
SentenceTransformer based on sbintuitions/sarashina-embedding-v2-1b
This is a sentence-transformers model finetuned from sbintuitions/sarashina-embedding-v2-1b on the jsts dataset. It maps sentences & paragraphs to a 1792-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
Model Details
Model Description
- Model Type: Sentence Transformer
- Base model: sbintuitions/sarashina-embedding-v2-1b
- Maximum Sequence Length: 8192 tokens
- Output Dimensionality: 1792 dimensions
- Similarity Function: Cosine Similarity
- Training Dataset:
- Language: jpn
Model Sources
- Documentation: Sentence Transformers Documentation
- Repository: Sentence Transformers on GitHub
- Hugging Face: Sentence Transformers on Hugging Face
Full Model Architecture
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False, 'architecture': 'LlamaModel'})
(1): Pooling({'word_embedding_dimension': 1792, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': True, 'include_prompt': False})
)
Usage
Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
pip install -U sentence-transformers
Then you can load this model and run inference.
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka")
# Run inference
sentences = [
'樹木に囲まれた芝生の上に三頭のキリンが立っています。',
'芝生の上に数頭のキリンが歩いています。',
'茶色のテーブルの上にピザと飲み物が置かれています。',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1792]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.9453, 0.4754],
# [0.9453, 1.0000, 0.5004],
# [0.4754, 0.5004, 1.0000]])
Evaluation
Metrics
Semantic Similarity
- Datasets:
sts-dev-1792,sts-test-1792andsts-test-1792 - Evaluated with
EmbeddingSimilarityEvaluatorwith these parameters:{ "truncate_dim": 1792 }
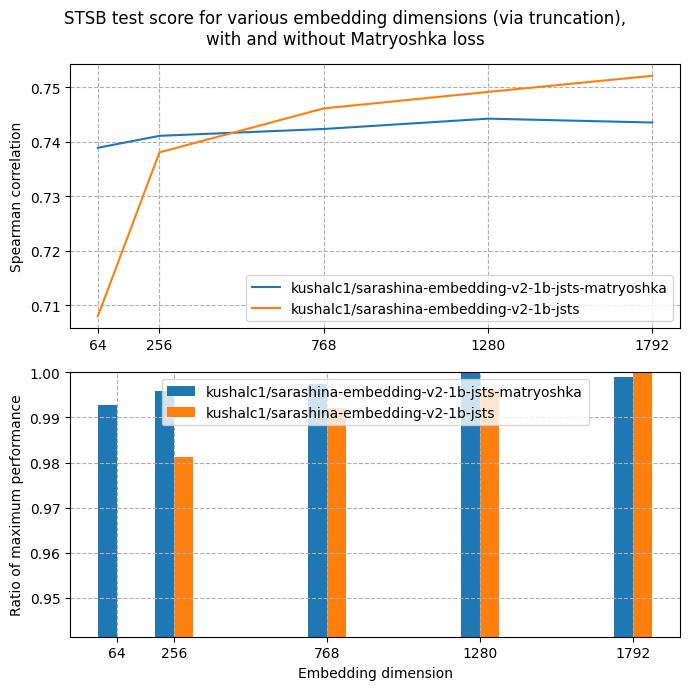
| Metric | sts-dev-1792 | sts-test-1792 |
|---|---|---|
| pearson_cosine | 0.8088 | 0.8088 |
| spearman_cosine | 0.7435 | 0.7435 |
Semantic Similarity
- Datasets:
sts-dev-1280,sts-test-1280andsts-test-1280 - Evaluated with
EmbeddingSimilarityEvaluatorwith these parameters:{ "truncate_dim": 1280 }
| Metric | sts-dev-1280 | sts-test-1280 |
|---|---|---|
| pearson_cosine | 0.8078 | 0.8078 |
| spearman_cosine | 0.7442 | 0.7442 |
Semantic Similarity
- Datasets:
sts-dev-768,sts-test-768andsts-test-768 - Evaluated with
EmbeddingSimilarityEvaluatorwith these parameters:{ "truncate_dim": 768 }
| Metric | sts-dev-768 | sts-test-768 |
|---|---|---|
| pearson_cosine | 0.8049 | 0.8049 |
| spearman_cosine | 0.7423 | 0.7423 |
Semantic Similarity
- Datasets:
sts-dev-256,sts-test-256andsts-test-256 - Evaluated with
EmbeddingSimilarityEvaluatorwith these parameters:{ "truncate_dim": 256 }
| Metric | sts-dev-256 | sts-test-256 |
|---|---|---|
| pearson_cosine | 0.8022 | 0.8022 |
| spearman_cosine | 0.7411 | 0.7411 |
Semantic Similarity
- Datasets:
sts-dev-64,sts-test-64andsts-test-64 - Evaluated with
EmbeddingSimilarityEvaluatorwith these parameters:{ "truncate_dim": 64 }
| Metric | sts-dev-64 | sts-test-64 |
|---|---|---|
| pearson_cosine | 0.7972 | 0.7972 |
| spearman_cosine | 0.7389 | 0.7389 |
Training Details
Training Dataset
jsts
- Dataset: jsts at b3d3097
- Size: 12,451 training samples
- Columns:
sentence1,sentence2, andscore - Approximate statistics based on the first 1000 samples:
sentence1 sentence2 score type string string float details - min: 5 tokens
- mean: 10.64 tokens
- max: 35 tokens
- min: 3 tokens
- mean: 10.53 tokens
- max: 30 tokens
- min: 0.0
- mean: 2.32
- max: 5.0
- Samples:
sentence1 sentence2 score 川べりでサーフボードを持った人たちがいます。トイレの壁に黒いタオルがかけられています。0.0二人の男性がジャンボジェット機を見ています。2人の男性が、白い飛行機を眺めています。3.799999952316284男性が子供を抱き上げて立っています。坊主頭の男性が子供を抱いて立っています。4.0 - Loss:
MatryoshkaLosswith these parameters:{ "loss": "MultipleNegativesRankingLoss", "matryoshka_dims": [ 1792, 1280, 768, 256, 64 ], "matryoshka_weights": [ 1, 1, 1, 1, 1 ], "n_dims_per_step": -1 }
Evaluation Dataset
jsts
- Dataset: jsts at b3d3097
- Size: 1,457 evaluation samples
- Columns:
sentence1,sentence2, andscore - Approximate statistics based on the first 1000 samples:
sentence1 sentence2 score type string string float details - min: 5 tokens
- mean: 10.78 tokens
- max: 34 tokens
- min: 3 tokens
- mean: 10.63 tokens
- max: 37 tokens
- min: 0.0
- mean: 2.22
- max: 5.0
- Samples:
sentence1 sentence2 score レンガの建物の前を、乳母車を押した女性が歩いています。厩舎で馬と女性とが寄り添っています。0.0山の上に顔の白い牛が2頭います。曇り空の山肌で、牛が2匹草を食んでいます。2.4000000953674316バナナを持った人が道路を通行しています。道の上をバナナを背負った男性が歩いています。3.5999999046325684 - Loss:
MatryoshkaLosswith these parameters:{ "loss": "MultipleNegativesRankingLoss", "matryoshka_dims": [ 1792, 1280, 768, 256, 64 ], "matryoshka_weights": [ 1, 1, 1, 1, 1 ], "n_dims_per_step": -1 }
Training Hyperparameters
Non-Default Hyperparameters
eval_strategy: stepsper_device_train_batch_size: 16per_device_eval_batch_size: 16num_train_epochs: 4warmup_ratio: 0.1fp16: True
All Hyperparameters
Click to expand
overwrite_output_dir: Falsedo_predict: Falseeval_strategy: stepsprediction_loss_only: Trueper_device_train_batch_size: 16per_device_eval_batch_size: 16per_gpu_train_batch_size: Noneper_gpu_eval_batch_size: Nonegradient_accumulation_steps: 1eval_accumulation_steps: Nonetorch_empty_cache_steps: Nonelearning_rate: 5e-05weight_decay: 0.0adam_beta1: 0.9adam_beta2: 0.999adam_epsilon: 1e-08max_grad_norm: 1.0num_train_epochs: 4max_steps: -1lr_scheduler_type: linearlr_scheduler_kwargs: {}warmup_ratio: 0.1warmup_steps: 0log_level: passivelog_level_replica: warninglog_on_each_node: Truelogging_nan_inf_filter: Truesave_safetensors: Truesave_on_each_node: Falsesave_only_model: Falserestore_callback_states_from_checkpoint: Falseno_cuda: Falseuse_cpu: Falseuse_mps_device: Falseseed: 42data_seed: Nonejit_mode_eval: Falseuse_ipex: Falsebf16: Falsefp16: Truefp16_opt_level: O1half_precision_backend: autobf16_full_eval: Falsefp16_full_eval: Falsetf32: Nonelocal_rank: 0ddp_backend: Nonetpu_num_cores: Nonetpu_metrics_debug: Falsedebug: []dataloader_drop_last: Falsedataloader_num_workers: 0dataloader_prefetch_factor: Nonepast_index: -1disable_tqdm: Falseremove_unused_columns: Truelabel_names: Noneload_best_model_at_end: Falseignore_data_skip: Falsefsdp: []fsdp_min_num_params: 0fsdp_config: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}fsdp_transformer_layer_cls_to_wrap: Noneaccelerator_config: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}parallelism_config: Nonedeepspeed: Nonelabel_smoothing_factor: 0.0optim: adamw_torch_fusedoptim_args: Noneadafactor: Falsegroup_by_length: Falselength_column_name: lengthddp_find_unused_parameters: Noneddp_bucket_cap_mb: Noneddp_broadcast_buffers: Falsedataloader_pin_memory: Truedataloader_persistent_workers: Falseskip_memory_metrics: Trueuse_legacy_prediction_loop: Falsepush_to_hub: Falseresume_from_checkpoint: Nonehub_model_id: Nonehub_strategy: every_savehub_private_repo: Nonehub_always_push: Falsehub_revision: Nonegradient_checkpointing: Falsegradient_checkpointing_kwargs: Noneinclude_inputs_for_metrics: Falseinclude_for_metrics: []eval_do_concat_batches: Truefp16_backend: autopush_to_hub_model_id: Nonepush_to_hub_organization: Nonemp_parameters:auto_find_batch_size: Falsefull_determinism: Falsetorchdynamo: Noneray_scope: lastddp_timeout: 1800torch_compile: Falsetorch_compile_backend: Nonetorch_compile_mode: Noneinclude_tokens_per_second: Falseinclude_num_input_tokens_seen: Falseneftune_noise_alpha: Noneoptim_target_modules: Nonebatch_eval_metrics: Falseeval_on_start: Falseuse_liger_kernel: Falseliger_kernel_config: Noneeval_use_gather_object: Falseaverage_tokens_across_devices: Falseprompts: Nonebatch_sampler: batch_samplermulti_dataset_batch_sampler: proportionalrouter_mapping: {}learning_rate_mapping: {}
Training Logs
| Epoch | Step | Training Loss | Validation Loss | sts-dev-1792_spearman_cosine | sts-dev-1280_spearman_cosine | sts-dev-768_spearman_cosine | sts-dev-256_spearman_cosine | sts-dev-64_spearman_cosine | sts-test-1792_spearman_cosine | sts-test-1280_spearman_cosine | sts-test-768_spearman_cosine | sts-test-256_spearman_cosine | sts-test-64_spearman_cosine |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1284 | 100 | 4.911 | 6.2373 | 0.7573 | 0.7572 | 0.7517 | 0.7350 | 0.7114 | - | - | - | - | - |
| 0.2567 | 200 | 5.8664 | 7.9813 | 0.6739 | 0.6692 | 0.6636 | 0.6500 | 0.6146 | - | - | - | - | - |
| 0.3851 | 300 | 7.259 | 7.9829 | 0.6831 | 0.6815 | 0.6797 | 0.6698 | 0.6529 | - | - | - | - | - |
| 0.5135 | 400 | 7.1234 | 7.5810 | 0.6878 | 0.6887 | 0.6881 | 0.6819 | 0.6679 | - | - | - | - | - |
| 0.6418 | 500 | 7.233 | 6.9384 | 0.6628 | 0.6694 | 0.6658 | 0.6662 | 0.6583 | - | - | - | - | - |
| 0.7702 | 600 | 7.0228 | 7.0102 | 0.6352 | 0.6364 | 0.6346 | 0.6310 | 0.6246 | - | - | - | - | - |
| 0.8986 | 700 | 6.539 | 6.7671 | 0.6411 | 0.6415 | 0.6403 | 0.6394 | 0.6346 | - | - | - | - | - |
| 1.0270 | 800 | 6.2863 | 7.5846 | 0.6120 | 0.6342 | 0.6314 | 0.6266 | 0.6189 | - | - | - | - | - |
| 1.1553 | 900 | 5.7608 | 6.7480 | 0.6773 | 0.6790 | 0.6758 | 0.6748 | 0.6691 | - | - | - | - | - |
| 1.2837 | 1000 | 5.672 | 6.6481 | 0.6846 | 0.6836 | 0.6817 | 0.6834 | 0.6794 | - | - | - | - | - |
| 1.4121 | 1100 | 5.7371 | 6.6843 | 0.6945 | 0.6953 | 0.6966 | 0.6939 | 0.6891 | - | - | - | - | - |
| 1.5404 | 1200 | 5.8827 | 6.6863 | 0.6903 | 0.6940 | 0.6922 | 0.6883 | 0.6834 | - | - | - | - | - |
| 1.6688 | 1300 | 5.6242 | 6.6517 | 0.6856 | 0.6857 | 0.6847 | 0.6809 | 0.6762 | - | - | - | - | - |
| 1.7972 | 1400 | 5.5211 | 6.1428 | 0.7134 | 0.7123 | 0.7117 | 0.7065 | 0.7022 | - | - | - | - | - |
| 1.9255 | 1500 | 5.4882 | 6.0439 | 0.7227 | 0.7227 | 0.7214 | 0.7192 | 0.7134 | - | - | - | - | - |
| 2.0539 | 1600 | 5.4436 | 6.0361 | 0.7199 | 0.7203 | 0.7191 | 0.7201 | 0.7143 | - | - | - | - | - |
| 2.1823 | 1700 | 4.366 | 6.1447 | 0.7286 | 0.7290 | 0.7274 | 0.7283 | 0.7231 | - | - | - | - | - |
| 2.3107 | 1800 | 4.6607 | 6.1692 | 0.7365 | 0.7356 | 0.7344 | 0.7303 | 0.7263 | - | - | - | - | - |
| 2.4390 | 1900 | 4.3651 | 6.2109 | 0.7178 | 0.7169 | 0.7149 | 0.7134 | 0.7125 | - | - | - | - | - |
| 2.5674 | 2000 | 4.4692 | 6.1421 | 0.7237 | 0.7233 | 0.7214 | 0.7192 | 0.7150 | - | - | - | - | - |
| 2.6958 | 2100 | 4.434 | 5.9462 | 0.7275 | 0.7267 | 0.7260 | 0.7253 | 0.7203 | - | - | - | - | - |
| 2.8241 | 2200 | 4.2634 | 6.0055 | 0.7218 | 0.7216 | 0.7205 | 0.7196 | 0.7177 | - | - | - | - | - |
| 2.9525 | 2300 | 4.2524 | 5.8834 | 0.7297 | 0.7308 | 0.7302 | 0.7282 | 0.7245 | - | - | - | - | - |
| 3.0809 | 2400 | 3.5146 | 6.2635 | 0.7430 | 0.7425 | 0.7416 | 0.7402 | 0.7357 | - | - | - | - | - |
| 3.2092 | 2500 | 3.0137 | 6.1396 | 0.7455 | 0.7441 | 0.7430 | 0.7410 | 0.7377 | - | - | - | - | - |
| 3.3376 | 2600 | 2.9956 | 6.2779 | 0.7426 | 0.7427 | 0.7407 | 0.7402 | 0.7371 | - | - | - | - | - |
| 3.4660 | 2700 | 3.0125 | 6.2415 | 0.7459 | 0.7457 | 0.7435 | 0.7425 | 0.7378 | - | - | - | - | - |
| 3.5944 | 2800 | 3.2683 | 6.2214 | 0.7407 | 0.7407 | 0.7385 | 0.7378 | 0.7342 | - | - | - | - | - |
| 3.7227 | 2900 | 2.7818 | 6.2854 | 0.7444 | 0.7442 | 0.7422 | 0.7411 | 0.7390 | - | - | - | - | - |
| 3.8511 | 3000 | 2.7216 | 6.2760 | 0.7425 | 0.7429 | 0.7411 | 0.7401 | 0.7378 | - | - | - | - | - |
| 3.9795 | 3100 | 2.8901 | 6.2306 | 0.7435 | 0.7442 | 0.7423 | 0.7411 | 0.7389 | - | - | - | - | - |
| -1 | -1 | - | - | - | - | - | - | - | 0.7435 | 0.7442 | 0.7423 | 0.7411 | 0.7389 |
Framework Versions
- Python: 3.12.6
- Sentence Transformers: 5.2.0
- Transformers: 4.56.0
- PyTorch: 2.8.0+cu129
- Accelerate: 1.10.1
- Datasets: 4.4.2
- Tokenizers: 0.22.0
Citation
BibTeX
Sentence Transformers
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
MatryoshkaLoss
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
MultipleNegativesRankingLoss
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 33
Model tree for kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka
Base model
sbintuitions/sarashina2.2-1b
Finetuned
sbintuitions/sarashina-embedding-v2-1b
Dataset used to train kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka
Evaluation results
- Pearson Cosine on sts dev 1792self-reported0.809
- Spearman Cosine on sts dev 1792self-reported0.743
- Pearson Cosine on sts dev 1280self-reported0.808
- Spearman Cosine on sts dev 1280self-reported0.744
- Pearson Cosine on sts dev 768self-reported0.805
- Spearman Cosine on sts dev 768self-reported0.742
- Pearson Cosine on sts dev 256self-reported0.802
- Spearman Cosine on sts dev 256self-reported0.741
- Pearson Cosine on sts dev 64self-reported0.797
- Spearman Cosine on sts dev 64self-reported0.739