Spaces:
Running


Running
Rework demo to English with default Gradio theme
Browse files- Translate all UI text from Chinese to English
- Remove custom purple gradient CSS, use default Gradio theme
- Add local example images for 5 demo categories
- Update example prompts to English
- Translate all code comments to English
- README.md +1 -1
- app.py +168 -425
- examples/ie.jpg +0 -0
- examples/parsing.jpg +0 -0
- examples/spotting.jpg +0 -0
- examples/translation.jpg +0 -0
- examples/vqa.jpg +0 -0
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🏃
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: yellow
|
|
|
|
| 1 |
---
|
| 2 |
+
title: HunyuanOCR-EN
|
| 3 |
emoji: 🏃
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: yellow
|
app.py
CHANGED
|
@@ -4,7 +4,7 @@ import numpy as np
|
|
| 4 |
from PIL import Image
|
| 5 |
import spaces
|
| 6 |
from transformers import AutoProcessor
|
| 7 |
-
from qwen_vl_utils import process_vision_info
|
| 8 |
from transformers import HunYuanVLForConditionalGeneration
|
| 9 |
import gradio as gr
|
| 10 |
from argparse import ArgumentParser
|
|
@@ -15,10 +15,9 @@ import tempfile
|
|
| 15 |
import hashlib
|
| 16 |
import gc
|
| 17 |
|
| 18 |
-
#
|
| 19 |
-
os.environ['TOKENIZERS_PARALLELISM'] = 'false'
|
| 20 |
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = '1'
|
| 21 |
-
# 禁用 PyTorch 的 JIT 融合优化(在某些情况下会导致首次运行极慢)
|
| 22 |
# torch._C._jit_set_profiling_executor(False)
|
| 23 |
# torch._C._jit_set_profiling_mode(False)
|
| 24 |
|
|
@@ -55,35 +54,35 @@ def _get_args():
|
|
| 55 |
|
| 56 |
|
| 57 |
def _load_model_processor(args):
|
| 58 |
-
# ZeroGPU
|
| 59 |
-
#
|
| 60 |
-
print(f"[INFO]
|
| 61 |
-
print(f"[INFO]
|
| 62 |
|
| 63 |
model = HunYuanVLForConditionalGeneration.from_pretrained(
|
| 64 |
args.checkpoint_path,
|
| 65 |
-
attn_implementation="eager", # ZeroGPU
|
| 66 |
torch_dtype=torch.bfloat16,
|
| 67 |
-
device_map="auto", #
|
| 68 |
)
|
| 69 |
-
|
| 70 |
-
#
|
| 71 |
if hasattr(model, 'gradient_checkpointing_disable'):
|
| 72 |
model.gradient_checkpointing_disable()
|
| 73 |
-
print(f"[INFO]
|
| 74 |
-
|
| 75 |
-
#
|
| 76 |
model.eval()
|
| 77 |
-
print(f"[INFO]
|
| 78 |
|
| 79 |
processor = AutoProcessor.from_pretrained(args.checkpoint_path, use_fast=False, trust_remote_code=True)
|
| 80 |
|
| 81 |
-
print(f"[INFO]
|
| 82 |
return model, processor
|
| 83 |
|
| 84 |
|
| 85 |
def _parse_text(text):
|
| 86 |
-
"""
|
| 87 |
# if text is None:
|
| 88 |
# return text
|
| 89 |
text = text.replace("<trans>", "").replace("</trans>", "")
|
|
@@ -91,10 +90,10 @@ def _parse_text(text):
|
|
| 91 |
|
| 92 |
|
| 93 |
def _remove_image_special(text):
|
| 94 |
-
"""
|
| 95 |
# if text is None:
|
| 96 |
# return text
|
| 97 |
-
# #
|
| 98 |
# import re
|
| 99 |
# text = re.sub(r'<image>|</image>|<img>|</img>', '', text)
|
| 100 |
# return text
|
|
@@ -102,7 +101,7 @@ def _remove_image_special(text):
|
|
| 102 |
|
| 103 |
|
| 104 |
def _gc():
|
| 105 |
-
"""
|
| 106 |
gc.collect()
|
| 107 |
if torch.cuda.is_available():
|
| 108 |
torch.cuda.empty_cache()
|
|
@@ -128,11 +127,11 @@ def clean_repeated_substrings(text):
|
|
| 128 |
|
| 129 |
|
| 130 |
def _launch_demo(args, model, processor):
|
| 131 |
-
#
|
| 132 |
first_call = [True]
|
| 133 |
-
|
| 134 |
-
#
|
| 135 |
-
#
|
| 136 |
@spaces.GPU(duration=120)
|
| 137 |
def call_local_model(messages):
|
| 138 |
import time
|
|
@@ -140,12 +139,12 @@ def _launch_demo(args, model, processor):
|
|
| 140 |
start_time = time.time()
|
| 141 |
|
| 142 |
if first_call[0]:
|
| 143 |
-
print(f"[INFO] ==========
|
| 144 |
first_call[0] = False
|
| 145 |
else:
|
| 146 |
-
print(f"[INFO] ==========
|
| 147 |
-
|
| 148 |
-
print(f"[DEBUG] ==========
|
| 149 |
print(f"[DEBUG] Python version: {sys.version}")
|
| 150 |
print(f"[DEBUG] PyTorch version: {torch.__version__}")
|
| 151 |
print(f"[DEBUG] CUDA available: {torch.cuda.is_available()}")
|
|
@@ -156,38 +155,38 @@ def _launch_demo(args, model, processor):
|
|
| 156 |
print(f"[DEBUG] GPU Memory allocated: {torch.cuda.memory_allocated(0) / 1024**3:.2f} GB")
|
| 157 |
print(f"[DEBUG] GPU Memory reserved: {torch.cuda.memory_reserved(0) / 1024**3:.2f} GB")
|
| 158 |
|
| 159 |
-
#
|
| 160 |
model_device = next(model.parameters()).device
|
| 161 |
print(f"[DEBUG] Model device: {model_device}")
|
| 162 |
print(f"[DEBUG] Model dtype: {next(model.parameters()).dtype}")
|
| 163 |
-
|
| 164 |
if str(model_device) == 'cpu':
|
| 165 |
-
print(f"[ERROR]
|
| 166 |
if torch.cuda.is_available():
|
| 167 |
move_start = time.time()
|
| 168 |
model.cuda()
|
| 169 |
move_time = time.time() - move_start
|
| 170 |
print(f"[DEBUG] Model device after cuda(): {next(model.parameters()).device}")
|
| 171 |
-
print(f"[DEBUG]
|
| 172 |
else:
|
| 173 |
-
print(f"[CRITICAL] CUDA
|
| 174 |
-
print(f"[CRITICAL]
|
| 175 |
else:
|
| 176 |
-
print(f"[INFO]
|
| 177 |
|
| 178 |
messages = [messages]
|
| 179 |
|
| 180 |
-
#
|
| 181 |
texts = [
|
| 182 |
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
|
| 183 |
for msg in messages
|
| 184 |
]
|
| 185 |
-
print(f"[DEBUG]
|
| 186 |
-
|
| 187 |
image_inputs, video_inputs = process_vision_info(messages)
|
| 188 |
-
print(f"[DEBUG]
|
| 189 |
-
|
| 190 |
-
#
|
| 191 |
if image_inputs:
|
| 192 |
for idx, img in enumerate(image_inputs):
|
| 193 |
if hasattr(img, 'size'):
|
|
@@ -195,10 +194,7 @@ def _launch_demo(args, model, processor):
|
|
| 195 |
elif isinstance(img, np.ndarray):
|
| 196 |
print(f"[DEBUG] Image {idx} shape: {img.shape}")
|
| 197 |
|
| 198 |
-
print(f"[DEBUG]
|
| 199 |
-
processor_start = time.time()
|
| 200 |
-
|
| 201 |
-
print(f"[DEBUG] 开始 processor 编码输入...")
|
| 202 |
processor_start = time.time()
|
| 203 |
inputs = processor(
|
| 204 |
text=texts,
|
|
@@ -207,27 +203,26 @@ def _launch_demo(args, model, processor):
|
|
| 207 |
padding=True,
|
| 208 |
return_tensors="pt",
|
| 209 |
)
|
| 210 |
-
print(f"[DEBUG] Processor
|
| 211 |
-
|
| 212 |
-
#
|
| 213 |
to_device_start = time.time()
|
| 214 |
inputs = inputs.to('cuda' if torch.cuda.is_available() else 'cpu')
|
| 215 |
-
print(f"[DEBUG]
|
| 216 |
-
print(f"[DEBUG]
|
| 217 |
print(f"[DEBUG] Input IDs shape: {inputs.input_ids.shape}")
|
| 218 |
print(f"[DEBUG] Input device: {inputs.input_ids.device}")
|
| 219 |
print(f"[DEBUG] Input sequence length: {inputs.input_ids.shape[1]}")
|
| 220 |
|
| 221 |
-
#
|
| 222 |
gen_start = time.time()
|
| 223 |
-
print(f"[DEBUG] ==========
|
| 224 |
-
|
| 225 |
-
#
|
| 226 |
-
|
| 227 |
-
max_new_tokens = 2048 # 从 8192 降到 2048,大幅提速
|
| 228 |
print(f"[DEBUG] max_new_tokens: {max_new_tokens}")
|
| 229 |
-
|
| 230 |
-
#
|
| 231 |
token_count = [0]
|
| 232 |
last_time = [gen_start]
|
| 233 |
|
|
@@ -237,49 +232,49 @@ def _launch_demo(args, model, processor):
|
|
| 237 |
if token_count[0] % 10 == 0 or (current_time - last_time[0]) > 2.0:
|
| 238 |
elapsed = current_time - gen_start
|
| 239 |
tokens_per_sec = token_count[0] / elapsed if elapsed > 0 else 0
|
| 240 |
-
print(f"[DEBUG]
|
| 241 |
last_time[0] = current_time
|
| 242 |
return False
|
| 243 |
|
| 244 |
with torch.no_grad():
|
| 245 |
-
print(f"[DEBUG]
|
| 246 |
-
|
| 247 |
-
#
|
| 248 |
-
print(f"[DEBUG]
|
| 249 |
forward_test_start = time.time()
|
| 250 |
try:
|
| 251 |
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
|
| 252 |
test_outputs = model(**inputs, use_cache=False)
|
| 253 |
-
print(f"[DEBUG]
|
| 254 |
except Exception as e:
|
| 255 |
-
print(f"[WARNING]
|
| 256 |
-
|
| 257 |
-
print(f"[DEBUG]
|
| 258 |
generate_call_start = time.time()
|
| 259 |
|
| 260 |
try:
|
| 261 |
-
#
|
| 262 |
generated_ids = model.generate(
|
| 263 |
**inputs,
|
| 264 |
max_new_tokens=max_new_tokens,
|
| 265 |
do_sample=False,
|
| 266 |
temperature=0
|
| 267 |
)
|
| 268 |
-
print(f"[DEBUG] model.generate()
|
| 269 |
except Exception as e:
|
| 270 |
-
print(f"[ERROR]
|
| 271 |
import traceback
|
| 272 |
traceback.print_exc()
|
| 273 |
raise
|
| 274 |
|
| 275 |
-
print(f"[DEBUG]
|
| 276 |
-
|
| 277 |
gen_time = time.time() - gen_start
|
| 278 |
-
print(f"[DEBUG] ==========
|
| 279 |
-
print(f"[DEBUG]
|
| 280 |
print(f"[DEBUG] Output shape: {generated_ids.shape}")
|
| 281 |
-
|
| 282 |
-
#
|
| 283 |
if "input_ids" in inputs:
|
| 284 |
input_ids = inputs.input_ids
|
| 285 |
else:
|
|
@@ -290,8 +285,8 @@ def _launch_demo(args, model, processor):
|
|
| 290 |
]
|
| 291 |
|
| 292 |
actual_tokens = len(generated_ids_trimmed[0])
|
| 293 |
-
print(f"[DEBUG]
|
| 294 |
-
print(f"[DEBUG]
|
| 295 |
|
| 296 |
output_texts = processor.batch_decode(
|
| 297 |
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
|
@@ -299,10 +294,10 @@ def _launch_demo(args, model, processor):
|
|
| 299 |
|
| 300 |
|
| 301 |
total_time = time.time() - start_time
|
| 302 |
-
print(f"[DEBUG] ==========
|
| 303 |
-
print(f"[DEBUG]
|
| 304 |
-
print(f"[DEBUG]
|
| 305 |
-
print(f"[DEBUG]
|
| 306 |
output_texts[0] = clean_repeated_substrings(output_texts[0])
|
| 307 |
return output_texts
|
| 308 |
|
|
@@ -324,7 +319,7 @@ def _launch_demo(args, model, processor):
|
|
| 324 |
content = []
|
| 325 |
for q, a in history_cp:
|
| 326 |
if isinstance(q, (tuple, list)):
|
| 327 |
-
#
|
| 328 |
img_path = q[0]
|
| 329 |
if img_path.startswith(('http://', 'https://')):
|
| 330 |
content.append({'type': 'image', 'image': img_path})
|
|
@@ -337,7 +332,7 @@ def _launch_demo(args, model, processor):
|
|
| 337 |
content = []
|
| 338 |
messages.pop()
|
| 339 |
|
| 340 |
-
#
|
| 341 |
response_list = call_local_model(messages)
|
| 342 |
response = response_list[0] if response_list else ""
|
| 343 |
|
|
@@ -365,7 +360,7 @@ def _launch_demo(args, model, processor):
|
|
| 365 |
_chatbot[-1] = (_chatbot[-1][0], None)
|
| 366 |
else:
|
| 367 |
_chatbot.append((chatbot_item[0], None))
|
| 368 |
-
#
|
| 369 |
_chatbot_gen = predict(_chatbot, task_history)
|
| 370 |
for _chatbot in _chatbot_gen:
|
| 371 |
yield _chatbot
|
|
@@ -391,26 +386,26 @@ def _launch_demo(args, model, processor):
|
|
| 391 |
return history, task_history
|
| 392 |
|
| 393 |
def download_url_image(url):
|
| 394 |
-
"""
|
| 395 |
try:
|
| 396 |
-
#
|
| 397 |
url_hash = hashlib.md5(url.encode()).hexdigest()
|
| 398 |
temp_dir = tempfile.gettempdir()
|
| 399 |
temp_path = os.path.join(temp_dir, f"hyocr_demo_{url_hash}.png")
|
| 400 |
-
|
| 401 |
-
#
|
| 402 |
if os.path.exists(temp_path):
|
| 403 |
return temp_path
|
| 404 |
-
|
| 405 |
-
#
|
| 406 |
response = requests.get(url, timeout=10)
|
| 407 |
response.raise_for_status()
|
| 408 |
with open(temp_path, 'wb') as f:
|
| 409 |
f.write(response.content)
|
| 410 |
return temp_path
|
| 411 |
except Exception as e:
|
| 412 |
-
print(f"
|
| 413 |
-
return url #
|
| 414 |
|
| 415 |
def reset_user_input():
|
| 416 |
return gr.update(value='')
|
|
@@ -421,336 +416,98 @@ def _launch_demo(args, model, processor):
|
|
| 421 |
_gc()
|
| 422 |
return []
|
| 423 |
|
| 424 |
-
#
|
| 425 |
EXAMPLE_IMAGES = {
|
| 426 |
-
"spotting": "
|
| 427 |
-
"parsing": "
|
| 428 |
-
"ie": "
|
| 429 |
-
"vqa": "
|
| 430 |
-
"translation": "
|
| 431 |
-
# "spotting": "examples/spotting.jpg",
|
| 432 |
-
# "parsing": "examples/parsing.jpg",
|
| 433 |
-
# "ie": "examples/ie.jpg",
|
| 434 |
-
# "vqa": "examples/vqa.jpg",
|
| 435 |
-
# "translation": "examples/translation.jpg"
|
| 436 |
}
|
| 437 |
|
| 438 |
-
with gr.Blocks(
|
| 439 |
-
|
| 440 |
-
|
| 441 |
-
}
|
| 442 |
-
.gradio-container {
|
| 443 |
-
max-width: 100% !important;
|
| 444 |
-
padding: 0 40px !important;
|
| 445 |
-
}
|
| 446 |
-
.header-section {
|
| 447 |
-
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
|
| 448 |
-
padding: 30px 0;
|
| 449 |
-
margin: -20px -40px 30px -40px;
|
| 450 |
-
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
|
| 451 |
-
}
|
| 452 |
-
.header-content {
|
| 453 |
-
max-width: 1600px;
|
| 454 |
-
margin: 0 auto;
|
| 455 |
-
padding: 0 40px;
|
| 456 |
-
display: flex;
|
| 457 |
-
align-items: center;
|
| 458 |
-
gap: 20px;
|
| 459 |
-
}
|
| 460 |
-
.header-logo {
|
| 461 |
-
height: 60px;
|
| 462 |
-
}
|
| 463 |
-
.header-text h1 {
|
| 464 |
-
color: white;
|
| 465 |
-
font-size: 32px;
|
| 466 |
-
font-weight: bold;
|
| 467 |
-
margin: 0 0 5px 0;
|
| 468 |
-
}
|
| 469 |
-
.header-text p {
|
| 470 |
-
color: rgba(255,255,255,0.9);
|
| 471 |
-
margin: 0;
|
| 472 |
-
font-size: 14px;
|
| 473 |
-
}
|
| 474 |
-
.main-container {
|
| 475 |
-
max-width: 1800px;
|
| 476 |
-
margin: 0 auto;
|
| 477 |
-
}
|
| 478 |
-
.chatbot {
|
| 479 |
-
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.08) !important;
|
| 480 |
-
border-radius: 12px !important;
|
| 481 |
-
border: 1px solid #e5e7eb !important;
|
| 482 |
-
background: white !important;
|
| 483 |
-
}
|
| 484 |
-
.input-panel {
|
| 485 |
-
background: white;
|
| 486 |
-
padding: 20px;
|
| 487 |
-
border-radius: 12px;
|
| 488 |
-
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.08);
|
| 489 |
-
border: 1px solid #e5e7eb;
|
| 490 |
-
}
|
| 491 |
-
.input-box textarea {
|
| 492 |
-
border: 2px solid #e5e7eb !important;
|
| 493 |
-
border-radius: 8px !important;
|
| 494 |
-
font-size: 14px !important;
|
| 495 |
-
}
|
| 496 |
-
.input-box textarea:focus {
|
| 497 |
-
border-color: #667eea !important;
|
| 498 |
-
}
|
| 499 |
-
.btn-primary {
|
| 500 |
-
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%) !important;
|
| 501 |
-
border: none !important;
|
| 502 |
-
color: white !important;
|
| 503 |
-
font-weight: 500 !important;
|
| 504 |
-
padding: 10px 24px !important;
|
| 505 |
-
font-size: 14px !important;
|
| 506 |
-
}
|
| 507 |
-
.btn-primary:hover {
|
| 508 |
-
transform: translateY(-1px) !important;
|
| 509 |
-
box-shadow: 0 4px 12px rgba(102, 126, 234, 0.4) !important;
|
| 510 |
-
}
|
| 511 |
-
.btn-secondary {
|
| 512 |
-
background: white !important;
|
| 513 |
-
border: 2px solid #667eea !important;
|
| 514 |
-
color: #667eea !important;
|
| 515 |
-
padding: 8px 20px !important;
|
| 516 |
-
font-size: 14px !important;
|
| 517 |
-
}
|
| 518 |
-
.btn-secondary:hover {
|
| 519 |
-
background: #f0f4ff !important;
|
| 520 |
-
}
|
| 521 |
-
.example-grid {
|
| 522 |
-
display: grid;
|
| 523 |
-
grid-template-columns: repeat(4, 1fr);
|
| 524 |
-
gap: 20px;
|
| 525 |
-
margin-top: 30px;
|
| 526 |
-
}
|
| 527 |
-
.example-card {
|
| 528 |
-
background: white;
|
| 529 |
-
border-radius: 12px;
|
| 530 |
-
overflow: hidden;
|
| 531 |
-
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.08);
|
| 532 |
-
border: 1px solid #e5e7eb;
|
| 533 |
-
transition: all 0.3s ease;
|
| 534 |
-
}
|
| 535 |
-
.example-card:hover {
|
| 536 |
-
transform: translateY(-4px);
|
| 537 |
-
box-shadow: 0 8px 20px rgba(102, 126, 234, 0.15);
|
| 538 |
-
border-color: #667eea;
|
| 539 |
-
}
|
| 540 |
-
.example-image-wrapper {
|
| 541 |
-
width: 100%;
|
| 542 |
-
height: 180px;
|
| 543 |
-
overflow: hidden;
|
| 544 |
-
background: #f5f7fa;
|
| 545 |
-
}
|
| 546 |
-
.example-image-wrapper img {
|
| 547 |
-
width: 100%;
|
| 548 |
-
height: 100%;
|
| 549 |
-
object-fit: cover;
|
| 550 |
-
}
|
| 551 |
-
.example-btn {
|
| 552 |
-
width: 100% !important;
|
| 553 |
-
white-space: pre-wrap !important;
|
| 554 |
-
text-align: left !important;
|
| 555 |
-
padding: 16px !important;
|
| 556 |
-
background: white !important;
|
| 557 |
-
border: none !important;
|
| 558 |
-
border-top: 1px solid #e5e7eb !important;
|
| 559 |
-
color: #1f2937 !important;
|
| 560 |
-
font-size: 14px !important;
|
| 561 |
-
line-height: 1.6 !important;
|
| 562 |
-
transition: all 0.3s ease !important;
|
| 563 |
-
font-weight: 500 !important;
|
| 564 |
-
}
|
| 565 |
-
.example-btn:hover {
|
| 566 |
-
background: #f9fafb !important;
|
| 567 |
-
color: #667eea !important;
|
| 568 |
-
}
|
| 569 |
-
.feature-section {
|
| 570 |
-
background: white;
|
| 571 |
-
padding: 24px;
|
| 572 |
-
border-radius: 12px;
|
| 573 |
-
margin-top: 30px;
|
| 574 |
-
box-shadow: 0 2px 8px rgba(0, 0, 0, 0.08);
|
| 575 |
-
border: 1px solid #e5e7eb;
|
| 576 |
-
}
|
| 577 |
-
.section-title {
|
| 578 |
-
font-size: 18px;
|
| 579 |
-
font-weight: 600;
|
| 580 |
-
color: #1f2937;
|
| 581 |
-
margin-bottom: 20px;
|
| 582 |
-
padding-bottom: 12px;
|
| 583 |
-
border-bottom: 2px solid #e5e7eb;
|
| 584 |
-
}
|
| 585 |
-
""") as demo:
|
| 586 |
-
# 顶部导航栏
|
| 587 |
-
gr.HTML("""
|
| 588 |
-
<div class="header-section">
|
| 589 |
-
<div class="header-content">
|
| 590 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/6ef6928b21b323b2b00115f86a779d8f.png?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763450355%3B1794554415&q-key-time=1763450355%3B1794554415&q-header-list=host&q-url-param-list=&q-signature=41328696dc34571324aa18c791c1196192e729c6" class="header-logo"/>
|
| 591 |
-
<div class="header-text">
|
| 592 |
-
<h1>HunyuanOCR</h1>
|
| 593 |
-
<p>Powered by Tencent Hunyuan Team</p>
|
| 594 |
-
</div>
|
| 595 |
-
</div>
|
| 596 |
-
</div>
|
| 597 |
-
""")
|
| 598 |
|
| 599 |
-
with gr.Column(
|
| 600 |
-
#
|
| 601 |
chatbot = gr.Chatbot(
|
| 602 |
-
label='
|
| 603 |
height=600,
|
| 604 |
bubble_full_width=False,
|
| 605 |
layout="bubble",
|
| 606 |
show_copy_button=True,
|
| 607 |
-
avatar_images=(None, "https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/6ef6928b21b323b2b00115f86a779d8f.png?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763450355%3B1794554415&q-key-time=1763450355%3B1794554415&q-header-list=host&q-url-param-list=&q-signature=41328696dc34571324aa18c791c1196192e729c6"),
|
| 608 |
-
elem_classes=["chatbot"]
|
| 609 |
)
|
| 610 |
-
|
| 611 |
-
#
|
| 612 |
-
with gr.Group(
|
| 613 |
query = gr.Textbox(
|
| 614 |
-
lines=2,
|
| 615 |
-
label='
|
| 616 |
-
placeholder='
|
| 617 |
-
elem_classes=["input-box"],
|
| 618 |
show_label=False
|
| 619 |
)
|
| 620 |
-
|
| 621 |
with gr.Row():
|
| 622 |
-
addfile_btn = gr.UploadButton('
|
| 623 |
-
submit_btn = gr.Button('
|
| 624 |
-
regen_btn = gr.Button('
|
| 625 |
-
empty_bin = gr.Button('
|
| 626 |
-
|
| 627 |
-
# 示例区域 - 5列网格布局
|
| 628 |
-
gr.HTML('<div class="section-title">📚 快速体验示例 - 点击下方卡片快速加载</div>')
|
| 629 |
|
|
|
|
|
|
|
|
|
|
| 630 |
with gr.Row():
|
| 631 |
-
|
| 632 |
-
|
| 633 |
-
|
| 634 |
-
|
| 635 |
-
|
| 636 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/23cc43af9376b948f3febaf4ce854a8a.jpg?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763523817%3B1794627877&q-key-time=1763523817%3B1794627877&q-header-list=host&q-url-param-list=&q-signature=8ebd6a9d3ed7eba73bb783c337349db9c29972e2" alt="文字检测识别"/>
|
| 637 |
-
</div>
|
| 638 |
-
""")
|
| 639 |
-
example_1_btn = gr.Button("🔍 文字检测和识别", elem_classes=["example-btn"])
|
| 640 |
-
|
| 641 |
-
# 示例2:parsing
|
| 642 |
-
with gr.Column(scale=1):
|
| 643 |
-
with gr.Group(elem_classes=["example-card"]):
|
| 644 |
-
gr.HTML("""
|
| 645 |
-
<div class="example-image-wrapper">
|
| 646 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/c4997ebd1be9f7c3e002fabba8b46cb7.jpg?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763523818%3B1794627878&q-key-time=1763523818%3B1794627878&q-header-list=host&q-url-param-list=&q-signature=d2cd12be4c7902821c8c82203e4642624046911a" alt="文档解析"/>
|
| 647 |
-
</div>
|
| 648 |
-
""")
|
| 649 |
-
example_2_btn = gr.Button("📋 文档解析", elem_classes=["example-btn"])
|
| 650 |
-
|
| 651 |
-
# 示例3:ie
|
| 652 |
-
with gr.Column(scale=1):
|
| 653 |
-
with gr.Group(elem_classes=["example-card"]):
|
| 654 |
-
gr.HTML("""
|
| 655 |
-
<div class="example-image-wrapper">
|
| 656 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/7c67c0f78e4423d51644a325da1f8e85.jpg?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763523818%3B1794627878&q-key-time=1763523818%3B1794627878&q-header-list=host&q-url-param-list=&q-signature=803648f3253706f654faf1423869fd9e00e7056e" alt="信息抽取"/>
|
| 657 |
-
</div>
|
| 658 |
-
""")
|
| 659 |
-
example_3_btn = gr.Button("🎯 信息抽取", elem_classes=["example-btn"])
|
| 660 |
-
|
| 661 |
-
# 示例4:VQA
|
| 662 |
-
with gr.Column(scale=1):
|
| 663 |
-
with gr.Group(elem_classes=["example-card"]):
|
| 664 |
-
gr.HTML("""
|
| 665 |
-
<div class="example-image-wrapper">
|
| 666 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/fea0865d1c70c53aaa2ab91cd0e787f5.jpg?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763523818%3B1794627878&q-key-time=1763523818%3B1794627878&q-header-list=host&q-url-param-list=&q-signature=a92b94e298a11aea130d730d3b16ee761acc3f4c" alt="视觉问答"/>
|
| 667 |
-
</div>
|
| 668 |
-
""")
|
| 669 |
-
example_4_btn = gr.Button("💬 视觉问答", elem_classes=["example-btn"])
|
| 670 |
-
|
| 671 |
-
# 示例5:translation
|
| 672 |
-
with gr.Column(scale=1):
|
| 673 |
-
with gr.Group(elem_classes=["example-card"]):
|
| 674 |
-
gr.HTML("""
|
| 675 |
-
<div class="example-image-wrapper">
|
| 676 |
-
<img src="https://hunyuan-multimodal-1258344703.cos.ap-guangzhou.myqcloud.com/hunyuan_multimodal/mllm_data/d1af99d35e9db9e820ebebb5bc68993a.jpg?q-sign-algorithm=sha1&q-ak=AKIDbLEFMUYZgyERZnygUQLC7xkQ1hTAzulX&q-sign-time=1763967603%3B1795071663&q-key-time=1763967603%3B1795071663&q-header-list=host&q-url-param-list=&q-signature=a57080c0b3d4c76ea74b88c6291f9004241c9d49" alt="图片翻译"/>
|
| 677 |
-
</div>
|
| 678 |
-
""")
|
| 679 |
-
example_5_btn = gr.Button("🌐 图片翻译", elem_classes=["example-btn"])
|
| 680 |
|
| 681 |
task_history = gr.State([])
|
| 682 |
|
| 683 |
|
| 684 |
-
#
|
| 685 |
def load_example_1(history, task_hist):
|
| 686 |
-
prompt = "
|
| 687 |
-
|
| 688 |
-
|
| 689 |
-
|
| 690 |
-
# 清空对话历史
|
| 691 |
-
history = []
|
| 692 |
-
task_hist = []
|
| 693 |
-
history = history + [((image_path,), None)]
|
| 694 |
-
task_hist = task_hist + [((image_path,), None)]
|
| 695 |
return history, task_hist, prompt
|
| 696 |
-
|
| 697 |
-
|
| 698 |
-
|
| 699 |
-
# 示例2:场景文字
|
| 700 |
def load_example_2(history, task_hist):
|
| 701 |
-
prompt = "
|
| 702 |
-
|
| 703 |
-
|
| 704 |
-
|
| 705 |
-
# 清空对话历史
|
| 706 |
-
history = []
|
| 707 |
-
task_hist = []
|
| 708 |
-
history = history + [((image_path,), None)]
|
| 709 |
-
task_hist = task_hist + [((image_path,), None)]
|
| 710 |
return history, task_hist, prompt
|
| 711 |
-
|
| 712 |
-
|
| 713 |
-
|
| 714 |
-
# 示例3:表格提取
|
| 715 |
def load_example_3(history, task_hist):
|
| 716 |
-
prompt = "
|
| 717 |
-
|
| 718 |
-
|
| 719 |
-
|
| 720 |
-
# 清空对话历史
|
| 721 |
-
history = []
|
| 722 |
-
task_hist = []
|
| 723 |
-
history = history + [((image_path,), None)]
|
| 724 |
-
task_hist = task_hist + [((image_path,), None)]
|
| 725 |
return history, task_hist, prompt
|
| 726 |
-
|
| 727 |
-
#
|
| 728 |
def load_example_4(history, task_hist):
|
| 729 |
-
prompt = "
|
| 730 |
-
|
| 731 |
-
|
| 732 |
-
|
| 733 |
-
# 清空对话历史
|
| 734 |
-
history = []
|
| 735 |
-
task_hist = []
|
| 736 |
-
history = history + [((image_path,), None)]
|
| 737 |
-
task_hist = task_hist + [((image_path,), None)]
|
| 738 |
return history, task_hist, prompt
|
| 739 |
-
|
| 740 |
-
#
|
| 741 |
def load_example_5(history, task_hist):
|
| 742 |
-
prompt = "
|
| 743 |
-
|
| 744 |
-
|
| 745 |
-
|
| 746 |
-
# 清空对话历史
|
| 747 |
-
history = []
|
| 748 |
-
task_hist = []
|
| 749 |
-
history = history + [((image_path,), None)]
|
| 750 |
-
task_hist = task_hist + [((image_path,), None)]
|
| 751 |
return history, task_hist, prompt
|
| 752 |
|
| 753 |
-
#
|
| 754 |
example_1_btn.click(load_example_1, [chatbot, task_history], [chatbot, task_history, query])
|
| 755 |
example_2_btn.click(load_example_2, [chatbot, task_history], [chatbot, task_history, query])
|
| 756 |
example_3_btn.click(load_example_3, [chatbot, task_history], [chatbot, task_history, query])
|
|
@@ -764,43 +521,29 @@ def _launch_demo(args, model, processor):
|
|
| 764 |
regen_btn.click(regenerate, [chatbot, task_history], [chatbot], show_progress=True)
|
| 765 |
addfile_btn.upload(add_file, [chatbot, task_history, addfile_btn], [chatbot, task_history], show_progress=True)
|
| 766 |
|
| 767 |
-
#
|
| 768 |
with gr.Row():
|
| 769 |
with gr.Column(scale=1):
|
| 770 |
-
gr.
|
| 771 |
-
|
| 772 |
-
|
| 773 |
-
|
| 774 |
-
|
| 775 |
-
|
| 776 |
-
|
| 777 |
-
<li><strong>✏️ 视觉问答</strong> - 支持以文本为中心的开放式问答</li>
|
| 778 |
-
<li><strong>🌍 跨语言翻译</strong> - 支持中英互译及14+语种译为中英文</li>
|
| 779 |
-
</ul>
|
| 780 |
-
</div>
|
| 781 |
""")
|
| 782 |
-
|
| 783 |
with gr.Column(scale=1):
|
| 784 |
-
gr.
|
| 785 |
-
|
| 786 |
-
|
| 787 |
-
|
| 788 |
-
|
| 789 |
-
|
| 790 |
-
<li><strong>文件大小</strong> - 建议单张图片不超过 10MB,支持 JPG/PNG 格式</li>
|
| 791 |
-
<li><strong>使用场景</strong> - 适用于文字检测识别、文档数字化、票据识别、信息提取、文字图片翻译等</li>
|
| 792 |
-
<li><strong>合规使用</strong> - 仅供学习研究,请遵守法律法规,尊重隐私权</li>
|
| 793 |
-
</ul>
|
| 794 |
-
</div>
|
| 795 |
""")
|
| 796 |
-
|
| 797 |
-
#
|
| 798 |
-
gr.
|
| 799 |
-
<div style="text-align: center; color: #9ca3af; font-size: 13px; margin-top: 40px; padding: 20px; border-top: 1px solid #e5e7eb;">
|
| 800 |
-
<p style="margin: 0;">© 2025 Tencent Hunyuan Team. All rights reserved.</p>
|
| 801 |
-
<p style="margin: 5px 0 0 0;">本系统基于 HunyuanOCR 构建 | 仅供学习研究使用</p>
|
| 802 |
-
</div>
|
| 803 |
-
""")
|
| 804 |
|
| 805 |
demo.queue().launch(
|
| 806 |
share=args.share,
|
|
|
|
| 4 |
from PIL import Image
|
| 5 |
import spaces
|
| 6 |
from transformers import AutoProcessor
|
| 7 |
+
from qwen_vl_utils import process_vision_info
|
| 8 |
from transformers import HunYuanVLForConditionalGeneration
|
| 9 |
import gradio as gr
|
| 10 |
from argparse import ArgumentParser
|
|
|
|
| 15 |
import hashlib
|
| 16 |
import gc
|
| 17 |
|
| 18 |
+
# Optimization: Set environment variables
|
| 19 |
+
os.environ['TOKENIZERS_PARALLELISM'] = 'false'
|
| 20 |
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = '1'
|
|
|
|
| 21 |
# torch._C._jit_set_profiling_executor(False)
|
| 22 |
# torch._C._jit_set_profiling_mode(False)
|
| 23 |
|
|
|
|
| 54 |
|
| 55 |
|
| 56 |
def _load_model_processor(args):
|
| 57 |
+
# ZeroGPU: Model loads on CPU, uses eager mode
|
| 58 |
+
# Automatically moves to GPU within @spaces.GPU decorator
|
| 59 |
+
print(f"[INFO] Loading model (ZeroGPU uses eager mode)")
|
| 60 |
+
print(f"[INFO] CUDA available at load time: {torch.cuda.is_available()}")
|
| 61 |
|
| 62 |
model = HunYuanVLForConditionalGeneration.from_pretrained(
|
| 63 |
args.checkpoint_path,
|
| 64 |
+
attn_implementation="eager", # Required for ZeroGPU (starts on CPU)
|
| 65 |
torch_dtype=torch.bfloat16,
|
| 66 |
+
device_map="auto", # Let ZeroGPU manage device placement
|
| 67 |
)
|
| 68 |
+
|
| 69 |
+
# Disable gradient checkpointing for faster inference
|
| 70 |
if hasattr(model, 'gradient_checkpointing_disable'):
|
| 71 |
model.gradient_checkpointing_disable()
|
| 72 |
+
print(f"[INFO] Gradient checkpointing disabled")
|
| 73 |
+
|
| 74 |
+
# Set to evaluation mode
|
| 75 |
model.eval()
|
| 76 |
+
print(f"[INFO] Model set to eval mode")
|
| 77 |
|
| 78 |
processor = AutoProcessor.from_pretrained(args.checkpoint_path, use_fast=False, trust_remote_code=True)
|
| 79 |
|
| 80 |
+
print(f"[INFO] Model loaded, device: {next(model.parameters()).device}")
|
| 81 |
return model, processor
|
| 82 |
|
| 83 |
|
| 84 |
def _parse_text(text):
|
| 85 |
+
"""Parse text, handle special formatting"""
|
| 86 |
# if text is None:
|
| 87 |
# return text
|
| 88 |
text = text.replace("<trans>", "").replace("</trans>", "")
|
|
|
|
| 90 |
|
| 91 |
|
| 92 |
def _remove_image_special(text):
|
| 93 |
+
"""Remove image special tokens"""
|
| 94 |
# if text is None:
|
| 95 |
# return text
|
| 96 |
+
# # Remove image special tokens
|
| 97 |
# import re
|
| 98 |
# text = re.sub(r'<image>|</image>|<img>|</img>', '', text)
|
| 99 |
# return text
|
|
|
|
| 101 |
|
| 102 |
|
| 103 |
def _gc():
|
| 104 |
+
"""Garbage collection"""
|
| 105 |
gc.collect()
|
| 106 |
if torch.cuda.is_available():
|
| 107 |
torch.cuda.empty_cache()
|
|
|
|
| 127 |
|
| 128 |
|
| 129 |
def _launch_demo(args, model, processor):
|
| 130 |
+
# Track first call
|
| 131 |
first_call = [True]
|
| 132 |
+
|
| 133 |
+
# Uses closure to access model and processor
|
| 134 |
+
# Duration increased to 120s to avoid timeout during peak hours
|
| 135 |
@spaces.GPU(duration=120)
|
| 136 |
def call_local_model(messages):
|
| 137 |
import time
|
|
|
|
| 139 |
start_time = time.time()
|
| 140 |
|
| 141 |
if first_call[0]:
|
| 142 |
+
print(f"[INFO] ========== First inference call ==========")
|
| 143 |
first_call[0] = False
|
| 144 |
else:
|
| 145 |
+
print(f"[INFO] ========== Subsequent inference call ==========")
|
| 146 |
+
|
| 147 |
+
print(f"[DEBUG] ========== Starting inference ==========")
|
| 148 |
print(f"[DEBUG] Python version: {sys.version}")
|
| 149 |
print(f"[DEBUG] PyTorch version: {torch.__version__}")
|
| 150 |
print(f"[DEBUG] CUDA available: {torch.cuda.is_available()}")
|
|
|
|
| 155 |
print(f"[DEBUG] GPU Memory allocated: {torch.cuda.memory_allocated(0) / 1024**3:.2f} GB")
|
| 156 |
print(f"[DEBUG] GPU Memory reserved: {torch.cuda.memory_reserved(0) / 1024**3:.2f} GB")
|
| 157 |
|
| 158 |
+
# Ensure model is on GPU
|
| 159 |
model_device = next(model.parameters()).device
|
| 160 |
print(f"[DEBUG] Model device: {model_device}")
|
| 161 |
print(f"[DEBUG] Model dtype: {next(model.parameters()).dtype}")
|
| 162 |
+
|
| 163 |
if str(model_device) == 'cpu':
|
| 164 |
+
print(f"[ERROR] Model on CPU! Attempting to move to GPU...")
|
| 165 |
if torch.cuda.is_available():
|
| 166 |
move_start = time.time()
|
| 167 |
model.cuda()
|
| 168 |
move_time = time.time() - move_start
|
| 169 |
print(f"[DEBUG] Model device after cuda(): {next(model.parameters()).device}")
|
| 170 |
+
print(f"[DEBUG] Model moved to GPU in: {move_time:.2f}s")
|
| 171 |
else:
|
| 172 |
+
print(f"[CRITICAL] CUDA unavailable! Running on CPU will be slow!")
|
| 173 |
+
print(f"[CRITICAL] This may be due to ZeroGPU resource constraints")
|
| 174 |
else:
|
| 175 |
+
print(f"[INFO] Model already on GPU: {model_device}")
|
| 176 |
|
| 177 |
messages = [messages]
|
| 178 |
|
| 179 |
+
# Build input using processor
|
| 180 |
texts = [
|
| 181 |
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
|
| 182 |
for msg in messages
|
| 183 |
]
|
| 184 |
+
print(f"[DEBUG] Template built, elapsed: {time.time() - start_time:.2f}s")
|
| 185 |
+
|
| 186 |
image_inputs, video_inputs = process_vision_info(messages)
|
| 187 |
+
print(f"[DEBUG] Image processing done, elapsed: {time.time() - start_time:.2f}s")
|
| 188 |
+
|
| 189 |
+
# Check image input size
|
| 190 |
if image_inputs:
|
| 191 |
for idx, img in enumerate(image_inputs):
|
| 192 |
if hasattr(img, 'size'):
|
|
|
|
| 194 |
elif isinstance(img, np.ndarray):
|
| 195 |
print(f"[DEBUG] Image {idx} shape: {img.shape}")
|
| 196 |
|
| 197 |
+
print(f"[DEBUG] Starting processor encoding...")
|
|
|
|
|
|
|
|
|
|
| 198 |
processor_start = time.time()
|
| 199 |
inputs = processor(
|
| 200 |
text=texts,
|
|
|
|
| 203 |
padding=True,
|
| 204 |
return_tensors="pt",
|
| 205 |
)
|
| 206 |
+
print(f"[DEBUG] Processor encoding done, elapsed: {time.time() - processor_start:.2f}s")
|
| 207 |
+
|
| 208 |
+
# Ensure inputs on GPU
|
| 209 |
to_device_start = time.time()
|
| 210 |
inputs = inputs.to('cuda' if torch.cuda.is_available() else 'cpu')
|
| 211 |
+
print(f"[DEBUG] Inputs moved to device, elapsed: {time.time() - to_device_start:.2f}s")
|
| 212 |
+
print(f"[DEBUG] Input preparation done, total elapsed: {time.time() - start_time:.2f}s")
|
| 213 |
print(f"[DEBUG] Input IDs shape: {inputs.input_ids.shape}")
|
| 214 |
print(f"[DEBUG] Input device: {inputs.input_ids.device}")
|
| 215 |
print(f"[DEBUG] Input sequence length: {inputs.input_ids.shape[1]}")
|
| 216 |
|
| 217 |
+
# Generation
|
| 218 |
gen_start = time.time()
|
| 219 |
+
print(f"[DEBUG] ========== Starting token generation ==========")
|
| 220 |
+
|
| 221 |
+
# Optimized max_new_tokens for OCR tasks
|
| 222 |
+
max_new_tokens = 2048
|
|
|
|
| 223 |
print(f"[DEBUG] max_new_tokens: {max_new_tokens}")
|
| 224 |
+
|
| 225 |
+
# Progress callback
|
| 226 |
token_count = [0]
|
| 227 |
last_time = [gen_start]
|
| 228 |
|
|
|
|
| 232 |
if token_count[0] % 10 == 0 or (current_time - last_time[0]) > 2.0:
|
| 233 |
elapsed = current_time - gen_start
|
| 234 |
tokens_per_sec = token_count[0] / elapsed if elapsed > 0 else 0
|
| 235 |
+
print(f"[DEBUG] Generated {token_count[0]} tokens, speed: {tokens_per_sec:.2f} tokens/s, elapsed: {elapsed:.2f}s")
|
| 236 |
last_time[0] = current_time
|
| 237 |
return False
|
| 238 |
|
| 239 |
with torch.no_grad():
|
| 240 |
+
print(f"[DEBUG] Entered torch.no_grad() context, elapsed: {time.time() - start_time:.2f}s")
|
| 241 |
+
|
| 242 |
+
# Test forward pass
|
| 243 |
+
print(f"[DEBUG] Testing forward pass...")
|
| 244 |
forward_test_start = time.time()
|
| 245 |
try:
|
| 246 |
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
|
| 247 |
test_outputs = model(**inputs, use_cache=False)
|
| 248 |
+
print(f"[DEBUG] Forward pass test successful, elapsed: {time.time() - forward_test_start:.2f}s")
|
| 249 |
except Exception as e:
|
| 250 |
+
print(f"[WARNING] Forward pass test failed: {e}")
|
| 251 |
+
|
| 252 |
+
print(f"[DEBUG] Starting model.generate()... (elapsed: {time.time() - start_time:.2f}s)")
|
| 253 |
generate_call_start = time.time()
|
| 254 |
|
| 255 |
try:
|
| 256 |
+
# Deterministic generation
|
| 257 |
generated_ids = model.generate(
|
| 258 |
**inputs,
|
| 259 |
max_new_tokens=max_new_tokens,
|
| 260 |
do_sample=False,
|
| 261 |
temperature=0
|
| 262 |
)
|
| 263 |
+
print(f"[DEBUG] model.generate() returned, elapsed: {time.time() - generate_call_start:.2f}s")
|
| 264 |
except Exception as e:
|
| 265 |
+
print(f"[ERROR] Generation failed: {e}")
|
| 266 |
import traceback
|
| 267 |
traceback.print_exc()
|
| 268 |
raise
|
| 269 |
|
| 270 |
+
print(f"[DEBUG] Exited torch.no_grad() context")
|
| 271 |
+
|
| 272 |
gen_time = time.time() - gen_start
|
| 273 |
+
print(f"[DEBUG] ========== Generation complete ==========")
|
| 274 |
+
print(f"[DEBUG] Generation time: {gen_time:.2f}s")
|
| 275 |
print(f"[DEBUG] Output shape: {generated_ids.shape}")
|
| 276 |
+
|
| 277 |
+
# Decode output
|
| 278 |
if "input_ids" in inputs:
|
| 279 |
input_ids = inputs.input_ids
|
| 280 |
else:
|
|
|
|
| 285 |
]
|
| 286 |
|
| 287 |
actual_tokens = len(generated_ids_trimmed[0])
|
| 288 |
+
print(f"[DEBUG] Actual tokens generated: {actual_tokens}")
|
| 289 |
+
print(f"[DEBUG] Time per token: {gen_time/actual_tokens if actual_tokens > 0 else 0:.3f}s")
|
| 290 |
|
| 291 |
output_texts = processor.batch_decode(
|
| 292 |
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
|
|
|
| 294 |
|
| 295 |
|
| 296 |
total_time = time.time() - start_time
|
| 297 |
+
print(f"[DEBUG] ========== All done ==========")
|
| 298 |
+
print(f"[DEBUG] Total time: {total_time:.2f}s")
|
| 299 |
+
print(f"[DEBUG] Output length: {len(output_texts[0])} chars")
|
| 300 |
+
print(f"[DEBUG] Output preview: {output_texts[0][:100]}...")
|
| 301 |
output_texts[0] = clean_repeated_substrings(output_texts[0])
|
| 302 |
return output_texts
|
| 303 |
|
|
|
|
| 319 |
content = []
|
| 320 |
for q, a in history_cp:
|
| 321 |
if isinstance(q, (tuple, list)):
|
| 322 |
+
# Check if URL or local path
|
| 323 |
img_path = q[0]
|
| 324 |
if img_path.startswith(('http://', 'https://')):
|
| 325 |
content.append({'type': 'image', 'image': img_path})
|
|
|
|
| 332 |
content = []
|
| 333 |
messages.pop()
|
| 334 |
|
| 335 |
+
# Call model to get response
|
| 336 |
response_list = call_local_model(messages)
|
| 337 |
response = response_list[0] if response_list else ""
|
| 338 |
|
|
|
|
| 360 |
_chatbot[-1] = (_chatbot[-1][0], None)
|
| 361 |
else:
|
| 362 |
_chatbot.append((chatbot_item[0], None))
|
| 363 |
+
# Use outer predict function
|
| 364 |
_chatbot_gen = predict(_chatbot, task_history)
|
| 365 |
for _chatbot in _chatbot_gen:
|
| 366 |
yield _chatbot
|
|
|
|
| 386 |
return history, task_history
|
| 387 |
|
| 388 |
def download_url_image(url):
|
| 389 |
+
"""Download URL image to local temp file"""
|
| 390 |
try:
|
| 391 |
+
# Use URL hash as filename to avoid duplicate downloads
|
| 392 |
url_hash = hashlib.md5(url.encode()).hexdigest()
|
| 393 |
temp_dir = tempfile.gettempdir()
|
| 394 |
temp_path = os.path.join(temp_dir, f"hyocr_demo_{url_hash}.png")
|
| 395 |
+
|
| 396 |
+
# Return cached file if exists
|
| 397 |
if os.path.exists(temp_path):
|
| 398 |
return temp_path
|
| 399 |
+
|
| 400 |
+
# Download image
|
| 401 |
response = requests.get(url, timeout=10)
|
| 402 |
response.raise_for_status()
|
| 403 |
with open(temp_path, 'wb') as f:
|
| 404 |
f.write(response.content)
|
| 405 |
return temp_path
|
| 406 |
except Exception as e:
|
| 407 |
+
print(f"Failed to download image: {url}, error: {e}")
|
| 408 |
+
return url # Return original URL on failure
|
| 409 |
|
| 410 |
def reset_user_input():
|
| 411 |
return gr.update(value='')
|
|
|
|
| 416 |
_gc()
|
| 417 |
return []
|
| 418 |
|
| 419 |
+
# Example image paths - local files
|
| 420 |
EXAMPLE_IMAGES = {
|
| 421 |
+
"spotting": "examples/spotting.jpg",
|
| 422 |
+
"parsing": "examples/parsing.jpg",
|
| 423 |
+
"ie": "examples/ie.jpg",
|
| 424 |
+
"vqa": "examples/vqa.jpg",
|
| 425 |
+
"translation": "examples/translation.jpg"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 426 |
}
|
| 427 |
|
| 428 |
+
with gr.Blocks() as demo:
|
| 429 |
+
# Header
|
| 430 |
+
gr.Markdown("# HunyuanOCR\n*Powered by Tencent Hunyuan Team*")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 431 |
|
| 432 |
+
with gr.Column():
|
| 433 |
+
# Chat area
|
| 434 |
chatbot = gr.Chatbot(
|
| 435 |
+
label='Chat',
|
| 436 |
height=600,
|
| 437 |
bubble_full_width=False,
|
| 438 |
layout="bubble",
|
| 439 |
show_copy_button=True,
|
|
|
|
|
|
|
| 440 |
)
|
| 441 |
+
|
| 442 |
+
# Input panel
|
| 443 |
+
with gr.Group():
|
| 444 |
query = gr.Textbox(
|
| 445 |
+
lines=2,
|
| 446 |
+
label='Enter your question',
|
| 447 |
+
placeholder='Upload an image first, then enter your question. Example: Detect and recognize text in this image.',
|
|
|
|
| 448 |
show_label=False
|
| 449 |
)
|
| 450 |
+
|
| 451 |
with gr.Row():
|
| 452 |
+
addfile_btn = gr.UploadButton('Upload Image', file_types=['image'])
|
| 453 |
+
submit_btn = gr.Button('Send', variant="primary", scale=3)
|
| 454 |
+
regen_btn = gr.Button('Regenerate')
|
| 455 |
+
empty_bin = gr.Button('Clear')
|
|
|
|
|
|
|
|
|
|
| 456 |
|
| 457 |
+
# Examples section
|
| 458 |
+
gr.Markdown("### Quick Examples - Click to load")
|
| 459 |
+
|
| 460 |
with gr.Row():
|
| 461 |
+
example_1_btn = gr.Button("Text Detection")
|
| 462 |
+
example_2_btn = gr.Button("Document Parsing")
|
| 463 |
+
example_3_btn = gr.Button("Info Extraction")
|
| 464 |
+
example_4_btn = gr.Button("Visual Q&A")
|
| 465 |
+
example_5_btn = gr.Button("Translation")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 466 |
|
| 467 |
task_history = gr.State([])
|
| 468 |
|
| 469 |
|
| 470 |
+
# Example 1: Text Detection
|
| 471 |
def load_example_1(history, task_hist):
|
| 472 |
+
prompt = "Detect and recognize all text in this image. Output the text with bounding box coordinates."
|
| 473 |
+
image_path = EXAMPLE_IMAGES["spotting"]
|
| 474 |
+
history = [((image_path,), None)]
|
| 475 |
+
task_hist = [((image_path,), None)]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 476 |
return history, task_hist, prompt
|
| 477 |
+
|
| 478 |
+
# Example 2: Document Parsing
|
|
|
|
|
|
|
| 479 |
def load_example_2(history, task_hist):
|
| 480 |
+
prompt = "Extract all text from this document in markdown format. Use HTML for tables and LaTeX for equations. Parse in reading order."
|
| 481 |
+
image_path = EXAMPLE_IMAGES["parsing"]
|
| 482 |
+
history = [((image_path,), None)]
|
| 483 |
+
task_hist = [((image_path,), None)]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 484 |
return history, task_hist, prompt
|
| 485 |
+
|
| 486 |
+
# Example 3: Information Extraction
|
|
|
|
|
|
|
| 487 |
def load_example_3(history, task_hist):
|
| 488 |
+
prompt = "Extract the following fields from this receipt and return as JSON: ['total', 'subtotal', 'tax', 'date', 'items']"
|
| 489 |
+
image_path = EXAMPLE_IMAGES["ie"]
|
| 490 |
+
history = [((image_path,), None)]
|
| 491 |
+
task_hist = [((image_path,), None)]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 492 |
return history, task_hist, prompt
|
| 493 |
+
|
| 494 |
+
# Example 4: Visual Q&A
|
| 495 |
def load_example_4(history, task_hist):
|
| 496 |
+
prompt = "Look at this chart and answer: Which quarter had the highest revenue? What was the Sales value in Q4?"
|
| 497 |
+
image_path = EXAMPLE_IMAGES["vqa"]
|
| 498 |
+
history = [((image_path,), None)]
|
| 499 |
+
task_hist = [((image_path,), None)]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 500 |
return history, task_hist, prompt
|
| 501 |
+
|
| 502 |
+
# Example 5: Translation
|
| 503 |
def load_example_5(history, task_hist):
|
| 504 |
+
prompt = "Translate all text in this image to English."
|
| 505 |
+
image_path = EXAMPLE_IMAGES["translation"]
|
| 506 |
+
history = [((image_path,), None)]
|
| 507 |
+
task_hist = [((image_path,), None)]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 508 |
return history, task_hist, prompt
|
| 509 |
|
| 510 |
+
# Bind events
|
| 511 |
example_1_btn.click(load_example_1, [chatbot, task_history], [chatbot, task_history, query])
|
| 512 |
example_2_btn.click(load_example_2, [chatbot, task_history], [chatbot, task_history, query])
|
| 513 |
example_3_btn.click(load_example_3, [chatbot, task_history], [chatbot, task_history, query])
|
|
|
|
| 521 |
regen_btn.click(regenerate, [chatbot, task_history], [chatbot], show_progress=True)
|
| 522 |
addfile_btn.upload(add_file, [chatbot, task_history, addfile_btn], [chatbot, task_history], show_progress=True)
|
| 523 |
|
| 524 |
+
# Feature descriptions
|
| 525 |
with gr.Row():
|
| 526 |
with gr.Column(scale=1):
|
| 527 |
+
gr.Markdown("""
|
| 528 |
+
### Core Features
|
| 529 |
+
- **Text Detection & Recognition** - Multi-scene text detection and recognition
|
| 530 |
+
- **Document Parsing** - Automatic document structure recognition
|
| 531 |
+
- **Information Extraction** - Extract structured data from receipts and forms
|
| 532 |
+
- **Visual Q&A** - Text-centric open-ended question answering
|
| 533 |
+
- **Translation** - Translate text in images across 14+ languages
|
|
|
|
|
|
|
|
|
|
|
|
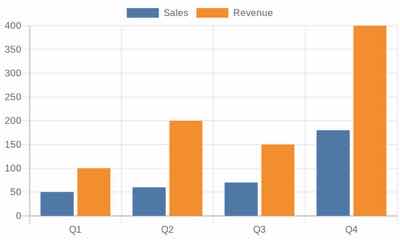
|
| 534 |
""")
|
| 535 |
+
|
| 536 |
with gr.Column(scale=1):
|
| 537 |
+
gr.Markdown("""
|
| 538 |
+
### Usage Tips
|
| 539 |
+
- **Inference** - For production, use VLLM for better performance
|
| 540 |
+
- **Image Quality** - Ensure images are clear, well-lit, and not heavily skewed
|
| 541 |
+
- **File Size** - Recommended max 10MB per image, JPG/PNG format
|
| 542 |
+
- **Use Cases** - OCR, document digitization, receipt recognition, translation
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 543 |
""")
|
| 544 |
+
|
| 545 |
+
# Footer
|
| 546 |
+
gr.Markdown("---\n*2025 Tencent Hunyuan Team. For research and educational use.*")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 547 |
|
| 548 |
demo.queue().launch(
|
| 549 |
share=args.share,
|
examples/ie.jpg
ADDED

|
examples/parsing.jpg
ADDED

|
examples/spotting.jpg
ADDED

|
examples/translation.jpg
ADDED
|
|
examples/vqa.jpg
ADDED
|