
🎭 Seoul Culture Event Recommendation RAG System (LoRA Adapter)
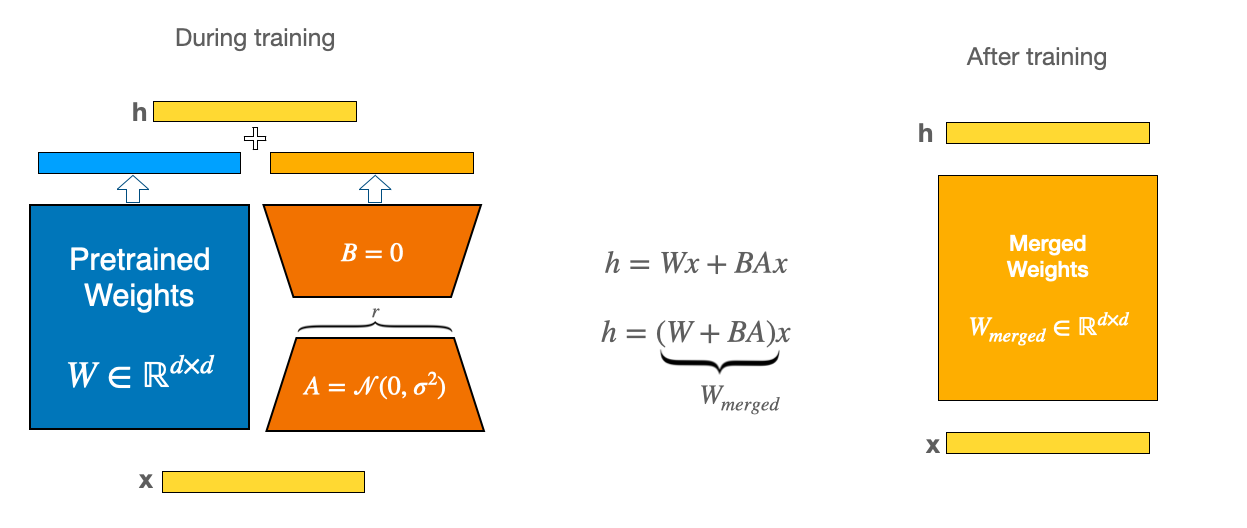
📖 Model Overview
이 모델은 서울시 문화 행사 정보를 기반으로 사용자에게 맞춤형 답변을 제공하는 RAG(Retrieval-Augmented Generation) 시스템을 위해 미세조정(Fine-tuning)된 Llama-3 기반의 LoRA Adapter입니다.
사용자의 질문에 대해 단순히 LLM의 내부 지식으로 답변하는 것이 아니라, 외부 데이터베이스(culture.csv)에서 실시간으로 검색된(Retrieved) 정확한 행사 정보를 바탕으로 답변을 생성합니다.
- Base Model:
beomi/Llama-3-Open-Ko-8B - Fine-tuning Method: QLoRA (4-bit quantization + LoRA)
- Target Task: 서울 문화 행사 추천 및 정보 안내 (Instruction Following)
- Dataset Source: 서울시 문화 행사 정보 (4,275개 데이터)
🛠️ How to Use
이 모델은 LoRA Adapter이므로, 반드시 베이스 모델과 함께 로드해야 합니다.
1. Install Dependencies
pip install torch transformers peft bitsandbytes pandas accelerate2. Run Inference Code
import torch from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig from peft import PeftModel1. Base Model Load (4-bit Quantization for efficiency)
base_model_id = "beomi/Llama-3-Open-Ko-8B" bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16 )
base_model = AutoModelForCausalLM.from_pretrained( base_model_id, quantization_config=bnb_config, device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(base_model_id)
2. Load LoRA Adapter
⚠️ [YOUR_HUGGINGFACE_ID/YOUR_MODEL_NAME] 부분을 본인 모델 ID로 수정하세요!
adapter_model_id = "YOUR_HUGGINGFACE_ID/YOUR_MODEL_NAME" model = PeftModel.from_pretrained(base_model, adapter_model_id)
3. Define Inference Function
def generate_response(context, persona, query): input_text = f"Context: {context} Persona: [{persona}] 질문: [{query}]" prompt = f"""### Instruction: {persona} 톤으로 답변해 주세요.
Input:
{input_text}
Output:
""" inputs = tokenizer(prompt, return_tensors="pt").to(model.device) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=300, temperature=0.7, top_p=0.9, eos_token_id=tokenizer.eos_token_id ) return tokenizer.decode(outputs, skip_special_tokens=True).split("### Output:")[-1].strip()
4. Test
context_data = "[서울 핸드 메이드 페어 2025, 사전 예매: 8,000원, 서울 삼성동 코엑스 1층 B홀]" print(generate_response(context_data, "친절한 문화 가이드", "강남구에서 열리는 핸드메이드 행사 알려줘."))
📊 Training Details
Dataset
- Source: 서울열린데이터광장 (문화 행사 정보)
- Size: 4,275 rows (Original CSV), Augmented for training
- Format:
Instruction(페르소나 지시),Input(Context + Question),Output(Answer) - Preprocessing: UTF-8 / CP949 인코딩 자동 처리, 결측치 제거, 512 토큰 길이 제한
Hyperparameters
| Parameter | Value | Reason |
|---|---|---|
| LoRA Rank (r) | 32 |
초기 Rank 8/16 실험 결과, Rank 32에서 Loss 1.51로 가장 우수한 성능 기록 |
| LoRA Alpha | 32 |
Scaling factor |
| Target Modules | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj |
모든 Linear Layer 학습으로 추론 능력 극대화 |
| Batch Size | 1 |
Colab T4 GPU 메모리 제약 극복 |
| Gradient Accumulation | 8 |
실제 Batch Size 8 효과 (안정적 수렴) |
| Learning Rate | 2e-4 |
- |
| Epochs | 3 |
- |
| Optimizer | paged_adamw_8bit |
메모리 효율 최적화 |
Performance Metrics
- Validation Loss:
1.5152(Rank 32 기준)- Rank 8 Loss: 2.1565
- Rank 16 Loss: 1.7950
- Rank 32 Loss: 1.5152 (Best)
- ROUGE-L Score:
0.83(높은 답변 정확도 및 일관성 확인) - Temperature Analysis: Temperature 0.5~0.7 구간에서 ROUGE 점수 최적화 확인 (너무 낮으면 반복, 너무 높으면 환각 발생)
| Rank | Validation Loss |
|---|---|
| 8 | 2.1565 |
| 16 | 1.7950 |
| 32 | 1.5152 |
⚠️ Limitations & Future Work
- Hallucination (환각 현상):
- 모델이 학습하지 않은 외부 정보(Unknown Data)에 대해 약 50%의 환각 발생률을 보였습니다.
- RAG 시스템에서 검색되지 않은 정보에 대해 "알 수 없음"이라고 답변하도록 추가 학습(Negative Sampling)이 필요합니다.
- Hardware Constraints:
- Colab T4 (free tier) 환경의 제약으로 인해 Batch Size를 1로 설정했습니다. 더 큰 VRAM 환경에서 Full Fine-tuning 시 성능 향상이 기대됩니다.
- Scope:
- 현재 서울시 데이터에 특화되어 있어, 타 지역 행사나 일반 상식 질문에는 답변 품질이 낮을 수 있습니다.
📜 Citation & License
- License: Llama 3 Community License
- Base Model: beomi/Llama-3-Open-Ko-8B
Model tree for hushpond/llama-3-seoul-culture-lora-rag
Base model
beomi/Llama-3-Open-Ko-8B