
End of training
Browse files- README.md +2 -1
- all_results.json +13 -0
- eval_results.json +8 -0
- train_results.json +9 -0
- trainer_state.json +0 -0
- training_eval_loss.png +0 -0
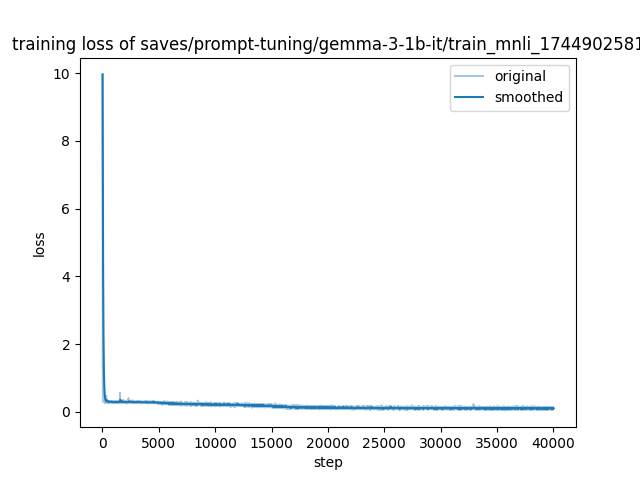
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: gemma
|
|
| 4 |
base_model: google/gemma-3-1b-it
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: train_mnli_1744902581
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# train_mnli_1744902581
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 0.1030
|
| 21 |
- Num Input Tokens Seen: 64338040
|
|
|
|
| 4 |
base_model: google/gemma-3-1b-it
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- prompt-tuning
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: train_mnli_1744902581
|
|
|
|
| 16 |
|
| 17 |
# train_mnli_1744902581
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it) on the mnli dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.1030
|
| 22 |
- Num Input Tokens Seen: 64338040
|
all_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.810792457955137,
|
| 3 |
+
"eval_loss": 0.1030457615852356,
|
| 4 |
+
"eval_runtime": 451.3434,
|
| 5 |
+
"eval_samples_per_second": 87.009,
|
| 6 |
+
"eval_steps_per_second": 21.753,
|
| 7 |
+
"num_input_tokens_seen": 64338040,
|
| 8 |
+
"total_flos": 2.6940758928884736e+17,
|
| 9 |
+
"train_loss": 0.16186581058874727,
|
| 10 |
+
"train_runtime": 106353.8903,
|
| 11 |
+
"train_samples_per_second": 6.018,
|
| 12 |
+
"train_steps_per_second": 0.376
|
| 13 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.810792457955137,
|
| 3 |
+
"eval_loss": 0.1030457615852356,
|
| 4 |
+
"eval_runtime": 451.3434,
|
| 5 |
+
"eval_samples_per_second": 87.009,
|
| 6 |
+
"eval_steps_per_second": 21.753,
|
| 7 |
+
"num_input_tokens_seen": 64338040
|
| 8 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.810792457955137,
|
| 3 |
+
"num_input_tokens_seen": 64338040,
|
| 4 |
+
"total_flos": 2.6940758928884736e+17,
|
| 5 |
+
"train_loss": 0.16186581058874727,
|
| 6 |
+
"train_runtime": 106353.8903,
|
| 7 |
+
"train_samples_per_second": 6.018,
|
| 8 |
+
"train_steps_per_second": 0.376
|
| 9 |
+
}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_eval_loss.png
ADDED

|
training_loss.png
ADDED
|