
End of training
Browse files- .gitattributes +1 -0
- README.md +3 -2
- all_results.json +13 -0
- eval_results.json +8 -0
- train_results.json +9 -0
- trainer_state.json +3 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
.gitattributes
CHANGED
|
@@ -35,3 +35,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
trainer_log.jsonl filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
trainer_log.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
trainer_state.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3-8B-Instruct
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: train_qqp_1754652135
|
|
@@ -15,9 +16,9 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# train_qqp_1754652135
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
-
- Loss: 0.
|
| 21 |
- Num Input Tokens Seen: 250787112
|
| 22 |
|
| 23 |
## Model description
|
|
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3-8B-Instruct
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- prefix-tuning
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: train_qqp_1754652135
|
|
|
|
| 16 |
|
| 17 |
# train_qqp_1754652135
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the qqp dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.1866
|
| 22 |
- Num Input Tokens Seen: 250787112
|
| 23 |
|
| 24 |
## Model description
|
all_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 10.0,
|
| 3 |
+
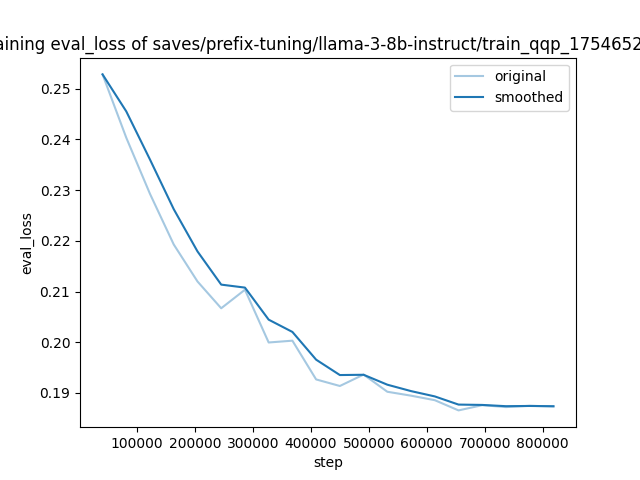
"eval_loss": 0.18655052781105042,
|
| 4 |
+
"eval_runtime": 1568.4964,
|
| 5 |
+
"eval_samples_per_second": 23.197,
|
| 6 |
+
"eval_steps_per_second": 5.8,
|
| 7 |
+
"num_input_tokens_seen": 250787112,
|
| 8 |
+
"total_flos": 1.1292830305610564e+19,
|
| 9 |
+
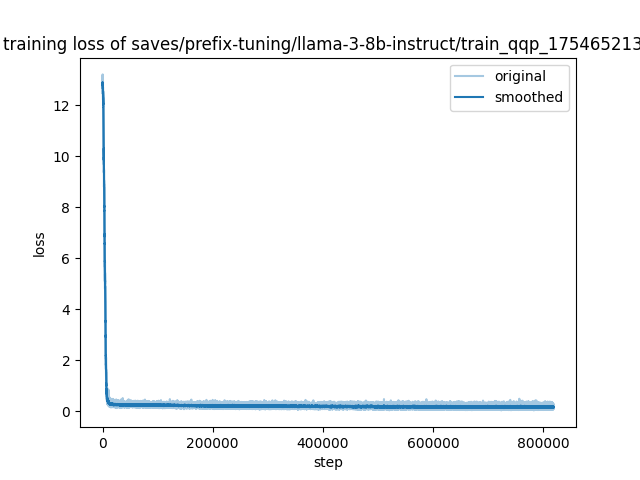
"train_loss": 0.25612748204947167,
|
| 10 |
+
"train_runtime": 332664.6174,
|
| 11 |
+
"train_samples_per_second": 9.844,
|
| 12 |
+
"train_steps_per_second": 2.461
|
| 13 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 10.0,
|
| 3 |
+
"eval_loss": 0.18655052781105042,
|
| 4 |
+
"eval_runtime": 1568.4964,
|
| 5 |
+
"eval_samples_per_second": 23.197,
|
| 6 |
+
"eval_steps_per_second": 5.8,
|
| 7 |
+
"num_input_tokens_seen": 250787112
|
| 8 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 10.0,
|
| 3 |
+
"num_input_tokens_seen": 250787112,
|
| 4 |
+
"total_flos": 1.1292830305610564e+19,
|
| 5 |
+
"train_loss": 0.25612748204947167,
|
| 6 |
+
"train_runtime": 332664.6174,
|
| 7 |
+
"train_samples_per_second": 9.844,
|
| 8 |
+
"train_steps_per_second": 2.461
|
| 9 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7e72919f8ecdcbb1059dbb215fc0fc5ed6b31238b6d8a7eac82dc5d0c4d90743
|
| 3 |
+
size 35553345
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|