
zRzRzRzRzRzRzR
commited on
Commit
·
9fcd12a
1
Parent(s):
2942382
fix readme
Browse files
README.md
CHANGED
|
@@ -26,9 +26,9 @@ pipeline_tag: text-generation
|
|
| 26 |
|
| 27 |
**GLM-4.7**, your new coding partner, is coming with the following features:
|
| 28 |
|
| 29 |
-
- **Core Coding**: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +
|
| 30 |
- **Vibe Coding**: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
|
| 31 |
-
- **Tool Using**: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via
|
| 32 |
- **Complex Reasoning**: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
|
| 33 |
|
| 34 |
You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
|
|
@@ -57,14 +57,14 @@ You can also see significant improvements in many other scenarios such as chat,
|
|
| 57 |
| BrowseComp-Zh | 66.6 | 49.5 | 62.3 | 65.0 | - | 42.4 | 63.0 | - |
|
| 58 |
| τ²-Bench | 87.4 | 75.2 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 |
|
| 59 |
|
| 60 |
-
> AGI is a long journey, and benchmarks are only one way to evaluate
|
| 61 |
|
| 62 |
|
| 63 |
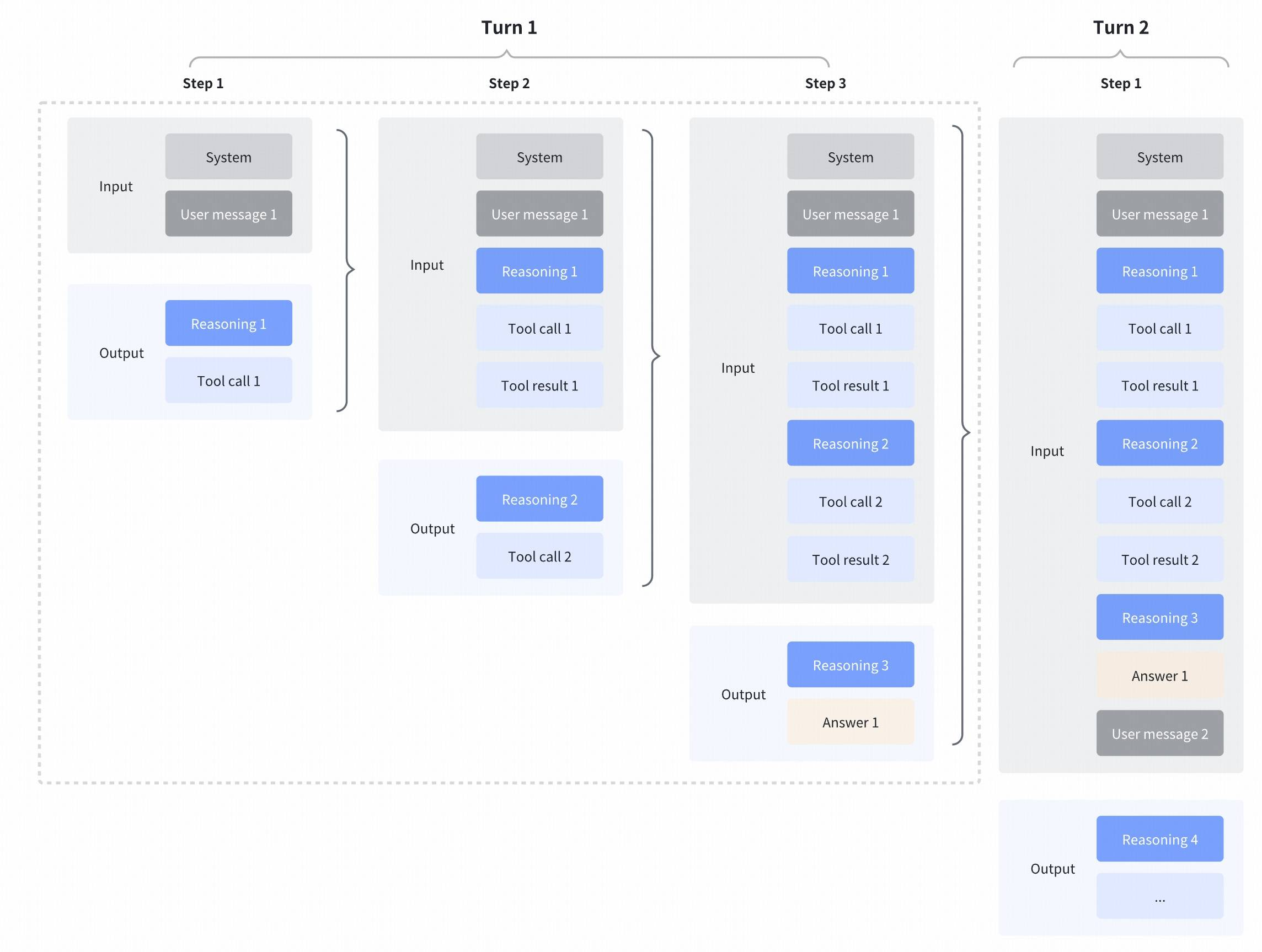
## Getting started with GLM-4.7
|
| 64 |
|
| 65 |
### Interleaved Thinking & Preserved Thinking
|
| 66 |
|
| 67 |
-
|
| 68 |
|
| 69 |
GLM-4.7 further enhances **Interleaved Thinking** (a feature introduced since GLM-4.5) and introduces **Preserved Thinking** and **Turn-level Thinking**. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
|
| 70 |
- **Interleaved Thinking**: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
|
|
|
|
| 214 |
archivePrefix={arXiv},
|
| 215 |
primaryClass={cs.CL},
|
| 216 |
url={https://arxiv.org/abs/2508.06471},
|
| 217 |
+
}
|
|
|