 213 bits per transform
+ { 17, 22, 24 }, // 213 bits per transform
+ { 17, 24, 22 }, // 213 bits per transform
+ { 18, 21, 24 }, // 213 bits per transform
+ { 18, 24, 21 }, // 213 bits per transform
+ { 19, 20, 24 }, // 213 bits per transform
+ { 19, 24, 20 }, // 213 bits per transform
+ { 20, 19, 24 }, // 213 bits per transform
+ { 20, 24, 19 }, // 213 bits per transform
+ { 21, 18, 24 }, // 213 bits per transform
+ { 21, 24, 18 }, // 213 bits per transform
+ { 22, 17, 24 }, // 213 bits per transform
+ { 22, 24, 17 }, // 213 bits per transform
+ { 23, 16, 24 }, // 213 bits per transform
+ { 23, 24, 16 }, // 213 bits per transform
+ { 24, 7, 24 }, // 213 bits per transform
+ { 24, 16, 23 }, // 213 bits per transform
+ { 24, 17, 22 }, // 213 bits per transform
+ { 24, 18, 21 }, // 213 bits per transform
+ { 24, 19, 20 }, // 213 bits per transform
+ { 24, 20, 19 }, // 213 bits per transform
+ { 24, 21, 18 }, // 213 bits per transform
+ { 24, 22, 17 }, // 213 bits per transform
+ { 24, 23, 16 }, // 213 bits per transform
+ { 24, 24, 7 }, // 213 bits per transform
+ { 8, 24, 24 }, // 216 bits per transform
+ { 17, 23, 24 }, // 216 bits per transform
+ { 17, 24, 23 }, // 216 bits per transform
+ { 18, 22, 24 }, // 216 bits per transform
+ { 18, 24, 22 }, // 216 bits per transform
+ { 19, 21, 24 }, // 216 bits per transform
+ { 19, 24, 21 }, // 216 bits per transform
+ { 20, 20, 24 }, // 216 bits per transform
+ { 20, 24, 20 }, // 216 bits per transform
+ { 21, 19, 24 }, // 216 bits per transform
+ { 21, 24, 19 }, // 216 bits per transform
+ { 22, 18, 24 }, // 216 bits per transform
+ { 22, 24, 18 }, // 216 bits per transform
+ { 23, 17, 24 }, // 216 bits per transform
+ { 23, 24, 17 }, // 216 bits per transform
+ { 24, 8, 24 }, // 216 bits per transform
+ { 24, 17, 23 }, // 216 bits per transform
+ { 24, 18, 22 }, // 216 bits per transform
+ { 24, 19, 21 }, // 216 bits per transform
+ { 24, 20, 20 }, // 216 bits per transform
+ { 24, 21, 19 }, // 216 bits per transform
+ { 24, 22, 18 }, // 216 bits per transform
+ { 24, 23, 17 }, // 216 bits per transform
+ { 24, 24, 8 }, // 216 bits per transform
+ { 9, 24, 24 }, // 219 bits per transform
+ { 18, 23, 24 }, // 219 bits per transform
+ { 18, 24, 23 }, // 219 bits per transform
+ { 19, 22, 24 }, // 219 bits per transform
+ { 19, 24, 22 }, // 219 bits per transform
+ { 20, 21, 24 }, // 219 bits per transform
+ { 20, 24, 21 }, // 219 bits per transform
+ { 21, 20, 24 }, // 219 bits per transform
+ { 21, 24, 20 }, // 219 bits per transform
+ { 22, 19, 24 }, // 219 bits per transform
+ { 22, 24, 19 }, // 219 bits per transform
+ { 23, 18, 24 }, // 219 bits per transform
+ { 23, 24, 18 }, // 219 bits per transform
+ { 24, 9, 24 }, // 219 bits per transform
+ { 24, 18, 23 }, // 219 bits per transform
+ { 24, 19, 22 }, // 219 bits per transform
+ { 24, 20, 21 }, // 219 bits per transform
+ { 24, 21, 20 }, // 219 bits per transform
+ { 24, 22, 19 }, // 219 bits per transform
+ { 24, 23, 18 }, // 219 bits per transform
+ { 24, 24, 9 }, // 219 bits per transform
+ { 10, 24, 24 }, // 222 bits per transform
+ { 19, 23, 24 }, // 222 bits per transform
+ { 19, 24, 23 }, // 222 bits per transform
+ { 20, 22, 24 }, // 222 bits per transform
+ { 20, 24, 22 }, // 222 bits per transform
+ { 21, 21, 24 }, // 222 bits per transform
+ { 21, 24, 21 }, // 222 bits per transform
+ { 22, 20, 24 }, // 222 bits per transform
+ { 22, 24, 20 }, // 222 bits per transform
+ { 23, 19, 24 }, // 222 bits per transform
+ { 23, 24, 19 }, // 222 bits per transform
+ { 24, 10, 24 }, // 222 bits per transform
+ { 24, 19, 23 }, // 222 bits per transform
+ { 24, 20, 22 }, // 222 bits per transform
+ { 24, 21, 21 }, // 222 bits per transform
+ { 24, 22, 20 }, // 222 bits per transform
+ { 24, 23, 19 }, // 222 bits per transform
+ { 24, 24, 10 }, // 222 bits per transform
+ { 11, 24, 24 }, // 225 bits per transform
+ { 20, 23, 24 }, // 225 bits per transform
+ { 20, 24, 23 }, // 225 bits per transform
+ { 21, 22, 24 }, // 225 bits per transform
+ { 21, 24, 22 }, // 225 bits per transform
+ { 22, 21, 24 }, // 225 bits per transform
+ { 22, 24, 21 }, // 225 bits per transform
+ { 23, 20, 24 }, // 225 bits per transform
+ { 23, 24, 20 }, // 225 bits per transform
+ { 24, 11, 24 }, // 225 bits per transform
+ { 24, 20, 23 }, // 225 bits per transform
+ { 24, 21, 22 }, // 225 bits per transform
+ { 24, 22, 21 }, // 225 bits per transform
+ { 24, 23, 20 }, // 225 bits per transform
+ { 24, 24, 11 }, // 225 bits per transform
+ { 12, 24, 24 }, // 228 bits per transform
+ { 21, 23, 24 }, // 228 bits per transform
+ { 21, 24, 23 }, // 228 bits per transform
+ { 22, 22, 24 }, // 228 bits per transform
+ { 22, 24, 22 }, // 228 bits per transform
+ { 23, 21, 24 }, // 228 bits per transform
+ { 23, 24, 21 }, // 228 bits per transform
+ { 24, 12, 24 }, // 228 bits per transform
+ { 24, 21, 23 }, // 228 bits per transform
+ { 24, 22, 22 }, // 228 bits per transform
+ { 24, 23, 21 }, // 228 bits per transform
+ { 24, 24, 12 }, // 228 bits per transform
+ { 13, 24, 24 }, // 231 bits per transform
+ { 22, 23, 24 }, // 231 bits per transform
+ { 22, 24, 23 }, // 231 bits per transform
+ { 23, 22, 24 }, // 231 bits per transform
+ { 23, 24, 22 }, // 231 bits per transform
+ { 24, 13, 24 }, // 231 bits per transform
+ { 24, 22, 23 }, // 231 bits per transform
+ { 24, 23, 22 }, // 231 bits per transform
+ { 24, 24, 13 }, // 231 bits per transform
+ { 14, 24, 24 }, // 234 bits per transform
+ { 23, 23, 24 }, // 234 bits per transform
+ { 23, 24, 23 }, // 234 bits per transform
+ { 24, 14, 24 }, // 234 bits per transform
+ { 24, 23, 23 }, // 234 bits per transform
+ { 24, 24, 14 }, // 234 bits per transform
+ { 15, 24, 24 }, // 237 bits per transform
+ { 24, 15, 24 }, // 237 bits per transform
+ { 24, 24, 15 }, // 237 bits per transform
+ { 16, 24, 24 }, // 240 bits per transform
+ { 24, 16, 24 }, // 240 bits per transform
+ { 24, 24, 16 }, // 240 bits per transform
+ { 17, 24, 24 }, // 243 bits per transform
+ { 24, 17, 24 }, // 243 bits per transform
+ { 24, 24, 17 }, // 243 bits per transform
+ { 18, 24, 24 }, // 246 bits per transform
+ { 24, 18, 24 }, // 246 bits per transform
+ { 24, 24, 18 }, // 246 bits per transform
+ { 19, 24, 24 }, // 249 bits per transform
+ { 24, 19, 24 }, // 249 bits per transform
+ { 24, 24, 19 }, // 249 bits per transform
+ { 20, 24, 24 }, // 252 bits per transform
+ { 24, 20, 24 }, // 252 bits per transform
+ { 24, 24, 20 }, // 252 bits per transform
+ { 21, 24, 24 }, // 255 bits per transform
+ { 24, 21, 24 }, // 255 bits per transform
+ { 24, 24, 21 }, // 255 bits per transform
+ { 22, 24, 24 }, // 258 bits per transform
+ { 24, 22, 24 }, // 258 bits per transform
+ { 24, 24, 22 }, // 258 bits per transform
+ { 23, 24, 24 }, // 261 bits per transform
+ { 24, 23, 24 }, // 261 bits per transform
+ { 24, 24, 23 }, // 261 bits per transform
+ { 24, 24, 24 }, // 288 bits per transform
};
}
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -334,8 +334,8 @@ namespace acl
}
else
{
- const uint64_t raw_sample_u64 = *safe_ptr_cast<const uint64_t>(raw_sample_ptr);
- memcpy_bits(animated_track_data_begin, out_bit_offset, &raw_sample_u64, 0, num_bits_at_bit_rate);
+ const uint64_t* raw_sample_u64 = safe_ptr_cast<const uint64_t>(raw_sample_ptr);
+ memcpy_bits(animated_track_data_begin, out_bit_offset, raw_sample_u64, 0, num_bits_at_bit_rate);
}
out_bit_offset += num_bits_at_bit_rate;
@@ -478,12 +478,29 @@ namespace acl
auto group_entry_action = [&segment, &format_per_track_group](animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)
{
const transform_streams& bone_stream = segment.bone_streams[bone_index];
+
+ uint32_t bit_rate;
if (group_type == animation_track_type8::rotation)
- format_per_track_group[group_size] = (uint8_t)get_num_bits_at_bit_rate(bone_stream.rotations.get_bit_rate());
+ bit_rate = bone_stream.rotations.get_bit_rate();
else if (group_type == animation_track_type8::translation)
- format_per_track_group[group_size] = (uint8_t)get_num_bits_at_bit_rate(bone_stream.translations.get_bit_rate());
+ bit_rate = bone_stream.translations.get_bit_rate();
else
- format_per_track_group[group_size] = (uint8_t)get_num_bits_at_bit_rate(bone_stream.scales.get_bit_rate());
+ bit_rate = bone_stream.scales.get_bit_rate();
+
+ const uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ ACL_ASSERT(num_bits <= 32, "Expected 32 bits or less");
+
+ // We only have 25 bit rates and the largest number of bits is 32 (highest bit rate).
+ // This would require 6 bits to store in the per sub-track metadata but it would leave
+ // most of the entries unused.
+ // Instead, we store the number of bits on 5 bits which has a max value of 31.
+ // To do so, we remap 32 to 31 since that value is unused.
+ // This leaves 3 unused bits in our per sub-track metadata.
+ // These will later be needed:
+ // - 1 bit to dictate if rotations contain 3 or 4 components (to allow mixing full quats in with packed quats)
+ // - 2 bits to dictate which rotation component is dropped (to allow the largest component to be dropped over our segment)
+
+ format_per_track_group[group_size] = (bit_rate == k_highest_bit_rate) ? 31 : (uint8_t)num_bits;
};
auto group_flush_action = [&format_per_track_data, format_per_track_data_end, &format_per_track_group](animation_track_type8 group_type, uint32_t group_size)
diff --git a/includes/acl/compression/impl/write_track_metadata.h b/includes/acl/compression/impl/write_track_metadata.h
--- a/includes/acl/compression/impl/write_track_metadata.h
+++ b/includes/acl/compression/impl/write_track_metadata.h
@@ -179,16 +179,13 @@ namespace acl
float* data = reinterpret_cast<float*>(output_buffer);
data[0] = desc.precision;
data[1] = desc.shell_distance;
- data[2] = desc.constant_rotation_threshold_angle;
- data[3] = desc.constant_translation_threshold;
- data[4] = desc.constant_scale_threshold;
- rtm::quat_store(desc.default_value.rotation, data + 5);
- rtm::vector_store3(desc.default_value.translation, data + 9);
- rtm::vector_store3(desc.default_value.scale, data + 12);
+ rtm::quat_store(desc.default_value.rotation, data + 2);
+ rtm::vector_store3(desc.default_value.translation, data + 6);
+ rtm::vector_store3(desc.default_value.scale, data + 9);
}
- output_buffer += sizeof(float) * 15;
+ output_buffer += sizeof(float) * 12;
}
}
diff --git a/includes/acl/core/compressed_tracks_version.h b/includes/acl/core/compressed_tracks_version.h
--- a/includes/acl/core/compressed_tracks_version.h
+++ b/includes/acl/core/compressed_tracks_version.h
@@ -70,6 +70,7 @@ namespace acl
//v01_99_99 = 6, // ACL v2.0.0-wip
v02_00_00 = 7, // ACL v2.0.0
v02_01_99 = 8, // ACL v2.1.0-wip
+ v02_01_99_1 = 9, // ACL v2.1.0-wip (removed constant thresholds in track desc, increased bit rates, remapped raw num bits to 31 in compressed tracks)
//////////////////////////////////////////////////////////////////////////
// First version marker, this is equal to the first version supported: ACL 2.0.0
@@ -79,7 +80,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Always assigned to the latest version supported.
- latest = v02_01_99,
+ latest = v02_01_99_1,
};
ACL_IMPL_VERSION_NAMESPACE_END
diff --git a/includes/acl/core/fwd.h b/includes/acl/core/fwd.h
--- a/includes/acl/core/fwd.h
+++ b/includes/acl/core/fwd.h
@@ -82,14 +82,31 @@ namespace acl
namespace acl_impl
{
template <class item_type, bool is_const>
- class iterator_impl;
+ class array_iterator_impl;
+
+ template <class item_type, bool is_const>
+ class array_reverse_iterator_impl;
}
+ //ACL_DEPRECATED("Renamed to array_iterator, to be removed in v3.0")
+ template <class item_type>
+ using iterator = acl_impl::array_iterator_impl<item_type, false>;
+
+ template <class item_type>
+ using array_iterator = acl_impl::array_iterator_impl<item_type, false>;
+
+ template <class item_type>
+ using array_reverse_iterator = acl_impl::array_reverse_iterator_impl<item_type, false>;
+
+ //ACL_DEPRECATED("Renamed to const_array_iterator, to be removed in v3.0")
+ template <class item_type>
+ using const_iterator = acl_impl::array_iterator_impl<item_type, true>;
+
template <class item_type>
- using iterator = acl_impl::iterator_impl<item_type, false>;
+ using const_array_iterator = acl_impl::array_iterator_impl<item_type, true>;
template <class item_type>
- using const_iterator = acl_impl::iterator_impl<item_type, true>;
+ using const_array_reverse_iterator = acl_impl::array_reverse_iterator_impl<item_type, true>;
struct invalid_ptr_offset;
template<typename data_type, typename offset_type> class ptr_offset;
diff --git a/includes/acl/core/impl/compiler_utils.h b/includes/acl/core/impl/compiler_utils.h
--- a/includes/acl/core/impl/compiler_utils.h
+++ b/includes/acl/core/impl/compiler_utils.h
@@ -118,5 +118,5 @@ namespace acl
// When enabled, constant sub-tracks will use the weighted average of every sample instead of the first sample
// Disabled by default, most clips have no measurable gain but some clips suffer greatly, needs to be investigated, possibly a bug somewhere
+// Note: Code has been removed in the pull request that closes: https://github.com/nfrechette/acl/issues/353
//#define ACL_IMPL_ENABLE_WEIGHTED_AVERAGE_CONSTANT_SUB_TRACKS
-
diff --git a/includes/acl/core/impl/compressed_tracks.impl.h b/includes/acl/core/impl/compressed_tracks.impl.h
--- a/includes/acl/core/impl/compressed_tracks.impl.h
+++ b/includes/acl/core/impl/compressed_tracks.impl.h
@@ -238,6 +238,10 @@ namespace acl
if (version >= compressed_tracks_version16::v02_01_99)
track_description_size += sizeof(float) * 10;
+ // ACL 2.1 removes: constant thresholds
+ if (version >= compressed_tracks_version16::v02_01_99_1)
+ track_description_size -= sizeof(float) * 3;
+
const float* description_data = reinterpret_cast<const float*>(descriptions + (size_t(track_index) * track_description_size));
// Because the data has already been compressed, any track output remapping has already happened
@@ -246,15 +250,17 @@ namespace acl
out_description.parent_index = parent_track_indices[track_index];
out_description.precision = description_data[0];
out_description.shell_distance = description_data[1];
- out_description.constant_rotation_threshold_angle = description_data[2];
- out_description.constant_translation_threshold = description_data[3];
- out_description.constant_scale_threshold = description_data[4];
+ // ACL 2.1 adds: default_value
if (version >= compressed_tracks_version16::v02_01_99)
{
- out_description.default_value.rotation = rtm::quat_load(description_data + 5);
- out_description.default_value.translation = rtm::vector_load3(description_data + 9);
- out_description.default_value.scale = rtm::vector_load3(description_data + 12);
+ // ACL 2.1 removes: constant thresholds
+ if (version < compressed_tracks_version16::v02_01_99_1)
+ description_data += 3;
+
+ out_description.default_value.rotation = rtm::quat_load(description_data + 2);
+ out_description.default_value.translation = rtm::vector_load3(description_data + 6);
+ out_description.default_value.scale = rtm::vector_load3(description_data + 9);
}
else
{
diff --git a/includes/acl/core/impl/track_desc.impl.h b/includes/acl/core/impl/track_desc.impl.h
--- a/includes/acl/core/impl/track_desc.impl.h
+++ b/includes/acl/core/impl/track_desc.impl.h
@@ -55,15 +55,6 @@ namespace acl
if (shell_distance < 0.0F || !rtm::scalar_is_finite(shell_distance))
return error_result("Invalid shell_distance");
- if (constant_rotation_threshold_angle < 0.0F || !rtm::scalar_is_finite(constant_rotation_threshold_angle))
- return error_result("Invalid constant_rotation_threshold_angle");
-
- if (constant_translation_threshold < 0.0F || !rtm::scalar_is_finite(constant_translation_threshold))
- return error_result("Invalid constant_translation_threshold");
-
- if (constant_scale_threshold < 0.0F || !rtm::scalar_is_finite(constant_scale_threshold))
- return error_result("Invalid constant_scale_threshold");
-
if (!rtm::qvv_is_finite(default_value))
return error_result("Invalid default_value must be finite");
diff --git a/includes/acl/core/impl/variable_bit_rates.h b/includes/acl/core/impl/variable_bit_rates.h
--- a/includes/acl/core/impl/variable_bit_rates.h
+++ b/includes/acl/core/impl/variable_bit_rates.h
@@ -38,15 +38,19 @@ namespace acl
namespace acl_impl
{
- // Bit rate 0 is reserved for tracks that are constant in a segment
- constexpr uint8_t k_bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+ // Used by ACL 2.0 and earlier
+ constexpr uint8_t k_bit_rate_num_bits_v0[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+
+ // Used by ACL 2.1 and later
+ constexpr uint8_t k_bit_rate_num_bits[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 32 };
+ // Bit rate 0 is reserved for tracks that are constant in a segment
constexpr uint8_t k_invalid_bit_rate = 0xFF;
constexpr uint8_t k_lowest_bit_rate = 1;
constexpr uint8_t k_highest_bit_rate = sizeof(k_bit_rate_num_bits) - 1;
constexpr uint32_t k_num_bit_rates = sizeof(k_bit_rate_num_bits);
- static_assert(k_num_bit_rates == 19, "Expecting 19 bit rates");
+ static_assert(k_num_bit_rates == 25, "Expecting 25 bit rates");
inline uint32_t get_num_bits_at_bit_rate(uint32_t bit_rate)
{
diff --git a/includes/acl/core/iterator.h b/includes/acl/core/iterator.h
--- a/includes/acl/core/iterator.h
+++ b/includes/acl/core/iterator.h
@@ -39,12 +39,12 @@ namespace acl
namespace acl_impl
{
template <class item_type, bool is_const>
- class iterator_impl
+ class array_iterator_impl
{
public:
using item_ptr_type = typename std::conditional<is_const, const item_type*, item_type*>::type;
- constexpr iterator_impl(item_ptr_type items, size_t num_items) : m_items(items), m_num_items(num_items) {}
+ constexpr array_iterator_impl(item_ptr_type items, size_t num_items) : m_items(items), m_num_items(num_items) {}
constexpr item_ptr_type begin() const { return m_items; }
constexpr item_ptr_type end() const { return m_items + m_num_items; }
@@ -53,24 +53,90 @@ namespace acl
item_ptr_type m_items;
size_t m_num_items;
};
+
+ template <class item_type, bool is_const>
+ class array_reverse_iterator_impl
+ {
+ public:
+ using item_ptr_type = typename std::conditional<is_const, const item_type*, item_type*>::type;
+
+ constexpr array_reverse_iterator_impl(item_ptr_type items, size_t num_items) : m_items(items), m_num_items(num_items) {}
+
+ constexpr std::reverse_iterator<item_ptr_type> begin() const { return std::reverse_iterator<item_ptr_type>(m_items + m_num_items); }
+ constexpr std::reverse_iterator<item_ptr_type> end() const { return std::reverse_iterator<item_ptr_type>(m_items); }
+
+ private:
+ item_ptr_type m_items;
+ size_t m_num_items;
+ };
+ }
+
+ //ACL_DEPRECATED("Renamed to array_iterator, to be removed in v3.0")
+ template <class item_type>
+ using iterator = acl_impl::array_iterator_impl<item_type, false>;
+
+ template <class item_type>
+ using array_iterator = acl_impl::array_iterator_impl<item_type, false>;
+
+ //ACL_DEPRECATED("Renamed to const_array_iterator, to be removed in v3.0")
+ template <class item_type>
+ using const_iterator = acl_impl::array_iterator_impl<item_type, true>;
+
+ template <class item_type>
+ using const_array_iterator = acl_impl::array_iterator_impl<item_type, true>;
+
+ template <class item_type, size_t num_items>
+ array_iterator<item_type> make_iterator(item_type (&items)[num_items])
+ {
+ return array_iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type, size_t num_items>
+ const_array_iterator<item_type> make_iterator(item_type const (&items)[num_items])
+ {
+ return const_array_iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type>
+ array_iterator<item_type> make_iterator(item_type* items, size_t num_items)
+ {
+ return array_iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type>
+ const_array_iterator<item_type> make_iterator(const item_type* items, size_t num_items)
+ {
+ return const_array_iterator<item_type>(items, num_items);
}
template <class item_type>
- using iterator = acl_impl::iterator_impl<item_type, false>;
+ using array_reverse_iterator = acl_impl::array_reverse_iterator_impl<item_type, false>;
template <class item_type>
- using const_iterator = acl_impl::iterator_impl<item_type, true>;
+ using const_array_reverse_iterator = acl_impl::array_reverse_iterator_impl<item_type, true>;
template <class item_type, size_t num_items>
- iterator<item_type> make_iterator(item_type (&items)[num_items])
+ array_reverse_iterator<item_type> make_reverse_iterator(item_type(&items)[num_items])
{
- return iterator<item_type>(items, num_items);
+ return array_reverse_iterator<item_type>(items, num_items);
}
template <class item_type, size_t num_items>
- const_iterator<item_type> make_iterator(item_type const (&items)[num_items])
+ const_array_reverse_iterator<item_type> make_reverse_iterator(item_type const (&items)[num_items])
+ {
+ return const_array_reverse_iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type>
+ array_reverse_iterator<item_type> make_reverse_iterator(item_type* items, size_t num_items)
+ {
+ return array_reverse_iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type>
+ const_array_reverse_iterator<item_type> make_reverse_iterator(const item_type* items, size_t num_items)
{
- return const_iterator<item_type>(items, num_items);
+ return const_array_reverse_iterator<item_type>(items, num_items);
}
ACL_IMPL_VERSION_NAMESPACE_END
diff --git a/includes/acl/core/track_desc.h b/includes/acl/core/track_desc.h
--- a/includes/acl/core/track_desc.h
+++ b/includes/acl/core/track_desc.h
@@ -25,6 +25,7 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/version.h"
+#include "acl/core/error.h"
#include "acl/core/error_result.h"
#include "acl/core/track_types.h"
#include "acl/core/impl/compiler_utils.h"
@@ -70,6 +71,15 @@ namespace acl
error_result is_valid() const;
};
+ // Disable warning for implicit constructor using deprecated members
+#if defined(RTM_COMPILER_CLANG)
+ #pragma clang diagnostic push
+ #pragma clang diagnostic ignored "-Wdeprecated-declarations"
+#elif defined(RTM_COMPILER_GCC)
+ #pragma GCC diagnostic push
+ #pragma GCC diagnostic ignored "-Wdeprecated-declarations"
+#endif
+
//////////////////////////////////////////////////////////////////////////
// This structure describes the various settings for transform tracks.
// Used by: quatf, qvvf
@@ -126,12 +136,14 @@ namespace acl
// was chosen. You will typically NEVER need to change this, the value has been
// selected to be as safe as possible and is independent of game engine units.
// Defaults to '0.00284714461' radians
+ ACL_DEPRECATED("Replaced by error metric, to be removed in v3.0")
float constant_rotation_threshold_angle = 0.00284714461F;
//////////////////////////////////////////////////////////////////////////
// Threshold value to use when detecting if translation tracks are constant or default.
// Note that you will need to change this value if your units are not in centimeters.
// Defaults to '0.001' centimeters.
+ ACL_DEPRECATED("Replaced by error metric, to be removed in v3.0")
float constant_translation_threshold = 0.001F;
//////////////////////////////////////////////////////////////////////////
@@ -139,6 +151,7 @@ namespace acl
// There are no units for scale as such a value that was deemed safe was selected
// as a default.
// Defaults to '0.00001'
+ ACL_DEPRECATED("Replaced by error metric, to be removed in v3.0")
float constant_scale_threshold = 0.00001F;
uint32_t padding = 0;
@@ -154,6 +167,12 @@ namespace acl
error_result is_valid() const;
};
+#if defined(RTM_COMPILER_CLANG)
+ #pragma clang diagnostic pop
+#elif defined(RTM_COMPILER_GCC)
+ #pragma GCC diagnostic pop
+#endif
+
ACL_IMPL_VERSION_NAMESPACE_END
}
diff --git a/includes/acl/core/variable_bit_rates.h b/includes/acl/core/variable_bit_rates.h
--- a/includes/acl/core/variable_bit_rates.h
+++ b/includes/acl/core/variable_bit_rates.h
@@ -38,7 +38,7 @@ namespace acl
// Bit rate 0 is reserved for tracks that are constant in a segment
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
- constexpr uint8_t k_bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+ constexpr uint8_t k_bit_rate_num_bits[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 32 };
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
constexpr uint8_t k_invalid_bit_rate = 0xFF;
@@ -47,16 +47,15 @@ namespace acl
constexpr uint8_t k_lowest_bit_rate = 1;
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
- constexpr uint8_t k_highest_bit_rate = 18;
+ constexpr uint8_t k_highest_bit_rate = 24;
- ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
- constexpr uint32_t k_num_bit_rates = 19;
+ static_assert(get_array_size(k_bit_rate_num_bits) == 25, "Expecting 25 bit rates");
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
inline uint32_t get_num_bits_at_bit_rate(uint32_t bit_rate)
{
- ACL_ASSERT(bit_rate <= 18, "Invalid bit rate: %u", bit_rate);
- constexpr uint8_t bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+ ACL_ASSERT(bit_rate <= 24, "Invalid bit rate: %u", bit_rate);
+ constexpr uint8_t bit_rate_num_bits[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 32 };
return bit_rate_num_bits[bit_rate];
}
@@ -65,7 +64,7 @@ namespace acl
constexpr bool is_constant_bit_rate(uint32_t bit_rate) { return bit_rate == 0; }
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
- constexpr bool is_raw_bit_rate(uint32_t bit_rate) { return bit_rate == 18; }
+ constexpr bool is_raw_bit_rate(uint32_t bit_rate) { return bit_rate == 24; }
ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
struct BoneBitRate
diff --git a/includes/acl/decompression/impl/decompression_version_selector.h b/includes/acl/decompression/impl/decompression_version_selector.h
--- a/includes/acl/decompression/impl/decompression_version_selector.h
+++ b/includes/acl/decompression/impl/decompression_version_selector.h
@@ -106,6 +106,30 @@ namespace acl
RTM_FORCE_INLINE static void decompress_track(context_type& context, uint32_t track_index, track_writer_type& writer) { acl_impl::decompress_track_v0<decompression_settings_type>(context, track_index, writer); }
};
+ template<>
+ struct decompression_version_selector<compressed_tracks_version16::v02_01_99_1>
+ {
+ static constexpr bool is_version_supported(compressed_tracks_version16 version) { return version == compressed_tracks_version16::v02_01_99_1; }
+
+ template<class decompression_settings_type, class context_type, class database_settings_type>
+ RTM_FORCE_INLINE static bool initialize(context_type& context, const compressed_tracks& tracks, const database_context<database_settings_type>* database) { return acl_impl::initialize_v0<decompression_settings_type>(context, tracks, database); }
+
+ template<class context_type>
+ RTM_FORCE_INLINE static bool is_dirty(const context_type& context, const compressed_tracks& tracks) { return acl_impl::is_dirty_v0(context, tracks); }
+
+ template<class decompression_settings_type, class context_type>
+ RTM_FORCE_INLINE static void set_looping_policy(context_type& context, sample_looping_policy policy) { acl_impl::set_looping_policy_v0<decompression_settings_type>(context, policy); }
+
+ template<class decompression_settings_type, class context_type>
+ RTM_FORCE_INLINE static void seek(context_type& context, float sample_time, sample_rounding_policy rounding_policy) { acl_impl::seek_v0<decompression_settings_type>(context, sample_time, rounding_policy); }
+
+ template<class decompression_settings_type, class track_writer_type, class context_type>
+ RTM_FORCE_INLINE static void decompress_tracks(context_type& context, track_writer_type& writer) { acl_impl::decompress_tracks_v0<decompression_settings_type>(context, writer); }
+
+ template<class decompression_settings_type, class track_writer_type, class context_type>
+ RTM_FORCE_INLINE static void decompress_track(context_type& context, uint32_t track_index, track_writer_type& writer) { acl_impl::decompress_track_v0<decompression_settings_type>(context, track_index, writer); }
+ };
+
//////////////////////////////////////////////////////////////////////////
// Not optimized for any particular version.
//////////////////////////////////////////////////////////////////////////
@@ -126,6 +150,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
return acl_impl::initialize_v0<decompression_settings_type>(context, tracks, database);
default:
ACL_ASSERT(false, "Unsupported version");
@@ -141,6 +166,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
return acl_impl::is_dirty_v0(context, tracks);
default:
ACL_ASSERT(false, "Unsupported version");
@@ -156,6 +182,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
acl_impl::set_looping_policy_v0<decompression_settings_type>(context, policy);
break;
default:
@@ -172,6 +199,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
acl_impl::seek_v0<decompression_settings_type>(context, sample_time, rounding_policy);
break;
default:
@@ -188,6 +216,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
acl_impl::decompress_tracks_v0<decompression_settings_type>(context, writer);
break;
default:
@@ -204,6 +233,7 @@ namespace acl
{
case compressed_tracks_version16::v02_00_00:
case compressed_tracks_version16::v02_01_99:
+ case compressed_tracks_version16::v02_01_99_1:
acl_impl::decompress_track_v0<decompression_settings_type>(context, track_index, writer);
break;
default:
diff --git a/includes/acl/decompression/impl/scalar_track_decompression.h b/includes/acl/decompression/impl/scalar_track_decompression.h
--- a/includes/acl/decompression/impl/scalar_track_decompression.h
+++ b/includes/acl/decompression/impl/scalar_track_decompression.h
@@ -223,11 +223,19 @@ namespace acl
const track_type8 track_type = header.track_type;
+ const compressed_tracks_version16 version = context.get_version();
+ const uint8_t* num_bits_at_bit_rate = version == compressed_tracks_version16::v02_00_00 ? k_bit_rate_num_bits_v0 : k_bit_rate_num_bits;
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ const uint32_t max_bit_rate = version == compressed_tracks_version16::v02_00_00 ? sizeof(k_bit_rate_num_bits_v0) : sizeof(k_bit_rate_num_bits);
+#endif
+
for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
{
const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t bit_rate = metadata.bit_rate;
+ ACL_ASSERT(bit_rate < max_bit_rate, "Invalid bit rate: %u", bit_rate);
+ const uint32_t num_bits_per_component = num_bits_at_bit_rate[bit_rate];
rtm::scalarf alpha = interpolation_alpha;
if (decompression_settings_type::is_per_track_rounding_supported())
@@ -241,7 +249,7 @@ namespace acl
if (track_type == track_type8::float1f && decompression_settings_type::is_track_type_supported(track_type8::float1f))
{
rtm::scalarf value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
{
value = rtm::scalar_load(constant_values);
constant_values += 1;
@@ -250,7 +258,7 @@ namespace acl
{
rtm::scalarf value0;
rtm::scalarf value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset0);
value1 = unpack_scalarf_32_unsafe(animated_values, track_bit_offset1);
@@ -279,7 +287,7 @@ namespace acl
else if (track_type == track_type8::float2f && decompression_settings_type::is_track_type_supported(track_type8::float2f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
{
value = rtm::vector_load(constant_values);
constant_values += 2;
@@ -288,7 +296,7 @@ namespace acl
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector2_64_unsafe(animated_values, track_bit_offset0);
value1 = unpack_vector2_64_unsafe(animated_values, track_bit_offset1);
@@ -317,7 +325,7 @@ namespace acl
else if (track_type == track_type8::float3f && decompression_settings_type::is_track_type_supported(track_type8::float3f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
{
value = rtm::vector_load(constant_values);
constant_values += 3;
@@ -326,7 +334,7 @@ namespace acl
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector3_96_unsafe(animated_values, track_bit_offset0);
value1 = unpack_vector3_96_unsafe(animated_values, track_bit_offset1);
@@ -355,7 +363,7 @@ namespace acl
else if (track_type == track_type8::float4f && decompression_settings_type::is_track_type_supported(track_type8::float4f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
{
value = rtm::vector_load(constant_values);
constant_values += 4;
@@ -364,7 +372,7 @@ namespace acl
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
@@ -393,7 +401,7 @@ namespace acl
else if (track_type == track_type8::vector4f && decompression_settings_type::is_track_type_supported(track_type8::vector4f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
{
value = rtm::vector_load(constant_values);
constant_values += 4;
@@ -402,7 +410,7 @@ namespace acl
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
@@ -467,6 +475,13 @@ namespace acl
interpolation_alpha = rtm::scalar_set(apply_rounding_policy(context.interpolation_alpha, rounding_policy_));
}
+ const compressed_tracks_version16 version = context.get_version();
+ const uint8_t* num_bits_at_bit_rate = version == compressed_tracks_version16::v02_00_00 ? k_bit_rate_num_bits_v0 : k_bit_rate_num_bits;
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ const uint32_t max_bit_rate = version == compressed_tracks_version16::v02_00_00 ? sizeof(k_bit_rate_num_bits_v0) : sizeof(k_bit_rate_num_bits);
+#endif
+
const float* constant_values = scalars_header.get_track_constant_values();
const float* range_values = scalars_header.get_track_range_values();
@@ -478,32 +493,34 @@ namespace acl
for (uint32_t scan_track_index = 0; scan_track_index < track_index; ++scan_track_index)
{
const acl_impl::track_metadata& metadata = per_track_metadata[scan_track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t bit_rate = metadata.bit_rate;
+ ACL_ASSERT(bit_rate < max_bit_rate, "Invalid bit rate: %u", bit_rate);
+ const uint32_t num_bits_per_component = num_bits_at_bit_rate[bit_rate];
track_bit_offset += num_bits_per_component * num_element_components;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
constant_values += num_element_components;
- else if (!is_raw_bit_rate(bit_rate))
+ else if (num_bits_per_component < 32) // Not raw bit rate
range_values += num_element_components * 2;
}
const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
- const uint8_t bit_rate = metadata.bit_rate;
- const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ const uint32_t bit_rate = metadata.bit_rate;
+ ACL_ASSERT(bit_rate < max_bit_rate, "Invalid bit rate: %u", bit_rate);
+ const uint32_t num_bits_per_component = num_bits_at_bit_rate[bit_rate];
const uint8_t* animated_values = scalars_header.get_track_animated_values();
if (track_type == track_type8::float1f && decompression_settings_type::is_track_type_supported(track_type8::float1f))
{
rtm::scalarf value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
value = rtm::scalar_load(constant_values);
else
{
rtm::scalarf value0;
rtm::scalarf value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_scalarf_32_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
value1 = unpack_scalarf_32_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
@@ -527,13 +544,13 @@ namespace acl
else if (track_type == track_type8::float2f && decompression_settings_type::is_track_type_supported(track_type8::float2f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
value = rtm::vector_load(constant_values);
else
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector2_64_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
value1 = unpack_vector2_64_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
@@ -557,13 +574,13 @@ namespace acl
else if (track_type == track_type8::float3f && decompression_settings_type::is_track_type_supported(track_type8::float3f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
value = rtm::vector_load(constant_values);
else
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector3_96_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
value1 = unpack_vector3_96_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
@@ -587,13 +604,13 @@ namespace acl
else if (track_type == track_type8::float4f && decompression_settings_type::is_track_type_supported(track_type8::float4f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
value = rtm::vector_load(constant_values);
else
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
value1 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
@@ -617,13 +634,13 @@ namespace acl
else if (track_type == track_type8::vector4f && decompression_settings_type::is_track_type_supported(track_type8::vector4f))
{
rtm::vector4f value;
- if (is_constant_bit_rate(bit_rate))
+ if (num_bits_per_component == 0) // Constant bit rate
value = rtm::vector_load(constant_values);
else
{
rtm::vector4f value0;
rtm::vector4f value1;
- if (is_raw_bit_rate(bit_rate))
+ if (num_bits_per_component == 32) // Raw bit rate
{
value0 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[0] + track_bit_offset);
value1 = unpack_vector4_128_unsafe(animated_values, context.key_frame_bit_offsets[1] + track_bit_offset);
diff --git a/includes/acl/decompression/impl/transform_animated_track_cache.h b/includes/acl/decompression/impl/transform_animated_track_cache.h
--- a/includes/acl/decompression/impl/transform_animated_track_cache.h
+++ b/includes/acl/decompression/impl/transform_animated_track_cache.h
@@ -517,6 +517,10 @@ namespace acl
uint32_t num_to_unpack, segment_animated_sampling_context_v0& segment_sampling_context)
{
const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
+ const compressed_tracks_version16 version = get_version<decompression_settings_type>(decomp_context.get_version());
+
+ // See write_format_per_track_data(..) for details
+ const uint32_t num_raw_bit_rate_bits = version >= compressed_tracks_version16::v02_01_99_1 ? 31 : 32;
uint32_t segment_range_ignore_mask = 0;
uint32_t clip_range_ignore_mask = 0;
@@ -582,7 +586,7 @@ namespace acl
sample_segment_range_ignore_mask = 0xFF; // Ignore segment range
sample_clip_range_ignore_mask = 0x00;
}
- else if (num_bits_at_bit_rate == 32) // Raw bit rate
+ else if (num_bits_at_bit_rate == num_raw_bit_rate_bits) // Raw bit rate
{
rotation_as_vec = unpack_vector3_96_unsafe(animated_track_data, animated_track_data_bit_offset);
animated_track_data_bit_offset += 96;
@@ -688,6 +692,10 @@ namespace acl
const clip_animated_sampling_context_v0& clip_sampling_context, const segment_animated_sampling_context_v0& segment_sampling_context)
{
const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
+ const compressed_tracks_version16 version = get_version<decompression_settings_type>(decomp_context.get_version());
+
+ // See write_format_per_track_data(..) for details
+ const uint32_t num_raw_bit_rate_bits = version >= compressed_tracks_version16::v02_01_99_1 ? 31 : 32;
uint32_t segment_range_ignore_mask = 0;
uint32_t clip_range_ignore_mask = 0;
@@ -707,13 +715,23 @@ namespace acl
{
default:
case 3:
- skip_size += format_per_track_data[2];
+ {
+ // TODO: Can we do an alternate more efficient implementation? We want to increment by one if num bits == 31
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[2];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 2:
- skip_size += format_per_track_data[1];
+ {
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[1];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 1:
- skip_size += format_per_track_data[0];
+ {
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[0];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 0:
// Nothing to skip
@@ -762,7 +780,7 @@ namespace acl
segment_range_ignore_mask = 0xFF; // Ignore segment range
clip_range_ignore_mask = 0x00;
}
- else if (num_bits_at_bit_rate == 32) // Raw bit rate
+ else if (num_bits_at_bit_rate == num_raw_bit_rate_bits) // Raw bit rate
{
rotation_as_vec = unpack_vector3_96_unsafe(animated_track_data, animated_track_data_bit_offset);
segment_range_ignore_mask = 0xFF; // Ignore segment range
@@ -856,6 +874,10 @@ namespace acl
const clip_animated_sampling_context_v0& clip_sampling_context, segment_animated_sampling_context_v0& segment_sampling_context)
{
const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
+ const compressed_tracks_version16 version = get_version<decompression_settings_adapter_type>(decomp_context.get_version());
+
+ // See write_format_per_track_data(..) for details
+ const uint32_t num_raw_bit_rate_bits = version >= compressed_tracks_version16::v02_01_99_1 ? 31 : 32;
const uint8_t* format_per_track_data = segment_sampling_context.format_per_track_data;
const uint8_t* segment_range_data = segment_sampling_context.segment_range_data;
@@ -884,7 +906,7 @@ namespace acl
segment_range_data += sizeof(uint16_t) * 3;
range_ignore_flags = 0x01; // Skip segment only
}
- else if (num_bits_at_bit_rate == 32) // Raw bit rate
+ else if (num_bits_at_bit_rate == num_raw_bit_rate_bits) // Raw bit rate
{
sample = unpack_vector3_96_unsafe(animated_track_data, animated_track_data_bit_offset);
animated_track_data_bit_offset += 96;
@@ -973,6 +995,10 @@ namespace acl
const clip_animated_sampling_context_v0& clip_sampling_context, const segment_animated_sampling_context_v0& segment_sampling_context)
{
const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
+ const compressed_tracks_version16 version = get_version<decompression_settings_adapter_type>(decomp_context.get_version());
+
+ // See write_format_per_track_data(..) for details
+ const uint32_t num_raw_bit_rate_bits = version >= compressed_tracks_version16::v02_01_99_1 ? 31 : 32;
const uint8_t* format_per_track_data = segment_sampling_context.format_per_track_data;
const uint8_t* segment_range_data = segment_sampling_context.segment_range_data;
@@ -996,13 +1022,23 @@ namespace acl
{
default:
case 3:
- skip_size += format_per_track_data[2];
+ {
+ // TODO: Can we do an alternate more efficient implementation? We want to increment by one if num bits == 31
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[2];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 2:
- skip_size += format_per_track_data[1];
+ {
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[1];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 1:
- skip_size += format_per_track_data[0];
+ {
+ const uint32_t num_bits_at_bit_rate = format_per_track_data[0];
+ skip_size += (num_bits_at_bit_rate == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate;
+ }
ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
case 0:
// Nothing to skip
@@ -1021,7 +1057,7 @@ namespace acl
sample = unpack_vector3_u48_unsafe(segment_range_data);
range_ignore_flags = 0x01; // Skip segment only
}
- else if (num_bits_at_bit_rate == 32) // Raw bit rate
+ else if (num_bits_at_bit_rate == num_raw_bit_rate_bits) // Raw bit rate
{
sample = unpack_vector3_96_unsafe(animated_track_data, animated_track_data_bit_offset);
range_ignore_flags = 0x03; // Skip clip and segment
@@ -1066,13 +1102,21 @@ namespace acl
}
// Force inline this function, we only use it to keep the code readable
+ template<class decompression_settings_adapter_type>
RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK void count_animated_group_bit_size(
+ const persistent_transform_decompression_context_v0& decomp_context,
const uint8_t* format_per_track_data0, const uint8_t* format_per_track_data1, uint32_t num_groups_to_skip,
uint32_t& out_group_bit_size_per_component0, uint32_t& out_group_bit_size_per_component1)
{
+ const compressed_tracks_version16 version = get_version<decompression_settings_adapter_type>(decomp_context.get_version());
+
+ // See write_format_per_track_data(..) for details
+ const uint32_t num_raw_bit_rate_bits = version >= compressed_tracks_version16::v02_01_99_1 ? 31 : 32;
+
// TODO: Do the same with NEON
#if defined(RTM_AVX_INTRINSICS)
- __m128i zero = _mm_setzero_si128();
+ const __m128i zero = _mm_setzero_si128();
+ const __m128i num_raw_bit_rate_bits_v = _mm_set1_epi32(num_raw_bit_rate_bits);
__m128i group_bit_size_per_component0_v = zero;
__m128i group_bit_size_per_component1_v = zero;
@@ -1083,8 +1127,27 @@ namespace acl
const __m128i group_bit_size_per_component0_u8 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(format_per_track_data0 + group_offset));
const __m128i group_bit_size_per_component1_u8 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(format_per_track_data1 + group_offset));
- group_bit_size_per_component0_v = _mm_add_epi32(group_bit_size_per_component0_v, _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component0_u8, zero), zero));
- group_bit_size_per_component1_v = _mm_add_epi32(group_bit_size_per_component1_v, _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component1_u8, zero), zero));
+ // Unpack from uint8_t to uint32_t
+ __m128i group_bit_size_per_component0_u32 = _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component0_u8, zero), zero);
+ __m128i group_bit_size_per_component1_u32 = _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component1_u8, zero), zero);
+
+ if (version >= compressed_tracks_version16::v02_01_99_1)
+ {
+ // If the number of bits is 31, we are the raw bit rate and we need to add 1 (we'll add 31 below, and 1 more for a total of 32 bits)
+ // If the number of bits is 31, our mask's value will be 0xFFFFFFFF which is -1, otherwise it is 0x00000000
+ const __m128i is_raw_num_bits0 = _mm_cmpeq_epi32(group_bit_size_per_component0_u32, num_raw_bit_rate_bits_v);
+ const __m128i is_raw_num_bits1 = _mm_cmpeq_epi32(group_bit_size_per_component1_u32, num_raw_bit_rate_bits_v);
+
+ // We subtract the mask value directly, it is either -1 or 0
+ group_bit_size_per_component0_u32 = _mm_sub_epi32(group_bit_size_per_component0_u32, is_raw_num_bits0);
+ group_bit_size_per_component1_u32 = _mm_sub_epi32(group_bit_size_per_component1_u32, is_raw_num_bits1);
+ }
+ else
+ (void)num_raw_bit_rate_bits_v;
+
+ // Add how many bits per component we have
+ group_bit_size_per_component0_v = _mm_add_epi32(group_bit_size_per_component0_v, group_bit_size_per_component0_u32);
+ group_bit_size_per_component1_v = _mm_add_epi32(group_bit_size_per_component1_v, group_bit_size_per_component1_u32);
}
// Now we sum horizontally
@@ -1099,17 +1162,28 @@ namespace acl
for (uint32_t group_index = 0; group_index < num_groups_to_skip; ++group_index)
{
- group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 0];
- group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 0];
+ // TODO: Can we do an alternate more efficient implementation? We want to increment by one if num bits == 31
+
+ const uint32_t num_bits_at_bit_rate_0_0 = format_per_track_data0[(group_index * 4) + 0];
+ const uint32_t num_bits_at_bit_rate_1_0 = format_per_track_data1[(group_index * 4) + 0];
+ const uint32_t num_bits_at_bit_rate_0_1 = format_per_track_data0[(group_index * 4) + 1];
+ const uint32_t num_bits_at_bit_rate_1_1 = format_per_track_data1[(group_index * 4) + 1];
+ const uint32_t num_bits_at_bit_rate_0_2 = format_per_track_data0[(group_index * 4) + 2];
+ const uint32_t num_bits_at_bit_rate_1_2 = format_per_track_data1[(group_index * 4) + 2];
+ const uint32_t num_bits_at_bit_rate_0_3 = format_per_track_data0[(group_index * 4) + 3];
+ const uint32_t num_bits_at_bit_rate_1_3 = format_per_track_data1[(group_index * 4) + 3];
+
+ group_bit_size_per_component0 += (num_bits_at_bit_rate_0_0 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_0_0;
+ group_bit_size_per_component1 += (num_bits_at_bit_rate_1_0 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_1_0;
- group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 1];
- group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 1];
+ group_bit_size_per_component0 += (num_bits_at_bit_rate_0_1 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_0_1;
+ group_bit_size_per_component1 += (num_bits_at_bit_rate_1_1 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_1_1;
- group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 2];
- group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 2];
+ group_bit_size_per_component0 += (num_bits_at_bit_rate_0_2 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_0_2;
+ group_bit_size_per_component1 += (num_bits_at_bit_rate_1_2 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_1_2;
- group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 3];
- group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 3];
+ group_bit_size_per_component0 += (num_bits_at_bit_rate_0_3 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_0_3;
+ group_bit_size_per_component1 += (num_bits_at_bit_rate_1_3 == num_raw_bit_rate_bits) ? 32 : num_bits_at_bit_rate_1_3;
}
out_group_bit_size_per_component0 = group_bit_size_per_component0;
@@ -1603,7 +1677,7 @@ namespace acl
uint32_t group_bit_size_per_component0;
uint32_t group_bit_size_per_component1;
- count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
+ count_animated_group_bit_size<decompression_settings_type>(decomp_context, format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
@@ -1777,7 +1851,7 @@ namespace acl
uint32_t group_bit_size_per_component0;
uint32_t group_bit_size_per_component1;
- count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
+ count_animated_group_bit_size<decompression_settings_adapter_type>(decomp_context, format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
@@ -1899,7 +1973,7 @@ namespace acl
uint32_t group_bit_size_per_component0;
uint32_t group_bit_size_per_component1;
- count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
+ count_animated_group_bit_size<decompression_settings_adapter_type>(decomp_context, format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
diff --git a/includes/acl/decompression/impl/transform_decompression_context.h b/includes/acl/decompression/impl/transform_decompression_context.h
--- a/includes/acl/decompression/impl/transform_decompression_context.h
+++ b/includes/acl/decompression/impl/transform_decompression_context.h
@@ -120,6 +120,7 @@ namespace acl
static constexpr vector_format8 get_vector_format(const persistent_transform_decompression_context_v0& context) { return context.translation_format; }
static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_translation_format_supported(format); }
static constexpr bool is_per_track_rounding_supported() { return decompression_settings_type::is_per_track_rounding_supported(); }
+ static constexpr compressed_tracks_version16 version_supported() { return decompression_settings_type::version_supported(); }
};
template<class decompression_settings_type>
@@ -130,6 +131,7 @@ namespace acl
static constexpr vector_format8 get_vector_format(const persistent_transform_decompression_context_v0& context) { return context.scale_format; }
static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_scale_format_supported(format); }
static constexpr bool is_per_track_rounding_supported() { return decompression_settings_type::is_per_track_rounding_supported(); }
+ static constexpr compressed_tracks_version16 version_supported() { return decompression_settings_type::version_supported(); }
};
// Returns the statically known number of rotation formats supported by the decompression settings
@@ -189,6 +191,12 @@ namespace acl
// otherwise we always interpolate
: format == rotation_format8::quatf_full ? (interpolation_alpha > 0.0F && interpolation_alpha < 1.0F) : true;
}
+
+ template<class decompression_settings_type>
+ constexpr compressed_tracks_version16 get_version(compressed_tracks_version16 version)
+ {
+ return decompression_settings_type::version_supported() == compressed_tracks_version16::any ? version : decompression_settings_type::version_supported();
+ }
}
ACL_IMPL_VERSION_NAMESPACE_END
diff --git a/includes/acl/io/clip_reader.h b/includes/acl/io/clip_reader.h
--- a/includes/acl/io/clip_reader.h
+++ b/includes/acl/io/clip_reader.h
@@ -187,9 +187,6 @@ namespace acl
float m_additive_base_sample_rate = 0.0F;
bool m_has_settings = false;
- float m_constant_rotation_threshold_angle = 0.0F;
- float m_constant_translation_threshold = 0.0F;
- float m_constant_scale_threshold = 0.0F;
float m_error_threshold = 0.0F;
sjson::StringView* m_bone_names = nullptr;
@@ -420,9 +417,6 @@ namespace acl
if (!get_vector_format(scale_format.c_str(), out_settings->scale_format))
goto invalid_value_error;
- m_constant_rotation_threshold_angle = float(constant_rotation_threshold_angle);
- m_constant_translation_threshold = float(constant_translation_threshold);
- m_constant_scale_threshold = float(constant_scale_threshold);
m_error_threshold = float(error_threshold);
}
@@ -597,12 +591,7 @@ namespace acl
desc.shell_distance = vertex_distance;
if (m_has_settings)
- {
desc.precision = m_error_threshold;
- desc.constant_rotation_threshold_angle = m_constant_rotation_threshold_angle;
- desc.constant_translation_threshold = m_constant_translation_threshold;
- desc.constant_scale_threshold = m_constant_scale_threshold;
- }
// Create a dummy track for now to hold our arguments
(*tracks)[i] = track_qvvf::make_ref(desc, nullptr, 0, 30.0F);
@@ -816,9 +805,11 @@ namespace acl
m_parser.try_read("parent_index", transform_desc.parent_index, k_invalid_track_index);
transform_desc.shell_distance = read_optional_float("shell_distance", transform_desc.shell_distance);
- transform_desc.constant_rotation_threshold_angle = read_optional_float("constant_rotation_threshold_angle", transform_desc.constant_rotation_threshold_angle);
- transform_desc.constant_translation_threshold = read_optional_float("constant_translation_threshold", transform_desc.constant_translation_threshold);
- transform_desc.constant_scale_threshold = read_optional_float("constant_scale_threshold", transform_desc.constant_scale_threshold);
+
+ // Deprecated, no longer used
+ read_optional_float("constant_rotation_threshold_angle", -1.0F);
+ read_optional_float("constant_translation_threshold", -1.0F);
+ read_optional_float("constant_scale_threshold", -1.0F);
scalar_desc.output_index = output_index;
transform_desc.output_index = output_index;
diff --git a/includes/acl/io/clip_writer.h b/includes/acl/io/clip_writer.h
--- a/includes/acl/io/clip_writer.h
+++ b/includes/acl/io/clip_writer.h
@@ -121,9 +121,6 @@ namespace acl
writer["output_index"] = desc.output_index;
writer["parent_index"] = desc.parent_index;
writer["shell_distance"] = format_hex_float(desc.shell_distance, buffer, sizeof(buffer));
- writer["constant_rotation_threshold_angle"] = format_hex_float(desc.constant_rotation_threshold_angle, buffer, sizeof(buffer));
- writer["constant_translation_threshold"] = format_hex_float(desc.constant_translation_threshold, buffer, sizeof(buffer));
- writer["constant_scale_threshold"] = format_hex_float(desc.constant_scale_threshold, buffer, sizeof(buffer));
writer["bind_rotation"] = [&](sjson::ArrayWriter& rotation_writer)
{
rotation_writer.push(acl_impl::format_hex_float(rtm::quat_get_x(desc.default_value.rotation), buffer, sizeof(buffer)));
diff --git a/includes/acl/math/scalar_packing.h b/includes/acl/math/scalar_packing.h
--- a/includes/acl/math/scalar_packing.h
+++ b/includes/acl/math/scalar_packing.h
@@ -112,7 +112,7 @@ namespace acl
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 8 bytes from it
inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
- ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+ ACL_ASSERT(num_bits <= 23, "This function does not support reading more than 23 bits per component");
struct PackedTableEntry
{
@@ -125,14 +125,14 @@ namespace acl
uint32_t mask;
};
- // TODO: We technically don't need the first 3 entries, which could save a few bytes
- alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[24] =
{
PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ PackedTableEntry(20), PackedTableEntry(21), PackedTableEntry(22), PackedTableEntry(23),
};
#if defined(RTM_SSE2_INTRINSICS)
diff --git a/includes/acl/math/vector4_packing.h b/includes/acl/math/vector4_packing.h
--- a/includes/acl/math/vector4_packing.h
+++ b/includes/acl/math/vector4_packing.h
@@ -225,24 +225,43 @@ namespace acl
uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), num_bits);
uint32_t vector_w = pack_scalar_unsigned(rtm::vector_get_w(vector), num_bits);
- uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
- vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
- vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
- vector_u64 = byte_swap(vector_u64);
+ if (num_bits * 3 >= 64)
+ {
+ // First 3 components don't fit in 64 bits, write [xy] first, and partial [zw] after
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 = byte_swap(vector_u64);
- unaligned_write(vector_u64, out_vector_data);
+ unaligned_write(vector_u64, out_vector_data);
- uint32_t vector_u32 = vector_w << (32 - num_bits);
- vector_u32 = byte_swap(vector_u32);
+ vector_u64 = static_cast<uint64_t>(vector_z) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_w) << (64 - num_bits * 2);
+ vector_u64 = byte_swap(vector_u64);
+
+ memcpy_bits(out_vector_data, uint64_t(num_bits) * 2, &vector_u64, 0, uint64_t(num_bits) * 2);
+ }
+ else
+ {
+ // Write out [xyz] first, they fit in 64 bits for sure and write out partial [w] after
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
+ vector_u64 = byte_swap(vector_u64);
- const uint32_t bit_offset = num_bits * 3;
- memcpy_bits(out_vector_data, bit_offset, &vector_u32, 0, num_bits);
+ unaligned_write(vector_u64, out_vector_data);
+
+ uint32_t vector_u32 = vector_w << (32 - num_bits);
+ vector_u32 = byte_swap(vector_u32);
+
+ const uint32_t bit_offset = num_bits * 3;
+ memcpy_bits(out_vector_data, bit_offset, &vector_u32, 0, num_bits);
+ }
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
- ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+ ACL_ASSERT(num_bits <= 23, "This function does not support reading more than 23 bits per component");
struct PackedTableEntry
{
@@ -255,14 +274,14 @@ namespace acl
uint32_t mask;
};
- // TODO: We technically don't need the first 3 entries, which could save a few bytes
- alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[24] =
{
PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ PackedTableEntry(20), PackedTableEntry(21), PackedTableEntry(22), PackedTableEntry(23),
};
#if defined(RTM_SSE2_INTRINSICS)
@@ -807,12 +826,30 @@ namespace acl
uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), num_bits);
- uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
- vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
- vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
- vector_u64 = byte_swap(vector_u64);
+ if (num_bits * 3 >= 64)
+ {
+ // All 3 components don't fit in 64 bits, write [xy] first, and partial [z] after
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 = byte_swap(vector_u64);
- unaligned_write(vector_u64, out_vector_data);
+ unaligned_write(vector_u64, out_vector_data);
+
+ uint32_t vector_u32 = vector_z << (32 - num_bits);
+ vector_u32 = byte_swap(vector_u32);
+
+ memcpy_bits(out_vector_data, uint64_t(num_bits) * 2, &vector_u32, 0, num_bits);
+ }
+ else
+ {
+ // All 3 components fit in 64 bits
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
+ vector_u64 = byte_swap(vector_u64);
+
+ unaligned_write(vector_u64, out_vector_data);
+ }
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
@@ -822,12 +859,30 @@ namespace acl
uint32_t vector_y = pack_scalar_signed(rtm::vector_get_y(vector), num_bits);
uint32_t vector_z = pack_scalar_signed(rtm::vector_get_z(vector), num_bits);
- uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
- vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
- vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
- vector_u64 = byte_swap(vector_u64);
+ if (num_bits * 3 >= 64)
+ {
+ // All 3 components don't fit in 64 bits, write [xy] first, and partial [z] after
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 = byte_swap(vector_u64);
- unaligned_write(vector_u64, out_vector_data);
+ unaligned_write(vector_u64, out_vector_data);
+
+ uint32_t vector_u32 = vector_z << (32 - num_bits);
+ vector_u32 = byte_swap(vector_u32);
+
+ memcpy_bits(out_vector_data, uint64_t(num_bits) * 2, &vector_u32, 0, num_bits);
+ }
+ else
+ {
+ // All 3 components fit in 64 bits
+ uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
+ vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
+ vector_u64 |= static_cast<uint64_t>(vector_z) << (64 - num_bits * 3);
+ vector_u64 = byte_swap(vector_u64);
+
+ unaligned_write(vector_u64, out_vector_data);
+ }
}
inline rtm::vector4f RTM_SIMD_CALL decay_vector3_uXX(rtm::vector4f_arg0 input, uint32_t num_bits)
@@ -860,7 +915,7 @@ namespace acl
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
- ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+ ACL_ASSERT(num_bits <= 23, "This function does not support reading more than 23 bits per component");
struct PackedTableEntry
{
@@ -873,14 +928,14 @@ namespace acl
uint32_t mask;
};
- // TODO: We technically don't need the first 3 entries, which could save a few bytes
- alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[24] =
{
PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ PackedTableEntry(20), PackedTableEntry(21), PackedTableEntry(22), PackedTableEntry(23),
};
#if defined(RTM_SSE2_INTRINSICS)
@@ -972,8 +1027,6 @@ namespace acl
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_sXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
- ACL_ASSERT(num_bits * 3 <= 64, "Attempting to read too many bits");
-
const rtm::vector4f unsigned_value = unpack_vector3_uXX_unsafe(num_bits, vector_data, bit_offset);
return rtm::vector_neg_mul_sub(unsigned_value, -2.0F, rtm::vector_set(-1.0F));
}
@@ -997,7 +1050,7 @@ namespace acl
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector2_uXX_unsafe(uint32_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
- ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+ ACL_ASSERT(num_bits <= 23, "This function does not support reading more than 23 bits per component");
struct PackedTableEntry
{
@@ -1010,14 +1063,14 @@ namespace acl
uint32_t mask;
};
- // TODO: We technically don't need the first 3 entries, which could save a few bytes
- alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[24] =
{
PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ PackedTableEntry(20), PackedTableEntry(21), PackedTableEntry(22), PackedTableEntry(23),
};
#if defined(RTM_SSE2_INTRINSICS)
diff --git a/tools/acl_compressor/acl_compressor.py b/tools/acl_compressor/acl_compressor.py
--- a/tools/acl_compressor/acl_compressor.py
+++ b/tools/acl_compressor/acl_compressor.py
@@ -174,7 +174,7 @@ def create_csv(options):
csv_data['stats_bit_rate_csv_file'] = stats_bit_rate_csv_file
print('Generating CSV file {} ...'.format(stats_bit_rate_csv_filename))
- print('Algorithm Name,0,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,32', file = stats_bit_rate_csv_file)
+ print('Algorithm Name,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,32', file = stats_bit_rate_csv_file)
if options['csv_animated_size']:
stats_animated_size_csv_filename = os.path.join(stat_dir, 'stats_animated_size.csv')
@@ -457,7 +457,7 @@ def aggregate_stats(agg_run_stats, run_stats):
agg_data['total_duration'] = 0.0
agg_data['max_error'] = 0
agg_data['num_runs'] = 0
- agg_data['bit_rates'] = [0] * 19
+ agg_data['bit_rates'] = [0] * 25
agg_data['compressed_size'] = []
# Detailed stats
@@ -504,7 +504,7 @@ def aggregate_stats(agg_run_stats, run_stats):
if 'segments' in run_stats and len(run_stats['segments']) > 0:
for segment in run_stats['segments']:
if 'bit_rate_counts' in segment:
- for i in range(19):
+ for i in range(25):
agg_data['bit_rates'][i] += segment['bit_rate_counts'][i]
# Detailed stats
@@ -659,6 +659,8 @@ def run_stat_parsing(options, stat_queue, result_queue):
result_queue.put(('progress', stat_filename))
except sjson.ParseException:
print('Failed to parse SJSON file: {}'.format(stat_filename.replace('\\\\?\\', '')))
+ except TypeError:
+ print('Failed to process SJSON file: {}'.format(stat_filename.replace('\\\\?\\', '')))
# Done
results = {}
@@ -712,7 +714,7 @@ def aggregate_job_stats(agg_job_results, job_results):
agg_job_results['agg_run_stats'][key]['max_error'] = max(agg_job_results['agg_run_stats'][key]['max_error'], job_results['agg_run_stats'][key]['max_error'])
agg_job_results['agg_run_stats'][key]['num_runs'] += job_results['agg_run_stats'][key]['num_runs']
agg_job_results['agg_run_stats'][key]['compressed_size'] += job_results['agg_run_stats'][key]['compressed_size']
- for i in range(19):
+ for i in range(25):
agg_job_results['agg_run_stats'][key]['bit_rates'][i] += job_results['agg_run_stats'][key]['bit_rates'][i]
# Detailed stats
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -1003,13 +1003,23 @@ static int safe_main_impl(int argc, char* argv[])
if (!read_acl_sjson_file(allocator, options, sjson_type, sjson_clip, sjson_track_list))
return -1;
- transform_tracks = std::move(sjson_clip.track_list);
- base_clip = std::move(sjson_clip.additive_base_track_list);
- additive_format = sjson_clip.additive_format;
- bind_pose = std::move(sjson_clip.bind_pose);
- use_external_config = sjson_clip.has_settings;
- settings = sjson_clip.settings;
- scalar_tracks = std::move(sjson_track_list.track_list);
+ use_external_config = sjson_track_list.has_settings;
+ settings = sjson_track_list.settings;
+
+ if (sjson_type == sjson_file_type::raw_track_list && sjson_track_list.track_list.get_track_type() == track_type8::qvvf)
+ {
+ // Re-interpret things as a raw clip
+ transform_tracks = std::move(track_array_cast<track_array_qvvf>(sjson_track_list.track_list));
+ sjson_type = sjson_file_type::raw_clip;
+ }
+ else
+ {
+ transform_tracks = std::move(sjson_clip.track_list);
+ base_clip = std::move(sjson_clip.additive_base_track_list);
+ additive_format = sjson_clip.additive_format;
+ bind_pose = std::move(sjson_clip.bind_pose);
+ scalar_tracks = std::move(sjson_track_list.track_list);
+ }
}
#if DEBUG_MEGA_LARGE_CLIP
diff --git a/tools/acl_compressor/sources/validate_tracks.cpp b/tools/acl_compressor/sources/validate_tracks.cpp
--- a/tools/acl_compressor/sources/validate_tracks.cpp
+++ b/tools/acl_compressor/sources/validate_tracks.cpp
@@ -542,9 +542,6 @@ void validate_metadata(const track_array& raw_tracks, const compressed_tracks& t
ACL_ASSERT(parent_track_output_index == compressed_desc.parent_index, "Unexpected parent track index");
ACL_ASSERT(raw_desc.precision == compressed_desc.precision, "Unexpected precision");
ACL_ASSERT(raw_desc.shell_distance == compressed_desc.shell_distance, "Unexpected shell_distance");
- ACL_ASSERT(raw_desc.constant_rotation_threshold_angle == compressed_desc.constant_rotation_threshold_angle, "Unexpected constant_rotation_threshold_angle");
- ACL_ASSERT(raw_desc.constant_translation_threshold == compressed_desc.constant_translation_threshold, "Unexpected constant_translation_threshold");
- ACL_ASSERT(raw_desc.constant_scale_threshold == compressed_desc.constant_scale_threshold, "Unexpected constant_scale_threshold");
ACL_ASSERT(rtm::quat_near_equal(raw_desc.default_value.rotation, compressed_desc.default_value.rotation, 0.0F), "Unexpected default_value.rotation");
ACL_ASSERT(rtm::vector_all_near_equal3(raw_desc.default_value.translation, compressed_desc.default_value.translation, 0.0F), "Unexpected default_value.translation");
@@ -621,9 +618,6 @@ static void compare_raw_with_compressed(iallocator& allocator, const track_array
ACL_ASSERT(raw_desc.parent_index == desc.parent_index, "Unexpected parent index");
ACL_ASSERT(raw_desc.precision == desc.precision, "Unexpected precision");
ACL_ASSERT(raw_desc.shell_distance == desc.shell_distance, "Unexpected shell_distance");
- ACL_ASSERT(raw_desc.constant_rotation_threshold_angle == desc.constant_rotation_threshold_angle, "Unexpected constant_rotation_threshold_angle");
- ACL_ASSERT(raw_desc.constant_translation_threshold == desc.constant_translation_threshold, "Unexpected constant_translation_threshold");
- ACL_ASSERT(raw_desc.constant_scale_threshold == desc.constant_scale_threshold, "Unexpected constant_scale_threshold");
ACL_ASSERT(rtm::quat_near_equal(raw_desc.default_value.rotation, desc.default_value.rotation, 0.0F), "Unexpected default_value.rotation");
ACL_ASSERT(rtm::vector_all_near_equal3(raw_desc.default_value.translation, desc.default_value.translation, 0.0F), "Unexpected default_value.translation");
ACL_ASSERT(rtm::vector_all_near_equal3(raw_desc.default_value.scale, desc.default_value.scale, 0.0F), "Unexpected default_value.scale");
diff --git a/tools/calc_local_bit_rates.py b/tools/calc_local_bit_rates.py
--- a/tools/calc_local_bit_rates.py
+++ b/tools/calc_local_bit_rates.py
@@ -2,7 +2,8 @@
import sys
-k_bit_rate_num_bits = [ 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 ]
+# ACL_BIT_RATE_EXPANSION: Added 1, 2, 20, 21, 22, and 23.
+k_bit_rate_num_bits = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 32 ]
k_highest_bit_rate = len(k_bit_rate_num_bits) - 1
k_lowest_bit_rate = 1
diff --git a/tools/format_reference.acl.sjson b/tools/format_reference.acl.sjson
--- a/tools/format_reference.acl.sjson
+++ b/tools/format_reference.acl.sjson
@@ -9,8 +9,8 @@
// The ACL file format version
// version = 1 // Initial version
// version = 2 // Introduced clip compression settings
-//version = 3 // Introduced additive clip related data
-//version = 4 // Introduced track list related data
+// version = 3 // Introduced additive clip related data
+// version = 4 // Introduced track list related data
version = 5 // Renamed enums for 2.0 and other related changes
// BEGIN CLIP RELATED DATA
@@ -83,18 +83,22 @@ settings =
// Threshold angle value to use when detecting if a rotation track is constant
// Defaults to '0.00284714461' radians
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_rotation_threshold_angle = 0.00284714461
// Threshold value to use when detecting if a translation track is constant
// Defaults to '0.001' centimeters
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_translation_threshold = 0.001
// Threshold value to use when detecting if a scale track is constant
// Defaults to '0.00001'
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_scale_threshold = 0.00001
// The error threshold used when optimizing the bit rate
// Defaults to '0.01' centimeters
+ // DEPRECATED, NO LONGER USED OR NECESSARY
error_threshold = 0.01
}
@@ -237,14 +241,17 @@ tracks =
// The constant rotation detection threshold
// Transforms only
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_rotation_threshold_angle = 0.1
// The constant translation detection threshold
// Transforms only
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_translation_threshold = 0.1
// The constant scale detection threshold
// Transforms only
+ // DEPRECATED, NO LONGER USED OR NECESSARY
constant_scale_threshold = 0.1
// Bind pose transform information. All three are optional
diff --git a/tools/vs_visualizers/acl.natvis b/tools/vs_visualizers/acl.natvis
--- a/tools/vs_visualizers/acl.natvis
+++ b/tools/vs_visualizers/acl.natvis
@@ -27,9 +27,6 @@
<Item Name="precision" Condition="m_category == acl::track_category8::scalarf">m_desc.scalar.precision</Item>
<Item Name="precision" Condition="m_category == acl::track_category8::transformf">m_desc.transform.precision</Item>
<Item Name="shell_distance" Condition="m_category == acl::track_category8::transformf">m_desc.transform.shell_distance</Item>
- <Item Name="constant_rotation_threshold_angle" Condition="m_category == acl::track_category8::transformf">m_desc.transform.constant_rotation_threshold_angle</Item>
- <Item Name="constant_translation_threshold" Condition="m_category == acl::track_category8::transformf">m_desc.transform.constant_translation_threshold</Item>
- <Item Name="constant_scale_threshold" Condition="m_category == acl::track_category8::transformf">m_desc.transform.constant_scale_threshold</Item>
<Item Name="output_index" Condition="m_category == acl::track_category8::scalarf">m_desc.scalar.output_index</Item>
<Item Name="output_index" Condition="m_category == acl::track_category8::transformf">m_desc.transform.output_index</Item>
<Item Name="parent_index" Condition="m_category == acl::track_category8::transformf">m_desc.transform.parent_index</Item>
@@ -175,8 +172,8 @@
<Size>m_num_samples</Size>
<!-- TODO: Support stride -->
<ValuePointer Condition="m_type == acl::animation_track_type8::rotation">(rtm::float4f*)m_samples</ValuePointer>
- <ValuePointer Condition="m_type == acl::animation_track_type8::translation">(rtm::float3f*)m_samples</ValuePointer>
- <ValuePointer Condition="m_type == acl::animation_track_type8::scale">(rtm::float3f*)m_samples</ValuePointer>
+ <ValuePointer Condition="m_type == acl::animation_track_type8::translation">(rtm::float4f*)m_samples</ValuePointer>
+ <ValuePointer Condition="m_type == acl::animation_track_type8::scale">(rtm::float4f*)m_samples</ValuePointer>
</ArrayItems>
</Expand>
|
diff --git a/tests/sources/core/test_iterator.cpp b/tests/sources/core/test_iterator.cpp
--- a/tests/sources/core/test_iterator.cpp
+++ b/tests/sources/core/test_iterator.cpp
@@ -31,22 +31,25 @@
using namespace acl;
-TEST_CASE("iterator", "[core][iterator]")
+TEST_CASE("array_iterator", "[core][iterator]")
{
- constexpr uint32_t num_items = 3;
- uint32_t items[num_items];
-
- auto i = iterator<uint32_t>(items, num_items);
-
SECTION("mutable returns correct type")
{
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_iterator<uint32_t>(items, num_items);
+
CHECK(std::is_same<uint32_t*, decltype(i.begin())>::value);
CHECK(std::is_same<uint32_t*, decltype(i.end())>::value);
}
SECTION("const returns correct type")
{
- auto ci = const_iterator<uint32_t>(items, num_items);
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_iterator<uint32_t>(items, num_items);
CHECK(std::is_same<const uint32_t*, decltype(ci.begin())>::value);
CHECK(std::is_same<const uint32_t*, decltype(ci.end())>::value);
@@ -54,14 +57,128 @@ TEST_CASE("iterator", "[core][iterator]")
SECTION("bounds are correct")
{
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_iterator<uint32_t>(items, num_items);
+
CHECK(i.begin() == items + 0);
CHECK(i.end() == items + num_items);
}
+ SECTION("const bounds are correct")
+ {
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_iterator<uint32_t>(items, num_items);
+
+ CHECK(ci.begin() == items + 0);
+ CHECK(ci.end() == items + num_items);
+ }
+
SECTION("make_iterator matches")
{
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_iterator<uint32_t>(items, num_items);
auto j = make_iterator(items);
+
+ CHECK(i.begin() == j.begin());
+ CHECK(i.end() == j.end());
+ }
+
+ SECTION("make_iterator const matches")
+ {
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_iterator<uint32_t>(items, num_items);
+ auto cj = make_iterator(items);
+
+ CHECK(ci.begin() == cj.begin());
+ CHECK(ci.end() == cj.end());
+ }
+}
+
+TEST_CASE("array_reverse_iterator", "[core][iterator]")
+{
+ SECTION("mutable returns correct type")
+ {
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_reverse_iterator<uint32_t>(items, num_items);
+
+ CHECK(std::is_same<uint32_t*, decltype(&*i.begin())>::value);
+ CHECK(std::is_same<uint32_t*, decltype(&*i.end())>::value);
+ }
+
+ SECTION("const returns correct type")
+ {
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_reverse_iterator<uint32_t>(items, num_items);
+
+ CHECK(std::is_same<const uint32_t*, decltype(&*ci.begin())>::value);
+ CHECK(std::is_same<const uint32_t*, decltype(&*ci.end())>::value);
+ }
+
+ // Suppress warning about array bounds check around 'items - 1' since we don't read from that value, it is a false positive
+#if defined(RTM_COMPILER_GCC)
+ #pragma GCC diagnostic push
+ #pragma GCC diagnostic ignored "-Warray-bounds"
+#endif
+
+ SECTION("bounds are correct")
+ {
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_reverse_iterator<uint32_t>(items, num_items);
+
+ CHECK(&*i.begin() == items + num_items - 1);
+ CHECK(&*i.end() == items - 1);
+ }
+
+ SECTION("const bounds are correct")
+ {
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_reverse_iterator<uint32_t>(items, num_items);
+
+ CHECK(&*ci.begin() == items + num_items - 1);
+ CHECK(&*ci.end() == items - 1);
+ }
+
+#if defined(RTM_COMPILER_GCC)
+ #pragma GCC diagnostic pop
+#endif
+
+ SECTION("make_reverse_iterator matches")
+ {
+ constexpr size_t num_items = 3;
+ uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto i = array_reverse_iterator<uint32_t>(items, num_items);
+ auto j = make_reverse_iterator(items);
+
CHECK(i.begin() == j.begin());
CHECK(i.end() == j.end());
}
+
+ SECTION("make_reverse_iterator const matches")
+ {
+ constexpr size_t num_items = 3;
+ const uint32_t items[num_items] = { 0, 1, 2 };
+
+ auto ci = const_array_reverse_iterator<uint32_t>(items, num_items);
+ auto cj = make_reverse_iterator(items);
+
+ CHECK(ci.begin() == cj.begin());
+ CHECK(ci.end() == cj.end());
+ }
}
diff --git a/tests/sources/io/test_reader_writer.cpp b/tests/sources/io/test_reader_writer.cpp
--- a/tests/sources/io/test_reader_writer.cpp
+++ b/tests/sources/io/test_reader_writer.cpp
@@ -158,9 +158,6 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
desc1.precision = 0.001F;
desc1.parent_index = 0;
desc1.shell_distance = 0.1241F;
- desc1.constant_rotation_threshold_angle = 21.0F;
- desc1.constant_translation_threshold = 0.11F;
- desc1.constant_scale_threshold = 12.0F;
track_qvvf track1 = track_qvvf::make_reserve(desc1, allocator, num_samples, 32.0F);
track1[0].rotation = rtm::quat_from_euler(1.1F, 1.5F, 1.7F);
track1[0].translation = rtm::vector_set(0.0221F, 10.6F, 22.3F);
@@ -263,9 +260,6 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
CHECK(file_track.get_description().parent_index == ref_track.get_description().parent_index);
CHECK(rtm::scalar_near_equal(file_track.get_description().precision, ref_track.get_description().precision, 0.0F));
CHECK(rtm::scalar_near_equal(file_track.get_description().shell_distance, ref_track.get_description().shell_distance, 0.0F));
- CHECK(rtm::scalar_near_equal(file_track.get_description().constant_rotation_threshold_angle, ref_track.get_description().constant_rotation_threshold_angle, 0.0F));
- CHECK(rtm::scalar_near_equal(file_track.get_description().constant_translation_threshold, ref_track.get_description().constant_translation_threshold, 0.0F));
- CHECK(rtm::scalar_near_equal(file_track.get_description().constant_scale_threshold, ref_track.get_description().constant_scale_threshold, 0.0F));
CHECK(file_track.get_num_samples() == ref_track.get_num_samples());
CHECK(file_track.get_output_index() == ref_track.get_output_index());
CHECK(file_track.get_sample_rate() == ref_track.get_sample_rate());
diff --git a/tests/sources/math/test_scalar_packing.cpp b/tests/sources/math/test_scalar_packing.cpp
--- a/tests/sources/math/test_scalar_packing.cpp
+++ b/tests/sources/math/test_scalar_packing.cpp
@@ -31,13 +31,16 @@
using namespace acl;
using namespace rtm;
-struct UnalignedBuffer
+namespace
{
- uint32_t padding0;
- uint16_t padding1;
- uint8_t buffer[250];
-};
-static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
+ struct UnalignedBuffer
+ {
+ uint32_t padding0;
+ uint16_t padding1;
+ uint8_t buffer[250];
+ };
+ static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
+}
TEST_CASE("scalar packing math", "[math][scalar][packing]")
{
@@ -111,47 +114,52 @@ TEST_CASE("unpack_scalarf_96_unsafe", "[math][scalar][packing]")
}
}
-TEST_CASE("unpack_scalarf_uXX_unsafe", "[math][scalar][packing]")
+static uint32_t test_unpack_scalarf_uXX_unsafe(uint32_t start_bit_rate, uint32_t end_bit_rate)
{
- {
- UnalignedBuffer tmp0;
- alignas(16) uint8_t buffer[64];
+ const uint32_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- uint32_t num_errors = 0;
- vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
- pack_vector2_uXX_unsafe(vec0, 16, &buffer[0]);
- scalarf scalar1 = unpack_scalarf_uXX_unsafe(16, &buffer[0], 0);
- if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
- num_errors++;
+ UnalignedBuffer tmp0;
+ alignas(16) uint8_t buffer[64];
- for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ uint32_t num_errors = 0;
+
+ for (uint32_t bit_rate = start_bit_rate; bit_rate < end_bit_rate; ++bit_rate)
+ {
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
+ for (uint32_t value = 0; value <= max_value; ++value)
{
- uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
- uint32_t max_value = (1 << num_bits) - 1;
- for (uint32_t value = 0; value <= max_value; ++value)
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+
+ vector4f vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
+ pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
+ scalarf scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &buffer[0], 0);
+ if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
+ num_errors++;
+
+ for (size_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
{
- const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const uint32_t offset = offsets[offset_idx];
- vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
- pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
- scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &buffer[0], 0);
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
+ scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
num_errors++;
-
- {
- const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
- {
- const uint8_t offset = offsets[offset_idx];
-
- memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
- scalar1 = unpack_scalarf_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
- if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
- num_errors++;
- }
- }
}
}
- CHECK(num_errors == 0);
}
+
+ return num_errors;
+}
+
+TEST_CASE("unpack_scalarf_uXX_unsafe part0", "[math][scalar][packing]")
+{
+ uint32_t num_errors = test_unpack_scalarf_uXX_unsafe(1, acl_impl::k_highest_bit_rate - 1);
+ CHECK(num_errors == 0);
+}
+
+TEST_CASE("unpack_scalarf_uXX_unsafe part1", "[math][scalar][packing]")
+{
+ uint32_t num_errors = test_unpack_scalarf_uXX_unsafe(acl_impl::k_highest_bit_rate - 1, acl_impl::k_highest_bit_rate);
+ CHECK(num_errors == 0);
}
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -34,13 +34,16 @@
using namespace acl;
using namespace rtm;
-struct UnalignedBuffer
+namespace
{
- uint32_t padding0;
- uint16_t padding1;
- uint8_t buffer[250];
-};
-static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
+ struct UnalignedBuffer
+ {
+ uint32_t padding0;
+ uint16_t padding1;
+ uint8_t buffer[250];
+ };
+ static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
+}
TEST_CASE("pack_vector4_128", "[math][vector4][packing]")
{
@@ -141,49 +144,65 @@ TEST_CASE("pack_vector4_32", "[math][vector4][packing]")
}
}
-TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
+static uint32_t test_pack_vector4_XX(uint32_t start_bit_rate, uint32_t end_bit_rate)
{
- {
- UnalignedBuffer tmp0;
- alignas(16) uint8_t buffer[64];
+ const uint32_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- uint32_t num_errors = 0;
- vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
- pack_vector4_uXX_unsafe(vec0, 16, &buffer[0]);
- vector4f vec1 = unpack_vector4_uXX_unsafe(16, &buffer[0], 0);
- if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
- num_errors++;
+ const vector4f vzero = vector_set(0.0F);
+ const vector4f vone = vector_set(1.0F);
+
+ UnalignedBuffer tmp0;
+ alignas(16) uint8_t buffer[64];
+ uint32_t num_errors = 0;
- for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ for (uint32_t bit_rate = start_bit_rate; bit_rate < end_bit_rate; ++bit_rate)
+ {
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
+
+ // 4 values at a time to speed things up
+ for (uint32_t value = 0; value <= max_value; value += 4)
{
- uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
- uint32_t max_value = (1 << num_bits) - 1;
- for (uint32_t value = 0; value <= max_value; ++value)
+ vector4f vec0 = vector_clamp(vector_set(
+ unpack_scalar_unsigned(value, num_bits),
+ unpack_scalar_unsigned(std::min(value + 1, max_value), num_bits),
+ unpack_scalar_unsigned(std::min(value + 2, max_value), num_bits),
+ unpack_scalar_unsigned(std::min(value + 3, max_value), num_bits)), vzero, vone);
+
+ pack_vector4_uXX_unsafe(vec0, num_bits, &buffer[0]);
+ vector4f vec1 = unpack_vector4_uXX_unsafe(num_bits, &buffer[0], 0);
+ if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
+ num_errors++;
+
+ for (size_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
{
- const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const uint32_t offset = offsets[offset_idx];
- vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
- pack_vector4_uXX_unsafe(vec0, num_bits, &buffer[0]);
- vec1 = unpack_vector4_uXX_unsafe(num_bits, &buffer[0], 0);
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
+ vec1 = unpack_vector4_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
-
- {
- const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
- {
- const uint8_t offset = offsets[offset_idx];
-
- memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
- vec1 = unpack_vector4_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
- if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
- num_errors++;
- }
- }
}
}
- CHECK(num_errors == 0);
}
+
+ return num_errors;
+}
+
+// Test is slow, split it into two parts, second highest bit rate on its own
+// Highest bit rate is full precision float32, it uses a different function
+TEST_CASE("pack_vector4_XX part0", "[math][vector4][packing]")
+{
+ // Test every possible input up to second highest bit rate
+ uint32_t num_errors = test_pack_vector4_XX(1, acl_impl::k_highest_bit_rate - 1);
+ CHECK(num_errors == 0);
+}
+
+TEST_CASE("pack_vector4_XX part1", "[math][vector4][packing]")
+{
+ // Test every possible input for second highest bit rate
+ uint32_t num_errors = test_pack_vector4_XX(acl_impl::k_highest_bit_rate - 1, acl_impl::k_highest_bit_rate);
+ CHECK(num_errors == 0);
}
TEST_CASE("pack_vector3_96", "[math][vector4][packing]")
@@ -363,115 +382,125 @@ TEST_CASE("pack_vector3_24", "[math][vector4][packing]")
}
}
-TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
+static uint32_t test_pack_vector3_XX(uint32_t start_bit_rate, uint32_t end_bit_rate)
{
+ const uint32_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
+
+ const vector4f vzero = vector_set(0.0F);
+ const vector4f vone = vector_set(1.0F);
+ const vector4f vneg_one = vector_set(-1.0F);
+
+ UnalignedBuffer tmp0;
+ alignas(16) uint8_t buffer[64];
+
+ uint32_t num_errors = 0;
+
+ for (uint32_t bit_rate = start_bit_rate; bit_rate < end_bit_rate; ++bit_rate)
{
- UnalignedBuffer tmp0;
- alignas(16) uint8_t buffer[64];
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
- uint32_t num_errors = 0;
- vector4f vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
- pack_vector3_sXX_unsafe(vec0, 16, &buffer[0]);
- vector4f vec1 = unpack_vector3_sXX_unsafe(16, &buffer[0], 0);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
-
- vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16));
- pack_vector3_uXX_unsafe(vec0, 16, &buffer[0]);
- vec1 = unpack_vector3_uXX_unsafe(16, &buffer[0], 0);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
-
- for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ // 3 values at a time to speed things up
+ for (uint32_t value = 0; value <= max_value; value += 3)
{
- uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
- uint32_t max_value = (1 << num_bits) - 1;
- for (uint32_t value = 0; value <= max_value; ++value)
+ vector4f vec0 = vector_clamp(vector_set(
+ unpack_scalar_unsigned(value, num_bits),
+ unpack_scalar_unsigned(std::min(value + 1, max_value), num_bits),
+ unpack_scalar_unsigned(std::min(value + 2, max_value), num_bits)), vzero, vone);
+
+ pack_vector3_uXX_unsafe(vec0, num_bits, &buffer[0]);
+ vector4f vec1 = unpack_vector3_uXX_unsafe(num_bits, &buffer[0], 0);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
+ num_errors++;
+
+ for (size_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
{
- const float value_signed = scalar_clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
- const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const uint32_t offset = offsets[offset_idx];
- vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
- pack_vector3_uXX_unsafe(vec0, num_bits, &buffer[0]);
- vec1 = unpack_vector3_uXX_unsafe(num_bits, &buffer[0], 0);
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 3);
+ vec1 = unpack_vector3_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
+ }
+
+ vec0 = vector_clamp(vector_set(
+ unpack_scalar_signed(value, num_bits),
+ unpack_scalar_signed(std::min(value + 1, max_value), num_bits),
+ unpack_scalar_signed(std::min(value + 2, max_value), num_bits)), vneg_one, vone);
- {
- const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
- {
- const uint8_t offset = offsets[offset_idx];
-
- memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 3);
- vec1 = unpack_vector3_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
- }
- }
-
- vec0 = vector_set(value_signed, value_signed, value_signed);
- pack_vector3_sXX_unsafe(vec0, num_bits, &buffer[0]);
- vec1 = unpack_vector3_sXX_unsafe(num_bits, &buffer[0], 0);
+ pack_vector3_sXX_unsafe(vec0, num_bits, &buffer[0]);
+ vec1 = unpack_vector3_sXX_unsafe(num_bits, &buffer[0], 0);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
+ num_errors++;
+
+ for (size_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
+ {
+ const uint32_t offset = offsets[offset_idx];
+
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 3);
+ vec1 = unpack_vector3_sXX_unsafe(num_bits, &tmp0.buffer[0], offset);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
-
- {
- const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
- {
- const uint8_t offset = offsets[offset_idx];
-
- memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 3);
- vec1 = unpack_vector3_sXX_unsafe(num_bits, &tmp0.buffer[0], offset);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
- }
- }
}
}
- CHECK(num_errors == 0);
}
+
+ return num_errors;
+}
+
+// Test is slow, split it into two parts, second highest bit rate on its own
+// Highest bit rate is full precision float32, it uses a different function
+TEST_CASE("pack_vector3_XX part0", "[math][vector4][packing]")
+{
+ // Test every possible input up to second highest bit rate
+ uint32_t num_errors = test_pack_vector3_XX(1, acl_impl::k_highest_bit_rate - 1);
+ CHECK(num_errors == 0);
+}
+
+TEST_CASE("pack_vector3_XX part1", "[math][vector4][packing]")
+{
+ // Test every possible input for second highest bit rate
+ uint32_t num_errors = test_pack_vector3_XX(acl_impl::k_highest_bit_rate - 1, acl_impl::k_highest_bit_rate);
+ CHECK(num_errors == 0);
}
TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
{
- {
- uint32_t num_errors = 0;
+ const vector4f vzero = vector_set(0.0F);
+ const vector4f vone = vector_set(1.0F);
+ const vector4f vneg_one = vector_set(-1.0F);
- vector4f vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
- vector4f vec1 = decay_vector3_sXX(vec0, 16);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
+ uint32_t num_errors = 0;
- vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16));
- vec1 = decay_vector3_uXX(vec0, 16);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ {
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
- for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ // 3 values at a time to speed things up
+ for (uint32_t value = 0; value <= max_value; value += 3)
{
- uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
- uint32_t max_value = (1 << num_bits) - 1;
- for (uint32_t value = 0; value <= max_value; ++value)
- {
- const float value_signed = scalar_clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
- const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ vector4f vec0 = vector_clamp(vector_set(
+ unpack_scalar_signed(value, num_bits),
+ unpack_scalar_signed(std::min(value + 1, max_value), num_bits),
+ unpack_scalar_signed(std::min(value + 2, max_value), num_bits)), vneg_one, vone);
- vec0 = vector_set(value_signed, value_signed, value_signed);
- vec1 = decay_vector3_sXX(vec0, num_bits);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
+ vector4f vec1 = decay_vector3_sXX(vec0, num_bits);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
+ num_errors++;
- vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
- vec1 = decay_vector3_uXX(vec0, num_bits);
- if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
- num_errors++;
- }
- }
+ vec0 = vector_clamp(vector_set(
+ unpack_scalar_unsigned(value, num_bits),
+ unpack_scalar_unsigned(std::min(value + 1, max_value), num_bits),
+ unpack_scalar_unsigned(std::min(value + 2, max_value), num_bits)), vzero, vone);
- CHECK(num_errors == 0);
+ vec1 = decay_vector3_uXX(vec0, num_bits);
+ if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
+ num_errors++;
+ }
}
+
+ CHECK(num_errors == 0);
}
TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
@@ -505,49 +534,65 @@ TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
}
}
-TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
+static uint32_t test_pack_vector2_XX(uint32_t start_bit_rate, uint32_t end_bit_rate)
{
- {
- UnalignedBuffer tmp0;
- alignas(16) uint8_t buffer[64];
+ const uint32_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- uint32_t num_errors = 0;
- vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
- pack_vector2_uXX_unsafe(vec0, 16, &buffer[0]);
- vector4f vec1 = unpack_vector2_uXX_unsafe(16, &buffer[0], 0);
- if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
- num_errors++;
+ const vector4f vzero = vector_set(0.0F);
+ const vector4f vone = vector_set(1.0F);
+
+ UnalignedBuffer tmp0;
+ alignas(16) uint8_t buffer[64];
+
+ uint32_t num_errors = 0;
- for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
+ for (uint32_t bit_rate = start_bit_rate; bit_rate < end_bit_rate; ++bit_rate)
+ {
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
+ uint32_t max_value = (1 << num_bits) - 1;
+
+ // 2 values at a time to speed things up
+ for (uint32_t value = 0; value <= max_value; value += 2)
{
- uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
- uint32_t max_value = (1 << num_bits) - 1;
- for (uint32_t value = 0; value <= max_value; ++value)
+ vector4f vec0 = vector_clamp(vector_set(
+ unpack_scalar_unsigned(value, num_bits),
+ unpack_scalar_unsigned(std::min(value + 1, max_value), num_bits),
+ 0.0F), vzero, vone);
+
+ pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
+ vector4f vec1 = unpack_vector2_uXX_unsafe(num_bits, &buffer[0], 0);
+ if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
+ num_errors++;
+
+ for (size_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
{
- const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const uint32_t offset = offsets[offset_idx];
- vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
- pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
- vec1 = unpack_vector2_uXX_unsafe(num_bits, &buffer[0], 0);
+ memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
+ vec1 = unpack_vector2_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
num_errors++;
-
- {
- const uint8_t offsets[] = { 0, 1, 5, 31, 32, 33, 63, 64, 65, 93 };
- for (uint8_t offset_idx = 0; offset_idx < get_array_size(offsets); ++offset_idx)
- {
- const uint8_t offset = offsets[offset_idx];
-
- memcpy_bits(&tmp0.buffer[0], offset, &buffer[0], 0, size_t(num_bits) * 4);
- vec1 = unpack_vector2_uXX_unsafe(num_bits, &tmp0.buffer[0], offset);
- if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
- num_errors++;
- }
- }
}
}
- CHECK(num_errors == 0);
}
+
+ return num_errors;
+}
+
+// Test is slow, split it into two parts, second highest bit rate on its own
+// Highest bit rate is full precision float32, it uses a different function
+TEST_CASE("pack_vector2_XX part0", "[math][vector4][packing]")
+{
+ // Test every possible input up to second highest bit rate
+ uint32_t num_errors = test_pack_vector2_XX(1, acl_impl::k_highest_bit_rate - 1);
+ CHECK(num_errors == 0);
+}
+
+TEST_CASE("pack_vector2_XX part1", "[math][vector4][packing]")
+{
+ // Test every possible input for second highest bit rate
+ uint32_t num_errors = test_pack_vector2_XX(acl_impl::k_highest_bit_rate - 1, acl_impl::k_highest_bit_rate);
+ CHECK(num_errors == 0);
}
TEST_CASE("misc vector4 packing", "[math][vector4][packing]")
|
Use object space shell distance to detect constant and default sub-tracks instead of threshold
Partially implemented through #373, we need to push further and make sure to remove the constant sub-track thresholds in the compression settings.
| 2023-01-14T03:23:13
|
cpp
|
Hard
|
|
nfrechette/acl
| 206
|
nfrechette__acl-206
|
[
"195"
] |
b7e5fb87e9fe1bb8e588ac3dbf435df3026600b3
|
diff --git a/cmake/Toolchain-Android.cmake b/cmake/Toolchain-Android.cmake
--- a/cmake/Toolchain-Android.cmake
+++ b/cmake/Toolchain-Android.cmake
@@ -4,3 +4,6 @@ set(CMAKE_SYSTEM_NAME Android)
# Use the clang tool set because it's support for C++11 is superior
set(CMAKE_GENERATOR_TOOLSET DefaultClang)
+
+# Make sure we use all our processors when building
+set(CMAKE_ANDROID_PROCESS_MAX $ENV{NUMBER_OF_PROCESSORS})
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/decoder.h
@@ -115,33 +115,54 @@ namespace acl
{
static constexpr size_t k_num_samples_to_interpolate = 2;
- inline static Quat_32 interpolate_rotation(const Quat_32 rotations[k_num_samples_to_interpolate], float interpolation_alpha)
+ inline static Quat_32 ACL_SIMD_CALL interpolate_rotation(Quat_32Arg0 rotation0, Quat_32Arg1 rotation1, float interpolation_alpha)
{
- return quat_lerp(rotations[0], rotations[1], interpolation_alpha);
+ return quat_lerp(rotation0, rotation1, interpolation_alpha);
}
- inline static Vector4_32 interpolate_vector4(const Vector4_32 vectors[k_num_samples_to_interpolate], float interpolation_alpha)
+ inline static Quat_32 ACL_SIMD_CALL interpolate_rotation(Quat_32Arg0 rotation0, Quat_32Arg1 rotation1, Quat_32Arg2 rotation2, Quat_32Arg3 rotation3, float interpolation_alpha)
{
- return vector_lerp(vectors[0], vectors[1], interpolation_alpha);
+ (void)rotation1;
+ (void)rotation2;
+ (void)rotation3;
+ (void)interpolation_alpha;
+ return rotation0; // Not implemented, we use linear interpolation
}
- // // offsets
- uint32_t track_index; // 0 | 0
- uint32_t constant_track_data_offset; // 4 | 4
- uint32_t clip_range_data_offset; // 8 | 8
+ inline static Vector4_32 ACL_SIMD_CALL interpolate_vector4(Vector4_32Arg0 vector0, Vector4_32Arg1 vector1, float interpolation_alpha)
+ {
+ return vector_lerp(vector0, vector1, interpolation_alpha);
+ }
+
+ inline static Vector4_32 ACL_SIMD_CALL interpolate_vector4(Vector4_32Arg0 vector0, Vector4_32Arg1 vector1, Vector4_32Arg2 vector2, Vector4_32Arg3 vector3, float interpolation_alpha)
+ {
+ (void)vector1;
+ (void)vector2;
+ (void)vector3;
+ (void)interpolation_alpha;
+ return vector0; // Not implemented, we use linear interpolation
+ }
+
+ // // offsets
+ uint32_t track_index; // 0 | 0
+ uint32_t constant_track_data_offset; // 4 | 4
+ uint32_t clip_range_data_offset; // 8 | 8
+
+ uint32_t format_per_track_data_offset; // 12 | 12
+ uint32_t segment_range_data_offset; // 16 | 16
- uint32_t format_per_track_data_offset; // 12 | 12
- uint32_t segment_range_data_offset; // 16 | 16
+ uint32_t key_frame_byte_offsets[2]; // 20 | 20 // Fixed quantization
+ uint32_t key_frame_bit_offsets[2]; // 28 | 28 // Variable quantization
- uint32_t key_frame_byte_offsets[2]; // 20 | 20 // Fixed quantization
- uint32_t key_frame_bit_offsets[2]; // 28 | 28 // Variable quantization
+ uint8_t padding[28]; // 36 | 36
- uint8_t padding[28]; // 36 | 36
+ Vector4_32 vectors[k_num_samples_to_interpolate]; // 64 | 64
+ Vector4_32 padding0[2]; // 96 | 96
- // Total size: 64 | 64
+ // Total size: 128 | 128
};
- static_assert(sizeof(SamplingContext) == 64, "Unexpected size");
+ static_assert(sizeof(SamplingContext) == 128, "Unexpected size");
// We use adapters to wrap the DecompressionSettings
// This allows us to re-use the code for skipping and decompressing Vector3 samples
diff --git a/includes/acl/decompression/decompress_data.h b/includes/acl/decompression/decompress_data.h
--- a/includes/acl/decompression/decompress_data.h
+++ b/includes/acl/decompression/decompress_data.h
@@ -25,6 +25,7 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/compiler_utils.h"
+#include "acl/core/memory_utils.h"
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -712,6 +713,8 @@ namespace acl
template <class SettingsType, class DecompressionContextType, class SamplingContextType>
inline Quat_32 ACL_SIMD_CALL decompress_and_interpolate_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
{
+ static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
+
Quat_32 interpolated_rotation;
const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
@@ -757,10 +760,12 @@ namespace acl
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
- Vector4_32 rotations_as_vec[num_key_frames];
+ // This part is fairly complex, we'll loop and write to the stack (sampling context)
+ Vector4_32* rotations_as_vec = &sampling_context.vectors[0];
// Range ignore flags are used to skip range normalization at the clip and/or segment levels
// Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
+ // By default, we never ignore range reduction
uint32_t range_ignore_flags = 0;
if (rotation_format == RotationFormat8::QuatDropW_Variable && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_Variable))
@@ -844,81 +849,192 @@ namespace acl
}
}
+ // Load our samples to avoid working with the stack now that things can be unrolled.
+ // We unroll because even if we work from the stack, with 2 samples the compiler always
+ // unrolls but it fails to keep the values in registers, working from the stack which
+ // is inefficient.
+ Vector4_32 rotation_as_vec0 = rotations_as_vec[0];
+ Vector4_32 rotation_as_vec1 = rotations_as_vec[1];
+ Vector4_32 rotation_as_vec2;
+ Vector4_32 rotation_as_vec3;
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ rotation_as_vec2 = rotations_as_vec[2];
+ rotation_as_vec3 = rotations_as_vec[3];
+ }
+ else
+ {
+ rotation_as_vec2 = rotation_as_vec0;
+ rotation_as_vec3 = rotation_as_vec0;
+ }
+
+ const uint32_t num_rotation_components = decomp_context.num_rotation_components;
+
if (are_segment_rotations_normalized)
{
+ const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (num_rotation_components * sizeof(uint8_t));
+
if (rotation_format == RotationFormat8::QuatDropW_Variable && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_Variable))
{
- uint32_t ignore_bit_mask = 0x00000001u << ((num_key_frames - 1) * 2);
- for (size_t i = 0; i < num_key_frames; ++i)
+ constexpr uint32_t ignore_mask = 0x00000001u << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+
+ if (static_condition<num_key_frames == 4>::test())
{
- if ((range_ignore_flags & ignore_bit_mask) == 0)
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
- rotations_as_vec[i] = vector_mul_add(rotations_as_vec[i], segment_range_extent, segment_range_min);
+ rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
}
- ignore_bit_mask >>= 2;
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+
+ rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ }
}
}
else
{
if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
{
- for (size_t i = 0; i < num_key_frames; ++i)
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)), true);
+ const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
+ const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
+
+ rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
+ const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
- rotations_as_vec[i] = vector_mul_add(rotations_as_vec[i], segment_range_extent, segment_range_min);
+ rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ {
+ const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
+ const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
+
+ rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
+ const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
+
+ rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ }
}
}
else
{
- for (size_t i = 0; i < num_key_frames; ++i)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+
+ rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
- rotations_as_vec[i] = vector_mul_add(rotations_as_vec[i], segment_range_extent, segment_range_min);
+ rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ }
}
}
}
- sampling_context.segment_range_data_offset += decomp_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ sampling_context.segment_range_data_offset += num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
}
if (are_clip_rotations_normalized)
{
const Vector4_32 clip_range_min = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const Vector4_32 clip_range_extent = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (decomp_context.num_rotation_components * sizeof(float)));
+ const Vector4_32 clip_range_extent = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (num_rotation_components * sizeof(float)));
- uint32_t ignore_bit_mask = 0x00000002u << ((num_key_frames - 1) * 2);
- for (size_t i = 0; i < num_key_frames; ++i)
+ constexpr uint32_t ignore_mask = 0x00000002u << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ rotation_as_vec0 = vector_mul_add(rotation_as_vec0, clip_range_extent, clip_range_min);
+
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
+ rotation_as_vec1 = vector_mul_add(rotation_as_vec1, clip_range_extent, clip_range_min);
+
+ if (static_condition<num_key_frames == 4>::test())
{
- if ((range_ignore_flags & ignore_bit_mask) == 0)
- rotations_as_vec[i] = vector_mul_add(rotations_as_vec[i], clip_range_extent, clip_range_min);
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
+ rotation_as_vec2 = vector_mul_add(rotation_as_vec2, clip_range_extent, clip_range_min);
- ignore_bit_mask >>= 2;
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ rotation_as_vec3 = vector_mul_add(rotation_as_vec3, clip_range_extent, clip_range_min);
}
- sampling_context.clip_range_data_offset += decomp_context.num_rotation_components * sizeof(float) * 2;
+ sampling_context.clip_range_data_offset += num_rotation_components * sizeof(float) * 2;
}
- Quat_32 rotations[num_key_frames];
- if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
+ // No-op conversion
+ Quat_32 rotation0 = vector_to_quat(rotation_as_vec0);
+ Quat_32 rotation1 = vector_to_quat(rotation_as_vec1);
+ Quat_32 rotation2 = vector_to_quat(rotation_as_vec2);
+ Quat_32 rotation3 = vector_to_quat(rotation_as_vec3);
+
+ if (rotation_format != RotationFormat8::Quat_128 || !settings.is_rotation_format_supported(RotationFormat8::Quat_128))
{
- for (size_t i = 0; i < num_key_frames; ++i)
- rotations[i] = vector_to_quat(rotations_as_vec[i]);
+ // We dropped the W component
+ rotation0 = quat_from_positive_w(rotation_as_vec0);
+ rotation1 = quat_from_positive_w(rotation_as_vec1);
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ rotation2 = quat_from_positive_w(rotation_as_vec2);
+ rotation3 = quat_from_positive_w(rotation_as_vec3);
+ }
}
+
+ if (static_condition<num_key_frames == 4>::test())
+ interpolated_rotation = SamplingContextType::interpolate_rotation(rotation0, rotation1, rotation2, rotation3, decomp_context.interpolation_alpha);
else
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- rotations[i] = quat_from_positive_w(rotations_as_vec[i]);
- }
+ interpolated_rotation = SamplingContextType::interpolate_rotation(rotation0, rotation1, decomp_context.interpolation_alpha);
- interpolated_rotation = SamplingContextType::interpolate_rotation(rotations, decomp_context.interpolation_alpha);
ACL_ASSERT(quat_is_finite(interpolated_rotation), "Rotation is not valid!");
ACL_ASSERT(quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
}
@@ -931,6 +1047,8 @@ namespace acl
template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
inline Vector4_32 ACL_SIMD_CALL decompress_and_interpolate_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
{
+ static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
+
Vector4_32 interpolated_vector;
const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
@@ -958,10 +1076,12 @@ namespace acl
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
- Vector4_32 vectors[num_key_frames];
+ // This part is fairly complex, we'll loop and write to the stack (sampling context)
+ Vector4_32* vectors = &sampling_context.vectors[0];
// Range ignore flags are used to skip range normalization at the clip and/or segment levels
// Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
+ // By default, we never ignore range reduction
uint32_t range_ignore_flags = 0;
if (format == VectorFormat8::Vector3_Variable && settings.is_vector_format_supported(VectorFormat8::Vector3_Variable))
@@ -1030,21 +1150,66 @@ namespace acl
}
}
+ // Load our samples to avoid working with the stack now that things can be unrolled.
+ // We unroll because even if we work from the stack, with 2 samples the compiler always
+ // unrolls but it fails to keep the values in registers, working from the stack which
+ // is inefficient.
+ Vector4_32 vector0 = vectors[0];
+ Vector4_32 vector1 = vectors[1];
+ Vector4_32 vector2;
+ Vector4_32 vector3;
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ vector2 = vectors[2];
+ vector3 = vectors[3];
+ }
+ else
+ {
+ vector2 = vector0;
+ vector3 = vector0;
+ }
+
const RangeReductionFlags8 range_reduction_flag = settings.get_range_reduction_flag();
if (are_any_enum_flags_set(segment_range_reduction, range_reduction_flag))
{
- uint32_t ignore_bit_mask = 0x00000001u << ((num_key_frames - 1) * 2);
- for (size_t i = 0; i < num_key_frames; ++i)
+ const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t));
+
+ constexpr uint32_t ignore_mask = 0x00000001u << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+
+ vector0 = vector_mul_add(vector0, segment_range_extent, segment_range_min);
+ }
+
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
{
- if (format != VectorFormat8::Vector3_Variable || !settings.is_vector_format_supported(VectorFormat8::Vector3_Variable) || (range_ignore_flags & ignore_bit_mask) == 0)
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+
+ vector1 = vector_mul_add(vector1, segment_range_extent, segment_range_min);
+ }
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t)));
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
- vectors[i] = vector_mul_add(vectors[i], segment_range_extent, segment_range_min);
+ vector2 = vector_mul_add(vector2, segment_range_extent, segment_range_min);
}
- ignore_bit_mask >>= 2;
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ {
+ const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+
+ vector3 = vector_mul_add(vector3, segment_range_extent, segment_range_min);
+ }
}
sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
@@ -1055,19 +1220,30 @@ namespace acl
const Vector4_32 clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
const Vector4_32 clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
- uint32_t ignore_bit_mask = 0x00000002u << ((num_key_frames - 1) * 2);
- for (size_t i = 0; i < num_key_frames; ++i)
+ constexpr uint32_t ignore_mask = 0x00000002u << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ vector0 = vector_mul_add(vector0, clip_range_extent, clip_range_min);
+
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
+ vector1 = vector_mul_add(vector1, clip_range_extent, clip_range_min);
+
+ if (static_condition<num_key_frames == 4>::test())
{
- if ((range_ignore_flags & ignore_bit_mask) == 0)
- vectors[i] = vector_mul_add(vectors[i], clip_range_extent, clip_range_min);
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
+ vector2 = vector_mul_add(vector2, clip_range_extent, clip_range_min);
- ignore_bit_mask >>= 2;
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ vector3 = vector_mul_add(vector3, clip_range_extent, clip_range_min);
}
sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
}
- interpolated_vector = SamplingContextType::interpolate_vector4(vectors, decomp_context.interpolation_alpha);
+ if (static_condition<num_key_frames == 4>::test())
+ interpolated_vector = SamplingContextType::interpolate_vector4(vector0, vector1, vector2, vector3, decomp_context.interpolation_alpha);
+ else
+ interpolated_vector = SamplingContextType::interpolate_vector4(vector0, vector1, decomp_context.interpolation_alpha);
+
ACL_ASSERT(vector_is_finite3(interpolated_vector), "Vector is not valid!");
}
}
diff --git a/tools/acl_compressor/main_android/CMakeLists.txt b/tools/acl_compressor/main_android/CMakeLists.txt
--- a/tools/acl_compressor/main_android/CMakeLists.txt
+++ b/tools/acl_compressor/main_android/CMakeLists.txt
@@ -4,8 +4,8 @@ project(acl_compressor)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_ANDROID_ARCH armv7-a)
-set(CMAKE_ANDROID_API_MIN 21)
-set(CMAKE_ANDROID_API 21)
+set(CMAKE_ANDROID_API_MIN 24)
+set(CMAKE_ANDROID_API 24)
set(CMAKE_ANDROID_GUI 1)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/bin")
@@ -58,6 +58,7 @@ set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SKIP_ANT_STEP 0)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD 1)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD_CONFIG_PATH proguard-android.txt)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SECURE_PROPS_PATH /definitely/insecure)
+set_target_properties(${PROJECT_NAME} PROPERTIES VS_GLOBAL_AndroidBuildSystem "AntBuild") # Use Ant as our build system
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DIRECTORIES $<TARGET_FILE_DIR:${PROJECT_NAME}>)
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DEPENDENCIES ${PROJECT_NAME}.so)
diff --git a/tools/acl_decompressor/main_android/CMakeLists.txt b/tools/acl_decompressor/main_android/CMakeLists.txt
--- a/tools/acl_decompressor/main_android/CMakeLists.txt
+++ b/tools/acl_decompressor/main_android/CMakeLists.txt
@@ -4,8 +4,8 @@ project(acl_decompressor)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_ANDROID_ARCH armv7-a)
-set(CMAKE_ANDROID_API_MIN 21)
-set(CMAKE_ANDROID_API 21)
+set(CMAKE_ANDROID_API_MIN 24)
+set(CMAKE_ANDROID_API 24)
set(CMAKE_ANDROID_GUI 1)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/bin")
@@ -78,6 +78,7 @@ set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SKIP_ANT_STEP 0)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD 1)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD_CONFIG_PATH proguard-android.txt)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SECURE_PROPS_PATH /definitely/insecure)
+set_target_properties(${PROJECT_NAME} PROPERTIES VS_GLOBAL_AndroidBuildSystem "AntBuild") # Use Ant as our build system
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DIRECTORIES $<TARGET_FILE_DIR:${PROJECT_NAME}>)
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DEPENDENCIES ${PROJECT_NAME}.so)
diff --git a/tools/regression_tester_android/CMakeLists.txt b/tools/regression_tester_android/CMakeLists.txt
--- a/tools/regression_tester_android/CMakeLists.txt
+++ b/tools/regression_tester_android/CMakeLists.txt
@@ -4,8 +4,8 @@ project(acl_regression_tester_android)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_ANDROID_ARCH armv7-a)
-set(CMAKE_ANDROID_API_MIN 21)
-set(CMAKE_ANDROID_API 21)
+set(CMAKE_ANDROID_API_MIN 24)
+set(CMAKE_ANDROID_API 24)
set(CMAKE_ANDROID_GUI 1)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/bin")
@@ -70,7 +70,7 @@ if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
endif()
-# Disable allocation track since if we fail a regression test, we'll throw an exception
+# Disable allocation tracking since if we fail a regression test, we'll throw an exception
# and fail to free memory, leading to a crash in the allocator
add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
@@ -83,6 +83,7 @@ set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SKIP_ANT_STEP 0)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD 1)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD_CONFIG_PATH proguard-android.txt)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SECURE_PROPS_PATH /definitely/insecure)
+set_target_properties(${PROJECT_NAME} PROPERTIES VS_GLOBAL_AndroidBuildSystem "AntBuild") # Use Ant as our build system
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DIRECTORIES $<TARGET_FILE_DIR:${PROJECT_NAME}>)
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DEPENDENCIES ${PROJECT_NAME}.so)
|
diff --git a/tests/main_android/CMakeLists.txt b/tests/main_android/CMakeLists.txt
--- a/tests/main_android/CMakeLists.txt
+++ b/tests/main_android/CMakeLists.txt
@@ -4,8 +4,8 @@ project(acl_unit_tests)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_ANDROID_ARCH armv7-a)
-set(CMAKE_ANDROID_API_MIN 21)
-set(CMAKE_ANDROID_API 21)
+set(CMAKE_ANDROID_API_MIN 24)
+set(CMAKE_ANDROID_API 24)
set(CMAKE_ANDROID_GUI 1)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/bin")
@@ -60,6 +60,7 @@ set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SKIP_ANT_STEP 0)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD 1)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_PROGUARD_CONFIG_PATH proguard-android.txt)
set_target_properties(${PROJECT_NAME} PROPERTIES ANDROID_SECURE_PROPS_PATH /definitely/insecure)
+set_target_properties(${PROJECT_NAME} PROPERTIES VS_GLOBAL_AndroidBuildSystem "AntBuild") # Use Ant as our build system
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DIRECTORIES $<TARGET_FILE_DIR:${PROJECT_NAME}>)
set_property(TARGET ${PROJECT_NAME} PROPERTY ANDROID_NATIVE_LIB_DEPENDENCIES ${PROJECT_NAME}.so)
|
Use switch instead of loop for sample decompression
Vs2015 often fails to unroll the loops, use switch without breaks up to 4
No need to support 1/3, only 2/4.
| 2019-05-11T16:53:19
|
cpp
|
Hard
|
|
nfrechette/acl
| 217
|
nfrechette__acl-217
|
[
"71"
] |
eb64595d10a386bd8b2f9186b68b308cbe931368
|
diff --git a/.gitmodules b/.gitmodules
--- a/.gitmodules
+++ b/.gitmodules
@@ -5,3 +5,7 @@
[submodule "external/catch2"]
path = external/catch2
url = https://github.com/catchorg/Catch2
+[submodule "external/rtm"]
+ path = external/rtm
+ url = https://github.com/nfrechette/rtm.git
+ branch = develop
diff --git a/cmake/CMakeCompiler.cmake b/cmake/CMakeCompiler.cmake
--- a/cmake/CMakeCompiler.cmake
+++ b/cmake/CMakeCompiler.cmake
@@ -21,6 +21,7 @@ macro(setup_default_compiler_flags _project_name)
endif()
else()
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
if(USE_POPCNT_INSTRUCTIONS)
@@ -49,6 +50,7 @@ macro(setup_default_compiler_flags _project_name)
endif()
else()
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
if(USE_POPCNT_INSTRUCTIONS)
diff --git a/external/README.md b/external/README.md
--- a/external/README.md
+++ b/external/README.md
@@ -1,13 +1,19 @@
# External dependencies
-Good news! There are no external dependencies needed by this library at runtime unless you use the [ACL file format](../docs/the_acl_file_format.md)!
+## Runtime dependencies
-## Catch2
+### Realtime Math
+
+[Reamtime Math v1.0.0-develop](https://github.com/nfrechette/rtm/releases/tag/v1.0.0) (MIT License) is used for some math types and functions. Its usage is currently limited but a full transition to use it exclusively will occur for ACL v2.0.
+
+## Development dependencies
+
+### Catch2
[Catch2 v2.5.0](https://github.com/catchorg/Catch2/releases/tag/v2.5.0) (Boost Software License v1.0) is used by our [unit tests](../tests). You will only need it if you run the unit tests and it is included as-is without modifications.
-## sjson-cpp
+### sjson-cpp
-[sjson-cpp v0.6.0](https://github.com/nfrechette/sjson-cpp/releases/tag/v0.6.0) (MIT License) is used by our ACL file format [clip reader](../includes/acl/io/clip_reader.h) and [clip writer](../includes/acl/io/clip_writer.h) as well as by the [acl_compressor](../tools/acl_compressor) tool used for regression testing and profiling. Unless you use our ACL file format at runtime (which you shouldn't), you will not have this dependency included at all.
+[sjson-cpp v0.6.0-develop](https://github.com/nfrechette/sjson-cpp/releases/tag/v0.6.0) (MIT License) is used by our [ACL file format](../docs/the_acl_file_format.md) [clip reader](../includes/acl/io/clip_reader.h) and [clip writer](../includes/acl/io/clip_writer.h) as well as by the [acl_compressor](../tools/acl_compressor) tool used for regression testing and profiling. Unless you use our ACL file format at runtime (which you shouldn't), you will not have this dependency included at all.
In fact, to use any of these things you must include `sjson-cpp` relevant headers manually before you include the ACL headers that need them. For convenience, you can use the included version here or your own version as long as the API remains compatible.
diff --git a/external/rtm b/external/rtm
new file mode 160000
--- /dev/null
+++ b/external/rtm
@@ -0,0 +1 @@
+Subproject commit 50cc1f278f0a8e37ca845c71db2440eb39e98677
diff --git a/external/sjson-cpp b/external/sjson-cpp
--- a/external/sjson-cpp
+++ b/external/sjson-cpp
@@ -1 +1 @@
-Subproject commit 7813d990aef4416f5517b9fb9e66033dfad661ae
+Subproject commit 7395b10557f5ade3d1ab826db1adfb052050dea5
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/decoder.h
@@ -269,7 +269,7 @@ namespace acl
// allows various decompression actions to be performed in a clip.
//
// Both the constructor and destructor are public because it is safe to place
- // instances of this context on the stack or as members variables.
+ // instances of this context on the stack or as member variables.
//
// This compression algorithm is the simplest by far and as such it offers
// the fastest compression and decompression. Every sample is retained and
diff --git a/includes/acl/compression/compress.h b/includes/acl/compression/compress.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/compress.h
@@ -0,0 +1,170 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/error.h"
+#include "acl/core/error_result.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/scope_profiler.h"
+#include "acl/compression/compression_settings.h"
+#include "acl/compression/output_stats.h"
+#include "acl/compression/track_array.h"
+#include "acl/compression/impl/constant_track_impl.h"
+#include "acl/compression/impl/normalize_track_impl.h"
+#include "acl/compression/impl/quantize_track_impl.h"
+#include "acl/compression/impl/track_list_context.h"
+#include "acl/compression/impl/track_range_impl.h"
+#include "acl/compression/impl/write_compression_stats_impl.h"
+#include "acl/compression/impl/write_track_data_impl.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // Compresses a track array with uniform sampling.
+ //
+ // This compression algorithm is the simplest by far and as such it offers
+ // the fastest compression and decompression. Every sample is retained and
+ // every track has the same number of samples playing back at the same
+ // sample rate. This means that when we sample at a particular time within
+ // the clip, we can trivially calculate the offsets required to read the
+ // desired data. All the data is sorted in order to ensure all reads are
+ // as contiguous as possible for optimal cache locality during decompression.
+ //
+ // allocator: The allocator instance to use to allocate and free memory.
+ // track_list: The track list to compress.
+ // settings: The compression settings to use.
+ // out_compressed_tracks: The resulting compressed tracks. The caller owns the returned memory and must free it.
+ // out_stats: Stat output structure.
+ //////////////////////////////////////////////////////////////////////////
+ inline ErrorResult compress_track_list(IAllocator& allocator, const track_array& track_list, const compression_settings& settings, compressed_tracks*& out_compressed_tracks, OutputStats& out_stats)
+ {
+ using namespace acl_impl;
+
+ (void)settings; // todo?
+
+ ErrorResult error_result = track_list.is_valid();
+ if (error_result.any())
+ return error_result;
+
+ ScopeProfiler compression_time;
+
+ track_list_context context;
+ initialize_context(allocator, track_list, context);
+
+ extract_track_ranges(context);
+ extract_constant_tracks(context);
+ normalize_tracks(context);
+ quantize_tracks(context);
+
+ // Done transforming our input tracks, time to pack them into their final form
+ const uint32_t per_track_metadata_size = write_track_metadata(context, nullptr);
+ const uint32_t constant_values_size = write_track_constant_values(context, nullptr);
+ const uint32_t range_values_size = write_track_range_values(context, nullptr);
+ const uint32_t animated_num_bits = write_track_animated_values(context, nullptr);
+ const uint32_t animated_values_size = (animated_num_bits + 7) / 8; // Round up to nearest byte
+ const uint32_t num_bits_per_frame = animated_num_bits / context.num_samples;
+
+ uint32_t buffer_size = 0;
+ buffer_size += sizeof(compressed_tracks); // Headers
+ ACL_ASSERT(is_aligned_to(buffer_size, alignof(track_metadata)), "Invalid alignment");
+ buffer_size += per_track_metadata_size; // Per track metadata
+ buffer_size = align_to(buffer_size, 4); // Align constant values
+ buffer_size += constant_values_size; // Constant values
+ ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
+ buffer_size += range_values_size; // Range values
+ ACL_ASSERT(is_aligned_to(buffer_size, 4), "Invalid alignment");
+ buffer_size += animated_values_size; // Animated values
+ buffer_size += 15; // Ensure we have sufficient padding for unaligned 16 byte loads
+
+ uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, alignof(compressed_tracks));
+ std::memset(buffer, 0, buffer_size);
+
+ const uint8_t* buffer_start = buffer;
+ out_compressed_tracks = reinterpret_cast<compressed_tracks*>(buffer);
+
+ raw_buffer_header* buffer_header = safe_ptr_cast<raw_buffer_header>(buffer);
+ buffer += sizeof(raw_buffer_header);
+
+ tracks_header* header = safe_ptr_cast<tracks_header>(buffer);
+ buffer += sizeof(tracks_header);
+
+ // Write our primary header
+ header->tag = k_compressed_tracks_tag;
+ header->version = get_algorithm_version(AlgorithmType8::UniformlySampled);
+ header->algorithm_type = AlgorithmType8::UniformlySampled;
+ header->track_type = track_list.get_track_type();
+ header->num_tracks = context.num_tracks;
+ header->num_samples = context.num_samples;
+ header->sample_rate = context.sample_rate;
+ header->num_bits_per_frame = num_bits_per_frame;
+
+ header->metadata_per_track = buffer - buffer_start;
+ buffer += per_track_metadata_size;
+ buffer = align_to(buffer, 4);
+ header->track_constant_values = buffer - buffer_start;
+ buffer += constant_values_size;
+ header->track_range_values = buffer - buffer_start;
+ buffer += range_values_size;
+ header->track_animated_values = buffer - buffer_start;
+ buffer += animated_values_size;
+ buffer += 15;
+
+ ACL_ASSERT(buffer_start + buffer_size == buffer, "Buffer size and pointer mismatch");
+
+ // Write our compressed data
+ track_metadata* per_track_metadata = header->get_track_metadata();
+ write_track_metadata(context, per_track_metadata);
+
+ float* constant_values = header->get_track_constant_values();
+ write_track_constant_values(context, constant_values);
+
+ float* range_values = header->get_track_range_values();
+ write_track_range_values(context, range_values);
+
+ uint8_t* animated_values = header->get_track_animated_values();
+ write_track_animated_values(context, animated_values);
+
+ // Finish the raw buffer header
+ buffer_header->size = buffer_size;
+ buffer_header->hash = hash32(safe_ptr_cast<const uint8_t>(header), buffer_size - sizeof(raw_buffer_header)); // Hash everything but the raw buffer header
+
+ compression_time.stop();
+
+#if defined(SJSON_CPP_WRITER)
+ if (out_stats.logging != StatLogging::None)
+ write_compression_stats(context, *out_compressed_tracks, compression_time, out_stats);
+#endif
+
+ return ErrorResult();
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -269,6 +269,15 @@ namespace acl
settings.segmenting.range_reduction = RangeReductionFlags8::AllTracks;
return settings;
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Encapsulates all the compression settings.
+ // Note: Currently only used by scalar track compression which contain no global settings.
+ struct compression_settings
+ {
+ compression_settings()
+ {}
+ };
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/constant_track_impl.h b/includes/acl/compression/impl/constant_track_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/constant_track_impl.h
@@ -0,0 +1,77 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/bitset.h"
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/compression/impl/track_list_context.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline bool is_scalarf_track_constant(const track& track_, const track_range& range)
+ {
+ const track_desc_scalarf& desc = track_.get_description<track_desc_scalarf>();
+ return range.is_constant(desc.constant_threshold);
+ }
+
+ inline void extract_constant_tracks(track_list_context& context)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ const BitSetDescription bitset_desc = BitSetDescription::make_from_num_bits(context.num_tracks);
+
+ context.constant_tracks_bitset = allocate_type_array<uint32_t>(*context.allocator, bitset_desc.get_size());
+ bitset_reset(context.constant_tracks_bitset, bitset_desc, false);
+
+ for (uint32_t track_index = 0; track_index < context.num_tracks; ++track_index)
+ {
+ const track& mut_track = context.track_list[track_index];
+ const track_range& range = context.range_list[track_index];
+
+ bool is_constant = false;
+ switch (range.category)
+ {
+ case track_category8::scalarf:
+ is_constant = is_scalarf_track_constant(mut_track, range);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track category");
+ break;
+ }
+
+ bitset_set(context.constant_tracks_bitset, bitset_desc, track_index, is_constant);
+ }
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/normalize_track_impl.h b/includes/acl/compression/impl/normalize_track_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/normalize_track_impl.h
@@ -0,0 +1,104 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/compression/impl/track_list_context.h"
+
+#include <rtm/mask4i.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline void normalize_scalarf_track(track& mut_track, const scalarf_range& range)
+ {
+ ACL_ASSERT(mut_track.is_owner(), "Track must be writable");
+
+ using namespace rtm;
+
+ const vector4f one = rtm::vector_set(1.0f);
+ const vector4f zero = vector_zero();
+
+ track_vector4f& typed_track = track_cast<track_vector4f>(mut_track);
+
+ const uint32_t num_samples = mut_track.get_num_samples();
+
+ const vector4f range_min = range.get_min();
+ const vector4f range_extent = range.get_extent();
+ const mask4i is_range_zero_mask = vector_less_than(range_extent, rtm::vector_set(0.000000001f));
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ // normalized value is between [0.0 .. 1.0]
+ // value = (normalized value * range extent) + range min
+ // normalized value = (value - range min) / range extent
+ const vector4f sample = typed_track[sample_index];
+
+ vector4f normalized_sample = vector_div(vector_sub(sample, range_min), range_extent);
+
+ // Clamp because the division might be imprecise
+ normalized_sample = vector_min(normalized_sample, one);
+ normalized_sample = vector_select(is_range_zero_mask, zero, normalized_sample);
+
+ ACL_ASSERT(vector_all_greater_equal(normalized_sample, zero) && vector_all_less_equal(normalized_sample, one), "Invalid normalized value. 0.0 <= [%f, %f, %f, %f] <= 1.0", vector_get_x(normalized_sample), vector_get_y(normalized_sample), vector_get_z(normalized_sample), vector_get_w(normalized_sample));
+
+ typed_track[sample_index] = normalized_sample;
+ }
+ }
+
+ inline void normalize_tracks(track_list_context& context)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ for (uint32_t track_index = 0; track_index < context.num_tracks; ++track_index)
+ {
+ const bool is_track_constant = context.is_constant(track_index);
+ if (is_track_constant)
+ continue; // Constant tracks don't need to be modified
+
+ const track_range& range = context.range_list[track_index];
+ track& mut_track = context.track_list[track_index];
+
+ switch (range.category)
+ {
+ case track_category8::scalarf:
+ normalize_scalarf_track(mut_track, range.range.scalarf);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track category");
+ break;
+ }
+ }
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/quantize_track_impl.h b/includes/acl/compression/impl/quantize_track_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/quantize_track_impl.h
@@ -0,0 +1,181 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/track_types.h"
+#include "acl/compression/impl/track_list_context.h"
+
+#include <rtm/mask4i.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct quantization_scales
+ {
+ rtm::vector4f max_value;
+ rtm::vector4f inv_max_value;
+
+ quantization_scales(uint32_t num_bits)
+ {
+ ACL_ASSERT(num_bits > 0, "Cannot decay with 0 bits");
+ ACL_ASSERT(num_bits < 31, "Attempting to decay on too many bits");
+
+ const float max_value_ = safe_to_float((1 << num_bits) - 1);
+ max_value = rtm::vector_set(max_value_);
+ inv_max_value = rtm::vector_set(1.0f / max_value_);
+ }
+ };
+
+ // Decays the input value through quantization by packing and unpacking a normalized input value
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector4_uXX(rtm::vector4f_arg0 value, const quantization_scales& scales)
+ {
+ using namespace rtm;
+
+ ACL_ASSERT(vector_all_greater_equal(value, vector_zero()) && vector_all_less_equal(value, rtm::vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f, %f", vector_get_x(value), vector_get_y(value), vector_get_z(value), vector_get_w(value));
+
+ const vector4f packed_value = vector_symmetric_round(vector_mul(value, scales.max_value));
+ const vector4f decayed_value = vector_mul(packed_value, scales.inv_max_value);
+ return decayed_value;
+ }
+
+ // Packs a normalized input value through quantization
+ inline rtm::vector4f RTM_SIMD_CALL pack_vector4_uXX(rtm::vector4f_arg0 value, const quantization_scales& scales)
+ {
+ using namespace rtm;
+
+ ACL_ASSERT(vector_all_greater_equal(value, vector_zero()) && vector_all_less_equal(value, rtm::vector_set(1.0f)), "Expected normalized unsigned input value: %f, %f, %f, %f", vector_get_x(value), vector_get_y(value), vector_get_z(value), vector_get_w(value));
+
+ return vector_symmetric_round(vector_mul(value, scales.max_value));
+ }
+
+ inline void quantize_scalarf_track(track_list_context& context, uint32_t track_index)
+ {
+ using namespace rtm;
+
+ const track& ref_track = (*context.reference_list)[track_index];
+ track_vector4f& mut_track = track_cast<track_vector4f>(context.track_list[track_index]);
+ ACL_ASSERT(mut_track.is_owner(), "Track must be writable");
+
+ const vector4f precision = vector_load1(&mut_track.get_description().precision);
+ const uint32_t ref_element_size = ref_track.get_sample_size();
+ const uint32_t num_samples = mut_track.get_num_samples();
+
+ const scalarf_range& range = context.range_list[track_index].range.scalarf;
+ const vector4f range_min = range.get_min();
+ const vector4f range_extent = range.get_extent();
+
+ vector4f raw_sample = vector_zero();
+ uint8_t best_bit_rate = k_highest_bit_rate; // Default to raw if we fail to find something better
+
+ // First we look for the best bit rate possible that keeps us within our precision target
+ for (uint8_t bit_rate = k_highest_bit_rate - 1; bit_rate != 0; --bit_rate) // Skip the raw bit rate and the constant bit rate
+ {
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
+ const quantization_scales scales(num_bits_at_bit_rate);
+
+ bool is_error_to_high = false;
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ std::memcpy(&raw_sample, ref_track[sample_index], ref_element_size);
+
+ const vector4f normalized_sample = mut_track[sample_index];
+
+ // Decay our value through quantization
+ const vector4f decayed_normalized_sample = decay_vector4_uXX(normalized_sample, scales);
+
+ // Undo normalization
+ const vector4f decayed_sample = vector_mul_add(decayed_normalized_sample, range_extent, range_min);
+
+ const vector4f delta = vector_abs(vector_sub(raw_sample, decayed_sample));
+ if (!vector_all_less_equal(delta, precision))
+ {
+ is_error_to_high = true;
+ break;
+ }
+ }
+
+ if (is_error_to_high)
+ break; // Our error is too high, use the previous bit rate
+
+ // We were accurate enough, this is the best bit rate so far
+ best_bit_rate = bit_rate;
+ }
+
+ context.bit_rate_list[track_index].scalar.value = best_bit_rate;
+
+ // Done, update our track with the final result
+ if (best_bit_rate == k_highest_bit_rate)
+ {
+ // We can't quantize this track, keep it raw
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ std::memcpy(&mut_track[sample_index], ref_track[sample_index], ref_element_size);
+ }
+ else
+ {
+ // Use the selected bit rate to quantize our track
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(best_bit_rate);
+ const quantization_scales scales(num_bits_at_bit_rate);
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ mut_track[sample_index] = pack_vector4_uXX(mut_track[sample_index], scales);
+ }
+ }
+
+ inline void quantize_tracks(track_list_context& context)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ context.bit_rate_list = allocate_type_array<track_bit_rate>(*context.allocator, context.num_tracks);
+
+ for (uint32_t track_index = 0; track_index < context.num_tracks; ++track_index)
+ {
+ const bool is_track_constant = context.is_constant(track_index);
+ if (is_track_constant)
+ continue; // Constant tracks don't need to be modified
+
+ const track_range& range = context.range_list[track_index];
+
+ switch (range.category)
+ {
+ case track_category8::scalarf:
+ quantize_scalarf_track(context, track_index);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track category");
+ break;
+ }
+ }
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/track_list_context.h b/includes/acl/compression/impl/track_list_context.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/track_list_context.h
@@ -0,0 +1,223 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/compression/track_array.h"
+#include "acl/compression/impl/track_range.h"
+
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct scalar_bit_rate
+ {
+ uint8_t value;
+ };
+
+ struct qvv_bit_rate
+ {
+ uint8_t rotation;
+ uint8_t translation;
+ uint8_t scale;
+ };
+
+ union track_bit_rate
+ {
+ scalar_bit_rate scalar;
+ qvv_bit_rate qvv;
+
+ track_bit_rate() : qvv{k_invalid_bit_rate, k_invalid_bit_rate, k_invalid_bit_rate} {}
+ };
+
+ struct track_list_context
+ {
+ IAllocator* allocator;
+ const track_array* reference_list;
+
+ track_array track_list;
+
+ track_range* range_list;
+ uint32_t* constant_tracks_bitset;
+ track_bit_rate* bit_rate_list;
+ uint32_t* track_output_indices;
+
+ uint32_t num_tracks;
+ uint32_t num_output_tracks;
+ uint32_t num_samples;
+ float sample_rate;
+ float duration;
+
+ track_list_context()
+ : allocator(nullptr)
+ , reference_list(nullptr)
+ , track_list()
+ , range_list(nullptr)
+ , constant_tracks_bitset(nullptr)
+ , bit_rate_list(nullptr)
+ , track_output_indices(nullptr)
+ , num_tracks(0)
+ , num_output_tracks(0)
+ , num_samples(0)
+ , sample_rate(0.0f)
+ , duration(0.0f)
+ {}
+
+ ~track_list_context()
+ {
+ if (allocator != nullptr)
+ {
+ deallocate_type_array(*allocator, range_list, num_tracks);
+
+ const BitSetDescription bitset_desc = BitSetDescription::make_from_num_bits(num_tracks);
+ deallocate_type_array(*allocator, constant_tracks_bitset, bitset_desc.get_size());
+
+ deallocate_type_array(*allocator, bit_rate_list, num_tracks);
+
+ deallocate_type_array(*allocator, track_output_indices, num_output_tracks);
+ }
+ }
+
+ bool is_valid() const { return allocator != nullptr; }
+ bool is_constant(uint32_t track_index) const { return bitset_test(constant_tracks_bitset, BitSetDescription::make_from_num_bits(num_tracks), track_index); }
+ };
+
+ // Promote scalar tracks to vector tracks for SIMD alignment and padding
+ inline track_array copy_and_promote_track_list(IAllocator& allocator, const track_array& ref_track_list)
+ {
+ using namespace rtm;
+
+ const uint32_t num_tracks = ref_track_list.get_num_tracks();
+ const uint32_t num_samples = ref_track_list.get_num_samples_per_track();
+ const float sample_rate = ref_track_list.get_sample_rate();
+
+ track_array out_track_list(allocator, num_tracks);
+
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const track& ref_track = ref_track_list[track_index];
+ track& out_track = out_track_list[track_index];
+
+ switch (ref_track.get_type())
+ {
+ case track_type8::float1f:
+ {
+ const track_float1f& typed_ref_track = track_cast<const track_float1f>(ref_track);
+ track_vector4f track = track_vector4f::make_reserve(ref_track.get_description<track_desc_scalarf>(), allocator, num_samples, sample_rate);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ track[sample_index] = vector_load1(&typed_ref_track[sample_index]);
+ out_track = std::move(track);
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const track_float2f& typed_ref_track = track_cast<const track_float2f>(ref_track);
+ track_vector4f track = track_vector4f::make_reserve(ref_track.get_description<track_desc_scalarf>(), allocator, num_samples, sample_rate);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ track[sample_index] = vector_load2(&typed_ref_track[sample_index]);
+ out_track = std::move(track);
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const track_float3f& typed_ref_track = track_cast<const track_float3f>(ref_track);
+ track_vector4f track = track_vector4f::make_reserve(ref_track.get_description<track_desc_scalarf>(), allocator, num_samples, sample_rate);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ track[sample_index] = vector_load3(&typed_ref_track[sample_index]);
+ out_track = std::move(track);
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const track_float4f& typed_ref_track = track_cast<const track_float4f>(ref_track);
+ track_vector4f track = track_vector4f::make_reserve(ref_track.get_description<track_desc_scalarf>(), allocator, num_samples, sample_rate);
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ track[sample_index] = vector_load(&typed_ref_track[sample_index]);
+ out_track = std::move(track);
+ break;
+ }
+ default:
+ // Copy as is
+ out_track = ref_track.get_copy(allocator);
+ break;
+ }
+ }
+
+ return out_track_list;
+ }
+
+ inline uint32_t* create_output_track_mapping(IAllocator& allocator, const track_array& track_list, uint32_t& out_num_output_tracks)
+ {
+ const uint32_t num_tracks = track_list.get_num_tracks();
+ uint32_t num_output_tracks = num_tracks;
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const uint32_t output_index = track_list[track_index].get_output_index();
+ if (output_index == k_invalid_track_index)
+ num_output_tracks--; // Stripped from the output
+ }
+
+ uint32_t* output_indices = allocate_type_array<uint32_t>(allocator, num_output_tracks);
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const uint32_t output_index = track_list[track_index].get_output_index();
+ if (output_index != k_invalid_bone_index)
+ output_indices[output_index] = track_index;
+ }
+
+ out_num_output_tracks = num_output_tracks;
+ return output_indices;
+ }
+
+ inline void initialize_context(IAllocator& allocator, const track_array& track_list, track_list_context& context)
+ {
+ ACL_ASSERT(track_list.is_valid().empty(), "Invalid track list");
+ ACL_ASSERT(!context.is_valid(), "Context already initialized");
+
+ context.allocator = &allocator;
+ context.reference_list = &track_list;
+ context.track_list = copy_and_promote_track_list(allocator, track_list);
+ context.range_list = nullptr;
+ context.constant_tracks_bitset = nullptr;
+ context.track_output_indices = nullptr;
+ context.num_tracks = track_list.get_num_tracks();
+ context.num_output_tracks = 0;
+ context.num_samples = track_list.get_num_samples_per_track();
+ context.sample_rate = track_list.get_sample_rate();
+ context.duration = track_list.get_duration();
+
+ context.track_output_indices = create_output_track_mapping(allocator, track_list, context.num_output_tracks);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/track_range.h b/includes/acl/compression/impl/track_range.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/track_range.h
@@ -0,0 +1,98 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/compression/track_array.h"
+
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ class scalarf_range
+ {
+ public:
+ static constexpr track_category8 type = track_category8::scalarf;
+
+ scalarf_range() : m_min(), m_extent() {}
+ scalarf_range(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent) : m_min(min), m_extent(extent) {}
+
+ static scalarf_range RTM_SIMD_CALL from_min_max(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max) { return scalarf_range(min, rtm::vector_sub(max, min)); }
+ static scalarf_range RTM_SIMD_CALL from_min_extent(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent) { return scalarf_range(min, extent); }
+
+ rtm::vector4f RTM_SIMD_CALL get_min() const { return m_min; }
+ rtm::vector4f RTM_SIMD_CALL get_max() const { return rtm::vector_add(m_min, m_extent); }
+
+ rtm::vector4f RTM_SIMD_CALL get_center() const { return rtm::vector_add(m_min, rtm::vector_mul(m_extent, 0.5f)); }
+ rtm::vector4f RTM_SIMD_CALL get_extent() const { return m_extent; }
+
+ bool is_constant(float threshold) const { return rtm::vector_all_less_than(rtm::vector_abs(m_extent), rtm::vector_set(threshold)); }
+
+ private:
+ rtm::vector4f m_min;
+ rtm::vector4f m_extent;
+ };
+
+ struct track_range
+ {
+ track_range() : range(), category(track_category8::scalarf) {}
+ track_range(const scalarf_range& range_) : range(range_), category(track_category8::scalarf) {}
+
+ bool is_constant(float threshold) const
+ {
+ switch (category)
+ {
+ case track_category8::scalarf: return range.scalarf.is_constant(threshold);
+ default:
+ ACL_ASSERT(false, "Invalid track category");
+ return false;
+ }
+ }
+
+ union range_union
+ {
+ scalarf_range scalarf;
+ // TODO: Add qvv range and scalard/i/q ranges
+
+ range_union() : scalarf(scalarf_range::from_min_extent(rtm::vector_zero(), rtm::vector_zero())) {}
+ range_union(const scalarf_range& range) : scalarf(range) {}
+ };
+
+ range_union range;
+ track_category8 category;
+
+ uint8_t padding[15];
+ };
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/track_range_impl.h b/includes/acl/compression/impl/track_range_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/track_range_impl.h
@@ -0,0 +1,86 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/compression/impl/track_list_context.h"
+
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline scalarf_range extract_scalarf_range(const track& track)
+ {
+ using namespace rtm;
+
+ vector4f min = rtm::vector_set(1e10f);
+ vector4f max = rtm::vector_set(-1e10f);
+
+ const uint32_t num_samples = track.get_num_samples();
+ const track_vector4f& typed_track = track_cast<const track_vector4f>(track);
+
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const vector4f sample = typed_track[sample_index];
+
+ min = vector_min(min, sample);
+ max = vector_max(max, sample);
+ }
+
+ return scalarf_range::from_min_max(min, max);
+ }
+
+ inline void extract_track_ranges(track_list_context& context)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ context.range_list = allocate_type_array<track_range>(*context.allocator, context.num_tracks);
+
+ for (uint32_t track_index = 0; track_index < context.num_tracks; ++track_index)
+ {
+ const track& track = context.track_list[track_index];
+
+ switch (track.get_category())
+ {
+ case track_category8::scalarf:
+ context.range_list[track_index] = extract_scalarf_range(track);
+ break;
+ default:
+ ACL_ASSERT(false, "Invalid track category");
+ break;
+ }
+ }
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/write_compression_stats_impl.h b/includes/acl/compression/impl/write_compression_stats_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/write_compression_stats_impl.h
@@ -0,0 +1,64 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/error.h"
+#include "acl/core/scope_profiler.h"
+#include "acl/compression/impl/track_list_context.h"
+#include "acl/compression/output_stats.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline void write_compression_stats(const track_list_context& context, const compressed_tracks& tracks, const ScopeProfiler& compression_time, OutputStats& stats)
+ {
+ ACL_ASSERT(stats.writer != nullptr, "Attempted to log stats without a writer");
+
+ const uint32_t raw_size = context.reference_list->get_raw_size();
+ const uint32_t compressed_size = tracks.get_size();
+ const double compression_ratio = double(raw_size) / double(compressed_size);
+
+ sjson::ObjectWriter& writer = *stats.writer;
+ writer["algorithm_name"] = get_algorithm_name(AlgorithmType8::UniformlySampled);
+ //writer["algorithm_uid"] = settings.get_hash();
+ //writer["clip_name"] = clip.get_name().c_str();
+ writer["raw_size"] = raw_size;
+ writer["compressed_size"] = compressed_size;
+ writer["compression_ratio"] = compression_ratio;
+ writer["compression_time"] = compression_time.get_elapsed_seconds();
+ writer["duration"] = context.duration;
+ writer["num_samples"] = context.num_samples;
+ writer["num_tracks"] = context.num_tracks;
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/write_track_data_impl.h b/includes/acl/compression/impl/write_track_data_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/write_track_data_impl.h
@@ -0,0 +1,188 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/impl/compressed_headers.h"
+#include "acl/compression/impl/track_list_context.h"
+
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline uint32_t write_track_metadata(const track_list_context& context, track_metadata* per_track_metadata)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ uint8_t* output_buffer = reinterpret_cast<uint8_t*>(per_track_metadata);
+ const uint8_t* output_buffer_start = output_buffer;
+
+ for (uint32_t output_index = 0; output_index < context.num_output_tracks; ++output_index)
+ {
+ const uint32_t track_index = context.track_output_indices[output_index];
+
+ if (per_track_metadata != nullptr)
+ per_track_metadata[output_index].bit_rate = context.is_constant(track_index) ? 0 : context.bit_rate_list[track_index].scalar.value;
+
+ output_buffer += sizeof(track_metadata);
+ }
+
+ return safe_static_cast<uint32_t>(output_buffer - output_buffer_start);
+ }
+
+ inline uint32_t write_track_constant_values(const track_list_context& context, float* constant_values)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ uint8_t* output_buffer = reinterpret_cast<uint8_t*>(constant_values);
+ const uint8_t* output_buffer_start = output_buffer;
+
+ for (uint32_t output_index = 0; output_index < context.num_output_tracks; ++output_index)
+ {
+ const uint32_t track_index = context.track_output_indices[output_index];
+
+ if (!context.is_constant(track_index))
+ continue;
+
+ const track& ref_track = (*context.reference_list)[track_index];
+ const uint32_t element_size = ref_track.get_sample_size();
+
+ if (constant_values != nullptr)
+ std::memcpy(output_buffer, ref_track[0], element_size);
+
+ output_buffer += element_size;
+ }
+
+ return safe_static_cast<uint32_t>(output_buffer - output_buffer_start);
+ }
+
+ inline uint32_t write_track_range_values(const track_list_context& context, float* range_values)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ uint8_t* output_buffer = reinterpret_cast<uint8_t*>(range_values);
+ const uint8_t* output_buffer_start = output_buffer;
+
+ for (uint32_t output_index = 0; output_index < context.num_output_tracks; ++output_index)
+ {
+ const uint32_t track_index = context.track_output_indices[output_index];
+
+ if (context.is_constant(track_index))
+ continue;
+
+ const uint8_t bit_rate = context.bit_rate_list[track_index].scalar.value;
+ if (is_raw_bit_rate(bit_rate))
+ continue;
+
+ const track& ref_track = (*context.reference_list)[track_index];
+ const track_range& range = context.range_list[track_index];
+
+ const uint32_t element_size = ref_track.get_sample_size();
+
+ if (range_values != nullptr)
+ {
+ // Only support scalarf for now
+ ACL_ASSERT(range.category == track_category8::scalarf, "Unsupported category");
+ const rtm::vector4f range_min = range.range.scalarf.get_min();
+ const rtm::vector4f range_extent = range.range.scalarf.get_extent();
+ std::memcpy(output_buffer, &range_min, element_size);
+ std::memcpy(output_buffer + element_size, &range_extent, element_size);
+ }
+
+ output_buffer += element_size; // Min
+ output_buffer += element_size; // Extent
+ }
+
+ return safe_static_cast<uint32_t>(output_buffer - output_buffer_start);
+ }
+
+ inline uint32_t write_track_animated_values(const track_list_context& context, uint8_t* animated_values)
+ {
+ ACL_ASSERT(context.is_valid(), "Invalid context");
+
+ uint8_t* output_buffer = animated_values;
+ uint64_t output_bit_offset = 0;
+
+ const uint32_t num_components = get_track_num_sample_elements(context.reference_list->get_track_type());
+ ACL_ASSERT(num_components <= 4, "Unexpected number of elements");
+
+ for (uint32_t sample_index = 0; sample_index < context.num_samples; ++sample_index)
+ {
+ for (uint32_t output_index = 0; output_index < context.num_output_tracks; ++output_index)
+ {
+ const uint32_t track_index = context.track_output_indices[output_index];
+
+ if (context.is_constant(track_index))
+ continue;
+
+ const track& ref_track = (*context.reference_list)[track_index];
+ const track& mut_track = context.track_list[track_index];
+
+ // Only support scalarf for now
+ ACL_ASSERT(ref_track.get_category() == track_category8::scalarf, "Unsupported category");
+
+ const scalar_bit_rate bit_rate = context.bit_rate_list[track_index].scalar;
+ const uint64_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate.value);
+
+ const track& src_track = is_raw_bit_rate(bit_rate.value) ? ref_track : mut_track;
+
+ const uint32_t* sample_u32 = safe_ptr_cast<const uint32_t>(src_track[sample_index]);
+ const float* sample_f32 = safe_ptr_cast<const float>(src_track[sample_index]);
+ for (uint32_t component_index = 0; component_index < num_components; ++component_index)
+ {
+ if (animated_values != nullptr)
+ {
+ uint32_t value;
+ if (is_raw_bit_rate(bit_rate.value))
+ value = byte_swap(sample_u32[component_index]);
+ else
+ {
+ // TODO: Hacked, our values are still as floats, cast to int, shift, and byte swap
+ // Ideally should be done in the cache/mutable track with SIMD
+ value = safe_static_cast<uint32_t>(sample_f32[component_index]);
+ value = value << (32 - num_bits_per_component);
+ value = byte_swap(value);
+ }
+
+ memcpy_bits(output_buffer, output_bit_offset, &value, 0, num_bits_per_component);
+ }
+
+ output_bit_offset += num_bits_per_component;
+ }
+ }
+ }
+
+ return safe_static_cast<uint32_t>(output_bit_offset);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/track.h b/includes/acl/compression/track.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/track.h
@@ -0,0 +1,493 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/track_traits.h"
+#include "acl/core/track_types.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // An untyped track of data. A track is a time series of values sampled
+ // uniformly over time at a specific sample rate. Tracks can either own
+ // their memory or reference an external buffer.
+ // For convenience, this type can be cast with the `track_cast(..)` family
+ // of functions. Each track type has the same size as every track description
+ // is contained within a union.
+ //////////////////////////////////////////////////////////////////////////
+ class track
+ {
+ public:
+ //////////////////////////////////////////////////////////////////////////
+ // Creates an empty, untyped track.
+ track()
+ : m_allocator(nullptr)
+ , m_data(nullptr)
+ , m_num_samples(0)
+ , m_stride(0)
+ , m_data_size(0)
+ , m_sample_rate(0.0f)
+ , m_type(track_type8::float1f)
+ , m_category(track_category8::scalarf)
+ , m_sample_size(0)
+ , m_desc()
+ {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move constructor for a track.
+ track(track&& other)
+ : m_allocator(other.m_allocator)
+ , m_data(other.m_data)
+ , m_num_samples(other.m_num_samples)
+ , m_stride(other.m_stride)
+ , m_data_size(other.m_data_size)
+ , m_sample_rate(other.m_sample_rate)
+ , m_type(other.m_type)
+ , m_category(other.m_category)
+ , m_sample_size(other.m_sample_size)
+ , m_desc(other.m_desc)
+ {
+ other.m_allocator = nullptr;
+ other.m_data = nullptr;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Destroys the track. If it owns the memory referenced, it will be freed.
+ ~track()
+ {
+ if (is_owner())
+ {
+ // We own the memory, free it
+ m_allocator->deallocate(m_data, m_data_size);
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move assignment for a track.
+ track& operator=(track&& other)
+ {
+ std::swap(m_allocator, other.m_allocator);
+ std::swap(m_data, other.m_data);
+ std::swap(m_num_samples, other.m_num_samples);
+ std::swap(m_stride, other.m_stride);
+ std::swap(m_data_size, other.m_data_size);
+ std::swap(m_sample_rate, other.m_sample_rate);
+ std::swap(m_type, other.m_type);
+ std::swap(m_category, other.m_category);
+ std::swap(m_sample_size, other.m_sample_size);
+ std::swap(m_desc, other.m_desc);
+ return *this;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a pointer to an untyped sample at the specified index.
+ void* operator[](uint32_t index)
+ {
+ // If we have an allocator, we own the memory and mutable pointers are allowed
+ ACL_ASSERT(is_owner(), "Mutable reference not allowed, create a copy instead");
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return m_allocator ? m_data + (index * m_stride) : nullptr;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a pointer to an untyped sample at the specified index.
+ const void* operator[](uint32_t index) const
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return m_data + (index * m_stride);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns true if the track owns its memory, false otherwise.
+ bool is_owner() const { return m_allocator != nullptr; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns true if the track owns its memory, false otherwise.
+ bool is_ref() const { return m_allocator == nullptr; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the number of samples contained within the track.
+ uint32_t get_num_samples() const { return m_num_samples; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the stride in bytes in between samples as layed out in memory.
+ // This is always sizeof(sample_type) unless the memory isn't owned internally.
+ uint32_t get_stride() const { return m_stride; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track type.
+ track_type8 get_type() const { return m_type; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track category.
+ track_category8 get_category() const { return m_category; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the size in bytes of each track sample.
+ uint32_t get_sample_size() const { return m_sample_size; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track sample rate.
+ // A track has its sampled uniformly distributed in time at a fixed rate (e.g. 30 samples per second).
+ float get_sample_rate() const { return m_sample_rate; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track output index.
+ // When compressing, it is often desirable to strip or re-order the tracks we output.
+ // This can be used to sort by LOD or to strip stale tracks. Tracks with an invalid
+ // track index are stripped in the output.
+ uint32_t get_output_index() const
+ {
+ switch (m_category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar.output_index;
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track description.
+ template<typename desc_type>
+ desc_type& get_description()
+ {
+ ACL_ASSERT(desc_type::category == m_category, "Unexpected track category");
+ switch (desc_type::category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar;
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track description.
+ template<typename desc_type>
+ const desc_type& get_description() const
+ {
+ ACL_ASSERT(desc_type::category == m_category, "Unexpected track category");
+ switch (desc_type::category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar;
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a copy of the track where the memory will be owned by the copy.
+ track get_copy(IAllocator& allocator) const
+ {
+ track track_;
+ track_.m_allocator = &allocator;
+ track_.m_data = reinterpret_cast<uint8_t*>(allocator.allocate(m_data_size));
+ track_.m_num_samples = m_num_samples;
+ track_.m_stride = m_stride;
+ track_.m_data_size = m_data_size;
+ track_.m_type = m_type;
+ track_.m_category = m_category;
+ track_.m_desc = m_desc;
+
+ std::memcpy(track_.m_data, m_data, m_data_size);
+
+ return track_;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns a reference to the track where the memory isn't owned.
+ track get_ref() const
+ {
+ track track_;
+ track_.m_allocator = nullptr;
+ track_.m_data = m_data;
+ track_.m_num_samples = m_num_samples;
+ track_.m_stride = m_stride;
+ track_.m_data_size = m_data_size;
+ track_.m_type = m_type;
+ track_.m_category = m_category;
+ track_.m_desc = m_desc;
+ return track_;
+ }
+
+ protected:
+ //////////////////////////////////////////////////////////////////////////
+ // We prohibit copying, use get_copy() and get_ref() instead.
+ track(const track&) = delete;
+ track& operator=(const track&) = delete;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Internal constructor.
+ // Creates an empty, untyped track.
+ track(track_type8 type, track_category8 category)
+ : m_allocator(nullptr)
+ , m_data(nullptr)
+ , m_num_samples(0)
+ , m_stride(0)
+ , m_data_size(0)
+ , m_sample_rate(0.0f)
+ , m_type(type)
+ , m_category(category)
+ , m_sample_size(0)
+ , m_desc()
+ {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Internal constructor.
+ track(IAllocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, track_type8 type, track_category8 category, uint8_t sample_size)
+ : m_allocator(allocator)
+ , m_data(data)
+ , m_num_samples(num_samples)
+ , m_stride(stride)
+ , m_data_size(data_size)
+ , m_sample_rate(sample_rate)
+ , m_type(type)
+ , m_category(category)
+ , m_sample_size(sample_size)
+ , m_desc()
+ {}
+
+ IAllocator* m_allocator; // Optional allocator that owns the memory
+ uint8_t* m_data; // Pointer to the samples
+
+ uint32_t m_num_samples; // The number of samples
+ uint32_t m_stride; // The stride in bytes in between samples as layed out in memory
+ size_t m_data_size; // The total size of the buffer used by the samples
+
+ float m_sample_rate; // The track sample rate
+
+ track_type8 m_type; // The track type
+ track_category8 m_category; // The track category
+ uint16_t m_sample_size; // The size in bytes of each sample
+
+ //////////////////////////////////////////////////////////////////////////
+ // A union of every track description.
+ // This ensures every track has the same size regardless of its type.
+ union desc_union
+ {
+ track_desc_scalarf scalar;
+ // TODO: Add other description types here
+
+ desc_union() : scalar() {}
+ desc_union(const track_desc_scalarf& desc) : scalar(desc) {}
+ };
+
+ desc_union m_desc; // The track description
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // A typed track of data. See `track` for details.
+ //////////////////////////////////////////////////////////////////////////
+ template<track_type8 track_type_>
+ class track_typed final : public track
+ {
+ public:
+ //////////////////////////////////////////////////////////////////////////
+ // The track type.
+ static constexpr track_type8 type = track_type_;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The track category.
+ static constexpr track_category8 category = track_traits<track_type_>::category;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The type of each sample in this track.
+ using sample_type = typename track_traits<track_type_>::sample_type;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The type of the track description.
+ using desc_type = typename track_traits<track_type_>::desc_type;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Constructs an empty typed track.
+ track_typed() : track(type, category) { static_assert(sizeof(track_typed) == sizeof(track), "You cannot add member variables to this class"); }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move assignment for a track.
+ track_typed(track_typed&& other) : track(std::forward<track>(other)) {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move assignment for a track.
+ track_typed& operator=(track_typed&& other) { return track::operator=(std::forward<track>(other)); }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the sample at the specified index.
+ // If this track does not own the memory, mutable references aren't allowed and an
+ // invalid reference will be returned, leading to a crash.
+ sample_type& operator[](uint32_t index)
+ {
+ // If we have an allocator, we own the memory and mutable references are allowed
+ ACL_ASSERT(is_owner(), "Mutable reference not allowed, create a copy instead");
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return m_allocator ? *reinterpret_cast<sample_type*>(m_data + (index * m_stride)) : *reinterpret_cast<sample_type*>(0x42);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the sample at the specified index.
+ const sample_type& operator[](uint32_t index) const
+ {
+ ACL_ASSERT(index < m_num_samples, "Invalid sample index. %u >= %u", index, m_num_samples);
+ return *reinterpret_cast<const sample_type*>(m_data + (index * m_stride));
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track description.
+ desc_type& get_description()
+ {
+ switch (category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar;
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track description.
+ const desc_type& get_description() const
+ {
+ switch (category)
+ {
+ default:
+ case track_category8::scalarf: return m_desc.scalar;
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track type.
+ track_type8 get_type() const { return type; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track category.
+ track_category8 get_category() const { return category; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Creates a track that copies the data and owns the memory.
+ static track_typed<track_type_> make_copy(const desc_type& desc, IAllocator& allocator, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
+ {
+ const size_t data_size = size_t(num_samples) * sizeof(sample_type);
+ const uint8_t* data_raw = reinterpret_cast<const uint8_t*>(data);
+
+ // Copy the data manually to avoid preserving the stride
+ sample_type* data_copy = reinterpret_cast<sample_type*>(allocator.allocate(data_size));
+ for (uint32_t index = 0; index < num_samples; ++index)
+ data_copy[index] = *reinterpret_cast<sample_type*>(data_raw + (index * stride));
+
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data_copy), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Creates a track and preallocates but does not initialize the memory that it owns.
+ static track_typed<track_type_> make_reserve(const desc_type& desc, IAllocator& allocator, uint32_t num_samples, float sample_rate)
+ {
+ const size_t data_size = size_t(num_samples) * sizeof(sample_type);
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(allocator.allocate(data_size)), num_samples, sizeof(sample_type), data_size, sample_rate, desc);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Creates a track and takes ownership of the already allocated memory.
+ static track_typed<track_type_> make_owner(const desc_type& desc, IAllocator& allocator, sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
+ {
+ const size_t data_size = size_t(num_samples) * stride;
+ return track_typed<track_type_>(&allocator, reinterpret_cast<uint8_t*>(data), num_samples, stride, data_size, sample_rate, desc);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Creates a track that just references the data without owning it.
+ static track_typed<track_type_> make_ref(const desc_type& desc, const sample_type* data, uint32_t num_samples, float sample_rate, uint32_t stride = sizeof(sample_type))
+ {
+ const size_t data_size = size_t(num_samples) * stride;
+ return track_typed<track_type_>(nullptr, const_cast<uint8_t*>(reinterpret_cast<const uint8_t*>(data)), num_samples, stride, data_size, sample_rate, desc);
+ }
+
+ private:
+ //////////////////////////////////////////////////////////////////////////
+ // We prohibit copying, use get_copy() and get_ref() instead.
+ track_typed(const track_typed&) = delete;
+ track_typed& operator=(const track_typed&) = delete;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Internal constructor.
+ track_typed(IAllocator* allocator, uint8_t* data, uint32_t num_samples, uint32_t stride, size_t data_size, float sample_rate, const desc_type& desc)
+ : track(allocator, data, num_samples, stride, data_size, sample_rate, type, category, sizeof(sample_type))
+ {
+ m_desc = desc;
+ }
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Casts an untyped track into the desired track type while asserting for safety.
+ template<typename track_type>
+ inline track_type& track_cast(track& track_)
+ {
+ ACL_ASSERT(track_type::type == track_.get_type(), "Unexpected track type");
+ return static_cast<track_type&>(track_);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Casts an untyped track into the desired track type while asserting for safety.
+ template<typename track_type>
+ inline const track_type& track_cast(const track& track_)
+ {
+ ACL_ASSERT(track_type::type == track_.get_type(), "Unexpected track type");
+ return static_cast<const track_type&>(track_);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Casts an untyped track into the desired track type. Returns nullptr if the types
+ // are not compatible or if the input is nullptr.
+ template<typename track_type>
+ inline track_type* track_cast(track* track_)
+ {
+ if (track_ == nullptr || track_type::type != track_->get_type())
+ return nullptr;
+
+ return static_cast<track_type*>(track_);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Casts an untyped track into the desired track type. Returns nullptr if the types
+ // are not compatible or if the input is nullptr.
+ template<typename track_type>
+ inline const track_type* track_cast(const track* track_)
+ {
+ if (track_ == nullptr || track_type::type != track_->get_type())
+ return nullptr;
+
+ return static_cast<const track_type*>(track_);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Create aliases for the various typed track types.
+
+ using track_float1f = track_typed<track_type8::float1f>;
+ using track_float2f = track_typed<track_type8::float2f>;
+ using track_float3f = track_typed<track_type8::float3f>;
+ using track_float4f = track_typed<track_type8::float4f>;
+ using track_vector4f = track_typed<track_type8::vector4f>;
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/track_array.h b/includes/acl/compression/track_array.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/track_array.h
@@ -0,0 +1,301 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/error_result.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/track_writer.h"
+#include "acl/compression/track.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+#include <limits>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // An array of tracks.
+ // Although each track contained within is untyped, each track must have
+ // the same type. They must all have the same sample rate and the same
+ // number of samples.
+ //////////////////////////////////////////////////////////////////////////
+ class track_array
+ {
+ public:
+ //////////////////////////////////////////////////////////////////////////
+ // Constructs an empty track array.
+ track_array()
+ : m_allocator(nullptr)
+ , m_tracks(nullptr)
+ , m_num_tracks(0)
+ {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Constructs an array with the specified number of tracks.
+ // Tracks will be empty and untyped by default.
+ track_array(IAllocator& allocator, uint32_t num_tracks)
+ : m_allocator(&allocator)
+ , m_tracks(allocate_type_array<track>(allocator, num_tracks))
+ , m_num_tracks(num_tracks)
+ {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move constructor for a track array.
+ track_array(track_array&& other)
+ : m_allocator(other.m_allocator)
+ , m_tracks(other.m_tracks)
+ , m_num_tracks(other.m_num_tracks)
+ {
+ other.m_allocator = nullptr; // Make sure we don't free our data since we no longer own it
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Destroys a track array.
+ ~track_array()
+ {
+ if (m_allocator != nullptr)
+ deallocate_type_array(*m_allocator, m_tracks, m_num_tracks);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Move assignment for a track array.
+ track_array& operator=(track_array&& other)
+ {
+ std::swap(m_allocator, other.m_allocator);
+ std::swap(m_tracks, other.m_tracks);
+ std::swap(m_num_tracks, other.m_num_tracks);
+ return *this;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the number of tracks contained in this array.
+ uint32_t get_num_tracks() const { return m_num_tracks; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the number of samples per track in this array.
+ uint32_t get_num_samples_per_track() const { return m_allocator != nullptr && m_num_tracks > 0 ? m_tracks->get_num_samples() : 0; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track type for tracks in this array.
+ track_type8 get_track_type() const { return m_allocator != nullptr && m_num_tracks > 0 ? m_tracks->get_type() : track_type8::float1f; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track category for tracks in this array.
+ track_category8 get_track_category() const { return m_allocator != nullptr && m_num_tracks > 0 ? m_tracks->get_category() : track_category8::scalarf; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the sample rate for tracks in this array.
+ float get_sample_rate() const { return m_allocator != nullptr && m_num_tracks > 0 ? m_tracks->get_sample_rate() : 0.0f; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the duration for tracks in this array.
+ float get_duration() const { return m_allocator != nullptr && m_num_tracks > 0 ? calculate_duration(uint32_t(m_tracks->get_num_samples()), m_tracks->get_sample_rate()) : 0.0f; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track at the specified index.
+ track& operator[](uint32_t index)
+ {
+ ACL_ASSERT(index < m_num_tracks, "Invalid track index. %u >= %u", index, m_num_tracks);
+ return m_tracks[index];
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track at the specified index.
+ const track& operator[](uint32_t index) const
+ {
+ ACL_ASSERT(index < m_num_tracks, "Invalid track index. %u >= %u", index, m_num_tracks);
+ return m_tracks[index];
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Iterator begin() and end() implementations.
+ track* begin() { return m_tracks; }
+ const track* begin() const { return m_tracks; }
+ const track* end() { return m_tracks + m_num_tracks; }
+ const track* end() const { return m_tracks + m_num_tracks; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether a track array is valid or not.
+ // An array is valid if:
+ // - It is empty
+ // - All tracks have the same type
+ // - All tracks have the same number of samples
+ // - All tracks have the same sample rate
+ ErrorResult is_valid() const
+ {
+ const track_type8 type = get_track_type();
+ const uint32_t num_samples = get_num_samples_per_track();
+ const float sample_rate = get_sample_rate();
+
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track& track_ = m_tracks[track_index];
+ if (track_.get_type() != type)
+ return ErrorResult("Tracks must all have the same type within an array");
+
+ if (track_.get_num_samples() != num_samples)
+ return ErrorResult("Track array requires the same number of samples in every track");
+
+ if (track_.get_sample_rate() != sample_rate)
+ return ErrorResult("Track array requires the same sample rate in every track");
+ }
+
+ return ErrorResult();
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Sample all tracks within this array at the specified sample time and
+ // desired rounding policy. Track samples are written out using the `track_writer` provided.
+ template<class track_writer_type>
+ inline void sample_tracks(float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Sample a single track within this array at the specified sample time and
+ // desired rounding policy. The track sample is written out using the `track_writer` provided.
+ template<class track_writer_type>
+ inline void sample_track(uint32_t track_index, float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the raw size for this track array. Note that this differs from the actual
+ // memory used by an instance of this class. It is meant for comparison against
+ // the compressed size.
+ uint32_t get_raw_size() const;
+
+ private:
+ //////////////////////////////////////////////////////////////////////////
+ // We prohibit copying
+ track_array(const track_array&) = delete;
+ track_array& operator=(const track_array&) = delete;
+
+ IAllocator* m_allocator; // The allocator used to allocate our tracks
+ track* m_tracks; // The track list
+ uint32_t m_num_tracks; // The number of tracks
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+
+ template<class track_writer_type>
+ inline void track_array::sample_tracks(float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const
+ {
+ ACL_ASSERT(is_valid().empty(), "Invalid track array");
+
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ sample_track(track_index, sample_time, rounding_policy, writer);
+ }
+
+ template<class track_writer_type>
+ inline void track_array::sample_track(uint32_t track_index, float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const
+ {
+ ACL_ASSERT(is_valid().empty(), "Invalid track array");
+ ACL_ASSERT(track_index < m_num_tracks, "Invalid track index");
+
+ const track& track_ = m_tracks[track_index];
+ const uint32_t num_samples = track_.get_num_samples();
+ const float sample_rate = track_.get_sample_rate();
+
+ uint32_t key_frame0;
+ uint32_t key_frame1;
+ float interpolation_alpha;
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, interpolation_alpha);
+
+ switch (track_.get_type())
+ {
+ case track_type8::float1f:
+ {
+ const track_float1f& track__ = track_cast<track_float1f>(track_);
+
+ const rtm::scalarf value0 = rtm::scalar_load(&track__[key_frame0]);
+ const rtm::scalarf value1 = rtm::scalar_load(&track__[key_frame1]);
+ const rtm::scalarf value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
+ writer.write_float1(track_index, value);
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const track_float2f& track__ = track_cast<track_float2f>(track_);
+
+ const rtm::vector4f value0 = rtm::vector_load2(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load2(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float2(track_index, value);
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const track_float3f& track__ = track_cast<track_float3f>(track_);
+
+ const rtm::vector4f value0 = rtm::vector_load3(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load3(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float3(track_index, value);
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const track_float4f& track__ = track_cast<track_float4f>(track_);
+
+ const rtm::vector4f value0 = rtm::vector_load(&track__[key_frame0]);
+ const rtm::vector4f value1 = rtm::vector_load(&track__[key_frame1]);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_float4(track_index, value);
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const track_vector4f& track__ = track_cast<track_vector4f>(track_);
+
+ const rtm::vector4f value0 = track__[key_frame0];
+ const rtm::vector4f value1 = track__[key_frame1];
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ writer.write_vector4(track_index, value);
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Invalid track type");
+ break;
+ }
+ }
+
+ uint32_t track_array::get_raw_size() const
+ {
+ const uint32_t num_samples = get_num_samples_per_track();
+
+ uint32_t total_size = 0;
+ for (uint32_t track_index = 0; track_index < m_num_tracks; ++track_index)
+ {
+ const track& track_ = m_tracks[track_index];
+ total_size += num_samples * track_.get_sample_size();
+ }
+
+ return total_size;
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/track_error.h b/includes/acl/compression/track_error.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/track_error.h
@@ -0,0 +1,168 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/error.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/impl/debug_track_writer.h"
+#include "acl/compression/track_array.h"
+#include "acl/decompression/decompress.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // A struct that contains the raw track index that has the worst error,
+ // its error, and the sample time at which it happens.
+ //////////////////////////////////////////////////////////////////////////
+ struct track_error
+ {
+ track_error() : index(k_invalid_track_index), error(0.0f), sample_time(0.0f) {}
+
+ //////////////////////////////////////////////////////////////////////////
+ // The raw track index with the worst error.
+ uint32_t index;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The worst error for the raw track index.
+ float error;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The sample time that has the worst error.
+ float sample_time;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates the worst compression error between a raw track array and its
+ // compressed tracks.
+ inline track_error calculate_compression_error(IAllocator& allocator, const track_array& raw_tracks, const compressed_tracks& tracks)
+ {
+ using namespace acl_impl;
+
+ track_error result;
+
+ const float duration = tracks.get_duration();
+ const float sample_rate = tracks.get_sample_rate();
+ const uint32_t num_tracks = tracks.get_num_tracks();
+ const uint32_t num_samples = tracks.get_num_samples_per_track();
+ const track_type8 track_type = raw_tracks.get_track_type();
+
+ decompression_context<debug_decompression_settings> context;
+ context.initialize(tracks);
+
+ debug_track_writer raw_tracks_writer(allocator, track_type, num_tracks);
+ debug_track_writer raw_track_writer(allocator, track_type, num_tracks);
+ debug_track_writer lossy_tracks_writer(allocator, track_type, num_tracks);
+ debug_track_writer lossy_track_writer(allocator, track_type, num_tracks);
+
+ const rtm::vector4f zero = rtm::vector_zero();
+
+ // Regression test
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const float sample_time = min(float(sample_index) / sample_rate, duration);
+
+ raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::None, raw_tracks_writer);
+
+ context.seek(sample_time, SampleRoundingPolicy::None);
+ context.decompress_tracks(lossy_tracks_writer);
+
+ // Validate decompress_tracks
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ const uint32_t output_index = track_.get_output_index();
+ if (output_index == k_invalid_track_index)
+ continue; // Track is being stripped, ignore it
+
+ rtm::vector4f error = zero;
+
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ {
+ const float raw_value = raw_tracks_writer.read_float1(track_index);
+ const float lossy_value = lossy_tracks_writer.read_float1(output_index);
+ error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float2(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float2(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, zero);
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float3(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float3(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, zero);
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float4(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float4(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_vector4(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_vector4(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+
+ const float max_error = rtm::vector_get_max_component(error);
+ if (max_error > result.error)
+ {
+ result.error = max_error;
+ result.index = track_index;
+ result.sample_time = sample_time;
+ }
+ }
+ }
+
+ return result;
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/compressed_tracks.h b/includes/acl/core/compressed_tracks.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/compressed_tracks.h
@@ -0,0 +1,155 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/algorithm_types.h"
+#include "acl/core/algorithm_versions.h"
+#include "acl/core/compiler_utils.h"
+#include "acl/core/error_result.h"
+#include "acl/core/hash.h"
+#include "acl/core/utils.h"
+#include "acl/core/impl/compressed_headers.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ class compressed_tracks;
+
+ namespace acl_impl
+ {
+ ////////////////////////////////////////////////////////////////////////////////
+ // A known tag value to distinguish compressed tracks from other things.
+ static constexpr uint32_t k_compressed_tracks_tag = 0xac11ac11;
+
+ const tracks_header& get_tracks_header(const compressed_tracks& tracks);
+ }
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // An instance of a compressed tracks.
+ // The compressed data immediately follows this instance in memory.
+ // The total size of the buffer can be queried with `get_size()`.
+ ////////////////////////////////////////////////////////////////////////////////
+ class alignas(16) compressed_tracks final
+ {
+ public:
+ ////////////////////////////////////////////////////////////////////////////////
+ // Returns the algorithm type used to compress the tracks.
+ AlgorithmType8 get_algorithm_type() const { return m_tracks_header.algorithm_type; }
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // Returns the size in bytes of the compressed tracks.
+ // Includes the 'compressed_tracks' instance size.
+ uint32_t get_size() const { return m_buffer_header.size; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the hash for the compressed tracks.
+ // This is only used for sanity checking in case of memory corruption.
+ uint32_t get_hash() const { return m_buffer_header.hash; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the number of tracks contained.
+ uint32_t get_num_tracks() const { return m_tracks_header.num_tracks; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the number of samples each track contains.
+ uint32_t get_num_samples_per_track() const { return m_tracks_header.num_samples; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the duration of each track.
+ float get_duration() const { return calculate_duration(m_tracks_header.num_samples, m_tracks_header.sample_rate); }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the sample rate used by each track.
+ float get_sample_rate() const { return m_tracks_header.sample_rate; }
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // Returns true if the compressed tracks are valid and usable.
+ // This mainly validates some invariants as well as ensuring that the
+ // memory has not been corrupted.
+ //
+ // check_hash: If true, the compressed tracks hash will also be compared.
+ ErrorResult is_valid(bool check_hash) const
+ {
+ if (!is_aligned_to(this, alignof(compressed_tracks)))
+ return ErrorResult("Invalid alignment");
+
+ if (m_tracks_header.tag != acl_impl::k_compressed_tracks_tag)
+ return ErrorResult("Invalid tag");
+
+ if (!is_valid_algorithm_type(m_tracks_header.algorithm_type))
+ return ErrorResult("Invalid algorithm type");
+
+ if (m_tracks_header.version != get_algorithm_version(m_tracks_header.algorithm_type))
+ return ErrorResult("Invalid algorithm version");
+
+ if (check_hash)
+ {
+ const uint32_t hash = hash32(safe_ptr_cast<const uint8_t>(&m_tracks_header), m_buffer_header.size - sizeof(acl_impl::raw_buffer_header));
+ if (hash != m_buffer_header.hash)
+ return ErrorResult("Invalid hash");
+ }
+
+ return ErrorResult();
+ }
+
+ private:
+ ////////////////////////////////////////////////////////////////////////////////
+ // Hide everything
+ compressed_tracks() = delete;
+ compressed_tracks(const compressed_tracks&) = delete;
+ compressed_tracks(compressed_tracks&&) = delete;
+ compressed_tracks* operator=(const compressed_tracks&) = delete;
+ compressed_tracks* operator=(compressed_tracks&&) = delete;
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // Raw buffer header that isn't included in the hash.
+ ////////////////////////////////////////////////////////////////////////////////
+
+ acl_impl::raw_buffer_header m_buffer_header;
+
+ ////////////////////////////////////////////////////////////////////////////////
+ // Everything starting here is included in the hash.
+ ////////////////////////////////////////////////////////////////////////////////
+
+ acl_impl::tracks_header m_tracks_header;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Compressed data follows here in memory.
+ //////////////////////////////////////////////////////////////////////////
+
+ friend const acl_impl::tracks_header& acl_impl::get_tracks_header(const compressed_tracks& tracks);
+ };
+
+ namespace acl_impl
+ {
+ // Hide this implementation, it shouldn't be needed in user-space
+ inline const tracks_header& get_tracks_header(const compressed_tracks& tracks) { return tracks.m_tracks_header; }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/impl/compressed_headers.h b/includes/acl/core/impl/compressed_headers.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/impl/compressed_headers.h
@@ -0,0 +1,104 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/track_types.h"
+#include "acl/core/algorithm_types.h"
+#include "acl/core/compiler_utils.h"
+#include "acl/core/ptr_offset.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct raw_buffer_header
+ {
+ // Total size in bytes of the raw buffer.
+ uint32_t size;
+
+ // Hash of the raw buffer.
+ uint32_t hash;
+ };
+
+ struct track_metadata
+ {
+ uint8_t bit_rate;
+ };
+
+ struct tracks_header
+ {
+ // Serialization tag used to distinguish raw buffer types.
+ uint32_t tag;
+
+ // Serialization version used to compress the tracks.
+ uint16_t version;
+
+ // Algorithm type used to compress the tracks.
+ AlgorithmType8 algorithm_type;
+
+ // Type of the tracks contained in this compressed stream.
+ track_type8 track_type;
+
+ // The total number of tracks.
+ uint32_t num_tracks;
+
+ // The total number of samples per track.
+ uint32_t num_samples;
+
+ // The sample rate our tracks use.
+ float sample_rate; // TODO: Store duration as float instead?
+
+ // The number of bits used for a whole frame of data.
+ // The sum of one sample per track with all bit rates taken into account.
+ uint32_t num_bits_per_frame;
+
+ // Various data offsets relative to the start of this header.
+ PtrOffset32<track_metadata> metadata_per_track;
+ PtrOffset32<float> track_constant_values;
+ PtrOffset32<float> track_range_values;
+ PtrOffset32<uint8_t> track_animated_values;
+
+ //////////////////////////////////////////////////////////////////////////
+
+ track_metadata* get_track_metadata() { return metadata_per_track.add_to(this); }
+ const track_metadata* get_track_metadata() const { return metadata_per_track.add_to(this); }
+
+ float* get_track_constant_values() { return track_constant_values.add_to(this); }
+ const float* get_track_constant_values() const { return track_constant_values.add_to(this); }
+
+ float* get_track_range_values() { return track_range_values.add_to(this); }
+ const float* get_track_range_values() const { return track_range_values.add_to(this); }
+
+ uint8_t* get_track_animated_values() { return track_animated_values.add_to(this); }
+ const uint8_t* get_track_animated_values() const { return track_animated_values.add_to(this); }
+ };
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/impl/debug_track_writer.h b/includes/acl/core/impl/debug_track_writer.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/impl/debug_track_writer.h
@@ -0,0 +1,143 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/track_types.h"
+#include "acl/core/track_writer.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct debug_track_writer final : public track_writer
+ {
+ debug_track_writer(IAllocator& allocator_, track_type8 type_, uint32_t num_tracks_)
+ : allocator(allocator_)
+ , tracks_typed{ nullptr }
+ , buffer_size(0)
+ , num_tracks(num_tracks_)
+ , type(type_)
+ {
+ // Large enough to accommodate the largest type
+ buffer_size = sizeof(rtm::vector4f) * num_tracks_;
+ tracks_typed.any = allocator_.allocate(buffer_size, alignof(rtm::vector4f));
+ }
+
+ ~debug_track_writer()
+ {
+ allocator.deallocate(tracks_typed.any, buffer_size);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float1(uint32_t track_index, rtm::scalarf_arg0 value)
+ {
+ rtm::scalar_store(value, &tracks_typed.float1f[track_index]);
+ }
+
+ float read_float1(uint32_t track_index) const
+ {
+ return tracks_typed.float1f[track_index];
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float2(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ rtm::vector_store2(value, &tracks_typed.float2f[track_index]);
+ }
+
+ rtm::vector4f read_float2(uint32_t track_index) const
+ {
+ return rtm::vector_load2(&tracks_typed.float2f[track_index]);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float3(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ rtm::vector_store3(value, &tracks_typed.float3f[track_index]);
+ }
+
+ rtm::vector4f read_float3(uint32_t track_index) const
+ {
+ return rtm::vector_load3(&tracks_typed.float3f[track_index]);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float4(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ rtm::vector_store(value, &tracks_typed.float4f[track_index]);
+ }
+
+ rtm::vector4f read_float4(uint32_t track_index) const
+ {
+ return rtm::vector_load(&tracks_typed.float4f[track_index]);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_vector4(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ tracks_typed.vector4f[track_index] = value;
+ }
+
+ rtm::vector4f read_vector4(uint32_t track_index) const
+ {
+ return tracks_typed.vector4f[track_index];
+ }
+
+ union ptr_union
+ {
+ void* any;
+ float* float1f;
+ rtm::float2f* float2f;
+ rtm::float3f* float3f;
+ rtm::float4f* float4f;
+ rtm::vector4f* vector4f;
+ };
+
+ IAllocator& allocator;
+
+ ptr_union tracks_typed;
+ size_t buffer_size;
+ uint32_t num_tracks;
+
+ track_type8 type;
+ };
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/track_traits.h b/includes/acl/core/track_traits.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/track_traits.h
@@ -0,0 +1,97 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/track_types.h"
+
+#include <rtm/types.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // Type tracks for tracks.
+ // Each trait contains:
+ // - The category of the track
+ // - The type of each sample in the track
+ // - The type of the track description
+ //////////////////////////////////////////////////////////////////////////
+ template<track_type8 track_type>
+ struct track_traits {};
+
+ //////////////////////////////////////////////////////////////////////////
+ // Specializations for each track type.
+
+ template<>
+ struct track_traits<track_type8::float1f>
+ {
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ using sample_type = float;
+ using desc_type = track_desc_scalarf;
+ };
+
+ template<>
+ struct track_traits<track_type8::float2f>
+ {
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ using sample_type = rtm::float2f;
+ using desc_type = track_desc_scalarf;
+ };
+
+ template<>
+ struct track_traits<track_type8::float3f>
+ {
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ using sample_type = rtm::float3f;
+ using desc_type = track_desc_scalarf;
+ };
+
+ template<>
+ struct track_traits<track_type8::float4f>
+ {
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ using sample_type = rtm::float4f;
+ using desc_type = track_desc_scalarf;
+ };
+
+ template<>
+ struct track_traits<track_type8::vector4f>
+ {
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ using sample_type = rtm::vector4f;
+ using desc_type = track_desc_scalarf;
+ };
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/track_types.h b/includes/acl/core/track_types.h
--- a/includes/acl/core/track_types.h
+++ b/includes/acl/core/track_types.h
@@ -25,6 +25,7 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/compiler_utils.h"
+#include "acl/core/memory_utils.h"
#include <cstdint>
#include <cstring>
@@ -97,6 +98,132 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
+ //////////////////////////////////////////////////////////////////////////
+ // We only support up to 4294967295 tracks. We reserve 4294967295 for the invalid index
+ constexpr uint32_t k_invalid_track_index = 0xFFFFFFFFu;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The various supported track types.
+ // Note: be careful when changing values here as they might be serialized.
+ enum class track_type8 : uint8_t
+ {
+ float1f = 0,
+ float2f = 1,
+ float3f = 2,
+ float4f = 3,
+ vector4f = 4,
+
+ //float1d = 5,
+ //float2d = 6,
+ //float3d = 7,
+ //float4d = 8,
+ //vector4d = 9,
+
+ //quatf = 10,
+ //quatd = 11,
+
+ //qvvf = 12,
+ //qvvd = 13,
+
+ //int1i = 14,
+ //int2i = 15,
+ //int3i = 16,
+ //int4i = 17,
+ //vector4i = 18,
+
+ //int1q = 19,
+ //int2q = 20,
+ //int3q = 21,
+ //int4q = 22,
+ //vector4q = 23,
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // The categories of track types.
+ enum class track_category8 : uint8_t
+ {
+ scalarf = 0,
+ //scalard = 1,
+ //scalari = 2,
+ //scalarq = 3,
+ //transformf = 4,
+ //transformd = 5,
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // This structure describes the various settings for floating point scalar tracks.
+ // Used by: float1f, float2f, float3f, float4f, vector4f
+ struct track_desc_scalarf
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // The track category for this description.
+ static constexpr track_category8 category = track_category8::scalarf;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The track output index. When writing out the compressed data stream, this index
+ // will be used instead of the track index. This allows custom reordering for things
+ // like LOD sorting or skeleton remapping. A value of 'k_invalid_track_index' will strip the track
+ // from the compressed data stream. Output indices must be unique and contiguous.
+ uint32_t output_index;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The per component precision threshold to try and attain when optimizing the bit rate.
+ // If the error is below the precision threshold, we will remove bits until we reach it without
+ // exceeding it. If the error is above the precision threshold, we will add more bits until
+ // we lower it underneath.
+ float precision;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The per component precision threshold used to detect constant tracks.
+ // A constant track is a track that has a single repeating value across every sample.
+ // TODO: Use the precision?
+ float constant_threshold;
+ };
+
+#if 0 // TODO: Add support for this
+ //////////////////////////////////////////////////////////////////////////
+ // This structure describes the various settings for transform tracks.
+ // Used by: quatf, qvvf
+ struct track_desc_transformf
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // The track category for this description.
+ static constexpr track_category8 category = track_category8::transformf;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The track output index. When writing out the compressed data stream, this index
+ // will be used instead of the track index. This allows custom reordering for things
+ // like LOD sorting or skeleton remapping. A value of 'k_invalid_track_index' will strip the track
+ // from the compressed data stream. Output indices must be unique and contiguous.
+ uint32_t output_index;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The index of the parent transform track or `k_invalid_track_index` if it has no parent.
+ uint32_t parent_index;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The shell precision threshold to try and attain when optimizing the bit rate.
+ // If the error is below the precision threshold, we will remove bits until we reach it without
+ // exceeding it. If the error is above the precision threshold, we will add more bits until
+ // we lower it underneath.
+ float precision;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The error is measured on a rigidly deformed shell around every transform at the specified distance.
+ float shell_distance;
+
+ //////////////////////////////////////////////////////////////////////////
+ // TODO: Use the precision and shell distance?
+ float constant_rotation_threshold;
+ float constant_translation_threshold;
+ float constant_scale_threshold;
+ };
+#endif
+
+ // TODO: Add transform description?
+
+ //////////////////////////////////////////////////////////////////////////
+
// Bit rate 0 is reserved for tracks that are constant in a segment
constexpr uint8_t k_bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
@@ -296,6 +423,92 @@ namespace acl
{
return format == VectorFormat8::Vector3_Variable;
}
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the string representation for the provided track type.
+ // TODO: constexpr
+ inline const char* get_track_type_name(track_type8 type)
+ {
+ switch (type)
+ {
+ case track_type8::float1f: return "float1f";
+ case track_type8::float2f: return "float2f";
+ case track_type8::float3f: return "float3f";
+ case track_type8::float4f: return "float4f";
+ case track_type8::vector4f: return "vector4f";
+ default: return "<Invalid>";
+ }
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track type from its string representation.
+ // Returns true on success, false otherwise.
+ inline bool get_track_type(const char* type, track_type8& out_type)
+ {
+ // Entries in the same order as the enum integral value
+ static const char* k_track_type_names[] =
+ {
+ "float1f",
+ "float2f",
+ "float3f",
+ "float4f",
+ "vector4f",
+ };
+
+ static_assert(get_array_size(k_track_type_names) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+
+ for (size_t type_index = 0; type_index < get_array_size(k_track_type_names); ++type_index)
+ {
+ const char* type_name = k_track_type_names[type_index];
+ if (std::strncmp(type, type_name, std::strlen(type_name)) == 0)
+ {
+ out_type = safe_static_cast<track_type8>(type_index);
+ return true;
+ }
+ }
+
+ return false;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the track category for the provided track type.
+ inline track_category8 get_track_category(track_type8 type)
+ {
+ // Entries in the same order as the enum integral value
+ static constexpr track_category8 k_track_type_to_category[]
+ {
+ track_category8::scalarf, // float1f
+ track_category8::scalarf, // float2f
+ track_category8::scalarf, // float3f
+ track_category8::scalarf, // float4f
+ track_category8::scalarf, // vector4f
+ };
+
+ static_assert(get_array_size(k_track_type_to_category) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+
+ ACL_ASSERT(type <= track_type8::vector4f, "Unexpected track type");
+ return type <= track_type8::vector4f ? k_track_type_to_category[static_cast<uint32_t>(type)] : track_category8::scalarf;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Returns the num of elements within a sample for the provided track type.
+ inline uint32_t get_track_num_sample_elements(track_type8 type)
+ {
+ // Entries in the same order as the enum integral value
+ static constexpr uint32_t k_track_type_to_num_elements[]
+ {
+ 1, // float1f
+ 2, // float2f
+ 3, // float3f
+ 4, // float4f
+ 4, // vector4f
+ };
+
+ static_assert(get_array_size(k_track_type_to_num_elements) == (size_t)track_type8::vector4f + 1, "Unexpected array size");
+
+ ACL_ASSERT(type <= track_type8::vector4f, "Unexpected track type");
+ return type <= track_type8::vector4f ? k_track_type_to_num_elements[static_cast<uint32_t>(type)] : 0;
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/track_writer.h b/includes/acl/core/track_writer.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/track_writer.h
@@ -0,0 +1,87 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+
+#include <rtm/types.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // We use a struct like this to allow an arbitrary format on the end user side.
+ // Since our decode function is templated on this type implemented by the user,
+ // the callbacks can trivially be inlined and customized.
+ // Only called functions need to be overridden and implemented.
+ //////////////////////////////////////////////////////////////////////////
+ struct track_writer
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float1(uint32_t track_index, rtm::scalarf_arg0 value)
+ {
+ (void)track_index;
+ (void)value;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float2(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ (void)track_index;
+ (void)value;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float3(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ (void)track_index;
+ (void)value;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_float4(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ (void)track_index;
+ (void)value;
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Called by the decoder to write out a value for a specified track index.
+ void write_vector4(uint32_t track_index, rtm::vector4f_arg0 value)
+ {
+ (void)track_index;
+ (void)value;
+ }
+ };
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/decompress.h b/includes/acl/decompression/decompress.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/decompression/decompress.h
@@ -0,0 +1,670 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/error.h"
+#include "acl/core/iallocator.h"
+#include "acl/core/interpolation_utils.h"
+#include "acl/core/track_traits.h"
+#include "acl/core/track_types.h"
+#include "acl/core/track_writer.h"
+#include "acl/decompression/impl/track_sampling_impl.h"
+#include "acl/math/rtm_casts.h"
+
+#include <rtm/types.h>
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+#include <type_traits>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // Deriving from this struct and overriding these constexpr functions
+ // allow you to control which code is stripped for maximum performance.
+ // With these, you can:
+ // - Support only a subset of the formats and statically strip the rest
+ // - Force a single format and statically strip the rest
+ // - Decide all of this at runtime by not making the overrides constexpr
+ //
+ // By default, all formats are supported.
+ //////////////////////////////////////////////////////////////////////////
+ struct decompression_settings
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // Whether or not to clamp the sample time when `seek(..)` is called. Defaults to true.
+ constexpr bool clamp_sample_time() const { return true; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Whether or not the specified track type is supported. Defaults to true.
+ // If a track type is statically known not to be supported, the compiler can strip
+ // the associated code.
+ constexpr bool is_track_type_supported(track_type8 /*type*/) const { return true; }
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // These are debug settings, everything is enabled and nothing is stripped.
+ // It will have the worst performance but allows every feature.
+ //////////////////////////////////////////////////////////////////////////
+ struct debug_decompression_settings : public decompression_settings {};
+
+ //////////////////////////////////////////////////////////////////////////
+ // These are the default settings. Only the generally optimal settings
+ // are enabled and will offer the overall best performance.
+ //////////////////////////////////////////////////////////////////////////
+ struct default_decompression_settings : public decompression_settings {};
+
+ //////////////////////////////////////////////////////////////////////////
+ // Decompression context for the uniformly sampled algorithm. The context
+ // allows various decompression actions to be performed on a compressed track list.
+ //
+ // Both the constructor and destructor are public because it is safe to place
+ // instances of this context on the stack or as member variables.
+ //
+ // This compression algorithm is the simplest by far and as such it offers
+ // the fastest compression and decompression. Every sample is retained and
+ // every track has the same number of samples playing back at the same
+ // sample rate. This means that when we sample at a particular time within
+ // the track list, we can trivially calculate the offsets required to read the
+ // desired data. All the data is sorted in order to ensure all reads are
+ // as contiguous as possible for optimal cache locality during decompression.
+ //////////////////////////////////////////////////////////////////////////
+ template<class decompression_settings_type>
+ class decompression_context
+ {
+ public:
+ //////////////////////////////////////////////////////////////////////////
+ // Constructs a context instance with an optional allocator instance.
+ // The default constructor for the `decompression_settings_type` will be used.
+ // If an allocator is provided, it will be used in `release()` to free the context.
+ inline decompression_context(IAllocator* allocator = nullptr);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Constructs a context instance from a set of static settings and an optional allocator instance.
+ // If an allocator is provided, it will be used in `release()` to free the context.
+ inline decompression_context(const decompression_settings_type& settings, IAllocator* allocator = nullptr);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Destructs a context instance.
+ inline ~decompression_context();
+
+ //////////////////////////////////////////////////////////////////////////
+ // Initializes the context instance to a particular compressed tracks instance.
+ inline void initialize(const compressed_tracks& tracks);
+
+ inline bool is_dirty(const compressed_tracks& tracks);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Seeks within the compressed tracks to a particular point in time with the
+ // desired rounding policy.
+ inline void seek(float sample_time, SampleRoundingPolicy rounding_policy);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Decompress every track at the current sample time.
+ // The track_writer_type allows complete control over how the tracks are written out.
+ template<class track_writer_type>
+ inline void decompress_tracks(track_writer_type& writer);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Decompress a single track at the current sample time.
+ // The track_writer_type allows complete control over how the track is written out.
+ template<class track_writer_type>
+ inline void decompress_track(uint32_t track_index, track_writer_type& writer);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Releases the context instance if it contains an allocator reference.
+ inline void release();
+
+ private:
+ decompression_context(const decompression_context& other) = delete;
+ decompression_context& operator=(const decompression_context& other) = delete;
+
+ // Internal context data
+ acl_impl::persistent_decompression_context m_context;
+
+ // The static settings used to strip out code at runtime
+ decompression_settings_type m_settings;
+
+ // The optional allocator instance used to allocate this instance
+ IAllocator* m_allocator;
+
+ static_assert(std::is_base_of<decompression_settings, decompression_settings_type>::value, "decompression_settings_type must derive from decompression_settings!");
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // Allocates and constructs an instance of the decompression context
+ template<class decompression_settings_type>
+ inline decompression_context<decompression_settings_type>* make_decompression_context(IAllocator& allocator)
+ {
+ return allocate_type<decompression_context<decompression_settings_type>>(allocator, &allocator);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Allocates and constructs an instance of the decompression context
+ template<class decompression_settings_type>
+ inline decompression_context<decompression_settings_type>* make_decompression_context(IAllocator& allocator, const decompression_settings_type& settings)
+ {
+ return allocate_type<decompression_context<decompression_settings_type>>(allocator, settings, &allocator);
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // decompression_context implementation
+
+ template<class decompression_settings_type>
+ inline decompression_context<decompression_settings_type>::decompression_context(IAllocator* allocator)
+ : m_context()
+ , m_settings()
+ , m_allocator(allocator)
+ {
+ m_context.tracks = nullptr; // Only member used to detect if we are initialized
+ }
+
+ template<class decompression_settings_type>
+ inline decompression_context<decompression_settings_type>::decompression_context(const decompression_settings_type& settings, IAllocator* allocator)
+ : m_context()
+ , m_settings(settings)
+ , m_allocator(allocator)
+ {
+ m_context.tracks = nullptr; // Only member used to detect if we are initialized
+ }
+
+ template<class decompression_settings_type>
+ inline decompression_context<decompression_settings_type>::~decompression_context()
+ {
+ release();
+ }
+
+ template<class decompression_settings_type>
+ inline void decompression_context<decompression_settings_type>::initialize(const compressed_tracks& tracks)
+ {
+ ACL_ASSERT(tracks.is_valid(false).empty(), "Compressed tracks are not valid");
+ ACL_ASSERT(tracks.get_algorithm_type() == AlgorithmType8::UniformlySampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(AlgorithmType8::UniformlySampled));
+
+ m_context.tracks = &tracks;
+ m_context.tracks_hash = tracks.get_hash();
+ m_context.duration = tracks.get_duration();
+ m_context.sample_time = -1.0f;
+ m_context.interpolation_alpha = 0.0;
+ }
+
+ template<class decompression_settings_type>
+ inline bool decompression_context<decompression_settings_type>::is_dirty(const compressed_tracks& tracks)
+ {
+ if (m_context.tracks != &tracks)
+ return true;
+
+ if (m_context.tracks_hash != tracks.get_hash())
+ return true;
+
+ return false;
+ }
+
+ template<class decompression_settings_type>
+ inline void decompression_context<decompression_settings_type>::seek(float sample_time, SampleRoundingPolicy rounding_policy)
+ {
+ ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
+
+ // Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
+ if (m_settings.clamp_sample_time())
+ sample_time = rtm::scalar_clamp(sample_time, 0.0f, m_context.duration);
+
+ if (m_context.sample_time == sample_time)
+ return;
+
+ m_context.sample_time = sample_time;
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
+
+ uint32_t key_frame0;
+ uint32_t key_frame1;
+ find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, m_context.interpolation_alpha);
+
+ m_context.key_frame_bit_offsets[0] = key_frame0 * header.num_bits_per_frame;
+ m_context.key_frame_bit_offsets[1] = key_frame1 * header.num_bits_per_frame;
+ }
+
+ template<class decompression_settings_type>
+ template<class track_writer_type>
+ inline void decompression_context<decompression_settings_type>::decompress_tracks(track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
+
+ const acl_impl::track_metadata* per_track_metadata = header.get_track_metadata();
+ const float* constant_values = header.get_track_constant_values();
+ const float* range_values = header.get_track_range_values();
+ const uint8_t* animated_values = header.get_track_animated_values();
+
+ uint32_t track_bit_offset0 = m_context.key_frame_bit_offsets[0];
+ uint32_t track_bit_offset1 = m_context.key_frame_bit_offsets[1];
+
+ for (uint32_t track_index = 0; track_index < header.num_tracks; ++track_index)
+ {
+ const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint8_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+
+ if (header.track_type == track_type8::float1f && m_settings.is_track_type_supported(track_type8::float1f))
+ {
+ rtm::scalarf value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::scalar_load(constant_values);
+ constant_values += 1;
+ }
+ else
+ {
+ rtm::scalarf value0;
+ rtm::scalarf value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = acl_impl::unpack_scalarf_96_unsafe(animated_values, track_bit_offset0);
+ value1 = acl_impl::unpack_scalarf_96_unsafe(animated_values, track_bit_offset1);
+ }
+ else
+ {
+ value0 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
+
+ const rtm::scalarf range_min = rtm::scalar_load(range_values);
+ const rtm::scalarf range_extent = rtm::scalar_load(range_values + 1);
+ value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
+ value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::scalar_lerp(value0, value1, m_context.interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ range_values += 2;
+ }
+
+ writer.write_float1(track_index, value);
+ }
+ else if (header.track_type == track_type8::float2f && m_settings.is_track_type_supported(track_type8::float2f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 2;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, track_bit_offset1));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 2);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 2;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ range_values += 4;
+ }
+
+ writer.write_float2(track_index, value);
+ }
+ else if (header.track_type == track_type8::float3f && m_settings.is_track_type_supported(track_type8::float3f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 3;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, track_bit_offset1));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 3);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 3;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ range_values += 6;
+ }
+
+ writer.write_float3(track_index, value);
+ }
+ else if (header.track_type == track_type8::float4f && m_settings.is_track_type_supported(track_type8::float4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 4;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset1));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 4;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ range_values += 8;
+ }
+
+ writer.write_float4(track_index, value);
+ }
+ else if (header.track_type == track_type8::vector4f && m_settings.is_track_type_supported(track_type8::vector4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ {
+ value = rtm::vector_load(constant_values);
+ constant_values += 4;
+ }
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset1));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
+ value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+
+ const uint32_t num_sample_bits = num_bits_per_component * 4;
+ track_bit_offset0 += num_sample_bits;
+ track_bit_offset1 += num_sample_bits;
+ range_values += 8;
+ }
+
+ writer.write_vector4(track_index, value);
+ }
+ }
+ }
+
+ template<class decompression_settings_type>
+ template<class track_writer_type>
+ inline void decompression_context<decompression_settings_type>::decompress_track(uint32_t track_index, track_writer_type& writer)
+ {
+ static_assert(std::is_base_of<track_writer, track_writer_type>::value, "track_writer_type must derive from track_writer");
+ ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
+ ACL_ASSERT(track_index < m_context.tracks->get_num_tracks(), "Invalid track index");
+
+ const acl_impl::tracks_header& header = acl_impl::get_tracks_header(*m_context.tracks);
+
+ const float* constant_values = header.get_track_constant_values();
+ const float* range_values = header.get_track_range_values();
+
+ const uint32_t num_element_components = get_track_num_sample_elements(header.track_type);
+ uint32_t track_bit_offset = 0;
+
+ const acl_impl::track_metadata* per_track_metadata = header.get_track_metadata();
+ for (uint32_t scan_track_index = 0; scan_track_index < track_index; ++scan_track_index)
+ {
+ const acl_impl::track_metadata& metadata = per_track_metadata[scan_track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ track_bit_offset += num_bits_per_component * num_element_components;
+
+ if (is_constant_bit_rate(bit_rate))
+ constant_values += num_element_components;
+ else
+ range_values += num_element_components * 2;
+ }
+
+ const acl_impl::track_metadata& metadata = per_track_metadata[track_index];
+ const uint8_t bit_rate = metadata.bit_rate;
+ const uint8_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+
+ const uint8_t* animated_values = header.get_track_animated_values();
+
+ if (header.track_type == track_type8::float1f && m_settings.is_track_type_supported(track_type8::float1f))
+ {
+ rtm::scalarf value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::scalar_load(constant_values);
+ else
+ {
+ rtm::scalarf value0;
+ rtm::scalarf value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = acl_impl::unpack_scalarf_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = acl_impl::unpack_scalarf_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
+ }
+ else
+ {
+ value0 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = acl_impl::unpack_scalarf_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
+
+ const rtm::scalarf range_min = rtm::scalar_load(range_values);
+ const rtm::scalarf range_extent = rtm::scalar_load(range_values + num_element_components);
+ value0 = rtm::scalar_mul_add(value0, range_extent, range_min);
+ value1 = rtm::scalar_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::scalar_lerp(value0, value1, m_context.interpolation_alpha);
+ }
+
+ writer.write_float1(track_index, value);
+ }
+ else if (header.track_type == track_type8::float2f && m_settings.is_track_type_supported(track_type8::float2f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+ }
+
+ writer.write_float2(track_index, value);
+ }
+ else if (header.track_type == track_type8::float3f && m_settings.is_track_type_supported(track_type8::float3f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+ }
+
+ writer.write_float3(track_index, value);
+ }
+ else if (header.track_type == track_type8::float4f && m_settings.is_track_type_supported(track_type8::float4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+ }
+
+ writer.write_float4(track_index, value);
+ }
+ else if (header.track_type == track_type8::vector4f && m_settings.is_track_type_supported(track_type8::vector4f))
+ {
+ rtm::vector4f value;
+ if (is_constant_bit_rate(bit_rate))
+ value = rtm::vector_load(constant_values);
+ else
+ {
+ rtm::vector4f value0;
+ rtm::vector4f value1;
+ if (is_raw_bit_rate(bit_rate))
+ {
+ value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ }
+ else
+ {
+ value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
+ value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+
+ const rtm::vector4f range_min = rtm::vector_load(range_values);
+ const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
+ value0 = rtm::vector_mul_add(value0, range_extent, range_min);
+ value1 = rtm::vector_mul_add(value1, range_extent, range_min);
+ }
+
+ value = rtm::vector_lerp(value0, value1, m_context.interpolation_alpha);
+ }
+
+ writer.write_vector4(track_index, value);
+ }
+ }
+
+ template<class decompression_settings_type>
+ inline void decompression_context<decompression_settings_type>::release()
+ {
+ IAllocator* allocator = m_allocator;
+ if (allocator != nullptr)
+ {
+ m_allocator = nullptr;
+ deallocate_type<decompression_context>(*allocator, this);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/track_sampling_impl.h b/includes/acl/decompression/impl/track_sampling_impl.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/decompression/impl/track_sampling_impl.h
@@ -0,0 +1,172 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/core/compressed_tracks.h"
+
+#include <rtm/scalarf.h>
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ struct alignas(64) persistent_decompression_context
+ {
+ // Clip related data // offsets
+ const compressed_tracks* tracks; // 0 | 0
+
+ uint32_t tracks_hash; // 4 | 8
+
+ float duration; // 8 | 12
+
+ // Seeking related data
+ float interpolation_alpha; // 12 | 16
+ float sample_time; // 16 | 20
+
+ uint32_t key_frame_bit_offsets[2]; // 20 | 24 // Variable quantization
+
+ uint8_t padding_tail[sizeof(void*) == 4 ? 36 : 32];
+
+ //////////////////////////////////////////////////////////////////////////
+
+ inline bool is_initialized() const { return tracks != nullptr; }
+ };
+
+ // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
+ inline rtm::scalarf ACL_SIMD_CALL unpack_scalarf_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ {
+#if defined(ACL_SSE2_INTRINSICS)
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint32_t x32 = uint32_t(vector_u64);
+
+ return _mm_castsi128_ps(_mm_set1_epi32(x32));
+#elif defined(ACL_NEON_INTRINSICS)
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint64_t x64 = vector_u64;
+
+ const uint32x2_t xy = vcreate_u32(x64);
+ return vget_lane_f32(vreinterpret_f32_u32(xy), 0);
+#else
+ const uint32_t byte_offset = bit_offset / 8;
+ const uint32_t shift_offset = bit_offset % 8;
+ uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
+ vector_u64 = byte_swap(vector_u64);
+ vector_u64 <<= shift_offset;
+ vector_u64 >>= 32;
+
+ const uint64_t x64 = vector_u64;
+
+ const float x = aligned_load<float>(&x64);
+
+ return rtm::scalar_set(x);
+#endif
+ }
+
+ // Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
+ inline rtm::scalarf ACL_SIMD_CALL unpack_scalarf_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ {
+ ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
+
+ struct PackedTableEntry
+ {
+ constexpr PackedTableEntry(uint8_t num_bits_)
+ : max_value(num_bits_ == 0 ? 1.0f : (1.0f / float((1 << num_bits_) - 1)))
+ , mask((1 << num_bits_) - 1)
+ {}
+
+ float max_value;
+ uint32_t mask;
+ };
+
+ // TODO: We technically don't need the first 3 entries, which could save a few bytes
+ alignas(64) static constexpr PackedTableEntry k_packed_constants[20] =
+ {
+ PackedTableEntry(0), PackedTableEntry(1), PackedTableEntry(2), PackedTableEntry(3),
+ PackedTableEntry(4), PackedTableEntry(5), PackedTableEntry(6), PackedTableEntry(7),
+ PackedTableEntry(8), PackedTableEntry(9), PackedTableEntry(10), PackedTableEntry(11),
+ PackedTableEntry(12), PackedTableEntry(13), PackedTableEntry(14), PackedTableEntry(15),
+ PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
+ };
+
+#if defined(ACL_SSE2_INTRINSICS)
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
+
+ const __m128 value = _mm_cvtsi32_ss(inv_max_value, x32 & mask);
+ return _mm_mul_ss(value, inv_max_value);
+#elif defined(ACL_NEON_INTRINSICS)
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const float inv_max_value = k_packed_constants[num_bits].max_value;
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8)));
+
+ const int32_t value_u32 = x32 & mask;
+ const float value_f32 = static_cast<float>(value_u32);
+ return value_f32 * inv_max_value;
+#else
+ const uint32_t bit_shift = 32 - num_bits;
+ const uint32_t mask = k_packed_constants[num_bits].mask;
+ const float inv_max_value = k_packed_constants[num_bits].max_value;
+
+ uint32_t byte_offset = bit_offset / 8;
+ uint32_t vector_u32 = unaligned_load<uint32_t>(vector_data + byte_offset);
+ vector_u32 = byte_swap(vector_u32);
+ const uint32_t x32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
+
+ return rtm::scalar_set(static_cast<float>(x32) * inv_max_value);
+#endif
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/io/clip_reader.h b/includes/acl/io/clip_reader.h
--- a/includes/acl/io/clip_reader.h
+++ b/includes/acl/io/clip_reader.h
@@ -29,6 +29,7 @@
#include "acl/io/clip_reader_error.h"
#include "acl/compression/animation_clip.h"
#include "acl/compression/compression_settings.h"
+#include "acl/compression/track_array.h"
#include "acl/compression/skeleton.h"
#include "acl/core/algorithm_types.h"
#include "acl/core/compiler_utils.h"
@@ -42,6 +43,36 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
+ //////////////////////////////////////////////////////////////////////////
+ // Enum to describe each type of raw content that an SJSON ACL file might contain.
+ enum class sjson_file_type
+ {
+ unknown,
+ raw_clip,
+ raw_track_list,
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // A raw clip with transform tracks
+ struct sjson_raw_clip
+ {
+ std::unique_ptr<AnimationClip, Deleter<AnimationClip>> clip;
+ std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>> skeleton;
+
+ bool has_settings;
+ AlgorithmType8 algorithm_type;
+ CompressionSettings settings;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // A raw track list
+ struct sjson_raw_track_list
+ {
+ track_array track_list;
+ };
+
+ //////////////////////////////////////////////////////////////////////////
+ // An SJSON ACL file reader.
class ClipReader
{
public:
@@ -56,28 +87,94 @@ namespace acl
{
}
+ ACL_DEPRECATED("Use get_file_type() and read_raw_clip(..) instead, to be removed in v2.0")
bool read_settings(bool& out_has_settings, AlgorithmType8& out_algorithm_type, CompressionSettings& out_settings)
{
reset_state();
- return read_version() && read_clip_header() && read_settings(&out_has_settings, &out_algorithm_type, &out_settings);
+ return read_version() && read_raw_clip_header() && read_settings(&out_has_settings, &out_algorithm_type, &out_settings);
}
+ ACL_DEPRECATED("Use get_file_type() and read_raw_clip(..) instead, to be removed in v2.0")
bool read_skeleton(std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>>& skeleton)
{
reset_state();
- return read_version() && read_clip_header() && read_settings(nullptr, nullptr, nullptr) && create_skeleton(skeleton);
+ return read_version() && read_raw_clip_header() && read_settings(nullptr, nullptr, nullptr) && create_skeleton(skeleton);
}
+ ACL_DEPRECATED("Use get_file_type() and read_raw_clip(..) instead, to be removed in v2.0")
bool read_clip(std::unique_ptr<AnimationClip, Deleter<AnimationClip>>& clip, const RigidSkeleton& skeleton)
{
reset_state();
- return read_version() && read_clip_header() && read_settings(nullptr, nullptr, nullptr) && read_skeleton() && create_clip(clip, skeleton) && read_tracks(*clip, skeleton) && nothing_follows();
+ return read_version() && read_raw_clip_header() && read_settings(nullptr, nullptr, nullptr) && read_skeleton() && create_clip(clip, skeleton) && read_tracks(*clip, skeleton) && nothing_follows();
+ }
+
+ sjson_file_type get_file_type()
+ {
+ reset_state();
+
+ if (!read_version())
+ return sjson_file_type::unknown;
+
+ if (m_parser.object_begins("clip"))
+ return sjson_file_type::raw_clip;
+
+ if (m_parser.object_begins("track_list"))
+ return sjson_file_type::raw_track_list;
+
+ return sjson_file_type::unknown;
+ }
+
+ bool read_raw_clip(sjson_raw_clip& out_data)
+ {
+ reset_state();
+
+ if (!read_version())
+ return false;
+
+ if (!read_raw_clip_header())
+ return false;
+
+ if (!read_settings(&out_data.has_settings, &out_data.algorithm_type, &out_data.settings))
+ return false;
+
+ if (!create_skeleton(out_data.skeleton))
+ return false;
+
+ if (!create_clip(out_data.clip, *out_data.skeleton))
+ return false;
+
+ if (!read_tracks(*out_data.clip, *out_data.skeleton))
+ return false;
+
+ return nothing_follows();
+ }
+
+ bool read_raw_track_list(sjson_raw_track_list& out_data)
+ {
+ reset_state();
+
+ if (!read_version())
+ return false;
+
+ if (!read_raw_track_list_header())
+ return false;
+
+ bool has_settings; // Not used
+ AlgorithmType8 algorithm_type; // Not used
+ CompressionSettings settings; // Not used
+ if (!read_settings(&has_settings, &algorithm_type, &settings))
+ return false;
+
+ if (!create_track_list(out_data.track_list))
+ return false;
+
+ return nothing_follows();
}
- ClipReaderError get_error() { return m_error; }
+ ClipReaderError get_error() const { return m_error; }
private:
IAllocator& m_allocator;
@@ -108,7 +205,7 @@ namespace acl
return false;
}
- if (m_version > 3)
+ if (m_version > 4)
{
set_error(ClipReaderError::UnsupportedVersion);
return false;
@@ -117,7 +214,7 @@ namespace acl
return true;
}
- bool read_clip_header()
+ bool read_raw_clip_header()
{
sjson::StringView additive_format;
@@ -191,6 +288,49 @@ namespace acl
return false;
}
+ bool read_raw_track_list_header()
+ {
+ if (!m_parser.object_begins("track_list"))
+ goto error;
+
+ if (!m_parser.read("name", m_clip_name))
+ goto error;
+
+ double num_samples;
+ if (!m_parser.read("num_samples", num_samples))
+ goto error;
+
+ m_num_samples = static_cast<uint32_t>(num_samples);
+ if (static_cast<double>(m_num_samples) != num_samples)
+ {
+ set_error(ClipReaderError::UnsignedIntegerExpected);
+ return false;
+ }
+
+ double sample_rate;
+ if (!m_parser.read("sample_rate", sample_rate))
+ goto error;
+
+ m_sample_rate = static_cast<float>(sample_rate);
+ if (m_sample_rate <= 0.0f)
+ {
+ set_error(ClipReaderError::PositiveValueExpected);
+ return false;
+ }
+
+ // Optional value
+ m_parser.try_read("is_binary_exact", m_is_binary_exact, false);
+
+ if (!m_parser.object_ends())
+ goto error;
+
+ return true;
+
+ error:
+ m_error = m_parser.get_error();
+ return false;
+ }
+
bool read_settings(bool* out_has_settings, AlgorithmType8* out_algorithm_type, CompressionSettings* out_settings)
{
if (!m_parser.try_object_begins("settings"))
@@ -366,6 +506,21 @@ namespace acl
return UInt64ToDouble(value_u64).dbl;
}
+ static float hex_to_float(const sjson::StringView& value)
+ {
+ union UInt32ToFloat
+ {
+ uint32_t u32;
+ float flt;
+
+ constexpr explicit UInt32ToFloat(uint32_t u32_value) : u32(u32_value) {}
+ };
+
+ ACL_ASSERT(value.size() <= 16, "Invalid binary exact double value");
+ uint32_t value_u32 = std::strtoul(value.c_str(), nullptr, 16);
+ return UInt32ToFloat(value_u32).flt;
+ }
+
static Quat_64 hex_to_quat(const sjson::StringView values[4])
{
return quat_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]), hex_to_double(values[3]));
@@ -376,6 +531,19 @@ namespace acl
return vector_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]));
}
+ static rtm::float4f hex_to_float4f(const sjson::StringView values[4], uint32_t num_components)
+ {
+ ACL_ASSERT(num_components <= 4, "Invalid number of components");
+
+ rtm::float4f result = { 0.0f, 0.0f, 0.0f, 0.0f };
+ float* result_ptr = &result.x;
+
+ for (uint32_t component_index = 0; component_index < num_components; ++num_components)
+ result_ptr[component_index] = hex_to_float(values[component_index]);
+
+ return result;
+ }
+
bool process_each_bone(RigidBone* bones, uint16_t& num_bones)
{
bool counting = bones == nullptr;
@@ -483,6 +651,267 @@ namespace acl
return true;
}
+ bool process_track_list(track* tracks, uint32_t& num_tracks)
+ {
+ const bool counting = tracks == nullptr;
+ track dummy;
+ track_type8 track_list_type = track_type8::float1f;
+
+ num_tracks = 0;
+
+ if (!m_parser.array_begins("tracks"))
+ goto error;
+
+ for (uint32_t i = 0; !m_parser.try_array_ends(); ++i)
+ {
+ track& track_ = counting ? dummy : tracks[i];
+
+ if (!m_parser.object_begins())
+ goto error;
+
+ sjson::StringView name;
+ if (!m_parser.read("name", name))
+ goto error;
+
+ // TODO: Store track name somewhere for debugging purposes
+
+ sjson::StringView type;
+ if (!m_parser.read("type", type))
+ goto error;
+
+ track_type8 track_type;
+ if (!get_track_type(type.c_str(), track_type))
+ {
+ m_error.error = ClipReaderError::InvalidTrackType;
+ return false;
+ }
+
+ if (num_tracks == 0)
+ track_list_type = track_type;
+ else if (track_type != track_list_type)
+ {
+ m_error.error = ClipReaderError::InvalidTrackType;
+ return false;
+ }
+
+ const uint32_t num_components = get_track_num_sample_elements(track_type);
+ ACL_ASSERT(num_components > 0 && num_components <= 4, "Cannot have 0 or more than 4 components");
+
+ float precision;
+ m_parser.try_read("precision", precision, 0.0001f);
+
+ float constant_threshold;
+ m_parser.try_read("constant_threshold", constant_threshold, 0.00001f);
+
+ uint32_t output_index;
+ m_parser.try_read("output_index", output_index, i);
+
+ track_desc_scalarf scalar_desc;
+ scalar_desc.output_index = output_index;
+ scalar_desc.precision = precision;
+ scalar_desc.constant_threshold = constant_threshold;
+
+ if (!m_parser.array_begins("data"))
+ goto error;
+
+ union track_samples_ptr_union
+ {
+ void* any;
+ float* float1f;
+ rtm::float2f* float2f;
+ rtm::float3f* float3f;
+ rtm::float4f* float4f;
+ rtm::vector4f* vector4f;
+ };
+ track_samples_ptr_union track_samples_typed = { nullptr };
+
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ track_samples_typed.float1f = allocate_type_array<float>(m_allocator, m_num_samples);
+ break;
+ case track_type8::float2f:
+ track_samples_typed.float2f = allocate_type_array<rtm::float2f>(m_allocator, m_num_samples);
+ break;
+ case track_type8::float3f:
+ track_samples_typed.float3f = allocate_type_array<rtm::float3f>(m_allocator, m_num_samples);
+ break;
+ case track_type8::float4f:
+ track_samples_typed.float4f = allocate_type_array<rtm::float4f>(m_allocator, m_num_samples);
+ break;
+ case track_type8::vector4f:
+ track_samples_typed.vector4f = allocate_type_array<rtm::vector4f>(m_allocator, m_num_samples);
+ break;
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+
+ bool has_error = false;
+ for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
+ {
+ if (!m_parser.array_begins())
+ {
+ has_error = true;
+ break;
+ }
+
+ if (m_is_binary_exact)
+ {
+ // TODO: Add test that uses this
+ sjson::StringView values[4];
+ if (m_parser.read(values, num_components))
+ {
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ {
+ const rtm::float4f value = hex_to_float4f(values, num_components);
+ std::memcpy(track_samples_typed.float1f + (sample_index * num_components), &value, sizeof(float) * num_components);
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+ }
+ else
+ {
+ has_error = true;
+ break;
+ }
+ }
+ else
+ {
+ double values[4];
+ if (m_parser.read(values, num_components))
+ {
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ case track_type8::float2f:
+ case track_type8::float3f:
+ case track_type8::float4f:
+ case track_type8::vector4f:
+ {
+ const rtm::float4f value = { static_cast<float>(values[0]), static_cast<float>(values[1]), static_cast<float>(values[2]), static_cast<float>(values[3])};
+ std::memcpy(track_samples_typed.float1f + (sample_index * num_components), &value, sizeof(float) * num_components);
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+ }
+ else
+ {
+ has_error = true;
+ break;
+ }
+ }
+
+ if (!has_error && !m_parser.array_ends())
+ {
+ has_error = true;
+ break;
+ }
+ }
+
+ if (!has_error && !m_parser.array_ends())
+ {
+ has_error = true;
+ break;
+ }
+
+ if (!has_error && !m_parser.object_ends())
+ {
+ has_error = true;
+ break;
+ }
+
+ if (has_error)
+ {
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ deallocate_type_array<float>(m_allocator, track_samples_typed.float1f, m_num_samples);
+ break;
+ case track_type8::float2f:
+ deallocate_type_array<rtm::float2f>(m_allocator, track_samples_typed.float2f, m_num_samples);
+ break;
+ case track_type8::float3f:
+ deallocate_type_array<rtm::float3f>(m_allocator, track_samples_typed.float3f, m_num_samples);
+ break;
+ case track_type8::float4f:
+ deallocate_type_array<rtm::float4f>(m_allocator, track_samples_typed.float4f, m_num_samples);
+ break;
+ case track_type8::vector4f:
+ deallocate_type_array<rtm::vector4f>(m_allocator, track_samples_typed.vector4f, m_num_samples);
+ break;
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+ }
+ else
+ {
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ track_ = track_float1f::make_owner(scalar_desc, m_allocator, track_samples_typed.float1f, m_num_samples, m_sample_rate);
+ break;
+ case track_type8::float2f:
+ track_ = track_float2f::make_owner(scalar_desc, m_allocator, track_samples_typed.float2f, m_num_samples, m_sample_rate);
+ break;
+ case track_type8::float3f:
+ track_ = track_float3f::make_owner(scalar_desc, m_allocator, track_samples_typed.float3f, m_num_samples, m_sample_rate);
+ break;
+ case track_type8::float4f:
+ track_ = track_float4f::make_owner(scalar_desc, m_allocator, track_samples_typed.float4f, m_num_samples, m_sample_rate);
+ break;
+ case track_type8::vector4f:
+ track_ = track_vector4f::make_owner(scalar_desc, m_allocator, track_samples_typed.vector4f, m_num_samples, m_sample_rate);
+ break;
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+ }
+
+ num_tracks++;
+ }
+
+ return true;
+
+ error:
+ m_error = m_parser.get_error();
+ return false;
+ }
+
+ bool create_track_list(track_array& track_list)
+ {
+ const sjson::ParserState before_tracks = m_parser.save_state();
+
+ uint32_t num_tracks;
+ if (!process_track_list(nullptr, num_tracks))
+ return false;
+
+ m_parser.restore_state(before_tracks);
+
+ track_list = track_array(m_allocator, num_tracks);
+
+ if (!process_track_list(track_list.begin(), num_tracks))
+ return false;
+
+ ACL_ASSERT(num_tracks == track_list.get_num_tracks(), "Number of tracks read mismatch");
+
+ return true;
+ }
+
bool read_tracks(AnimationClip& clip, const RigidSkeleton& skeleton)
{
std::unique_ptr<AnimationClip, Deleter<AnimationClip>> base_clip;
diff --git a/includes/acl/io/clip_reader_error.h b/includes/acl/io/clip_reader_error.h
--- a/includes/acl/io/clip_reader_error.h
+++ b/includes/acl/io/clip_reader_error.h
@@ -45,6 +45,7 @@ namespace acl
InvalidCompressionSetting,
InvalidAdditiveClipFormat,
PositiveValueExpected,
+ InvalidTrackType,
};
ClipReaderError()
@@ -76,6 +77,8 @@ namespace acl
return "Invalid additive clip format provided";
case PositiveValueExpected:
return "A positive value is expected here";
+ case InvalidTrackType:
+ return "Invalid raw track type";
default:
return sjson::ParserError::get_description();
}
diff --git a/includes/acl/math/rtm_casts.h b/includes/acl/math/rtm_casts.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/math/rtm_casts.h
@@ -0,0 +1,63 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/compiler_utils.h"
+#include "acl/math/vector4_32.h"
+
+#include <rtm/vector4f.h>
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ //////////////////////////////////////////////////////////////////////////
+ // Casts an ACL Vector4_32 into a RTM vector4f.
+ // When SIMD intrinsics are enabled, this is a no-op.
+ inline rtm::vector4f RTM_SIMD_CALL vector_acl2rtm(Vector4_32Arg0 value)
+ {
+#if defined(RTM_SSE2_INTRINSICS) || defined(RTM_NEON_INTRINSICS)
+ return value;
+#else
+ return rtm::vector4f{value.x, value.y, value.z, value.w};
+#endif
+ }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Casts a RTM vector4f into an ACL Vector4_32.
+ // When SIMD intrinsics are enabled, this is a no-op.
+ inline Vector4_32 RTM_SIMD_CALL vector_rtm2acl(rtm::vector4f_arg0 value)
+ {
+#if defined(RTM_SSE2_INTRINSICS) || defined(RTM_NEON_INTRINSICS)
+ return value;
+#else
+ return Vector4_32{value.x, value.y, value.z, value.w};
+#endif
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/make.py b/make.py
--- a/make.py
+++ b/make.py
@@ -10,7 +10,7 @@
import zipfile
# The current test/decompression data version in use
-current_test_data = 'test_data_v2'
+current_test_data = 'test_data_v3'
current_decomp_data = 'decomp_data_v4'
def parse_argv():
diff --git a/tools/acl_compressor/main_android/CMakeLists.txt b/tools/acl_compressor/main_android/CMakeLists.txt
--- a/tools/acl_compressor/main_android/CMakeLists.txt
+++ b/tools/acl_compressor/main_android/CMakeLists.txt
@@ -15,6 +15,7 @@ set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY "${PROJECT_BINARY_DIR}/lib")
set(CMAKE_ANDROID_JAVA_SOURCE_DIR "${PROJECT_SOURCE_DIR}/java")
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
include_directories("${PROJECT_SOURCE_DIR}/../includes")
@@ -47,6 +48,7 @@ target_compile_options(${PROJECT_NAME} PRIVATE -g)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
target_include_directories(${PROJECT_NAME} PUBLIC jni)
diff --git a/tools/acl_compressor/main_generic/CMakeLists.txt b/tools/acl_compressor/main_generic/CMakeLists.txt
--- a/tools/acl_compressor/main_generic/CMakeLists.txt
+++ b/tools/acl_compressor/main_generic/CMakeLists.txt
@@ -4,6 +4,7 @@ project(acl_compressor CXX)
set(CMAKE_CXX_STANDARD 11)
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
include_directories("${PROJECT_SOURCE_DIR}/../includes")
@@ -35,6 +36,7 @@ endif()
# Abort on failure, easier to debug issues this way
add_definitions(-DACL_ON_ASSERT_ABORT)
+add_definitions(-DRTM_ON_ASSERT_ABORT)
add_definitions(-DSJSON_CPP_ON_ASSERT_ABORT)
install(TARGETS ${PROJECT_NAME} RUNTIME DESTINATION bin)
diff --git a/tools/acl_compressor/main_ios/CMakeLists.txt b/tools/acl_compressor/main_ios/CMakeLists.txt
--- a/tools/acl_compressor/main_ios/CMakeLists.txt
+++ b/tools/acl_compressor/main_ios/CMakeLists.txt
@@ -16,6 +16,7 @@ set(MACOSX_BUNDLE_GUI_IDENTIFIER "com.acl.acl-compressor")
set(MACOSX_BUNDLE_BUNDLE_NAME "acl-compressor")
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
include_directories("${PROJECT_SOURCE_DIR}/../includes")
@@ -37,4 +38,5 @@ add_executable(${PROJECT_NAME} MACOSX_BUNDLE ${ALL_COMMON_SOURCE_FILES} ${ALL_MA
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -45,13 +45,17 @@
#include "acl/core/range_reduction_types.h"
#include "acl/core/ansi_allocator.h"
#include "acl/core/string.h"
-#include "acl/compression/skeleton.h"
+#include "acl/core/impl/debug_track_writer.h"
#include "acl/compression/animation_clip.h"
+#include "acl/compression/compress.h"
+#include "acl/compression/skeleton.h"
+#include "acl/compression/skeleton_error_metric.h"
+#include "acl/compression/stream/write_decompression_stats.h"
+#include "acl/compression/track_error.h"
#include "acl/compression/utils.h"
+#include "acl/decompression/decompress.h"
#include "acl/io/clip_reader.h"
#include "acl/io/clip_writer.h" // Included just so we compile it to test for basic errors
-#include "acl/compression/skeleton_error_metric.h"
-#include "acl/compression/stream/write_decompression_stats.h"
#include "acl/algorithm/uniformly_sampled/encoder.h"
#include "acl/algorithm/uniformly_sampled/decoder.h"
@@ -497,6 +501,188 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
deallocate_type_array(allocator, lossy_pose_transforms, num_bones);
}
+static void validate_accuracy(IAllocator& allocator, const track_array& raw_tracks, const compressed_tracks& tracks, double regression_error_threshold)
+{
+ (void)allocator;
+ (void)raw_tracks;
+ (void)tracks;
+ (void)regression_error_threshold;
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ using namespace acl_impl;
+
+ const float regression_error_thresholdf = static_cast<float>(regression_error_threshold);
+ const rtm::vector4f regression_error_thresholdv = rtm::vector_set(regression_error_thresholdf);
+ (void)regression_error_thresholdf;
+ (void)regression_error_thresholdv;
+
+ const float duration = tracks.get_duration();
+ const float sample_rate = tracks.get_sample_rate();
+ const uint32_t num_tracks = tracks.get_num_tracks();
+ const uint32_t num_samples = tracks.get_num_samples_per_track();
+ const track_type8 track_type = raw_tracks.get_track_type();
+
+ ACL_ASSERT(duration == raw_tracks.get_duration(), "Duration mismatch");
+ ACL_ASSERT(sample_rate == raw_tracks.get_sample_rate(), "Sample rate mismatch");
+ ACL_ASSERT(num_tracks <= raw_tracks.get_num_tracks(), "Num tracks mismatch");
+ ACL_ASSERT(num_samples == raw_tracks.get_num_samples_per_track(), "Num samples mismatch");
+
+ decompression_context<debug_decompression_settings> context;
+ context.initialize(tracks);
+
+ debug_track_writer raw_tracks_writer(allocator, track_type, num_tracks);
+ debug_track_writer raw_track_writer(allocator, track_type, num_tracks);
+ debug_track_writer lossy_tracks_writer(allocator, track_type, num_tracks);
+ debug_track_writer lossy_track_writer(allocator, track_type, num_tracks);
+
+ const rtm::vector4f zero = rtm::vector_zero();
+
+ // Regression test
+ for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
+ {
+ const float sample_time = min(float(sample_index) / sample_rate, duration);
+
+ raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::None, raw_tracks_writer);
+
+ context.seek(sample_time, SampleRoundingPolicy::None);
+ context.decompress_tracks(lossy_tracks_writer);
+
+ // Validate decompress_tracks
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ const uint32_t output_index = track_.get_output_index();
+ if (output_index == k_invalid_track_index)
+ continue; // Track is being stripped, ignore it
+
+ rtm::vector4f error = zero;
+
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ {
+ const float raw_value = raw_tracks_writer.read_float1(track_index);
+ const float lossy_value = lossy_tracks_writer.read_float1(output_index);
+ error = rtm::vector_set(rtm::scalar_abs(raw_value - lossy_value));
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float2(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float2(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::c, rtm::mix4::d>(error, zero);
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float3(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float3(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ error = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::z, rtm::mix4::d>(error, zero);
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_float4(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_float4(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const rtm::vector4f raw_value = raw_tracks_writer.read_vector4(track_index);
+ const rtm::vector4f lossy_value = lossy_tracks_writer.read_vector4(output_index);
+ error = rtm::vector_abs(rtm::vector_sub(raw_value, lossy_value));
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+
+ (void)error;
+ ACL_ASSERT(rtm::vector_is_finite(error), "Returned error is not a finite value");
+ ACL_ASSERT(rtm::vector_all_less_than(error, regression_error_thresholdv), "Error too high for track %u at time %f", track_index, sample_time);
+ }
+
+ // Validate decompress_track
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
+ const track& track_ = raw_tracks[track_index];
+ const uint32_t output_index = track_.get_output_index();
+ if (output_index == k_invalid_track_index)
+ continue; // Track is being stripped, ignore it
+
+ raw_tracks.sample_track(track_index, sample_time, SampleRoundingPolicy::None, raw_track_writer);
+ context.decompress_track(output_index, lossy_track_writer);
+
+ switch (track_type)
+ {
+ case track_type8::float1f:
+ {
+ const float raw_value_ = raw_tracks_writer.read_float1(track_index);
+ const float lossy_value_ = lossy_tracks_writer.read_float1(output_index);
+ const float raw_value = raw_track_writer.read_float1(track_index);
+ const float lossy_value = lossy_track_writer.read_float1(output_index);
+ ACL_ASSERT(rtm::scalar_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::scalar_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::scalar_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ break;
+ }
+ case track_type8::float2f:
+ {
+ const rtm::vector4f raw_value_ = raw_tracks_writer.read_float2(track_index);
+ const rtm::vector4f lossy_value_ = lossy_tracks_writer.read_float2(output_index);
+ const rtm::vector4f raw_value = raw_track_writer.read_float2(track_index);
+ const rtm::vector4f lossy_value = lossy_track_writer.read_float2(output_index);
+ ACL_ASSERT(rtm::vector_all_near_equal2(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal2(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal2(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ break;
+ }
+ case track_type8::float3f:
+ {
+ const rtm::vector4f raw_value_ = raw_tracks_writer.read_float3(track_index);
+ const rtm::vector4f lossy_value_ = lossy_tracks_writer.read_float3(output_index);
+ const rtm::vector4f raw_value = raw_track_writer.read_float3(track_index);
+ const rtm::vector4f lossy_value = lossy_track_writer.read_float3(output_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal3(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal3(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ break;
+ }
+ case track_type8::float4f:
+ {
+ const rtm::vector4f raw_value_ = raw_tracks_writer.read_float4(track_index);
+ const rtm::vector4f lossy_value_ = lossy_tracks_writer.read_float4(output_index);
+ const rtm::vector4f raw_value = raw_track_writer.read_float4(track_index);
+ const rtm::vector4f lossy_value = lossy_track_writer.read_float4(output_index);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ break;
+ }
+ case track_type8::vector4f:
+ {
+ const rtm::vector4f raw_value_ = raw_tracks_writer.read_vector4(track_index);
+ const rtm::vector4f lossy_value_ = lossy_tracks_writer.read_vector4(output_index);
+ const rtm::vector4f raw_value = raw_track_writer.read_vector4(track_index);
+ const rtm::vector4f lossy_value = lossy_track_writer.read_vector4(output_index);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value, lossy_value, regression_error_thresholdf), "Error too high for track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(raw_value_, raw_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ ACL_ASSERT(rtm::vector_all_near_equal(lossy_value_, lossy_value), "Failed to sample track %u at time %f", track_index, sample_time);
+ break;
+ }
+ default:
+ ACL_ASSERT(false, "Unsupported track type");
+ break;
+ }
+ }
+ }
+#endif // defined(ACL_HAS_ASSERT_CHECKS)
+}
+
static void try_algorithm(const Options& options, IAllocator& allocator, const AnimationClip& clip, const CompressionSettings& settings, AlgorithmType8 algorithm_type, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
{
(void)runs_writer;
@@ -576,12 +762,64 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const A
try_algorithm_impl(nullptr);
}
-static bool read_clip(IAllocator& allocator, const Options& options,
- std::unique_ptr<AnimationClip, Deleter<AnimationClip>>& out_clip,
- std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>>& out_skeleton,
- bool& has_settings,
- AlgorithmType8& out_algorithm_type,
- CompressionSettings& out_settings)
+static void try_algorithm(const Options& options, IAllocator& allocator, const track_array& track_list, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
+{
+ (void)runs_writer;
+
+ auto try_algorithm_impl = [&](sjson::ObjectWriter* stats_writer)
+ {
+ if (track_list.get_num_tracks() == 0)
+ return;
+
+ compression_settings settings;
+
+ OutputStats stats(logging, stats_writer);
+ compressed_tracks* compressed_tracks_ = nullptr;
+ const ErrorResult error_result = compress_track_list(allocator, track_list, settings, compressed_tracks_, stats);
+
+ ACL_ASSERT(error_result.empty(), error_result.c_str()); (void)error_result;
+ ACL_ASSERT(compressed_tracks_->is_valid(true).empty(), "Compressed tracks are invalid");
+
+#if defined(SJSON_CPP_WRITER)
+ if (logging != StatLogging::None)
+ {
+ const track_error error = calculate_compression_error(allocator, track_list, *compressed_tracks_);
+
+ stats_writer->insert("max_error", error.error);
+ stats_writer->insert("worst_track", error.index);
+ stats_writer->insert("worst_time", error.sample_time);
+
+ // TODO: measure decompression performance
+ //if (are_any_enum_flags_set(logging, StatLogging::SummaryDecompression))
+ //write_decompression_performance_stats(allocator, settings, *compressed_clip, logging, *stats_writer);
+ }
+#endif
+
+ if (options.regression_testing)
+ validate_accuracy(allocator, track_list, *compressed_tracks_, regression_error_threshold);
+
+ if (options.output_bin_filename != nullptr)
+ {
+ std::ofstream output_file_stream(options.output_bin_filename, std::ios_base::out | std::ios_base::binary | std::ios_base::trunc);
+ if (output_file_stream.is_open())
+ output_file_stream.write(reinterpret_cast<const char*>(compressed_tracks_), compressed_tracks_->get_size());
+ }
+
+ allocator.deallocate(compressed_tracks_, compressed_tracks_->get_size());
+ };
+
+#if defined(SJSON_CPP_WRITER)
+ if (runs_writer != nullptr)
+ runs_writer->push([&](sjson::ObjectWriter& writer) { try_algorithm_impl(&writer); });
+ else
+#endif
+ try_algorithm_impl(nullptr);
+}
+
+static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
+ sjson_file_type& out_file_type,
+ sjson_raw_clip& out_raw_clip,
+ sjson_raw_track_list& out_raw_track_list)
{
char* sjson_file_buffer = nullptr;
size_t file_size = 0;
@@ -636,18 +874,33 @@ static bool read_clip(IAllocator& allocator, const Options& options,
ClipReader reader(allocator, sjson_file_buffer, file_size - 1);
#endif
- if (!reader.read_settings(has_settings, out_algorithm_type, out_settings)
- || !reader.read_skeleton(out_skeleton)
- || !reader.read_clip(out_clip, *out_skeleton))
+ const sjson_file_type ftype = reader.get_file_type();
+ out_file_type = ftype;
+
+ bool success = false;
+ switch (ftype)
{
- ClipReaderError err = reader.get_error();
- printf("\nError on line %d column %d: %s\n", err.line, err.column, err.get_description());
- deallocate_type_array(allocator, sjson_file_buffer, file_size);
- return false;
+ case sjson_file_type::unknown:
+ default:
+ printf("\nUnknown file type\n");
+ break;
+ case sjson_file_type::raw_clip:
+ success = reader.read_raw_clip(out_raw_clip);
+ break;
+ case sjson_file_type::raw_track_list:
+ success = reader.read_raw_track_list(out_raw_track_list);
+ break;
+ }
+
+ if (!success)
+ {
+ const ClipReaderError err = reader.get_error();
+ if (err.error != ClipReaderError::None)
+ printf("\nError on line %d column %d: %s\n", err.line, err.column, err.get_description());
}
deallocate_type_array(allocator, sjson_file_buffer, file_size);
- return true;
+ return success;
}
static bool read_config(IAllocator& allocator, const Options& options, AlgorithmType8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
@@ -908,8 +1161,21 @@ static int safe_main_impl(int argc, char* argv[])
AlgorithmType8 algorithm_type = AlgorithmType8::UniformlySampled;
CompressionSettings settings;
- if (!is_input_acl_bin_file && !read_clip(allocator, options, clip, skeleton, use_external_config, algorithm_type, settings))
- return -1;
+ sjson_file_type sjson_type = sjson_file_type::unknown;
+ sjson_raw_clip sjson_clip;
+ sjson_raw_track_list sjson_track_list;
+
+ if (!is_input_acl_bin_file)
+ {
+ if (!read_acl_sjson_file(allocator, options, sjson_type, sjson_clip, sjson_track_list))
+ return -1;
+
+ clip = std::move(sjson_clip.clip);
+ skeleton = std::move(sjson_clip.skeleton);
+ use_external_config = sjson_clip.has_settings;
+ algorithm_type = sjson_clip.algorithm_type;
+ settings = sjson_clip.settings;
+ }
double regression_error_threshold = 0.1;
@@ -919,7 +1185,7 @@ static int safe_main_impl(int argc, char* argv[])
if (options.config_filename != nullptr && std::strlen(options.config_filename) != 0)
#endif
{
- // Override whatever the ACL clip might have contained
+ // Override whatever the ACL SJSON file might have contained
algorithm_type = AlgorithmType8::UniformlySampled;
settings = CompressionSettings();
@@ -929,9 +1195,10 @@ static int safe_main_impl(int argc, char* argv[])
use_external_config = true;
}
+ // TODO: Make a unique_ptr
AnimationClip* base_clip = nullptr;
- if (!is_input_acl_bin_file)
+ if (!is_input_acl_bin_file && sjson_type == sjson_file_type::raw_clip)
{
// Grab whatever clip we might have read from the sjson file and cast the const away so we can manage the memory
base_clip = const_cast<AnimationClip*>(clip->get_additive_base());
@@ -1004,84 +1271,91 @@ static int safe_main_impl(int argc, char* argv[])
}
#endif
}
- else if (use_external_config)
+ else if (sjson_type == sjson_file_type::raw_clip)
{
- ACL_ASSERT(algorithm_type == AlgorithmType8::UniformlySampled, "Only UniformlySampled is supported for now");
+ if (use_external_config)
+ {
+ ACL_ASSERT(algorithm_type == AlgorithmType8::UniformlySampled, "Only UniformlySampled is supported for now");
- if (options.compression_level_specified)
- settings.level = options.compression_level;
+ if (options.compression_level_specified)
+ settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
- }
- else if (options.exhaustive_compression)
- {
- const bool use_segmenting_options[] = { false, true };
- for (size_t segmenting_option_index = 0; segmenting_option_index < get_array_size(use_segmenting_options); ++segmenting_option_index)
+ try_algorithm(options, allocator, *clip, settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ }
+ else if (options.exhaustive_compression)
{
- const bool use_segmenting = use_segmenting_options[segmenting_option_index];
-
- CompressionSettings uniform_tests[] =
+ const bool use_segmenting_options[] = { false, true };
+ for (size_t segmenting_option_index = 0; segmenting_option_index < get_array_size(use_segmenting_options); ++segmenting_option_index)
{
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
+ const bool use_segmenting = use_segmenting_options[segmenting_option_index];
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
+ CompressionSettings uniform_tests[] =
+ {
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, use_segmenting),
- };
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
- for (CompressionSettings test_settings : uniform_tests)
- {
- test_settings.error_metric = settings.error_metric;
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, use_segmenting),
+ };
- try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ for (CompressionSettings test_settings : uniform_tests)
+ {
+ test_settings.error_metric = settings.error_metric;
+
+ try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ }
}
- }
- {
- CompressionSettings uniform_tests[] =
{
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
+ CompressionSettings uniform_tests[] =
+ {
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
+ make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
+ make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, true, RangeReductionFlags8::AllTracks),
- };
+ make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, true, RangeReductionFlags8::AllTracks),
+ };
- for (CompressionSettings test_settings : uniform_tests)
- {
- test_settings.error_metric = settings.error_metric;
+ for (CompressionSettings test_settings : uniform_tests)
+ {
+ test_settings.error_metric = settings.error_metric;
- if (options.compression_level_specified)
- test_settings.level = options.compression_level;
+ if (options.compression_level_specified)
+ test_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ }
}
}
- }
- else
- {
- CompressionSettings default_settings = get_default_compression_settings();
- default_settings.error_metric = settings.error_metric;
+ else
+ {
+ CompressionSettings default_settings = get_default_compression_settings();
+ default_settings.error_metric = settings.error_metric;
- if (options.compression_level_specified)
- default_settings.level = options.compression_level;
+ if (options.compression_level_specified)
+ default_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, default_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, default_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ }
+ }
+ else if (sjson_type == sjson_file_type::raw_track_list)
+ {
+ try_algorithm(options, allocator, sjson_track_list.track_list, logging, runs_writer, regression_error_threshold);
}
};
diff --git a/tools/acl_decompressor/main_android/CMakeLists.txt b/tools/acl_decompressor/main_android/CMakeLists.txt
--- a/tools/acl_decompressor/main_android/CMakeLists.txt
+++ b/tools/acl_decompressor/main_android/CMakeLists.txt
@@ -17,6 +17,7 @@ set(CMAKE_ANDROID_JAVA_SOURCE_DIR "${PROJECT_SOURCE_DIR}/java")
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/sources")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
# Setup resources
@@ -67,6 +68,7 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
target_include_directories(${PROJECT_NAME} PUBLIC jni)
diff --git a/tools/acl_decompressor/main_generic/CMakeLists.txt b/tools/acl_decompressor/main_generic/CMakeLists.txt
--- a/tools/acl_decompressor/main_generic/CMakeLists.txt
+++ b/tools/acl_decompressor/main_generic/CMakeLists.txt
@@ -6,6 +6,7 @@ set(CMAKE_CXX_STANDARD 11)
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/sources")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
# Grab all of our common source files
diff --git a/tools/acl_decompressor/main_ios/CMakeLists.txt b/tools/acl_decompressor/main_ios/CMakeLists.txt
--- a/tools/acl_decompressor/main_ios/CMakeLists.txt
+++ b/tools/acl_decompressor/main_ios/CMakeLists.txt
@@ -18,6 +18,7 @@ set(MACOSX_BUNDLE_BUNDLE_NAME "acl-decompressor")
include_directories("${PROJECT_SOURCE_DIR}/../../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../acl_compressor/sources")
+include_directories("${PROJECT_SOURCE_DIR}/../../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../../external/sjson-cpp/includes")
# Setup resources
@@ -56,6 +57,7 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
target_link_libraries(${PROJECT_NAME} "-framework CoreFoundation")
diff --git a/tools/format_reference.acl.sjson b/tools/format_reference.acl.sjson
--- a/tools/format_reference.acl.sjson
+++ b/tools/format_reference.acl.sjson
@@ -4,12 +4,18 @@
// Compressed clip filenames should have the form: *.acl.zip
// Note: a compressed clip is just a zipped raw clip.
-// Each clip file contains the information of a single clip.
+// Each file contains the information of a single clip or track list (but not both).
// The ACL file format version
-version = 123
+// version = 1 // Initial version
+// version = 2 // Introduced clip compression settings
+//version = 3 // Introduced additive clip related data
+version = 4 // Introduced track list related data
-// Clip general information
+// BEGIN CLIP RELATED DATA
+
+// Clip general information.
+// Optional, if present clip settings, bones, and tracks must be present as well.
// Must come first, before settings, bones, and tracks
clip =
{
@@ -48,7 +54,7 @@ clip =
additive_base_sample_rate = 30
}
-// Optional compression settings.
+// Optional clip compression settings.
// Must come before bones
settings =
{
@@ -107,7 +113,7 @@ settings =
error_threshold = 0.01
}
-// Reference skeleton, list of bones (any order)
+// Reference clip skeleton, list of bones (any order)
// Must come before tracks
bones =
[
@@ -138,7 +144,7 @@ bones =
}
]
-// Animation data, list of tracks (any order)
+// Animation data, list of clip tracks (any order)
tracks =
[
{
@@ -175,3 +181,74 @@ tracks =
]
}
]
+
+// END CLIP RELATED DATA
+// BEGIN TRACK LIST RELATED DATA
+
+// List general information.
+// Optional, if present clip settings and tracks must be present as well.
+// Must come first, before settings and tracks
+track_list =
+{
+ // Track list properties can come in any order
+
+ // List name, handy for debugging. Optional, filename will be used if missing.
+ name = "A clip"
+
+ // Number of samples per track. All tracks must have the same number of samples.
+ // List duration in seconds = (num_samples - 1) / sample_rate
+ // Regardless of sample_rate, if we have a single sample, we have a 0.0 duration
+ // and thus represent a static snapshot.
+ num_samples = 73
+
+ // List sample rate in samples per second. All tracks must have the same sample rate.
+ sample_rate = 30
+
+ // Whether floating point values are stored in hexadecimal and thus binary exact. Optional, defaults to 'false'.
+ is_binary_exact = true
+}
+
+// Optional list compression settings.
+// Must come before tracks
+settings =
+{
+}
+
+// List of raw tracks
+tracks =
+[
+ {
+ // Track properties can come in any order
+
+ // Track name, optional
+ name = "Right Hand IK"
+
+ // Track type (float1f, float2f, float3f, float4f)
+ type = float4f
+
+ // The precision target used when optimizing the bit rate
+ // Defaults to '0.0001' units
+ precision = 0.0001
+
+ // The constant track detection threshold
+ // Defaults to '0.00001' units
+ constant_threshold = 0.00001
+
+ // The track output index. When writing out the compressed data stream, this index
+ // will be used instead of the track index. This allows custom reordering for things
+ // like LOD sorting or skeleton remapping. A value of 'k_invalid_track_index' (0xFFFFFFFF) will strip the track
+ // from the compressed data stream. Output indices must be unique and contiguous.
+ // Defaults to the track index
+ output_index = 12
+
+ // Track data
+ data =
+ [
+ [ 0.0, 0.0, 0.0, 1.0 ]
+ [ 1.0, 0.0, 0.0, 0.0 ]
+ // The number of samples here must match num_samples
+ ]
+ }
+]
+
+// END TRACK LIST RELATED DATA
diff --git a/tools/regression_tester_android/CMakeLists.txt b/tools/regression_tester_android/CMakeLists.txt
--- a/tools/regression_tester_android/CMakeLists.txt
+++ b/tools/regression_tester_android/CMakeLists.txt
@@ -17,6 +17,7 @@ set(CMAKE_ANDROID_JAVA_SOURCE_DIR "${PROJECT_SOURCE_DIR}/java")
include_directories("${PROJECT_SOURCE_DIR}/../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../acl_compressor/includes")
include_directories("${PROJECT_SOURCE_DIR}/../acl_compressor/sources")
+include_directories("${PROJECT_SOURCE_DIR}/../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/sjson-cpp/includes")
# Setup resources
@@ -63,11 +64,13 @@ target_compile_options(${PROJECT_NAME} PRIVATE -g)
# Throw on failure to allow us to catch them and recover
add_definitions(-DACL_ON_ASSERT_THROW)
+add_definitions(-DRTM_ON_ASSERT_THROW)
add_definitions(-DSJSON_CPP_ON_ASSERT_THROW)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
# Disable allocation tracking since if we fail a regression test, we'll throw an exception
diff --git a/tools/regression_tester_ios/CMakeLists.txt b/tools/regression_tester_ios/CMakeLists.txt
--- a/tools/regression_tester_ios/CMakeLists.txt
+++ b/tools/regression_tester_ios/CMakeLists.txt
@@ -18,6 +18,7 @@ set(MACOSX_BUNDLE_BUNDLE_NAME "acl-regression-tester")
include_directories("${PROJECT_SOURCE_DIR}/../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../acl_compressor/includes")
include_directories("${PROJECT_SOURCE_DIR}/../acl_compressor/sources")
+include_directories("${PROJECT_SOURCE_DIR}/../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/sjson-cpp/includes")
# Setup resources
@@ -51,6 +52,7 @@ add_executable(${PROJECT_NAME} MACOSX_BUNDLE ${ALL_MAIN_SOURCE_FILES} ${ALL_COMM
# Throw on failure to allow us to catch them and recover
add_definitions(-DACL_ON_ASSERT_THROW)
+add_definitions(-DRTM_ON_ASSERT_THROW)
add_definitions(-DSJSON_CPP_ON_ASSERT_THROW)
# Disable allocation track since if we fail a regression test, we'll throw an exception
@@ -60,6 +62,7 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
target_link_libraries(${PROJECT_NAME} "-framework CoreFoundation")
diff --git a/tools/vs_visualizers/acl.natvis b/tools/vs_visualizers/acl.natvis
--- a/tools/vs_visualizers/acl.natvis
+++ b/tools/vs_visualizers/acl.natvis
@@ -47,4 +47,51 @@
<DisplayString>size={m_size}, num_bits={m_size * 32}</DisplayString>
</Type>
+ <Type Name="acl::track">
+ <DisplayString>num_samples={m_num_samples}, type={m_type}</DisplayString>
+ <Expand>
+ <Item Name="num_samples">m_num_samples</Item>
+ <Item Name="stride">m_stride</Item>
+ <Item Name="type">m_type</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::float1f">m_desc.scalar.precision</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::float2f">m_desc.scalar.precision</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::float3f">m_desc.scalar.precision</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::float4f">m_desc.scalar.precision</Item>
+ <Item Name="precision" Condition="m_type == acl::track_type8::vector4f">m_desc.scalar.precision</Item>
+ <Item Name="is_ref">m_allocator == nullptr</Item>
+ <ArrayItems>
+ <Size>m_num_samples</Size>
+ <ValuePointer Condition="m_type == acl::track_type8::float1f">(float*)m_data</ValuePointer>
+ <ValuePointer Condition="m_type == acl::track_type8::float2f">(rtm::float2f*)m_data</ValuePointer>
+ <ValuePointer Condition="m_type == acl::track_type8::float3f">(rtm::float3f*)m_data</ValuePointer>
+ <ValuePointer Condition="m_type == acl::track_type8::float4f">(rtm::float4f*)m_data</ValuePointer>
+ <ValuePointer Condition="m_type == acl::track_type8::vector4f">(rtm::vector4f*)m_data</ValuePointer>
+ </ArrayItems>
+ </Expand>
+ </Type>
+
+ <Type Name="acl::track_array">
+ <DisplayString>num_tracks={m_num_tracks}</DisplayString>
+ <Expand>
+ <Item Name="num_tracks">m_num_tracks</Item>
+ <ArrayItems>
+ <Size>m_num_tracks</Size>
+ <ValuePointer>m_tracks</ValuePointer>
+ </ArrayItems>
+ </Expand>
+ </Type>
+
+ <Type Name="acl::acl_impl::scalarf_range">
+ <DisplayString>min={m_min}, extent={m_extent}</DisplayString>
+ </Type>
+
+ <Type Name="acl::acl_impl::track_range">
+ <DisplayString Condition="category == acl::track_category8::scalarf">{range.scalarf}</DisplayString>
+ <Expand>
+ <Item Name="category">category</Item>
+ <Item Name="min" Condition="category == acl::track_category8::scalarf">range.scalarf.m_min</Item>
+ <Item Name="extent" Condition="category == acl::track_category8::scalarf">range.scalarf.m_extent</Item>
+ </Expand>
+ </Type>
+
</AutoVisualizer>
|
diff --git a/test_data/README.md b/test_data/README.md
--- a/test_data/README.md
+++ b/test_data/README.md
@@ -7,7 +7,8 @@ This directory is to contain all the relevant data to perform regression testing
Find the latest test data zip file located on Google Drive and save it into this directory. If your data ever becomes stale, the python script will indicate as such and you will need to perform this step again. The zip file contains a number of clips from the [Carnegie-Mellon University](../docs/cmu_performance.md) database that were hand selected. A readme file within the zip file details this.
* **v1** Test data [link](https://drive.google.com/open?id=1psNO0riJ6RlD5_vsvPh2vPsgEBvLN3Hr)
-* **v2** Test data [link](https://drive.google.com/open?id=192CWjNRwlskgdqakNI-k8dv-EefXwxtU) (**Latest**)
+* **v2** Test data [link](https://drive.google.com/open?id=192CWjNRwlskgdqakNI-k8dv-EefXwxtU)
+* **v3** Test data [link](https://drive.google.com/file/d/1ZxQp1-q_stN2MIgyQm6v6FP2zg6GmNPk/view?usp=sharing) (**Latest**)
## Running the tests
|
Implement non-hierarchical track support
It is common to have animation clips also add animated data that isn't a bone. Things like IK weights, blend shape weights, etc. We should support compressing stand-alone tracks of type: float1, float2, float3, float4.
No segmenting support for now.
API description:
* raw_track_list (contains a list of raw_track which contains a track and track_description)
* compressed_track_list (mostly opaque type?)
* track_description (track type, error threshold, etc)
* float1_track, float2_track, etc
* quat_track
* transform_track
* decompress_track(...)
* decompress_track_list(...)
A regression test should be added.
|
Progress in on-going and this should land in develop sometime in August.
| 2019-08-15T03:57:08
|
cpp
|
Hard
|
nfrechette/acl
| 251
|
nfrechette__acl-251
|
[
"250"
] |
e51de59fa6f3c8a0775e0dad63fe0c28aaf8874e
|
diff --git a/docs/compressing_a_raw_clip.md b/docs/compressing_a_raw_clip.md
--- a/docs/compressing_a_raw_clip.md
+++ b/docs/compressing_a_raw_clip.md
@@ -8,10 +8,6 @@ The compression level used will dictate how much time to spend optimizing the va
While we support various [rotation and vector quantization formats](rotation_and_vector_formats.md), the *variable* variants are generally the best. It is safe to use them for all your clips but if you do happen to run into issues with some exotic clips, you can easily fallback to less aggressive variants.
-[Segmenting](http://nfrechette.github.io/2016/11/10/anim_compression_uniform_segmenting/) ensures that large clips are split into smaller segments and compressed independently to allow a smaller memory footprint as well as faster compression and decompression.
-
-[Range reduction](range_reduction.md) is important and also something you will want to enable for all your tracks both at the clip and segment level.
-
Selecting the right [error metric](error_metrics.md) is important and you will want to carefully pick the one that best approximates how your game engine performs skinning.
The last important setting to choose is the `error_threshold`. This is used in conjunction with the error metric and the virtual vertex distance from the [skeleton](creating_a_skeleton.md) in order to guarantee that a certain quality is maintained. A default value of **0.01cm** is safe to use and it most likely should never be changed unless the units you are using differ. If you do run into issues where compression artifacts are visible, in all likelihood the virtual vertex distance used on the problematic bones is not conservative enough.
@@ -22,13 +18,10 @@ The last important setting to choose is the `error_threshold`. This is used in c
using namespace acl;
CompressionSettings settings;
-settings.level = CompressionLevel8::Medium;
-settings.rotation_format = RotationFormat8::QuatDropW_Variable;
-settings.translation_format = VectorFormat8::Vector3_Variable;
-settings.scale_format = VectorFormat8::Vector3_Variable;
-settings.range_reduction = RangeReductionFlags8::AllTracks;
-settings.segmenting.enabled = true;
-settings.segmenting.range_reduction = RangeReductionFlags8::AllTracks;
+settings.level = compression_level8::medium;
+settings.rotation_format = rotation_format8::quatf_drop_w_variable;
+settings.translation_format = vector_format8::vector3f_variable;
+settings.scale_format = vector_format8::vector3f_variable;
qvvf_transform_error_metric error_metric;
settings.error_metric = &error_metric;
diff --git a/docs/decompressing_a_clip.md b/docs/decompressing_a_clip.md
--- a/docs/decompressing_a_clip.md
+++ b/docs/decompressing_a_clip.md
@@ -11,14 +11,14 @@ using namespace acl::uniformly_sampled;
DecompressionContext<DefaultDecompressionSettings> context;
context.initialize(*compressed_clip);
-context.seek(sample_time, SampleRoundingPolicy::None);
+context.seek(sample_time, sample_rounding_policy::none);
context.decompress_bone(bone_index, &rotation, &translation, &scale);
```
As shown, a context must be initialized with a compressed clip instance. Some context objects such as the one used by uniform sampling can be re-used by any compressed clip and does not need to be re-created while others might require this. In order to detect when this might be required, the function `is_dirty(const CompressedClip& clip)` is provided. Some context objects cannot be created on the stack and must be dynamically allocated with an allocator instance. The functions `make_decompression_context(...)` are provided for this purpose.
-You can seek anywhere in a clip but you will need to handle looping manually in your game engine. When seeking, you must also provide a `SampleRoundingPolicy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
+You can seek anywhere in a clip but you will need to handle looping manually in your game engine. When seeking, you must also provide a `sample_rounding_policy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
Every decompression function supported by the context is prefixed with `decompress_`. Uniform sampling supports decompressing a whole pose with a custom `OutputWriter` for optimized pose writing. You can implement your own and coerce to your own math types. The type is templated on the `decompress_pose` function in order to be easily inlined.
diff --git a/docs/decompressing_a_track_list.md b/docs/decompressing_a_track_list.md
--- a/docs/decompressing_a_track_list.md
+++ b/docs/decompressing_a_track_list.md
@@ -12,7 +12,7 @@ using namespace acl;
decompression_context<default_decompression_settings> context;
context.initialize(*tracks);
-context.seek(sample_time, SampleRoundingPolicy::None);
+context.seek(sample_time, sample_rounding_policy::none);
// create an instance of 'track_writer' so we can write the output somewhere
context.decompress_track(track_index, my_track_writer); // a single track
@@ -21,7 +21,7 @@ context.decompress_tracks(my_track_writer); // all tracks
As shown, a context must be initialized with a compressed track list instance. Some context objects such as the one used by uniform sampling can be re-used by any compressed track list and does not need to be re-created while others might require this. In order to detect when this might be required, the function `is_dirty(const compressed_tracks& tracks)` is provided. Some context objects cannot be created on the stack and must be dynamically allocated with an allocator instance. The functions `make_decompression_context(...)` are provided for this purpose.
-You can seek anywhere in a track list but you will need to handle looping manually in your game engine. When seeking, you must also provide a `SampleRoundingPolicy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
+You can seek anywhere in a track list but you will need to handle looping manually in your game engine. When seeking, you must also provide a `sample_rounding_policy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
Every decompression function supported by the context is prefixed with `decompress_*`. A `track_writer` is used for optimized output writing. You can implement your own and coerce to your own math types. The type is templated on the `decompress_*` functions in order to be easily inlined.
diff --git a/docs/range_reduction.md b/docs/range_reduction.md
--- a/docs/range_reduction.md
+++ b/docs/range_reduction.md
@@ -6,7 +6,7 @@ Range reduction is performed by calculating the range of possible values in a li
This is an important optimization to keep the memory footprint as low as possible because it typically allows us to increase the precision retained on the normalized values.
-This feature can be enabled at the clip level where entire tracks are quantized over their full range as well as at the segment level where they are normalized over the segment only. Enabling the feature at the segment level requires it to also be enabled at the clip level because we store the range information in quantized form.
+This feature can be enabled at the clip level where entire tracks are quantized over their full range as well as at the segment level where they are normalized over the segment only. Enabling the feature at the segment level requires it to also be enabled at the clip level because we store the range information in quantized form. This is entirely controlled by the underlying compression algorithm.
Additional reading:
diff --git a/docs/rotation_and_vector_formats.md b/docs/rotation_and_vector_formats.md
--- a/docs/rotation_and_vector_formats.md
+++ b/docs/rotation_and_vector_formats.md
@@ -2,20 +2,10 @@ In order to save memory, quantization is used on sampled values to reduce their
# Vector formats
-Note that in order to be able to use some of these formats, track data needs to have [range reduction](range_reduction.md) applied at least at the clip level.
-
-### Vector3 96
+### Vector3 Full
Simple full precision format. Each component `[X, Y, Z]` is stored with full floating point precision using `float32`.
-### Vector3 48
-
-Each component `[X, Y, Z]` is stored with `uint16_t`. This format requires range reduction to be enabled.
-
-### Vector3 32
-
-The code supports storing each component `[X, Y, Z]` on an arbitrary number of bits but we hard coded `[11, 11, 10]` for our purposes. This format requires range reduction to be enabled.
-
### Vector3 Variable
The compression algorithm will search for the optimal bit rate among **19** possible values. An algorithm will select which bit rate to use for each track while keeping the memory footprint and error as low as possible. This format requires range reduction to be enabled.
@@ -24,7 +14,7 @@ The compression algorithm will search for the optimal bit rate among **19** poss
Internally, rotation formats reuse the vector formats with some tweaks.
-### Quat 128
+### Quat Full
A full precision quaternion format. Each component `[X, Y, Z, W]` is stored with full precision using `float32`.
@@ -32,18 +22,10 @@ A full precision quaternion format. Each component `[X, Y, Z, W]` is stored with
Every rotation can be represented by two distinct and opposite quaternions: a quaternion and its negated opposite. This is possible because [quaternions represent a hypersphere](https://en.wikipedia.org/wiki/Quaternions_and_spatial_rotation#The_hypersphere_of_rotations). As such, a component can be dropped and trivially reconstructed with a square root simply by ensuring that the component is positive and the quaternion normalized during compression.
-### Quat 96
+### Quat Full
Same as Vector3 96 above to store `[X, Y, Z]`.
-### Quat 48
-
-Same as Vector3 48 above to store `[X, Y, Z]`.
-
-### Quat 32
-
-Same as Vector3 32 above to store `[X, Y, Z]`.
-
### Quat Variable
See [Vector3 Variable](rotation_and_vector_formats.md#vector3-variable)
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/decoder.h
@@ -90,8 +90,8 @@ namespace acl
uint32_t clip_hash; // 28 | 48
- uint8_t num_rotation_components; // 32 | 52
- uint8_t has_mixed_packing; // 33 | 53
+ range_reduction_flags8 range_reduction; // 32 | 52
+ uint8_t num_rotation_components; // 33 | 53
uint8_t padding0[2]; // 34 | 54
@@ -100,18 +100,17 @@ namespace acl
const uint8_t* segment_range_data[2]; // 44 | 72
const uint8_t* animated_track_data[2]; // 52 | 88
- uint32_t key_frame_byte_offsets[2]; // 60 | 104 // Fixed quantization
- uint32_t key_frame_bit_offsets[2]; // 68 | 112 // Variable quantization
+ uint32_t key_frame_bit_offsets[2]; // 60 | 104
- float interpolation_alpha; // 76 | 120
- float sample_time; // 80 | 124
+ float interpolation_alpha; // 68 | 112
+ float sample_time; // 76 | 120
- uint8_t padding1[sizeof(void*) == 4 ? 44 : 64]; // 84 | 128 // 64 bit has a full cache line of padding, can't have 0 length array
+ uint8_t padding1[sizeof(void*) == 4 ? 52 : 4]; // 80 | 124
- // Total size: 128 | 192
+ // Total size: 128 | 128
};
- static_assert(sizeof(DecompressionContext) == (sizeof(void*) == 4 ? 128 : 192), "Unexpected size");
+ static_assert(sizeof(DecompressionContext) == 128, "Unexpected size");
struct alignas(k_cache_line_size) SamplingContext
{
@@ -153,18 +152,16 @@ namespace acl
uint32_t format_per_track_data_offset; // 12 | 12
uint32_t segment_range_data_offset; // 16 | 16
- uint32_t key_frame_byte_offsets[2]; // 20 | 20 // Fixed quantization
- uint32_t key_frame_bit_offsets[2]; // 28 | 28 // Variable quantization
+ uint32_t key_frame_bit_offsets[2]; // 20 | 20
- uint8_t padding[28]; // 36 | 36
+ uint8_t padding[4]; // 28 | 28
- rtm::vector4f vectors[k_num_samples_to_interpolate]; // 64 | 64
- rtm::vector4f padding0[2]; // 96 | 96
+ rtm::vector4f vectors[k_num_samples_to_interpolate]; // 32 | 32
- // Total size: 128 | 128
+ // Total size: 64 | 64
};
- static_assert(sizeof(SamplingContext) == 128, "Unexpected size");
+ static_assert(sizeof(SamplingContext) == 64, "Unexpected size");
// We use adapters to wrap the DecompressionSettings
// This allows us to re-use the code for skipping and decompressing Vector3 samples
@@ -174,15 +171,11 @@ namespace acl
{
explicit TranslationDecompressionSettingsAdapter(const SettingsType& settings_) : settings(settings_) {}
- constexpr RangeReductionFlags8 get_range_reduction_flag() const { return RangeReductionFlags8::Translations; }
- inline rtm::vector4f RTM_SIMD_CALL get_default_value() const { return rtm::vector_zero(); }
- constexpr VectorFormat8 get_vector_format(const ClipHeader& header) const { return settings.get_translation_format(header.translation_format); }
- constexpr bool is_vector_format_supported(VectorFormat8 format) const { return settings.is_translation_format_supported(format); }
-
- // Just forward the calls
- constexpr RangeReductionFlags8 get_clip_range_reduction(RangeReductionFlags8 flags) const { return settings.get_clip_range_reduction(flags); }
- constexpr RangeReductionFlags8 get_segment_range_reduction(RangeReductionFlags8 flags) const { return settings.get_segment_range_reduction(flags); }
- constexpr bool supports_mixed_packing() const { return settings.supports_mixed_packing(); }
+ constexpr range_reduction_flags8 get_range_reduction_flag() const { return range_reduction_flags8::translations; }
+ rtm::vector4f RTM_SIMD_CALL get_default_value() const { return rtm::vector_zero(); }
+ vector_format8 get_vector_format(const ClipHeader& header) const { return settings.get_translation_format(header.translation_format); }
+ bool is_vector_format_supported(vector_format8 format) const { return settings.is_translation_format_supported(format); }
+ bool are_range_reduction_flags_supported(range_reduction_flags8 flags) const { return settings.are_range_reduction_flags_supported(flags); }
SettingsType settings;
};
@@ -195,15 +188,11 @@ namespace acl
, default_scale(header.default_scale ? rtm::vector_set(1.0F) : rtm::vector_zero())
{}
- constexpr RangeReductionFlags8 get_range_reduction_flag() const { return RangeReductionFlags8::Scales; }
- inline rtm::vector4f RTM_SIMD_CALL get_default_value() const { return default_scale; }
- constexpr VectorFormat8 get_vector_format(const ClipHeader& header) const { return settings.get_scale_format(header.scale_format); }
- constexpr bool is_vector_format_supported(VectorFormat8 format) const { return settings.is_scale_format_supported(format); }
-
- // Just forward the calls
- constexpr RangeReductionFlags8 get_clip_range_reduction(RangeReductionFlags8 flags) const { return settings.get_clip_range_reduction(flags); }
- constexpr RangeReductionFlags8 get_segment_range_reduction(RangeReductionFlags8 flags) const { return settings.get_segment_range_reduction(flags); }
- constexpr bool supports_mixed_packing() const { return settings.supports_mixed_packing(); }
+ constexpr range_reduction_flags8 get_range_reduction_flag() const { return range_reduction_flags8::scales; }
+ rtm::vector4f RTM_SIMD_CALL get_default_value() const { return default_scale; }
+ vector_format8 get_vector_format(const ClipHeader& header) const { return settings.get_scale_format(header.scale_format); }
+ bool is_vector_format_supported(vector_format8 format) const { return settings.is_scale_format_supported(format); }
+ bool are_range_reduction_flags_supported(range_reduction_flags8 flags) const { return settings.are_range_reduction_flags_supported(flags); }
SettingsType settings;
uint8_t padding[get_required_padding<SettingsType, rtm::vector4f>()];
@@ -223,20 +212,15 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct DecompressionSettings
{
- constexpr bool is_rotation_format_supported(RotationFormat8 /*format*/) const { return true; }
- constexpr bool is_translation_format_supported(VectorFormat8 /*format*/) const { return true; }
- constexpr bool is_scale_format_supported(VectorFormat8 /*format*/) const { return true; }
- constexpr RotationFormat8 get_rotation_format(RotationFormat8 format) const { return format; }
- constexpr VectorFormat8 get_translation_format(VectorFormat8 format) const { return format; }
- constexpr VectorFormat8 get_scale_format(VectorFormat8 format) const { return format; }
+ constexpr bool is_rotation_format_supported(rotation_format8 /*format*/) const { return true; }
+ constexpr bool is_translation_format_supported(vector_format8 /*format*/) const { return true; }
+ constexpr bool is_scale_format_supported(vector_format8 /*format*/) const { return true; }
+ constexpr rotation_format8 get_rotation_format(rotation_format8 format) const { return format; }
+ constexpr vector_format8 get_translation_format(vector_format8 format) const { return format; }
+ constexpr vector_format8 get_scale_format(vector_format8 format) const { return format; }
- constexpr bool are_clip_range_reduction_flags_supported(RangeReductionFlags8 /*flags*/) const { return true; }
- constexpr bool are_segment_range_reduction_flags_supported(RangeReductionFlags8 /*flags*/) const { return true; }
- constexpr RangeReductionFlags8 get_clip_range_reduction(RangeReductionFlags8 flags) const { return flags; }
- constexpr RangeReductionFlags8 get_segment_range_reduction(RangeReductionFlags8 flags) const { return flags; }
-
- // Whether tracks must all be variable or all fixed width, or if they can be mixed and require padding.
- constexpr bool supports_mixed_packing() const { return true; }
+ constexpr bool are_range_reduction_flags_supported(range_reduction_flags8 /*flags*/) const { return true; }
+ constexpr range_reduction_flags8 get_range_reduction(range_reduction_flags8 flags) const { return flags; }
// Whether to explicitly disable floating point exceptions during decompression.
// This has a cost, exceptions are usually disabled globally and do not need to be
@@ -255,21 +239,19 @@ namespace acl
// These are the default settings. Only the generally optimal settings
// are enabled and will offer the overall best performance.
//
- // Note: Segment range reduction supports AllTracks or None because it can
+ // Note: Segment range reduction supports all_tracks or none because it can
// be disabled if there is a single segment.
//////////////////////////////////////////////////////////////////////////
struct DefaultDecompressionSettings : DecompressionSettings
{
- constexpr bool is_rotation_format_supported(RotationFormat8 format) const { return format == RotationFormat8::QuatDropW_Variable; }
- constexpr bool is_translation_format_supported(VectorFormat8 format) const { return format == VectorFormat8::Vector3_Variable; }
- constexpr bool is_scale_format_supported(VectorFormat8 format) const { return format == VectorFormat8::Vector3_Variable; }
- constexpr RotationFormat8 get_rotation_format(RotationFormat8 /*format*/) const { return RotationFormat8::QuatDropW_Variable; }
- constexpr VectorFormat8 get_translation_format(VectorFormat8 /*format*/) const { return VectorFormat8::Vector3_Variable; }
- constexpr VectorFormat8 get_scale_format(VectorFormat8 /*format*/) const { return VectorFormat8::Vector3_Variable; }
-
- constexpr RangeReductionFlags8 get_clip_range_reduction(RangeReductionFlags8 /*flags*/) const { return RangeReductionFlags8::AllTracks; }
-
- constexpr bool supports_mixed_packing() const { return false; }
+ constexpr bool is_rotation_format_supported(rotation_format8 format) const { return format == rotation_format8::quatf_drop_w_variable; }
+ constexpr bool is_translation_format_supported(vector_format8 format) const { return format == vector_format8::vector3f_variable; }
+ constexpr bool is_scale_format_supported(vector_format8 format) const { return format == vector_format8::vector3f_variable; }
+ constexpr rotation_format8 get_rotation_format(rotation_format8 /*format*/) const { return rotation_format8::quatf_drop_w_variable; }
+ constexpr vector_format8 get_translation_format(vector_format8 /*format*/) const { return vector_format8::vector3f_variable; }
+ constexpr vector_format8 get_scale_format(vector_format8 /*format*/) const { return vector_format8::vector3f_variable; }
+
+ constexpr range_reduction_flags8 get_range_reduction(range_reduction_flags8 /*flags*/) const { return range_reduction_flags8::all_tracks; }
};
//////////////////////////////////////////////////////////////////////////
@@ -316,7 +298,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Seeks within the compressed clip to a particular point in time
- void seek(float sample_time, SampleRoundingPolicy rounding_policy);
+ void seek(float sample_time, sample_rounding_policy rounding_policy);
//////////////////////////////////////////////////////////////////////////
// Decompress a full pose at the current sample time.
@@ -393,17 +375,13 @@ namespace acl
inline void DecompressionContext<DecompressionSettingsType>::initialize(const CompressedClip& clip)
{
ACL_ASSERT(clip.is_valid(false).empty(), "CompressedClip is not valid");
- ACL_ASSERT(clip.get_algorithm_type() == AlgorithmType8::UniformlySampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(clip.get_algorithm_type()), get_algorithm_name(AlgorithmType8::UniformlySampled));
+ ACL_ASSERT(clip.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(clip.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
const ClipHeader& header = get_clip_header(clip);
- const RotationFormat8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
- const VectorFormat8 translation_format = m_settings.get_translation_format(header.translation_format);
- const VectorFormat8 scale_format = m_settings.get_translation_format(header.scale_format);
-
-#if defined(ACL_HAS_ASSERT_CHECKS)
- const RangeReductionFlags8 clip_range_reduction = m_settings.get_clip_range_reduction(header.clip_range_reduction);
- const RangeReductionFlags8 segment_range_reduction = m_settings.get_segment_range_reduction(header.segment_range_reduction);
+ const rotation_format8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
+ const vector_format8 translation_format = m_settings.get_translation_format(header.translation_format);
+ const vector_format8 scale_format = m_settings.get_translation_format(header.scale_format);
ACL_ASSERT(rotation_format == header.rotation_format, "Statically compiled rotation format (%s) differs from the compressed rotation format (%s)!", get_rotation_format_name(rotation_format), get_rotation_format_name(header.rotation_format));
ACL_ASSERT(m_settings.is_rotation_format_supported(rotation_format), "Rotation format (%s) isn't statically supported!", get_rotation_format_name(rotation_format));
@@ -411,11 +389,6 @@ namespace acl
ACL_ASSERT(m_settings.is_translation_format_supported(translation_format), "Translation format (%s) isn't statically supported!", get_vector_format_name(translation_format));
ACL_ASSERT(scale_format == header.scale_format, "Statically compiled scale format (%s) differs from the compressed scale format (%s)!", get_vector_format_name(scale_format), get_vector_format_name(header.scale_format));
ACL_ASSERT(m_settings.is_scale_format_supported(scale_format), "Scale format (%s) isn't statically supported!", get_vector_format_name(scale_format));
- ACL_ASSERT((clip_range_reduction & header.clip_range_reduction) == header.clip_range_reduction, "Statically compiled clip range reduction settings (%u) differs from the compressed settings (%u)!", clip_range_reduction, header.clip_range_reduction);
- ACL_ASSERT(m_settings.are_clip_range_reduction_flags_supported(clip_range_reduction), "Clip range reduction settings (%u) aren't statically supported!", clip_range_reduction);
- ACL_ASSERT((segment_range_reduction & header.segment_range_reduction) == header.segment_range_reduction, "Statically compiled segment range reduction settings (%u) differs from the compressed settings (%u)!", segment_range_reduction, header.segment_range_reduction);
- ACL_ASSERT(m_settings.are_segment_range_reduction_flags_supported(segment_range_reduction), "Segment range reduction settings (%u) aren't statically supported!", segment_range_reduction);
-#endif
m_context.clip = &clip;
m_context.clip_hash = clip.get_hash();
@@ -436,13 +409,21 @@ namespace acl
const uint32_t num_tracks_per_bone = header.has_scale ? 3 : 2;
m_context.bitset_desc = BitSetDescription::make_from_num_bits(header.num_bones * num_tracks_per_bone);
- m_context.num_rotation_components = rotation_format == RotationFormat8::Quat_128 ? 4 : 3;
- // If all tracks are variable, no need for any extra padding except at the very end of the data
- // If our tracks are mixed variable/not variable, we need to add some padding to ensure alignment
- const bool is_every_format_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
- const bool is_any_format_variable = is_rotation_format_variable(rotation_format) || is_vector_format_variable(translation_format) || is_vector_format_variable(scale_format);
- m_context.has_mixed_packing = !is_every_format_variable && is_any_format_variable;
+ range_reduction_flags8 range_reduction = range_reduction_flags8::none;
+ if (is_rotation_format_variable(rotation_format))
+ range_reduction |= range_reduction_flags8::rotations;
+ if (is_vector_format_variable(translation_format))
+ range_reduction |= range_reduction_flags8::translations;
+ if (is_vector_format_variable(scale_format))
+ range_reduction |= range_reduction_flags8::scales;
+
+ m_context.range_reduction = m_settings.get_range_reduction(range_reduction);
+
+ ACL_ASSERT((m_context.range_reduction & range_reduction) == range_reduction, "Statically compiled range reduction flags (%u) differ from the compressed flags (%u)!", m_context.range_reduction, range_reduction);
+ ACL_ASSERT(m_settings.are_range_reduction_flags_supported(m_context.range_reduction), "Range reduction flags (%u) aren't statically supported!", m_context.range_reduction);
+
+ m_context.num_rotation_components = rotation_format == rotation_format8::quatf_full ? 4 : 3;
}
template<class DecompressionSettingsType>
@@ -458,7 +439,7 @@ namespace acl
}
template<class DecompressionSettingsType>
- inline void DecompressionContext<DecompressionSettingsType>::seek(float sample_time, SampleRoundingPolicy rounding_policy)
+ inline void DecompressionContext<DecompressionSettingsType>::seek(float sample_time, sample_rounding_policy rounding_policy)
{
ACL_ASSERT(m_context.clip != nullptr, "Context is not initialized");
@@ -540,8 +521,6 @@ namespace acl
m_context.animated_track_data[0] = header.get_track_data(*segment_header0);
m_context.animated_track_data[1] = header.get_track_data(*segment_header1);
- m_context.key_frame_byte_offsets[0] = (segment_key_frame0 * segment_header0->animated_pose_bit_size) / 8;
- m_context.key_frame_byte_offsets[1] = (segment_key_frame1 * segment_header1->animated_pose_bit_size) / 8;
m_context.key_frame_bit_offsets[0] = segment_key_frame0 * segment_header0->animated_pose_bit_size;
m_context.key_frame_bit_offsets[1] = segment_key_frame1 * segment_header1->animated_pose_bit_size;
}
@@ -574,8 +553,6 @@ namespace acl
sampling_context.clip_range_data_offset = 0;
sampling_context.format_per_track_data_offset = 0;
sampling_context.segment_range_data_offset = 0;
- sampling_context.key_frame_byte_offsets[0] = m_context.key_frame_byte_offsets[0];
- sampling_context.key_frame_byte_offsets[1] = m_context.key_frame_byte_offsets[1];
sampling_context.key_frame_bit_offsets[0] = m_context.key_frame_bit_offsets[0];
sampling_context.key_frame_bit_offsets[1] = m_context.key_frame_bit_offsets[1];
@@ -634,18 +611,15 @@ namespace acl
const acl_impl::ScaleDecompressionSettingsAdapter<DecompressionSettingsType> scale_adapter(m_settings, header);
acl_impl::SamplingContext sampling_context;
- sampling_context.key_frame_byte_offsets[0] = m_context.key_frame_byte_offsets[0];
- sampling_context.key_frame_byte_offsets[1] = m_context.key_frame_byte_offsets[1];
sampling_context.key_frame_bit_offsets[0] = m_context.key_frame_bit_offsets[0];
sampling_context.key_frame_bit_offsets[1] = m_context.key_frame_bit_offsets[1];
- const RotationFormat8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
- const VectorFormat8 translation_format = m_settings.get_translation_format(header.translation_format);
- const VectorFormat8 scale_format = m_settings.get_translation_format(header.scale_format);
+ const rotation_format8 rotation_format = m_settings.get_rotation_format(header.rotation_format);
+ const vector_format8 translation_format = m_settings.get_translation_format(header.translation_format);
+ const vector_format8 scale_format = m_settings.get_translation_format(header.scale_format);
const bool are_all_tracks_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
- const bool has_mixed_padding_or_fixed_quantization = (m_settings.supports_mixed_packing() && m_context.has_mixed_packing) || !are_all_tracks_variable;
- if (has_mixed_padding_or_fixed_quantization)
+ if (!are_all_tracks_variable)
{
// Slow path, not optimized yet because it's more complex and shouldn't be used in production anyway
sampling_context.track_index = 0;
@@ -752,28 +726,31 @@ namespace acl
const uint32_t num_animated_rotations = sample_bone_index - num_constant_rotations;
const uint32_t num_animated_translations = sample_bone_index - num_constant_translations;
- const RotationFormat8 packed_rotation_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ const rotation_format8 packed_rotation_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
const uint32_t packed_rotation_size = get_packed_rotation_size(packed_rotation_format);
uint32_t constant_track_data_offset = (num_constant_rotations - num_default_rotations) * packed_rotation_size;
- constant_track_data_offset += (num_constant_translations - num_default_translations) * get_packed_vector_size(VectorFormat8::Vector3_96);
+ constant_track_data_offset += (num_constant_translations - num_default_translations) * get_packed_vector_size(vector_format8::vector3f_full);
uint32_t clip_range_data_offset = 0;
uint32_t segment_range_data_offset = 0;
- const RangeReductionFlags8 clip_range_reduction = m_settings.get_clip_range_reduction(header.clip_range_reduction);
- const RangeReductionFlags8 segment_range_reduction = m_settings.get_segment_range_reduction(header.segment_range_reduction);
- if (are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Rotations))
+ const range_reduction_flags8 range_reduction = m_context.range_reduction;
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
+ {
clip_range_data_offset += m_context.num_rotation_components * sizeof(float) * 2 * num_animated_rotations;
- if (are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Rotations))
- segment_range_data_offset += m_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_rotations;
+ if (header.num_segments > 1)
+ segment_range_data_offset += m_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_rotations;
+ }
- if (are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Translations))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::translations))
+ {
clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_translations;
- if (are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Translations))
- segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_translations;
+ if (header.num_segments > 1)
+ segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_translations;
+ }
uint32_t num_animated_tracks = num_animated_rotations + num_animated_translations;
if (header.has_scale)
@@ -781,13 +758,15 @@ namespace acl
const uint32_t num_animated_scales = sample_bone_index - num_constant_scales;
num_animated_tracks += num_animated_scales;
- constant_track_data_offset += (num_constant_scales - num_default_scales) * get_packed_vector_size(VectorFormat8::Vector3_96);
+ constant_track_data_offset += (num_constant_scales - num_default_scales) * get_packed_vector_size(vector_format8::vector3f_full);
- if (are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Scales))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) && m_settings.are_range_reduction_flags_supported(range_reduction_flags8::scales))
+ {
clip_range_data_offset += k_clip_range_reduction_vector3_range_size * num_animated_scales;
- if (are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Scales))
- segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_scales;
+ if (header.num_segments > 1)
+ segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2 * num_animated_scales;
+ }
}
sampling_context.track_index = track_index;
diff --git a/includes/acl/algorithm/uniformly_sampled/encoder.h b/includes/acl/algorithm/uniformly_sampled/encoder.h
--- a/includes/acl/algorithm/uniformly_sampled/encoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/encoder.h
@@ -96,6 +96,24 @@ namespace acl
ScopeProfiler compression_time;
+ // If every track is retains full precision, we disable segmenting since it provides no benefit
+ if (!is_rotation_format_variable(settings.rotation_format) && !is_vector_format_variable(settings.translation_format) && !is_vector_format_variable(settings.scale_format))
+ {
+ settings.segmenting.ideal_num_samples = 0xFFFF;
+ settings.segmenting.max_num_samples = 0xFFFF;
+ }
+
+ // Variable bit rate tracks need range reduction
+ range_reduction_flags8 range_reduction = range_reduction_flags8::none;
+ if (is_rotation_format_variable(settings.rotation_format))
+ range_reduction |= range_reduction_flags8::rotations;
+
+ if (is_vector_format_variable(settings.translation_format))
+ range_reduction |= range_reduction_flags8::translations;
+
+ if (is_vector_format_variable(settings.scale_format))
+ range_reduction |= range_reduction_flags8::scales;
+
const uint32_t num_samples = clip.get_num_samples();
const RigidSkeleton& skeleton = clip.get_skeleton();
@@ -119,28 +137,20 @@ namespace acl
compact_constant_streams(allocator, clip_context, settings.constant_rotation_threshold_angle, settings.constant_translation_threshold, settings.constant_scale_threshold);
uint32_t clip_range_data_size = 0;
- if (settings.range_reduction != RangeReductionFlags8::None)
+ if (range_reduction != range_reduction_flags8::none)
{
- normalize_clip_streams(clip_context, settings.range_reduction);
- clip_range_data_size = get_stream_range_data_size(clip_context, settings.range_reduction, settings.rotation_format);
+ normalize_clip_streams(clip_context, range_reduction);
+ clip_range_data_size = get_stream_range_data_size(clip_context, range_reduction, settings.rotation_format);
}
- if (settings.segmenting.enabled)
- {
- segment_streams(allocator, clip_context, settings.segmenting);
-
- // If we have a single segment, disable range reduction since it won't help
- if (clip_context.num_segments == 1)
- settings.segmenting.range_reduction = RangeReductionFlags8::None;
+ segment_streams(allocator, clip_context, settings.segmenting);
- if (settings.segmenting.range_reduction != RangeReductionFlags8::None)
- {
- extract_segment_bone_ranges(allocator, clip_context);
- normalize_segment_streams(clip_context, settings.segmenting.range_reduction);
- }
+ // If we have a single segment, skip segment range reduction since it won't help
+ if (range_reduction != range_reduction_flags8::none && clip_context.num_segments > 1)
+ {
+ extract_segment_bone_ranges(allocator, clip_context);
+ normalize_segment_streams(clip_context, range_reduction);
}
- else
- settings.segmenting.range_reduction = RangeReductionFlags8::None;
quantize_streams(allocator, clip_context, settings, skeleton, raw_clip_context, additive_base_clip_context, out_stats);
@@ -149,7 +159,7 @@ namespace acl
const uint32_t constant_data_size = get_constant_data_size(clip_context, output_bone_mapping, num_output_bones);
- calculate_animated_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format, output_bone_mapping, num_output_bones);
+ calculate_animated_data_size(clip_context, output_bone_mapping, num_output_bones);
const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
@@ -219,7 +229,7 @@ namespace acl
uint8_t* buffer = allocate_type_array_aligned<uint8_t>(allocator, buffer_size, 16);
- CompressedClip* compressed_clip = make_compressed_clip(buffer, buffer_size, AlgorithmType8::UniformlySampled);
+ CompressedClip* compressed_clip = make_compressed_clip(buffer, buffer_size, algorithm_type8::uniformly_sampled);
ClipHeader& header = get_clip_header(*compressed_clip);
header.num_bones = num_output_bones;
@@ -227,10 +237,8 @@ namespace acl
header.rotation_format = settings.rotation_format;
header.translation_format = settings.translation_format;
header.scale_format = settings.scale_format;
- header.clip_range_reduction = settings.range_reduction;
- header.segment_range_reduction = settings.segmenting.range_reduction;
header.has_scale = clip_context.has_scale ? 1 : 0;
- header.default_scale = additive_base_clip == nullptr || clip.get_additive_format() != AdditiveClipFormat8::Additive1;
+ header.default_scale = additive_base_clip == nullptr || clip.get_additive_format() != additive_clip_format8::additive1;
header.num_samples = num_samples;
header.sample_rate = clip.get_sample_rate();
header.segment_start_indices_offset = sizeof(ClipHeader);
@@ -255,12 +263,12 @@ namespace acl
else
header.constant_track_data_offset = InvalidPtrOffset();
- if (settings.range_reduction != RangeReductionFlags8::None)
- write_clip_range_data(clip_context, settings.range_reduction, header.get_clip_range_data(), clip_range_data_size, output_bone_mapping, num_output_bones);
+ if (range_reduction != range_reduction_flags8::none)
+ write_clip_range_data(clip_context, range_reduction, header.get_clip_range_data(), clip_range_data_size, output_bone_mapping, num_output_bones);
else
header.clip_range_data_offset = InvalidPtrOffset();
- write_segment_data(clip_context, settings, header, output_bone_mapping, num_output_bones);
+ write_segment_data(clip_context, settings, range_reduction, header, output_bone_mapping, num_output_bones);
finalize_compressed_clip(*compressed_clip);
diff --git a/includes/acl/compression/animation_clip.h b/includes/acl/compression/animation_clip.h
--- a/includes/acl/compression/animation_clip.h
+++ b/includes/acl/compression/animation_clip.h
@@ -93,7 +93,7 @@ namespace acl
, m_sample_rate(sample_rate)
, m_num_bones(skeleton.get_num_bones())
, m_additive_base_clip(nullptr)
- , m_additive_format(AdditiveClipFormat8::None)
+ , m_additive_format(additive_clip_format8::none)
, m_name(allocator, name)
{
m_bones = allocate_type_array<AnimatedBone>(allocator, m_num_bones);
@@ -166,7 +166,7 @@ namespace acl
// - rounding_policy: The rounding policy to use when sampling
// - out_local_pose: An array of at least 'num_transforms' to output the data in
// - num_transforms: The number of transforms in the output array
- void sample_pose(float sample_time, SampleRoundingPolicy rounding_policy, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
+ void sample_pose(float sample_time, sample_rounding_policy rounding_policy, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
{
ACL_ASSERT(m_num_bones > 0, "Invalid number of bones: %u", m_num_bones);
ACL_ASSERT(m_num_bones == num_transforms, "Number of transforms does not match the number of bones: %u != %u", num_transforms, m_num_bones);
@@ -209,7 +209,7 @@ namespace acl
// - num_transforms: The number of transforms in the output array
void sample_pose(float sample_time, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
{
- sample_pose(sample_time, SampleRoundingPolicy::None, out_local_pose, num_transforms);
+ sample_pose(sample_time, sample_rounding_policy::none, out_local_pose, num_transforms);
}
//////////////////////////////////////////////////////////////////////////
@@ -227,7 +227,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Sets the base animation clip and marks this instance as an additive clip of the provided format
- void set_additive_base(const AnimationClip* base_clip, AdditiveClipFormat8 additive_format) { m_additive_base_clip = base_clip; m_additive_format = additive_format; }
+ void set_additive_base(const AnimationClip* base_clip, additive_clip_format8 additive_format) { m_additive_base_clip = base_clip; m_additive_format = additive_format; }
//////////////////////////////////////////////////////////////////////////
// Returns the additive base clip, if any
@@ -235,7 +235,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Returns the additive format of this clip, if any
- AdditiveClipFormat8 get_additive_format() const { return m_additive_format; }
+ additive_clip_format8 get_additive_format() const { return m_additive_format; }
//////////////////////////////////////////////////////////////////////////
// Checks if the instance of this clip is valid and returns an error if it isn't
@@ -366,7 +366,7 @@ namespace acl
const AnimationClip* m_additive_base_clip;
// If we have an additive base, this is the format we are in
- AdditiveClipFormat8 m_additive_format;
+ additive_clip_format8 m_additive_format;
// The name of the clip
String m_name;
diff --git a/includes/acl/compression/animation_track.h b/includes/acl/compression/animation_track.h
--- a/includes/acl/compression/animation_track.h
+++ b/includes/acl/compression/animation_track.h
@@ -69,7 +69,7 @@ namespace acl
, m_sample_data(nullptr)
, m_num_samples(0)
, m_sample_rate(0.0F)
- , m_type(AnimationTrackType8::Rotation)
+ , m_type(animation_track_type8::rotation)
{}
AnimationTrack(AnimationTrack&& other)
@@ -89,7 +89,7 @@ namespace acl
// - num_samples: The number of samples in this track
// - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
// - type: The track type
- AnimationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate, AnimationTrackType8 type)
+ AnimationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate, animation_track_type8 type)
: m_allocator(&allocator)
, m_sample_data(allocate_type_array_aligned<double>(allocator, size_t(num_samples) * get_animation_track_sample_size(type), alignof(rtm::vector4d)))
, m_num_samples(num_samples)
@@ -119,14 +119,14 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Returns the number of values per sample
// TODO: constexpr
- static uint32_t get_animation_track_sample_size(AnimationTrackType8 type)
+ static uint32_t get_animation_track_sample_size(animation_track_type8 type)
{
switch (type)
{
default:
- case AnimationTrackType8::Rotation: return 4;
- case AnimationTrackType8::Translation: return 3;
- case AnimationTrackType8::Scale: return 3;
+ case animation_track_type8::rotation: return 4;
+ case animation_track_type8::translation: return 3;
+ case animation_track_type8::scale: return 3;
}
}
@@ -143,7 +143,7 @@ namespace acl
float m_sample_rate;
// The track type
- AnimationTrackType8 m_type;
+ animation_track_type8 m_type;
};
//////////////////////////////////////////////////////////////////////////
@@ -163,7 +163,7 @@ namespace acl
// - num_samples: The number of samples in this track
// - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
AnimationRotationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, AnimationTrackType8::Rotation)
+ : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::rotation)
{
rtm::quatd* samples = safe_ptr_cast<rtm::quatd>(&m_sample_data[0]);
std::fill(samples, samples + num_samples, rtm::quat_identity());
@@ -229,7 +229,7 @@ namespace acl
// - num_samples: The number of samples in this track
// - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
AnimationTranslationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, AnimationTrackType8::Translation)
+ : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::translation)
{
std::fill(m_sample_data, m_sample_data + (num_samples * 3), 0.0);
}
@@ -293,7 +293,7 @@ namespace acl
// - num_samples: The number of samples in this track
// - sample_rate: The rate at which samples are recorded (e.g. 30 means 30 FPS)
AnimationScaleTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
- : AnimationTrack(allocator, num_samples, sample_rate, AnimationTrackType8::Scale)
+ : AnimationTrack(allocator, num_samples, sample_rate, animation_track_type8::scale)
{
rtm::vector4d defaultScale = rtm::vector_set(1.0);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
diff --git a/includes/acl/compression/compress.h b/includes/acl/compression/compress.h
--- a/includes/acl/compression/compress.h
+++ b/includes/acl/compression/compress.h
@@ -124,8 +124,8 @@ namespace acl
// Write our primary header
header->tag = k_compressed_tracks_tag;
- header->version = get_algorithm_version(AlgorithmType8::UniformlySampled);
- header->algorithm_type = AlgorithmType8::UniformlySampled;
+ header->version = get_algorithm_version(algorithm_type8::uniformly_sampled);
+ header->algorithm_type = algorithm_type8::uniformly_sampled;
header->track_type = track_list.get_track_type();
header->num_tracks = context.num_tracks;
header->num_samples = context.num_samples;
diff --git a/includes/acl/compression/compression_level.h b/includes/acl/compression/compression_level.h
--- a/includes/acl/compression/compression_level.h
+++ b/includes/acl/compression/compression_level.h
@@ -34,16 +34,18 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
////////////////////////////////////////////////////////////////////////////////
- // CompressionLevel8 represents how aggressively we attempt to reduce the memory
+ // compression_level8 represents how aggressively we attempt to reduce the memory
// footprint. Higher levels will try more permutations and bit rates. The higher
// the level, the slower the compression but the smaller the memory footprint.
- enum class CompressionLevel8 : uint8_t
+ enum class compression_level8 : uint8_t
{
- Lowest = 0, // Same as Medium for now
- Low = 1, // Same as Medium for now
- Medium = 2,
- High = 3,
- Highest = 4,
+ lowest = 0, // Same as medium for now
+ low = 1, // Same as medium for now
+ medium = 2,
+ high = 3,
+ highest = 4,
+
+ //lossless = 255, // Not implemented, reserved
};
//////////////////////////////////////////////////////////////////////////
@@ -51,55 +53,65 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Returns a string representing the compression level.
// TODO: constexpr
- inline const char* get_compression_level_name(CompressionLevel8 level)
+ inline const char* get_compression_level_name(compression_level8 level)
{
switch (level)
{
- case CompressionLevel8::Lowest: return "Lowest";
- case CompressionLevel8::Low: return "Low";
- case CompressionLevel8::Medium: return "Medium";
- case CompressionLevel8::High: return "High";
- case CompressionLevel8::Highest: return "Highest";
+ case compression_level8::lowest: return "lowest";
+ case compression_level8::low: return "low";
+ case compression_level8::medium: return "medium";
+ case compression_level8::high: return "high";
+ case compression_level8::highest: return "highest";
default: return "<Invalid>";
}
}
//////////////////////////////////////////////////////////////////////////
// Returns the compression level from its string representation.
- inline bool get_compression_level(const char* level_name, CompressionLevel8& out_level)
+ inline bool get_compression_level(const char* level_name, compression_level8& out_level)
{
- const char* level_lowest = "Lowest";
- if (std::strncmp(level_name, level_lowest, std::strlen(level_lowest)) == 0)
+ const char* level_lowest = "Lowest"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* level_lowest_new = "lowest";
+ if (std::strncmp(level_name, level_lowest, std::strlen(level_lowest)) == 0
+ || std::strncmp(level_name, level_lowest_new, std::strlen(level_lowest_new)) == 0)
{
- out_level = CompressionLevel8::Lowest;
+ out_level = compression_level8::lowest;
return true;
}
- const char* level_low = "Low";
- if (std::strncmp(level_name, level_low, std::strlen(level_low)) == 0)
+ const char* level_low = "Low"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* level_low_new = "low";
+ if (std::strncmp(level_name, level_low, std::strlen(level_low)) == 0
+ || std::strncmp(level_name, level_low_new, std::strlen(level_low_new)) == 0)
{
- out_level = CompressionLevel8::Low;
+ out_level = compression_level8::low;
return true;
}
- const char* level_medium = "Medium";
- if (std::strncmp(level_name, level_medium, std::strlen(level_medium)) == 0)
+ const char* level_medium = "Medium"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* level_medium_new = "medium";
+ if (std::strncmp(level_name, level_medium, std::strlen(level_medium)) == 0
+ || std::strncmp(level_name, level_medium_new, std::strlen(level_medium_new)) == 0)
{
- out_level = CompressionLevel8::Medium;
+ out_level = compression_level8::medium;
return true;
}
- const char* level_highest = "Highest";
- if (std::strncmp(level_name, level_highest, std::strlen(level_highest)) == 0)
+ const char* level_highest = "Highest"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* level_highest_new = "highest";
+ if (std::strncmp(level_name, level_highest, std::strlen(level_highest)) == 0
+ || std::strncmp(level_name, level_highest_new, std::strlen(level_highest_new)) == 0)
{
- out_level = CompressionLevel8::Highest;
+ out_level = compression_level8::highest;
return true;
}
- const char* level_high = "High";
- if (std::strncmp(level_name, level_high, std::strlen(level_high)) == 0)
+ const char* level_high = "High"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* level_high_new = "high";
+ if (std::strncmp(level_name, level_high, std::strlen(level_high)) == 0
+ || std::strncmp(level_name, level_high_new, std::strlen(level_high_new)) == 0)
{
- out_level = CompressionLevel8::High;
+ out_level = compression_level8::high;
return true;
}
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -43,13 +43,12 @@ namespace acl
{
//////////////////////////////////////////////////////////////////////////
// Encapsulates all the compression settings related to segmenting.
+ // Segmenting ensures that large clips are split into smaller segments and
+ // compressed independently to allow a smaller memory footprint as well as
+ // faster compression and decompression.
+ // See also: http://nfrechette.github.io/2016/11/10/anim_compression_uniform_segmenting/
struct SegmentingSettings
{
- //////////////////////////////////////////////////////////////////////////
- // Whether to enable segmenting or not
- // Defaults to 'false'
- bool enabled;
-
//////////////////////////////////////////////////////////////////////////
// How many samples to try and fit in our segments
// Defaults to '16'
@@ -60,16 +59,9 @@ namespace acl
// Defaults to '31'
uint16_t max_num_samples;
- //////////////////////////////////////////////////////////////////////////
- // Whether to use range reduction or not at the segment level
- // Defaults to 'None'
- RangeReductionFlags8 range_reduction;
-
SegmentingSettings()
- : enabled(false)
- , ideal_num_samples(16)
+ : ideal_num_samples(16)
, max_num_samples(31)
- , range_reduction(RangeReductionFlags8::None)
{}
//////////////////////////////////////////////////////////////////////////
@@ -77,10 +69,8 @@ namespace acl
uint32_t get_hash() const
{
uint32_t hash_value = 0;
- hash_value = hash_combine(hash_value, hash32(enabled));
hash_value = hash_combine(hash_value, hash32(ideal_num_samples));
hash_value = hash_combine(hash_value, hash32(max_num_samples));
- hash_value = hash_combine(hash_value, hash32(range_reduction));
return hash_value;
}
@@ -89,9 +79,6 @@ namespace acl
// Returns nullptr if the settings are valid.
ErrorResult is_valid() const
{
- if (!enabled)
- return ErrorResult();
-
if (ideal_num_samples < 8)
return ErrorResult("ideal_num_samples must be greater or equal to 8");
@@ -110,19 +97,14 @@ namespace acl
// The compression level determines how aggressively we attempt to reduce the memory
// footprint. Higher levels will try more permutations and bit rates. The higher
// the level, the slower the compression but the smaller the memory footprint.
- CompressionLevel8 level;
+ compression_level8 level;
//////////////////////////////////////////////////////////////////////////
// The rotation, translation, and scale formats to use. See functions get_rotation_format(..) and get_vector_format(..)
- // Defaults to raw: 'Quat_128' and 'Vector3_96'
- RotationFormat8 rotation_format;
- VectorFormat8 translation_format;
- VectorFormat8 scale_format;
-
- //////////////////////////////////////////////////////////////////////////
- // Whether to use range reduction or not at the clip level
- // Defaults to 'None'
- RangeReductionFlags8 range_reduction;
+ // Defaults to raw: 'quatf_full' and 'vector3f_full'
+ rotation_format8 rotation_format;
+ vector_format8 translation_format;
+ vector_format8 scale_format;
//////////////////////////////////////////////////////////////////////////
// Segmenting settings, if used
@@ -135,7 +117,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Threshold angle when detecting if rotation tracks are constant or default.
- // See the Quat_32 quat_near_identity for details about how the default threshold
+ // See the rtm::quatf quat_near_identity for details about how the default threshold
// was chosen. You will typically NEVER need to change this, the value has been
// selected to be as safe as possible and is independent of game engine units.
// Defaults to '0.00284714461' radians
@@ -163,11 +145,10 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Default constructor sets things up to perform no compression and to leave things raw.
CompressionSettings()
- : level(CompressionLevel8::Low)
- , rotation_format(RotationFormat8::Quat_128)
- , translation_format(VectorFormat8::Vector3_96)
- , scale_format(VectorFormat8::Vector3_96)
- , range_reduction(RangeReductionFlags8::None)
+ : level(compression_level8::low)
+ , rotation_format(rotation_format8::quatf_full)
+ , translation_format(vector_format8::vector3f_full)
+ , scale_format(vector_format8::vector3f_full)
, segmenting()
, error_metric(nullptr)
, constant_rotation_threshold_angle(rtm::radians(0.00284714461F))
@@ -185,10 +166,8 @@ namespace acl
hash_value = hash_combine(hash_value, hash32(rotation_format));
hash_value = hash_combine(hash_value, hash32(translation_format));
hash_value = hash_combine(hash_value, hash32(scale_format));
- hash_value = hash_combine(hash_value, hash32(range_reduction));
- if (segmenting.enabled)
- hash_value = hash_combine(hash_value, segmenting.get_hash());
+ hash_value = hash_combine(hash_value, segmenting.get_hash());
if (error_metric != nullptr)
hash_value = hash_combine(hash_value, error_metric->get_hash());
@@ -207,28 +186,6 @@ namespace acl
// Returns nullptr if the settings are valid.
ErrorResult is_valid() const
{
- if (translation_format != VectorFormat8::Vector3_96)
- {
- const bool has_clip_range_reduction = are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations);
- const bool has_segment_range_reduction = segmenting.enabled && are_any_enum_flags_set(segmenting.range_reduction, RangeReductionFlags8::Translations);
- if (!has_clip_range_reduction && !has_segment_range_reduction)
- return ErrorResult("This translation format requires range reduction to be enabled at the clip or segment level");
- }
-
- if (scale_format != VectorFormat8::Vector3_96)
- {
- const bool has_clip_range_reduction = are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales);
- const bool has_segment_range_reduction = segmenting.enabled && are_any_enum_flags_set(segmenting.range_reduction, RangeReductionFlags8::Scales);
- if (!has_clip_range_reduction && !has_segment_range_reduction)
- return ErrorResult("This scale format requires range reduction to be enabled at the clip or segment level");
- }
-
- if (segmenting.enabled && segmenting.range_reduction != RangeReductionFlags8::None)
- {
- if ((range_reduction & segmenting.range_reduction) != segmenting.range_reduction)
- return ErrorResult("Per segment range reduction requires per clip range reduction to be enabled");
- }
-
if (error_metric == nullptr)
return ErrorResult("error_metric cannot be NULL");
@@ -263,13 +220,10 @@ namespace acl
inline CompressionSettings get_default_compression_settings()
{
CompressionSettings settings;
- settings.level = CompressionLevel8::Medium;
- settings.rotation_format = RotationFormat8::QuatDropW_Variable;
- settings.translation_format = VectorFormat8::Vector3_Variable;
- settings.scale_format = VectorFormat8::Vector3_Variable;
- settings.range_reduction = RangeReductionFlags8::AllTracks;
- settings.segmenting.enabled = true;
- settings.segmenting.range_reduction = RangeReductionFlags8::AllTracks;
+ settings.level = compression_level8::medium;
+ settings.rotation_format = rotation_format8::quatf_drop_w_variable;
+ settings.translation_format = vector_format8::vector3f_variable;
+ settings.scale_format = vector_format8::vector3f_variable;
return settings;
}
diff --git a/includes/acl/compression/impl/clip_context.h b/includes/acl/compression/impl/clip_context.h
--- a/includes/acl/compression/impl/clip_context.h
+++ b/includes/acl/compression/impl/clip_context.h
@@ -63,7 +63,7 @@ namespace acl
bool has_scale;
bool has_additive_base;
- AdditiveClipFormat8 additive_format;
+ additive_clip_format8 additive_format;
// Stat tracking
uint32_t decomp_touched_bytes;
@@ -119,9 +119,9 @@ namespace acl
bone_stream.parent_bone_index = skel_bone.parent_index;
bone_stream.output_index = bone.output_index;
- bone_stream.rotations = RotationTrackStream(allocator, num_samples, sizeof(rtm::quatf), sample_rate, RotationFormat8::Quat_128);
- bone_stream.translations = TranslationTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, VectorFormat8::Vector3_96);
- bone_stream.scales = ScaleTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, VectorFormat8::Vector3_96);
+ bone_stream.rotations = RotationTrackStream(allocator, num_samples, sizeof(rtm::quatf), sample_rate, rotation_format8::quatf_full);
+ bone_stream.translations = TranslationTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, vector_format8::vector3f_full);
+ bone_stream.scales = ScaleTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, vector_format8::vector3f_full);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
diff --git a/includes/acl/compression/impl/compact_constant_streams.h b/includes/acl/compression/impl/compact_constant_streams.h
--- a/includes/acl/compression/impl/compact_constant_streams.h
+++ b/includes/acl/compression/impl/compact_constant_streams.h
@@ -52,12 +52,10 @@ namespace acl
switch (track.get_rotation_format())
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
return rtm::vector_to_quat(rotation);
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
return rtm::quat_from_positive_w(rotation);
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(track.get_rotation_format()));
diff --git a/includes/acl/compression/impl/compressed_clip_impl.h b/includes/acl/compression/impl/compressed_clip_impl.h
--- a/includes/acl/compression/impl/compressed_clip_impl.h
+++ b/includes/acl/compression/impl/compressed_clip_impl.h
@@ -33,7 +33,7 @@ namespace acl
{
namespace acl_impl
{
- inline CompressedClip* make_compressed_clip(void* buffer, uint32_t size, AlgorithmType8 type)
+ inline CompressedClip* make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type)
{
return new(buffer) CompressedClip(size, type);
}
diff --git a/includes/acl/compression/impl/convert_rotation_streams.h b/includes/acl/compression/impl/convert_rotation_streams.h
--- a/includes/acl/compression/impl/convert_rotation_streams.h
+++ b/includes/acl/compression/impl/convert_rotation_streams.h
@@ -40,18 +40,18 @@ namespace acl
{
namespace acl_impl
{
- inline rtm::vector4f RTM_SIMD_CALL convert_rotation(rtm::vector4f_arg0 rotation, RotationFormat8 from, RotationFormat8 to)
+ inline rtm::vector4f RTM_SIMD_CALL convert_rotation(rtm::vector4f_arg0 rotation, rotation_format8 from, rotation_format8 to)
{
- ACL_ASSERT(from == RotationFormat8::Quat_128, "Source rotation format must be a full precision quaternion");
+ ACL_ASSERT(from == rotation_format8::quatf_full, "Source rotation format must be a full precision quaternion");
(void)from;
- const RotationFormat8 high_precision_format = get_rotation_variant(to) == RotationVariant8::Quat ? RotationFormat8::Quat_128 : RotationFormat8::QuatDropW_96;
+ const rotation_format8 high_precision_format = get_rotation_variant(to) == rotation_variant8::quat ? rotation_format8::quatf_full : rotation_format8::quatf_drop_w_full;
switch (high_precision_format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
// Original format, nothing to do
return rotation;
- case RotationFormat8::QuatDropW_96:
+ case rotation_format8::quatf_drop_w_full:
// Drop W, we just ensure it is positive and write it back, the W component can be ignored afterwards
return rtm::quat_to_vector(rtm::quat_ensure_positive_w(rtm::vector_to_quat(rotation)));
default:
@@ -60,13 +60,13 @@ namespace acl
}
}
- inline void convert_rotation_streams(IAllocator& allocator, SegmentContext& segment, RotationFormat8 rotation_format)
+ inline void convert_rotation_streams(IAllocator& allocator, SegmentContext& segment, rotation_format8 rotation_format)
{
- const RotationFormat8 high_precision_format = get_rotation_variant(rotation_format) == RotationVariant8::Quat ? RotationFormat8::Quat_128 : RotationFormat8::QuatDropW_96;
+ const rotation_format8 high_precision_format = get_rotation_variant(rotation_format) == rotation_variant8::quat ? rotation_format8::quatf_full : rotation_format8::quatf_drop_w_full;
for (BoneStreams& bone_stream : segment.bone_iterator())
{
- // We convert our rotation stream in place. We assume that the original format is Quat_128 stored as rtm::quatf
+ // We convert our rotation stream in place. We assume that the original format is quatf_full stored as rtm::quatf
// For all other formats, we keep the same sample size and either keep Quat_32 or use rtm::vector4f
ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::quatf), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(rtm::quatf));
@@ -80,10 +80,10 @@ namespace acl
switch (high_precision_format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
// Original format, nothing to do
break;
- case RotationFormat8::QuatDropW_96:
+ case rotation_format8::quatf_drop_w_full:
// Drop W, we just ensure it is positive and write it back, the W component can be ignored afterwards
rotation = rtm::quat_ensure_positive_w(rotation);
break;
@@ -99,7 +99,7 @@ namespace acl
}
}
- inline void convert_rotation_streams(IAllocator& allocator, ClipContext& clip_context, RotationFormat8 rotation_format)
+ inline void convert_rotation_streams(IAllocator& allocator, ClipContext& clip_context, rotation_format8 rotation_format)
{
for (SegmentContext& segment : clip_context.segment_iterator())
convert_rotation_streams(allocator, segment, rotation_format);
diff --git a/includes/acl/compression/impl/normalize_streams.h b/includes/acl/compression/impl/normalize_streams.h
--- a/includes/acl/compression/impl/normalize_streams.h
+++ b/includes/acl/compression/impl/normalize_streams.h
@@ -210,13 +210,11 @@ namespace acl
#if defined(ACL_HAS_ASSERT_CHECKS)
switch (bone_stream.rotations.get_rotation_format())
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
ACL_ASSERT(rtm::vector_all_greater_equal(normalized_rotation, zero) && rtm::vector_all_less_equal(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_rotation), rtm::vector_get_y(normalized_rotation), rtm::vector_get_z(normalized_rotation), rtm::vector_get_w(normalized_rotation));
break;
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
ACL_ASSERT(rtm::vector_all_greater_equal3(normalized_rotation, zero) && rtm::vector_all_less_equal3(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_rotation), rtm::vector_get_y(normalized_rotation), rtm::vector_get_z(normalized_rotation));
break;
}
@@ -309,50 +307,50 @@ namespace acl
}
}
- inline void normalize_clip_streams(ClipContext& clip_context, RangeReductionFlags8 range_reduction)
+ inline void normalize_clip_streams(ClipContext& clip_context, range_reduction_flags8 range_reduction)
{
ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must contain a single segment!");
SegmentContext& segment = clip_context.segments[0];
const bool has_scale = segment_context_has_scale(segment);
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations))
{
normalize_rotation_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
clip_context.are_rotations_normalized = true;
}
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations))
{
normalize_translation_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
clip_context.are_translations_normalized = true;
}
- if (has_scale && are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales))
+ if (has_scale && are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales))
{
normalize_scale_streams(segment.bone_streams, clip_context.ranges, segment.num_bones);
clip_context.are_scales_normalized = true;
}
}
- inline void normalize_segment_streams(ClipContext& clip_context, RangeReductionFlags8 range_reduction)
+ inline void normalize_segment_streams(ClipContext& clip_context, range_reduction_flags8 range_reduction)
{
for (SegmentContext& segment : clip_context.segment_iterator())
{
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations))
{
normalize_rotation_streams(segment.bone_streams, segment.ranges, segment.num_bones);
segment.are_rotations_normalized = true;
}
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations))
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations))
{
normalize_translation_streams(segment.bone_streams, segment.ranges, segment.num_bones);
segment.are_translations_normalized = true;
}
const bool has_scale = segment_context_has_scale(segment);
- if (has_scale && are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales))
+ if (has_scale && are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales))
{
normalize_scale_streams(segment.bone_streams, segment.ranges, segment.num_bones);
segment.are_scales_normalized = true;
@@ -364,18 +362,18 @@ namespace acl
{
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations) && !bone_stream.is_rotation_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) && !bone_stream.is_rotation_constant)
{
- if (bone_stream.rotations.get_rotation_format() == RotationFormat8::Quat_128)
+ if (bone_stream.rotations.get_rotation_format() == rotation_format8::quatf_full)
range_data_size += k_segment_range_reduction_num_bytes_per_component * 8;
else
range_data_size += k_segment_range_reduction_num_bytes_per_component * 6;
}
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations) && !bone_stream.is_translation_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) && !bone_stream.is_translation_constant)
range_data_size += k_segment_range_reduction_num_bytes_per_component * 6;
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales) && !bone_stream.is_scale_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) && !bone_stream.is_scale_constant)
range_data_size += k_segment_range_reduction_num_bytes_per_component * 6;
}
diff --git a/includes/acl/compression/impl/quantize_streams.h b/includes/acl/compression/impl/quantize_streams.h
--- a/includes/acl/compression/impl/quantize_streams.h
+++ b/includes/acl/compression/impl/quantize_streams.h
@@ -258,7 +258,7 @@ namespace acl
QuantizationContext& operator=(QuantizationContext&&) = delete;
};
- inline void quantize_fixed_rotation_stream(IAllocator& allocator, const RotationTrackStream& raw_stream, RotationFormat8 rotation_format, bool are_rotations_normalized, RotationTrackStream& out_quantized_stream)
+ inline void quantize_fixed_rotation_stream(IAllocator& allocator, const RotationTrackStream& raw_stream, rotation_format8 rotation_format, RotationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -275,22 +275,13 @@ namespace acl
switch (rotation_format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
pack_vector4_128(rtm::quat_to_vector(rotation), quantized_ptr);
break;
- case RotationFormat8::QuatDropW_96:
+ case rotation_format8::quatf_drop_w_full:
pack_vector3_96(rtm::quat_to_vector(rotation), quantized_ptr);
break;
- case RotationFormat8::QuatDropW_48:
- if (are_rotations_normalized)
- pack_vector3_u48_unsafe(rtm::quat_to_vector(rotation), quantized_ptr);
- else
- pack_vector3_s48_unsafe(rtm::quat_to_vector(rotation), quantized_ptr);
- break;
- case RotationFormat8::QuatDropW_32:
- pack_vector3_32(rtm::quat_to_vector(rotation), 11, 11, 10, are_rotations_normalized, quantized_ptr);
- break;
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_drop_w_variable:
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(rotation_format));
break;
@@ -300,7 +291,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_rotation_stream(QuantizationContext& context, uint16_t bone_index, RotationFormat8 rotation_format)
+ inline void quantize_fixed_rotation_stream(QuantizationContext& context, uint16_t bone_index, rotation_format8 rotation_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -310,11 +301,10 @@ namespace acl
if (bone_stream.is_rotation_default)
return;
- const bool are_rotations_normalized = context.clip.are_rotations_normalized && !bone_stream.is_rotation_constant;
- quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, rotation_format, are_rotations_normalized, bone_stream.rotations);
+ quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, rotation_format, bone_stream.rotations);
}
- inline void quantize_variable_rotation_stream(QuantizationContext& context, const RotationTrackStream& raw_clip_stream, const RotationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, bool are_rotations_normalized, RotationTrackStream& out_quantized_stream)
+ inline void quantize_variable_rotation_stream(QuantizationContext& context, const RotationTrackStream& raw_clip_stream, const RotationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, RotationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
@@ -322,14 +312,12 @@ namespace acl
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
const float sample_rate = raw_segment_stream.get_sample_rate();
- RotationTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, RotationFormat8::QuatDropW_Variable, bit_rate);
+ RotationTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, rotation_format8::quatf_drop_w_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
- ACL_ASSERT(are_rotations_normalized, "Cannot drop a constant track if it isn't normalized");
-
rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
- rotation = convert_rotation(rotation, RotationFormat8::Quat_128, RotationFormat8::QuatDropW_Variable);
+ rotation = convert_rotation(rotation, rotation_format8::quatf_full, rotation_format8::quatf_drop_w_variable);
const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_range);
@@ -347,16 +335,13 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
- rotation = convert_rotation(rotation, RotationFormat8::Quat_128, RotationFormat8::QuatDropW_Variable);
+ rotation = convert_rotation(rotation, rotation_format8::quatf_full, rotation_format8::quatf_drop_w_variable);
pack_vector3_96(rotation, quantized_ptr);
}
else
{
const rtm::quatf rotation = raw_segment_stream.get_raw_sample<rtm::quatf>(sample_index);
- if (are_rotations_normalized)
- pack_vector3_uXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
- else
- pack_vector3_sXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
+ pack_vector3_uXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
}
}
}
@@ -375,23 +360,21 @@ namespace acl
return;
const BoneStreams& raw_bone_stream = context.raw_bone_streams[bone_index];
- const RotationFormat8 highest_bit_rate = get_highest_variant_precision(RotationVariant8::QuatDropW);
- const TrackStreamRange invalid_range;
- const TrackStreamRange& bone_range = context.clip.are_rotations_normalized ? context.clip.ranges[bone_index].rotation : invalid_range;
- const bool are_rotations_normalized = context.clip.are_rotations_normalized && !bone_stream.is_rotation_constant;
+ const rotation_format8 highest_bit_rate = get_highest_variant_precision(rotation_variant8::quat_drop_w);
+ const TrackStreamRange& bone_range = context.clip.ranges[bone_index].rotation;
// If our format is variable, we keep them fixed at the highest bit rate in the variant
if (bone_stream.is_rotation_constant)
- quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, highest_bit_rate, are_rotations_normalized, bone_stream.rotations);
+ quantize_fixed_rotation_stream(context.allocator, bone_stream.rotations, highest_bit_rate, bone_stream.rotations);
else
- quantize_variable_rotation_stream(context, raw_bone_stream.rotations, bone_stream.rotations, bone_range, bit_rate, are_rotations_normalized, bone_stream.rotations);
+ quantize_variable_rotation_stream(context, raw_bone_stream.rotations, bone_stream.rotations, bone_range, bit_rate, bone_stream.rotations);
}
- inline void quantize_fixed_translation_stream(IAllocator& allocator, const TranslationTrackStream& raw_stream, VectorFormat8 translation_format, TranslationTrackStream& out_quantized_stream)
+ inline void quantize_fixed_translation_stream(IAllocator& allocator, const TranslationTrackStream& raw_stream, vector_format8 translation_format, TranslationTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
+ ACL_ASSERT(raw_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
const uint32_t num_samples = raw_stream.get_num_samples();
const uint32_t sample_size = get_packed_vector_size(translation_format);
@@ -405,16 +388,10 @@ namespace acl
switch (translation_format)
{
- case VectorFormat8::Vector3_96:
+ case vector_format8::vector3f_full:
pack_vector3_96(translation, quantized_ptr);
break;
- case VectorFormat8::Vector3_48:
- pack_vector3_u48_unsafe(translation, quantized_ptr);
- break;
- case VectorFormat8::Vector3_32:
- pack_vector3_32(translation, 11, 11, 10, true, quantized_ptr);
- break;
- case VectorFormat8::Vector3_Variable:
+ case vector_format8::vector3f_variable:
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(translation_format));
break;
@@ -424,7 +401,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_translation_stream(QuantizationContext& context, uint16_t bone_index, VectorFormat8 translation_format)
+ inline void quantize_fixed_translation_stream(QuantizationContext& context, uint16_t bone_index, vector_format8 translation_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -435,7 +412,7 @@ namespace acl
return;
// Constant translation tracks store the remaining sample with full precision
- const VectorFormat8 format = bone_stream.is_translation_constant ? VectorFormat8::Vector3_96 : translation_format;
+ const vector_format8 format = bone_stream.is_translation_constant ? vector_format8::vector3f_full : translation_format;
quantize_fixed_translation_stream(context.allocator, bone_stream.translations, format, bone_stream.translations);
}
@@ -444,12 +421,12 @@ namespace acl
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_segment_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
+ ACL_ASSERT(raw_segment_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
const float sample_rate = raw_segment_stream.get_sample_rate();
- TranslationTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, VectorFormat8::Vector3_Variable, bit_rate);
+ TranslationTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, vector_format8::vector3f_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
@@ -493,22 +470,21 @@ namespace acl
if (bone_stream.is_translation_default)
return;
- const TrackStreamRange invalid_range;
- const TrackStreamRange& bone_range = context.clip.are_translations_normalized ? context.clip.ranges[bone_index].translation : invalid_range;
+ const TrackStreamRange& bone_range = context.clip.ranges[bone_index].translation;
const BoneStreams& raw_bone_stream = context.raw_bone_streams[bone_index];
// Constant translation tracks store the remaining sample with full precision
if (bone_stream.is_translation_constant)
- quantize_fixed_translation_stream(context.allocator, bone_stream.translations, VectorFormat8::Vector3_96, bone_stream.translations);
+ quantize_fixed_translation_stream(context.allocator, bone_stream.translations, vector_format8::vector3f_full, bone_stream.translations);
else
quantize_variable_translation_stream(context, raw_bone_stream.translations, bone_stream.translations, bone_range, bit_rate, bone_stream.translations);
}
- inline void quantize_fixed_scale_stream(IAllocator& allocator, const ScaleTrackStream& raw_stream, VectorFormat8 scale_format, ScaleTrackStream& out_quantized_stream)
+ inline void quantize_fixed_scale_stream(IAllocator& allocator, const ScaleTrackStream& raw_stream, vector_format8 scale_format, ScaleTrackStream& out_quantized_stream)
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
+ ACL_ASSERT(raw_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
const uint32_t num_samples = raw_stream.get_num_samples();
const uint32_t sample_size = get_packed_vector_size(scale_format);
@@ -522,16 +498,10 @@ namespace acl
switch (scale_format)
{
- case VectorFormat8::Vector3_96:
+ case vector_format8::vector3f_full:
pack_vector3_96(scale, quantized_ptr);
break;
- case VectorFormat8::Vector3_48:
- pack_vector3_u48_unsafe(scale, quantized_ptr);
- break;
- case VectorFormat8::Vector3_32:
- pack_vector3_32(scale, 11, 11, 10, true, quantized_ptr);
- break;
- case VectorFormat8::Vector3_Variable:
+ case vector_format8::vector3f_variable:
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(scale_format));
break;
@@ -541,7 +511,7 @@ namespace acl
out_quantized_stream = std::move(quantized_stream);
}
- inline void quantize_fixed_scale_stream(QuantizationContext& context, uint16_t bone_index, VectorFormat8 scale_format)
+ inline void quantize_fixed_scale_stream(QuantizationContext& context, uint16_t bone_index, vector_format8 scale_format)
{
ACL_ASSERT(bone_index < context.num_bones, "Invalid bone index: %u", bone_index);
@@ -552,7 +522,7 @@ namespace acl
return;
// Constant scale tracks store the remaining sample with full precision
- const VectorFormat8 format = bone_stream.is_scale_constant ? VectorFormat8::Vector3_96 : scale_format;
+ const vector_format8 format = bone_stream.is_scale_constant ? vector_format8::vector3f_full : scale_format;
quantize_fixed_scale_stream(context.allocator, bone_stream.scales, format, bone_stream.scales);
}
@@ -561,12 +531,12 @@ namespace acl
{
// We expect all our samples to have the same width of sizeof(rtm::vector4f)
ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
- ACL_ASSERT(raw_segment_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
+ ACL_ASSERT(raw_segment_stream.get_vector_format() == vector_format8::vector3f_full, "Expected a vector3f_full vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
const float sample_rate = raw_segment_stream.get_sample_rate();
- ScaleTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, VectorFormat8::Vector3_Variable, bit_rate);
+ ScaleTrackStream quantized_stream(context.allocator, num_samples, sample_size, sample_rate, vector_format8::vector3f_variable, bit_rate);
if (is_constant_bit_rate(bit_rate))
{
@@ -610,13 +580,12 @@ namespace acl
if (bone_stream.is_scale_default)
return;
- const TrackStreamRange invalid_range;
- const TrackStreamRange& bone_range = context.clip.are_scales_normalized ? context.clip.ranges[bone_index].scale : invalid_range;
+ const TrackStreamRange& bone_range = context.clip.ranges[bone_index].scale;
const BoneStreams& raw_bone_stream = context.raw_bone_streams[bone_index];
// Constant scale tracks store the remaining sample with full precision
if (bone_stream.is_scale_constant)
- quantize_fixed_scale_stream(context.allocator, bone_stream.scales, VectorFormat8::Vector3_96, bone_stream.scales);
+ quantize_fixed_scale_stream(context.allocator, bone_stream.scales, vector_format8::vector3f_full, bone_stream.scales);
else
quantize_variable_scale_stream(context, raw_bone_stream.scales, bone_stream.scales, bone_range, bit_rate, bone_stream.scales);
}
@@ -1070,7 +1039,7 @@ namespace acl
return num_bones_in_chain;
}
- inline void initialize_bone_bit_rates(const SegmentContext& segment, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, BoneBitRate* out_bit_rate_per_bone)
+ inline void initialize_bone_bit_rates(const SegmentContext& segment, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, BoneBitRate* out_bit_rate_per_bone)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
@@ -1227,7 +1196,7 @@ namespace acl
break;
}
- if (settings.level >= CompressionLevel8::High)
+ if (settings.level >= compression_level8::high)
{
// The second permutation increases the bit rate of 2 track/bones
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
@@ -1259,7 +1228,7 @@ namespace acl
}
}
- if (settings.level >= CompressionLevel8::Highest)
+ if (settings.level >= compression_level8::highest)
{
// The third permutation increases the bit rate of 3 track/bones
std::fill(bone_chain_permutation, bone_chain_permutation + context.num_bones, uint8_t(0));
@@ -1441,7 +1410,7 @@ namespace acl
// not, sibling bones will remain fairly close in their error. Some packed rotation formats, namely
// drop W component can have a high error even with raw values, it is assumed that if such a format
// is used then a best effort approach to reach the error threshold is entirely fine.
- if (error >= settings.error_threshold && context.settings.rotation_format == RotationFormat8::Quat_128)
+ if (error >= settings.error_threshold && context.settings.rotation_format == rotation_format8::quatf_full)
{
// From child to parent, max out the bit rate
for (int16_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
diff --git a/includes/acl/compression/impl/sample_streams.h b/includes/acl/compression/impl/sample_streams.h
--- a/includes/acl/compression/impl/sample_streams.h
+++ b/includes/acl/compression/impl/sample_streams.h
@@ -46,23 +46,18 @@ namespace acl
{
namespace acl_impl
{
- inline rtm::vector4f RTM_SIMD_CALL load_rotation_sample(const uint8_t* ptr, RotationFormat8 format, uint8_t bit_rate, bool is_normalized)
+ inline rtm::vector4f RTM_SIMD_CALL load_rotation_sample(const uint8_t* ptr, rotation_format8 format, uint8_t bit_rate)
{
switch (format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
return unpack_vector4_128(ptr);
- case RotationFormat8::QuatDropW_96:
+ case rotation_format8::quatf_drop_w_full:
return unpack_vector3_96_unsafe(ptr);
- case RotationFormat8::QuatDropW_48:
- return is_normalized ? unpack_vector3_u48_unsafe(ptr) : unpack_vector3_s48_unsafe(ptr);
- case RotationFormat8::QuatDropW_32:
- return unpack_vector3_32(11, 11, 10, is_normalized, ptr);
- case RotationFormat8::QuatDropW_Variable:
- {
+ case rotation_format8::quatf_drop_w_variable:
+ ACL_ASSERT(bit_rate != k_invalid_bit_rate, "Invalid bit rate!");
if (is_constant_bit_rate(bit_rate))
{
- ACL_ASSERT(is_normalized, "Cannot drop a constant track if it isn't normalized");
return unpack_vector3_u48_unsafe(ptr);
}
else if (is_raw_bit_rate(bit_rate))
@@ -70,29 +65,21 @@ namespace acl
else
{
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- if (is_normalized)
- return unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, ptr, 0);
- else
- return unpack_vector3_sXX_unsafe(num_bits_at_bit_rate, ptr, 0);
+ return unpack_vector3_uXX_unsafe(num_bits_at_bit_rate, ptr, 0);
}
- }
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
return rtm::vector_zero();
}
}
- inline rtm::vector4f RTM_SIMD_CALL load_vector_sample(const uint8_t* ptr, VectorFormat8 format, uint8_t bit_rate)
+ inline rtm::vector4f RTM_SIMD_CALL load_vector_sample(const uint8_t* ptr, vector_format8 format, uint8_t bit_rate)
{
switch (format)
{
- case VectorFormat8::Vector3_96:
+ case vector_format8::vector3f_full:
return unpack_vector3_96_unsafe(ptr);
- case VectorFormat8::Vector3_48:
- return unpack_vector3_u48_unsafe(ptr);
- case VectorFormat8::Vector3_32:
- return unpack_vector3_32(11, 11, 10, true, ptr);
- case VectorFormat8::Vector3_Variable:
+ case vector_format8::vector3f_variable:
ACL_ASSERT(bit_rate != k_invalid_bit_rate, "Invalid bit rate!");
if (is_constant_bit_rate(bit_rate))
return unpack_vector3_u48_unsafe(ptr);
@@ -109,16 +96,14 @@ namespace acl
}
}
- inline rtm::quatf RTM_SIMD_CALL rotation_to_quat_32(rtm::vector4f_arg0 rotation, RotationFormat8 format)
+ inline rtm::quatf RTM_SIMD_CALL rotation_to_quat_32(rtm::vector4f_arg0 rotation, rotation_format8 format)
{
switch (format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
return rtm::vector_to_quat(rotation);
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
return rtm::quat_from_positive_w(rotation);
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
@@ -130,19 +115,18 @@ namespace acl
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
- const bool are_rotations_normalized = clip_context->are_rotations_normalized;
- const RotationFormat8 format = bone_steams.rotations.get_rotation_format();
+ const rotation_format8 format = bone_steams.rotations.get_rotation_format();
const uint8_t bit_rate = bone_steams.rotations.get_bit_rate();
- if (format == RotationFormat8::QuatDropW_Variable && is_constant_bit_rate(bit_rate))
+ if (format == rotation_format8::quatf_drop_w_variable && is_constant_bit_rate(bit_rate))
sample_index = 0;
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
- rtm::vector4f packed_rotation = acl_impl::load_rotation_sample(quantized_ptr, format, bit_rate, are_rotations_normalized);
+ rtm::vector4f packed_rotation = acl_impl::load_rotation_sample(quantized_ptr, format, bit_rate);
- if (are_rotations_normalized && !is_raw_bit_rate(bit_rate))
+ if (clip_context->are_rotations_normalized && !is_raw_bit_rate(bit_rate))
{
if (segment->are_rotations_normalized && !is_constant_bit_rate(bit_rate))
{
@@ -169,26 +153,25 @@ namespace acl
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
- const bool are_rotations_normalized = clip_context->are_rotations_normalized;
- const RotationFormat8 format = bone_steams.rotations.get_rotation_format();
+ const rotation_format8 format = bone_steams.rotations.get_rotation_format();
rtm::vector4f rotation;
if (is_constant_bit_rate(bit_rate))
{
const uint8_t* quantized_ptr = raw_bone_steams.rotations.get_raw_sample_ptr(segment->clip_sample_offset);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, RotationFormat8::Quat_128, k_invalid_bit_rate, are_rotations_normalized);
- rotation = convert_rotation(rotation, RotationFormat8::Quat_128, format);
+ rotation = acl_impl::load_rotation_sample(quantized_ptr, rotation_format8::quatf_full, k_invalid_bit_rate);
+ rotation = convert_rotation(rotation, rotation_format8::quatf_full, format);
}
else if (is_raw_bit_rate(bit_rate))
{
const uint8_t* quantized_ptr = raw_bone_steams.rotations.get_raw_sample_ptr(segment->clip_sample_offset + sample_index);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, RotationFormat8::Quat_128, k_invalid_bit_rate, are_rotations_normalized);
- rotation = convert_rotation(rotation, RotationFormat8::Quat_128, format);
+ rotation = acl_impl::load_rotation_sample(quantized_ptr, rotation_format8::quatf_full, k_invalid_bit_rate);
+ rotation = convert_rotation(rotation, rotation_format8::quatf_full, format);
}
else
{
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
- rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0, are_rotations_normalized);
+ rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0);
}
// Pack and unpack at our desired bit rate
@@ -197,9 +180,6 @@ namespace acl
if (is_constant_bit_rate(bit_rate))
{
- ACL_ASSERT(are_rotations_normalized, "Cannot drop a constant track if it isn't normalized");
- ACL_ASSERT(segment->are_rotations_normalized, "Cannot drop a constant track if it isn't normalized");
-
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_bone_range.rotation);
@@ -207,12 +187,10 @@ namespace acl
}
else if (is_raw_bit_rate(bit_rate))
packed_rotation = rotation;
- else if (are_rotations_normalized)
- packed_rotation = decay_vector3_uXX(rotation, num_bits_at_bit_rate);
else
- packed_rotation = decay_vector3_sXX(rotation, num_bits_at_bit_rate);
+ packed_rotation = decay_vector3_uXX(rotation, num_bits_at_bit_rate);
- if (are_rotations_normalized && !is_raw_bit_rate(bit_rate))
+ if (!is_raw_bit_rate(bit_rate))
{
if (segment->are_rotations_normalized && !is_constant_bit_rate(bit_rate))
{
@@ -235,37 +213,32 @@ namespace acl
return acl_impl::rotation_to_quat_32(packed_rotation, format);
}
- inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index, RotationFormat8 desired_format)
+ inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index, rotation_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
- const bool are_rotations_normalized = clip_context->are_rotations_normalized && !bone_steams.is_rotation_constant;
+
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
- const RotationFormat8 format = bone_steams.rotations.get_rotation_format();
+ const rotation_format8 format = bone_steams.rotations.get_rotation_format();
- const rtm::vector4f rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0, are_rotations_normalized);
+ const rtm::vector4f rotation = acl_impl::load_rotation_sample(quantized_ptr, format, 0);
// Pack and unpack in our desired format
rtm::vector4f packed_rotation;
switch (desired_format)
{
- case RotationFormat8::Quat_128:
- case RotationFormat8::QuatDropW_96:
+ case rotation_format8::quatf_full:
+ case rotation_format8::quatf_drop_w_full:
packed_rotation = rotation;
break;
- case RotationFormat8::QuatDropW_48:
- packed_rotation = are_rotations_normalized ? decay_vector3_u48(rotation) : decay_vector3_s48(rotation);
- break;
- case RotationFormat8::QuatDropW_32:
- packed_rotation = are_rotations_normalized ? decay_vector3_u32(rotation, 11, 11, 10) : decay_vector3_s32(rotation, 11, 11, 10);
- break;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(desired_format));
packed_rotation = rtm::vector_zero();
break;
}
+ const bool are_rotations_normalized = clip_context->are_rotations_normalized && !bone_steams.is_rotation_constant;
if (are_rotations_normalized)
{
if (segment->are_rotations_normalized)
@@ -295,10 +268,10 @@ namespace acl
const ClipContext* clip_context = segment->clip;
const bool are_translations_normalized = clip_context->are_translations_normalized;
- const VectorFormat8 format = bone_steams.translations.get_vector_format();
+ const vector_format8 format = bone_steams.translations.get_vector_format();
const uint8_t bit_rate = bone_steams.translations.get_bit_rate();
- if (format == VectorFormat8::Vector3_Variable && is_constant_bit_rate(bit_rate))
+ if (format == vector_format8::vector3f_variable && is_constant_bit_rate(bit_rate))
sample_index = 0;
const uint8_t* quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
@@ -332,7 +305,7 @@ namespace acl
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
- const VectorFormat8 format = bone_steams.translations.get_vector_format();
+ const vector_format8 format = bone_steams.translations.get_vector_format();
const uint8_t* quantized_ptr;
if (is_constant_bit_rate(bit_rate))
@@ -389,13 +362,13 @@ namespace acl
return packed_translation;
}
- inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index, vector_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
const bool are_translations_normalized = clip_context->are_translations_normalized && !bone_steams.is_translation_constant;
const uint8_t* quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
- const VectorFormat8 format = bone_steams.translations.get_vector_format();
+ const vector_format8 format = bone_steams.translations.get_vector_format();
const rtm::vector4f translation = acl_impl::load_vector_sample(quantized_ptr, format, 0);
@@ -404,17 +377,9 @@ namespace acl
switch (desired_format)
{
- case VectorFormat8::Vector3_96:
+ case vector_format8::vector3f_full:
packed_translation = translation;
break;
- case VectorFormat8::Vector3_48:
- ACL_ASSERT(are_translations_normalized, "Translations must be normalized to support this format");
- packed_translation = decay_vector3_u48(translation);
- break;
- case VectorFormat8::Vector3_32:
- ACL_ASSERT(are_translations_normalized, "Translations must be normalized to support this format");
- packed_translation = decay_vector3_u32(translation, 11, 11, 10);
- break;
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(desired_format));
packed_translation = rtm::vector_zero();
@@ -450,10 +415,10 @@ namespace acl
const ClipContext* clip_context = segment->clip;
const bool are_scales_normalized = clip_context->are_scales_normalized;
- const VectorFormat8 format = bone_steams.scales.get_vector_format();
+ const vector_format8 format = bone_steams.scales.get_vector_format();
const uint8_t bit_rate = bone_steams.scales.get_bit_rate();
- if (format == VectorFormat8::Vector3_Variable && is_constant_bit_rate(bit_rate))
+ if (format == vector_format8::vector3f_variable && is_constant_bit_rate(bit_rate))
sample_index = 0;
const uint8_t* quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
@@ -487,7 +452,7 @@ namespace acl
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
- const VectorFormat8 format = bone_steams.scales.get_vector_format();
+ const vector_format8 format = bone_steams.scales.get_vector_format();
const uint8_t* quantized_ptr;
if (is_constant_bit_rate(bit_rate))
@@ -544,13 +509,13 @@ namespace acl
return packed_scale;
}
- inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index, vector_format8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
const bool are_scales_normalized = clip_context->are_scales_normalized && !bone_steams.is_scale_constant;
const uint8_t* quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
- const VectorFormat8 format = bone_steams.scales.get_vector_format();
+ const vector_format8 format = bone_steams.scales.get_vector_format();
const rtm::vector4f scale = acl_impl::load_vector_sample(quantized_ptr, format, 0);
@@ -559,17 +524,9 @@ namespace acl
switch (desired_format)
{
- case VectorFormat8::Vector3_96:
+ case vector_format8::vector3f_full:
packed_scale = scale;
break;
- case VectorFormat8::Vector3_48:
- ACL_ASSERT(are_scales_normalized, "Scales must be normalized to support this format");
- packed_scale = decay_vector3_u48(scale);
- break;
- case VectorFormat8::Vector3_32:
- ACL_ASSERT(are_scales_normalized, "Scales must be normalized to support this format");
- packed_scale = decay_vector3_u32(scale, 11, 11, 10);
- break;
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(desired_format));
packed_scale = scale;
@@ -617,7 +574,7 @@ namespace acl
// Our samples are uniform, grab the nearest samples
const ClipContext* clip_context = segment.clip;
- find_linear_interpolation_samples_with_sample_rate(clip_context->num_samples, clip_context->sample_rate, sample_time, SampleRoundingPolicy::Nearest, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(clip_context->num_samples, clip_context->sample_rate, sample_time, sample_rounding_policy::nearest, key0, key1, interpolation_alpha);
// Offset for the current segment and clamp
key0 = key0 - segment.clip_sample_offset;
@@ -657,7 +614,7 @@ namespace acl
const uint32_t num_samples = bone_stream.rotations.get_num_samples();
const float sample_rate = bone_stream.rotations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -681,7 +638,7 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_rotation_variable, RotationFormat8 rotation_format)
+ ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_rotation_variable, rotation_format8 rotation_format)
{
rtm::quatf rotation;
if (bone_stream.is_rotation_default)
@@ -705,7 +662,7 @@ namespace acl
const uint32_t num_samples = bone_stream.rotations.get_num_samples();
const float sample_rate = bone_stream.rotations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -758,7 +715,7 @@ namespace acl
const uint32_t num_samples = bone_stream.translations.get_num_samples();
const float sample_rate = bone_stream.translations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -782,13 +739,13 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_translation_variable, VectorFormat8 translation_format)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_translation_variable, vector_format8 translation_format)
{
rtm::vector4f translation;
if (bone_stream.is_translation_default)
translation = rtm::vector_zero();
else if (bone_stream.is_translation_constant)
- translation = get_translation_sample(raw_bone_stream, 0, VectorFormat8::Vector3_96);
+ translation = get_translation_sample(raw_bone_stream, 0, vector_format8::vector3f_full);
else
{
uint32_t key0;
@@ -799,7 +756,7 @@ namespace acl
const uint32_t num_samples = bone_stream.translations.get_num_samples();
const float sample_rate = bone_stream.translations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -852,7 +809,7 @@ namespace acl
const uint32_t num_samples = bone_stream.scales.get_num_samples();
const float sample_rate = bone_stream.scales.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -876,13 +833,13 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_scale_variable, VectorFormat8 scale_format, rtm::vector4f_arg0 default_scale)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_scale_variable, vector_format8 scale_format, rtm::vector4f_arg0 default_scale)
{
rtm::vector4f scale;
if (bone_stream.is_scale_default)
scale = default_scale;
else if (bone_stream.is_scale_constant)
- scale = get_scale_sample(raw_bone_stream, 0, VectorFormat8::Vector3_96);
+ scale = get_scale_sample(raw_bone_stream, 0, vector_format8::vector3f_full);
else
{
uint32_t key0;
@@ -893,7 +850,7 @@ namespace acl
const uint32_t num_samples = bone_stream.scales.get_num_samples();
const float sample_rate = bone_stream.scales.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -1073,7 +1030,7 @@ namespace acl
}
}
- inline void sample_streams(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_streams(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
@@ -1130,7 +1087,7 @@ namespace acl
}
}
- inline void sample_stream(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_stream(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
@@ -1177,7 +1134,7 @@ namespace acl
out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
- inline void sample_streams_hierarchical(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_streams_hierarchical(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
diff --git a/includes/acl/compression/impl/segment_streams.h b/includes/acl/compression/impl/segment_streams.h
--- a/includes/acl/compression/impl/segment_streams.h
+++ b/includes/acl/compression/impl/segment_streams.h
@@ -40,9 +40,6 @@ namespace acl
{
inline void segment_streams(IAllocator& allocator, ClipContext& clip_context, const SegmentingSettings& settings)
{
- if (!settings.enabled)
- return;
-
ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must have a single segment.");
ACL_ASSERT(settings.ideal_num_samples <= settings.max_num_samples, "Invalid num samples for segmenting settings. %u > %u", settings.ideal_num_samples, settings.max_num_samples);
diff --git a/includes/acl/compression/impl/track_bit_rate_database.h b/includes/acl/compression/impl/track_bit_rate_database.h
--- a/includes/acl/compression/impl/track_bit_rate_database.h
+++ b/includes/acl/compression/impl/track_bit_rate_database.h
@@ -211,9 +211,9 @@ namespace acl
BitSetDescription m_bitset_desc;
BitSetIndexRef m_bitref_constant;
- RotationFormat8 m_rotation_format;
- VectorFormat8 m_translation_format;
- VectorFormat8 m_scale_format;
+ rotation_format8 m_rotation_format;
+ vector_format8 m_translation_format;
+ vector_format8 m_scale_format;
bool m_is_rotation_variable;
bool m_is_translation_variable;
bool m_is_scale_variable;
@@ -634,7 +634,7 @@ namespace acl
const uint32_t num_samples = bone_stream.rotations.get_num_samples();
const float sample_rate = bone_stream.rotations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -741,7 +741,7 @@ namespace acl
else
{
// Not cached
- translation = get_translation_sample(m_raw_bone_streams[track_index], 0, VectorFormat8::Vector3_96);
+ translation = get_translation_sample(m_raw_bone_streams[track_index], 0, vector_format8::vector3f_full);
cached_samples[0] = translation;
bitset_set(validity_bitset, m_bitref_constant, true);
@@ -766,7 +766,7 @@ namespace acl
const uint32_t num_samples = bone_stream.translations.get_num_samples();
const float sample_rate = bone_stream.translations.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
@@ -869,7 +869,7 @@ namespace acl
else
{
// Not cached
- scale = get_scale_sample(m_raw_bone_streams[track_index], 0, VectorFormat8::Vector3_96);
+ scale = get_scale_sample(m_raw_bone_streams[track_index], 0, vector_format8::vector3f_full);
cached_samples[0] = scale;
bitset_set(validity_bitset, m_bitref_constant, true);
@@ -894,7 +894,7 @@ namespace acl
const uint32_t num_samples = bone_stream.scales.get_num_samples();
const float sample_rate = bone_stream.scales.get_sample_rate();
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, SampleRoundingPolicy::None, key0, key1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, context.sample_time, sample_rounding_policy::none, key0, key1, interpolation_alpha);
}
else
{
diff --git a/includes/acl/compression/impl/track_stream.h b/includes/acl/compression/impl/track_stream.h
--- a/includes/acl/compression/impl/track_stream.h
+++ b/includes/acl/compression/impl/track_stream.h
@@ -83,23 +83,23 @@ namespace acl
uint32_t get_num_samples() const { return m_num_samples; }
uint32_t get_sample_size() const { return m_sample_size; }
float get_sample_rate() const { return m_sample_rate; }
- AnimationTrackType8 get_track_type() const { return m_type; }
+ animation_track_type8 get_track_type() const { return m_type; }
uint8_t get_bit_rate() const { return m_bit_rate; }
bool is_bit_rate_variable() const { return m_bit_rate != k_invalid_bit_rate; }
float get_duration() const { return calculate_duration(m_num_samples, m_sample_rate); }
uint32_t get_packed_sample_size() const
{
- if (m_type == AnimationTrackType8::Rotation)
+ if (m_type == animation_track_type8::rotation)
return get_packed_rotation_size(m_format.rotation);
else
return get_packed_vector_size(m_format.vector);
}
protected:
- TrackStream(AnimationTrackType8 type, TrackFormat8 format) : m_allocator(nullptr), m_samples(nullptr), m_num_samples(0), m_sample_size(0), m_sample_rate(0.0F), m_type(type), m_format(format), m_bit_rate(0) {}
+ TrackStream(animation_track_type8 type, track_format8 format) : m_allocator(nullptr), m_samples(nullptr), m_num_samples(0), m_sample_size(0), m_sample_rate(0.0F), m_type(type), m_format(format), m_bit_rate(0) {}
- TrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, AnimationTrackType8 type, TrackFormat8 format, uint8_t bit_rate)
+ TrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, animation_track_type8 type, track_format8 format, uint8_t bit_rate)
: m_allocator(&allocator)
, m_samples(reinterpret_cast<uint8_t*>(allocator.allocate(sample_size * num_samples + k_padding, 16)))
, m_num_samples(num_samples)
@@ -170,17 +170,17 @@ namespace acl
uint32_t m_sample_size;
float m_sample_rate;
- AnimationTrackType8 m_type;
- TrackFormat8 m_format;
+ animation_track_type8 m_type;
+ track_format8 m_format;
uint8_t m_bit_rate;
};
class RotationTrackStream final : public TrackStream
{
public:
- RotationTrackStream() : TrackStream(AnimationTrackType8::Rotation, TrackFormat8(RotationFormat8::Quat_128)) {}
- RotationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, RotationFormat8 format, uint8_t bit_rate = k_invalid_bit_rate)
- : TrackStream(allocator, num_samples, sample_size, sample_rate, AnimationTrackType8::Rotation, TrackFormat8(format), bit_rate)
+ RotationTrackStream() : TrackStream(animation_track_type8::rotation, track_format8(rotation_format8::quatf_full)) {}
+ RotationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, rotation_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ : TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::rotation, track_format8(format), bit_rate)
{}
RotationTrackStream(const RotationTrackStream&) = delete;
RotationTrackStream(RotationTrackStream&& other)
@@ -202,15 +202,15 @@ namespace acl
return copy;
}
- RotationFormat8 get_rotation_format() const { return m_format.rotation; }
+ rotation_format8 get_rotation_format() const { return m_format.rotation; }
};
class TranslationTrackStream final : public TrackStream
{
public:
- TranslationTrackStream() : TrackStream(AnimationTrackType8::Translation, TrackFormat8(VectorFormat8::Vector3_96)) {}
- TranslationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, VectorFormat8 format, uint8_t bit_rate = k_invalid_bit_rate)
- : TrackStream(allocator, num_samples, sample_size, sample_rate, AnimationTrackType8::Translation, TrackFormat8(format), bit_rate)
+ TranslationTrackStream() : TrackStream(animation_track_type8::translation, track_format8(vector_format8::vector3f_full)) {}
+ TranslationTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ : TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::translation, track_format8(format), bit_rate)
{}
TranslationTrackStream(const TranslationTrackStream&) = delete;
TranslationTrackStream(TranslationTrackStream&& other)
@@ -232,15 +232,15 @@ namespace acl
return copy;
}
- VectorFormat8 get_vector_format() const { return m_format.vector; }
+ vector_format8 get_vector_format() const { return m_format.vector; }
};
class ScaleTrackStream final : public TrackStream
{
public:
- ScaleTrackStream() : TrackStream(AnimationTrackType8::Scale, TrackFormat8(VectorFormat8::Vector3_96)) {}
- ScaleTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, VectorFormat8 format, uint8_t bit_rate = k_invalid_bit_rate)
- : TrackStream(allocator, num_samples, sample_size, sample_rate, AnimationTrackType8::Scale, TrackFormat8(format), bit_rate)
+ ScaleTrackStream() : TrackStream(animation_track_type8::scale, track_format8(vector_format8::vector3f_full)) {}
+ ScaleTrackStream(IAllocator& allocator, uint32_t num_samples, uint32_t sample_size, float sample_rate, vector_format8 format, uint8_t bit_rate = k_invalid_bit_rate)
+ : TrackStream(allocator, num_samples, sample_size, sample_rate, animation_track_type8::scale, track_format8(format), bit_rate)
{}
ScaleTrackStream(const ScaleTrackStream&) = delete;
ScaleTrackStream(ScaleTrackStream&& other)
@@ -262,7 +262,7 @@ namespace acl
return copy;
}
- VectorFormat8 get_vector_format() const { return m_format.vector; }
+ vector_format8 get_vector_format() const { return m_format.vector; }
};
// For a rotation track, the extent only tells us if the track is constant or not
diff --git a/includes/acl/compression/impl/write_compression_stats_impl.h b/includes/acl/compression/impl/write_compression_stats_impl.h
--- a/includes/acl/compression/impl/write_compression_stats_impl.h
+++ b/includes/acl/compression/impl/write_compression_stats_impl.h
@@ -49,7 +49,7 @@ namespace acl
const double compression_ratio = double(raw_size) / double(compressed_size);
sjson::ObjectWriter& writer = *stats.writer;
- writer["algorithm_name"] = get_algorithm_name(AlgorithmType8::UniformlySampled);
+ writer["algorithm_name"] = get_algorithm_name(algorithm_type8::uniformly_sampled);
//writer["algorithm_uid"] = settings.get_hash();
//writer["clip_name"] = clip.get_name().c_str();
writer["raw_size"] = raw_size;
diff --git a/includes/acl/compression/impl/write_decompression_stats.h b/includes/acl/compression/impl/write_decompression_stats.h
--- a/includes/acl/compression/impl/write_decompression_stats.h
+++ b/includes/acl/compression/impl/write_decompression_stats.h
@@ -139,7 +139,7 @@ namespace acl
{
// If we want the cache warm, decompress everything once to prime it
DecompressionContextType* context = contexts[0];
- context->seek(sample_time, SampleRoundingPolicy::None);
+ context->seek(sample_time, sample_rounding_policy::none);
context->decompress_pose(pose_writer);
}
@@ -154,7 +154,7 @@ namespace acl
// If we measure with a cold CPU cache, we use a different context every time otherwise we use the first one
DecompressionContextType* context = is_cold_cache_profiling ? contexts[clip_index] : contexts[0];
- context->seek(sample_time, SampleRoundingPolicy::None);
+ context->seek(sample_time, sample_rounding_policy::none);
switch (decompression_function)
{
@@ -304,17 +304,15 @@ namespace acl
switch (compressed_clip.get_algorithm_type())
{
- case AlgorithmType8::UniformlySampled:
+ case algorithm_type8::uniformly_sampled:
{
#if defined(ACL_HAS_ASSERT_CHECKS)
// If we can, we use a fast-path that simulates what a real game engine would use
// by disabling the things they normally wouldn't care about like deprecated formats
// and debugging features
- const bool use_uniform_fast_path = settings.rotation_format == RotationFormat8::QuatDropW_Variable
- && settings.translation_format == VectorFormat8::Vector3_Variable
- && settings.scale_format == VectorFormat8::Vector3_Variable
- && are_all_enum_flags_set(settings.range_reduction, RangeReductionFlags8::AllTracks)
- && settings.segmenting.enabled;
+ const bool use_uniform_fast_path = settings.rotation_format == rotation_format8::quatf_drop_w_variable
+ && settings.translation_format == vector_format8::vector3f_variable
+ && settings.scale_format == vector_format8::vector3f_variable;
ACL_ASSERT(use_uniform_fast_path, "We do not support profiling the debug code path");
#endif
diff --git a/includes/acl/compression/impl/write_range_data.h b/includes/acl/compression/impl/write_range_data.h
--- a/includes/acl/compression/impl/write_range_data.h
+++ b/includes/acl/compression/impl/write_range_data.h
@@ -44,11 +44,11 @@ namespace acl
{
namespace acl_impl
{
- inline uint32_t get_stream_range_data_size(const ClipContext& clip_context, RangeReductionFlags8 range_reduction, RotationFormat8 rotation_format)
+ inline uint32_t get_stream_range_data_size(const ClipContext& clip_context, range_reduction_flags8 range_reduction, rotation_format8 rotation_format)
{
- const uint32_t rotation_size = are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations) ? get_range_reduction_rotation_size(rotation_format) : 0;
- const uint32_t translation_size = are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations) ? k_clip_range_reduction_vector3_range_size : 0;
- const uint32_t scale_size = are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales) ? k_clip_range_reduction_vector3_range_size : 0;
+ const uint32_t rotation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) ? get_range_reduction_rotation_size(rotation_format) : 0;
+ const uint32_t translation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) ? k_clip_range_reduction_vector3_range_size : 0;
+ const uint32_t scale_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) ? k_clip_range_reduction_vector3_range_size : 0;
uint32_t range_data_size = 0;
// Only use the first segment, it contains the necessary information
@@ -101,7 +101,7 @@ namespace acl
}
inline void write_range_track_data(const BoneStreams* bone_streams, const BoneRanges* bone_ranges,
- RangeReductionFlags8 range_reduction, bool is_clip_range_data,
+ range_reduction_flags8 range_reduction, bool is_clip_range_data,
uint8_t* range_data, uint32_t range_data_size,
const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
@@ -122,14 +122,14 @@ namespace acl
// value = (normalized value * range extent) + range min
// normalized value = (value - range min) / range extent
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations) && !bone_stream.is_rotation_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) && !bone_stream.is_rotation_constant)
{
const rtm::vector4f range_min = bone_range.rotation.get_min();
const rtm::vector4f range_extent = bone_range.rotation.get_extent();
if (is_clip_range_data)
{
- const uint32_t range_member_size = bone_stream.rotations.get_rotation_format() == RotationFormat8::Quat_128 ? (sizeof(float) * 4) : (sizeof(float) * 3);
+ const uint32_t range_member_size = bone_stream.rotations.get_rotation_format() == rotation_format8::quatf_full ? (sizeof(float) * 4) : (sizeof(float) * 3);
std::memcpy(range_data, &range_min, range_member_size);
range_data += range_member_size;
@@ -138,7 +138,7 @@ namespace acl
}
else
{
- if (bone_stream.rotations.get_rotation_format() == RotationFormat8::Quat_128)
+ if (bone_stream.rotations.get_rotation_format() == rotation_format8::quatf_full)
{
pack_vector4_32(range_min, true, range_data);
range_data += sizeof(uint8_t) * 4;
@@ -164,10 +164,10 @@ namespace acl
}
}
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Translations) && !bone_stream.is_translation_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) && !bone_stream.is_translation_constant)
write_range_track_data_impl(bone_stream.translations, bone_range.translation, is_clip_range_data, range_data);
- if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Scales) && !bone_stream.is_scale_constant)
+ if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) && !bone_stream.is_scale_constant)
write_range_track_data_impl(bone_stream.scales, bone_range.scale, is_clip_range_data, range_data);
ACL_ASSERT(range_data <= range_data_end, "Invalid range data offset. Wrote too much data.");
@@ -176,7 +176,7 @@ namespace acl
ACL_ASSERT(range_data == range_data_end, "Invalid range data offset. Wrote too little data.");
}
- inline void write_clip_range_data(const ClipContext& clip_context, RangeReductionFlags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void write_clip_range_data(const ClipContext& clip_context, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
// Only use the first segment, it contains the necessary information
const SegmentContext& segment = clip_context.segments[0];
@@ -184,7 +184,7 @@ namespace acl
write_range_track_data(segment.bone_streams, clip_context.ranges, range_reduction, true, range_data, range_data_size, output_bone_mapping, num_output_bones);
}
- inline void write_segment_range_data(const SegmentContext& segment, RangeReductionFlags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void write_segment_range_data(const SegmentContext& segment, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
write_range_track_data(segment.bone_streams, segment.ranges, range_reduction, false, range_data, range_data_size, output_bone_mapping, num_output_bones);
}
diff --git a/includes/acl/compression/impl/write_segment_data.h b/includes/acl/compression/impl/write_segment_data.h
--- a/includes/acl/compression/impl/write_segment_data.h
+++ b/includes/acl/compression/impl/write_segment_data.h
@@ -72,7 +72,7 @@ namespace acl
}
}
- inline void write_segment_data(const ClipContext& clip_context, const CompressionSettings& settings, ClipHeader& header, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void write_segment_data(const ClipContext& clip_context, const CompressionSettings& settings, range_reduction_flags8 range_reduction, ClipHeader& header, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
SegmentHeader* segment_headers = header.get_segment_headers();
const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip_context, settings.rotation_format, settings.translation_format, settings.scale_format);
@@ -88,12 +88,12 @@ namespace acl
segment_header.format_per_track_data_offset = InvalidPtrOffset();
if (segment.range_data_size > 0)
- write_segment_range_data(segment, settings.segmenting.range_reduction, header.get_segment_range_data(segment_header), segment.range_data_size, output_bone_mapping, num_output_bones);
+ write_segment_range_data(segment, range_reduction, header.get_segment_range_data(segment_header), segment.range_data_size, output_bone_mapping, num_output_bones);
else
segment_header.range_data_offset = InvalidPtrOffset();
if (segment.animated_data_size > 0)
- write_animated_track_data(segment, settings.rotation_format, settings.translation_format, settings.scale_format, header.get_track_data(segment_header), segment.animated_data_size, output_bone_mapping, num_output_bones);
+ write_animated_track_data(segment, header.get_track_data(segment_header), segment.animated_data_size, output_bone_mapping, num_output_bones);
else
segment_header.track_data_offset = InvalidPtrOffset();
}
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -46,7 +46,7 @@ namespace acl
{
namespace acl_impl
{
- inline void write_summary_segment_stats(const SegmentContext& segment, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, sjson::ObjectWriter& writer)
+ inline void write_summary_segment_stats(const SegmentContext& segment, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, sjson::ObjectWriter& writer)
{
writer["segment_index"] = segment.segment_index;
writer["num_samples"] = segment.num_samples;
@@ -228,7 +228,7 @@ namespace acl
const double compression_ratio = double(raw_size) / double(compressed_size);
sjson::ObjectWriter& writer = *stats.writer;
- writer["algorithm_name"] = get_algorithm_name(AlgorithmType8::UniformlySampled);
+ writer["algorithm_name"] = get_algorithm_name(algorithm_type8::uniformly_sampled);
writer["algorithm_uid"] = settings.get_hash();
writer["clip_name"] = clip.get_name().c_str();
writer["raw_size"] = raw_size;
@@ -241,7 +241,6 @@ namespace acl
writer["rotation_format"] = get_rotation_format_name(settings.rotation_format);
writer["translation_format"] = get_vector_format_name(settings.translation_format);
writer["scale_format"] = get_vector_format_name(settings.scale_format);
- writer["range_reduction"] = get_range_reduction_name(settings.range_reduction);
writer["has_scale"] = clip_context.has_scale;
writer["error_metric"] = settings.error_metric->get_name();
@@ -302,16 +301,12 @@ namespace acl
writer["num_animated_tracks"] = num_animated_tracks;
}
- if (settings.segmenting.enabled)
+ writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
{
- writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
- {
- segmenting_writer["num_segments"] = header.num_segments;
- segmenting_writer["range_reduction"] = get_range_reduction_name(settings.segmenting.range_reduction);
- segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
- segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
- };
- }
+ segmenting_writer["num_segments"] = header.num_segments;
+ segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
+ segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
+ };
writer["segments"] = [&](sjson::ArrayWriter& segments_writer)
{
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -63,23 +63,21 @@ namespace acl
return constant_data_size;
}
- inline void get_animated_variable_bit_rate_data_size(const TrackStream& track_stream, bool has_mixed_packing, uint32_t num_samples, uint32_t& out_num_animated_data_bits, uint32_t& out_num_animated_pose_bits)
+ inline void get_animated_variable_bit_rate_data_size(const TrackStream& track_stream, uint32_t num_samples, uint32_t& out_num_animated_data_bits, uint32_t& out_num_animated_pose_bits)
{
const uint8_t bit_rate = track_stream.get_bit_rate();
- uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
- if (has_mixed_packing)
- num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
out_num_animated_data_bits += num_bits_at_bit_rate * num_samples;
out_num_animated_pose_bits += num_bits_at_bit_rate;
}
- inline void calculate_animated_data_size(const TrackStream& track_stream, bool has_mixed_packing, uint32_t& num_animated_data_bits, uint32_t& num_animated_pose_bits)
+ inline void calculate_animated_data_size(const TrackStream& track_stream, uint32_t& num_animated_data_bits, uint32_t& num_animated_pose_bits)
{
const uint32_t num_samples = track_stream.get_num_samples();
if (track_stream.is_bit_rate_variable())
{
- get_animated_variable_bit_rate_data_size(track_stream, has_mixed_packing, num_samples, num_animated_data_bits, num_animated_pose_bits);
+ get_animated_variable_bit_rate_data_size(track_stream, num_samples, num_animated_data_bits, num_animated_pose_bits);
}
else
{
@@ -89,14 +87,8 @@ namespace acl
}
}
- inline void calculate_animated_data_size(ClipContext& clip_context, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void calculate_animated_data_size(ClipContext& clip_context, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
- // If all tracks are variable, no need for any extra padding except at the very end of the data
- // If our tracks are mixed variable/not variable, we need to add some padding to ensure alignment
- const bool is_every_format_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
- const bool is_any_format_variable = is_rotation_format_variable(rotation_format) || is_vector_format_variable(translation_format) || is_vector_format_variable(scale_format);
- const bool has_mixed_packing = !is_every_format_variable && is_any_format_variable;
-
for (SegmentContext& segment : clip_context.segment_iterator())
{
uint32_t num_animated_data_bits = 0;
@@ -108,13 +100,13 @@ namespace acl
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_constant)
- calculate_animated_data_size(bone_stream.rotations, has_mixed_packing, num_animated_data_bits, num_animated_pose_bits);
+ calculate_animated_data_size(bone_stream.rotations, num_animated_data_bits, num_animated_pose_bits);
if (!bone_stream.is_translation_constant)
- calculate_animated_data_size(bone_stream.translations, has_mixed_packing, num_animated_data_bits, num_animated_pose_bits);
+ calculate_animated_data_size(bone_stream.translations, num_animated_data_bits, num_animated_pose_bits);
if (!bone_stream.is_scale_constant)
- calculate_animated_data_size(bone_stream.scales, has_mixed_packing, num_animated_data_bits, num_animated_pose_bits);
+ calculate_animated_data_size(bone_stream.scales, num_animated_data_bits, num_animated_pose_bits);
}
segment.animated_data_size = align_to(num_animated_data_bits, 8) / 8;
@@ -122,7 +114,7 @@ namespace acl
}
}
- inline uint32_t get_format_per_track_data_size(const ClipContext& clip_context, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format)
+ inline uint32_t get_format_per_track_data_size(const ClipContext& clip_context, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
@@ -198,20 +190,22 @@ namespace acl
ACL_ASSERT(constant_data == constant_data_end, "Invalid constant data offset. Wrote too little data.");
}
- inline void write_animated_track_data(const TrackStream& track_stream, uint32_t sample_index, bool has_mixed_packing, uint8_t* animated_track_data_begin, uint8_t*& out_animated_track_data, uint64_t& out_bit_offset)
+ inline void write_animated_track_data(const TrackStream& track_stream, uint32_t sample_index, uint8_t* animated_track_data_begin, uint8_t*& out_animated_track_data, uint64_t& out_bit_offset)
{
+ const uint8_t* raw_sample_ptr = track_stream.get_raw_sample_ptr(sample_index);
+
if (track_stream.is_bit_rate_variable())
{
const uint8_t bit_rate = track_stream.get_bit_rate();
- uint64_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
+ const uint64_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
// Track is constant, our constant sample is stored in the range information
ACL_ASSERT(!is_constant_bit_rate(bit_rate), "Cannot write constant variable track data");
- const uint8_t* raw_sample_ptr = track_stream.get_raw_sample_ptr(sample_index);
if (is_raw_bit_rate(bit_rate))
{
const uint32_t* raw_sample_u32 = safe_ptr_cast<const uint32_t>(raw_sample_ptr);
+
const uint32_t x = byte_swap(raw_sample_u32[0]);
memcpy_bits(animated_track_data_begin, out_bit_offset + 0, &x, 0, 32);
const uint32_t y = byte_swap(raw_sample_u32[1]);
@@ -225,23 +219,34 @@ namespace acl
memcpy_bits(animated_track_data_begin, out_bit_offset, &raw_sample_u64, 0, num_bits_at_bit_rate);
}
- if (has_mixed_packing)
- num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
-
out_bit_offset += num_bits_at_bit_rate;
out_animated_track_data = animated_track_data_begin + (out_bit_offset / 8);
}
else
{
- const uint8_t* raw_sample_ptr = track_stream.get_raw_sample_ptr(sample_index);
+ const uint32_t* raw_sample_u32 = safe_ptr_cast<const uint32_t>(raw_sample_ptr);
+
+ const uint32_t x = byte_swap(raw_sample_u32[0]);
+ memcpy_bits(animated_track_data_begin, out_bit_offset + 0, &x, 0, 32);
+ const uint32_t y = byte_swap(raw_sample_u32[1]);
+ memcpy_bits(animated_track_data_begin, out_bit_offset + 32, &y, 0, 32);
+ const uint32_t z = byte_swap(raw_sample_u32[2]);
+ memcpy_bits(animated_track_data_begin, out_bit_offset + 64, &z, 0, 32);
+
const uint32_t sample_size = track_stream.get_packed_sample_size();
- std::memcpy(out_animated_track_data, raw_sample_ptr, sample_size);
- out_animated_track_data += sample_size;
- out_bit_offset = (out_animated_track_data - animated_track_data_begin) * 8;
+ const bool has_w_component = sample_size == (sizeof(float) * 4);
+ if (has_w_component)
+ {
+ const uint32_t w = byte_swap(raw_sample_u32[3]);
+ memcpy_bits(animated_track_data_begin, out_bit_offset + 96, &w, 0, 32);
+ }
+
+ out_bit_offset += has_w_component ? 128 : 96;
+ out_animated_track_data = animated_track_data_begin + (out_bit_offset / 8);
}
}
- inline void write_animated_track_data(const SegmentContext& segment, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, uint8_t* animated_track_data, uint32_t animated_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
+ inline void write_animated_track_data(const SegmentContext& segment, uint8_t* animated_track_data, uint32_t animated_data_size, const uint16_t* output_bone_mapping, uint16_t num_output_bones)
{
ACL_ASSERT(animated_track_data != nullptr, "'animated_track_data' cannot be null!");
(void)animated_data_size;
@@ -252,12 +257,6 @@ namespace acl
const uint8_t* animated_track_data_end = add_offset_to_ptr<uint8_t>(animated_track_data, animated_data_size);
#endif
- // If all tracks are variable, no need for any extra padding except at the very end of the data
- // If our tracks are mixed variable/not variable, we need to add some padding to ensure alignment
- const bool is_every_format_variable = is_rotation_format_variable(rotation_format) && is_vector_format_variable(translation_format) && is_vector_format_variable(scale_format);
- const bool is_any_format_variable = is_rotation_format_variable(rotation_format) || is_vector_format_variable(translation_format) || is_vector_format_variable(scale_format);
- const bool has_mixed_packing = !is_every_format_variable && is_any_format_variable;
-
uint64_t bit_offset = 0;
// Data is sorted first by time, second by bone.
@@ -270,13 +269,13 @@ namespace acl
const BoneStreams& bone_stream = segment.bone_streams[bone_index];
if (!bone_stream.is_rotation_constant && !is_constant_bit_rate(bone_stream.rotations.get_bit_rate()))
- write_animated_track_data(bone_stream.rotations, sample_index, has_mixed_packing, animated_track_data_begin, animated_track_data, bit_offset);
+ write_animated_track_data(bone_stream.rotations, sample_index, animated_track_data_begin, animated_track_data, bit_offset);
if (!bone_stream.is_translation_constant && !is_constant_bit_rate(bone_stream.translations.get_bit_rate()))
- write_animated_track_data(bone_stream.translations, sample_index, has_mixed_packing, animated_track_data_begin, animated_track_data, bit_offset);
+ write_animated_track_data(bone_stream.translations, sample_index, animated_track_data_begin, animated_track_data, bit_offset);
if (!bone_stream.is_scale_constant && !is_constant_bit_rate(bone_stream.scales.get_bit_rate()))
- write_animated_track_data(bone_stream.scales, sample_index, has_mixed_packing, animated_track_data_begin, animated_track_data, bit_offset);
+ write_animated_track_data(bone_stream.scales, sample_index, animated_track_data_begin, animated_track_data, bit_offset);
ACL_ASSERT(animated_track_data <= animated_track_data_end, "Invalid animated track data offset. Wrote too much data.");
}
diff --git a/includes/acl/compression/skeleton_error_metric.h b/includes/acl/compression/skeleton_error_metric.h
--- a/includes/acl/compression/skeleton_error_metric.h
+++ b/includes/acl/compression/skeleton_error_metric.h
@@ -448,7 +448,7 @@ namespace acl
// This error metric should be used whenever a clip is additive or relative.
// Note that this can cause inaccuracy when dealing with shear/skew.
//////////////////////////////////////////////////////////////////////////
- template<AdditiveClipFormat8 additive_format>
+ template<additive_clip_format8 additive_format>
class additive_qvvf_transform_error_metric : public qvvf_transform_error_metric
{
public:
@@ -457,10 +457,10 @@ namespace acl
switch (additive_format)
{
default:
- case AdditiveClipFormat8::None: return "additive_qvvf_transform_error_metric<None>";
- case AdditiveClipFormat8::Relative: return "additive_qvvf_transform_error_metric<Relative>";
- case AdditiveClipFormat8::Additive0: return "additive_qvvf_transform_error_metric<Additive0>";
- case AdditiveClipFormat8::Additive1: return "additive_qvvf_transform_error_metric<Additive1>";
+ case additive_clip_format8::none: return "additive_qvvf_transform_error_metric<none>";
+ case additive_clip_format8::relative: return "additive_qvvf_transform_error_metric<relative>";
+ case additive_clip_format8::additive0: return "additive_qvvf_transform_error_metric<additive0>";
+ case additive_clip_format8::additive1: return "additive_qvvf_transform_error_metric<additive1>";
}
}
diff --git a/includes/acl/compression/track_array.h b/includes/acl/compression/track_array.h
--- a/includes/acl/compression/track_array.h
+++ b/includes/acl/compression/track_array.h
@@ -174,13 +174,13 @@ namespace acl
// Sample all tracks within this array at the specified sample time and
// desired rounding policy. Track samples are written out using the `track_writer` provided.
template<class track_writer_type>
- void sample_tracks(float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const;
+ void sample_tracks(float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const;
//////////////////////////////////////////////////////////////////////////
// Sample a single track within this array at the specified sample time and
// desired rounding policy. The track sample is written out using the `track_writer` provided.
template<class track_writer_type>
- void sample_track(uint32_t track_index, float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const;
+ void sample_track(uint32_t track_index, float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const;
//////////////////////////////////////////////////////////////////////////
// Returns the raw size for this track array. Note that this differs from the actual
@@ -325,7 +325,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
template<class track_writer_type>
- inline void track_array::sample_tracks(float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const
+ inline void track_array::sample_tracks(float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const
{
ACL_ASSERT(is_valid().empty(), "Invalid track array");
@@ -334,7 +334,7 @@ namespace acl
}
template<class track_writer_type>
- inline void track_array::sample_track(uint32_t track_index, float sample_time, SampleRoundingPolicy rounding_policy, track_writer_type& writer) const
+ inline void track_array::sample_track(uint32_t track_index, float sample_time, sample_rounding_policy rounding_policy, track_writer_type& writer) const
{
ACL_ASSERT(is_valid().empty(), "Invalid track array");
ACL_ASSERT(track_index < m_num_tracks, "Invalid track index");
diff --git a/includes/acl/compression/track_error.h b/includes/acl/compression/track_error.h
--- a/includes/acl/compression/track_error.h
+++ b/includes/acl/compression/track_error.h
@@ -93,9 +93,9 @@ namespace acl
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::Nearest, raw_tracks_writer);
+ raw_tracks.sample_tracks(sample_time, sample_rounding_policy::nearest, raw_tracks_writer);
- context.seek(sample_time, SampleRoundingPolicy::Nearest);
+ context.seek(sample_time, sample_rounding_policy::nearest);
context.decompress_tracks(lossy_tracks_writer);
// Validate decompress_tracks
diff --git a/includes/acl/compression/utils.h b/includes/acl/compression/utils.h
--- a/includes/acl/compression/utils.h
+++ b/includes/acl/compression/utils.h
@@ -142,9 +142,9 @@ namespace acl
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_local_pose, num_bones);
+ clip.sample_pose(sample_time, sample_rounding_policy::nearest, raw_local_pose, num_bones);
- context.seek(sample_time, SampleRoundingPolicy::Nearest);
+ context.seek(sample_time, sample_rounding_policy::nearest);
context.decompress_pose(pose_writer);
// Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
@@ -166,7 +166,7 @@ namespace acl
{
const float normalized_sample_time = additive_num_samples > 1 ? (sample_time / clip_duration) : 0.0F;
const float additive_sample_time = additive_num_samples > 1 ? (normalized_sample_time * additive_duration) : 0.0F;
- additive_base_clip->sample_pose(additive_sample_time, SampleRoundingPolicy::Nearest, base_local_pose, num_bones);
+ additive_base_clip->sample_pose(additive_sample_time, sample_rounding_policy::nearest, base_local_pose, num_bones);
if (needs_conversion)
error_metric.convert_transforms(convert_transforms_args_base, base_local_pose_converted);
diff --git a/includes/acl/core/additive_utils.h b/includes/acl/core/additive_utils.h
--- a/includes/acl/core/additive_utils.h
+++ b/includes/acl/core/additive_utils.h
@@ -37,79 +37,87 @@ namespace acl
{
//////////////////////////////////////////////////////////////////////////
// Describes the format used by the additive clip.
- enum class AdditiveClipFormat8 : uint8_t
+ enum class additive_clip_format8 : uint8_t
{
//////////////////////////////////////////////////////////////////////////
// Clip is not additive
- None = 0,
+ none = 0,
//////////////////////////////////////////////////////////////////////////
// Clip is in relative space, transform_mul or equivalent is used to combine them.
// transform = transform_mul(additive_transform, base_transform)
- Relative = 1,
+ relative = 1,
//////////////////////////////////////////////////////////////////////////
// Clip is in additive space where scale is combined with: base_scale * additive_scale
// transform = transform_add0(additive_transform, base_transform)
- Additive0 = 2,
+ additive0 = 2,
//////////////////////////////////////////////////////////////////////////
// Clip is in additive space where scale is combined with: base_scale * (1.0 + additive_scale)
// transform = transform_add1(additive_transform, base_transform)
- Additive1 = 3,
+ additive1 = 3,
};
//////////////////////////////////////////////////////////////////////////
// TODO: constexpr
- inline const char* get_additive_clip_format_name(AdditiveClipFormat8 format)
+ inline const char* get_additive_clip_format_name(additive_clip_format8 format)
{
switch (format)
{
- case AdditiveClipFormat8::None: return "None";
- case AdditiveClipFormat8::Relative: return "Relative";
- case AdditiveClipFormat8::Additive0: return "Additive0";
- case AdditiveClipFormat8::Additive1: return "Additive1";
+ case additive_clip_format8::none: return "none";
+ case additive_clip_format8::relative: return "relative";
+ case additive_clip_format8::additive0: return "additive0";
+ case additive_clip_format8::additive1: return "additive1";
default: return "<Invalid>";
}
}
- inline bool get_additive_clip_format(const char* format, AdditiveClipFormat8& out_format)
+ inline bool get_additive_clip_format(const char* format, additive_clip_format8& out_format)
{
- const char* none_format = "None";
- if (std::strncmp(format, none_format, std::strlen(none_format)) == 0)
+ const char* none_format = "None"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* none_format_new = "none";
+ if (std::strncmp(format, none_format, std::strlen(none_format)) == 0
+ || std::strncmp(format, none_format_new, std::strlen(none_format_new)) == 0)
{
- out_format = AdditiveClipFormat8::None;
+ out_format = additive_clip_format8::none;
return true;
}
- const char* relative_format = "Relative";
- if (std::strncmp(format, relative_format, std::strlen(relative_format)) == 0)
+ const char* relative_format = "Relative"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* relative_format_new = "relative";
+ if (std::strncmp(format, relative_format, std::strlen(relative_format)) == 0
+ || std::strncmp(format, relative_format_new, std::strlen(relative_format_new)) == 0)
{
- out_format = AdditiveClipFormat8::Relative;
+ out_format = additive_clip_format8::relative;
return true;
}
- const char* additive0_format = "Additive0";
- if (std::strncmp(format, additive0_format, std::strlen(additive0_format)) == 0)
+ const char* additive0_format = "Additive0"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* additive0_format_new = "additive0";
+ if (std::strncmp(format, additive0_format, std::strlen(additive0_format)) == 0
+ || std::strncmp(format, additive0_format_new, std::strlen(additive0_format_new)) == 0)
{
- out_format = AdditiveClipFormat8::Additive0;
+ out_format = additive_clip_format8::additive0;
return true;
}
- const char* additive1_format = "Additive1";
- if (std::strncmp(format, additive1_format, std::strlen(additive1_format)) == 0)
+ const char* additive1_format = "Additive1"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* additive1_format_new = "additive1";
+ if (std::strncmp(format, additive1_format, std::strlen(additive1_format)) == 0
+ || std::strncmp(format, additive1_format_new, std::strlen(additive1_format_new)) == 0)
{
- out_format = AdditiveClipFormat8::Additive1;
+ out_format = additive_clip_format8::additive1;
return true;
}
return false;
}
- inline rtm::vector4f RTM_SIMD_CALL get_default_scale(AdditiveClipFormat8 additive_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_default_scale(additive_clip_format8 additive_format)
{
- return additive_format == AdditiveClipFormat8::Additive1 ? rtm::vector_zero() : rtm::vector_set(1.0F);
+ return additive_format == additive_clip_format8::additive1 ? rtm::vector_zero() : rtm::vector_set(1.0F);
}
inline rtm::qvvf RTM_SIMD_CALL transform_add0(rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
@@ -135,27 +143,27 @@ namespace acl
return rtm::qvv_set(rotation, translation, rtm::vector_set(1.0F));
}
- inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base(AdditiveClipFormat8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
+ inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base(additive_clip_format8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
switch (additive_format)
{
default:
- case AdditiveClipFormat8::None: return additive;
- case AdditiveClipFormat8::Relative: return rtm::qvv_mul(additive, base);
- case AdditiveClipFormat8::Additive0: return transform_add0(base, additive);
- case AdditiveClipFormat8::Additive1: return transform_add1(base, additive);
+ case additive_clip_format8::none: return additive;
+ case additive_clip_format8::relative: return rtm::qvv_mul(additive, base);
+ case additive_clip_format8::additive0: return transform_add0(base, additive);
+ case additive_clip_format8::additive1: return transform_add1(base, additive);
}
}
- inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base_no_scale(AdditiveClipFormat8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
+ inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base_no_scale(additive_clip_format8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
switch (additive_format)
{
default:
- case AdditiveClipFormat8::None: return additive;
- case AdditiveClipFormat8::Relative: return rtm::qvv_mul_no_scale(additive, base);
- case AdditiveClipFormat8::Additive0: return transform_add_no_scale(base, additive);
- case AdditiveClipFormat8::Additive1: return transform_add_no_scale(base, additive);
+ case additive_clip_format8::none: return additive;
+ case additive_clip_format8::relative: return rtm::qvv_mul_no_scale(additive, base);
+ case additive_clip_format8::additive0: return transform_add_no_scale(base, additive);
+ case additive_clip_format8::additive1: return transform_add_no_scale(base, additive);
}
}
diff --git a/includes/acl/core/algorithm_types.h b/includes/acl/core/algorithm_types.h
--- a/includes/acl/core/algorithm_types.h
+++ b/includes/acl/core/algorithm_types.h
@@ -34,14 +34,14 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
////////////////////////////////////////////////////////////////////////////////
- // AlgorithmType8 is an enum that represents every supported algorithm.
+ // algorithm_type8 is an enum that represents every supported algorithm.
//
// BE CAREFUL WHEN CHANGING VALUES IN THIS ENUM
// The algorithm type is serialized in the compressed data, if you change a value
// the compressed clips will be invalid. If you do, bump the appropriate algorithm versions.
- enum class AlgorithmType8 : uint8_t
+ enum class algorithm_type8 : uint8_t
{
- UniformlySampled = 0,
+ uniformly_sampled = 0,
//LinearKeyReduction = 1,
//SplineKeyReduction = 2,
};
@@ -52,13 +52,13 @@ namespace acl
// Returns true if the algorithm type is a valid value. Used to validate if
// memory has been corrupted.
// TODO: constexpr
- inline bool is_valid_algorithm_type(AlgorithmType8 type)
+ inline bool is_valid_algorithm_type(algorithm_type8 type)
{
switch (type)
{
- case AlgorithmType8::UniformlySampled:
- //case AlgorithmType8::LinearKeyReduction:
- //case AlgorithmType8::SplineKeyReduction:
+ case algorithm_type8::uniformly_sampled:
+ //case algorithm_type8::LinearKeyReduction:
+ //case algorithm_type8::SplineKeyReduction:
return true;
default:
return false;
@@ -68,13 +68,13 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Returns a string of the algorithm name suitable for display.
// TODO: constexpr
- inline const char* get_algorithm_name(AlgorithmType8 type)
+ inline const char* get_algorithm_name(algorithm_type8 type)
{
switch (type)
{
- case AlgorithmType8::UniformlySampled: return "UniformlySampled";
- //case AlgorithmType8::LinearKeyReduction: return "LinearKeyReduction";
- //case AlgorithmType8::SplineKeyReduction: return "SplineKeyReduction";
+ case algorithm_type8::uniformly_sampled: return "uniformly_sampled";
+ //case algorithm_type8::LinearKeyReduction: return "LinearKeyReduction";
+ //case algorithm_type8::SplineKeyReduction: return "SplineKeyReduction";
default: return "<Invalid>";
}
}
@@ -84,12 +84,14 @@ namespace acl
//
// type: A string representing the algorithm name to parse. It must match the get_algorithm_name(..) output.
// out_type: On success, it will contain the the parsed algorithm type otherwise it is left untouched.
- inline bool get_algorithm_type(const char* type, AlgorithmType8& out_type)
+ inline bool get_algorithm_type(const char* type, algorithm_type8& out_type)
{
- const char* uniformly_sampled_name = "UniformlySampled";
- if (std::strncmp(type, uniformly_sampled_name, std::strlen(uniformly_sampled_name)) == 0)
+ const char* uniformly_sampled_name = "UniformlySampled"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* uniformly_sampled_name_new = "uniformly_sampled";
+ if (std::strncmp(type, uniformly_sampled_name, std::strlen(uniformly_sampled_name)) == 0
+ || std::strncmp(type, uniformly_sampled_name_new, std::strlen(uniformly_sampled_name_new)) == 0)
{
- out_type = AlgorithmType8::UniformlySampled;
+ out_type = algorithm_type8::uniformly_sampled;
return true;
}
diff --git a/includes/acl/core/algorithm_versions.h b/includes/acl/core/algorithm_versions.h
--- a/includes/acl/core/algorithm_versions.h
+++ b/includes/acl/core/algorithm_versions.h
@@ -39,13 +39,13 @@ namespace acl
// still supported by the library or if it must be re-compressed. As such,
// changes to the binary format require incrementing the version number.
// TODO: constexpr
- inline uint16_t get_algorithm_version(AlgorithmType8 type)
+ inline uint16_t get_algorithm_version(algorithm_type8 type)
{
switch (type)
{
- case AlgorithmType8::UniformlySampled: return 5;
- //case AlgorithmType8::LinearKeyReduction: return 0;
- //case AlgorithmType8::SplineKeyReduction: return 0;
+ case algorithm_type8::uniformly_sampled: return 6;
+ //case algorithm_type8::LinearKeyReduction: return 0;
+ //case algorithm_type8::SplineKeyReduction: return 0;
default: return 0xFFFF;
}
}
diff --git a/includes/acl/core/compressed_clip.h b/includes/acl/core/compressed_clip.h
--- a/includes/acl/core/compressed_clip.h
+++ b/includes/acl/core/compressed_clip.h
@@ -43,7 +43,7 @@ namespace acl
namespace acl_impl
{
- CompressedClip* make_compressed_clip(void* buffer, uint32_t size, AlgorithmType8 type);
+ CompressedClip* make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type);
void finalize_compressed_clip(CompressedClip& compressed_clip);
}
@@ -56,7 +56,7 @@ namespace acl
public:
////////////////////////////////////////////////////////////////////////////////
// Returns the algorithm type used to compress the clip.
- AlgorithmType8 get_algorithm_type() const { return m_type; }
+ algorithm_type8 get_algorithm_type() const { return m_type; }
////////////////////////////////////////////////////////////////////////////////
// Returns the size in bytes of the compressed clip.
@@ -107,7 +107,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Constructs a compressed clip instance
- CompressedClip(uint32_t size, AlgorithmType8 type)
+ CompressedClip(uint32_t size, algorithm_type8 type)
: m_size(size)
, m_hash(hash32(safe_ptr_cast<const uint8_t>(this) + k_hash_skip_size, size - k_hash_skip_size))
, m_tag(k_compressed_clip_tag)
@@ -139,7 +139,7 @@ namespace acl
uint16_t m_version;
// Algorithm type used to compress the clip.
- AlgorithmType8 m_type;
+ algorithm_type8 m_type;
// Unused memory left as padding
uint8_t m_padding;
@@ -147,7 +147,7 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// Friend function used to construct compressed clip instances. Should only
// be called by encoders.
- friend CompressedClip* acl_impl::make_compressed_clip(void* buffer, uint32_t size, AlgorithmType8 type);
+ friend CompressedClip* acl_impl::make_compressed_clip(void* buffer, uint32_t size, algorithm_type8 type);
////////////////////////////////////////////////////////////////////////////////
// Friend function to finalize a compressed clip once all memory has been written within.
@@ -189,13 +189,9 @@ namespace acl
uint16_t num_segments;
// The rotation/translation/scale format used.
- RotationFormat8 rotation_format;
- VectorFormat8 translation_format;
- VectorFormat8 scale_format; // TODO: Make this optional?
-
- // The clip/segment range reduction format used.
- RangeReductionFlags8 clip_range_reduction;
- RangeReductionFlags8 segment_range_reduction;
+ rotation_format8 rotation_format;
+ vector_format8 translation_format;
+ vector_format8 scale_format; // TODO: Make this optional?
// Whether or not we have scale (bool).
uint8_t has_scale;
@@ -203,7 +199,7 @@ namespace acl
// Whether the default scale is 0,0,0 or 1,1,1 (bool/bit).
uint8_t default_scale;
- uint8_t padding[1];
+ uint8_t padding[3];
// The total number of samples per track our clip contained.
uint32_t num_samples;
diff --git a/includes/acl/core/compressed_tracks.h b/includes/acl/core/compressed_tracks.h
--- a/includes/acl/core/compressed_tracks.h
+++ b/includes/acl/core/compressed_tracks.h
@@ -59,7 +59,7 @@ namespace acl
public:
////////////////////////////////////////////////////////////////////////////////
// Returns the algorithm type used to compress the tracks.
- AlgorithmType8 get_algorithm_type() const { return m_tracks_header.algorithm_type; }
+ algorithm_type8 get_algorithm_type() const { return m_tracks_header.algorithm_type; }
////////////////////////////////////////////////////////////////////////////////
// Returns the size in bytes of the compressed tracks.
diff --git a/includes/acl/core/impl/compressed_headers.h b/includes/acl/core/impl/compressed_headers.h
--- a/includes/acl/core/impl/compressed_headers.h
+++ b/includes/acl/core/impl/compressed_headers.h
@@ -60,7 +60,7 @@ namespace acl
uint16_t version;
// Algorithm type used to compress the tracks.
- AlgorithmType8 algorithm_type;
+ algorithm_type8 algorithm_type;
// Type of the tracks contained in this compressed stream.
track_type8 track_type;
diff --git a/includes/acl/core/interpolation_utils.h b/includes/acl/core/interpolation_utils.h
--- a/includes/acl/core/interpolation_utils.h
+++ b/includes/acl/core/interpolation_utils.h
@@ -38,28 +38,28 @@ namespace acl
{
//////////////////////////////////////////////////////////////////////////
// This enum dictates how interpolation samples are calculated based on the sample time.
- enum class SampleRoundingPolicy
+ enum class sample_rounding_policy
{
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation alpha lies in between.
- None,
+ none,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 0.0.
- Floor,
+ floor,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 1.0.
- Ceil,
+ ceil,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 0.0 or 1.0 depending
// on which sample is nearest.
- Nearest,
+ nearest,
};
//////////////////////////////////////////////////////////////////////////
@@ -68,7 +68,7 @@ namespace acl
// The returned sample indices are clamped and do not loop.
// If the sample rate is available, prefer using find_linear_interpolation_samples_with_sample_rate
// instead. It is faster and more accurate.
- inline void find_linear_interpolation_samples_with_duration(uint32_t num_samples, float duration, float sample_time, SampleRoundingPolicy rounding_policy,
+ inline void find_linear_interpolation_samples_with_duration(uint32_t num_samples, float duration, float sample_time, sample_rounding_policy rounding_policy,
uint32_t& out_sample_index0, uint32_t& out_sample_index1, float& out_interpolation_alpha)
{
// Samples are evenly spaced, trivially calculate the indices that we need
@@ -93,16 +93,16 @@ namespace acl
switch (rounding_policy)
{
default:
- case SampleRoundingPolicy::None:
+ case sample_rounding_policy::none:
out_interpolation_alpha = interpolation_alpha;
break;
- case SampleRoundingPolicy::Floor:
+ case sample_rounding_policy::floor:
out_interpolation_alpha = 0.0F;
break;
- case SampleRoundingPolicy::Ceil:
+ case sample_rounding_policy::ceil:
out_interpolation_alpha = 1.0F;
break;
- case SampleRoundingPolicy::Nearest:
+ case sample_rounding_policy::nearest:
out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
break;
}
@@ -112,7 +112,7 @@ namespace acl
// Calculates the sample indices and the interpolation required to linearly
// interpolate when the samples are uniform.
// The returned sample indices are clamped and do not loop.
- inline void find_linear_interpolation_samples_with_sample_rate(uint32_t num_samples, float sample_rate, float sample_time, SampleRoundingPolicy rounding_policy,
+ inline void find_linear_interpolation_samples_with_sample_rate(uint32_t num_samples, float sample_rate, float sample_time, sample_rounding_policy rounding_policy,
uint32_t& out_sample_index0, uint32_t& out_sample_index1, float& out_interpolation_alpha)
{
// Samples are evenly spaced, trivially calculate the indices that we need
@@ -139,16 +139,16 @@ namespace acl
switch (rounding_policy)
{
default:
- case SampleRoundingPolicy::None:
+ case sample_rounding_policy::none:
out_interpolation_alpha = interpolation_alpha;
break;
- case SampleRoundingPolicy::Floor:
+ case sample_rounding_policy::floor:
out_interpolation_alpha = 0.0F;
break;
- case SampleRoundingPolicy::Ceil:
+ case sample_rounding_policy::ceil:
out_interpolation_alpha = 1.0F;
break;
- case SampleRoundingPolicy::Nearest:
+ case sample_rounding_policy::nearest:
out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
break;
}
diff --git a/includes/acl/core/range_reduction_types.h b/includes/acl/core/range_reduction_types.h
--- a/includes/acl/core/range_reduction_types.h
+++ b/includes/acl/core/range_reduction_types.h
@@ -40,50 +40,50 @@ namespace acl
constexpr uint32_t k_clip_range_reduction_vector3_range_size = sizeof(float) * 6;
////////////////////////////////////////////////////////////////////////////////
- // RangeReductionFlags8 represents the types of range reduction we support as a bit field.
+ // range_reduction_flags8 represents the types of range reduction we support as a bit field.
//
// BE CAREFUL WHEN CHANGING VALUES IN THIS ENUM
// The range reduction strategy is serialized in the compressed data, if you change a value
// the compressed clips will be invalid. If you do, bump the appropriate algorithm versions.
- enum class RangeReductionFlags8 : uint8_t
+ enum class range_reduction_flags8 : uint8_t
{
- None = 0x00,
+ none = 0x00,
// Flags to determine which tracks have range reduction applied
- Rotations = 0x01,
- Translations = 0x02,
- Scales = 0x04,
+ rotations = 0x01,
+ translations = 0x02,
+ scales = 0x04,
//Properties = 0x08, // TODO: Implement this
- AllTracks = 0x07,
+ all_tracks = 0x07, // rotations | translations | scales
};
- ACL_IMPL_ENUM_FLAGS_OPERATORS(RangeReductionFlags8)
+ ACL_IMPL_ENUM_FLAGS_OPERATORS(range_reduction_flags8)
//////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
// Returns a string of the algorithm name suitable for display.
// TODO: constexpr
- inline const char* get_range_reduction_name(RangeReductionFlags8 flags)
+ inline const char* get_range_reduction_name(range_reduction_flags8 flags)
{
// Some compilers have trouble with constexpr operator| with enums in a case switch statement
- if (flags == RangeReductionFlags8::None)
- return "RangeReduction::None";
- else if (flags == RangeReductionFlags8::Rotations)
- return "RangeReduction::Rotations";
- else if (flags == RangeReductionFlags8::Translations)
- return "RangeReduction::Translations";
- else if (flags == RangeReductionFlags8::Scales)
- return "RangeReduction::Scales";
- else if (flags == (RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations))
- return "RangeReduction::Rotations | RangeReduction::Translations";
- else if (flags == (RangeReductionFlags8::Rotations | RangeReductionFlags8::Scales))
- return "RangeReduction::Rotations | RangeReduction::Scales";
- else if (flags == (RangeReductionFlags8::Translations | RangeReductionFlags8::Scales))
- return "RangeReduction::Translations | RangeReduction::Scales";
- else if (flags == (RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations | RangeReductionFlags8::Scales))
- return "RangeReduction::Rotations | RangeReduction::Translations | RangeReduction::Scales";
+ if (flags == range_reduction_flags8::none)
+ return "range_reduction::none";
+ else if (flags == range_reduction_flags8::rotations)
+ return "range_reduction::rotations";
+ else if (flags == range_reduction_flags8::translations)
+ return "range_reduction::translations";
+ else if (flags == range_reduction_flags8::scales)
+ return "range_reduction::scales";
+ else if (flags == (range_reduction_flags8::rotations | range_reduction_flags8::translations))
+ return "range_reduction::rotations | range_reduction::translations";
+ else if (flags == (range_reduction_flags8::rotations | range_reduction_flags8::scales))
+ return "range_reduction::rotations | range_reduction::scales";
+ else if (flags == (range_reduction_flags8::translations | range_reduction_flags8::scales))
+ return "range_reduction::translations | range_reduction::scales";
+ else if (flags == (range_reduction_flags8::rotations | range_reduction_flags8::translations | range_reduction_flags8::scales))
+ return "range_reduction::rotations | range_reduction::translations | range_reduction::scales";
else
return "<Invalid>";
}
diff --git a/includes/acl/core/track_types.h b/includes/acl/core/track_types.h
--- a/includes/acl/core/track_types.h
+++ b/includes/acl/core/track_types.h
@@ -37,13 +37,17 @@ namespace acl
// BE CAREFUL WHEN CHANGING VALUES IN THIS ENUM
// The rotation format is serialized in the compressed data, if you change a value
// the compressed clips will be invalid. If you do, bump the appropriate algorithm versions.
- enum class RotationFormat8 : uint8_t
+ enum class rotation_format8 : uint8_t
{
- Quat_128 = 0, // Full precision quaternion, [x,y,z,w] stored with float32
- QuatDropW_96 = 1, // Full precision quaternion, [x,y,z] stored with float32 (w is dropped)
- QuatDropW_48 = 2, // Quantized quaternion, [x,y,z] stored with [16,16,16] bits (w is dropped)
- QuatDropW_32 = 3, // Quantized quaternion, [x,y,z] stored with [11,11,10] bits (w is dropped)
- QuatDropW_Variable = 4, // Quantized quaternion, [x,y,z] stored with [N,N,N] bits (w is dropped, same number of bits per component)
+ quatf_full = 0, // Full precision quaternion, [x,y,z,w] stored with float32
+ //quatf_variable = 5, // TODO Quantized quaternion, [x,y,z,w] stored with [N,N,N,N] bits (same number of bits per component)
+ quatf_drop_w_full = 1, // Full precision quaternion, [x,y,z] stored with float32 (w is dropped)
+ quatf_drop_w_variable = 4, // Quantized quaternion, [x,y,z] stored with [N,N,N] bits (w is dropped, same number of bits per component)
+
+ //quatf_optimal = 100, // Mix of quatf_variable and quatf_drop_w_variable
+
+ //reserved = 2, // Legacy value, no longer used
+ //reserved = 3, // Legacy value, no longer used
// TODO: Implement these
//Quat_32_Largest, // Quantized quaternion, [?,?,?] stored with [10,10,10] bits (largest component is dropped, component index stored on 2 bits)
//QuatLog_96, // Full precision quaternion logarithm, [x,y,z] stored with float 32
@@ -55,37 +59,38 @@ namespace acl
// BE CAREFUL WHEN CHANGING VALUES IN THIS ENUM
// The vector format is serialized in the compressed data, if you change a value
// the compressed clips will be invalid. If you do, bump the appropriate algorithm versions.
- enum class VectorFormat8 : uint8_t
+ enum class vector_format8 : uint8_t
{
- Vector3_96 = 0, // Full precision vector3, [x,y,z] stored with float32
- Vector3_48 = 1, // Quantized vector3, [x,y,z] stored with [16,16,16] bits
- Vector3_32 = 2, // Quantized vector3, [x,y,z] stored with [11,11,10] bits
- Vector3_Variable = 3, // Quantized vector3, [x,y,z] stored with [N,N,N] bits (same number of bits per component)
+ vector3f_full = 0, // Full precision vector3f, [x,y,z] stored with float32
+ vector3f_variable = 3, // Quantized vector3f, [x,y,z] stored with [N,N,N] bits (same number of bits per component)
+
+ //reserved = 1, // Legacy value, no longer used
+ //reserved = 2, // Legacy value, no longer used
};
- union TrackFormat8
+ union track_format8
{
- RotationFormat8 rotation;
- VectorFormat8 vector;
+ rotation_format8 rotation;
+ vector_format8 vector;
- TrackFormat8() {}
- explicit TrackFormat8(RotationFormat8 format) : rotation(format) {}
- explicit TrackFormat8(VectorFormat8 format) : vector(format) {}
+ track_format8() {}
+ explicit track_format8(rotation_format8 format) : rotation(format) {}
+ explicit track_format8(vector_format8 format) : vector(format) {}
};
- enum class AnimationTrackType8 : uint8_t
+ enum class animation_track_type8 : uint8_t
{
- Rotation,
- Translation,
- Scale,
+ rotation,
+ translation,
+ scale,
};
- enum class RotationVariant8 : uint8_t
+ enum class rotation_variant8 : uint8_t
{
- Quat,
- QuatDropW,
- //QuatDropLargest,
- //QuatLog,
+ quat,
+ quat_drop_w,
+ //quat_drop_largest,
+ //quat_log,
};
//////////////////////////////////////////////////////////////////////////
@@ -226,10 +231,6 @@ namespace acl
static_assert(k_num_bit_rates == 19, "Expecting 19 bit rates");
- // If all tracks are variable, no need for any extra padding except at the very end of the data
- // If our tracks are mixed variable/not variable, we need to add some padding to ensure alignment
- constexpr uint32_t k_mixed_packing_alignment_num_bits = 16;
-
inline uint32_t get_num_bits_at_bit_rate(uint8_t bit_rate)
{
ACL_ASSERT(bit_rate <= k_highest_bit_rate, "Invalid bit rate: %u", bit_rate);
@@ -250,53 +251,43 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// TODO: constexpr
- inline const char* get_rotation_format_name(RotationFormat8 format)
+ inline const char* get_rotation_format_name(rotation_format8 format)
{
switch (format)
{
- case RotationFormat8::Quat_128: return "Quat_128";
- case RotationFormat8::QuatDropW_96: return "QuatDropW_96";
- case RotationFormat8::QuatDropW_48: return "QuatDropW_48";
- case RotationFormat8::QuatDropW_32: return "QuatDropW_32";
- case RotationFormat8::QuatDropW_Variable: return "QuatDropW_Variable";
- default: return "<Invalid>";
+ case rotation_format8::quatf_full: return "quatf_full";
+ case rotation_format8::quatf_drop_w_full: return "quatf_drop_w_full";
+ case rotation_format8::quatf_drop_w_variable: return "quatf_drop_w_variable";
+ default: return "<Invalid>";
}
}
- inline bool get_rotation_format(const char* format, RotationFormat8& out_format)
+ inline bool get_rotation_format(const char* format, rotation_format8& out_format)
{
- const char* quat_128_format = "Quat_128";
- if (std::strncmp(format, quat_128_format, std::strlen(quat_128_format)) == 0)
+ const char* quat_128_format = "Quat_128"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* quatf_full_format = "quatf_full";
+ if (std::strncmp(format, quat_128_format, std::strlen(quat_128_format)) == 0
+ || std::strncmp(format, quatf_full_format, std::strlen(quatf_full_format)) == 0)
{
- out_format = RotationFormat8::Quat_128;
+ out_format = rotation_format8::quatf_full;
return true;
}
- const char* quatdropw_96_format = "QuatDropW_96";
- if (std::strncmp(format, quatdropw_96_format, std::strlen(quatdropw_96_format)) == 0)
+ const char* quatdropw_96_format = "QuatDropW_96"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* quatf_drop_w_full_format = "quatf_drop_w_full";
+ if (std::strncmp(format, quatdropw_96_format, std::strlen(quatdropw_96_format)) == 0
+ || std::strncmp(format, quatf_drop_w_full_format, std::strlen(quatf_drop_w_full_format)) == 0)
{
- out_format = RotationFormat8::QuatDropW_96;
+ out_format = rotation_format8::quatf_drop_w_full;
return true;
}
- const char* quatdropw_48_format = "QuatDropW_48";
- if (std::strncmp(format, quatdropw_48_format, std::strlen(quatdropw_48_format)) == 0)
+ const char* quatdropw_variable_format = "QuatDropW_Variable"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* quatf_drop_w_variable_format = "quatf_drop_w_variable";
+ if (std::strncmp(format, quatdropw_variable_format, std::strlen(quatdropw_variable_format)) == 0
+ || std::strncmp(format, quatf_drop_w_variable_format, std::strlen(quatf_drop_w_variable_format)) == 0)
{
- out_format = RotationFormat8::QuatDropW_48;
- return true;
- }
-
- const char* quatdropw_32_format = "QuatDropW_32";
- if (std::strncmp(format, quatdropw_32_format, std::strlen(quatdropw_32_format)) == 0)
- {
- out_format = RotationFormat8::QuatDropW_32;
- return true;
- }
-
- const char* quatdropw_variable_format = "QuatDropW_Variable";
- if (std::strncmp(format, quatdropw_variable_format, std::strlen(quatdropw_variable_format)) == 0)
- {
- out_format = RotationFormat8::QuatDropW_Variable;
+ out_format = rotation_format8::quatf_drop_w_variable;
return true;
}
@@ -304,45 +295,33 @@ namespace acl
}
// TODO: constexpr
- inline const char* get_vector_format_name(VectorFormat8 format)
+ inline const char* get_vector_format_name(vector_format8 format)
{
switch (format)
{
- case VectorFormat8::Vector3_96: return "Vector3_96";
- case VectorFormat8::Vector3_48: return "Vector3_48";
- case VectorFormat8::Vector3_32: return "Vector3_32";
- case VectorFormat8::Vector3_Variable: return "Vector3_Variable";
- default: return "<Invalid>";
+ case vector_format8::vector3f_full: return "vector3f_full";
+ case vector_format8::vector3f_variable: return "vector3f_variable";
+ default: return "<Invalid>";
}
}
- inline bool get_vector_format(const char* format, VectorFormat8& out_format)
+ inline bool get_vector_format(const char* format, vector_format8& out_format)
{
- const char* vector3_96_format = "Vector3_96";
- if (std::strncmp(format, vector3_96_format, std::strlen(vector3_96_format)) == 0)
- {
- out_format = VectorFormat8::Vector3_96;
- return true;
- }
-
- const char* vector3_48_format = "Vector3_48";
- if (std::strncmp(format, vector3_48_format, std::strlen(vector3_48_format)) == 0)
- {
- out_format = VectorFormat8::Vector3_48;
- return true;
- }
-
- const char* vector3_32_format = "Vector3_32";
- if (std::strncmp(format, vector3_32_format, std::strlen(vector3_32_format)) == 0)
+ const char* vector3_96_format = "Vector3_96"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* vector3f_full_format = "vector3f_full";
+ if (std::strncmp(format, vector3_96_format, std::strlen(vector3_96_format)) == 0
+ || std::strncmp(format, vector3f_full_format, std::strlen(vector3f_full_format)) == 0)
{
- out_format = VectorFormat8::Vector3_32;
+ out_format = vector_format8::vector3f_full;
return true;
}
- const char* vector3_variable_format = "Vector3_Variable";
- if (std::strncmp(format, vector3_variable_format, std::strlen(vector3_variable_format)) == 0)
+ const char* vector3_variable_format = "Vector3_Variable"; // ACL_DEPRECATED Legacy name, keep for backwards compatibility, remove in 3.0
+ const char* vector3f_variable_format = "vector3f_variable";
+ if (std::strncmp(format, vector3_variable_format, std::strlen(vector3_variable_format)) == 0
+ || std::strncmp(format, vector3f_variable_format, std::strlen(vector3f_variable_format)) == 0)
{
- out_format = VectorFormat8::Vector3_Variable;
+ out_format = vector_format8::vector3f_variable;
return true;
}
@@ -350,70 +329,42 @@ namespace acl
}
// TODO: constexpr
- inline RotationVariant8 get_rotation_variant(RotationFormat8 rotation_format)
+ inline rotation_variant8 get_rotation_variant(rotation_format8 rotation_format)
{
switch (rotation_format)
{
- case RotationFormat8::Quat_128:
- return RotationVariant8::Quat;
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- case RotationFormat8::QuatDropW_Variable:
- return RotationVariant8::QuatDropW;
+ case rotation_format8::quatf_full:
+ return rotation_variant8::quat;
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
+ return rotation_variant8::quat_drop_w;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(rotation_format));
- return RotationVariant8::Quat;
+ return rotation_variant8::quat;
}
}
// TODO: constexpr
- inline RotationFormat8 get_lowest_variant_precision(RotationVariant8 variant)
+ inline rotation_format8 get_highest_variant_precision(rotation_variant8 variant)
{
switch (variant)
{
- case RotationVariant8::Quat: return RotationFormat8::Quat_128;
- case RotationVariant8::QuatDropW: return RotationFormat8::QuatDropW_32;
+ case rotation_variant8::quat: return rotation_format8::quatf_full;
+ case rotation_variant8::quat_drop_w: return rotation_format8::quatf_drop_w_full;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %u", (uint32_t)variant);
- return RotationFormat8::Quat_128;
+ return rotation_format8::quatf_full;
}
}
- // TODO: constexpr
- inline RotationFormat8 get_highest_variant_precision(RotationVariant8 variant)
+ constexpr bool is_rotation_format_variable(rotation_format8 rotation_format)
{
- switch (variant)
- {
- case RotationVariant8::Quat: return RotationFormat8::Quat_128;
- case RotationVariant8::QuatDropW: return RotationFormat8::QuatDropW_96;
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %u", (uint32_t)variant);
- return RotationFormat8::Quat_128;
- }
- }
-
- // TODO: constexpr
- inline bool is_rotation_format_variable(RotationFormat8 rotation_format)
- {
- switch (rotation_format)
- {
- case RotationFormat8::Quat_128:
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- return false;
- case RotationFormat8::QuatDropW_Variable:
- return true;
- default:
- ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(rotation_format));
- return false;
- }
+ return rotation_format == rotation_format8::quatf_drop_w_variable;
}
- constexpr bool is_vector_format_variable(VectorFormat8 format)
+ constexpr bool is_vector_format_variable(vector_format8 format)
{
- return format == VectorFormat8::Vector3_Variable;
+ return format == vector_format8::vector3f_variable;
}
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/decompression/decompress.h b/includes/acl/decompression/decompress.h
--- a/includes/acl/decompression/decompress.h
+++ b/includes/acl/decompression/decompress.h
@@ -131,7 +131,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Seeks within the compressed tracks to a particular point in time with the
// desired rounding policy.
- void seek(float sample_time, SampleRoundingPolicy rounding_policy);
+ void seek(float sample_time, sample_rounding_policy rounding_policy);
//////////////////////////////////////////////////////////////////////////
// Decompress every track at the current sample time.
@@ -212,7 +212,7 @@ namespace acl
inline void decompression_context<decompression_settings_type>::initialize(const compressed_tracks& tracks)
{
ACL_ASSERT(tracks.is_valid(false).empty(), "Compressed tracks are not valid");
- ACL_ASSERT(tracks.get_algorithm_type() == AlgorithmType8::UniformlySampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(AlgorithmType8::UniformlySampled));
+ ACL_ASSERT(tracks.get_algorithm_type() == algorithm_type8::uniformly_sampled, "Invalid algorithm type [%s], expected [%s]", get_algorithm_name(tracks.get_algorithm_type()), get_algorithm_name(algorithm_type8::uniformly_sampled));
m_context.tracks = &tracks;
m_context.tracks_hash = tracks.get_hash();
@@ -234,7 +234,7 @@ namespace acl
}
template<class decompression_settings_type>
- inline void decompression_context<decompression_settings_type>::seek(float sample_time, SampleRoundingPolicy rounding_policy)
+ inline void decompression_context<decompression_settings_type>::seek(float sample_time, sample_rounding_policy rounding_policy)
{
ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
diff --git a/includes/acl/decompression/impl/decompress_data.h b/includes/acl/decompression/impl/decompress_data.h
--- a/includes/acl/decompression/impl/decompress_data.h
+++ b/includes/acl/decompression/impl/decompress_data.h
@@ -44,12 +44,12 @@ namespace acl
const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
if (!is_sample_default)
{
- const RotationFormat8 rotation_format = settings.get_rotation_format(header.rotation_format);
+ const rotation_format8 rotation_format = settings.get_rotation_format(header.rotation_format);
const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
if (is_sample_constant)
{
- const RotationFormat8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
sampling_context.constant_track_data_offset += get_packed_rotation_size(packed_format);
}
else
@@ -61,15 +61,9 @@ namespace acl
for (size_t i = 0; i < num_key_frames; ++i)
{
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_byte_offsets[i] = decomp_context.key_frame_bit_offsets[i] / 8;
}
sampling_context.format_per_track_data_offset++;
@@ -77,23 +71,19 @@ namespace acl
else
{
const uint32_t rotation_size = get_packed_rotation_size(rotation_format);
+ const uint32_t num_bits_at_bit_rate = rotation_size == (sizeof(float) * 4) ? 128 : 96;
for (size_t i = 0; i < num_key_frames; ++i)
- {
- sampling_context.key_frame_byte_offsets[i] += rotation_size;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_bit_offsets[i] = sampling_context.key_frame_byte_offsets[i] * 8;
- }
+ sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
}
- const RangeReductionFlags8 clip_range_reduction = settings.get_clip_range_reduction(header.clip_range_reduction);
- if (are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Rotations))
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations) && settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
+ {
sampling_context.clip_range_data_offset += decomp_context.num_rotation_components * sizeof(float) * 2;
- const RangeReductionFlags8 segment_range_reduction = settings.get_segment_range_reduction(header.segment_range_reduction);
- if (are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Rotations))
- sampling_context.segment_range_data_offset += decomp_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ if (header.num_segments > 1)
+ sampling_context.segment_range_data_offset += decomp_context.num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
}
}
@@ -111,53 +101,40 @@ namespace acl
if (is_sample_constant)
{
// Constant Vector3 tracks store the remaining sample with full precision
- sampling_context.constant_track_data_offset += get_packed_vector_size(VectorFormat8::Vector3_96);
+ sampling_context.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
}
else
{
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
- const VectorFormat8 format = settings.get_vector_format(header);
+ const vector_format8 format = settings.get_vector_format(header);
if (is_vector_format_variable(format))
{
for (size_t i = 0; i < num_key_frames; ++i)
{
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
- uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- num_bits_at_bit_rate = align_to(num_bits_at_bit_rate, k_mixed_packing_alignment_num_bits);
+ const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate) * 3; // 3 components
sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_byte_offsets[i] = sampling_context.key_frame_bit_offsets[i] / 8;
}
sampling_context.format_per_track_data_offset++;
}
else
{
- const uint32_t sample_size = get_packed_vector_size(format);
-
for (size_t i = 0; i < num_key_frames; ++i)
- {
- sampling_context.key_frame_byte_offsets[i] += sample_size;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_bit_offsets[i] = sampling_context.key_frame_byte_offsets[i] * 8;
- }
+ sampling_context.key_frame_bit_offsets[i] += 96;
}
- const RangeReductionFlags8 range_reduction_flag = settings.get_range_reduction_flag();
+ const range_reduction_flags8 range_reduction_flag = settings.get_range_reduction_flag();
- const RangeReductionFlags8 clip_range_reduction = settings.get_clip_range_reduction(header.clip_range_reduction);
- if (are_any_enum_flags_set(clip_range_reduction, range_reduction_flag))
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag) && settings.are_range_reduction_flags_supported(range_reduction_flag))
+ {
sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
- const RangeReductionFlags8 segment_range_reduction = settings.get_segment_range_reduction(header.segment_range_reduction);
- if (are_any_enum_flags_set(segment_range_reduction, range_reduction_flag))
- sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
+ if (header.num_segments > 1)
+ sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
}
}
@@ -179,19 +156,15 @@ namespace acl
}
else
{
- const RotationFormat8 rotation_format = settings.get_rotation_format(header.rotation_format);
+ const rotation_format8 rotation_format = settings.get_rotation_format(header.rotation_format);
const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
if (is_sample_constant)
{
- if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
+ if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
interpolated_rotation = unpack_quat_128(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == RotationFormat8::QuatDropW_96 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_96))
+ else if (rotation_format == rotation_format8::quatf_drop_w_full && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == RotationFormat8::QuatDropW_48 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_48))
- interpolated_rotation = unpack_quat_48(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == RotationFormat8::QuatDropW_32 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_32))
- interpolated_rotation = unpack_quat_32(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- else if (rotation_format == RotationFormat8::QuatDropW_Variable && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_Variable))
+ else if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
interpolated_rotation = unpack_quat_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
else
{
@@ -202,16 +175,11 @@ namespace acl
ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
- const RotationFormat8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
sampling_context.constant_track_data_offset += get_packed_rotation_size(packed_format);
}
else
{
- const RangeReductionFlags8 clip_range_reduction = settings.get_clip_range_reduction(header.clip_range_reduction);
- const RangeReductionFlags8 segment_range_reduction = settings.get_segment_range_reduction(header.segment_range_reduction);
- const bool are_clip_rotations_normalized = are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Rotations);
- const bool are_segment_rotations_normalized = are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Rotations);
-
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
// This part is fairly complex, we'll loop and write to the stack (sampling context)
@@ -222,15 +190,13 @@ namespace acl
// By default, we never ignore range reduction
uint32_t range_ignore_flags = 0;
- if (rotation_format == RotationFormat8::QuatDropW_Variable && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_Variable))
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
for (size_t i = 0; i < num_key_frames; ++i)
{
range_ignore_flags <<= 2;
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
-
- // Promote to 32bit to avoid zero extending instructions on x64
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
if (is_constant_bit_rate(bit_rate))
@@ -244,62 +210,30 @@ namespace acl
range_ignore_flags |= 0x00000003U; // Skip clip and segment
}
else
- {
- if (are_clip_rotations_normalized)
- rotations_as_vec[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- else
- rotations_as_vec[i] = unpack_vector3_sXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- }
-
- uint32_t num_bits_read = num_bits_at_bit_rate * 3;
+ rotations_as_vec[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- num_bits_read = align_to(num_bits_read, k_mixed_packing_alignment_num_bits);
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_read;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_byte_offsets[i] = sampling_context.key_frame_bit_offsets[i] / 8;
+ sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
}
sampling_context.format_per_track_data_offset++;
}
else
{
- if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- rotations_as_vec[i] = unpack_vector4_128(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
- else if (rotation_format == RotationFormat8::QuatDropW_96 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_96))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
- else if (rotation_format == RotationFormat8::QuatDropW_48 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_48))
+ if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
{
for (size_t i = 0; i < num_key_frames; ++i)
{
- if (are_clip_rotations_normalized)
- rotations_as_vec[i] = unpack_vector3_u48_unsafe(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- else
- rotations_as_vec[i] = unpack_vector3_s48_unsafe(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
+ rotations_as_vec[i] = unpack_vector4_128_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
+ sampling_context.key_frame_bit_offsets[i] += 128;
}
}
- else if (rotation_format == RotationFormat8::QuatDropW_32 && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_32))
+ else if (rotation_format == rotation_format8::quatf_drop_w_full && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_full))
{
for (size_t i = 0; i < num_key_frames; ++i)
- rotations_as_vec[i] = unpack_vector3_32(11, 11, 10, are_clip_rotations_normalized, decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
-
- const uint32_t rotation_size = get_packed_rotation_size(rotation_format);
-
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- sampling_context.key_frame_byte_offsets[i] += rotation_size;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_bit_offsets[i] = sampling_context.key_frame_byte_offsets[i] * 8;
+ {
+ rotations_as_vec[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
+ sampling_context.key_frame_bit_offsets[i] += 96;
+ }
}
}
@@ -325,79 +259,46 @@ namespace acl
const uint32_t num_rotation_components = decomp_context.num_rotation_components;
- if (are_segment_rotations_normalized)
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::rotations) && settings.are_range_reduction_flags_supported(range_reduction_flags8::rotations))
{
- const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
- const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (num_rotation_components * sizeof(uint8_t));
-
- if (rotation_format == RotationFormat8::QuatDropW_Variable && settings.is_rotation_format_supported(RotationFormat8::QuatDropW_Variable))
+ if (header.num_segments > 1)
{
- constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
-
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
-
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
- }
-
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
-
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (num_rotation_components * sizeof(uint8_t));
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
- }
- }
- }
- else
- {
- if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && settings.is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
+ constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
{
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
}
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
{
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
}
if (static_condition<num_key_frames == 4>::test())
{
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
{
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
}
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
{
- const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
- const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
}
@@ -405,44 +306,77 @@ namespace acl
}
else
{
+ if (rotation_format == rotation_format8::quatf_full && settings.is_rotation_format_supported(rotation_format8::quatf_full))
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
- rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
- }
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ }
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
- rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
- }
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
- if (static_condition<num_key_frames == 4>::test())
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
+
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
+
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ }
+ }
+ }
+ else
{
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
- rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
}
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
- rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ }
+
+ if (static_condition<num_key_frames == 4>::test())
+ {
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ }
+
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ }
}
}
}
- }
- sampling_context.segment_range_data_offset += num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
- }
+ sampling_context.segment_range_data_offset += num_rotation_components * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
- if (are_clip_rotations_normalized)
- {
const rtm::vector4f clip_range_min = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
const rtm::vector4f clip_range_extent = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (num_rotation_components * sizeof(float)));
@@ -471,7 +405,7 @@ namespace acl
rtm::quatf rotation2 = rtm::vector_to_quat(rotation_as_vec2);
rtm::quatf rotation3 = rtm::vector_to_quat(rotation_as_vec3);
- if (rotation_format != RotationFormat8::Quat_128 || !settings.is_rotation_format_supported(RotationFormat8::Quat_128))
+ if (rotation_format != rotation_format8::quatf_full || !settings.is_rotation_format_supported(rotation_format8::quatf_full))
{
// We dropped the W component
rotation0 = rtm::quat_from_positive_w(rotation_as_vec0);
@@ -520,13 +454,11 @@ namespace acl
interpolated_vector = unpack_vector3_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
- sampling_context.constant_track_data_offset += get_packed_vector_size(VectorFormat8::Vector3_96);
+ sampling_context.constant_track_data_offset += get_packed_vector_size(vector_format8::vector3f_full);
}
else
{
- const VectorFormat8 format = settings.get_vector_format(header);
- const RangeReductionFlags8 clip_range_reduction = settings.get_clip_range_reduction(header.clip_range_reduction);
- const RangeReductionFlags8 segment_range_reduction = settings.get_segment_range_reduction(header.segment_range_reduction);
+ const vector_format8 format = settings.get_vector_format(header);
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
@@ -538,15 +470,13 @@ namespace acl
// By default, we never ignore range reduction
uint32_t range_ignore_flags = 0;
- if (format == VectorFormat8::Vector3_Variable && settings.is_vector_format_supported(VectorFormat8::Vector3_Variable))
+ if (format == vector_format8::vector3f_variable && settings.is_vector_format_supported(vector_format8::vector3f_variable))
{
for (size_t i = 0; i < num_key_frames; ++i)
{
range_ignore_flags <<= 2;
const uint8_t bit_rate = decomp_context.format_per_track_data[i][sampling_context.format_per_track_data_offset];
-
- // Promote to 32bit to avoid zero extending instructions on x64
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
if (is_constant_bit_rate(bit_rate))
@@ -562,45 +492,20 @@ namespace acl
else
vectors[i] = unpack_vector3_uXX_unsafe(uint8_t(num_bits_at_bit_rate), decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
- uint32_t num_bits_read = num_bits_at_bit_rate * 3;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- num_bits_read = align_to(num_bits_read, k_mixed_packing_alignment_num_bits);
-
- sampling_context.key_frame_bit_offsets[i] += num_bits_read;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_byte_offsets[i] = sampling_context.key_frame_bit_offsets[i] / 8;
+ sampling_context.key_frame_bit_offsets[i] += num_bits_at_bit_rate * 3;
}
sampling_context.format_per_track_data_offset++;
}
else
{
- if (format == VectorFormat8::Vector3_96 && settings.is_vector_format_supported(VectorFormat8::Vector3_96))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
- else if (format == VectorFormat8::Vector3_48 && settings.is_vector_format_supported(VectorFormat8::Vector3_48))
+ if (format == vector_format8::vector3f_full && settings.is_vector_format_supported(vector_format8::vector3f_full))
{
for (size_t i = 0; i < num_key_frames; ++i)
- vectors[i] = unpack_vector3_u48_unsafe(decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
- else if (format == VectorFormat8::Vector3_32 && settings.is_vector_format_supported(VectorFormat8::Vector3_32))
- {
- for (size_t i = 0; i < num_key_frames; ++i)
- vectors[i] = unpack_vector3_32(11, 11, 10, true, decomp_context.animated_track_data[i] + sampling_context.key_frame_byte_offsets[i]);
- }
-
- const uint32_t sample_size = get_packed_vector_size(format);
-
- for (size_t i = 0; i < num_key_frames; ++i)
- {
- sampling_context.key_frame_byte_offsets[i] += sample_size;
-
- if (settings.supports_mixed_packing() && decomp_context.has_mixed_packing)
- sampling_context.key_frame_bit_offsets[i] = sampling_context.key_frame_byte_offsets[i] * 8;
+ {
+ vectors[i] = unpack_vector3_96_unsafe(decomp_context.animated_track_data[i], sampling_context.key_frame_bit_offsets[i]);
+ sampling_context.key_frame_bit_offsets[i] += 96;
+ }
}
}
@@ -624,53 +529,53 @@ namespace acl
vector3 = vector0;
}
- const RangeReductionFlags8 range_reduction_flag = settings.get_range_reduction_flag();
- if (are_any_enum_flags_set(segment_range_reduction, range_reduction_flag))
+ const range_reduction_flags8 range_reduction_flag = settings.get_range_reduction_flag();
+ if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flag) && settings.are_range_reduction_flags_supported(range_reduction_flag))
{
- const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
- const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t));
-
- constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
- if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ if (header.num_segments > 1)
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+ const uint32_t segment_range_min_offset = sampling_context.segment_range_data_offset;
+ const uint32_t segment_range_extent_offset = sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t));
- vector0 = rtm::vector_mul_add(vector0, segment_range_extent, segment_range_min);
- }
-
- if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- {
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+ constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
+ if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
- vector1 = rtm::vector_mul_add(vector1, segment_range_extent, segment_range_min);
- }
+ vector0 = rtm::vector_mul_add(vector0, segment_range_extent, segment_range_min);
+ }
- if (static_condition<num_key_frames == 4>::test())
- {
- if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
+ if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
- vector2 = rtm::vector_mul_add(vector2, segment_range_extent, segment_range_min);
+ vector1 = rtm::vector_mul_add(vector1, segment_range_extent, segment_range_min);
}
- if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ if (static_condition<num_key_frames == 4>::test())
{
- const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+
+ vector2 = rtm::vector_mul_add(vector2, segment_range_extent, segment_range_min);
+ }
- vector3 = rtm::vector_mul_add(vector3, segment_range_extent, segment_range_min);
+ if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
+ {
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+
+ vector3 = rtm::vector_mul_add(vector3, segment_range_extent, segment_range_min);
+ }
}
- }
- sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
- }
+ sampling_context.segment_range_data_offset += 3 * k_segment_range_reduction_num_bytes_per_component * 2;
+ }
- if (are_any_enum_flags_set(clip_range_reduction, range_reduction_flag))
- {
const rtm::vector4f clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
const rtm::vector4f clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
diff --git a/includes/acl/io/clip_reader.h b/includes/acl/io/clip_reader.h
--- a/includes/acl/io/clip_reader.h
+++ b/includes/acl/io/clip_reader.h
@@ -63,7 +63,7 @@ namespace acl
std::unique_ptr<RigidSkeleton, Deleter<RigidSkeleton>> skeleton;
bool has_settings;
- AlgorithmType8 algorithm_type;
+ algorithm_type8 algorithm_type;
CompressionSettings settings;
};
@@ -142,7 +142,7 @@ namespace acl
return false;
bool has_settings; // Not used
- AlgorithmType8 algorithm_type; // Not used
+ algorithm_type8 algorithm_type; // Not used
CompressionSettings settings; // Not used
if (!read_settings(&has_settings, &algorithm_type, &settings))
return false;
@@ -165,7 +165,7 @@ namespace acl
float m_sample_rate;
sjson::StringView m_clip_name;
bool m_is_binary_exact;
- AdditiveClipFormat8 m_additive_format;
+ additive_clip_format8 m_additive_format;
sjson::StringView m_additive_base_name;
uint32_t m_additive_base_num_samples;
float m_additive_base_sample_rate;
@@ -184,7 +184,7 @@ namespace acl
return false;
}
- if (m_version > 4)
+ if (m_version > 5)
{
set_error(ClipReaderError::UnsupportedVersion);
return false;
@@ -234,7 +234,7 @@ namespace acl
m_parser.try_read("is_binary_exact", m_is_binary_exact, false);
// Optional value
- m_parser.try_read("additive_format", additive_format, "None");
+ m_parser.try_read("additive_format", additive_format, "none");
if (!get_additive_clip_format(additive_format.c_str(), m_additive_format))
{
set_error(ClipReaderError::InvalidAdditiveClipFormat);
@@ -309,7 +309,7 @@ namespace acl
return false;
}
- bool read_settings(bool* out_has_settings, AlgorithmType8* out_algorithm_type, CompressionSettings* out_settings)
+ bool read_settings(bool* out_has_settings, algorithm_type8* out_algorithm_type, CompressionSettings* out_settings)
{
if (!m_parser.try_object_begins("settings"))
{
@@ -335,30 +335,30 @@ namespace acl
double constant_scale_threshold;
double error_threshold;
- bool segmenting_enabled = default_settings.segmenting.enabled;
double segmenting_ideal_num_samples = double(default_settings.segmenting.ideal_num_samples);
double segmenting_max_num_samples = double(default_settings.segmenting.max_num_samples);
- bool segmenting_rotation_range_reduction = are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Rotations);
- bool segmenting_translation_range_reduction = are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Translations);
- bool segmenting_scale_range_reduction = are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Scales);
- m_parser.try_read("algorithm_name", algorithm_name, get_algorithm_name(AlgorithmType8::UniformlySampled));
+ m_parser.try_read("algorithm_name", algorithm_name, get_algorithm_name(algorithm_type8::uniformly_sampled));
m_parser.try_read("level", compression_level, get_compression_level_name(default_settings.level));
m_parser.try_read("rotation_format", rotation_format, get_rotation_format_name(default_settings.rotation_format));
m_parser.try_read("translation_format", translation_format, get_vector_format_name(default_settings.translation_format));
m_parser.try_read("scale_format", scale_format, get_vector_format_name(default_settings.scale_format));
- m_parser.try_read("rotation_range_reduction", rotation_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Rotations));
- m_parser.try_read("translation_range_reduction", translation_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Translations));
- m_parser.try_read("scale_range_reduction", scale_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Scales));
+ m_parser.try_read("rotation_range_reduction", rotation_range_reduction, false); // Legacy, no longer used
+ m_parser.try_read("translation_range_reduction", translation_range_reduction, false); // Legacy, no longer used
+ m_parser.try_read("scale_range_reduction", scale_range_reduction, false); // Legacy, no longer used
if (m_parser.try_object_begins("segmenting"))
{
- m_parser.try_read("enabled", segmenting_enabled, default_settings.segmenting.enabled);
+ bool segmenting_enabled;
+ bool segmenting_rotation_range_reduction;
+ bool segmenting_translation_range_reduction;
+ bool segmenting_scale_range_reduction;
+ m_parser.try_read("enabled", segmenting_enabled, false); // Legacy, no longer used
m_parser.try_read("ideal_num_samples", segmenting_ideal_num_samples, double(default_settings.segmenting.ideal_num_samples));
m_parser.try_read("max_num_samples", segmenting_max_num_samples, double(default_settings.segmenting.max_num_samples));
- m_parser.try_read("rotation_range_reduction", segmenting_rotation_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Rotations));
- m_parser.try_read("translation_range_reduction", segmenting_translation_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Translations));
- m_parser.try_read("scale_range_reduction", segmenting_scale_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Scales));
+ m_parser.try_read("rotation_range_reduction", segmenting_rotation_range_reduction, false); // Legacy, no longer used
+ m_parser.try_read("translation_range_reduction", segmenting_translation_range_reduction, false); // Legacy, no longer used
+ m_parser.try_read("scale_range_reduction", segmenting_scale_range_reduction, false); // Legacy, no longer used
if (!m_parser.is_valid() || !m_parser.object_ends())
goto parsing_error;
@@ -391,34 +391,9 @@ namespace acl
if (!get_vector_format(scale_format.c_str(), out_settings->scale_format))
goto invalid_value_error;
- RangeReductionFlags8 range_reduction = RangeReductionFlags8::None;
- if (rotation_range_reduction)
- range_reduction |= RangeReductionFlags8::Rotations;
-
- if (translation_range_reduction)
- range_reduction |= RangeReductionFlags8::Translations;
-
- if (scale_range_reduction)
- range_reduction |= RangeReductionFlags8::Scales;
-
- out_settings->range_reduction = range_reduction;
-
- out_settings->segmenting.enabled = segmenting_enabled;
out_settings->segmenting.ideal_num_samples = uint16_t(segmenting_ideal_num_samples);
out_settings->segmenting.max_num_samples = uint16_t(segmenting_max_num_samples);
- RangeReductionFlags8 segmenting_range_reduction = RangeReductionFlags8::None;
- if (rotation_range_reduction)
- segmenting_range_reduction |= RangeReductionFlags8::Rotations;
-
- if (translation_range_reduction)
- segmenting_range_reduction |= RangeReductionFlags8::Translations;
-
- if (scale_range_reduction)
- segmenting_range_reduction |= RangeReductionFlags8::Scales;
-
- out_settings->segmenting.range_reduction = segmenting_range_reduction;
-
out_settings->constant_rotation_threshold_angle = rtm::radians(float(constant_rotation_threshold_angle));
out_settings->constant_translation_threshold = float(constant_translation_threshold);
out_settings->constant_scale_threshold = float(constant_scale_threshold);
diff --git a/includes/acl/io/clip_writer.h b/includes/acl/io/clip_writer.h
--- a/includes/acl/io/clip_writer.h
+++ b/includes/acl/io/clip_writer.h
@@ -98,7 +98,7 @@ namespace acl
writer.insert_newline();
}
- inline void write_sjson_settings(AlgorithmType8 algorithm, const CompressionSettings& settings, sjson::Writer& writer)
+ inline void write_sjson_settings(algorithm_type8 algorithm, const CompressionSettings& settings, sjson::Writer& writer)
{
writer["settings"] = [&](sjson::ObjectWriter& settings_writer)
{
@@ -107,18 +107,11 @@ namespace acl
settings_writer["rotation_format"] = get_rotation_format_name(settings.rotation_format);
settings_writer["translation_format"] = get_vector_format_name(settings.translation_format);
settings_writer["scale_format"] = get_vector_format_name(settings.scale_format);
- settings_writer["rotation_range_reduction"] = are_any_enum_flags_set(settings.range_reduction, RangeReductionFlags8::Rotations);
- settings_writer["translation_range_reduction"] = are_any_enum_flags_set(settings.range_reduction, RangeReductionFlags8::Translations);
- settings_writer["scale_range_reduction"] = are_any_enum_flags_set(settings.range_reduction, RangeReductionFlags8::Scales);
settings_writer["segmenting"] = [&](sjson::ObjectWriter& segmenting_writer)
{
- segmenting_writer["enabled"] = settings.segmenting.enabled;
segmenting_writer["ideal_num_samples"] = settings.segmenting.ideal_num_samples;
segmenting_writer["max_num_samples"] = settings.segmenting.max_num_samples;
- segmenting_writer["rotation_range_reduction"] = are_any_enum_flags_set(settings.segmenting.range_reduction, RangeReductionFlags8::Rotations);
- segmenting_writer["translation_range_reduction"] = are_any_enum_flags_set(settings.segmenting.range_reduction, RangeReductionFlags8::Translations);
- segmenting_writer["scale_range_reduction"] = are_any_enum_flags_set(settings.segmenting.range_reduction, RangeReductionFlags8::Scales);
};
settings_writer["constant_rotation_threshold_angle"] = settings.constant_rotation_threshold_angle.as_radians();
@@ -266,7 +259,7 @@ namespace acl
};
}
- inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, AlgorithmType8 algorithm, const CompressionSettings* settings, const char* acl_filename)
+ inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, algorithm_type8 algorithm, const CompressionSettings* settings, const char* acl_filename)
{
if (acl_filename == nullptr)
return "'acl_filename' cannot be NULL!";
@@ -291,7 +284,7 @@ namespace acl
sjson::FileStreamWriter stream_writer(file);
sjson::Writer writer(stream_writer);
- writer["version"] = 3;
+ writer["version"] = 5;
writer.insert_newline();
write_sjson_clip(clip, writer);
@@ -317,7 +310,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, const char* acl_filename)
{
- return acl_impl::write_acl_clip(skeleton, clip, AlgorithmType8::UniformlySampled, nullptr, acl_filename);
+ return acl_impl::write_acl_clip(skeleton, clip, algorithm_type8::uniformly_sampled, nullptr, acl_filename);
}
//////////////////////////////////////////////////////////////////////////
@@ -325,7 +318,7 @@ namespace acl
// and compression settings.
// Returns an error string on failure, null on success.
//////////////////////////////////////////////////////////////////////////
- inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, AlgorithmType8 algorithm, const CompressionSettings& settings, const char* acl_filename)
+ inline const char* write_acl_clip(const RigidSkeleton& skeleton, const AnimationClip& clip, algorithm_type8 algorithm, const CompressionSettings& settings, const char* acl_filename)
{
return acl_impl::write_acl_clip(skeleton, clip, algorithm, &settings, acl_filename);
}
@@ -361,7 +354,7 @@ namespace acl
sjson::FileStreamWriter stream_writer(file);
sjson::Writer writer(stream_writer);
- writer["version"] = 4;
+ writer["version"] = 5;
writer.insert_newline();
writer["track_list"] = [&](sjson::ObjectWriter& header_writer)
diff --git a/includes/acl/math/quat_packing.h b/includes/acl/math/quat_packing.h
--- a/includes/acl/math/quat_packing.h
+++ b/includes/acl/math/quat_packing.h
@@ -91,31 +91,27 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// TODO: constexpr
- inline uint32_t get_packed_rotation_size(RotationFormat8 format)
+ inline uint32_t get_packed_rotation_size(rotation_format8 format)
{
switch (format)
{
- case RotationFormat8::Quat_128: return sizeof(float) * 4;
- case RotationFormat8::QuatDropW_96: return sizeof(float) * 3;
- case RotationFormat8::QuatDropW_48: return sizeof(uint16_t) * 3;
- case RotationFormat8::QuatDropW_32: return sizeof(uint32_t);
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_full: return sizeof(float) * 4;
+ case rotation_format8::quatf_drop_w_full: return sizeof(float) * 3;
+ case rotation_format8::quatf_drop_w_variable:
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
return 0;
}
}
- inline uint32_t get_range_reduction_rotation_size(RotationFormat8 format)
+ inline uint32_t get_range_reduction_rotation_size(rotation_format8 format)
{
switch (format)
{
- case RotationFormat8::Quat_128:
+ case rotation_format8::quatf_full:
return sizeof(float) * 8;
- case RotationFormat8::QuatDropW_96:
- case RotationFormat8::QuatDropW_48:
- case RotationFormat8::QuatDropW_32:
- case RotationFormat8::QuatDropW_Variable:
+ case rotation_format8::quatf_drop_w_full:
+ case rotation_format8::quatf_drop_w_variable:
return sizeof(float) * 6;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
diff --git a/includes/acl/math/vector4_packing.h b/includes/acl/math/vector4_packing.h
--- a/includes/acl/math/vector4_packing.h
+++ b/includes/acl/math/vector4_packing.h
@@ -51,7 +51,7 @@ namespace acl
return rtm::vector_load(vector_data);
}
- // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
+ // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 23 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_128_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
#if defined(RTM_SSE2_INTRINSICS)
@@ -445,7 +445,7 @@ namespace acl
return rtm::vector_load(vector_data);
}
- // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
+ // Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 19 bytes from it
inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
#if defined(RTM_SSE2_INTRINSICS)
@@ -1081,14 +1081,12 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// TODO: constexpr
- inline uint32_t get_packed_vector_size(VectorFormat8 format)
+ inline uint32_t get_packed_vector_size(vector_format8 format)
{
switch (format)
{
- case VectorFormat8::Vector3_96: return sizeof(float) * 3;
- case VectorFormat8::Vector3_48: return sizeof(uint16_t) * 3;
- case VectorFormat8::Vector3_32: return sizeof(uint32_t);
- case VectorFormat8::Vector3_Variable:
+ case vector_format8::vector3f_full: return sizeof(float) * 3;
+ case vector_format8::vector3f_variable:
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(format));
return 0;
diff --git a/make.py b/make.py
--- a/make.py
+++ b/make.py
@@ -449,7 +449,7 @@ def do_prepare_decompression_test_data(test_data_dir, args):
if not filename.endswith('.config.sjson'):
continue
- if not filename == 'uniformly_sampled_quant_var_2_medium.config.sjson':
+ if not filename == 'uniformly_sampled_quant_medium.config.sjson':
continue
config_filename = os.path.join(dirpath, filename)
diff --git a/tools/acl_compressor/acl_compressor.py b/tools/acl_compressor/acl_compressor.py
--- a/tools/acl_compressor/acl_compressor.py
+++ b/tools/acl_compressor/acl_compressor.py
@@ -393,60 +393,40 @@ def compress_clips(options):
return stat_files
-def shorten_range_reduction(range_reduction):
- if range_reduction == 'RangeReduction::None':
- return 'RR:None'
- elif range_reduction == 'RangeReduction::Rotations':
- return 'RR:Rot'
- elif range_reduction == 'RangeReduction::Translations':
- return 'RR:Trans'
- elif range_reduction == 'RangeReduction::Scales':
- return 'RR:Scale'
- elif range_reduction == 'RangeReduction::Rotations | RangeReduction::Translations':
- return 'RR:Rot|Trans'
- elif range_reduction == 'RangeReduction::Rotations | RangeReduction::Scales':
- return 'RR:Rot|Scale'
- elif range_reduction == 'RangeReduction::Translations | RangeReduction::Scales':
- return 'RR:Trans|Scale'
- elif range_reduction == 'RangeReduction::Rotations | RangeReduction::Translations | RangeReduction::Scales':
- return 'RR:Rot|Trans|Scale'
- else:
- return 'RR:???'
-
def shorten_rotation_format(format):
- if format == 'Quat_128':
+ if format == 'quatf_full':
return 'R:Quat'
- elif format == 'QuatDropW_96':
+ elif format == 'quatf_drop_w_full':
return 'R:QuatNoW96'
elif format == 'QuatDropW_48':
return 'R:QuatNoW48'
elif format == 'QuatDropW_32':
return 'R:QuatNoW32'
- elif format == 'QuatDropW_Variable':
+ elif format == 'quatf_drop_w_variable':
return 'R:QuatNoWVar'
else:
return 'R:???'
def shorten_translation_format(format):
- if format == 'Vector3_96':
+ if format == 'vector3f_full':
return 'T:Vec3_96'
elif format == 'Vector3_48':
return 'T:Vec3_48'
elif format == 'Vector3_32':
return 'T:Vec3_32'
- elif format == 'Vector3_Variable':
+ elif format == 'vector3f_variable':
return 'T:Vec3Var'
else:
return 'T:???'
def shorten_scale_format(format):
- if format == 'Vector3_96':
+ if format == 'vector3f_full':
return 'S:Vec3_96'
elif format == 'Vector3_48':
return 'S:Vec3_48'
elif format == 'Vector3_32':
return 'S:Vec3_32'
- elif format == 'Vector3_Variable':
+ elif format == 'vector3f_variable':
return 'S:Vec3Var'
else:
return 'S:???'
@@ -534,7 +514,6 @@ def run_stat_parsing(options, stat_queue, result_queue):
if len(run_stats) == 0:
continue
- run_stats['range_reduction'] = shorten_range_reduction(run_stats['range_reduction'])
run_stats['filename'] = stat_filename.replace('\\\\?\\', '')
run_stats['clip_name'] = os.path.splitext(os.path.basename(stat_filename))[0]
run_stats['rotation_format'] = shorten_rotation_format(run_stats['rotation_format'])
@@ -545,12 +524,11 @@ def run_stat_parsing(options, stat_queue, result_queue):
run_stats['duration'] = 0.0
if 'segmenting' in run_stats:
- run_stats['segmenting']['range_reduction'] = shorten_range_reduction(run_stats['segmenting']['range_reduction'])
- run_stats['desc'] = '{}|{}|{}, Clip {}, Segment {}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'], run_stats['range_reduction'], run_stats['segmenting']['range_reduction'])
- run_stats['csv_desc'] = '{}|{}|{} Clip {} Segment {}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'], run_stats['range_reduction'], run_stats['segmenting']['range_reduction'])
+ run_stats['desc'] = '{}|{}|{}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'])
+ run_stats['csv_desc'] = '{}|{}|{}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'])
else:
- run_stats['desc'] = '{}|{}|{}, Clip {}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'], run_stats['range_reduction'])
- run_stats['csv_desc'] = '{}|{}|{} Clip {}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'], run_stats['range_reduction'])
+ run_stats['desc'] = '{}|{}|{}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'])
+ run_stats['csv_desc'] = '{}|{}|{}'.format(run_stats['rotation_format'], run_stats['translation_format'], run_stats['scale_format'])
aggregate_stats(agg_run_stats, run_stats)
track_best_runs(best_runs, run_stats)
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -140,7 +140,7 @@ struct Options
const char* output_bin_filename;
- CompressionLevel8 compression_level;
+ compression_level8 compression_level;
bool compression_level_specified;
bool regression_testing;
@@ -173,7 +173,7 @@ struct Options
, output_stats_filename(nullptr)
, output_stats_file(nullptr)
, output_bin_filename(nullptr)
- , compression_level(CompressionLevel8::Lowest)
+ , compression_level(compression_level8::lowest)
, compression_level_specified(false)
, regression_testing(false)
, profile_decompression(false)
@@ -447,7 +447,7 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- context.seek(sample_time, SampleRoundingPolicy::Nearest);
+ context.seek(sample_time, sample_rounding_policy::nearest);
context.decompress_pose(pose_writer);
// Validate decompress_bone for rotations only
@@ -532,9 +532,9 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
// We use the nearest sample to accurately measure the loss that happened, if any
- raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::Nearest, raw_tracks_writer);
+ raw_tracks.sample_tracks(sample_time, sample_rounding_policy::nearest, raw_tracks_writer);
- context.seek(sample_time, SampleRoundingPolicy::Nearest);
+ context.seek(sample_time, sample_rounding_policy::nearest);
context.decompress_tracks(lossy_tracks_writer);
// Validate decompress_tracks
@@ -605,7 +605,7 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
continue; // Track is being stripped, ignore it
// We use the nearest sample to accurately measure the loss that happened, if any
- raw_tracks.sample_track(track_index, sample_time, SampleRoundingPolicy::Nearest, raw_track_writer);
+ raw_tracks.sample_track(track_index, sample_time, sample_rounding_policy::nearest, raw_track_writer);
context.decompress_track(output_index, lossy_track_writer);
switch (track_type)
@@ -674,7 +674,7 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
#endif // defined(ACL_HAS_ASSERT_CHECKS)
}
-static void try_algorithm(const Options& options, IAllocator& allocator, const AnimationClip& clip, const CompressionSettings& settings, AlgorithmType8 algorithm_type, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
+static void try_algorithm(const Options& options, IAllocator& allocator, const AnimationClip& clip, const CompressionSettings& settings, algorithm_type8 algorithm_type, StatLogging logging, sjson::ArrayWriter* runs_writer, double regression_error_threshold)
{
(void)runs_writer;
@@ -688,7 +688,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const A
ErrorResult error_result; (void)error_result;
switch (algorithm_type)
{
- case AlgorithmType8::UniformlySampled:
+ case algorithm_type8::uniformly_sampled:
error_result = uniformly_sampled::compress_clip(allocator, clip, settings, compressed_clip, stats);
break;
}
@@ -706,7 +706,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const A
BoneError bone_error;
switch (algorithm_type)
{
- case AlgorithmType8::UniformlySampled:
+ case algorithm_type8::uniformly_sampled:
{
uniformly_sampled::DecompressionContext<uniformly_sampled::DebugDecompressionSettings> context;
context.initialize(*compressed_clip);
@@ -731,7 +731,7 @@ static void try_algorithm(const Options& options, IAllocator& allocator, const A
switch (algorithm_type)
{
- case AlgorithmType8::UniformlySampled:
+ case algorithm_type8::uniformly_sampled:
{
uniformly_sampled::DecompressionContext<uniformly_sampled::DebugDecompressionSettings> context;
context.initialize(*compressed_clip);
@@ -914,7 +914,7 @@ static bool read_acl_sjson_file(IAllocator& allocator, const Options& options,
return success;
}
-static bool read_config(IAllocator& allocator, Options& options, AlgorithmType8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
+static bool read_config(IAllocator& allocator, Options& options, algorithm_type8& out_algorithm_type, CompressionSettings& out_settings, double& out_regression_error_threshold)
{
#if defined(__ANDROID__)
sjson::Parser parser(options.config_buffer, options.config_buffer_size - 1);
@@ -938,7 +938,7 @@ static bool read_config(IAllocator& allocator, Options& options, AlgorithmType8&
return false;
}
- if (version != 1.0)
+ if (version != 2.0)
{
printf("Unsupported version: %f\n", version);
return false;
@@ -995,56 +995,6 @@ static bool read_config(IAllocator& allocator, Options& options, AlgorithmType8&
return false;
}
- RangeReductionFlags8 range_reduction = RangeReductionFlags8::None;
-
- bool rotation_range_reduction;
- parser.try_read("rotation_range_reduction", rotation_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Rotations));
- if (rotation_range_reduction)
- range_reduction |= RangeReductionFlags8::Rotations;
-
- bool translation_range_reduction;
- parser.try_read("translation_range_reduction", translation_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Translations));
- if (translation_range_reduction)
- range_reduction |= RangeReductionFlags8::Translations;
-
- bool scale_range_reduction;
- parser.try_read("scale_range_reduction", scale_range_reduction, are_any_enum_flags_set(default_settings.range_reduction, RangeReductionFlags8::Scales));
- if (scale_range_reduction)
- range_reduction |= RangeReductionFlags8::Scales;
-
- out_settings.range_reduction = range_reduction;
-
- if (parser.object_begins("segmenting"))
- {
- parser.try_read("enabled", out_settings.segmenting.enabled, false);
-
- range_reduction = RangeReductionFlags8::None;
- parser.try_read("rotation_range_reduction", rotation_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Rotations));
- parser.try_read("translation_range_reduction", translation_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Translations));
- parser.try_read("scale_range_reduction", scale_range_reduction, are_any_enum_flags_set(default_settings.segmenting.range_reduction, RangeReductionFlags8::Scales));
-
- if (rotation_range_reduction)
- range_reduction |= RangeReductionFlags8::Rotations;
-
- if (translation_range_reduction)
- range_reduction |= RangeReductionFlags8::Translations;
-
- if (scale_range_reduction)
- range_reduction |= RangeReductionFlags8::Scales;
-
- out_settings.segmenting.range_reduction = range_reduction;
-
- if (!parser.object_ends())
- {
- uint32_t line;
- uint32_t column;
- parser.get_position(line, column);
-
- printf("Error on line %d column %d: Expected segmenting object to end\n", line, column);
- return false;
- }
- }
-
double constant_rotation_threshold_angle;
parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, default_settings.constant_rotation_threshold_angle.as_radians());
out_settings.constant_rotation_threshold_angle = rtm::radians(float(constant_rotation_threshold_angle));
@@ -1076,16 +1026,16 @@ static bool read_config(IAllocator& allocator, Options& options, AlgorithmType8&
return true;
}
-static itransform_error_metric* create_additive_error_metric(IAllocator& allocator, AdditiveClipFormat8 format)
+static itransform_error_metric* create_additive_error_metric(IAllocator& allocator, additive_clip_format8 format)
{
switch (format)
{
- case AdditiveClipFormat8::Relative:
- return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Relative>>(allocator);
- case AdditiveClipFormat8::Additive0:
- return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Additive0>>(allocator);
- case AdditiveClipFormat8::Additive1:
- return allocate_type<additive_qvvf_transform_error_metric<AdditiveClipFormat8::Additive1>>(allocator);
+ case additive_clip_format8::relative:
+ return allocate_type<additive_qvvf_transform_error_metric<additive_clip_format8::relative>>(allocator);
+ case additive_clip_format8::additive0:
+ return allocate_type<additive_qvvf_transform_error_metric<additive_clip_format8::additive0>>(allocator);
+ case additive_clip_format8::additive1:
+ return allocate_type<additive_qvvf_transform_error_metric<additive_clip_format8::additive1>>(allocator);
default:
return nullptr;
}
@@ -1098,13 +1048,13 @@ static void create_additive_base_clip(const Options& options, AnimationClip& cli
const uint32_t num_samples = clip.get_num_samples();
AnimatedBone* bones = clip.get_bones();
- AdditiveClipFormat8 additive_format = AdditiveClipFormat8::None;
+ additive_clip_format8 additive_format = additive_clip_format8::none;
if (options.is_bind_pose_relative)
- additive_format = AdditiveClipFormat8::Relative;
+ additive_format = additive_clip_format8::relative;
else if (options.is_bind_pose_additive0)
- additive_format = AdditiveClipFormat8::Additive0;
+ additive_format = additive_clip_format8::additive0;
else if (options.is_bind_pose_additive1)
- additive_format = AdditiveClipFormat8::Additive1;
+ additive_format = additive_clip_format8::additive1;
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
@@ -1144,17 +1094,12 @@ static void create_additive_base_clip(const Options& options, AnimationClip& cli
clip.set_additive_base(&out_base_clip, additive_format);
}
-static CompressionSettings make_settings(RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format,
- RangeReductionFlags8 clip_range_reduction,
- bool use_segmenting = false, RangeReductionFlags8 segment_range_reduction = RangeReductionFlags8::None)
+static CompressionSettings make_settings(rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format)
{
CompressionSettings settings;
settings.rotation_format = rotation_format;
settings.translation_format = translation_format;
settings.scale_format = scale_format;
- settings.range_reduction = clip_range_reduction;
- settings.segmenting.enabled = use_segmenting;
- settings.segmenting.range_reduction = segment_range_reduction;
return settings;
}
#endif // defined(ACL_USE_SJSON)
@@ -1186,7 +1131,7 @@ static int safe_main_impl(int argc, char* argv[])
#endif
bool use_external_config = false;
- AlgorithmType8 algorithm_type = AlgorithmType8::UniformlySampled;
+ algorithm_type8 algorithm_type = algorithm_type8::uniformly_sampled;
CompressionSettings settings;
sjson_file_type sjson_type = sjson_file_type::unknown;
@@ -1214,7 +1159,7 @@ static int safe_main_impl(int argc, char* argv[])
#endif
{
// Override whatever the ACL SJSON file might have contained
- algorithm_type = AlgorithmType8::UniformlySampled;
+ algorithm_type = algorithm_type8::uniformly_sampled;
settings = CompressionSettings();
if (!read_config(allocator, options, algorithm_type, settings, regression_error_threshold))
@@ -1311,60 +1256,41 @@ static int safe_main_impl(int argc, char* argv[])
{
if (use_external_config)
{
- ACL_ASSERT(algorithm_type == AlgorithmType8::UniformlySampled, "Only UniformlySampled is supported for now");
+ ACL_ASSERT(algorithm_type == algorithm_type8::uniformly_sampled, "Only uniformly_sampled is supported for now");
if (options.compression_level_specified)
settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
}
else if (options.exhaustive_compression)
{
- const bool use_segmenting_options[] = { false, true };
- for (size_t segmenting_option_index = 0; segmenting_option_index < get_array_size(use_segmenting_options); ++segmenting_option_index)
{
- const bool use_segmenting = use_segmenting_options[segmenting_option_index];
-
CompressionSettings uniform_tests[] =
{
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
-
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::None, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
+ make_settings(rotation_format8::quatf_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
+ make_settings(rotation_format8::quatf_drop_w_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, use_segmenting),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, use_segmenting),
-
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, use_segmenting),
+ make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_full),
+ make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_variable),
};
for (CompressionSettings test_settings : uniform_tests)
{
test_settings.error_metric = settings.error_metric;
- try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, test_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
}
}
{
CompressionSettings uniform_tests[] =
{
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::Quat_128, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
-
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations, true, RangeReductionFlags8::Rotations),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_96, VectorFormat8::Vector3_96, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Translations, true, RangeReductionFlags8::Translations),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_96, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations, true, RangeReductionFlags8::Rotations | RangeReductionFlags8::Translations),
+ make_settings(rotation_format8::quatf_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
+ make_settings(rotation_format8::quatf_drop_w_full, vector_format8::vector3f_full, vector_format8::vector3f_full),
- make_settings(RotationFormat8::QuatDropW_Variable, VectorFormat8::Vector3_Variable, VectorFormat8::Vector3_Variable, RangeReductionFlags8::AllTracks, true, RangeReductionFlags8::AllTracks),
+ make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_full),
+ make_settings(rotation_format8::quatf_drop_w_variable, vector_format8::vector3f_variable, vector_format8::vector3f_variable),
};
for (CompressionSettings test_settings : uniform_tests)
@@ -1374,7 +1300,7 @@ static int safe_main_impl(int argc, char* argv[])
if (options.compression_level_specified)
test_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, test_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, test_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
}
}
}
@@ -1386,7 +1312,7 @@ static int safe_main_impl(int argc, char* argv[])
if (options.compression_level_specified)
default_settings.level = options.compression_level;
- try_algorithm(options, allocator, *clip, default_settings, AlgorithmType8::UniformlySampled, logging, runs_writer, regression_error_threshold);
+ try_algorithm(options, allocator, *clip, default_settings, algorithm_type8::uniformly_sampled, logging, runs_writer, regression_error_threshold);
}
}
else if (sjson_type == sjson_file_type::raw_track_list)
diff --git a/tools/acl_decompressor/main_android/jni/main.cpp b/tools/acl_decompressor/main_android/jni/main.cpp
--- a/tools/acl_decompressor/main_android/jni/main.cpp
+++ b/tools/acl_decompressor/main_android/jni/main.cpp
@@ -119,7 +119,7 @@ extern "C" jint Java_com_acl_decompressor_MainActivity_nativeMain(JNIEnv* env, j
}
// Only decompress with a single configuration for now
- configs.erase(std::remove_if(configs.begin(), configs.end(), [](const std::string& config_filename) { return config_filename != "uniformly_sampled_quant_var_2_medium.config.sjson"; }), configs.end());
+ configs.erase(std::remove_if(configs.begin(), configs.end(), [](const std::string& config_filename) { return config_filename != "uniformly_sampled_quant_medium.config.sjson"; }), configs.end());
const int num_configs = (int)configs.size();
const int num_clips = (int)clips.size();
diff --git a/tools/acl_decompressor/main_ios/main.cpp b/tools/acl_decompressor/main_ios/main.cpp
--- a/tools/acl_decompressor/main_ios/main.cpp
+++ b/tools/acl_decompressor/main_ios/main.cpp
@@ -107,7 +107,7 @@ int main(int argc, char* argv[])
return result;
// Only decompress with a single configuration for now
- configs.erase(std::remove_if(configs.begin(), configs.end(), [](const std::string& config_filename) { return config_filename != "uniformly_sampled_quant_var_2_medium.config.sjson"; }), configs.end());
+ configs.erase(std::remove_if(configs.begin(), configs.end(), [](const std::string& config_filename) { return config_filename != "uniformly_sampled_quant_medium.config.sjson"; }), configs.end());
char output_directory[1024];
std::strcpy(output_directory, getenv("HOME"));
diff --git a/tools/format_reference.acl.sjson b/tools/format_reference.acl.sjson
--- a/tools/format_reference.acl.sjson
+++ b/tools/format_reference.acl.sjson
@@ -10,7 +10,8 @@
// version = 1 // Initial version
// version = 2 // Introduced clip compression settings
//version = 3 // Introduced additive clip related data
-version = 4 // Introduced track list related data
+//version = 4 // Introduced track list related data
+version = 5 // Renamed enums for 2.0 and other related changes
// BEGIN CLIP RELATED DATA
@@ -37,9 +38,9 @@ clip =
// Introduced in version 2.
is_binary_exact = true
- // Additive format of base clip, if present. Optional, defaults to 'None'.
+ // Additive format of base clip, if present. Optional, defaults to 'none'.
// Introduced in version 3.
- additive_format = "None"
+ additive_format = "none"
// The additive base clip name. Optional, defaults to empty string.
// Introduced in version 3.
@@ -59,28 +60,18 @@ clip =
settings =
{
// The name of the algorithm to use. See function get_algorithm_type(..)
- // Defaults to 'UniformlySampled'
- algorithm_name = "UniformlySampled"
+ // Defaults to 'uniformly_sampled'
+ algorithm_name = "uniformly_sampled"
// The rotation, translation, and scale formats to use. See functions get_rotation_format(..) and get_vector_format(..)
- // Defaults to raw: 'Quat_128' and 'Vector3_96'
- rotation_format = "Quat_128"
- translation_format = "Vector3_96"
- scale_format = "Vector3_96"
-
- // Whether to use range reduction or not at the clip level
- // Defaults to 'false'
- rotation_range_reduction = false
- translation_range_reduction = false
- scale_range_reduction = false
+ // Defaults to raw: 'quatf_full' and 'vector3f_full'
+ rotation_format = "quatf_full"
+ translation_format = "vector3f_full"
+ scale_format = "vector3f_full"
// Settings used when segmenting clips
// Optional
segmenting = {
- // Whether to enable segmenting or not
- // Defaults to 'false'
- enabled = false
-
// How many samples to try and fit in our segments
// Defaults to '16'
ideal_num_samples = 16
@@ -88,12 +79,6 @@ settings =
// Maximum number of samples per segment
// Defaults to '31'
max_num_samples = 31
-
- // Whether to use range reduction or not at the segment level
- // Defaults to 'false'
- rotation_range_reduction = false
- translation_range_reduction = false
- scale_range_reduction = false
}
// Threshold angle value to use when detecting if a rotation track is constant
|
diff --git a/test_data/configs/uniformly_sampled_mixed_var_0.config.sjson b/test_data/configs/uniformly_sampled_mixed_var_0.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_mixed_var_0.config.sjson
@@ -0,0 +1,11 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "Medium"
+
+rotation_format = "quatf_full"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_mixed_var_1.config.sjson b/test_data/configs/uniformly_sampled_mixed_var_1.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_mixed_var_1.config.sjson
@@ -0,0 +1,11 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "Medium"
+
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_full"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_16_0.config.sjson b/test_data/configs/uniformly_sampled_quant_16_0.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_16_0.config.sjson
+++ /dev/null
@@ -1,17 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-rotation_format = "QuatDropW_48"
-translation_format = "Vector3_48"
-scale_format = "Vector3_48"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = false
-}
-
-regression_error_threshold = 1.0
diff --git a/test_data/configs/uniformly_sampled_quant_16_1.config.sjson b/test_data/configs/uniformly_sampled_quant_16_1.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_16_1.config.sjson
+++ /dev/null
@@ -1,17 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-rotation_format = "QuatDropW_48"
-translation_format = "Vector3_48"
-scale_format = "Vector3_48"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-}
-
-regression_error_threshold = 1.0
diff --git a/test_data/configs/uniformly_sampled_quant_16_2.config.sjson b/test_data/configs/uniformly_sampled_quant_16_2.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_16_2.config.sjson
+++ /dev/null
@@ -1,21 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-rotation_format = "QuatDropW_48"
-translation_format = "Vector3_48"
-scale_format = "Vector3_48"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
-
-regression_error_threshold = 1.0
diff --git a/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson b/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson
--- a/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson
+++ b/test_data/configs/uniformly_sampled_quant_bind_relative.config.sjson
@@ -1,24 +1,12 @@
-version = 1
+version = 2
-algorithm_name = "UniformlySampled"
+algorithm_name = "uniformly_sampled"
level = "Medium"
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
regression_error_threshold = 0.075
is_bind_pose_relative = true
diff --git a/test_data/configs/uniformly_sampled_quant_high.config.sjson b/test_data/configs/uniformly_sampled_quant_high.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_quant_high.config.sjson
@@ -0,0 +1,11 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "High"
+
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_highest.config.sjson b/test_data/configs/uniformly_sampled_quant_highest.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_quant_highest.config.sjson
@@ -0,0 +1,11 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "Highest"
+
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_medium.config.sjson b/test_data/configs/uniformly_sampled_quant_medium.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_quant_medium.config.sjson
@@ -0,0 +1,11 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "Medium"
+
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson b/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson
--- a/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson
+++ b/test_data/configs/uniformly_sampled_quant_mtx_error.config.sjson
@@ -1,24 +1,12 @@
-version = 1
+version = 2
-algorithm_name = "UniformlySampled"
+algorithm_name = "uniformly_sampled"
level = "Medium"
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
regression_error_threshold = 0.075
use_matrix_error_metric = true
diff --git a/test_data/configs/uniformly_sampled_quant_var_0_high.config.sjson b/test_data/configs/uniformly_sampled_quant_var_0_high.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_0_high.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "High"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = false
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_0_highest.config.sjson b/test_data/configs/uniformly_sampled_quant_var_0_highest.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_0_highest.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Highest"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = false
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_0_medium.config.sjson b/test_data/configs/uniformly_sampled_quant_var_0_medium.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_0_medium.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Medium"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = false
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_1_high.config.sjson b/test_data/configs/uniformly_sampled_quant_var_1_high.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_1_high.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "High"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_1_highest.config.sjson b/test_data/configs/uniformly_sampled_quant_var_1_highest.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_1_highest.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Highest"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_1_medium.config.sjson b/test_data/configs/uniformly_sampled_quant_var_1_medium.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_1_medium.config.sjson
+++ /dev/null
@@ -1,19 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Medium"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_2_high.config.sjson b/test_data/configs/uniformly_sampled_quant_var_2_high.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_2_high.config.sjson
+++ /dev/null
@@ -1,23 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "High"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_2_highest.config.sjson b/test_data/configs/uniformly_sampled_quant_var_2_highest.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_2_highest.config.sjson
+++ /dev/null
@@ -1,23 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Highest"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_quant_var_2_medium.config.sjson b/test_data/configs/uniformly_sampled_quant_var_2_medium.config.sjson
deleted file mode 100644
--- a/test_data/configs/uniformly_sampled_quant_var_2_medium.config.sjson
+++ /dev/null
@@ -1,23 +0,0 @@
-version = 1
-
-algorithm_name = "UniformlySampled"
-
-level = "Medium"
-
-rotation_format = "QuatDropW_Variable"
-translation_format = "Vector3_Variable"
-scale_format = "Vector3_Variable"
-
-rotation_range_reduction = true
-translation_range_reduction = true
-scale_range_reduction = true
-
-segmenting = {
- enabled = true
-
- rotation_range_reduction = true
- translation_range_reduction = true
- scale_range_reduction = true
-}
-
-regression_error_threshold = 0.075
diff --git a/test_data/configs/uniformly_sampled_raw.config.sjson b/test_data/configs/uniformly_sampled_raw.config.sjson
--- a/test_data/configs/uniformly_sampled_raw.config.sjson
+++ b/test_data/configs/uniformly_sampled_raw.config.sjson
@@ -1,13 +1,9 @@
-version = 1
+version = 2
-algorithm_name = "UniformlySampled"
+algorithm_name = "uniformly_sampled"
-rotation_format = "Quat_128"
-translation_format = "Vector3_96"
-scale_format = "Vector3_96"
+rotation_format = "quatf_full"
+translation_format = "vector3f_full"
+scale_format = "vector3f_full"
-segmenting = {
- enabled = false
-}
-
-regression_error_threshold = 0.01
+regression_error_threshold = 0.001
diff --git a/test_data/reference.config.sjson b/test_data/reference.config.sjson
--- a/test_data/reference.config.sjson
+++ b/test_data/reference.config.sjson
@@ -1,35 +1,16 @@
// A version identifier, make sure to use the latest supported number
-version = 1
+//version = 1 // initial version
+version = 2 // cleanup with 2.0
// The name of the algorithm to use. See function get_algorithm_type(..)
// Required
-algorithm_name = "UniformlySampled"
+algorithm_name = "uniformly_sampled"
// The rotation, translation, and scale formats to use. See functions get_rotation_format(..) and get_vector_format(..)
-// Defaults to raw: Quat_128 and Vector3_96
-rotation_format = "Quat_128"
-translation_format = "Vector3_96"
-scale_format = "Vector3_96"
-
-// Whether to use range reduction or not at the clip level
-// Defaults to 'false'
-rotation_range_reduction = false
-translation_range_reduction = false
-scale_range_reduction = false
-
-// Settings used when segmenting clips
-// Optional
-segmenting = {
- // Whether to enable segmenting or not
- // Defaults to 'false'
- enabled = false
-
- // Whether to use range reduction or not at the segment level
- // Defaults to 'false'
- rotation_range_reduction = false
- translation_range_reduction = false
- scale_range_reduction = false
-}
+// Defaults to raw: quatf_full and vector3f_full
+rotation_format = "quatf_full"
+translation_format = "vector3f_full"
+scale_format = "vector3f_full"
// Threshold angle value to use when detecting if a rotation track is constant
// Defaults to '0.00284714461' radians
diff --git a/tests/sources/core/test_ansi_allocator.cpp b/tests/sources/core/test_ansi_allocator.cpp
--- a/tests/sources/core/test_ansi_allocator.cpp
+++ b/tests/sources/core/test_ansi_allocator.cpp
@@ -36,17 +36,17 @@ using namespace acl;
TEST_CASE("ANSI allocator", "[core][memory]")
{
ANSIAllocator allocator;
- REQUIRE(allocator.get_allocation_count() == 0);
+ CHECK(allocator.get_allocation_count() == 0);
void* ptr0 = allocator.allocate(32);
- REQUIRE(allocator.get_allocation_count() == 1);
+ CHECK(allocator.get_allocation_count() == 1);
void* ptr1 = allocator.allocate(48, 256);
- REQUIRE(allocator.get_allocation_count() == 2);
- REQUIRE(is_aligned_to(ptr1, 256));
+ CHECK(allocator.get_allocation_count() == 2);
+ CHECK(is_aligned_to(ptr1, 256));
allocator.deallocate(ptr1, 48);
- REQUIRE(allocator.get_allocation_count() == 1);
+ CHECK(allocator.get_allocation_count() == 1);
allocator.deallocate(ptr0, 32);
- REQUIRE(allocator.get_allocation_count() == 0);
+ CHECK(allocator.get_allocation_count() == 0);
}
diff --git a/tests/sources/core/test_bit_manip_utils.cpp b/tests/sources/core/test_bit_manip_utils.cpp
--- a/tests/sources/core/test_bit_manip_utils.cpp
+++ b/tests/sources/core/test_bit_manip_utils.cpp
@@ -30,34 +30,34 @@ using namespace acl;
TEST_CASE("bit_manip_utils", "[core][utils]")
{
- REQUIRE(count_set_bits(uint8_t(0x00)) == 0);
- REQUIRE(count_set_bits(uint8_t(0x01)) == 1);
- REQUIRE(count_set_bits(uint8_t(0x10)) == 1);
- REQUIRE(count_set_bits(uint8_t(0xFF)) == 8);
-
- REQUIRE(count_set_bits(uint16_t(0x0000)) == 0);
- REQUIRE(count_set_bits(uint16_t(0x0001)) == 1);
- REQUIRE(count_set_bits(uint16_t(0x1000)) == 1);
- REQUIRE(count_set_bits(uint16_t(0x1001)) == 2);
- REQUIRE(count_set_bits(uint16_t(0xFFFF)) == 16);
-
- REQUIRE(count_set_bits(uint32_t(0x00000000)) == 0);
- REQUIRE(count_set_bits(uint32_t(0x00000001)) == 1);
- REQUIRE(count_set_bits(uint32_t(0x10000000)) == 1);
- REQUIRE(count_set_bits(uint32_t(0x10101001)) == 4);
- REQUIRE(count_set_bits(uint32_t(0xFFFFFFFF)) == 32);
-
- REQUIRE(count_set_bits(uint64_t(0x0000000000000000ULL)) == 0);
- REQUIRE(count_set_bits(uint64_t(0x0000000000000001ULL)) == 1);
- REQUIRE(count_set_bits(uint64_t(0x1000000000000000ULL)) == 1);
- REQUIRE(count_set_bits(uint64_t(0x1000100001010101ULL)) == 6);
- REQUIRE(count_set_bits(uint64_t(0xFFFFFFFFFFFFFFFFULL)) == 64);
-
- REQUIRE(rotate_bits_left(0x00000010, 0) == 0x00000010);
- REQUIRE(rotate_bits_left(0x10000010, 1) == 0x20000020);
- REQUIRE(rotate_bits_left(0x10000010, 2) == 0x40000040);
- REQUIRE(rotate_bits_left(0x10000010, 3) == 0x80000080);
- REQUIRE(rotate_bits_left(0x10000010, 4) == 0x00000101);
-
- REQUIRE(and_not(0x00000010, 0x10101011) == 0x10101001);
+ CHECK(count_set_bits(uint8_t(0x00)) == 0);
+ CHECK(count_set_bits(uint8_t(0x01)) == 1);
+ CHECK(count_set_bits(uint8_t(0x10)) == 1);
+ CHECK(count_set_bits(uint8_t(0xFF)) == 8);
+
+ CHECK(count_set_bits(uint16_t(0x0000)) == 0);
+ CHECK(count_set_bits(uint16_t(0x0001)) == 1);
+ CHECK(count_set_bits(uint16_t(0x1000)) == 1);
+ CHECK(count_set_bits(uint16_t(0x1001)) == 2);
+ CHECK(count_set_bits(uint16_t(0xFFFF)) == 16);
+
+ CHECK(count_set_bits(uint32_t(0x00000000)) == 0);
+ CHECK(count_set_bits(uint32_t(0x00000001)) == 1);
+ CHECK(count_set_bits(uint32_t(0x10000000)) == 1);
+ CHECK(count_set_bits(uint32_t(0x10101001)) == 4);
+ CHECK(count_set_bits(uint32_t(0xFFFFFFFF)) == 32);
+
+ CHECK(count_set_bits(uint64_t(0x0000000000000000ULL)) == 0);
+ CHECK(count_set_bits(uint64_t(0x0000000000000001ULL)) == 1);
+ CHECK(count_set_bits(uint64_t(0x1000000000000000ULL)) == 1);
+ CHECK(count_set_bits(uint64_t(0x1000100001010101ULL)) == 6);
+ CHECK(count_set_bits(uint64_t(0xFFFFFFFFFFFFFFFFULL)) == 64);
+
+ CHECK(rotate_bits_left(0x00000010, 0) == 0x00000010);
+ CHECK(rotate_bits_left(0x10000010, 1) == 0x20000020);
+ CHECK(rotate_bits_left(0x10000010, 2) == 0x40000040);
+ CHECK(rotate_bits_left(0x10000010, 3) == 0x80000080);
+ CHECK(rotate_bits_left(0x10000010, 4) == 0x00000101);
+
+ CHECK(and_not(0x00000010, 0x10101011) == 0x10101001);
}
diff --git a/tests/sources/core/test_enum_utils.cpp b/tests/sources/core/test_enum_utils.cpp
--- a/tests/sources/core/test_enum_utils.cpp
+++ b/tests/sources/core/test_enum_utils.cpp
@@ -43,13 +43,13 @@ ACL_IMPL_ENUM_FLAGS_OPERATORS(TestEnum)
TEST_CASE("enum utils", "[core][utils]")
{
- REQUIRE(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::All) == true);
- REQUIRE(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One) == true);
- REQUIRE(are_any_enum_flags_set(TestEnum::All, TestEnum::One | TestEnum::Two) == true);
- REQUIRE(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::Four) == false);
-
- REQUIRE(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One | TestEnum::Two) == true);
- REQUIRE(are_all_enum_flags_set(TestEnum::One, TestEnum::One | TestEnum::Two) == false);
- REQUIRE(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One) == true);
- REQUIRE(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::All) == false);
+ CHECK(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::All) == true);
+ CHECK(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One) == true);
+ CHECK(are_any_enum_flags_set(TestEnum::All, TestEnum::One | TestEnum::Two) == true);
+ CHECK(are_any_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::Four) == false);
+
+ CHECK(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One | TestEnum::Two) == true);
+ CHECK(are_all_enum_flags_set(TestEnum::One, TestEnum::One | TestEnum::Two) == false);
+ CHECK(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::One) == true);
+ CHECK(are_all_enum_flags_set(TestEnum::One | TestEnum::Two, TestEnum::All) == false);
}
diff --git a/tests/sources/core/test_error_result.cpp b/tests/sources/core/test_error_result.cpp
--- a/tests/sources/core/test_error_result.cpp
+++ b/tests/sources/core/test_error_result.cpp
@@ -33,18 +33,18 @@ using namespace acl;
TEST_CASE("ErrorResult", "[core][error]")
{
- REQUIRE(ErrorResult().any() == false);
- REQUIRE(ErrorResult().empty() == true);
- REQUIRE(std::strlen(ErrorResult().c_str()) == 0);
+ CHECK(ErrorResult().any() == false);
+ CHECK(ErrorResult().empty() == true);
+ CHECK(std::strlen(ErrorResult().c_str()) == 0);
- REQUIRE(ErrorResult("failed").any() == true);
- REQUIRE(ErrorResult("failed").empty() == false);
- REQUIRE(std::strcmp(ErrorResult("failed").c_str(), "failed") == 0);
+ CHECK(ErrorResult("failed").any() == true);
+ CHECK(ErrorResult("failed").empty() == false);
+ CHECK(std::strcmp(ErrorResult("failed").c_str(), "failed") == 0);
ErrorResult tmp("failed");
- REQUIRE(tmp.any() == true);
+ CHECK(tmp.any() == true);
tmp.reset();
- REQUIRE(tmp.any() == false);
- REQUIRE(tmp.empty() == true);
- REQUIRE(std::strlen(tmp.c_str()) == 0);
+ CHECK(tmp.any() == false);
+ CHECK(tmp.empty() == true);
+ CHECK(std::strlen(tmp.c_str()) == 0);
}
diff --git a/tests/sources/core/test_interpolation_utils.cpp b/tests/sources/core/test_interpolation_utils.cpp
--- a/tests/sources/core/test_interpolation_utils.cpp
+++ b/tests/sources/core/test_interpolation_utils.cpp
@@ -37,101 +37,101 @@ TEST_CASE("interpolation utils", "[core][utils]")
uint32_t key0;
uint32_t key1;
float alpha;
- find_linear_interpolation_samples_with_duration(31, 1.0F, 0.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 0.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 0);
- REQUIRE(key1 == 1);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 0);
+ CHECK(key1 == 1);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 1.0F / 30.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 1.0F / 30.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 1);
- REQUIRE(key1 == 2);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 1);
+ CHECK(key1 == 2);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.5F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.5F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 1.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 1.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 30);
- REQUIRE(key1 == 30);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 30);
+ CHECK(key1 == 30);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, SampleRoundingPolicy::Floor, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, sample_rounding_policy::floor, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, SampleRoundingPolicy::Ceil, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 2.5F / 30.0F, sample_rounding_policy::ceil, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 1.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 1.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 2.4F / 30.0F, SampleRoundingPolicy::Nearest, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 2.4F / 30.0F, sample_rounding_policy::nearest, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_duration(31, 1.0F, 2.6F / 30.0F, SampleRoundingPolicy::Nearest, key0, key1, alpha);
+ find_linear_interpolation_samples_with_duration(31, 1.0F, 2.6F / 30.0F, sample_rounding_policy::nearest, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 1.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 1.0F, error_threshold));
//////////////////////////////////////////////////////////////////////////
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 0.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 0.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 0);
- REQUIRE(key1 == 1);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 0);
+ CHECK(key1 == 1);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 1.0F / 30.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 1.0F / 30.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 1);
- REQUIRE(key1 == 2);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 1);
+ CHECK(key1 == 2);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.5F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.5F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 1.0F, SampleRoundingPolicy::None, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 1.0F, sample_rounding_policy::none, key0, key1, alpha);
- REQUIRE(key0 == 30);
- REQUIRE(key1 == 30);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 30);
+ CHECK(key1 == 30);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, SampleRoundingPolicy::Floor, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, sample_rounding_policy::floor, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, SampleRoundingPolicy::Ceil, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.5F / 30.0F, sample_rounding_policy::ceil, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 1.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 1.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.4F / 30.0F, SampleRoundingPolicy::Nearest, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.4F / 30.0F, sample_rounding_policy::nearest, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 0.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 0.0F, error_threshold));
- find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.6F / 30.0F, SampleRoundingPolicy::Nearest, key0, key1, alpha);
+ find_linear_interpolation_samples_with_sample_rate(31, 30.0F, 2.6F / 30.0F, sample_rounding_policy::nearest, key0, key1, alpha);
- REQUIRE(key0 == 2);
- REQUIRE(key1 == 3);
- REQUIRE(scalar_near_equal(alpha, 1.0F, error_threshold));
+ CHECK(key0 == 2);
+ CHECK(key1 == 3);
+ CHECK(scalar_near_equal(alpha, 1.0F, error_threshold));
}
diff --git a/tests/sources/core/test_iterator.cpp b/tests/sources/core/test_iterator.cpp
--- a/tests/sources/core/test_iterator.cpp
+++ b/tests/sources/core/test_iterator.cpp
@@ -40,21 +40,21 @@ TEST_CASE("iterator", "[core][iterator]")
SECTION("mutable returns correct type")
{
- REQUIRE(std::is_same<uint32_t*, decltype(i.begin())>::value);
- REQUIRE(std::is_same<uint32_t*, decltype(i.end())>::value);
+ CHECK(std::is_same<uint32_t*, decltype(i.begin())>::value);
+ CHECK(std::is_same<uint32_t*, decltype(i.end())>::value);
}
SECTION("const returns correct type")
{
auto ci = ConstIterator<uint32_t>(items, num_items);
- REQUIRE(std::is_same<const uint32_t*, decltype(ci.begin())>::value);
- REQUIRE(std::is_same<const uint32_t*, decltype(ci.end())>::value);
+ CHECK(std::is_same<const uint32_t*, decltype(ci.begin())>::value);
+ CHECK(std::is_same<const uint32_t*, decltype(ci.end())>::value);
}
SECTION("bounds are correct")
{
- REQUIRE(i.begin() == items + 0);
- REQUIRE(i.end() == items + num_items);
+ CHECK(i.begin() == items + 0);
+ CHECK(i.end() == items + num_items);
}
}
diff --git a/tests/sources/core/test_memory_utils.cpp b/tests/sources/core/test_memory_utils.cpp
--- a/tests/sources/core/test_memory_utils.cpp
+++ b/tests/sources/core/test_memory_utils.cpp
@@ -41,32 +41,32 @@ TEST_CASE("misc tests", "[core][memory]")
num_powers_of_two++;
}
- REQUIRE(num_powers_of_two == 17);
- REQUIRE(is_power_of_two(1) == true);
- REQUIRE(is_power_of_two(2) == true);
- REQUIRE(is_power_of_two(4) == true);
- REQUIRE(is_power_of_two(8) == true);
- REQUIRE(is_power_of_two(16) == true);
- REQUIRE(is_power_of_two(32) == true);
- REQUIRE(is_power_of_two(64) == true);
- REQUIRE(is_power_of_two(128) == true);
- REQUIRE(is_power_of_two(256) == true);
- REQUIRE(is_power_of_two(512) == true);
- REQUIRE(is_power_of_two(1024) == true);
- REQUIRE(is_power_of_two(2048) == true);
- REQUIRE(is_power_of_two(4096) == true);
- REQUIRE(is_power_of_two(8192) == true);
- REQUIRE(is_power_of_two(16384) == true);
- REQUIRE(is_power_of_two(32768) == true);
- REQUIRE(is_power_of_two(65536) == true);
-
- REQUIRE(is_alignment_valid<int32_t>(0) == false);
- REQUIRE(is_alignment_valid<int32_t>(4) == true);
- REQUIRE(is_alignment_valid<int32_t>(8) == true);
- REQUIRE(is_alignment_valid<int32_t>(2) == false);
- REQUIRE(is_alignment_valid<int32_t>(5) == false);
- REQUIRE(is_alignment_valid<int64_t>(8) == true);
- REQUIRE(is_alignment_valid<int64_t>(16) == true);
+ CHECK(num_powers_of_two == 17);
+ CHECK(is_power_of_two(1) == true);
+ CHECK(is_power_of_two(2) == true);
+ CHECK(is_power_of_two(4) == true);
+ CHECK(is_power_of_two(8) == true);
+ CHECK(is_power_of_two(16) == true);
+ CHECK(is_power_of_two(32) == true);
+ CHECK(is_power_of_two(64) == true);
+ CHECK(is_power_of_two(128) == true);
+ CHECK(is_power_of_two(256) == true);
+ CHECK(is_power_of_two(512) == true);
+ CHECK(is_power_of_two(1024) == true);
+ CHECK(is_power_of_two(2048) == true);
+ CHECK(is_power_of_two(4096) == true);
+ CHECK(is_power_of_two(8192) == true);
+ CHECK(is_power_of_two(16384) == true);
+ CHECK(is_power_of_two(32768) == true);
+ CHECK(is_power_of_two(65536) == true);
+
+ CHECK(is_alignment_valid<int32_t>(0) == false);
+ CHECK(is_alignment_valid<int32_t>(4) == true);
+ CHECK(is_alignment_valid<int32_t>(8) == true);
+ CHECK(is_alignment_valid<int32_t>(2) == false);
+ CHECK(is_alignment_valid<int32_t>(5) == false);
+ CHECK(is_alignment_valid<int64_t>(8) == true);
+ CHECK(is_alignment_valid<int64_t>(16) == true);
struct alignas(8) Tmp
{
@@ -74,34 +74,34 @@ TEST_CASE("misc tests", "[core][memory]")
int32_t value; // Aligned to 4 bytes
};
Tmp tmp;
- REQUIRE(is_aligned_to(&tmp.padding, 8) == true);
- REQUIRE(is_aligned_to(&tmp.value, 4) == true);
- REQUIRE(is_aligned_to(&tmp.value, 2) == true);
- REQUIRE(is_aligned_to(&tmp.value, 1) == true);
- REQUIRE(is_aligned_to(&tmp.value, 8) == false);
-
- REQUIRE(is_aligned_to(4, 4) == true);
- REQUIRE(is_aligned_to(4, 2) == true);
- REQUIRE(is_aligned_to(4, 1) == true);
- REQUIRE(is_aligned_to(4, 8) == false);
- REQUIRE(is_aligned_to(6, 4) == false);
- REQUIRE(is_aligned_to(6, 2) == true);
- REQUIRE(is_aligned_to(6, 1) == true);
-
- REQUIRE(is_aligned_to(align_to(5, 4), 4) == true);
- REQUIRE(align_to(5, 4) == 8);
- REQUIRE(is_aligned_to(align_to(8, 4), 4) == true);
- REQUIRE(align_to(8, 4) == 8);
+ CHECK(is_aligned_to(&tmp.padding, 8) == true);
+ CHECK(is_aligned_to(&tmp.value, 4) == true);
+ CHECK(is_aligned_to(&tmp.value, 2) == true);
+ CHECK(is_aligned_to(&tmp.value, 1) == true);
+ CHECK(is_aligned_to(&tmp.value, 8) == false);
+
+ CHECK(is_aligned_to(4, 4) == true);
+ CHECK(is_aligned_to(4, 2) == true);
+ CHECK(is_aligned_to(4, 1) == true);
+ CHECK(is_aligned_to(4, 8) == false);
+ CHECK(is_aligned_to(6, 4) == false);
+ CHECK(is_aligned_to(6, 2) == true);
+ CHECK(is_aligned_to(6, 1) == true);
+
+ CHECK(is_aligned_to(align_to(5, 4), 4) == true);
+ CHECK(align_to(5, 4) == 8);
+ CHECK(is_aligned_to(align_to(8, 4), 4) == true);
+ CHECK(align_to(8, 4) == 8);
void* ptr = (void*)0x00000000;
- REQUIRE(align_to(ptr, 4) == (void*)0x00000000);
- REQUIRE(align_to(ptr, 8) == (void*)0x00000000);
+ CHECK(align_to(ptr, 4) == (void*)0x00000000);
+ CHECK(align_to(ptr, 8) == (void*)0x00000000);
ptr = (void*)0x00000001;
- REQUIRE(align_to(ptr, 4) == (void*)0x00000004);
- REQUIRE(align_to(ptr, 8) == (void*)0x00000008);
+ CHECK(align_to(ptr, 4) == (void*)0x00000004);
+ CHECK(align_to(ptr, 8) == (void*)0x00000008);
ptr = (void*)0x00000004;
- REQUIRE(align_to(ptr, 4) == (void*)0x00000004);
- REQUIRE(align_to(ptr, 8) == (void*)0x00000008);
+ CHECK(align_to(ptr, 4) == (void*)0x00000004);
+ CHECK(align_to(ptr, 8) == (void*)0x00000008);
struct alignas(8) Align8
{
@@ -110,32 +110,32 @@ TEST_CASE("misc tests", "[core][memory]")
const size_t padding0 = get_required_padding<float, Align8>();
const size_t padding1 = get_required_padding<uint8_t, Align8>();
- REQUIRE(padding0 == 4);
- REQUIRE(padding1 == 7);
+ CHECK(padding0 == 4);
+ CHECK(padding1 == 7);
int32_t array[8];
- REQUIRE(get_array_size(array) == (sizeof(array) / sizeof(array[0])));
+ CHECK(get_array_size(array) == (sizeof(array) / sizeof(array[0])));
}
TEST_CASE("raw memory support", "[core][memory]")
{
uint8_t buffer[1024];
uint8_t* ptr = &buffer[32];
- REQUIRE(add_offset_to_ptr<uint8_t>(ptr, 23) == ptr + 23);
- REQUIRE(add_offset_to_ptr<uint8_t>(ptr, 64) == ptr + 64);
+ CHECK(add_offset_to_ptr<uint8_t>(ptr, 23) == ptr + 23);
+ CHECK(add_offset_to_ptr<uint8_t>(ptr, 64) == ptr + 64);
uint16_t value16 = 0x04FE;
- REQUIRE(byte_swap(value16) == 0xFE04);
+ CHECK(byte_swap(value16) == 0xFE04);
uint32_t value32 = 0x04FE78AB;
- REQUIRE(byte_swap(value32) == 0xAB78FE04);
+ CHECK(byte_swap(value32) == 0xAB78FE04);
uint64_t value64 = uint64_t(0x04FE78AB0098DC56ULL);
- REQUIRE(byte_swap(value64) == uint64_t(0x56DC9800AB78FE04ULL));
+ CHECK(byte_swap(value64) == uint64_t(0x56DC9800AB78FE04ULL));
uint8_t unaligned_value_buffer[5] = { 0x00, 0x00, 0x00, 0x00, 0x00 };
std::memcpy(&unaligned_value_buffer[1], &value32, sizeof(uint32_t));
- REQUIRE(unaligned_load<uint32_t>(&unaligned_value_buffer[1]) == value32);
+ CHECK(unaligned_load<uint32_t>(&unaligned_value_buffer[1]) == value32);
}
TEST_CASE("memcpy_bits", "[core][memory]")
@@ -143,28 +143,28 @@ TEST_CASE("memcpy_bits", "[core][memory]")
uint64_t dest = uint64_t(~0ULL);
uint64_t src = byte_swap(uint64_t(0x5555555555555555ULL));
memcpy_bits(&dest, 1, &src, 0, 64 - 3);
- REQUIRE(dest == byte_swap(uint64_t(0xAAAAAAAAAAAAAAABULL)));
+ CHECK(dest == byte_swap(uint64_t(0xAAAAAAAAAAAAAAABULL)));
dest = byte_swap(uint64_t(0x0F00FF0000000000ULL));
src = byte_swap(uint64_t(0x3800000000000000ULL));
memcpy_bits(&dest, 0, &src, 2, 5);
- REQUIRE(dest == byte_swap(uint64_t(0xE700FF0000000000ULL)));
+ CHECK(dest == byte_swap(uint64_t(0xE700FF0000000000ULL)));
dest = byte_swap(uint64_t(0x0F00FF0000000000ULL));
src = byte_swap(uint64_t(0x3800000000000000ULL));
memcpy_bits(&dest, 1, &src, 2, 5);
- REQUIRE(dest == byte_swap(uint64_t(0x7300FF0000000000ULL)));
+ CHECK(dest == byte_swap(uint64_t(0x7300FF0000000000ULL)));
dest = 0;
src = uint64_t(~0ULL);
memcpy_bits(&dest, 1, &src, 0, 7);
- REQUIRE(dest == byte_swap(uint64_t(0x7F00000000000000ULL)));
+ CHECK(dest == byte_swap(uint64_t(0x7F00000000000000ULL)));
memcpy_bits(&dest, 8, &src, 0, 8);
- REQUIRE(dest == byte_swap(uint64_t(0x7FFF000000000000ULL)));
+ CHECK(dest == byte_swap(uint64_t(0x7FFF000000000000ULL)));
memcpy_bits(&dest, 0, &src, 0, 64);
- REQUIRE(dest == uint64_t(~0ULL));
+ CHECK(dest == uint64_t(~0ULL));
}
enum class UnsignedEnum : uint32_t
diff --git a/tests/sources/core/test_ptr_offset.cpp b/tests/sources/core/test_ptr_offset.cpp
--- a/tests/sources/core/test_ptr_offset.cpp
+++ b/tests/sources/core/test_ptr_offset.cpp
@@ -30,13 +30,13 @@ using namespace acl;
TEST_CASE("ptr_offset", "[core][memory]")
{
- REQUIRE(PtrOffset32<uint8_t>(InvalidPtrOffset()).is_valid() == false);
+ CHECK(PtrOffset32<uint8_t>(InvalidPtrOffset()).is_valid() == false);
PtrOffset32<uint8_t> offset(32);
- REQUIRE(offset.is_valid() == true);
+ CHECK(offset.is_valid() == true);
uint8_t* ptr = nullptr;
- REQUIRE(offset.add_to(ptr) == (ptr + 32));
- REQUIRE(offset.add_to(ptr) == offset.safe_add_to(ptr));
- REQUIRE(uint32_t(offset) == 32);
+ CHECK(offset.add_to(ptr) == (ptr + 32));
+ CHECK(offset.add_to(ptr) == offset.safe_add_to(ptr));
+ CHECK(uint32_t(offset) == 32);
}
diff --git a/tests/sources/core/test_string.cpp b/tests/sources/core/test_string.cpp
--- a/tests/sources/core/test_string.cpp
+++ b/tests/sources/core/test_string.cpp
@@ -39,27 +39,27 @@ TEST_CASE("String", "[core][string]")
{
ANSIAllocator allocator;
- REQUIRE(String().size() == 0);
- REQUIRE(String().c_str() != nullptr);
- REQUIRE(String(allocator, "").size() == 0);
- REQUIRE(String(allocator, "").c_str() != nullptr);
+ CHECK(String().size() == 0);
+ CHECK(String().c_str() != nullptr);
+ CHECK(String(allocator, "").size() == 0);
+ CHECK(String(allocator, "").c_str() != nullptr);
const char* str0 = "this is a test string";
const char* str1 = "this is not a test string";
const char* str2 = "this is a test asset!";
- REQUIRE(String(allocator, str0) == str0);
- REQUIRE(String(allocator, str0) != str1);
- REQUIRE(String(allocator, str0) != str2);
- REQUIRE(String(allocator, str0) == String(allocator, str0));
- REQUIRE(String(allocator, str0) != String(allocator, str1));
- REQUIRE(String(allocator, str0) != String(allocator, str2));
- REQUIRE(String(allocator, str0).c_str() != str0);
- REQUIRE(String(allocator, str0).size() == std::strlen(str0));
- REQUIRE(String(allocator, str0, 4) == String(allocator, str1, 4));
- REQUIRE(String(allocator, str0, 4) == "this");
+ CHECK(String(allocator, str0) == str0);
+ CHECK(String(allocator, str0) != str1);
+ CHECK(String(allocator, str0) != str2);
+ CHECK(String(allocator, str0) == String(allocator, str0));
+ CHECK(String(allocator, str0) != String(allocator, str1));
+ CHECK(String(allocator, str0) != String(allocator, str2));
+ CHECK(String(allocator, str0).c_str() != str0);
+ CHECK(String(allocator, str0).size() == std::strlen(str0));
+ CHECK(String(allocator, str0, 4) == String(allocator, str1, 4));
+ CHECK(String(allocator, str0, 4) == "this");
- REQUIRE(String().empty() == true);
- REQUIRE(String(allocator, "").empty() == true);
- REQUIRE(String(allocator, str0).empty() == false);
+ CHECK(String().empty() == true);
+ CHECK(String(allocator, "").empty() == true);
+ CHECK(String(allocator, str0).empty() == false);
}
diff --git a/tests/sources/core/test_utils.cpp b/tests/sources/core/test_utils.cpp
--- a/tests/sources/core/test_utils.cpp
+++ b/tests/sources/core/test_utils.cpp
@@ -34,15 +34,15 @@ using namespace rtm;
TEST_CASE("misc utils", "[core][utils]")
{
- REQUIRE(calculate_num_samples(0.0F, 30.0F) == 0);
- REQUIRE(calculate_num_samples(1.0F, 30.0F) == 31);
- REQUIRE(calculate_num_samples(1.0F, 24.0F) == 25);
- REQUIRE(calculate_num_samples(1.0F / 30.F, 30.0F) == 2);
- REQUIRE(calculate_num_samples(std::numeric_limits<float>::infinity(), 30.0F) == 1);
+ CHECK(calculate_num_samples(0.0F, 30.0F) == 0);
+ CHECK(calculate_num_samples(1.0F, 30.0F) == 31);
+ CHECK(calculate_num_samples(1.0F, 24.0F) == 25);
+ CHECK(calculate_num_samples(1.0F / 30.F, 30.0F) == 2);
+ CHECK(calculate_num_samples(std::numeric_limits<float>::infinity(), 30.0F) == 1);
- REQUIRE(calculate_duration(0, 30.0F) == 0.0F);
- REQUIRE(calculate_duration(1, 30.0F) == std::numeric_limits<float>::infinity());
- REQUIRE(calculate_duration(1, 8.0F) == std::numeric_limits<float>::infinity());
- REQUIRE(scalar_near_equal(calculate_duration(31, 30.0F), 1.0F, 1.0E-8F));
- REQUIRE(scalar_near_equal(calculate_duration(9, 8.0F), 1.0F, 1.0E-8F));
+ CHECK(calculate_duration(0, 30.0F) == 0.0F);
+ CHECK(calculate_duration(1, 30.0F) == std::numeric_limits<float>::infinity());
+ CHECK(calculate_duration(1, 8.0F) == std::numeric_limits<float>::infinity());
+ CHECK(scalar_near_equal(calculate_duration(31, 30.0F), 1.0F, 1.0E-8F));
+ CHECK(scalar_near_equal(calculate_duration(9, 8.0F), 1.0F, 1.0E-8F));
}
diff --git a/tests/sources/io/test_reader_writer.cpp b/tests/sources/io/test_reader_writer.cpp
--- a/tests/sources/io/test_reader_writer.cpp
+++ b/tests/sources/io/test_reader_writer.cpp
@@ -208,15 +208,12 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
settings.constant_scale_threshold = 1.123F;
settings.constant_translation_threshold = 0.124F;
settings.error_threshold = 0.23F;
- settings.level = CompressionLevel8::High;
- settings.range_reduction = RangeReductionFlags8::Rotations | RangeReductionFlags8::Scales;
- settings.rotation_format = RotationFormat8::QuatDropW_48;
- settings.scale_format = VectorFormat8::Vector3_96;
- settings.translation_format = VectorFormat8::Vector3_32;
- settings.segmenting.enabled = false;
+ settings.level = compression_level8::high;
+ settings.rotation_format = rotation_format8::quatf_drop_w_variable;
+ settings.scale_format = vector_format8::vector3f_variable;
+ settings.translation_format = vector_format8::vector3f_variable;
settings.segmenting.ideal_num_samples = 23;
settings.segmenting.max_num_samples = 123;
- settings.segmenting.range_reduction = RangeReductionFlags8::Translations;
const uint32_t filename_size = k_max_filename_size;
char filename[filename_size] = { 0 };
@@ -227,7 +224,7 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
get_temporary_filename(filename, filename_size, "clip_");
// Write the clip to a temporary file
- error = write_acl_clip(skeleton, clip, AlgorithmType8::UniformlySampled, settings, filename);
+ error = write_acl_clip(skeleton, clip, algorithm_type8::uniformly_sampled, settings, filename);
if (error == nullptr)
break; // Everything worked, stop trying
@@ -267,7 +264,7 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
const bool success = reader.read_raw_clip(file_clip);
REQUIRE(success);
- CHECK(file_clip.algorithm_type == AlgorithmType8::UniformlySampled);
+ CHECK(file_clip.algorithm_type == algorithm_type8::uniformly_sampled);
CHECK(file_clip.has_settings);
CHECK(file_clip.settings.get_hash() == settings.get_hash());
CHECK(file_clip.skeleton->get_num_bones() == num_bones);
diff --git a/tests/sources/math/test_quat_packing.cpp b/tests/sources/math/test_quat_packing.cpp
--- a/tests/sources/math/test_quat_packing.cpp
+++ b/tests/sources/math/test_quat_packing.cpp
@@ -45,50 +45,46 @@ TEST_CASE("quat packing math", "[math][quat][packing]")
UnalignedBuffer tmp0;
pack_quat_128(quat0, &tmp0.buffer[0]);
quatf quat1 = unpack_quat_128(&tmp0.buffer[0]);
- REQUIRE(quat_get_x(quat0) == quat_get_x(quat1));
- REQUIRE(quat_get_y(quat0) == quat_get_y(quat1));
- REQUIRE(quat_get_z(quat0) == quat_get_z(quat1));
- REQUIRE(quat_get_w(quat0) == quat_get_w(quat1));
+ CHECK(quat_get_x(quat0) == quat_get_x(quat1));
+ CHECK(quat_get_y(quat0) == quat_get_y(quat1));
+ CHECK(quat_get_z(quat0) == quat_get_z(quat1));
+ CHECK(quat_get_w(quat0) == quat_get_w(quat1));
}
{
UnalignedBuffer tmp0;
pack_quat_96(quat0, &tmp0.buffer[0]);
quatf quat1 = unpack_quat_96_unsafe(&tmp0.buffer[0]);
- REQUIRE(quat_get_x(quat0) == quat_get_x(quat1));
- REQUIRE(quat_get_y(quat0) == quat_get_y(quat1));
- REQUIRE(quat_get_z(quat0) == quat_get_z(quat1));
- REQUIRE(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-4F));
+ CHECK(quat_get_x(quat0) == quat_get_x(quat1));
+ CHECK(quat_get_y(quat0) == quat_get_y(quat1));
+ CHECK(quat_get_z(quat0) == quat_get_z(quat1));
+ CHECK(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-4F));
}
{
UnalignedBuffer tmp0;
pack_quat_48(quat0, &tmp0.buffer[0]);
quatf quat1 = unpack_quat_48(&tmp0.buffer[0]);
- REQUIRE(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-4F));
- REQUIRE(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-4F));
- REQUIRE(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-4F));
- REQUIRE(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-4F));
+ CHECK(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-4F));
+ CHECK(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-4F));
+ CHECK(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-4F));
+ CHECK(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-4F));
}
{
UnalignedBuffer tmp0;
pack_quat_32(quat0, &tmp0.buffer[0]);
quatf quat1 = unpack_quat_32(&tmp0.buffer[0]);
- REQUIRE(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-3F));
- REQUIRE(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-3F));
- REQUIRE(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-3F));
- REQUIRE(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-3F));
+ CHECK(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-3F));
+ CHECK(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-3F));
+ CHECK(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-3F));
+ CHECK(scalar_near_equal(quat_get_w(quat0), quat_get_w(quat1), 1.0E-3F));
}
- REQUIRE(get_packed_rotation_size(RotationFormat8::Quat_128) == 16);
- REQUIRE(get_packed_rotation_size(RotationFormat8::QuatDropW_96) == 12);
- REQUIRE(get_packed_rotation_size(RotationFormat8::QuatDropW_48) == 6);
- REQUIRE(get_packed_rotation_size(RotationFormat8::QuatDropW_32) == 4);
+ CHECK(get_packed_rotation_size(rotation_format8::quatf_full) == 16);
+ CHECK(get_packed_rotation_size(rotation_format8::quatf_drop_w_full) == 12);
- REQUIRE(get_range_reduction_rotation_size(RotationFormat8::Quat_128) == 32);
- REQUIRE(get_range_reduction_rotation_size(RotationFormat8::QuatDropW_96) == 24);
- REQUIRE(get_range_reduction_rotation_size(RotationFormat8::QuatDropW_48) == 24);
- REQUIRE(get_range_reduction_rotation_size(RotationFormat8::QuatDropW_32) == 24);
- REQUIRE(get_range_reduction_rotation_size(RotationFormat8::QuatDropW_Variable) == 24);
+ CHECK(get_range_reduction_rotation_size(rotation_format8::quatf_full) == 32);
+ CHECK(get_range_reduction_rotation_size(rotation_format8::quatf_drop_w_full) == 24);
+ CHECK(get_range_reduction_rotation_size(rotation_format8::quatf_drop_w_variable) == 24);
}
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -48,7 +48,7 @@ TEST_CASE("pack_vector4_128", "[math][vector4][packing]")
vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 1891.019231829F, 0.913912387F);
pack_vector4_128(vec0, &tmp.buffer[0]);
vector4f vec1 = unpack_vector4_128(&tmp.buffer[0]);
- REQUIRE(std::memcmp(&vec0, &vec1, sizeof(vector4f)) == 0);
+ CHECK(std::memcmp(&vec0, &vec1, sizeof(vector4f)) == 0);
}
{
@@ -84,7 +84,7 @@ TEST_CASE("pack_vector4_128", "[math][vector4][packing]")
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -110,7 +110,7 @@ TEST_CASE("pack_vector4_64", "[math][vector4][packing]")
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -136,7 +136,7 @@ TEST_CASE("pack_vector4_32", "[math][vector4][packing]")
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -181,7 +181,7 @@ TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
}
}
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -193,7 +193,7 @@ TEST_CASE("pack_vector3_96", "[math][vector4][packing]")
vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F);
pack_vector3_96(vec0, &tmp0.buffer[0]);
vector4f vec1 = unpack_vector3_96_unsafe(&tmp0.buffer[0]);
- REQUIRE(vector_all_near_equal3(vec0, vec1, 1.0E-6F));
+ CHECK(vector_all_near_equal3(vec0, vec1, 1.0E-6F));
uint32_t x = unaligned_load<uint32_t>(&tmp0.buffer[0]);
x = byte_swap(x);
@@ -218,7 +218,7 @@ TEST_CASE("pack_vector3_96", "[math][vector4][packing]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -244,7 +244,7 @@ TEST_CASE("pack_vector3_48", "[math][vector4][packing]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -267,7 +267,7 @@ TEST_CASE("decay_vector3_48", "[math][vector4][decay]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -301,7 +301,7 @@ TEST_CASE("pack_vector3_32", "[math][vector4][packing]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -332,7 +332,7 @@ TEST_CASE("decay_vector3_32", "[math][vector4][decay]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -358,7 +358,7 @@ TEST_CASE("pack_vector3_24", "[math][vector4][packing]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -429,7 +429,7 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
}
}
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -469,7 +469,7 @@ TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
}
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -500,7 +500,7 @@ TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
num_errors++;
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
@@ -545,13 +545,11 @@ TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
}
}
}
- REQUIRE(num_errors == 0);
+ CHECK(num_errors == 0);
}
}
TEST_CASE("misc vector4 packing", "[math][vector4][packing]")
{
- REQUIRE(get_packed_vector_size(VectorFormat8::Vector3_96) == 12);
- REQUIRE(get_packed_vector_size(VectorFormat8::Vector3_48) == 6);
- REQUIRE(get_packed_vector_size(VectorFormat8::Vector3_32) == 4);
+ CHECK(get_packed_vector_size(vector_format8::vector3f_full) == 12);
}
|
Remove range reduction from compression settings
Range reduction should be controlled by the algorithm entirely. It served only to debug by being exposed but the code is now very stable. Cleaning this up will reduce the maintenance burden and avoid potentially using an invalid setting combination by simplifying the API.
When variable bit rates are used, range reduction should always be enabled. It increases accuracy considerably and it reduces the memory footprint. It also increases the compression speed. Range reduction is only disabled if a track retains full precision in which case there is no point it applying range reduction since we retain every sample with full precision.
| 2019-12-11T05:32:47
|
cpp
|
Hard
|
|
nfrechette/acl
| 538
|
nfrechette__acl-538
|
[
"536"
] |
16aec74ff32df522a97c1d006e2e8e4984bad89f
|
diff --git a/.github/workflows/build_pull_request.yml b/.github/workflows/build_pull_request.yml
--- a/.github/workflows/build_pull_request.yml
+++ b/.github/workflows/build_pull_request.yml
@@ -9,243 +9,6 @@ on:
- '**/*.md'
jobs:
- linux-xenial:
- runs-on: ubuntu-latest
- strategy:
- matrix:
- compiler: [clang4]
- steps:
- - name: Git checkout
- uses: actions/checkout@v4
- with:
- submodules: 'recursive'
- - name: Building (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -build'
- - name: Running unit tests (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -build'
- - name: Running unit tests (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -build'
- - name: Running unit tests (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -build'
- - name: Running unit tests (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -build'
- - name: Running unit tests (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -build'
- - name: Running unit tests (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-xenial:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -unit_test'
-
- linux-bionic:
- runs-on: ubuntu-latest
- strategy:
- matrix:
- compiler: [gcc5, gcc6, gcc7, gcc8, clang5, clang6, clang7, clang8, clang9, clang10]
- steps:
- - name: Git checkout
- uses: actions/checkout@v4
- with:
- submodules: 'recursive'
- - name: Building (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -build'
- - name: Running unit tests (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -build'
- - name: Running unit tests (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -build'
- - name: Running unit tests (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -build'
- - name: Running unit tests (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -build'
- - name: Running unit tests (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -build'
- - name: Running unit tests (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-bionic:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -unit_test'
-
- linux-focal:
- runs-on: ubuntu-latest
- strategy:
- matrix:
- compiler: [gcc9, gcc10, gcc11, clang11, clang12, clang13, clang14]
- steps:
- - name: Git checkout
- uses: actions/checkout@v4
- with:
- submodules: 'recursive'
- - name: Building (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -build'
- - name: Running unit tests (debug-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -build'
- - name: Running unit tests (debug-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Debug -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -build'
- - name: Running unit tests (release-x86)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x86 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -build'
- - name: Running unit tests (release-x64)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -build'
- - name: Running unit tests (release-x64 nosimd)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -nosimd -unit_test'
- - name: Clean
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -clean_only'
- - name: Building (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -build'
- - name: Running unit tests (release-x64 AVX)
- uses: docker://ghcr.io/nfrechette/toolchain-amd64-focal:v1
- with:
- args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -unit_test'
-
linux-lunar:
runs-on: ubuntu-latest
strategy:
@@ -325,47 +88,6 @@ jobs:
with:
args: 'python3 make.py -ci -compiler ${{ matrix.compiler }} -config Release -cpu x64 -avx -unit_test'
- osx-13:
- runs-on: macos-13
- strategy:
- matrix:
- compiler: [xcode14]
- steps:
- - name: Git checkout
- uses: actions/checkout@v4
- with:
- submodules: 'recursive'
- - name: Setup ${{ matrix.compiler }} compiler
- run: ./tools/setup_osx_compiler.sh ${{ matrix.compiler }}
- - name: Building (debug-x64)
- run: python3 make.py -ci -compiler osx -config Debug -cpu x64 -build
- - name: Running unit tests (debug-x64)
- run: python3 make.py -ci -compiler osx -config Debug -cpu x64 -unit_test
- - name: Clean
- run: python3 make.py -ci -clean_only
- - name: Building (release-x64)
- run: python3 make.py -ci -compiler osx -config Release -cpu x64 -build
- - name: Running unit tests (release-x64)
- run: python3 make.py -ci -compiler osx -config Release -cpu x64 -unit_test
- - name: Clean
- run: python3 make.py -ci -clean_only
- - name: Building (release-x64 nosimd)
- run: python3 make.py -ci -compiler osx -config Release -cpu x64 -nosimd -build
- - name: Running unit tests (release-x64 nosimd)
- run: python3 make.py -ci -compiler osx -config Release -cpu x64 -nosimd -unit_test
- - name: Clean
- run: python3 make.py -ci -clean_only
- - name: Building for iOS (debug-arm64)
- run: python3 make.py -ci -compiler ios -config Debug -build
- - name: Clean
- run: python3 make.py -ci -clean_only
- - name: Building for iOS (release-arm64)
- run: python3 make.py -ci -compiler ios -config Release -build
- - name: Clean
- run: python3 make.py -ci -clean_only
- - name: Building for iOS (release-arm64 nosimd)
- run: python3 make.py -ci -compiler ios -config Release -build -nosimd
-
osx-14:
runs-on: macos-14
strategy:
@@ -434,31 +156,6 @@ jobs:
with:
args: 'python3 make.py -ci -compiler emscripten -config release -unit_test'
- vs2019:
- runs-on: windows-2019
- strategy:
- matrix:
- compiler: [vs2019, vs2019-clang]
- build_config: [debug, release]
- cpu: [x86, x64, arm64]
- simd: [-simd, -nosimd, -avx]
- exclude:
- # Don't run arm64 with clang
- - compiler: vs2019-clang
- cpu: arm64
- # Don't run AVX with arm64
- - cpu: arm64
- simd: -avx
- steps:
- - name: Git checkout
- uses: actions/checkout@v4
- with:
- submodules: 'recursive'
- - name: Building (${{ matrix.build_config }}-${{ matrix.cpu }})
- run: python3 make.py -ci -compiler ${{ matrix.compiler }} -config ${{ matrix.build_config }} -cpu ${{ matrix.cpu }} -build ${{ matrix.simd }}
- - name: Running unit tests (${{ matrix.build_config }}-${{ matrix.cpu }})
- run: python3 make.py -ci -compiler ${{ matrix.compiler }} -config ${{ matrix.build_config }} -cpu ${{ matrix.cpu }} -unit_test ${{ matrix.simd }}
-
vs2022:
runs-on: windows-2022
strategy:
diff --git a/CMakeLists.txt b/CMakeLists.txt
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -1,4 +1,4 @@
-cmake_minimum_required (VERSION 3.20)
+cmake_minimum_required(VERSION 3.2...3.25)
project(acl CXX)
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "${PROJECT_SOURCE_DIR}/cmake")
diff --git a/README.md b/README.md
--- a/README.md
+++ b/README.md
@@ -1,6 +1,5 @@
[](https://cla-assistant.io/nfrechette/acl)
[](#contributors-)
-[](https://ci.appveyor.com/project/nfrechette/acl)
[](https://github.com/nfrechette/acl/actions)
[](https://sonarcloud.io/dashboard?id=nfrechette_acl)
[](https://github.com/nfrechette/acl/releases)
@@ -44,20 +43,17 @@ Much thought was put into designing the library for it to be as flexible and pow
## Supported platforms
-* Windows VS2015 x86 and x64
-* Windows (VS2017 to VS2022) x86, x64, and ARM64
-* Windows (VS2017 to VS2022) with clang x86 and x64
-* Linux (gcc 5 to 13) x86 and x64
-* Linux (clang 4 to 15) x86 and x64
-* OS X (12.5, 13.2, 14.2) x64 and ARM64
-* Android (NDK 21) ARMv7-A and ARM64
-* iOS (Xcode 10.3, 11.7, 12.5, 13.2, 14.2) ARM64
-* Emscripten (1.39.11) WASM
-* MSYS2 x64
+Continuous integration tests a variety of platforms and configurations but it generally runs as-is anywhere where C++11 (or later) is supported. CI currently tests:
-The above supported platform list is only what is tested every release but if it compiles, it should run just fine.
+* Windows VS2022: x86, x64, ARM64
+* Linux GCC 12+: x86, x64
+* Linux Clang 15+: x86, x64
+* OS X XCode 15+: ARM64
+* Emscripten 1.39.11: WASM
-The [Unreal Engine](https://www.unrealengine.com/en-US/blog) is supported through a plugin found [here](https://github.com/nfrechette/acl-ue4-plugin).
+Each releases is also manually tested on iOS and Android.
+
+The [Unreal Engine](https://www.unrealengine.com/en-US/blog) is supported through a plugin originally found [here](https://github.com/nfrechette/acl-ue4-plugin) although it is now distributed with a more recent version as part of each engine release since UE 5.13.
## Getting started
diff --git a/appveyor.yml b/appveyor.yml
deleted file mode 100644
--- a/appveyor.yml
+++ /dev/null
@@ -1,40 +0,0 @@
-version: 2.1.99.{build}
-
-environment:
- PYTHON: "C:\\Python36-x64\\python.exe"
- matrix:
- - toolchain: msvc
- - toolchain: clang
-
-image:
- - Visual Studio 2015
- - Visual Studio 2017
-
-configuration:
- - Release
-
-platform:
- - x86
- - x64
- - arm64
-
-matrix:
- exclude:
- - image: Visual Studio 2015
- platform: arm64
- - image: Visual Studio 2015
- toolchain: clang
- - image: Visual Studio 2017
- toolchain: clang
-
-init:
-# Only run latest compiler on push, run everything on pull request
-- ps: if (!$env:APPVEYOR_PULL_REQUEST_NUMBER -and $env:APPVEYOR_BUILD_WORKER_IMAGE -ne "Visual Studio 2019") {Exit-AppveyorBuild}
-
-install:
-- cmd: >-
- git submodule update --init --recursive
-
-build_script:
-- cmd: >-
- .\tools\appveyor_ci.bat "%APPVEYOR_BUILD_WORKER_IMAGE%" %platform% %configuration% %toolchain% "%PYTHON%"
diff --git a/includes/acl/core/impl/compiler_utils.h b/includes/acl/core/impl/compiler_utils.h
--- a/includes/acl/core/impl/compiler_utils.h
+++ b/includes/acl/core/impl/compiler_utils.h
@@ -130,10 +130,12 @@ namespace acl
}
//////////////////////////////////////////////////////////////////////////
-// Wraps the __has_attribute pre-processor macro to handle non-clang and early
-// GCC compilers
+// Wraps the __has_attribute and __has_cpp_attribute pre-processor macros
+// to allow for C++ language feature detection
//////////////////////////////////////////////////////////////////////////
-#if defined(__has_attribute)
+#if defined(__has_cpp_attribute)
+ #define ACL_HAS_ATTRIBUTE(x) __has_cpp_attribute(x)
+#elif defined(__has_attribute)
#define ACL_HAS_ATTRIBUTE(x) __has_attribute(x)
#else
#define ACL_HAS_ATTRIBUTE(x) 0
@@ -141,9 +143,11 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Silence compiler warnings within switch cases that fall through
-// Note: C++17 has [[fallthrough]];
//////////////////////////////////////////////////////////////////////////
-#if ACL_HAS_ATTRIBUTE(fallthrough)
+#if RTM_CPP_VERSION >= RTM_CPP_VERSION_17
+ #define ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL [[fallthrough]]
+#elif ACL_HAS_ATTRIBUTE(fallthrough) && (defined(RTM_COMPILER_GCC) || defined(RTM_COMPILER_CLANG))
+ // For pre-C++17 support in GCC/Clang
#define ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL __attribute__ ((fallthrough))
#else
#define ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL (void)0
@@ -161,7 +165,11 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Allows us to specify branch hints
//////////////////////////////////////////////////////////////////////////
-#if defined(RTM_COMPILER_CLANG) || RTM_CPP_VERSION >= RTM_CPP_VERSION_20
+#if RTM_CPP_VERSION >= RTM_CPP_VERSION_20
+ #define ACL_BRANCH_LIKELY [[likely]]
+ #define ACL_BRANCH_UNLIKELY [[unlikely]]
+#elif defined(RTM_COMPILER_CLANG) && ACL_HAS_ATTRIBUTE(likely) && ACL_HAS_ATTRIBUTE(unlikely)
+ // Clang supported the same syntax as C++20 much earlier
#define ACL_BRANCH_LIKELY [[likely]]
#define ACL_BRANCH_UNLIKELY [[unlikely]]
#else
diff --git a/tools/acl_compressor/main_android/app/src/main/cpp/CMakeLists.txt b/tools/acl_compressor/main_android/app/src/main/cpp/CMakeLists.txt
--- a/tools/acl_compressor/main_android/app/src/main/cpp/CMakeLists.txt
+++ b/tools/acl_compressor/main_android/app/src/main/cpp/CMakeLists.txt
@@ -1,4 +1,4 @@
-cmake_minimum_required (VERSION 3.6)
+cmake_minimum_required(VERSION 3.2...3.25)
project(acl_compressor CXX)
# Project root is <acl-dir>\tools\compressor\main_android
diff --git a/tools/acl_decompressor/main_android/app/src/main/cpp/CMakeLists.txt b/tools/acl_decompressor/main_android/app/src/main/cpp/CMakeLists.txt
--- a/tools/acl_decompressor/main_android/app/src/main/cpp/CMakeLists.txt
+++ b/tools/acl_decompressor/main_android/app/src/main/cpp/CMakeLists.txt
@@ -1,4 +1,4 @@
-cmake_minimum_required (VERSION 3.6)
+cmake_minimum_required(VERSION 3.2...3.25)
project(acl_decompressor CXX)
# Project root is <acl-dir>\tools\decompressor\main_android
diff --git a/tools/regression_tester_android/app/src/main/cpp/CMakeLists.txt b/tools/regression_tester_android/app/src/main/cpp/CMakeLists.txt
--- a/tools/regression_tester_android/app/src/main/cpp/CMakeLists.txt
+++ b/tools/regression_tester_android/app/src/main/cpp/CMakeLists.txt
@@ -1,4 +1,4 @@
-cmake_minimum_required (VERSION 3.6)
+cmake_minimum_required(VERSION 3.2...3.25)
project(acl_regression_tester_android CXX)
# Project root is <acl-dir>\tools\regression_tester_android
|
diff --git a/tests/main_android/app/src/main/cpp/CMakeLists.txt b/tests/main_android/app/src/main/cpp/CMakeLists.txt
--- a/tests/main_android/app/src/main/cpp/CMakeLists.txt
+++ b/tests/main_android/app/src/main/cpp/CMakeLists.txt
@@ -1,4 +1,4 @@
-cmake_minimum_required (VERSION 3.6)
+cmake_minimum_required(VERSION 3.2...3.25)
project(acl_unit_tests CXX)
# Project root is <acl-dir>\tests\main_android
|
Upgrade minimum cmake version to compile with cmake 4
Hi, I'm currently trying to integrate acl into [o3de](https://github.com/o3de/o3de). Currently I use cmake 4.0.3 and I was stuck with the following error:
```
CMake Error at build/windows/_deps/acl-src/CMakeLists.txt:1 (cmake_minimum_required):
Compatibility with CMake < 3.5 has been removed from CMake.
Update the VERSION argument <min> value. Or, use the <min>...<max> syntax
to tell CMake that the project requires at least <min> but has been updated
to work with policies introduced by <max> or earlier.
Or, add -DCMAKE_POLICY_VERSION_MINIMUM=3.5 to try configuring anyway.
```
Is the build script reliant on old cmake behavior or is it safe to simply bump the cmake version?
|
Hello and thanks for reaching out!
ACL is a header only library and so you shouldn't need to run it with CMake in order to use it as an end user.
CMake is exclusively used by the tools and test harness for internal development. CMake does not produce binaries or artifacts that you would need to use for non-development purposes.
I ran into this error as well as it broke CI when they updated the image. I attempted a fix in a branch not yet merged into `develop` but ran into other issues. Simply bumping the min version means that older toolchains that are limited to using older CMake versions break (e.g. not so old Android NDK, sadly). I haven't decided yet if I will drop support for older toolchains. As recently as ~3 years ago, users in China were still using ACL with GCC 4.9... The nature of game development means that some teams that maintain live games opt to stop updating their toolchains. This was more prevalent before C++14 when using compiler extensions was much more common.
The build scripts don't rely on any particular CMake features from the past decade, they should work with any version AFAIK although I've seen warnings with newer versions which can be ignored.
For the time being, I would recommend you avoid running CMake with ACL for non-development purposes. Is that an option for you? In my experience, changes to ACL are rarely necessary for integration and unless you plan to develop new features in ACL, it shouldn't be necessary to use CMake with it.
My plan to tackle this is to attempt to use the <max> version specifier in hope that it can suppress this error. If it fails, I may have no choice but to remove older toolchains or find some other way to work around it.
Note that you will likely run into the same issue with the 2 dependencies ACL relies on: Realtime Math is required and uses the same CMake scripts (more or less) and sjson-cpp while optional uses the same patterns as well.
Cheers,
Nicholas
Using the 'max' version argument seems to resolve this issue. I'll be merging a fix shortly, within the next few days (at most).
| 2025-08-16T11:52:33
|
cpp
|
Hard
|
nfrechette/acl
| 240
|
nfrechette__acl-240
|
[
"170"
] |
9fa7ad1ad1dbc11136329a17d368acd045c27a99
|
diff --git a/cmake/CMakeCompiler.cmake b/cmake/CMakeCompiler.cmake
--- a/cmake/CMakeCompiler.cmake
+++ b/cmake/CMakeCompiler.cmake
@@ -20,7 +20,6 @@ macro(setup_default_compiler_flags _project_name)
target_compile_options(${_project_name} PRIVATE "/arch:AVX")
endif()
else()
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
@@ -49,7 +48,6 @@ macro(setup_default_compiler_flags _project_name)
target_compile_options(${_project_name} PRIVATE "-msse4.1")
endif()
else()
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/docs/misc_integration_details.md b/docs/misc_integration_details.md
--- a/docs/misc_integration_details.md
+++ b/docs/misc_integration_details.md
@@ -4,9 +4,9 @@
A small number of defines are exposed and can be used to finetune the behavior.
-### ACL_NO_INTRINSICS
+### RTM_NO_INTRINSICS
-This define prevents the usage of intrinsics unless explicitly requested by the integration manually (e.g. you can still defined `ACL_SSE2_INTRINSICS` yourself). Everything will default to pure scalar implementations.
+This define prevents the usage of intrinsics unless explicitly requested by the integration manually (e.g. you can still defined `RTM_SSE2_INTRINSICS` yourself). Everything will default to pure scalar implementations.
### ACL_USE_POPCOUNT
diff --git a/external/README.md b/external/README.md
--- a/external/README.md
+++ b/external/README.md
@@ -4,7 +4,7 @@
### Realtime Math
-[Reamtime Math v1.1.0](https://github.com/nfrechette/rtm/releases/tag/v1.1.0) (MIT License) is used for some math types and functions. Its usage is currently limited but a full transition to use it exclusively will occur for ACL v2.0. Needed only by the SJSON IO reader/writer and the scalar track compression/decompression API.
+[Reamtime Math v1.1.0-develop](https://github.com/nfrechette/rtm/releases/tag/v1.1.0) (MIT License) is used for some math types and functions. Its usage is currently limited but a full transition to use it exclusively will occur for ACL v2.0. Needed only by the SJSON IO reader/writer and the scalar track compression/decompression API.
## Development dependencies
diff --git a/external/rtm b/external/rtm
--- a/external/rtm
+++ b/external/rtm
@@ -1 +1 @@
-Subproject commit f4ec074cc4e5f07c26f71cf7cdf3c5644ec0da46
+Subproject commit 817753c3800d23e9583f25532f707b944d5ce54c
diff --git a/includes/acl/algorithm/uniformly_sampled/decoder.h b/includes/acl/algorithm/uniformly_sampled/decoder.h
--- a/includes/acl/algorithm/uniformly_sampled/decoder.h
+++ b/includes/acl/algorithm/uniformly_sampled/decoder.h
@@ -33,12 +33,13 @@
#include "acl/core/interpolation_utils.h"
#include "acl/core/range_reduction_types.h"
#include "acl/core/utils.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/quat_packing.h"
#include "acl/decompression/decompress_data.h"
#include "acl/decompression/output_writer.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -116,12 +117,12 @@ namespace acl
{
static constexpr size_t k_num_samples_to_interpolate = 2;
- inline static Quat_32 ACL_SIMD_CALL interpolate_rotation(Quat_32Arg0 rotation0, Quat_32Arg1 rotation1, float interpolation_alpha)
+ inline static rtm::quatf RTM_SIMD_CALL interpolate_rotation(rtm::quatf_arg0 rotation0, rtm::quatf_arg1 rotation1, float interpolation_alpha)
{
- return quat_lerp(rotation0, rotation1, interpolation_alpha);
+ return rtm::quat_lerp(rotation0, rotation1, interpolation_alpha);
}
- inline static Quat_32 ACL_SIMD_CALL interpolate_rotation(Quat_32Arg0 rotation0, Quat_32Arg1 rotation1, Quat_32Arg2 rotation2, Quat_32Arg3 rotation3, float interpolation_alpha)
+ inline static rtm::quatf RTM_SIMD_CALL interpolate_rotation(rtm::quatf_arg0 rotation0, rtm::quatf_arg1 rotation1, rtm::quatf_arg2 rotation2, rtm::quatf_arg3 rotation3, float interpolation_alpha)
{
(void)rotation1;
(void)rotation2;
@@ -130,12 +131,12 @@ namespace acl
return rotation0; // Not implemented, we use linear interpolation
}
- inline static Vector4_32 ACL_SIMD_CALL interpolate_vector4(Vector4_32Arg0 vector0, Vector4_32Arg1 vector1, float interpolation_alpha)
+ inline static rtm::vector4f RTM_SIMD_CALL interpolate_vector4(rtm::vector4f_arg0 vector0, rtm::vector4f_arg1 vector1, float interpolation_alpha)
{
- return vector_lerp(vector0, vector1, interpolation_alpha);
+ return rtm::vector_lerp(vector0, vector1, interpolation_alpha);
}
- inline static Vector4_32 ACL_SIMD_CALL interpolate_vector4(Vector4_32Arg0 vector0, Vector4_32Arg1 vector1, Vector4_32Arg2 vector2, Vector4_32Arg3 vector3, float interpolation_alpha)
+ inline static rtm::vector4f RTM_SIMD_CALL interpolate_vector4(rtm::vector4f_arg0 vector0, rtm::vector4f_arg1 vector1, rtm::vector4f_arg2 vector2, rtm::vector4f_arg3 vector3, float interpolation_alpha)
{
(void)vector1;
(void)vector2;
@@ -144,23 +145,23 @@ namespace acl
return vector0; // Not implemented, we use linear interpolation
}
- // // offsets
- uint32_t track_index; // 0 | 0
- uint32_t constant_track_data_offset; // 4 | 4
- uint32_t clip_range_data_offset; // 8 | 8
+ // // offsets
+ uint32_t track_index; // 0 | 0
+ uint32_t constant_track_data_offset; // 4 | 4
+ uint32_t clip_range_data_offset; // 8 | 8
- uint32_t format_per_track_data_offset; // 12 | 12
- uint32_t segment_range_data_offset; // 16 | 16
+ uint32_t format_per_track_data_offset; // 12 | 12
+ uint32_t segment_range_data_offset; // 16 | 16
- uint32_t key_frame_byte_offsets[2]; // 20 | 20 // Fixed quantization
- uint32_t key_frame_bit_offsets[2]; // 28 | 28 // Variable quantization
+ uint32_t key_frame_byte_offsets[2]; // 20 | 20 // Fixed quantization
+ uint32_t key_frame_bit_offsets[2]; // 28 | 28 // Variable quantization
- uint8_t padding[28]; // 36 | 36
+ uint8_t padding[28]; // 36 | 36
- Vector4_32 vectors[k_num_samples_to_interpolate]; // 64 | 64
- Vector4_32 padding0[2]; // 96 | 96
+ rtm::vector4f vectors[k_num_samples_to_interpolate]; // 64 | 64
+ rtm::vector4f padding0[2]; // 96 | 96
- // Total size: 128 | 128
+ // Total size: 128 | 128
};
static_assert(sizeof(SamplingContext) == 128, "Unexpected size");
@@ -174,7 +175,7 @@ namespace acl
explicit TranslationDecompressionSettingsAdapter(const SettingsType& settings_) : settings(settings_) {}
constexpr RangeReductionFlags8 get_range_reduction_flag() const { return RangeReductionFlags8::Translations; }
- inline Vector4_32 ACL_SIMD_CALL get_default_value() const { return vector_zero_32(); }
+ inline rtm::vector4f RTM_SIMD_CALL get_default_value() const { return rtm::vector_zero(); }
constexpr VectorFormat8 get_vector_format(const ClipHeader& header) const { return settings.get_translation_format(header.translation_format); }
constexpr bool is_vector_format_supported(VectorFormat8 format) const { return settings.is_translation_format_supported(format); }
@@ -191,11 +192,11 @@ namespace acl
{
explicit ScaleDecompressionSettingsAdapter(const SettingsType& settings_, const ClipHeader& header)
: settings(settings_)
- , default_scale(header.default_scale ? vector_set(1.0F) : vector_zero_32())
+ , default_scale(header.default_scale ? rtm::vector_set(1.0F) : rtm::vector_zero())
{}
constexpr RangeReductionFlags8 get_range_reduction_flag() const { return RangeReductionFlags8::Scales; }
- inline Vector4_32 ACL_SIMD_CALL get_default_value() const { return default_scale; }
+ inline rtm::vector4f RTM_SIMD_CALL get_default_value() const { return default_scale; }
constexpr VectorFormat8 get_vector_format(const ClipHeader& header) const { return settings.get_scale_format(header.scale_format); }
constexpr bool is_vector_format_supported(VectorFormat8 format) const { return settings.is_scale_format_supported(format); }
@@ -205,8 +206,8 @@ namespace acl
constexpr bool supports_mixed_packing() const { return settings.supports_mixed_packing(); }
SettingsType settings;
- uint8_t padding[get_required_padding<SettingsType, Vector4_32>()];
- Vector4_32 default_scale;
+ uint8_t padding[get_required_padding<SettingsType, rtm::vector4f>()];
+ rtm::vector4f default_scale;
};
}
@@ -326,7 +327,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Decompress a single bone at the current sample time.
// Each track entry is optional
- void decompress_bone(uint16_t sample_bone_index, Quat_32* out_rotation, Vector4_32* out_translation, Vector4_32* out_scale);
+ void decompress_bone(uint16_t sample_bone_index, rtm::quatf* out_rotation, rtm::vector4f* out_translation, rtm::vector4f* out_scale);
//////////////////////////////////////////////////////////////////////////
// Releases the context instance if it contains an allocator reference
@@ -463,7 +464,7 @@ namespace acl
// Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
// TODO: Make it optional via DecompressionSettingsType?
- sample_time = clamp(sample_time, 0.0F, m_context.clip_duration);
+ sample_time = rtm::scalar_clamp(sample_time, 0.0F, m_context.clip_duration);
if (m_context.sample_time == sample_time)
return;
@@ -583,7 +584,7 @@ namespace acl
skip_over_rotation(m_settings, header, m_context, sampling_context);
else
{
- const Quat_32 rotation = decompress_and_interpolate_rotation(m_settings, header, m_context, sampling_context);
+ const rtm::quatf rotation = decompress_and_interpolate_rotation(m_settings, header, m_context, sampling_context);
writer.write_bone_rotation(bone_index, rotation);
}
@@ -591,7 +592,7 @@ namespace acl
skip_over_vector(translation_adapter, header, m_context, sampling_context);
else
{
- const Vector4_32 translation = decompress_and_interpolate_vector(translation_adapter, header, m_context, sampling_context);
+ const rtm::vector4f translation = decompress_and_interpolate_vector(translation_adapter, header, m_context, sampling_context);
writer.write_bone_translation(bone_index, translation);
}
@@ -602,7 +603,7 @@ namespace acl
}
else
{
- const Vector4_32 scale = header.has_scale ? decompress_and_interpolate_vector(scale_adapter, header, m_context, sampling_context) : scale_adapter.get_default_value();
+ const rtm::vector4f scale = header.has_scale ? decompress_and_interpolate_vector(scale_adapter, header, m_context, sampling_context) : scale_adapter.get_default_value();
writer.write_bone_scale(bone_index, scale);
}
}
@@ -612,7 +613,7 @@ namespace acl
}
template<class DecompressionSettingsType>
- inline void DecompressionContext<DecompressionSettingsType>::decompress_bone(uint16_t sample_bone_index, Quat_32* out_rotation, Vector4_32* out_translation, Vector4_32* out_scale)
+ inline void DecompressionContext<DecompressionSettingsType>::decompress_bone(uint16_t sample_bone_index, rtm::quatf* out_rotation, rtm::vector4f* out_translation, rtm::vector4f* out_scale)
{
ACL_ASSERT(m_context.clip != nullptr, "Context is not initialized");
ACL_ASSERT(m_context.sample_time >= 0.0f, "Context not set to a valid sample time");
diff --git a/includes/acl/compression/animation_clip.h b/includes/acl/compression/animation_clip.h
--- a/includes/acl/compression/animation_clip.h
+++ b/includes/acl/compression/animation_clip.h
@@ -32,9 +32,10 @@
#include "acl/core/interpolation_utils.h"
#include "acl/core/string.h"
#include "acl/core/utils.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
-#include "acl/math/transform_32.h"
+
+#include <rtm/quatf.h>
+#include <rtm/qvvf.h>
+#include <rtm/vector4f.h>
#include <cstdint>
@@ -195,7 +196,7 @@ namespace acl
// - rounding_policy: The rounding policy to use when sampling
// - out_local_pose: An array of at least 'num_transforms' to output the data in
// - num_transforms: The number of transforms in the output array
- void sample_pose(float sample_time, SampleRoundingPolicy rounding_policy, Transform_32* out_local_pose, uint16_t num_transforms) const
+ void sample_pose(float sample_time, SampleRoundingPolicy rounding_policy, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
{
ACL_ASSERT(m_num_bones > 0, "Invalid number of bones: %u", m_num_bones);
ACL_ASSERT(m_num_bones == num_transforms, "Number of transforms does not match the number of bones: %u != %u", num_transforms, m_num_bones);
@@ -204,7 +205,7 @@ namespace acl
const float clip_duration = get_duration();
// Clamp for safety, the caller should normally handle this but in practice, it often isn't the case
- sample_time = clamp(sample_time, 0.0F, clip_duration);
+ sample_time = rtm::scalar_clamp(sample_time, 0.0F, clip_duration);
uint32_t sample_index0;
uint32_t sample_index1;
@@ -215,19 +216,19 @@ namespace acl
{
const AnimatedBone& bone = m_bones[bone_index];
- const Quat_32 rotation0 = quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index0)));
- const Quat_32 rotation1 = quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index1)));
- const Quat_32 rotation = quat_lerp(rotation0, rotation1, interpolation_alpha);
+ const rtm::quatf rotation0 = rtm::quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index0)));
+ const rtm::quatf rotation1 = rtm::quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index1)));
+ const rtm::quatf rotation = rtm::quat_lerp(rotation0, rotation1, interpolation_alpha);
- const Vector4_32 translation0 = vector_cast(bone.translation_track.get_sample(sample_index0));
- const Vector4_32 translation1 = vector_cast(bone.translation_track.get_sample(sample_index1));
- const Vector4_32 translation = vector_lerp(translation0, translation1, interpolation_alpha);
+ const rtm::vector4f translation0 = rtm::vector_cast(bone.translation_track.get_sample(sample_index0));
+ const rtm::vector4f translation1 = rtm::vector_cast(bone.translation_track.get_sample(sample_index1));
+ const rtm::vector4f translation = rtm::vector_lerp(translation0, translation1, interpolation_alpha);
- const Vector4_32 scale0 = vector_cast(bone.scale_track.get_sample(sample_index0));
- const Vector4_32 scale1 = vector_cast(bone.scale_track.get_sample(sample_index1));
- const Vector4_32 scale = vector_lerp(scale0, scale1, interpolation_alpha);
+ const rtm::vector4f scale0 = rtm::vector_cast(bone.scale_track.get_sample(sample_index0));
+ const rtm::vector4f scale1 = rtm::vector_cast(bone.scale_track.get_sample(sample_index1));
+ const rtm::vector4f scale = rtm::vector_lerp(scale0, scale1, interpolation_alpha);
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
@@ -236,7 +237,7 @@ namespace acl
// - sample_time: The time at which to sample the clip
// - out_local_pose: An array of at least 'num_transforms' to output the data in
// - num_transforms: The number of transforms in the output array
- void sample_pose(float sample_time, Transform_32* out_local_pose, uint16_t num_transforms) const
+ void sample_pose(float sample_time, rtm::qvvf* out_local_pose, uint16_t num_transforms) const
{
sample_pose(sample_time, SampleRoundingPolicy::None, out_local_pose, num_transforms);
}
@@ -336,7 +337,7 @@ namespace acl
// bone has a scale sample that isn't equivalent to the default scale.
bool has_scale(float threshold) const
{
- const Vector4_32 default_scale = get_default_scale(m_additive_format);
+ const rtm::vector4f default_scale = get_default_scale(m_additive_format);
for (uint16_t bone_index = 0; bone_index < m_num_bones; ++bone_index)
{
@@ -344,25 +345,25 @@ namespace acl
const uint32_t num_samples = bone.scale_track.get_num_samples();
if (num_samples != 0)
{
- const Vector4_32 scale = vector_cast(bone.scale_track.get_sample(0));
+ const rtm::vector4f scale = rtm::vector_cast(bone.scale_track.get_sample(0));
- Vector4_32 min = scale;
- Vector4_32 max = scale;
+ rtm::vector4f min = scale;
+ rtm::vector4f max = scale;
for (uint32_t sample_index = 1; sample_index < num_samples; ++sample_index)
{
- const Vector4_32 sample = vector_cast(bone.scale_track.get_sample(sample_index));
+ const rtm::vector4f sample = rtm::vector_cast(bone.scale_track.get_sample(sample_index));
- min = vector_min(min, sample);
- max = vector_max(max, sample);
+ min = rtm::vector_min(min, sample);
+ max = rtm::vector_max(max, sample);
}
- const Vector4_32 extent = vector_sub(max, min);
- const bool is_constant = vector_all_less_than3(vector_abs(extent), vector_set(threshold));
+ const rtm::vector4f extent = rtm::vector_sub(max, min);
+ const bool is_constant = rtm::vector_all_less_than3(rtm::vector_abs(extent), rtm::vector_set(threshold));
if (!is_constant)
return true; // Not constant means we have scale
- const bool is_default = vector_all_near_equal3(scale, default_scale, threshold);
+ const bool is_default = rtm::vector_all_near_equal3(scale, default_scale, threshold);
if (!is_default)
return true; // Constant but not default means we have scale
}
diff --git a/includes/acl/compression/animation_track.h b/includes/acl/compression/animation_track.h
--- a/includes/acl/compression/animation_track.h
+++ b/includes/acl/compression/animation_track.h
@@ -28,8 +28,9 @@
#include "acl/core/iallocator.h"
#include "acl/core/error.h"
#include "acl/core/track_types.h"
-#include "acl/math/quat_64.h"
-#include "acl/math/vector4_64.h"
+
+#include <rtm/quatd.h>
+#include <rtm/vector4d.h>
#include <cstdint>
#include <utility>
@@ -90,7 +91,7 @@ namespace acl
// - type: The track type
AnimationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate, AnimationTrackType8 type)
: m_allocator(&allocator)
- , m_sample_data(allocate_type_array_aligned<double>(allocator, size_t(num_samples) * get_animation_track_sample_size(type), alignof(Vector4_64)))
+ , m_sample_data(allocate_type_array_aligned<double>(allocator, size_t(num_samples) * get_animation_track_sample_size(type), alignof(rtm::vector4d)))
, m_num_samples(num_samples)
, m_sample_rate(sample_rate)
, m_type(type)
@@ -148,7 +149,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// A raw rotation track.
//
- // Holds a track made of 'Quat_64' entries.
+ // Holds a track made of 'rtm::quatd' entries.
//////////////////////////////////////////////////////////////////////////
class AnimationRotationTrack final : public AnimationTrack
{
@@ -165,15 +166,15 @@ namespace acl
AnimationRotationTrack(IAllocator& allocator, uint32_t num_samples, uint32_t sample_rate)
: AnimationTrack(allocator, num_samples, float(sample_rate), AnimationTrackType8::Rotation)
{
- Quat_64* samples = safe_ptr_cast<Quat_64>(&m_sample_data[0]);
- std::fill(samples, samples + num_samples, quat_identity_64());
+ rtm::quatd* samples = safe_ptr_cast<rtm::quatd>(&m_sample_data[0]);
+ std::fill(samples, samples + num_samples, rtm::quat_identity());
}
AnimationRotationTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
: AnimationTrack(allocator, num_samples, sample_rate, AnimationTrackType8::Rotation)
{
- Quat_64* samples = safe_ptr_cast<Quat_64>(&m_sample_data[0]);
- std::fill(samples, samples + num_samples, quat_identity_64());
+ rtm::quatd* samples = safe_ptr_cast<rtm::quatd>(&m_sample_data[0]);
+ std::fill(samples, samples + num_samples, rtm::quat_identity());
}
AnimationRotationTrack(AnimationRotationTrack&& other)
@@ -188,23 +189,23 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Sets a sample value at a particular index
- VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const Quat_64& rotation)
+ VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const rtm::quatd& rotation)
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(quat_is_finite(rotation), "Invalid rotation: [%f, %f, %f, %f]", quat_get_x(rotation), quat_get_y(rotation), quat_get_z(rotation), quat_get_w(rotation));
- ACL_ASSERT(quat_is_normalized(rotation), "Rotation not normalized: [%f, %f, %f, %f]", quat_get_x(rotation), quat_get_y(rotation), quat_get_z(rotation), quat_get_w(rotation));
+ ACL_ASSERT(rtm::quat_is_finite(rotation), "Invalid rotation: [%f, %f, %f, %f]", rtm::quat_get_x(rotation), rtm::quat_get_y(rotation), rtm::quat_get_z(rotation), rtm::quat_get_w(rotation));
+ ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation not normalized: [%f, %f, %f, %f]", rtm::quat_get_x(rotation), rtm::quat_get_y(rotation), rtm::quat_get_z(rotation), rtm::quat_get_w(rotation));
const uint32_t sample_size = get_animation_track_sample_size(m_type);
ACL_ASSERT(sample_size == 4, "Invalid sample size. %u != 4", sample_size);
double* sample = &m_sample_data[sample_index * sample_size];
- quat_unaligned_write(rotation, sample);
+ rtm::quat_store(rotation, sample);
}
//////////////////////////////////////////////////////////////////////////
// Retrieves a sample value at a particular index
- Quat_64 get_sample(uint32_t sample_index) const
+ rtm::quatd get_sample(uint32_t sample_index) const
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
@@ -212,7 +213,7 @@ namespace acl
const uint32_t sample_size = get_animation_track_sample_size(m_type);
const double* sample = &m_sample_data[sample_index * sample_size];
- return quat_unaligned_load(sample);
+ return rtm::quat_load(sample);
}
AnimationRotationTrack(const AnimationRotationTrack&) = delete;
@@ -260,22 +261,22 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Sets a sample value at a particular index
- void set_sample(uint32_t sample_index, const Vector4_64& translation)
+ void set_sample(uint32_t sample_index, const rtm::vector4d& translation)
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(vector_is_finite3(translation), "Invalid translation: [%f, %f, %f]", vector_get_x(translation), vector_get_y(translation), vector_get_z(translation));
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Invalid translation: [%f, %f, %f]", rtm::vector_get_x(translation), rtm::vector_get_y(translation), rtm::vector_get_z(translation));
const uint32_t sample_size = get_animation_track_sample_size(m_type);
ACL_ASSERT(sample_size == 3, "Invalid sample size. %u != 3", sample_size);
double* sample = &m_sample_data[sample_index * sample_size];
- vector_unaligned_write3(translation, sample);
+ rtm::vector_store3(translation, sample);
}
//////////////////////////////////////////////////////////////////////////
// Retrieves a sample value at a particular index
- Vector4_64 get_sample(uint32_t sample_index) const
+ rtm::vector4d get_sample(uint32_t sample_index) const
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
@@ -283,7 +284,7 @@ namespace acl
const uint32_t sample_size = get_animation_track_sample_size(m_type);
const double* sample = &m_sample_data[sample_index * sample_size];
- return vector_unaligned_load3(sample);
+ return rtm::vector_load3(sample);
}
AnimationTranslationTrack(const AnimationTranslationTrack&) = delete;
@@ -310,17 +311,17 @@ namespace acl
AnimationScaleTrack(IAllocator& allocator, uint32_t num_samples, uint32_t sample_rate)
: AnimationTrack(allocator, num_samples, float(sample_rate), AnimationTrackType8::Scale)
{
- Vector4_64 defaultScale = vector_set(1.0);
+ rtm::vector4d defaultScale = rtm::vector_set(1.0);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- vector_unaligned_write3(defaultScale, m_sample_data + (sample_index * 3));
+ rtm::vector_store3(defaultScale, m_sample_data + (sample_index * 3));
}
AnimationScaleTrack(IAllocator& allocator, uint32_t num_samples, float sample_rate)
: AnimationTrack(allocator, num_samples, sample_rate, AnimationTrackType8::Scale)
{
- Vector4_64 defaultScale = vector_set(1.0);
+ rtm::vector4d defaultScale = rtm::vector_set(1.0);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
- vector_unaligned_write3(defaultScale, m_sample_data + (sample_index * 3));
+ rtm::vector_store3(defaultScale, m_sample_data + (sample_index * 3));
}
AnimationScaleTrack(AnimationScaleTrack&& other)
@@ -335,22 +336,22 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Sets a sample value at a particular index
- VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const Vector4_64& scale)
+ VS2015_HACK_NO_INLINE void set_sample(uint32_t sample_index, const rtm::vector4d& scale)
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
- ACL_ASSERT(vector_is_finite3(scale), "Invalid scale: [%f, %f, %f]", vector_get_x(scale), vector_get_y(scale), vector_get_z(scale));
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Invalid scale: [%f, %f, %f]", rtm::vector_get_x(scale), rtm::vector_get_y(scale), rtm::vector_get_z(scale));
const uint32_t sample_size = get_animation_track_sample_size(m_type);
ACL_ASSERT(sample_size == 3, "Invalid sample size. %u != 3", sample_size);
double* sample = &m_sample_data[sample_index * sample_size];
- vector_unaligned_write3(scale, sample);
+ rtm::vector_store3(scale, sample);
}
//////////////////////////////////////////////////////////////////////////
// Retrieves a sample value at a particular index
- Vector4_64 get_sample(uint32_t sample_index) const
+ rtm::vector4d get_sample(uint32_t sample_index) const
{
ACL_ASSERT(is_initialized(), "Track is not initialized");
ACL_ASSERT(sample_index < m_num_samples, "Invalid sample index. %u >= %u", sample_index, m_num_samples);
@@ -358,7 +359,7 @@ namespace acl
const uint32_t sample_size = get_animation_track_sample_size(m_type);
const double* sample = &m_sample_data[sample_index * sample_size];
- return vector_unaligned_load3(sample);
+ return rtm::vector_load3(sample);
}
AnimationScaleTrack(const AnimationScaleTrack&) = delete;
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -31,7 +31,9 @@
#include "acl/core/range_reduction_types.h"
#include "acl/compression/compression_level.h"
#include "acl/compression/skeleton_error_metric.h"
-#include "acl/math/scalar_32.h"
+
+#include <rtm/anglef.h>
+#include <rtm/scalarf.h>
#include <cstdint>
@@ -137,7 +139,7 @@ namespace acl
// was chosen. You will typically NEVER need to change this, the value has been
// selected to be as safe as possible and is independent of game engine units.
// Defaults to '0.00284714461' radians
- float constant_rotation_threshold_angle;
+ rtm::anglef constant_rotation_threshold_angle;
//////////////////////////////////////////////////////////////////////////
// Threshold value to use when detecting if translation tracks are constant or default.
@@ -168,7 +170,7 @@ namespace acl
, range_reduction(RangeReductionFlags8::None)
, segmenting()
, error_metric(nullptr)
- , constant_rotation_threshold_angle(0.00284714461F)
+ , constant_rotation_threshold_angle(rtm::radians(0.00284714461F))
, constant_translation_threshold(0.001F)
, constant_scale_threshold(0.00001F)
, error_threshold(0.01F)
@@ -230,16 +232,17 @@ namespace acl
if (error_metric == nullptr)
return ErrorResult("error_metric cannot be NULL");
- if (constant_rotation_threshold_angle < 0.0F || !is_finite(constant_rotation_threshold_angle))
+ const float rotation_threshold_angle = constant_rotation_threshold_angle.as_radians();
+ if (rotation_threshold_angle < 0.0F || !rtm::scalar_is_finite(rotation_threshold_angle))
return ErrorResult("Invalid constant_rotation_threshold_angle");
- if (constant_translation_threshold < 0.0F || !is_finite(constant_translation_threshold))
+ if (constant_translation_threshold < 0.0F || !rtm::scalar_is_finite(constant_translation_threshold))
return ErrorResult("Invalid constant_translation_threshold");
- if (constant_scale_threshold < 0.0F || !is_finite(constant_scale_threshold))
+ if (constant_scale_threshold < 0.0F || !rtm::scalar_is_finite(constant_scale_threshold))
return ErrorResult("Invalid constant_scale_threshold");
- if (error_threshold < 0.0F || !is_finite(error_threshold))
+ if (error_threshold < 0.0F || !rtm::scalar_is_finite(error_threshold))
return ErrorResult("Invalid error_threshold");
return segmenting.is_valid();
diff --git a/includes/acl/compression/impl/quantize_track_impl.h b/includes/acl/compression/impl/quantize_track_impl.h
--- a/includes/acl/compression/impl/quantize_track_impl.h
+++ b/includes/acl/compression/impl/quantize_track_impl.h
@@ -49,7 +49,7 @@ namespace acl
ACL_ASSERT(num_bits > 0, "Cannot decay with 0 bits");
ACL_ASSERT(num_bits < 31, "Attempting to decay on too many bits");
- const float max_value_ = safe_to_float((1 << num_bits) - 1);
+ const float max_value_ = rtm::scalar_safe_to_float((1 << num_bits) - 1);
max_value = rtm::vector_set(max_value_);
inv_max_value = rtm::vector_set(1.0F / max_value_);
}
diff --git a/includes/acl/compression/impl/track_bit_rate_database.h b/includes/acl/compression/impl/track_bit_rate_database.h
--- a/includes/acl/compression/impl/track_bit_rate_database.h
+++ b/includes/acl/compression/impl/track_bit_rate_database.h
@@ -29,6 +29,10 @@
#include "acl/compression/stream/sample_streams.h"
#include "acl/compression/stream/track_stream.h"
+#include <rtm/quatf.h>
+#include <rtm/qvvf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
// 0 = disabled, 1 = enabled
@@ -145,8 +149,8 @@ namespace acl
void set_segment(const BoneStreams* bone_streams, uint32_t num_transforms, uint32_t num_samples_per_track);
- void sample(const single_track_query& query, float sample_time, Transform_32* out_transforms, uint32_t num_transforms);
- void sample(const hierarchical_track_query& query, float sample_time, Transform_32* out_transforms, uint32_t num_transforms);
+ void sample(const single_track_query& query, float sample_time, rtm::qvvf* out_transforms, uint32_t num_transforms);
+ void sample(const hierarchical_track_query& query, float sample_time, rtm::qvvf* out_transforms, uint32_t num_transforms);
private:
track_bit_rate_database(const track_bit_rate_database&) = delete;
@@ -157,13 +161,13 @@ namespace acl
void find_cache_entries(uint32_t track_index, const BoneBitRate& bit_rates, uint32_t& out_rotation_cache_index, uint32_t& out_translation_cache_index, uint32_t& out_scale_cache_index);
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Quat_32 ACL_SIMD_CALL sample_rotation(const sample_context& context, uint32_t rotation_cache_index);
+ ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, uint32_t rotation_cache_index);
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_translation(const sample_context& context, uint32_t translation_cache_index);
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, uint32_t translation_cache_index);
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_scale(const sample_context& context, uint32_t scale_cache_index);
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, uint32_t scale_cache_index);
struct transform_cache_entry
{
@@ -192,7 +196,7 @@ namespace acl
static int32_t find_bit_rate_index(const bit_rates_union& bit_rates, uint32_t search_bit_rate);
};
- Vector4_32 m_default_scale;
+ rtm::vector4f m_default_scale;
IAllocator& m_allocator;
const BoneStreams* m_mutable_bone_streams;
@@ -327,7 +331,7 @@ namespace acl
// We allocate a single float buffer to accommodate 4 bit rates for every rot/trans/scale track of each transform.
// Each track is padded and aligned to ensure that it starts on a cache line boundary.
- const uint32_t track_size = align_to<uint32_t>(sizeof(Vector4_32) * num_samples_per_track, 64);
+ const uint32_t track_size = align_to<uint32_t>(sizeof(rtm::vector4f) * num_samples_per_track, 64);
m_track_size = track_size;
const uint32_t data_size = track_size * num_cached_tracks;
@@ -571,18 +575,18 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Quat_32 ACL_SIMD_CALL track_bit_rate_database::sample_rotation(const sample_context& context, uint32_t rotation_cache_index)
+ ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL track_bit_rate_database::sample_rotation(const sample_context& context, uint32_t rotation_cache_index)
{
const uint32_t track_index = context.track_index;
const BoneStreams& bone_stream = m_mutable_bone_streams[track_index];
- Quat_32 rotation;
+ rtm::quatf rotation;
if (bone_stream.is_rotation_default)
- rotation = quat_identity_32();
+ rotation = rtm::quat_identity();
else if (bone_stream.is_rotation_constant)
{
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * rotation_cache_index);
- Quat_32* cached_samples = safe_ptr_cast<Quat_32>(m_data + (m_track_size * rotation_cache_index));
+ rtm::quatf* cached_samples = safe_ptr_cast<rtm::quatf>(m_data + (m_track_size * rotation_cache_index));
if (bitset_test(validity_bitset, m_bitref_constant))
{
@@ -603,7 +607,7 @@ namespace acl
// If we are uniform, normalize now. Variable will interpolate and normalize after.
if (static_condition<distribution == SampleDistribution8::Uniform>::test())
- rotation = quat_normalize(rotation);
+ rotation = rtm::quat_normalize(rotation);
cached_samples[0] = rotation;
bitset_set(validity_bitset, m_bitref_constant, true);
@@ -618,7 +622,7 @@ namespace acl
const BoneStreams& raw_bone_stream = m_raw_bone_streams[track_index];
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * rotation_cache_index);
- Quat_32* cached_samples = safe_ptr_cast<Quat_32>(m_data + (m_track_size * rotation_cache_index));
+ rtm::quatf* cached_samples = safe_ptr_cast<rtm::quatf>(m_data + (m_track_size * rotation_cache_index));
uint32_t key0;
uint32_t key1;
@@ -637,8 +641,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Quat_32 sample0;
- Quat_32 sample1;
+ rtm::quatf sample0;
+ rtm::quatf sample1;
const BitSetIndexRef bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
@@ -660,7 +664,7 @@ namespace acl
// If we are uniform, normalize now. Variable will interpolate and normalize after.
if (static_condition<distribution == SampleDistribution8::Uniform>::test())
- sample0 = quat_normalize(sample0);
+ sample0 = rtm::quat_normalize(sample0);
cached_samples[key0] = sample0;
bitset_set(validity_bitset, bitref0, true);
@@ -698,7 +702,7 @@ namespace acl
#endif
}
- rotation = quat_lerp(sample0, sample1, interpolation_alpha);
+ rotation = rtm::quat_lerp(sample0, sample1, interpolation_alpha);
}
else
{
@@ -710,18 +714,18 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL track_bit_rate_database::sample_translation(const sample_context& context, uint32_t translation_cache_index)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL track_bit_rate_database::sample_translation(const sample_context& context, uint32_t translation_cache_index)
{
const uint32_t track_index = context.track_index;
const BoneStreams& bone_stream = m_mutable_bone_streams[track_index];
- Vector4_32 translation;
+ rtm::vector4f translation;
if (bone_stream.is_translation_default)
- translation = vector_zero_32();
+ translation = rtm::vector_zero();
else if (bone_stream.is_translation_constant)
{
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * translation_cache_index);
- Vector4_32* cached_samples = safe_ptr_cast<Vector4_32>(m_data + (m_track_size * translation_cache_index));
+ rtm::vector4f* cached_samples = safe_ptr_cast<rtm::vector4f>(m_data + (m_track_size * translation_cache_index));
if (bitset_test(validity_bitset, m_bitref_constant))
{
@@ -750,7 +754,7 @@ namespace acl
const BoneStreams& raw_bone_stream = m_raw_bone_streams[track_index];
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * translation_cache_index);
- Vector4_32* cached_samples = safe_ptr_cast<Vector4_32>(m_data + (m_track_size * translation_cache_index));
+ rtm::vector4f* cached_samples = safe_ptr_cast<rtm::vector4f>(m_data + (m_track_size * translation_cache_index));
uint32_t key0;
uint32_t key1;
@@ -769,8 +773,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Vector4_32 sample0;
- Vector4_32 sample1;
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
const BitSetIndexRef bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
@@ -826,7 +830,7 @@ namespace acl
#endif
}
- translation = vector_lerp(sample0, sample1, interpolation_alpha);
+ translation = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
else
{
@@ -838,18 +842,18 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL track_bit_rate_database::sample_scale(const sample_context& context, uint32_t scale_cache_index)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL track_bit_rate_database::sample_scale(const sample_context& context, uint32_t scale_cache_index)
{
const uint32_t track_index = context.track_index;
const BoneStreams& bone_stream = m_mutable_bone_streams[track_index];
- Vector4_32 scale;
+ rtm::vector4f scale;
if (bone_stream.is_scale_default)
scale = m_default_scale;
else if (bone_stream.is_scale_constant)
{
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * scale_cache_index);
- Vector4_32* cached_samples = safe_ptr_cast<Vector4_32>(m_data + (m_track_size * scale_cache_index));
+ rtm::vector4f* cached_samples = safe_ptr_cast<rtm::vector4f>(m_data + (m_track_size * scale_cache_index));
if (bitset_test(validity_bitset, m_bitref_constant))
{
@@ -878,7 +882,7 @@ namespace acl
const BoneStreams& raw_bone_stream = m_raw_bone_streams[track_index];
uint32_t* validity_bitset = m_track_entry_bitsets + (m_bitset_desc.get_size() * scale_cache_index);
- Vector4_32* cached_samples = safe_ptr_cast<Vector4_32>(m_data + (m_track_size * scale_cache_index));
+ rtm::vector4f* cached_samples = safe_ptr_cast<rtm::vector4f>(m_data + (m_track_size * scale_cache_index));
uint32_t key0;
uint32_t key1;
@@ -897,8 +901,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Vector4_32 sample0;
- Vector4_32 sample1;
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
const BitSetIndexRef bitref0(m_bitset_desc, key0);
if (bitset_test(validity_bitset, bitref0))
@@ -954,7 +958,7 @@ namespace acl
#endif
}
- scale = vector_lerp(sample0, sample1, interpolation_alpha);
+ scale = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
else
{
@@ -965,7 +969,7 @@ namespace acl
return scale;
}
- inline void track_bit_rate_database::sample(const single_track_query& query, float sample_time, Transform_32* out_local_pose, uint32_t num_transforms)
+ inline void track_bit_rate_database::sample(const single_track_query& query, float sample_time, rtm::qvvf* out_local_pose, uint32_t num_transforms)
{
ACL_ASSERT(query.m_database == this, "Query has not been built for this database");
ACL_ASSERT(out_local_pose != nullptr, "Cannot write to null output local pose");
@@ -986,9 +990,9 @@ namespace acl
context.sample_time = sample_time;
context.bit_rates = query.m_bit_rates;
- Quat_32 rotation;
- Vector4_32 translation;
- Vector4_32 scale;
+ rtm::quatf rotation;
+ rtm::vector4f translation;
+ rtm::vector4f scale;
if (segment_context->distribution == SampleDistribution8::Uniform)
{
rotation = sample_rotation<SampleDistribution8::Uniform>(context, query.m_rotation_cache_index);
@@ -1002,10 +1006,10 @@ namespace acl
scale = sample_scale<SampleDistribution8::Variable>(context, query.m_scale_cache_index);
}
- out_local_pose[query.m_track_index] = transform_set(rotation, translation, scale);
+ out_local_pose[query.m_track_index] = rtm::qvv_set(rotation, translation, scale);
}
- inline void track_bit_rate_database::sample(const hierarchical_track_query& query, float sample_time, Transform_32* out_local_pose, uint32_t num_transforms)
+ inline void track_bit_rate_database::sample(const hierarchical_track_query& query, float sample_time, rtm::qvvf* out_local_pose, uint32_t num_transforms)
{
ACL_ASSERT(out_local_pose != nullptr, "Cannot write to null output local pose");
ACL_ASSERT(num_transforms > 0, "Cannot write to empty output local pose");
@@ -1034,11 +1038,11 @@ namespace acl
context.track_index = current_track_index;
context.bit_rates = query.m_bit_rates[current_track_index];
- const Quat_32 rotation = sample_rotation<SampleDistribution8::Uniform>(context, indices.rotation_cache_index);
- const Vector4_32 translation = sample_translation<SampleDistribution8::Uniform>(context, indices.translation_cache_index);
- const Vector4_32 scale = sample_scale<SampleDistribution8::Uniform>(context, indices.scale_cache_index);
+ const rtm::quatf rotation = sample_rotation<SampleDistribution8::Uniform>(context, indices.rotation_cache_index);
+ const rtm::vector4f translation = sample_translation<SampleDistribution8::Uniform>(context, indices.translation_cache_index);
+ const rtm::vector4f scale = sample_scale<SampleDistribution8::Uniform>(context, indices.scale_cache_index);
- out_local_pose[current_track_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_track_index] = rtm::qvv_set(rotation, translation, scale);
current_track_index = bone_stream.parent_bone_index;
}
}
@@ -1053,11 +1057,11 @@ namespace acl
context.track_index = current_track_index;
context.bit_rates = query.m_bit_rates[current_track_index];
- const Quat_32 rotation = sample_rotation<SampleDistribution8::Variable>(context, indices.rotation_cache_index);
- const Vector4_32 translation = sample_translation<SampleDistribution8::Variable>(context, indices.translation_cache_index);
- const Vector4_32 scale = sample_scale<SampleDistribution8::Variable>(context, indices.scale_cache_index);
+ const rtm::quatf rotation = sample_rotation<SampleDistribution8::Variable>(context, indices.rotation_cache_index);
+ const rtm::vector4f translation = sample_translation<SampleDistribution8::Variable>(context, indices.translation_cache_index);
+ const rtm::vector4f scale = sample_scale<SampleDistribution8::Variable>(context, indices.scale_cache_index);
- out_local_pose[current_track_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_track_index] = rtm::qvv_set(rotation, translation, scale);
current_track_index = bone_stream.parent_bone_index;
}
}
diff --git a/includes/acl/compression/skeleton.h b/includes/acl/compression/skeleton.h
--- a/includes/acl/compression/skeleton.h
+++ b/includes/acl/compression/skeleton.h
@@ -29,7 +29,8 @@
#include "acl/core/error.h"
#include "acl/core/iallocator.h"
#include "acl/core/string.h"
-#include "acl/math/transform_64.h"
+
+#include <rtm/qvvd.h>
#include <cstdint>
@@ -136,7 +137,7 @@ namespace acl
, bone_chain(nullptr)
, vertex_distance(1.0F)
, parent_index(k_invalid_bone_index)
- , bind_transform(transform_identity_64())
+ , bind_transform(rtm::qvv_identity())
{
(void)padding;
}
@@ -189,7 +190,7 @@ namespace acl
// The bind transform is in its parent's local space
// Note that the scale is ignored and this value is only used by the additive error metrics
- Transform_64 bind_transform;
+ rtm::qvvd bind_transform;
};
//////////////////////////////////////////////////////////////////////////
@@ -235,9 +236,9 @@ namespace acl
ACL_ASSERT(bone.bone_chain == nullptr, "Bone chain should be calculated internally");
ACL_ASSERT(is_root || bone.parent_index < bone_index, "Bones must be sorted parent first");
- ACL_ASSERT(quat_is_finite(bone.bind_transform.rotation), "Bind rotation is invalid: [%f, %f, %f, %f]", quat_get_x(bone.bind_transform.rotation), quat_get_y(bone.bind_transform.rotation), quat_get_z(bone.bind_transform.rotation), quat_get_w(bone.bind_transform.rotation));
- ACL_ASSERT(quat_is_normalized(bone.bind_transform.rotation), "Bind rotation isn't normalized: [%f, %f, %f, %f]", quat_get_x(bone.bind_transform.rotation), quat_get_y(bone.bind_transform.rotation), quat_get_z(bone.bind_transform.rotation), quat_get_w(bone.bind_transform.rotation));
- ACL_ASSERT(vector_is_finite3(bone.bind_transform.translation), "Bind translation is invalid: [%f, %f, %f]", vector_get_x(bone.bind_transform.translation), vector_get_y(bone.bind_transform.translation), vector_get_z(bone.bind_transform.translation));
+ ACL_ASSERT(rtm::quat_is_finite(bone.bind_transform.rotation), "Bind rotation is invalid: [%f, %f, %f, %f]", rtm::quat_get_x(bone.bind_transform.rotation), rtm::quat_get_y(bone.bind_transform.rotation), rtm::quat_get_z(bone.bind_transform.rotation), rtm::quat_get_w(bone.bind_transform.rotation));
+ ACL_ASSERT(rtm::quat_is_normalized(bone.bind_transform.rotation), "Bind rotation isn't normalized: [%f, %f, %f, %f]", rtm::quat_get_x(bone.bind_transform.rotation), rtm::quat_get_y(bone.bind_transform.rotation), rtm::quat_get_z(bone.bind_transform.rotation), rtm::quat_get_w(bone.bind_transform.rotation));
+ ACL_ASSERT(rtm::vector_is_finite3(bone.bind_transform.translation), "Bind translation is invalid: [%f, %f, %f]", rtm::vector_get_x(bone.bind_transform.translation), rtm::vector_get_y(bone.bind_transform.translation), rtm::vector_get_z(bone.bind_transform.translation));
// If we have a parent, mark it as not being a leaf bone (it has at least one child)
if (!is_root)
@@ -251,7 +252,7 @@ namespace acl
m_bones[bone_index] = std::move(bone);
// Input scale is ignored and always set to [1.0, 1.0, 1.0]
- m_bones[bone_index].bind_transform.scale = vector_set(1.0);
+ m_bones[bone_index].bind_transform.scale = rtm::vector_set(1.0);
}
m_num_leaf_bones = safe_static_cast<uint16_t>(bitset_count_set_bits(is_leaf_bitset, bone_bitset_desc));
diff --git a/includes/acl/compression/skeleton_error_metric.h b/includes/acl/compression/skeleton_error_metric.h
--- a/includes/acl/compression/skeleton_error_metric.h
+++ b/includes/acl/compression/skeleton_error_metric.h
@@ -27,11 +27,12 @@
#include "acl/core/additive_utils.h"
#include "acl/core/compiler_utils.h"
#include "acl/core/hash.h"
-#include "acl/math/affine_matrix_32.h"
-#include "acl/math/transform_32.h"
-#include "acl/math/scalar_32.h"
#include "acl/compression/skeleton.h"
+#include <rtm/matrix3x4f.h>
+#include <rtm/qvvf.h>
+#include <rtm/scalarf.h>
+
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
@@ -45,11 +46,11 @@ namespace acl
virtual const char* get_name() const = 0;
virtual uint32_t get_hash() const = 0;
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const = 0;
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const = 0;
+ virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
+ virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const = 0;
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const = 0;
+ virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
+ virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const = 0;
};
// Uses a mix of Transform_32 and AffineMatrix_32 arithmetic.
@@ -64,7 +65,7 @@ namespace acl
virtual const char* get_name() const override { return "TransformMatrixErrorMetric"; }
virtual uint32_t get_hash() const override { return hash32("TransformMatrixErrorMetric"); }
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
@@ -72,53 +73,53 @@ namespace acl
const RigidBone& bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, bone.vertex_distance);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
- const Vector4_32 raw_vtx0 = transform_position(raw_local_pose[bone_index], vtx0);
- const Vector4_32 lossy_vtx0 = transform_position(lossy_local_pose[bone_index], vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_local_pose[bone_index]);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position(raw_local_pose[bone_index], vtx1);
- const Vector4_32 lossy_vtx1 = transform_position(lossy_local_pose[bone_index], vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_local_pose[bone_index]);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const Vector4_32 raw_vtx2 = transform_position(raw_local_pose[bone_index], vtx2);
- const Vector4_32 lossy_vtx2 = transform_position(lossy_local_pose[bone_index], vtx2);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_local_pose[bone_index]);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
const RigidBone& bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_local_pose[bone_index], vtx0);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_local_pose[bone_index], vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_local_pose[bone_index]);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_local_pose[bone_index], vtx1);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_local_pose[bone_index], vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_local_pose[bone_index]);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
- AffineMatrix_32 raw_obj_mtx = matrix_from_transform(raw_local_pose[0]);
- AffineMatrix_32 lossy_obj_mtx = matrix_from_transform(lossy_local_pose[0]);
+ rtm::matrix3x4f raw_obj_mtx = rtm::matrix_from_qvv(raw_local_pose[0]);
+ rtm::matrix3x4f lossy_obj_mtx = rtm::matrix_from_qvv(lossy_local_pose[0]);
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -126,38 +127,38 @@ namespace acl
for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_mtx = matrix_mul(matrix_from_transform(raw_local_pose[chain_bone_index]), raw_obj_mtx);
- lossy_obj_mtx = matrix_mul(matrix_from_transform(lossy_local_pose[chain_bone_index]), lossy_obj_mtx);
+ raw_obj_mtx = rtm::matrix_mul(rtm::matrix_from_qvv(raw_local_pose[chain_bone_index]), raw_obj_mtx);
+ lossy_obj_mtx = rtm::matrix_mul(rtm::matrix_from_qvv(lossy_local_pose[chain_bone_index]), lossy_obj_mtx);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, target_bone.vertex_distance);
-
- const Vector4_32 raw_vtx0 = matrix_mul_position(raw_obj_mtx, vtx0);
- const Vector4_32 raw_vtx1 = matrix_mul_position(raw_obj_mtx, vtx1);
- const Vector4_32 raw_vtx2 = matrix_mul_position(raw_obj_mtx, vtx2);
- const Vector4_32 lossy_vtx0 = matrix_mul_position(lossy_obj_mtx, vtx0);
- const Vector4_32 lossy_vtx1 = matrix_mul_position(lossy_obj_mtx, vtx1);
- const Vector4_32 lossy_vtx2 = matrix_mul_position(lossy_obj_mtx, vtx2);
-
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
-
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
+
+ const rtm::vector4f raw_vtx0 = rtm::matrix_mul_point3(vtx0, raw_obj_mtx);
+ const rtm::vector4f raw_vtx1 = rtm::matrix_mul_point3(vtx1, raw_obj_mtx);
+ const rtm::vector4f raw_vtx2 = rtm::matrix_mul_point3(vtx2, raw_obj_mtx);
+ const rtm::vector4f lossy_vtx0 = rtm::matrix_mul_point3(vtx0, lossy_obj_mtx);
+ const rtm::vector4f lossy_vtx1 = rtm::matrix_mul_point3(vtx1, lossy_obj_mtx);
+ const rtm::vector4f lossy_vtx2 = rtm::matrix_mul_point3(vtx2, lossy_obj_mtx);
+
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
- Transform_32 raw_obj_transform = raw_local_pose[0];
- Transform_32 lossy_obj_transform = lossy_local_pose[0];
+ rtm::qvvf raw_obj_transform = raw_local_pose[0];
+ rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -165,24 +166,24 @@ namespace acl
for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = transform_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = transform_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
+ raw_obj_transform = rtm::qvv_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
+ lossy_obj_transform = rtm::qvv_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_obj_transform, vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_obj_transform, vtx1);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_obj_transform, vtx0);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_obj_transform, vtx1);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
};
@@ -194,7 +195,7 @@ namespace acl
virtual const char* get_name() const override { return "TransformErrorMetric"; }
virtual uint32_t get_hash() const override { return hash32("TransformErrorMetric"); }
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
@@ -202,53 +203,53 @@ namespace acl
const RigidBone& bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, bone.vertex_distance);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
- const Vector4_32 raw_vtx0 = transform_position(raw_local_pose[bone_index], vtx0);
- const Vector4_32 lossy_vtx0 = transform_position(lossy_local_pose[bone_index], vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_local_pose[bone_index]);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position(raw_local_pose[bone_index], vtx1);
- const Vector4_32 lossy_vtx1 = transform_position(lossy_local_pose[bone_index], vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_local_pose[bone_index]);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const Vector4_32 raw_vtx2 = transform_position(raw_local_pose[bone_index], vtx2);
- const Vector4_32 lossy_vtx2 = transform_position(lossy_local_pose[bone_index], vtx2);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_local_pose[bone_index]);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
const RigidBone& bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_local_pose[bone_index], vtx0);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_local_pose[bone_index], vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_local_pose[bone_index]);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_local_pose[bone_index], vtx1);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_local_pose[bone_index], vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_local_pose[bone_index]);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_local_pose[bone_index]);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
- Transform_32 raw_obj_transform = raw_local_pose[0];
- Transform_32 lossy_obj_transform = lossy_local_pose[0];
+ rtm::qvvf raw_obj_transform = raw_local_pose[0];
+ rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -256,38 +257,38 @@ namespace acl
for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = transform_mul(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = transform_mul(lossy_local_pose[chain_bone_index], lossy_obj_transform);
+ raw_obj_transform = rtm::qvv_mul(raw_local_pose[chain_bone_index], raw_obj_transform);
+ lossy_obj_transform = rtm::qvv_mul(lossy_local_pose[chain_bone_index], lossy_obj_transform);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, target_bone.vertex_distance);
-
- const Vector4_32 raw_vtx0 = transform_position(raw_obj_transform, vtx0);
- const Vector4_32 raw_vtx1 = transform_position(raw_obj_transform, vtx1);
- const Vector4_32 raw_vtx2 = transform_position(raw_obj_transform, vtx2);
- const Vector4_32 lossy_vtx0 = transform_position(lossy_obj_transform, vtx0);
- const Vector4_32 lossy_vtx1 = transform_position(lossy_obj_transform, vtx1);
- const Vector4_32 lossy_vtx2 = transform_position(lossy_obj_transform, vtx2);
-
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
-
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
+
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_obj_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_obj_transform);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_obj_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_obj_transform);
+
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
(void)base_local_pose;
- Transform_32 raw_obj_transform = raw_local_pose[0];
- Transform_32 lossy_obj_transform = lossy_local_pose[0];
+ rtm::qvvf raw_obj_transform = raw_local_pose[0];
+ rtm::qvvf lossy_obj_transform = lossy_local_pose[0];
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -295,24 +296,24 @@ namespace acl
for (; chain_bone_it != chain_bone_end; ++chain_bone_it)
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = transform_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
- lossy_obj_transform = transform_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
+ raw_obj_transform = rtm::qvv_mul_no_scale(raw_local_pose[chain_bone_index], raw_obj_transform);
+ lossy_obj_transform = rtm::qvv_mul_no_scale(lossy_local_pose[chain_bone_index], lossy_obj_transform);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_obj_transform, vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_obj_transform, vtx1);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_obj_transform, vtx0);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_obj_transform, vtx1);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
};
@@ -337,64 +338,64 @@ namespace acl
virtual uint32_t get_hash() const override { return hash32(get_name()); }
- virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
const RigidBone& bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, bone.vertex_distance);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, bone.vertex_distance);
- const Transform_32 raw_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
- const Transform_32 lossy_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
+ const rtm::qvvf raw_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
+ const rtm::qvvf lossy_transform = apply_additive_to_base(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
- const Vector4_32 raw_vtx0 = transform_position(raw_transform, vtx0);
- const Vector4_32 lossy_vtx0 = transform_position(lossy_transform, vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_transform);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position(raw_transform, vtx1);
- const Vector4_32 lossy_vtx1 = transform_position(lossy_transform, vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_transform);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- const Vector4_32 raw_vtx2 = transform_position(raw_transform, vtx2);
- const Vector4_32 lossy_vtx2 = transform_position(lossy_transform, vtx2);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_transform);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_transform);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_local_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
const RigidBone& bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, bone.vertex_distance, 0.0F);
- const Transform_32 raw_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
- const Transform_32 lossy_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
+ const rtm::qvvf raw_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], raw_local_pose[bone_index]);
+ const rtm::qvvf lossy_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[bone_index], lossy_local_pose[bone_index]);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_transform, vtx0);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_transform, vtx0);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_transform);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_transform, vtx1);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_transform, vtx1);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_transform);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
- virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- Transform_32 raw_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], raw_local_pose[0]);
- Transform_32 lossy_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], lossy_local_pose[0]);
+ rtm::qvvf raw_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], raw_local_pose[0]);
+ rtm::qvvf lossy_obj_transform = apply_additive_to_base(additive_format, base_local_pose[0], lossy_local_pose[0]);
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -403,37 +404,37 @@ namespace acl
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = transform_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
- lossy_obj_transform = transform_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
+ raw_obj_transform = rtm::qvv_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
+ lossy_obj_transform = rtm::qvv_mul(apply_additive_to_base(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
// Note that because we have scale, we must measure all three axes
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 vtx2 = vector_set(0.0F, 0.0F, target_bone.vertex_distance);
-
- const Vector4_32 raw_vtx0 = transform_position(raw_obj_transform, vtx0);
- const Vector4_32 raw_vtx1 = transform_position(raw_obj_transform, vtx1);
- const Vector4_32 raw_vtx2 = transform_position(raw_obj_transform, vtx2);
- const Vector4_32 lossy_vtx0 = transform_position(lossy_obj_transform, vtx0);
- const Vector4_32 lossy_vtx1 = transform_position(lossy_obj_transform, vtx1);
- const Vector4_32 lossy_vtx2 = transform_position(lossy_obj_transform, vtx2);
-
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
- const float vtx2_error = vector_distance3(raw_vtx2, lossy_vtx2);
-
- return max(max(vtx0_error, vtx1_error), vtx2_error);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx2 = rtm::vector_set(0.0F, 0.0F, target_bone.vertex_distance);
+
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3(vtx0, raw_obj_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3(vtx1, raw_obj_transform);
+ const rtm::vector4f raw_vtx2 = rtm::qvv_mul_point3(vtx2, raw_obj_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3(vtx0, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3(vtx1, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx2 = rtm::qvv_mul_point3(vtx2, lossy_obj_transform);
+
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx2_error = rtm::vector_distance3(raw_vtx2, lossy_vtx2);
+
+ return rtm::scalar_max(rtm::scalar_max(vtx0_error, vtx1_error), vtx2_error);
}
- virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const Transform_32* raw_local_pose, const Transform_32* base_local_pose, const Transform_32* lossy_local_pose, uint16_t bone_index) const override
+ virtual float calculate_object_bone_error_no_scale(const RigidSkeleton& skeleton, const rtm::qvvf* raw_local_pose, const rtm::qvvf* base_local_pose, const rtm::qvvf* lossy_local_pose, uint16_t bone_index) const override
{
ACL_ASSERT(bone_index < skeleton.get_num_bones(), "Invalid bone index: %u", bone_index);
- Transform_32 raw_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], raw_local_pose[0]);
- Transform_32 lossy_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], lossy_local_pose[0]);
+ rtm::qvvf raw_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], raw_local_pose[0]);
+ rtm::qvvf lossy_obj_transform = apply_additive_to_base_no_scale(additive_format, base_local_pose[0], lossy_local_pose[0]);
const BoneChain bone_chain = skeleton.get_bone_chain(bone_index);
auto chain_bone_it = ++bone_chain.begin(); // Skip root bone
@@ -442,24 +443,24 @@ namespace acl
{
const uint16_t chain_bone_index = *chain_bone_it;
- raw_obj_transform = transform_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
- lossy_obj_transform = transform_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
+ raw_obj_transform = rtm::qvv_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], raw_local_pose[chain_bone_index]), raw_obj_transform);
+ lossy_obj_transform = rtm::qvv_mul_no_scale(apply_additive_to_base_no_scale(additive_format, base_local_pose[chain_bone_index], lossy_local_pose[chain_bone_index]), lossy_obj_transform);
}
const RigidBone& target_bone = skeleton.get_bone(bone_index);
- const Vector4_32 vtx0 = vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
- const Vector4_32 vtx1 = vector_set(0.0F, target_bone.vertex_distance, 0.0F);
+ const rtm::vector4f vtx0 = rtm::vector_set(target_bone.vertex_distance, 0.0F, 0.0F);
+ const rtm::vector4f vtx1 = rtm::vector_set(0.0F, target_bone.vertex_distance, 0.0F);
- const Vector4_32 raw_vtx0 = transform_position_no_scale(raw_obj_transform, vtx0);
- const Vector4_32 raw_vtx1 = transform_position_no_scale(raw_obj_transform, vtx1);
- const Vector4_32 lossy_vtx0 = transform_position_no_scale(lossy_obj_transform, vtx0);
- const Vector4_32 lossy_vtx1 = transform_position_no_scale(lossy_obj_transform, vtx1);
+ const rtm::vector4f raw_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, raw_obj_transform);
+ const rtm::vector4f raw_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, raw_obj_transform);
+ const rtm::vector4f lossy_vtx0 = rtm::qvv_mul_point3_no_scale(vtx0, lossy_obj_transform);
+ const rtm::vector4f lossy_vtx1 = rtm::qvv_mul_point3_no_scale(vtx1, lossy_obj_transform);
- const float vtx0_error = vector_distance3(raw_vtx0, lossy_vtx0);
- const float vtx1_error = vector_distance3(raw_vtx1, lossy_vtx1);
+ const float vtx0_error = rtm::vector_distance3(raw_vtx0, lossy_vtx0);
+ const float vtx1_error = rtm::vector_distance3(raw_vtx1, lossy_vtx1);
- return max(vtx0_error, vtx1_error);
+ return rtm::scalar_max(vtx0_error, vtx1_error);
}
};
}
diff --git a/includes/acl/compression/stream/clip_context.h b/includes/acl/compression/stream/clip_context.h
--- a/includes/acl/compression/stream/clip_context.h
+++ b/includes/acl/compression/stream/clip_context.h
@@ -33,6 +33,9 @@
#include "acl/compression/compression_settings.h"
#include "acl/compression/stream/segment_context.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -97,7 +100,7 @@ namespace acl
out_clip_context.additive_format = clip.get_additive_format();
bool has_scale = false;
- const Vector4_32 default_scale = get_default_scale(clip.get_additive_format());
+ const rtm::vector4f default_scale = get_default_scale(clip.get_additive_format());
SegmentContext& segment = out_clip_context.segments[0];
@@ -114,28 +117,28 @@ namespace acl
bone_stream.parent_bone_index = skel_bone.parent_index;
bone_stream.output_index = bone.output_index;
- bone_stream.rotations = RotationTrackStream(allocator, num_samples, sizeof(Quat_32), sample_rate, RotationFormat8::Quat_128);
- bone_stream.translations = TranslationTrackStream(allocator, num_samples, sizeof(Vector4_32), sample_rate, VectorFormat8::Vector3_96);
- bone_stream.scales = ScaleTrackStream(allocator, num_samples, sizeof(Vector4_32), sample_rate, VectorFormat8::Vector3_96);
+ bone_stream.rotations = RotationTrackStream(allocator, num_samples, sizeof(rtm::quatf), sample_rate, RotationFormat8::Quat_128);
+ bone_stream.translations = TranslationTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, VectorFormat8::Vector3_96);
+ bone_stream.scales = ScaleTrackStream(allocator, num_samples, sizeof(rtm::vector4f), sample_rate, VectorFormat8::Vector3_96);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Quat_32 rotation = quat_normalize(quat_cast(bone.rotation_track.get_sample(sample_index)));
+ const rtm::quatf rotation = rtm::quat_normalize(rtm::quat_cast(bone.rotation_track.get_sample(sample_index)));
bone_stream.rotations.set_raw_sample(sample_index, rotation);
- const Vector4_32 translation = vector_cast(bone.translation_track.get_sample(sample_index));
+ const rtm::vector4f translation = rtm::vector_cast(bone.translation_track.get_sample(sample_index));
bone_stream.translations.set_raw_sample(sample_index, translation);
- const Vector4_32 scale = vector_cast(bone.scale_track.get_sample(sample_index));
+ const rtm::vector4f scale = rtm::vector_cast(bone.scale_track.get_sample(sample_index));
bone_stream.scales.set_raw_sample(sample_index, scale);
}
bone_stream.is_rotation_constant = num_samples == 1;
- bone_stream.is_rotation_default = bone_stream.is_rotation_constant && quat_near_identity(quat_cast(bone.rotation_track.get_sample(0)), settings.constant_rotation_threshold_angle);
+ bone_stream.is_rotation_default = bone_stream.is_rotation_constant && rtm::quat_near_identity(rtm::quat_cast(bone.rotation_track.get_sample(0)), settings.constant_rotation_threshold_angle);
bone_stream.is_translation_constant = num_samples == 1;
- bone_stream.is_translation_default = bone_stream.is_translation_constant && vector_all_near_equal3(vector_cast(bone.translation_track.get_sample(0)), vector_zero_32(), settings.constant_translation_threshold);
+ bone_stream.is_translation_default = bone_stream.is_translation_constant && rtm::vector_all_near_equal3(rtm::vector_cast(bone.translation_track.get_sample(0)), rtm::vector_zero(), settings.constant_translation_threshold);
bone_stream.is_scale_constant = num_samples == 1;
- bone_stream.is_scale_default = bone_stream.is_scale_constant && vector_all_near_equal3(vector_cast(bone.scale_track.get_sample(0)), default_scale, settings.constant_scale_threshold);
+ bone_stream.is_scale_default = bone_stream.is_scale_constant && rtm::vector_all_near_equal3(rtm::vector_cast(bone.scale_track.get_sample(0)), default_scale, settings.constant_scale_threshold);
has_scale |= !bone_stream.is_scale_default;
diff --git a/includes/acl/compression/stream/compact_constant_streams.h b/includes/acl/compression/stream/compact_constant_streams.h
--- a/includes/acl/compression/stream/compact_constant_streams.h
+++ b/includes/acl/compression/stream/compact_constant_streams.h
@@ -27,16 +27,18 @@
#include "acl/core/iallocator.h"
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
-#include "acl/math/vector4_32.h"
#include "acl/compression/stream/clip_context.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- inline bool is_rotation_track_constant(const RotationTrackStream& rotations, float threshold_angle)
+ inline bool is_rotation_track_constant(const RotationTrackStream& rotations, rtm::anglef threshold_angle)
{
// Calculating the average rotation and comparing every rotation in the track to it
// to determine if we are within the threshold seems overkill. We can't use the min/max for the range
@@ -44,45 +46,45 @@ namespace acl
// the first rotation, and compare everything else to it.
auto sample_to_quat = [](const RotationTrackStream& track, uint32_t sample_index)
{
- const Vector4_32 rotation = track.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f rotation = track.get_raw_sample<rtm::vector4f>(sample_index);
switch (track.get_rotation_format())
{
case RotationFormat8::Quat_128:
- return vector_to_quat(rotation);
+ return rtm::vector_to_quat(rotation);
case RotationFormat8::QuatDropW_96:
case RotationFormat8::QuatDropW_48:
case RotationFormat8::QuatDropW_32:
case RotationFormat8::QuatDropW_Variable:
- return quat_from_positive_w(rotation);
+ return rtm::quat_from_positive_w(rotation);
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(track.get_rotation_format()));
- return vector_to_quat(rotation);
+ return rtm::vector_to_quat(rotation);
}
};
- const Quat_32 ref_rotation = sample_to_quat(rotations, 0);
- const Quat_32 inv_ref_rotation = quat_conjugate(ref_rotation);
+ const rtm::quatf ref_rotation = sample_to_quat(rotations, 0);
+ const rtm::quatf inv_ref_rotation = rtm::quat_conjugate(ref_rotation);
const uint32_t num_samples = rotations.get_num_samples();
for (uint32_t sample_index = 1; sample_index < num_samples; ++sample_index)
{
- const Quat_32 rotation = sample_to_quat(rotations, sample_index);
- const Quat_32 delta = quat_normalize(quat_mul(inv_ref_rotation, rotation));
- if (!quat_near_identity(delta, threshold_angle))
+ const rtm::quatf rotation = sample_to_quat(rotations, sample_index);
+ const rtm::quatf delta = rtm::quat_normalize(rtm::quat_mul(inv_ref_rotation, rotation));
+ if (!rtm::quat_near_identity(delta, threshold_angle))
return false;
}
return true;
}
- inline void compact_constant_streams(IAllocator& allocator, ClipContext& clip_context, float rotation_threshold_angle, float translation_threshold, float scale_threshold)
+ inline void compact_constant_streams(IAllocator& allocator, ClipContext& clip_context, rtm::anglef rotation_threshold_angle, float translation_threshold, float scale_threshold)
{
ACL_ASSERT(clip_context.num_segments == 1, "ClipContext must contain a single segment!");
SegmentContext& segment = clip_context.segments[0];
const uint16_t num_bones = clip_context.num_bones;
- const Vector4_32 default_scale = get_default_scale(clip_context.additive_format);
+ const rtm::vector4f default_scale = get_default_scale(clip_context.additive_format);
uint16_t num_default_bone_scales = 0;
// When a stream is constant, we only keep the first sample
@@ -91,48 +93,48 @@ namespace acl
BoneStreams& bone_stream = segment.bone_streams[bone_index];
BoneRanges& bone_range = clip_context.ranges[bone_index];
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(Vector4_32), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(Vector4_32));
- ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(Vector4_32), "Unexpected translation sample size. %u != %u", bone_stream.translations.get_sample_size(), sizeof(Vector4_32));
- ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(Vector4_32), "Unexpected scale sample size. %u != %u", bone_stream.scales.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(rtm::vector4f));
+ ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", bone_stream.translations.get_sample_size(), sizeof(rtm::vector4f));
+ ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", bone_stream.scales.get_sample_size(), sizeof(rtm::vector4f));
if (is_rotation_track_constant(bone_stream.rotations, rotation_threshold_angle))
{
RotationTrackStream constant_stream(allocator, 1, bone_stream.rotations.get_sample_size(), bone_stream.rotations.get_sample_rate(), bone_stream.rotations.get_rotation_format());
- Vector4_32 rotation = bone_stream.rotations.get_raw_sample<Vector4_32>(0);
+ rtm::vector4f rotation = bone_stream.rotations.get_raw_sample<rtm::vector4f>(0);
constant_stream.set_raw_sample(0, rotation);
bone_stream.rotations = std::move(constant_stream);
bone_stream.is_rotation_constant = true;
- bone_stream.is_rotation_default = quat_near_identity(vector_to_quat(rotation), rotation_threshold_angle);
+ bone_stream.is_rotation_default = rtm::quat_near_identity(rtm::vector_to_quat(rotation), rotation_threshold_angle);
- bone_range.rotation = TrackStreamRange::from_min_extent(rotation, vector_zero_32());
+ bone_range.rotation = TrackStreamRange::from_min_extent(rotation, rtm::vector_zero());
}
if (bone_range.translation.is_constant(translation_threshold))
{
TranslationTrackStream constant_stream(allocator, 1, bone_stream.translations.get_sample_size(), bone_stream.translations.get_sample_rate(), bone_stream.translations.get_vector_format());
- Vector4_32 translation = bone_stream.translations.get_raw_sample<Vector4_32>(0);
+ rtm::vector4f translation = bone_stream.translations.get_raw_sample<rtm::vector4f>(0);
constant_stream.set_raw_sample(0, translation);
bone_stream.translations = std::move(constant_stream);
bone_stream.is_translation_constant = true;
- bone_stream.is_translation_default = vector_all_near_equal3(translation, vector_zero_32(), translation_threshold);
+ bone_stream.is_translation_default = rtm::vector_all_near_equal3(translation, rtm::vector_zero(), translation_threshold);
- bone_range.translation = TrackStreamRange::from_min_extent(translation, vector_zero_32());
+ bone_range.translation = TrackStreamRange::from_min_extent(translation, rtm::vector_zero());
}
if (bone_range.scale.is_constant(scale_threshold))
{
ScaleTrackStream constant_stream(allocator, 1, bone_stream.scales.get_sample_size(), bone_stream.scales.get_sample_rate(), bone_stream.scales.get_vector_format());
- Vector4_32 scale = bone_stream.scales.get_raw_sample<Vector4_32>(0);
+ rtm::vector4f scale = bone_stream.scales.get_raw_sample<rtm::vector4f>(0);
constant_stream.set_raw_sample(0, scale);
bone_stream.scales = std::move(constant_stream);
bone_stream.is_scale_constant = true;
- bone_stream.is_scale_default = vector_all_near_equal3(scale, default_scale, scale_threshold);
+ bone_stream.is_scale_default = rtm::vector_all_near_equal3(scale, default_scale, scale_threshold);
- bone_range.scale = TrackStreamRange::from_min_extent(scale, vector_zero_32());
+ bone_range.scale = TrackStreamRange::from_min_extent(scale, rtm::vector_zero());
num_default_bone_scales += bone_stream.is_scale_default ? 1 : 0;
}
diff --git a/includes/acl/compression/stream/convert_rotation_streams.h b/includes/acl/compression/stream/convert_rotation_streams.h
--- a/includes/acl/compression/stream/convert_rotation_streams.h
+++ b/includes/acl/compression/stream/convert_rotation_streams.h
@@ -27,17 +27,18 @@
#include "acl/core/iallocator.h"
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
#include "acl/compression/stream/clip_context.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- inline Vector4_32 ACL_SIMD_CALL convert_rotation(Vector4_32Arg0 rotation, RotationFormat8 from, RotationFormat8 to)
+ inline rtm::vector4f RTM_SIMD_CALL convert_rotation(rtm::vector4f_arg0 rotation, RotationFormat8 from, RotationFormat8 to)
{
ACL_ASSERT(from == RotationFormat8::Quat_128, "Source rotation format must be a full precision quaternion");
(void)from;
@@ -50,7 +51,7 @@ namespace acl
return rotation;
case RotationFormat8::QuatDropW_96:
// Drop W, we just ensure it is positive and write it back, the W component can be ignored afterwards
- return quat_to_vector(quat_ensure_positive_w(vector_to_quat(rotation)));
+ return rtm::quat_to_vector(rtm::quat_ensure_positive_w(rtm::vector_to_quat(rotation)));
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(to));
return rotation;
@@ -63,17 +64,17 @@ namespace acl
for (BoneStreams& bone_stream : segment.bone_iterator())
{
- // We convert our rotation stream in place. We assume that the original format is Quat_128 stored as Quat_32
- // For all other formats, we keep the same sample size and either keep Quat_32 or use Vector4_32
- ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(Quat_32), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(Quat_32));
+ // We convert our rotation stream in place. We assume that the original format is Quat_128 stored as rtm::quatf
+ // For all other formats, we keep the same sample size and either keep Quat_32 or use rtm::vector4f
+ ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::quatf), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(rtm::quatf));
const uint32_t num_samples = bone_stream.rotations.get_num_samples();
const float sample_rate = bone_stream.rotations.get_sample_rate();
- RotationTrackStream converted_stream(allocator, num_samples, sizeof(Quat_32), sample_rate, high_precision_format);
+ RotationTrackStream converted_stream(allocator, num_samples, sizeof(rtm::quatf), sample_rate, high_precision_format);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- Quat_32 rotation = bone_stream.rotations.get_raw_sample<Quat_32>(sample_index);
+ rtm::quatf rotation = bone_stream.rotations.get_raw_sample<rtm::quatf>(sample_index);
switch (high_precision_format)
{
@@ -82,7 +83,7 @@ namespace acl
break;
case RotationFormat8::QuatDropW_96:
// Drop W, we just ensure it is positive and write it back, the W component can be ignored afterwards
- rotation = quat_ensure_positive_w(rotation);
+ rotation = rtm::quat_ensure_positive_w(rotation);
break;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(high_precision_format));
diff --git a/includes/acl/compression/stream/normalize_streams.h b/includes/acl/compression/stream/normalize_streams.h
--- a/includes/acl/compression/stream/normalize_streams.h
+++ b/includes/acl/compression/stream/normalize_streams.h
@@ -30,10 +30,10 @@
#include "acl/core/enum_utils.h"
#include "acl/core/track_types.h"
#include "acl/core/range_reduction_types.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
#include "acl/compression/stream/clip_context.h"
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -44,16 +44,16 @@ namespace acl
{
inline TrackStreamRange calculate_track_range(const TrackStream& stream)
{
- Vector4_32 min = vector_set(1e10F);
- Vector4_32 max = vector_set(-1e10F);
+ rtm::vector4f min = rtm::vector_set(1e10F);
+ rtm::vector4f max = rtm::vector_set(-1e10F);
const uint32_t num_samples = stream.get_num_samples();
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Vector4_32 sample = stream.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f sample = stream.get_raw_sample<rtm::vector4f>(sample_index);
- min = vector_min(min, sample);
- max = vector_max(max, sample);
+ min = rtm::vector_min(min, sample);
+ max = rtm::vector_max(max, sample);
}
return TrackStreamRange::from_min_max(min, max);
@@ -91,11 +91,11 @@ namespace acl
inline void extract_segment_bone_ranges(IAllocator& allocator, ClipContext& clip_context)
{
- const Vector4_32 one = vector_set(1.0F);
- const Vector4_32 zero = vector_zero_32();
+ const rtm::vector4f one = rtm::vector_set(1.0F);
+ const rtm::vector4f zero = rtm::vector_zero();
const float max_range_value_flt = float((1 << k_segment_range_reduction_num_bits_per_component) - 1);
- const Vector4_32 max_range_value = vector_set(max_range_value_flt);
- const Vector4_32 inv_max_range_value = vector_set(1.0F / max_range_value_flt);
+ const rtm::vector4f max_range_value = rtm::vector_set(max_range_value_flt);
+ const rtm::vector4f inv_max_range_value = rtm::vector_set(1.0F / max_range_value_flt);
// Segment ranges are always normalized and live between [0.0 ... 1.0]
@@ -104,37 +104,37 @@ namespace acl
// In our compressed format, we store the minimum value of the track range quantized on 8 bits.
// To get the best accuracy, we pick the value closest to the true minimum that is slightly lower.
// This is to ensure that we encompass the lowest value even after quantization.
- const Vector4_32 range_min = range.get_min();
- const Vector4_32 scaled_min = vector_mul(range_min, max_range_value);
- const Vector4_32 quantized_min0 = vector_clamp(vector_floor(scaled_min), zero, max_range_value);
- const Vector4_32 quantized_min1 = vector_max(vector_sub(quantized_min0, one), zero);
+ const rtm::vector4f range_min = range.get_min();
+ const rtm::vector4f scaled_min = rtm::vector_mul(range_min, max_range_value);
+ const rtm::vector4f quantized_min0 = rtm::vector_clamp(rtm::vector_floor(scaled_min), zero, max_range_value);
+ const rtm::vector4f quantized_min1 = rtm::vector_max(rtm::vector_sub(quantized_min0, one), zero);
- const Vector4_32 padded_range_min0 = vector_mul(quantized_min0, inv_max_range_value);
- const Vector4_32 padded_range_min1 = vector_mul(quantized_min1, inv_max_range_value);
+ const rtm::vector4f padded_range_min0 = rtm::vector_mul(quantized_min0, inv_max_range_value);
+ const rtm::vector4f padded_range_min1 = rtm::vector_mul(quantized_min1, inv_max_range_value);
// Check if min0 is below or equal to our original range minimum value, if it is, it is good
// enough to use otherwise min1 is guaranteed to be lower.
- const Vector4_32 is_min0_lower_mask = vector_less_equal(padded_range_min0, range_min);
- const Vector4_32 padded_range_min = vector_blend(is_min0_lower_mask, padded_range_min0, padded_range_min1);
+ const rtm::mask4i is_min0_lower_mask = rtm::vector_less_equal(padded_range_min0, range_min);
+ const rtm::vector4f padded_range_min = rtm::vector_select(is_min0_lower_mask, padded_range_min0, padded_range_min1);
// The story is different for the extent. We do not store the max, instead we use the extent
// for performance reasons: a single mul/add is required to reconstruct the original value.
// Now that our minimum value changed, our extent also changed.
// We want to pick the extent value that brings us closest to our original max value while
// being slightly larger to encompass it.
- const Vector4_32 range_max = range.get_max();
- const Vector4_32 range_extent = vector_sub(range_max, padded_range_min);
- const Vector4_32 scaled_extent = vector_mul(range_extent, max_range_value);
- const Vector4_32 quantized_extent0 = vector_clamp(vector_ceil(scaled_extent), zero, max_range_value);
- const Vector4_32 quantized_extent1 = vector_min(vector_add(quantized_extent0, one), max_range_value);
+ const rtm::vector4f range_max = range.get_max();
+ const rtm::vector4f range_extent = rtm::vector_sub(range_max, padded_range_min);
+ const rtm::vector4f scaled_extent = rtm::vector_mul(range_extent, max_range_value);
+ const rtm::vector4f quantized_extent0 = rtm::vector_clamp(rtm::vector_ceil(scaled_extent), zero, max_range_value);
+ const rtm::vector4f quantized_extent1 = rtm::vector_min(rtm::vector_add(quantized_extent0, one), max_range_value);
- const Vector4_32 padded_range_extent0 = vector_mul(quantized_extent0, inv_max_range_value);
- const Vector4_32 padded_range_extent1 = vector_mul(quantized_extent1, inv_max_range_value);
+ const rtm::vector4f padded_range_extent0 = rtm::vector_mul(quantized_extent0, inv_max_range_value);
+ const rtm::vector4f padded_range_extent1 = rtm::vector_mul(quantized_extent1, inv_max_range_value);
// Check if extent0 is above or equal to our original range maximum value, if it is, it is good
// enough to use otherwise extent1 is guaranteed to be higher.
- const Vector4_32 is_extent0_higher_mask = vector_greater_equal(padded_range_extent0, range_max);
- const Vector4_32 padded_range_extent = vector_blend(is_extent0_higher_mask, padded_range_extent0, padded_range_extent1);
+ const rtm::mask4i is_extent0_higher_mask = rtm::vector_greater_equal(padded_range_extent0, range_max);
+ const rtm::vector4f padded_range_extent = rtm::vector_select(is_extent0_higher_mask, padded_range_extent0, padded_range_extent1);
return TrackStreamRange::from_min_extent(padded_range_min, padded_range_extent);
};
@@ -162,30 +162,30 @@ namespace acl
}
}
- inline Vector4_32 ACL_SIMD_CALL normalize_sample(Vector4_32Arg0 sample, const TrackStreamRange& range)
+ inline rtm::vector4f RTM_SIMD_CALL normalize_sample(rtm::vector4f_arg0 sample, const TrackStreamRange& range)
{
- const Vector4_32 range_min = range.get_min();
- const Vector4_32 range_extent = range.get_extent();
- const Vector4_32 is_range_zero_mask = vector_less_than(range_extent, vector_set(0.000000001F));
+ const rtm::vector4f range_min = range.get_min();
+ const rtm::vector4f range_extent = range.get_extent();
+ const rtm::mask4i is_range_zero_mask = rtm::vector_less_than(range_extent, rtm::vector_set(0.000000001F));
- Vector4_32 normalized_sample = vector_div(vector_sub(sample, range_min), range_extent);
+ rtm::vector4f normalized_sample = rtm::vector_div(rtm::vector_sub(sample, range_min), range_extent);
// Clamp because the division might be imprecise
- normalized_sample = vector_min(normalized_sample, vector_set(1.0F));
- return vector_blend(is_range_zero_mask, vector_zero_32(), normalized_sample);
+ normalized_sample = rtm::vector_min(normalized_sample, rtm::vector_set(1.0F));
+ return rtm::vector_select(is_range_zero_mask, rtm::vector_zero(), normalized_sample);
}
inline void normalize_rotation_streams(BoneStreams* bone_streams, const BoneRanges* bone_ranges, uint16_t num_bones)
{
- const Vector4_32 one = vector_set(1.0F);
- const Vector4_32 zero = vector_zero_32();
+ const rtm::vector4f one = rtm::vector_set(1.0F);
+ const rtm::vector4f zero = rtm::vector_zero();
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
BoneStreams& bone_stream = bone_streams[bone_index];
const BoneRanges& bone_range = bone_ranges[bone_index];
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(Vector4_32), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(bone_stream.rotations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", bone_stream.rotations.get_sample_size(), sizeof(rtm::vector4f));
// Constant or default tracks are not normalized
if (bone_stream.is_rotation_constant)
@@ -193,32 +193,32 @@ namespace acl
const uint32_t num_samples = bone_stream.rotations.get_num_samples();
- const Vector4_32 range_min = bone_range.rotation.get_min();
- const Vector4_32 range_extent = bone_range.rotation.get_extent();
- const Vector4_32 is_range_zero_mask = vector_less_than(range_extent, vector_set(0.000000001F));
+ const rtm::vector4f range_min = bone_range.rotation.get_min();
+ const rtm::vector4f range_extent = bone_range.rotation.get_extent();
+ const rtm::mask4i is_range_zero_mask = rtm::vector_less_than(range_extent, rtm::vector_set(0.000000001F));
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
// normalized value is between [0.0 .. 1.0]
// value = (normalized value * range extent) + range min
// normalized value = (value - range min) / range extent
- const Vector4_32 rotation = bone_stream.rotations.get_raw_sample<Vector4_32>(sample_index);
- Vector4_32 normalized_rotation = vector_div(vector_sub(rotation, range_min), range_extent);
+ const rtm::vector4f rotation = bone_stream.rotations.get_raw_sample<rtm::vector4f>(sample_index);
+ rtm::vector4f normalized_rotation = rtm::vector_div(rtm::vector_sub(rotation, range_min), range_extent);
// Clamp because the division might be imprecise
- normalized_rotation = vector_min(normalized_rotation, one);
- normalized_rotation = vector_blend(is_range_zero_mask, zero, normalized_rotation);
+ normalized_rotation = rtm::vector_min(normalized_rotation, one);
+ normalized_rotation = rtm::vector_select(is_range_zero_mask, zero, normalized_rotation);
#if defined(ACL_HAS_ASSERT_CHECKS)
switch (bone_stream.rotations.get_rotation_format())
{
case RotationFormat8::Quat_128:
- ACL_ASSERT(vector_all_greater_equal(normalized_rotation, zero) && vector_all_less_equal(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f, %f] <= 1.0", vector_get_x(normalized_rotation), vector_get_y(normalized_rotation), vector_get_z(normalized_rotation), vector_get_w(normalized_rotation));
+ ACL_ASSERT(rtm::vector_all_greater_equal(normalized_rotation, zero) && rtm::vector_all_less_equal(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_rotation), rtm::vector_get_y(normalized_rotation), rtm::vector_get_z(normalized_rotation), rtm::vector_get_w(normalized_rotation));
break;
case RotationFormat8::QuatDropW_96:
case RotationFormat8::QuatDropW_48:
case RotationFormat8::QuatDropW_32:
case RotationFormat8::QuatDropW_Variable:
- ACL_ASSERT(vector_all_greater_equal3(normalized_rotation, zero) && vector_all_less_equal3(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f] <= 1.0", vector_get_x(normalized_rotation), vector_get_y(normalized_rotation), vector_get_z(normalized_rotation));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(normalized_rotation, zero) && rtm::vector_all_less_equal3(normalized_rotation, one), "Invalid normalized rotation. 0.0 <= [%f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_rotation), rtm::vector_get_y(normalized_rotation), rtm::vector_get_z(normalized_rotation));
break;
}
#endif
@@ -230,16 +230,16 @@ namespace acl
inline void normalize_translation_streams(BoneStreams* bone_streams, const BoneRanges* bone_ranges, uint16_t num_bones)
{
- const Vector4_32 one = vector_set(1.0F);
- const Vector4_32 zero = vector_zero_32();
+ const rtm::vector4f one = rtm::vector_set(1.0F);
+ const rtm::vector4f zero = rtm::vector_zero();
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
BoneStreams& bone_stream = bone_streams[bone_index];
const BoneRanges& bone_range = bone_ranges[bone_index];
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(Vector4_32), "Unexpected translation sample size. %u != %u", bone_stream.translations.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(bone_stream.translations.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", bone_stream.translations.get_sample_size(), sizeof(rtm::vector4f));
// Constant or default tracks are not normalized
if (bone_stream.is_translation_constant)
@@ -247,22 +247,22 @@ namespace acl
const uint32_t num_samples = bone_stream.translations.get_num_samples();
- const Vector4_32 range_min = bone_range.translation.get_min();
- const Vector4_32 range_extent = bone_range.translation.get_extent();
- const Vector4_32 is_range_zero_mask = vector_less_than(range_extent, vector_set(0.000000001F));
+ const rtm::vector4f range_min = bone_range.translation.get_min();
+ const rtm::vector4f range_extent = bone_range.translation.get_extent();
+ const rtm::mask4i is_range_zero_mask = rtm::vector_less_than(range_extent, rtm::vector_set(0.000000001F));
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
// normalized value is between [0.0 .. 1.0]
// value = (normalized value * range extent) + range min
// normalized value = (value - range min) / range extent
- const Vector4_32 translation = bone_stream.translations.get_raw_sample<Vector4_32>(sample_index);
- Vector4_32 normalized_translation = vector_div(vector_sub(translation, range_min), range_extent);
+ const rtm::vector4f translation = bone_stream.translations.get_raw_sample<rtm::vector4f>(sample_index);
+ rtm::vector4f normalized_translation = rtm::vector_div(rtm::vector_sub(translation, range_min), range_extent);
// Clamp because the division might be imprecise
- normalized_translation = vector_min(normalized_translation, one);
- normalized_translation = vector_blend(is_range_zero_mask, zero, normalized_translation);
+ normalized_translation = rtm::vector_min(normalized_translation, one);
+ normalized_translation = rtm::vector_select(is_range_zero_mask, zero, normalized_translation);
- ACL_ASSERT(vector_all_greater_equal3(normalized_translation, zero) && vector_all_less_equal3(normalized_translation, one), "Invalid normalized translation. 0.0 <= [%f, %f, %f] <= 1.0", vector_get_x(normalized_translation), vector_get_y(normalized_translation), vector_get_z(normalized_translation));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(normalized_translation, zero) && rtm::vector_all_less_equal3(normalized_translation, one), "Invalid normalized translation. 0.0 <= [%f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_translation), rtm::vector_get_y(normalized_translation), rtm::vector_get_z(normalized_translation));
bone_stream.translations.set_raw_sample(sample_index, normalized_translation);
}
@@ -271,16 +271,16 @@ namespace acl
inline void normalize_scale_streams(BoneStreams* bone_streams, const BoneRanges* bone_ranges, uint16_t num_bones)
{
- const Vector4_32 one = vector_set(1.0F);
- const Vector4_32 zero = vector_zero_32();
+ const rtm::vector4f one = rtm::vector_set(1.0F);
+ const rtm::vector4f zero = rtm::vector_zero();
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
BoneStreams& bone_stream = bone_streams[bone_index];
const BoneRanges& bone_range = bone_ranges[bone_index];
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(Vector4_32), "Unexpected scale sample size. %u != %u", bone_stream.scales.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(bone_stream.scales.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", bone_stream.scales.get_sample_size(), sizeof(rtm::vector4f));
// Constant or default tracks are not normalized
if (bone_stream.is_scale_constant)
@@ -288,22 +288,22 @@ namespace acl
const uint32_t num_samples = bone_stream.scales.get_num_samples();
- const Vector4_32 range_min = bone_range.scale.get_min();
- const Vector4_32 range_extent = bone_range.scale.get_extent();
- const Vector4_32 is_range_zero_mask = vector_less_than(range_extent, vector_set(0.000000001F));
+ const rtm::vector4f range_min = bone_range.scale.get_min();
+ const rtm::vector4f range_extent = bone_range.scale.get_extent();
+ const rtm::mask4i is_range_zero_mask = rtm::vector_less_than(range_extent, rtm::vector_set(0.000000001F));
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
// normalized value is between [0.0 .. 1.0]
// value = (normalized value * range extent) + range min
// normalized value = (value - range min) / range extent
- const Vector4_32 scale = bone_stream.scales.get_raw_sample<Vector4_32>(sample_index);
- Vector4_32 normalized_scale = vector_div(vector_sub(scale, range_min), range_extent);
+ const rtm::vector4f scale = bone_stream.scales.get_raw_sample<rtm::vector4f>(sample_index);
+ rtm::vector4f normalized_scale = rtm::vector_div(rtm::vector_sub(scale, range_min), range_extent);
// Clamp because the division might be imprecise
- normalized_scale = vector_min(normalized_scale, one);
- normalized_scale = vector_blend(is_range_zero_mask, zero, normalized_scale);
+ normalized_scale = rtm::vector_min(normalized_scale, one);
+ normalized_scale = rtm::vector_select(is_range_zero_mask, zero, normalized_scale);
- ACL_ASSERT(vector_all_greater_equal3(normalized_scale, zero) && vector_all_less_equal3(normalized_scale, one), "Invalid normalized scale. 0.0 <= [%f, %f, %f] <= 1.0", vector_get_x(normalized_scale), vector_get_y(normalized_scale), vector_get_z(normalized_scale));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(normalized_scale, zero) && rtm::vector_all_less_equal3(normalized_scale, one), "Invalid normalized scale. 0.0 <= [%f, %f, %f] <= 1.0", rtm::vector_get_x(normalized_scale), rtm::vector_get_y(normalized_scale), rtm::vector_get_z(normalized_scale));
bone_stream.scales.set_raw_sample(sample_index, normalized_scale);
}
diff --git a/includes/acl/compression/stream/quantize_streams.h b/includes/acl/compression/stream/quantize_streams.h
--- a/includes/acl/compression/stream/quantize_streams.h
+++ b/includes/acl/compression/stream/quantize_streams.h
@@ -28,9 +28,7 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
#include "acl/core/utils.h"
-#include "acl/math/quat_32.h"
#include "acl/math/quat_packing.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/vector4_packing.h"
#include "acl/compression/impl/track_bit_rate_database.h"
#include "acl/compression/impl/transform_bit_rate_permutations.h"
@@ -41,6 +39,9 @@
#include "acl/compression/skeleton_error_metric.h"
#include "acl/compression/compression_settings.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstddef>
#include <cstdint>
@@ -78,9 +79,9 @@ namespace acl
const BoneStreams* raw_bone_streams;
- Transform_32* additive_local_pose;
- Transform_32* raw_local_pose;
- Transform_32* lossy_local_pose;
+ rtm::qvvf* additive_local_pose;
+ rtm::qvvf* raw_local_pose;
+ rtm::qvvf* lossy_local_pose;
BoneBitRate* bit_rate_per_bone;
@@ -108,9 +109,9 @@ namespace acl
local_query.bind(database);
object_query.bind(database);
- additive_local_pose = clip_.has_additive_base ? allocate_type_array<Transform_32>(allocator, num_bones) : nullptr;
- raw_local_pose = allocate_type_array<Transform_32>(allocator, num_bones);
- lossy_local_pose = allocate_type_array<Transform_32>(allocator, num_bones);
+ additive_local_pose = clip_.has_additive_base ? allocate_type_array<rtm::qvvf>(allocator, num_bones) : nullptr;
+ raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
bit_rate_per_bone = allocate_type_array<BoneBitRate>(allocator, num_bones);
}
@@ -141,8 +142,8 @@ namespace acl
inline void quantize_fixed_rotation_stream(IAllocator& allocator, const RotationTrackStream& raw_stream, RotationFormat8 rotation_format, bool are_rotations_normalized, RotationTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected rotation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
const uint32_t num_samples = raw_stream.get_num_samples();
const uint32_t rotation_sample_size = get_packed_rotation_size(rotation_format);
@@ -151,25 +152,25 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Quat_32 rotation = raw_stream.get_raw_sample<Quat_32>(sample_index);
+ const rtm::quatf rotation = raw_stream.get_raw_sample<rtm::quatf>(sample_index);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(sample_index);
switch (rotation_format)
{
case RotationFormat8::Quat_128:
- pack_vector4_128(quat_to_vector(rotation), quantized_ptr);
+ pack_vector4_128(rtm::quat_to_vector(rotation), quantized_ptr);
break;
case RotationFormat8::QuatDropW_96:
- pack_vector3_96(quat_to_vector(rotation), quantized_ptr);
+ pack_vector3_96(rtm::quat_to_vector(rotation), quantized_ptr);
break;
case RotationFormat8::QuatDropW_48:
if (are_rotations_normalized)
- pack_vector3_u48_unsafe(quat_to_vector(rotation), quantized_ptr);
+ pack_vector3_u48_unsafe(rtm::quat_to_vector(rotation), quantized_ptr);
else
- pack_vector3_s48_unsafe(quat_to_vector(rotation), quantized_ptr);
+ pack_vector3_s48_unsafe(rtm::quat_to_vector(rotation), quantized_ptr);
break;
case RotationFormat8::QuatDropW_32:
- pack_vector3_32(quat_to_vector(rotation), 11, 11, 10, are_rotations_normalized, quantized_ptr);
+ pack_vector3_32(rtm::quat_to_vector(rotation), 11, 11, 10, are_rotations_normalized, quantized_ptr);
break;
case RotationFormat8::QuatDropW_Variable:
default:
@@ -197,8 +198,8 @@ namespace acl
inline void quantize_variable_rotation_stream(QuantizationContext& context, const RotationTrackStream& raw_clip_stream, const RotationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, bool are_rotations_normalized, RotationTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected rotation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected rotation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
const uint32_t sample_size = sizeof(uint64_t) * 2;
@@ -209,10 +210,10 @@ namespace acl
{
ACL_ASSERT(are_rotations_normalized, "Cannot drop a constant track if it isn't normalized");
- Vector4_32 rotation = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index);
+ rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
rotation = convert_rotation(rotation, RotationFormat8::Quat_128, RotationFormat8::QuatDropW_Variable);
- const Vector4_32 normalized_rotation = normalize_sample(rotation, clip_range);
+ const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_range);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
pack_vector3_u48_unsafe(normalized_rotation, quantized_ptr);
@@ -227,17 +228,17 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- Vector4_32 rotation = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index + sample_index);
+ rtm::vector4f rotation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
rotation = convert_rotation(rotation, RotationFormat8::Quat_128, RotationFormat8::QuatDropW_Variable);
pack_vector3_96(rotation, quantized_ptr);
}
else
{
- const Quat_32 rotation = raw_segment_stream.get_raw_sample<Quat_32>(sample_index);
+ const rtm::quatf rotation = raw_segment_stream.get_raw_sample<rtm::quatf>(sample_index);
if (are_rotations_normalized)
- pack_vector3_uXX_unsafe(quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
+ pack_vector3_uXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
else
- pack_vector3_sXX_unsafe(quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
+ pack_vector3_sXX_unsafe(rtm::quat_to_vector(rotation), num_bits_at_bit_rate, quantized_ptr);
}
}
}
@@ -270,8 +271,8 @@ namespace acl
inline void quantize_fixed_translation_stream(IAllocator& allocator, const TranslationTrackStream& raw_stream, VectorFormat8 translation_format, TranslationTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected translation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(raw_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
const uint32_t num_samples = raw_stream.get_num_samples();
@@ -281,7 +282,7 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Vector4_32 translation = raw_stream.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f translation = raw_stream.get_raw_sample<rtm::vector4f>(sample_index);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(sample_index);
switch (translation_format)
@@ -323,8 +324,8 @@ namespace acl
inline void quantize_variable_translation_stream(QuantizationContext& context, const TranslationTrackStream& raw_clip_stream, const TranslationTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, TranslationTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected translation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected translation sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(raw_segment_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
@@ -334,8 +335,8 @@ namespace acl
if (is_constant_bit_rate(bit_rate))
{
- const Vector4_32 translation = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index);
- const Vector4_32 normalized_translation = normalize_sample(translation, clip_range);
+ const rtm::vector4f translation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
+ const rtm::vector4f normalized_translation = normalize_sample(translation, clip_range);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
pack_vector3_u48_unsafe(normalized_translation, quantized_ptr);
@@ -350,12 +351,12 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- const Vector4_32 translation = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index + sample_index);
+ const rtm::vector4f translation = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
pack_vector3_96(translation, quantized_ptr);
}
else
{
- const Vector4_32 translation = raw_segment_stream.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f translation = raw_segment_stream.get_raw_sample<rtm::vector4f>(sample_index);
pack_vector3_uXX_unsafe(translation, num_bits_at_bit_rate, quantized_ptr);
}
}
@@ -387,8 +388,8 @@ namespace acl
inline void quantize_fixed_scale_stream(IAllocator& allocator, const ScaleTrackStream& raw_stream, VectorFormat8 scale_format, ScaleTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected scale sample size. %u != %u", raw_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", raw_stream.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(raw_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_stream.get_vector_format()));
const uint32_t num_samples = raw_stream.get_num_samples();
@@ -398,7 +399,7 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Vector4_32 scale = raw_stream.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f scale = raw_stream.get_raw_sample<rtm::vector4f>(sample_index);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(sample_index);
switch (scale_format)
@@ -440,8 +441,8 @@ namespace acl
inline void quantize_variable_scale_stream(QuantizationContext& context, const ScaleTrackStream& raw_clip_stream, const ScaleTrackStream& raw_segment_stream, const TrackStreamRange& clip_range, uint8_t bit_rate, ScaleTrackStream& out_quantized_stream)
{
- // We expect all our samples to have the same width of sizeof(Vector4_32)
- ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(Vector4_32), "Unexpected scale sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(Vector4_32));
+ // We expect all our samples to have the same width of sizeof(rtm::vector4f)
+ ACL_ASSERT(raw_segment_stream.get_sample_size() == sizeof(rtm::vector4f), "Unexpected scale sample size. %u != %u", raw_segment_stream.get_sample_size(), sizeof(rtm::vector4f));
ACL_ASSERT(raw_segment_stream.get_vector_format() == VectorFormat8::Vector3_96, "Expected a Vector3_96 vector format, found: %s", get_vector_format_name(raw_segment_stream.get_vector_format()));
const uint32_t num_samples = is_constant_bit_rate(bit_rate) ? 1 : raw_segment_stream.get_num_samples();
@@ -451,8 +452,8 @@ namespace acl
if (is_constant_bit_rate(bit_rate))
{
- const Vector4_32 scale = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index);
- const Vector4_32 normalized_scale = normalize_sample(scale, clip_range);
+ const rtm::vector4f scale = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index);
+ const rtm::vector4f normalized_scale = normalize_sample(scale, clip_range);
uint8_t* quantized_ptr = quantized_stream.get_raw_sample_ptr(0);
pack_vector3_u48_unsafe(normalized_scale, quantized_ptr);
@@ -467,12 +468,12 @@ namespace acl
if (is_raw_bit_rate(bit_rate))
{
- const Vector4_32 scale = raw_clip_stream.get_raw_sample<Vector4_32>(context.segment_sample_start_index + sample_index);
+ const rtm::vector4f scale = raw_clip_stream.get_raw_sample<rtm::vector4f>(context.segment_sample_start_index + sample_index);
pack_vector3_96(scale, quantized_ptr);
}
else
{
- const Vector4_32 scale = raw_segment_stream.get_raw_sample<Vector4_32>(sample_index);
+ const rtm::vector4f scale = raw_segment_stream.get_raw_sample<rtm::vector4f>(sample_index);
pack_vector3_uXX_unsafe(scale, num_bits_at_bit_rate, quantized_ptr);
}
}
@@ -517,7 +518,7 @@ namespace acl
{
// Sample our streams and calculate the error
// The sample time is calculated from the full clip duration to be consistent with decompression
- const float sample_time = min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
+ const float sample_time = rtm::scalar_min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
sample_stream(context.raw_bone_streams, context.num_bones, sample_time, target_bone_index, context.raw_local_pose);
@@ -536,7 +537,7 @@ namespace acl
else
error = error_metric.calculate_local_bone_error_no_scale(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
- max_error = max(max_error, error);
+ max_error = rtm::scalar_max(max_error, error);
if (stop_condition == error_scan_stop_condition::until_error_too_high && error >= settings.error_threshold)
break;
}
@@ -557,7 +558,7 @@ namespace acl
{
// Sample our streams and calculate the error
// The sample time is calculated from the full clip duration to be consistent with decompression
- const float sample_time = min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
+ const float sample_time = rtm::scalar_min(float(context.segment_sample_start_index + sample_index) / context.sample_rate, context.clip_duration);
sample_streams_hierarchical(context.raw_bone_streams, context.num_bones, sample_time, target_bone_index, context.raw_local_pose);
@@ -576,7 +577,7 @@ namespace acl
else
error = error_metric.calculate_object_bone_error_no_scale(context.skeleton, context.raw_local_pose, context.additive_local_pose, context.lossy_local_pose, target_bone_index);
- max_error = max(max_error, error);
+ max_error = rtm::scalar_max(max_error, error);
if (stop_condition == error_scan_stop_condition::until_error_too_high && error >= settings.error_threshold)
break;
}
diff --git a/includes/acl/compression/stream/sample_streams.h b/includes/acl/compression/stream/sample_streams.h
--- a/includes/acl/compression/stream/sample_streams.h
+++ b/includes/acl/compression/stream/sample_streams.h
@@ -28,15 +28,16 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
#include "acl/core/utils.h"
-#include "acl/math/quat_32.h"
#include "acl/math/quat_packing.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/vector4_packing.h"
-#include "acl/math/transform_32.h"
#include "acl/compression/stream/track_stream.h"
#include "acl/compression/stream/normalize_streams.h"
#include "acl/compression/stream/convert_rotation_streams.h"
+#include <rtm/quatf.h>
+#include <rtm/qvvf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -45,7 +46,7 @@ namespace acl
{
namespace impl
{
- inline Vector4_32 ACL_SIMD_CALL load_rotation_sample(const uint8_t* ptr, RotationFormat8 format, uint8_t bit_rate, bool is_normalized)
+ inline rtm::vector4f RTM_SIMD_CALL load_rotation_sample(const uint8_t* ptr, RotationFormat8 format, uint8_t bit_rate, bool is_normalized)
{
switch (format)
{
@@ -77,11 +78,11 @@ namespace acl
}
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
- return vector_zero_32();
+ return rtm::vector_zero();
}
}
- inline Vector4_32 ACL_SIMD_CALL load_vector_sample(const uint8_t* ptr, VectorFormat8 format, uint8_t bit_rate)
+ inline rtm::vector4f RTM_SIMD_CALL load_vector_sample(const uint8_t* ptr, VectorFormat8 format, uint8_t bit_rate)
{
switch (format)
{
@@ -104,29 +105,29 @@ namespace acl
}
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(format));
- return vector_zero_32();
+ return rtm::vector_zero();
}
}
- inline Quat_32 ACL_SIMD_CALL rotation_to_quat_32(Vector4_32Arg0 rotation, RotationFormat8 format)
+ inline rtm::quatf RTM_SIMD_CALL rotation_to_quat_32(rtm::vector4f_arg0 rotation, RotationFormat8 format)
{
switch (format)
{
case RotationFormat8::Quat_128:
- return vector_to_quat(rotation);
+ return rtm::vector_to_quat(rotation);
case RotationFormat8::QuatDropW_96:
case RotationFormat8::QuatDropW_48:
case RotationFormat8::QuatDropW_32:
case RotationFormat8::QuatDropW_Variable:
- return quat_from_positive_w(rotation);
+ return rtm::quat_from_positive_w(rotation);
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(format));
- return quat_identity_32();
+ return rtm::quat_identity();
}
}
}
- inline Quat_32 ACL_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
+ inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -140,7 +141,7 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
- Vector4_32 packed_rotation = impl::load_rotation_sample(quantized_ptr, format, bit_rate, are_rotations_normalized);
+ rtm::vector4f packed_rotation = impl::load_rotation_sample(quantized_ptr, format, bit_rate, are_rotations_normalized);
if (are_rotations_normalized && !is_raw_bit_rate(bit_rate))
{
@@ -148,31 +149,31 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.rotation.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.rotation.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.rotation.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.rotation.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.rotation.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
}
return impl::rotation_to_quat_32(packed_rotation, format);
}
- inline Quat_32 ACL_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
+ inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
const bool are_rotations_normalized = clip_context->are_rotations_normalized;
const RotationFormat8 format = bone_steams.rotations.get_rotation_format();
- Vector4_32 rotation;
+ rtm::vector4f rotation;
if (is_constant_bit_rate(bit_rate))
{
const uint8_t* quantized_ptr = raw_bone_steams.rotations.get_raw_sample_ptr(segment->clip_sample_offset);
@@ -193,7 +194,7 @@ namespace acl
// Pack and unpack at our desired bit rate
const uint32_t num_bits_at_bit_rate = get_num_bits_at_bit_rate(bit_rate);
- Vector4_32 packed_rotation;
+ rtm::vector4f packed_rotation;
if (is_constant_bit_rate(bit_rate))
{
@@ -201,7 +202,7 @@ namespace acl
ACL_ASSERT(segment->are_rotations_normalized, "Cannot drop a constant track if it isn't normalized");
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const Vector4_32 normalized_rotation = normalize_sample(rotation, clip_bone_range.rotation);
+ const rtm::vector4f normalized_rotation = normalize_sample(rotation, clip_bone_range.rotation);
packed_rotation = decay_vector3_u48(normalized_rotation);
}
@@ -218,24 +219,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.rotation.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.rotation.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.rotation.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.rotation.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.rotation.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
}
return impl::rotation_to_quat_32(packed_rotation, format);
}
- inline Quat_32 ACL_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index, RotationFormat8 desired_format)
+ inline rtm::quatf RTM_SIMD_CALL get_rotation_sample(const BoneStreams& bone_steams, uint32_t sample_index, RotationFormat8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -243,10 +244,10 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.rotations.get_raw_sample_ptr(sample_index);
const RotationFormat8 format = bone_steams.rotations.get_rotation_format();
- const Vector4_32 rotation = impl::load_rotation_sample(quantized_ptr, format, 0, are_rotations_normalized);
+ const rtm::vector4f rotation = impl::load_rotation_sample(quantized_ptr, format, 0, are_rotations_normalized);
// Pack and unpack in our desired format
- Vector4_32 packed_rotation;
+ rtm::vector4f packed_rotation;
switch (desired_format)
{
@@ -262,7 +263,7 @@ namespace acl
break;
default:
ACL_ASSERT(false, "Invalid or unsupported rotation format: %s", get_rotation_format_name(desired_format));
- packed_rotation = vector_zero_32();
+ packed_rotation = rtm::vector_zero();
break;
}
@@ -272,24 +273,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.rotation.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.rotation.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.rotation.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.rotation.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.rotation.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.rotation.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.rotation.get_extent();
- packed_rotation = vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
+ packed_rotation = rtm::vector_mul_add(packed_rotation, clip_range_extent, clip_range_min);
}
return impl::rotation_to_quat_32(packed_rotation, format);
}
- inline Vector4_32 ACL_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
+ inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -303,7 +304,7 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
- Vector4_32 packed_translation = impl::load_vector_sample(quantized_ptr, format, bit_rate);
+ rtm::vector4f packed_translation = impl::load_vector_sample(quantized_ptr, format, bit_rate);
if (are_translations_normalized && !is_raw_bit_rate(bit_rate))
{
@@ -311,24 +312,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.translation.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.translation.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.translation.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.translation.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.translation.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
}
return packed_translation;
}
- inline Vector4_32 ACL_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
+ inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -342,19 +343,19 @@ namespace acl
else
quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
- const Vector4_32 translation = impl::load_vector_sample(quantized_ptr, format, 0);
+ const rtm::vector4f translation = impl::load_vector_sample(quantized_ptr, format, 0);
ACL_ASSERT(clip_context->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
- Vector4_32 packed_translation;
+ rtm::vector4f packed_translation;
if (is_constant_bit_rate(bit_rate))
{
ACL_ASSERT(segment->are_translations_normalized, "Translations must be normalized to support variable bit rates.");
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const Vector4_32 normalized_translation = normalize_sample(translation, clip_bone_range.translation);
+ const rtm::vector4f normalized_translation = normalize_sample(translation, clip_bone_range.translation);
packed_translation = decay_vector3_u48(normalized_translation);
}
@@ -372,24 +373,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.translation.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.translation.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.translation.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.translation.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.translation.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
}
return packed_translation;
}
- inline Vector4_32 ACL_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_translation_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -397,10 +398,10 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.translations.get_raw_sample_ptr(sample_index);
const VectorFormat8 format = bone_steams.translations.get_vector_format();
- const Vector4_32 translation = impl::load_vector_sample(quantized_ptr, format, 0);
+ const rtm::vector4f translation = impl::load_vector_sample(quantized_ptr, format, 0);
// Pack and unpack in our desired format
- Vector4_32 packed_translation;
+ rtm::vector4f packed_translation;
switch (desired_format)
{
@@ -417,7 +418,7 @@ namespace acl
break;
default:
ACL_ASSERT(false, "Invalid or unsupported vector format: %s", get_vector_format_name(desired_format));
- packed_translation = vector_zero_32();
+ packed_translation = rtm::vector_zero();
break;
}
@@ -427,24 +428,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- Vector4_32 segment_range_min = segment_bone_range.translation.get_min();
- Vector4_32 segment_range_extent = segment_bone_range.translation.get_extent();
+ rtm::vector4f segment_range_min = segment_bone_range.translation.get_min();
+ rtm::vector4f segment_range_extent = segment_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- Vector4_32 clip_range_min = clip_bone_range.translation.get_min();
- Vector4_32 clip_range_extent = clip_bone_range.translation.get_extent();
+ rtm::vector4f clip_range_min = clip_bone_range.translation.get_min();
+ rtm::vector4f clip_range_extent = clip_bone_range.translation.get_extent();
- packed_translation = vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
+ packed_translation = rtm::vector_mul_add(packed_translation, clip_range_extent, clip_range_min);
}
return packed_translation;
}
- inline Vector4_32 ACL_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index)
+ inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -458,7 +459,7 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
- Vector4_32 packed_scale = impl::load_vector_sample(quantized_ptr, format, bit_rate);
+ rtm::vector4f packed_scale = impl::load_vector_sample(quantized_ptr, format, bit_rate);
if (are_scales_normalized && !is_raw_bit_rate(bit_rate))
{
@@ -466,24 +467,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.scale.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.scale.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.scale.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.scale.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.scale.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
}
return packed_scale;
}
- inline Vector4_32 ACL_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
+ inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, const BoneStreams& raw_bone_steams, uint32_t sample_index, uint8_t bit_rate)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -497,19 +498,19 @@ namespace acl
else
quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
- const Vector4_32 scale = impl::load_vector_sample(quantized_ptr, format, 0);
+ const rtm::vector4f scale = impl::load_vector_sample(quantized_ptr, format, 0);
ACL_ASSERT(clip_context->are_scales_normalized, "Scales must be normalized to support variable bit rates.");
// Pack and unpack at our desired bit rate
- Vector4_32 packed_scale;
+ rtm::vector4f packed_scale;
if (is_constant_bit_rate(bit_rate))
{
ACL_ASSERT(segment->are_scales_normalized, "Translations must be normalized to support variable bit rates.");
const BoneRanges& clip_bone_range = segment->clip->ranges[bone_steams.bone_index];
- const Vector4_32 normalized_scale = normalize_sample(scale, clip_bone_range.scale);
+ const rtm::vector4f normalized_scale = normalize_sample(scale, clip_bone_range.scale);
packed_scale = decay_vector3_u48(normalized_scale);
}
@@ -527,24 +528,24 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- const Vector4_32 segment_range_min = segment_bone_range.scale.get_min();
- const Vector4_32 segment_range_extent = segment_bone_range.scale.get_extent();
+ const rtm::vector4f segment_range_min = segment_bone_range.scale.get_min();
+ const rtm::vector4f segment_range_extent = segment_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- const Vector4_32 clip_range_min = clip_bone_range.scale.get_min();
- const Vector4_32 clip_range_extent = clip_bone_range.scale.get_extent();
+ const rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
+ const rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
}
return packed_scale;
}
- inline Vector4_32 ACL_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_scale_sample(const BoneStreams& bone_steams, uint32_t sample_index, VectorFormat8 desired_format)
{
const SegmentContext* segment = bone_steams.segment;
const ClipContext* clip_context = segment->clip;
@@ -552,10 +553,10 @@ namespace acl
const uint8_t* quantized_ptr = bone_steams.scales.get_raw_sample_ptr(sample_index);
const VectorFormat8 format = bone_steams.scales.get_vector_format();
- const Vector4_32 scale = impl::load_vector_sample(quantized_ptr, format, 0);
+ const rtm::vector4f scale = impl::load_vector_sample(quantized_ptr, format, 0);
// Pack and unpack in our desired format
- Vector4_32 packed_scale;
+ rtm::vector4f packed_scale;
switch (desired_format)
{
@@ -582,18 +583,18 @@ namespace acl
{
const BoneRanges& segment_bone_range = segment->ranges[bone_steams.bone_index];
- Vector4_32 segment_range_min = segment_bone_range.scale.get_min();
- Vector4_32 segment_range_extent = segment_bone_range.scale.get_extent();
+ rtm::vector4f segment_range_min = segment_bone_range.scale.get_min();
+ rtm::vector4f segment_range_extent = segment_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, segment_range_extent, segment_range_min);
}
const BoneRanges& clip_bone_range = clip_context->ranges[bone_steams.bone_index];
- Vector4_32 clip_range_min = clip_bone_range.scale.get_min();
- Vector4_32 clip_range_extent = clip_bone_range.scale.get_extent();
+ rtm::vector4f clip_range_min = clip_bone_range.scale.get_min();
+ rtm::vector4f clip_range_extent = clip_bone_range.scale.get_extent();
- packed_scale = vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
+ packed_scale = rtm::vector_mul_add(packed_scale, clip_range_extent, clip_range_min);
}
return packed_scale;
@@ -642,13 +643,13 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Quat_32 ACL_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream)
+ ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream)
{
- Quat_32 rotation;
+ rtm::quatf rotation;
if (bone_stream.is_rotation_default)
- rotation = quat_identity_32();
+ rotation = rtm::quat_identity();
else if (bone_stream.is_rotation_constant)
- rotation = quat_normalize(get_rotation_sample(bone_stream, 0));
+ rotation = rtm::quat_normalize(get_rotation_sample(bone_stream, 0));
else
{
uint32_t key0;
@@ -668,26 +669,26 @@ namespace acl
interpolation_alpha = 0.0F;
}
- const Quat_32 sample0 = get_rotation_sample(bone_stream, key0);
+ const rtm::quatf sample0 = get_rotation_sample(bone_stream, key0);
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const Quat_32 sample1 = get_rotation_sample(bone_stream, key1);
- rotation = quat_lerp(sample0, sample1, interpolation_alpha);
+ const rtm::quatf sample1 = get_rotation_sample(bone_stream, key1);
+ rotation = rtm::quat_lerp(sample0, sample1, interpolation_alpha);
}
else
- rotation = quat_normalize(sample0);
+ rotation = rtm::quat_normalize(sample0);
}
return rotation;
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Quat_32 ACL_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_rotation_variable, RotationFormat8 rotation_format)
+ ACL_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_rotation_variable, RotationFormat8 rotation_format)
{
- Quat_32 rotation;
+ rtm::quatf rotation;
if (bone_stream.is_rotation_default)
- rotation = quat_identity_32();
+ rotation = rtm::quat_identity();
else if (bone_stream.is_rotation_constant)
{
if (is_rotation_variable)
@@ -695,7 +696,7 @@ namespace acl
else
rotation = get_rotation_sample(raw_bone_stream, 0, rotation_format);
- rotation = quat_normalize(rotation);
+ rotation = rtm::quat_normalize(rotation);
}
else
{
@@ -716,8 +717,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Quat_32 sample0;
- Quat_32 sample1;
+ rtm::quatf sample0;
+ rtm::quatf sample1;
if (is_rotation_variable)
{
sample0 = get_rotation_sample(bone_stream, raw_bone_stream, key0, context.bit_rates.rotation);
@@ -734,20 +735,20 @@ namespace acl
}
if (static_condition<distribution == SampleDistribution8::Variable>::test())
- rotation = quat_lerp(sample0, sample1, interpolation_alpha);
+ rotation = rtm::quat_lerp(sample0, sample1, interpolation_alpha);
else
- rotation = quat_normalize(sample0);
+ rotation = rtm::quat_normalize(sample0);
}
return rotation;
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream)
{
- Vector4_32 translation;
+ rtm::vector4f translation;
if (bone_stream.is_translation_default)
- translation = vector_zero_32();
+ translation = rtm::vector_zero();
else if (bone_stream.is_translation_constant)
translation = get_translation_sample(bone_stream, 0);
else
@@ -769,12 +770,12 @@ namespace acl
interpolation_alpha = 0.0F;
}
- const Vector4_32 sample0 = get_translation_sample(bone_stream, key0);
+ const rtm::vector4f sample0 = get_translation_sample(bone_stream, key0);
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const Vector4_32 sample1 = get_translation_sample(bone_stream, key1);
- translation = vector_lerp(sample0, sample1, interpolation_alpha);
+ const rtm::vector4f sample1 = get_translation_sample(bone_stream, key1);
+ translation = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
else
translation = sample0;
@@ -784,11 +785,11 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_translation_variable, VectorFormat8 translation_format)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_translation_variable, VectorFormat8 translation_format)
{
- Vector4_32 translation;
+ rtm::vector4f translation;
if (bone_stream.is_translation_default)
- translation = vector_zero_32();
+ translation = rtm::vector_zero();
else if (bone_stream.is_translation_constant)
translation = get_translation_sample(raw_bone_stream, 0, VectorFormat8::Vector3_96);
else
@@ -810,8 +811,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Vector4_32 sample0;
- Vector4_32 sample1;
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
if (is_translation_variable)
{
sample0 = get_translation_sample(bone_stream, raw_bone_stream, key0, context.bit_rates.translation);
@@ -828,7 +829,7 @@ namespace acl
}
if (static_condition<distribution == SampleDistribution8::Variable>::test())
- translation = vector_lerp(sample0, sample1, interpolation_alpha);
+ translation = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
else
translation = sample0;
}
@@ -837,9 +838,9 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, Vector4_32Arg0 default_scale)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, rtm::vector4f_arg0 default_scale)
{
- Vector4_32 scale;
+ rtm::vector4f scale;
if (bone_stream.is_scale_default)
scale = default_scale;
else if (bone_stream.is_scale_constant)
@@ -863,12 +864,12 @@ namespace acl
interpolation_alpha = 0.0F;
}
- const Vector4_32 sample0 = get_scale_sample(bone_stream, key0);
+ const rtm::vector4f sample0 = get_scale_sample(bone_stream, key0);
if (static_condition<distribution == SampleDistribution8::Variable>::test())
{
- const Vector4_32 sample1 = get_scale_sample(bone_stream, key1);
- scale = vector_lerp(sample0, sample1, interpolation_alpha);
+ const rtm::vector4f sample1 = get_scale_sample(bone_stream, key1);
+ scale = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
else
scale = sample0;
@@ -878,9 +879,9 @@ namespace acl
}
template<SampleDistribution8 distribution>
- ACL_FORCE_INLINE Vector4_32 ACL_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_scale_variable, VectorFormat8 scale_format, Vector4_32Arg0 default_scale)
+ ACL_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_scale(const sample_context& context, const BoneStreams& bone_stream, const BoneStreams& raw_bone_stream, bool is_scale_variable, VectorFormat8 scale_format, rtm::vector4f_arg0 default_scale)
{
- Vector4_32 scale;
+ rtm::vector4f scale;
if (bone_stream.is_scale_default)
scale = default_scale;
else if (bone_stream.is_scale_constant)
@@ -904,8 +905,8 @@ namespace acl
interpolation_alpha = 0.0F;
}
- Vector4_32 sample0;
- Vector4_32 sample1;
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
if (is_scale_variable)
{
sample0 = get_scale_sample(bone_stream, raw_bone_stream, key0, context.bit_rates.scale);
@@ -922,7 +923,7 @@ namespace acl
}
if (static_condition<distribution == SampleDistribution8::Variable>::test())
- scale = vector_lerp(sample0, sample1, interpolation_alpha);
+ scale = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
else
scale = sample0;
}
@@ -931,10 +932,10 @@ namespace acl
}
}
- inline void sample_streams(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, Transform_32* out_local_pose)
+ inline void sample_streams(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, rtm::qvvf* out_local_pose)
{
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -955,11 +956,11 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, default_scale) : default_scale;
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
else
@@ -970,21 +971,21 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, default_scale) : default_scale;
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
}
- inline void sample_stream(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, uint16_t bone_index, Transform_32* out_local_pose)
+ inline void sample_stream(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, uint16_t bone_index, rtm::qvvf* out_local_pose)
{
(void)num_bones;
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -1000,9 +1001,9 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
- Quat_32 rotation;
- Vector4_32 translation;
- Vector4_32 scale;
+ rtm::quatf rotation;
+ rtm::vector4f translation;
+ rtm::vector4f scale;
if (segment_context->distribution == SampleDistribution8::Uniform)
{
rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream);
@@ -1016,15 +1017,15 @@ namespace acl
scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, default_scale) : default_scale;
}
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
- inline void sample_streams_hierarchical(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, uint16_t bone_index, Transform_32* out_local_pose)
+ inline void sample_streams_hierarchical(const BoneStreams* bone_streams, uint16_t num_bones, float sample_time, uint16_t bone_index, rtm::qvvf* out_local_pose)
{
(void)num_bones;
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -1046,11 +1047,11 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[current_bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, default_scale) : default_scale;
- out_local_pose[current_bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
current_bone_index = bone_stream.parent_bone_index;
}
}
@@ -1063,24 +1064,24 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[current_bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, default_scale) : default_scale;
- out_local_pose[current_bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
current_bone_index = bone_stream.parent_bone_index;
}
}
}
- inline void sample_streams(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, Transform_32* out_local_pose)
+ inline void sample_streams(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
const bool is_scale_variable = is_vector_format_variable(scale_format);
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -1103,11 +1104,11 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
const BoneStreams& raw_bone_steam = raw_bone_steams[bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_rotation_variable, rotation_format);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_translation_variable, translation_format);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_scale_variable, scale_format, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_rotation_variable, rotation_format);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_translation_variable, translation_format);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_steam, is_scale_variable, scale_format, default_scale) : default_scale;
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
else
@@ -1120,16 +1121,16 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
const BoneStreams& raw_bone_steam = raw_bone_steams[bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_rotation_variable, rotation_format);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_translation_variable, translation_format);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_scale_variable, scale_format, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_rotation_variable, rotation_format);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_translation_variable, translation_format);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, raw_bone_steam, is_scale_variable, scale_format, default_scale) : default_scale;
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
}
- inline void sample_stream(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, Transform_32* out_local_pose)
+ inline void sample_stream(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
@@ -1138,7 +1139,7 @@ namespace acl
const bool is_scale_variable = is_vector_format_variable(scale_format);
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -1156,9 +1157,9 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[bone_index];
const BoneStreams& raw_bone_stream = raw_bone_steams[bone_index];
- Quat_32 rotation;
- Vector4_32 translation;
- Vector4_32 scale;
+ rtm::quatf rotation;
+ rtm::vector4f translation;
+ rtm::vector4f scale;
if (segment_context->distribution == SampleDistribution8::Uniform)
{
rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
@@ -1172,10 +1173,10 @@ namespace acl
scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format, default_scale) : default_scale;
}
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
- inline void sample_streams_hierarchical(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, Transform_32* out_local_pose)
+ inline void sample_streams_hierarchical(const BoneStreams* bone_streams, const BoneStreams* raw_bone_steams, uint16_t num_bones, float sample_time, uint16_t bone_index, const BoneBitRate* bit_rates, RotationFormat8 rotation_format, VectorFormat8 translation_format, VectorFormat8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
@@ -1184,7 +1185,7 @@ namespace acl
const bool is_scale_variable = is_vector_format_variable(scale_format);
const SegmentContext* segment_context = bone_streams->segment;
- const Vector4_32 default_scale = get_default_scale(segment_context->clip->additive_format);
+ const rtm::vector4f default_scale = get_default_scale(segment_context->clip->additive_format);
const bool has_scale = segment_context->clip->has_scale;
uint32_t sample_key;
@@ -1208,11 +1209,11 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[current_bone_index];
const BoneStreams& raw_bone_stream = raw_bone_steams[current_bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Uniform>(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format, default_scale) : default_scale;
- out_local_pose[current_bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
current_bone_index = bone_stream.parent_bone_index;
}
}
@@ -1227,32 +1228,32 @@ namespace acl
const BoneStreams& bone_stream = bone_streams[current_bone_index];
const BoneStreams& raw_bone_stream = raw_bone_steams[current_bone_index];
- const Quat_32 rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
- const Vector4_32 translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
- const Vector4_32 scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format, default_scale) : default_scale;
+ const rtm::quatf rotation = acl_impl::sample_rotation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_rotation_variable, rotation_format);
+ const rtm::vector4f translation = acl_impl::sample_translation<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_translation_variable, translation_format);
+ const rtm::vector4f scale = has_scale ? acl_impl::sample_scale<SampleDistribution8::Variable>(context, bone_stream, raw_bone_stream, is_scale_variable, scale_format, default_scale) : default_scale;
- out_local_pose[current_bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[current_bone_index] = rtm::qvv_set(rotation, translation, scale);
current_bone_index = bone_stream.parent_bone_index;
}
}
}
- inline void sample_streams(const BoneStreams* bone_streams, uint16_t num_bones, uint32_t sample_index, Transform_32* out_local_pose)
+ inline void sample_streams(const BoneStreams* bone_streams, uint16_t num_bones, uint32_t sample_index, rtm::qvvf* out_local_pose)
{
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
const BoneStreams& bone_stream = bone_streams[bone_index];
const uint32_t rotation_sample_index = !bone_stream.is_rotation_constant ? sample_index : 0;
- const Quat_32 rotation = get_rotation_sample(bone_stream, rotation_sample_index);
+ const rtm::quatf rotation = get_rotation_sample(bone_stream, rotation_sample_index);
const uint32_t translation_sample_index = !bone_stream.is_translation_constant ? sample_index : 0;
- const Vector4_32 translation = get_translation_sample(bone_stream, translation_sample_index);
+ const rtm::vector4f translation = get_translation_sample(bone_stream, translation_sample_index);
const uint32_t scale_sample_index = !bone_stream.is_scale_constant ? sample_index : 0;
- const Vector4_32 scale = get_scale_sample(bone_stream, scale_sample_index);
+ const rtm::vector4f scale = get_scale_sample(bone_stream, scale_sample_index);
- out_local_pose[bone_index] = transform_set(rotation, translation, scale);
+ out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
}
}
diff --git a/includes/acl/compression/stream/track_stream.h b/includes/acl/compression/stream/track_stream.h
--- a/includes/acl/compression/stream/track_stream.h
+++ b/includes/acl/compression/stream/track_stream.h
@@ -29,11 +29,12 @@
#include "acl/core/error.h"
#include "acl/core/track_types.h"
#include "acl/core/utils.h"
-#include "acl/math/quat_32.h"
#include "acl/math/quat_packing.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/vector4_packing.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -58,18 +59,18 @@ namespace acl
}
template<typename SampleType>
- SampleType ACL_SIMD_CALL get_raw_sample(uint32_t sample_index) const
+ SampleType RTM_SIMD_CALL get_raw_sample(uint32_t sample_index) const
{
const uint8_t* ptr = get_raw_sample_ptr(sample_index);
return *safe_ptr_cast<const SampleType>(ptr);
}
-#if defined(ACL_NO_INTRINSICS)
+#if defined(RTM_NO_INTRINSICS)
template<typename SampleType>
- void ACL_SIMD_CALL set_raw_sample(uint32_t sample_index, const SampleType& sample)
+ void RTM_SIMD_CALL set_raw_sample(uint32_t sample_index, const SampleType& sample)
#else
template<typename SampleType>
- void ACL_SIMD_CALL set_raw_sample(uint32_t sample_index, SampleType sample)
+ void RTM_SIMD_CALL set_raw_sample(uint32_t sample_index, SampleType sample)
#endif
{
ACL_ASSERT(m_sample_size == sizeof(SampleType), "Unexpected sample size. %u != %u", m_sample_size, sizeof(SampleType));
@@ -291,37 +292,37 @@ namespace acl
class TrackStreamRange
{
public:
- static TrackStreamRange ACL_SIMD_CALL from_min_max(Vector4_32Arg0 min, Vector4_32Arg1 max)
+ static TrackStreamRange RTM_SIMD_CALL from_min_max(rtm::vector4f_arg0 min, rtm::vector4f_arg1 max)
{
- return TrackStreamRange(min, vector_sub(max, min));
+ return TrackStreamRange(min, rtm::vector_sub(max, min));
}
- static TrackStreamRange ACL_SIMD_CALL from_min_extent(Vector4_32Arg0 min, Vector4_32Arg1 extent)
+ static TrackStreamRange RTM_SIMD_CALL from_min_extent(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent)
{
return TrackStreamRange(min, extent);
}
TrackStreamRange()
- : m_min(vector_zero_32())
- , m_extent(vector_zero_32())
+ : m_min(rtm::vector_zero())
+ , m_extent(rtm::vector_zero())
{}
- Vector4_32 ACL_SIMD_CALL get_min() const { return m_min; }
- Vector4_32 ACL_SIMD_CALL get_max() const { return vector_add(m_min, m_extent); }
+ rtm::vector4f RTM_SIMD_CALL get_min() const { return m_min; }
+ rtm::vector4f RTM_SIMD_CALL get_max() const { return rtm::vector_add(m_min, m_extent); }
- Vector4_32 ACL_SIMD_CALL get_center() const { return vector_add(m_min, vector_mul(m_extent, 0.5F)); }
- Vector4_32 ACL_SIMD_CALL get_extent() const { return m_extent; }
+ rtm::vector4f RTM_SIMD_CALL get_center() const { return rtm::vector_add(m_min, rtm::vector_mul(m_extent, 0.5F)); }
+ rtm::vector4f RTM_SIMD_CALL get_extent() const { return m_extent; }
- bool is_constant(float threshold) const { return vector_all_less_than(vector_abs(m_extent), vector_set(threshold)); }
+ bool is_constant(float threshold) const { return rtm::vector_all_less_than(rtm::vector_abs(m_extent), rtm::vector_set(threshold)); }
private:
- TrackStreamRange(const Vector4_32& min, const Vector4_32& extent)
+ TrackStreamRange(rtm::vector4f_arg0 min, rtm::vector4f_arg1 extent)
: m_min(min)
, m_extent(extent)
{}
- Vector4_32 m_min;
- Vector4_32 m_extent;
+ rtm::vector4f m_min;
+ rtm::vector4f m_extent;
};
struct BoneRanges
diff --git a/includes/acl/compression/stream/write_decompression_stats.h b/includes/acl/compression/stream/write_decompression_stats.h
--- a/includes/acl/compression/stream/write_decompression_stats.h
+++ b/includes/acl/compression/stream/write_decompression_stats.h
@@ -34,6 +34,8 @@
#include "acl/compression/output_stats.h"
#include "acl/decompression/default_output_writer.h"
+#include <rtm/scalard.h>
+
#include <algorithm>
#include <thread>
#include <chrono>
@@ -66,7 +68,7 @@ namespace acl
PlaybackDirection playback_direction, DecompressionFunction decompression_function,
CompressedClip* compressed_clips[k_num_decompression_evaluations],
DecompressionContextType* contexts[k_num_decompression_evaluations],
- CPUCacheFlusher* cache_flusher, Transform_32* lossy_pose_transforms)
+ CPUCacheFlusher* cache_flusher, rtm::qvvf* lossy_pose_transforms)
{
const ClipHeader& clip_header = get_clip_header(*compressed_clips[0]);
const float duration = calculate_duration(clip_header.num_samples, clip_header.sample_rate);
@@ -77,7 +79,7 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < k_num_decompression_samples; ++sample_index)
{
const float normalized_sample_time = float(sample_index) / float(k_num_decompression_samples - 1);
- sample_times[sample_index] = clamp(normalized_sample_time, 0.0F, 1.0F) * duration;
+ sample_times[sample_index] = rtm::scalar_clamp(normalized_sample_time, 0.0F, 1.0F) * duration;
}
switch (playback_direction)
@@ -171,8 +173,8 @@ namespace acl
if (are_any_enum_flags_set(logging, StatLogging::ExhaustiveDecompression))
data_writer.push(elapsed_ms);
- clip_min_ms = min(clip_min_ms, elapsed_ms);
- clip_max_ms = max(clip_max_ms, elapsed_ms);
+ clip_min_ms = rtm::scalar_min(clip_min_ms, elapsed_ms);
+ clip_max_ms = rtm::scalar_max(clip_max_ms, elapsed_ms);
clip_total_ms += elapsed_ms;
clip_time_ms[sample_index] = elapsed_ms;
}
@@ -187,9 +189,9 @@ namespace acl
};
}
- inline void write_memcpy_performance_stats(IAllocator& allocator, sjson::ObjectWriter& writer, CPUCacheFlusher* cache_flusher, Transform_32* lossy_pose_transforms, uint16_t num_bones)
+ inline void write_memcpy_performance_stats(IAllocator& allocator, sjson::ObjectWriter& writer, CPUCacheFlusher* cache_flusher, rtm::qvvf* lossy_pose_transforms, uint16_t num_bones)
{
- Transform_32* memcpy_src_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
+ rtm::qvvf* memcpy_src_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
double decompression_time_ms = 1000000.0;
for (uint32_t pass_index = 0; pass_index < 3; ++pass_index)
@@ -197,7 +199,7 @@ namespace acl
if (cache_flusher != nullptr)
{
cache_flusher->begin_flushing();
- cache_flusher->flush_buffer(memcpy_src_transforms, sizeof(Transform_32) * num_bones);
+ cache_flusher->flush_buffer(memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
cache_flusher->end_flushing();
// Now that the cache is cold, yield our time slice and wait for a new one
@@ -210,35 +212,35 @@ namespace acl
// to help keep it warm and minimize the risk that we'll be interrupted during decompression
std::this_thread::sleep_for(std::chrono::nanoseconds(1));
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
}
double execution_count;
ScopeProfiler timer;
if (cache_flusher != nullptr)
{
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
execution_count = 1.0;
}
else
{
// Warm cache is too fast, execute multiple times and divide by the count
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
- std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(Transform_32) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
+ std::memcpy(lossy_pose_transforms, memcpy_src_transforms, sizeof(rtm::qvvf) * num_bones);
execution_count = 10.0;
}
timer.stop();
const double elapsed_ms = timer.get_elapsed_milliseconds() / execution_count;
- decompression_time_ms = min(decompression_time_ms, elapsed_ms);
+ decompression_time_ms = rtm::scalar_min(decompression_time_ms, elapsed_ms);
}
writer[cache_flusher != nullptr ? "memcpy_cold" : "memcpy_warm"] = [&](sjson::ObjectWriter& memcpy_writer)
@@ -258,7 +260,7 @@ namespace acl
CPUCacheFlusher* cache_flusher = allocate_type<CPUCacheFlusher>(allocator);
const ClipHeader& clip_header = get_clip_header(*compressed_clips[0]);
- Transform_32* lossy_pose_transforms = allocate_type_array<Transform_32>(allocator, clip_header.num_bones);
+ rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, clip_header.num_bones);
const uint32_t num_bytes_per_bone = (4 + 3 + 3) * sizeof(float); // Rotation, Translation, Scale
writer["pose_size"] = uint32_t(clip_header.num_bones) * num_bytes_per_bone;
diff --git a/includes/acl/compression/stream/write_range_data.h b/includes/acl/compression/stream/write_range_data.h
--- a/includes/acl/compression/stream/write_range_data.h
+++ b/includes/acl/compression/stream/write_range_data.h
@@ -30,12 +30,12 @@
#include "acl/core/enum_utils.h"
#include "acl/core/track_types.h"
#include "acl/core/range_reduction_types.h"
-#include "acl/math/quat_32.h"
#include "acl/math/quat_packing.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/vector4_packing.h"
#include "acl/compression/stream/clip_context.h"
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -68,16 +68,16 @@ namespace acl
inline void write_range_track_data_impl(const TrackStream& track, const TrackStreamRange& range, bool is_clip_range_data, uint8_t*& out_range_data)
{
- const Vector4_32 range_min = range.get_min();
- const Vector4_32 range_extent = range.get_extent();
+ const rtm::vector4f range_min = range.get_min();
+ const rtm::vector4f range_extent = range.get_extent();
if (is_clip_range_data)
{
const uint32_t range_member_size = sizeof(float) * 3;
- std::memcpy(out_range_data, vector_as_float_ptr(range_min), range_member_size);
+ std::memcpy(out_range_data, &range_min, range_member_size);
out_range_data += range_member_size;
- std::memcpy(out_range_data, vector_as_float_ptr(range_extent), range_member_size);
+ std::memcpy(out_range_data, &range_extent, range_member_size);
out_range_data += range_member_size;
}
else
@@ -123,16 +123,16 @@ namespace acl
if (are_any_enum_flags_set(range_reduction, RangeReductionFlags8::Rotations) && !bone_stream.is_rotation_constant)
{
- const Vector4_32 range_min = bone_range.rotation.get_min();
- const Vector4_32 range_extent = bone_range.rotation.get_extent();
+ const rtm::vector4f range_min = bone_range.rotation.get_min();
+ const rtm::vector4f range_extent = bone_range.rotation.get_extent();
if (is_clip_range_data)
{
const uint32_t range_member_size = bone_stream.rotations.get_rotation_format() == RotationFormat8::Quat_128 ? (sizeof(float) * 4) : (sizeof(float) * 3);
- std::memcpy(range_data, vector_as_float_ptr(range_min), range_member_size);
+ std::memcpy(range_data, &range_min, range_member_size);
range_data += range_member_size;
- std::memcpy(range_data, vector_as_float_ptr(range_extent), range_member_size);
+ std::memcpy(range_data, &range_extent, range_member_size);
range_data += range_member_size;
}
else
diff --git a/includes/acl/compression/stream/write_stats.h b/includes/acl/compression/stream/write_stats.h
--- a/includes/acl/compression/stream/write_stats.h
+++ b/includes/acl/compression/stream/write_stats.h
@@ -101,9 +101,9 @@ namespace acl
const uint16_t num_bones = skeleton.get_num_bones();
const bool has_scale = segment_context_has_scale(segment);
- Transform_32* raw_local_pose = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* base_local_pose = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* lossy_local_pose = allocate_type_array<Transform_32>(allocator, num_bones);
+ rtm::qvvf* raw_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* base_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* lossy_local_pose = allocate_type_array<rtm::qvvf>(allocator, num_bones);
const float sample_rate = raw_clip_context.sample_rate;
const float ref_duration = calculate_duration(raw_clip_context.num_samples, sample_rate);
@@ -114,7 +114,7 @@ namespace acl
{
for (uint32_t sample_index = 0; sample_index < segment.num_samples; ++sample_index)
{
- const float sample_time = min(float(segment.clip_sample_offset + sample_index) / sample_rate, ref_duration);
+ const float sample_time = rtm::scalar_min(float(segment.clip_sample_offset + sample_index) / sample_rate, ref_duration);
sample_streams(raw_clip_context.segments[0].bone_streams, num_bones, sample_time, raw_local_pose);
sample_streams(segment.bone_streams, num_bones, sample_time, lossy_local_pose);
diff --git a/includes/acl/compression/stream/write_stream_data.h b/includes/acl/compression/stream/write_stream_data.h
--- a/includes/acl/compression/stream/write_stream_data.h
+++ b/includes/acl/compression/stream/write_stream_data.h
@@ -28,9 +28,6 @@
#include "acl/core/iallocator.h"
#include "acl/core/error.h"
#include "acl/core/compressed_clip.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/quat_packing.h"
-#include "acl/math/vector4_32.h"
#include "acl/compression/stream/clip_context.h"
#include <cstdint>
diff --git a/includes/acl/compression/track_error.h b/includes/acl/compression/track_error.h
--- a/includes/acl/compression/track_error.h
+++ b/includes/acl/compression/track_error.h
@@ -90,7 +90,7 @@ namespace acl
// Regression test
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const float sample_time = min(float(sample_index) / sample_rate, duration);
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
// We use the nearest sample to accurately measure the loss that happened, if any
raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::Nearest, raw_tracks_writer);
diff --git a/includes/acl/compression/utils.h b/includes/acl/compression/utils.h
--- a/includes/acl/compression/utils.h
+++ b/includes/acl/compression/utils.h
@@ -65,17 +65,17 @@ namespace acl
const uint32_t additive_num_samples = additive_base_clip != nullptr ? additive_base_clip->get_num_samples() : 0;
const float additive_duration = additive_base_clip != nullptr ? additive_base_clip->get_duration() : 0.0F;
- Transform_32* raw_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* base_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* lossy_pose_transforms = allocate_type_array<Transform_32>(allocator, num_output_bones);
- Transform_32* lossy_remapped_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
+ rtm::qvvf* raw_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* base_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_output_bones);
+ rtm::qvvf* lossy_remapped_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
BoneError bone_error;
DefaultOutputWriter pose_writer(lossy_pose_transforms, num_output_bones);
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const float sample_time = min(float(sample_index) / sample_rate, clip_duration);
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_pose_transforms, num_bones);
@@ -92,7 +92,7 @@ namespace acl
// Perform remapping by copying the raw pose first and we overwrite with the decompressed pose if
// the data is available
- std::memcpy(lossy_remapped_pose_transforms, raw_pose_transforms, sizeof(Transform_32) * num_bones);
+ std::memcpy(lossy_remapped_pose_transforms, raw_pose_transforms, sizeof(rtm::qvvf) * num_bones);
for (uint16_t output_index = 0; output_index < num_output_bones; ++output_index)
{
const uint16_t bone_index = output_bone_mapping[output_index];
diff --git a/includes/acl/core/additive_utils.h b/includes/acl/core/additive_utils.h
--- a/includes/acl/core/additive_utils.h
+++ b/includes/acl/core/additive_utils.h
@@ -25,8 +25,9 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/compiler_utils.h"
-#include "acl/math/transform_32.h"
-#include "acl/math/transform_64.h"
+
+#include <rtm/qvvd.h>
+#include <rtm/qvvf.h>
#include <cstdint>
@@ -106,77 +107,77 @@ namespace acl
return false;
}
- inline Vector4_32 ACL_SIMD_CALL get_default_scale(AdditiveClipFormat8 additive_format)
+ inline rtm::vector4f RTM_SIMD_CALL get_default_scale(AdditiveClipFormat8 additive_format)
{
- return additive_format == AdditiveClipFormat8::Additive1 ? vector_zero_32() : vector_set(1.0F);
+ return additive_format == AdditiveClipFormat8::Additive1 ? rtm::vector_zero() : rtm::vector_set(1.0F);
}
- inline Transform_32 ACL_SIMD_CALL transform_add0(Transform_32Arg0 base, Transform_32Arg1 additive)
+ inline rtm::qvvf RTM_SIMD_CALL transform_add0(rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
- const Quat_32 rotation = quat_mul(additive.rotation, base.rotation);
- const Vector4_32 translation = vector_add(additive.translation, base.translation);
- const Vector4_32 scale = vector_mul(additive.scale, base.scale);
- return transform_set(rotation, translation, scale);
+ const rtm::quatf rotation = rtm::quat_mul(additive.rotation, base.rotation);
+ const rtm::vector4f translation = rtm::vector_add(additive.translation, base.translation);
+ const rtm::vector4f scale = rtm::vector_mul(additive.scale, base.scale);
+ return rtm::qvv_set(rotation, translation, scale);
}
- inline Transform_32 ACL_SIMD_CALL transform_add1(Transform_32Arg0 base, Transform_32Arg1 additive)
+ inline rtm::qvvf RTM_SIMD_CALL transform_add1(rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
- const Quat_32 rotation = quat_mul(additive.rotation, base.rotation);
- const Vector4_32 translation = vector_add(additive.translation, base.translation);
- const Vector4_32 scale = vector_mul(vector_add(vector_set(1.0F), additive.scale), base.scale);
- return transform_set(rotation, translation, scale);
+ const rtm::quatf rotation = rtm::quat_mul(additive.rotation, base.rotation);
+ const rtm::vector4f translation = rtm::vector_add(additive.translation, base.translation);
+ const rtm::vector4f scale = rtm::vector_mul(rtm::vector_add(rtm::vector_set(1.0F), additive.scale), base.scale);
+ return rtm::qvv_set(rotation, translation, scale);
}
- inline Transform_32 ACL_SIMD_CALL transform_add_no_scale(Transform_32Arg0 base, Transform_32Arg1 additive)
+ inline rtm::qvvf RTM_SIMD_CALL transform_add_no_scale(rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
- const Quat_32 rotation = quat_mul(additive.rotation, base.rotation);
- const Vector4_32 translation = vector_add(additive.translation, base.translation);
- return transform_set(rotation, translation, vector_set(1.0F));
+ const rtm::quatf rotation = rtm::quat_mul(additive.rotation, base.rotation);
+ const rtm::vector4f translation = rtm::vector_add(additive.translation, base.translation);
+ return rtm::qvv_set(rotation, translation, rtm::vector_set(1.0F));
}
- inline Transform_32 ACL_SIMD_CALL apply_additive_to_base(AdditiveClipFormat8 additive_format, Transform_32Arg1 base, Transform_32ArgN additive)
+ inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base(AdditiveClipFormat8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
switch (additive_format)
{
default:
case AdditiveClipFormat8::None: return additive;
- case AdditiveClipFormat8::Relative: return transform_mul(additive, base);
+ case AdditiveClipFormat8::Relative: return rtm::qvv_mul(additive, base);
case AdditiveClipFormat8::Additive0: return transform_add0(base, additive);
case AdditiveClipFormat8::Additive1: return transform_add1(base, additive);
}
}
- inline Transform_32 ACL_SIMD_CALL apply_additive_to_base_no_scale(AdditiveClipFormat8 additive_format, Transform_32Arg1 base, Transform_32ArgN additive)
+ inline rtm::qvvf RTM_SIMD_CALL apply_additive_to_base_no_scale(AdditiveClipFormat8 additive_format, rtm::qvvf_arg0 base, rtm::qvvf_arg1 additive)
{
switch (additive_format)
{
default:
case AdditiveClipFormat8::None: return additive;
- case AdditiveClipFormat8::Relative: return transform_mul_no_scale(additive, base);
+ case AdditiveClipFormat8::Relative: return rtm::qvv_mul_no_scale(additive, base);
case AdditiveClipFormat8::Additive0: return transform_add_no_scale(base, additive);
case AdditiveClipFormat8::Additive1: return transform_add_no_scale(base, additive);
}
}
- inline Transform_64 convert_to_relative(const Transform_64& base, const Transform_64& transform)
+ inline rtm::qvvd convert_to_relative(const rtm::qvvd& base, const rtm::qvvd& transform)
{
- return transform_mul(transform, transform_inverse(base));
+ return rtm::qvv_mul(transform, rtm::qvv_inverse(base));
}
- inline Transform_64 convert_to_additive0(const Transform_64& base, const Transform_64& transform)
+ inline rtm::qvvd convert_to_additive0(const rtm::qvvd& base, const rtm::qvvd& transform)
{
- const Quat_64 rotation = quat_mul(transform.rotation, quat_conjugate(base.rotation));
- const Vector4_64 translation = vector_sub(transform.translation, base.translation);
- const Vector4_64 scale = vector_div(transform.scale, base.scale);
- return transform_set(rotation, translation, scale);
+ const rtm::quatd rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
+ const rtm::vector4d translation = rtm::vector_sub(transform.translation, base.translation);
+ const rtm::vector4d scale = rtm::vector_div(transform.scale, base.scale);
+ return rtm::qvv_set(rotation, translation, scale);
}
- inline Transform_64 convert_to_additive1(const Transform_64& base, const Transform_64& transform)
+ inline rtm::qvvd convert_to_additive1(const rtm::qvvd& base, const rtm::qvvd& transform)
{
- const Quat_64 rotation = quat_mul(transform.rotation, quat_conjugate(base.rotation));
- const Vector4_64 translation = vector_sub(transform.translation, base.translation);
- const Vector4_64 scale = vector_sub(vector_mul(transform.scale, vector_reciprocal(base.scale)), vector_set(1.0));
- return transform_set(rotation, translation, scale);
+ const rtm::quatd rotation = rtm::quat_mul(transform.rotation, rtm::quat_conjugate(base.rotation));
+ const rtm::vector4d translation = rtm::vector_sub(transform.translation, base.translation);
+ const rtm::vector4d scale = rtm::vector_sub(rtm::vector_mul(transform.scale, rtm::vector_reciprocal(base.scale)), rtm::vector_set(1.0));
+ return rtm::qvv_set(rotation, translation, scale);
}
}
diff --git a/includes/acl/core/bit_manip_utils.h b/includes/acl/core/bit_manip_utils.h
--- a/includes/acl/core/bit_manip_utils.h
+++ b/includes/acl/core/bit_manip_utils.h
@@ -26,11 +26,12 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
-#include "acl/math/math.h"
+
+#include <rtm/math.h>
#include <cstdint>
-#if !defined(ACL_USE_POPCOUNT) && !defined(ACL_NO_INTRINSICS)
+#if !defined(ACL_USE_POPCOUNT) && !defined(RTM_NO_INTRINSICS)
// TODO: Enable this for PlayStation 4 as well, what is the define and can we use it in public code?
#if defined(_DURANGO) || defined(_XBOX_ONE)
// Enable pop-count type instructions on Xbox One
@@ -42,7 +43,7 @@
#include <nmmintrin.h>
#endif
-#if defined(ACL_AVX_INTRINSICS)
+#if defined(RTM_AVX_INTRINSICS)
// Use BMI
#include <ammintrin.h> // MSVC uses this header for _andn_u32 BMI intrinsic
#include <immintrin.h> // Intel documentation says _andn_u32 and others are here
@@ -58,7 +59,7 @@ namespace acl
{
#if defined(ACL_USE_POPCOUNT)
return (uint8_t)_mm_popcnt_u32(value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
return (uint8_t)vget_lane_u64(vcnt_u8(vcreate_u8(value)), 0);
#else
value = value - ((value >> 1) & 0x55);
@@ -71,7 +72,7 @@ namespace acl
{
#if defined(ACL_USE_POPCOUNT)
return (uint16_t)_mm_popcnt_u32(value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
return (uint16_t)vget_lane_u64(vpaddl_u8(vcnt_u8(vcreate_u8(value))), 0);
#else
value = value - ((value >> 1) & 0x5555);
@@ -84,7 +85,7 @@ namespace acl
{
#if defined(ACL_USE_POPCOUNT)
return _mm_popcnt_u32(value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
return (uint32_t)vget_lane_u64(vpaddl_u16(vpaddl_u8(vcnt_u8(vcreate_u8(value)))), 0);
#else
value = value - ((value >> 1) & 0x55555555);
@@ -97,7 +98,7 @@ namespace acl
{
#if defined(ACL_USE_POPCOUNT)
return _mm_popcnt_u64(value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
return vget_lane_u64(vpaddl_u32(vpaddl_u16(vpaddl_u8(vcnt_u8(vcreate_u8(value))))), 0);
#else
value = value - ((value >> 1) & 0x5555555555555555ULL);
diff --git a/includes/acl/core/floating_point_exceptions.h b/includes/acl/core/floating_point_exceptions.h
--- a/includes/acl/core/floating_point_exceptions.h
+++ b/includes/acl/core/floating_point_exceptions.h
@@ -25,7 +25,8 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/compiler_utils.h"
-#include "acl/math/math.h"
+
+#include <rtm/math.h>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -36,9 +37,9 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct fp_environment
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
unsigned int exception_mask;
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
// TODO: Implement on ARM. API to do this is not consistent across Android, Windows ARM, and iOS
// and on top of it, most ARM CPUs out there do not raise the SIGFPE trap so they are silent
#endif
@@ -49,7 +50,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
inline void enable_fp_exceptions(fp_environment& out_old_env)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
// We only care about SSE and not x87
// Clear any exceptions that might have been raised already
_MM_SET_EXCEPTION_STATE(0);
@@ -68,7 +69,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
inline void disable_fp_exceptions(fp_environment& out_old_env)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
// We only care about SSE and not x87
// Cache the exception mask we had so we can restore it later
out_old_env.exception_mask = _MM_GET_EXCEPTION_MASK();
@@ -84,7 +85,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
inline void restore_fp_exceptions(const fp_environment& env)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
// We only care about SSE and not x87
// Clear any exceptions that might have been raised already
_MM_SET_EXCEPTION_STATE(0);
diff --git a/includes/acl/core/interpolation_utils.h b/includes/acl/core/interpolation_utils.h
--- a/includes/acl/core/interpolation_utils.h
+++ b/includes/acl/core/interpolation_utils.h
@@ -26,7 +26,8 @@
#include "acl/core/error.h"
#include "acl/core/compiler_utils.h"
-#include "acl/math/scalar_32.h"
+
+#include <rtm/scalarf.h>
#include <cstdint>
#include <algorithm>
@@ -76,7 +77,7 @@ namespace acl
ACL_ASSERT(num_samples > 0, "Invalid num_samples: %u", num_samples);
const float sample_rate = duration == 0.0F ? 0.0F : (float(num_samples - 1) / duration);
- ACL_ASSERT(sample_rate >= 0.0F && is_finite(sample_rate), "Invalid sample_rate: %f", sample_rate);
+ ACL_ASSERT(sample_rate >= 0.0F && rtm::scalar_is_finite(sample_rate), "Invalid sample_rate: %f", sample_rate);
const float sample_index = sample_time * sample_rate;
const uint32_t sample_index0 = static_cast<uint32_t>(sample_index);
@@ -102,7 +103,7 @@ namespace acl
out_interpolation_alpha = 1.0F;
break;
case SampleRoundingPolicy::Nearest:
- out_interpolation_alpha = floor(interpolation_alpha + 0.5F);
+ out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
break;
}
}
@@ -155,7 +156,7 @@ namespace acl
out_interpolation_alpha = 1.0F;
break;
case SampleRoundingPolicy::Nearest:
- out_interpolation_alpha = floor(interpolation_alpha + 0.5F);
+ out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
break;
}
}
diff --git a/includes/acl/core/memory_cache.h b/includes/acl/core/memory_cache.h
--- a/includes/acl/core/memory_cache.h
+++ b/includes/acl/core/memory_cache.h
@@ -26,7 +26,8 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/iallocator.h"
-#include "acl/math/vector4_32.h"
+
+#include <rtm/vector4f.h>
#include <cstdint>
@@ -62,7 +63,7 @@ namespace acl
(void)buffer;
(void)buffer_size;
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
constexpr size_t k_cache_line_size = 64;
const uint8_t* buffer_start = reinterpret_cast<const uint8_t*>(buffer);
@@ -84,9 +85,10 @@ namespace acl
ACL_ASSERT(m_is_flushing, "begin_flushing() not called");
m_is_flushing = false;
-#if !defined(ACL_SSE2_INTRINSICS)
+#if !defined(RTM_SSE2_INTRINSICS)
+ const rtm::vector4f one = rtm::vector_set(1.0F);
for (size_t entry_index = 0; entry_index < k_num_buffer_entries; ++entry_index)
- m_buffer[entry_index] = vector_add(m_buffer[entry_index], vector_set(1.0f));
+ m_buffer[entry_index] = rtm::vector_add(m_buffer[entry_index], one);
#endif
}
@@ -94,7 +96,7 @@ namespace acl
CPUCacheFlusher(const CPUCacheFlusher& other) = delete;
CPUCacheFlusher& operator=(const CPUCacheFlusher& other) = delete;
-#if !defined(ACL_SSE2_INTRINSICS)
+#if !defined(RTM_SSE2_INTRINSICS)
// TODO: get an official CPU cache size
#if defined(__ANDROID__)
// Nexus 5X has 2MB cache
@@ -104,9 +106,9 @@ namespace acl
static constexpr size_t k_cache_size = 9 * 1024 * 1024;
#endif
- static constexpr size_t k_num_buffer_entries = k_cache_size / sizeof(Vector4_32);
+ static constexpr size_t k_num_buffer_entries = k_cache_size / sizeof(rtm::vector4f);
- Vector4_32 m_buffer[k_num_buffer_entries];
+ rtm::vector4f m_buffer[k_num_buffer_entries];
#endif
bool m_is_flushing;
diff --git a/includes/acl/core/utils.h b/includes/acl/core/utils.h
--- a/includes/acl/core/utils.h
+++ b/includes/acl/core/utils.h
@@ -27,7 +27,8 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
#include "acl/core/memory_utils.h"
-#include "acl/math/scalar_32.h"
+
+#include <rtm/scalarf.h>
#include <cstdint>
#include <limits>
@@ -56,7 +57,7 @@ namespace acl
return 1; // An infinite duration, we have a single sample (static pose)
// Otherwise we have at least 1 sample
- return safe_static_cast<uint32_t>(floor((duration * float(sample_rate)) + 0.5F)) + 1;
+ return safe_static_cast<uint32_t>(rtm::scalar_floor((duration * float(sample_rate)) + 0.5F)) + 1;
}
//////////////////////////////////////////////////////////////////////////
@@ -78,7 +79,7 @@ namespace acl
return 1; // An infinite duration, we have a single sample (static pose)
// Otherwise we have at least 1 sample
- return safe_static_cast<uint32_t>(floor((duration * sample_rate) + 0.5F)) + 1;
+ return safe_static_cast<uint32_t>(rtm::scalar_floor((duration * sample_rate) + 0.5F)) + 1;
}
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/decompression/decompress.h b/includes/acl/decompression/decompress.h
--- a/includes/acl/decompression/decompress.h
+++ b/includes/acl/decompression/decompress.h
@@ -34,7 +34,6 @@
#include "acl/core/track_types.h"
#include "acl/core/track_writer.h"
#include "acl/decompression/impl/track_sampling_impl.h"
-#include "acl/math/rtm_casts.h"
#include "acl/math/vector4_packing.h"
#include <rtm/types.h>
@@ -340,13 +339,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, track_bit_offset1));
+ value0 = unpack_vector2_64_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector2_64_unsafe(animated_values, track_bit_offset1);
}
else
{
- value0 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+ value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + 2);
@@ -378,13 +377,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, track_bit_offset1));
+ value0 = unpack_vector3_96_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector3_96_unsafe(animated_values, track_bit_offset1);
}
else
{
- value0 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+ value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + 3);
@@ -416,13 +415,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset1));
+ value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
}
else
{
- value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
@@ -454,13 +453,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, track_bit_offset1));
+ value0 = unpack_vector4_128_unsafe(animated_values, track_bit_offset0);
+ value1 = unpack_vector4_128_unsafe(animated_values, track_bit_offset1);
}
else
{
- value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0));
- value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1));
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset0);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, track_bit_offset1);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + 4);
@@ -567,13 +566,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector2_64_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
}
else
{
- value0 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector2_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
@@ -597,13 +596,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector3_96_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
}
else
{
- value0 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector3_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
@@ -627,13 +626,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
}
else
{
- value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
@@ -657,13 +656,13 @@ namespace acl
rtm::vector4f value1;
if (is_raw_bit_rate(bit_rate))
{
- value0 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_128_unsafe(animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
}
else
{
- value0 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset));
- value1 = vector_acl2rtm(unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset));
+ value0 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[0] + track_bit_offset);
+ value1 = unpack_vector4_uXX_unsafe(num_bits_per_component, animated_values, m_context.key_frame_bit_offsets[1] + track_bit_offset);
const rtm::vector4f range_min = rtm::vector_load(range_values);
const rtm::vector4f range_extent = rtm::vector_load(range_values + num_element_components);
diff --git a/includes/acl/decompression/decompress_data.h b/includes/acl/decompression/decompress_data.h
--- a/includes/acl/decompression/decompress_data.h
+++ b/includes/acl/decompression/decompress_data.h
@@ -27,6 +27,10 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/memory_utils.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+#include <rtm/packing/quatf.h>
+
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
@@ -328,7 +332,7 @@ namespace acl
template<size_t num_key_frames, class SettingsType, class DecompressionContextType, class SamplingContextType>
//ACL_DEPRECATED("Use decompress_and_interpolate_rotation instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_rotations(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Quat_32* out_rotations)
+ inline TimeSeriesType8 decompress_rotations(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::quatf* out_rotations)
{
TimeSeriesType8 time_series_type;
@@ -336,7 +340,7 @@ namespace acl
const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
if (is_sample_default)
{
- out_rotations[0] = quat_identity_32();
+ out_rotations[0] = rtm::quat_identity();
time_series_type = TimeSeriesType8::ConstantDefault;
}
else
@@ -345,7 +349,7 @@ namespace acl
const bool is_sample_constant = bitset_test(decomp_context.constant_tracks_bitset, track_index_bit_ref);
if (is_sample_constant)
{
- Quat_32 rotation;
+ rtm::quatf rotation;
if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
rotation = unpack_quat_128(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
@@ -360,7 +364,7 @@ namespace acl
else
{
ACL_ASSERT(false, "Unrecognized rotation format");
- rotation = quat_identity_32();
+ rotation = rtm::quat_identity();
}
out_rotations[0] = rotation;
@@ -376,7 +380,7 @@ namespace acl
const bool are_clip_rotations_normalized = are_any_enum_flags_set(clip_range_reduction, RangeReductionFlags8::Rotations);
const bool are_segment_rotations_normalized = are_any_enum_flags_set(segment_range_reduction, RangeReductionFlags8::Rotations);
- Vector4_32 rotations[num_key_frames];
+ rtm::vector4f rotations[num_key_frames];
bool ignore_clip_range[num_key_frames] = { false };
bool ignore_segment_range[num_key_frames] = { false };
@@ -466,10 +470,10 @@ namespace acl
{
if (!ignore_segment_range[i])
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
- rotations[i] = vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
+ rotations[i] = rtm::vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
}
}
}
@@ -479,20 +483,20 @@ namespace acl
{
for (size_t i = 0; i < num_key_frames; ++i)
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)), true);
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)), true);
- rotations[i] = vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
+ rotations[i] = rtm::vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
}
}
else
{
for (size_t i = 0; i < num_key_frames; ++i)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (decomp_context.num_rotation_components * sizeof(uint8_t)));
- rotations[i] = vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
+ rotations[i] = rtm::vector_mul_add(rotations[i], segment_range_extent, segment_range_min);
}
}
}
@@ -502,13 +506,13 @@ namespace acl
if (are_clip_rotations_normalized)
{
- const Vector4_32 clip_range_min = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const Vector4_32 clip_range_extent = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (decomp_context.num_rotation_components * sizeof(float)));
+ const rtm::vector4f clip_range_min = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (decomp_context.num_rotation_components * sizeof(float)));
for (size_t i = 0; i < num_key_frames; ++i)
{
if (!ignore_clip_range[i])
- rotations[i] = vector_mul_add(rotations[i], clip_range_extent, clip_range_min);
+ rotations[i] = rtm::vector_mul_add(rotations[i], clip_range_extent, clip_range_min);
}
sampling_context.clip_range_data_offset += decomp_context.num_rotation_components * sizeof(float) * 2;
@@ -517,12 +521,12 @@ namespace acl
if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
{
for (size_t i = 0; i < num_key_frames; ++i)
- out_rotations[i] = vector_to_quat(rotations[i]);
+ out_rotations[i] = rtm::vector_to_quat(rotations[i]);
}
else
{
for (size_t i = 0; i < num_key_frames; ++i)
- out_rotations[i] = quat_from_positive_w(rotations[i]);
+ out_rotations[i] = rtm::quat_from_positive_w(rotations[i]);
}
time_series_type = TimeSeriesType8::Varying;
@@ -535,28 +539,28 @@ namespace acl
template<class SettingsType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_rotation instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Quat_32* out_rotations)
+ inline TimeSeriesType8 decompress_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::quatf* out_rotations)
{
return decompress_rotations<1>(settings, header, decomp_context, sampling_context, out_rotations);
}
template<class SettingsType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_rotation instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_rotations_in_two_key_frames(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Quat_32* out_rotations)
+ inline TimeSeriesType8 decompress_rotations_in_two_key_frames(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::quatf* out_rotations)
{
return decompress_rotations<2>(settings, header, decomp_context, sampling_context, out_rotations);
}
template<class SettingsType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_rotation instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_rotations_in_four_key_frames(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Quat_32* out_rotations)
+ inline TimeSeriesType8 decompress_rotations_in_four_key_frames(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::quatf* out_rotations)
{
return decompress_rotations<4>(settings, header, decomp_context, sampling_context, out_rotations);
}
template<size_t num_key_frames, class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
//ACL_DEPRECATED("Use decompress_and_interpolate_vector instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_vectors(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Vector4_32* out_vectors)
+ inline TimeSeriesType8 decompress_vectors(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::vector4f* out_vectors)
{
TimeSeriesType8 time_series_type;
@@ -657,10 +661,10 @@ namespace acl
{
if (format != VectorFormat8::Vector3_Variable || !settings.is_vector_format_supported(VectorFormat8::Vector3_Variable) || !ignore_segment_range[i])
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t)));
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[i] + sampling_context.segment_range_data_offset + (3 * sizeof(uint8_t)));
- out_vectors[i] = vector_mul_add(out_vectors[i], segment_range_extent, segment_range_min);
+ out_vectors[i] = rtm::vector_mul_add(out_vectors[i], segment_range_extent, segment_range_min);
}
}
@@ -669,13 +673,13 @@ namespace acl
if (are_any_enum_flags_set(clip_range_reduction, range_reduction_flag))
{
- const Vector4_32 clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const Vector4_32 clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
+ const rtm::vector4f clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
for (size_t i = 0; i < num_key_frames; ++i)
{
if (!ignore_clip_range[i])
- out_vectors[i] = vector_mul_add(out_vectors[i], clip_range_extent, clip_range_min);
+ out_vectors[i] = rtm::vector_mul_add(out_vectors[i], clip_range_extent, clip_range_min);
}
sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
@@ -691,37 +695,37 @@ namespace acl
template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_vector instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Vector4_32* out_vectors)
+ inline TimeSeriesType8 decompress_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::vector4f* out_vectors)
{
return decompress_vectors<1>(settings, header, decomp_context, sampling_context, out_vectors);
}
template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_vector instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_vectors_in_two_key_frames(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Vector4_32* out_vectors)
+ inline TimeSeriesType8 decompress_vectors_in_two_key_frames(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::vector4f* out_vectors)
{
return decompress_vectors<2>(settings, header, decomp_context, sampling_context, out_vectors);
}
template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
ACL_DEPRECATED("Use decompress_and_interpolate_vector instead, to be removed in v2.0")
- inline TimeSeriesType8 decompress_vectors_in_four_key_frames(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, Vector4_32* out_vectors)
+ inline TimeSeriesType8 decompress_vectors_in_four_key_frames(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context, rtm::vector4f* out_vectors)
{
return decompress_vectors<4>(settings, header, decomp_context, sampling_context, out_vectors);
}
template <class SettingsType, class DecompressionContextType, class SamplingContextType>
- inline Quat_32 ACL_SIMD_CALL decompress_and_interpolate_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
+ inline rtm::quatf RTM_SIMD_CALL decompress_and_interpolate_rotation(const SettingsType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
{
static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
- Quat_32 interpolated_rotation;
+ rtm::quatf interpolated_rotation;
const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
if (is_sample_default)
{
- interpolated_rotation = quat_identity_32();
+ interpolated_rotation = rtm::quat_identity();
}
else
{
@@ -742,11 +746,11 @@ namespace acl
else
{
ACL_ASSERT(false, "Unrecognized rotation format");
- interpolated_rotation = quat_identity_32();
+ interpolated_rotation = rtm::quat_identity();
}
- ACL_ASSERT(quat_is_finite(interpolated_rotation), "Rotation is not valid!");
- ACL_ASSERT(quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
+ ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
const RotationFormat8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
sampling_context.constant_track_data_offset += get_packed_rotation_size(packed_format);
@@ -761,7 +765,7 @@ namespace acl
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
// This part is fairly complex, we'll loop and write to the stack (sampling context)
- Vector4_32* rotations_as_vec = &sampling_context.vectors[0];
+ rtm::vector4f* rotations_as_vec = &sampling_context.vectors[0];
// Range ignore flags are used to skip range normalization at the clip and/or segment levels
// Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
@@ -853,10 +857,10 @@ namespace acl
// We unroll because even if we work from the stack, with 2 samples the compiler always
// unrolls but it fails to keep the values in registers, working from the stack which
// is inefficient.
- Vector4_32 rotation_as_vec0 = rotations_as_vec[0];
- Vector4_32 rotation_as_vec1 = rotations_as_vec[1];
- Vector4_32 rotation_as_vec2;
- Vector4_32 rotation_as_vec3;
+ rtm::vector4f rotation_as_vec0 = rotations_as_vec[0];
+ rtm::vector4f rotation_as_vec1 = rotations_as_vec[1];
+ rtm::vector4f rotation_as_vec2;
+ rtm::vector4f rotation_as_vec3;
if (static_condition<num_key_frames == 4>::test())
{
@@ -881,36 +885,36 @@ namespace acl
constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
- rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
}
if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
- rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
}
if (static_condition<num_key_frames == 4>::test())
{
if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
- rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
}
if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
- rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
}
}
}
@@ -919,66 +923,66 @@ namespace acl
if (rotation_format == RotationFormat8::Quat_128 && settings.is_rotation_format_supported(RotationFormat8::Quat_128))
{
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[0] + segment_range_extent_offset, true);
- rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
}
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[1] + segment_range_extent_offset, true);
- rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
}
if (static_condition<num_key_frames == 4>::test())
{
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[2] + segment_range_extent_offset, true);
- rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
}
{
- const Vector4_32 segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
- const Vector4_32 segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
+ const rtm::vector4f segment_range_min = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_min_offset, true);
+ const rtm::vector4f segment_range_extent = unpack_vector4_32(decomp_context.segment_range_data[3] + segment_range_extent_offset, true);
- rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
}
}
}
else
{
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
- rotation_as_vec0 = vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, segment_range_extent, segment_range_min);
}
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
- rotation_as_vec1 = vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, segment_range_extent, segment_range_min);
}
if (static_condition<num_key_frames == 4>::test())
{
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
- rotation_as_vec2 = vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, segment_range_extent, segment_range_min);
}
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
- rotation_as_vec3 = vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, segment_range_extent, segment_range_min);
}
}
}
@@ -989,44 +993,44 @@ namespace acl
if (are_clip_rotations_normalized)
{
- const Vector4_32 clip_range_min = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const Vector4_32 clip_range_extent = vector_unaligned_load_32(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (num_rotation_components * sizeof(float)));
+ const rtm::vector4f clip_range_min = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = rtm::vector_load(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (num_rotation_components * sizeof(float)));
constexpr uint32_t ignore_mask = 0x00000002U << ((num_key_frames - 1) * 2);
if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- rotation_as_vec0 = vector_mul_add(rotation_as_vec0, clip_range_extent, clip_range_min);
+ rotation_as_vec0 = rtm::vector_mul_add(rotation_as_vec0, clip_range_extent, clip_range_min);
if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- rotation_as_vec1 = vector_mul_add(rotation_as_vec1, clip_range_extent, clip_range_min);
+ rotation_as_vec1 = rtm::vector_mul_add(rotation_as_vec1, clip_range_extent, clip_range_min);
if (static_condition<num_key_frames == 4>::test())
{
if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- rotation_as_vec2 = vector_mul_add(rotation_as_vec2, clip_range_extent, clip_range_min);
+ rotation_as_vec2 = rtm::vector_mul_add(rotation_as_vec2, clip_range_extent, clip_range_min);
if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- rotation_as_vec3 = vector_mul_add(rotation_as_vec3, clip_range_extent, clip_range_min);
+ rotation_as_vec3 = rtm::vector_mul_add(rotation_as_vec3, clip_range_extent, clip_range_min);
}
sampling_context.clip_range_data_offset += num_rotation_components * sizeof(float) * 2;
}
// No-op conversion
- Quat_32 rotation0 = vector_to_quat(rotation_as_vec0);
- Quat_32 rotation1 = vector_to_quat(rotation_as_vec1);
- Quat_32 rotation2 = vector_to_quat(rotation_as_vec2);
- Quat_32 rotation3 = vector_to_quat(rotation_as_vec3);
+ rtm::quatf rotation0 = rtm::vector_to_quat(rotation_as_vec0);
+ rtm::quatf rotation1 = rtm::vector_to_quat(rotation_as_vec1);
+ rtm::quatf rotation2 = rtm::vector_to_quat(rotation_as_vec2);
+ rtm::quatf rotation3 = rtm::vector_to_quat(rotation_as_vec3);
if (rotation_format != RotationFormat8::Quat_128 || !settings.is_rotation_format_supported(RotationFormat8::Quat_128))
{
// We dropped the W component
- rotation0 = quat_from_positive_w(rotation_as_vec0);
- rotation1 = quat_from_positive_w(rotation_as_vec1);
+ rotation0 = rtm::quat_from_positive_w(rotation_as_vec0);
+ rotation1 = rtm::quat_from_positive_w(rotation_as_vec1);
if (static_condition<num_key_frames == 4>::test())
{
- rotation2 = quat_from_positive_w(rotation_as_vec2);
- rotation3 = quat_from_positive_w(rotation_as_vec3);
+ rotation2 = rtm::quat_from_positive_w(rotation_as_vec2);
+ rotation3 = rtm::quat_from_positive_w(rotation_as_vec3);
}
}
@@ -1035,8 +1039,8 @@ namespace acl
else
interpolated_rotation = SamplingContextType::interpolate_rotation(rotation0, rotation1, decomp_context.interpolation_alpha);
- ACL_ASSERT(quat_is_finite(interpolated_rotation), "Rotation is not valid!");
- ACL_ASSERT(quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
+ ACL_ASSERT(rtm::quat_is_finite(interpolated_rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(interpolated_rotation), "Rotation is not normalized!");
}
}
@@ -1045,11 +1049,11 @@ namespace acl
}
template<class SettingsAdapterType, class DecompressionContextType, class SamplingContextType>
- inline Vector4_32 ACL_SIMD_CALL decompress_and_interpolate_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
+ inline rtm::vector4f RTM_SIMD_CALL decompress_and_interpolate_vector(const SettingsAdapterType& settings, const ClipHeader& header, const DecompressionContextType& decomp_context, SamplingContextType& sampling_context)
{
static_assert(SamplingContextType::k_num_samples_to_interpolate == 2 || SamplingContextType::k_num_samples_to_interpolate == 4, "Unsupported number of samples");
- Vector4_32 interpolated_vector;
+ rtm::vector4f interpolated_vector;
const BitSetIndexRef track_index_bit_ref(decomp_context.bitset_desc, sampling_context.track_index);
const bool is_sample_default = bitset_test(decomp_context.default_tracks_bitset, track_index_bit_ref);
@@ -1064,7 +1068,7 @@ namespace acl
{
// Constant translation tracks store the remaining sample with full precision
interpolated_vector = unpack_vector3_96_unsafe(decomp_context.constant_track_data + sampling_context.constant_track_data_offset);
- ACL_ASSERT(vector_is_finite3(interpolated_vector), "Vector is not valid!");
+ ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
sampling_context.constant_track_data_offset += get_packed_vector_size(VectorFormat8::Vector3_96);
}
@@ -1077,7 +1081,7 @@ namespace acl
constexpr size_t num_key_frames = SamplingContextType::k_num_samples_to_interpolate;
// This part is fairly complex, we'll loop and write to the stack (sampling context)
- Vector4_32* vectors = &sampling_context.vectors[0];
+ rtm::vector4f* vectors = &sampling_context.vectors[0];
// Range ignore flags are used to skip range normalization at the clip and/or segment levels
// Each sample has two bits like so: sample 0 clip, sample 0 segment, sample 1 clip, sample 1 segment, etc
@@ -1154,10 +1158,10 @@ namespace acl
// We unroll because even if we work from the stack, with 2 samples the compiler always
// unrolls but it fails to keep the values in registers, working from the stack which
// is inefficient.
- Vector4_32 vector0 = vectors[0];
- Vector4_32 vector1 = vectors[1];
- Vector4_32 vector2;
- Vector4_32 vector3;
+ rtm::vector4f vector0 = vectors[0];
+ rtm::vector4f vector1 = vectors[1];
+ rtm::vector4f vector2;
+ rtm::vector4f vector3;
if (static_condition<num_key_frames == 4>::test())
{
@@ -1179,36 +1183,36 @@ namespace acl
constexpr uint32_t ignore_mask = 0x00000001U << ((num_key_frames - 1) * 2);
if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[0] + segment_range_extent_offset);
- vector0 = vector_mul_add(vector0, segment_range_extent, segment_range_min);
+ vector0 = rtm::vector_mul_add(vector0, segment_range_extent, segment_range_min);
}
if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[1] + segment_range_extent_offset);
- vector1 = vector_mul_add(vector1, segment_range_extent, segment_range_min);
+ vector1 = rtm::vector_mul_add(vector1, segment_range_extent, segment_range_min);
}
if (static_condition<num_key_frames == 4>::test())
{
if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[2] + segment_range_extent_offset);
- vector2 = vector_mul_add(vector2, segment_range_extent, segment_range_min);
+ vector2 = rtm::vector_mul_add(vector2, segment_range_extent, segment_range_min);
}
if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
{
- const Vector4_32 segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
- const Vector4_32 segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
+ const rtm::vector4f segment_range_min = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_min_offset);
+ const rtm::vector4f segment_range_extent = unpack_vector3_u24_unsafe(decomp_context.segment_range_data[3] + segment_range_extent_offset);
- vector3 = vector_mul_add(vector3, segment_range_extent, segment_range_min);
+ vector3 = rtm::vector_mul_add(vector3, segment_range_extent, segment_range_min);
}
}
@@ -1217,23 +1221,23 @@ namespace acl
if (are_any_enum_flags_set(clip_range_reduction, range_reduction_flag))
{
- const Vector4_32 clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
- const Vector4_32 clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
+ const rtm::vector4f clip_range_min = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset);
+ const rtm::vector4f clip_range_extent = unpack_vector3_96_unsafe(decomp_context.clip_range_data + sampling_context.clip_range_data_offset + (3 * sizeof(float)));
constexpr uint32_t ignore_mask = 0x00000002U << ((num_key_frames - 1) * 2);
if ((range_ignore_flags & (ignore_mask >> 0)) == 0)
- vector0 = vector_mul_add(vector0, clip_range_extent, clip_range_min);
+ vector0 = rtm::vector_mul_add(vector0, clip_range_extent, clip_range_min);
if ((range_ignore_flags & (ignore_mask >> 2)) == 0)
- vector1 = vector_mul_add(vector1, clip_range_extent, clip_range_min);
+ vector1 = rtm::vector_mul_add(vector1, clip_range_extent, clip_range_min);
if (static_condition<num_key_frames == 4>::test())
{
if ((range_ignore_flags & (ignore_mask >> 4)) == 0)
- vector2 = vector_mul_add(vector2, clip_range_extent, clip_range_min);
+ vector2 = rtm::vector_mul_add(vector2, clip_range_extent, clip_range_min);
if ((range_ignore_flags & (ignore_mask >> 8)) == 0)
- vector3 = vector_mul_add(vector3, clip_range_extent, clip_range_min);
+ vector3 = rtm::vector_mul_add(vector3, clip_range_extent, clip_range_min);
}
sampling_context.clip_range_data_offset += k_clip_range_reduction_vector3_range_size;
@@ -1244,7 +1248,7 @@ namespace acl
else
interpolated_vector = SamplingContextType::interpolate_vector4(vector0, vector1, decomp_context.interpolation_alpha);
- ACL_ASSERT(vector_is_finite3(interpolated_vector), "Vector is not valid!");
+ ACL_ASSERT(rtm::vector_is_finite3(interpolated_vector), "Vector is not valid!");
}
}
diff --git a/includes/acl/decompression/default_output_writer.h b/includes/acl/decompression/default_output_writer.h
--- a/includes/acl/decompression/default_output_writer.h
+++ b/includes/acl/decompression/default_output_writer.h
@@ -26,7 +26,8 @@
#include "acl/core/compiler_utils.h"
#include "acl/decompression/output_writer.h"
-#include "acl/math/math_types.h"
+
+#include <rtm/types.h>
#include <cstdint>
@@ -40,7 +41,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct DefaultOutputWriter : OutputWriter
{
- DefaultOutputWriter(Transform_32* transforms, uint16_t num_transforms)
+ DefaultOutputWriter(rtm::qvvf* transforms, uint16_t num_transforms)
: m_transforms(transforms)
, m_num_transforms(num_transforms)
{
@@ -48,25 +49,25 @@ namespace acl
ACL_ASSERT(num_transforms != 0, "Transforms array cannot be empty");
}
- void write_bone_rotation(uint16_t bone_index, const Quat_32& rotation)
+ void RTM_SIMD_CALL write_bone_rotation(uint16_t bone_index, rtm::quatf_arg0 rotation)
{
ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
m_transforms[bone_index].rotation = rotation;
}
- void write_bone_translation(uint16_t bone_index, const Vector4_32& translation)
+ void RTM_SIMD_CALL write_bone_translation(uint16_t bone_index, rtm::vector4f_arg0 translation)
{
ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
m_transforms[bone_index].translation = translation;
}
- void write_bone_scale(uint16_t bone_index, const Vector4_32& scale)
+ void RTM_SIMD_CALL write_bone_scale(uint16_t bone_index, rtm::vector4f_arg0 scale)
{
ACL_ASSERT(bone_index < m_num_transforms, "Invalid bone index. %u >= %u", bone_index, m_num_transforms);
m_transforms[bone_index].scale = scale;
}
- Transform_32* m_transforms;
+ rtm::qvvf* m_transforms;
uint16_t m_num_transforms;
};
}
diff --git a/includes/acl/decompression/impl/track_sampling_impl.h b/includes/acl/decompression/impl/track_sampling_impl.h
--- a/includes/acl/decompression/impl/track_sampling_impl.h
+++ b/includes/acl/decompression/impl/track_sampling_impl.h
@@ -61,9 +61,9 @@ namespace acl
};
// Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
- inline rtm::scalarf ACL_SIMD_CALL unpack_scalarf_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -74,7 +74,7 @@ namespace acl
const uint32_t x32 = uint32_t(vector_u64);
return _mm_castsi128_ps(_mm_set1_epi32(x32));
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -103,7 +103,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline rtm::scalarf ACL_SIMD_CALL unpack_scalarf_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::scalarf RTM_SIMD_CALL unpack_scalarf_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -128,7 +128,7 @@ namespace acl
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
};
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
const uint32_t mask = k_packed_constants[num_bits].mask;
const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
@@ -140,7 +140,7 @@ namespace acl
const __m128 value = _mm_cvtsi32_ss(inv_max_value, x32 & mask);
return _mm_mul_ss(value, inv_max_value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
const uint32_t mask = k_packed_constants[num_bits].mask;
const float inv_max_value = k_packed_constants[num_bits].max_value;
diff --git a/includes/acl/decompression/output_writer.h b/includes/acl/decompression/output_writer.h
--- a/includes/acl/decompression/output_writer.h
+++ b/includes/acl/decompression/output_writer.h
@@ -25,8 +25,9 @@
////////////////////////////////////////////////////////////////////////////////
#include "acl/core/compiler_utils.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
+
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
#include <cstdint>
@@ -57,7 +58,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Called by the decoder to write out a quaternion rotation value for a specified bone index.
- void write_bone_rotation(uint16_t bone_index, const Quat_32& rotation)
+ void RTM_SIMD_CALL write_bone_rotation(uint16_t bone_index, rtm::quatf_arg0 rotation)
{
(void)bone_index;
(void)rotation;
@@ -65,7 +66,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Called by the decoder to write out a translation value for a specified bone index.
- void write_bone_translation(uint16_t bone_index, const Vector4_32& translation)
+ void RTM_SIMD_CALL write_bone_translation(uint16_t bone_index, rtm::vector4f_arg0 translation)
{
(void)bone_index;
(void)translation;
@@ -73,7 +74,7 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Called by the decoder to write out a scale value for a specified bone index.
- void write_bone_scale(uint16_t bone_index, const Vector4_32& scale)
+ void RTM_SIMD_CALL write_bone_scale(uint16_t bone_index, rtm::vector4f_arg0 scale)
{
(void)bone_index;
(void)scale;
diff --git a/includes/acl/io/clip_reader.h b/includes/acl/io/clip_reader.h
--- a/includes/acl/io/clip_reader.h
+++ b/includes/acl/io/clip_reader.h
@@ -37,6 +37,9 @@
#include "acl/core/string.h"
#include "acl/core/unique_ptr.h"
+#include <rtm/quatd.h>
+#include <rtm/vector4d.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -385,7 +388,7 @@ namespace acl
goto parsing_error;
}
- m_parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, double(default_settings.constant_rotation_threshold_angle));
+ m_parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, double(default_settings.constant_rotation_threshold_angle.as_radians()));
m_parser.try_read("constant_translation_threshold", constant_translation_threshold, double(default_settings.constant_translation_threshold));
m_parser.try_read("constant_scale_threshold", constant_scale_threshold, double(default_settings.constant_scale_threshold));
m_parser.try_read("error_threshold", error_threshold, double(default_settings.error_threshold));
@@ -440,7 +443,7 @@ namespace acl
out_settings->segmenting.range_reduction = segmenting_range_reduction;
- out_settings->constant_rotation_threshold_angle = float(constant_rotation_threshold_angle);
+ out_settings->constant_rotation_threshold_angle = rtm::radians(float(constant_rotation_threshold_angle));
out_settings->constant_translation_threshold = float(constant_translation_threshold);
out_settings->constant_scale_threshold = float(constant_scale_threshold);
out_settings->error_threshold = float(error_threshold);
@@ -520,14 +523,14 @@ namespace acl
return UInt32ToFloat(value_u32).flt;
}
- static Quat_64 hex_to_quat(const sjson::StringView values[4])
+ static rtm::quatd hex_to_quat(const sjson::StringView values[4])
{
- return quat_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]), hex_to_double(values[3]));
+ return rtm::quat_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]), hex_to_double(values[3]));
}
- static Vector4_64 hex_to_vector3(const sjson::StringView values[3])
+ static rtm::vector4d hex_to_vector3(const sjson::StringView values[3])
{
- return vector_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]));
+ return rtm::vector_set(hex_to_double(values[0]), hex_to_double(values[1]), hex_to_double(values[2]));
}
static rtm::float4f hex_to_float4f(const sjson::StringView values[4], uint32_t num_components)
@@ -609,15 +612,15 @@ namespace acl
{
double rotation[4] = { 0.0, 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_rotation", rotation, 4, 0.0) && !counting)
- bone.bind_transform.rotation = quat_unaligned_load(&rotation[0]);
+ bone.bind_transform.rotation = rtm::quat_load(&rotation[0]);
double translation[3] = { 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_translation", translation, 3, 0.0) && !counting)
- bone.bind_transform.translation = vector_unaligned_load3(&translation[0]);
+ bone.bind_transform.translation = rtm::vector_load3(&translation[0]);
double scale[3] = { 0.0, 0.0, 0.0 };
if (m_parser.try_read("bind_scale", scale, 3, 0.0) && !counting)
- bone.bind_transform.scale = vector_unaligned_load3(&scale[0]);
+ bone.bind_transform.scale = rtm::vector_load3(&scale[0]);
}
if (!m_parser.object_ends())
@@ -943,7 +946,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.rotation_track.set_sample(sample_index, quat_identity_64());
+ bone.rotation_track.set_sample(sample_index, rtm::quat_identity());
}
if (m_parser.try_array_begins("translations"))
@@ -954,7 +957,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.translation_track.set_sample(sample_index, vector_zero_64());
+ bone.translation_track.set_sample(sample_index, rtm::vector_zero());
}
if (m_parser.try_array_begins("scales"))
@@ -965,7 +968,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_additive_base_num_samples; ++sample_index)
- bone.scale_track.set_sample(sample_index, vector_set(1.0));
+ bone.scale_track.set_sample(sample_index, rtm::vector_set(1.0));
}
if (!m_parser.object_ends())
@@ -1002,7 +1005,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.rotation_track.set_sample(sample_index, quat_identity_64());
+ bone.rotation_track.set_sample(sample_index, rtm::quat_identity());
}
if (m_parser.try_array_begins("translations"))
@@ -1013,7 +1016,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.translation_track.set_sample(sample_index, vector_zero_64());
+ bone.translation_track.set_sample(sample_index, rtm::vector_zero());
}
if (m_parser.try_array_begins("scales"))
@@ -1024,7 +1027,7 @@ namespace acl
else
{
for (uint32_t sample_index = 0; sample_index < m_num_samples; ++sample_index)
- bone.scale_track.set_sample(sample_index, vector_set(1.0));
+ bone.scale_track.set_sample(sample_index, rtm::vector_set(1.0));
}
if (!m_parser.object_ends())
@@ -1047,7 +1050,7 @@ namespace acl
if (!m_parser.array_begins())
return false;
- Quat_64 rotation;
+ rtm::quatd rotation;
if (m_is_binary_exact)
{
@@ -1063,7 +1066,7 @@ namespace acl
if (!m_parser.read(values, 4))
return false;
- rotation = quat_unaligned_load(values);
+ rotation = rtm::quat_load(values);
}
if (!m_parser.array_ends())
@@ -1082,7 +1085,7 @@ namespace acl
if (!m_parser.array_begins())
return false;
- Vector4_64 translation;
+ rtm::vector4d translation;
if (m_is_binary_exact)
{
@@ -1098,7 +1101,7 @@ namespace acl
if (!m_parser.read(values, 3))
return false;
- translation = vector_unaligned_load3(values);
+ translation = rtm::vector_load3(values);
}
if (!m_parser.array_ends())
@@ -1117,7 +1120,7 @@ namespace acl
if (!m_parser.array_begins())
return false;
- Vector4_64 scale;
+ rtm::vector4d scale;
if (m_is_binary_exact)
{
@@ -1133,7 +1136,7 @@ namespace acl
if (!m_parser.read(values, 3))
return false;
- scale = vector_unaligned_load3(values);
+ scale = rtm::vector_load3(values);
}
if (!m_parser.array_ends())
diff --git a/includes/acl/io/clip_writer.h b/includes/acl/io/clip_writer.h
--- a/includes/acl/io/clip_writer.h
+++ b/includes/acl/io/clip_writer.h
@@ -34,6 +34,9 @@
#include "acl/core/iallocator.h"
#include "acl/core/error.h"
+#include <rtm/quatd.h>
+#include <rtm/vector4d.h>
+
#include <cstdint>
#include <cinttypes>
#include <cstdio>
@@ -118,7 +121,7 @@ namespace acl
segmenting_writer["scale_range_reduction"] = are_any_enum_flags_set(settings.segmenting.range_reduction, RangeReductionFlags8::Scales);
};
- settings_writer["constant_rotation_threshold_angle"] = settings.constant_rotation_threshold_angle;
+ settings_writer["constant_rotation_threshold_angle"] = settings.constant_rotation_threshold_angle.as_radians();
settings_writer["constant_translation_threshold"] = settings.constant_translation_threshold;
settings_writer["constant_scale_threshold"] = settings.constant_scale_threshold;
settings_writer["error_threshold"] = settings.error_threshold;
@@ -147,34 +150,34 @@ namespace acl
bone_writer["parent"] = bone.is_root() ? "" : parent_bone.name.c_str();
bone_writer["vertex_distance"] = bone.vertex_distance;
- if (!quat_near_identity(bone.bind_transform.rotation))
+ if (!rtm::quat_near_identity(bone.bind_transform.rotation))
{
bone_writer["bind_rotation"] = [&](sjson::ArrayWriter& rot_writer)
{
- rot_writer.push(format_hex_double(quat_get_x(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_y(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_z(bone.bind_transform.rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_w(bone.bind_transform.rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_x(bone.bind_transform.rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_y(bone.bind_transform.rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_z(bone.bind_transform.rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_w(bone.bind_transform.rotation), buffer, sizeof(buffer)));
};
}
- if (!vector_all_near_equal3(bone.bind_transform.translation, vector_zero_64()))
+ if (!rtm::vector_all_near_equal3(bone.bind_transform.translation, rtm::vector_zero()))
{
bone_writer["bind_translation"] = [&](sjson::ArrayWriter& trans_writer)
{
- trans_writer.push(format_hex_double(vector_get_x(bone.bind_transform.translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(vector_get_y(bone.bind_transform.translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(vector_get_z(bone.bind_transform.translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_x(bone.bind_transform.translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_y(bone.bind_transform.translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_z(bone.bind_transform.translation), buffer, sizeof(buffer)));
};
}
- if (!vector_all_near_equal3(bone.bind_transform.scale, vector_set(1.0)))
+ if (!rtm::vector_all_near_equal3(bone.bind_transform.scale, rtm::vector_set(1.0)))
{
bone_writer["bind_scale"] = [&](sjson::ArrayWriter& scale_writer)
{
- scale_writer.push(format_hex_double(vector_get_x(bone.bind_transform.scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(vector_get_y(bone.bind_transform.scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(vector_get_z(bone.bind_transform.scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_x(bone.bind_transform.scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_y(bone.bind_transform.scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_z(bone.bind_transform.scale), buffer, sizeof(buffer)));
};
}
});
@@ -209,13 +212,13 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_rotation_samples; ++sample_index)
{
- const Quat_64 rotation = bone.rotation_track.get_sample(sample_index);
+ const rtm::quatd rotation = bone.rotation_track.get_sample(sample_index);
rotations_writer.push([&](sjson::ArrayWriter& rot_writer)
{
- rot_writer.push(format_hex_double(quat_get_x(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_y(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_z(rotation), buffer, sizeof(buffer)));
- rot_writer.push(format_hex_double(quat_get_w(rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_x(rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_y(rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_z(rotation), buffer, sizeof(buffer)));
+ rot_writer.push(format_hex_double(rtm::quat_get_w(rotation), buffer, sizeof(buffer)));
});
rotations_writer.push_newline();
}
@@ -229,12 +232,12 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_translation_samples; ++sample_index)
{
- const Vector4_64 translation = bone.translation_track.get_sample(sample_index);
+ const rtm::vector4d translation = bone.translation_track.get_sample(sample_index);
translations_writer.push([&](sjson::ArrayWriter& trans_writer)
{
- trans_writer.push(format_hex_double(vector_get_x(translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(vector_get_y(translation), buffer, sizeof(buffer)));
- trans_writer.push(format_hex_double(vector_get_z(translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_x(translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_y(translation), buffer, sizeof(buffer)));
+ trans_writer.push(format_hex_double(rtm::vector_get_z(translation), buffer, sizeof(buffer)));
});
translations_writer.push_newline();
}
@@ -248,12 +251,12 @@ namespace acl
for (uint32_t sample_index = 0; sample_index < num_scale_samples; ++sample_index)
{
- const Vector4_64 scale = bone.scale_track.get_sample(sample_index);
+ const rtm::vector4d scale = bone.scale_track.get_sample(sample_index);
scales_writer.push([&](sjson::ArrayWriter& scale_writer)
{
- scale_writer.push(format_hex_double(vector_get_x(scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(vector_get_y(scale), buffer, sizeof(buffer)));
- scale_writer.push(format_hex_double(vector_get_z(scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_x(scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_y(scale), buffer, sizeof(buffer)));
+ scale_writer.push(format_hex_double(rtm::vector_get_z(scale), buffer, sizeof(buffer)));
});
scales_writer.push_newline();
}
diff --git a/includes/acl/math/affine_matrix_32.h b/includes/acl/math/affine_matrix_32.h
deleted file mode 100644
--- a/includes/acl/math/affine_matrix_32.h
+++ /dev/null
@@ -1,380 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/math/math.h"
-#include "acl/math/vector4_32.h"
-#include "acl/math/quat_32.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // An 4x4 affine matrix represents a 3D rotation, 3D translation, and 3D scale.
- // It properly deals with skew/shear when present but once scale with mirroring is combined,
- // it cannot be safely extracted back.
- //
- // Affine matrices have their last column always equal to [0, 0, 0, 1]
- //
- // X axis == forward
- // Y axis == right
- // Z axis == up
- //////////////////////////////////////////////////////////////////////////
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_set(Vector4_32Arg0 x_axis, Vector4_32Arg1 y_axis, Vector4_32Arg2 z_axis, Vector4_32Arg3 w_axis)
- {
- ACL_ASSERT(vector_get_w(x_axis) == 0.0F, "X axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(y_axis) == 0.0F, "Y axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(z_axis) == 0.0F, "Z axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(w_axis) == 1.0F, "W axis does not have a W component == 1.0");
- return AffineMatrix_32{x_axis, y_axis, z_axis, w_axis};
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_set(Quat_32Arg0 quat, Vector4_32Arg1 translation, Vector4_32Arg2 scale)
- {
- ACL_ASSERT(quat_is_normalized(quat), "Quaternion is not normalized");
-
- const float x2 = quat_get_x(quat) + quat_get_x(quat);
- const float y2 = quat_get_y(quat) + quat_get_y(quat);
- const float z2 = quat_get_z(quat) + quat_get_z(quat);
- const float xx = quat_get_x(quat) * x2;
- const float xy = quat_get_x(quat) * y2;
- const float xz = quat_get_x(quat) * z2;
- const float yy = quat_get_y(quat) * y2;
- const float yz = quat_get_y(quat) * z2;
- const float zz = quat_get_z(quat) * z2;
- const float wx = quat_get_w(quat) * x2;
- const float wy = quat_get_w(quat) * y2;
- const float wz = quat_get_w(quat) * z2;
-
- Vector4_32 x_axis = vector_mul(vector_set(1.0F - (yy + zz), xy + wz, xz - wy, 0.0F), vector_get_x(scale));
- Vector4_32 y_axis = vector_mul(vector_set(xy - wz, 1.0F - (xx + zz), yz + wx, 0.0F), vector_get_y(scale));
- Vector4_32 z_axis = vector_mul(vector_set(xz + wy, yz - wx, 1.0F - (xx + yy), 0.0F), vector_get_z(scale));
- Vector4_32 w_axis = vector_set(vector_get_x(translation), vector_get_y(translation), vector_get_z(translation), 1.0F);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_identity_32()
- {
- return matrix_set(vector_set(1.0F, 0.0F, 0.0F, 0.0F), vector_set(0.0F, 1.0F, 0.0F, 0.0F), vector_set(0.0F, 0.0F, 1.0F, 0.0F), vector_set(0.0F, 0.0F, 0.0F, 1.0F));
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_cast(const AffineMatrix_64& input)
- {
- return matrix_set(vector_cast(input.x_axis), vector_cast(input.y_axis), vector_cast(input.z_axis), vector_cast(input.w_axis));
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_from_quat(Quat_32Arg0 quat)
- {
- ACL_ASSERT(quat_is_normalized(quat), "Quaternion is not normalized");
-
- const float x2 = quat_get_x(quat) + quat_get_x(quat);
- const float y2 = quat_get_y(quat) + quat_get_y(quat);
- const float z2 = quat_get_z(quat) + quat_get_z(quat);
- const float xx = quat_get_x(quat) * x2;
- const float xy = quat_get_x(quat) * y2;
- const float xz = quat_get_x(quat) * z2;
- const float yy = quat_get_y(quat) * y2;
- const float yz = quat_get_y(quat) * z2;
- const float zz = quat_get_z(quat) * z2;
- const float wx = quat_get_w(quat) * x2;
- const float wy = quat_get_w(quat) * y2;
- const float wz = quat_get_w(quat) * z2;
-
- Vector4_32 x_axis = vector_set(1.0F - (yy + zz), xy + wz, xz - wy, 0.0F);
- Vector4_32 y_axis = vector_set(xy - wz, 1.0F - (xx + zz), yz + wx, 0.0F);
- Vector4_32 z_axis = vector_set(xz + wy, yz - wx, 1.0F - (xx + yy), 0.0F);
- Vector4_32 w_axis = vector_set(0.0F, 0.0F, 0.0F, 1.0F);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_from_translation(Vector4_32Arg0 translation)
- {
- return matrix_set(vector_set(1.0F, 0.0F, 0.0F, 0.0F), vector_set(0.0F, 1.0F, 0.0F, 0.0F), vector_set(0.0F, 0.0F, 1.0F, 0.0F), vector_set(vector_get_x(translation), vector_get_y(translation), vector_get_z(translation), 1.0F));
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_from_scale(Vector4_32Arg0 scale)
- {
- return matrix_set(vector_set(vector_get_x(scale), 0.0F, 0.0F, 0.0F), vector_set(0.0F, vector_get_y(scale), 0.0F, 0.0F), vector_set(0.0F, 0.0F, vector_get_z(scale), 0.0F), vector_set(0.0F, 0.0F, 0.0F, 1.0F));
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_from_transform(Transform_32Arg0 transform)
- {
- return matrix_set(transform.rotation, transform.translation, transform.scale);
- }
-
- inline const Vector4_32& matrix_get_axis(const AffineMatrix_32& input, MatrixAxis axis)
- {
- switch (axis)
- {
- case MatrixAxis::X: return input.x_axis;
- case MatrixAxis::Y: return input.y_axis;
- case MatrixAxis::Z: return input.z_axis;
- case MatrixAxis::W: return input.w_axis;
- default:
- ACL_ASSERT(false, "Invalid matrix axis");
- return input.x_axis;
- }
- }
-
- inline Vector4_32& matrix_get_axis(AffineMatrix_32& input, MatrixAxis axis)
- {
- switch (axis)
- {
- case MatrixAxis::X: return input.x_axis;
- case MatrixAxis::Y: return input.y_axis;
- case MatrixAxis::Z: return input.z_axis;
- case MatrixAxis::W: return input.w_axis;
- default:
- ACL_ASSERT(false, "Invalid matrix axis");
- return input.x_axis;
- }
- }
-
- constexpr Vector4_32 ACL_SIMD_CALL matrix_get_axis(Vector4_32Arg0 x_axis, Vector4_32Arg1 y_axis, Vector4_32Arg2 z_axis, Vector4_32Arg3 w_axis, MatrixAxis axis)
- {
- return axis == MatrixAxis::X ? x_axis : (axis == MatrixAxis::Y ? y_axis : (axis == MatrixAxis::Z ? z_axis : w_axis));
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_from_matrix(AffineMatrix_32Arg0 input)
- {
- if (vector_all_near_equal3(input.x_axis, vector_zero_32()) || vector_all_near_equal3(input.y_axis, vector_zero_32()) || vector_all_near_equal3(input.z_axis, vector_zero_32()))
- {
- // Zero scale not supported, return the identity
- return quat_identity_32();
- }
-
- const float mtx_trace = vector_get_x(input.x_axis) + vector_get_y(input.y_axis) + vector_get_z(input.z_axis);
- if (mtx_trace > 0.0F)
- {
- const float inv_trace = sqrt_reciprocal(mtx_trace + 1.0F);
- const float half_inv_trace = inv_trace * 0.5F;
-
- const float x = (vector_get_z(input.y_axis) - vector_get_y(input.z_axis)) * half_inv_trace;
- const float y = (vector_get_x(input.z_axis) - vector_get_z(input.x_axis)) * half_inv_trace;
- const float z = (vector_get_y(input.x_axis) - vector_get_x(input.y_axis)) * half_inv_trace;
- const float w = reciprocal(inv_trace) * 0.5F;
-
- return quat_normalize(quat_set(x, y, z, w));
- }
- else
- {
- int8_t best_axis = 0;
- if (vector_get_y(input.y_axis) > vector_get_x(input.x_axis))
- best_axis = 1;
- if (vector_get_z(input.z_axis) > vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(best_axis)))
- best_axis = 2;
-
- const int8_t next_best_axis = (best_axis + 1) % 3;
- const int8_t next_next_best_axis = (next_best_axis + 1) % 3;
-
- const float mtx_pseudo_trace = 1.0F +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(next_best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(next_next_best_axis));
-
- const float inv_pseudo_trace = sqrt_reciprocal(mtx_pseudo_trace);
- const float half_inv_pseudo_trace = inv_pseudo_trace * 0.5F;
-
- float quat_values[4];
- quat_values[best_axis] = reciprocal(inv_pseudo_trace) * 0.5F;
- quat_values[next_best_axis] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(next_best_axis)) +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(best_axis)));
- quat_values[next_next_best_axis] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(next_next_best_axis)) +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(best_axis)));
- quat_values[3] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(next_next_best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(next_best_axis)));
-
- return quat_normalize(quat_unaligned_load(&quat_values[0]));
- }
- }
-
- // Multiplication order is as follow: local_to_world = matrix_mul(local_to_object, object_to_world)
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_mul(AffineMatrix_32Arg0 lhs, AffineMatrix_32ArgN rhs)
- {
- Vector4_32 tmp = vector_mul(vector_mix_xxxx(lhs.x_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.x_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.x_axis), rhs.z_axis, tmp);
- Vector4_32 x_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.y_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.y_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.y_axis), rhs.z_axis, tmp);
- Vector4_32 y_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.z_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.z_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.z_axis), rhs.z_axis, tmp);
- Vector4_32 z_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.w_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.w_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.w_axis), rhs.z_axis, tmp);
- Vector4_32 w_axis = vector_add(rhs.w_axis, tmp);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline Vector4_32 ACL_SIMD_CALL matrix_mul_position(AffineMatrix_32Arg0 lhs, Vector4_32Arg4 rhs)
- {
- Vector4_32 tmp0;
- Vector4_32 tmp1;
-
- tmp0 = vector_mul(vector_mix_xxxx(rhs), lhs.x_axis);
- tmp0 = vector_mul_add(vector_mix_yyyy(rhs), lhs.y_axis, tmp0);
- tmp1 = vector_mul_add(vector_mix_zzzz(rhs), lhs.z_axis, lhs.w_axis);
-
- return vector_add(tmp0, tmp1);
- }
-
- namespace math_impl
- {
- // Note: This is a generic matrix 4x4 transpose, the resulting matrix is no longer
- // affine because the last column is no longer [0,0,0,1]
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_transpose(AffineMatrix_32Arg0 input)
- {
- Vector4_32 tmp0 = vector_mix_xyab(input.x_axis, input.y_axis);
- Vector4_32 tmp1 = vector_mix_zwcd(input.x_axis, input.y_axis);
- Vector4_32 tmp2 = vector_mix_xyab(input.z_axis, input.w_axis);
- Vector4_32 tmp3 = vector_mix_zwcd(input.z_axis, input.w_axis);
-
- Vector4_32 x_axis = vector_mix_xzac(tmp0, tmp2);
- Vector4_32 y_axis = vector_mix_ywbd(tmp0, tmp2);
- Vector4_32 z_axis = vector_mix_xzac(tmp1, tmp3);
- Vector4_32 w_axis = vector_mix_ywbd(tmp1, tmp3);
- return AffineMatrix_32{ x_axis, y_axis, z_axis, w_axis };
- }
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_inverse(AffineMatrix_32Arg0 input)
- {
- // TODO: This is a generic matrix inverse function, implement the affine version?
- AffineMatrix_32 input_transposed = math_impl::matrix_transpose(input);
-
- Vector4_32 v00 = vector_mix_xxyy(input_transposed.z_axis);
- Vector4_32 v01 = vector_mix_xxyy(input_transposed.x_axis);
- Vector4_32 v02 = vector_mix_xzac(input_transposed.z_axis, input_transposed.x_axis);
- Vector4_32 v10 = vector_mix_zwzw(input_transposed.w_axis);
- Vector4_32 v11 = vector_mix_zwzw(input_transposed.y_axis);
- Vector4_32 v12 = vector_mix_ywbd(input_transposed.w_axis, input_transposed.y_axis);
-
- Vector4_32 d0 = vector_mul(v00, v10);
- Vector4_32 d1 = vector_mul(v01, v11);
- Vector4_32 d2 = vector_mul(v02, v12);
-
- v00 = vector_mix_zwzw(input_transposed.z_axis);
- v01 = vector_mix_zwzw(input_transposed.x_axis);
- v02 = vector_mix_ywbd(input_transposed.z_axis, input_transposed.x_axis);
- v10 = vector_mix_xxyy(input_transposed.w_axis);
- v11 = vector_mix_xxyy(input_transposed.y_axis);
- v12 = vector_mix_xzac(input_transposed.w_axis, input_transposed.y_axis);
-
- d0 = vector_neg_mul_sub(v00, v10, d0);
- d1 = vector_neg_mul_sub(v01, v11, d1);
- d2 = vector_neg_mul_sub(v02, v12, d2);
-
- v00 = vector_mix_yzxy(input_transposed.y_axis);
- v01 = vector_mix_zxyx(input_transposed.x_axis);
- v02 = vector_mix_yzxy(input_transposed.w_axis);
- Vector4_32 v03 = vector_mix_zxyx(input_transposed.z_axis);
- v10 = vector_mix_bywx(d0, d2);
- v11 = vector_mix_wbyz(d0, d2);
- v12 = vector_mix_dywx(d1, d2);
- Vector4_32 v13 = vector_mix_wdyz(d1, d2);
-
- Vector4_32 c0 = vector_mul(v00, v10);
- Vector4_32 c2 = vector_mul(v01, v11);
- Vector4_32 c4 = vector_mul(v02, v12);
- Vector4_32 c6 = vector_mul(v03, v13);
-
- v00 = vector_mix_zwyz(input_transposed.y_axis);
- v01 = vector_mix_wzwy(input_transposed.x_axis);
- v02 = vector_mix_zwyz(input_transposed.w_axis);
- v03 = vector_mix_wzwy(input_transposed.z_axis);
- v10 = vector_mix_wxya(d0, d2);
- v11 = vector_mix_zyax(d0, d2);
- v12 = vector_mix_wxyc(d1, d2);
- v13 = vector_mix_zycx(d1, d2);
-
- c0 = vector_neg_mul_sub(v00, v10, c0);
- c2 = vector_neg_mul_sub(v01, v11, c2);
- c4 = vector_neg_mul_sub(v02, v12, c4);
- c6 = vector_neg_mul_sub(v03, v13, c6);
-
- v00 = vector_mix_wxwx(input_transposed.y_axis);
- v01 = vector_mix_ywxz(input_transposed.x_axis);
- v02 = vector_mix_wxwx(input_transposed.w_axis);
- v03 = vector_mix_ywxz(input_transposed.z_axis);
- v10 = vector_mix_zbaz(d0, d2);
- v11 = vector_mix_bxwa(d0, d2);
- v12 = vector_mix_zdcz(d1, d2);
- v13 = vector_mix_dxwc(d1, d2);
-
- Vector4_32 c1 = vector_neg_mul_sub(v00, v10, c0);
- c0 = vector_mul_add(v00, v10, c0);
- Vector4_32 c3 = vector_mul_add(v01, v11, c2);
- c2 = vector_neg_mul_sub(v01, v11, c2);
- Vector4_32 c5 = vector_neg_mul_sub(v02, v12, c4);
- c4 = vector_mul_add(v02, v12, c4);
- Vector4_32 c7 = vector_mul_add(v03, v13, c6);
- c6 = vector_neg_mul_sub(v03, v13, c6);
-
- Vector4_32 x_axis = vector_mix_xbzd(c0, c1);
- Vector4_32 y_axis = vector_mix_xbzd(c2, c3);
- Vector4_32 z_axis = vector_mix_xbzd(c4, c5);
- Vector4_32 w_axis = vector_mix_xbzd(c6, c7);
-
- float det = vector_dot(x_axis, input_transposed.x_axis);
- Vector4_32 inv_det = vector_set(reciprocal(det));
-
- x_axis = vector_mul(x_axis, inv_det);
- y_axis = vector_mul(y_axis, inv_det);
- z_axis = vector_mul(z_axis, inv_det);
- w_axis = vector_mul(w_axis, inv_det);
-
-#if defined(ACL_NO_INTRINSICS)
- w_axis = vector_set(vector_get_x(w_axis), vector_get_y(w_axis), vector_get_z(w_axis), 1.0f);
-#endif
-
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_32 ACL_SIMD_CALL matrix_remove_scale(AffineMatrix_32Arg0 input)
- {
- AffineMatrix_32 result;
- result.x_axis = vector_normalize3(input.x_axis);
- result.y_axis = vector_normalize3(input.y_axis);
- result.z_axis = vector_normalize3(input.z_axis);
- result.w_axis = input.w_axis;
- return result;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/affine_matrix_64.h b/includes/acl/math/affine_matrix_64.h
deleted file mode 100644
--- a/includes/acl/math/affine_matrix_64.h
+++ /dev/null
@@ -1,381 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/math/math.h"
-#include "acl/math/vector4_64.h"
-#include "acl/math/quat_64.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // An 4x4 affine matrix represents a 3D rotation, 3D translation, and 3D scale.
- // It properly deals with skew/shear when present but once scale with mirroring is combined,
- // it cannot be safely extracted back.
- //
- // Affine matrices have their last column always equal to [0, 0, 0, 1]
- //
- // X axis == forward
- // Y axis == right
- // Z axis == up
- //////////////////////////////////////////////////////////////////////////
-
- inline AffineMatrix_64 matrix_set(const Vector4_64& x_axis, const Vector4_64& y_axis, const Vector4_64& z_axis, const Vector4_64& w_axis)
- {
- ACL_ASSERT(vector_get_w(x_axis) == 0.0, "X axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(y_axis) == 0.0, "Y axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(z_axis) == 0.0, "Z axis does not have a W component == 0.0");
- ACL_ASSERT(vector_get_w(w_axis) == 1.0, "W axis does not have a W component == 1.0");
- return AffineMatrix_64{x_axis, y_axis, z_axis, w_axis};
- }
-
- inline AffineMatrix_64 matrix_set(const Quat_64& quat, const Vector4_64& translation, const Vector4_64& scale)
- {
- ACL_ASSERT(quat_is_normalized(quat), "Quaternion is not normalized");
-
- const double x2 = quat_get_x(quat) + quat_get_x(quat);
- const double y2 = quat_get_y(quat) + quat_get_y(quat);
- const double z2 = quat_get_z(quat) + quat_get_z(quat);
- const double xx = quat_get_x(quat) * x2;
- const double xy = quat_get_x(quat) * y2;
- const double xz = quat_get_x(quat) * z2;
- const double yy = quat_get_y(quat) * y2;
- const double yz = quat_get_y(quat) * z2;
- const double zz = quat_get_z(quat) * z2;
- const double wx = quat_get_w(quat) * x2;
- const double wy = quat_get_w(quat) * y2;
- const double wz = quat_get_w(quat) * z2;
-
- Vector4_64 x_axis = vector_mul(vector_set(1.0 - (yy + zz), xy + wz, xz - wy, 0.0), vector_get_x(scale));
- Vector4_64 y_axis = vector_mul(vector_set(xy - wz, 1.0 - (xx + zz), yz + wx, 0.0), vector_get_y(scale));
- Vector4_64 z_axis = vector_mul(vector_set(xz + wy, yz - wx, 1.0 - (xx + yy), 0.0), vector_get_z(scale));
- Vector4_64 w_axis = vector_set(vector_get_x(translation), vector_get_y(translation), vector_get_z(translation), 1.0);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_64 matrix_identity_64()
- {
- return matrix_set(vector_set(1.0, 0.0, 0.0, 0.0), vector_set(0.0, 1.0, 0.0, 0.0), vector_set(0.0, 0.0, 1.0, 0.0), vector_set(0.0, 0.0, 0.0, 1.0));
- }
-
- inline AffineMatrix_64 matrix_cast(const AffineMatrix_32& input)
- {
- return matrix_set(vector_cast(input.x_axis), vector_cast(input.y_axis), vector_cast(input.z_axis), vector_cast(input.w_axis));
- }
-
- inline AffineMatrix_64 matrix_from_quat(const Quat_64& quat)
- {
- ACL_ASSERT(quat_is_normalized(quat), "Quaternion is not normalized");
-
- const double x2 = quat_get_x(quat) + quat_get_x(quat);
- const double y2 = quat_get_y(quat) + quat_get_y(quat);
- const double z2 = quat_get_z(quat) + quat_get_z(quat);
- const double xx = quat_get_x(quat) * x2;
- const double xy = quat_get_x(quat) * y2;
- const double xz = quat_get_x(quat) * z2;
- const double yy = quat_get_y(quat) * y2;
- const double yz = quat_get_y(quat) * z2;
- const double zz = quat_get_z(quat) * z2;
- const double wx = quat_get_w(quat) * x2;
- const double wy = quat_get_w(quat) * y2;
- const double wz = quat_get_w(quat) * z2;
-
- Vector4_64 x_axis = vector_set(1.0 - (yy + zz), xy + wz, xz - wy, 0.0);
- Vector4_64 y_axis = vector_set(xy - wz, 1.0 - (xx + zz), yz + wx, 0.0);
- Vector4_64 z_axis = vector_set(xz + wy, yz - wx, 1.0 - (xx + yy), 0.0);
- Vector4_64 w_axis = vector_set(0.0, 0.0, 0.0, 1.0);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_64 matrix_from_translation(const Vector4_64& translation)
- {
- return matrix_set(vector_set(1.0, 0.0, 0.0, 0.0), vector_set(0.0, 1.0, 0.0, 0.0), vector_set(0.0, 0.0, 1.0, 0.0), vector_set(vector_get_x(translation), vector_get_y(translation), vector_get_z(translation), 1.0));
- }
-
- inline AffineMatrix_64 matrix_from_scale(const Vector4_64& scale)
- {
- ACL_ASSERT(!vector_any_near_equal3(scale, vector_zero_64()), "Scale cannot be zero");
- return matrix_set(vector_set(vector_get_x(scale), 0.0, 0.0, 0.0), vector_set(0.0, vector_get_y(scale), 0.0, 0.0), vector_set(0.0, 0.0, vector_get_z(scale), 0.0), vector_set(0.0, 0.0, 0.0, 1.0));
- }
-
- inline AffineMatrix_64 matrix_from_transform(const Transform_64& transform)
- {
- return matrix_set(transform.rotation, transform.translation, transform.scale);
- }
-
- inline const Vector4_64& matrix_get_axis(const AffineMatrix_64& input, MatrixAxis axis)
- {
- switch (axis)
- {
- case MatrixAxis::X: return input.x_axis;
- case MatrixAxis::Y: return input.y_axis;
- case MatrixAxis::Z: return input.z_axis;
- case MatrixAxis::W: return input.w_axis;
- default:
- ACL_ASSERT(false, "Invalid matrix axis");
- return input.x_axis;
- }
- }
-
- inline Vector4_64& matrix_get_axis(AffineMatrix_64& input, MatrixAxis axis)
- {
- switch (axis)
- {
- case MatrixAxis::X: return input.x_axis;
- case MatrixAxis::Y: return input.y_axis;
- case MatrixAxis::Z: return input.z_axis;
- case MatrixAxis::W: return input.w_axis;
- default:
- ACL_ASSERT(false, "Invalid matrix axis");
- return input.x_axis;
- }
- }
-
- constexpr const Vector4_64& matrix_get_axis(const Vector4_64& x_axis, const Vector4_64& y_axis, const Vector4_64& z_axis, const Vector4_64& w_axis, MatrixAxis axis)
- {
- return axis == MatrixAxis::X ? x_axis : (axis == MatrixAxis::Y ? y_axis : (axis == MatrixAxis::Z ? z_axis : w_axis));
- }
-
- inline Quat_64 quat_from_matrix(const AffineMatrix_64& input)
- {
- if (vector_all_near_equal3(input.x_axis, vector_zero_64()) || vector_all_near_equal3(input.y_axis, vector_zero_64()) || vector_all_near_equal3(input.z_axis, vector_zero_64()))
- {
- // Zero scale not supported, return the identity
- return quat_identity_64();
- }
-
- const double mtx_trace = vector_get_x(input.x_axis) + vector_get_y(input.y_axis) + vector_get_z(input.z_axis);
- if (mtx_trace > 0.0)
- {
- const double inv_trace = sqrt_reciprocal(mtx_trace + 1.0);
- const double half_inv_trace = inv_trace * 0.5;
-
- const double x = (vector_get_z(input.y_axis) - vector_get_y(input.z_axis)) * half_inv_trace;
- const double y = (vector_get_x(input.z_axis) - vector_get_z(input.x_axis)) * half_inv_trace;
- const double z = (vector_get_y(input.x_axis) - vector_get_x(input.y_axis)) * half_inv_trace;
- const double w = reciprocal(inv_trace) * 0.5;
-
- return quat_normalize(quat_set(x, y, z, w));
- }
- else
- {
- int8_t best_axis = 0;
- if (vector_get_y(input.y_axis) > vector_get_x(input.x_axis))
- best_axis = 1;
- if (vector_get_z(input.z_axis) > vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(best_axis)))
- best_axis = 2;
-
- const int8_t next_best_axis = (best_axis + 1) % 3;
- const int8_t next_next_best_axis = (next_best_axis + 1) % 3;
-
- const double mtx_pseudo_trace = 1.0 +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(next_best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(next_next_best_axis));
-
- const double inv_pseudo_trace = sqrt_reciprocal(mtx_pseudo_trace);
- const double half_inv_pseudo_trace = inv_pseudo_trace * 0.5;
-
- double quat_values[4];
- quat_values[best_axis] = reciprocal(inv_pseudo_trace) * 0.5;
- quat_values[next_best_axis] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(next_best_axis)) +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(best_axis)));
- quat_values[next_next_best_axis] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(best_axis)), VectorMix(next_next_best_axis)) +
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(best_axis)));
- quat_values[3] = half_inv_pseudo_trace *
- (vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_best_axis)), VectorMix(next_next_best_axis)) -
- vector_get_component(matrix_get_axis(input.x_axis, input.y_axis, input.z_axis, input.w_axis, MatrixAxis(next_next_best_axis)), VectorMix(next_best_axis)));
-
- return quat_normalize(quat_unaligned_load(&quat_values[0]));
- }
- }
-
- // Multiplication order is as follow: local_to_world = matrix_mul(local_to_object, object_to_world)
- inline AffineMatrix_64 matrix_mul(const AffineMatrix_64& lhs, const AffineMatrix_64& rhs)
- {
- Vector4_64 tmp = vector_mul(vector_mix_xxxx(lhs.x_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.x_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.x_axis), rhs.z_axis, tmp);
- Vector4_64 x_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.y_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.y_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.y_axis), rhs.z_axis, tmp);
- Vector4_64 y_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.z_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.z_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.z_axis), rhs.z_axis, tmp);
- Vector4_64 z_axis = tmp;
-
- tmp = vector_mul(vector_mix_xxxx(lhs.w_axis), rhs.x_axis);
- tmp = vector_mul_add(vector_mix_yyyy(lhs.w_axis), rhs.y_axis, tmp);
- tmp = vector_mul_add(vector_mix_zzzz(lhs.w_axis), rhs.z_axis, tmp);
- Vector4_64 w_axis = vector_add(rhs.w_axis, tmp);
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline Vector4_64 matrix_mul_position(const AffineMatrix_64& lhs, const Vector4_64& rhs)
- {
- Vector4_64 tmp0;
- Vector4_64 tmp1;
-
- tmp0 = vector_mul(vector_mix_xxxx(rhs), lhs.x_axis);
- tmp0 = vector_mul_add(vector_mix_yyyy(rhs), lhs.y_axis, tmp0);
- tmp1 = vector_mul_add(vector_mix_zzzz(rhs), lhs.z_axis, lhs.w_axis);
-
- return vector_add(tmp0, tmp1);
- }
-
- namespace math_impl
- {
- // Note: This is a generic matrix 4x4 transpose, the resulting matrix is no longer
- // affine because the last column is no longer [0,0,0,1]
- inline AffineMatrix_64 matrix_transpose(const AffineMatrix_64& input)
- {
- Vector4_64 tmp0 = vector_mix_xyab(input.x_axis, input.y_axis);
- Vector4_64 tmp1 = vector_mix_zwcd(input.x_axis, input.y_axis);
- Vector4_64 tmp2 = vector_mix_xyab(input.z_axis, input.w_axis);
- Vector4_64 tmp3 = vector_mix_zwcd(input.z_axis, input.w_axis);
-
- Vector4_64 x_axis = vector_mix_xzac(tmp0, tmp2);
- Vector4_64 y_axis = vector_mix_ywbd(tmp0, tmp2);
- Vector4_64 z_axis = vector_mix_xzac(tmp1, tmp3);
- Vector4_64 w_axis = vector_mix_ywbd(tmp1, tmp3);
- return AffineMatrix_64{ x_axis, y_axis, z_axis, w_axis };
- }
- }
-
- inline AffineMatrix_64 matrix_inverse(const AffineMatrix_64& input)
- {
- // TODO: This is a generic matrix inverse function, implement the affine version?
- AffineMatrix_64 input_transposed = math_impl::matrix_transpose(input);
-
- Vector4_64 v00 = vector_mix_xxyy(input_transposed.z_axis);
- Vector4_64 v01 = vector_mix_xxyy(input_transposed.x_axis);
- Vector4_64 v02 = vector_mix_xzac(input_transposed.z_axis, input_transposed.x_axis);
- Vector4_64 v10 = vector_mix_zwzw(input_transposed.w_axis);
- Vector4_64 v11 = vector_mix_zwzw(input_transposed.y_axis);
- Vector4_64 v12 = vector_mix_ywbd(input_transposed.w_axis, input_transposed.y_axis);
-
- Vector4_64 d0 = vector_mul(v00, v10);
- Vector4_64 d1 = vector_mul(v01, v11);
- Vector4_64 d2 = vector_mul(v02, v12);
-
- v00 = vector_mix_zwzw(input_transposed.z_axis);
- v01 = vector_mix_zwzw(input_transposed.x_axis);
- v02 = vector_mix_ywbd(input_transposed.z_axis, input_transposed.x_axis);
- v10 = vector_mix_xxyy(input_transposed.w_axis);
- v11 = vector_mix_xxyy(input_transposed.y_axis);
- v12 = vector_mix_xzac(input_transposed.w_axis, input_transposed.y_axis);
-
- d0 = vector_neg_mul_sub(v00, v10, d0);
- d1 = vector_neg_mul_sub(v01, v11, d1);
- d2 = vector_neg_mul_sub(v02, v12, d2);
-
- v00 = vector_mix_yzxy(input_transposed.y_axis);
- v01 = vector_mix_zxyx(input_transposed.x_axis);
- v02 = vector_mix_yzxy(input_transposed.w_axis);
- Vector4_64 v03 = vector_mix_zxyx(input_transposed.z_axis);
- v10 = vector_mix_bywx(d0, d2);
- v11 = vector_mix_wbyz(d0, d2);
- v12 = vector_mix_dywx(d1, d2);
- Vector4_64 v13 = vector_mix_wdyz(d1, d2);
-
- Vector4_64 c0 = vector_mul(v00, v10);
- Vector4_64 c2 = vector_mul(v01, v11);
- Vector4_64 c4 = vector_mul(v02, v12);
- Vector4_64 c6 = vector_mul(v03, v13);
-
- v00 = vector_mix_zwyz(input_transposed.y_axis);
- v01 = vector_mix_wzwy(input_transposed.x_axis);
- v02 = vector_mix_zwyz(input_transposed.w_axis);
- v03 = vector_mix_wzwy(input_transposed.z_axis);
- v10 = vector_mix_wxya(d0, d2);
- v11 = vector_mix_zyax(d0, d2);
- v12 = vector_mix_wxyc(d1, d2);
- v13 = vector_mix_zycx(d1, d2);
-
- c0 = vector_neg_mul_sub(v00, v10, c0);
- c2 = vector_neg_mul_sub(v01, v11, c2);
- c4 = vector_neg_mul_sub(v02, v12, c4);
- c6 = vector_neg_mul_sub(v03, v13, c6);
-
- v00 = vector_mix_wxwx(input_transposed.y_axis);
- v01 = vector_mix_ywxz(input_transposed.x_axis);
- v02 = vector_mix_wxwx(input_transposed.w_axis);
- v03 = vector_mix_ywxz(input_transposed.z_axis);
- v10 = vector_mix_zbaz(d0, d2);
- v11 = vector_mix_bxwa(d0, d2);
- v12 = vector_mix_zdcz(d1, d2);
- v13 = vector_mix_dxwc(d1, d2);
-
- Vector4_64 c1 = vector_neg_mul_sub(v00, v10, c0);
- c0 = vector_mul_add(v00, v10, c0);
- Vector4_64 c3 = vector_mul_add(v01, v11, c2);
- c2 = vector_neg_mul_sub(v01, v11, c2);
- Vector4_64 c5 = vector_neg_mul_sub(v02, v12, c4);
- c4 = vector_mul_add(v02, v12, c4);
- Vector4_64 c7 = vector_mul_add(v03, v13, c6);
- c6 = vector_neg_mul_sub(v03, v13, c6);
-
- Vector4_64 x_axis = vector_mix_xbzd(c0, c1);
- Vector4_64 y_axis = vector_mix_xbzd(c2, c3);
- Vector4_64 z_axis = vector_mix_xbzd(c4, c5);
- Vector4_64 w_axis = vector_mix_xbzd(c6, c7);
-
- double det = vector_dot(x_axis, input_transposed.x_axis);
- Vector4_64 inv_det = vector_set(reciprocal(det));
-
- x_axis = vector_mul(x_axis, inv_det);
- y_axis = vector_mul(y_axis, inv_det);
- z_axis = vector_mul(z_axis, inv_det);
- w_axis = vector_mul(w_axis, inv_det);
-
-#if defined(ACL_NO_INTRINSICS)
- w_axis = vector_set(vector_get_x(w_axis), vector_get_y(w_axis), vector_get_z(w_axis), 1.0);
-#endif
-
- return matrix_set(x_axis, y_axis, z_axis, w_axis);
- }
-
- inline AffineMatrix_64 matrix_remove_scale(const AffineMatrix_64& input)
- {
- AffineMatrix_64 result;
- result.x_axis = vector_normalize3(input.x_axis);
- result.y_axis = vector_normalize3(input.y_axis);
- result.z_axis = vector_normalize3(input.z_axis);
- result.w_axis = input.w_axis;
- return result;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/math.h b/includes/acl/math/math.h
deleted file mode 100644
--- a/includes/acl/math/math.h
+++ /dev/null
@@ -1,105 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-//#define ACL_NO_INTRINSICS
-
-#if !defined(ACL_NO_INTRINSICS)
- #if defined(__AVX__)
- #define ACL_AVX_INTRINSICS
- #define ACL_SSE4_INTRINSICS
- #define ACL_SSE3_INTRINSICS
- #define ACL_SSE2_INTRINSICS
- #endif
-
- #if defined(__SSE4_1__)
- #define ACL_SSE4_INTRINSICS
- #define ACL_SSE3_INTRINSICS
- #define ACL_SSE2_INTRINSICS
- #endif
-
- #if defined(__SSSE3__)
- #define ACL_SSE3_INTRINSICS
- #define ACL_SSE2_INTRINSICS
- #endif
-
- #if defined(__SSE2__) || defined(_M_IX86) || defined(_M_X64)
- #define ACL_SSE2_INTRINSICS
- #endif
-
- #if defined(__ARM_NEON) || defined(_M_ARM) || defined(_M_ARM64)
- #define ACL_NEON_INTRINSICS
-
- #if defined(__aarch64__) || defined(_M_ARM64)
- #define ACL_NEON64_INTRINSICS
- #endif
- #endif
-
- #if !defined(ACL_SSE2_INTRINSICS) && !defined(ACL_NEON_INTRINSICS)
- #define ACL_NO_INTRINSICS
- #endif
-#endif
-
-#if defined(ACL_SSE2_INTRINSICS)
- #include <xmmintrin.h>
- #include <emmintrin.h>
-
- // With MSVC and SSE2, we can use the __vectorcall calling convention to pass vector types and aggregates by value through registers
- // for improved code generation
- #if defined(_MSC_VER) && !defined(_M_ARM) && !defined(_MANAGED) && !defined(_M_CEE) && (!defined(_M_IX86_FP) || (_M_IX86_FP > 1)) && !defined(ACL_SIMD_CALL)
- #if ((_MSC_FULL_VER >= 170065501) && (_MSC_VER < 1800)) || (_MSC_FULL_VER >= 180020418)
- #define ACL_USE_VECTORCALL
- #endif
- #endif
-#endif
-
-#if defined(ACL_SSE3_INTRINSICS)
- #include <pmmintrin.h>
-#endif
-
-#if defined(ACL_SSE4_INTRINSICS)
- #include <smmintrin.h>
-#endif
-
-#if defined(ACL_AVX_INTRINSICS)
- #include <immintrin.h>
-#endif
-
-#if defined(ACL_NEON64_INTRINSICS) && defined(_M_ARM64)
- // MSVC specific header
- #include <arm64_neon.h>
-#elif defined(ACL_NEON_INTRINSICS)
- #include <arm_neon.h>
-#endif
-
-#if !defined(ACL_SIMD_CALL)
- #if defined(ACL_USE_VECTORCALL)
- #define ACL_SIMD_CALL __vectorcall
- #else
- #define ACL_SIMD_CALL
- #endif
-#endif
-
-#include "acl/math/math_types.h"
diff --git a/includes/acl/math/math_types.h b/includes/acl/math/math_types.h
deleted file mode 100644
--- a/includes/acl/math/math_types.h
+++ /dev/null
@@ -1,279 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/math/math.h"
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace math_impl
- {
- union Converter
- {
- double dbl;
- uint64_t u64;
- float flt[2];
-
- explicit constexpr Converter(uint64_t value) : u64(value) {}
- explicit constexpr Converter(double value) : dbl(value) {}
- explicit constexpr Converter(float value) : flt{value, value} {}
-
- constexpr operator double() const { return dbl; }
- constexpr operator float() const { return flt[0]; }
- };
-
- constexpr Converter get_mask_value(bool is_true)
- {
- return Converter(is_true ? uint64_t(0xFFFFFFFFFFFFFFFFULL) : uint64_t(0));
- }
-
- constexpr double select(double mask, double if_true, double if_false)
- {
- return Converter(mask).u64 == 0 ? if_false : if_true;
- }
-
- constexpr float select(float mask, float if_true, float if_false)
- {
- return Converter(mask).u64 == 0 ? if_false : if_true;
- }
- }
-
-#if defined(ACL_SSE2_INTRINSICS)
- typedef __m128 Quat_32;
- typedef __m128 Vector4_32;
-
- struct Quat_64
- {
- __m128d xy;
- __m128d zw;
- };
-
- struct Vector4_64
- {
- __m128d xy;
- __m128d zw;
- };
-#elif defined(ACL_NEON_INTRINSICS)
- typedef float32x4_t Quat_32;
- typedef float32x4_t Vector4_32;
-
- struct alignas(16) Quat_64
- {
- double x;
- double y;
- double z;
- double w;
- };
-
- struct alignas(16) Vector4_64
- {
- double x;
- double y;
- double z;
- double w;
- };
-#else
- struct alignas(16) Quat_32
- {
- float x;
- float y;
- float z;
- float w;
- };
-
- struct alignas(16) Vector4_32
- {
- float x;
- float y;
- float z;
- float w;
- };
-
- struct alignas(16) Quat_64
- {
- double x;
- double y;
- double z;
- double w;
- };
-
- struct alignas(16) Vector4_64
- {
- double x;
- double y;
- double z;
- double w;
- };
-#endif
-
- struct Transform_32
- {
- Quat_32 rotation;
- Vector4_32 translation;
- Vector4_32 scale;
- };
-
- struct Transform_64
- {
- Quat_64 rotation;
- Vector4_64 translation;
- Vector4_64 scale;
- };
-
- struct AffineMatrix_32
- {
- Vector4_32 x_axis;
- Vector4_32 y_axis;
- Vector4_32 z_axis;
- Vector4_32 w_axis;
- };
-
- struct AffineMatrix_64
- {
- Vector4_64 x_axis;
- Vector4_64 y_axis;
- Vector4_64 z_axis;
- Vector4_64 w_axis;
- };
-
- enum class VectorMix
- {
- X = 0,
- Y = 1,
- Z = 2,
- W = 3,
-
- A = 4,
- B = 5,
- C = 6,
- D = 7,
- };
-
- enum class MatrixAxis
- {
- X = 0,
- Y = 1,
- Z = 2,
- W = 3,
- };
-
- // The result is sometimes required as part of an immediate for an intrinsic
- // and as such we much know the value at compile time and constexpr isn't always evaluated.
- // Required at least on GCC 5 in Debug
- #define IS_VECTOR_MIX_ARG_XYZW(arg) (int32_t(arg) >= int32_t(VectorMix::X) && int32_t(arg) <= int32_t(VectorMix::W))
- #define IS_VECTOR_MIX_ARG_ABCD(arg) (int32_t(arg) >= int32_t(VectorMix::A) && int32_t(arg) <= int32_t(VectorMix::D))
- #define GET_VECTOR_MIX_COMPONENT_INDEX(arg) (IS_VECTOR_MIX_ARG_XYZW(arg) ? int8_t(arg) : (int8_t(arg) - 4))
-
- namespace math_impl
- {
- constexpr bool is_vector_mix_arg_xyzw(VectorMix arg) { return int32_t(arg) >= int32_t(VectorMix::X) && int32_t(arg) <= int32_t(VectorMix::W); }
- constexpr bool is_vector_mix_arg_abcd(VectorMix arg) { return int32_t(arg) >= int32_t(VectorMix::A) && int32_t(arg) <= int32_t(VectorMix::D); }
- constexpr int8_t get_vector_mix_component_index(VectorMix arg) { return is_vector_mix_arg_xyzw(arg) ? int8_t(arg) : (int8_t(arg) - 4); }
- }
-
- //////////////////////////////////////////////////////////////////////////
-
-#if defined(ACL_USE_VECTORCALL)
- // On x64 with __vectorcall, the first 6x vector4 arguments can be passed by value in a register, everything else afterwards is passed by const&
- using Vector4_32Arg0 = const Vector4_32;
- using Vector4_32Arg1 = const Vector4_32;
- using Vector4_32Arg2 = const Vector4_32;
- using Vector4_32Arg3 = const Vector4_32;
- using Vector4_32Arg4 = const Vector4_32;
- using Vector4_32Arg5 = const Vector4_32;
- using Vector4_32ArgN = const Vector4_32&;
-
- using Quat_32Arg0 = const Quat_32;
- using Quat_32Arg1 = const Quat_32;
- using Quat_32Arg2 = const Quat_32;
- using Quat_32Arg3 = const Quat_32;
- using Quat_32Arg4 = const Quat_32;
- using Quat_32Arg5 = const Quat_32;
- using Quat_32ArgN = const Quat_32&;
-
- // With __vectorcall, vector aggregates are also passed by register
- using Transform_32Arg0 = const Transform_32;
- using Transform_32Arg1 = const Transform_32;
- using Transform_32ArgN = const Transform_32&;
-
- using AffineMatrix_32Arg0 = const AffineMatrix_32;
- using AffineMatrix_32ArgN = const AffineMatrix_32&;
-#elif defined(ACL_NEON_INTRINSICS)
- // On ARM NEON, the first 4x vector4 arguments can be passed by value in a register, everything else afterwards is passed by const&
- using Vector4_32Arg0 = const Vector4_32;
- using Vector4_32Arg1 = const Vector4_32;
- using Vector4_32Arg2 = const Vector4_32;
- using Vector4_32Arg3 = const Vector4_32;
- using Vector4_32Arg4 = const Vector4_32&;
- using Vector4_32Arg5 = const Vector4_32&;
- using Vector4_32ArgN = const Vector4_32&;
-
- using Quat_32Arg0 = const Quat_32;
- using Quat_32Arg1 = const Quat_32;
- using Quat_32Arg2 = const Quat_32;
- using Quat_32Arg3 = const Quat_32;
- using Quat_32Arg4 = const Quat_32&;
- using Quat_32Arg5 = const Quat_32&;
- using Quat_32ArgN = const Quat_32&;
-
- using Transform_32Arg0 = const Transform_32&;
- using Transform_32Arg1 = const Transform_32&;
- using Transform_32ArgN = const Transform_32&;
-
- using AffineMatrix_32Arg0 = const AffineMatrix_32&;
- using AffineMatrix_32ArgN = const AffineMatrix_32&;
-#else
- // On every other platform, everything is passed by const&
- using Vector4_32Arg0 = const Vector4_32&;
- using Vector4_32Arg1 = const Vector4_32&;
- using Vector4_32Arg2 = const Vector4_32&;
- using Vector4_32Arg3 = const Vector4_32&;
- using Vector4_32Arg4 = const Vector4_32&;
- using Vector4_32Arg5 = const Vector4_32&;
- using Vector4_32ArgN = const Vector4_32&;
-
- using Quat_32Arg0 = const Quat_32&;
- using Quat_32Arg1 = const Quat_32&;
- using Quat_32Arg2 = const Quat_32&;
- using Quat_32Arg3 = const Quat_32&;
- using Quat_32Arg4 = const Quat_32&;
- using Quat_32Arg5 = const Quat_32&;
- using Quat_32ArgN = const Quat_32&;
-
- using Transform_32Arg0 = const Transform_32&;
- using Transform_32Arg1 = const Transform_32&;
- using Transform_32ArgN = const Transform_32&;
-
- using AffineMatrix_32Arg0 = const AffineMatrix_32&;
- using AffineMatrix_32ArgN = const AffineMatrix_32&;
-#endif
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/quat_32.h b/includes/acl/math/quat_32.h
deleted file mode 100644
--- a/includes/acl/math/quat_32.h
+++ /dev/null
@@ -1,598 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/core/memory_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/scalar_32.h"
-#include "acl/math/vector4_32.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- inline Quat_32 ACL_SIMD_CALL quat_set(float x, float y, float z, float w)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_set_ps(w, z, y, x);
-#elif defined(ACL_NEON_INTRINSICS)
-#if 1
- float32x2_t V0 = vcreate_f32(((uint64_t)*(const uint32_t*)&x) | ((uint64_t)(*(const uint32_t*)&y) << 32));
- float32x2_t V1 = vcreate_f32(((uint64_t)*(const uint32_t*)&z) | ((uint64_t)(*(const uint32_t*)&w) << 32));
- return vcombine_f32(V0, V1);
-#else
- float __attribute__((aligned(16))) data[4] = { x, y, z, w };
- return vld1q_f32(data);
-#endif
-#else
- return Quat_32{ x, y, z, w };
-#endif
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_unaligned_load(const float* input)
- {
- ACL_ASSERT(is_aligned(input), "Invalid alignment");
- return quat_set(input[0], input[1], input[2], input[3]);
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_identity_32()
- {
- return quat_set(0.0F, 0.0F, 0.0F, 1.0F);
- }
-
- inline Quat_32 ACL_SIMD_CALL vector_to_quat(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS) || defined(ACL_NEON_INTRINSICS)
- return input;
-#else
- return Quat_32{ input.x, input.y, input.z, input.w };
-#endif
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_cast(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_shuffle_ps(_mm_cvtpd_ps(input.xy), _mm_cvtpd_ps(input.zw), _MM_SHUFFLE(1, 0, 1, 0));
-#else
- return quat_set(float(input.x), float(input.y), float(input.z), float(input.w));
-#endif
- }
-
- inline float ACL_SIMD_CALL quat_get_x(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(input);
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 0);
-#else
- return input.x;
-#endif
- }
-
- inline float ACL_SIMD_CALL quat_get_y(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(1, 1, 1, 1)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 1);
-#else
- return input.y;
-#endif
- }
-
- inline float ACL_SIMD_CALL quat_get_z(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(2, 2, 2, 2)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 2);
-#else
- return input.z;
-#endif
- }
-
- inline float ACL_SIMD_CALL quat_get_w(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(3, 3, 3, 3)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 3);
-#else
- return input.w;
-#endif
- }
-
- inline void ACL_SIMD_CALL quat_unaligned_write(Quat_32Arg0 input, float* output)
- {
- output[0] = quat_get_x(input);
- output[1] = quat_get_y(input);
- output[2] = quat_get_z(input);
- output[3] = quat_get_w(input);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- inline Quat_32 ACL_SIMD_CALL quat_conjugate(Quat_32Arg0 input)
- {
- return quat_set(-quat_get_x(input), -quat_get_y(input), -quat_get_z(input), quat_get_w(input));
- }
-
- // Multiplication order is as follow: local_to_world = quat_mul(local_to_object, object_to_world)
- inline Quat_32 ACL_SIMD_CALL quat_mul(Quat_32Arg0 lhs, Quat_32Arg1 rhs)
- {
-#if defined(ACL_SSE4_INTRINSICS) && 0
- // TODO: Profile this, the accuracy is the same as with SSE2, should be binary exact
- constexpr __m128 signs_x = { 1.0F, 1.0F, 1.0F, -1.0F };
- constexpr __m128 signs_y = { 1.0F, -1.0F, 1.0F, 1.0F };
- constexpr __m128 signs_z = { 1.0F, 1.0F, -1.0F, 1.0F };
- constexpr __m128 signs_w = { 1.0F, -1.0F, -1.0F, -1.0F };
- // x = dot(rhs.wxyz, lhs.xwzy * signs_x)
- // y = dot(rhs.wxyz, lhs.yzwx * signs_y)
- // z = dot(rhs.wxyz, lhs.zyxw * signs_z)
- // w = dot(rhs.wxyz, lhs.wxyz * signs_w)
- __m128 rhs_wxyz = _mm_shuffle_ps(rhs, rhs, _MM_SHUFFLE(2, 1, 0, 3));
- __m128 lhs_xwzy = _mm_shuffle_ps(lhs, lhs, _MM_SHUFFLE(1, 2, 3, 0));
- __m128 lhs_yzwx = _mm_shuffle_ps(lhs, lhs, _MM_SHUFFLE(0, 3, 2, 1));
- __m128 lhs_zyxw = _mm_shuffle_ps(lhs, lhs, _MM_SHUFFLE(3, 0, 1, 2));
- __m128 lhs_wxyz = _mm_shuffle_ps(lhs, lhs, _MM_SHUFFLE(2, 1, 0, 3));
- __m128 x = _mm_dp_ps(rhs_wxyz, _mm_mul_ps(lhs_xwzy, signs_x), 0xFF);
- __m128 y = _mm_dp_ps(rhs_wxyz, _mm_mul_ps(lhs_yzwx, signs_y), 0xFF);
- __m128 z = _mm_dp_ps(rhs_wxyz, _mm_mul_ps(lhs_zyxw, signs_z), 0xFF);
- __m128 w = _mm_dp_ps(rhs_wxyz, _mm_mul_ps(lhs_wxyz, signs_w), 0xFF);
- __m128 xxyy = _mm_shuffle_ps(x, y, _MM_SHUFFLE(0, 0, 0, 0));
- __m128 zzww = _mm_shuffle_ps(z, w, _MM_SHUFFLE(0, 0, 0, 0));
- return _mm_shuffle_ps(xxyy, zzww, _MM_SHUFFLE(2, 0, 2, 0));
-#elif defined(ACL_SSE2_INTRINSICS)
- constexpr __m128 control_wzyx = { 0.0F, -0.0F, 0.0F, -0.0F };
- constexpr __m128 control_zwxy = { 0.0F, 0.0F, -0.0F, -0.0F };
- constexpr __m128 control_yxwz = { -0.0F, 0.0F, 0.0F, -0.0F };
-
- __m128 r_xxxx = _mm_shuffle_ps(rhs, rhs, _MM_SHUFFLE(0, 0, 0, 0));
- __m128 r_yyyy = _mm_shuffle_ps(rhs, rhs, _MM_SHUFFLE(1, 1, 1, 1));
- __m128 r_zzzz = _mm_shuffle_ps(rhs, rhs, _MM_SHUFFLE(2, 2, 2, 2));
- __m128 r_wwww = _mm_shuffle_ps(rhs, rhs, _MM_SHUFFLE(3, 3, 3, 3));
-
- __m128 lxrw_lyrw_lzrw_lwrw = _mm_mul_ps(r_wwww, lhs);
- __m128 l_wzyx = _mm_shuffle_ps(lhs, lhs, _MM_SHUFFLE(0, 1, 2, 3));
-
- __m128 lwrx_lzrx_lyrx_lxrx = _mm_mul_ps(r_xxxx, l_wzyx);
- __m128 l_zwxy = _mm_shuffle_ps(l_wzyx, l_wzyx, _MM_SHUFFLE(2, 3, 0, 1));
-
- __m128 lwrx_nlzrx_lyrx_nlxrx = _mm_xor_ps(lwrx_lzrx_lyrx_lxrx, control_wzyx);
-
- __m128 lzry_lwry_lxry_lyry = _mm_mul_ps(r_yyyy, l_zwxy);
- __m128 l_yxwz = _mm_shuffle_ps(l_zwxy, l_zwxy, _MM_SHUFFLE(0, 1, 2, 3));
-
- __m128 lzry_lwry_nlxry_nlyry = _mm_xor_ps(lzry_lwry_lxry_lyry, control_zwxy);
-
- __m128 lyrz_lxrz_lwrz_lzrz = _mm_mul_ps(r_zzzz, l_yxwz);
- __m128 result0 = _mm_add_ps(lxrw_lyrw_lzrw_lwrw, lwrx_nlzrx_lyrx_nlxrx);
-
- __m128 nlyrz_lxrz_lwrz_wlzrz = _mm_xor_ps(lyrz_lxrz_lwrz_lzrz, control_yxwz);
- __m128 result1 = _mm_add_ps(lzry_lwry_nlxry_nlyry, nlyrz_lxrz_lwrz_wlzrz);
- return _mm_add_ps(result0, result1);
-#elif defined(ACL_NEON_INTRINSICS)
- alignas(16) constexpr float control_wzyx_f[4] = { 1.0F, -1.0F, 1.0F, -1.0F };
- alignas(16) constexpr float control_zwxy_f[4] = { 1.0F, 1.0F, -1.0F, -1.0F };
- alignas(16) constexpr float control_yxwz_f[4] = { -1.0F, 1.0F, 1.0F, -1.0F };
-
- const float32x4_t control_wzyx = *reinterpret_cast<const float32x4_t*>(&control_wzyx_f[0]);
- const float32x4_t control_zwxy = *reinterpret_cast<const float32x4_t*>(&control_zwxy_f[0]);
- const float32x4_t control_yxwz = *reinterpret_cast<const float32x4_t*>(&control_yxwz_f[0]);
-
- float32x2_t r_xy = vget_low_f32(rhs);
- float32x2_t r_zw = vget_high_f32(rhs);
-
- float32x4_t lxrw_lyrw_lzrw_lwrw = vmulq_lane_f32(lhs, r_zw, 1);
-
- float32x4_t l_yxwz = vrev64q_f32(lhs);
- float32x4_t l_wzyx = vcombine_f32(vget_high_f32(l_yxwz), vget_low_f32(l_yxwz));
- float32x4_t lwrx_lzrx_lyrx_lxrx = vmulq_lane_f32(l_wzyx, r_xy, 0);
-
-#if defined(RTM_NEON64_INTRINSICS)
- float32x4_t result0 = vfmaq_f32(lxrw_lyrw_lzrw_lwrw, lwrx_lzrx_lyrx_lxrx, control_wzyx);
-#else
- float32x4_t result0 = vmlaq_f32(lxrw_lyrw_lzrw_lwrw, lwrx_lzrx_lyrx_lxrx, control_wzyx);
-#endif
-
- float32x4_t l_zwxy = vrev64q_f32(l_wzyx);
- float32x4_t lzry_lwry_lxry_lyry = vmulq_lane_f32(l_zwxy, r_xy, 1);
-
-#if defined(RTM_NEON64_INTRINSICS)
- float32x4_t result1 = vfmaq_f32(result0, lzry_lwry_lxry_lyry, control_zwxy);
-#else
- float32x4_t result1 = vmlaq_f32(result0, lzry_lwry_lxry_lyry, control_zwxy);
-#endif
-
- float32x4_t lyrz_lxrz_lwrz_lzrz = vmulq_lane_f32(l_yxwz, r_zw, 0);
-
-#if defined(RTM_NEON64_INTRINSICS)
- return vfmaq_f32(result1, lyrz_lxrz_lwrz_lzrz, control_yxwz);
-#else
- return vmlaq_f32(result1, lyrz_lxrz_lwrz_lzrz, control_yxwz);
-#endif
-#else
- float lhs_x = quat_get_x(lhs);
- float lhs_y = quat_get_y(lhs);
- float lhs_z = quat_get_z(lhs);
- float lhs_w = quat_get_w(lhs);
-
- float rhs_x = quat_get_x(rhs);
- float rhs_y = quat_get_y(rhs);
- float rhs_z = quat_get_z(rhs);
- float rhs_w = quat_get_w(rhs);
-
- float x = (rhs_w * lhs_x) + (rhs_x * lhs_w) + (rhs_y * lhs_z) - (rhs_z * lhs_y);
- float y = (rhs_w * lhs_y) - (rhs_x * lhs_z) + (rhs_y * lhs_w) + (rhs_z * lhs_x);
- float z = (rhs_w * lhs_z) + (rhs_x * lhs_y) - (rhs_y * lhs_x) + (rhs_z * lhs_w);
- float w = (rhs_w * lhs_w) - (rhs_x * lhs_x) - (rhs_y * lhs_y) - (rhs_z * lhs_z);
-
- return quat_set(x, y, z, w);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL quat_rotate(Quat_32Arg0 rotation, Vector4_32Arg1 vector)
- {
- Quat_32 vector_quat = quat_set(vector_get_x(vector), vector_get_y(vector), vector_get_z(vector), 0.0F);
- Quat_32 inv_rotation = quat_conjugate(rotation);
- return quat_to_vector(quat_mul(quat_mul(inv_rotation, vector_quat), rotation));
- }
-
- inline float ACL_SIMD_CALL quat_length_squared(Quat_32Arg0 input)
- {
- return vector_length_squared(quat_to_vector(input));
- }
-
- inline float ACL_SIMD_CALL quat_length(Quat_32Arg0 input)
- {
- return vector_length(quat_to_vector(input));
- }
-
- inline float ACL_SIMD_CALL quat_length_reciprocal(Quat_32Arg0 input)
- {
- return vector_length_reciprocal(quat_to_vector(input));
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_normalize(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // We first calculate the dot product to get the length squared: dot(input, input)
- __m128 x2_y2_z2_w2 = _mm_mul_ps(input, input);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
-
- // Keep the dot product result as a scalar within the first lane, it is faster to
- // calculate the reciprocal square root of a single lane VS all 4 lanes
- __m128 dot = x2y2z2w2_0_0_0;
-
- // Calculate the reciprocal square root to get the inverse length of our vector
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- __m128 half = _mm_set_ss(0.5F);
- __m128 input_half_v = _mm_mul_ss(dot, half);
- __m128 x0 = _mm_rsqrt_ss(dot);
-
- // First iteration
- __m128 x1 = _mm_mul_ss(x0, x0);
- x1 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x1));
- x1 = _mm_add_ss(_mm_mul_ss(x0, x1), x0);
-
- // Second iteration
- __m128 x2 = _mm_mul_ss(x1, x1);
- x2 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x2));
- x2 = _mm_add_ss(_mm_mul_ss(x1, x2), x1);
-
- // Broadcast the vector length reciprocal to all 4 lanes in order to multiply it with the vector
- __m128 inv_len = _mm_shuffle_ps(x2, x2, _MM_SHUFFLE(0, 0, 0, 0));
-
- // Multiply the rotation by it's inverse length in order to normalize it
- return _mm_mul_ps(input, inv_len);
-#elif defined (ACL_NEON_INTRINSICS)
- // Use sqrt/div/mul to normalize because the sqrt/div are faster than rsqrt
- float inv_len = 1.0F / sqrt(vector_length_squared(input));
- return vector_mul(input, inv_len);
-#else
- // Reciprocal is more accurate to normalize with
- float inv_len = quat_length_reciprocal(input);
- return vector_to_quat(vector_mul(quat_to_vector(input), inv_len));
-#endif
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_lerp(Quat_32Arg0 start, Quat_32Arg1 end, float alpha)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // Calculate the vector4 dot product: dot(start, end)
- __m128 dot;
-#if defined(ACL_SSE4_INTRINSICS)
- // The dpps instruction isn't as accurate but we don't care here, we only need the sign of the
- // dot product. If both rotations are on opposite ends of the hypersphere, the result will be
- // very negative. If we are on the edge, the rotations are nearly opposite but not quite which
- // means that the linear interpolation here will have terrible accuracy to begin with. It is designed
- // for interpolating rotations that are reasonably close together. The bias check is mainly necessary
- // because the W component is often kept positive which flips the sign.
- // Using the dpps instruction reduces the number of registers that we need and helps the function get
- // inlined.
- dot = _mm_dp_ps(start, end, 0xFF);
-#else
- {
- __m128 x2_y2_z2_w2 = _mm_mul_ps(start, end);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
- // Shuffle the dot product to all SIMD lanes, there is no _mm_and_ss and loading
- // the constant from memory with the 'and' instruction is faster, it uses fewer registers
- // and fewer instructions
- dot = _mm_shuffle_ps(x2y2z2w2_0_0_0, x2y2z2w2_0_0_0, _MM_SHUFFLE(0, 0, 0, 0));
- }
-#endif
-
- // Calculate the bias, if the dot product is positive or zero, there is no bias
- // but if it is negative, we want to flip the 'end' rotation XYZW components
- __m128 bias = _mm_and_ps(dot, _mm_set_ps1(-0.0F));
-
- // Lerp the rotation after applying the bias
- __m128 interpolated_rotation = _mm_add_ps(_mm_mul_ps(_mm_sub_ps(_mm_xor_ps(end, bias), start), _mm_set_ps1(alpha)), start);
-
- // Now we need to normalize the resulting rotation. We first calculate the
- // dot product to get the length squared: dot(interpolated_rotation, interpolated_rotation)
- __m128 x2_y2_z2_w2 = _mm_mul_ps(interpolated_rotation, interpolated_rotation);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
-
- // Keep the dot product result as a scalar within the first lane, it is faster to
- // calculate the reciprocal square root of a single lane VS all 4 lanes
- dot = x2y2z2w2_0_0_0;
-
- // Calculate the reciprocal square root to get the inverse length of our vector
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- __m128 half = _mm_set_ss(0.5F);
- __m128 input_half_v = _mm_mul_ss(dot, half);
- __m128 x0 = _mm_rsqrt_ss(dot);
-
- // First iteration
- __m128 x1 = _mm_mul_ss(x0, x0);
- x1 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x1));
- x1 = _mm_add_ss(_mm_mul_ss(x0, x1), x0);
-
- // Second iteration
- __m128 x2 = _mm_mul_ss(x1, x1);
- x2 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x2));
- x2 = _mm_add_ss(_mm_mul_ss(x1, x2), x1);
-
- // Broadcast the vector length reciprocal to all 4 lanes in order to multiply it with the vector
- __m128 inv_len = _mm_shuffle_ps(x2, x2, _MM_SHUFFLE(0, 0, 0, 0));
-
- // Multiply the rotation by it's inverse length in order to normalize it
- return _mm_mul_ps(interpolated_rotation, inv_len);
-#elif defined (ACL_NEON64_INTRINSICS)
- // On ARM64 with NEON, we load 1.0 once and use it twice which is faster than
- // using a AND/XOR with the bias (same number of instructions)
- float dot = vector_dot(start, end);
- float bias = dot >= 0.0F ? 1.0F : -1.0F;
- Vector4_32 interpolated_rotation = vector_neg_mul_sub(vector_neg_mul_sub(end, bias, start), alpha, start);
- // Use sqrt/div/mul to normalize because the sqrt/div are faster than rsqrt
- float inv_len = 1.0F / sqrt(vector_length_squared(interpolated_rotation));
- return vector_mul(interpolated_rotation, inv_len);
-#elif defined(ACL_NEON_INTRINSICS)
- // Calculate the vector4 dot product: dot(start, end)
- float32x4_t x2_y2_z2_w2 = vmulq_f32(start, end);
- float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
- float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
- float32x2_t x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
- float32x2_t x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
-
- // Calculate the bias, if the dot product is positive or zero, there is no bias
- // but if it is negative, we want to flip the 'end' rotation XYZW components
- // On ARM-v7-A, the AND/XOR trick is faster than the cmp/fsel
- uint32x2_t bias = vand_u32(vreinterpret_u32_f32(x2y2z2w2), vdup_n_u32(0x80000000U));
-
- // Lerp the rotation after applying the bias
- float32x4_t end_biased = vreinterpretq_f32_u32(veorq_u32(vreinterpretq_u32_f32(end), vcombine_u32(bias, bias)));
- float32x4_t interpolated_rotation = vmlaq_n_f32(start, vsubq_f32(end_biased, start), alpha);
-
- // Now we need to normalize the resulting rotation. We first calculate the
- // dot product to get the length squared: dot(interpolated_rotation, interpolated_rotation)
- x2_y2_z2_w2 = vmulq_f32(interpolated_rotation, interpolated_rotation);
- x2_y2 = vget_low_f32(x2_y2_z2_w2);
- z2_w2 = vget_high_f32(x2_y2_z2_w2);
- x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
- x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
-
- float dot = vget_lane_f32(x2y2z2w2, 0);
-
- // Use sqrt/div/mul to normalize because the sqrt/div are faster than rsqrt
- float inv_len = 1.0F / sqrt(dot);
- return vector_mul(interpolated_rotation, inv_len);
-#else
- // To ensure we take the shortest path, we apply a bias if the dot product is negative
- Vector4_32 start_vector = quat_to_vector(start);
- Vector4_32 end_vector = quat_to_vector(end);
- float dot = vector_dot(start_vector, end_vector);
- float bias = dot >= 0.0F ? 1.0F : -1.0F;
- Vector4_32 interpolated_rotation = vector_neg_mul_sub(vector_neg_mul_sub(end_vector, bias, start_vector), alpha, start_vector);
- // TODO: Test with this instead: Rotation = (B * Alpha) + (A * (Bias * (1.f - Alpha)));
- //Vector4_32 value = vector_add(vector_mul(end_vector, alpha), vector_mul(start_vector, bias * (1.0f - alpha)));
- return quat_normalize(vector_to_quat(interpolated_rotation));
-#endif
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_neg(Quat_32Arg0 input)
- {
-#if defined(ACL_NEON_INTRINSICS)
- return vnegq_f32(input);
-#else
- return vector_to_quat(vector_mul(quat_to_vector(input), -1.0F));
-#endif
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_ensure_positive_w(Quat_32Arg0 input)
- {
- return quat_get_w(input) >= 0.0F ? input : quat_neg(input);
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_from_positive_w(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE4_INTRINSICS)
- __m128 x2y2z2 = _mm_mul_ps(input, input);
- __m128 one = _mm_set_ss(1.0F);
- __m128 w_squared = _mm_sub_ss(_mm_sub_ss(_mm_sub_ss(one, x2y2z2), _mm_shuffle_ps(x2y2z2, x2y2z2, _MM_SHUFFLE(1, 1, 1, 1))), _mm_shuffle_ps(x2y2z2, x2y2z2, _MM_SHUFFLE(2, 2, 2, 2)));
- w_squared = _mm_andnot_ps(_mm_set_ss(-0.0F), w_squared);
- __m128 w = _mm_sqrt_ss(w_squared);
- return _mm_insert_ps(input, w, 0x30);
-#elif defined(ACL_SSE2_INTRINSICS)
- __m128 x2y2z2 = _mm_mul_ps(input, input);
- __m128 one = _mm_set_ss(1.0F);
- __m128 w_squared = _mm_sub_ss(_mm_sub_ss(_mm_sub_ss(one, x2y2z2), _mm_shuffle_ps(x2y2z2, x2y2z2, _MM_SHUFFLE(1, 1, 1, 1))), _mm_shuffle_ps(x2y2z2, x2y2z2, _MM_SHUFFLE(2, 2, 2, 2)));
- w_squared = _mm_andnot_ps(_mm_set_ss(-0.0F), w_squared);
- __m128 w = _mm_sqrt_ss(w_squared);
- __m128 input_wyzx = _mm_shuffle_ps(input, input, _MM_SHUFFLE(0, 2, 1, 3));
- __m128 result_wyzx = _mm_move_ss(input_wyzx, w);
- return _mm_shuffle_ps(result_wyzx, result_wyzx, _MM_SHUFFLE(0, 2, 1, 3));
-#elif defined(ACL_NEON_INTRINSICS) && 0
- // TODO: This is slower on ARMv7-A, measure again on ARM64, fewer instructions but the first
- // sub is dependent on the result of the mul where the C impl below pipelines a bit better it seems
- float32x4_t x2y2z2 = vmulq_f32(input, input);
- float w_squared = ((1.0F - vgetq_lane_f32(x2y2z2, 0)) - vgetq_lane_f32(x2y2z2, 1)) - vgetq_lane_f32(x2y2z2, 2);
- float w = acl::sqrt(acl::abs(w_squared));
- return vsetq_lane_f32(w, input, 3);
-#else
- // Operation order is important here, due to rounding, ((1.0 - (X*X)) - Y*Y) - Z*Z is more accurate than 1.0 - dot3(xyz, xyz)
- float w_squared = ((1.0F - vector_get_x(input) * vector_get_x(input)) - vector_get_y(input) * vector_get_y(input)) - vector_get_z(input) * vector_get_z(input);
- // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
- // to ensure the resulting quaternion is always normalized with a positive W component
- float w = sqrt(abs(w_squared));
- return quat_set(vector_get_x(input), vector_get_y(input), vector_get_z(input), w);
-#endif
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Conversion to/from axis/angle/euler
-
- inline void ACL_SIMD_CALL quat_to_axis_angle(Quat_32Arg0 input, Vector4_32& out_axis, float& out_angle)
- {
- constexpr float epsilon = 1.0E-8F;
- constexpr float epsilon_squared = epsilon * epsilon;
-
- out_angle = acos(quat_get_w(input)) * 2.0F;
-
- float scale_sq = max(1.0F - quat_get_w(input) * quat_get_w(input), 0.0F);
- out_axis = scale_sq >= epsilon_squared ? vector_div(vector_set(quat_get_x(input), quat_get_y(input), quat_get_z(input)), vector_set(sqrt(scale_sq))) : vector_set(1.0F, 0.0F, 0.0F);
- }
-
- inline Vector4_32 ACL_SIMD_CALL quat_get_axis(Quat_32Arg0 input)
- {
- constexpr float epsilon = 1.0E-8F;
- constexpr float epsilon_squared = epsilon * epsilon;
-
- float scale_sq = max(1.0F - quat_get_w(input) * quat_get_w(input), 0.0F);
- return scale_sq >= epsilon_squared ? vector_div(vector_set(quat_get_x(input), quat_get_y(input), quat_get_z(input)), vector_set(sqrt(scale_sq))) : vector_set(1.0F, 0.0F, 0.0F);
- }
-
- inline float ACL_SIMD_CALL quat_get_angle(Quat_32Arg0 input)
- {
- return acos(quat_get_w(input)) * 2.0F;
- }
-
- inline Quat_32 ACL_SIMD_CALL quat_from_axis_angle(Vector4_32Arg0 axis, float angle)
- {
- float s;
- float c;
- sincos(0.5F * angle, s, c);
-
- return quat_set(s * vector_get_x(axis), s * vector_get_y(axis), s * vector_get_z(axis), c);
- }
-
- // Pitch is around the Y axis (right)
- // Yaw is around the Z axis (up)
- // Roll is around the X axis (forward)
- inline Quat_32 ACL_SIMD_CALL quat_from_euler(float pitch, float yaw, float roll)
- {
- float sp;
- float sy;
- float sr;
- float cp;
- float cy;
- float cr;
-
- sincos(pitch * 0.5F, sp, cp);
- sincos(yaw * 0.5F, sy, cy);
- sincos(roll * 0.5F, sr, cr);
-
- return quat_set(cr * sp * sy - sr * cp * cy,
- -cr * sp * cy - sr * cp * sy,
- cr * cp * sy - sr * sp * cy,
- cr * cp * cy + sr * sp * sy);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- inline bool ACL_SIMD_CALL quat_is_finite(Quat_32Arg0 input)
- {
- return is_finite(quat_get_x(input)) && is_finite(quat_get_y(input)) && is_finite(quat_get_z(input)) && is_finite(quat_get_w(input));
- }
-
- inline bool ACL_SIMD_CALL quat_is_normalized(Quat_32Arg0 input, float threshold = 0.00001F)
- {
- float length_squared = quat_length_squared(input);
- return abs(length_squared - 1.0F) < threshold;
- }
-
- inline bool ACL_SIMD_CALL quat_near_equal(Quat_32Arg0 lhs, Quat_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_all_near_equal(quat_to_vector(lhs), quat_to_vector(rhs), threshold);
- }
-
- inline bool ACL_SIMD_CALL quat_near_identity(Quat_32Arg0 input, float threshold_angle = 0.00284714461F)
- {
- // Because of floating point precision, we cannot represent very small rotations.
- // The closest float to 1.0 that is not 1.0 itself yields:
- // acos(0.99999994f) * 2.0f = 0.000690533954 rad
- //
- // An error threshold of 1.e-6f is used by default.
- // acos(1.f - 1.e-6f) * 2.0f = 0.00284714461 rad
- // acos(1.f - 1.e-7f) * 2.0f = 0.00097656250 rad
- //
- // We don't really care about the angle value itself, only if it's close to 0.
- // This will happen whenever quat.w is close to 1.0.
- // If the quat.w is close to -1.0, the angle will be near 2*PI which is close to
- // a negative 0 rotation. By forcing quat.w to be positive, we'll end up with
- // the shortest path.
- const float positive_w_angle = acos(abs(quat_get_w(input))) * 2.0F;
- return positive_w_angle < threshold_angle;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/quat_64.h b/includes/acl/math/quat_64.h
deleted file mode 100644
--- a/includes/acl/math/quat_64.h
+++ /dev/null
@@ -1,307 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/core/memory_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/scalar_64.h"
-#include "acl/math/vector4_64.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- inline Quat_64 quat_set(double x, double y, double z, double w)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Quat_64{ _mm_set_pd(y, x), _mm_set_pd(w, z) };
-#else
- return Quat_64{ x, y, z, w };
-#endif
- }
-
- inline Quat_64 quat_unaligned_load(const double* input)
- {
- return quat_set(input[0], input[1], input[2], input[3]);
- }
-
- inline Quat_64 quat_identity_64()
- {
- return quat_set(0.0, 0.0, 0.0, 1.0);
- }
-
- inline Quat_64 vector_to_quat(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Quat_64{ input.xy, input.zw };
-#else
- return Quat_64{ input.x, input.y, input.z, input.w };
-#endif
- }
-
- inline Quat_64 quat_cast(const Quat_32& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Quat_64{ _mm_cvtps_pd(input), _mm_cvtps_pd(_mm_shuffle_ps(input, input, _MM_SHUFFLE(3, 2, 3, 2))) };
-#elif defined(ACL_NEON_INTRINSICS)
- return Quat_64{ double(vgetq_lane_f32(input, 0)), double(vgetq_lane_f32(input, 1)), double(vgetq_lane_f32(input, 2)), double(vgetq_lane_f32(input, 3)) };
-#else
- return Quat_64{ double(input.x), double(input.y), double(input.z), double(input.w) };
-#endif
- }
-
- inline double quat_get_x(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(input.xy);
-#else
- return input.x;
-#endif
- }
-
- inline double quat_get_y(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(_mm_shuffle_pd(input.xy, input.xy, 1));
-#else
- return input.y;
-#endif
- }
-
- inline double quat_get_z(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(input.zw);
-#else
- return input.z;
-#endif
- }
-
- inline double quat_get_w(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(_mm_shuffle_pd(input.zw, input.zw, 1));
-#else
- return input.w;
-#endif
- }
-
- inline void quat_unaligned_write(const Quat_64& input, double* output)
- {
- output[0] = quat_get_x(input);
- output[1] = quat_get_y(input);
- output[2] = quat_get_z(input);
- output[3] = quat_get_w(input);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- inline Quat_64 quat_conjugate(const Quat_64& input)
- {
- return quat_set(-quat_get_x(input), -quat_get_y(input), -quat_get_z(input), quat_get_w(input));
- }
-
- // Multiplication order is as follow: local_to_world = quat_mul(local_to_object, object_to_world)
- inline Quat_64 quat_mul(const Quat_64& lhs, const Quat_64& rhs)
- {
- double lhs_x = quat_get_x(lhs);
- double lhs_y = quat_get_y(lhs);
- double lhs_z = quat_get_z(lhs);
- double lhs_w = quat_get_w(lhs);
-
- double rhs_x = quat_get_x(rhs);
- double rhs_y = quat_get_y(rhs);
- double rhs_z = quat_get_z(rhs);
- double rhs_w = quat_get_w(rhs);
-
- double x = (rhs_w * lhs_x) + (rhs_x * lhs_w) + (rhs_y * lhs_z) - (rhs_z * lhs_y);
- double y = (rhs_w * lhs_y) - (rhs_x * lhs_z) + (rhs_y * lhs_w) + (rhs_z * lhs_x);
- double z = (rhs_w * lhs_z) + (rhs_x * lhs_y) - (rhs_y * lhs_x) + (rhs_z * lhs_w);
- double w = (rhs_w * lhs_w) - (rhs_x * lhs_x) - (rhs_y * lhs_y) - (rhs_z * lhs_z);
-
- return quat_set(x, y, z, w);
- }
-
- inline Vector4_64 quat_rotate(const Quat_64& rotation, const Vector4_64& vector)
- {
- Quat_64 vector_quat = quat_set(vector_get_x(vector), vector_get_y(vector), vector_get_z(vector), 0.0);
- Quat_64 inv_rotation = quat_conjugate(rotation);
- return quat_to_vector(quat_mul(quat_mul(inv_rotation, vector_quat), rotation));
- }
-
- inline double quat_length_squared(const Quat_64& input)
- {
- // TODO: Use dot instruction
- return (quat_get_x(input) * quat_get_x(input)) + (quat_get_y(input) * quat_get_y(input)) + (quat_get_z(input) * quat_get_z(input)) + (quat_get_w(input) * quat_get_w(input));
- }
-
- inline double quat_length(const Quat_64& input)
- {
- // TODO: Use intrinsics to avoid scalar coercion
- return sqrt(quat_length_squared(input));
- }
-
- inline double quat_length_reciprocal(const Quat_64& input)
- {
- // TODO: Use recip instruction
- return 1.0 / quat_length(input);
- }
-
- inline Quat_64 quat_normalize(const Quat_64& input)
- {
- // TODO: Use high precision recip sqrt function and vector_mul
- double length = quat_length(input);
- //float length_recip = quat_length_reciprocal(input);
- Vector4_64 input_vector = quat_to_vector(input);
- //return vector_to_quat(vector_mul(input_vector, length_recip));
- return vector_to_quat(vector_div(input_vector, vector_set(length)));
- }
-
- inline Quat_64 quat_lerp(const Quat_64& start, const Quat_64& end, double alpha)
- {
- // To ensure we take the shortest path, we apply a bias if the dot product is negative
- Vector4_64 start_vector = quat_to_vector(start);
- Vector4_64 end_vector = quat_to_vector(end);
- double dot = vector_dot(start_vector, end_vector);
- double bias = dot >= 0.0 ? 1.0 : -1.0;
- // TODO: Test with this instead: Rotation = (B * Alpha) + (A * (Bias * (1.f - Alpha)));
- Vector4_64 value = vector_add(start_vector, vector_mul(vector_sub(vector_mul(end_vector, bias), start_vector), alpha));
- //Vector4_64 value = vector_add(vector_mul(end_vector, alpha), vector_mul(start_vector, bias * (1.0 - alpha)));
- return quat_normalize(vector_to_quat(value));
- }
-
- inline Quat_64 quat_neg(const Quat_64& input)
- {
- return vector_to_quat(vector_mul(quat_to_vector(input), -1.0));
- }
-
- inline Quat_64 quat_ensure_positive_w(const Quat_64& input)
- {
- return quat_get_w(input) >= 0.0 ? input : quat_neg(input);
- }
-
- inline Quat_64 quat_from_positive_w(const Vector4_64& input)
- {
- // Operation order is important here, due to rounding, ((1.0 - (X*X)) - Y*Y) - Z*Z is more accurate than 1.0 - dot3(xyz, xyz)
- double w_squared = ((1.0 - vector_get_x(input) * vector_get_x(input)) - vector_get_y(input) * vector_get_y(input)) - vector_get_z(input) * vector_get_z(input);
- // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
- // to ensure the resulting quaternion is always normalized with a positive W component
- double w = sqrt(abs(w_squared));
- return quat_set(vector_get_x(input), vector_get_y(input), vector_get_z(input), w);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Conversion to/from axis/angle/euler
-
- inline void quat_to_axis_angle(const Quat_64& input, Vector4_64& out_axis, double& out_angle)
- {
- constexpr double epsilon = 1.0e-8;
- constexpr double epsilon_squared = epsilon * epsilon;
-
- out_angle = acos(quat_get_w(input)) * 2.0;
-
- double scale_sq = max(1.0 - quat_get_w(input) * quat_get_w(input), 0.0);
- out_axis = scale_sq >= epsilon_squared ? vector_div(vector_set(quat_get_x(input), quat_get_y(input), quat_get_z(input)), vector_set(sqrt(scale_sq))) : vector_set(1.0, 0.0, 0.0);
- }
-
- inline Vector4_64 quat_get_axis(const Quat_64& input)
- {
- constexpr double epsilon = 1.0e-8;
- constexpr double epsilon_squared = epsilon * epsilon;
-
- double scale_sq = max(1.0 - quat_get_w(input) * quat_get_w(input), 0.0);
- return scale_sq >= epsilon_squared ? vector_div(vector_set(quat_get_x(input), quat_get_y(input), quat_get_z(input)), vector_set(sqrt(scale_sq))) : vector_set(1.0, 0.0, 0.0);
- }
-
- inline double quat_get_angle(const Quat_64& input)
- {
- return acos(quat_get_w(input)) * 2.0;
- }
-
- inline Quat_64 quat_from_axis_angle(const Vector4_64& axis, double angle)
- {
- double s;
- double c;
- sincos(0.5 * angle, s, c);
-
- return quat_set(s * vector_get_x(axis), s * vector_get_y(axis), s * vector_get_z(axis), c);
- }
-
- // Pitch is around the Y axis (right)
- // Yaw is around the Z axis (up)
- // Roll is around the X axis (forward)
- inline Quat_64 quat_from_euler(double pitch, double yaw, double roll)
- {
- double sp;
- double sy;
- double sr;
- double cp;
- double cy;
- double cr;
-
- sincos(pitch * 0.5, sp, cp);
- sincos(yaw * 0.5, sy, cy);
- sincos(roll * 0.5, sr, cr);
-
- return quat_set(cr * sp * sy - sr * cp * cy,
- -cr * sp * cy - sr * cp * sy,
- cr * cp * sy - sr * sp * cy,
- cr * cp * cy + sr * sp * sy);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- inline bool quat_is_finite(const Quat_64& input)
- {
- return is_finite(quat_get_x(input)) && is_finite(quat_get_y(input)) && is_finite(quat_get_z(input)) && is_finite(quat_get_w(input));
- }
-
- inline bool quat_is_normalized(const Quat_64& input, double threshold = 0.00001)
- {
- double length_squared = quat_length_squared(input);
- return abs(length_squared - 1.0) < threshold;
- }
-
- inline bool quat_near_equal(const Quat_64& lhs, const Quat_64& rhs, double threshold = 0.00001)
- {
- return vector_all_near_equal(quat_to_vector(lhs), quat_to_vector(rhs), threshold);
- }
-
- inline bool quat_near_identity(const Quat_64& input, double threshold_angle = 0.00284714461)
- {
- // See the Quat_32 version of quat_near_identity for details.
- const double positive_w_angle = acos(abs(quat_get_w(input))) * 2.0;
- return positive_w_angle < threshold_angle;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/quat_packing.h b/includes/acl/math/quat_packing.h
--- a/includes/acl/math/quat_packing.h
+++ b/includes/acl/math/quat_packing.h
@@ -28,69 +28,71 @@
#include "acl/core/error.h"
#include "acl/core/memory_utils.h"
#include "acl/core/track_types.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/scalar_packing.h"
#include "acl/math/vector4_packing.h"
+#include <rtm/quatf.h>
+#include <rtm/vector4f.h>
+#include <rtm/packing/quatf.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
- inline void ACL_SIMD_CALL pack_quat_128(Quat_32Arg0 rotation, uint8_t* out_rotation_data)
+ inline void RTM_SIMD_CALL pack_quat_128(rtm::quatf_arg0 rotation, uint8_t* out_rotation_data)
{
- pack_vector4_128(quat_to_vector(rotation), out_rotation_data);
+ pack_vector4_128(rtm::quat_to_vector(rotation), out_rotation_data);
}
- inline Quat_32 ACL_SIMD_CALL unpack_quat_128(const uint8_t* data_ptr)
+ inline rtm::quatf RTM_SIMD_CALL unpack_quat_128(const uint8_t* data_ptr)
{
- return vector_to_quat(unpack_vector4_128(data_ptr));
+ return rtm::vector_to_quat(unpack_vector4_128(data_ptr));
}
- inline void ACL_SIMD_CALL pack_quat_96(Quat_32Arg0 rotation, uint8_t* out_rotation_data)
+ inline void RTM_SIMD_CALL pack_quat_96(rtm::quatf_arg0 rotation, uint8_t* out_rotation_data)
{
- Vector4_32 rotation_xyz = quat_to_vector(quat_ensure_positive_w(rotation));
+ rtm::vector4f rotation_xyz = rtm::quat_to_vector(rtm::quat_ensure_positive_w(rotation));
pack_vector3_96(rotation_xyz, out_rotation_data);
}
// Assumes the 'data_ptr' is padded in order to load up to 16 bytes from it
- inline Quat_32 ACL_SIMD_CALL unpack_quat_96_unsafe(const uint8_t* data_ptr)
+ inline rtm::quatf RTM_SIMD_CALL unpack_quat_96_unsafe(const uint8_t* data_ptr)
{
- Vector4_32 rotation_xyz = unpack_vector3_96_unsafe(data_ptr);
- return quat_from_positive_w(rotation_xyz);
+ rtm::vector4f rotation_xyz = unpack_vector3_96_unsafe(data_ptr);
+ return rtm::quat_from_positive_w(rotation_xyz);
}
ACL_DEPRECATED("Use unpack_quat_96_unsafe instead, to be removed in v2.0")
- inline Quat_32 ACL_SIMD_CALL unpack_quat_96(const uint8_t* data_ptr)
+ inline rtm::quatf RTM_SIMD_CALL unpack_quat_96(const uint8_t* data_ptr)
{
- Vector4_32 rotation_xyz = vector_unaligned_load3_32(data_ptr);
- return quat_from_positive_w(rotation_xyz);
+ rtm::vector4f rotation_xyz = rtm::vector_load3(data_ptr);
+ return rtm::quat_from_positive_w(rotation_xyz);
}
- inline void ACL_SIMD_CALL pack_quat_48(Quat_32Arg0 rotation, uint8_t* out_rotation_data)
+ inline void RTM_SIMD_CALL pack_quat_48(rtm::quatf_arg0 rotation, uint8_t* out_rotation_data)
{
- Vector4_32 rotation_xyz = quat_to_vector(quat_ensure_positive_w(rotation));
+ rtm::vector4f rotation_xyz = rtm::quat_to_vector(rtm::quat_ensure_positive_w(rotation));
pack_vector3_s48_unsafe(rotation_xyz, out_rotation_data);
}
- inline Quat_32 ACL_SIMD_CALL unpack_quat_48(const uint8_t* data_ptr)
+ inline rtm::quatf RTM_SIMD_CALL unpack_quat_48(const uint8_t* data_ptr)
{
- Vector4_32 rotation_xyz = unpack_vector3_s48_unsafe(data_ptr);
- return quat_from_positive_w(rotation_xyz);
+ rtm::vector4f rotation_xyz = unpack_vector3_s48_unsafe(data_ptr);
+ return rtm::quat_from_positive_w(rotation_xyz);
}
- inline void ACL_SIMD_CALL pack_quat_32(Quat_32Arg0 rotation, uint8_t* out_rotation_data)
+ inline void RTM_SIMD_CALL pack_quat_32(rtm::quatf_arg0 rotation, uint8_t* out_rotation_data)
{
- Vector4_32 rotation_xyz = quat_to_vector(quat_ensure_positive_w(rotation));
+ rtm::vector4f rotation_xyz = rtm::quat_to_vector(rtm::quat_ensure_positive_w(rotation));
pack_vector3_32(rotation_xyz, 11, 11, 10, false, out_rotation_data);
}
- inline Quat_32 ACL_SIMD_CALL unpack_quat_32(const uint8_t* data_ptr)
+ inline rtm::quatf RTM_SIMD_CALL unpack_quat_32(const uint8_t* data_ptr)
{
- Vector4_32 rotation_xyz = unpack_vector3_32(11, 11, 10, false, data_ptr);
- return quat_from_positive_w(rotation_xyz);
+ rtm::vector4f rotation_xyz = unpack_vector3_32(11, 11, 10, false, data_ptr);
+ return rtm::quat_from_positive_w(rotation_xyz);
}
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/math/rtm_casts.h b/includes/acl/math/rtm_casts.h
deleted file mode 100644
--- a/includes/acl/math/rtm_casts.h
+++ /dev/null
@@ -1,63 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2019 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/math/vector4_32.h"
-
-#include <rtm/vector4f.h>
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Casts an ACL Vector4_32 into a RTM vector4f.
- // When SIMD intrinsics are enabled, this is a no-op.
- inline rtm::vector4f RTM_SIMD_CALL vector_acl2rtm(Vector4_32Arg0 value)
- {
-#if defined(RTM_SSE2_INTRINSICS) || defined(RTM_NEON_INTRINSICS)
- return value;
-#else
- return rtm::vector4f{value.x, value.y, value.z, value.w};
-#endif
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Casts a RTM vector4f into an ACL Vector4_32.
- // When SIMD intrinsics are enabled, this is a no-op.
- inline Vector4_32 RTM_SIMD_CALL vector_rtm2acl(rtm::vector4f_arg0 value)
- {
-#if defined(RTM_SSE2_INTRINSICS) || defined(RTM_NEON_INTRINSICS)
- return value;
-#else
- return Vector4_32{value.x, value.y, value.z, value.w};
-#endif
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/scalar_32.h b/includes/acl/math/scalar_32.h
deleted file mode 100644
--- a/includes/acl/math/scalar_32.h
+++ /dev/null
@@ -1,215 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/math/math.h"
-
-#include <algorithm>
-#include <cmath>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- // TODO: Get a higher precision number
- constexpr float k_pi_32 = 3.141592654F;
-
- inline float floor(float input)
- {
-#if defined(ACL_SSE4_INTRINSICS)
- const __m128 value = _mm_set_ps1(input);
- return _mm_cvtss_f32(_mm_round_ss(value, value, 0x9));
-#else
- return std::floor(input);
-#endif
- }
-
- inline float ceil(float input)
- {
-#if defined(ACL_SSE4_INTRINSICS)
- const __m128 value = _mm_set_ps1(input);
- return _mm_cvtss_f32(_mm_round_ss(value, value, 0xA));
-#else
- return std::ceil(input);
-#endif
- }
-
- inline float clamp(float input, float min, float max)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_min_ss(_mm_max_ss(_mm_set_ps1(input), _mm_set_ps1(min)), _mm_set_ps1(max)));
-#else
- return std::min(std::max(input, min), max);
-#endif
- }
-
- inline float abs(float input)
- {
- return std::fabs(input);
- }
-
- inline float sqrt(float input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_sqrt_ss(_mm_set_ps1(input)));
-#else
- return std::sqrt(input);
-#endif
- }
-
-#if defined(_MSC_VER) && _MSC_VER >= 1920 && defined(_M_X64) && defined(ACL_SSE2_INTRINSICS) && !defined(ACL_AVX_INTRINSICS)
- // HACK!!! Visual Studio 2019 has a code generation bug triggered by the code below, disable optimizations for now
- // Bug only happens with x64 SSE2, not with AVX nor with x86
- #pragma optimize("", off)
-#endif
- inline float sqrt_reciprocal(float input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- __m128 input_v = _mm_set_ss(input);
- __m128 half = _mm_set_ss(0.5F);
- __m128 input_half_v = _mm_mul_ss(input_v, half);
- __m128 x0 = _mm_rsqrt_ss(input_v);
-
- // First iteration
- __m128 x1 = _mm_mul_ss(x0, x0);
- x1 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x1));
- x1 = _mm_add_ss(_mm_mul_ss(x0, x1), x0);
-
- // Second iteration
- __m128 x2 = _mm_mul_ss(x1, x1);
- x2 = _mm_sub_ss(half, _mm_mul_ss(input_half_v, x2));
- x2 = _mm_add_ss(_mm_mul_ss(x1, x2), x1);
-
- return _mm_cvtss_f32(x2);
-#else
- return 1.0F / sqrt(input);
-#endif
- }
-#if defined(_MSC_VER) && _MSC_VER >= 1920 && defined(_M_X64) && defined(ACL_SSE2_INTRINSICS) && !defined(ACL_AVX_INTRINSICS)
- // HACK!!! See comment above
- #pragma optimize("", on)
-#endif
-
- inline float reciprocal(float input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- __m128 input_v = _mm_set_ps1(input);
- __m128 x0 = _mm_rcp_ss(input_v);
-
- // First iteration
- __m128 x1 = _mm_sub_ss(_mm_add_ss(x0, x0), _mm_mul_ss(input_v, _mm_mul_ss(x0, x0)));
-
- // Second iteration
- __m128 x2 = _mm_sub_ss(_mm_add_ss(x1, x1), _mm_mul_ss(input_v, _mm_mul_ss(x1, x1)));
-
- return _mm_cvtss_f32(x2);
-#else
- return 1.0F / input;
-#endif
- }
-
- inline float sin(float angle)
- {
- return std::sin(angle);
- }
-
- inline float cos(float angle)
- {
- return std::cos(angle);
- }
-
- inline void sincos(float angle, float& out_sin, float& out_cos)
- {
- out_sin = sin(angle);
- out_cos = cos(angle);
- }
-
- inline float acos(float value)
- {
- return std::acos(value);
- }
-
- inline float atan2(float left, float right)
- {
- return std::atan2(left, right);
- }
-
- inline float min(float left, float right)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_min_ss(_mm_set_ps1(left), _mm_set_ps1(right)));
-#else
- return std::min(left, right);
-#endif
- }
-
- inline float max(float left, float right)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_max_ss(_mm_set_ps1(left), _mm_set_ps1(right)));
-#else
- return std::max(left, right);
-#endif
- }
-
- constexpr float deg2rad(float deg)
- {
- return (deg / 180.0F) * k_pi_32;
- }
-
- inline bool scalar_near_equal(float lhs, float rhs, float threshold)
- {
- return abs(lhs - rhs) < threshold;
- }
-
- inline bool is_finite(float input)
- {
- return std::isfinite(input);
- }
-
- inline float symmetric_round(float input)
- {
- return input >= 0.0F ? floor(input + 0.5F) : ceil(input - 0.5F);
- }
-
- inline float fraction(float value)
- {
- return value - floor(value);
- }
-
- template<typename SrcIntegralType>
- inline float safe_to_float(SrcIntegralType input)
- {
- float input_f = float(input);
- ACL_ASSERT(SrcIntegralType(input_f) == input, "Convertion to float would result in truncation");
- return input_f;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/scalar_64.h b/includes/acl/math/scalar_64.h
deleted file mode 100644
--- a/includes/acl/math/scalar_64.h
+++ /dev/null
@@ -1,147 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/math/math.h"
-
-#include <algorithm>
-#include <cmath>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- // TODO: Get a higher precision number
- constexpr double k_pi_64 = 3.141592654;
-
- inline double floor(double input)
- {
- return std::floor(input);
- }
-
- inline double ceil(double input)
- {
- return std::ceil(input);
- }
-
- inline double clamp(double input, double min, double max)
- {
- return std::min(std::max(input, min), max);
- }
-
- inline double abs(double input)
- {
- return std::fabs(input);
- }
-
- inline double sqrt(double input)
- {
- return std::sqrt(input);
- }
-
- inline double sqrt_reciprocal(double input)
- {
- // TODO: Use recip instruction
- return 1.0 / sqrt(input);
- }
-
- inline double reciprocal(double input)
- {
- return 1.0 / input;
- }
-
- inline double sin(double angle)
- {
- return std::sin(angle);
- }
-
- inline double cos(double angle)
- {
- return std::cos(angle);
- }
-
- inline void sincos(double angle, double& out_sin, double& out_cos)
- {
- out_sin = sin(angle);
- out_cos = cos(angle);
- }
-
- inline double acos(double value)
- {
- return std::acos(value);
- }
-
- inline double atan2(double left, double right)
- {
- return std::atan2(left, right);
- }
-
- inline double min(double left, double right)
- {
- return std::min(left, right);
- }
-
- inline double max(double left, double right)
- {
- return std::max(left, right);
- }
-
- constexpr double deg2rad(double deg)
- {
- return (deg / 180.0) * k_pi_64;
- }
-
- inline bool scalar_near_equal(double lhs, double rhs, double threshold)
- {
- return abs(lhs - rhs) < threshold;
- }
-
- inline bool is_finite(double input)
- {
- return std::isfinite(input);
- }
-
- inline double symmetric_round(double input)
- {
- return input >= 0.0 ? floor(input + 0.5) : ceil(input - 0.5);
- }
-
- inline double fraction(double value)
- {
- return value - floor(value);
- }
-
- template<typename SrcIntegralType>
- inline double safe_to_double(SrcIntegralType input)
- {
- double input_f = double(input);
- ACL_ASSERT(SrcIntegralType(input_f) == input, "Convertion to double would result in truncation");
- return input_f;
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/scalar_packing.h b/includes/acl/math/scalar_packing.h
--- a/includes/acl/math/scalar_packing.h
+++ b/includes/acl/math/scalar_packing.h
@@ -26,7 +26,8 @@
#include "acl/core/compiler_utils.h"
#include "acl/core/error.h"
-#include "acl/math/scalar_32.h"
+
+#include <rtm/scalarf.h>
#include <cstdint>
@@ -39,7 +40,7 @@ namespace acl
ACL_ASSERT(num_bits < 31, "Attempting to pack on too many bits");
ACL_ASSERT(input >= 0.0F && input <= 1.0F, "Expected normalized unsigned input value: %f", input);
const uint32_t max_value = (1 << num_bits) - 1;
- return static_cast<uint32_t>(symmetric_round(input * safe_to_float(max_value)));
+ return static_cast<uint32_t>(rtm::scalar_symmetric_round(input * rtm::scalar_safe_to_float(max_value)));
}
inline float unpack_scalar_unsigned(uint32_t input, uint8_t num_bits)
@@ -48,8 +49,8 @@ namespace acl
const uint32_t max_value = (1 << num_bits) - 1;
ACL_ASSERT(input <= max_value, "Input value too large: %ull", input);
// For performance reasons, unpacking is faster when multiplying with the reciprocal
- const float inv_max_value = 1.0F / safe_to_float(max_value);
- return safe_to_float(input) * inv_max_value;
+ const float inv_max_value = 1.0F / rtm::scalar_safe_to_float(max_value);
+ return rtm::scalar_safe_to_float(input) * inv_max_value;
}
inline uint32_t pack_scalar_signed(float input, uint8_t num_bits)
diff --git a/includes/acl/math/transform_32.h b/includes/acl/math/transform_32.h
deleted file mode 100644
--- a/includes/acl/math/transform_32.h
+++ /dev/null
@@ -1,124 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/quat_32.h"
-#include "acl/math/vector4_32.h"
-#include "acl/math/affine_matrix_32.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- constexpr Transform_32 ACL_SIMD_CALL transform_set(Quat_32Arg0 rotation, Vector4_32Arg1 translation, Vector4_32Arg2 scale)
- {
- return Transform_32{ rotation, translation, scale };
- }
-
- inline Transform_32 ACL_SIMD_CALL transform_identity_32()
- {
- return transform_set(quat_identity_32(), vector_zero_32(), vector_set(1.0F));
- }
-
- inline Transform_32 ACL_SIMD_CALL transform_cast(const Transform_64& input)
- {
- return Transform_32{ quat_cast(input.rotation), vector_cast(input.translation), vector_cast(input.scale) };
- }
-
- // Multiplication order is as follow: local_to_world = transform_mul(local_to_object, object_to_world)
- // NOTE: When scale is present, multiplication will not properly handle skew/shear, use affine matrices instead
- inline Transform_32 ACL_SIMD_CALL transform_mul(Transform_32Arg0 lhs, Transform_32Arg1 rhs)
- {
- const Vector4_32 min_scale = vector_min(lhs.scale, rhs.scale);
- const Vector4_32 scale = vector_mul(lhs.scale, rhs.scale);
-
- if (vector_any_less_than3(min_scale, vector_zero_32()))
- {
- // If we have negative scale, we go through a matrix
- const AffineMatrix_32 lhs_mtx = matrix_from_transform(lhs);
- const AffineMatrix_32 rhs_mtx = matrix_from_transform(rhs);
- AffineMatrix_32 result_mtx = matrix_mul(lhs_mtx, rhs_mtx);
- result_mtx = matrix_remove_scale(result_mtx);
-
- const Vector4_32 sign = vector_sign(scale);
- result_mtx.x_axis = vector_mul(result_mtx.x_axis, vector_mix_xxxx(sign));
- result_mtx.y_axis = vector_mul(result_mtx.y_axis, vector_mix_yyyy(sign));
- result_mtx.z_axis = vector_mul(result_mtx.z_axis, vector_mix_zzzz(sign));
-
- const Quat_32 rotation = quat_from_matrix(result_mtx);
- const Vector4_32 translation = result_mtx.w_axis;
- return transform_set(rotation, translation, scale);
- }
- else
- {
- const Quat_32 rotation = quat_mul(lhs.rotation, rhs.rotation);
- const Vector4_32 translation = vector_add(quat_rotate(rhs.rotation, vector_mul(lhs.translation, rhs.scale)), rhs.translation);
- return transform_set(rotation, translation, scale);
- }
- }
-
- // Multiplication order is as follow: local_to_world = transform_mul(local_to_object, object_to_world)
- inline Transform_32 ACL_SIMD_CALL transform_mul_no_scale(Transform_32Arg0 lhs, Transform_32Arg1 rhs)
- {
- const Quat_32 rotation = quat_mul(lhs.rotation, rhs.rotation);
- const Vector4_32 translation = vector_add(quat_rotate(rhs.rotation, lhs.translation), rhs.translation);
- return transform_set(rotation, translation, vector_set(1.0F));
- }
-
- inline Vector4_32 ACL_SIMD_CALL transform_position(Transform_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
- return vector_add(quat_rotate(lhs.rotation, vector_mul(lhs.scale, rhs)), lhs.translation);
- }
-
- inline Vector4_32 ACL_SIMD_CALL transform_position_no_scale(Transform_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
- return vector_add(quat_rotate(lhs.rotation, rhs), lhs.translation);
- }
-
- inline Transform_32 ACL_SIMD_CALL transform_inverse(Transform_32Arg0 input)
- {
- const Quat_32 inv_rotation = quat_conjugate(input.rotation);
- const Vector4_32 inv_scale = vector_reciprocal(input.scale);
- const Vector4_32 inv_translation = vector_neg(quat_rotate(inv_rotation, vector_mul(input.translation, inv_scale)));
- return transform_set(inv_rotation, inv_translation, inv_scale);
- }
-
- inline Transform_32 ACL_SIMD_CALL transform_inverse_no_scale(Transform_32Arg0 input)
- {
- const Quat_32 inv_rotation = quat_conjugate(input.rotation);
- const Vector4_32 inv_translation = vector_neg(quat_rotate(inv_rotation, input.translation));
- return transform_set(inv_rotation, inv_translation, vector_set(1.0F));
- }
-
- inline Transform_32 ACL_SIMD_CALL transform_normalize(Transform_32Arg0 input)
- {
- const Quat_32 rotation = quat_normalize(input.rotation);
- return transform_set(rotation, input.translation, input.scale);
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/transform_64.h b/includes/acl/math/transform_64.h
deleted file mode 100644
--- a/includes/acl/math/transform_64.h
+++ /dev/null
@@ -1,124 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/quat_64.h"
-#include "acl/math/vector4_64.h"
-#include "acl/math/affine_matrix_64.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- constexpr Transform_64 transform_set(const Quat_64& rotation, const Vector4_64& translation, const Vector4_64& scale)
- {
- return Transform_64{ rotation, translation, scale };
- }
-
- inline Transform_64 transform_identity_64()
- {
- return transform_set(quat_identity_64(), vector_zero_64(), vector_set(1.0));
- }
-
- inline Transform_64 transform_cast(const Transform_32& input)
- {
- return Transform_64{ quat_cast(input.rotation), vector_cast(input.translation), vector_cast(input.scale) };
- }
-
- // Multiplication order is as follow: local_to_world = transform_mul(local_to_object, object_to_world)
- // NOTE: When scale is present, multiplication will not properly handle skew/shear, use affine matrices instead
- inline Transform_64 transform_mul(const Transform_64& lhs, const Transform_64& rhs)
- {
- const Vector4_64 min_scale = vector_min(lhs.scale, rhs.scale);
- const Vector4_64 scale = vector_mul(lhs.scale, rhs.scale);
-
- if (vector_any_less_than3(min_scale, vector_zero_64()))
- {
- // If we have negative scale, we go through a matrix
- const AffineMatrix_64 lhs_mtx = matrix_from_transform(lhs);
- const AffineMatrix_64 rhs_mtx = matrix_from_transform(rhs);
- AffineMatrix_64 result_mtx = matrix_mul(lhs_mtx, rhs_mtx);
- result_mtx = matrix_remove_scale(result_mtx);
-
- const Vector4_64 sign = vector_sign(scale);
- result_mtx.x_axis = vector_mul(result_mtx.x_axis, vector_mix_xxxx(sign));
- result_mtx.y_axis = vector_mul(result_mtx.y_axis, vector_mix_yyyy(sign));
- result_mtx.z_axis = vector_mul(result_mtx.z_axis, vector_mix_zzzz(sign));
-
- const Quat_64 rotation = quat_from_matrix(result_mtx);
- const Vector4_64 translation = result_mtx.w_axis;
- return transform_set(rotation, translation, scale);
- }
- else
- {
- const Quat_64 rotation = quat_mul(lhs.rotation, rhs.rotation);
- const Vector4_64 translation = vector_add(quat_rotate(rhs.rotation, vector_mul(lhs.translation, rhs.scale)), rhs.translation);
- return transform_set(rotation, translation, scale);
- }
- }
-
- // Multiplication order is as follow: local_to_world = transform_mul(local_to_object, object_to_world)
- inline Transform_64 transform_mul_no_scale(const Transform_64& lhs, const Transform_64& rhs)
- {
- const Quat_64 rotation = quat_mul(lhs.rotation, rhs.rotation);
- const Vector4_64 translation = vector_add(quat_rotate(rhs.rotation, lhs.translation), rhs.translation);
- return transform_set(rotation, translation, vector_set(1.0));
- }
-
- inline Vector4_64 transform_position(const Transform_64& lhs, const Vector4_64& rhs)
- {
- return vector_add(quat_rotate(lhs.rotation, vector_mul(lhs.scale, rhs)), lhs.translation);
- }
-
- inline Vector4_64 transform_position_no_scale(const Transform_64& lhs, const Vector4_64& rhs)
- {
- return vector_add(quat_rotate(lhs.rotation, rhs), lhs.translation);
- }
-
- inline Transform_64 transform_inverse(const Transform_64& input)
- {
- const Quat_64 inv_rotation = quat_conjugate(input.rotation);
- const Vector4_64 inv_scale = vector_reciprocal(input.scale);
- const Vector4_64 inv_translation = vector_neg(quat_rotate(inv_rotation, vector_mul(input.translation, inv_scale)));
- return transform_set(inv_rotation, inv_translation, inv_scale);
- }
-
- inline Transform_64 transform_inverse_no_scale(const Transform_64& input)
- {
- const Quat_64 inv_rotation = quat_conjugate(input.rotation);
- const Vector4_64 inv_translation = vector_neg(quat_rotate(inv_rotation, input.translation));
- return transform_set(inv_rotation, inv_translation, vector_set(1.0));
- }
-
- inline Transform_64 transform_normalize(const Transform_64& input)
- {
- const Quat_64 rotation = quat_normalize(input.rotation);
- return transform_set(rotation, input.translation, input.scale);
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_32.h b/includes/acl/math/vector4_32.h
deleted file mode 100644
--- a/includes/acl/math/vector4_32.h
+++ /dev/null
@@ -1,968 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/core/memory_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/scalar_32.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- inline Vector4_32 ACL_SIMD_CALL vector_set(float x, float y, float z, float w)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_set_ps(w, z, y, x);
-#elif defined(ACL_NEON_INTRINSICS)
-#if 1
- float32x2_t V0 = vcreate_f32(((uint64_t)*(const uint32_t*)&x) | ((uint64_t)(*(const uint32_t*)&y) << 32));
- float32x2_t V1 = vcreate_f32(((uint64_t)*(const uint32_t*)&z) | ((uint64_t)(*(const uint32_t*)&w) << 32));
- return vcombine_f32(V0, V1);
-#else
- float __attribute__((aligned(16))) data[4] = { x, y, z, w };
- return vld1q_f32(data);
-#endif
-#else
- return Vector4_32{ x, y, z, w };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_set(float x, float y, float z)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_set_ps(0.0F, z, y, x);
-#elif defined(ACL_NEON_INTRINSICS)
-#if 1
- float32x2_t V0 = vcreate_f32(((uint64_t)*(const uint32_t*)&x) | ((uint64_t)(*(const uint32_t*)&y) << 32));
- float32x2_t V1 = vcreate_f32((uint64_t)*(const uint32_t*)&z);
- return vcombine_f32(V0, V1);
-#else
- float __attribute__((aligned(16))) data[4] = { x, y, z };
- return vld1q_f32(data);
-#endif
-#else
- return Vector4_32{ x, y, z, 0.0f };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_set(float xyzw)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_set_ps1(xyzw);
-#elif defined(ACL_NEON_INTRINSICS)
- return vdupq_n_f32(xyzw);
-#else
- return Vector4_32{ xyzw, xyzw, xyzw, xyzw };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_unaligned_load(const float* input)
- {
- return vector_set(input[0], input[1], input[2], input[3]);
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_unaligned_load3(const float* input)
- {
- return vector_set(input[0], input[1], input[2], 0.0F);
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_unaligned_load_32(const uint8_t* input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_loadu_ps((const float*)input);
-#elif defined(ACL_NEON_INTRINSICS)
- return vreinterpretq_f32_u8(vld1q_u8(input));
-#else
- Vector4_32 result;
- std::memcpy(&result, input, sizeof(Vector4_32));
- return result;
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_unaligned_load3_32(const uint8_t* input)
- {
- float input_f[3];
- std::memcpy(&input_f[0], input, sizeof(float) * 3);
- return vector_set(input_f[0], input_f[1], input_f[2], 0.0F);
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_zero_32()
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_setzero_ps();
-#else
- return vector_set(0.0F);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL quat_to_vector(Quat_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS) || defined(ACL_NEON_INTRINSICS)
- return input;
-#else
- return Vector4_32{ input.x, input.y, input.z, input.w };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_cast(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_shuffle_ps(_mm_cvtpd_ps(input.xy), _mm_cvtpd_ps(input.zw), _MM_SHUFFLE(1, 0, 1, 0));
-#else
- return vector_set(float(input.x), float(input.y), float(input.z), float(input.w));
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_get_x(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(input);
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 0);
-#else
- return input.x;
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_get_y(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(1, 1, 1, 1)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 1);
-#else
- return input.y;
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_get_z(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(2, 2, 2, 2)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 2);
-#else
- return input.z;
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_get_w(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtss_f32(_mm_shuffle_ps(input, input, _MM_SHUFFLE(3, 3, 3, 3)));
-#elif defined(ACL_NEON_INTRINSICS)
- return vgetq_lane_f32(input, 3);
-#else
- return input.w;
-#endif
- }
-
- template<VectorMix component_index>
- inline float ACL_SIMD_CALL vector_get_component(Vector4_32Arg0 input)
- {
- switch (component_index)
- {
- case VectorMix::A:
- case VectorMix::X: return vector_get_x(input);
- case VectorMix::B:
- case VectorMix::Y: return vector_get_y(input);
- case VectorMix::C:
- case VectorMix::Z: return vector_get_z(input);
- case VectorMix::D:
- case VectorMix::W: return vector_get_w(input);
- default:
- ACL_ASSERT(false, "Invalid component index");
- return 0.0F;
- }
- }
-
- inline float ACL_SIMD_CALL vector_get_component(Vector4_32Arg0 input, VectorMix component_index)
- {
- switch (component_index)
- {
- case VectorMix::A:
- case VectorMix::X: return vector_get_x(input);
- case VectorMix::B:
- case VectorMix::Y: return vector_get_y(input);
- case VectorMix::C:
- case VectorMix::Z: return vector_get_z(input);
- case VectorMix::D:
- case VectorMix::W: return vector_get_w(input);
- default:
- ACL_ASSERT(false, "Invalid component index");
- return 0.0F;
- }
- }
-
- inline const float* ACL_SIMD_CALL vector_as_float_ptr(const Vector4_32& input)
- {
- return reinterpret_cast<const float*>(&input);
- }
-
- inline void ACL_SIMD_CALL vector_unaligned_write(Vector4_32Arg0 input, float* output)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- _mm_storeu_ps(output, input);
-#else
- output[0] = vector_get_x(input);
- output[1] = vector_get_y(input);
- output[2] = vector_get_z(input);
- output[3] = vector_get_w(input);
-#endif
- }
-
- inline void ACL_SIMD_CALL vector_unaligned_write3(Vector4_32Arg0 input, float* output)
- {
- output[0] = vector_get_x(input);
- output[1] = vector_get_y(input);
- output[2] = vector_get_z(input);
- }
-
- inline void ACL_SIMD_CALL vector_unaligned_write(Vector4_32Arg0 input, uint8_t* output)
- {
- std::memcpy(output, &input, sizeof(Vector4_32));
- }
-
- inline void ACL_SIMD_CALL vector_unaligned_write3(Vector4_32Arg0 input, uint8_t* output)
- {
- std::memcpy(output, &input, sizeof(float) * 3);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- inline Vector4_32 ACL_SIMD_CALL vector_add(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_add_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vaddq_f32(lhs, rhs);
-#else
- return vector_set(lhs.x + rhs.x, lhs.y + rhs.y, lhs.z + rhs.z, lhs.w + rhs.w);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_sub(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_sub_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vsubq_f32(lhs, rhs);
-#else
- return vector_set(lhs.x - rhs.x, lhs.y - rhs.y, lhs.z - rhs.z, lhs.w - rhs.w);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mul(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_mul_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmulq_f32(lhs, rhs);
-#else
- return vector_set(lhs.x * rhs.x, lhs.y * rhs.y, lhs.z * rhs.z, lhs.w * rhs.w);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mul(Vector4_32Arg0 lhs, float rhs)
- {
-#if defined(ACL_NEON_INTRINSICS)
- return vmulq_n_f32(lhs, rhs);
-#else
- return vector_mul(lhs, vector_set(rhs));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_div(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_div_ps(lhs, rhs);
-#elif defined (ACL_NEON64_INTRINSICS)
- return vdivq_f32(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- float32x4_t x0 = vrecpeq_f32(rhs);
-
- // First iteration
- float32x4_t x1 = vmulq_f32(x0, vrecpsq_f32(x0, rhs));
-
- // Second iteration
- float32x4_t x2 = vmulq_f32(x1, vrecpsq_f32(x1, rhs));
- return vmulq_f32(lhs, x2);
-#else
- return vector_set(lhs.x / rhs.x, lhs.y / rhs.y, lhs.z / rhs.z, lhs.w / rhs.w);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_max(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_max_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmaxq_f32(lhs, rhs);
-#else
- return vector_set(max(lhs.x, rhs.x), max(lhs.y, rhs.y), max(lhs.z, rhs.z), max(lhs.w, rhs.w));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_min(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_min_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vminq_f32(lhs, rhs);
-#else
- return vector_set(min(lhs.x, rhs.x), min(lhs.y, rhs.y), min(lhs.z, rhs.z), min(lhs.w, rhs.w));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_clamp(Vector4_32Arg0 input, Vector4_32Arg1 min, Vector4_32Arg2 max)
- {
- return vector_min(max, vector_max(min, input));
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_abs(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return vector_max(vector_sub(_mm_setzero_ps(), input), input);
-#elif defined(ACL_NEON_INTRINSICS)
- return vabsq_f32(input);
-#else
- return vector_set(abs(input.x), abs(input.y), abs(input.z), abs(input.w));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_neg(Vector4_32Arg0 input)
- {
-#if defined(ACL_NEON_INTRINSICS)
- return vnegq_f32(input);
-#else
- return vector_mul(input, -1.0F);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_reciprocal(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- __m128 x0 = _mm_rcp_ps(input);
-
- // First iteration
- __m128 x1 = _mm_sub_ps(_mm_add_ps(x0, x0), _mm_mul_ps(input, _mm_mul_ps(x0, x0)));
-
- // Second iteration
- __m128 x2 = _mm_sub_ps(_mm_add_ps(x1, x1), _mm_mul_ps(input, _mm_mul_ps(x1, x1)));
- return x2;
-#elif defined(ACL_NEON_INTRINSICS)
- // Perform two passes of Newton-Raphson iteration on the hardware estimate
- float32x4_t x0 = vrecpeq_f32(input);
-
- // First iteration
- float32x4_t x1 = vmulq_f32(x0, vrecpsq_f32(x0, input));
-
- // Second iteration
- float32x4_t x2 = vmulq_f32(x1, vrecpsq_f32(x1, input));
- return x2;
-#else
- return vector_div(vector_set(1.0F), input);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_ceil(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE4_INTRINSICS)
- return _mm_ceil_ps(input);
-#else
- return vector_set(ceil(vector_get_x(input)), ceil(vector_get_y(input)), ceil(vector_get_z(input)), ceil(vector_get_w(input)));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_floor(Vector4_32Arg0 input)
- {
-#if defined(ACL_SSE4_INTRINSICS)
- return _mm_floor_ps(input);
-#else
- return vector_set(floor(vector_get_x(input)), floor(vector_get_y(input)), floor(vector_get_z(input)), floor(vector_get_w(input)));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_cross3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
- return vector_set(vector_get_y(lhs) * vector_get_z(rhs) - vector_get_z(lhs) * vector_get_y(rhs),
- vector_get_z(lhs) * vector_get_x(rhs) - vector_get_x(lhs) * vector_get_z(rhs),
- vector_get_x(lhs) * vector_get_y(rhs) - vector_get_y(lhs) * vector_get_x(rhs));
- }
-
- inline float ACL_SIMD_CALL vector_dot(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE4_INTRINSICS) && 0
- // SSE4 dot product instruction isn't precise enough
- return _mm_cvtss_f32(_mm_dp_ps(lhs, rhs, 0xFF));
-#elif defined(ACL_SSE2_INTRINSICS)
- __m128 x2_y2_z2_w2 = _mm_mul_ps(lhs, rhs);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
- return _mm_cvtss_f32(x2y2z2w2_0_0_0);
-#elif defined(ACL_NEON_INTRINSICS)
- float32x4_t x2_y2_z2_w2 = vmulq_f32(lhs, rhs);
- float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
- float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
- float32x2_t x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
- float32x2_t x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
- return vget_lane_f32(x2y2z2w2, 0);
-#else
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs)) + (vector_get_w(lhs) * vector_get_w(rhs));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_vdot(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE4_INTRINSICS) && 0
- // SSE4 dot product instruction isn't precise enough
- return _mm_dp_ps(lhs, rhs, 0xFF);
-#elif defined(ACL_SSE2_INTRINSICS)
- __m128 x2_y2_z2_w2 = _mm_mul_ps(lhs, rhs);
- __m128 z2_w2_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 3, 2));
- __m128 x2z2_y2w2_0_0 = _mm_add_ps(x2_y2_z2_w2, z2_w2_0_0);
- __m128 y2w2_0_0_0 = _mm_shuffle_ps(x2z2_y2w2_0_0, x2z2_y2w2_0_0, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2z2w2_0_0_0 = _mm_add_ps(x2z2_y2w2_0_0, y2w2_0_0_0);
- return _mm_shuffle_ps(x2y2z2w2_0_0_0, x2y2z2w2_0_0_0, _MM_SHUFFLE(0, 0, 0, 0));
-#elif defined(ACL_NEON_INTRINSICS)
- float32x4_t x2_y2_z2_w2 = vmulq_f32(lhs, rhs);
- float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
- float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
- float32x2_t x2z2_y2w2 = vadd_f32(x2_y2, z2_w2);
- float32x2_t x2y2z2w2 = vpadd_f32(x2z2_y2w2, x2z2_y2w2);
- return vcombine_f32(x2y2z2w2, x2y2z2w2);
-#else
- return vector_set(vector_dot(lhs, rhs));
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_dot3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE4_INTRINSICS) && 0
- // SSE4 dot product instruction isn't precise enough
- return _mm_cvtss_f32(_mm_dp_ps(lhs, rhs, 0x7F));
-#elif defined(ACL_SSE2_INTRINSICS)
- __m128 x2_y2_z2_w2 = _mm_mul_ps(lhs, rhs);
- __m128 y2_0_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 0, 1));
- __m128 x2y2_0_0_0 = _mm_add_ss(x2_y2_z2_w2, y2_0_0_0);
- __m128 z2_0_0_0 = _mm_shuffle_ps(x2_y2_z2_w2, x2_y2_z2_w2, _MM_SHUFFLE(0, 0, 0, 2));
- __m128 x2y2z2_0_0_0 = _mm_add_ss(x2y2_0_0_0, z2_0_0_0);
- return _mm_cvtss_f32(x2y2z2_0_0_0);
-#elif defined(ACL_NEON_INTRINSICS)
- float32x4_t x2_y2_z2_w2 = vmulq_f32(lhs, rhs);
- float32x2_t x2_y2 = vget_low_f32(x2_y2_z2_w2);
- float32x2_t z2_w2 = vget_high_f32(x2_y2_z2_w2);
- float32x2_t x2y2_x2y2 = vpadd_f32(x2_y2, x2_y2);
- float32x2_t z2_z2 = vdup_lane_f32(z2_w2, 0);
- float32x2_t x2y2z2_x2y2z2 = vadd_f32(x2y2_x2y2, z2_z2);
- return vget_lane_f32(x2y2z2_x2y2z2, 0);
-#else
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs));
-#endif
- }
-
- inline float ACL_SIMD_CALL vector_length_squared(Vector4_32Arg0 input)
- {
- return vector_dot(input, input);
- }
-
- inline float ACL_SIMD_CALL vector_length_squared3(Vector4_32Arg0 input)
- {
- return vector_dot3(input, input);
- }
-
- inline float ACL_SIMD_CALL vector_length(Vector4_32Arg0 input)
- {
- return sqrt(vector_length_squared(input));
- }
-
- inline float ACL_SIMD_CALL vector_length3(Vector4_32Arg0 input)
- {
- return sqrt(vector_length_squared3(input));
- }
-
- inline float ACL_SIMD_CALL vector_length_reciprocal(Vector4_32Arg0 input)
- {
- return sqrt_reciprocal(vector_length_squared(input));
- }
-
- inline float ACL_SIMD_CALL vector_length_reciprocal3(Vector4_32Arg0 input)
- {
- return sqrt_reciprocal(vector_length_squared3(input));
- }
-
- inline float ACL_SIMD_CALL vector_distance3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
- return vector_length3(vector_sub(rhs, lhs));
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_normalize3(Vector4_32Arg0 input, float threshold = 1.0E-8F)
- {
- // Reciprocal is more accurate to normalize with
- const float len_sq = vector_length_squared3(input);
- if (len_sq >= threshold)
- return vector_mul(input, sqrt_reciprocal(len_sq));
- else
- return input;
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_fraction(Vector4_32Arg0 input)
- {
- return vector_set(fraction(vector_get_x(input)), fraction(vector_get_y(input)), fraction(vector_get_z(input)), fraction(vector_get_w(input)));
- }
-
- // output = (input * scale) + offset
- inline Vector4_32 ACL_SIMD_CALL vector_mul_add(Vector4_32Arg0 input, Vector4_32Arg1 scale, Vector4_32Arg2 offset)
- {
-#if defined(ACL_NEON64_INTRINSICS)
- return vfmaq_f32(offset, input, scale);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmlaq_f32(offset, input, scale);
-#else
- return vector_add(vector_mul(input, scale), offset);
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mul_add(Vector4_32Arg0 input, float scale, Vector4_32Arg2 offset)
- {
-#if defined(ACL_NEON64_INTRINSICS)
- return vfmaq_n_f32(offset, input, scale);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmlaq_n_f32(offset, input, scale);
-#else
- return vector_add(vector_mul(input, scale), offset);
-#endif
- }
-
- // output = offset - (input * scale)
- inline Vector4_32 ACL_SIMD_CALL vector_neg_mul_sub(Vector4_32Arg0 input, Vector4_32Arg1 scale, Vector4_32Arg2 offset)
- {
-#if defined(ACL_NEON64_INTRINSICS)
- return vfmsq_f32(offset, input, scale);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmlsq_f32(offset, input, scale);
-#else
- return vector_sub(offset, vector_mul(input, scale));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_neg_mul_sub(Vector4_32Arg0 input, float scale, Vector4_32Arg2 offset)
- {
-#if defined(ACL_NEON64_INTRINSICS)
- return vfmsq_n_f32(offset, input, scale);
-#elif defined(ACL_NEON_INTRINSICS)
- return vmlsq_n_f32(offset, input, scale);
-#else
- return vector_sub(offset, vector_mul(input, scale));
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_lerp(Vector4_32Arg0 start, Vector4_32Arg1 end, float alpha)
- {
- return vector_mul_add(vector_sub(end, start), alpha, start);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- inline Vector4_32 ACL_SIMD_CALL vector_less_than(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cmplt_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vcltq_f32(lhs, rhs);
-#else
- return Vector4_32{ math_impl::get_mask_value(lhs.x < rhs.x), math_impl::get_mask_value(lhs.y < rhs.y), math_impl::get_mask_value(lhs.z < rhs.z), math_impl::get_mask_value(lhs.w < rhs.w) };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_less_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cmple_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vcleq_f32(lhs, rhs);
-#else
- return Vector4_32{ math_impl::get_mask_value(lhs.x <= rhs.x), math_impl::get_mask_value(lhs.y <= rhs.y), math_impl::get_mask_value(lhs.z <= rhs.z), math_impl::get_mask_value(lhs.w <= rhs.w) };
-#endif
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_greater_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cmpge_ps(lhs, rhs);
-#elif defined(ACL_NEON_INTRINSICS)
- return vcgeq_f32(lhs, rhs);
-#else
- return Vector4_32{ math_impl::get_mask_value(lhs.x >= rhs.x), math_impl::get_mask_value(lhs.y >= rhs.y), math_impl::get_mask_value(lhs.z >= rhs.z), math_impl::get_mask_value(lhs.w >= rhs.w) };
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_less_than(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmplt_ps(lhs, rhs)) == 0xF;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcltq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) == 0xFFFFFFFFU;
-#else
- return lhs.x < rhs.x && lhs.y < rhs.y && lhs.z < rhs.z && lhs.w < rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_less_than3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmplt_ps(lhs, rhs)) & 0x7) == 0x7;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcltq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) == 0x00FFFFFFU;
-#else
- return lhs.x < rhs.x && lhs.y < rhs.y && lhs.z < rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_less_than(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmplt_ps(lhs, rhs)) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcltq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) != 0;
-#else
- return lhs.x < rhs.x || lhs.y < rhs.y || lhs.z < rhs.z || lhs.w < rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_less_than3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmplt_ps(lhs, rhs)) & 0x7) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcltq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) != 0;
-#else
- return lhs.x < rhs.x || lhs.y < rhs.y || lhs.z < rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_less_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmple_ps(lhs, rhs)) == 0xF;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcleq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) == 0xFFFFFFFFU;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y && lhs.z <= rhs.z && lhs.w <= rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_less_equal2(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmple_ps(lhs, rhs)) & 0x3) == 0x3;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x2_t mask = vcle_f32(vget_low_f32(lhs), vget_low_f32(rhs));
- return vget_lane_u64(mask, 0) == 0xFFFFFFFFFFFFFFFFULL;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_less_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmple_ps(lhs, rhs)) & 0x7) == 0x7;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcleq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) == 0x00FFFFFFU;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y && lhs.z <= rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_less_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmple_ps(lhs, rhs)) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcleq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) != 0;
-#else
- return lhs.x <= rhs.x || lhs.y <= rhs.y || lhs.z <= rhs.z || lhs.w <= rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_less_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmple_ps(lhs, rhs)) & 0x7) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcleq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) != 0;
-#else
- return lhs.x <= rhs.x || lhs.y <= rhs.y || lhs.z <= rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_greater_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmpge_ps(lhs, rhs)) == 0xF;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcgeq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) == 0xFFFFFFFFU;
-#else
- return lhs.x >= rhs.x && lhs.y >= rhs.y && lhs.z >= rhs.z && lhs.w >= rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_greater_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmpge_ps(lhs, rhs)) & 0x7) == 0x7;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcgeq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) == 0x00FFFFFFU;
-#else
- return lhs.x >= rhs.x && lhs.y >= rhs.y && lhs.z >= rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_greater_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_movemask_ps(_mm_cmpge_ps(lhs, rhs)) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcgeq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) != 0;
-#else
- return lhs.x >= rhs.x || lhs.y >= rhs.y || lhs.z >= rhs.z || lhs.w >= rhs.w;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_any_greater_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return (_mm_movemask_ps(_mm_cmpge_ps(lhs, rhs)) & 0x7) != 0;
-#elif defined(ACL_NEON_INTRINSICS)
- uint32x4_t mask = vcgeq_f32(lhs, rhs);
- uint8x8x2_t mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15 = vzip_u8(vget_low_u8(mask), vget_high_u8(mask));
- uint16x4x2_t mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15 = vzip_u16(mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[0], mask_0_8_1_9_2_10_3_11_4_12_5_13_6_14_7_15.val[1]);
- return (vget_lane_u32(mask_0_8_4_12_1_9_5_13_2_10_6_14_3_11_7_15.val[0], 0) & 0x00FFFFFFU) != 0;
-#else
- return lhs.x >= rhs.x || lhs.y >= rhs.y || lhs.z >= rhs.z;
-#endif
- }
-
- inline bool ACL_SIMD_CALL vector_all_near_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_all_less_equal(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool ACL_SIMD_CALL vector_all_near_equal2(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_all_less_equal2(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool ACL_SIMD_CALL vector_all_near_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_all_less_equal3(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool ACL_SIMD_CALL vector_any_near_equal(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_any_less_equal(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool ACL_SIMD_CALL vector_any_near_equal3(Vector4_32Arg0 lhs, Vector4_32Arg1 rhs, float threshold = 0.00001F)
- {
- return vector_any_less_equal3(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool ACL_SIMD_CALL vector_is_finite(Vector4_32Arg0 input)
- {
- return is_finite(vector_get_x(input)) && is_finite(vector_get_y(input)) && is_finite(vector_get_z(input)) && is_finite(vector_get_w(input));
- }
-
- inline bool ACL_SIMD_CALL vector_is_finite3(Vector4_32Arg0 input)
- {
- return is_finite(vector_get_x(input)) && is_finite(vector_get_y(input)) && is_finite(vector_get_z(input));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Swizzling, permutations, and mixing
-
- inline Vector4_32 ACL_SIMD_CALL vector_blend(Vector4_32Arg0 mask, Vector4_32Arg1 if_true, Vector4_32Arg2 if_false)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_or_ps(_mm_andnot_ps(mask, if_false), _mm_and_ps(if_true, mask));
-#elif defined(ACL_NEON_INTRINSICS)
- return vbslq_f32(mask, if_true, if_false);
-#else
- return Vector4_32{ math_impl::select(mask.x, if_true.x, if_false.x), math_impl::select(mask.y, if_true.y, if_false.y), math_impl::select(mask.z, if_true.z, if_false.z), math_impl::select(mask.w, if_true.w, if_false.w) };
-#endif
- }
-
- template<VectorMix comp0, VectorMix comp1, VectorMix comp2, VectorMix comp3>
- inline Vector4_32 ACL_SIMD_CALL vector_mix(Vector4_32Arg0 input0, Vector4_32Arg1 input1)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- // All four components come from input 0
- if (math_impl::is_vector_mix_arg_xyzw(comp0) && math_impl::is_vector_mix_arg_xyzw(comp1) && math_impl::is_vector_mix_arg_xyzw(comp2) && math_impl::is_vector_mix_arg_xyzw(comp3))
- return _mm_shuffle_ps(input0, input0, _MM_SHUFFLE(int(comp3) % 4, int(comp2) % 4, int(comp1) % 4, int(comp0) % 4));
-
- // All four components come from input 1
- if (math_impl::is_vector_mix_arg_abcd(comp0) && math_impl::is_vector_mix_arg_abcd(comp1) && math_impl::is_vector_mix_arg_abcd(comp2) && math_impl::is_vector_mix_arg_abcd(comp3))
- return _mm_shuffle_ps(input1, input1, _MM_SHUFFLE(int(comp3) % 4, int(comp2) % 4, int(comp1) % 4, int(comp0) % 4));
-
- // First two components come from input 0, second two come from input 1
- if (math_impl::is_vector_mix_arg_xyzw(comp0) && math_impl::is_vector_mix_arg_xyzw(comp1) && math_impl::is_vector_mix_arg_abcd(comp2) && math_impl::is_vector_mix_arg_abcd(comp3))
- return _mm_shuffle_ps(input0, input1, _MM_SHUFFLE(int(comp3) % 4, int(comp2) % 4, int(comp1) % 4, int(comp0) % 4));
-
- // First two components come from input 1, second two come from input 0
- if (math_impl::is_vector_mix_arg_abcd(comp0) && math_impl::is_vector_mix_arg_abcd(comp1) && math_impl::is_vector_mix_arg_xyzw(comp2) && math_impl::is_vector_mix_arg_xyzw(comp3))
- return _mm_shuffle_ps(input1, input0, _MM_SHUFFLE(int(comp3) % 4, int(comp2) % 4, int(comp1) % 4, int(comp0) % 4));
-
- // Low words from both inputs are interleaved
- if (static_condition<comp0 == VectorMix::X && comp1 == VectorMix::A && comp2 == VectorMix::Y && comp3 == VectorMix::B>::test())
- return _mm_unpacklo_ps(input0, input1);
-
- // Low words from both inputs are interleaved
- if (static_condition<comp0 == VectorMix::A && comp1 == VectorMix::X && comp2 == VectorMix::B && comp3 == VectorMix::Y>::test())
- return _mm_unpacklo_ps(input1, input0);
-
- // High words from both inputs are interleaved
- if (static_condition<comp0 == VectorMix::Z && comp1 == VectorMix::C && comp2 == VectorMix::W && comp3 == VectorMix::D>::test())
- return _mm_unpackhi_ps(input0, input1);
-
- // High words from both inputs are interleaved
- if (static_condition<comp0 == VectorMix::C && comp1 == VectorMix::Z && comp2 == VectorMix::D && comp3 == VectorMix::W>::test())
- return _mm_unpackhi_ps(input1, input0);
-#endif // defined(ACL_SSE2_INTRINSICS)
-
- // Slow code path, not yet optimized or not using intrinsics
- const float x = math_impl::is_vector_mix_arg_xyzw(comp0) ? vector_get_component<comp0>(input0) : vector_get_component<comp0>(input1);
- const float y = math_impl::is_vector_mix_arg_xyzw(comp1) ? vector_get_component<comp1>(input0) : vector_get_component<comp1>(input1);
- const float z = math_impl::is_vector_mix_arg_xyzw(comp2) ? vector_get_component<comp2>(input0) : vector_get_component<comp2>(input1);
- const float w = math_impl::is_vector_mix_arg_xyzw(comp3) ? vector_get_component<comp3>(input0) : vector_get_component<comp3>(input1);
- return vector_set(x, y, z, w);
- }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xxxx(Vector4_32Arg0 input) { return vector_mix<VectorMix::X, VectorMix::X, VectorMix::X, VectorMix::X>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_yyyy(Vector4_32Arg0 input) { return vector_mix<VectorMix::Y, VectorMix::Y, VectorMix::Y, VectorMix::Y>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zzzz(Vector4_32Arg0 input) { return vector_mix<VectorMix::Z, VectorMix::Z, VectorMix::Z, VectorMix::Z>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wwww(Vector4_32Arg0 input) { return vector_mix<VectorMix::W, VectorMix::W, VectorMix::W, VectorMix::W>(input, input); }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xxyy(Vector4_32Arg0 input) { return vector_mix<VectorMix::X, VectorMix::X, VectorMix::Y, VectorMix::Y>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xzyw(Vector4_32Arg0 input) { return vector_mix<VectorMix::X, VectorMix::Z, VectorMix::Y, VectorMix::W>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_yzxy(Vector4_32Arg0 input) { return vector_mix<VectorMix::Y, VectorMix::Z, VectorMix::X, VectorMix::Y>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_ywxz(Vector4_32Arg0 input) { return vector_mix<VectorMix::Y, VectorMix::W, VectorMix::X, VectorMix::Z>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zxyx(Vector4_32Arg0 input) { return vector_mix<VectorMix::Z, VectorMix::X, VectorMix::Y, VectorMix::X>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zwyz(Vector4_32Arg0 input) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::Y, VectorMix::Z>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zwzw(Vector4_32Arg0 input) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::Z, VectorMix::W>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wxwx(Vector4_32Arg0 input) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::W, VectorMix::X>(input, input); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wzwy(Vector4_32Arg0 input) { return vector_mix<VectorMix::W, VectorMix::Z, VectorMix::W, VectorMix::Y>(input, input); }
-
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xyab(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::X, VectorMix::Y, VectorMix::A, VectorMix::B>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xzac(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::X, VectorMix::Z, VectorMix::A, VectorMix::C>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xbxb(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::X, VectorMix::B, VectorMix::X, VectorMix::B>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_xbzd(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::X, VectorMix::B, VectorMix::Z, VectorMix::D>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_ywbd(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Y, VectorMix::W, VectorMix::B, VectorMix::D>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zyax(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Z, VectorMix::Y, VectorMix::A, VectorMix::X>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zycx(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Z, VectorMix::Y, VectorMix::C, VectorMix::X>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zwcd(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::C, VectorMix::D>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zbaz(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Z, VectorMix::B, VectorMix::A, VectorMix::Z>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_zdcz(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::Z, VectorMix::D, VectorMix::C, VectorMix::Z>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wxya(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::Y, VectorMix::A>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wxyc(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::Y, VectorMix::C>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wbyz(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::W, VectorMix::B, VectorMix::Y, VectorMix::Z>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_wdyz(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::W, VectorMix::D, VectorMix::Y, VectorMix::Z>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_bxwa(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::B, VectorMix::X, VectorMix::W, VectorMix::A>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_bywx(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::B, VectorMix::Y, VectorMix::W, VectorMix::X>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_dxwc(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::D, VectorMix::X, VectorMix::W, VectorMix::C>(input0, input1); }
- inline Vector4_32 ACL_SIMD_CALL vector_mix_dywx(Vector4_32Arg0 input0, Vector4_32Arg1 input1) { return vector_mix<VectorMix::D, VectorMix::Y, VectorMix::W, VectorMix::X>(input0, input1); }
-
- //////////////////////////////////////////////////////////////////////////
- // Misc
-
- inline Vector4_32 ACL_SIMD_CALL vector_sign(Vector4_32Arg0 input)
- {
- Vector4_32 mask = vector_greater_equal(input, vector_zero_32());
- return vector_blend(mask, vector_set(1.0F), vector_set(-1.0F));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns per component the rounded input using a symmetric algorithm.
- // symmetric_round(1.5) = 2.0
- // symmetric_round(1.2) = 1.0
- // symmetric_round(-1.5) = -2.0
- // symmetric_round(-1.2) = -1.0
- //////////////////////////////////////////////////////////////////////////
- inline Vector4_32 ACL_SIMD_CALL vector_symmetric_round(Vector4_32Arg0 input)
- {
- const Vector4_32 half = vector_set(0.5F);
- const Vector4_32 floored = vector_floor(vector_add(input, half));
- const Vector4_32 ceiled = vector_ceil(vector_sub(input, half));
- const Vector4_32 is_greater_equal = vector_greater_equal(input, vector_zero_32());
- return vector_blend(is_greater_equal, floored, ceiled);
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_64.h b/includes/acl/math/vector4_64.h
deleted file mode 100644
--- a/includes/acl/math/vector4_64.h
+++ /dev/null
@@ -1,767 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/compiler_utils.h"
-#include "acl/core/error.h"
-#include "acl/core/memory_utils.h"
-#include "acl/math/math.h"
-#include "acl/math/scalar_64.h"
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- inline Vector4_64 vector_set(double x, double y, double z, double w)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_set_pd(y, x), _mm_set_pd(w, z) };
-#else
- return Vector4_64{ x, y, z, w };
-#endif
- }
-
- inline Vector4_64 vector_set(double x, double y, double z)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_set_pd(y, x), _mm_set_pd(0.0, z) };
-#else
- return Vector4_64{ x, y, z, 0.0 };
-#endif
- }
-
- inline Vector4_64 vector_set(double xyzw)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xyzw_pd = _mm_set1_pd(xyzw);
- return Vector4_64{ xyzw_pd, xyzw_pd };
-#else
- return Vector4_64{ xyzw, xyzw, xyzw, xyzw };
-#endif
- }
-
- inline Vector4_64 vector_unaligned_load(const double* input)
- {
- ACL_ASSERT(is_aligned_to(input, 4), "Invalid alignment");
- return vector_set(input[0], input[1], input[2], input[3]);
- }
-
- inline Vector4_64 vector_unaligned_load3(const double* input)
- {
- ACL_ASSERT(is_aligned_to(input, 4), "Invalid alignment");
- return vector_set(input[0], input[1], input[2], 0.0);
- }
-
- inline Vector4_64 vector_unaligned_load_64(const uint8_t* input)
- {
- Vector4_64 result;
- std::memcpy(&result, input, sizeof(Vector4_64));
- return result;
- }
-
- inline Vector4_64 vector_unaligned_load3_64(const uint8_t* input)
- {
- double input_f[3];
- std::memcpy(&input_f[0], input, sizeof(double) * 3);
- return vector_set(input_f[0], input_f[1], input_f[2], 0.0);
- }
-
- inline Vector4_64 vector_zero_64()
- {
- return vector_set(0.0, 0.0, 0.0, 0.0);
- }
-
- inline Vector4_64 quat_to_vector(const Quat_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ input.xy, input.zw };
-#else
- return Vector4_64{ input.x, input.y, input.z, input.w };
-#endif
- }
-
- inline Vector4_64 vector_cast(const Vector4_32& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_cvtps_pd(input), _mm_cvtps_pd(_mm_shuffle_ps(input, input, _MM_SHUFFLE(3, 2, 3, 2))) };
-#elif defined(ACL_NEON_INTRINSICS)
- return Vector4_64{ double(vgetq_lane_f32(input, 0)), double(vgetq_lane_f32(input, 1)), double(vgetq_lane_f32(input, 2)), double(vgetq_lane_f32(input, 3)) };
-#else
- return Vector4_64{ double(input.x), double(input.y), double(input.z), double(input.w) };
-#endif
- }
-
- inline double vector_get_x(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(input.xy);
-#else
- return input.x;
-#endif
- }
-
- inline double vector_get_y(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(_mm_shuffle_pd(input.xy, input.xy, 1));
-#else
- return input.y;
-#endif
- }
-
- inline double vector_get_z(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(input.zw);
-#else
- return input.z;
-#endif
- }
-
- inline double vector_get_w(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return _mm_cvtsd_f64(_mm_shuffle_pd(input.zw, input.zw, 1));
-#else
- return input.w;
-#endif
- }
-
- template<VectorMix component_index>
- inline double vector_get_component(const Vector4_64& input)
- {
- switch (component_index)
- {
- case VectorMix::A:
- case VectorMix::X: return vector_get_x(input);
- case VectorMix::B:
- case VectorMix::Y: return vector_get_y(input);
- case VectorMix::C:
- case VectorMix::Z: return vector_get_z(input);
- case VectorMix::D:
- case VectorMix::W: return vector_get_w(input);
- default:
- ACL_ASSERT(false, "Invalid component index");
- return 0.0;
- }
- }
-
- inline double vector_get_component(const Vector4_64& input, VectorMix component_index)
- {
- switch (component_index)
- {
- case VectorMix::A:
- case VectorMix::X: return vector_get_x(input);
- case VectorMix::B:
- case VectorMix::Y: return vector_get_y(input);
- case VectorMix::C:
- case VectorMix::Z: return vector_get_z(input);
- case VectorMix::D:
- case VectorMix::W: return vector_get_w(input);
- default:
- ACL_ASSERT(false, "Invalid component index");
- return 0.0;
- }
- }
-
- inline const double* vector_as_double_ptr(const Vector4_64& input)
- {
- return reinterpret_cast<const double*>(&input);
- }
-
- inline void vector_unaligned_write(const Vector4_64& input, double* output)
- {
- ACL_ASSERT(is_aligned_to(output, 4), "Invalid alignment");
- output[0] = vector_get_x(input);
- output[1] = vector_get_y(input);
- output[2] = vector_get_z(input);
- output[3] = vector_get_w(input);
- }
-
- inline void vector_unaligned_write3(const Vector4_64& input, double* output)
- {
- ACL_ASSERT(is_aligned_to(output, 4), "Invalid alignment");
- output[0] = vector_get_x(input);
- output[1] = vector_get_y(input);
- output[2] = vector_get_z(input);
- }
-
- inline void vector_unaligned_write(const Vector4_64& input, uint8_t* output)
- {
- std::memcpy(output, &input, sizeof(Vector4_64));
- }
-
- inline void vector_unaligned_write3(const Vector4_64& input, uint8_t* output)
- {
- std::memcpy(output, &input, sizeof(double) * 3);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- inline Vector4_64 vector_add(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_add_pd(lhs.xy, rhs.xy), _mm_add_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(lhs.x + rhs.x, lhs.y + rhs.y, lhs.z + rhs.z, lhs.w + rhs.w);
-#endif
- }
-
- inline Vector4_64 vector_sub(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_sub_pd(lhs.xy, rhs.xy), _mm_sub_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(lhs.x - rhs.x, lhs.y - rhs.y, lhs.z - rhs.z, lhs.w - rhs.w);
-#endif
- }
-
- inline Vector4_64 vector_mul(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_mul_pd(lhs.xy, rhs.xy), _mm_mul_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(lhs.x * rhs.x, lhs.y * rhs.y, lhs.z * rhs.z, lhs.w * rhs.w);
-#endif
- }
-
- inline Vector4_64 vector_mul(const Vector4_64& lhs, double rhs)
- {
- return vector_mul(lhs, vector_set(rhs));
- }
-
- inline Vector4_64 vector_div(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_div_pd(lhs.xy, rhs.xy), _mm_div_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(lhs.x / rhs.x, lhs.y / rhs.y, lhs.z / rhs.z, lhs.w / rhs.w);
-#endif
- }
-
- inline Vector4_64 vector_max(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_max_pd(lhs.xy, rhs.xy), _mm_max_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(max(lhs.x, rhs.x), max(lhs.y, rhs.y), max(lhs.z, rhs.z), max(lhs.w, rhs.w));
-#endif
- }
-
- inline Vector4_64 vector_min(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- return Vector4_64{ _mm_min_pd(lhs.xy, rhs.xy), _mm_min_pd(lhs.zw, rhs.zw) };
-#else
- return vector_set(min(lhs.x, rhs.x), min(lhs.y, rhs.y), min(lhs.z, rhs.z), min(lhs.w, rhs.w));
-#endif
- }
-
- inline Vector4_64 vector_clamp(const Vector4_64& input, const Vector4_64& min, const Vector4_64& max)
- {
- return vector_min(max, vector_max(min, input));
- }
-
- inline Vector4_64 vector_abs(const Vector4_64& input)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- Vector4_64 zero{ _mm_setzero_pd(), _mm_setzero_pd() };
- return vector_max(vector_sub(zero, input), input);
-#else
- return vector_set(abs(input.x), abs(input.y), abs(input.z), abs(input.w));
-#endif
- }
-
- inline Vector4_64 vector_neg(const Vector4_64& input)
- {
- return vector_mul(input, -1.0);
- }
-
- inline Vector4_64 vector_reciprocal(const Vector4_64& input)
- {
- return vector_div(vector_set(1.0), input);
- }
-
- inline Vector4_64 vector_ceil(const Vector4_64& input)
- {
- return vector_set(ceil(vector_get_x(input)), ceil(vector_get_y(input)), ceil(vector_get_z(input)), ceil(vector_get_w(input)));
- }
-
- inline Vector4_64 vector_floor(const Vector4_64& input)
- {
- return vector_set(floor(vector_get_x(input)), floor(vector_get_y(input)), floor(vector_get_z(input)), floor(vector_get_w(input)));
- }
-
- inline Vector4_64 vector_cross3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
- return vector_set(vector_get_y(lhs) * vector_get_z(rhs) - vector_get_z(lhs) * vector_get_y(rhs),
- vector_get_z(lhs) * vector_get_x(rhs) - vector_get_x(lhs) * vector_get_z(rhs),
- vector_get_x(lhs) * vector_get_y(rhs) - vector_get_y(lhs) * vector_get_x(rhs));
- }
-
- inline double vector_dot(const Vector4_64& lhs, const Vector4_64& rhs)
- {
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs)) + (vector_get_w(lhs) * vector_get_w(rhs));
- }
-
- inline Vector4_64 vector_vdot(const Vector4_64& lhs, const Vector4_64& rhs)
- {
- return vector_set(vector_dot(lhs, rhs));
- }
-
- inline double vector_dot3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs));
- }
-
- inline double vector_length_squared(const Vector4_64& input)
- {
- return vector_dot(input, input);
- }
-
- inline double vector_length_squared3(const Vector4_64& input)
- {
- return vector_dot3(input, input);
- }
-
- inline double vector_length(const Vector4_64& input)
- {
- return sqrt(vector_length_squared(input));
- }
-
- inline double vector_length3(const Vector4_64& input)
- {
- return sqrt(vector_length_squared3(input));
- }
-
- inline double vector_length_reciprocal(const Vector4_64& input)
- {
- return 1.0 / vector_length(input);
- }
-
- inline double vector_length_reciprocal3(const Vector4_64& input)
- {
- return 1.0 / vector_length3(input);
- }
-
- inline double vector_distance3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
- return vector_length3(vector_sub(rhs, lhs));
- }
-
- inline Vector4_64 vector_normalize3(const Vector4_64& input, double threshold = 1.0e-8)
- {
- // Reciprocal is more accurate to normalize with
- const double len_sq = vector_length_squared3(input);
- if (len_sq >= threshold)
- return vector_mul(input, sqrt_reciprocal(len_sq));
- else
- return input;
- }
-
- inline Vector4_64 vector_fraction(const Vector4_64& input)
- {
- return vector_set(fraction(vector_get_x(input)), fraction(vector_get_y(input)), fraction(vector_get_z(input)), fraction(vector_get_w(input)));
- }
-
- // output = (input * scale) + offset
- inline Vector4_64 vector_mul_add(const Vector4_64& input, const Vector4_64& scale, const Vector4_64& offset)
- {
- return vector_add(vector_mul(input, scale), offset);
- }
-
- inline Vector4_64 vector_mul_add(const Vector4_64& input, double scale, const Vector4_64& offset)
- {
- return vector_add(vector_mul(input, scale), offset);
- }
-
- // output = offset - (input * scale)
- inline Vector4_64 vector_neg_mul_sub(const Vector4_64& input, const Vector4_64& scale, const Vector4_64& offset)
- {
- return vector_sub(offset, vector_mul(input, scale));
- }
-
- inline Vector4_64 vector_neg_mul_sub(const Vector4_64& input, double scale, const Vector4_64& offset)
- {
- return vector_sub(offset, vector_mul(input, scale));
- }
-
- inline Vector4_64 vector_lerp(const Vector4_64& start, const Vector4_64& end, double alpha)
- {
- return vector_mul_add(vector_sub(end, start), alpha, start);
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- inline Vector4_64 vector_less_than(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmplt_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmplt_pd(lhs.zw, rhs.zw);
- return Vector4_64{xy_lt_pd, zw_lt_pd};
-#else
- return Vector4_64{math_impl::get_mask_value(lhs.x < rhs.x), math_impl::get_mask_value(lhs.y < rhs.y), math_impl::get_mask_value(lhs.z < rhs.z), math_impl::get_mask_value(lhs.w < rhs.w)};
-#endif
- }
-
- inline Vector4_64 vector_less_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmple_pd(lhs.zw, rhs.zw);
- return Vector4_64{ xy_lt_pd, zw_lt_pd };
-#else
- return Vector4_64{ math_impl::get_mask_value(lhs.x <= rhs.x), math_impl::get_mask_value(lhs.y <= rhs.y), math_impl::get_mask_value(lhs.z <= rhs.z), math_impl::get_mask_value(lhs.w <= rhs.w) };
-#endif
- }
-
- inline Vector4_64 vector_greater_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_ge_pd = _mm_cmpge_pd(lhs.xy, rhs.xy);
- __m128d zw_ge_pd = _mm_cmpge_pd(lhs.zw, rhs.zw);
- return Vector4_64{ xy_ge_pd, zw_ge_pd };
-#else
- return Vector4_64{ math_impl::get_mask_value(lhs.x >= rhs.x), math_impl::get_mask_value(lhs.y >= rhs.y), math_impl::get_mask_value(lhs.z >= rhs.z), math_impl::get_mask_value(lhs.w >= rhs.w) };
-#endif
- }
-
- inline bool vector_all_less_than(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmplt_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmplt_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_lt_pd) & _mm_movemask_pd(zw_lt_pd)) == 3;
-#else
- return lhs.x < rhs.x && lhs.y < rhs.y && lhs.z < rhs.z && lhs.w < rhs.w;
-#endif
- }
-
- inline bool vector_all_less_than3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmplt_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmplt_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_lt_pd) == 3 && (_mm_movemask_pd(zw_lt_pd) & 1) == 1;
-#else
- return lhs.x < rhs.x && lhs.y < rhs.y && lhs.z < rhs.z;
-#endif
- }
-
- inline bool vector_any_less_than(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmplt_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmplt_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_lt_pd) | _mm_movemask_pd(zw_lt_pd)) != 0;
-#else
- return lhs.x < rhs.x || lhs.y < rhs.y || lhs.z < rhs.z || lhs.w < rhs.w;
-#endif
- }
-
- inline bool vector_any_less_than3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_lt_pd = _mm_cmplt_pd(lhs.xy, rhs.xy);
- __m128d zw_lt_pd = _mm_cmplt_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_lt_pd) != 0 || (_mm_movemask_pd(zw_lt_pd) & 0x1) != 0;
-#else
- return lhs.x < rhs.x || lhs.y < rhs.y || lhs.z < rhs.z;
-#endif
- }
-
- inline bool vector_all_less_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_le_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- __m128d zw_le_pd = _mm_cmple_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_le_pd) & _mm_movemask_pd(zw_le_pd)) == 3;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y && lhs.z <= rhs.z && lhs.w <= rhs.w;
-#endif
- }
-
- inline bool vector_all_less_equal2(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_le_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- return _mm_movemask_pd(xy_le_pd) == 3;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y;
-#endif
- }
-
- inline bool vector_all_less_equal3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_le_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- __m128d zw_le_pd = _mm_cmple_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_le_pd) == 3 && (_mm_movemask_pd(zw_le_pd) & 1) != 0;
-#else
- return lhs.x <= rhs.x && lhs.y <= rhs.y && lhs.z <= rhs.z;
-#endif
- }
-
- inline bool vector_any_less_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_le_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- __m128d zw_le_pd = _mm_cmple_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_le_pd) | _mm_movemask_pd(zw_le_pd)) != 0;
-#else
- return lhs.x <= rhs.x || lhs.y <= rhs.y || lhs.z <= rhs.z || lhs.w <= rhs.w;
-#endif
- }
-
- inline bool vector_any_less_equal3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_le_pd = _mm_cmple_pd(lhs.xy, rhs.xy);
- __m128d zw_le_pd = _mm_cmple_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_le_pd) != 0 || (_mm_movemask_pd(zw_le_pd) & 1) != 0;
-#else
- return lhs.x <= rhs.x || lhs.y <= rhs.y || lhs.z <= rhs.z;
-#endif
- }
-
- inline bool vector_all_greater_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_ge_pd = _mm_cmpge_pd(lhs.xy, rhs.xy);
- __m128d zw_ge_pd = _mm_cmpge_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_ge_pd) & _mm_movemask_pd(zw_ge_pd)) == 3;
-#else
- return lhs.x >= rhs.x && lhs.y >= rhs.y && lhs.z >= rhs.z && lhs.w >= rhs.w;
-#endif
- }
-
- inline bool vector_all_greater_equal3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_ge_pd = _mm_cmpge_pd(lhs.xy, rhs.xy);
- __m128d zw_ge_pd = _mm_cmpge_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_ge_pd) == 3 && (_mm_movemask_pd(zw_ge_pd) & 1) != 0;
-#else
- return lhs.x >= rhs.x && lhs.y >= rhs.y && lhs.z >= rhs.z;
-#endif
- }
-
- inline bool vector_any_greater_equal(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_ge_pd = _mm_cmpge_pd(lhs.xy, rhs.xy);
- __m128d zw_ge_pd = _mm_cmpge_pd(lhs.zw, rhs.zw);
- return (_mm_movemask_pd(xy_ge_pd) | _mm_movemask_pd(zw_ge_pd)) != 0;
-#else
- return lhs.x >= rhs.x || lhs.y >= rhs.y || lhs.z >= rhs.z || lhs.w >= rhs.w;
-#endif
- }
-
- inline bool vector_any_greater_equal3(const Vector4_64& lhs, const Vector4_64& rhs)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy_ge_pd = _mm_cmpge_pd(lhs.xy, rhs.xy);
- __m128d zw_ge_pd = _mm_cmpge_pd(lhs.zw, rhs.zw);
- return _mm_movemask_pd(xy_ge_pd) != 0 || (_mm_movemask_pd(zw_ge_pd) & 1) != 0;
-#else
- return lhs.x >= rhs.x || lhs.y >= rhs.y || lhs.z >= rhs.z;
-#endif
- }
-
- inline bool vector_all_near_equal(const Vector4_64& lhs, const Vector4_64& rhs, double threshold = 0.00001)
- {
- return vector_all_less_equal(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool vector_all_near_equal2(const Vector4_64& lhs, const Vector4_64& rhs, double threshold = 0.00001)
- {
- return vector_all_less_equal2(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool vector_all_near_equal3(const Vector4_64& lhs, const Vector4_64& rhs, double threshold = 0.00001)
- {
- return vector_all_less_equal3(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool vector_any_near_equal(const Vector4_64& lhs, const Vector4_64& rhs, double threshold = 0.00001)
- {
- return vector_any_less_equal(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool vector_any_near_equal3(const Vector4_64& lhs, const Vector4_64& rhs, double threshold = 0.00001)
- {
- return vector_any_less_equal3(vector_abs(vector_sub(lhs, rhs)), vector_set(threshold));
- }
-
- inline bool vector_is_finite(const Vector4_64& input)
- {
- return is_finite(vector_get_x(input)) && is_finite(vector_get_y(input)) && is_finite(vector_get_z(input)) && is_finite(vector_get_w(input));
- }
-
- inline bool vector_is_finite3(const Vector4_64& input)
- {
- return is_finite(vector_get_x(input)) && is_finite(vector_get_y(input)) && is_finite(vector_get_z(input));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Swizzling, permutations, and mixing
-
- inline Vector4_64 vector_blend(const Vector4_64& mask, const Vector4_64& if_true, const Vector4_64& if_false)
- {
-#if defined(ACL_SSE2_INTRINSICS)
- __m128d xy = _mm_or_pd(_mm_andnot_pd(mask.xy, if_false.xy), _mm_and_pd(if_true.xy, mask.xy));
- __m128d zw = _mm_or_pd(_mm_andnot_pd(mask.zw, if_false.zw), _mm_and_pd(if_true.zw, mask.zw));
- return Vector4_64{ xy, zw };
-#else
- return Vector4_64{ math_impl::select(mask.x, if_true.x, if_false.x), math_impl::select(mask.y, if_true.y, if_false.y), math_impl::select(mask.z, if_true.z, if_false.z), math_impl::select(mask.w, if_true.w, if_false.w) };
-#endif
- }
-
- template<VectorMix comp0, VectorMix comp1, VectorMix comp2, VectorMix comp3>
- inline Vector4_64 vector_mix(const Vector4_64& input0, const Vector4_64& input1)
- {
- if (math_impl::is_vector_mix_arg_xyzw(comp0) && math_impl::is_vector_mix_arg_xyzw(comp1) && math_impl::is_vector_mix_arg_xyzw(comp2) && math_impl::is_vector_mix_arg_xyzw(comp3))
- {
- // All four components come from input 0
- return vector_set(vector_get_component(input0, comp0), vector_get_component(input0, comp1), vector_get_component(input0, comp2), vector_get_component(input0, comp3));
- }
-
- if (math_impl::is_vector_mix_arg_abcd(comp0) && math_impl::is_vector_mix_arg_abcd(comp1) && math_impl::is_vector_mix_arg_abcd(comp2) && math_impl::is_vector_mix_arg_abcd(comp3))
- {
- // All four components come from input 1
- return vector_set(vector_get_component(input1, comp0), vector_get_component(input1, comp1), vector_get_component(input1, comp2), vector_get_component(input1, comp3));
- }
-
- if (static_condition<(comp0 == VectorMix::X || comp0 == VectorMix::Y) && (comp1 == VectorMix::X || comp1 == VectorMix::Y) && (comp2 == VectorMix::A || comp2 == VectorMix::B) && (comp3 == VectorMix::A && comp3 == VectorMix::B)>::test())
- {
- // First two components come from input 0, second two come from input 1
- return vector_set(vector_get_component(input0, comp0), vector_get_component(input0, comp1), vector_get_component(input1, comp2), vector_get_component(input1, comp3));
- }
-
- if (static_condition<(comp0 == VectorMix::A || comp0 == VectorMix::B) && (comp1 == VectorMix::A && comp1 == VectorMix::B) && (comp2 == VectorMix::X || comp2 == VectorMix::Y) && (comp3 == VectorMix::X || comp3 == VectorMix::Y)>::test())
- {
- // First two components come from input 1, second two come from input 0
- return vector_set(vector_get_component(input1, comp0), vector_get_component(input1, comp1), vector_get_component(input0, comp2), vector_get_component(input0, comp3));
- }
-
- if (static_condition<comp0 == VectorMix::X && comp1 == VectorMix::A && comp2 == VectorMix::Y && comp3 == VectorMix::B>::test())
- {
- // Low words from both inputs are interleaved
- return vector_set(vector_get_component(input0, comp0), vector_get_component(input1, comp1), vector_get_component(input0, comp2), vector_get_component(input1, comp3));
- }
-
- if (static_condition<comp0 == VectorMix::A && comp1 == VectorMix::X && comp2 == VectorMix::B && comp3 == VectorMix::Y>::test())
- {
- // Low words from both inputs are interleaved
- return vector_set(vector_get_component(input1, comp0), vector_get_component(input0, comp1), vector_get_component(input1, comp2), vector_get_component(input0, comp3));
- }
-
- if (static_condition<comp0 == VectorMix::Z && comp1 == VectorMix::C && comp2 == VectorMix::W && comp3 == VectorMix::D>::test())
- {
- // High words from both inputs are interleaved
- return vector_set(vector_get_component(input0, comp0), vector_get_component(input1, comp1), vector_get_component(input0, comp2), vector_get_component(input1, comp3));
- }
-
- if (static_condition<comp0 == VectorMix::C && comp1 == VectorMix::Z && comp2 == VectorMix::D && comp3 == VectorMix::W>::test())
- {
- // High words from both inputs are interleaved
- return vector_set(vector_get_component(input1, comp0), vector_get_component(input0, comp1), vector_get_component(input1, comp2), vector_get_component(input0, comp3));
- }
-
- // Slow code path, not yet optimized
- //ACL_ASSERT(false, "vector_mix permutation not handled");
- const double x = math_impl::is_vector_mix_arg_xyzw(comp0) ? vector_get_component<comp0>(input0) : vector_get_component<comp0>(input1);
- const double y = math_impl::is_vector_mix_arg_xyzw(comp1) ? vector_get_component<comp1>(input0) : vector_get_component<comp1>(input1);
- const double z = math_impl::is_vector_mix_arg_xyzw(comp2) ? vector_get_component<comp2>(input0) : vector_get_component<comp2>(input1);
- const double w = math_impl::is_vector_mix_arg_xyzw(comp3) ? vector_get_component<comp3>(input0) : vector_get_component<comp3>(input1);
- return vector_set(x, y, z, w);
- }
-
- inline Vector4_64 vector_mix_xxxx(const Vector4_64& input) { return vector_mix<VectorMix::X, VectorMix::X, VectorMix::X, VectorMix::X>(input, input); }
- inline Vector4_64 vector_mix_yyyy(const Vector4_64& input) { return vector_mix<VectorMix::Y, VectorMix::Y, VectorMix::Y, VectorMix::Y>(input, input); }
- inline Vector4_64 vector_mix_zzzz(const Vector4_64& input) { return vector_mix<VectorMix::Z, VectorMix::Z, VectorMix::Z, VectorMix::Z>(input, input); }
- inline Vector4_64 vector_mix_wwww(const Vector4_64& input) { return vector_mix<VectorMix::W, VectorMix::W, VectorMix::W, VectorMix::W>(input, input); }
-
- inline Vector4_64 vector_mix_xxyy(const Vector4_64& input) { return vector_mix<VectorMix::X, VectorMix::X, VectorMix::Y, VectorMix::Y>(input, input); }
- inline Vector4_64 vector_mix_xzyw(const Vector4_64& input) { return vector_mix<VectorMix::X, VectorMix::Z, VectorMix::Y, VectorMix::W>(input, input); }
- inline Vector4_64 vector_mix_yzxy(const Vector4_64& input) { return vector_mix<VectorMix::Y, VectorMix::Z, VectorMix::X, VectorMix::Y>(input, input); }
- inline Vector4_64 vector_mix_ywxz(const Vector4_64& input) { return vector_mix<VectorMix::Y, VectorMix::W, VectorMix::X, VectorMix::Z>(input, input); }
- inline Vector4_64 vector_mix_zxyx(const Vector4_64& input) { return vector_mix<VectorMix::Z, VectorMix::X, VectorMix::Y, VectorMix::X>(input, input); }
- inline Vector4_64 vector_mix_zwyz(const Vector4_64& input) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::Y, VectorMix::Z>(input, input); }
- inline Vector4_64 vector_mix_zwzw(const Vector4_64& input) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::Z, VectorMix::W>(input, input); }
- inline Vector4_64 vector_mix_wxwx(const Vector4_64& input) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::W, VectorMix::X>(input, input); }
- inline Vector4_64 vector_mix_wzwy(const Vector4_64& input) { return vector_mix<VectorMix::W, VectorMix::Z, VectorMix::W, VectorMix::Y>(input, input); }
-
- inline Vector4_64 vector_mix_xyab(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::X, VectorMix::Y, VectorMix::A, VectorMix::B>(input0, input1); }
- inline Vector4_64 vector_mix_xzac(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::X, VectorMix::Z, VectorMix::A, VectorMix::C>(input0, input1); }
- inline Vector4_64 vector_mix_xbxb(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::X, VectorMix::B, VectorMix::X, VectorMix::B>(input0, input1); }
- inline Vector4_64 vector_mix_xbzd(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::X, VectorMix::B, VectorMix::Z, VectorMix::D>(input0, input1); }
- inline Vector4_64 vector_mix_ywbd(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Y, VectorMix::W, VectorMix::B, VectorMix::D>(input0, input1); }
- inline Vector4_64 vector_mix_zyax(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Z, VectorMix::Y, VectorMix::A, VectorMix::X>(input0, input1); }
- inline Vector4_64 vector_mix_zycx(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Z, VectorMix::Y, VectorMix::C, VectorMix::X>(input0, input1); }
- inline Vector4_64 vector_mix_zwcd(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Z, VectorMix::W, VectorMix::C, VectorMix::D>(input0, input1); }
- inline Vector4_64 vector_mix_zbaz(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Z, VectorMix::B, VectorMix::A, VectorMix::Z>(input0, input1); }
- inline Vector4_64 vector_mix_zdcz(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::Z, VectorMix::D, VectorMix::C, VectorMix::Z>(input0, input1); }
- inline Vector4_64 vector_mix_wxya(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::Y, VectorMix::A>(input0, input1); }
- inline Vector4_64 vector_mix_wxyc(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::W, VectorMix::X, VectorMix::Y, VectorMix::C>(input0, input1); }
- inline Vector4_64 vector_mix_wbyz(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::W, VectorMix::B, VectorMix::Y, VectorMix::Z>(input0, input1); }
- inline Vector4_64 vector_mix_wdyz(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::W, VectorMix::D, VectorMix::Y, VectorMix::Z>(input0, input1); }
- inline Vector4_64 vector_mix_bxwa(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::B, VectorMix::X, VectorMix::W, VectorMix::A>(input0, input1); }
- inline Vector4_64 vector_mix_bywx(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::B, VectorMix::Y, VectorMix::W, VectorMix::X>(input0, input1); }
- inline Vector4_64 vector_mix_dxwc(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::D, VectorMix::X, VectorMix::W, VectorMix::C>(input0, input1); }
- inline Vector4_64 vector_mix_dywx(const Vector4_64& input0, const Vector4_64& input1) { return vector_mix<VectorMix::D, VectorMix::Y, VectorMix::W, VectorMix::X>(input0, input1); }
-
- //////////////////////////////////////////////////////////////////////////
- // Misc
-
- inline Vector4_64 vector_sign(const Vector4_64& input)
- {
- Vector4_64 mask = vector_greater_equal(input, vector_zero_64());
- return vector_blend(mask, vector_set(1.0), vector_set(-1.0));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Returns per component the rounded input using a symmetric algorithm.
- // symmetric_round(1.5) = 2.0
- // symmetric_round(1.2) = 1.0
- // symmetric_round(-1.5) = -2.0
- // symmetric_round(-1.2) = -1.0
- //////////////////////////////////////////////////////////////////////////
- inline Vector4_64 vector_symmetric_round(const Vector4_64& input)
- {
- const Vector4_64 half = vector_set(0.5);
- const Vector4_64 floored = vector_floor(vector_add(input, half));
- const Vector4_64 ceiled = vector_ceil(vector_sub(input, half));
- const Vector4_64 is_greater_equal = vector_greater_equal(input, vector_zero_64());
- return vector_blend(is_greater_equal, floored, ceiled);
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/math/vector4_packing.h b/includes/acl/math/vector4_packing.h
--- a/includes/acl/math/vector4_packing.h
+++ b/includes/acl/math/vector4_packing.h
@@ -28,9 +28,10 @@
#include "acl/core/error.h"
#include "acl/core/memory_utils.h"
#include "acl/core/track_types.h"
-#include "acl/math/vector4_32.h"
#include "acl/math/scalar_packing.h"
+#include <rtm/vector4f.h>
+
#include <cstdint>
ACL_IMPL_FILE_PRAGMA_PUSH
@@ -40,20 +41,20 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// vector4 packing and decay
- inline void ACL_SIMD_CALL pack_vector4_128(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector4_128(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- vector_unaligned_write(vector, out_vector_data);
+ rtm::vector_store(vector, out_vector_data);
}
- inline Vector4_32 ACL_SIMD_CALL unpack_vector4_128(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_128(const uint8_t* vector_data)
{
- return vector_unaligned_load_32(vector_data);
+ return rtm::vector_load(vector_data);
}
// Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector4_128_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_128_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -85,7 +86,7 @@ namespace acl
const uint32_t w32 = uint32_t(vector_u64);
return _mm_castsi128_ps(_mm_set_epi32(w32, z32, y32, x32));
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -154,16 +155,16 @@ namespace acl
const float z = aligned_load<float>(&z64);
const float w = aligned_load<float>(&w64);
- return vector_set(x, y, z, w);
+ return rtm::vector_set(x, y, z, w);
#endif
}
- inline void ACL_SIMD_CALL pack_vector4_64(Vector4_32Arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector4_64(rtm::vector4f_arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
{
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), 16) : pack_scalar_signed(vector_get_x(vector), 16);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), 16) : pack_scalar_signed(vector_get_y(vector), 16);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), 16) : pack_scalar_signed(vector_get_z(vector), 16);
- uint32_t vector_w = is_unsigned ? pack_scalar_unsigned(vector_get_w(vector), 16) : pack_scalar_signed(vector_get_w(vector), 16);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), 16) : pack_scalar_signed(rtm::vector_get_x(vector), 16);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), 16) : pack_scalar_signed(rtm::vector_get_y(vector), 16);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), 16) : pack_scalar_signed(rtm::vector_get_z(vector), 16);
+ uint32_t vector_w = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_w(vector), 16) : pack_scalar_signed(rtm::vector_get_w(vector), 16);
uint16_t* data = safe_ptr_cast<uint16_t>(out_vector_data);
data[0] = safe_static_cast<uint16_t>(vector_x);
@@ -172,7 +173,7 @@ namespace acl
data[3] = safe_static_cast<uint16_t>(vector_w);
}
- inline Vector4_32 ACL_SIMD_CALL unpack_vector4_64(const uint8_t* vector_data, bool is_unsigned)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_64(const uint8_t* vector_data, bool is_unsigned)
{
const uint16_t* data_ptr_u16 = safe_ptr_cast<const uint16_t>(vector_data);
uint16_t x16 = data_ptr_u16[0];
@@ -183,15 +184,15 @@ namespace acl
float y = is_unsigned ? unpack_scalar_unsigned(y16, 16) : unpack_scalar_signed(y16, 16);
float z = is_unsigned ? unpack_scalar_unsigned(z16, 16) : unpack_scalar_signed(z16, 16);
float w = is_unsigned ? unpack_scalar_unsigned(w16, 16) : unpack_scalar_signed(w16, 16);
- return vector_set(x, y, z, w);
+ return rtm::vector_set(x, y, z, w);
}
- inline void ACL_SIMD_CALL pack_vector4_32(Vector4_32Arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector4_32(rtm::vector4f_arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
{
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), 8) : pack_scalar_signed(vector_get_x(vector), 8);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), 8) : pack_scalar_signed(vector_get_y(vector), 8);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), 8) : pack_scalar_signed(vector_get_z(vector), 8);
- uint32_t vector_w = is_unsigned ? pack_scalar_unsigned(vector_get_w(vector), 8) : pack_scalar_signed(vector_get_w(vector), 8);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), 8) : pack_scalar_signed(rtm::vector_get_x(vector), 8);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), 8) : pack_scalar_signed(rtm::vector_get_y(vector), 8);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), 8) : pack_scalar_signed(rtm::vector_get_z(vector), 8);
+ uint32_t vector_w = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_w(vector), 8) : pack_scalar_signed(rtm::vector_get_w(vector), 8);
out_vector_data[0] = safe_static_cast<uint8_t>(vector_x);
out_vector_data[1] = safe_static_cast<uint8_t>(vector_y);
@@ -199,7 +200,7 @@ namespace acl
out_vector_data[3] = safe_static_cast<uint8_t>(vector_w);
}
- inline Vector4_32 ACL_SIMD_CALL unpack_vector4_32(const uint8_t* vector_data, bool is_unsigned)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_32(const uint8_t* vector_data, bool is_unsigned)
{
uint8_t x8 = vector_data[0];
uint8_t y8 = vector_data[1];
@@ -209,16 +210,16 @@ namespace acl
float y = is_unsigned ? unpack_scalar_unsigned(y8, 8) : unpack_scalar_signed(y8, 8);
float z = is_unsigned ? unpack_scalar_unsigned(z8, 8) : unpack_scalar_signed(z8, 8);
float w = is_unsigned ? unpack_scalar_unsigned(w8, 8) : unpack_scalar_signed(w8, 8);
- return vector_set(x, y, z, w);
+ return rtm::vector_set(x, y, z, w);
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector4_uXX_unsafe(Vector4_32Arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector4_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_unsigned(vector_get_x(vector), num_bits);
- uint32_t vector_y = pack_scalar_unsigned(vector_get_y(vector), num_bits);
- uint32_t vector_z = pack_scalar_unsigned(vector_get_z(vector), num_bits);
- uint32_t vector_w = pack_scalar_unsigned(vector_get_w(vector), num_bits);
+ uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
+ uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
+ uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), num_bits);
+ uint32_t vector_w = pack_scalar_unsigned(rtm::vector_get_w(vector), num_bits);
uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
@@ -233,7 +234,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector4_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector4_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -258,7 +259,7 @@ namespace acl
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
};
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
const __m128i mask = _mm_castps_si128(_mm_load_ps1((const float*)&k_packed_constants[num_bits].mask));
const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
@@ -293,7 +294,7 @@ namespace acl
int_value = _mm_and_si128(int_value, mask);
const __m128 value = _mm_cvtepi32_ps(int_value);
return _mm_mul_ps(value, inv_max_value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
uint32x4_t mask = vdupq_n_u32(k_packed_constants[num_bits].mask);
float inv_max_value = k_packed_constants[num_bits].max_value;
@@ -361,14 +362,14 @@ namespace acl
vector_u32 = byte_swap(vector_u32);
const uint32_t w32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
- return vector_mul(vector_set(float(x32), float(y32), float(z32), float(w32)), inv_max_value);
+ return rtm::vector_mul(rtm::vector_set(float(x32), float(y32), float(z32), float(w32)), inv_max_value);
#endif
}
// Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector2_64_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector2_64_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -387,7 +388,7 @@ namespace acl
// TODO: Convert to u64 first before set1_epi64 or equivalent?
return _mm_castsi128_ps(_mm_set_epi32(y32, x32, y32, x32));
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -426,28 +427,28 @@ namespace acl
const float x = aligned_load<float>(&x64);
const float y = aligned_load<float>(&y64);
- return vector_set(x, y, x, y);
+ return rtm::vector_set(x, y, x, y);
#endif
}
//////////////////////////////////////////////////////////////////////////
// vector3 packing and decay
- inline void ACL_SIMD_CALL pack_vector3_96(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_96(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- vector_unaligned_write3(vector, out_vector_data);
+ rtm::vector_store3(vector, out_vector_data);
}
// Assumes the 'vector_data' is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_96_unsafe(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_96_unsafe(const uint8_t* vector_data)
{
- return vector_unaligned_load_32(vector_data);
+ return rtm::vector_load(vector_data);
}
// Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_96_unsafe(const uint8_t* vector_data, uint32_t bit_offset)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -472,7 +473,7 @@ namespace acl
const uint32_t z32 = uint32_t(vector_u64);
return _mm_castsi128_ps(_mm_set_epi32(x32, z32, y32, x32));
-#elif defined(ACL_NEON64_INTRINSICS) && defined(__clang__) && __clang_major__ == 3 && __clang_minor__ == 8
+#elif defined(RTM_NEON64_INTRINSICS) && defined(__clang__) && __clang_major__ == 3 && __clang_minor__ == 8
// Clang 3.8 has a bug in its codegen and we have to use a slightly slower impl to avoid it
// This is a pretty old version but UE 4.23 still uses it on android
const uint32_t byte_offset = bit_offset / 8;
@@ -493,7 +494,7 @@ namespace acl
const uint32x4_t xyz32 = vcombine_u32(xy32, vreinterpret_u32_u64(z64));
return vreinterpretq_f32_u32(xyz32);
-#elif defined(ACL_NEON64_INTRINSICS)
+#elif defined(RTM_NEON64_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset + 0);
@@ -516,7 +517,7 @@ namespace acl
const uint32x2_t z = vcreate_u32(z64);
const uint32x4_t value_u32 = vcombine_u32(xy, z);
return vreinterpretq_f32_u32(value_u32);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t byte_offset = bit_offset / 8;
const uint32_t shift_offset = bit_offset % 8;
@@ -563,13 +564,13 @@ namespace acl
const float y = aligned_load<float>(&y64);
const float z = aligned_load<float>(&z64);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
#endif
}
// Assumes the 'vector_data' is in big-endian order and is padded in order to load up to 16 bytes from it
ACL_DEPRECATED("Use unpack_vector3_96_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_96(const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_96(const uint8_t* vector_data, uint32_t bit_offset)
{
uint32_t byte_offset = bit_offset / 8;
uint64_t vector_u64 = unaligned_load<uint64_t>(vector_data + byte_offset);
@@ -601,21 +602,21 @@ namespace acl
const float y = aligned_load<float>(&y64);
const float z = aligned_load<float>(&z64);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
ACL_DEPRECATED("Use unpack_vector3_96_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_96(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_96(const uint8_t* vector_data)
{
- return vector_unaligned_load3_32(vector_data);
+ return rtm::vector_load3(vector_data);
}
// Assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_u48_unsafe(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_u48_unsafe(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_unsigned(vector_get_x(vector), 16);
- uint32_t vector_y = pack_scalar_unsigned(vector_get_y(vector), 16);
- uint32_t vector_z = pack_scalar_unsigned(vector_get_z(vector), 16);
+ uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), 16);
+ uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), 16);
+ uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), 16);
uint16_t* data = safe_ptr_cast<uint16_t>(out_vector_data);
data[0] = safe_static_cast<uint16_t>(vector_x);
@@ -624,11 +625,11 @@ namespace acl
}
// Assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_s48_unsafe(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_s48_unsafe(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_signed(vector_get_x(vector), 16);
- uint32_t vector_y = pack_scalar_signed(vector_get_y(vector), 16);
- uint32_t vector_z = pack_scalar_signed(vector_get_z(vector), 16);
+ uint32_t vector_x = pack_scalar_signed(rtm::vector_get_x(vector), 16);
+ uint32_t vector_y = pack_scalar_signed(rtm::vector_get_y(vector), 16);
+ uint32_t vector_z = pack_scalar_signed(rtm::vector_get_z(vector), 16);
uint16_t* data = safe_ptr_cast<uint16_t>(out_vector_data);
data[0] = safe_static_cast<uint16_t>(vector_x);
@@ -637,11 +638,11 @@ namespace acl
}
ACL_DEPRECATED("Use pack_vector3_u48_unsafe and pack_vector3_s48_unsafe instead, to be removed in v2.0")
- inline void ACL_SIMD_CALL pack_vector3_48(Vector4_32Arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_48(rtm::vector4f_arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
{
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), 16) : pack_scalar_signed(vector_get_x(vector), 16);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), 16) : pack_scalar_signed(vector_get_y(vector), 16);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), 16) : pack_scalar_signed(vector_get_z(vector), 16);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), 16) : pack_scalar_signed(rtm::vector_get_x(vector), 16);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), 16) : pack_scalar_signed(rtm::vector_get_y(vector), 16);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), 16) : pack_scalar_signed(rtm::vector_get_z(vector), 16);
uint16_t* data = safe_ptr_cast<uint16_t>(out_vector_data);
data[0] = safe_static_cast<uint16_t>(vector_x);
@@ -650,15 +651,15 @@ namespace acl
}
// Assumes the 'vector_data' is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_u48_unsafe(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_u48_unsafe(const uint8_t* vector_data)
{
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
__m128i zero = _mm_setzero_si128();
__m128i x16y16z16 = _mm_loadu_si128((const __m128i*)vector_data);
__m128i x32y32z32 = _mm_unpacklo_epi16(x16y16z16, zero);
__m128 value = _mm_cvtepi32_ps(x32y32z32);
return _mm_mul_ps(value, _mm_set_ps1(1.0F / 65535.0F));
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
uint8x8_t x8y8z8 = vld1_u8(vector_data);
uint16x4_t x16y16z16 = vreinterpret_u16_u8(x8y8z8);
uint32x4_t x32y32z32 = vmovl_u16(x16y16z16);
@@ -673,19 +674,19 @@ namespace acl
float x = unpack_scalar_unsigned(x16, 16);
float y = unpack_scalar_unsigned(y16, 16);
float z = unpack_scalar_unsigned(z16, 16);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
#endif
}
// Assumes the 'vector_data' is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_s48_unsafe(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_s48_unsafe(const uint8_t* vector_data)
{
- const Vector4_32 unsigned_value = unpack_vector3_u48_unsafe(vector_data);
- return vector_neg_mul_sub(unsigned_value, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f unsigned_value = unpack_vector3_u48_unsafe(vector_data);
+ return rtm::vector_neg_mul_sub(unsigned_value, -2.0F, rtm::vector_set(-1.0F));
}
ACL_DEPRECATED("Use unpack_vector3_u48_unsafe and unpack_vector3_s48_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_48(const uint8_t* vector_data, bool is_unsigned)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_48(const uint8_t* vector_data, bool is_unsigned)
{
const uint16_t* data_ptr_u16 = safe_ptr_cast<const uint16_t>(vector_data);
uint16_t x16 = data_ptr_u16[0];
@@ -694,43 +695,43 @@ namespace acl
float x = is_unsigned ? unpack_scalar_unsigned(x16, 16) : unpack_scalar_signed(x16, 16);
float y = is_unsigned ? unpack_scalar_unsigned(y16, 16) : unpack_scalar_signed(y16, 16);
float z = is_unsigned ? unpack_scalar_unsigned(z16, 16) : unpack_scalar_signed(z16, 16);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_u48(Vector4_32Arg0 input)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_u48(rtm::vector4f_arg0 input)
{
- ACL_ASSERT(vector_all_greater_equal3(input, vector_zero_32()) && vector_all_less_equal3(input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(input), vector_get_y(input), vector_get_z(input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(input, rtm::vector_zero()) && rtm::vector_all_less_equal3(input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(input), rtm::vector_get_y(input), rtm::vector_get_z(input));
const float max_value = float((1 << 16) - 1);
const float inv_max_value = 1.0F / max_value;
- const Vector4_32 packed = vector_symmetric_round(vector_mul(input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
return decayed;
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_s48(Vector4_32Arg0 input)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_s48(rtm::vector4f_arg0 input)
{
- const Vector4_32 half = vector_set(0.5F);
- const Vector4_32 unsigned_input = vector_mul_add(input, half, half);
+ const rtm::vector4f half = rtm::vector_set(0.5F);
+ const rtm::vector4f unsigned_input = rtm::vector_mul_add(input, half, half);
- ACL_ASSERT(vector_all_greater_equal3(unsigned_input, vector_zero_32()) && vector_all_less_equal3(unsigned_input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(unsigned_input), vector_get_y(unsigned_input), vector_get_z(unsigned_input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(unsigned_input, rtm::vector_zero()) && rtm::vector_all_less_equal3(unsigned_input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(unsigned_input), rtm::vector_get_y(unsigned_input), rtm::vector_get_z(unsigned_input));
- const float max_value = safe_to_float((1 << 16) - 1);
+ const float max_value = rtm::scalar_safe_to_float((1 << 16) - 1);
const float inv_max_value = 1.0F / max_value;
- const Vector4_32 packed = vector_symmetric_round(vector_mul(unsigned_input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
- return vector_neg_mul_sub(decayed, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(unsigned_input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
+ return rtm::vector_neg_mul_sub(decayed, -2.0F, rtm::vector_set(-1.0F));
}
- inline void ACL_SIMD_CALL pack_vector3_32(Vector4_32Arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_32(rtm::vector4f_arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), XBits) : pack_scalar_signed(vector_get_x(vector), XBits);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), YBits) : pack_scalar_signed(vector_get_y(vector), YBits);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), ZBits) : pack_scalar_signed(vector_get_z(vector), ZBits);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), XBits) : pack_scalar_signed(rtm::vector_get_x(vector), XBits);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), YBits) : pack_scalar_signed(rtm::vector_get_y(vector), YBits);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), ZBits) : pack_scalar_signed(rtm::vector_get_z(vector), ZBits);
uint32_t vector_u32 = (vector_x << (YBits + ZBits)) | (vector_y << ZBits) | vector_z;
@@ -740,42 +741,42 @@ namespace acl
data[1] = safe_static_cast<uint16_t>(vector_u32 & 0xFFFF);
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_u32(Vector4_32Arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_u32(rtm::vector4f_arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
- ACL_ASSERT(vector_all_greater_equal3(input, vector_zero_32()) && vector_all_less_equal(input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(input), vector_get_y(input), vector_get_z(input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(input, rtm::vector_zero()) && rtm::vector_all_less_equal(input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(input), rtm::vector_get_y(input), rtm::vector_get_z(input));
const float max_value_x = float((1 << XBits) - 1);
const float max_value_y = float((1 << YBits) - 1);
const float max_value_z = float((1 << ZBits) - 1);
- const Vector4_32 max_value = vector_set(max_value_x, max_value_y, max_value_z, max_value_z);
- const Vector4_32 inv_max_value = vector_reciprocal(max_value);
+ const rtm::vector4f max_value = rtm::vector_set(max_value_x, max_value_y, max_value_z, max_value_z);
+ const rtm::vector4f inv_max_value = rtm::vector_reciprocal(max_value);
- const Vector4_32 packed = vector_symmetric_round(vector_mul(input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
return decayed;
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_s32(Vector4_32Arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_s32(rtm::vector4f_arg0 input, uint8_t XBits, uint8_t YBits, uint8_t ZBits)
{
- const Vector4_32 half = vector_set(0.5F);
- const Vector4_32 unsigned_input = vector_mul_add(input, half, half);
+ const rtm::vector4f half = rtm::vector_set(0.5F);
+ const rtm::vector4f unsigned_input = rtm::vector_mul_add(input, half, half);
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
- ACL_ASSERT(vector_all_greater_equal3(unsigned_input, vector_zero_32()) && vector_all_less_equal(unsigned_input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(unsigned_input), vector_get_y(unsigned_input), vector_get_z(unsigned_input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(unsigned_input, rtm::vector_zero()) && rtm::vector_all_less_equal(unsigned_input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(unsigned_input), rtm::vector_get_y(unsigned_input), rtm::vector_get_z(unsigned_input));
const float max_value_x = float((1 << XBits) - 1);
const float max_value_y = float((1 << YBits) - 1);
const float max_value_z = float((1 << ZBits) - 1);
- const Vector4_32 max_value = vector_set(max_value_x, max_value_y, max_value_z, max_value_z);
- const Vector4_32 inv_max_value = vector_reciprocal(max_value);
+ const rtm::vector4f max_value = rtm::vector_set(max_value_x, max_value_y, max_value_z, max_value_z);
+ const rtm::vector4f inv_max_value = rtm::vector_reciprocal(max_value);
- const Vector4_32 packed = vector_symmetric_round(vector_mul(unsigned_input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
- return vector_neg_mul_sub(decayed, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(unsigned_input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
+ return rtm::vector_neg_mul_sub(decayed, -2.0F, rtm::vector_set(-1.0F));
}
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_32(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_32(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data)
{
ACL_ASSERT(XBits + YBits + ZBits == 32, "Sum of XYZ bits does not equal 32!");
@@ -788,15 +789,15 @@ namespace acl
float x = is_unsigned ? unpack_scalar_unsigned(x32, XBits) : unpack_scalar_signed(x32, XBits);
float y = is_unsigned ? unpack_scalar_unsigned(y32, YBits) : unpack_scalar_signed(y32, YBits);
float z = is_unsigned ? unpack_scalar_unsigned(z32, ZBits) : unpack_scalar_signed(z32, ZBits);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
// Assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_u24_unsafe(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_u24_unsafe(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_unsigned(vector_get_x(vector), 8);
- uint32_t vector_y = pack_scalar_unsigned(vector_get_y(vector), 8);
- uint32_t vector_z = pack_scalar_unsigned(vector_get_z(vector), 8);
+ uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), 8);
+ uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), 8);
+ uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), 8);
out_vector_data[0] = safe_static_cast<uint8_t>(vector_x);
out_vector_data[1] = safe_static_cast<uint8_t>(vector_y);
@@ -804,11 +805,11 @@ namespace acl
}
// Assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_s24_unsafe(Vector4_32Arg0 vector, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_s24_unsafe(rtm::vector4f_arg0 vector, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_signed(vector_get_x(vector), 8);
- uint32_t vector_y = pack_scalar_signed(vector_get_y(vector), 8);
- uint32_t vector_z = pack_scalar_signed(vector_get_z(vector), 8);
+ uint32_t vector_x = pack_scalar_signed(rtm::vector_get_x(vector), 8);
+ uint32_t vector_y = pack_scalar_signed(rtm::vector_get_y(vector), 8);
+ uint32_t vector_z = pack_scalar_signed(rtm::vector_get_z(vector), 8);
out_vector_data[0] = safe_static_cast<uint8_t>(vector_x);
out_vector_data[1] = safe_static_cast<uint8_t>(vector_y);
@@ -816,11 +817,11 @@ namespace acl
}
ACL_DEPRECATED("Use pack_vector3_u24_unsafe and pack_vector3_s24_unsafe instead, to be removed in v2.0")
- inline void ACL_SIMD_CALL pack_vector3_24(Vector4_32Arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_24(rtm::vector4f_arg0 vector, bool is_unsigned, uint8_t* out_vector_data)
{
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), 8) : pack_scalar_signed(vector_get_x(vector), 8);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), 8) : pack_scalar_signed(vector_get_y(vector), 8);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), 8) : pack_scalar_signed(vector_get_z(vector), 8);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), 8) : pack_scalar_signed(rtm::vector_get_x(vector), 8);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), 8) : pack_scalar_signed(rtm::vector_get_y(vector), 8);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), 8) : pack_scalar_signed(rtm::vector_get_z(vector), 8);
out_vector_data[0] = safe_static_cast<uint8_t>(vector_x);
out_vector_data[1] = safe_static_cast<uint8_t>(vector_y);
@@ -828,9 +829,9 @@ namespace acl
}
// Assumes the 'vector_data' is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_u24_unsafe(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_u24_unsafe(const uint8_t* vector_data)
{
-#if defined(ACL_SSE2_INTRINSICS) && 0
+#if defined(RTM_SSE2_INTRINSICS) && 0
// This implementation leverages fast fixed point coercion, it relies on the
// input being positive and normalized as well as fixed point (division by 256, not 255)
// TODO: Enable this, it's a bit faster but requires compensating with the clip range to avoid losing precision
@@ -842,14 +843,14 @@ namespace acl
__m128i x32y32z32 = _mm_unpacklo_epi16(x16y16z16, zero);
__m128i segment_extent_i32 = _mm_or_si128(_mm_slli_epi32(x32y32z32, 23 - 8), exponent);
return _mm_sub_ps(_mm_castsi128_ps(segment_extent_i32), _mm_castsi128_ps(exponent));
-#elif defined(ACL_SSE2_INTRINSICS)
+#elif defined(RTM_SSE2_INTRINSICS)
__m128i zero = _mm_setzero_si128();
__m128i x8y8z8 = _mm_loadu_si128((const __m128i*)vector_data);
__m128i x16y16z16 = _mm_unpacklo_epi8(x8y8z8, zero);
__m128i x32y32z32 = _mm_unpacklo_epi16(x16y16z16, zero);
__m128 value = _mm_cvtepi32_ps(x32y32z32);
return _mm_mul_ps(value, _mm_set_ps1(1.0F / 255.0F));
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
uint8x8_t x8y8z8 = vld1_u8(vector_data);
uint16x8_t x16y16z16 = vmovl_u8(x8y8z8);
uint32x4_t x32y32z32 = vmovl_u16(vget_low_u16(x16y16z16));
@@ -863,19 +864,19 @@ namespace acl
float x = unpack_scalar_unsigned(x8, 8);
float y = unpack_scalar_unsigned(y8, 8);
float z = unpack_scalar_unsigned(z8, 8);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
#endif
}
// Assumes the 'vector_data' is padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_s24_unsafe(const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_s24_unsafe(const uint8_t* vector_data)
{
- const Vector4_32 unsigned_value = unpack_vector3_u24_unsafe(vector_data);
- return vector_neg_mul_sub(unsigned_value, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f unsigned_value = unpack_vector3_u24_unsafe(vector_data);
+ return rtm::vector_neg_mul_sub(unsigned_value, -2.0F, rtm::vector_set(-1.0F));
}
ACL_DEPRECATED("Use unpack_vector3_u24_unsafe and unpack_vector3_s24_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_24(const uint8_t* vector_data, bool is_unsigned)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_24(const uint8_t* vector_data, bool is_unsigned)
{
uint8_t x8 = vector_data[0];
uint8_t y8 = vector_data[1];
@@ -883,15 +884,15 @@ namespace acl
float x = is_unsigned ? unpack_scalar_unsigned(x8, 8) : unpack_scalar_signed(x8, 8);
float y = is_unsigned ? unpack_scalar_unsigned(y8, 8) : unpack_scalar_signed(y8, 8);
float z = is_unsigned ? unpack_scalar_unsigned(z8, 8) : unpack_scalar_signed(z8, 8);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_uXX_unsafe(Vector4_32Arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_unsigned(vector_get_x(vector), num_bits);
- uint32_t vector_y = pack_scalar_unsigned(vector_get_y(vector), num_bits);
- uint32_t vector_z = pack_scalar_unsigned(vector_get_z(vector), num_bits);
+ uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
+ uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
+ uint32_t vector_z = pack_scalar_unsigned(rtm::vector_get_z(vector), num_bits);
uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
@@ -902,11 +903,11 @@ namespace acl
}
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector3_sXX_unsafe(Vector4_32Arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_sXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_signed(vector_get_x(vector), num_bits);
- uint32_t vector_y = pack_scalar_signed(vector_get_y(vector), num_bits);
- uint32_t vector_z = pack_scalar_signed(vector_get_z(vector), num_bits);
+ uint32_t vector_x = pack_scalar_signed(rtm::vector_get_x(vector), num_bits);
+ uint32_t vector_y = pack_scalar_signed(rtm::vector_get_y(vector), num_bits);
+ uint32_t vector_z = pack_scalar_signed(rtm::vector_get_z(vector), num_bits);
uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
@@ -918,46 +919,46 @@ namespace acl
// Assumes the 'out_vector_data' is padded in order to write up to 8 bytes to it
ACL_DEPRECATED("Use pack_vector3_uXX_unsafe and pack_vector3_sXX_unsafe instead, to be removed in v2.0")
- inline void ACL_SIMD_CALL pack_vector3_n(Vector4_32Arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector3_n(rtm::vector4f_arg0 vector, uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, uint8_t* out_vector_data)
{
- uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(vector_get_x(vector), XBits) : pack_scalar_signed(vector_get_x(vector), XBits);
- uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(vector_get_y(vector), YBits) : pack_scalar_signed(vector_get_y(vector), YBits);
- uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(vector_get_z(vector), ZBits) : pack_scalar_signed(vector_get_z(vector), ZBits);
+ uint32_t vector_x = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_x(vector), XBits) : pack_scalar_signed(rtm::vector_get_x(vector), XBits);
+ uint32_t vector_y = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_y(vector), YBits) : pack_scalar_signed(rtm::vector_get_y(vector), YBits);
+ uint32_t vector_z = is_unsigned ? pack_scalar_unsigned(rtm::vector_get_z(vector), ZBits) : pack_scalar_signed(rtm::vector_get_z(vector), ZBits);
uint64_t vector_u64 = (static_cast<uint64_t>(vector_x) << (YBits + ZBits)) | (static_cast<uint64_t>(vector_y) << ZBits) | static_cast<uint64_t>(vector_z);
unaligned_write(vector_u64, out_vector_data);
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_uXX(Vector4_32Arg0 input, uint32_t num_bits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_uXX(rtm::vector4f_arg0 input, uint32_t num_bits)
{
- ACL_ASSERT(vector_all_greater_equal3(input, vector_zero_32()) && vector_all_less_equal3(input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(input), vector_get_y(input), vector_get_z(input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(input, rtm::vector_zero()) && rtm::vector_all_less_equal3(input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(input), rtm::vector_get_y(input), rtm::vector_get_z(input));
- const float max_value = safe_to_float((1 << num_bits) - 1);
+ const float max_value = rtm::scalar_safe_to_float((1 << num_bits) - 1);
const float inv_max_value = 1.0F / max_value;
- const Vector4_32 packed = vector_symmetric_round(vector_mul(input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
return decayed;
}
- inline Vector4_32 ACL_SIMD_CALL decay_vector3_sXX(Vector4_32Arg0 input, uint32_t num_bits)
+ inline rtm::vector4f RTM_SIMD_CALL decay_vector3_sXX(rtm::vector4f_arg0 input, uint32_t num_bits)
{
- const Vector4_32 half = vector_set(0.5F);
- const Vector4_32 unsigned_input = vector_mul_add(input, half, half);
+ const rtm::vector4f half = rtm::vector_set(0.5F);
+ const rtm::vector4f unsigned_input = rtm::vector_mul_add(input, half, half);
- ACL_ASSERT(vector_all_greater_equal3(unsigned_input, vector_zero_32()) && vector_all_less_equal3(unsigned_input, vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", vector_get_x(unsigned_input), vector_get_y(unsigned_input), vector_get_z(unsigned_input));
+ ACL_ASSERT(rtm::vector_all_greater_equal3(unsigned_input, rtm::vector_zero()) && rtm::vector_all_less_equal3(unsigned_input, rtm::vector_set(1.0F)), "Expected normalized unsigned input value: %f, %f, %f", rtm::vector_get_x(unsigned_input), rtm::vector_get_y(unsigned_input), rtm::vector_get_z(unsigned_input));
- const float max_value = safe_to_float((1 << num_bits) - 1);
+ const float max_value = rtm::scalar_safe_to_float((1 << num_bits) - 1);
const float inv_max_value = 1.0F / max_value;
- const Vector4_32 packed = vector_symmetric_round(vector_mul(unsigned_input, max_value));
- const Vector4_32 decayed = vector_mul(packed, inv_max_value);
- return vector_neg_mul_sub(decayed, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f packed = rtm::vector_symmetric_round(rtm::vector_mul(unsigned_input, max_value));
+ const rtm::vector4f decayed = rtm::vector_mul(packed, inv_max_value);
+ return rtm::vector_neg_mul_sub(decayed, -2.0F, rtm::vector_set(-1.0F));
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -982,7 +983,7 @@ namespace acl
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
};
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
const __m128i mask = _mm_castps_si128(_mm_load_ps1((const float*)&k_packed_constants[num_bits].mask));
const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
@@ -1010,7 +1011,7 @@ namespace acl
int_value = _mm_and_si128(int_value, mask);
const __m128 value = _mm_cvtepi32_ps(int_value);
return _mm_mul_ps(value, inv_max_value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
uint32x4_t mask = vdupq_n_u32(k_packed_constants[num_bits].mask);
float inv_max_value = k_packed_constants[num_bits].max_value;
@@ -1064,22 +1065,22 @@ namespace acl
vector_u32 = byte_swap(vector_u32);
const uint32_t z32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
- return vector_mul(vector_set(float(x32), float(y32), float(z32)), inv_max_value);
+ return rtm::vector_mul(rtm::vector_set(float(x32), float(y32), float(z32)), inv_max_value);
#endif
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_sXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_sXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits * 3 <= 64, "Attempting to read too many bits");
- const Vector4_32 unsigned_value = unpack_vector3_uXX_unsafe(num_bits, vector_data, bit_offset);
- return vector_neg_mul_sub(unsigned_value, -2.0F, vector_set(-1.0F));
+ const rtm::vector4f unsigned_value = unpack_vector3_uXX_unsafe(num_bits, vector_data, bit_offset);
+ return rtm::vector_neg_mul_sub(unsigned_value, -2.0F, rtm::vector_set(-1.0F));
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 8 bytes from it
ACL_DEPRECATED("Use unpack_vector3_uXX_unsafe and unpack_vector3_sXX_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_n(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_n(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data)
{
uint64_t vector_u64 = *safe_ptr_cast<const uint64_t>(vector_data);
uint32_t x64 = safe_static_cast<uint32_t>(vector_u64 >> (YBits + ZBits));
@@ -1088,12 +1089,12 @@ namespace acl
float x = is_unsigned ? unpack_scalar_unsigned(x64, XBits) : unpack_scalar_signed(x64, XBits);
float y = is_unsigned ? unpack_scalar_unsigned(y64, YBits) : unpack_scalar_signed(y64, YBits);
float z = is_unsigned ? unpack_scalar_unsigned(z64, ZBits) : unpack_scalar_signed(z64, ZBits);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 12 bytes from it
ACL_DEPRECATED("Use unpack_vector3_uXX_unsafe and unpack_vector3_sXX_unsafe instead, to be removed in v2.0")
- inline Vector4_32 ACL_SIMD_CALL unpack_vector3_n(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector3_n(uint8_t XBits, uint8_t YBits, uint8_t ZBits, bool is_unsigned, const uint8_t* vector_data, uint32_t bit_offset)
{
uint8_t num_bits_to_read = XBits + YBits + ZBits;
@@ -1124,17 +1125,17 @@ namespace acl
const float x = is_unsigned ? unpack_scalar_unsigned(x32, XBits) : unpack_scalar_signed(x32, XBits);
const float y = is_unsigned ? unpack_scalar_unsigned(y32, YBits) : unpack_scalar_signed(y32, YBits);
const float z = is_unsigned ? unpack_scalar_unsigned(z32, ZBits) : unpack_scalar_signed(z32, ZBits);
- return vector_set(x, y, z);
+ return rtm::vector_set(x, y, z);
}
//////////////////////////////////////////////////////////////////////////
// vector2 packing and decay
// Packs data in big-endian order and assumes the 'out_vector_data' is padded in order to write up to 16 bytes to it
- inline void ACL_SIMD_CALL pack_vector2_uXX_unsafe(Vector4_32Arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
+ inline void RTM_SIMD_CALL pack_vector2_uXX_unsafe(rtm::vector4f_arg0 vector, uint8_t num_bits, uint8_t* out_vector_data)
{
- uint32_t vector_x = pack_scalar_unsigned(vector_get_x(vector), num_bits);
- uint32_t vector_y = pack_scalar_unsigned(vector_get_y(vector), num_bits);
+ uint32_t vector_x = pack_scalar_unsigned(rtm::vector_get_x(vector), num_bits);
+ uint32_t vector_y = pack_scalar_unsigned(rtm::vector_get_y(vector), num_bits);
uint64_t vector_u64 = static_cast<uint64_t>(vector_x) << (64 - num_bits * 1);
vector_u64 |= static_cast<uint64_t>(vector_y) << (64 - num_bits * 2);
@@ -1144,7 +1145,7 @@ namespace acl
}
// Assumes the 'vector_data' is in big-endian order and padded in order to load up to 16 bytes from it
- inline Vector4_32 ACL_SIMD_CALL unpack_vector2_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
+ inline rtm::vector4f RTM_SIMD_CALL unpack_vector2_uXX_unsafe(uint8_t num_bits, const uint8_t* vector_data, uint32_t bit_offset)
{
ACL_ASSERT(num_bits <= 19, "This function does not support reading more than 19 bits per component");
@@ -1169,7 +1170,7 @@ namespace acl
PackedTableEntry(16), PackedTableEntry(17), PackedTableEntry(18), PackedTableEntry(19),
};
-#if defined(ACL_SSE2_INTRINSICS)
+#if defined(RTM_SSE2_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
const __m128i mask = _mm_castps_si128(_mm_load_ps1((const float*)&k_packed_constants[num_bits].mask));
const __m128 inv_max_value = _mm_load_ps1(&k_packed_constants[num_bits].max_value);
@@ -1190,7 +1191,7 @@ namespace acl
int_value = _mm_and_si128(int_value, mask);
const __m128 value = _mm_cvtepi32_ps(int_value);
return _mm_mul_ps(value, inv_max_value);
-#elif defined(ACL_NEON_INTRINSICS)
+#elif defined(RTM_NEON_INTRINSICS)
const uint32_t bit_shift = 32 - num_bits;
uint32x2_t mask = vdup_n_u32(k_packed_constants[num_bits].mask);
float inv_max_value = k_packed_constants[num_bits].max_value;
@@ -1229,7 +1230,7 @@ namespace acl
vector_u32 = byte_swap(vector_u32);
const uint32_t y32 = (vector_u32 >> (bit_shift - (bit_offset % 8))) & mask;
- return vector_mul(vector_set(float(x32), float(y32), 0.0F, 0.0F), inv_max_value);
+ return rtm::vector_mul(rtm::vector_set(float(x32), float(y32), 0.0F, 0.0F), inv_max_value);
#endif
}
diff --git a/tools/acl_compressor/main_android/CMakeLists.txt b/tools/acl_compressor/main_android/CMakeLists.txt
--- a/tools/acl_compressor/main_android/CMakeLists.txt
+++ b/tools/acl_compressor/main_android/CMakeLists.txt
@@ -50,7 +50,6 @@ target_compile_options(${PROJECT_NAME} PRIVATE -g)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/acl_compressor/main_ios/CMakeLists.txt b/tools/acl_compressor/main_ios/CMakeLists.txt
--- a/tools/acl_compressor/main_ios/CMakeLists.txt
+++ b/tools/acl_compressor/main_ios/CMakeLists.txt
@@ -40,7 +40,6 @@ add_executable(${PROJECT_NAME} MACOSX_BUNDLE ${ALL_COMMON_SOURCE_FILES} ${ALL_MA
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -426,16 +426,16 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
const uint32_t additive_num_samples = additive_base_clip != nullptr ? additive_base_clip->get_num_samples() : 0;
const float additive_duration = additive_base_clip != nullptr ? additive_base_clip->get_duration() : 0.0F;
- Transform_32* raw_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* base_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
- Transform_32* lossy_pose_transforms = allocate_type_array<Transform_32>(allocator, num_bones);
+ rtm::qvvf* raw_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* base_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
+ rtm::qvvf* lossy_pose_transforms = allocate_type_array<rtm::qvvf>(allocator, num_bones);
DefaultOutputWriter pose_writer(lossy_pose_transforms, num_bones);
// Regression test
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const float sample_time = min(float(sample_index) / sample_rate, clip_duration);
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
// We use the nearest sample to accurately measure the loss that happened, if any
clip.sample_pose(sample_time, SampleRoundingPolicy::Nearest, raw_pose_transforms, num_bones);
@@ -455,44 +455,44 @@ static void validate_accuracy(IAllocator& allocator, const AnimationClip& clip,
{
const float error = error_metric.calculate_object_bone_error(skeleton, raw_pose_transforms, base_pose_transforms, lossy_pose_transforms, bone_index);
(void)error;
- ACL_ASSERT(is_finite(error), "Returned error is not a finite value");
+ ACL_ASSERT(rtm::scalar_is_finite(error), "Returned error is not a finite value");
ACL_ASSERT(error < regression_error_threshold, "Error too high for bone %u: %f at time %f", bone_index, error, sample_time);
}
// Validate decompress_bone for rotations only
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- Quat_32 rotation;
+ rtm::quatf rotation;
context.decompress_bone(bone_index, &rotation, nullptr, nullptr);
- ACL_ASSERT(quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
}
// Validate decompress_bone for translations only
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- Vector4_32 translation;
+ rtm::vector4f translation;
context.decompress_bone(bone_index, nullptr, &translation, nullptr);
- ACL_ASSERT(vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
}
// Validate decompress_bone for scales only
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- Vector4_32 scale;
+ rtm::vector4f scale;
context.decompress_bone(bone_index, nullptr, nullptr, &scale);
- ACL_ASSERT(vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
}
// Validate decompress_bone
for (uint16_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- Quat_32 rotation;
- Vector4_32 translation;
- Vector4_32 scale;
+ rtm::quatf rotation;
+ rtm::vector4f translation;
+ rtm::vector4f scale;
context.decompress_bone(bone_index, &rotation, &translation, &scale);
- ACL_ASSERT(quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
- ACL_ASSERT(vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
- ACL_ASSERT(vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::quat_near_equal(rotation, lossy_pose_transforms[bone_index].rotation), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(translation, lossy_pose_transforms[bone_index].translation), "Failed to sample bone index: %u", bone_index);
+ ACL_ASSERT(rtm::vector_all_near_equal3(scale, lossy_pose_transforms[bone_index].scale), "Failed to sample bone index: %u", bone_index);
}
}
@@ -522,7 +522,7 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
const uint32_t num_samples = tracks.get_num_samples_per_track();
const track_type8 track_type = raw_tracks.get_track_type();
- ACL_ASSERT(scalar_near_equal(duration, raw_tracks.get_duration(), 1.0E-7F), "Duration mismatch");
+ ACL_ASSERT(rtm::scalar_near_equal(duration, raw_tracks.get_duration(), 1.0E-7F), "Duration mismatch");
ACL_ASSERT(sample_rate == raw_tracks.get_sample_rate(), "Sample rate mismatch");
ACL_ASSERT(num_tracks <= raw_tracks.get_num_tracks(), "Num tracks mismatch");
ACL_ASSERT(num_samples == raw_tracks.get_num_samples_per_track(), "Num samples mismatch");
@@ -540,7 +540,7 @@ static void validate_accuracy(IAllocator& allocator, const track_array& raw_trac
// Regression test
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const float sample_time = min(float(sample_index) / sample_rate, duration);
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
// We use the nearest sample to accurately measure the loss that happened, if any
raw_tracks.sample_tracks(sample_time, SampleRoundingPolicy::Nearest, raw_tracks_writer);
@@ -1056,7 +1056,10 @@ static bool read_config(IAllocator& allocator, const Options& options, Algorithm
}
}
- parser.try_read("constant_rotation_threshold_angle", out_settings.constant_rotation_threshold_angle, default_settings.constant_rotation_threshold_angle);
+ double constant_rotation_threshold_angle;
+ parser.try_read("constant_rotation_threshold_angle", constant_rotation_threshold_angle, default_settings.constant_rotation_threshold_angle.as_radians());
+ out_settings.constant_rotation_threshold_angle = rtm::radians(float(constant_rotation_threshold_angle));
+
parser.try_read("constant_translation_threshold", out_settings.constant_translation_threshold, default_settings.constant_translation_threshold);
parser.try_read("constant_scale_threshold", out_settings.constant_scale_threshold, default_settings.constant_scale_threshold);
parser.try_read("error_threshold", out_settings.error_threshold, default_settings.error_threshold);
@@ -1112,17 +1115,17 @@ static void create_additive_base_clip(const Options& options, AnimationClip& cli
// Get the bind transform and make sure it has no scale
const RigidBone& skel_bone = skeleton.get_bone(bone_index);
- const Transform_64 bind_transform = transform_set(skel_bone.bind_transform.rotation, skel_bone.bind_transform.translation, vector_set(1.0));
+ const rtm::qvvd bind_transform = rtm::qvv_set(skel_bone.bind_transform.rotation, skel_bone.bind_transform.translation, rtm::vector_set(1.0));
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const Quat_64 rotation = quat_normalize(anim_bone.rotation_track.get_sample(sample_index));
- const Vector4_64 translation = anim_bone.translation_track.get_sample(sample_index);
- const Vector4_64 scale = anim_bone.scale_track.get_sample(sample_index);
+ const rtm::quatd rotation = rtm::quat_normalize(anim_bone.rotation_track.get_sample(sample_index));
+ const rtm::vector4d translation = anim_bone.translation_track.get_sample(sample_index);
+ const rtm::vector4d scale = anim_bone.scale_track.get_sample(sample_index);
- const Transform_64 bone_transform = transform_set(rotation, translation, scale);
+ const rtm::qvvd bone_transform = rtm::qvv_set(rotation, translation, scale);
- Transform_64 bind_local_transform = bone_transform;
+ rtm::qvvd bind_local_transform = bone_transform;
if (options.is_bind_pose_relative)
bind_local_transform = convert_to_relative(bind_transform, bone_transform);
else if (options.is_bind_pose_additive0)
diff --git a/tools/acl_decompressor/main_android/CMakeLists.txt b/tools/acl_decompressor/main_android/CMakeLists.txt
--- a/tools/acl_decompressor/main_android/CMakeLists.txt
+++ b/tools/acl_decompressor/main_android/CMakeLists.txt
@@ -67,7 +67,6 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/acl_decompressor/main_ios/CMakeLists.txt b/tools/acl_decompressor/main_ios/CMakeLists.txt
--- a/tools/acl_decompressor/main_ios/CMakeLists.txt
+++ b/tools/acl_decompressor/main_ios/CMakeLists.txt
@@ -56,7 +56,6 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/regression_tester_android/CMakeLists.txt b/tools/regression_tester_android/CMakeLists.txt
--- a/tools/regression_tester_android/CMakeLists.txt
+++ b/tools/regression_tester_android/CMakeLists.txt
@@ -69,7 +69,6 @@ add_definitions(-DSJSON_CPP_ON_ASSERT_THROW)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
diff --git a/tools/regression_tester_ios/CMakeLists.txt b/tools/regression_tester_ios/CMakeLists.txt
--- a/tools/regression_tester_ios/CMakeLists.txt
+++ b/tools/regression_tester_ios/CMakeLists.txt
@@ -61,7 +61,6 @@ add_definitions(-DACL_NO_ALLOCATOR_TRACKING)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
add_definitions(-DRTM_NO_INTRINSICS)
endif()
|
diff --git a/tests/main_android/CMakeLists.txt b/tests/main_android/CMakeLists.txt
--- a/tests/main_android/CMakeLists.txt
+++ b/tests/main_android/CMakeLists.txt
@@ -54,7 +54,7 @@ add_definitions(-DRTM_ON_ASSERT_THROW)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
# Enable SJSON when needed
diff --git a/tests/main_ios/CMakeLists.txt b/tests/main_ios/CMakeLists.txt
--- a/tests/main_ios/CMakeLists.txt
+++ b/tests/main_ios/CMakeLists.txt
@@ -44,7 +44,7 @@ add_definitions(-DRTM_ON_ASSERT_THROW)
# Disable SIMD if not needed
if(NOT USE_SIMD_INSTRUCTIONS)
- add_definitions(-DACL_NO_INTRINSICS)
+ add_definitions(-DRTM_NO_INTRINSICS)
endif()
# Enable SJSON when needed
diff --git a/tests/sources/core/test_interpolation_utils.cpp b/tests/sources/core/test_interpolation_utils.cpp
--- a/tests/sources/core/test_interpolation_utils.cpp
+++ b/tests/sources/core/test_interpolation_utils.cpp
@@ -25,9 +25,10 @@
#include <catch.hpp>
#include <acl/core/interpolation_utils.h>
-#include <acl/math/scalar_32.h>
+#include <rtm/scalarf.h>
using namespace acl;
+using namespace rtm;
TEST_CASE("interpolation utils", "[core][utils]")
{
diff --git a/tests/sources/core/test_utils.cpp b/tests/sources/core/test_utils.cpp
--- a/tests/sources/core/test_utils.cpp
+++ b/tests/sources/core/test_utils.cpp
@@ -25,11 +25,12 @@
#include <catch.hpp>
#include <acl/core/utils.h>
-#include <acl/math/scalar_32.h>
+#include <rtm/scalarf.h>
#include <limits>
using namespace acl;
+using namespace rtm;
TEST_CASE("misc utils", "[core][utils]")
{
diff --git a/tests/sources/io/test_reader_writer.cpp b/tests/sources/io/test_reader_writer.cpp
--- a/tests/sources/io/test_reader_writer.cpp
+++ b/tests/sources/io/test_reader_writer.cpp
@@ -36,8 +36,10 @@
#include <acl/core/ansi_allocator.h>
#include <acl/io/clip_reader.h>
#include <acl/io/clip_writer.h>
-#include <acl/math/math.h>
-#include <acl/math/scalar_32.h>
+
+#include <rtm/angled.h>
+#include <rtm/qvvd.h>
+#include <rtm/scalarf.h>
#include <chrono>
#include <cstdio>
@@ -97,7 +99,7 @@
using namespace acl;
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
#ifdef _WIN32
constexpr uint32_t k_max_filename_size = MAX_PATH;
#else
@@ -133,7 +135,7 @@ static void get_temporary_filename(char* filename, uint32_t filename_size, const
TEST_CASE("sjson_clip_reader_writer", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint16_t num_bones = 3;
@@ -141,17 +143,17 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
bones[0].name = String(allocator, "root");
bones[0].vertex_distance = 4.0F;
bones[0].parent_index = k_invalid_bone_index;
- bones[0].bind_transform = transform_identity_64();
+ bones[0].bind_transform = rtm::qvv_identity();
bones[1].name = String(allocator, "bone1");
bones[1].vertex_distance = 3.0F;
bones[1].parent_index = 0;
- bones[1].bind_transform = transform_set(quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 0.5), vector_set(3.2, 8.2, 5.1), vector_set(1.0));
+ bones[1].bind_transform = rtm::qvv_set(rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.5), rtm::vector_set(3.2, 8.2, 5.1), rtm::vector_set(1.0));
bones[2].name = String(allocator, "bone2");
bones[2].vertex_distance = 2.0F;
bones[2].parent_index = 1;
- bones[2].bind_transform = transform_set(quat_from_axis_angle(vector_set(0.0, 0.0, 1.0), k_pi_64 * 0.25), vector_set(6.3, 9.4, 1.5), vector_set(1.0));
+ bones[2].bind_transform = rtm::qvv_set(rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.25), rtm::vector_set(6.3, 9.4, 1.5), rtm::vector_set(1.0));
RigidSkeleton skeleton(allocator, bones, num_bones);
@@ -160,49 +162,49 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
AnimatedBone* animated_bones = clip.get_bones();
animated_bones[0].output_index = 0;
- animated_bones[0].rotation_track.set_sample(0, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 0.1));
- animated_bones[0].rotation_track.set_sample(1, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 0.2));
- animated_bones[0].rotation_track.set_sample(2, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 0.3));
- animated_bones[0].rotation_track.set_sample(3, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 0.4));
- animated_bones[0].translation_track.set_sample(0, vector_set(3.2, 1.4, 9.4));
- animated_bones[0].translation_track.set_sample(1, vector_set(3.3, 1.5, 9.5));
- animated_bones[0].translation_track.set_sample(2, vector_set(3.4, 1.6, 9.6));
- animated_bones[0].translation_track.set_sample(3, vector_set(3.5, 1.7, 9.7));
- animated_bones[0].scale_track.set_sample(0, vector_set(1.0, 1.5, 1.1));
- animated_bones[0].scale_track.set_sample(1, vector_set(1.1, 1.6, 1.2));
- animated_bones[0].scale_track.set_sample(2, vector_set(1.2, 1.7, 1.3));
- animated_bones[0].scale_track.set_sample(3, vector_set(1.3, 1.8, 1.4));
+ animated_bones[0].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.1));
+ animated_bones[0].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.2));
+ animated_bones[0].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.3));
+ animated_bones[0].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 0.4));
+ animated_bones[0].translation_track.set_sample(0, rtm::vector_set(3.2, 1.4, 9.4));
+ animated_bones[0].translation_track.set_sample(1, rtm::vector_set(3.3, 1.5, 9.5));
+ animated_bones[0].translation_track.set_sample(2, rtm::vector_set(3.4, 1.6, 9.6));
+ animated_bones[0].translation_track.set_sample(3, rtm::vector_set(3.5, 1.7, 9.7));
+ animated_bones[0].scale_track.set_sample(0, rtm::vector_set(1.0, 1.5, 1.1));
+ animated_bones[0].scale_track.set_sample(1, rtm::vector_set(1.1, 1.6, 1.2));
+ animated_bones[0].scale_track.set_sample(2, rtm::vector_set(1.2, 1.7, 1.3));
+ animated_bones[0].scale_track.set_sample(3, rtm::vector_set(1.3, 1.8, 1.4));
animated_bones[1].output_index = 2;
- animated_bones[1].rotation_track.set_sample(0, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 1.1));
- animated_bones[1].rotation_track.set_sample(1, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 1.2));
- animated_bones[1].rotation_track.set_sample(2, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 1.3));
- animated_bones[1].rotation_track.set_sample(3, quat_from_axis_angle(vector_set(0.0, 1.0, 0.0), k_pi_64 * 1.4));
- animated_bones[1].translation_track.set_sample(0, vector_set(5.2, 2.4, 13.4));
- animated_bones[1].translation_track.set_sample(1, vector_set(5.3, 2.5, 13.5));
- animated_bones[1].translation_track.set_sample(2, vector_set(5.4, 2.6, 13.6));
- animated_bones[1].translation_track.set_sample(3, vector_set(5.5, 2.7, 13.7));
- animated_bones[1].scale_track.set_sample(0, vector_set(2.0, 0.5, 4.1));
- animated_bones[1].scale_track.set_sample(1, vector_set(2.1, 0.6, 4.2));
- animated_bones[1].scale_track.set_sample(2, vector_set(2.2, 0.7, 4.3));
- animated_bones[1].scale_track.set_sample(3, vector_set(2.3, 0.8, 4.4));
+ animated_bones[1].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.1));
+ animated_bones[1].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.2));
+ animated_bones[1].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.3));
+ animated_bones[1].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 1.0, 0.0), rtm::constants::pi() * 1.4));
+ animated_bones[1].translation_track.set_sample(0, rtm::vector_set(5.2, 2.4, 13.4));
+ animated_bones[1].translation_track.set_sample(1, rtm::vector_set(5.3, 2.5, 13.5));
+ animated_bones[1].translation_track.set_sample(2, rtm::vector_set(5.4, 2.6, 13.6));
+ animated_bones[1].translation_track.set_sample(3, rtm::vector_set(5.5, 2.7, 13.7));
+ animated_bones[1].scale_track.set_sample(0, rtm::vector_set(2.0, 0.5, 4.1));
+ animated_bones[1].scale_track.set_sample(1, rtm::vector_set(2.1, 0.6, 4.2));
+ animated_bones[1].scale_track.set_sample(2, rtm::vector_set(2.2, 0.7, 4.3));
+ animated_bones[1].scale_track.set_sample(3, rtm::vector_set(2.3, 0.8, 4.4));
animated_bones[2].output_index = 1;
- animated_bones[2].rotation_track.set_sample(0, quat_from_axis_angle(vector_set(0.0, 0.0, 1.0), k_pi_64 * 0.7));
- animated_bones[2].rotation_track.set_sample(1, quat_from_axis_angle(vector_set(0.0, 0.0, 1.0), k_pi_64 * 0.8));
- animated_bones[2].rotation_track.set_sample(2, quat_from_axis_angle(vector_set(0.0, 0.0, 1.0), k_pi_64 * 0.9));
- animated_bones[2].rotation_track.set_sample(3, quat_from_axis_angle(vector_set(0.0, 0.0, 1.0), k_pi_64 * 0.4));
- animated_bones[2].translation_track.set_sample(0, vector_set(1.2, 123.4, 11.4));
- animated_bones[2].translation_track.set_sample(1, vector_set(1.3, 123.5, 11.5));
- animated_bones[2].translation_track.set_sample(2, vector_set(1.4, 123.6, 11.6));
- animated_bones[2].translation_track.set_sample(3, vector_set(1.5, 123.7, 11.7));
- animated_bones[2].scale_track.set_sample(0, vector_set(4.0, 2.5, 3.1));
- animated_bones[2].scale_track.set_sample(1, vector_set(4.1, 2.6, 3.2));
- animated_bones[2].scale_track.set_sample(2, vector_set(4.2, 2.7, 3.3));
- animated_bones[2].scale_track.set_sample(3, vector_set(4.3, 2.8, 3.4));
+ animated_bones[2].rotation_track.set_sample(0, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.7));
+ animated_bones[2].rotation_track.set_sample(1, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.8));
+ animated_bones[2].rotation_track.set_sample(2, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.9));
+ animated_bones[2].rotation_track.set_sample(3, rtm::quat_from_axis_angle(rtm::vector_set(0.0, 0.0, 1.0), rtm::constants::pi() * 0.4));
+ animated_bones[2].translation_track.set_sample(0, rtm::vector_set(1.2, 123.4, 11.4));
+ animated_bones[2].translation_track.set_sample(1, rtm::vector_set(1.3, 123.5, 11.5));
+ animated_bones[2].translation_track.set_sample(2, rtm::vector_set(1.4, 123.6, 11.6));
+ animated_bones[2].translation_track.set_sample(3, rtm::vector_set(1.5, 123.7, 11.7));
+ animated_bones[2].scale_track.set_sample(0, rtm::vector_set(4.0, 2.5, 3.1));
+ animated_bones[2].scale_track.set_sample(1, rtm::vector_set(4.1, 2.6, 3.2));
+ animated_bones[2].scale_track.set_sample(2, rtm::vector_set(4.2, 2.7, 3.3));
+ animated_bones[2].scale_track.set_sample(3, rtm::vector_set(4.3, 2.8, 3.4));
CompressionSettings settings;
- settings.constant_rotation_threshold_angle = 32.23F;
+ settings.constant_rotation_threshold_angle = rtm::radians(32.23F);
settings.constant_scale_threshold = 1.123F;
settings.constant_translation_threshold = 0.124F;
settings.error_threshold = 0.23F;
@@ -271,7 +273,7 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
CHECK(file_clip.skeleton->get_num_bones() == num_bones);
CHECK(file_clip.clip->get_num_bones() == num_bones);
CHECK(file_clip.clip->get_name() == clip.get_name());
- CHECK(scalar_near_equal(file_clip.clip->get_duration(), clip.get_duration(), 1.0E-8F));
+ CHECK(rtm::scalar_near_equal(file_clip.clip->get_duration(), clip.get_duration(), 1.0E-8F));
CHECK(file_clip.clip->get_num_samples() == clip.get_num_samples());
CHECK(file_clip.clip->get_sample_rate() == clip.get_sample_rate());
@@ -282,9 +284,9 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
CHECK(src_bone.name == file_bone.name);
CHECK(src_bone.vertex_distance == file_bone.vertex_distance);
CHECK(src_bone.parent_index == file_bone.parent_index);
- CHECK(quat_near_equal(src_bone.bind_transform.rotation, file_bone.bind_transform.rotation, 0.0));
- CHECK(vector_all_near_equal3(src_bone.bind_transform.translation, file_bone.bind_transform.translation, 0.0));
- CHECK(vector_all_near_equal3(src_bone.bind_transform.scale, file_bone.bind_transform.scale, 0.0));
+ CHECK(rtm::quat_near_equal(src_bone.bind_transform.rotation, file_bone.bind_transform.rotation, 0.0));
+ CHECK(rtm::vector_all_near_equal3(src_bone.bind_transform.translation, file_bone.bind_transform.translation, 0.0));
+ CHECK(rtm::vector_all_near_equal3(src_bone.bind_transform.scale, file_bone.bind_transform.scale, 0.0));
const AnimatedBone& src_animated_bone = clip.get_animated_bone(bone_index);
const AnimatedBone& file_animated_bone = file_clip.clip->get_animated_bone(bone_index);
@@ -292,9 +294,9 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- CHECK(quat_near_equal(src_animated_bone.rotation_track.get_sample(sample_index), file_animated_bone.rotation_track.get_sample(sample_index), 0.0));
- CHECK(vector_all_near_equal3(src_animated_bone.translation_track.get_sample(sample_index), file_animated_bone.translation_track.get_sample(sample_index), 0.0));
- CHECK(vector_all_near_equal3(src_animated_bone.scale_track.get_sample(sample_index), file_animated_bone.scale_track.get_sample(sample_index), 0.0));
+ CHECK(rtm::quat_near_equal(src_animated_bone.rotation_track.get_sample(sample_index), file_animated_bone.rotation_track.get_sample(sample_index), 0.0));
+ CHECK(rtm::vector_all_near_equal3(src_animated_bone.translation_track.get_sample(sample_index), file_animated_bone.translation_track.get_sample(sample_index), 0.0));
+ CHECK(rtm::vector_all_near_equal3(src_animated_bone.scale_track.get_sample(sample_index), file_animated_bone.scale_track.get_sample(sample_index), 0.0));
}
}
#endif
@@ -303,7 +305,7 @@ TEST_CASE("sjson_clip_reader_writer", "[io]")
TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint32_t num_tracks = 3;
@@ -415,7 +417,7 @@ TEST_CASE("sjson_track_list_reader_writer float1f", "[io]")
TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint32_t num_tracks = 3;
@@ -527,7 +529,7 @@ TEST_CASE("sjson_track_list_reader_writer float2f", "[io]")
TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint32_t num_tracks = 3;
@@ -639,7 +641,7 @@ TEST_CASE("sjson_track_list_reader_writer float3f", "[io]")
TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint32_t num_tracks = 3;
@@ -751,7 +753,7 @@ TEST_CASE("sjson_track_list_reader_writer float4f", "[io]")
TEST_CASE("sjson_track_list_reader_writer vector4f", "[io]")
{
// Only test the reader/writer on non-mobile platforms
-#if defined(ACL_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
+#if defined(RTM_SSE2_INTRINSICS) && defined(ACL_USE_SJSON)
ANSIAllocator allocator;
const uint32_t num_tracks = 3;
diff --git a/tests/sources/math/test_affine_matrix.cpp b/tests/sources/math/test_affine_matrix.cpp
deleted file mode 100644
--- a/tests/sources/math/test_affine_matrix.cpp
+++ /dev/null
@@ -1,247 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include <catch.hpp>
-
-#include <acl/math/affine_matrix_32.h>
-#include <acl/math/affine_matrix_64.h>
-#include <acl/math/transform_32.h>
-#include <acl/math/transform_64.h>
-
-using namespace acl;
-
-template<typename MatrixType, typename TransformType, typename FloatType>
-static void test_affine_matrix_impl(const MatrixType& identity, const FloatType threshold)
-{
- using QuatType = decltype(TransformType::rotation);
- using Vector4Type = decltype(TransformType::translation);
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0), FloatType(0.0));
- Vector4Type z_axis = vector_set(FloatType(7.0), FloatType(8.0), FloatType(9.0), FloatType(0.0));
- Vector4Type w_axis = vector_set(FloatType(10.0), FloatType(11.0), FloatType(12.0), FloatType(1.0));
- MatrixType mtx = matrix_set(x_axis, y_axis, z_axis, w_axis);
- REQUIRE(vector_all_near_equal(x_axis, mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(y_axis, mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(z_axis, mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(w_axis, mtx.w_axis, threshold));
- }
-
- {
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), identity.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), identity.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), identity.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0)), identity.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type translation = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0));
- MatrixType mtx = matrix_set(rotation_around_z, translation, vector_set(FloatType(1.0)));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(1.0)), mtx.w_axis, threshold));
-
- Vector4Type scale = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0));
- mtx = matrix_set(rotation_around_z, translation, scale);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(4.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(-5.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(6.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(1.0)), mtx.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- MatrixType mtx = matrix_from_quat(rotation_around_z);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0)), mtx.w_axis, threshold));
- }
-
- {
- MatrixType mtx = matrix_from_translation(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0)));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(1.0)), mtx.w_axis, threshold));
- }
-
- {
- MatrixType mtx = matrix_from_scale(vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0)));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(4.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(5.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(6.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0)), mtx.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type translation = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0));
- Vector4Type scale = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0));
- TransformType transform = transform_set(rotation_around_z, translation, scale);
- MatrixType mtx = matrix_from_transform(transform);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(4.0), FloatType(0.0), FloatType(0.0)), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(-5.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(6.0), FloatType(0.0)), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(1.0)), mtx.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type translation = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0));
- Vector4Type scale = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0));
- MatrixType mtx = matrix_set(rotation_around_z, translation, scale);
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx, MatrixAxis::X), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx, MatrixAxis::Y), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx, MatrixAxis::Z), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx, MatrixAxis::W), mtx.w_axis, threshold));
-
- const MatrixType mtx2 = mtx;
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx2, MatrixAxis::X), mtx2.x_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx2, MatrixAxis::Y), mtx2.y_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx2, MatrixAxis::Z), mtx2.z_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx2, MatrixAxis::W), mtx2.w_axis, threshold));
-
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx.x_axis, mtx.y_axis, mtx.z_axis, mtx.w_axis, MatrixAxis::X), mtx.x_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx.x_axis, mtx.y_axis, mtx.z_axis, mtx.w_axis, MatrixAxis::Y), mtx.y_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx.x_axis, mtx.y_axis, mtx.z_axis, mtx.w_axis, MatrixAxis::Z), mtx.z_axis, threshold));
- REQUIRE(vector_all_near_equal(matrix_get_axis(mtx.x_axis, mtx.y_axis, mtx.z_axis, mtx.w_axis, MatrixAxis::W), mtx.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- MatrixType mtx = matrix_from_quat(rotation_around_z);
- QuatType rotation = quat_from_matrix(mtx);
- REQUIRE(quat_near_equal(rotation_around_z, rotation, threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- MatrixType mtx_a = matrix_set(rotation_around_z, x_axis, vector_set(FloatType(1.0)));
- Vector4Type result = matrix_mul_position(mtx_a, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = matrix_mul_position(mtx_a, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0)), threshold));
-
- QuatType rotation_around_x = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)));
- MatrixType mtx_b = matrix_set(rotation_around_x, y_axis, vector_set(FloatType(1.0)));
- result = matrix_mul_position(mtx_b, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = matrix_mul_position(mtx_b, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(-1.0)), threshold));
-
- MatrixType mtx_ab = matrix_mul(mtx_a, mtx_b);
- MatrixType mtx_ba = matrix_mul(mtx_b, mtx_a);
- result = matrix_mul_position(mtx_ab, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(-1.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, matrix_mul_position(mtx_b, matrix_mul_position(mtx_a, x_axis)), threshold));
- result = matrix_mul_position(mtx_ab, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, matrix_mul_position(mtx_b, matrix_mul_position(mtx_a, y_axis)), threshold));
- result = matrix_mul_position(mtx_ba, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, matrix_mul_position(mtx_a, matrix_mul_position(mtx_b, x_axis)), threshold));
- result = matrix_mul_position(mtx_ba, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, matrix_mul_position(mtx_a, matrix_mul_position(mtx_b, y_axis)), threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0), FloatType(0.0));
- Vector4Type z_axis = vector_set(FloatType(7.0), FloatType(8.0), FloatType(9.0), FloatType(0.0));
- Vector4Type w_axis = vector_set(FloatType(10.0), FloatType(11.0), FloatType(12.0), FloatType(1.0));
- MatrixType mtx0 = matrix_set(x_axis, y_axis, z_axis, w_axis);
- MatrixType mtx1 = math_impl::matrix_transpose(mtx0);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(4.0), FloatType(7.0), FloatType(10.0)), mtx1.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(2.0), FloatType(5.0), FloatType(8.0), FloatType(11.0)), mtx1.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(3.0), FloatType(6.0), FloatType(9.0), FloatType(12.0)), mtx1.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0)), mtx1.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type translation = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0));
- Vector4Type scale = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0));
- MatrixType mtx = matrix_set(rotation_around_z, translation, scale);
- MatrixType inv_mtx = matrix_inverse(mtx);
- MatrixType result = matrix_mul(mtx, inv_mtx);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), result.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), result.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), result.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0)), result.w_axis, threshold));
- }
-
- {
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type translation = vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0));
- Vector4Type scale = vector_set(FloatType(4.0), FloatType(5.0), FloatType(6.0));
- MatrixType mtx0 = matrix_set(rotation_around_z, translation, scale);
- MatrixType mtx0_no_scale = matrix_remove_scale(mtx0);
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0)), mtx0_no_scale.x_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0)), mtx0_no_scale.y_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0)), mtx0_no_scale.z_axis, threshold));
- REQUIRE(vector_all_near_equal(vector_set(FloatType(1.0), FloatType(2.0), FloatType(3.0), FloatType(1.0)), mtx0_no_scale.w_axis, threshold));
- }
-}
-
-TEST_CASE("affine matrix 32 math", "[math][affinematrix]")
-{
- test_affine_matrix_impl<AffineMatrix_32, Transform_32, float>(matrix_identity_32(), 1.0E-4F);
-
- {
- Quat_32 rotation_around_z = quat_from_euler(deg2rad(0.0F), deg2rad(90.0F), deg2rad(0.0F));
- Vector4_32 translation = vector_set(1.0F, 2.0F, 3.0F);
- Vector4_32 scale = vector_set(4.0F, 5.0F, 6.0F);
- AffineMatrix_32 src = matrix_set(rotation_around_z, translation, scale);
- AffineMatrix_64 dst = matrix_cast(src);
- REQUIRE(vector_all_near_equal(vector_cast(src.x_axis), dst.x_axis, 1.0E-4));
- REQUIRE(vector_all_near_equal(vector_cast(src.y_axis), dst.y_axis, 1.0E-4));
- REQUIRE(vector_all_near_equal(vector_cast(src.z_axis), dst.z_axis, 1.0E-4));
- REQUIRE(vector_all_near_equal(vector_cast(src.w_axis), dst.w_axis, 1.0E-4));
- }
-}
-
-TEST_CASE("affine matrix 64 math", "[math][affinematrix]")
-{
- test_affine_matrix_impl<AffineMatrix_64, Transform_64, double>(matrix_identity_64(), 1.0E-4);
-
- {
- Quat_64 rotation_around_z = quat_from_euler(deg2rad(0.0), deg2rad(90.0), deg2rad(0.0));
- Vector4_64 translation = vector_set(1.0, 2.0, 3.0);
- Vector4_64 scale = vector_set(4.0, 5.0, 6.0);
- AffineMatrix_64 src = matrix_set(rotation_around_z, translation, scale);
- AffineMatrix_32 dst = matrix_cast(src);
- REQUIRE(vector_all_near_equal(vector_cast(src.x_axis), dst.x_axis, 1.0E-4f));
- REQUIRE(vector_all_near_equal(vector_cast(src.y_axis), dst.y_axis, 1.0E-4f));
- REQUIRE(vector_all_near_equal(vector_cast(src.z_axis), dst.z_axis, 1.0E-4f));
- REQUIRE(vector_all_near_equal(vector_cast(src.w_axis), dst.w_axis, 1.0E-4f));
- }
-}
diff --git a/tests/sources/math/test_quat.cpp b/tests/sources/math/test_quat.cpp
deleted file mode 100644
--- a/tests/sources/math/test_quat.cpp
+++ /dev/null
@@ -1,399 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include <catch.hpp>
-
-#include <acl/math/quat_32.h>
-#include <acl/math/quat_64.h>
-#include <acl/math/vector4_32.h>
-#include <acl/math/vector4_64.h>
-
-#include <limits>
-
-using namespace acl;
-
-template<typename QuatType, typename Vector4Type, typename FloatType>
-static Vector4Type quat_rotate_scalar(const QuatType& rotation, const Vector4Type& vector)
-{
- // (q.W*q.W-qv.qv)v + 2(qv.v)qv + 2 q.W (qv x v)
- Vector4Type qv = vector_set(quat_get_x(rotation), quat_get_y(rotation), quat_get_z(rotation));
- Vector4Type vOut = vector_mul(vector_cross3(qv, vector), FloatType(2.0) * quat_get_w(rotation));
- vOut = vector_add(vOut, vector_mul(vector, (quat_get_w(rotation) * quat_get_w(rotation)) - vector_dot(qv, qv)));
- vOut = vector_add(vOut, vector_mul(qv, FloatType(2.0) * vector_dot(qv, vector)));
- return vOut;
-}
-
-template<typename QuatType, typename Vector4Type, typename FloatType>
-static QuatType quat_mul_scalar(const QuatType& lhs, const QuatType& rhs)
-{
- FloatType lhs_raw[4] = { quat_get_x(lhs), quat_get_y(lhs), quat_get_z(lhs), quat_get_w(lhs) };
- FloatType rhs_raw[4] = { quat_get_x(rhs), quat_get_y(rhs), quat_get_z(rhs), quat_get_w(rhs) };
-
- FloatType x = (rhs_raw[3] * lhs_raw[0]) + (rhs_raw[0] * lhs_raw[3]) + (rhs_raw[1] * lhs_raw[2]) - (rhs_raw[2] * lhs_raw[1]);
- FloatType y = (rhs_raw[3] * lhs_raw[1]) - (rhs_raw[0] * lhs_raw[2]) + (rhs_raw[1] * lhs_raw[3]) + (rhs_raw[2] * lhs_raw[0]);
- FloatType z = (rhs_raw[3] * lhs_raw[2]) + (rhs_raw[0] * lhs_raw[1]) - (rhs_raw[1] * lhs_raw[0]) + (rhs_raw[2] * lhs_raw[3]);
- FloatType w = (rhs_raw[3] * lhs_raw[3]) - (rhs_raw[0] * lhs_raw[0]) - (rhs_raw[1] * lhs_raw[1]) - (rhs_raw[2] * lhs_raw[2]);
-
- return quat_set(x, y, z, w);
-}
-
-template<typename QuatType, typename FloatType>
-static FloatType scalar_dot(const QuatType& lhs, const QuatType& rhs)
-{
- return (quat_get_x(lhs) * quat_get_x(rhs)) + (quat_get_y(lhs) * quat_get_y(rhs)) + (quat_get_z(lhs) * quat_get_z(rhs)) + (quat_get_w(lhs) * quat_get_w(rhs));
-}
-
-template<typename QuatType, typename FloatType>
-static QuatType scalar_normalize(const QuatType& input)
-{
- FloatType inv_len = FloatType(1.0) / acl::sqrt(scalar_dot<QuatType, FloatType>(input, input));
- return quat_set(quat_get_x(input) * inv_len, quat_get_y(input) * inv_len, quat_get_z(input) * inv_len, quat_get_w(input) * inv_len);
-}
-
-template<typename QuatType, typename FloatType>
-static QuatType scalar_lerp(const QuatType& start, const QuatType& end, FloatType alpha)
-{
- FloatType dot = scalar_dot<QuatType, FloatType>(start, end);
- FloatType bias = dot >= FloatType(0.0) ? FloatType(1.0) : FloatType(-1.0);
- FloatType x = quat_get_x(start) + ((quat_get_x(end) * bias) - quat_get_x(start)) * alpha;
- FloatType y = quat_get_y(start) + ((quat_get_y(end) * bias) - quat_get_y(start)) * alpha;
- FloatType z = quat_get_z(start) + ((quat_get_z(end) * bias) - quat_get_z(start)) * alpha;
- FloatType w = quat_get_w(start) + ((quat_get_w(end) * bias) - quat_get_w(start)) * alpha;
- return quat_normalize(quat_set(x, y, z, w));
-}
-
-template<typename QuatType, typename Vector4Type, typename FloatType>
-static void test_quat_impl(const Vector4Type& zero, const QuatType& identity, const FloatType threshold)
-{
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- REQUIRE(quat_get_x(quat_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(0.0));
- REQUIRE(quat_get_y(quat_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(2.34));
- REQUIRE(quat_get_z(quat_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(-3.12));
- REQUIRE(quat_get_w(quat_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(10000.0));
-
- REQUIRE(quat_get_x(identity) == FloatType(0.0));
- REQUIRE(quat_get_y(identity) == FloatType(0.0));
- REQUIRE(quat_get_z(identity) == FloatType(0.0));
- REQUIRE(quat_get_w(identity) == FloatType(1.0));
-
- {
- struct alignas(16) Tmp
- {
- uint8_t padding0[8]; // 8 | 8
- FloatType values[4]; // 24 | 40
- uint8_t padding1[8]; // 32 | 48
- };
-
- Tmp tmp = { { 0 }, { FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0) }, {} };
- REQUIRE(quat_get_x(quat_unaligned_load(&tmp.values[0])) == tmp.values[0]);
- REQUIRE(quat_get_y(quat_unaligned_load(&tmp.values[0])) == tmp.values[1]);
- REQUIRE(quat_get_z(quat_unaligned_load(&tmp.values[0])) == tmp.values[2]);
- REQUIRE(quat_get_w(quat_unaligned_load(&tmp.values[0])) == tmp.values[3]);
- }
-
- {
- const Vector4Type vec = vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0));
- REQUIRE(quat_get_x(vector_to_quat(vec)) == vector_get_x(vec));
- REQUIRE(quat_get_y(vector_to_quat(vec)) == vector_get_y(vec));
- REQUIRE(quat_get_z(vector_to_quat(vec)) == vector_get_z(vec));
- REQUIRE(quat_get_w(vector_to_quat(vec)) == vector_get_w(vec));
- }
-
- {
- struct alignas(16) Tmp
- {
- uint8_t padding0[8]; // 8 | 8
- FloatType values[4]; // 24 | 40
- uint8_t padding1[8]; // 32 | 48
- };
-
- Tmp tmp = { { 0 }, { FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0) }, {} };
- quat_unaligned_write(quat_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), &tmp.values[0]);
- REQUIRE(tmp.values[0] == FloatType(0.0));
- REQUIRE(tmp.values[1] == FloatType(2.34));
- REQUIRE(tmp.values[2] == FloatType(-3.12));
- REQUIRE(tmp.values[3] == FloatType(10000.0));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- {
- QuatType quat = quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0)));
- QuatType quat_conj = quat_conjugate(quat);
- REQUIRE(quat_get_x(quat_conj) == -quat_get_x(quat));
- REQUIRE(quat_get_y(quat_conj) == -quat_get_y(quat));
- REQUIRE(quat_get_z(quat_conj) == -quat_get_z(quat));
- REQUIRE(quat_get_w(quat_conj) == quat_get_w(quat));
- }
-
- {
- QuatType quat0 = quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0)));
- QuatType quat1 = quat_from_euler(deg2rad(FloatType(45.0)), deg2rad(FloatType(60.0)), deg2rad(FloatType(120.0)));
- QuatType result = quat_mul(quat0, quat1);
- QuatType result_ref = quat_mul_scalar<QuatType, Vector4Type, FloatType>(quat0, quat1);
- REQUIRE(quat_near_equal(result, result_ref, threshold));
-
- quat0 = quat_set(FloatType(0.39564531008956383), FloatType(0.044254239301713752), FloatType(0.22768840967675355), FloatType(0.88863059760894492));
- quat1 = quat_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0));
- result = quat_mul(quat0, quat1);
- result_ref = quat_mul_scalar<QuatType, Vector4Type, FloatType>(quat0, quat1);
- REQUIRE(quat_near_equal(result, result_ref, threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type result = quat_rotate(rotation_around_z, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = quat_rotate(rotation_around_z, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0)), threshold));
-
- QuatType rotation_around_x = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)));
- result = quat_rotate(rotation_around_x, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0)), threshold));
- result = quat_rotate(rotation_around_x, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0)), threshold));
-
- QuatType rotation_xz = quat_mul(rotation_around_x, rotation_around_z);
- QuatType rotation_zx = quat_mul(rotation_around_z, rotation_around_x);
- result = quat_rotate(rotation_xz, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = quat_rotate(rotation_xz, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0)), threshold));
- result = quat_rotate(rotation_zx, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0)), threshold));
- result = quat_rotate(rotation_zx, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0)), threshold));
- }
-
- {
- const QuatType test_rotations[] = {
- identity,
- quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0))),
- quat_from_euler(deg2rad(FloatType(45.0)), deg2rad(FloatType(60.0)), deg2rad(FloatType(120.0))),
- quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(180.0)), deg2rad(FloatType(45.0))),
- quat_from_euler(deg2rad(FloatType(-120.0)), deg2rad(FloatType(-90.0)), deg2rad(FloatType(0.0))),
- quat_from_euler(deg2rad(FloatType(-0.01)), deg2rad(FloatType(0.02)), deg2rad(FloatType(-0.03))),
- };
-
- const Vector4Type test_vectors[] = {
- zero,
- vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0)),
- vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)),
- vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0)),
- vector_set(FloatType(45.0), FloatType(-60.0), FloatType(120.0)),
- vector_set(FloatType(-45.0), FloatType(60.0), FloatType(-120.0)),
- vector_set(FloatType(0.57735026918962576451), FloatType(0.57735026918962576451), FloatType(0.57735026918962576451)),
- vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0)),
- };
-
- for (size_t quat_index = 0; quat_index < get_array_size(test_rotations); ++quat_index)
- {
- const QuatType& rotation = test_rotations[quat_index];
- for (size_t vector_index = 0; vector_index < get_array_size(test_vectors); ++vector_index)
- {
- const Vector4Type& vector = test_vectors[vector_index];
- Vector4Type result = quat_rotate(rotation, vector);
- Vector4Type result_ref = quat_rotate_scalar<QuatType, Vector4Type, FloatType>(rotation, vector);
- REQUIRE(vector_all_near_equal3(result, result_ref, threshold));
- }
- }
- }
-
- {
- QuatType quat = quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0)));
- Vector4Type vec = quat_to_vector(quat);
-
- REQUIRE(scalar_near_equal(quat_length_squared(quat), vector_length_squared(vec), threshold));
- REQUIRE(scalar_near_equal(quat_length(quat), vector_length(vec), threshold));
- REQUIRE(scalar_near_equal(quat_length_reciprocal(quat), vector_length_reciprocal(vec), threshold));
- }
-
- {
- QuatType quat = quat_set(FloatType(-0.001138), FloatType(0.91623), FloatType(-1.624598), FloatType(0.715671));
- const QuatType scalar_normalize_result = scalar_normalize<QuatType, FloatType>(quat);
- const QuatType quat_normalize_result = quat_normalize(quat);
- REQUIRE(scalar_near_equal(quat_get_x(quat_normalize_result), quat_get_x(scalar_normalize_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_y(quat_normalize_result), quat_get_y(scalar_normalize_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_z(quat_normalize_result), quat_get_z(scalar_normalize_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_w(quat_normalize_result), quat_get_w(scalar_normalize_result), threshold));
- }
-
- {
- QuatType quat0 = quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0)));
- QuatType quat1 = quat_from_euler(deg2rad(FloatType(45.0)), deg2rad(FloatType(60.0)), deg2rad(FloatType(120.0)));
-
- QuatType scalar_result = scalar_lerp<QuatType, FloatType>(quat0, quat1, FloatType(0.33));
-
- REQUIRE(scalar_near_equal(quat_get_x(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_x(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_y(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_y(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_z(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_z(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_w(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_w(scalar_result), threshold));
-
- quat1 = quat_neg(quat1);
- REQUIRE(scalar_near_equal(quat_get_x(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_x(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_y(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_y(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_z(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_z(scalar_result), threshold));
- REQUIRE(scalar_near_equal(quat_get_w(quat_lerp(quat0, quat1, FloatType(0.33))), quat_get_w(scalar_result), threshold));
- }
-
- {
- QuatType quat0 = quat_from_euler(deg2rad(FloatType(30.0)), deg2rad(FloatType(-45.0)), deg2rad(FloatType(90.0)));
- QuatType quat1 = quat_neg(quat0);
-
- REQUIRE(quat_get_x(quat0) == -quat_get_x(quat1));
- REQUIRE(quat_get_y(quat0) == -quat_get_y(quat1));
- REQUIRE(quat_get_z(quat0) == -quat_get_z(quat1));
- REQUIRE(quat_get_w(quat0) == -quat_get_w(quat1));
- }
-
- {
- QuatType quat0 = quat_set(FloatType(0.39564531008956383), FloatType(0.044254239301713752), FloatType(0.22768840967675355), FloatType(-0.88863059760894492));
- QuatType quat1 = quat_ensure_positive_w(quat0);
- QuatType quat2 = quat_ensure_positive_w(quat1);
-
- REQUIRE(quat_get_x(quat0) == -quat_get_x(quat1));
- REQUIRE(quat_get_y(quat0) == -quat_get_y(quat1));
- REQUIRE(quat_get_z(quat0) == -quat_get_z(quat1));
- REQUIRE(quat_get_w(quat0) == -quat_get_w(quat1));
-
- REQUIRE(quat_get_x(quat2) == quat_get_x(quat1));
- REQUIRE(quat_get_y(quat2) == quat_get_y(quat1));
- REQUIRE(quat_get_z(quat2) == quat_get_z(quat1));
- REQUIRE(quat_get_w(quat2) == quat_get_w(quat1));
-
- Vector4Type vec1 = quat_to_vector(quat1);
- QuatType quat3 = quat_from_positive_w(vec1);
- REQUIRE(quat_get_x(quat1) == quat_get_x(quat3));
- REQUIRE(quat_get_y(quat1) == quat_get_y(quat3));
- REQUIRE(quat_get_z(quat1) == quat_get_z(quat3));
- REQUIRE(scalar_near_equal(quat_get_w(quat1), quat_get_w(quat3), threshold));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Conversion to/from axis/angle/euler
-
- {
- QuatType rotation = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type axis;
- FloatType angle;
- quat_to_axis_angle(rotation, axis, angle);
- REQUIRE(vector_all_near_equal3(axis, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0)), threshold));
- REQUIRE(vector_all_near_equal3(quat_get_axis(rotation), vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0)), threshold));
- REQUIRE(scalar_near_equal(quat_get_angle(rotation), deg2rad(FloatType(90.0)), threshold));
- }
-
- {
- QuatType rotation = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- Vector4Type axis;
- FloatType angle;
- quat_to_axis_angle(rotation, axis, angle);
- QuatType rotation_new = quat_from_axis_angle(axis, angle);
- REQUIRE(quat_near_equal(rotation, rotation_new, threshold));
- }
-
- {
- QuatType rotation = quat_set(FloatType(0.39564531008956383), FloatType(0.044254239301713752), FloatType(0.22768840967675355), FloatType(0.88863059760894492));
- Vector4Type axis_ref = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- axis_ref = quat_rotate(rotation, axis_ref);
- FloatType angle_ref = deg2rad(FloatType(57.0));
- QuatType result = quat_from_axis_angle(axis_ref, angle_ref);
- Vector4Type axis;
- FloatType angle;
- quat_to_axis_angle(result, axis, angle);
- REQUIRE(vector_all_near_equal3(axis, axis_ref, threshold));
- REQUIRE(scalar_near_equal(angle, angle_ref, threshold));
- }
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- {
- const FloatType inf = std::numeric_limits<FloatType>::infinity();
- const FloatType nan = std::numeric_limits<FloatType>::quiet_NaN();
- REQUIRE(quat_is_finite(identity) == true);
- REQUIRE(quat_is_finite(quat_set(inf, inf, inf, inf)) == false);
- REQUIRE(quat_is_finite(quat_set(inf, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(inf), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(1.0), FloatType(inf), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(inf))) == false);
- REQUIRE(quat_is_finite(quat_set(nan, nan, nan, nan)) == false);
- REQUIRE(quat_is_finite(quat_set(nan, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(nan), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(1.0), FloatType(nan), FloatType(1.0))) == false);
- REQUIRE(quat_is_finite(quat_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(nan))) == false);
- }
-
- {
- QuatType quat0 = quat_set(FloatType(0.39564531008956383), FloatType(0.044254239301713752), FloatType(0.22768840967675355), FloatType(0.88863059760894492));
- FloatType quat_len = quat_length(quat0);
- REQUIRE(scalar_near_equal(quat_len, FloatType(1.0), threshold));
- REQUIRE(quat_is_normalized(quat0) == true);
-
- QuatType quat1 = vector_to_quat(vector_mul(quat_to_vector(quat0), FloatType(1.1)));
- REQUIRE(quat_is_normalized(quat1) == false);
- }
-
- {
- REQUIRE(quat_near_equal(identity, identity, threshold) == true);
- REQUIRE(quat_near_equal(identity, quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(quat_near_equal(identity, quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(quat_near_equal(identity, quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(2.0)), FloatType(0.9999)) == false);
- }
-
- {
- REQUIRE(quat_near_identity(identity, threshold) == true);
- REQUIRE(quat_near_identity(quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(0.9999999)), FloatType(0.001)) == true);
- REQUIRE(quat_near_identity(quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(0.98)), FloatType(0.001)) == false);
- }
-}
-
-TEST_CASE("quat 32 math", "[math][quat]")
-{
- test_quat_impl<Quat_32, Vector4_32, float>(vector_zero_32(), quat_identity_32(), 1.0E-4F);
-
- const Quat_32 src = quat_set(0.39564531008956383F, 0.044254239301713752F, 0.22768840967675355F, 0.88863059760894492F);
- const Quat_64 dst = quat_cast(src);
- REQUIRE(scalar_near_equal(quat_get_x(dst), 0.39564531008956383, 1.0E-6));
- REQUIRE(scalar_near_equal(quat_get_y(dst), 0.044254239301713752, 1.0E-6));
- REQUIRE(scalar_near_equal(quat_get_z(dst), 0.22768840967675355, 1.0E-6));
- REQUIRE(scalar_near_equal(quat_get_w(dst), 0.88863059760894492, 1.0E-6));
-}
-
-TEST_CASE("quat 64 math", "[math][quat]")
-{
- test_quat_impl<Quat_64, Vector4_64, double>(vector_zero_64(), quat_identity_64(), 1.0E-6);
-
- const Quat_64 src = quat_set(0.39564531008956383, 0.044254239301713752, 0.22768840967675355, 0.88863059760894492);
- const Quat_32 dst = quat_cast(src);
- REQUIRE(scalar_near_equal(quat_get_x(dst), 0.39564531008956383f, 1.0E-6F));
- REQUIRE(scalar_near_equal(quat_get_y(dst), 0.044254239301713752f, 1.0E-6F));
- REQUIRE(scalar_near_equal(quat_get_z(dst), 0.22768840967675355f, 1.0E-6F));
- REQUIRE(scalar_near_equal(quat_get_w(dst), 0.88863059760894492f, 1.0E-6F));
-}
diff --git a/tests/sources/math/test_quat_packing.cpp b/tests/sources/math/test_quat_packing.cpp
--- a/tests/sources/math/test_quat_packing.cpp
+++ b/tests/sources/math/test_quat_packing.cpp
@@ -27,6 +27,7 @@
#include <acl/math/quat_packing.h>
using namespace acl;
+using namespace rtm;
TEST_CASE("quat packing math", "[math][quat][packing]")
{
@@ -38,12 +39,12 @@ TEST_CASE("quat packing math", "[math][quat][packing]")
};
static_assert((offsetof(UnalignedBuffer, buffer) % 2) == 0, "Minimum packing alignment is 2");
- const Quat_32 quat0 = quat_set(0.39564531008956383F, 0.044254239301713752F, 0.22768840967675355F, 0.88863059760894492F);
+ const quatf quat0 = quat_set(0.39564531008956383F, 0.044254239301713752F, 0.22768840967675355F, 0.88863059760894492F);
{
UnalignedBuffer tmp0;
pack_quat_128(quat0, &tmp0.buffer[0]);
- Quat_32 quat1 = unpack_quat_128(&tmp0.buffer[0]);
+ quatf quat1 = unpack_quat_128(&tmp0.buffer[0]);
REQUIRE(quat_get_x(quat0) == quat_get_x(quat1));
REQUIRE(quat_get_y(quat0) == quat_get_y(quat1));
REQUIRE(quat_get_z(quat0) == quat_get_z(quat1));
@@ -53,7 +54,7 @@ TEST_CASE("quat packing math", "[math][quat][packing]")
{
UnalignedBuffer tmp0;
pack_quat_96(quat0, &tmp0.buffer[0]);
- Quat_32 quat1 = unpack_quat_96_unsafe(&tmp0.buffer[0]);
+ quatf quat1 = unpack_quat_96_unsafe(&tmp0.buffer[0]);
REQUIRE(quat_get_x(quat0) == quat_get_x(quat1));
REQUIRE(quat_get_y(quat0) == quat_get_y(quat1));
REQUIRE(quat_get_z(quat0) == quat_get_z(quat1));
@@ -63,7 +64,7 @@ TEST_CASE("quat packing math", "[math][quat][packing]")
{
UnalignedBuffer tmp0;
pack_quat_48(quat0, &tmp0.buffer[0]);
- Quat_32 quat1 = unpack_quat_48(&tmp0.buffer[0]);
+ quatf quat1 = unpack_quat_48(&tmp0.buffer[0]);
REQUIRE(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-4F));
REQUIRE(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-4F));
REQUIRE(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-4F));
@@ -73,7 +74,7 @@ TEST_CASE("quat packing math", "[math][quat][packing]")
{
UnalignedBuffer tmp0;
pack_quat_32(quat0, &tmp0.buffer[0]);
- Quat_32 quat1 = unpack_quat_32(&tmp0.buffer[0]);
+ quatf quat1 = unpack_quat_32(&tmp0.buffer[0]);
REQUIRE(scalar_near_equal(quat_get_x(quat0), quat_get_x(quat1), 1.0E-3F));
REQUIRE(scalar_near_equal(quat_get_y(quat0), quat_get_y(quat1), 1.0E-3F));
REQUIRE(scalar_near_equal(quat_get_z(quat0), quat_get_z(quat1), 1.0E-3F));
diff --git a/tests/sources/math/test_scalar.cpp b/tests/sources/math/test_scalar.cpp
deleted file mode 100644
--- a/tests/sources/math/test_scalar.cpp
+++ /dev/null
@@ -1,164 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include <catch.hpp>
-
-#include <acl/math/scalar_32.h>
-#include <acl/math/scalar_64.h>
-
-#include <limits>
-
-using namespace acl;
-
-template<typename FloatType>
-static void test_scalar_impl(const FloatType pi, const FloatType threshold)
-{
- const FloatType half_pi = pi * FloatType(0.5);
- const FloatType two_pi = pi * FloatType(2.0);
-
- REQUIRE(acl::floor(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(acl::floor(FloatType(0.5)) == FloatType(0.0));
- REQUIRE(acl::floor(FloatType(2.5)) == FloatType(2.0));
- REQUIRE(acl::floor(FloatType(3.0)) == FloatType(3.0));
- REQUIRE(acl::floor(FloatType(-0.5)) == FloatType(-1.0));
- REQUIRE(acl::floor(FloatType(-2.5)) == FloatType(-3.0));
- REQUIRE(acl::floor(FloatType(-3.0)) == FloatType(-3.0));
-
- REQUIRE(acl::ceil(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(acl::ceil(FloatType(0.5)) == FloatType(1.0));
- REQUIRE(acl::ceil(FloatType(2.5)) == FloatType(3.0));
- REQUIRE(acl::ceil(FloatType(3.0)) == FloatType(3.0));
- REQUIRE(acl::ceil(FloatType(-0.5)) == FloatType(0.0));
- REQUIRE(acl::ceil(FloatType(-2.5)) == FloatType(-2.0));
- REQUIRE(acl::ceil(FloatType(-3.0)) == FloatType(-3.0));
-
- REQUIRE(clamp(FloatType(0.5), FloatType(0.0), FloatType(1.0)) == FloatType(0.5));
- REQUIRE(clamp(FloatType(-0.5), FloatType(0.0), FloatType(1.0)) == FloatType(0.0));
- REQUIRE(clamp(FloatType(1.5), FloatType(0.0), FloatType(1.0)) == FloatType(1.0));
-
- REQUIRE(acl::abs(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(acl::abs(FloatType(2.0)) == FloatType(2.0));
- REQUIRE(acl::abs(FloatType(-2.0)) == FloatType(2.0));
-
- REQUIRE(scalar_near_equal(FloatType(1.0), FloatType(1.0), FloatType(0.00001)) == true);
- REQUIRE(scalar_near_equal(FloatType(1.0), FloatType(1.000001), FloatType(0.00001)) == true);
- REQUIRE(scalar_near_equal(FloatType(1.0), FloatType(0.999999), FloatType(0.00001)) == true);
- REQUIRE(scalar_near_equal(FloatType(1.0), FloatType(1.001), FloatType(0.00001)) == false);
- REQUIRE(scalar_near_equal(FloatType(1.0), FloatType(0.999), FloatType(0.00001)) == false);
-
- REQUIRE(acl::sqrt(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(scalar_near_equal(acl::sqrt(FloatType(0.5)), std::sqrt(FloatType(0.5)), threshold));
- REQUIRE(scalar_near_equal(acl::sqrt(FloatType(32.5)), std::sqrt(FloatType(32.5)), threshold));
-
- REQUIRE(scalar_near_equal(acl::sqrt_reciprocal(FloatType(0.5)), FloatType(1.0) / std::sqrt(FloatType(0.5)), threshold));
- REQUIRE(scalar_near_equal(acl::sqrt_reciprocal(FloatType(32.5)), FloatType(1.0) / std::sqrt(FloatType(32.5)), threshold));
-
- REQUIRE(scalar_near_equal(acl::reciprocal(FloatType(0.5)), FloatType(1.0 / 0.5), threshold));
- REQUIRE(scalar_near_equal(acl::reciprocal(FloatType(32.5)), FloatType(1.0 / 32.5), threshold));
- REQUIRE(scalar_near_equal(acl::reciprocal(FloatType(-0.5)), FloatType(1.0 / -0.5), threshold));
- REQUIRE(scalar_near_equal(acl::reciprocal(FloatType(-32.5)), FloatType(1.0 / -32.5), threshold));
-
- const FloatType angles[] = { FloatType(0.0), pi, -pi, half_pi, -half_pi, FloatType(0.5), FloatType(32.5), FloatType(-0.5), FloatType(-32.5) };
-
- for (const FloatType angle : angles)
- {
- REQUIRE(scalar_near_equal(acl::sin(angle), std::sin(angle), threshold));
- REQUIRE(scalar_near_equal(acl::cos(angle), std::cos(angle), threshold));
-
- FloatType sin_result;
- FloatType cos_result;
- acl::sincos(angle, sin_result, cos_result);
- REQUIRE(scalar_near_equal(sin_result, std::sin(angle), threshold));
- REQUIRE(scalar_near_equal(cos_result, std::cos(angle), threshold));
- }
-
- REQUIRE(scalar_near_equal(acl::acos(FloatType(-1.0)), std::acos(FloatType(-1.0)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(-0.75)), std::acos(FloatType(-0.75)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(-0.5)), std::acos(FloatType(-0.5)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(-0.25)), std::acos(-FloatType(0.25)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(0.0)), std::acos(FloatType(0.0)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(0.25)), std::acos(FloatType(0.25)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(0.5)), std::acos(FloatType(0.5)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(0.75)), std::acos(FloatType(0.75)), threshold));
- REQUIRE(scalar_near_equal(acl::acos(FloatType(1.0)), std::acos(FloatType(1.0)), threshold));
-
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(-2.0), FloatType(-2.0)), std::atan2(FloatType(-2.0), FloatType(-2.0)), threshold));
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(-1.0), FloatType(-2.0)), std::atan2(FloatType(-1.0), FloatType(-2.0)), threshold));
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(-2.0), FloatType(-1.0)), std::atan2(FloatType(-2.0), FloatType(-1.0)), threshold));
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(2.0), FloatType(2.0)), std::atan2(FloatType(2.0), FloatType(2.0)), threshold));
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(1.0), FloatType(2.0)), std::atan2(FloatType(1.0), FloatType(2.0)), threshold));
- REQUIRE(scalar_near_equal(acl::atan2(FloatType(2.0), FloatType(1.0)), std::atan2(FloatType(2.0), FloatType(1.0)), threshold));
-
- REQUIRE(acl::min(FloatType(-0.5), FloatType(1.0)) == FloatType(-0.5));
- REQUIRE(acl::min(FloatType(1.0), FloatType(-0.5)) == FloatType(-0.5));
- REQUIRE(acl::min(FloatType(1.0), FloatType(1.0)) == FloatType(1.0));
-
- REQUIRE(acl::max(FloatType(-0.5), FloatType(1.0)) == FloatType(1.0));
- REQUIRE(acl::max(FloatType(1.0), FloatType(-0.5)) == FloatType(1.0));
- REQUIRE(acl::max(FloatType(1.0), FloatType(1.0)) == FloatType(1.0));
-
- REQUIRE(deg2rad(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(90.0)), half_pi, threshold));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(-90.0)), -half_pi, threshold));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(180.0)), pi, threshold));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(-180.0)), -pi, threshold));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(360.0)), two_pi, threshold));
- REQUIRE(scalar_near_equal(deg2rad(FloatType(-360.0)), -two_pi, threshold));
-
- REQUIRE(acl::is_finite(FloatType(0.0)) == true);
- REQUIRE(acl::is_finite(FloatType(32.0)) == true);
- REQUIRE(acl::is_finite(FloatType(-32.0)) == true);
- REQUIRE(acl::is_finite(std::numeric_limits<FloatType>::infinity()) == false);
- REQUIRE(acl::is_finite(std::numeric_limits<FloatType>::quiet_NaN()) == false);
- REQUIRE(acl::is_finite(std::numeric_limits<FloatType>::signaling_NaN()) == false);
-
- REQUIRE(symmetric_round(FloatType(-1.75)) == FloatType(-2.0));
- REQUIRE(symmetric_round(FloatType(-1.5)) == FloatType(-2.0));
- REQUIRE(symmetric_round(FloatType(-1.4999)) == FloatType(-1.0));
- REQUIRE(symmetric_round(FloatType(-0.5)) == FloatType(-1.0));
- REQUIRE(symmetric_round(FloatType(-0.4999)) == FloatType(0.0));
- REQUIRE(symmetric_round(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(symmetric_round(FloatType(0.4999)) == FloatType(0.0));
- REQUIRE(symmetric_round(FloatType(0.5)) == FloatType(1.0));
- REQUIRE(symmetric_round(FloatType(1.4999)) == FloatType(1.0));
- REQUIRE(symmetric_round(FloatType(1.5)) == FloatType(2.0));
- REQUIRE(symmetric_round(FloatType(1.75)) == FloatType(2.0));
-
- REQUIRE(fraction(FloatType(0.0)) == FloatType(0.0));
- REQUIRE(fraction(FloatType(1.0)) == FloatType(0.0));
- REQUIRE(fraction(FloatType(-1.0)) == FloatType(0.0));
- REQUIRE(scalar_near_equal(fraction(FloatType(0.25)), FloatType(0.25), threshold));
- REQUIRE(scalar_near_equal(fraction(FloatType(0.5)), FloatType(0.5), threshold));
- REQUIRE(scalar_near_equal(fraction(FloatType(0.75)), FloatType(0.75), threshold));
-}
-
-TEST_CASE("scalar 32 math", "[math][scalar]")
-{
- test_scalar_impl<float>(acl::k_pi_32, 1.0E-6F);
-}
-
-TEST_CASE("scalar 64 math", "[math][scalar]")
-{
- test_scalar_impl<double>(acl::k_pi_64, 1.0E-9);
-}
diff --git a/tests/sources/math/test_scalar_packing.cpp b/tests/sources/math/test_scalar_packing.cpp
--- a/tests/sources/math/test_scalar_packing.cpp
+++ b/tests/sources/math/test_scalar_packing.cpp
@@ -45,7 +45,7 @@ TEST_CASE("scalar packing math", "[math][scalar][packing]")
CHECK(pack_scalar_signed(-1.0F, num_bits) == 0);
CHECK(pack_scalar_signed(1.0F, num_bits) == max_value);
CHECK(unpack_scalar_signed(0, num_bits) == -1.0F);
- CHECK(scalar_near_equal(unpack_scalar_signed(max_value, num_bits), 1.0F, threshold));
+ CHECK(rtm::scalar_near_equal(unpack_scalar_signed(max_value, num_bits), 1.0F, threshold));
uint32_t num_errors = 0;
for (uint32_t value = 0; value < max_value; ++value)
diff --git a/tests/sources/math/test_transform.cpp b/tests/sources/math/test_transform.cpp
deleted file mode 100644
--- a/tests/sources/math/test_transform.cpp
+++ /dev/null
@@ -1,184 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include <catch.hpp>
-
-#include <acl/math/transform_32.h>
-#include <acl/math/transform_64.h>
-
-using namespace acl;
-
-template<typename TransformType, typename FloatType>
-static void test_transform_impl(const TransformType& identity, const FloatType threshold)
-{
- using QuatType = decltype(TransformType::rotation);
- using Vector4Type = decltype(TransformType::translation);
-
- {
- Vector4Type zero = vector_set(FloatType(0.0));
- Vector4Type one = vector_set(FloatType(1.0));
- QuatType q_identity = quat_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0));
- TransformType tmp = transform_set(q_identity, zero, one);
- REQUIRE(quat_near_equal(identity.rotation, tmp.rotation, threshold));
- REQUIRE(vector_all_near_equal3(identity.translation, tmp.translation, threshold));
- REQUIRE(vector_all_near_equal3(identity.scale, tmp.scale, threshold));
- REQUIRE(quat_near_equal(q_identity, tmp.rotation, threshold));
- REQUIRE(vector_all_near_equal3(zero, tmp.translation, threshold));
- REQUIRE(vector_all_near_equal3(one, tmp.scale, threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0));
- Vector4Type test_scale = vector_set(FloatType(1.2));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- TransformType transform_a = transform_set(rotation_around_z, x_axis, test_scale);
- Vector4Type result = transform_position(transform_a, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.2), FloatType(0.0)), threshold));
- result = transform_position(transform_a, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-0.2), FloatType(0.0), FloatType(0.0)), threshold));
-
- QuatType rotation_around_x = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)));
- TransformType transform_b = transform_set(rotation_around_x, y_axis, test_scale);
- result = transform_position(transform_b, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.2), FloatType(1.0), FloatType(0.0)), threshold));
- result = transform_position(transform_b, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(-1.2)), threshold));
-
- TransformType transform_ab = transform_mul(transform_a, transform_b);
- TransformType transform_ba = transform_mul(transform_b, transform_a);
- result = transform_position(transform_ab, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.2), FloatType(1.0), FloatType(-1.44)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position(transform_b, transform_position(transform_a, x_axis)), threshold));
- result = transform_position(transform_ab, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-0.24), FloatType(1.0), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position(transform_b, transform_position(transform_a, y_axis)), threshold));
- result = transform_position(transform_ba, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-0.2), FloatType(1.44), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position(transform_a, transform_position(transform_b, x_axis)), threshold));
- result = transform_position(transform_ba, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(-0.2), FloatType(0.0), FloatType(-1.44)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position(transform_a, transform_position(transform_b, y_axis)), threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- Vector4Type y_axis = vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- TransformType transform_a = transform_set(rotation_around_z, x_axis, vector_set(FloatType(1.0)));
- Vector4Type result = transform_position_no_scale(transform_a, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = transform_position_no_scale(transform_a, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0)), threshold));
-
- QuatType rotation_around_x = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)));
- TransformType transform_b = transform_set(rotation_around_x, y_axis, vector_set(FloatType(1.0)));
- result = transform_position_no_scale(transform_b, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(0.0)), threshold));
- result = transform_position_no_scale(transform_b, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(-1.0)), threshold));
-
- TransformType transform_ab = transform_mul_no_scale(transform_a, transform_b);
- TransformType transform_ba = transform_mul_no_scale(transform_b, transform_a);
- result = transform_position_no_scale(transform_ab, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(1.0), FloatType(1.0), FloatType(-1.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position_no_scale(transform_b, transform_position_no_scale(transform_a, x_axis)), threshold));
- result = transform_position_no_scale(transform_ab, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position_no_scale(transform_b, transform_position_no_scale(transform_a, y_axis)), threshold));
- result = transform_position_no_scale(transform_ba, x_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position_no_scale(transform_a, transform_position_no_scale(transform_b, x_axis)), threshold));
- result = transform_position_no_scale(transform_ba, y_axis);
- REQUIRE(vector_all_near_equal3(result, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0)), threshold));
- REQUIRE(vector_all_near_equal3(result, transform_position_no_scale(transform_a, transform_position_no_scale(transform_b, y_axis)), threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- Vector4Type test_scale = vector_set(FloatType(1.2));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- TransformType transform_a = transform_set(rotation_around_z, x_axis, test_scale);
- TransformType transform_b = transform_inverse(transform_a);
- TransformType transform_ab = transform_mul(transform_a, transform_b);
- REQUIRE(quat_near_equal(identity.rotation, transform_ab.rotation, threshold));
- REQUIRE(vector_all_near_equal3(identity.translation, transform_ab.translation, threshold));
- REQUIRE(vector_all_near_equal3(identity.scale, transform_ab.scale, threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
-
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- TransformType transform_a = transform_set(rotation_around_z, x_axis, vector_set(FloatType(1.0)));
- TransformType transform_b = transform_inverse_no_scale(transform_a);
- TransformType transform_ab = transform_mul_no_scale(transform_a, transform_b);
- REQUIRE(quat_near_equal(identity.rotation, transform_ab.rotation, threshold));
- REQUIRE(vector_all_near_equal3(identity.translation, transform_ab.translation, threshold));
- REQUIRE(vector_all_near_equal3(identity.scale, transform_ab.scale, threshold));
- }
-
- {
- Vector4Type x_axis = vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0));
- QuatType rotation_around_z = quat_from_euler(deg2rad(FloatType(0.0)), deg2rad(FloatType(90.0)), deg2rad(FloatType(0.0)));
- TransformType transform_a = transform_set(rotation_around_z, x_axis, vector_set(FloatType(1.0)));
- REQUIRE(quat_is_normalized(transform_normalize(transform_a).rotation, threshold));
-
- QuatType quat = quat_set(FloatType(-0.001138), FloatType(0.91623), FloatType(-1.624598), FloatType(0.715671));
- TransformType transform_b = transform_set(quat, x_axis, vector_set(FloatType(1.0)));
- REQUIRE(!quat_is_normalized(transform_b.rotation, threshold));
- REQUIRE(quat_is_normalized(transform_normalize(transform_b).rotation, threshold));
- }
-}
-
-TEST_CASE("transform 32 math", "[math][transform]")
-{
- test_transform_impl<Transform_32, float>(transform_identity_32(), 1.0E-4F);
-
- const Quat_32 src_rotation = quat_set(0.39564531008956383F, 0.044254239301713752F, 0.22768840967675355F, 0.88863059760894492F);
- const Vector4_32 src_translation = vector_set(-2.65F, 2.996113F, 0.68123521F);
- const Vector4_32 src_scale = vector_set(1.2F, 0.8F, 2.1F);
- const Transform_32 src = transform_set(src_rotation, src_translation, src_scale);
- const Transform_64 dst = transform_cast(src);
- REQUIRE(quat_near_equal(src.rotation, quat_cast(dst.rotation), 1.0E-6F));
- REQUIRE(vector_all_near_equal3(src.translation, vector_cast(dst.translation), 1.0E-6F));
- REQUIRE(vector_all_near_equal3(src.scale, vector_cast(dst.scale), 1.0E-6F));
-}
-
-TEST_CASE("transform 64 math", "[math][transform]")
-{
- test_transform_impl<Transform_64, double>(transform_identity_64(), 1.0E-6);
-
- const Quat_64 src_rotation = quat_set(0.39564531008956383, 0.044254239301713752, 0.22768840967675355, 0.88863059760894492);
- const Vector4_64 src_translation = vector_set(-2.65, 2.996113, 0.68123521);
- const Vector4_64 src_scale = vector_set(1.2, 0.8, 2.1);
- const Transform_64 src = transform_set(src_rotation, src_translation, src_scale);
- const Transform_32 dst = transform_cast(src);
- REQUIRE(quat_near_equal(src.rotation, quat_cast(dst.rotation), 1.0E-6));
- REQUIRE(vector_all_near_equal3(src.translation, vector_cast(dst.translation), 1.0E-6));
- REQUIRE(vector_all_near_equal3(src.scale, vector_cast(dst.scale), 1.0E-6));
-}
diff --git a/tests/sources/math/test_vector4_32.cpp b/tests/sources/math/test_vector4_32.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32.cpp
+++ /dev/null
@@ -1,43 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 32 math", "[math][vector4]")
-{
-#if defined(ACL_NO_INTRINSICS)
- const float threshold = 1.0E-4F;
-#else
- const float threshold = 1.0E-5F;
-#endif
-
- test_vector4_impl<Vector4_32, Quat_32, float>(vector_zero_32(), quat_identity_32(), threshold);
-
- const Vector4_32 src = vector_set(-2.65F, 2.996113F, 0.68123521F, -5.9182F);
- const Vector4_64 dst = vector_cast(src);
- REQUIRE(scalar_near_equal(vector_get_x(dst), -2.65, 1.0E-6));
- REQUIRE(scalar_near_equal(vector_get_y(dst), 2.996113, 1.0E-6));
- REQUIRE(scalar_near_equal(vector_get_z(dst), 0.68123521, 1.0E-6));
- REQUIRE(scalar_near_equal(vector_get_w(dst), -5.9182, 1.0E-6));
-}
diff --git a/tests/sources/math/test_vector4_32_mix_a.cpp b/tests/sources/math/test_vector4_32_mix_a.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_a.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<A * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::A>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_b.cpp b/tests/sources/math/test_vector4_32_mix_b.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_b.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<B * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::B>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_c.cpp b/tests/sources/math/test_vector4_32_mix_c.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_c.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<C * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::C>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_d.cpp b/tests/sources/math/test_vector4_32_mix_d.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_d.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<D * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::D>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_w.cpp b/tests/sources/math/test_vector4_32_mix_w.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_w.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<W * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::W>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_x.cpp b/tests/sources/math/test_vector4_32_mix_x.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_x.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<X * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::X>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_y.cpp b/tests/sources/math/test_vector4_32_mix_y.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_y.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<Y * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::Y>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_32_mix_z.cpp b/tests/sources/math/test_vector4_32_mix_z.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_32_mix_z.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("Vector4_32 vector_mix<Z * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_32, float, VectorMix::Z>(1.0E-6F);
-}
diff --git a/tests/sources/math/test_vector4_64.cpp b/tests/sources/math/test_vector4_64.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64.cpp
+++ /dev/null
@@ -1,37 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 math", "[math][vector4]")
-{
- test_vector4_impl<Vector4_64, Quat_64, double>(vector_zero_64(), quat_identity_64(), 1.0E-9);
-
- const Vector4_64 src = vector_set(-2.65, 2.996113, 0.68123521, -5.9182);
- const Vector4_32 dst = vector_cast(src);
- REQUIRE(scalar_near_equal(vector_get_x(dst), -2.65F, 1.0E-6F));
- REQUIRE(scalar_near_equal(vector_get_y(dst), 2.996113F, 1.0E-6F));
- REQUIRE(scalar_near_equal(vector_get_z(dst), 0.68123521F, 1.0E-6F));
- REQUIRE(scalar_near_equal(vector_get_w(dst), -5.9182F, 1.0E-6F));
-}
diff --git a/tests/sources/math/test_vector4_64_mix_a.cpp b/tests/sources/math/test_vector4_64_mix_a.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_a.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<A * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::A>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_b.cpp b/tests/sources/math/test_vector4_64_mix_b.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_b.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<B * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::B>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_c.cpp b/tests/sources/math/test_vector4_64_mix_c.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_c.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<C * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::C>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_d.cpp b/tests/sources/math/test_vector4_64_mix_d.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_d.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<D * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::D>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_w.cpp b/tests/sources/math/test_vector4_64_mix_w.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_w.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<W * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::W>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_x.cpp b/tests/sources/math/test_vector4_64_mix_x.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_x.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<X * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::X>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_y.cpp b/tests/sources/math/test_vector4_64_mix_y.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_y.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<Y * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::Y>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_64_mix_z.cpp b/tests/sources/math/test_vector4_64_mix_z.cpp
deleted file mode 100644
--- a/tests/sources/math/test_vector4_64_mix_z.cpp
+++ /dev/null
@@ -1,30 +0,0 @@
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "test_vector4_impl.h"
-
-TEST_CASE("vector4 64 vector_mix<Z * * *>", "[math][vector4]")
-{
- test_vector4_vector_mix_impl<Vector4_64, double, VectorMix::Z>(1.0E-9);
-}
diff --git a/tests/sources/math/test_vector4_impl.h b/tests/sources/math/test_vector4_impl.h
deleted file mode 100644
--- a/tests/sources/math/test_vector4_impl.h
+++ /dev/null
@@ -1,659 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2018 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include <catch.hpp>
-
-#include <acl/math/vector4_32.h>
-#include <acl/math/vector4_64.h>
-#include <acl/math/quat_32.h>
-#include <acl/math/quat_64.h>
-
-#include <cstring>
-#include <limits>
-
-using namespace acl;
-
-template<typename Vector4Type>
-inline Vector4Type vector_unaligned_load_raw(const uint8_t* input);
-
-template<>
-inline Vector4_32 vector_unaligned_load_raw<Vector4_32>(const uint8_t* input)
-{
- return vector_unaligned_load_32(input);
-}
-
-template<>
-inline Vector4_64 vector_unaligned_load_raw<Vector4_64>(const uint8_t* input)
-{
- return vector_unaligned_load_64(input);
-}
-
-template<typename Vector4Type>
-inline Vector4Type vector_unaligned_load3_raw(const uint8_t* input);
-
-template<>
-inline Vector4_32 vector_unaligned_load3_raw<Vector4_32>(const uint8_t* input)
-{
- return vector_unaligned_load3_32(input);
-}
-
-template<>
-inline Vector4_64 vector_unaligned_load3_raw<Vector4_64>(const uint8_t* input)
-{
- return vector_unaligned_load3_64(input);
-}
-
-template<typename Vector4Type, typename FloatType>
-inline const FloatType* vector_as_float_ptr_raw(const Vector4Type& input);
-
-template<>
-inline const float* vector_as_float_ptr_raw<Vector4_32, float>(const Vector4_32& input)
-{
- return vector_as_float_ptr(input);
-}
-
-template<>
-inline const double* vector_as_float_ptr_raw<Vector4_64, double>(const Vector4_64& input)
-{
- return vector_as_double_ptr(input);
-}
-
-template<typename Vector4Type>
-inline Vector4Type scalar_cross3(const Vector4Type& lhs, const Vector4Type& rhs)
-{
- return vector_set(vector_get_y(lhs) * vector_get_z(rhs) - vector_get_z(lhs) * vector_get_y(rhs),
- vector_get_z(lhs) * vector_get_x(rhs) - vector_get_x(lhs) * vector_get_z(rhs),
- vector_get_x(lhs) * vector_get_y(rhs) - vector_get_y(lhs) * vector_get_x(rhs));
-}
-
-template<typename Vector4Type, typename FloatType>
-inline FloatType scalar_dot(const Vector4Type& lhs, const Vector4Type& rhs)
-{
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs)) + (vector_get_w(lhs) * vector_get_w(rhs));
-}
-
-template<typename Vector4Type, typename FloatType>
-inline FloatType scalar_dot3(const Vector4Type& lhs, const Vector4Type& rhs)
-{
- return (vector_get_x(lhs) * vector_get_x(rhs)) + (vector_get_y(lhs) * vector_get_y(rhs)) + (vector_get_z(lhs) * vector_get_z(rhs));
-}
-
-template<typename Vector4Type, typename FloatType>
-inline Vector4Type scalar_normalize3(const Vector4Type& input, FloatType threshold)
-{
- FloatType len_sq = scalar_dot3<Vector4Type, FloatType>(input, input);
- if (len_sq >= threshold)
- {
- FloatType inv_len = acl::sqrt_reciprocal(len_sq);
- return vector_set(vector_get_x(input) * inv_len, vector_get_y(input) * inv_len, vector_get_z(input) * inv_len);
- }
- else
- return input;
-}
-
-template<typename Vector4Type, typename QuatType, typename FloatType>
-void test_vector4_impl(const Vector4Type& zero, const QuatType& identity, const FloatType threshold)
-{
- struct alignas(16) Tmp
- {
- uint8_t padding0[8]; // 8 | 8
- FloatType values[4]; // 24 | 40
- uint8_t padding1[8]; // 32 | 48
- };
-
- Tmp tmp = { { 0 }, { FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0) }, {} };
- alignas(16) uint8_t buffer[64];
-
- const FloatType test_value0_flt[4] = { FloatType(2.0), FloatType(9.34), FloatType(-54.12), FloatType(6000.0) };
- const FloatType test_value1_flt[4] = { FloatType(0.75), FloatType(-4.52), FloatType(44.68), FloatType(-54225.0) };
- const FloatType test_value2_flt[4] = { FloatType(-2.65), FloatType(2.996113), FloatType(0.68123521), FloatType(-5.9182) };
- const Vector4Type test_value0 = vector_set(test_value0_flt[0], test_value0_flt[1], test_value0_flt[2], test_value0_flt[3]);
- const Vector4Type test_value1 = vector_set(test_value1_flt[0], test_value1_flt[1], test_value1_flt[2], test_value1_flt[3]);
- const Vector4Type test_value2 = vector_set(test_value2_flt[0], test_value2_flt[1], test_value2_flt[2], test_value2_flt[3]);
-
- //////////////////////////////////////////////////////////////////////////
- // Setters, getters, and casts
-
- REQUIRE(vector_get_x(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(0.0));
- REQUIRE(vector_get_y(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(2.34));
- REQUIRE(vector_get_z(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(-3.12));
- REQUIRE(vector_get_w(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(10000.0));
-
- REQUIRE(vector_get_x(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12))) == FloatType(0.0));
- REQUIRE(vector_get_y(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12))) == FloatType(2.34));
- REQUIRE(vector_get_z(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12))) == FloatType(-3.12));
-
- REQUIRE(vector_get_x(vector_set(FloatType(-3.12))) == FloatType(-3.12));
- REQUIRE(vector_get_y(vector_set(FloatType(-3.12))) == FloatType(-3.12));
- REQUIRE(vector_get_z(vector_set(FloatType(-3.12))) == FloatType(-3.12));
- REQUIRE(vector_get_w(vector_set(FloatType(-3.12))) == FloatType(-3.12));
-
- REQUIRE(vector_get_x(zero) == FloatType(0.0));
- REQUIRE(vector_get_y(zero) == FloatType(0.0));
- REQUIRE(vector_get_z(zero) == FloatType(0.0));
- REQUIRE(vector_get_w(zero) == FloatType(0.0));
-
- REQUIRE(vector_get_x(vector_unaligned_load(&tmp.values[0])) == tmp.values[0]);
- REQUIRE(vector_get_y(vector_unaligned_load(&tmp.values[0])) == tmp.values[1]);
- REQUIRE(vector_get_z(vector_unaligned_load(&tmp.values[0])) == tmp.values[2]);
- REQUIRE(vector_get_w(vector_unaligned_load(&tmp.values[0])) == tmp.values[3]);
-
- REQUIRE(vector_get_x(vector_unaligned_load3(&tmp.values[0])) == tmp.values[0]);
- REQUIRE(vector_get_y(vector_unaligned_load3(&tmp.values[0])) == tmp.values[1]);
- REQUIRE(vector_get_z(vector_unaligned_load3(&tmp.values[0])) == tmp.values[2]);
-
- std::memcpy(&buffer[1], &tmp.values[0], sizeof(tmp.values));
- REQUIRE(vector_get_x(vector_unaligned_load_raw<Vector4Type>(&buffer[1])) == tmp.values[0]);
- REQUIRE(vector_get_y(vector_unaligned_load_raw<Vector4Type>(&buffer[1])) == tmp.values[1]);
- REQUIRE(vector_get_z(vector_unaligned_load_raw<Vector4Type>(&buffer[1])) == tmp.values[2]);
- REQUIRE(vector_get_w(vector_unaligned_load_raw<Vector4Type>(&buffer[1])) == tmp.values[3]);
-
- REQUIRE(vector_get_x(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])) == tmp.values[0]);
- REQUIRE(vector_get_y(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])) == tmp.values[1]);
- REQUIRE(vector_get_z(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])) == tmp.values[2]);
-
- REQUIRE(vector_get_x(quat_to_vector(identity)) == quat_get_x(identity));
- REQUIRE(vector_get_y(quat_to_vector(identity)) == quat_get_y(identity));
- REQUIRE(vector_get_z(quat_to_vector(identity)) == quat_get_z(identity));
- REQUIRE(vector_get_w(quat_to_vector(identity)) == quat_get_w(identity));
-
- REQUIRE(vector_get_component<VectorMix::X>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(0.0));
- REQUIRE(vector_get_component<VectorMix::Y>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(2.34));
- REQUIRE(vector_get_component<VectorMix::Z>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(-3.12));
- REQUIRE(vector_get_component<VectorMix::W>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(10000.0));
-
- REQUIRE(vector_get_component<VectorMix::A>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(0.0));
- REQUIRE(vector_get_component<VectorMix::B>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(2.34));
- REQUIRE(vector_get_component<VectorMix::C>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(-3.12));
- REQUIRE(vector_get_component<VectorMix::D>(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0))) == FloatType(10000.0));
-
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::X) == FloatType(0.0));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::Y) == FloatType(2.34));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::Z) == FloatType(-3.12));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::W) == FloatType(10000.0));
-
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::A) == FloatType(0.0));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::B) == FloatType(2.34));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::C) == FloatType(-3.12));
- REQUIRE(vector_get_component(vector_set(FloatType(0.0), FloatType(2.34), FloatType(-3.12), FloatType(10000.0)), VectorMix::D) == FloatType(10000.0));
-
- REQUIRE((vector_as_float_ptr_raw<Vector4Type, FloatType>(vector_unaligned_load(&tmp.values[0]))[0] == tmp.values[0]));
- REQUIRE((vector_as_float_ptr_raw<Vector4Type, FloatType>(vector_unaligned_load(&tmp.values[0]))[1] == tmp.values[1]));
- REQUIRE((vector_as_float_ptr_raw<Vector4Type, FloatType>(vector_unaligned_load(&tmp.values[0]))[2] == tmp.values[2]));
- REQUIRE((vector_as_float_ptr_raw<Vector4Type, FloatType>(vector_unaligned_load(&tmp.values[0]))[3] == tmp.values[3]));
-
- vector_unaligned_write(test_value0, &tmp.values[0]);
- REQUIRE(vector_get_x(test_value0) == tmp.values[0]);
- REQUIRE(vector_get_y(test_value0) == tmp.values[1]);
- REQUIRE(vector_get_z(test_value0) == tmp.values[2]);
- REQUIRE(vector_get_w(test_value0) == tmp.values[3]);
-
- vector_unaligned_write3(test_value1, &tmp.values[0]);
- REQUIRE(vector_get_x(test_value1) == tmp.values[0]);
- REQUIRE(vector_get_y(test_value1) == tmp.values[1]);
- REQUIRE(vector_get_z(test_value1) == tmp.values[2]);
- REQUIRE(vector_get_w(test_value0) == tmp.values[3]);
-
- vector_unaligned_write3(test_value1, &buffer[1]);
- REQUIRE(vector_get_x(test_value1) == vector_get_x(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])));
- REQUIRE(vector_get_y(test_value1) == vector_get_y(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])));
- REQUIRE(vector_get_z(test_value1) == vector_get_z(vector_unaligned_load3_raw<Vector4Type>(&buffer[1])));
-
- //////////////////////////////////////////////////////////////////////////
- // Arithmetic
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_add(test_value0, test_value1)), test_value0_flt[0] + test_value1_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_add(test_value0, test_value1)), test_value0_flt[1] + test_value1_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_add(test_value0, test_value1)), test_value0_flt[2] + test_value1_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_add(test_value0, test_value1)), test_value0_flt[3] + test_value1_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_sub(test_value0, test_value1)), test_value0_flt[0] - test_value1_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_sub(test_value0, test_value1)), test_value0_flt[1] - test_value1_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_sub(test_value0, test_value1)), test_value0_flt[2] - test_value1_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_sub(test_value0, test_value1)), test_value0_flt[3] - test_value1_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_mul(test_value0, test_value1)), test_value0_flt[0] * test_value1_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_mul(test_value0, test_value1)), test_value0_flt[1] * test_value1_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_mul(test_value0, test_value1)), test_value0_flt[2] * test_value1_flt[2], threshold));
- // We have a strange codegen bug with gcc5, use the Catch near equal impl instead
- REQUIRE(vector_get_w(vector_mul(test_value0, test_value1)) == Approx(test_value0_flt[3] * test_value1_flt[3]).margin(threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_mul(test_value0, FloatType(2.34))), test_value0_flt[0] * FloatType(2.34), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_mul(test_value0, FloatType(2.34))), test_value0_flt[1] * FloatType(2.34), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_mul(test_value0, FloatType(2.34))), test_value0_flt[2] * FloatType(2.34), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_mul(test_value0, FloatType(2.34))), test_value0_flt[3] * FloatType(2.34), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_div(test_value0, test_value1)), test_value0_flt[0] / test_value1_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_div(test_value0, test_value1)), test_value0_flt[1] / test_value1_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_div(test_value0, test_value1)), test_value0_flt[2] / test_value1_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_div(test_value0, test_value1)), test_value0_flt[3] / test_value1_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_max(test_value0, test_value1)), acl::max(test_value0_flt[0], test_value1_flt[0]), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_max(test_value0, test_value1)), acl::max(test_value0_flt[1], test_value1_flt[1]), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_max(test_value0, test_value1)), acl::max(test_value0_flt[2], test_value1_flt[2]), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_max(test_value0, test_value1)), acl::max(test_value0_flt[3], test_value1_flt[3]), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_min(test_value0, test_value1)), acl::min(test_value0_flt[0], test_value1_flt[0]), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_min(test_value0, test_value1)), acl::min(test_value0_flt[1], test_value1_flt[1]), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_min(test_value0, test_value1)), acl::min(test_value0_flt[2], test_value1_flt[2]), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_min(test_value0, test_value1)), acl::min(test_value0_flt[3], test_value1_flt[3]), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_abs(test_value0)), acl::abs(test_value0_flt[0]), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_abs(test_value0)), acl::abs(test_value0_flt[1]), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_abs(test_value0)), acl::abs(test_value0_flt[2]), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_abs(test_value0)), acl::abs(test_value0_flt[3]), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_neg(test_value0)), -test_value0_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_neg(test_value0)), -test_value0_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_neg(test_value0)), -test_value0_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_neg(test_value0)), -test_value0_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_reciprocal(test_value0)), acl::reciprocal(test_value0_flt[0]), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_reciprocal(test_value0)), acl::reciprocal(test_value0_flt[1]), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_reciprocal(test_value0)), acl::reciprocal(test_value0_flt[2]), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_reciprocal(test_value0)), acl::reciprocal(test_value0_flt[3]), threshold));
-
- const Vector4Type scalar_cross3_result = scalar_cross3<Vector4Type>(test_value0, test_value1);
- const Vector4Type vector_cross3_result = vector_cross3(test_value0, test_value1);
- REQUIRE(scalar_near_equal(vector_get_x(vector_cross3_result), vector_get_x(scalar_cross3_result), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_cross3_result), vector_get_y(scalar_cross3_result), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_cross3_result), vector_get_z(scalar_cross3_result), threshold));
-
- const FloatType test_value10_flt[4] = { FloatType(-0.001138), FloatType(0.91623), FloatType(-1.624598), FloatType(0.715671) };
- const FloatType test_value11_flt[4] = { FloatType(0.1138), FloatType(-0.623), FloatType(1.4598), FloatType(-0.5671) };
- const Vector4Type test_value10 = vector_set(test_value10_flt[0], test_value10_flt[1], test_value10_flt[2], test_value10_flt[3]);
- const Vector4Type test_value11 = vector_set(test_value11_flt[0], test_value11_flt[1], test_value11_flt[2], test_value11_flt[3]);
- const FloatType scalar_dot_result = scalar_dot<Vector4Type, FloatType>(test_value10, test_value11);
- const FloatType vector_dot_result = vector_dot(test_value10, test_value11);
- REQUIRE(scalar_near_equal(vector_dot_result, scalar_dot_result, threshold));
-
- const FloatType scalar_dot3_result = scalar_dot3<Vector4Type, FloatType>(test_value10, test_value11);
- const FloatType vector_dot3_result = vector_dot3(test_value10, test_value11);
- REQUIRE(scalar_near_equal(vector_dot3_result, scalar_dot3_result, threshold));
-
- const Vector4Type vector_vdot_result = vector_vdot(test_value10, test_value11);
- REQUIRE(scalar_near_equal(vector_get_x(vector_vdot_result), scalar_dot_result, threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_vdot_result), scalar_dot_result, threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_vdot_result), scalar_dot_result, threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_vdot_result), scalar_dot_result, threshold));
-
- REQUIRE(scalar_near_equal(scalar_dot<Vector4Type, FloatType>(test_value0, test_value0), vector_length_squared(test_value0), threshold));
- REQUIRE(scalar_near_equal(scalar_dot3<Vector4Type, FloatType>(test_value0, test_value0), vector_length_squared3(test_value0), threshold));
-
- REQUIRE(scalar_near_equal(acl::sqrt(scalar_dot<Vector4Type, FloatType>(test_value0, test_value0)), vector_length(test_value0), threshold));
- REQUIRE(scalar_near_equal(acl::sqrt(scalar_dot3<Vector4Type, FloatType>(test_value0, test_value0)), vector_length3(test_value0), threshold));
-
- REQUIRE(scalar_near_equal(acl::sqrt_reciprocal(scalar_dot<Vector4Type, FloatType>(test_value0, test_value0)), vector_length_reciprocal(test_value0), threshold));
- REQUIRE(scalar_near_equal(acl::sqrt_reciprocal(scalar_dot3<Vector4Type, FloatType>(test_value0, test_value0)), vector_length_reciprocal3(test_value0), threshold));
-
- const Vector4Type test_value_diff = vector_sub(test_value0, test_value1);
- REQUIRE(scalar_near_equal(acl::sqrt(scalar_dot3<Vector4Type, FloatType>(test_value_diff, test_value_diff)), vector_distance3(test_value0, test_value1), threshold));
-
- const Vector4Type scalar_normalize3_result = scalar_normalize3<Vector4Type, FloatType>(test_value0, threshold);
- const Vector4Type vector_normalize3_result = vector_normalize3(test_value0, threshold);
- REQUIRE(scalar_near_equal(vector_get_x(vector_normalize3_result), vector_get_x(scalar_normalize3_result), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_normalize3_result), vector_get_y(scalar_normalize3_result), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_normalize3_result), vector_get_z(scalar_normalize3_result), threshold));
-
- const Vector4Type scalar_normalize3_result0 = scalar_normalize3<Vector4Type, FloatType>(zero, threshold);
- const Vector4Type vector_normalize3_result0 = vector_normalize3(zero, threshold);
- REQUIRE(scalar_near_equal(vector_get_x(vector_normalize3_result0), vector_get_x(scalar_normalize3_result0), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_normalize3_result0), vector_get_y(scalar_normalize3_result0), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_normalize3_result0), vector_get_z(scalar_normalize3_result0), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_lerp(test_value10, test_value11, FloatType(0.33))), ((test_value11_flt[0] - test_value10_flt[0]) * FloatType(0.33)) + test_value10_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_lerp(test_value10, test_value11, FloatType(0.33))), ((test_value11_flt[1] - test_value10_flt[1]) * FloatType(0.33)) + test_value10_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_lerp(test_value10, test_value11, FloatType(0.33))), ((test_value11_flt[2] - test_value10_flt[2]) * FloatType(0.33)) + test_value10_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_lerp(test_value10, test_value11, FloatType(0.33))), ((test_value11_flt[3] - test_value10_flt[3]) * FloatType(0.33)) + test_value10_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_fraction(test_value0)), acl::fraction(test_value0_flt[0]), threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_fraction(test_value0)), acl::fraction(test_value0_flt[1]), threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_fraction(test_value0)), acl::fraction(test_value0_flt[2]), threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_fraction(test_value0)), acl::fraction(test_value0_flt[3]), threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_mul_add(test_value10, test_value11, test_value2)), (test_value10_flt[0] * test_value11_flt[0]) + test_value2_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_mul_add(test_value10, test_value11, test_value2)), (test_value10_flt[1] * test_value11_flt[1]) + test_value2_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_mul_add(test_value10, test_value11, test_value2)), (test_value10_flt[2] * test_value11_flt[2]) + test_value2_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_mul_add(test_value10, test_value11, test_value2)), (test_value10_flt[3] * test_value11_flt[3]) + test_value2_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[0] * test_value11_flt[0]) + test_value2_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[1] * test_value11_flt[0]) + test_value2_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[2] * test_value11_flt[0]) + test_value2_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[3] * test_value11_flt[0]) + test_value2_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[0] * -test_value11_flt[0]) + test_value2_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[1] * -test_value11_flt[1]) + test_value2_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[2] * -test_value11_flt[2]) + test_value2_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[3] * -test_value11_flt[3]) + test_value2_flt[3], threshold));
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[0] * -test_value11_flt[0]) + test_value2_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[1] * -test_value11_flt[0]) + test_value2_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[2] * -test_value11_flt[0]) + test_value2_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[3] * -test_value11_flt[0]) + test_value2_flt[3], threshold));
-
- //////////////////////////////////////////////////////////////////////////
- // Comparisons and masking
-
- REQUIRE((vector_get_x(vector_less_than(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[0] < test_value1_flt[0]));
- REQUIRE((vector_get_y(vector_less_than(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[1] < test_value1_flt[1]));
- REQUIRE((vector_get_z(vector_less_than(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[2] < test_value1_flt[2]));
- REQUIRE((vector_get_w(vector_less_than(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[3] < test_value1_flt[3]));
-
- REQUIRE((vector_get_x(vector_greater_equal(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[0] >= test_value1_flt[0]));
- REQUIRE((vector_get_y(vector_greater_equal(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[1] >= test_value1_flt[1]));
- REQUIRE((vector_get_z(vector_greater_equal(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[2] >= test_value1_flt[2]));
- REQUIRE((vector_get_w(vector_greater_equal(test_value0, test_value1)) != FloatType(0.0)) == (test_value0_flt[3] >= test_value1_flt[3]));
-
- REQUIRE(vector_all_less_than(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0))) == true);
- REQUIRE(vector_all_less_than(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0))) == false);
- REQUIRE(vector_all_less_than(zero, zero) == false);
-
- REQUIRE(vector_all_less_than3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_than3(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than3(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than3(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_than3(zero, zero) == false);
-
- REQUIRE(vector_any_less_than(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0))) == true);
- REQUIRE(vector_any_less_than(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0))) == true);
- REQUIRE(vector_any_less_than(zero, zero) == false);
-
- REQUIRE(vector_any_less_than3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than3(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than3(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than3(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_than3(zero, zero) == false);
-
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0))) == true);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(1.0))) == true);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(-1.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(0.0), FloatType(-1.0))) == false);
- REQUIRE(vector_all_less_equal(zero, zero) == true);
-
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(0.0), FloatType(-1.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal2(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal2(zero, zero) == true);
-
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(0.0), FloatType(1.0), FloatType(0.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(-1.0), FloatType(0.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(0.0), FloatType(-1.0), FloatType(0.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal3(zero, vector_set(FloatType(0.0), FloatType(0.0), FloatType(-1.0), FloatType(0.0))) == false);
- REQUIRE(vector_all_less_equal3(zero, zero) == true);
-
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0))) == true);
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0))) == true);
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(-1.0))) == true);
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(-1.0))) == true);
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(1.0))) == true);
- REQUIRE(vector_any_less_equal(zero, vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0))) == false);
- REQUIRE(vector_any_less_equal(zero, zero) == true);
-
- REQUIRE(vector_any_less_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_equal3(zero, vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_equal3(zero, vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_equal3(zero, vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(0.0))) == true);
- REQUIRE(vector_any_less_equal3(zero, vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0))) == false);
- REQUIRE(vector_any_less_equal3(zero, zero) == true);
-
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), zero) == true);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(0.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(0.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_all_greater_equal(zero, zero) == true);
-
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(0.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(0.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_all_greater_equal3(zero, zero) == true);
-
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(0.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(-1.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(0.0), FloatType(-1.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(-1.0)), zero) == false);
- REQUIRE(vector_any_greater_equal(zero, zero) == true);
-
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(-1.0), FloatType(1.0), FloatType(-1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(0.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(-1.0), FloatType(0.0), FloatType(-1.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(0.0), FloatType(0.0)), zero) == true);
- REQUIRE(vector_any_greater_equal3(vector_set(FloatType(-1.0), FloatType(-1.0), FloatType(-1.0), FloatType(0.0)), zero) == false);
- REQUIRE(vector_any_greater_equal3(zero, zero) == true);
-
- REQUIRE(vector_all_near_equal(zero, zero, threshold) == true);
- REQUIRE(vector_all_near_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_all_near_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), FloatType(1.0)) == true);
- REQUIRE(vector_all_near_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), FloatType(0.9999)) == false);
-
- REQUIRE(vector_all_near_equal2(zero, zero, threshold) == true);
- REQUIRE(vector_all_near_equal2(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_all_near_equal2(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_all_near_equal2(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(0.9999)) == false);
-
- REQUIRE(vector_all_near_equal3(zero, zero, threshold) == true);
- REQUIRE(vector_all_near_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_all_near_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_all_near_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(0.9999)) == false);
-
- REQUIRE(vector_any_near_equal(zero, zero, threshold) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(1.0), FloatType(2.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(1.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(2.0), FloatType(1.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(1.0), FloatType(2.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(1.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(2.0), FloatType(1.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(1.0)), FloatType(0.9999)) == false);
-
- REQUIRE(vector_any_near_equal3(zero, zero, threshold) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(1.0), FloatType(2.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(2.0), FloatType(1.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0001)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(1.0), FloatType(2.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(2.0), FloatType(1.0), FloatType(2.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(2.0), FloatType(2.0), FloatType(1.0), FloatType(2.0)), FloatType(1.0)) == true);
- REQUIRE(vector_any_near_equal3(zero, vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(2.0)), FloatType(0.9999)) == false);
-
- const FloatType inf = std::numeric_limits<FloatType>::infinity();
- const FloatType nan = std::numeric_limits<FloatType>::quiet_NaN();
- REQUIRE(vector_is_finite(zero) == true);
- REQUIRE(vector_is_finite(vector_set(inf, inf, inf, inf)) == false);
- REQUIRE(vector_is_finite(vector_set(inf, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(inf), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(1.0), FloatType(inf), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(inf))) == false);
- REQUIRE(vector_is_finite(vector_set(nan, nan, nan, nan)) == false);
- REQUIRE(vector_is_finite(vector_set(nan, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(nan), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(1.0), FloatType(nan), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(nan))) == false);
-
- REQUIRE(vector_is_finite3(zero) == true);
- REQUIRE(vector_is_finite3(vector_set(inf, inf, inf, inf)) == false);
- REQUIRE(vector_is_finite3(vector_set(inf, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(inf), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(inf), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(inf))) == true);
- REQUIRE(vector_is_finite3(vector_set(nan, nan, nan, nan)) == false);
- REQUIRE(vector_is_finite3(vector_set(nan, FloatType(1.0), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(nan), FloatType(1.0), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(nan), FloatType(1.0))) == false);
- REQUIRE(vector_is_finite3(vector_set(FloatType(1.0), FloatType(1.0), FloatType(1.0), FloatType(nan))) == true);
-
- //////////////////////////////////////////////////////////////////////////
- // Swizzling, permutations, and mixing
-
- REQUIRE(scalar_near_equal(vector_get_x(vector_blend(vector_less_than(zero, vector_set(FloatType(1.0))), test_value0, test_value1)), test_value0_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_blend(vector_less_than(zero, vector_set(FloatType(1.0))), test_value0, test_value1)), test_value0_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_blend(vector_less_than(zero, vector_set(FloatType(1.0))), test_value0, test_value1)), test_value0_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_blend(vector_less_than(zero, vector_set(FloatType(1.0))), test_value0, test_value1)), test_value0_flt[3], threshold));
- REQUIRE(scalar_near_equal(vector_get_x(vector_blend(vector_less_than(vector_set(FloatType(1.0)), zero), test_value0, test_value1)), test_value1_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_blend(vector_less_than(vector_set(FloatType(1.0)), zero), test_value0, test_value1)), test_value1_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_blend(vector_less_than(vector_set(FloatType(1.0)), zero), test_value0, test_value1)), test_value1_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_blend(vector_less_than(vector_set(FloatType(1.0)), zero), test_value0, test_value1)), test_value1_flt[3], threshold));
-
- //////////////////////////////////////////////////////////////////////////
- // Misc
-
- auto scalar_sign = [](FloatType value) { return value >= FloatType(0.0) ? FloatType(1.0) : FloatType(-1.0); };
- REQUIRE(vector_get_x(vector_sign(test_value0)) == scalar_sign(test_value0_flt[0]));
- REQUIRE(vector_get_y(vector_sign(test_value0)) == scalar_sign(test_value0_flt[1]));
- REQUIRE(vector_get_z(vector_sign(test_value0)) == scalar_sign(test_value0_flt[2]));
- REQUIRE(vector_get_w(vector_sign(test_value0)) == scalar_sign(test_value0_flt[3]));
-
- {
- const Vector4Type input0 = vector_set(FloatType(-1.75), FloatType(-1.5), FloatType(-1.4999), FloatType(-0.5));
- const Vector4Type input1 = vector_set(FloatType(-0.4999), FloatType(0.0), FloatType(0.4999), FloatType(0.5));
- const Vector4Type input2 = vector_set(FloatType(1.4999), FloatType(1.5), FloatType(1.75), FloatType(0.0));
-
- const Vector4Type result0 = vector_symmetric_round(input0);
- const Vector4Type result1 = vector_symmetric_round(input1);
- const Vector4Type result2 = vector_symmetric_round(input2);
-
- REQUIRE(vector_get_x(result0) == symmetric_round(vector_get_x(input0)));
- REQUIRE(vector_get_y(result0) == symmetric_round(vector_get_y(input0)));
- REQUIRE(vector_get_z(result0) == symmetric_round(vector_get_z(input0)));
- REQUIRE(vector_get_w(result0) == symmetric_round(vector_get_w(input0)));
- REQUIRE(vector_get_x(result1) == symmetric_round(vector_get_x(input1)));
- REQUIRE(vector_get_y(result1) == symmetric_round(vector_get_y(input1)));
- REQUIRE(vector_get_z(result1) == symmetric_round(vector_get_z(input1)));
- REQUIRE(vector_get_w(result1) == symmetric_round(vector_get_w(input1)));
- REQUIRE(vector_get_x(result2) == symmetric_round(vector_get_x(input2)));
- REQUIRE(vector_get_y(result2) == symmetric_round(vector_get_y(input2)));
- REQUIRE(vector_get_z(result2) == symmetric_round(vector_get_z(input2)));
- REQUIRE(vector_get_w(result2) == symmetric_round(vector_get_w(input2)));
- }
-}
-
-template<typename Vector4Type, typename FloatType, VectorMix XArg>
-void test_vector4_vector_mix_impl(const FloatType threshold)
-{
- const FloatType test_value0_flt[4] = { FloatType(2.0), FloatType(9.34), FloatType(-54.12), FloatType(6000.0) };
- const FloatType test_value1_flt[4] = { FloatType(0.75), FloatType(-4.52), FloatType(44.68), FloatType(-54225.0) };
-
- const Vector4Type test_value0 = vector_set(test_value0_flt[0], test_value0_flt[1], test_value0_flt[2], test_value0_flt[3]);
- const Vector4Type test_value1 = vector_set(test_value1_flt[0], test_value1_flt[1], test_value1_flt[2], test_value1_flt[3]);
-
- Vector4Type results[8 * 8 * 8];
- uint32_t index = 0;
-
-#define ACL_TEST_MIX_XYZ(comp0, comp1, comp2) \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::X>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::Y>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::Z>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::W>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::A>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::B>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::C>(test_value0, test_value1); \
- results[index++] = vector_mix<comp0, comp1, comp2, VectorMix::D>(test_value0, test_value1)
-
-#define ACL_TEST_MIX_XY(comp0, comp1) \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::X); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::Y); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::Z); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::W); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::A); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::B); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::C); \
- ACL_TEST_MIX_XYZ(comp0, comp1, VectorMix::D)
-
-#define ACL_TEST_MIX_X(comp0) \
- ACL_TEST_MIX_XY(comp0, VectorMix::X); \
- ACL_TEST_MIX_XY(comp0, VectorMix::Y); \
- ACL_TEST_MIX_XY(comp0, VectorMix::Z); \
- ACL_TEST_MIX_XY(comp0, VectorMix::W); \
- ACL_TEST_MIX_XY(comp0, VectorMix::A); \
- ACL_TEST_MIX_XY(comp0, VectorMix::B); \
- ACL_TEST_MIX_XY(comp0, VectorMix::C); \
- ACL_TEST_MIX_XY(comp0, VectorMix::D)
-
- // This generates 8*8*8 = 512 unit tests... it takes a while to compile and uses a lot of stack space
- ACL_TEST_MIX_X(XArg);
-
- auto verify_mix = [&](int comp0, int comp1, int comp2, int comp3, const Vector4Type& actual)
- {
- INFO("vector_mix<" << comp0 << ", " << comp1 << ", " << comp2 << ", " << comp3 << ">");
-
- const Vector4Type expected = vector_set(
- math_impl::is_vector_mix_arg_xyzw((VectorMix)comp0) ? test_value0_flt[comp0 - (int)VectorMix::X] : test_value1_flt[comp0 - (int)VectorMix::A],
- math_impl::is_vector_mix_arg_xyzw((VectorMix)comp1) ? test_value0_flt[comp1 - (int)VectorMix::X] : test_value1_flt[comp1 - (int)VectorMix::A],
- math_impl::is_vector_mix_arg_xyzw((VectorMix)comp2) ? test_value0_flt[comp2 - (int)VectorMix::X] : test_value1_flt[comp2 - (int)VectorMix::A],
- math_impl::is_vector_mix_arg_xyzw((VectorMix)comp3) ? test_value0_flt[comp3 - (int)VectorMix::X] : test_value1_flt[comp3 - (int)VectorMix::A]);
-
- REQUIRE(vector_all_near_equal(expected, actual, threshold));
- };
-
- index = 0;
-
- const int comp0 = (int)XArg;
- for (int comp1 = 0; comp1 < 8; ++comp1)
- for (int comp2 = 0; comp2 < 8; ++comp2)
- for (int comp3 = 0; comp3 < 8; ++comp3)
- verify_mix(comp0, comp1, comp2, comp3, results[index++]);
-
-#undef ACL_TEST_MIX_X
-#undef ACL_TEST_MIX_XY
-#undef ACL_TEST_MIX_XYZ
-}
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -24,12 +24,14 @@
#include <catch.hpp>
-#include <acl/math/scalar_32.h>
#include <acl/math/vector4_packing.h>
+#include <rtm/scalarf.h>
+
#include <cstring>
using namespace acl;
+using namespace rtm;
struct UnalignedBuffer
{
@@ -43,16 +45,16 @@ TEST_CASE("pack_vector4_128", "[math][vector4][packing]")
{
{
UnalignedBuffer tmp;
- Vector4_32 vec0 = vector_set(6123.123812F, 19237.01293127F, 1891.019231829F, 0.913912387F);
+ vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 1891.019231829F, 0.913912387F);
pack_vector4_128(vec0, &tmp.buffer[0]);
- Vector4_32 vec1 = unpack_vector4_128(&tmp.buffer[0]);
- REQUIRE(std::memcmp(&vec0, &vec1, sizeof(Vector4_32)) == 0);
+ vector4f vec1 = unpack_vector4_128(&tmp.buffer[0]);
+ REQUIRE(std::memcmp(&vec0, &vec1, sizeof(vector4f)) == 0);
}
{
UnalignedBuffer tmp0;
UnalignedBuffer tmp1;
- Vector4_32 vec0 = vector_set(6123.123812F, 19237.01293127F, 1891.019231829F, 0.913912387F);
+ vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 1891.019231829F, 0.913912387F);
pack_vector4_128(vec0, &tmp0.buffer[0]);
uint32_t x = unaligned_load<uint32_t>(&tmp0.buffer[0]);
@@ -78,7 +80,7 @@ TEST_CASE("pack_vector4_128", "[math][vector4][packing]")
const uint8_t offset = offsets[offset_idx];
memcpy_bits(&tmp1.buffer[0], offset, &tmp0.buffer[0], 0, 128);
- Vector4_32 vec1 = unpack_vector4_128_unsafe(&tmp1.buffer[0], offset);
+ vector4f vec1 = unpack_vector4_128_unsafe(&tmp1.buffer[0], offset);
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
}
@@ -96,9 +98,9 @@ TEST_CASE("pack_vector4_64", "[math][vector4][packing]")
const float value_signed = unpack_scalar_signed(value, 16);
const float value_unsigned = unpack_scalar_unsigned(value, 16);
- Vector4_32 vec0 = vector_set(value_signed);
+ vector4f vec0 = vector_set(value_signed);
pack_vector4_64(vec0, false, &tmp.buffer[0]);
- Vector4_32 vec1 = unpack_vector4_64(&tmp.buffer[0], false);
+ vector4f vec1 = unpack_vector4_64(&tmp.buffer[0], false);
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -119,12 +121,12 @@ TEST_CASE("pack_vector4_32", "[math][vector4][packing]")
uint32_t num_errors = 0;
for (uint32_t value = 0; value < 256; ++value)
{
- const float value_signed = min(unpack_scalar_signed(value, 8), 1.0F);
- const float value_unsigned = min(unpack_scalar_unsigned(value, 8), 1.0F);
+ const float value_signed = scalar_min(unpack_scalar_signed(value, 8), 1.0F);
+ const float value_unsigned = scalar_min(unpack_scalar_unsigned(value, 8), 1.0F);
- Vector4_32 vec0 = vector_set(value_signed);
+ vector4f vec0 = vector_set(value_signed);
pack_vector4_32(vec0, false, &tmp.buffer[0]);
- Vector4_32 vec1 = unpack_vector4_32(&tmp.buffer[0], false);
+ vector4f vec1 = unpack_vector4_32(&tmp.buffer[0], false);
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -145,9 +147,9 @@ TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
alignas(16) uint8_t buffer[64];
uint32_t num_errors = 0;
- Vector4_32 vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
+ vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
pack_vector4_uXX_unsafe(vec0, 16, &buffer[0]);
- Vector4_32 vec1 = unpack_vector4_uXX_unsafe(16, &buffer[0], 0);
+ vector4f vec1 = unpack_vector4_uXX_unsafe(16, &buffer[0], 0);
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -157,7 +159,7 @@ TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
- const float value_unsigned = clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
pack_vector4_uXX_unsafe(vec0, num_bits, &buffer[0]);
@@ -188,9 +190,9 @@ TEST_CASE("pack_vector3_96", "[math][vector4][packing]")
{
UnalignedBuffer tmp0;
UnalignedBuffer tmp1;
- Vector4_32 vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F);
+ vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F);
pack_vector3_96(vec0, &tmp0.buffer[0]);
- Vector4_32 vec1 = unpack_vector3_96_unsafe(&tmp0.buffer[0]);
+ vector4f vec1 = unpack_vector3_96_unsafe(&tmp0.buffer[0]);
REQUIRE(vector_all_near_equal3(vec0, vec1, 1.0E-6F));
uint32_t x = unaligned_load<uint32_t>(&tmp0.buffer[0]);
@@ -230,9 +232,9 @@ TEST_CASE("pack_vector3_48", "[math][vector4][packing]")
const float value_signed = unpack_scalar_signed(value, 16);
const float value_unsigned = unpack_scalar_unsigned(value, 16);
- Vector4_32 vec0 = vector_set(value_signed, value_signed, value_signed);
+ vector4f vec0 = vector_set(value_signed, value_signed, value_signed);
pack_vector3_s48_unsafe(vec0, &tmp0.buffer[0]);
- Vector4_32 vec1 = unpack_vector3_s48_unsafe(&tmp0.buffer[0]);
+ vector4f vec1 = unpack_vector3_s48_unsafe(&tmp0.buffer[0]);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -255,8 +257,8 @@ TEST_CASE("decay_vector3_48", "[math][vector4][decay]")
const float value_signed = unpack_scalar_signed(value, 16);
const float value_unsigned = unpack_scalar_unsigned(value, 16);
- Vector4_32 vec0 = vector_set(value_signed, value_signed, value_signed);
- Vector4_32 vec1 = decay_vector3_s48(vec0);
+ vector4f vec0 = vector_set(value_signed, value_signed, value_signed);
+ vector4f vec1 = decay_vector3_s48(vec0);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -287,9 +289,9 @@ TEST_CASE("pack_vector3_32", "[math][vector4][packing]")
const float value_unsigned_xy = unpack_scalar_unsigned(value_xy, num_bits_xy);
const float value_unsigned_z = unpack_scalar_unsigned(value_z, num_bits_z);
- Vector4_32 vec0 = vector_set(value_signed_xy, value_signed_xy, value_signed_z);
+ vector4f vec0 = vector_set(value_signed_xy, value_signed_xy, value_signed_z);
pack_vector3_32(vec0, 11, 11, 10, false, &tmp0.buffer[0]);
- Vector4_32 vec1 = unpack_vector3_32(11, 11, 10, false, &tmp0.buffer[0]);
+ vector4f vec1 = unpack_vector3_32(11, 11, 10, false, &tmp0.buffer[0]);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -320,8 +322,8 @@ TEST_CASE("decay_vector3_32", "[math][vector4][decay]")
const float value_unsigned_xy = unpack_scalar_unsigned(value_xy, num_bits_xy);
const float value_unsigned_z = unpack_scalar_unsigned(value_z, num_bits_z);
- Vector4_32 vec0 = vector_set(value_signed_xy, value_signed_xy, value_signed_z);
- Vector4_32 vec1 = decay_vector3_s32(vec0, num_bits_xy, num_bits_xy, num_bits_z);
+ vector4f vec0 = vector_set(value_signed_xy, value_signed_xy, value_signed_z);
+ vector4f vec1 = decay_vector3_s32(vec0, num_bits_xy, num_bits_xy, num_bits_z);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -341,12 +343,12 @@ TEST_CASE("pack_vector3_24", "[math][vector4][packing]")
uint32_t num_errors = 0;
for (uint32_t value = 0; value < 256; ++value)
{
- const float value_signed = min(unpack_scalar_signed(value, 8), 1.0F);
- const float value_unsigned = min(unpack_scalar_unsigned(value, 8), 1.0F);
+ const float value_signed = scalar_min(unpack_scalar_signed(value, 8), 1.0F);
+ const float value_unsigned = scalar_min(unpack_scalar_unsigned(value, 8), 1.0F);
- Vector4_32 vec0 = vector_set(value_signed, value_signed, value_signed);
+ vector4f vec0 = vector_set(value_signed, value_signed, value_signed);
pack_vector3_s24_unsafe(vec0, &tmp0.buffer[0]);
- Vector4_32 vec1 = unpack_vector3_s24_unsafe(&tmp0.buffer[0]);
+ vector4f vec1 = unpack_vector3_s24_unsafe(&tmp0.buffer[0]);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -367,9 +369,9 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
alignas(16) uint8_t buffer[64];
uint32_t num_errors = 0;
- Vector4_32 vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
+ vector4f vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
pack_vector3_sXX_unsafe(vec0, 16, &buffer[0]);
- Vector4_32 vec1 = unpack_vector3_sXX_unsafe(16, &buffer[0], 0);
+ vector4f vec1 = unpack_vector3_sXX_unsafe(16, &buffer[0], 0);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -385,8 +387,8 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
- const float value_signed = clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
- const float value_unsigned = clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const float value_signed = scalar_clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
pack_vector3_uXX_unsafe(vec0, num_bits, &buffer[0]);
@@ -436,8 +438,8 @@ TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
{
uint32_t num_errors = 0;
- Vector4_32 vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
- Vector4_32 vec1 = decay_vector3_sXX(vec0, 16);
+ vector4f vec0 = vector_set(unpack_scalar_signed(0, 16), unpack_scalar_signed(12355, 16), unpack_scalar_signed(43222, 16));
+ vector4f vec1 = decay_vector3_sXX(vec0, 16);
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -452,8 +454,8 @@ TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
- const float value_signed = clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
- const float value_unsigned = clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const float value_signed = scalar_clamp(unpack_scalar_signed(value, num_bits), -1.0F, 1.0F);
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
vec0 = vector_set(value_signed, value_signed, value_signed);
vec1 = decay_vector3_sXX(vec0, num_bits);
@@ -476,7 +478,7 @@ TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
{
UnalignedBuffer tmp0;
UnalignedBuffer tmp1;
- Vector4_32 vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F, 0.1816253F);
+ vector4f vec0 = vector_set(6123.123812F, 19237.01293127F, 0.913912387F, 0.1816253F);
pack_vector4_128(vec0, &tmp0.buffer[0]);
uint32_t x = unaligned_load<uint32_t>(&tmp0.buffer[0]);
@@ -494,7 +496,7 @@ TEST_CASE("pack_vector2_64", "[math][vector4][packing]")
const uint8_t offset = offsets[offset_idx];
memcpy_bits(&tmp1.buffer[0], offset, &tmp0.buffer[0], 0, 64);
- Vector4_32 vec1 = unpack_vector2_64_unsafe(&tmp1.buffer[0], offset);
+ vector4f vec1 = unpack_vector2_64_unsafe(&tmp1.buffer[0], offset);
if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
num_errors++;
}
@@ -509,9 +511,9 @@ TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
alignas(16) uint8_t buffer[64];
uint32_t num_errors = 0;
- Vector4_32 vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
+ vector4f vec0 = vector_set(unpack_scalar_unsigned(0, 16), unpack_scalar_unsigned(12355, 16), unpack_scalar_unsigned(43222, 16), unpack_scalar_unsigned(54432, 16));
pack_vector2_uXX_unsafe(vec0, 16, &buffer[0]);
- Vector4_32 vec1 = unpack_vector2_uXX_unsafe(16, &buffer[0], 0);
+ vector4f vec1 = unpack_vector2_uXX_unsafe(16, &buffer[0], 0);
if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
num_errors++;
@@ -521,7 +523,7 @@ TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
- const float value_unsigned = clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
+ const float value_unsigned = scalar_clamp(unpack_scalar_unsigned(value, num_bits), 0.0F, 1.0F);
vec0 = vector_set(value_unsigned, value_unsigned, value_unsigned);
pack_vector2_uXX_unsafe(vec0, num_bits, &buffer[0]);
|
Integrate and switch to Realtime Math
The ACL math code has been moved into its own depot Realtime Math (https://github.com/nfrechette/rtm) for easier maintenance and added flexibility.
The types and naming convention changed a bit which will break compilation as such a complete refactor is required and a major version bump as well. Because the code was mostly moved and cleaned up, the risk involved is very low.
The dependency should be added under external, documented, and as a sub-module.
| 2019-11-22T03:19:43
|
cpp
|
Hard
|
|
nfrechette/acl
| 239
|
nfrechette__acl-239
|
[
"139"
] |
4774c3a2dffe5b171a2259cd5680c948e7a4e1e4
|
diff --git a/tools/acl_compressor/main_android/AndroidManifest.xml b/tools/acl_compressor/main_android/AndroidManifest.xml
--- a/tools/acl_compressor/main_android/AndroidManifest.xml
+++ b/tools/acl_compressor/main_android/AndroidManifest.xml
@@ -1,6 +1,6 @@
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
- package="com.acl"
+ package="com.acl.compressor"
android:versionCode="1"
android:versionName="1.0">
<uses-sdk android:minSdkVersion="3" />
diff --git a/tools/acl_compressor/main_android/CMakeLists.txt b/tools/acl_compressor/main_android/CMakeLists.txt
--- a/tools/acl_compressor/main_android/CMakeLists.txt
+++ b/tools/acl_compressor/main_android/CMakeLists.txt
@@ -36,7 +36,7 @@ file(GLOB_RECURSE ALL_MAIN_SOURCE_FILES LIST_DIRECTORIES false
create_source_groups("${ALL_MAIN_SOURCE_FILES}" ${PROJECT_SOURCE_DIR})
# Add resource files
-set(JAVA_FILES java/com/acl/MainActivity.java)
+set(JAVA_FILES java/com/acl/compressor/MainActivity.java)
set(RESOURCE_FILES res/values/strings.xml)
set(ANDROID_FILES AndroidManifest.xml)
diff --git a/tools/acl_compressor/main_android/java/com/acl/MainActivity.java b/tools/acl_compressor/main_android/java/com/acl/compressor/MainActivity.java
similarity index 95%
rename from tools/acl_compressor/main_android/java/com/acl/MainActivity.java
rename to tools/acl_compressor/main_android/java/com/acl/compressor/MainActivity.java
--- a/tools/acl_compressor/main_android/java/com/acl/MainActivity.java
+++ b/tools/acl_compressor/main_android/java/com/acl/compressor/MainActivity.java
@@ -1,4 +1,4 @@
-package com.acl;
+package com.acl.compressor;
import android.app.Activity;
import android.widget.TextView;
diff --git a/tools/acl_compressor/main_android/jni/main.cpp b/tools/acl_compressor/main_android/jni/main.cpp
--- a/tools/acl_compressor/main_android/jni/main.cpp
+++ b/tools/acl_compressor/main_android/jni/main.cpp
@@ -26,7 +26,7 @@
#include <jni.h>
-extern "C" jint Java_com_acl_MainActivity_nativeMain(JNIEnv* env, jobject caller)
+extern "C" jint Java_com_acl_compressor_MainActivity_nativeMain(JNIEnv* env, jobject caller)
{
char* argv[1] = { nullptr };
return main_impl(0, argv);
diff --git a/tools/acl_decompressor/main_android/CMakeLists.txt b/tools/acl_decompressor/main_android/CMakeLists.txt
--- a/tools/acl_decompressor/main_android/CMakeLists.txt
+++ b/tools/acl_decompressor/main_android/CMakeLists.txt
@@ -50,7 +50,7 @@ file(GLOB_RECURSE ALL_MAIN_SOURCE_FILES LIST_DIRECTORIES false ${PROJECT_SOURCE_
create_source_groups("${ALL_MAIN_SOURCE_FILES}" ${PROJECT_SOURCE_DIR})
# Add resource files
-set(JAVA_FILES java/com/acl/MainActivity.java)
+set(JAVA_FILES java/com/acl/decompressor/MainActivity.java)
set(RESOURCE_FILES "${PROJECT_RESOURCE_DIR}/values/strings.xml")
set(ANDROID_FILES "${PROJECT_BINARY_DIR}/AndroidManifest.xml")
diff --git a/tools/acl_decompressor/main_android/java/com/acl/MainActivity.java b/tools/acl_decompressor/main_android/java/com/acl/decompressor/MainActivity.java
similarity index 96%
rename from tools/acl_decompressor/main_android/java/com/acl/MainActivity.java
rename to tools/acl_decompressor/main_android/java/com/acl/decompressor/MainActivity.java
--- a/tools/acl_decompressor/main_android/java/com/acl/MainActivity.java
+++ b/tools/acl_decompressor/main_android/java/com/acl/decompressor/MainActivity.java
@@ -1,4 +1,4 @@
-package com.acl;
+package com.acl.decompressor;
import android.app.Activity;
import android.content.res.AssetManager;
diff --git a/tools/acl_decompressor/main_android/jni/main.cpp b/tools/acl_decompressor/main_android/jni/main.cpp
--- a/tools/acl_decompressor/main_android/jni/main.cpp
+++ b/tools/acl_decompressor/main_android/jni/main.cpp
@@ -102,7 +102,7 @@ static int read_metadata(AAssetManager* asset_manager, std::vector<std::string>&
return result;
}
-extern "C" jint Java_com_acl_MainActivity_nativeMain(JNIEnv* env, jobject caller, jobject java_asset_manager, jstring java_output_directory)
+extern "C" jint Java_com_acl_decompressor_MainActivity_nativeMain(JNIEnv* env, jobject caller, jobject java_asset_manager, jstring java_output_directory)
{
AAssetManager* asset_manager = AAssetManager_fromJava(env, java_asset_manager);
diff --git a/tools/regression_tester_android/CMakeLists.txt b/tools/regression_tester_android/CMakeLists.txt
--- a/tools/regression_tester_android/CMakeLists.txt
+++ b/tools/regression_tester_android/CMakeLists.txt
@@ -50,7 +50,7 @@ file(GLOB_RECURSE ALL_MAIN_SOURCE_FILES LIST_DIRECTORIES false ${PROJECT_SOURCE_
create_source_groups("${ALL_MAIN_SOURCE_FILES}" ${PROJECT_SOURCE_DIR})
# Add resource files
-set(JAVA_FILES java/com/acl/MainActivity.java)
+set(JAVA_FILES java/com/acl/regression_tests/MainActivity.java)
set(RESOURCE_FILES "${PROJECT_RESOURCE_DIR}/values/strings.xml")
set(ANDROID_FILES "${PROJECT_BINARY_DIR}/AndroidManifest.xml")
diff --git a/tools/regression_tester_android/jni/main.cpp b/tools/regression_tester_android/jni/main.cpp
--- a/tools/regression_tester_android/jni/main.cpp
+++ b/tools/regression_tester_android/jni/main.cpp
@@ -102,7 +102,7 @@ static int read_metadata(AAssetManager* asset_manager, std::vector<std::string>&
return result;
}
-extern "C" jint Java_com_acl_MainActivity_nativeMain(JNIEnv* env, jobject caller, jobject java_asset_manager)
+extern "C" jint Java_com_acl_regression_1tests_MainActivity_nativeMain(JNIEnv* env, jobject caller, jobject java_asset_manager)
{
AAssetManager* asset_manager = AAssetManager_fromJava(env, java_asset_manager);
|
diff --git a/tests/main_android/AndroidManifest.xml b/tests/main_android/AndroidManifest.xml
--- a/tests/main_android/AndroidManifest.xml
+++ b/tests/main_android/AndroidManifest.xml
@@ -1,6 +1,6 @@
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
- package="com.acl"
+ package="com.acl.unit_tests"
android:versionCode="1"
android:versionName="1.0">
<uses-sdk android:minSdkVersion="3" />
diff --git a/tests/main_android/CMakeLists.txt b/tests/main_android/CMakeLists.txt
--- a/tests/main_android/CMakeLists.txt
+++ b/tests/main_android/CMakeLists.txt
@@ -36,7 +36,7 @@ file(GLOB_RECURSE ALL_MAIN_SOURCE_FILES LIST_DIRECTORIES false
create_source_groups("${ALL_MAIN_SOURCE_FILES}" ${PROJECT_SOURCE_DIR})
# Add resource files
-set(JAVA_FILES java/com/acl/MainActivity.java)
+set(JAVA_FILES java/com/acl/unit_tests/MainActivity.java)
set(RESOURCE_FILES res/values/strings.xml)
set(ANDROID_FILES AndroidManifest.xml)
diff --git a/tests/main_android/java/com/acl/MainActivity.java b/tests/main_android/java/com/acl/unit_tests/MainActivity.java
similarity index 96%
rename from tests/main_android/java/com/acl/MainActivity.java
rename to tests/main_android/java/com/acl/unit_tests/MainActivity.java
--- a/tests/main_android/java/com/acl/MainActivity.java
+++ b/tests/main_android/java/com/acl/unit_tests/MainActivity.java
@@ -1,4 +1,4 @@
-package com.acl;
+package com.acl.unit_tests;
import android.app.Activity;
import android.widget.TextView;
diff --git a/tests/main_android/jni/main.cpp b/tests/main_android/jni/main.cpp
--- a/tests/main_android/jni/main.cpp
+++ b/tests/main_android/jni/main.cpp
@@ -27,12 +27,12 @@
#include <jni.h>
-extern "C" jint Java_com_acl_MainActivity_getNumUnitTestCases(JNIEnv* env, jobject caller)
+extern "C" jint Java_com_acl_unit_1tests_MainActivity_getNumUnitTestCases(JNIEnv* env, jobject caller)
{
return Catch::getRegistryHub().getTestCaseRegistry().getAllTests().size();
}
-extern "C" jint Java_com_acl_MainActivity_runUnitTests(JNIEnv* env, jobject caller)
+extern "C" jint Java_com_acl_unit_1tests_MainActivity_runUnitTests(JNIEnv* env, jobject caller)
{
int result = Catch::Session().run();
diff --git a/tools/regression_tester_android/java/com/acl/MainActivity.java b/tools/regression_tester_android/java/com/acl/regression_tests/MainActivity.java
similarity index 95%
rename from tools/regression_tester_android/java/com/acl/MainActivity.java
rename to tools/regression_tester_android/java/com/acl/regression_tests/MainActivity.java
--- a/tools/regression_tester_android/java/com/acl/MainActivity.java
+++ b/tools/regression_tester_android/java/com/acl/regression_tests/MainActivity.java
@@ -1,4 +1,4 @@
-package com.acl;
+package com.acl.regression_tests;
import android.app.Activity;
import android.content.res.AssetManager;
|
Change android package names for tools
Because they all have the same `com.acl` package name, when we deploy to a phone, they get constantly overwritten which is annoying.
| 2019-11-19T02:57:26
|
cpp
|
Hard
|
|
nfrechette/acl
| 453
|
nfrechette__acl-453
|
[
"360"
] |
68aac1a9ddeb456c39bce64b70622c4597b21ff8
|
diff --git a/includes/acl/compression/compression_settings.h b/includes/acl/compression/compression_settings.h
--- a/includes/acl/compression/compression_settings.h
+++ b/includes/acl/compression/compression_settings.h
@@ -131,6 +131,56 @@ namespace acl
error_result is_valid() const;
};
+ //////////////////////////////////////////////////////////////////////////
+ // Encapsulates all frame stripping compression settings.
+ // A keyframe represents all samples at a particular point in time.
+ // Keyframe stripping is a destructive process and visual fidelity can degrade
+ // considerably. If a keyframe is identified as a stripping candidate, it is
+ // entirely removed and reconstructed through linear interpolation of its
+ // neighbors. Removing whole keyframes ensures that decompression remains
+ // very fast.
+ //
+ // Note that stripping is not always appropriate and it may yield unacceptable
+ // results. Here are known problematic scenarios:
+ // - high velocity animations can lose a lot of momentum, yielding a swimming-
+ // like motion
+ // - synchronized animations can become out of sync if keyframes are unevenly
+ // removed leading to missed contacts
+ // - contacts and motion apex can be missed if key keyframes are removed
+ //
+ // Transform tracks only.
+ struct compression_keyframe_stripping_settings
+ {
+ //////////////////////////////////////////////////////////////////////////
+ // Whether or not to enable keyframe stripping.
+ // See [compression_keyframe_stripping_settings] for details.
+ // Defaults to 'false'
+ bool enable_stripping = false;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The minimum proportion of keyframes that should be stripped.
+ // Proportion value must be between 0.0 and 1.0.
+ // Defaults to '0.0' (no stripping)
+ float proportion = 0.0F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // The threshold error below which to strip keyframes.
+ // Keyframes that yield an error below or equal to this threshold will
+ // be removed. Keyframes that contribute more error than the threshold
+ // are retained.
+ // Defaults to '0.0' centimeters (no stripping)
+ float threshold = 0.0F;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Calculates a hash from the internal state to uniquely identify a configuration.
+ uint32_t get_hash() const;
+
+ //////////////////////////////////////////////////////////////////////////
+ // Checks if everything is valid and if it isn't, returns an error string.
+ // Returns nullptr if the settings are valid.
+ error_result is_valid() const;
+ };
+
//////////////////////////////////////////////////////////////////////////
// Encapsulates all the compression settings.
struct compression_settings
@@ -170,6 +220,11 @@ namespace acl
// See `sample_looping_policy` for details.
bool optimize_loops = false;
+ //////////////////////////////////////////////////////////////////////////
+ // Keyframe stripping related settings. See [compression_keyframe_stripping_settings].
+ // Transform tracks only.
+ compression_keyframe_stripping_settings keyframe_stripping;
+
//////////////////////////////////////////////////////////////////////////
// These are optional metadata that can be added to compressed clips.
compression_metadata_settings metadata;
diff --git a/includes/acl/compression/impl/clip_context.h b/includes/acl/compression/impl/clip_context.h
--- a/includes/acl/compression/impl/clip_context.h
+++ b/includes/acl/compression/impl/clip_context.h
@@ -199,6 +199,7 @@ namespace acl
bool are_scales_normalized = false;
bool has_scale = false;
bool has_additive_base = false;
+ bool has_stripped_keyframes = false;
uint32_t num_leaf_transforms = 0;
diff --git a/includes/acl/compression/impl/compress.database.impl.h b/includes/acl/compression/impl/compress.database.impl.h
--- a/includes/acl/compression/impl/compress.database.impl.h
+++ b/includes/acl/compression/impl/compress.database.impl.h
@@ -444,7 +444,7 @@ namespace acl
return sample_indices;
}
- inline void rewrite_segment_headers(const database_tier_mapping& tier_mapping, uint32_t tracks_index, const transform_tracks_header& input_transforms_header, const segment_header* headers, uint32_t segment_data_base_offset, segment_tier0_header* out_headers)
+ inline void rewrite_segment_headers(const database_tier_mapping& tier_mapping, uint32_t tracks_index, const transform_tracks_header& input_transforms_header, const segment_header* headers, uint32_t segment_data_base_offset, stripped_segment_header_t* out_headers)
{
const bitset_description desc = bitset_description::make_from_num_bits<32>();
@@ -488,7 +488,7 @@ namespace acl
inline void rewrite_segment_data(const database_tier_mapping& tier_mapping, uint32_t tracks_index,
const transform_tracks_header& input_transforms_header, const segment_header* input_headers,
- transform_tracks_header& output_transforms_header, const segment_tier0_header* output_headers)
+ transform_tracks_header& output_transforms_header, const stripped_segment_header_t* output_headers)
{
for (uint32_t segment_index = 0; segment_index < input_transforms_header.num_segments; ++segment_index)
{
@@ -562,7 +562,7 @@ namespace acl
// Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
const uint32_t segment_start_indices_size = clip_error.num_segments > 1 ? (uint32_t(sizeof(uint32_t)) * (clip_error.num_segments + 1)) : 0;
- const uint32_t segment_headers_size = sizeof(segment_tier0_header) * clip_error.num_segments;
+ const uint32_t segment_headers_size = sizeof(stripped_segment_header_t) * clip_error.num_segments;
// Range data follows constant data, use that to calculate our size
const uint32_t constant_data_size = (uint32_t)input_transforms_header.clip_range_data_offset - (uint32_t)input_transforms_header.constant_track_data_offset;
@@ -593,6 +593,8 @@ namespace acl
buffer_size = align_to(buffer_size, 4); // Align range data
buffer_size += clip_range_data_size; // Range data
+ uint32_t num_remaining_keyframes = 0;
+
// Per segment data
for (uint32_t segment_index = 0; segment_index < input_transforms_header.num_segments; ++segment_index)
{
@@ -618,11 +620,15 @@ namespace acl
const uint32_t num_animated_frames = bitset_count_set_bits(&sample_indices, desc);
const uint32_t animated_data_size = ((num_animated_frames * input_segment_headers[segment_index].animated_pose_bit_size) + 7) / 8;
+ num_remaining_keyframes += num_animated_frames;
+
// TODO: Variable bit rate doesn't need alignment
buffer_size = align_to(buffer_size, 4); // Align animated data
buffer_size += animated_data_size; // Animated track data
}
+ const uint32_t num_stripped_keyframes = input_header.num_samples - num_remaining_keyframes;
+
// Optional metadata
const uint32_t metadata_start_offset = align_to(buffer_size, 4);
const uint32_t metadata_track_list_name_size = get_metadata_track_list_name_size(input_metadata_header);
@@ -670,6 +676,7 @@ namespace acl
std::memcpy(header, &input_header, sizeof(tracks_header));
header->set_has_database(true);
+ header->set_has_stripped_keyframes(num_stripped_keyframes != 0);
header->set_has_metadata(metadata_size != 0);
transform_tracks_header* transforms_header = safe_ptr_cast<transform_tracks_header>(buffer);
@@ -699,7 +706,7 @@ namespace acl
// Write our new segment headers
const uint32_t segment_data_base_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
- rewrite_segment_headers(tier_mapping, list_index, input_transforms_header, input_segment_headers, segment_data_base_offset, transforms_header->get_segment_tier0_headers());
+ rewrite_segment_headers(tier_mapping, list_index, input_transforms_header, input_segment_headers, segment_data_base_offset, transforms_header->get_stripped_segment_headers());
// Copy our sub-track types, they do not change
std::memcpy(transforms_header->get_sub_track_types(), input_transforms_header.get_sub_track_types(), packed_sub_track_buffer_size);
@@ -711,7 +718,7 @@ namespace acl
std::memcpy(transforms_header->get_clip_range_data(), input_transforms_header.get_clip_range_data(), clip_range_data_size);
// Write our new segment data
- rewrite_segment_data(tier_mapping, list_index, input_transforms_header, input_segment_headers, *transforms_header, transforms_header->get_segment_tier0_headers());
+ rewrite_segment_data(tier_mapping, list_index, input_transforms_header, input_segment_headers, *transforms_header, transforms_header->get_stripped_segment_headers());
if (metadata_size != 0)
{
@@ -1256,6 +1263,9 @@ namespace acl
if (tracks->has_database())
return error_result("Compressed track instance is already bound to a database");
+ if (tracks->has_stripped_keyframes())
+ return error_result("Compressed track instance has keyframes stripped");
+
const tracks_header& header = get_tracks_header(*tracks);
if (!header.get_has_metadata())
return error_result("Compressed track instance does not contain any metadata");
diff --git a/includes/acl/compression/impl/compress.transform.impl.h b/includes/acl/compression/impl/compress.transform.impl.h
--- a/includes/acl/compression/impl/compress.transform.impl.h
+++ b/includes/acl/compression/impl/compress.transform.impl.h
@@ -42,6 +42,7 @@
#include "acl/compression/impl/track_stream.h"
#include "acl/compression/impl/convert_rotation_streams.h"
#include "acl/compression/impl/compact_constant_streams.h"
+#include "acl/compression/impl/keyframe_stripping.h"
#include "acl/compression/impl/normalize_streams.h"
#include "acl/compression/impl/optimize_looping.h"
#include "acl/compression/impl/quantize_streams.h"
@@ -119,9 +120,16 @@ namespace acl
// Segmenting settings are an implementation detail
compression_segmenting_settings segmenting_settings;
- // If we enable database support, include the metadata we need
+ // If we enable database support or keyframe stripping, include the metadata we need
+ bool remove_contributing_error = false;
if (settings.enable_database_support)
settings.metadata.include_contributing_error = true;
+ else if (settings.keyframe_stripping.enable_stripping)
+ {
+ // If we only enable the contributing error for keyframe stripping, make sure to strip it afterwards
+ remove_contributing_error = !settings.metadata.include_contributing_error;
+ settings.metadata.include_contributing_error = true;
+ }
// If every track is retains full precision, we disable segmenting since it provides no benefit
if (!is_rotation_format_variable(settings.rotation_format) && !is_vector_format_variable(settings.translation_format) && !is_vector_format_variable(settings.scale_format))
@@ -215,6 +223,14 @@ namespace acl
// Find how many bits we need per sub-track and quantize everything
quantize_streams(allocator, lossy_clip_context, settings, raw_clip_context, additive_base_clip_context, out_stats);
+ // Remove whole keyframes as needed
+ strip_keyframes(allocator, lossy_clip_context, settings);
+
+ // Compression is done! Time to pack things.
+
+ if (remove_contributing_error)
+ settings.metadata.include_contributing_error = false;
+
const bool has_trivial_defaults = has_trivial_default_values(track_list, additive_format, lossy_clip_context);
uint32_t num_output_bones = 0;
@@ -239,7 +255,8 @@ namespace acl
// Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
const uint32_t segment_start_indices_size = lossy_clip_context.num_segments > 1 ? (uint32_t(sizeof(uint32_t)) * (lossy_clip_context.num_segments + 1)) : 0;
- const uint32_t segment_headers_size = sizeof(segment_header) * lossy_clip_context.num_segments;
+ const uint32_t segment_header_type_size = lossy_clip_context.has_stripped_keyframes ? sizeof(stripped_segment_header_t) : sizeof(segment_header);
+ const uint32_t segment_headers_size = segment_header_type_size * lossy_clip_context.num_segments;
uint32_t buffer_size = 0;
// Per clip data
@@ -269,8 +286,8 @@ namespace acl
{
constexpr uint32_t k_cache_line_byte_size = 64;
lossy_clip_context.decomp_touched_bytes = clip_header_size + clip_data_size;
- lossy_clip_context.decomp_touched_bytes += sizeof(uint32_t) * 4; // We touch at most 4 segment start indices
- lossy_clip_context.decomp_touched_bytes += sizeof(segment_header) * 2; // We touch at most 2 segment headers
+ lossy_clip_context.decomp_touched_bytes += sizeof(uint32_t) * 4; // We touch at most 4 segment start indices
+ lossy_clip_context.decomp_touched_bytes += segment_header_type_size * 2; // We touch at most 2 segment headers
lossy_clip_context.decomp_touched_cache_lines = align_to(clip_header_size, k_cache_line_byte_size) / k_cache_line_byte_size;
lossy_clip_context.decomp_touched_cache_lines += align_to(clip_data_size, k_cache_line_byte_size) / k_cache_line_byte_size;
lossy_clip_context.decomp_touched_cache_lines += 1; // All 4 segment start indices should fit in a cache line
@@ -358,6 +375,7 @@ namespace acl
header->set_default_scale(!is_additive || additive_format != additive_clip_format8::additive1 ? 1 : 0);
header->set_has_database(false);
header->set_has_trivial_default_values(has_trivial_defaults);
+ header->set_has_stripped_keyframes(lossy_clip_context.has_stripped_keyframes);
header->set_is_wrap_optimized(lossy_clip_context.looping_policy == sample_looping_policy::wrap);
header->set_has_metadata(metadata_size != 0);
diff --git a/includes/acl/compression/impl/compression_settings.impl.h b/includes/acl/compression/impl/compression_settings.impl.h
--- a/includes/acl/compression/impl/compression_settings.impl.h
+++ b/includes/acl/compression/impl/compression_settings.impl.h
@@ -86,6 +86,27 @@ namespace acl
return error_result();
}
+ inline uint32_t compression_keyframe_stripping_settings::get_hash() const
+ {
+ uint32_t hash_value = 0;
+ hash_value = hash_combine(hash_value, hash32(enable_stripping));
+ hash_value = hash_combine(hash_value, hash32(proportion));
+ hash_value = hash_combine(hash_value, hash32(threshold));
+
+ return hash_value;
+ }
+
+ inline error_result compression_keyframe_stripping_settings::is_valid() const
+ {
+ if (!rtm::scalar_is_finite(proportion) || proportion < 0.0F || proportion > 1.0F)
+ return error_result("proportion must be in the range [0.0, 1.0]");
+
+ if (!rtm::scalar_is_finite(threshold) || threshold < 0.0F)
+ return error_result("threshold must be positive definite");
+
+ return error_result();
+ }
+
inline uint32_t compression_settings::get_hash() const
{
uint32_t hash_value = 0;
@@ -99,6 +120,7 @@ namespace acl
hash_value = hash_combine(hash_value, enable_database_support);
hash_value = hash_combine(hash_value, optimize_loops);
+ hash_value = hash_combine(hash_value, keyframe_stripping.get_hash());
hash_value = hash_combine(hash_value, metadata.get_hash());
return hash_value;
@@ -109,10 +131,17 @@ namespace acl
if (error_metric == nullptr)
return error_result("error_metric cannot be NULL");
+ const error_result keyframe_stripping_result = keyframe_stripping.is_valid();
+ if (keyframe_stripping_result.any())
+ return keyframe_stripping_result;
+
const error_result metadata_result = metadata.is_valid();
if (metadata_result.any())
return metadata_result;
+ if (keyframe_stripping.enable_stripping && enable_database_support)
+ return error_result("Cannot enable keyframe stripping with database support");
+
return error_result();
}
diff --git a/includes/acl/compression/impl/keyframe_stripping.h b/includes/acl/compression/impl/keyframe_stripping.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/keyframe_stripping.h
@@ -0,0 +1,113 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2023 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/version.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/compression/compression_settings.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ ACL_IMPL_VERSION_NAMESPACE_BEGIN
+
+ namespace acl_impl
+ {
+ struct clip_frame_contributing_error_t
+ {
+ uint32_t segment_index;
+ frame_contributing_error contributing_error;
+ };
+
+ inline void strip_keyframes(iallocator& allocator, clip_context& lossy_clip_context, const compression_settings& settings)
+ {
+ if (!settings.keyframe_stripping.enable_stripping)
+ return; // We don't want to strip keyframes, nothing to do
+
+ const bitset_description hard_keyframes_desc = bitset_description::make_from_num_bits<32>();
+ const uint32_t num_keyframes = lossy_clip_context.num_samples;
+
+ clip_frame_contributing_error_t* contributing_error_per_keyframe = allocate_type_array<clip_frame_contributing_error_t>(allocator, num_keyframes);
+
+ for (segment_context& segment : lossy_clip_context.segment_iterator())
+ {
+ // Copy the contributing error of each keyframe, we'll sort them later
+ for (uint32_t keyframe_index = 0; keyframe_index < segment.num_samples; ++keyframe_index)
+ contributing_error_per_keyframe[segment.clip_sample_offset + keyframe_index] = { segment.segment_index, segment.contributing_error[keyframe_index] };
+
+ // Initialize which keyframes are retained, we'll strip them later
+ bitset_set_range(&segment.hard_keyframes, hard_keyframes_desc, 0, segment.num_samples, true);
+ }
+
+ // Sort the contributing error of every keyframe within the clip
+ auto sort_predicate = [](const clip_frame_contributing_error_t& lhs, const clip_frame_contributing_error_t& rhs) { return lhs.contributing_error.error < rhs.contributing_error.error; };
+ std::sort(contributing_error_per_keyframe, contributing_error_per_keyframe + num_keyframes, sort_predicate);
+
+ // First determine how many we wish to strip based on proportion
+ // A frame is movable if it isn't the first or last frame of a segment
+ // If we have more than 1 frame, we can remove 2 frames per segment
+ // We know that the only way to get a segment with 1 frame is if the whole clip contains
+ // a single frame and thus has one segment
+ // If we have 0 or 1 frame, none are movable
+ const uint32_t num_movable_frames = num_keyframes >= 2 ? (num_keyframes - (lossy_clip_context.num_segments * 2)) : 0;
+
+ // First estimate how many keyframes to strip using the desired minimum proportion to strip
+ uint32_t num_keyframes_to_strip = std::min<uint32_t>(num_movable_frames, uint32_t(settings.keyframe_stripping.proportion * float(num_keyframes)));
+
+ // Then scan starting until we find our threshold if its above the proportion
+ for (; num_keyframes_to_strip < num_movable_frames; ++num_keyframes_to_strip)
+ {
+ if (contributing_error_per_keyframe[num_keyframes_to_strip].contributing_error.error > settings.keyframe_stripping.threshold)
+ break; // The error exceeds our threshold, stop stripping keyframes
+ }
+
+ ACL_ASSERT(num_keyframes_to_strip <= num_movable_frames, "Cannot strip more than the number of movable keyframes");
+
+ // Now that we know how many keyframes to strip, remove them
+ for (uint32_t index = 0; index < num_keyframes_to_strip; ++index)
+ {
+ const clip_frame_contributing_error_t& contributing_error = contributing_error_per_keyframe[index];
+
+ segment_context& keyframe_segment = lossy_clip_context.segments[contributing_error.segment_index];
+
+ const uint32_t segment_keyframe_index = contributing_error.contributing_error.index;
+ ACL_ASSERT(segment_keyframe_index != 0 && segment_keyframe_index < (keyframe_segment.num_samples - 1), "Cannot strip the first and last sample of a segment");
+
+ bitset_set(&keyframe_segment.hard_keyframes, hard_keyframes_desc, segment_keyframe_index, false);
+ }
+
+ deallocate_type_array(allocator, contributing_error_per_keyframe, num_keyframes);
+
+ lossy_clip_context.has_stripped_keyframes = num_keyframes_to_strip != 0;
+ }
+ }
+
+ ACL_IMPL_VERSION_NAMESPACE_END
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/segment_context.h b/includes/acl/compression/impl/segment_context.h
--- a/includes/acl/compression/impl/segment_context.h
+++ b/includes/acl/compression/impl/segment_context.h
@@ -92,6 +92,7 @@ namespace acl
uint32_t clip_sample_offset = 0;
uint32_t segment_index = 0;
+ uint32_t hard_keyframes = 0; // Bit set of which keyframes are hard and retained when keyframe stripping is used
bool are_rotations_normalized = false;
bool are_translations_normalized = false;
diff --git a/includes/acl/compression/impl/track_error.impl.h b/includes/acl/compression/impl/track_error.impl.h
--- a/includes/acl/compression/impl/track_error.impl.h
+++ b/includes/acl/compression/impl/track_error.impl.h
@@ -437,8 +437,14 @@ namespace acl
args.sample_rate = raw_tracks.get_sample_rate();
args.track_type = raw_tracks.get_track_type();
- // We use the nearest sample to accurately measure the loss that happened, if any
- args.rounding_policy = sample_rounding_policy::nearest;
+ // We use the nearest sample to accurately measure the loss that happened, if any but only if all data is loaded
+ // If we have a database with some data missing, we can't use the nearest samples, we have to interpolate
+ // TODO: Check if all the data is loaded, always interpolate for now
+ const compressed_tracks& tracks = *context.get_compressed_tracks();
+ if (tracks.has_database() || tracks.has_stripped_keyframes())
+ args.rounding_policy = sample_rounding_policy::none;
+ else
+ args.rounding_policy = sample_rounding_policy::nearest;
return calculate_scalar_track_error(allocator, args);
}
@@ -535,14 +541,12 @@ namespace acl
// We use the nearest sample to accurately measure the loss that happened, if any but only if all data is loaded
// If we have a database with some data missing, we can't use the nearest samples, we have to interpolate
- args.rounding_policy = sample_rounding_policy::nearest;
-
+ // TODO: Check if all the data is loaded, always interpolate for now
const compressed_tracks& tracks = *context.get_compressed_tracks();
- if (tracks.has_database())
- {
- // TODO: Check if all the data is loaded, always interpolate for now
+ if (tracks.has_database() || tracks.has_stripped_keyframes())
args.rounding_policy = sample_rounding_policy::none;
- }
+ else
+ args.rounding_policy = sample_rounding_policy::nearest;
if (raw_tracks.get_track_type() != track_type8::qvvf)
return calculate_scalar_track_error(allocator, args);
@@ -652,14 +656,12 @@ namespace acl
// We use the nearest sample to accurately measure the loss that happened, if any but only if all data is loaded
// If we have a database with some data missing, we can't use the nearest samples, we have to interpolate
- args.rounding_policy = sample_rounding_policy::nearest;
-
+ // TODO: Check if all the data is loaded, always interpolate for now
const compressed_tracks& tracks = *context.get_compressed_tracks();
- if (tracks.has_database())
- {
- // TODO: Check if all the data is loaded, always interpolate for now
+ if (tracks.has_database() || tracks.has_stripped_keyframes())
args.rounding_policy = sample_rounding_policy::none;
- }
+ else
+ args.rounding_policy = sample_rounding_policy::nearest;
args.error_metric = &error_metric;
@@ -720,14 +722,12 @@ namespace acl
// We use the nearest sample to accurately measure the loss that happened, if any but only if all data is loaded
// If we have a database with some data missing, we can't use the nearest samples, we have to interpolate
- args.rounding_policy = sample_rounding_policy::nearest;
-
+ // TODO: Check if all the data is loaded, always interpolate for now
const compressed_tracks* tracks1 = context1.get_compressed_tracks();
- if (tracks0->has_database() || tracks1->has_database())
- {
- // TODO: Check if all the data is loaded, always interpolate for now
+ if (tracks0->has_database() || tracks1->has_database() || tracks0->has_stripped_keyframes() || tracks1->has_stripped_keyframes())
args.rounding_policy = sample_rounding_policy::none;
- }
+ else
+ args.rounding_policy = sample_rounding_policy::nearest;
return calculate_scalar_track_error(allocator, args);
}
diff --git a/includes/acl/compression/impl/write_segment_data.h b/includes/acl/compression/impl/write_segment_data.h
--- a/includes/acl/compression/impl/write_segment_data.h
+++ b/includes/acl/compression/impl/write_segment_data.h
@@ -69,26 +69,53 @@ namespace acl
uint32_t size_written = 0;
const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip, settings.rotation_format, settings.translation_format, settings.scale_format);
+ const bool has_stripped_keyframes = clip.has_stripped_keyframes;
+ stripped_segment_header_t* stripped_segment_headers = reinterpret_cast<stripped_segment_header_t*>(segment_headers);
uint32_t segment_data_offset = segment_data_start_offset;
for (uint32_t segment_index = 0; segment_index < clip.num_segments; ++segment_index)
{
const segment_context& segment = clip.segments[segment_index];
- segment_header& header = segment_headers[segment_index];
- ACL_ASSERT(header.animated_pose_bit_size == 0, "Buffer overrun detected");
+ if (has_stripped_keyframes)
+ {
+ stripped_segment_header_t& header = stripped_segment_headers[segment_index];
+
+ ACL_ASSERT(header.animated_pose_bit_size == 0, "Buffer overrun detected");
+
+ header.animated_pose_bit_size = segment.animated_pose_bit_size;
+ header.animated_rotation_bit_size = segment.animated_rotation_bit_size;
+ header.animated_translation_bit_size = segment.animated_translation_bit_size;
+ header.segment_data = segment_data_offset;
+ header.sample_indices = segment.hard_keyframes;
+
+ segment_data_offset = align_to(segment_data_offset + format_per_track_data_size, 2); // Aligned to 2 bytes
+ segment_data_offset = align_to(segment_data_offset + segment.range_data_size, 4); // Aligned to 4 bytes
+ segment_data_offset = segment_data_offset + segment.animated_data_size;
+
+ size_written += sizeof(stripped_segment_header_t);
+
+ ACL_ASSERT((segment_data_offset - (uint32_t)header.segment_data) == segment.segment_data_size, "Unexpected segment size");
+ }
+ else
+ {
+ segment_header& header = segment_headers[segment_index];
- header.animated_pose_bit_size = segment.animated_pose_bit_size;
- header.animated_rotation_bit_size = segment.animated_rotation_bit_size;
- header.animated_translation_bit_size = segment.animated_translation_bit_size;
- header.segment_data = segment_data_offset;
+ ACL_ASSERT(header.animated_pose_bit_size == 0, "Buffer overrun detected");
- segment_data_offset = align_to(segment_data_offset + format_per_track_data_size, 2); // Aligned to 2 bytes
- segment_data_offset = align_to(segment_data_offset + segment.range_data_size, 4); // Aligned to 4 bytes
- segment_data_offset = segment_data_offset + segment.animated_data_size;
- size_written += sizeof(segment_header);
+ header.animated_pose_bit_size = segment.animated_pose_bit_size;
+ header.animated_rotation_bit_size = segment.animated_rotation_bit_size;
+ header.animated_translation_bit_size = segment.animated_translation_bit_size;
+ header.segment_data = segment_data_offset;
- ACL_ASSERT((segment_data_offset - (uint32_t)header.segment_data) == segment.segment_data_size, "Unexpected segment size");
+ segment_data_offset = align_to(segment_data_offset + format_per_track_data_size, 2); // Aligned to 2 bytes
+ segment_data_offset = align_to(segment_data_offset + segment.range_data_size, 4); // Aligned to 4 bytes
+ segment_data_offset = segment_data_offset + segment.animated_data_size;
+
+ size_written += sizeof(segment_header);
+
+ ACL_ASSERT((segment_data_offset - (uint32_t)header.segment_data) == segment.segment_data_size, "Unexpected segment size");
+ }
}
return size_written;
@@ -97,6 +124,8 @@ namespace acl
inline uint32_t write_segment_data(const clip_context& clip, const compression_settings& settings, range_reduction_flags8 range_reduction, segment_header* segment_headers, transform_tracks_header& header, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
const uint32_t format_per_track_data_size = get_format_per_track_data_size(clip, settings.rotation_format, settings.translation_format, settings.scale_format);
+ const bool has_stripped_keyframes = clip.has_stripped_keyframes;
+ stripped_segment_header_t* stripped_segment_headers = reinterpret_cast<stripped_segment_header_t*>(segment_headers);
uint32_t size_written = 0;
@@ -104,12 +133,21 @@ namespace acl
for (uint32_t segment_index = 0; segment_index < num_segments; ++segment_index)
{
const segment_context& segment = clip.segments[segment_index];
- segment_header& segment_header_ = segment_headers[segment_index];
uint8_t* format_per_track_data = nullptr;
uint8_t* range_data = nullptr;
uint8_t* animated_data = nullptr;
- header.get_segment_data(segment_header_, format_per_track_data, range_data, animated_data);
+
+ if (has_stripped_keyframes)
+ {
+ stripped_segment_header_t& segment_header_ = stripped_segment_headers[segment_index];
+ header.get_segment_data(segment_header_, format_per_track_data, range_data, animated_data);
+ }
+ else
+ {
+ segment_header& segment_header_ = segment_headers[segment_index];
+ header.get_segment_data(segment_header_, format_per_track_data, range_data, animated_data);
+ }
ACL_ASSERT(format_per_track_data[0] == 0, "Buffer overrun detected");
ACL_ASSERT(range_data[0] == 0, "Buffer overrun detected");
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -225,7 +225,7 @@ namespace acl
inline uint32_t calculate_clip_metadata_common_size(const clip_context& clip, const compressed_tracks& compressed_clip)
{
- const uint32_t segment_header_size = compressed_clip.has_database() ? sizeof(segment_tier0_header) : sizeof(segment_header);
+ const uint32_t segment_header_size = compressed_clip.has_database() || compressed_clip.has_stripped_keyframes() ? sizeof(stripped_segment_header_t) : sizeof(segment_header);
uint32_t result = 0;
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -123,6 +123,8 @@ namespace acl
inline void calculate_animated_data_size(clip_context& clip, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
+ const bitset_description hard_keyframes_desc = bitset_description::make_from_num_bits<32>();
+
for (segment_context& segment : clip.segment_iterator())
{
uint32_t num_animated_pose_rotation_data_bits = 0;
@@ -145,7 +147,8 @@ namespace acl
}
const uint32_t num_animated_pose_bits = num_animated_pose_rotation_data_bits + num_animated_pose_translation_data_bits + num_animated_pose_scale_data_bits;
- const uint32_t num_animated_data_bits = num_animated_pose_bits * segment.num_samples;
+ const uint32_t num_stored_samples = clip.has_stripped_keyframes ? bitset_count_set_bits(&segment.hard_keyframes, hard_keyframes_desc) : segment.num_samples;
+ const uint32_t num_animated_data_bits = num_animated_pose_bits * num_stored_samples;
segment.animated_rotation_bit_size = num_animated_pose_rotation_data_bits;
segment.animated_translation_bit_size = num_animated_pose_translation_data_bits;
@@ -372,6 +375,8 @@ namespace acl
const uint8_t* animated_track_data_start = animated_track_data;
const uint8_t* animated_track_data_end = add_offset_to_ptr<uint8_t>(animated_track_data, animated_data_size);
+ const bool has_stripped_keyframes = segment.clip->has_stripped_keyframes;
+ const bitset_description hard_keyframes_desc = bitset_description::make_from_num_bits<32>();
uint64_t bit_offset = 0;
@@ -413,9 +418,11 @@ namespace acl
ACL_ASSERT(animated_track_data <= animated_track_data_end, "Invalid animated track data offset. Wrote too much data."); (void)animated_track_data_end;
};
- // TODO: Use a group writer context object to avoid alloc/free/work in loop for every sample when it doesn't change
for (uint32_t sample_index = 0; sample_index < segment.num_samples; ++sample_index)
{
+ if (has_stripped_keyframes && !bitset_test(&segment.hard_keyframes, hard_keyframes_desc, sample_index))
+ continue; // This keyframe has been stripped, skip it
+
auto group_entry_action = [&segment, sample_index, &group_animated_track_data, &group_bit_offset](animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)
{
(void)group_size;
@@ -444,8 +451,12 @@ namespace acl
if (bit_offset != 0)
animated_track_data = animated_track_data_begin + ((bit_offset + 7) / 8);
- ACL_ASSERT((bit_offset == 0 && segment.num_samples == 0) || ((bit_offset / segment.num_samples) == segment.animated_pose_bit_size), "Unexpected number of bits written");
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ const uint32_t num_stored_samples = has_stripped_keyframes ? bitset_count_set_bits(&segment.hard_keyframes, hard_keyframes_desc) : segment.num_samples;
+ ACL_ASSERT((bit_offset == 0 && segment.num_samples == 0) || ((bit_offset / num_stored_samples) == segment.animated_pose_bit_size), "Unexpected number of bits written");
ACL_ASSERT(animated_track_data == animated_track_data_end, "Invalid animated track data offset. Wrote too little data.");
+#endif
+
return safe_static_cast<uint32_t>(animated_track_data - animated_track_data_start);
}
diff --git a/includes/acl/core/compressed_tracks.h b/includes/acl/core/compressed_tracks.h
--- a/includes/acl/core/compressed_tracks.h
+++ b/includes/acl/core/compressed_tracks.h
@@ -126,6 +126,11 @@ namespace acl
// Only supported with qvv transform tracks.
bool has_trivial_default_values() const;
+ //////////////////////////////////////////////////////////////////////////
+ // Returns whether or not this clip has had keyframes stripped.
+ // Only supported with qvv transform tracks.
+ bool has_stripped_keyframes() const;
+
//////////////////////////////////////////////////////////////////////////
// Returns the default scale value used during compression.
// Depending on the additive type, this value will either be 0 or 1.
diff --git a/includes/acl/core/impl/compressed_headers.h b/includes/acl/core/impl/compressed_headers.h
--- a/includes/acl/core/impl/compressed_headers.h
+++ b/includes/acl/core/impl/compressed_headers.h
@@ -100,7 +100,8 @@ namespace acl
// Bits [4, 8): rotation format (4 bits)
// Bit 8: has database?
// Bit 9: has trivial default values? Non-trivial default values indicate that extra data beyond the clip will be needed at decompression (e.g. bind pose)
- // Bits [10, 30): unused (20 bits)
+ // Bit 10: has stripped keyframes?
+ // Bits [11, 30): unused (19 bits)
// Bit 30: is wrap optimized? See sample_looping_policy for details.
// Bit 31: has metadata?
@@ -119,6 +120,8 @@ namespace acl
void set_has_database(bool has_database) { ACL_ASSERT(track_type == track_type8::qvvf, "Transform tracks only"); misc_packed = (misc_packed & ~(1 << 8)) | (static_cast<uint32_t>(has_database) << 8); }
bool get_has_trivial_default_values() const { ACL_ASSERT(track_type == track_type8::qvvf, "Transform tracks only"); return (misc_packed & (1 << 9)) != 0; }
void set_has_trivial_default_values(bool has_trivial_default_values) { ACL_ASSERT(track_type == track_type8::qvvf, "Transform tracks only"); misc_packed = (misc_packed & ~(1 << 9)) | (static_cast<uint32_t>(has_trivial_default_values) << 9); }
+ bool get_has_stripped_keyframes() const { ACL_ASSERT(track_type == track_type8::qvvf, "Transform tracks only"); return (misc_packed & (1 << 10)) != 0; }
+ void set_has_stripped_keyframes(bool has_stripped_keyframes) { ACL_ASSERT(track_type == track_type8::qvvf, "Transform tracks only"); misc_packed = (misc_packed & ~(1 << 10)) | (static_cast<uint32_t>(has_stripped_keyframes) << 10); }
// Common
bool get_is_wrap_optimized() const { return (misc_packed & (1 << 30)) != 0; }
@@ -185,27 +188,11 @@ namespace acl
////////////////////////////////////////////////////////////////////////////////
// A compressed clip segment header. Each segment is built from a uniform number
// of samples per track. A clip is split into one or more segments.
- // Only valid when a clip is split into a database.
+ // Only valid when a clip is split into a database or when keyframe stripping is enabled.
////////////////////////////////////////////////////////////////////////////////
- struct segment_tier0_header
+ struct stripped_segment_header_t : segment_header
{
- // Same layout as segment_header with new data at the end to allow safe usage under the segment_header type
-
- // Number of bits used by a fully animated pose (excludes default/constant tracks).
- uint32_t animated_pose_bit_size;
-
- // Number of bits used by a fully animated pose per sub-track type (excludes default/constant tracks).
- uint32_t animated_rotation_bit_size;
- uint32_t animated_translation_bit_size;
-
- // Offset to the animated segment data, relative to the start of the transform_tracks_header
- // Segment data is partitioned as follows:
- // - format per variable track (no alignment)
- // - range data per variable track (only when more than one segment) (2 byte alignment)
- // - track data sorted per sample then per track (4 byte alignment)
- ptr_offset32<uint8_t> segment_data;
-
- // Bit set of which sample indices are stored in this clip (tier 0).
+ // Bit set of which sample indices are stored in this clip (database tier 0).
uint32_t sample_indices;
};
@@ -256,11 +243,11 @@ namespace acl
// Offset to the database metadata header.
ptr_offset32<tracks_database_header> database_header_offset;
- // Offset to the segment headers data (tier 0 if split into database).
+ // Offset to the segment headers data.
union
{
- ptr_offset32<segment_header> segment_headers_offset;
- ptr_offset32<segment_tier0_header> segment_tier0_headers_offset;
+ ptr_offset32<segment_header> segment_headers_offset;
+ ptr_offset32<stripped_segment_header_t> stripped_segment_headers_offset;
};
// Offset to the packed sub-track types.
@@ -288,8 +275,8 @@ namespace acl
segment_header* get_segment_headers() { return segment_headers_offset.add_to(this); }
const segment_header* get_segment_headers() const { return segment_headers_offset.add_to(this); }
- segment_tier0_header* get_segment_tier0_headers() { return segment_tier0_headers_offset.add_to(this); }
- const segment_tier0_header* get_segment_tier0_headers() const { return segment_tier0_headers_offset.add_to(this); }
+ stripped_segment_header_t* get_stripped_segment_headers() { return stripped_segment_headers_offset.add_to(this); }
+ const stripped_segment_header_t* get_stripped_segment_headers() const { return stripped_segment_headers_offset.add_to(this); }
packed_sub_track_types* get_sub_track_types() { return sub_track_types_offset.add_to(this); }
const packed_sub_track_types* get_sub_track_types() const { return sub_track_types_offset.add_to(this); }
diff --git a/includes/acl/core/impl/compressed_tracks.impl.h b/includes/acl/core/impl/compressed_tracks.impl.h
--- a/includes/acl/core/impl/compressed_tracks.impl.h
+++ b/includes/acl/core/impl/compressed_tracks.impl.h
@@ -124,6 +124,8 @@ namespace acl
inline bool compressed_tracks::has_trivial_default_values() const { return acl_impl::get_tracks_header(*this).get_has_trivial_default_values(); }
+ inline bool compressed_tracks::has_stripped_keyframes() const { return acl_impl::get_tracks_header(*this).get_has_stripped_keyframes(); }
+
inline int32_t compressed_tracks::get_default_scale() const { return acl_impl::get_tracks_header(*this).get_default_scale(); }
inline sample_looping_policy compressed_tracks::get_looping_policy() const
diff --git a/includes/acl/decompression/impl/transform_track_decompression.h b/includes/acl/decompression/impl/transform_track_decompression.h
--- a/includes/acl/decompression/impl/transform_track_decompression.h
+++ b/includes/acl/decompression/impl/transform_track_decompression.h
@@ -250,7 +250,7 @@ namespace acl
// These two pointers are the same, the compiler should optimize one out, only here for type safety later
const segment_header* segment_headers = transform_header.get_segment_headers();
- const segment_tier0_header* segment_tier0_headers = transform_header.get_segment_tier0_headers();
+ const stripped_segment_header_t* segment_tier0_headers = transform_header.get_stripped_segment_headers();
const uint32_t num_segments = transform_header.num_segments;
@@ -260,14 +260,16 @@ namespace acl
const bool has_database = is_database_supported && tracks->has_database();
const database_context_v0* db = context.db;
+ const bool has_stripped_keyframes = has_database || tracks->has_stripped_keyframes();
+
if (num_segments == 1)
{
// Key frame 0 and 1 are in the only segment present
// This is a really common case and when it happens, we don't store the segment start index (zero)
- if (is_database_supported && has_database)
+ if (has_stripped_keyframes)
{
- const segment_tier0_header* segment_tier0_header0 = segment_tier0_headers;
+ const stripped_segment_header_t* segment_tier0_header0 = segment_tier0_headers;
// This will cache miss
uint32_t sample_indices0 = segment_tier0_header0->sample_indices;
@@ -404,10 +406,10 @@ namespace acl
segment_key_frame0 = key_frame0 - segment_start_indices[segment_index0];
segment_key_frame1 = key_frame1 - segment_start_indices[segment_index1];
- if (is_database_supported && has_database)
+ if (has_stripped_keyframes)
{
- const segment_tier0_header* segment_tier0_header0 = segment_tier0_headers + segment_index0;
- const segment_tier0_header* segment_tier0_header1 = segment_tier0_headers + segment_index1;
+ const stripped_segment_header_t* segment_tier0_header0 = segment_tier0_headers + segment_index0;
+ const stripped_segment_header_t* segment_tier0_header1 = segment_tier0_headers + segment_index1;
// This will cache miss
uint32_t sample_indices0 = segment_tier0_header0->sample_indices;
@@ -541,7 +543,7 @@ namespace acl
context.animated_track_data[1] = context.animated_track_data[0];
}
- if (is_database_supported && has_database)
+ if (has_database)
{
// Update our pointers if the data lives within the database
if (db_animated_track_data0 != nullptr)
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -852,6 +852,18 @@ static bool read_config(iallocator& allocator, Options& options, compression_set
if (parser.try_read("low_importance_tier", low_importance_tier, default_database_settings.low_importance_tier_proportion))
out_database_settings.low_importance_tier_proportion = low_importance_tier;
+ bool keyframe_stripping_enable;
+ if (parser.try_read("keyframe_stripping_enable", keyframe_stripping_enable, default_settings.keyframe_stripping.enable_stripping))
+ out_settings.keyframe_stripping.enable_stripping = keyframe_stripping_enable;
+
+ float keyframe_stripping_proportion;
+ if (parser.try_read("keyframe_stripping_proportion", keyframe_stripping_proportion, default_settings.keyframe_stripping.proportion))
+ out_settings.keyframe_stripping.proportion = keyframe_stripping_proportion;
+
+ float keyframe_stripping_threshold;
+ if (parser.try_read("keyframe_stripping_threshold", keyframe_stripping_threshold, default_settings.keyframe_stripping.threshold))
+ out_settings.keyframe_stripping.threshold = keyframe_stripping_threshold;
+
if (!parser.is_valid() || !parser.remainder_is_comments_and_whitespace())
{
uint32_t line;
diff --git a/tools/acl_compressor/sources/validate_tracks.cpp b/tools/acl_compressor/sources/validate_tracks.cpp
--- a/tools/acl_compressor/sources/validate_tracks.cpp
+++ b/tools/acl_compressor/sources/validate_tracks.cpp
@@ -193,6 +193,11 @@ void validate_accuracy(
{
for (sample_rounding_policy policy : make_iterator(rounding_policies))
{
+ // When we have stripped keyframes or a partially streamed database, the floor/ceil/nearest do not behave the same way with per-track
+ // The values reconstructed may not match, no need to validate
+ if (compressed_tracks_.has_stripped_keyframes() && policy != sample_rounding_policy::none)
+ continue;
+
context.seek(sample_time, policy);
context.decompress_tracks(track_writer);
|
diff --git a/test_data/configs/uniformly_sampled_keyframe_stripping.config.sjson b/test_data/configs/uniformly_sampled_keyframe_stripping.config.sjson
new file mode 100644
--- /dev/null
+++ b/test_data/configs/uniformly_sampled_keyframe_stripping.config.sjson
@@ -0,0 +1,15 @@
+version = 2
+
+algorithm_name = "uniformly_sampled"
+
+level = "Medium"
+
+rotation_format = "quatf_drop_w_variable"
+translation_format = "vector3f_variable"
+scale_format = "vector3f_variable"
+
+regression_error_threshold = 0.6
+
+keyframe_stripping_enable = true
+keyframe_stripping_proportion = 0.0
+keyframe_stripping_threshold = 0.5
|
Allow frame stripping per clip
Frame stripping is currently only implemented at the database level. But, we could also support it per clip very easily.
We should expose a new flag in the compression settings to optionally drop whole key frames up to some percentage.
We should always remove whole key frames that keep us below the current error threshold. These are safe to remove. However, doing so will increase the compression time perhaps considerably compared to what we have now. The current 'Medium' compression level should become 'Low' with 'Medium' and up now performing the safe key frame removal automatically.
|
> We should always remove whole key frames that keep us below the current error threshold.
If you're actively working on this part now, we're happy to wait for 2.1. Otherwise, I can take a stab at it. LMK.
I haven't begun working towards 2.1 yet so go ahead!
I will begin work on this shortly, stay tuned!
| 2023-03-18T02:27:21
|
cpp
|
Hard
|
nfrechette/acl
| 327
|
nfrechette__acl-327
|
[
"119"
] |
597e0a7c7ef54ac4e871bf73d5f029393c56535f
|
diff --git a/includes/acl/compression/impl/animated_track_utils.h b/includes/acl/compression/impl/animated_track_utils.h
--- a/includes/acl/compression/impl/animated_track_utils.h
+++ b/includes/acl/compression/impl/animated_track_utils.h
@@ -84,137 +84,45 @@ namespace acl
get_num_sub_tracks(segment, animated_group_filter_action, out_num_animated_rotation_sub_tracks, out_num_animated_translation_sub_tracks, out_num_animated_scale_sub_tracks);
}
- inline animation_track_type8* calculate_sub_track_groups(const SegmentContext& segment, const uint32_t* output_bone_mapping, uint32_t num_output_bones, uint32_t& out_num_groups,
- const std::function<bool(animation_track_type8 group_type, uint32_t bone_index)>& group_filter_action)
- {
- uint32_t num_rotation_sub_tracks = 0;
- uint32_t num_translation_sub_tracks = 0;
- uint32_t num_scale_sub_tracks = 0;
- get_num_sub_tracks(segment, group_filter_action, num_rotation_sub_tracks, num_translation_sub_tracks, num_scale_sub_tracks);
-
- const uint32_t num_rotation_groups = (num_rotation_sub_tracks + 3) / 4;
- const uint32_t num_translation_groups = (num_translation_sub_tracks + 3) / 4;
- const uint32_t num_scale_groups = (num_scale_sub_tracks + 3) / 4;
- const uint32_t num_groups = num_rotation_groups + num_translation_groups + num_scale_groups;
-
- animation_track_type8* sub_track_groups = allocate_type_array<animation_track_type8>(*segment.clip->allocator, num_groups);
- std::memset(sub_track_groups, 0xFF, num_groups * sizeof(animation_track_type8));
-
- // Simulate reading in groups of 4
- uint32_t num_cached_rotations = 0;
- uint32_t num_left_rotations = num_rotation_sub_tracks;
-
- uint32_t num_cached_translations = 0;
- uint32_t num_left_translations = num_translation_sub_tracks;
-
- uint32_t num_cached_scales = 0;
- uint32_t num_left_scales = num_scale_sub_tracks;
-
- uint32_t current_group_index = 0;
-
- for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- if ((output_index % 4) == 0)
- {
- if (num_cached_rotations < 4 && num_left_rotations != 0)
- {
- sub_track_groups[current_group_index++] = animation_track_type8::rotation;
- const uint32_t num_unpacked = std::min<uint32_t>(num_left_rotations, 4);
- num_left_rotations -= num_unpacked;
- num_cached_rotations += num_unpacked;
- }
-
- if (num_cached_translations < 4 && num_left_translations != 0)
- {
- sub_track_groups[current_group_index++] = animation_track_type8::translation;
- const uint32_t num_unpacked = std::min<uint32_t>(num_left_translations, 4);
- num_left_translations -= num_unpacked;
- num_cached_translations += num_unpacked;
- }
-
- if (num_cached_scales < 4 && num_left_scales != 0)
- {
- sub_track_groups[current_group_index++] = animation_track_type8::scale;
- const uint32_t num_unpacked = std::min<uint32_t>(num_left_scales, 4);
- num_left_scales -= num_unpacked;
- num_cached_scales += num_unpacked;
- }
- }
-
- const uint32_t bone_index = output_bone_mapping[output_index];
-
- if (group_filter_action(animation_track_type8::rotation, bone_index))
- num_cached_rotations--; // Consumed
-
- if (group_filter_action(animation_track_type8::translation, bone_index))
- num_cached_translations--; // Consumed
-
- if (group_filter_action(animation_track_type8::scale, bone_index))
- num_cached_scales--; // Consumed
- }
-
- ACL_ASSERT(current_group_index == num_groups, "Unexpected number of groups written");
-
- out_num_groups = num_groups;
- return sub_track_groups;
- }
-
inline void group_writer(const SegmentContext& segment, const uint32_t* output_bone_mapping, uint32_t num_output_bones,
const std::function<bool(animation_track_type8 group_type, uint32_t bone_index)>& group_filter_action,
const std::function<void(animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)>& group_entry_action,
const std::function<void(animation_track_type8 group_type, uint32_t group_size)>& group_flush_action)
{
- uint32_t num_groups = 0;
- animation_track_type8* sub_track_groups = calculate_sub_track_groups(segment, output_bone_mapping, num_output_bones, num_groups, group_filter_action);
+ // Data is ordered in groups of 4 animated sub-tracks (e.g rot0, rot1, rot2, rot3)
+ // Groups are sorted per sub-track type. All rotation groups come first followed by translations then scales.
+ // The last group of each sub-track may or may not have padding. The last group might be less than 4 sub-tracks.
- uint32_t group_size = 0;
-
- uint32_t rotation_output_index = 0;
- uint32_t translation_output_index = 0;
- uint32_t scale_output_index = 0;
- for (uint32_t group_index = 0; group_index < num_groups; ++group_index)
+ const auto group_writer_impl = [output_bone_mapping, num_output_bones, &group_filter_action, &group_entry_action, &group_flush_action](animation_track_type8 group_type)
{
- const animation_track_type8 group_type = sub_track_groups[group_index];
+ uint32_t group_size = 0;
- if (group_type == animation_track_type8::rotation)
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
{
- for (; group_size < 4 && rotation_output_index < num_output_bones; ++rotation_output_index)
- {
- const uint32_t bone_index = output_bone_mapping[rotation_output_index];
+ const uint32_t bone_index = output_bone_mapping[output_index];
- if (group_filter_action(animation_track_type8::rotation, bone_index))
- group_entry_action(group_type, group_size++, bone_index);
- }
- }
- else if (group_type == animation_track_type8::translation)
- {
- for (; group_size < 4 && translation_output_index < num_output_bones; ++translation_output_index)
- {
- const uint32_t bone_index = output_bone_mapping[translation_output_index];
+ if (group_filter_action(group_type, bone_index))
+ group_entry_action(group_type, group_size++, bone_index);
- if (group_filter_action(animation_track_type8::translation, bone_index))
- group_entry_action(group_type, group_size++, bone_index);
- }
- }
- else // scale
- {
- for (; group_size < 4 && scale_output_index < num_output_bones; ++scale_output_index)
+ if (group_size == 4)
{
- const uint32_t bone_index = output_bone_mapping[scale_output_index];
-
- if (group_filter_action(animation_track_type8::scale, bone_index))
- group_entry_action(group_type, group_size++, bone_index);
+ // Group full, write it out and move onto to the next group
+ group_flush_action(group_type, group_size);
+ group_size = 0;
}
}
- ACL_ASSERT(group_size != 0, "Group cannot be empty");
+ // If group has leftover tracks, write it out
+ if (group_size != 0)
+ group_flush_action(group_type, group_size);
+ };
- // Group full or we ran out of tracks, write it out and move onto to the next group
- group_flush_action(group_type, group_size);
- group_size = 0;
- }
+ // Output sub-tracks in natural order: rot, trans, scale
+ group_writer_impl(animation_track_type8::rotation);
+ group_writer_impl(animation_track_type8::translation);
- deallocate_type_array(*segment.clip->allocator, sub_track_groups, num_groups);
+ if (segment.clip->has_scale)
+ group_writer_impl(animation_track_type8::scale);
}
inline void animated_group_writer(const SegmentContext& segment, const uint32_t* output_bone_mapping, uint32_t num_output_bones,
@@ -235,24 +143,6 @@ namespace acl
group_writer(segment, output_bone_mapping, num_output_bones, animated_group_filter_action, group_entry_action, group_flush_action);
}
-
- inline void constant_group_writer(const SegmentContext& segment, const uint32_t* output_bone_mapping, uint32_t num_output_bones,
- const std::function<void(animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)>& group_entry_action,
- const std::function<void(animation_track_type8 group_type, uint32_t group_size)>& group_flush_action)
- {
- const auto constant_group_filter_action = [&](animation_track_type8 group_type, uint32_t bone_index)
- {
- const BoneStreams& bone_stream = segment.bone_streams[bone_index];
- if (group_type == animation_track_type8::rotation)
- return !bone_stream.is_rotation_default && bone_stream.is_rotation_constant;
- else if (group_type == animation_track_type8::translation)
- return !bone_stream.is_translation_default && bone_stream.is_translation_constant;
- else
- return !bone_stream.is_scale_default && bone_stream.is_scale_constant;
- };
-
- group_writer(segment, output_bone_mapping, num_output_bones, constant_group_filter_action, group_entry_action, group_flush_action);
- }
}
}
diff --git a/includes/acl/compression/impl/compress.database.impl.h b/includes/acl/compression/impl/compress.database.impl.h
--- a/includes/acl/compression/impl/compress.database.impl.h
+++ b/includes/acl/compression/impl/compress.database.impl.h
@@ -445,6 +445,8 @@ namespace acl
const uint32_t animated_pose_bit_size = headers[segment_index].animated_pose_bit_size;
out_headers[segment_index].animated_pose_bit_size = animated_pose_bit_size;
+ out_headers[segment_index].animated_rotation_bit_size = headers[segment_index].animated_rotation_bit_size;
+ out_headers[segment_index].animated_translation_bit_size = headers[segment_index].animated_translation_bit_size;
out_headers[segment_index].segment_data = segment_data_offset;
out_headers[segment_index].sample_indices = build_sample_indices(tier_mapping, tracks_index, segment_index);
@@ -540,8 +542,14 @@ namespace acl
const optional_metadata_header& input_metadata_header = get_optional_metadata_header(*input_tracks);
const uint32_t num_sub_tracks_per_bone = input_header.get_has_scale() ? 3 : 2;
- const uint32_t num_sub_tracks = input_header.num_tracks * num_sub_tracks_per_bone;
- const bitset_description bitset_desc = bitset_description::make_from_num_bits(num_sub_tracks);
+
+ // Calculate how many sub-track packed entries we have
+ // Each sub-track is 2 bits packed within a 32 bit entry
+ // For each sub-track type, we round up to simplify bookkeeping
+ // For example, if we have 3 tracks made up of rotation/translation we'll have one entry for each with unused padding
+ // All rotation types come first, followed by all translation types, and with scale types at the end when present
+ const uint32_t num_sub_track_entries = ((input_header.num_tracks + k_num_sub_tracks_per_packed_entry - 1) / k_num_sub_tracks_per_packed_entry) * num_sub_tracks_per_bone;
+ const uint32_t packed_sub_track_buffer_size = num_sub_track_entries * sizeof(packed_sub_track_types);
// Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
const uint32_t segment_start_indices_size = clip_error.num_segments > 1 ? (sizeof(uint32_t) * (clip_error.num_segments + 1)) : 0;
@@ -550,11 +558,8 @@ namespace acl
// Range data follows constant data, use that to calculate our size
const uint32_t constant_data_size = (uint32_t)input_transforms_header.clip_range_data_offset - (uint32_t)input_transforms_header.constant_track_data_offset;
- // Animated group size type data follows the range data, use that to calculate our size
- const uint32_t clip_range_data_size = (uint32_t)input_transforms_header.animated_group_types_offset - (uint32_t)input_transforms_header.clip_range_data_offset;
-
- // The data from our first segment follows the animated group types, use that to calculate our size
- const uint32_t animated_group_types_size = (uint32_t)input_segment_headers[0].segment_data - (uint32_t)input_transforms_header.animated_group_types_offset;
+ // The data from our first segment follows the clip range data, use that to calculate our size
+ const uint32_t clip_range_data_size = (uint32_t)input_segment_headers[0].segment_data - (uint32_t)input_transforms_header.clip_range_data_offset;
// Calculate the new size of our clip
uint32_t buffer_size = 0;
@@ -572,14 +577,12 @@ namespace acl
buffer_size = align_to(buffer_size, 4); // Align database header
buffer_size += sizeof(tracks_database_header); // Database header
- buffer_size = align_to(buffer_size, 4); // Align bitsets
- buffer_size += bitset_desc.get_num_bytes(); // Default tracks bitset
- buffer_size += bitset_desc.get_num_bytes(); // Constant tracks bitset
+ buffer_size = align_to(buffer_size, 4); // Align sub-track types
+ buffer_size += packed_sub_track_buffer_size; // Packed sub-track types sorted by type
buffer_size = align_to(buffer_size, 4); // Align constant track data
buffer_size += constant_data_size; // Constant track data
buffer_size = align_to(buffer_size, 4); // Align range data
buffer_size += clip_range_data_size; // Range data
- buffer_size += animated_group_types_size; // Our animated group types
// Per segment data
for (uint32_t segment_index = 0; segment_index < input_transforms_header.num_segments; ++segment_index)
@@ -669,11 +672,9 @@ namespace acl
const uint32_t segment_start_indices_offset = align_to<uint32_t>(sizeof(transform_tracks_header), 4); // Relative to the start of our transform_tracks_header
transforms_header->database_header_offset = align_to(segment_start_indices_offset + segment_start_indices_size, 4);
transforms_header->segment_headers_offset = align_to(transforms_header->database_header_offset + sizeof(tracks_database_header), 4);
- transforms_header->default_tracks_bitset_offset = align_to(transforms_header->segment_headers_offset + segment_headers_size, 4);
- transforms_header->constant_tracks_bitset_offset = transforms_header->default_tracks_bitset_offset + bitset_desc.get_num_bytes();
- transforms_header->constant_track_data_offset = align_to(transforms_header->constant_tracks_bitset_offset + bitset_desc.get_num_bytes(), 4);
+ transforms_header->sub_track_types_offset = align_to(transforms_header->segment_headers_offset + segment_headers_size, 4);
+ transforms_header->constant_track_data_offset = align_to(transforms_header->sub_track_types_offset + packed_sub_track_buffer_size, 4);
transforms_header->clip_range_data_offset = align_to(transforms_header->constant_track_data_offset + constant_data_size, 4);
- transforms_header->animated_group_types_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
// Copy our segment start indices, they do not change
if (input_transforms_header.has_multiple_segments())
@@ -688,12 +689,11 @@ namespace acl
clip_header_offset += sizeof(database_runtime_segment_header) * input_transforms_header.num_segments;
// Write our new segment headers
- const uint32_t segment_data_base_offset = transforms_header->animated_group_types_offset + animated_group_types_size;
+ const uint32_t segment_data_base_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
write_segment_headers(tier_mapping, list_index, input_transforms_header, input_segment_headers, segment_data_base_offset, transforms_header->get_segment_tier0_headers());
- // Copy our bitsets, they do not change
- std::memcpy(transforms_header->get_default_tracks_bitset(), input_transforms_header.get_default_tracks_bitset(), bitset_desc.get_num_bytes());
- std::memcpy(transforms_header->get_constant_tracks_bitset(), input_transforms_header.get_constant_tracks_bitset(), bitset_desc.get_num_bytes());
+ // Copy our sub-track types, they do not change
+ std::memcpy(transforms_header->get_sub_track_types(), input_transforms_header.get_sub_track_types(), packed_sub_track_buffer_size);
// Copy our constant track data, it does not change
std::memcpy(transforms_header->get_constant_track_data(), input_transforms_header.get_constant_track_data(), constant_data_size);
@@ -701,9 +701,6 @@ namespace acl
// Copy our clip range data, it does not change
std::memcpy(transforms_header->get_clip_range_data(), input_transforms_header.get_clip_range_data(), clip_range_data_size);
- // Copy our animated group type data, it does not change
- std::memcpy(transforms_header->get_animated_group_types(), input_transforms_header.get_animated_group_types(), animated_group_types_size);
-
// Write our new segment data
write_segment_data(tier_mapping, list_index, input_transforms_header, input_segment_headers, *transforms_header, transforms_header->get_segment_tier0_headers());
@@ -1085,7 +1082,7 @@ namespace acl
uint8_t* animated_data = segment_chunk_header.samples_offset.add_to(bulk_data);
const uint32_t size = write_segment_data(segment_frames, num_segment_frames, animated_data);
- ACL_ASSERT(size == segment_data_size, "Unexpected segment data size"); (void)size;
+ ACL_ASSERT(size == segment_data_size, "Unexpected segment data size"); (void)size; (void)segment_data_size;
chunk_segment_index++;
}
diff --git a/includes/acl/compression/impl/compress.impl.h b/includes/acl/compression/impl/compress.impl.h
--- a/includes/acl/compression/impl/compress.impl.h
+++ b/includes/acl/compression/impl/compress.impl.h
@@ -46,8 +46,8 @@
#include "acl/compression/impl/segment_streams.h"
#include "acl/compression/impl/write_segment_data.h"
#include "acl/compression/impl/write_stats.h"
-#include "acl/compression/impl/write_stream_bitsets.h"
#include "acl/compression/impl/write_stream_data.h"
+#include "acl/compression/impl/write_sub_track_types.h"
#include "acl/compression/impl/write_track_metadata.h"
#include <cstdint>
@@ -127,7 +127,7 @@ namespace acl
{
// Normalize our samples into the clip wide ranges per bone
normalize_clip_streams(lossy_clip_context, range_reduction);
- clip_range_data_size = get_stream_range_data_size(lossy_clip_context, range_reduction, settings.rotation_format);
+ clip_range_data_size = get_clip_range_data_size(lossy_clip_context, range_reduction, settings.rotation_format);
}
segment_streams(allocator, lossy_clip_context, settings.segmenting);
@@ -154,24 +154,15 @@ namespace acl
uint32_t num_animated_variable_sub_tracks_padded = 0;
const uint32_t format_per_track_data_size = get_format_per_track_data_size(lossy_clip_context, settings.rotation_format, settings.translation_format, settings.scale_format, &num_animated_variable_sub_tracks_padded);
- auto animated_group_filter_action = [&](animation_track_type8 group_type, uint32_t bone_index)
- {
- const BoneStreams& bone_stream = lossy_clip_context.segments[0].bone_streams[bone_index];
- if (group_type == animation_track_type8::rotation)
- return !bone_stream.is_rotation_constant;
- else if (group_type == animation_track_type8::translation)
- return !bone_stream.is_translation_constant;
- else
- return !bone_stream.is_scale_constant;
- };
-
- uint32_t num_animated_groups = 0;
- animation_track_type8* animated_sub_track_groups = calculate_sub_track_groups(lossy_clip_context.segments[0], output_bone_mapping, num_output_bones, num_animated_groups, animated_group_filter_action);
- const uint32_t animated_group_types_size = sizeof(animation_track_type8) * (num_animated_groups + 1); // Includes terminator
-
const uint32_t num_sub_tracks_per_bone = lossy_clip_context.has_scale ? 3 : 2;
- const uint32_t num_sub_tracks = num_output_bones * num_sub_tracks_per_bone;
- const bitset_description bitset_desc = bitset_description::make_from_num_bits(num_sub_tracks);
+
+ // Calculate how many sub-track packed entries we have
+ // Each sub-track is 2 bits packed within a 32 bit entry
+ // For each sub-track type, we round up to simplify bookkeeping
+ // For example, if we have 3 tracks made up of rotation/translation we'll have one entry for each with unused padding
+ // All rotation types come first, followed by all translation types, and with scale types at the end when present
+ const uint32_t num_sub_track_entries = ((num_output_bones + k_num_sub_tracks_per_packed_entry - 1) / k_num_sub_tracks_per_packed_entry) * num_sub_tracks_per_bone;
+ const uint32_t packed_sub_track_buffer_size = num_sub_track_entries * sizeof(packed_sub_track_types);
// Adding an extra index at the end to delimit things, the index is always invalid: 0xFFFFFFFF
const uint32_t segment_start_indices_size = lossy_clip_context.num_segments > 1 ? (sizeof(uint32_t) * (lossy_clip_context.num_segments + 1)) : 0;
@@ -189,17 +180,15 @@ namespace acl
buffer_size += segment_start_indices_size; // Segment start indices
buffer_size = align_to(buffer_size, 4); // Align segment headers
buffer_size += segment_headers_size; // Segment headers
- buffer_size = align_to(buffer_size, 4); // Align bitsets
+ buffer_size = align_to(buffer_size, 4); // Align sub-track types
const uint32_t clip_segment_header_size = buffer_size - clip_header_size;
- buffer_size += bitset_desc.get_num_bytes(); // Default tracks bitset
- buffer_size += bitset_desc.get_num_bytes(); // Constant tracks bitset
+ buffer_size += packed_sub_track_buffer_size; // Packed sub-track types sorted by type
buffer_size = align_to(buffer_size, 4); // Align constant track data
buffer_size += constant_data_size; // Constant track data
buffer_size = align_to(buffer_size, 4); // Align range data
buffer_size += clip_range_data_size; // Range data
- buffer_size += animated_group_types_size; // Our animated group types
const uint32_t clip_data_size = buffer_size - clip_segment_header_size - clip_header_size;
@@ -310,22 +299,19 @@ namespace acl
const uint32_t segment_start_indices_offset = align_to<uint32_t>(sizeof(transform_tracks_header), 4); // Relative to the start of our transform_tracks_header
transforms_header->database_header_offset = invalid_ptr_offset();
transforms_header->segment_headers_offset = align_to(segment_start_indices_offset + segment_start_indices_size, 4);
- transforms_header->default_tracks_bitset_offset = align_to(transforms_header->segment_headers_offset + segment_headers_size, 4);
- transforms_header->constant_tracks_bitset_offset = transforms_header->default_tracks_bitset_offset + bitset_desc.get_num_bytes();
- transforms_header->constant_track_data_offset = align_to(transforms_header->constant_tracks_bitset_offset + bitset_desc.get_num_bytes(), 4);
+ transforms_header->sub_track_types_offset = align_to(transforms_header->segment_headers_offset + segment_headers_size, 4);
+ transforms_header->constant_track_data_offset = align_to(transforms_header->sub_track_types_offset + packed_sub_track_buffer_size, 4);
transforms_header->clip_range_data_offset = align_to(transforms_header->constant_track_data_offset + constant_data_size, 4);
- transforms_header->animated_group_types_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
uint32_t written_segment_start_indices_size = 0;
if (lossy_clip_context.num_segments > 1)
written_segment_start_indices_size = write_segment_start_indices(lossy_clip_context, transforms_header->get_segment_start_indices());
- const uint32_t segment_data_start_offset = transforms_header->animated_group_types_offset + animated_group_types_size;
+ const uint32_t segment_data_start_offset = transforms_header->clip_range_data_offset + clip_range_data_size;
const uint32_t written_segment_headers_size = write_segment_headers(lossy_clip_context, settings, transforms_header->get_segment_headers(), segment_data_start_offset);
- uint32_t written_bitset_size = 0;
- written_bitset_size += write_default_track_bitset(lossy_clip_context, transforms_header->get_default_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
- written_bitset_size += write_constant_track_bitset(lossy_clip_context, transforms_header->get_constant_tracks_bitset(), bitset_desc, output_bone_mapping, num_output_bones);
+ uint32_t written_sub_track_buffer_size = 0;
+ written_sub_track_buffer_size += write_packed_sub_track_types(lossy_clip_context, transforms_header->get_sub_track_types(), output_bone_mapping, num_output_bones);
uint32_t written_constant_data_size = 0;
if (constant_data_size != 0)
@@ -335,8 +321,6 @@ namespace acl
if (range_reduction != range_reduction_flags8::none)
written_clip_range_data_size = write_clip_range_data(lossy_clip_context, range_reduction, transforms_header->get_clip_range_data(), clip_range_data_size, output_bone_mapping, num_output_bones);
- const uint32_t written_animated_group_types_size = write_animated_group_types(animated_sub_track_groups, num_animated_groups, transforms_header->get_animated_group_types(), animated_group_types_size);
-
const uint32_t written_segment_data_size = write_segment_data(lossy_clip_context, settings, range_reduction, transforms_header->get_segment_headers(), *transforms_header, output_bone_mapping, num_output_bones);
// Optional metadata header is last
@@ -411,13 +395,12 @@ namespace acl
buffer += written_segment_start_indices_size;
buffer = align_to(buffer, 4); // Align segment headers
buffer += written_segment_headers_size;
- buffer = align_to(buffer, 4); // Align bitsets
- buffer += written_bitset_size;
+ buffer = align_to(buffer, 4); // Align sub-track types
+ buffer += written_sub_track_buffer_size;
buffer = align_to(buffer, 4); // Align constant track data
buffer += written_constant_data_size;
buffer = align_to(buffer, 4); // Align range data
buffer += written_clip_range_data_size;
- buffer += written_animated_group_types_size;
buffer += written_segment_data_size;
if (metadata_size != 0)
@@ -435,10 +418,9 @@ namespace acl
ACL_ASSERT(written_segment_start_indices_size == segment_start_indices_size, "Wrote too little or too much data");
ACL_ASSERT(written_segment_headers_size == segment_headers_size, "Wrote too little or too much data");
ACL_ASSERT(written_segment_data_size == segment_data_size, "Wrote too little or too much data");
- ACL_ASSERT(written_bitset_size == (bitset_desc.get_num_bytes() * 2), "Wrote too little or too much data");
+ ACL_ASSERT(written_sub_track_buffer_size == packed_sub_track_buffer_size, "Wrote too little or too much data");
ACL_ASSERT(written_constant_data_size == constant_data_size, "Wrote too little or too much data");
ACL_ASSERT(written_clip_range_data_size == clip_range_data_size, "Wrote too little or too much data");
- ACL_ASSERT(written_animated_group_types_size == animated_group_types_size, "Wrote too little or too much data");
ACL_ASSERT(writter_metadata_track_list_name_size == metadata_track_list_name_size, "Wrote too little or too much data");
ACL_ASSERT(written_metadata_track_names_size == metadata_track_names_size, "Wrote too little or too much data");
ACL_ASSERT(written_metadata_parent_track_indices_size == metadata_parent_track_indices_size, "Wrote too little or too much data");
@@ -455,11 +437,10 @@ namespace acl
#else
(void)written_segment_start_indices_size;
(void)written_segment_headers_size;
- (void)written_bitset_size;
+ (void)written_sub_track_buffer_size;
(void)written_constant_data_size;
(void)written_clip_range_data_size;
(void)written_segment_data_size;
- (void)written_animated_group_types_size;
(void)segment_data_size;
(void)buffer_start;
#endif
@@ -471,7 +452,6 @@ namespace acl
write_stats(allocator, track_list, lossy_clip_context, *out_compressed_tracks, settings, range_reduction, raw_clip_context, additive_base_clip_context, compression_time, out_stats);
#endif
- deallocate_type_array(allocator, animated_sub_track_groups, num_animated_groups);
deallocate_type_array(allocator, output_bone_mapping, num_output_bones);
destroy_clip_context(lossy_clip_context);
destroy_clip_context(raw_clip_context);
diff --git a/includes/acl/compression/impl/write_range_data.h b/includes/acl/compression/impl/write_range_data.h
--- a/includes/acl/compression/impl/write_range_data.h
+++ b/includes/acl/compression/impl/write_range_data.h
@@ -49,7 +49,7 @@ namespace acl
{
namespace acl_impl
{
- inline uint32_t get_stream_range_data_size(const clip_context& clip, range_reduction_flags8 range_reduction, rotation_format8 rotation_format)
+ inline uint32_t get_clip_range_data_size(const clip_context& clip, range_reduction_flags8 range_reduction, rotation_format8 rotation_format)
{
const uint32_t rotation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) ? get_range_reduction_rotation_size(rotation_format) : 0;
const uint32_t translation_size = are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) ? k_clip_range_reduction_vector3_range_size : 0;
@@ -73,117 +73,6 @@ namespace acl
return range_data_size;
}
- inline void write_range_track_data_impl(const TrackStream& track, const TrackStreamRange& range, bool is_clip_range_data, uint8_t*& out_range_data)
- {
- const rtm::vector4f range_min = range.get_min();
- const rtm::vector4f range_extent = range.get_extent();
-
- if (is_clip_range_data)
- {
- const uint32_t range_member_size = sizeof(float) * 3;
-
- std::memcpy(out_range_data, &range_min, range_member_size);
- out_range_data += range_member_size;
- std::memcpy(out_range_data, &range_extent, range_member_size);
- out_range_data += range_member_size;
- }
- else
- {
- if (is_constant_bit_rate(track.get_bit_rate()))
- {
- const uint8_t* sample_ptr = track.get_raw_sample_ptr(0);
- std::memcpy(out_range_data, sample_ptr, sizeof(uint16_t) * 3);
- out_range_data += sizeof(uint16_t) * 3;
- }
- else
- {
- pack_vector3_u24_unsafe(range_min, out_range_data);
- out_range_data += sizeof(uint8_t) * 3;
- pack_vector3_u24_unsafe(range_extent, out_range_data);
- out_range_data += sizeof(uint8_t) * 3;
- }
- }
- }
-
- inline uint32_t write_range_track_data(const BoneStreams* bone_streams, const BoneRanges* bone_ranges,
- range_reduction_flags8 range_reduction, bool is_clip_range_data,
- uint8_t* range_data, uint32_t range_data_size,
- const uint32_t* output_bone_mapping, uint32_t num_output_bones)
- {
- ACL_ASSERT(range_data != nullptr, "'range_data' cannot be null!");
- (void)range_data_size;
-
-#if defined(ACL_HAS_ASSERT_CHECKS)
- const uint8_t* range_data_end = add_offset_to_ptr<uint8_t>(range_data, range_data_size);
-#endif
-
- const uint8_t* range_data_start = range_data;
-
- for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- const uint32_t bone_index = output_bone_mapping[output_index];
- const BoneStreams& bone_stream = bone_streams[bone_index];
- const BoneRanges& bone_range = bone_ranges[bone_index];
-
- // normalized value is between [0.0 .. 1.0]
- // value = (normalized value * range extent) + range min
- // normalized value = (value - range min) / range extent
-
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::rotations) && !bone_stream.is_rotation_constant)
- {
- const rtm::vector4f range_min = bone_range.rotation.get_min();
- const rtm::vector4f range_extent = bone_range.rotation.get_extent();
-
- if (is_clip_range_data)
- {
- const uint32_t range_member_size = bone_stream.rotations.get_rotation_format() == rotation_format8::quatf_full ? (sizeof(float) * 4) : (sizeof(float) * 3);
-
- std::memcpy(range_data, &range_min, range_member_size);
- range_data += range_member_size;
- std::memcpy(range_data, &range_extent, range_member_size);
- range_data += range_member_size;
- }
- else
- {
- if (bone_stream.rotations.get_rotation_format() == rotation_format8::quatf_full)
- {
- pack_vector4_32(range_min, true, range_data);
- range_data += sizeof(uint8_t) * 4;
- pack_vector4_32(range_extent, true, range_data);
- range_data += sizeof(uint8_t) * 4;
- }
- else
- {
- if (is_constant_bit_rate(bone_stream.rotations.get_bit_rate()))
- {
- const uint8_t* rotation = bone_stream.rotations.get_raw_sample_ptr(0);
- std::memcpy(range_data, rotation, sizeof(uint16_t) * 3);
- range_data += sizeof(uint16_t) * 3;
- }
- else
- {
- pack_vector3_u24_unsafe(range_min, range_data);
- range_data += sizeof(uint8_t) * 3;
- pack_vector3_u24_unsafe(range_extent, range_data);
- range_data += sizeof(uint8_t) * 3;
- }
- }
- }
- }
-
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::translations) && !bone_stream.is_translation_constant)
- write_range_track_data_impl(bone_stream.translations, bone_range.translation, is_clip_range_data, range_data);
-
- if (are_any_enum_flags_set(range_reduction, range_reduction_flags8::scales) && !bone_stream.is_scale_constant)
- write_range_track_data_impl(bone_stream.scales, bone_range.scale, is_clip_range_data, range_data);
-
- ACL_ASSERT(range_data <= range_data_end, "Invalid range data offset. Wrote too much data.");
- }
-
- ACL_ASSERT(range_data == range_data_end, "Invalid range data offset. Wrote too little data.");
- return safe_static_cast<uint32_t>(range_data - range_data_start);
- }
-
inline uint32_t write_clip_range_data(const clip_context& clip, range_reduction_flags8 range_reduction, uint8_t* range_data, uint32_t range_data_size, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
{
// Only use the first segment, it contains the necessary information
@@ -193,12 +82,8 @@ namespace acl
(void)range_data_size;
// Data is ordered in groups of 4 animated sub-tracks (e.g rot0, rot1, rot2, rot3)
- // Order depends on animated track order. If we have 6 animated rotation tracks before the first animated
- // translation track, we'll have 8 animated rotation sub-tracks followed by 4 animated translation sub-tracks.
- // Once we reach the end, there is no extra padding. The last group might be less than 4 sub-tracks.
- // This is because we always process 4 animated sub-tracks at a time and cache the results.
-
- // Groups are written in the order of first use and as such are sorted by their lowest sub-track index.
+ // Groups are sorted per sub-track type. All rotation groups come first followed by translations then scales.
+ // The last group of each sub-track may or may not have padding. The last group might be less than 4 sub-tracks.
#if defined(ACL_HAS_ASSERT_CHECKS)
const uint8_t* range_data_end = add_offset_to_ptr<uint8_t>(range_data, range_data_size);
@@ -327,12 +212,8 @@ namespace acl
(void)range_data_size;
// Data is ordered in groups of 4 animated sub-tracks (e.g rot0, rot1, rot2, rot3)
- // Order depends on animated track order. If we have 6 animated rotation tracks before the first animated
- // translation track, we'll have 8 animated rotation sub-tracks followed by 4 animated translation sub-tracks.
- // Once we reach the end, there is no extra padding. The last group might be less than 4 sub-tracks.
- // This is because we always process 4 animated sub-tracks at a time and cache the results.
-
- // Groups are written in the order of first use and as such are sorted by their lowest sub-track index.
+ // Groups are sorted per sub-track type. All rotation groups come first followed by translations then scales.
+ // The last group of each sub-track may or may not have padding. The last group might be less than 4 sub-tracks.
// normalized value is between [0.0 .. 1.0]
// value = (normalized value * range extent) + range min
diff --git a/includes/acl/compression/impl/write_segment_data.h b/includes/acl/compression/impl/write_segment_data.h
--- a/includes/acl/compression/impl/write_segment_data.h
+++ b/includes/acl/compression/impl/write_segment_data.h
@@ -76,6 +76,8 @@ namespace acl
ACL_ASSERT(header.animated_pose_bit_size == 0, "Buffer overrun detected");
header.animated_pose_bit_size = segment.animated_pose_bit_size;
+ header.animated_rotation_bit_size = segment.animated_rotation_bit_size;
+ header.animated_translation_bit_size = segment.animated_translation_bit_size;
header.segment_data = segment_data_offset;
segment_data_offset = align_to(segment_data_offset + format_per_track_data_size, 2); // Aligned to 2 bytes
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -344,7 +344,7 @@ namespace acl
uint32_t result = 0;
for (const SegmentContext& segment : clip.segment_iterator())
- result += align_to(segment.animated_rotation_bit_size, 8) / 8; // Convert bits to bytes;
+ result += align_to(segment.animated_rotation_bit_size * segment.num_samples, 8) / 8; // Convert bits to bytes;
return result;
}
@@ -354,7 +354,7 @@ namespace acl
uint32_t result = 0;
for (const SegmentContext& segment : clip.segment_iterator())
- result += align_to(segment.animated_translation_bit_size, 8) / 8; // Convert bits to bytes;
+ result += align_to(segment.animated_translation_bit_size * segment.num_samples, 8) / 8; // Convert bits to bytes;
return result;
}
@@ -364,7 +364,7 @@ namespace acl
uint32_t result = 0;
for (const SegmentContext& segment : clip.segment_iterator())
- result += align_to(segment.animated_scale_bit_size, 8) / 8; // Convert bits to bytes;
+ result += align_to(segment.animated_scale_bit_size * segment.num_samples, 8) / 8; // Convert bits to bytes;
return result;
}
diff --git a/includes/acl/compression/impl/write_stream_bitsets.h b/includes/acl/compression/impl/write_stream_bitsets.h
deleted file mode 100644
--- a/includes/acl/compression/impl/write_stream_bitsets.h
+++ /dev/null
@@ -1,102 +0,0 @@
-#pragma once
-
-////////////////////////////////////////////////////////////////////////////////
-// The MIT License (MIT)
-//
-// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy
-// of this software and associated documentation files (the "Software"), to deal
-// in the Software without restriction, including without limitation the rights
-// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-// copies of the Software, and to permit persons to whom the Software is
-// furnished to do so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-////////////////////////////////////////////////////////////////////////////////
-
-#include "acl/core/error.h"
-#include "acl/core/bitset.h"
-#include "acl/core/impl/compiler_utils.h"
-#include "acl/compression/impl/clip_context.h"
-
-#include <cstdint>
-
-ACL_IMPL_FILE_PRAGMA_PUSH
-
-namespace acl
-{
- namespace acl_impl
- {
- inline uint32_t write_default_track_bitset(const clip_context& clip, uint32_t* default_tracks_bitset, bitset_description bitset_desc, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
- {
- ACL_ASSERT(default_tracks_bitset != nullptr, "'default_tracks_bitset' cannot be null!");
-
- // Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip.segments[0];
-
- uint32_t default_track_offset = 0;
- uint32_t size_written = 0;
-
- bitset_reset(default_tracks_bitset, bitset_desc, false);
-
- for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- const uint32_t bone_index = output_bone_mapping[output_index];
- const BoneStreams& bone_stream = segment.bone_streams[bone_index];
-
- bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_rotation_default);
- bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_translation_default);
-
- if (clip.has_scale)
- bitset_set(default_tracks_bitset, bitset_desc, default_track_offset++, bone_stream.is_scale_default);
-
- size_written += clip.has_scale ? 3 : 2;
- }
-
- ACL_ASSERT(default_track_offset <= bitset_desc.get_num_bits(), "Too many tracks found for bitset");
- return ((size_written + 31) / 32) * sizeof(uint32_t); // Convert bits to bytes
- }
-
- inline uint32_t write_constant_track_bitset(const clip_context& clip, uint32_t* constant_tracks_bitset, bitset_description bitset_desc, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
- {
- ACL_ASSERT(constant_tracks_bitset != nullptr, "'constant_tracks_bitset' cannot be null!");
-
- // Only use the first segment, it contains the necessary information
- const SegmentContext& segment = clip.segments[0];
-
- uint32_t constant_track_offset = 0;
- uint32_t size_written = 0;
-
- bitset_reset(constant_tracks_bitset, bitset_desc, false);
-
- for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
- {
- const uint32_t bone_index = output_bone_mapping[output_index];
- const BoneStreams& bone_stream = segment.bone_streams[bone_index];
-
- bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_rotation_constant);
- bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_translation_constant);
-
- if (clip.has_scale)
- bitset_set(constant_tracks_bitset, bitset_desc, constant_track_offset++, bone_stream.is_scale_constant);
-
- size_written += clip.has_scale ? 3 : 2;
- }
-
- ACL_ASSERT(constant_track_offset <= bitset_desc.get_num_bits(), "Too many tracks found for bitset");
- return ((size_written + 31) / 32) * sizeof(uint32_t); // Convert bits to bytes
- }
- }
-}
-
-ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -141,13 +141,12 @@ namespace acl
calculate_animated_data_size(bone_stream.scales, num_animated_pose_scale_data_bits);
}
- const uint32_t num_samples = segment.num_samples;
const uint32_t num_animated_pose_bits = num_animated_pose_rotation_data_bits + num_animated_pose_translation_data_bits + num_animated_pose_scale_data_bits;
- const uint32_t num_animated_data_bits = num_animated_pose_bits * num_samples;
+ const uint32_t num_animated_data_bits = num_animated_pose_bits * segment.num_samples;
- segment.animated_rotation_bit_size = num_animated_pose_rotation_data_bits * num_samples;
- segment.animated_translation_bit_size = num_animated_pose_translation_data_bits * num_samples;
- segment.animated_scale_bit_size = num_animated_pose_scale_data_bits * num_samples;
+ segment.animated_rotation_bit_size = num_animated_pose_rotation_data_bits;
+ segment.animated_translation_bit_size = num_animated_pose_translation_data_bits;
+ segment.animated_scale_bit_size = num_animated_pose_scale_data_bits;
segment.animated_data_size = align_to(num_animated_data_bits, 8) / 8;
segment.animated_pose_bit_size = num_animated_pose_bits;
}
@@ -208,86 +207,6 @@ namespace acl
const uint8_t* constant_data_start = constant_data;
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- // Data is ordered in groups of 4 constant sub-tracks (e.g rot0, rot1, rot2, rot3)
- // Order depends on animated track order. If we have 6 constant rotation tracks before the first constant
- // translation track, we'll have 8 constant rotation sub-tracks followed by 4 constant translation sub-tracks.
- // Once we reach the end, there is no extra padding. The last group might be less than 4 sub-tracks.
- // This is because we always process 4 constant sub-tracks at a time and cache the results.
-
- // Groups are written in the order of first use and as such are sorted by their lowest sub-track index.
-
- // If our rotation format drops the W component, we swizzle the data to store XXXX, YYYY, ZZZZ
- const bool swizzle_rotations = get_rotation_variant(rotation_format) == rotation_variant8::quat_drop_w;
-
- float xxxx_group[4];
- float yyyy_group[4];
- float zzzz_group[4];
- rtm::vector4f constant_group4[4];
- rtm::float3f constant_group3[4];
-
- auto group_entry_action = [&](animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)
- {
- const BoneStreams& bone_stream = segment.bone_streams[bone_index];
-
- if (group_type == animation_track_type8::rotation)
- {
- if (swizzle_rotations)
- {
- const rtm::vector4f sample = bone_stream.rotations.get_raw_sample<rtm::vector4f>(0);
- xxxx_group[group_size] = rtm::vector_get_x(sample);
- yyyy_group[group_size] = rtm::vector_get_y(sample);
- zzzz_group[group_size] = rtm::vector_get_z(sample);
- }
- else
- {
- const rtm::vector4f sample = bone_stream.rotations.get_raw_sample<rtm::vector4f>(0);
- constant_group4[group_size] = sample;
- }
- }
- else if (group_type == animation_track_type8::translation)
- {
- const rtm::vector4f sample = bone_stream.translations.get_raw_sample<rtm::vector4f>(0);
- rtm::vector_store3(sample, &constant_group3[group_size]);
- }
- else
- {
- const rtm::vector4f sample = bone_stream.scales.get_raw_sample<rtm::vector4f>(0);
- rtm::vector_store3(sample, &constant_group3[group_size]);
- }
- };
-
- auto group_flush_action = [&](animation_track_type8 group_type, uint32_t group_size)
- {
- if (group_type == animation_track_type8::rotation)
- {
- if (swizzle_rotations)
- {
- std::memcpy(constant_data, &xxxx_group[0], group_size * sizeof(float));
- constant_data += group_size * sizeof(float);
- std::memcpy(constant_data, &yyyy_group[0], group_size * sizeof(float));
- constant_data += group_size * sizeof(float);
- std::memcpy(constant_data, &zzzz_group[0], group_size * sizeof(float));
- constant_data += group_size * sizeof(float);
- }
- else
- {
- // If we don't swizzle, we have a full quaternion
- std::memcpy(constant_data, &constant_group4[0], group_size * sizeof(rtm::vector4f));
- constant_data += group_size * sizeof(rtm::vector4f);
- }
- }
- else
- {
- std::memcpy(constant_data, &constant_group3[0], group_size * sizeof(rtm::float3f));
- constant_data += group_size * sizeof(rtm::float3f);
- }
-
- ACL_ASSERT(constant_data <= constant_data_end, "Invalid constant data offset. Wrote too much data.");
- };
-
- constant_group_writer(segment, output_bone_mapping, num_output_bones, group_entry_action, group_flush_action);
-#else
// If our rotation format drops the W component, we swizzle the data to store XXXX, YYYY, ZZZZ
const bool swizzle_rotations = get_rotation_variant(rotation_format) == rotation_variant8::quat_drop_w;
float xxxx[4];
@@ -382,13 +301,12 @@ namespace acl
}
}
}
-#endif
ACL_ASSERT(constant_data == constant_data_end, "Invalid constant data offset. Wrote too little data.");
return safe_static_cast<uint32_t>(constant_data - constant_data_start);
}
- inline void write_animated_track_data(const TrackStream& track_stream, uint32_t sample_index, uint8_t* animated_track_data_begin, uint8_t*& out_animated_track_data, uint64_t& out_bit_offset)
+ inline void write_animated_sample(const TrackStream& track_stream, uint32_t sample_index, uint8_t* animated_track_data_begin, uint64_t& out_bit_offset)
{
const uint8_t* raw_sample_ptr = track_stream.get_raw_sample_ptr(sample_index);
@@ -418,7 +336,6 @@ namespace acl
}
out_bit_offset += num_bits_at_bit_rate;
- out_animated_track_data = animated_track_data_begin + (out_bit_offset / 8);
}
else
{
@@ -440,7 +357,6 @@ namespace acl
}
out_bit_offset += has_w_component ? 128 : 96;
- out_animated_track_data = animated_track_data_begin + (out_bit_offset / 8);
}
}
@@ -457,26 +373,19 @@ namespace acl
const uint8_t* animated_track_data_start = animated_track_data;
uint64_t bit_offset = 0;
- uint32_t num_samples = 0;
// Data is sorted first by time, second by bone.
// This ensures that all bones are contiguous in memory when we sample a particular time.
// Data is ordered in groups of 4 animated sub-tracks (e.g rot0, rot1, rot2, rot3)
- // Order depends on animated track order. If we have 6 animated rotation tracks before the first animated
- // translation track, we'll have 8 animated rotation sub-tracks followed by 4 animated translation sub-tracks.
- // Once we reach the end, there is no extra padding. The last group might be less than 4 sub-tracks.
- // This is because we always process 4 animated sub-tracks at a time and cache the results.
-
- // Groups are written in the order of first use and as such are sorted by their lowest sub-track index.
+ // Groups are sorted per sub-track type. All rotation groups come first followed by translations then scales.
+ // The last group of each sub-track may or may not have padding. The last group might be less than 4 sub-tracks.
// For animated samples, when we have a constant bit rate (bit rate 0), we do not store samples
// and as such the group that contains that sub-track won't contain 4 samples.
// The largest sample is a full precision vector4f, we can contain at most 4 samples
alignas(16) uint8_t group_animated_track_data[sizeof(rtm::vector4f) * 4];
uint64_t group_bit_offset = 0;
- uint32_t num_group_samples = 0;
- uint8_t* dummy_animated_track_data_ptr = nullptr;
auto group_filter_action = [&](animation_track_type8 group_type, uint32_t bone_index)
{
@@ -491,15 +400,12 @@ namespace acl
auto group_flush_action = [&](animation_track_type8 group_type, uint32_t group_size)
{
(void)group_type;
-
- if (group_size == 0)
- return; // Empty group, skip
+ (void)group_size;
memcpy_bits(animated_track_data_begin, bit_offset, &group_animated_track_data[0], 0, group_bit_offset);
bit_offset += group_bit_offset;
group_bit_offset = 0;
- num_group_samples = 0;
animated_track_data = animated_track_data_begin + (bit_offset / 8);
@@ -509,8 +415,6 @@ namespace acl
// TODO: Use a group writer context object to avoid alloc/free/work in loop for every sample when it doesn't change
for (uint32_t sample_index = 0; sample_index < segment.num_samples; ++sample_index)
{
- num_samples++;
-
auto group_entry_action = [&](animation_track_type8 group_type, uint32_t group_size, uint32_t bone_index)
{
(void)group_size;
@@ -519,26 +423,17 @@ namespace acl
if (group_type == animation_track_type8::rotation)
{
if (!is_constant_bit_rate(bone_stream.rotations.get_bit_rate()))
- {
- write_animated_track_data(bone_stream.rotations, sample_index, group_animated_track_data, dummy_animated_track_data_ptr, group_bit_offset);
- num_group_samples++;
- }
+ write_animated_sample(bone_stream.rotations, sample_index, group_animated_track_data, group_bit_offset);
}
else if (group_type == animation_track_type8::translation)
{
if (!is_constant_bit_rate(bone_stream.translations.get_bit_rate()))
- {
- write_animated_track_data(bone_stream.translations, sample_index, group_animated_track_data, dummy_animated_track_data_ptr, group_bit_offset);
- num_group_samples++;
- }
+ write_animated_sample(bone_stream.translations, sample_index, group_animated_track_data, group_bit_offset);
}
else
{
if (!is_constant_bit_rate(bone_stream.scales.get_bit_rate()))
- {
- write_animated_track_data(bone_stream.scales, sample_index, group_animated_track_data, dummy_animated_track_data_ptr, group_bit_offset);
- num_group_samples++;
- }
+ write_animated_sample(bone_stream.scales, sample_index, group_animated_track_data, group_bit_offset);
}
};
@@ -548,7 +443,7 @@ namespace acl
if (bit_offset != 0)
animated_track_data = animated_track_data_begin + ((bit_offset + 7) / 8);
- ACL_ASSERT((bit_offset == 0 && num_samples == 0) || ((bit_offset / num_samples) == segment.animated_pose_bit_size), "Unexpected number of bits written");
+ ACL_ASSERT((bit_offset == 0 && segment.num_samples == 0) || ((bit_offset / segment.num_samples) == segment.animated_pose_bit_size), "Unexpected number of bits written");
ACL_ASSERT(animated_track_data == animated_track_data_end, "Invalid animated track data offset. Wrote too little data.");
return safe_static_cast<uint32_t>(animated_track_data - animated_track_data_start);
}
@@ -565,12 +460,8 @@ namespace acl
const uint8_t* format_per_track_data_start = format_per_track_data;
// Data is ordered in groups of 4 animated sub-tracks (e.g rot0, rot1, rot2, rot3)
- // Order depends on animated track order. If we have 6 animated rotation tracks before the first animated
- // translation track, we'll have 8 animated rotation sub-tracks followed by 4 animated translation sub-tracks.
- // Once we reach the end, there is no extra padding. The last group might be less than 4 sub-tracks.
- // This is because we always process 4 animated sub-tracks at a time and cache the results.
-
- // Groups are written in the order of first use and as such are sorted by their lowest sub-track index.
+ // Groups are sorted per sub-track type. All rotation groups come first followed by translations then scales.
+ // The last group of each sub-track may or may not have padding. The last group might be less than 4 sub-tracks.
// To keep decompression simpler, rotations are padded to 4 elements even if the last group is partial
uint8_t format_per_track_group[4];
@@ -615,21 +506,6 @@ namespace acl
return safe_static_cast<uint32_t>(format_per_track_data - format_per_track_data_start);
}
-
- inline uint32_t write_animated_group_types(const animation_track_type8* animated_sub_track_groups, uint32_t num_animated_groups, animation_track_type8* animated_sub_track_groups_data, uint32_t animated_sub_track_groups_data_size)
- {
- (void)animated_sub_track_groups_data_size;
-
- const animation_track_type8* animated_sub_track_groups_data_start = animated_sub_track_groups_data;
-
- std::memcpy(animated_sub_track_groups_data, animated_sub_track_groups, sizeof(animation_track_type8) * num_animated_groups);
- animated_sub_track_groups_data += num_animated_groups;
- animated_sub_track_groups_data[0] = static_cast<animation_track_type8>(0xFF); // Terminator
- animated_sub_track_groups_data++;
-
- ACL_ASSERT(animated_sub_track_groups_data == animated_sub_track_groups_data_start + animated_sub_track_groups_data_size, "Too little or too much data written");
- return static_cast<uint32_t>(animated_sub_track_groups_data - animated_sub_track_groups_data_start);
- }
}
}
diff --git a/includes/acl/compression/impl/write_sub_track_types.h b/includes/acl/compression/impl/write_sub_track_types.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/compression/impl/write_sub_track_types.h
@@ -0,0 +1,164 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2017 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/error.h"
+#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/impl/compressed_headers.h"
+#include "acl/compression/impl/clip_context.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ inline uint32_t write_packed_sub_track_types(const clip_context& clip, packed_sub_track_types* out_packed_types, const uint32_t* output_bone_mapping, uint32_t num_output_bones)
+ {
+ ACL_ASSERT(out_packed_types != nullptr, "'out_packed_types' cannot be null!");
+
+ // Only use the first segment, it contains the necessary information
+ const SegmentContext& segment = clip.segments[0];
+
+ uint32_t packed_entry_index = 0;
+ uint32_t packed_entry_size = 0;
+ uint32_t packed_entry = 0;
+
+ // Write rotations
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
+ {
+ if (packed_entry_size == 16)
+ {
+ // We are starting a new entry, write our old one out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+
+ const uint32_t bone_index = output_bone_mapping[output_index];
+ const BoneStreams& bone_stream = segment.bone_streams[bone_index];
+
+ uint32_t packed_type;
+ if (bone_stream.is_rotation_default)
+ packed_type = 0; // Default
+ else if (bone_stream.is_rotation_constant)
+ packed_type = 1; // Constant
+ else
+ packed_type = 2; // Animated
+
+ const uint32_t packed_index = output_index % 16;
+ packed_entry |= packed_type << ((15 - packed_index) * 2);
+ packed_entry_size++;
+ }
+
+ if (packed_entry_size != 0)
+ {
+ // We have a partial entry, write it out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+
+ // Write translations
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
+ {
+ if (packed_entry_size == 16)
+ {
+ // We are starting a new entry, write our old one out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+
+ const uint32_t bone_index = output_bone_mapping[output_index];
+ const BoneStreams& bone_stream = segment.bone_streams[bone_index];
+
+ uint32_t packed_type;
+ if (bone_stream.is_translation_default)
+ packed_type = 0; // Default
+ else if (bone_stream.is_translation_constant)
+ packed_type = 1; // Constant
+ else
+ packed_type = 2; // Animated
+
+ const uint32_t packed_index = output_index % 16;
+ packed_entry |= packed_type << ((15 - packed_index) * 2);
+ packed_entry_size++;
+ }
+
+ if (packed_entry_size != 0)
+ {
+ // We have a partial entry, write it out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+
+ if (clip.has_scale)
+ {
+ // Write translations
+ for (uint32_t output_index = 0; output_index < num_output_bones; ++output_index)
+ {
+ if (packed_entry_size == 16)
+ {
+ // We are starting a new entry, write our old one out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+
+ const uint32_t bone_index = output_bone_mapping[output_index];
+ const BoneStreams& bone_stream = segment.bone_streams[bone_index];
+
+ uint32_t packed_type;
+ if (bone_stream.is_scale_default)
+ packed_type = 0; // Default
+ else if (bone_stream.is_scale_constant)
+ packed_type = 1; // Constant
+ else
+ packed_type = 2; // Animated
+
+ const uint32_t packed_index = output_index % 16;
+ packed_entry |= packed_type << ((15 - packed_index) * 2);
+ packed_entry_size++;
+ }
+
+ if (packed_entry_size != 0)
+ {
+ // We have a partial entry, write it out
+ out_packed_types[packed_entry_index++] = packed_sub_track_types{ packed_entry };
+ packed_entry_size = 0;
+ packed_entry = 0;
+ }
+ }
+
+ return packed_entry_index * sizeof(packed_sub_track_types);
+ }
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/error.h b/includes/acl/core/error.h
--- a/includes/acl/core/error.h
+++ b/includes/acl/core/error.h
@@ -45,7 +45,7 @@ ACL_IMPL_FILE_PRAGMA_PUSH
// Throwing:
// In order to enable the throwing behavior, simply define the macro ACL_ON_ASSERT_THROW:
// #define ACL_ON_ASSERT_THROW
-// Note that the type of the exception thrown is std::runtime_error.
+// Note that the type of the exception thrown is acl::runtime_assert.
//
// Custom function:
// In order to enable the custom function calling behavior, define the macro ACL_ON_ASSERT_CUSTOM
diff --git a/includes/acl/core/impl/compressed_headers.h b/includes/acl/core/impl/compressed_headers.h
--- a/includes/acl/core/impl/compressed_headers.h
+++ b/includes/acl/core/impl/compressed_headers.h
@@ -36,9 +36,6 @@
#include <atomic>
#include <cstdint>
-// This is a bit slower because of the added bookkeeping when we unpack
-//#define ACL_IMPL_USE_CONSTANT_GROUPS
-
ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
@@ -160,6 +157,10 @@ namespace acl
// Number of bits used by a fully animated pose (excludes default/constant tracks).
uint32_t animated_pose_bit_size;
+ // Number of bits used by a fully animated pose per sub-track type (excludes default/constant tracks).
+ uint32_t animated_rotation_bit_size;
+ uint32_t animated_translation_bit_size;
+
// Offset to the animated segment data, relative to the start of the transform_tracks_header
// Segment data is partitioned as follows:
// - format per variable track (no alignment)
@@ -180,6 +181,10 @@ namespace acl
// Number of bits used by a fully animated pose (excludes default/constant tracks).
uint32_t animated_pose_bit_size;
+ // Number of bits used by a fully animated pose per sub-track type (excludes default/constant tracks).
+ uint32_t animated_rotation_bit_size;
+ uint32_t animated_translation_bit_size;
+
// Offset to the animated segment data, relative to the start of the transform_tracks_header
// Segment data is partitioned as follows:
// - format per variable track (no alignment)
@@ -224,6 +229,18 @@ namespace acl
const database_runtime_clip_header* get_clip_header(const void* base) const { return clip_header_offset.add_to(base); }
};
+ //////////////////////////////////////////////////////////////////////////
+ // A 32 bit integer that contains packed sub-track types.
+ // Each sub-track type is packed on 2 bits starting with the MSB.
+ // 0 = default/padding, 1 = constant, 2 = animated
+ //////////////////////////////////////////////////////////////////////////
+ struct packed_sub_track_types
+ {
+ uint32_t types;
+ };
+
+ const uint32_t k_num_sub_tracks_per_packed_entry = 16; // 2 bits each within a 32 bit entry
+
// Header for transform 'compressed_tracks'
struct transform_tracks_header
{
@@ -234,12 +251,12 @@ namespace acl
uint32_t num_animated_variable_sub_tracks; // Might be padded with dummy tracks for alignment
uint32_t num_animated_rotation_sub_tracks;
uint32_t num_animated_translation_sub_tracks;
- uint32_t num_animated_scale_sub_tracks; // TODO: Not needed?
+ uint32_t num_animated_scale_sub_tracks;
// The number of constant sub-track samples stored, does not include default samples
uint32_t num_constant_rotation_samples;
uint32_t num_constant_translation_samples;
- uint32_t num_constant_scale_samples; // TODO: Not needed?
+ uint32_t num_constant_scale_samples;
// Offset to the database metadata header.
ptr_offset32<tracks_database_header> database_header_offset;
@@ -251,18 +268,14 @@ namespace acl
ptr_offset32<segment_tier0_header> segment_tier0_headers_offset;
};
- // Offsets to the default/constant tracks bitsets.
- ptr_offset32<uint32_t> default_tracks_bitset_offset;
- ptr_offset32<uint32_t> constant_tracks_bitset_offset;
+ // Offset to the packed sub-track types.
+ ptr_offset32<packed_sub_track_types> sub_track_types_offset;
// Offset to the constant tracks data.
ptr_offset32<uint8_t> constant_track_data_offset;
// Offset to the clip range data.
- ptr_offset32<uint8_t> clip_range_data_offset; // TODO: Make this offset optional? Only present if normalized
-
- // Offset to the animated group types. Ends with an invalid group type of 0xFF.
- ptr_offset32<animation_track_type8> animated_group_types_offset;
+ ptr_offset32<uint8_t> clip_range_data_offset; // TODO: Make this offset optional? Only present if using variable bit rate
//////////////////////////////////////////////////////////////////////////
@@ -283,14 +296,8 @@ namespace acl
segment_tier0_header* get_segment_tier0_headers() { return segment_tier0_headers_offset.add_to(this); }
const segment_tier0_header* get_segment_tier0_headers() const { return segment_tier0_headers_offset.add_to(this); }
- animation_track_type8* get_animated_group_types() { return animated_group_types_offset.add_to(this); }
- const animation_track_type8* get_animated_group_types() const { return animated_group_types_offset.add_to(this); }
-
- uint32_t* get_default_tracks_bitset() { return default_tracks_bitset_offset.add_to(this); }
- const uint32_t* get_default_tracks_bitset() const { return default_tracks_bitset_offset.add_to(this); }
-
- uint32_t* get_constant_tracks_bitset() { return constant_tracks_bitset_offset.add_to(this); }
- const uint32_t* get_constant_tracks_bitset() const { return constant_tracks_bitset_offset.add_to(this); }
+ packed_sub_track_types* get_sub_track_types() { return sub_track_types_offset.add_to(this); }
+ const packed_sub_track_types* get_sub_track_types() const { return sub_track_types_offset.add_to(this); }
uint8_t* get_constant_track_data() { return constant_track_data_offset.add_to(this); }
const uint8_t* get_constant_track_data() const { return constant_track_data_offset.add_to(this); }
@@ -391,8 +398,8 @@ namespace acl
std::atomic<uint64_t> tier_metadata[2];
};
- // Header for runtime database clips
- struct database_runtime_clip_header
+ // Header for runtime database clips, 8 byte alignment to match database_runtime_segment_header
+ struct alignas(8) database_runtime_clip_header
{
// Hash of the compressed clip stored in this entry
uint32_t clip_hash;
diff --git a/includes/acl/core/memory_utils.h b/includes/acl/core/memory_utils.h
--- a/includes/acl/core/memory_utils.h
+++ b/includes/acl/core/memory_utils.h
@@ -288,6 +288,9 @@ namespace acl
// We copy bits assuming big-endian ordering for 'dest' and 'src'
inline void memcpy_bits(void* dest, uint64_t dest_bit_offset, const void* src, uint64_t src_bit_offset, uint64_t num_bits_to_copy)
{
+ if (num_bits_to_copy == 0)
+ return; // Nothing to copy
+
while (true)
{
uint64_t src_byte_offset = src_bit_offset / 8;
diff --git a/includes/acl/decompression/database/impl/database.impl.h b/includes/acl/decompression/database/impl/database.impl.h
--- a/includes/acl/decompression/database/impl/database.impl.h
+++ b/includes/acl/decompression/database/impl/database.impl.h
@@ -53,10 +53,11 @@ namespace acl
const uint32_t low_bitset_size = low_desc.get_num_bytes();
uint32_t runtime_data_size = 0;
- runtime_data_size += medium_bitset_size; // Loaded chunks
- runtime_data_size += medium_bitset_size; // Streaming chunks
- runtime_data_size += low_bitset_size; // Loaded chunks
- runtime_data_size += low_bitset_size; // Streaming chunks
+ runtime_data_size += medium_bitset_size; // Loaded chunks
+ runtime_data_size += medium_bitset_size; // Streaming chunks
+ runtime_data_size += low_bitset_size; // Loaded chunks
+ runtime_data_size += low_bitset_size; // Streaming chunks
+ runtime_data_size = align_to(runtime_data_size, 8); // Align runtime headers
runtime_data_size += num_clips * sizeof(database_runtime_clip_header);
runtime_data_size += num_segments * sizeof(database_runtime_segment_header);
@@ -122,7 +123,7 @@ namespace acl
// Allocate a single buffer for everything we need. This is faster to allocate and it ensures better virtual
// memory locality which should help reduce the cost of TLB misses.
const uint32_t runtime_data_size = acl_impl::calculate_runtime_data_size(database);
- uint8_t* runtime_data_buffer = allocate_type_array<uint8_t>(allocator, runtime_data_size);
+ uint8_t* runtime_data_buffer = allocate_type_array_aligned<uint8_t>(allocator, runtime_data_size, 16);
// Initialize everything to 0
std::memset(runtime_data_buffer, 0, runtime_data_size);
@@ -139,7 +140,7 @@ namespace acl
m_context.streaming_chunks[1] = reinterpret_cast<uint32_t*>(runtime_data_buffer);
runtime_data_buffer += low_bitset_size;
- m_context.clip_segment_headers = runtime_data_buffer;
+ m_context.clip_segment_headers = align_to(runtime_data_buffer, 8); // Align runtime headers
// Copy our clip hashes to setup our headers
const uint32_t num_clips = header.num_clips;
@@ -250,7 +251,7 @@ namespace acl
// Allocate a single buffer for everything we need. This is faster to allocate and it ensures better virtual
// memory locality which should help reduce the cost of TLB misses.
const uint32_t runtime_data_size = acl_impl::calculate_runtime_data_size(database);
- uint8_t* runtime_data_buffer = allocate_type_array<uint8_t>(allocator, runtime_data_size);
+ uint8_t* runtime_data_buffer = allocate_type_array_aligned<uint8_t>(allocator, runtime_data_size, 16);
// Initialize everything to 0
std::memset(runtime_data_buffer, 0, runtime_data_size);
@@ -267,7 +268,7 @@ namespace acl
m_context.streaming_chunks[1] = reinterpret_cast<uint32_t*>(runtime_data_buffer);
runtime_data_buffer += low_bitset_size;
- m_context.clip_segment_headers = runtime_data_buffer;
+ m_context.clip_segment_headers = align_to(runtime_data_buffer, 8); // Align runtime headers
// Copy our clip hashes to setup our headers
const uint32_t num_clips = header.num_clips;
diff --git a/includes/acl/decompression/impl/transform_animated_track_cache.h b/includes/acl/decompression/impl/transform_animated_track_cache.h
--- a/includes/acl/decompression/impl/transform_animated_track_cache.h
+++ b/includes/acl/decompression/impl/transform_animated_track_cache.h
@@ -38,10 +38,46 @@
#include <cstdint>
#define ACL_IMPL_USE_ANIMATED_PREFETCH
-//#define ACL_IMPL_USE_AVX_DECOMP
+
+// On x86/x64 platforms the prefetching instruction can have a long latency and it requires
+// a few other registers to compute the address which is problematic when registers are scarce.
+// As such, we attempt to hide the prefetching behind longer latency instructions like square-roots
+// and divisions.
+// On other platforms (e.g. ARM), the instruction is cheaper and we have more registers which gives
+// the compiler more freedom to hide the address calculation cost between other instructions.
+// Because the CPU is generally slower as well, we want to prefetch as soon as possible without
+// waiting for the next expensive instruction.
+// If your target CPU has a high clock rate, you might benefit from disabling early prefetching
+#if !defined(ACL_NO_EARLY_PREFETCHING) && !defined(ACL_IMPL_PREFETCH_EARLY)
+ #if !defined(RTM_SSE2_INTRINSICS)
+ #define ACL_IMPL_PREFETCH_EARLY
+ #endif
+#endif
+
+// This defined enables the SIMD 8 wide AVX decompression code path
+// Note that currently, it is often slower than the regular SIMD 4 wide AVX code path
+// On Intel Haswell and AMD Zen2 CPUs, the 8 wide code is measurably slower
+// Perhaps it is faster on newer Intel CPUs but I don't have one to test with
+// Enable at your own risk
+//#define ACL_IMPL_USE_AVX_8_WIDE_DECOMP
+
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ #if !defined(RTM_AVX_INTRINSICS)
+ // AVX isn't enabled, disable the 8 wide code path
+ #undef ACL_IMPL_USE_AVX_8_WIDE_DECOMP
+ #endif
+#endif
ACL_IMPL_FILE_PRAGMA_PUSH
+// We only initialize some variables when we need them which prompts the compiler to complain
+// The usage is perfectly safe and because this code is VERY hot and needs to be as fast as possible,
+// we disable the warning to avoid zeroing out things we don't need
+#if defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic push
+ #pragma GCC diagnostic ignored "-Wmaybe-uninitialized"
+#endif
+
namespace acl
{
namespace acl_impl
@@ -81,15 +117,479 @@ namespace acl
uint32_t animated_track_data_bit_offset; // Bit offset of the current animated sub-track
};
- struct animated_group_cursor_v0
+ struct alignas(32) segment_animated_scratch_v0
{
- clip_animated_sampling_context_v0 clip_sampling_context;
- segment_animated_sampling_context_v0 segment_sampling_context[2];
- uint32_t group_size;
+ // We store out potential range data in SOA form and we have no W, just XYZ
+ // To facilitate AVX and wider SIMD usage, we store our data interleaved in a single contiguous array
+ // Segment 0 has a base offset of 0 bytes and afterwards every write has a 32 byte offset
+ // Segment 1 has a base offset of 16 bytes and afterwards every write has a 32 byte offset
+
+ // segment_range_min_xxxx0, segment_range_min_xxxx1, segment_range_min_yyyy0, segment_range_min_yyyy1, segment_range_min_zzzz0, segment_range_min_zzzz1
+ rtm::vector4f segment_range_min[6];
+
+ // segment_range_extent_xxxx0, segment_range_extent_xxxx1, segment_range_extent_yyyy0, segment_range_extent_yyyy1, segment_range_extent_zzzz0, segment_range_extent_zzzz1
+ rtm::vector4f segment_range_extent[6];
};
+#if defined(RTM_SSE2_INTRINSICS)
+ using range_reduction_masks_t = __m128i;
+#elif defined(RTM_NEON_INTRINSICS)
+ using range_reduction_masks_t = int16x8_t;
+#else
+ using range_reduction_masks_t = uint64_t;
+#endif
+
+ // About 9 cycles with AVX on Skylake
+ inline ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_segment_range_data(const uint8_t* segment_range_data, uint32_t scratch_offset, segment_animated_scratch_v0& output_scratch)
+ {
+ // Segment range is packed: min.xxxx, min.yyyy, min.zzzz, extent.xxxx, extent.yyyy, extent.zzzz
+
+#if defined(RTM_SSE2_INTRINSICS)
+ const __m128i zero = _mm_setzero_si128();
+
+ const __m128i segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8 = _mm_loadu_si128((const __m128i*)segment_range_data);
+ const __m128i segment_range_extent_yyyy_zzzz_u8 = _mm_loadu_si128((const __m128i*)(segment_range_data + 16));
+
+ // Convert from u8 to u32
+ const __m128i segment_range_min_xxxx_yyyy_u16 = _mm_unpacklo_epi8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8, zero);
+ const __m128i segment_range_min_zzzz_extent_xxxx_u16 = _mm_unpackhi_epi8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8, zero);
+ const __m128i segment_range_extent_yyyy_zzzz_u16 = _mm_unpacklo_epi8(segment_range_extent_yyyy_zzzz_u8, zero);
+
+ __m128i segment_range_min_xxxx_u32 = _mm_unpacklo_epi16(segment_range_min_xxxx_yyyy_u16, zero);
+ __m128i segment_range_min_yyyy_u32 = _mm_unpackhi_epi16(segment_range_min_xxxx_yyyy_u16, zero);
+ __m128i segment_range_min_zzzz_u32 = _mm_unpacklo_epi16(segment_range_min_zzzz_extent_xxxx_u16, zero);
+
+ const __m128i segment_range_extent_xxxx_u32 = _mm_unpackhi_epi16(segment_range_min_zzzz_extent_xxxx_u16, zero);
+ const __m128i segment_range_extent_yyyy_u32 = _mm_unpacklo_epi16(segment_range_extent_yyyy_zzzz_u16, zero);
+ const __m128i segment_range_extent_zzzz_u32 = _mm_unpackhi_epi16(segment_range_extent_yyyy_zzzz_u16, zero);
+
+ __m128 segment_range_min_xxxx = _mm_cvtepi32_ps(segment_range_min_xxxx_u32);
+ __m128 segment_range_min_yyyy = _mm_cvtepi32_ps(segment_range_min_yyyy_u32);
+ __m128 segment_range_min_zzzz = _mm_cvtepi32_ps(segment_range_min_zzzz_u32);
+
+ __m128 segment_range_extent_xxxx = _mm_cvtepi32_ps(segment_range_extent_xxxx_u32);
+ __m128 segment_range_extent_yyyy = _mm_cvtepi32_ps(segment_range_extent_yyyy_u32);
+ __m128 segment_range_extent_zzzz = _mm_cvtepi32_ps(segment_range_extent_zzzz_u32);
+
+ const __m128 normalization_value = _mm_set_ps1(1.0F / 255.0F);
+
+ segment_range_min_xxxx = _mm_mul_ps(segment_range_min_xxxx, normalization_value);
+ segment_range_min_yyyy = _mm_mul_ps(segment_range_min_yyyy, normalization_value);
+ segment_range_min_zzzz = _mm_mul_ps(segment_range_min_zzzz, normalization_value);
+
+ segment_range_extent_xxxx = _mm_mul_ps(segment_range_extent_xxxx, normalization_value);
+ segment_range_extent_yyyy = _mm_mul_ps(segment_range_extent_yyyy, normalization_value);
+ segment_range_extent_zzzz = _mm_mul_ps(segment_range_extent_zzzz, normalization_value);
+#elif defined(RTM_NEON_INTRINSICS)
+ const uint8x16_t segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8 = vld1q_u8(segment_range_data);
+ const uint8x8_t segment_range_extent_yyyy_zzzz_u8 = vld1_u8(segment_range_data + 16);
+
+ // Convert from u8 to u32
+ const uint16x8_t segment_range_min_xxxx_yyyy_u16 = vmovl_u8(vget_low_u8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8));
+ const uint16x8_t segment_range_min_zzzz_extent_xxxx_u16 = vmovl_u8(vget_high_u8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8));
+ const uint16x8_t segment_range_extent_yyyy_zzzz_u16 = vmovl_u8(segment_range_extent_yyyy_zzzz_u8);
+
+ uint32x4_t segment_range_min_xxxx_u32 = vmovl_u16(vget_low_u16(segment_range_min_xxxx_yyyy_u16));
+ uint32x4_t segment_range_min_yyyy_u32 = vmovl_u16(vget_high_u16(segment_range_min_xxxx_yyyy_u16));
+ uint32x4_t segment_range_min_zzzz_u32 = vmovl_u16(vget_low_u16(segment_range_min_zzzz_extent_xxxx_u16));
+
+ const uint32x4_t segment_range_extent_xxxx_u32 = vmovl_u16(vget_high_u16(segment_range_min_zzzz_extent_xxxx_u16));
+ const uint32x4_t segment_range_extent_yyyy_u32 = vmovl_u16(vget_low_u16(segment_range_extent_yyyy_zzzz_u16));
+ const uint32x4_t segment_range_extent_zzzz_u32 = vmovl_u16(vget_high_u16(segment_range_extent_yyyy_zzzz_u16));
+
+ float32x4_t segment_range_min_xxxx = vcvtq_f32_u32(segment_range_min_xxxx_u32);
+ float32x4_t segment_range_min_yyyy = vcvtq_f32_u32(segment_range_min_yyyy_u32);
+ float32x4_t segment_range_min_zzzz = vcvtq_f32_u32(segment_range_min_zzzz_u32);
+
+ float32x4_t segment_range_extent_xxxx = vcvtq_f32_u32(segment_range_extent_xxxx_u32);
+ float32x4_t segment_range_extent_yyyy = vcvtq_f32_u32(segment_range_extent_yyyy_u32);
+ float32x4_t segment_range_extent_zzzz = vcvtq_f32_u32(segment_range_extent_zzzz_u32);
+
+ const float normalization_value = 1.0F / 255.0F;
+
+ segment_range_min_xxxx = vmulq_n_f32(segment_range_min_xxxx, normalization_value);
+ segment_range_min_yyyy = vmulq_n_f32(segment_range_min_yyyy, normalization_value);
+ segment_range_min_zzzz = vmulq_n_f32(segment_range_min_zzzz, normalization_value);
+
+ segment_range_extent_xxxx = vmulq_n_f32(segment_range_extent_xxxx, normalization_value);
+ segment_range_extent_yyyy = vmulq_n_f32(segment_range_extent_yyyy, normalization_value);
+ segment_range_extent_zzzz = vmulq_n_f32(segment_range_extent_zzzz, normalization_value);
+#else
+ rtm::vector4f segment_range_min_xxxx = rtm::vector_set(float(segment_range_data[0]), float(segment_range_data[1]), float(segment_range_data[2]), float(segment_range_data[3]));
+ rtm::vector4f segment_range_min_yyyy = rtm::vector_set(float(segment_range_data[4]), float(segment_range_data[5]), float(segment_range_data[6]), float(segment_range_data[7]));
+ rtm::vector4f segment_range_min_zzzz = rtm::vector_set(float(segment_range_data[8]), float(segment_range_data[9]), float(segment_range_data[10]), float(segment_range_data[11]));
+
+ rtm::vector4f segment_range_extent_xxxx = rtm::vector_set(float(segment_range_data[12]), float(segment_range_data[13]), float(segment_range_data[14]), float(segment_range_data[15]));
+ rtm::vector4f segment_range_extent_yyyy = rtm::vector_set(float(segment_range_data[16]), float(segment_range_data[17]), float(segment_range_data[18]), float(segment_range_data[19]));
+ rtm::vector4f segment_range_extent_zzzz = rtm::vector_set(float(segment_range_data[20]), float(segment_range_data[21]), float(segment_range_data[22]), float(segment_range_data[23]));
+
+ const float normalization_value = 1.0F / 255.0F;
+
+ segment_range_min_xxxx = rtm::vector_mul(segment_range_min_xxxx, normalization_value);
+ segment_range_min_yyyy = rtm::vector_mul(segment_range_min_yyyy, normalization_value);
+ segment_range_min_zzzz = rtm::vector_mul(segment_range_min_zzzz, normalization_value);
+
+ segment_range_extent_xxxx = rtm::vector_mul(segment_range_extent_xxxx, normalization_value);
+ segment_range_extent_yyyy = rtm::vector_mul(segment_range_extent_yyyy, normalization_value);
+ segment_range_extent_zzzz = rtm::vector_mul(segment_range_extent_zzzz, normalization_value);
+#endif
+
+#if defined(ACL_IMPL_PREFETCH_EARLY)
+ // Prefetch the next cache line even if we don't have any data left
+ // By the time we unpack again, it will have arrived in the CPU cache
+ // If our format is full precision, we have at most 4 samples per cache line
+ // If our format is drop W, we have at most 5.33 samples per cache line
+
+ // If our pointer was already aligned to a cache line before we unpacked our 4 values,
+ // it now points to the first byte of the next cache line. Any offset between 0-63 will fetch it.
+ // If our pointer had some offset into a cache line, we might have spanned 2 cache lines.
+ // If this happens, we probably already read some data from the next cache line in which
+ // case we don't need to prefetch it and we can go to the next one. Any offset after the end
+ // of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
+ // Prefetch 4 samples ahead in all levels of the CPU cache
+ ACL_IMPL_ANIMATED_PREFETCH(segment_range_data + 64);
+#endif
+
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ // With AVX, we must duplicate our data for the first segment in case we don't have a second segment
+ if (scratch_offset == 0)
+ {
+ // First segment data is duplicated
+ // Use 256 bit stores to avoid doing too many stores which might stall
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_min[0]), _mm256_set_m128(segment_range_min_xxxx, segment_range_min_xxxx));
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_min[2]), _mm256_set_m128(segment_range_min_yyyy, segment_range_min_yyyy));
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_min[4]), _mm256_set_m128(segment_range_min_zzzz, segment_range_min_zzzz));
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_extent[0]), _mm256_set_m128(segment_range_extent_xxxx, segment_range_extent_xxxx));
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_extent[2]), _mm256_set_m128(segment_range_extent_yyyy, segment_range_extent_yyyy));
+ _mm256_store_ps(reinterpret_cast<float*>(&output_scratch.segment_range_extent[4]), _mm256_set_m128(segment_range_extent_zzzz, segment_range_extent_zzzz));
+ }
+ else
+ {
+ // Second segment overwrites our data
+ output_scratch.segment_range_min[1] = segment_range_min_xxxx;
+ output_scratch.segment_range_min[3] = segment_range_min_yyyy;
+ output_scratch.segment_range_min[5] = segment_range_min_zzzz;
+ output_scratch.segment_range_extent[1] = segment_range_extent_xxxx;
+ output_scratch.segment_range_extent[3] = segment_range_extent_yyyy;
+ output_scratch.segment_range_extent[5] = segment_range_extent_zzzz;
+ }
+#else
+ output_scratch.segment_range_min[scratch_offset + 0] = segment_range_min_xxxx;
+ output_scratch.segment_range_min[scratch_offset + 2] = segment_range_min_yyyy;
+ output_scratch.segment_range_min[scratch_offset + 4] = segment_range_min_zzzz;
+ output_scratch.segment_range_extent[scratch_offset + 0] = segment_range_extent_xxxx;
+ output_scratch.segment_range_extent[scratch_offset + 2] = segment_range_extent_yyyy;
+ output_scratch.segment_range_extent[scratch_offset + 4] = segment_range_extent_zzzz;
+#endif
+ }
+
+ // About 19 cycles with AVX on Skylake
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL remap_segment_range_data4(const segment_animated_scratch_v0& segment_scratch, uint32_t scratch_offset, range_reduction_masks_t range_reduction_masks,
+ rtm::vector4f& xxxx, rtm::vector4f& yyyy, rtm::vector4f& zzzz)
+ {
+ // Load and mask out our segment range data
+ const rtm::vector4f one_v = rtm::vector_set(1.0F);
+
+ rtm::vector4f segment_range_min_xxxx = segment_scratch.segment_range_min[scratch_offset + 0];
+ rtm::vector4f segment_range_min_yyyy = segment_scratch.segment_range_min[scratch_offset + 2];
+ rtm::vector4f segment_range_min_zzzz = segment_scratch.segment_range_min[scratch_offset + 4];
+
+ rtm::vector4f segment_range_extent_xxxx = segment_scratch.segment_range_extent[scratch_offset + 0];
+ rtm::vector4f segment_range_extent_yyyy = segment_scratch.segment_range_extent[scratch_offset + 2];
+ rtm::vector4f segment_range_extent_zzzz = segment_scratch.segment_range_extent[scratch_offset + 4];
+
+#if defined(RTM_SSE2_INTRINSICS)
+ // Mask out the segment min we ignore
+ const rtm::mask4f segment_range_ignore_mask_v = _mm_castsi128_ps(_mm_unpacklo_epi16(range_reduction_masks, range_reduction_masks));
+
+ segment_range_min_xxxx = _mm_andnot_ps(segment_range_ignore_mask_v, segment_range_min_xxxx);
+ segment_range_min_yyyy = _mm_andnot_ps(segment_range_ignore_mask_v, segment_range_min_yyyy);
+ segment_range_min_zzzz = _mm_andnot_ps(segment_range_ignore_mask_v, segment_range_min_zzzz);
+#elif defined(RTM_NEON_INTRINSICS)
+ // Mask out the segment min we ignore
+ const uint32x4_t segment_range_ignore_mask_v = vreinterpretq_u32_s32(vmovl_s16(vget_low_s16(range_reduction_masks)));
+
+ segment_range_min_xxxx = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(segment_range_min_xxxx), segment_range_ignore_mask_v));
+ segment_range_min_yyyy = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(segment_range_min_yyyy), segment_range_ignore_mask_v));
+ segment_range_min_zzzz = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(segment_range_min_zzzz), segment_range_ignore_mask_v));
+#else
+ const rtm::vector4f zero_v = rtm::vector_zero();
+
+ const uint32_t segment_range_mask_u32 = uint32_t(range_reduction_masks);
+ const rtm::mask4f segment_range_ignore_mask_v = rtm::mask_set((segment_range_mask_u32 & 0x000000FF) != 0, (segment_range_mask_u32 & 0x0000FF00) != 0, (segment_range_mask_u32 & 0x00FF0000) != 0, (segment_range_mask_u32 & 0xFF000000) != 0);
+
+ segment_range_min_xxxx = rtm::vector_select(segment_range_ignore_mask_v, zero_v, segment_range_min_xxxx);
+ segment_range_min_yyyy = rtm::vector_select(segment_range_ignore_mask_v, zero_v, segment_range_min_yyyy);
+ segment_range_min_zzzz = rtm::vector_select(segment_range_ignore_mask_v, zero_v, segment_range_min_zzzz);
+#endif
+
+ // Mask out the segment extent we ignore
+ segment_range_extent_xxxx = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_xxxx);
+ segment_range_extent_yyyy = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_yyyy);
+ segment_range_extent_zzzz = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_zzzz);
+
+ // Remap
+ xxxx = rtm::vector_mul_add(xxxx, segment_range_extent_xxxx, segment_range_min_xxxx);
+ yyyy = rtm::vector_mul_add(yyyy, segment_range_extent_yyyy, segment_range_min_yyyy);
+ zzzz = rtm::vector_mul_add(zzzz, segment_range_extent_zzzz, segment_range_min_zzzz);
+ }
+
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL remap_segment_range_data_avx8(const segment_animated_scratch_v0& segment_scratch,
+ range_reduction_masks_t range_reduction_masks0, range_reduction_masks_t range_reduction_masks1,
+ __m256& xxxx0_xxxx1, __m256& yyyy0_yyyy1, __m256& zzzz0_zzzz1)
+ {
+ // Load and mask out our segment range data
+ const __m256 one_v = _mm256_set1_ps(1.0F);
+
+ __m256 segment_range_min_xxxx0_xxxx1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_min[0]));
+ __m256 segment_range_min_yyyy0_yyyy1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_min[2]));
+ __m256 segment_range_min_zzzz0_zzzz1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_min[4]));
+
+ __m256 segment_range_extent_xxxx0_xxxx1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_extent[0]));
+ __m256 segment_range_extent_yyyy0_yyyy1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_extent[2]));
+ __m256 segment_range_extent_zzzz0_zzzz1 = _mm256_load_ps(reinterpret_cast<const float*>(&segment_scratch.segment_range_extent[4]));
+
+ // Mask out the segment min we ignore
+ const __m128 segment_range_ignore_mask_v0 = _mm_castsi128_ps(_mm_unpacklo_epi16(range_reduction_masks0, range_reduction_masks0));
+ const __m128 segment_range_ignore_mask_v1 = _mm_castsi128_ps(_mm_unpacklo_epi16(range_reduction_masks1, range_reduction_masks1));
+
+ const __m256 segment_range_mask0_mask1 = _mm256_set_m128(segment_range_ignore_mask_v1, segment_range_ignore_mask_v0);
+
+ segment_range_min_xxxx0_xxxx1 = _mm256_andnot_ps(segment_range_mask0_mask1, segment_range_min_xxxx0_xxxx1);
+ segment_range_min_yyyy0_yyyy1 = _mm256_andnot_ps(segment_range_mask0_mask1, segment_range_min_yyyy0_yyyy1);
+ segment_range_min_zzzz0_zzzz1 = _mm256_andnot_ps(segment_range_mask0_mask1, segment_range_min_zzzz0_zzzz1);
+
+ segment_range_extent_xxxx0_xxxx1 = _mm256_blendv_ps(segment_range_extent_xxxx0_xxxx1, one_v, segment_range_mask0_mask1);
+ segment_range_extent_yyyy0_yyyy1 = _mm256_blendv_ps(segment_range_extent_yyyy0_yyyy1, one_v, segment_range_mask0_mask1);
+ segment_range_extent_zzzz0_zzzz1 = _mm256_blendv_ps(segment_range_extent_zzzz0_zzzz1, one_v, segment_range_mask0_mask1);
+
+ xxxx0_xxxx1 = _mm256_add_ps(_mm256_mul_ps(xxxx0_xxxx1, segment_range_extent_xxxx0_xxxx1), segment_range_min_xxxx0_xxxx1);
+ yyyy0_yyyy1 = _mm256_add_ps(_mm256_mul_ps(yyyy0_yyyy1, segment_range_extent_yyyy0_yyyy1), segment_range_min_yyyy0_yyyy1);
+ zzzz0_zzzz1 = _mm256_add_ps(_mm256_mul_ps(zzzz0_zzzz1, segment_range_extent_zzzz0_zzzz1), segment_range_min_zzzz0_zzzz1);
+ }
+#endif
+
+ // About 24 cycles with AVX on Skylake
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL remap_clip_range_data4(const uint8_t* clip_range_data, uint32_t num_to_unpack,
+ range_reduction_masks_t range_reduction_masks0, range_reduction_masks_t range_reduction_masks1,
+ rtm::vector4f& xxxx0, rtm::vector4f& yyyy0, rtm::vector4f& zzzz0,
+ rtm::vector4f& xxxx1, rtm::vector4f& yyyy1, rtm::vector4f& zzzz1)
+ {
+ // Always load 4x rotations, we might contain garbage in a few lanes but it's fine
+ const uint32_t load_size = num_to_unpack * sizeof(float);
+
+#if defined(RTM_SSE2_INTRINSICS)
+ const __m128 clip_range_mask0 = _mm_castsi128_ps(_mm_unpackhi_epi16(range_reduction_masks0, range_reduction_masks0));
+ const __m128 clip_range_mask1 = _mm_castsi128_ps(_mm_unpackhi_epi16(range_reduction_masks1, range_reduction_masks1));
+#elif defined(RTM_NEON_INTRINSICS)
+ const float32x4_t clip_range_mask0 = vreinterpretq_f32_s32(vmovl_s16(vget_high_s16(range_reduction_masks0)));
+ const float32x4_t clip_range_mask1 = vreinterpretq_f32_s32(vmovl_s16(vget_high_s16(range_reduction_masks1)));
+#else
+ const uint32_t clip_range_mask_u32_0 = uint32_t(range_reduction_masks0 >> 32);
+ const uint32_t clip_range_mask_u32_1 = uint32_t(range_reduction_masks1 >> 32);
+ const rtm::mask4f clip_range_mask0 = rtm::mask_set((clip_range_mask_u32_0 & 0x000000FF) != 0, (clip_range_mask_u32_0 & 0x0000FF00) != 0, (clip_range_mask_u32_0 & 0x00FF0000) != 0, (clip_range_mask_u32_0 & 0xFF000000) != 0);
+ const rtm::mask4f clip_range_mask1 = rtm::mask_set((clip_range_mask_u32_1 & 0x000000FF) != 0, (clip_range_mask_u32_1 & 0x0000FF00) != 0, (clip_range_mask_u32_1 & 0x00FF0000) != 0, (clip_range_mask_u32_1 & 0xFF000000) != 0);
+#endif
+
+ const rtm::vector4f clip_range_min_xxxx = rtm::vector_load(clip_range_data + load_size * 0);
+ const rtm::vector4f clip_range_min_yyyy = rtm::vector_load(clip_range_data + load_size * 1);
+ const rtm::vector4f clip_range_min_zzzz = rtm::vector_load(clip_range_data + load_size * 2);
+
+ const rtm::vector4f clip_range_extent_xxxx = rtm::vector_load(clip_range_data + load_size * 3);
+ const rtm::vector4f clip_range_extent_yyyy = rtm::vector_load(clip_range_data + load_size * 4);
+ const rtm::vector4f clip_range_extent_zzzz = rtm::vector_load(clip_range_data + load_size * 5);
+
+ // Mask out the clip ranges we ignore
+#if defined(RTM_SSE2_INTRINSICS)
+ const rtm::vector4f clip_range_min_xxxx0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_xxxx);
+ const rtm::vector4f clip_range_min_yyyy0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_yyyy);
+ const rtm::vector4f clip_range_min_zzzz0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_zzzz);
+
+ const rtm::vector4f clip_range_min_xxxx1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_xxxx);
+ const rtm::vector4f clip_range_min_yyyy1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_yyyy);
+ const rtm::vector4f clip_range_min_zzzz1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_zzzz);
+#elif defined(RTM_NEON_INTRINSICS)
+ const rtm::vector4f clip_range_min_xxxx0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_xxxx), vreinterpretq_u32_f32(clip_range_mask0)));
+ const rtm::vector4f clip_range_min_yyyy0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_yyyy), vreinterpretq_u32_f32(clip_range_mask0)));
+ const rtm::vector4f clip_range_min_zzzz0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_zzzz), vreinterpretq_u32_f32(clip_range_mask0)));
+
+ const rtm::vector4f clip_range_min_xxxx1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_xxxx), vreinterpretq_u32_f32(clip_range_mask1)));
+ const rtm::vector4f clip_range_min_yyyy1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_yyyy), vreinterpretq_u32_f32(clip_range_mask1)));
+ const rtm::vector4f clip_range_min_zzzz1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_zzzz), vreinterpretq_u32_f32(clip_range_mask1)));
+#else
+ const rtm::vector4f zero_v = rtm::vector_zero();
+
+ const rtm::vector4f clip_range_min_xxxx0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_xxxx);
+ const rtm::vector4f clip_range_min_yyyy0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_yyyy);
+ const rtm::vector4f clip_range_min_zzzz0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_zzzz);
+
+ const rtm::vector4f clip_range_min_xxxx1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_xxxx);
+ const rtm::vector4f clip_range_min_yyyy1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_yyyy);
+ const rtm::vector4f clip_range_min_zzzz1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_zzzz);
+#endif
+
+ const rtm::vector4f one_v = rtm::vector_set(1.0F);
+
+ const rtm::vector4f clip_range_extent_xxxx0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_xxxx);
+ const rtm::vector4f clip_range_extent_yyyy0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_yyyy);
+ const rtm::vector4f clip_range_extent_zzzz0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_zzzz);
+
+ const rtm::vector4f clip_range_extent_xxxx1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_xxxx);
+ const rtm::vector4f clip_range_extent_yyyy1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_yyyy);
+ const rtm::vector4f clip_range_extent_zzzz1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_zzzz);
+
+ xxxx0 = rtm::vector_mul_add(xxxx0, clip_range_extent_xxxx0, clip_range_min_xxxx0);
+ yyyy0 = rtm::vector_mul_add(yyyy0, clip_range_extent_yyyy0, clip_range_min_yyyy0);
+ zzzz0 = rtm::vector_mul_add(zzzz0, clip_range_extent_zzzz0, clip_range_min_zzzz0);
+
+ xxxx1 = rtm::vector_mul_add(xxxx1, clip_range_extent_xxxx1, clip_range_min_xxxx1);
+ yyyy1 = rtm::vector_mul_add(yyyy1, clip_range_extent_yyyy1, clip_range_min_yyyy1);
+ zzzz1 = rtm::vector_mul_add(zzzz1, clip_range_extent_zzzz1, clip_range_min_zzzz1);
+ }
+
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL remap_clip_range_data_avx8(const uint8_t* clip_range_data, uint32_t num_to_unpack,
+ range_reduction_masks_t range_reduction_masks0, range_reduction_masks_t range_reduction_masks1,
+ __m256& xxxx0_xxxx1, __m256& yyyy0_yyyy1, __m256& zzzz0_zzzz1)
+ {
+ const __m256 one_v = _mm256_set1_ps(1.0F);
+
+ // Always load 4x rotations, we might contain garbage in a few lanes but it's fine
+ const uint32_t load_size = num_to_unpack * sizeof(float);
+
+ const __m128 clip_range_mask0 = _mm_castsi128_ps(_mm_unpackhi_epi16(range_reduction_masks0, range_reduction_masks0));
+ const __m128 clip_range_mask1 = _mm_castsi128_ps(_mm_unpackhi_epi16(range_reduction_masks1, range_reduction_masks1));
+
+ const __m256 clip_range_mask0_mask1 = _mm256_set_m128(clip_range_mask1, clip_range_mask0);
+
+ const rtm::vector4f clip_range_min_xxxx = rtm::vector_load(clip_range_data + load_size * 0);
+ const rtm::vector4f clip_range_min_yyyy = rtm::vector_load(clip_range_data + load_size * 1);
+ const rtm::vector4f clip_range_min_zzzz = rtm::vector_load(clip_range_data + load_size * 2);
+
+ const rtm::vector4f clip_range_extent_xxxx = rtm::vector_load(clip_range_data + load_size * 3);
+ const rtm::vector4f clip_range_extent_yyyy = rtm::vector_load(clip_range_data + load_size * 4);
+ const rtm::vector4f clip_range_extent_zzzz = rtm::vector_load(clip_range_data + load_size * 5);
+
+ __m256 clip_range_min_xxxx_xxxx = _mm256_set_m128(clip_range_min_xxxx, clip_range_min_xxxx);
+ __m256 clip_range_min_yyyy_yyyy = _mm256_set_m128(clip_range_min_yyyy, clip_range_min_yyyy);
+ __m256 clip_range_min_zzzz_zzzz = _mm256_set_m128(clip_range_min_zzzz, clip_range_min_zzzz);
+
+ __m256 clip_range_extent_xxxx_xxxx = _mm256_set_m128(clip_range_extent_xxxx, clip_range_extent_xxxx);
+ __m256 clip_range_extent_yyyy_yyyy = _mm256_set_m128(clip_range_extent_yyyy, clip_range_extent_yyyy);
+ __m256 clip_range_extent_zzzz_zzzz = _mm256_set_m128(clip_range_extent_zzzz, clip_range_extent_zzzz);
+
+ // Mask out the clip ranges we ignore
+ clip_range_min_xxxx_xxxx = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_xxxx_xxxx);
+ clip_range_min_yyyy_yyyy = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_yyyy_yyyy);
+ clip_range_min_zzzz_zzzz = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_zzzz_zzzz);
+
+ clip_range_extent_xxxx_xxxx = _mm256_blendv_ps(clip_range_extent_xxxx_xxxx, one_v, clip_range_mask0_mask1);
+ clip_range_extent_yyyy_yyyy = _mm256_blendv_ps(clip_range_extent_yyyy_yyyy, one_v, clip_range_mask0_mask1);
+ clip_range_extent_zzzz_zzzz = _mm256_blendv_ps(clip_range_extent_zzzz_zzzz, one_v, clip_range_mask0_mask1);
+
+ xxxx0_xxxx1 = _mm256_add_ps(_mm256_mul_ps(xxxx0_xxxx1, clip_range_extent_xxxx_xxxx), clip_range_min_xxxx_xxxx);
+ yyyy0_yyyy1 = _mm256_add_ps(_mm256_mul_ps(yyyy0_yyyy1, clip_range_extent_yyyy_yyyy), clip_range_min_yyyy_yyyy);
+ zzzz0_zzzz1 = _mm256_add_ps(_mm256_mul_ps(zzzz0_zzzz1, clip_range_extent_zzzz_zzzz), clip_range_min_zzzz_zzzz);
+ }
+#endif
+
+ // About 31 cycles with AVX on Skylake
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL quat_from_positive_w4(rtm::vector4f_arg0 xxxx, rtm::vector4f_arg1 yyyy, rtm::vector4f_arg2 zzzz)
+ {
+ const rtm::vector4f xxxx_squared = rtm::vector_mul(xxxx, xxxx);
+ const rtm::vector4f yyyy_squared = rtm::vector_mul(yyyy, yyyy);
+ const rtm::vector4f zzzz_squared = rtm::vector_mul(zzzz, zzzz);
+ const rtm::vector4f wwww_squared = rtm::vector_sub(rtm::vector_sub(rtm::vector_sub(rtm::vector_set(1.0F), xxxx_squared), yyyy_squared), zzzz_squared);
+
+ // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
+ // to ensure the resulting quaternion is always normalized with a positive W component
+ return rtm::vector_sqrt(rtm::vector_abs(wwww_squared));
+ }
+
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK __m256 RTM_SIMD_CALL quat_from_positive_w_avx8(__m256 xxxx0_xxxx1, __m256 yyyy0_yyyy1, __m256 zzzz0_zzzz1)
+ {
+ const __m256 one_v = _mm256_set1_ps(1.0F);
+
+ const __m256 xxxx0_xxxx1_squared = _mm256_mul_ps(xxxx0_xxxx1, xxxx0_xxxx1);
+ const __m256 yyyy0_yyyy1_squared = _mm256_mul_ps(yyyy0_yyyy1, yyyy0_yyyy1);
+ const __m256 zzzz0_zzzz1_squared = _mm256_mul_ps(zzzz0_zzzz1, zzzz0_zzzz1);
+
+ const __m256 wwww0_wwww1_squared = _mm256_sub_ps(_mm256_sub_ps(_mm256_sub_ps(one_v, xxxx0_xxxx1_squared), yyyy0_yyyy1_squared), zzzz0_zzzz1_squared);
+
+ const __m256i abs_mask = _mm256_set1_epi32(0x7FFFFFFFULL);
+ const __m256 wwww0_wwww1_squared_abs = _mm256_and_ps(wwww0_wwww1_squared, _mm256_castsi256_ps(abs_mask));
+
+ return _mm256_sqrt_ps(wwww0_wwww1_squared_abs);
+ }
+#endif
+
+ // About 28 cycles with AVX on Skylake
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL quat_lerp4(
+ rtm::vector4f_arg0 xxxx0, rtm::vector4f_arg1 yyyy0, rtm::vector4f_arg2 zzzz0, rtm::vector4f_arg3 wwww0,
+ rtm::vector4f_arg4 xxxx1, rtm::vector4f_arg5 yyyy1, rtm::vector4f_arg6 zzzz1, rtm::vector4f_arg7 wwww1,
+ float interpolation_alpha,
+ rtm::vector4f& interp_xxxx, rtm::vector4f& interp_yyyy, rtm::vector4f& interp_zzzz, rtm::vector4f& interp_wwww)
+ {
+ // Calculate the vector4 dot product: dot(start, end)
+ const rtm::vector4f xxxx_squared = rtm::vector_mul(xxxx0, xxxx1);
+ const rtm::vector4f yyyy_squared = rtm::vector_mul(yyyy0, yyyy1);
+ const rtm::vector4f zzzz_squared = rtm::vector_mul(zzzz0, zzzz1);
+ const rtm::vector4f wwww_squared = rtm::vector_mul(wwww0, wwww1);
+
+ const rtm::vector4f dot4 = rtm::vector_add(rtm::vector_add(rtm::vector_add(xxxx_squared, yyyy_squared), zzzz_squared), wwww_squared);
+
+ // Calculate the bias, if the dot product is positive or zero, there is no bias
+ // but if it is negative, we want to flip the 'end' rotation XYZW components
+ const rtm::vector4f neg_zero = rtm::vector_set(-0.0F);
+ const rtm::vector4f bias = acl_impl::vector_and(dot4, neg_zero);
+
+ // Apply our bias to the 'end'
+ const rtm::vector4f xxxx1_with_bias = acl_impl::vector_xor(xxxx1, bias);
+ const rtm::vector4f yyyy1_with_bias = acl_impl::vector_xor(yyyy1, bias);
+ const rtm::vector4f zzzz1_with_bias = acl_impl::vector_xor(zzzz1, bias);
+ const rtm::vector4f wwww1_with_bias = acl_impl::vector_xor(wwww1, bias);
+
+ // Lerp the rotation after applying the bias
+ // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
+ const rtm::vector4f alpha = rtm::vector_set(interpolation_alpha);
+
+ interp_xxxx = rtm::vector_mul_add(xxxx1_with_bias, alpha, rtm::vector_neg_mul_sub(xxxx0, alpha, xxxx0));
+ interp_yyyy = rtm::vector_mul_add(yyyy1_with_bias, alpha, rtm::vector_neg_mul_sub(yyyy0, alpha, yyyy0));
+ interp_zzzz = rtm::vector_mul_add(zzzz1_with_bias, alpha, rtm::vector_neg_mul_sub(zzzz0, alpha, zzzz0));
+ interp_wwww = rtm::vector_mul_add(wwww1_with_bias, alpha, rtm::vector_neg_mul_sub(wwww0, alpha, wwww0));
+ }
+
+ // About 9 cycles with AVX on Skylake
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL quat_normalize4(rtm::vector4f& xxxx, rtm::vector4f& yyyy, rtm::vector4f& zzzz, rtm::vector4f& wwww)
+ {
+ const rtm::vector4f xxxx_squared = rtm::vector_mul(xxxx, xxxx);
+ const rtm::vector4f yyyy_squared = rtm::vector_mul(yyyy, yyyy);
+ const rtm::vector4f zzzz_squared = rtm::vector_mul(zzzz, zzzz);
+ const rtm::vector4f wwww_squared = rtm::vector_mul(wwww, wwww);
+
+ const rtm::vector4f dot4 = rtm::vector_add(rtm::vector_add(rtm::vector_add(xxxx_squared, yyyy_squared), zzzz_squared), wwww_squared);
+
+ const rtm::vector4f len4 = rtm::vector_sqrt(dot4);
+ const rtm::vector4f inv_len4 = rtm::vector_div(rtm::vector_set(1.0F), len4);
+
+ xxxx = rtm::vector_mul(xxxx, inv_len4);
+ yyyy = rtm::vector_mul(yyyy, inv_len4);
+ zzzz = rtm::vector_mul(zzzz, inv_len4);
+ wwww = rtm::vector_mul(wwww, inv_len4);
+ }
+
template<class decompression_settings_type>
- inline ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::mask4f RTM_SIMD_CALL unpack_animated_quat(const persistent_transform_decompression_context_v0& decomp_context, rtm::vector4f output_scratch[4],
+ inline ACL_DISABLE_SECURITY_COOKIE_CHECK range_reduction_masks_t RTM_SIMD_CALL unpack_animated_quat(const persistent_transform_decompression_context_v0& decomp_context, rtm::vector4f output_scratch[4],
uint32_t num_to_unpack, segment_animated_sampling_context_v0& segment_sampling_context)
{
const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
@@ -105,6 +605,10 @@ namespace acl
// For SIMD, can we load constant samples and write them to scratch? Afterwards its the same as packed on 16 bits
// We get 4 short branches (test, cmp, 6x loads, 3x ORs, 3x writes, load immediate) followed by a common code path for all 4 samples
+ // Maybe we can write in SOA order directly, and we could even write the scaling value per lane, load ones multiply 3 times for xyz in SOA
+
+ // Try inlining the unpacking functions
+
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
// Our decompressed rotation as a vector4
@@ -202,206 +706,36 @@ namespace acl
// case we don't need to prefetch it and we can go to the next one. Any offset after the end
// of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
// Prefetch 4 samples ahead in all levels of the CPU cache
- ACL_IMPL_ANIMATED_PREFETCH(format_per_track_data + 63);
+#if defined(ACL_IMPL_PREFETCH_EARLY)
ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_track_data_bit_offset / 8) + 63);
+#endif
// Update our pointers
if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
+#if defined(ACL_IMPL_PREFETCH_EARLY)
+ // Prefetch the next cache line in all levels of the CPU cache
+ ACL_IMPL_ANIMATED_PREFETCH(format_per_track_data + 64);
+#endif
+
// Skip our used metadata data, all groups are padded to 4 elements
segment_sampling_context.format_per_track_data = format_per_track_data + 4;
}
segment_sampling_context.animated_track_data_bit_offset = animated_track_data_bit_offset;
- // Swizzle our samples into SOA form
- // TODO: Optimize for NEON
- rtm::vector4f tmp0 = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::a, rtm::mix4::b>(output_scratch[0], output_scratch[1]);
- rtm::vector4f tmp1 = rtm::vector_mix<rtm::mix4::z, rtm::mix4::w, rtm::mix4::c, rtm::mix4::d>(output_scratch[0], output_scratch[1]);
- rtm::vector4f tmp2 = rtm::vector_mix<rtm::mix4::x, rtm::mix4::y, rtm::mix4::a, rtm::mix4::b>(output_scratch[2], output_scratch[3]);
- rtm::vector4f tmp3 = rtm::vector_mix<rtm::mix4::z, rtm::mix4::w, rtm::mix4::c, rtm::mix4::d>(output_scratch[2], output_scratch[3]);
-
- rtm::vector4f sample_xxxx = rtm::vector_mix<rtm::mix4::x, rtm::mix4::z, rtm::mix4::a, rtm::mix4::c>(tmp0, tmp2);
- rtm::vector4f sample_yyyy = rtm::vector_mix<rtm::mix4::y, rtm::mix4::w, rtm::mix4::b, rtm::mix4::d>(tmp0, tmp2);
- rtm::vector4f sample_zzzz = rtm::vector_mix<rtm::mix4::x, rtm::mix4::z, rtm::mix4::a, rtm::mix4::c>(tmp1, tmp3);
-
- rtm::mask4f clip_range_ignore_mask_v32f; // function's return value
+ range_reduction_masks_t range_reduction_masks; // function's return value
if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
- // TODO: Move range remapping out of here and do it with AVX together with quat W reconstruction
-
- const rtm::vector4f one_v = rtm::vector_set(1.0F);
-
#if defined(RTM_SSE2_INTRINSICS)
const __m128i ignore_masks_v8 = _mm_set_epi32(0, 0, clip_range_ignore_mask, segment_range_ignore_mask);
- const __m128i ignore_masks_v16 = _mm_unpacklo_epi8(ignore_masks_v8, ignore_masks_v8);
+ range_reduction_masks = _mm_unpacklo_epi8(ignore_masks_v8, ignore_masks_v8);
#elif defined(RTM_NEON_INTRINSICS)
const int8x8_t ignore_masks_v8 = vcreate_s8((uint64_t(clip_range_ignore_mask) << 32) | segment_range_ignore_mask);
- const int16x8_t ignore_masks_v16 = vmovl_s8(ignore_masks_v8);
-#endif
-
- if (decomp_context.has_segments)
- {
- // TODO: prefetch segment data earlier, as soon as we are done loading
-
- // Segment range is packed: min.xxxx, min.yyyy, min.zzzz, extent.xxxx, extent.yyyy, extent.zzzz
-
-#if defined(RTM_SSE2_INTRINSICS)
- const __m128i zero = _mm_setzero_si128();
-
- const __m128i segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8 = _mm_loadu_si128((const __m128i*)segment_range_data);
- const __m128i segment_range_extent_yyyy_zzzz_u8 = _mm_loadu_si128((const __m128i*)(segment_range_data + 16));
-
- // Convert from u8 to u32
- const __m128i segment_range_min_xxxx_yyyy_u16 = _mm_unpacklo_epi8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8, zero);
- const __m128i segment_range_min_zzzz_extent_xxxx_u16 = _mm_unpackhi_epi8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8, zero);
- const __m128i segment_range_extent_yyyy_zzzz_u16 = _mm_unpacklo_epi8(segment_range_extent_yyyy_zzzz_u8, zero);
-
- __m128i segment_range_min_xxxx_u32 = _mm_unpacklo_epi16(segment_range_min_xxxx_yyyy_u16, zero);
- __m128i segment_range_min_yyyy_u32 = _mm_unpackhi_epi16(segment_range_min_xxxx_yyyy_u16, zero);
- __m128i segment_range_min_zzzz_u32 = _mm_unpacklo_epi16(segment_range_min_zzzz_extent_xxxx_u16, zero);
-
- const __m128i segment_range_extent_xxxx_u32 = _mm_unpackhi_epi16(segment_range_min_zzzz_extent_xxxx_u16, zero);
- const __m128i segment_range_extent_yyyy_u32 = _mm_unpacklo_epi16(segment_range_extent_yyyy_zzzz_u16, zero);
- const __m128i segment_range_extent_zzzz_u32 = _mm_unpackhi_epi16(segment_range_extent_yyyy_zzzz_u16, zero);
-
- // Mask out the segment min we ignore
- const __m128i segment_range_ignore_mask_u32 = _mm_unpacklo_epi16(ignore_masks_v16, ignore_masks_v16);
-
- segment_range_min_xxxx_u32 = _mm_andnot_si128(segment_range_ignore_mask_u32, segment_range_min_xxxx_u32);
- segment_range_min_yyyy_u32 = _mm_andnot_si128(segment_range_ignore_mask_u32, segment_range_min_yyyy_u32);
- segment_range_min_zzzz_u32 = _mm_andnot_si128(segment_range_ignore_mask_u32, segment_range_min_zzzz_u32);
-
- __m128 segment_range_min_xxxx = _mm_cvtepi32_ps(segment_range_min_xxxx_u32);
- __m128 segment_range_min_yyyy = _mm_cvtepi32_ps(segment_range_min_yyyy_u32);
- __m128 segment_range_min_zzzz = _mm_cvtepi32_ps(segment_range_min_zzzz_u32);
-
- __m128 segment_range_extent_xxxx = _mm_cvtepi32_ps(segment_range_extent_xxxx_u32);
- __m128 segment_range_extent_yyyy = _mm_cvtepi32_ps(segment_range_extent_yyyy_u32);
- __m128 segment_range_extent_zzzz = _mm_cvtepi32_ps(segment_range_extent_zzzz_u32);
-
- const __m128 normalization_value = _mm_set_ps1(1.0F / 255.0F);
-
- segment_range_min_xxxx = _mm_mul_ps(segment_range_min_xxxx, normalization_value);
- segment_range_min_yyyy = _mm_mul_ps(segment_range_min_yyyy, normalization_value);
- segment_range_min_zzzz = _mm_mul_ps(segment_range_min_zzzz, normalization_value);
-
- segment_range_extent_xxxx = _mm_mul_ps(segment_range_extent_xxxx, normalization_value);
- segment_range_extent_yyyy = _mm_mul_ps(segment_range_extent_yyyy, normalization_value);
- segment_range_extent_zzzz = _mm_mul_ps(segment_range_extent_zzzz, normalization_value);
-
- const rtm::mask4f segment_range_ignore_mask_v = _mm_castsi128_ps(segment_range_ignore_mask_u32);
-#elif defined(RTM_NEON_INTRINSICS)
- const uint8x16_t segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8 = vld1q_u8(segment_range_data);
- const uint8x8_t segment_range_extent_yyyy_zzzz_u8 = vld1_u8(segment_range_data + 16);
-
- // Convert from u8 to u32
- const uint16x8_t segment_range_min_xxxx_yyyy_u16 = vmovl_u8(vget_low_u8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8));
- const uint16x8_t segment_range_min_zzzz_extent_xxxx_u16 = vmovl_u8(vget_high_u8(segment_range_min_xxxx_yyyy_zzzz_extent_xxxx_u8));
- const uint16x8_t segment_range_extent_yyyy_zzzz_u16 = vmovl_u8(segment_range_extent_yyyy_zzzz_u8);
-
- uint32x4_t segment_range_min_xxxx_u32 = vmovl_u16(vget_low_u16(segment_range_min_xxxx_yyyy_u16));
- uint32x4_t segment_range_min_yyyy_u32 = vmovl_u16(vget_high_u16(segment_range_min_xxxx_yyyy_u16));
- uint32x4_t segment_range_min_zzzz_u32 = vmovl_u16(vget_low_u16(segment_range_min_zzzz_extent_xxxx_u16));
-
- const uint32x4_t segment_range_extent_xxxx_u32 = vmovl_u16(vget_high_u16(segment_range_min_zzzz_extent_xxxx_u16));
- const uint32x4_t segment_range_extent_yyyy_u32 = vmovl_u16(vget_low_u16(segment_range_extent_yyyy_zzzz_u16));
- const uint32x4_t segment_range_extent_zzzz_u32 = vmovl_u16(vget_high_u16(segment_range_extent_yyyy_zzzz_u16));
-
- // Mask out the segment min we ignore
- const uint32x4_t segment_range_ignore_mask_u32 = vreinterpretq_u32_s32(vmovl_s16(vget_low_s16(ignore_masks_v16)));
-
- segment_range_min_xxxx_u32 = vbicq_u32(segment_range_min_xxxx_u32, segment_range_ignore_mask_u32);
- segment_range_min_yyyy_u32 = vbicq_u32(segment_range_min_yyyy_u32, segment_range_ignore_mask_u32);
- segment_range_min_zzzz_u32 = vbicq_u32(segment_range_min_zzzz_u32, segment_range_ignore_mask_u32);
-
- float32x4_t segment_range_min_xxxx = vcvtq_f32_u32(segment_range_min_xxxx_u32);
- float32x4_t segment_range_min_yyyy = vcvtq_f32_u32(segment_range_min_yyyy_u32);
- float32x4_t segment_range_min_zzzz = vcvtq_f32_u32(segment_range_min_zzzz_u32);
-
- float32x4_t segment_range_extent_xxxx = vcvtq_f32_u32(segment_range_extent_xxxx_u32);
- float32x4_t segment_range_extent_yyyy = vcvtq_f32_u32(segment_range_extent_yyyy_u32);
- float32x4_t segment_range_extent_zzzz = vcvtq_f32_u32(segment_range_extent_zzzz_u32);
-
- const float normalization_value = 1.0F / 255.0F;
-
- segment_range_min_xxxx = vmulq_n_f32(segment_range_min_xxxx, normalization_value);
- segment_range_min_yyyy = vmulq_n_f32(segment_range_min_yyyy, normalization_value);
- segment_range_min_zzzz = vmulq_n_f32(segment_range_min_zzzz, normalization_value);
-
- segment_range_extent_xxxx = vmulq_n_f32(segment_range_extent_xxxx, normalization_value);
- segment_range_extent_yyyy = vmulq_n_f32(segment_range_extent_yyyy, normalization_value);
- segment_range_extent_zzzz = vmulq_n_f32(segment_range_extent_zzzz, normalization_value);
-
- const rtm::mask4f segment_range_ignore_mask_v = vreinterpretq_f32_u32(segment_range_ignore_mask_u32);
-#else
- rtm::vector4f segment_range_min_xxxx = rtm::vector_set(float(segment_range_data[0]), float(segment_range_data[1]), float(segment_range_data[2]), float(segment_range_data[3]));
- rtm::vector4f segment_range_min_yyyy = rtm::vector_set(float(segment_range_data[4]), float(segment_range_data[5]), float(segment_range_data[6]), float(segment_range_data[7]));
- rtm::vector4f segment_range_min_zzzz = rtm::vector_set(float(segment_range_data[8]), float(segment_range_data[9]), float(segment_range_data[10]), float(segment_range_data[11]));
-
- rtm::vector4f segment_range_extent_xxxx = rtm::vector_set(float(segment_range_data[12]), float(segment_range_data[13]), float(segment_range_data[14]), float(segment_range_data[15]));
- rtm::vector4f segment_range_extent_yyyy = rtm::vector_set(float(segment_range_data[16]), float(segment_range_data[17]), float(segment_range_data[18]), float(segment_range_data[19]));
- rtm::vector4f segment_range_extent_zzzz = rtm::vector_set(float(segment_range_data[20]), float(segment_range_data[21]), float(segment_range_data[22]), float(segment_range_data[23]));
-
- const float normalization_value = 1.0F / 255.0F;
-
- segment_range_min_xxxx = rtm::vector_mul(segment_range_min_xxxx, normalization_value);
- segment_range_min_yyyy = rtm::vector_mul(segment_range_min_yyyy, normalization_value);
- segment_range_min_zzzz = rtm::vector_mul(segment_range_min_zzzz, normalization_value);
-
- segment_range_extent_xxxx = rtm::vector_mul(segment_range_extent_xxxx, normalization_value);
- segment_range_extent_yyyy = rtm::vector_mul(segment_range_extent_yyyy, normalization_value);
- segment_range_extent_zzzz = rtm::vector_mul(segment_range_extent_zzzz, normalization_value);
-
- // Mask out the segment min we ignore
- if (segment_range_ignore_mask & 0x000000FF)
- {
- segment_range_min_xxxx = rtm::vector_set_x(segment_range_min_xxxx, 0.0F);
- segment_range_min_yyyy = rtm::vector_set_x(segment_range_min_yyyy, 0.0F);
- segment_range_min_zzzz = rtm::vector_set_x(segment_range_min_zzzz, 0.0F);
- }
-
- if (segment_range_ignore_mask & 0x0000FF00)
- {
- segment_range_min_xxxx = rtm::vector_set_y(segment_range_min_xxxx, 0.0F);
- segment_range_min_yyyy = rtm::vector_set_y(segment_range_min_yyyy, 0.0F);
- segment_range_min_zzzz = rtm::vector_set_y(segment_range_min_zzzz, 0.0F);
- }
-
- if (segment_range_ignore_mask & 0x00FF0000)
- {
- segment_range_min_xxxx = rtm::vector_set_z(segment_range_min_xxxx, 0.0F);
- segment_range_min_yyyy = rtm::vector_set_z(segment_range_min_yyyy, 0.0F);
- segment_range_min_zzzz = rtm::vector_set_z(segment_range_min_zzzz, 0.0F);
- }
-
- if (segment_range_ignore_mask & 0xFF000000)
- {
- segment_range_min_xxxx = rtm::vector_set_w(segment_range_min_xxxx, 0.0F);
- segment_range_min_yyyy = rtm::vector_set_w(segment_range_min_yyyy, 0.0F);
- segment_range_min_zzzz = rtm::vector_set_w(segment_range_min_zzzz, 0.0F);
- }
-
- const rtm::mask4f segment_range_ignore_mask_v = rtm::mask_set((segment_range_ignore_mask & 0x000000FF) != 0, (segment_range_ignore_mask & 0x0000FF00) != 0, (segment_range_ignore_mask & 0x00FF0000) != 0, (segment_range_ignore_mask & 0xFF000000) != 0);
-#endif
-
- // Mask out the segment extent we ignore
- segment_range_extent_xxxx = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_xxxx);
- segment_range_extent_yyyy = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_yyyy);
- segment_range_extent_zzzz = rtm::vector_select(segment_range_ignore_mask_v, one_v, segment_range_extent_zzzz);
-
- sample_xxxx = rtm::vector_mul_add(sample_xxxx, segment_range_extent_xxxx, segment_range_min_xxxx);
- sample_yyyy = rtm::vector_mul_add(sample_yyyy, segment_range_extent_yyyy, segment_range_min_yyyy);
- sample_zzzz = rtm::vector_mul_add(sample_zzzz, segment_range_extent_zzzz, segment_range_min_zzzz);
- }
-
-#if defined(RTM_SSE2_INTRINSICS)
- clip_range_ignore_mask_v32f = _mm_castsi128_ps(_mm_unpackhi_epi16(ignore_masks_v16, ignore_masks_v16));
-#elif defined(RTM_NEON_INTRINSICS)
- clip_range_ignore_mask_v32f = vreinterpretq_f32_s32(vmovl_s16(vget_high_s16(ignore_masks_v16)));
+ range_reduction_masks = vmovl_s8(ignore_masks_v8);
#else
- clip_range_ignore_mask_v32f = rtm::mask_set((clip_range_ignore_mask & 0x000000FF) != 0, (clip_range_ignore_mask & 0x0000FF00) != 0, (clip_range_ignore_mask & 0x00FF0000) != 0, (clip_range_ignore_mask & 0xFF000000) != 0);
+ range_reduction_masks = (uint64_t(clip_range_ignore_mask) << 32) | segment_range_ignore_mask;
#endif
// Skip our used segment range data, all groups are padded to 4 elements
@@ -409,35 +743,19 @@ namespace acl
// Update our ptr
segment_sampling_context.segment_range_data = segment_range_data;
-
- // Prefetch the next cache line even if we don't have any data left
- // By the time we unpack again, it will have arrived in the CPU cache
- // If our format is full precision, we have at most 4 samples per cache line
- // If our format is drop W, we have at most 5.33 samples per cache line
-
- // If our pointer was already aligned to a cache line before we unpacked our 4 values,
- // it now points to the first byte of the next cache line. Any offset between 0-63 will fetch it.
- // If our pointer had some offset into a cache line, we might have spanned 2 cache lines.
- // If this happens, we probably already read some data from the next cache line in which
- // case we don't need to prefetch it and we can go to the next one. Any offset after the end
- // of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
- // Prefetch 4 samples ahead in all levels of the CPU cache
- ACL_IMPL_ANIMATED_PREFETCH(segment_range_data + 63);
}
else
{
- const rtm::vector4f sample_wwww = rtm::vector_mix<rtm::mix4::y, rtm::mix4::w, rtm::mix4::b, rtm::mix4::d>(tmp1, tmp3);
- output_scratch[3] = sample_wwww;
-
- // TODO: Optimize for SSE/NEON, codegen for this might not be optimal
- clip_range_ignore_mask_v32f = rtm::mask_set(0U, 0U, 0U, 0U); // Won't be used, just initialize it to something
+#if defined(RTM_SSE2_INTRINSICS)
+ range_reduction_masks = _mm_setzero_si128();
+#elif defined(RTM_NEON_INTRINSICS)
+ range_reduction_masks = vcombine_s16(vcreate_s16(0ULL), vcreate_s16(0ULL));
+#else
+ range_reduction_masks = 0ULL;
+#endif
}
- output_scratch[0] = sample_xxxx;
- output_scratch[1] = sample_yyyy;
- output_scratch[2] = sample_zzzz;
-
- return clip_range_ignore_mask_v32f;
+ return range_reduction_masks;
}
template<class decompression_settings_type>
@@ -720,9 +1038,9 @@ namespace acl
// case we don't need to prefetch it and we can go to the next one. Any offset after the end
// of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
// Prefetch 4 samples ahead in all levels of the CPU cache
- ACL_IMPL_ANIMATED_PREFETCH(format_per_track_data + 63);
+ ACL_IMPL_ANIMATED_PREFETCH(format_per_track_data + 60);
ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_track_data_bit_offset / 8) + 63);
- ACL_IMPL_ANIMATED_PREFETCH(segment_range_data + 63);
+ ACL_IMPL_ANIMATED_PREFETCH(segment_range_data + 48);
}
template<class decompression_settings_adapter_type>
@@ -823,6 +1141,66 @@ namespace acl
return sample;
}
+ // Force inline this function, we only use it to keep the code readable
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void count_animated_group_bit_size(
+ const uint8_t* format_per_track_data0, const uint8_t* format_per_track_data1, uint32_t num_groups_to_skip,
+ uint32_t& out_group_bit_size_per_component0, uint32_t& out_group_bit_size_per_component1)
+ {
+ // TODO: Do the same with NEON
+#if defined(RTM_AVX_INTRINSICS)
+ __m128i zero = _mm_setzero_si128();
+ __m128i group_bit_size_per_component0_v = zero;
+ __m128i group_bit_size_per_component1_v = zero;
+
+ // We add 4 at a time in SIMD
+ for (uint32_t group_index = 0; group_index < num_groups_to_skip; ++group_index)
+ {
+ const __m128i group_bit_size_per_component0_u8 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(format_per_track_data0 + (group_index * 4)));
+ const __m128i group_bit_size_per_component1_u8 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(format_per_track_data1 + (group_index * 4)));
+
+ group_bit_size_per_component0_v = _mm_add_epi32(group_bit_size_per_component0_v, _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component0_u8, zero), zero));
+ group_bit_size_per_component1_v = _mm_add_epi32(group_bit_size_per_component1_v, _mm_unpacklo_epi16(_mm_unpacklo_epi8(group_bit_size_per_component1_u8, zero), zero));
+ }
+
+ // Now we sum horizontally
+ group_bit_size_per_component0_v = _mm_hadd_epi32(_mm_hadd_epi32(group_bit_size_per_component0_v, group_bit_size_per_component0_v), group_bit_size_per_component0_v);
+ group_bit_size_per_component1_v = _mm_hadd_epi32(_mm_hadd_epi32(group_bit_size_per_component1_v, group_bit_size_per_component1_v), group_bit_size_per_component1_v);
+
+ out_group_bit_size_per_component0 = _mm_cvtsi128_si32(group_bit_size_per_component0_v);
+ out_group_bit_size_per_component1 = _mm_cvtsi128_si32(group_bit_size_per_component1_v);
+#else
+ uint32_t group_bit_size_per_component0 = 0;
+ uint32_t group_bit_size_per_component1 = 0;
+
+ for (uint32_t group_index = 0; group_index < num_groups_to_skip; ++group_index)
+ {
+ group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 0];
+ group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 0];
+
+ group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 1];
+ group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 1];
+
+ group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 2];
+ group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 2];
+
+ group_bit_size_per_component0 += format_per_track_data0[(group_index * 4) + 3];
+ group_bit_size_per_component1 += format_per_track_data1[(group_index * 4) + 3];
+ }
+
+ out_group_bit_size_per_component0 = group_bit_size_per_component0;
+ out_group_bit_size_per_component1 = group_bit_size_per_component1;
+#endif
+ }
+
+ // Performance notes:
+ // - Using SOA after unpacking vec3 appears to be slightly slower. Full groups aren't super common
+ // because animated translation/scale isn't common. But even with clips with lots of full groups,
+ // SOA remains slightly slower. It seems the longer dependency chains offsets the gain from
+ // using all SIMD lanes.
+ // - Removing the unpack prefetches seems to harm performance, especially on mobile
+ // I also tried reworking them to be more optimal for single segment usage but while I could get
+ // a small win on desktop, mobile remained under performing.
+
struct animated_track_cache_v0
{
track_cache_quatf_v0 rotations;
@@ -833,49 +1211,100 @@ namespace acl
rtm::vector4f scratch0[4];
rtm::vector4f scratch1[4];
- clip_animated_sampling_context_v0 clip_sampling_context;
+ clip_animated_sampling_context_v0 clip_sampling_context_rotations;
+ clip_animated_sampling_context_v0 clip_sampling_context_translations;
+ clip_animated_sampling_context_v0 clip_sampling_context_scales;
- segment_animated_sampling_context_v0 segment_sampling_context[2];
+ segment_animated_sampling_context_v0 segment_sampling_context_rotations[2];
+ segment_animated_sampling_context_v0 segment_sampling_context_translations[2];
+ segment_animated_sampling_context_v0 segment_sampling_context_scales[2];
- ACL_DISABLE_SECURITY_COOKIE_CHECK void get_rotation_cursor(animated_group_cursor_v0& cursor) const
+ template<class decompression_settings_type, class decompression_settings_translation_adapter_type>
+ void ACL_DISABLE_SECURITY_COOKIE_CHECK initialize(const persistent_transform_decompression_context_v0& decomp_context)
{
- cursor.clip_sampling_context = clip_sampling_context;
- cursor.segment_sampling_context[0] = segment_sampling_context[0];
- cursor.segment_sampling_context[1] = segment_sampling_context[1];
- cursor.group_size = std::min<uint32_t>(rotations.num_left_to_unpack, 4);
- }
+ const transform_tracks_header& transform_header = get_transform_tracks_header(*decomp_context.tracks);
- ACL_DISABLE_SECURITY_COOKIE_CHECK void get_translation_cursor(animated_group_cursor_v0& cursor) const
- {
- cursor.clip_sampling_context = clip_sampling_context;
- cursor.segment_sampling_context[0] = segment_sampling_context[0];
- cursor.segment_sampling_context[1] = segment_sampling_context[1];
- cursor.group_size = std::min<uint32_t>(translations.num_left_to_unpack, 4);
- }
+ const segment_header* segment0 = decomp_context.segment_offsets[0].add_to(decomp_context.tracks);
+ const segment_header* segment1 = decomp_context.segment_offsets[1].add_to(decomp_context.tracks);
- ACL_DISABLE_SECURITY_COOKIE_CHECK void get_scale_cursor(animated_group_cursor_v0& cursor) const
- {
- cursor.clip_sampling_context = clip_sampling_context;
- cursor.segment_sampling_context[0] = segment_sampling_context[0];
- cursor.segment_sampling_context[1] = segment_sampling_context[1];
- cursor.group_size = std::min<uint32_t>(scales.num_left_to_unpack, 4);
- }
+ const uint8_t* animated_track_data0 = decomp_context.animated_track_data[0];
+ const uint8_t* animated_track_data1 = decomp_context.animated_track_data[1];
- void ACL_DISABLE_SECURITY_COOKIE_CHECK initialize(const persistent_transform_decompression_context_v0& decomp_context)
- {
- clip_sampling_context.clip_range_data = decomp_context.clip_range_data.add_to(decomp_context.tracks);
+ const uint8_t* clip_range_data_rotations = transform_header.get_clip_range_data();
+ clip_sampling_context_rotations.clip_range_data = clip_range_data_rotations;
- segment_sampling_context[0].format_per_track_data = decomp_context.format_per_track_data[0];
- segment_sampling_context[0].segment_range_data = decomp_context.segment_range_data[0];
- segment_sampling_context[0].animated_track_data = decomp_context.animated_track_data[0];
- segment_sampling_context[0].animated_track_data_bit_offset = decomp_context.key_frame_bit_offsets[0];
+ const uint8_t* format_per_track_data_rotations0 = decomp_context.format_per_track_data[0];
+ const uint8_t* segment_range_data_rotations0 = decomp_context.segment_range_data[0];
+ const uint32_t animated_track_data_bit_offset_rotations0 = decomp_context.key_frame_bit_offsets[0];
+ segment_sampling_context_rotations[0].format_per_track_data = format_per_track_data_rotations0;
+ segment_sampling_context_rotations[0].segment_range_data = segment_range_data_rotations0;
+ segment_sampling_context_rotations[0].animated_track_data = animated_track_data0;
+ segment_sampling_context_rotations[0].animated_track_data_bit_offset = animated_track_data_bit_offset_rotations0;
- segment_sampling_context[1].format_per_track_data = decomp_context.format_per_track_data[1];
- segment_sampling_context[1].segment_range_data = decomp_context.segment_range_data[1];
- segment_sampling_context[1].animated_track_data = decomp_context.animated_track_data[1];
- segment_sampling_context[1].animated_track_data_bit_offset = decomp_context.key_frame_bit_offsets[1];
+ const uint8_t* format_per_track_data_rotations1 = decomp_context.format_per_track_data[1];
+ const uint8_t* segment_range_data_rotations1 = decomp_context.segment_range_data[1];
+ const uint32_t animated_track_data_bit_offset_rotations1 = decomp_context.key_frame_bit_offsets[1];
+ segment_sampling_context_rotations[1].format_per_track_data = format_per_track_data_rotations1;
+ segment_sampling_context_rotations[1].segment_range_data = segment_range_data_rotations1;
+ segment_sampling_context_rotations[1].animated_track_data = animated_track_data1;
+ segment_sampling_context_rotations[1].animated_track_data_bit_offset = animated_track_data_bit_offset_rotations1;
- const transform_tracks_header& transform_header = get_transform_tracks_header(*decomp_context.tracks);
+ const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
+ const bool are_rotations_variable = rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable);
+
+ const uint32_t num_animated_rotation_sub_tracks_padded = align_to(transform_header.num_animated_rotation_sub_tracks, 4);
+
+ // Rotation range data follows translations, no padding
+ const uint32_t rotation_clip_range_data_size = are_rotations_variable ? (sizeof(rtm::float3f) * 2) : 0;
+ const uint8_t* clip_range_data_translations = clip_range_data_rotations + (transform_header.num_animated_rotation_sub_tracks * rotation_clip_range_data_size);
+ clip_sampling_context_translations.clip_range_data = clip_range_data_translations;
+
+ // Rotation metadata is padded to 4 sub-tracks (1 byte each)
+ const uint32_t rotation_per_track_metadata_size = are_rotations_variable ? 1 : 0;
+ const uint8_t* format_per_track_data_translations0 = format_per_track_data_rotations0 + (num_animated_rotation_sub_tracks_padded * rotation_per_track_metadata_size);
+ const uint8_t* format_per_track_data_translations1 = format_per_track_data_rotations1 + (num_animated_rotation_sub_tracks_padded * rotation_per_track_metadata_size);
+ segment_sampling_context_translations[0].format_per_track_data = format_per_track_data_translations0;
+ segment_sampling_context_translations[1].format_per_track_data = format_per_track_data_translations1;
+
+ // Rotation range data is padded to 4 sub-tracks (6 bytes each)
+ const uint32_t rotation_segment_range_data_size = are_rotations_variable ? 6 : 0;
+ const uint8_t* segment_range_data_translations0 = segment_range_data_rotations0 + (num_animated_rotation_sub_tracks_padded * rotation_segment_range_data_size);
+ const uint8_t* segment_range_data_translations1 = segment_range_data_rotations1 + (num_animated_rotation_sub_tracks_padded * rotation_segment_range_data_size);
+ segment_sampling_context_translations[0].segment_range_data = segment_range_data_translations0;
+ segment_sampling_context_translations[1].segment_range_data = segment_range_data_translations1;
+
+ // Every sub-track uses the same base animated track data pointer
+ segment_sampling_context_translations[0].animated_track_data = animated_track_data0;
+ segment_sampling_context_translations[1].animated_track_data = animated_track_data1;
+
+ const uint32_t animated_track_data_bit_offset_translations0 = animated_track_data_bit_offset_rotations0 + segment0->animated_rotation_bit_size;
+ const uint32_t animated_track_data_bit_offset_translations1 = animated_track_data_bit_offset_rotations1 + segment1->animated_rotation_bit_size;
+ segment_sampling_context_translations[0].animated_track_data_bit_offset = animated_track_data_bit_offset_translations0;
+ segment_sampling_context_translations[1].animated_track_data_bit_offset = animated_track_data_bit_offset_translations1;
+
+ if (decomp_context.has_scale)
+ {
+ const vector_format8 translation_format = get_vector_format<decompression_settings_translation_adapter_type>(decompression_settings_translation_adapter_type::get_vector_format(decomp_context));
+ const bool are_translations_variable = translation_format == vector_format8::vector3f_variable && decompression_settings_translation_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable);
+
+ // Scale data just follows the translation data without any extra padding
+ const uint32_t translation_clip_range_data_size = are_translations_variable ? (sizeof(rtm::float3f) * 2) : 0;
+ clip_sampling_context_scales.clip_range_data = clip_range_data_translations + (transform_header.num_animated_translation_sub_tracks * translation_clip_range_data_size);
+
+ const uint32_t translation_per_track_metadata_size = are_translations_variable ? 1 : 0;
+ segment_sampling_context_scales[0].format_per_track_data = format_per_track_data_translations0 + (transform_header.num_animated_translation_sub_tracks * translation_per_track_metadata_size);
+ segment_sampling_context_scales[1].format_per_track_data = format_per_track_data_translations1 + (transform_header.num_animated_translation_sub_tracks * translation_per_track_metadata_size);
+
+ const uint32_t translation_segment_range_data_size = are_translations_variable ? 6 : 0;
+ segment_sampling_context_scales[0].segment_range_data = segment_range_data_translations0 + (transform_header.num_animated_translation_sub_tracks * translation_segment_range_data_size);
+ segment_sampling_context_scales[1].segment_range_data = segment_range_data_translations1 + (transform_header.num_animated_translation_sub_tracks * translation_segment_range_data_size);
+
+ segment_sampling_context_scales[0].animated_track_data = animated_track_data0;
+ segment_sampling_context_scales[1].animated_track_data = animated_track_data1;
+
+ segment_sampling_context_scales[0].animated_track_data_bit_offset = animated_track_data_bit_offset_translations0 + segment0->animated_translation_bit_size;
+ segment_sampling_context_scales[1].animated_track_data_bit_offset = animated_track_data_bit_offset_translations1 + segment1->animated_translation_bit_size;
+ }
rotations.num_left_to_unpack = transform_header.num_animated_rotation_sub_tracks;
translations.num_left_to_unpack = transform_header.num_animated_translation_sub_tracks;
@@ -885,7 +1314,7 @@ namespace acl
template<class decompression_settings_type>
void ACL_DISABLE_SECURITY_COOKIE_CHECK unpack_rotation_group(const persistent_transform_decompression_context_v0& decomp_context)
{
- uint32_t num_left_to_unpack = rotations.num_left_to_unpack;
+ const uint32_t num_left_to_unpack = rotations.num_left_to_unpack;
if (num_left_to_unpack == 0)
return; // Nothing left to do, we are done
@@ -895,252 +1324,173 @@ namespace acl
return; // Enough cached, nothing to do
const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- num_left_to_unpack -= num_to_unpack;
- rotations.num_left_to_unpack = num_left_to_unpack;
+ rotations.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
// Write index will be either 0 or 4 here since we always unpack 4 at a time
- uint32_t cache_write_index = rotations.cache_write_index % 8;
+ const uint32_t cache_write_index = rotations.cache_write_index % 8;
rotations.cache_write_index += num_to_unpack;
- const rtm::mask4f clip_range_mask0 = unpack_animated_quat<decompression_settings_type>(decomp_context, scratch0, num_to_unpack, segment_sampling_context[0]);
- const rtm::mask4f clip_range_mask1 = unpack_animated_quat<decompression_settings_type>(decomp_context, scratch1, num_to_unpack, segment_sampling_context[1]);
-
- rtm::vector4f scratch0_xxxx = scratch0[0];
- rtm::vector4f scratch0_yyyy = scratch0[1];
- rtm::vector4f scratch0_zzzz = scratch0[2];
- rtm::vector4f scratch0_wwww;
-
- rtm::vector4f scratch1_xxxx = scratch1[0];
- rtm::vector4f scratch1_yyyy = scratch1[1];
- rtm::vector4f scratch1_zzzz = scratch1[2];
- rtm::vector4f scratch1_wwww;
-
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- __m256 scratch_xxxx0_xxxx1 = _mm256_set_m128(scratch1_xxxx, scratch0_xxxx);
- __m256 scratch_yyyy0_yyyy1 = _mm256_set_m128(scratch1_yyyy, scratch0_yyyy);
- __m256 scratch_zzzz0_zzzz1 = _mm256_set_m128(scratch1_zzzz, scratch0_zzzz);
+ const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
- const __m256 one_v = _mm256_set1_ps(1.0F);
-#endif
+ segment_animated_scratch_v0 segment_scratch;
- // If we have a variable bit rate, we perform range reduction, skip the data we used
- const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
+ // We start by unpacking our segment range data into our scratch memory
+ // We often only use a single segment to interpolate, we can avoid redundant work
if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
- const uint8_t* clip_range_data = clip_sampling_context.clip_range_data;
+ if (decomp_context.has_segments)
+ {
+ unpack_segment_range_data(segment_sampling_context_rotations[0].segment_range_data, 0, segment_scratch);
- // Always load 4x rotations, we might contain garbage in a few lanes but it's fine
- const uint32_t load_size = num_to_unpack * sizeof(float);
+ // We are interpolating between two segments (rare)
+ if (!decomp_context.uses_single_segment)
+ unpack_segment_range_data(segment_sampling_context_rotations[1].segment_range_data, 1, segment_scratch);
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- __m256 clip_range_mask0_mask1 = _mm256_set_m128(clip_range_mask1, clip_range_mask0);
+#if !defined(ACL_IMPL_PREFETCH_EARLY)
+ // Our segment range data takes 24 bytes per group (4 samples, 6 bytes each), each cache line fits 2.67 groups
+ // Prefetch every time while alternating between both segments
+ ACL_IMPL_ANIMATED_PREFETCH(segment_sampling_context_rotations[cache_write_index % 2].segment_range_data + 64);
#endif
+ }
+ }
- const rtm::vector4f clip_range_min_xxxx = rtm::vector_load(clip_range_data + load_size * 0);
- const rtm::vector4f clip_range_min_yyyy = rtm::vector_load(clip_range_data + load_size * 1);
- const rtm::vector4f clip_range_min_zzzz = rtm::vector_load(clip_range_data + load_size * 2);
+ const range_reduction_masks_t range_reduction_masks0 = unpack_animated_quat<decompression_settings_type>(decomp_context, scratch0, num_to_unpack, segment_sampling_context_rotations[0]);
+ const range_reduction_masks_t range_reduction_masks1 = unpack_animated_quat<decompression_settings_type>(decomp_context, scratch1, num_to_unpack, segment_sampling_context_rotations[1]);
- const rtm::vector4f clip_range_extent_xxxx = rtm::vector_load(clip_range_data + load_size * 3);
- const rtm::vector4f clip_range_extent_yyyy = rtm::vector_load(clip_range_data + load_size * 4);
- const rtm::vector4f clip_range_extent_zzzz = rtm::vector_load(clip_range_data + load_size * 5);
+ // Swizzle our samples into SOA form
+ rtm::vector4f scratch0_xxxx;
+ rtm::vector4f scratch0_yyyy;
+ rtm::vector4f scratch0_zzzz;
+ rtm::vector4f scratch0_wwww;
+ RTM_MATRIXF_TRANSPOSE_4X4(scratch0[0], scratch0[1], scratch0[2], scratch0[3], scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww);
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- __m256 clip_range_min_xxxx_xxxx = _mm256_set_m128(clip_range_min_xxxx, clip_range_min_xxxx);
- __m256 clip_range_min_yyyy_yyyy = _mm256_set_m128(clip_range_min_yyyy, clip_range_min_yyyy);
- __m256 clip_range_min_zzzz_zzzz = _mm256_set_m128(clip_range_min_zzzz, clip_range_min_zzzz);
+ rtm::vector4f scratch1_xxxx;
+ rtm::vector4f scratch1_yyyy;
+ rtm::vector4f scratch1_zzzz;
+ rtm::vector4f scratch1_wwww;
+ RTM_MATRIXF_TRANSPOSE_4X4(scratch1[0], scratch1[1], scratch1[2], scratch1[3], scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww);
- __m256 clip_range_extent_xxxx_xxxx = _mm256_set_m128(clip_range_extent_xxxx, clip_range_extent_xxxx);
- __m256 clip_range_extent_yyyy_yyyy = _mm256_set_m128(clip_range_extent_yyyy, clip_range_extent_yyyy);
- __m256 clip_range_extent_zzzz_zzzz = _mm256_set_m128(clip_range_extent_zzzz, clip_range_extent_zzzz);
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ __m256 scratch_xxxx0_xxxx1 = _mm256_set_m128(scratch1_xxxx, scratch0_xxxx);
+ __m256 scratch_yyyy0_yyyy1 = _mm256_set_m128(scratch1_yyyy, scratch0_yyyy);
+ __m256 scratch_zzzz0_zzzz1 = _mm256_set_m128(scratch1_zzzz, scratch0_zzzz);
#endif
- // Mask out the clip ranges we ignore
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- clip_range_min_xxxx_xxxx = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_xxxx_xxxx);
- clip_range_min_yyyy_yyyy = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_yyyy_yyyy);
- clip_range_min_zzzz_zzzz = _mm256_andnot_ps(clip_range_mask0_mask1, clip_range_min_zzzz_zzzz);
-#elif defined(RTM_SSE2_INTRINSICS)
- const rtm::vector4f clip_range_min_xxxx0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_xxxx);
- const rtm::vector4f clip_range_min_yyyy0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_yyyy);
- const rtm::vector4f clip_range_min_zzzz0 = _mm_andnot_ps(clip_range_mask0, clip_range_min_zzzz);
-
- const rtm::vector4f clip_range_min_xxxx1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_xxxx);
- const rtm::vector4f clip_range_min_yyyy1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_yyyy);
- const rtm::vector4f clip_range_min_zzzz1 = _mm_andnot_ps(clip_range_mask1, clip_range_min_zzzz);
-#elif defined(RTM_NEON_INTRINSICS)
- const rtm::vector4f clip_range_min_xxxx0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_xxxx), vreinterpretq_u32_f32(clip_range_mask0)));
- const rtm::vector4f clip_range_min_yyyy0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_yyyy), vreinterpretq_u32_f32(clip_range_mask0)));
- const rtm::vector4f clip_range_min_zzzz0 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_zzzz), vreinterpretq_u32_f32(clip_range_mask0)));
-
- const rtm::vector4f clip_range_min_xxxx1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_xxxx), vreinterpretq_u32_f32(clip_range_mask1)));
- const rtm::vector4f clip_range_min_yyyy1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_yyyy), vreinterpretq_u32_f32(clip_range_mask1)));
- const rtm::vector4f clip_range_min_zzzz1 = vreinterpretq_f32_u32(vbicq_u32(vreinterpretq_u32_f32(clip_range_min_zzzz), vreinterpretq_u32_f32(clip_range_mask1)));
+ // If we have a variable bit rate, we perform range reduction, skip the data we used
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ {
+ if (decomp_context.has_segments)
+ {
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ remap_segment_range_data_avx8(segment_scratch, range_reduction_masks0, range_reduction_masks1, scratch_xxxx0_xxxx1, scratch_yyyy0_yyyy1, scratch_zzzz0_zzzz1);
#else
- const rtm::vector4f zero_v = rtm::vector_zero();
-
- const rtm::vector4f clip_range_min_xxxx0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_xxxx);
- const rtm::vector4f clip_range_min_yyyy0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_yyyy);
- const rtm::vector4f clip_range_min_zzzz0 = rtm::vector_select(clip_range_mask0, zero_v, clip_range_min_zzzz);
-
- const rtm::vector4f clip_range_min_xxxx1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_xxxx);
- const rtm::vector4f clip_range_min_yyyy1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_yyyy);
- const rtm::vector4f clip_range_min_zzzz1 = rtm::vector_select(clip_range_mask1, zero_v, clip_range_min_zzzz);
+ remap_segment_range_data4(segment_scratch, 0, range_reduction_masks0, scratch0_xxxx, scratch0_yyyy, scratch0_zzzz);
+ remap_segment_range_data4(segment_scratch, uint32_t(!decomp_context.uses_single_segment), range_reduction_masks1, scratch1_xxxx, scratch1_yyyy, scratch1_zzzz);
#endif
+ }
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- clip_range_extent_xxxx_xxxx = _mm256_blendv_ps(clip_range_extent_xxxx_xxxx, one_v, clip_range_mask0_mask1);
- clip_range_extent_yyyy_yyyy = _mm256_blendv_ps(clip_range_extent_yyyy_yyyy, one_v, clip_range_mask0_mask1);
- clip_range_extent_zzzz_zzzz = _mm256_blendv_ps(clip_range_extent_zzzz_zzzz, one_v, clip_range_mask0_mask1);
+ const uint8_t* clip_range_data = clip_sampling_context_rotations.clip_range_data;
- scratch_xxxx0_xxxx1 = _mm256_add_ps(_mm256_mul_ps(scratch_xxxx0_xxxx1, clip_range_extent_xxxx_xxxx), clip_range_min_xxxx_xxxx);
- scratch_yyyy0_yyyy1 = _mm256_add_ps(_mm256_mul_ps(scratch_yyyy0_yyyy1, clip_range_extent_yyyy_yyyy), clip_range_min_yyyy_yyyy);
- scratch_zzzz0_zzzz1 = _mm256_add_ps(_mm256_mul_ps(scratch_zzzz0_zzzz1, clip_range_extent_zzzz_zzzz), clip_range_min_zzzz_zzzz);
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ remap_clip_range_data_avx8(clip_range_data, num_to_unpack, range_reduction_masks0, range_reduction_masks1, scratch_xxxx0_xxxx1, scratch_yyyy0_yyyy1, scratch_zzzz0_zzzz1);
#else
- const rtm::vector4f one_v = rtm::vector_set(1.0F);
-
- const rtm::vector4f clip_range_extent_xxxx0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_xxxx);
- const rtm::vector4f clip_range_extent_yyyy0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_yyyy);
- const rtm::vector4f clip_range_extent_zzzz0 = rtm::vector_select(clip_range_mask0, one_v, clip_range_extent_zzzz);
-
- const rtm::vector4f clip_range_extent_xxxx1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_xxxx);
- const rtm::vector4f clip_range_extent_yyyy1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_yyyy);
- const rtm::vector4f clip_range_extent_zzzz1 = rtm::vector_select(clip_range_mask1, one_v, clip_range_extent_zzzz);
-
- scratch0_xxxx = rtm::vector_mul_add(scratch0_xxxx, clip_range_extent_xxxx0, clip_range_min_xxxx0);
- scratch0_yyyy = rtm::vector_mul_add(scratch0_yyyy, clip_range_extent_yyyy0, clip_range_min_yyyy0);
- scratch0_zzzz = rtm::vector_mul_add(scratch0_zzzz, clip_range_extent_zzzz0, clip_range_min_zzzz0);
-
- scratch1_xxxx = rtm::vector_mul_add(scratch1_xxxx, clip_range_extent_xxxx1, clip_range_min_xxxx1);
- scratch1_yyyy = rtm::vector_mul_add(scratch1_yyyy, clip_range_extent_yyyy1, clip_range_min_yyyy1);
- scratch1_zzzz = rtm::vector_mul_add(scratch1_zzzz, clip_range_extent_zzzz1, clip_range_min_zzzz1);
+ remap_clip_range_data4(clip_range_data, num_to_unpack, range_reduction_masks0, range_reduction_masks1, scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch1_xxxx, scratch1_yyyy, scratch1_zzzz);
#endif
// Skip our data
clip_range_data += num_to_unpack * sizeof(rtm::float3f) * 2;
- clip_sampling_context.clip_range_data = clip_range_data;
+ clip_sampling_context_rotations.clip_range_data = clip_range_data;
- // Clip range data is 24-32 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
- ACL_IMPL_ANIMATED_PREFETCH(clip_range_data + 63);
- ACL_IMPL_ANIMATED_PREFETCH(clip_range_data + 127);
+#if defined(ACL_IMPL_PREFETCH_EARLY)
+ // Clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
+ ACL_IMPL_ANIMATED_PREFETCH(clip_range_data + 64);
+ ACL_IMPL_ANIMATED_PREFETCH(clip_range_data + 128);
+#endif
}
- // For interpolation later
- rtm::vector4f xxxx_squared;
- rtm::vector4f yyyy_squared;
- rtm::vector4f zzzz_squared;
-
// Reconstruct our quaternion W component in SOA
if (rotation_format != rotation_format8::quatf_full || !decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
{
- // quat_from_positive_w_soa
-#if defined(RTM_AVX_INTRINSICS) && defined(ACL_IMPL_USE_AVX_DECOMP)
- const __m256 scratch_xxxx0_xxxx1_squared = _mm256_mul_ps(scratch_xxxx0_xxxx1, scratch_xxxx0_xxxx1);
- const __m256 scratch_yyyy0_yyyy1_squared = _mm256_mul_ps(scratch_yyyy0_yyyy1, scratch_yyyy0_yyyy1);
- const __m256 scratch_zzzz0_zzzz1_squared = _mm256_mul_ps(scratch_zzzz0_zzzz1, scratch_zzzz0_zzzz1);
-
- const __m256 scratch_wwww0_wwww1_squared = _mm256_sub_ps(_mm256_sub_ps(_mm256_sub_ps(one_v, scratch_xxxx0_xxxx1_squared), scratch_yyyy0_yyyy1_squared), scratch_zzzz0_zzzz1_squared);
-
- const __m256i abs_mask = _mm256_set1_epi32(0x7FFFFFFFULL);
- const __m256 scratch_wwww0_wwww1_squared_abs = _mm256_and_ps(scratch_wwww0_wwww1_squared, _mm256_castsi256_ps(abs_mask));
-
- __m256 scratch_wwww0_wwww1 = _mm256_sqrt_ps(scratch_wwww0_wwww1_squared_abs);
+#if defined(ACL_IMPL_USE_AVX_8_WIDE_DECOMP)
+ const __m256 scratch_wwww0_wwww1 = quat_from_positive_w_avx8(scratch_xxxx0_xxxx1, scratch_yyyy0_yyyy1, scratch_zzzz0_zzzz1);
- // Try and help the compiler hide the latency from the square-root
+ // This is the last AVX step, unpack everything
scratch0_xxxx = _mm256_extractf128_ps(scratch_xxxx0_xxxx1, 0);
scratch1_xxxx = _mm256_extractf128_ps(scratch_xxxx0_xxxx1, 1);
scratch0_yyyy = _mm256_extractf128_ps(scratch_yyyy0_yyyy1, 0);
scratch1_yyyy = _mm256_extractf128_ps(scratch_yyyy0_yyyy1, 1);
scratch0_zzzz = _mm256_extractf128_ps(scratch_zzzz0_zzzz1, 0);
scratch1_zzzz = _mm256_extractf128_ps(scratch_zzzz0_zzzz1, 1);
-
- xxxx_squared = rtm::vector_mul(scratch0_xxxx, scratch1_xxxx);
- yyyy_squared = rtm::vector_mul(scratch0_yyyy, scratch1_yyyy);
- zzzz_squared = rtm::vector_mul(scratch0_zzzz, scratch1_zzzz);
-
scratch0_wwww = _mm256_extractf128_ps(scratch_wwww0_wwww1, 0);
scratch1_wwww = _mm256_extractf128_ps(scratch_wwww0_wwww1, 1);
#else
- const rtm::vector4f scratch0_xxxx_squared = rtm::vector_mul(scratch0_xxxx, scratch0_xxxx);
- const rtm::vector4f scratch0_yyyy_squared = rtm::vector_mul(scratch0_yyyy, scratch0_yyyy);
- const rtm::vector4f scratch0_zzzz_squared = rtm::vector_mul(scratch0_zzzz, scratch0_zzzz);
- const rtm::vector4f scratch0_wwww_squared = rtm::vector_sub(rtm::vector_sub(rtm::vector_sub(rtm::vector_set(1.0F), scratch0_xxxx_squared), scratch0_yyyy_squared), scratch0_zzzz_squared);
-
- const rtm::vector4f scratch1_xxxx_squared = rtm::vector_mul(scratch1_xxxx, scratch1_xxxx);
- const rtm::vector4f scratch1_yyyy_squared = rtm::vector_mul(scratch1_yyyy, scratch1_yyyy);
- const rtm::vector4f scratch1_zzzz_squared = rtm::vector_mul(scratch1_zzzz, scratch1_zzzz);
- const rtm::vector4f scratch1_wwww_squared = rtm::vector_sub(rtm::vector_sub(rtm::vector_sub(rtm::vector_set(1.0F), scratch1_xxxx_squared), scratch1_yyyy_squared), scratch1_zzzz_squared);
-
- // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
- // to ensure the resulting quaternion is always normalized with a positive W component
- scratch0_wwww = rtm::vector_sqrt(rtm::vector_abs(scratch0_wwww_squared));
- scratch1_wwww = rtm::vector_sqrt(rtm::vector_abs(scratch1_wwww_squared));
-
- // Try and help the compiler hide the latency from the square-root
- xxxx_squared = rtm::vector_mul(scratch0_xxxx, scratch1_xxxx);
- yyyy_squared = rtm::vector_mul(scratch0_yyyy, scratch1_yyyy);
- zzzz_squared = rtm::vector_mul(scratch0_zzzz, scratch1_zzzz);
+ scratch0_wwww = quat_from_positive_w4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz);
+
+#if !defined(ACL_IMPL_PREFETCH_EARLY)
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ {
+ // Our segment per track metadata takes 4 bytes per group (4 samples, 1 byte each), each cache line fits 16 groups
+ // Prefetch every other 8th group
+ // We prefetch here because we have a square-root in quat_from_positive_w4(..) that we'll wait after
+ // This allows us to insert the prefetch basically for free in its shadow
+ // Branching is faster than prefetching every time and alternating between the two
+ if (cache_write_index == 0)
+ ACL_IMPL_ANIMATED_PREFETCH(segment_sampling_context_rotations[0].format_per_track_data + 64);
+ else if (cache_write_index == 4)
+ ACL_IMPL_ANIMATED_PREFETCH(segment_sampling_context_rotations[1].format_per_track_data + 64);
+ }
#endif
- }
- else
- {
- xxxx_squared = rtm::vector_mul(scratch0_xxxx, scratch1_xxxx);
- yyyy_squared = rtm::vector_mul(scratch0_yyyy, scratch1_yyyy);
- zzzz_squared = rtm::vector_mul(scratch0_zzzz, scratch1_zzzz);
- scratch0_wwww = scratch0[3];
- scratch1_wwww = scratch1[3];
+ scratch1_wwww = quat_from_positive_w4(scratch1_xxxx, scratch1_yyyy, scratch1_zzzz);
+
+#if !defined(ACL_IMPL_PREFETCH_EARLY)
+ if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
+ {
+ // Our clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
+ // Each group is 96 bytes (4 samples, 24 bytes each), each cache line fits 0.67 groups
+ // We prefetch here because we have a square-root in quat_from_positive_w4(..) that we'll wait after
+ // This allows us to insert the prefetch basically for free in its shadow
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_rotations.clip_range_data + 64);
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_rotations.clip_range_data + 128);
+ }
+#endif
+#endif
}
// Interpolate linearly and store our rotations in SOA
{
- // Calculate the vector4 dot product: dot(start, end)
- //const rtm::vector4f xxxx_squared = rtm::vector_mul(scratch0_xxxx, scratch1_xxxx);
- //const rtm::vector4f yyyy_squared = rtm::vector_mul(scratch0_yyyy, scratch1_yyyy);
- //const rtm::vector4f zzzz_squared = rtm::vector_mul(scratch0_zzzz, scratch1_zzzz);
- const rtm::vector4f wwww_squared = rtm::vector_mul(scratch0_wwww, scratch1_wwww);
-
- const rtm::vector4f dot4 = rtm::vector_add(rtm::vector_add(rtm::vector_add(xxxx_squared, yyyy_squared), zzzz_squared), wwww_squared);
-
- // Calculate the bias, if the dot product is positive or zero, there is no bias
- // but if it is negative, we want to flip the 'end' rotation XYZW components
- const rtm::vector4f neg_zero = rtm::vector_set(-0.0F);
- const rtm::vector4f bias = acl_impl::vector_and(dot4, neg_zero);
-
- // Apply our bias to the 'end'
- scratch1_xxxx = acl_impl::vector_xor(scratch1_xxxx, bias);
- scratch1_yyyy = acl_impl::vector_xor(scratch1_yyyy, bias);
- scratch1_zzzz = acl_impl::vector_xor(scratch1_zzzz, bias);
- scratch1_wwww = acl_impl::vector_xor(scratch1_wwww, bias);
-
- // Lerp the rotation after applying the bias
- // ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
- const rtm::vector4f alpha = rtm::vector_set(decomp_context.interpolation_alpha);
-
- rtm::vector4f interp_xxxx = rtm::vector_mul_add(scratch1_xxxx, alpha, rtm::vector_neg_mul_sub(scratch0_xxxx, alpha, scratch0_xxxx));
- rtm::vector4f interp_yyyy = rtm::vector_mul_add(scratch1_yyyy, alpha, rtm::vector_neg_mul_sub(scratch0_yyyy, alpha, scratch0_yyyy));
- rtm::vector4f interp_zzzz = rtm::vector_mul_add(scratch1_zzzz, alpha, rtm::vector_neg_mul_sub(scratch0_zzzz, alpha, scratch0_zzzz));
- rtm::vector4f interp_wwww = rtm::vector_mul_add(scratch1_wwww, alpha, rtm::vector_neg_mul_sub(scratch0_wwww, alpha, scratch0_wwww));
+ // Interpolate our quaternions without normalizing just yet
+ rtm::vector4f interp_xxxx;
+ rtm::vector4f interp_yyyy;
+ rtm::vector4f interp_zzzz;
+ rtm::vector4f interp_wwww;
+ quat_lerp4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww,
+ scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww,
+ decomp_context.interpolation_alpha,
+ interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
// Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards before using
+ // Make sure to normalize afterwards if we need to
const bool normalize_rotations = decompression_settings_type::normalize_rotations();
if (normalize_rotations)
- {
- const rtm::vector4f interp_xxxx_squared = rtm::vector_mul(interp_xxxx, interp_xxxx);
- const rtm::vector4f interp_yyyy_squared = rtm::vector_mul(interp_yyyy, interp_yyyy);
- const rtm::vector4f interp_zzzz_squared = rtm::vector_mul(interp_zzzz, interp_zzzz);
- const rtm::vector4f interp_wwww_squared = rtm::vector_mul(interp_wwww, interp_wwww);
+ quat_normalize4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
- const rtm::vector4f interp_dot4 = rtm::vector_add(rtm::vector_add(rtm::vector_add(interp_xxxx_squared, interp_yyyy_squared), interp_zzzz_squared), interp_wwww_squared);
-
- const rtm::vector4f interp_len = rtm::vector_sqrt(interp_dot4);
- const rtm::vector4f interp_inv_len = rtm::vector_div(rtm::vector_set(1.0F), interp_len);
-
- interp_xxxx = rtm::vector_mul(interp_xxxx, interp_inv_len);
- interp_yyyy = rtm::vector_mul(interp_yyyy, interp_inv_len);
- interp_zzzz = rtm::vector_mul(interp_zzzz, interp_inv_len);
- interp_wwww = rtm::vector_mul(interp_wwww, interp_inv_len);
+#if !defined(ACL_IMPL_PREFETCH_EARLY)
+ {
+ // Our animated variable bit packed data uses at most 32 bits per component
+ // When we use raw data, that means each group uses 64 bytes (4 bytes per component, 4 components, 4 samples in group), we have 1 group per cache line
+ // When we use variable data, the highest bit rate uses 32 bits per component and thus our upper bound is 48 bytes per group (4 bytes per component, 3 components, 4 samples in group), we have 1.33 group per cache line
+ // In practice, the highest bit rate is rare and the second higher uses 19 bits per component which brings us to 28.5 bytes per group, leading to 2.24 group per cache line
+ // We prefetch both key frames every time to help hide TLB miss latency in large clips
+ // We prefetch here because we have a square-root and division in quat_normalize4(..) that we'll wait after
+ // This allows us to insert the prefetch basically for free in their shadow
+ const uint8_t* animated_track_data = segment_sampling_context_rotations[0].animated_track_data + 64; // One cache line ahead
+ const uint32_t animated_bit_offset0 = segment_sampling_context_rotations[0].animated_track_data_bit_offset;
+ const uint32_t animated_bit_offset1 = segment_sampling_context_rotations[1].animated_track_data_bit_offset;
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset0 / 8));
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset1 / 8));
}
+#endif
// Swizzle out our 4 samples
rtm::vector4f sample0;
@@ -1159,77 +1509,59 @@ namespace acl
}
template<class decompression_settings_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_rotation_group(const persistent_transform_decompression_context_v0& decomp_context)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_rotation_groups(const persistent_transform_decompression_context_v0& decomp_context, uint32_t num_groups_to_skip)
{
const uint32_t num_left_to_unpack = rotations.num_left_to_unpack;
- ACL_ASSERT(num_left_to_unpack != 0, "Cannot skip rotations that aren't present");
+ const uint32_t num_to_skip = num_groups_to_skip * 4;
+ ACL_ASSERT(num_to_skip < num_left_to_unpack, "Cannot skip rotations that aren't present");
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- rotations.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
+ rotations.num_left_to_unpack = num_left_to_unpack - num_to_skip;
const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
if (rotation_format == rotation_format8::quatf_drop_w_variable && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_drop_w_variable))
{
- const uint8_t* format_per_track_data0 = segment_sampling_context[0].format_per_track_data;
- const uint8_t* format_per_track_data1 = segment_sampling_context[1].format_per_track_data;
+ const uint8_t* format_per_track_data0 = segment_sampling_context_rotations[0].format_per_track_data;
+ const uint8_t* format_per_track_data1 = segment_sampling_context_rotations[1].format_per_track_data;
- uint32_t group_size0 = 0;
- uint32_t group_size1 = 0;
+ uint32_t group_bit_size_per_component0;
+ uint32_t group_bit_size_per_component1;
+ count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
- // Fall-through intentional
- switch (num_to_unpack)
- {
- default:
- case 4:
- group_size0 += format_per_track_data0[3];
- group_size1 += format_per_track_data1[3];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 3:
- group_size0 += format_per_track_data0[2];
- group_size1 += format_per_track_data1[2];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 2:
- group_size0 += format_per_track_data0[1];
- group_size1 += format_per_track_data1[1];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 1:
- group_size0 += format_per_track_data0[0];
- group_size1 += format_per_track_data1[0];
- }
+ const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
+ const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
- // Per track data and segment range are always padded to 4 samples
- segment_sampling_context[0].format_per_track_data += 4;
- segment_sampling_context[0].segment_range_data += 6 * 4;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size0 * 3;
- segment_sampling_context[1].format_per_track_data += 4;
- segment_sampling_context[1].segment_range_data += 6 * 4;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size1 * 3;
+ segment_sampling_context_rotations[0].format_per_track_data = format_per_track_data0 + format_per_track_data_skip_size;
+ segment_sampling_context_rotations[0].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_rotations[0].animated_track_data_bit_offset += group_bit_size_per_component0 * 3;
- clip_sampling_context.clip_range_data += sizeof(rtm::float3f) * 2 * num_to_unpack;
+ segment_sampling_context_rotations[1].format_per_track_data = format_per_track_data1 + format_per_track_data_skip_size;
+ segment_sampling_context_rotations[1].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_rotations[1].animated_track_data_bit_offset += group_bit_size_per_component1 * 3;
+
+ clip_sampling_context_rotations.clip_range_data += sizeof(rtm::float3f) * 2 * 4 * num_groups_to_skip;
}
else
{
- uint32_t group_size;
+ uint32_t group_bit_size;
if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
- group_size = 32 * 4 * num_to_unpack;
+ group_bit_size = 32 * 4 * 4 * num_groups_to_skip;
else // drop w full
- group_size = 32 * 3 * num_to_unpack;
+ group_bit_size = 32 * 3 * 4 * num_groups_to_skip;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size;
+ segment_sampling_context_rotations[0].animated_track_data_bit_offset += group_bit_size;
+ segment_sampling_context_rotations[1].animated_track_data_bit_offset += group_bit_size;
}
}
template<class decompression_settings_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::quatf RTM_SIMD_CALL unpack_rotation_within_group(const persistent_transform_decompression_context_v0& decomp_context, const animated_group_cursor_v0& group_cursor, uint32_t unpack_index)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::quatf RTM_SIMD_CALL unpack_rotation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
{
- ACL_ASSERT(unpack_index < group_cursor.group_size, "Cannot unpack sample that isn't present");
+ ACL_ASSERT(unpack_index < rotations.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
- const clip_animated_sampling_context_v0& cursor_clip_sampling_context = group_cursor.clip_sampling_context;
- const uint32_t group_size = group_cursor.group_size;
+ const uint32_t group_size = std::min<uint32_t>(rotations.num_left_to_unpack, 4);
- const rtm::vector4f sample_as_vec0 = unpack_single_animated_quat<decompression_settings_type>(decomp_context, unpack_index, group_size, cursor_clip_sampling_context, group_cursor.segment_sampling_context[0]);
- const rtm::vector4f sample_as_vec1 = unpack_single_animated_quat<decompression_settings_type>(decomp_context, unpack_index, group_size, cursor_clip_sampling_context, group_cursor.segment_sampling_context[1]);
+ const rtm::vector4f sample_as_vec0 = unpack_single_animated_quat<decompression_settings_type>(decomp_context, unpack_index, group_size, clip_sampling_context_rotations, segment_sampling_context_rotations[0]);
+ const rtm::vector4f sample_as_vec1 = unpack_single_animated_quat<decompression_settings_type>(decomp_context, unpack_index, group_size, clip_sampling_context_rotations, segment_sampling_context_rotations[1]);
rtm::quatf sample0;
rtm::quatf sample1;
@@ -1266,27 +1598,27 @@ namespace acl
template<class decompression_settings_adapter_type>
ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_translation_group(const persistent_transform_decompression_context_v0& decomp_context)
{
- uint32_t num_left_to_unpack = translations.num_left_to_unpack;
+ const uint32_t num_left_to_unpack = translations.num_left_to_unpack;
if (num_left_to_unpack == 0)
return; // Nothing left to do, we are done
- // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
+ // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
const uint32_t num_cached = translations.get_num_cached();
if (num_cached >= 4)
return; // Enough cached, nothing to do
const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- num_left_to_unpack -= num_to_unpack;
- translations.num_left_to_unpack = num_left_to_unpack;
+ translations.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
// Write index will be either 0 or 4 here since we always unpack 4 at a time
- uint32_t cache_write_index = translations.cache_write_index % 8;
+ const uint32_t cache_write_index = translations.cache_write_index % 8;
translations.cache_write_index += num_to_unpack;
- unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch0, num_to_unpack, clip_sampling_context, segment_sampling_context[0]);
- unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context, segment_sampling_context[1]);
+ unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch0, num_to_unpack, clip_sampling_context_translations, segment_sampling_context_translations[0]);
+ unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context_translations, segment_sampling_context_translations[1]);
- const float interpolation_alpha = decomp_context.interpolation_alpha;
+ const rtm::scalarf interpolation_alpha = rtm::scalar_set(decomp_context.interpolation_alpha);
+ rtm::vector4f* cache_ptr = &translations.cached_samples[cache_write_index];
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
const rtm::vector4f sample0 = scratch0[unpack_index];
@@ -1294,84 +1626,68 @@ namespace acl
const rtm::vector4f sample = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
- translations.cached_samples[cache_write_index] = sample;
- cache_write_index++;
+ cache_ptr[unpack_index] = sample;
}
- // If we have some range reduction, skip the data we read
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::translations))
- clip_sampling_context.clip_range_data += num_to_unpack * sizeof(rtm::float3f) * 2;
+ // If we have clip range data, skip it
+ const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
+ if (format == vector_format8::vector3f_variable && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable))
+ {
+ clip_sampling_context_translations.clip_range_data += num_to_unpack * sizeof(rtm::float3f) * 2;
- // Clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
- ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context.clip_range_data + 63);
- ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context.clip_range_data + 127);
+ // Clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_translations.clip_range_data + 64);
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_translations.clip_range_data + 128);
+ }
}
template<class decompression_settings_adapter_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_translation_group(const persistent_transform_decompression_context_v0& decomp_context)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_translation_groups(const persistent_transform_decompression_context_v0& decomp_context, uint32_t num_groups_to_skip)
{
const uint32_t num_left_to_unpack = translations.num_left_to_unpack;
- ACL_ASSERT(num_left_to_unpack != 0, "Cannot skip translations that aren't present");
+ const uint32_t num_to_skip = num_groups_to_skip * 4;
+ ACL_ASSERT(num_to_skip < num_left_to_unpack, "Cannot skip translations that aren't present");
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- translations.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
+ translations.num_left_to_unpack = num_left_to_unpack - num_to_skip;
const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
if (format == vector_format8::vector3f_variable && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable))
{
- const uint8_t* format_per_track_data0 = segment_sampling_context[0].format_per_track_data;
- const uint8_t* format_per_track_data1 = segment_sampling_context[1].format_per_track_data;
+ const uint8_t* format_per_track_data0 = segment_sampling_context_translations[0].format_per_track_data;
+ const uint8_t* format_per_track_data1 = segment_sampling_context_translations[1].format_per_track_data;
- uint32_t group_size0 = 0;
- uint32_t group_size1 = 0;
+ uint32_t group_bit_size_per_component0;
+ uint32_t group_bit_size_per_component1;
+ count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
- // Fall-through intentional
- switch (num_to_unpack)
- {
- default:
- case 4:
- group_size0 += format_per_track_data0[3];
- group_size1 += format_per_track_data1[3];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 3:
- group_size0 += format_per_track_data0[2];
- group_size1 += format_per_track_data1[2];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 2:
- group_size0 += format_per_track_data0[1];
- group_size1 += format_per_track_data1[1];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 1:
- group_size0 += format_per_track_data0[0];
- group_size1 += format_per_track_data1[0];
- }
+ const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
+ const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
+
+ segment_sampling_context_translations[0].format_per_track_data = format_per_track_data0 + format_per_track_data_skip_size;
+ segment_sampling_context_translations[0].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_translations[0].animated_track_data_bit_offset += group_bit_size_per_component0 * 3;
- segment_sampling_context[0].format_per_track_data += num_to_unpack;
- segment_sampling_context[0].segment_range_data += 6 * num_to_unpack;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size0 * 3;
- segment_sampling_context[1].format_per_track_data += num_to_unpack;
- segment_sampling_context[1].segment_range_data += 6 * num_to_unpack;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size1 * 3;
+ segment_sampling_context_translations[1].format_per_track_data = format_per_track_data1 + format_per_track_data_skip_size;
+ segment_sampling_context_translations[1].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_translations[1].animated_track_data_bit_offset += group_bit_size_per_component1 * 3;
- clip_sampling_context.clip_range_data += sizeof(rtm::float3f) * 2 * num_to_unpack;
+ clip_sampling_context_translations.clip_range_data += sizeof(rtm::float3f) * 2 * 4 * num_groups_to_skip;
}
else
{
- const uint32_t group_size = 32 * 3 * num_to_unpack;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size;
+ const uint32_t group_bit_size = 32 * 3 * 4 * num_groups_to_skip;
+ segment_sampling_context_translations[0].animated_track_data_bit_offset += group_bit_size;
+ segment_sampling_context_translations[1].animated_track_data_bit_offset += group_bit_size;
}
}
template<class decompression_settings_adapter_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_translation_within_group(const persistent_transform_decompression_context_v0& decomp_context, const animated_group_cursor_v0& group_cursor, uint32_t unpack_index)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_translation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
{
- ACL_ASSERT(unpack_index < group_cursor.group_size, "Cannot unpack sample that isn't present");
-
- const clip_animated_sampling_context_v0& cursor_clip_sampling_context = group_cursor.clip_sampling_context;
+ ACL_ASSERT(unpack_index < translations.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
- const rtm::vector4f sample0 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, cursor_clip_sampling_context, group_cursor.segment_sampling_context[0]);
- const rtm::vector4f sample1 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, cursor_clip_sampling_context, group_cursor.segment_sampling_context[1]);
+ const rtm::vector4f sample0 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_translations, segment_sampling_context_translations[0]);
+ const rtm::vector4f sample1 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_translations, segment_sampling_context_translations[1]);
return rtm::vector_lerp(sample0, sample1, decomp_context.interpolation_alpha);
}
@@ -1386,27 +1702,27 @@ namespace acl
template<class decompression_settings_adapter_type>
ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_scale_group(const persistent_transform_decompression_context_v0& decomp_context)
{
- uint32_t num_left_to_unpack = scales.num_left_to_unpack;
+ const uint32_t num_left_to_unpack = scales.num_left_to_unpack;
if (num_left_to_unpack == 0)
return; // Nothing left to do, we are done
- // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
+ // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
const uint32_t num_cached = scales.get_num_cached();
if (num_cached >= 4)
return; // Enough cached, nothing to do
const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- num_left_to_unpack -= num_to_unpack;
- scales.num_left_to_unpack = num_left_to_unpack;
+ scales.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
// Write index will be either 0 or 4 here since we always unpack 4 at a time
- uint32_t cache_write_index = scales.cache_write_index % 8;
+ const uint32_t cache_write_index = scales.cache_write_index % 8;
scales.cache_write_index += num_to_unpack;
- unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch0, num_to_unpack, clip_sampling_context, segment_sampling_context[0]);
- unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context, segment_sampling_context[1]);
+ unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch0, num_to_unpack, clip_sampling_context_scales, segment_sampling_context_scales[0]);
+ unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context_scales, segment_sampling_context_scales[1]);
- const float interpolation_alpha = decomp_context.interpolation_alpha;
+ const rtm::scalarf interpolation_alpha = rtm::scalar_set(decomp_context.interpolation_alpha);
+ rtm::vector4f* cache_ptr = &scales.cached_samples[cache_write_index];
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
const rtm::vector4f sample0 = scratch0[unpack_index];
@@ -1414,80 +1730,70 @@ namespace acl
const rtm::vector4f sample = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
- scales.cached_samples[cache_write_index] = sample;
- cache_write_index++;
+ cache_ptr[unpack_index] = sample;
}
- // If we have some range reduction, skip the data we read
- if (are_any_enum_flags_set(decomp_context.range_reduction, range_reduction_flags8::scales))
- clip_sampling_context.clip_range_data += num_to_unpack * sizeof(rtm::float3f) * 2;
+ // If we have clip range data, skip it
+ const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
+ if (format == vector_format8::vector3f_variable && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable))
+ {
+ clip_sampling_context_scales.clip_range_data += num_to_unpack * sizeof(rtm::float3f) * 2;
- // Clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
- ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context.clip_range_data + 63);
- ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context.clip_range_data + 127);
+ // Clip range data is 24 bytes per sub-track and as such we need to prefetch two cache lines ahead to process 4 sub-tracks
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_scales.clip_range_data + 64);
+ ACL_IMPL_ANIMATED_PREFETCH(clip_sampling_context_scales.clip_range_data + 128);
+ }
}
template<class decompression_settings_adapter_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_scale_group(const persistent_transform_decompression_context_v0& decomp_context)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_scale_groups(const persistent_transform_decompression_context_v0& decomp_context, uint32_t num_groups_to_skip)
{
const uint32_t num_left_to_unpack = scales.num_left_to_unpack;
- ACL_ASSERT(num_left_to_unpack != 0, "Cannot skip scales that aren't present");
+ const uint32_t num_to_skip = num_groups_to_skip * 4;
+ ACL_ASSERT(num_to_skip < num_left_to_unpack, "Cannot skip scales that aren't present");
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- scales.num_left_to_unpack = num_left_to_unpack - num_to_unpack;
+ scales.num_left_to_unpack = num_left_to_unpack - num_to_skip;
const vector_format8 format = get_vector_format<decompression_settings_adapter_type>(decompression_settings_adapter_type::get_vector_format(decomp_context));
if (format == vector_format8::vector3f_variable && decompression_settings_adapter_type::is_vector_format_supported(vector_format8::vector3f_variable))
{
- const uint8_t* format_per_track_data0 = segment_sampling_context[0].format_per_track_data;
- const uint8_t* format_per_track_data1 = segment_sampling_context[1].format_per_track_data;
+ const uint8_t* format_per_track_data0 = segment_sampling_context_scales[0].format_per_track_data;
+ const uint8_t* format_per_track_data1 = segment_sampling_context_scales[1].format_per_track_data;
- uint32_t group_size0 = 0;
- uint32_t group_size1 = 0;
+ uint32_t group_bit_size_per_component0;
+ uint32_t group_bit_size_per_component1;
+ count_animated_group_bit_size(format_per_track_data0, format_per_track_data1, num_groups_to_skip, group_bit_size_per_component0, group_bit_size_per_component1);
- // Fall-through intentional
- switch (num_to_unpack)
- {
- default:
- case 4:
- group_size0 += format_per_track_data0[3];
- group_size1 += format_per_track_data1[3];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 3:
- group_size0 += format_per_track_data0[2];
- group_size1 += format_per_track_data1[2];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 2:
- group_size0 += format_per_track_data0[1];
- group_size1 += format_per_track_data1[1];
- ACL_SWITCH_CASE_FALLTHROUGH_INTENTIONAL;
- case 1:
- group_size0 += format_per_track_data0[0];
- group_size1 += format_per_track_data1[0];
- }
+ const uint32_t format_per_track_data_skip_size = num_groups_to_skip * 4;
+ const uint32_t segment_range_data_skip_size = num_groups_to_skip * 6 * 4;
- segment_sampling_context[0].format_per_track_data += num_to_unpack;
- segment_sampling_context[0].segment_range_data += 6 * num_to_unpack;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size0 * 3;
- segment_sampling_context[1].format_per_track_data += num_to_unpack;
- segment_sampling_context[1].segment_range_data += 6 * num_to_unpack;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size1 * 3;
+ segment_sampling_context_scales[0].format_per_track_data = format_per_track_data0 + format_per_track_data_skip_size;
+ segment_sampling_context_scales[0].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_scales[0].animated_track_data_bit_offset += group_bit_size_per_component0 * 3;
- clip_sampling_context.clip_range_data += sizeof(rtm::float3f) * 2 * num_to_unpack;
+ segment_sampling_context_scales[1].format_per_track_data = format_per_track_data1 + format_per_track_data_skip_size;
+ segment_sampling_context_scales[1].segment_range_data += segment_range_data_skip_size;
+ segment_sampling_context_scales[1].animated_track_data_bit_offset += group_bit_size_per_component1 * 3;
+
+ clip_sampling_context_scales.clip_range_data += sizeof(rtm::float3f) * 2 * 4 * num_groups_to_skip;
}
else
{
- const uint32_t group_size = 32 * 3 * num_to_unpack;
- segment_sampling_context[0].animated_track_data_bit_offset += group_size;
- segment_sampling_context[1].animated_track_data_bit_offset += group_size;
+ const uint32_t group_bit_size = 32 * 3 * 4 * num_groups_to_skip;
+ segment_sampling_context_scales[0].animated_track_data_bit_offset += group_bit_size;
+ segment_sampling_context_scales[1].animated_track_data_bit_offset += group_bit_size;
}
}
template<class decompression_settings_adapter_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_scale_within_group(const persistent_transform_decompression_context_v0& decomp_context, const animated_group_cursor_v0& group_cursor, uint32_t unpack_index)
+ ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_scale_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
{
- // Same as translation but a different adapter
- return unpack_translation_within_group<decompression_settings_adapter_type>(decomp_context, group_cursor, unpack_index);
+ ACL_ASSERT(unpack_index < scales.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
+
+ const rtm::vector4f sample0 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_scales, segment_sampling_context_scales[0]);
+ const rtm::vector4f sample1 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_scales, segment_sampling_context_scales[1]);
+
+ return rtm::vector_lerp(sample0, sample1, decomp_context.interpolation_alpha);
}
ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL consume_scale()
@@ -1499,4 +1805,9 @@ namespace acl
};
}
}
+
+#if defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic pop
+#endif
+
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/transform_constant_track_cache.h b/includes/acl/decompression/impl/transform_constant_track_cache.h
--- a/includes/acl/decompression/impl/transform_constant_track_cache.h
+++ b/includes/acl/decompression/impl/transform_constant_track_cache.h
@@ -36,10 +36,17 @@
#include <cstdint>
#define ACL_IMPL_USE_CONSTANT_PREFETCH
-//#define ACL_IMPL_VEC3_UNPACK
ACL_IMPL_FILE_PRAGMA_PUSH
+// We only initialize some variables when we need them which prompts the compiler to complain
+// The usage is perfectly safe and because this code is VERY hot and needs to be as fast as possible,
+// we disable the warning to avoid zeroing out things we don't need
+#if defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic push
+ #pragma GCC diagnostic ignored "-Wmaybe-uninitialized"
+#endif
+
namespace acl
{
#if defined(ACL_IMPL_USE_CONSTANT_PREFETCH)
@@ -50,154 +57,39 @@ namespace acl
namespace acl_impl
{
- template<class decompression_settings_type>
- ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_constant_quat(const persistent_transform_decompression_context_v0& decomp_context, track_cache_quatf_v0& track_cache, const uint8_t*& constant_data)
+ struct constant_track_cache_v0
{
- // Prefetch the next cache line even if we don't have any data left
- // By the time we unpack again, it will have arrived in the CPU cache
- // If our format is full precision, we have at most 4 samples per cache line
- // If our format is drop W, we have at most 5.33 samples per cache line
-
- // If our pointer was already aligned to a cache line before we unpacked our 4 values,
- // it now points to the first byte of the next cache line. Any offset between 0-63 will fetch it.
- // If our pointer had some offset into a cache line, we might have spanned 2 cache lines.
- // If this happens, we probably already read some data from the next cache line in which
- // case we don't need to prefetch it and we can go to the next one. Any offset after the end
- // of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
- // Prefetch 4 samples ahead in all levels of the CPU cache
-
- uint32_t num_left_to_unpack = track_cache.num_left_to_unpack;
- if (num_left_to_unpack == 0)
- return; // Nothing left to do, we are done
-
- // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
- const uint32_t num_cached = track_cache.get_num_cached();
- if (num_cached >= 4)
- return; // Enough cached, nothing to do
-
- const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
-
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- num_left_to_unpack -= num_to_unpack;
- track_cache.num_left_to_unpack = num_left_to_unpack;
-
- // Write index will be either 0 or 4 here since we always unpack 4 at a time
- uint32_t cache_write_index = track_cache.cache_write_index % 8;
- track_cache.cache_write_index += num_to_unpack;
-
- const uint8_t* constant_track_data = constant_data;
-
- if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
- {
- for (uint32_t unpack_index = num_to_unpack; unpack_index != 0; --unpack_index)
- {
- // Unpack
- const rtm::quatf sample = unpack_quat_128(constant_track_data);
-
- ACL_ASSERT(rtm::quat_is_finite(sample), "Rotation is not valid!");
- ACL_ASSERT(rtm::quat_is_normalized(sample), "Rotation is not normalized!");
+ track_cache_quatf_v0 rotations;
- // Cache
- track_cache.cached_samples[cache_write_index] = sample;
- cache_write_index++;
+ // Points to our packed sub-track data
+ const uint8_t* constant_data_rotations;
+ const uint8_t* constant_data_translations;
+ const uint8_t* constant_data_scales;
- // Update our read ptr
- constant_track_data += sizeof(rtm::float4f);
- }
- }
- else
+ template<class decompression_settings_type>
+ ACL_DISABLE_SECURITY_COOKIE_CHECK void initialize(const persistent_transform_decompression_context_v0& decomp_context)
{
- // Unpack
- // Always load 4x rotations, we might contain garbage in a few lanes but it's fine
- const uint32_t load_size = num_to_unpack * sizeof(float);
-
- const rtm::vector4f xxxx = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 0));
- const rtm::vector4f yyyy = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 1));
- const rtm::vector4f zzzz = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 2));
-
- // Update our read ptr
- constant_track_data += load_size * 3;
-
- // quat_from_positive_w_soa
- const rtm::vector4f wwww_squared = rtm::vector_sub(rtm::vector_sub(rtm::vector_sub(rtm::vector_set(1.0F), rtm::vector_mul(xxxx, xxxx)), rtm::vector_mul(yyyy, yyyy)), rtm::vector_mul(zzzz, zzzz));
-
- // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
- // to ensure the resulting quaternion is always normalized with a positive W component
- const rtm::vector4f wwww = rtm::vector_sqrt(rtm::vector_abs(wwww_squared));
+ const transform_tracks_header& transform_header = get_transform_tracks_header(*decomp_context.tracks);
- rtm::vector4f sample0;
- rtm::vector4f sample1;
- rtm::vector4f sample2;
- rtm::vector4f sample3;
- RTM_MATRIXF_TRANSPOSE_4X4(xxxx, yyyy, zzzz, wwww, sample0, sample1, sample2, sample3);
+ rotations.num_left_to_unpack = transform_header.num_constant_rotation_samples;
- // Cache
- rtm::quatf* cache_ptr = &track_cache.cached_samples[cache_write_index];
- cache_ptr[0] = rtm::vector_to_quat(sample0);
- cache_ptr[1] = rtm::vector_to_quat(sample1);
- cache_ptr[2] = rtm::vector_to_quat(sample2);
- cache_ptr[3] = rtm::vector_to_quat(sample3);
+ const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
+ const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
+ const uint32_t packed_rotation_size = get_packed_rotation_size(packed_format);
+ const uint32_t packed_translation_size = get_packed_vector_size(vector_format8::vector3f_full);
-#if defined(ACL_HAS_ASSERT_CHECKS)
- for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
- {
- ACL_ASSERT(rtm::quat_is_finite(track_cache.cached_samples[cache_write_index + unpack_index]), "Rotation is not valid!");
- ACL_ASSERT(rtm::quat_is_normalized(track_cache.cached_samples[cache_write_index + unpack_index]), "Rotation is not normalized!");
- }
-#endif
+ constant_data_rotations = transform_header.get_constant_track_data();
+ constant_data_translations = constant_data_rotations + packed_rotation_size * transform_header.num_constant_rotation_samples;
+ constant_data_scales = constant_data_translations + packed_translation_size * transform_header.num_constant_translation_samples;
}
- // Update our pointer
- constant_data = constant_track_data;
-
- ACL_IMPL_CONSTANT_PREFETCH(constant_track_data + 63);
- }
-
-#if defined(ACL_IMPL_VEC3_UNPACK)
- inline void unpack_constant_vector3(track_cache_vector4f_v0& track_cache, const uint8_t*& constant_data)
- {
- uint32_t num_left_to_unpack = track_cache.num_left_to_unpack;
- if (num_left_to_unpack == 0)
- return; // Nothing left to do, we are done
-
- const uint32_t packed_size = get_packed_vector_size(vector_format8::vector3f_full);
-
- // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
- const uint32_t num_cached = track_cache.get_num_cached();
- if (num_cached < 4)
+ template<class decompression_settings_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_rotation_group(const persistent_transform_decompression_context_v0& decomp_context)
{
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
- num_left_to_unpack -= num_to_unpack;
- track_cache.num_left_to_unpack = num_left_to_unpack;
-
- // Write index will be either 0 or 4 here since we always unpack 4 at a time
- uint32_t cache_write_index = track_cache.cache_write_index % 8;
- track_cache.cache_write_index += num_to_unpack;
-
- const uint8_t* constant_track_data = constant_data;
-
- for (uint32_t unpack_index = num_to_unpack; unpack_index != 0; --unpack_index)
- {
- // Unpack
- // Constant vector3 tracks store the remaining sample with full precision
- const rtm::vector4f sample = unpack_vector3_96_unsafe(constant_track_data);
- ACL_ASSERT(rtm::vector_is_finite3(sample), "Vector3 is not valid!");
-
- // TODO: Fill in W component with something sensible?
-
- // Cache
- track_cache.cached_samples[cache_write_index] = sample;
- cache_write_index++;
-
- // Update our read ptr
- constant_track_data += packed_size;
- }
-
- constant_data = constant_track_data;
-
// Prefetch the next cache line even if we don't have any data left
// By the time we unpack again, it will have arrived in the CPU cache
- // With our full precision format, we have at most 5.33 samples per cache line
+ // If our format is full precision, we have at most 4 samples per cache line
+ // If our format is drop W, we have at most 5.33 samples per cache line
// If our pointer was already aligned to a cache line before we unpacked our 4 values,
// it now points to the first byte of the next cache line. Any offset between 0-63 will fetch it.
@@ -206,84 +98,90 @@ namespace acl
// case we don't need to prefetch it and we can go to the next one. Any offset after the end
// of this cache line will fetch it. For safety, we prefetch 63 bytes ahead.
// Prefetch 4 samples ahead in all levels of the CPU cache
- ACL_IMPL_CONSTANT_PREFETCH(constant_track_data + 63);
- }
- }
-#endif
- struct constant_track_cache_v0
- {
- track_cache_quatf_v0 rotations;
+ uint32_t num_left_to_unpack = rotations.num_left_to_unpack;
+ if (num_left_to_unpack == 0)
+ return; // Nothing left to do, we are done
-#if defined(ACL_IMPL_VEC3_UNPACK)
- track_cache_vector4f_v0 translations;
- track_cache_vector4f_v0 scales;
-#endif
+ // If we have less than 4 cached samples, unpack 4 more and prefetch the next cache line
+ const uint32_t num_cached = rotations.get_num_cached();
+ if (num_cached >= 4)
+ return; // Enough cached, nothing to do
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- // How many we have left to unpack in total
- uint32_t num_left_to_unpack_translations;
- uint32_t num_left_to_unpack_scales;
+ const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
- // How many we have cached (faked for translations/scales)
- uint32_t num_unpacked_translations = 0;
- uint32_t num_unpacked_scales = 0;
+ const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 4);
+ num_left_to_unpack -= num_to_unpack;
+ rotations.num_left_to_unpack = num_left_to_unpack;
- // How many we have left in our group
- uint32_t num_group_translations[2];
- uint32_t num_group_scales[2];
+ // Write index will be either 0 or 4 here since we always unpack 4 at a time
+ uint32_t cache_write_index = rotations.cache_write_index % 8;
+ rotations.cache_write_index += num_to_unpack;
- const uint8_t* constant_data;
- const uint8_t* constant_data_translations[2];
- const uint8_t* constant_data_scales[2];
-#else
- // Points to our packed sub-track data
- const uint8_t* constant_data_rotations;
- const uint8_t* constant_data_translations;
- const uint8_t* constant_data_scales;
-#endif
+ const uint8_t* constant_track_data = constant_data_rotations;
- template<class decompression_settings_type>
- ACL_DISABLE_SECURITY_COOKIE_CHECK void initialize(const persistent_transform_decompression_context_v0& decomp_context)
- {
- const transform_tracks_header& transform_header = get_transform_tracks_header(*decomp_context.tracks);
+ if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
+ {
+ for (uint32_t unpack_index = num_to_unpack; unpack_index != 0; --unpack_index)
+ {
+ // Unpack
+ const rtm::quatf sample = unpack_quat_128(constant_track_data);
- rotations.num_left_to_unpack = transform_header.num_constant_rotation_samples;
+ ACL_ASSERT(rtm::quat_is_finite(sample), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(sample), "Rotation is not normalized!");
-#if defined(ACL_IMPL_VEC3_UNPACK)
- translations.num_left_to_unpack = transform_header.num_constant_translation_samples;
- scales.num_left_to_unpack = transform_header.num_constant_scale_samples;
-#endif
+ // Cache
+ rotations.cached_samples[cache_write_index] = sample;
+ cache_write_index++;
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- num_left_to_unpack_translations = transform_header.num_constant_translation_samples;
- num_left_to_unpack_scales = transform_header.num_constant_scale_samples;
+ // Update our read ptr
+ constant_track_data += sizeof(rtm::float4f);
+ }
+ }
+ else
+ {
+ // Unpack
+ // Always load 4x rotations, we might contain garbage in a few lanes but it's fine
+ const uint32_t load_size = num_to_unpack * sizeof(float);
- constant_data = decomp_context.constant_track_data;
- constant_data_translations[0] = constant_data_translations[1] = nullptr;
- constant_data_scales[0] = constant_data_scales[1] = nullptr;
- num_group_translations[0] = num_group_translations[1] = 0;
- num_group_scales[0] = num_group_scales[1] = 0;
-#else
- const rotation_format8 rotation_format = get_rotation_format<decompression_settings_type>(decomp_context.rotation_format);
- const rotation_format8 packed_format = is_rotation_format_variable(rotation_format) ? get_highest_variant_precision(get_rotation_variant(rotation_format)) : rotation_format;
- const uint32_t packed_rotation_size = get_packed_rotation_size(packed_format);
- const uint32_t packed_translation_size = get_packed_vector_size(vector_format8::vector3f_full);
+ const rtm::vector4f xxxx = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 0));
+ const rtm::vector4f yyyy = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 1));
+ const rtm::vector4f zzzz = rtm::vector_load(reinterpret_cast<const float*>(constant_track_data + load_size * 2));
- constant_data_rotations = decomp_context.constant_track_data.add_to(decomp_context.tracks);
- constant_data_translations = constant_data_rotations + packed_rotation_size * transform_header.num_constant_rotation_samples;
- constant_data_scales = constant_data_translations + packed_translation_size * transform_header.num_constant_translation_samples;
-#endif
- }
+ // Update our read ptr
+ constant_track_data += load_size * 3;
- template<class decompression_settings_type>
- ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_rotation_group(const persistent_transform_decompression_context_v0& decomp_context)
- {
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- unpack_constant_quat<decompression_settings_type>(decomp_context, rotations, constant_data);
-#else
- unpack_constant_quat<decompression_settings_type>(decomp_context, rotations, constant_data_rotations);
+ // quat_from_positive_w_soa
+ const rtm::vector4f wwww_squared = rtm::vector_sub(rtm::vector_sub(rtm::vector_sub(rtm::vector_set(1.0F), rtm::vector_mul(xxxx, xxxx)), rtm::vector_mul(yyyy, yyyy)), rtm::vector_mul(zzzz, zzzz));
+
+ // w_squared can be negative either due to rounding or due to quantization imprecision, we take the absolute value
+ // to ensure the resulting quaternion is always normalized with a positive W component
+ const rtm::vector4f wwww = rtm::vector_sqrt(rtm::vector_abs(wwww_squared));
+
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(xxxx, yyyy, zzzz, wwww, sample0, sample1, sample2, sample3);
+
+ // Cache
+ rtm::quatf* cache_ptr = &rotations.cached_samples[cache_write_index];
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+
+#if defined(ACL_HAS_ASSERT_CHECKS)
+ for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
+ {
+ ACL_ASSERT(rtm::quat_is_finite(rotations.cached_samples[cache_write_index + unpack_index]), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(rotations.cached_samples[cache_write_index + unpack_index]), "Rotation is not normalized!");
+ }
#endif
+ }
+
+ // Update our pointer
+ constant_data_rotations = constant_track_data;
}
template<class decompression_settings_type>
@@ -347,33 +245,6 @@ namespace acl
return rotations.cached_samples[cache_read_index % 8];
}
- ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_translation_group()
- {
-#if defined(ACL_IMPL_VEC3_UNPACK)
- unpack_constant_vector3(translations, constant_data_translations);
-#else
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- if (num_left_to_unpack_translations == 0 || num_unpacked_translations >= 4)
- return; // Enough unpacked or nothing to do
-
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack_translations, 4);
- num_left_to_unpack_translations -= num_to_unpack;
-
- // If we have data already unpacked, store in index 1 otherwise store in 0
- const uint32_t unpack_index = num_unpacked_translations > 0 ? 1 : 0;
- constant_data_translations[unpack_index] = constant_data;
- num_group_translations[unpack_index] = num_to_unpack;
- constant_data += sizeof(rtm::float3f) * num_to_unpack;
-
- num_unpacked_translations += num_to_unpack;
-
- ACL_IMPL_CONSTANT_PREFETCH(constant_data + 63);
-#else
- ACL_IMPL_CONSTANT_PREFETCH(constant_data_translations + 63);
-#endif
-#endif
- }
-
ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_translation_groups(uint32_t num_groups_to_skip)
{
const uint8_t* constant_track_data = constant_data_translations;
@@ -400,58 +271,10 @@ namespace acl
ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL consume_translation()
{
-#if defined(ACL_IMPL_VEC3_UNPACK)
- ACL_ASSERT(translations.cache_read_index < translations.cache_write_index, "Attempting to consume a constant sample that isn't cached");
- const uint32_t cache_read_index = translations.cache_read_index++;
- return translations.cached_samples[cache_read_index % 8];
-#else
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- const rtm::vector4f sample = rtm::vector_load(constant_data_translations[0]);
- num_group_translations[0]--;
- num_unpacked_translations--;
-
- // If we finished reading from the first group, swap it out otherwise increment our entry
- if (num_group_translations[0] == 0)
- {
- constant_data_translations[0] = constant_data_translations[1];
- num_group_translations[0] = num_group_translations[1];
- }
- else
- constant_data_translations[0] += sizeof(rtm::float3f);
-#else
const rtm::vector4f sample = rtm::vector_load(constant_data_translations);
ACL_ASSERT(rtm::vector_is_finite3(sample), "Sample is not valid!");
constant_data_translations += sizeof(rtm::float3f);
-#endif
return sample;
-#endif
- }
-
- ACL_DISABLE_SECURITY_COOKIE_CHECK void unpack_scale_group()
- {
-#if defined(ACL_IMPL_VEC3_UNPACK)
- unpack_constant_vector3(scales, constant_data_scales);
-#else
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- if (num_left_to_unpack_scales == 0 || num_unpacked_scales >= 4)
- return; // Enough unpacked or nothing to do
-
- const uint32_t num_to_unpack = std::min<uint32_t>(num_left_to_unpack_scales, 4);
- num_left_to_unpack_scales -= num_to_unpack;
-
- // If we have data already unpacked, store in index 1 otherwise store in 0
- const uint32_t unpack_index = num_unpacked_scales > 0 ? 1 : 0;
- constant_data_scales[unpack_index] = constant_data;
- num_group_scales[unpack_index] = num_to_unpack;
- constant_data += sizeof(rtm::float3f) * num_to_unpack;
-
- num_unpacked_scales += num_to_unpack;
-
- ACL_IMPL_CONSTANT_PREFETCH(constant_data + 63);
-#else
- ACL_IMPL_CONSTANT_PREFETCH(constant_data_scales + 63);
-#endif
-#endif
}
ACL_DISABLE_SECURITY_COOKIE_CHECK void skip_scale_groups(uint32_t num_groups_to_skip)
@@ -480,33 +303,16 @@ namespace acl
ACL_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL consume_scale()
{
-#if defined(ACL_IMPL_VEC3_UNPACK)
- ACL_ASSERT(scales.cache_read_index < scales.cache_write_index, "Attempting to consume a constant sample that isn't cached");
- const uint32_t cache_read_index = scales.cache_read_index++;
- return scales.cached_samples[cache_read_index % 8];
-#else
-#if defined(ACL_IMPL_USE_CONSTANT_GROUPS)
- const rtm::vector4f scale = rtm::vector_load(constant_data_scales[0]);
- num_group_scales[0]--;
- num_unpacked_scales--;
-
- // If we finished reading from the first group, swap it out otherwise increment our entry
- if (num_group_scales[0] == 0)
- {
- constant_data_scales[0] = constant_data_scales[1];
- num_group_scales[0] = num_group_scales[1];
- }
- else
- constant_data_scales[0] += sizeof(rtm::float3f);
-#else
const rtm::vector4f scale = rtm::vector_load(constant_data_scales);
constant_data_scales += sizeof(rtm::float3f);
-#endif
return scale;
-#endif
}
};
}
}
+#if defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic pop
+#endif
+
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/decompression/impl/transform_decompression_context.h b/includes/acl/decompression/impl/transform_decompression_context.h
--- a/includes/acl/decompression/impl/transform_decompression_context.h
+++ b/includes/acl/decompression/impl/transform_decompression_context.h
@@ -42,49 +42,46 @@ namespace acl
{
struct alignas(64) persistent_transform_decompression_context_v0
{
- // Clip related data // offsets
+ // Clip related data // offsets
// Only member used to detect if we are initialized, must be first
- const compressed_tracks* tracks; // 0 | 0
+ const compressed_tracks* tracks; // 0 | 0
// Database context, optional
- const database_context_v0* db; // 4 | 8
+ const database_context_v0* db; // 4 | 8
- // Offsets relative to the 'tracks' pointer
- ptr_offset32<uint32_t> constant_tracks_bitset; // 8 | 16
- ptr_offset32<uint8_t> constant_track_data; // 12 | 20
- ptr_offset32<uint32_t> default_tracks_bitset; // 16 | 24
- ptr_offset32<uint8_t> clip_range_data; // 20 | 28
+ uint32_t clip_hash; // 8 | 16
- float clip_duration; // 24 | 32
+ float clip_duration; // 12 | 20
- bitset_description bitset_desc; // 28 | 36
+ rotation_format8 rotation_format; // 16 | 24
+ vector_format8 translation_format; // 17 | 25
+ vector_format8 scale_format; // 18 | 26
- uint32_t clip_hash; // 32 | 40
+ uint8_t has_scale; // 19 | 27
+ uint8_t has_segments; // 20 | 28
- rotation_format8 rotation_format; // 36 | 44
- vector_format8 translation_format; // 37 | 45
- vector_format8 scale_format; // 38 | 46
- range_reduction_flags8 range_reduction; // 39 | 47
+ uint8_t padding0[22]; // 21 | 29
- uint8_t num_rotation_components; // 40 | 48
- uint8_t has_segments; // 41 | 49
+ // Seeking related data
+ uint8_t uses_single_segment; // 43 | 51
- uint8_t padding0[2]; // 42 | 50
+ float sample_time; // 44 | 52
- // Seeking related data
- float sample_time; // 44 | 52
+ // Offsets relative to the 'tracks' pointer
+ ptr_offset32<segment_header> segment_offsets[2]; // 48 | 56
- const uint8_t* format_per_track_data[2]; // 48 | 56
- const uint8_t* segment_range_data[2]; // 56 | 72
- const uint8_t* animated_track_data[2]; // 64 | 88
+ const uint8_t* format_per_track_data[2]; // 56 | 64
+ const uint8_t* segment_range_data[2]; // 64 | 80
+ const uint8_t* animated_track_data[2]; // 72 | 96
- uint32_t key_frame_bit_offsets[2]; // 72 | 104
+ // Offsets relative to the 'animated_track_data' pointers
+ uint32_t key_frame_bit_offsets[2]; // 80 | 112
- float interpolation_alpha; // 80 | 112
+ float interpolation_alpha; // 88 | 120
- uint8_t padding1[sizeof(void*) == 4 ? 44 : 12]; // 84 | 116
+ uint8_t padding1[sizeof(void*) == 4 ? 36 : 4]; // 92 | 124
- // Total size: 128 | 128
+ // Total size: 128 | 128
//////////////////////////////////////////////////////////////////////////
diff --git a/includes/acl/decompression/impl/transform_track_decompression.h b/includes/acl/decompression/impl/transform_track_decompression.h
--- a/includes/acl/decompression/impl/transform_track_decompression.h
+++ b/includes/acl/decompression/impl/transform_track_decompression.h
@@ -49,6 +49,8 @@
#include <cstdint>
#include <type_traits>
+#define ACL_IMPL_USE_SEEK_PREFETCH
+
ACL_IMPL_FILE_PRAGMA_PUSH
#if defined(ACL_COMPILER_MSVC)
@@ -62,6 +64,12 @@ namespace acl
{
namespace acl_impl
{
+#if defined(ACL_IMPL_USE_SEEK_PREFETCH)
+#define ACL_IMPL_SEEK_PREFETCH(ptr) memory_prefetch(ptr)
+#else
+#define ACL_IMPL_SEEK_PREFETCH(ptr) (void)(ptr)
+#endif
+
template<class decompression_settings_type>
constexpr bool is_database_supported_impl()
{
@@ -95,35 +103,11 @@ namespace acl
context.clip_hash = tracks.get_hash();
context.clip_duration = calculate_duration(header.num_samples, header.sample_rate);
context.sample_time = -1.0F;
- context.default_tracks_bitset = ptr_offset32<uint32_t>(&tracks, transform_header.get_default_tracks_bitset());
- context.constant_tracks_bitset = ptr_offset32<uint32_t>(&tracks, transform_header.get_constant_tracks_bitset());
- context.constant_track_data = ptr_offset32<uint8_t>(&tracks, transform_header.get_constant_track_data());
- context.clip_range_data = ptr_offset32<uint8_t>(&tracks, transform_header.get_clip_range_data());
-
- for (uint32_t key_frame_index = 0; key_frame_index < 2; ++key_frame_index)
- {
- context.format_per_track_data[key_frame_index] = nullptr;
- context.segment_range_data[key_frame_index] = nullptr;
- context.animated_track_data[key_frame_index] = nullptr;
- }
-
- const bool has_scale = header.get_has_scale();
- const uint32_t num_tracks_per_bone = has_scale ? 3 : 2;
- context.bitset_desc = bitset_description::make_from_num_bits(header.num_tracks * num_tracks_per_bone);
-
- range_reduction_flags8 range_reduction = range_reduction_flags8::none;
- if (is_rotation_format_variable(rotation_format))
- range_reduction |= range_reduction_flags8::rotations;
- if (is_vector_format_variable(translation_format))
- range_reduction |= range_reduction_flags8::translations;
- if (is_vector_format_variable(scale_format))
- range_reduction |= range_reduction_flags8::scales;
context.rotation_format = rotation_format;
context.translation_format = translation_format;
context.scale_format = scale_format;
- context.range_reduction = range_reduction;
- context.num_rotation_components = rotation_format == rotation_format8::quatf_full ? 4 : 3;
+ context.has_scale = header.get_has_scale();
context.has_segments = transform_header.has_multiple_segments();
return true;
@@ -150,11 +134,21 @@ namespace acl
if (context.sample_time == sample_time)
return;
- context.sample_time = sample_time;
-
const tracks_header& header = get_tracks_header(*context.tracks);
const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
+ // Prefetch our sub-track types, we'll need them soon when we start decompressing
+ // Most clips will have their sub-track types fit into 1 or 2 cache lines, we'll prefetch 2
+ // to be safe
+ {
+ const uint8_t* sub_track_types = reinterpret_cast<const uint8_t*>(transform_header.get_sub_track_types());
+
+ ACL_IMPL_SEEK_PREFETCH(sub_track_types);
+ ACL_IMPL_SEEK_PREFETCH(sub_track_types + 64);
+ }
+
+ context.sample_time = sample_time;
+
uint32_t key_frame0;
uint32_t key_frame1;
find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, key_frame0, key_frame1, context.interpolation_alpha);
@@ -426,12 +420,24 @@ namespace acl
}
}
+ {
+ // Prefetch our constant rotation data, we'll need it soon when we start decompressing and we are about to cache miss on the segment headers
+ const uint8_t* constant_data_rotations = transform_header.get_constant_track_data();
+ ACL_IMPL_SEEK_PREFETCH(constant_data_rotations);
+ ACL_IMPL_SEEK_PREFETCH(constant_data_rotations + 64);
+ }
+
+ const bool uses_single_segment = segment_header0 == segment_header1;
+ context.uses_single_segment = uses_single_segment;
+
// Cache miss if we don't access the db data
transform_header.get_segment_data(*segment_header0, context.format_per_track_data[0], context.segment_range_data[0], context.animated_track_data[0]);
// More often than not the two segments are identical, when this is the case, just copy our pointers
- if (segment_header0 != segment_header1)
+ if (!uses_single_segment)
+ {
transform_header.get_segment_data(*segment_header1, context.format_per_track_data[1], context.segment_range_data[1], context.animated_track_data[1]);
+ }
else
{
context.format_per_track_data[1] = context.format_per_track_data[0];
@@ -451,150 +457,924 @@ namespace acl
context.key_frame_bit_offsets[0] = segment_key_frame0 * segment_header0->animated_pose_bit_size;
context.key_frame_bit_offsets[1] = segment_key_frame1 * segment_header1->animated_pose_bit_size;
+
+ context.segment_offsets[0] = ptr_offset32<segment_header>(context.tracks, segment_header0);
+ context.segment_offsets[1] = ptr_offset32<segment_header>(context.tracks, segment_header1);
}
- // TODO: Stage bitset decomp
+
// TODO: Merge the per track format and segment range info into a single buffer? Less to prefetch and used together
- // TODO: How do we hide the cache miss after the seek to read the segment header? What work can we do while we prefetch?
- // TODO: Port vector3 decomp to use SOA
- // TODO: Unroll quat unpacking and convert to SOA
- // TODO: Use AVX where we can
// TODO: Remove segment data alignment, no longer required?
- template<class decompression_settings_type, class track_writer_type>
- inline void decompress_tracks_v0(const persistent_transform_decompression_context_v0& context, track_writer_type& writer)
+ // Force inline this function, we only use it to keep the code readable
+ template<class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_default_rotation_sub_tracks(
+ const packed_sub_track_types* rotation_sub_track_types, uint32_t last_entry_index, uint32_t padding_mask,
+ rtm::quatf_arg0 default_rotation, track_writer_type& writer)
{
- ACL_ASSERT(context.sample_time >= 0.0f, "Context not set to a valid sample time");
- if (context.sample_time < 0.0F)
- return; // Invalid sample time, we didn't seek yet
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ uint32_t packed_entry = rotation_sub_track_types[entry_index].types;
- // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
- // Disable floating point exceptions to avoid issues.
- fp_environment fp_env;
- if (decompression_settings_type::disable_fp_exeptions())
- disable_fp_exceptions(fp_env);
+ // Mask out everything but default sub-tracks, this way we can early out when we iterate
+ // Each sub-track is either 0 (default), 1 (constant), or 2 (animated)
+ // By flipping the bits with logical NOT, 0 becomes 3, 1 becomes 2, and 2 becomes 1
+ // We then subtract 1 from every group so 3 becomes 2, 2 becomes 1, and 1 becomes 0
+ // Finally, we mask out everything but the second bit for each sub-track
+ // After this, our original default tracks are equal to 2, our constant tracks are equal to 1, and our animated tracks are equal to 0
+ // Testing for default tracks can be done by testing the second bit of each group (same as animated track testing)
+ packed_entry = (~packed_entry - 0x55555555) & 0xAAAAAAAA;
- const tracks_header& header = get_tracks_header(*context.tracks);
+ // Because our last entry might have padding with 0 (default), we have to strip any padding we might have
+ const uint32_t entry_padding_mask = (entry_index == last_entry_index) ? padding_mask : 0xFFFFFFFF;
+ packed_entry &= entry_padding_mask;
- using translation_adapter = acl_impl::translation_decompression_settings_adapter<decompression_settings_type>;
- using scale_adapter = acl_impl::scale_decompression_settings_adapter<decompression_settings_type>;
+ uint32_t curr_entry_track_index = track_index;
- const rtm::vector4f default_translation = rtm::vector_zero();
- const rtm::vector4f default_scale = rtm::vector_set(float(header.get_default_scale()));
- const bool has_scale = header.get_has_scale();
- const uint32_t num_tracks = header.num_tracks;
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
- const uint32_t* default_tracks_bitset = context.default_tracks_bitset.add_to(context.tracks);
- const uint32_t* constant_tracks_bitset = context.constant_tracks_bitset.add_to(context.tracks);
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
+ {
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
- constant_track_cache_v0 constant_track_cache;
- constant_track_cache.initialize<decompression_settings_type>(context);
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
- animated_track_cache_v0 animated_track_cache;
- animated_track_cache.initialize(context);
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no default sub-tracks, skip it
+
+ if ((packed_group & 0x80000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index0))
+ writer.write_rotation(track_index0, default_rotation);
+ }
+
+ if ((packed_group & 0x20000000) != 0)
+ {
+ const uint32_t track_index1 = curr_group_track_index + 1;
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index1))
+ writer.write_rotation(track_index1, default_rotation);
+ }
+
+ if ((packed_group & 0x08000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index2))
+ writer.write_rotation(track_index2, default_rotation);
+ }
- uint32_t sub_track_index = 0;
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index3))
+ writer.write_rotation(track_index3, default_rotation);
+ }
+ }
+ }
+ }
- for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ // Force inline this function, we only use it to keep the code readable
+ template<class decompression_settings_type, class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_constant_rotation_sub_tracks(
+ const packed_sub_track_types* rotation_sub_track_types, uint32_t last_entry_index,
+ const persistent_transform_decompression_context_v0& context,
+ constant_track_cache_v0& constant_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
{
- if ((track_index % 4) == 0)
+ // Mask out everything but constant sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0x55555555U, rotation_sub_track_types[entry_index].types);
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
{
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0x55000000) == 0)
+ continue; // This group contains no constant sub-tracks, skip it
+
// Unpack our next 4 tracks
constant_track_cache.unpack_rotation_group<decompression_settings_type>(context);
- constant_track_cache.unpack_translation_group();
+ if ((packed_group & 0x40000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::quatf rotation = constant_track_cache.consume_rotation();
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index0))
+ writer.write_rotation(track_index0, rotation);
+ }
+
+ if ((packed_group & 0x10000000) != 0)
+ {
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::quatf rotation = constant_track_cache.consume_rotation();
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index1))
+ writer.write_rotation(track_index1, rotation);
+ }
+
+ if ((packed_group & 0x04000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::quatf rotation = constant_track_cache.consume_rotation();
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index2))
+ writer.write_rotation(track_index2, rotation);
+ }
+
+ if ((packed_group & 0x01000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::quatf rotation = constant_track_cache.consume_rotation();
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index3))
+ writer.write_rotation(track_index3, rotation);
+ }
+ }
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class decompression_settings_type, class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_animated_rotation_sub_tracks(
+ const packed_sub_track_types* rotation_sub_track_types, uint32_t last_entry_index,
+ const persistent_transform_decompression_context_v0& context,
+ animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ // Mask out everything but animated sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0xAAAAAAAAU, rotation_sub_track_types[entry_index].types);
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
+ {
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no animated sub-tracks, skip it
+
+ // Unpack our next 4 tracks
animated_track_cache.unpack_rotation_group<decompression_settings_type>(context);
+
+ if ((packed_group & 0x80000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::quatf rotation = animated_track_cache.consume_rotation();
+
+ ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index0))
+ writer.write_rotation(track_index0, rotation);
+ }
+
+ if ((packed_group & 0x20000000) != 0)
+ {
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::quatf rotation = animated_track_cache.consume_rotation();
+
+ ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index1))
+ writer.write_rotation(track_index1, rotation);
+ }
+
+ if ((packed_group & 0x08000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::quatf rotation = animated_track_cache.consume_rotation();
+
+ ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index2))
+ writer.write_rotation(track_index2, rotation);
+ }
+
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::quatf rotation = animated_track_cache.consume_rotation();
+
+ ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
+ ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
+
+ if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index3))
+ writer.write_rotation(track_index3, rotation);
+ }
+ }
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_default_translation_sub_tracks(
+ const packed_sub_track_types* translation_sub_track_types, uint32_t last_entry_index, uint32_t padding_mask,
+ rtm::vector4f_arg0 default_translation, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ uint32_t packed_entry = translation_sub_track_types[entry_index].types;
+
+ // Mask out everything but default sub-tracks, this way we can early out when we iterate
+ // Each sub-track is either 0 (default), 1 (constant), or 2 (animated)
+ // By flipping the bits with logical NOT, 0 becomes 3, 1 becomes 2, and 2 becomes 1
+ // We then subtract 1 from every group so 3 becomes 2, 2 becomes 1, and 1 becomes 0
+ // Finally, we mask out everything but the second bit for each sub-track
+ // After this, our original default tracks are equal to 2, our constant tracks are equal to 1, and our animated tracks are equal to 0
+ // Testing for default tracks can be done by testing the second bit of each group (same as animated track testing)
+ packed_entry = (~packed_entry - 0x55555555) & 0xAAAAAAAA;
+
+ // Because our last entry might have padding with 0 (default), we have to strip any padding we might have
+ const uint32_t entry_padding_mask = (entry_index == last_entry_index) ? padding_mask : 0xFFFFFFFF;
+ packed_entry &= entry_padding_mask;
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
+ {
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no default sub-tracks, skip it
+
+ if ((packed_group & 0x80000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index0))
+ writer.write_translation(track_index0, default_translation);
+ }
+
+ if ((packed_group & 0x20000000) != 0)
+ {
+ const uint32_t track_index1 = curr_group_track_index + 1;
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index1))
+ writer.write_translation(track_index1, default_translation);
+ }
+
+ if ((packed_group & 0x08000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index2))
+ writer.write_translation(track_index2, default_translation);
+ }
+
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index3))
+ writer.write_translation(track_index3, default_translation);
+ }
+ }
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_constant_translation_sub_tracks(
+ const packed_sub_track_types* translation_sub_track_types, uint32_t last_entry_index,
+ constant_track_cache_v0& constant_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ // Mask out everything but constant sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0x55555555U, translation_sub_track_types[entry_index].types);
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
+ {
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0x55000000) == 0)
+ continue; // This group contains no constant sub-tracks, skip it
+
+ if ((packed_group & 0x40000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::vector4f translation = constant_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index0))
+ writer.write_translation(track_index0, translation);
+ }
+
+ if ((packed_group & 0x10000000) != 0)
+ {
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::vector4f translation = constant_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index1))
+ writer.write_translation(track_index1, translation);
+ }
+
+ if ((packed_group & 0x04000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::vector4f translation = constant_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index2))
+ writer.write_translation(track_index2, translation);
+ }
+
+ if ((packed_group & 0x01000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::vector4f translation = constant_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index3))
+ writer.write_translation(track_index3, translation);
+ }
+ }
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class translation_adapter, class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_animated_translation_sub_tracks(
+ const packed_sub_track_types* translation_sub_track_types, uint32_t last_entry_index,
+ const persistent_transform_decompression_context_v0& context,
+ animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ // Mask out everything but animated sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0xAAAAAAAAU, translation_sub_track_types[entry_index].types);
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
+ {
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no animated sub-tracks, skip it
+
+ // Unpack our next 4 tracks
animated_track_cache.unpack_translation_group<translation_adapter>(context);
- if (has_scale)
+ if ((packed_group & 0x80000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::vector4f translation = animated_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index0))
+ writer.write_translation(track_index0, translation);
+ }
+
+ if ((packed_group & 0x20000000) != 0)
{
- constant_track_cache.unpack_scale_group();
- animated_track_cache.unpack_scale_group<scale_adapter>(context);
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::vector4f translation = animated_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index1))
+ writer.write_translation(track_index1, translation);
+ }
+
+ if ((packed_group & 0x08000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::vector4f translation = animated_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index2))
+ writer.write_translation(track_index2, translation);
+ }
+
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::vector4f translation = animated_track_cache.consume_translation();
+
+ ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+
+ if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index3))
+ writer.write_translation(track_index3, translation);
}
}
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_default_scale_sub_tracks(
+ const packed_sub_track_types* scale_sub_track_types, uint32_t last_entry_index, uint32_t padding_mask,
+ rtm::vector4f_arg0 default_scale, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ uint32_t packed_entry = scale_sub_track_types[entry_index].types;
+ // Mask out everything but default sub-tracks, this way we can early out when we iterate
+ // Each sub-track is either 0 (default), 1 (constant), or 2 (animated)
+ // By flipping the bits with logical NOT, 0 becomes 3, 1 becomes 2, and 2 becomes 1
+ // We then subtract 1 from every group so 3 becomes 2, 2 becomes 1, and 1 becomes 0
+ // Finally, we mask out everything but the second bit for each sub-track
+ // After this, our original default tracks are equal to 2, our constant tracks are equal to 1, and our animated tracks are equal to 0
+ // Testing for default tracks can be done by testing the second bit of each group (same as animated track testing)
+ packed_entry = (~packed_entry - 0x55555555) & 0xAAAAAAAA;
+
+ // Because our last entry might have padding with 0 (default), we have to strip any padding we might have
+ const uint32_t entry_padding_mask = (entry_index == last_entry_index) ? padding_mask : 0xFFFFFFFF;
+ packed_entry &= entry_padding_mask;
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
{
- const bitset_index_ref track_index_bit_ref(context.bitset_desc, sub_track_index);
- const bool is_sample_default = bitset_test(default_tracks_bitset, track_index_bit_ref);
- rtm::quatf rotation;
- if (is_sample_default)
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no default sub-tracks, skip it
+
+ if ((packed_group & 0x80000000) != 0)
{
- rotation = rtm::quat_identity();
+ const uint32_t track_index0 = curr_group_track_index + 0;
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index0))
+ writer.write_scale(track_index0, default_scale);
}
- else
+
+ if ((packed_group & 0x20000000) != 0)
{
- const bool is_sample_constant = bitset_test(constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- rotation = constant_track_cache.consume_rotation();
- else
- rotation = animated_track_cache.consume_rotation();
+ const uint32_t track_index1 = curr_group_track_index + 1;
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index1))
+ writer.write_scale(track_index1, default_scale);
}
- ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
- ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
+ if ((packed_group & 0x08000000) != 0)
+ {
+ const uint32_t track_index2 = curr_group_track_index + 2;
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index2))
+ writer.write_scale(track_index2, default_scale);
+ }
- if (!track_writer_type::skip_all_rotations() && !writer.skip_track_rotation(track_index))
- writer.write_rotation(track_index, rotation);
- sub_track_index++;
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index3))
+ writer.write_scale(track_index3, default_scale);
+ }
}
+ }
+ }
+ // Force inline this function, we only use it to keep the code readable
+ template<class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_constant_scale_sub_tracks(
+ const packed_sub_track_types* scale_sub_track_types, uint32_t last_entry_index,
+ constant_track_cache_v0& constant_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ // Mask out everything but constant sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0x55555555U, scale_sub_track_types[entry_index].types);
+
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
{
- const bitset_index_ref track_index_bit_ref(context.bitset_desc, sub_track_index);
- const bool is_sample_default = bitset_test(default_tracks_bitset, track_index_bit_ref);
- rtm::vector4f translation;
- if (is_sample_default)
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0x55000000) == 0)
+ continue; // This group contains no constant sub-tracks, skip it
+
+ if ((packed_group & 0x40000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::vector4f scale = constant_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index0))
+ writer.write_scale(track_index0, scale);
+ }
+
+ if ((packed_group & 0x10000000) != 0)
{
- translation = default_translation;
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::vector4f scale = constant_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index1))
+ writer.write_scale(track_index1, scale);
}
- else
+
+ if ((packed_group & 0x04000000) != 0)
{
- const bool is_sample_constant = bitset_test(constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- translation = constant_track_cache.consume_translation();
- else
- translation = animated_track_cache.consume_translation();
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::vector4f scale = constant_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index2))
+ writer.write_scale(track_index2, scale);
}
- ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
+ if ((packed_group & 0x01000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::vector4f scale = constant_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
- if (!track_writer_type::skip_all_translations() && !writer.skip_track_translation(track_index))
- writer.write_translation(track_index, translation);
- sub_track_index++;
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index3))
+ writer.write_scale(track_index3, scale);
+ }
}
+ }
+ }
+
+ // Force inline this function, we only use it to keep the code readable
+ template<class scale_adapter, class track_writer_type>
+ ACL_FORCE_INLINE ACL_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_animated_scale_sub_tracks(
+ const packed_sub_track_types* scale_sub_track_types, uint32_t last_entry_index,
+ const persistent_transform_decompression_context_v0& context,
+ animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
+ {
+ for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
+ {
+ // Mask out everything but animated sub-tracks, this way we can early out when we iterate
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ uint32_t packed_entry = and_not(~0xAAAAAAAAU, scale_sub_track_types[entry_index].types);
- if (has_scale)
+ uint32_t curr_entry_track_index = track_index;
+
+ // We might early out below, always skip 16 tracks
+ track_index += 16;
+
+ // Process 4 sub-tracks at a time
+ while (packed_entry != 0)
{
- const bitset_index_ref track_index_bit_ref(context.bitset_desc, sub_track_index);
- const bool is_sample_default = bitset_test(default_tracks_bitset, track_index_bit_ref);
- rtm::vector4f scale;
- if (is_sample_default)
+ const uint32_t packed_group = packed_entry;
+ const uint32_t curr_group_track_index = curr_entry_track_index;
+
+ // Move to the next group
+ packed_entry <<= 8;
+ curr_entry_track_index += 4;
+
+ if ((packed_group & 0xAA000000) == 0)
+ continue; // This group contains no animated sub-tracks, skip it
+
+ // Unpack our next 4 tracks
+ animated_track_cache.unpack_scale_group<scale_adapter>(context);
+
+ if ((packed_group & 0x80000000) != 0)
+ {
+ const uint32_t track_index0 = curr_group_track_index + 0;
+ const rtm::vector4f scale = animated_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index0))
+ writer.write_scale(track_index0, scale);
+ }
+
+ if ((packed_group & 0x20000000) != 0)
{
- scale = default_scale;
+ const uint32_t track_index1 = curr_group_track_index + 1;
+ const rtm::vector4f scale = animated_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index1))
+ writer.write_scale(track_index1, scale);
}
- else
+
+ if ((packed_group & 0x08000000) != 0)
{
- const bool is_sample_constant = bitset_test(constant_tracks_bitset, track_index_bit_ref);
- if (is_sample_constant)
- scale = constant_track_cache.consume_scale();
- else
- scale = animated_track_cache.consume_scale();
+ const uint32_t track_index2 = curr_group_track_index + 2;
+ const rtm::vector4f scale = animated_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index2))
+ writer.write_scale(track_index2, scale);
}
- ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+ if ((packed_group & 0x02000000) != 0)
+ {
+ const uint32_t track_index3 = curr_group_track_index + 3;
+ const rtm::vector4f scale = animated_track_cache.consume_scale();
+
+ ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
+
+ if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index3))
+ writer.write_scale(track_index3, scale);
+ }
+ }
+ }
+ }
+
+ template<class decompression_settings_type, class track_writer_type>
+ inline void decompress_tracks_v0(const persistent_transform_decompression_context_v0& context, track_writer_type& writer)
+ {
+ ACL_ASSERT(context.sample_time >= 0.0f, "Context not set to a valid sample time");
+ if (context.sample_time < 0.0F)
+ return; // Invalid sample time, we didn't seek yet
+
+ // Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
+ // Disable floating point exceptions to avoid issues.
+ fp_environment fp_env;
+ if (decompression_settings_type::disable_fp_exeptions())
+ disable_fp_exceptions(fp_env);
+
+ const tracks_header& header = get_tracks_header(*context.tracks);
+
+ using translation_adapter = acl_impl::translation_decompression_settings_adapter<decompression_settings_type>;
+ using scale_adapter = acl_impl::scale_decompression_settings_adapter<decompression_settings_type>;
+
+ const rtm::quatf default_rotation = rtm::quat_identity();
+ const rtm::vector4f default_translation = rtm::vector_zero();
+ const rtm::vector4f default_scale = rtm::vector_set(float(header.get_default_scale()));
+ const uint32_t has_scale = context.has_scale;
+ const uint32_t num_tracks = header.num_tracks;
+
+ const packed_sub_track_types* sub_track_types = get_transform_tracks_header(*context.tracks).get_sub_track_types();
+ const uint32_t num_sub_track_entries = (num_tracks + k_num_sub_tracks_per_packed_entry - 1) / k_num_sub_tracks_per_packed_entry;
+ const uint32_t num_padded_sub_tracks = (num_sub_track_entries * k_num_sub_tracks_per_packed_entry) - num_tracks;
+ const uint32_t last_entry_index = num_sub_track_entries - 1;
+
+ // Build a mask to strip the extra sub-tracks we don't need that live in the padding
+ // They are set to 0 which means they would be 'default' sub-tracks but they don't really exist
+ // If we have no padding, we retain every sub-track
+ // Sub-tracks that are kept have their bits set to 1 to mask them with logical AND later
+ const uint32_t padding_mask = num_padded_sub_tracks != 0 ? ~(0xFFFFFFFF >> ((k_num_sub_tracks_per_packed_entry - num_padded_sub_tracks) * 2)) : 0xFFFFFFFF;
+
+ const packed_sub_track_types* rotation_sub_track_types = sub_track_types;
+ const packed_sub_track_types* translation_sub_track_types = rotation_sub_track_types + num_sub_track_entries;
+ const packed_sub_track_types* scale_sub_track_types = translation_sub_track_types + num_sub_track_entries;
+
+ constant_track_cache_v0 constant_track_cache;
+ constant_track_cache.initialize<decompression_settings_type>(context);
+
+ {
+ // By now, our bit sets (1-2 cache lines) constant rotations (2 cache lines) have landed in the L2
+ // We prefetched them ahead in the seek(..) function call and due to cache misses when seeking,
+ // their latency should be fully hidden.
+ // Prefetch our 3rd constant rotation cache line to prime the hardware prefetcher and do the same for constant translations
+
+ ACL_IMPL_SEEK_PREFETCH(constant_track_cache.constant_data_rotations + 128);
+ ACL_IMPL_SEEK_PREFETCH(constant_track_cache.constant_data_translations);
+ ACL_IMPL_SEEK_PREFETCH(constant_track_cache.constant_data_translations + 64);
+ ACL_IMPL_SEEK_PREFETCH(constant_track_cache.constant_data_translations + 128);
+ }
+
+ animated_track_cache_v0 animated_track_cache;
+ animated_track_cache.initialize<decompression_settings_type, translation_adapter>(context);
+
+ {
+ // Start prefetching the per track metadata of both segments
+ // They might live in a different memory page than the clip's header and constant data
+ // and we need to prime VMEM translation and the TLB
+
+ ACL_IMPL_SEEK_PREFETCH(context.format_per_track_data[0]);
+ ACL_IMPL_SEEK_PREFETCH(context.format_per_track_data[1]);
+ }
+
+ // TODO: The first time we iterate over the sub-track types, unpack it into our output pose as a temporary buffer
+ // We can build a linked list
+ // Store on the stack the first animated rot/trans/scale
+ // For its rot/trans/scale, write instead the index of the next animated rot/trans/scale
+ // We can even unpack it first on its own
+ // Writer can expose this with something like write_rotation_index/read_rotation_index
+ // The writer can then allocate a separate buffer for this or re-use the pose buffer
+ // When the time comes to write our animated samples, we can unpack 4, grab the next 4 entries from the linked
+ // list and write our samples. We can do this until all samples are written which should be faster than iterating a bit set
+ // since it'll allow us to quickly skip entries we don't care about. The same scheme can be used for constant/default tracks.
+ // When we unpack our bitset, we can also count the number of entries for each type to help iterate
+
+ // Unpack our default rotation sub-tracks
+ // Default rotation sub-tracks are uncommon, this shouldn't take much more than 50 cycles
+ unpack_default_rotation_sub_tracks(rotation_sub_track_types, last_entry_index, padding_mask, default_rotation, writer);
+
+ // Unpack our constant rotation sub-tracks
+ // Constant rotation sub-tracks are very common, this should take at least 200 cycles
+ unpack_constant_rotation_sub_tracks<decompression_settings_type>(rotation_sub_track_types, last_entry_index, context, constant_track_cache, writer);
+
+ // By now, our constant translations (3 cache lines) have landed in L2 after our prefetching has completed
+ // We typically will do enough work above to hide the latency
+ // We do not prefetch our constant scales because scale is fairly rare
+ // Instead, we prefetch our segment range and animated data
+ // The second key frame of animated data might not live in the same memory page even if we use a single segment
+ // so this allows us to prime the TLB as well
+ {
+ const uint8_t* segment_range_data0 = animated_track_cache.segment_sampling_context_rotations[0].segment_range_data;
+ const uint8_t* segment_range_data1 = animated_track_cache.segment_sampling_context_rotations[1].segment_range_data;
+ const uint8_t* animated_data0 = animated_track_cache.segment_sampling_context_rotations[0].animated_track_data;
+ const uint8_t* animated_data1 = animated_track_cache.segment_sampling_context_rotations[1].animated_track_data;
+ const uint8_t* frame_animated_data0 = animated_data0 + (animated_track_cache.segment_sampling_context_rotations[0].animated_track_data_bit_offset / 8);
+ const uint8_t* frame_animated_data1 = animated_data1 + (animated_track_cache.segment_sampling_context_rotations[1].animated_track_data_bit_offset / 8);
+
+ ACL_IMPL_SEEK_PREFETCH(segment_range_data0);
+ ACL_IMPL_SEEK_PREFETCH(segment_range_data0 + 64);
+ ACL_IMPL_SEEK_PREFETCH(segment_range_data1);
+ ACL_IMPL_SEEK_PREFETCH(segment_range_data1 + 64);
+ ACL_IMPL_SEEK_PREFETCH(frame_animated_data0);
+ ACL_IMPL_SEEK_PREFETCH(frame_animated_data1);
+ }
+
+ // Unpack our default translation sub-tracks
+ // Default translation sub-tracks are rare, this shouldn't take much more than 50 cycles
+ unpack_default_translation_sub_tracks(translation_sub_track_types, last_entry_index, padding_mask, default_translation, writer);
+ // Unpack our constant translation sub-tracks
+ // Constant translation sub-tracks are very common, this should take at least 200 cycles
+ unpack_constant_translation_sub_tracks(translation_sub_track_types, last_entry_index, constant_track_cache, writer);
+
+ if (has_scale)
+ {
+ // Unpack our default scale sub-tracks
+ // Scale sub-tracks are almost always default, this should take at least 200 cycles
+ unpack_default_scale_sub_tracks(scale_sub_track_types, last_entry_index, padding_mask, default_scale, writer);
+
+ // Unpack our constant scale sub-tracks
+ // Constant scale sub-tracks are very rare, this shouldn't take much more than 50 cycles
+ unpack_constant_scale_sub_tracks(scale_sub_track_types, last_entry_index, constant_track_cache, writer);
+ }
+ else
+ {
+ // No scale present, everything is just the default value
+ // This shouldn't take much more than 50 cycles
+ for (uint32_t track_index = 0; track_index < num_tracks; ++track_index)
+ {
if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index))
- writer.write_scale(track_index, scale);
- sub_track_index++;
+ writer.write_scale(track_index, default_scale);
}
- else if (!track_writer_type::skip_all_scales() && !writer.skip_track_scale(track_index))
- writer.write_scale(track_index, default_scale);
}
+ {
+ // By now the first few cache lines of our segment data has landed in the L2
+ // Prefetch ahead some more to prime the hardware prefetcher
+ // We also start prefetching the clip range data since we'll need it soon and we need to prime the TLB
+ // and the hardware prefetcher
+
+ const uint8_t* per_track_metadata0 = animated_track_cache.segment_sampling_context_rotations[0].format_per_track_data;
+ const uint8_t* per_track_metadata1 = animated_track_cache.segment_sampling_context_rotations[1].format_per_track_data;
+ const uint8_t* animated_data0 = animated_track_cache.segment_sampling_context_rotations[0].animated_track_data;
+ const uint8_t* animated_data1 = animated_track_cache.segment_sampling_context_rotations[1].animated_track_data;
+ const uint8_t* frame_animated_data0 = animated_data0 + (animated_track_cache.segment_sampling_context_rotations[0].animated_track_data_bit_offset / 8);
+ const uint8_t* frame_animated_data1 = animated_data1 + (animated_track_cache.segment_sampling_context_rotations[1].animated_track_data_bit_offset / 8);
+
+ ACL_IMPL_SEEK_PREFETCH(per_track_metadata0 + 64);
+ ACL_IMPL_SEEK_PREFETCH(per_track_metadata1 + 64);
+ ACL_IMPL_SEEK_PREFETCH(frame_animated_data0 + 64);
+ ACL_IMPL_SEEK_PREFETCH(frame_animated_data1 + 64);
+ ACL_IMPL_SEEK_PREFETCH(animated_track_cache.clip_sampling_context_rotations.clip_range_data);
+ ACL_IMPL_SEEK_PREFETCH(animated_track_cache.clip_sampling_context_rotations.clip_range_data + 64);
+
+ // TODO: Can we prefetch the translation data ahead instead to prime the TLB?
+ }
+
+ // Unpack our variable sub-tracks
+ // Sub-track data is sorted by type: rotations ... translations ... scales ...
+ // We process everything linearly in order, this should help the hardware prefetcher work with us
+ // We use quite a few memory streams:
+ // - segment per track metadata: 1 per segment
+ // - segment range data: 1 per segment
+ // - animated frame data: 2 (might be in different segments or in database)
+ // - clip range data: 1
+ // We thus need between 5 and 7 memory streams which is a lot.
+ // This is why the unpacking code uses manual software prefetching to ensure prefetching happens.
+ // Removing the manual prefetching slows down the execution on Zen2 and a Pixel 3.
+ // Quite a few of these memory streams might live in separate memory pages if the clip is large
+ // and might thus require TLB misses
+
+ // TODO: Unpack 4, then iterate over tracks to write?
+ // Can we keep the rotations in registers? Does it matter?
+
+ // Unpack rotations first
+ // Animated rotation sub-tracks are very common, this should take at least 400 cycles
+ unpack_animated_rotation_sub_tracks<decompression_settings_type>(rotation_sub_track_types, last_entry_index, context, animated_track_cache, writer);
+
+ // Unpack translations second
+ // Animated translation sub-tracks are common, this should take at least 200 cycles
+ unpack_animated_translation_sub_tracks<translation_adapter>(translation_sub_track_types, last_entry_index, context, animated_track_cache, writer);
+
+ // Unpack scales last
+ // Animated scale sub-tracks are very rare, this shouldn't take much more than 100 cycles
+ if (has_scale)
+ unpack_animated_scale_sub_tracks<scale_adapter>(scale_sub_track_types, last_entry_index, context, animated_track_cache, writer);
+
if (decompression_settings_type::disable_fp_exeptions())
restore_fp_exceptions(fp_env);
}
+ // We only initialize some variables when we need them which prompts the compiler to complain
+ // The usage is perfectly safe and because this code is VERY hot and needs to be as fast as possible,
+ // we disable the warning to avoid zeroing out things we don't need
+#if defined(ACL_COMPILER_MSVC)
+ #pragma warning(push)
+ // warning C4701: potentially uninitialized local variable
+ #pragma warning(disable : 4701)
+#elif defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic push
+ #pragma GCC diagnostic ignored "-Wmaybe-uninitialized"
+#endif
+
template<class decompression_settings_type, class track_writer_type>
inline void decompress_track_v0(const persistent_transform_decompression_context_v0& context, uint32_t track_index, track_writer_type& writer)
{
@@ -603,9 +1383,10 @@ namespace acl
return; // Invalid sample time, we didn't seek yet
const tracks_header& tracks_header_ = get_tracks_header(*context.tracks);
- ACL_ASSERT(track_index < tracks_header_.num_tracks, "Invalid track index");
+ const uint32_t num_tracks = tracks_header_.num_tracks;
+ ACL_ASSERT(track_index < num_tracks, "Invalid track index");
- if (track_index >= tracks_header_.num_tracks)
+ if (track_index >= num_tracks)
return; // Invalid track index
// Due to the SIMD operations, we sometimes overflow in the SIMD lanes not used.
@@ -620,27 +1401,36 @@ namespace acl
const rtm::quatf default_rotation = rtm::quat_identity();
const rtm::vector4f default_translation = rtm::vector_zero();
const rtm::vector4f default_scale = rtm::vector_set(float(tracks_header_.get_default_scale()));
- const bool has_scale = tracks_header_.get_has_scale();
+ const uint32_t has_scale = context.has_scale;
+
+ const packed_sub_track_types* sub_track_types = get_transform_tracks_header(*context.tracks).get_sub_track_types();
+ const uint32_t num_sub_track_entries = (num_tracks + k_num_sub_tracks_per_packed_entry - 1) / k_num_sub_tracks_per_packed_entry;
+
+ const packed_sub_track_types* rotation_sub_track_types = sub_track_types;
+ const packed_sub_track_types* translation_sub_track_types = rotation_sub_track_types + num_sub_track_entries;
- const uint32_t* default_tracks_bitset = context.default_tracks_bitset.add_to(context.tracks);
- const uint32_t* constant_tracks_bitset = context.constant_tracks_bitset.add_to(context.tracks);
+ // If we have no scale, we'll load the rotation sub-track types and mask it out to avoid branching, forcing it to be the default value
+ const packed_sub_track_types* scale_sub_track_types = has_scale ? (translation_sub_track_types + num_sub_track_entries) : sub_track_types;
- // To decompress a single track, we need a few things:
- // - if our rot/trans/scale is the default value, this is a trivial bitset lookup
- // - constant and animated sub-tracks need to know which group they below to so it can be unpacked
+ // Build a mask to strip out the scale sub-track types if we have no scale present
+ // has_scale is either 0 or 1, negating yields 0 (0x00000000) or -1 (0xFFFFFFFF)
+ // Equivalent to: has_scale ? 0xFFFFFFFF : 0x00000000
+ const uint32_t scale_sub_track_mask = -int32_t(has_scale);
- const uint32_t num_tracks_per_bone = has_scale ? 3 : 2;
- const uint32_t sub_track_index = track_index * num_tracks_per_bone;
+ const uint32_t sub_track_entry_index = track_index / 16;
+ const uint32_t packed_index = track_index % 16;
- const bitset_index_ref rotation_sub_track_index_bit_ref(context.bitset_desc, sub_track_index + 0);
- const bitset_index_ref translation_sub_track_index_bit_ref(context.bitset_desc, sub_track_index + 1);
- const bitset_index_ref scale_sub_track_index_bit_ref(context.bitset_desc, sub_track_index + 2);
+ // Shift our sub-track types so that the sub-track we care about ends up in the LSB position
+ const uint32_t packed_shift = (15 - packed_index) * 2;
- const bool is_rotation_default = bitset_test(default_tracks_bitset, rotation_sub_track_index_bit_ref);
- const bool is_translation_default = bitset_test(default_tracks_bitset, translation_sub_track_index_bit_ref);
- const bool is_scale_default = has_scale ? bitset_test(default_tracks_bitset, scale_sub_track_index_bit_ref) : true;
+ const uint32_t rotation_sub_track_type = (rotation_sub_track_types[sub_track_entry_index].types >> packed_shift) & 0x3;
+ const uint32_t translation_sub_track_type = (translation_sub_track_types[sub_track_entry_index].types >> packed_shift) & 0x3;
+ const uint32_t scale_sub_track_type = scale_sub_track_mask & (scale_sub_track_types[sub_track_entry_index].types >> packed_shift) & 0x3;
- if (is_rotation_default && is_translation_default && is_scale_default)
+ // Combine all three so we can quickly test if all are default and if any are constant/animated
+ const uint32_t combined_sub_track_type = rotation_sub_track_type | translation_sub_track_type | scale_sub_track_type;
+
+ if (combined_sub_track_type == 0)
{
// Everything is default
writer.write_rotation(track_index, default_rotation);
@@ -649,232 +1439,119 @@ namespace acl
return;
}
- const bool is_rotation_constant = !is_rotation_default && bitset_test(constant_tracks_bitset, rotation_sub_track_index_bit_ref);
- const bool is_translation_constant = !is_translation_default && bitset_test(constant_tracks_bitset, translation_sub_track_index_bit_ref);
- const bool is_scale_constant = !is_scale_default && has_scale ? bitset_test(constant_tracks_bitset, scale_sub_track_index_bit_ref) : false;
-
- const bool is_rotation_animated = !is_rotation_default && !is_rotation_constant;
- const bool is_translation_animated = !is_translation_default && !is_translation_constant;
- const bool is_scale_animated = !is_scale_default && !is_scale_constant;
-
- uint32_t num_default_rotations = 0;
- uint32_t num_default_translations = 0;
- uint32_t num_default_scales = 0;
uint32_t num_constant_rotations = 0;
uint32_t num_constant_translations = 0;
uint32_t num_constant_scales = 0;
+ uint32_t num_animated_rotations = 0;
+ uint32_t num_animated_translations = 0;
+ uint32_t num_animated_scales = 0;
- if (has_scale)
- {
- uint32_t rotation_track_bit_mask = 0x92492492; // b100100100..
- uint32_t translation_track_bit_mask = 0x49249249; // b010010010..
- uint32_t scale_track_bit_mask = 0x24924924; // b001001001..
+ const uint32_t last_entry_index = track_index / k_num_sub_tracks_per_packed_entry;
+ const uint32_t num_padded_sub_tracks = ((last_entry_index + 1) * k_num_sub_tracks_per_packed_entry) - track_index;
- const uint32_t last_offset = sub_track_index / 32;
- uint32_t offset = 0;
- for (; offset < last_offset; ++offset)
- {
- const uint32_t default_value = default_tracks_bitset[offset];
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
- num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
-
- const uint32_t constant_value = constant_tracks_bitset[offset];
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
-
- // Because the number of tracks in a 32 bit value isn't a multiple of the number of tracks we have (3),
- // we have to cycle the masks. There are 3 possible masks, just swap them.
- const uint32_t old_rotation_track_bit_mask = rotation_track_bit_mask;
- rotation_track_bit_mask = translation_track_bit_mask;
- translation_track_bit_mask = scale_track_bit_mask;
- scale_track_bit_mask = old_rotation_track_bit_mask;
- }
+ // Build a mask to strip the extra sub-tracks we don't need that live in the padding
+ // They are set to 0 which means they would be 'default' sub-tracks but they don't really exist
+ // If we have no padding, we retain every sub-track
+ // Sub-tracks that are kept have their bits set to 0 to mask them with logical ANDNOT later
+ const uint32_t padding_mask = num_padded_sub_tracks != 0 ? (0xFFFFFFFF >> ((k_num_sub_tracks_per_packed_entry - num_padded_sub_tracks) * 2)) : 0x00000000;
- const uint32_t remaining_tracks = sub_track_index % 32;
- if (remaining_tracks != 0)
- {
- const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
- const uint32_t default_value = and_not(not_up_to_track_mask, default_tracks_bitset[offset]);
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
- num_default_scales += count_set_bits(default_value & scale_track_bit_mask);
-
- const uint32_t constant_value = and_not(not_up_to_track_mask, constant_tracks_bitset[offset]);
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- num_constant_scales += count_set_bits(constant_value & scale_track_bit_mask);
- }
- }
- else
+ for (uint32_t sub_track_entry_index_ = 0; sub_track_entry_index_ <= last_entry_index; ++sub_track_entry_index_)
{
- const uint32_t rotation_track_bit_mask = 0xAAAAAAAA; // b10101010..
- const uint32_t translation_track_bit_mask = 0x55555555; // b01010101..
+ // Our last entry might contain more information than we need so we strip the padding we don't need
+ const uint32_t entry_padding_mask = (sub_track_entry_index_ == last_entry_index) ? padding_mask : 0x00000000;
- const uint32_t last_offset = sub_track_index / 32;
- uint32_t offset = 0;
- for (; offset < last_offset; ++offset)
- {
- const uint32_t default_value = default_tracks_bitset[offset];
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
+ // Use and_not(..) to load our sub-track types directly from memory on x64 with BMI
+ const uint32_t rotation_sub_track_type_ = and_not(entry_padding_mask, rotation_sub_track_types[sub_track_entry_index_].types);
+ const uint32_t translation_sub_track_type_ = and_not(entry_padding_mask, translation_sub_track_types[sub_track_entry_index_].types);
+ const uint32_t scale_sub_track_type_ = scale_sub_track_mask & and_not(entry_padding_mask, scale_sub_track_types[sub_track_entry_index_].types);
- const uint32_t constant_value = constant_tracks_bitset[offset];
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- }
+ num_constant_rotations += count_set_bits(rotation_sub_track_type_ & 0x55555555);
+ num_animated_rotations += count_set_bits(rotation_sub_track_type_ & 0xAAAAAAAA);
- const uint32_t remaining_tracks = sub_track_index % 32;
- if (remaining_tracks != 0)
- {
- const uint32_t not_up_to_track_mask = ((1 << (32 - remaining_tracks)) - 1);
- const uint32_t default_value = and_not(not_up_to_track_mask, default_tracks_bitset[offset]);
- num_default_rotations += count_set_bits(default_value & rotation_track_bit_mask);
- num_default_translations += count_set_bits(default_value & translation_track_bit_mask);
-
- const uint32_t constant_value = and_not(not_up_to_track_mask, constant_tracks_bitset[offset]);
- num_constant_rotations += count_set_bits(constant_value & rotation_track_bit_mask);
- num_constant_translations += count_set_bits(constant_value & translation_track_bit_mask);
- }
+ num_constant_translations += count_set_bits(translation_sub_track_type_ & 0x55555555);
+ num_animated_translations += count_set_bits(translation_sub_track_type_ & 0xAAAAAAAA);
+
+ num_constant_scales += count_set_bits(scale_sub_track_type_ & 0x55555555);
+ num_animated_scales += count_set_bits(scale_sub_track_type_ & 0xAAAAAAAA);
}
- uint32_t rotation_group_index = 0;
- uint32_t translation_group_index = 0;
- uint32_t scale_group_index = 0;
+ uint32_t rotation_group_sample_index;
+ uint32_t translation_group_sample_index;
+ uint32_t scale_group_sample_index;
constant_track_cache_v0 constant_track_cache;
// Skip the constant track data
- if (is_rotation_constant || is_translation_constant || is_scale_constant)
+ if ((combined_sub_track_type & 1) != 0)
{
+ // TODO: Can we init just what we need?
constant_track_cache.initialize<decompression_settings_type>(context);
// Calculate how many constant groups of each sub-track type we need to skip
// Constant groups are easy to skip since they are contiguous in memory, we can just skip N trivially
- // Tracks that are default are also constant
// Unpack the groups we need and skip the tracks before us
- if (is_rotation_constant)
+ if (rotation_sub_track_type & 1)
{
- const uint32_t num_constant_rotations_packed = num_constant_rotations - num_default_rotations;
- const uint32_t num_rotation_constant_groups_to_skip = num_constant_rotations_packed / 4;
+ rotation_group_sample_index = num_constant_rotations % 4;
+
+ const uint32_t num_rotation_constant_groups_to_skip = num_constant_rotations / 4;
if (num_rotation_constant_groups_to_skip != 0)
constant_track_cache.skip_rotation_groups<decompression_settings_type>(context, num_rotation_constant_groups_to_skip);
-
- rotation_group_index = num_constant_rotations_packed % 4;
}
- if (is_translation_constant)
+ if (translation_sub_track_type & 1)
{
- const uint32_t num_constant_translations_packed = num_constant_translations - num_default_translations;
- const uint32_t num_translation_constant_groups_to_skip = num_constant_translations_packed / 4;
+ translation_group_sample_index = num_constant_translations % 4;
+
+ const uint32_t num_translation_constant_groups_to_skip = num_constant_translations / 4;
if (num_translation_constant_groups_to_skip != 0)
constant_track_cache.skip_translation_groups(num_translation_constant_groups_to_skip);
-
- translation_group_index = num_constant_translations_packed % 4;
}
- if (is_scale_constant)
+ if (scale_sub_track_type & 1)
{
- const uint32_t num_constant_scales_packed = num_constant_scales - num_default_scales;
- const uint32_t num_scale_constant_groups_to_skip = num_constant_scales_packed / 4;
+ scale_group_sample_index = num_constant_scales % 4;
+
+ const uint32_t num_scale_constant_groups_to_skip = num_constant_scales / 4;
if (num_scale_constant_groups_to_skip != 0)
constant_track_cache.skip_scale_groups(num_scale_constant_groups_to_skip);
-
- scale_group_index = num_constant_scales_packed % 4;
}
}
- else
- {
- // Fake init to avoid compiler warning...
- constant_track_cache.rotations.num_left_to_unpack = 0;
- constant_track_cache.constant_data_rotations = nullptr;
- constant_track_cache.constant_data_translations = nullptr;
- constant_track_cache.constant_data_scales = nullptr;
- }
animated_track_cache_v0 animated_track_cache;
- animated_group_cursor_v0 rotation_group_cursor;
- animated_group_cursor_v0 translation_group_cursor;
- animated_group_cursor_v0 scale_group_cursor;
// Skip the animated track data
- if (is_rotation_animated || is_translation_animated || is_scale_animated)
+ if ((combined_sub_track_type & 2) != 0)
{
- animated_track_cache.initialize(context);
-
- // Calculate how many animated groups of each sub-track type we need to skip
- // Skipping animated groups is a bit more complicated because they are interleaved in the order
- // they are needed
-
- // Tracks that are default are also constant
- const uint32_t num_animated_rotations = track_index - num_constant_rotations;
-
- if (is_rotation_animated)
- rotation_group_index = num_animated_rotations % 4;
+ // TODO: Can we init just what we need?
+ animated_track_cache.initialize<decompression_settings_type, translation_adapter>(context);
- const uint32_t num_animated_translations = track_index - num_constant_translations;
-
- if (is_translation_animated)
- translation_group_index = num_animated_translations % 4;
-
- const uint32_t num_animated_scales = has_scale ? (track_index - num_constant_scales) : 0;
-
- if (is_scale_animated)
- scale_group_index = num_animated_scales % 4;
-
- uint32_t num_rotations_to_unpack = is_rotation_animated ? num_animated_rotations : ~0U;
- uint32_t num_translations_to_unpack = is_translation_animated ? num_animated_translations : ~0U;
- uint32_t num_scales_to_unpack = is_scale_animated ? num_animated_scales : ~0U;
-
- uint32_t num_animated_groups_to_unpack = is_rotation_animated + is_translation_animated + is_scale_animated;
+ if (rotation_sub_track_type & 2)
+ {
+ rotation_group_sample_index = num_animated_rotations % 4;
- const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
- const animation_track_type8* group_types = transform_header.get_animated_group_types();
+ const uint32_t num_groups_to_skip = num_animated_rotations / 4;
+ if (num_groups_to_skip != 0)
+ animated_track_cache.skip_rotation_groups<decompression_settings_type>(context, num_groups_to_skip);
+ }
- while (num_animated_groups_to_unpack != 0)
+ if (translation_sub_track_type & 2)
{
- const animation_track_type8 group_type = *group_types;
- group_types++;
- ACL_ASSERT(group_type != static_cast<animation_track_type8>(0xFF), "Reached terminator");
+ translation_group_sample_index = num_animated_translations % 4;
- if (group_type == animation_track_type8::rotation)
- {
- if (num_rotations_to_unpack < 4)
- {
- // This is the group we need, cache our cursor
- animated_track_cache.get_rotation_cursor(rotation_group_cursor);
- num_animated_groups_to_unpack--;
- }
-
- animated_track_cache.skip_rotation_group<decompression_settings_type>(context);
- num_rotations_to_unpack -= 4;
- }
- else if (group_type == animation_track_type8::translation)
- {
- if (num_translations_to_unpack < 4)
- {
- // This is the group we need, cache our cursor
- animated_track_cache.get_translation_cursor(translation_group_cursor);
- num_animated_groups_to_unpack--;
- }
+ const uint32_t num_groups_to_skip = num_animated_translations / 4;
+ if (num_groups_to_skip != 0)
+ animated_track_cache.skip_translation_groups<translation_adapter>(context, num_groups_to_skip);
+ }
- animated_track_cache.skip_translation_group<translation_adapter>(context);
- num_translations_to_unpack -= 4;
- }
- else // scale
- {
- if (num_scales_to_unpack < 4)
- {
- // This is the group we need, cache our cursor
- animated_track_cache.get_scale_cursor(scale_group_cursor);
- num_animated_groups_to_unpack--;
- }
+ if (scale_sub_track_type & 2)
+ {
+ scale_group_sample_index = num_animated_scales % 4;
- animated_track_cache.skip_scale_group<scale_adapter>(context);
- num_scales_to_unpack -= 4;
- }
+ const uint32_t num_groups_to_skip = num_animated_scales / 4;
+ if (num_groups_to_skip != 0)
+ animated_track_cache.skip_scale_groups<scale_adapter>(context, num_groups_to_skip);
}
}
@@ -882,36 +1559,36 @@ namespace acl
{
rtm::quatf rotation;
- if (is_rotation_default)
+ if (rotation_sub_track_type == 0)
rotation = default_rotation;
- else if (is_rotation_constant)
- rotation = constant_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_index);
+ else if (rotation_sub_track_type & 1)
+ rotation = constant_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_sample_index);
else
- rotation = animated_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_cursor, rotation_group_index);
+ rotation = animated_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_sample_index);
writer.write_rotation(track_index, rotation);
}
{
rtm::vector4f translation;
- if (is_translation_default)
+ if (translation_sub_track_type == 0)
translation = default_translation;
- else if (is_translation_constant)
- translation = constant_track_cache.unpack_translation_within_group(translation_group_index);
+ else if (translation_sub_track_type & 1)
+ translation = constant_track_cache.unpack_translation_within_group(translation_group_sample_index);
else
- translation = animated_track_cache.unpack_translation_within_group<translation_adapter>(context, translation_group_cursor, translation_group_index);
+ translation = animated_track_cache.unpack_translation_within_group<translation_adapter>(context, translation_group_sample_index);
writer.write_translation(track_index, translation);
}
{
rtm::vector4f scale;
- if (is_scale_default)
+ if (scale_sub_track_type == 0)
scale = default_scale;
- else if (is_scale_constant)
- scale = constant_track_cache.unpack_scale_within_group(scale_group_index);
+ else if (scale_sub_track_type & 1)
+ scale = constant_track_cache.unpack_scale_within_group(scale_group_sample_index);
else
- scale = animated_track_cache.unpack_scale_within_group<scale_adapter>(context, scale_group_cursor, scale_group_index);
+ scale = animated_track_cache.unpack_scale_within_group<scale_adapter>(context, scale_group_sample_index);
writer.write_scale(track_index, scale);
}
@@ -919,6 +1596,13 @@ namespace acl
if (decompression_settings_type::disable_fp_exeptions())
restore_fp_exceptions(fp_env);
}
+
+ // Restore our warnings
+#if defined(ACL_COMPILER_MSVC)
+ #pragma warning(pop)
+#elif defined(ACL_COMPILER_GCC)
+ #pragma GCC diagnostic pop
+#endif
}
}
diff --git a/make.py b/make.py
--- a/make.py
+++ b/make.py
@@ -305,7 +305,6 @@ def do_generate_solution(build_dir, cmake_script_dir, test_data_dir, decomp_data
if compiler == 'emscripten':
cmake_cmd = 'emcmake cmake .. -DCMAKE_INSTALL_PREFIX="{}" {}'.format(build_dir, ' '.join(extra_switches))
else:
- cmake_cmd = 'cmake .. -DCMAKE_INSTALL_PREFIX="{}" {}'.format(build_dir, ' '.join(extra_switches))
cmake_generator = get_generator(compiler, cpu)
if not cmake_generator:
print('Using default generator')
@@ -316,12 +315,14 @@ def do_generate_solution(build_dir, cmake_script_dir, test_data_dir, decomp_data
generator_suffix = 'Clang CL'
print('Using generator: {} {}'.format(cmake_generator, generator_suffix))
- cmake_cmd += ' -G "{}"'.format(cmake_generator)
+ extra_switches.append('-G "{}"'.format(cmake_generator))
cmake_arch = get_architecture(compiler, cpu)
if cmake_arch:
print('Using architecture: {}'.format(cmake_arch))
- cmake_cmd += ' -A {}'.format(cmake_arch)
+ extra_switches.append('-A {}'.format(cmake_arch))
+
+ cmake_cmd = 'cmake .. -DCMAKE_INSTALL_PREFIX="{}" {}'.format(build_dir, ' '.join(extra_switches))
result = subprocess.call(cmake_cmd, shell=True)
if result != 0:
@@ -748,7 +749,7 @@ def run_clip_regression_test(cmd_queue, completed_queue, failed_queue, failure_l
all_threads_done = True
for thread in threads:
- if thread.isAlive():
+ if thread.is_alive():
all_threads_done = False
if all_threads_done:
diff --git a/tools/acl_compressor/acl_compressor.py b/tools/acl_compressor/acl_compressor.py
--- a/tools/acl_compressor/acl_compressor.py
+++ b/tools/acl_compressor/acl_compressor.py
@@ -337,7 +337,7 @@ def compress_clips(options):
cmd = '{} -acl="{}" -stats="{}" -level={}'.format(compressor_exe_path, acl_filename, stat_filename, options['level'])
if out_dir:
- out_filename = os.path.join(options['out'], filename.replace('.acl.sjson', '.acl.bin'))
+ out_filename = os.path.join(options['out'], filename.replace('.acl.sjson', '.acl'))
cmd = '{} -out="{}"'.format(cmd, out_filename)
if options['stat_detailed']:
@@ -381,7 +381,7 @@ def compress_clips(options):
all_threads_done = True
for thread in threads:
- if thread.isAlive():
+ if thread.is_alive():
all_threads_done = False
if all_threads_done:
diff --git a/tools/acl_compressor/sources/validate_database.cpp b/tools/acl_compressor/sources/validate_database.cpp
--- a/tools/acl_compressor/sources/validate_database.cpp
+++ b/tools/acl_compressor/sources/validate_database.cpp
@@ -464,7 +464,7 @@ void validate_db(iallocator& allocator, const track_array_qvvf& raw_tracks, cons
ACL_ASSERT(db01->contains(*db_tracks01[1]), "Database should contain our clip");
}
- // Reference error with the bulk data inline and everything loaded
+ // Reference error without the database with everything highest quality
track_error high_quality_tier_error_ref;
{
acl::decompression_context<debug_transform_decompression_settings_with_db> context;
diff --git a/tools/acl_decompressor/acl_decompressor.py b/tools/acl_decompressor/acl_decompressor.py
--- a/tools/acl_decompressor/acl_decompressor.py
+++ b/tools/acl_decompressor/acl_decompressor.py
@@ -329,7 +329,7 @@ def decompress_clips(options):
all_threads_done = True
for thread in threads:
- if thread.isAlive():
+ if thread.is_alive():
all_threads_done = False
if all_threads_done:
diff --git a/tools/acl_decompressor/main_generic/main.cpp b/tools/acl_decompressor/main_generic/main.cpp
--- a/tools/acl_decompressor/main_generic/main.cpp
+++ b/tools/acl_decompressor/main_generic/main.cpp
@@ -171,9 +171,10 @@ static bool read_metadata_file(const char* metadata_filename, const char*& out_m
int main(int argc, char* argv[])
{
-#if defined(_WIN32) && 0
- // Set the process affinity to physical core 6 (out of 12), on Ryzen 2950X it is the fastest core of the Die 1
- const DWORD_PTR physical_core_index = 6;
+#if defined(_WIN32)
+ // To improve the consistency of the performance results, pin our process to a specific processor core
+ // Set the process affinity to physical core 6, on Ryzen 2950X it is the fastest core of the Die 1
+ const DWORD_PTR physical_core_index = 5;
const DWORD_PTR logical_core_index = physical_core_index * 2;
SetProcessAffinityMask(GetCurrentProcess(), 1 << logical_core_index);
#endif
diff --git a/tools/acl_decompressor/sources/benchmark.cpp b/tools/acl_decompressor/sources/benchmark.cpp
--- a/tools/acl_decompressor/sources/benchmark.cpp
+++ b/tools/acl_decompressor/sources/benchmark.cpp
@@ -40,19 +40,40 @@
#include <string>
#include <vector>
-// TODO: get an official CPU cache size
-#if defined(RTM_SSE2_INTRINSICS)
- static constexpr uint32_t k_cache_size = 33 * 1024 * 1024; // Assume 32 MB cache
- static constexpr uint32_t k_num_tlb_entries = 4000;
-#elif defined(__ANDROID__)
- static constexpr uint32_t k_cache_size = 3 * 1024 * 1024; // Pixel 3 has 2 MB cache
- static constexpr uint32_t k_num_tlb_entries = 100;
-#else
- static constexpr uint32_t k_cache_size = 9 * 1024 * 1024; // iPad Pro has 8 MB cache
- static constexpr uint32_t k_num_tlb_entries = 2000;
-#endif
+//////////////////////////////////////////////////////////////////////////
+// Constants
+
+static constexpr uint32_t k_cpu_cache_size = 8 * 1024 * 1024; // Assume a 8 MB cache which is common for L3 modules (iPad, Zen2)
+
+// In practice, CPUs do not always evict the least recently used cache line.
+// To ensure every cache line is evicted, we allocate our buffer 4x larger than the CPU cache.
+// We use a custom memset function to make sure that streaming writes aren't used which would
+// bypass the CPU cache and not evict anything.
+static constexpr uint32_t k_flush_buffer_size = k_cpu_cache_size * 4;
+
+// The VMEM Level 1 translation has 512 entries each spanning 1 GB. We'll assume that in the real world
+// there is a reasonable chance that memory touched will live within the same 1 GB region and thus be
+// in some level of the CPU cache.
-static constexpr uint32_t k_page_size = 4 * 1024; // 4 KB is standard
+// The VMEM Level 2 translation has 512 entries each spanning 2 MB.
+// This means the cache line we load to find a page offset contains a span of 16 MB within it (a cache
+// line contains 8 entries).
+// To ensure we don't touch cache lines that belong to our input buffer as we flush the CPU cache,
+// we add sufficient padding at both ends of the flush buffer. Since we'll access it linearly,
+// the hardware prefetcher might pull in cache lines ahead. We assume it won't pull more than 4 cache
+// lines ahead. This means we need this much padding on each end: 4 * 16 MB = 64 MB
+static constexpr uint32_t k_vmem_padding = 16 * 1024 * 1024;
+static constexpr uint32_t k_padded_flush_buffer_size = k_vmem_padding + k_flush_buffer_size + k_vmem_padding;
+
+// We allocate 100 copies of the compressed clip and align them to reduce the flush cost
+// by flushing only when we loop around. We pad each copy to 16 MB to ensure no VMEM entry sharing in L2.
+// A compressed clip that takes less than 160 MB would end up using 16 MB * 100 = 1.56 GB
+static constexpr uint32_t k_num_copies = 220;
+
+// Align our clip copy buffer to a 2 MB boundary to further reduce VMEM noise
+static constexpr uint32_t k_clip_buffer_alignment = 2 * 1024 * 1024;
+
+//////////////////////////////////////////////////////////////////////////
enum class PlaybackDirection
{
@@ -74,11 +95,11 @@ struct benchmark_state
acl::compressed_tracks** decompression_instances = nullptr;
acl::decompression_context<acl::default_transform_decompression_settings>* decompression_contexts = nullptr;
- uint8_t* clip_mega_buffer = nullptr;
+ uint8_t* clip_copy_buffer = nullptr;
+ uint8_t* flush_buffer = nullptr;
- uint32_t num_copies = 0;
uint32_t pose_size = 0;
- uint32_t clip_buffer_size = 0;
+ uint32_t clip_copy_buffer_size = 0;
};
acl::ansi_allocator s_allocator;
@@ -86,72 +107,74 @@ static benchmark_state s_benchmark_state;
void clear_benchmark_state()
{
- acl::deallocate_type_array(s_allocator, s_benchmark_state.decompression_contexts, s_benchmark_state.num_copies);
- acl::deallocate_type_array(s_allocator, s_benchmark_state.decompression_instances, s_benchmark_state.num_copies);
- acl::deallocate_type_array(s_allocator, s_benchmark_state.clip_mega_buffer, s_benchmark_state.num_copies * size_t(s_benchmark_state.clip_buffer_size));
+ acl::deallocate_type_array(s_allocator, s_benchmark_state.decompression_contexts, k_num_copies);
+ acl::deallocate_type_array(s_allocator, s_benchmark_state.decompression_instances, k_num_copies);
+ acl::deallocate_type_array(s_allocator, s_benchmark_state.clip_copy_buffer, s_benchmark_state.clip_copy_buffer_size);
+ acl::deallocate_type_array(s_allocator, s_benchmark_state.flush_buffer, k_padded_flush_buffer_size);
s_benchmark_state = benchmark_state();
}
+static void allocate_static_buffers()
+{
+ if (s_benchmark_state.flush_buffer != nullptr)
+ return; // Already allocated
+
+ s_benchmark_state.decompression_instances = acl::allocate_type_array<acl::compressed_tracks*>(s_allocator, k_num_copies);
+ s_benchmark_state.decompression_contexts = acl::allocate_type_array<acl::decompression_context<acl::default_transform_decompression_settings>>(s_allocator, k_num_copies);
+ s_benchmark_state.flush_buffer = acl::allocate_type_array<uint8_t>(s_allocator, k_padded_flush_buffer_size);
+}
+
static void setup_benchmark_state(acl::compressed_tracks& compressed_tracks)
{
+ allocate_static_buffers();
+
const uint32_t num_tracks = compressed_tracks.get_num_tracks();
const uint32_t compressed_size = compressed_tracks.get_size();
const uint32_t num_bytes_per_track = (4 + 3 + 3) * sizeof(float); // Rotation, Translation, Scale
const uint32_t pose_size = num_tracks * num_bytes_per_track;
- // We want to divide our CPU cache into the number of poses it can hold
- const uint32_t num_poses_in_cpu_cache = (k_cache_size + pose_size - 1) / pose_size;
-
- // We want our CPU cache to be cold when we decompress so we duplicate the clip and switch every iteration.
- // Each decompression call will interpolate 2 poses, assume we touch 'pose_size * 2' bytes and at least once memory page.
- const uint32_t num_copies = std::max<uint32_t>((num_poses_in_cpu_cache + 1) / 2, k_num_tlb_entries);
-
- // Align each buffer to a large multiple of our page size to avoid virtual memory translation noise.
- // When we decompress, our memory is sure to be cold and we want to make it reasonably cold.
- // This is why we use multiple clips to avoid the CPU cache being re-used.
- // However, that is not where it stops. When we hit a cache miss, we also need to translate the
- // virtual address used into a physical address. To do this, the CPU first checks if it already
- // translated an address in the same memory page. This is why we pad the buffer to make sure the
- // next clip in memory doesn't share a page. If we have a TLB miss, it triggers the hardware
- // page walk. This in turn uses the virtual address to lookup in a series of tables where the physical
- // memory lies. On x64, this series of tables is 4 (or 5) levels deep and they live in physical memory. Reading
- // them can in turn trigger cache misses and TLB misses. They can also be prefetched by the hardware
- // since their memory is just ordinary data that lives in the CPU cache and RAM like everything else.
- // To force as many cache misses there as possible and to minimize the impact of prefetching, we thus
- // align each buffer to spread them out in memory.
- const uint32_t clip_buffer_alignment = k_page_size * 32;
-
- // Make sure to pad our buffers with a page size to avoid TLB noise
- // Also make sure we can contain at least one full pose to handle memcpy decompression
- const uint32_t clip_buffer_size = acl::align_to(std::max<uint32_t>(compressed_size, pose_size), clip_buffer_alignment);
-
- printf("Pose size: %u, num copies: %u\n", pose_size, num_copies);
-
- acl::compressed_tracks** decompression_instances = acl::allocate_type_array<acl::compressed_tracks*>(s_allocator, num_copies);
- uint8_t* clip_mega_buffer = acl::allocate_type_array_aligned<uint8_t>(s_allocator, num_copies * size_t(clip_buffer_size), k_page_size);
+ // Each clip is rounded up to a multiple of our VMEM padding
+ const uint32_t padded_clip_size = acl::align_to(compressed_size, k_vmem_padding);
+ const uint32_t clip_buffer_size = padded_clip_size * k_num_copies;
+
+ acl::compressed_tracks** decompression_instances = s_benchmark_state.decompression_instances;
+ acl::decompression_context<acl::default_transform_decompression_settings>* decompression_contexts = s_benchmark_state.decompression_contexts;
+ uint8_t* clip_copy_buffer = s_benchmark_state.clip_copy_buffer;
+
+ if (clip_buffer_size > s_benchmark_state.clip_copy_buffer_size)
+ {
+ // Allocate our new clip copy buffer
+ clip_copy_buffer = acl::allocate_type_array_aligned<uint8_t>(s_allocator, clip_buffer_size, k_clip_buffer_alignment);
+
+ s_benchmark_state.clip_copy_buffer = clip_copy_buffer;
+ s_benchmark_state.clip_copy_buffer_size = clip_buffer_size;
+ }
+
+ printf("Pose size: %u bytes, clip size: %.2f MB\n", pose_size, double(compressed_size) / (1024.0 * 1024.0));
// Create our copies
- for (uint32_t copy_index = 0; copy_index < num_copies; ++copy_index)
+ for (uint32_t copy_index = 0; copy_index < k_num_copies; ++copy_index)
{
- uint8_t* buffer = clip_mega_buffer + copy_index * size_t(clip_buffer_size);
+ uint8_t* buffer = clip_copy_buffer + (copy_index * padded_clip_size);
std::memcpy(buffer, &compressed_tracks, compressed_size);
decompression_instances[copy_index] = reinterpret_cast<acl::compressed_tracks*>(buffer);
}
- acl::decompression_context<acl::default_transform_decompression_settings>* decompression_contexts = acl::allocate_type_array<acl::decompression_context<acl::default_transform_decompression_settings>>(s_allocator, num_copies);
- for (uint32_t instance_index = 0; instance_index < num_copies; ++instance_index)
+ // Create our decompression contexts
+ for (uint32_t instance_index = 0; instance_index < k_num_copies; ++instance_index)
decompression_contexts[instance_index].initialize(*decompression_instances[instance_index]);
s_benchmark_state.compressed_tracks = &compressed_tracks;
- s_benchmark_state.decompression_instances = decompression_instances;
- s_benchmark_state.decompression_contexts = decompression_contexts;
- s_benchmark_state.clip_mega_buffer = clip_mega_buffer;
- s_benchmark_state.num_copies = num_copies;
s_benchmark_state.pose_size = pose_size;
- s_benchmark_state.clip_buffer_size = clip_buffer_size;
+}
+
+static void memset_impl(uint8_t* buffer, size_t buffer_size, uint8_t value)
+{
+ for (uint8_t* ptr = buffer; ptr < buffer + buffer_size; ++ptr)
+ *ptr = value;
}
static void benchmark_decompression(benchmark::State& state)
@@ -161,11 +184,7 @@ static void benchmark_decompression(benchmark::State& state)
const DecompressionFunction decompression_function = static_cast<DecompressionFunction>(state.range(2));
if (s_benchmark_state.compressed_tracks != &compressed_tracks)
- {
- // We have a new clip, clear out our old state and start over
- clear_benchmark_state();
- setup_benchmark_state(compressed_tracks);
- }
+ setup_benchmark_state(compressed_tracks); // We have a new clip, setup everything
const float duration = compressed_tracks.get_duration();
@@ -192,16 +211,24 @@ static void benchmark_decompression(benchmark::State& state)
acl::compressed_tracks** decompression_instances = s_benchmark_state.decompression_instances;
acl::decompression_context<acl::default_transform_decompression_settings>* decompression_contexts = s_benchmark_state.decompression_contexts;
- const uint32_t num_copies = s_benchmark_state.num_copies;
+ uint8_t* flush_buffer = s_benchmark_state.flush_buffer;
const uint32_t pose_size = s_benchmark_state.pose_size;
const uint32_t num_tracks = compressed_tracks.get_num_tracks();
acl::acl_impl::debug_track_writer pose_writer(s_allocator, acl::track_type8::qvvf, num_tracks);
+ // Flush the CPU cache
+ memset_impl(flush_buffer + k_vmem_padding, k_flush_buffer_size, 1);
+
uint32_t current_context_index = 0;
uint32_t current_sample_index = 0;
+ uint8_t flush_value = 2;
for (auto _ : state)
{
+ (void)_;
+
+ const auto start = std::chrono::high_resolution_clock::now();
+
const float sample_time = sample_times[current_sample_index];
acl::decompression_context<acl::default_transform_decompression_settings>& context = decompression_contexts[current_context_index];
@@ -221,15 +248,23 @@ static void benchmark_decompression(benchmark::State& state)
break;
}
+ const auto end = std::chrono::high_resolution_clock::now();
+ const auto elapsed_seconds = std::chrono::duration_cast<std::chrono::duration<double>>(end - start);
+ state.SetIterationTime(elapsed_seconds.count());
+
// Move on to the next context and sample
// We only move on to the next sample once every context has been touched
- ++current_context_index;
- if (current_context_index >= num_copies)
+ current_context_index++;
+ if (current_context_index >= k_num_copies)
{
current_context_index = 0;
- ++current_sample_index;
+ current_sample_index++;
+
if (current_sample_index >= k_num_decompression_samples)
current_sample_index = 0;
+
+ // Flush the CPU cache
+ memset_impl(flush_buffer + k_vmem_padding, k_flush_buffer_size, flush_value++);
}
}
@@ -387,16 +422,14 @@ bool prepare_clip(const std::string& clip_name, const acl::compressed_tracks& ra
bench->ArgNames({ "", "Dir", "Func" });
// Sometimes the numbers are slightly different from run to run, we'll run a few times
- bench->Repetitions(20);
+ bench->Repetitions(3);
- bench->ComputeStatistics("min", [](const std::vector<double>& v)
- {
- return *std::min_element(std::begin(v), std::end(v));
- });
- bench->ComputeStatistics("max", [](const std::vector<double>& v)
- {
- return *std::max_element(std::begin(v), std::end(v));
- });
+ // Use manual timing since we clear the CPU cache explicitly
+ bench->UseManualTime();
+
+ // Add min/max tracking
+ bench->ComputeStatistics("min", [](const std::vector<double>& v) { return *std::min_element(std::begin(v), std::end(v)); });
+ bench->ComputeStatistics("max", [](const std::vector<double>& v) { return *std::max_element(std::begin(v), std::end(v)); });
out_compressed_clips.push_back(compressed_tracks);
return true;
diff --git a/tools/appveyor_ci.bat b/tools/appveyor_ci.bat
--- a/tools/appveyor_ci.bat
+++ b/tools/appveyor_ci.bat
@@ -30,6 +30,12 @@ GOTO :next
:clang
IF /i %WORKER_IMAGE%=="Visual Studio 2019" SET COMPILER=vs2019-clang
IF /i %WORKER_IMAGE%=="Previous Visual Studio 2019" SET COMPILER=vs2019-clang
+
+REM HACK!!! Disable clang build for now with appveyor since vcpkg breaks the compiler detection of cmake
+REM Fake build success
+echo VS2019 clang build is disabled for now due to issues with vcpkg breaking compiler detection with cmake
+exit /B 0
+
GOTO :next
:next
diff --git a/tools/vs_visualizers/acl.natvis b/tools/vs_visualizers/acl.natvis
--- a/tools/vs_visualizers/acl.natvis
+++ b/tools/vs_visualizers/acl.natvis
@@ -155,4 +155,15 @@
</Expand>
</Type>
+ <Type Name="acl::acl_impl::packed_sub_track_types">
+ <Expand>
+ <IndexListItems>
+ <Size>16</Size>
+ <ValueNode Condition="((types >> ((15 - $i) * 2)) & 0x3) == 0">"default"</ValueNode>
+ <ValueNode Condition="((types >> ((15 - $i) * 2)) & 0x3) == 1">"constant"</ValueNode>
+ <ValueNode Condition="((types >> ((15 - $i) * 2)) & 0x3) == 2">"animated"</ValueNode>
+ </IndexListItems>
+ </Expand>
+ </Type>
+
</AutoVisualizer>
|
diff --git a/tests/main_android/app/src/main/cpp/CMakeLists.txt b/tests/main_android/app/src/main/cpp/CMakeLists.txt
--- a/tests/main_android/app/src/main/cpp/CMakeLists.txt
+++ b/tests/main_android/app/src/main/cpp/CMakeLists.txt
@@ -8,7 +8,7 @@ set(PROJECT_ROOT_DIR "${PROJECT_SOURCE_DIR}/../../../..")
include_directories("${PROJECT_ROOT_DIR}/../../includes")
include_directories("${PROJECT_ROOT_DIR}/../../external/rtm/includes")
-include_directories("${PROJECT_ROOT_DIR}/../../external/catch2/single_include/catch2")
+include_directories("${PROJECT_ROOT_DIR}/../../external/catch2/single_include")
if(USE_SJSON)
include_directories("${PROJECT_ROOT_DIR}/../../external/sjson-cpp/includes")
diff --git a/tests/main_android/app/src/main/cpp/main.cpp b/tests/main_android/app/src/main/cpp/main.cpp
--- a/tests/main_android/app/src/main/cpp/main.cpp
+++ b/tests/main_android/app/src/main/cpp/main.cpp
@@ -23,7 +23,7 @@
////////////////////////////////////////////////////////////////////////////////
#define CATCH_CONFIG_RUNNER
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <jni.h>
diff --git a/tests/main_emscripten/CMakeLists.txt b/tests/main_emscripten/CMakeLists.txt
--- a/tests/main_emscripten/CMakeLists.txt
+++ b/tests/main_emscripten/CMakeLists.txt
@@ -6,7 +6,7 @@ set(CMAKE_CXX_STANDARD 11)
include_directories("${PROJECT_SOURCE_DIR}/../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/sjson-cpp/includes")
-include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include/catch2")
+include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include")
# Grab all of our test source files
file(GLOB_RECURSE ALL_TEST_SOURCE_FILES LIST_DIRECTORIES false
@@ -32,14 +32,14 @@ target_compile_options(${PROJECT_NAME} PRIVATE -Werror) # Treat warnings as e
# Exceptions are not enabled by default, enable them
target_compile_options(${PROJECT_NAME} PRIVATE -fexceptions)
-target_link_libraries(${PROJECT_NAME} "-s DISABLE_EXCEPTION_CATCHING=0")
+target_link_libraries(${PROJECT_NAME} PRIVATE "-s DISABLE_EXCEPTION_CATCHING=0")
-target_link_libraries(${PROJECT_NAME} "-s NODERAWFS=1") # Enable the raw node file system
-target_link_libraries(${PROJECT_NAME} -lnodefs.js) # Link the node file system
+target_link_libraries(${PROJECT_NAME} PRIVATE "-s NODERAWFS=1") # Enable the raw node file system
+target_link_libraries(${PROJECT_NAME} PRIVATE -lnodefs.js) # Link the node file system
-target_link_libraries(${PROJECT_NAME} "-s ENVIRONMENT=node") # Force the environment to node
+target_link_libraries(${PROJECT_NAME} PRIVATE "-s ENVIRONMENT=node") # Force the environment to node
-target_link_libraries(${PROJECT_NAME} "-s ALLOW_MEMORY_GROWTH=1") # Allow dynamic memory allocation
+target_link_libraries(${PROJECT_NAME} PRIVATE "-s ALLOW_MEMORY_GROWTH=1") # Allow dynamic memory allocation
# Setup Catch2 so we can find and execute the unit tests with CTest
set(OptionalCatchTestLauncher node)
diff --git a/tests/main_emscripten/main.cpp b/tests/main_emscripten/main.cpp
--- a/tests/main_emscripten/main.cpp
+++ b/tests/main_emscripten/main.cpp
@@ -23,7 +23,7 @@
////////////////////////////////////////////////////////////////////////////////
#define CATCH_CONFIG_RUNNER
-#include <catch.hpp>
+#include <catch2/catch.hpp>
int main(int argc, char* argv[])
{
diff --git a/tests/main_generic/CMakeLists.txt b/tests/main_generic/CMakeLists.txt
--- a/tests/main_generic/CMakeLists.txt
+++ b/tests/main_generic/CMakeLists.txt
@@ -6,7 +6,7 @@ set(CMAKE_CXX_STANDARD 11)
include_directories("${PROJECT_SOURCE_DIR}/../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/rtm/includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/sjson-cpp/includes")
-include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include/catch2")
+include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include")
# Grab all of our test source files
file(GLOB_RECURSE ALL_TEST_SOURCE_FILES LIST_DIRECTORIES false
@@ -25,8 +25,8 @@ add_executable(${PROJECT_NAME} ${ALL_TEST_SOURCE_FILES} ${ALL_MAIN_SOURCE_FILES}
list(APPEND CMAKE_MODULE_PATH "${PROJECT_SOURCE_DIR}/../../external/catch2/contrib")
include(CTest)
-include(ParseAndAddCatchTests)
-ParseAndAddCatchTests(${PROJECT_NAME})
+include(Catch)
+catch_discover_tests(${PROJECT_NAME})
setup_default_compiler_flags(${PROJECT_NAME})
diff --git a/tests/main_generic/main.cpp b/tests/main_generic/main.cpp
--- a/tests/main_generic/main.cpp
+++ b/tests/main_generic/main.cpp
@@ -23,7 +23,7 @@
////////////////////////////////////////////////////////////////////////////////
#define CATCH_CONFIG_RUNNER
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#ifdef _WIN32
#include <conio.h>
diff --git a/tests/main_ios/CMakeLists.txt b/tests/main_ios/CMakeLists.txt
--- a/tests/main_ios/CMakeLists.txt
+++ b/tests/main_ios/CMakeLists.txt
@@ -17,7 +17,7 @@ set(MACOSX_BUNDLE_BUNDLE_NAME "acl-unit-tests")
include_directories("${PROJECT_SOURCE_DIR}/../../includes")
include_directories("${PROJECT_SOURCE_DIR}/../../external/rtm/includes")
-include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include/catch2")
+include_directories("${PROJECT_SOURCE_DIR}/../../external/catch2/single_include")
if(USE_SJSON)
include_directories("${PROJECT_SOURCE_DIR}/../../external/sjson-cpp/includes")
diff --git a/tests/main_ios/main.cpp b/tests/main_ios/main.cpp
--- a/tests/main_ios/main.cpp
+++ b/tests/main_ios/main.cpp
@@ -23,7 +23,7 @@
////////////////////////////////////////////////////////////////////////////////
#define CATCH_CONFIG_RUNNER
-#include <catch.hpp>
+#include <catch2/catch.hpp>
int main(int argc, char* argv[])
{
diff --git a/tests/sources/core/test_ansi_allocator.cpp b/tests/sources/core/test_ansi_allocator.cpp
--- a/tests/sources/core/test_ansi_allocator.cpp
+++ b/tests/sources/core/test_ansi_allocator.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
// Enable allocation tracking
#define ACL_ALLOCATOR_TRACK_NUM_ALLOCATIONS
diff --git a/tests/sources/core/test_bit_manip_utils.cpp b/tests/sources/core/test_bit_manip_utils.cpp
--- a/tests/sources/core/test_bit_manip_utils.cpp
+++ b/tests/sources/core/test_bit_manip_utils.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/bit_manip_utils.h>
diff --git a/tests/sources/core/test_bitset.cpp b/tests/sources/core/test_bitset.cpp
--- a/tests/sources/core/test_bitset.cpp
+++ b/tests/sources/core/test_bitset.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/bitset.h>
diff --git a/tests/sources/core/test_enum_utils.cpp b/tests/sources/core/test_enum_utils.cpp
--- a/tests/sources/core/test_enum_utils.cpp
+++ b/tests/sources/core/test_enum_utils.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/enum_utils.h>
diff --git a/tests/sources/core/test_error_result.cpp b/tests/sources/core/test_error_result.cpp
--- a/tests/sources/core/test_error_result.cpp
+++ b/tests/sources/core/test_error_result.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/error_result.h>
diff --git a/tests/sources/core/test_interpolation_utils.cpp b/tests/sources/core/test_interpolation_utils.cpp
--- a/tests/sources/core/test_interpolation_utils.cpp
+++ b/tests/sources/core/test_interpolation_utils.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/interpolation_utils.h>
#include <rtm/scalarf.h>
diff --git a/tests/sources/core/test_iterator.cpp b/tests/sources/core/test_iterator.cpp
--- a/tests/sources/core/test_iterator.cpp
+++ b/tests/sources/core/test_iterator.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/iterator.h>
#include <acl/core/memory_utils.h>
diff --git a/tests/sources/core/test_memory_utils.cpp b/tests/sources/core/test_memory_utils.cpp
--- a/tests/sources/core/test_memory_utils.cpp
+++ b/tests/sources/core/test_memory_utils.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/memory_utils.h>
@@ -165,6 +165,17 @@ TEST_CASE("memcpy_bits", "[core][memory]")
memcpy_bits(&dest, 0, &src, 0, 64);
CHECK(dest == uint64_t(~0ULL));
+
+ dest = 0;
+ src = uint64_t(~0ULL);
+ memcpy_bits(&dest, 0, &src, 0, 0);
+ CHECK(dest == 0);
+
+ memcpy_bits(&dest, 0, nullptr, 0, 0);
+ CHECK(dest == 0);
+
+ memcpy_bits(nullptr, 0, &src, 0, 0);
+ CHECK(dest == 0);
}
enum class UnsignedEnum : uint32_t
diff --git a/tests/sources/core/test_ptr_offset.cpp b/tests/sources/core/test_ptr_offset.cpp
--- a/tests/sources/core/test_ptr_offset.cpp
+++ b/tests/sources/core/test_ptr_offset.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/ptr_offset.h>
diff --git a/tests/sources/core/test_string.cpp b/tests/sources/core/test_string.cpp
--- a/tests/sources/core/test_string.cpp
+++ b/tests/sources/core/test_string.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
// Enable allocation tracking
#define ACL_ALLOCATOR_TRACK_NUM_ALLOCATIONS
diff --git a/tests/sources/core/test_utils.cpp b/tests/sources/core/test_utils.cpp
--- a/tests/sources/core/test_utils.cpp
+++ b/tests/sources/core/test_utils.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/utils.h>
#include <rtm/scalarf.h>
diff --git a/tests/sources/io/test_reader_writer.cpp b/tests/sources/io/test_reader_writer.cpp
--- a/tests/sources/io/test_reader_writer.cpp
+++ b/tests/sources/io/test_reader_writer.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
// Enable allocation tracking
#define ACL_ALLOCATOR_TRACK_NUM_ALLOCATIONS
diff --git a/tests/sources/math/test_quat_packing.cpp b/tests/sources/math/test_quat_packing.cpp
--- a/tests/sources/math/test_quat_packing.cpp
+++ b/tests/sources/math/test_quat_packing.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/math/quat_packing.h>
diff --git a/tests/sources/math/test_scalar_packing.cpp b/tests/sources/math/test_scalar_packing.cpp
--- a/tests/sources/math/test_scalar_packing.cpp
+++ b/tests/sources/math/test_scalar_packing.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/variable_bit_rates.h>
#include <acl/math/scalar_packing.h>
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -22,7 +22,7 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include <catch.hpp>
+#include <catch2/catch.hpp>
#include <acl/core/variable_bit_rates.h>
#include <acl/math/vector4_packing.h>
|
Add staged rotation decompression
When decompressing, a number of things happen:
* Data is unpacked
* Rotations are converted to their final format (W reconstructed)
* Interpolation between two samples (rotations are normalized here as well)
* We write the data into the output buffer
Being able to break down these into states could allow faster decompression. AVX and wider SIMD registers could be used for the rotation conversion and the interpolation of several inputs at the same time in a Structure of Array form.
Splitting things into stages will reduce the current decompression function size by splitting it up and it might improve its inlinability.
Instead of unpacking, reconstructing the W, interpolating and normalizing all in the same function, we would work as follow:
* Unpack up to 8 rotations into a buffer into XXXX, YYYY, ZZZZ form (6x writes per rotation)
* Once we have 8 rotations, reconstruct their W (75% fewer floating point operations) 4 at a time, interleaved to reduce stalls (we have plenty of registers on ARM64 and probably enough on x64)
* Interpolate our rotations 4 at a time (25-75% fewer floating point operations), interleaved
* Swizzle our 4 rotations back into AoS (8x shuffles), interleaved
* Write the 4 rotations with the pose writer
Staged decompression will add a bit of complexity and a few more instructions to manage all of it on top of extra read/writes into the stack/L1 but we will reduce dramatically the number of floating point operations. Right now, reconstructing the W uses scalar mul/sub operations, a scalar sqrt, and scalar abs. Interpolation does 2x dot products with partial SIMD mul/add operations (where some lanes are unused) with a scalar comparison/fsel and a scalar sqrt. All of these operations operate mostly on 1 SIMD lane, sometimes 2. Staged decompression will allow 100% SIMD lane utilization for all floating math involved and even though the overall instruction count might go up, we will be reducing the number of expensive instructions (instead of 12 scalar sqrt for 4 bones, we'll be doing 3 SIMD sqrt) and interleaving will reduce the likelihood of stalls in the pipeline (all 12 scalar sqrt stall on the result but the interleaved SIMD sqrt can have their latency hidden).
Staged decompression also has another hidden benefit. It will allow time for hardware prefetching to work its magic in the background. By doing all of this every 8 bones, while working entirely in the L1 and in registers the prefetching will pull the next cache lines, hiding the memory latency.
|
A good first pass has been made with very promising results. This is clearly the way forward but more work remains.
| 2021-02-09T22:13:12
|
cpp
|
Hard
|
nfrechette/acl
| 203
|
nfrechette__acl-203
|
[
"192"
] |
b5992efd597fa7e527d61d16d24f777688463646
|
diff --git a/includes/acl/compression/stream/write_decompression_stats.h b/includes/acl/compression/stream/write_decompression_stats.h
--- a/includes/acl/compression/stream/write_decompression_stats.h
+++ b/includes/acl/compression/stream/write_decompression_stats.h
@@ -130,7 +130,9 @@ namespace acl
cache_flusher->flush_buffer(compressed_clips[clip_index], compressed_clips[clip_index]->get_size());
}
cache_flusher->end_flushing();
-
+ }
+ else
+ {
// If we want the cache warm, decompress everything once to prime it
DecompressionContextType* context = contexts[0];
context->seek(sample_time, SampleRoundingPolicy::None);
diff --git a/includes/acl/math/quat_32.h b/includes/acl/math/quat_32.h
--- a/includes/acl/math/quat_32.h
+++ b/includes/acl/math/quat_32.h
@@ -220,14 +220,29 @@ namespace acl
float32x4_t l_yxwz = vrev64q_f32(lhs);
float32x4_t l_wzyx = vcombine_f32(vget_high_f32(l_yxwz), vget_low_f32(l_yxwz));
float32x4_t lwrx_lzrx_lyrx_lxrx = vmulq_f32(r_xxxx, l_wzyx);
+
+#if defined(ACL_NEON64_INTRINSICS)
+ float32x4_t result0 = vfmaq_f32(lxrw_lyrw_lzrw_lwrw, lwrx_lzrx_lyrx_lxrx, control_wzyx);
+#else
float32x4_t result0 = vmlaq_f32(lxrw_lyrw_lzrw_lwrw, lwrx_lzrx_lyrx_lxrx, control_wzyx);
+#endif
float32x4_t l_zwxy = vrev64q_u32(l_wzyx);
float32x4_t lzry_lwry_lxry_lyry = vmulq_f32(r_yyyy, l_zwxy);
+
+#if defined(ACL_NEON64_INTRINSICS)
+ float32x4_t result1 = vfmaq_f32(result0, lzry_lwry_lxry_lyry, control_zwxy);
+#else
float32x4_t result1 = vmlaq_f32(result0, lzry_lwry_lxry_lyry, control_zwxy);
+#endif
float32x4_t lyrz_lxrz_lwrz_lzrz = vmulq_f32(r_zzzz, l_yxwz);
+
+#if defined(ACL_NEON64_INTRINSICS)
+ return vfmaq_f32(result1, lyrz_lxrz_lwrz_lzrz, control_yxwz);
+#else
return vmlaq_f32(result1, lyrz_lxrz_lwrz_lzrz, control_yxwz);
+#endif
#else
float lhs_x = quat_get_x(lhs);
float lhs_y = quat_get_y(lhs);
@@ -390,7 +405,7 @@ namespace acl
// using a AND/XOR with the bias (same number of instructions)
float dot = vector_dot(start, end);
float bias = dot >= 0.0f ? 1.0f : -1.0f;
- Vector4_32 interpolated_rotation = vector_mul_add(vector_sub(vector_mul(end, bias), start), alpha, start);
+ Vector4_32 interpolated_rotation = vector_neg_mul_sub(vector_neg_mul_sub(end, bias, start), alpha, start);
// Use sqrt/div/mul to normalize because the sqrt/div are faster than rsqrt
float inv_len = 1.0f / sqrt(vector_length_squared(interpolated_rotation));
return vector_mul(interpolated_rotation, inv_len);
@@ -430,7 +445,7 @@ namespace acl
Vector4_32 end_vector = quat_to_vector(end);
float dot = vector_dot(start_vector, end_vector);
float bias = dot >= 0.0f ? 1.0f : -1.0f;
- Vector4_32 interpolated_rotation = vector_mul_add(vector_sub(vector_mul(end_vector, bias), start_vector), alpha, start_vector);
+ Vector4_32 interpolated_rotation = vector_neg_mul_sub(vector_neg_mul_sub(end_vector, bias, start_vector), alpha, start_vector);
// TODO: Test with this instead: Rotation = (B * Alpha) + (A * (Bias * (1.f - Alpha)));
//Vector4_32 value = vector_add(vector_mul(end_vector, alpha), vector_mul(start_vector, bias * (1.0f - alpha)));
return quat_normalize(vector_to_quat(interpolated_rotation));
diff --git a/includes/acl/math/vector4_32.h b/includes/acl/math/vector4_32.h
--- a/includes/acl/math/vector4_32.h
+++ b/includes/acl/math/vector4_32.h
@@ -547,7 +547,9 @@ namespace acl
// output = (input * scale) + offset
inline Vector4_32 ACL_SIMD_CALL vector_mul_add(Vector4_32Arg0 input, Vector4_32Arg1 scale, Vector4_32Arg2 offset)
{
-#if defined(ACL_NEON_INTRINSICS)
+#if defined(ACL_NEON64_INTRINSICS)
+ return vfmaq_f32(offset, input, scale);
+#elif defined(ACL_NEON_INTRINSICS)
return vmlaq_f32(offset, input, scale);
#else
return vector_add(vector_mul(input, scale), offset);
@@ -556,7 +558,9 @@ namespace acl
inline Vector4_32 ACL_SIMD_CALL vector_mul_add(Vector4_32Arg0 input, float scale, Vector4_32Arg2 offset)
{
-#if defined(ACL_NEON_INTRINSICS)
+#if defined(ACL_NEON64_INTRINSICS)
+ return vfmaq_n_f32(offset, input, scale);
+#elif defined(ACL_NEON_INTRINSICS)
return vmlaq_n_f32(offset, input, scale);
#else
return vector_add(vector_mul(input, scale), offset);
@@ -566,13 +570,26 @@ namespace acl
// output = offset - (input * scale)
inline Vector4_32 ACL_SIMD_CALL vector_neg_mul_sub(Vector4_32Arg0 input, Vector4_32Arg1 scale, Vector4_32Arg2 offset)
{
-#if defined(ACL_NEON_INTRINSICS)
+#if defined(ACL_NEON64_INTRINSICS)
+ return vfmsq_f32(offset, input, scale);
+#elif defined(ACL_NEON_INTRINSICS)
return vmlsq_f32(offset, input, scale);
#else
return vector_sub(offset, vector_mul(input, scale));
#endif
}
+ inline Vector4_32 ACL_SIMD_CALL vector_neg_mul_sub(Vector4_32Arg0 input, float scale, Vector4_32Arg2 offset)
+ {
+#if defined(ACL_NEON64_INTRINSICS)
+ return vfmsq_n_f32(offset, input, scale);
+#elif defined(ACL_NEON_INTRINSICS)
+ return vmlsq_n_f32(offset, input, scale);
+#else
+ return vector_sub(offset, vector_mul(input, scale));
+#endif
+ }
+
inline Vector4_32 ACL_SIMD_CALL vector_lerp(Vector4_32Arg0 start, Vector4_32Arg1 end, float alpha)
{
return vector_mul_add(vector_sub(end, start), alpha, start);
diff --git a/includes/acl/math/vector4_64.h b/includes/acl/math/vector4_64.h
--- a/includes/acl/math/vector4_64.h
+++ b/includes/acl/math/vector4_64.h
@@ -407,6 +407,11 @@ namespace acl
return vector_sub(offset, vector_mul(input, scale));
}
+ inline Vector4_64 vector_neg_mul_sub(const Vector4_64& input, double scale, const Vector4_64& offset)
+ {
+ return vector_sub(offset, vector_mul(input, scale));
+ }
+
inline Vector4_64 vector_lerp(const Vector4_64& start, const Vector4_64& end, double alpha)
{
return vector_mul_add(vector_sub(end, start), alpha, start);
diff --git a/tools/graph_generation/gen_decomp_delta_stats.py b/tools/graph_generation/gen_decomp_delta_stats.py
--- a/tools/graph_generation/gen_decomp_delta_stats.py
+++ b/tools/graph_generation/gen_decomp_delta_stats.py
@@ -39,8 +39,8 @@ def bytes_to_mb(num_bytes):
return num_bytes / (1024 * 1024)
if __name__ == "__main__":
- if len(sys.argv) != 2:
- print('Usage: python gen_decomp_delta_stats.py <path/to/input_file.sjson>')
+ if len(sys.argv) != 2 and len(sys.argv) != 3:
+ print('Usage: python gen_decomp_delta_stats.py <path/to/input_file.sjson> [-warm]')
sys.exit(1)
input_sjson_file = sys.argv[1]
@@ -56,9 +56,13 @@ def bytes_to_mb(num_bytes):
input_sjson_data = sjson.loads(file.read())
clip_names = []
+ if len(sys.argv) == 3 and sys.argv[2] == '-warm':
+ label = 'warm'
+ else:
+ label = 'cold'
- decomp_delta_cold_us_csv_file = open('decomp_delta_cold_forward_stats_us.csv', 'w')
- decomp_delta_cold_mbsec_csv_file = open('decomp_delta_cold_forward_stats_mbsec.csv', 'w')
+ decomp_delta_us_csv_file = open('decomp_delta_{}_forward_stats_us.csv'.format(label), 'w')
+ decomp_delta_mbsec_csv_file = open('decomp_delta_{}_forward_stats_mbsec.csv'.format(label), 'w')
pose_size_per_clip = {}
per_entry_data = []
@@ -68,11 +72,11 @@ def bytes_to_mb(num_bytes):
if len(clip_names) == 0:
clip_names = get_clip_names(entry['stats_dir'])
- print('Variants,Config,Version,{}'.format(','.join(clip_names)), file = decomp_delta_cold_us_csv_file)
- print('Variants,Config,Version,{}'.format(','.join(clip_names)), file = decomp_delta_cold_mbsec_csv_file)
+ print('Variants,Config,Version,{}'.format(','.join(clip_names)), file = decomp_delta_us_csv_file)
+ print('Variants,Config,Version,{}'.format(','.join(clip_names)), file = decomp_delta_mbsec_csv_file)
- pose_cold_medians_ms = {}
- bone_cold_medians_ms = {}
+ pose_medians_ms = {}
+ bone_medians_ms = {}
clip_names = []
stat_files = get_clip_stat_files(entry['stats_dir'])
@@ -86,11 +90,11 @@ def bytes_to_mb(num_bytes):
run_data = clip_sjson_data['runs'][0]['decompression_time_per_sample']
- forward_data_pose_cold = run_data['forward_pose_cold']['data']
- forward_data_bone_cold = run_data['forward_bone_cold']['data']
+ forward_data_pose = run_data['forward_pose_{}'.format(label)]['data']
+ forward_data_bone = run_data['forward_bone_{}'.format(label)]['data']
- pose_cold_medians_ms[clip_name] = numpy.median(forward_data_pose_cold)
- bone_cold_medians_ms[clip_name] = numpy.median(forward_data_bone_cold)
+ pose_medians_ms[clip_name] = numpy.median(forward_data_pose)
+ bone_medians_ms[clip_name] = numpy.median(forward_data_bone)
if 'pose_size' in clip_sjson_data['runs'][0]:
pose_size = clip_sjson_data['runs'][0]['pose_size']
@@ -99,39 +103,39 @@ def bytes_to_mb(num_bytes):
data = {}
data['name'] = entry['name']
data['version'] = entry['version']
- data['pose_cold_medians_ms'] = pose_cold_medians_ms
- data['bone_cold_medians_ms'] = bone_cold_medians_ms
+ data['pose_medians_ms'] = pose_medians_ms
+ data['bone_medians_ms'] = bone_medians_ms
data['clip_names'] = clip_names
per_entry_data.append(data)
for data in per_entry_data:
- pose_cold_medians_ms = data['pose_cold_medians_ms']
- bone_cold_medians_ms = data['bone_cold_medians_ms']
+ pose_medians_ms = data['pose_medians_ms']
+ bone_medians_ms = data['bone_medians_ms']
clip_names = data['clip_names']
- pose_cold_medians_us = []
- bone_cold_medians_us = []
- pose_cold_medians_mbsec = []
- bone_cold_medians_mbsec = []
+ pose_medians_us = []
+ bone_medians_us = []
+ pose_medians_mbsec = []
+ bone_medians_mbsec = []
for clip_name in clip_names:
pose_size = pose_size_per_clip[clip_name]
- pose_cold_median_ms = pose_cold_medians_ms[clip_name]
- bone_cold_median_ms = bone_cold_medians_ms[clip_name]
+ pose_cold_median_ms = pose_medians_ms[clip_name]
+ bone_cold_median_ms = bone_medians_ms[clip_name]
# Convert the elapsed time from milliseconds into microseconds
- pose_cold_medians_us.append(str(ms_to_us(pose_cold_median_ms)))
- bone_cold_medians_us.append(str(ms_to_us(bone_cold_median_ms)))
+ pose_medians_us.append(str(ms_to_us(pose_cold_median_ms)))
+ bone_medians_us.append(str(ms_to_us(bone_cold_median_ms)))
# Convert the speed into MB/sec
- pose_cold_medians_mbsec.append(str(bytes_to_mb(pose_size) / ms_to_s(pose_cold_median_ms)))
- bone_cold_medians_mbsec.append(str(bytes_to_mb(pose_size) / ms_to_s(bone_cold_median_ms)))
+ pose_medians_mbsec.append(str(bytes_to_mb(pose_size) / ms_to_s(pose_cold_median_ms)))
+ bone_medians_mbsec.append(str(bytes_to_mb(pose_size) / ms_to_s(bone_cold_median_ms)))
- print('decompress_pose,{},{},{}'.format(data['name'], data['version'], ','.join(pose_cold_medians_us)), file = decomp_delta_cold_us_csv_file)
- print('decompress_bone,{},{},{}'.format(data['name'], data['version'], ','.join(bone_cold_medians_us)), file = decomp_delta_cold_us_csv_file)
+ print('decompress_pose,{},{},{}'.format(data['name'], data['version'], ','.join(pose_medians_us)), file = decomp_delta_us_csv_file)
+ print('decompress_bone,{},{},{}'.format(data['name'], data['version'], ','.join(bone_medians_us)), file = decomp_delta_us_csv_file)
- print('decompress_pose,{},{},{}'.format(data['name'], data['version'], ','.join(pose_cold_medians_mbsec)), file = decomp_delta_cold_mbsec_csv_file)
- print('decompress_bone,{},{},{}'.format(data['name'], data['version'], ','.join(bone_cold_medians_mbsec)), file = decomp_delta_cold_mbsec_csv_file)
+ print('decompress_pose,{},{},{}'.format(data['name'], data['version'], ','.join(pose_medians_mbsec)), file = decomp_delta_mbsec_csv_file)
+ print('decompress_bone,{},{},{}'.format(data['name'], data['version'], ','.join(bone_medians_mbsec)), file = decomp_delta_mbsec_csv_file)
- decomp_delta_cold_us_csv_file.close()
- decomp_delta_cold_mbsec_csv_file.close()
+ decomp_delta_us_csv_file.close()
+ decomp_delta_mbsec_csv_file.close()
|
diff --git a/tests/sources/math/test_vector4_impl.h b/tests/sources/math/test_vector4_impl.h
--- a/tests/sources/math/test_vector4_impl.h
+++ b/tests/sources/math/test_vector4_impl.h
@@ -350,15 +350,20 @@ void test_vector4_impl(const Vector4Type& zero, const QuatType& identity, const
REQUIRE(scalar_near_equal(vector_get_w(vector_mul_add(test_value10, test_value11, test_value2)), (test_value10_flt[3] * test_value11_flt[3]) + test_value2_flt[3], threshold));
REQUIRE(scalar_near_equal(vector_get_x(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[0] * test_value11_flt[0]) + test_value2_flt[0], threshold));
- REQUIRE(scalar_near_equal(vector_get_y(vector_mul_add(test_value10, test_value11_flt[1], test_value2)), (test_value10_flt[1] * test_value11_flt[1]) + test_value2_flt[1], threshold));
- REQUIRE(scalar_near_equal(vector_get_z(vector_mul_add(test_value10, test_value11_flt[2], test_value2)), (test_value10_flt[2] * test_value11_flt[2]) + test_value2_flt[2], threshold));
- REQUIRE(scalar_near_equal(vector_get_w(vector_mul_add(test_value10, test_value11_flt[3], test_value2)), (test_value10_flt[3] * test_value11_flt[3]) + test_value2_flt[3], threshold));
+ REQUIRE(scalar_near_equal(vector_get_y(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[1] * test_value11_flt[0]) + test_value2_flt[1], threshold));
+ REQUIRE(scalar_near_equal(vector_get_z(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[2] * test_value11_flt[0]) + test_value2_flt[2], threshold));
+ REQUIRE(scalar_near_equal(vector_get_w(vector_mul_add(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[3] * test_value11_flt[0]) + test_value2_flt[3], threshold));
REQUIRE(scalar_near_equal(vector_get_x(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[0] * -test_value11_flt[0]) + test_value2_flt[0], threshold));
REQUIRE(scalar_near_equal(vector_get_y(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[1] * -test_value11_flt[1]) + test_value2_flt[1], threshold));
REQUIRE(scalar_near_equal(vector_get_z(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[2] * -test_value11_flt[2]) + test_value2_flt[2], threshold));
REQUIRE(scalar_near_equal(vector_get_w(vector_neg_mul_sub(test_value10, test_value11, test_value2)), (test_value10_flt[3] * -test_value11_flt[3]) + test_value2_flt[3], threshold));
+ REQUIRE(scalar_near_equal(vector_get_x(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[0] * -test_value11_flt[0]) + test_value2_flt[0], threshold));
+ REQUIRE(scalar_near_equal(vector_get_y(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[1] * -test_value11_flt[0]) + test_value2_flt[1], threshold));
+ REQUIRE(scalar_near_equal(vector_get_z(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[2] * -test_value11_flt[0]) + test_value2_flt[2], threshold));
+ REQUIRE(scalar_near_equal(vector_get_w(vector_neg_mul_sub(test_value10, test_value11_flt[0], test_value2)), (test_value10_flt[3] * -test_value11_flt[0]) + test_value2_flt[3], threshold));
+
//////////////////////////////////////////////////////////////////////////
// Comparisons and masking
|
Look into ARM NEON fused multiply-add: vfmaq_f32
`vfmaq_f32(...)`
|
Decompression is about 2% faster on my Pixel 3.
| 2019-05-04T04:15:25
|
cpp
|
Hard
|
nfrechette/acl
| 408
|
nfrechette__acl-408
|
[
"396"
] |
60041175b9f15996b22a4d1da25ea315aa5e5755
|
diff --git a/docs/README.md b/docs/README.md
--- a/docs/README.md
+++ b/docs/README.md
@@ -12,6 +12,7 @@ ACL aims to support a few core algorithms that are well suited for production us
* [Compressing tracks](compressing_raw_tracks.md)
* [Decompressing tracks](decompressing_a_track_list.md)
* [Handling looping playback](handling_looping_playback.md)
+* [Handling per track rounding](handling_per_track_rounding.md)
* [Database and streaming support](database_support.md)
* [Other considerations](misc_integration_details.md)
* [Migrating from an earlier ACL version](migrating.md)
diff --git a/docs/decompressing_a_track_list.md b/docs/decompressing_a_track_list.md
--- a/docs/decompressing_a_track_list.md
+++ b/docs/decompressing_a_track_list.md
@@ -21,7 +21,7 @@ context.decompress_tracks(my_track_writer); // all tracks
As shown, a context must be initialized with a compressed track list instance. Some context objects such as the one used by uniform sampling can be re-used by any compressed track list and does not need to be re-created while others might require this. In order to detect when this might be required, the function `is_dirty(const compressed_tracks& tracks)` is provided. Some context objects cannot be created on the stack and must be dynamically allocated with an allocator instance. The functions `make_decompression_context(...)` are provided for this purpose.
-You can seek anywhere in a track list but you will need to handle looping manually in your game engine (e.g. by calling `fmod`). When seeking, you must also provide a `sample_rounding_policy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details.
+You can seek anywhere in a track list but you will need to handle looping manually in your game engine (e.g. by calling `fmod`). When seeking, you must also provide a `sample_rounding_policy` to dictate how the interpolation is to be performed. See [here](../includes/acl/core/interpolation_utils.h) for details. ACL handles various rounding modes: `none` will interpolate, `floor` will return the first sample before the sample time (when you need to step animations frame by frame), `ceil` will return the first sample after the sample time, `nearest` will return the closest sample to the sample time, and `per_track` allows you to specify through the `track_writer` the rounding mode per track. See also [handling per track rounding](handling_per_track_rounding.md).
You can override the looping policy by calling `context.set_looping_policy(policy);`. This is only necessary if you perform your own loop optimization before compressing with ACL. See [how to handle looping playback](handling_looping_playback.md) for details.
diff --git a/docs/handling_looping_playback.md b/docs/handling_looping_playback.md
--- a/docs/handling_looping_playback.md
+++ b/docs/handling_looping_playback.md
@@ -7,7 +7,7 @@ There are typically two ways to handle looping playback:
ACL supports both approaches and will pick the optimal one during compression (tunable in the compression settings). This is controlled through the usage of the `sample_looping_policy` enum found in its [header](../includes/acl/core/sample_looping_policy.h). It is best to let ACL handle this and to not override this value.
-See also [this blog post](todo) for details.
+See also [this blog post](https://nfrechette.github.io/2022/04/03/anim_compression_looping/) for details.
## Clamp policy
diff --git a/docs/handling_per_track_rounding.md b/docs/handling_per_track_rounding.md
new file mode 100644
--- /dev/null
+++ b/docs/handling_per_track_rounding.md
@@ -0,0 +1,19 @@
+# Handling per track rounding
+
+When sampling raw or compressed tracks, a `sample_rounding_policy` is provided to control whether or not we should interpolate and what to return. For most use cases, the same rounding policy can be used for all tracks but ACL also supports the host runtime to specify per track which rounding policy should be used. This feature is disabled by default by the default `decompression_settings` because it isn't common and it adds a bit of overhead. To enable and use this feature, you need to:
+
+* Enable the feature in your `decompression_settings`, see `decompression_settings::is_per_track_rounding_supported()`.
+* Provide the `seek(..)` function with `sample_rounding_policy::per_track`.
+* Implement the rounding policy query function in your `track_writer`, see `track_writer::get_rounding_policy(..)`.
+
+When the feature is enabled in the `decompression_settings`, ACL will calculate all possible samples it might need per track as opposed to just one when all tracks use the same rounding policy. This is cheaper than it sounds. By default, ACL always interpolates (using a stable interpolation function) even when `floor`, `ceil`, and `nearest` are used. When `per_track` is used, we retain both samples used to interpolate (for `floor` and `ceil`), we find the nearest and retain it, and we interpolate as well as we otherwise would. Although we do extra work, the added instructions can often execute in the shadow of more expensive ones that surround them which makes this very cheap.
+
+See also [this blog post](TODO) for details.
+
+## Database support
+
+Using per track rounding may not behave as intended if a partially streamed database is used. For performance reasons, unlike the modes above, only a single value will be interpolated: the one at the specified sample time. This means that if we have 3 samples A, B, C and you sample between B and C with 'floor', if B has been moved to a database and is missing, B (interpolated) is not returned. Normally, A and C would be used to interpolate at the sample time specified as such we do not calculate where B lies. As a result of this, A would be returned unlike the behavior of 'floor' when used to sample all tracks. This is the behavior chosen by design. During decompression, samples are unpacked and interpolated before we know which track they belong to. As such, when the per track mode is used, we output 4 samples (instead of just the one we need), one for each possible mode above. One we know which sample we need (among the 4), we can simply index with the rounding mode to grab it. This is very fast and the cost is largely hidden. Supporting the same behavior as the rounding modes above when a partially streamed in database is used would require us to interpolate 3 samples instead of 1 which would be a lot more expensive for rotation sub-tracks. It would also add a lot of code complexity. For those reasons, the behavior differs.
+
+A [future task](https://github.com/nfrechette/acl/issues/392) will allow tracks to be split into different layers where database settings can be independent. This will allow us to place special tracks into their own layer where key frames are not removed.
+
+A [separate task](https://github.com/nfrechette/acl/issues/407) may allow us to specify per track whether the values can be interpolated or not. This would allow us to detect boundary key frames (where the value changes) and retain those we need to ensure that the end result is identical.
diff --git a/includes/acl/compression/impl/quantize_streams.h b/includes/acl/compression/impl/quantize_streams.h
--- a/includes/acl/compression/impl/quantize_streams.h
+++ b/includes/acl/compression/impl/quantize_streams.h
@@ -29,7 +29,7 @@
#include "acl/core/error.h"
#include "acl/core/time_utils.h"
#include "acl/core/track_formats.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/math/quat_packing.h"
#include "acl/math/vector4_packing.h"
#include "acl/compression/impl/track_bit_rate_database.h"
@@ -116,7 +116,7 @@ namespace acl
uint8_t* lossy_object_pose; // 1 per transform
size_t metric_transform_size;
- BoneBitRate* bit_rate_per_bone; // 1 per transform
+ transform_bit_rates* bit_rate_per_bone; // 1 per transform
uint32_t* parent_transform_indices; // 1 per transform
uint32_t* self_transform_indices; // 1 per transform
@@ -170,7 +170,7 @@ namespace acl
base_object_transforms = clip_.has_additive_base ? allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones * clip_.segments->num_samples, 64) : nullptr;
local_transforms_converted = needs_conversion ? allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones, 64) : nullptr;
lossy_object_pose = allocate_type_array_aligned<uint8_t>(allocator, metric_transform_size_ * num_bones, 64);
- bit_rate_per_bone = allocate_type_array<BoneBitRate>(allocator, num_bones);
+ bit_rate_per_bone = allocate_type_array<transform_bit_rates>(allocator, num_bones);
parent_transform_indices = allocate_type_array<uint32_t>(allocator, num_bones);
self_transform_indices = allocate_type_array<uint32_t>(allocator, num_bones);
chain_bone_indices = allocate_type_array<uint32_t>(allocator, num_bones);
@@ -842,7 +842,7 @@ namespace acl
// 0: if the segment track is normalized, it can be constant within the segment
// 1: if the segment track isn't normalized, it starts at the lowest bit rate
// 255: if the track is constant/default for the whole clip
- const BoneBitRate bone_bit_rates = context.bit_rate_per_bone[bone_index];
+ const transform_bit_rates bone_bit_rates = context.bit_rate_per_bone[bone_index];
if (bone_bit_rates.rotation == k_invalid_bit_rate && bone_bit_rates.translation == k_invalid_bit_rate && bone_bit_rates.scale == k_invalid_bit_rate)
{
@@ -852,7 +852,7 @@ namespace acl
continue; // Every track bit rate is constant/default, nothing else to do
}
- BoneBitRate best_bit_rates = bone_bit_rates;
+ transform_bit_rates best_bit_rates = bone_bit_rates;
float best_error = 1.0E10F;
uint32_t prev_transform_size = ~0U;
bool is_error_good_enough = false;
@@ -1001,12 +1001,12 @@ namespace acl
return bit_rate >= k_highest_bit_rate ? bit_rate : std::min<uint32_t>(bit_rate + increment, k_highest_bit_rate);
}
- inline float increase_bone_bit_rate(quantization_context& context, uint32_t bone_index, uint32_t num_increments, float old_error, BoneBitRate& out_best_bit_rates)
+ inline float increase_bone_bit_rate(quantization_context& context, uint32_t bone_index, uint32_t num_increments, float old_error, transform_bit_rates& out_best_bit_rates)
{
- const BoneBitRate bone_bit_rates = context.bit_rate_per_bone[bone_index];
+ const transform_bit_rates bone_bit_rates = context.bit_rate_per_bone[bone_index];
const uint32_t num_scale_increments = context.has_scale ? num_increments : 0;
- BoneBitRate best_bit_rates = bone_bit_rates;
+ transform_bit_rates best_bit_rates = bone_bit_rates;
float best_error = old_error;
for (uint32_t rotation_increment = 0; rotation_increment <= num_increments; ++rotation_increment)
@@ -1029,7 +1029,7 @@ namespace acl
continue;
}
- context.bit_rate_per_bone[bone_index] = BoneBitRate{ (uint8_t)rotation_bit_rate, (uint8_t)translation_bit_rate, (uint8_t)scale_bit_rate };
+ context.bit_rate_per_bone[bone_index] = transform_bit_rates{ (uint8_t)rotation_bit_rate, (uint8_t)translation_bit_rate, (uint8_t)scale_bit_rate };
const float error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_error_too_high);
if (error < best_error)
@@ -1056,7 +1056,7 @@ namespace acl
return best_error;
}
- inline float calculate_bone_permutation_error(quantization_context& context, BoneBitRate* permutation_bit_rates, uint8_t* bone_chain_permutation, uint32_t bone_index, BoneBitRate* best_bit_rates, float old_error)
+ inline float calculate_bone_permutation_error(quantization_context& context, transform_bit_rates* permutation_bit_rates, uint8_t* bone_chain_permutation, uint32_t bone_index, transform_bit_rates* best_bit_rates, float old_error)
{
const float error_threshold = context.error_threshold;
float best_error = old_error;
@@ -1064,7 +1064,7 @@ namespace acl
do
{
// Copy our current bit rates to the permutation rates
- std::memcpy(permutation_bit_rates, context.bit_rate_per_bone, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(permutation_bit_rates, context.bit_rate_per_bone, sizeof(transform_bit_rates) * context.num_bones);
bool is_permutation_valid = false;
const uint32_t num_bones_in_chain = context.num_bones_in_chain;
@@ -1074,7 +1074,7 @@ namespace acl
{
// Increase bit rate
const uint32_t chain_bone_index = context.chain_bone_indices[chain_link_index];
- BoneBitRate chain_bone_best_bit_rates;
+ transform_bit_rates chain_bone_best_bit_rates;
increase_bone_bit_rate(context, chain_bone_index, bone_chain_permutation[chain_link_index], old_error, chain_bone_best_bit_rates);
is_permutation_valid |= chain_bone_best_bit_rates.rotation != permutation_bit_rates[chain_bone_index].rotation;
is_permutation_valid |= chain_bone_best_bit_rates.translation != permutation_bit_rates[chain_bone_index].translation;
@@ -1094,7 +1094,7 @@ namespace acl
if (permutation_error < best_error)
{
best_error = permutation_error;
- std::memcpy(best_bit_rates, permutation_bit_rates, sizeof(BoneBitRate) * context.num_bones);
+ std::memcpy(best_bit_rates, permutation_bit_rates, sizeof(transform_bit_rates) * context.num_bones);
if (permutation_error < error_threshold)
break;
@@ -1115,7 +1115,7 @@ namespace acl
return num_bones_in_chain;
}
- inline void initialize_bone_bit_rates(const segment_context& segment, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, BoneBitRate* out_bit_rate_per_bone)
+ inline void initialize_bone_bit_rates(const segment_context& segment, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, transform_bit_rates* out_bit_rate_per_bone)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
@@ -1124,7 +1124,7 @@ namespace acl
const uint32_t num_bones = segment.num_bones;
for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
{
- BoneBitRate& bone_bit_rate = out_bit_rate_per_bone[bone_index];
+ transform_bit_rates& bone_bit_rate = out_bit_rate_per_bone[bone_index];
const bool rotation_supports_constant_tracks = segment.are_rotations_normalized;
if (is_rotation_variable && !segment.bone_streams[bone_index].is_rotation_constant)
@@ -1156,7 +1156,7 @@ namespace acl
for (uint32_t bone_index = 0; bone_index < context.num_bones; ++bone_index)
{
- const BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[bone_index];
+ const transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[bone_index];
if (is_rotation_variable)
quantize_variable_rotation_stream(context, bone_index, bone_bit_rate.rotation);
@@ -1232,10 +1232,10 @@ namespace acl
// [bone 0] + 0 [bone 1] + 0 [bone 2] + 3 (9)
uint8_t* bone_chain_permutation = allocate_type_array<uint8_t>(context.allocator, context.num_bones);
- BoneBitRate* permutation_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
- BoneBitRate* best_permutation_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
- BoneBitRate* best_bit_rates = allocate_type_array<BoneBitRate>(context.allocator, context.num_bones);
- std::memcpy(best_bit_rates, context.bit_rate_per_bone, sizeof(BoneBitRate) * context.num_bones);
+ transform_bit_rates* permutation_bit_rates = allocate_type_array<transform_bit_rates>(context.allocator, context.num_bones);
+ transform_bit_rates* best_permutation_bit_rates = allocate_type_array<transform_bit_rates>(context.allocator, context.num_bones);
+ transform_bit_rates* best_bit_rates = allocate_type_array<transform_bit_rates>(context.allocator, context.num_bones);
+ std::memcpy(best_bit_rates, context.bit_rate_per_bone, sizeof(transform_bit_rates) * context.num_bones);
const uint32_t num_bones = context.num_bones;
for (uint32_t bone_index = 0; bone_index < num_bones; ++bone_index)
@@ -1268,7 +1268,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1283,7 +1283,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1298,7 +1298,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1315,7 +1315,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1330,7 +1330,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1346,7 +1346,7 @@ namespace acl
if (error < best_error)
{
best_error = error;
- std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(best_bit_rates, best_permutation_bit_rates, sizeof(transform_bit_rates) * num_bones);
if (error < error_threshold)
break;
@@ -1368,8 +1368,8 @@ namespace acl
for (uint32_t i = 0; i < context.num_bones; ++i)
{
- const BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[i];
- const BoneBitRate& best_bone_bit_rate = best_bit_rates[i];
+ const transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[i];
+ const transform_bit_rates& best_bone_bit_rate = best_bit_rates[i];
bool rotation_differs = bone_bit_rate.rotation != best_bone_bit_rate.rotation;
bool translation_differs = bone_bit_rate.translation != best_bone_bit_rate.translation;
bool scale_differs = bone_bit_rate.scale != best_bone_bit_rate.scale;
@@ -1378,7 +1378,7 @@ namespace acl
}
#endif
- std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(transform_bit_rates) * num_bones);
}
}
@@ -1391,8 +1391,8 @@ namespace acl
for (uint32_t i = 0; i < context.num_bones; ++i)
{
- const BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[i];
- const BoneBitRate& best_bone_bit_rate = best_bit_rates[i];
+ const transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[i];
+ const transform_bit_rates& best_bone_bit_rate = best_bit_rates[i];
bool rotation_differs = bone_bit_rate.rotation != best_bone_bit_rate.rotation;
bool translation_differs = bone_bit_rate.translation != best_bone_bit_rate.translation;
bool scale_differs = bone_bit_rate.scale != best_bone_bit_rate.scale;
@@ -1401,7 +1401,7 @@ namespace acl
}
#endif
- std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(BoneBitRate) * num_bones);
+ std::memcpy(context.bit_rate_per_bone, best_bit_rates, sizeof(transform_bit_rates) * num_bones);
}
// Our error remains too high, this should be rare.
@@ -1419,15 +1419,15 @@ namespace acl
// that yield the smallest error BUT increasing the bit rate does NOT always means
// that the error will reduce and improve. It could get worse in which case we'll do nothing.
- BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
+ transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
// Copy original values
- BoneBitRate best_bone_bit_rate = bone_bit_rate;
+ transform_bit_rates best_bone_bit_rate = bone_bit_rate;
float best_bit_rate_error = error;
while (error >= error_threshold)
{
- static_assert(offsetof(BoneBitRate, rotation) == 0 && offsetof(BoneBitRate, scale) == sizeof(BoneBitRate) - 1, "Invalid BoneBitRate offsets");
+ static_assert(offsetof(transform_bit_rates, rotation) == 0 && offsetof(transform_bit_rates, scale) == sizeof(transform_bit_rates) - 1, "Invalid BoneBitRate offsets");
uint8_t& smallest_bit_rate = *std::min_element<uint8_t*>(&bone_bit_rate.rotation, &bone_bit_rate.scale + 1);
if (smallest_bit_rate >= k_highest_bit_rate)
@@ -1494,7 +1494,7 @@ namespace acl
for (int32_t chain_link_index = num_bones_in_chain - 1; chain_link_index >= 0; --chain_link_index)
{
const uint32_t chain_bone_index = context.chain_bone_indices[chain_link_index];
- BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
+ transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[chain_bone_index];
bone_bit_rate.rotation = std::max<uint8_t>(bone_bit_rate.rotation, k_highest_bit_rate);
bone_bit_rate.translation = std::max<uint8_t>(bone_bit_rate.translation, k_highest_bit_rate);
bone_bit_rate.scale = std::max<uint8_t>(bone_bit_rate.scale, k_highest_bit_rate);
@@ -1518,7 +1518,7 @@ namespace acl
context.num_bones_in_chain = num_bones_in_chain;
float error = calculate_max_error_at_bit_rate_object(context, bone_index, error_scan_stop_condition::until_end_of_segment);
- const BoneBitRate& bone_bit_rate = context.bit_rate_per_bone[bone_index];
+ const transform_bit_rates& bone_bit_rate = context.bit_rate_per_bone[bone_index];
printf("%u: %u | %u | %u => %f %s\n", bone_index, bone_bit_rate.rotation, bone_bit_rate.translation, bone_bit_rate.scale, error, error >= error_threshold ? "!" : "");
}
#endif
diff --git a/includes/acl/compression/impl/quantize_track_impl.h b/includes/acl/compression/impl/quantize_track_impl.h
--- a/includes/acl/compression/impl/quantize_track_impl.h
+++ b/includes/acl/compression/impl/quantize_track_impl.h
@@ -26,7 +26,7 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/track_types.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/compression/impl/track_list_context.h"
#include <rtm/mask4i.h>
diff --git a/includes/acl/compression/impl/sample_streams.h b/includes/acl/compression/impl/sample_streams.h
--- a/includes/acl/compression/impl/sample_streams.h
+++ b/includes/acl/compression/impl/sample_streams.h
@@ -29,7 +29,7 @@
#include "acl/core/error.h"
#include "acl/core/time_utils.h"
#include "acl/core/track_formats.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/math/quat_packing.h"
#include "acl/math/vector4_packing.h"
#include "acl/compression/impl/track_stream.h"
@@ -633,7 +633,7 @@ namespace acl
uint32_t sample_key;
float sample_time;
- BoneBitRate bit_rates;
+ transform_bit_rates bit_rates;
};
inline uint32_t get_uniform_sample_key(const segment_context& segment, float sample_time)
@@ -838,7 +838,7 @@ namespace acl
}
}
- inline void sample_streams(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_streams(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
const bool is_rotation_variable = is_rotation_format_variable(rotation_format);
const bool is_translation_variable = is_vector_format_variable(translation_format);
@@ -870,7 +870,7 @@ namespace acl
}
}
- inline void sample_stream(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_stream(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
@@ -900,7 +900,7 @@ namespace acl
out_local_pose[bone_index] = rtm::qvv_set(rotation, translation, scale);
}
- inline void sample_streams_hierarchical(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const BoneBitRate* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
+ inline void sample_streams_hierarchical(const transform_streams* bone_streams, const transform_streams* raw_bone_steams, uint32_t num_bones, float sample_time, uint32_t bone_index, const transform_bit_rates* bit_rates, rotation_format8 rotation_format, vector_format8 translation_format, vector_format8 scale_format, rtm::qvvf* out_local_pose)
{
(void)num_bones;
diff --git a/includes/acl/compression/impl/track_array.impl.h b/includes/acl/compression/impl/track_array.impl.h
--- a/includes/acl/compression/impl/track_array.impl.h
+++ b/includes/acl/compression/impl/track_array.impl.h
@@ -215,7 +215,22 @@ namespace acl
uint32_t key_frame0;
uint32_t key_frame1;
float interpolation_alpha;
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, rounding_policy, m_looping_policy, key_frame0, key_frame1, interpolation_alpha);
+
+ // Allow per track usage, keeps the code simpler to maintain
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, sample_rounding_policy::per_track, m_looping_policy, key_frame0, key_frame1, interpolation_alpha);
+
+ const float no_rounding_alpha = apply_rounding_policy(interpolation_alpha, sample_rounding_policy::none);
+
+ const float interpolation_alpha_per_policy[k_num_sample_rounding_policies] =
+ {
+ no_rounding_alpha, // none
+ apply_rounding_policy(interpolation_alpha, sample_rounding_policy::floor),
+ apply_rounding_policy(interpolation_alpha, sample_rounding_policy::ceil),
+ apply_rounding_policy(interpolation_alpha, sample_rounding_policy::nearest),
+
+ // We'll assert if we attempt to use this, but in case they are skipped/disabled, we interpolate
+ no_rounding_alpha, // per_track
+ };
switch (track_type)
{
@@ -224,9 +239,13 @@ namespace acl
{
const track_float1f& track__ = track_cast<track_float1f>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::scalarf value0 = rtm::scalar_load(&track__[key_frame0]);
const rtm::scalarf value1 = rtm::scalar_load(&track__[key_frame1]);
- const rtm::scalarf value = rtm::scalar_lerp(value0, value1, rtm::scalar_set(interpolation_alpha));
+ const rtm::scalarf value = rtm::scalar_lerp(value0, value1, rtm::scalar_set(alpha));
writer.write_float1(track_index, value);
}
break;
@@ -235,9 +254,13 @@ namespace acl
{
const track_float2f& track__ = track_cast<track_float2f>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::vector4f value0 = rtm::vector_load2(&track__[key_frame0]);
const rtm::vector4f value1 = rtm::vector_load2(&track__[key_frame1]);
- const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, alpha);
writer.write_float2(track_index, value);
}
break;
@@ -246,9 +269,13 @@ namespace acl
{
const track_float3f& track__ = track_cast<track_float3f>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::vector4f value0 = rtm::vector_load3(&track__[key_frame0]);
const rtm::vector4f value1 = rtm::vector_load3(&track__[key_frame1]);
- const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, alpha);
writer.write_float3(track_index, value);
}
break;
@@ -257,9 +284,13 @@ namespace acl
{
const track_float4f& track__ = track_cast<track_float4f>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::vector4f value0 = rtm::vector_load(&track__[key_frame0]);
const rtm::vector4f value1 = rtm::vector_load(&track__[key_frame1]);
- const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, alpha);
writer.write_float4(track_index, value);
}
break;
@@ -268,9 +299,13 @@ namespace acl
{
const track_vector4f& track__ = track_cast<track_vector4f>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::vector4f value0 = track__[key_frame0];
const rtm::vector4f value1 = track__[key_frame1];
- const rtm::vector4f value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ const rtm::vector4f value = rtm::vector_lerp(value0, value1, alpha);
writer.write_vector4(track_index, value);
}
break;
@@ -279,11 +314,15 @@ namespace acl
{
const track_qvvf& track__ = track_cast<track_qvvf>(m_tracks[track_index]);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+ const float alpha = interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)];
+
const rtm::qvvf& value0 = track__[key_frame0];
const rtm::qvvf& value1 = track__[key_frame1];
- const rtm::quatf rotation = rtm::quat_lerp(value0.rotation, value1.rotation, interpolation_alpha);
- const rtm::vector4f translation = rtm::vector_lerp(value0.translation, value1.translation, interpolation_alpha);
- const rtm::vector4f scale = rtm::vector_lerp(value0.scale, value1.scale, interpolation_alpha);
+ const rtm::quatf rotation = rtm::quat_lerp(value0.rotation, value1.rotation, alpha);
+ const rtm::vector4f translation = rtm::vector_lerp(value0.translation, value1.translation, alpha);
+ const rtm::vector4f scale = rtm::vector_lerp(value0.scale, value1.scale, alpha);
writer.write_rotation(track_index, rotation);
writer.write_translation(track_index, translation);
writer.write_scale(track_index, scale);
@@ -310,10 +349,13 @@ namespace acl
const float duration = get_finite_duration();
sample_time = rtm::scalar_clamp(sample_time, 0.0F, duration);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
uint32_t key_frame0;
uint32_t key_frame1;
float interpolation_alpha;
- find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, rounding_policy, m_looping_policy, key_frame0, key_frame1, interpolation_alpha);
+ find_linear_interpolation_samples_with_sample_rate(num_samples, sample_rate, sample_time, rounding_policy_, m_looping_policy, key_frame0, key_frame1, interpolation_alpha);
switch (track_.get_type())
{
diff --git a/includes/acl/compression/impl/track_bit_rate_database.h b/includes/acl/compression/impl/track_bit_rate_database.h
--- a/includes/acl/compression/impl/track_bit_rate_database.h
+++ b/includes/acl/compression/impl/track_bit_rate_database.h
@@ -27,7 +27,7 @@
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/iallocator.h"
#include "acl/core/track_formats.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/compression/impl/sample_streams.h"
#include "acl/compression/impl/track_stream.h"
@@ -66,7 +66,7 @@ namespace acl
}
void bind(track_bit_rate_database& database);
- void build(uint32_t track_index, const BoneBitRate* bit_rates, const transform_streams* bone_streams);
+ void build(uint32_t track_index, const transform_bit_rates* bit_rates, const transform_streams* bone_streams);
private:
hierarchical_track_query(const hierarchical_track_query&) = delete;
@@ -82,7 +82,7 @@ namespace acl
iallocator& m_allocator;
track_bit_rate_database* m_database;
uint32_t m_track_index;
- const BoneBitRate* m_bit_rates;
+ const transform_bit_rates* m_bit_rates;
transform_indices* m_indices;
uint32_t m_num_transforms;
@@ -102,10 +102,10 @@ namespace acl
{}
inline uint32_t get_track_index() const { return m_track_index; }
- inline const BoneBitRate& get_bit_rates() const { return m_bit_rates; }
+ inline const transform_bit_rates& get_bit_rates() const { return m_bit_rates; }
void bind(track_bit_rate_database& database);
- void build(uint32_t track_index, const BoneBitRate& bit_rates);
+ void build(uint32_t track_index, const transform_bit_rates& bit_rates);
private:
single_track_query(const single_track_query&) = delete;
@@ -113,7 +113,7 @@ namespace acl
track_bit_rate_database* m_database;
uint32_t m_track_index;
- BoneBitRate m_bit_rates;
+ transform_bit_rates m_bit_rates;
uint32_t m_rotation_cache_index;
uint32_t m_translation_cache_index;
@@ -139,7 +139,7 @@ namespace acl
}
void bind(track_bit_rate_database& database);
- void build(const BoneBitRate* bit_rates);
+ void build(const transform_bit_rates* bit_rates);
private:
every_track_query(const every_track_query&) = delete;
@@ -154,7 +154,7 @@ namespace acl
iallocator& m_allocator;
track_bit_rate_database* m_database;
- const BoneBitRate* m_bit_rates;
+ const transform_bit_rates* m_bit_rates;
transform_indices* m_indices;
uint32_t m_num_transforms;
@@ -168,7 +168,7 @@ namespace acl
uint8_t bit_rates[4];
bit_rates_union() : value(0xFFFFFFFFU) {}
- explicit bit_rates_union(const BoneBitRate& input) : bit_rates{ input.rotation, input.translation, input.scale, 0 } {}
+ explicit bit_rates_union(const transform_bit_rates& input) : bit_rates{ input.rotation, input.translation, input.scale, 0 } {}
inline bool operator==(bit_rates_union other) const { return value == other.value; }
inline bool operator!=(bit_rates_union other) const { return value != other.value; }
@@ -196,7 +196,7 @@ namespace acl
track_bit_rate_database(const track_bit_rate_database&) = delete;
track_bit_rate_database& operator=(const track_bit_rate_database&) = delete;
- void find_cache_entries(uint32_t track_index, const BoneBitRate& bit_rates, uint32_t& out_rotation_cache_index, uint32_t& out_translation_cache_index, uint32_t& out_scale_cache_index);
+ void find_cache_entries(uint32_t track_index, const transform_bit_rates& bit_rates, uint32_t& out_rotation_cache_index, uint32_t& out_translation_cache_index, uint32_t& out_scale_cache_index);
RTM_FORCE_INLINE rtm::quatf RTM_SIMD_CALL sample_rotation(const sample_context& context, uint32_t rotation_cache_index);
RTM_FORCE_INLINE rtm::vector4f RTM_SIMD_CALL sample_translation(const sample_context& context, uint32_t translation_cache_index);
@@ -278,7 +278,7 @@ namespace acl
m_num_transforms = database.m_num_transforms;
}
- inline void hierarchical_track_query::build(uint32_t track_index, const BoneBitRate* bit_rates, const transform_streams* bone_streams)
+ inline void hierarchical_track_query::build(uint32_t track_index, const transform_bit_rates* bit_rates, const transform_streams* bone_streams)
{
ACL_ASSERT(m_database != nullptr, "Query not bound to a database");
ACL_ASSERT(track_index < m_num_transforms, "Invalid track index");
@@ -289,7 +289,7 @@ namespace acl
uint32_t current_track_index = track_index;
while (current_track_index != k_invalid_track_index)
{
- const BoneBitRate& current_bit_rates = bit_rates[current_track_index];
+ const transform_bit_rates& current_bit_rates = bit_rates[current_track_index];
transform_indices& indices = m_indices[current_track_index];
m_database->find_cache_entries(current_track_index, current_bit_rates, indices.rotation_cache_index, indices.translation_cache_index, indices.scale_cache_index);
@@ -305,7 +305,7 @@ namespace acl
m_database = &database;
}
- inline void single_track_query::build(uint32_t track_index, const BoneBitRate& bit_rates)
+ inline void single_track_query::build(uint32_t track_index, const transform_bit_rates& bit_rates)
{
ACL_ASSERT(m_database != nullptr, "Query not bound to a database");
@@ -324,7 +324,7 @@ namespace acl
m_num_transforms = database.m_num_transforms;
}
- inline void every_track_query::build(const BoneBitRate* bit_rates)
+ inline void every_track_query::build(const transform_bit_rates* bit_rates)
{
ACL_ASSERT(m_database != nullptr, "Query not bound to a database");
@@ -332,7 +332,7 @@ namespace acl
for (uint32_t transform_index = 0; transform_index < m_num_transforms; ++transform_index)
{
- const BoneBitRate& current_bit_rates = bit_rates[transform_index];
+ const transform_bit_rates& current_bit_rates = bit_rates[transform_index];
transform_indices& indices = m_indices[transform_index];
m_database->find_cache_entries(transform_index, current_bit_rates, indices.rotation_cache_index, indices.translation_cache_index, indices.scale_cache_index);
@@ -422,7 +422,7 @@ namespace acl
#endif
}
- inline void track_bit_rate_database::find_cache_entries(uint32_t track_index, const BoneBitRate& bit_rates, uint32_t& out_rotation_cache_index, uint32_t& out_translation_cache_index, uint32_t& out_scale_cache_index)
+ inline void track_bit_rate_database::find_cache_entries(uint32_t track_index, const transform_bit_rates& bit_rates, uint32_t& out_rotation_cache_index, uint32_t& out_translation_cache_index, uint32_t& out_scale_cache_index)
{
// Memory layout:
// track 0
diff --git a/includes/acl/compression/impl/track_list_context.h b/includes/acl/compression/impl/track_list_context.h
--- a/includes/acl/compression/impl/track_list_context.h
+++ b/includes/acl/compression/impl/track_list_context.h
@@ -28,7 +28,7 @@
#include "acl/core/iallocator.h"
#include "acl/core/bitset.h"
#include "acl/core/track_desc.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/compression/track_array.h"
#include "acl/compression/impl/track_range.h"
diff --git a/includes/acl/compression/impl/track_stream.h b/includes/acl/compression/impl/track_stream.h
--- a/includes/acl/compression/impl/track_stream.h
+++ b/includes/acl/compression/impl/track_stream.h
@@ -30,7 +30,7 @@
#include "acl/core/time_utils.h"
#include "acl/core/track_formats.h"
#include "acl/core/track_types.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/math/quat_packing.h"
#include "acl/math/vector4_packing.h"
diff --git a/includes/acl/compression/impl/write_range_data.h b/includes/acl/compression/impl/write_range_data.h
--- a/includes/acl/compression/impl/write_range_data.h
+++ b/includes/acl/compression/impl/write_range_data.h
@@ -31,7 +31,7 @@
#include "acl/core/track_formats.h"
#include "acl/core/track_types.h"
#include "acl/core/range_reduction_types.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/math/quat_packing.h"
#include "acl/math/vector4_packing.h"
#include "acl/compression/impl/animated_track_utils.h"
diff --git a/includes/acl/compression/impl/write_stats.h b/includes/acl/compression/impl/write_stats.h
--- a/includes/acl/compression/impl/write_stats.h
+++ b/includes/acl/compression/impl/write_stats.h
@@ -28,7 +28,7 @@
#include "acl/core/time_utils.h"
#include "acl/core/track_formats.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/compression/transform_error_metrics.h"
#include "acl/compression/track_error.h"
diff --git a/includes/acl/compression/impl/write_stream_data.h b/includes/acl/compression/impl/write_stream_data.h
--- a/includes/acl/compression/impl/write_stream_data.h
+++ b/includes/acl/compression/impl/write_stream_data.h
@@ -28,7 +28,7 @@
#include "acl/core/iallocator.h"
#include "acl/core/error.h"
#include "acl/core/track_formats.h"
-#include "acl/core/variable_bit_rates.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/compression/impl/animated_track_utils.h"
#include "acl/compression/impl/clip_context.h"
diff --git a/includes/acl/compression/impl/write_track_data_impl.h b/includes/acl/compression/impl/write_track_data_impl.h
--- a/includes/acl/compression/impl/write_track_data_impl.h
+++ b/includes/acl/compression/impl/write_track_data_impl.h
@@ -24,9 +24,9 @@
// SOFTWARE.
////////////////////////////////////////////////////////////////////////////////
-#include "acl/core/variable_bit_rates.h"
#include "acl/core/impl/compiler_utils.h"
#include "acl/core/impl/compressed_headers.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/compression/impl/track_list_context.h"
#include <rtm/vector4f.h>
diff --git a/includes/acl/core/impl/debug_track_writer.h b/includes/acl/core/impl/debug_track_writer.h
--- a/includes/acl/core/impl/debug_track_writer.h
+++ b/includes/acl/core/impl/debug_track_writer.h
@@ -280,6 +280,22 @@ namespace acl
const rtm::qvvf* default_sub_tracks;
};
+
+ //////////////////////////////////////////////////////////////////////////
+ // Same as debug_track_writer but the rounding policy is supported per track.
+ //////////////////////////////////////////////////////////////////////////
+ struct debug_track_writer_per_track_rounding final : public debug_track_writer
+ {
+ debug_track_writer_per_track_rounding(iallocator& allocator_, track_type8 type_, uint32_t num_tracks_)
+ : debug_track_writer(allocator_, type_, num_tracks_)
+ , rounding_policy(sample_rounding_policy::per_track)
+ {
+ }
+
+ sample_rounding_policy get_rounding_policy(uint32_t /*track_index*/) const { return rounding_policy; }
+
+ sample_rounding_policy rounding_policy;
+ };
}
}
diff --git a/includes/acl/core/impl/interpolation_utils.impl.h b/includes/acl/core/impl/interpolation_utils.impl.h
--- a/includes/acl/core/impl/interpolation_utils.impl.h
+++ b/includes/acl/core/impl/interpolation_utils.impl.h
@@ -111,23 +111,7 @@ namespace acl
out_sample_index0 = sample_index0;
out_sample_index1 = sample_index1;
-
- switch (rounding_policy)
- {
- default:
- case sample_rounding_policy::none:
- out_interpolation_alpha = interpolation_alpha;
- break;
- case sample_rounding_policy::floor:
- out_interpolation_alpha = 0.0F;
- break;
- case sample_rounding_policy::ceil:
- out_interpolation_alpha = 1.0F;
- break;
- case sample_rounding_policy::nearest:
- out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
- break;
- }
+ out_interpolation_alpha = apply_rounding_policy(interpolation_alpha, rounding_policy);
}
//////////////////////////////////////////////////////////////////////////
@@ -210,23 +194,7 @@ namespace acl
out_sample_index0 = sample_index0;
out_sample_index1 = sample_index1;
-
- switch (rounding_policy)
- {
- default:
- case sample_rounding_policy::none:
- out_interpolation_alpha = interpolation_alpha;
- break;
- case sample_rounding_policy::floor:
- out_interpolation_alpha = 0.0F;
- break;
- case sample_rounding_policy::ceil:
- out_interpolation_alpha = 1.0F;
- break;
- case sample_rounding_policy::nearest:
- out_interpolation_alpha = rtm::scalar_floor(interpolation_alpha + 0.5F);
- break;
- }
+ out_interpolation_alpha = apply_rounding_policy(interpolation_alpha, rounding_policy);
}
//////////////////////////////////////////////////////////////////////////
@@ -266,11 +234,32 @@ namespace acl
const float interpolation_alpha = (sample_index - float(sample_index0)) / float(sample_index1 - sample_index0);
ACL_ASSERT(interpolation_alpha >= 0.0F && interpolation_alpha <= 1.0F, "Invalid interpolation alpha: 0.0 <= %f <= 1.0", interpolation_alpha);
- if (rounding_policy == sample_rounding_policy::none)
+ // If we don't round, we'll interpolate and we need the alpha value unchanged
+ // If we require the value per track, we might need the alpha value unchanged as well, rounding is handled later
+ if (rounding_policy == sample_rounding_policy::none || rounding_policy == sample_rounding_policy::per_track)
return interpolation_alpha;
else // sample_rounding_policy::nearest
return rtm::scalar_floor(interpolation_alpha + 0.5F);
}
+
+ inline float apply_rounding_policy(float interpolation_alpha, sample_rounding_policy policy)
+ {
+ switch (policy)
+ {
+ default:
+ case sample_rounding_policy::none:
+ case sample_rounding_policy::per_track:
+ // If we don't round, we'll interpolate and we need the alpha value unchanged
+ // If we require the value per track, we might need the alpha value unchanged as well, rounding is handled later
+ return interpolation_alpha;
+ case sample_rounding_policy::floor:
+ return 0.0F;
+ case sample_rounding_policy::ceil:
+ return 1.0F;
+ case sample_rounding_policy::nearest:
+ return rtm::scalar_floor(interpolation_alpha + 0.5F);
+ }
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/impl/variable_bit_rates.h b/includes/acl/core/impl/variable_bit_rates.h
new file mode 100644
--- /dev/null
+++ b/includes/acl/core/impl/variable_bit_rates.h
@@ -0,0 +1,67 @@
+#pragma once
+
+////////////////////////////////////////////////////////////////////////////////
+// The MIT License (MIT)
+//
+// Copyright (c) 2020 Nicholas Frechette & Animation Compression Library contributors
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included in all
+// copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+////////////////////////////////////////////////////////////////////////////////
+
+#include "acl/core/error.h"
+#include "acl/core/impl/compiler_utils.h"
+
+#include <cstdint>
+
+ACL_IMPL_FILE_PRAGMA_PUSH
+
+namespace acl
+{
+ namespace acl_impl
+ {
+ // Bit rate 0 is reserved for tracks that are constant in a segment
+ constexpr uint8_t k_bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+
+ constexpr uint8_t k_invalid_bit_rate = 0xFF;
+ constexpr uint8_t k_lowest_bit_rate = 1;
+ constexpr uint8_t k_highest_bit_rate = sizeof(k_bit_rate_num_bits) - 1;
+ constexpr uint32_t k_num_bit_rates = sizeof(k_bit_rate_num_bits);
+
+ static_assert(k_num_bit_rates == 19, "Expecting 19 bit rates");
+
+ inline uint32_t get_num_bits_at_bit_rate(uint32_t bit_rate)
+ {
+ ACL_ASSERT(bit_rate <= k_highest_bit_rate, "Invalid bit rate: %u", bit_rate);
+ return k_bit_rate_num_bits[bit_rate];
+ }
+
+ // Track is constant, our constant sample is stored in the range information
+ constexpr bool is_constant_bit_rate(uint32_t bit_rate) { return bit_rate == 0; }
+ constexpr bool is_raw_bit_rate(uint32_t bit_rate) { return bit_rate == k_highest_bit_rate; }
+
+ struct transform_bit_rates
+ {
+ uint8_t rotation;
+ uint8_t translation;
+ uint8_t scale;
+ };
+ }
+}
+
+ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/interpolation_utils.h b/includes/acl/core/interpolation_utils.h
--- a/includes/acl/core/interpolation_utils.h
+++ b/includes/acl/core/interpolation_utils.h
@@ -104,6 +104,10 @@ namespace acl
// interpolate when the samples are uniform.
// This function does not support looping.
float find_linear_interpolation_alpha(float sample_index, uint32_t sample_index0, uint32_t sample_index1, sample_rounding_policy rounding_policy);
+
+ //////////////////////////////////////////////////////////////////////////
+ // Modify an interpolation alpha value given a sample rounding policy
+ float apply_rounding_policy(float interpolation_alpha, sample_rounding_policy policy);
}
#include "acl/core/impl/interpolation_utils.impl.h"
diff --git a/includes/acl/core/iterator.h b/includes/acl/core/iterator.h
--- a/includes/acl/core/iterator.h
+++ b/includes/acl/core/iterator.h
@@ -57,6 +57,18 @@ namespace acl
template <class item_type>
using const_iterator = acl_impl::iterator_impl<item_type, true>;
+
+ template <class item_type, size_t num_items>
+ iterator<item_type> make_iterator(item_type (&items)[num_items])
+ {
+ return iterator<item_type>(items, num_items);
+ }
+
+ template <class item_type, size_t num_items>
+ const_iterator<item_type> make_iterator(item_type const (&items)[num_items])
+ {
+ return const_iterator<item_type>(items, num_items);
+ }
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/sample_rounding_policy.h b/includes/acl/core/sample_rounding_policy.h
--- a/includes/acl/core/sample_rounding_policy.h
+++ b/includes/acl/core/sample_rounding_policy.h
@@ -30,29 +30,78 @@ namespace acl
{
//////////////////////////////////////////////////////////////////////////
// This enum dictates how interpolation samples are calculated based on the sample time.
+ // DO NOT CHANGE THESE VALUES AS THEY ARE USED TO INDEX INTO FIXED SIZED BUFFERS THAT MAY NOT
+ // ACCOMODATE ALL VALUES.
enum class sample_rounding_policy
{
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation alpha lies in between.
- none,
+ none = 0,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 0.0.
- floor,
+ //
+ // Note that when this is used to sample a clip with a partially streamed database
+ // the sample returned is the same that would have been had the database been
+ // fully streamed in. Meaning that if we have 3 samples A, B, C and you sample
+ // between B and C, normally B would be returned. If B has been moved into the
+ // database and is missing, B will be reconstructed through interpolation.
+ floor = 1,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 1.0.
- ceil,
+ //
+ // Note that when this is used to sample a clip with a partially streamed database
+ // the sample returned is the same that would have been had the database been
+ // fully streamed in. Meaning that if we have 3 samples A, B, C and you sample
+ // between A and B, normally B would be returned. If B has been moved into the
+ // database and is missing, B will be reconstructed through interpolation.
+ ceil = 2,
//////////////////////////////////////////////////////////////////////////
// If the sample time lies between two samples, both sample indices
// are returned and the interpolation will be 0.0 or 1.0 depending
// on which sample is nearest.
- nearest,
+ //
+ // Note that this behaves similarly to floor and ceil above when used with a partially
+ // streamed database.
+ nearest = 3,
+
+ //////////////////////////////////////////////////////////////////////////
+ // Specifies that the rounding policy must be queried for every track independently.
+ // Note that this feature can be enabled/disabled in the 'decompression_settings' struct
+ // provided during decompression. Since this is a niche feature, the default settings
+ // disable it.
+ //
+ // WARNING: Using per track rounding may not behave as intended if a partially streamed
+ // database is used. For performance reasons, unlike the modes above, only a single value
+ // will be interpolated: the one at the specified sample time. This means that if we have
+ // 3 samples A, B, C and you sample between B and C with 'floor', if B has been moved to
+ // a database and is missing, B (interpolated) is not returned. Normally, A and C would be
+ // used to interpolate at the sample time specified as such we do not calculate where B lies.
+ // As a result of this, A would be returned unlike the behavior of 'floor' when used to sample
+ // all tracks. This is the behavior chosen by design. During decompression, samples are
+ // unpacked and interpolated before we know which track they belong to. As such, when the
+ // per track mode is used, we output 4 samples (instead of just the one we need), one for
+ // each possible mode above. One we know which sample we need (among the 4), we can simply
+ // index with the rounding mode to grab it. This is very fast and the cost is largely hidden.
+ // Supporting the same behavior as the rounding modes above when a partially streamed in
+ // database is used would require us to interpolate 3 samples instead of 1 which would be
+ // a lot more expensive for rotation sub-tracks. It would also add a lot of code complexity.
+ // For those reasons, the behavior differs. A future task will allow tracks to be split
+ // into different layers where database settings can be independent. This will allow us
+ // to place special tracks into their own layer where key frames are not removed. A separate
+ // task may allow us to specify per track whether the values can be interpolated or not.
+ // This would allow us to detect boundary key frames (where the value changes) and retain
+ // those we need to ensure that the end result is identical.
+ per_track = 4,
};
+
+ // The number of sample rounding policies
+ constexpr size_t k_num_sample_rounding_policies = 5;
}
ACL_IMPL_FILE_PRAGMA_POP
diff --git a/includes/acl/core/track_writer.h b/includes/acl/core/track_writer.h
--- a/includes/acl/core/track_writer.h
+++ b/includes/acl/core/track_writer.h
@@ -77,6 +77,17 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
struct track_writer
{
+ //////////////////////////////////////////////////////////////////////////
+ // Common track writing
+
+ //////////////////////////////////////////////////////////////////////////
+ // This allows the host runtime to control which rounding policy to use per track.
+ // To enable this, make sure that the 'decompression_settings' supports this feature
+ // and provide 'sample_rounding_policy::per_track' to the seek function.
+ // This function cannot return the 'per_track' value. We do so here to force an
+ // assert at runtime if the caller attempts to use it but does not override this.
+ constexpr sample_rounding_policy get_rounding_policy(uint32_t /*track_index*/) const { return sample_rounding_policy::per_track; }
+
//////////////////////////////////////////////////////////////////////////
// Scalar track writing
@@ -146,7 +157,7 @@ namespace acl
rtm::vector4f RTM_SIMD_CALL get_variable_default_scale(uint32_t /*track_index*/) const { return rtm::vector_set(1.0F); }
//////////////////////////////////////////////////////////////////////////
- // These allow the caller of decompress_pose to control which track types they are interested in.
+ // These allow host runtimes to control which track types they are interested in.
// This information allows the codecs to avoid unpacking values that are not needed.
// Must be static constexpr!
static constexpr bool skip_all_rotations() { return false; }
@@ -154,7 +165,7 @@ namespace acl
static constexpr bool skip_all_scales() { return false; }
//////////////////////////////////////////////////////////////////////////
- // These allow the caller of decompress_pose to control which tracks they are interested in.
+ // These allow host runtimes to control which tracks they are interested in.
// This information allows the codecs to avoid unpacking values that are not needed.
// Must be non-static member functions!
constexpr bool skip_track_rotation(uint32_t /*track_index*/) const { return false; }
diff --git a/includes/acl/core/variable_bit_rates.h b/includes/acl/core/variable_bit_rates.h
--- a/includes/acl/core/variable_bit_rates.h
+++ b/includes/acl/core/variable_bit_rates.h
@@ -34,25 +34,37 @@ ACL_IMPL_FILE_PRAGMA_PUSH
namespace acl
{
// Bit rate 0 is reserved for tracks that are constant in a segment
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
constexpr uint8_t k_bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
constexpr uint8_t k_invalid_bit_rate = 0xFF;
+
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
constexpr uint8_t k_lowest_bit_rate = 1;
- constexpr uint8_t k_highest_bit_rate = sizeof(k_bit_rate_num_bits) - 1;
- constexpr uint32_t k_num_bit_rates = sizeof(k_bit_rate_num_bits);
- static_assert(k_num_bit_rates == 19, "Expecting 19 bit rates");
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
+ constexpr uint8_t k_highest_bit_rate = 18;
+
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
+ constexpr uint32_t k_num_bit_rates = 19;
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
inline uint32_t get_num_bits_at_bit_rate(uint32_t bit_rate)
{
- ACL_ASSERT(bit_rate <= k_highest_bit_rate, "Invalid bit rate: %u", bit_rate);
- return k_bit_rate_num_bits[bit_rate];
+ ACL_ASSERT(bit_rate <= 18, "Invalid bit rate: %u", bit_rate);
+ constexpr uint8_t bit_rate_num_bits[] = { 0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 32 };
+ return bit_rate_num_bits[bit_rate];
}
// Track is constant, our constant sample is stored in the range information
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
constexpr bool is_constant_bit_rate(uint32_t bit_rate) { return bit_rate == 0; }
- constexpr bool is_raw_bit_rate(uint32_t bit_rate) { return bit_rate == k_highest_bit_rate; }
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
+ constexpr bool is_raw_bit_rate(uint32_t bit_rate) { return bit_rate == 18; }
+
+ ACL_DEPRECATED("Internal implementation detail; to be removed in v3.0")
struct BoneBitRate
{
uint8_t rotation;
diff --git a/includes/acl/decompression/decompression_settings.h b/includes/acl/decompression/decompression_settings.h
--- a/includes/acl/decompression/decompression_settings.h
+++ b/includes/acl/decompression/decompression_settings.h
@@ -118,6 +118,15 @@ namespace acl
// Must be static constexpr!
static constexpr bool is_wrapping_supported() { return true; }
+ //////////////////////////////////////////////////////////////////////////
+ // Whether or not to enable 'sample_rounding_policy::per_track' support.
+ // If support is disabled and that value is provided to the seek(..) function,
+ // the runtime will assert.
+ // See 'sample_rounding_policy' for details.
+ // Enabled by default.
+ // Must be static constexpr!
+ static constexpr bool is_per_track_rounding_supported() { return true; }
+
//////////////////////////////////////////////////////////////////////////
// The database settings to use when decompressing.
// By default, the database isn't supported.
@@ -156,6 +165,10 @@ namespace acl
//////////////////////////////////////////////////////////////////////////
// Only support scalar tracks
static constexpr bool is_track_type_supported(track_type8 type) { return type != track_type8::qvvf; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Disabled by default since it is an uncommon feature
+ static constexpr bool is_per_track_rounding_supported() { return false; }
};
//////////////////////////////////////////////////////////////////////////
@@ -174,6 +187,10 @@ namespace acl
static constexpr bool is_rotation_format_supported(rotation_format8 format) { return format == rotation_format8::quatf_drop_w_variable; }
static constexpr bool is_translation_format_supported(vector_format8 format) { return format == vector_format8::vector3f_variable; }
static constexpr bool is_scale_format_supported(vector_format8 format) { return format == vector_format8::vector3f_variable; }
+
+ //////////////////////////////////////////////////////////////////////////
+ // Disabled by default since it is an uncommon feature
+ static constexpr bool is_per_track_rounding_supported() { return false; }
};
}
diff --git a/includes/acl/decompression/impl/decompress.impl.h b/includes/acl/decompression/impl/decompress.impl.h
--- a/includes/acl/decompression/impl/decompress.impl.h
+++ b/includes/acl/decompression/impl/decompress.impl.h
@@ -120,6 +120,7 @@ namespace acl
{
ACL_ASSERT(m_context.is_initialized(), "Context is not initialized");
ACL_ASSERT(rtm::scalar_is_finite(sample_time), "Invalid sample time");
+ ACL_ASSERT(rounding_policy != sample_rounding_policy::per_track || decompression_settings_type::is_per_track_rounding_supported(), "Per track rounding must be enabled");
if (!m_context.is_initialized())
return; // Context is not initialized
diff --git a/includes/acl/decompression/impl/scalar_track_decompression.h b/includes/acl/decompression/impl/scalar_track_decompression.h
--- a/includes/acl/decompression/impl/scalar_track_decompression.h
+++ b/includes/acl/decompression/impl/scalar_track_decompression.h
@@ -28,8 +28,8 @@
#include "acl/core/compressed_tracks_version.h"
#include "acl/core/interpolation_utils.h"
#include "acl/core/track_writer.h"
-#include "acl/core/variable_bit_rates.h"
#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/decompression/database/database.h"
#include "acl/math/scalar_packing.h"
#include "acl/math/vector4_packing.h"
@@ -71,14 +71,16 @@ namespace acl
uint32_t key_frame_bit_offsets[2]; // 20 | 24 // Variable quantization
uint8_t looping_policy; // 28 | 32
+ uint8_t rounding_policy; // 29 | 33
- uint8_t padding_tail[sizeof(void*) == 4 ? 35 : 31]; // 29 | 33
+ uint8_t padding_tail[sizeof(void*) == 4 ? 34 : 30]; // 30 | 34
//////////////////////////////////////////////////////////////////////////
const compressed_tracks* get_compressed_tracks() const { return tracks; }
compressed_tracks_version16 get_version() const { return tracks->get_version(); }
sample_looping_policy get_looping_policy() const { return static_cast<sample_looping_policy>(looping_policy); }
+ sample_rounding_policy get_rounding_policy() const { return static_cast<sample_rounding_policy>(rounding_policy); }
bool is_initialized() const { return tracks != nullptr; }
void reset() { tracks = nullptr; }
};
@@ -96,7 +98,6 @@ namespace acl
context.tracks = &tracks;
context.tracks_hash = tracks.get_hash();
context.sample_time = -1.0F;
- context.interpolation_alpha = 0.0;
if (decompression_settings_type::is_wrapping_supported())
{
@@ -152,7 +153,7 @@ namespace acl
if (decompression_settings_type::clamp_sample_time())
sample_time = rtm::scalar_clamp(sample_time, 0.0F, context.duration);
- if (context.sample_time == sample_time)
+ if (context.sample_time == sample_time && context.get_rounding_policy() == rounding_policy)
return;
context.sample_time = sample_time;
@@ -164,6 +165,8 @@ namespace acl
uint32_t key_frame1;
find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, looping_policy_, key_frame0, key_frame1, context.interpolation_alpha);
+ context.rounding_policy = static_cast<uint8_t>(rounding_policy);
+
const acl_impl::scalar_tracks_header& scalars_header = acl_impl::get_scalar_tracks_header(*context.tracks);
context.key_frame_bit_offsets[0] = key_frame0 * scalars_header.num_bits_per_frame;
@@ -191,6 +194,22 @@ namespace acl
const acl_impl::scalar_tracks_header& scalars_header = acl_impl::get_scalar_tracks_header(*context.tracks);
const rtm::scalarf interpolation_alpha = rtm::scalar_set(context.interpolation_alpha);
+ const sample_rounding_policy rounding_policy = static_cast<sample_rounding_policy>(context.rounding_policy);
+
+ float interpolation_alpha_per_policy[k_num_sample_rounding_policies];
+ if (decompression_settings_type::is_per_track_rounding_supported())
+ {
+ const float alpha = context.interpolation_alpha;
+ const float no_rounding_alpha = apply_rounding_policy(alpha, sample_rounding_policy::none);
+
+ interpolation_alpha_per_policy[static_cast<int>(sample_rounding_policy::none)] = no_rounding_alpha;
+ interpolation_alpha_per_policy[static_cast<int>(sample_rounding_policy::floor)] = apply_rounding_policy(alpha, sample_rounding_policy::floor);
+ interpolation_alpha_per_policy[static_cast<int>(sample_rounding_policy::ceil)] = apply_rounding_policy(alpha, sample_rounding_policy::ceil);
+ interpolation_alpha_per_policy[static_cast<int>(sample_rounding_policy::nearest)] = apply_rounding_policy(alpha, sample_rounding_policy::nearest);
+ // We'll assert if we attempt to use this, but in case they are skipped/disabled, we interpolate
+ interpolation_alpha_per_policy[static_cast<int>(sample_rounding_policy::per_track)] = no_rounding_alpha;
+ }
+
const acl_impl::track_metadata* per_track_metadata = scalars_header.get_track_metadata();
const float* constant_values = scalars_header.get_track_constant_values();
const float* range_values = scalars_header.get_track_range_values();
@@ -207,6 +226,15 @@ namespace acl
const uint8_t bit_rate = metadata.bit_rate;
const uint32_t num_bits_per_component = get_num_bits_at_bit_rate(bit_rate);
+ rtm::scalarf alpha = interpolation_alpha;
+ if (decompression_settings_type::is_per_track_rounding_supported())
+ {
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ alpha = rtm::scalar_set(interpolation_alpha_per_policy[static_cast<int>(rounding_policy_)]);
+ }
+
if (track_type == track_type8::float1f && decompression_settings_type::is_track_type_supported(track_type8::float1f))
{
rtm::scalarf value;
@@ -236,7 +264,7 @@ namespace acl
range_values += 2;
}
- value = rtm::scalar_lerp(value0, value1, interpolation_alpha);
+ value = rtm::scalar_lerp(value0, value1, alpha);
const uint32_t num_sample_bits = num_bits_per_component;
track_bit_offset0 += num_sample_bits;
@@ -274,7 +302,7 @@ namespace acl
range_values += 4;
}
- value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ value = rtm::vector_lerp(value0, value1, alpha);
const uint32_t num_sample_bits = num_bits_per_component * 2;
track_bit_offset0 += num_sample_bits;
@@ -312,7 +340,7 @@ namespace acl
range_values += 6;
}
- value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ value = rtm::vector_lerp(value0, value1, alpha);
const uint32_t num_sample_bits = num_bits_per_component * 3;
track_bit_offset0 += num_sample_bits;
@@ -350,7 +378,7 @@ namespace acl
range_values += 8;
}
- value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ value = rtm::vector_lerp(value0, value1, alpha);
const uint32_t num_sample_bits = num_bits_per_component * 4;
track_bit_offset0 += num_sample_bits;
@@ -388,7 +416,7 @@ namespace acl
range_values += 8;
}
- value = rtm::vector_lerp(value0, value1, interpolation_alpha);
+ value = rtm::vector_lerp(value0, value1, alpha);
const uint32_t num_sample_bits = num_bits_per_component * 4;
track_bit_offset0 += num_sample_bits;
@@ -425,7 +453,16 @@ namespace acl
disable_fp_exceptions(fp_env);
const scalar_tracks_header& scalars_header = get_scalar_tracks_header(*context.tracks);
- const rtm::scalarf interpolation_alpha = rtm::scalar_set(context.interpolation_alpha);
+
+ rtm::scalarf interpolation_alpha = rtm::scalar_set(context.interpolation_alpha);
+ if (decompression_settings_type::is_per_track_rounding_supported())
+ {
+ const sample_rounding_policy rounding_policy = static_cast<sample_rounding_policy>(context.rounding_policy);
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ interpolation_alpha = rtm::scalar_set(apply_rounding_policy(context.interpolation_alpha, rounding_policy_));
+ }
const float* constant_values = scalars_header.get_track_constant_values();
const float* range_values = scalars_header.get_track_range_values();
diff --git a/includes/acl/decompression/impl/track_cache.h b/includes/acl/decompression/impl/track_cache.h
--- a/includes/acl/decompression/impl/track_cache.h
+++ b/includes/acl/decompression/impl/track_cache.h
@@ -44,7 +44,7 @@ namespace acl
{
namespace acl_impl
{
- template<typename cached_type, uint32_t cache_size>
+ template<typename cached_type, uint32_t cache_size, uint32_t num_rounding_modes>
struct track_cache_v0
{
// Our cached type
@@ -53,8 +53,11 @@ namespace acl
// Our cache size
static constexpr uint32_t k_cache_size = cache_size;
+ // How many rounding modes we cache
+ static constexpr uint32_t k_num_rounding_modes = num_rounding_modes;
+
// Our cached values
- type cached_samples[cache_size];
+ type cached_samples[num_rounding_modes][cache_size];
// The index to write the next cache entry when we unpack
// Effective index value is modulo k_cache_size what is stored here, guaranteed to never wrap
@@ -84,11 +87,11 @@ namespace acl
using type = rtm::vector4f;
};
- template<uint32_t cache_size>
- using track_cache_quatf_v0 = track_cache_v0<track_cache_quatf_trait, cache_size>;
+ template<uint32_t cache_size, uint32_t num_rounding_modes>
+ using track_cache_quatf_v0 = track_cache_v0<track_cache_quatf_trait, cache_size, num_rounding_modes>;
- template<uint32_t cache_size>
- using track_cache_vector4f_v0 = track_cache_v0<track_cache_vector4f_trait, cache_size>;
+ template<uint32_t cache_size, uint32_t num_rounding_modes>
+ using track_cache_vector4f_v0 = track_cache_v0<track_cache_vector4f_trait, cache_size, num_rounding_modes>;
}
}
diff --git a/includes/acl/decompression/impl/transform_animated_track_cache.h b/includes/acl/decompression/impl/transform_animated_track_cache.h
--- a/includes/acl/decompression/impl/transform_animated_track_cache.h
+++ b/includes/acl/decompression/impl/transform_animated_track_cache.h
@@ -546,7 +546,7 @@ namespace acl
RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL quat_lerp4(
rtm::vector4f_arg0 xxxx0, rtm::vector4f_arg1 yyyy0, rtm::vector4f_arg2 zzzz0, rtm::vector4f_arg3 wwww0,
rtm::vector4f_arg4 xxxx1, rtm::vector4f_arg5 yyyy1, rtm::vector4f_arg6 zzzz1, rtm::vector4f_arg7 wwww1,
- float interpolation_alpha,
+ rtm::vector4f_argn interpolation_alpha,
rtm::vector4f& interp_xxxx, rtm::vector4f& interp_yyyy, rtm::vector4f& interp_zzzz, rtm::vector4f& interp_wwww)
{
// Calculate the vector4 dot product: dot(start, end)
@@ -570,12 +570,10 @@ namespace acl
// Lerp the rotation after applying the bias
// ((1.0 - alpha) * start) + (alpha * (end ^ bias)) == (start - alpha * start) + (alpha * (end ^ bias))
- const rtm::vector4f alpha = rtm::vector_set(interpolation_alpha);
-
- interp_xxxx = rtm::vector_mul_add(xxxx1_with_bias, alpha, rtm::vector_neg_mul_sub(xxxx0, alpha, xxxx0));
- interp_yyyy = rtm::vector_mul_add(yyyy1_with_bias, alpha, rtm::vector_neg_mul_sub(yyyy0, alpha, yyyy0));
- interp_zzzz = rtm::vector_mul_add(zzzz1_with_bias, alpha, rtm::vector_neg_mul_sub(zzzz0, alpha, zzzz0));
- interp_wwww = rtm::vector_mul_add(wwww1_with_bias, alpha, rtm::vector_neg_mul_sub(wwww0, alpha, wwww0));
+ interp_xxxx = rtm::vector_mul_add(xxxx1_with_bias, interpolation_alpha, rtm::vector_neg_mul_sub(xxxx0, interpolation_alpha, xxxx0));
+ interp_yyyy = rtm::vector_mul_add(yyyy1_with_bias, interpolation_alpha, rtm::vector_neg_mul_sub(yyyy0, interpolation_alpha, yyyy0));
+ interp_zzzz = rtm::vector_mul_add(zzzz1_with_bias, interpolation_alpha, rtm::vector_neg_mul_sub(zzzz0, interpolation_alpha, zzzz0));
+ interp_wwww = rtm::vector_mul_add(wwww1_with_bias, interpolation_alpha, rtm::vector_neg_mul_sub(wwww0, interpolation_alpha, wwww0));
}
// About 9 cycles with AVX on Skylake
@@ -1214,9 +1212,11 @@ namespace acl
struct animated_track_cache_v0
{
- track_cache_quatf_v0<8> rotations;
- track_cache_vector4f_v0<8> translations;
- track_cache_vector4f_v0<8> scales;
+ static constexpr uint32_t k_num_rounding_modes = 4; // none, floor, ceil, nearest
+
+ track_cache_quatf_v0<8, k_num_rounding_modes> rotations;
+ track_cache_vector4f_v0<8, k_num_rounding_modes> translations;
+ track_cache_vector4f_v0<8, k_num_rounding_modes> scales;
// Scratch space when we decompress our samples before we interpolate
rtm::vector4f scratch0[4];
@@ -1470,68 +1470,192 @@ namespace acl
// Interpolate linearly and store our rotations in SOA
{
- rtm::vector4f interp_xxxx;
- rtm::vector4f interp_yyyy;
- rtm::vector4f interp_zzzz;
- rtm::vector4f interp_wwww;
+ const float interpolation_alpha = decomp_context.interpolation_alpha;
+ const rtm::vector4f interpolation_alpha_v = rtm::vector_set(interpolation_alpha);
- const bool should_interpolate = should_interpolate_samples<decompression_settings_type>(rotation_format, decomp_context.interpolation_alpha);
- if (should_interpolate)
+ if (decompression_settings_type::is_per_track_rounding_supported())
{
- // Interpolate our quaternions without normalizing just yet
- quat_lerp4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww,
- scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww,
- decomp_context.interpolation_alpha,
- interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
-
- // Due to the interpolation, the result might not be anywhere near normalized!
- // Make sure to normalize afterwards if we need to
- constexpr bool normalize_rotations = decompression_settings_type::normalize_rotations();
- if (normalize_rotations)
- quat_normalize4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
+ // If we support per track rounding, we have to retain everything
+ // Write both floor/ceil samples and interpolate as well
+ // When we consume the sample, we'll pick the right one according to the rounding policy
+
+ // We swizzle and store the floor/ceil first because we have sqrt instructions in flight
+ // from above. Most of the shuffles below can execute without any dependency.
+ // We should have enough registers to avoid spilling and there is enough work to perform
+ // to avoid any dependencies and fully hide the sqrt costs. That being said, there is
+ // quite a bit of work to do and we might still be CPU bound below.
+
+ {
+ // Swizzle out our 4 floor samples
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww, sample0, sample1, sample2, sample3);
+
+ rtm::quatf* cache_ptr = &rotations.cached_samples[static_cast<int>(sample_rounding_policy::floor)][cache_write_index];
+
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+ }
+
+ {
+ // Swizzle out our 4 floor ceil
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww, sample0, sample1, sample2, sample3);
+
+ rtm::quatf* cache_ptr = &rotations.cached_samples[static_cast<int>(sample_rounding_policy::ceil)][cache_write_index];
+
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+ }
+
+ {
+ // Find nearest and swizzle it out
+ const rtm::mask4f use_sample0 = rtm::vector_less_than(interpolation_alpha_v, rtm::vector_set(0.5F));
+
+ const rtm::vector4f nearest_xxxx = rtm::vector_select(use_sample0, scratch0_xxxx, scratch1_xxxx);
+ const rtm::vector4f nearest_yyyy = rtm::vector_select(use_sample0, scratch0_yyyy, scratch1_yyyy);
+ const rtm::vector4f nearest_zzzz = rtm::vector_select(use_sample0, scratch0_zzzz, scratch1_zzzz);
+ const rtm::vector4f nearest_wwww = rtm::vector_select(use_sample0, scratch0_wwww, scratch1_wwww);
+
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(nearest_xxxx, nearest_yyyy, nearest_zzzz, nearest_wwww, sample0, sample1, sample2, sample3);
+
+ rtm::quatf* cache_ptr = &rotations.cached_samples[static_cast<int>(sample_rounding_policy::nearest)][cache_write_index];
+
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+ }
+
+ {
+ rtm::vector4f interp_xxxx;
+ rtm::vector4f interp_yyyy;
+ rtm::vector4f interp_zzzz;
+ rtm::vector4f interp_wwww;
+
+ // Interpolate our quaternions without normalizing just yet
+ quat_lerp4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww,
+ scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww,
+ interpolation_alpha_v,
+ interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards if we need to
+ constexpr bool normalize_rotations = decompression_settings_type::normalize_rotations();
+ if (normalize_rotations)
+ quat_normalize4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
+
+#if !defined(ACL_IMPL_PREFETCH_EARLY)
+ {
+ // Our animated variable bit packed data uses at most 32 bits per component
+ // When we use raw data, that means each group uses 64 bytes (4 bytes per component, 4 components, 4 samples in group), we have 1 group per cache line
+ // When we use variable data, the highest bit rate uses 32 bits per component and thus our upper bound is 48 bytes per group (4 bytes per component, 3 components, 4 samples in group), we have 1.33 group per cache line
+ // In practice, the highest bit rate is rare and the second higher uses 19 bits per component which brings us to 28.5 bytes per group, leading to 2.24 group per cache line
+ // We prefetch both key frames every time to help hide TLB miss latency in large clips
+ // We prefetch here because we have a square-root and division in quat_normalize4(..) that we'll wait after
+ // This allows us to insert the prefetch basically for free in their shadow
+ const uint8_t* animated_track_data = segment_sampling_context_rotations[0].animated_track_data + 64; // One cache line ahead
+ const uint32_t animated_bit_offset0 = segment_sampling_context_rotations[0].animated_track_data_bit_offset;
+ const uint32_t animated_bit_offset1 = segment_sampling_context_rotations[1].animated_track_data_bit_offset;
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset0 / 8));
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset1 / 8));
+ }
+#endif
+
+ // Swizzle out our 4 samples
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww, sample0, sample1, sample2, sample3);
+
+ rtm::quatf* cache_ptr = &rotations.cached_samples[static_cast<int>(sample_rounding_policy::none)][cache_write_index];
+
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+ }
}
else
{
- // If we don't interpolate, just pick the sample we need, it is already normalized after reconstructing
- // the W component or it was raw to begin with
- const rtm::mask4f use_sample0 = rtm::vector_less_equal(rtm::vector_set(decomp_context.interpolation_alpha), rtm::vector_zero());
-
- interp_xxxx = rtm::vector_select(use_sample0, scratch0_xxxx, scratch1_xxxx);
- interp_yyyy = rtm::vector_select(use_sample0, scratch0_yyyy, scratch1_yyyy);
- interp_zzzz = rtm::vector_select(use_sample0, scratch0_zzzz, scratch1_zzzz);
- interp_wwww = rtm::vector_select(use_sample0, scratch0_wwww, scratch1_wwww);
- }
+ rtm::vector4f interp_xxxx;
+ rtm::vector4f interp_yyyy;
+ rtm::vector4f interp_zzzz;
+ rtm::vector4f interp_wwww;
+
+ const bool should_interpolate = should_interpolate_samples<decompression_settings_type>(rotation_format, interpolation_alpha);
+ if (should_interpolate)
+ {
+ // Interpolate our quaternions without normalizing just yet
+ quat_lerp4(scratch0_xxxx, scratch0_yyyy, scratch0_zzzz, scratch0_wwww,
+ scratch1_xxxx, scratch1_yyyy, scratch1_zzzz, scratch1_wwww,
+ interpolation_alpha_v,
+ interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
+
+ // Due to the interpolation, the result might not be anywhere near normalized!
+ // Make sure to normalize afterwards if we need to
+ constexpr bool normalize_rotations = decompression_settings_type::normalize_rotations();
+ if (normalize_rotations)
+ quat_normalize4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww);
+ }
+ else
+ {
+ // If we don't interpolate, just pick the sample we need, it is already normalized after reconstructing
+ // the W component or it was raw to begin with
+ const rtm::mask4f use_sample0 = rtm::vector_less_equal(rtm::vector_set(interpolation_alpha), rtm::vector_zero());
+
+ interp_xxxx = rtm::vector_select(use_sample0, scratch0_xxxx, scratch1_xxxx);
+ interp_yyyy = rtm::vector_select(use_sample0, scratch0_yyyy, scratch1_yyyy);
+ interp_zzzz = rtm::vector_select(use_sample0, scratch0_zzzz, scratch1_zzzz);
+ interp_wwww = rtm::vector_select(use_sample0, scratch0_wwww, scratch1_wwww);
+ }
#if !defined(ACL_IMPL_PREFETCH_EARLY)
- {
- // Our animated variable bit packed data uses at most 32 bits per component
- // When we use raw data, that means each group uses 64 bytes (4 bytes per component, 4 components, 4 samples in group), we have 1 group per cache line
- // When we use variable data, the highest bit rate uses 32 bits per component and thus our upper bound is 48 bytes per group (4 bytes per component, 3 components, 4 samples in group), we have 1.33 group per cache line
- // In practice, the highest bit rate is rare and the second higher uses 19 bits per component which brings us to 28.5 bytes per group, leading to 2.24 group per cache line
- // We prefetch both key frames every time to help hide TLB miss latency in large clips
- // We prefetch here because we have a square-root and division in quat_normalize4(..) that we'll wait after
- // This allows us to insert the prefetch basically for free in their shadow
- const uint8_t* animated_track_data = segment_sampling_context_rotations[0].animated_track_data + 64; // One cache line ahead
- const uint32_t animated_bit_offset0 = segment_sampling_context_rotations[0].animated_track_data_bit_offset;
- const uint32_t animated_bit_offset1 = segment_sampling_context_rotations[1].animated_track_data_bit_offset;
- ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset0 / 8));
- ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset1 / 8));
- }
+ {
+ // Our animated variable bit packed data uses at most 32 bits per component
+ // When we use raw data, that means each group uses 64 bytes (4 bytes per component, 4 components, 4 samples in group), we have 1 group per cache line
+ // When we use variable data, the highest bit rate uses 32 bits per component and thus our upper bound is 48 bytes per group (4 bytes per component, 3 components, 4 samples in group), we have 1.33 group per cache line
+ // In practice, the highest bit rate is rare and the second higher uses 19 bits per component which brings us to 28.5 bytes per group, leading to 2.24 group per cache line
+ // We prefetch both key frames every time to help hide TLB miss latency in large clips
+ // We prefetch here because we have a square-root and division in quat_normalize4(..) that we'll wait after
+ // This allows us to insert the prefetch basically for free in their shadow
+ const uint8_t* animated_track_data = segment_sampling_context_rotations[0].animated_track_data + 64; // One cache line ahead
+ const uint32_t animated_bit_offset0 = segment_sampling_context_rotations[0].animated_track_data_bit_offset;
+ const uint32_t animated_bit_offset1 = segment_sampling_context_rotations[1].animated_track_data_bit_offset;
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset0 / 8));
+ ACL_IMPL_ANIMATED_PREFETCH(animated_track_data + (animated_bit_offset1 / 8));
+ }
#endif
- // Swizzle out our 4 samples
- rtm::vector4f sample0;
- rtm::vector4f sample1;
- rtm::vector4f sample2;
- rtm::vector4f sample3;
- RTM_MATRIXF_TRANSPOSE_4X4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww, sample0, sample1, sample2, sample3);
+ // Swizzle out our 4 samples
+ rtm::vector4f sample0;
+ rtm::vector4f sample1;
+ rtm::vector4f sample2;
+ rtm::vector4f sample3;
+ RTM_MATRIXF_TRANSPOSE_4X4(interp_xxxx, interp_yyyy, interp_zzzz, interp_wwww, sample0, sample1, sample2, sample3);
- rtm::quatf* cache_ptr = &rotations.cached_samples[cache_write_index];
+ // Always first rounding mode (none)
+ rtm::quatf* cache_ptr = &rotations.cached_samples[static_cast<int>(sample_rounding_policy::none)][cache_write_index];
- cache_ptr[0] = rtm::vector_to_quat(sample0);
- cache_ptr[1] = rtm::vector_to_quat(sample1);
- cache_ptr[2] = rtm::vector_to_quat(sample2);
- cache_ptr[3] = rtm::vector_to_quat(sample3);
+ cache_ptr[0] = rtm::vector_to_quat(sample0);
+ cache_ptr[1] = rtm::vector_to_quat(sample1);
+ cache_ptr[2] = rtm::vector_to_quat(sample2);
+ cache_ptr[3] = rtm::vector_to_quat(sample3);
+ }
}
}
@@ -1581,7 +1705,7 @@ namespace acl
}
template<class decompression_settings_type>
- RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::quatf RTM_SIMD_CALL unpack_rotation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
+ RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::quatf RTM_SIMD_CALL unpack_rotation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index, float interpolation_alpha)
{
ACL_ASSERT(unpack_index < rotations.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
@@ -1608,32 +1732,32 @@ namespace acl
rtm::quatf result;
- const bool should_interpolate = should_interpolate_samples<decompression_settings_type>(rotation_format, decomp_context.interpolation_alpha);
+ const bool should_interpolate = should_interpolate_samples<decompression_settings_type>(rotation_format, interpolation_alpha);
if (should_interpolate)
{
// Due to the interpolation, the result might not be anywhere near normalized!
// Make sure to normalize afterwards before using
constexpr bool normalize_rotations = decompression_settings_type::normalize_rotations();
if (normalize_rotations)
- result = rtm::quat_lerp(sample0, sample1, decomp_context.interpolation_alpha);
+ result = rtm::quat_lerp(sample0, sample1, interpolation_alpha);
else
- result = quat_lerp_no_normalization(sample0, sample1, decomp_context.interpolation_alpha);
+ result = quat_lerp_no_normalization(sample0, sample1, interpolation_alpha);
}
else
{
// If we don't interpolate, just pick the sample we need, it is already normalized after reconstructing
// the W component or it was raw to begin with
- result = decomp_context.interpolation_alpha <= 0.0F ? sample0 : sample1;
+ result = interpolation_alpha <= 0.0F ? sample0 : sample1;
}
return result;
}
- RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::quatf& consume_rotation()
+ RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::quatf& consume_rotation(sample_rounding_policy policy)
{
ACL_ASSERT(rotations.cache_read_index < rotations.cache_write_index, "Attempting to consume an animated sample that isn't cached");
const uint32_t cache_read_index = rotations.cache_read_index++;
- return rotations.cached_samples[cache_read_index % 8];
+ return rotations.cached_samples[static_cast<int>(policy)][cache_read_index % 8];
}
template<class decompression_settings_adapter_type>
@@ -1659,15 +1783,33 @@ namespace acl
unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context_translations, segment_sampling_context_translations[1]);
const rtm::vector4f interpolation_alpha = rtm::vector_set(decomp_context.interpolation_alpha);
- rtm::vector4f* cache_ptr = &translations.cached_samples[cache_write_index];
+ const rtm::mask4f use_sample0 = rtm::vector_less_than(interpolation_alpha, rtm::vector_set(0.5F));
+
+ // If we support per track rounding, we have to retain everything
+ // Write both floor/ceil/nearest samples and interpolate as well
+ // When we consume the sample, we'll pick the right one according to the rounding policy
+
+ rtm::vector4f* cache_ptr_none = &translations.cached_samples[static_cast<int>(sample_rounding_policy::none)][cache_write_index];
+ rtm::vector4f* cache_ptr_floor = &translations.cached_samples[static_cast<int>(sample_rounding_policy::floor)][cache_write_index];
+ rtm::vector4f* cache_ptr_ceil = &translations.cached_samples[static_cast<int>(sample_rounding_policy::ceil)][cache_write_index];
+ rtm::vector4f* cache_ptr_nearest = &translations.cached_samples[static_cast<int>(sample_rounding_policy::nearest)][cache_write_index];
+
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
const rtm::vector4f sample0 = scratch0[unpack_index];
const rtm::vector4f sample1 = scratch1[unpack_index];
+ if (decompression_settings_adapter_type::is_per_track_rounding_supported())
+ {
+ // These stores have no dependency and can be dispatched right away
+ cache_ptr_floor[unpack_index] = sample0;
+ cache_ptr_ceil[unpack_index] = sample1;
+ cache_ptr_nearest[unpack_index] = rtm::vector_select(use_sample0, sample0, sample1);
+ }
+
const rtm::vector4f sample = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
- cache_ptr[unpack_index] = sample;
+ cache_ptr_none[unpack_index] = sample;
}
// If we have clip range data, skip it
@@ -1723,21 +1865,21 @@ namespace acl
}
template<class decompression_settings_adapter_type>
- RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_translation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
+ RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_translation_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index, float interpolation_alpha)
{
ACL_ASSERT(unpack_index < translations.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
const rtm::vector4f sample0 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_translations, segment_sampling_context_translations[0]);
const rtm::vector4f sample1 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_translations, segment_sampling_context_translations[1]);
- return rtm::vector_lerp(sample0, sample1, decomp_context.interpolation_alpha);
+ return rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
- RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::vector4f& consume_translation()
+ RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::vector4f& consume_translation(sample_rounding_policy policy)
{
ACL_ASSERT(translations.cache_read_index < translations.cache_write_index, "Attempting to consume an animated sample that isn't cached");
const uint32_t cache_read_index = translations.cache_read_index++;
- return translations.cached_samples[cache_read_index % 8];
+ return translations.cached_samples[static_cast<int>(policy)][cache_read_index % 8];
}
template<class decompression_settings_adapter_type>
@@ -1763,15 +1905,33 @@ namespace acl
unpack_animated_vector3<decompression_settings_adapter_type>(decomp_context, scratch1, num_to_unpack, clip_sampling_context_scales, segment_sampling_context_scales[1]);
const rtm::vector4f interpolation_alpha = rtm::vector_set(decomp_context.interpolation_alpha);
- rtm::vector4f* cache_ptr = &scales.cached_samples[cache_write_index];
+ const rtm::mask4f use_sample0 = rtm::vector_less_than(interpolation_alpha, rtm::vector_set(0.5F));
+
+ // If we support per track rounding, we have to retain everything
+ // Write both floor/ceil/nearest samples and interpolate as well
+ // When we consume the sample, we'll pick the right one according to the rounding policy
+
+ rtm::vector4f* cache_ptr_none = &scales.cached_samples[static_cast<int>(sample_rounding_policy::none)][cache_write_index];
+ rtm::vector4f* cache_ptr_floor = &scales.cached_samples[static_cast<int>(sample_rounding_policy::floor)][cache_write_index];
+ rtm::vector4f* cache_ptr_ceil = &scales.cached_samples[static_cast<int>(sample_rounding_policy::ceil)][cache_write_index];
+ rtm::vector4f* cache_ptr_nearest = &scales.cached_samples[static_cast<int>(sample_rounding_policy::nearest)][cache_write_index];
+
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
const rtm::vector4f sample0 = scratch0[unpack_index];
const rtm::vector4f sample1 = scratch1[unpack_index];
+ if (decompression_settings_adapter_type::is_per_track_rounding_supported())
+ {
+ // These stores have no dependency and can be dispatched right away
+ cache_ptr_floor[unpack_index] = sample0;
+ cache_ptr_ceil[unpack_index] = sample1;
+ cache_ptr_nearest[unpack_index] = rtm::vector_select(use_sample0, sample0, sample1);
+ }
+
const rtm::vector4f sample = rtm::vector_lerp(sample0, sample1, interpolation_alpha);
- cache_ptr[unpack_index] = sample;
+ cache_ptr_none[unpack_index] = sample;
}
// If we have clip range data, skip it
@@ -1827,21 +1987,21 @@ namespace acl
}
template<class decompression_settings_adapter_type>
- RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_scale_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index)
+ RTM_DISABLE_SECURITY_COOKIE_CHECK rtm::vector4f RTM_SIMD_CALL unpack_scale_within_group(const persistent_transform_decompression_context_v0& decomp_context, uint32_t unpack_index, float interpolation_alpha)
{
ACL_ASSERT(unpack_index < scales.num_left_to_unpack && unpack_index < 4, "Cannot unpack sample that isn't present");
const rtm::vector4f sample0 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_scales, segment_sampling_context_scales[0]);
const rtm::vector4f sample1 = unpack_single_animated_vector3<decompression_settings_adapter_type>(decomp_context, unpack_index, clip_sampling_context_scales, segment_sampling_context_scales[1]);
- return rtm::vector_lerp(sample0, sample1, decomp_context.interpolation_alpha);
+ return rtm::vector_lerp(sample0, sample1, interpolation_alpha);
}
- RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::vector4f& consume_scale()
+ RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK const rtm::vector4f& consume_scale(sample_rounding_policy policy)
{
ACL_ASSERT(scales.cache_read_index < scales.cache_write_index, "Attempting to consume an animated sample that isn't cached");
const uint32_t cache_read_index = scales.cache_read_index++;
- return scales.cached_samples[cache_read_index % 8];
+ return scales.cached_samples[static_cast<int>(policy)][cache_read_index % 8];
}
};
}
diff --git a/includes/acl/decompression/impl/transform_constant_track_cache.h b/includes/acl/decompression/impl/transform_constant_track_cache.h
--- a/includes/acl/decompression/impl/transform_constant_track_cache.h
+++ b/includes/acl/decompression/impl/transform_constant_track_cache.h
@@ -80,7 +80,7 @@ namespace acl
// CMU has 64.41%, Paragon has 47.69%, and Fortnite has 62.84%.
// Following these numbers, it is common for clips to have at least 10 constant rotation samples to unpack.
- track_cache_quatf_v0<32> rotations;
+ track_cache_quatf_v0<32, 1> rotations;
// Points to our packed sub-track data
const uint8_t* constant_data_rotations;
@@ -126,7 +126,7 @@ namespace acl
rotations.cache_write_index += num_to_unpack;
const uint8_t* constant_track_data = constant_data_rotations;
- rtm::quatf* cache_ptr = &rotations.cached_samples[cache_write_index];
+ rtm::quatf* cache_ptr = &rotations.cached_samples[0][cache_write_index];
if (rotation_format == rotation_format8::quatf_full && decompression_settings_type::is_rotation_format_supported(rotation_format8::quatf_full))
{
@@ -188,7 +188,7 @@ namespace acl
num_to_unpack = std::min<uint32_t>(num_left_to_unpack, 16);
for (uint32_t unpack_index = 0; unpack_index < num_to_unpack; ++unpack_index)
{
- const rtm::quatf rotation = rotations.cached_samples[cache_write_index + unpack_index];
+ const rtm::quatf rotation = rotations.cached_samples[0][cache_write_index + unpack_index];
ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
@@ -257,7 +257,7 @@ namespace acl
{
ACL_ASSERT(rotations.cache_read_index < rotations.cache_write_index, "Attempting to consume a constant sample that isn't cached");
const uint32_t cache_read_index = rotations.cache_read_index++;
- return rotations.cached_samples[cache_read_index % 32];
+ return rotations.cached_samples[0][cache_read_index % 32];
}
RTM_DISABLE_SECURITY_COOKIE_CHECK void skip_translation_groups(uint32_t num_groups_to_skip)
diff --git a/includes/acl/decompression/impl/transform_decompression_context.h b/includes/acl/decompression/impl/transform_decompression_context.h
--- a/includes/acl/decompression/impl/transform_decompression_context.h
+++ b/includes/acl/decompression/impl/transform_decompression_context.h
@@ -70,9 +70,10 @@ namespace acl
uint8_t looping_policy; // 21 | 29
- uint8_t padding0[21]; // 22 | 30
+ uint8_t padding0[20]; // 22 | 30
// Seeking related data
+ uint8_t rounding_policy; // 42 | 50
uint8_t uses_single_segment; // 43 | 51
float sample_time; // 44 | 52
@@ -89,6 +90,7 @@ namespace acl
float interpolation_alpha; // 88 | 120
+ // Can't have a 0 byte array, add a whole cache line as padding
uint8_t padding1[sizeof(void*) == 4 ? 36 : 4]; // 92 | 124
// Total size: 128 | 128
@@ -98,6 +100,7 @@ namespace acl
const compressed_tracks* get_compressed_tracks() const { return tracks; }
compressed_tracks_version16 get_version() const { return tracks->get_version(); }
sample_looping_policy get_looping_policy() const { return static_cast<sample_looping_policy>(looping_policy); }
+ sample_rounding_policy get_rounding_policy() const { return static_cast<sample_rounding_policy>(rounding_policy); }
bool is_initialized() const { return tracks != nullptr; }
void reset() { tracks = nullptr; }
};
@@ -114,6 +117,7 @@ namespace acl
static constexpr range_reduction_flags8 get_range_reduction_flag() { return range_reduction_flags8::translations; }
static constexpr vector_format8 get_vector_format(const persistent_transform_decompression_context_v0& context) { return context.translation_format; }
static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_translation_format_supported(format); }
+ static constexpr bool is_per_track_rounding_supported() { return decompression_settings_type::is_per_track_rounding_supported(); }
};
template<class decompression_settings_type>
@@ -123,6 +127,7 @@ namespace acl
static constexpr range_reduction_flags8 get_range_reduction_flag() { return range_reduction_flags8::scales; }
static constexpr vector_format8 get_vector_format(const persistent_transform_decompression_context_v0& context) { return context.scale_format; }
static constexpr bool is_vector_format_supported(vector_format8 format) { return decompression_settings_type::is_scale_format_supported(format); }
+ static constexpr bool is_per_track_rounding_supported() { return decompression_settings_type::is_per_track_rounding_supported(); }
};
// Returns the statically known number of rotation formats supported by the decompression settings
diff --git a/includes/acl/decompression/impl/transform_track_decompression.h b/includes/acl/decompression/impl/transform_track_decompression.h
--- a/includes/acl/decompression/impl/transform_track_decompression.h
+++ b/includes/acl/decompression/impl/transform_track_decompression.h
@@ -32,8 +32,8 @@
#include "acl/core/range_reduction_types.h"
#include "acl/core/track_formats.h"
#include "acl/core/track_writer.h"
-#include "acl/core/variable_bit_rates.h"
#include "acl/core/impl/compiler_utils.h"
+#include "acl/core/impl/variable_bit_rates.h"
#include "acl/decompression/database/database.h"
#include "acl/decompression/impl/transform_animated_track_cache.h"
#include "acl/decompression/impl/transform_constant_track_cache.h"
@@ -162,7 +162,7 @@ namespace acl
if (decompression_settings_type::clamp_sample_time())
sample_time = rtm::scalar_clamp(sample_time, 0.0F, context.clip_duration);
- if (context.sample_time == sample_time)
+ if (context.sample_time == sample_time && context.get_rounding_policy() == rounding_policy)
return;
const transform_tracks_header& transform_header = get_transform_tracks_header(*context.tracks);
@@ -186,6 +186,8 @@ namespace acl
uint32_t key_frame1;
find_linear_interpolation_samples_with_sample_rate(header.num_samples, header.sample_rate, sample_time, rounding_policy, looping_policy_, key_frame0, key_frame1, context.interpolation_alpha);
+ context.rounding_policy = static_cast<uint8_t>(rounding_policy);
+
uint32_t segment_key_frame0;
uint32_t segment_key_frame1;
@@ -256,7 +258,9 @@ namespace acl
key_frame1 = count_leading_zeros(candidate_indices1);
// Calculate our new interpolation alpha
- context.interpolation_alpha = find_linear_interpolation_alpha(sample_index, key_frame0, key_frame1, rounding_policy);
+ // We used the rounding policy above to snap to the correct key frame earlier but we might need to interpolate now
+ // if key frames have been removed
+ context.interpolation_alpha = find_linear_interpolation_alpha(sample_index, key_frame0, key_frame1, sample_rounding_policy::none);
// Find where our data lives (clip or database tier X)
sample_indices0 = segment_tier0_header0->sample_indices;
@@ -408,7 +412,9 @@ namespace acl
const uint32_t clip_key_frame1 = segment_start_indices[segment_index1] + segment_key_frame1;
// Calculate our new interpolation alpha
- context.interpolation_alpha = find_linear_interpolation_alpha(sample_index, clip_key_frame0, clip_key_frame1, rounding_policy);
+ // We used the rounding policy above to snap to the correct key frame earlier but we might need to interpolate now
+ // if key frames have been removed
+ context.interpolation_alpha = find_linear_interpolation_alpha(sample_index, clip_key_frame0, clip_key_frame1, sample_rounding_policy::none);
// Find where our data lives (clip or database tier X)
sample_indices0 = segment_tier0_header0->sample_indices;
@@ -504,6 +510,9 @@ namespace acl
// TODO: Merge the per track format and segment range info into a single buffer? Less to prefetch and used together
// TODO: Remove segment data alignment, no longer required?
+ // TODO: sample_rounding_policy ends up being signed extended on x64 from a 32 bit value into 64 bit (edx -> rax)
+ // I tried using uint32_t and uint64_t as its underlying type but code generation remained the same
+ // Would using a raw uint32_t below instead of the typed enum help avoid the extra instruction?
// Force inline this function, we only use it to keep the code readable
@@ -690,6 +699,8 @@ namespace acl
const persistent_transform_decompression_context_v0& context,
animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
{
+ const sample_rounding_policy rounding_policy = context.get_rounding_policy();
+
for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
{
// Mask out everything but animated sub-tracks, this way we can early out when we iterate
@@ -720,7 +731,19 @@ namespace acl
if ((packed_group & 0x80000000) != 0)
{
const uint32_t track_index0 = curr_group_track_index + 0;
- const rtm::quatf& rotation = animated_track_cache.consume_rotation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index0) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::quatf& rotation = animated_track_cache.consume_rotation(rounding_policy_);
ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
@@ -732,7 +755,19 @@ namespace acl
if ((packed_group & 0x20000000) != 0)
{
const uint32_t track_index1 = curr_group_track_index + 1;
- const rtm::quatf& rotation = animated_track_cache.consume_rotation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index1) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::quatf& rotation = animated_track_cache.consume_rotation(rounding_policy_);
ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
@@ -744,7 +779,19 @@ namespace acl
if ((packed_group & 0x08000000) != 0)
{
const uint32_t track_index2 = curr_group_track_index + 2;
- const rtm::quatf& rotation = animated_track_cache.consume_rotation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index2) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::quatf& rotation = animated_track_cache.consume_rotation(rounding_policy_);
ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
@@ -756,7 +803,19 @@ namespace acl
if ((packed_group & 0x02000000) != 0)
{
const uint32_t track_index3 = curr_group_track_index + 3;
- const rtm::quatf& rotation = animated_track_cache.consume_rotation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index3) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::quatf& rotation = animated_track_cache.consume_rotation(rounding_policy_);
ACL_ASSERT(rtm::quat_is_finite(rotation), "Rotation is not valid!");
ACL_ASSERT(rtm::quat_is_normalized(rotation), "Rotation is not normalized!");
@@ -962,12 +1021,14 @@ namespace acl
}
// Force inline this function, we only use it to keep the code readable
- template<class translation_adapter, class track_writer_type>
+ template<class decompression_settings_adapter_type, class track_writer_type>
RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_animated_translation_sub_tracks(
const packed_sub_track_types* translation_sub_track_types, uint32_t last_entry_index,
const persistent_transform_decompression_context_v0& context,
animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
{
+ const sample_rounding_policy rounding_policy = context.get_rounding_policy();
+
for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
{
// Mask out everything but animated sub-tracks, this way we can early out when we iterate
@@ -993,12 +1054,24 @@ namespace acl
continue; // This group contains no animated sub-tracks, skip it
// Unpack our next 4 tracks
- animated_track_cache.unpack_translation_group<translation_adapter>(context);
+ animated_track_cache.unpack_translation_group<decompression_settings_adapter_type>(context);
if ((packed_group & 0x80000000) != 0)
{
const uint32_t track_index0 = curr_group_track_index + 0;
- const rtm::vector4f& translation = animated_track_cache.consume_translation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index0) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& translation = animated_track_cache.consume_translation(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
@@ -1009,7 +1082,19 @@ namespace acl
if ((packed_group & 0x20000000) != 0)
{
const uint32_t track_index1 = curr_group_track_index + 1;
- const rtm::vector4f& translation = animated_track_cache.consume_translation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index1) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& translation = animated_track_cache.consume_translation(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
@@ -1020,7 +1105,19 @@ namespace acl
if ((packed_group & 0x08000000) != 0)
{
const uint32_t track_index2 = curr_group_track_index + 2;
- const rtm::vector4f& translation = animated_track_cache.consume_translation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index2) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& translation = animated_track_cache.consume_translation(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
@@ -1031,7 +1128,19 @@ namespace acl
if ((packed_group & 0x02000000) != 0)
{
const uint32_t track_index3 = curr_group_track_index + 3;
- const rtm::vector4f& translation = animated_track_cache.consume_translation();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index3) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& translation = animated_track_cache.consume_translation(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(translation), "Translation is not valid!");
@@ -1241,12 +1350,14 @@ namespace acl
}
// Force inline this function, we only use it to keep the code readable
- template<class scale_adapter, class track_writer_type>
+ template<class decompression_settings_adapter_type, class track_writer_type>
RTM_FORCE_INLINE RTM_DISABLE_SECURITY_COOKIE_CHECK void RTM_SIMD_CALL unpack_animated_scale_sub_tracks(
const packed_sub_track_types* scale_sub_track_types, uint32_t last_entry_index,
const persistent_transform_decompression_context_v0& context,
animated_track_cache_v0& animated_track_cache, track_writer_type& writer)
{
+ const sample_rounding_policy rounding_policy = context.get_rounding_policy();
+
for (uint32_t entry_index = 0, track_index = 0; entry_index <= last_entry_index; ++entry_index)
{
// Mask out everything but animated sub-tracks, this way we can early out when we iterate
@@ -1272,12 +1383,24 @@ namespace acl
continue; // This group contains no animated sub-tracks, skip it
// Unpack our next 4 tracks
- animated_track_cache.unpack_scale_group<scale_adapter>(context);
+ animated_track_cache.unpack_scale_group<decompression_settings_adapter_type>(context);
if ((packed_group & 0x80000000) != 0)
{
const uint32_t track_index0 = curr_group_track_index + 0;
- const rtm::vector4f& scale = animated_track_cache.consume_scale();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index0) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& scale = animated_track_cache.consume_scale(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
@@ -1288,7 +1411,19 @@ namespace acl
if ((packed_group & 0x20000000) != 0)
{
const uint32_t track_index1 = curr_group_track_index + 1;
- const rtm::vector4f& scale = animated_track_cache.consume_scale();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index1) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& scale = animated_track_cache.consume_scale(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
@@ -1299,7 +1434,19 @@ namespace acl
if ((packed_group & 0x08000000) != 0)
{
const uint32_t track_index2 = curr_group_track_index + 2;
- const rtm::vector4f& scale = animated_track_cache.consume_scale();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index2) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& scale = animated_track_cache.consume_scale(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
@@ -1310,7 +1457,19 @@ namespace acl
if ((packed_group & 0x02000000) != 0)
{
const uint32_t track_index3 = curr_group_track_index + 3;
- const rtm::vector4f& scale = animated_track_cache.consume_scale();
+
+ // We need the true rounding policy to be statically known when per track rounding is not supported
+ // When it isn't supported, we always use 'none' since the interpolation alpha was properly calculated
+ // and rounding has already been performed for us.
+ const sample_rounding_policy rounding_policy_ =
+ decompression_settings_adapter_type::is_per_track_rounding_supported() &&
+ rounding_policy == sample_rounding_policy::per_track ?
+ writer.get_rounding_policy(track_index3) :
+ sample_rounding_policy::none;
+
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ const rtm::vector4f& scale = animated_track_cache.consume_scale(rounding_policy_);
ACL_ASSERT(rtm::vector_is_finite3(scale), "Scale is not valid!");
@@ -1768,6 +1927,16 @@ namespace acl
// Finally reached our desired track, unpack it
+ float interpolation_alpha = context.interpolation_alpha;
+ if (decompression_settings_type::is_per_track_rounding_supported())
+ {
+ const sample_rounding_policy rounding_policy = context.get_rounding_policy();
+ const sample_rounding_policy rounding_policy_ = rounding_policy == sample_rounding_policy::per_track ? writer.get_rounding_policy(track_index) : rounding_policy;
+ ACL_ASSERT(rounding_policy_ != sample_rounding_policy::per_track, "track_writer::get_rounding_policy() cannot return per_track");
+
+ interpolation_alpha = apply_rounding_policy(interpolation_alpha, rounding_policy_);
+ }
+
if (rotation_sub_track_type == 0)
{
if (default_rotation_mode != default_sub_track_mode::skipped)
@@ -1784,7 +1953,7 @@ namespace acl
if (rotation_sub_track_type & 1)
rotation = constant_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_sample_index);
else
- rotation = animated_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_sample_index);
+ rotation = animated_track_cache.unpack_rotation_within_group<decompression_settings_type>(context, rotation_group_sample_index, interpolation_alpha);
writer.write_rotation(track_index, rotation);
}
@@ -1805,7 +1974,7 @@ namespace acl
if (translation_sub_track_type & 1)
translation = constant_track_cache.unpack_translation_within_group(translation_group_sample_index);
else
- translation = animated_track_cache.unpack_translation_within_group<translation_adapter>(context, translation_group_sample_index);
+ translation = animated_track_cache.unpack_translation_within_group<translation_adapter>(context, translation_group_sample_index, interpolation_alpha);
writer.write_translation(track_index, translation);
}
@@ -1826,7 +1995,7 @@ namespace acl
if (scale_sub_track_type & 1)
scale = constant_track_cache.unpack_scale_within_group(scale_group_sample_index);
else
- scale = animated_track_cache.unpack_scale_within_group<scale_adapter>(context, scale_group_sample_index);
+ scale = animated_track_cache.unpack_scale_within_group<scale_adapter>(context, scale_group_sample_index, interpolation_alpha);
writer.write_scale(track_index, scale);
}
diff --git a/tools/acl_compressor/includes/acl_compressor.h b/tools/acl_compressor/includes/acl_compressor.h
--- a/tools/acl_compressor/includes/acl_compressor.h
+++ b/tools/acl_compressor/includes/acl_compressor.h
@@ -28,3 +28,33 @@ bool is_acl_sjson_file(const char* filename);
bool is_acl_bin_file(const char* filename);
int main_impl(int argc, char* argv[]);
+
+#if defined(ACL_USE_SJSON)
+#include "acl/core/compressed_database.h"
+#include "acl/core/compressed_tracks.h"
+#include "acl/core/iallocator.h"
+#include "acl/compression/compression_settings.h"
+#include "acl/compression/track_array.h"
+#include "acl/compression/transform_error_metrics.h"
+#include "acl/decompression/decompression_settings.h"
+
+void validate_accuracy(acl::iallocator& allocator,
+ const acl::track_array_qvvf& raw_tracks, const acl::track_array_qvvf& additive_base_tracks,
+ const acl::itransform_error_metric& error_metric,
+ const acl::compressed_tracks& compressed_tracks_,
+ double regression_error_threshold);
+
+void validate_accuracy(acl::iallocator& allocator, const acl::track_array& raw_tracks, const acl::compressed_tracks& tracks, double regression_error_threshold);
+
+void validate_metadata(const acl::track_array& raw_tracks, const acl::compressed_tracks& tracks);
+void validate_convert(acl::iallocator& allocator, const acl::track_array& raw_tracks);
+
+void validate_db(acl::iallocator& allocator, const acl::track_array_qvvf& raw_tracks, const acl::track_array_qvvf& additive_base_tracks,
+ const acl::compression_database_settings& settings, const acl::itransform_error_metric& error_metric,
+ const acl::compressed_tracks& compressed_tracks0, const acl::compressed_tracks& compressed_tracks1);
+
+struct debug_transform_decompression_settings_with_db final : public acl::debug_transform_decompression_settings
+{
+ using database_settings_type = acl::debug_database_settings;
+};
+#endif
diff --git a/tools/acl_compressor/sources/acl_compressor.cpp b/tools/acl_compressor/sources/acl_compressor.cpp
--- a/tools/acl_compressor/sources/acl_compressor.cpp
+++ b/tools/acl_compressor/sources/acl_compressor.cpp
@@ -392,16 +392,6 @@ static bool parse_options(int argc, char** argv, Options& options)
}
#if defined(ACL_USE_SJSON)
-#if defined(ACL_HAS_ASSERT_CHECKS)
-// We extern our regression test functions for simplicity
-extern void validate_accuracy(iallocator& allocator, const track_array_qvvf& raw_tracks, const track_array_qvvf& additive_base_tracks, const itransform_error_metric& error_metric, const compressed_tracks& compressed_tracks_, double regression_error_threshold);
-extern void validate_accuracy(iallocator& allocator, const track_array& raw_tracks, const compressed_tracks& tracks, double regression_error_threshold);
-extern void validate_metadata(const track_array& raw_tracks, const compressed_tracks& tracks);
-extern void validate_convert(iallocator& allocator, const track_array& raw_tracks);
-extern void validate_db(iallocator& allocator, const track_array_qvvf& raw_tracks, const track_array_qvvf& additive_base_tracks,
- const compression_database_settings& settings, const itransform_error_metric& error_metric,
- const compressed_tracks& compressed_tracks0, const compressed_tracks& compressed_tracks1);
-#endif
static void try_algorithm(const Options& options, iallocator& allocator, const track_array_qvvf& transform_tracks,
const track_array_qvvf& additive_base, additive_clip_format8 additive_format,
diff --git a/tools/acl_compressor/sources/validate_database.cpp b/tools/acl_compressor/sources/validate_database.cpp
--- a/tools/acl_compressor/sources/validate_database.cpp
+++ b/tools/acl_compressor/sources/validate_database.cpp
@@ -40,11 +40,6 @@
using namespace acl;
#if defined(ACL_USE_SJSON) && defined(ACL_HAS_ASSERT_CHECKS)
-struct debug_transform_decompression_settings_with_db final : public acl::debug_transform_decompression_settings
-{
- using database_settings_type = acl::debug_database_settings;
-};
-
static void stream_in_database_tier(database_context<debug_database_settings>& context, const debug_database_streamer& streamer, const compressed_database& db, quality_tier tier)
{
const uint32_t num_chunks = db.get_num_chunks(tier);
diff --git a/tools/acl_compressor/sources/validate_tracks.cpp b/tools/acl_compressor/sources/validate_tracks.cpp
--- a/tools/acl_compressor/sources/validate_tracks.cpp
+++ b/tools/acl_compressor/sources/validate_tracks.cpp
@@ -46,7 +46,7 @@ void validate_transform_tracks(const acl::acl_impl::debug_track_writer& referenc
// Make sure constant default sub-tracks match the skipped sub-tracks
const rtm::qvvf transform = tracks.read_qvv(track_index);
- ACL_ASSERT(rtm::vector_all_near_equal(rtm::quat_to_vector(ref_transform.rotation), rtm::quat_to_vector(transform.rotation), quat_error_threshold), "Failed to sample bone index: %u", track_index);
+ ACL_ASSERT(rtm::vector_all_near_equal(rtm::quat_to_vector(rtm::quat_ensure_positive_w(ref_transform.rotation)), rtm::quat_to_vector(rtm::quat_ensure_positive_w(transform.rotation)), quat_error_threshold), "Failed to sample bone index: %u", track_index);
ACL_ASSERT(rtm::vector_all_near_equal3(ref_transform.translation, transform.translation, vec3_error_threshold), "Failed to sample bone index: %u", track_index);
ACL_ASSERT(rtm::vector_all_near_equal3(ref_transform.scale, transform.scale, vec3_error_threshold), "Failed to sample bone index: %u", track_index);
}
@@ -93,12 +93,12 @@ void validate_accuracy(
ACL_ASSERT(error.error < regression_error_threshold, "Error too high for bone %u: %f at time %f", error.index, error.error, error.sample_time);
const uint32_t num_tracks = compressed_tracks_.get_num_tracks();
- const float clip_duration = compressed_tracks_.get_finite_duration();
+ const float duration = compressed_tracks_.get_finite_duration();
const float sample_rate = compressed_tracks_.get_sample_rate();
// Calculate the number of samples from the duration to account for the repeating
// first frame at the end when wrapping is used
- const uint32_t num_samples = calculate_num_samples(clip_duration, sample_rate);
+ const uint32_t num_samples = calculate_num_samples(duration, sample_rate);
debug_track_writer track_writer(allocator, track_type8::qvvf, num_tracks);
track_writer.initialize_with_defaults(raw_tracks);
@@ -110,6 +110,9 @@ void validate_accuracy(
debug_track_writer_variable_defaults track_writer_variable(allocator, track_type8::qvvf, num_tracks);
track_writer_variable.default_sub_tracks = track_writer.tracks_typed.qvvf;
+ debug_track_writer_per_track_rounding track_writer_per_track_rounding(allocator, track_type8::qvvf, num_tracks);
+ track_writer_per_track_rounding.initialize_with_defaults(raw_tracks);
+
{
// Try to decompress something at 0.0, if we have no tracks or samples, it should be handled
context.seek(0.0F, rounding_policy);
@@ -118,6 +121,7 @@ void validate_accuracy(
context.decompress_tracks(track_writer_variable);
}
+ // Basic sanity checks
if (num_samples != 0)
{
debug_track_writer track_writer_clamped(allocator, track_type8::qvvf, num_tracks);
@@ -130,7 +134,7 @@ void validate_accuracy(
validate_transform_tracks(track_writer, track_writer_clamped, quat_error_threshold, vec3_error_threshold);
// Make sure clamping works properly at the end of the clip
- const float last_sample_time = rtm::scalar_min(float(num_samples - 1) / sample_rate, clip_duration);
+ const float last_sample_time = rtm::scalar_min(float(num_samples - 1) / sample_rate, duration);
// When using the wrap looping policy, the last sample time will yield the first sample since we completely wrap
context.seek(last_sample_time, rounding_policy);
@@ -141,12 +145,31 @@ void validate_accuracy(
context.decompress_tracks(track_writer_clamped);
validate_transform_tracks(track_writer, track_writer_clamped, quat_error_threshold, vec3_error_threshold);
+
+ // Test a few samples with all rounding modes per track
+ const float sample_times[] = { 0.0F, duration * 0.2F, duration * 0.5F, duration * 0.75F, duration };
+ const sample_rounding_policy rounding_policies[] = { sample_rounding_policy::none, sample_rounding_policy::floor, sample_rounding_policy::ceil, sample_rounding_policy::nearest };
+
+ for (float sample_time : make_iterator(sample_times))
+ {
+ for (sample_rounding_policy policy : make_iterator(rounding_policies))
+ {
+ context.seek(sample_time, policy);
+ context.decompress_tracks(track_writer);
+
+ track_writer_per_track_rounding.rounding_policy = policy;
+ context.seek(sample_time, sample_rounding_policy::per_track);
+ context.decompress_tracks(track_writer_per_track_rounding);
+
+ validate_transform_tracks(track_writer, track_writer_per_track_rounding, quat_error_threshold, vec3_error_threshold);
+ }
+ }
}
// Regression test
for (uint32_t sample_index = 0; sample_index < num_samples; ++sample_index)
{
- const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, clip_duration);
+ const float sample_time = rtm::scalar_min(float(sample_index) / sample_rate, duration);
// We use the nearest sample to accurately measure the loss that happened, if any
context.seek(sample_time, rounding_policy);
@@ -282,12 +305,15 @@ void validate_accuracy(
debug_track_writer lossy_tracks_writer(allocator, track_type, num_tracks);
debug_track_writer lossy_track_writer(allocator, track_type, num_tracks);
+ debug_track_writer_per_track_rounding track_writer_per_track_rounding(allocator, track_type, num_tracks);
+
{
// Try to decompress something at 0.0, if we have no tracks or samples, it should be handled
context.seek(0.0F, rounding_policy);
context.decompress_tracks(lossy_tracks_writer);
}
+ // Basic sanity checks
if (num_samples != 0)
{
debug_track_writer track_writer_clamped(allocator, track_type, num_tracks);
@@ -309,6 +335,25 @@ void validate_accuracy(
context.decompress_tracks(track_writer_clamped);
validate_scalar_tracks(raw_tracks, raw_tracks_writer, track_writer_clamped, regression_error_thresholdv, last_sample_time_clamp + 1.0F);
+
+ // Test a few samples with all rounding modes per track
+ const float sample_times[] = { 0.0F, duration * 0.2F, duration * 0.5F, duration * 0.75F, duration };
+ const sample_rounding_policy rounding_policies[] = { sample_rounding_policy::none, sample_rounding_policy::floor, sample_rounding_policy::ceil, sample_rounding_policy::nearest };
+
+ for (float sample_time : make_iterator(sample_times))
+ {
+ for (sample_rounding_policy policy : make_iterator(rounding_policies))
+ {
+ context.seek(sample_time, policy);
+ context.decompress_tracks(lossy_tracks_writer);
+
+ track_writer_per_track_rounding.rounding_policy = policy;
+ context.seek(sample_time, sample_rounding_policy::per_track);
+ context.decompress_tracks(track_writer_per_track_rounding);
+
+ validate_scalar_tracks(raw_tracks, lossy_tracks_writer, track_writer_per_track_rounding, regression_error_thresholdv, sample_time);
+ }
+ }
}
// Regression test
|
diff --git a/tests/sources/core/test_interpolation_utils.cpp b/tests/sources/core/test_interpolation_utils.cpp
--- a/tests/sources/core/test_interpolation_utils.cpp
+++ b/tests/sources/core/test_interpolation_utils.cpp
@@ -358,4 +358,18 @@ TEST_CASE("interpolation utils", "[core][utils]")
CHECK(scalar_near_equal(find_linear_interpolation_alpha(1.5F, 0, 2, sample_rounding_policy::nearest), 1.0F, error_threshold));
CHECK(scalar_near_equal(find_linear_interpolation_alpha(1.5F, 0, 3, sample_rounding_policy::nearest), 1.0F, error_threshold));
CHECK(scalar_near_equal(find_linear_interpolation_alpha(1.5F, 1, 4, sample_rounding_policy::nearest), 0.0F, error_threshold));
+
+ //////////////////////////////////////////////////////////////////////////
+
+ CHECK(scalar_near_equal(apply_rounding_policy(0.2F, sample_rounding_policy::none), 0.2F, error_threshold));
+ CHECK(apply_rounding_policy(0.2F, sample_rounding_policy::floor) == 0.0F);
+ CHECK(apply_rounding_policy(0.2F, sample_rounding_policy::ceil) == 1.0F);
+ CHECK(apply_rounding_policy(0.2F, sample_rounding_policy::nearest) == 0.0F);
+ CHECK(scalar_near_equal(apply_rounding_policy(0.2F, sample_rounding_policy::per_track), 0.2F, error_threshold));
+
+ CHECK(scalar_near_equal(apply_rounding_policy(0.8F, sample_rounding_policy::none), 0.8F, error_threshold));
+ CHECK(apply_rounding_policy(0.8F, sample_rounding_policy::floor) == 0.0F);
+ CHECK(apply_rounding_policy(0.8F, sample_rounding_policy::ceil) == 1.0F);
+ CHECK(apply_rounding_policy(0.8F, sample_rounding_policy::nearest) == 1.0F);
+ CHECK(scalar_near_equal(apply_rounding_policy(0.8F, sample_rounding_policy::per_track), 0.8F, error_threshold));
}
diff --git a/tests/sources/core/test_iterator.cpp b/tests/sources/core/test_iterator.cpp
--- a/tests/sources/core/test_iterator.cpp
+++ b/tests/sources/core/test_iterator.cpp
@@ -57,4 +57,11 @@ TEST_CASE("iterator", "[core][iterator]")
CHECK(i.begin() == items + 0);
CHECK(i.end() == items + num_items);
}
+
+ SECTION("make_iterator matches")
+ {
+ auto j = make_iterator(items);
+ CHECK(i.begin() == j.begin());
+ CHECK(i.end() == j.end());
+ }
}
diff --git a/tests/sources/math/test_scalar_packing.cpp b/tests/sources/math/test_scalar_packing.cpp
--- a/tests/sources/math/test_scalar_packing.cpp
+++ b/tests/sources/math/test_scalar_packing.cpp
@@ -24,7 +24,7 @@
#include <catch2/catch.hpp>
-#include <acl/core/variable_bit_rates.h>
+#include <acl/core/impl/variable_bit_rates.h>
#include <acl/math/scalar_packing.h>
#include <acl/math/vector4_packing.h>
@@ -124,9 +124,9 @@ TEST_CASE("unpack_scalarf_uXX_unsafe", "[math][scalar][packing]")
if (!scalar_near_equal(vector_get_x(vec0), scalar_cast(scalar1), 1.0E-6F))
num_errors++;
- for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
{
- uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
diff --git a/tests/sources/math/test_vector4_packing.cpp b/tests/sources/math/test_vector4_packing.cpp
--- a/tests/sources/math/test_vector4_packing.cpp
+++ b/tests/sources/math/test_vector4_packing.cpp
@@ -24,7 +24,7 @@
#include <catch2/catch.hpp>
-#include <acl/core/variable_bit_rates.h>
+#include <acl/core/impl/variable_bit_rates.h>
#include <acl/math/vector4_packing.h>
#include <rtm/scalarf.h>
@@ -154,9 +154,9 @@ TEST_CASE("pack_vector4_XX", "[math][vector4][packing]")
if (!vector_all_near_equal(vec0, vec1, 1.0E-6F))
num_errors++;
- for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
{
- uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -382,9 +382,9 @@ TEST_CASE("pack_vector3_XX", "[math][vector4][packing]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
- for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
{
- uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -449,9 +449,9 @@ TEST_CASE("decay_vector3_XX", "[math][vector4][decay]")
if (!vector_all_near_equal3(vec0, vec1, 1.0E-6F))
num_errors++;
- for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
{
- uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
@@ -518,9 +518,9 @@ TEST_CASE("pack_vector2_XX", "[math][vector4][packing]")
if (!vector_all_near_equal2(vec0, vec1, 1.0E-6F))
num_errors++;
- for (uint8_t bit_rate = 1; bit_rate < k_highest_bit_rate; ++bit_rate)
+ for (uint8_t bit_rate = 1; bit_rate < acl_impl::k_highest_bit_rate; ++bit_rate)
{
- uint32_t num_bits = get_num_bits_at_bit_rate(bit_rate);
+ uint32_t num_bits = acl_impl::get_num_bits_at_bit_rate(bit_rate);
uint32_t max_value = (1 << num_bits) - 1;
for (uint32_t value = 0; value <= max_value; ++value)
{
|
Add support for per sub-track sample rounding mode
In certain circumstances, tracks need different rounding modes when sampling. For example, an IK target might move and we would like to not interpolate between certain samples or any of its samples. Another case might be a looping clip that has root motion where wrapping is used. We would want to interpolate the whole pose, but snap the root motion to the nearest sample to avoid interpolating the start/end samples together. This is ideally not how looping clips with root motion should be handled as it strips some of the root motion out that way but it should be supported by ACL.
Technically, this can already be supported by splitting clips into multiple clips through bind pose stripping and decompressing them one by one with their relevant rounding mode. While this works, it isn't very efficient as the clip header and some of the metadata will be duplicated.
To do so, the decompression settings should specify whether to use the rounding mode provided to the seek function or to query the track writer for the rounding mode for each sub-track. Something like `per-sub-track-rounding-mode-supported()`. Since this feature isn't commonly needed, it should be possible for host runtimes to disable it during code generation to ensure optimal performance.
A new rounding mode should be introduced `per_sub_track` and code should handle it where relevant.
During decompression, if the per sub-track rounding mode is used, we should query it for animated sub-tracks. That rounding mode can then only influence the interpolation alpha since the samples we use cannot change since they depend on the sampling time. The new rounding mode can then be used to snap the interpolation alpha to the correct position.
| 2022-04-14T02:58:32
|
cpp
|
Hard
|
|
cpputest/cpputest
| 1,785
|
cpputest__cpputest-1785
|
[
"1784"
] |
49bae1944af67053f7560df3e99cbefc3e120b83
|
diff --git a/.github/workflows/basic.yml b/.github/workflows/basic.yml
--- a/.github/workflows/basic.yml
+++ b/.github/workflows/basic.yml
@@ -78,7 +78,7 @@ jobs:
steps:
- name: Checkout
uses: actions/checkout@main
- - run: brew install automake
+ - run: brew install automake libtool
if: ${{ startswith(matrix.os, 'macos') }}
- if: ${{ matrix.cxx }}
run: echo "CXX=${{ matrix.cxx }}" >> $GITHUB_ENV
diff --git a/CppUTest.vcproj b/CppUTest.vcproj
--- a/CppUTest.vcproj
+++ b/CppUTest.vcproj
@@ -41,7 +41,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="0"
- AdditionalIncludeDirectories=".\include\Platforms\VisualCpp,.\include"
+ AdditionalIncludeDirectories=".\include"
PreprocessorDefinitions="WIN32;_DEBUG;_LIB;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG"
BasicRuntimeChecks="3"
RuntimeLibrary="3"
@@ -112,7 +112,7 @@
Name="VCCLCompilerTool"
Optimization="0"
InlineFunctionExpansion="1"
- AdditionalIncludeDirectories=".\include\Platforms\VisualCpp,.\include"
+ AdditionalIncludeDirectories=".\include"
PreprocessorDefinitions="WIN32;NDEBUG;_LIB;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG"
StringPooling="true"
RuntimeLibrary="0"
diff --git a/CppUTest.vcxproj b/CppUTest.vcxproj
--- a/CppUTest.vcxproj
+++ b/CppUTest.vcxproj
@@ -74,7 +74,7 @@
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Debug|Win32'">
<ClCompile>
<Optimization>Disabled</Optimization>
- <AdditionalIncludeDirectories>.\include;.\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>.\include;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<PreprocessorDefinitions>_LIB;WIN32;_DEBUG;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG;%(PreprocessorDefinitions)</PreprocessorDefinitions>
<BasicRuntimeChecks>EnableFastChecks</BasicRuntimeChecks>
<RuntimeLibrary>MultiThreadedDebugDLL</RuntimeLibrary>
@@ -106,7 +106,7 @@
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Debug|x64'">
<ClCompile>
<Optimization>Disabled</Optimization>
- <AdditionalIncludeDirectories>.\include;.\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>.\include;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<PreprocessorDefinitions>_LIB;WIN32;_DEBUG;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG;%(PreprocessorDefinitions)</PreprocessorDefinitions>
<BasicRuntimeChecks>EnableFastChecks</BasicRuntimeChecks>
<RuntimeLibrary>MultiThreadedDebugDLL</RuntimeLibrary>
@@ -138,7 +138,7 @@
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Release|Win32'">
<ClCompile>
<Optimization>Disabled</Optimization>
- <AdditionalIncludeDirectories>.\include;.\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>.\include;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<InlineFunctionExpansion>OnlyExplicitInline</InlineFunctionExpansion>
<PreprocessorDefinitions>WIN32;NDEBUG;_LIB;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG;%(PreprocessorDefinitions)</PreprocessorDefinitions>
<StringPooling>true</StringPooling>
@@ -173,7 +173,7 @@
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Release|x64'">
<ClCompile>
<Optimization>Disabled</Optimization>
- <AdditionalIncludeDirectories>.\include;.\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>.\include;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<InlineFunctionExpansion>OnlyExplicitInline</InlineFunctionExpansion>
<PreprocessorDefinitions>WIN32;NDEBUG;_LIB;STDC_WANT_SECURE_LIB;CPPUTEST_USE_LONG_LONG;%(PreprocessorDefinitions)</PreprocessorDefinitions>
<StringPooling>true</StringPooling>
diff --git a/build/alltests.mmp b/build/alltests.mmp
--- a/build/alltests.mmp
+++ b/build/alltests.mmp
@@ -29,7 +29,7 @@ TARGET cpputest.exe
TARGETTYPE exe
UID 0x00000000 0x03A6305A
-USERINCLUDE ..\include ..\include\CppUTest ..\include\Platforms\Symbian ..\tests
+USERINCLUDE ..\include ..\include\CppUTest ..\tests
SYSTEMINCLUDE \epoc32\include \epoc32\include\stdapis
STATICLIBRARY libcrt0.lib
diff --git a/build/cpputest.mmp b/build/cpputest.mmp
--- a/build/cpputest.mmp
+++ b/build/cpputest.mmp
@@ -29,7 +29,7 @@ TARGET cpputest.lib
TARGETTYPE LIB
UID 0x00000000 0x03A6305A
-USERINCLUDE ..\include ..\include\CppUTest ..\include\Platforms\Symbian
+USERINCLUDE ..\include ..\include\CppUTest
SYSTEMINCLUDE \epoc32\include \epoc32\include\stdapis
SOURCEPATH ..\src\CppUTest
diff --git a/cmake/warnings.cmake b/cmake/warnings.cmake
--- a/cmake/warnings.cmake
+++ b/cmake/warnings.cmake
@@ -16,6 +16,7 @@ if(
-Wswitch-enum
-Wconversion
-Wsign-conversion
+ -Wmissing-include-dirs
-Wno-padded
-Wno-disabled-macro-expansion
-Wno-reserved-id-macro
diff --git a/examples/AllTests/AllTests.vcproj b/examples/AllTests/AllTests.vcproj
--- a/examples/AllTests/AllTests.vcproj
+++ b/examples/AllTests/AllTests.vcproj
@@ -45,7 +45,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="2"
- AdditionalIncludeDirectories="../../include,../../include/Platforms/VisualCpp,../ApplicationLib"
+ AdditionalIncludeDirectories="../../include,../ApplicationLib"
PreprocessorDefinitions="WIN32;NDEBUG;_CONSOLE"
BasicRuntimeChecks="0"
RuntimeLibrary="3"
@@ -140,7 +140,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="0"
- AdditionalIncludeDirectories="../../include,../../include/Platforms/VisualCpp,../ApplicationLib"
+ AdditionalIncludeDirectories="../../include,../ApplicationLib"
PreprocessorDefinitions="WIN32;_DEBUG;_CONSOLE"
BasicRuntimeChecks="3"
RuntimeLibrary="3"
diff --git a/examples/ApplicationLib/ApplicationLib.vcproj b/examples/ApplicationLib/ApplicationLib.vcproj
--- a/examples/ApplicationLib/ApplicationLib.vcproj
+++ b/examples/ApplicationLib/ApplicationLib.vcproj
@@ -42,7 +42,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="0"
- AdditionalIncludeDirectories="../../include,../../include/Platforms/VisualCpp"
+ AdditionalIncludeDirectories="../../include"
PreprocessorDefinitions="WIN32;_DEBUG;_LIB"
BasicRuntimeChecks="3"
RuntimeLibrary="3"
@@ -116,7 +116,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="2"
- AdditionalIncludeDirectories="../../include,../../include/Platforms/VisualCpp"
+ AdditionalIncludeDirectories="../../include"
PreprocessorDefinitions="WIN32;NDEBUG;_LIB"
BasicRuntimeChecks="0"
RuntimeLibrary="3"
diff --git a/platforms/Dos/Makefile b/platforms/Dos/Makefile
--- a/platforms/Dos/Makefile
+++ b/platforms/Dos/Makefile
@@ -18,7 +18,6 @@ COMMONFLAGS := \
-q -c -os -oc -d0 -we -w=3 -ml -zm \
-dCPPUTEST_MEM_LEAK_DETECTION_DISABLED=1 -dCPPUTEST_STD_CPP_LIB_DISABLED=1 \
-i$(call convert_paths,$(CPPUTEST_HOME)/include) \
- -i$(call convert_paths,$(CPPUTEST_HOME)/include/Platforms/Dos) \
-i$(call convert_paths,$(WATCOM)/h) -i$(call convert_paths,$(WATCOM)/h/nt) \
# Disable W303 unreferenced parameter - PUNUSED is GNU-specific
diff --git a/platforms/armcc/Makefile b/platforms/armcc/Makefile
--- a/platforms/armcc/Makefile
+++ b/platforms/armcc/Makefile
@@ -29,7 +29,6 @@ COMPONENT_NAME := CppUTest
INCLUDE_DIRS :=\
$(CPPUTEST_HOME)/include \
- $(CPPUTEST_HOME)/include/Platforms/armcc \
# armcc system include path
SYS_INCLUDE_DIRS:=$(KEIL_DIR)/include
diff --git a/scripts/VS2010Templates/CppUTest_VS2010.props b/scripts/VS2010Templates/CppUTest_VS2010.props
--- a/scripts/VS2010Templates/CppUTest_VS2010.props
+++ b/scripts/VS2010Templates/CppUTest_VS2010.props
@@ -2,9 +2,9 @@
<Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<ImportGroup Label="PropertySheets" />
<PropertyGroup Label="UserMacros">
- <CPPUTEST_INCLUDE_PATHS>$(CPPUTEST_HOME)\include;$(CPPUTEST_HOME)\include\CppUTestExt\CppUTestGTest;$(CPPUTEST_HOME)\include\CppUTestExt\CppUTestGMock;$(CPPUTEST_HOME)\include\Platforms\VisualCpp</CPPUTEST_INCLUDE_PATHS>
+ <CPPUTEST_INCLUDE_PATHS>$(CPPUTEST_HOME)\include;$(CPPUTEST_HOME)\include\CppUTestExt\CppUTestGTest;$(CPPUTEST_HOME)\include\CppUTestExt\CppUTestGMock</CPPUTEST_INCLUDE_PATHS>
<CPPUTEST_LIB_PATHS>$(CPPUTEST_HOME)\lib</CPPUTEST_LIB_PATHS>
- <CPPUTEST_FORCED_INCLUDES>$(CPPUTEST_HOME)\include\Platforms\VisualCpp\Platform.h;$(CPPUTEST_HOME)\include\CppUTest\MemoryLeakDetectorMallocMacros.h;</CPPUTEST_FORCED_INCLUDES>
+ <CPPUTEST_FORCED_INCLUDES>$(CPPUTEST_HOME)\include\CppUTest\MemoryLeakDetectorMallocMacros.h;</CPPUTEST_FORCED_INCLUDES>
<CPPUTEST_LIB_DEPENDENCIES>CppUTest.lib</CPPUTEST_LIB_DEPENDENCIES>
</PropertyGroup>
<PropertyGroup />
diff --git a/scripts/templates/ProjectTemplate/ProjectMakefile b/scripts/templates/ProjectTemplate/ProjectMakefile
--- a/scripts/templates/ProjectTemplate/ProjectMakefile
+++ b/scripts/templates/ProjectTemplate/ProjectMakefile
@@ -32,7 +32,6 @@ INCLUDE_DIRS =\
include \
include/* \
$(CPPUTEST_HOME)/include/ \
- $(CPPUTEST_HOME)/include/Platforms/Gcc\
mocks
CPPUTEST_WARNINGFLAGS = -Wall -Werror -Wswitch-default
diff --git a/src/CppUTest/CMakeLists.txt b/src/CppUTest/CMakeLists.txt
--- a/src/CppUTest/CMakeLists.txt
+++ b/src/CppUTest/CMakeLists.txt
@@ -53,9 +53,12 @@ if(CPPUTEST_PLATFORM)
PRIVATE
${CMAKE_CURRENT_LIST_DIR}/../Platforms/${CPPUTEST_PLATFORM}/UtestPlatform.cpp
)
+endif()
+
+if(CPPUTEST_PLATFORM STREQUAL "c2000")
target_include_directories(CppUTest
PUBLIC
- $<BUILD_INTERFACE:${CMAKE_CURRENT_LIST_DIR}/../../include/Platforms/${CPPUTEST_PLATFORM}>
+ $<BUILD_INTERFACE:${CMAKE_CURRENT_LIST_DIR}/../../include/Platforms/c2000>
)
endif()
|
diff --git a/tests/AllTests.vcproj b/tests/AllTests.vcproj
--- a/tests/AllTests.vcproj
+++ b/tests/AllTests.vcproj
@@ -45,7 +45,7 @@
Name="VCCLCompilerTool"
Optimization="0"
InlineFunctionExpansion="1"
- AdditionalIncludeDirectories="..\include,..\include\Platforms\VisualCpp"
+ AdditionalIncludeDirectories="..\include"
PreprocessorDefinitions="WIN32;NDEBUG;_CONSOLE;CPPUTEST_USE_LONG_LONG"
StringPooling="true"
RuntimeLibrary="0"
@@ -129,7 +129,7 @@
<Tool
Name="VCCLCompilerTool"
Optimization="0"
- AdditionalIncludeDirectories="..\include,..\include\Platforms\VisualCpp"
+ AdditionalIncludeDirectories="..\include"
PreprocessorDefinitions="_CONSOLE;WIN32;_DEBUG;CPPUTEST_USE_LONG_LONG"
BasicRuntimeChecks="3"
RuntimeLibrary="3"
diff --git a/tests/AllTests.vcxproj b/tests/AllTests.vcxproj
--- a/tests/AllTests.vcxproj
+++ b/tests/AllTests.vcxproj
@@ -92,7 +92,7 @@
<FunctionLevelLinking>true</FunctionLevelLinking>
<WarningLevel>Level3</WarningLevel>
<SuppressStartupBanner>true</SuppressStartupBanner>
- <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;..\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<DebugInformationFormat>OldStyle</DebugInformationFormat>
<TreatWarningAsError>true</TreatWarningAsError>
</ClCompile>
@@ -131,7 +131,7 @@
<FunctionLevelLinking>true</FunctionLevelLinking>
<WarningLevel>Level3</WarningLevel>
<SuppressStartupBanner>true</SuppressStartupBanner>
- <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;..\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<DebugInformationFormat>OldStyle</DebugInformationFormat>
<TreatWarningAsError>true</TreatWarningAsError>
</ClCompile>
@@ -162,7 +162,7 @@
</Midl>
<ClCompile>
<Optimization>Disabled</Optimization>
- <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;..\include\Platforms\VisualCpp;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>..\include;..\include\CppUTestExt\CppUTestGTest;..\include\CppUTestExt\CppUTestGMock;%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
<PreprocessorDefinitions>_CONSOLE;WIN32;_DEBUG;CPPUTEST_USE_LONG_LONG;%(PreprocessorDefinitions)</PreprocessorDefinitions>
<BasicRuntimeChecks>EnableFastChecks</BasicRuntimeChecks>
<RuntimeLibrary>MultiThreadedDebugDLL</RuntimeLibrary>
|
Can't compile CppUTest with GCC when `-Werror=missing-include-dirs` is set
Hi,
it seems that CppUTest is not able to compile with GCC when `-Werror=missing-include-dirs` is set, as the directory `include/Platforms/Gcc` does not exist:
```
cc1plus.exe: error: C:/mydir/.build/gcc-x86_64-w64-mingw32/Release/_deps/cpputest-src/src/CppUTest/../../include/Platforms/Gcc: No such file or directory [-Werror=missing-include-dirs]
```
(built with Windows 10, GCC from w64devkit 1.17.0, cmake 3.27.4)
As far as I see, there are two possible solutions:
1. Remove the missing directory from the following places:
- https://github.com/cpputest/cpputest/blob/49bae1944af67053f7560df3e99cbefc3e120b83/scripts/templates/ProjectTemplate/ProjectMakefile#L35
- https://github.com/cpputest/cpputest/blob/49bae1944af67053f7560df3e99cbefc3e120b83/platforms/Eclipse-Cygwin/.project#L1188
- Find a workaround for CMake: https://github.com/cpputest/cpputest/blob/49bae1944af67053f7560df3e99cbefc3e120b83/src/CppUTest/CMakeLists.txt#L58
- Possible workaround for CMake: only reffering to this directory if it exists
2. Create a dummy folder `include/Platforms/Gcc` with an empty `.gitkeep` file in it (to ensure that it is kept by git)
- Do this for the other major platforms mentioned in https://github.com/cpputest/cpputest/blob/49bae1944af67053f7560df3e99cbefc3e120b83/CMakeLists.txt#L68 as well
| 2024-04-23T03:03:32
|
cpp
|
Easy
|
|
cpputest/cpputest
| 1,620
|
cpputest__cpputest-1620
|
[
"1616"
] |
9137c6f2d52c6a9a5f9fb6c83fda191ca63c879f
|
diff --git a/.github/workflows/basic.yml b/.github/workflows/basic.yml
--- a/.github/workflows/basic.yml
+++ b/.github/workflows/basic.yml
@@ -108,7 +108,6 @@ jobs:
-B build
-S .
-D CMAKE_CXX_STANDARD=${{ matrix.cpp_version }}
- -D WERROR=ON
if: ${{ matrix.cpp_version }}
- name: Build
run: cmake --build build --verbose
diff --git a/.github/workflows/extended.yml b/.github/workflows/extended.yml
--- a/.github/workflows/extended.yml
+++ b/.github/workflows/extended.yml
@@ -37,8 +37,8 @@ jobs:
-B cpputest_build
-D CMAKE_BUILD_TYPE=Debug
-D CMAKE_CXX_STANDARD=11
- -D COVERAGE=ON
- -D LONGLONG=ON
+ -D CPPUTEST_COVERAGE=ON
+ -D CPPUTEST_EXAMPLES=OFF
- name: Build
run: cmake --build cpputest_build
- name: Test
diff --git a/CMakeLists.txt b/CMakeLists.txt
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -7,9 +7,9 @@ project(CppUTest
VERSION 4.0
)
-if (CMAKE_VERSION GREATER_EQUAL "3.21")
+if (CMAKE_VERSION VERSION_GREATER_EQUAL "3.21")
# PROJECT_IS_TOP_LEVEL is defined automatically
-elseif(CMAKE_CURRENT_BINARY_DIR STREQUAL CMAKE_BINARY_DIR)
+elseif (CMAKE_CURRENT_BINARY_DIR STREQUAL CMAKE_BINARY_DIR)
set(PROJECT_IS_TOP_LEVEL TRUE)
else()
set(PROJECT_IS_TOP_LEVEL FALSE)
@@ -24,26 +24,43 @@ if (EXISTS "${CMAKE_BINARY_DIR}/conanbuildinfo.cmake")
conan_basic_setup()
endif()
-option(STD_C "Use the standard C library" ON)
-option(STD_CPP "Use the standard C++ library" ON)
-option(CPPUTEST_FLAGS "Use the CFLAGS/CXXFLAGS/LDFLAGS set by CppUTest" ON)
-option(MEMORY_LEAK_DETECTION "Enable memory leak detection" ON)
-option(EXTENSIONS "Use the CppUTest extension library" ON)
-option(LONGLONG "Support long long" OFF)
-option(MAP_FILE "Enable the creation of a map file" OFF)
-option(COVERAGE "Enable running with coverage" OFF)
-option(WERROR "Compile with warnings as errors" OFF)
+include(CTest)
-option(TESTS "Compile and make tests for the code?" ON)
-option(TESTS_DETAILED "Run each test separately instead of grouped?" OFF)
-option(TESTS_BUILD_DISCOVER "Build time test discover" ON)
+include(CMakeDependentOption)
+option(CPPUTEST_STD_C_LIB_DISABLED "Disable the standard C library")
+cmake_dependent_option(CPPUTEST_STD_CPP_LIB_DISABLED "Use the standard C++ library"
+ OFF "NOT CPPUTEST_STD_C_LIB_DISABLED" ON)
+option(CPPUTEST_FLAGS "Use the CFLAGS/CXXFLAGS/LDFLAGS set by CppUTest" ON)
+cmake_dependent_option(CPPUTEST_MEM_LEAK_DETECTION_DISABLED "Enable memory leak detection"
+ OFF "NOT BORLAND;NOT CPPUTEST_STD_C_LIB_DISABLED" ON)
+option(CPPUTEST_EXTENSIONS "Use the CppUTest extension library" ON)
-option(EXAMPLES "Compile and make examples?" OFF)
+include(CheckTypeSize)
+check_type_size("long long" SIZEOF_LONGLONG)
+cmake_dependent_option(CPPUTEST_USE_LONG_LONG "Support long long"
+ YES "HAVE_SIZEOF_LONGLONG" OFF)
+
+cmake_dependent_option(CPPUTEST_MAP_FILE "Enable the creation of a map file"
+ OFF "NOT MSVC" OFF)
+cmake_dependent_option(CPPUTEST_COVERAGE "Enable running with coverage"
+ OFF "NOT MSVC" OFF)
+cmake_dependent_option(CPPUTEST_WERROR
+ "Compile with warnings as errors"
+ ON "PROJECT_IS_TOP_LEVEL" OFF
+)
+cmake_dependent_option(CPPUTEST_BUILD_TESTING "Compile and make tests for CppUTest"
+ ${PROJECT_IS_TOP_LEVEL} "BUILD_TESTING" OFF)
+option(CPPUTEST_TESTS_DETAILED "Run each test separately instead of grouped?" OFF)
+cmake_dependent_option(CPPUTEST_TEST_DISCOVERY "Build time test discover"
+ ON "CPPUTEST_BUILD_TESTING;NOT IAR" OFF)
-option(VERBOSE_CONFIG "Print configuration to stdout during generation" ON)
+option(CPPUTEST_EXAMPLES "Compile and make examples?" ${PROJECT_IS_TOP_LEVEL})
+option(CPPUTEST_VERBOSE_CONFIG "Print configuration to stdout during generation" ${PROJECT_IS_TOP_LEVEL})
-option(LIBNAME_POSTFIX_BITSIZE "Add architecture bitsize (32/64) to the library name?" OFF)
-option(LIBNAME_POSTFIX_DEBUG "Add indication of debug compilation to the library name?" OFF)
+cmake_dependent_option(CPPUTEST_LIBNAME_POSTFIX_BITSIZE "Add architecture bitsize (32/64) to the library name?"
+ OFF "PROJECT_IS_TOP_LEVEL" OFF)
+cmake_dependent_option(CPPUTEST_LIBNAME_POSTFIX_DEBUG "Add indication of debug compilation to the library name?"
+ OFF "PROJECT_IS_TOP_LEVEL" OFF)
if(CMAKE_PROJECT_NAME STREQUAL PROJECT_NAME) # Don't change users' build type.
# Multi-configuration generators don't have a single build type.
@@ -64,7 +81,7 @@ set(CppUTest_PKGCONFIG_FILE cpputest.pc)
set( CppUTestLibName "CppUTest" )
set( CppUTestExtLibName "CppUTestExt" )
-if(LIBNAME_POSTFIX_BITSIZE)
+if(CPPUTEST_LIBNAME_POSTFIX_BITSIZE)
if( "${CMAKE_SIZEOF_VOID_P}" STREQUAL "8" )
set( CppUTestLibName "${CppUTestLibName}64" )
set( CppUTestExtLibName "${CppUTestExtLibName}64" )
@@ -72,7 +89,7 @@ if(LIBNAME_POSTFIX_BITSIZE)
set( CppUTestLibName "${CppUTestLibName}32" )
set( CppUTestExtLibName "${CppUTestExtLibName}32" )
endif()
-endif(LIBNAME_POSTFIX_BITSIZE)
+endif()
list(APPEND CMAKE_MODULE_PATH "${CMAKE_CURRENT_SOURCE_DIR}/cmake/Modules")
if(NOT PROJECT_IS_TOP_LEVEL)
@@ -80,13 +97,10 @@ if(NOT PROJECT_IS_TOP_LEVEL)
endif()
include(CppUTestConfigurationOptions)
-include(CTest)
include(CppUTestBuildTimeDiscoverTests)
include(CppUTestNormalizeTestOutputLocation)
include(GNUInstallDirs)
-enable_testing()
-
add_subdirectory(src/CppUTest)
# Check for symbols before setting a lot of stuff
@@ -100,28 +114,11 @@ check_cxx_symbol_exists(waitpid "sys/wait.h" CPPUTEST_HAVE_WAITPID)
check_cxx_symbol_exists(gettimeofday "sys/time.h" CPPUTEST_HAVE_GETTIMEOFDAY)
check_cxx_symbol_exists(pthread_mutex_lock "pthread.h" CPPUTEST_HAVE_PTHREAD_MUTEX_LOCK)
-if(DEFINED HAS_NAN)
- message(DEPRECATION
- "The HAS_NAN cache variable has been deprecated. "
- "CPPUTEST_HAS_NAN is assessed automatically, "
- "but can be assigned manually."
- )
- set(CPPUTEST_HAS_NAN ${HAS_NAN})
-endif()
if(NOT DEFINED CPPUTEST_HAS_NAN)
check_cxx_symbol_exists(NAN "math.h" CPPUTEST_HAS_NAN)
endif()
-if(DEFINED HAS_INF)
- message(DEPRECATION
- "The HAS_INF cache variable has been deprecated. "
- "CPPUTEST_HAS_INF is assessed automatically, "
- "but can be assigned manually."
- )
- set(CPPUTEST_HAS_INF ${HAS_INF})
-endif()
if(NOT DEFINED CPPUTEST_HAS_INF)
- include(CheckCXXSymbolExists)
check_cxx_symbol_exists(INFINITY "math.h" CPPUTEST_HAS_INF)
endif()
@@ -158,20 +155,20 @@ target_compile_definitions(${CppUTestLibName}
$<BUILD_INTERFACE:HAVE_CONFIG_H>
)
-if (EXTENSIONS)
+if (CPPUTEST_EXTENSIONS)
add_subdirectory(src/CppUTestExt)
-endif (EXTENSIONS)
+endif ()
-if (TESTS)
+if (CPPUTEST_BUILD_TESTING)
add_subdirectory(tests/CppUTest)
- if (EXTENSIONS)
+ if (CPPUTEST_EXTENSIONS)
add_subdirectory(tests/CppUTestExt)
- endif (EXTENSIONS)
-endif (TESTS)
+ endif ()
+endif ()
-if (EXAMPLES)
+if (CPPUTEST_EXAMPLES)
add_subdirectory(examples)
-endif(EXAMPLES)
+endif()
if(PROJECT_IS_TOP_LEVEL)
set (INCLUDE_INSTALL_DIR "${CMAKE_INSTALL_INCLUDEDIR}")
@@ -239,7 +236,7 @@ if(PROJECT_IS_TOP_LEVEL)
endif()
endif()
-if(VERBOSE_CONFIG)
+if(CPPUTEST_VERBOSE_CONFIG)
message("
-------------------------------------------------------
CppUTest Version ${PROJECT_VERSION}
@@ -252,23 +249,23 @@ Current compiler options:
CppUTest LDFLAGS: ${CPPUTEST_LD_FLAGS}
Features configured in CppUTest:
- Memory Leak Detection: ${MEMORY_LEAK_DETECTION}
- Compiling Extensions: ${EXTENSIONS}
- Support Long Long: ${LONGLONG}
+ Memory Leak Detection Disabled: ${CPPUTEST_MEM_LEAK_DETECTION_DISABLED}
+ Compiling Extensions: ${CPPUTEST_EXTENSIONS}
+ Support Long Long: ${CPPUTEST_USE_LONG_LONG}
Use CppUTest flags: ${CPPUTEST_FLAGS}
- Using Standard C library: ${STD_C}
- Using Standard C++ library: ${STD_CPP}
+ Disable Standard C library: ${CPPUTEST_STD_C_LIB_DISABLED}
+ Disable Standard C++ library: ${CPPUTEST_STD_CPP_LIB_DISABLED}
- Generating map file: ${MAP_FILE}
- Compiling with coverage: ${COVERAGE}
+ Generating map file: ${CPPUTEST_MAP_FILE}
+ Compiling with coverage: ${CPPUTEST_COVERAGE}
- Compile and run self-tests ${TESTS}
- Run self-tests separately ${TESTS_DETAILED}
+ Compile and run self-tests ${CPPUTEST_BUILD_TESTING}
+ Run self-tests separately ${CPPUTEST_TESTS_DETAILED}
Library name options:
- Add architecture bitsize (32/64) ${LIBNAME_POSTFIX_BITSIZE}
- Add debug compilation indicator ${LIBNAME_POSTFIX_DEBUG}
+ Add architecture bitsize (32/64) ${CPPUTEST_LIBNAME_POSTFIX_BITSIZE}
+ Add debug compilation indicator ${CPPUTEST_LIBNAME_POSTFIX_DEBUG}
-------------------------------------------------------
")
diff --git a/cmake/Modules/CppUTestBuildTimeDiscoverTests.cmake b/cmake/Modules/CppUTestBuildTimeDiscoverTests.cmake
--- a/cmake/Modules/CppUTestBuildTimeDiscoverTests.cmake
+++ b/cmake/Modules/CppUTestBuildTimeDiscoverTests.cmake
@@ -24,7 +24,7 @@ function (cpputest_buildtime_discover_tests tgt)
TARGET ${tgt} POST_BUILD
COMMAND
${CMAKE_COMMAND}
- -D "TESTS_DETAILED:BOOL=${TESTS_DETAILED}"
+ -D "TESTS_DETAILED:BOOL=${CPPUTEST_TESTS_DETAILED}"
-D "EXECUTABLE=$<TARGET_FILE:${tgt}>"
-D "EMULATOR=$<TARGET_PROPERTY:${tgt},CROSSCOMPILING_EMULATOR>"
-P "${_DISCOVER_SCRIPT}"
diff --git a/cmake/Modules/CppUTestConfigurationOptions.cmake b/cmake/Modules/CppUTestConfigurationOptions.cmake
--- a/cmake/Modules/CppUTestConfigurationOptions.cmake
+++ b/cmake/Modules/CppUTestConfigurationOptions.cmake
@@ -7,26 +7,20 @@ if (MSVC)
elseif (IAR)
set(CPP_PLATFORM Iar)
unset(CMAKE_CXX_EXTENSION_COMPILE_OPTION)
- set(TESTS_BUILD_DISCOVER OFF)
# Set up the CMake variables for the linker
set(LINKER_SCRIPT "${CppUTest_SOURCE_DIR}/platforms/iar/CppUTestTest.icf")
set(CMAKE_C_LINK_FLAGS "--semihosting --config ${LINKER_SCRIPT} --map mapfile.map")
set(CMAKE_CXX_LINK_FLAGS "--semihosting --config ${LINKER_SCRIPT} --map mapfile.map")
elseif (BORLAND)
set(CPP_PLATFORM Borland)
- set(MEMORY_LEAK_DETECTION OFF)
- set(LONGLONG OFF)
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} -w-8008 -w-8066")
-elseif (STD_C)
+elseif (NOT CPPUTEST_STD_C_LIB_DISABLED)
if(NOT CPP_PLATFORM)
set(CPP_PLATFORM Gcc)
endif(NOT CPP_PLATFORM)
else (MSVC)
- set(STD_CPP False)
- set(MEMORY_LEAK_DETECTION False)
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} -nostdinc")
set(CPPUTEST_LD_FLAGS "${CPPUTEST_LD_FLAGS} -nostdinc")
- set(CPPUTEST_STD_C_LIB_DISABLED 1)
set(CPP_PLATFORM GccNoStdC)
endif (MSVC)
@@ -34,14 +28,13 @@ if (CMAKE_PROJECT_NAME STREQUAL PROJECT_NAME)
include(CppUTestWarningFlags)
endif ()
-if (NOT STD_CPP)
- set(CPPUTEST_STD_CPP_LIB_DISABLED 1)
- if (STD_C AND NOT MSVC)
+if (CPPUTEST_STD_CPP_LIB_DISABLED)
+ if (NOT CPPUTEST_STD_C_LIB_DISABLED AND NOT MSVC)
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} -nostdinc++")
- endif (STD_C AND NOT MSVC)
-endif (NOT STD_CPP)
+ endif ()
+endif ()
-if (MEMORY_LEAK_DETECTION)
+if (NOT CPPUTEST_MEM_LEAK_DETECTION_DISABLED)
if (MSVC)
set(CPPUTEST_C_FLAGS "${CPPUTEST_C_FLAGS} /FI \"${CppUTest_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorMallocMacros.h\"")
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} /FI \"${CppUTest_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorMallocMacros.h\"")
@@ -54,19 +47,13 @@ if (MEMORY_LEAK_DETECTION)
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} -include \"${CppUTest_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorNewMacros.h\"")
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} -include \"${CppUTest_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorMallocMacros.h\"")
endif (MSVC)
-else (MEMORY_LEAK_DETECTION)
- set(CPPUTEST_MEM_LEAK_DETECTION_DISABLED 1)
-endif (MEMORY_LEAK_DETECTION)
-
-if (LONGLONG)
- set(CPPUTEST_USE_LONG_LONG 1)
-endif (LONGLONG)
+endif ()
-if (MAP_FILE AND NOT MSVC)
+if (CPPUTEST_MAP_FILE AND NOT MSVC)
set(CPPUTEST_LD_FLAGS "${CPPUTEST_LD_FLAGS} -Wl,-Map,$<.map.txt")
-endif (MAP_FILE AND NOT MSVC)
+endif ()
-if (COVERAGE AND NOT MSVC)
+if (CPPUTEST_COVERAGE AND NOT MSVC)
set(CPPUTEST_C_FLAGS "${CPPUTEST_C_FLAGS} --coverage")
set(CPPUTEST_CXX_FLAGS "${CPPUTEST_CXX_FLAGS} --coverage")
set(CMAKE_BUILD_TYPE "Debug")
@@ -85,16 +72,6 @@ if (COVERAGE AND NOT MSVC)
)
endif()
-if(DEFINED C++11)
- message(DEPRECATION
- "The C++11 option is deprecated. "
- "Set CMAKE_CXX_STANDARD explicitly."
- )
- if(C++11 AND NOT CMAKE_CXX_STANDARD)
- set(CMAKE_CXX_STANDARD 11)
- endif()
-endif()
-
if (CMAKE_CXX_STANDARD)
set(CMAKE_CXX_EXTENSIONS OFF)
endif ()
diff --git a/cmake/Modules/CppUTestWarningFlags.cmake b/cmake/Modules/CppUTestWarningFlags.cmake
--- a/cmake/Modules/CppUTestWarningFlags.cmake
+++ b/cmake/Modules/CppUTestWarningFlags.cmake
@@ -44,9 +44,9 @@ else (MSVC)
Wno-long-long
)
- if (WERROR)
+ if (CPPUTEST_WERROR)
list(APPEND WARNING_C_FLAGS Werror)
- endif (WERROR)
+ endif ()
set(WARNING_C_ONLY_FLAGS
diff --git a/config.h.cmake b/config.h.cmake
--- a/config.h.cmake
+++ b/config.h.cmake
@@ -2,8 +2,7 @@
#define CONFIG_H_
#cmakedefine CPPUTEST_MEM_LEAK_DETECTION_DISABLED
-#cmakedefine CPPUTEST_USE_LONG_LONG
-#cmakedefine CPPUTEST_HAVE_LONG_LONG_INT
+#cmakedefine01 CPPUTEST_USE_LONG_LONG
#cmakedefine CPPUTEST_HAVE_STRDUP
#cmakedefine CPPUTEST_HAVE_FORK
@@ -18,7 +17,7 @@
#cmakedefine CPPUTEST_HAVE_STRUCT_TIMESPEC
#ifdef CPPUTEST_HAVE_STRUCT_TIMESPEC
-// Apply workaround for MinGW timespec redefinition (pthread.h / time.h)
+/* Apply workaround for MinGW timespec redefinition (pthread.h / time.h) */
#define _TIMESPEC_DEFINED 1
#endif
diff --git a/examples/AllTests/CMakeLists.txt b/examples/AllTests/CMakeLists.txt
--- a/examples/AllTests/CMakeLists.txt
+++ b/examples/AllTests/CMakeLists.txt
@@ -13,6 +13,10 @@ target_include_directories(ExampleTests
.
)
+target_compile_options(ExampleTests
+ PRIVATE $<$<BOOL:${MSVC}>:/wd4723>
+)
+
target_link_libraries(ExampleTests
PRIVATE
ApplicationLib
diff --git a/include/CppUTest/CppUTestConfig.h b/include/CppUTest/CppUTestConfig.h
--- a/include/CppUTest/CppUTestConfig.h
+++ b/include/CppUTest/CppUTestConfig.h
@@ -281,7 +281,7 @@
#endif
#endif
-#ifdef CPPUTEST_USE_LONG_LONG
+#if CPPUTEST_USE_LONG_LONG
typedef long long cpputest_longlong;
typedef unsigned long long cpputest_ulonglong;
#else
diff --git a/include/CppUTest/MemoryLeakDetector.h b/include/CppUTest/MemoryLeakDetector.h
--- a/include/CppUTest/MemoryLeakDetector.h
+++ b/include/CppUTest/MemoryLeakDetector.h
@@ -58,7 +58,7 @@ struct SimpleStringBuffer
SimpleStringBuffer();
void clear();
- void add(const char* format, ...) _check_format_(printf, 2, 3);
+ void add(const char* format, ...) _check_format_(CPPUTEST_CHECK_FORMAT_TYPE, 2, 3);
void addMemoryDump(const void* memory, size_t memorySize);
char* toString();
diff --git a/scripts/appveyor_ci_build.ps1 b/scripts/appveyor_ci_build.ps1
--- a/scripts/appveyor_ci_build.ps1
+++ b/scripts/appveyor_ci_build.ps1
@@ -77,7 +77,7 @@ switch -Wildcard ($env:Platform)
{
$toolchain_filename = Get-ClangToolchainFilename
$toolchain_path = (Join-Path (Split-Path $MyInvocation.MyCommand.Path) "..\cmake\$toolchain_filename")
- $toolchain = "-DCMAKE_TOOLCHAIN_FILE=$toolchain_path"
+ $toolchain = "-DCMAKE_TOOLCHAIN_FILE=$toolchain_path -DCPPUTEST_WERROR=OFF"
}
# Add mingw to the path
diff --git a/src/CppUTest/CMakeLists.txt b/src/CppUTest/CMakeLists.txt
--- a/src/CppUTest/CMakeLists.txt
+++ b/src/CppUTest/CMakeLists.txt
@@ -47,7 +47,7 @@ add_library(${CppUTestLibName}
${PROJECT_SOURCE_DIR}/include/CppUTest/SimpleMutex.h
)
-if(LIBNAME_POSTFIX_DEBUG)
+if(CPPUTEST_LIBNAME_POSTFIX_DEBUG)
set_target_properties(${CppUTestLibName} PROPERTIES DEBUG_POSTFIX "d")
endif()
diff --git a/src/CppUTestExt/CMakeLists.txt b/src/CppUTestExt/CMakeLists.txt
--- a/src/CppUTestExt/CMakeLists.txt
+++ b/src/CppUTestExt/CMakeLists.txt
@@ -41,7 +41,7 @@ target_link_libraries(${CppUTestExtLibName} ${CPPUNIT_EXTERNAL_LIBRARIES})
target_link_libraries(${CppUTestExtLibName} PUBLIC ${CppUTestLibName})
-if(LIBNAME_POSTFIX_DEBUG)
+if(CPPUTEST_LIBNAME_POSTFIX_DEBUG)
set_target_properties(${CppUTestExtLibName} PROPERTIES DEBUG_POSTFIX "d")
endif()
|
diff --git a/tests/CppUTest/CMakeLists.txt b/tests/CppUTest/CMakeLists.txt
--- a/tests/CppUTest/CMakeLists.txt
+++ b/tests/CppUTest/CMakeLists.txt
@@ -56,6 +56,6 @@ add_executable(CppUTestTests ${CppUTestTests_src})
cpputest_normalize_test_output_location(CppUTestTests)
target_link_libraries(CppUTestTests ${CppUTestLibName} ${THREAD_LIB})
-if (TESTS_BUILD_DISCOVER)
+if (CPPUTEST_TEST_DISCOVERY)
cpputest_buildtime_discover_tests(CppUTestTests)
endif()
diff --git a/tests/CppUTestExt/CMakeLists.txt b/tests/CppUTestExt/CMakeLists.txt
--- a/tests/CppUTestExt/CMakeLists.txt
+++ b/tests/CppUTestExt/CMakeLists.txt
@@ -38,6 +38,6 @@ add_executable(CppUTestExtTests ${CppUTestExtTests_src})
cpputest_normalize_test_output_location(CppUTestExtTests)
target_link_libraries(CppUTestExtTests ${CppUTestLibName} ${CppUTestExtLibName} ${THREAD_LIB} ${CPPUNIT_EXTERNAL_LIBRARIES})
-if (TESTS_BUILD_DISCOVER)
+if (CPPUTEST_TEST_DISCOVERY)
cpputest_buildtime_discover_tests(CppUTestExtTests)
endif()
|
CMake options not "scoped" to CppUTest
I'm trying to integrate CppUTest into my project using [CPM.cmake](https://github.com/cpm-cmake/CPM.cmake), but unfortunately the CMake [options specified in `CMakeLists.txt`](https://github.com/cpputest/cpputest/blob/v4.0/CMakeLists.txt#L60-L77) are not scoped to the CppUTest project (e.g. prefixed with `CPPUTEST_`).
I haven't checked if there are other "global" CMake variables/things that CppUTest uses that should be scoped, but I can imagine that they exist as well.
A problem that might arise is that another CMake-based project also define an option named `TESTS` to enable/disable its tests (or any of the other options CppUTest has defined).
That means that I will no longer be able to disable the tests for CppUTest but enable them for the other project.
Currently there is not yet a problem for me and as long as others do scope their options correctly there won't be a "collision". However, I think it would be a good idea to address this in a future release (even though this will be a breaking change).
For reference, also see the [Preparing projects for CPM.cmake](https://github.com/cpm-cmake/CPM.cmake/wiki/Preparing-projects-for-CPM.cmake) wiki page.
Although this might sound CPM.cmake specific, in reality this can also lead to problems if using `FetchContent` or Git submodules in a project that also uses CMake.
|
There are a bunch of CMake PRs open and will gradually be integrated. Did these also solve this?
I don't have any PRs that address this yet. Fixing this would technically be a breaking change (for CMake users).
| 2022-08-20T04:01:50
|
cpp
|
Easy
|
cpputest/cpputest
| 1,502
|
cpputest__cpputest-1502
|
[
"1497"
] |
2e177fa09f2f46f6bd936227433fc56a7b4292b7
|
diff --git a/include/CppUTest/CommandLineArguments.h b/include/CppUTest/CommandLineArguments.h
--- a/include/CppUTest/CommandLineArguments.h
+++ b/include/CppUTest/CommandLineArguments.h
@@ -47,6 +47,7 @@ class CommandLineArguments
bool isColor() const;
bool isListingTestGroupNames() const;
bool isListingTestGroupAndCaseNames() const;
+ bool isListingTestLocations() const;
bool isRunIgnored() const;
size_t getRepeatCount() const;
bool isShuffling() const;
@@ -80,6 +81,7 @@ class CommandLineArguments
bool runTestsAsSeperateProcess_;
bool listTestGroupNames_;
bool listTestGroupAndCaseNames_;
+ bool listTestLocations_;
bool runIgnored_;
bool reversing_;
bool crashOnFail_;
diff --git a/include/CppUTest/TestRegistry.h b/include/CppUTest/TestRegistry.h
--- a/include/CppUTest/TestRegistry.h
+++ b/include/CppUTest/TestRegistry.h
@@ -55,6 +55,7 @@ class TestRegistry
virtual void reverseTests();
virtual void listTestGroupNames(TestResult& result);
virtual void listTestGroupAndCaseNames(TestResult& result);
+ virtual void listTestLocations(TestResult& result);
virtual void setNameFilters(const TestFilter* filters);
virtual void setGroupFilters(const TestFilter* filters);
virtual void installPlugin(TestPlugin* plugin);
diff --git a/src/CppUTest/CommandLineArguments.cpp b/src/CppUTest/CommandLineArguments.cpp
--- a/src/CppUTest/CommandLineArguments.cpp
+++ b/src/CppUTest/CommandLineArguments.cpp
@@ -30,7 +30,7 @@
#include "CppUTest/PlatformSpecificFunctions.h"
CommandLineArguments::CommandLineArguments(int ac, const char *const *av) :
- ac_(ac), av_(av), needHelp_(false), verbose_(false), veryVerbose_(false), color_(false), runTestsAsSeperateProcess_(false), listTestGroupNames_(false), listTestGroupAndCaseNames_(false), runIgnored_(false), reversing_(false), crashOnFail_(false), shuffling_(false), shufflingPreSeeded_(false), repeat_(1), shuffleSeed_(0), groupFilters_(NULLPTR), nameFilters_(NULLPTR), outputType_(OUTPUT_ECLIPSE)
+ ac_(ac), av_(av), needHelp_(false), verbose_(false), veryVerbose_(false), color_(false), runTestsAsSeperateProcess_(false), listTestGroupNames_(false), listTestGroupAndCaseNames_(false), listTestLocations_(false), runIgnored_(false), reversing_(false), crashOnFail_(false), shuffling_(false), shufflingPreSeeded_(false), repeat_(1), shuffleSeed_(0), groupFilters_(NULLPTR), nameFilters_(NULLPTR), outputType_(OUTPUT_ECLIPSE)
{
}
@@ -65,6 +65,7 @@ bool CommandLineArguments::parse(TestPlugin* plugin)
else if (argument == "-b") reversing_ = true;
else if (argument == "-lg") listTestGroupNames_ = true;
else if (argument == "-ln") listTestGroupAndCaseNames_ = true;
+ else if (argument == "-ll") listTestLocations_ = true;
else if (argument == "-ri") runIgnored_ = true;
else if (argument == "-f") crashOnFail_ = true;
else if (argument.startsWith("-r")) setRepeatCount(ac_, av_, i);
@@ -171,6 +172,11 @@ bool CommandLineArguments::isListingTestGroupAndCaseNames() const
return listTestGroupAndCaseNames_;
}
+bool CommandLineArguments::isListingTestLocations() const
+{
+ return listTestLocations_;
+}
+
bool CommandLineArguments::isRunIgnored() const
{
return runIgnored_;
diff --git a/src/CppUTest/CommandLineTestRunner.cpp b/src/CppUTest/CommandLineTestRunner.cpp
--- a/src/CppUTest/CommandLineTestRunner.cpp
+++ b/src/CppUTest/CommandLineTestRunner.cpp
@@ -120,6 +120,13 @@ int CommandLineTestRunner::runAllTests()
return 0;
}
+ if (arguments_->isListingTestLocations())
+ {
+ TestResult tr(*output_);
+ registry_->listTestLocations(tr);
+ return 0;
+ }
+
if (arguments_->isReversing())
registry_->reverseTests();
diff --git a/src/CppUTest/TestRegistry.cpp b/src/CppUTest/TestRegistry.cpp
--- a/src/CppUTest/TestRegistry.cpp
+++ b/src/CppUTest/TestRegistry.cpp
@@ -123,6 +123,26 @@ void TestRegistry::listTestGroupAndCaseNames(TestResult& result)
result.print(groupAndNameList.asCharString());
}
+void TestRegistry::listTestLocations(TestResult& result)
+{
+ SimpleString testLocations;
+
+ for (UtestShell *test = tests_; test != NULLPTR; test = test->getNext()) {
+ SimpleString testLocation;
+ testLocation += test->getGroup();
+ testLocation += ".";
+ testLocation += test->getName();
+ testLocation += ".";
+ testLocation += test->getFile();
+ testLocation += ".";
+ testLocation += StringFromFormat("%d\n",test->getLineNumber());
+
+ testLocations += testLocation;
+ }
+
+ result.print(testLocations.asCharString());
+}
+
bool TestRegistry::endOfGroup(UtestShell* test)
{
return (!test || !test->getNext() || test->getGroup() != test->getNext()->getGroup());
|
diff --git a/tests/CppUTest/CommandLineTestRunnerTest.cpp b/tests/CppUTest/CommandLineTestRunnerTest.cpp
--- a/tests/CppUTest/CommandLineTestRunnerTest.cpp
+++ b/tests/CppUTest/CommandLineTestRunnerTest.cpp
@@ -269,6 +269,16 @@ TEST(CommandLineTestRunner, listTestGroupAndCaseNamesShouldWorkProperly)
STRCMP_CONTAINS("group1.test1", commandLineTestRunner.fakeConsoleOutputWhichIsReallyABuffer->getOutput().asCharString());
}
+TEST(CommandLineTestRunner, listTestLocationsShouldWorkProperly)
+{
+ const char* argv[] = { "tests.exe", "-ll" };
+
+ CommandLineTestRunnerWithStringBufferOutput commandLineTestRunner(2, argv, ®istry);
+ commandLineTestRunner.runAllTestsMain();
+
+ STRCMP_CONTAINS("group1.test1", commandLineTestRunner.fakeConsoleOutputWhichIsReallyABuffer->getOutput().asCharString());
+}
+
TEST(CommandLineTestRunner, randomShuffleSeedIsPrintedAndRandFuncIsExercised)
{
// more than 1 item in test list ensures that shuffle algorithm calls rand_()
diff --git a/tests/CppUTest/TestRegistryTest.cpp b/tests/CppUTest/TestRegistryTest.cpp
--- a/tests/CppUTest/TestRegistryTest.cpp
+++ b/tests/CppUTest/TestRegistryTest.cpp
@@ -361,6 +361,29 @@ TEST(TestRegistry, listTestGroupAndCaseNames_shouldListBackwardsGroupATestaAfter
STRCMP_EQUAL("GROUP_A.test_aa GROUP_B.test_b GROUP_A.test_a", s.asCharString());
}
+TEST(TestRegistry, listTestLocations_shouldListBackwardsGroupATestaAfterGroupAtestaa)
+{
+ test1->setGroupName("GROUP_A");
+ test1->setTestName("test_a");
+ test1->setFileName("cpptest_simple/my_tests/testa.cpp");
+ test1->setLineNumber(100);
+ myRegistry->addTest(test1);
+ test2->setGroupName("GROUP_B");
+ test2->setTestName("test_b");
+ test2->setFileName("cpptest_simple/my tests/testb.cpp");
+ test2->setLineNumber(200);
+ myRegistry->addTest(test2);
+ test3->setGroupName("GROUP_A");
+ test3->setTestName("test_aa");
+ test3->setFileName("cpptest_simple/my_tests/testaa.cpp");
+ test3->setLineNumber(300);
+ myRegistry->addTest(test3);
+
+ myRegistry->listTestLocations(*result);
+ SimpleString s = output->getOutput();
+ STRCMP_EQUAL("GROUP_A.test_aa.cpptest_simple/my_tests/testaa.cpp.300\nGROUP_B.test_b.cpptest_simple/my tests/testb.cpp.200\nGROUP_A.test_a.cpptest_simple/my_tests/testa.cpp.100\n", s.asCharString());
+}
+
TEST(TestRegistry, shuffleEmptyListIsNoOp)
{
CHECK_TRUE(myRegistry->getFirstTest() == NULLPTR);
|
Request: Option to display source file and line numbers for each test
I am working with someone on a Visual Studio Code Extension for cpputest.
One option it has is to be able to click on a test in the gui and it brings you to the source code for that test.
It currently does this by running objdump on the binary. This has turned out to be very slow. 1 minute on a test executable with 1000 tests.
It would be better/faster if there was a way to compile in the source code and line numbers for each test and make that available via a command line option.
Any chance this could be included in a future release?
|
It would be something that I would accept a pull request from. It should be trivial as this info is already stored. We also already have two other command line options (the -l ones) that list things without executing the code.
| 2021-11-05T13:37:57
|
cpp
|
Easy
|
cpputest/cpputest
| 1,842
|
cpputest__cpputest-1842
|
[
"1822"
] |
ed6176f611f18c5d06fa01c562935a1a8d4c702d
|
diff --git a/CppUTest.vcproj b/CppUTest.vcproj
--- a/CppUTest.vcproj
+++ b/CppUTest.vcproj
@@ -947,6 +947,10 @@
RelativePath=".\include\CppUTest\MemoryLeakDetector.h"
>
</File>
+ <File
+ RelativePath=".\include\CppUTest\MemoryLeakDetectorForceInclude.h"
+ >
+ </File>
<File
RelativePath=".\include\CppUTest\MemoryLeakDetectorMallocMacros.h"
>
diff --git a/CppUTest.vcxproj b/CppUTest.vcxproj
--- a/CppUTest.vcxproj
+++ b/CppUTest.vcxproj
@@ -271,6 +271,7 @@
<ClInclude Include="include\cpputest\platformspecificfunctions_c.h" />
<ClInclude Include="include\CppUTest\TeamCityTestOutput.h" />
<ClInclude Include="include\CppUTest\MemoryLeakDetector.h" />
+ <ClInclude Include="include\CppUTest\MemoryLeakDetectorForceInclude.h" />
<ClInclude Include="include\CppUTest\MemoryLeakDetectorMallocMacros.h" />
<ClInclude Include="include\CppUTest\MemoryLeakDetectorNewMacros.h" />
<ClInclude Include="include\CppUTest\MemoryLeakWarningPlugin.h" />
diff --git a/Makefile.am b/Makefile.am
--- a/Makefile.am
+++ b/Makefile.am
@@ -77,6 +77,7 @@ include_cpputest_HEADERS = \
include/CppUTest/CppUTestConfig.h \
include/CppUTest/JUnitTestOutput.h \
include/CppUTest/MemoryLeakDetector.h \
+ include/CppUTest/MemoryLeakDetectorForceInclude.h \
include/CppUTest/MemoryLeakDetectorMallocMacros.h \
include/CppUTest/MemoryLeakDetectorNewMacros.h \
include/CppUTest/MemoryLeakWarningPlugin.h \
diff --git a/include/CppUTest/MemoryLeakDetectorForceInclude.h b/include/CppUTest/MemoryLeakDetectorForceInclude.h
new file mode 100644
--- /dev/null
+++ b/include/CppUTest/MemoryLeakDetectorForceInclude.h
@@ -0,0 +1,4 @@
+// Not all toolchains support multiple force includes (namely IAR),
+// so we wrap the two in a single header.
+#include "MemoryLeakDetectorMallocMacros.h"
+#include "MemoryLeakDetectorNewMacros.h"
diff --git a/include/CppUTest/MemoryLeakDetectorNewMacros.h b/include/CppUTest/MemoryLeakDetectorNewMacros.h
--- a/include/CppUTest/MemoryLeakDetectorNewMacros.h
+++ b/include/CppUTest/MemoryLeakDetectorNewMacros.h
@@ -40,11 +40,15 @@
#undef strdup
#undef strndup
#undef CPPUTEST_USE_STRDUP_MACROS
+ #define CPPUTEST_REINCLUDE_MALLOC_MEMORY_LEAK_DETECTOR
#endif
#endif
#include <new>
#include <memory>
#include <string>
+ #ifdef CPPUTEST_REINCLUDE_MALLOC_MEMORY_LEAK_DETECTOR
+ #include "MemoryLeakDetectorMallocMacros.h"
+ #endif
#endif
/* Some toolkits, e.g. MFC, provide their own new overloads with signature (size_t, const char *, int).
@@ -89,5 +93,3 @@
#define CPPUTEST_USE_NEW_MACROS 1
#endif
-
-#include "MemoryLeakDetectorMallocMacros.h"
diff --git a/platforms/iar/CppUTest.ewp b/platforms/iar/CppUTest.ewp
--- a/platforms/iar/CppUTest.ewp
+++ b/platforms/iar/CppUTest.ewp
@@ -262,8 +262,7 @@
</option>
<option>
<name>IExtraOptions</name>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorNewMacros.h</state>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorMallocMacros.h</state>
+ <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorForceInclude.h</state>
</option>
<option>
<name>CCLangConformance</name>
diff --git a/platforms/iar/CppUTestExt.ewp b/platforms/iar/CppUTestExt.ewp
--- a/platforms/iar/CppUTestExt.ewp
+++ b/platforms/iar/CppUTestExt.ewp
@@ -262,8 +262,7 @@
</option>
<option>
<name>IExtraOptions</name>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorNewMacros.h</state>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorMallocMacros.h</state>
+ <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorForceInclude.h</state>
</option>
<option>
<name>CCLangConformance</name>
diff --git a/platforms/iar/CppUTestExtTest.ewp b/platforms/iar/CppUTestExtTest.ewp
--- a/platforms/iar/CppUTestExtTest.ewp
+++ b/platforms/iar/CppUTestExtTest.ewp
@@ -262,8 +262,7 @@
</option>
<option>
<name>IExtraOptions</name>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorNewMacros.h</state>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorMallocMacros.h</state>
+ <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorForceInclude.h</state>
</option>
<option>
<name>CCLangConformance</name>
diff --git a/platforms/iar/CppUTestTest.ewp b/platforms/iar/CppUTestTest.ewp
--- a/platforms/iar/CppUTestTest.ewp
+++ b/platforms/iar/CppUTestTest.ewp
@@ -262,8 +262,7 @@
</option>
<option>
<name>IExtraOptions</name>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorNewMacros.h</state>
- <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorMallocMacros.h</state>
+ <state>--preinclude $PROJ_DIR$\..\..\include\CppUTest\MemoryLeakDetectorForceInclude.h</state>
</option>
<option>
<name>CCLangConformance</name>
diff --git a/src/CppUTest/CMakeLists.txt b/src/CppUTest/CMakeLists.txt
--- a/src/CppUTest/CMakeLists.txt
+++ b/src/CppUTest/CMakeLists.txt
@@ -39,6 +39,7 @@ add_library(CppUTest
${PROJECT_SOURCE_DIR}/include/CppUTest/TestFilter.h
${PROJECT_SOURCE_DIR}/include/CppUTest/TestTestingFixture.h
${PROJECT_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorNewMacros.h
+ ${PROJECT_SOURCE_DIR}/include/CppUTest/MemoryLeakDetectorForceInclude.h
${PROJECT_SOURCE_DIR}/include/CppUTest/TestHarness.h
${PROJECT_SOURCE_DIR}/include/CppUTest/Utest.h
${PROJECT_SOURCE_DIR}/include/CppUTest/MemoryLeakWarningPlugin.h
@@ -107,10 +108,7 @@ if(NOT CPPUTEST_MEM_LEAK_DETECTION_DISABLED)
endif()
target_compile_options(CppUTest
PUBLIC
- # Not all toolchains support multiple force includes (namely IAR),
- # so C and C++ each get their own.
- "$<$<COMPILE_LANGUAGE:C>:${force_include}CppUTest/MemoryLeakDetectorMallocMacros.h>"
- "$<$<COMPILE_LANGUAGE:CXX>:${force_include}CppUTest/MemoryLeakDetectorNewMacros.h>"
+ ${force_include}CppUTest/MemoryLeakDetectorForceInclude.h
)
endif()
|
diff --git a/tests/AllTests.vcproj b/tests/AllTests.vcproj
--- a/tests/AllTests.vcproj
+++ b/tests/AllTests.vcproj
@@ -136,7 +136,7 @@
WarningLevel="3"
SuppressStartupBanner="true"
DebugInformationFormat="4"
- ForcedIncludeFiles="CppUTest/MemoryLeakDetectorMallocMacros.h,CppUTest/MemoryLeakDetectorNewMacros.h"
+ ForcedIncludeFiles="CppUTest/MemoryLeakDetectorForceInclude.h"
/>
<Tool
Name="VCManagedResourceCompilerTool"
|
old Visual C++ builds are broken.
#1808 broke the old Visual C++ builds in AppVeyor. I didn't notice when I opened the MR. Since it merged all pipelines are failing.
I don't have a Windows machine or know Visual C++ well enough to understand why it broke or how to fix it.
https://ci.appveyor.com/project/basvodde/cpputest/builds/50614045
| 2025-01-22T03:40:17
|
cpp
|
Easy
|
|
cpputest/cpputest
| 1,554
|
cpputest__cpputest-1554
|
[
"1545"
] |
3ba61abc3ab033b02667a5799d4cb66e2fd72c07
|
diff --git a/cmake/Modules/CppUTestConfigurationOptions.cmake b/cmake/Modules/CppUTestConfigurationOptions.cmake
--- a/cmake/Modules/CppUTestConfigurationOptions.cmake
+++ b/cmake/Modules/CppUTestConfigurationOptions.cmake
@@ -63,13 +63,13 @@ if (LONGLONG)
set(CPPUTEST_USE_LONG_LONG 1)
endif (LONGLONG)
-if (HAS_INF)
- set(CPPUTEST_HAS_INF 1)
-endif (HAS_INF)
+if (NOT HAS_INF)
+ set(CPPUTEST_NO_INF 1)
+endif (NOT HAS_INF)
-if (HAS_NAN)
- set(CPPUTEST_HAS_NAN 1)
-endif (HAS_NAN)
+if (NOT HAS_NAN)
+ set(CPPUTEST_NO_NAN 1)
+endif (NOT HAS_NAN)
if (MAP_FILE AND NOT MSVC)
set(CPPUTEST_LD_FLAGS "${CPPUTEST_LD_FLAGS} -Wl,-Map,$<.map.txt")
diff --git a/config.h.cmake b/config.h.cmake
--- a/config.h.cmake
+++ b/config.h.cmake
@@ -4,8 +4,8 @@
#cmakedefine CPPUTEST_MEM_LEAK_DETECTION_DISABLED
#cmakedefine CPPUTEST_USE_LONG_LONG
-#cmakedefine CPPUTEST_HAS_INF
-#cmakedefine CPPUTEST_HAS_NAN
+#cmakedefine CPPUTEST_NO_INF
+#cmakedefine CPPUTEST_NO_NAN
#cmakedefine CPPUTEST_STD_C_LIB_DISABLED
#cmakedefine CPPUTEST_STD_CPP_LIB_DISABLED
diff --git a/include/CppUTest/CppUTestConfig.h b/include/CppUTest/CppUTestConfig.h
--- a/include/CppUTest/CppUTestConfig.h
+++ b/include/CppUTest/CppUTestConfig.h
@@ -334,5 +334,17 @@ typedef struct cpputest_ulonglong cpputest_ulonglong;
#pragma clang diagnostic pop
#endif
+/* Borland v5.4 does not have a NaN or Inf value */
+#if defined(CPPUTEST_NO_INF)
+#define CPPUTEST_HAS_INF 0
+#else
+#define CPPUTEST_HAS_INF 1
+#endif
+#if defined(CPPUTEST_NO_NAN)
+#define CPPUTEST_HAS_NAN 0
+#else
+#define CPPUTEST_HAS_NAN 1
+#endif
+
#endif
|
diff --git a/tests/CppUTest/UtestTest.cpp b/tests/CppUTest/UtestTest.cpp
--- a/tests/CppUTest/UtestTest.cpp
+++ b/tests/CppUTest/UtestTest.cpp
@@ -60,21 +60,33 @@ static volatile double zero = 0.0;
TEST(UtestShell, compareDoubles)
{
- double not_a_number = zero / zero;
- double infinity = 1 / zero;
CHECK(doubles_equal(1.0, 1.001, 0.01));
+ CHECK(!doubles_equal(1.0, 1.1, 0.05));
+ double a = 1.2345678;
+ CHECK(doubles_equal(a, a, 0.000000001));
+}
+
+#if CPPUTEST_HAS_NAN == 1
+TEST(UtestShell, compareDoublesNaN)
+{
+ double not_a_number = zero / zero;
CHECK(!doubles_equal(not_a_number, 1.001, 0.01));
CHECK(!doubles_equal(1.0, not_a_number, 0.01));
CHECK(!doubles_equal(1.0, 1.001, not_a_number));
- CHECK(!doubles_equal(1.0, 1.1, 0.05));
+}
+#endif
+
+#if CPPUTEST_HAS_INF == 1
+TEST(UtestShell, compareDoublesInf)
+{
+ double infinity = 1 / zero;
CHECK(!doubles_equal(infinity, 1.0, 0.01));
CHECK(!doubles_equal(1.0, infinity, 0.01));
CHECK(doubles_equal(1.0, -1.0, infinity));
CHECK(doubles_equal(infinity, infinity, 0.01));
CHECK(doubles_equal(infinity, infinity, infinity));
- double a = 1.2345678;
- CHECK(doubles_equal(a, a, 0.000000001));
}
+#endif
TEST(UtestShell, FailWillIncreaseTheAmountOfChecks)
{
|
Borland v5.4 throws a runtime error on division by zero: tests\CppUTest\UtestTest.cpp
This is similar to #1544
The Borland v5.4 compiler does not have a NaN or Inf .
if one wants the program to catch the division by zero error, and not crash, it has to contain an signal handler that catches the exception and deal with it itself.
From the help file:
>For / and %, op2 must be nonzero op2 = 0 results in an error. (You can't divide by zero.)
For tests/CppUTests/UtestTest.cpp this means that the following test fails with a NUMERICAL error.
```
static volatile double zero = 0.0;
TEST(UtestShell, compareDoubles)
{
double not_a_number = zero / zero;
double infinity = 1 / zero;
CHECK(doubles_equal(1.0, 1.001, 0.01));
CHECK(!doubles_equal(not_a_number, 1.001, 0.01));
CHECK(!doubles_equal(1.0, not_a_number, 0.01));
CHECK(!doubles_equal(1.0, 1.001, not_a_number));
CHECK(!doubles_equal(1.0, 1.1, 0.05));
CHECK(!doubles_equal(infinity, 1.0, 0.01));
CHECK(!doubles_equal(1.0, infinity, 0.01));
CHECK(doubles_equal(1.0, -1.0, infinity));
CHECK(doubles_equal(infinity, infinity, 0.01));
CHECK(doubles_equal(infinity, infinity, infinity));
double a = 1.2345678;
CHECK(doubles_equal(a, a, 0.000000001));
}
```
How should we remove this one test when compiling with Borland v5.4?
This is part of #1493
|
There are in fact only three of those CHECKs that have any chance of passing.
```
CHECK(doubles_equal(1.0, 1.001, 0.01));
CHECK(!doubles_equal(1.0, 1.1, 0.05));
double a = 1.2345678;
CHECK(doubles_equal(a, a, 0.000000001));
```
Perhaps split the test in NaN, infinity and others ? Then have a check for the support for NaN and the support for infinity and turn these off in BC ?
Yep.
Question. Not sure how to test for NaN and Inf support. Will have to do some homework.
You can just leave it on by default and then turn it off for the BC. Just would like to avoid compiler specific switches in any file and prefer capability specific switches (well... prefer no switches at all but that is not an option)
| 2022-03-24T07:44:21
|
cpp
|
Easy
|
GothenburgBitFactory/timewarrior
| 566
|
GothenburgBitFactory__timewarrior-566
|
[
"205"
] |
910acafbc0a2fc7d0c1f77b30831173f34871bd6
|
diff --git a/src/CMakeLists.txt b/src/CMakeLists.txt
--- a/src/CMakeLists.txt
+++ b/src/CMakeLists.txt
@@ -14,6 +14,8 @@ set (timew_SRCS AtomicFile.cpp AtomicFile.h
DatetimeParser.cpp DatetimeParser.h
Exclusion.cpp Exclusion.h
Extensions.cpp Extensions.h
+ ExtensionsTable.cpp ExtensionsTable.h
+ GapsTable.cpp GapsTable.h
Interval.cpp Interval.h
IntervalFactory.cpp IntervalFactory.h
IntervalFilter.cpp IntervalFilter.h
@@ -25,8 +27,11 @@ set (timew_SRCS AtomicFile.cpp AtomicFile.h
Journal.cpp Journal.h
Range.cpp Range.h
Rules.cpp Rules.h
+ SummaryTable.cpp SummaryTable.h
+ TagDescription.cpp TagDescription.h
TagInfo.cpp TagInfo.h
TagInfoDatabase.cpp TagInfoDatabase.h
+ TagsTable.cpp TagsTable.h
Transaction.cpp Transaction.h
TransactionsFactory.cpp TransactionsFactory.h
UndoAction.cpp UndoAction.h
diff --git a/src/ExtensionsTable.cpp b/src/ExtensionsTable.cpp
new file mode 100644
--- /dev/null
+++ b/src/ExtensionsTable.cpp
@@ -0,0 +1,89 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#include <Extensions.h>
+#include <ExtensionsTable.h>
+#include <FS.h>
+#include <timew.h>
+
+///////////////////////////////////////////////////////////////////////////////
+ExtensionsTable::Builder ExtensionsTable::builder ()
+{
+ return {};
+}
+
+///////////////////////////////////////////////////////////////////////////////
+ExtensionsTable::Builder& ExtensionsTable::Builder::withExtensions (const Extensions& extensions)
+{
+ _extensions = extensions;
+ return *this;
+}
+
+///////////////////////////////////////////////////////////////////////////////
+Table ExtensionsTable::Builder::build ()
+{
+ int terminalWidth = getTerminalWidth ();
+
+ Table table;
+ table.width (terminalWidth);
+ table.colorHeader (Color ("underline"));
+ table.add ("Extension", true);
+ table.add ("Status", true);
+
+ for (auto &ext: _extensions.all ())
+ {
+ File program (ext);
+
+ // Show program name.
+ auto row = table.addRow ();
+ table.set (row, 0, program.name ());
+
+ // Show extension status.
+ std::string status;
+
+ if (!program.readable ())
+ {
+ status = "Not readable";
+ }
+ else if (!program.executable ())
+ {
+ status = "No executable";
+ }
+ else
+ {
+ status = "Active";
+ }
+
+ if (program.is_link ())
+ {
+ status += " (link)";
+ }
+
+ table.set (row, 1, status);
+ }
+
+ return table;
+}
diff --git a/src/ExtensionsTable.h b/src/ExtensionsTable.h
new file mode 100644
--- /dev/null
+++ b/src/ExtensionsTable.h
@@ -0,0 +1,50 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#ifndef INCLUDED_EXTENSIONSTABLE
+#define INCLUDED_EXTENSIONSTABLE
+
+#include <Extensions.h>
+#include <Table.h>
+
+class ExtensionsTable
+{
+ class Builder
+ {
+ public:
+ Builder& withExtensions (const Extensions &);
+
+ Table build ();
+
+ private:
+ Extensions _extensions;
+ };
+
+public:
+ static Builder builder ();
+};
+
+#endif //INCLUDED_EXTENSIONSTABLE
diff --git a/src/GapsTable.cpp b/src/GapsTable.cpp
new file mode 100644
--- /dev/null
+++ b/src/GapsTable.cpp
@@ -0,0 +1,116 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#include <Duration.h>
+#include <GapsTable.h>
+#include <format.h>
+#include <timew.h>
+
+///////////////////////////////////////////////////////////////////////////////
+GapsTable::Builder GapsTable::builder ()
+{
+ return {};
+}
+
+///////////////////////////////////////////////////////////////////////////////
+GapsTable::Builder& GapsTable::Builder::withRange (const Range &range)
+{
+ _range = range;
+ return *this;
+}
+
+///////////////////////////////////////////////////////////////////////////////
+GapsTable::Builder& GapsTable::Builder::withIntervals (const std::vector <Range> &intervals)
+{
+ _intervals = intervals;
+ return *this;
+}
+
+///////////////////////////////////////////////////////////////////////////////
+Table GapsTable::Builder::build ()
+{
+ int terminalWidth = getTerminalWidth ();
+
+ Table table;
+ table.width (terminalWidth);
+ table.colorHeader (Color ("underline"));
+ table.add ("Wk");
+ table.add ("Date");
+ table.add ("Day");
+ table.add ("Start", false);
+ table.add ("End", false);
+ table.add ("Time", false);
+ table.add ("Total", false);
+
+ // Each day is rendered separately.
+ time_t grand_total = 0;
+ Datetime previous;
+ for (Datetime day = _range.start; day < _range.end; day++)
+ {
+ auto day_range = getFullDay (day);
+ time_t daily_total = 0;
+
+ int row = -1;
+ for (auto &gap: subset (day_range, _intervals))
+ {
+ row = table.addRow ();
+
+ if (day != previous)
+ {
+ table.set (row, 0, format ("W{1}", day.week ()));
+ table.set (row, 1, day.toString ("Y-M-D"));
+ table.set (row, 2, Datetime::dayNameShort (day.dayOfWeek ()));
+ previous = day;
+ }
+
+ // Intersect track with day.
+ auto today = day_range.intersect (gap);
+ if (gap.is_open ())
+ {
+ today.end = Datetime ();
+ }
+
+ table.set (row, 3, today.start.toString ("h:N:S"));
+ table.set (row, 4, (gap.is_open () ? "-" : today.end.toString ("h:N:S")));
+ table.set (row, 5, Duration (today.total ()).formatHours ());
+
+ daily_total += today.total ();
+ }
+
+ if (row != -1)
+ {
+ table.set (row, 6, Duration (daily_total).formatHours ());
+ }
+
+ grand_total += daily_total;
+ }
+
+ // Add the total.
+ table.set (table.addRow (), 6, " ", Color ("underline"));
+ table.set (table.addRow (), 6, Duration (grand_total).formatHours ());
+
+ return table;
+}
diff --git a/src/GapsTable.h b/src/GapsTable.h
new file mode 100644
--- /dev/null
+++ b/src/GapsTable.h
@@ -0,0 +1,54 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#ifndef INCLUDED_GAPSTABLE
+#define INCLUDED_GAPSTABLE
+
+#include <Interval.h>
+#include <Range.h>
+#include <Table.h>
+#include <vector>
+
+class GapsTable
+{
+ class Builder
+ {
+ public:
+ Builder& withRange (const Range &);
+ Builder& withIntervals (const std::vector <Range> &);
+
+ Table build ();
+
+ private:
+ std::vector <Range> _intervals;
+ Range _range;
+ };
+
+public:
+ static Builder builder ();
+};
+
+#endif //INCLUDED_GAPSTABLE
diff --git a/src/SummaryTable.cpp b/src/SummaryTable.cpp
new file mode 100644
--- /dev/null
+++ b/src/SummaryTable.cpp
@@ -0,0 +1,271 @@
+////////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+////////////////////////////////////////////////////////////////////////////////
+
+#include <Datetime.h>
+#include <SummaryTable.h>
+#include <Table.h>
+#include <format.h>
+#include <timew.h>
+#include <utf8.h>
+#include <utility>
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder SummaryTable::builder ()
+{
+ return {};
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withWeekFormat (const std::string& format)
+{
+ _week_fmt = format;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withDateFormat (const std::string& format)
+{
+ _date_fmt = format;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withTimeFormat (const std::string& format)
+{
+ _time_fmt = format;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withAnnotations (const bool show)
+{
+ _show_annotations = show;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withIds (bool show, Color color)
+{
+ _show_ids = show;
+ _color_id = color;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder & SummaryTable::Builder::withTags (bool show, std::map <std::string, Color>& colors)
+{
+ _show_tags = show;
+ _color_tags = std::move (colors);
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withWeekdays (const bool show)
+{
+ _show_weekdays = show;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withWeeks (const bool show)
+{
+ _show_weeks = show;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder& SummaryTable::Builder::withRange (const Range& range)
+{
+ _range = range;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+SummaryTable::Builder & SummaryTable::Builder::withIntervals (const std::vector<Interval>& tracked)
+{
+ _tracked = tracked;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+Table SummaryTable::Builder::build ()
+{
+ const auto dates_col_offset = _show_weeks ? 1 : 0;
+ const auto weekdays_col_offset = dates_col_offset;
+ const auto ids_col_offset = weekdays_col_offset + (_show_weekdays ? 1: 0);
+ const auto tags_col_offset = ids_col_offset + (_show_ids ? 1 : 0);
+ const auto annotation_col_offset = tags_col_offset + (_show_tags ? 1 : 0);
+ const auto start_col_offset = annotation_col_offset + (_show_annotations ? 1 : 0);
+
+ const auto weeks_col_index = 0;
+ const auto dates_col_index = 0 + dates_col_offset;
+ const auto weekdays_col_index = 1 + weekdays_col_offset;
+ const auto ids_col_index = 1 + ids_col_offset;
+ const auto tags_col_index = 1 + tags_col_offset;
+ const auto annotation_col_index = 1 + annotation_col_offset;
+ const auto start_col_index = 1 + start_col_offset;
+ const auto end_col_index = 2 + start_col_offset;
+ const auto duration_col_index = 3 + start_col_offset;
+ const auto total_col_index = 4 + start_col_offset;
+
+ int terminalWidth = getTerminalWidth ();
+
+ Table table;
+ table.width (terminalWidth);
+ table.colorHeader (Color ("underline"));
+
+ if (_show_weeks)
+ {
+ table.add ("Wk");
+ }
+
+ table.add ("Date");
+
+ if (_show_weekdays)
+ {
+ table.add ("Day");
+ }
+
+ if (_show_ids)
+ {
+ table.add ("ID");
+ }
+
+ if (_show_tags)
+ {
+ table.add ("Tags");
+ }
+
+ if (_show_annotations)
+ {
+ table.add ("Annotation");
+ }
+
+ table.add ("Start", false);
+ table.add ("End", false);
+ table.add ("Time", false);
+ table.add ("Total", false);
+
+ // Each day is rendered separately.
+ time_t grand_total = 0;
+ Datetime previous;
+
+ auto days_start = _range.is_started () ? _range.start : _tracked.front ().start;
+ auto days_end = _range.is_ended () ? _range.end : _tracked.back ().end;
+
+ const auto now = Datetime ();
+
+ if (days_end == 0)
+ {
+ days_end = now;
+ }
+
+ for (Datetime day = days_start.startOfDay (); day < days_end; ++day)
+ {
+ auto day_range = getFullDay (day);
+ time_t daily_total = 0;
+
+ int row = -1;
+ for (auto& track : subset (day_range, _tracked))
+ {
+ // Make sure the track only represents one day.
+ if ((track.is_open () && day > now))
+ {
+ continue;
+ }
+
+ row = table.addRow ();
+
+ if (day != previous)
+ {
+ if (_show_weeks)
+ {
+ table.set (row, weeks_col_index, format (_week_fmt, day.week ()));
+ }
+
+ table.set (row, dates_col_index, day.toString (_date_fmt));
+
+ if (_show_weekdays)
+ {
+ table.set (row, weekdays_col_index, Datetime::dayNameShort (day.dayOfWeek ()));
+ }
+
+ previous = day;
+ }
+
+ // Intersect track with day.
+ auto today = day_range.intersect (track);
+
+ if (track.is_open () && track.start > now)
+ {
+ today.end = track.start;
+ }
+ else if (track.is_open () && day <= now && today.end > now)
+ {
+ today.end = now;
+ }
+
+ if (_show_ids)
+ {
+ table.set (row, ids_col_index, format ("@{1}", track.id), _color_id);
+ }
+
+ if (_show_tags)
+ {
+ auto tags_string = join (", ", track.tags ());
+ table.set (row, tags_col_index, tags_string, summaryIntervalColor (_color_tags, track.tags ()));
+ }
+
+ if (_show_annotations)
+ {
+ table.set (row, annotation_col_index, track.getAnnotation ());
+ }
+
+ const auto total = today.total ();
+
+ table.set (row, start_col_index, today.start.toString (_time_fmt));
+ table.set (row, end_col_index, (track.is_open () ? "-" : today.end.toString (_time_fmt)));
+ table.set (row, duration_col_index, Duration (total).formatHours ());
+
+ daily_total += total;
+ }
+
+ if (row != -1)
+ {
+ table.set (row, total_col_index, Duration (daily_total).formatHours ());
+ }
+
+ grand_total += daily_total;
+ }
+
+ // Add the total.
+ table.set (table.addRow (), total_col_index, " ", Color ("underline"));
+ table.set (table.addRow (), total_col_index, Duration (grand_total).formatHours ());
+
+ return table;
+}
+
+////////////////////////////////////////////////////////////////////////////////
diff --git a/src/SummaryTable.h b/src/SummaryTable.h
new file mode 100644
--- /dev/null
+++ b/src/SummaryTable.h
@@ -0,0 +1,77 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#ifndef INCLUDED_SUMMARYTABLE
+#define INCLUDED_SUMMARYTABLE
+
+#include <Color.h>
+#include <Interval.h>
+#include <Range.h>
+#include <Table.h>
+#include <map>
+
+class SummaryTable
+{
+ class Builder
+ {
+ public:
+ Builder& withWeekFormat (const std::string &);
+ Builder& withDateFormat (const std::string &);
+ Builder& withTimeFormat (const std::string &);
+
+ Builder& withAnnotations (bool);
+ Builder& withIds (bool, Color);
+ Builder& withTags (bool, std::map <std::string, Color>&);
+ Builder& withWeeks (bool);
+ Builder& withWeekdays (bool);
+
+ Builder& withRange (const Range &);
+ Builder& withIntervals (const std::vector <Interval>&);
+
+ Table build ();
+
+ private:
+ std::string _week_fmt;
+ std::string _date_fmt;
+ std::string _time_fmt;
+
+ bool _show_annotations;
+ bool _show_ids;
+ bool _show_tags;
+ bool _show_weekdays;
+ bool _show_weeks;
+
+ Range _range;
+ std::vector <Interval> _tracked;
+ Color _color_id;
+ std::map <std::string, Color> _color_tags;
+ };
+
+public:
+ static Builder builder ();
+};
+
+#endif // INCLUDED_SUMMARYTABLE
diff --git a/src/TagDescription.cpp b/src/TagDescription.cpp
new file mode 100644
--- /dev/null
+++ b/src/TagDescription.cpp
@@ -0,0 +1,35 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#include <Color.h>
+#include <TagDescription.h>
+#include <utility>
+
+TagDescription::TagDescription (std::string name, Color color, std::string description) :
+ name (std::move (name)),
+ color (color),
+ description (std::move (description))
+{}
diff --git a/src/TagDescription.h b/src/TagDescription.h
new file mode 100644
--- /dev/null
+++ b/src/TagDescription.h
@@ -0,0 +1,42 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#ifndef INCLUDED_TAGDESCRIPTION
+#define INCLUDED_TAGDESCRIPTION
+
+#include <string>
+
+class TagDescription
+{
+public:
+ TagDescription (std::string , Color, std::string );
+
+ std::string name;
+ Color color;
+ std::string description;
+};
+
+#endif //INCLUDED_TAGDESCRIPTION
diff --git a/src/TagsTable.cpp b/src/TagsTable.cpp
new file mode 100644
--- /dev/null
+++ b/src/TagsTable.cpp
@@ -0,0 +1,64 @@
+////////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+////////////////////////////////////////////////////////////////////////////////
+
+#include <TagsTable.h>
+#include <timew.h>
+
+////////////////////////////////////////////////////////////////////////////////
+TagsTable::Builder TagsTable::builder ()
+{
+ return {};
+}
+
+////////////////////////////////////////////////////////////////////////////////
+TagsTable::Builder& TagsTable::Builder::withTagDescriptions (std::vector <TagDescription>& tagDescriptions)
+{
+ _tagDescriptions = tagDescriptions;
+ return *this;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+Table TagsTable::Builder::build ()
+{
+ int terminalWidth = getTerminalWidth ();
+
+ Table table;
+ table.width (terminalWidth);
+ table.colorHeader (Color ("underline"));
+ table.add ("Tag");
+ table.add ("Description");
+
+ for (const auto& tagDescription : _tagDescriptions)
+ {
+ auto row = table.addRow ();
+ table.set (row, 0, tagDescription.name, tagDescription.color);
+ table.set (row, 1, tagDescription.description);
+ }
+
+ return table;
+}
+
+////////////////////////////////////////////////////////////////////////////////
diff --git a/src/TagsTable.h b/src/TagsTable.h
new file mode 100644
--- /dev/null
+++ b/src/TagsTable.h
@@ -0,0 +1,51 @@
+//////////////////////////////////////////////////////////////////////////////
+//
+// Copyright 2023, Gothenburg Bit Factory.
+//
+// Permission is hereby granted, free of charge, to any person obtaining a copy
+// of this software and associated documentation files (the "Software"), to deal
+// in the Software without restriction, including without limitation the rights
+// to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+// copies of the Software, and to permit persons to whom the Software is
+// furnished to do so, subject to the following conditions:
+//
+// The above copyright notice and this permission notice shall be included
+// in all copies or substantial portions of the Software.
+//
+// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
+// OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
+// THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+// SOFTWARE.
+//
+// https://www.opensource.org/licenses/mit-license.php
+//
+//////////////////////////////////////////////////////////////////////////////
+
+#ifndef INCLUDED_TAGSTABLEBUILDER
+#define INCLUDED_TAGSTABLEBUILDER
+
+#include <Table.h>
+#include <TagDescription.h>
+#include <vector>
+
+class TagsTable
+{
+ class Builder
+ {
+ public:
+ Builder& withTagDescriptions (std::vector <TagDescription>&);
+
+ Table build ();
+
+ private:
+ std::vector <TagDescription> _tagDescriptions {};
+ };
+
+public:
+ static Builder builder ();
+};
+
+#endif //INCLUDED_TAGSTABLEBUILDER
diff --git a/src/commands/CmdExtensions.cpp b/src/commands/CmdExtensions.cpp
--- a/src/commands/CmdExtensions.cpp
+++ b/src/commands/CmdExtensions.cpp
@@ -1,6 +1,6 @@
////////////////////////////////////////////////////////////////////////////////
//
-// Copyright 2016 - 2019, 2022, Thomas Lauf, Paul Beckingham, Federico Hernandez.
+// Copyright 2016 - 2019, 2022 - 2023, Gothenburg Bit Factory.
//
// Permission is hereby granted, free of charge, to any person obtaining a copy
// of this software and associated documentation files (the "Software"), to deal
@@ -24,7 +24,7 @@
//
////////////////////////////////////////////////////////////////////////////////
-#include <Table.h>
+#include <ExtensionsTable.h>
#include <commands.h>
#include <iostream>
#include <paths.h>
@@ -33,30 +33,9 @@
// Enumerate all extensions.
int CmdExtensions (const Extensions& extensions)
{
- Table table;
- table.width (1024);
- table.colorHeader (Color ("underline"));
- table.add ("Extension", true);
- table.add ("Status", true);
-
- for (auto& ext : extensions.all ())
- {
- File program (ext);
-
- // Show program name.
- auto row = table.addRow ();
- table.set (row, 0, program.name ());
-
- // Show extension status.
- std::string perms;
- if (! program.readable ()) perms = "Not readable";
- else if (! program.executable ()) perms = "No executable";
- else perms = "Active";
-
- if (program.is_link ()) perms += " (link)";
-
- table.set (row, 1, perms);
- }
+ auto table = ExtensionsTable::builder()
+ .withExtensions (extensions)
+ .build ();
Directory extDir (paths::extensionsDir ());
@@ -66,6 +45,7 @@ int CmdExtensions (const Extensions& extensions)
<< '\n'
<< table.render ()
<< '\n';
+
return 0;
}
diff --git a/src/commands/CmdGaps.cpp b/src/commands/CmdGaps.cpp
--- a/src/commands/CmdGaps.cpp
+++ b/src/commands/CmdGaps.cpp
@@ -1,6 +1,6 @@
////////////////////////////////////////////////////////////////////////////////
//
-// Copyright 2016 - 2023, Thomas Lauf, Paul Beckingham, Federico Hernandez.
+// Copyright 2016 - 2023, Gothenburg Bit Factory.
//
// Permission is hereby granted, free of charge, to any person obtaining a copy
// of this software and associated documentation files (the "Software"), to deal
@@ -25,9 +25,8 @@
////////////////////////////////////////////////////////////////////////////////
#include <Duration.h>
-#include <Table.h>
+#include <GapsTable.h>
#include <commands.h>
-#include <format.h>
#include <iostream>
#include <timew.h>
@@ -62,71 +61,24 @@ int CmdGaps (
untracked = getUntracked (database, rules, filter);
}
- Table table;
- table.width (1024);
- table.colorHeader (Color ("underline"));
- table.add ("Wk");
- table.add ("Date");
- table.add ("Day");
- table.add ("Start", false);
- table.add ("End", false);
- table.add ("Time", false);
- table.add ("Total", false);
-
- // Each day is rendered separately.
- time_t grand_total = 0;
- Datetime previous;
- for (Datetime day = range.start; day < range.end; day++)
+ if (untracked.empty ())
{
- auto day_range = getFullDay (day);
- time_t daily_total = 0;
-
- int row = -1;
- for (auto& gap : subset (day_range, untracked))
+ if (verbose)
{
- row = table.addRow ();
-
- if (day != previous)
- {
- table.set (row, 0, format ("W{1}", day.week ()));
- table.set (row, 1, day.toString ("Y-M-D"));
- table.set (row, 2, Datetime::dayNameShort (day.dayOfWeek ()));
- previous = day;
- }
-
- // Intersect track with day.
- auto today = day_range.intersect (gap);
- if (gap.is_open ())
- today.end = Datetime ();
-
- table.set (row, 3, today.start.toString ("h:N:S"));
- table.set (row, 4, (gap.is_open () ? "-" : today.end.toString ("h:N:S")));
- table.set (row, 5, Duration (today.total ()).formatHours ());
-
- daily_total += today.total ();
+ std::cout << "No gaps found.\n";
}
-
- if (row != -1)
- table.set (row, 6, Duration (daily_total).formatHours ());
-
- grand_total += daily_total;
}
-
- // Add the total.
- table.set (table.addRow (), 6, " ", Color ("underline"));
- table.set (table.addRow (), 6, Duration (grand_total).formatHours ());
-
- if (table.rows () > 2)
+ else
{
+ auto table = GapsTable::builder ()
+ .withRange (range)
+ .withIntervals (untracked)
+ .build ();
+
std::cout << '\n'
<< table.render ()
<< '\n';
}
- else
- {
- if (verbose)
- std::cout << "No gaps found.\n";
- }
return 0;
}
diff --git a/src/commands/CmdSummary.cpp b/src/commands/CmdSummary.cpp
--- a/src/commands/CmdSummary.cpp
+++ b/src/commands/CmdSummary.cpp
@@ -24,10 +24,10 @@
//
////////////////////////////////////////////////////////////////////////////////
-#include <Duration.h>
#include <IntervalFilterAllInRange.h>
#include <IntervalFilterAllWithTags.h>
#include <IntervalFilterAndGroup.h>
+#include <SummaryTable.h>
#include <Table.h>
#include <commands.h>
#include <format.h>
@@ -92,10 +92,7 @@ int CmdSummary (
// Map tags to colors.
Color colorID (rules.getBoolean ("color") ? rules.get ("theme.colors.ids") : "");
-
- const auto week_fmt = "W{1}";
- const auto date_fmt = "Y-M-D";
- const auto time_fmt = "h:N:S";
+ auto tagColorMap = createTagColorMap (rules, tracked);
const auto show_weeks = rules.getBoolean ("reports.summary.weeks", true);
const auto show_weekdays = rules.getBoolean ("reports.summary.weekdays", true);
@@ -104,162 +101,18 @@ int CmdSummary (
const auto show_annotations = cli.getComplementaryHint ("annotations", rules.getBoolean ("reports.summary.annotations"));
const auto show_holidays = cli.getComplementaryHint ("holidays", rules.getBoolean ("reports.summary.holidays"));
- const auto dates_col_offset = show_weeks ? 1 : 0;
- const auto weekdays_col_offset = dates_col_offset;
- const auto ids_col_offset = weekdays_col_offset + (show_weekdays ? 1: 0);
- const auto tags_col_offset = ids_col_offset + (show_ids ? 1 : 0);
- const auto annotation_col_offset = tags_col_offset + (show_tags ? 1 : 0);
- const auto start_col_offset = annotation_col_offset + (show_annotations ? 1 : 0);
-
- const auto weeks_col_index = 0;
- const auto dates_col_index = 0 + dates_col_offset;
- const auto weekdays_col_index = 1 + weekdays_col_offset;
- const auto ids_col_index = 1 + ids_col_offset;
- const auto tags_col_index = 1 + tags_col_offset;
- const auto annotation_col_index = 1 + annotation_col_offset;
- const auto start_col_index = 1 + start_col_offset;
- const auto end_col_index = 2 + start_col_offset;
- const auto duration_col_index = 3 + start_col_offset;
- const auto total_col_index = 4 + start_col_offset;
-
- Table table;
- table.width (1024);
- table.colorHeader (Color ("underline"));
-
- if (show_weeks)
- {
- table.add ("Wk");
- }
-
- table.add ("Date");
-
- if (show_weekdays)
- {
- table.add ("Day");
- }
-
- if (show_ids)
- {
- table.add ("ID");
- }
-
- if (show_tags)
- {
- table.add ("Tags");
- }
-
- if (show_annotations)
- {
- table.add ("Annotation");
- }
-
- table.add ("Start", false);
- table.add ("End", false);
- table.add ("Time", false);
- table.add ("Total", false);
-
- // Each day is rendered separately.
- time_t grand_total = 0;
- Datetime previous;
-
- auto days_start = range.is_started() ? range.start : tracked.front ().start;
- auto days_end = range.is_ended() ? range.end : tracked.back ().end;
-
- const auto now = Datetime ();
-
- if (days_end == 0)
- {
- days_end = now;
- }
-
- for (Datetime day = days_start.startOfDay (); day < days_end; ++day)
- {
- auto day_range = getFullDay (day);
- time_t daily_total = 0;
-
- int row = -1;
- for (auto& track : subset (day_range, tracked))
- {
- // Make sure the track only represents one day.
- if ((track.is_open () && day > now))
- {
- continue;
- }
-
- row = table.addRow ();
-
- if (day != previous)
- {
- if (show_weeks)
- {
- table.set (row, weeks_col_index, format (week_fmt, day.week ()));
- }
-
- table.set (row, dates_col_index, day.toString (date_fmt));
-
- if (show_weekdays)
- {
- table.set (row, weekdays_col_index, Datetime::dayNameShort (day.dayOfWeek ()));
- }
-
- previous = day;
- }
-
- // Intersect track with day.
- auto today = day_range.intersect (track);
-
- if (track.is_open() && track.start > now)
- {
- today.end = track.start;
- }
- else if (track.is_open () && day <= now && today.end > now)
- {
- today.end = now;
- }
-
- if (show_ids)
- {
- table.set (row, ids_col_index, format ("@{1}", track.id), colorID);
- }
-
- if (show_tags)
- {
- std::string tags_string = join (", ", track.tags ());
- table.set (row, tags_col_index, tags_string, summaryIntervalColor (rules, track.tags ()));
- }
-
- if (show_annotations)
- {
- auto annotation = track.getAnnotation ();
-
- if (utf8_length (annotation) > 15)
- {
- annotation = utf8_substr (annotation, 0, 12) + "...";
- }
-
- table.set (row, annotation_col_index, annotation);
- }
-
- const auto total = today.total ();
-
- table.set (row, start_col_index, today.start.toString (time_fmt));
- table.set (row, end_col_index, (track.is_open () ? "-" : today.end.toString (time_fmt)));
- table.set (row, duration_col_index, Duration (total).formatHours ());
-
- daily_total += total;
- }
-
- if (row != -1)
- {
- table.set (row, total_col_index, Duration (daily_total).formatHours ());
- }
-
- grand_total += daily_total;
- }
-
- // Add the total.
- table.set (table.addRow (), total_col_index, " ", Color ("underline"));
- table.set (table.addRow (), total_col_index, Duration (grand_total).formatHours ());
+ auto table = SummaryTable::builder ()
+ .withWeekFormat ("W{1}")
+ .withDateFormat ("Y-M-D")
+ .withTimeFormat ("h:N:S")
+ .withWeeks (show_weeks)
+ .withWeekdays (show_weekdays)
+ .withIds (show_ids, colorID)
+ .withTags (show_tags, tagColorMap)
+ .withAnnotations (show_annotations)
+ .withRange (range)
+ .withIntervals (tracked)
+ .build ();
std::cout << '\n'
<< table.render ()
@@ -270,11 +123,11 @@ int CmdSummary (
}
////////////////////////////////////////////////////////////////////////////////
-std::string renderHolidays (const std::map<Datetime, std::string> &holidays)
+std::string renderHolidays (const std::map<Datetime, std::string>& holidays)
{
std::stringstream out;
- for (auto &entry : holidays)
+ for (auto& entry : holidays)
{
out << entry.first.toString ("Y-M-D")
<< " "
diff --git a/src/commands/CmdTags.cpp b/src/commands/CmdTags.cpp
--- a/src/commands/CmdTags.cpp
+++ b/src/commands/CmdTags.cpp
@@ -1,6 +1,6 @@
////////////////////////////////////////////////////////////////////////////////
//
-// Copyright 2016 - 2023, Thomas Lauf, Paul Beckingham, Federico Hernandez.
+// Copyright 2016 - 2023, Gothenburg Bit Factory.
//
// Permission is hereby granted, free of charge, to any person obtaining a copy
// of this software and associated documentation files (the "Software"), to deal
@@ -29,6 +29,8 @@
#include <IntervalFilterAllWithTags.h>
#include <IntervalFilterAndGroup.h>
#include <Table.h>
+#include <TagDescription.h>
+#include <TagsTable.h>
#include <commands.h>
#include <iostream>
#include <set>
@@ -51,37 +53,39 @@ int CmdTags (
std::set <std::string> tags;
for (const auto& interval : getTracked (database, rules, filtering))
- for (auto& tag : interval.tags ())
+ {
+ for (const auto& tag : interval.tags ())
+ {
tags.insert (tag);
+ }
+ }
// Shows all tags.
- if (! tags.empty ())
+ if (tags.empty ())
{
- Table table;
- table.width (1024);
- table.colorHeader (Color ("underline"));
- table.add ("Tag");
- table.add ("Description");
- // TODO Show all tag metadata.
-
- for (auto& tag : tags)
+ if (verbose)
{
- auto row = table.addRow ();
- table.set (row, 0, tag, tagColor (rules, tag));
+ std::cout << "No data found.\n";
+ }
+ }
+ else
+ {
+ std::vector <TagDescription> tagDescriptions;
+ for (const auto& tag: tags)
+ {
auto name = std::string ("tags.") + tag + ".description";
- table.set (row, 1, rules.has (name) ? rules.get (name) : "-");
+ tagDescriptions.emplace_back (tag, tagColor (rules, tag), rules.has (name) ? rules.get (name) : "-");
}
+ auto table = TagsTable::builder()
+ .withTagDescriptions (tagDescriptions)
+ .build ();
+
std::cout << '\n'
<< table.render ()
<< '\n';
}
- else
- {
- if (verbose)
- std::cout << "No data found.\n";
- }
return 0;
}
diff --git a/src/helper.cpp b/src/helper.cpp
--- a/src/helper.cpp
+++ b/src/helper.cpp
@@ -27,11 +27,15 @@
#include <Datetime.h>
#include <Duration.h>
#include <IntervalFactory.h>
+#include <Table.h>
#include <format.h>
#include <iomanip>
#include <map>
#include <sstream>
+#include <string>
+#include <sys/ioctl.h>
#include <timew.h>
+#include <unistd.h>
#include <vector>
////////////////////////////////////////////////////////////////////////////////
@@ -50,6 +54,21 @@ Color summaryIntervalColor (
return c;
}
+////////////////////////////////////////////////////////////////////////////////
+Color summaryIntervalColor (
+ std::map <std::string, Color>& tagColors,
+ const std::set <std::string>& tags)
+{
+ Color c;
+
+ for (const auto& tag : tags)
+ {
+ c.blend (tagColors[tag]);
+ }
+
+ return c;
+}
+
////////////////////////////////////////////////////////////////////////////////
// Select a color to represent the interval on a chart.
Color chartIntervalColor (
@@ -410,6 +429,30 @@ std::map <std::string, Color> createTagColorMap (
return mapping;
}
+////////////////////////////////////////////////////////////////////////////////
+std::map <std::string, Color> createTagColorMap (const Rules& rules, const std::vector <Interval>& intervals)
+{
+ std::set <std::string> tags;
+
+ for (const auto& interval : intervals)
+ {
+ tags.insert (interval.tags ().begin (), interval.tags ().end ());
+ }
+
+ std::map <std::string, Color> mapping;
+
+ for (const auto& tag : tags)
+ {
+ std::string key = "tags." + tag + ".color";
+ if (rules.has (key))
+ {
+ mapping[tag] = Color (rules.get (key));
+ }
+ }
+
+ return mapping;
+}
+
////////////////////////////////////////////////////////////////////////////////
int quantizeToNMinutes (const int minutes, const int N)
{
@@ -472,3 +515,20 @@ std::string minimalDelta (const Datetime& left, const Datetime& right)
}
////////////////////////////////////////////////////////////////////////////////
+int getTerminalWidth ()
+{
+ int terminalWidth;
+#ifdef TIOCGSIZE
+ struct ttysize ts{};
+ ioctl (STDIN_FILENO, TIOCGSIZE, &ts);
+ terminalWidth = ts.ts_cols;
+#elif defined(TIOCGWINSZ)
+ struct winsize ts {};
+ ioctl(STDIN_FILENO, TIOCGWINSZ, &ts);
+ terminalWidth = ts.ws_col;
+#endif
+
+ return terminalWidth > 0 ? terminalWidth : 80;
+}
+
+////////////////////////////////////////////////////////////////////////////////
diff --git a/src/timew.h b/src/timew.h
--- a/src/timew.h
+++ b/src/timew.h
@@ -69,6 +69,7 @@ int dispatchCommand (const CLI&, Database&, Journal&, Rules&, const Extensions&)
// helper.cpp
Color summaryIntervalColor (const Rules&, const std::set <std::string>&);
+Color summaryIntervalColor (std::map <std::string, Color>&, const std::set <std::string>&);
Color chartIntervalColor (const std::set <std::string>&, const std::map <std::string, Color>&);
Color tagColor (const Rules&, const std::string&);
std::string intervalSummarize (const Rules&, const Interval&);
@@ -76,10 +77,12 @@ bool expandIntervalHint (const std::string&, Range&);
std::string jsonFromIntervals (const std::vector <Interval>&);
Palette createPalette (const Rules&);
std::map <std::string, Color> createTagColorMap (const Rules&, Palette&, const std::vector <Interval>&);
+std::map <std::string, Color> createTagColorMap (const Rules& rules, const std::vector <Interval>& intervals);
int quantizeToNMinutes (int, int);
bool findHint (const CLI&, const std::string&);
std::string minimalDelta (const Datetime&, const Datetime&);
+int getTerminalWidth () ;
// log.cpp
void enableDebugMode (bool);
|
diff --git a/test/summary.t b/test/summary.t
--- a/test/summary.t
+++ b/test/summary.t
@@ -352,15 +352,14 @@ W\d{1,2} \d{4}-\d{2}-\d{2} .{3} ?0:00:00 0:00:00 0:00:00 0:00:00
[ ]+0:00:00
""")
- def test_multibyte_char_annotation_truncated(self):
- """Summary correctly truncates long annotation containing multibyte characters"""
- # Using a blue heart emoji as an example of a multibyte (4 bytes in
- # this case) character.
- long_enough_annotation = "a" + "\N{blue heart}" * 20
- self.t("track FOO sod - sod")
+ def test_multibyte_char_annotation_wrapped(self):
+ """Summary correctly wraps long annotation containing multibyte characters"""
+ # Using a blue heart emoji as an example of a multibyte (4 bytes in this case) character.
+ long_enough_annotation = "'" + ("a" + "💙" * 5 + " ") * 5 + "'"
+ self.t("track FOO sod - sond")
self.t("anno @1 " + long_enough_annotation)
code, out, err = self.t("summary :anno")
- self.assertIn("a" + "\N{blue heart}" * 11 + "...", out)
+ self.assertRegex(out, r"(a💙{5} )\s{0,11}0:00:00")
if __name__ == "__main__":
|
Wrap annotations in summary
Please wrap the annotation into multiple colums, otherwise it doesn't make too much sense if you can't read it in the summary:
```
timew summary :annotations :id oas
Wk Date Day ID Tags Annotation Start End Time Total
W6 2019-02-07 Thu @1 +123, oas Working my a... 0:31:51 0:32:50 0:00:59 0:00:59
0:00:59
```
i.e. like this:
```
timew summary :annotations :id oas
Wk Date Day ID Tags Annotation Start End Time Total
W6 2019-02-07 Thu @1 +123, oas Working my ass 0:31:51 0:32:50 0:00:59 0:00:59
off after an al-
ready long day
0:00:59
```
|
While you are at it, it will also be useful to allow the summary report to be wider. This will be very useful if the report contains more or longer fields as shown above (numerous tags and annotations).
Perhaps this relates to all timew output which might be premised on a standard screen width.
A wider screen width (or report width) preference could be specified in timewarrior.cfg.
@grovesteyn You write that you can configure this in timewarrior.cfg, but how? Unfortunately the documentation is very poor and I can't find anything at all. What do I have to enter in the config so that the column width of the annotation becomes wider with the "summary" command?
> @grovesteyn You write that you can configure this in timewarrior.cfg, but how?
Currently, the maximum length of 15 chars for the annotations column in the summary is [hard-coded and can't be configured](https://github.com/GothenburgBitFactory/timewarrior/blob/c8a85850ea01befc652e57fd6c2de73a1ed0eee9/src/commands/CmdSummary.cpp#L233).
(I believe @grovesteyn was proposing one possible way to change the configuration (by saying "could be specified in timewarrior.cfg"), and not referring to something that is already implemented.)
Making the annotations column length in summary configurable seems to be a fairly simple change, I wonder whether author(s) would be interested in a patch and, in such case, whether they have any concerns that should be taken care of in implementation proposals.
I'd be happy if a PR making the maximum width of the annotations column configurable would also take unicode character widths into account (see https://github.com/GothenburgBitFactory/timewarrior/pull/529#issuecomment-1508193650).
A more complete solution (apart from wrapping) would be to let the annotations column width grow until the summary table hits the terminal width an only then to apply the cut off. 🤔 (Currently, the summary table width is [fixed to 1024 characters](https://github.com/GothenburgBitFactory/timewarrior/blob/84fdf76f9aba22d9badbcbdf92942714cb5e254f/src/commands/CmdSummary.cpp#L124).)
| 2023-10-29T10:36:37
|
cpp
|
Easy
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.